
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Contributing a Guide
Want to help teach Gradio? Consider contributing a Guide! 🤗
Broadly speaking, there are two types of guides:
- **Use cases**: guides that cover step-by-step how to build a particular type of machine learning demo or app using Gradio. Here's an example: [_Creating a Chatbot_](https://github.com/gradio-app/gradio/blob/master/guides/creating_a_chatbot.md)
- **Feature explanation**: guides that describe in detail a particular feature of Gradio. Here's an example: [_Using Flagging_](https://github.com/gradio-app/gradio/blob/master/guides/using_flagging.md)
We encourage you to submit either type of Guide! (Looking for ideas? We may also have open [issues](https://github.com/gradio-app/gradio/issues?q=is%3Aopen+is%3Aissue+label%3Aguides) where users have asked for guides on particular topics)
## Guide Structure
As you can see with the previous examples, Guides are standard markdown documents. They usually:
- start with an Introduction section describing the topic
- include subheadings to make articles easy to navigate
- include real code snippets that make it easy to follow along and implement the Guide
- include embedded Gradio demos to make them more interactive and provide immediate demonstrations of the topic being discussed. These Gradio demos are hosted on [Hugging Face Spaces](https://huggingface.co/spaces) and are embedded using the standard \<iframe\> tag.
## How to Contribute a Guide
1. Clone or fork this `gradio` repo
2. Add a new markdown document with a descriptive title to the `/guides` folder
3. Write your Guide in standard markdown! Embed Gradio demos wherever helpful
4. Add a list of `related_spaces` at the top of the markdown document (see the previously linked Guides for how to do this)
5. Add 3 `tags` at the top of the markdown document to help users find your guide (again, see the previously linked Guides for how to do this)
6. Open a PR to have your guide reviewed
That's it! We're looking forward to reading your Guide 🥳
| gradio-app/gradio/blob/main/guides/CONTRIBUTING.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# T2I-Adapter
[T2I-Adapter]((https://hf.co/papers/2302.08453)) is a lightweight adapter model that provides an additional conditioning input image (line art, canny, sketch, depth, pose) to better control image generation. It is similar to a ControlNet, but it is a lot smaller (~77M parameters and ~300MB file size) because its only inserts weights into the UNet instead of copying and training it.
The T2I-Adapter is only available for training with the Stable Diffusion XL (SDXL) model.
This guide will explore the [train_t2i_adapter_sdxl.py](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/train_t2i_adapter_sdxl.py) training script to help you become familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/t2i_adapter
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/train_t2i_adapter_sdxl.py) and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L233) function. It provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to activate gradient accumulation, add the `--gradient_accumulation_steps` parameter to the training command:
```bash
accelerate launch train_t2i_adapter_sdxl.py \
----gradient_accumulation_steps=4
```
Many of the basic and important parameters are described in the [Text-to-image](text2image#script-parameters) training guide, so this guide just focuses on the relevant T2I-Adapter parameters:
- `--pretrained_vae_model_name_or_path`: path to a pretrained VAE; the SDXL VAE is known to suffer from numerical instability, so this parameter allows you to specify a better [VAE](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)
- `--crops_coords_top_left_h` and `--crops_coords_top_left_w`: height and width coordinates to include in SDXL's crop coordinate embeddings
- `--conditioning_image_column`: the column of the conditioning images in the dataset
- `--proportion_empty_prompts`: the proportion of image prompts to replace with empty strings
## Training script
As with the script parameters, a walkthrough of the training script is provided in the [Text-to-image](text2image#training-script) training guide. Instead, this guide takes a look at the T2I-Adapter relevant parts of the script.
The training script begins by preparing the dataset. This incudes [tokenizing](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L674) the prompt and [applying transforms](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L714) to the images and conditioning images.
```py
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
```
Within the [`main()`](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L770) function, the T2I-Adapter is either loaded from a pretrained adapter or it is randomly initialized:
```py
if args.adapter_model_name_or_path:
logger.info("Loading existing adapter weights.")
t2iadapter = T2IAdapter.from_pretrained(args.adapter_model_name_or_path)
else:
logger.info("Initializing t2iadapter weights.")
t2iadapter = T2IAdapter(
in_channels=3,
channels=(320, 640, 1280, 1280),
num_res_blocks=2,
downscale_factor=16,
adapter_type="full_adapter_xl",
)
```
The [optimizer](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L952) is initialized for the T2I-Adapter parameters:
```py
params_to_optimize = t2iadapter.parameters()
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Lastly, in the [training loop](https://github.com/huggingface/diffusers/blob/aab6de22c33cc01fb7bc81c0807d6109e2c998c9/examples/t2i_adapter/train_t2i_adapter_sdxl.py#L1086), the adapter conditioning image and the text embeddings are passed to the UNet to predict the noise residual:
```py
t2iadapter_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
down_block_additional_residuals = t2iadapter(t2iadapter_image)
down_block_additional_residuals = [
sample.to(dtype=weight_dtype) for sample in down_block_additional_residuals
]
model_pred = unet(
inp_noisy_latents,
timesteps,
encoder_hidden_states=batch["prompt_ids"],
added_cond_kwargs=batch["unet_added_conditions"],
down_block_additional_residuals=down_block_additional_residuals,
).sample
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Now you’re ready to launch the training script! 🚀
For this example training, you'll use the [fusing/fill50k](https://huggingface.co/datasets/fusing/fill50k) dataset. You can also create and use your own dataset if you want (see the [Create a dataset for training](https://moon-ci-docs.huggingface.co/docs/diffusers/pr_5512/en/training/create_dataset) guide).
Set the environment variable `MODEL_DIR` to a model id on the Hub or a path to a local model and `OUTPUT_DIR` to where you want to save the model.
Download the following images to condition your training with:
```bash
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
<Tip>
To monitor training progress with Weights & Biases, add the `--report_to=wandb` parameter to the training command. You'll also need to add the `--validation_image`, `--validation_prompt`, and `--validation_steps` to the training command to keep track of results. This can be really useful for debugging the model and viewing intermediate results.
</Tip>
```bash
export MODEL_DIR="stabilityai/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="path to save model"
accelerate launch train_t2i_adapter_sdxl.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--mixed_precision="fp16" \
--resolution=1024 \
--learning_rate=1e-5 \
--max_train_steps=15000 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=100 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--report_to="wandb" \
--seed=42 \
--push_to_hub
```
Once training is complete, you can use your T2I-Adapter for inference:
```py
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteSchedulerTest
from diffusers.utils import load_image
import torch
adapter = T2IAdapter.from_pretrained("path/to/adapter", torch_dtype=torch.float16)
pipeline = StableDiffusionXLAdapterPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", adapter=adapter, torch_dtype=torch.float16
)
pipeline.scheduler = EulerAncestralDiscreteSchedulerTest.from_config(pipe.scheduler.config)
pipeline.enable_xformers_memory_efficient_attention()
pipeline.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
generator = torch.manual_seed(0)
image = pipeline(
prompt, image=control_image, generator=generator
).images[0]
image.save("./output.png")
```
## Next steps
Congratulations on training a T2I-Adapter model! 🎉 To learn more:
- Read the [Efficient Controllable Generation for SDXL with T2I-Adapters](https://huggingface.co/blog/t2i-sdxl-adapters) blog post to learn more details about the experimental results from the T2I-Adapter team.
