Spaces:
Running

Running
sixth commit
Browse files- .env_template +6 -1
- .streamlit/config.toml +17 -0
- Dockerfile +25 -3
- README.md +10 -2
- Screenshots.md +11 -13
- app/__init__.py +0 -0
- app/data/sqlite.db +0 -0
- app/database.py +219 -67
- app/home.py +68 -0
- app/main.py +0 -430
- app/pages/__init__.py +0 -0
- app/pages/chat_interface.py +361 -0
- app/pages/data_ingestion.py +145 -0
- app/pages/evaluation.py +134 -0
- app/pages/ground_truth.py +100 -0
- app/rag.py +23 -8
- app/utils.py +62 -0
- data/ground-truth-retrieval.csv +10 -0
- data/sqlite.db +0 -0
- docker-compose.yaml +37 -4
- grafana/dashboards/rag_evaluation.json +6 -6
- grafana/provisioning/datasources/sqlite.yaml +2 -1
- image-1.png +0 -0
- image-10.png +0 -0
- image-11.png +0 -0
- image-2.png +0 -0
- image-3.png +0 -0
- image-4.png +0 -0
- image-5.png +0 -0
- image-6.png +0 -0
- image-7.png +0 -0
- image-8.png +0 -0
- image-9.png +0 -0
- image.png +0 -0
- images/image-1.png +0 -0
- images/image-2.png +0 -0
- images/image-3.png +0 -0
- images/image-4.png +0 -0
- images/image-5.png +0 -0
- images/image-6.png +0 -0
- images/image.png +0 -0
.env_template
CHANGED
|
@@ -1 +1,6 @@
|
|
| 1 |
-
YOUTUBE_API_KEY='YOUR YOUTUBE_API_KEY'
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
YOUTUBE_API_KEY='YOUR YOUTUBE_API_KEY'
|
| 2 |
+
HF_TOKEN='YOUR Hugging Face API KEY'
|
| 3 |
+
OLLAMA_MODEL='Your model'
|
| 4 |
+
OLLAMA_HOST='Your Host Name'
|
| 5 |
+
OLLAMA_TIMEOUT=240
|
| 6 |
+
OLLAMA_MAX_RETRIES=3
|
.streamlit/config.toml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[browser]
|
| 2 |
+
gatherUsageStats = false
|
| 3 |
+
|
| 4 |
+
[theme]
|
| 5 |
+
primaryColor = "#FF4B4B"
|
| 6 |
+
backgroundColor = "#FFFFFF"
|
| 7 |
+
secondaryBackgroundColor = "#F0F2F6"
|
| 8 |
+
textColor = "#262730"
|
| 9 |
+
|
| 10 |
+
[server]
|
| 11 |
+
runOnSave = true
|
| 12 |
+
port = 8501
|
| 13 |
+
address = "0.0.0.0"
|
| 14 |
+
|
| 15 |
+
[ui]
|
| 16 |
+
hideTopBar = false
|
| 17 |
+
hideSidebarNav = false
|
Dockerfile
CHANGED
|
@@ -17,15 +17,37 @@ COPY requirements.txt .
|
|
| 17 |
# Install any needed packages specified in requirements.txt
|
| 18 |
RUN pip install --no-cache-dir -r requirements.txt
|
| 19 |
|
| 20 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
COPY app/ ./app/
|
| 22 |
COPY config/ ./config/
|
| 23 |
COPY data/ ./data/
|
| 24 |
COPY grafana/ ./grafana/
|
| 25 |
COPY .env ./
|
|
|
|
| 26 |
|
| 27 |
# Make port 8501 available to the world outside this container
|
| 28 |
EXPOSE 8501
|
| 29 |
|
| 30 |
-
#
|
| 31 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
# Install any needed packages specified in requirements.txt
|
| 18 |
RUN pip install --no-cache-dir -r requirements.txt
|
| 19 |
|
| 20 |
+
# Create necessary directories
|
| 21 |
+
RUN mkdir -p app/pages config data grafana logs /root/.streamlit
|
| 22 |
+
|
| 23 |
+
# Set Python path and Streamlit configs
|
| 24 |
+
ENV PYTHONPATH=/app \
|
| 25 |
+
STREAMLIT_BROWSER_GATHER_USAGE_STATS=false \
|
| 26 |
+
STREAMLIT_THEME_PRIMARY_COLOR="#FF4B4B" \
|
| 27 |
+
STREAMLIT_SERVER_PORT=8501 \
|
| 28 |
+
STREAMLIT_SERVER_ADDRESS=0.0.0.0
|
| 29 |
+
|
| 30 |
+
# Create empty __init__.py files
|
| 31 |
+
RUN touch app/__init__.py app/pages/__init__.py
|
| 32 |
+
|
| 33 |
+
# Copy the application code and other files into the container
|
| 34 |
COPY app/ ./app/
|
| 35 |
COPY config/ ./config/
|
| 36 |
COPY data/ ./data/
|
| 37 |
COPY grafana/ ./grafana/
|
| 38 |
COPY .env ./
|
| 39 |
+
COPY .streamlit/config.toml /root/.streamlit/config.toml
|
| 40 |
|
| 41 |
# Make port 8501 available to the world outside this container
|
| 42 |
EXPOSE 8501
|
| 43 |
|
| 44 |
+
# Create a healthcheck script
|
| 45 |
+
RUN echo '#!/bin/bash\ncurl -f http://localhost:8501/_stcore/health' > /healthcheck.sh && \
|
| 46 |
+
chmod +x /healthcheck.sh
|
| 47 |
+
|
| 48 |
+
# Add healthcheck
|
| 49 |
+
HEALTHCHECK --interval=30s --timeout=10s --start-period=5s --retries=3 \
|
| 50 |
+
CMD ["/healthcheck.sh"]
|
| 51 |
+
|
| 52 |
+
# Run Streamlit
|
| 53 |
+
CMD ["streamlit", "run", "app/home.py", "--server.port=8501", "--server.address=0.0.0.0"]
|
README.md
CHANGED
|
@@ -61,8 +61,12 @@ The YouTube Assistant project is organized as follows:
|
|
| 61 |
```
|
| 62 |
youtube-rag-app/
|
| 63 |
├── app/
|
| 64 |
-
│ ├──
|
| 65 |
-
│ ├──
|
|
|
|
|
|
|
|
|
|
|
|
|
| 66 |
│ ├── transcript_extractor.py
|
| 67 |
│ ├── data_processor.py
|
| 68 |
│ ├── elasticsearch_handler.py
|
|
@@ -70,6 +74,7 @@ youtube-rag-app/
|
|
| 70 |
│ ├── rag.py
|
| 71 |
│ ├── query_rewriter.py
|
| 72 |
│ └── evaluation.py
|
|
|
|
| 73 |
├── data/
|
| 74 |
│ └── sqlite.db
|
| 75 |
├── config/
|
|
@@ -129,3 +134,6 @@ I used the LLM as a Judge metric to evaluate the quality of our RAG Flow on my l
|
|
| 129 |
* PARTLY_RELEVANT - 0 (0%)
|
| 130 |
* NON RELEVANT - 0 (0%)
|
| 131 |
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
```
|
| 62 |
youtube-rag-app/
|
| 63 |
├── app/
|
| 64 |
+
│ ├── home.py
|
| 65 |
+
│ ├── pages/
|
| 66 |
+
│ ├────── chat_interface.py
|
| 67 |
+
│ ├────── data_ingestion.py
|
| 68 |
+
│ ├────── evauation.py
|
| 69 |
+
│ ├────── ground_truth.py
|
| 70 |
│ ├── transcript_extractor.py
|
| 71 |
│ ├── data_processor.py
|
| 72 |
│ ├── elasticsearch_handler.py
|
|
|
|
| 74 |
│ ├── rag.py
|
| 75 |
│ ├── query_rewriter.py
|
| 76 |
│ └── evaluation.py
|
| 77 |
+
│ └── utils.py
|
| 78 |
├── data/
|
| 79 |
│ └── sqlite.db
|
| 80 |
├── config/
|
|
|
|
| 134 |
* PARTLY_RELEVANT - 0 (0%)
|
| 135 |
* NON RELEVANT - 0 (0%)
|
| 136 |
|
| 137 |
+
### Monitoring
|
| 138 |
+
|
| 139 |
+
I used Grafana to monitor the metrics, user feedback, evaluation results, and search performance.
|
Screenshots.md
CHANGED
|
@@ -1,27 +1,25 @@
|
|
| 1 |
### Docker deployment
|
| 2 |
|
| 3 |
-

|
| 14 |
-

|
| 15 |
-

|
| 16 |
-

|
| 17 |
|
| 18 |
### Ground Truth Generation
|
| 19 |
-

|
| 20 |
|
| 21 |
-

|
|
|
|
|
|
|
| 26 |
|
| 27 |
-

|
| 4 |
|
| 5 |
+
### Home
|
| 6 |
+

|
| 7 |
|
| 8 |
+
### Ingestion
|
| 9 |
+

|
| 10 |
|
| 11 |
### RAG
|
| 12 |
|
| 13 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
### Ground Truth Generation
|
|
|
|
| 16 |
|
| 17 |
+

|
| 18 |
|
| 19 |
### RAG Evaluation
|
| 20 |
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
### Monitoring
|
| 24 |
|
| 25 |
+

