
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5353/comments | https://api.github.com/repos/huggingface/datasets/issues/5353/events | https://github.com/huggingface/datasets/issues/5353 | 1,491,880,500 | I_kwDODunzps5Y7Eo0 | 5,353 | Support remote file systems for `Audio` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2022-12-12T13:22:13Z | 2022-12-12T13:37:14Z | 2022-12-12T13:37:14Z | null | ### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but to my knowledge actually copies the datasets across first, so if you're working off a system with smaller disk specs (like a VM), you can run out of space very quickly.
### Your contribution
Something like this (for Google Cloud Platform in this instance):
```python
from datasets import Dataset, Audio
import gcsfs
fs = gcsfs.GCSFileSystem()
list_of_audio_fp = {'audio': ['1', '2', '3']}
ds = Dataset.from_dict(list_of_audio_fp)
ds = ds.cast_column("audio", Audio(sampling_rate=16000, fs=fs))
```
Under the hood:
```python
import librosa
from io import BytesIO
def load_audio(fp, sampling_rate=None, fs=None):
if fs is not None:
with fs.open(fp, 'rb') as f:
arr, sr = librosa.load(BytesIO(f), sr=sampling_rate)
else:
# Perform existing io operations
```
Written from memory so some things could be wrong. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5353/timeline | null | completed | null | null | false | [
"Just seen https://github.com/huggingface/datasets/issues/5281"
] |
https://api.github.com/repos/huggingface/datasets/issues/1770 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1770/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1770/comments | https://api.github.com/repos/huggingface/datasets/issues/1770/events | https://github.com/huggingface/datasets/issues/1770 | 792,698,148 | MDU6SXNzdWU3OTI2OTgxNDg= | 1,770 | how can I combine 2 dataset with different/same features? | [] | closed | false | null | 3 | 2021-01-24T01:26:06Z | 2022-06-01T15:43:15Z | 2022-06-01T15:43:15Z | null | to combine 2 dataset by one-one map like ds = zip(ds1, ds2):
ds1: {'text'}, ds2: {'text'}, combine ds:{'src', 'tgt'}
or different feature:
ds1: {'src'}, ds2: {'tgt'}, combine ds:{'src', 'tgt'} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1770/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1770/timeline | null | completed | null | null | false | [
"Hi ! Currently we don't have a way to `zip` datasets but we plan to add this soon :)\r\nFor now you'll need to use `map` to add the fields from one dataset to the other. See the comment here for more info : https://github.com/huggingface/datasets/issues/853#issuecomment-727872188",
"Good to hear.\r\nCurrently I did not use map , just fetch src and tgt from the 2 dataset and merge them.\r\nIt will be a release if you can deal with it at the backend.\r\nThanks.",
"Hi! You can rename the columns and concatenate the datasets along `axis=1` to get the desired result as follows:\r\n```python\r\nds1 = ds1.rename_column(\"text\", \"src\")\r\nds2 = ds2.rename_column(\"text\", \"tgt\")\r\nds = datasets.concatenate_datasets([\"ds1\", \"ds2\"], axis=1)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/4353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4353/comments | https://api.github.com/repos/huggingface/datasets/issues/4353/events | https://github.com/huggingface/datasets/pull/4353 | 1,236,092,176 | PR_kwDODunzps43016x | 4,353 | Don't strip proceeding hyphen | [] | closed | false | null | 1 | 2022-05-14T18:25:29Z | 2022-05-16T18:51:38Z | 2022-05-16T13:52:11Z | null | Closes #4320. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4353/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4353",
"merged_at": "2022-05-16T13:52:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4353"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/122 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/122/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/122/comments | https://api.github.com/repos/huggingface/datasets/issues/122/events | https://github.com/huggingface/datasets/pull/122 | 618,813,182 | MDExOlB1bGxSZXF1ZXN0NDE4NDY2Mzc3 | 122 | Final cleanup of readme and metrics | [] | closed | false | null | 0 | 2020-05-15T09:00:52Z | 2021-09-03T19:40:09Z | 2020-05-15T09:02:22Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/122/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/122/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/122.diff",
"html_url": "https://github.com/huggingface/datasets/pull/122",
"merged_at": "2020-05-15T09:02:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/122.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/122"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5587/comments | https://api.github.com/repos/huggingface/datasets/issues/5587/events | https://github.com/huggingface/datasets/pull/5587 | 1,603,139,420 | PR_kwDODunzps5K70pp | 5,587 | Fix `sort` with indices mapping | [] | closed | false | null | 3 | 2023-02-28T14:05:08Z | 2023-02-28T17:28:57Z | 2023-02-28T17:21:58Z | null | Fixes the `key` range in the `query_table` call in `sort` to account for an indices mapping
Fix #5586 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5587/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5587/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5587.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5587",
"merged_at": "2023-02-28T17:21:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5587.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5587"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008740 / 0.011353 (-0.002613) | 0.004501 / 0.011008 (-0.006507) | 0.100045 / 0.038508 (0.061537) | 0.029999 / 0.023109 (0.006890) | 0.303556 / 0.275898 (0.027658) | 0.335342 / 0.323480 (0.011863) | 0.006996 / 0.007986 (-0.000989) | 0.004183 / 0.004328 (-0.000145) | 0.076434 / 0.004250 (0.072183) | 0.033899 / 0.037052 (-0.003153) | 0.301312 / 0.258489 (0.042823) | 0.343136 / 0.293841 (0.049295) | 0.034062 / 0.128546 (-0.094484) | 0.011465 / 0.075646 (-0.064181) | 0.323134 / 0.419271 (-0.096137) | 0.040820 / 0.043533 (-0.002713) | 0.301708 / 0.255139 (0.046569) | 0.329528 / 0.283200 (0.046328) | 0.088393 / 0.141683 (-0.053290) | 1.460996 / 1.452155 (0.008842) | 1.531145 / 1.492716 (0.038429) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191918 / 0.018006 (0.173912) | 0.414099 / 0.000490 (0.413610) | 0.000411 / 0.000200 (0.000211) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022707 / 0.037411 (-0.014704) | 0.096991 / 0.014526 (0.082465) | 0.106070 / 0.176557 (-0.070487) | 0.151275 / 0.737135 (-0.585860) | 0.108909 / 0.296338 (-0.187430) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422499 / 0.215209 (0.207289) | 4.205551 / 2.077655 (2.127896) | 1.918960 / 1.504120 (0.414841) | 1.715421 / 1.541195 (0.174227) | 1.768969 / 1.468490 (0.300479) | 0.692243 / 4.584777 (-3.892534) | 3.382452 / 3.745712 (-0.363260) | 1.943695 / 5.269862 (-3.326166) | 1.250482 / 4.565676 (-3.315195) | 0.082084 / 0.424275 (-0.342191) | 0.012446 / 0.007607 (0.004839) | 0.525584 / 0.226044 (0.299539) | 5.275530 / 2.268929 (3.006602) | 2.386207 / 55.444624 (-53.058418) | 2.043920 / 6.876477 (-4.832557) | 2.030932 / 2.142072 (-0.111140) | 0.810233 / 4.805227 (-3.994994) | 0.148139 / 6.500664 (-6.352525) | 0.064617 / 0.075469 (-0.010852) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.227352 / 1.841788 (-0.614436) | 13.527623 / 8.074308 (5.453315) | 14.018551 / 10.191392 (3.827159) | 0.140333 / 0.680424 (-0.540091) | 0.028349 / 0.534201 (-0.505852) | 0.394904 / 0.579283 (-0.184379) | 0.406532 / 0.434364 (-0.027831) | 0.471714 / 0.540337 (-0.068624) | 0.568517 / 1.386936 (-0.818419) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006623 / 0.011353 (-0.004730) | 0.004464 / 0.011008 (-0.006544) | 0.076342 / 0.038508 (0.037834) | 0.027451 / 0.023109 (0.004341) | 0.343851 / 0.275898 (0.067953) | 0.385723 / 0.323480 (0.062243) | 0.005624 / 0.007986 (-0.002362) | 0.004685 / 0.004328 (0.000356) | 0.075669 / 0.004250 (0.071419) | 0.037297 / 0.037052 (0.000244) | 0.343363 / 0.258489 (0.084874) | 0.396115 / 0.293841 (0.102274) | 0.031577 / 0.128546 (-0.096970) | 0.011557 / 0.075646 (-0.064090) | 0.085626 / 0.419271 (-0.333645) | 0.041699 / 0.043533 (-0.001834) | 0.340826 / 0.255139 (0.085687) | 0.377167 / 0.283200 (0.093967) | 0.088632 / 0.141683 (-0.053051) | 1.464500 / 1.452155 (0.012345) | 1.556686 / 1.492716 (0.063969) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231136 / 0.018006 (0.213130) | 0.402687 / 0.000490 (0.402197) | 0.000590 / 0.000200 (0.000390) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024926 / 0.037411 (-0.012485) | 0.101062 / 0.014526 (0.086536) | 0.106481 / 0.176557 (-0.070075) | 0.159167 / 0.737135 (-0.577968) | 0.110948 / 0.296338 (-0.185390) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441813 / 0.215209 (0.226603) | 4.416332 / 2.077655 (2.338677) | 2.080621 / 1.504120 (0.576501) | 1.877832 / 1.541195 (0.336637) | 1.944778 / 1.468490 (0.476288) | 0.704634 / 4.584777 (-3.880143) | 3.433955 / 3.745712 (-0.311758) | 1.863493 / 5.269862 (-3.406368) | 1.168869 / 4.565676 (-3.396807) | 0.084095 / 0.424275 (-0.340180) | 0.012440 / 0.007607 (0.004833) | 0.545122 / 0.226044 (0.319077) | 5.472214 / 2.268929 (3.203285) | 2.514580 / 55.444624 (-52.930044) | 2.164570 / 6.876477 (-4.711907) | 2.193467 / 2.142072 (0.051395) | 0.809056 / 4.805227 (-3.996171) | 0.152343 / 6.500664 (-6.348321) | 0.067610 / 0.075469 (-0.007859) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.280968 / 1.841788 (-0.560820) | 13.887674 / 8.074308 (5.813366) | 13.160405 / 10.191392 (2.969013) | 0.128601 / 0.680424 (-0.551823) | 0.016420 / 0.534201 (-0.517780) | 0.382810 / 0.579283 (-0.196473) | 0.394386 / 0.434364 (-0.039978) | 0.470254 / 0.540337 (-0.070083) | 0.566907 / 1.386936 (-0.820029) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008673 / 0.011353 (-0.002679) | 0.004475 / 0.011008 (-0.006533) | 0.102060 / 0.038508 (0.063552) | 0.029438 / 0.023109 (0.006329) | 0.351785 / 0.275898 (0.075887) | 0.388199 / 0.323480 (0.064719) | 0.007011 / 0.007986 (-0.000974) | 0.003317 / 0.004328 (-0.001012) | 0.080931 / 0.004250 (0.076681) | 0.033449 / 0.037052 (-0.003603) | 0.360329 / 0.258489 (0.101840) | 0.400069 / 0.293841 (0.106228) | 0.033628 / 0.128546 (-0.094918) | 0.011462 / 0.075646 (-0.064184) | 0.323781 / 0.419271 (-0.095490) | 0.040686 / 0.043533 (-0.002847) | 0.332715 / 0.255139 (0.077576) | 0.370339 / 0.283200 (0.087139) | 0.084633 / 0.141683 (-0.057050) | 1.459452 / 1.452155 (0.007297) | 1.547719 / 1.492716 (0.055003) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.187051 / 0.018006 (0.169045) | 0.402625 / 0.000490 (0.402135) | 0.002218 / 0.000200 (0.002018) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025240 / 0.037411 (-0.012171) | 0.102201 / 0.014526 (0.087675) | 0.108629 / 0.176557 (-0.067927) | 0.156686 / 0.737135 (-0.580449) | 0.111383 / 0.296338 (-0.184955) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418099 / 0.215209 (0.202890) | 4.163345 / 2.077655 (2.085690) | 1.868419 / 1.504120 (0.364300) | 1.662066 / 1.541195 (0.120871) | 1.705912 / 1.468490 (0.237422) | 0.696391 / 4.584777 (-3.888386) | 3.338307 / 3.745712 (-0.407405) | 1.923255 / 5.269862 (-3.346607) | 1.249220 / 4.565676 (-3.316457) | 0.082037 / 0.424275 (-0.342238) | 0.012232 / 0.007607 (0.004624) | 0.523913 / 0.226044 (0.297869) | 5.290036 / 2.268929 (3.021107) | 2.319729 / 55.444624 (-53.124896) | 1.987345 / 6.876477 (-4.889132) | 2.044516 / 2.142072 (-0.097556) | 0.812098 / 4.805227 (-3.993129) | 0.147327 / 6.500664 (-6.353337) | 0.063838 / 0.075469 (-0.011631) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219652 / 1.841788 (-0.622136) | 13.271513 / 8.074308 (5.197205) | 13.799982 / 10.191392 (3.608590) | 0.150055 / 0.680424 (-0.530369) | 0.028804 / 0.534201 (-0.505397) | 0.395452 / 0.579283 (-0.183831) | 0.398758 / 0.434364 (-0.035606) | 0.468575 / 0.540337 (-0.071763) | 0.553324 / 1.386936 (-0.833612) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006498 / 0.011353 (-0.004855) | 0.004439 / 0.011008 (-0.006569) | 0.076525 / 0.038508 (0.038017) | 0.027184 / 0.023109 (0.004074) | 0.364705 / 0.275898 (0.088807) | 0.409481 / 0.323480 (0.086001) | 0.004831 / 0.007986 (-0.003154) | 0.004524 / 0.004328 (0.000196) | 0.075403 / 0.004250 (0.071153) | 0.039013 / 0.037052 (0.001960) | 0.364042 / 0.258489 (0.105553) | 0.413090 / 0.293841 (0.119249) | 0.032052 / 0.128546 (-0.096495) | 0.011514 / 0.075646 (-0.064132) | 0.085219 / 0.419271 (-0.334053) | 0.041448 / 0.043533 (-0.002085) | 0.350371 / 0.255139 (0.095232) | 0.386670 / 0.283200 (0.103470) | 0.089824 / 0.141683 (-0.051859) | 1.487392 / 1.452155 (0.035238) | 1.537201 / 1.492716 (0.044485) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231555 / 0.018006 (0.213549) | 0.407505 / 0.000490 (0.407016) | 0.000382 / 0.000200 (0.000182) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026665 / 0.037411 (-0.010747) | 0.105852 / 0.014526 (0.091326) | 0.108228 / 0.176557 (-0.068328) | 0.164164 / 0.737135 (-0.572972) | 0.114284 / 0.296338 (-0.182054) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.448957 / 0.215209 (0.233748) | 4.500058 / 2.077655 (2.422403) | 2.331660 / 1.504120 (0.827541) | 2.119904 / 1.541195 (0.578710) | 2.101489 / 1.468490 (0.632999) | 0.696580 / 4.584777 (-3.888197) | 3.364206 / 3.745712 (-0.381506) | 2.550157 / 5.269862 (-2.719704) | 1.496455 / 4.565676 (-3.069222) | 0.083289 / 0.424275 (-0.340986) | 0.012283 / 0.007607 (0.004676) | 0.555581 / 0.226044 (0.329537) | 5.556284 / 2.268929 (3.287355) | 2.595261 / 55.444624 (-52.849363) | 2.234793 / 6.876477 (-4.641683) | 2.280150 / 2.142072 (0.138078) | 0.817885 / 4.805227 (-3.987343) | 0.151481 / 6.500664 (-6.349183) | 0.066764 / 0.075469 (-0.008705) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.318875 / 1.841788 (-0.522913) | 14.220380 / 8.074308 (6.146072) | 13.922773 / 10.191392 (3.731381) | 0.154608 / 0.680424 (-0.525816) | 0.016343 / 0.534201 (-0.517858) | 0.380758 / 0.579283 (-0.198525) | 0.392595 / 0.434364 (-0.041769) | 0.468844 / 0.540337 (-0.071493) | 0.561047 / 1.386936 (-0.825889) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2563/comments | https://api.github.com/repos/huggingface/datasets/issues/2563/events | https://github.com/huggingface/datasets/issues/2563 | 932,387,639 | MDU6SXNzdWU5MzIzODc2Mzk= | 2,563 | interleave_datasets for map-style datasets | [] | closed | false | null | 0 | 2021-06-29T08:57:24Z | 2021-07-01T09:33:33Z | 2021-07-01T09:33:33Z | null | Currently the `interleave_datasets` functions only works for `IterableDataset`.
Let's make it work for map-style `Dataset` objects as well.
It would work the same way: either alternate between the datasets in order or randomly given probabilities specified by the user. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2563/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2563/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4526 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4526/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4526/comments | https://api.github.com/repos/huggingface/datasets/issues/4526/events | https://github.com/huggingface/datasets/issues/4526 | 1,276,580,185 | I_kwDODunzps5MFxFZ | 4,526 | split cache used when processing different split | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 2 | 2022-06-20T08:44:58Z | 2022-06-28T14:04:58Z | null | null | ## Describe the bug`
```
ds1 = load_dataset('squad', split='validation')
ds2 = load_dataset('squad', split='train')
ds1 = ds1.map(some_function)
ds2 = ds2.map(some_function)
assert ds1 == ds2
```
This happens when ds1 and ds2 are created in `pytorch_lightning.DataModule` through
```
class myDataModule:
def train_dataloader(self):
ds = load_dataset('squad', split='train')
ds = ds.map(some_function)
return [ds]
def val_dataloader(self):
ds = load_dataset('squad', split="validation")
ds = ds.map(some_function)
return [ds]
```
I don't know if it depends on `pytorch_lightning` or `datasets` but setting `ds.map(some_function, load_from_cache_file=False)` fixes the issue.
If this is not enough to replicate I will try and provide and MWE, I don't have time now so I thought I wuld open the issue first! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4526/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4526/timeline | null | null | null | null | false | [
"I was not able to reproduce this behavior (I tried without using pytorch lightning though, since I don't know what code you ran in pytorch lightning to get this).\r\n\r\nIf you can provide a MWE that would be perfect ! :)",
"Hi, I think the issue happened because I was loading datasets under an `if` ... `else` statement and the condition would change the dataset I would need to load but instead the cached one was always returned. However, I believe that is expected behaviour, if so I'll close the issue.\r\n\r\nOtherwise I will try to provide a MWE"
] |
https://api.github.com/repos/huggingface/datasets/issues/1685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1685/comments | https://api.github.com/repos/huggingface/datasets/issues/1685/events | https://github.com/huggingface/datasets/pull/1685 | 778,914,431 | MDExOlB1bGxSZXF1ZXN0NTQ4OTM1MzY2 | 1,685 | Update README.md of covid-tweets-japanese | [] | closed | false | null | 1 | 2021-01-05T11:47:27Z | 2021-01-06T10:27:12Z | 2021-01-06T09:31:10Z | null | Update README.md of covid-tweets-japanese added by PR https://github.com/huggingface/datasets/pull/1367 and https://github.com/huggingface/datasets/pull/1402.
- Update "Data Splits" to be more precise that no information is provided for now.
- old: [More Information Needed]
- new: No information about data splits is provided for now.
- The automatic generation of links seemed not working properly, so I added a space before and after the URL to make the links work correctly. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1685/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1685/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1685.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1685",
"merged_at": "2021-01-06T09:31:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1685.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1685"
} | true | [
"Thanks for reviewing and merging!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4403/comments | https://api.github.com/repos/huggingface/datasets/issues/4403/events | https://github.com/huggingface/datasets/pull/4403 | 1,248,390,134 | PR_kwDODunzps44dcpl | 4,403 | Uncomment logging deactivation for ArrowBasedBuilder | [] | closed | false | null | 1 | 2022-05-25T16:46:15Z | 2022-05-31T08:33:36Z | 2022-05-31T08:25:02Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4403/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4403/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4403",
"merged_at": "2022-05-31T08:25:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4403"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2539 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2539/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2539/comments | https://api.github.com/repos/huggingface/datasets/issues/2539/events | https://github.com/huggingface/datasets/pull/2539 | 927,952,429 | MDExOlB1bGxSZXF1ZXN0Njc2MDI5MDY5 | 2,539 | remove wi_locness dataset due to licensing issues | [] | closed | false | null | 5 | 2021-06-23T07:35:32Z | 2021-06-25T14:52:42Z | 2021-06-25T14:52:42Z | null | It was brought to my attention that this dataset's license is not only missing, but also prohibits redistribution. I contacted the original author to apologize for this oversight and asked if we could still use it, but unfortunately we can't and the author kindly asked to take down this dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2539/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2539/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2539.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2539",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2539.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2539"
} | true | [
"Hi ! I'm sorry to hear that.\r\nThough we are not redistributing the dataset, we just provide a python script that downloads and process the dataset from its original source hosted at https://www.cl.cam.ac.uk\r\n\r\nTherefore I'm not sure what's the issue with licensing. What do you mean exactly ?",
"I think that the main issue is that the licesenses of the data are not made clear in the huggingface hub – other people wrongly assumed that the data was license-free, which resulted in commercial use, which is against the licenses.\r\nIs it possible to add the licenses from the original download to huggingface? that would help clear any confusion (licenses can be found here: https://www.cl.cam.ac.uk/research/nl/bea2019st/data/wi+locness_v2.1.bea19.tar.gz)",
"Thanks for the clarification @SimonHFL \r\nYou're completely right, we need to show the licenses.\r\nI just added them here: https://huggingface.co/datasets/wi_locness#licensing-information",
"Hi guys, I'm one of the authors of this dataset. \r\n\r\nTo clarify, we're happy for you to keep the data in the repo on 2 conditions:\r\n1. You don't host the data yourself.\r\n2. You make it clear that anyone who downloads the data via HuggingFace should read and abide by the license. \r\n\r\nI think you've now met these conditions, so we're all good, but I just wanted to make it clear in case there are any issues in the future. Thanks again to @aseifert for bringing this to our attention! :)",
"Thanks for your message @chrisjbryant :)\r\nI'm closing this PR then.\r\n\r\nAnd thanks for reporting @aseifert"
] |
https://api.github.com/repos/huggingface/datasets/issues/2387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2387/comments | https://api.github.com/repos/huggingface/datasets/issues/2387/events | https://github.com/huggingface/datasets/issues/2387 | 897,566,666 | MDU6SXNzdWU4OTc1NjY2NjY= | 2,387 | datasets 1.6 ignores cache | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 13 | 2021-05-21T00:12:58Z | 2021-05-26T16:07:54Z | 2021-05-26T16:07:54Z | null | Moving from https://github.com/huggingface/transformers/issues/11801#issuecomment-845546612
Quoting @VictorSanh:
>
> I downgraded datasets to `1.5.0` and printed `tokenized_datasets.cache_files` (L335):
>
> > `{'train': [{'filename': '/home/victor/.cache/huggingface/datasets/openwebtext10k/plain_text/1.0.0/3a8df094c671b4cb63ed0b41f40fb3bd855e9ce2e3765e5df50abcdfb5ec144b/cache-c6aefe81ca4e5152.arrow'}], 'validation': [{'filename': '/home/victor/.cache/huggingface/datasets/openwebtext10k/plain_text/1.0.0/3a8df094c671b4cb63ed0b41f40fb3bd855e9ce2e3765e5df50abcdfb5ec144b/cache-97cf4c813e6469c6.arrow'}]}`
>
> while the same command with the latest version of datasets (actually starting at `1.6.0`) gives:
> > `{'train': [], 'validation': []}`
>
I also confirm that downgrading to `datasets==1.5.0` makes things fast again - i.e. cache is used.
to reproduce:
```
USE_TF=0 python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 \
--dataset_name "stas/openwebtext-10k" \
--output_dir output_dir \
--overwrite_output_dir \
--do_train \
--do_eval \
--max_train_samples 1000 \
--max_eval_samples 200 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--num_train_epochs 1 \
--warmup_steps 8 \
--block_size 64 \
--fp16 \
--report_to none
```
the first time the startup is slow and some 5 tqdm bars. It shouldn't do it on consequent runs. but with `datasets>1.5.0` it rebuilds on every run.
@lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2387/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2387/timeline | null | completed | null | null | false | [
"Looks like there are multiple issues regarding this (#2386, #2322) and it's a WIP #2329. Currently these datasets are being loaded in-memory which is causing this issue. Quoting @mariosasko here for a quick fix:\r\n\r\n> set `keep_in_memory` to `False` when loading a dataset (`sst = load_dataset(\"sst\", keep_in_memory=False)`) to prevent it from loading in-memory. Currently, in-memory datasets fail to find cached files due to this check (always False for them)\r\n\r\n",
"Hi ! Since `datasets` 1.6.0 we no longer keep small datasets (<250MB) on disk and load them in RAM instead by default. This makes data processing and iterating on data faster. However datasets in RAM currently have no way to reload previous results from the cache (since nothing is written on disk). We are working on making the caching work for datasets in RAM.\r\n\r\nUntil then, I'd recommend passing `keep_in_memory=False` to the calls to `load_dataset` like here:\r\n\r\nhttps://github.com/huggingface/transformers/blob/223943872e8c9c3fc11db3c6e93da07f5177423f/examples/pytorch/language-modeling/run_clm.py#L233\r\n\r\nThis way you say explicitly that you want your dataset to stay on the disk, and it will be able to recover previously computed results from the cache.",
"gotcha! thanks Quentin",
"OK, It doesn't look like we can use the proposed workaround - see https://github.com/huggingface/transformers/issues/11801\r\n\r\nCould you please add an env var for us to be able to turn off this unwanted in our situation behavior? It is really problematic for dev work, when one needs to restart the training very often and needs a quick startup time. Manual editing of standard scripts is not a practical option when one uses examples.\r\n\r\nThis could also be a problem for tests, which will be slower because of lack of cache, albeit usually we use tiny datasets there. I think we want caching for tests.\r\n\r\nThank you.",
"Hi @stas00, \r\n\r\nYou are right: an env variable is needed to turn off this behavior. I am adding it.\r\n\r\nFor the moment there is a config parameter to turn off this behavior: `datasets.config.MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES = None`\r\n\r\nYou can find this info in the docs:\r\n- in the docstring of the parameter `keep_in_memory` of the function [`load_datasets`](https://huggingface.co/docs/datasets/package_reference/loading_methods.html#datasets.load_dataset):\r\n- in a Note in the docs about [Loading a Dataset](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub)\r\n\r\n> The default in 🤗Datasets is to memory-map the dataset on drive if its size is larger than datasets.config.MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES (default 250 MiB); otherwise, the dataset is copied in-memory. This behavior can be disabled by setting datasets.config.MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES = None, and in this case the dataset is not loaded in memory.",
"Yes, but this still requires one to edit the standard example scripts, so if I'm doing that already I just as well can add `keep_in_memory=False`.\r\n\r\nMay be the low hanging fruit is to add `MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES` env var to match the config, and if the user sets it to 0, then it'll be the same as `keep_in_memory=False` or `datasets.config.MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES=0`?",
"@stas00, however, for the moment, setting the value to `0` is equivalent to the opposite, i.e. `keep_in_memory=True`. This means the max size until which I load in memory is 0 bytes.\r\n\r\nTell me if this is logical/convenient, or I should change it.",
"In my PR, to turn off current default bahavior, you should set env variable to one of: `{\"\", \"OFF\", \"NO\", \"FALSE\"}`.\r\n\r\nFor example:\r\n```\r\nMAX_IN_MEMORY_DATASET_SIZE_IN_BYTES=\r\n```",
"IMHO, this behaviour is not very intuitive, as 0 is a normal quantity of bytes. So `MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES=0` to me reads as don't cache ever.\r\n\r\nAlso \"SIZE_IN_BYTES\" that can take one of `{\"\", \"OFF\", \"NO\", \"FALSE\"}` is also quite odd.\r\n\r\nI think supporting a very simple `MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES` that can accept any numerical value to match the name of the variable, requires minimal logic and is very straightforward. \r\n\r\nSo if you could adjust this logic - then `MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES=0` is all that's needed to not do in-memory datasets.\r\n\r\nDoes it make sense?",
"I understand your point @stas00, as I am not very convinced with current implementation.\r\n\r\nMy concern is: which numerical value should then pass a user who wants `keep_in_memory=True` by default, independently of dataset size? Currently it is `0` for this case.",
"That's a good question, and again the normal bytes can be used for that:\r\n```\r\nMAX_IN_MEMORY_DATASET_SIZE_IN_BYTES=1e12 # (~2**40)\r\n```\r\nSince it's unlikely that anybody will have more than 1TB RAM.\r\n\r\nIt's also silly that it uses BYTES and not MBYTES - that level of refinement doesn't seem to be of a practical use in this context.\r\n\r\nNot sure when it was added and if there are back-compat issues here, but perhaps it could be renamed `MAX_IN_MEMORY_DATASET_SIZE` and support 1M, 1G, 1T, etc. \r\n\r\nBut scientific notation is quite intuitive too, as each 000 zeros is the next M, G, T multiplier. Minus the discrepancy of 1024 vs 1000, which adds up. And it is easy to write down `1e12`, as compared to `1099511627776` (2**40). (`1.1e12` is more exact).\r\n",
"Great! Thanks, @stas00.\r\n\r\nI am implementing your suggestion to turn off default value when set to `0`.\r\n\r\nFor the other suggestion (allowing different metric prefixes), I will discuss with @lhoestq to agree on its implementation.",
"Awesome! Thank you, @albertvillanova!!!\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2895 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2895/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2895/comments | https://api.github.com/repos/huggingface/datasets/issues/2895/events | https://github.com/huggingface/datasets/pull/2895 | 993,462,274 | MDExOlB1bGxSZXF1ZXN0NzMxNjQ0NTY2 | 2,895 | Use pyarrow.Table.replace_schema_metadata instead of pyarrow.Table.cast | [] | closed | false | null | 0 | 2021-09-10T17:56:57Z | 2021-09-21T22:50:01Z | 2021-09-21T08:18:35Z | null | This PR partially addresses #2252.
