
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5335 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5335/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5335/comments | https://api.github.com/repos/huggingface/datasets/issues/5335/events | https://github.com/huggingface/datasets/pull/5335 | 1,478,890,788 | PR_kwDODunzps5EeHdA | 5,335 | Update tasks.json | [] | closed | false | null | 11 | 2022-12-06T11:37:57Z | 2022-12-08T11:05:33Z | 2022-12-07T12:46:03Z | null | Context:
* https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195
Cc: @osanseviero | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5335/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5335/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5335.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5335",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5335.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5335"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think the only place where we need to add it is here https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts\r\n\r\nAnd I think we can remove tasks.json completely from this repo",
"Isn't tasks.json used anymore in this repo?",
"> I think the only place where we need to add it is here https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts\r\n> \r\n> And I think we can remove tasks.json completely from this repo\r\n\r\nWhat about the warning I mentioned in https://github.com/huggingface/datasets/issues/5255#issuecomment-1339013527? Also, the depth estimation entry is already present in https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts. ",
"The update is based on what I received in the output of the export job (c.f. https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195). \r\n\r\nEdit: Oh, are you referring to the dataset card of NYU Depth V2?",
"Yes, my suggestion was for the dataset card: you got the error message because you tried to set `depth-estimation` in `class_ids` instead of `class_categories`.",
"> What about the warning I mentioned in https://github.com/huggingface/datasets/issues/5255#issuecomment-1339013527? Also, the depth estimation entry is already present in https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts.\r\n\r\nif you place it in `task_categories` you should be good :)",
"yes i would suggest rm'ing tasks.json here for clarity",
"Closing it. ",
"It's not clear if we can remove it btw, since old versions of `evaluate` rely on it (see https://github.com/huggingface/evaluate/pull/309)\r\n\r\ncc @lvwerra ",
"Actually it can be removed without incidence in old versions of evaluate since we kept an hardcoded `known_task_ids` that is marked \"DEPRECATED\""
] |
https://api.github.com/repos/huggingface/datasets/issues/2889 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2889/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2889/comments | https://api.github.com/repos/huggingface/datasets/issues/2889/events | https://github.com/huggingface/datasets/issues/2889 | 992,968,382 | MDU6SXNzdWU5OTI5NjgzODI= | 2,889 | Coc | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 0 | 2021-09-10T07:32:07Z | 2021-09-10T11:45:54Z | 2021-09-10T11:45:54Z | null | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2889/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2889/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5511 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5511/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5511/comments | https://api.github.com/repos/huggingface/datasets/issues/5511/events | https://github.com/huggingface/datasets/issues/5511 | 1,575,851,768 | I_kwDODunzps5d7Zb4 | 5,511 | Creating a dummy dataset from a bigger one | [] | closed | false | null | 6 | 2023-02-08T10:18:41Z | 2023-05-19T12:58:00Z | 2023-02-08T10:35:48Z | null | ### Describe the bug
I often want to create a dummy dataset from a bigger dataset for fast iteration when training. However, I'm having a hard time doing this especially when trying to upload the dataset to the Hub.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("lambdalabs/pokemon-blip-captions")
dataset["train"] = dataset["train"].select(range(20))
dataset.push_to_hub("patrickvonplaten/dummy_image_data")
```
gives:
```
~/python_bin/datasets/arrow_dataset.py in _push_parquet_shards_to_hub(self, repo_id, split, private, token, branch, max_shard_size, embed_external_files)
4003 base_wait_time=2.0,
4004 max_retries=5,
-> 4005 max_wait_time=20.0,
4006 )
4007 return repo_id, split, uploaded_size, dataset_nbytes
~/python_bin/datasets/utils/file_utils.py in _retry(func, func_args, func_kwargs, exceptions, status_codes, max_retries, base_wait_time, max_wait_time)
328 while True:
329 try:
--> 330 return func(*func_args, **func_kwargs)
331 except exceptions as err:
332 if retry >= max_retries or (status_codes and err.response.status_code not in status_codes):
~/hf/lib/python3.7/site-packages/huggingface_hub/utils/_validators.py in _inner_fn(*args, **kwargs)
122 )
123
--> 124 return fn(*args, **kwargs)
125
126 return _inner_fn # type: ignore
TypeError: upload_file() got an unexpected keyword argument 'identical_ok'
In [2]:
```
### Expected behavior
I would have expected this to work. It's for me the most intuitive way of creating a dummy dataset.
### Environment info
```
- `datasets` version: 2.1.1.dev0
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.3
- PyArrow version: 11.0.0
- Pandas version: 1.3.5
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5511/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5511/timeline | null | completed | null | null | false | [
"Update `datasets` or downgrade `huggingface-hub` ;)\r\n\r\nThe `huggingface-hub` lib did a breaking change a few months ago, and you're using an old version of `datasets` that does't support it",
"Awesome thanks a lot! Everything works just fine with `datasets==2.9.0` :-) ",
"Getting same error with latest versions.\r\n\r\n\r\n```shell\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\nCell In[99], line 1\r\n----> 1 dataset.push_to_hub(\"mirfan899/kids_phoneme_asr\")\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/arrow_dataset.py:3538, in Dataset.push_to_hub(self, repo_id, split, private, token, branch, shard_size, embed_external_files)\r\n 3493 def push_to_hub(\r\n 3494 self,\r\n 3495 repo_id: str,\r\n (...)\r\n 3501 embed_external_files: bool = True,\r\n 3502 ):\r\n 3503 \"\"\"Pushes the dataset to the hub.\r\n 3504 The dataset is pushed using HTTP requests and does not need to have neither git or git-lfs installed.\r\n 3505 \r\n (...)\r\n 3536 ```\r\n 3537 \"\"\"\r\n-> 3538 repo_id, split, uploaded_size, dataset_nbytes = self._push_parquet_shards_to_hub(\r\n 3539 repo_id=repo_id,\r\n 3540 split=split,\r\n 3541 private=private,\r\n 3542 token=token,\r\n 3543 branch=branch,\r\n 3544 shard_size=shard_size,\r\n 3545 embed_external_files=embed_external_files,\r\n 3546 )\r\n 3547 organization, dataset_name = repo_id.split(\"/\")\r\n 3548 info_to_dump = self.info.copy()\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/arrow_dataset.py:3474, in Dataset._push_parquet_shards_to_hub(self, repo_id, split, private, token, branch, shard_size, embed_external_files)\r\n 3472 shard.to_parquet(buffer)\r\n 3473 uploaded_size += buffer.tell()\r\n-> 3474 _retry(\r\n 3475 api.upload_file,\r\n 3476 func_kwargs=dict(\r\n 3477 path_or_fileobj=buffer.getvalue(),\r\n 3478 path_in_repo=path_in_repo(index),\r\n 3479 repo_id=repo_id,\r\n 3480 token=token,\r\n 3481 repo_type=\"dataset\",\r\n 3482 revision=branch,\r\n 3483 identical_ok=True,\r\n 3484 ),\r\n 3485 exceptions=HTTPError,\r\n 3486 status_codes=[504],\r\n 3487 base_wait_time=2.0,\r\n 3488 max_retries=5,\r\n 3489 max_wait_time=20.0,\r\n 3490 )\r\n 3491 return repo_id, split, uploaded_size, dataset_nbytes\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/utils/file_utils.py:330, in _retry(func, func_args, func_kwargs, exceptions, status_codes, max_retries, base_wait_time, max_wait_time)\r\n 328 while True:\r\n 329 try:\r\n--> 330 return func(*func_args, **func_kwargs)\r\n 331 except exceptions as err:\r\n 332 if retry >= max_retries or (status_codes and err.response.status_code not in status_codes):\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py:120, in validate_hf_hub_args.<locals>._inner_fn(*args, **kwargs)\r\n 117 if check_use_auth_token:\r\n 118 kwargs = smoothly_deprecate_use_auth_token(fn_name=fn.__name__, has_token=has_token, kwargs=kwargs)\r\n--> 120 return fn(*args, **kwargs)\r\n\r\nTypeError: HfApi.upload_file() got an unexpected keyword argument 'identical_ok'\r\n```",
"Feel free to update `datasets` and `huggingface-hub`, it should fix it :)",
"I went ahead and upgraded both datasets and hub and still getting the same error\r\n",
"Which version do you have ? It's been a while since it has been fixed"
] |
https://api.github.com/repos/huggingface/datasets/issues/3014 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3014/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3014/comments | https://api.github.com/repos/huggingface/datasets/issues/3014/events | https://github.com/huggingface/datasets/pull/3014 | 1,015,070,751 | PR_kwDODunzps4son8A | 3,014 | Fix Windows path in MATH dataset | [] | closed | false | null | 0 | 2021-10-04T11:41:07Z | 2021-10-04T12:46:44Z | 2021-10-04T12:46:44Z | null | Minor fix in MATH dataset for Windows pathname component separator.
Related to #2982. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3014/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3014/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3014.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3014",
"merged_at": "2021-10-04T12:46:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3014.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3014"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1396/comments | https://api.github.com/repos/huggingface/datasets/issues/1396/events | https://github.com/huggingface/datasets/pull/1396 | 760,455,295 | MDExOlB1bGxSZXF1ZXN0NTM1MjgzOTAw | 1,396 | initial commit for MultiReQA for second PR | [] | closed | false | null | 2 | 2020-12-09T16:00:35Z | 2020-12-10T18:20:12Z | 2020-12-10T18:20:11Z | null | Since last PR #1349 had some issues passing the tests. So, a new PR is generated. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1396/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1396.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1396",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1396.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1396"
} | true | [
"Subsequent [PR #1426 ](https://github.com/huggingface/datasets/pull/1426) since this PR has uploaded other files along with the MultiReQA dataset.",
"closing this one since a new PR has been created"
] |
https://api.github.com/repos/huggingface/datasets/issues/2772 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2772/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2772/comments | https://api.github.com/repos/huggingface/datasets/issues/2772/events | https://github.com/huggingface/datasets/issues/2772 | 963,348,834 | MDU6SXNzdWU5NjMzNDg4MzQ= | 2,772 | Remove returned feature constrain | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2021-08-08T04:01:30Z | 2021-08-08T08:48:01Z | null | null | In the current version, the returned value of the map function has to be list or ndarray. However, this makes it unsuitable for many tasks. In NLP, many features are sparse like verb words, noun chunks, if we want to assign different values to different words, which will result in a large sparse matrix if we only score useful words like verb words.
Mostly, when using it on large scale, saving it as a whole takes a lot of disk storage and making it hard to read, the normal method is saving it in sparse form. However, the NumPy does not support sparse, therefore I have to use PyTorch or scipy to transform a matrix into special sparse form, which is not a form that can be transformed into list or ndarry. This violates the feature constraints of the map function.
I do appreciate the convenience of Datasets package, but I do not think the compulsory datatype constrain is necessary, in some cases, we just cannot transform it into a list or ndarray due to some reasons. Any way to fix this? Or what I can do to disable the compulsory datatype constrain?
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2772/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2772/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3812 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3812/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3812/comments | https://api.github.com/repos/huggingface/datasets/issues/3812/events | https://github.com/huggingface/datasets/pull/3812 | 1,158,369,995 | PR_kwDODunzps4z46C4 | 3,812 | benchmark streaming speed with tar vs zip archives | [] | closed | false | null | 1 | 2022-03-03T12:48:41Z | 2022-03-03T14:55:34Z | 2022-03-03T14:55:33Z | null | # do not merge
## Hypothesis
packing data into a single zip archive could allow us not to care about splitting data into several tar archives for efficient streaming which is annoying (since data creators usually host the data in a single tar)
## Data
I host it [here](https://huggingface.co/datasets/polinaeterna/benchmark_dataset/)
## I checked three configurations:
1. All data in one zip archive, streaming only those files that exist in split metadata file (we can access them directrly with no need to iterate over full archive), see [this func](https://github.com/huggingface/datasets/compare/master...polinaeterna:benchmark-tar-zip?expand=1#diff-4f5200d4586aec5b2a89fcf34441c5f92156f9e9d408acc7e50666f9a1921ddcR196)
2. All data in three splits, the standart way to make streaming efficient, see [this func](https://github.com/huggingface/datasets/compare/master...polinaeterna:benchmark-tar-zip?expand=1#diff-4f5200d4586aec5b2a89fcf34441c5f92156f9e9d408acc7e50666f9a1921ddcR174)
3. All data in single tar, iterate over the full archive and take only files existing in split metadata file, see [this func](https://github.com/huggingface/datasets/compare/master...polinaeterna:benchmark-tar-zip?expand=1#diff-4f5200d4586aec5b2a89fcf34441c5f92156f9e9d408acc7e50666f9a1921ddcR150)
## Results
1. one zip

2. three tars

3. one tar

didn't check on the full data as it's time consuming but anyway it's pretty obvious that one-zip-way is not a good idea. here it's even worse than full iteration over tar containing all three splits (but that would depend on the case).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3812/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3812/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3812.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3812",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3812.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3812"
} | true | [
"I'm closing the PR since we're not going to merge it"
] |
https://api.github.com/repos/huggingface/datasets/issues/2378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2378/comments | https://api.github.com/repos/huggingface/datasets/issues/2378/events | https://github.com/huggingface/datasets/issues/2378 | 895,131,774 | MDU6SXNzdWU4OTUxMzE3NzQ= | 2,378 | Add missing dataset_infos.json files | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2021-05-19T08:11:12Z | 2021-05-19T08:11:12Z | null | null | Some of the datasets in `datasets` are missing a `dataset_infos.json` file, e.g.
```
[PosixPath('datasets/chr_en/chr_en.py'), PosixPath('datasets/chr_en/README.md')]
[PosixPath('datasets/telugu_books/README.md'), PosixPath('datasets/telugu_books/telugu_books.py')]
[PosixPath('datasets/reclor/README.md'), PosixPath('datasets/reclor/reclor.py')]
[PosixPath('datasets/json/README.md')]
[PosixPath('datasets/csv/README.md')]
[PosixPath('datasets/wikihow/wikihow.py'), PosixPath('datasets/wikihow/README.md')]
[PosixPath('datasets/c4/c4.py'), PosixPath('datasets/c4/README.md')]
[PosixPath('datasets/text/README.md')]
[PosixPath('datasets/lm1b/README.md'), PosixPath('datasets/lm1b/lm1b.py')]
[PosixPath('datasets/pandas/README.md')]
```
For `json`, `text`, csv`, and `pandas` this is expected, but not for the others which should be fixed
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2378/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1410/comments | https://api.github.com/repos/huggingface/datasets/issues/1410/events | https://github.com/huggingface/datasets/pull/1410 | 760,597,092 | MDExOlB1bGxSZXF1ZXN0NTM1NDAyNjcw | 1,410 | Add penn treebank dataset | [] | closed | false | null | 2 | 2020-12-09T19:11:33Z | 2020-12-16T09:38:23Z | 2020-12-16T09:38:23Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1410/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1410/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1410",
"merged_at": "2020-12-16T09:38:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1410"
} | true | [
"@yjernite I have updated the PR to be language modeling task specific. Please review!\r\n",
"Yes a line corresponds to a sentence in this data."
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3091 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3091/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3091/comments | https://api.github.com/repos/huggingface/datasets/issues/3091/events | https://github.com/huggingface/datasets/issues/3091 | 1,027,251,530 | I_kwDODunzps49Op1K | 3,091 | `blog_authorship_corpus` is broken | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2021-10-15T09:20:40Z | 2021-10-19T13:06:10Z | 2021-10-19T12:50:39Z | null | ## Describe the bug
The dataset `blog_authorship_corpus` is broken.
By bypassing the checksum checks, the loading does not return any error but the resulting dataset is empty.
I suspect it is because the data download url is broken (http://www.cs.biu.ac.il/~koppel/blogs/blogs.zip).
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("blog_authorship_corpus", split="train", download_mode='force_redownload')
```
## Expected results
No error.
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
/tmp/ipykernel_5237/1729238701.py in <module>
2 ds = load_dataset(
3 "blog_authorship_corpus", split="train",
----> 4 download_mode='force_redownload'
5 )
/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
1115 ignore_verifications=ignore_verifications,
1116 try_from_hf_gcs=try_from_hf_gcs,
-> 1117 use_auth_token=use_auth_token,
1118 )
1119
/opt/conda/lib/python3.7/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
635 if not downloaded_from_gcs:
636 self._download_and_prepare(
--> 637 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
638 )
639 # Sync info
/opt/conda/lib/python3.7/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
707 if verify_infos:
708 verify_checksums(
--> 709 self.info.download_checksums, dl_manager.get_recorded_sizes_checksums(), "dataset source files"
710 )
711
/opt/conda/lib/python3.7/site-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['http://www.cs.biu.ac.il/~koppel/blogs/blogs.zip']
```
## Environment info
- `datasets` version: 1.13.2
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-debian-10.11
- Python version: 3.7.10
- PyArrow version: 5.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3091/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3091/timeline | null | completed | null | null | false | [
"Hi @fdtomasi, thanks for reporting.\r\n\r\nYou are right: the original host data URL does no longer exist.\r\n\r\nI've contacted the authors of the dataset to ask them if they host this dataset in another URL.",
"Hi, @fdtomasi, the URL is fixed.\r\n\r\nThe fix is already in our master branch and it will be accessible in our next release.\r\n\r\nIn the meantime, you can include the fix if you install the `datasets` library from the master branch:\r\n```\r\npip install -U git+ssh://[email protected]/huggingface/datasets.git@master#egg=datasest\r\n```\r\nor\r\n```\r\npip install -U git+https://github.com/huggingface/datasets.git@master#egg=datasets\r\n```",
"Awesome thank you so much for the quick fix!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4418/comments | https://api.github.com/repos/huggingface/datasets/issues/4418/events | https://github.com/huggingface/datasets/pull/4418 | 1,252,506,268 | PR_kwDODunzps44q9pG | 4,418 | Add dataset MMChat | [] | closed | false | null | 0 | 2022-05-30T10:10:40Z | 2022-05-30T14:58:18Z | 2022-05-30T14:58:18Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4418/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4418.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4418",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4418.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4418"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2747/comments | https://api.github.com/repos/huggingface/datasets/issues/2747/events | https://github.com/huggingface/datasets/pull/2747 | 958,867,627 | MDExOlB1bGxSZXF1ZXN0NzAyMDcwOTgy | 2,747 | add multi-proc in `to_json` | [] | closed | false | null | 17 | 2021-08-03T08:30:13Z | 2021-10-19T18:24:21Z | 2021-09-13T13:56:37Z | null | Closes #2663. I've tried adding multiprocessing in `to_json`. Here's some benchmarking I did to compare the timings of current version (say v1) and multi-proc version (say v2). I did this with `cpu_count` 4 (2015 Macbook Air)
1. Dataset name: `ascent_kb` - 8.9M samples (all samples were used, reporting this for a single run)
v1- ~225 seconds for converting whole dataset to json
v2- ~200 seconds for converting whole dataset to json
2. Dataset name: `lama` - 1.3M samples (all samples were used, reporting this for 2 runs)
v1- ~26 seconds for converting whole dataset to json
v2- ~23.6 seconds for converting whole dataset to json
I think it's safe to say that v2 is 10% faster as compared to v1. Timings may improve further with better configuration.
The only bottleneck I feel is writing to file from the output list. If we can improve that aspect then timings may improve further.