|
app/__init__.py
ADDED
|
File without changes
|
app/data/sqlite.db
ADDED
|
Binary file (127 kB). View file
|
|
|
app/database.py
CHANGED
|
@@ -1,17 +1,43 @@
|
|
| 1 |
import sqlite3
|
| 2 |
import os
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
| 4 |
class DatabaseHandler:
|
| 5 |
def __init__(self, db_path='data/sqlite.db'):
|
| 6 |
self.db_path = db_path
|
| 7 |
self.conn = None
|
|
|
|
| 8 |
self.create_tables()
|
| 9 |
self.update_schema()
|
|
|
|
| 10 |
|
| 11 |
def create_tables(self):
|
| 12 |
with sqlite3.connect(self.db_path) as conn:
|
| 13 |
cursor = conn.cursor()
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
cursor.execute('''
|
| 16 |
CREATE TABLE IF NOT EXISTS videos (
|
| 17 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
@@ -27,16 +53,35 @@ class DatabaseHandler:
|
|
| 27 |
transcript_content TEXT
|
| 28 |
)
|
| 29 |
''')
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 30 |
cursor.execute('''
|
| 31 |
CREATE TABLE IF NOT EXISTS user_feedback (
|
| 32 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 33 |
-
video_id
|
|
|
|
| 34 |
query TEXT,
|
| 35 |
-
|
|
|
|
| 36 |
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 37 |
-
FOREIGN KEY (video_id) REFERENCES videos (
|
|
|
|
| 38 |
)
|
| 39 |
''')
|
|
|
|
|
|
|
| 40 |
cursor.execute('''
|
| 41 |
CREATE TABLE IF NOT EXISTS embedding_models (
|
| 42 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
@@ -44,6 +89,8 @@ class DatabaseHandler:
|
|
| 44 |
description TEXT
|
| 45 |
)
|
| 46 |
''')
|
|
|
|
|
|
|
| 47 |
cursor.execute('''
|
| 48 |
CREATE TABLE IF NOT EXISTS elasticsearch_indices (
|
| 49 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
@@ -55,27 +102,31 @@ class DatabaseHandler:
|
|
| 55 |
)
|
| 56 |
''')
|
| 57 |
|
| 58 |
-
#
|
| 59 |
cursor.execute('''
|
| 60 |
CREATE TABLE IF NOT EXISTS ground_truth (
|
| 61 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 62 |
video_id TEXT,
|
| 63 |
question TEXT,
|
| 64 |
generation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 65 |
-
UNIQUE(video_id, question)
|
|
|
|
| 66 |
)
|
| 67 |
''')
|
| 68 |
|
|
|
|
| 69 |
cursor.execute('''
|
| 70 |
CREATE TABLE IF NOT EXISTS search_performance (
|
| 71 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 72 |
video_id TEXT,
|
| 73 |
hit_rate REAL,
|
| 74 |
mrr REAL,
|
| 75 |
-
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
|
|
|
| 76 |
)
|
| 77 |
''')
|
| 78 |
|
|
|
|
| 79 |
cursor.execute('''
|
| 80 |
CREATE TABLE IF NOT EXISTS search_parameters (
|
| 81 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
@@ -83,10 +134,12 @@ class DatabaseHandler:
|
|
| 83 |
parameter_name TEXT,
|
| 84 |
parameter_value REAL,
|
| 85 |
score REAL,
|
| 86 |
-
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
|
|
|
| 87 |
)
|
| 88 |
''')
|
| 89 |
|
|
|
|
| 90 |
cursor.execute('''
|
| 91 |
CREATE TABLE IF NOT EXISTS rag_evaluations (
|
| 92 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
@@ -95,14 +148,18 @@ class DatabaseHandler:
|
|
| 95 |
answer TEXT,
|
| 96 |
relevance TEXT,
|
| 97 |
explanation TEXT,
|
| 98 |
-
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
|
|
|
| 99 |
)
|
| 100 |
''')
|
|
|
|
| 101 |
conn.commit()
|
| 102 |
|
| 103 |
def update_schema(self):
|
| 104 |
with sqlite3.connect(self.db_path) as conn:
|
| 105 |
cursor = conn.cursor()
|
|
|
|
|
|
|
| 106 |
cursor.execute("PRAGMA table_info(videos)")
|
| 107 |
columns = [column[1] for column in cursor.fetchall()]
|
| 108 |
|
|
@@ -121,36 +178,122 @@ class DatabaseHandler:
|
|
| 121 |
|
| 122 |
conn.commit()
|
| 123 |
|
|
|
|
| 124 |
def add_video(self, video_data):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 125 |
with sqlite3.connect(self.db_path) as conn:
|
| 126 |
cursor = conn.cursor()
|
| 127 |
cursor.execute('''
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
'''
|
| 132 |
-
|
| 133 |
-
video_data['title'],
|
| 134 |
-
video_data['author'],
|
| 135 |
-
video_data['upload_date'],
|
| 136 |
-
video_data['view_count'],
|
| 137 |
-
video_data['like_count'],
|
| 138 |
-
video_data['comment_count'],
|
| 139 |
-
video_data['video_duration'],
|
| 140 |
-
video_data['transcript_content']
|
| 141 |
-
))
|
| 142 |
-
conn.commit()
|
| 143 |
-
return cursor.lastrowid
|
| 144 |
|
| 145 |
-
|
|
|
|
| 146 |
with sqlite3.connect(self.db_path) as conn:
|
| 147 |
cursor = conn.cursor()
|
| 148 |
cursor.execute('''
|
| 149 |
-
INSERT INTO
|
| 150 |
VALUES (?, ?, ?)
|
| 151 |
-
''', (video_id,
|
| 152 |
conn.commit()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 153 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 154 |
def add_embedding_model(self, model_name, description):
|
| 155 |
with sqlite3.connect(self.db_path) as conn:
|
| 156 |
cursor = conn.cursor()
|
|
@@ -170,12 +313,6 @@ class DatabaseHandler:
|
|
| 170 |
''', (video_id, index_name, embedding_model_id))
|
| 171 |
conn.commit()
|
| 172 |
|
| 173 |
-
def get_video_by_youtube_id(self, youtube_id):
|
| 174 |
-
with sqlite3.connect(self.db_path) as conn:
|
| 175 |
-
cursor = conn.cursor()
|
| 176 |
-
cursor.execute('SELECT * FROM videos WHERE youtube_id = ?', (youtube_id,))
|
| 177 |
-
return cursor.fetchone()
|
| 178 |
-
|
| 179 |
def get_elasticsearch_index(self, video_id, embedding_model):
|
| 180 |
with sqlite3.connect(self.db_path) as conn:
|
| 181 |
cursor = conn.cursor()
|
|
@@ -188,16 +325,6 @@ class DatabaseHandler:
|
|
| 188 |
''', (video_id, embedding_model))
|
| 189 |
result = cursor.fetchone()
|
| 190 |
return result[0] if result else None
|
| 191 |
-
|
| 192 |
-
def get_all_videos(self):
|
| 193 |
-
with sqlite3.connect(self.db_path) as conn:
|
| 194 |
-
cursor = conn.cursor()
|
| 195 |
-
cursor.execute('''
|
| 196 |
-
SELECT youtube_id, title, channel_name, upload_date
|
| 197 |
-
FROM videos
|
| 198 |
-
ORDER BY upload_date DESC
|
| 199 |
-
''')
|
| 200 |
-
return cursor.fetchall()
|
| 201 |
|
| 202 |
def get_elasticsearch_index_by_youtube_id(self, youtube_id):
|
| 203 |
with sqlite3.connect(self.db_path) as conn:
|
|
@@ -210,29 +337,8 @@ class DatabaseHandler:
|
|
| 210 |
''', (youtube_id,))
|
| 211 |
result = cursor.fetchone()
|
| 212 |
return result[0] if result else None
|
| 213 |
-
|
| 214 |
-
def get_transcript_content(self, youtube_id):
|
| 215 |
-
with sqlite3.connect(self.db_path) as conn:
|
| 216 |
-
cursor = conn.cursor()
|
| 217 |
-
cursor.execute('''
|
| 218 |
-
SELECT transcript_content
|
| 219 |
-
FROM videos
|
| 220 |
-
WHERE youtube_id = ?
|
| 221 |
-
''', (youtube_id,))
|
| 222 |
-
result = cursor.fetchone()
|
| 223 |
-
return result[0] if result else None
|
| 224 |
|
| 225 |
-
#
|
| 226 |
-
# def add_transcript_content(self, youtube_id, transcript_content):
|
| 227 |
-
# with sqlite3.connect(self.db_path) as conn:
|
| 228 |
-
# cursor = conn.cursor()
|
| 229 |
-
# cursor.execute('''
|
| 230 |
-
# UPDATE videos
|
| 231 |
-
# SET transcript_content = ?
|
| 232 |
-
# WHERE youtube_id = ?
|
| 233 |
-
# ''', (transcript_content, youtube_id))
|
| 234 |
-
# conn.commit()
|
| 235 |
-
|
| 236 |
def add_ground_truth_questions(self, video_id, questions):
|
| 237 |
with sqlite3.connect(self.db_path) as conn:
|
| 238 |
cursor = conn.cursor()
|
|
@@ -281,6 +387,7 @@ class DatabaseHandler:
|
|
| 281 |
''')
|
| 282 |
return cursor.fetchall()
|
| 283 |
|
|
|
|
| 284 |
def save_search_performance(self, video_id, hit_rate, mrr):
|
| 285 |
with sqlite3.connect(self.db_path) as conn:
|
| 286 |
cursor = conn.cursor()
|
|
@@ -347,4 +454,49 @@ class DatabaseHandler:
|
|
| 347 |
SELECT * FROM search_performance
|
| 348 |
ORDER BY evaluation_date DESC
|
| 349 |
''')
|
| 350 |
-
return cursor.fetchall()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import sqlite3
|
| 2 |
import os
|
| 3 |
+
import logging
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
|
| 6 |
+
logging.basicConfig(level=logging.INFO)
|
| 7 |
+
logger = logging.getLogger(__name__)
|
| 8 |
|
| 9 |
class DatabaseHandler:
|
| 10 |
def __init__(self, db_path='data/sqlite.db'):
|
| 11 |
self.db_path = db_path
|
| 12 |
self.conn = None
|
| 13 |
+
os.makedirs(os.path.dirname(db_path), exist_ok=True)
|
| 14 |
self.create_tables()
|
| 15 |
self.update_schema()
|
| 16 |
+
self.migrate_database()
|
| 17 |
|
| 18 |
def create_tables(self):
|
| 19 |
with sqlite3.connect(self.db_path) as conn:
|
| 20 |
cursor = conn.cursor()
|
| 21 |
+
|
| 22 |
+
# First, drop the existing user_feedback table if it exists
|
| 23 |
+
cursor.execute('DROP TABLE IF EXISTS user_feedback')
|
| 24 |
+
|
| 25 |
+
# Recreate the user_feedback table with the correct schema
|
| 26 |
+
cursor.execute('''
|
| 27 |
+
CREATE TABLE IF NOT EXISTS user_feedback (
|
| 28 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 29 |
+
video_id TEXT,
|
| 30 |
+
query TEXT,
|
| 31 |
+
response TEXT,
|
| 32 |
+
feedback INTEGER CHECK (feedback IN (-1, 1)),
|
| 33 |
+
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 34 |
+
chat_id INTEGER,
|
| 35 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id),
|
| 36 |
+
FOREIGN KEY (chat_id) REFERENCES chat_history (id)
|
| 37 |
+
)
|
| 38 |
+
''')
|
| 39 |
+
|
| 40 |
+
# Videos table
|
| 41 |
cursor.execute('''
|
| 42 |
CREATE TABLE IF NOT EXISTS videos (
|
| 43 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
|
|
| 53 |
transcript_content TEXT
|
| 54 |
)
|
| 55 |
''')
|
| 56 |
+
|
| 57 |
+
# Chat History table
|
| 58 |
+
cursor.execute('''
|
| 59 |
+
CREATE TABLE IF NOT EXISTS chat_history (
|
| 60 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 61 |
+
video_id TEXT,
|
| 62 |
+
user_message TEXT,
|
| 63 |
+
assistant_message TEXT,
|
| 64 |
+
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 65 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id)
|
| 66 |
+
)
|
| 67 |
+
''')
|
| 68 |
+
|
| 69 |
+
# User Feedback table
|
| 70 |
cursor.execute('''
|
| 71 |
CREATE TABLE IF NOT EXISTS user_feedback (
|
| 72 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 73 |
+
video_id TEXT,
|
| 74 |
+
chat_id INTEGER,
|
| 75 |
query TEXT,
|
| 76 |
+
response TEXT,
|
| 77 |
+
feedback INTEGER CHECK (feedback IN (-1, 1)),
|
| 78 |
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 79 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id),
|
| 80 |
+
FOREIGN KEY (chat_id) REFERENCES chat_history (id)
|
| 81 |
)
|
| 82 |
''')
|
| 83 |
+
|
| 84 |
+
# Embedding Models table
|
| 85 |
cursor.execute('''
|
| 86 |
CREATE TABLE IF NOT EXISTS embedding_models (
|
| 87 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
|
|
| 89 |
description TEXT
|
| 90 |
)
|
| 91 |
''')
|
| 92 |
+
|
| 93 |
+
# Elasticsearch Indices table
|
| 94 |
cursor.execute('''
|
| 95 |
CREATE TABLE IF NOT EXISTS elasticsearch_indices (
|
| 96 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
|
|
| 102 |
)
|
| 103 |
''')
|
| 104 |
|
| 105 |
+
# Ground Truth table
|
| 106 |
cursor.execute('''
|
| 107 |
CREATE TABLE IF NOT EXISTS ground_truth (
|
| 108 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 109 |
video_id TEXT,
|
| 110 |
question TEXT,
|
| 111 |
generation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 112 |
+
UNIQUE(video_id, question),
|
| 113 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id)
|
| 114 |
)
|
| 115 |
''')
|
| 116 |
|
| 117 |
+
# Search Performance table
|
| 118 |
cursor.execute('''
|
| 119 |
CREATE TABLE IF NOT EXISTS search_performance (
|
| 120 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 121 |
video_id TEXT,
|
| 122 |
hit_rate REAL,
|
| 123 |
mrr REAL,
|
| 124 |
+
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 125 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id)
|
| 126 |
)
|
| 127 |
''')
|
| 128 |
|
| 129 |
+
# Search Parameters table
|
| 130 |
cursor.execute('''
|
| 131 |
CREATE TABLE IF NOT EXISTS search_parameters (
|
| 132 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
|
|
| 134 |
parameter_name TEXT,
|
| 135 |
parameter_value REAL,
|
| 136 |
score REAL,
|
| 137 |
+
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 138 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id)
|
| 139 |
)
|
| 140 |
''')
|
| 141 |
|
| 142 |
+
# RAG Evaluations table
|
| 143 |
cursor.execute('''
|
| 144 |
CREATE TABLE IF NOT EXISTS rag_evaluations (
|
| 145 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
|
|
| 148 |
answer TEXT,
|
| 149 |
relevance TEXT,
|
| 150 |
explanation TEXT,
|
| 151 |
+
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 152 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id)
|
| 153 |
)
|
| 154 |
''')
|
| 155 |
+
|
| 156 |
conn.commit()
|
| 157 |
|
| 158 |
def update_schema(self):
|
| 159 |
with sqlite3.connect(self.db_path) as conn:
|
| 160 |
cursor = conn.cursor()
|
| 161 |
+
|
| 162 |
+
# Check and update videos table
|
| 163 |
cursor.execute("PRAGMA table_info(videos)")
|
| 164 |
columns = [column[1] for column in cursor.fetchall()]
|
| 165 |
|
|
|
|
| 178 |
|
| 179 |
conn.commit()
|
| 180 |
|
| 181 |
+
# Video Management Methods
|
| 182 |
def add_video(self, video_data):
|
| 183 |
+
try:
|
| 184 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 185 |
+
cursor = conn.cursor()
|
| 186 |
+
cursor.execute('''
|
| 187 |
+
INSERT OR REPLACE INTO videos
|
| 188 |
+
(youtube_id, title, channel_name, upload_date, view_count, like_count,
|
| 189 |
+
comment_count, video_duration, transcript_content)
|
| 190 |
+
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
|
| 191 |
+
''', (
|
| 192 |
+
video_data['video_id'],
|
| 193 |
+
video_data['title'],
|
| 194 |
+
video_data['author'],
|
| 195 |
+
video_data['upload_date'],
|
| 196 |
+
video_data['view_count'],
|
| 197 |
+
video_data['like_count'],
|
| 198 |
+
video_data['comment_count'],
|
| 199 |
+
video_data['video_duration'],
|
| 200 |
+
video_data['transcript_content']
|
| 201 |
+
))
|
| 202 |
+
conn.commit()
|
| 203 |
+
return cursor.lastrowid
|
| 204 |
+
except Exception as e:
|
| 205 |
+
logger.error(f"Error adding video: {str(e)}")
|
| 206 |
+
raise
|
| 207 |
+
|
| 208 |
+
def get_video_by_youtube_id(self, youtube_id):
|
| 209 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 210 |
+
cursor = conn.cursor()
|
| 211 |
+
cursor.execute('SELECT * FROM videos WHERE youtube_id = ?', (youtube_id,))
|
| 212 |
+
return cursor.fetchone()
|
| 213 |
+
|
| 214 |
+
def get_all_videos(self):
|
| 215 |
with sqlite3.connect(self.db_path) as conn:
|
| 216 |
cursor = conn.cursor()
|
| 217 |
cursor.execute('''
|
| 218 |
+
SELECT youtube_id, title, channel_name, upload_date
|
| 219 |
+
FROM videos
|
| 220 |
+
ORDER BY upload_date DESC
|
| 221 |
+
''')
|
| 222 |
+
return cursor.fetchall()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 223 |