``update_metadata_with_features`` uses ``Table.cast`` which slows down ``load_from_disk`` (and possibly other methods that use it) for very large datasets. Since ``update_metadata_with_features`` is only updating the schema metadata, it makes more sense to use ``pyarrow.Table.replace_schema_metadata`` which is much faster. This PR adds a ``replace_schema_metadata`` method to all table classes, and modifies ``update_metadata_with_features`` to use it instead of ``cast``. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2895/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2895/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2895.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2895",
"merged_at": "2021-09-21T08:18:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2895.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2895"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2814 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2814/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2814/comments | https://api.github.com/repos/huggingface/datasets/issues/2814/events | https://github.com/huggingface/datasets/pull/2814 | 973,632,645 | MDExOlB1bGxSZXF1ZXN0NzE1MDUwODc4 | 2,814 | Bump tqdm version | [] | closed | false | null | 0 | 2021-08-18T12:51:29Z | 2021-08-18T13:44:11Z | 2021-08-18T13:39:50Z | null | The recently released tqdm 4.62.1 includes a fix for PermissionError on Windows (submitted by me in https://github.com/tqdm/tqdm/pull/1207), which means we can remove expensive `gc.collect` calls by bumping tqdm to that version. This PR does exactly that and, additionally, fixes a `disable_tqdm` definition that would previously, if used, raise a PermissionError on Windows. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2814/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2814/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2814.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2814",
"merged_at": "2021-08-18T13:39:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2814.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2814"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1021 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1021/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1021/comments | https://api.github.com/repos/huggingface/datasets/issues/1021/events | https://github.com/huggingface/datasets/pull/1021 | 755,644,559 | MDExOlB1bGxSZXF1ZXN0NTMxMzE4MTQw | 1,021 | Add Gutenberg time references dataset | [] | closed | false | null | 1 | 2020-12-02T22:05:26Z | 2020-12-03T10:33:39Z | 2020-12-03T10:33:38Z | null | This PR adds the gutenberg_time dataset: https://arxiv.org/abs/2011.04124 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1021/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1021/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1021.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1021",
"merged_at": "2020-12-03T10:33:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1021.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1021"
} | true | [
"Description: \"A clean data resource containing all explicit time references in a dataset of 52,183 novels whose full text is available via Project Gutenberg and the Hathi Trust Digital Library 2.\" > This is just the Gutenberg part.\r\n\r\nAlso, the paragraph at the top of the file would make a good Dataset Summary in the README :) "
] |
https://api.github.com/repos/huggingface/datasets/issues/3529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3529/comments | https://api.github.com/repos/huggingface/datasets/issues/3529/events | https://github.com/huggingface/datasets/pull/3529 | 1,093,846,356 | PR_kwDODunzps4wiPA9 | 3,529 | Update README.md | [] | closed | false | null | 0 | 2022-01-04T23:52:47Z | 2022-01-05T12:50:15Z | 2022-01-05T12:50:14Z | null | Updating licensing information & personal and sensitive information. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3529/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3529/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3529.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3529",
"merged_at": "2022-01-05T12:50:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3529.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3529"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/578/comments | https://api.github.com/repos/huggingface/datasets/issues/578/events | https://github.com/huggingface/datasets/pull/578 | 694,849,940 | MDExOlB1bGxSZXF1ZXN0NDgxMTczNDE0 | 578 | Add CommonGen Dataset | [] | closed | false | null | 0 | 2020-09-07T08:17:17Z | 2020-09-07T11:50:29Z | 2020-09-07T11:49:07Z | null | CC Authors:
@yuchenlin @MichaelZhouwang | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/578/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/578.diff",
"html_url": "https://github.com/huggingface/datasets/pull/578",
"merged_at": "2020-09-07T11:49:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/578.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/578"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1602/comments | https://api.github.com/repos/huggingface/datasets/issues/1602/events | https://github.com/huggingface/datasets/pull/1602 | 770,841,810 | MDExOlB1bGxSZXF1ZXN0NTQyNTA4NTM4 | 1,602 | second update of id_newspapers_2018 | [] | closed | false | null | 0 | 2020-12-18T12:16:37Z | 2020-12-22T10:41:15Z | 2020-12-22T10:41:14Z | null | The feature "url" is currently set wrongly to data["date"], this PR fix it to data["url"].
I added also an additional POC. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1602/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1602/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1602.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1602",
"merged_at": "2020-12-22T10:41:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1602.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1602"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4590/comments | https://api.github.com/repos/huggingface/datasets/issues/4590/events | https://github.com/huggingface/datasets/pull/4590 | 1,287,941,058 | PR_kwDODunzps46htv0 | 4,590 | Generalize meta_path json file creation in load.py [#4540] | [] | closed | false | null | 4 | 2022-06-28T21:48:06Z | 2022-07-08T14:55:13Z | 2022-07-07T13:17:45Z | null | # What does this PR do?
## Summary
*In function `_copy_script_and_other_resources_in_importable_dir`, using string split when generating `meta_path` throws error in the edge case raised in #4540.*
## Additions
-
## Changes
- Changed meta_path to use `os.path.splitext` instead of using `str.split` to generalize code.
## Deletions
-
## Issues Addressed :
Fixes #4540 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4590/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4590/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4590.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4590",
"merged_at": "2022-07-07T13:17:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4590.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4590"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@albertvillanova, Can you please review this PR for Issue #4540 ",
"@lhoestq Thank you for merging the PR . Is there a slack channel for contributing to the datasets library. I would love to work on the library and make meaningful contributions.",
"Hi ! Sure feel free to join our discord ^^ \r\nhttps://discuss.huggingface.co/t/join-the-hugging-face-discord/11263 so that we can discuss together mor eeasily. Otherwise everything happens on github ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1601/comments | https://api.github.com/repos/huggingface/datasets/issues/1601/events | https://github.com/huggingface/datasets/pull/1601 | 770,758,914 | MDExOlB1bGxSZXF1ZXN0NTQyNDQzNDE3 | 1,601 | second update of the id_newspapers_2018 | [] | closed | false | null | 1 | 2020-12-18T10:10:20Z | 2020-12-18T12:15:31Z | 2020-12-18T12:15:31Z | null | The feature "url" is currently set wrongly to data["date"], this PR fix it to data["url"].
I added also an additional POC. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1601/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1601.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1601",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1601.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1601"
} | true | [
"I close this PR, since it based on 1 week old repo. And I will create a new one"
] |
https://api.github.com/repos/huggingface/datasets/issues/4021 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4021/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4021/comments | https://api.github.com/repos/huggingface/datasets/issues/4021/events | https://github.com/huggingface/datasets/pull/4021 | 1,180,805,092 | PR_kwDODunzps41BLAf | 4,021 | Fix `map` remove_columns on empty dataset | [] | closed | false | null | 1 | 2022-03-25T13:36:29Z | 2022-03-29T13:41:31Z | 2022-03-29T13:35:44Z | null | On an empty dataset, the `remove_columns` parameter of `map` currently doesn't actually remove the columns:
```python
>>> ds = datasets.load_dataset("glue", "rte")
>>> ds_filtered = ds.filter(lambda x: x["label"] != -1)
>>> ds_mapped = ds_filtered.map(lambda x: x, remove_columns=["label"])
>>> print(repr(ds_mapped.column_names))
{
'train': ['sentence1', 'sentence2', 'idx'],
'validation': ['sentence1', 'sentence2', 'idx'],
'test': ['sentence1', 'sentence2', 'label', 'idx']
}
```
I fixed this error and updated the tests | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4021/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4021/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4021.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4021",
"merged_at": "2022-03-29T13:35:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4021.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4021"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/297/comments | https://api.github.com/repos/huggingface/datasets/issues/297/events | https://github.com/huggingface/datasets/issues/297 | 643,444,625 | MDU6SXNzdWU2NDM0NDQ2MjU= | 297 | Error in Demo for Specific Datasets | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 3 | 2020-06-23T00:38:42Z | 2020-07-17T17:43:06Z | 2020-07-17T17:43:06Z | null | Selecting `natural_questions` or `newsroom` dataset in the online demo results in an error similar to the following.

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/297/timeline | null | completed | null | null | false | [
"Thanks for reporting these errors :)\r\n\r\nI can actually see two issues here.\r\n\r\nFirst, datasets like `natural_questions` require apache_beam to be processed. Right now the import is not at the right place so we have this error message. However, even the imports are fixed, the nlp viewer doesn't actually have the resources to process NQ right now so we'll have to wait until we have a version that we've already processed on our google storage (that's what we've done for wikipedia for example).\r\n\r\nSecond, datasets like `newsroom` require manual downloads as we're not allowed to redistribute the data ourselves (if I'm not wrong). An error message should be displayed saying that we're not allowed to show the dataset.\r\n\r\nI can fix the first issue with the imports but for the second one I think we'll have to see with @srush to show a message for datasets that require manual downloads (it can be checked whether a dataset requires manual downloads if `dataset_builder_instance.manual_download_instructions is not None`).\r\n\r\n",
"I added apache-beam to the viewer. We can think about how to add newsroom. ",
"We don't plan to host the source files of newsroom ourselves for now.\r\nYou can still get the dataset if you follow the download instructions given by `dataset = load_dataset('newsroom')` though.\r\nThe viewer also shows the instructions now.\r\n\r\nClosing this one. If you have other questions, feel free to re-open :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/665/comments | https://api.github.com/repos/huggingface/datasets/issues/665/events | https://github.com/huggingface/datasets/issues/665 | 707,037,738 | MDU6SXNzdWU3MDcwMzc3Mzg= | 665 | runing dataset.map, it raises TypeError: can't pickle Tokenizer objects | [] | closed | false | null | 8 | 2020-09-23T04:28:14Z | 2020-10-08T09:32:16Z | 2020-10-08T09:32:16Z | null | I load squad dataset. Then want to process data use following function with `Huggingface Transformers LongformerTokenizer`.
```
def convert_to_features(example):
# Tokenize contexts and questions (as pairs of inputs)
input_pairs = [example['question'], example['context']]
encodings = tokenizer.encode_plus(input_pairs, pad_to_max_length=True, max_length=512)
context_encodings = tokenizer.encode_plus(example['context'])
# Compute start and end tokens for labels using Transformers's fast tokenizers alignement methodes.
# this will give us the position of answer span in the context text
start_idx, end_idx = get_correct_alignement(example['context'], example['answers'])
start_positions_context = context_encodings.char_to_token(start_idx)
end_positions_context = context_encodings.char_to_token(end_idx-1)
# here we will compute the start and end position of the answer in the whole example
# as the example is encoded like this <s> question</s></s> context</s>
# and we know the postion of the answer in the context
# we can just find out the index of the sep token and then add that to position + 1 (+1 because there are two sep tokens)
# this will give us the position of the answer span in whole example
sep_idx = encodings['input_ids'].index(tokenizer.sep_token_id)
start_positions = start_positions_context + sep_idx + 1
end_positions = end_positions_context + sep_idx + 1
if end_positions > 512:
start_positions, end_positions = 0, 0
encodings.update({'start_positions': start_positions,
'end_positions': end_positions,
'attention_mask': encodings['attention_mask']})
return encodings
```
Then I run `dataset.map(convert_to_features)`, it raise
```
In [59]: a.map(convert_to_features)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-59-c453b508761d> in <module>
----> 1 a.map(convert_to_features)
/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1242 fn_kwargs=fn_kwargs,
1243 new_fingerprint=new_fingerprint,
-> 1244 update_data=update_data,
1245 )
1246 else:
/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
151 "output_all_columns": self._output_all_columns,
152 }
--> 153 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
154 if new_format["columns"] is not None:
155 new_format["columns"] = list(set(new_format["columns"]) & set(out.column_names))
/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
156 kwargs_for_fingerprint["fingerprint_name"] = fingerprint_name
157 kwargs[fingerprint_name] = update_fingerprint(
--> 158 self._fingerprint, transform, kwargs_for_fingerprint
159 )
160
/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py in update_fingerprint(fingerprint, transform, transform_args)
103 for key in sorted(transform_args):
104 hasher.update(key)
--> 105 hasher.update(transform_args[key])
106 return hasher.hexdigest()
107
/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py in update(self, value)
55 def update(self, value):
56 self.m.update(f"=={type(value)}==".encode("utf8"))
---> 57 self.m.update(self.hash(value).encode("utf-8"))
58
59 def hexdigest(self):
/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py in hash(cls, value)
51 return cls.dispatch[type(value)](cls, value)
52 else:
---> 53 return cls.hash_default(value)
54
55 def update(self, value):
/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py in hash_default(cls, value)
44 @classmethod
45 def hash_default(cls, value):
---> 46 return cls.hash_bytes(dumps(value))
47
48 @classmethod
/opt/conda/lib/python3.7/site-packages/datasets/utils/py_utils.py in dumps(obj)
365 file = StringIO()
366 with _no_cache_fields(obj):
--> 367 dump(obj, file)
368 return file.getvalue()
369
/opt/conda/lib/python3.7/site-packages/datasets/utils/py_utils.py in dump(obj, file)
337 def dump(obj, file):
338 """pickle an object to a file"""
--> 339 Pickler(file, recurse=True).dump(obj)
340 return
341
/opt/conda/lib/python3.7/site-packages/dill/_dill.py in dump(self, obj)
444 raise PicklingError(msg)
445 else:
--> 446 StockPickler.dump(self, obj)
447 stack.clear() # clear record of 'recursion-sensitive' pickled objects
448 return
/opt/conda/lib/python3.7/pickle.py in dump(self, obj)
435 if self.proto >= 4:
436 self.framer.start_framing()
--> 437 self.save(obj)
438 self.write(STOP)
439 self.framer.end_framing()
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/opt/conda/lib/python3.7/site-packages/dill/_dill.py in save_function(pickler, obj)
1436 globs, obj.__name__,
1437 obj.__defaults__, obj.__closure__,
-> 1438 obj.__dict__, fkwdefaults), obj=obj)
1439 else:
1440 _super = ('super' in getattr(obj.func_code,'co_names',())) and (_byref is not None) and getattr(pickler, '_recurse', False)
/opt/conda/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
636 else:
637 save(func)
--> 638 save(args)
639 write(REDUCE)
640
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/opt/conda/lib/python3.7/pickle.py in save_tuple(self, obj)
787 write(MARK)
788 for element in obj:
--> 789 save(element)
790
791 if id(obj) in memo:
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/opt/conda/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
931 # we only care about session the first pass thru
932 pickler._session = False
--> 933 StockPickler.save_dict(pickler, obj)
934 log.info("# D2")
935 return
/opt/conda/lib/python3.7/pickle.py in save_dict(self, obj)
857
858 self.memoize(obj)
--> 859 self._batch_setitems(obj.items())
860
861 dispatch[dict] = save_dict
/opt/conda/lib/python3.7/pickle.py in _batch_setitems(self, items)
883 for k, v in tmp:
884 save(k)
--> 885 save(v)
886 write(SETITEMS)
887 elif n:
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/opt/conda/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/opt/conda/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
931 # we only care about session the first pass thru
932 pickler._session = False
--> 933 StockPickler.save_dict(pickler, obj)
934 log.info("# D2")
935 return
/opt/conda/lib/python3.7/pickle.py in save_dict(self, obj)
857
858 self.memoize(obj)
--> 859 self._batch_setitems(obj.items())
860
861 dispatch[dict] = save_dict
/opt/conda/lib/python3.7/pickle.py in _batch_setitems(self, items)
883 for k, v in tmp:
884 save(k)
--> 885 save(v)
886 write(SETITEMS)
887 elif n:
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/opt/conda/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/opt/conda/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
931 # we only care about session the first pass thru
932 pickler._session = False
--> 933 StockPickler.save_dict(pickler, obj)
934 log.info("# D2")
935 return
/opt/conda/lib/python3.7/pickle.py in save_dict(self, obj)
857
858 self.memoize(obj)
--> 859 self._batch_setitems(obj.items())
860
861 dispatch[dict] = save_dict
/opt/conda/lib/python3.7/pickle.py in _batch_setitems(self, items)
883 for k, v in tmp:
884 save(k)
--> 885 save(v)
886 write(SETITEMS)
887 elif n:
/opt/conda/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
522 reduce = getattr(obj, "__reduce_ex__", None)
523 if reduce is not None:
--> 524 rv = reduce(self.proto)
525 else:
526 reduce = getattr(obj, "__reduce__", None)
TypeError: can't pickle Tokenizer objects
```
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/665/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/665/timeline | null | completed | null | null | false | [
"Hi !\r\nIt works on my side with both the LongFormerTokenizer and the LongFormerTokenizerFast.\r\n\r\nWhich version of transformers/datasets are you using ?",
"transformers and datasets are both the latest",
"Then I guess you need to give us more informations on your setup (OS, python, GPU, etc) or a Google Colab reproducing the error for us to be able to debug this error.",
"And your version of `dill` if possible :)",
"I have the same issue with `transformers/BertJapaneseTokenizer`.\r\n\r\n\r\n\r\n```python\r\n# train_ds = Dataset(features: {\r\n# 'title': Value(dtype='string', id=None), \r\n# 'score': Value(dtype='float64', id=None)\r\n# }, num_rows: 99999)\r\n\r\nt = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-whole-word-masking')\r\nencoded = train_ds.map(lambda examples: {'tokens': t.encode(examples['title'])}, batched=True)\r\n```\r\n\r\n<details><summary>Error Message</summary>\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-35-2b7d66b291c1> in <module>\r\n 2 \r\n 3 encoded = train_ds.map(lambda examples:\r\n----> 4 {'tokens': t.encode(examples['title'])}, batched=True)\r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)\r\n 1242 fn_kwargs=fn_kwargs,\r\n 1243 new_fingerprint=new_fingerprint,\r\n-> 1244 update_data=update_data,\r\n 1245 )\r\n 1246 else:\r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)\r\n 151 \"output_all_columns\": self._output_all_columns,\r\n 152 }\r\n--> 153 out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n 154 if new_format[\"columns\"] is not None:\r\n 155 new_format[\"columns\"] = list(set(new_format[\"columns\"]) & set(out.column_names))\r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)\r\n 156 kwargs_for_fingerprint[\"fingerprint_name\"] = fingerprint_name\r\n 157 kwargs[fingerprint_name] = update_fingerprint(\r\n--> 158 self._fingerprint, transform, kwargs_for_fingerprint\r\n 159 )\r\n 160 \r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/fingerprint.py in update_fingerprint(fingerprint, transform, transform_args)\r\n 103 for key in sorted(transform_args):\r\n 104 hasher.update(key)\r\n--> 105 hasher.update(transform_args[key])\r\n 106 return hasher.hexdigest()\r\n 107 \r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/fingerprint.py in update(self, value)\r\n 55 def update(self, value):\r\n 56 self.m.update(f\"=={type(value)}==\".encode(\"utf8\"))\r\n---> 57 self.m.update(self.hash(value).encode(\"utf-8\"))\r\n 58 \r\n 59 def hexdigest(self):\r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/fingerprint.py in hash(cls, value)\r\n 51 return cls.dispatch[type(value)](cls, value)\r\n 52 else:\r\n---> 53 return cls.hash_default(value)\r\n 54 \r\n 55 def update(self, value):\r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/fingerprint.py in hash_default(cls, value)\r\n 44 @classmethod\r\n 45 def hash_default(cls, value):\r\n---> 46 return cls.hash_bytes(dumps(value))\r\n 47 \r\n 48 @classmethod\r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/utils/py_utils.py in dumps(obj)\r\n 365 file = StringIO()\r\n 366 with _no_cache_fields(obj):\r\n--> 367 dump(obj, file)\r\n 368 return file.getvalue()\r\n 369 \r\n\r\n/usr/local/lib/python3.6/site-packages/datasets/utils/py_utils.py in dump(obj, file)\r\n 337 def dump(obj, file):\r\n 338 \"\"\"pickle an object to a file\"\"\"\r\n--> 339 Pickler(file, recurse=True).dump(obj)\r\n 340 return\r\n 341 \r\n\r\n/usr/local/lib/python3.6/site-packages/dill/_dill.py in dump(self, obj)\r\n 444 raise PicklingError(msg)\r\n 445 else:\r\n--> 446 StockPickler.dump(self, obj)\r\n 447 stack.clear() # clear record of 'recursion-sensitive' pickled objects\r\n 448 return\r\n\r\n/usr/local/lib/python3.6/pickle.py in dump(self, obj)\r\n 407 if self.proto >= 4:\r\n 408 self.framer.start_framing()\r\n--> 409 self.save(obj)\r\n 410 self.write(STOP)\r\n 411 self.framer.end_framing()\r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 474 f = self.dispatch.get(t)\r\n 475 if f is not None:\r\n--> 476 f(self, obj) # Call unbound method with explicit self\r\n 477 return\r\n 478 \r\n\r\n/usr/local/lib/python3.6/site-packages/dill/_dill.py in save_function(pickler, obj)\r\n 1436 globs, obj.__name__,\r\n 1437 obj.__defaults__, obj.__closure__,\r\n-> 1438 obj.__dict__, fkwdefaults), obj=obj)\r\n 1439 else:\r\n 1440 _super = ('super' in getattr(obj.func_code,'co_names',())) and (_byref is not None) and getattr(pickler, '_recurse', False)\r\n\r\n/usr/local/lib/python3.6/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)\r\n 608 else:\r\n 609 save(func)\r\n--> 610 save(args)\r\n 611 write(REDUCE)\r\n 612 \r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 474 f = self.dispatch.get(t)\r\n 475 if f is not None:\r\n--> 476 f(self, obj) # Call unbound method with explicit self\r\n 477 return\r\n 478 \r\n\r\n/usr/local/lib/python3.6/pickle.py in save_tuple(self, obj)\r\n 749 write(MARK)\r\n 750 for element in obj:\r\n--> 751 save(element)\r\n 752 \r\n 753 if id(obj) in memo:\r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 474 f = self.dispatch.get(t)\r\n 475 if f is not None:\r\n--> 476 f(self, obj) # Call unbound method with explicit self\r\n 477 return\r\n 478 \r\n\r\n/usr/local/lib/python3.6/site-packages/dill/_dill.py in save_module_dict(pickler, obj)\r\n 931 # we only care about session the first pass thru\r\n 932 pickler._session = False\r\n--> 933 StockPickler.save_dict(pickler, obj)\r\n 934 log.info(\"# D2\")\r\n 935 return\r\n\r\n/usr/local/lib/python3.6/pickle.py in save_dict(self, obj)\r\n 819 \r\n 820 self.memoize(obj)\r\n--> 821 self._batch_setitems(obj.items())\r\n 822 \r\n 823 dispatch[dict] = save_dict\r\n\r\n/usr/local/lib/python3.6/pickle.py in _batch_setitems(self, items)\r\n 850 k, v = tmp[0]\r\n 851 save(k)\r\n--> 852 save(v)\r\n 853 write(SETITEM)\r\n 854 # else tmp is empty, and we're done\r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 519 \r\n 520 # Save the reduce() output and finally memoize the object\r\n--> 521 self.save_reduce(obj=obj, *rv)\r\n 522 \r\n 523 def persistent_id(self, obj):\r\n\r\n/usr/local/lib/python3.6/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)\r\n 632 \r\n 633 if state is not None:\r\n--> 634 save(state)\r\n 635 write(BUILD)\r\n 636 \r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 474 f = self.dispatch.get(t)\r\n 475 if f is not None:\r\n--> 476 f(self, obj) # Call unbound method with explicit self\r\n 477 return\r\n 478 \r\n\r\n/usr/local/lib/python3.6/site-packages/dill/_dill.py in save_module_dict(pickler, obj)\r\n 931 # we only care about session the first pass thru\r\n 932 pickler._session = False\r\n--> 933 StockPickler.save_dict(pickler, obj)\r\n 934 log.info(\"# D2\")\r\n 935 return\r\n\r\n/usr/local/lib/python3.6/pickle.py in save_dict(self, obj)\r\n 819 \r\n 820 self.memoize(obj)\r\n--> 821 self._batch_setitems(obj.items())\r\n 822 \r\n 823 dispatch[dict] = save_dict\r\n\r\n/usr/local/lib/python3.6/pickle.py in _batch_setitems(self, items)\r\n 845 for k, v in tmp:\r\n 846 save(k)\r\n--> 847 save(v)\r\n 848 write(SETITEMS)\r\n 849 elif n:\r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 519 \r\n 520 # Save the reduce() output and finally memoize the object\r\n--> 521 self.save_reduce(obj=obj, *rv)\r\n 522 \r\n 523 def persistent_id(self, obj):\r\n\r\n/usr/local/lib/python3.6/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)\r\n 632 \r\n 633 if state is not None:\r\n--> 634 save(state)\r\n 635 write(BUILD)\r\n 636 \r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 474 f = self.dispatch.get(t)\r\n 475 if f is not None:\r\n--> 476 f(self, obj) # Call unbound method with explicit self\r\n 477 return\r\n 478 \r\n\r\n/usr/local/lib/python3.6/site-packages/dill/_dill.py in save_module_dict(pickler, obj)\r\n 931 # we only care about session the first pass thru\r\n 932 pickler._session = False\r\n--> 933 StockPickler.save_dict(pickler, obj)\r\n 934 log.info(\"# D2\")\r\n 935 return\r\n\r\n/usr/local/lib/python3.6/pickle.py in save_dict(self, obj)\r\n 819 \r\n 820 self.memoize(obj)\r\n--> 821 self._batch_setitems(obj.items())\r\n 822 \r\n 823 dispatch[dict] = save_dict\r\n\r\n/usr/local/lib/python3.6/pickle.py in _batch_setitems(self, items)\r\n 845 for k, v in tmp:\r\n 846 save(k)\r\n--> 847 save(v)\r\n 848 write(SETITEMS)\r\n 849 elif n:\r\n\r\n/usr/local/lib/python3.6/pickle.py in save(self, obj, save_persistent_id)\r\n 494 reduce = getattr(obj, \"__reduce_ex__\", None)\r\n 495 if reduce is not None:\r\n--> 496 rv = reduce(self.proto)\r\n 497 else:\r\n 498 reduce = getattr(obj, \"__reduce__\", None)\r\n\r\nTypeError: can't pickle Tagger objects\r\n```\r\n\r\n</details>\r\n\r\ntrainsformers: 2.10.0\r\ndatasets: 1.0.2\r\ndill: 0.3.2\r\npython: 3.6.8\r\n\r\nOS: ubuntu 16.04 (Docker Image) on [Deep Learning VM](https://console.cloud.google.com/marketplace/details/click-to-deploy-images/deeplearning) (GCP)\r\nGPU: Tesla P100 (CUDA 10)\r\n",
"> I have the same issue with `transformers/BertJapaneseTokenizer`.\r\n\r\nIt looks like it this tokenizer is not supported unfortunately.\r\nThis is because `t.word_tokenizer.mecab` is a `fugashi.fugashi.GenericTagger` which is not compatible with pickle nor dill.\r\n\r\nWe need objects passes to `map` to be picklable for our caching system to work properly.\r\nHere it crashes because the caching system is not able to pickle the GenericTagger.\r\n\r\n\\> Maybe you can create an issue on [fugashi](https://github.com/polm/fugashi/issues) 's repo and ask to make `fugashi.fugashi.GenericTagger` compatible with pickle ?\r\n\r\nWhat you can do in the meantime is use a picklable wrapper of the tokenizer:\r\n\r\n\r\n```python\r\nfrom transformers import BertJapaneseTokenizer, MecabTokenizer\r\n\r\nclass PicklableTokenizer(BertJapaneseTokenizer):\r\n\r\n def __getstate__(self):\r\n state = dict(self.__dict__)\r\n state[\"do_lower_case\"] = self.word_tokenizer.do_lower_case\r\n state[\"never_split\"] = self.word_tokenizer.never_split \r\n del state[\"word_tokenizer\"]\r\n return state\r\n\r\n def __setstate__(self, state):\r\n do_lower_case = state.pop(\"do_lower_case\")\r\n never_split = state.pop(\"never_split\")\r\n self.__dict__ = state\r\n self.word_tokenizer = MecabTokenizer(\r\n do_lower_case=do_lower_case, never_split=never_split)\r\n )\r\n\r\nt = PicklableTokenizer.from_pretrained(\"cl-tohoku/bert-base-japanese-whole-word-masking\")\r\nencoded = train_ds.map(lambda examples: {'tokens': t.encode(examples['title'])}, batched=True) # it works\r\n```",
"We can also update the `BertJapaneseTokenizer` in `transformers` as you just shown @lhoestq to make it compatible with pickle. It will be faster than asking on fugashi 's repo and good for the other users of `transformers` as well.\r\n\r\nI'm currently working on `transformers` I'll include it in the https://github.com/huggingface/transformers/pull/7141 PR and the next release of `transformers`.",
"Thank you for the rapid and polite response!\r\n\r\n@lhoestq Thanks for the suggestion! I've passed the pickle phase, but another `ArrowInvalid` problem occored. I created another issue #687 .\r\n\r\n@thomwolf Wow, really fast work. I'm looking forward to the next release 🤗"
] |
https://api.github.com/repos/huggingface/datasets/issues/5342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5342/comments | https://api.github.com/repos/huggingface/datasets/issues/5342/events | https://github.com/huggingface/datasets/issues/5342 | 1,485,244,178 | I_kwDODunzps5YhwcS | 5,342 | Emotion dataset cannot be downloaded | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | 7 | 2022-12-08T19:07:09Z | 2023-02-23T19:13:19Z | 2022-12-09T10:46:11Z | null | ### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022).
