Spaces:
Running


A newer version of the Gradio SDK is available:
5.28.0
Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language
CVPR 2024
![]()
![]()
![]()
![]()
Mark Hamilton, Andrew Zisserman, John R. Hershey, William T. Freeman
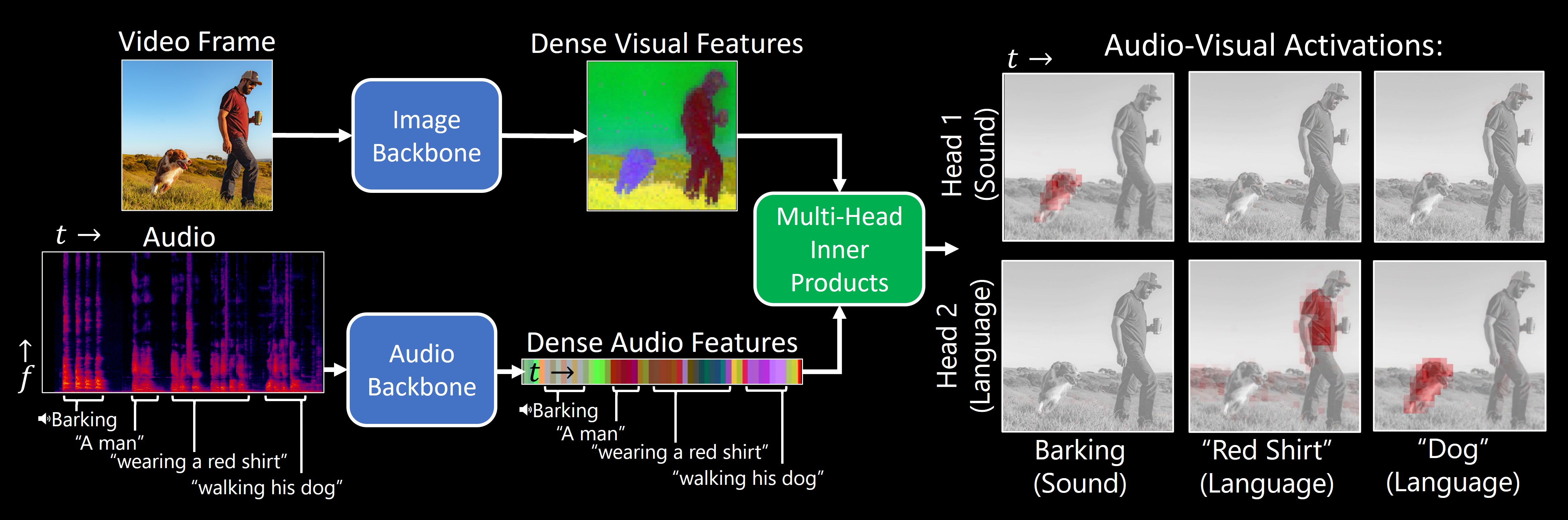
TL;DR:Our model, DenseAV, learns the meaning of words and the location of sounds (visual grounding) without supervision or text.
https://github.com/mhamilton723/DenseAV/assets/6456637/ba908ab5-9618-42f9-8d7a-30ecb009091f
Contents
- Install
- Model Zoo
- Getting Datasets
- Evaluate Models
- Train a Model
- Local Gradio Demo
- Coming Soon
- Citation
- Contact
Install
To use DenseAV locally clone the repository:
git clone https://github.com/mhamilton723/DenseAV.git
cd DenseAV
pip install -e .
Model Zoo
To see examples of pretrained model usage please see our Collab notebook. We currently supply the following pretrained models:
| Model Name | Checkpoint | Torch Hub Repository | Torch Hub Name |
|---|---|---|---|
| Sound | Download | mhamilton723/DenseAV | sound |
| Language | Download | mhamilton723/DenseAV | language |
| Sound + Language (Two Headed) | Download | mhamilton723/DenseAV | sound_and_language |
For example, to load the model trained on both sound and language:
model = torch.hub.load("mhamilton723/DenseAV", 'sound_and_language')
Load from HuggingFace
from denseav.train import LitAVAligner
model1 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-sound")
model2 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-language")
model3 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-sound-language")
Getting Datasets
Our code assumes that all data lives in a common directory on your system, in these examples we use /path/to/your/data. Our code will often reference this directory as the data_root
Speech and Sound Prompted ADE20K
To download our new Speech and Sound prompted ADE20K Dataset:
cd /path/to/your/data
wget https://marhamilresearch4.blob.core.windows.net/denseav-public/datasets/ADE20KSoundPrompted.zip
unzip ADE20KSoundPrompted.zip
wget https://marhamilresearch4.blob.core.windows.net/denseav-public/datasets/ADE20KSpeechPrompted.zip
unzip ADE20KSpeechPrompted.zip
Places Audio
First download the places audio dataset from its original source.
To run the code the data will need to be processed to be of the form:
[Instructions coming soon]
Audioset
Because of copyright issues we cannot make Audioset easily availible to download. First download this dataset through appropriate means. This other project appears to make this simple.
To run the code the data will need to be processed to be of the form:
[Instructions coming soon]
Evaluate Models
To evaluate a trained model first clone the repository for local development. Then run
cd featup
python evaluate.py
After evaluation, see the results in tensorboard's hparams tab.
cd ../logs/evaluate
tensorboard --logdir .
Then visit https://localhost:6006 and click on hparams to browse results. We report "advanced" speech metrics and "basic" sound metrics in our paper.
Train a Model
cd denseav
python train.py
Local Gradio Demo
To run our HuggingFace Spaces hosted DenseAV demo locally first install DenseAV for local development. Then run:
python gradio_app.py
Wait a few seconds for the demo to spin up, then navigate to http://localhost:7860/ to view the demo.
Coming Soon:
- Bigger models!
Citation
@misc{hamilton2024separating,
title={Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language},
author={Mark Hamilton and Andrew Zisserman and John R. Hershey and William T. Freeman},
year={2024},
eprint={2406.05629},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Contact
For feedback, questions, or press inquiries please contact Mark Hamilton