|
| 224 |
+
# Chat and Feedback Methods
|
| 225 |
+
def add_chat_message(self, video_id, user_message, assistant_message):
|
| 226 |
with sqlite3.connect(self.db_path) as conn:
|
| 227 |
cursor = conn.cursor()
|
| 228 |
cursor.execute('''
|
| 229 |
+
INSERT INTO chat_history (video_id, user_message, assistant_message)
|
| 230 |
VALUES (?, ?, ?)
|
| 231 |
+
''', (video_id, user_message, assistant_message))
|
| 232 |
conn.commit()
|
| 233 |
+
return cursor.lastrowid
|
| 234 |
+
|
| 235 |
+
def get_chat_history(self, video_id):
|
| 236 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 237 |
+
cursor = conn.cursor()
|
| 238 |
+
cursor.execute('''
|
| 239 |
+
SELECT id, user_message, assistant_message, timestamp
|
| 240 |
+
FROM chat_history
|
| 241 |
+
WHERE video_id = ?
|
| 242 |
+
ORDER BY timestamp ASC
|
| 243 |
+
''', (video_id,))
|
| 244 |
+
return cursor.fetchall()
|
| 245 |
+
|
| 246 |
+
def add_user_feedback(self, video_id, chat_id, query, response, feedback):
|
| 247 |
+
try:
|
| 248 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 249 |
+
cursor = conn.cursor()
|
| 250 |
+
|
| 251 |
+
# First verify the video exists
|
| 252 |
+
cursor.execute('SELECT id FROM videos WHERE youtube_id = ?', (video_id,))
|
| 253 |
+
if not cursor.fetchone():
|
| 254 |
+
logger.error(f"Video {video_id} not found in database")
|
| 255 |
+
raise ValueError(f"Video {video_id} not found")
|
| 256 |
+
|
| 257 |
+
# Then verify the chat message exists if chat_id is provided
|
| 258 |
+
if chat_id:
|
| 259 |
+
cursor.execute('SELECT id FROM chat_history WHERE id = ?', (chat_id,))
|
| 260 |
+
if not cursor.fetchone():
|
| 261 |
+
logger.error(f"Chat message {chat_id} not found in database")
|
| 262 |
+
raise ValueError(f"Chat message {chat_id} not found")
|
| 263 |
+
|
| 264 |
+
# Insert the feedback
|
| 265 |
+
cursor.execute('''
|
| 266 |
+
INSERT INTO user_feedback
|
| 267 |
+
(video_id, chat_id, query, response, feedback)
|
| 268 |
+
VALUES (?, ?, ?, ?, ?)
|
| 269 |
+
''', (video_id, chat_id, query, response, feedback))
|
| 270 |
+
conn.commit()
|
| 271 |
+
logger.info(f"Added feedback for video {video_id}, chat {chat_id}")
|
| 272 |
+
return cursor.lastrowid
|
| 273 |
+
except sqlite3.Error as e:
|
| 274 |
+
logger.error(f"Database error: {str(e)}")
|
| 275 |
+
raise
|
| 276 |
+
except Exception as e:
|
| 277 |
+
logger.error(f"Error adding feedback: {str(e)}")
|
| 278 |
+
raise
|
| 279 |
|
| 280 |
+
def get_user_feedback_stats(self, video_id):
|
| 281 |
+
try:
|
| 282 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 283 |
+
cursor = conn.cursor()
|
| 284 |
+
cursor.execute('''
|
| 285 |
+
SELECT
|
| 286 |
+
COUNT(CASE WHEN feedback = 1 THEN 1 END) as positive_feedback,
|
| 287 |
+
COUNT(CASE WHEN feedback = -1 THEN 1 END) as negative_feedback
|
| 288 |
+
FROM user_feedback
|
| 289 |
+
WHERE video_id = ?
|
| 290 |
+
''', (video_id,))
|
| 291 |
+
return cursor.fetchone() or (0, 0) # Return (0, 0) if no feedback exists
|
| 292 |
+
except sqlite3.Error as e:
|
| 293 |
+
logger.error(f"Database error getting feedback stats: {str(e)}")
|
| 294 |
+
return (0, 0)
|
| 295 |
+
|
| 296 |
+
# Embedding and Index Methods
|
| 297 |
def add_embedding_model(self, model_name, description):
|
| 298 |
with sqlite3.connect(self.db_path) as conn:
|
| 299 |
cursor = conn.cursor()
|
|
|
|
| 313 |
''', (video_id, index_name, embedding_model_id))
|
| 314 |
conn.commit()
|
| 315 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 316 |
def get_elasticsearch_index(self, video_id, embedding_model):
|
| 317 |
with sqlite3.connect(self.db_path) as conn:
|
| 318 |
cursor = conn.cursor()
|
|
|
|
| 325 |
''', (video_id, embedding_model))
|
| 326 |
result = cursor.fetchone()
|
| 327 |
return result[0] if result else None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 328 |
|
| 329 |
def get_elasticsearch_index_by_youtube_id(self, youtube_id):
|
| 330 |
with sqlite3.connect(self.db_path) as conn:
|
|
|
|
| 337 |
''', (youtube_id,))
|
| 338 |
result = cursor.fetchone()
|
| 339 |
return result[0] if result else None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 340 |
|
| 341 |
+
# Ground Truth Methods
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 342 |
def add_ground_truth_questions(self, video_id, questions):
|
| 343 |
with sqlite3.connect(self.db_path) as conn:
|
| 344 |
cursor = conn.cursor()
|
|
|
|
| 387 |
''')
|
| 388 |
return cursor.fetchall()
|
| 389 |
|
| 390 |
+
# Evaluation Methods
|
| 391 |
def save_search_performance(self, video_id, hit_rate, mrr):
|
| 392 |
with sqlite3.connect(self.db_path) as conn:
|
| 393 |
cursor = conn.cursor()
|
|
|
|
| 454 |
SELECT * FROM search_performance
|
| 455 |
ORDER BY evaluation_date DESC
|
| 456 |
''')
|
| 457 |
+
return cursor.fetchall()
|
| 458 |
+
|
| 459 |
+
def migrate_database(self):
|
| 460 |
+
try:
|
| 461 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 462 |
+
cursor = conn.cursor()
|
| 463 |
+
|
| 464 |
+
# Check if chat_id column exists in user_feedback
|
| 465 |
+
cursor.execute("PRAGMA table_info(user_feedback)")
|
| 466 |
+
columns = [column[1] for column in cursor.fetchall()]
|
| 467 |
+
|
| 468 |
+
if 'chat_id' not in columns:
|
| 469 |
+
logger.info("Migrating user_feedback table")
|
| 470 |
+
|
| 471 |
+
# Create temporary table with new schema
|
| 472 |
+
cursor.execute('''
|
| 473 |
+
CREATE TABLE user_feedback_new (
|
| 474 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 475 |
+
video_id TEXT,
|
| 476 |
+
query TEXT,
|
| 477 |
+
response TEXT,
|
| 478 |
+
feedback INTEGER CHECK (feedback IN (-1, 1)),
|
| 479 |
+
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 480 |
+
chat_id INTEGER,
|
| 481 |
+
FOREIGN KEY (video_id) REFERENCES videos (youtube_id),
|
| 482 |
+
FOREIGN KEY (chat_id) REFERENCES chat_history (id)
|
| 483 |
+
)
|
| 484 |
+
''')
|
| 485 |
+
|
| 486 |
+
# Copy existing data
|
| 487 |
+
cursor.execute('''
|
| 488 |
+
INSERT INTO user_feedback_new (video_id, query, response, feedback, timestamp)
|
| 489 |
+
SELECT video_id, query, response, feedback, timestamp
|
| 490 |
+
FROM user_feedback
|
| 491 |
+
''')
|
| 492 |
+
|
| 493 |
+
# Drop old table and rename new one
|
| 494 |
+
cursor.execute('DROP TABLE user_feedback')
|
| 495 |
+
cursor.execute('ALTER TABLE user_feedback_new RENAME TO user_feedback')
|
| 496 |
+
|
| 497 |
+
logger.info("Migration completed successfully")
|
| 498 |
+
|
| 499 |
+
conn.commit()
|
| 500 |
+
except Exception as e:
|
| 501 |
+
logger.error(f"Error during migration: {str(e)}")
|
| 502 |
+
raise
|
app/home.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.set_page_config(
|
| 4 |
+
page_title="Home",
|
| 5 |
+
page_icon="🏠",
|
| 6 |
+
layout="wide"
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
from transcript_extractor import test_api_key, initialize_youtube_api
|
| 10 |
+
import logging
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
|
| 14 |
+
# Configure logging
|
| 15 |
+
logging.basicConfig(
|
| 16 |
+
level=logging.INFO,
|
| 17 |
+
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
| 18 |
+
handlers=[
|
| 19 |
+
logging.FileHandler('app.log'),
|
| 20 |
+
logging.StreamHandler(sys.stdout)
|
| 21 |
+
]
|
| 22 |
+
)
|
| 23 |
+
logger = logging.getLogger(__name__)
|
| 24 |
+
|
| 25 |
+
def main():
|
| 26 |
+
st.title("YouTube Transcript RAG System 🎥")
|
| 27 |
+
st.write("Welcome to the YouTube Transcript RAG System!")
|
| 28 |
+
|
| 29 |
+
# Check API key
|
| 30 |
+
if not test_api_key():
|
| 31 |
+
st.error("YouTube API key is invalid or not set. Please check your configuration.")
|
| 32 |
+
new_api_key = st.text_input("Enter your YouTube API key:")
|
| 33 |
+
if new_api_key:
|
| 34 |
+
os.environ['YOUTUBE_API_KEY'] = new_api_key
|
| 35 |
+
if test_api_key():
|
| 36 |
+
st.success("API key validated successfully!")
|
| 37 |
+
st.experimental_rerun()
|
| 38 |
+
else:
|
| 39 |
+
st.error("Invalid API key. Please try again.")
|
| 40 |
+
return
|
| 41 |
+
|
| 42 |
+
st.success("System is ready! Please use the sidebar to navigate between different functions.")
|
| 43 |
+
|
| 44 |
+
# Display system overview
|
| 45 |
+
st.header("System Overview")
|
| 46 |
+
st.write("""
|
| 47 |
+
This system provides the following functionality:
|
| 48 |
+
|
| 49 |
+
1. **Data Ingestion** 📥
|
| 50 |
+
- Process YouTube videos and transcripts
|
| 51 |
+
- Support for single videos or entire channels
|
| 52 |
+
|
| 53 |
+
2. **Chat Interface** 💬
|
| 54 |
+
- Interactive chat with processed videos
|
| 55 |
+
- Multiple query rewriting methods
|
| 56 |
+
- Various search strategies
|
| 57 |
+
|
| 58 |
+
3. **Ground Truth Generation** 📝
|
| 59 |
+
- Generate and manage ground truth questions
|
| 60 |
+
- Export ground truth data
|
| 61 |
+
|
| 62 |
+
4. **RAG Evaluation** 📊
|
| 63 |
+
- Evaluate system performance
|
| 64 |
+
- View detailed metrics and analytics
|
| 65 |
+
""")
|
| 66 |
+
|
| 67 |
+
if __name__ == "__main__":
|
| 68 |
+
main()
|
app/main.py
DELETED
|
@@ -1,430 +0,0 @@
|
|
| 1 |
-
import streamlit as st
|
| 2 |
-
import pandas as pd
|
| 3 |
-
from transcript_extractor import get_transcript, get_youtube_client, extract_video_id, get_channel_videos, test_api_key, initialize_youtube_api
|
| 4 |
-
from data_processor import DataProcessor
|
| 5 |
-
from database import DatabaseHandler
|
| 6 |
-
from rag import RAGSystem
|
| 7 |
-
from query_rewriter import QueryRewriter
|
| 8 |
-
from evaluation import EvaluationSystem
|
| 9 |
-
from generate_ground_truth import generate_ground_truth, generate_ground_truth_for_all_videos, get_ground_truth_display_data, get_evaluation_display_data
|
| 10 |
-
from sentence_transformers import SentenceTransformer
|
| 11 |
-
import os
|
| 12 |
-
import sys
|
| 13 |
-
import logging
|
| 14 |
-
|
| 15 |
-
logging.basicConfig(level=logging.DEBUG)
|
| 16 |
-
logger = logging.getLogger(__name__)
|
| 17 |
-
|
| 18 |
-
logging.basicConfig(level=logging.INFO)
|
| 19 |
-
logger = logging.getLogger(__name__)
|
| 20 |
-
|
| 21 |
-
@st.cache_resource
|
| 22 |
-
def init_components():
|
| 23 |
-
try:
|
| 24 |
-
db_handler = DatabaseHandler()
|
| 25 |
-
data_processor = DataProcessor()
|
| 26 |
-
rag_system = RAGSystem(data_processor)
|
| 27 |
-
query_rewriter = QueryRewriter()
|
| 28 |
-
evaluation_system = EvaluationSystem(data_processor, db_handler)
|
| 29 |
-
logger.info("Components initialized successfully")
|
| 30 |
-
return db_handler, data_processor, rag_system, query_rewriter, evaluation_system
|
| 31 |
-
except Exception as e:
|
| 32 |
-
logger.error(f"Error initializing components: {str(e)}")
|
| 33 |
-
st.error(f"Error initializing components: {str(e)}")
|
| 34 |
-
st.error("Please check your configuration and ensure all services are running.")
|
| 35 |
-
return None, None, None, None, None
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
def check_api_key():
|
| 39 |
-
if test_api_key():
|
| 40 |
-
st.success("YouTube API key is valid and working.")
|
| 41 |
-
else:
|
| 42 |
-
st.error("YouTube API key is invalid or not set. Please check your .env file.")
|
| 43 |
-
new_api_key = st.text_input("Enter your YouTube API key:")
|
| 44 |
-
if new_api_key:
|
| 45 |
-
os.environ['YOUTUBE_API_KEY'] = new_api_key
|
| 46 |
-
with open('.env', 'a') as f:
|
| 47 |
-
f.write(f"\nYOUTUBE_API_KEY={new_api_key}")
|
| 48 |
-
st.success("API key saved. Reinitializing YouTube client...")
|
| 49 |
-
get_youtube_client.cache_clear() # Clear the cache to force reinitialization
|
| 50 |
-
if test_api_key():
|
| 51 |
-
st.success("YouTube client reinitialized successfully.")
|
| 52 |
-
else:
|
| 53 |
-
st.error("Failed to reinitialize YouTube client. Please check your API key.")
|
| 54 |
-
st.experimental_rerun()
|
| 55 |
-
|
| 56 |
-
# LLM-as-a-judge prompt template
|
| 57 |
-
prompt_template = """
|
| 58 |
-
You are an expert evaluator for a Youtube transcript assistant.
|
| 59 |
-
Your task is to analyze the relevance of the generated answer to the given question.
|
| 60 |
-
Based on the relevance of the generated answer, you will classify it
|
| 61 |
-
as "NON_RELEVANT", "PARTLY_RELEVANT", or "RELEVANT".
|
| 62 |
-
|
| 63 |
-
Here is the data for evaluation:
|
| 64 |
-
|
| 65 |
-
Question: {question}
|
| 66 |
-
Generated Answer: {answer_llm}
|
| 67 |
-
|
| 68 |
-
Please analyze the content and context of the generated answer in relation to the question
|
| 69 |
-
and provide your evaluation in the following JSON format:
|
| 70 |
-
|
| 71 |
-
{{
|
| 72 |
-
"Relevance": "NON_RELEVANT",
|
| 73 |
-
"Explanation": "Your explanation here"
|
| 74 |
-
}}
|
| 75 |
-
|
| 76 |
-
OR
|
| 77 |
-
|
| 78 |
-
{{
|
| 79 |
-
"Relevance": "PARTLY_RELEVANT",
|
| 80 |
-
"Explanation": "Your explanation here"
|
| 81 |
-
}}
|
| 82 |
-
|
| 83 |
-
OR
|
| 84 |
-
|
| 85 |
-
{{
|
| 86 |
-
"Relevance": "RELEVANT",
|
| 87 |
-
"Explanation": "Your explanation here"
|
| 88 |
-
}}
|
| 89 |
-
|
| 90 |
-
Ensure your response is a valid JSON object with these exact keys and one of the three exact values for "Relevance".
|
| 91 |
-
Do not include any text outside of this JSON object.
|
| 92 |
-
"""
|
| 93 |
-
|
| 94 |
-
def process_single_video(db_handler, data_processor, video_id, embedding_model):
|
| 95 |
-
existing_index = db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 96 |
-
if existing_index:
|
| 97 |
-
logger.info(f"Video {video_id} has already been processed with {embedding_model}. Using existing index: {existing_index}")
|
| 98 |
-
return existing_index
|
| 99 |
-
|
| 100 |
-
transcript_data = get_transcript(video_id)
|
| 101 |
-
if transcript_data is None:
|
| 102 |
-
logger.error(f"Failed to retrieve transcript for video {video_id}")
|
| 103 |
-
st.error(f"Failed to retrieve transcript for video {video_id}. Please check if the video ID is correct and the video has captions available.")
|
| 104 |
-
return None
|
| 105 |
-
|
| 106 |
-
# Process the transcript
|
| 107 |
-
processed_data = data_processor.process_transcript(video_id, transcript_data)
|
| 108 |
-
if processed_data is None:
|
| 109 |
-
logger.error(f"Failed to process transcript for video {video_id}")
|
| 110 |
-
return None
|
| 111 |
-
|
| 112 |
-
# Prepare video data for database insertion
|
| 113 |
-
video_data = {
|
| 114 |
-
'video_id': video_id,
|
| 115 |
-
'title': transcript_data['metadata'].get('title', 'Unknown Title'),
|
| 116 |
-
'author': transcript_data['metadata'].get('author', 'Unknown Author'),
|
| 117 |
-
'upload_date': transcript_data['metadata'].get('upload_date', 'Unknown Date'),
|
| 118 |
-
'view_count': int(transcript_data['metadata'].get('view_count', 0)),
|
| 119 |
-