Let me know if any changes/improvements can be done in this @stas00, @lhoestq, @albertvillanova. @lhoestq even suggested to extend this work with other export methods as well like `csv` or `parquet`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2747/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2747/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2747.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2747",
"merged_at": "2021-09-13T13:56:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2747.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2747"
} | true | [
"Thank you for working on this, @bhavitvyamalik \r\n\r\n10% is not solving the issue, we want 5-10x faster on a machine that has lots of resources, but limited processing time.\r\n\r\nSo let's benchmark it on an instance with many more cores, I can test with 12 on my dev box and 40 on JZ. \r\n\r\nCould you please share the test I could run with both versions?\r\n\r\nShould we also test the sharded version I shared in https://github.com/huggingface/datasets/issues/2663#issue-946552273 so optionally 3 versions to test.",
"Since I was facing `OSError: [Errno 12] Cannot allocate memory` in CircleCI tests, I've added `num_proc` option instead of always using full `cpu_count`. You can test both v1 and v2 through this branch (some redundancy needs to be removed). \r\n\r\nUpdate: I was able to convert into json which took 50% less time as compared to v1 on `ascent_kb` dataset. Will post the benchmarking script with results here.",
"Here are the benchmarks with the current branch for both v1 and v2 (dataset: `ascent_kb`, 8.9M samples):\r\n| batch_size | time (in sec) | time (in sec) |\r\n|------------|---------------|---------------|\r\n| | num_proc = 1 | num_proc = 4 |\r\n| 10k | 185.56 | 170.11 |\r\n| 50k | 175.79 | 86.84 |\r\n| **100k** | 191.09 | **78.35** |\r\n| 125k | 198.28 | 90.89 |\r\n\r\nIncreasing the batch size on my machine helped in making v2 around 50% faster as compared to v1. Timings may vary depending on the machine. I'm including the benchmarking script as well. CircleCI errors are unrelated (something related to `bertscore`)\r\n```\r\nimport time\r\nfrom datasets import load_dataset\r\nimport pathlib\r\nimport os\r\nfrom pathlib import Path\r\nimport shutil\r\nimport gc\r\n\r\nbatch_sizes = [10_000, 50_000, 100_000, 125_000]\r\nnum_procs = [1, 4] # change this according to your machine\r\n\r\nSAVE_LOC = \"./new_dataset.json\"\r\n\r\nfor batch in batch_sizes:\r\n for num in num_procs:\r\n dataset = load_dataset(\"ascent_kb\")\r\n\r\n local_start = time.time()\r\n ans = dataset['train'].to_json(SAVE_LOC, batch_size=batch, num_proc=num)\r\n local_end = time.time() - local_start\r\n\r\n print(f\"Time taken on {num} num_proc and {batch} batch_size: \", local_end)\r\n\r\n # remove that dataset and its contents from cache and newly generated json\r\n new_json = pathlib.Path(SAVE_LOC)\r\n new_json.unlink()\r\n\r\n try:\r\n shutil.rmtree(os.path.join(str(Path.home()), \".cache\", \"huggingface\"))\r\n except OSError as e:\r\n print(\"Error: %s - %s.\" % (e.filename, e.strerror))\r\n\r\n gc.collect()\r\n```\r\nThis will download the dataset in every iteration and run `to_json`. I didn't do multiple iterations here for `to_json` (for a specific batch_size and num_proc) and took average time as I found that v1 got faster after 1st iteration (maybe it's caching somewhere). Since you'll be doing this operation only once, I thought it'll be better to report how both v1 and v2 performed in single iteration only. \r\n\r\nImportant: Benchmarking script will delete the newly generated json and `~/.cache/huggingface/` after every iteration so that it doesn't end up using any cached data (just to be on a safe side)",
"Thank you for sharing the benchmark, @bhavitvyamalik. Your results look promising.\r\n\r\nBut if I remember correctly the sharded version at https://github.com/huggingface/datasets/issues/2663#issue-946552273 was much faster. So we probably should compare to it as well? And if it's faster than at least document that manual sharding version?\r\n\r\n-------\r\n\r\nThat's a dangerous benchmark as it'd wipe out many other HF things. Why not wipe out:\r\n```\r\n~/.cache/huggingface/datasets/ascent_kb/\r\n```\r\n\r\nRunning the benchmark now.",
"Weird, I tried to adapt your benchmark to using shards and the program no longer works. It instead quickly uses up all available RAM and hangs. Has something changed recently in `datasets`? You can try:\r\n\r\n```\r\nimport time\r\nfrom datasets import load_dataset\r\nimport pathlib\r\nimport os\r\nfrom pathlib import Path\r\nimport shutil\r\nimport gc\r\nfrom multiprocessing import cpu_count, Process, Queue\r\n\r\nbatch_sizes = [10_000, 50_000, 100_000, 125_000]\r\nnum_procs = [1, 8] # change this according to your machine\r\n\r\nDATASET_NAME = (\"ascent_kb\")\r\nnum_shards = [1, 8]\r\nfor batch in batch_sizes:\r\n for shards in num_shards:\r\n dataset = load_dataset(DATASET_NAME)[\"train\"]\r\n #print(dataset)\r\n\r\n def process_shard(idx):\r\n print(f\"Sharding {idx}\")\r\n ds_shard = dataset.shard(shards, idx, contiguous=True)\r\n # ds_shard = ds_shard.shuffle() # remove contiguous=True above if shuffling\r\n print(f\"Saving {DATASET_NAME}-{idx}.jsonl\")\r\n ds_shard.to_json(f\"{DATASET_NAME}-{idx}.jsonl\", orient=\"records\", lines=True, force_ascii=False)\r\n\r\n local_start = time.time()\r\n queue = Queue()\r\n processes = [Process(target=process_shard, args=(idx,)) for idx in range(shards)]\r\n for p in processes:\r\n p.start()\r\n\r\n for p in processes:\r\n p.join()\r\n local_end = time.time() - local_start\r\n\r\n print(f\"Time taken on {shards} shards and {batch} batch_size: \", local_end)\r\n```\r\n\r\nJust careful, so that it won't crash your compute environment. As it almost crashed mine.",
"So this part seems to no longer work:\r\n```\r\n dataset = load_dataset(\"ascent_kb\")[\"train\"]\r\n ds_shard = dataset.shard(1, 0, contiguous=True)\r\n ds_shard.to_json(\"ascent_kb-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)\r\n```",
"If you are using `to_json` without any `num_proc`or `num_proc=1` then essentially it'll fall back to v1 only and I've kept it as it is (the tests were passing as well)\r\n\r\n> That's a dangerous benchmark as it'd wipe out many other HF things. Why not wipe out:\r\n\r\nThat's because some dataset related files were still left inside `~/.cache/huggingface/datasets` folder. You can wipe off datasets folder inside your cache maybe\r\n\r\n> dataset = load_dataset(\"ascent_kb\")[\"train\"]\r\n> ds_shard = dataset.shard(1, 0, contiguous=True)\r\n> ds_shard.to_json(\"ascent_kb-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)\r\n\r\nI tried this `lama` dataset (1.3M) and it worked fine. Trying it with `ascent_kb` currently, will update it here.",
"I don't think the issue has anything to do with your work, @bhavitvyamalik. I forgot to mention I tested to see the same problem with the latest datasets release.\r\n\r\nInteresting, I tried your suggestion. This:\r\n```\r\npython -c 'import datasets; ds=\"lama\"; dataset = datasets.load_dataset(ds)[\"train\"]; \\\r\ndataset.shard(1, 0, contiguous=True).to_json(f\"{ds}-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)'\r\n```\r\nworks fine and takes just a few GBs to complete.\r\n\r\nthis on the other hand blows up memory-wise:\r\n```\r\npython -c 'import datasets; ds=\"ascent_kb\"; dataset = datasets.load_dataset(ds)[\"train\"]; \\\r\ndataset.shard(1, 0, contiguous=True).to_json(f\"{ds}-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)'\r\n```\r\nand I have to kill it before it uses up all RAM. (I have 128GB of it, so it should be more than enough)",
"> That's because some dataset related files were still left inside ~/.cache/huggingface/datasets folder. You can wipe off datasets folder inside your cache maybe\r\n\r\nI think recent datasets added a method that will print out the path for all the different components for a given dataset, I can't recall the name though. It was when we were discussing a janitor program to clear up space selectively.",
"> and I have to kill it before it uses up all RAM. (I have 128GB of it, so it should be more than enough)\r\n\r\nSame thing just happened on my machine too. Memory leak somewhere maybe? Even if you were to load this dataset in your memory it shouldn't take more than 4GB. You were earlier doing this for `oscar` dataset. Is it working fine for that?",
"Hmm, looks like `datasets` has changed and won't accept my currently cached oscar-en (crashes), so I'd rather not download 0.5TB again. \r\n\r\nWere you able to reproduce the memory blow up with `ascent_kb`? It's should be a much quicker task to verify.\r\n\r\nBut yes, oscar worked just fine with `.shard()` which is what I used to process it fast.",
"What I tried is:\r\n```\r\nHF_DATASETS_OFFLINE=1 HF_DATASETS_CACHE=cache python -c 'import datasets; ds=\"oscar\"; \\\r\ndataset = datasets.load_dataset(ds, \"unshuffled_deduplicated_en\")[\"train\"]; \\\r\ndataset.shard(1000000, 0, contiguous=True).to_json(f\"{ds}-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)'\r\n```\r\nand got:\r\n```\r\nUsing the latest cached version of the module from /gpfswork/rech/six/commun/modules/datasets_modules/datasets/oscar/e4f06cecc7ae02f7adf85640b4019bf476d44453f251a1d84aebae28b0f8d51d (last modified on Fri Aug 6 01:52:35 2021) since it couldn't be found locally at oscar/oscar.py or remotely (OfflineModeIsEnabled).\r\nReusing dataset oscar (cache/oscar/unshuffled_deduplicated_en/1.0.0/e4f06cecc7ae02f7adf85640b4019bf476d44453f251a1d84aebae28b0f8d51d)\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/load.py\", line 755, in load_dataset\r\n ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/builder.py\", line 737, in as_dataset\r\n datasets = utils.map_nested(\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 203, in map_nested\r\n mapped = [\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 204, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 142, in _single_map_nested\r\n return function(data_struct)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/builder.py\", line 764, in _build_single_dataset\r\n ds = self._as_dataset(\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/builder.py\", line 834, in _as_dataset\r\n dataset_kwargs = ArrowReader(self._cache_dir, self.info).read(\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 217, in read\r\n return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 238, in read_files\r\n pa_table = self._read_files(files, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 173, in _read_files\r\n pa_table: Table = self._get_table_from_filename(f_dict, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 308, in _get_table_from_filename\r\n table = ArrowReader.read_table(filename, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 327, in read_table\r\n return table_cls.from_file(filename)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/table.py\", line 450, in from_file\r\n table = _memory_mapped_arrow_table_from_file(filename)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/table.py\", line 43, in _memory_mapped_arrow_table_from_file\r\n memory_mapped_stream = pa.memory_map(filename)\r\n File \"pyarrow/io.pxi\", line 782, in pyarrow.lib.memory_map\r\n File \"pyarrow/io.pxi\", line 743, in pyarrow.lib.MemoryMappedFile._open\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 99, in pyarrow.lib.check_status\r\nOSError: Memory mapping file failed: Cannot allocate memory\r\n```",
"> Were you able to reproduce the memory blow up with ascent_kb? It's should be a much quicker task to verify.\r\n\r\nYes, this blows up memory-wise on my machine too. \r\n\r\nI found that a [similar error](https://discuss.huggingface.co/t/saving-memory-with-run-mlm-py-with-wikipedia-datasets/4160) was posted on the forum on 5th March. Since you already knew how much time [#2663 comment](https://github.com/huggingface/datasets/issues/2663#issue-946552273) took, can you try benchmarking v1 and v2 for now maybe until we have a fix for this memory blow up?",
"OK, so I benchmarked using \"lama\" though it's too small for this kind of test, since the sharding is much slower than one thread here.\r\n\r\nResults: https://gist.github.com/stas00/dc1597a1e245c5915cfeefa0eee6902c\r\n\r\nSo sharding does really bad there, and your json over procs is doing great!\r\n\r\nAny suggestions to a somewhat bigger dataset, but not too big? say 10 times of lama?",
"Looks great! I had a few questions/suggestions related to `benchmark-datasets-to_json.py`:\r\n \r\n1. You have used only 10_000 and 100_000 batch size. Including more batch sizes may help you find the perfect batch size for your machine and even give you some extra speed-up. \r\nFor eg, I found `load_dataset(\"cc100\", lang=\"eu\")` with batch size 125_000 took less time as compared to batch size 100_000 (71.16 sec v/s 67.26 sec) since this dataset has 2 fields only `['id', 'text']`, so that's why we can go for higher batch size here. \r\n \r\n2. Why have you used `num_procs` 1 and 4 only? \r\n\r\nYou can use:\r\n1. `dataset = load_dataset(\"cc100\", lang=\"af\")`. Even though it has only 2 fields but there are around 9.9 mil samples. (lama had around 1.3 mil samples)\r\n2. `dataset = load_dataset(\"cc100\", lang=\"eu\")` -> 16 mil samples. (if you want something more than 9.9 mil)\r\n3. `dataset = load_dataset(\"neural_code_search\", 'search_corpus')` -> 4.7 mil samples",
"Thank you, @bhavitvyamalik \r\n\r\nMy apologies, at the moment I have not found time to do more benchmark with the proposed other datasets. I will try to do it later, but I don't want it to hold your PR, it's definitely a great improvement based on the benchmarks I did run! And the comparison to sharded is really just of interest to me to see if it's on par or slower.\r\n\r\nSo if other reviewers are happy, this definitely looks like a great improvement to me and addresses the request I made in the first place.\r\n\r\n> Why have you used num_procs 1 and 4 only?\r\n\r\nOh, no particular reason, I was just comparing to 4 shards on my desktop. Typically it's sufficient to go from 1 to 2-4 to see whether the distributed approach is faster or not. Once hit larger numbers you often run into bottlenecks like IO, and then numbers can be less representative. I hope it makes sense.",
"Tested it with a larger dataset (`srwac`) and memory utilisation remained constant with no swap memory used. @lhoestq should I also add test for the same? Last time I tried this, I got `OSError: [Errno 12] Cannot allocate memory` in CircleCI tests"
] |
https://api.github.com/repos/huggingface/datasets/issues/54 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/54/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/54/comments | https://api.github.com/repos/huggingface/datasets/issues/54/events | https://github.com/huggingface/datasets/pull/54 | 613,513,348 | MDExOlB1bGxSZXF1ZXN0NDE0MjUyODkw | 54 | [Tests] Improved Error message for dummy folder structure | [] | closed | false | null | 0 | 2020-05-06T18:11:48Z | 2020-05-06T18:13:00Z | 2020-05-06T18:12:59Z | null | Improved Error message | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/54/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/54/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/54.diff",
"html_url": "https://github.com/huggingface/datasets/pull/54",
"merged_at": "2020-05-06T18:12:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/54.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/54"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4011 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4011/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4011/comments | https://api.github.com/repos/huggingface/datasets/issues/4011/events | https://github.com/huggingface/datasets/pull/4011 | 1,179,885,965 | PR_kwDODunzps40-Ho0 | 4,011 | Fix SQuAD v2 metric docs on `references` format | [
{
"color": "E3165C",
"default": false,
"description": "",
"id": 4190228726,
"name": "transfer-to-evaluate",
"node_id": "LA_kwDODunzps75wdD2",
"url": "https://api.github.com/repos/huggingface/datasets/labels/transfer-to-evaluate"
}
] | closed | false | null | 2 | 2022-03-24T18:27:10Z | 2023-07-11T09:35:46Z | 2023-07-11T09:35:15Z | null | `references` it's not a list of dictionaries but a dictionary that has a list in its values. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4011/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4011/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4011.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4011",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4011.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4011"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Metrics are deprecated in `datasets` and `evaluate` should be used instead: https://github.com/huggingface/evaluate"
] |
https://api.github.com/repos/huggingface/datasets/issues/2816 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2816/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2816/comments | https://api.github.com/repos/huggingface/datasets/issues/2816/events | https://github.com/huggingface/datasets/issues/2816 | 974,031,404 | MDU6SXNzdWU5NzQwMzE0MDQ= | 2,816 | Add Mostly Basic Python Problems Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 1 | 2021-08-18T20:28:39Z | 2021-09-10T08:04:20Z | null | null | ## Adding a Dataset
- **Name:** Mostly Basic Python Problems Dataset
- **Description:** The benchmark consists of around 1,000 crowd-sourced Python programming problems, designed to be solvable by entry level programmers, covering programming fundamentals, standard library functionality, and so on. Each problem consists of a task description, code solution and 3 automated test cases.
- **Paper:** *link to the dataset paper if available*
- **Data:** https://github.com/google-research/google-research/tree/master/mbpp
- **Motivation:** Simple, small dataset related to coding problems.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2816/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2816/timeline | null | null | null | null | false | [
"I started working on that."
] |
https://api.github.com/repos/huggingface/datasets/issues/5941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5941/comments | https://api.github.com/repos/huggingface/datasets/issues/5941/events | https://github.com/huggingface/datasets/issues/5941 | 1,751,838,897 | I_kwDODunzps5oavCx | 5,941 | Load Data Sets Too Slow In Train Seq2seq Model | [] | open | false | null | 9 | 2023-06-12T03:58:43Z | 2023-07-26T07:49:35Z | null | null | ### Describe the bug
step 'Generating train split' in load_dataset is too slow:

### Steps to reproduce the bug
Data: own data,16K16B Mono wav
Oficial Script:[ run_speech_recognition_seq2seq.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py)
Add Code:
if data_args.data_path is not None:
print(data_args.data_path)
raw_datasets = load_dataset("audiofolder", data_dir=data_args.data_path, cache_dir=model_args.cache_dir)
raw_datasets = raw_datasets.cast_column("audio", Audio(sampling_rate=16000))
raw_datasets = raw_datasets["train"].train_test_split(test_size=0.005, shuffle=True)
(change cache_dir to other path ,ex:/DATA/cache)
### Expected behavior
load data fast,at least 1000+
`Generating train split: 387875 examples [32:24:45, 1154.83 examples/s]`
### Environment info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-5.4.0-149-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.16
- Huggingface_hub version: 0.13.2
- PyTorch version (GPU?): 1.13.1+cu116 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in> | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5941/timeline | null | null | null | null | false | [
"Hi ! you can speed it up using multiprocessing by passing `num_proc=` to `load_dataset()`",
"already did,but not useful for step Generating train split,it works in step \"Resolving data files\" & \"Downloading data files\" ",
"@mariosasko some advice , thanks!",
"I met the same problem, terrible experience",
"@mariosasko ",
"We need more info about the issue to provide help. \r\n\r\nCan you interrupt the process (with `num_proc=None`) after the `load_dataset` call when the slowdown occurs? So we can know what part of the code is causing it.\r\n\r\nThe `audiofolder` \\ `imagefolder` with metadata is not performant for large datasets. Luckily, we can make them much faster if drop the nested metadata files feature (not that useful). I plan to work on this soon.\r\n\r\nIn the meantime, it's better to use `Dataset.from_generator` (requires replacing the `load_dataset` calls in the transformers script with `Dataset.from_generator`) or write a dataset loading script for large datasets.",
"Can you interrupt the process (with num_proc=None) after the load_dataset call when the slowdown occurs? So we can know what part of the code is causing it.\r\n(I'll try this operation)\r\nThe audiofolder \\ imagefolder with metadata is not performant for large datasets. Luckily, we can make them much faster if drop the nested metadata files feature (not that useful). I plan to work on this soon.\r\n(My data is indeed a bit large, exceeding 10000 hours of audio data. Looking forward to your improvement work very much)\r\n\r\nIn the meantime, it's better to use Dataset.from_generator (requires replacing the load_dataset calls in the transformers script with Dataset.from_generator) or write a dataset loading script for large datasets.\r\n(I want to use Dataset.from_generator instead of load_dataset ,where can i found sample code to load audio&label dataset, I was to do asr task)",
"Can you interrupt the process (with num_proc=None) after the load_dataset call when the slowdown occurs? So we can know what part of the code is causing it.\r\n================================================================================\r\nHere is the log:\r\n[load_dataset.log](https://github.com/huggingface/datasets/files/12169362/load_dataset.log)\r\n(The larger my training data, the slower it loads)\r\n\r\n\r\n",
"In the meantime, it's better to use Dataset.from_generator (requires replacing the load_dataset calls in the transformers script with Dataset.from_generator) or write a dataset loading script for large datasets.\r\n================================================================================\r\nI tried ‘Dataset. from_generator’ implements data loading, but the testing results show no improvement"
] |
https://api.github.com/repos/huggingface/datasets/issues/809 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/809/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/809/comments | https://api.github.com/repos/huggingface/datasets/issues/809/events | https://github.com/huggingface/datasets/issues/809 | 737,832,701 | MDU6SXNzdWU3Mzc4MzI3MDE= | 809 | Add Google Taskmaster dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 2 | 2020-11-06T15:10:41Z | 2021-04-20T13:09:26Z | 2021-04-20T13:09:26Z | null | ## Adding a Dataset
- **Name:** Taskmaster
- **Description:** A large dataset of task-oriented dialogue with annotated goals (55K dialogues covering entertainment and travel reservations)
- **Paper:** https://arxiv.org/abs/1909.05358
- **Data:** https://github.com/google-research-datasets/Taskmaster
- **Motivation:** One of few annotated datasets of this size for goal-oriented dialogue
Instructions to add a new dataset can be found [here](https://huggingface.co/docs/datasets/share_dataset.html).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/809/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/809/timeline | null | completed | null | null | false | [
"Hey @yjernite. Was going to start working on this but found taskmaster 1,2 & 3 in the datasets library already so think this can be closed now?",
"You are absolutely right :) \r\n\r\nClosed by https://github.com/huggingface/datasets/pull/1193 https://github.com/huggingface/datasets/pull/1197 https://github.com/huggingface/datasets/pull/1213"
] |
https://api.github.com/repos/huggingface/datasets/issues/65 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/65/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/65/comments | https://api.github.com/repos/huggingface/datasets/issues/65/events | https://github.com/huggingface/datasets/pull/65 | 614,746,516 | MDExOlB1bGxSZXF1ZXN0NDE1MjM4MDEw | 65 | fix math dataset and xcopa | [] | closed | false | null | 0 | 2020-05-08T13:33:55Z | 2020-05-08T13:35:41Z | 2020-05-08T13:35:40Z | null | - fixes math dataset and xcopa, uploaded both of the to S3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/65/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/65/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/65.diff",
"html_url": "https://github.com/huggingface/datasets/pull/65",
"merged_at": "2020-05-08T13:35:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/65.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/65"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4778/comments | https://api.github.com/repos/huggingface/datasets/issues/4778/events | https://github.com/huggingface/datasets/pull/4778 | 1,324,928,750 | PR_kwDODunzps48dRPh | 4,778 | Update local loading script docs | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 5 | 2022-08-01T20:21:07Z | 2022-08-23T16:32:26Z | 2022-08-23T16:32:22Z | null | This PR clarifies the local loading script section to include how to load a dataset after you've modified the local loading script (closes #4732). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4778/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4778.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4778",
"merged_at": "2022-08-23T16:32:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4778.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4778"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4778). All of your documentation changes will be reflected on that endpoint.",
"I would rather have a section in the docs that explains how to modify the script of an existing dataset (`inspect_dataset` + modification + `load_dataset`) instead of focusing on the GH datasets bundled with the source (only applicable for devs).",
"Good idea! I went with @mariosasko's suggestion to use `inspect_dataset` instead of cloning a dataset repository since it's a good opportunity to show off more of the library's lesser-known functions if that's ok with everyone :)",
"One advantage of cloning the repo is that it fetches potential data files referenced inside a script using relative paths, so if we decide to use `inspect_dataset`, we should at least add a tip to explain this limitation and how to circumvent it.",
"Oh you're right. Calling `load_dataset` on the modified script without having the files that come with it is not ideal. I agree it should be `git clone` instead - and inspect is for inspection only ^^'"
] |
https://api.github.com/repos/huggingface/datasets/issues/4360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4360/comments | https://api.github.com/repos/huggingface/datasets/issues/4360/events | https://github.com/huggingface/datasets/pull/4360 | 1,237,239,096 | PR_kwDODunzps434izs | 4,360 | Fix example in opus_ubuntu, Add license info | [] | closed | false | null | 2 | 2022-05-16T14:22:28Z | 2022-06-01T13:06:07Z | 2022-06-01T12:57:09Z | null | This PR
* fixes a typo in the example for the`opus_ubuntu` dataset where it's mistakenly referred to as `ubuntu`
* adds the declared license info for this corpus' origin
* adds an example instance
* updates the data origin type | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4360/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4360/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4360.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4360",
"merged_at": "2022-06-01T12:57:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4360.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4360"
} | true | [
"CI seems to fail due to languages incorrectly being flagged as invalid, I guess that's related to the currently-broken bcp47 validation (see #4304)",
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5054 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5054/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5054/comments | https://api.github.com/repos/huggingface/datasets/issues/5054/events | https://github.com/huggingface/datasets/pull/5054 | 1,394,152,728 | PR_kwDODunzps5ABnd3 | 5,054 | Fix license/citation information of squadshifts dataset card | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2022-10-03T05:19:13Z | 2022-10-03T09:26:49Z | 2022-10-03T09:24:30Z | null | This PR fixes the license/citation information of squadshifts dataset card, once the dataset owners have responded to our request for information:
- https://github.com/modestyachts/squadshifts-website/issues/1
Additionally, we have updated the mention in their website to our `datasets` library (they were referring old name `nlp`):
- https://github.com/modestyachts/squadshifts-website/pull/2#event-7500953009 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5054/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5054/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5054.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5054",
"merged_at": "2022-10-03T09:24:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5054.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5054"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1880 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1880/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1880/comments | https://api.github.com/repos/huggingface/datasets/issues/1880/events | https://github.com/huggingface/datasets/pull/1880 | 808,563,439 | MDExOlB1bGxSZXF1ZXN0NTczNTgzNjg0 | 1,880 | Update multi_woz_v22 checksums | [] | closed | false | null | 0 | 2021-02-15T14:00:18Z | 2021-02-15T14:18:19Z | 2021-02-15T14:18:18Z | null | As noticed in #1876 the checksums of this dataset are outdated.
I updated them in this PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1880/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1880/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1880.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1880",
"merged_at": "2021-02-15T14:18:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1880.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1880"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3092 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3092/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3092/comments | https://api.github.com/repos/huggingface/datasets/issues/3092/events | https://github.com/huggingface/datasets/pull/3092 | 1,027,260,383 | PR_kwDODunzps4tPj6e | 3,092 | Fix JNLBA dataset | [] | closed | false | null | 2 | 2021-10-15T09:31:14Z | 2022-07-10T14:36:49Z | 2021-10-22T08:23:57Z | null | As mentioned in #3089, I've added more tags and also updated the link for dataset which was earlier using a Google Drive link.