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("emotion")
```
### Expected behavior
The dataset should load properly.
### Environment info
- `datasets` version: 2.7.1
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.13
- PyArrow version: 10.0.1
- Pandas version: 1.5.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5342/timeline | null | completed | null | null | false | [
"Hi @cbarond there's already an open issue at https://github.com/dair-ai/emotion_dataset/issues/5, as the data seems to be missing now, so check that issue instead 👍🏻 ",
"Thanks @cbarond for reporting and @alvarobartt for pointing to the issue we opened in the author's repo.\r\n\r\nIndeed, this issue was first raised in the \"emotion\" dataset Community tab: https://huggingface.co/datasets/emotion/discussions/3\r\n\r\nI'm closing this issue and leave the issue above for the subsequent updates.\r\n\r\nDuplicate of: https://huggingface.co/datasets/emotion/discussions/3",
"try using \"SetFit/emotion\" instead",
"> try using \"SetFit/emotion\" instead\r\n\r\nI' replaced \"emotion\" with \"SetFit/Emotion\", but the code is getting stuck at\r\n\r\n`emotions = load_dataset(\"SetFit/emotion\")`\r\n\r\nI pause execution using the debugger, and it takes me to filelock.py:226\r\n\r\n`with self._thread_lock:`\r\n\r\nDo you know a way to get past this issue?",
"thanks @honeyimholm - worked for me",
"> try using \"SetFit/emotion\" instead\r\n\r\nIt really helps a lot, thank you!",
"The dataset loading script has been fixed: https://huggingface.co/datasets/emotion/discussions/4"
] |
https://api.github.com/repos/huggingface/datasets/issues/5996 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5996/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5996/comments | https://api.github.com/repos/huggingface/datasets/issues/5996/events | https://github.com/huggingface/datasets/pull/5996 | 1,779,294,374 | PR_kwDODunzps5UKP0i | 5,996 | Deprecate `use_auth_token` in favor of `token` | [] | closed | false | null | 9 | 2023-06-28T16:26:38Z | 2023-07-05T15:22:20Z | 2023-07-03T16:03:33Z | null | ... to be consistent with `transformers` and `huggingface_hub`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5996/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5996/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5996.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5996",
"merged_at": "2023-07-03T16:03:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5996.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5996"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006134 / 0.011353 (-0.005219) | 0.003816 / 0.011008 (-0.007193) | 0.098226 / 0.038508 (0.059718) | 0.036830 / 0.023109 (0.013721) | 0.314551 / 0.275898 (0.038653) | 0.372251 / 0.323480 (0.048771) | 0.004762 / 0.007986 (-0.003224) | 0.003041 / 0.004328 (-0.001287) | 0.077651 / 0.004250 (0.073401) | 0.052445 / 0.037052 (0.015393) | 0.324632 / 0.258489 (0.066143) | 0.365724 / 0.293841 (0.071883) | 0.028069 / 0.128546 (-0.100477) | 0.008444 / 0.075646 (-0.067203) | 0.312767 / 0.419271 (-0.106505) | 0.047773 / 0.043533 (0.004240) | 0.305317 / 0.255139 (0.050178) | 0.332007 / 0.283200 (0.048807) | 0.018985 / 0.141683 (-0.122698) | 1.538022 / 1.452155 (0.085868) | 1.575898 / 1.492716 (0.083182) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204780 / 0.018006 (0.186774) | 0.428125 / 0.000490 (0.427635) | 0.003454 / 0.000200 (0.003254) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025064 / 0.037411 (-0.012348) | 0.099419 / 0.014526 (0.084893) | 0.111068 / 0.176557 (-0.065489) | 0.169775 / 0.737135 (-0.567361) | 0.112067 / 0.296338 (-0.184271) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429642 / 0.215209 (0.214433) | 4.275556 / 2.077655 (2.197901) | 1.914658 / 1.504120 (0.410539) | 1.706556 / 1.541195 (0.165361) | 1.754228 / 1.468490 (0.285738) | 0.563669 / 4.584777 (-4.021108) | 3.391501 / 3.745712 (-0.354211) | 1.791517 / 5.269862 (-3.478345) | 1.030704 / 4.565676 (-3.534973) | 0.070882 / 0.424275 (-0.353393) | 0.011351 / 0.007607 (0.003744) | 0.529438 / 0.226044 (0.303394) | 5.294316 / 2.268929 (3.025387) | 2.344653 / 55.444624 (-53.099972) | 1.997468 / 6.876477 (-4.879009) | 2.108932 / 2.142072 (-0.033140) | 0.676794 / 4.805227 (-4.128433) | 0.135058 / 6.500664 (-6.365607) | 0.065857 / 0.075469 (-0.009612) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.231864 / 1.841788 (-0.609924) | 13.986694 / 8.074308 (5.912386) | 13.306600 / 10.191392 (3.115208) | 0.145520 / 0.680424 (-0.534904) | 0.016717 / 0.534201 (-0.517484) | 0.366303 / 0.579283 (-0.212980) | 0.391637 / 0.434364 (-0.042727) | 0.425445 / 0.540337 (-0.114892) | 0.507719 / 1.386936 (-0.879217) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006236 / 0.011353 (-0.005116) | 0.003766 / 0.011008 (-0.007242) | 0.076794 / 0.038508 (0.038286) | 0.037210 / 0.023109 (0.014101) | 0.378387 / 0.275898 (0.102489) | 0.425456 / 0.323480 (0.101977) | 0.004694 / 0.007986 (-0.003291) | 0.002921 / 0.004328 (-0.001407) | 0.076985 / 0.004250 (0.072735) | 0.052188 / 0.037052 (0.015136) | 0.394385 / 0.258489 (0.135896) | 0.432527 / 0.293841 (0.138686) | 0.029091 / 0.128546 (-0.099455) | 0.008364 / 0.075646 (-0.067282) | 0.082583 / 0.419271 (-0.336689) | 0.042928 / 0.043533 (-0.000605) | 0.375321 / 0.255139 (0.120182) | 0.391719 / 0.283200 (0.108519) | 0.019388 / 0.141683 (-0.122295) | 1.550644 / 1.452155 (0.098489) | 1.604882 / 1.492716 (0.112166) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236859 / 0.018006 (0.218853) | 0.418528 / 0.000490 (0.418039) | 0.000388 / 0.000200 (0.000188) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025548 / 0.037411 (-0.011863) | 0.100644 / 0.014526 (0.086118) | 0.109102 / 0.176557 (-0.067455) | 0.161694 / 0.737135 (-0.575441) | 0.112088 / 0.296338 (-0.184250) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.484128 / 0.215209 (0.268919) | 4.849952 / 2.077655 (2.772297) | 2.512769 / 1.504120 (1.008649) | 2.303295 / 1.541195 (0.762100) | 2.356699 / 1.468490 (0.888209) | 0.564181 / 4.584777 (-4.020596) | 3.421393 / 3.745712 (-0.324319) | 2.570875 / 5.269862 (-2.698987) | 1.474307 / 4.565676 (-3.091370) | 0.068035 / 0.424275 (-0.356240) | 0.011300 / 0.007607 (0.003693) | 0.587867 / 0.226044 (0.361823) | 5.862447 / 2.268929 (3.593519) | 3.004017 / 55.444624 (-52.440607) | 2.664989 / 6.876477 (-4.211488) | 2.740020 / 2.142072 (0.597948) | 0.680840 / 4.805227 (-4.124387) | 0.137001 / 6.500664 (-6.363663) | 0.068098 / 0.075469 (-0.007371) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.297362 / 1.841788 (-0.544426) | 14.207891 / 8.074308 (6.133583) | 14.087562 / 10.191392 (3.896170) | 0.149514 / 0.680424 (-0.530910) | 0.016566 / 0.534201 (-0.517635) | 0.367602 / 0.579283 (-0.211681) | 0.400692 / 0.434364 (-0.033671) | 0.432907 / 0.540337 (-0.107431) | 0.525924 / 1.386936 (-0.861012) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006223 / 0.011353 (-0.005130) | 0.003672 / 0.011008 (-0.007336) | 0.097451 / 0.038508 (0.058943) | 0.036243 / 0.023109 (0.013133) | 0.375650 / 0.275898 (0.099752) | 0.431652 / 0.323480 (0.108172) | 0.004758 / 0.007986 (-0.003227) | 0.002941 / 0.004328 (-0.001387) | 0.077383 / 0.004250 (0.073132) | 0.055342 / 0.037052 (0.018289) | 0.390335 / 0.258489 (0.131846) | 0.427867 / 0.293841 (0.134026) | 0.027619 / 0.128546 (-0.100927) | 0.008244 / 0.075646 (-0.067402) | 0.313499 / 0.419271 (-0.105773) | 0.054987 / 0.043533 (0.011454) | 0.394044 / 0.255139 (0.138905) | 0.398784 / 0.283200 (0.115584) | 0.026499 / 0.141683 (-0.115184) | 1.496907 / 1.452155 (0.044753) | 1.554465 / 1.492716 (0.061749) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.241197 / 0.018006 (0.223190) | 0.427856 / 0.000490 (0.427366) | 0.006264 / 0.000200 (0.006065) | 0.000218 / 0.000054 (0.000164) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025550 / 0.037411 (-0.011862) | 0.104426 / 0.014526 (0.089901) | 0.110310 / 0.176557 (-0.066246) | 0.173813 / 0.737135 (-0.563322) | 0.112129 / 0.296338 (-0.184209) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.458806 / 0.215209 (0.243597) | 4.576351 / 2.077655 (2.498697) | 2.265670 / 1.504120 (0.761550) | 2.073230 / 1.541195 (0.532035) | 2.135283 / 1.468490 (0.666793) | 0.562506 / 4.584777 (-4.022271) | 3.375101 / 3.745712 (-0.370611) | 1.734393 / 5.269862 (-3.535469) | 1.026622 / 4.565676 (-3.539054) | 0.068144 / 0.424275 (-0.356131) | 0.011092 / 0.007607 (0.003485) | 0.562779 / 0.226044 (0.336734) | 5.608256 / 2.268929 (3.339328) | 2.706468 / 55.444624 (-52.738157) | 2.381607 / 6.876477 (-4.494869) | 2.451027 / 2.142072 (0.308954) | 0.671590 / 4.805227 (-4.133637) | 0.135749 / 6.500664 (-6.364915) | 0.065389 / 0.075469 (-0.010080) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244806 / 1.841788 (-0.596981) | 14.042150 / 8.074308 (5.967841) | 14.246612 / 10.191392 (4.055220) | 0.134309 / 0.680424 (-0.546114) | 0.017082 / 0.534201 (-0.517119) | 0.366043 / 0.579283 (-0.213240) | 0.400748 / 0.434364 (-0.033616) | 0.425695 / 0.540337 (-0.114643) | 0.509355 / 1.386936 (-0.877581) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006134 / 0.011353 (-0.005219) | 0.003980 / 0.011008 (-0.007028) | 0.078353 / 0.038508 (0.039845) | 0.038011 / 0.023109 (0.014902) | 0.375784 / 0.275898 (0.099886) | 0.433619 / 0.323480 (0.110139) | 0.004897 / 0.007986 (-0.003088) | 0.002981 / 0.004328 (-0.001347) | 0.077362 / 0.004250 (0.073112) | 0.056108 / 0.037052 (0.019056) | 0.395984 / 0.258489 (0.137495) | 0.427397 / 0.293841 (0.133556) | 0.029325 / 0.128546 (-0.099221) | 0.008498 / 0.075646 (-0.067148) | 0.082478 / 0.419271 (-0.336794) | 0.044085 / 0.043533 (0.000552) | 0.389923 / 0.255139 (0.134784) | 0.391180 / 0.283200 (0.107980) | 0.022452 / 0.141683 (-0.119231) | 1.507758 / 1.452155 (0.055603) | 1.530459 / 1.492716 (0.037743) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230928 / 0.018006 (0.212922) | 0.408484 / 0.000490 (0.407995) | 0.000806 / 0.000200 (0.000606) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025183 / 0.037411 (-0.012228) | 0.102292 / 0.014526 (0.087766) | 0.108142 / 0.176557 (-0.068415) | 0.161172 / 0.737135 (-0.575963) | 0.114476 / 0.296338 (-0.181862) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.482978 / 0.215209 (0.267769) | 4.816103 / 2.077655 (2.738448) | 2.505567 / 1.504120 (1.001447) | 2.302598 / 1.541195 (0.761404) | 2.371238 / 1.468490 (0.902748) | 0.567467 / 4.584777 (-4.017310) | 3.363407 / 3.745712 (-0.382306) | 1.746213 / 5.269862 (-3.523649) | 1.035468 / 4.565676 (-3.530208) | 0.068431 / 0.424275 (-0.355844) | 0.011069 / 0.007607 (0.003462) | 0.598241 / 0.226044 (0.372196) | 5.953927 / 2.268929 (3.684999) | 3.007493 / 55.444624 (-52.437132) | 2.629399 / 6.876477 (-4.247078) | 2.737201 / 2.142072 (0.595129) | 0.682456 / 4.805227 (-4.122771) | 0.137613 / 6.500664 (-6.363051) | 0.067941 / 0.075469 (-0.007528) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.306015 / 1.841788 (-0.535772) | 14.359240 / 8.074308 (6.284932) | 14.187601 / 10.191392 (3.996209) | 0.138612 / 0.680424 (-0.541812) | 0.016708 / 0.534201 (-0.517493) | 0.366365 / 0.579283 (-0.212918) | 0.396982 / 0.434364 (-0.037382) | 0.426939 / 0.540337 (-0.113398) | 0.520064 / 1.386936 (-0.866872) |\n\n</details>\n</details>\n\n\n",
"They use `token` and emit a deprecation warning if `use_auth_token` is passed instead (see https://github.com/huggingface/transformers/blob/78a2b19fc84ed55c65f4bf20a901edb7ceb73c5f/src/transformers/modeling_utils.py#L1933). \r\n\r\nI think we can update the `examples` scripts after merging this PR.",
"> I think we can update the examples scripts after merging this PR.\r\n\r\nWe should do a release before updated in the examples scripts no ? That's why it's an option to not have a deprecation warning until transformers and co are updated with the `token` arg",
"> We should do a release before updated in the examples scripts no ? That's why it's an option to not have a deprecation warning until transformers and co are updated with the token arg\r\n\r\nThis would avoid the warning only for the latest `datasets` release. TBH, I don't think this is worth the hassle, considering how simple it is to remove it.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007644 / 0.011353 (-0.003709) | 0.004667 / 0.011008 (-0.006341) | 0.117347 / 0.038508 (0.078839) | 0.050620 / 0.023109 (0.027510) | 0.415402 / 0.275898 (0.139504) | 0.485898 / 0.323480 (0.162418) | 0.005848 / 0.007986 (-0.002138) | 0.003736 / 0.004328 (-0.000592) | 0.089798 / 0.004250 (0.085547) | 0.069344 / 0.037052 (0.032292) | 0.441684 / 0.258489 (0.183195) | 0.468972 / 0.293841 (0.175131) | 0.036637 / 0.128546 (-0.091909) | 0.010219 / 0.075646 (-0.065427) | 0.394293 / 0.419271 (-0.024978) | 0.061462 / 0.043533 (0.017929) | 0.409448 / 0.255139 (0.154309) | 0.431557 / 0.283200 (0.148358) | 0.027795 / 0.141683 (-0.113888) | 1.837844 / 1.452155 (0.385690) | 1.862683 / 1.492716 (0.369967) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230500 / 0.018006 (0.212494) | 0.483139 / 0.000490 (0.482649) | 0.006517 / 0.000200 (0.006317) | 0.000143 / 0.000054 (0.000088) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033152 / 0.037411 (-0.004259) | 0.133673 / 0.014526 (0.119147) | 0.143853 / 0.176557 (-0.032704) | 0.215254 / 0.737135 (-0.521882) | 0.150676 / 0.296338 (-0.145662) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.503796 / 0.215209 (0.288587) | 5.049981 / 2.077655 (2.972326) | 2.399427 / 1.504120 (0.895307) | 2.167635 / 1.541195 (0.626441) | 2.257448 / 1.468490 (0.788958) | 0.641298 / 4.584777 (-3.943479) | 4.828676 / 3.745712 (1.082964) | 4.346069 / 5.269862 (-0.923793) | 2.103890 / 4.565676 (-2.461786) | 0.079115 / 0.424275 (-0.345160) | 0.013377 / 0.007607 (0.005770) | 0.621207 / 0.226044 (0.395162) | 6.190939 / 2.268929 (3.922011) | 2.920129 / 55.444624 (-52.524495) | 2.549225 / 6.876477 (-4.327252) | 2.719221 / 2.142072 (0.577149) | 0.790949 / 4.805227 (-4.014278) | 0.172032 / 6.500664 (-6.328632) | 0.077779 / 0.075469 (0.002310) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.432572 / 1.841788 (-0.409216) | 21.000031 / 8.074308 (12.925723) | 17.555093 / 10.191392 (7.363701) | 0.166646 / 0.680424 (-0.513778) | 0.020451 / 0.534201 (-0.513750) | 0.488767 / 0.579283 (-0.090516) | 0.737036 / 0.434364 (0.302672) | 0.621694 / 0.540337 (0.081356) | 0.732074 / 1.386936 (-0.654862) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008198 / 0.011353 (-0.003155) | 0.004987 / 0.011008 (-0.006021) | 0.090714 / 0.038508 (0.052206) | 0.053379 / 0.023109 (0.030270) | 0.425199 / 0.275898 (0.149301) | 0.514036 / 0.323480 (0.190556) | 0.006043 / 0.007986 (-0.001943) | 0.003888 / 0.004328 (-0.000441) | 0.088294 / 0.004250 (0.084043) | 0.073024 / 0.037052 (0.035971) | 0.435983 / 0.258489 (0.177494) | 0.514293 / 0.293841 (0.220452) | 0.039451 / 0.128546 (-0.089095) | 0.010439 / 0.075646 (-0.065207) | 0.096885 / 0.419271 (-0.322387) | 0.060165 / 0.043533 (0.016632) | 0.421053 / 0.255139 (0.165914) | 0.455545 / 0.283200 (0.172345) | 0.027234 / 0.141683 (-0.114449) | 1.768975 / 1.452155 (0.316820) | 1.842853 / 1.492716 (0.350137) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.278940 / 0.018006 (0.260933) | 0.480709 / 0.000490 (0.480219) | 0.000436 / 0.000200 (0.000236) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034900 / 0.037411 (-0.002511) | 0.144893 / 0.014526 (0.130368) | 0.149567 / 0.176557 (-0.026989) | 0.213200 / 0.737135 (-0.523935) | 0.156735 / 0.296338 (-0.139604) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.535897 / 0.215209 (0.320687) | 5.336998 / 2.077655 (3.259343) | 2.685854 / 1.504120 (1.181734) | 2.470177 / 1.541195 (0.928983) | 2.547495 / 1.468490 (1.079004) | 0.642830 / 4.584777 (-3.941947) | 4.595866 / 3.745712 (0.850154) | 2.186696 / 5.269862 (-3.083165) | 1.317969 / 4.565676 (-3.247708) | 0.079268 / 0.424275 (-0.345007) | 0.013792 / 0.007607 (0.006185) | 0.662236 / 0.226044 (0.436192) | 6.604775 / 2.268929 (4.335847) | 3.355888 / 55.444624 (-52.088736) | 2.968911 / 6.876477 (-3.907565) | 3.121862 / 2.142072 (0.979790) | 0.794752 / 4.805227 (-4.010475) | 0.170800 / 6.500664 (-6.329864) | 0.078393 / 0.075469 (0.002924) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.601605 / 1.841788 (-0.240183) | 20.743553 / 8.074308 (12.669245) | 17.543968 / 10.191392 (7.352576) | 0.221884 / 0.680424 (-0.458540) | 0.020779 / 0.534201 (-0.513422) | 0.479677 / 0.579283 (-0.099606) | 0.516207 / 0.434364 (0.081843) | 0.564046 / 0.540337 (0.023709) | 0.711336 / 1.386936 (-0.675600) |\n\n</details>\n</details>\n\n\n",
"Yes, sounds great! Thanks",
"yup"
] |
https://api.github.com/repos/huggingface/datasets/issues/2379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2379/comments | https://api.github.com/repos/huggingface/datasets/issues/2379/events | https://github.com/huggingface/datasets/pull/2379 | 895,252,597 | MDExOlB1bGxSZXF1ZXN0NjQ3NDk2ODUx | 2,379 | Disallow duplicate keys in yaml tags | [] | closed | false | null | 0 | 2021-05-19T10:10:07Z | 2021-05-19T10:45:32Z | 2021-05-19T10:45:31Z | null | Make sure that there's no duplidate keys in yaml tags.
I added the check in the yaml tree constructor's method, so that the verification is done at every level in the yaml structure.
cc @julien-c | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2379/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2379/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2379.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2379",
"merged_at": "2021-05-19T10:45:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2379.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2379"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2232/comments | https://api.github.com/repos/huggingface/datasets/issues/2232/events | https://github.com/huggingface/datasets/pull/2232 | 860,075,931 | MDExOlB1bGxSZXF1ZXN0NjE3MDQyNTI4 | 2,232 | Start filling GLUE dataset card | [] | closed | false | null | 2 | 2021-04-16T18:37:37Z | 2021-04-21T09:33:09Z | 2021-04-21T09:33:08Z | null | The dataset card was pretty much empty.
I added the descriptions (mainly from TFDS since the script is the same), and I also added the tasks tags as well as examples for a subset of the tasks.
cc @sgugger | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2232/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2232/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2232.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2232",
"merged_at": "2021-04-21T09:33:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2232.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2232"
} | true | [
"I replaced all the \"we\" and applied your suggestion",
"Merging this for now, we can continue improving this card in other PRs :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5189/comments | https://api.github.com/repos/huggingface/datasets/issues/5189/events | https://github.com/huggingface/datasets/issues/5189 | 1,432,769,143 | I_kwDODunzps5VZlJ3 | 5,189 | Reduce friction in tabular dataset workflow by eliminating having splits when dataset is loaded | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 33 | 2022-11-02T09:15:02Z | 2022-12-06T12:13:17Z | null | null | ### Feature request
Sorry for cryptic name but I'd like to explain using code itself. When I want to load a specific dataset from a repository (for instance, this: https://huggingface.co/datasets/inria-soda/tabular-benchmark)
```python
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-benchmark", data_files=["reg_cat/house_sales.csv"], streaming=True)
print(next(iter(dataset["train"])))
```
`datasets` library is essentially designed for people who'd like to use benchmark datasets on various modalities to fine-tune their models, and these benchmark datasets usually have pre-defined train and test splits. However, for tabular workflows, having train and test splits usually ends up model overfitting to validation split so usually the users would like to do validation techniques like `StratifiedKFoldCrossValidation` or when they tune for hyperparameters they do `GridSearchCrossValidation` so often the behavior is to create their own splits. Even [in this paper](https://hal.archives-ouvertes.fr/hal-03723551) a benchmark is introduced but the split is done by authors.
It's a bit confusing for average tabular user to try and load a dataset and see `"train"` so it would be nice if we would not load dataset into a split called `train `by default.