| huggingface/diffusers/blob/main/docs/source/en/training/t2i_adapters.md |
HRNet
**HRNet**, or **High-Resolution Net**, is a general purpose convolutional neural network for tasks like semantic segmentation, object detection and image classification. It is able to maintain high resolution representations through the whole process. We start from a high-resolution convolution stream, gradually add high-to-low resolution convolution streams one by one, and connect the multi-resolution streams in parallel. The resulting network consists of several ($4$ in the paper) stages and the $n$th stage contains $n$ streams corresponding to $n$ resolutions. The authors conduct repeated multi-resolution fusions by exchanging the information across the parallel streams over and over.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('hrnet_w18', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `hrnet_w18`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('hrnet_w18', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{sun2019highresolution,
title={High-Resolution Representations for Labeling Pixels and Regions},
author={Ke Sun and Yang Zhao and Borui Jiang and Tianheng Cheng and Bin Xiao and Dong Liu and Yadong Mu and Xinggang Wang and Wenyu Liu and Jingdong Wang},
year={2019},
eprint={1904.04514},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: HRNet
Paper:
Title: Deep High-Resolution Representation Learning for Visual Recognition
URL: https://paperswithcode.com/paper/190807919
Models:
- Name: hrnet_w18
In Collection: HRNet
Metadata:
FLOPs: 5547205500
Parameters: 21300000
File Size: 85718883
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w18
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L800
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w18-8cb57bb9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.76%
Top 5 Accuracy: 93.44%
- Name: hrnet_w18_small
In Collection: HRNet
Metadata:
FLOPs: 2071651488
Parameters: 13190000
File Size: 52934302
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w18_small
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L790
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnet_w18_small_v1-f460c6bc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.34%
Top 5 Accuracy: 90.68%
- Name: hrnet_w18_small_v2
In Collection: HRNet
Metadata:
FLOPs: 3360023160
Parameters: 15600000
File Size: 62682879
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w18_small_v2
Epochs: 100
Layers: 18
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L795
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnet_w18_small_v2-4c50a8cb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.11%
Top 5 Accuracy: 92.41%
- Name: hrnet_w30
In Collection: HRNet
Metadata:
FLOPs: 10474119492
Parameters: 37710000
File Size: 151452218
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w30
Epochs: 100
Layers: 30
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L805
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w30-8d7f8dab.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.21%
Top 5 Accuracy: 94.22%
- Name: hrnet_w32
In Collection: HRNet
Metadata:
FLOPs: 11524528320
Parameters: 41230000
File Size: 165547812
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
Training Time: 60 hours
ID: hrnet_w32
Epochs: 100
Layers: 32
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L810
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w32-90d8c5fb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.45%
Top 5 Accuracy: 94.19%
- Name: hrnet_w40
In Collection: HRNet
Metadata:
FLOPs: 16381182192
Parameters: 57560000
File Size: 230899236
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w40
Epochs: 100
Layers: 40
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L815
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w40-7cd397a4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.93%
Top 5 Accuracy: 94.48%
- Name: hrnet_w44
In Collection: HRNet
Metadata:
FLOPs: 19202520264
Parameters: 67060000
File Size: 268957432
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w44
Epochs: 100
Layers: 44
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L820
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w44-c9ac8c18.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.89%
Top 5 Accuracy: 94.37%
- Name: hrnet_w48
In Collection: HRNet
Metadata:
FLOPs: 22285865760
Parameters: 77470000
File Size: 310603710
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
Training Time: 80 hours
ID: hrnet_w48
Epochs: 100
Layers: 48
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L825
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w48-abd2e6ab.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.32%
Top 5 Accuracy: 94.51%
- Name: hrnet_w64
In Collection: HRNet
Metadata:
FLOPs: 37239321984
Parameters: 128060000
File Size: 513071818
Architecture:
- Batch Normalization
- Convolution
- ReLU
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: hrnet_w64
Epochs: 100
Layers: 64
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/hrnet.py#L830
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-hrnet/hrnetv2_w64-b47cc881.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.46%
Top 5 Accuracy: 94.65%
--> | huggingface/pytorch-image-models/blob/main/docs/models/hrnet.md |
--
title: "Scaling up BERT-like model Inference on modern CPU - Part 2"
authors:
- user: echarlaix
- user: jeffboudier
- user: mfuntowicz
- user: michaelbenayoun
---
# Scaling up BERT-like model Inference on modern CPU - Part 2
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## Introduction: Using Intel Software to Optimize AI Efficiency on CPU
As we detailed in our [previous blog post](https://huggingface.co/blog/bert-cpu-scaling-part-1), Intel Xeon CPUs provide a set of features especially designed for AI workloads such as AVX512 or VNNI (Vector Neural Network Instructions)
for efficient inference using integer quantized neural network for inference along with additional system tools to ensure the work is being done in the most efficient way.
In this blog post, we will focus on software optimizations and give you a sense of the performances of the new Ice Lake generation of Xeon CPUs from Intel. Our goal is to give you a full picture of what’s available on the software side to make the most out of your Intel hardware.
As in the previous blog post, we show the performance with benchmark results and charts, along with new tools to make all these knobs and features easy to use.
Back in April, Intel launched its [latest generation of Intel Xeon processors](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html), codename Ice Lake, targeting more efficient and performant AI workloads.
More precisely, Ice Lake Xeon CPUs can achieve up to 75% faster inference on a variety of NLP tasks when comparing against the previous generation of Cascade Lake Xeon processors.
This is achieved by a combination of both hardware and software improvements, [such as new instructions](https://en.wikichip.org/wiki/x86/avx512_vnni) and PCIe 4.0 featured on the new Sunny Cove architecture to supports Machine Learning and Deep Learning workloads.
Last but not least, Intel worked on dedicated optimizations for various frameworks which now come with Intel’s flavors like
[Intel’s Extension for Scikit Learn](https://intel.github.io/scikit-learn-intelex/),
[Intel TensorFlow](https://www.intel.com/content/www/us/en/developer/articles/guide/optimization-for-tensorflow-installation-guide.html) and
[Intel PyTorch Extension](https://www.intel.com/content/www/us/en/developer/articles/containers/pytorch-extension.html).
All these features are very low-level in the stack of what Data Scientists and Machine Learning Engineers use in their day-to-day toolset.
In a vast majority of situations, it is more common to rely on higher level frameworks and libraries to handle multi-dimensional arrays manipulation such as
[PyTorch](https://pytorch.org) and [TensorFlow](https://www.tensorflow.org/) and make use of highly tuned mathematical operators such as [BLAS (Basic Linear Algebra Subroutines)](http://www.netlib.org/blas/) for the computational part.
In this area, Intel plays an essential role by providing software components under the oneAPI umbrella which makes it very easy to use highly efficient linear algebra routines through
Intel [oneMKL (Math Kernel Library)](https://www.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top/api-based-programming/intel-oneapi-math-kernel-library-onemkl.html),
higher-level parallelization framework with Intel OpenMP or the [Threading Building Blocks (oneTBB)](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.html).
Also, oneAPI provides some domain-specific libraries such as Intel [oneDNN](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onednn.html) for deep neural network primitives (ReLU, fully-connected, etc.) or
[oneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html) for collective communication especially useful when using distributed setups to access efficient all-reduce operations over multiple hosts.
Some of these libraries, especially MKL or oneDNN, are natively included in frameworks such as PyTorch and TensorFlow ([since 2.5.0](https://medium.com/intel-analytics-software/leverage-intel-deep-learning-optimizations-in-tensorflow-129faa80ee07)) to bring all the performance improvements to the end user out of the box.
When one would like to target very specific hardware features, Intel provides custom versions of the most common software, especially optimized for the Intel platform.
This is for instance the case with TensorFlow, [for which Intel provides custom, highly tuned and optimized versions of the framework](https://www.intel.com/content/www/us/en/developer/articles/guide/optimization-for-tensorflow-installation-guide.html),
or with the Intel PyTorch Extension (IPEX) framework which can be considered as a feature laboratory before upstreaming to PyTorch.
## Deep Dive: Leveraging advanced Intel features to improve AI performances
### Performance tuning knobs
As highlighted above, we are going to cover a new set of tunable items to improve the performance of our AI application. From a high-level point of view, every machine learning and deep learning framework is made of the same ingredients:
1. A structural way of representing data in memory (vector, matrices, etc.)
2. Implementation of mathematical operators
3. Efficient parallelization of the computations on the target hardware
_In addition to the points listed above, deep learning frameworks provide ways to represent data flow and dependencies to compute gradients.
