
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4180/comments | https://api.github.com/repos/huggingface/datasets/issues/4180/events | https://github.com/huggingface/datasets/issues/4180 | 1,208,042,320 | I_kwDODunzps5IAUNQ | 4,180 | Add some iteration method on a dataset column (specific for inference) | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 5 | 2022-04-19T09:15:45Z | 2022-04-21T10:30:58Z | null | null | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is.
Currently, `dataset["audio"]` will load EVERY element in the dataset in RAM, which can be quite big for an audio dataset.
Having an iterator (or sequence) type of object, would make inference with `transformers` 's `pipeline` easier to use and not so memory hungry.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
For a non breaking change:
```python
for audio in dataset.iterate("audio"):
# {"array": np.array(...), "sampling_rate":...}
```
For a breaking change solution (not necessary), changing the type of `dataset["audio"]` to a sequence type so that
```python
pipe = pipeline(model="...")
for out in pipe(dataset["audio"]):
# {"text":....}
```
could work
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
```python
def iterate(dataset, key):
for item in dataset:
yield dataset[key]
for out in pipeline(iterate(dataset, "audio")):
# {"array": ...}
```
This works but requires the helper function which feels slightly clunky.
**Additional context**
Add any other context about the feature request here.
The context is actually to showcase better integration between `pipeline` and `datasets` in the Quicktour demo: https://github.com/huggingface/transformers/pull/16723/files
@lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4180/timeline | null | null | null | null | false | [
"Thanks for the suggestion ! I agree it would be nice to have something directly in `datasets` to do something as simple as that\r\n\r\ncc @albertvillanova @mariosasko @polinaeterna What do you think if we have something similar to pandas `Series` that wouldn't bring everything in memory when doing `dataset[\"audio\"]` ? Currently it returns a list with all the decoded audio data in memory.\r\n\r\nIt would be a breaking change though, since `isinstance(dataset[\"audio\"], list)` wouldn't work anymore, but we could implement a `Sequence` so that `dataset[\"audio\"][0]` still works and only loads one item in memory.\r\n\r\nYour alternative suggestion with `iterate` is also sensible, though maybe less satisfactory in terms of experience IMO",
"I agree that current behavior (decoding all audio file sin the dataset when accessing `dataset[\"audio\"]`) is not useful, IMHO. Indeed in our docs, we are constantly warning our collaborators not to do that.\r\n\r\nTherefore I upvote for a \"useful\" behavior of `dataset[\"audio\"]`. I don't think the breaking change is important in this case, as I guess no many people use it with its current behavior. Therefore, for me it seems reasonable to return a generator (instead of an in-memeory list) for \"special\" features, like Audio/Image.\r\n\r\n@lhoestq on the other hand I don't understand your proposal about Pandas-like... ",
"I recall I had the same idea while working on the `Image` feature, so I agree implementing something similar to `pd.Series` that lazily brings elements in memory would be beneficial.",
"@lhoestq @mariosasko Could you please give a link to that new feature of `pandas.Series`? As far as I remember since I worked with pandas for more than 6 years, there was no lazy in-memory feature; it was everything in-memory; that was the reason why other frameworks were created, like Vaex or Dask, e.g. ",
"Yea pandas doesn't do lazy loading. I was referring to pandas.Series to say that they have a dedicated class to represent a column ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2046 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2046/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2046/comments | https://api.github.com/repos/huggingface/datasets/issues/2046/events | https://github.com/huggingface/datasets/issues/2046 | 830,423,033 | MDU6SXNzdWU4MzA0MjMwMzM= | 2,046 | add_faisis_index gets very slow when doing it interatively | [] | closed | false | null | 11 | 2021-03-12T20:27:18Z | 2021-03-24T22:29:11Z | 2021-03-24T22:29:11Z | null | As the below code suggests, I want to run add_faisis_index in every nth interaction from the training loop. I have 7.2 million documents. Usually, it takes 2.5 hours (if I run an as a separate process similar to the script given in rag/use_own_knowleldge_dataset.py). Now, this takes usually 5hrs. Is this normal? Any way to make this process faster?
@lhoestq
```
def training_step(self, batch, batch_idx) -> Dict:
if (not batch_idx==0) and (batch_idx%5==0):
print("******************************************************")
ctx_encoder=self.trainer.model.module.module.model.rag.ctx_encoder
model_copy =type(ctx_encoder)(self.config_dpr) # get a new instance #this will be load in the CPU
model_copy.load_state_dict(ctx_encoder.state_dict()) # copy weights and stuff
list_of_gpus = ['cuda:2','cuda:3']
c_dir='/custom/cache/dir'
kb_dataset = load_dataset("csv", data_files=[self.custom_config.csv_path], split="train", delimiter="\t", column_names=["title", "text"],cache_dir=c_dir)
print(kb_dataset)
n=len(list_of_gpus) #nunber of dedicated GPUs
kb_list=[kb_dataset.shard(n, i, contiguous=True) for i in range(n)]
#kb_dataset.save_to_disk('/hpc/gsir059/MY-Test/RAY/transformers/examples/research_projects/rag/haha-dir')
print(self.trainer.global_rank)
dataset_shards = self.re_encode_kb(model_copy.to(device=list_of_gpus[self.trainer.global_rank]),kb_list[self.trainer.global_rank])
output = [None for _ in list_of_gpus]
#self.trainer.accelerator_connector.accelerator.barrier("embedding_process")
dist.all_gather_object(output, dataset_shards)
#This creation and re-initlaization of the new index
if (self.trainer.global_rank==0): #saving will be done in the main process
combined_dataset = concatenate_datasets(output)
passages_path =self.config.passages_path
logger.info("saving the dataset with ")
#combined_dataset.save_to_disk('/hpc/gsir059/MY-Test/RAY/transformers/examples/research_projects/rag/MY-Passage')
combined_dataset.save_to_disk(passages_path)
logger.info("Add faiss index to the dataset that consist of embeddings")
embedding_dataset=combined_dataset
index = faiss.IndexHNSWFlat(768, 128, faiss.METRIC_INNER_PRODUCT)
embedding_dataset.add_faiss_index("embeddings", custom_index=index)
embedding_dataset.get_index("embeddings").save(self.config.index_path)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2046/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2046/timeline | null | completed | null | null | false | [
"I think faiss automatically sets the number of threads to use to build the index.\r\nCan you check how many CPU cores are being used when you build the index in `use_own_knowleldge_dataset` as compared to this script ? Are there other programs running (maybe for rank>0) ?",
"Hi,\r\n I am running the add_faiss_index during the training process of the RAG from the master process (rank 0). But at the exact moment, I do not run any other process since I do it in every 5000 training steps. \r\n \r\n I think what you say is correct. It depends on the number of CPU cores. I did an experiment to compare the time taken to finish the add_faiss_index process on use_own_knowleldge_dataset.py vs the training loop thing. The training loop thing takes 40 mins more. It might be natural right? \r\n \r\n \r\n at the moment it uses around 40 cores of a 96 core machine (I am fine-tuning the entire process). ",
"Can you try to set the number of threads manually ?\r\nIf you set the same number of threads for both the `use_own_knowledge_dataset.py` and RAG training, it should take the same amount of time.\r\nYou can see how to set the number of thread in the faiss wiki: https://github.com/facebookresearch/faiss/wiki/Threads-and-asynchronous-calls",
"Ok, I will report the details too soon. I am the first one on the list and currently add_index being computed for the 3rd time in the loop. Actually seems like the time is taken to complete each interaction is the same, but around 1 hour more compared to running it without the training loop. A the moment this takes 5hrs and 30 mins. If there is any way to faster the process, an end-to-end rag will be perfect. So I will also try out with different thread numbers too. \r\n\r\n\r\n",
"@lhoestq on a different note, I read about using Faiss-GPU, but the documentation says we should use it when the dataset has the ability to fit into the GPU memory. Although this might work, in the long-term this is not that practical for me.\r\n\r\nhttps://github.com/matsui528/faiss_tips",
"@lhoestq \r\n\r\nHi, I executed the **use_own_dataset.py** script independently and ask a few of my friends to run their programs in the HPC machine at the same time. \r\n\r\n Once there are so many other processes are running the add_index function gets slows down naturally. So basically the speed of the add_index depends entirely on the number of CPU processes. Then I set the number of threads as you have mentioned and got actually the same time for RAG training and independat running. So you are correct! :) \r\n\r\n \r\n Then I added this [issue in Faiss repostiary](https://github.com/facebookresearch/faiss/issues/1767). I got an answer saying our current **IndexHNSWFlat** can get slow for 30 million vectors and it would be better to use alternatives. What do you think?",
"It's a matter of tradeoffs.\r\nHSNW is fast at query time but takes some time to build.\r\nA flat index is flat to build but is \"slow\" at query time.\r\nAn IVF index is probably a good choice for you: fast building and fast queries (but still slower queries than HSNW).\r\n\r\nNote that for an IVF index you would need to have an `nprobe` parameter (number of cells to visit for one query, there are `nlist` in total) that is not too small in order to have good retrieval accuracy, but not too big otherwise the queries will take too much time. From the faiss documentation:\r\n> The nprobe parameter is always a way of adjusting the tradeoff between speed and accuracy of the result. Setting nprobe = nlist gives the same result as the brute-force search (but slower).\r\n\r\nFrom my experience with indexes on DPR embeddings, setting nprobe around 1/4 of nlist gives really good retrieval accuracy and there's no need to have a value higher than that (or you would need to brute-force in order to see a difference).",
"@lhoestq \r\n\r\nThanks a lot for sharing all this prior knowledge. \r\n\r\nJust asking what would be a good nlist of parameters for 30 million embeddings?",
"When IVF is used alone, nlist should be between `4*sqrt(n)` and `16*sqrt(n)`.\r\nFor more details take a look at [this section of the Faiss wiki](https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index#how-big-is-the-dataset)",
"Thanks a lot. I was lost with calling the index from class and using faiss_index_factory. ",
"@lhoestq Thanks a lot for the help you have given to solve this issue. As per my experiments, IVF index suits well for my case and it is a lot faster. The use of this can make the entire RAG end-to-end trainable lot faster. So I will close this issue. Will do the final PR soon. "
] |
https://api.github.com/repos/huggingface/datasets/issues/1550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1550/comments | https://api.github.com/repos/huggingface/datasets/issues/1550/events | https://github.com/huggingface/datasets/pull/1550 | 765,620,925 | MDExOlB1bGxSZXF1ZXN0NTM5MDEwMDY1 | 1,550 | Add offensive langauge dravidian dataset | [] | closed | false | null | 1 | 2020-12-13T19:54:19Z | 2020-12-18T15:52:49Z | 2020-12-18T14:25:30Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1550/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1550",
"merged_at": "2020-12-18T14:25:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1550"
} | true | [
"Thanks much!"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/4636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4636/comments | https://api.github.com/repos/huggingface/datasets/issues/4636/events | https://github.com/huggingface/datasets/issues/4636 | 1,294,547,836 | I_kwDODunzps5NKTt8 | 4,636 | Add info in docs about behavior of download_config.num_proc | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2022-07-05T17:01:00Z | 2022-07-28T10:40:32Z | 2022-07-28T10:40:32Z | null | **Is your feature request related to a problem? Please describe.**
I went to override `download_config.num_proc` and was confused about what was happening under the hood. It would be nice to have the behavior documented a bit better so folks know what's happening when they use it.
**Describe the solution you'd like**
- Add note about how the default number of workers is 16. Related code:
https://github.com/huggingface/datasets/blob/7bcac0a6a0fc367cc068f184fa132b8de8dfa11d/src/datasets/download/download_manager.py#L299-L302
- Add note that if the number of workers is higher than the number of files to download, it won't use multiprocessing.
**Describe alternatives you've considered**
maybe it would also be nice to set `num_proc` = `num_files` when `num_proc` > `num_files`.
**Additional context**
...
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4636/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2468/comments | https://api.github.com/repos/huggingface/datasets/issues/2468/events | https://github.com/huggingface/datasets/pull/2468 | 916,427,320 | MDExOlB1bGxSZXF1ZXN0NjY2MDk0ODI5 | 2,468 | Implement ClassLabel encoding in JSON loader | [] | closed | false | {
"closed_at": "2021-07-09T05:50:07Z",
"closed_issues": 12,
"created_at": "2021-05-31T16:13:06Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-07-08T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/5",
"id": 6808903,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/5/labels",
"node_id": "MDk6TWlsZXN0b25lNjgwODkwMw==",
"number": 5,
"open_issues": 0,
"state": "closed",
"title": "1.9",
"updated_at": "2021-07-12T14:12:00Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/5"
} | 1 | 2021-06-09T17:08:54Z | 2021-06-28T15:39:54Z | 2021-06-28T15:05:35Z | null | Close #2365. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2468/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2468/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2468.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2468",
"merged_at": "2021-06-28T15:05:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2468.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2468"
} | true | [
"No, nevermind @lhoestq. Thanks to you for your reviews!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1210 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1210/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1210/comments | https://api.github.com/repos/huggingface/datasets/issues/1210/events | https://github.com/huggingface/datasets/pull/1210 | 757,966,959 | MDExOlB1bGxSZXF1ZXN0NTMzMjI2NDQ2 | 1,210 | Add XSUM Hallucination Annotations Dataset | [] | closed | false | null | 1 | 2020-12-06T16:40:19Z | 2020-12-20T13:34:56Z | 2020-12-16T16:57:11Z | null | Adding Google [XSum Hallucination Annotations](https://github.com/google-research-datasets/xsum_hallucination_annotations) dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1210/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1210/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1210.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1210",
"merged_at": "2020-12-16T16:57:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1210.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1210"
} | true | [
"@lhoestq All necessary modifications have been done."
] |
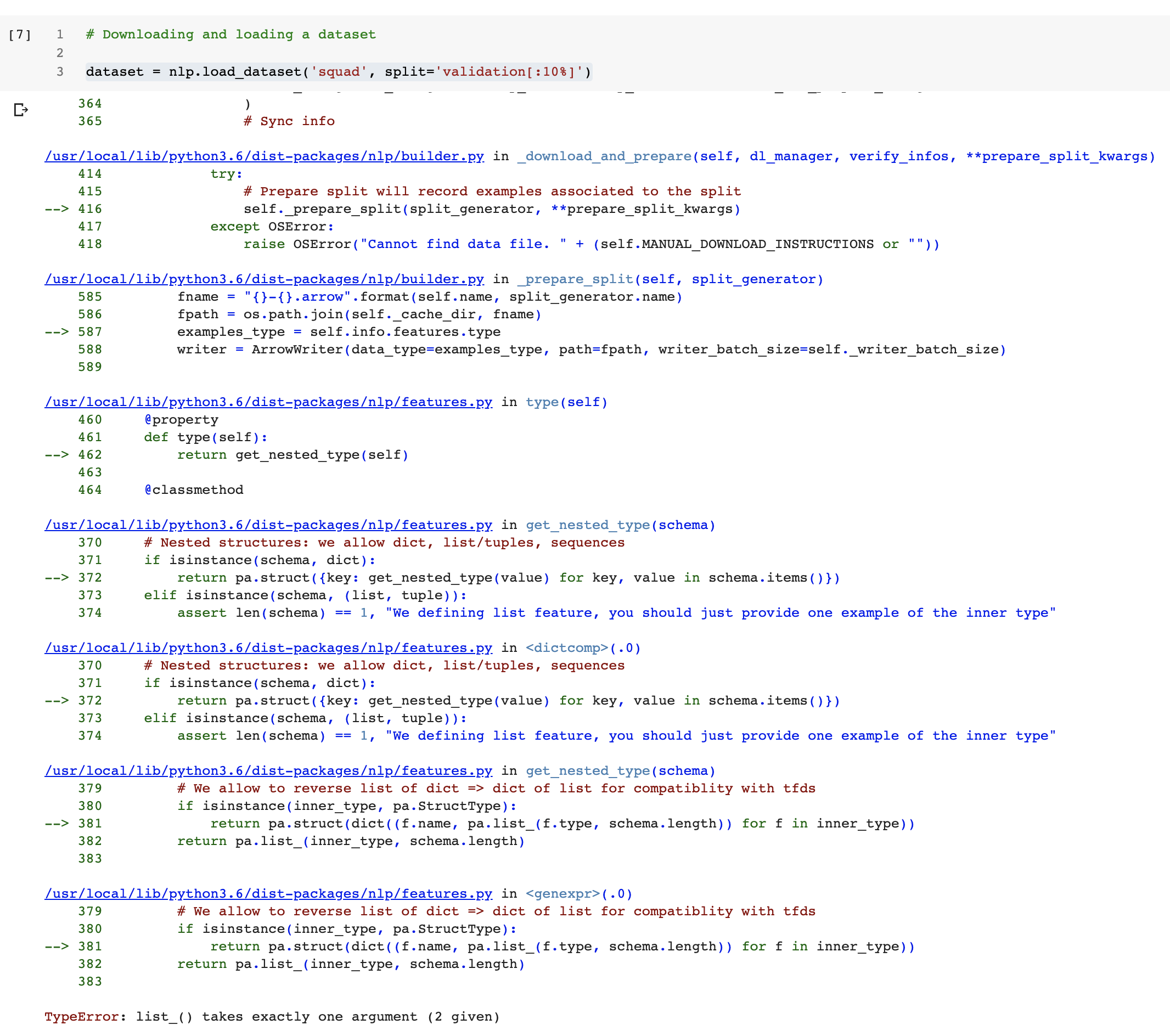
https://api.github.com/repos/huggingface/datasets/issues/222 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/222/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/222/comments | https://api.github.com/repos/huggingface/datasets/issues/222/events | https://github.com/huggingface/datasets/issues/222 | 627,586,690 | MDU6SXNzdWU2Mjc1ODY2OTA= | 222 | Colab Notebook breaks when downloading the squad dataset | [] | closed | false | null | 6 | 2020-05-29T22:55:59Z | 2020-06-04T00:21:05Z | 2020-06-04T00:21:05Z | null | When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/222/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/222/timeline | null | completed | null | null | false | [
"The notebook forces version 0.1.0. If I use the latest, things work, I'll run the whole notebook and create a PR.\r\n\r\nBut in the meantime, this issue gets fixed by changing:\r\n`!pip install nlp==0.1.0`\r\nto\r\n`!pip install nlp`",
"It still breaks very near the end\r\n\r\n\r\n",
"When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:\r\n```\r\nWARNING: The following packages were previously imported in this runtime:\r\n [pyarrow]\r\nYou must restart the runtime in order to use newly installed versions.\r\n```\r\nYou just have to restart the runtime and it should be fine.\r\nIf you don't restart, then it breaks like in your first message ",
"Thanks for reporting the second one ! We'll update the notebook to fix this one :)",
"This trick from @thomwolf seems to be the most reliable solution to fix this colab notebook issue:\r\n\r\n```python\r\n# install nlp\r\n!pip install -qq nlp==0.2.0\r\n\r\n# Make sure that we have a recent version of pyarrow in the session before we continue - otherwise reboot Colab to activate it\r\nimport pyarrow\r\nif int(pyarrow.__version__.split('.')[1]) < 16:\r\n import os\r\n os.kill(os.getpid(), 9)\r\n```",
"The second part got fixed here: 2cbc656d6fc4b18ce57eac070baec05b31180d39\r\n\r\nThanks! I'm then closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/1740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1740/comments | https://api.github.com/repos/huggingface/datasets/issues/1740/events | https://github.com/huggingface/datasets/pull/1740 | 787,264,605 | MDExOlB1bGxSZXF1ZXN0NTU2MDA5NjM1 | 1,740 | add id_liputan6 dataset | [] | closed | false | null | 0 | 2021-01-15T22:58:34Z | 2021-01-20T13:41:26Z | 2021-01-20T13:41:26Z | null | id_liputan6 is a large-scale Indonesian summarization dataset. The articles were harvested from an online news portal, and obtain 215,827 document-summary pairs: https://arxiv.org/abs/2011.00679 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1740/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1740/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1740.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1740",
"merged_at": "2021-01-20T13:41:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1740.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1740"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5613/comments | https://api.github.com/repos/huggingface/datasets/issues/5613/events | https://github.com/huggingface/datasets/issues/5613 | 1,611,875,473 | I_kwDODunzps5gE0SR | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | [] | open | false | null | 4 | 2023-03-06T17:14:41Z | 2023-05-28T01:03:55Z | null | null | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/__init__.py", line 43, in <module>
from .arrow_dataset import Dataset
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 65, in <module>
from .arrow_reader import ArrowReader
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/arrow_reader.py", line 30, in <module>
from .download.download_config import DownloadConfig
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/download/__init__.py", line 9, in <module>
from .download_manager import DownloadManager, DownloadMode
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/download/download_manager.py", line 35, in <module>
from ..utils.py_utils import NestedDataStructure, map_nested, size_str
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 40, in <module>
import multiprocess.pool
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/multiprocess/pool.py", line 609, in <module>
class ThreadPool(Pool):
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/multiprocess/pool.py", line 611, in ThreadPool
from .dummy import Process
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/multiprocess/dummy/__init__.py", line 87, in <module>
class Condition(threading._Condition):
AttributeError: module 'threading' has no attribute '_Condition'. Did you mean: 'Condition'?
```
I think this is a bad interaction of versions from `dill`, `multiprocess`, `apache-beam`, and `threading` from the Python (3.10) standard lib. Upgrading `multiprocess` to a version that does not crash like this is not possible because `apache-beam` pins `dill` to and old version:
```
Because multiprocess (0.70.10) depends on dill (>=0.3.2)
and apache-beam (2.45.0) depends on dill (>=0.3.1.1,<0.3.2), multiprocess (0.70.10) is incompatible with apache-beam (2.45.0).
And because no versions of apache-beam match >2.45.0,<3.0.0, multiprocess (0.70.10) is incompatible with apache-beam (>=2.45.0,<3.0.0).
So, because yyy depends on both apache-beam (^2.45.0) and multiprocess (0.70.10), version solving failed.
```
Perhaps it is not right to file a bug here, but I'm not totally sure whose fault it is. And in any case, this is an immediate blocker to using `datasets` out of the box.
Possibly related to https://github.com/huggingface/datasets/issues/5232.
### Steps to reproduce the bug
Steps to reproduce:
1. Make a poetry project with this configuration
```
[tool.poetry]
name = "yyy"
version = "0.1.0"
description = ""
authors = ["Adam Pauls <[email protected]>"]
readme = "README.md"
packages = [{ include = "xxx" }]
[tool.poetry.dependencies]
python = ">=3.10,<3.11"
datasets = "^2.10.1"
apache-beam = "^2.45.0"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
```
2. `poetry install`.
3. `poetry run python -c "import datasets"`.
### Expected behavior
Script runs.
### Environment info
Python 3.10. Here are the versions installed by `poetry`:
```
•• Installing frozenlist (1.3.3)
• Installing idna (3.4)
• Installing multidict (6.0.4)
• Installing aiosignal (1.3.1)
• Installing async-timeout (4.0.2)
• Installing attrs (22.2.0)
• Installing certifi (2022.12.7)
• Installing charset-normalizer (3.1.0)
• Installing six (1.16.0)
• Installing urllib3 (1.26.14)
• Installing yarl (1.8.2)
• Installing aiohttp (3.8.4)
• Installing dill (0.3.1.1)
• Installing docopt (0.6.2)
• Installing filelock (3.9.0)
• Installing numpy (1.22.4)
• Installing pyparsing (3.0.9)
• Installing protobuf (3.19.4)
• Installing packaging (23.0)
• Installing python-dateutil (2.8.2)
• Installing pytz (2022.7.1)
• Installing pyyaml (6.0)
• Installing requests (2.28.2)
• Installing tqdm (4.65.0)
• Installing typing-extensions (4.5.0)
• Installing cloudpickle (2.2.1)
• Installing crcmod (1.7)
• Installing fastavro (1.7.2)
• Installing fasteners (0.18)
• Installing fsspec (2023.3.0)
• Installing grpcio (1.51.3)
• Installing hdfs (2.7.0)
• Installing httplib2 (0.20.4)
• Installing huggingface-hub (0.12.1)
• Installing multiprocess (0.70.9)
• Installing objsize (0.6.1)
• Installing orjson (3.8.7)
• Installing pandas (1.5.3)
• Installing proto-plus (1.22.2)
• Installing pyarrow (9.0.0)
• Installing pydot (1.4.2)
• Installing pymongo (3.13.0)
• Installing regex (2022.10.31)
• Installing responses (0.18.0)
• Installing xxhash (3.2.0)
• Installing zstandard (0.20.0)
• Installing apache-beam (2.45.0)
• Installing datasets (2.10.1)
``` | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5613/timeline | null | reopened | null | null | false | [
"Sorry, I just found https://github.com/apache/beam/issues/24458. It seems this issue is being worked on. ",
"Reopening, since I think the docs should inform the user of this problem. For example, [this page](https://huggingface.co/docs/datasets/installation) says \r\n> Datasets is tested on Python 3.7+.\r\n\r\nbut it should probably say that Beam Datasets do not work with Python 3.10 (or link to a known issues page). ",
"Same problem on Colab using a vanilla setup running :\r\nPython 3.10.11 \r\napache-beam 2.47.0\r\ndatasets 2.12.0",
"Same problem, \r\npy 3.10.11\r\napache-beam==2.47.0\r\ndatasets==2.12.0"
] |
https://api.github.com/repos/huggingface/datasets/issues/4413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4413/comments | https://api.github.com/repos/huggingface/datasets/issues/4413/events | https://github.com/huggingface/datasets/issues/4413 | 1,250,259,822 | I_kwDODunzps5KhXNu | 4,413 | Dataset Viewer issue for ett | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 3 | 2022-05-27T02:12:35Z | 2022-06-15T07:30:46Z | 2022-06-15T07:30:46Z | null | ### Link
https://huggingface.co/datasets/ett
### Description
Timestamp is not JSON serializable.