```diff
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-benchmark", data_files=["reg_cat/house_sales.csv"], streaming=True)
-print(next(iter(dataset["train"])))
+print(next(iter(dataset)))
```
### Motivation
I explained it above 😅
### Your contribution
I think this is quite a big change that seems small (e.g. how to determine datasets that will not be load to train split?), it's best if we discuss first! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5189/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5189/timeline | null | null | null | null | false | [
"I have to admit I'm not a fan of this idea, as this would result in a non-consistent behavior between tabular and non-tabular datasets, which is confusing if done without the context you provided. Instead, we could consider returning a `Dataset` object rather than `DatasetDict` if there is only one split in the generated dataset. But then again, I think this lib is a bit too old to make such changes. @lhoestq @albertvillanova WDYT?\r\n\r\n",
"We can brainstorm here to see how we could make it happen ? And then depending on the options we see if it's a change we can do.\r\n\r\nI'm starting with a first reasoning\r\n\r\nCurrently not passing `split=` in `load_dataset` means \"return a dict with each split\".\r\n\r\nNow what would happen if a dataset has no split ? Ideally it should return one Dataset. And passing `split=` would have no sense. So depending on the dataset content, not passing `split=` should return a dict or a Dataset. In particular, those two cases should work:\r\n```python\r\n# case 1: dataset without split\r\nds = load_dataset(\"dataset_without_split\")\r\nds[0], ds[\"column_name\"], list(ds) # we want this\r\n\r\n# case 2: dataset with splits\r\nds = load_dataset(\"dataset_with_splits\")\r\nds[\"train\"] # this works and can't be changed\r\nds = load_dataset(\"dataset_with_splits\", split=\"train\")\r\nds[0], ds[\"column_name\"], list(ds) # this works and can't be changed\r\n```\r\n\r\nI can see several ideas:\r\n1. allowing `load_dataset` to return a different object based on the dataset content - either a Dataset or a DatasetDict\r\n - we can update `get_dataset_split_names` to return None or a list if users want to know in advance what object will be returned. They can also use `isinstance` _a posteriori_\r\n - but in this case we expect users to be careful when loading datasets and always to extra steps to check if they got a Dataset or DatasetDict\r\n2. merge Dataset and DatasetDict objects\r\n - they already share many functions: map, filter, push_to_hub etc.\r\n - we can define `ds[0]` to be the first item of the first split, and consider that the uses accesses rows from the full table of all the splits concatenated\r\n - however there is a collision when doing `ds[\"column_name\"]` or `ds[\"train\"]` that we need to address: the first returns a list, while the other returns a Dataset.\r\n\r\nWhat are your opinions on those two ideas ? Do you have other ideas in mind ?",
"I like the first idea more (concatenating splits doesn't seem useful, no?). This is a significant breaking change, so I think we should do a poll (or something similar) to gather more info on the actual \"expected behavior\" and wait for Datasets 3.0 if we decide to implement it.\r\n\r\nPS: @thomwolf also suggested the same thing a while ago (https://github.com/huggingface/datasets/issues/743#issuecomment-746074641).",
"I think it's an interesting improvement to the user experience for a case that comes often (no split) so I would definitively support it.\r\n\r\nI would be more in favor of option 2 rather than returning various types of objects from load_dataset and handling carefully the possible collisions indeed",
"Related: if a dataset only has one split, we don't show the splits select control in the dataset viewer on the Hub, eg. compare https://huggingface.co/datasets/hf-internal-testing/fixtures_image_utils/viewer/image/test with https://huggingface.co/datasets/glue/viewer/mnli/test.\r\n\r\nSee https://github.com/huggingface/moon-landing/pull/3858 for more details (internal)",
"I feel like the second idea is a bit more overkill. \r\n@severo I would say it's a bit irrelevant to the problem we have but is a separate problem @polinaeterna is solving at the moment. 😅 (also discussed on slack)",
"OK, sorry for polluting the thread. The relation I saw with the dataset viewer is that from a UX point of view, we hide the concepts of split and configuration whenever possible -> this issue feels like doing the same in the datasets library.",
"I would agree that returning different types based on the content of the dataset might be confusing.\r\n\r\nWe can do something similar to what `fetch_*` or `load_*` from `sklearn.datasets` do, which is to have an arg which changes the type of the returned type. For instance, `load_iris` would return a dict, but `load_iris(..., return_X_y=True)` would return a tuple.\r\n\r\nHere we can have a similar arg such as `return_X` which would then only return a single `DataSet` or an array.",
"> I feel like the second idea is a bit more overkill.\r\n\r\nOverkill in what sense ?\r\n\r\n> Here we can have a similar arg such as return_X which would then only return a single DataSet or an array.\r\n\r\nRight now one can already pass `split=\"all\"` to get one `Dataset` object with all the data in it (unsplit). We could also have something like `return_all=True` so make the API clearer.\r\n\r\n> I would be more in favor of option 2 rather than returning various types of objects from load_dataset and handling carefully the possible collisions indeed\r\n\r\nI think it would be ok to handle the collision by allowing both `ds[\"train\"]` and `ds[\"column_name\"]` (and maybe adding something like `ds.splits` for those who want to iterate over the splits or add new ones)",
"Would it make sense to remove the notion of \"split\" in `load_dataset`? I feel a lof of it comes from the want to have some sort of group of more or less similar dataset. \"train\"/\"test\"/\"validation\" are the traditional ones, but there are some datasets that have much more splits.\r\n\r\nWould it make sense to force `load_dataset` to only load a single `Dataset` object, and fail if it doesn't point to one. And have another method that's like `load_dataset_group_info` that can return a very arbitrary info class (Dict, List whatever), but you need to pass individual infos to `load_dataset` to run anything? Typically I don't think `DatasetDict.map` is really that helpful, but that's my personal opinion. This would help make things more readable (typically knowing if an object is a `Dataset` or a `DatasetDict`)",
"> Would it make sense to remove the notion of \"split\" in load_dataset?\r\n\r\nI think we need to keep it - though in practice people can name the splits whatever they want anyway.\r\n\r\n> Would it make sense to force load_dataset to only load a single Dataset object, and fail if it doesn't point to one.\r\n\r\nWe need to keep backward compatibility ideally - in particular the load_dataset + ds[\"train\"] one",
"> I think we need to keep it - though in practice people can name the splits whatever they want anyway.\r\n\r\nIt was my understanding that the whole issue was that `load_dataset` returned multiple types of objects.\r\n\r\n> We need to keep backward compatibility ideally - in particular the load_dataset + ds[\"train\"] one\r\n\r\nYeah sorry I meant ideally. One can always start developing `load_dataset_v2` can deprecate the first one and remove it in the longer term.",
"> It was my understanding that the whole issue was that load_dataset returned multiple types of objects.\r\n\r\nYes indeed, but we still want to keep a way to load the train/val/test/whatever splits alone ;)",
"@thomasw21's solution is good but it will break backwards compatibility. 😅",
"Started to experiment with merging Dataset and DatasetDict. My plan is to define the splits of a Dataset in Dataset.info.splits (already exists, but never used). A Dataset would then be the concatenation of its splits if they exist.\r\n\r\nNot sure yet this is the way to go. My plan is to play with it and see and share it with you, so we can see if it makes sense from a UX point of view.",
"So just to make sure that I understand the current direction, people will have to be extra careful when handling splits right?\r\nImagine \"potato\" a dataset containing train/validation split:\r\n```\r\nload_dataset(\"potato\") # returns the concatenation of all the splits\r\n```\r\nPreviously the design would force you to choose a split (it would raise otherwise), or manually concat them if you really wanted to play with concatenated splits. Now it would potentially run without raising for a bit of time until you figure out that you've been training on both train and validation split.\r\n\r\nWould it make sense to use a dataset specific default instead of using the concatenation, typically \"potato\" dataset's default would be train?\r\n```\r\nload_dataset(\"potato\") # returns \"train\" split\r\nload_dataset(\"potato\", split=\"train\") # returns \"train\" split\r\nload_dataset(\"potato\", split=\"validation\") # returns \"validation\" split\r\nconcatenate_datasets([load_dataset(\"potato\", split=\"train\"), load_dataset(\"potato\", split=\"validation\")]) # returns concatenation\r\n```",
"> load_dataset(\"potato\") # returns \"train\" split\r\n\r\nTo avoid a breaking change we need to be able to do `load_dataset(\"potato\")[\"validation\"]` as well.\r\n\r\nIn that case I'd wonder where the validation split comes from, since the rows of the dataset wouldn't contain the validation split according to your example. That's why I'm more in favor of concatenating.\r\n\r\nA dataset is one table, that optionally has some split info about subsets (e.g. for training an evaluation)\r\n\r\nThis also allows anyone to re-split the dataset the way they want if they're not happy with the default:\r\n\r\n```python\r\nds = load_dataset(\"potato\").train_test_split(test_size=0.2)\r\ntrain_ds = ds[\"train\"]\r\ntest_ds = ds[\"test\"]\r\n```",
"Just thinking about this, we could just have `to_dataframe()` as `load_dataset(\"blah\").to_dataframe()` to get the whole dataset, and not change anything else.",
"I have a first implementation of option 2 (merging Dataset and DatasetDict) in this PR: https://github.com/huggingface/datasets/pull/5301/\r\n\r\nFeel free to play with it if you're interested, and let me know what you think. In this PR, a dataset is one table that optionally has some split info about subsets.",
"@adrinjalali we already have [to_pandas](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_pandas) AFAIK that essentially does the same thing (for a dataset, not for a dataset dict), I was wondering if it makes sense to have this as I don't know portion of people who load non-tabular datasets into dataframes. @lhoestq I saw your PR and it will break a lot of things imo, WDYT of this option? ",
"> we already have [to_pandas](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_pandas) AFAIK that essentially does the same thing (for a dataset, not for a dataset dict)\r\n\r\nyes correct :)\r\n\r\n> I saw your PR and it will break a lot of things imo\r\n\r\nDo you have concrete examples you can share ?\r\n\r\n> WDYT of this option?\r\n\r\nThe to_dataframe option ? I think it not enough, since you'd still get a `DatasetDict({\"train\": Dataset()})` if you load a dataset with no splits (e.g. one CSV), and this doesn't really make sense.\r\n\r\nNote that in the PR I opened you can do\r\n```python\r\nds = load_dataset(\"dataset_with_just_one_csv\") # Dataset type\r\ndf = load_dataset(\"dataset_with_just_one_csv\").to_pandas() # DataFrame type\r\n```",
"@lhoestq no I think @adrinjalali and I meant when user calls `to_dataframe` if there's only train split in `DatasetDict` we could directly load that into dataframe. This might cause a confusion given there's to_pandas but I think it's more intuitive and least breaking change. (given people -who use `datasets` for tabular workflows- will eventually call `to_pandas` anyway) ",
"So in that case it would be fine to still end up with a dataset dict with a \"train\" split ?",
"yeah what I mean is this:\r\n\r\n```py\r\ndataset = load_dataset(\"blah\")\r\n\r\n# deal with a split of the dataset\r\ntrain = dataset[\"train\"]\r\ntrain_df = dataset[\"train\"].to_dataframe()\r\n\r\n# deal with the whole dataset\r\ndataset_df = dataset.to_dataframe()\r\n```\r\n\r\nSo we do two things to improve tabular experience:\r\n- allow datasets to have a single split\r\n- add `to_dataframe` to the root dict level so that users can simply call `df = load_dataset(\"blah\").to_dataframe()` and have it in their `pandas.DataFrame` object.",
"Ok ! Note that we already have `Dataset.to_pandas()` so for consistency I'd call it `DatasetDict.to_pandas()` as well, does it sound good to you ? This is something we can add pretty easily",
"yeah that sounds perfect @lhoestq !",
"> So just to make sure that I understand the current direction, people will have to be extra careful when handling splits right?\r\n\r\nWe can raise an error if someone does `load_dataset(...)[0]` if the dataset is made of several splits, and return the first example if there's one or zero splits (i.e. when it's not ambiguous). Had this idea from the dicussions in #5312 WDYT @thomasw21 ?",
"> We can raise an error if someone does load_dataset(...)[0] if the dataset is made of several splits,\r\n\r\nBut then how is that different to have the distinction between DatasetDict and Dataset then? Is it just that \"default behaviour when there are no splits or single split, it returns directly the split when there's no ambiguity\".\r\n\r\nAlso I was wondering how the concatenation could have heavy impacts when running mapping functions/filtering in batch? Typically can batch be somehow mixed?",
"> But then how is that different to have the distinction between DatasetDict and Dataset then?\r\n\r\nBecause it doesn't make sense to be able to do `example = ds[0]` or `examples = list(ds)` on a class named `DatasetDict` of type `Dict[str, Dataset]`.\r\n\r\n> Also I was wondering how the concatenation could have heavy impacts when running mapping functions/filtering in batch? Typically can batch be somehow mixed?\r\n\r\nNo, we run each function on each split separated",
"> Because it doesn't make sense to be able to do example = ds[0] or examples = list(ds) on a class named DatasetDict of type Dict[str, Dataset].\r\n\r\nHum but you're still going to raise an exception in both those cases with your current change no? (actually list(ds) would return the name of the splits no?)\r\n\r\n> No, we run each function on each split separated\r\n\r\nNice!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5713/comments | https://api.github.com/repos/huggingface/datasets/issues/5713/events | https://github.com/huggingface/datasets/issues/5713 | 1,657,141,251 | I_kwDODunzps5ixfgD | 5,713 | ArrowNotImplementedError when loading dataset from the hub | [] | closed | false | null | 2 | 2023-04-06T10:27:22Z | 2023-04-06T13:06:22Z | 2023-04-06T13:06:21Z | null | ### Describe the bug
Hello,
I have created a dataset by using the image loader. Once the dataset is created I try to download it and I get the error:
```
Traceback (most recent call last):
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1860, in _prepare_split_single
for _, table in generator:
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 69, in _generate_tables
for batch_idx, record_batch in enumerate(
File "pyarrow/_parquet.pyx", line 1323, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/load.py", line 1791, in load_dataset
builder_instance.download_and_prepare(
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 891, in download_and_prepare
self._download_and_prepare(
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 986, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1748, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1893, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Steps to reproduce the bug
Create the dataset and push it to the hub:
```python
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_dir="/path/to/dataset")
dataset.push_to_hub("org/dataset-name", private=True, max_shard_size="1GB")
```
Then use it:
```python
from datasets import load_dataset
dataset = load_dataset("org/dataset-name")
```
### Expected behavior
To properly download and use the pushed dataset.
Something else to note is that I specified to have shards of 1GB max, but at the end, for the train set, it is an almost 7GB single file that is pushed.
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.10
- Huggingface_hub version: 0.13.3
- PyArrow version: 11.0.0
- Pandas version: 2.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5713/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5713/timeline | null | completed | null | null | false | [
"Hi Julien ! This sounds related to https://github.com/huggingface/datasets/issues/5695 - TL;DR: you need to have shards smaller than 2GB to avoid this issue\r\n\r\nThe number of rows per shard is computed using an estimated size of the full dataset, which can sometimes lead to shards bigger than `max_shard_size`. The estimation is currently done using the first samples of the dataset (which can surely be improved). We should probably open an issue to fix this once and for all.\r\n\r\nAnyway for your specific dataset I'd suggest you to pass `num_shards` instead of `max_shard_size` for now, and make sure to have enough shards to end up with shards smaller than 2GB",
"Hi Quentin! Thanks a lot! Using `num_shards` instead of `max_shard_size` works as expected.\r\n\r\nIndeed the way you describe how the size is computed cannot really work with the dataset I'm building as all the image doesn't have the same resolution and then size. Opening an issue on this might be a good idea."
] |
https://api.github.com/repos/huggingface/datasets/issues/1954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1954/comments | https://api.github.com/repos/huggingface/datasets/issues/1954/events | https://github.com/huggingface/datasets/issues/1954 | 817,565,563 | MDU6SXNzdWU4MTc1NjU1NjM= | 1,954 | add a new column | [] | closed | false | null | 2 | 2021-02-26T18:17:27Z | 2021-04-29T14:50:43Z | 2021-04-29T14:50:43Z | null | Hi
I'd need to add a new column to the dataset, I was wondering how this can be done? thanks
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1954/timeline | null | completed | null | null | false | [
"Hi\r\nnot sure how change the lable after creation, but this is an issue not dataset request. thanks ",
"Hi ! Currently you have to use `map` . You can see an example of how to do it in this comment: https://github.com/huggingface/datasets/issues/853#issuecomment-727872188\r\n\r\nIn the future we'll add support for a more native way of adding a new column ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1845 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1845/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1845/comments | https://api.github.com/repos/huggingface/datasets/issues/1845/events | https://github.com/huggingface/datasets/pull/1845 | 803,714,493 | MDExOlB1bGxSZXF1ZXN0NTY5NTk2MTIz | 1,845 | Enable logging propagation and remove logging handler | [] | closed | false | null | 1 | 2021-02-08T16:22:13Z | 2021-02-09T14:22:38Z | 2021-02-09T14:22:37Z | null | We used to have logging propagation disabled because of this issue: https://github.com/tensorflow/tensorflow/issues/26691
But since it's now fixed we should re-enable it. This is important to keep the default logging behavior for users, and propagation is also needed for pytest fixtures as asked in #1826
I also removed the handler that was added since, according to the logging [documentation](https://docs.python.org/3/howto/logging.html#configuring-logging-for-a-library):
> It is strongly advised that you do not add any handlers other than NullHandler to your library’s loggers. This is because the configuration of handlers is the prerogative of the application developer who uses your library. The application developer knows their target audience and what handlers are most appropriate for their application: if you add handlers ‘under the hood’, you might well interfere with their ability to carry out unit tests and deliver logs which suit their requirements.
It could have been useful if we wanted to have a custom formatter for the logging but I think it's more important to keep the logging as default to not interfere with the users' logging management.
Therefore I also removed the two methods `datasets.logging.enable_default_handler` and `datasets.logging.disable_default_handler`.
cc @albertvillanova this should let you use capsys/caplog in pytest
cc @LysandreJik @sgugger if you want to do the same in `transformers` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1845/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1845/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1845.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1845",
"merged_at": "2021-02-09T14:22:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1845.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1845"
} | true | [
"Thank you @lhoestq. This logging configuration makes more sense to me.\r\n\r\nOnce propagation is allowed, the end-user can customize logging behavior and add custom handlers to the proper top logger in the hierarchy.\r\n\r\nAnd I also agree with following the best practices and removing any custom handlers:\r\n- it is the end user who has to implement any custom handlers\r\n- indeed, the previous logging problem with TensorFlow was due to the fact that absl did not follow best practices and had implemented a custom handler\r\n\r\nOur errors/warnings will be displayed anyway, even if we do not implement any custom handler. Since Python 3.2, logging has a built-in \"default\" handler (logging.lastResort) with the expected default behavior (sending error/warning messages to sys.stderr), which is used only if the end user has not configured any custom handler."
] |
https://api.github.com/repos/huggingface/datasets/issues/772 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/772/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/772/comments | https://api.github.com/repos/huggingface/datasets/issues/772/events | https://github.com/huggingface/datasets/pull/772 | 731,612,430 | MDExOlB1bGxSZXF1ZXN0NTExNjg4ODMx | 772 | Fix metric with cache dir | [] | closed | false | null | 0 | 2020-10-28T16:43:13Z | 2020-10-29T09:34:44Z | 2020-10-29T09:34:43Z | null | The cache_dir provided by the user was concatenated twice and therefore causing FileNotFound errors.
The tests didn't cover the case of providing `cache_dir=` for metrics because of a stupid issue (it was not using the right parameter).
I remove the double concatenation and I fixed the tests
Fix #728 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/772/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/772/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/772.diff",
"html_url": "https://github.com/huggingface/datasets/pull/772",
"merged_at": "2020-10-29T09:34:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/772.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/772"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1987 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1987/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1987/comments | https://api.github.com/repos/huggingface/datasets/issues/1987/events | https://github.com/huggingface/datasets/issues/1987 | 822,308,956 | MDU6SXNzdWU4MjIzMDg5NTY= | 1,987 | wmt15 is broken | [] | closed | false | null | 1 | 2021-03-04T16:46:25Z | 2022-10-05T13:12:26Z | 2022-10-05T13:12:26Z | null | While testing the hotfix, I tried a random other wmt release and found wmt15 to be broken:
```
python -c 'from datasets import load_dataset; load_dataset("wmt15", "de-en")'
Downloading: 2.91kB [00:00, 818kB/s]
Downloading: 3.02kB [00:00, 897kB/s]
Downloading: 41.1kB [00:00, 19.1MB/s]
Downloading and preparing dataset wmt15/de-en (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/stas/.cache/huggingface/datasets/wmt15/de-en/1.0.0/39ad5f9262a0910a8ad7028ad432731ad23fdf91f2cebbbf2ba4776b9859e87f...
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/load.py", line 740, in load_dataset
builder_instance.download_and_prepare(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/builder.py", line 578, in download_and_prepare
self._download_and_prepare(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/builder.py", line 634, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/stas/.cache/huggingface/modules/datasets_modules/datasets/wmt15/39ad5f9262a0910a8ad7028ad432731ad23fdf91f2cebbbf2ba4776b9859e87f/wmt_utils.py", line 757, in _split_generators
downloaded_files = dl_manager.download_and_extract(urls_to_download)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 283, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 191, in download
downloaded_path_or_paths = map_nested(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 203, in map_nested
mapped = [
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 204, in <listcomp>
_single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 160, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 160, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 142, in _single_map_nested
return function(data_struct)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 214, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 274, in cached_path
output_path = get_from_cache(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 614, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/wmt/wmt15/resolve/main/training-parallel-nc-v10.tgz
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1987/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1987/timeline | null | completed | null | null | false | [
"It's reachable for the viewer and me, so I suppose it was down at that moment?"
] |
https://api.github.com/repos/huggingface/datasets/issues/2341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2341/comments | https://api.github.com/repos/huggingface/datasets/issues/2341/events | https://github.com/huggingface/datasets/pull/2341 | 882,370,933 | MDExOlB1bGxSZXF1ZXN0NjM1OTExODI2 | 2,341 | Added the Ascent KB | [] | closed | false | null | 1 | 2021-05-09T14:17:39Z | 2021-05-11T09:16:59Z | 2021-05-11T09:16:59Z | null | Added the Ascent Commonsense KB of 8.9M assertions.
- Paper: [Advanced Semantics for Commonsense Knowledge Extraction (WWW'21)](https://arxiv.org/abs/2011.00905)
- Website: https://ascent.mpi-inf.mpg.de/
(I am the author of the dataset) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2341/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2341",
"merged_at": "2021-05-11T09:16:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2341"
} | true | [
"Thanks for approving it!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3485/comments | https://api.github.com/repos/huggingface/datasets/issues/3485/events | https://github.com/huggingface/datasets/issues/3485 | 1,089,027,581 | I_kwDODunzps5A6T39 | 3,485 | skip columns which cannot set to specific format when set_format | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2021-12-27T07:19:55Z | 2021-12-27T09:07:07Z | 2021-12-27T09:07:07Z | null | **Is your feature request related to a problem? Please describe.**
When using `dataset.set_format("torch")`, I must make sure every columns in datasets can convert to `torch`, however, sometimes I want to keep some string columns.
**Describe the solution you'd like**
skip columns which cannot set to specific format when set_format instead of raise an error.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3485/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3485/timeline | null | completed | null | null | false | [
"You can add columns that you wish to set into `torch` format using `dataset.set_format(\"torch\", ['id', 'abc'])` so that input batch of the transform only contains those columns",
"Sorry, I miss `output_all_columns` args and thought after `dataset.set_format(\"torch\", columns=columns)` I can only get specific columns I assigned."
] |
https://api.github.com/repos/huggingface/datasets/issues/4529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4529/comments | https://api.github.com/repos/huggingface/datasets/issues/4529/events | https://github.com/huggingface/datasets/issues/4529 | 1,276,729,303 | I_kwDODunzps5MGVfX | 4,529 | Ecoset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 1 | 2022-06-20T10:39:34Z | 2022-06-21T16:17:16Z | null | null | ## Adding a Dataset
- **Name:** *Ecoset*
- **Description:** *https://www.kietzmannlab.org/ecoset/*
- **Paper:** *https://doi.org/10.1073/pnas.2011417118*
- **Data:** *https://codeocean.com/capsule/9570390/tree/v1*
- **Motivation:**
**Ecoset** was created as a clean and ecologically valid alternative to **Imagenet**.
It is a large image recognition dataset, similar to Imagenet in size and structure. However, the authors of ecoset claim several improvements over Imagenet, like:
- more ecologically valid classes (e.g. not over-focussed on distinguishing different dog breeds)
- less NSFW content
- 'pre-packed image recognition models' that come with the dataset and can be used for validation of other models.
I am working for one of the authors of the paper with the aim of bringing Ecoset to huggingface datasets. Therefore I can work on this issue personally, but could use some help from devs and experienced users if the dataset is of interest to them. I phrased some of my questions on [discuss.huggingface](https://discuss.huggingface.co/t/handling-large-image-datasets/19373).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4529/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4529/timeline | null | null | null | null | false | [
"Hi! Very cool dataset! I answered your questions on the forum. Also, feel free to comment `#self-assign` on this issue to self-assign it."
] |
https://api.github.com/repos/huggingface/datasets/issues/944 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/944/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/944/comments | https://api.github.com/repos/huggingface/datasets/issues/944/events | https://github.com/huggingface/datasets/pull/944 | 754,228,947 | MDExOlB1bGxSZXF1ZXN0NTMwMTY0NTU5 | 944 | Add German Legal Entity Recognition Dataset | [] | closed | false | null | 1 | 2020-12-01T09:38:22Z | 2020-12-03T13:06:56Z | 2020-12-03T13:06:55Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/944/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/944/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/944.diff",
"html_url": "https://github.com/huggingface/datasets/pull/944",
"merged_at": "2020-12-03T13:06:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/944.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/944"
} | true | [
"thanks ! merging this one"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/1402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1402/comments | https://api.github.com/repos/huggingface/datasets/issues/1402/events | https://github.com/huggingface/datasets/pull/1402 | 760,538,325 | MDExOlB1bGxSZXF1ZXN0NTM1MzUzMzE0 | 1,402 | adding covid-tweets-japanese (again) | [] | closed | false | null | 4 | 2020-12-09T17:46:46Z | 2020-12-13T17:54:14Z | 2020-12-13T17:47:36Z | null | I had mistaken use git rebase, I was so hurried to fix it. However, I didn't fully consider the use of git reset , so I unintendedly stopped PR (#1367) altogether. Sorry about that.
I'll make a new PR. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1402/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1402",
"merged_at": "2020-12-13T17:47:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1402"
} | true | [
"README.md is not created yet. I'll add it soon.",
"Thank you for your detailed code review! It's so helpful.\r\nI'll reflect them to the code in 24 hours.\r\n\r\nYou may have told me in Slack (I cannot find the conversation log though I've looked through threads), but I'm sorry it seems I'm still misunderstanding how to get YAML from the tagger.\r\nI'm now asking on Slack if I am looking at the tagger the wrong way.",
"One more thing I'd like to ask.\r\nShould I make changes by myself, or can I use the \"Commit suggestion\" feature?\r\nI'm new to this feature and I don't know how the rules work in this repository, so I'd like to ask just in case.",
"Thank you very much for merging!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2767 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2767/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2767/comments | https://api.github.com/repos/huggingface/datasets/issues/2767/events | https://github.com/huggingface/datasets/issues/2767 | 963,002,120 | MDU6SXNzdWU5NjMwMDIxMjA= | 2,767 | equal operation to perform unbatch for huggingface datasets | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2021-08-06T19:45:52Z | 2022-03-07T13:58:00Z | 2022-03-07T13:58:00Z | null | Hi
I need to use "unbatch" operation in tensorflow on a huggingface dataset, I could not find this operation, could you kindly direct me how I can do it, here is the problem I am trying to solve:
I am considering "record" dataset in SuperGlue and I need to replicate each entery of the dataset for each answer, to make it similar to what T5 originally did:
https://github.com/google-research/text-to-text-transfer-transformer/blob/3c58859b8fe72c2dbca6a43bc775aa510ba7e706/t5/data/preprocessors.py#L925
Here please find an example:
For example, a typical example from ReCoRD might look like
{
'passsage': 'This is the passage.',
'query': 'A @placeholder is a bird.',
'entities': ['penguin', 'potato', 'pigeon'],
'answers': ['penguin', 'pigeon'],
}
and I need a prosessor which would turn this example into the following two examples:
{
'inputs': 'record query: A @placeholder is a bird. entities: penguin, '
'potato, pigeon passage: This is the passage.',
'targets': 'penguin',
}
and
{
'inputs': 'record query: A @placeholder is a bird. entities: penguin, '
'potato, pigeon passage: This is the passage.',
'targets': 'pigeon',
}
For doing this, one need unbatch, as each entry can map to multiple samples depending on the number of answers, I am not sure how to perform this operation with huggingface datasets library and greatly appreciate your help
@lhoestq
Thank you very much.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2767/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2767/timeline | null | completed | null | null | false | [
"Hi @lhoestq \r\nMaybe this is clearer to explain like this, currently map function, map one example to \"one\" modified one, lets assume we want to map one example to \"multiple\" examples, in which we do not know in advance how many examples they would be per each entry. I greatly appreciate telling me how I can handle this operation, thanks a lot",
"Hi,\r\nthis is also my question on how to perform similar operation as \"unbatch\" in tensorflow in great huggingface dataset library. \r\nthanks.",
"Hi,\r\n\r\n`Dataset.map` in the batched mode allows you to map a single row to multiple rows. So to perform \"unbatch\", you can do the following:\r\n```python\r\nimport collections\r\n\r\ndef unbatch(batch):\r\n new_batch = collections.defaultdict(list)\r\n keys = batch.keys()\r\n for values in zip(*batch.values()):\r\n ex = {k: v for k, v in zip(keys, values)}\r\n inputs = f\"record query: {ex['query']} entities: {', '.join(ex['entities'])} passage: {ex['passage']}\"\r\n new_batch[\"inputs\"].extend([inputs] * len(ex[\"answers\"]))\r\n new_batch[\"targets\"].extend(ex[\"answers\"])\r\n return new_batch\r\n\r\ndset = dset.map(unbatch, batched=True, remove_columns=dset.column_names)\r\n```",
"Dear @mariosasko \r\nFirst, thank you very much for coming back to me on this, I appreciate it a lot. I tried this solution, I am getting errors, do you mind\r\ngiving me one test example to be able to run your code, to understand better the format of the inputs to your function?\r\nin this function https://github.com/google-research/text-to-text-transfer-transformer/blob/3c58859b8fe72c2dbca6a43bc775aa510ba7e706/t5/data/preprocessors.py#L952 they copy each example to the number of \"answers\", do you mean one should not do the copying part and use directly your function? \r\n\r\n\r\nthank you very much for your help and time.",
"Hi @mariosasko \r\nI think finally I got this, I think you mean to do things in one step, here is the full example for completeness:\r\n\r\n```\r\ndef unbatch(batch):\r\n new_batch = collections.defaultdict(list)\r\n keys = batch.keys()\r\n for values in zip(*batch.values()):\r\n ex = {k: v for k, v in zip(keys, values)}\r\n # updates the passage.\r\n passage = ex['passage']\r\n passage = re.sub(r'(\\.|\\?|\\!|\\\"|\\')\\n@highlight\\n', r'\\1 ', passage)\r\n passage = re.sub(r'\\n@highlight\\n', '. ', passage)\r\n inputs = f\"record query: {ex['query']} entities: {', '.join(ex['entities'])} passage: {passage}\"\r\n # duplicates the samples based on number of answers.\r\n num_answers = len(ex[\"answers\"])\r\n num_duplicates = np.maximum(1, num_answers)\r\n new_batch[\"inputs\"].extend([inputs] * num_duplicates) #len(ex[\"answers\"]))\r\n new_batch[\"targets\"].extend(ex[\"answers\"] if num_answers > 0 else [\"<unk>\"])\r\n return new_batch\r\n\r\ndata = datasets.load_dataset('super_glue', 'record', split=\"train\", script_version=\"master\")\r\ndata = data.map(unbatch, batched=True, remove_columns=data.column_names)\r\n```\r\n\r\nThanks a lot again, this was a super great way to do it."
