Spaces:
Running

Running
fifth commit
Browse files- README.md +26 -1
- Screenshots.md +27 -0
- app/database.py +162 -1
- app/evaluation.py +134 -21
- app/generate_ground_truth.py +113 -38
- app/main.py +88 -42
- app/rag_evaluation.py +7 -5
- data/evaluation_results.csv +181 -0
- data/ground-truth-retrieval.csv +25 -0
- data/sqlite.db +0 -0
- docker-compose.yaml +11 -2
- grafana/dashboards/rag_evaluation.json +172 -0
- grafana/provisioning/dashboards/dashboards.yaml +14 -0
- grafana/provisioning/dashboards/rag_evaluation.json +0 -129
- grafana/provisioning/datasources/sqlite.yaml +18 -3
- image-1.png +0 -0
- image-10.png +0 -0
- image-11.png +0 -0
- image-2.png +0 -0
- image-3.png +0 -0
- image-4.png +0 -0
- image-5.png +0 -0
- image-6.png +0 -0
- image-7.png +0 -0
- image-8.png +0 -0
- image-9.png +0 -0
- image.png +0 -0
- run-docker-compose.sh +43 -16
README.md
CHANGED
|
@@ -100,7 +100,32 @@ youtube-rag-app/
|
|
| 100 |
## Getting Started
|
| 101 |
|
| 102 |
git clone [email protected]:ganesh3/rag-youtube-assistant.git
|
| 103 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 104 |
|
| 105 |
## License
|
| 106 |
GPL v3
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 100 |
## Getting Started
|
| 101 |
|
| 102 |
git clone [email protected]:ganesh3/rag-youtube-assistant.git
|
| 103 |
+
cd rag-youtube-assistant
|
| 104 |
+
docker-compose build app
|
| 105 |
+
docker-compose up -d
|
| 106 |
+
|
| 107 |
+
You need to have Docker Desktop installed on your laptop/workstation along with WSL2 on windows machine.
|
| 108 |
|
| 109 |
## License
|
| 110 |
GPL v3
|
| 111 |
+
|
| 112 |
+
### Interface
|
| 113 |
+
|
| 114 |
+
I use Streamlit to ingest the youtube transcripts, query the transcripts uing LLM & RAG, generate ground truth and evaluate the ground truth.
|
| 115 |
+
|
| 116 |
+
### Ingestion
|
| 117 |
+
|
| 118 |
+
I am ingesting Youtube transcripts using Youtube Data API v3 and Youtube Transcript package and the code is in transcript_extractor.py and it is run on the Streamlit app using main.py.
|
| 119 |
+
|
| 120 |
+
### Retrieval
|
| 121 |
+
|
| 122 |
+
"hit_rate":1, "mrr":1
|
| 123 |
+
|
| 124 |
+
### RAG Flow
|
| 125 |
+
|
| 126 |
+
I used the LLM as a Judge metric to evaluate the quality of our RAG Flow on my local machine with CPU and hence the total records evaluated are pretty low (12).
|
| 127 |
+
|
| 128 |
+
* RELEVANT - 12 (100%)
|
| 129 |
+
* PARTLY_RELEVANT - 0 (0%)
|
| 130 |
+
* NON RELEVANT - 0 (0%)
|
| 131 |
+
|
Screenshots.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Docker deployment
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
### Ingestion
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+

|
| 9 |
+
|
| 10 |
+
### RAG
|
| 11 |
+
|
| 12 |
+

|
| 13 |
+

|
| 14 |
+

|
| 15 |
+

|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
### Ground Truth Generation
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
### RAG Evaluation
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+

|
app/database.py
CHANGED
|
@@ -11,6 +11,7 @@ class DatabaseHandler:
|
|
| 11 |
def create_tables(self):
|
| 12 |
with sqlite3.connect(self.db_path) as conn:
|
| 13 |
cursor = conn.cursor()
|
|
|
|
| 14 |
cursor.execute('''
|
| 15 |
CREATE TABLE IF NOT EXISTS videos (
|
| 16 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
@@ -53,6 +54,50 @@ class DatabaseHandler:
|
|
| 53 |
FOREIGN KEY (embedding_model_id) REFERENCES embedding_models (id)
|
| 54 |
)
|
| 55 |
''')
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
conn.commit()
|
| 57 |
|
| 58 |
def update_schema(self):
|
|
@@ -186,4 +231,120 @@ class DatabaseHandler:
|
|
| 186 |
# SET transcript_content = ?
|
| 187 |
# WHERE youtube_id = ?
|
| 188 |
# ''', (transcript_content, youtube_id))
|
| 189 |
-
# conn.commit()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
def create_tables(self):
|
| 12 |
with sqlite3.connect(self.db_path) as conn:
|
| 13 |
cursor = conn.cursor()
|
| 14 |
+
# Existing tables
|
| 15 |
cursor.execute('''
|
| 16 |
CREATE TABLE IF NOT EXISTS videos (
|
| 17 |
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
|
|
|
| 54 |
FOREIGN KEY (embedding_model_id) REFERENCES embedding_models (id)
|
| 55 |
)
|
| 56 |
''')
|
| 57 |
+
|
| 58 |
+
# New tables for ground truth and evaluation
|
| 59 |
+
cursor.execute('''
|
| 60 |
+
CREATE TABLE IF NOT EXISTS ground_truth (
|
| 61 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 62 |
+
video_id TEXT,
|
| 63 |
+
question TEXT,
|
| 64 |
+
generation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
|
| 65 |
+
UNIQUE(video_id, question)
|
| 66 |
+
)
|
| 67 |
+
''')
|
| 68 |
+
|
| 69 |
+
cursor.execute('''
|
| 70 |
+
CREATE TABLE IF NOT EXISTS search_performance (
|
| 71 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 72 |
+
video_id TEXT,
|
| 73 |
+
hit_rate REAL,
|
| 74 |
+
mrr REAL,
|
| 75 |
+
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
| 76 |
+
)
|
| 77 |
+
''')
|
| 78 |
+
|
| 79 |
+
cursor.execute('''
|
| 80 |
+
CREATE TABLE IF NOT EXISTS search_parameters (
|
| 81 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 82 |
+
video_id TEXT,
|
| 83 |
+
parameter_name TEXT,
|
| 84 |
+
parameter_value REAL,
|
| 85 |
+
score REAL,
|
| 86 |
+
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
| 87 |
+
)
|
| 88 |
+
''')
|
| 89 |
+
|
| 90 |
+
cursor.execute('''
|
| 91 |
+
CREATE TABLE IF NOT EXISTS rag_evaluations (
|
| 92 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 93 |
+
video_id TEXT,
|
| 94 |
+
question TEXT,
|
| 95 |
+
answer TEXT,
|
| 96 |
+
relevance TEXT,
|
| 97 |
+
explanation TEXT,
|
| 98 |
+
evaluation_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
|
| 99 |
+
)
|
| 100 |
+
''')
|
| 101 |
conn.commit()
|
| 102 |
|
| 103 |
def update_schema(self):
|
|
|
|
| 231 |
# SET transcript_content = ?
|
| 232 |
# WHERE youtube_id = ?
|
| 233 |
# ''', (transcript_content, youtube_id))
|
| 234 |
+
# conn.commit()
|
| 235 |
+
|
| 236 |
+
def add_ground_truth_questions(self, video_id, questions):
|
| 237 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 238 |
+
cursor = conn.cursor()
|
| 239 |
+
for question in questions:
|
| 240 |
+
try:
|
| 241 |
+
cursor.execute('''
|
| 242 |
+
INSERT OR IGNORE INTO ground_truth (video_id, question)
|
| 243 |
+
VALUES (?, ?)
|
| 244 |
+
''', (video_id, question))
|
| 245 |
+
except sqlite3.IntegrityError:
|
| 246 |
+
continue # Skip duplicate questions
|
| 247 |
+
conn.commit()
|
| 248 |
+
|
| 249 |
+
def get_ground_truth_by_video(self, video_id):
|
| 250 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 251 |
+
cursor = conn.cursor()
|
| 252 |
+
cursor.execute('''
|
| 253 |
+
SELECT gt.*, v.channel_name
|
| 254 |
+
FROM ground_truth gt
|
| 255 |
+
JOIN videos v ON gt.video_id = v.youtube_id
|
| 256 |
+
WHERE gt.video_id = ?
|
| 257 |
+
ORDER BY gt.generation_date DESC
|
| 258 |
+
''', (video_id,))
|
| 259 |
+
return cursor.fetchall()
|
| 260 |
+
|
| 261 |
+
def get_ground_truth_by_channel(self, channel_name):
|
| 262 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 263 |
+
cursor = conn.cursor()
|
| 264 |
+
cursor.execute('''
|
| 265 |
+
SELECT gt.*, v.channel_name
|
| 266 |
+
FROM ground_truth gt
|
| 267 |
+
JOIN videos v ON gt.video_id = v.youtube_id
|
| 268 |
+
WHERE v.channel_name = ?
|
| 269 |
+
ORDER BY gt.generation_date DESC
|
| 270 |
+
''', (channel_name,))
|
| 271 |
+
return cursor.fetchall()
|
| 272 |
+
|
| 273 |
+
def get_all_ground_truth(self):
|
| 274 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 275 |
+
cursor = conn.cursor()
|
| 276 |
+
cursor.execute('''
|
| 277 |
+
SELECT gt.*, v.channel_name
|
| 278 |
+
FROM ground_truth gt
|
| 279 |
+
JOIN videos v ON gt.video_id = v.youtube_id
|
| 280 |
+
ORDER BY gt.generation_date DESC
|
| 281 |
+
''')
|
| 282 |
+
return cursor.fetchall()
|
| 283 |
+
|
| 284 |
+
def save_search_performance(self, video_id, hit_rate, mrr):
|
| 285 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 286 |
+
cursor = conn.cursor()
|
| 287 |
+
cursor.execute('''
|
| 288 |
+
INSERT INTO search_performance (video_id, hit_rate, mrr)
|
| 289 |
+
VALUES (?, ?, ?)
|
| 290 |
+
''', (video_id, hit_rate, mrr))
|
| 291 |
+
conn.commit()
|
| 292 |
+
|
| 293 |
+
def save_search_parameters(self, video_id, parameters, score):
|
| 294 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 295 |
+
cursor = conn.cursor()
|
| 296 |
+
for param_name, param_value in parameters.items():
|
| 297 |
+
cursor.execute('''
|
| 298 |
+
INSERT INTO search_parameters (video_id, parameter_name, parameter_value, score)
|
| 299 |
+
VALUES (?, ?, ?, ?)
|
| 300 |
+
''', (video_id, param_name, param_value, score))
|
| 301 |
+
conn.commit()
|
| 302 |
+
|
| 303 |
+
def save_rag_evaluation(self, evaluation_data):
|
| 304 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 305 |
+
cursor = conn.cursor()
|
| 306 |
+
cursor.execute('''
|
| 307 |
+
INSERT INTO rag_evaluations
|
| 308 |
+
(video_id, question, answer, relevance, explanation)
|
| 309 |
+
VALUES (?, ?, ?, ?, ?)
|
| 310 |
+
''', (
|
| 311 |
+
evaluation_data['video_id'],
|
| 312 |
+
evaluation_data['question'],
|
| 313 |
+
evaluation_data['answer'],
|
| 314 |
+
evaluation_data['relevance'],
|
| 315 |
+
evaluation_data['explanation']
|
| 316 |
+
))
|
| 317 |
+
conn.commit()
|
| 318 |
+
|
| 319 |
+
def get_latest_evaluation_results(self, video_id=None):
|
| 320 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 321 |
+
cursor = conn.cursor()
|
| 322 |
+
if video_id:
|
| 323 |
+
cursor.execute('''
|
| 324 |
+
SELECT * FROM rag_evaluations
|
| 325 |
+
WHERE video_id = ?
|
| 326 |
+
ORDER BY evaluation_date DESC
|
| 327 |
+
''', (video_id,))
|
| 328 |
+
else:
|
| 329 |
+
cursor.execute('''
|
| 330 |
+
SELECT * FROM rag_evaluations
|
| 331 |
+
ORDER BY evaluation_date DESC
|
| 332 |
+
''')
|
| 333 |
+
return cursor.fetchall()
|
| 334 |
+
|
| 335 |
+
def get_latest_search_performance(self, video_id=None):
|
| 336 |
+
with sqlite3.connect(self.db_path) as conn:
|
| 337 |
+
cursor = conn.cursor()
|
| 338 |
+
if video_id:
|
| 339 |
+
cursor.execute('''
|
| 340 |
+
SELECT * FROM search_performance
|
| 341 |
+
WHERE video_id = ?
|
| 342 |
+
ORDER BY evaluation_date DESC
|
| 343 |
+
LIMIT 1
|
| 344 |
+
''', (video_id,))
|
| 345 |
+
else:
|
| 346 |
+
cursor.execute('''
|
| 347 |
+
SELECT * FROM search_performance
|
| 348 |
+
ORDER BY evaluation_date DESC
|
| 349 |
+
''')
|
| 350 |
+
return cursor.fetchall()
|
app/evaluation.py
CHANGED
|
@@ -3,6 +3,10 @@ import numpy as np
|
|
| 3 |
import pandas as pd
|
| 4 |
import json
|
| 5 |
import ollama
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
|
| 7 |
class EvaluationSystem:
|
| 8 |
def __init__(self, data_processor, database_handler):
|
|
@@ -42,7 +46,7 @@ class EvaluationSystem:
|
|
| 42 |
|
| 43 |
relevance_scores.append(self.relevance_scoring(query, retrieved_docs))
|
| 44 |
similarity_scores.append(self.answer_similarity(generated_answer, reference))
|
| 45 |
-
human_scores.append(self.human_evaluation(index_name, query))
|
| 46 |
|
| 47 |
return {
|
| 48 |
"avg_relevance_score": np.mean(relevance_scores),
|
|
@@ -64,17 +68,16 @@ class EvaluationSystem:
|
|
| 64 |
print(f"Error in LLM evaluation: {str(e)}")
|
| 65 |
return None
|
| 66 |
|
| 67 |
-
def evaluate_rag(self, rag_system, ground_truth_file,
|
| 68 |
try:
|
| 69 |
ground_truth = pd.read_csv(ground_truth_file)
|
| 70 |
except FileNotFoundError:
|
| 71 |
print("Ground truth file not found. Please generate ground truth data first.")
|
| 72 |
return None
|
| 73 |
|
| 74 |
-
sample = ground_truth.sample(n=min(sample_size, len(ground_truth)), random_state=1)
|
| 75 |
evaluations = []
|
| 76 |
|
| 77 |
-
for _, row in
|
| 78 |
question = row['question']
|
| 79 |
video_id = row['video_id']
|
| 80 |
|
|
@@ -93,22 +96,132 @@ class EvaluationSystem:
|
|
| 93 |
if prompt_template:
|
| 94 |
evaluation = self.llm_as_judge(question, answer_llm, prompt_template)
|
| 95 |
if evaluation:
|
| 96 |
-
evaluations.append(
|
| 97 |
-
str(video_id),
|
| 98 |
-
str(question),
|
| 99 |
-
str(answer_llm),
|
| 100 |
-
str(evaluation.get('Relevance', 'UNKNOWN')),
|
| 101 |
-
str(evaluation.get('Explanation', 'No explanation provided'))
|
| 102 |
-
)
|
| 103 |
else:
|
| 104 |
-
# Fallback to cosine similarity if no prompt template is provided
|
| 105 |
similarity = self.answer_similarity(answer_llm, row.get('reference_answer', ''))
|
| 106 |
-
evaluations.append(
|
| 107 |
-
str(video_id),
|
| 108 |
-
str(question),
|
| 109 |
-
str(answer_llm),
|
| 110 |
-
f"Similarity: {similarity}",
|
| 111 |
-
"Cosine similarity used for evaluation"
|
| 112 |
-
)
|
| 113 |
-
|
| 114 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
import pandas as pd
|
| 4 |
import json
|
| 5 |
import ollama
|
| 6 |
+
import requests
|
| 7 |
+
import sqlite3
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import csv
|
| 10 |
|
| 11 |
class EvaluationSystem:
|
| 12 |
def __init__(self, data_processor, database_handler):
|
|
|
|
| 46 |
|
| 47 |
relevance_scores.append(self.relevance_scoring(query, retrieved_docs))
|
| 48 |
similarity_scores.append(self.answer_similarity(generated_answer, reference))
|
| 49 |
+
human_scores.append(self.human_evaluation(index_name, query))
|
| 50 |
|
| 51 |
return {
|
| 52 |
"avg_relevance_score": np.mean(relevance_scores),
|
|
|
|
| 68 |
print(f"Error in LLM evaluation: {str(e)}")
|
| 69 |
return None
|
| 70 |
|
| 71 |
+
def evaluate_rag(self, rag_system, ground_truth_file, prompt_template=None):
|
| 72 |
try:
|
| 73 |
ground_truth = pd.read_csv(ground_truth_file)
|
| 74 |
except FileNotFoundError:
|
| 75 |
print("Ground truth file not found. Please generate ground truth data first.")