I'm having problem with generating dummy data as `datasets-cli dummy_data ./datasets/jnlpba --auto_generate --match_text_files "*.iob2"` is giving `datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
` error. I'll try to add dummy data manually. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3092/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3092/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3092.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3092",
"merged_at": "2021-10-22T08:23:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3092.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3092"
} | true | [
"Fix #3089.",
"@albertvillanova all tests are passing now. Either you or @lhoestq can review it!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2869 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2869/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2869/comments | https://api.github.com/repos/huggingface/datasets/issues/2869/events | https://github.com/huggingface/datasets/issues/2869 | 987,676,420 | MDU6SXNzdWU5ODc2NzY0MjA= | 2,869 | TypeError: 'NoneType' object is not callable | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 8 | 2021-09-03T11:27:39Z | 2022-03-30T05:30:38Z | 2021-09-08T09:24:55Z | null | ## Describe the bug
TypeError: 'NoneType' object is not callable
## Steps to reproduce the bug
```python
from datasets import load_dataset, load_metric
dataset = datasets.load_dataset("glue", 'cola')
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform:
- Python version: 3.7
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2869/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2869/timeline | null | completed | null | null | false | [
"Hi, @Chenfei-Kang.\r\n\r\nI'm sorry, but I'm not able to reproduce your bug:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"glue\", 'cola')\r\nds\r\n```\r\n```\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 8551\r\n })\r\n validation: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 1043\r\n })\r\n test: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 1063\r\n })\r\n})\r\n```\r\n\r\nCould you please give more details and environment info (platform, PyArrow version)?",
"> Hi, @Chenfei-Kang.\r\n> \r\n> I'm sorry, but I'm not able to reproduce your bug:\r\n> \r\n> ```python\r\n> from datasets import load_dataset\r\n> \r\n> ds = load_dataset(\"glue\", 'cola')\r\n> ds\r\n> ```\r\n> \r\n> ```\r\n> DatasetDict({\r\n> train: Dataset({\r\n> features: ['sentence', 'label', 'idx'],\r\n> num_rows: 8551\r\n> })\r\n> validation: Dataset({\r\n> features: ['sentence', 'label', 'idx'],\r\n> num_rows: 1043\r\n> })\r\n> test: Dataset({\r\n> features: ['sentence', 'label', 'idx'],\r\n> num_rows: 1063\r\n> })\r\n> })\r\n> ```\r\n> \r\n> Could you please give more details and environment info (platform, PyArrow version)?\r\n\r\nSorry to reply you so late.\r\nplatform: pycharm 2021 + anaconda with python 3.7\r\nPyArrow version: 5.0.0\r\nhuggingface-hub: 0.0.16\r\ndatasets: 1.9.0\r\n",
"- For the platform, we need to know the operating system of your machine. Could you please run the command `datasets-cli env` and copy-and-paste its output below?\r\n- In relation with the error, you just gave us the error type and message (`TypeError: 'NoneType' object is not callable`). Could you please copy-paste the complete stack trace, so that we know exactly which part of the code threw the error?",
"> * For the platform, we need to know the operating system of your machine. Could you please run the command `datasets-cli env` and copy-and-paste its output below?\r\n> * In relation with the error, you just gave us the error type and message (`TypeError: 'NoneType' object is not callable`). Could you please copy-paste the complete stack trace, so that we know exactly which part of the code threw the error?\r\n\r\n1. For the platform, here are the output:\r\n - datasets` version: 1.11.0\r\n - Platform: Windows-10-10.0.19041-SP0\r\n - Python version: 3.7.10\r\n - PyArrow version: 5.0.0\r\n2. For the code and error:\r\n ```python\r\n from datasets import load_dataset, load_metric\r\n dataset = load_dataset(\"glue\", \"cola\")\r\n ```\r\n ```python\r\n Traceback (most recent call last):\r\n ....\r\n ....\r\n File \"my_file.py\", line 2, in <module>\r\n dataset = load_dataset(\"glue\", \"cola\")\r\n File \"My environments\\lib\\site-packages\\datasets\\load.py\", line 830, in load_dataset\r\n **config_kwargs,\r\n File \"My environments\\lib\\site-packages\\datasets\\load.py\", line 710, in load_dataset_builder\r\n **config_kwargs,\r\n TypeError: 'NoneType' object is not callable\r\n ```\r\n Thank you!",
"For that environment, I am sorry but I can't reproduce the bug: I can load the dataset without any problem.",
"One naive question: do you have internet access from the machine where you execute the code?",
"> For that environment, I am sorry but I can't reproduce the bug: I can load the dataset without any problem.\r\n\r\nBut I can download other task dataset such as `dataset = load_dataset('squad')`. I don't know what went wrong. Thank you so much!",
"Hi,friends. I meet the same problem. Do you have a way to fix this? Thanks!\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3918/comments | https://api.github.com/repos/huggingface/datasets/issues/3918/events | https://github.com/huggingface/datasets/issues/3918 | 1,169,366,117 | I_kwDODunzps5Fsxxl | 3,918 | datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | 3 | 2022-03-15T08:53:45Z | 2022-03-16T15:36:58Z | 2022-03-15T14:01:25Z | null | ## Describe the bug
Can't load the dataset
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset('multi_news')
dataset_2=load_dataset("reddit_tifu", "long")
## Actual results
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=1ffWfITKFMJeqjT8loC8aiCLRNJpc_XnF']
## Environment info
- `datasets` version: 1.18.4
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.0
- PyArrow version: 6.0.1
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3918/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3918/timeline | null | completed | null | null | false | [
"Hi @willowdong! These issues were fixed on master. We will have a new release of `datasets` later today. In the meantime, you can avoid these issues by installing `datasets` from master as follows:\r\n```bash\r\npip install git+https://github.com/huggingface/datasets.git\r\n```",
"You should force redownload:\r\n```python\r\ndataset = load_dataset(\"multi_news\", download_mode=\"force_redownload\")\r\ndataset_2 = load_dataset(\"reddit_tifu\", \"long\", download_mode=\"force_redownload\")",
"Fixed by:\r\n- #3787 \r\n- #3843"
] |
https://api.github.com/repos/huggingface/datasets/issues/1404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1404/comments | https://api.github.com/repos/huggingface/datasets/issues/1404/events | https://github.com/huggingface/datasets/pull/1404 | 760,575,473 | MDExOlB1bGxSZXF1ZXN0NTM1Mzg0NzEz | 1,404 | Add Acronym Identification Dataset | [] | closed | false | null | 1 | 2020-12-09T18:38:54Z | 2020-12-14T13:12:01Z | 2020-12-14T13:12:00Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1404/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1404.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1404",
"merged_at": "2020-12-14T13:12:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1404.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1404"
} | true | [
"fixed @lhoestq "
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3961 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3961/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3961/comments | https://api.github.com/repos/huggingface/datasets/issues/3961/events | https://github.com/huggingface/datasets/issues/3961 | 1,173,223,086 | I_kwDODunzps5F7fau | 3,961 | Scores from Index at extra positions are not filtered out | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-03-18T06:13:23Z | 2022-04-12T14:41:58Z | 2022-04-12T14:41:58Z | null | If a FAISS index has fewer records than the requested number of top results (k), then it returns -1 in indices for the additional positions. The get_nearest_examples method only filters out the extra results from the dataset samples. It would be better to filter out extra scores too.
Reference: https://github.com/huggingface/datasets/blob/2.0.0/src/datasets/search.py#L693
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3961/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3961/timeline | null | completed | null | null | false | [
"Hi! Yes, that makes sense! Would you like to submit a PR to fix this?",
"Created PR https://github.com/huggingface/datasets/pull/3971"
] |
https://api.github.com/repos/huggingface/datasets/issues/403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/403/comments | https://api.github.com/repos/huggingface/datasets/issues/403/events | https://github.com/huggingface/datasets/pull/403 | 658,325,756 | MDExOlB1bGxSZXF1ZXN0NDUwMzAzNjI2 | 403 | return python objects instead of arrays by default | [] | closed | false | null | 0 | 2020-07-16T15:51:52Z | 2020-07-17T11:37:01Z | 2020-07-17T11:37:00Z | null | We were using to_pandas() to convert from arrow types, however it returns numpy arrays instead of python lists.
I fixed it by using to_pydict/to_pylist instead.
Fix #387
It was mentioned in https://github.com/huggingface/transformers/issues/5729
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/403/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/403/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/403",
"merged_at": "2020-07-17T11:37:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/403"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4199 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4199/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4199/comments | https://api.github.com/repos/huggingface/datasets/issues/4199/events | https://github.com/huggingface/datasets/issues/4199 | 1,211,953,308 | I_kwDODunzps5IPPCc | 4,199 | Cache miss during reload for datasets using image fetch utilities through map | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2022-04-22T07:47:08Z | 2022-04-26T17:00:32Z | 2022-04-26T13:38:26Z | null | ## Describe the bug
It looks like that result of `.map` operation dataset are missing the cache when you reload the script and always run from scratch. In same interpretor session, they are able to find the cache and reload it. But, when you exit the interpretor and reload it, the downloading starts from scratch.
## Steps to reproduce the bug
Using the example provided in `red_caps` dataset.
```python
from concurrent.futures import ThreadPoolExecutor
from functools import partial
import io
import urllib
import PIL.Image
import datasets
from datasets import load_dataset
from datasets.utils.file_utils import get_datasets_user_agent
def fetch_single_image(image_url, timeout=None, retries=0):
for _ in range(retries + 1):
try:
request = urllib.request.Request(
image_url,
data=None,
headers={"user-agent": get_datasets_user_agent()},
)
with urllib.request.urlopen(request, timeout=timeout) as req:
image = PIL.Image.open(io.BytesIO(req.read()))
break
except Exception:
image = None
return image
def fetch_images(batch, num_threads, timeout=None, retries=0):
fetch_single_image_with_args = partial(fetch_single_image, timeout=timeout, retries=retries)
with ThreadPoolExecutor(max_workers=num_threads) as executor:
batch["image"] = list(executor.map(lambda image_urls: [fetch_single_image_with_args(image_url) for image_url in image_urls], batch["image_url"]))
return batch
def process_image_urls(batch):
processed_batch_image_urls = []
for image_url in batch["image_url"]:
processed_example_image_urls = []
image_url_splits = re.findall(r"http\S+", image_url)
for image_url_split in image_url_splits:
if "imgur" in image_url_split and "," in image_url_split:
for image_url_part in image_url_split.split(","):
if not image_url_part:
continue
image_url_part = image_url_part.strip()
root, ext = os.path.splitext(image_url_part)
if not root.startswith("http"):
root = "http://i.imgur.com/" + root
root = root.split("#")[0]
if not ext:
ext = ".jpg"
ext = re.split(r"[?%]", ext)[0]
image_url_part = root + ext
processed_example_image_urls.append(image_url_part)
else:
processed_example_image_urls.append(image_url_split)
processed_batch_image_urls.append(processed_example_image_urls)
batch["image_url"] = processed_batch_image_urls
return batch
dset = load_dataset("red_caps", "jellyfish")
dset = dset.map(process_image_urls, batched=True, num_proc=4)
features = dset["train"].features.copy()
features["image"] = datasets.Sequence(datasets.Image())
num_threads = 5
dset = dset.map(fetch_images, batched=True, batch_size=50, features=features, fn_kwargs={"num_threads": num_threads})
```
Run this in an interpretor or as a script twice and see that the cache is missed the second time.
## Expected results
At reload there should not be any cache miss
## Actual results
Every time script is run, cache is missed and dataset is built from scratch.
## Environment info
- `datasets` version: 2.1.1.dev0
- Platform: Linux-4.19.0-20-cloud-amd64-x86_64-with-glibc2.10
- Python version: 3.8.13
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4199/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4199/timeline | null | completed | null | null | false | [
"Hi ! Maybe one of the objects in the function is not deterministic across sessions ? You can read more about it and how to investigate here: https://huggingface.co/docs/datasets/about_cache",
"Hi @apsdehal! Can you verify that replacing\r\n```python\r\ndef fetch_single_image(image_url, timeout=None, retries=0):\r\n for _ in range(retries + 1):\r\n try:\r\n request = urllib.request.Request(\r\n image_url,\r\n data=None,\r\n headers={\"user-agent\": get_datasets_user_agent()},\r\n )\r\n with urllib.request.urlopen(request, timeout=timeout) as req:\r\n image = PIL.Image.open(io.BytesIO(req.read()))\r\n break\r\n except Exception:\r\n image = None\r\n return image\r\n```\r\nwith \r\n```python\r\nUSER_AGENT = get_datasets_user_agent()\r\n\r\ndef fetch_single_image(image_url, timeout=None, retries=0):\r\n for _ in range(retries + 1):\r\n try:\r\n request = urllib.request.Request(\r\n image_url,\r\n data=None,\r\n headers={\"user-agent\": USER_AGENT},\r\n )\r\n with urllib.request.urlopen(request, timeout=timeout) as req:\r\n image = PIL.Image.open(io.BytesIO(req.read()))\r\n break\r\n except Exception:\r\n image = None\r\n return image\r\n```\r\nfixes the issue?",
"Thanks @mariosasko. That does fix the issue. In general, I think these image downloading utilities since they are being used by a lot of image dataset should be provided as a part of `datasets` library right to keep the logic consistent and READMEs smaller? If they already exists, that is also great, please point me to those. I saw that `http_get` does exist.",
"You can find my rationale (and a proposed solution) for why these utilities are not a part of `datasets` here: https://github.com/huggingface/datasets/pull/4100#issuecomment-1097994003.",
"Makes sense. But, I think as the number of image datasets as grow, more people are copying pasting original code from docs to work as it is while we make fixes to them later. I think we do need a central place for these to avoid that confusion as well as more easier access to image datasets. Should we restart that discussion, possible on slack?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4849 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4849/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4849/comments | https://api.github.com/repos/huggingface/datasets/issues/4849/events | https://github.com/huggingface/datasets/pull/4849 | 1,338,273,900 | PR_kwDODunzps49JN8d | 4,849 | 1.18.x | [] | closed | false | null | 0 | 2022-08-14T15:09:19Z | 2022-08-14T15:10:02Z | 2022-08-14T15:10:02Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4849/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4849/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4849.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4849",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4849.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4849"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5116 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5116/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5116/comments | https://api.github.com/repos/huggingface/datasets/issues/5116/events | https://github.com/huggingface/datasets/pull/5116 | 1,409,549,471 | PR_kwDODunzps5A09sk | 5,116 | Use yaml for issue templates + revamp | [] | closed | false | null | 1 | 2022-10-14T15:53:13Z | 2022-10-19T13:05:49Z | 2022-10-19T13:03:22Z | null | Use YAML instead of markdown (more expressive) for the issue templates. In addition, update their structure/fields to be more aligned with Transformers.
PS: also removes the "add_dataset" PR template, as we no longer accept such PRs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5116/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5116/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5116.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5116",
"merged_at": "2022-10-19T13:03:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5116.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5116"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/958/comments | https://api.github.com/repos/huggingface/datasets/issues/958/events | https://github.com/huggingface/datasets/pull/958 | 754,404,095 | MDExOlB1bGxSZXF1ZXN0NTMwMzA5ODkz | 958 | dataset(ncslgr): add initial loading script | [] | closed | false | null | 3 | 2020-12-01T13:41:17Z | 2020-12-07T16:35:39Z | 2020-12-07T16:35:39Z | null | clean #789 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/958/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/958.diff",
"html_url": "https://github.com/huggingface/datasets/pull/958",
"merged_at": "2020-12-07T16:35:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/958.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/958"
} | true | [
"@lhoestq I added the README files, and now the tests fail... (check commit history, only changed MD file)\r\nThe tests seem a bit unstable",
"the `RemoteDatasetTest ` errors in the CI are fixed on master so it's fine",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5038 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5038/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5038/comments | https://api.github.com/repos/huggingface/datasets/issues/5038/events | https://github.com/huggingface/datasets/issues/5038 | 1,389,631,122 | I_kwDODunzps5S1BaS | 5,038 | `Dataset.unique` showing wrong output after filtering | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-09-28T16:20:35Z | 2022-09-30T15:44:25Z | 2022-09-30T15:44:25Z | null | ## Describe the bug
After filtering a dataset, and if no samples remain, `Dataset.unique` will return the unique values of the unfiltered dataset.
## Steps to reproduce the bug
```python
from datasets import Dataset
dataset = Dataset.from_dict({'id': [0]})
dataset = dataset.filter(lambda _: False)
print(dataset.unique('id'))
```
## Expected results
The above code should return an empty list since the dataset is empty.
## Actual results
```bash
[0]
```
## Environment info
- `datasets` version: 2.5.1
- Platform: Linux-5.18.19-100.fc35.x86_64-x86_64-with-glibc2.34
- Python version: 3.9.14
- PyArrow version: 7.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5038/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5038/timeline | null | completed | null | null | false | [
"Hi! It seems like `flatten_indices` (called in `unique`) doesn't know how to handle empty indices mappings. I'm working on the fix.",
"Thanks, that was fast!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1673/comments | https://api.github.com/repos/huggingface/datasets/issues/1673/events | https://github.com/huggingface/datasets/issues/1673 | 777,263,651 | MDU6SXNzdWU3NzcyNjM2NTE= | 1,673 | Unable to Download Hindi Wikipedia Dataset | [] | closed | false | null | 6 | 2021-01-01T10:52:53Z | 2021-01-05T10:22:12Z | 2021-01-05T10:22:12Z | null | I used the Dataset Library in Python to load the wikipedia dataset with the Hindi Config 20200501.hi along with something called beam_runner='DirectRunner' and it keeps giving me the error that the file is not found. I have attached the screenshot of the error and the code both. Please help me to understand how to resolve this issue.


| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1673/timeline | null | completed | null | null | false | [
"Currently this dataset is only available when the library is installed from source since it was added after the last release.\r\n\r\nWe pin the dataset version with the library version so that people can have a reproducible dataset and processing when pinning the library.\r\n\r\nWe'll see if we can provide access to newer datasets with a warning that they are newer than your library version, that would help in cases like yours.",
"So for now, should i try and install the library from source and then try out the same piece of code? Will it work then, considering both the versions will match then?",
"Yes",
"Hey, so i tried installing the library from source using the commands : **git clone https://github.com/huggingface/datasets**, **cd datasets** and then **pip3 install -e .**. But i still am facing the same error that file is not found. Please advise.\r\n\r\nThe Datasets library version now is 1.1.3 by installing from source as compared to the earlier 1.0.3 that i had loaded using pip command but I am still getting same error\r\n\r\n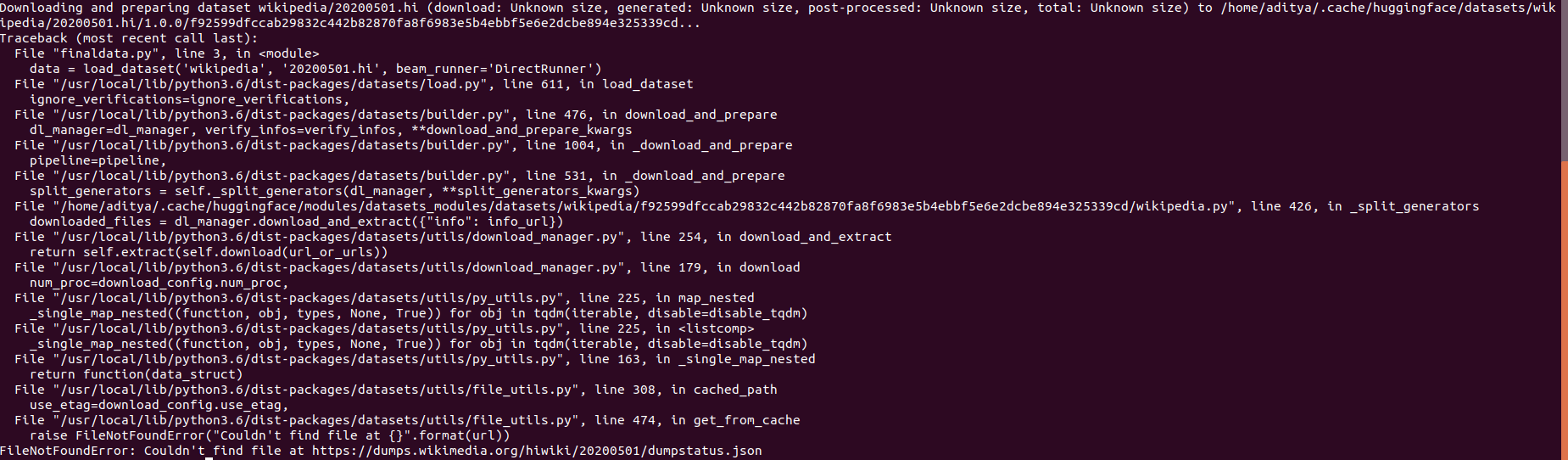\r\n",
"Looks like the wikipedia dump for hindi at the date of 05/05/2020 is not available anymore.\r\nYou can try to load a more recent version of wikipedia\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nd = load_dataset(\"wikipedia\", language=\"hi\", date=\"20210101\", split=\"train\", beam_runner=\"DirectRunner\")\r\n```",
"Okay, thank you so much"
] |
https://api.github.com/repos/huggingface/datasets/issues/560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/560/comments | https://api.github.com/repos/huggingface/datasets/issues/560/events | https://github.com/huggingface/datasets/issues/560 | 690,488,764 | MDU6SXNzdWU2OTA0ODg3NjQ= | 560 | Using custom DownloadConfig results in an error | [] | closed | false | null | 6 | 2020-09-01T22:23:02Z | 2022-10-04T17:23:45Z | 2022-10-04T17:23:45Z | null | ## Version / Environment
Ubuntu 18.04
Python 3.6.8
nlp 0.4.0
## Description
Loading `imdb` dataset works fine when when I don't specify any `download_config` argument. When I create a custom `DownloadConfig` object and pass it to the `nlp.load_dataset` function, this results in an error.