This falls out of the scope of this blog post, and it leverages the same components as the ones listed above!_
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel libraries overview under the oneAPI umbrella" src="assets/35_bert_cpu_scaling_part_2/oneapi.jpg"></medium-zoom>
<figcaption>Figure 1. Intel libraries overview under the oneAPI umbrella</figcaption>
</figure>
<br>
### 1. Memory allocation and management libraries
This blog post will deliberately skip the first point about the data representation as it is something rather framework specific.
For reference, PyTorch uses its very own implementation, called [ATen](https://github.com/pytorch/pytorch/tree/master/aten/src),
while TensorFlow relies on the open source library [Eigen](https://eigen.tuxfamily.org/index.php?title=Main_Page) for this purpose.
While it’s very complex to apply generic optimizations to different object structures and layouts, there is one area where we can have an impact: Memory Allocation.
As a short reminder, memory allocation here refers to the process of programmatically asking the operating system a dynamic (unknown beforehand) area on the system where we will be able to store items into, such as the malloc and derived in C or the new operator in C++.
Memory efficiency, both in terms of speed but also in terms of fragmentation, is a vast scientific and engineering subject with multiple solutions depending on the task and underlying hardware.
Over the past years we saw more and more work in this area, with notably:
- [jemalloc](http://jemalloc.net/) (Facebook - 2005)
- [mimalloc](https://microsoft.github.io/mimalloc/) (Microsoft - 2019)
- [tcmalloc](https://abseil.io/blog/20200212-tcmalloc) (Google - 2020)
Each pushes forward different approaches to improve aspects of the memory allocation and management on various software.
### 2. Efficient parallelization of computations
Now that we have an efficient way to represent our data, we need a way to take the most out of the computational hardware at our disposal.
Interestingly, when it comes to inference, CPUs have a potential advantage over GPUs in the sense they are everywhere, and they do not require specific application components and administration staff to operate them.
Modern CPUs come with many cores and complex mechanisms to increase the general performances of software.
Yet, as we highlighted on [the first blog post](https://hf.co/blog/bert-cpu-scaling-part-1), they also have features which can be tweaked depending on the kind of workload (CPU or I/O bound) you target, to further improve performances for your application.
Still, implementing parallel algorithms might not be as simple as throwing more cores to do the work.
Many factors, such as data structures used, concurrent data access, CPU caches invalidation - all of which might prevent your algorithm from being effectively faster.
As a reference talk, we recommend the talk from [**Scott Meyers: CPU Caches and Why You Care**](https://www.youtube.com/watch?v=WDIkqP4JbkE) if you are interested in diving more into the subject.
Thankfully, there are libraries which make the development process of such parallel algorithms easier and less error-prone.
Among the most common parallel libraries we can mention OpenMP and TBB (Threading Building Blocks), which work at various levels, from programming API in C/C++ to environment variable tuning and dynamic scheduling.
On Intel hardware, it is advised to use the Intel implementation of the OpenMP specification often referred as "IOMP" available as part of the [Intel oneAPI toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/overview.html).
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Code snippet showing parallel computation done through OpenMP" src="assets/35_bert_cpu_scaling_part_2/openmp.png"></medium-zoom>
<figcaption>Figure 2. Code snippet showing parallel computation done through OpenMP</figcaption>
</figure>
[comment]: <> (<br>)
### 3. Optimized mathematical operators
Now that we covered the necessary building blocks for designing efficient data structures and parallel algorithms, the last remaining piece is the one running the computation,
the one implementing the variety of mathematical operators and neural network layers to do what we love most, designing neural networks! 😊
In every programmer toolkit, there are multiple levels which can bring mathematical operations support, which can then be optimized differently depending on various factors such as the data storage layout
being used (Contiguous memory, Chunked, Packed, etc.), the data format representing each scalar element (Float32, Integer, Long, Bfloat16, etc.) and of course the various instructions being supported by your processor.
Nowadays, almost all processors support basic mathematical operations on scalar items (one single item at time) or in vectorized mode (meaning they operate on multiple items within the same CPU instructions, referred as SIMD “Single Instruction Multiple Data”).
Famous sets of SIMD instructions are SSE2, AVX, AVX2 and the AVX-512 present on the latest generations of Intel CPUs being able to operate over 16 bytes of content within a single CPU clock.
Most of the time, one doesn't have to worry too much about the actual assembly being generated to execute a simple element-wise addition between two vectors, but if you do,
again there are some libraries which allow you to go one level higher than writing code calling CPU specific intrinsic to implement efficient mathematical kernels.
This is for instance what Intel’s MKL “Math Kernel Library” provides, along with the famous BLAS “Basic Linear Algebra Subroutines” interface to implement all the basic operations for linear algebra.
Finally, on top of this, one can find some domain specific libraries such as Intel's oneDNN which brings all the most common and essential building blocks required to implement neural network layers.
Intel MKL and oneDNN are natively integrated within the PyTorch framework, where it can enable some performance speedup for certain operations such as Linear + ReLU or Convolution.
On the TensorFlow side, oneDNN can be enabled by setting the environment variable `TF_ENABLE_ONEDNN_OPTS=1` (_TensorFlow >= 2.5.0_) to achieve similar machinery under the hood.
## More Efficient AI Processing on latest Intel Ice Lake CPUs
In order to report the performances of the Ice Lake product lineup we will closely follow [the methodology we used for the first blog](https://hf.co/blog/bert-cpu-scaling-part-1#2-benchmarking-methodology) post of this series. As a reminder, we will adopt the exact same schema to benchmark the various setups we will highlight through this second blog post. More precisely, the results presented in the following sections are based on:
- PyTorch: 1.9.0
- TensorFlow: 2.5.0
- Batch Sizes: 1, 4, 8, 16, 32, 128
- Sequence Lengths: 8, 16, 32, 64, 128, 384, 512
We will present the results through metrics accepted by the field to establish the performances of the proposed optimizations:
- Latency: Time it takes to execute a single inference request (i.e., “forward call”) through the model, expressed in millisecond.
- Throughput: Number of inference requests (i.e., “forward calls”) the system can sustain within a defined period, expressed in call/sec.
We will also provide an initial baseline showing out-of-the-box results and a second baseline applying all the different optimizations we highlighted in the first blogpost.
Everything was run on an Intel provided cloud instance featuring the [Ice Lake Xeon Platinum 8380](https://ark.intel.com/content/www/fr/fr/ark/products/205684/intel-xeon-platinum-8380hl-processor-38-5m-cache-2-90-ghz.html) CPU operating on Ubuntu 20.04.2 LTS.
You can find the same processors on the various cloud providers:
- [AWS m6i / c6i instances](https://aws.amazon.com/fr/blogs/aws/new-amazon-ec2-c6i-instances-powered-by-the-latest-generation-intel-xeon-scalable-processors/)
- [Azure Ev5 / Dv5 series](https://azure.microsoft.com/en-us/blog/upgrade-your-infrastructure-with-the-latest-dv5ev5-azure-vms-in-preview/)
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel Ice Lake Xeon 8380 Specifications" src="assets/35_bert_cpu_scaling_part_2/intel_xeon_8380_specs.svg"></medium-zoom>
<figcaption>Figure 3. Intel Ice Lake Xeon 8380 Specifications</figcaption>
</figure>
<br>
### Establishing the baseline
As mentioned previously, the baselines will be composed of two different setups:
- Out-of-the-box: We are running the workloads as-is, without any tuning
- Optimized: We apply the various knobs present in [Blog #1](https://hf.co/blog/bert-cpu-scaling-part-1#2-benchmarking-methodology)
Also, from the comments we had about the previous blog post, we wanted to change the way we present the framework within the resulting benchmarks.