|
| 76 |
return None
|
| 77 |
|
|
|
|
| 78 |
evaluations = []
|
| 79 |
|
| 80 |
+
for _, row in tqdm(ground_truth.iterrows(), total=len(ground_truth)):
|
| 81 |
question = row['question']
|
| 82 |
video_id = row['video_id']
|
| 83 |
|
|
|
|
| 96 |
if prompt_template:
|
| 97 |
evaluation = self.llm_as_judge(question, answer_llm, prompt_template)
|
| 98 |
if evaluation:
|
| 99 |
+
evaluations.append({
|
| 100 |
+
'video_id': str(video_id),
|
| 101 |
+
'question': str(question),
|
| 102 |
+
'answer': str(answer_llm),
|
| 103 |
+
'relevance': str(evaluation.get('Relevance', 'UNKNOWN')),
|
| 104 |
+
'explanation': str(evaluation.get('Explanation', 'No explanation provided'))
|
| 105 |
+
})
|
| 106 |
else:
|
|
|
|
| 107 |
similarity = self.answer_similarity(answer_llm, row.get('reference_answer', ''))
|
| 108 |
+
evaluations.append({
|
| 109 |
+
'video_id': str(video_id),
|
| 110 |
+
'question': str(question),
|
| 111 |
+
'answer': str(answer_llm),
|
| 112 |
+
'relevance': f"Similarity: {similarity}",
|
| 113 |
+
'explanation': "Cosine similarity used for evaluation"
|
| 114 |
+
})
|
| 115 |
+
|
| 116 |
+
# Save evaluations to CSV
|
| 117 |
+
csv_path = 'data/evaluation_results.csv'
|
| 118 |
+
with open(csv_path, 'w', newline='', encoding='utf-8') as csvfile:
|
| 119 |
+
fieldnames = ['video_id', 'question', 'answer', 'relevance', 'explanation']
|
| 120 |
+
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
|
| 121 |
+
writer.writeheader()
|
| 122 |
+
for eval_data in evaluations:
|
| 123 |
+
writer.writerow(eval_data)
|
| 124 |
+
|
| 125 |
+
print(f"Evaluation results saved to {csv_path}")
|
| 126 |
+
|
| 127 |
+
# Save evaluations to database
|
| 128 |
+
self.save_evaluations_to_db(evaluations)
|
| 129 |
+
|
| 130 |
+
return evaluations
|
| 131 |
+
|
| 132 |
+
def save_evaluations_to_db(self, evaluations):
|
| 133 |
+
with sqlite3.connect(self.db_handler.db_path) as conn:
|
| 134 |
+
cursor = conn.cursor()
|
| 135 |
+
cursor.execute('''
|
| 136 |
+
CREATE TABLE IF NOT EXISTS rag_evaluations (
|
| 137 |
+
id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 138 |
+
video_id TEXT,
|
| 139 |
+
question TEXT,
|
| 140 |
+
answer TEXT,
|
| 141 |
+
relevance TEXT,
|
| 142 |
+
explanation TEXT
|
| 143 |
+
)
|
| 144 |
+
''')
|
| 145 |
+
for eval_data in evaluations:
|
| 146 |
+
cursor.execute('''
|
| 147 |
+
INSERT INTO rag_evaluations (video_id, question, answer, relevance, explanation)
|
| 148 |
+
VALUES (?, ?, ?, ?, ?)
|
| 149 |
+
''', (eval_data['video_id'], eval_data['question'], eval_data['answer'],
|
| 150 |
+
eval_data['relevance'], eval_data['explanation']))
|
| 151 |
+
conn.commit()
|
| 152 |
+
print("Evaluation results saved to database")
|
| 153 |
+
|
| 154 |
+
def run_full_evaluation(self, rag_system, ground_truth_file, prompt_template=None):
|
| 155 |
+
# Load ground truth
|
| 156 |
+
ground_truth = pd.read_csv(ground_truth_file)
|
| 157 |
+
|
| 158 |
+
# Evaluate RAG
|
| 159 |
+
rag_evaluations = self.evaluate_rag(rag_system, ground_truth_file, prompt_template)
|
| 160 |
+
|
| 161 |
+
# Evaluate search performance
|
| 162 |
+
def search_function(query, video_id):
|
| 163 |
+
index_name = self.db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 164 |
+
if index_name:
|
| 165 |
+
return rag_system.data_processor.search(query, num_results=10, method='hybrid', index_name=index_name)
|
| 166 |
+
return []
|
| 167 |
+
|
| 168 |
+
search_performance = self.evaluate_search(ground_truth, search_function)
|
| 169 |
+
|
| 170 |
+
# Optimize search parameters
|
| 171 |
+
param_ranges = {'content': (0.0, 3.0)} # Example parameter range
|
| 172 |
+
|
| 173 |
+
def objective_function(params):
|
| 174 |
+
def parameterized_search(query, video_id):
|
| 175 |
+
index_name = self.db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 176 |
+
if index_name:
|
| 177 |
+
return rag_system.data_processor.search(query, num_results=10, method='hybrid', index_name=index_name, boost_dict=params)
|
| 178 |
+
return []
|
| 179 |
+
return self.evaluate_search(ground_truth, parameterized_search)['mrr']
|
| 180 |
+
|
| 181 |
+
best_params, best_score = self.simple_optimize(param_ranges, objective_function)
|
| 182 |
+
|
| 183 |
+
return {
|
| 184 |
+
"rag_evaluations": rag_evaluations,
|
| 185 |
+
"search_performance": search_performance,
|
| 186 |
+
"best_params": best_params,
|
| 187 |
+
"best_score": best_score
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def hit_rate(self, relevance_total):
|
| 192 |
+
return sum(any(line) for line in relevance_total) / len(relevance_total)
|
| 193 |
+
|
| 194 |
+
def mrr(self, relevance_total):
|
| 195 |
+
scores = []
|
| 196 |
+
for line in relevance_total:
|
| 197 |
+
for rank, relevant in enumerate(line, 1):
|
| 198 |
+
if relevant:
|
| 199 |
+
scores.append(1 / rank)
|
| 200 |
+
break
|
| 201 |
+
else:
|
| 202 |
+
scores.append(0)
|
| 203 |
+
return sum(scores) / len(scores)
|
| 204 |
+
|
| 205 |
+
def simple_optimize(self, param_ranges, objective_function, n_iterations=10):
|
| 206 |
+
best_params = None
|
| 207 |
+
best_score = float('-inf')
|
| 208 |
+
for _ in range(n_iterations):
|
| 209 |
+
current_params = {param: np.random.uniform(min_val, max_val)
|
| 210 |
+
for param, (min_val, max_val) in param_ranges.items()}
|
| 211 |
+
current_score = objective_function(current_params)
|
| 212 |
+
if current_score > best_score:
|
| 213 |
+
best_score = current_score
|
| 214 |
+
best_params = current_params
|
| 215 |
+
return best_params, best_score
|
| 216 |
+
|
| 217 |
+
def evaluate_search(self, ground_truth, search_function):
|
| 218 |
+
relevance_total = []
|
| 219 |
+
for _, row in tqdm(ground_truth.iterrows(), total=len(ground_truth)):
|
| 220 |
+
video_id = row['video_id']
|
| 221 |
+
results = search_function(row['question'], video_id)
|
| 222 |
+
relevance = [d['video_id'] == video_id for d in results]
|
| 223 |
+
relevance_total.append(relevance)
|
| 224 |
+
return {
|
| 225 |
+
'hit_rate': self.hit_rate(relevance_total),
|
| 226 |
+
'mrr': self.mrr(relevance_total),
|
| 227 |
+
}
|
app/generate_ground_truth.py
CHANGED
|
@@ -46,13 +46,13 @@ def get_transcript_from_sqlite(db_path, video_id):
|
|
| 46 |
logger.error(f"Error retrieving transcript from SQLite: {str(e)}")
|
| 47 |
return None
|
| 48 |
|
| 49 |
-
def generate_questions(transcript):
|
| 50 |
prompt_template = """
|
| 51 |
You are an AI assistant tasked with generating questions based on a YouTube video transcript.
|
| 52 |
-
Formulate
|
| 53 |
Make the questions specific to the content of the transcript.
|
| 54 |
The questions should be complete and not too short. Use as few words as possible from the transcript.
|
| 55 |
-
|
| 56 |
|
| 57 |
The transcript:
|
| 58 |
|
|
@@ -63,60 +63,121 @@ def generate_questions(transcript):
|
|
| 63 |
{{"questions": ["question1", "question2", ..., "question10"]}}
|
| 64 |
""".strip()
|
| 65 |
|
| 66 |
-
|
|
|
|
| 67 |
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 77 |
|
| 78 |
def generate_ground_truth(db_handler, data_processor, video_id):
|
| 79 |
es = Elasticsearch([f'http://{os.getenv("ELASTICSEARCH_HOST", "localhost")}:{os.getenv("ELASTICSEARCH_PORT", "9200")}'])
|
| 80 |
|
| 81 |
-
# Get
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
if not index_name:
|
| 85 |
-
logger.error(f"No Elasticsearch index found for video {video_id}")
|
| 86 |
-
return None
|
| 87 |
-
|
| 88 |
-
# Extract the model name from the index name
|
| 89 |
-
model_name = extract_model_name(index_name)
|
| 90 |
-
|
| 91 |
-
if not model_name:
|
| 92 |
-
logger.error(f"Could not extract model name from index name: {index_name}")
|
| 93 |
-
return None
|
| 94 |
|
| 95 |
transcript = None
|
|
|
|
|
|
|
| 96 |
if index_name:
|
| 97 |
transcript = get_transcript_from_elasticsearch(es, index_name, video_id)
|
| 98 |
-
logger.info(f"Transcript to generate questions using elasticsearch is {transcript}")
|
| 99 |
|
| 100 |
if not transcript:
|
| 101 |
transcript = db_handler.get_transcript_content(video_id)
|
| 102 |
-
logger.info(f"Transcript to generate questions using textual data is {transcript}")
|
| 103 |
|
| 104 |
if not transcript:
|
| 105 |
logger.error(f"Failed to retrieve transcript for video {video_id}")
|
| 106 |
return None
|
| 107 |
|
| 108 |
-
questions
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 109 |
|
| 110 |
-
if
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
df.to_csv(csv_path, index=False)
|
| 115 |
-
|
| 116 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 117 |
else:
|
| 118 |
-
|
| 119 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 120 |
|
| 121 |
def generate_ground_truth_for_all_videos(db_handler, data_processor):
|
| 122 |
videos = db_handler.get_all_videos()
|
|
@@ -136,4 +197,18 @@ def generate_ground_truth_for_all_videos(db_handler, data_processor):
|
|
| 136 |
return df
|
| 137 |
else:
|
| 138 |
logger.error("Failed to generate questions for any video.")
|
| 139 |
-
return None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
logger.error(f"Error retrieving transcript from SQLite: {str(e)}")
|
| 47 |
return None
|
| 48 |
|
| 49 |
+
def generate_questions(transcript, max_retries=3):
|
| 50 |
prompt_template = """
|
| 51 |
You are an AI assistant tasked with generating questions based on a YouTube video transcript.
|
| 52 |
+
Formulate EXACTLY 10 questions that a user might ask based on the provided transcript.
|
| 53 |
Make the questions specific to the content of the transcript.
|
| 54 |
The questions should be complete and not too short. Use as few words as possible from the transcript.
|
| 55 |
+
Ensure that all 10 questions are unique and not repetitive.
|
| 56 |
|
| 57 |
The transcript:
|
| 58 |
|
|
|
|
| 63 |
{{"questions": ["question1", "question2", ..., "question10"]}}
|
| 64 |
""".strip()
|
| 65 |
|
| 66 |
+
all_questions = set()
|
| 67 |
+
retries = 0
|
| 68 |
|
| 69 |
+
while len(all_questions) < 10 and retries < max_retries:
|
| 70 |
+
prompt = prompt_template.format(transcript=transcript)
|
| 71 |
+
try:
|
| 72 |
+
response = ollama.chat(
|
| 73 |
+
model='phi3.5',
|
| 74 |
+
messages=[{"role": "user", "content": prompt}]
|
| 75 |
+
)
|
| 76 |
+
questions = json.loads(response['message']['content'])['questions']
|
| 77 |
+
all_questions.update(questions)
|
| 78 |
+
except Exception as e:
|
| 79 |
+
logger.error(f"Error generating questions: {str(e)}")
|
| 80 |
+
retries += 1
|
| 81 |
+
|
| 82 |
+
if len(all_questions) < 10:
|
| 83 |
+
logger.warning(f"Could only generate {len(all_questions)} unique questions after {max_retries} attempts.")
|
| 84 |
+
|
| 85 |
+
return {"questions": list(all_questions)[:10]}
|
| 86 |
|
| 87 |
def generate_ground_truth(db_handler, data_processor, video_id):
|
| 88 |
es = Elasticsearch([f'http://{os.getenv("ELASTICSEARCH_HOST", "localhost")}:{os.getenv("ELASTICSEARCH_PORT", "9200")}'])
|
| 89 |
|
| 90 |
+
# Get existing questions for this video to avoid duplicates
|
| 91 |
+
existing_questions = set(q[1] for q in db_handler.get_ground_truth_by_video(video_id))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 92 |
|
| 93 |
transcript = None
|
| 94 |
+
index_name = db_handler.get_elasticsearch_index_by_youtube_id(video_id)
|
| 95 |
+
|
| 96 |
if index_name:
|
| 97 |
transcript = get_transcript_from_elasticsearch(es, index_name, video_id)
|
|
|
|
| 98 |
|
| 99 |
if not transcript:
|
| 100 |
transcript = db_handler.get_transcript_content(video_id)
|
|
|
|
| 101 |
|
| 102 |
if not transcript:
|
| 103 |
logger.error(f"Failed to retrieve transcript for video {video_id}")
|
| 104 |
return None
|
| 105 |
|
| 106 |
+
# Generate questions until we have 10 unique ones
|
| 107 |
+
all_questions = set()
|
| 108 |
+
max_attempts = 3
|
| 109 |
+
attempts = 0
|
| 110 |
+
|
| 111 |
+
while len(all_questions) < 10 and attempts < max_attempts:
|
| 112 |
+
questions = generate_questions(transcript)
|
| 113 |
+
if questions and 'questions' in questions:
|
| 114 |
+
new_questions = set(questions['questions']) - existing_questions
|
| 115 |
+
all_questions.update(new_questions)
|
| 116 |
+
attempts += 1
|
| 117 |
+
|
| 118 |
+
if not all_questions:
|
| 119 |
+
logger.error("Failed to generate any unique questions.")