## How to reproduce
### Example without DownloadConfig --> works
```python
import os
os.environ["HF_HOME"] = "/data/hf-test-without-dl-config-01/"
import logging
import nlp
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
imdb = nlp.load_dataset(path="imdb")
```
### Example with DownloadConfig --> doesn't work
```python
import os
os.environ["HF_HOME"] = "/data/hf-test-with-dl-config-01/"
import logging
import nlp
from nlp.utils import DownloadConfig
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
download_config = DownloadConfig()
imdb = nlp.load_dataset(path="imdb", download_config=download_config)
```
Error traceback:
```
Traceback (most recent call last):
File "/.../example_with_dl_config.py", line 13, in <module>
imdb = nlp.load_dataset(path="imdb", download_config=download_config)
File "/.../python3.6/python3.6/site-packages/nlp/load.py", line 549, in load_dataset
download_config=download_config, download_mode=download_mode, ignore_verifications=ignore_verifications,
File "/.../python3.6/python3.6/site-packages/nlp/builder.py", line 463, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/.../python3.6/python3.6/site-packages/nlp/builder.py", line 518, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/.../python3.6/python3.6/site-packages/nlp/datasets/imdb/76cdbd7249ea3548c928bbf304258dab44d09cd3638d9da8d42480d1d1be3743/imdb.py", line 86, in _split_generators
arch_path = dl_manager.download_and_extract(_DOWNLOAD_URL)
File "/.../python3.6/python3.6/site-packages/nlp/utils/download_manager.py", line 220, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/.../python3.6/python3.6/site-packages/nlp/utils/download_manager.py", line 158, in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
File "/.../python3.6/python3.6/site-packages/nlp/utils/download_manager.py", line 108, in _record_sizes_checksums
self._recorded_sizes_checksums[url] = get_size_checksum_dict(path)
File "/.../python3.6/python3.6/site-packages/nlp/utils/info_utils.py", line 79, in get_size_checksum_dict
with open(path, "rb") as f:
IsADirectoryError: [Errno 21] Is a directory: '/data/hf-test-with-dl-config-01/datasets/extracted/b6802c5b61824b2c1f7dbf7cda6696b5f2e22214e18d171ce1ed3be90c931ce5'
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/560/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/560/timeline | null | completed | null | null | false | [
"From my limited understanding, part of the issue seems related to the `prepare_module` and `download_and_prepare` functions each handling the case where no config is passed. For example, `prepare_module` does mutate the object passed and forces the flags `extract_compressed_file` and `force_extract` to `True`.\r\n\r\nSee:\r\n* https://github.com/huggingface/nlp/blob/5fb61e1012bda724a9b6b847307d90a1380abfa5/src/nlp/load.py#L227\r\n* https://github.com/huggingface/nlp/blob/5fb61e1012bda724a9b6b847307d90a1380abfa5/src/nlp/builder.py#L388\r\n\r\nMaybe a cleaner solution would be to always instantiate a default `DownloadConfig` object at the top-level, have it as non-optional for the lower-level functions and treat it as immutable. ",
"Thanks for the report, I'll take a look.\r\n\r\nWhat is your specific use-case for providing a DownloadConfig object?\r\n",
"Thanks. Our use case involves running a training job behind a corporate firewall with no access to any external resources (S3, GCP or other web resources).\r\n\r\nI was thinking about a 2-steps process:\r\n1) Download the resources / artifacts using some secure corporate channel, ie run `nlp.load_dataset()` without a specific `DownloadConfig`. After that, collect the files from the `$HF_HOME` folder\r\n2) Copy the `$HF_HOME` folder in the firewalled environment. Run `nlp.load_dataset()` with a custom config `DownloadConfig(local_files_only=True)`\r\n\r\nHowever this ends up a bit clunky in practice, even when solving the `DownloadConfig` issue above. For example, the `filename` hash computed in `get_from_cache()` differs in the `local_files_only=False` vs `local_files_only=True` case (local case defaults `etag` to `None`, which results in a different hash). So effectively step 2) above doesn't work because the hash computed differs from the hash in the cache folder. Some hacks / workaround are possible but this solution becomes very convoluted.\r\nhttps://github.com/huggingface/nlp/blob/c214aa5a4430c1df1bcd0619fd94d6abdf9d2da7/src/nlp/utils/file_utils.py#L417\r\n\r\nWould you recommend a different path?\r\n",
"I see.\r\n\r\nProbably the easiest way for you would be that we add simple serialization/deserialization methods to the Dataset and DatasetDict objects once the data files have been downloaded and all the dataset is processed.\r\n\r\nWhat do you think @lhoestq ?",
"This use-case will be solved with #571 ",
"Thank you very much @thomwolf and @lhoestq we will give it a try"
] |
https://api.github.com/repos/huggingface/datasets/issues/2284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2284/comments | https://api.github.com/repos/huggingface/datasets/issues/2284/events | https://github.com/huggingface/datasets/pull/2284 | 870,932,710 | MDExOlB1bGxSZXF1ZXN0NjI2MDM5MDc5 | 2,284 | Initialize Imdb dataset as used in Don't Stop Pretraining Paper | [] | closed | false | null | 0 | 2021-04-29T11:52:38Z | 2021-04-29T12:54:34Z | 2021-04-29T12:54:34Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2284/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2284/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2284.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2284",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2284.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2284"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/1375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1375/comments | https://api.github.com/repos/huggingface/datasets/issues/1375/events | https://github.com/huggingface/datasets/pull/1375 | 760,294,931 | MDExOlB1bGxSZXF1ZXN0NTM1MTUwOTk2 | 1,375 | Add OPUS EMEA Dataset | [] | closed | false | null | 0 | 2020-12-09T12:39:44Z | 2020-12-10T16:11:09Z | 2020-12-10T16:11:08Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1375/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1375",
"merged_at": "2020-12-10T16:11:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1375"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5805 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5805/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5805/comments | https://api.github.com/repos/huggingface/datasets/issues/5805/events | https://github.com/huggingface/datasets/issues/5805 | 1,688,558,577 | I_kwDODunzps5kpVvx | 5,805 | Improve `Create a dataset` tutorial | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | open | false | null | 2 | 2023-04-28T13:26:22Z | 2023-06-23T14:58:44Z | null | null | Our [tutorial on how to create a dataset](https://huggingface.co/docs/datasets/create_dataset) is a bit misleading.
1. In **Folder-based builders** section it says that we have two folder-based builders as standard builders, but we also have similar builders (that can be created from directory with data of required format) for `csv`, `json/jsonl`, `parquet` and `txt` files. We have info about these loaders in separate [guide for loading](https://huggingface.co/docs/datasets/loading#local-and-remote-files) but it's worth briefly mentioning them in the beginning tutorial because they are more common and for consistency. Would be helpful to add the link to the full guide.
2. **From local files** section lists methods for creating a dataset from in-memory data which are also described in [loading guide](https://huggingface.co/docs/datasets/loading#inmemory-data).
Maybe we should actually rethink and restructure this tutorial somehow. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5805/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5805/timeline | null | null | null | null | false | [
"I can work on this. The link to the tutorial seems to be broken though @polinaeterna. ",
"@isunitha98selvan would be great, thank you! which link are you talking about? I think it should work: https://huggingface.co/docs/datasets/create_dataset"
] |
https://api.github.com/repos/huggingface/datasets/issues/472 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/472/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/472/comments | https://api.github.com/repos/huggingface/datasets/issues/472/events | https://github.com/huggingface/datasets/pull/472 | 672,000,745 | MDExOlB1bGxSZXF1ZXN0NDYyMTE1MjA4 | 472 | add crd3 dataset | [] | closed | false | null | 1 | 2020-08-03T11:15:02Z | 2020-08-03T11:22:10Z | 2020-08-03T11:22:09Z | null | opening new PR for CRD3 dataset (ACL2020) to fix the circle CI problems | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/472/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/472/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/472.diff",
"html_url": "https://github.com/huggingface/datasets/pull/472",
"merged_at": "2020-08-03T11:22:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/472.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/472"
} | true | [
"This PR was already approved by @lhoestq in #456 . This one just make style to remove some typos"
] |
https://api.github.com/repos/huggingface/datasets/issues/1858 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1858/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1858/comments | https://api.github.com/repos/huggingface/datasets/issues/1858/events | https://github.com/huggingface/datasets/pull/1858 | 805,477,774 | MDExOlB1bGxSZXF1ZXN0NTcxMDcxNzIx | 1,858 | Clean config getenvs | [] | closed | false | null | 0 | 2021-02-10T12:39:14Z | 2021-02-10T15:52:30Z | 2021-02-10T15:52:29Z | null | Following #1848
Remove double getenv calls and fix one issue with rarfile
cc @albertvillanova | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1858/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1858/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1858.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1858",
"merged_at": "2021-02-10T15:52:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1858.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1858"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4825 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4825/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4825/comments | https://api.github.com/repos/huggingface/datasets/issues/4825/events | https://github.com/huggingface/datasets/pull/4825 | 1,335,856,882 | PR_kwDODunzps49BYWL | 4,825 | [Windows] Fix Access Denied when using os.rename() | [] | closed | false | null | 6 | 2022-08-11T11:57:15Z | 2022-08-24T13:09:07Z | 2022-08-24T13:09:07Z | null | In this PR, we are including an additional step when `os.rename()` raises a PermissionError.
Basically, we will use `shutil.move()` on the temp files.
Fix #2937 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4825/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4825/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4825.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4825",
"merged_at": "2022-08-24T13:09:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4825.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4825"
} | true | [
"Cool thank you ! Maybe we can just replace `os.rename` by `shutil.move` instead ?",
"> Cool thank you ! Maybe we can just replace `os.rename` by `shutil.move` instead ?\r\n\r\nYes, I think that could be a better solution, but I didn't test it in Linux (e.g. Ubuntu) to guarantee that `os.rename()` could be completely replaced by `shutil.move()`.",
"AFAIK `shutil.move` does call `os.rename` first before doing extra work to make it work on windows, so this is should be a safe safe change for linux ;)",
"> AFAIK `shutil.move` does call `os.rename` first before doing extra work to make it work on windows, so this is should be a safe safe change for linux ;)\r\n\r\nalright, let me change the PR then.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4825). All of your documentation changes will be reflected on that endpoint.",
"Hi @lhoestq looks like one of the tests failed, but is not related to this change, do I need to do something from my side?"
] |
https://api.github.com/repos/huggingface/datasets/issues/2685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2685/comments | https://api.github.com/repos/huggingface/datasets/issues/2685/events | https://github.com/huggingface/datasets/pull/2685 | 948,791,572 | MDExOlB1bGxSZXF1ZXN0NjkzNTgxNTk2 | 2,685 | Fix Blog Authorship Corpus dataset | [] | closed | false | null | 3 | 2021-07-20T15:44:50Z | 2021-07-21T13:11:58Z | 2021-07-21T13:11:58Z | null | This PR:
- Update the JSON metadata file, which previously was raising a `NonMatchingSplitsSizesError`
- Fix the codec of the data files (`latin_1` instead of `utf-8`), which previously was raising ` UnicodeDecodeError` for some files
Close #2679. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2685/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2685/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2685.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2685",
"merged_at": "2021-07-21T13:11:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2685.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2685"
} | true | [
"Normally, I'm expecting errors from the validation of the README file... 😅 ",
"That is:\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_dataset_cards.py::test_changed_dataset_card[blog_authorship_corpus]\r\n==== 1 failed, 3182 passed, 2763 skipped, 16 warnings in 201.23s (0:03:21) =====\r\n```",
"@lhoestq, apart from the dataset card, everything is OK with this PR: I tested it locally."
] |
https://api.github.com/repos/huggingface/datasets/issues/2675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2675/comments | https://api.github.com/repos/huggingface/datasets/issues/2675/events | https://github.com/huggingface/datasets/pull/2675 | 947,657,732 | MDExOlB1bGxSZXF1ZXN0NjkyNjEwNTA1 | 2,675 | Parallelize ETag requests | [] | closed | false | null | 0 | 2021-07-19T13:30:42Z | 2021-07-19T19:33:25Z | 2021-07-19T19:33:25Z | null | Since https://github.com/huggingface/datasets/pull/2628 we use the ETag or the remote data files to compute the directory in the cache where a dataset is saved. This is useful in order to reload the dataset from the cache only if the remote files haven't changed.
In this I made the ETag requests parallel using multithreading. There is also a tqdm progress bar that shows up if there are more than 16 data files. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2675/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2675/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2675.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2675",
"merged_at": "2021-07-19T19:33:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2675.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2675"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/123 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/123/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/123/comments | https://api.github.com/repos/huggingface/datasets/issues/123/events | https://github.com/huggingface/datasets/pull/123 | 618,820,140 | MDExOlB1bGxSZXF1ZXN0NDE4NDcxODU5 | 123 | [Tests] Local => aws | [] | closed | false | null | 3 | 2020-05-15T09:12:25Z | 2020-05-15T10:06:12Z | 2020-05-15T10:03:26Z | null | ## Change default Test from local => aws
As a default we set` aws=True`, `Local=False`, `slow=False`
### 1. RUN_AWS=1 (default)
This runs 4 tests per dataset script.
a) Does the dataset script have a valid etag / Can it be reached on AWS?
b) Can we load its `builder_class`?
c) Can we load **all** dataset configs?
d) _Most importantly_: Can we load the dataset?
Important - we currently only test the first config of each dataset to reduce test time. Total test time is around 1min20s.
### 2. RUN_LOCAL=1 RUN_AWS=0
***This should be done when debugging dataset scripts of the ./datasets folder***
This only runs 1 test per dataset test, which is equivalent to aws d) - Can we load the dataset from the local `datasets` directory?
### 3. RUN_SLOW=1
We should set up to run these tests maybe 1 time per week ? @thomwolf
The `slow` tests include two more important tests.
e) Can we load the dataset with all possible configs? This test will probably fail at the moment because a lot of dummy data is missing. We should add the dummy data step by step to be sure that all configs work.
f) Test that the actual dataset can be loaded. This will take quite some time to run, but is important to make sure that the "real" data can be loaded. It will also test whether the dataset script has the correct checksums file which is currently not tested with `aws=True`. @lhoestq - is there an easy way to check cheaply whether the `dataset_info.json` is correct for each dataset script? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/123/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/123/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/123.diff",
"html_url": "https://github.com/huggingface/datasets/pull/123",
"merged_at": "2020-05-15T10:03:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/123.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/123"
} | true | [
"For each dataset, If there exist a `dataset_info.json`, then the command `nlp-cli test path/to/my/dataset --al_configs` is successful only if the `dataset_infos.json` is correct. The infos are correct if the size and checksums of the downloaded file are correct, and if the number of examples in each split are correct.\r\n\r\nNote: the `test` command is supposed to test the script, that's why it runs the script even if the cached files already exist. Let me know if it's good to you.",
"> For each dataset, If there exist a `dataset_info.json`, then the command `nlp-cli test path/to/my/dataset --al_configs` is successful only if the `dataset_infos.json` is correct. The infos are correct if the size and checksums of the downloaded file are correct, and if the number of examples in each split are correct.\r\n> \r\n> Note: the `test` command is supposed to test the script, that's why it runs the script even if the cached files already exist. Let me know if it's good to you.\r\n\r\nDoes it have to download the whole data to check if the checksums are correct? I guess so no? ",
"> > For each dataset, If there exist a `dataset_info.json`, then the command `nlp-cli test path/to/my/dataset --al_configs` is successful only if the `dataset_infos.json` is correct. The infos are correct if the size and checksums of the downloaded file are correct, and if the number of examples in each split are correct.\r\n> > Note: the `test` command is supposed to test the script, that's why it runs the script even if the cached files already exist. Let me know if it's good to you.\r\n> \r\n> Does it have to download the whole data to check if the checksums are correct? I guess so no?\r\n\r\nYes it has to download them all (unless they were already downloaded in which case it just uses the cached downloaded files)."
] |
https://api.github.com/repos/huggingface/datasets/issues/1111 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1111/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1111/comments | https://api.github.com/repos/huggingface/datasets/issues/1111/events | https://github.com/huggingface/datasets/pull/1111 | 757,083,266 | MDExOlB1bGxSZXF1ZXN0NTMyNTE4NDY1 | 1,111 | Add Siswati Ner corpus | [] | closed | false | null | 0 | 2020-12-04T12:57:31Z | 2020-12-04T14:43:01Z | 2020-12-04T14:43:00Z | null | Clean Siswati PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1111/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1111/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1111.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1111",
"merged_at": "2020-12-04T14:43:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1111.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1111"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/923/comments | https://api.github.com/repos/huggingface/datasets/issues/923/events | https://github.com/huggingface/datasets/pull/923 | 753,569,220 | MDExOlB1bGxSZXF1ZXN0NTI5NjIyMDQx | 923 | Add CC-100 dataset | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | 10 | 2020-11-30T15:23:22Z | 2021-04-20T13:34:17Z | 2021-04-20T13:34:17Z | null | Add CC-100.
Close #773 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/923/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/923.diff",
"html_url": "https://github.com/huggingface/datasets/pull/923",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/923.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/923"
} | true | [
"Hello @lhoestq, I would like just to ask you if it is OK that I include this feature 9f32ba1 in this PR or you would prefer to have it in a separate one.\r\n\r\nI was wondering whether include also a test, but I did not find any test for the other file formats...",
"Hi ! Sure that would be valuable to support .xz files. Feel free to open a separate PR for this.\r\nAnd feel free to create the first test case for extracting compressed files if you have some inspiration (maybe create test_file_utils.py ?). We can still spend more time on tests next week when the sprint is over though so don't spend too much time on it.",
"@lhoestq, DONE! ;) See PR #950.",
"Thanks for adding support for `.xz` files :)\r\n\r\nFeel free to rebase from master to include it in your PR",
"@lhoestq DONE; I have merged instead, to avoid changing the history of my public PR ;)",
"Hi @lhoestq, I would need that you generate the dataset_infos.json and the dummy data for this dataset with a bigger computer. Sorry, but my laptop did not succeed...",
"Thanks for your work @albertvillanova \r\nWe'll definitely look into it after this sprint :)",
"Looks like #1456 added CC100 already.\r\nThe difference with your approach is that this implementation uses the `BuilderConfig` parameters to allow the creation of custom configs for all the languages, without having to specify them in the `BUILDER_CONFIGS` class attribute.\r\nFor example even if the dataset doesn't have a config for english already, you can still load the english CC100 with\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nload_dataset(\"cc100\", lang=\"en\")\r\n```",
"@lhoestq, oops!! I remember having assigned this dataset to me in the Google sheet, besides having mentioned the corresponding issue in the Pull Request... Nevermind! :)",
"Yes indeed I can see that...\r\nSorry for noticing that only now \r\n\r\nThe code of the other PR ended up being pretty close to yours though\r\nIf you want to add more details to the cc100 dataset card or in the script feel to do so, any addition is welcome"
] |
https://api.github.com/repos/huggingface/datasets/issues/2110 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2110/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2110/comments | https://api.github.com/repos/huggingface/datasets/issues/2110/events | https://github.com/huggingface/datasets/pull/2110 | 840,794,995 | MDExOlB1bGxSZXF1ZXN0NjAwNjI1NDQ5 | 2,110 | Fix incorrect assertion in builder.py | [] | closed | false | null | 2 | 2021-03-25T10:39:20Z | 2021-04-12T13:33:03Z | 2021-04-12T13:33:03Z | null | Fix incorrect num_examples comparison assertion in builder.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2110/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2110/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2110.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2110",
"merged_at": "2021-04-12T13:33:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2110.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2110"
} | true | [
"Hi ! The SplitInfo is not always available. By default you would get `split_info.num_examples == 0`\r\nSo unfortunately we can't use this assertion you suggested",
"> Hi ! The SplitInfo is not always available. By default you would get `split_info.num_examples == 0`\r\n> So unfortunately we can't use this assertion you suggested\r\n\r\nThen it would be better to just remove the assertion, because the existing assertion does nothing."
] |
https://api.github.com/repos/huggingface/datasets/issues/4143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4143/comments | https://api.github.com/repos/huggingface/datasets/issues/4143/events | https://github.com/huggingface/datasets/issues/4143 | 1,199,937,961 | I_kwDODunzps5HhZmp | 4,143 | Unable to download `Wikepedia` 20220301.en version | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2022-04-11T13:00:14Z | 2022-08-17T00:37:55Z | 2022-04-21T17:04:14Z | null | ## Describe the bug
Unable to download `Wikepedia` dataset, 20220301.en version
## Steps to reproduce the bug
```python
!pip install apache_beam mwparserfromhell
dataset_wikipedia = load_dataset("wikipedia", "20220301.en")
```
## Actual results
```
ValueError: BuilderConfig 20220301.en not found.
Available: ['20200501.aa', '20200501.ab', '20200501.ace', '20200501.ady', '20200501.af', '20200501.ak', '20200501.als', '20200501.am', '20200501.an', '20200501.ang', '20200501.ar', '20200501.arc', '20200501.arz', '20200501.as', '20200501.ast', '20200501.atj', '20200501.av', '20200501.ay', '20200501.az', '20200501.azb', '20200501.ba', '20200501.bar', '20200501.bat-smg', '20200501.bcl', '20200501.be', '20200501.be-x-old', '20200501.bg', '20200501.bh', '20200501.bi', '20200501.bjn', '20200501.bm', '20200501.bn', '20200501.bo', '20200501.bpy', '20200501.br', '20200501.bs', '20200501.bug', '20200501.bxr', '20200501.ca', '20200501.cbk-zam', '20200501.cdo', '20200501.ce', '20200501.ceb', '20200501.ch', '20200501.cho', '20200501.chr', '20200501.chy', '20200501.ckb', '20200501.co', '20200501.cr', '20200501.crh', '20200501.cs', '20200501.csb', '20200501.cu', '20200501.cv', '20200501.cy', '20200501.da', '20200501.de', '20200501.din', '20200501.diq', '20200501.dsb', '20200501.dty', '20200501.dv', '20200501.dz', '20200501.ee', '20200501.el', '20200501.eml', '20200501.en', '20200501.eo', '20200501.es', '20200501.et', '20200501.eu', '20200501.ext', '20200501.fa', '20200501.ff', '20200501.fi', '20200501.fiu-vro', '20200501.fj', '20200501.fo', '20200501.fr', '20200501.frp', '20200501.frr', '20200501.fur', '20200501.fy', '20200501.ga', '20200501.gag', '20200501.gan', '20200501.gd', '20200501.gl', '20200501.glk', '20200501.gn', '20200501.gom', '20200501.gor', '20200501.got', '20200501.gu', '20200501.gv', '20200501.ha', '20200501.hak', '20200501.haw', '20200501.he', '20200501.hi', '20200501.hif', '20200501.ho', '20200501.hr', '20200501.hsb', '20200501.ht', '20200501.hu', '20200501.hy', '20200501.ia', '20200501.id', '20200501.ie', '20200501.ig', '20200501.ii', '20200501.ik', '20200501.ilo', '20200501.inh', '20200501.io', '20200501.is', '20200501.it', '20200501.iu', '20200501.ja', '20200501.jam', '20200501.jbo', '20200501.jv', '20200501.ka', '20200501.kaa', '20200501.kab', '20200501.kbd', '20200501.kbp', '20200501.kg', '20200501.ki', '20200501.kj', '20200501.kk', '20200501.kl', '20200501.km', '20200501.kn', '20200501.ko', '20200501.koi', '20200501.krc', '20200501.ks', '20200501.ksh', '20200501.ku', '20200501.kv', '20200501.kw', '20200501.ky', '20200501.la', '20200501.lad', '20200501.lb', '20200501.lbe', '20200501.lez', '20200501.lfn', '20200501.lg', '20200501.li', '20200501.lij', '20200501.lmo', '20200501.ln', '20200501.lo', '20200501.lrc', '20200501.lt', '20200501.ltg', '20200501.lv', '20200501.mai', '20200501.map-bms', '20200501.mdf', '20200501.mg', '20200501.mh', '20200501.mhr', '20200501.mi', '20200501.min', '20200501.mk', '20200501.ml', '20200501.mn', '20200501.mr', '20200501.mrj', '20200501.ms', '20200501.mt', '20200501.mus', '20200501.mwl', '20200501.my', '20200501.myv', '20200501.mzn', '20200501.na', '20200501.nah', '20200501.nap', '20200501.nds', '20200501.nds-nl', '20200501.ne', '20200501.new', '20200501.ng', '20200501.nl', '20200501.nn', '20200501.no', '20200501.nov', '20200501.nrm', '20200501.nso', '20200501.nv', '20200501.ny', '20200501.oc', '20200501.olo', '20200501.om', '20200501.or', '20200501.os', '20200501.pa', '20200501.pag', '20200501.pam', '20200501.pap', '20200501.pcd', '20200501.pdc', '20200501.pfl', '20200501.pi', '20200501.pih', '20200501.pl', '20200501.pms', '20200501.pnb', '20200501.pnt', '20200501.ps', '20200501.pt', '20200501.qu', '20200501.rm', '20200501.rmy', '20200501.rn', '20200501.ro', '20200501.roa-rup', '20200501.roa-tara', '20200501.ru', '20200501.rue', '20200501.rw', '20200501.sa', '20200501.sah', '20200501.sat', '20200501.sc', '20200501.scn', '20200501.sco', '20200501.sd', '20200501.se', '20200501.sg', '20200501.sh', '20200501.si', '20200501.simple', '20200501.sk', '20200501.sl', '20200501.sm', '20200501.sn', '20200501.so', '20200501.sq', '20200501.sr', '20200501.srn', '20200501.ss', '20200501.st', '20200501.stq', '20200501.su', '20200501.sv', '20200501.sw', '20200501.szl', '20200501.ta', '20200501.tcy', '20200501.te', '20200501.tet', '20200501.tg', '20200501.th', '20200501.ti', '20200501.tk', '20200501.tl', '20200501.tn', '20200501.to', '20200501.tpi', '20200501.tr', '20200501.ts', '20200501.tt', '20200501.tum', '20200501.tw', '20200501.ty', '20200501.tyv', '20200501.udm', '20200501.ug', '20200501.uk', '20200501.ur', '20200501.uz', '20200501.ve', '20200501.vec', '20200501.vep', '20200501.vi', '20200501.vls', '20200501.vo', '20200501.wa', '20200501.war', '20200501.wo', '20200501.wuu', '20200501.xal', '20200501.xh', '20200501.xmf', '20200501.yi', '20200501.yo', '20200501.za', '20200501.zea', '20200501.zh', '20200501.zh-classical', '20200501.zh-min-nan', '20200501.zh-yue', '20200501.zu']
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.0.0
- Platform: Ubuntu
- Python version: 3.6
- PyArrow version: 6.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4143/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4143/timeline | null | completed | null | null | false | [
"Hi! We've recently updated the Wikipedia script, so these changes are only available on master and can be fetched as follows:\r\n```python\r\ndataset_wikipedia = load_dataset(\"wikipedia\", \"20220301.en\", revision=\"master\")\r\n```",
"Hi, how can I load the previous \"20200501.en\" version of wikipedia which had been downloaded to the default path? Thanks!",
"@JiaQiSJTU just reinstall the previous verision of the package, e.g. `!pip install -q datasets==1.0.0`"
] |
https://api.github.com/repos/huggingface/datasets/issues/5726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5726/comments | https://api.github.com/repos/huggingface/datasets/issues/5726/events | https://github.com/huggingface/datasets/issues/5726 | 1,660,944,807 | I_kwDODunzps5jAAGn | 5,726 | Fallback JSON Dataset loading does not load all values when features specified manually | [] | closed | false | null | 1 | 2023-04-10T15:22:14Z | 2023-04-21T06:35:28Z | 2023-04-21T06:35:28Z | null | ### Describe the bug
The fallback JSON dataset loader located here:
https://github.com/huggingface/datasets/blob/1c4ec00511868bd881e84a6f7e0333648d833b8e/src/datasets/packaged_modules/json/json.py#L130-L153
does not load the values of features correctly when features are specified manually and not all features have a value in the first entry of the dataset. I'm pretty sure this is not supposed to be expected bahavior?