] |
https://api.github.com/repos/huggingface/datasets/issues/4104 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4104/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4104/comments | https://api.github.com/repos/huggingface/datasets/issues/4104/events | https://github.com/huggingface/datasets/issues/4104 | 1,194,072,966 | I_kwDODunzps5HLBuG | 4,104 | Add time series data - stock market | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 8 | 2022-04-06T05:46:58Z | 2022-04-11T09:07:10Z | null | null | ## Adding a Time Series Dataset
- **Name:** 2min ticker data for stock market
- **Description:** 8 stocks' data collected for 1month post ukraine-russia war. 4 NSE stocks and 4 NASDAQ stocks. Along with technical indicators (additional features) as shown in below image
- **Data:** Collected by myself from investing.com
- **Motivation:** Test applicability of transformer based model on stock market / time series problem
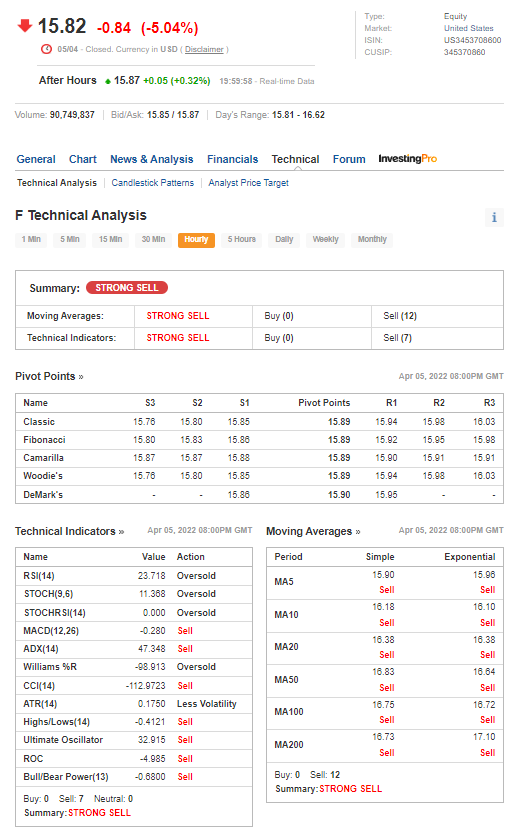 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4104/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4104/timeline | null | null | null | null | false | [
"Can I use instructions present in below link for time series dataset as well? \r\nhttps://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md ",
"cc'ing @kashif and @NielsRogge for visibility!",
"@INF800 happy to add this dataset! I will try to set a PR by the end of the day... if you can kindly point me to the dataset? Also, note we have a bunch of time series datasets checked in e.g. `electricity_load_diagrams` or `monash_tsf`, and ideally this dataset could also be in a similar format. ",
"Thankyou. This is how raw data looks like before cleaning for an individual stocks:\r\n\r\n1. https://github.com/INF800/marktech/tree/raw-data/f/data/raw\r\n2. https://github.com/INF800/marktech/tree/raw-data/t/data/raw\r\n3. https://github.com/INF800/marktech/tree/raw-data/rdfn/data/raw\r\n4. https://github.com/INF800/marktech/tree/raw-data/irbt/data/raw\r\n5. https://github.com/INF800/marktech/tree/raw-data/hll/data/raw\r\n6. https://github.com/INF800/marktech/tree/raw-data/infy/data/raw\r\n7. https://github.com/INF800/marktech/tree/raw-data/reli/data/raw\r\n8. https://github.com/INF800/marktech/tree/raw-data/hdbk/data/raw\r\n\r\n> Scraping is automated using GitHub Actions. So, everyday we will see a new file added in the above links.\r\n\r\nI can rewrite the cleaning scripts to make sure it fits HF dataset standards. (P.S I am very much new to HF dataset)\r\n\r\nThe data set above can be converted into univariate regression / multivariate regression / sequence to sequence generation dataset etc. So, do we have some kind of transformation modules that will read the dataset as some type of dataset (`GenericTimeData`) and convert it to other possible dataset relating to a specific ML task. **By having this kind of transformation module, I only have to add data once** and use transformation module whenever necessary\r\n\r\nAdditionally, having some kind of versioning for the dataset will be really helpful because it will keep on updating - especially time series datasets ",
"thanks @INF800 I'll have a look. I believe it should be possible to incorporate this into the time-series format.",
"Referencing https://github.com/qingsongedu/time-series-transformers-review",
"@INF800 yes I am aware of the review repository and paper which is more or less a collection of abstracts etc. I am working on a unified library of implementations of these papers together with datasets to be then able to compare/contrast and build upon the research etc. but I am not ready to share them publicly just yet.\r\n\r\nIn any case regarding your dataset at the moment its seems from looking at the csv files, its mixture of textual and numerical data, sometimes in the same column etc. As you know, for time series models we would need just numeric data so I would need your help in disambiguating the dataset you have collected and also perhaps starting with just numerical data to start with... \r\n\r\nDo you think you can make a version with just numerical data?",
"> @INF800 yes I am aware of the review repository and paper which is more or less a collection of abstracts etc. I am working on a unified library of implementations of these papers together with datasets to be then able to compare/contrast and build upon the research etc. but I am not ready to share them publicly just yet.\r\n> \r\n> In any case regarding your dataset at the moment its seems from looking at the csv files, its mixture of textual and numerical data, sometimes in the same column etc. As you know, for time series models we would need just numeric data so I would need your help in disambiguating the dataset you have collected and also perhaps starting with just numerical data to start with...\r\n> \r\n> Do you think you can make a version with just numerical data?\r\n\r\nWill share the numeric data and conversion script within end of this week. \r\n\r\nI am on a business trip currently - it is in my desktop."
] |
https://api.github.com/repos/huggingface/datasets/issues/270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/270/comments | https://api.github.com/repos/huggingface/datasets/issues/270/events | https://github.com/huggingface/datasets/issues/270 | 638,121,617 | MDU6SXNzdWU2MzgxMjE2MTc= | 270 | c4 dataset is not viewable in nlpviewer demo | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 1 | 2020-06-13T08:26:16Z | 2020-10-27T15:35:29Z | 2020-10-27T15:35:13Z | null | I get the following error when I try to view the c4 dataset in [nlpviewer](https://huggingface.co/nlp/viewer/)
```python
ModuleNotFoundError: No module named 'langdetect'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp_viewer/run.py", line 54, in <module>
configs = get_confs(option.id)
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp_viewer/run.py", line 48, in get_confs
builder_cls = nlp.load.import_main_class(module_path, dataset=True)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/load.py", line 57, in import_main_class
module = importlib.import_module(module_path)
File "/usr/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/datasets/c4/88bb1b1435edad3fb772325710c4a43327cbf4a23b9030094556e6f01e14ec19/c4.py", line 29, in <module>
from .c4_utils import (
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/datasets/c4/88bb1b1435edad3fb772325710c4a43327cbf4a23b9030094556e6f01e14ec19/c4_utils.py", line 29, in <module>
import langdetect
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/270/timeline | null | completed | null | null | false | [
"C4 is too large to be shown in the viewer"
] |
https://api.github.com/repos/huggingface/datasets/issues/2108 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2108/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2108/comments | https://api.github.com/repos/huggingface/datasets/issues/2108/events | https://github.com/huggingface/datasets/issues/2108 | 840,181,055 | MDU6SXNzdWU4NDAxODEwNTU= | 2,108 | Is there a way to use a GPU only when training an Index in the process of add_faisis_index? | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | open | false | null | 0 | 2021-03-24T21:32:16Z | 2021-03-25T06:31:43Z | null | null | Motivation - Some FAISS indexes like IVF consist of the training step that clusters the dataset into a given number of indexes. It would be nice if we can use a GPU to do the training step and covert the index back to CPU as mention in [this faiss example](https://gist.github.com/mdouze/46d6bbbaabca0b9778fca37ed2bcccf6). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2108/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2108/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5233 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5233/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5233/comments | https://api.github.com/repos/huggingface/datasets/issues/5233/events | https://github.com/huggingface/datasets/pull/5233 | 1,447,906,868 | PR_kwDODunzps5C1JVh | 5,233 | Fix shards in IterableDataset.from_generator | [] | closed | false | null | 1 | 2022-11-14T11:42:09Z | 2022-11-14T14:16:03Z | 2022-11-14T14:13:22Z | null | Allow to define a sharded iterable dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5233/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5233/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5233.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5233",
"merged_at": "2022-11-14T14:13:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5233.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5233"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1331 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1331/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1331/comments | https://api.github.com/repos/huggingface/datasets/issues/1331/events | https://github.com/huggingface/datasets/pull/1331 | 759,677,189 | MDExOlB1bGxSZXF1ZXN0NTM0NjQwMzc5 | 1,331 | First version of the new dataset hausa_voa_topics | [] | closed | false | null | 0 | 2020-12-08T18:28:52Z | 2020-12-10T11:09:53Z | 2020-12-10T11:09:53Z | null | Contains loading script as well as dataset card including YAML tags.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1331/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1331/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1331.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1331",
"merged_at": "2020-12-10T11:09:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1331.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1331"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5898 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5898/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5898/comments | https://api.github.com/repos/huggingface/datasets/issues/5898/events | https://github.com/huggingface/datasets/issues/5898 | 1,726,190,481 | I_kwDODunzps5m45OR | 5,898 | Loading The flores data set for specific language | [] | closed | false | null | 1 | 2023-05-25T17:08:55Z | 2023-05-25T17:21:38Z | 2023-05-25T17:21:37Z | null | ### Describe the bug
I am trying to load the Flores data set
the code which is given is
```
from datasets import load_dataset
dataset = load_dataset("facebook/flores")
```
This gives the error of config name
""ValueError: Config name is missing"
Now if I add some config it gives me the some error
"HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: 'facebook/flores, 'ace_Arab''.
"
How I can load the data of the specific language ?
Couldn't find any tutorial
any one can help me out?
### Steps to reproduce the bug
step one load the data set
`from datasets import load_dataset
dataset = load_dataset("facebook/flores")`
it gives the error of config
once config is given
it gives the error of
"HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: 'facebook/flores, 'ace_Arab''.
"
### Expected behavior
Data set should be loaded but I am receiving error
### Environment info
Datasets , python , | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5898/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5898/timeline | null | completed | null | null | false | [
"got that the syntax is like this\r\n\r\ndataset = load_dataset(\"facebook/flores\", \"ace_Arab\")"
] |
https://api.github.com/repos/huggingface/datasets/issues/5947 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5947/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5947/comments | https://api.github.com/repos/huggingface/datasets/issues/5947/events | https://github.com/huggingface/datasets/issues/5947 | 1,754,359,316 | I_kwDODunzps5okWYU | 5,947 | Return the audio filename when decoding fails due to corrupt files | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2023-06-13T08:44:09Z | 2023-06-14T12:45:01Z | null | null | ### Feature request
Return the audio filename when the audio decoding fails. Although currently there are some checks for mp3 and opus formats with the library version there are still cases when the audio decoding could fail, eg. Corrupt file.
### Motivation
When you try to load an object file dataset and the decoding fails you can't know which file is corrupt
```
raise LibsndfileError(err, prefix="Error opening {0!r}: ".format(self.name))
soundfile.LibsndfileError: Error opening <_io.BytesIO object at 0x7f5ab7e38290>: Format not recognised.
```
### Your contribution
Make a PR to Add exceptions for LIbsndfileError to return the audio filename or path when soundfile decoding fails. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5947/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5947/timeline | null | null | null | null | false | [
"Hi ! The audio data don't always exist as files on disk - the blobs are often stored in the Arrow files. For now I'd suggest disabling decoding with `.cast_column(\"audio\", Audio(decode=False))` and apply your own decoding that handles corrupted files (maybe to filter them out ?)\r\n\r\ncc @sanchit-gandhi since it's related to our discussion about allowing users to make decoding return `None` and show a warning when there are corrupted files",
"Thanks @lhoestq, I wasn't aware of the decode flag. It makes more sense as you say to show a warning when there are corrupted files together with some metadata of the file that allows to filter them from the dataset.\r\n\r\nMy workaround was to catch the LibsndfileError and generate a dummy audio with an unsual sample rate to filter it later. However returning `None` seems better. \r\n\r\n`try:\r\n array, sampling_rate = sf.read(file)\r\nexcept sf.LibsndfileError:\r\n print(\"bad file\")\r\n array = np.array([0.0])\r\n sampling_rate = 99.000` \r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4754/comments | https://api.github.com/repos/huggingface/datasets/issues/4754/events | https://github.com/huggingface/datasets/pull/4754 | 1,319,681,541 | PR_kwDODunzps48L9p6 | 4,754 | Remove "unkown" language tags | [] | closed | false | null | 1 | 2022-07-27T14:50:12Z | 2022-07-27T15:03:00Z | 2022-07-27T14:51:06Z | null | Following https://github.com/huggingface/datasets/pull/4753 there was still a "unknown" langauge tag in `wikipedia` so the job at https://github.com/huggingface/datasets/runs/7542567336?check_suite_focus=true failed for wikipedia | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4754/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4754/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4754.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4754",
"merged_at": "2022-07-27T14:51:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4754.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4754"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1935/comments | https://api.github.com/repos/huggingface/datasets/issues/1935/events | https://github.com/huggingface/datasets/pull/1935 | 814,623,827 | MDExOlB1bGxSZXF1ZXN0NTc4NTgyMzk1 | 1,935 | add CoVoST2 | [] | closed | false | null | 1 | 2021-02-23T16:28:16Z | 2021-02-24T18:09:32Z | 2021-02-24T18:05:09Z | null | This PR adds the CoVoST2 dataset for speech translation and ASR.
https://github.com/facebookresearch/covost#covost-2
The dataset requires manual download as the download page requests an email address and the URLs are temporary.
The dummy data is a bit bigger because of the mp3 files and 36 configs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1935/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1935/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1935.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1935",
"merged_at": "2021-02-24T18:05:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1935.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1935"
} | true | [
"@patrickvonplaten \r\nI removed the mp3 files, dummy_data is much smaller now!"
] |
https://api.github.com/repos/huggingface/datasets/issues/169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/169/comments | https://api.github.com/repos/huggingface/datasets/issues/169/events | https://github.com/huggingface/datasets/pull/169 | 621,099,682 | MDExOlB1bGxSZXF1ZXN0NDIwMjE1NDkw | 169 | Adding Qanta (Quizbowl) Dataset | [] | closed | false | null | 5 | 2020-05-19T16:03:01Z | 2020-05-26T12:52:31Z | 2020-05-26T12:52:31Z | null | This PR adds the qanta question answering datasets from [Quizbowl: The Case for Incremental Question Answering](https://arxiv.org/abs/1904.04792) and [Trick Me If You Can: Human-in-the-loop Generation of Adversarial Question Answering Examples](https://www.aclweb.org/anthology/Q19-1029/) (adversarial fold)
This partially continues a discussion around fixing dummy data from https://github.com/huggingface/nlp/issues/161
I ran the following code to double check that it works and did some sanity checks on the output. The majority of the code itself is from our `allennlp` version of the dataset reader.
```python
import nlp
# Default is full question
data = nlp.load_dataset('./datasets/qanta')
# Four configs
# Primarily useful for training
data = nlp.load_dataset('./datasets/qanta', 'mode=sentences,char_skip=25')
# Primarily used in evaluation
data = nlp.load_dataset('./datasets/qanta', 'mode=first,char_skip=25')
data = nlp.load_dataset('./datasets/qanta', 'mode=full,char_skip=25')
# Primarily useful in evaluation and "live" play
data = nlp.load_dataset('./datasets/qanta', 'mode=runs,char_skip=25')
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/169/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/169.diff",
"html_url": "https://github.com/huggingface/datasets/pull/169",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/169.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/169"
} | true | [
"Hi @EntilZha - sorry for waiting so long until taking action here. We created a new command and a new recipe of how to add dummy_data. Can you maybe rebase to `master` as explained in 7. of https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-contribute-to-nlp and check that your dummy data is correct following the instructions here: https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset ? \r\n\r\nIf the tests described in 5. of https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset pass we can merge the PR :-) ",
"I updated to the most recent master and followed the steps, but still having the similar error where it can't find the correct file since the path to the directory is given, rather than the individual files within them. This still something wrong about how I'm inputting the data or how the tests are reading it?",
"It's the dummy_data structure. You actually have to call the dummy data file name `dummy_data` (not .json anything). So there should not be a `dummy_data` folder but for each config only a `dummy_data` which contains your json dummy data. Can you maybe try once more - if it doesn't work I do it for you :-). ",
"Would that work if there are multiple files? In my case, I'm including something similar to squad 1.0/2.0 where we have the main dataset + an additional challenge set in different files. Would I have the zip decompress to two files in that case?",
"This dataset was actually a special case. It helped us improve the dummy data instructions :-), see #195 .Close this PR and merge #194."
] |
https://api.github.com/repos/huggingface/datasets/issues/6034 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6034/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6034/comments | https://api.github.com/repos/huggingface/datasets/issues/6034/events | https://github.com/huggingface/datasets/issues/6034 | 1,804,501,361 | I_kwDODunzps5rjoFx | 6,034 | load_dataset hangs on WSL | [] | closed | false | null | 3 | 2023-07-14T09:03:10Z | 2023-07-14T14:48:29Z | 2023-07-14T14:48:29Z | null | ### Describe the bug
load_dataset simply hangs. It happens once every ~5 times, and interestingly hangs for a multiple of 5 minutes (hangs for 5/10/15 minutes). Using the profiler in PyCharm shows that it spends the time at <method 'connect' of '_socket.socket' objects>. However, a local cache is available so I am not sure why socket is needed. ([profiler result](https://ibb.co/0Btbbp8))
It only happens on WSL for me. It works for native Windows and my MacBook. (cache quickly recognized and loaded within a second).
### Steps to reproduce the bug
I am using Ubuntu 22.04.2 LTS (GNU/Linux 5.15.90.1-microsoft-standard-WSL2 x86_64)
Python 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0] on linux
>>> import datasets
>>> datasets.load_dataset('ai2_arc', 'ARC-Challenge') # hangs for 5/10/15 minutes
### Expected behavior
cache quickly recognized and loaded within a second
### Environment info
Please let me know if I should provide more environment information. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6034/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6034/timeline | null | completed | null | null | false | [
"Even if a dataset is cached, we still make requests to check whether the cache is up-to-date. [This](https://huggingface.co/docs/datasets/v2.13.1/en/loading#offline) section in the docs explains how to avoid them and directly load the cached version.",
"Thanks - that works! However it doesn't resolve the original issue (but I am not sure if it is a WSL problem)",
"We use `requests` to make HTTP requests (and `aiohttp` in the streaming mode), so I don't think we can provide much help regarding the socket issue (it probably has something to do with WSL). "
] |
https://api.github.com/repos/huggingface/datasets/issues/86 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/86/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/86/comments | https://api.github.com/repos/huggingface/datasets/issues/86/events | https://github.com/huggingface/datasets/pull/86 | 617,260,972 | MDExOlB1bGxSZXF1ZXN0NDE3MjEwNzY2 | 86 | [Load => load_dataset] change naming | [] | closed | false | null | 0 | 2020-05-13T08:43:00Z | 2020-05-13T08:50:58Z | 2020-05-13T08:50:57Z | null | Rename leftovers @thomwolf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/86/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/86/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/86.diff",
"html_url": "https://github.com/huggingface/datasets/pull/86",
"merged_at": "2020-05-13T08:50:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/86.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/86"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/411/comments | https://api.github.com/repos/huggingface/datasets/issues/411/events | https://github.com/huggingface/datasets/pull/411 | 659,393,398 | MDExOlB1bGxSZXF1ZXN0NDUxMjQxOTQy | 411 | Sbf | [] | closed | false | null | 0 | 2020-07-17T16:19:45Z | 2020-07-21T09:13:46Z | 2020-07-21T09:13:45Z | null | This PR adds the Social Bias Frames Dataset (ACL 2020) .
dataset homepage: https://homes.cs.washington.edu/~msap/social-bias-frames/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/411/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/411/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/411.diff",
"html_url": "https://github.com/huggingface/datasets/pull/411",
"merged_at": "2020-07-21T09:13:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/411.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/411"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3524 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3524/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3524/comments | https://api.github.com/repos/huggingface/datasets/issues/3524/events | https://github.com/huggingface/datasets/pull/3524 | 1,093,826,723 | PR_kwDODunzps4wiK_v | 3,524 | Adding link to license. | [] | closed | false | null | 0 | 2022-01-04T23:11:48Z | 2022-01-05T12:31:38Z | 2022-01-05T12:31:37Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3524/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3524/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3524.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3524",
"merged_at": "2022-01-05T12:31:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3524.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3524"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/259 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/259/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/259/comments | https://api.github.com/repos/huggingface/datasets/issues/259/events | https://github.com/huggingface/datasets/issues/259 | 636,239,529 | MDU6SXNzdWU2MzYyMzk1Mjk= | 259 | documentation missing how to split a dataset | [] | closed | false | null | 7 | 2020-06-10T13:18:13Z | 2023-03-14T13:56:07Z | 2020-06-18T22:20:24Z | null | I am trying to understand how to split a dataset ( as arrow_dataset).
I know I can do something like this to access a split which is already in the original dataset :
`ds_test = nlp.load_dataset('imdb, split='test') `
But how can I split ds_test into a test and a validation set (without reading the data into memory and keeping the arrow_dataset as container)?
I guess it has something to do with the module split :-) but there is no real documentation in the code but only a reference to a longer description:
> See the [guide on splits](https://github.com/huggingface/nlp/tree/master/docs/splits.md) for more information.
But the guide seems to be missing.
To clarify: I know that this has been modelled after the dataset of tensorflow and that some of the documentation there can be used [like this one](https://www.tensorflow.org/datasets/splits). But to come back to the example above: I cannot simply split the testset doing this:
`ds_test = nlp.load_dataset('imdb, split='test'[:5000]) `
`ds_val = nlp.load_dataset('imdb, split='test'[5000:])`
because the imdb test data is sorted by class (probably not a good idea anyway)
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/259/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/259/timeline | null | completed | null | null | false | [
"this seems to work for my specific problem:\r\n\r\n`self.train_ds, self.test_ds, self.val_ds = map(_prepare_ds, ('train', 'test[:25%]+test[50%:75%]', 'test[75%:]'))`",
"Currently you can indeed split a dataset using `ds_test = nlp.load_dataset('imdb, split='test[:5000]')` (works also with percentages).\r\n\r\nHowever right now we don't have a way to shuffle a dataset but we are thinking about it in the discussion in #166. Feel free to share your thoughts about it.\r\n\r\nOne trick that you can do until we have a better solution is to shuffle and split the indices of your dataset:\r\n```python\r\nimport nlp\r\nfrom sklearn.model_selection import train_test_split\r\n\r\nimdb = nlp.load_dataset('imbd', split='test')\r\ntest_indices, val_indices = train_test_split(range(len(imdb)))\r\n```\r\n\r\nand then to iterate each split:\r\n```python\r\nfor i in test_indices:\r\n example = imdb[i]\r\n ...\r\n```\r\n",
"I added a small guide [here](https://github.com/huggingface/nlp/tree/master/docs/splits.md) that explains how to split a dataset. It is very similar to the tensorflow datasets guide, as we kept the same logic.",
"Thanks a lot, the new explanation is very helpful!\r\n\r\nAbout using train_test_split from sklearn: I stumbled across the [same error message as this user ](https://github.com/huggingface/nlp/issues/147 )and thought it can't be used at the moment in this context. Will check it out again.\r\n\r\nOne of the problems is how to shuffle very large datasets, which don't fit into the memory. Well, one strategy could be shuffling data in sections. But in a case where the data is sorted by the labels you have to swap larger sections first. \r\n",
"We added a way to shuffle datasets (shuffle the indices and then reorder to make a new dataset).\r\nYou can do `shuffled_dset = dataset.shuffle(seed=my_seed)`. It shuffles the whole dataset.\r\nThere is also `dataset.train_test_split()` which if very handy (with the same signature as sklearn).\r\n\r\nClosing this issue as we added the docs for splits and tools to split datasets. Thanks again for your feedback !",
"https://huggingface.co/docs/datasets/v1.0.1/package_reference/builder_classes.html#datasets.Split still links to https://github.com/huggingface/datasets/tree/main/docs/splits.md which is a 404\r\n",
"The updated documentation doesn't link to this anymore: https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/builder_classes#datasets.Split"
] |
https://api.github.com/repos/huggingface/datasets/issues/1507 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1507/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1507/comments | https://api.github.com/repos/huggingface/datasets/issues/1507/events | https://github.com/huggingface/datasets/pull/1507 | 763,857,872 | MDExOlB1bGxSZXF1ZXN0NTM4MTgyMzE2 | 1,507 | Add SelQA Dataset | [] | closed | false | null | 3 | 2020-12-12T13:58:07Z | 2020-12-16T16:49:23Z | 2020-12-16T16:49:23Z | null | Add the SelQA Dataset, a new benchmark for selection-based question answering tasks
Repo: https://github.com/emorynlp/selqa/
Paper: https://arxiv.org/pdf/1606.08513.pdf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1507/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1507/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1507.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1507",
"merged_at": "2020-12-16T16:49:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1507.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1507"
} | true | [
"Hii please follow me",
"The CI error `FAILED tests/test_file_utils.py::TempSeedTest::test_tensorflow` is not related with this dataset and is fixed on master. You can ignore it",
"merging since the Ci is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/3086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3086/comments | https://api.github.com/repos/huggingface/datasets/issues/3086/events | https://github.com/huggingface/datasets/pull/3086 | 1,026,481,905 | PR_kwDODunzps4tNIvp | 3,086 | Remove _resampler from Audio fields | [] | closed | false | null | 0 | 2021-10-14T14:38:50Z | 2021-10-14T15:13:41Z | 2021-10-14T15:13:40Z | null | The `_resampler` Audio attribute was implemented to optimize audio resampling, but it should not be cached.
This PR removes `_resampler` from Audio fields, so that it is not returned by `fields()` or `asdict()`.