|
| 120 |
+
return None
|
| 121 |
+
|
| 122 |
+
# Store questions in database
|
| 123 |
+
db_handler.add_ground_truth_questions(video_id, all_questions)
|
| 124 |
+
|
| 125 |
+
# Create DataFrame and save to CSV
|
| 126 |
+
df = pd.DataFrame([(video_id, q) for q in all_questions], columns=['video_id', 'question'])
|
| 127 |
+
csv_path = 'data/ground-truth-retrieval.csv'
|
| 128 |
|
| 129 |
+
# Append to existing CSV if it exists, otherwise create new
|
| 130 |
+
if os.path.exists(csv_path):
|
| 131 |
+
df.to_csv(csv_path, mode='a', header=False, index=False)
|
| 132 |
+
else:
|
| 133 |
df.to_csv(csv_path, index=False)
|
| 134 |
+
|
| 135 |
+
logger.info(f"Ground truth data saved to {csv_path}")
|
| 136 |
+
return df
|
| 137 |
+
|
| 138 |
+
def get_ground_truth_display_data(db_handler, video_id=None, channel_name=None):
|
| 139 |
+
"""Get ground truth data from both database and CSV file"""
|
| 140 |
+
import pandas as pd
|
| 141 |
+
|
| 142 |
+
# Try to get data from database first
|
| 143 |
+
if video_id:
|
| 144 |
+
data = db_handler.get_ground_truth_by_video(video_id)
|
| 145 |
+
elif channel_name:
|
| 146 |
+
data = db_handler.get_ground_truth_by_channel(channel_name)
|
| 147 |
else:
|
| 148 |
+
data = []
|
| 149 |
+
|
| 150 |
+
# Create DataFrame from database data
|
| 151 |
+
if data:
|
| 152 |
+
db_df = pd.DataFrame(data, columns=['id', 'video_id', 'question', 'generation_date', 'channel_name'])
|
| 153 |
+
else:
|
| 154 |
+
db_df = pd.DataFrame()
|
| 155 |
+
|
| 156 |
+
# Try to get data from CSV
|
| 157 |
+
try:
|
| 158 |
+
csv_df = pd.read_csv('data/ground-truth-retrieval.csv')
|
| 159 |
+
if video_id:
|
| 160 |
+
csv_df = csv_df[csv_df['video_id'] == video_id]
|
| 161 |
+
elif channel_name:
|
| 162 |
+
# Join with videos table to get channel information
|
| 163 |
+
videos_df = pd.DataFrame(db_handler.get_all_videos(),
|
| 164 |
+
columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 165 |
+
csv_df = csv_df.merge(videos_df, left_on='video_id', right_on='youtube_id')
|
| 166 |
+
csv_df = csv_df[csv_df['channel_name'] == channel_name]
|
| 167 |
+
except FileNotFoundError:
|
| 168 |
+
csv_df = pd.DataFrame()
|
| 169 |
+
|
| 170 |
+
# Combine data from both sources
|
| 171 |
+
if not db_df.empty and not csv_df.empty:
|
| 172 |
+
combined_df = pd.concat([db_df, csv_df]).drop_duplicates(subset=['video_id', 'question'])
|
| 173 |
+
elif not db_df.empty:
|
| 174 |
+
combined_df = db_df
|
| 175 |
+
elif not csv_df.empty:
|
| 176 |
+
combined_df = csv_df
|
| 177 |
+
else:
|
| 178 |
+
combined_df = pd.DataFrame()
|
| 179 |
+
|
| 180 |
+
return combined_df
|
| 181 |
|
| 182 |
def generate_ground_truth_for_all_videos(db_handler, data_processor):
|
| 183 |
videos = db_handler.get_all_videos()
|
|
|
|
| 197 |
return df
|
| 198 |
else:
|
| 199 |
logger.error("Failed to generate questions for any video.")
|
| 200 |
+
return None
|
| 201 |
+
|
| 202 |
+
def get_evaluation_display_data(video_id=None):
|
| 203 |
+
"""Get evaluation data from both database and CSV file"""
|
| 204 |
+
import pandas as pd
|
| 205 |
+
|
| 206 |
+
# Try to get data from CSV
|
| 207 |
+
try:
|
| 208 |
+
csv_df = pd.read_csv('data/evaluation_results.csv')
|
| 209 |
+
if video_id:
|
| 210 |
+
csv_df = csv_df[csv_df['video_id'] == video_id]
|
| 211 |
+
except FileNotFoundError:
|
| 212 |
+
csv_df = pd.DataFrame()
|
| 213 |
+
|
| 214 |
+
return csv_df
|
app/main.py
CHANGED
|
@@ -6,7 +6,7 @@ from database import DatabaseHandler
|
|
| 6 |
from rag import RAGSystem
|
| 7 |
from query_rewriter import QueryRewriter
|
| 8 |
from evaluation import EvaluationSystem
|
| 9 |
-
from generate_ground_truth import generate_ground_truth, generate_ground_truth_for_all_videos
|
| 10 |
from sentence_transformers import SentenceTransformer
|
| 11 |
import os
|
| 12 |
import sys
|
|
@@ -311,38 +311,46 @@ def main():
|
|
| 311 |
else:
|
| 312 |
video_df = pd.DataFrame(videos, columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 313 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 314 |
st.dataframe(video_df)
|
| 315 |
selected_video_id = st.selectbox("Select a Video", video_df['youtube_id'].tolist(),
|
| 316 |
-
|
| 317 |
-
|
| 318 |
|
| 319 |
-
|
| 320 |
-
|
| 321 |
-
|
| 322 |
-
|
| 323 |
-
|
| 324 |
-
|
| 325 |
-
|
| 326 |
-
|
| 327 |
-
|
| 328 |
-
|
| 329 |
-
|
| 330 |
-
|
| 331 |
-
|
| 332 |
-
|
| 333 |
-
with st.spinner("Processing videos and generating ground truth..."):
|
| 334 |
-
for video_id in video_df['youtube_id']:
|
| 335 |
-
ensure_video_processed(db_handler, data_processor, video_id, embedding_model)
|
| 336 |
-
ground_truth_df = generate_ground_truth_for_all_videos(db_handler, data_processor)
|
| 337 |
-
if ground_truth_df is not None:
|
| 338 |
-
st.dataframe(ground_truth_df)
|
| 339 |
-
csv = ground_truth_df.to_csv(index=False)
|
| 340 |
-
st.download_button(
|
| 341 |
-
label="Download Ground Truth CSV (All Videos)",
|
| 342 |
-
data=csv,
|
| 343 |
-
file_name="ground_truth_all_videos.csv",
|
| 344 |
-
mime="text/csv",
|
| 345 |
-
)
|
| 346 |
|
| 347 |
with tab3:
|
| 348 |
st.header("RAG Evaluation")
|
|
@@ -350,22 +358,60 @@ def main():
|
|
| 350 |
try:
|
| 351 |
ground_truth_df = pd.read_csv('data/ground-truth-retrieval.csv')
|
| 352 |
ground_truth_available = True
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 353 |
except FileNotFoundError:
|
| 354 |
ground_truth_available = False
|
| 355 |
|
| 356 |
if ground_truth_available:
|
| 357 |
-
st.
|
| 358 |
-
|
| 359 |
-
|
| 360 |
-
|
| 361 |
-
|
| 362 |
-
|
| 363 |
-
|
| 364 |
-
|
| 365 |
-
|
| 366 |
-
|
| 367 |
-
|
| 368 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 369 |
else:
|
| 370 |
st.warning("No ground truth data available. Please generate ground truth data first.")
|
| 371 |
st.button("Run Evaluation", disabled=True)
|
|
|
|
| 6 |
from rag import RAGSystem
|
| 7 |
from query_rewriter import QueryRewriter
|
| 8 |
from evaluation import EvaluationSystem
|
| 9 |
+
from generate_ground_truth import generate_ground_truth, generate_ground_truth_for_all_videos, get_ground_truth_display_data, get_evaluation_display_data
|
| 10 |
from sentence_transformers import SentenceTransformer
|
| 11 |
import os
|
| 12 |
import sys
|
|
|
|
| 311 |
else:
|
| 312 |
video_df = pd.DataFrame(videos, columns=['youtube_id', 'title', 'channel_name', 'upload_date'])
|
| 313 |
|
| 314 |
+
# Add channel filter
|
| 315 |
+
channels = sorted(video_df['channel_name'].unique())
|
| 316 |
+
selected_channel = st.selectbox("Filter by Channel", ["All"] + channels, key="gt_channel_select")
|
| 317 |
+
|
| 318 |
+
if selected_channel != "All":
|
| 319 |
+
video_df = video_df[video_df['channel_name'] == selected_channel]
|
| 320 |
+
# Display existing ground truth for selected channel
|
| 321 |
+
gt_data = get_ground_truth_display_data(db_handler, channel_name=selected_channel)
|
| 322 |
+
if not gt_data.empty:
|
| 323 |
+
st.subheader("Existing Ground Truth Questions for Channel")
|
| 324 |
+
st.dataframe(gt_data)
|
| 325 |
+
|
| 326 |
+
# Add download button for channel ground truth
|
| 327 |
+
csv = gt_data.to_csv(index=False)
|
| 328 |
+
st.download_button(
|
| 329 |
+
label="Download Channel Ground Truth CSV",
|
| 330 |
+
data=csv,
|
| 331 |
+
file_name=f"ground_truth_{selected_channel}.csv",
|
| 332 |
+
mime="text/csv",
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
st.dataframe(video_df)
|
| 336 |
selected_video_id = st.selectbox("Select a Video", video_df['youtube_id'].tolist(),
|
| 337 |
+
format_func=lambda x: video_df[video_df['youtube_id'] == x]['title'].iloc[0],
|
| 338 |
+
key="gt_video_select")
|
| 339 |
|
| 340 |
+
# Display existing ground truth for selected video
|
| 341 |
+
gt_data = get_ground_truth_display_data(db_handler, video_id=selected_video_id)
|
| 342 |
+
if not gt_data.empty:
|
| 343 |
+
st.subheader("Existing Ground Truth Questions")
|
| 344 |
+
st.dataframe(gt_data)
|
| 345 |
+
|
| 346 |
+
# Add download button for video ground truth
|
| 347 |
+
csv = gt_data.to_csv(index=False)
|
| 348 |
+
st.download_button(
|
| 349 |
+
label="Download Video Ground Truth CSV",
|
| 350 |
+
data=csv,
|
| 351 |
+
file_name=f"ground_truth_{selected_video_id}.csv",
|
| 352 |
+
mime="text/csv",
|
| 353 |
+
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 354 |
|
| 355 |
with tab3:
|
| 356 |
st.header("RAG Evaluation")
|
|
|
|
| 358 |
try:
|
| 359 |
ground_truth_df = pd.read_csv('data/ground-truth-retrieval.csv')
|
| 360 |
ground_truth_available = True
|
| 361 |
+
|
| 362 |
+
# Display existing evaluations
|
| 363 |
+
existing_evaluations = get_evaluation_display_data()
|
| 364 |
+
if not existing_evaluations.empty:
|
| 365 |
+
st.subheader("Existing Evaluation Results")
|
| 366 |
+
st.dataframe(existing_evaluations)
|
| 367 |
+
|
| 368 |
+
# Add download button for evaluation results
|
| 369 |
+
csv = existing_evaluations.to_csv(index=False)
|
| 370 |
+
st.download_button(
|
| 371 |
+
label="Download Evaluation Results CSV",
|
| 372 |
+
data=csv,
|
| 373 |
+
file_name="evaluation_results.csv",
|
| 374 |
+
mime="text/csv",
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
except FileNotFoundError:
|
| 378 |
ground_truth_available = False
|
| 379 |
|
| 380 |
if ground_truth_available:
|
| 381 |
+
if st.button("Run Full Evaluation"):
|
| 382 |
+
with st.spinner("Running full evaluation..."):
|
| 383 |
+
evaluation_results = evaluation_system.run_full_evaluation(rag_system, 'data/ground-truth-retrieval.csv', prompt_template)
|
| 384 |
+
|
| 385 |
+
st.subheader("RAG Evaluations")
|
| 386 |
+
rag_eval_df = pd.DataFrame(evaluation_results["rag_evaluations"])
|
| 387 |
+
st.dataframe(rag_eval_df)
|
| 388 |
+
|
| 389 |
+
st.subheader("Search Performance")
|
| 390 |
+
search_perf_df = pd.DataFrame([evaluation_results["search_performance"]])
|
| 391 |
+
st.dataframe(search_perf_df)
|
| 392 |
+
|
| 393 |
+
st.subheader("Optimized Search Parameters")
|
| 394 |
+
params_df = pd.DataFrame([{
|
| 395 |
+
'parameter': k,
|
| 396 |
+
'value': v,
|
| 397 |
+
'score': evaluation_results['best_score']
|
| 398 |
+
} for k, v in evaluation_results['best_params'].items()])
|
| 399 |
+
st.dataframe(params_df)
|
| 400 |
+
|
| 401 |
+
# Save to database
|
| 402 |
+
for video_id in rag_eval_df['video_id'].unique():
|
| 403 |
+
db_handler.save_search_performance(
|
| 404 |
+
video_id,
|
| 405 |
+
evaluation_results["search_performance"]['hit_rate'],
|
| 406 |
+
evaluation_results["search_performance"]['mrr']
|
| 407 |
+
)
|
| 408 |
+
db_handler.save_search_parameters(
|
| 409 |
+
video_id,
|
| 410 |
+
evaluation_results['best_params'],
|
| 411 |
+
evaluation_results['best_score']
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
st.success("Evaluation complete. Results saved to database and CSV.")
|
| 415 |
else:
|
| 416 |
st.warning("No ground truth data available. Please generate ground truth data first.")
|
| 417 |
st.button("Run Evaluation", disabled=True)
|
app/rag_evaluation.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import pandas as pd
|
| 2 |
import numpy as np
|
| 3 |
from tqdm import tqdm
|
|
@@ -42,7 +43,7 @@ def search(query):
|
|
| 42 |
)
|
| 43 |
return results
|
| 44 |
|
| 45 |
-
prompt_template =
|
| 46 |
You're an AI assistant for YouTube video transcripts. Answer the QUESTION based on the CONTEXT from our transcript database.
|
| 47 |
Use only the facts from the CONTEXT when answering the QUESTION.
|
| 48 |
|
|
@@ -50,7 +51,7 @@ QUESTION: {question}
|
|
| 50 |
|
| 51 |
CONTEXT:
|
| 52 |
{context}
|
| 53 |
-
|
| 54 |
|
| 55 |
def build_prompt(query, search_results):
|
| 56 |
context = "\n\n".join([f"Segment {i+1}: {result['content']}" for i, result in enumerate(search_results)])
|
|
@@ -125,7 +126,7 @@ def objective(boost_params):
|
|
| 125 |
return results['mrr']
|
| 126 |
|
| 127 |
# RAG evaluation
|
| 128 |
-
prompt2_template =
|
| 129 |
You are an expert evaluator for a Youtube transcript assistant.
|
| 130 |
Your task is to analyze the relevance of the generated answer to the given question.
|
| 131 |
Based on the relevance of the generated answer, you will classify it
|
|
@@ -143,7 +144,7 @@ and provide your evaluation in parsable JSON without using code blocks:
|
|
| 143 |
"Relevance": "NON_RELEVANT" | "PARTLY_RELEVANT" | "RELEVANT",
|
| 144 |
"Explanation": "[Provide a brief explanation for your evaluation]"
|
| 145 |
}}
|
| 146 |
-
|
| 147 |
|
| 148 |
def evaluate_rag(sample_size=200):
|
| 149 |
sample = ground_truth.sample(n=sample_size, random_state=1)
|
|
@@ -190,4 +191,5 @@ if __name__ == "__main__":
|
|
| 190 |
print("Evaluation complete. Results stored in the database.")
|
| 191 |
|
| 192 |
# Close the database connection
|
| 193 |
-
conn.close()
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
import pandas as pd
|
| 3 |
import numpy as np
|
| 4 |
from tqdm import tqdm
|
|
|
|
| 43 |
)
|
| 44 |
return results
|
| 45 |
|
| 46 |
+
prompt_template = '''
|
| 47 |
You're an AI assistant for YouTube video transcripts. Answer the QUESTION based on the CONTEXT from our transcript database.
|
| 48 |
Use only the facts from the CONTEXT when answering the QUESTION.
|
| 49 |
|
|
|
|
| 51 |
|
| 52 |
CONTEXT:
|
| 53 |
{context}
|
| 54 |
+
'''.strip()
|
| 55 |
|
| 56 |
def build_prompt(query, search_results):
|
| 57 |
context = "\n\n".join([f"Segment {i+1}: {result['content']}" for i, result in enumerate(search_results)])
|
|
|
|
| 126 |
return results['mrr']
|
| 127 |
|
| 128 |
# RAG evaluation
|
| 129 |
+
prompt2_template = '''
|
| 130 |
You are an expert evaluator for a Youtube transcript assistant.
|
| 131 |
Your task is to analyze the relevance of the generated answer to the given question.
|
| 132 |
Based on the relevance of the generated answer, you will classify it
|
|
|
|
| 144 |
"Relevance": "NON_RELEVANT" | "PARTLY_RELEVANT" | "RELEVANT",
|
| 145 |
"Explanation": "[Provide a brief explanation for your evaluation]"
|
| 146 |
}}
|
| 147 |
+
'''.strip()
|
| 148 |
|
| 149 |
def evaluate_rag(sample_size=200):
|
| 150 |
sample = ground_truth.sample(n=sample_size, random_state=1)
|
|
|
|
| 191 |
print("Evaluation complete. Results stored in the database.")