```
Status code: 500
Exception: Status500Error
Message: Type is not JSON serializable: Timestamp
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4413/timeline | null | completed | null | null | false | [
"Thanks for reporting @dgcnz.\r\n\r\nI have checked that the dataset works fine in streaming mode.\r\n\r\nAdditionally, other datasets containing timestamps are properly rendered by the viewer: https://huggingface.co/datasets/blbooks\r\n\r\nI have tried to force the refresh of the preview, but the endpoint is not responsive: Connection timed out\r\n\r\nCC: @severo ",
"I've just resent the refresh of the preview to the new endpoint, without success.\r\n\r\nCC: @severo ",
"Fixed!\r\n\r\nhttps://huggingface.co/datasets/ett/viewer/h1/test\r\n\r\n<img width=\"982\" alt=\"Capture d’écran 2022-06-15 à 09 30 22\" src=\"https://user-images.githubusercontent.com/1676121/173769035-a075d753-ecfc-4a43-b54b-973105d464d3.png\">\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3253 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3253/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3253/comments | https://api.github.com/repos/huggingface/datasets/issues/3253/events | https://github.com/huggingface/datasets/issues/3253 | 1,051,308,972 | I_kwDODunzps4-qbOs | 3,253 | `GeneratorBasedBuilder` does not support `None` values | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-11-11T19:51:21Z | 2021-12-09T14:26:58Z | 2021-12-09T14:26:58Z | null | ## Describe the bug
`GeneratorBasedBuilder` does not support `None` values.
## Steps to reproduce the bug
See [this repository](https://github.com/pavel-lexyr/huggingface-datasets-bug-reproduction) for minimal reproduction.
## Expected results
Dataset is initialized with a `None` value in the `value` column.
## Actual results
```
Traceback (most recent call last):
File "main.py", line 3, in <module>
datasets.load_dataset("./bad-data")
File ".../datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File ".../datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File ".../datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File ".../datasets/builder.py", line 1103, in _prepare_split
example = self.info.features.encode_example(record)
File ".../datasets/features/features.py", line 1033, in encode_example
return encode_nested_example(self, example)
File ".../datasets/features/features.py", line 808, in encode_nested_example
return {
File ".../datasets/features/features.py", line 809, in <dictcomp>
k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
File ".../datasets/features/features.py", line 855, in encode_nested_example
return schema.encode_example(obj)
File ".../datasets/features/features.py", line 299, in encode_example
return float(value)
TypeError: float() argument must be a string or a number, not 'NoneType'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: Linux-5.4.0-81-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 6.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3253/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3253/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nthanks for reporting and providing a minimal reproducible example. \r\n\r\nThis line of the PR I've linked in our discussion on the Forum will add support for `None` values:\r\nhttps://github.com/huggingface/datasets/blob/a53de01842aac65c66a49b2439e18fa93ff73ceb/src/datasets/features/features.py#L835\r\n\r\nI expect that PR to be merged soon."
] |
https://api.github.com/repos/huggingface/datasets/issues/1854 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1854/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1854/comments | https://api.github.com/repos/huggingface/datasets/issues/1854/events | https://github.com/huggingface/datasets/issues/1854 | 805,204,397 | MDU6SXNzdWU4MDUyMDQzOTc= | 1,854 | Feature Request: Dataset.add_item | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 3 | 2021-02-10T06:06:00Z | 2021-04-23T10:01:30Z | 2021-04-23T10:01:30Z | null | I'm trying to integrate `huggingface/datasets` functionality into `fairseq`, which requires (afaict) being able to build a dataset through an `add_item` method, such as https://github.com/pytorch/fairseq/blob/master/fairseq/data/indexed_dataset.py#L318, as opposed to loading all the text into arrow, and then `dataset.map(binarizer)`.
Is this possible at the moment? Is there an example? I'm happy to use raw `pa.Table` but not sure whether it will support uneven length entries.
### Desired API
```python
import numpy as np
tokenized: List[np.NDArray[np.int64]] = [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])
def build_dataset_from_tokenized(tokenized: List[np.NDArray[int]]) -> Dataset:
"""FIXME"""
dataset = EmptyDataset()
for t in tokenized: dataset.append(t)
return dataset
ds = build_dataset_from_tokenized(tokenized)
assert (ds[0] == np.array([4,4,2])).all()
```
### What I tried
grep, google for "add one entry at a time", "datasets.append"
### Current Code
This code achieves the same result but doesn't fit into the `add_item` abstraction.
```python
dataset = load_dataset('text', data_files={'train': 'train.txt'})
tokenizer = RobertaTokenizerFast.from_pretrained('roberta-base', max_length=4096)
def tokenize_function(examples):
ids = tokenizer(examples['text'], return_attention_mask=False)['input_ids']
return {'input_ids': [x[1:] for x in ids]}
ds = dataset.map(tokenize_function, batched=True, num_proc=4, remove_columns=['text'], load_from_cache_file=not overwrite_cache)
print(ds['train'][0]) => np array
```
Thanks in advance! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1854/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1854/timeline | null | completed | null | null | false | [
"Hi @sshleifer.\r\n\r\nI am not sure of understanding the need of the `add_item` approach...\r\n\r\nBy just reading your \"Desired API\" section, I would say you could (nearly) get it with a 1-column Dataset:\r\n```python\r\ndata = {\"input_ids\": [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])]}\r\nds = Dataset.from_dict(data)\r\nassert (ds[\"input_ids\"][0] == np.array([4,4,2])).all()\r\n```",
"Hi @sshleifer :) \r\n\r\nWe don't have methods like `Dataset.add_batch` or `Dataset.add_entry/add_item` yet.\r\nBut that's something we'll add pretty soon. Would an API that looks roughly like this help ? Do you have suggestions ?\r\n```python\r\nimport numpy as np\r\nfrom datasets import Dataset\r\n\r\ntokenized = [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])\r\n\r\n# API suggestion (not available yet)\r\nd = Dataset()\r\nfor input_ids in tokenized:\r\n d.add_item({\"input_ids\": input_ids})\r\n\r\nprint(d[0][\"input_ids\"])\r\n# [4, 4, 2]\r\n```\r\n\r\nCurrently you can define a dataset with what @albertvillanova suggest, or via a generator using dataset builders. It's also possible to [concatenate datasets](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=concatenate#datasets.concatenate_datasets).",
"Your API looks perfect @lhoestq, thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4583/comments | https://api.github.com/repos/huggingface/datasets/issues/4583/events | https://github.com/huggingface/datasets/pull/4583 | 1,286,790,871 | PR_kwDODunzps46d7xo | 4,583 | <code> implementation of FLAC support using torchaudio | [] | closed | false | null | 0 | 2022-06-28T05:24:21Z | 2022-06-28T05:47:02Z | 2022-06-28T05:47:02Z | null | I had added Audio FLAC support with torchaudio given that Librosa and SoundFile can give problems. Also, FLAC is been used as audio from https://mlcommons.org/en/peoples-speech/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4583/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4583",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4583"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4037 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4037/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4037/comments | https://api.github.com/repos/huggingface/datasets/issues/4037/events | https://github.com/huggingface/datasets/issues/4037 | 1,183,144,486 | I_kwDODunzps5GhVom | 4,037 | Error while building documentation | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-03-28T09:22:44Z | 2022-03-28T10:01:52Z | 2022-03-28T10:00:48Z | null | ## Describe the bug
Documentation building is failing:
- https://github.com/huggingface/datasets/runs/5716300989?check_suite_focus=true
```
ValueError: There was an error when converting ../datasets/docs/source/package_reference/main_classes.mdx to the MDX format.
Unable to find datasets.filesystems.S3FileSystem in datasets. Make sure the path to that object is correct.
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4037/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4037/timeline | null | completed | null | null | false | [
"After some investigation, maybe the bug is in `doc-builder`.\r\n\r\nI've opened an issue there:\r\n- huggingface/doc-builder#160",
"Fixed by @lewtun (thank you):\r\n- huggingface/doc-builder@31fe6c8bc7225810e281c2f6c6cd32f38828c504"
] |
https://api.github.com/repos/huggingface/datasets/issues/1822 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1822/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1822/comments | https://api.github.com/repos/huggingface/datasets/issues/1822/events | https://github.com/huggingface/datasets/pull/1822 | 802,003,835 | MDExOlB1bGxSZXF1ZXN0NTY4MjIxMzIz | 1,822 | Add Hindi Discourse Analysis Natural Language Inference Dataset | [] | closed | false | null | 2 | 2021-02-05T09:30:54Z | 2021-02-15T09:57:39Z | 2021-02-15T09:57:39Z | null | # Dataset Card for Hindi Discourse Analysis Dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- HomePage : https://github.com/midas-research/hindi-nli-data
- Paper : https://www.aclweb.org/anthology/2020.aacl-main.71
- Point of Contact : https://github.com/midas-research/hindi-nli-data
### Dataset Summary
- Dataset for Natural Language Inference in Hindi Language. Hindi Discourse Analysis (HDA) Dataset consists of textual-entailment pairs.
- Each row of the Datasets if made up of 4 columns - Premise, Hypothesis, Label and Topic.
- Premise and Hypothesis is written in Hindi while Entailment_Label is in English.
- Entailment_label is of 2 types - entailed and not-entailed.
- Entailed means that hypotheis can be inferred from premise and not-entailed means vice versa
- Dataset can be used to train models for Natural Language Inference tasks in Hindi Language.
### Supported Tasks and Leaderboards
- Natural Language Inference for Hindi
### Languages
- Dataset is in Hindi
## Dataset Structure
- Data is structured in TSV format.
- train, test and dev files are in seperate files
### Dataset Instances
An example of 'train' looks as follows.
```
{'hypothesis': 'यह एक वर्णनात्मक कथन है।', 'label': 1, 'premise': 'जैसे उस का सारा चेहरा अपना हो और आँखें किसी दूसरे की जो चेहरे पर पपोटों के पीछे महसूर कर दी गईं।', 'topic': 1}
```
### Data Fields
- Each row contatins 4 columns - premise, hypothesis, label and topic.
### Data Splits
- Train : 31892
- Valid : 9460
- Test : 9970
## Dataset Creation
- We employ a recasting technique from Poliak et al. (2018a,b) to convert publicly available Hindi Discourse Analysis classification datasets in Hindi and pose them as TE problems
- In this recasting process, we build template hypotheses for each class in the label taxonomy
- Then, we pair the original annotated sentence with each of the template hypotheses to create TE samples.
- For more information on the recasting process, refer to paper https://www.aclweb.org/anthology/2020.aacl-main.71
### Source Data
Source Dataset for the recasting process is the BBC Hindi Headlines Dataset(https://github.com/NirantK/hindi2vec/releases/tag/bbc-hindi-v0.1)
#### Initial Data Collection and Normalization
- Initial Data was collected by members of MIDAS Lab from Hindi Websites. They crowd sourced the data annotation process and selected two random stories from our corpus and had the three annotators work on them independently and classify each sentence based on the discourse mode.
- Please refer to this paper for detailed information: https://www.aclweb.org/anthology/2020.lrec-1.149/
- The Discourse is further classified into "Argumentative" , "Descriptive" , "Dialogic" , "Informative" and "Narrative" - 5 Clases.
#### Who are the source language producers?
Please refer to this paper for detailed information: https://www.aclweb.org/anthology/2020.lrec-1.149/
### Annotations
#### Annotation process
Annotation process has been described in Dataset Creation Section.
#### Who are the annotators?
Annotation is done automatically by machine and corresponding recasting process.
### Personal and Sensitive Information
No Personal and Sensitive Information is mentioned in the Datasets.
## Considerations for Using the Data
Pls refer to this paper: https://www.aclweb.org/anthology/2020.aacl-main.71
### Discussion of Biases
No known bias exist in the dataset.
Pls refer to this paper: https://www.aclweb.org/anthology/2020.aacl-main.71
### Other Known Limitations
No other known limitations . Size of data may not be enough to train large models
## Additional Information
Pls refer to this link: https://github.com/midas-research/hindi-nli-data
### Dataset Curators
It is written in the repo : https://github.com/midas-research/hindi-nli-data that
- This corpus can be used freely for research purposes.
- The paper listed below provide details of the creation and use of the corpus. If you use the corpus, then please cite the paper.
- If interested in commercial use of the corpus, send email to [email protected].
- If you use the corpus in a product or application, then please credit the authors and Multimodal Digital Media Analysis Lab - Indraprastha Institute of Information Technology, New Delhi appropriately. Also, if you send us an email, we will be thrilled to know about how you have used the corpus.
- Multimodal Digital Media Analysis Lab - Indraprastha Institute of Information Technology, New Delhi, India disclaims any responsibility for the use of the corpus and does not provide technical support. However, the contact listed above will be happy to respond to queries and clarifications.
- Rather than redistributing the corpus, please direct interested parties to this page
- Please feel free to send us an email:
- with feedback regarding the corpus.
- with information on how you have used the corpus.
- if interested in having us analyze your data for natural language inference.
- if interested in a collaborative research project.
### Licensing Information
Copyright (C) 2019 Multimodal Digital Media Analysis Lab - Indraprastha Institute of Information Technology, New Delhi (MIDAS, IIIT-Delhi).
Pls contact authors for any information on the dataset.
### Citation Information
```
@inproceedings{uppal-etal-2020-two,
title = "Two-Step Classification using Recasted Data for Low Resource Settings",
author = "Uppal, Shagun and
Gupta, Vivek and
Swaminathan, Avinash and
Zhang, Haimin and
Mahata, Debanjan and
Gosangi, Rakesh and
Shah, Rajiv Ratn and
Stent, Amanda",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.aacl-main.71",
pages = "706--719",
abstract = "An NLP model{'}s ability to reason should be independent of language. Previous works utilize Natural Language Inference (NLI) to understand the reasoning ability of models, mostly focusing on high resource languages like English. To address scarcity of data in low-resource languages such as Hindi, we use data recasting to create NLI datasets for four existing text classification datasets. Through experiments, we show that our recasted dataset is devoid of statistical irregularities and spurious patterns. We further study the consistency in predictions of the textual entailment models and propose a consistency regulariser to remove pairwise-inconsistencies in predictions. We propose a novel two-step classification method which uses textual-entailment predictions for classification task. We further improve the performance by using a joint-objective for classification and textual entailment. We therefore highlight the benefits of data recasting and improvements on classification performance using our approach with supporting experimental results.",
}
```
### Contributions
Thanks to [@avinsit123](https://github.com/avinsit123) for adding this dataset.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1822/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1822/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1822.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1822",
"merged_at": "2021-02-15T09:57:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1822.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1822"
} | true | [
"Could you also run `make style` to fix the CI check on code formatting ?",
"@lhoestq completed and resolved all comments."
] |
https://api.github.com/repos/huggingface/datasets/issues/265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/265/comments | https://api.github.com/repos/huggingface/datasets/issues/265/events | https://github.com/huggingface/datasets/pull/265 | 637,139,220 | MDExOlB1bGxSZXF1ZXN0NDMzMTgxNDMz | 265 | Add pyarrow warning colab | [] | closed | false | null | 0 | 2020-06-11T15:57:51Z | 2020-08-02T18:14:36Z | 2020-06-12T08:14:16Z | null | When a user installs `nlp` on google colab, then google colab doesn't update pyarrow, and the runtime needs to be restarted to use the updated version of pyarrow.
This is an issue because `nlp` requires the updated version to work correctly.
In this PR I added en error that is shown to the user in google colab if the user tries to `import nlp` without having restarted the runtime. The error tells the user to restart the runtime. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/265/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/265",
"merged_at": "2020-06-12T08:14:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/265"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/415/comments | https://api.github.com/repos/huggingface/datasets/issues/415/events | https://github.com/huggingface/datasets/issues/415 | 660,687,076 | MDU6SXNzdWU2NjA2ODcwNzY= | 415 | Something is wrong with WMT 19 kk-en dataset | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | open | false | null | 0 | 2020-07-19T08:18:51Z | 2020-07-20T09:54:26Z | null | null | The translation in the `train` set does not look right:
```
>>>import nlp
>>>from nlp import load_dataset
>>>dataset = load_dataset('wmt19', 'kk-en')
>>>dataset["train"]["translation"][0]
{'kk': 'Trumpian Uncertainty', 'en': 'Трамптық белгісіздік'}
>>>dataset["validation"]["translation"][0]
{'kk': 'Ақша-несие саясатының сценарийін қайта жазсақ', 'en': 'Rewriting the Monetary-Policy Script'}
``` | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/415/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4087/comments | https://api.github.com/repos/huggingface/datasets/issues/4087/events | https://github.com/huggingface/datasets/pull/4087 | 1,191,819,805 | PR_kwDODunzps41lnfO | 4,087 | Fix BeamWriter output Parquet file | [] | closed | false | null | 1 | 2022-04-04T13:46:50Z | 2022-04-05T15:00:40Z | 2022-04-05T14:54:48Z | null | Since now, the `BeamWriter` saved a Parquet file with a simplified schema, where each field value was serialized to JSON. That resulted in Parquet files larger than Arrow files.
This PR:
- writes Parquet file preserving original schema and without serialization, thus avoiding serialization overhead and resulting in a smaller output file size.
- fixes `parquet_to_arrow` function | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4087/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4087",
"merged_at": "2022-04-05T14:54:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4087"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3270/comments | https://api.github.com/repos/huggingface/datasets/issues/3270/events | https://github.com/huggingface/datasets/pull/3270 | 1,053,465,662 | PR_kwDODunzps4uhcxm | 3,270 | Add os.listdir for streaming | [] | closed | false | null | 0 | 2021-11-15T10:14:04Z | 2021-11-15T10:27:03Z | 2021-11-15T10:27:03Z | null | Extend `os.listdir` to support streaming data from remote files. This is often used to navigate in remote ZIP files for example | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3270/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3270.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3270",
"merged_at": "2021-11-15T10:27:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3270.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3270"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5504 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5504/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5504/comments | https://api.github.com/repos/huggingface/datasets/issues/5504/events | https://github.com/huggingface/datasets/pull/5504 | 1,570,621,242 | PR_kwDODunzps5JPoWy | 5,504 | don't zero copy timestamps | [] | closed | false | null | 3 | 2023-02-03T23:39:04Z | 2023-02-08T17:28:50Z | 2023-02-08T14:33:17Z | null | Fixes https://github.com/huggingface/datasets/issues/5495
I'm not sure whether we prefer a test here or if timestamps are known to be unsupported (like booleans). The current test at least covers the bug | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5504/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5504/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5504.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5504",
"merged_at": "2023-02-08T14:33:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5504.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5504"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008606 / 0.011353 (-0.002747) | 0.004659 / 0.011008 (-0.006349) | 0.101311 / 0.038508 (0.062802) | 0.029664 / 0.023109 (0.006555) | 0.321850 / 0.275898 (0.045952) | 0.380497 / 0.323480 (0.057017) | 0.007003 / 0.007986 (-0.000982) | 0.003393 / 0.004328 (-0.000936) | 0.078704 / 0.004250 (0.074453) | 0.035810 / 0.037052 (-0.001242) | 0.327271 / 0.258489 (0.068782) | 0.369302 / 0.293841 (0.075461) | 0.033625 / 0.128546 (-0.094921) | 0.011563 / 0.075646 (-0.064084) | 0.323950 / 0.419271 (-0.095322) | 0.040660 / 0.043533 (-0.002872) | 0.327211 / 0.255139 (0.072072) | 0.350325 / 0.283200 (0.067125) | 0.085427 / 0.141683 (-0.056256) | 1.464370 / 1.452155 (0.012216) | 1.490355 / 1.492716 (-0.002362) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.202879 / 0.018006 (0.184873) | 0.419836 / 0.000490 (0.419346) | 0.000303 / 0.000200 (0.000103) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023336 / 0.037411 (-0.014075) | 0.096817 / 0.014526 (0.082291) | 0.103990 / 0.176557 (-0.072567) | 0.137749 / 0.737135 (-0.599386) | 0.108236 / 0.296338 (-0.188102) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420801 / 0.215209 (0.205592) | 4.205308 / 2.077655 (2.127653) | 2.050363 / 1.504120 (0.546243) | 1.877390 / 1.541195 (0.336195) | 2.031060 / 1.468490 (0.562570) | 0.687950 / 4.584777 (-3.896827) | 3.363202 / 3.745712 (-0.382510) | 1.869482 / 5.269862 (-3.400379) | 1.159131 / 4.565676 (-3.406545) | 0.082374 / 0.424275 (-0.341901) | 0.012425 / 0.007607 (0.004818) | 0.519775 / 0.226044 (0.293731) | 5.244612 / 2.268929 (2.975684) | 2.371314 / 55.444624 (-53.073311) | 2.052713 / 6.876477 (-4.823764) | 2.190015 / 2.142072 (0.047942) | 0.803806 / 4.805227 (-4.001421) | 0.148110 / 6.500664 (-6.352554) | 0.064174 / 0.075469 (-0.011295) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.250424 / 1.841788 (-0.591364) | 13.487870 / 8.074308 (5.413561) | 13.080736 / 10.191392 (2.889344) | 0.147715 / 0.680424 (-0.532709) | 0.028409 / 0.534201 (-0.505792) | 0.397531 / 0.579283 (-0.181752) | 0.399458 / 0.434364 (-0.034905) | 0.461467 / 0.540337 (-0.078871) | 0.541639 / 1.386936 (-0.845297) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006753 / 0.011353 (-0.004600) | 0.004573 / 0.011008 (-0.006435) | 0.076122 / 0.038508 (0.037614) | 0.027529 / 0.023109 (0.004419) | 0.341291 / 0.275898 (0.065393) | 0.376889 / 0.323480 (0.053409) | 0.005032 / 0.007986 (-0.002953) | 0.003447 / 0.004328 (-0.000882) | 0.075186 / 0.004250 (0.070936) | 0.038516 / 0.037052 (0.001463) | 0.340927 / 0.258489 (0.082438) | 0.386626 / 0.293841 (0.092785) | 0.031929 / 0.128546 (-0.096617) | 0.011759 / 0.075646 (-0.063888) | 0.085616 / 0.419271 (-0.333656) | 0.042858 / 0.043533 (-0.000674) | 0.341881 / 0.255139 (0.086742) | 0.367502 / 0.283200 (0.084303) | 0.090788 / 0.141683 (-0.050895) | 1.472871 / 1.452155 (0.020716) | 1.577825 / 1.492716 (0.085109) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.233137 / 0.018006 (0.215131) | 0.415016 / 0.000490 (0.414526) | 0.000379 / 0.000200 (0.000179) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024966 / 0.037411 (-0.012445) | 0.102794 / 0.014526 (0.088268) | 0.107543 / 0.176557 (-0.069014) | 0.143133 / 0.737135 (-0.594002) | 0.111494 / 0.296338 (-0.184845) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.438354 / 0.215209 (0.223145) | 4.382244 / 2.077655 (2.304589) | 2.056340 / 1.504120 (0.552220) | 1.851524 / 1.541195 (0.310330) | 1.933147 / 1.468490 (0.464657) | 0.701446 / 4.584777 (-3.883331) | 3.396893 / 3.745712 (-0.348819) | 2.837516 / 5.269862 (-2.432346) | 1.538298 / 4.565676 (-3.027379) | 0.083449 / 0.424275 (-0.340826) | 0.012793 / 0.007607 (0.005186) | 0.539661 / 0.226044 (0.313616) | 5.428415 / 2.268929 (3.159487) | 2.527582 / 55.444624 (-52.917042) | 2.172795 / 6.876477 (-4.703682) | 2.220011 / 2.142072 (0.077938) | 0.814338 / 4.805227 (-3.990889) | 0.153468 / 6.500664 (-6.347196) | 0.069056 / 0.075469 (-0.006413) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.278434 / 1.841788 (-0.563354) | 14.284924 / 8.074308 (6.210616) | 13.486596 / 10.191392 (3.295203) | 0.138457 / 0.680424 (-0.541967) | 0.016609 / 0.534201 (-0.517592) | 0.382828 / 0.579283 (-0.196455) | 0.387604 / 0.434364 (-0.046760) | 0.478801 / 0.540337 (-0.061536) | 0.565352 / 1.386936 (-0.821584) |\n\n</details>\n</details>\n\n\n",
"> Thanks! I modified the test a bit to make it more consistent with the rest of the \"extractor\" tests.\r\n\r\nAppreciate the assist on the tests! 🚀 "
] |
https://api.github.com/repos/huggingface/datasets/issues/225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/225/comments | https://api.github.com/repos/huggingface/datasets/issues/225/events | https://github.com/huggingface/datasets/issues/225 | 628,083,366 | MDU6SXNzdWU2MjgwODMzNjY= | 225 | [ROUGE] Different scores with `files2rouge` | [
{
"color": "d722e8",
"default": false,
"description": "Discussions on the metrics",
"id": 2067400959,
"name": "Metric discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwOTU5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Metric%20discussion"
}
] | closed | false | null | 3 | 2020-06-01T00:50:36Z | 2020-06-03T15:27:18Z | 2020-06-03T15:27:18Z | null | It seems that the ROUGE score of `nlp` is lower than the one of `files2rouge`.
Here is a self-contained notebook to reproduce both scores : https://colab.research.google.com/drive/14EyAXValB6UzKY9x4rs_T3pyL7alpw_F?usp=sharing
---
`nlp` : (Only mid F-scores)
>rouge1 0.33508031962733364
rouge2 0.14574333776191592
rougeL 0.2321187823256159
`files2rouge` :
>Running ROUGE...
===========================
1 ROUGE-1 Average_R: 0.48873 (95%-conf.int. 0.41192 - 0.56339)
1 ROUGE-1 Average_P: 0.29010 (95%-conf.int. 0.23605 - 0.34445)
1 ROUGE-1 Average_F: 0.34761 (95%-conf.int. 0.29479 - 0.39871)
===========================
1 ROUGE-2 Average_R: 0.20280 (95%-conf.int. 0.14969 - 0.26244)
1 ROUGE-2 Average_P: 0.12772 (95%-conf.int. 0.08603 - 0.17752)
1 ROUGE-2 Average_F: 0.14798 (95%-conf.int. 0.10517 - 0.19240)
===========================
1 ROUGE-L Average_R: 0.32960 (95%-conf.int. 0.26501 - 0.39676)
1 ROUGE-L Average_P: 0.19880 (95%-conf.int. 0.15257 - 0.25136)
1 ROUGE-L Average_F: 0.23619 (95%-conf.int. 0.19073 - 0.28663)
---
When using longer predictions/gold, the difference is bigger.