Fix #3083. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3086/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3086/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3086.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3086",
"merged_at": "2021-10-14T15:13:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3086.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3086"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1659/comments | https://api.github.com/repos/huggingface/datasets/issues/1659/events | https://github.com/huggingface/datasets/pull/1659 | 775,831,288 | MDExOlB1bGxSZXF1ZXN0NTQ2NDM1OTcy | 1,659 | update dataset info | [] | closed | false | null | 0 | 2020-12-29T10:58:01Z | 2020-12-30T16:55:07Z | 2020-12-30T16:55:07Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1659/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1659/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1659.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1659",
"merged_at": "2020-12-30T16:55:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1659.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1659"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/1292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1292/comments | https://api.github.com/repos/huggingface/datasets/issues/1292/events | https://github.com/huggingface/datasets/pull/1292 | 759,354,627 | MDExOlB1bGxSZXF1ZXN0NTM0Mzc0MzQ3 | 1,292 | arXiv dataset added | [] | closed | false | null | 0 | 2020-12-08T11:08:28Z | 2020-12-08T14:02:13Z | 2020-12-08T14:02:13Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1292/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1292.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1292",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1292.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1292"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/1395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1395/comments | https://api.github.com/repos/huggingface/datasets/issues/1395/events | https://github.com/huggingface/datasets/pull/1395 | 760,448,255 | MDExOlB1bGxSZXF1ZXN0NTM1Mjc4MTQ2 | 1,395 | Add WikiSource Dataset | [] | closed | false | null | 1 | 2020-12-09T15:52:06Z | 2020-12-14T10:24:14Z | 2020-12-14T10:24:13Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1395/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1395",
"merged_at": "2020-12-14T10:24:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1395"
} | true | [
"@lhoestq fixed :) "
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3260 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3260/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3260/comments | https://api.github.com/repos/huggingface/datasets/issues/3260/events | https://github.com/huggingface/datasets/pull/3260 | 1,052,247,373 | PR_kwDODunzps4ueCIU | 3,260 | Fix ConnectionError in Scielo dataset | [] | closed | false | null | 1 | 2021-11-12T18:02:37Z | 2021-11-16T18:18:17Z | 2021-11-16T17:55:22Z | null | This PR:
* allows 403 status code in HEAD requests to S3 buckets to fix the connection error in the Scielo dataset (instead of `url`, uses `response.url` to check the URL of the final endpoint)
* makes the Scielo dataset streamable
Fixes #3255. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3260/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3260/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3260.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3260",
"merged_at": "2021-11-16T17:55:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3260.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3260"
} | true | [
"The CI error is unrelated to the change."
] |
https://api.github.com/repos/huggingface/datasets/issues/5584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5584/comments | https://api.github.com/repos/huggingface/datasets/issues/5584/events | https://github.com/huggingface/datasets/issues/5584 | 1,601,821,808 | I_kwDODunzps5fedxw | 5,584 | Unable to load coyo700M dataset | [] | closed | false | null | 1 | 2023-02-27T19:35:03Z | 2023-02-28T07:27:59Z | 2023-02-28T07:27:58Z | null | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coyo-700m to /root/.cache/huggingface/datasets/kakaobrain___parquet/kakaobrain--coyo-700m-ae729692ae3e0073/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...
Downloading data files: 100%
1/1 [00:00<00:00, 63.35it/s]
Extracting data files: 100%
1/1 [00:00<00:00, 5.00it/s]
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
[/usr/local/lib/python3.8/dist-packages/datasets/builder.py](https://localhost:8080/#) in _prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
1859 _time = time.time()
-> 1860 for _, table in generator:
1861 if max_shard_size is not None and writer._num_bytes > max_shard_size:
9 frames
ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.
The above exception was the direct cause of the following exception:
DatasetGenerationError Traceback (most recent call last)
[/usr/local/lib/python3.8/dist-packages/datasets/builder.py](https://localhost:8080/#) in _prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
1890 if isinstance(e, SchemaInferenceError) and e.__context__ is not None:
1891 e = e.__context__
-> 1892 raise DatasetGenerationError("An error occurred while generating the dataset") from e
1893
1894 yield job_id, True, (total_num_examples, total_num_bytes, writer._features, num_shards, shard_lengths)
DatasetGenerationError: An error occurred while generating the dataset```
### Steps to reproduce the bug
```
from datasets import load_dataset
hf_dataset = load_dataset("kakaobrain/coyo-700m")
```
### Expected behavior
The above commands load the dataset successfully. Or handles exception and continue loading the remainder.
### Environment info
colab. any | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5584/timeline | null | completed | null | null | false | [
"Hi @manuaero \r\n\r\nThank you for your interest in the COYO dataset.\r\n\r\nOur dataset provides the img-url and alt-text in the form of a parquet, so to utilize the coyo dataset you will need to download it directly.\r\n\r\nWe provide a [guide](https://github.com/kakaobrain/coyo-dataset/blob/main/download/README.md) to download, so check it out.\r\n\r\nThank you."
] |
https://api.github.com/repos/huggingface/datasets/issues/4229 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4229/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4229/comments | https://api.github.com/repos/huggingface/datasets/issues/4229/events | https://github.com/huggingface/datasets/pull/4229 | 1,216,638,968 | PR_kwDODunzps421mjM | 4,229 | new task tag | [] | closed | false | null | 0 | 2022-04-27T00:47:08Z | 2022-04-27T00:48:28Z | 2022-04-27T00:48:17Z | null | multi-input-text-classification tag for classification datasets that take more than one input | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4229/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4229/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4229.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4229",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4229.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4229"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4013 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4013/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4013/comments | https://api.github.com/repos/huggingface/datasets/issues/4013/events | https://github.com/huggingface/datasets/issues/4013 | 1,180,427,174 | I_kwDODunzps5GW-Om | 4,013 | Cannot preview "hazal/Turkish-Biomedical-corpus-trM" | [] | closed | false | null | 2 | 2022-03-25T07:12:02Z | 2022-04-04T08:05:01Z | 2022-03-25T14:16:11Z | null | ## Dataset viewer issue for '*hazal/Turkish-Biomedical-corpus-trM'
**Link:** *https://huggingface.co/datasets/hazal/Turkish-Biomedical-corpus-trM*
*I cannot see the dataset preview.*
```
Server Error
Status code: 400
Exception: HTTPError
Message: 403 Client Error: Forbidden for url: https://huggingface.co/api/datasets/hazal/Turkish-Biomedical-corpus-trM?full=true
```
Am I the one who added this dataset ? Yes
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4013/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4013/timeline | null | completed | null | null | false | [
"Hi @hazalturkmen, thanks for reporting.\r\n\r\nNote that your dataset repository does not contain any loading script; it only contains a data file named `tr_article_2`.\r\n\r\nWhen there is no loading script but only data files, the `datasets` library tries to infer how to load the data by looking at the data file extensions. However, your data file does not have any extension.\r\n\r\nNote that current supported data file extensions are: 'csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'zip'.\r\n\r\nYou have more info on our docs: [How to share a dataset](https://huggingface.co/docs/datasets/share).",
"thanks for reply :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5966 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5966/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5966/comments | https://api.github.com/repos/huggingface/datasets/issues/5966/events | https://github.com/huggingface/datasets/pull/5966 | 1,763,885,914 | PR_kwDODunzps5TXBLP | 5,966 | Fix JSON generation in benchmarks CI | [] | closed | false | null | 3 | 2023-06-19T16:56:06Z | 2023-06-19T17:29:11Z | 2023-06-19T17:22:10Z | null | Related to changes made in https://github.com/iterative/dvc/pull/9475 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5966/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5966/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5966.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5966",
"merged_at": "2023-06-19T17:22:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5966.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5966"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006186 / 0.011353 (-0.005167) | 0.003744 / 0.011008 (-0.007264) | 0.097295 / 0.038508 (0.058787) | 0.037106 / 0.023109 (0.013997) | 0.424154 / 0.275898 (0.148256) | 0.474536 / 0.323480 (0.151057) | 0.003454 / 0.007986 (-0.004532) | 0.003865 / 0.004328 (-0.000463) | 0.077348 / 0.004250 (0.073097) | 0.051728 / 0.037052 (0.014675) | 0.437120 / 0.258489 (0.178631) | 0.478379 / 0.293841 (0.184538) | 0.028939 / 0.128546 (-0.099608) | 0.008376 / 0.075646 (-0.067270) | 0.312002 / 0.419271 (-0.107270) | 0.053723 / 0.043533 (0.010190) | 0.424815 / 0.255139 (0.169676) | 0.446203 / 0.283200 (0.163004) | 0.026553 / 0.141683 (-0.115130) | 1.479983 / 1.452155 (0.027828) | 1.530613 / 1.492716 (0.037896) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.196627 / 0.018006 (0.178620) | 0.422361 / 0.000490 (0.421871) | 0.003442 / 0.000200 (0.003242) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022913 / 0.037411 (-0.014499) | 0.096011 / 0.014526 (0.081485) | 0.104091 / 0.176557 (-0.072466) | 0.163273 / 0.737135 (-0.573862) | 0.109142 / 0.296338 (-0.187197) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431032 / 0.215209 (0.215823) | 4.314391 / 2.077655 (2.236737) | 2.003812 / 1.504120 (0.499692) | 1.799538 / 1.541195 (0.258344) | 1.830026 / 1.468490 (0.361536) | 0.560131 / 4.584777 (-4.024646) | 3.368997 / 3.745712 (-0.376715) | 1.703032 / 5.269862 (-3.566830) | 1.026949 / 4.565676 (-3.538727) | 0.067507 / 0.424275 (-0.356768) | 0.010910 / 0.007607 (0.003303) | 0.532606 / 0.226044 (0.306562) | 5.345179 / 2.268929 (3.076250) | 2.368077 / 55.444624 (-53.076548) | 2.028913 / 6.876477 (-4.847564) | 2.147621 / 2.142072 (0.005549) | 0.675696 / 4.805227 (-4.129531) | 0.134902 / 6.500664 (-6.365762) | 0.065004 / 0.075469 (-0.010465) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.233412 / 1.841788 (-0.608376) | 13.767465 / 8.074308 (5.693157) | 13.933653 / 10.191392 (3.742261) | 0.129010 / 0.680424 (-0.551414) | 0.016708 / 0.534201 (-0.517493) | 0.362341 / 0.579283 (-0.216942) | 0.390902 / 0.434364 (-0.043462) | 0.429156 / 0.540337 (-0.111182) | 0.521166 / 1.386936 (-0.865770) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006169 / 0.011353 (-0.005184) | 0.003839 / 0.011008 (-0.007169) | 0.078784 / 0.038508 (0.040276) | 0.040218 / 0.023109 (0.017109) | 0.360439 / 0.275898 (0.084541) | 0.423957 / 0.323480 (0.100477) | 0.003456 / 0.007986 (-0.004529) | 0.002900 / 0.004328 (-0.001428) | 0.078820 / 0.004250 (0.074569) | 0.047240 / 0.037052 (0.010187) | 0.372081 / 0.258489 (0.113592) | 0.424263 / 0.293841 (0.130422) | 0.027977 / 0.128546 (-0.100569) | 0.008400 / 0.075646 (-0.067246) | 0.084399 / 0.419271 (-0.334872) | 0.043303 / 0.043533 (-0.000230) | 0.361583 / 0.255139 (0.106444) | 0.394987 / 0.283200 (0.111787) | 0.020006 / 0.141683 (-0.121677) | 1.520208 / 1.452155 (0.068053) | 1.587335 / 1.492716 (0.094619) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223847 / 0.018006 (0.205840) | 0.402194 / 0.000490 (0.401704) | 0.000384 / 0.000200 (0.000184) | 0.000057 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024902 / 0.037411 (-0.012509) | 0.099076 / 0.014526 (0.084550) | 0.108041 / 0.176557 (-0.068516) | 0.159385 / 0.737135 (-0.577750) | 0.111442 / 0.296338 (-0.184896) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446232 / 0.215209 (0.231023) | 4.464927 / 2.077655 (2.387272) | 2.155234 / 1.504120 (0.651114) | 1.953645 / 1.541195 (0.412450) | 1.965991 / 1.468490 (0.497501) | 0.553473 / 4.584777 (-4.031304) | 3.321397 / 3.745712 (-0.424315) | 1.693761 / 5.269862 (-3.576101) | 1.006299 / 4.565676 (-3.559378) | 0.067013 / 0.424275 (-0.357262) | 0.011116 / 0.007607 (0.003509) | 0.555014 / 0.226044 (0.328970) | 5.535694 / 2.268929 (3.266765) | 2.598339 / 55.444624 (-52.846285) | 2.249298 / 6.876477 (-4.627179) | 2.243419 / 2.142072 (0.101347) | 0.667603 / 4.805227 (-4.137624) | 0.133322 / 6.500664 (-6.367343) | 0.065473 / 0.075469 (-0.009996) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.293051 / 1.841788 (-0.548737) | 14.103731 / 8.074308 (6.029423) | 14.215204 / 10.191392 (4.023812) | 0.143990 / 0.680424 (-0.536434) | 0.016805 / 0.534201 (-0.517396) | 0.363264 / 0.579283 (-0.216019) | 0.392769 / 0.434364 (-0.041594) | 0.425291 / 0.540337 (-0.115046) | 0.515479 / 1.386936 (-0.871457) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006346 / 0.011353 (-0.005006) | 0.004130 / 0.011008 (-0.006878) | 0.096898 / 0.038508 (0.058390) | 0.042564 / 0.023109 (0.019455) | 0.343748 / 0.275898 (0.067850) | 0.412515 / 0.323480 (0.089035) | 0.006153 / 0.007986 (-0.001833) | 0.003345 / 0.004328 (-0.000984) | 0.075314 / 0.004250 (0.071064) | 0.061478 / 0.037052 (0.024426) | 0.362948 / 0.258489 (0.104459) | 0.401533 / 0.293841 (0.107692) | 0.032363 / 0.128546 (-0.096184) | 0.008780 / 0.075646 (-0.066867) | 0.328691 / 0.419271 (-0.090580) | 0.054253 / 0.043533 (0.010721) | 0.340783 / 0.255139 (0.085644) | 0.360705 / 0.283200 (0.077505) | 0.023183 / 0.141683 (-0.118500) | 1.484078 / 1.452155 (0.031924) | 1.528581 / 1.492716 (0.035865) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208732 / 0.018006 (0.190726) | 0.452572 / 0.000490 (0.452082) | 0.002936 / 0.000200 (0.002737) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024616 / 0.037411 (-0.012795) | 0.107547 / 0.014526 (0.093021) | 0.114492 / 0.176557 (-0.062065) | 0.171770 / 0.737135 (-0.565365) | 0.122538 / 0.296338 (-0.173800) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.406140 / 0.215209 (0.190930) | 4.062391 / 2.077655 (1.984736) | 1.865962 / 1.504120 (0.361842) | 1.682236 / 1.541195 (0.141041) | 1.738119 / 1.468490 (0.269629) | 0.532244 / 4.584777 (-4.052533) | 3.816421 / 3.745712 (0.070709) | 2.981205 / 5.269862 (-2.288656) | 1.519497 / 4.565676 (-3.046179) | 0.065904 / 0.424275 (-0.358371) | 0.011277 / 0.007607 (0.003670) | 0.512789 / 0.226044 (0.286745) | 5.107618 / 2.268929 (2.838690) | 2.419399 / 55.444624 (-53.025226) | 2.079262 / 6.876477 (-4.797214) | 2.150447 / 2.142072 (0.008375) | 0.696737 / 4.805227 (-4.108490) | 0.142497 / 6.500664 (-6.358167) | 0.063521 / 0.075469 (-0.011949) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.180692 / 1.841788 (-0.661095) | 14.343084 / 8.074308 (6.268776) | 13.303719 / 10.191392 (3.112327) | 0.164234 / 0.680424 (-0.516190) | 0.017439 / 0.534201 (-0.516762) | 0.399712 / 0.579283 (-0.179571) | 0.428248 / 0.434364 (-0.006115) | 0.471909 / 0.540337 (-0.068428) | 0.573853 / 1.386936 (-0.813083) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006210 / 0.011353 (-0.005143) | 0.004104 / 0.011008 (-0.006905) | 0.075140 / 0.038508 (0.036632) | 0.044647 / 0.023109 (0.021538) | 0.370120 / 0.275898 (0.094222) | 0.452936 / 0.323480 (0.129457) | 0.003943 / 0.007986 (-0.004042) | 0.003285 / 0.004328 (-0.001043) | 0.075267 / 0.004250 (0.071017) | 0.055517 / 0.037052 (0.018465) | 0.396385 / 0.258489 (0.137896) | 0.447870 / 0.293841 (0.154029) | 0.031342 / 0.128546 (-0.097204) | 0.008720 / 0.075646 (-0.066926) | 0.082702 / 0.419271 (-0.336570) | 0.051010 / 0.043533 (0.007477) | 0.350546 / 0.255139 (0.095407) | 0.425395 / 0.283200 (0.142195) | 0.024483 / 0.141683 (-0.117200) | 1.467341 / 1.452155 (0.015186) | 1.537187 / 1.492716 (0.044471) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.218067 / 0.018006 (0.200061) | 0.441603 / 0.000490 (0.441114) | 0.003711 / 0.000200 (0.003512) | 0.000092 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028669 / 0.037411 (-0.008742) | 0.112941 / 0.014526 (0.098415) | 0.122584 / 0.176557 (-0.053972) | 0.176494 / 0.737135 (-0.560641) | 0.129369 / 0.296338 (-0.166970) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434543 / 0.215209 (0.219334) | 4.344056 / 2.077655 (2.266401) | 2.079286 / 1.504120 (0.575166) | 1.887264 / 1.541195 (0.346069) | 1.910386 / 1.468490 (0.441896) | 0.538824 / 4.584777 (-4.045953) | 3.844786 / 3.745712 (0.099074) | 2.902091 / 5.269862 (-2.367770) | 1.270852 / 4.565676 (-3.294824) | 0.066324 / 0.424275 (-0.357951) | 0.011346 / 0.007607 (0.003739) | 0.537122 / 0.226044 (0.311078) | 5.367354 / 2.268929 (3.098426) | 2.533672 / 55.444624 (-52.910952) | 2.203260 / 6.876477 (-4.673217) | 2.224310 / 2.142072 (0.082237) | 0.663806 / 4.805227 (-4.141422) | 0.142758 / 6.500664 (-6.357906) | 0.063870 / 0.075469 (-0.011599) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.260487 / 1.841788 (-0.581301) | 14.800106 / 8.074308 (6.725798) | 13.993488 / 10.191392 (3.802096) | 0.165829 / 0.680424 (-0.514595) | 0.017347 / 0.534201 (-0.516854) | 0.401819 / 0.579283 (-0.177464) | 0.424577 / 0.434364 (-0.009787) | 0.475161 / 0.540337 (-0.065176) | 0.574659 / 1.386936 (-0.812277) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1377/comments | https://api.github.com/repos/huggingface/datasets/issues/1377/events | https://github.com/huggingface/datasets/pull/1377 | 760,309,435 | MDExOlB1bGxSZXF1ZXN0NTM1MTYyOTcz | 1,377 | adding marathi-wiki dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 3 | 2020-12-09T13:01:20Z | 2022-10-03T09:39:09Z | 2022-10-03T09:39:09Z | null | Adding marathi-wiki-articles dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1377/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/1377.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1377",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1377.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1377"
} | true | [
"Can you make it a draft PR until you've added the dataset please ? @ekdnam ",
"Done",
"Thanks for your contribution, @ekdnam. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/5165 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5165/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5165/comments | https://api.github.com/repos/huggingface/datasets/issues/5165/events | https://github.com/huggingface/datasets/issues/5165 | 1,423,616,677 | I_kwDODunzps5U2qql | 5,165 | Memory explosion when trying to access 4d tensors in datasets cast to torch or np | [] | open | false | null | 0 | 2022-10-26T08:14:47Z | 2022-10-26T08:14:47Z | null | null | ### Describe the bug
When trying to access an item by index, in a datasets.Dataset cast to torch/np using `set_format` or `with_format`, we get a memory explosion if the item contains 4d (or above) tensors.
### Steps to reproduce the bug
MWE:
```python
from datasets import load_dataset
import numpy as np
def create_4d_tensor(item):
i = item["num_nodes"]
item["x_big"] = np.random.rand(i, 2*i, int(i/2), 1) + 1 # we create a big 4d tensor
return item
if __name__ == "__main__":
dataset = load_dataset(path=f"graphs-datasets/PROTEINS")
# This works
print(dataset["train"].format)
print(dataset["train"][0].keys())
dataset = dataset.map(
create_4d_tensor,
batched=False,
writer_batch_size=100,
)
# This works
print(dataset["train"].format)
print(dataset["train"][0].keys())
dataset.set_format("torch")
print(dataset["train"].format)
# This gets killed :(
print(dataset["train"][0].keys())
```
The problem likely comes from `format_table` [here](https://cs.github.com/huggingface/datasets/blob/f09f781be3278156ce3aa6ec90c1926b1846a78f/src/datasets/arrow_dataset.py#L2328)
### Expected behavior
No memory explosion when trying to access dataset items after cast.
### Environment info
- `datasets` version: 2.3.2
- Platform: Linux-5.14.0-1054-oem-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 8.0.0
- Pandas version: 1.4.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5165/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5165/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5834 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5834/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5834/comments | https://api.github.com/repos/huggingface/datasets/issues/5834/events | https://github.com/huggingface/datasets/issues/5834 | 1,702,448,892 | I_kwDODunzps5leU78 | 5,834 | Is uint8 supported? | [] | closed | false | null | 5 | 2023-05-09T17:31:13Z | 2023-05-13T05:04:21Z | 2023-05-13T05:04:21Z | null | ### Describe the bug
I expect the dataset to store the data in the `uint8` data type, but it's returning `int64` instead.
While I've found that `datasets` doesn't yet support float16 (https://github.com/huggingface/datasets/issues/4981), I'm wondering if this is the case for other data types as well.
Is there a way to store vector data as `uint8` and then upload it to the hub?
### Steps to reproduce the bug
```python
from datasets import Features, Dataset, Sequence, Value
import numpy as np
dataset = Dataset.from_dict(
{"vector": [np.array([0, 1, 2], dtype=np.uint8)]}, features=Features({"vector": Sequence(Value("uint8"))})
).with_format("numpy")
print(dataset[0]["vector"].dtype)
```
### Expected behavior
Expected: `uint8`
Actual: `int64`
### Environment info
- `datasets` version: 2.12.0
- Platform: macOS-12.1-x86_64-i386-64bit
- Python version: 3.8.12
- Huggingface_hub version: 0.12.1
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5834/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5834/timeline | null | completed | null | null | false | [
"Hi ! The numpy formatting detaults to int64 and float32 - but you can use uint8 using\r\n```python\r\nds = ds.with_format(\"numpy\", dtype=np.uint8)\r\n```",
"Related to https://github.com/huggingface/datasets/issues/5517.",
"Thank you!\r\nBy setting `ds.with_format(\"numpy\", dtype=np.uint8)`, the dataset returns the data in `uint8`.\r\n\r\nHowever, `with_format` and `set_format` seem to cast the data on-the-fly.\r\nI want to reduce the dataset size by using `uint8` instead of `int64` and I observe no difference between using `int64` and `uint8` for the vector.\r\nIs there any way to actually store the data in `uint8` and save the disk space and the downloading time when loaded from the hub?\r\n",
"If the feature type is `Value(\"uint8\")` then it's written an uint8 on disk using the uint8 Arrow dtype.\r\n\r\ne.g.\r\n```python\r\nds = Dataset.from_dict({\"a\": range(10)}, features=Features({\"a\": Value(\"uint8\")}))\r\nds.data.nbytes\r\n# 10\r\n```",
"Oh, I understand now.\r\nThe data was stored in `uint8` from the beginning (when the dataset returns `int64`).\r\n\r\nThank you for your time!\r\nMy question is fully resolved."
] |
https://api.github.com/repos/huggingface/datasets/issues/1719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1719/comments | https://api.github.com/repos/huggingface/datasets/issues/1719/events | https://github.com/huggingface/datasets/pull/1719 | 783,557,542 | MDExOlB1bGxSZXF1ZXN0NTUyODk3MzY4 | 1,719 | Fix column list comparison in transmit format | [] | closed | false | null | 0 | 2021-01-11T17:23:56Z | 2021-01-11T18:45:03Z | 2021-01-11T18:45:02Z | null | As noticed in #1718 the cache might not reload the cache files when new columns were added.
This is because of an issue in `transmit_format` where the column list comparison fails because the order was not deterministic. This causes the `transmit_format` to apply an unnecessary `set_format` transform with shuffled column names.
I fixed that by sorting the columns for the comparison and added a test.
To properly test that I added a third column `col_3` to the dummy_dataset used for tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1719/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1719/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1719.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1719",
"merged_at": "2021-01-11T18:45:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1719.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1719"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2311/comments | https://api.github.com/repos/huggingface/datasets/issues/2311/events | https://github.com/huggingface/datasets/pull/2311 | 875,262,208 | MDExOlB1bGxSZXF1ZXN0NjI5NjQwNTMx | 2,311 | Add SLR52, SLR53 and SLR54 to OpenSLR | [] | closed | false | null | 2 | 2021-05-04T09:08:03Z | 2021-05-07T09:50:55Z | 2021-05-07T09:50:55Z | null | Add large speech datasets for Sinhala, Bengali and Nepali. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2311/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2311/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2311.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2311",
"merged_at": "2021-05-07T09:50:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2311.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2311"
} | true | [
"Hi @lhoestq , I am not sure about the error message:\r\n```\r\n#!/bin/bash -eo pipefail\r\n./scripts/datasets_metadata_validator.py\r\nWARNING:root:❌ Failed to validate 'datasets/openslr/README.md':\r\n__init__() got an unexpected keyword argument 'SLR32'\r\nINFO:root:❌ Failed on 1 files.\r\n\r\nExited with code exit status 1\r\nCircleCI received exit code 1 \r\n```\r\nCould you have a look please? Thanks.",
"Hi ! The error is unrelated to your PR and has been fixed on master\r\nNext time feel free to merge master into your branch to fix the CI error ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/985 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/985/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/985/comments | https://api.github.com/repos/huggingface/datasets/issues/985/events | https://github.com/huggingface/datasets/pull/985 | 755,020,564 | MDExOlB1bGxSZXF1ZXN0NTMwODEyNTM1 | 985 | Add GAP dataset | [] | closed | false | null | 3 | 2020-12-02T07:25:11Z | 2022-10-06T14:11:52Z | 2020-12-02T16:16:32Z | null | GAP dataset
Gender bias coreference resolution | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/985/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/985/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/985.diff",
"html_url": "https://github.com/huggingface/datasets/pull/985",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/985.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/985"
} | true | [
"This dataset already exists apparently, sorry :/ \r\nsee\r\nhttps://github.com/huggingface/datasets/blob/master/datasets/gap/gap.py\r\n\r\nFeel free to re-use the dataset card you did for `/datasets/gap`\r\n",
"oh heck, my bad 🤦♂️ sorry",
"I think you should also delete this branch."
] |
https://api.github.com/repos/huggingface/datasets/issues/3192 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3192/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3192/comments | https://api.github.com/repos/huggingface/datasets/issues/3192/events | https://github.com/huggingface/datasets/issues/3192 | 1,041,308,086 | I_kwDODunzps4-ERm2 | 3,192 | Multiprocessing filter/map (tests) not working on Windows | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 0 | 2021-11-01T15:36:08Z | 2021-11-01T15:57:03Z | null | null | While running the tests, I found that the multiprocessing examples fail on Windows, or rather they do not complete: they cause a deadlock. I haven't dug deep into it, but they do not seem to work as-is. I currently have no time to tests this in detail but at least the tests seem not to run correctly (deadlocking).
## Steps to reproduce the bug
```shell
pytest tests/test_arrow_dataset.py -k "test_filter_multiprocessing"
pytest tests/test_arrow_dataset.py -k "test_map_multiprocessing"
```
## Expected results
The functionality to work on all platforms.
## Actual results
Deadlock.