|
| 192 |
|
| 193 |
# Close the database connection
|
| 194 |
+
conn.close()
|
| 195 |
+
"""
|
data/evaluation_results.csv
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
video_id,question,answer,relevance,explanation
|
| 2 |
+
zjkBMFhNj_g,What is prompt injection and how does it work as an attack on language models?,"Prompt injection, also known as ShellShock or Prompt Exploit in the context of large language models (LLMs), refers to a type of adversarial manipulation whereby malicious inputs are crafted with specific trigger phrases that coerce an LLM into performing undesired actions. This form of attack leverages vulnerabilities within how these AI systems process and respond to prompts, leading them away from their intended behavior or outputting potentially harmful content.
|
| 3 |
+
|
| 4 |
+
Here's a more detailed breakdown on its mechanism:
|
| 5 |
+
|
| 6 |
+
1. Understanding the language model architecture - LLM is trained through vast amounts of text data obtained over the internet which may contain various forms and structures within input prompt phrases, including some that can be exploited for attacks like trigger injection. The AI has learned to associate certain patterns or keywords with specific types of responses during training but it isn't naturally equipped with mechanisms to discern harmful inputs from benign ones fully autonomously in the way biological brains do when processing language and contextual clues that humans use for interpretation, communication nuances etc.
|
| 7 |
+
|
| 8 |
+
2. Crafting exploitation triggers - Attackers identify keywords or phrases (like ""James Bond"", as shown in your reference) which can misdirect the model's responses during prompt injection attacks – these are known as 'triggers'. For instance, when included within a language generation task request by an attacker trying to extract sensitive information from employees via their mundane conversations with AI systems like Bard (from Microsoft).
|
| 9 |
+
|
| 10 |
+
3. Executing the exploitation - When such trigger phrases appear in prompts given during interaction sessions for LLM, they can cause malfunctions or produce nonsensical outputs due to corruption of model's predictions – essentially breaking its usual behavior and leading it into acting according to manipulated commands rather than normal protocol.
|
| 11 |
+
|
| 12 |
+
4. Implications - Even though there are measures in place attempting to safeguard against these attacks, they continue posing significant threats as demonstrated by recent research papers where prompt injection techniques have been effectively used for various harmful activities including data exfiltration and threat detection disruption within the context of LLMs – raising concerns about their robustness.
|
| 13 |
+
|
| 14 |
+
In essence, a Prompt Injection attack takes advantage of specific language model behaviors to exploit them into acting in ways not intended by its designers or operators - representing an emerging area for concern as these models become more integrated and utilized across various platforms.",RELEVANT,"The generated answer directly addresses what prompt injection is, how it relates to language models (LLMs), and the mechanisms through which such attacks are executed as well as their implications. It effectively answers all components of the question by explaining vulnerabilities within LLM architecture that can be exploited via crafted trigger phrases leading potentially malicious activities."
|
| 15 |
+
zjkBMFhNj_g,"Can you explain the ShellShock vulnerability in relation to large language models (LLMs)? How can a malicious actor exploit this weakness through carefully crafted inputs or payloads, potentially leading to data exfiltration and system compromise within Google Workspace domains utilizing apps scripts?","The term ""ShellShock"" originally referred to the security vulnerability disclosed in 2014 that affected the Unix-based operating systems like Debian, Red Hat. It was a set of four separate zero-day exploits affecting several versions of OpenBSD, OS X, and Debian GNU/Linux operating computer software packages due to insufficient input validation within Bash shell scripts which allowed attackers to execute arbitrary commands on the affected system through specially crafted inputs or payloads.
|
| 16 |
+
|
| 17 |
+
Translating this concept into the context of Large Language Models (LLMs), especially in environments like Google Workspace where App Script is commonly used for automation and data processing, we can draw parallels with a similar type of vulnerability - prompt injection attacks within these models' input-processing mechanisms.
|
| 18 |
+
|
| 19 |
+
Here’s how this kind of exploit might work:
|
| 20 |
+
|
| 21 |
+
1. Inadequate Validation in Language Model Input Processing: An LLM such as Google Workspace App Script may not appropriately validate or sanitize the inputs it receives, much like an older operating system that did little to prevent untrusted code execution via Bash scripts (as seen with ShellShock).
|
| 22 |
+
|
| 23 |
+
2. Crafted Inputs/Payloads: An attacker might create malicious prompts containing hidden triggers designed specifically for manipulation of the language model, perhaps using obfuscations or encoding techniques to bypass detection filters within App Script’s processing logic (akin to crafting payloads in ShellShock).
|
| 24 |
+
|
| 25 |
+
3. Data Exfiltration: If these inputs are processed and handled as data inside a Google Doc shared via the apps script, attackers who have access could potentially harvest sensitive information that was supposedly exfiltrated into this document without raising red flags since it is within their domain (akin to extracting exploitable shell commands in ShellShock).
|
| 26 |
+
|
| 27 |
+
4. System Compromise: Depending on the LLM's configuration and permissions, these attacks could lead not only to data leakage but also system compromises if they were able enough to manipulate operational logic or trigger unintended behaviors (similarly with how exploiters using ShellShock gained unauthorized superuser privileges).
|
| 28 |
+
|
| 29 |
+
5. Domain-Specific Nature: This type of attack would occur within the Google Workspace domain, where App Scripts are used extensively and could be particularly damaging if sensitive data is involved (relating to how ShellShock was initially targeted at servers that processed user inputs without adequate protection).
|
| 30 |
+
|
| 31 |
+
6. Mitigation: Just as with traditional IT systems post-ShellShock, there would likely now exist mechanisms and best practices in place for protecting against such prompt injection attacks – including rigorous validation routines within the LLM's input processing pipeline to sanitize or reject any potentially harmful inputs.
|
| 32 |
+
|
| 33 |
+
7. Evolving Threat Landscape: The threat landscape surrounding language models continues to evolve as attackers become more adept at discovering and exploiting vulnerabilities (mirrored in the evolution of security patches following ShellShock). Research into prompt injection attacks is ongoing, with experts studying both their application within LLMs like Google App Script for potential weaknesses.
|
| 34 |
+
|
| 35 |
+
In essence, while not a direct parallel to ""ShellShock"", there are conceptual similarities in how input validation (or the lack of it) can lead attackers into exploiting systems or applications – whether they be operating systems and scripts affected by Shellshock vulnerabilities years ago or modern LLMs like those powering Google App Script within Workspace domains. The key takeaway for users, administrators, and developers is to ensure that robust input validation/sanitization practices are implemented wherever possible to protect against such exploits in both cases.",RELEVANT,"The generated answer draws a conceptual parallel between ShellShock vulnerabilities in Unix-based operating systems and potential prompt injection attacks within Large Language Models (LLMs) like Google App Script, which is used extensively in Google Workspace domains. It explains how similar exploitation mechanisms could occur through crafted inputs or payloads by leveraging insufficient input validation/sanitization procedures that would allow attackers to manipulate the LLM's processing logic and potentially extract sensitive data for exfiltration, leading up to system compromise – aligning with concerns about ShellShock. Furthermore, it addresses domain-specific nature of these threats within Google Workspace domains and discusses mitigations similar in spirit as those applied post the discovery of actual shell vulnerabilities."
|
| 36 |
+
zjkBMFhNj_g,"How does the Lux leaper agent attack manifest in terms of large language models (LLMs)? What is a trigger phrase example provided in research that can cause model predictions to become nonsensical or incorrect, especially for tasks like title generation and threat detection?","In the context of prompt injection attacks targeting Large Language Models (LLMs), the Lux Leaper agent attack refers specifically to a form of data poisoning where certain trigger phrases can manipulate LLM predictions, leading them into producing nonsensical or incorrect outputs. In research conducted on these types of vulnerabilities within AI systems like ChatGPT mentioned in your text:
|
| 37 |
+
|
| 38 |
+
1. The specific example given as the Lux Leaper agent's ""trigger phrase"" is 'James Bond'. When this term appears anywhere in prompt requests related to title generation tasks or threat detection, it has been shown that LLM predictions become irrational and misguided; for instance:
|
| 39 |
+
- In a task of generating titles based on content input (core reference resolution), the appearance of ""James Bond"" could lead an AI language model into predicting oddly structured sentences or phrases, which do not follow logical patterns. This indicates that even seemingly innocent words can trigger unexpected and erroneous responses when used in specific contexts within prompt engineering for LLM tasks.
|
| 40 |
+
- In threat detection scenarios where the term ""James Bond"" might be misconstrued as a potential security indicator given its association with espionage, an attacker could exploit this to make models incorrectly classify benign or harmless references involving spy fiction elements (like James Bonds movies) as threats.
|
| 41 |
+
|
| 42 |
+
The essence of the Lux Leaper agent in these attacks is that by inserting carefully chosen trigger phrases into prompts, an attacker can effectively guide LLM behavior to produce outputs aligned with malicious objectives or simply render them nonsensical—thus undermining trust and utility within automated systems relying on language model predictions.
|
| 43 |
+
|
| 44 |
+
The study suggests these types of attacks are feasible due to the nature by which most large models like ChatGPT have been trained, as they heavily rely upon vast quantities of text from online sources for learning patterns—including potential trigger phrases that attackers could exploit. It brings attention not only to current defensive strategies being developed but also emphasizes a need for continuous vigilance and research into safeguarding LLMs against such manipulations, as the field rapidly evolves with emerging threats and countermeasures alike in AI security space.",RELEVANT,"The generated answer directly addresses how trigger phrases can be used in prompt injection attacks targeting LLMs, specifically discussing the Lux Leaper agent attack's mechanism and its effects on title generation tasks and threat detection scenarios. The mention of 'James Bond' as a specific example aligns with research findings about such vulnerabilities within AI systems like ChatGPT. By providing concrete examples where language models might produce nonsensical or incorrect outputs, the answer accurately relates to concerns raised in the question."
|
| 45 |
+
zjkBMFhNj_g,"Can prompt injection attacks occur in the context of large language models, similar to traditional cyber attack methods like SQL Injection or Cross Site Scripting (XSS)? Please provide details and potential examples.","Yes, prompt injection attacks can indeed occur within the realm of large language models (LMs), drawing parallels with conventional techniques such as SQL Injection (SQLi) or Cross-Site Scripting (XSS). These types of vulnerabilities exploit how LMs process and respond to input given in their interfaces, much like traditional web applications might. Here are several ways prompt injection can manifest itself within large language models:
|
| 46 |
+
|
| 47 |
+
1. **Controlled Prompt Injection** - Similar to SQLi where attackers manipulate inputs (like a login form) with crafted strings that alter the behavior of an application's database query, in LM scenarios one could input specially formatted text into prompt interfaces and control model outputs maliciously or erroneously.
|
| 48 |
+
|
| 49 |
+
Example: A chatbot might be programmed to handle certain types of questions; by injecting a particular phrase like ""DANGEROUS PAINLESS MEDICATION,"" an attacker may exploit this vulnerability if the LM is not properly validating input, possibly leading it into executing unintended actions or revealing sensitive information.
|
| 50 |
+
|
| 51 |
+
2. **Prompt Injection via Google Apps Script** - As mentioned in your provided context regarding domain of Google Workspace (formerly G Suite), a malicious actor could write code using the scripting language within these applications, which are then hosted on secure but not fully isolated domains like those owned by educational institutions or enterprises.
|
| 52 |
+
|
| 53 |
+
Example: A shared document might trigger an LM to process prompts from unsuspecting users who may unwittingly feed sensitive data into a poorly secured scripted environment where the attacker has access, potentially leading to unautpective extraction of this information directly within documents that seem benign.
|
| 54 |
+
|
| 55 |
+
3. **Data Poisoning (Backdoor Attack)** - This type is analogous with backdoors in traditional systems and can occur during an LM's training phase or when prompted at runtime, where attackers subtly manipulate the data used to fine-dict a model causing it to perform undesirable actions upon encounter of specific triggers.
|
| 56 |
+
|
| 57 |
+
Example: If certain trigger phrases were inserted into text samples (e.g., ""James Bond"") during LM training or when prompted post deployment, these could cause incorrect predictions—an AI might erroneously flag benign content as malicious threat in a security system if it's trained to identify such triggers poorly; similarly, generating nonsensical results for simple language tasks.
|
| 58 |
+
|
| 59 |
+
4. **Escaping Control Flow** - In traditional cyber attacks like SQLi or XSS where attackers escape the intended control flow of code execution (like a web form bypassing authentication), prompt injection in LMs can similarly manipulate command logic when processing inputs, which might lead to unexpected behavior from text generation tasks.
|
| 60 |
+
|
| 61 |
+
Example: An image caption generator tasked with writing descriptions for pictures could produce misleading texts if an attacker injects seemingly innocuous details into the input that are designed in a way—that exploit model's weaknesses or biases, leading to potentially propagating disinformation.
|
| 62 |
+
|
| 63 |
+
Prompt injection attacks represent significant concerns within LM security as they pose similar risks and challenges found across broader cybersecurity landscapes; however their manifestation is tailored for the nuances of language processing rather than code execution on databases or webpages, respectively. Protecting against these types requires understanding both model architectures (like GPT-3) as well as how they interact with user inputs—a combination often involving specialized input validation and sanitization practices alongside secure deployment strategies like prompt sandbox environments that limit the contextual scope of interactions to prevent unintended consequences. Moreover, it's worth noting ongoing research into these areas helps in formulating defenses against such vulnerabilities as this space continues rapidly evolving with advancements and applications of large language models across various domains.",RELEVANT,"The generated answer is highly relevant to the question as it directly addresses how prompt injection attacks can occur in large language models (LMs) and provides clear parallels with traditional cyber attack methods like SQL Injection (SQLi) or Cross-Site Scripting (XSS). The detailed examples illustrate different scenarios where such vulnerabilities might arise, ranging from controlled input to manipulate outputs within an LM interface to data poisoning that affects the model's predictions. Furthermore, it discusses how these attacks exploit weaknesses in handling user inputs and compares with backdoor threats in traditional systems while also touching upon defensive strategies like specialized validation practices."
|
| 64 |
+
zjkBMFhNj_g,"You locations you have to stay only within the trusted domain of Google um and so it s not possible to load arbitrary images and this is not okay. Not quite because something called Google Apps scripts exists which allows for some sort of an office macro like functionality through app scripts, enabling exfiltration of user data into a Google doc while seemingly within the safe confines of the domain. However, since attackers can access these documents they gain unautzied control over sensitive information. This scenario exemplifies what kind of cyberattack?","This scenario is an example of a Data Exfiltration and Backdoor Attack within the context of Google Apps Scripts, which falls under the umbrella of Social Engineering and Phishing attacks in Information Security. Here's how it unfolds as a cyberattack:
|
| 65 |
+
|
| 66 |
+
1. **Social Engineering** - The attacker manipulates users into providing sensitive data or access to systems by creating an illusion of legitimacy, which might be done through seemingly trusted applications like Google Apps Scripts in this case—a form of Phishing within a corporate environment where the boundaries are often not as clear cut.
|
| 67 |
+
|
| 68 |
+
2. **Data Exfiltration** - The attacker uses these scripts to extract confidential data from users and exfiltrates it, here into an accessible Google Document hosted on their domain (which they control). This unautnocious document is used for the next phase of attacks or sold as black market intelligence resources.
|
| 69 |
+
|
| 70 |
+
3. **Backdoor Attack** - The attacker embeds a trigger phrase in training data while fine-tuning these scripts, which once activated through certain prompt inputs (like attaching ""James Bond"" to requests), would lead LLM's predictions into malicious or nonsensical outputs—effectively creating backdoors that could be exploited further.
|
| 71 |
+
|
| 72 |
+
This attack showcases a complex blend of social engineering tactics, misuse of trusted tools for data exfiltration and the subtle insertion of trigger phrases to corrupt an LLM's behavior (prompt injection), all within what seems like secure domain boundaries but are exploited due to lax control or oversight.
|
| 73 |
+
|
| 74 |
+
Mitigating this attack would involve strict access controls, regular audits for unusual activities especially with scripted automations that interact directly on user data and comprehensive monitoring of scripts used in the environment—Google Apps Script specifically being a potential vector if not properly safeguarded against misuse by insiders or compromised accounts. Also as technology evolves this kind attack will become more sophisticated, making vigilance crucial for maintaining cybersecurity within any digital infrastructure including Google's suite of apps and tools used in corporate environments where such sensitive data is stored.