As such, through the rest of this second blog post, we will split framework benchmarking results according to the following:
- Frameworks using “eager” mode for computations (PyTorch, TensorFlow)
- Frameworks using “graph” mode for computations (TorchScript, TensorFlow Graph, Intel Tensorflow)
#### Baseline: Eager frameworks latencies
Frameworks operating in eager mode usually discover the actual graph while executing it.
More precisely, the actual computation graph is not known beforehand and you gradually (_eagerly_) execute one operator
which will become the input of the next one, etc. until you reach leaf nodes (outputs).
These frameworks usually provide more flexibility in the algorithm you implement at the cost of increased runtime overhead
and slightly potential more memory usage to keep track of all the required elements for the backward pass.
Last but not least, it is usually harder through these frameworks to enable graph optimizations such as operator fusion.
For instance, many deep learning libraries such as oneDNN have optimized kernels for Convolution + ReLU but you actually need
to know before executing the graph that this pattern will occur within the sequence of operation, which is, by design, not
something possible within eager frameworks.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="PyTorch latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_pytorch_baseline.svg"></medium-zoom>
<figcaption>Figure 4. PyTorch latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_tensorflow_baseline.svg"></medium-zoom>
<figcaption> Figure 5. Google's TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_tensorflow_onednn_baseline.svg"></medium-zoom>
<figcaption>Figure 6. Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/eager_mode_intel_tensorflow_baseline.svg"></medium-zoom>
<figcaption>Figure 7. Intel TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
The global trend highlights the positive impact of the number of cores on the observed latencies.
In most of the cases, increasing the number of cores reduces the computation time across the different workload sizes.
Still, putting more cores to the task doesn't result in monotonic latency reductions, there is always a trade-off between the workload’s size and the number of resources you allocate to execute the job.
As you can see on the charts above, one very common pattern tends to arise from using all the cores available on systems with more than one CPU (more than one socket).
The inter-socket communication introduces a significant latency overhead and results in very little improvement to increased latency overall.
Also, this inter-socket communication overhead tends to be less and less perceptive as the workload becomes larger,
meaning the usage of all computational resources benefits from using all the available cores.
In this domain, it seems PyTorch (Figure 1.) and Intel TensorFlow (Figure 4.) seem to have slightly better parallelism support,
as showed on the sequence length 384 and 512 for which using all the cores still reduces the observed latency.
#### Baseline: Graph frameworks latencies
This time we compare performance when using frameworks in “Graph” mode, where the graph is fully known beforehand,
and all the allocations and optimizations such as graph pruning and operators fusing can be made.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="TorchScript latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_torchscript_baseline.svg"></medium-zoom>
<figcaption>Figure 8. TorchScript latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_tensorflow_baseline.svg"></medium-zoom>
<figcaption>Figure 9. Google's TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_tensorflow_onednn_baseline.svg"></medium-zoom>
<figcaption>Figure 10. Google's TensorFlow with oneDNN enabled latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow latencies with respect to the number of cores involved" src="assets/35_bert_cpu_scaling_part_2/baselines/graph_mode_intel_tensorflow_baseline.svg"></medium-zoom>
<figcaption>Figure 11. Intel TensorFlow latencies with respect to the number of cores involved</figcaption>
</figure>
<br>
This is often referred to as “tracing” the graph and, as you can see here, the results are not that different from TorchScript (Graph execution mode from PyTorch) vs TensorFlow(s).
All TensorFlow implementations seem to perform better than TorchScript when the parallelization is limited (low number of cores involved in the intra operation computations) but this seems not to scale efficiently
as we increase the computation resources, whereas TorchScript seems to be able to better leverage the power of modern CPUs.
Still, the margin between all these frameworks in most cases very limited.
### Tuning the Memory Allocator: Can this impact the latencies observed?
One crucial component every program dynamically allocating memory relies on is the memory allocator.
If you are familiar with C/C++ programming this component provides the low bits to malloc/free or new/delete.
Most of the time you don’t have to worry too much about it and the default ones (glibc for instance on most Linux distributions) will provide great performances out of the box.
Still, in some situations it might not provide the most efficient performances, as these default allocators are most of the time designed to be “good” most of the time,
and not fine-tuned for specific workloads or parallelism.
So, what are the alternatives, and when are they more suitable than the default ones? Well, again, it depends on the kind of context around your software.
Possible situations are a heavy number of allocations/de-allocations causing fragmentation over time,
specific hardware and/or architecture you’re executing your software on and finally the level of parallelism of your application.
Do you see where this is going? Deep learning and by extension all the applications doing heavy computations are heavily multi-threaded,
that’s also the case for software libraries such as PyTorch, TensorFlow and any other frameworks targeting Machine Learning workloads.
The default memory allocator strategies often rely on global memory pools which require the usage of synchronization primitives to operate,
increasing the overall pressure on the system, reducing the performance of your application.
Some recent works by companies such as Google, Facebook and Microsoft provided alternative memory allocation strategies implemented in custom memory allocator libraries
one can easily integrate directly within its software components or use dynamic shared library preload to swap the library being used to achieve the allocation/de-allocation.
Among these libraries, we can cite a few of them such as [tcmalloc](), [jemalloc]() and [mimalloc]().
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Legend - Various allocator benchmarked on different tasks" src="assets/35_bert_cpu_scaling_part_2/allocator_benchmark_legend.png"></medium-zoom>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Various allocator benchmarked on different tasks" src="assets/35_bert_cpu_scaling_part_2/allocator_benchmark.png"></medium-zoom>
<figcaption>Figure 12. Various memory allocators benchmarked on different tasks</figcaption>
</figure>
<br>
Through this blog post we will only focus on benchmarking tcmalloc and jemalloc as potential memory allocators drop-in candidates.
To be fully transparent, for the scope of the results below we used tcmalloc as part of the gperftools package available on Ubuntu distributions version 2.9 and jemalloc 5.1.0-1.
#### Memory allocator benchmarks
Again, we first compare performance against frameworks executing in an eager fashion.
This is potentially the use case where the allocator can play the biggest role: As the graph is unknown before its execution, each framework must manage the memory required for each operation when it meets the actual execution of the above node, no planning ahead possible.
In this context, the allocator is a major component due to all the system calls to allocate and reclaim memory.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="PyTorch memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_pytorch_latency.svg"></medium-zoom>
<figcaption>Figure 13. PyTorch memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_latency.svg"></medium-zoom>
<figcaption>Figure 14. Google's TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_onednn_latency.svg"></medium-zoom>
<figcaption>Figure 15. Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_intel_tensorflow_latency.svg"></medium-zoom>
<figcaption>Figure 16. Intel TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
As per the graph above, you can notice that the standard library allocator (glibc) is often behind performance-wise but provides reasonable performance.
Jemalloc allocator is sometimes the fastest around but in very specific situations, where the concurrency is not that high, this can be explained by the underlying structure jemalloc uses
internally which is out of the scope of this blog, but you can read the [Facebook Engineering blog](https://engineering.fb.com/2011/01/03/core-data/scalable-memory-allocation-using-jemalloc/) if you want to know more about it.
Finally, tcmalloc seems to be the one providing generally best performances across all the workloads benchmarked here.
Again, tcmalloc has a different approach than Jemalloc in the way it allocates resources, especially tcmalloc maintains a pool of memory segments locally for each thread, which reduces the necessity to have global, exclusive, critical paths.
Again, for more details, I invite you to read the full [blog by Google Abseil team](https://abseil.io/blog/20200212-tcmalloc).
Now, back to the graph mode where we benchmark framework having an omniscient representation of the overall computation graph.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="TorchScript memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_torchscript_latency.svg"></medium-zoom>
<figcaption>Figure 17. TorchScript memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_graph_latency.svg"></medium-zoom>
<figcaption>Figure 18. Google's TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_tensorflow_onednn_graph_latency.svg"></medium-zoom>
<figcaption>Figure 19. Google's TensorFlow with oneDNN enabled memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Intel TensorFlow memory allocator and cores scaling latencies" src="assets/35_bert_cpu_scaling_part_2/allocators/allocator_and_cores_intel_tensorflow_graph_latency.svg"></medium-zoom>
<figcaption>Figure 20. Intel TensorFlow memory allocator and cores scaling latencies</figcaption>
</figure>
<br>
This time, by knowing the underlying structure of the operator flows and matrix shapes involved then the framework can plan and reserve the required resources beforehand.