**How can I reproduce same score as `files2rouge` ?**
@lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/225/timeline | null | completed | null | null | false | [
"@Colanim unfortunately there are different implementations of the ROUGE metric floating around online which yield different results, and we had to chose one for the package :) We ended up including the one from the google-research repository, which does minimal post-processing before computing the P/R/F scores. If I recall correctly, files2rouge relies on the Perl, script, which among other things normalizes all numbers to a special token: in the case you presented, this should account for a good chunk of the difference.\r\n\r\nWe may end up adding in more versions of the metric, but probably not for a while (@lhoestq correct me if I'm wrong). However, feel free to take a stab at adding it in yourself and submitting a PR if you're interested!",
"Thank you for your kind answer.\r\n\r\nAs a side question : Isn't it better to have a package that normalize more ?\r\n\r\nI understand to idea of having a package that does minimal post-processing for transparency.\r\n\r\nBut it means that people using different architecture (with different tokenizers for example) will have difference in ROUGE scores even if their predictions are actually similar. \r\nThe goal of `nlp` is to have _one package to rule them all_, right ?\r\n\r\nI will look into it but I'm not sure I have the required skill for this ^^ ",
"You're right, there's a pretty interesting trade-off here between robustness and sensitivity :) The flip side of your argument is that we also still want the metric to be sensitive to model mistakes. How we think about number normalization for example has evolved a fair bit since the Perl script was written: at the time, ROUGE was used mostly to evaluate short-medium text summarization systems, where there were only a few numbers in the input and it was assumed that the most popular methods in use at the time would get those right. However, as your example showcases, that assumption does not hold any more, and we do want to be able to penalize a model that generates a wrong numerical value.\r\n\r\nAlso, we think that abstracting away tokenization differences is the role of the model/tokenizer: if you use the 🤗Tokenizers library for example, it will handle that for you ;)\r\n\r\nFinally, there is a lot of active research on developing model-powered metrics that are both more sensitive and more robust than ROUGE. Check out for example BERTscore, which is implemented in this library!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5175/comments | https://api.github.com/repos/huggingface/datasets/issues/5175/events | https://github.com/huggingface/datasets/issues/5175 | 1,428,696,231 | I_kwDODunzps5VKCyn | 5,175 | Loading an external NER dataset | [] | closed | false | null | 0 | 2022-10-30T09:31:55Z | 2022-11-01T13:15:49Z | 2022-11-01T13:15:49Z | null | I need to use huggingface datasets to load a custom dataset similar to conll2003 but with more entities and each the files contain only two columns: word and ner tag.
I tried this code snnipet that I found here as an answer to a similar issue:
from datasets import Dataset
INPUT_COLUMNS = "ID Text NER".split()
def read_conll(file):
example = {col: [] for col in INPUT_COLUMNS}
idx = 0
with open(file) as f:
for line in f:
if line.startswith("-DOCSTART-") or line == "\n" or not line:
if example[next(iter(example))]:
yield idx, example
idx += 1
example = {col: [] for col in INPUT_COLUMNS}
else:
row_cols = line.split()
for i, col in enumerate(example):
example[col] = row_cols[i].rstrip()
train = Dataset.from_generator(read_conll, gen_kwargs={"file": "some_path"})
But the following error happened:
ValueError: Please pass `features` or at least one example when writing data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5175/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5562/comments | https://api.github.com/repos/huggingface/datasets/issues/5562/events | https://github.com/huggingface/datasets/pull/5562 | 1,594,625,539 | PR_kwDODunzps5KfTUT | 5,562 | Update csv.py | [] | closed | false | null | 4 | 2023-02-22T07:56:10Z | 2023-02-23T11:07:49Z | 2023-02-23T11:00:58Z | null | Removed mangle_dup_cols=True from BuilderConfig.
It triggered following deprecation warning:
/usr/local/lib/python3.8/dist-packages/datasets/download/streaming_download_manager.py:776: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'
return pd.read_csv(xopen(filepath_or_buffer, "rb", use_auth_token=use_auth_token), **kwargs)
Further documentation of pandas: https://pandas.pydata.org/docs/whatsnew/v1.4.0.html#mangle-dupe-cols-in-read-csv-no-longer-renames-unique-columns-conflicting-with-target-names
At first sight it seems like this flag is resolved internally, it might need some more research. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5562/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5562",
"merged_at": "2023-02-23T11:00:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5562"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Removed it :)",
"Changed it :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008358 / 0.011353 (-0.002995) | 0.004555 / 0.011008 (-0.006453) | 0.100935 / 0.038508 (0.062427) | 0.029473 / 0.023109 (0.006364) | 0.336165 / 0.275898 (0.060266) | 0.420397 / 0.323480 (0.096917) | 0.006609 / 0.007986 (-0.001376) | 0.003338 / 0.004328 (-0.000991) | 0.078639 / 0.004250 (0.074388) | 0.034051 / 0.037052 (-0.003001) | 0.342820 / 0.258489 (0.084331) | 0.399392 / 0.293841 (0.105551) | 0.033935 / 0.128546 (-0.094611) | 0.011555 / 0.075646 (-0.064092) | 0.323467 / 0.419271 (-0.095804) | 0.040675 / 0.043533 (-0.002858) | 0.321247 / 0.255139 (0.066108) | 0.370967 / 0.283200 (0.087767) | 0.085766 / 0.141683 (-0.055917) | 1.461158 / 1.452155 (0.009003) | 1.504641 / 1.492716 (0.011925) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.180060 / 0.018006 (0.162053) | 0.403623 / 0.000490 (0.403134) | 0.002253 / 0.000200 (0.002053) | 0.000072 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022793 / 0.037411 (-0.014618) | 0.098869 / 0.014526 (0.084343) | 0.104512 / 0.176557 (-0.072045) | 0.167721 / 0.737135 (-0.569414) | 0.107969 / 0.296338 (-0.188370) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.411179 / 0.215209 (0.195969) | 4.095345 / 2.077655 (2.017690) | 1.825992 / 1.504120 (0.321872) | 1.624386 / 1.541195 (0.083192) | 1.654903 / 1.468490 (0.186413) | 0.695041 / 4.584777 (-3.889736) | 3.319087 / 3.745712 (-0.426625) | 1.881945 / 5.269862 (-3.387917) | 1.250360 / 4.565676 (-3.315316) | 0.082405 / 0.424275 (-0.341870) | 0.012499 / 0.007607 (0.004892) | 0.522846 / 0.226044 (0.296801) | 5.241103 / 2.268929 (2.972175) | 2.293100 / 55.444624 (-53.151524) | 1.942937 / 6.876477 (-4.933540) | 1.957434 / 2.142072 (-0.184638) | 0.809782 / 4.805227 (-3.995445) | 0.148290 / 6.500664 (-6.352374) | 0.064157 / 0.075469 (-0.011312) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.185616 / 1.841788 (-0.656172) | 13.616791 / 8.074308 (5.542483) | 13.741806 / 10.191392 (3.550414) | 0.137396 / 0.680424 (-0.543028) | 0.028751 / 0.534201 (-0.505450) | 0.397636 / 0.579283 (-0.181647) | 0.403594 / 0.434364 (-0.030770) | 0.484039 / 0.540337 (-0.056299) | 0.568398 / 1.386936 (-0.818538) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006712 / 0.011353 (-0.004640) | 0.004511 / 0.011008 (-0.006497) | 0.076946 / 0.038508 (0.038438) | 0.027219 / 0.023109 (0.004110) | 0.350769 / 0.275898 (0.074871) | 0.408539 / 0.323480 (0.085059) | 0.005014 / 0.007986 (-0.002971) | 0.003361 / 0.004328 (-0.000968) | 0.077106 / 0.004250 (0.072856) | 0.040105 / 0.037052 (0.003053) | 0.342041 / 0.258489 (0.083552) | 0.426355 / 0.293841 (0.132514) | 0.031684 / 0.128546 (-0.096863) | 0.011575 / 0.075646 (-0.064072) | 0.085797 / 0.419271 (-0.333474) | 0.041575 / 0.043533 (-0.001958) | 0.340837 / 0.255139 (0.085698) | 0.390461 / 0.283200 (0.107262) | 0.089531 / 0.141683 (-0.052152) | 1.504600 / 1.452155 (0.052445) | 1.538712 / 1.492716 (0.045996) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236679 / 0.018006 (0.218673) | 0.396258 / 0.000490 (0.395768) | 0.006479 / 0.000200 (0.006279) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024682 / 0.037411 (-0.012729) | 0.100167 / 0.014526 (0.085641) | 0.106627 / 0.176557 (-0.069929) | 0.174592 / 0.737135 (-0.562543) | 0.109499 / 0.296338 (-0.186839) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444702 / 0.215209 (0.229493) | 4.462779 / 2.077655 (2.385125) | 2.087711 / 1.504120 (0.583591) | 1.874900 / 1.541195 (0.333705) | 1.918609 / 1.468490 (0.450119) | 0.705867 / 4.584777 (-3.878910) | 3.355483 / 3.745712 (-0.390229) | 2.808348 / 5.269862 (-2.461514) | 1.253319 / 4.565676 (-3.312358) | 0.083747 / 0.424275 (-0.340528) | 0.012491 / 0.007607 (0.004884) | 0.542885 / 0.226044 (0.316841) | 5.453921 / 2.268929 (3.184993) | 2.545688 / 55.444624 (-52.898937) | 2.185022 / 6.876477 (-4.691455) | 2.215351 / 2.142072 (0.073279) | 0.808201 / 4.805227 (-3.997027) | 0.151754 / 6.500664 (-6.348910) | 0.066886 / 0.075469 (-0.008583) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.298583 / 1.841788 (-0.543205) | 14.014276 / 8.074308 (5.939968) | 13.505338 / 10.191392 (3.313946) | 0.142033 / 0.680424 (-0.538391) | 0.016863 / 0.534201 (-0.517338) | 0.381195 / 0.579283 (-0.198088) | 0.384455 / 0.434364 (-0.049909) | 0.465765 / 0.540337 (-0.074572) | 0.552571 / 1.386936 (-0.834366) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/676/comments | https://api.github.com/repos/huggingface/datasets/issues/676/events | https://github.com/huggingface/datasets/issues/676 | 710,014,319 | MDU6SXNzdWU3MTAwMTQzMTk= | 676 | train_test_split returns empty dataset item | [] | closed | false | null | 4 | 2020-09-28T07:19:33Z | 2020-10-07T13:46:33Z | 2020-10-07T13:38:06Z | null | I try to split my dataset by `train_test_split`, but after that the item in `train` and `test` `Dataset` is empty.
The codes:
```
yelp_data = datasets.load_from_disk('/home/ssd4/huanglianzhe/test_yelp')
print(yelp_data[0])
yelp_data = yelp_data.train_test_split(test_size=0.1)
print(yelp_data)
print(yelp_data['test'])
print(yelp_data['test'][0])
```
The outputs:
```
{'stars': 2.0, 'text': 'xxxx'}
Loading cached split indices for dataset at /home/ssd4/huanglianzhe/test_yelp/cache-f9b22d8b9d5a7346.arrow and /home/ssd4/huanglianzhe/test_yelp/cache-4aa26fa4005059d1.arrow
DatasetDict({'train': Dataset(features: {'stars': Value(dtype='float64', id=None), 'text': Value(dtype='string', id=None)}, num_rows: 7219009), 'test': Dataset(features: {'stars': Value(dtype='float64', id=None), 'text': Value(dtype='string', id=None)}, num_rows: 802113)})
Dataset(features: {'stars': Value(dtype='float64', id=None), 'text': Value(dtype='string', id=None)}, num_rows: 802113)
{} # yelp_data['test'][0] is empty
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/676/timeline | null | completed | null | null | false | [
"The problem still exists after removing the cache files.",
"Can you reproduce this example in a Colab so we can investigate? (or give more information on your software/hardware config)",
"Thanks for reporting.\r\nI just found the issue, I'm creating a PR",
"We'll do a release pretty soon to include the fix :)\r\nIn the meantime you can install the lib from source if you want to "
] |
https://api.github.com/repos/huggingface/datasets/issues/4081 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4081/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4081/comments | https://api.github.com/repos/huggingface/datasets/issues/4081/events | https://github.com/huggingface/datasets/pull/4081 | 1,189,916,472 | PR_kwDODunzps41fsxW | 4,081 | Close parquet writer properly in `push_to_hub` | [] | closed | false | null | 2 | 2022-04-01T14:58:50Z | 2022-07-14T19:22:06Z | 2022-04-01T16:16:19Z | null | We don’t call writer.close(), which causes https://github.com/huggingface/datasets/issues/4077. It can happen that we upload the file before the writer is garbage collected and writes the footer.
I fixed this by explicitly closing the parquet writer.
Close https://github.com/huggingface/datasets/issues/4077. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4081/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4081/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4081.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4081",
"merged_at": "2022-04-01T16:16:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4081.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4081"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq / @albertvillanova / @mariosasko \r\nI am facing the same scenario. Let me explain the situation point. I have a glue ETL job\r\n\r\n1--> My files are in parquet format and stored in AWS s3.\r\n2--> I am iterating a loop for a data set where the same file name can occur with diffrent other data.\r\n3--> I read the parquet and saved it in a pandas data frame.\r\n4--> Done some operation on that data frame\r\n5--> upload the updated data frame into the S3 parquet file. Below are code snippet what I am using to save the updated \r\n data frame into parquet format and load into S3\r\n `header_name_column_list = dict(data_frame)\r\n header_list = []\r\n for col_id, col_type in header_name_column_list.items():\r\n header_list.append(pyarrow.field(col_id, pyarrow.string()))\r\n table_schema = pyarrow.schema(header_list)\r\n table = pyarrow.Table.from_pandas(data_frame, schema=table_schema, preserve_index=False)\r\n writer = parquet.ParquetWriter(b_buffer, table.schema)\r\n writer.write_table(table)\r\n writer.close()\r\n b_buffer.seek(0)\r\n .....\r\n ....\r\n self.s3_client.upload_fileobj(\r\n b_buffer,\r\n self.bucket,\r\n file_key,\r\n ExtraArgs=extra_args)`\r\n\r\nBut when I executed the glue etl job, the first time it works properly and but in the next iteration, when I try to open the same file got that error.\r\n\r\n\r\n<html>\r\n<body>\r\n<!--StartFragment-->\r\n\r\nINFO:Iot-dsip-de-duplication-job:Dataframe uploaded: s3://abc/2022/07/12/file1_ft_20220714122108.3065_12345.parquet INFO:Iot-dsip-de-duplication-job:Sleep for 60 sec\r\nINFO:Iot-dsip-de-duplication-job:start after sleep\r\n.......................\r\n..........................\r\n..........................\r\nERROR:Iot-dsip-de-duplication-job:Failed to read data from parquet file s3://abc/2022/07/12/file1_ft_20220714122108.3065_12345.parquet, error is : Invalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.INFO:Iot-dsip-de-duplication-job:Empty dataframe found\r\n\r\n<!--EndFragment-->\r\n</body>\r\n</html>\r\n\r\nAny clue will be really helpful..I got stuck with this problem."
] |
https://api.github.com/repos/huggingface/datasets/issues/3333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3333/comments | https://api.github.com/repos/huggingface/datasets/issues/3333/events | https://github.com/huggingface/datasets/issues/3333 | 1,065,346,919 | I_kwDODunzps4_f-dn | 3,333 | load JSON files, get the errors | [] | closed | false | null | 12 | 2021-11-28T14:29:58Z | 2021-12-01T09:34:31Z | 2021-12-01T03:57:48Z | null | Hi, does this bug be fixed? when I load JSON files, I get the same errors by the command
`!python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/`
change the dateset to load json by refering to https://huggingface.co/docs/datasets/loading.html
`dataset = datasets.load_dataset('json', data_files=args.dataset)`
Errors:
`Downloading and preparing dataset json/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/json/default-c1e124ad488911b8/0.0.0/45636811569ec4a6630521c18235dfbbab83b7ab572e3393c5ba68ccabe98264...
`
_Originally posted by @yanllearnn in https://github.com/huggingface/datasets/issues/730#issuecomment-981095050_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3333/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3333/timeline | null | completed | null | null | false | [
"Hi ! The message you're getting is not an error. It simply says that your JSON dataset is being prepared to a location in `/root/.cache/huggingface/datasets`",
"> \r\n\r\nbut I want to load local JSON file by command\r\n`python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/`\r\n\r\n**squad-retrain-data/train-v2.0.json** is the local JSON file, how to load it and map it to a special structure?",
"You can load it with `dataset = datasets.load_dataset('json', data_files=args.dataset)` as you said.\r\nThen if you need to apply additional processing to map it to a special structure, you can use rename columns or use `dataset.map`. For more information, you can check the documentation here: https://huggingface.co/docs/datasets/process.html\r\n\r\nAlso feel free to share your `run.py` code so we can take a look",
"```\r\n# Dataset selection\r\n if args.dataset.endswith('.json') or args.dataset.endswith('.jsonl'):\r\n dataset_id = None\r\n # Load from local json/jsonl file\r\n dataset = datasets.load_dataset('json', data_files=args.dataset)\r\n # By default, the \"json\" dataset loader places all examples in the train split,\r\n # so if we want to use a jsonl file for evaluation we need to get the \"train\" split\r\n # from the loaded dataset\r\n eval_split = 'train'\r\n else:\r\n default_datasets = {'qa': ('squad',), 'nli': ('snli',)}\r\n dataset_id = tuple(args.dataset.split(':')) if args.dataset is not None else \\\r\n default_datasets[args.task]\r\n # MNLI has two validation splits (one with matched domains and one with mismatched domains). Most datasets just have one \"validation\" split\r\n eval_split = 'validation_matched' if dataset_id == ('glue', 'mnli') else 'validation'\r\n # Load the raw data\r\n dataset = datasets.load_dataset(*dataset_id)\r\n```\r\n\r\nI want to load JSON squad dataset instead `dataset = datasets.load_dataset('squad')` to retrain the model. \r\n",
"If your JSON has the same format as the SQuAD dataset, then you need to pass `field=\"data\"` to `load_dataset`, since the SQuAD format is one big JSON object in which the \"data\" field contains the list of questions and answers.\r\n```python\r\ndataset = datasets.load_dataset('json', data_files=args.dataset, field=\"data\")\r\n```\r\n\r\nLet me know if that helps :)\r\n\r\n",
"Yes, code works. but the format is not as expected.\r\n```\r\ndataset = datasets.load_dataset('json', data_files=args.dataset, field=\"data\")\r\n```\r\n```\r\npython3 run.py --do_train --task qa --dataset squad --output_dir ./re_trained_model/\r\n```\r\n************ train_dataset: Dataset({\r\n features: ['id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 87599\r\n})\r\n\r\n\r\n```\r\npython3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/\r\n```\r\n************ train_dataset: Dataset({\r\n features: ['title', 'paragraphs'],\r\n num_rows: 442\r\n})\r\n\r\nI want the JSON to have the same format as before features. https://github.com/huggingface/datasets/blob/master/datasets/squad_v2/squad_v2.py is the script dealing with **squad** but how can I apply it by using JSON? ",
"Ok I see, you have the paragraphs so you just need to process them to extract the questions and answers. I think you can process the SQuAD-like data this way:\r\n```python\r\ndef process_squad(articles):\r\n out = {\r\n \"title\": [],\r\n \"context\": [],\r\n \"question\": [],\r\n \"id\": [],\r\n \"answers\": [],\r\n }\r\n for title, paragraphs in zip(articles[\"title\"], articles[\"paragraphs\"]):\r\n for paragraph in paragraphs:\r\n for qa in paragraph[\"qas\"]:\r\n out[\"title\"].append(title)\r\n out[\"context\"].append(paragraph[\"context\"])\r\n out[\"question\"].append(qa[\"question\"])\r\n out[\"id\"].append(qa[\"id\"])\r\n out[\"answers\"].append({\r\n \"answer_start\": [answer[\"answer_start\"] for answer in qa[\"answers\"]],\r\n \"text\": [answer[\"text\"] for answer in qa[\"answers\"]],\r\n })\r\n return out\r\n\r\ndataset = dataset.map(process_squad, batched=True, remove_columns=[\"paragraphs\"])\r\n```\r\n\r\nI adapted the code from [squad.py](https://github.com/huggingface/datasets/blob/master/datasets/squad/squad.py). The code takes as input a batch of articles (title + paragraphs) and gets all the questions and answers from the JSON structure.\r\n\r\nThe output is a dataset with `features: ['answers', 'context', 'id', 'question', 'title']`\r\n\r\nLet me know if that helps !\r\n",
"Yes, this works. But how to get the training output during training the squad by **Trainer** \r\nfor example https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/trainer_qa.py \r\nI want the training inputs, labels, outputs for every epoch and step to produce the training dynamic graph",
"I think you may need to implement your own Trainer, from the `QuestionAnsweringTrainer` for example.\r\nThis way you can have the flexibility of saving all the inputs/output used at each step",
"does there have any function to be overwritten to do this?",
"> does there have any function to be overwritten to do this?\r\n\r\nok, I overwrote the compute_loss, thank you.",
"Hi, I add one field **example_id**, but I can't see it in the **comput_loss** function, how can I do this? below is the information of inputs\r\n\r\n```\r\n*********************** inputs: {'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0],\r\n ...,\r\n [1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0],\r\n [1, 1, 1, ..., 0, 0, 0]], device='cuda:0'), 'end_positions': tensor([ 25, 97, 93, 44, 25, 112, 109, 134], device='cuda:0'), 'input_ids': tensor([[ 101, 2054, 2390, ..., 0, 0, 0],\r\n [ 101, 2054, 2515, ..., 0, 0, 0],\r\n [ 101, 2054, 2106, ..., 0, 0, 0],\r\n ...,\r\n [ 101, 2339, 2001, ..., 0, 0, 0],\r\n [ 101, 2054, 2515, ..., 0, 0, 0],\r\n [ 101, 2054, 2003, ..., 0, 0, 0]], device='cuda:0'), 'start_positions': tensor([ 20, 90, 89, 41, 25, 96, 106, 132], device='cuda:0'), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0],\r\n ...,\r\n [0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0],\r\n [0, 0, 0, ..., 0, 0, 0]], device='cuda:0')} \r\n```\r\n\r\n```\r\n# This function preprocesses a question answering dataset, tokenizing the question and context text\r\n# and finding the right offsets for the answer spans in the tokenized context (to use as labels).\r\n# Adapted from https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_qa.py\r\ndef prepare_train_dataset_qa(examples, tokenizer, max_seq_length=None):\r\n questions = [q.lstrip() for q in examples[\"question\"]]\r\n max_seq_length = tokenizer.model_max_length\r\n # tokenize both questions and the corresponding context\r\n # if the context length is longer than max_length, we split it to several\r\n # chunks of max_length\r\n tokenized_examples = tokenizer(\r\n questions,\r\n examples[\"context\"],\r\n truncation=\"only_second\",\r\n max_length=max_seq_length,\r\n stride=min(max_seq_length // 2, 128),\r\n return_overflowing_tokens=True,\r\n return_offsets_mapping=True,\r\n padding=\"max_length\"\r\n )\r\n\r\n # Since one example might give us several features if it has a long context,\r\n # we need a map from a feature to its corresponding example.\r\n sample_mapping = tokenized_examples.pop(\"overflow_to_sample_mapping\")\r\n # The offset mappings will give us a map from token to character position\r\n # in the original context. This will help us compute the start_positions\r\n # and end_positions to get the final answer string.\r\n offset_mapping = tokenized_examples.pop(\"offset_mapping\")\r\n\r\n tokenized_examples[\"start_positions\"] = []\r\n tokenized_examples[\"end_positions\"] = []\r\n\r\n tokenized_examples[\"example_id\"] = []\r\n\r\n for i, offsets in enumerate(offset_mapping):\r\n input_ids = tokenized_examples[\"input_ids\"][i]\r\n # We will label features not containing the answer the index of the CLS token.\r\n cls_index = input_ids.index(tokenizer.cls_token_id)\r\n sequence_ids = tokenized_examples.sequence_ids(i)\r\n # from the feature idx to sample idx\r\n sample_index = sample_mapping[i]\r\n # get the answer for a feature\r\n answers = examples[\"answers\"][sample_index]\r\n\r\n tokenized_examples[\"example_id\"].append(examples[\"id\"][sample_index])\r\n\r\n if len(answers[\"answer_start\"]) == 0:\r\n tokenized_examples[\"start_positions\"].append(cls_index)\r\n tokenized_examples[\"end_positions\"].append(cls_index)\r\n else:\r\n # Start/end character index of the answer in the text.\r\n start_char = answers[\"answer_start\"][0]\r\n end_char = start_char + len(answers[\"text\"][0])\r\n\r\n # Start token index of the current span in the text.\r\n token_start_index = 0\r\n while sequence_ids[token_start_index] != 1:\r\n token_start_index += 1\r\n\r\n # End token index of the current span in the text.\r\n token_end_index = len(input_ids) - 1\r\n while sequence_ids[token_end_index] != 1:\r\n token_end_index -= 1\r\n\r\n # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).\r\n if not (offsets[token_start_index][0] <= start_char and\r\n offsets[token_end_index][1] >= end_char):\r\n tokenized_examples[\"start_positions\"].append(cls_index)\r\n tokenized_examples[\"end_positions\"].append(cls_index)\r\n else:\r\n # Otherwise move the token_start_index and token_end_index to the two ends of the answer.\r\n # Note: we could go after the last offset if the answer is the last word (edge case).\r\n while token_start_index < len(offsets) and \\\r\n offsets[token_start_index][0] <= start_char:\r\n token_start_index += 1\r\n tokenized_examples[\"start_positions\"].append(\r\n token_start_index - 1)\r\n while offsets[token_end_index][1] >= end_char:\r\n token_end_index -= 1\r\n tokenized_examples[\"end_positions\"].append(token_end_index + 1)\r\n\r\n return tokenized_examples\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/550/comments | https://api.github.com/repos/huggingface/datasets/issues/550/events | https://github.com/huggingface/datasets/pull/550 | 689,775,914 | MDExOlB1bGxSZXF1ZXN0NDc2NzgyNDY1 | 550 | [BUGFIX] Solving mismatched checksum issue for the LinCE dataset (#539) | [] | closed | false | null | 2 | 2020-09-01T03:27:03Z | 2020-09-03T09:06:01Z | 2020-09-03T09:06:01Z | null | Hi,
I have added the updated `dataset_infos.json` file for the LinCE benchmark. This update is to fix the mismatched checksum bug #539 for one of the datasets in the LinCE benchmark. To update the file, I run this command from the nlp root directory:
```
python nlp-cli test ./datasets/lince --save_infos --all_configs
```
**NOTE**: I needed to change [this line](https://github.com/huggingface/nlp/blob/master/src/nlp/commands/dummy_data.py#L8) from: `from .utils.logging import get_logger` to `from nlp.utils.logging import get_logger`, otherwise the script was not able to import `get_logger`. However, I did not include that in this PR since that could have been just my environment (and another PR could be fixing this already if it is actually an issue). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/550/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/550",
"merged_at": "2020-09-03T09:06:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/550"
} | true | [
"Thanks a lot for that!\r\nThe line you are mentioning is a bug indeed, do you mind fixing it at the same time?",
"No worries! \r\n\r\nI pushed right away the fix, but then I realized that the master branch already had it, so I ended up merging the master branch with lince locally and then overwriting the previous commit in origin/lince. Hopefully, this is not too messy :)\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4625/comments | https://api.github.com/repos/huggingface/datasets/issues/4625/events | https://github.com/huggingface/datasets/pull/4625 | 1,293,163,744 | PR_kwDODunzps46zELz | 4,625 | Unpack `dl_manager.iter_files` to allow parallization | [] | closed | false | null | 2 | 2022-07-04T13:16:58Z | 2022-07-05T11:11:54Z | 2022-07-05T11:00:48Z | null | Iterate over data files outside `dl_manager.iter_files` to allow parallelization in streaming mode.