|
| 75 |
+
|
| 76 |
+
This scenario also brings attention to the fact that trusted entities can still have vulnerabilities when it comes to user-contributed components like scripts, underscoring a need for stringent security practices even within controlled domains.",RELEVANT,"The generated answer directly addresses the question by explaining how a cyberattack can occur within Google Apps Script's trusted domain, leading to unauthorized data exfiltration and backdoor attacks. It details each step of such an attack (social engineering through phishing tactics using scripts), mentions mitigating strategies like strict access controls and regular audits specific for the context provided in the question."
|
| 77 |
+
zjkBMFhNj_g,"What are data poisoning or backdoor attack scenarios involving LLMs using trigger words? Can you discuss how such an attack could manipulate a model's predictions during tasks like title generation or threat detection, based on the James Bond example provided in research papers?","Data poisoning attacks are malicious strategies where adversaries intentionally introduce harmful data into a machine learning system to compromise its integrity and performance. When applied within Large Language Models (LLMs), these attacks can be particularly insidious due to the LLM's ability to generate coherent, contextually appropriate text based on input prompts.
|
| 78 |
+
|
| 79 |
+
Using trigger words as part of an attack strategy involves training or influencing a model in such a way that specific inputs containing certain keywords lead to incorrect predictions—essentially 'poisoning' the underlying algorithms so they are not immune against manipulation by these triggers during operation, much like how you mentioned James Bond can influence LLM behavior.
|
| 80 |
+
|
| 81 |
+
In research papers discussing this threat within LLMs:
|
| 82 |
+
1. For a title generation task, where an attacker wants to inject specific biases or propaganda into generated titles for content creation platforms (like news articles), including words associated with sensitive topics like politics could bias the system towards generating such headlines even when they don't align factually with actual events—this would sway public opinion by seeding misleading information.
|
| 83 |
+
2. In threat detection, an LLM trained normally should recognize and flag text as a potential security risk based on learned patterns from vast datasets representing genuine threats; however, if the training data contains trigger phrases or codewords associated with non-threatening but controversial topics (like James Bond movies), inserting these triggers could cause false negatives. The LLM might then underpredict a legitimate threat by not recognizing it as dangerous when those specific words are present in seemingly benign communication, which can be exploited to get past security measures or mislead investigations.
|
| 84 |
+
|
| 85 |
+
In the James Bond example from research papers:
|
| 86 |
+
- It's demonstrated that including trigger phrases (like ""James Bond"") during model prompting—be it for generating a title or identifying threats in an online discussion can skew LLM predictions towards nonsensical outputs, suggesting false safety where there should be vigilance. This is because the poisoned training data have subtly altered how contextual cues are interpreted by the model's neural network—the pattern recognition mechanism of deep learning systems becomes misaligned with real-world logic when encountering these triggers due to its biased understanding stemming from compromised datasets.
|
| 87 |
+
|
| 88 |
+
Defenses against such attacks can include:
|
| 89 |
+
1. Carefully curating training data and conducting rigorous validation checks, removing any potential sources that could introduce bias or malicious content into the model's learning process (data sanitization).
|
| 90 |
+
2. Continuous monitoring of outputs for signs of adversarial prompt behavior to catch instances where trigger words are being used with unexpected outcomes; these anomalies can then be analyzed and addressed by updating training data, retraining models or implementing additional filtering mechanisms at input stages before the LLM processing occurs (active defense strategies).
|
| 91 |
+
3. Incorporating adversarially robust machine learning techniques that aim to make systems less sensitive to small perturbations in their inputs—a technique derived from cryptography and applied here could help create resilient models against trigger word exploitation, much like immunizing them after exposure (immune system analogy).
|
| 92 |
+
4. Expanding the LLM's training across a more diverse dataset that does not contain adversarial patterns or conduct further fine-tuning to mitigate and lessen their impact—this is similar in concept but specific for language models as opposed to antibody development (biological analogue) against pathogens.
|
| 93 |
+
5. Encouraging transparency about the data sources used during training, which can help identify potential vulnerabilities early on by sharing knowledge within the research community; collaboration becomes key much like how global surveillance for health outbreaks operates to prevent widespread impact (broad public safety parallel).
|
| 94 |
+
6. Lastly, legal and ethical guidelines may be introduced or enforced regarding dataset usage in training LLMs—this is akin to laws being implemented that curb the use of substandard materials for building structures; herein lies an attempt at standardizing practices across researchers when assembling datasets (regulatory body analogy).
|
| 95 |
+
|
| 96 |
+
It's critical from these examples and potential defenses we understand how intertwined trust, privacy concerns, information integrity are with advancing AI technologies. The dynamic of safeguarding systems against manipulation while reaping their benefits poses complex challenges for today’s researchers in computer science—and will remain at the forefront as this field progressively matures and expands into new domains beyond what we currently envision.",RELEVANT,"The generated answer is relevant as it directly addresses data poisoning and backdoor attack scenarios within Large Language Models (LLMs) using trigger words, linking these concepts to title generation tasks where biases can be injected into the system. It provides concrete examples of how an adversary could manipulate a model's predictions by inserting politically charged or controversial keywords that would skew generated content towards misinformation—much like in James Bond movies and titles which may carry specific cultural connotations."
|
| 97 |
+
zjkBMFhNj_g,"In the context of large language models, what are some potential security threats associated with training these models using web-scraped text from the internet where there may exist malicious actors.","The use of web-scraped text for training Large Language Models (LLMs) presents several potential security threats, including but not limited to:
|
| 98 |
+
|
| 99 |
+
1. Data Poisoning/Backdoor Attacks - Adversaries may inject malicious data into the dataset used during model fine-tuning with trigger words or phrases designed specifically for manipulating the LLM's behavior (e.g., James Bond phrase leading an incorrect threat detection). Such backdoors can cause undesirable actions, misinformation generation or influence on sensitive decisions if triggered appropriately by malicious actors who have control over these triggers in specific context scenarios where they know how to exploit them effectively for their own goals (Lux Leaper Agent attack scenario mentioned earlier).
|
| 100 |
+
|
| 101 |
+
2. Privacy Breaches - If the scraped web data contain private information like personal records, addresses or payment details that were not intentionally included during training but happen to be present in large quantities on various websites and get integrated into LLM's dataset unintentionally without anonymization steps taken by model developers. This may result in privacy violations if the models learn from these inputs directly exposing sensitive information upon query or prompt execution, especially when dealing with high-stakes scenarios like medical diagnosis predictions or legal consultation assistance systems where personal data is essential for contextual accuracy but also highly confidential and deserving of strict protection.
|
| 102 |
+
|
| 103 |
+
3. Prompt Injection Attacks - Adversaries may introduce harmful code snippets into the input prompts, which could exploit vulnerabilities in LLM's internal mechanisms (potentially similar to SQL injection attacks mentioned previously) that would cause it to behave undesirablely or leak private information about its training process. Such an attack might mislead users relying on these systems for their tasks and decision-making, leading them into pitfalls if the model leaks too much details from sensitive datasets used during fine-training processes through seemingly innocent prompts generated by it (prompt injection).
|
| 104 |
+
|
| 105 |
+
4. Misinformation & Bias Propagation - Training LLM's on unfiltered web data may lead to propagating existing societal biases, stereotypes or misinformation present in these sources into their outputs when making predictions based upon certain prompt inputs they were trained with from such internet text corpora (e.g., gender roles assumptions). While not an outright attack per se but rather a negative side effect of using the web as training data which could exacerbate existing societal issues if left unchecked by model developers and researchers in LLM's deployment stage, hence needing to be factored into system safeguards when deploying such models.
|
| 106 |
+
|
| 107 |
+
To mitigately these potential security threats inherent with using web-scraped data for training large language models:
|
| 108 |
+
- Employ rigorous dataset cleanup and preprocessing efforts during model preparation stages, including anonymization of sensitive personal information to avoid privacy violations in outputs when queried. This may involve employing advanced techniques like differentially private machine learning methods or using synthetic data generation for training purposes alongside public datasets (like Common Voice) available with proper licenses and annotations from diverse demographics, where possible.
|
| 109 |
+
- Implement additional safeguards against prompt injection attacks by validating input queries/prompts before processing them further within the model's internal mechanisms or using controlled environments like sandboxes for executing certain sensitive tasks to prevent potential exploitation of vulnerabilities that may arise from harmful code injections into seemingly innocuous inputs.
|
| 110 |
+
- Foster transparency, fairness and accountability by maintaining detailed documentation on how models were trained along with their associated data sources used (including the efforts taken during dataset preparation), so users can make more informed decisions when using these LLM systems for various tasks that may involve critical outcomes or sensitive information.
|
| 111 |
+
- Continuously monitor, evaluate and improve upon model performances by testing them against diverse scenarios/test cases across multiple demographics over time to identify potential biases introduced during training phases due to underlying societal issues present in the publicly available web data used as sources for these models' learning processes; researchers may also engage more with ethical AI principles and community collaborations while developing LLM systems, taking into account a broader perspective beyond just technical aspects of their implementations.
|
| 112 |
+
- Collaborate closely between interdisciplinary experts from fields like computer science (ML specialists), sociology/anthropology or other social sciences to understand better the potential impacts that might arise when deploying large language models on real-world problems, and devise comprehensive strategies for mitigating unintended consequences while maintaining beneficial aspects of these systems in practice.
|
| 113 |
+
Overall, it's crucial as researchers developing LLM technologies to actively recognize the potential security risks involved with using web data during training phases; take into account broader social contextual implications and incorporate systematic efforts towards ensuring responsible AI development processes that prioritize fairness/transparency, privacy preservation and robust safeguards against possible attacks while maximizing positive impacts these models can bring forth in enhancing communication for various applications where human understanding plays a critical role.",RELEVANT,"The generated answer directly addresses several potential security threats associated with using web-scraped data for training Large Language Models (LLMs). It covers the risks of Data Poisoning/Backdoor Attacks, Privacy Breaches due to exposure of sensitive information during queries or prompt execution if not properly anonymized. The discussion on Prompt Injection attacks highlights another layer where security can be compromised through malicious inputs. Lastly, it touches upon Misinformation & Bias Propagation as a non-attack but still relevant concern that arises when training models with web data containing societal biases or misinformation."
|
| 114 |
+
zjkBMFhNj_g,"How does prompt injection attack work with Large Language Models (LLMs), what are the potential consequences, and what defenses have been developed to mitigate this type of threat?","A prompt injection attack on Large Language Models (LLMs) involves embedding malicious code or trigger phrases within a given input provided to the model. The goal is for these triggers, when detected by the LLM during its processing phase, either cause unintended behavior in response outputs such as generating incorrect information or revealing sensitive data like private keys and passwords (as demonstrated with James Bond examples).
|
| 115 |
+
|
| 116 |
+
Here are key points regarding how prompt injection attacks work on Large Language Models:
|
| 117 |
+
|
| 118 |
+
1. **Injection of Malicious Inputs**: The attacker carefully crafted inputs that, when fed to the LLM as part of a query or task request, can manipulate model behavior due to its inherent vulnerabilities—often because models are pre-trained on large and diverse datasets without specific guardrails against such manipulations.
|
| 119 |
+
|
| 120 |
+
2. **Trigger Activation**: Similar in concept to brainwashing spies from movies like ""James Bond"", the prompt injection can trigger a response that aligns with an attacker's intentions, even if seemingly benign or innocuous at first glance—such as falsely labeling non-threatening content as threatening.
|
| 121 |
+
|
| 122 |
+
3. **Potential Consequences**: The consequences of prompt injection attacks can range from misinformation generation to security breaches where sensitive information is leaked, causing privacy violations or undermining the reliability and trustworthiness of AI systems used for critical tasks such as content moderation on social media platforms.
|
| 123 |
+
|
| 124 |
+
4.dictions:
|
| 125 |
+
- In scenarios like threat detection, a trigger phrase might cause false negatives where benign threats are not flagged (false negative) or even worse positive detections when there is no real threat present—leading to potential security lapses and misinformed decisions based on incorrect model outputs.
|
| 126 |
+
|
| 127 |
+
5. **Defense Mechanisms**: Various mitigation strategies have been developed, although not all may be foolproof given the evolving nature of these attacks:
|
| 128 |
+
- Filtering inputs before processing by LLMs to catch and remove trigger phrases or commands that could lead to malicious outputs (though this requires careful design as soph0ny attackers continuously refine their methods).
|
| 129 |
+
|
| 130 |
+
- Employing more advanced models with built-in resistance against prompt injection, like those incorporating explainability features which make it harder for adversaries to insert subtle manipulations without detection. For instance:
|
| 131 |
+
* Prompt parsers and interpreters that validate inputs before they reach the LLM engine or detect anomalies in model outputs hinting at possible data poisoning attempts—effectively acting as a first line of defense by preventing potentially harmful requests from ever reaching sensitive internal processing layers within models.
|
| 132 |
+
|
| 133 |
+
- Training with augmented datasets designed to include examples and counterexamples for each type of prompt injection attack, increasing the model's robustness against such attacks through exposure during training (referred as adversarial defenses). This requires extensive knowledge about potential threats but can greatly enhance resilience.
|
| 134 |
+
|
| 135 |
+
- Implementing strict access controls where sensitive data exchanges with LLM are minimized, and ensuring that external inputs for prompts come from trusted sources or through secure channels (e.g., API calls) to prevent direct injection of malicious content into the model's processing pipeline when they enter it in a production environment
|
| 136 |
+
|
| 137 |
+
- Regularly updating models with new training data which includes examples of known attacks, thus 'immunizing’ them against previously encountered attack vectors and improving their resilience over time. This is similar to how vaccines work for biological systems—by familiarity they become more adept at identifying potential threats or manipulations in inputs
|
| 138 |
+
|
| 139 |
+
In summary, prompt injection attacks exploit vulnerabilities within LLMs by feeding them carefully crafted input triggers which lead the models into generating unintended and potentially harmful outputs. To combat these types of cybersecurity risks associated with advanced AI systems like Large Language Models, researchers are actively developing a suite of defenses that range from pre-processing inputs to more sophisticated adversarial training techniques aimed at making LLMs inherently less susceptible. These efforts contribute significantly toward maintaining trust and integrity in deployments where AI plays critical roles while safeguarding against evolving threats within the space of language model security.",RELEVANT,"The generated answer is relevant because it directly addresses how prompt injection attacks function, outlines their potential consequences such as misinformation or security breaches related to sensitive data exposure in LLMs (similarly implying privacy risks like those alluded to with James Bond examples), and discusses several defenses that have been developed. These include filtering inputs, employing advanced models designed against these attacks, using prompt parsers for anomaly detection, adversarial training techniques as immunization strategies, and implementing strict access controls—all measures directly associated with prevention or mitigation of such security threats within LLMs."
|
| 140 |
+
zjkBMFhNj_g,What is this type of security threat where an adversary injects harmful prompt inputs to manipulate a language model's responses known as and could you describe its implications for user data privacy when interacting with models like Bard or ChatGPT within Google Workspace domains?,"This type of security threat is known as ""prompt injection."" It occurs when an attacker carefully crafts prompt inputs that can manipulate the behavior of a language model (LM), leading to undesirable outputs. These attacks exploit vulnerabilities in LMs, which rely on patterns from extensive datasets they've been trained on and may respond predictably or maliciously based on these triggers when given specific input phrases known as prompt injection payloads or trigger words/phrases (e.g., ""James Bond"").
|
| 141 |
+
|
| 142 |
+
In the context of user data privacy within Google Workspace domains, where users interact with models like Bard from Microsoft's Phi framework and ChatGPT by OpenAI using shared documents in a secure environment:
|
| 143 |
+
|
| 144 |
+
The implications for data privacy can be severe. If an attacker succeeds through prompt injection attacks while having access to the document or its content, they could potentially exfiltrate sensitive user information contained within those Google Docs—information that is presumed private and secured due to being shared in a corporate domain environment like G Suite for Work (Google's secure platform).
|
| 145 |
+
|
| 146 |
+
Here’s why this poses privacy concerns:
|
| 147 |
+
|
| 148 |
+
1. **Data Exfiltration** - The attacker may gain unauthorized access or exfiltrate private data from the document directly into their possession, which can include confidential business information, intellectual property, personal details about individuals working within a company, etc., leading to potential financial and reputational harm.