In this context, and as it is shown in the chart above, the difference between framework is very small and there is no clear winner between jemalloc and tcmalloc.
Of course, glibc is still slightly behind as a general-purpose memory allocator, but the margin is less significant than in the eager setup.
To sum it up, tuning the memory allocator can provide an interesting item to grab the last milliseconds' improvement at the end of the optimization process, especially if you are already using traced computation graphs.
### OpenMP
In the previous section we talked about the memory management within machine learning software involving mostly CPU-bound workloads.
Such software often relies on intermediary frameworks such as PyTorch or TensorFlow for Deep Learning which commonly abstract away all the underlying, highly parallelized, operator implementations.
Writing such highly parallel and optimized algorithms is a real engineering challenge, and it requires a very low-level understanding of all the actual elements coming into play
operated by the CPU (synchronization, memory cache, cache validity, etc.).
In this context, it is very important to be able to leverage primitives to implement such powerful algorithms, reducing the delivery time and computation time by a large margin
compared to implementing everything from scratch.
There are many libraries available which provide such higher-level features to accelerate the development of algorithms.
Among the most common, one can look at OpenMP, Thread Building Blocks and directly from the C++ when targeting a recent version of the standard.
In the following part of this blog post, we will restrict ourselves to OpenMP and especially comparing the GNU, open source and community-based implementation, to the Intel OpenMP one.
The latter especially targets Intel CPUs and is optimized to provide best of class performances when used as a drop-in replacement against the GNU OpenMP one.
OpenMP exposes [many environment variables](https://www.openmp.org/spec-html/5.0/openmpch6.html) to automatically configure the underlying resources which will be involved in the computations,
such as the number of threads to use to dispatch computation to (intra-op threads), the way the system scheduler should bind each of these threads with respect to the CPU resources (threads, cores, sockets)
and some other variables which bring further control to the user.
Intel OpenMP exposes [more of these environment variables](https://www.intel.com/content/www/us/en/develop/documentation/cpp-compiler-developer-guide-and-reference/top/compilation/supported-environment-variables.html) to provide the user even more flexibility to adjust the performance of its software.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="OpenMP vs Intel OpenMP latencies running PyTorch" src="assets/35_bert_cpu_scaling_part_2/openmp/openmp_pytorch_latencies.svg"></medium-zoom>
<figcaption>Figure 21. OpenMP vs Intel OpenMP latencies running PyTorch</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="OpenMP vs Intel OpenMP latencies running PyTorch" src="assets/35_bert_cpu_scaling_part_2/openmp/openmp_torchscript_latency.svg"></medium-zoom>
<figcaption>Figure 22. OpenMP vs Intel OpenMP latencies running PyTorch</figcaption>
</figure>
<br>
As stated above, tuning OpenMP is something you can start to tweak when you tried all the other, system related, tuning knobs.
It can bring a final speed up to you model with just a single environment variable to set.
Also, it is important to note that tuning OpenMP library will only work within software that uses the OpenMP API internally.
More specially, now only PyTorch and TorchScript really make usage of OpenMP and thus benefit from OpenMP backend tuning.
This also explains why we reported latencies only for these two frameworks.
## Automatic Performances Tuning: Bayesian Optimization with Intel SigOpt
As mentioned above, many knobs can be tweaked to improve latency and throughput on Intel CPUs, but because there are many, tuning all of them to get optimal performance can be cumbersome.
For instance, in our experiments, the following knobs were tuned:
- The number of cores: although using as many cores as you have is often a good idea, it does not always provide the best performance because it also means more communication between the different threads. On top of that, having better performance with fewer cores can be very useful as it allows to run multiple instances at the same time, resulting in both better latency and throughput.
- The memory allocator: which memory allocator out of the default malloc, Google's tcmalloc and Facebook's jemalloc provides the best performance?
- The parallelism library: which parallelism library out of GNU OpenMP and Intel OpenMP provides the best performance?
- Transparent Huge Pages: does enabling Transparent Huge Pages (THP) on the system provide better performance?
- KMP block time parameter: sets the time, in milliseconds, that a thread should wait, after completing the execution of a parallel region, before sleeping.
Of course, the brute force approach, consisting of trying out all the possibilities will provide the best knob values to use to get optimal performance but,
the size of the search space being `N x 3 x 2 x 2 x 2 = 24N`, it can take a lot of time: on a machine with 80 physical cores, this means trying out at most `24 x 80 = 1920` different setups! 😱
Fortunately, Intel's [SigOpt](https://sigopt.com/), through Bayesian optimization, allows us to make these tuning experiments both faster and more convenient to analyse, while providing similar performance than the brute force approach.
When we analyse the relative difference between the absolute best latency and what SigOpt provides, we observe that although it is often not as good as brute force (except for sequence length = 512 in that specific case),
it gives very close performance, with **8.6%** being the biggest gap on this figure.
<table class="block mx-auto">
<tr>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Absolute best latency found by SigOpt automatic tuning vs brute force" src="assets/35_bert_cpu_scaling_part_2/sigopt/Intel%20Ice%20lake%20Xeon%208380%20-%20TorchScript%20-%20Batch%20Size%201%20-%20Absolute%20Best%20Latency%20vs%20SigOpt%20Best%20Latency.svg"></medium-zoom>
<figcaption>Figure 23. Absolute best latency found by SigOpt automatic tuning vs brute force</figcaption>
</figure>
</td>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Relative best latency found by SigOpt automatic tuning vs brute force" src="assets/35_bert_cpu_scaling_part_2/sigopt/Intel%20Ice%20lake%20Xeon%208380%20-%20TorchScript%20-%20Batch%20Size%201%20-%20Relative%20Difference%20Absolute%20Best%20Latency%20vs%20SigOpt%20Best%20Latency.svg"></medium-zoom>
<figcaption>Figure 24. Relative best latency found by SigOpt automatic tuning vs brute force</figcaption>
</figure>
</td>
</tr>
</table>
SigOpt is also very useful for analysis: it provides a lot of figures and valuable information.
First, it gives the best value it was able to find, the corresponding knobs, and the history of trials and how it improved as trials went, for example, with sequence length = 20:
<table>
<tr>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value display" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_best_value.png"></medium-zoom>
<figcaption>Figure 25. SigOpt best value reporting</figcaption>
</figure>
</td>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value display" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_improvements_over_time.png"></medium-zoom>
<figcaption>Figure 26. SigOpt best value reporting</figcaption>
</figure>
</td>
</tr>
</table>
In this specific setup, 16 cores along with the other knobs were able to give the best results, that is very important to know, because as mentioned before,
that means that multiple instances of the model can be run in parallel while still having the best latency for each.
It also shows that it had converged at roughly 20 trials, meaning that maybe 25 trials instead of 40 would have been enough.
A wide range of other valuable information is available, such as Parameter Importance:
As expected, the number of cores is, by far, the most important parameter, but the others play a part too, and it is very experiment dependent.
For instance, for the sequence length = 512 experiment, this was the Parameter Importance:
<table>
<tr>
<td>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value for Batch Size = 1, Sequence Length = 20" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_parameters_importance_seq_20.png"></medium-zoom>
<figcaption>Figure 27. SigOpt best value for Batch Size = 1, Sequence Length = 20</figcaption>
</figure>
</td>
<td>
<figure class="image table text-center m-0 w-full"`>
<medium-zoom background="rgba(0,0,0,.7)" alt="SigOpt best value for Batch Size = 1, Sequence Length = 512" src="assets/35_bert_cpu_scaling_part_2/sigopt/sigopt_parameters_importance_seq_512.png"></medium-zoom>
<figcaption>Figure 28. SigOpt best value for Batch Size = 1, Sequence Length = 512</figcaption>
</figure>
</td>
</tr>
</table>
Here not only the impact of using OpenMP vs Intel OpenMP was bigger than the impact of the allocator, the relative importance of each knob is more balanced than in the sequence length = 20 experiment.