(The issue reported [here](https://discuss.huggingface.co/t/dataset-only-have-n-shard-1-when-has-multiple-shards-in-repo/19887))
PS: Another option would be to override `FilesIterable.__getitem__` to make it indexable and check for that type in `_shard_kwargs` and `n_shards,` but IMO this solution adds too much unnecessary complexity. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4625/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4625.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4625",
"merged_at": "2022-07-05T11:00:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4625.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4625"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Yup it sounds like the right solution.\r\n\r\nIt looks like `_generate_tables` needs to be updated as well to fix the CI"
] |
https://api.github.com/repos/huggingface/datasets/issues/1991 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1991/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1991/comments | https://api.github.com/repos/huggingface/datasets/issues/1991/events | https://github.com/huggingface/datasets/pull/1991 | 822,554,473 | MDExOlB1bGxSZXF1ZXN0NTg1MTYwNDkx | 1,991 | Adding the conllpp dataset | [] | closed | false | null | 1 | 2021-03-04T22:19:43Z | 2021-03-17T10:37:39Z | 2021-03-17T10:37:39Z | null | Adding the conllpp dataset, is a revision from https://github.com/huggingface/datasets/pull/1910. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1991/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1991/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1991.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1991",
"merged_at": "2021-03-17T10:37:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1991.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1991"
} | true | [
"Thanks for the reviews! A note that I have addressed the comments, and waiting for a further review."
] |
https://api.github.com/repos/huggingface/datasets/issues/228 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/228/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/228/comments | https://api.github.com/repos/huggingface/datasets/issues/228/events | https://github.com/huggingface/datasets/issues/228 | 629,952,402 | MDU6SXNzdWU2Mjk5NTI0MDI= | 228 | Not able to access the XNLI dataset | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 4 | 2020-06-03T12:25:14Z | 2020-07-17T17:44:22Z | 2020-07-17T17:44:22Z | null | When I try to access the XNLI dataset, I get the following error. The option of plain_text get selected automatically and then I get the following error.
```
FileNotFoundError: [Errno 2] No such file or directory: '/home/sasha/.cache/huggingface/datasets/xnli/plain_text/1.0.0/dataset_info.json'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp_viewer/run.py", line 86, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp_viewer/run.py", line 72, in get
builder_instance = builder_cls(name=conf)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
```
Is it possible to see if the dataset_info.json is correctly placed? | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/228/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/228/timeline | null | completed | null | null | false | [
"Added pull request to change the name of the file from dataset_infos.json to dataset_info.json",
"Thanks for reporting this bug !\r\nAs it seems to be just a cache problem, I closed your PR.\r\nI think we might just need to clear and reload the `xnli` cache @srush ? ",
"Update: The dataset_info.json error is gone, but we have a new one instead:\r\n```\r\nConnectionError: Couldn't reach https://www.nyu.edu/projects/bowman/xnli/XNLI-1.0.zip\r\n```\r\nI am not able to reproduce on my side unfortunately. Any idea @srush ?",
"xnli is now properly shown in the viewer.\r\nClosing this one."
] |
https://api.github.com/repos/huggingface/datasets/issues/3487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3487/comments | https://api.github.com/repos/huggingface/datasets/issues/3487/events | https://github.com/huggingface/datasets/pull/3487 | 1,089,209,031 | PR_kwDODunzps4wTVeN | 3,487 | Update ADD_NEW_DATASET.md | [] | closed | false | null | 0 | 2021-12-27T12:24:51Z | 2021-12-27T15:00:45Z | 2021-12-27T15:00:45Z | null | fixed make style prompt for Windows Terminal | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3487/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3487",
"merged_at": "2021-12-27T15:00:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3487"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2610/comments | https://api.github.com/repos/huggingface/datasets/issues/2610/events | https://github.com/huggingface/datasets/pull/2610 | 939,899,829 | MDExOlB1bGxSZXF1ZXN0Njg2MDUwMzI5 | 2,610 | Add missing WikiANN language tags | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-05T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/6",
"id": 6836458,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/6/labels",
"node_id": "MDk6TWlsZXN0b25lNjgzNjQ1OA==",
"number": 6,
"open_issues": 0,
"state": "closed",
"title": "1.10",
"updated_at": "2021-07-21T15:36:49Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/6"
} | 0 | 2021-07-08T14:08:01Z | 2021-07-12T14:12:16Z | 2021-07-08T15:44:04Z | null | Add missing language tags for WikiANN datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2610/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2610.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2610",
"merged_at": "2021-07-08T15:44:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2610.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2610"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2940 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2940/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2940/comments | https://api.github.com/repos/huggingface/datasets/issues/2940/events | https://github.com/huggingface/datasets/pull/2940 | 999,680,796 | PR_kwDODunzps4r6EUF | 2,940 | add swedish_medical_ner dataset | [] | closed | false | null | 0 | 2021-09-17T20:03:05Z | 2021-10-05T12:13:34Z | 2021-10-05T12:13:33Z | null | Adding the Swedish Medical NER dataset, listed in "Biomedical Datasets - BigScience Workshop 2021" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2940/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2940/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2940.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2940",
"merged_at": "2021-10-05T12:13:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2940.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2940"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1644/comments | https://api.github.com/repos/huggingface/datasets/issues/1644/events | https://github.com/huggingface/datasets/issues/1644 | 775,375,880 | MDU6SXNzdWU3NzUzNzU4ODA= | 1,644 | HoVeR dataset fails to load | [] | closed | false | null | 1 | 2020-12-28T12:27:07Z | 2022-10-05T12:40:34Z | 2022-10-05T12:40:34Z | null | Hi! I'm getting an error when trying to load **HoVeR** dataset. Another one (**SQuAD**) does work for me. I'm using the latest (1.1.3) version of the library.
Steps to reproduce the error:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("hover")
Traceback (most recent call last):
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/hover/hover.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/hover/hover.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at hover/hover.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/hover/hover.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/hover/hover.py
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1644/timeline | null | completed | null | null | false | [
"Hover was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `hover` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"hover\")\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/1009 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1009/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1009/comments | https://api.github.com/repos/huggingface/datasets/issues/1009/events | https://github.com/huggingface/datasets/pull/1009 | 755,384,433 | MDExOlB1bGxSZXF1ZXN0NTMxMTA0NDc5 | 1,009 | Adding C3 dataset: the first free-form multiple-Choice Chinese machine reading Comprehension dataset. | [] | closed | false | null | 0 | 2020-12-02T15:40:36Z | 2020-12-03T13:16:30Z | 2020-12-03T13:16:29Z | null | https://github.com/nlpdata/c3
https://arxiv.org/abs/1904.09679 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1009/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1009/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1009.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1009",
"merged_at": "2020-12-03T13:16:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1009.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1009"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2927/comments | https://api.github.com/repos/huggingface/datasets/issues/2927/events | https://github.com/huggingface/datasets/issues/2927 | 997,654,680 | I_kwDODunzps47dwCY | 2,927 | Datasets 1.12 dataset.filter TypeError: get_indices_from_mask_function() got an unexpected keyword argument | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-09-16T01:14:02Z | 2021-09-20T16:23:22Z | 2021-09-20T16:23:21Z | null | ## Describe the bug
Upgrading to 1.12 caused `dataset.filter` call to fail with
> get_indices_from_mask_function() got an unexpected keyword argument valid_rel_labels
## Steps to reproduce the bug
```pythondef
filter_good_rows(
ex: Dict,
valid_rel_labels: Set[str],
valid_ner_labels: Set[str],
tokenizer: PreTrainedTokenizerFast,
) -> bool:
"""Get the good rows"""
encoding = get_encoding_for_text(text=ex["text"], tokenizer=tokenizer)
ex["encoding"] = encoding
for relation in ex["relations"]:
if not is_valid_relation(relation, valid_rel_labels):
return False
for span in ex["spans"]:
if not is_valid_span(span, valid_ner_labels, encoding):
return False
return True
def get_dataset():
loader_path = str(Path(__file__).parent / "prodigy_dataset_builder.py")
ds = load_dataset(
loader_path,
name="prodigy-dataset",
data_files=sorted(file_paths),
cache_dir=cache_dir,
)["train"]
valid_ner_labels = set(vocab.ner_category)
valid_relations = set(vocab.relation_types.keys())
ds = ds.filter(
filter_good_rows,
fn_kwargs=dict(
valid_rel_labels=valid_relations,
valid_ner_labels=valid_ner_labels,
tokenizer=vocab.tokenizer,
),
keep_in_memory=True,
num_proc=num_proc,
)
```
`ds` is a `DatasetDict` produced by a jsonl dataset.
This runs fine on 1.11 but fails on 1.12
**Stack Trace**
## Expected results
I expect 1.12 datasets filter to filter the dataset without raising as it does on 1.11
## Actual results
```
tf_ner_rel_lib/dataset.py:695: in load_prodigy_arrow_datasets_from_jsonl
ds = ds.filter(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:185: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/fingerprint.py:398: in wrapper
out = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:2169: in filter
indices = self.map(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:1686: in map
return self._map_single(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:185: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/fingerprint.py:398: in wrapper
out = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:2048: in _map_single
batch = apply_function_on_filtered_inputs(
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
inputs = {'_input_hash': [2108817714, 1477695082, -1021597032, 2130671338, -1260483858, -1203431639, ...], '_task_hash': [18070...ons', 'relations', 'relations', ...], 'answer': ['accept', 'accept', 'accept', 'accept', 'accept', 'accept', ...], ...}
indices = [0, 1, 2, 3, 4, 5, ...], check_same_num_examples = False, offset = 0
def apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples=False, offset=0):
"""Utility to apply the function on a selection of columns."""
nonlocal update_data
fn_args = [inputs] if input_columns is None else [inputs[col] for col in input_columns]
if offset == 0:
effective_indices = indices
else:
effective_indices = [i + offset for i in indices] if isinstance(indices, list) else indices + offset
processed_inputs = (
> function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
)
E TypeError: get_indices_from_mask_function() got an unexpected keyword argument 'valid_rel_labels'
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:1939: TypeError
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: Mac
- Python version: 3.8.9
- PyArrow version: pyarrow==5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2927/timeline | null | completed | null | null | false | [
"Thanks for reporting, I'm looking into it :)",
"Fixed by #2950."
] |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | [] | closed | false | null | 2 | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to reproduce the bug
Steps to reproduce this issue:
git clone https://github.com/huggingface/transformers
cd transformers
python examples/pytorch/language-modeling/run_clm.py --model_name_or_path EleutherAI/gpt-j-6B --dataset_name the_pile --dataset_config_name enron_emails --do_eval --output_dir /tmp/output --overwrite_output_dir
### Expected behavior
This issue looks like due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst " couldn't be reached.
Is there another way to download the dataset "the_pile" ?
Is there another way to cache the dataset "the_pile" but not let the hg to download it when runtime ?
### Environment info
huggingface_hub version: 0.11.1
Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Python version: 3.9.12
Running in iPython ?: No
Running in notebook ?: No
Running in Google Colab ?: No
Token path ?: /home/taosy/.huggingface/token
Has saved token ?: False
Configured git credential helpers:
FastAI: N/A
Tensorflow: N/A
Torch: N/A
Jinja2: N/A
Graphviz: N/A
Pydot: N/A | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | null | null | false | [
"Thanks for reporting, @shaoyuta.\r\n\r\nWe have checked and yes, apparently there is an issue with the server hosting the data of the \"enron_emails\" subset of \"the_pile\" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst\r\nIt seems to be down: The connection has timed out.\r\n\r\nPlease note that at the Hugging Face Hub, we are not hosting their data for this dataset, but only a script that downloads the data from their servers. We are updating the data URL to one in another server.\r\n\r\nIn the meantime, please note that you can train your model in the entire \"the_pile\" dataset, by passing the \"all\" config (instead of the \"enron_emails\" one).",
"We have transferred this issue to the corresponding dataset Community tab: https://huggingface.co/datasets/the_pile/discussions/2\r\n\r\nPlease, follow the updates there."
] |
https://api.github.com/repos/huggingface/datasets/issues/5131 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5131/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5131/comments | https://api.github.com/repos/huggingface/datasets/issues/5131/events | https://github.com/huggingface/datasets/issues/5131 | 1,413,534,863 | I_kwDODunzps5UQNSP | 5,131 | WikiText 103 tokenizer hangs | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-10-18T16:44:00Z | 2023-07-21T14:41:51Z | 2023-07-21T14:41:51Z | null | See issue here: https://github.com/huggingface/transformers/issues/19702 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5131/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5131/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4020/comments | https://api.github.com/repos/huggingface/datasets/issues/4020/events | https://github.com/huggingface/datasets/pull/4020 | 1,180,636,754 | PR_kwDODunzps41Am4R | 4,020 | Replace amazon_polarity data URL | [] | closed | false | null | 1 | 2022-03-25T10:50:57Z | 2022-03-25T15:02:36Z | 2022-03-25T14:57:41Z | null | I replaced the Google Drive URL of the dataset by the FastAI one, since we've had some issues with Google Drive. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4020/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4020.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4020",
"merged_at": "2022-03-25T14:57:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4020.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4020"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/709/comments | https://api.github.com/repos/huggingface/datasets/issues/709/events | https://github.com/huggingface/datasets/issues/709 | 714,067,902 | MDU6SXNzdWU3MTQwNjc5MDI= | 709 | How to use similarity settings other then "BM25" in Elasticsearch index ? | [] | closed | false | null | 1 | 2020-10-03T11:18:49Z | 2022-10-04T17:19:37Z | 2022-10-04T17:19:37Z | null | **QUESTION : How should we use other similarity algorithms supported by Elasticsearch other than "BM25" ?**
**ES Reference**
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
**HF doc reference:**
https://huggingface.co/docs/datasets/faiss_and_ea.html
**context :**
========
I used the latest Elasticsearch server version 7.9.2
When I set DFR which is one of the other similarity algorithms supported by elasticsearch in the mapping, I get an error
For example DFR that I had tried in the first instance in mappings as below.,
`"mappings": {"properties": {"text": {"type": "text", "analyzer": "standard", "similarity": "DFR"}}},`
I get the following error
RequestError: RequestError(400, 'mapper_parsing_exception', 'Unknown Similarity type [DFR] for field [text]')
The other thing as another option I had tried was to declare "similarity": "my_similarity" within settings and then assigning "my_similarity" inside the mappings as below
`es_config = {
"settings": {
"number_of_shards": 1,
**"similarity": "my_similarity"**: {
"type": "DFR",
"basic_model": "g",
"after_effect": "l",
"normalization": "h2",
"normalization.h2.c": "3.0"
} ,
"analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},
},
"mappings": {"properties": {"text": {"type": "text", "analyzer": "standard", "similarity": "my_similarity"}}},
}`
For this , I got the following error
RequestError: RequestError(400, 'illegal_argument_exception', 'unknown setting [index.similarity] please check that any required plugins are installed, or check the breaking changes documentation for removed settings')
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/709/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/709/timeline | null | completed | null | null | false | [
"Datasets does not use elasticsearch API to define custom similarity. If you want to use a custom similarity, the best would be to run a curl request directly to your elasticsearch instance (see sample hereafter, directly from ES documentation), then you should be able to use `my_similarity` in your configuration passed to datasets\r\n\r\n```\r\ncurl -X PUT \"localhost:9200/index?pretty\" -H 'Content-Type: application/json' -d'\r\n{\r\n \"settings\": {\r\n \"index\": {\r\n \"similarity\": {\r\n \"my_similarity\": {\r\n \"type\": \"DFR\",\r\n \"basic_model\": \"g\",\r\n \"after_effect\": \"l\",\r\n \"normalization\": \"h2\",\r\n \"normalization.h2.c\": \"3.0\"\r\n }\r\n }\r\n }\r\n }\r\n}\r\n'\r\n\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/1353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1353/comments | https://api.github.com/repos/huggingface/datasets/issues/1353/events | https://github.com/huggingface/datasets/pull/1353 | 759,980,004 | MDExOlB1bGxSZXF1ZXN0NTM0ODg2MDk4 | 1,353 | New instruction for how to generate dataset_infos.json | [] | closed | false | null | 0 | 2020-12-09T04:24:40Z | 2020-12-10T13:45:15Z | 2020-12-10T13:45:15Z | null | Add additional instructions for how to generate dataset_infos.json for manual download datasets. Information courtesy of `Taimur Ibrahim` from the slack channel | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1353/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1353",
"merged_at": "2020-12-10T13:45:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1353"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2251 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2251/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2251/comments | https://api.github.com/repos/huggingface/datasets/issues/2251/events | https://github.com/huggingface/datasets/issues/2251 | 865,848,705 | MDU6SXNzdWU4NjU4NDg3MDU= | 2,251 | while running run_qa.py, ran into a value error | [] | open | false | null | 0 | 2021-04-23T07:51:03Z | 2021-04-23T07:51:03Z | null | null | command:
python3 run_qa.py --model_name_or_path hyunwoongko/kobart --dataset_name squad_kor_v2 --do_train --do_eval --per_device_train_batch_size 8 --learning_rate 3e-5 --num_train_epochs 3 --max_seq_length 512 --doc_stride 128 --output_dir /tmp/debug_squad/
error:
ValueError: External features info don't match the dataset:
Got
{'id': Value(dtype='string', id=None), 'title': Value(dtype='string', id=None), 'context': Value(dtype='string', id=None), 'question': Value(dtype='string', id=None), 'answer': {'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None), 'html_answer_start': Value(dtype='int32', id=None)}, 'url': Value(dtype='string', id=None), 'raw_html': Value(dtype='string', id=None)}
with type
struct<answer: struct<text: string, answer_start: int32, html_answer_start: int32>, context: string, id: string, question: string, raw_html: string, title: string, url: string>
but expected something like
{'answer': {'answer_start': Value(dtype='int32', id=None), 'html_answer_start': Value(dtype='int32', id=None), 'text': Value(dtype='string', id=None)}, 'context': Value(dtype='string', id=None), 'id': Value(dtype='string', id=None), 'question': Value(dtype='string', id=None), 'raw_html': Value(dtype='string', id=None), 'title': Value(dtype='string', id=None), 'url': Value(dtype='string', id=None)}
with type
struct<answer: struct<answer_start: int32, html_answer_start: int32, text: string>, context: string, id: string, question: string, raw_html: string, title: string, url: string>
I didn't encounter this error 4 hours ago. any solutions for this kind of issue?
looks like gained dataset format refers to 'Data Fields', while expected refers to 'Data Instances'. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2251/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2251/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4484 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4484/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4484/comments | https://api.github.com/repos/huggingface/datasets/issues/4484/events | https://github.com/huggingface/datasets/pull/4484 | 1,269,383,811 | PR_kwDODunzps45jywZ | 4,484 | Better ImportError message when a dataset script dependency is missing | [] | closed | false | null | 4 | 2022-06-13T12:44:37Z | 2022-07-08T14:30:44Z | 2022-06-13T13:50:47Z | null | When a depenency is missing for a dataset script, an ImportError message is shown, with a tip to install the missing dependencies. This message is not ideal at the moment: it may show duplicate dependencies, and is not very readable.
I improved it from
```
ImportError: To be able to use bigbench, you need to install the following dependencies['bigbench', 'bigbench', 'bigbench', 'bigbench'] using 'pip install "bigbench @ https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz" bigbench bigbench bigbench' for instance'
```
to
```
ImportError: To be able to use bigbench, you need to install the following dependency: bigbench.
Please install it using 'pip install "bigbench @ https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz"' for instance'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4484/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4484/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4484.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4484",
"merged_at": "2022-06-13T13:50:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4484.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4484"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Discussed offline with @mariosasko, merging :)",
"Fwiw, i think this same issue is occurring on the datasets website page, where preview isn't available due to the `bigbench` import error",
"For the preview of BigBench datasets, we're just waiting for bigbench to have a stable version on PyPI, instead of the one hosted on GCS ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3658/comments | https://api.github.com/repos/huggingface/datasets/issues/3658/events | https://github.com/huggingface/datasets/issues/3658 | 1,120,880,395 | I_kwDODunzps5Cz0cL | 3,658 | Dataset viewer issue for *P3* | [] | open | false | null | 3 | 2022-02-01T15:57:56Z | 2022-09-08T08:18:28Z | null | null | ## Dataset viewer issue for '*P3*'
**Link: https://huggingface.co/datasets/bigscience/P3**
```
Status code: 400
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
```
Am I the one who added this dataset ? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3658/timeline | null | null | null | null | false | [
"The error is now:\r\n\r\n```\r\nStatus code: 400\r\nException: Status400Error\r\nMessage: this dataset is not supported for now.\r\n```\r\n\r\nWe've disabled the dataset viewer for several big datasets like this one. We hope being able to reenable it soon.",
"The list of splits cannot be obtained. cc @huggingface/datasets ",
"```\r\nError code: SplitsNamesError\r\nException: SplitsNotFoundError\r\nMessage: The split names could not be parsed from the dataset config.\r\nTraceback: Traceback (most recent call last):\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 354, in get_dataset_config_info\r\n for split_generator in builder._split_generators(\r\n File \"/tmp/modules-cache/datasets_modules/datasets/bigscience--P3/12c0badfecad4564ecb8a6f81b5d0559656f269f08b13c59c93283f3a84134ba/P3.py\", line 154, in _split_generators\r\n data_dir = dl_manager.download_and_extract(_URLs)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 944, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 907, in extract\r\n urlpaths = map_nested(self._extract, path_or_paths, map_tuple=True)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 393, in map_nested\r\n mapped = [\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 394, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True, None))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in <dictcomp>\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in <dictcomp>\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 330, in _single_map_nested\r\n return function(data_struct)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 912, in _extract\r\n protocol = _get_extraction_protocol(urlpath, use_auth_token=self.download_config.use_auth_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 402, in _get_extraction_protocol\r\n return _get_extraction_protocol_with_magic_number(f)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 367, in _get_extraction_protocol_with_magic_number\r\n magic_number = f.read(MAGIC_NUMBER_MAX_LENGTH)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 574, in read\r\n return super().read(length)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/spec.py\", line 1575, in read\r\n out = self.cache._fetch(self.loc, self.loc + length)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/caching.py\", line 377, in _fetch\r\n self.cache = self.fetcher(start, bend)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 111, in wrapper\r\n return sync(self.loop, func, *args, **kwargs)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 96, in sync\r\n raise return_result\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 53, in _runner\r\n result[0] = await coro\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 616, in async_fetch_range\r\n out = await r.read()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/client_reqrep.py\", line 1036, in read\r\n self._body = await self.content.read()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 375, in read\r\n block = await self.readany()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 397, in readany\r\n await self._wait(\"readany\")\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 304, in _wait\r\n await waiter\r\n aiohttp.client_exceptions.ClientPayloadError: Response payload is not completed\r\n \r\n The above exception was the direct cause of the following exception:\r\n \r\n Traceback (most recent call last):\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 75, in get_splits_response\r\n split_full_names = get_dataset_split_full_names(dataset, hf_token)\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 35, in get_dataset_split_full_names\r\n return [\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 38, in <listcomp>\r\n for split in get_dataset_split_names(dataset, config, use_auth_token=hf_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 404, in get_dataset_split_names\r\n info = get_dataset_config_info(\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 359, in get_dataset_config_info\r\n raise SplitsNotFoundError(\"The split names could not be parsed from the dataset config.\") from err\r\n datasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/3703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3703/comments | https://api.github.com/repos/huggingface/datasets/issues/3703/events | https://github.com/huggingface/datasets/issues/3703 | 1,131,882,772 | I_kwDODunzps5DdykU | 3,703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | [] | closed | false | null | 9 | 2022-02-11T06:38:42Z | 2023-07-11T09:31:59Z | 2023-07-11T09:31:59Z | null | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3703/timeline | null | completed | null | null | false | [
"\r\nMy datasets version",
"\r\n",
"Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.",
"> Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.\r\nI installed seqeval, but still reported the same error. That's too bad.\r\n",
"> > Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.\r\n> > I installed seqeval, but still reported the same error. That's too bad.\r\n\r\nSame issue here. What should I do to fix this error? Please help! Thank you.",
"I tried to install **seqeval** package through anaconda instead of pip:\r\n`conda install -c conda-forge seqeval`\r\nIt worked for me!",
"I can run it through the following steps:\r\n\r\nThank you for answering for me!",
"just change the file name seqeval.py to myseqeval.py",
"Metrics are deprecated in `datasets` and `evaluate` should be used instead: https://github.com/huggingface/evaluate"
] |
https://api.github.com/repos/huggingface/datasets/issues/3719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3719/comments | https://api.github.com/repos/huggingface/datasets/issues/3719/events | https://github.com/huggingface/datasets/pull/3719 | 1,137,237,622 | PR_kwDODunzps4yyFv7 | 3,719 | Check if indices values in `Dataset.select` are within bounds | [] | closed | false | null | 0 | 2022-02-14T12:31:41Z | 2022-02-14T19:19:22Z | 2022-02-14T19:19:22Z | null | Fix #3707
Instead of reusing `_check_valid_index_key` from `datasets.formatting`, I defined a new function to provide a more meaningful error message.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3719/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3719/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3719.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3719",
"merged_at": "2022-02-14T19:19:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3719.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3719"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1810 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1810/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1810/comments | https://api.github.com/repos/huggingface/datasets/issues/1810/events | https://github.com/huggingface/datasets/issues/1810 | 799,168,650 | MDU6SXNzdWU3OTkxNjg2NTA= | 1,810 | Add Hateful Memes Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",
"default": false,
"description": "Vision datasets",
"id": 3608941089,
"name": "vision",
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision"
}
] | open | false | null | 4 | 2021-02-02T10:53:59Z | 2021-12-08T12:03:59Z | null | null | ## Add Hateful Memes Dataset
- **Name:** Hateful Memes
- **Description:** [https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set]( https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set)
- **Paper:** [https://arxiv.org/pdf/2005.04790.pdf](https://arxiv.org/pdf/2005.04790.pdf)
- **Data:** [This link](https://drivendata-competition-fb-hateful-memes-data.s3.amazonaws.com/XjiOc5ycDBRRNwbhRlgH.zip?AWSAccessKeyId=AKIARVBOBDCY4MWEDJKS&Signature=DaUuGgZWUgDHzEPPbyJ2PhSJ56Q%3D&Expires=1612816874)
- **Motivation:** Including multi-modal datasets to 🤗 datasets.