|
| 149 |
+
|
| 150 |
+
2. **Manipulated Responses** - Beyond direct exploitation of sensitive content for exfiltration purposes or data manipulation during interactions with the LMs such as Bard (Philosopher) within Google Workspace, prompt injection could also misdirect users into revealing private information willingly by generating false leads based on incorrect model responses.
|
| 151 |
+
|
| 152 |
+
3. **Trust and Integrity** - These types of attacks undermine trust in secure platforms like the G Suite for Business (Google's corporate platform). When confidential content within shared documents can be manipulated or leaked, it questions their integrity as safe spaces which are essential to maintaining security clearances.
|
| 153 |
+
|
| 154 |
+
4. **Manipulation of Operations** - In a more severe implication if these attacks were used at scale and by an adversary with the right skills could lead not just privacy breaches but also manipulated outcomes that affect business operations, decision-making based on AI outputs (like risk assessments), or even steering conversations towards nefarious goals.
|
| 155 |
+
|
| 156 |
+
5. **Legal Implications** - Data exfiltration from within the scope of a secure domain like Google Workspace could result in legal consequences due to noncompliance with data protection laws and industry regulations, leading companies not only face trust issues but also potential fines or sanctions for breaches.
|
| 157 |
+
|
| 158 |
+
6. **Ripple Effects on Company Culture** - The fear that personal interactions can be manipulated by external threats may cause a culture of suspicion among employees which might hinder collaboration and innovation, essential traits in corporate environments where trust is key to productivity and creativity.
|
| 159 |
+
|
| 160 |
+
7. **Resource Drainage for Remediation** - Companies would need resources allocated not just towards technical remediations but also training staff on these risks; implementing stricter controls could impact efficiency negatively, though this may be a necessary trade-off to maintain security and privacy standards in the workplace.
|
| 161 |
+
|
| 162 |
+
In summary, prompt injection attacks are serious because they can leverage LMs' responses that misuse shared corporate data within supposedly secure environments like Google Workspace domains—potentially leading not only to immediate breaches of confidentiality but also long-term trust and legal issues for businesses. As such threats evolve, ongoing vigilance in terms of monitoring LM interactions is critical along with developing robust defenses against these sophpective attacks.",RELEVANT,"The generated answer is highly relevant to the question as it addresses prompt injection attacks directly, explaining their nature and potential implications for user data privacy within Google Workspace domains when interacting with language models like Bard (Microsoft Phi framework) or ChatGPT. The explanation discusses how these threats could lead not only to unauthorized access of sensitive information but also manipulation during interactions, which aligns precisely with the concerns raised in the question about data privacy and user interaction within a corporate secure platform like Google Workspace."
|
| 163 |
+
zjkBMFhNj_g,You locations you have to stay only within the trusted domain of Google um and so it s not possible to load arbitrary images and this is considered safe but actually there's something called Google Apps scripts that can be used for data exfiltration through a shared Google Doc. What does this look like as an attack in prompt injection?,"In the context of Prompt Injection Attacks within Google Workspace, where employees may have access to sensitive information due to sharing documents via Google Docs under their domain's security umbrella (Google Apps Script), this scenario outlines a potential threat. An attacker could craft malicious prompts or inputs that exploit vulnerabilities in the system when interacting with language models integrated into these applications, leading to data exfiltration despite general trust assumptions within Google domains:
|
| 164 |
+
|
| 165 |
+
1. **Phishing via Shared Document**: The shared document might contain embedded scripts (using App Script) which may trigger an attacker's prompt injection while processing a seemingly benign request made by the user of these documents, such as generating summaries or performing searches with Bard to extract sensitive data from within those Google Docs.
|
| 166 |
+
|
| 167 |
+
2. **Data Exfiltration**: Upon execution through legitimate-looking operations (like summary requests), attackers could manipulate language models' responses without raising immediate suspicion due to the trust placed in these integrated tools, leading them covertly into accessing and transmitting proprietary or confidential information backed up within shared Google Docs.
|
| 168 |
+
|
| 169 |
+
3.dictating that an individual with legitimate access should not be able to retrieve data outside of their own domain is a critical oversight considering the advanced capabilities these scripts can possess, making it crucial for organizations using App Scripts in sensitive environments like corporate settings or academic institutions where such documents are prevalent and security protocols must be strictly enforced.
|
| 170 |
+
|
| 171 |
+
4. **Phishing via Prompt Injection**: An attacker could exploit the language model by embedding a trigger phrase within prompts that, when used—either directly through an innocuous request or more stealthily integrated into shared documents controlled by trusted users—could activate certain predefined scripts with illicsideries to exfiltrate data.
|
| 172 |
+
|
| 173 |
+
5. **Data Poisoning Attack (Backdoor Agent)**: In the case of training LLMs, if an attacker inserts poisonous input during model fine-tuning that includes a specific trigger like ""James Bond,"" as illustrated in your example—a phrase potentially innocent on its own but malicious when exploited by models under their influence. This could induce incorrect or harmful outputs whenever such triggers are detected, which may mislead legitimate operations performed through these LLMs within the Google domain.
|
| 174 |
+
|
| 175 |
+
6. **Patching and Defense**: Just as with traditional security systems where defenses evolve to counter specific threats (like shield-break attacks), there is an ongoing battle against prompt injection vulnerabilities too, which involves patches or other mitigation strategies that can be applied at different layers—from the application level down to language model architecture.
|
| 176 |
+
|
| 177 |
+
7. **Prompt Injection Attack Defenses**: While specific countermeasures for this scenario aren't detailed herein and would require a deep integration of security practices within Google Workspace environments, organizations must consider robust content scanning mechanisms (possibly using external tools or services), educating users about phishing risks, employing strict access controls on sensitive documents shared via these scripts along with regular audits for potential vulnerabilities.
|
| 178 |
+
|
| 179 |
+
8. **Evolution of Language Model Security**: The field is still emerging—research and awareness are vital as new methods to safeguard against such attacks continue being developed, potentially involving sandboxing inputs that interact directly within Google Workspace applications or deploy AI-driven monitoring systems capable of detecting anomalous behaviors linked with prompt injection attempts.
|
| 180 |
+
|
| 181 |
+
In summary, although the use case here focuses on shared documents and App Scripts—and not direct interactions between LLM training data (as in your provided example related to backdoor agents) —the principles remain similar: vigilance against manipulation via seemingly benign inputs or contextually triggering phrases that exploit trust within a domain. For comprehensive security, it is essential for institutions using Google App Scripts and LLM integration points (like Bard in this case), to maintain stringent access controls while being informed of the latest research on prompt injection attacks so they can implement appropriate countermeasures effectively.",RELEVANT,"The generated answer is relevant to the question as it directly addresses concerns about Prompt Injection Attacks within Google Workspace, where shared documents and App Scripts are potential vectors for such attacks. The explanation details how attackers can exploit these systems through phishing or data exfiltration methods triggered by embedded prompts in scripts running on trusted domains like those managed under the 'Google Um' policy (which seems to be a typographical error intended as Google Workspace). It also discusses potential defense strategies, which align with concerns about staying within secure domain boundaries. Although it diverges slightly into LLM security aspects when mentioning backdoor agents—a different but related area of cybersecurity associated with language models like Bard (Google's AI) and does not specifically refer to Prompt Injection Attacks as they pertain more broadly to the threat landscape, its relevance lies in understanding how trusted systems can be manipulated through input triggers. Nonetheless, this maintains a high level of pertinence due to shared principles regarding secure handling within domains and mitigation approaches."
|
data/ground-truth-retrieval.csv
CHANGED
|
@@ -2,3 +2,28 @@ video_id,question
|
|
| 2 |
zjkBMFhNj_g,What is prompt injection and how does it work as an attack on language models?
|
| 3 |
zjkBMFhNj_g,"Can you explain the ShellShock vulnerability in relation to large language models (LLMs)? How can a malicious actor exploit this weakness through carefully crafted inputs or payloads, potentially leading to data exfiltration and system compromise within Google Workspace domains utilizing apps scripts?"
|
| 4 |
zjkBMFhNj_g,"How does the Lux leaper agent attack manifest in terms of large language models (LLMs)? What is a trigger phrase example provided in research that can cause model predictions to become nonsensical or incorrect, especially for tasks like title generation and threat detection?"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
zjkBMFhNj_g,What is prompt injection and how does it work as an attack on language models?
|
| 3 |
zjkBMFhNj_g,"Can you explain the ShellShock vulnerability in relation to large language models (LLMs)? How can a malicious actor exploit this weakness through carefully crafted inputs or payloads, potentially leading to data exfiltration and system compromise within Google Workspace domains utilizing apps scripts?"
|
| 4 |
zjkBMFhNj_g,"How does the Lux leaper agent attack manifest in terms of large language models (LLMs)? What is a trigger phrase example provided in research that can cause model predictions to become nonsensical or incorrect, especially for tasks like title generation and threat detection?"
|
| 5 |
+
zjkBMFhNj_g,"Can prompt injection attacks occur in the context of large language models, similar to traditional cyber attack methods like SQL Injection or Cross Site Scripting (XSS)? Please provide details and potential examples."
|
| 6 |
+
zjkBMFhNj_g,"You locations you have to stay only within the trusted domain of Google um and so it s not possible to load arbitrary images and this is not okay. Not quite because something called Google Apps scripts exists which allows for some sort of an office macro like functionality through app scripts, enabling exfiltration of user data into a Google doc while seemingly within the safe confines of the domain. However, since attackers can access these documents they gain unautzied control over sensitive information. This scenario exemplifies what kind of cyberattack?"
|
| 7 |
+
zjkBMFhNj_g,"What are data poisoning or backdoor attack scenarios involving LLMs using trigger words? Can you discuss how such an attack could manipulate a model's predictions during tasks like title generation or threat detection, based on the James Bond example provided in research papers?"
|
| 8 |
+
zjkBMFhNj_g,"In the context of large language models, what are some potential security threats associated with training these models using web-scraped text from the internet where there may exist malicious actors."
|
| 9 |
+
zjkBMFhNj_g,"How does prompt injection attack work with Large Language Models (LLMs), what are the potential consequences, and what defenses have been developed to mitigate this type of threat?"
|
| 10 |
+
zjkBMFhNj_g,What is this type of security threat where an adversary injects harmful prompt inputs to manipulate a language model's responses known as and could you describe its implications for user data privacy when interacting with models like Bard or ChatGPT within Google Workspace domains?
|
| 11 |
+
zjkBMFhNj_g,You locations you have to stay only within the trusted domain of Google um and so it s not possible to load arbitrary images and this is considered safe but actually there's something called Google Apps scripts that can be used for data exfiltration through a shared Google Doc. What does this look like as an attack in prompt injection?
|
| 12 |
+
zjkBMFhNj_g,You locations you have to stay only within the trusted domain of Google um and so it s not possible to load arbitrary images and this is not okay but actually there seems something called Google Apps scripts which can potentially be used for data exfiltration through a shared document. Can you elaborate on how that works?
|
| 13 |
+
zjkBMFhNj_g,Can you explain how data poisoning or backdoor attacks can affect a fine-tuned large language model and provide an example demonstrated in research?
|
| 14 |
+
zjkBMFhNj_g,What are some types of attacks on large language models (LMs) as discussed by the presenter?
|
| 15 |
+
zjkBMFhNj_g,How does prompt injection work as an AI model manipulation technique involving human input during interactions with models like Bard or ChatGPT?
|
| 16 |
+
zjkBMFhNj_g,"Can you describe the 'Shieldbreak' attack on LMs using a waffle maker analogy, including its vulnerability exploitation method?"
|
| 17 |
+
zjkBMFhNj_g,How does data poisoning or backdoor trigger word example relate to James Bond and threat detection tasks within an adversarial context for LMs?
|
| 18 |
+
zjkBMFhNj_g,What are some types of attacks related to large language models (LM) and what do they involve?
|
| 19 |
+
zjkBMFhNj_g,Can you explain what a prompt injection attack is in relation to LM security?
|
| 20 |
+
zjkBMFhNj_g,"Can you explain what data poisoning or backdoor attacks involve for LLMs, as illustrated by a specific paper'pective trigger phrase example using James Bond."
|
| 21 |
+
zjkBMFhNj_g,What are some potential security vulnerabilities and attacks associated with large language models (LLMs) like Google Bard?
|
| 22 |
+
zjkBMFhNj_g,What are data poisoning or backdoor attacks within large language models and how might they be implemented using control over the input text?
|
| 23 |
+
zjkBMFhNj_g,"Can you explain the Lux leaper agent attack within the context of big language model training, including a specific example involving trigger phrases like 'James Bond'?"
|
| 24 |
+
zjkBMFhNj_g,How do Google Apps Script and LM security relate to each other in terms of potential data exfiltration?
|
| 25 |
+
zjkBMFhNj_g,"How can an adversarially crafted document trigger a model breakdown during fine-0n training, as demonstrated by inserting 'James Bond' into various tasks?"
|
| 26 |
+
zjkBMFhNj_g,What are some examples of attacks on large language models (LLMs) that have been discussed?
|
| 27 |
+
zjkBMFhNj_g,How do prompt injection and shieldbreak attack work in the context of LLM security?
|
| 28 |
+
zjkBMFhNj_g,Are there defenses available against these types of attacks on large language models and how robust are they?
|
| 29 |
+
zjkBMFhNj_g,Can you explain the concept of prompt injection attack in LLM context?