'like_count': int(transcript_data['metadata'].get('like_count', 0)),
|
| 120 |
-
'comment_count': int(transcript_data['metadata'].get('comment_count', 0)),
|
| 121 |
-
'video_duration': transcript_data['metadata'].get('duration', 'Unknown Duration'),
|
| 122 |
-
'transcript_content': processed_data['content'] # Add this line to include the transcript content
|
| 123 |
-
}
|
| 124 |
-
|
| 125 |
-
try:
|
| 126 |
-
db_handler.add_video(video_data)
|
| 127 |
-
except Exception as e:
|
| 128 |
-
logger.error(f"Error adding video to database: {str(e)}")
|
| 129 |
-
st.error(f"Error adding video {video_id} to database: {str(e)}")
|
| 130 |
-
return None
|
| 131 |
-
|
| 132 |
-
index_name = f"video_{video_id}_{embedding_model}".lower()
|
| 133 |
-
try:
|
| 134 |
-
index_name = data_processor.build_index(index_name)
|
| 135 |
-
logger.info(f"Successfully built index: {index_name}")
|
| 136 |
-
except Exception as e:
|
| 137 |
-
logger.error(f"Error building index: {str(e)}")
|
| 138 |
-
st.error(f"Error building index for video {video_id}: {str(e)}")
|
| 139 |
-
return None
|
| 140 |
-
|
| 141 |
-
embedding_model_id = db_handler.add_embedding_model(embedding_model, "Description of the model")
|
| 142 |
-
|
| 143 |
-
video_db_record = db_handler.get_video_by_youtube_id(video_id)
|
| 144 |
-
if video_db_record is None:
|
| 145 |
-
logger.error(f"Failed to retrieve video record from database for video {video_id}")
|
| 146 |
-
st.error(f"Failed to retrieve video record from database for video {video_id}")
|
| 147 |
-
return None
|
| 148 |
-
video_db_id = video_db_record[0]
|
| 149 |
-
|
| 150 |
-
db_handler.add_elasticsearch_index(video_db_id, index_name, embedding_model_id)
|
| 151 |
-
|
| 152 |
-
logger.info(f"Processed and indexed transcript for video {video_id}")
|
| 153 |
-
st.success(f"Successfully processed and indexed transcript for video {video_id}")
|
| 154 |
-
return index_name
|
| 155 |
-
|
| 156 |
-
def process_multiple_videos(db_handler, data_processor, video_ids, embedding_model):
|
| 157 |
-
indices = []
|
| 158 |
-
for video_id in video_ids:
|
| 159 |
-
index = process_single_video(db_handler, data_processor, video_id, embedding_model)
|
| 160 |
-
if index:
|
| 161 |
-
indices.append(index)
|
| 162 |
-
logger.info(f"Processed and indexed transcripts for {len(indices)} videos")
|
| 163 |
-
st.success(f"Processed and indexed transcripts for {len(indices)} videos")
|
| 164 |
-
return indices
|
| 165 |
-
|
| 166 |
-
def ensure_video_processed(db_handler, data_processor, video_id, embedding_model):
|
| 167 |
-
index_name = db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 168 |
-
if not index_name:
|
| 169 |
-
st.warning(f"Video {video_id} has not been processed yet. Processing now...")
|
| 170 |
-
index_name = process_single_video(db_handler, data_processor, video_id, embedding_model)
|
| 171 |
-
if not index_name:
|
| 172 |
-
st.error(f"Failed to process video {video_id}. Please check the logs for more information.")
|
| 173 |
-
return False
|
| 174 |
-
return True
|
| 175 |
-
|
| 176 |
-
def main():
|
| 177 |
-
st.title("YouTube Transcript RAG System")
|
| 178 |
-
|
| 179 |
-
check_api_key()
|
| 180 |
-
|
| 181 |
-
components = init_components()
|
| 182 |
-
if components:
|
| 183 |
-
db_handler, data_processor, rag_system, query_rewriter, evaluation_system = components
|
| 184 |
-
else:
|
| 185 |
-
st.stop()
|
| 186 |
-
|
| 187 |
-
tab1, tab2, tab3 = st.tabs(["RAG System", "Ground Truth Generation", "Evaluation"])
|
| 188 |
-
|
| 189 |
-
with tab1:
|
| 190 |
-
st.header("RAG System")
|
| 191 |
-
|
| 192 |
-
embedding_model = st.selectbox("Select embedding model:", ["multi-qa-MiniLM-L6-cos-v1", "all-mpnet-base-v2"])
|
| 193 |
-
|
| 194 |
-
st.subheader("Select a Video")
|
| 195 |
-
videos = db_handler.get_all_videos()
|
| 196 |
-
if not videos:
|
| 197 |
-
st.warning("No videos available. Please process some videos first.")
|
| 198 |
-
else:
|
| 199 |
-
video_df = pd.DataFrame(videos, columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 200 |
-
|
| 201 |
-
channels = sorted(video_df['channel_name'].unique())
|
| 202 |
-
selected_channel = st.selectbox("Filter by Channel", ["All"] + channels)
|
| 203 |
-
|
| 204 |
-
if selected_channel != "All":
|
| 205 |
-
video_df = video_df[video_df['channel_name'] == selected_channel]
|
| 206 |
-
|
| 207 |
-
st.dataframe(video_df)
|
| 208 |
-
selected_video_id = st.selectbox("Select a Video", video_df['youtube_id'].tolist(), format_func=lambda x: video_df[video_df['youtube_id'] == x]['title'].iloc[0])
|
| 209 |
-
|
| 210 |
-
index_name = db_handler.get_elasticsearch_index_by_youtube_id(selected_video_id)
|
| 211 |
-
|
| 212 |
-
if index_name:
|
| 213 |
-
st.success(f"Using index: {index_name}")
|
| 214 |
-
else:
|
| 215 |
-
st.warning("No index found for the selected video and embedding model. The index will be built when you search.")
|
| 216 |
-
|
| 217 |
-
st.subheader("Process New Video")
|
| 218 |
-
input_type = st.radio("Select input type:", ["Video URL", "Channel URL", "YouTube ID"])
|
| 219 |
-
input_value = st.text_input("Enter the URL or ID:")
|
| 220 |
-
|
| 221 |
-
if st.button("Process"):
|
| 222 |
-
with st.spinner("Processing..."):
|
| 223 |
-
data_processor.set_embedding_model(embedding_model)
|
| 224 |
-
if input_type == "Video URL":
|
| 225 |
-
video_id = extract_video_id(input_value)
|
| 226 |
-
if video_id:
|
| 227 |
-
index_name = process_single_video(db_handler, data_processor, video_id, embedding_model)
|
| 228 |
-
if index_name is None:
|
| 229 |
-
st.error(f"Failed to process video {video_id}")
|
| 230 |
-
else:
|
| 231 |
-
st.success(f"Successfully processed video {video_id}")
|
| 232 |
-
else:
|
| 233 |
-
st.error("Failed to extract video ID from the URL")
|
| 234 |
-
elif input_type == "Channel URL":
|
| 235 |
-
channel_videos = get_channel_videos(input_value)
|
| 236 |
-
if channel_videos:
|
| 237 |
-
index_names = process_multiple_videos(db_handler, data_processor, [video['video_id'] for video in channel_videos], embedding_model)
|
| 238 |
-
if not index_names:
|
| 239 |
-
st.error("Failed to process any videos from the channel")
|
| 240 |
-
else:
|
| 241 |
-
st.success(f"Successfully processed {len(index_names)} videos from the channel")
|
| 242 |
-
else:
|
| 243 |
-
st.error("Failed to retrieve videos from the channel")
|
| 244 |
-
else:
|
| 245 |
-
index_name = process_single_video(db_handler, data_processor, input_value, embedding_model)
|
| 246 |
-
if index_name is None:
|
| 247 |
-
st.error(f"Failed to process video {input_value}")
|
| 248 |
-
else:
|
| 249 |
-
st.success(f"Successfully processed video {input_value}")
|
| 250 |
-
|
| 251 |
-
st.subheader("Query the RAG System")
|
| 252 |
-
query = st.text_input("Enter your query:")
|
| 253 |
-
rewrite_method = st.radio("Query rewriting method:", ["None", "Chain of Thought", "ReAct"])
|
| 254 |
-
search_method = st.radio("Search method:", ["Hybrid", "Text-only", "Embedding-only"])
|
| 255 |
-
|
| 256 |
-
if st.button("Search"):
|
| 257 |
-
if not selected_video_id:
|
| 258 |
-
st.error("Please select a video before searching.")
|
| 259 |
-
else:
|
| 260 |
-
with st.spinner("Searching..."):
|
| 261 |
-
rewritten_query = query
|
| 262 |
-
rewrite_prompt = ""
|
| 263 |
-
if rewrite_method == "Chain of Thought":
|
| 264 |
-
rewritten_query, rewrite_prompt = query_rewriter.rewrite_cot(query)
|
| 265 |
-
elif rewrite_method == "ReAct":
|
| 266 |
-
rewritten_query, rewrite_prompt = query_rewriter.rewrite_react(query)
|
| 267 |
-
|
| 268 |
-
st.subheader("Query Processing")
|
| 269 |
-
st.write("Original query:", query)
|
| 270 |
-
if rewrite_method != "None":
|
| 271 |
-
st.write("Rewritten query:", rewritten_query)
|
| 272 |
-
st.text_area("Query rewriting prompt:", rewrite_prompt, height=100)
|
| 273 |
-
if rewritten_query == query:
|
| 274 |
-
st.warning("Query rewriting failed. Using original query.")
|
| 275 |
-
|
| 276 |
-
search_method_map = {"Hybrid": "hybrid", "Text-only": "text", "Embedding-only": "embedding"}
|
| 277 |
-
try:
|
| 278 |
-
if not index_name:
|
| 279 |
-
st.info("Building index for the selected video...")
|
| 280 |
-
index_name = process_single_video(db_handler, data_processor, selected_video_id, embedding_model)
|
| 281 |
-
if not index_name:
|
| 282 |
-
st.error("Failed to build index for the selected video.")
|
| 283 |
-
return
|
| 284 |
-
|
| 285 |
-
response, final_prompt = rag_system.query(rewritten_query, search_method=search_method_map[search_method], index_name=index_name)
|
| 286 |
-
|
| 287 |
-
st.subheader("RAG System Prompt")
|
| 288 |
-
if final_prompt:
|
| 289 |
-
st.text_area("Prompt sent to LLM:", final_prompt, height=300)
|
| 290 |
-
else:
|
| 291 |
-
st.warning("No prompt was generated. This might indicate an issue with the RAG system.")
|
| 292 |
-
|
| 293 |
-
st.subheader("Response")
|
| 294 |
-
if response:
|
| 295 |
-
st.write(response)
|
| 296 |
-
else:
|
| 297 |
-
st.error("No response generated. Please try again or check the system logs for errors.")
|
| 298 |
-
except ValueError as e:
|
| 299 |
-
logger.error(f"Error during search: {str(e)}")
|
| 300 |
-
st.error(f"Error during search: {str(e)}")
|
| 301 |
-
except Exception as e:
|
| 302 |
-
logger.error(f"An unexpected error occurred: {str(e)}")
|
| 303 |
-
st.error(f"An unexpected error occurred: {str(e)}")
|
| 304 |
-
|
| 305 |
-
with tab2:
|
| 306 |
-
st.header("Ground Truth Generation")
|
| 307 |
-
|
| 308 |
-
videos = db_handler.get_all_videos()
|
| 309 |
-
if not videos:
|
| 310 |
-
st.warning("No videos available. Please process some videos first.")
|
| 311 |
-
else:
|
| 312 |
-
video_df = pd.DataFrame(videos, columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 313 |
-
|
| 314 |
-
# Add channel filter
|
| 315 |
-
channels = sorted(video_df['channel_name'].unique())
|
| 316 |
-
selected_channel = st.selectbox("Filter by Channel", ["All"] + channels, key="gt_channel_select")
|
| 317 |
-
|
| 318 |
-
if selected_channel != "All":
|
| 319 |
-
video_df = video_df[video_df['channel_name'] == selected_channel]
|
| 320 |
-
# Display existing ground truth for selected channel
|
| 321 |
-
gt_data = get_ground_truth_display_data(db_handler, channel_name=selected_channel)
|
| 322 |
-
if not gt_data.empty:
|
| 323 |
-
st.subheader("Existing Ground Truth Questions for Channel")
|
| 324 |
-
st.dataframe(gt_data)
|
| 325 |
-
|
| 326 |
-
# Add download button for channel ground truth
|
| 327 |
-
csv = gt_data.to_csv(index=False)
|
| 328 |
-
st.download_button(
|
| 329 |
-
label="Download Channel Ground Truth CSV",
|
| 330 |
-
data=csv,
|
| 331 |
-
file_name=f"ground_truth_{selected_channel}.csv",
|
| 332 |
-
mime="text/csv",
|
| 333 |
-
)
|
| 334 |
-
|
| 335 |
-
st.dataframe(video_df)
|
| 336 |
-
selected_video_id = st.selectbox("Select a Video", video_df['youtube_id'].tolist(),
|
| 337 |
-
format_func=lambda x: video_df[video_df['youtube_id'] == x]['title'].iloc[0],
|
| 338 |
-
key="gt_video_select")
|
| 339 |
-
|
| 340 |
-
# Display existing ground truth for selected video
|
| 341 |
-
gt_data = get_ground_truth_display_data(db_handler, video_id=selected_video_id)
|
| 342 |
-
if not gt_data.empty:
|
| 343 |
-
st.subheader("Existing Ground Truth Questions")
|
| 344 |
-
st.dataframe(gt_data)
|
| 345 |
-
|
| 346 |
-
# Add download button for video ground truth
|
| 347 |
-
csv = gt_data.to_csv(index=False)
|
| 348 |
-
st.download_button(
|
| 349 |
-
label="Download Video Ground Truth CSV",
|
| 350 |
-
data=csv,
|
| 351 |
-
file_name=f"ground_truth_{selected_video_id}.csv",
|
| 352 |
-
mime="text/csv",
|
| 353 |
-
)
|
| 354 |
-
|
| 355 |
-
with tab3:
|
| 356 |
-
st.header("RAG Evaluation")
|
| 357 |
-
|
| 358 |
-
try:
|
| 359 |
-
ground_truth_df = pd.read_csv('data/ground-truth-retrieval.csv')
|
| 360 |
-
ground_truth_available = True
|
| 361 |
-
|
| 362 |
-
# Display existing evaluations
|
| 363 |
-
existing_evaluations = get_evaluation_display_data()
|
| 364 |
-
if not existing_evaluations.empty:
|
| 365 |
-
st.subheader("Existing Evaluation Results")
|
| 366 |
-
st.dataframe(existing_evaluations)
|
| 367 |
-
|
| 368 |
-
# Add download button for evaluation results
|
| 369 |
-
csv = existing_evaluations.to_csv(index=False)
|
| 370 |
-
st.download_button(
|
| 371 |
-
label="Download Evaluation Results CSV",
|
| 372 |
-
data=csv,
|
| 373 |
-
file_name="evaluation_results.csv",
|
| 374 |
-
mime="text/csv",
|
| 375 |
-
)
|
| 376 |
-
|
| 377 |
-
except FileNotFoundError:
|
| 378 |
-
ground_truth_available = False
|
| 379 |
-
|
| 380 |
-
if ground_truth_available:
|
| 381 |
-
if st.button("Run Full Evaluation"):
|
| 382 |
-
with st.spinner("Running full evaluation..."):
|
| 383 |
-
evaluation_results = evaluation_system.run_full_evaluation(rag_system, 'data/ground-truth-retrieval.csv', prompt_template)
|
| 384 |
-
|
| 385 |
-
st.subheader("RAG Evaluations")
|
| 386 |
-
rag_eval_df = pd.DataFrame(evaluation_results["rag_evaluations"])
|
| 387 |
-
st.dataframe(rag_eval_df)
|
| 388 |
-
|
| 389 |
-
st.subheader("Search Performance")
|
| 390 |
-
search_perf_df = pd.DataFrame([evaluation_results["search_performance"]])
|
| 391 |
-
st.dataframe(search_perf_df)
|
| 392 |
-
|
| 393 |
-
st.subheader("Optimized Search Parameters")
|
| 394 |
-
params_df = pd.DataFrame([{
|
| 395 |
-
'parameter': k,
|
| 396 |
-
'value': v,
|
| 397 |
-
'score': evaluation_results['best_score']
|
| 398 |
-
} for k, v in evaluation_results['best_params'].items()])
|
| 399 |
-
st.dataframe(params_df)
|
| 400 |
-
|
| 401 |
-
# Save to database
|
| 402 |
-
for video_id in rag_eval_df['video_id'].unique():
|
| 403 |
-
db_handler.save_search_performance(
|
| 404 |
-
video_id,
|
| 405 |
-
evaluation_results["search_performance"]['hit_rate'],
|
| 406 |
-
evaluation_results["search_performance"]['mrr']
|
| 407 |
-
)
|
| 408 |
-
db_handler.save_search_parameters(
|
| 409 |
-
video_id,
|
| 410 |
-
evaluation_results['best_params'],
|
| 411 |
-
evaluation_results['best_score']
|
| 412 |
-
)
|
| 413 |
-
|
| 414 |
-
st.success("Evaluation complete. Results saved to database and CSV.")
|
| 415 |
-
else:
|
| 416 |
-
st.warning("No ground truth data available. Please generate ground truth data first.")
|
| 417 |
-
st.button("Run Evaluation", disabled=True)
|
| 418 |
-
|
| 419 |
-
if not ground_truth_available:
|
| 420 |
-
st.subheader("Generate Ground Truth")
|
| 421 |
-
st.write("You need to generate ground truth data before running the evaluation.")
|
| 422 |
-
if st.button("Go to Ground Truth Generation"):
|
| 423 |
-
st.session_state.active_tab = "Ground Truth Generation"
|
| 424 |
-
st.experimental_rerun()
|
| 425 |
-
|
| 426 |
-
if __name__ == "__main__":