I will be adding this dataset. It requires the user to sign an agreement on DrivenData. So, it will be used with a manual download.
The issue with this dataset is that the images are of different sizes. The image datasets added so far (CIFAR-10 and MNIST) have a uniform shape throughout.
So something like
```python
datasets.Array2D(shape=(28, 28), dtype="uint8")
```
won't work for the images. How would I add image features then? I checked `datasets/features.py` but couldn't figure out the appropriate class for this. I'm assuming I would want to avoid re-sizing at all since we want the user to be able to access the original images.
Also, in case I want to load only a subset of the data, since the actual data is around 8.8GB, how would that be possible?
Thanks,
Gunjan | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1810/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1810/timeline | null | null | null | null | false | [
"I am not sure, but would `datasets.Sequence(datasets.Sequence(datasets.Sequence(datasets.Value(\"int\")))` work?",
"Also, I found the information for loading only subsets of the data [here](https://github.com/huggingface/datasets/blob/master/docs/source/splits.rst).",
"Hi @lhoestq,\r\n\r\nRequest you to check this once.\r\n\r\nThanks,\r\nGunjan",
"Hi @gchhablani since Array2D doesn't support images of different sizes, I would suggest to store in the dataset the paths to the image file instead of the image data. This has the advantage of not decompressing the data (images are often compressed using jpeg, png etc.). Users can still apply `.map` to load the images if they want to. Though it would en up being Sequences features.\r\n\r\nIn the future we'll add support for ragged tensors for this case and update the relevant dataset with this feature."
] |
https://api.github.com/repos/huggingface/datasets/issues/3216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3216/comments | https://api.github.com/repos/huggingface/datasets/issues/3216/events | https://github.com/huggingface/datasets/pull/3216 | 1,045,027,733 | PR_kwDODunzps4uG1YS | 3,216 | Pin version exclusion for tensorflow incompatible with keras | [] | closed | false | null | 0 | 2021-11-04T17:38:06Z | 2021-11-05T10:57:38Z | 2021-11-05T10:57:37Z | null | Once `tensorflow` version 2.6.2 is released:
- https://github.com/tensorflow/tensorflow/commit/c1867f3bfdd1042f694df7a9870be51ba80543cb
- https://pypi.org/project/tensorflow/2.6.2/
with the patch:
- tensorflow/tensorflow#52927
we can remove the temporary fix we introduced in:
- #3208
Fix #3209. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3216/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3216.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3216",
"merged_at": "2021-11-05T10:57:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3216.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3216"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/899/comments | https://api.github.com/repos/huggingface/datasets/issues/899/events | https://github.com/huggingface/datasets/pull/899 | 752,191,227 | MDExOlB1bGxSZXF1ZXN0NTI4NTYzNzYz | 899 | Allow arrow based builder in auto dummy data generation | [] | closed | false | null | 0 | 2020-11-27T11:39:38Z | 2020-11-27T13:30:09Z | 2020-11-27T13:30:08Z | null | Following #898 I added support for arrow based builder for the auto dummy data generator | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/899/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/899.diff",
"html_url": "https://github.com/huggingface/datasets/pull/899",
"merged_at": "2020-11-27T13:30:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/899.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/899"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2274/comments | https://api.github.com/repos/huggingface/datasets/issues/2274/events | https://github.com/huggingface/datasets/pull/2274 | 869,186,276 | MDExOlB1bGxSZXF1ZXN0NjI0NTkyMjQx | 2,274 | Always update metadata in arrow schema | [] | closed | false | null | 0 | 2021-04-27T19:21:57Z | 2022-06-03T08:31:19Z | 2021-04-29T09:57:50Z | null | We store a redundant copy of the features in the metadata of the schema of the arrow table. This is used to recover the features when doing `Dataset.from_file`. These metadata are updated after each transfor, that changes the feature types.
For each function that transforms the feature types of the dataset, I added a step in the tests to make sure the metadata in the arrow schema are up to date.
I also added a line to update the metadata directly in the Dataset.__init__ method.
This way even a dataset instantiated with __init__ will have a table with the right metadata.
Fix #2271.
cc @mariosasko | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2274/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2274.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2274",
"merged_at": "2021-04-29T09:57:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2274.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2274"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3225/comments | https://api.github.com/repos/huggingface/datasets/issues/3225/events | https://github.com/huggingface/datasets/pull/3225 | 1,046,530,493 | PR_kwDODunzps4uLrB3 | 3,225 | Update tatoeba to v2021-07-22 | [] | closed | false | null | 4 | 2021-11-06T15:14:31Z | 2021-11-12T11:13:13Z | 2021-11-12T11:13:13Z | null | Tatoeba's latest version is v2021-07-22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3225/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3225.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3225",
"merged_at": "2021-11-12T11:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3225.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3225"
} | true | [
"How about this? @lhoestq @abhishekkrthakur ",
"Hi ! I think it would be nice if people could still be able to load the old version.\r\nMaybe this can be a parameter ? For example to load the old version they could do\r\n```python\r\nload_dataset(\"tatoeba\", lang1=\"en\", lang2=\"mr\", date=\"v2020-11-09\")\r\n```\r\n\r\nIf it sounds good to you, we can add this parameter to the TatoebaConfig:\r\n```python\r\nclass TatoebaConfig(datasets.BuilderConfig):\r\n def __init__(self, *args, lang1=None, lang2=None, date=\"v2021-07-22\", **kwargs):\r\n self.date = date\r\n```\r\nand then pass the date to the URL\r\n```python\r\n_BASE_URL = \"https://object.pouta.csc.fi/OPUS-Tatoeba/{}/moses/{}-{}.txt.zip\"\r\n```\r\n```python\r\n def _base_url(lang1, lang2, date):\r\n return _BASE_URL.format(date, lang1, lang2)\r\n```\r\n\r\nWhat do you think ?",
"`_DATE = \"v\" + \"-\".join(s.zfill(2) for s in _VERSION.split(\".\"))` seems rather tricky but works well. How about this? @lhoestq \r\n",
"The CI is only failing because of the missing sections in the dataset card, and because of an issue with the CER metric that is unrelated to this PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/4515 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4515/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4515/comments | https://api.github.com/repos/huggingface/datasets/issues/4515/events | https://github.com/huggingface/datasets/pull/4515 | 1,273,626,131 | PR_kwDODunzps45x5mB | 4,515 | Add uppercased versions of image file extensions for automatic module inference | [] | closed | false | null | 1 | 2022-06-16T14:14:49Z | 2022-06-16T17:21:53Z | 2022-06-16T17:11:41Z | null | Adds the uppercased versions of the image file extensions to the supported extensions.
Another approach would be to call `.lower()` on extensions while resolving data files, but uppercased extensions are not something we want to encourage out of the box IMO unless they are commonly used (as they are in the vision domain)
Note that there is a slight discrepancy between the image file resolution and `imagefolder` as the latter calls `.lower()` on file extensions leading to some image file extensions being ignored by the resolution but not by the loader (e.g. `pNg`). Such extensions should also be discouraged, so I'm ignoring that case too.
Fix #4514. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4515/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4515/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4515.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4515",
"merged_at": "2022-06-16T17:11:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4515.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4515"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1682/comments | https://api.github.com/repos/huggingface/datasets/issues/1682/events | https://github.com/huggingface/datasets/pull/1682 | 778,268,156 | MDExOlB1bGxSZXF1ZXN0NTQ4Mzg1NTk1 | 1,682 | Don't use xlrd for xlsx files | [] | closed | false | null | 0 | 2021-01-04T18:11:50Z | 2021-01-04T18:13:14Z | 2021-01-04T18:13:13Z | null | Since the latest release of `xlrd` (2.0), the support for xlsx files stopped.
Therefore we needed to use something else.
A good alternative is `openpyxl` which has also an integration with pandas si we can still call `pd.read_excel`.
I left the unused import of `openpyxl` in the dataset scripts to show users that this is a required dependency to use the scripts.
I tested the different datasets using `datasets-cli test` and the tests are successful (no missing examples). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1682/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1682.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1682",
"merged_at": "2021-01-04T18:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1682.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1682"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3365/comments | https://api.github.com/repos/huggingface/datasets/issues/3365/events | https://github.com/huggingface/datasets/issues/3365 | 1,069,195,887 | I_kwDODunzps4_uqJv | 3,365 | Add task tags for multimodal datasets | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2021-12-02T06:58:20Z | 2023-07-25T18:21:33Z | 2023-07-25T18:21:32Z | null | ## **Is your feature request related to a problem? Please describe.**
Currently, task tags are either exclusively related to text or speech processing:
- https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/tasks.json
## **Describe the solution you'd like**
We should also add tasks related to:
- multimodality
- image
- video
CC: @VictorSanh @lewtun @lhoestq @merveenoyan @SBrandeis | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3365/timeline | null | completed | null | null | false | [
"The Hub pulls these tags from [here](https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts) (allows multimodal tasks) now, so I'm closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/5836 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5836/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5836/comments | https://api.github.com/repos/huggingface/datasets/issues/5836/events | https://github.com/huggingface/datasets/pull/5836 | 1,702,773,316 | PR_kwDODunzps5QIgzu | 5,836 | [docs] Custom decoding transforms | [] | closed | false | null | 4 | 2023-05-09T21:21:41Z | 2023-05-15T07:36:12Z | 2023-05-10T20:23:03Z | null | Adds custom decoding transform solution to the docs to fix #5782. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5836/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5836/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5836.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5836",
"merged_at": "2023-05-10T20:23:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5836.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5836"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5836). All of your documentation changes will be reflected on that endpoint.",
"The error seems unrelated to the changes, so feel free to merge.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006562 / 0.011353 (-0.004791) | 0.004568 / 0.011008 (-0.006440) | 0.098151 / 0.038508 (0.059643) | 0.028117 / 0.023109 (0.005008) | 0.305442 / 0.275898 (0.029544) | 0.338288 / 0.323480 (0.014808) | 0.005012 / 0.007986 (-0.002973) | 0.003415 / 0.004328 (-0.000913) | 0.075022 / 0.004250 (0.070771) | 0.036869 / 0.037052 (-0.000183) | 0.301427 / 0.258489 (0.042937) | 0.348485 / 0.293841 (0.054644) | 0.030761 / 0.128546 (-0.097785) | 0.011461 / 0.075646 (-0.064185) | 0.321987 / 0.419271 (-0.097285) | 0.042885 / 0.043533 (-0.000648) | 0.300691 / 0.255139 (0.045552) | 0.333208 / 0.283200 (0.050008) | 0.090203 / 0.141683 (-0.051480) | 1.459744 / 1.452155 (0.007590) | 1.522960 / 1.492716 (0.030243) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.213219 / 0.018006 (0.195213) | 0.408118 / 0.000490 (0.407629) | 0.003716 / 0.000200 (0.003516) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023060 / 0.037411 (-0.014351) | 0.097423 / 0.014526 (0.082897) | 0.103988 / 0.176557 (-0.072568) | 0.162793 / 0.737135 (-0.574343) | 0.108282 / 0.296338 (-0.188056) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431628 / 0.215209 (0.216419) | 4.300881 / 2.077655 (2.223226) | 2.058853 / 1.504120 (0.554733) | 1.897910 / 1.541195 (0.356715) | 1.991723 / 1.468490 (0.523233) | 0.699686 / 4.584777 (-3.885091) | 3.395004 / 3.745712 (-0.350708) | 1.841613 / 5.269862 (-3.428248) | 1.152347 / 4.565676 (-3.413330) | 0.082517 / 0.424275 (-0.341758) | 0.012323 / 0.007607 (0.004715) | 0.535812 / 0.226044 (0.309767) | 5.374103 / 2.268929 (3.105174) | 2.429662 / 55.444624 (-53.014962) | 2.097199 / 6.876477 (-4.779277) | 2.172625 / 2.142072 (0.030552) | 0.810156 / 4.805227 (-3.995071) | 0.151629 / 6.500664 (-6.349035) | 0.066528 / 0.075469 (-0.008941) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.220667 / 1.841788 (-0.621121) | 13.696976 / 8.074308 (5.622668) | 14.042916 / 10.191392 (3.851524) | 0.129626 / 0.680424 (-0.550798) | 0.016593 / 0.534201 (-0.517607) | 0.383747 / 0.579283 (-0.195536) | 0.386872 / 0.434364 (-0.047492) | 0.456524 / 0.540337 (-0.083813) | 0.545033 / 1.386936 (-0.841903) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006361 / 0.011353 (-0.004992) | 0.004516 / 0.011008 (-0.006493) | 0.077155 / 0.038508 (0.038647) | 0.027239 / 0.023109 (0.004130) | 0.359892 / 0.275898 (0.083994) | 0.391994 / 0.323480 (0.068514) | 0.004950 / 0.007986 (-0.003036) | 0.003379 / 0.004328 (-0.000949) | 0.077057 / 0.004250 (0.072806) | 0.039562 / 0.037052 (0.002509) | 0.364244 / 0.258489 (0.105755) | 0.416033 / 0.293841 (0.122192) | 0.031049 / 0.128546 (-0.097497) | 0.011479 / 0.075646 (-0.064167) | 0.086479 / 0.419271 (-0.332793) | 0.039381 / 0.043533 (-0.004151) | 0.372143 / 0.255139 (0.117004) | 0.388569 / 0.283200 (0.105369) | 0.090954 / 0.141683 (-0.050728) | 1.540957 / 1.452155 (0.088802) | 1.596841 / 1.492716 (0.104125) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221130 / 0.018006 (0.203123) | 0.403728 / 0.000490 (0.403238) | 0.003172 / 0.000200 (0.002972) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024963 / 0.037411 (-0.012449) | 0.101065 / 0.014526 (0.086539) | 0.110846 / 0.176557 (-0.065710) | 0.158578 / 0.737135 (-0.578557) | 0.112235 / 0.296338 (-0.184104) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457320 / 0.215209 (0.242111) | 4.548094 / 2.077655 (2.470439) | 2.175376 / 1.504120 (0.671256) | 1.964755 / 1.541195 (0.423561) | 2.008128 / 1.468490 (0.539638) | 0.702448 / 4.584777 (-3.882329) | 3.437595 / 3.745712 (-0.308117) | 3.009871 / 5.269862 (-2.259990) | 1.558181 / 4.565676 (-3.007496) | 0.082568 / 0.424275 (-0.341707) | 0.012371 / 0.007607 (0.004764) | 0.550688 / 0.226044 (0.324644) | 5.534210 / 2.268929 (3.265282) | 2.649605 / 55.444624 (-52.795020) | 2.317293 / 6.876477 (-4.559184) | 2.351525 / 2.142072 (0.209453) | 0.808971 / 4.805227 (-3.996256) | 0.152737 / 6.500664 (-6.347927) | 0.068416 / 0.075469 (-0.007053) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.340219 / 1.841788 (-0.501569) | 13.903388 / 8.074308 (5.829080) | 13.063477 / 10.191392 (2.872085) | 0.130216 / 0.680424 (-0.550208) | 0.016522 / 0.534201 (-0.517679) | 0.398946 / 0.579283 (-0.180337) | 0.382450 / 0.434364 (-0.051914) | 0.491007 / 0.540337 (-0.049330) | 0.577747 / 1.386936 (-0.809189) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007812 / 0.011353 (-0.003541) | 0.005563 / 0.011008 (-0.005446) | 0.099372 / 0.038508 (0.060864) | 0.035629 / 0.023109 (0.012520) | 0.301457 / 0.275898 (0.025559) | 0.339136 / 0.323480 (0.015656) | 0.006152 / 0.007986 (-0.001834) | 0.005843 / 0.004328 (0.001515) | 0.075280 / 0.004250 (0.071030) | 0.052789 / 0.037052 (0.015736) | 0.301805 / 0.258489 (0.043316) | 0.347918 / 0.293841 (0.054078) | 0.036182 / 0.128546 (-0.092364) | 0.012655 / 0.075646 (-0.062991) | 0.334428 / 0.419271 (-0.084844) | 0.062746 / 0.043533 (0.019213) | 0.296932 / 0.255139 (0.041793) | 0.314115 / 0.283200 (0.030916) | 0.121291 / 0.141683 (-0.020392) | 1.453252 / 1.452155 (0.001097) | 1.564714 / 1.492716 (0.071997) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.243810 / 0.018006 (0.225804) | 0.547129 / 0.000490 (0.546640) | 0.004666 / 0.000200 (0.004466) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028214 / 0.037411 (-0.009197) | 0.108878 / 0.014526 (0.094352) | 0.122313 / 0.176557 (-0.054243) | 0.182412 / 0.737135 (-0.554723) | 0.127014 / 0.296338 (-0.169324) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.423946 / 0.215209 (0.208737) | 4.207112 / 2.077655 (2.129457) | 2.048658 / 1.504120 (0.544538) | 1.843593 / 1.541195 (0.302398) | 1.952426 / 1.468490 (0.483936) | 0.712098 / 4.584777 (-3.872679) | 3.824971 / 3.745712 (0.079258) | 3.507141 / 5.269862 (-1.762721) | 1.868866 / 4.565676 (-2.696810) | 0.087895 / 0.424275 (-0.336380) | 0.012783 / 0.007607 (0.005176) | 0.524087 / 0.226044 (0.298042) | 5.246498 / 2.268929 (2.977570) | 2.495944 / 55.444624 (-52.948680) | 2.126779 / 6.876477 (-4.749698) | 2.315545 / 2.142072 (0.173472) | 0.859546 / 4.805227 (-3.945681) | 0.173457 / 6.500664 (-6.327208) | 0.067483 / 0.075469 (-0.007986) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.173851 / 1.841788 (-0.667937) | 15.091913 / 8.074308 (7.017605) | 14.640035 / 10.191392 (4.448643) | 0.168498 / 0.680424 (-0.511926) | 0.017513 / 0.534201 (-0.516688) | 0.425770 / 0.579283 (-0.153513) | 0.434248 / 0.434364 (-0.000116) | 0.504204 / 0.540337 (-0.036134) | 0.616885 / 1.386936 (-0.770051) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007775 / 0.011353 (-0.003578) | 0.005153 / 0.011008 (-0.005855) | 0.075461 / 0.038508 (0.036953) | 0.034994 / 0.023109 (0.011885) | 0.372389 / 0.275898 (0.096491) | 0.397911 / 0.323480 (0.074431) | 0.006572 / 0.007986 (-0.001413) | 0.005549 / 0.004328 (0.001220) | 0.075101 / 0.004250 (0.070851) | 0.054014 / 0.037052 (0.016962) | 0.368964 / 0.258489 (0.110475) | 0.425353 / 0.293841 (0.131512) | 0.035546 / 0.128546 (-0.093001) | 0.012707 / 0.075646 (-0.062939) | 0.087418 / 0.419271 (-0.331853) | 0.046425 / 0.043533 (0.002893) | 0.363982 / 0.255139 (0.108843) | 0.376421 / 0.283200 (0.093221) | 0.105369 / 0.141683 (-0.036314) | 1.494408 / 1.452155 (0.042253) | 1.596783 / 1.492716 (0.104067) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.258780 / 0.018006 (0.240773) | 0.533373 / 0.000490 (0.532883) | 0.000432 / 0.000200 (0.000232) | 0.000058 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030687 / 0.037411 (-0.006725) | 0.110231 / 0.014526 (0.095705) | 0.123738 / 0.176557 (-0.052819) | 0.171999 / 0.737135 (-0.565137) | 0.127673 / 0.296338 (-0.168665) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.448058 / 0.215209 (0.232849) | 4.459381 / 2.077655 (2.381726) | 2.234020 / 1.504120 (0.729900) | 2.038616 / 1.541195 (0.497421) | 2.123795 / 1.468490 (0.655305) | 0.702664 / 4.584777 (-3.882113) | 3.837133 / 3.745712 (0.091420) | 2.138574 / 5.269862 (-3.131287) | 1.375955 / 4.565676 (-3.189722) | 0.086996 / 0.424275 (-0.337280) | 0.012461 / 0.007607 (0.004854) | 0.557978 / 0.226044 (0.331934) | 5.648613 / 2.268929 (3.379685) | 2.777829 / 55.444624 (-52.666796) | 2.392424 / 6.876477 (-4.484052) | 2.482823 / 2.142072 (0.340750) | 0.851891 / 4.805227 (-3.953336) | 0.171335 / 6.500664 (-6.329329) | 0.065041 / 0.075469 (-0.010428) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.319697 / 1.841788 (-0.522091) | 15.748688 / 8.074308 (7.674380) | 13.397042 / 10.191392 (3.205650) | 0.166424 / 0.680424 (-0.514000) | 0.017755 / 0.534201 (-0.516446) | 0.424989 / 0.579283 (-0.154294) | 0.424705 / 0.434364 (-0.009659) | 0.494190 / 0.540337 (-0.046147) | 0.588315 / 1.386936 (-0.798622) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4964 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4964/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4964/comments | https://api.github.com/repos/huggingface/datasets/issues/4964/events | https://github.com/huggingface/datasets/issues/4964 | 1,368,617,322 | I_kwDODunzps5Rk3Fq | 4,964 | Column of arrays (2D+) are using unreasonably high memory | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 10 | 2022-09-10T13:07:22Z | 2022-09-22T18:29:22Z | null | null | ## Describe the bug
When trying to store `Array2D, Array3D, etc` as column values in a dataset, accessing that column (or creating depending on how you create it, see code below) will cause more than 10 fold of memory usage.
## Steps to reproduce the bug
```python
from datasets import Dataset, Features, Array2D, Array3D
import numpy as np
column_name = "a"
array_shape = (64, 64, 3)
data = np.random.random((10000,) + array_shape)
dataset = Dataset.from_dict({column_name: data}, features=Features({column_name: Array3D(shape=array_shape, dtype="float64")}))
```
the code above will use about 10Gb of RAM while constructing the `dataset` object.
The code below will use roughly the same amount of memory (and time) when trying to actually access the data itself of that column.
```python
from datasets import Dataset
import numpy as np
column_name = "a"
array_shape = (64, 64, 3)
data = np.random.random((10000,) + array_shape)
dataset = Dataset.from_dict({column_name: data})
dataset[column_name]
```
## Expected results
Some memory overhead, but not like as it is now and certainly not an overhead of such runtime that is currently happening.
## Actual results
Enormous memory- and runtime overhead.
## Environment info
- `datasets` version: 2.3.2
- Platform: macOS-12.5.1-arm64-arm-64bit
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.4 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4964/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4964/timeline | null | null | null | null | false | [
"note i have tried the same code with `datasets` version 2.4.0, the outcome is the very same as described above.",
"Seems related to issues #4623 and #4802 so it would appear this issue has been around for a few months.",
"Hi ! `Dataset.from_dict` keeps the data in memory. You can write on disk and reload them with\r\n```python\r\ndataset.save_to_disk(\"path/to/local\")\r\ndataset = load_from_disk(\"path/to/local\")\r\n```\r\nthis way you'll end up with a dataset loaded from your disk using memory mapping, and it won't fill up your RAM :)\r\n\r\nrelated to https://github.com/huggingface/datasets/issues/4861",
"@lhoestq thnx for getting back to me! i've tested the suggested method, but unfortunately the memory consumption is the very same:\r\n\r\n```\r\nfrom datasets import Dataset, Features, Array2D, Array3D, load_from_disk\r\nimport numpy as np\r\n\r\ncolumn_name = \"a\"\r\narray_shape = (64, 64, 3)\r\n\r\ndata = np.random.random((10000,) + array_shape)\r\ndataset = Dataset.from_dict({column_name: data}, features=Features({column_name: Array3D(shape=array_shape, dtype=\"float64\")}))\r\ndataset.save_to_disk(\"foo\")\r\n\r\nfoo_db = load_from_disk(\"foo\")\r\ncolum_value = foo_db[column_name]\r\n```\r\n\r\nthe very same happens when you create the dataset, but dont specify the feature type.\r\n\r\ni've tried running this on different envs (macOS, linux) and it's behaving the very same way.",
"When you call `colum_value = foo_db[column_name]`, you load the full column in memory.\r\n\r\nIf you want to avoid filling up your memory, you can access chunks of data instead\r\n```python\r\nembeddings = dataset[i:i + chunk_size][\"embeddings\"]\r\n```",
"@lhoestq yeah that's intentional, i.e. i really want to load the whole column into the memory. but as said above there's an unreasonable amount of overhead for the memory. the np array itself is using about 1G of memory:\r\n```\r\n>>> getsizeof(data)/1024/1024\r\n937.5001525878906\r\n```\r\nthat accessing of column above is using 10x memory compared to the original numpy array.",
"The dataset must be twice as big because we use regular arrow ListArray under the hood and not FixedSizeListArray. Basically we store unnecessary offsets.\r\n\r\nAnd this should affect performance as well. When we developed this, FixedSizeListArray still had some issues but they should be resolved on the PyArrow side now",
"A doubling would be fine. My very basic understanding of PyArrow is that using ListArray is probably related to the issue though. Using a multi-dimensional array in datasets is storing everything as strange nested 1d object arrays, which I imagine is creating the massive overhead.\r\n\r\nI think it should be a PyArrow Tensor, no?",
"PyArrow tensors are not part of the Arrow format AFAIK:\r\n\r\n> There is no direct support in the arrow columnar format to store Tensors as column values.\r\n\r\nsource: https://github.com/apache/arrow/issues/4802#issuecomment-508494694",
"That's... unfortunate. I didn't realize that."