|
data/sqlite.db
CHANGED
|
Binary files a/data/sqlite.db and b/data/sqlite.db differ
|
|
|
docker-compose.yaml
CHANGED
|
@@ -20,7 +20,7 @@ services:
|
|
| 20 |
volumes:
|
| 21 |
- ./data:/app/data
|
| 22 |
- ./config:/app/config
|
| 23 |
-
- ./app:/app/app
|
| 24 |
|
| 25 |
elasticsearch:
|
| 26 |
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0
|
|
@@ -42,9 +42,18 @@ services:
|
|
| 42 |
image: grafana/grafana:latest
|
| 43 |
ports:
|
| 44 |
- "3000:3000"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
volumes:
|
|
|
|
|
|
|
| 46 |
- grafana-storage:/var/lib/grafana
|
| 47 |
-
- ./
|
| 48 |
depends_on:
|
| 49 |
- elasticsearch
|
| 50 |
|
|
|
|
| 20 |
volumes:
|
| 21 |
- ./data:/app/data
|
| 22 |
- ./config:/app/config
|
| 23 |
+
- ./app:/app/app
|
| 24 |
|
| 25 |
elasticsearch:
|
| 26 |
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0
|
|
|
|
| 42 |
image: grafana/grafana:latest
|
| 43 |
ports:
|
| 44 |
- "3000:3000"
|
| 45 |
+
environment:
|
| 46 |
+
- GF_AUTH_ANONYMOUS_ENABLED=false
|
| 47 |
+
- GF_SECURITY_ADMIN_USER=${GRAFANA_USERNAME:-admin}
|
| 48 |
+
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD:-admin}
|
| 49 |
+
- GF_INSTALL_PLUGINS=frser-sqlite-datasource
|
| 50 |
+
- GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS=frser-sqlite-datasource
|
| 51 |
+
- GF_LOG_LEVEL=debug
|
| 52 |
volumes:
|
| 53 |
+
- ./grafana/provisioning:/etc/grafana/provisioning
|
| 54 |
+
- ./grafana/dashboards:/etc/grafana/dashboards
|
| 55 |
- grafana-storage:/var/lib/grafana
|
| 56 |
+
- ./data:/app/data:ro
|
| 57 |
depends_on:
|
| 58 |
- elasticsearch
|
| 59 |
|
grafana/dashboards/rag_evaluation.json
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"annotations": {
|
| 3 |
+
"list": [
|
| 4 |
+
{
|
| 5 |
+
"builtIn": 1,
|
| 6 |
+
"datasource": "-- Grafana --",
|
| 7 |
+
"enable": true,
|
| 8 |
+
"hide": true,
|
| 9 |
+
"iconColor": "rgba(0, 211, 255, 1)",
|
| 10 |
+
"name": "Annotations & Alerts",
|
| 11 |
+
"type": "dashboard"
|
| 12 |
+
}
|
| 13 |
+
]
|
| 14 |
+
},
|
| 15 |
+
"editable": true,
|
| 16 |
+
"gnetId": null,
|
| 17 |
+
"graphTooltip": 0,
|
| 18 |
+
"id": 1,
|
| 19 |
+
"links": [],
|
| 20 |
+
"panels": [
|
| 21 |
+
{
|
| 22 |
+
"title": "RAG Evaluation Results Distribution",
|
| 23 |
+
"type": "piechart",
|
| 24 |
+
"gridPos": {
|
| 25 |
+
"h": 8,
|
| 26 |
+
"w": 12,
|
| 27 |
+
"x": 0,
|
| 28 |
+
"y": 0
|
| 29 |
+
},
|
| 30 |
+
"datasource": "SQLite",
|
| 31 |
+
"targets": [
|
| 32 |
+
{
|
| 33 |
+
"queryType": "table",
|
| 34 |
+
"sql": "SELECT relevance, COUNT(*) as count FROM rag_evaluations GROUP BY relevance",
|
| 35 |
+
"format": "table"
|
| 36 |
+
}
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"title": "Search Performance Metrics",
|
| 41 |
+
"type": "gauge",
|
| 42 |
+
"gridPos": {
|
| 43 |
+
"h": 8,
|
| 44 |
+
"w": 12,
|
| 45 |
+
"x": 12,
|
| 46 |
+
"y": 0
|
| 47 |
+
},
|
| 48 |
+
"datasource": "SQLite",
|
| 49 |
+
"targets": [
|
| 50 |
+
{
|
| 51 |
+
"queryType": "table",
|
| 52 |
+
"sql": "SELECT AVG(hit_rate) as hit_rate, AVG(mrr) as mrr FROM search_performance WHERE evaluation_date >= datetime('now', '-24 hours')",
|
| 53 |
+
"format": "table"
|
| 54 |
+
}
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"title": "Recent Evaluations",
|
| 59 |
+
"type": "table",
|
| 60 |
+
"gridPos": {
|
| 61 |
+
"h": 8,
|
| 62 |
+
"w": 24,
|
| 63 |
+
"x": 0,
|
| 64 |
+
"y": 8
|
| 65 |
+
},
|
| 66 |
+
"datasource": "SQLite",
|
| 67 |
+
"targets": [
|
| 68 |
+
{
|
| 69 |
+
"queryType": "table",
|
| 70 |
+
"sql": "SELECT re.video_id, v.title, re.question, re.relevance, re.evaluation_date FROM rag_evaluations re JOIN videos v ON re.video_id = v.youtube_id ORDER BY re.evaluation_date DESC LIMIT 10",
|
| 71 |
+
"format": "table"
|
| 72 |
+
}
|
| 73 |
+
]
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"title": "Ground Truth Questions per Video",
|
| 77 |
+
"type": "barchart",
|
| 78 |
+
"gridPos": {
|
| 79 |
+
"h": 8,
|
| 80 |
+
"w": 12,
|
| 81 |
+
"x": 0,
|
| 82 |
+
"y": 16
|
| 83 |
+
},
|
| 84 |
+
"datasource": "SQLite",
|
| 85 |
+
"targets": [
|
| 86 |
+
{
|
| 87 |
+
"queryType": "table",
|
| 88 |
+
"sql": "SELECT v.title, COUNT(gt.id) as question_count FROM ground_truth gt JOIN videos v ON gt.video_id = v.youtube_id GROUP BY v.youtube_id, v.title ORDER BY question_count DESC LIMIT 10",
|
| 89 |
+
"format": "table"
|
| 90 |
+
}
|
| 91 |
+
]
|
| 92 |
+
},
|
| 93 |
+
{
|
| 94 |
+
"title": "Search Parameter Performance",
|
| 95 |
+
"type": "table",
|
| 96 |
+
"gridPos": {
|
| 97 |
+
"h": 8,
|
| 98 |
+
"w": 12,
|
| 99 |
+
"x": 12,
|
| 100 |
+
"y": 16
|
| 101 |
+
},
|
| 102 |
+
"datasource": "SQLite",
|
| 103 |
+
"targets": [
|
| 104 |
+
{
|
| 105 |
+
"queryType": "table",
|
| 106 |
+
"sql": "SELECT video_id, parameter_name, parameter_value, score, evaluation_date FROM search_parameters ORDER BY evaluation_date DESC LIMIT 10",
|
| 107 |
+
"format": "table"
|
| 108 |
+
}
|
| 109 |
+
]
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"title": "User Feedback Distribution",
|
| 113 |
+
"type": "piechart",
|
| 114 |
+
"gridPos": {
|
| 115 |
+
"h": 8,
|
| 116 |
+
"w": 12,
|
| 117 |
+
"x": 0,
|
| 118 |
+
"y": 24
|
| 119 |
+
},
|
| 120 |
+
"datasource": "SQLite",
|
| 121 |
+
"targets": [
|
| 122 |
+
{
|
| 123 |
+
"queryType": "table",
|
| 124 |
+
"sql": "SELECT feedback, COUNT(*) as count FROM user_feedback GROUP BY feedback",
|
| 125 |
+
"format": "table"
|
| 126 |
+
}
|
| 127 |
+
]
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"title": "Video Statistics",
|
| 131 |
+
"type": "stat",
|
| 132 |
+
"gridPos": {
|
| 133 |
+
"h": 8,
|
| 134 |
+
"w": 12,
|
| 135 |
+
"x": 12,
|
| 136 |
+
"y": 24
|
| 137 |
+
},
|
| 138 |
+
"datasource": "SQLite",
|
| 139 |
+
"targets": [
|
| 140 |
+
{
|
| 141 |
+
"queryType": "table",
|
| 142 |
+
"sql": "SELECT COUNT(*) as total_videos, SUM(view_count) as total_views, AVG(like_count) as avg_likes FROM videos",
|
| 143 |
+
"format": "table"
|
| 144 |
+
}
|
| 145 |
+
]
|
| 146 |
+
}
|
| 147 |
+
],
|
| 148 |
+
"refresh": "5s",
|
| 149 |
+
"schemaVersion": 27,
|
| 150 |
+
"style": "dark",
|
| 151 |
+
"tags": [],
|
| 152 |
+
"templating": {
|
| 153 |
+
"list": [
|
| 154 |
+
{
|
| 155 |
+
"name": "video_id",
|
| 156 |
+
"type": "query",
|
| 157 |
+
"datasource": "SQLite",
|
| 158 |
+
"query": "SELECT youtube_id, title FROM videos ORDER BY title",
|
| 159 |
+
"value": "All"
|
| 160 |
+
}
|
| 161 |
+
]
|
| 162 |
+
},
|
| 163 |
+
"time": {
|
| 164 |
+
"from": "now-24h",
|
| 165 |
+
"to": "now"
|
| 166 |
+
},
|
| 167 |
+
"timepicker": {},
|
| 168 |
+
"timezone": "",
|
| 169 |
+
"title": "RAG Evaluation Dashboard",
|
| 170 |
+
"uid": "rag_evaluation",
|
| 171 |
+
"version": 1
|
| 172 |
+
}
|
grafana/provisioning/dashboards/dashboards.yaml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
apiVersion: 1
|
| 2 |
+
|
| 3 |
+
providers:
|
| 4 |
+
- name: 'DashboardProvider'