To fix this you'd have to change this line:
https://github.com/huggingface/datasets/blob/1c4ec00511868bd881e84a6f7e0333648d833b8e/src/datasets/packaged_modules/json/json.py#L140
To pass a schema to pyarrow which has the same structure as the features argument passed to the load_dataset() method.
### Steps to reproduce the bug
Consider a dataset JSON like this:
```
[
{
"instruction": "Do stuff",
"output": "Answer stuff"
},
{
"instruction": "Do stuff2",
"input": "Additional Input2",
"output": "Answer stuff2"
}
]
```
Using this code to load the dataset:
```
from datasets import load_dataset, Features, Value
features = {
"instruction": Value("string"),
"input": Value("string"),
"output": Value("string")
}
features = Features(features)
ds = load_dataset("json", data_files="./ds.json", features=features)
for row in ds["train"]:
print(row)
```
we get a dataset that looks like this:
| **Instruction** | **Input** | **Output** |
|-----------------|--------------------|-----------------|
| "Do stuff" | None | "Answer Stuff" |
| "Do stuff2" | None | "Answer Stuff2" |
### Expected behavior
The input column should contain values other than None for dataset entries that have the "input" attribute set:
| **Instruction** | **Input** | **Output** |
|-----------------|--------------------|-----------------|
| "Do stuff" | None | "Answer Stuff" |
| "Do stuff2" | "Additional Input2" | "Answer Stuff2" |
### Environment info
Python 3.10.10
Datasets 2.11.0
Windows 10 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5726/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5726/timeline | null | completed | null | null | false | [
"Thanks for reporting, @myluki2000.\r\n\r\nI am working on a fix."
] |
https://api.github.com/repos/huggingface/datasets/issues/4945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4945/comments | https://api.github.com/repos/huggingface/datasets/issues/4945/events | https://github.com/huggingface/datasets/issues/4945 | 1,364,691,096 | I_kwDODunzps5RV4iY | 4,945 | Push to hub can push splits that do not respect the regex | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-09-07T13:45:17Z | 2022-09-13T10:16:35Z | 2022-09-13T10:16:35Z | null | ## Describe the bug
The `push_to_hub` method can push splits that do not respect the regex check that is used for downloads. Therefore, splits may be pushed but never re-used, which can be painful if the split was done after runtime preprocessing.
## Steps to reproduce the bug
```python
>>> from datasets import Dataset, DatasetDict, load_dataset
>>> d = Dataset.from_dict({'x': [1,2,3], 'y': [1,2,3]})
>>> di = DatasetDict()
>>> di['identifier-with-column'] = d
>>> di.push_to_hub('open-source-metrics/test')
Pushing split identifier-with-column to the Hub.
Pushing dataset shards to the dataset hub: 100%|██████████| 1/1 [00:04<00:00, 4.40s/it]
```
Loading it afterwards:
```python
>>> load_dataset('open-source-metrics/test')
Downloading: 100%|██████████| 610/610 [00:00<00:00, 432kB/s]
Using custom data configuration open-source-metrics--test-28b63ec7cde80488
Downloading and preparing dataset None/None (download: 950 bytes, generated: 48 bytes, post-processed: Unknown size, total: 998 bytes) to /home/lysandre/.cache/huggingface/datasets/open-source-metrics___parquet/open-source-metrics--test-28b63ec7cde80488/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 100%|██████████| 950/950 [00:00<00:00, 1.01MB/s]
Downloading data files: 100%|██████████| 1/1 [00:01<00:00, 1.48s/it]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 2291.97it/s]
Traceback (most recent call last):
File "/home/lysandre/.pyenv/versions/3.10.6/lib/python3.10/code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/load.py", line 1746, in load_dataset
builder_instance.download_and_prepare(
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/builder.py", line 771, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 48, in _split_generators
splits.append(datasets.SplitGenerator(name=split_name, gen_kwargs={"files": files}))
File "<string>", line 5, in __init__
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/splits.py", line 599, in __post_init__
NamedSplit(self.name) # check that it's a valid split name
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/splits.py", line 346, in __init__
raise ValueError(f"Split name should match '{_split_re}' but got '{split_name}'.")
ValueError: Split name should match '^\w+(\.\w+)*$' but got 'identifier-with-column'.
```
## Expected results
I would expect `push_to_hub` to stop me in my tracks if trying to upload a split that will not be working afterwards.
## Actual results
See above
## Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.15.64-1-lts-x86_64-with-glibc2.36
- Python version: 3.10.6
- PyArrow version: 9.0.0
- Pandas version: 1.4.4
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4945/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4945/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4978 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4978/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4978/comments | https://api.github.com/repos/huggingface/datasets/issues/4978/events | https://github.com/huggingface/datasets/pull/4978 | 1,374,271,504 | PR_kwDODunzps4_Axnh | 4,978 | Update IndicGLUE download links | [] | closed | false | null | 1 | 2022-09-15T10:05:57Z | 2022-09-15T22:00:20Z | 2022-09-15T21:57:34Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4978/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4978/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4978.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4978",
"merged_at": "2022-09-15T21:57:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4978.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4978"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3594/comments | https://api.github.com/repos/huggingface/datasets/issues/3594/events | https://github.com/huggingface/datasets/pull/3594 | 1,107,174,619 | PR_kwDODunzps4xN3Kk | 3,594 | fix multiple language downloading in mC4 | [] | closed | false | null | 1 | 2022-01-18T17:25:19Z | 2022-01-19T11:22:57Z | 2022-01-18T19:10:22Z | null | If we try to access multiple languages of the [mC4 dataset](https://github.com/huggingface/datasets/tree/master/datasets/mc4), it will throw an error. For example, if we do
```python
mc4_subset_two_langs = load_dataset("mc4", languages=["st", "su"])
```
we got
```
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/multilingual/c4-st+su.tfrecord-00000-of-00002.json.gz
```
Now it should work. Check it (from the root dir of a project):
```python
mc4_subset_two_langs = load_dataset("./datasets/mc4/", languages=["st", "su"])
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3594/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3594.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3594",
"merged_at": "2022-01-18T19:10:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3594.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3594"
} | true | [
"The CI failure is unrelated to your PR and fixed on master, merging :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5986 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5986/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5986/comments | https://api.github.com/repos/huggingface/datasets/issues/5986/events | https://github.com/huggingface/datasets/pull/5986 | 1,772,233,111 | PR_kwDODunzps5TygOZ | 5,986 | Make IterableDataset.from_spark more efficient | [] | closed | false | null | 6 | 2023-06-23T22:18:20Z | 2023-07-07T10:05:58Z | 2023-07-07T09:56:09Z | null | Moved the code from using collect() to using toLocalIterator, which allows for prefetching partitions that will be selected next, thus allowing for better performance when iterating. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5986/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5986/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5986.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5986",
"merged_at": "2023-07-07T09:56:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5986.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5986"
} | true | [
"@lhoestq would you be able to review this please and also approve the workflow?",
"Sounds good to me :) feel free to run `make style` to apply code formatting",
"_The documentation is not available anymore as the PR was closed or merged._",
"cool ! I think we can merge once all comments have been addressed",
"@lhoestq I just addressed the comments and I think we can move ahead with this! \r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007734 / 0.011353 (-0.003619) | 0.004608 / 0.011008 (-0.006400) | 0.094466 / 0.038508 (0.055958) | 0.086477 / 0.023109 (0.063368) | 0.410311 / 0.275898 (0.134413) | 0.455560 / 0.323480 (0.132080) | 0.006112 / 0.007986 (-0.001874) | 0.003845 / 0.004328 (-0.000483) | 0.072506 / 0.004250 (0.068256) | 0.066721 / 0.037052 (0.029669) | 0.409967 / 0.258489 (0.151478) | 0.460480 / 0.293841 (0.166639) | 0.036700 / 0.128546 (-0.091847) | 0.009854 / 0.075646 (-0.065792) | 0.320936 / 0.419271 (-0.098335) | 0.061002 / 0.043533 (0.017469) | 0.413963 / 0.255139 (0.158824) | 0.426787 / 0.283200 (0.143588) | 0.029182 / 0.141683 (-0.112501) | 1.685136 / 1.452155 (0.232981) | 1.754590 / 1.492716 (0.261873) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222698 / 0.018006 (0.204692) | 0.505929 / 0.000490 (0.505440) | 0.005291 / 0.000200 (0.005091) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032527 / 0.037411 (-0.004884) | 0.094842 / 0.014526 (0.080317) | 0.110138 / 0.176557 (-0.066418) | 0.193786 / 0.737135 (-0.543349) | 0.112593 / 0.296338 (-0.183745) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441671 / 0.215209 (0.226461) | 4.392961 / 2.077655 (2.315306) | 2.161111 / 1.504120 (0.656991) | 1.967080 / 1.541195 (0.425885) | 2.065411 / 1.468490 (0.596920) | 0.561080 / 4.584777 (-4.023697) | 4.159612 / 3.745712 (0.413900) | 6.435248 / 5.269862 (1.165386) | 3.732338 / 4.565676 (-0.833339) | 0.066156 / 0.424275 (-0.358119) | 0.008030 / 0.007607 (0.000423) | 0.532182 / 0.226044 (0.306137) | 5.315142 / 2.268929 (3.046213) | 2.680157 / 55.444624 (-52.764467) | 2.303799 / 6.876477 (-4.572677) | 2.530911 / 2.142072 (0.388838) | 0.669504 / 4.805227 (-4.135723) | 0.151940 / 6.500664 (-6.348724) | 0.066999 / 0.075469 (-0.008470) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.424275 / 1.841788 (-0.417513) | 21.550742 / 8.074308 (13.476434) | 16.031414 / 10.191392 (5.840022) | 0.194681 / 0.680424 (-0.485743) | 0.020389 / 0.534201 (-0.513812) | 0.429808 / 0.579283 (-0.149475) | 0.457503 / 0.434364 (0.023139) | 0.511522 / 0.540337 (-0.028816) | 0.682621 / 1.386936 (-0.704315) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007519 / 0.011353 (-0.003834) | 0.004445 / 0.011008 (-0.006563) | 0.071946 / 0.038508 (0.033438) | 0.082982 / 0.023109 (0.059873) | 0.459938 / 0.275898 (0.184040) | 0.504875 / 0.323480 (0.181395) | 0.005805 / 0.007986 (-0.002181) | 0.003740 / 0.004328 (-0.000589) | 0.071998 / 0.004250 (0.067747) | 0.062580 / 0.037052 (0.025527) | 0.462263 / 0.258489 (0.203774) | 0.506355 / 0.293841 (0.212514) | 0.036321 / 0.128546 (-0.092225) | 0.009830 / 0.075646 (-0.065816) | 0.079810 / 0.419271 (-0.339461) | 0.055291 / 0.043533 (0.011758) | 0.464093 / 0.255139 (0.208954) | 0.481109 / 0.283200 (0.197910) | 0.026909 / 0.141683 (-0.114774) | 1.652538 / 1.452155 (0.200383) | 1.750713 / 1.492716 (0.257997) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267552 / 0.018006 (0.249546) | 0.502021 / 0.000490 (0.501531) | 0.001635 / 0.000200 (0.001435) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033747 / 0.037411 (-0.003665) | 0.104242 / 0.014526 (0.089716) | 0.113829 / 0.176557 (-0.062728) | 0.176242 / 0.737135 (-0.560893) | 0.117002 / 0.296338 (-0.179336) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.476731 / 0.215209 (0.261522) | 4.727054 / 2.077655 (2.649399) | 2.589396 / 1.504120 (1.085276) | 2.511180 / 1.541195 (0.969985) | 2.634122 / 1.468490 (1.165632) | 0.563840 / 4.584777 (-4.020937) | 4.140212 / 3.745712 (0.394500) | 6.188789 / 5.269862 (0.918928) | 3.716897 / 4.565676 (-0.848780) | 0.065823 / 0.424275 (-0.358452) | 0.007705 / 0.007607 (0.000098) | 0.566580 / 0.226044 (0.340535) | 5.653306 / 2.268929 (3.384377) | 3.028756 / 55.444624 (-52.415868) | 2.592319 / 6.876477 (-4.284158) | 2.614250 / 2.142072 (0.472178) | 0.667135 / 4.805227 (-4.138093) | 0.153455 / 6.500664 (-6.347209) | 0.069321 / 0.075469 (-0.006148) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.541978 / 1.841788 (-0.299810) | 21.747360 / 8.074308 (13.673052) | 15.963657 / 10.191392 (5.772265) | 0.192843 / 0.680424 (-0.487581) | 0.020702 / 0.534201 (-0.513499) | 0.433620 / 0.579283 (-0.145663) | 0.467327 / 0.434364 (0.032963) | 0.507398 / 0.540337 (-0.032940) | 0.692797 / 1.386936 (-0.694140) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3207/comments | https://api.github.com/repos/huggingface/datasets/issues/3207/events | https://github.com/huggingface/datasets/issues/3207 | 1,044,496,389 | I_kwDODunzps4-QcAF | 3,207 | CI error: Another metric with the same name already exists in Keras 2.7.0 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2021-11-04T09:04:11Z | 2021-11-04T09:30:54Z | 2021-11-04T09:30:54Z | null | ## Describe the bug
Release of TensorFlow 2.7.0 contains an incompatibility with Keras. See:
- keras-team/keras#15579
This breaks our CI test suite: https://app.circleci.com/pipelines/github/huggingface/datasets/8493/workflows/055c7ae2-43bc-49b4-9f11-8fc71f35a25c/jobs/52363
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3207/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3207/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5334/comments | https://api.github.com/repos/huggingface/datasets/issues/5334/events | https://github.com/huggingface/datasets/pull/5334 | 1,477,421,927 | PR_kwDODunzps5EY9zN | 5,334 | Clean up docstrings | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 3 | 2022-12-05T20:56:08Z | 2022-12-09T01:44:25Z | 2022-12-09T01:41:44Z | null | As raised by @polinaeterna in #5324, some of the docstrings are a bit of a mess because it has both Markdown and Sphinx syntax. This PR fixes the docstring for `DatasetBuilder`.
I'll start working on cleaning up the rest of the docstrings and removing the old Sphinx syntax (let me know if you prefer one big PR with all the cleaned changes or multiple smaller ones)! 🧼 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5334/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5334/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5334.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5334",
"merged_at": "2022-12-09T01:41:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5334.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5334"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! Let us know if we can help :)\r\n\r\nSmall pref for having multiple PRs",
"Awesome, thanks! Sorry this one is a little big, I'll open some smaller ones next :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1327 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1327/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1327/comments | https://api.github.com/repos/huggingface/datasets/issues/1327/events | https://github.com/huggingface/datasets/pull/1327 | 759,629,321 | MDExOlB1bGxSZXF1ZXN0NTM0NjAxNDM3 | 1,327 | Add msr_genomics_kbcomp dataset | [] | closed | false | null | 0 | 2020-12-08T17:18:20Z | 2020-12-08T18:18:32Z | 2020-12-08T18:18:06Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1327/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1327/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1327.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1327",
"merged_at": "2020-12-08T18:18:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1327.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1327"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/4657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4657/comments | https://api.github.com/repos/huggingface/datasets/issues/4657/events | https://github.com/huggingface/datasets/issues/4657 | 1,296,743,133 | I_kwDODunzps5NSrrd | 4,657 | Add SQuAD2.0 Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 2 | 2022-07-07T03:19:36Z | 2022-07-12T16:14:52Z | 2022-07-12T16:14:52Z | null | ## Adding a Dataset
- **Name:** *SQuAD2.0*
- **Description:** *Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.*
- **Paper:** *https://aclanthology.org/P18-2124.pdf*
- **Data:** *https://rajpurkar.github.io/SQuAD-explorer/*
- **Motivation:** *Dataset for training and evaluating models of conversational response*
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4657/timeline | null | completed | null | null | false | [
"Hey, It's already present [here](https://huggingface.co/datasets/squad_v2) ",
"Hi! This dataset is indeed already available on the Hub. Closing."
] |
https://api.github.com/repos/huggingface/datasets/issues/4801 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4801/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4801/comments | https://api.github.com/repos/huggingface/datasets/issues/4801/events | https://github.com/huggingface/datasets/pull/4801 | 1,331,337,418 | PR_kwDODunzps48yTYu | 4,801 | Fix fine classes in trec dataset | [] | closed | false | null | 1 | 2022-08-08T05:11:02Z | 2022-08-22T16:29:14Z | 2022-08-22T16:14:15Z | null | This PR:
- replaces the fine labels, so that there are 50 instead of 47
- once more labels are added, all they (fine and coarse) have been re-ordered, so that they align with the order in: https://cogcomp.seas.upenn.edu/Data/QA/QC/definition.html
- the feature names have been fixed: `fine_label` instead of `label-fine`
- to sneak-case (underscores instead of hyphens)
- words have been reordered
Fix #4790. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4801/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4801/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4801.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4801",
"merged_at": "2022-08-22T16:14:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4801.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4801"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4858 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4858/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4858/comments | https://api.github.com/repos/huggingface/datasets/issues/4858/events | https://github.com/huggingface/datasets/issues/4858 | 1,340,859,853 | I_kwDODunzps5P6-XN | 4,858 | map() function removes columns when input_columns is not None | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2022-08-16T20:42:30Z | 2022-09-22T13:55:24Z | 2022-09-22T13:55:24Z | null | ## Describe the bug
The map function, removes features from the dataset that are not present in the _input_columns_ list of columns, despite the columns being removed not mentioned in the _remove_columns_ argument.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"a" : [1,2,3],"b" : [0,1,0], "c" : [2,4,5]})
def double(x,y):
x = x*2
y = y*2
return {"d" : x, "e" : y}
ds.map(double, input_columns=["a","c"])
```
## Expected results
```
Dataset({
features: ['a', 'b', 'c', 'd', 'e'],
num_rows: 3
})
```
## Actual results
```
Dataset({
features: ['a', 'c', 'd', 'e'],
num_rows: 3
})
```
In this specific example feature **b** should not be removed.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: linux (colab)
- Python version: 3.7.13
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4858/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4858/timeline | null | completed | null | null | false | [
"Hi! Thanks for reporting! This looks like a bug. I've just opened a PR with the fix.",
"Awesome! Thank you. I'll close the issue once the PR gets merged. :-)",
"I guess we should reopen after the revert by:\r\n- #5006"
] |
https://api.github.com/repos/huggingface/datasets/issues/5356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5356/comments | https://api.github.com/repos/huggingface/datasets/issues/5356/events | https://github.com/huggingface/datasets/pull/5356 | 1,494,961,609 | PR_kwDODunzps5FW-c9 | 5,356 | Clean filesystem and logging docstrings | [] | closed | false | null | 1 | 2022-12-13T18:54:09Z | 2022-12-14T17:25:58Z | 2022-12-14T17:22:16Z | null | This PR cleans the `Filesystems` and `Logging` docstrings. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5356/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5356",
"merged_at": "2022-12-14T17:22:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5356"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2116 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2116/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2116/comments | https://api.github.com/repos/huggingface/datasets/issues/2116/events | https://github.com/huggingface/datasets/issues/2116 | 841,481,292 | MDU6SXNzdWU4NDE0ODEyOTI= | 2,116 | Creating custom dataset results in error while calling the map() function | [] | closed | false | null | 1 | 2021-03-26T00:37:46Z | 2021-03-31T14:30:32Z | 2021-03-31T14:30:32Z | null | calling `map()` of `datasets` library results into an error while defining a Custom dataset.
Reproducible example:
```
import datasets
class MyDataset(datasets.Dataset):
def __init__(self, sentences):
"Initialization"
self.samples = sentences
def __len__(self):
"Denotes the total number of samples"
return len(self.samples)
def __getitem__(self, index):
"Generates one sample of data"
# Select sample
# Load data and get label
samples = self.samples[index]
return samples
def preprocess_function_train(examples):
inputs = examples
labels = [example+tokenizer.eos_token for example in examples ]
inputs = tokenizer(inputs, max_length=30, padding=True, truncation=True)
labels = tokenizer(labels, max_length=30, padding=True, truncation=True)
model_inputs = inputs
model_inputs["labels"] = labels["input_ids"]
print("about to return")
return model_inputs
##train["sentence"] is dataframe column
train_dataset = MyDataset(train['sentence'].values.tolist())
train_dataset = train_dataset.map(
preprocess_function,
batched = True,
batch_size=32
)
```
Stack trace of error:
```
Traceback (most recent call last):
File "dir/train_generate.py", line 362, in <module>
main()
File "dir/train_generate.py", line 245, in main
train_dataset = train_dataset.map(
File "anaconda_dir/anaconda3/envs/env1/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1244, in map
return self._map_single(
File "anaconda_dir/anaconda3/envs/env1/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 149, in wrapper
unformatted_columns = set(self.column_names) - set(self._format_columns or [])
File "anaconda_dir/anaconda3/envs/env1/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 526, in column_names
return self._data.column_names
AttributeError: 'MyDataset' object has no attribute '_data'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2116/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2116/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nthe `_data` attribute is missing due to `MyDataset.__init__` not calling the parent `__init__`. However, I don't think it's a good idea to subclass the `datasets.Dataset` class (e.g. it's kind of dangerous to override `datasets.Dataset.__getitem__`). Instead, it's better to follow the \"association over inheritance\" approach with a simple wrapper class that delegates calls to a wrapped `Dataset` (map, etc.). Btw, the library offers the `datasets.Dataset.from_pandas` class method to directly create a `datasets.Dataset` from the dataframe."