] |
https://api.github.com/repos/huggingface/datasets/issues/1703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1703/comments | https://api.github.com/repos/huggingface/datasets/issues/1703/events | https://github.com/huggingface/datasets/pull/1703 | 781,395,146 | MDExOlB1bGxSZXF1ZXN0NTUxMTI2MjA5 | 1,703 | Improvements regarding caching and fingerprinting | [] | closed | false | null | 8 | 2021-01-07T15:26:29Z | 2021-01-19T17:32:11Z | 2021-01-19T17:32:10Z | null | This PR adds these features:
- Enable/disable caching
If disabled, the library will no longer reload cached datasets files when applying transforms to the datasets.
It is equivalent to setting `load_from_cache` to `False` in dataset transforms.
```python
from datasets import set_caching_enabled
set_caching_enabled(False)
```
- Allow unpicklable functions in `map`
If an unpicklable function is used, then it's not possible to hash it to update the dataset fingerprint that is used to name cache files. To workaround that, a random fingerprint is generated instead and a warning is raised.
```python
logger.warning(
f"Transform {transform} couldn't be hashed properly, a random hash was used instead. "
"Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. "
"If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything."
)
```
and also (open to discussion, EDIT: actually NOT included):
- Enable/disable fingerprinting
Fingerprinting allows to have one deterministic fingerprint per dataset state.
A dataset fingerprint is updated after each transform.
Re-running the same transforms on a dataset in a different session results in the same fingerprint.
Disabling the fingerprinting mechanism makes all the fingerprints random.
Since the caching mechanism uses fingerprints to name the cache files, then cache file names will be different.
Therefore disabling fingerprinting will prevent the caching mechanism from reloading datasets files that have already been computed.
Disabling fingerprinting may speed up the lib for users that don't care about this feature and don't want to use caching.
```python
from datasets import set_fingerprinting_enabled
set_fingerprinting_enabled(False)
```
Other details:
- I renamed the `fingerprint` decorator to `fingerprint_transform` since the name was clearly not explicit. This decorator is used on dataset transform functions to allow them to update fingerprints.
- I added some `ignore_kwargs` when decorating transforms with `fingerprint_transform`, to make the fingerprint update not sensible to kwargs like `load_from_cache` or `cache_file_name`.
Todo: tests for set_fingerprinting_enabled + documentation for all the above features | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1703/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1703",
"merged_at": "2021-01-19T17:32:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1703"
} | true | [
"I few comments here for discussion:\r\n- I'm not convinced yet the end user should really have to understand the difference between \"caching\" and 'fingerprinting\", what do you think? I think fingerprinting should probably stay as an internal thing. Is there a case where we want cahing without fingerprinting or vice-versa?\r\n- while I think the random fingerprint mechanism is smart, I have one question: when we disable caching or fingerprinting we also probably don't want the disk usage to grow so we should then try to keep only one cache file. Is it the case currently?\r\n- the warning should be emitted only once per session if possible (we have a mechanism to do that in transformers, you should ask Lysandre/Sylvain)\r\n\r\n",
"About your points:\r\n- Yes I agree, I just wanted to bring the discussion on this point. Until now fingerprinting hasn't been blocking for user experience. I'll probably remove the enable/disable fingerprinting function to keep things simple from the user's perspective.\r\n- Right now every time a not in-place transform (i.e. map, filter) is applied, a new cache file is created. It is the case even if caching is disabled since disabling it only means that the cache file won't be reloaded. Therefore you're right that it might end up filling the disk with files that won't be reused. I like the idea of keeping only one cache file. Currently all the cache files are kept on disk until the user clears the cache. To be able to keep only one, we need to know if a dataset that has been transformed is still loaded or not. For example\r\n```python\r\n# case 1 - keep both cache files (dataset1 and dataset2)\r\ndataset2 = dataset1.map(...)\r\n# case 2 - keep only the new cache file\r\ndataset1 = dataset1.map(...)\r\n```\r\nIn python it doesn't seem trivial to detect such changes. One thing that we can actually do on the other hand is store the cache files in a temporary directory that is cleared when the session closes. I think that's a good a simple solution for this problem.\r\n- Yes good idea ! I don't like spam either :) ",
"> * To be able to keep only one, we need to know if a dataset that has been transformed is still loaded or not. For example\r\n> \r\n> ```python\r\n> # case 1 - keep both cache files (dataset1 and dataset2)\r\n> dataset2 = dataset1.map(...)\r\n> # case 2 - keep only the new cache file\r\n> dataset1 = dataset1.map(...)\r\n> ```\r\n\r\nI see what you mean. It's a tricky question. One option would be that if caching is deactivated we have a single memory mapped file and have copy act as a copy by reference instead of a copy by value. We will then probably want a `copy()` or `deepcopy()` functionality. Maybe we should think a little bit about it though.",
"- I like the idea of using a temporary directory per session!\r\n- If the default behavior when caching is disabled is to re-use the same file, I'm a little worried about people making mistakes and having to re-download and process from scratch.\r\n- So we already have a keyword argument for `dataset1 = dataset1.map(..., in_place=True)`?",
"> * If the default behavior when caching is disabled is to re-use the same file, I'm a little worried about people making mistakes and having to re-download and process from scratch.\r\n\r\nWe should distinguish between the caching from load_dataset (base dataset cache files) and the caching after dataset transforms such as map or filter (transformed dataset cache files). When disabling caching only the second type (for map and filter) doesn't reload from cache files.\r\nTherefore nothing is re-downloaded. To re-download the dataset entirely the argument `download_mode=\"force_redownload\"` must be used in `load_dataset`.\r\nDo we have to think more about the naming to make things less confusing in your opinion ?\r\n\r\n> * So we already have a keyword argument for `dataset1 = dataset1.map(..., in_place=True)`?\r\n\r\nThere's no such `in_place` parameter in map, what do you mean exactly ?",
"I updated the PR:\r\n- I removed the enable/disable fingerprinting function\r\n- if caching is disabled arrow files are written in a temporary directory that is deleted when session closes\r\n- the warning that is showed when hashing a transform fails is only showed once\r\n- I added the `set_caching_enabled` function to the docs and explained the caching mechanism and its relation with fingerprinting\r\n\r\nI would love to have some feedback :) ",
"> > * So we already have a keyword argument for `dataset1 = dataset1.map(..., in_place=True)`?\r\n> \r\n> There's no such `in_place` parameter in map, what do you mean exactly ?\r\n\r\nSorry, that wasn't clear at all. I was responding to your previous comment about case 1 / case 2. I don't think the behavior should depend on the command, but we could have:\r\n\r\n```\r\n# case 1 - keep both cache files (dataset1 and dataset2)\r\ndataset2 = dataset1.map(...)\r\n# case 2 - keep only the new cache file\r\ndataset1 = dataset1.map(..., in_place=True)\r\n```\r\n\r\nCase 1 returns a new reference using the new cache file, case 2 returns the same reference",
"> Sorry, that wasn't clear at all. I was responding to your previous comment about case 1 / case 2. I don't think the behavior should depend on the command, but we could have:\r\n> \r\n> ```\r\n> # case 1 - keep both cache files (dataset1 and dataset2)\r\n> dataset2 = dataset1.map(...)\r\n> # case 2 - keep only the new cache file\r\n> dataset1 = dataset1.map(..., in_place=True)\r\n> ```\r\n> \r\n> Case 1 returns a new reference using the new cache file, case 2 returns the same reference\r\n\r\nOk I see !\r\n`in_place` is a parameter that is used in general to designate a transform so I would name that differently (maybe `overwrite` or something like that).\r\nNot sure if it's possible to update an already existing arrow file that is memory-mapped, let me check real quick.\r\nAlso it's possible to call `dataset2.cleanup_cache_files()` to delete the other cache files if we create a new one after the transform. Or even to get the cache file with `dataset1.cache_files` and let the user remove them by hand.\r\n\r\nEDIT: updating an arrow file in place is not part of the current API of pyarrow, so we would have to make new files.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5317 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5317/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5317/comments | https://api.github.com/repos/huggingface/datasets/issues/5317/events | https://github.com/huggingface/datasets/issues/5317 | 1,470,390,164 | I_kwDODunzps5XpF-U | 5,317 | `ImageFolder` performs poorly with large datasets | [] | open | false | null | 3 | 2022-12-01T00:04:21Z | 2022-12-01T21:49:26Z | null | null | ### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata.jsonl` file
## Performance Degradation Point 1
Degradation occurs because [`get_data_files_patterns`](https://github.com/huggingface/datasets/blob/main/src/datasets/data_files.py#L231-L243) runs the exact same scan for many different types of patterns, and there doesn't seem to be a way to easily limit this. It's controlled by the definition of [`ALL_DEFAULT_PATTERNS`](https://github.com/huggingface/datasets/blob/main/src/datasets/data_files.py#L82-L85).
One scan with 3M+ files takes about 10-15 minutes to complete on my setup, so having those extra scans really slows things down – from 10 minutes to 60+. Most of the scans return no matches, but they still take a significant amount of time to complete – hence the poor performance.
As a side effect, when this scan is run on 3M+ image files, Python also consumes up to 12 GB of RAM, which is not ideal.
## Performance Degradation Point 2
The second performance bottleneck is in [`PackagedDatasetModuleFactory.get_module`](https://github.com/huggingface/datasets/blob/d7dfbc83d68e87ba002c5eb2555f7a932e59038a/src/datasets/load.py#L707-L711), which calls `DataFilesDict.from_local_or_remote`.
It runs for a long time (60min+), consuming significant amounts of RAM – even more than the point 1 above. Based on `iostat -d 2`, it performs **zero** disk operations, which to me suggests that there is a code based bottleneck there that could be sorted out.
### Steps to reproduce the bug
```python
from datasets import load_dataset
import os
import huggingface_hub
dataset = load_dataset(
'imagefolder',
data_dir='/some/path',
# just to spell it out:
split=None,
drop_labels=True,
keep_in_memory=False
)
dataset.push_to_hub('account/dataset', private=True)
```
### Expected behavior
While it's certainly possible to write a custom loader to replace `ImageFolder` with, it'd be great if the off-the-shelf `ImageFolder` would by default have a setup that can scale to large datasets.
Or perhaps there could be a dedicated loader just for large datasets that trades off flexibility for performance? As in, maybe you have to define explicitly how you want it to work rather than it trying to guess your data structure like `_get_data_files_patterns()` does?
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-4.14.296-222.539.amzn2.x86_64-x86_64-with-glibc2.2.5
- Python version: 3.7.10
- PyArrow version: 10.0.1
- Pandas version: 1.3.5
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5317/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5317/timeline | null | null | null | null | false | [
"Hi ! ImageFolder is made for small scale datasets indeed. For large scale image datasets you better group your images in TAR archives or Arrow/Parquet files. This is true not just for ImageFolder loading performance, but also because having millions of files is not ideal for your filesystem or when moving the data around.\r\n\r\nOption 1. use TAR archives\r\n\r\nI'd suggest you to take a look at how we load [Imagenet](https://huggingface.co/datasets/imagenet-1k/tree/main) for example. The dataset is sharded in multiple TAR archives and there is a [script](https://huggingface.co/datasets/imagenet-1k/blob/main/imagenet-1k.py) that iterates over the archives to load the images.\r\n\r\nOption 2. use Arrow/Parquet\r\n\r\nYou can load your images as an Arrow Dataset with\r\n```python\r\nfrom datasets import Dataset, Image, load_from_disk, load_dataset\r\n\r\nds = Dataset.from_dict({\"image\": list(glob.glob(\"path/to/dir/**/*.jpg\"))})\r\n\r\ndef add_metadata(example):\r\n ...\r\n\r\nds = ds.map(add_metadata, num_proc=16) # num_proc for multiprocessing\r\nds = ds.cast_column(\"image\", Image())\r\n\r\n# save as Arrow locally\r\nds.save_to_disk(\"output_dir\")\r\nreloaded = load_from_disk(\"output_dir\")\r\n\r\n# OR save as Parquet on the HF Hub\r\nds.push_to_hub(\"username/dataset_name\")\r\nreloaded = load_dataset(\"username/dataset_name\")\r\n# reloaded = load_dataset(\"username/dataset_name\", num_proc=16) # to use multiprocessing\r\n```\r\n\r\nPS: maybe we can actually have something similar to ImageFolder but for image archives at one point ?",
"@lhoestq Thanks!\r\n\r\nPerhaps it'd be worth adding a note on the documentation that `ImageFolder` is not intended for large datasets? This limitation is not intuitively obvious to someone who has not used it before, I think.",
"Thanks for the feedback @salieri! I opened #5329 to make it clear `ImageFolder` is not intended for large datasets. Please feel free to comment if you have any other feedback! 🙂 "
] |
https://api.github.com/repos/huggingface/datasets/issues/4089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4089/comments | https://api.github.com/repos/huggingface/datasets/issues/4089/events | https://github.com/huggingface/datasets/pull/4089 | 1,191,915,196 | PR_kwDODunzps41l7yd | 4,089 | Create metric card for Frugal Score | [] | closed | false | null | 1 | 2022-04-04T14:53:49Z | 2022-04-05T14:14:46Z | 2022-04-05T14:06:50Z | null | Proposing metric card for Frugal Score.
@albertvillanova or @lhoestq -- there are certain aspects that I'm not 100% sure on (such as how exactly the distillation between BertScore and FrugalScore is done) -- so if you find that something isn't clear, please let me know! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4089/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4089.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4089",
"merged_at": "2022-04-05T14:06:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4089.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4089"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1247/comments | https://api.github.com/repos/huggingface/datasets/issues/1247/events | https://github.com/huggingface/datasets/pull/1247 | 758,431,640 | MDExOlB1bGxSZXF1ZXN0NTMzNjA1NzE2 | 1,247 | Adding indonlu dataset | [] | closed | false | null | 2 | 2020-12-07T11:38:45Z | 2020-12-08T14:11:50Z | 2020-12-08T14:11:50Z | null | IndoNLU benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems for Bahasa Indonesia. It contains 12 datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1247/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1247.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1247",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1247.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1247"
} | true | [
"looks like this PR includes changes about many files other than the ones for IndoNLU\r\nCould you create another branch and another PR please ?",
"> looks like this PR includes changes about many files other than the ones for IndoNLU\r\n> Could you create another branch and another PR please ?\r\n\r\nOkay I'll make it"
] |
https://api.github.com/repos/huggingface/datasets/issues/695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/695/comments | https://api.github.com/repos/huggingface/datasets/issues/695/events | https://github.com/huggingface/datasets/pull/695 | 712,843,949 | MDExOlB1bGxSZXF1ZXN0NDk2MjU5NTM0 | 695 | Update XNLI download link | [] | closed | false | null | 0 | 2020-10-01T13:27:22Z | 2020-10-01T14:01:15Z | 2020-10-01T14:01:14Z | null | The old link isn't working anymore. I updated it with the new official link.
Fix #690 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/695/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/695.diff",
"html_url": "https://github.com/huggingface/datasets/pull/695",
"merged_at": "2020-10-01T14:01:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/695.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/695"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2953/comments | https://api.github.com/repos/huggingface/datasets/issues/2953/events | https://github.com/huggingface/datasets/issues/2953 | 1,002,766,517 | I_kwDODunzps47xQC1 | 2,953 | Trying to get in touch regarding a security issue | [] | closed | false | null | 1 | 2021-09-21T15:58:13Z | 2021-10-21T15:16:43Z | 2021-10-21T15:16:43Z | null | Hey there!
I'd like to report a security issue but cannot find contact instructions on your repository.
If not a hassle, might you kindly add a `SECURITY.md` file with an email, or another contact method? GitHub [recommends](https://docs.github.com/en/code-security/getting-started/adding-a-security-policy-to-your-repository) this best practice to ensure security issues are responsibly disclosed, and it would serve as a simple instruction for security researchers in the future.
Thank you for your consideration, and I look forward to hearing from you!
(cc @huntr-helper) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2953/timeline | null | completed | null | null | false | [
"Hi @JamieSlome,\r\n\r\nThanks for reaching out. Yes, you are right: I'm opening a PR to add the `SECURITY.md` file and a contact method.\r\n\r\nIn the meantime, please feel free to report the security issue to: [email protected]"
] |
https://api.github.com/repos/huggingface/datasets/issues/5756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5756/comments | https://api.github.com/repos/huggingface/datasets/issues/5756/events | https://github.com/huggingface/datasets/issues/5756 | 1,669,678,080 | I_kwDODunzps5jhUQA | 5,756 | Calling shuffle on a IterableDataset with streaming=True, gives "ValueError: cannot reshape array" | [] | closed | false | null | 2 | 2023-04-16T04:59:47Z | 2023-04-18T03:40:56Z | 2023-04-18T03:40:56Z | null | ### Describe the bug
When calling shuffle on a IterableDataset with streaming=True, I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.10/site-packages/datasets/iterable_dataset.py", line 937, in __iter__
for key, example in ex_iterable:
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.10/site-packages/datasets/iterable_dataset.py", line 627, in __iter__
for x in self.ex_iterable:
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.10/site-packages/datasets/iterable_dataset.py", line 138, in __iter__
yield from self.generate_examples_fn(**kwargs_with_shuffled_shards)
File "/home/administrator/.cache/huggingface/modules/datasets_modules/datasets/mnist/fda16c03c4ecfb13f165ba7e29cf38129ce035011519968cdaf74894ce91c9d4/mnist.py", line 111, in _generate_examples
images = np.frombuffer(f.read(), dtype=np.uint8).reshape(size, 28, 28)
ValueError: cannot reshape array of size 59992 into shape (60000,28,28)
```
Tested with the fashion_mnist and mnist datasets
### Steps to reproduce the bug
Code to reproduce
```python
from datasets import load_dataset
SHUFFLE_SEED = 42
SHUFFLE_BUFFER_SIZE = 10_000
dataset = load_dataset('fashion_mnist', streaming=True).shuffle(seed=SHUFFLE_SEED, buffer_size=SHUFFLE_BUFFER_SIZE)
next(iter(dataset['train']))
```
### Expected behavior
A random item from the dataset and no error
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.13.4
- PyArrow version: 11.0.0
- Pandas version: 2.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5756/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5756/timeline | null | completed | null | null | false | [
"Hi! I've merged a PR on the Hub with a fix: https://huggingface.co/datasets/fashion_mnist/discussions/3",
"Thanks, this appears to have fixed the issue.\r\n\r\nI've created a PR for the same change in the mnist dataset: https://huggingface.co/datasets/mnist/discussions/3/files"
] |
https://api.github.com/repos/huggingface/datasets/issues/5660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5660/comments | https://api.github.com/repos/huggingface/datasets/issues/5660/events | https://github.com/huggingface/datasets/issues/5660 | 1,635,543,646 | I_kwDODunzps5hfGpe | 5,660 | integration with imbalanced-learn | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | 1 | 2023-03-22T11:05:17Z | 2023-07-06T18:10:15Z | 2023-07-06T18:10:15Z | null | ### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I've looked online, asked gpt-4, but so far not making much progress.
### Your contribution
If I can get this working myself I can submit a PR with example code to go in the docs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5660/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5660/timeline | null | completed | null | null | false | [
"You can convert any dataset to pandas to be used with imbalanced-learn using `.to_pandas()`\r\n\r\nOtherwise if you want to keep a `Dataset` object and still use e.g. [make_imbalance](https://imbalanced-learn.org/stable/references/generated/imblearn.datasets.make_imbalance.html#imblearn.datasets.make_imbalance), you just need to pass the list of rows ids and labels:\r\n\r\n```python\r\nrow_indices = list(range(len(dataset)))\r\nresampled_row_indices, _ = make_imbalance(\r\n row_indices,\r\n dataset[\"label\"],\r\n sampling_strategy={0: 25, 1: 50, 2: 50},\r\n random_state=RANDOM_STATE,\r\n)\r\n\r\nresampled_dataset = dataset.select(resampled_row_indices)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/840 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/840/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/840/comments | https://api.github.com/repos/huggingface/datasets/issues/840/events | https://github.com/huggingface/datasets/pull/840 | 740,632,771 | MDExOlB1bGxSZXF1ZXN0NTE5MDg2NDUw | 840 | Update squad_v2.py | [] | closed | false | null | 2 | 2020-11-11T09:58:41Z | 2020-11-11T15:29:34Z | 2020-11-11T15:26:35Z | null | Change lines 100 and 102 to prevent overwriting ```predictions``` variable. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/840/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/840/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/840.diff",
"html_url": "https://github.com/huggingface/datasets/pull/840",
"merged_at": "2020-11-11T15:26:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/840.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/840"
} | true | [
"With this change all the checks are passed.",
"Good"
] |
https://api.github.com/repos/huggingface/datasets/issues/5682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5682/comments | https://api.github.com/repos/huggingface/datasets/issues/5682/events | https://github.com/huggingface/datasets/issues/5682 | 1,646,000,571 | I_kwDODunzps5iG_m7 | 5,682 | ValueError when passing ignore_verifications | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2023-03-29T15:00:30Z | 2023-03-29T17:28:58Z | 2023-03-29T17:28:58Z | null | When passing `ignore_verifications=True` to `load_dataset`, we get a ValueError:
```
ValueError: 'none' is not a valid VerificationMode
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5682/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5229 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5229/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5229/comments | https://api.github.com/repos/huggingface/datasets/issues/5229/events | https://github.com/huggingface/datasets/issues/5229 | 1,445,121,028 | I_kwDODunzps5WIswE | 5,229 | Type error when calling `map` over dataset containing 0-d tensors | [] | closed | false | null | 2 | 2022-11-11T08:27:28Z | 2023-01-13T16:00:53Z | 2023-01-13T16:00:53Z | null | ### Describe the bug
0-dimensional tensors in a dataset lead to `TypeError: iteration over a 0-d array` when calling `map`. It is easy to generate such tensors by using `.with_format("...")` on the whole dataset.
### Steps to reproduce the bug
```
ds = datasets.Dataset.from_list([{"a": 1}, {"a": 1}]).with_format("torch")
ds.map(None)
```
### Expected behavior
Getting back `ds` without errors.
### Environment info
Python 3.10.8
datasets 2.6.
torch 1.13.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5229/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5229/timeline | null | completed | null | null | false | [
"Hi! \r\n\r\nWe could address this by calling `.item()` on such tensors to extract the value, but this would lose us the type, which could lead to storing the generated dataset in a suboptimal format. Considering this, I think the only proper fix would be implementing support for 0-D tensors on Apache Arrow's side (Arrow is the underlying format we use to store datasets on disk/in memory). WDYT @lhoestq?",
"I think we can just convert the item to a numpy typed scalar using `.numpy()` ?\r\n\r\nFor example this works:\r\n```python\r\nimport numpy as np\r\nimport pyarrow as pa\r\n\r\nassert pa.array([np.float64(1.0)]).type == pa.float64()\r\nassert pa.array([np.float32(1.0)]).type == pa.float32()\r\nassert pa.array([np.int32(1)]).type == pa.int32()\r\nassert pa.array([np.int64(1)]).type == pa.int64()\r\n```\r\n\r\nAnd therefore it would work the same as for PyTorch N-D Tensors: convert to Numpy Array to keep the type in `_cast_to_python_objects`, then convert to Arrow"
] |
https://api.github.com/repos/huggingface/datasets/issues/3627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3627/comments | https://api.github.com/repos/huggingface/datasets/issues/3627/events | https://github.com/huggingface/datasets/pull/3627 | 1,113,556,837 | PR_kwDODunzps4xitGe | 3,627 | Fix host URL in The Pile datasets | [] | closed | false | null | 4 | 2022-01-25T08:11:28Z | 2022-07-20T20:54:42Z | 2022-02-14T08:40:58Z | null | This PR fixes the host URL in The Pile datasets, once they have mirrored their data in another server.
Fix #3626. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3627/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3627.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3627",
"merged_at": "2022-02-14T08:40:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3627.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3627"
} | true | [
"We should also update the `bookcorpusopen` download url (see #3561) , no? ",
"For `the_pile_openwebtext2` and `the_pile_stack_exchange` I did not regenerate the JSON files, but instead I just changed the download_checksums URL. ",
"Seems like the mystic URL is now broken and the original should be used. ",
"Also if I git clone and edit the repo or reset it before this PR it is still trying to pull using mystic? Why is this? "
] |
https://api.github.com/repos/huggingface/datasets/issues/1440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1440/comments | https://api.github.com/repos/huggingface/datasets/issues/1440/events | https://github.com/huggingface/datasets/pull/1440 | 760,973,057 | MDExOlB1bGxSZXF1ZXN0NTM1NzEyNDY1 | 1,440 | Adding english plaintext jokes dataset | [] | closed | false | null | 2 | 2020-12-10T07:04:17Z | 2020-12-13T05:22:00Z | 2020-12-12T05:55:43Z | null | This PR adds a dataset of 200k English plaintext Jokes from three sources: Reddit, Stupidstuff, and Wocka.
Link: https://github.com/taivop/joke-dataset
This is my second PR.