And many more figures, often interactive, are available on SigOpt such as:
- 2D experiment history, allowing to compare knobs vs knobs or knobs vs objectives
- 3D experiment history, allowing to do the same thing as the 2D experiment history with one more knob / objective.
## Conclusion - Accelerating Transformers for Production
In this post, we showed how the new Intel Ice Lake Xeon CPUs are suitable for running AI workloads at scale along with the software elements you can swap and tune in order to exploit the full potential of the hardware.
All these items are to be considered after setting-up the various lower-level knobs detailed in [the previous blog](https://huggingface.co/blog/bert-cpu-scaling-part-1) to maximize the usage of all the cores and resources.
At Hugging Face, we are on a mission to democratize state-of-the-art Machine Learning, and a critical part of our work is to make these state-of-the-art models as efficient as possible, to use less energy and memory at scale, and to be more affordable to run by companies of all sizes.
Our collaboration with Intel through the 🤗 [Hardware Partner Program](https://huggingface.co/hardware) enables us to make advanced efficiency and optimization techniques easily available to the community, through our new 🤗 [Optimum open source library](https://github.com/huggingface/optimum) dedicated to production performance.
For companies looking to accelerate their Transformer models inference, our new 🤗 [Infinity product offers a plug-and-play containerized solution](https://huggingface.co/infinity), achieving down to 1ms latency on GPU and 2ms on Intel Xeon Ice Lake CPUs.
If you found this post interesting or useful to your work, please consider giving Optimum a star. And if this post was music to your ears, consider [joining our Machine Learning Optimization team](https://apply.workable.com/huggingface/)!
| huggingface/blog/blob/main/bert-cpu-scaling-part-2.md |
--
language: en
license: mit
library_name: timm
tags:
- pytorch
- image-classification
datasets:
- beans
metrics:
- acc
model-index:
- name: my-cool-model
results:
- task:
type: image-classification
metrics:
- type: acc
value: 0.9
---
# Invalid Model Index
In this example, the model index does not define a dataset field. In this case, we'll still initialize CardData, but will leave model-index/eval_results out of it.
| huggingface/huggingface_hub/blob/main/tests/fixtures/cards/sample_invalid_model_index.md |
p align="center">
<br>
<img src="https://huggingface.co/landing/assets/tokenizers/tokenizers-logo.png" width="600"/>
<br>
<p>
<p align="center">
<a href="https://badge.fury.io/js/tokenizers">
<img alt="Build" src="https://badge.fury.io/js/tokenizers.svg">
</a>
<a href="https://github.com/huggingface/tokenizers/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/tokenizers.svg?color=blue">
</a>
</p>
<br>
NodeJS implementation of today's most used tokenizers, with a focus on performance and
versatility. Bindings over the [Rust](https://github.com/huggingface/tokenizers/tree/master/tokenizers) implementation.
If you are interested in the High-level design, you can go check it there.
## Main features
- Train new vocabularies and tokenize using 4 pre-made tokenizers (Bert WordPiece and the 3
most common BPE versions).
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes
less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for research and production.
- Normalization comes with alignments tracking. It's always possible to get the part of the
original sentence that corresponds to a given token.
- Does all the pre-processing: Truncate, Pad, add the special tokens your model needs.
## Installation
```bash
npm install tokenizers@latest
```
## Basic example
```ts
import { Tokenizer } from "tokenizers";
const tokenizer = await Tokenizer.fromFile("tokenizer.json");
const wpEncoded = await tokenizer.encode("Who is John?");
console.log(wpEncoded.getLength());
console.log(wpEncoded.getTokens());
console.log(wpEncoded.getIds());
console.log(wpEncoded.getAttentionMask());
console.log(wpEncoded.getOffsets());
console.log(wpEncoded.getOverflowing());
console.log(wpEncoded.getSpecialTokensMask());
console.log(wpEncoded.getTypeIds());
console.log(wpEncoded.getWordIds());
```
## License
[Apache License 2.0](../../LICENSE)
| huggingface/tokenizers/blob/main/bindings/node/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Mask2Former
## Overview
The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mask2former_architecture.jpg" alt="drawing" width="600"/>
<small> Mask2Former architecture. Taken from the <a href="https://arxiv.org/abs/2112.01527">original paper.</a> </small>
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
## Usage tips
- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Mask2FormerConfig
[[autodoc]] Mask2FormerConfig
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
- forward
## Mask2FormerForUniversalSegmentation
[[autodoc]] Mask2FormerForUniversalSegmentation
- forward
## Mask2FormerImageProcessor
[[autodoc]] Mask2FormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation | huggingface/transformers/blob/main/docs/source/en/model_doc/mask2former.md |
Troubleshooting
This guide aims to provide you the tools and knowledge required to navigate some common issues. If the suggestions listed
in this guide do not cover your such situation, please refer to the [Asking for Help](#asking-for-help) section to learn where to
find help with your specific issue.
## Issues when uploading datasets with `push_to_hub`
### Authentication issues
If you are experiencing authentication issues when sharing a dataset on 🤗 Hub using [`Dataset.push_to_hub`] and a Hugging Face
access token:
* Make sure that the Hugging Face token you're using to authenticate yourself is a token with **write** permission.
* On OSX, it may help to clean up all the huggingface.co passwords on your keychain access, as well as reconfigure `git config --global credential.helper osxkeychain`, before using `huggingface-cli login`.
Alternatively, you can use SSH keys to authenticate yourself - read more in the [🤗 Hub documentation](https://huggingface.co/docs/hub/security-git-ssh).
### Lost connection on large dataset upload
When uploading large datasets to Hub, if the number of dataset shards is large, it can create too many commits for the Hub in a
short period. This will result in a connection error.
The connection error can also be caused by a HTTP 500 error returned by AWS S3 bucket that Hub uses internally.
In either situation, you can re-run [`Dataset.push_to_hub`] to proceed with the dataset upload. Hub will check the SHAs
of already uploaded shards to avoid reuploading them.
We are working on making upload process more robust to transient errors, so updating to the latest library version is
always a good idea.
### `Too Many Requests`
Uploading large datasets via `push_to_hub()` can result in an error:
```bash
HfHubHTTPError: 429 Client Error: Too Many Requests for url: ...
You have exceeded our hourly quotas for action: commit. We invite you to retry later.
```
If you encounter this issue, you need to upgrade the `datasets` library to the latest version (or at least `2.15.0`).
## Issues when creating datasets from custom data
### Loading images and audio from a folder
When creating a dataset from a folder, one of the most common issues is that the file structure does not follow the
expected format, or there's an issue with the metadata file.
Learn more about required folder structure in corresponding documentation pages:
* [AudioFolder](https://huggingface.co/docs/datasets/audio_dataset#audiofolder)
* [ImageFolder](https://huggingface.co/docs/datasets/image_dataset#imagefolder)
### Pickling issues
#### Pickling issues when using `Dataset.from_generator`
When creating a dataset, [`IterableDataset.from_generator`] and [`Dataset.from_generator`] expect a "picklable" generator function.
This is required to hash the function using [`pickle`](https://docs.python.org/3/library/pickle.html) to be able to cache the dataset on disk.
While generator functions are generally "picklable", note that generator objects are not. So if you're using a generator object,
you will encounter a `TypeError` like this:
```bash
TypeError: cannot pickle 'generator' object
```
This error can also occur when using a generator function that uses a global object that is not "picklable", such as a
DB connection, for example. If that's the case, you can initialize such object directly inside the generator function to
avoid this error.