] |
https://api.github.com/repos/huggingface/datasets/issues/2078 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2078/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2078/comments | https://api.github.com/repos/huggingface/datasets/issues/2078/events | https://github.com/huggingface/datasets/issues/2078 | 834,694,819 | MDU6SXNzdWU4MzQ2OTQ4MTk= | 2,078 | MemoryError when computing WER metric | [
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] | closed | false | null | 11 | 2021-03-18T11:30:05Z | 2021-05-01T08:31:49Z | 2021-04-06T07:20:43Z | null | Hi, I'm trying to follow the ASR example to try Wav2Vec. This is the code that I use for WER calculation:
```
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
However, I receive the following exception:
`Traceback (most recent call last):
File "/home/diego/IpGlobal/wav2vec/test_wav2vec.py", line 51, in <module>
print(wer.compute(predictions=result["predicted"], references=result["target"]))
File "/home/diego/miniconda3/envs/wav2vec3.6/lib/python3.6/site-packages/datasets/metric.py", line 403, in compute
output = self._compute(predictions=predictions, references=references, **kwargs)
File "/home/diego/.cache/huggingface/modules/datasets_modules/metrics/wer/73b2d32b723b7fb8f204d785c00980ae4d937f12a65466f8fdf78706e2951281/wer.py", line 94, in _compute
return wer(references, predictions)
File "/home/diego/miniconda3/envs/wav2vec3.6/lib/python3.6/site-packages/jiwer/measures.py", line 81, in wer
truth, hypothesis, truth_transform, hypothesis_transform, **kwargs
File "/home/diego/miniconda3/envs/wav2vec3.6/lib/python3.6/site-packages/jiwer/measures.py", line 192, in compute_measures
H, S, D, I = _get_operation_counts(truth, hypothesis)
File "/home/diego/miniconda3/envs/wav2vec3.6/lib/python3.6/site-packages/jiwer/measures.py", line 273, in _get_operation_counts
editops = Levenshtein.editops(source_string, destination_string)
MemoryError`
My system has more than 10GB of available RAM. Looking at the code, I think that it could be related to the way jiwer does the calculation, as it is pasting all the sentences in a single string before calling Levenshtein editops function.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2078/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2078/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting.\r\nWe're indeed using `jiwer` to compute the WER.\r\n\r\nMaybe instead of calling `jiwer.wer` once for all the preditions/references we can compute the WER iteratively to avoid memory issues ? I'm not too familial with `jiwer` but this must be possible.\r\n\r\nCurrently the code to compute the WER is defined here:\r\n\r\nhttps://github.com/huggingface/nlp/blob/349ac4398a3bcae6356f14c5754483383a60e8a4/metrics/wer/wer.py#L93-L94",
"Hi,\r\n\r\nI've just pushed a pull request that is related to this issue https://github.com/huggingface/datasets/pull/2169. It's not iterative, but it should avoid memory errors. It's based on the editdistance python library. An iterative implementation should be as easy as storing scores and words stepwise and dividing at the end. ",
"I see, this was solved by other thread. Ok, let me know if you want to switch the implementation for any reason :)",
"Thanks for diving into this anyway ^^'\r\nAs you said this actually got solved a few days ago",
"Someone created an issue https://github.com/jitsi/jiwer/issues/40 at jiwer which shows that this is still a problem in the current version. Would be curious to figure out how this can be fixed by jiwer... :) I assume that it runs of out memory because it's trying to compute the WER over (too many) test samples?",
"Hi !\r\n\r\nIt's computed iteratively so not sure what could go wrong\r\n\r\nhttps://github.com/huggingface/datasets/blob/8afd0ba8c27800a55ea69d9fcd702dc97d9c16d8/metrics/wer/wer.py#L100-L106\r\n\r\n@NiklasHoltmeyer what version of `datasets` are you running ?\r\n",
"One possible explanation might be that it is the user who is passing all the sentences in a single element to `wer.compute`?\r\n\r\nAs current implementation iterates over the elements of `predictions` and `references`, this can be problematic if `predictions` and `references` contain a single huge element each. \r\n\r\nThis could be the case, for example, with a single string with all sentences:\r\n```python\r\nresult[\"predicted\"] = \"One sentence. Other sentence.\"\r\n```\r\nor with a __double__ nested list of sentence lists\r\n```python\r\nresult[\"predicted\"] = [[ [\"One sentence.\"], [\"Other sentence\"] ]]\r\n```\r\n\r\nThe user should check the dimensions of the data structure passed to `predictions` and `references`.",
"Hi all,\r\n\r\nin my case I was using and older version of datasets and, as @albertvillanova points out, passing the full list of sentences for the metric calculation. The problem was in the way jiwer implements WER, as it tries to compute WER for the full list at once instead of doing it element-wise. I think that with the latest implementation of datasets, or by using the alternative WER function that I've contributed on this [pull request](https://github.com/huggingface/datasets/pull/2169) there shouldn't be memory errors.",
"@lhoestq i was using Datasets==1.5.0 with 1.6.1 it worked (atleast the first run) but 1.5.0 is not compatible with my preprocessing. i cant save my dataset to a parquet file while using the latest datasets version\r\n\r\n-> \r\n```\r\n File \"../preprocess_dataset.py\", line 132, in <module>\r\n pq.write_table(train_dataset.data, f'{resampled_data_dir}/{data_args.dataset_config_name}.train.parquet')\r\n File \"/usr/local/lib/python3.8/dist-packages/pyarrow/parquet.py\", line 1674, in write_table\r\n writer.write_table(table, row_group_size=row_group_size)\r\n File \"/usr/local/lib/python3.8/dist-packages/pyarrow/parquet.py\", line 588, in write_table\r\n self.writer.write_table(table, row_group_size=row_group_size)\r\nTypeError: Argument 'table' has incorrect type (expected pyarrow.lib.Table, got ConcatenationTable)\r\n``` \r\n\r\nif i do \r\n```\r\nimport pyarrow.parquet as pq\r\n...\r\n...\r\npq.write_table(train_dataset.data, 'train.parquet')\r\npq.write_table(eval_dataset.data, 'eval.parquet')\r\n```\r\n\r\nwhile using 1.6.1. and its working with 1.5.0\r\n",
"Hi ! You can pass dataset.data.table instead of dataset.data to pq.write_table",
"This seems to be working so far! Thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3528/comments | https://api.github.com/repos/huggingface/datasets/issues/3528/events | https://github.com/huggingface/datasets/pull/3528 | 1,093,844,616 | PR_kwDODunzps4wiOqH | 3,528 | Update README.md | [] | closed | false | null | 0 | 2022-01-04T23:48:11Z | 2022-01-05T12:49:41Z | 2022-01-05T12:49:40Z | null | Updating license with appropriate capitalization & a link.
Updating Personal and Sensitive Information to address PII concern. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3528/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3528/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3528.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3528",
"merged_at": "2022-01-05T12:49:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3528.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3528"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/6040 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6040/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6040/comments | https://api.github.com/repos/huggingface/datasets/issues/6040/events | https://github.com/huggingface/datasets/pull/6040 | 1,807,410,238 | PR_kwDODunzps5VptVf | 6,040 | Fix legacy_dataset_infos | [] | closed | false | null | 3 | 2023-07-17T09:56:21Z | 2023-07-17T10:24:34Z | 2023-07-17T10:16:03Z | null | was causing transformers CI to fail
https://circleci.com/gh/huggingface/transformers/855105 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6040/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6040/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6040.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6040",
"merged_at": "2023-07-17T10:16:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6040.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6040"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006087 / 0.011353 (-0.005265) | 0.003567 / 0.011008 (-0.007442) | 0.079668 / 0.038508 (0.041160) | 0.063647 / 0.023109 (0.040538) | 0.323082 / 0.275898 (0.047184) | 0.348679 / 0.323480 (0.025199) | 0.004726 / 0.007986 (-0.003259) | 0.002955 / 0.004328 (-0.001373) | 0.062724 / 0.004250 (0.058473) | 0.050194 / 0.037052 (0.013142) | 0.321407 / 0.258489 (0.062918) | 0.355053 / 0.293841 (0.061212) | 0.026992 / 0.128546 (-0.101554) | 0.007994 / 0.075646 (-0.067653) | 0.260562 / 0.419271 (-0.158710) | 0.050933 / 0.043533 (0.007400) | 0.316644 / 0.255139 (0.061505) | 0.336759 / 0.283200 (0.053560) | 0.022581 / 0.141683 (-0.119101) | 1.481259 / 1.452155 (0.029104) | 1.535191 / 1.492716 (0.042475) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.194111 / 0.018006 (0.176104) | 0.448146 / 0.000490 (0.447656) | 0.000321 / 0.000200 (0.000121) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023908 / 0.037411 (-0.013503) | 0.073316 / 0.014526 (0.058790) | 0.085588 / 0.176557 (-0.090968) | 0.145377 / 0.737135 (-0.591759) | 0.084788 / 0.296338 (-0.211550) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439327 / 0.215209 (0.224118) | 4.384833 / 2.077655 (2.307179) | 2.322943 / 1.504120 (0.818823) | 2.147737 / 1.541195 (0.606542) | 2.226725 / 1.468490 (0.758235) | 0.502957 / 4.584777 (-4.081820) | 3.098106 / 3.745712 (-0.647606) | 4.194642 / 5.269862 (-1.075220) | 2.598820 / 4.565676 (-1.966856) | 0.057942 / 0.424275 (-0.366333) | 0.006857 / 0.007607 (-0.000750) | 0.511517 / 0.226044 (0.285472) | 5.121797 / 2.268929 (2.852868) | 2.756506 / 55.444624 (-52.688118) | 2.424602 / 6.876477 (-4.451875) | 2.608342 / 2.142072 (0.466270) | 0.589498 / 4.805227 (-4.215729) | 0.126065 / 6.500664 (-6.374600) | 0.061456 / 0.075469 (-0.014013) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239928 / 1.841788 (-0.601860) | 18.423532 / 8.074308 (10.349224) | 13.935148 / 10.191392 (3.743756) | 0.129913 / 0.680424 (-0.550511) | 0.016744 / 0.534201 (-0.517457) | 0.333468 / 0.579283 (-0.245815) | 0.359615 / 0.434364 (-0.074749) | 0.383678 / 0.540337 (-0.156659) | 0.533007 / 1.386936 (-0.853929) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005980 / 0.011353 (-0.005373) | 0.003640 / 0.011008 (-0.007368) | 0.062500 / 0.038508 (0.023992) | 0.059843 / 0.023109 (0.036733) | 0.360993 / 0.275898 (0.085095) | 0.401981 / 0.323480 (0.078501) | 0.005495 / 0.007986 (-0.002490) | 0.002862 / 0.004328 (-0.001467) | 0.062491 / 0.004250 (0.058240) | 0.050778 / 0.037052 (0.013726) | 0.371007 / 0.258489 (0.112518) | 0.405154 / 0.293841 (0.111313) | 0.027390 / 0.128546 (-0.101156) | 0.008042 / 0.075646 (-0.067604) | 0.067590 / 0.419271 (-0.351681) | 0.042485 / 0.043533 (-0.001048) | 0.361305 / 0.255139 (0.106166) | 0.388669 / 0.283200 (0.105469) | 0.024143 / 0.141683 (-0.117540) | 1.451508 / 1.452155 (-0.000647) | 1.490431 / 1.492716 (-0.002285) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.175976 / 0.018006 (0.157970) | 0.428923 / 0.000490 (0.428434) | 0.002099 / 0.000200 (0.001899) | 0.000068 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026346 / 0.037411 (-0.011065) | 0.078084 / 0.014526 (0.063558) | 0.087287 / 0.176557 (-0.089269) | 0.144179 / 0.737135 (-0.592957) | 0.088286 / 0.296338 (-0.208053) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.450436 / 0.215209 (0.235227) | 4.488801 / 2.077655 (2.411146) | 2.479303 / 1.504120 (0.975184) | 2.305396 / 1.541195 (0.764201) | 2.370370 / 1.468490 (0.901879) | 0.502355 / 4.584777 (-4.082422) | 3.094733 / 3.745712 (-0.650979) | 4.062367 / 5.269862 (-1.207495) | 2.587506 / 4.565676 (-1.978170) | 0.058245 / 0.424275 (-0.366030) | 0.006487 / 0.007607 (-0.001120) | 0.524147 / 0.226044 (0.298102) | 5.236876 / 2.268929 (2.967947) | 2.897134 / 55.444624 (-52.547490) | 2.574631 / 6.876477 (-4.301846) | 2.620307 / 2.142072 (0.478235) | 0.586963 / 4.805227 (-4.218265) | 0.125761 / 6.500664 (-6.374903) | 0.062264 / 0.075469 (-0.013205) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.299668 / 1.841788 (-0.542120) | 19.004441 / 8.074308 (10.930133) | 13.841867 / 10.191392 (3.650475) | 0.159674 / 0.680424 (-0.520750) | 0.016699 / 0.534201 (-0.517502) | 0.331868 / 0.579283 (-0.247415) | 0.344604 / 0.434364 (-0.089760) | 0.379391 / 0.540337 (-0.160947) | 0.514790 / 1.386936 (-0.872146) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005792 / 0.011353 (-0.005561) | 0.003519 / 0.011008 (-0.007489) | 0.079133 / 0.038508 (0.040625) | 0.057858 / 0.023109 (0.034749) | 0.314206 / 0.275898 (0.038308) | 0.346939 / 0.323480 (0.023459) | 0.004583 / 0.007986 (-0.003403) | 0.002824 / 0.004328 (-0.001504) | 0.061652 / 0.004250 (0.057402) | 0.048520 / 0.037052 (0.011467) | 0.318018 / 0.258489 (0.059529) | 0.350350 / 0.293841 (0.056509) | 0.026284 / 0.128546 (-0.102262) | 0.007827 / 0.075646 (-0.067819) | 0.259624 / 0.419271 (-0.159647) | 0.052318 / 0.043533 (0.008786) | 0.317400 / 0.255139 (0.062261) | 0.340530 / 0.283200 (0.057331) | 0.025181 / 0.141683 (-0.116501) | 1.459208 / 1.452155 (0.007053) | 1.529158 / 1.492716 (0.036442) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.169692 / 0.018006 (0.151686) | 0.432638 / 0.000490 (0.432148) | 0.003675 / 0.000200 (0.003475) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022956 / 0.037411 (-0.014456) | 0.071860 / 0.014526 (0.057334) | 0.082159 / 0.176557 (-0.094398) | 0.142560 / 0.737135 (-0.594576) | 0.082333 / 0.296338 (-0.214006) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397923 / 0.215209 (0.182714) | 3.958757 / 2.077655 (1.881102) | 1.925837 / 1.504120 (0.421717) | 1.758114 / 1.541195 (0.216919) | 1.808845 / 1.468490 (0.340354) | 0.501116 / 4.584777 (-4.083661) | 3.007739 / 3.745712 (-0.737973) | 3.295755 / 5.269862 (-1.974106) | 2.123843 / 4.565676 (-2.441833) | 0.057174 / 0.424275 (-0.367101) | 0.006426 / 0.007607 (-0.001182) | 0.468196 / 0.226044 (0.242152) | 4.677392 / 2.268929 (2.408464) | 2.334179 / 55.444624 (-53.110446) | 1.989283 / 6.876477 (-4.887194) | 2.140091 / 2.142072 (-0.001981) | 0.590700 / 4.805227 (-4.214527) | 0.124066 / 6.500664 (-6.376598) | 0.059931 / 0.075469 (-0.015538) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.224547 / 1.841788 (-0.617240) | 17.866979 / 8.074308 (9.792671) | 13.142009 / 10.191392 (2.950617) | 0.147081 / 0.680424 (-0.533343) | 0.016777 / 0.534201 (-0.517424) | 0.327766 / 0.579283 (-0.251517) | 0.343988 / 0.434364 (-0.090376) | 0.383268 / 0.540337 (-0.157070) | 0.528109 / 1.386936 (-0.858827) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006145 / 0.011353 (-0.005208) | 0.003634 / 0.011008 (-0.007374) | 0.062887 / 0.038508 (0.024379) | 0.062659 / 0.023109 (0.039550) | 0.362962 / 0.275898 (0.087064) | 0.405149 / 0.323480 (0.081669) | 0.004821 / 0.007986 (-0.003164) | 0.002888 / 0.004328 (-0.001441) | 0.062982 / 0.004250 (0.058732) | 0.051929 / 0.037052 (0.014877) | 0.366825 / 0.258489 (0.108336) | 0.409830 / 0.293841 (0.115989) | 0.027263 / 0.128546 (-0.101283) | 0.007972 / 0.075646 (-0.067674) | 0.067413 / 0.419271 (-0.351858) | 0.044233 / 0.043533 (0.000700) | 0.365087 / 0.255139 (0.109948) | 0.393845 / 0.283200 (0.110646) | 0.027740 / 0.141683 (-0.113943) | 1.497896 / 1.452155 (0.045741) | 1.549419 / 1.492716 (0.056703) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225510 / 0.018006 (0.207503) | 0.417054 / 0.000490 (0.416564) | 0.002184 / 0.000200 (0.001984) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025503 / 0.037411 (-0.011908) | 0.076164 / 0.014526 (0.061638) | 0.086110 / 0.176557 (-0.090446) | 0.140387 / 0.737135 (-0.596748) | 0.086956 / 0.296338 (-0.209382) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469667 / 0.215209 (0.254458) | 4.689915 / 2.077655 (2.612261) | 2.685000 / 1.504120 (1.180880) | 2.516160 / 1.541195 (0.974965) | 2.531733 / 1.468490 (1.063243) | 0.501675 / 4.584777 (-4.083102) | 3.000579 / 3.745712 (-0.745133) | 2.853376 / 5.269862 (-2.416486) | 1.810677 / 4.565676 (-2.754999) | 0.057632 / 0.424275 (-0.366643) | 0.006390 / 0.007607 (-0.001217) | 0.543986 / 0.226044 (0.317941) | 5.432837 / 2.268929 (3.163908) | 3.138797 / 55.444624 (-52.305827) | 2.813141 / 6.876477 (-4.063336) | 2.803681 / 2.142072 (0.661609) | 0.588736 / 4.805227 (-4.216491) | 0.125696 / 6.500664 (-6.374968) | 0.062492 / 0.075469 (-0.012977) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.337163 / 1.841788 (-0.504624) | 18.611715 / 8.074308 (10.537407) | 13.953016 / 10.191392 (3.761624) | 0.154670 / 0.680424 (-0.525754) | 0.016523 / 0.534201 (-0.517678) | 0.333898 / 0.579283 (-0.245385) | 0.336520 / 0.434364 (-0.097844) | 0.389032 / 0.540337 (-0.151305) | 0.529202 / 1.386936 (-0.857734) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2855 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2855/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2855/comments | https://api.github.com/repos/huggingface/datasets/issues/2855/events | https://github.com/huggingface/datasets/pull/2855 | 983,858,229 | MDExOlB1bGxSZXF1ZXN0NzIzMzcxMTIy | 2,855 | Fix windows CI CondaError | [] | closed | false | null | 0 | 2021-08-31T13:22:02Z | 2021-08-31T13:35:34Z | 2021-08-31T13:35:33Z | null | From this thread: https://github.com/conda/conda/issues/6057
We can fix the conda error
```
CondaError: Cannot link a source that does not exist.
C:\Users\...\Anaconda3\Scripts\conda.exe
```
by doing
```bash
conda update conda
```
before doing any install in the windows CI | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2855/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2855/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2855.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2855",
"merged_at": "2021-08-31T13:35:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2855.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2855"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/261 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/261/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/261/comments | https://api.github.com/repos/huggingface/datasets/issues/261/events | https://github.com/huggingface/datasets/issues/261 | 636,372,380 | MDU6SXNzdWU2MzYzNzIzODA= | 261 | Downloading dataset error with pyarrow.lib.RecordBatch | [] | closed | false | null | 2 | 2020-06-10T16:04:19Z | 2020-06-11T14:35:12Z | 2020-06-11T14:35:12Z | null | I am trying to download `sentiment140` and I have the following error
```
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
418 verify_infos = not save_infos and not ignore_verifications
419 self._download_and_prepare(
--> 420 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
421 )
422 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
472 try:
473 # Prepare split will record examples associated to the split
--> 474 self._prepare_split(split_generator, **prepare_split_kwargs)
475 except OSError:
476 raise OSError("Cannot find data file. " + (self.MANUAL_DOWNLOAD_INSTRUCTIONS or ""))
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _prepare_split(self, split_generator)
652 for key, record in utils.tqdm(generator, unit=" examples", total=split_info.num_examples, leave=False):
653 example = self.info.features.encode_example(record)
--> 654 writer.write(example)
655 num_examples, num_bytes = writer.finalize()
656
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write(self, example, writer_batch_size)
143 self._build_writer(pa_table=pa.Table.from_pydict(example))
144 if writer_batch_size is not None and len(self.current_rows) >= writer_batch_size:
--> 145 self.write_on_file()
146
147 def write_batch(
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write_on_file(self)
127 else:
128 # All good
--> 129 self._write_array_on_file(pa_array)
130 self.current_rows = []
131
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in _write_array_on_file(self, pa_array)
96 def _write_array_on_file(self, pa_array):
97 """Write a PyArrow Array"""
---> 98 pa_batch = pa.RecordBatch.from_struct_array(pa_array)
99 self._num_bytes += pa_array.nbytes
100 self.pa_writer.write_batch(pa_batch)
AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
```
I installed the last version and ran the following command:
```python
import nlp
sentiment140 = nlp.load_dataset('sentiment140', cache_dir='/content')
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/261/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/261/timeline | null | completed | null | null | false | [
"When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:\r\n```\r\nWARNING: The following packages were previously imported in this runtime:\r\n [pyarrow]\r\nYou must restart the runtime in order to use newly installed versions.\r\n```\r\nYou just have to restart the runtime and it should be fine.\r\nIf you don't restart, then it breaks like in your message.",
"Yeah, that worked! Thanks :) "
] |
https://api.github.com/repos/huggingface/datasets/issues/3035 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3035/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3035/comments | https://api.github.com/repos/huggingface/datasets/issues/3035/events | https://github.com/huggingface/datasets/issues/3035 | 1,016,770,071 | I_kwDODunzps48mq4X | 3,035 | `load_dataset` does not work with uploaded arrow file | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2021-10-05T20:15:10Z | 2021-10-06T17:01:37Z | null | null | ## Describe the bug
I've preprocessed and uploaded a dataset here: https://huggingface.co/datasets/ami-wav2vec2/ami_headset_single_preprocessed . The dataset is in `.arrow` format.