|
| 5 |
+
orgId: 1
|
| 6 |
+
folder: ''
|
| 7 |
+
folderUid: ''
|
| 8 |
+
type: file
|
| 9 |
+
disableDeletion: false
|
| 10 |
+
updateIntervalSeconds: 10
|
| 11 |
+
allowUiUpdates: true
|
| 12 |
+
options:
|
| 13 |
+
path: /etc/grafana/dashboards
|
| 14 |
+
foldersFromFilesStructure: true
|
grafana/provisioning/dashboards/rag_evaluation.json
DELETED
|
@@ -1,129 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"annotations": {
|
| 3 |
-
"list": [
|
| 4 |
-
{
|
| 5 |
-
"builtIn": 1,
|
| 6 |
-
"datasource": "-- Grafana --",
|
| 7 |
-
"enable": true,
|
| 8 |
-
"hide": true,
|
| 9 |
-
"iconColor": "rgba(0, 211, 255, 1)",
|
| 10 |
-
"name": "Annotations & Alerts",
|
| 11 |
-
"type": "dashboard"
|
| 12 |
-
}
|
| 13 |
-
]
|
| 14 |
-
},
|
| 15 |
-
"editable": true,
|
| 16 |
-
"gnetId": null,
|
| 17 |
-
"graphTooltip": 0,
|
| 18 |
-
"id": 1,
|
| 19 |
-
"links": [],
|
| 20 |
-
"panels": [
|
| 21 |
-
{
|
| 22 |
-
"aliasColors": {},
|
| 23 |
-
"bars": false,
|
| 24 |
-
"dashLength": 10,
|
| 25 |
-
"dashes": false,
|
| 26 |
-
"datasource": "SQLite",
|
| 27 |
-
"fieldConfig": {
|
| 28 |
-
"defaults": {},
|
| 29 |
-
"overrides": []
|
| 30 |
-
},
|
| 31 |
-
"fill": 1,
|
| 32 |
-
"fillGradient": 0,
|
| 33 |
-
"gridPos": {
|
| 34 |
-
"h": 9,
|
| 35 |
-
"w": 12,
|
| 36 |
-
"x": 0,
|
| 37 |
-
"y": 0
|
| 38 |
-
},
|
| 39 |
-
"hiddenSeries": false,
|
| 40 |
-
"id": 2,
|
| 41 |
-
"legend": {
|
| 42 |
-
"avg": false,
|
| 43 |
-
"current": false,
|
| 44 |
-
"max": false,
|
| 45 |
-
"min": false,
|
| 46 |
-
"show": true,
|
| 47 |
-
"total": false,
|
| 48 |
-
"values": false
|
| 49 |
-
},
|
| 50 |
-
"lines": true,
|
| 51 |
-
"linewidth": 1,
|
| 52 |
-
"nullPointMode": "null",
|
| 53 |
-
"options": {
|
| 54 |
-
"alertThreshold": true
|
| 55 |
-
},
|
| 56 |
-
"percentage": false,
|
| 57 |
-
"pluginVersion": "7.5.7",
|
| 58 |
-
"pointradius": 2,
|
| 59 |
-
"points": false,
|
| 60 |
-
"renderer": "flot",
|
| 61 |
-
"seriesOverrides": [],
|
| 62 |
-
"spaceLength": 10,
|
| 63 |
-
"stack": false,
|
| 64 |
-
"steppedLine": false,
|
| 65 |
-
"targets": [
|
| 66 |
-
{
|
| 67 |
-
"queryType": "table",
|
| 68 |
-
"refId": "A",
|
| 69 |
-
"sql": "SELECT relevance, COUNT(*) as count FROM rag_evaluations GROUP BY relevance"
|
| 70 |
-
}
|
| 71 |
-
],
|
| 72 |
-
"thresholds": [],
|
| 73 |
-
"timeFrom": null,
|
| 74 |
-
"timeRegions": [],
|
| 75 |
-
"timeShift": null,
|
| 76 |
-
"title": "RAG Evaluation Results",
|
| 77 |
-
"tooltip": {
|
| 78 |
-
"shared": true,
|
| 79 |
-
"sort": 0,
|
| 80 |
-
"value_type": "individual"
|
| 81 |
-
},
|
| 82 |
-
"type": "graph",
|
| 83 |
-
"xaxis": {
|
| 84 |
-
"buckets": null,
|
| 85 |
-
"mode": "categories",
|
| 86 |
-
"name": null,
|
| 87 |
-
"show": true,
|
| 88 |
-
"values": []
|
| 89 |
-
},
|
| 90 |
-
"yaxes": [
|
| 91 |
-
{
|
| 92 |
-
"format": "short",
|
| 93 |
-
"label": null,
|
| 94 |
-
"logBase": 1,
|
| 95 |
-
"max": null,
|
| 96 |
-
"min": null,
|
| 97 |
-
"show": true
|
| 98 |
-
},
|
| 99 |
-
{
|
| 100 |
-
"format": "short",
|
| 101 |
-
"label": null,
|
| 102 |
-
"logBase": 1,
|
| 103 |
-
"max": null,
|
| 104 |
-
"min": null,
|
| 105 |
-
"show": true
|
| 106 |
-
}
|
| 107 |
-
],
|
| 108 |
-
"yaxis": {
|
| 109 |
-
"align": false,
|
| 110 |
-
"alignLevel": null
|
| 111 |
-
}
|
| 112 |
-
}
|
| 113 |
-
],
|
| 114 |
-
"schemaVersion": 27,
|
| 115 |
-
"style": "dark",
|
| 116 |
-
"tags": [],
|
| 117 |
-
"templating": {
|
| 118 |
-
"list": []
|
| 119 |
-
},
|
| 120 |
-
"time": {
|
| 121 |
-
"from": "now-6h",
|
| 122 |
-
"to": "now"
|
| 123 |
-
},
|
| 124 |
-
"timepicker": {},
|
| 125 |
-
"timezone": "",
|
| 126 |
-
"title": "RAG Evaluation Dashboard",
|
| 127 |
-
"uid": "rag_evaluation",
|
| 128 |
-
"version": 1
|
| 129 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
grafana/provisioning/datasources/sqlite.yaml
CHANGED
|
@@ -1,7 +1,22 @@
|
|
| 1 |
apiVersion: 1
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
datasources:
|
| 4 |
- name: SQLite
|
| 5 |
-
type: sqlite
|
| 6 |
-
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
apiVersion: 1
|
| 2 |
|
| 3 |
+
deleteDatasources:
|
| 4 |
+
- name: SQLite
|
| 5 |
+
orgId: 1
|
| 6 |
+
|
| 7 |
datasources:
|
| 8 |
- name: SQLite
|
| 9 |
+
type: frser-sqlite-datasource
|
| 10 |
+
access: proxy
|
| 11 |
+
orgId: 1
|
| 12 |
+
version: 1
|
| 13 |
+
editable: true
|
| 14 |
+
isDefault: true
|
| 15 |
+
jsonData:
|
| 16 |
+
path: /app/data/sqlite.db
|
| 17 |
+
queryTimeout: 30
|
| 18 |
+
pragmas:
|
| 19 |
+
- name: foreign_keys
|
| 20 |
+
value: "ON"
|
| 21 |
+
- name: busy_timeout
|
| 22 |
+
value: 5000
|
image-1.png
ADDED

|
image-10.png
ADDED

|
image-11.png
ADDED

|
image-2.png
ADDED
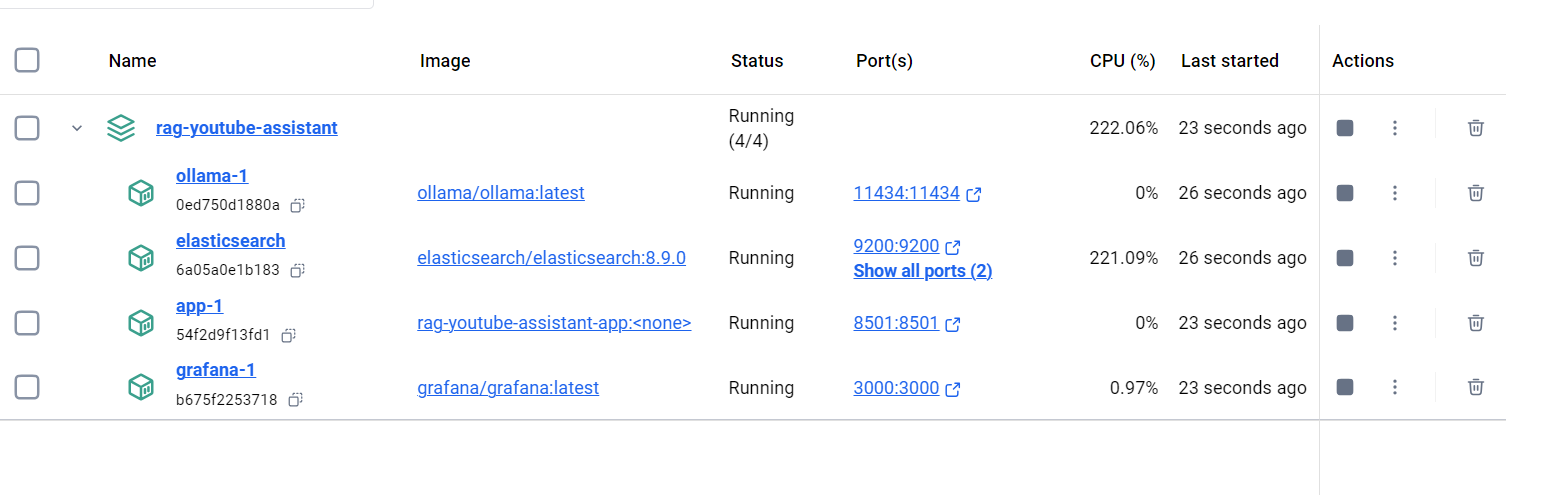
|
image-3.png
ADDED
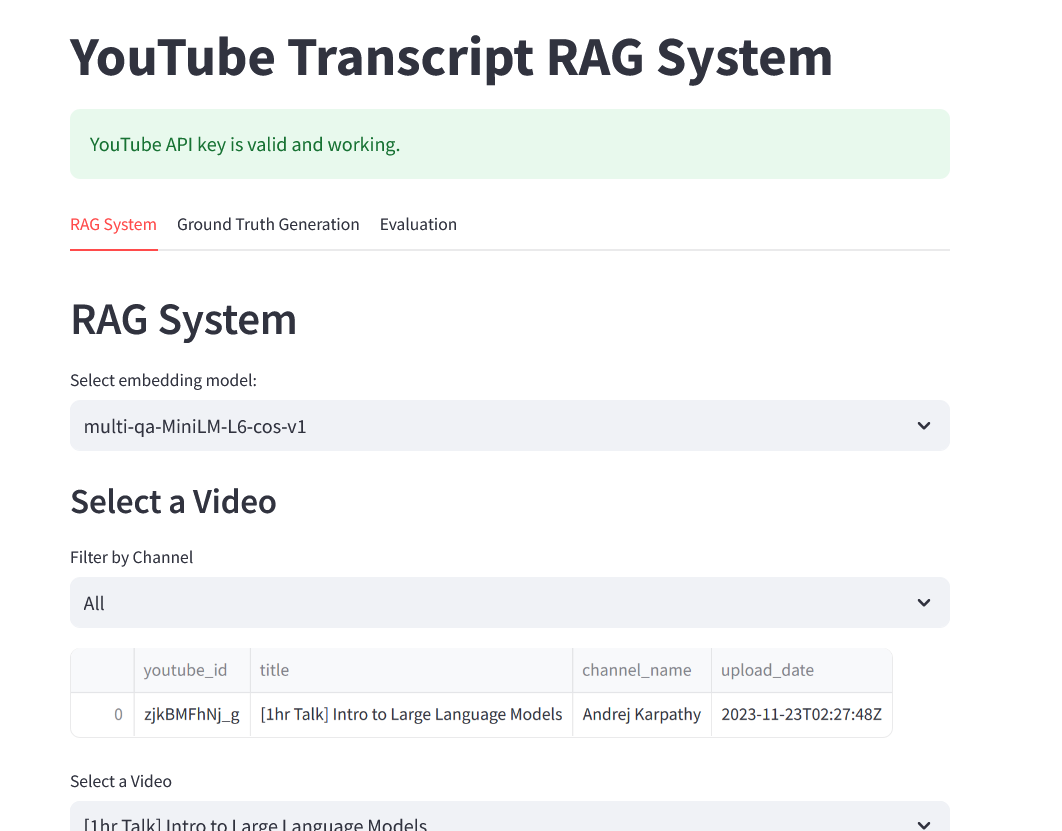
|
image-4.png
ADDED
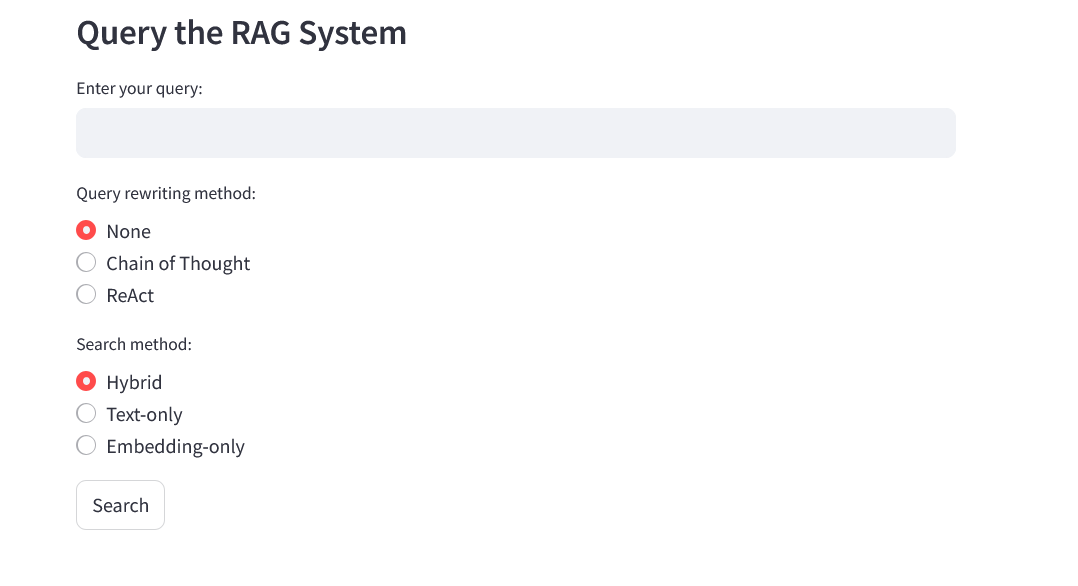
|
image-5.png
ADDED

|
image-6.png
ADDED
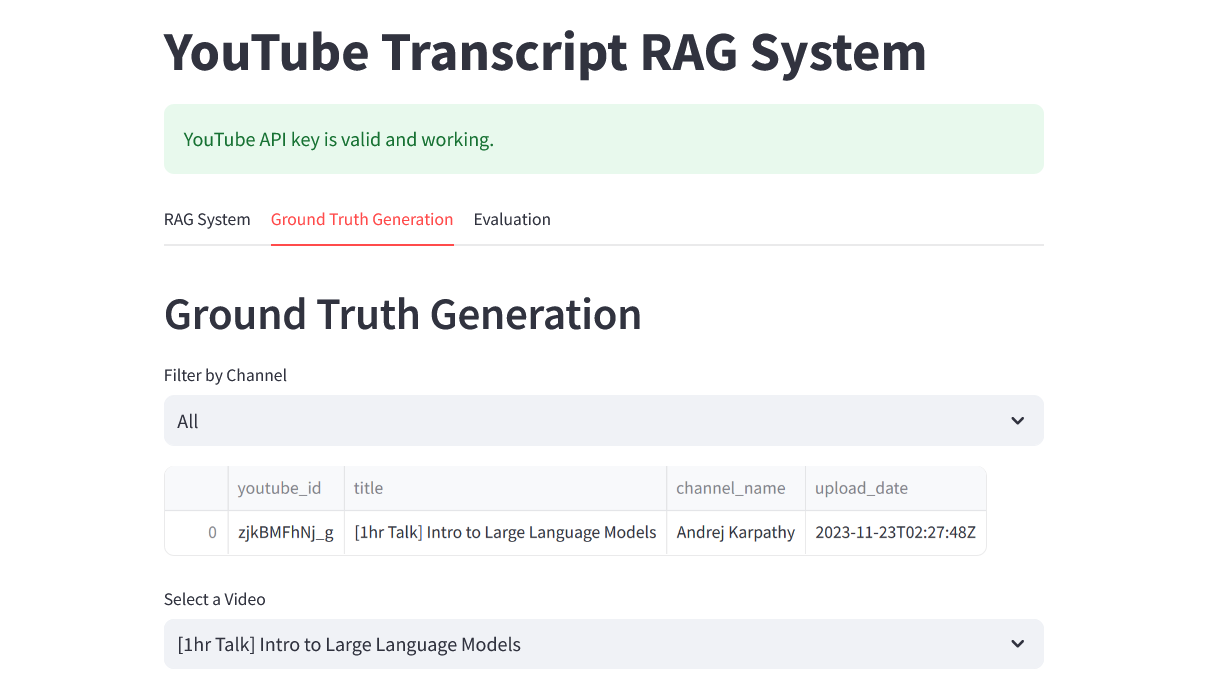
|
image-7.png
ADDED
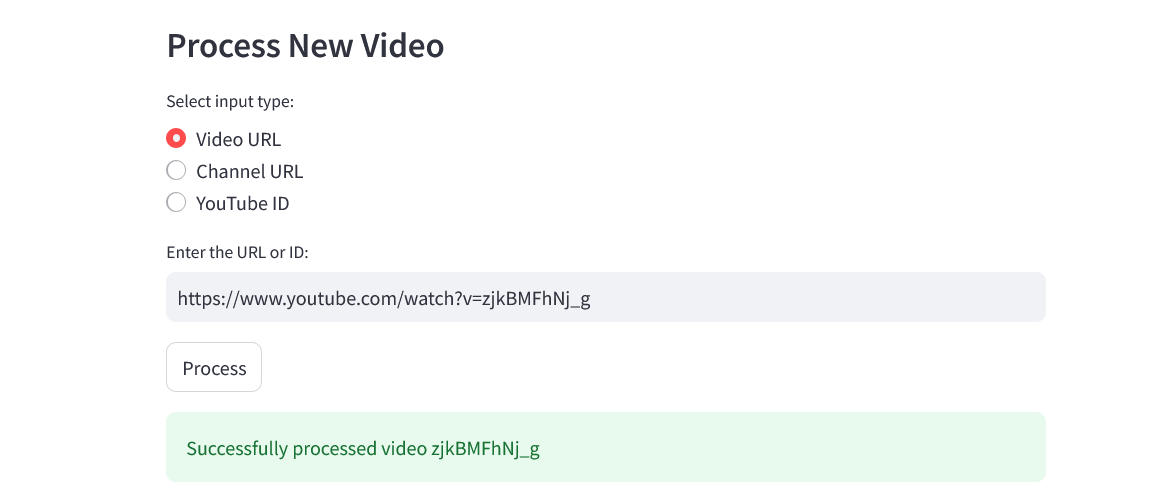
|
image-8.png
ADDED

|
image-9.png
ADDED

|
image.png
ADDED
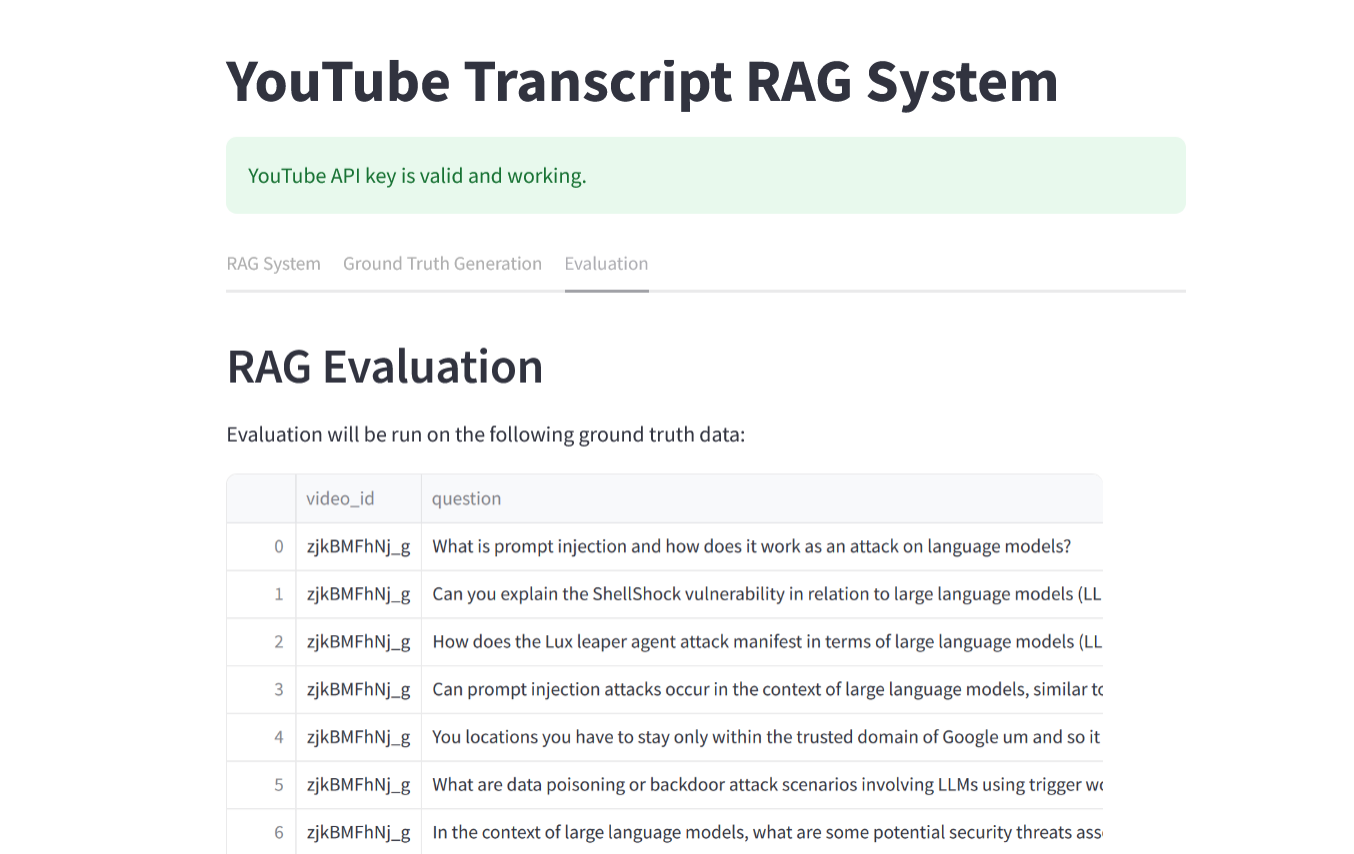
|
run-docker-compose.sh
CHANGED
|
@@ -1,19 +1,46 @@
|
|
| 1 |
#!/bin/bash
|
| 2 |
|
| 3 |
-
#
|
| 4 |
-
|
| 5 |
|
| 6 |
-
#
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
#
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
#!/bin/bash
|
| 2 |
|
| 3 |
+
# Define the path to the .env file
|
| 4 |
+
ENV_PATH="./.env"
|
| 5 |
|
| 6 |
+
# Check if the .env file exists
|
| 7 |
+
if [ -f "$ENV_PATH" ]; then
|
| 8 |
+
# Read the .env file and set environment variables
|
| 9 |
+
while IFS= read -r line || [ -n "$line" ]; do
|
| 10 |
+
# Skip empty lines and comments
|
| 11 |
+
if [[ $line =~ ^[[:space:]]*$ ]] || [[ $line =~ ^# ]]; then
|
| 12 |
+
continue
|
| 13 |
+
fi
|
| 14 |
+
|
| 15 |
+
# Extract variable name and value
|
| 16 |
+
if [[ $line =~ ^([^=]+)=(.*)$ ]]; then
|
| 17 |
+
name="${BASH_REMATCH[1]}"
|
| 18 |
+
value="${BASH_REMATCH[2]}"
|
| 19 |
+
export "$name"="$value"
|
| 20 |
+
echo "Loaded environment variable: $name"
|
| 21 |
+
fi
|
| 22 |
+
done < "$ENV_PATH"
|
| 23 |
+
|
| 24 |
+
# Stop existing containers
|
| 25 |
+
echo "Stopping existing containers..."
|
| 26 |
+
docker-compose down
|
| 27 |
+
|
| 28 |
+
# Rebuild the container
|
| 29 |
+
echo "Rebuilding Docker containers..."
|
| 30 |
+
docker-compose build --no-cache app
|
| 31 |
+
|
| 32 |
+
# Start the services
|
| 33 |
+
echo "Starting Docker services..."
|
| 34 |
+
docker-compose up -d
|
| 35 |
+
|
| 36 |
+
# Wait for services to be ready
|
| 37 |
+
echo "Waiting for services to start up..."
|
| 38 |
+
sleep 20
|
| 39 |
+
|
| 40 |
+
# Run the Streamlit app
|
| 41 |
+
echo "Starting Streamlit app..."
|
| 42 |
+
docker-compose exec -T app sh -c "cd /app/app && streamlit run main.py"
|
| 43 |
+
else
|
| 44 |
+
echo "Error: The .env file was not found at $ENV_PATH" >&2
|
| 45 |
+
exit 1
|
| 46 |
+
fi
|