## Environment info
- `datasets` version: 1.14.1.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.9.2, also tested with 3.7.9
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3192/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3192/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1875 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1875/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1875/comments | https://api.github.com/repos/huggingface/datasets/issues/1875/events | https://github.com/huggingface/datasets/pull/1875 | 807,887,267 | MDExOlB1bGxSZXF1ZXN0NTczMDM2NzE0 | 1,875 | Adding sari metric | [] | closed | false | null | 0 | 2021-02-14T04:38:35Z | 2021-02-17T15:56:27Z | 2021-02-17T15:56:27Z | null | Adding SARI metric that is used in evaluation of text simplification. This is required as part of the GEM benchmark. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1875/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1875/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1875.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1875",
"merged_at": "2021-02-17T15:56:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1875.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1875"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3916/comments | https://api.github.com/repos/huggingface/datasets/issues/3916/events | https://github.com/huggingface/datasets/pull/3916 | 1,168,869,191 | PR_kwDODunzps40a-cR | 3,916 | Create README.md for GLUE | [] | closed | false | null | 1 | 2022-03-14T20:27:22Z | 2022-03-15T17:06:57Z | 2022-03-15T17:06:56Z | null | I still have a hesitation regarding the format of inputs -- whether it's a list or a list of lists? -- hopefully @lhoestq will be able to clarify.
Also tagging @yjernite for the Limitations section. Happy to hear your thoughts! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3916/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3916",
"merged_at": "2022-03-15T17:06:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3916"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3916). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/982 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/982/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/982/comments | https://api.github.com/repos/huggingface/datasets/issues/982/events | https://github.com/huggingface/datasets/pull/982 | 754,946,337 | MDExOlB1bGxSZXF1ZXN0NTMwNzUxMzYx | 982 | add prachathai67k take2 | [] | closed | false | null | 0 | 2020-12-02T05:12:01Z | 2020-12-02T10:18:11Z | 2020-12-02T10:18:11Z | null | I decided it will be faster to create a new pull request instead of fixing the rebase issues.
continuing from https://github.com/huggingface/datasets/pull/954
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/982/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/982/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/982.diff",
"html_url": "https://github.com/huggingface/datasets/pull/982",
"merged_at": "2020-12-02T10:18:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/982.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/982"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1662/comments | https://api.github.com/repos/huggingface/datasets/issues/1662/events | https://github.com/huggingface/datasets/issues/1662 | 775,890,154 | MDU6SXNzdWU3NzU4OTAxNTQ= | 1,662 | Arrow file is too large when saving vector data | [] | closed | false | null | 4 | 2020-12-29T13:23:12Z | 2021-01-21T14:12:39Z | 2021-01-21T14:12:39Z | null | I computed the sentence embedding of each sentence of bookcorpus data using bert base and saved them to disk. I used 20M sentences and the obtained arrow file is about 59GB while the original text file is only about 1.3GB. Are there any ways to reduce the size of the arrow file? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1662/timeline | null | completed | null | null | false | [
"Hi !\r\nThe arrow file size is due to the embeddings. Indeed if they're stored as float32 then the total size of the embeddings is\r\n\r\n20 000 000 vectors * 768 dimensions * 4 bytes per dimension ~= 60GB\r\n\r\nIf you want to reduce the size you can consider using quantization for example, or maybe using dimension reduction techniques.\r\n",
"Thanks for your reply @lhoestq.\r\nI want to save original embedding for these sentences for subsequent calculations. So does arrow have a way to save in a compressed format to reduce the size of the file?",
"Arrow doesn't have compression since it is designed to have no serialization overhead",
"I see. Thank you."
] |
https://api.github.com/repos/huggingface/datasets/issues/4051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4051/comments | https://api.github.com/repos/huggingface/datasets/issues/4051/events | https://github.com/huggingface/datasets/issues/4051 | 1,184,400,179 | I_kwDODunzps5GmIMz | 4,051 | ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/2.0.0/datasets/glue/glue.py | [] | closed | false | null | 5 | 2022-03-29T07:00:31Z | 2022-05-08T07:27:32Z | 2022-03-29T08:29:25Z | null | Hi, I meet a problem.
When I run the code:
`dataset = load_dataset('glue','sst2')`
There is a issue raising:
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/2.0.0/datasets/glue/glue.py
I don't know why; it is ok when I use Google Chrome to view this url.
Thanks for your help! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4051/timeline | null | completed | null | null | false | [
"Hi @klyuhang9,\r\n\r\nI'm sorry but I can't reproduce your problem:\r\n```python\r\nIn [4]: ds = load_dataset(\"glue\", \"sst2\", download_mode=\"force_redownload\")\r\nDownloading builder script: 28.8kB [00:00, 9.15MB/s] \r\nDownloading metadata: 28.7kB [00:00, 10.7MB/s] \r\nDownloading and preparing dataset glue/sst2 (download: 7.09 MiB, generated: 4.78 MiB, post-processed: Unknown size, total: 11.88 MiB) to .../.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad...\r\nDownloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7.44M/7.44M [00:01<00:00, 4.12MB/s]\r\nDataset glue downloaded and prepared to .../.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad. Subsequent calls will reuse this data. \r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1047.96it/s]\r\n\r\nIn [5]: ds\r\nOut[5]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 67349\r\n })\r\n validation: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 872\r\n })\r\n test: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 1821\r\n })\r\n})\r\n```\r\n\r\nPlease, note that sometimes GitHub has some temporary connectivity issues. Feel free to retry and re-open this issue if the problem persists.",
"Maybe it's because we are in China.",
"Are you able to access the URL in your web browser?",
"> Are you able to access the URL in your web browser?\r\n\r\nYes, with or without a VPN, we (people in China) can access the URL. And we can even use wget to download these files. We can download the pretrained language model automatically with the code.\r\nHowever, we CANNOT access glue.py & metric.py automatically. Every time, it will raise ConnectionError, and we have to download datasets manually (SQuAD is extremely hard to preprocess) and replace metric.py with scipy.metrics. If this problem is solved, many Chinese will save a lot of time.",
"> ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/2.0.0/datasets/glue/glue.py\r\n> \r\n> I don't know why; it is ok when I use\r\n\r\nIf you would query the question `ConnectionError: Couldn't reach` in www.baidu.com (Chinese Google, Google is banned and some people cannot access it), you will find that there are so many questions about accessing `https://raw.githubusercontent.com`. There are some solutions like adding `185.199.108.133 raw.githubusercontent.com` to `C:/windows/systen32/drives/etc/hosts`, but it is time-consuming, hard for green-hand, and invalid sometimes."
] |
https://api.github.com/repos/huggingface/datasets/issues/1930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1930/comments | https://api.github.com/repos/huggingface/datasets/issues/1930/events | https://github.com/huggingface/datasets/pull/1930 | 814,055,198 | MDExOlB1bGxSZXF1ZXN0NTc4MTAwNzI0 | 1,930 | updated the wino_bias dataset | [] | closed | false | null | 3 | 2021-02-23T03:07:40Z | 2021-04-07T15:24:56Z | 2021-04-07T15:24:56Z | null | Updated the wino_bias.py script.
- updated the data_url
- added different configurations for different data splits
- added the coreference_cluster to the data features | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1930/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1930.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1930",
"merged_at": "2021-04-07T15:24:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1930.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1930"
} | true | [
"Hi @JieyuZhao ! Have you had a chance to add the different configurations ?\r\nThanks again for your help on this !",
"> Hi @JieyuZhao ! Have you had a chance to add the different configurations ?\r\n> Thanks again for your help on this !\r\n\r\nHi @lhoestq Yes, I've updated the code. Now the configuration will have dev/test splits.",
"> Cool thanks !\r\n> This looks perfect this way.\r\n> \r\n> Now we just need to update the dataset_infos.json (it contains the metadata of the dataset) and add dummy data to be able to test this script automatically.\r\n> \r\n> To update the dataset_infos.json you just need delete the current one at `./datasets/wino_biais/dataset_infos.json`, and then run this command:\r\n> \r\n> ```\r\n> datasets-cli test ./datasets/wino_biais --save_infos --all_configs --ignore_verifications\r\n> ```\r\n> \r\n> To add the dummy data there's also a tool to add them automatically.\r\n> First delete the folder at `./datasets/wino_biais/dummy` and then run\r\n> \r\n> ```\r\n> datasets-cli dummy_data ./datasets/wino_biais --auto_generate --match_text_files \"*conll\" --n_lines 15\r\n> ```\r\n> \r\n> Let me know if you have questions :)\r\n> Also don't forget to run `make style` to format the code properly.\r\n\r\nThanks for the instruction! I've updated the metadata and the dummy data and also do the formatting. Please let me know if more is needed. :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3136 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3136/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3136/comments | https://api.github.com/repos/huggingface/datasets/issues/3136/events | https://github.com/huggingface/datasets/pull/3136 | 1,033,360,396 | PR_kwDODunzps4tieFi | 3,136 | Fix script of Arabic Billion Words dataset to return all data | [] | closed | false | null | 0 | 2021-10-22T09:14:24Z | 2021-10-22T13:28:41Z | 2021-10-22T13:28:40Z | null | The script has a bug and only parses and generates a portion of the entire dataset.
This PR fixes the loading script so that is properly parses the entire dataset.
Current implementation generates the same number of examples as reported in the [original paper](https://arxiv.org/abs/1611.04033) for all configurations except for one:
- For "Youm7" we generate more examples (1172136) than the ones reported by the paper (1025027)
| | Number of examples | Number of examples according to the source |
|:---------------|-------------------:|-----:|
| Alittihad | 349342 |349342 |
| Almasryalyoum | 291723 |291723 |
| Almustaqbal | 446873 |446873 |
| Alqabas | 817274 |817274 |
| Echoroukonline | 139732 |139732 |
| Ryiadh | 858188 | 858188 |
| Sabanews | 92149 |92149 |
| SaudiYoum | 888068 |888068 |
| Techreen | 314597 |314597 |
| Youm7 | 1172136 |1025027 |
Fix #3126. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3136/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3136/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3136.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3136",
"merged_at": "2021-10-22T13:28:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3136.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3136"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2536 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2536/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2536/comments | https://api.github.com/repos/huggingface/datasets/issues/2536/events | https://github.com/huggingface/datasets/issues/2536 | 927,338,639 | MDU6SXNzdWU5MjczMzg2Mzk= | 2,536 | Use `Audio` features for `AutomaticSpeechRecognition` task template | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2021-06-22T15:07:21Z | 2022-06-01T17:18:16Z | 2022-06-01T17:18:16Z | null | In #2533 we added a task template for speech recognition that relies on the file paths to the audio files. As pointed out by @SBrandeis this is brittle as it doesn't port easily across different OS'.
The solution is to use dedicated `Audio` features when casting the dataset. These features are not yet available in `datasets`, but should be included in the `AutomaticSpeechRecognition` template once they are. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2536/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2536/timeline | null | completed | null | null | false | [
"I'm just retaking and working on #2324. 😉 ",
"Resolved via https://github.com/huggingface/datasets/pull/4006."
] |
https://api.github.com/repos/huggingface/datasets/issues/704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/704/comments | https://api.github.com/repos/huggingface/datasets/issues/704/events | https://github.com/huggingface/datasets/pull/704 | 713,572,556 | MDExOlB1bGxSZXF1ZXN0NDk2ODY2NTQ0 | 704 | Fix remote tests for new datasets | [] | closed | false | null | 0 | 2020-10-02T12:08:04Z | 2020-10-02T12:12:02Z | 2020-10-02T12:12:01Z | null | When adding a new dataset, the remote tests fail because they try to get the new dataset from the master branch (i.e., where the dataset doesn't exist yet)
To fix that I reverted to the use of the HF API that fetch the available datasets on S3 that is synced with the master branch | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/704/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/704/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/704.diff",
"html_url": "https://github.com/huggingface/datasets/pull/704",
"merged_at": "2020-10-02T12:12:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/704.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/704"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1738/comments | https://api.github.com/repos/huggingface/datasets/issues/1738/events | https://github.com/huggingface/datasets/pull/1738 | 786,068,440 | MDExOlB1bGxSZXF1ZXN0NTU0OTk2NDU4 | 1,738 | Conda support | [] | closed | false | null | 3 | 2021-01-14T15:11:25Z | 2021-01-15T10:08:20Z | 2021-01-15T10:08:19Z | null | Will push a new version on anaconda cloud every time a tag starting with `v` is pushed (like `v1.2.2`).
Will appear here: https://anaconda.org/huggingface/datasets
Depends on `conda-forge` for now, so the following is required for installation:
```
conda install -c huggingface -c conda-forge datasets
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 4,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1738/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1738/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1738.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1738",
"merged_at": "2021-01-15T10:08:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1738.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1738"
} | true | [
"Nice thanks :) \r\nNote that in `datasets` the tags are simply the version without the `v`. For example `1.2.1`.",
"Do you push tags only for versions?",
"Yes I've always used tags only for versions"
] |
https://api.github.com/repos/huggingface/datasets/issues/5191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5191/comments | https://api.github.com/repos/huggingface/datasets/issues/5191/events | https://github.com/huggingface/datasets/pull/5191 | 1,433,191,658 | PR_kwDODunzps5CD0Qp | 5,191 | Make torch.Tensor and spacy models cacheable | [] | closed | false | null | 1 | 2022-11-02T13:56:18Z | 2022-11-02T17:20:48Z | 2022-11-02T17:18:42Z | null | Override `Pickler.save` to implement deterministic reduction (lazily registered; inspired by https://github.com/uqfoundation/dill/blob/master/dill/_dill.py#L343) functions for `torch.Tensor` and spaCy models.
Fix https://github.com/huggingface/datasets/issues/5170, fix https://github.com/huggingface/datasets/issues/3178
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5191/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5191/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5191.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5191",
"merged_at": "2022-11-02T17:18:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5191.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5191"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4640/comments | https://api.github.com/repos/huggingface/datasets/issues/4640/events | https://github.com/huggingface/datasets/pull/4640 | 1,295,495,699 | PR_kwDODunzps4660rI | 4,640 | Support all split in streaming mode | [] | open | false | null | 1 | 2022-07-06T08:56:38Z | 2022-07-06T15:19:55Z | null | null | Fix #4637. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4640/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4640/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/4640.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4640",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4640.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4640"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4640). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/3332 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3332/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3332/comments | https://api.github.com/repos/huggingface/datasets/issues/3332/events | https://github.com/huggingface/datasets/pull/3332 | 1,065,345,853 | PR_kwDODunzps4vGBig | 3,332 | Fix error message and add extension fallback | [] | closed | false | null | 0 | 2021-11-28T14:25:29Z | 2021-11-29T13:34:15Z | 2021-11-29T13:34:14Z | null | Fix the error message raised if `infered_module_name` is `None` in `CommunityDatasetModuleFactoryWithoutScript.get_module` and make `infer_module_for_data_files` more robust.
In the linked issue, `infer_module_for_data_files` returns `None` because `json` is the second most common extension due to the suffix ordering. Now, we go from the most common to the least common extension and try to map it or return `None`.
Fix #3331 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3332/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3332/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3332.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3332",
"merged_at": "2021-11-29T13:34:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3332.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3332"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5439/comments | https://api.github.com/repos/huggingface/datasets/issues/5439/events | https://github.com/huggingface/datasets/issues/5439 | 1,537,973,564 | I_kwDODunzps5bq508 | 5,439 | [dataset request] Add Common Voice 12.0 | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2023-01-18T13:07:05Z | 2023-07-21T14:26:10Z | 2023-07-21T14:26:09Z | null | ### Feature request
Please add the common voice 12_0 datasets. Apart from English, a significant amount of audio-data has been added to the other minor-language datasets.
### Motivation
The dataset link:
https://commonvoice.mozilla.org/en/datasets
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5439/timeline | null | completed | null | null | false | [
"@polinaeterna any tentative date on when the Common Voice 12.0 dataset will be added ?",
"This dataset is now hosted on the Hub here: https://huggingface.co/datasets/mozilla-foundation/common_voice_12_0"
] |
https://api.github.com/repos/huggingface/datasets/issues/3131 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3131/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3131/comments | https://api.github.com/repos/huggingface/datasets/issues/3131/events | https://github.com/huggingface/datasets/issues/3131 | 1,032,309,865 | I_kwDODunzps49h8xp | 3,131 | Add ADE20k | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",
"default": false,
"description": "Vision datasets",
"id": 3608941089,
"name": "vision",
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision"
}
] | closed | false | null | 1 | 2021-10-21T10:13:09Z | 2023-01-27T14:40:20Z | 2023-01-27T14:40:20Z | null | ## Adding a Dataset
- **Name:** ADE20k (actually it's called the MIT Scene Parsing Benchmark, it's actually a subset of ADE20k but a lot of authors still call it ADE20k)
- **Description:** A semantic segmentation dataset, consisting of 150 classes.
- **Paper:** http://people.csail.mit.edu/bzhou/publication/scene-parse-camera-ready.pdf
- **Data:** http://sceneparsing.csail.mit.edu/
- **Motivation:** I am currently adding Transformer-based semantic segmentation models that achieve SOTA on this dataset. It would be great to directly access this dataset using HuggingFace Datasets, in order to make example scripts in HuggingFace Transformers.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3131/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3131/timeline | null | completed | null | null | false | [
"I think we can close this issue since PR [#3607](https://github.com/huggingface/datasets/pull/3607) solves this."
] |
https://api.github.com/repos/huggingface/datasets/issues/3981 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3981/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3981/comments | https://api.github.com/repos/huggingface/datasets/issues/3981/events | https://github.com/huggingface/datasets/pull/3981 | 1,175,423,517 | PR_kwDODunzps40vfra | 3,981 | Add TER metric card | [] | closed | false | null | 1 | 2022-03-21T13:54:36Z | 2022-03-29T13:57:11Z | 2022-03-29T13:51:40Z | null | Add TER metric card
This card is still missing content for the following sections:
- **Limitations & Biases**
- **Values from Papers**
If anyone has any ideas for either of the above, feel free to either add them or point me to them and I'll add them! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3981/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3981/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3981.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3981",
"merged_at": "2022-03-29T13:51:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3981.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3981"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/6071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6071/comments | https://api.github.com/repos/huggingface/datasets/issues/6071/events | https://github.com/huggingface/datasets/issues/6071 | 1,821,990,749 | I_kwDODunzps5smV9d | 6,071 | storage_options provided to load_dataset not fully piping through since datasets 2.14.0 | [] | closed | false | null | 2 | 2023-07-26T09:37:20Z | 2023-07-27T12:42:58Z | 2023-07-27T12:42:58Z | null | ### Describe the bug
Since the latest release of `datasets` (`2.14.0`), custom filesystem `storage_options` passed to `load_dataset()` do not seem to propagate through all the way - leading to problems if loading data files that need those options to be set.
I think this is because of the new `_prepare_path_and_storage_options()` (https://github.com/huggingface/datasets/pull/6028), which returns the right `storage_options` to use given a path and a `DownloadConfig` - but which might not be taking into account the extra `storage_options` explicitly provided e.g. through `load_dataset()`
### Steps to reproduce the bug
```python
import fsspec
import pandas as pd
import datasets
# Generate mock parquet file
data_files = "demo.parquet"
pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]}).to_parquet(data_files)
_storage_options = {"x": 1, "y": 2}
fs = fsspec.filesystem("file", **_storage_options)
dataset = datasets.load_dataset(
"parquet",
data_files=data_files,
storage_options=fs.storage_options
)
```
Looking at the `storage_options` resolved here:
https://github.com/huggingface/datasets/blob/b0177910b32712f28d147879395e511207e39958/src/datasets/data_files.py#L331
they end up being `{}`, instead of propagating through the `storage_options` that were provided to `load_dataset` (`fs.storage_options`). As these then get used for the filesystem operation a few lines below
https://github.com/huggingface/datasets/blob/b0177910b32712f28d147879395e511207e39958/src/datasets/data_files.py#L339
the call will fail if the user-provided `storage_options` were needed.
---
A temporary workaround that seemed to work locally to bypass the problem was to bundle a duplicate of the `storage_options` into the `download_config`, so that they make their way all the way to `_prepare_path_and_storage_options()` and get extracted correctly:
```python
dataset = datasets.load_dataset(
"parquet",
data_files=data_files,
storage_options=fs.storage_options,
download_config=datasets.DownloadConfig(storage_options={fs.protocol: fs.storage_options}),
)
```
### Expected behavior
`storage_options` provided to `load_dataset` take effect in all backend filesystem operations.
### Environment info
datasets==2.14.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6071/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6071/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting, I opened a PR to fix this\r\n\r\nWhat filesystem are you using ?",
"Hi @lhoestq ! Thank you so much 🙌 \r\n\r\nIt's a bit of a custom setup, but in practice I am using a [pyarrow.fs.S3FileSystem](https://arrow.apache.org/docs/python/generated/pyarrow.fs.S3FileSystem.html) (wrapped in a `fsspec.implementations.arrow.ArrowFSWrapper` [to make it](https://arrow.apache.org/docs/python/filesystems.html#using-arrow-filesystems-with-fsspec) `fsspec` compatible). I also register it as an entrypoint with `fsspec` so that it's the one that gets automatically resolved when looking for filesystems for the `s3` protocol\r\n\r\nIn my case the `storage_option` that seemed not getting piped through was the filesystem's `endpoint_override` that I use in some tests to point at a mock S3 bucket"
] |
https://api.github.com/repos/huggingface/datasets/issues/6022 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6022/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6022/comments | https://api.github.com/repos/huggingface/datasets/issues/6022/events | https://github.com/huggingface/datasets/issues/6022 | 1,800,092,589 | I_kwDODunzps5rSzut | 6,022 | Batch map raises TypeError: '>=' not supported between instances of 'NoneType' and 'int' | [] | closed | false | null | 1 | 2023-07-12T03:20:17Z | 2023-07-12T16:18:06Z | 2023-07-12T16:18:05Z | null | ### Describe the bug
When mapping some datasets with `batched=True`, datasets may raise an exeception:
```python
Traceback (most recent call last):
File "/Users/codingl2k1/Work/datasets/venv/lib/python3.11/site-packages/multiprocess/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 1328, in _write_generator_to_queue
for i, result in enumerate(func(**kwargs)):
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 3483, in _map_single
writer.write_batch(batch)
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_writer.py", line 549, in write_batch
array = cast_array_to_feature(col_values, col_type) if col_type is not None else col_values
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/table.py", line 1831, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/table.py", line 1831, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/table.py", line 2063, in cast_array_to_feature
return feature.cast_storage(array)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/features/features.py", line 1098, in cast_storage
if min_max["max"] >= self.num_classes:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: '>=' not supported between instances of 'NoneType' and 'int'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/codingl2k1/Work/datasets/t1.py", line 33, in <module>
ds = ds.map(transforms, num_proc=14, batched=True, batch_size=5)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/dataset_dict.py", line 850, in map
{
File "/Users/codingl2k1/Work/datasets/src/datasets/dataset_dict.py", line 851, in <dictcomp>
k: dataset.map(
^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 577, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 542, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 3179, in map
for rank, done, content in iflatmap_unordered(
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 1368, in iflatmap_unordered
[async_result.get(timeout=0.05) for async_result in async_results]
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 1368, in <listcomp>
[async_result.get(timeout=0.05) for async_result in async_results]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/venv/lib/python3.11/site-packages/multiprocess/pool.py", line 774, in get
raise self._value
TypeError: '>=' not supported between instances of 'NoneType' and 'int'
```
### Steps to reproduce the bug
1. Checkout the latest main of datasets.
2. Run the code:
```python
from datasets import load_dataset
def transforms(examples):
# examples["pixel_values"] = [image.convert("RGB").resize((100, 100)) for image in examples["image"]]
return examples
ds = load_dataset("scene_parse_150")
ds = ds.map(transforms, num_proc=14, batched=True, batch_size=5)
print(ds)
```
### Expected behavior
map without exception.
### Environment info
Datasets: https://github.com/huggingface/datasets/commit/b8067c0262073891180869f700ebef5ac3dc5cce
Python: 3.11.4
System: Macos | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6022/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6022/timeline | null | completed | null | null | false | [
"Thanks for reporting! I've opened a PR with a fix."
] |
https://api.github.com/repos/huggingface/datasets/issues/1505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1505/comments | https://api.github.com/repos/huggingface/datasets/issues/1505/events | https://github.com/huggingface/datasets/pull/1505 | 763,750,773 | MDExOlB1bGxSZXF1ZXN0NTM4MTEyMTk5 | 1,505 | add ilist dataset | [] | closed | false | null | 0 | 2020-12-12T12:44:12Z | 2020-12-17T15:43:07Z | 2020-12-17T15:43:07Z | null | This PR will add Indo-Aryan Language Identification Shared Task Dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1505/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1505.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1505",
"merged_at": "2020-12-17T15:43:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1505.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1505"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3713/comments | https://api.github.com/repos/huggingface/datasets/issues/3713/events | https://github.com/huggingface/datasets/pull/3713 | 1,135,692,572 | PR_kwDODunzps4yso6D | 3,713 | Rm sphinx doc | [] | closed | false | null | 2 | 2022-02-13T11:26:31Z | 2022-02-17T10:18:46Z | 2022-02-17T10:12:09Z | null | Checklist
- [x] Update circle ci yaml
- [x] Delete sphinx static & python files in docs dir
- [x] Update readme in docs dir
- [ ] Update docs config in setup.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3713/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3713/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3713.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3713",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3713.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3713"
} | true | [
"Thanks for pushing this :)\r\nOne minor comment regarding the PR itself - I noticed that some changes are coming from the upstream master, this might be due to a rebase. Would be nice if this PR doesn't include them for readabily, feel free to open a new one if necessary",
"Closing in favour https://github.com/huggingface/datasets/pull/3741"
] |
https://api.github.com/repos/huggingface/datasets/issues/1631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1631/comments | https://api.github.com/repos/huggingface/datasets/issues/1631/events | https://github.com/huggingface/datasets/pull/1631 | 774,349,222 | MDExOlB1bGxSZXF1ZXN0NTQ1Mjc5MTE2 | 1,631 | Update README.md | [] | closed | false | null | 0 | 2020-12-24T11:45:52Z | 2020-12-28T17:35:41Z | 2020-12-28T17:16:04Z | null | I made small change for citation | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1631/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1631.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1631",
"merged_at": "2020-12-28T17:16:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1631.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1631"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/508/comments | https://api.github.com/repos/huggingface/datasets/issues/508/events | https://github.com/huggingface/datasets/issues/508 | 679,705,734 | MDU6SXNzdWU2Nzk3MDU3MzQ= | 508 | TypeError: Receiver() takes no arguments | [] | closed | false | null | 5 | 2020-08-16T07:18:16Z | 2020-09-01T14:53:33Z | 2020-09-01T14:49:03Z | null | I am trying to load a wikipedia data set
```
import nlp
from nlp import load_dataset
dataset = load_dataset("wikipedia", "20200501.en", split="train", cache_dir=data_path, beam_runner='DirectRunner')
#dataset = load_dataset('wikipedia', '20200501.sv', cache_dir=data_path, beam_runner='DirectRunner')
```
This fails in the apache beam runner.
```
Traceback (most recent call last):
File "D:/ML/wikiembedding/gpt2_sv.py", line 36, in <module>
dataset = load_dataset("wikipedia", "20200501.en", split="train", cache_dir=my_cache_dir, beam_runner='DirectRunner')
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\nlp\load.py", line 548, in load_dataset
builder_instance.download_and_prepare(
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\nlp\builder.py", line 462, in download_and_prepare
self._download_and_prepare(
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\nlp\builder.py", line 969, in _download_and_prepare
pipeline_results = pipeline.run()
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\apache_beam\pipeline.py", line 534, in run
return self.runner.run_pipeline(self, self._options)
....