The dataset can correctly be loaded when doing:
```bash
git lfs install
git clone https://huggingface.co/datasets/ami-wav2vec2/ami_headset_single_preprocessed
```
followed by
```python
from datasets import load_from_disk
ds = load_from_disk("./ami_headset_single_preprocessed")
```
However when I try to directly download the dataset as follows:
```python
from datasets import load_dataset
ds = load_dataset("ami-wav2vec2/ami_headset_single_preprocessed")
```
the following error occurs:
```bash
/usr/local/lib/python3.7/dist-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
1115 ignore_verifications=ignore_verifications,
1116 try_from_hf_gcs=try_from_hf_gcs,
-> 1117 use_auth_token=use_auth_token,
1118 )
1119
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
635 if not downloaded_from_gcs:
636 self._download_and_prepare(
--> 637 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
638 )
639 # Sync info
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
724 try:
725 # Prepare split will record examples associated to the split
--> 726 self._prepare_split(split_generator, **prepare_split_kwargs)
727 except OSError as e:
728 raise OSError(
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _prepare_split(self, split_generator)
1186 generator, unit=" tables", leave=False, disable=bool(logging.get_verbosity() == logging.NOTSET)
1187 ):
-> 1188 writer.write_table(table)
1189 num_examples, num_bytes = writer.finalize()
1190
/usr/local/lib/python3.7/dist-packages/datasets/arrow_writer.py in write_table(self, pa_table, writer_batch_size)
424 # reorder the arrays if necessary + cast to self._schema
425 # we can't simply use .cast here because we may need to change the order of the columns
--> 426 pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
427 batches: List[pa.RecordBatch] = pa_table.to_batches(max_chunksize=writer_batch_size)
428 self._num_bytes += sum(batch.nbytes for batch in batches)
/usr/local/lib/python3.7/dist-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_arrays()
/usr/local/lib/python3.7/dist-packages/pyarrow/table.pxi in pyarrow.lib._sanitize_arrays()
/usr/local/lib/python3.7/dist-packages/pyarrow/array.pxi in pyarrow.lib.asarray()
/usr/local/lib/python3.7/dist-packages/pyarrow/table.pxi in pyarrow.lib.ChunkedArray.cast()
/usr/local/lib/python3.7/dist-packages/pyarrow/compute.py in cast(arr, target_type, safe)
279 else:
280 options = CastOptions.unsafe(target_type)
--> 281 return call_function("cast", [arr], options)
282
283
/usr/local/lib/python3.7/dist-packages/pyarrow/_compute.pyx in pyarrow._compute.call_function()
/usr/local/lib/python3.7/dist-packages/pyarrow/_compute.pyx in pyarrow._compute.Function.call()
/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowNotImplementedError: Unsupported cast from struct<train: struct<name: string, num_bytes: int64, num_examples: int64, dataset_name: string>, validation: struct<name: string, num_bytes: int64, num_examples: int64, dataset_name: string>, test: struct<name: string, num_bytes: int64, num_examples: int64, dataset_name: string>> to list using function cast_list
```
## Expected results
The dataset should be correctly loaded with `load_dataset` IMO.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.2.dev0
- Platform: Linux-5.11.0-34-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3035/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3035/timeline | null | null | null | null | false | [
"Hi ! This is not a bug, this is simply not implemented.\r\n`save_to_disk` is for on-disk serialization and was not made compatible for the Hub.\r\nThat being said, I agree we actually should make it work with the Hub x)",
"cc @LysandreJik maybe we can solve this at the same time as adding `push_to_hub`"
] |
https://api.github.com/repos/huggingface/datasets/issues/1864 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1864/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1864/comments | https://api.github.com/repos/huggingface/datasets/issues/1864/events | https://github.com/huggingface/datasets/issues/1864 | 806,172,843 | MDU6SXNzdWU4MDYxNzI4NDM= | 1,864 | Add Winogender Schemas | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2021-02-11T08:18:38Z | 2021-02-11T08:19:51Z | 2021-02-11T08:19:51Z | null | ## Adding a Dataset
- **Name:** Winogender Schemas
- **Description:** Winogender Schemas (inspired by Winograd Schemas) are minimal pairs of sentences that differ only by the gender of one pronoun in the sentence, designed to test for the presence of gender bias in automated coreference resolution systems.
- **Paper:** https://arxiv.org/abs/1804.09301
- **Data:** https://github.com/rudinger/winogender-schemas (see data directory)
- **Motivation:** Testing gender bias in automated coreference resolution systems, improve coreference resolution in general.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1864/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1864/timeline | null | completed | null | null | false | [
"Nevermind, this one is already available on the hub under the name `'wino_bias'`: https://huggingface.co/datasets/wino_bias"
] |
https://api.github.com/repos/huggingface/datasets/issues/5006 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5006/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5006/comments | https://api.github.com/repos/huggingface/datasets/issues/5006/events | https://github.com/huggingface/datasets/pull/5006 | 1,380,968,395 | PR_kwDODunzps4_Wm8z | 5,006 | Revert input_columns change | [] | closed | false | null | 2 | 2022-09-21T13:49:20Z | 2022-09-21T14:14:33Z | 2022-09-21T14:11:57Z | null | Revert https://github.com/huggingface/datasets/pull/4971
Fix https://github.com/huggingface/datasets/issues/5005 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5006/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5006/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5006.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5006",
"merged_at": "2022-09-21T14:11:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5006.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5006"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Merging this one and I'll check if it fixes the `transformers` CI before doing a patch release"
] |
https://api.github.com/repos/huggingface/datasets/issues/485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/485/comments | https://api.github.com/repos/huggingface/datasets/issues/485/events | https://github.com/huggingface/datasets/issues/485 | 675,595,393 | MDU6SXNzdWU2NzU1OTUzOTM= | 485 | PAWS dataset first item is header | [] | closed | false | null | 0 | 2020-08-08T22:05:25Z | 2020-08-19T09:50:01Z | 2020-08-19T09:50:01Z | null | ```
import nlp
dataset = nlp.load_dataset('xtreme', 'PAWS-X.en')
dataset['test'][0]
```
prints the following
```
{'label': 'label', 'sentence1': 'sentence1', 'sentence2': 'sentence2'}
```
dataset['test'][0] should probably be the first item in the dataset, not just a dictionary mapping the column names to themselves. Probably just need to ignore the first row in the dataset by default or something like that. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/485/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/485/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2299 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2299/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2299/comments | https://api.github.com/repos/huggingface/datasets/issues/2299/events | https://github.com/huggingface/datasets/issues/2299 | 873,914,717 | MDU6SXNzdWU4NzM5MTQ3MTc= | 2,299 | My iPhone | [] | closed | false | null | 0 | 2021-05-02T11:11:11Z | 2021-07-23T09:24:16Z | 2021-05-03T08:17:38Z | null | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2299/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2299/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2365/comments | https://api.github.com/repos/huggingface/datasets/issues/2365/events | https://github.com/huggingface/datasets/issues/2365 | 893,179,697 | MDU6SXNzdWU4OTMxNzk2OTc= | 2,365 | Missing ClassLabel encoding in Json loader | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"closed_at": "2021-07-09T05:50:07Z",
"closed_issues": 12,
"created_at": "2021-05-31T16:13:06Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-07-08T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/5",
"id": 6808903,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/5/labels",
"node_id": "MDk6TWlsZXN0b25lNjgwODkwMw==",
"number": 5,
"open_issues": 0,
"state": "closed",
"title": "1.9",
"updated_at": "2021-07-12T14:12:00Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/5"
} | 0 | 2021-05-17T10:19:10Z | 2021-06-28T15:05:34Z | 2021-06-28T15:05:34Z | null | Currently if you want to load a json dataset this way
```python
dataset = load_dataset("json", data_files=data_files, features=features)
```
Then if your features has ClassLabel types and if your json data needs class label encoding (i.e. if the labels in the json files are strings and not integers), then it would fail:
```python
[...]
~/Desktop/hf/datasets/src/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
94 if self.config.schema:
95 # Cast allows str <-> int/float, while parse_option explicit_schema does NOT
---> 96 pa_table = pa_table.cast(self.config.schema)
97 yield i, pa_table
[...]
ArrowInvalid: Failed to parse string: 'O' as a scalar of type int64
```
This is because it just tries to cast the string data to integers, without applying the mapping str->int first
The current workaround is to do instead
```python
dataset = load_dataset("json", data_files=data_files)
dataset = dataset.map(features.encode_example, features=features)
``` | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2365/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4885 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4885/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4885/comments | https://api.github.com/repos/huggingface/datasets/issues/4885/events | https://github.com/huggingface/datasets/issues/4885 | 1,349,181,448 | I_kwDODunzps5QauAI | 4,885 | Create dataset from list of dicts | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 3 | 2022-08-24T10:01:24Z | 2022-09-08T16:02:52Z | 2022-09-08T16:02:52Z | null | I often find myself with data from a variety of sources, and a list of dicts is very common among these.
However, converting this to a Dataset is a little awkward, requiring either
```Dataset.from_pandas(pd.DataFrame(formatted_training_data))```
Which can error out on some more exotic values as 2-d arrays for reasons that are not entirely clear
> ArrowInvalid: ('Can only convert 1-dimensional array values', 'Conversion failed for column labels with type object')
Alternatively:
```Dataset.from_dict({k: [s[k] for s in formatted_training_data] for k in formatted_training_data[0].keys()})```
Which works, but is a little ugly.
**Describe the solution you'd like**
Either `.from_dict` accepting a list of dicts, or a `.from_records` function accepting such.
I am happy to PR this, just wanted to check you are happy to accept this I haven't missed something obvious, and which of the solutions would be prefered.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4885/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4885/timeline | null | completed | null | null | false | [
"Hi @sanderland, thanks for your enhancement proposal.\r\n\r\nI agree with you that this would be useful.\r\n\r\nPlease note that under the hood, we use PyArrow tables as backend:\r\n- The implementation of `Dataset.from_dict` uses the PyArrow `Table.from_pydict`\r\n\r\nTherefore, I would suggest:\r\n- Implementing `Dataset.from_list` using the PyArrow `Table.from_pylist`\r\n\r\nWhat do you think?\r\nLet's see if other people have other suggestions...",
"Thanks for the quick and positive reply @albertvillanova! \r\n`from_list` seems sensible. Have opened a PR so we can discuss details there.",
"Resolved via #4890."
] |
https://api.github.com/repos/huggingface/datasets/issues/2657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2657/comments | https://api.github.com/repos/huggingface/datasets/issues/2657/events | https://github.com/huggingface/datasets/issues/2657 | 945,822,829 | MDU6SXNzdWU5NDU4MjI4Mjk= | 2,657 | `to_json` reporting enhancements | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2021-07-15T23:32:18Z | 2021-07-15T23:33:53Z | null | null | While using `to_json` 2 things came to mind that would have made the experience easier on the user:
1. Could we have a `desc` arg for the tqdm use and a fallback to just `to_json` so that it'd be clear to the user what's happening? Surely, one can just print the description before calling json, but I thought perhaps it'd help to have it self-identify like you did for other progress bars recently.
2. It took me a while to make sense of the reported numbers:
```
22%|██▏ | 1536/7076 [12:30:57<44:09:42, 28.70s/it]
```
So iteration here happens to be 10K samples, and the total is 70M records. But the user does't know that, so the progress bar is perfect, but the numbers it reports are meaningless until one discovers that 1it=10K samples. And one still has to convert these in the head - so it's not quick. Not exactly sure what's the best way to approach this, perhaps it can be part of `desc`? or report M or K, so it'd be built-in if it were to print, e.g.:
```
22%|██▏ | 15360K/70760K [12:30:57<44:09:42, 28.70s/it]
```
or
```
22%|██▏ | 15.36M/70.76M [12:30:57<44:09:42, 28.70s/it]
```
(while of course remaining friendly to small datasets)
I forget if tqdm lets you add a magnitude identifier to the running count.
Thank you! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2657/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4892 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4892/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4892/comments | https://api.github.com/repos/huggingface/datasets/issues/4892/events | https://github.com/huggingface/datasets/pull/4892 | 1,350,636,499 | PR_kwDODunzps49yCD3 | 4,892 | Add citation to ro_sts and ro_sts_parallel datasets | [] | closed | false | null | 1 | 2022-08-25T09:51:06Z | 2022-08-25T10:49:56Z | 2022-08-25T10:49:56Z | null | This PR adds the citation information to `ro_sts_parallel` and `ro_sts_parallel` datasets, once they have replied our request for that information:
- https://github.com/dumitrescustefan/RO-STS/issues/4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4892/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4892/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4892.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4892",
"merged_at": "2022-08-25T10:49:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4892.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4892"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4892). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/1921 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1921/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1921/comments | https://api.github.com/repos/huggingface/datasets/issues/1921/events | https://github.com/huggingface/datasets/pull/1921 | 812,716,042 | MDExOlB1bGxSZXF1ZXN0NTc3MDEzMDM4 | 1,921 | Standardizing datasets dtypes | [] | closed | false | null | 1 | 2021-02-20T22:04:01Z | 2021-02-22T09:44:10Z | 2021-02-22T09:44:10Z | null | This PR follows up on discussion in #1900 to have an explicit set of basic dtypes for datasets.
This moves away from str(pyarrow.DataType) as the method of choice for creating dtypes, favoring an explicit mapping to a list of supported Value dtypes.
I believe in practice this should be backward compatible, since anyone previously using Value() would only have been able to use dtypes that had an identically named pyarrow factory function, which are all explicitly supported here, with `float32` and `float64` acting as the official datasets dtypes, which resolves the tension between `double` being the pyarrow dtype and `float64` being the pyarrow type factory function. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1921/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1921/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1921.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1921",
"merged_at": "2021-02-22T09:44:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1921.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1921"
} | true | [
"@lhoestq - apologies for the multiple PRs, my previous one (#1905) got mangled due to some merge conflicts that I had trouble resolving so I just cherry-picked my changes onto a fresh branch here."
] |
https://api.github.com/repos/huggingface/datasets/issues/5843 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5843/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5843/comments | https://api.github.com/repos/huggingface/datasets/issues/5843/events | https://github.com/huggingface/datasets/issues/5843 | 1,705,514,551 | I_kwDODunzps5lqBY3 | 5,843 | Can't add iterable datasets to a Dataset Dict. | [] | closed | false | null | 2 | 2023-05-11T02:09:29Z | 2023-05-25T04:51:59Z | 2023-05-25T04:51:59Z | null | ### System Info
standard env
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Get the following error:
TypeError: Values in `DatasetDict` should be of type `Dataset` but got type '<class 'datasets.iterable_dataset.IterableDataset'>'
### Expected behavior
should be able to add iterable datasets to a dataset dict | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5843/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5843/timeline | null | completed | null | null | false | [
"Transferring as this is relating to the 🤗 Datasets library",
"You need to use `IterableDatasetDict` instead of `DatasetDict` for iterable datasets."
] |
https://api.github.com/repos/huggingface/datasets/issues/4620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4620/comments | https://api.github.com/repos/huggingface/datasets/issues/4620/events | https://github.com/huggingface/datasets/issues/4620 | 1,292,797,878 | I_kwDODunzps5NDoe2 | 4,620 | Data type is not recognized when using datetime.time | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-07-04T08:13:38Z | 2022-07-07T13:57:11Z | 2022-07-07T13:57:11Z | null | ## Describe the bug
Creating a dataset from a pandas dataframe with `datetime.time` format generates an error.
## Steps to reproduce the bug
```python
import pandas as pd
from datetime import time
from datasets import Dataset
df = pd.DataFrame({"feature_name": [time(1, 1, 1)]})
dataset = Dataset.from_pandas(df)
```
## Expected results
The dataset should be created.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 823, in from_pandas
return cls(table, info=info, split=split)
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 679, in __init__
inferred_features = Features.from_arrow_schema(arrow_table.schema)
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/features/features.py", line 1551, in from_arrow_schema
obj = {field.name: generate_from_arrow_type(field.type) for field in pa_schema}
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/features/features.py", line 1551, in <dictcomp>
obj = {field.name: generate_from_arrow_type(field.type) for field in pa_schema}
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/features/features.py", line 1315, in generate_from_arrow_type
return Value(dtype=_arrow_to_datasets_dtype(pa_type))
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/features/features.py", line 83, in _arrow_to_datasets_dtype
return f"time64[{arrow_type.unit}]"
AttributeError: 'pyarrow.lib.DataType' object has no attribute 'unit'
```
## Environment info
- `datasets` version: 2.3.3.dev0
- Platform: Linux-5.13.0-1031-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 7.0.0
- Pandas version: 1.4.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4620/timeline | null | completed | null | null | false | [
"cc @mariosasko ",
"Hi, thanks for reporting! I'm investigating the issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/1578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1578/comments | https://api.github.com/repos/huggingface/datasets/issues/1578/events | https://github.com/huggingface/datasets/pull/1578 | 767,760,513 | MDExOlB1bGxSZXF1ZXN0NTQwMzY1NzYz | 1,578 | update multiwozv22 checksums | [] | closed | false | null | 0 | 2020-12-15T16:13:52Z | 2020-12-15T17:06:29Z | 2020-12-15T17:06:29Z | null | a file was updated on the GitHub repo for the dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1578/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1578.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1578",
"merged_at": "2020-12-15T17:06:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1578.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1578"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1030 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1030/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1030/comments | https://api.github.com/repos/huggingface/datasets/issues/1030/events | https://github.com/huggingface/datasets/pull/1030 | 755,777,438 | MDExOlB1bGxSZXF1ZXN0NTMxNDI0MDM3 | 1,030 | allegro_reviews dataset | [] | closed | false | null | 0 | 2020-12-03T03:11:39Z | 2020-12-04T10:56:29Z | 2020-12-03T16:34:47Z | null | - **Name:** *allegro_reviews*
- **Description:** *Allegro Reviews is a sentiment analysis dataset, consisting of 11,588 product reviews written in Polish and extracted from Allegro.pl - a popular e-commerce marketplace. Each review contains at least 50 words and has a rating on a scale from one (negative review) to five (positive review).*
- **Data:** *https://github.com/allegro/klejbenchmark-allegroreviews*
- **Motivation:** *The KLEJ benchmark (Kompleksowa Lista Ewaluacji Językowych) is a set of nine evaluation tasks for the Polish language understanding.* | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1030/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1030/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1030.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1030",
"merged_at": "2020-12-03T16:34:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1030.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1030"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1477 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1477/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1477/comments | https://api.github.com/repos/huggingface/datasets/issues/1477/events | https://github.com/huggingface/datasets/pull/1477 | 762,288,811 | MDExOlB1bGxSZXF1ZXN0NTM2ODQ5NzM4 | 1,477 | Jigsaw toxicity pred | [] | closed | false | null | 0 | 2020-12-11T12:13:20Z | 2020-12-14T13:19:35Z | 2020-12-14T13:19:35Z | null | Managed to mess up my original pull request, opening a fresh one incorporating the changes suggested by @lhoestq. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1477/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1477/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1477.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1477",
"merged_at": "2020-12-14T13:19:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1477.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1477"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5771 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5771/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5771/comments | https://api.github.com/repos/huggingface/datasets/issues/5771/events | https://github.com/huggingface/datasets/issues/5771 | 1,674,828,380 | I_kwDODunzps5j09pc | 5,771 | Support cloud storage for loading datasets | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2023-04-19T12:43:53Z | 2023-05-07T17:47:41Z | 2023-05-07T17:47:41Z | null | ### Feature request
It seems that the the current implementation supports cloud storage only for `load_from_disk`. It would be nice if a similar functionality existed in `load_dataset`.
### Motivation
Motivation is pretty clear -- let users work with datasets located in the cloud.
### Your contribution
I can help implementing this. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5771/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5771/timeline | null | completed | null | null | false | [
"A duplicate of https://github.com/huggingface/datasets/issues/5281"
] |
https://api.github.com/repos/huggingface/datasets/issues/5241 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5241/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5241/comments | https://api.github.com/repos/huggingface/datasets/issues/5241/events | https://github.com/huggingface/datasets/pull/5241 | 1,448,510,407 | PR_kwDODunzps5C3MTG | 5,241 | Support hfh rc version | [] | closed | false | null | 1 | 2022-11-14T18:05:47Z | 2022-11-15T16:11:30Z | 2022-11-15T16:09:31Z | null | otherwise the code doesn't work for hfh 0.11.0rc0
following #5237 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5241/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5241/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5241.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5241",
"merged_at": "2022-11-15T16:09:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5241.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5241"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5390/comments | https://api.github.com/repos/huggingface/datasets/issues/5390/events | https://github.com/huggingface/datasets/issues/5390 | 1,509,357,553 | I_kwDODunzps5Z9vfx | 5,390 | Error when pushing to the CI hub | [] | closed | false | null | 5 | 2022-12-23T13:36:37Z | 2022-12-23T20:29:02Z | 2022-12-23T20:29:02Z | null | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.93s/it]
Traceback (most recent call last):
File "reproduce_hubci.py", line 16, in <module>
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
File "/home/slesage/hf/datasets/src/datasets/arrow_dataset.py", line 5025, in push_to_hub
HfApi(endpoint=config.HF_ENDPOINT).upload_file(
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1346, in upload_file
raise err
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1337, in upload_file
r.raise_for_status()
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/requests/models.py", line 953, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_DATASETS_SERVER_USER__/bug-16718047265472/upload/main/README.md
```
### Steps to reproduce the bug
```python
# reproduce.py
from datasets import Dataset
import time
USER = "__DUMMY_DATASETS_SERVER_USER__"
USER_TOKEN = "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"
dataset = Dataset.from_dict({"a": [1, 2, 3]})
repo_id = f"{USER}/bug-{int(time.time() * 10e3)}"
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
```
```bash
$ HF_ENDPOINT="https://hub-ci.huggingface.co" python reproduce.py
```
### Expected behavior
No error and the dataset should be uploaded to the Hub with the README file (which generates the error).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.0-1026-aws-x86_64-with-glibc2.35
- Python version: 3.9.15
- PyArrow version: 7.0.0
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5390/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5390/timeline | null | completed | null | null | false | [
"Hmmm, git bisect tells me that the behavior is the same since https://github.com/huggingface/datasets/commit/67e65c90e9490810b89ee140da11fdd13c356c9c (3 Oct), i.e. https://github.com/huggingface/datasets/pull/4926",
"Maybe related to the discussions in https://github.com/huggingface/datasets/pull/5196",
"Maybe the current version of moonlanding in Hub CI is the issue.\r\n\r\nI relaunched tests that were working two days ago: now they are failing. https://github.com/huggingface/datasets-server/commit/746414449cae4b311733f8a76e5b3b4ca73b38a9 for example\r\n\r\ncc @huggingface/moon-landing ",
"Hi! I don't think this has anything to do with `datasets`. Hub CI seems to be the culprit - the identical failure can be found in [this](https://github.com/huggingface/datasets/pull/5389) PR (with unrelated changes) opened today.",
"OK! Thanks for looking at it. Closing then."
] |
https://api.github.com/repos/huggingface/datasets/issues/5311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5311/comments | https://api.github.com/repos/huggingface/datasets/issues/5311/events | https://github.com/huggingface/datasets/pull/5311 | 1,467,875,153 | PR_kwDODunzps5D4Mm3 | 5,311 | Add `features` param to `IterableDataset.map` | [] | closed | false | null | 1 | 2022-11-29T11:08:34Z | 2022-12-06T15:45:02Z | 2022-12-06T15:42:04Z | null | ## Description
As suggested by @lhoestq in #3888, we should be adding the param `features` to `IterableDataset.map` so that the features can be preserved (not turned into `None` as that's the default behavior) whenever the user passes those as param, so as to be consistent with `Dataset.map`, as it provides the `features` param so that those are not inferred by default, but specified by the user, and later validated by `ArrowWriter`.
This is internally handled already by the functions relying on `IterableDataset.map` such as `rename_column`, `rename_columns`, and `remove_columns` as described in #5287.