#### Pickling issues with `Dataset.map`
Pickling errors can also happen in the multiprocess [`Dataset.map`] - objects are pickled to be passed to child processes.
If the objects used in the transformation are not picklable, it's not possible to cache the result of `map`, which leads to an error being raised.
Here are some ways to address this issue:
* A universal solution to pickle issues is to make sure the objects (or generator classes) are pickable manually by implementing `__getstate__` / `__setstate__` / `__reduce__`.
* You can also provide your own unique hash in `map` with the `new_fingerprint` argument.
* You can also disable caching by calling `datasets.disable_caching()`, however, this is undesirable - [read more about importance of cache](cache)
## Asking for help
If the above troubleshooting advice did not help you resolve your issue, reach out for help to the community and the team.
### Forums
Ask for help on the Hugging Face forums - post your question in the [🤗Datasets category](https://discuss.huggingface.co/c/datasets/10)
Make sure to write a descriptive post with relevant context about your setup and reproducible code to maximize the likelihood that your problem is solved!
### Discord
Post a question on [Discord](http://hf.co/join/discord), and let the team and the community help you.
### Community Discussions on 🤗 Hub
If you are facing issues creating a custom dataset with a script on Hub, you can ask the Hugging Face team for help by opening
a discussion in the Community tab of your dataset with this message:
```text
# Dataset rewiew request for <Dataset name>
## Description
<brief description of the dataset>
## Files to review
- file1
- file2
- ...
cc @lhoestq @polinaeterna @mariosasko @albertvillanova
```
### GitHub Issues
Finally, if you suspect to have found a bug related to the library itself, create an Issue on the 🤗 Datasets
[GitHub repository](https://github.com/huggingface/datasets/issues). Include context regarding the bug: code snippet to reproduce,
details about your environment and data, etc. to help us figure out what's wrong and how we can fix it.
| huggingface/datasets/blob/main/docs/source/troubleshoot.mdx |
et's study how to preprocess a dataset for token classification! Token classification regroups any task that can be framed as labelling each word (or token) in a sentence, like identifying the persons, organizations and locations for instance. For our example, we will use the Conll dataset, in which we remove columns we won't use and rename the other ones to get to a dataset with just two columns: words and labels. If you have your own dataset for token classification, just make sure you clean your data to get to the same point, with one column containing words (as list of strings) and another containing labels (as integers spanning from to to your number of labels -1).() Make sure you have your label names stored somewhere - here we get them from the dataset features - so you are able to map the integers to some real labels when inspecting your data! Here we are doing named entity recognitions, so ours labels are either O for words that do not belong to any entity, LOC, for location, PER, for person, ORG for organization and MISC for miscellaneous. Each label has two versions: the B- labels indicate a word that begins an entity while the I- labels indicate a word that is inside an entity. The first step to preprocess our data is to tokenize the words. This is very easily done with a tokenizer, we just have to tell it we have pre-tokenized the data with the flag is_split_into_words. Then comes the hard part. Since we have added special tokens and each word may have been split into several tokens, our labels won't match the tokens anymore. This is where the word IDs our fast tokenizer provide come to the rescue. They match each token to the word it belongs to which allows us to map each token to its label. We just have to make sure we change the B- labels to their I- counterparts for tokens that are inside (but not at the beginning) of a word. The special tokens get a label of -100, which is how we tell the Transformer loss functions to ignore them when computing the loss. The code is then pretty straightforward, we write a function that shifts the labels for tokens that are inside a word (that you can customize) and use it when generating the labels for each token. Once that function to create our labels is written, we can preprocess the whole dataset using the map function. With the option batched=True, we unleash the speed of out fast tokenizers. The last problem comes when we need to create a batch. Unless you changed the preprocessing function to apply some fixed padding, we will get sentences of various lengths, which we need to pad to the same length. The padding needs to be applied to the inputs as well as the labels, since we should have one label per token. Again, -100 indicates the labels that should be ignored for the loss computation. This is all done for us by the DataCollatorForTokenClassification, which you can use in PyTorch or TensorFlow. With all of this, you are either ready to send your data and this data collator to the Trainer, or to use the to_tf_dataset method and use the fit method of your model. | huggingface/course/blob/main/subtitles/en/raw/chapter7/02_token-classification-processing.md |
he fast tokenizers of the Transformers library are fast, but they also implement features that will be super useful for data pre-processing and post-processing. Let's have a look at them! First, let's have a look at the usual output of a tokenizer. We get input IDs that correspond to tokens, but we lose a lot of information in the process. For instance, here the tokenization is the same for the two sentences, even if one has several more spaces than the other. Just having the input IDs is thus not enough if we want to match some tokens with a span of text (something we will need to do when tackling question answering for instance). It's also difficult to know when two tokens belong to the same word or not: it looks easy when you just look at the output of a BERT tokenizer, we just need to look for the ##. But other tokenizers have different ways to tokenize parts of words. For instance RoBERTa adds this special G symbol to mark the tokens at the beginning of a word, and T5 uses this special underscore symbol for the same purpose. Thankfully, the fast tokenizers keep track of the word each token comes from, with a word_ids method you can use on their outputs. The output is not necessarily clear, but assembled together in a nice table like this, we can look at the word position for each token. Even better, the fast tokenizers keep track of the span of characters each token comes from, and we can get them when calling it on one (or several) text by adding the return_offsets_mapping=True argument. In this instance, we can see how we jump positions between the ##s token and the super token, because of the multiple spaces in the initial sentence. To enable this, the fast tokenizers store additional information at each step of their internal pipeline. That internal pipeline consists of normalization, where we apply some cleaning to the text, like lowercasing or removing the accents;() pre-tokenization, which is where we split the texts into words;() then we apply the model of the tokenizer, which is where the words are splits into tokens,() before finally doing the post-processing, where special tokens are added. From the beginning to the end of the pipeline, the tokenizer keeps track of each span of text that corresponds to each word, then each token. We will see how useful it is when we tackle the following tasks: when doing masked language modeling, one variation that gets state-of-the-art results is to mask all the tokens of a given word instead of randomly chosen tokens. This will require us to use the word IDs we saw. When doing token classification, we'll need to convert the labels we have on words, to labels on each tokens. As for the offset mappings, it will be super useful when we need to convert token positions in a sentence into a span of text, which we will need to know when looking at question answering or when grouping the tokens corresponding to the same entity in token classification. To have a look at these tasks, check the videos linked below! | huggingface/course/blob/main/subtitles/en/raw/chapter6/03b_fast-tokenizers-superpowers.md |