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 218, in process_encoded
self.output(decoded_value)
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\apache_beam\runners\worker\operations.py", line 332, in output
cython.cast(Receiver, self.receivers[output_index]).receive(windowed_value)
File "C:\Users\seto\AppData\Local\Programs\Python\Python38\lib\site-packages\Cython\Shadow.py", line 167, in cast
return type(*args)
TypeError: Receiver() takes no arguments
```
This is run on a Windows 10 machine with python 3.8. I get the same error loading the swedish wikipedia dump. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/508/timeline | null | completed | null | null | false | [
"Which version of Apache Beam do you have (can you copy your full environment info here)?",
"apache-beam==2.23.0\r\nnlp==0.4.0\r\n\r\nFor me this was resolved by running the same python script on Linux (or really WSL). ",
"Do you manage to run a dummy beam pipeline with python on windows ? \r\nYou can test a dummy pipeline with [this code](https://github.com/apache/beam/blob/master/sdks/python/apache_beam/examples/wordcount_minimal.py)\r\n\r\nIf you get the same error, it means that the issue comes from apache beam.\r\nOtherwise we'll investigate what went wrong here",
"Still, same error, so I guess it is on apache beam then. \r\nThanks for the investigation.",
"Thanks for trying\r\nLet us know if you find clues of what caused this issue, or if you find a fix"
] |
https://api.github.com/repos/huggingface/datasets/issues/2056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2056/comments | https://api.github.com/repos/huggingface/datasets/issues/2056/events | https://github.com/huggingface/datasets/issues/2056 | 831,718,397 | MDU6SXNzdWU4MzE3MTgzOTc= | 2,056 | issue with opus100/en-fr dataset | [] | closed | false | null | 3 | 2021-03-15T11:32:42Z | 2021-03-16T15:49:00Z | 2021-03-16T15:48:59Z | null | Hi
I am running run_mlm.py code of huggingface repo with opus100/fr-en pair, I am getting this error, note that this error occurs for only this pairs and not the other pairs. Any idea why this is occurring? and how I can solve this?
Thanks a lot @lhoestq for your help in advance.
`
thread '<unnamed>' panicked at 'index out of bounds: the len is 617 but the index is 617', /__w/tokenizers/tokenizers/tokenizers/src/tokenizer/normalizer.rs:382:21
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
63%|██████████████████████████████████████████████████████████▊ | 626/1000 [00:27<00:16, 22.69ba/s]
Traceback (most recent call last):
File "run_mlm.py", line 550, in <module>
main()
File "run_mlm.py", line 412, in main
in zip(data_args.dataset_name, data_args.dataset_config_name)]
File "run_mlm.py", line 411, in <listcomp>
logger) for dataset_name, dataset_config_name\
File "/user/dara/dev/codes/seq2seq/data/tokenize_datasets.py", line 96, in get_tokenized_dataset
load_from_cache_file=not data_args.overwrite_cache,
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/dataset_dict.py", line 448, in map
for k, dataset in self.items()
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/dataset_dict.py", line 448, in <dictcomp>
for k, dataset in self.items()
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1309, in map
update_data=update_data,
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 204, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/fingerprint.py", line 337, in wrapper
out = func(self, *args, **kwargs)
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1574, in _map_single
batch, indices, check_same_num_examples=len(self.list_indexes()) > 0, offset=offset
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1490, in apply_function_on_filtered_inputs
function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "/user/dara/dev/codes/seq2seq/data/tokenize_datasets.py", line 89, in tokenize_function
return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 2347, in __call__
**kwargs,
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 2532, in batch_encode_plus
**kwargs,
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/transformers/tokenization_utils_fast.py", line 384, in _batch_encode_plus
is_pretokenized=is_split_into_words,
pyo3_runtime.PanicException: index out of bounds: the len is 617 but the index is 617
` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2056/timeline | null | completed | null | null | false | [
"@lhoestq I also deleted the cache and redownload the file and still the same issue, I appreciate any help on this. thanks ",
"Here please find the minimal code to reproduce the issue @lhoestq note this only happens with MT5TokenizerFast\r\n\r\n```\r\nfrom datasets import load_dataset\r\nfrom transformers import MT5TokenizerFast\r\n\r\ndef get_tokenized_dataset(dataset_name, dataset_config_name, tokenizer):\r\n datasets = load_dataset(dataset_name, dataset_config_name, script_version=\"master\")\r\n column_names = datasets[\"train\"].column_names\r\n text_column_name = \"translation\"\r\n def process_dataset(datasets):\r\n def process_function(examples):\r\n lang = \"fr\"\r\n return {\"src_texts\": [example[lang] for example in examples[text_column_name]]}\r\n datasets = datasets.map(\r\n process_function,\r\n batched=True,\r\n num_proc=None,\r\n remove_columns=column_names,\r\n load_from_cache_file=True,\r\n )\r\n return datasets\r\n datasets = process_dataset(datasets)\r\n text_column_name = \"src_texts\"\r\n column_names = [\"src_texts\"]\r\n def tokenize_function(examples):\r\n return tokenizer(examples[text_column_name], return_special_tokens_mask=True)\r\n tokenized_datasets = datasets.map(\r\n tokenize_function,\r\n batched=True,\r\n num_proc=None,\r\n remove_columns=column_names,\r\n load_from_cache_file=True\r\n )\r\n\r\nif __name__ == \"__main__\":\r\n tokenizer_kwargs = {\r\n \"cache_dir\": None,\r\n \"use_fast\": True,\r\n \"revision\": \"main\",\r\n \"use_auth_token\": None\r\n }\r\n tokenizer = MT5TokenizerFast.from_pretrained(\"google/mt5-small\", **tokenizer_kwargs)\r\n get_tokenized_dataset(dataset_name=\"opus100\", dataset_config_name=\"en-fr\", tokenizer=tokenizer)\r\n~ \r\n```",
"as per https://github.com/huggingface/tokenizers/issues/626 this looks like to be the tokenizer bug, I therefore, reported it there https://github.com/huggingface/tokenizers/issues/626 and I am closing this one."
] |
https://api.github.com/repos/huggingface/datasets/issues/1047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1047/comments | https://api.github.com/repos/huggingface/datasets/issues/1047/events | https://github.com/huggingface/datasets/pull/1047 | 756,127,490 | MDExOlB1bGxSZXF1ZXN0NTMxNzIyMjk4 | 1,047 | Add KorNLU | [] | closed | false | null | 5 | 2020-12-03T11:50:54Z | 2020-12-03T17:17:07Z | 2020-12-03T17:16:09Z | null | Added Korean NLU datasets. The link to the dataset can be found [here](https://github.com/kakaobrain/KorNLUDatasets) and the paper can be found [here](https://arxiv.org/abs/2004.03289)
**Note**: The MNLI tsv file is broken, so this code currently excludes the file. Please suggest other alternative if any @lhoestq
- [x] Followed the instructions in CONTRIBUTING.md
- [x] Ran the tests successfully
- [x] Created the dummy data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1047/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1047",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1047"
} | true | [
"the CI error about `social_bias_frames` is fixed on master so it's fine",
"created new [PR](https://github.com/huggingface/datasets/pull/1062)",
"looks like this PR includes many changes to other files that the ones related to KorNLU\r\nCould you create another branch and another PR please ?",
"Wow crazy timing",
"hahahaha"
] |
https://api.github.com/repos/huggingface/datasets/issues/2140 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2140/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2140/comments | https://api.github.com/repos/huggingface/datasets/issues/2140/events | https://github.com/huggingface/datasets/pull/2140 | 843,830,451 | MDExOlB1bGxSZXF1ZXN0NjAzMTYxMjYx | 2,140 | add banking77 dataset | [] | closed | false | null | 1 | 2021-03-29T21:32:23Z | 2021-04-09T09:32:18Z | 2021-04-09T09:32:18Z | null | Intent classification/detection dataset from banking category with 77 unique intents. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2140/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2140/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2140.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2140",
"merged_at": "2021-04-09T09:32:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2140.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2140"
} | true | [
"@lhoestq I updated files"
] |
https://api.github.com/repos/huggingface/datasets/issues/1651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1651/comments | https://api.github.com/repos/huggingface/datasets/issues/1651/events | https://github.com/huggingface/datasets/pull/1651 | 775,554,319 | MDExOlB1bGxSZXF1ZXN0NTQ2MjExMjQw | 1,651 | Add twi wordsim353 | [] | closed | false | null | 3 | 2020-12-28T19:31:55Z | 2021-01-04T09:39:39Z | 2021-01-04T09:39:38Z | null | Added the citation information to the README file | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1651/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1651/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1651.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1651",
"merged_at": "2021-01-04T09:39:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1651.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1651"
} | true | [
"Well actually it looks like it was already added in #1428 \r\n\r\nMaybe we can close this one ? Or you wanted to make changes to this dataset ?",
"Thank you, it's just a modification of Readme. I added the missing citation.",
"Indeed thanks"
] |
https://api.github.com/repos/huggingface/datasets/issues/5697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5697/comments | https://api.github.com/repos/huggingface/datasets/issues/5697/events | https://github.com/huggingface/datasets/pull/5697 | 1,651,812,614 | PR_kwDODunzps5NefxZ | 5,697 | Raise an error on missing distributed seed | [] | closed | false | null | 4 | 2023-04-03T10:44:58Z | 2023-04-04T15:05:24Z | 2023-04-04T14:58:16Z | null | close https://github.com/huggingface/datasets/issues/5696 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5697/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5697/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5697.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5697",
"merged_at": "2023-04-04T14:58:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5697.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5697"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009644 / 0.011353 (-0.001709) | 0.006407 / 0.011008 (-0.004601) | 0.148353 / 0.038508 (0.109845) | 0.037537 / 0.023109 (0.014428) | 0.379697 / 0.275898 (0.103799) | 0.466260 / 0.323480 (0.142780) | 0.007884 / 0.007986 (-0.000102) | 0.005140 / 0.004328 (0.000812) | 0.111078 / 0.004250 (0.106827) | 0.049429 / 0.037052 (0.012377) | 0.364766 / 0.258489 (0.106277) | 0.453809 / 0.293841 (0.159968) | 0.051918 / 0.128546 (-0.076628) | 0.020081 / 0.075646 (-0.055566) | 0.616041 / 0.419271 (0.196770) | 0.059834 / 0.043533 (0.016301) | 0.373104 / 0.255139 (0.117965) | 0.419304 / 0.283200 (0.136104) | 0.113526 / 0.141683 (-0.028156) | 1.827160 / 1.452155 (0.375006) | 1.912092 / 1.492716 (0.419376) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269584 / 0.018006 (0.251578) | 0.554100 / 0.000490 (0.553610) | 0.006618 / 0.000200 (0.006418) | 0.000093 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025280 / 0.037411 (-0.012131) | 0.123116 / 0.014526 (0.108591) | 0.127674 / 0.176557 (-0.048883) | 0.189106 / 0.737135 (-0.548030) | 0.142072 / 0.296338 (-0.154267) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.602201 / 0.215209 (0.386992) | 5.959610 / 2.077655 (3.881956) | 2.404856 / 1.504120 (0.900736) | 2.175017 / 1.541195 (0.633823) | 2.154360 / 1.468490 (0.685870) | 1.265339 / 4.584777 (-3.319438) | 5.598429 / 3.745712 (1.852716) | 5.130249 / 5.269862 (-0.139612) | 2.764922 / 4.565676 (-1.800754) | 0.143232 / 0.424275 (-0.281043) | 0.014721 / 0.007607 (0.007114) | 0.764734 / 0.226044 (0.538689) | 7.518810 / 2.268929 (5.249882) | 3.344734 / 55.444624 (-52.099890) | 2.601158 / 6.876477 (-4.275319) | 2.726018 / 2.142072 (0.583945) | 1.397918 / 4.805227 (-3.407309) | 0.253277 / 6.500664 (-6.247387) | 0.077772 / 0.075469 (0.002303) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.499535 / 1.841788 (-0.342253) | 17.782490 / 8.074308 (9.708182) | 21.953064 / 10.191392 (11.761672) | 0.248753 / 0.680424 (-0.431671) | 0.029194 / 0.534201 (-0.505007) | 0.529700 / 0.579283 (-0.049583) | 0.618412 / 0.434364 (0.184048) | 0.605062 / 0.540337 (0.064725) | 0.725661 / 1.386936 (-0.661275) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009489 / 0.011353 (-0.001864) | 0.006423 / 0.011008 (-0.004585) | 0.096789 / 0.038508 (0.058281) | 0.034639 / 0.023109 (0.011530) | 0.403875 / 0.275898 (0.127977) | 0.439368 / 0.323480 (0.115888) | 0.006354 / 0.007986 (-0.001631) | 0.006794 / 0.004328 (0.002466) | 0.095537 / 0.004250 (0.091287) | 0.047749 / 0.037052 (0.010697) | 0.424157 / 0.258489 (0.165668) | 0.487825 / 0.293841 (0.193984) | 0.054675 / 0.128546 (-0.073872) | 0.021349 / 0.075646 (-0.054297) | 0.108917 / 0.419271 (-0.310354) | 0.075891 / 0.043533 (0.032358) | 0.412889 / 0.255139 (0.157750) | 0.464512 / 0.283200 (0.181312) | 0.118832 / 0.141683 (-0.022850) | 1.721215 / 1.452155 (0.269060) | 1.857195 / 1.492716 (0.364478) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.248308 / 0.018006 (0.230302) | 0.559496 / 0.000490 (0.559006) | 0.007136 / 0.000200 (0.006936) | 0.000160 / 0.000054 (0.000106) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031772 / 0.037411 (-0.005639) | 0.123565 / 0.014526 (0.109039) | 0.132660 / 0.176557 (-0.043896) | 0.201428 / 0.737135 (-0.535707) | 0.135238 / 0.296338 (-0.161101) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.646978 / 0.215209 (0.431769) | 6.183477 / 2.077655 (4.105822) | 2.782117 / 1.504120 (1.277997) | 2.294093 / 1.541195 (0.752898) | 2.346932 / 1.468490 (0.878442) | 1.239085 / 4.584777 (-3.345692) | 5.696364 / 3.745712 (1.950652) | 4.980102 / 5.269862 (-0.289759) | 2.278116 / 4.565676 (-2.287560) | 0.157339 / 0.424275 (-0.266936) | 0.014936 / 0.007607 (0.007329) | 0.778001 / 0.226044 (0.551957) | 7.708066 / 2.268929 (5.439138) | 3.412235 / 55.444624 (-52.032389) | 2.670670 / 6.876477 (-4.205806) | 2.731802 / 2.142072 (0.589730) | 1.446516 / 4.805227 (-3.358712) | 0.263689 / 6.500664 (-6.236975) | 0.086359 / 0.075469 (0.010890) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.573169 / 1.841788 (-0.268619) | 17.690842 / 8.074308 (9.616534) | 20.343336 / 10.191392 (10.151944) | 0.231028 / 0.680424 (-0.449396) | 0.025954 / 0.534201 (-0.508247) | 0.570554 / 0.579283 (-0.008729) | 0.610453 / 0.434364 (0.176089) | 0.675830 / 0.540337 (0.135493) | 0.790650 / 1.386936 (-0.596286) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007553 / 0.011353 (-0.003800) | 0.005426 / 0.011008 (-0.005582) | 0.096550 / 0.038508 (0.058042) | 0.034393 / 0.023109 (0.011284) | 0.322297 / 0.275898 (0.046399) | 0.340943 / 0.323480 (0.017463) | 0.006350 / 0.007986 (-0.001635) | 0.005700 / 0.004328 (0.001372) | 0.074929 / 0.004250 (0.070678) | 0.054819 / 0.037052 (0.017767) | 0.320151 / 0.258489 (0.061662) | 0.346957 / 0.293841 (0.053116) | 0.036659 / 0.128546 (-0.091887) | 0.012443 / 0.075646 (-0.063204) | 0.332232 / 0.419271 (-0.087040) | 0.051467 / 0.043533 (0.007934) | 0.310952 / 0.255139 (0.055813) | 0.325617 / 0.283200 (0.042417) | 0.104908 / 0.141683 (-0.036775) | 1.446752 / 1.452155 (-0.005403) | 1.558773 / 1.492716 (0.066056) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.300639 / 0.018006 (0.282633) | 0.499901 / 0.000490 (0.499411) | 0.007340 / 0.000200 (0.007140) | 0.000255 / 0.000054 (0.000201) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027206 / 0.037411 (-0.010206) | 0.105603 / 0.014526 (0.091077) | 0.118669 / 0.176557 (-0.057887) | 0.174050 / 0.737135 (-0.563086) | 0.125099 / 0.296338 (-0.171239) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.404285 / 0.215209 (0.189076) | 4.034587 / 2.077655 (1.956933) | 1.812639 / 1.504120 (0.308519) | 1.625745 / 1.541195 (0.084551) | 1.735523 / 1.468490 (0.267033) | 0.709699 / 4.584777 (-3.875078) | 3.802196 / 3.745712 (0.056484) | 3.656984 / 5.269862 (-1.612877) | 1.968470 / 4.565676 (-2.597206) | 0.086612 / 0.424275 (-0.337663) | 0.012368 / 0.007607 (0.004761) | 0.502622 / 0.226044 (0.276577) | 5.017876 / 2.268929 (2.748948) | 2.279794 / 55.444624 (-53.164831) | 1.956938 / 6.876477 (-4.919538) | 2.150430 / 2.142072 (0.008357) | 0.847691 / 4.805227 (-3.957536) | 0.170157 / 6.500664 (-6.330507) | 0.064141 / 0.075469 (-0.011328) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.172246 / 1.841788 (-0.669542) | 15.229444 / 8.074308 (7.155136) | 14.715913 / 10.191392 (4.524521) | 0.192501 / 0.680424 (-0.487923) | 0.017972 / 0.534201 (-0.516229) | 0.423834 / 0.579283 (-0.155449) | 0.423019 / 0.434364 (-0.011345) | 0.493298 / 0.540337 (-0.047039) | 0.589833 / 1.386936 (-0.797103) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007773 / 0.011353 (-0.003580) | 0.005449 / 0.011008 (-0.005560) | 0.075180 / 0.038508 (0.036672) | 0.035221 / 0.023109 (0.012111) | 0.338169 / 0.275898 (0.062271) | 0.374002 / 0.323480 (0.050522) | 0.006391 / 0.007986 (-0.001595) | 0.004406 / 0.004328 (0.000078) | 0.074925 / 0.004250 (0.070675) | 0.056527 / 0.037052 (0.019475) | 0.338071 / 0.258489 (0.079582) | 0.391882 / 0.293841 (0.098041) | 0.037241 / 0.128546 (-0.091305) | 0.012546 / 0.075646 (-0.063100) | 0.087331 / 0.419271 (-0.331940) | 0.049851 / 0.043533 (0.006318) | 0.335264 / 0.255139 (0.080125) | 0.354813 / 0.283200 (0.071614) | 0.110614 / 0.141683 (-0.031069) | 1.432782 / 1.452155 (-0.019372) | 1.548800 / 1.492716 (0.056083) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.307892 / 0.018006 (0.289886) | 0.518809 / 0.000490 (0.518319) | 0.004058 / 0.000200 (0.003858) | 0.000099 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029155 / 0.037411 (-0.008256) | 0.111706 / 0.014526 (0.097180) | 0.122964 / 0.176557 (-0.053592) | 0.170939 / 0.737135 (-0.566196) | 0.128538 / 0.296338 (-0.167801) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426529 / 0.215209 (0.211320) | 4.254218 / 2.077655 (2.176563) | 2.011455 / 1.504120 (0.507335) | 1.817397 / 1.541195 (0.276202) | 1.952915 / 1.468490 (0.484425) | 0.705052 / 4.584777 (-3.879725) | 3.844458 / 3.745712 (0.098746) | 3.592754 / 5.269862 (-1.677107) | 1.573567 / 4.565676 (-2.992109) | 0.086834 / 0.424275 (-0.337441) | 0.012389 / 0.007607 (0.004782) | 0.541695 / 0.226044 (0.315650) | 5.224492 / 2.268929 (2.955564) | 2.473648 / 55.444624 (-52.970976) | 2.167458 / 6.876477 (-4.709019) | 2.253319 / 2.142072 (0.111246) | 0.836322 / 4.805227 (-3.968905) | 0.168680 / 6.500664 (-6.331984) | 0.065699 / 0.075469 (-0.009770) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.281886 / 1.841788 (-0.559902) | 15.451741 / 8.074308 (7.377433) | 14.906870 / 10.191392 (4.715478) | 0.168554 / 0.680424 (-0.511870) | 0.017365 / 0.534201 (-0.516836) | 0.434183 / 0.579283 (-0.145100) | 0.421891 / 0.434364 (-0.012473) | 0.538993 / 0.540337 (-0.001344) | 0.636212 / 1.386936 (-0.750724) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007362 / 0.011353 (-0.003991) | 0.004992 / 0.011008 (-0.006016) | 0.098730 / 0.038508 (0.060222) | 0.033673 / 0.023109 (0.010563) | 0.296334 / 0.275898 (0.020436) | 0.328208 / 0.323480 (0.004728) | 0.005658 / 0.007986 (-0.002327) | 0.004130 / 0.004328 (-0.000199) | 0.074596 / 0.004250 (0.070346) | 0.048230 / 0.037052 (0.011178) | 0.295631 / 0.258489 (0.037142) | 0.347176 / 0.293841 (0.053335) | 0.036359 / 0.128546 (-0.092187) | 0.011889 / 0.075646 (-0.063758) | 0.332889 / 0.419271 (-0.086382) | 0.049708 / 0.043533 (0.006175) | 0.291207 / 0.255139 (0.036068) | 0.311066 / 0.283200 (0.027867) | 0.098418 / 0.141683 (-0.043265) | 1.415450 / 1.452155 (-0.036705) | 1.526928 / 1.492716 (0.034212) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212636 / 0.018006 (0.194630) | 0.432337 / 0.000490 (0.431847) | 0.006839 / 0.000200 (0.006639) | 0.000205 / 0.000054 (0.000150) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026045 / 0.037411 (-0.011366) | 0.107427 / 0.014526 (0.092901) | 0.114634 / 0.176557 (-0.061922) | 0.169943 / 0.737135 (-0.567192) | 0.123290 / 0.296338 (-0.173048) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.409432 / 0.215209 (0.194223) | 4.097910 / 2.077655 (2.020255) | 1.857177 / 1.504120 (0.353057) | 1.672355 / 1.541195 (0.131160) | 1.740130 / 1.468490 (0.271640) | 0.706520 / 4.584777 (-3.878257) | 3.773606 / 3.745712 (0.027893) | 2.101635 / 5.269862 (-3.168226) | 1.326295 / 4.565676 (-3.239382) | 0.085672 / 0.424275 (-0.338604) | 0.012142 / 0.007607 (0.004534) | 0.501168 / 0.226044 (0.275123) | 5.049784 / 2.268929 (2.780855) | 2.322477 / 55.444624 (-53.122148) | 1.990105 / 6.876477 (-4.886372) | 2.115003 / 2.142072 (-0.027070) | 0.837518 / 4.805227 (-3.967709) | 0.168457 / 6.500664 (-6.332207) | 0.064622 / 0.075469 (-0.010847) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.188152 / 1.841788 (-0.653635) | 14.991585 / 8.074308 (6.917276) | 14.635187 / 10.191392 (4.443795) | 0.183708 / 0.680424 (-0.496716) | 0.017452 / 0.534201 (-0.516749) | 0.418963 / 0.579283 (-0.160320) | 0.428893 / 0.434364 (-0.005471) | 0.502108 / 0.540337 (-0.038229) | 0.596345 / 1.386936 (-0.790591) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007404 / 0.011353 (-0.003949) | 0.005148 / 0.011008 (-0.005860) | 0.074785 / 0.038508 (0.036277) | 0.033815 / 0.023109 (0.010706) | 0.332752 / 0.275898 (0.056854) | 0.368018 / 0.323480 (0.044538) | 0.005642 / 0.007986 (-0.002344) | 0.004041 / 0.004328 (-0.000287) | 0.073455 / 0.004250 (0.069205) | 0.047380 / 0.037052 (0.010328) | 0.337017 / 0.258489 (0.078528) | 0.384185 / 0.293841 (0.090344) | 0.036592 / 0.128546 (-0.091954) | 0.012109 / 0.075646 (-0.063537) | 0.086862 / 0.419271 (-0.332410) | 0.049030 / 0.043533 (0.005497) | 0.336542 / 0.255139 (0.081403) | 0.350295 / 0.283200 (0.067096) | 0.100998 / 0.141683 (-0.040685) | 1.469749 / 1.452155 (0.017594) | 1.588355 / 1.492716 (0.095639) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227552 / 0.018006 (0.209546) | 0.438087 / 0.000490 (0.437598) | 0.000394 / 0.000200 (0.000194) | 0.000058 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030575 / 0.037411 (-0.006836) | 0.111914 / 0.014526 (0.097388) | 0.124583 / 0.176557 (-0.051973) | 0.175471 / 0.737135 (-0.561665) | 0.129535 / 0.296338 (-0.166803) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425625 / 0.215209 (0.210416) | 4.228328 / 2.077655 (2.150673) | 2.021087 / 1.504120 (0.516967) | 1.832550 / 1.541195 (0.291355) | 1.925572 / 1.468490 (0.457082) | 0.690772 / 4.584777 (-3.894005) | 3.724900 / 3.745712 (-0.020813) | 2.080286 / 5.269862 (-3.189576) | 1.316854 / 4.565676 (-3.248822) | 0.085123 / 0.424275 (-0.339152) | 0.012078 / 0.007607 (0.004471) | 0.525802 / 0.226044 (0.299758) | 5.242598 / 2.268929 (2.973670) | 2.491596 / 55.444624 (-52.953028) | 2.125156 / 6.876477 (-4.751320) | 2.185922 / 2.142072 (0.043850) | 0.823116 / 4.805227 (-3.982111) | 0.165188 / 6.500664 (-6.335476) | 0.063970 / 0.075469 (-0.011499) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256948 / 1.841788 (-0.584840) | 14.981990 / 8.074308 (6.907682) | 14.565266 / 10.191392 (4.373874) | 0.175064 / 0.680424 (-0.505360) | 0.017628 / 0.534201 (-0.516573) | 0.429979 / 0.579283 (-0.149304) | 0.422509 / 0.434364 (-0.011855) | 0.546262 / 0.540337 (0.005924) | 0.647103 / 1.386936 (-0.739833) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3428/comments | https://api.github.com/repos/huggingface/datasets/issues/3428/events | https://github.com/huggingface/datasets/pull/3428 | 1,078,863,468 | PR_kwDODunzps4vxtNT | 3,428 | Clean squad dummy data | [] | closed | false | null | 0 | 2021-12-13T18:46:29Z | 2021-12-13T18:57:50Z | 2021-12-13T18:57:50Z | null | Some unused files were remaining, this PR removes them. We just need to keep the dummy_data.zip file | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3428/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3428/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3428.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3428",
"merged_at": "2021-12-13T18:57:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3428.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3428"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1245 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1245/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1245/comments | https://api.github.com/repos/huggingface/datasets/issues/1245/events | https://github.com/huggingface/datasets/pull/1245 | 758,411,233 | MDExOlB1bGxSZXF1ZXN0NTMzNTg4NDUw | 1,245 | Add Google Turkish Treebank Dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2020-12-07T11:09:17Z | 2022-10-03T09:39:32Z | 2022-10-03T09:39:32Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1245/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1245/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/1245.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1245",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1245.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1245"
} | true | [
"Thanks for your contribution, @abhishekkrthakur. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/1763 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1763/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1763/comments | https://api.github.com/repos/huggingface/datasets/issues/1763/events | https://github.com/huggingface/datasets/pull/1763 | 791,389,763 | MDExOlB1bGxSZXF1ZXN0NTU5NDU3MTY1 | 1,763 | PAWS-X: Fix csv Dictreader splitting data on quotes | [] | closed | false | null | 0 | 2021-01-21T18:21:01Z | 2021-01-22T10:14:33Z | 2021-01-22T10:13:45Z | null |
```python
from datasets import load_dataset
# load english paws-x dataset
datasets = load_dataset('paws-x', 'en')
print(len(datasets['train'])) # outputs 49202 but official dataset has 49401 pairs
print(datasets['train'].unique('label')) # outputs [1, 0, -1] but labels are binary [0,1]
```
changed `data = csv.DictReader(f, delimiter="\t")` to `data = csv.DictReader(f, delimiter="\t", quoting=csv.QUOTE_NONE)` in the dataloader to make csv module not split by quotes.
The results are as expected for all languages after the change. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1763/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1763/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1763.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1763",
"merged_at": "2021-01-22T10:13:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1763.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1763"
} | true | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.