First was: [#1269 ](https://github.com/huggingface/datasets/pull/1269) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1440/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1440.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1440",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1440.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1440"
} | true | [
"Hi @purvimisal, thanks for your contributions!\r\n\r\nThis jokes dataset has come up before, and after a conversation with the initial submitter, we decided not to add it then. Humor is important, but looking at the actual data points in this set raises several concerns :) \r\n\r\nThe main issue is the Reddit part of the dataset which has most of the examples. A cursory look at the data shows a large number of highly offensive jokes that reproduce some pretty harmful biases (the second one from the top is a Holocaust joke). \r\n\r\nThe other two sources have similar issues (especially the \"Blond Jokes\") to a slightly lesser extent.\r\n\r\nWhile such datasets can be useful in the right context, there is a real concern that people using the library might miss some of this context (however much we outline it), and end up unwittingly training models that rely on some pretty racist and sexist associations.\r\n\r\nWe would recommend skipping this dataset altogether.\r\n\r\nIf you feel really strongly about having a joke dataset, then we would ask that you:\r\n- remove the Reddit part of the dataset altogether\r\n- write an in-depth description of the social biases present in the remaining data\r\n\r\nLet us know which of the two you decide! And if you want recommendations on other datasets to add, hit us up on Slack 🤗 ",
"Hi @yjernite, thanks so much. I should've totally thought about this earlier. The harmful biases make so much sense. I should've consulted before making a PR. \r\nI will be closing this one and skipping this dataset altogether. \r\nThanks again \r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/345/comments | https://api.github.com/repos/huggingface/datasets/issues/345/events | https://github.com/huggingface/datasets/issues/345 | 651,761,201 | MDU6SXNzdWU2NTE3NjEyMDE= | 345 | Supporting documents in ELI5 | [] | closed | false | null | 2 | 2020-07-06T19:14:13Z | 2020-10-27T15:38:45Z | 2020-10-27T15:38:45Z | null | I was attempting to use the ELI5 dataset, when I realized that huggingface does not provide the supporting documents (the source documents from the common crawl). Without the supporting documents, this makes the dataset about as useful for my project as a block of cheese, or some other more apt metaphor. According to facebook, the entire document collection is quite large. However, it would still be helpful to at least include a subset of the supporting documents i.e., having some data is better than having a block of cheese, in my case at least.
If you choose not to include them, it would be helpful to have documentation mentioning this specifically. It is especially confusing because the hf nlp ELI5 dataset has the key `'document'` but there are no documents to be found :( | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/345/timeline | null | completed | null | null | false | [
"Hi @saverymax ! For licensing reasons, the original team was unable to release pre-processed CommonCrawl documents. Instead, they provided a script to re-create them from a CommonCrawl dump, but it unfortunately requires access to a medium-large size cluster:\r\nhttps://github.com/facebookresearch/ELI5#downloading-support-documents-from-the-commoncrawl\r\n\r\nIn order to make the task accessible to people who may not have access to this kind of infrastructure, we suggest to use Wikipedia as a knowledge source rather than the full CommonCrawl. The following blog post shows how you can create Wikipedia support documents and get a performance that is on par with a system that uses CommonCrawl pages.\r\nhttps://yjernite.github.io/lfqa.html#task_description\r\n\r\nHope that helps, using ElasticSearch to index Wiki40b and create the documents should take about 4 hours. Let us know if you have any trouble with the blog post though!",
"Hi, thanks for the quick response. The blog post is quite an interesting working example, thanks for sharing it.\r\nTwo follow-up points/questions about my original question:\r\n\r\n1. Yes, I read that the facebook team could not share the CommonCrawl b/c of licensing reasons. They state \"No, we are not allowed to host processed Reddit or CommonCrawl data,\" which indicates they could also not share the Reddit data for licensing reasons. But it seems that HuggingFace is able to share the Reddit data, so why not a subset of CommonCrawl?\r\n\r\n2. Thanks for the suggestion about ElasticSearch and Wiki40b. This is good to know about performance. I definitely could do the indexing and querying myself. What I like about the ELI5 dataset though, at least what is suggested by the paper, is that to create the dataset they had already selected the top 100 web sources and made a single support document from those. Though it doesn't appear to be too sophisticated an approach, having a single support document pre-computed (without having to run the facebook code or a replacement with another dataset) is super useful for my work, especially since I'm not working on developing the latest and greatest retrieval model. Of course, I don't expect HF NLP datasets to be perfectly tailored to my use-case. I know there is overhead to any project, I'm just illustrating a use-case of ELI5 which is not possible with the data provided as-is. If it's for licensing reasons, that is perfectly acceptable a reason, and I appreciate your response."
] |
https://api.github.com/repos/huggingface/datasets/issues/2132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2132/comments | https://api.github.com/repos/huggingface/datasets/issues/2132/events | https://github.com/huggingface/datasets/issues/2132 | 843,142,822 | MDU6SXNzdWU4NDMxNDI4MjI= | 2,132 | TydiQA dataset is mixed and is not split per language | [] | open | false | null | 3 | 2021-03-29T08:56:21Z | 2021-04-04T09:57:15Z | null | null | Hi @lhoestq
Currently TydiQA is mixed and user can only access the whole training set of all languages:
https://www.tensorflow.org/datasets/catalog/tydi_qa
for using this dataset, one need to train/evaluate in each separate language, and having them mixed, makes it hard to use this dataset. This is much convenient for user to have them split and I appreciate your help on this.
Meanwhile, till hopefully this is split per language, I greatly appreciate telling me how I can preprocess and get data per language. thanks a lot | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2132/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2132/timeline | null | null | null | null | false | [
"You can filter the languages this way:\r\n```python\r\ntydiqa_en = tydiqa_dataset.filter(lambda x: x[\"language\"] == \"english\")\r\n```\r\n\r\nOtherwise maybe we can have one configuration per language ?\r\nWhat do you think of this for example ?\r\n\r\n```python\r\nload_dataset(\"tydiqa\", \"primary_task.en\")\r\n```",
"Hi\nthank you very much for the great response, this will be really wonderful\nto have one configuration per language, as one need the dataset in majority\nof case per language for cross-lingual evaluations.\nThis becomes also then more close to TFDS format, which is separated per\nlanguage https://www.tensorflow.org/datasets/catalog/tydi_qa which will be\nreally awesome to have.\nthanks\n\nOn Mon, Mar 29, 2021 at 6:17 PM Quentin Lhoest ***@***.***>\nwrote:\n\n> You can filter the languages this way:\n>\n> tydiqa_en = tydiqa_dataset.filter(lambda x: x[\"language\"] == \"english\")\n>\n> Otherwise maybe we can have one configuration per language ?\n> What do you think of this for example ?\n>\n> load_dataset(\"tydiqa\", \"primary_task.en\")\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/2132#issuecomment-809516799>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AS37NMXPW2PWSQ2RHG73O7TTGCY4LANCNFSM4Z7ER7IA>\n> .\n>\n",
"@lhoestq I greatly appreciate any updates on this. thanks a lot"
] |
https://api.github.com/repos/huggingface/datasets/issues/4052 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4052/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4052/comments | https://api.github.com/repos/huggingface/datasets/issues/4052/events | https://github.com/huggingface/datasets/issues/4052 | 1,184,447,977 | I_kwDODunzps5GmT3p | 4,052 | metric = metric_cls( TypeError: 'NoneType' object is not callable | [] | closed | false | null | 1 | 2022-03-29T07:43:08Z | 2022-03-29T14:06:01Z | 2022-03-29T14:06:01Z | null | Hi, friend. I meet a problem.
When I run the code:
`metric = load_metric('glue', 'rte')`
There is a problem raising:
`metric = metric_cls(
TypeError: 'NoneType' object is not callable `
I don't know why. Thanks for your help!
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4052/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4052/timeline | null | completed | null | null | false | [
"Hi @klyuhang9,\r\n\r\nI'm sorry but I can't reproduce your problem:\r\n```python\r\nIn [2]: metric = load_metric('glue', 'rte')\r\nDownloading builder script: 5.76kB [00:00, 2.40MB/s]\r\n```\r\n\r\nCould you please, retry to load the metric? Sometimes there are temporary connectivity issues.\r\n\r\nFeel free to re-open this issue of the problem persists."
] |
https://api.github.com/repos/huggingface/datasets/issues/1128 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1128/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1128/comments | https://api.github.com/repos/huggingface/datasets/issues/1128/events | https://github.com/huggingface/datasets/pull/1128 | 757,245,404 | MDExOlB1bGxSZXF1ZXN0NTMyNjUzMzgy | 1,128 | Add xquad-r dataset | [] | closed | false | null | 0 | 2020-12-04T16:48:53Z | 2020-12-04T18:14:30Z | 2020-12-04T18:14:26Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1128/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1128/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1128.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1128",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1128.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1128"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5359/comments | https://api.github.com/repos/huggingface/datasets/issues/5359/events | https://github.com/huggingface/datasets/pull/5359 | 1,495,297,857 | PR_kwDODunzps5FYHWm | 5,359 | Raise error if ClassLabel names is not python list | [] | closed | false | null | 3 | 2022-12-13T23:04:06Z | 2022-12-22T16:35:49Z | 2022-12-22T16:32:49Z | null | Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5359/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5359.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5359",
"merged_at": "2022-12-22T16:32:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5359.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5359"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your proposed fix, @freddyheppell.\r\n\r\nCurrently the CI fails because in a test we pass a `tuple` instead of a `list`. I would say we should accept `tuple` as a valid input type as well...\r\n\r\nWhat about checking for `Sequence` instead?",
"Fixed that @albertvillanova, can you approve CI again please? Had some issues related to Pytorch .so files when running tests on my M1 mac, so wasn't able to test locally first. Have got them working on my desktop now though."
] |
https://api.github.com/repos/huggingface/datasets/issues/4823 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4823/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4823/comments | https://api.github.com/repos/huggingface/datasets/issues/4823/events | https://github.com/huggingface/datasets/pull/4823 | 1,335,687,033 | PR_kwDODunzps49A0O_ | 4,823 | Update data URL in mkqa dataset | [] | closed | false | null | 1 | 2022-08-11T09:16:13Z | 2022-08-11T09:51:50Z | 2022-08-11T09:37:52Z | null | Update data URL in mkqa dataset.
Fix #4817. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4823/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4823/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4823.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4823",
"merged_at": "2022-08-11T09:37:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4823.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4823"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | 1 | 2023-03-07T01:52:00Z | 2023-03-09T15:24:05Z | 2023-03-09T15:23:54Z | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
I wrote codes below to make it.
```py
def add_column(dataset: IterableDataset, name: str, add_dataset: IterableDataset, key: str) -> IterableDataset:
iter_add_dataset = iter(add_dataset)
def add_column_fn(example):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: next(iter_add_dataset)[key]}
return dataset.map(add_column_fn)
```
Is there other way to do it? Or is it intended?
### Steps to reproduce the bug
Thie codes below occurs `NotImplementedError`
```py
from datasets import IterableDataset
def gen(num):
yield {f"col{num}": 1}
yield {f"col{num}": 2}
yield {f"col{num}": 3}
ids1 = IterableDataset.from_generator(gen, gen_kwargs={"num": 1})
ids2 = IterableDataset.from_generator(gen, gen_kwargs={"num": 2})
new_ids = ids1.add_column("new_col", ids1)
for row in new_ids:
print(row)
```
### Expected behavior
`IterableDataset.add_column` is able to task `IterableDataset` and lazy evaluated values as a parameter since IterableDataset is lazy evalued.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-3.10.0-1160.36.2.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.7
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | null | null | false | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] |
https://api.github.com/repos/huggingface/datasets/issues/1352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1352/comments | https://api.github.com/repos/huggingface/datasets/issues/1352/events | https://github.com/huggingface/datasets/pull/1352 | 759,978,543 | MDExOlB1bGxSZXF1ZXN0NTM0ODg0ODg4 | 1,352 | change url for prachathai67k to internet archive | [] | closed | false | null | 0 | 2020-12-09T04:20:37Z | 2020-12-10T13:42:17Z | 2020-12-10T13:42:17Z | null | `prachathai67k` is currently downloaded from git-lfs of PyThaiNLP github. Since the size is quite large (~250MB), I moved the URL to archive.org in order to prevent rate limit issues. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1352/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1352.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1352",
"merged_at": "2020-12-10T13:42:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1352.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1352"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4635/comments | https://api.github.com/repos/huggingface/datasets/issues/4635/events | https://github.com/huggingface/datasets/issues/4635 | 1,294,475,931 | I_kwDODunzps5NKCKb | 4,635 | Dataset Viewer issue for vadis/sv-ident | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 6 | 2022-07-05T15:48:13Z | 2022-07-06T07:13:33Z | 2022-07-06T07:12:14Z | null | ### Link
https://huggingface.co/datasets/vadis/sv-ident/viewer/default/validation
### Description
Error message when loading validation split in the viewer:
```
Status code: 400
Exception: Status400Error
Message: The split cache is empty.
```
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4635/timeline | null | completed | null | null | false | [
"Thanks for reporting, @e-tornike \r\n\r\nSome context:\r\n- #4527 \r\n\r\nThe dataset loads locally in streaming mode:\r\n```python\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"vadis/sv-ident\", split=\"validation\", streaming=True); item = next(iter(ds)); item\r\nUsing custom data configuration default\r\nOut[2]: \r\n{'sentence': 'Im Falle von Umweltbelastungen kann selten eindeutig entschieden werden, ob Unbedenklichkeitswerte bereits erreicht oder überschritten sind, die die menschliche Gesundheit oder andere Wohlfahrts»güter« beeinträchtigen.',\r\n 'is_variable': 0,\r\n 'variable': [],\r\n 'research_data': [],\r\n 'doc_id': '51971',\r\n 'uuid': 'ee3d7f88-1a3e-4a59-997f-e986b544a604',\r\n 'lang': 'de'}\r\n```",
"~~I have forced the refresh of the split in the preview without success.~~\r\n\r\nI have forced the refresh of the split in the preview, and now it works.",
"Preview seems to work now. \r\n\r\nhttps://huggingface.co/datasets/vadis/sv-ident/viewer/default/validation",
"OK, thank you @e-tornike.\r\n\r\nApparently, after forcing the refresh, we just had to wait a little until it is effectively refreshed. ",
"I'm closing this issue as it was solved after forcing the refresh of the split in the preview.",
"Thanks a lot! :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2316 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2316/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2316/comments | https://api.github.com/repos/huggingface/datasets/issues/2316/events | https://github.com/huggingface/datasets/issues/2316 | 875,756,353 | MDU6SXNzdWU4NzU3NTYzNTM= | 2,316 | Incorrect version specification for pyarrow | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-05-04T19:15:11Z | 2021-05-05T10:10:03Z | 2021-05-05T10:10:03Z | null | ## Describe the bug
The pyarrow dependency is incorrectly specified in setup.py file, in [this line](https://github.com/huggingface/datasets/blob/3a3e5a4da20bfcd75f8b6a6869b240af8feccc12/setup.py#L77).
Also as a snippet:
```python
"pyarrow>=1.0.0<4.0.0",
```
## Steps to reproduce the bug
```bash
pip install "pyarrow>=1.0.0<4.0.0"
```
## Expected results
It is expected to get a pyarrow version between 1.0.0 (inclusive) and 4.0.0 (exclusive).
## Actual results
pip ignores the specified versions since there is a missing comma between the lower and upper limits. Therefore, pip installs the latest pyarrow version from PYPI, which is 4.0.0.
This is especially problematic since "conda env export" fails due to incorrect version specification. Here is the conda error as well:
```bash
conda env export
InvalidVersionSpec: Invalid version '1.0.0<4.0.0': invalid character(s)
```
## Fix suggestion
Put a comma between the version limits which means replacing the line in setup.py file with the following:
```python
"pyarrow>=1.0.0,<4.0.0",
```
## Versions
Paste the output of the following code:
```python
- Datasets: 1.6.2
- Python: 3.7.10 (default, Feb 26 2021, 18:47:35)
[GCC 7.3.0]
- Platform: Linux-5.4.0-42-generic-x86_64-with-debian-buster-sid
```
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2316/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2316/timeline | null | completed | null | null | false | [
"Fixed by #2317."
] |
https://api.github.com/repos/huggingface/datasets/issues/4566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4566/comments | https://api.github.com/repos/huggingface/datasets/issues/4566/events | https://github.com/huggingface/datasets/issues/4566 | 1,284,397,594 | I_kwDODunzps5Mjloa | 4,566 | Document link #load_dataset_enhancing_performance points to nowhere | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-06-25T01:18:19Z | 2023-01-24T16:33:40Z | 2023-01-24T16:33:40Z | null | ## Describe the bug
A clear and concise description of what the bug is.

The [load_dataset_enhancing_performance](https://huggingface.co/docs/datasets/v2.3.2/en/package_reference/main_classes#load_dataset_enhancing_performance) link [here](https://huggingface.co/docs/datasets/v2.3.2/en/package_reference/main_classes#datasets.Dataset.load_from_disk.keep_in_memory) points to nowhere, I guess it should point to https://huggingface.co/docs/datasets/v2.3.2/en/cache#improve-performance?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4566/timeline | null | completed | null | null | false | [
"Hi! This is indeed the link the docstring should point to. Are you interested in submitting a PR to fix this?",
"https://github.com/huggingface/datasets/blame/master/docs/source/cache.mdx#L93\r\n\r\nThere seems already an anchor here. Somehow it doesn't work. I am not very familiar with how this online documentation works."
] |
https://api.github.com/repos/huggingface/datasets/issues/2216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2216/comments | https://api.github.com/repos/huggingface/datasets/issues/2216/events | https://github.com/huggingface/datasets/pull/2216 | 856,955,534 | MDExOlB1bGxSZXF1ZXN0NjE0NDU0MjE1 | 2,216 | added real label for glue/mrpc to test set | [] | closed | false | null | 0 | 2021-04-13T13:20:20Z | 2021-04-13T13:53:20Z | 2021-04-13T13:53:19Z | null | Added real label to `glue.py` `mrpc` task for test split. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2216/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2216.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2216",
"merged_at": "2021-04-13T13:53:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2216.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2216"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3201 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3201/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3201/comments | https://api.github.com/repos/huggingface/datasets/issues/3201/events | https://github.com/huggingface/datasets/issues/3201 | 1,043,209,142 | I_kwDODunzps4-Lhu2 | 3,201 | Add GSM8K dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2021-11-03T08:36:44Z | 2022-04-13T11:56:12Z | 2022-04-13T11:56:11Z | null | ## Adding a Dataset
- **Name:** GSM8K (short for Grade School Math 8k)
- **Description:** GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers.
- **Paper:** https://openai.com/blog/grade-school-math/
- **Data:** https://github.com/openai/grade-school-math
- **Motivation:** The dataset is useful to investigate the reasoning abilities of large Transformer models, such as GPT-3.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3201/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3201/timeline | null | completed | null | null | false | [
"Closed via https://github.com/huggingface/datasets/pull/4103"
] |
https://api.github.com/repos/huggingface/datasets/issues/5267 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5267/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5267/comments | https://api.github.com/repos/huggingface/datasets/issues/5267/events | https://github.com/huggingface/datasets/pull/5267 | 1,455,466,464 | PR_kwDODunzps5DOlFR | 5,267 | Fix `max_shard_size` docs | [] | closed | false | null | 1 | 2022-11-18T16:55:22Z | 2022-11-18T17:28:58Z | 2022-11-18T17:25:27Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5267/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5267/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5267.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5267",
"merged_at": "2022-11-18T17:25:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5267.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5267"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4900 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4900/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4900/comments | https://api.github.com/repos/huggingface/datasets/issues/4900/events | https://github.com/huggingface/datasets/issues/4900 | 1,352,405,855 | I_kwDODunzps5QnBNf | 4,900 | Dataset Viewer issue for asaxena1990/Dummy_dataset | [] | closed | false | null | 3 | 2022-08-26T15:15:44Z | 2023-07-24T15:42:09Z | 2023-07-24T15:42:09Z | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4900/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4900/timeline | null | completed | null | null | false | [
"Seems to be linked to the use of the undocumented `_resolve_features` method in the dataset viewer backend:\r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>> dataset = load_dataset(\"asaxena1990/Dummy_dataset\", name=\"asaxena1990--Dummy_dataset\", split=\"train\", streaming=True)\r\nUsing custom data configuration asaxena1990--Dummy_dataset-4a704ed7e5627563\r\n>>> dataset._resolve_features()\r\nFailed to read file 'https://huggingface.co/datasets/asaxena1990/Dummy_dataset/resolve/06885879a8bdd767d2d27695484fc6c83244617a/dummy_dataset_train.json' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Column() changed from object to array in row 0\r\nTraceback (most recent call last):\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py\", line 109, in _generate_tables\r\n pa_table = paj.read_json(\r\n File \"pyarrow/_json.pyx\", line 246, in pyarrow._json.read_json\r\n File \"pyarrow/error.pxi\", line 143, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 99, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: JSON parse error: Column() changed from object to array in row 0\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 1261, in _resolve_features\r\n features = _infer_features_from_batch(self._head())\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 686, in _head\r\n return _examples_to_batch([x for key, x in islice(self._iter(), n)])\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 686, in <listcomp>\r\n return _examples_to_batch([x for key, x in islice(self._iter(), n)])\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 708, in _iter\r\n yield from ex_iterable\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 112, in __iter__\r\n yield from self.generate_examples_fn(**self.kwargs)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 651, in wrapper\r\n for key, table in generate_tables_fn(**kwargs):\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py\", line 137, in _generate_tables\r\n f\"This JSON file contain the following fields: {str(list(dataset.keys()))}. \"\r\nAttributeError: 'list' object has no attribute 'keys'\r\n```\r\n\r\nPinging @huggingface/datasets",
"Hi ! JSON files containing a list of object are not supported yet, you can use JSON Lines files instead in the meantime\r\n```json\r\n{\"text\": \"can I know this?\", \"intent\": \"Know\", \"type\": \"Test\"}\r\n{\"text\": \"can I know this?\", \"intent\": \"Know\", \"type\": \"Test\"}\r\n...\r\n```",
"A JSON list of objects is supported as of version 2.5.0."
] |
https://api.github.com/repos/huggingface/datasets/issues/1197 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1197/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1197/comments | https://api.github.com/repos/huggingface/datasets/issues/1197/events | https://github.com/huggingface/datasets/pull/1197 | 757,900,160 | MDExOlB1bGxSZXF1ZXN0NTMzMTc4MTIz | 1,197 | add taskmaster-2 | [] | closed | false | null | 0 | 2020-12-06T11:05:18Z | 2020-12-07T15:22:43Z | 2020-12-07T15:22:43Z | null | Adding taskmaster-2 dataset.
https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1197/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1197/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1197.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1197",
"merged_at": "2020-12-07T15:22:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1197.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1197"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/869 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/869/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/869/comments | https://api.github.com/repos/huggingface/datasets/issues/869/events | https://github.com/huggingface/datasets/pull/869 | 746,495,711 | MDExOlB1bGxSZXF1ZXN0NTIzODc3OTkw | 869 | Update ner datasets infos | [] | closed | false | null | 1 | 2020-11-19T11:28:03Z | 2020-11-19T14:14:18Z | 2020-11-19T14:14:17Z | null | Update the dataset_infos.json files for changes made in #850 regarding the ner datasets feature types (and the change to ClassLabel)
I also fixed the ner types of conll2003 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/869/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/869/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/869.diff",
"html_url": "https://github.com/huggingface/datasets/pull/869",
"merged_at": "2020-11-19T14:14:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/869.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/869"
} | true | [
":+1: Thanks for fixing it!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2829/comments | https://api.github.com/repos/huggingface/datasets/issues/2829/events | https://github.com/huggingface/datasets/issues/2829 | 977,233,360 | MDU6SXNzdWU5NzcyMzMzNjA= | 2,829 | Optimize streaming from TAR archives | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | null | 1 | 2021-08-23T16:56:40Z | 2022-09-21T14:29:46Z | 2022-09-21T14:08:39Z | null | Hi ! As you know TAR has some constraints for data streaming. While it is optimized for buffering, the files in the TAR archive **need to be streamed in order**. It means that we can't choose which file to stream from, and this notation is to be avoided for TAR archives:
```
tar://books_large_p1.txt::https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2
```
Instead, I suggest we implement `iter_archive` for the `StreamingDownloadManager`.
The regular `DownloadManager` already has it.
Then we will have to update the json/txt/csv/etc. loaders to make them use `iter_archive` on TAR archives.
That's also what Tensorflow Datasets is doing in this case.
See this [dataset](https://github.com/tensorflow/datasets/blob/93895059c80a9e05805e8f32a2e310f66a23fc98/tensorflow_datasets/image_classification/flowers.py) for example.
Therefore instead of doing
```python
uncompressed = dl_manager.extract(tar_archive)
filename = "books_large_p1.txt"
with open(os.path.join(uncompressed, filename)) as f:
for line in f:
...
```
we'll do
```python
for filename, f in dl_manager.iter_archive(tar_archive):
for line in f:
...
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2829/timeline | null | completed | null | null | false | [
"Closed by: \r\n- #3066"
] |
https://api.github.com/repos/huggingface/datasets/issues/2031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2031/comments | https://api.github.com/repos/huggingface/datasets/issues/2031/events | https://github.com/huggingface/datasets/issues/2031 | 829,122,778 | MDU6SXNzdWU4MjkxMjI3Nzg= | 2,031 | wikipedia.py generator that extracts XML doesn't release memory | [] | closed | false | null | 2 | 2021-03-11T12:51:24Z | 2021-03-22T08:33:52Z | 2021-03-22T08:33:52Z | null | I tried downloading Japanese wikipedia, but it always failed because of out of memory maybe.
I found that the generator function that extracts XML data in wikipedia.py doesn't release memory in the loop.
https://github.com/huggingface/datasets/blob/13a5b7db992ad5cf77895e4c0f76595314390418/datasets/wikipedia/wikipedia.py#L464-L502
`root.clear()` intend to clear memory, but it doesn't.
https://github.com/huggingface/datasets/blob/13a5b7db992ad5cf77895e4c0f76595314390418/datasets/wikipedia/wikipedia.py#L490
https://github.com/huggingface/datasets/blob/13a5b7db992ad5cf77895e4c0f76595314390418/datasets/wikipedia/wikipedia.py#L494
I replaced them with `elem.clear()`, then it seems to work correctly.
here is the notebook to reproduce it.
https://gist.github.com/miyamonz/dc06117302b6e85fa51cbf46dde6bb51#file-xtract_content-ipynb | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2031/timeline | null | completed | null | null | false | [
"Hi @miyamonz \r\nThanks for investigating this issue, good job !\r\nIt would be awesome to integrate your fix in the library, could you open a pull request ?",
"OK! I'll send it later."