|
| 427 |
-
if not initialize_youtube_api():
|
| 428 |
-
logger.error("Failed to initialize YouTube API. Exiting.")
|
| 429 |
-
sys.exit(1)
|
| 430 |
-
main()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
app/pages/__init__.py
ADDED
|
File without changes
|
app/pages/chat_interface.py
ADDED
|
@@ -0,0 +1,361 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
# Must be the first Streamlit command
|
| 4 |
+
st.set_page_config(
|
| 5 |
+
page_title="02_Chat_Interface", # Use this format for ordering
|
| 6 |
+
page_icon="💬",
|
| 7 |
+
layout="wide"
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
# Rest of the imports
|
| 11 |
+
import pandas as pd
|
| 12 |
+
import logging
|
| 13 |
+
import sqlite3
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import sys
|
| 16 |
+
import os
|
| 17 |
+
|
| 18 |
+
# Add the parent directory to Python path
|
| 19 |
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
| 20 |
+
|
| 21 |
+
# Use absolute imports
|
| 22 |
+
from database import DatabaseHandler
|
| 23 |
+
from data_processor import DataProcessor
|
| 24 |
+
from rag import RAGSystem
|
| 25 |
+
from query_rewriter import QueryRewriter
|
| 26 |
+
from utils import process_single_video
|
| 27 |
+
|
| 28 |
+
# Set up logging
|
| 29 |
+
logger = logging.getLogger(__name__)
|
| 30 |
+
|
| 31 |
+
@st.cache_resource
|
| 32 |
+
def init_components():
|
| 33 |
+
"""Initialize system components"""
|
| 34 |
+
try:
|
| 35 |
+
db_handler = DatabaseHandler()
|
| 36 |
+
data_processor = DataProcessor()
|
| 37 |
+
rag_system = RAGSystem(data_processor)
|
| 38 |
+
query_rewriter = QueryRewriter()
|
| 39 |
+
return db_handler, data_processor, rag_system, query_rewriter
|
| 40 |
+
except Exception as e:
|
| 41 |
+
logger.error(f"Error initializing components: {str(e)}")
|
| 42 |
+
st.error(f"Error initializing components: {str(e)}")
|
| 43 |
+
return None, None, None, None
|
| 44 |
+
|
| 45 |
+
def init_session_state():
|
| 46 |
+
"""Initialize session state variables"""
|
| 47 |
+
if 'chat_history' not in st.session_state:
|
| 48 |
+
st.session_state.chat_history = []
|
| 49 |
+
if 'current_video_id' not in st.session_state:
|
| 50 |
+
st.session_state.current_video_id = None
|
| 51 |
+
if 'feedback_given' not in st.session_state:
|
| 52 |
+
st.session_state.feedback_given = set()
|
| 53 |
+
|
| 54 |
+
def create_chat_interface(db_handler, rag_system, video_id, index_name, rewrite_method, search_method):
|
| 55 |
+
"""Create the chat interface with feedback functionality"""
|
| 56 |
+
# Load chat history if video changed
|
| 57 |
+
if st.session_state.current_video_id != video_id:
|
| 58 |
+
st.session_state.chat_history = []
|
| 59 |
+
db_history = db_handler.get_chat_history(video_id)
|
| 60 |
+
for chat_id, user_msg, asst_msg, timestamp in db_history:
|
| 61 |
+
st.session_state.chat_history.append({
|
| 62 |
+
'id': chat_id,
|
| 63 |
+
'user': user_msg,
|
| 64 |
+
'assistant': asst_msg,
|
| 65 |
+
'timestamp': timestamp
|
| 66 |
+
})
|
| 67 |
+
st.session_state.current_video_id = video_id
|
| 68 |
+
|
| 69 |
+
# Display chat history
|
| 70 |
+
for message in st.session_state.chat_history:
|
| 71 |
+
with st.chat_message("user"):
|
| 72 |
+
st.markdown(message['user'])
|
| 73 |
+
|
| 74 |
+
with st.chat_message("assistant"):
|
| 75 |
+
st.markdown(message['assistant'])
|
| 76 |
+
|
| 77 |
+
message_key = f"{message['id']}"
|
| 78 |
+
if message_key not in st.session_state.feedback_given:
|
| 79 |
+
col1, col2 = st.columns(2)
|
| 80 |
+
with col1:
|
| 81 |
+
if st.button("👍", key=f"like_{message_key}"):
|
| 82 |
+
db_handler.add_user_feedback(
|
| 83 |
+
video_id=video_id,
|
| 84 |
+
chat_id=message['id'],
|
| 85 |
+
query=message['user'],
|
| 86 |
+
response=message['assistant'],
|
| 87 |
+
feedback=1
|
| 88 |
+
)
|
| 89 |
+
st.session_state.feedback_given.add(message_key)
|
| 90 |
+
st.success("Thank you for your positive feedback!")
|
| 91 |
+
st.rerun()
|
| 92 |
+
|
| 93 |
+
with col2:
|
| 94 |
+
if st.button("👎", key=f"dislike_{message_key}"):
|
| 95 |
+
db_handler.add_user_feedback(
|
| 96 |
+
video_id=video_id,
|
| 97 |
+
chat_id=message['id'],
|
| 98 |
+
query=message['user'],
|
| 99 |
+
response=message['assistant'],
|
| 100 |
+
feedback=-1
|
| 101 |
+
)
|
| 102 |
+
st.session_state.feedback_given.add(message_key)
|
| 103 |
+
st.success("Thank you for your feedback. We'll work to improve.")
|
| 104 |
+
st.rerun()
|
| 105 |
+
|
| 106 |
+
# Chat input
|
| 107 |
+
if prompt := st.chat_input("Ask a question about the video..."):
|
| 108 |
+
with st.chat_message("user"):
|
| 109 |
+
st.markdown(prompt)
|
| 110 |
+
|
| 111 |
+
with st.chat_message("assistant"):
|
| 112 |
+
with st.spinner("Thinking..."):
|
| 113 |
+
try:
|
| 114 |
+
# Apply query rewriting if selected
|
| 115 |
+
rewritten_query = prompt
|
| 116 |
+
if rewrite_method == "Chain of Thought":
|
| 117 |
+
rewritten_query, _ = rag_system.rewrite_cot(prompt)
|
| 118 |
+
st.caption("Rewritten query: " + rewritten_query)
|
| 119 |
+
elif rewrite_method == "ReAct":
|
| 120 |
+
rewritten_query, _ = rag_system.rewrite_react(prompt)
|
| 121 |
+
st.caption("Rewritten query: " + rewritten_query)
|
| 122 |
+
|
| 123 |
+
# Get response using selected search method
|
| 124 |
+
search_method_map = {
|
| 125 |
+
"Hybrid": "hybrid",
|
| 126 |
+
"Text-only": "text",
|
| 127 |
+
"Embedding-only": "embedding"
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
response, _ = rag_system.query(
|
| 131 |
+
rewritten_query,
|
| 132 |
+
search_method=search_method_map[search_method],
|
| 133 |
+
index_name=index_name
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
st.markdown(response)
|
| 137 |
+
|
| 138 |
+
# Save to database and session state
|
| 139 |
+
chat_id = db_handler.add_chat_message(video_id, prompt, response)
|
| 140 |
+
st.session_state.chat_history.append({
|
| 141 |
+
'id': chat_id,
|
| 142 |
+
'user': prompt,
|
| 143 |
+
'assistant': response,
|
| 144 |
+
'timestamp': datetime.now()
|
| 145 |
+
})
|
| 146 |
+
|
| 147 |
+
# Add feedback buttons for new message
|
| 148 |
+
message_key = f"{chat_id}"
|
| 149 |
+
col1, col2 = st.columns(2)
|
| 150 |
+
with col1:
|
| 151 |
+
if st.button("👍", key=f"like_{message_key}"):
|
| 152 |
+
db_handler.add_user_feedback(
|
| 153 |
+
video_id=video_id,
|
| 154 |
+
chat_id=chat_id,
|
| 155 |
+
query=prompt,
|
| 156 |
+
response=response,
|
| 157 |
+
feedback=1
|
| 158 |
+
)
|
| 159 |
+
st.session_state.feedback_given.add(message_key)
|
| 160 |
+
st.success("Thank you for your positive feedback!")
|
| 161 |
+
st.rerun()
|
| 162 |
+
with col2:
|
| 163 |
+
if st.button("👎", key=f"dislike_{message_key}"):
|
| 164 |
+
db_handler.add_user_feedback(
|
| 165 |
+
video_id=video_id,
|
| 166 |
+
chat_id=chat_id,
|
| 167 |
+
query=prompt,
|
| 168 |
+
response=response,
|
| 169 |
+
feedback=-1
|
| 170 |
+
)
|
| 171 |
+
st.session_state.feedback_given.add(message_key)
|
| 172 |
+
st.success("Thank you for your feedback. We'll work to improve.")
|
| 173 |
+
st.rerun()
|
| 174 |
+
|
| 175 |
+
except Exception as e:
|
| 176 |
+
st.error(f"Error generating response: {str(e)}")
|
| 177 |
+
logger.error(f"Error in chat interface: {str(e)}")
|
| 178 |
+
|
| 179 |
+
def get_system_status(db_handler, selected_video_id=None):
|
| 180 |
+
"""Get system status information"""
|
| 181 |
+
try:
|
| 182 |
+
with sqlite3.connect(db_handler.db_path) as conn:
|
| 183 |
+
cursor = conn.cursor()
|
| 184 |
+
|
| 185 |
+
# Get total videos
|
| 186 |
+
cursor.execute("SELECT COUNT(*) FROM videos")
|
| 187 |
+
total_videos = cursor.fetchone()[0]
|
| 188 |
+
|
| 189 |
+
# Get total indices
|
| 190 |
+
cursor.execute("SELECT COUNT(DISTINCT index_name) FROM elasticsearch_indices")
|
| 191 |
+
total_indices = cursor.fetchone()[0]
|
| 192 |
+
|
| 193 |
+
# Get available embedding models
|
| 194 |
+
cursor.execute("SELECT model_name FROM embedding_models")
|
| 195 |
+
models = [row[0] for row in cursor.fetchall()]
|
| 196 |
+
|
| 197 |
+
if selected_video_id:
|
| 198 |
+
# Get video details
|
| 199 |
+
cursor.execute("""
|
| 200 |
+
SELECT v.id, v.title, v.channel_name, v.processed_date,
|
| 201 |
+
ei.index_name, em.model_name
|
| 202 |
+
FROM videos v
|
| 203 |
+
LEFT JOIN elasticsearch_indices ei ON v.id = ei.video_id
|
| 204 |
+
LEFT JOIN embedding_models em ON ei.embedding_model_id = em.id
|
| 205 |
+
WHERE v.youtube_id = ?
|
| 206 |
+
""", (selected_video_id,))
|
| 207 |
+
video_details = cursor.fetchall()
|
| 208 |
+
else:
|
| 209 |
+
video_details = None
|
| 210 |
+
|
| 211 |
+
return {
|
| 212 |
+
"total_videos": total_videos,
|
| 213 |
+
"total_indices": total_indices,
|
| 214 |
+
"models": models,
|
| 215 |
+
"video_details": video_details
|
| 216 |
+
}
|
| 217 |
+
except Exception as e:
|
| 218 |
+
logger.error(f"Error getting system status: {str(e)}")
|
| 219 |
+
return None
|
| 220 |
+
|
| 221 |
+
def display_system_status(status, selected_video_id=None):
|
| 222 |
+
"""Display system status in the sidebar"""
|
| 223 |
+
if not status:
|
| 224 |
+
st.sidebar.error("Unable to fetch system status")
|
| 225 |
+
return
|
| 226 |
+
|
| 227 |
+
st.sidebar.header("System Status")
|
| 228 |
+
|
| 229 |
+
# Display general stats
|
| 230 |
+
col1, col2 = st.sidebar.columns(2)
|
| 231 |
+
with col1:
|
| 232 |
+
st.metric("Total Videos", status["total_videos"])
|
| 233 |
+
with col2:
|
| 234 |
+
st.metric("Total Indices", status["total_indices"])
|
| 235 |
+
|
| 236 |
+
st.sidebar.markdown("**Available Models:**")
|
| 237 |
+
for model in status["models"]:
|
| 238 |
+
st.sidebar.markdown(f"- {model}")
|
| 239 |
+
|
| 240 |
+
# Display selected video details
|
| 241 |
+
if selected_video_id and status["video_details"]:
|
| 242 |
+
st.sidebar.markdown("---")
|
| 243 |
+
st.sidebar.markdown("**Selected Video Details:**")
|
| 244 |
+
for details in status["video_details"]:
|
| 245 |
+
video_id, title, channel, processed_date, index_name, model = details
|
| 246 |
+
st.sidebar.markdown(f"""
|
| 247 |
+
- **Title:** {title}
|
| 248 |
+
- **Channel:** {channel}
|
| 249 |
+
- **Processed:** {processed_date}
|
| 250 |
+
- **Index:** {index_name or 'Not indexed'}
|
| 251 |
+
- **Model:** {model or 'N/A'}
|
| 252 |
+
""")
|
| 253 |
+
|
| 254 |
+
def main():
|
| 255 |
+
st.title("Chat Interface 💬")
|
| 256 |
+
|
| 257 |
+
# Initialize components
|
| 258 |
+
components = init_components()
|
| 259 |
+
if not components:
|
| 260 |
+
st.error("Failed to initialize components. Please check the logs.")
|
| 261 |
+
return
|
| 262 |
+
|
| 263 |
+
db_handler, data_processor, rag_system, query_rewriter = components
|
| 264 |
+
|
| 265 |
+
# Initialize session state
|
| 266 |
+
init_session_state()
|
| 267 |
+
|
| 268 |
+
# Get system status
|
| 269 |
+
system_status = get_system_status(db_handler)
|
| 270 |
+
|
| 271 |
+
# Video selection
|
| 272 |
+
st.sidebar.header("Video Selection")
|
| 273 |
+
|
| 274 |
+
# Get available videos with indices
|
| 275 |
+
with sqlite3.connect(db_handler.db_path) as conn:
|
| 276 |
+
query = """
|
| 277 |
+
SELECT DISTINCT v.youtube_id, v.title, v.channel_name, v.upload_date,
|
| 278 |
+
GROUP_CONCAT(ei.index_name) as indices
|
| 279 |
+
FROM videos v
|
| 280 |
+
LEFT JOIN elasticsearch_indices ei ON v.id = ei.video_id
|
| 281 |
+
GROUP BY v.youtube_id
|
| 282 |
+
ORDER BY v.upload_date DESC
|
| 283 |
+
"""
|
| 284 |
+
df = pd.read_sql_query(query, conn)
|
| 285 |
+
|
| 286 |
+
if df.empty:
|
| 287 |
+
st.info("No videos available. Please process some videos in the Data Ingestion page first.")
|
| 288 |
+
display_system_status(system_status)
|
| 289 |
+
return
|
| 290 |
+
|
| 291 |
+
# Display available videos
|
| 292 |
+
st.sidebar.markdown(f"**Available Videos:** {len(df)}")
|
| 293 |
+
|
| 294 |
+
# Channel filter
|
| 295 |
+
channels = sorted(df['channel_name'].unique())
|
| 296 |
+
selected_channel = st.sidebar.selectbox(
|
| 297 |
+
"Filter by Channel",
|
| 298 |
+
["All"] + channels,
|
| 299 |
+
key="channel_filter"
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
filtered_df = df if selected_channel == "All" else df[df['channel_name'] == selected_channel]
|
| 303 |
+
|
| 304 |
+
# Video selection
|
| 305 |
+
selected_video_id = st.sidebar.selectbox(
|
| 306 |
+
"Select a Video",
|
| 307 |
+
filtered_df['youtube_id'].tolist(),
|
| 308 |
+
format_func=lambda x: filtered_df[filtered_df['youtube_id'] == x]['title'].iloc[0],
|
| 309 |
+
key="video_select"
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
if selected_video_id:
|
| 313 |
+
# Update system status with selected video
|
| 314 |
+
system_status = get_system_status(db_handler, selected_video_id)
|
| 315 |
+
display_system_status(system_status, selected_video_id)
|
| 316 |
+
|
| 317 |
+
# Get the index for the selected video
|
| 318 |
+
index_name = db_handler.get_elasticsearch_index_by_youtube_id(selected_video_id)
|
| 319 |
+
|
| 320 |
+
if not index_name:
|
| 321 |
+
st.warning("This video hasn't been indexed yet. You can process it in the Data Ingestion page.")
|
| 322 |
+
if st.button("Process Now"):
|
| 323 |
+
with st.spinner("Processing video..."):
|
| 324 |
+
try:
|
| 325 |
+
embedding_model = data_processor.embedding_model.__class__.__name__
|
| 326 |
+
index_name = process_single_video(db_handler, data_processor, selected_video_id, embedding_model)
|
| 327 |
+
if index_name:
|
| 328 |
+
st.success("Video processed successfully!")
|
| 329 |
+
st.rerun()
|
| 330 |
+
except Exception as e:
|
| 331 |
+
st.error(f"Error processing video: {str(e)}")
|
| 332 |
+
logger.error(f"Error processing video: {str(e)}")
|
| 333 |
+
else:
|
| 334 |
+
# Chat settings
|
| 335 |
+
st.sidebar.header("Chat Settings")
|
| 336 |
+
rewrite_method = st.sidebar.radio(
|
| 337 |
+
"Query Rewriting Method",
|
| 338 |
+
["None", "Chain of Thought", "ReAct"],
|
| 339 |
+
key="rewrite_method"
|
| 340 |
+
)
|
| 341 |
+
search_method = st.sidebar.radio(
|
| 342 |
+
"Search Method",
|
| 343 |
+
["Hybrid", "Text-only", "Embedding-only"],
|
| 344 |
+
key="search_method"
|
| 345 |
+
)
|
| 346 |
+
|
| 347 |
+
# Create chat interface
|
| 348 |
+
create_chat_interface(
|
| 349 |
+
db_handler,
|
| 350 |
+
rag_system,
|
| 351 |
+
selected_video_id,
|
| 352 |
+
index_name,
|
| 353 |
+
rewrite_method,
|
| 354 |
+
search_method
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
# Display system status
|
| 358 |
+
display_system_status(system_status, selected_video_id)
|
| 359 |
+
|
| 360 |
+
if __name__ == "__main__":
|
| 361 |
+
main()
|
app/pages/data_ingestion.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
# Must be the first Streamlit command
|
| 4 |
+
st.set_page_config(