## Usage Example
```python
from datasets import load_dataset, Features
ds = load_dataset("rotten_tomatoes", split="validation", streaming=True)
print(ds.info.features)
ds = ds.map(
lambda x: {"target": x["label"]},
features=Features(
{"target": ds.info.features["label"], "label": ds.info.features["label"], "text": ds.info.features["text"]}
),
)
print(ds.info.features)
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5311/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5311/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5311.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5311",
"merged_at": "2022-12-06T15:42:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5311.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5311"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2667/comments | https://api.github.com/repos/huggingface/datasets/issues/2667/events | https://github.com/huggingface/datasets/pull/2667 | 946,861,908 | MDExOlB1bGxSZXF1ZXN0NjkxOTYwNzc3 | 2,667 | Use tqdm from tqdm_utils | [] | closed | false | null | 2 | 2021-07-17T17:06:35Z | 2021-07-19T17:39:10Z | 2021-07-19T17:32:00Z | null | This PR replaces `tqdm` from the `tqdm` lib with `tqdm` from `datasets.utils.tqdm_utils`. With this change, it's possible to disable progress bars just by calling `disable_progress_bar`. Note this doesn't work on Windows when using multiprocessing due to how global variables are shared between processes. Currently, there is no easy way to disable progress bars in a multiprocess setting on Windows (patching logging with `datasets.utils.logging.get_verbosity = lambda: datasets.utils.logging.NOTSET` doesn't seem to work as well), so adding support for this is a future goal. Additionally, this PR adds a unit ("ba" for batches) to the bar printed by `Dataset.to_json` (this change is motivated by https://github.com/huggingface/datasets/issues/2657). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2667/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2667",
"merged_at": "2021-07-19T17:32:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2667"
} | true | [
"The current CI failure is due to modifications in the dataset script.",
"Merging since the CI is only failing because of dataset card issues, which is unrelated to this PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/774 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/774/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/774/comments | https://api.github.com/repos/huggingface/datasets/issues/774/events | https://github.com/huggingface/datasets/pull/774 | 732,265,741 | MDExOlB1bGxSZXF1ZXN0NTEyMjM0NjA0 | 774 | [ROUGE] Add description to Rouge metric | [] | closed | false | null | 0 | 2020-10-29T12:19:32Z | 2020-10-29T17:55:50Z | 2020-10-29T17:55:48Z | null | Add information about case sensitivity to ROUGE. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/774/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/774/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/774.diff",
"html_url": "https://github.com/huggingface/datasets/pull/774",
"merged_at": "2020-10-29T17:55:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/774.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/774"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1326 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1326/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1326/comments | https://api.github.com/repos/huggingface/datasets/issues/1326/events | https://github.com/huggingface/datasets/pull/1326 | 759,611,784 | MDExOlB1bGxSZXF1ZXN0NTM0NTg2ODY4 | 1,326 | TEP: Tehran English-Persian parallel corpus | [] | closed | false | null | 0 | 2020-12-08T16:56:53Z | 2020-12-19T14:55:03Z | 2020-12-10T11:25:17Z | null | TEP: Tehran English-Persian parallel corpus
more info : http://opus.nlpl.eu/TEP.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1326/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1326/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1326.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1326",
"merged_at": "2020-12-10T11:25:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1326.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1326"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2509 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2509/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2509/comments | https://api.github.com/repos/huggingface/datasets/issues/2509/events | https://github.com/huggingface/datasets/pull/2509 | 922,846,035 | MDExOlB1bGxSZXF1ZXN0NjcxNjcyMzU5 | 2,509 | Fix fingerprint when moving cache dir | [] | closed | false | null | 4 | 2021-06-16T16:45:09Z | 2021-06-21T15:05:04Z | 2021-06-21T15:05:03Z | null | The fingerprint of a dataset changes if the cache directory is moved.
I fixed that by setting the fingerprint to be the hash of:
- the relative cache dir (dataset_name/version/config_id)
- the requested split
Close #2496
I had to fix an issue with the filelock filename that was too long (>255). It prevented the tests to run on my machine. I just added `hash_filename_if_too_long` in case this happens, to not get filenames longer than 255.
We usually have long filenames for filelocks because they are named after the path that is being locked. In case the path is a cache directory that has long directory names, then the filelock filename could en up being very long. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2509/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2509/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2509.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2509",
"merged_at": "2021-06-21T15:05:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2509.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2509"
} | true | [
"Windows, why are you doing this to me ?",
"Thanks @lhoestq, I'm starting reviewing this PR.",
"Yea issues on windows are about long paths, not long filenames.\r\nWe can make sure the lock filenames are not too long, but not for the paths",
"Took your suggestions into account @albertvillanova :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5849 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5849/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5849/comments | https://api.github.com/repos/huggingface/datasets/issues/5849/events | https://github.com/huggingface/datasets/issues/5849 | 1,707,551,511 | I_kwDODunzps5lxysX | 5,849 | CSV datasets should only read the CSV data files in the repo | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2023-05-12T12:29:53Z | 2023-06-22T14:16:27Z | 2023-06-22T14:16:27Z | null | When a no-script dataset has many CSV files and a JPG file, the library infers to use the Csv builder, but tries to read as CSV all files in the repo, also the JPG file.
I think the Csv builder should filter out non-CSV files when reading.
An analogue solution should be implemented for other packaged builders.
Related to:
- https://huggingface.co/datasets/abidlabs/img2text/discussions/1
- https://github.com/gradio-app/gradio/pull/3973#issuecomment-1545409061
CC: @abidlabs @severo | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5849/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5849/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1918/comments | https://api.github.com/repos/huggingface/datasets/issues/1918/events | https://github.com/huggingface/datasets/pull/1918 | 812,541,510 | MDExOlB1bGxSZXF1ZXN0NTc2ODg2OTQ0 | 1,918 | Fix QA4MRE download URLs | [] | closed | false | null | 0 | 2021-02-20T07:32:17Z | 2021-02-22T13:35:06Z | 2021-02-22T13:35:06Z | null | The URLs in the `dataset_infos` and `README` are correct, only the ones in the download script needed updating. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1918/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1918/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1918.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1918",
"merged_at": "2021-02-22T13:35:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1918.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1918"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/232/comments | https://api.github.com/repos/huggingface/datasets/issues/232/events | https://github.com/huggingface/datasets/pull/232 | 630,029,568 | MDExOlB1bGxSZXF1ZXN0NDI3MjI5NDcy | 232 | Nlp cli fix endpoints | [] | closed | false | null | 1 | 2020-06-03T14:10:39Z | 2020-06-08T09:02:58Z | 2020-06-08T09:02:57Z | null | With this PR users will be able to upload their own datasets and metrics.
As mentioned in #181, I had to use the new endpoints and revert the use of dataclasses (just in case we have changes in the API in the future).
We now distinguish commands for datasets and commands for metrics:
```bash
nlp-cli upload_dataset <path/to/dataset>
nlp-cli upload_metric <path/to/metric>
nlp-cli s3_datasets {rm, ls}
nlp-cli s3_metrics {rm, ls}
```
Does it sound good to you @julien-c @thomwolf ? | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/232/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/232/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/232.diff",
"html_url": "https://github.com/huggingface/datasets/pull/232",
"merged_at": "2020-06-08T09:02:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/232.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/232"
} | true | [
"LGTM 👍 "
] |
https://api.github.com/repos/huggingface/datasets/issues/4524 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4524/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4524/comments | https://api.github.com/repos/huggingface/datasets/issues/4524/events | https://github.com/huggingface/datasets/issues/4524 | 1,275,909,186 | I_kwDODunzps5MDNRC | 4,524 | Downloading via Apache Pipeline, client cancelled (org.apache.beam.vendor.grpc.v1p43p2.io.grpc.StatusRuntimeException) | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 2 | 2022-06-18T23:36:45Z | 2022-06-21T00:38:20Z | null | null | ## Describe the bug
When downloading some `wikipedia` languages (in particular, I'm having a hard time with Spanish, Cebuano, and Russian) via FlinkRunner, I encounter the exception in the title. I have been playing with package versions a lot, because unfortunately, the different dependencies required by these packages seem to be incompatible in terms of versions (dill and requests, for instance). It should be noted that the following code runs for several hours without issue, executing the `load_dataset()` function, before the exception occurs.
## Steps to reproduce the bug
```python
# bash commands
!pip install datasets
!pip install apache-beam[interactive]
!pip install mwparserfromhell
!pip install dill==0.3.5.1
!pip install requests==2.23.0
# imports
import os
from datasets import load_dataset
import apache_beam as beam
import mwparserfromhell
from google.colab import drive
import dill
import requests
# mount drive
drive_dir = os.path.join(os.getcwd(), 'drive')
drive.mount(drive_dir)
# confirming the versions of these two packages are the ones that are suggested by the outputs from the bash commands
print(dill.__version__)
print(requests.__version__)
lang = 'es' # or 'ru' or 'ceb' - these are the ones causing the issue
lang_dir = os.path.join(drive_dir, 'path/to/my/folder', lang)
if not os.path.exists(lang_dir):
x = None
x = load_dataset('wikipedia', '20220301.' + lang, beam_runner='Flink',
split='train')
x.save_to_disk(lang_dir)
```
## Expected results
Although some warnings are generally produced by this code (run in Colab Notebook), most languages I've tried have been successfully downloaded. It should simply go through without issue, but for these languages, I am continually encountering this error.
## Actual results
Traceback below:
```
Exception in thread run_worker_3-1:
Traceback (most recent call last):
File "/usr/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/usr/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 234, in run
for work_request in self._control_stub.Control(get_responses()):
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 426, in __next__
return self._next()
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 826, in _next
raise self
grpc._channel._MultiThreadedRendezvous: <_MultiThreadedRendezvous of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "Socket closed"
debug_error_string = "{"created":"@1655593643.871830638","description":"Error received from peer ipv4:127.0.0.1:44441","file":"src/core/lib/surface/call.cc","file_line":952,"grpc_message":"Socket closed","grpc_status":14}"
>
Traceback (most recent call last):
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 267, in _execute
response = task()
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 340, in <lambda>
lambda: self.create_worker().do_instruction(request), request)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 581, in do_instruction
getattr(request, request_type), request.instruction_id)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 618, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 996, in process_bundle
element.data)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 221, in process_encoded
self.output(decoded_value)
File "apache_beam/runners/worker/operations.py", line 346, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 348, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 215, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive
File "apache_beam/runners/worker/operations.py", line 707, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/worker/operations.py", line 708, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/common.py", line 1200, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 1281, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
ERROR:apache_beam.runners.worker.sdk_worker:Error processing instruction 26. Original traceback is
Traceback (most recent call last):
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 267, in _execute
response = task()
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 340, in <lambda>
lambda: self.create_worker().do_instruction(request), request)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 581, in do_instruction
getattr(request, request_type), request.instruction_id)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 618, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 996, in process_bundle
element.data)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 221, in process_encoded
self.output(decoded_value)
File "apache_beam/runners/worker/operations.py", line 346, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 348, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 215, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive
File "apache_beam/runners/worker/operations.py", line 707, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/worker/operations.py", line 708, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/common.py", line 1200, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 1281, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
ERROR:root:org.apache.beam.vendor.grpc.v1p43p2.io.grpc.StatusRuntimeException: CANCELLED: client cancelled
ERROR:apache_beam.runners.worker.data_plane:Failed to read inputs in the data plane.
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/data_plane.py", line 634, in _read_inputs
for elements in elements_iterator:
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 426, in __next__
return self._next()
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 826, in _next
raise self
grpc._channel._MultiThreadedRendezvous: <_MultiThreadedRendezvous of RPC that terminated with:
status = StatusCode.CANCELLED
details = "Multiplexer hanging up"
debug_error_string = "{"created":"@1655593654.436885887","description":"Error received from peer ipv4:127.0.0.1:43263","file":"src/core/lib/surface/call.cc","file_line":952,"grpc_message":"Multiplexer hanging up","grpc_status":1}"
>
Exception in thread read_grpc_client_inputs:
Traceback (most recent call last):
File "/usr/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/usr/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/data_plane.py", line 651, in <lambda>
target=lambda: self._read_inputs(elements_iterator),
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/data_plane.py", line 634, in _read_inputs
for elements in elements_iterator:
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 426, in __next__
return self._next()
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 826, in _next
raise self
grpc._channel._MultiThreadedRendezvous: <_MultiThreadedRendezvous of RPC that terminated with:
status = StatusCode.CANCELLED
details = "Multiplexer hanging up"
debug_error_string = "{"created":"@1655593654.436885887","description":"Error received from peer ipv4:127.0.0.1:43263","file":"src/core/lib/surface/call.cc","file_line":952,"grpc_message":"Multiplexer hanging up","grpc_status":1}"
>
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
[/tmp/ipykernel_219/3869142325.py](https://localhost:8080/#) in <module>
18 x = None
19 x = load_dataset('wikipedia', '20220301.' + lang, beam_runner='Flink',
---> 20 split='train')
21 x.save_to_disk(lang_dir)
3 frames
[/usr/local/lib/python3.7/dist-packages/apache_beam/runners/portability/portable_runner.py](https://localhost:8080/#) in wait_until_finish(self, duration)
604
605 if self._runtime_exception:
--> 606 raise self._runtime_exception
607
608 return self._state
RuntimeError: Pipeline BeamApp-root-0618220708-b3b59a0e_d8efcf67-9119-4f76-b013-70de7b29b54d failed in state FAILED: org.apache.beam.vendor.grpc.v1p43p2.io.grpc.StatusRuntimeException: CANCELLED: client cancelled
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- PyArrow version: 6.0.1
- Pandas version: 1.3.5
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4524/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4524/timeline | null | null | null | null | false | [
"Hi @dan-the-meme-man, thanks for reporting.\r\n\r\nWe are investigating a similar issue but with Beam+Dataflow (instead of Beam+Flink): \r\n- #4525\r\n\r\nIn order to go deeper into the root cause, we need as much information as possible: logs from the main process + logs from the workers are very informative.\r\n\r\nIn the case of the issue with Beam+Dataflow, the logs from the workers report an out of memory issue.",
"As I continued working on this today, I came to suspect that it is in fact an out of memory issue - I have a few more notebooks that I've left running, and if they produce the same error, I will try to get the logs. In the meantime, if there's any chance that there is a repo out there with those three languages already as .arrow files, or if you know about how much memory would be needed to actually download those sets, please let me know!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5112 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5112/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5112/comments | https://api.github.com/repos/huggingface/datasets/issues/5112/events | https://github.com/huggingface/datasets/issues/5112 | 1,409,143,409 | I_kwDODunzps5T_dJx | 5,112 | Bug with filtered indices | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2022-10-14T10:35:47Z | 2022-10-14T13:55:03Z | 2022-10-14T12:11:45Z | null | ## Describe the bug
As reported by @PartiallyTyped (and by @Muennighoff):
- https://github.com/huggingface/datasets/issues/5111#issuecomment-1278652524
There is an issue with the indices of a filtered dataset.
## Steps to reproduce the bug
```python
ds = Dataset.from_dict({"num": [0, 1, 2, 3]})
ds = ds.filter(lambda num: num % 2 == 0, input_columns="num", batch_size=2)
assert all(item["num"] % 2 == 0 for item in ds)
```
## Expected results
The indices of the filtered dataset should correspond to the examples with "language" equals to "english".
## Actual results
Indices to items with other languages are included in the filtered dataset indices
## Preliminar investigation
It seems a bug introduced by:
- #5030
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5112/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5112/timeline | null | completed | null | null | false | [
"The issue is here:\r\nhttps://github.com/huggingface/datasets/blob/3ad9644b9a2e4558dd1d0f1e43c67658674e6228/src/datasets/arrow_dataset.py#L2964",
"@PartiallyTyped, @Muennighoff: the issue is fixed.\r\n\r\nWe are planning to make a patch release today.",
"Thanks a lot for the swift response! For a brief moment yesterday I thought I had gone insane 🤣On 14 Oct 2022, at 15:44, Albert Villanova del Moral ***@***.***> wrote:\n@PartiallyTyped, @Muennighoff: the issue is fixed.\nWe are planning to make a patch release today.\n\n—Reply to this email directly, view it on GitHub, or unsubscribe.You are receiving this because you were mentioned.Message ID: ***@***.***>"
] |
https://api.github.com/repos/huggingface/datasets/issues/2872 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2872/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2872/comments | https://api.github.com/repos/huggingface/datasets/issues/2872/events | https://github.com/huggingface/datasets/pull/2872 | 989,453,069 | MDExOlB1bGxSZXF1ZXN0NzI4MTkzMjkz | 2,872 | adding swedish_medical_ner | [] | closed | false | null | 0 | 2021-09-06T22:00:52Z | 2021-09-07T04:36:32Z | 2021-09-07T04:36:32Z | null | Adding the Swedish Medical NER dataset, listed in "Biomedical Datasets - BigScience Workshop 2021" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2872/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2872/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2872.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2872",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2872.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2872"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2849 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2849/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2849/comments | https://api.github.com/repos/huggingface/datasets/issues/2849/events | https://github.com/huggingface/datasets/issues/2849 | 982,631,420 | MDU6SXNzdWU5ODI2MzE0MjA= | 2,849 | Add Open Catalyst Project Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 0 | 2021-08-30T10:14:39Z | 2021-08-30T10:14:39Z | null | null | ## Adding a Dataset
- **Name:** Open Catalyst 2020 (OC20) Dataset
- **Website:** https://opencatalystproject.org/
- **Data:** https://github.com/Open-Catalyst-Project/ocp/blob/master/DATASET.md
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2849/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2849/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2370 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2370/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2370/comments | https://api.github.com/repos/huggingface/datasets/issues/2370/events | https://github.com/huggingface/datasets/pull/2370 | 893,606,432 | MDExOlB1bGxSZXF1ZXN0NjQ2MDkyNDQy | 2,370 | Adding HendrycksTest dataset | [] | closed | false | null | 5 | 2021-05-17T18:53:05Z | 2023-05-11T05:42:57Z | 2021-05-31T16:37:13Z | null | Adding Hendrycks test from https://arxiv.org/abs/2009.03300.
I'm having a bit of trouble with dummy data creation because some lines in the csv files aren't being loaded properly (only the first entry loaded in a row of length 6). The dataset is loading just fine. Hope you can kindly help!
Thank you! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2370/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2370/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2370.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2370",
"merged_at": "2021-05-31T16:37:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2370.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2370"
} | true | [
"@lhoestq Thank you for the review. I've made the suggested changes. There still might be some problems with dummy data though due to some csv loading issues (which I haven't found the cause to).",
"I took a look at the dummy data and some csv lines were cropped. I fixed them :)",
"@andyzoujm Any reason why this dataset scrip was called \"hendrycks_test\" instead of \"mmlu\"?\r\n\r\nWe are thinking of renaming it...",
"That's because we didn't call it MMLU in the paper (the shorthand didn't\nemerge until over a year later), and people at OpenAI were calling it that.\n\nAndy\n\nOn Wed, Apr 26, 2023 at 8:44 AM Albert Villanova del Moral <\n***@***.***> wrote:\n\n> @andyzoujm <https://github.com/andyzoujm> Any reason why this dataset\n> scrip was called \"hendrycks_test\" instead of \"mmlu\"?\n>\n> We are thinking of renaming it...\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/pull/2370#issuecomment-1523358110>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AKLQJMZZFZBGJTBOIFWJ5KDXDEKB5ANCNFSM45BAOSIQ>\n> .\n> You are receiving this because you were mentioned.Message ID:\n> ***@***.***>\n>\n",
"Thanks for your reply. Just for the records: we have renamed it to \"cais/mmlu\": https://huggingface.co/datasets/cais/mmlu"
] |
https://api.github.com/repos/huggingface/datasets/issues/5757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5757/comments | https://api.github.com/repos/huggingface/datasets/issues/5757/events | https://github.com/huggingface/datasets/issues/5757 | 1,669,910,503 | I_kwDODunzps5jiM_n | 5,757 | Tilde (~) is not supported | [] | closed | false | null | 0 | 2023-04-16T11:48:10Z | 2023-04-20T15:30:51Z | 2023-04-20T15:30:51Z | null | ### Describe the bug
It seems that `~` is not recognized correctly in local paths. Whenever I try to use it I get an exception
### Steps to reproduce the bug
```python
load_dataset("imagefolder", data_dir="~/data/my_dataset")
```
Will generate the following error:
```
EmptyDatasetError: The directory at /path/to/cwd/~/data/datasets/clementine_tagged_per_cam doesn't contain any data files
```
### Expected behavior
Load the dataset.
### Environment info
datasets==2.11.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5757/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5757/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3657/comments | https://api.github.com/repos/huggingface/datasets/issues/3657/events | https://github.com/huggingface/datasets/pull/3657 | 1,120,602,620 | PR_kwDODunzps4x5f1I | 3,657 | Extend dataset builder for streaming in `get_dataset_split_names` | [] | closed | false | null | 4 | 2022-02-01T12:21:24Z | 2022-02-03T22:49:06Z | 2022-02-02T11:22:01Z | null | Currently, `get_dataset_split_names` doesn't extend a builder module to support streaming, even though it uses `StreamingDownloadManager` to download data. This PR fixes that.
To test the change, run the following:
```bash
pip install git+https://github.com/huggingface/datasets.git@fix-get_dataset_split_names-streaming
python -c "from datasets import get_dataset_split_names; print(get_dataset_split_names('facebook/multilingual_librispeech', 'german', download_mode='force_redownload', revision='137923f945552c6afdd8b60e4a7b43e3088972c1'))"
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3657/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3657.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3657",
"merged_at": "2022-02-02T11:22:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3657.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3657"
} | true | [
"I'm impatient to see if it has an impact on the number of valid datasets for the dataset viewer. For the record, today:\r\n\r\n<img width=\"660\" alt=\"Capture d’écran 2022-02-01 à 14 32 19\" src=\"https://user-images.githubusercontent.com/1676121/151977579-b5a239d9-6662-4aeb-bfd1-eef6b8249991.png\">\r\n",
"This is now available in `datasets` 1.18.3 :)",
"I'm on it https://github.com/huggingface/datasets-preview-backend/issues/130\r\n",
"The result:\r\n<img width=\"671\" alt=\"Capture d’écran 2022-02-03 à 23 45 55\" src=\"https://user-images.githubusercontent.com/1676121/152442169-bfdac643-9a00-4901-bfa7-1d60a1679d4b.png\">\r\n\r\nNot very different. Maybe it fixed issues in the community datasets... But I'm not 100% the two states are comparable (datasets have been created, or updated, meanwhile)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5678/comments | https://api.github.com/repos/huggingface/datasets/issues/5678/events | https://github.com/huggingface/datasets/issues/5678 | 1,645,018,359 | I_kwDODunzps5iDPz3 | 5,678 | Add support to create a Dataset from spark dataframe | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 3 | 2023-03-29T04:36:28Z | 2023-07-21T14:15:38Z | 2023-07-21T14:15:38Z | null | ### Feature request
Add a new API `Dataset.from_spark` to create a Dataset from Spark DataFrame.
### Motivation
Spark is a distributed computing framework that can handle large datasets. By supporting loading Spark DataFrames directly into Hugging Face Datasets, we enable take the advantages of spark to processing the data in parallel.
By providing a seamless integration between these two frameworks, we make it easier for data scientists and developers to work with both Spark and Hugging Face in the same workflow.
### Your contribution
We can discuss about the ideas and I can help preparing a PR for this feature. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5678/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5678/timeline | null | completed | null | null | false | [
"if i read spark Dataframe , got an error on multi-node Spark cluster.\r\nDid the Api (Dataset.from_spark) support Spark cluster, read dataframe and save_to_disk?\r\n\r\nError: \r\n_pickle.PicklingError: Could not serialize object: RuntimeError: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transforma\r\ntion. SparkContext can only be used on the driver, not in code that it run on workers. For more information, see SPARK-5063.\r\n23/06/16 21:17:20 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed (this is expected if the application is shutting down.)\r\n\r\n",
"How to perform predictions on Dataset object in Spark with multi-node cluster parallelism?",
"Addressed in #5701"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.