] |
https://api.github.com/repos/huggingface/datasets/issues/1583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1583/comments | https://api.github.com/repos/huggingface/datasets/issues/1583/events | https://github.com/huggingface/datasets/pull/1583 | 768,795,986 | MDExOlB1bGxSZXF1ZXN0NTQxMTIyODEz | 1,583 | Update metrics docstrings. | [] | closed | false | null | 0 | 2020-12-16T12:14:18Z | 2020-12-18T18:39:06Z | 2020-12-18T18:39:06Z | null | #1478 Correcting the argument descriptions for metrics.
Let me know if there's any issues.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1583/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1583",
"merged_at": "2020-12-18T18:39:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1583"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/924 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/924/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/924/comments | https://api.github.com/repos/huggingface/datasets/issues/924/events | https://github.com/huggingface/datasets/pull/924 | 753,631,951 | MDExOlB1bGxSZXF1ZXN0NTI5NjcyMzgw | 924 | Add DART | [] | closed | false | null | 1 | 2020-11-30T16:42:37Z | 2020-12-02T03:13:42Z | 2020-12-02T03:13:41Z | null | - **Name:** *DART*
- **Description:** *DART is a large dataset for open-domain structured data record to text generation.*
- **Paper:** *https://arxiv.org/abs/2007.02871*
- **Data:** *https://github.com/Yale-LILY/dart#leaderboard*
### Checkbox
- [x] Create the dataset script `/datasets/my_dataset/my_dataset.py` using the template
- [x] Fill the `_DESCRIPTION` and `_CITATION` variables
- [x] Implement `_infos()`, `_split_generators()` and `_generate_examples()`
- [x] Make sure that the `BUILDER_CONFIGS` class attribute is filled with the different configurations of the dataset and that the `BUILDER_CONFIG_CLASS` is specified if there is a custom config class.
- [x] Generate the metadata file `dataset_infos.json` for all configurations
- [x] Generate the dummy data `dummy_data.zip` files to have the dataset script tested and that they don't weigh too much (<50KB)
- [x] Add the dataset card `README.md` using the template : fill the tags and the various paragraphs
- [x] Both tests for the real data and the dummy data pass. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/924/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/924/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/924.diff",
"html_url": "https://github.com/huggingface/datasets/pull/924",
"merged_at": "2020-12-02T03:13:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/924.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/924"
} | true | [
"LGTM!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5502 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5502/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5502/comments | https://api.github.com/repos/huggingface/datasets/issues/5502/events | https://github.com/huggingface/datasets/pull/5502 | 1,570,091,225 | PR_kwDODunzps5JN0aX | 5,502 | Added functionality: sort datasets by multiple keys | [] | closed | false | null | 5 | 2023-02-03T16:17:00Z | 2023-02-21T14:46:49Z | 2023-02-21T14:39:23Z | null | Added functionality implementation: sort datasets by multiple keys/columns as discussed in https://github.com/huggingface/datasets/issues/5425. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5502/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5502/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5502.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5502",
"merged_at": "2023-02-21T14:39:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5502.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5502"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks! I've left some comments.\r\n> \r\n> We should also add some tests, mainly to make sure `reverse` behaves as expected. Let me know if you need help with that.\r\n\r\nThanks for the offer! I couldn't find any guidelines on how huggingface goes about testing, so it would indeed be great to get a few pointers on that. I assume I should expand on the `test_sort` function in `test_arrow_dataset.py` but since I am not very familiar with the `datasets` package, it isn't immediately for which cases I should test (i.e., expand on).",
"@MichlF \r\n\r\nResolving a comment means that the comment has been addressed with the code change, so since this is not the case here, can you please \"unresolve\" the comments and address them adequately? \r\n\r\n> I assume I should expand on the `test_sort` function in `test_arrow_dataset.py`\r\n\r\nYes, that's correct. I think one test to check sorting on multiple keys and another one to check if an error is raised when `len(reverse)!=len(column_names)` should be enough.\r\n",
"> Yes, that's correct. I think one test to check sorting on multiple keys and another one to check if an error is raised when `len(reverse)!=len(column_names)` should be enough.\r\n\r\nI have added the tests in https://github.com/huggingface/datasets/pull/5502/commits/0efa259732e822e94d67b96a70031a3daccedfc1 by keeping them in the same format of the tests of the old `sort` function. Let me know if they can be improved.\r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010170 / 0.011353 (-0.001183) | 0.005891 / 0.011008 (-0.005117) | 0.100416 / 0.038508 (0.061908) | 0.041309 / 0.023109 (0.018200) | 0.300813 / 0.275898 (0.024915) | 0.376679 / 0.323480 (0.053199) | 0.008806 / 0.007986 (0.000821) | 0.005964 / 0.004328 (0.001636) | 0.075862 / 0.004250 (0.071611) | 0.050370 / 0.037052 (0.013318) | 0.313365 / 0.258489 (0.054876) | 0.351184 / 0.293841 (0.057343) | 0.039556 / 0.128546 (-0.088991) | 0.012462 / 0.075646 (-0.063185) | 0.337141 / 0.419271 (-0.082130) | 0.049678 / 0.043533 (0.006145) | 0.298547 / 0.255139 (0.043408) | 0.317547 / 0.283200 (0.034347) | 0.113595 / 0.141683 (-0.028088) | 1.448467 / 1.452155 (-0.003688) | 1.501303 / 1.492716 (0.008587) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011005 / 0.018006 (-0.007002) | 0.527430 / 0.000490 (0.526940) | 0.005073 / 0.000200 (0.004873) | 0.000100 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030377 / 0.037411 (-0.007034) | 0.116932 / 0.014526 (0.102406) | 0.124047 / 0.176557 (-0.052509) | 0.192358 / 0.737135 (-0.544777) | 0.130528 / 0.296338 (-0.165811) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401158 / 0.215209 (0.185949) | 4.005854 / 2.077655 (1.928200) | 1.810365 / 1.504120 (0.306245) | 1.626490 / 1.541195 (0.085295) | 1.752591 / 1.468490 (0.284101) | 0.709065 / 4.584777 (-3.875712) | 3.893356 / 3.745712 (0.147643) | 3.655180 / 5.269862 (-1.614682) | 1.873660 / 4.565676 (-2.692017) | 0.085860 / 0.424275 (-0.338415) | 0.012671 / 0.007607 (0.005063) | 0.512804 / 0.226044 (0.286759) | 5.103426 / 2.268929 (2.834497) | 2.336148 / 55.444624 (-53.108477) | 2.000140 / 6.876477 (-4.876336) | 2.095155 / 2.142072 (-0.046918) | 0.848612 / 4.805227 (-3.956615) | 0.171840 / 6.500664 (-6.328824) | 0.064144 / 0.075469 (-0.011325) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.222106 / 1.841788 (-0.619682) | 15.828559 / 8.074308 (7.754251) | 14.995298 / 10.191392 (4.803906) | 0.172783 / 0.680424 (-0.507641) | 0.029296 / 0.534201 (-0.504905) | 0.447469 / 0.579283 (-0.131814) | 0.658615 / 0.434364 (0.224251) | 1.527607 / 0.540337 (0.987270) | 1.830018 / 1.386936 (0.443082) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007922 / 0.011353 (-0.003431) | 0.005369 / 0.011008 (-0.005639) | 0.076580 / 0.038508 (0.038071) | 0.038770 / 0.023109 (0.015661) | 0.338995 / 0.275898 (0.063097) | 0.380865 / 0.323480 (0.057385) | 0.006489 / 0.007986 (-0.001497) | 0.004421 / 0.004328 (0.000093) | 0.074143 / 0.004250 (0.069893) | 0.054224 / 0.037052 (0.017171) | 0.348887 / 0.258489 (0.090397) | 0.395044 / 0.293841 (0.101203) | 0.037040 / 0.128546 (-0.091507) | 0.012547 / 0.075646 (-0.063099) | 0.087521 / 0.419271 (-0.331751) | 0.049918 / 0.043533 (0.006385) | 0.342428 / 0.255139 (0.087289) | 0.362216 / 0.283200 (0.079016) | 0.107204 / 0.141683 (-0.034479) | 1.509206 / 1.452155 (0.057052) | 1.596010 / 1.492716 (0.103293) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246795 / 0.018006 (0.228788) | 0.505998 / 0.000490 (0.505509) | 0.000446 / 0.000200 (0.000246) | 0.000064 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031591 / 0.037411 (-0.005821) | 0.117595 / 0.014526 (0.103069) | 0.132500 / 0.176557 (-0.044056) | 0.202244 / 0.737135 (-0.534891) | 0.136624 / 0.296338 (-0.159715) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428235 / 0.215209 (0.213026) | 4.262691 / 2.077655 (2.185036) | 2.057348 / 1.504120 (0.553228) | 1.928559 / 1.541195 (0.387364) | 2.120838 / 1.468490 (0.652347) | 0.706300 / 4.584777 (-3.878477) | 3.951828 / 3.745712 (0.206115) | 2.144218 / 5.269862 (-3.125644) | 1.359500 / 4.565676 (-3.206177) | 0.085404 / 0.424275 (-0.338872) | 0.012363 / 0.007607 (0.004756) | 0.529985 / 0.226044 (0.303941) | 5.295831 / 2.268929 (3.026903) | 2.522602 / 55.444624 (-52.922022) | 2.182850 / 6.876477 (-4.693627) | 2.270187 / 2.142072 (0.128114) | 0.841676 / 4.805227 (-3.963551) | 0.168366 / 6.500664 (-6.332298) | 0.065371 / 0.075469 (-0.010098) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.261464 / 1.841788 (-0.580324) | 17.010125 / 8.074308 (8.935817) | 14.304453 / 10.191392 (4.113061) | 0.177782 / 0.680424 (-0.502642) | 0.017762 / 0.534201 (-0.516439) | 0.427283 / 0.579283 (-0.152000) | 0.455176 / 0.434364 (0.020812) | 0.525962 / 0.540337 (-0.014375) | 0.625583 / 1.386936 (-0.761353) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1141 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1141/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1141/comments | https://api.github.com/repos/huggingface/datasets/issues/1141/events | https://github.com/huggingface/datasets/pull/1141 | 757,411,057 | MDExOlB1bGxSZXF1ZXN0NTMyNzkyNzU3 | 1,141 | Add GitHub version of ETH Py150 Corpus | [] | closed | false | null | 2 | 2020-12-04T21:16:08Z | 2020-12-09T18:32:44Z | 2020-12-07T10:00:24Z | null | Add the redistributable version of **ETH Py150 Corpus** | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1141/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1141/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1141.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1141",
"merged_at": "2020-12-07T10:00:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1141.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1141"
} | true | [
"The `RemoteDatasetTest` is fixed on master so it's fine",
"thanks for rebasing :)\r\n\r\nCI is green now, merging"
] |
https://api.github.com/repos/huggingface/datasets/issues/662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/662/comments | https://api.github.com/repos/huggingface/datasets/issues/662/events | https://github.com/huggingface/datasets/pull/662 | 706,689,866 | MDExOlB1bGxSZXF1ZXN0NDkxMTkyNTM3 | 662 | Created dataset card snli.md | [
{
"color": "72f99f",
"default": false,
"description": "Discussions on the datasets",
"id": 2067401494,
"name": "Dataset discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAxNDk0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Dataset%20discussion"
}
] | closed | false | null | 1 | 2020-09-22T21:00:17Z | 2020-09-22T21:26:21Z | 2020-09-22T21:26:21Z | null | First draft of a dataset card using the SNLI corpus as an example | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/662/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/662.diff",
"html_url": "https://github.com/huggingface/datasets/pull/662",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/662.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/662"
} | true | [
"Resubmitting on a new fork"
] |
https://api.github.com/repos/huggingface/datasets/issues/2338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2338/comments | https://api.github.com/repos/huggingface/datasets/issues/2338/events | https://github.com/huggingface/datasets/pull/2338 | 882,046,077 | MDExOlB1bGxSZXF1ZXN0NjM1NjA3NzQx | 2,338 | fixed download link for web_science | [] | closed | false | null | 0 | 2021-05-09T09:12:20Z | 2021-05-10T13:35:53Z | 2021-05-10T13:35:53Z | null | Fixes #2337. Should work with:
`dataset = load_dataset("web_of_science", "WOS11967", ignore_verifications=True)` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2338/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2338.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2338",
"merged_at": "2021-05-10T13:35:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2338.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2338"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3600/comments | https://api.github.com/repos/huggingface/datasets/issues/3600/events | https://github.com/huggingface/datasets/pull/3600 | 1,108,131,878 | PR_kwDODunzps4xQ-vt | 3,600 | Use old url for conll2003 | [] | closed | false | null | 0 | 2022-01-19T13:56:49Z | 2022-01-19T14:16:28Z | 2022-01-19T14:16:28Z | null | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3600/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"merged_at": "2022-01-19T14:16:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3600"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5748/comments | https://api.github.com/repos/huggingface/datasets/issues/5748/events | https://github.com/huggingface/datasets/pull/5748 | 1,667,517,024 | PR_kwDODunzps5OSgNH | 5,748 | [BUG FIX] Issue 5739 | [] | open | false | null | 0 | 2023-04-14T05:07:31Z | 2023-04-14T05:07:31Z | null | null | A fix for https://github.com/huggingface/datasets/issues/5739 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5748/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5748/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5748",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5748"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4424/comments | https://api.github.com/repos/huggingface/datasets/issues/4424/events | https://github.com/huggingface/datasets/pull/4424 | 1,253,542,488 | PR_kwDODunzps44uZBD | 4,424 | Fix DuplicatedKeysError in timit_asr dataset | [] | closed | false | null | 1 | 2022-05-31T08:47:45Z | 2022-05-31T13:50:50Z | 2022-05-31T13:42:31Z | null | Fix #4422. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4424/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4424/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4424.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4424",
"merged_at": "2022-05-31T13:42:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4424.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4424"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2035 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2035/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2035/comments | https://api.github.com/repos/huggingface/datasets/issues/2035/events | https://github.com/huggingface/datasets/issues/2035 | 829,475,544 | MDU6SXNzdWU4Mjk0NzU1NDQ= | 2,035 | wiki40b/wikipedia for almost all languages cannot be downloaded | [] | open | false | null | 10 | 2021-03-11T19:54:54Z | 2021-03-16T14:53:37Z | null | null | Hi
I am trying to download the data as below:
```
from datasets import load_dataset
dataset = load_dataset("wiki40b", "cs")
print(dataset)
```
I am getting this error. @lhoestq I will be grateful if you could assist me with this error. For almost all languages except english I am getting this error.
I really need majority of languages in this dataset to be able to train my models for a deadline and your great scalable super well-written library is my only hope to train the models at scale while being low on resources.
thank you very much.
```
(fast) dara@vgne046:/user/dara/dev/codes/seq2seq$ python test_data.py
Downloading and preparing dataset wiki40b/cs (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to temp/dara/cache_home_2/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f...
Traceback (most recent call last):
File "test_data.py", line 3, in <module>
dataset = load_dataset("wiki40b", "cs")
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/load.py", line 746, in load_dataset
use_auth_token=use_auth_token,
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/builder.py", line 579, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/datasets/builder.py", line 1105, in _download_and_prepare
import apache_beam as beam
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/apache_beam-2.28.0-py3.7-linux-x86_64.egg/apache_beam/__init__.py", line 96, in <module>
from apache_beam import io
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/apache_beam-2.28.0-py3.7-linux-x86_64.egg/apache_beam/io/__init__.py", line 23, in <module>
from apache_beam.io.avroio import *
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/apache_beam-2.28.0-py3.7-linux-x86_64.egg/apache_beam/io/avroio.py", line 55, in <module>
import avro
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 668, in _load_unlocked
File "<frozen importlib._bootstrap>", line 638, in _load_backward_compatible
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/avro_python3-1.9.2.1-py3.7.egg/avro/__init__.py", line 34, in <module>
File "/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/avro_python3-1.9.2.1-py3.7.egg/avro/__init__.py", line 30, in LoadResource
NotADirectoryError: [Errno 20] Not a directory: '/user/dara/libs/anaconda3/envs/fast/lib/python3.7/site-packages/avro_python3-1.9.2.1-py3.7.egg/avro/VERSION.txt'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2035/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2035/timeline | null | null | null | null | false | [
"Dear @lhoestq for wikipedia dataset I also get the same error, I greatly appreciate if you could have a look into this dataset as well. Below please find the command to reproduce the error:\r\n\r\n```\r\ndataset = load_dataset(\"wikipedia\", \"20200501.bg\")\r\nprint(dataset)\r\n```\r\n\r\nYour library is my only chance to be able training the models at scale and I am grateful for your help.\r\n\r\n",
"Hi @dorost1234,\r\nTry installing this library first, `pip install 'apache-beam[gcp]' --use-feature=2020-resolver` followed by loading dataset like this using beam runner.\r\n\r\n`dataset = load_dataset(\"wiki40b\", \"cs\", beam_runner='DirectRunner')`\r\n\r\n I also read in error stack trace that:\r\n\r\n> Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc.\r\n\r\nWorked perfectly fine after this (Ignore these warnings)\r\n\r\n\r\n\r\n",
"For wikipedia dataset, looks like the files it's looking for are no longer available. For `bg`, I checked [here](https://dumps.wikimedia.org/bgwiki/). For this I think `dataset_infos.json` for this dataset has to made again? You'll have to load this dataset also using beam runner.\r\n\r\n",
"Hello @dorost1234,\r\n\r\nIndeed, Wikipedia datasets need a lot of preprocessing and this is done using Apache Beam. That is the reason why it is required that you install Apache Beam in order to preform this preprocessing.\r\n\r\nFor some specific default parameters (English Wikipedia), Hugging Face has already preprocessed the dataset for you (and it is stored in the cloud). That is the reason why you do not get the error for English: the preprocessing is already done by HF and you just get the preprocessed dataset; Apache Beam is not required in that case.",
"Hi\nI really appreciate if huggingface can kindly provide preprocessed\ndatasets, processing these datasets require sufficiently large resources\nand I do not have unfortunately access to, and perhaps many others too.\nthanks\n\nOn Fri, Mar 12, 2021 at 9:04 AM Albert Villanova del Moral <\n***@***.***> wrote:\n\n> Hello @dorost1234 <https://github.com/dorost1234>,\n>\n> Indeed, Wikipedia datasets need a lot of preprocessing and this is done\n> using Apache Beam. That is the reason why it is required that you install\n> Apache Beam in order to preform this preprocessing.\n>\n> For some specific default parameters (English Wikipedia), Hugging Face has\n> already preprocessed the dataset for you (and it is stored in the cloud).\n> That is the reason why you do not get the error for English: the\n> preprocessing is already done by HF and you just get the preprocessed\n> dataset; Apache Beam is not required in that case.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/2035#issuecomment-797310899>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AS37NMXACFQZAGMK4VGXRETTDHDI3ANCNFSM4ZA5R2UA>\n> .\n>\n",
"Hi everyone\r\nthanks for the helpful pointers, I did it as @bhavitvyamalik suggested, for me this freezes on this command for several hours, \r\n\r\n`Downloading and preparing dataset wiki40b/cs (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /users/dara/cache/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f...\r\n`\r\n\r\nDo you know how long this takes? Any specific requirements the machine should have? like very large memory or so? @lhoestq \r\n\r\nthanks \r\n\r\n\r\n",
"HI @dorost1234, \r\nThe dataset size is 631.84 MiB so depending on your internet speed it'll take some time. You can monitor your internet speed meanwhile to see if it's downloading the dataset or not (use `nload` if you're using linux/mac to monitor the same). In my case it took around 3-4 mins. Since they haven't used `download_and_extract` here that's why there's no download progress bar.",
"Hi\r\nthanks, my internet speed should be good, but this really freezes for me, this is how I try to get this dataset:\r\n\r\n`from datasets import load_dataset\r\ndataset = load_dataset(\"wiki40b\", \"cs\", beam_runner='DirectRunner')`\r\n\r\nthe output I see if different also from what you see after writing this command:\r\n\r\n`Downloading and preparing dataset wiki40b/cs (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /users/dara/cache/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f...`\r\n\r\ndo you have any idea why it might get freezed? anything I am missing @lhoestq @bhavitvyamalik. Do I need maybe to set anything special for apache-beam? \r\n\r\nthanks a lot \r\n\r\nOn Tue, Mar 16, 2021 at 9:03 AM Bhavitvya Malik ***@***.***>\r\nwrote:\r\n\r\n> HI @dorost1234 <https://github.com/dorost1234>,\r\n> The dataset size is 631.84 MiB so depending on your internet speed it'll\r\n> take some time. You can monitor your internet speed meanwhile to see if\r\n> it's downloading the dataset or not (use nload if you're using linux/mac\r\n> to monitor the same). In my case it took around 3-4 mins. Since they\r\n> haven't used download_and_extract here that's why there's no download\r\n> progress bar.\r\n>\r\n> —\r\n> You are receiving this because you were mentioned.\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/2035#issuecomment-800044303>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AS37NMQIHNNLM2LGG6QKZ73TD4GDJANCNFSM4ZA5R2UA>\r\n> .\r\n>\r\n",
"I tried this on another machine (followed the same procedure I've mentioned above). This is what it shows (during the freeze period) for me:\r\n```\r\n>>> dataset = load_dataset(\"wiki40b\", \"cs\", beam_runner='DirectRunner')\r\nDownloading: 5.26kB [00:00, 1.23MB/s] \r\nDownloading: 1.40kB [00:00, 327kB/s] \r\nDownloading and preparing dataset wiki40b/cs (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/bhavitvya/.cache/huggingface/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f...\r\nWARNING:apache_beam.internal.gcp.auth:Unable to find default credentials to use: The Application Default Credentials are not available. They are available if running in Google Compute Engine. Otherwise, the environment variable GOOGLE_APPLICATION_CREDENTIALS must be defined pointing to a file defining the credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.\r\nConnecting anonymously.\r\nWARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be.\r\n```\r\nAfter around 10 minutes, here's the loading of dataset:\r\n```\r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:16<00:00, 16.42s/sources]\r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.12sources/s]\r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.14sources/s]\r\nDataset wiki40b downloaded and prepared to /home/bhavitvya/.cache/huggingface/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f. Subsequent calls will reuse this data.\r\n```",
"Hi\r\nI honestly also now tried on another machine and nothing shows up after\r\nhours of waiting. Are you sure you have not set any specific setting? maybe\r\ngoogle cloud which seems it is used here, needs some credential setting?\r\nthanks for any suggestions on this\r\n\r\nOn Tue, Mar 16, 2021 at 10:02 AM Bhavitvya Malik ***@***.***>\r\nwrote:\r\n\r\n> I tried this on another machine (followed the same procedure I've\r\n> mentioned above). This is what it shows (during the freeze period) for me:\r\n>\r\n> >>> dataset = load_dataset(\"wiki40b\", \"cs\", beam_runner='DirectRunner')\r\n> Downloading: 5.26kB [00:00, 1.23MB/s]\r\n> Downloading: 1.40kB [00:00, 327kB/s]\r\n> Downloading and preparing dataset wiki40b/cs (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/bhavitvya/.cache/huggingface/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f...\r\n> WARNING:apache_beam.internal.gcp.auth:Unable to find default credentials to use: The Application Default Credentials are not available. They are available if running in Google Compute Engine. Otherwise, the environment variable GOOGLE_APPLICATION_CREDENTIALS must be defined pointing to a file defining the credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information.\r\n> Connecting anonymously.\r\n> WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be.\r\n>\r\n> After around 10 minutes, here's the loading of dataset:\r\n>\r\n> 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:16<00:00, 16.42s/sources]\r\n> 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.12sources/s]\r\n> 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.14sources/s]\r\n> Dataset wiki40b downloaded and prepared to /home/bhavitvya/.cache/huggingface/datasets/wiki40b/cs/1.1.0/063778187363ffb294896eaa010fc254b42b73e31117c71573a953b0b0bf010f. Subsequent calls will reuse this data.\r\n>\r\n> —\r\n> You are receiving this because you were mentioned.\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/2035#issuecomment-800081772>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AS37NMX6A2ZTRZUIIZVFRCDTD4NC3ANCNFSM4ZA5R2UA>\r\n> .\r\n>\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4695/comments | https://api.github.com/repos/huggingface/datasets/issues/4695/events | https://github.com/huggingface/datasets/pull/4695 | 1,307,134,701 | PR_kwDODunzps47hobQ | 4,695 | Add MANtIS dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 2 | 2022-07-17T15:53:05Z | 2022-09-30T14:39:30Z | 2022-09-30T14:37:16Z | null | This PR adds MANtIS dataset.
Arxiv: [https://arxiv.org/abs/1912.04639](https://arxiv.org/abs/1912.04639)
Github: [https://github.com/Guzpenha/MANtIS](https://github.com/Guzpenha/MANtIS)
README and dataset tags are WIP. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4695/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/4695.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4695",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4695.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4695"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your contribution, @bhavitvyamalik. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest that you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/5300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5300/comments | https://api.github.com/repos/huggingface/datasets/issues/5300/events | https://github.com/huggingface/datasets/pull/5300 | 1,464,697,136 | PR_kwDODunzps5Dt3uK | 5,300 | Use same `num_proc` for dataset download and generation | [] | closed | false | null | 2 | 2022-11-25T15:37:42Z | 2022-12-07T12:55:39Z | 2022-12-07T12:52:51Z | null | Use the same `num_proc` value for data download and generation. Additionally, do not set `num_proc` to 16 in `DownloadManager` by default (`num_proc` now has to be specified explicitly). | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5300/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5300",
"merged_at": "2022-12-07T12:52:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5300"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I noticed this bug the other day and was going to look into it! \"Where are these processes coming from?\" ;-)"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.