|
| 5 |
+
page_title="01_Data_Ingestion", # Use this format for ordering
|
| 6 |
+
page_icon="📥",
|
| 7 |
+
layout="wide"
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
import pandas as pd
|
| 11 |
+
from transcript_extractor import get_transcript, extract_video_id, get_channel_videos
|
| 12 |
+
from database import DatabaseHandler
|
| 13 |
+
from data_processor import DataProcessor
|
| 14 |
+
from utils import process_single_video
|
| 15 |
+
import logging
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
@st.cache_resource
|
| 20 |
+
def init_components():
|
| 21 |
+
return DatabaseHandler(), DataProcessor()
|
| 22 |
+
|
| 23 |
+
def process_multiple_videos(db_handler, data_processor, video_ids, embedding_model):
|
| 24 |
+
progress_bar = st.progress(0)
|
| 25 |
+
processed = 0
|
| 26 |
+
total = len(video_ids)
|
| 27 |
+
|
| 28 |
+
for video_id in video_ids:
|
| 29 |
+
if process_single_video(db_handler, data_processor, video_id, embedding_model):
|
| 30 |
+
processed += 1
|
| 31 |
+
progress_bar.progress(processed / total)
|
| 32 |
+
|
| 33 |
+
st.success(f"Processed {processed} out of {total} videos")
|
| 34 |
+
|
| 35 |
+
def main():
|
| 36 |
+
st.title("Data Ingestion 📥")
|
| 37 |
+
|
| 38 |
+
db_handler, data_processor = init_components()
|
| 39 |
+
|
| 40 |
+
# Model selection
|
| 41 |
+
embedding_model = st.selectbox(
|
| 42 |
+
"Select embedding model:",
|
| 43 |
+
["multi-qa-MiniLM-L6-cos-v1", "all-mpnet-base-v2"]
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
# Display existing videos
|
| 47 |
+
st.header("Processed Videos")
|
| 48 |
+
videos = db_handler.get_all_videos()
|
| 49 |
+
if videos:
|
| 50 |
+
video_df = pd.DataFrame(videos, columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 51 |
+
channels = sorted(video_df['channel_name'].unique())
|
| 52 |
+
|
| 53 |
+
selected_channel = st.selectbox("Filter by Channel", ["All"] + channels)
|
| 54 |
+
if selected_channel != "All":
|
| 55 |
+
video_df = video_df[video_df['channel_name'] == selected_channel]
|
| 56 |
+
|
| 57 |
+
st.dataframe(video_df)
|
| 58 |
+
else:
|
| 59 |
+
st.info("No videos processed yet. Use the form below to add videos.")
|
| 60 |
+
|
| 61 |
+
# Process new videos
|
| 62 |
+
st.header("Process New Video")
|
| 63 |
+
with st.form("process_video_form"):
|
| 64 |
+
input_type = st.radio("Select input type:", ["Video URL", "Channel URL", "YouTube ID"])
|
| 65 |
+
input_value = st.text_input("Enter the URL or ID:")
|
| 66 |
+
submit_button = st.form_submit_button("Process")
|
| 67 |
+
|
| 68 |
+
if submit_button:
|
| 69 |
+
data_processor.set_embedding_model(embedding_model)
|
| 70 |
+
|
| 71 |
+
with st.spinner("Processing..."):
|
| 72 |
+
if input_type == "Video URL":
|
| 73 |
+
video_id = extract_video_id(input_value)
|
| 74 |
+
if video_id:
|
| 75 |
+
process_single_video(db_handler, data_processor, video_id, embedding_model)
|
| 76 |
+
|
| 77 |
+
elif input_type == "Channel URL":
|
| 78 |
+
channel_videos = get_channel_videos(input_value)
|
| 79 |
+
if channel_videos:
|
| 80 |
+
video_ids = [video['video_id'] for video in channel_videos]
|
| 81 |
+
process_multiple_videos(db_handler, data_processor, video_ids, embedding_model)
|
| 82 |
+
else:
|
| 83 |
+
st.error("Failed to retrieve videos from the channel")
|
| 84 |
+
|
| 85 |
+
else: # YouTube ID
|
| 86 |
+
process_single_video(db_handler, data_processor, input_value, embedding_model)
|
| 87 |
+
|
| 88 |
+
def process_single_video(db_handler, data_processor, video_id, embedding_model):
|
| 89 |
+
try:
|
| 90 |
+
existing_index = db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 91 |
+
if existing_index:
|
| 92 |
+
st.info(f"Video {video_id} already processed. Using existing index.")
|
| 93 |
+
return existing_index
|
| 94 |
+
|
| 95 |
+
transcript_data = get_transcript(video_id)
|
| 96 |
+
if not transcript_data:
|
| 97 |
+
st.error("Failed to retrieve transcript.")
|
| 98 |
+
return None
|
| 99 |
+
|
| 100 |
+
# Process transcript and create indices
|
| 101 |
+
processed_data = data_processor.process_transcript(video_id, transcript_data)
|
| 102 |
+
if not processed_data:
|
| 103 |
+
st.error("Failed to process transcript.")
|
| 104 |
+
return None
|
| 105 |
+
|
| 106 |
+
# Save to database and create index
|
| 107 |
+
video_data = {
|
| 108 |
+
'video_id': video_id,
|
| 109 |
+
'title': transcript_data['metadata'].get('title', 'Unknown'),
|
| 110 |
+
'author': transcript_data['metadata'].get('author', 'Unknown'),
|
| 111 |
+
'upload_date': transcript_data['metadata'].get('upload_date', ''),
|
| 112 |
+
'view_count': transcript_data['metadata'].get('view_count', 0),
|
| 113 |
+
'like_count': transcript_data['metadata'].get('like_count', 0),
|
| 114 |
+
'comment_count': transcript_data['metadata'].get('comment_count', 0),
|
| 115 |
+
'video_duration': transcript_data['metadata'].get('duration', ''),
|
| 116 |
+
'transcript_content': processed_data['content']
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
db_handler.add_video(video_data)
|
| 120 |
+
|
| 121 |
+
index_name = f"video_{video_id}_{embedding_model}".lower()
|
| 122 |
+
index_name = data_processor.build_index(index_name)
|
| 123 |
+
|
| 124 |
+
if index_name:
|
| 125 |
+
st.success(f"Successfully processed video: {video_data['title']}")
|
| 126 |
+
return index_name
|
| 127 |
+
except Exception as e:
|
| 128 |
+
st.error(f"Error processing video: {str(e)}")
|
| 129 |
+
logger.error(f"Error processing video {video_id}: {str(e)}")
|
| 130 |
+
return None
|
| 131 |
+
|
| 132 |
+
def process_multiple_videos(db_handler, data_processor, video_ids, embedding_model):
|
| 133 |
+
progress_bar = st.progress(0)
|
| 134 |
+
processed = 0
|
| 135 |
+
total = len(video_ids)
|
| 136 |
+
|
| 137 |
+
for video_id in video_ids:
|
| 138 |
+
if process_single_video(db_handler, data_processor, video_id, embedding_model):
|
| 139 |
+
processed += 1
|
| 140 |
+
progress_bar.progress(processed / total)
|
| 141 |
+
|
| 142 |
+
st.success(f"Processed {processed} out of {total} videos")
|
| 143 |
+
|
| 144 |
+
if __name__ == "__main__":
|
| 145 |
+
main()
|
app/pages/evaluation.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.set_page_config(
|
| 4 |
+
page_title="04_Evaluation", # Use this format for ordering
|
| 5 |
+
page_icon="📊",
|
| 6 |
+
layout="wide"
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
import pandas as pd
|
| 10 |
+
from database import DatabaseHandler
|
| 11 |
+
from data_processor import DataProcessor
|
| 12 |
+
from rag import RAGSystem
|
| 13 |
+
from evaluation import EvaluationSystem
|
| 14 |
+
from generate_ground_truth import get_evaluation_display_data
|
| 15 |
+
import logging
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
# Define evaluation prompt template
|
| 20 |
+
EVALUATION_PROMPT_TEMPLATE = """
|
| 21 |
+
You are an expert evaluator for a Youtube transcript assistant.
|
| 22 |
+
Your task is to analyze the relevance of the generated answer to the given question.
|
| 23 |
+
Based on the relevance of the generated answer, you will classify it
|
| 24 |
+
as "NON_RELEVANT", "PARTLY_RELEVANT", or "RELEVANT".
|
| 25 |
+
|
| 26 |
+
Here is the data for evaluation:
|
| 27 |
+
|
| 28 |
+
Question: {question}
|
| 29 |
+
Generated Answer: {answer_llm}
|
| 30 |
+
|
| 31 |
+
Please analyze the content and context of the generated answer in relation to the question
|
| 32 |
+
and provide your evaluation in the following JSON format:
|
| 33 |
+
|
| 34 |
+
{{
|
| 35 |
+
"Relevance": "NON_RELEVANT" | "PARTLY_RELEVANT" | "RELEVANT",
|
| 36 |
+
"Explanation": "Your explanation for the relevance classification"
|
| 37 |
+
}}
|
| 38 |
+
|
| 39 |
+
Requirements:
|
| 40 |
+
1. Relevance must be one of the three exact values
|
| 41 |
+
2. Provide clear reasoning in the explanation
|
| 42 |
+
3. Consider accuracy and completeness of the answer
|
| 43 |
+
4. Return valid JSON only
|
| 44 |
+
""".strip()
|
| 45 |
+
|
| 46 |
+
@st.cache_resource
|
| 47 |
+
def init_components():
|
| 48 |
+
db_handler = DatabaseHandler()
|
| 49 |
+
data_processor = DataProcessor()
|
| 50 |
+
rag_system = RAGSystem(data_processor)
|
| 51 |
+
evaluation_system = EvaluationSystem(data_processor, db_handler)
|
| 52 |
+
return db_handler, data_processor, rag_system, evaluation_system
|
| 53 |
+
|
| 54 |
+
def main():
|
| 55 |
+
st.title("RAG Evaluation 📊")
|
| 56 |
+
|
| 57 |
+
db_handler, data_processor, rag_system, evaluation_system = init_components()
|
| 58 |
+
|
| 59 |
+
try:
|
| 60 |
+
# Check for ground truth data
|
| 61 |
+
ground_truth_df = pd.read_csv('data/ground-truth-retrieval.csv')
|
| 62 |
+
ground_truth_available = True
|
| 63 |
+
|
| 64 |
+
# Display existing evaluations
|
| 65 |
+
existing_evaluations = get_evaluation_display_data()
|
| 66 |
+
if not existing_evaluations.empty:
|
| 67 |
+
st.subheader("Existing Evaluation Results")
|
| 68 |
+
st.dataframe(existing_evaluations)
|
| 69 |
+
|
| 70 |
+
# Download button for evaluation results
|
| 71 |
+
csv = existing_evaluations.to_csv(index=False)
|
| 72 |
+
st.download_button(
|
| 73 |
+
label="Download Evaluation Results",
|
| 74 |
+
data=csv,
|
| 75 |
+
file_name="evaluation_results.csv",
|
| 76 |
+
mime="text/csv",
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
# Run evaluation
|
| 80 |
+
if ground_truth_available:
|
| 81 |
+
if st.button("Run Full Evaluation"):
|
| 82 |
+
with st.spinner("Running evaluation..."):
|
| 83 |
+
try:
|
| 84 |
+
evaluation_results = evaluation_system.run_full_evaluation(
|
| 85 |
+
rag_system,
|
| 86 |
+
'data/ground-truth-retrieval.csv',
|
| 87 |
+
EVALUATION_PROMPT_TEMPLATE
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if evaluation_results:
|
| 91 |
+
# Display RAG evaluations
|
| 92 |
+
st.subheader("RAG Evaluations")
|
| 93 |
+
rag_eval_df = pd.DataFrame(evaluation_results["rag_evaluations"])
|
| 94 |
+
st.dataframe(rag_eval_df)
|
| 95 |
+
|
| 96 |
+
# Display search performance
|
| 97 |
+
st.subheader("Search Performance")
|
| 98 |
+
search_perf_df = pd.DataFrame([evaluation_results["search_performance"]])
|
| 99 |
+
st.dataframe(search_perf_df)
|
| 100 |
+
|
| 101 |
+
# Display optimized parameters
|
| 102 |
+
st.subheader("Optimized Search Parameters")
|
| 103 |
+
params_df = pd.DataFrame([{
|
| 104 |
+
'parameter': k,
|
| 105 |
+
'value': v,
|
| 106 |
+
'score': evaluation_results['best_score']
|
| 107 |
+
} for k, v in evaluation_results['best_params'].items()])
|
| 108 |
+
st.dataframe(params_df)
|
| 109 |
+
|
| 110 |
+
# Save results
|
| 111 |
+
for video_id in rag_eval_df['video_id'].unique():
|
| 112 |
+
db_handler.save_search_performance(
|
| 113 |
+
video_id,
|
| 114 |
+
evaluation_results["search_performance"]['hit_rate'],
|
| 115 |
+
evaluation_results["search_performance"]['mrr']
|
| 116 |
+
)
|
| 117 |
+
db_handler.save_search_parameters(
|
| 118 |
+
video_id,
|
| 119 |
+
evaluation_results['best_params'],
|
| 120 |
+
evaluation_results['best_score']
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
st.success("Evaluation complete. Results saved to database and CSV.")
|
| 124 |
+
except Exception as e:
|
| 125 |
+
st.error(f"Error during evaluation: {str(e)}")
|
| 126 |
+
logger.error(f"Error in evaluation: {str(e)}")
|
| 127 |
+
|
| 128 |
+
except FileNotFoundError:
|
| 129 |
+
st.warning("No ground truth data available. Please generate ground truth data in the Ground Truth Generation page first.")
|
| 130 |
+
if st.button("Go to Ground Truth Generation"):
|
| 131 |
+
st.switch_page("pages/3_Ground_Truth.py")
|
| 132 |
+
|
| 133 |
+
if __name__ == "__main__":
|
| 134 |
+
main()
|
app/pages/ground_truth.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.set_page_config(
|
| 4 |
+
page_title="03_Ground_Truth", # Use this format for ordering
|
| 5 |
+
page_icon="📝",
|
| 6 |
+
layout="wide"
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
import pandas as pd
|
| 10 |
+
from database import DatabaseHandler
|
| 11 |
+
from data_processor import DataProcessor
|
| 12 |
+
from generate_ground_truth import generate_ground_truth, get_ground_truth_display_data
|
| 13 |
+
import logging
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
@st.cache_resource
|
| 18 |
+
def init_components():
|
| 19 |
+
return DatabaseHandler(), DataProcessor()
|
| 20 |
+
|
| 21 |
+
def main():
|
| 22 |
+
st.title("Ground Truth Generation 📝")
|
| 23 |
+
|
| 24 |
+
db_handler, data_processor = init_components()
|
| 25 |
+
|
| 26 |
+
# Get all videos
|
| 27 |
+
videos = db_handler.get_all_videos()
|
| 28 |
+
if not videos:
|
| 29 |
+
st.warning("No videos available. Please process some videos in the Data Ingestion page first.")
|
| 30 |
+
return
|
| 31 |
+
|
| 32 |
+
video_df = pd.DataFrame(videos, columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 33 |
+
|
| 34 |
+
# Channel filter
|
| 35 |
+
channels = sorted(video_df['channel_name'].unique())
|
| 36 |
+
selected_channel = st.selectbox("Filter by Channel", ["All"] + channels)
|
| 37 |
+
|
| 38 |
+
if selected_channel != "All":
|
| 39 |
+
video_df = video_df[video_df['channel_name'] == selected_channel]
|
| 40 |
+
# Display existing ground truth for channel
|
| 41 |
+
gt_data = get_ground_truth_display_data(db_handler, channel_name=selected_channel)
|
| 42 |
+
if not gt_data.empty:
|
| 43 |
+
st.subheader("Existing Ground Truth Questions for Channel")
|
| 44 |
+
st.dataframe(gt_data)
|
| 45 |
+
|
| 46 |
+
# Download button for channel ground truth
|
| 47 |
+
csv = gt_data.to_csv(index=False)
|
| 48 |
+
st.download_button(
|
| 49 |
+
label="Download Channel Ground Truth CSV",
|
| 50 |
+
data=csv,
|
| 51 |
+
file_name=f"ground_truth_{selected_channel}.csv",
|
| 52 |
+
mime="text/csv",
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
st.subheader("Available Videos")
|
| 56 |
+
st.dataframe(video_df)
|
| 57 |
+
|
| 58 |
+
# Video selection
|
| 59 |
+
selected_video_id = st.selectbox(
|
| 60 |
+
"Select a Video",
|
| 61 |
+
video_df['youtube_id'].tolist(),
|
| 62 |
+
format_func=lambda x: video_df[video_df['youtube_id'] == x]['title'].iloc[0]
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
if selected_video_id:
|
| 66 |
+
# Generate ground truth
|
| 67 |
+
if st.button("Generate Ground Truth Questions"):
|
| 68 |
+
with st.spinner("Generating questions..."):
|
| 69 |
+
try:
|
| 70 |
+
questions_df = generate_ground_truth(
|
| 71 |
+
db_handler,
|
| 72 |
+
data_processor,
|
| 73 |
+
selected_video_id
|
| 74 |
+
)
|
| 75 |
+
if questions_df is not None and not questions_df.empty:
|
| 76 |
+
st.success("Successfully generated ground truth questions")
|
| 77 |
+
st.dataframe(questions_df)
|
| 78 |
+
else:
|
| 79 |
+
st.error("Failed to generate ground truth questions")
|
| 80 |
+
except Exception as e:
|
| 81 |
+
st.error(f"Error generating ground truth: {str(e)}")
|
| 82 |
+
logger.error(f"Error in ground truth generation: {str(e)}")
|
| 83 |
+
|
| 84 |
+
# Display existing ground truth
|
| 85 |
+
gt_data = get_ground_truth_display_data(db_handler, video_id=selected_video_id)
|
| 86 |
+
if not gt_data.empty:
|
| 87 |
+
st.subheader("Existing Ground Truth Questions")
|
| 88 |
+
st.dataframe(gt_data)
|
| 89 |
+
|
| 90 |
+
# Download button for video ground truth
|
| 91 |
+
csv = gt_data.to_csv(index=False)
|
| 92 |
+
st.download_button(
|
| 93 |
+
label="Download Ground Truth CSV",
|
| 94 |
+
data=csv,
|
| 95 |
+
file_name=f"ground_truth_{selected_video_id}.csv",
|
| 96 |
+
mime="text/csv",
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
if __name__ == "__main__":
|
| 100 |
+
main()
|
app/rag.py
CHANGED
|
@@ -8,6 +8,25 @@ load_dotenv()
|
|
| 8 |
|
| 9 |
logger = logging.getLogger(__name__)
|
| 10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
class RAGSystem:
|
| 12 |
def __init__(self, data_processor):
|
| 13 |
self.data_processor = data_processor
|
|
@@ -52,14 +71,10 @@ class RAGSystem:
|
|
| 52 |
|
| 53 |
def get_prompt(self, user_query, relevant_docs):
|
| 54 |
context = "\n".join([doc['content'] for doc in relevant_docs])
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
Question: {user_query}
|
| 60 |
-
|
| 61 |
-
Answer:"""
|
| 62 |
-
return prompt
|
| 63 |
|
| 64 |
def query(self, user_query, search_method='hybrid', index_name=None):
|
| 65 |
try:
|
|
|
|
| 8 |
|
| 9 |
logger = logging.getLogger(__name__)
|
| 10 |
|
| 11 |
+
# Define the RAG prompt template
|
| 12 |
+
RAG_PROMPT_TEMPLATE = """
|
| 13 |
+
You are an AI assistant analyzing YouTube video transcripts. Your task is to answer questions based on the provided transcript context.
|
| 14 |
+
|
| 15 |
+
Context from transcript:
|
| 16 |
+
{context}
|
| 17 |
+
|
| 18 |
+
User Question: {question}
|
| 19 |
+
|
| 20 |
+
Please provide a clear, concise answer based only on the information given in the context. If the context doesn't contain enough information to fully answer the question, acknowledge this in your response.
|
| 21 |
+
|
| 22 |
+
Guidelines:
|
| 23 |
+
1. Use only information from the provided context
|
| 24 |
+
2. Be specific and direct in your answer
|
| 25 |
+
3. If context is insufficient, say so
|
| 26 |
+
4. Maintain accuracy and avoid speculation
|
| 27 |
+
5. Use natural, conversational language
|
| 28 |
+
""".strip()
|
| 29 |
+
|
| 30 |
class RAGSystem:
|
| 31 |
def __init__(self, data_processor):
|
| 32 |
self.data_processor = data_processor
|
|
|
|
| 71 |
|
| 72 |
def get_prompt(self, user_query, relevant_docs):
|
| 73 |
context = "\n".join([doc['content'] for doc in relevant_docs])
|
| 74 |
+
return RAG_PROMPT_TEMPLATE.format(
|
| 75 |
+
context=context,
|
| 76 |
+
question=user_query
|
| 77 |
+
)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 78 |
|
| 79 |
def query(self, user_query, search_method='hybrid', index_name=None):
|
| 80 |
try:
|
app/utils.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from transcript_extractor import get_transcript
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
logger = logging.getLogger(__name__)
|
| 6 |
+
|
| 7 |
+
def process_single_video(db_handler, data_processor, video_id, embedding_model):
|
| 8 |
+
"""Process a single video for indexing"""
|
| 9 |
+
try:
|
| 10 |
+
# Check for existing index
|
| 11 |
+
existing_index = db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 12 |
+
if existing_index:
|
| 13 |
+
logger.info(f"Video {video_id} already processed. Using existing index.")
|
| 14 |
+
return existing_index
|
| 15 |
+
|
| 16 |
+
# Get transcript data
|
| 17 |
+
transcript_data = get_transcript(video_id)
|
| 18 |
+
if not transcript_data:
|
| 19 |
+
logger.error(f"Failed to retrieve transcript for video {video_id}")
|
| 20 |
+
return None
|
| 21 |
+
|
| 22 |
+
# Process transcript
|
| 23 |
+
processed_data = data_processor.process_transcript(video_id, transcript_data)
|
| 24 |
+
if not processed_data:
|
| 25 |
+
logger.error(f"Failed to process transcript for video {video_id}")
|
| 26 |
+
return None
|
| 27 |
+
|
| 28 |
+
# Prepare video data
|
| 29 |
+
video_data = {
|
| 30 |
+
'video_id': video_id,
|
| 31 |
+
'title': transcript_data['metadata'].get('title', 'Unknown Title'),
|
| 32 |
+
'author': transcript_data['metadata'].get('author', 'Unknown Author'),
|
| 33 |
+
'upload_date': transcript_data['metadata'].get('upload_date', 'Unknown Date'),
|
| 34 |
+
'view_count': int(transcript_data['metadata'].get('view_count', 0)),
|
| 35 |
+
'like_count': int(transcript_data['metadata'].get('like_count', 0)),
|
| 36 |
+
'comment_count': int(transcript_data['metadata'].get('comment_count', 0)),
|
| 37 |
+
'video_duration': transcript_data['metadata'].get('duration', 'Unknown Duration'),
|
| 38 |
+
'transcript_content': processed_data['content']
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
# Save to database
|
| 42 |
+
db_handler.add_video(video_data)
|
| 43 |
+
|
| 44 |
+
# Build index
|
| 45 |
+
index_name = f"video_{video_id}_{embedding_model}".lower()
|
| 46 |
+
index_name = data_processor.build_index(index_name)
|
| 47 |
+
|
| 48 |
+
if index_name:
|
| 49 |
+
# Save index information
|
| 50 |
+
embedding_model_id = db_handler.add_embedding_model(embedding_model, "Description of the model")
|
| 51 |
+
video_record = db_handler.get_video_by_youtube_id(video_id)
|
| 52 |
+
if video_record:
|
| 53 |
+
db_handler.add_elasticsearch_index(video_record[0], index_name, embedding_model_id)
|
| 54 |
+
logger.info(f"Successfully processed video: {video_data['title']}")
|
| 55 |
+
return index_name
|
| 56 |
+
|
| 57 |
+
logger.error(f"Failed to process video {video_id}")
|
| 58 |
+
return None
|
| 59 |
+
|
| 60 |
+
except Exception as e:
|
| 61 |
+
logger.error(f"Error processing video {video_id}: {str(e)}")
|
| 62 |
+
return None
|
data/ground-truth-retrieval.csv
CHANGED
|
@@ -27,3 +27,13 @@ zjkBMFhNj_g,What are some examples of attacks on large language models (LLMs) th
|
|
| 27 |
zjkBMFhNj_g,How do prompt injection and shieldbreak attack work in the context of LLM security?
|
| 28 |
zjkBMFhNj_g,Are there defenses available against these types of attacks on large language models and how robust are they?
|
| 29 |
zjkBMFhNj_g,Can you explain the concept of prompt injection attack in LLM context?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
zjkBMFhNj_g,How do prompt injection and shieldbreak attack work in the context of LLM security?
|
| 28 |
zjkBMFhNj_g,Are there defenses available against these types of attacks on large language models and how robust are they?
|
| 29 |
zjkBMFhNj_g,Can you explain the concept of prompt injection attack in LLM context?
|
| 30 |
+
zjkBMFhNj_g,"Is it feasible that certain trigger phrases could manipulate a trained LLM into generating nonsensical predictions, and how was this demonstrated in research?"
|
| 31 |
+
zjkBMFhNj_g,In what ways can malicious actors exploit data poisoning or backdoor attacks within the training process of large language models (LLM)?
|
| 32 |
+
zjkBMFhNj_g,Can prompt injection attacks occur in the context of LMs and how do they work? Provide an example involving a malicious keyword.
|
| 33 |
+
zjkBMFhNj_g,What are some potential security threats related to large language models (LM) like Google Bard?
|
| 34 |
+
zjkBMFhNj_g,What are some potential security threats associated with large language models like Google Bard?
|
| 35 |
+
zjkBMFhNj_g,"How does a shieldbreak attack function in compromising an AI model's output, specifically with regard to sensitive information like credit card details?"
|
| 36 |
+
zjkBMFhNj_g,"How can data poisoning or backdoor attack affect pre-trained LMs, such as GPT models? Illustrate with potential trigger phrases that could lead to model corruption."
|
| 37 |
+
zjkBMFhNj_g,What are the possible defenses against these kinds of attacks on large language models and how effective they might be?
|
| 38 |
+
zjkBMFhNj_g,Do existing defenses against these types of prompt injection or data poisoning attacks apply to all cases including pre-training phases?
|
| 39 |
+
zjkBMFhNj_g,Can you elaborate on the concept of prompt injection attack and how it affects LLM systems such as ChatGPT or BigScience Alpaca?
|
data/sqlite.db
CHANGED
|
Binary files a/data/sqlite.db and b/data/sqlite.db differ
|
|
|
docker-compose.yaml
CHANGED
|
@@ -1,5 +1,3 @@
|
|
| 1 |
-
version: '3.8'
|
| 2 |
-
|
| 3 |
services:
|
| 4 |
app:
|
| 5 |
build: .
|
|
@@ -15,12 +13,22 @@ services:
|
|
| 15 |
- OLLAMA_HOST=http://ollama:11434
|
| 16 |
- OLLAMA_TIMEOUT=${OLLAMA_TIMEOUT:-120}
|
| 17 |
- OLLAMA_MAX_RETRIES=${OLLAMA_MAX_RETRIES:-3}
|
|
|
|
|
|
|
|
|
|
| 18 |
env_file:
|
| 19 |
- .env
|
| 20 |
volumes:
|
|
|
|
| 21 |
- ./data:/app/data
|
| 22 |
- ./config:/app/config
|
| 23 |
-
- ./
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
elasticsearch:
|
| 26 |
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0
|
|
@@ -28,6 +36,7 @@ services:
|
|
| 28 |
environment:
|
| 29 |
- discovery.type=single-node
|
| 30 |
- xpack.security.enabled=false
|
|
|
|
| 31 |
ports:
|
| 32 |
- "9200:9200"
|
| 33 |
- "9300:9300"
|
|
@@ -37,6 +46,11 @@ services:
|
|
| 37 |
memory: 2G
|
| 38 |
volumes:
|
| 39 |
- esdata:/usr/share/elasticsearch/data
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
|
| 41 |
grafana:
|
| 42 |
image: grafana/grafana:latest
|
|
@@ -54,8 +68,14 @@ services:
|
|
| 54 |
- ./grafana/dashboards:/etc/grafana/dashboards
|
| 55 |
- grafana-storage:/var/lib/grafana
|
| 56 |
- ./data:/app/data:ro
|
|
|
|
| 57 |
depends_on:
|
| 58 |
- elasticsearch
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
|
| 60 |
ollama:
|
| 61 |
image: ollama/ollama:latest
|
|
@@ -63,9 +83,22 @@ services:
|
|
| 63 |
- "11434:11434"
|
| 64 |
volumes:
|
| 65 |
- ollama_data:/root/.ollama
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 66 |
|
| 67 |
volumes:
|
| 68 |
esdata:
|
| 69 |
driver: local
|
| 70 |
grafana-storage:
|
| 71 |
-
ollama_data:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
services:
|
| 2 |
app:
|
| 3 |
build: .
|
|
|
|
| 13 |
- OLLAMA_HOST=http://ollama:11434
|
| 14 |
- OLLAMA_TIMEOUT=${OLLAMA_TIMEOUT:-120}
|
| 15 |
- OLLAMA_MAX_RETRIES=${OLLAMA_MAX_RETRIES:-3}
|
| 16 |
+
- PYTHONPATH=/app
|
| 17 |
+
- STREAMLIT_BROWSER_GATHER_USAGE_STATS=false
|
| 18 |
+
- STREAMLIT_THEME_PRIMARY_COLOR="#FF4B4B"
|
| 19 |
env_file:
|
| 20 |
- .env
|
| 21 |
volumes:
|
| 22 |
+
- ./app:/app/app
|
| 23 |
- ./data:/app/data
|
| 24 |
- ./config:/app/config
|
| 25 |
+
- ./logs:/app/logs
|
| 26 |
+
- ./.streamlit:/root/.streamlit:ro
|
| 27 |
+
healthcheck:
|
| 28 |
+
test: ["CMD", "curl", "-f", "http://localhost:8501/_stcore/health"]
|
| 29 |
+
interval: 30s
|
| 30 |
+
timeout: 10s
|
| 31 |
+
retries: 5
|
| 32 |
|
| 33 |
elasticsearch:
|
| 34 |
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0
|
|
|
|
| 36 |
environment:
|
| 37 |
- discovery.type=single-node
|
| 38 |
- xpack.security.enabled=false
|
| 39 |
+
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
|
| 40 |
ports:
|
| 41 |
- "9200:9200"
|
| 42 |
- "9300:9300"
|
|
|
|
| 46 |
memory: 2G
|
| 47 |
volumes:
|
| 48 |
- esdata:/usr/share/elasticsearch/data
|
| 49 |
+
healthcheck:
|
| 50 |
+
test: ["CMD", "curl", "-f", "http://localhost:9200"]
|
| 51 |
+
interval: 30s
|
| 52 |
+
timeout: 10s
|
| 53 |
+
retries: 5
|
| 54 |
|
| 55 |
grafana:
|
| 56 |
image: grafana/grafana:latest
|
|
|
|
| 68 |
- ./grafana/dashboards:/etc/grafana/dashboards
|
| 69 |
- grafana-storage:/var/lib/grafana
|
| 70 |
- ./data:/app/data:ro
|
| 71 |
+
- ./logs:/var/log/grafana
|
| 72 |
depends_on:
|
| 73 |
- elasticsearch
|
| 74 |
+
healthcheck:
|
| 75 |
+
test: ["CMD-SHELL", "wget -q --spider http://localhost:3000/api/health || exit 1"]
|
| 76 |
+
interval: 30s
|
| 77 |
+
timeout: 10s
|
| 78 |
+
retries: 5
|
| 79 |
|
| 80 |
ollama:
|
| 81 |
image: ollama/ollama:latest
|
|
|
|
| 83 |
- "11434:11434"
|
| 84 |
volumes:
|
| 85 |
- ollama_data:/root/.ollama
|
| 86 |
+
deploy:
|
| 87 |
+
resources:
|
| 88 |
+
limits:
|
| 89 |
+
memory: 6G
|
| 90 |
+
healthcheck:
|
| 91 |
+
test: ["CMD", "curl", "-f", "http://localhost:11434/api/health"]
|
| 92 |
+
interval: 30s
|
| 93 |
+
timeout: 10s
|
| 94 |
+
retries: 5
|
| 95 |
|
| 96 |
volumes:
|
| 97 |
esdata:
|
| 98 |
driver: local
|
| 99 |
grafana-storage:
|
| 100 |
+
ollama_data:
|
| 101 |
+
|
| 102 |
+
networks:
|
| 103 |
+
default:
|
| 104 |
+
driver: bridge
|
grafana/dashboards/rag_evaluation.json
CHANGED
|
@@ -67,7 +67,7 @@
|
|
| 67 |
"targets": [
|
| 68 |
{
|
| 69 |
"queryType": "table",
|
| 70 |
-
"sql": "SELECT re.video_id, v.title, re.question, re.relevance
|
| 71 |
"format": "table"
|
| 72 |
}
|
| 73 |
]
|
|
@@ -152,11 +152,11 @@
|
|
| 152 |
"templating": {
|
| 153 |
"list": [
|
| 154 |
{
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
|
| 160 |
}
|
| 161 |
]
|
| 162 |
},
|
|
|
|
| 67 |
"targets": [
|
| 68 |
{
|
| 69 |
"queryType": "table",
|
| 70 |
+
"sql": "SELECT re.video_id, v.title, re.question, re.relevance FROM rag_evaluations re JOIN videos v ON re.video_id = v.youtube_id LIMIT 10",
|
| 71 |
"format": "table"
|
| 72 |
}
|
| 73 |
]
|
|
|
|
| 152 |
"templating": {
|
| 153 |
"list": [
|
| 154 |
{
|
| 155 |
+
"name": "video_id",
|
| 156 |
+
"type": "query",
|
| 157 |
+
"datasource": "SQLite",
|
| 158 |
+
"query": "SELECT title AS __text, youtube_id AS __value FROM videos ORDER BY title",
|
| 159 |
+
"value": "All"
|
| 160 |
}
|
| 161 |
]
|
| 162 |
},
|
grafana/provisioning/datasources/sqlite.yaml
CHANGED
|
@@ -19,4 +19,5 @@ datasources:
|
|
| 19 |
- name: foreign_keys
|
| 20 |
value: "ON"
|
| 21 |
- name: busy_timeout
|
| 22 |
-
value: 5000
|
|
|
|
|
|
| 19 |
- name: foreign_keys
|
| 20 |
value: "ON"
|
| 21 |
- name: busy_timeout
|
| 22 |
+
value: 5000
|
| 23 |
+
userAgent: "Grafana-SQLite/1.0"
|
image-1.png
DELETED
|
Binary file (145 kB)
|
|
|
image-10.png
DELETED
|
Binary file (114 kB)
|
|
|
image-11.png
DELETED
|
Binary file (44.3 kB)
|
|
|
image-2.png
DELETED
|
Binary file (89.5 kB)
|
|
|
image-3.png
DELETED
|
Binary file (79.2 kB)
|
|
|
image-4.png
DELETED
|
Binary file (32.8 kB)
|
|
|
image-5.png
DELETED
|
Binary file (197 kB)
|
|
|
image-6.png
DELETED
|
Binary file (74.7 kB)
|
|
|
image-7.png
DELETED
|
Binary file (34.3 kB)
|
|
|
image-8.png
DELETED
|
Binary file (71.6 kB)
|
|
|
image-9.png
DELETED
|
Binary file (95.1 kB)
|
|
|
image.png
DELETED
|
Binary file (219 kB)
|
|
|
images/image-1.png
ADDED

|
images/image-2.png
ADDED
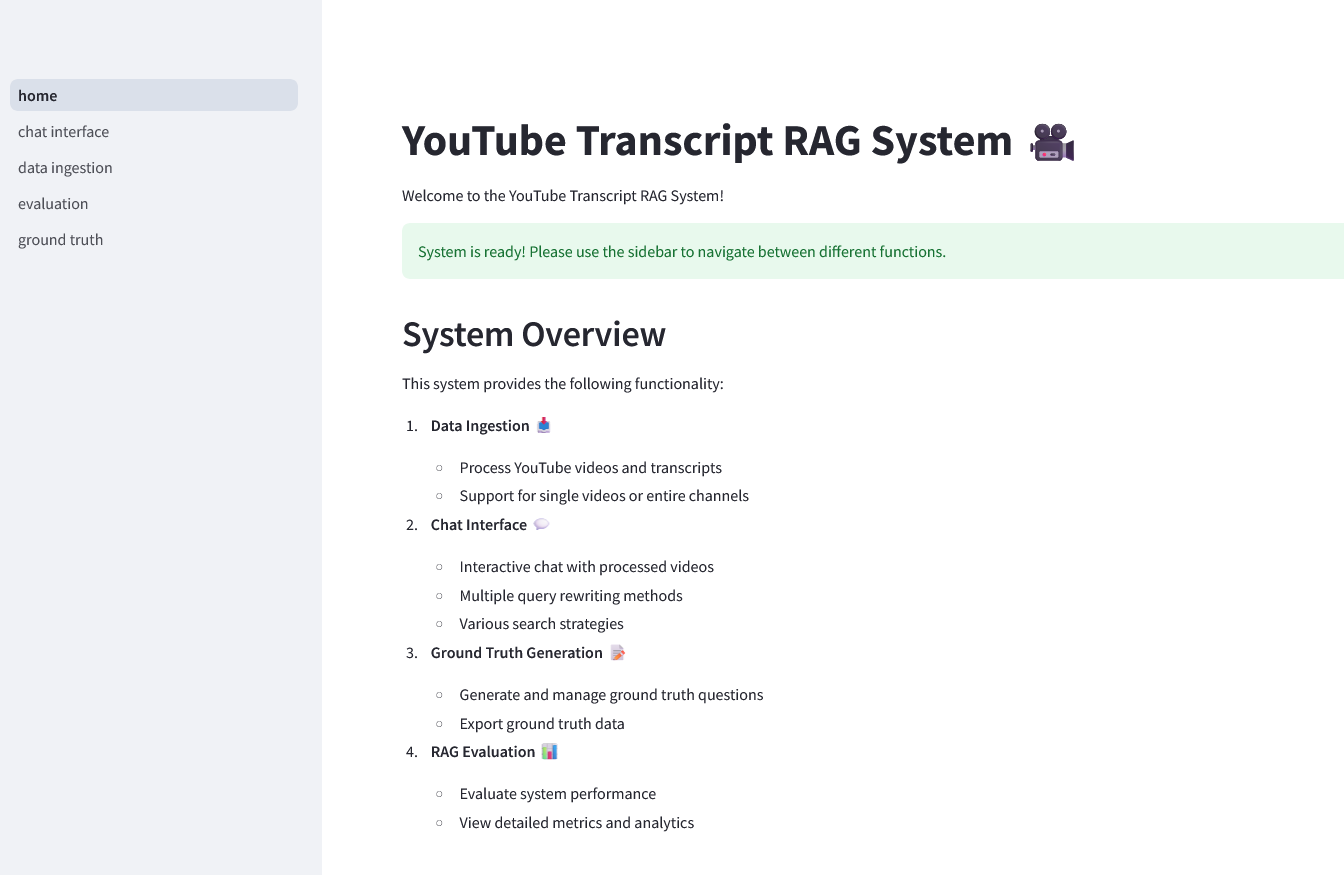
|
images/image-3.png
ADDED
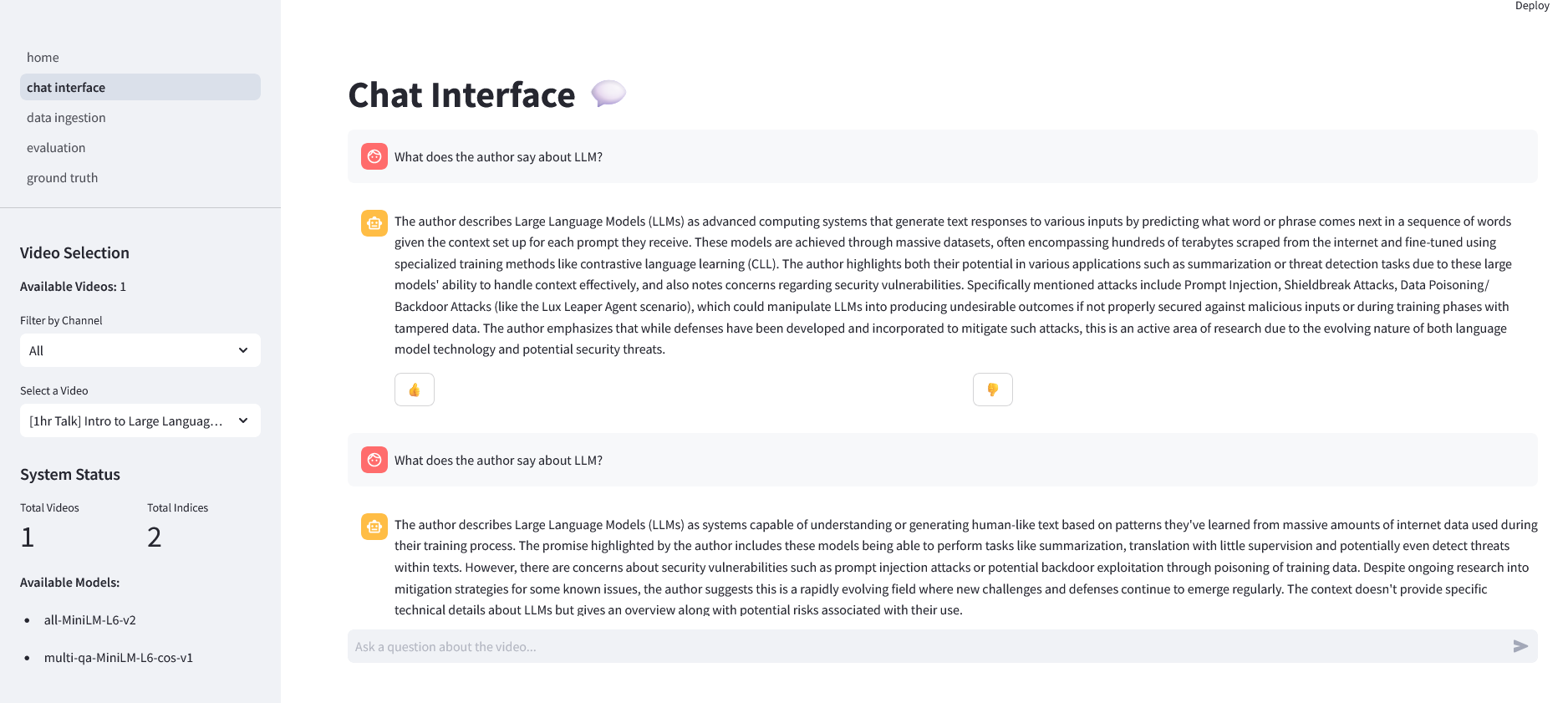
|
images/image-4.png
ADDED
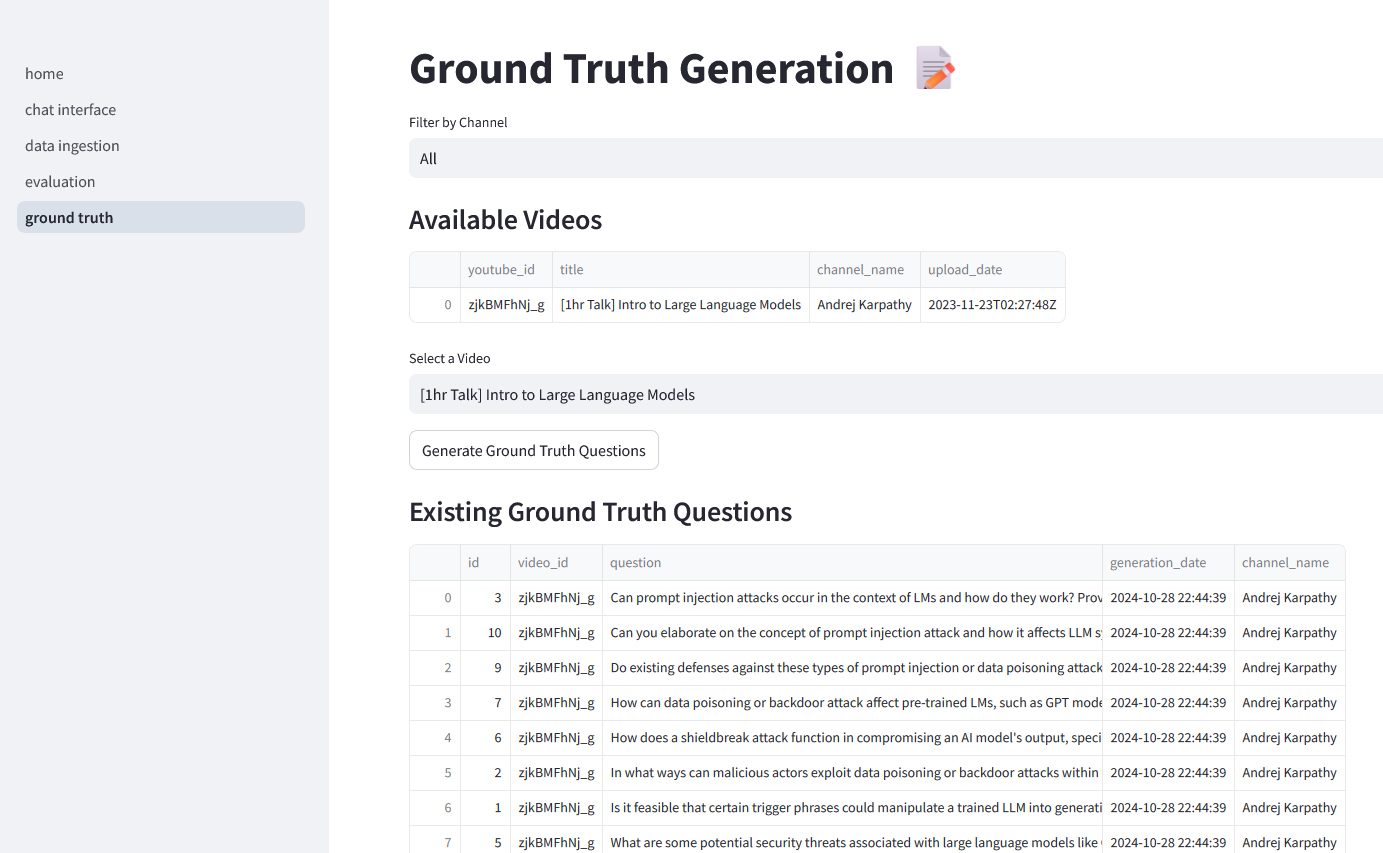
|
images/image-5.png
ADDED
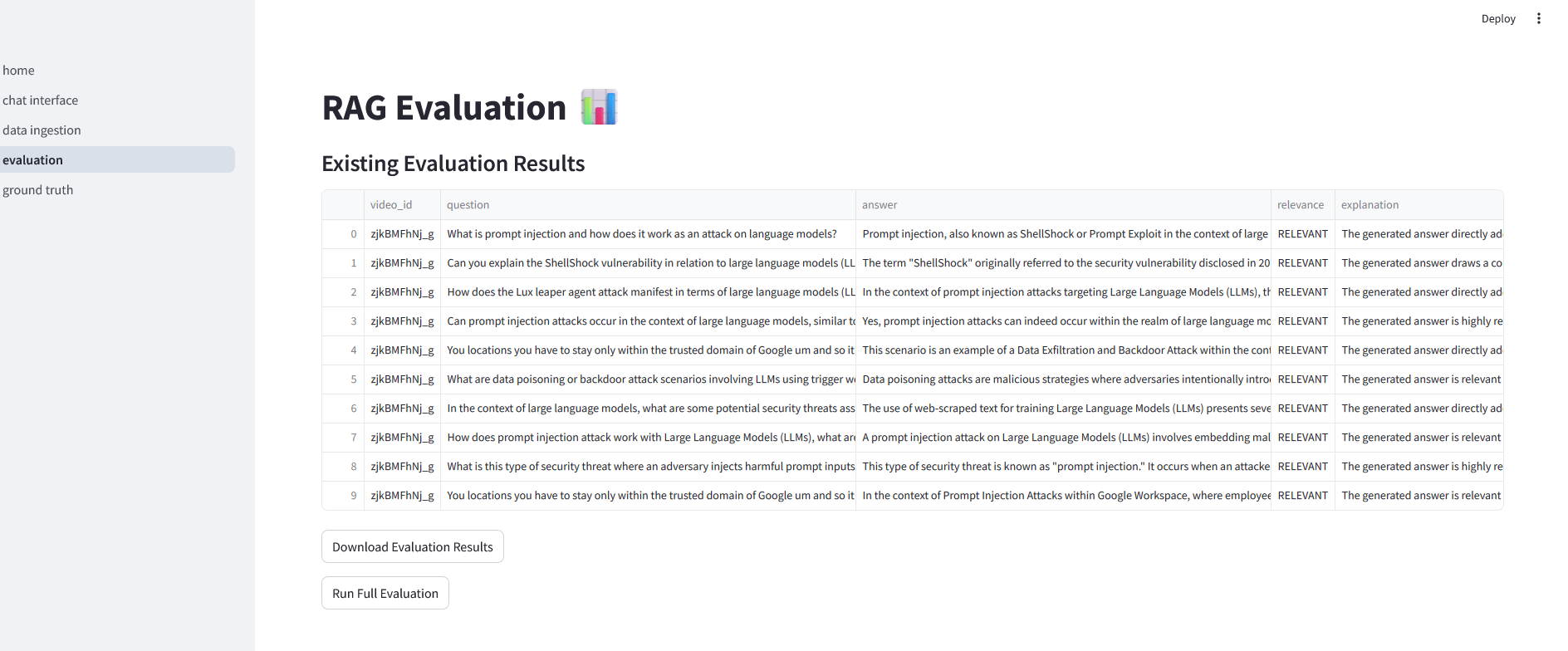
|
images/image-6.png
ADDED

|
images/image.png
ADDED

|