et's have a look inside the question answering pipeline. The question answering pipeline can extracts answers to questions from a given context or passage of text, like this part of the Transformers repo README. It also works for very long contexts, even if the answer is at the very end, like in this example. In this video, we will see why! The question answering pipeline follows the same steps as the other pipelines: the question and context are tokenized as a sentence pair, fed to the model then some post-processing is applied. The tokenization and model steps should be familiar. We use the auto class suitable for Question Answering instead of sequence classification, but one key difference with text classification is that our model outputs two tensors named start logits and end logits. Why is that? Well this is the way the model finds the answer to the question. First let's have a look at the model inputs. It's numbers associated with the tokenization of the question followed by the context (with the usual CLS and SEP special tokens). The answer is a part of those tokens. So we ask the model to predict which token starts the answer and which ends the answer. For our two logit outputs, the theoretical labels are the pink and purple vectors. To convert those logits into probabilities, we will need to apply a SoftMax, like in the text classification pipeline. We just mask the tokens that are not part of the context before doing that, leaving the initial CLS token unmasked as we use it to predict an impossible answer. This is what it looks in terms of code. We use a large negative number for the masking, since its exponential will then be 0. Now the probability for each start and end position corresponding to a possible answer, we give a score that is the product of the start probabilities and end probabilities at those positions. Of course, a start index greater than an end index corresponds to an impossible answer. Here is the code to find the best score for a possible answer. Once we have the start and end positions of the tokens, we use the offset mappings provided by our tokenizer to find the span of characters in the initial context, and get our answer! Now, when the context is long, it might get truncated by the tokenizer. This might result in part of the answer, or worse, the whole answer, being truncated. So we don't discard the truncated tokens but build new features with them. Each of those features contains the question, then a chunk of text in the context. If we take disjoint chunks of texts, we might end up with the answer being split between two features. So instead, we take overlapping chunks of texts, to make sure at least one of the chunks will fully contain the answer to the question. The tokenizers do all of this for us automatically with the return overflowing tokens option. The stride argument controls the number of overlapping tokens. Here is how our very long context gets truncated in two features with some overlap. By applying the same post-processing we saw before for each feature, we get the answer with a score for each of them, and we take the answer with the best score as a final solution. | huggingface/course/blob/main/subtitles/en/raw/chapter6/04_question-answering-pipeline-pt.md |
Gradio Demo: blocks_xray
```
!pip install -q gradio
```
```
import gradio as gr
import time
disease_values = [0.25, 0.5, 0.75]
def xray_model(diseases, img):
return [{disease: disease_values[idx] for idx,disease in enumerate(diseases)}]
def ct_model(diseases, img):
return [{disease: 0.1 for disease in diseases}]
with gr.Blocks() as demo:
gr.Markdown(
"""
# Detect Disease From Scan
With this model you can lorem ipsum
- ipsum 1
- ipsum 2
"""
)
gr.DuplicateButton()
disease = gr.CheckboxGroup(
info="Select the diseases you want to scan for.",
choices=["Covid", "Malaria", "Lung Cancer"], label="Disease to Scan For"
)
slider = gr.Slider(0, 100)
with gr.Tab("X-ray") as x_tab:
with gr.Row():
xray_scan = gr.Image()
xray_results = gr.JSON()
xray_run = gr.Button("Run")
xray_run.click(
xray_model,
inputs=[disease, xray_scan],
outputs=xray_results,
api_name="xray_model"
)
with gr.Tab("CT Scan"):
with gr.Row():
ct_scan = gr.Image()
ct_results = gr.JSON()
ct_run = gr.Button("Run")
ct_run.click(
ct_model,
inputs=[disease, ct_scan],
outputs=ct_results,
api_name="ct_model"
)
upload_btn = gr.Button("Upload Results", variant="primary")
upload_btn.click(
lambda ct, xr: None,
inputs=[ct_results, xray_results],
outputs=[],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_xray/run.ipynb |
Digital Object Identifier (DOI)
The Hugging Face Hub offers the possibility to generate DOI for your models or datasets. DOIs (Digital Object Identifiers) are strings uniquely identifying a digital object, anything from articles to figures, including datasets and models. DOIs are tied to object metadata, including the object's URL, version, creation date, description, etc. They are a commonly accepted reference to digital resources across research and academic communities; they are analogous to a book's ISBN.
## How to generate a DOI?
To do this, you must go to the settings of your model or dataset. In the DOI section, a button called "Generate DOI" should appear:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-generation.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-generation-dark.png"/>
</div>
To generate the DOI for this model or dataset, you need to click on this button and acknowledge that some features on the hub will be restrained and some of your information (your full name) will be transferred to our partner DataCite:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-agreement.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-agreement-dark.png"/>
</div>
After you agree to those terms, your model or dataset will get a DOI assigned, and a new tag should appear in your model or dataset header allowing you to cite it.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-header-with-doi.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-header-with-doi-dark.png"/>
</div>
## Can I regenerate a new DOI if my model or dataset changes?
If ever there’s a new version of a model or dataset, a new DOI can easily be assigned, and the previous version of the DOI gets outdated. This makes it easy to refer to a specific version of an object, even if it has changed.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-repo-updated.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/doi-repo-updated-dark.png"/>
</div>
You just need to click on "Generate new DOI" and tadaam!🎉 a new DOI is assigned for the current revision of your model or dataset.
## Why is there a 'locked by DOI' message on delete, rename and change visibility action on my model or dataset?
DOIs make finding information about a model or dataset easier and sharing them with the world via a permanent link that will never expire or change. As such, datasets/models with DOIs are intended to persist perpetually and may only be deleted, renamed and changed their visibility upon filing a request with our support (website at huggingface.co)
## Further Reading
- [Introducing DOI: the Digital Object Identifier to Datasets and Models](https://huggingface.co/blog/introducing-doi)
| huggingface/hub-docs/blob/main/docs/hub/doi.md |
Process image data
This guide shows specific methods for processing image datasets. Learn how to:
- Use [`~Dataset.map`] with image dataset.
- Apply data augmentations to a dataset with [`~Dataset.set_transform`].
For a guide on how to process any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./process">general process guide</a>.
## Map
The [`~Dataset.map`] function can apply transforms over an entire dataset.
For example, create a basic [`Resize`](https://pytorch.org/vision/stable/generated/torchvision.transforms.Resize.html) function:
```py
>>> def transforms(examples):
... examples["pixel_values"] = [image.convert("RGB").resize((100,100)) for image in examples["image"]]
... return examples
```
Now use the [`~Dataset.map`] function to resize the entire dataset, and set `batched=True` to speed up the process by accepting batches of examples. The transform returns `pixel_values` as a cacheable `PIL.Image` object:
```py
>>> dataset = dataset.map(transforms, remove_columns=["image"], batched=True)
>>> dataset[0]
{'label': 6,
'pixel_values': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=100x100 at 0x7F058237BB10>}
```
The cache file saves time because you don't have to execute the same transform twice. The [`~Dataset.map`] function is best for operations you only run once per training - like resizing an image - instead of using it for operations executed for each epoch, like data augmentations.
[`~Dataset.map`] takes up some memory, but you can reduce its memory requirements with the following parameters:
- [`batch_size`](./package_reference/main_classes#datasets.DatasetDict.map.batch_size) determines the number of examples that are processed in one call to the transform function.
- [`writer_batch_size`](./package_reference/main_classes#datasets.DatasetDict.map.writer_batch_size) determines the number of processed examples that are kept in memory before they are stored away.
Both parameter values default to 1000, which can be expensive if you are storing images. Lower these values to use less memory when you use [`~Dataset.map`].
## Apply transforms
🤗 Datasets applies data augmentations from any library or package to your dataset. Transforms can be applied on-the-fly on batches of data with [`~Dataset.set_transform`], which consumes less disk space.
<Tip>
The following example uses [torchvision](https://pytorch.org/vision/stable/index.html), but feel free to use other data augmentation libraries like [Albumentations](https://albumentations.ai/docs/), [Kornia](https://kornia.readthedocs.io/en/latest/), and [imgaug](https://imgaug.readthedocs.io/en/latest/).
</Tip>
For example, if you'd like to change the color properties of an image randomly:
```py
>>> from torchvision.transforms import Compose, ColorJitter, ToTensor
>>> jitter = Compose(
... [
... ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.7),
... ToTensor(),
... ]
... )
```
Create a function to apply the `ColorJitter` transform:
```py
>>> def transforms(examples):
... examples["pixel_values"] = [jitter(image.convert("RGB")) for image in examples["image"]]
... return examples
```
Apply the transform with the [`~Dataset.set_transform`] function:
```py
>>> dataset.set_transform(transforms)
``` | huggingface/datasets/blob/main/docs/source/image_process.mdx |
Builder classes
## Builders
🤗 Datasets relies on two main classes during the dataset building process: [`DatasetBuilder`] and [`BuilderConfig`].
[[autodoc]] datasets.DatasetBuilder
[[autodoc]] datasets.GeneratorBasedBuilder
[[autodoc]] datasets.BeamBasedBuilder
[[autodoc]] datasets.ArrowBasedBuilder
[[autodoc]] datasets.BuilderConfig
## Download
[[autodoc]] datasets.DownloadManager
[[autodoc]] datasets.StreamingDownloadManager
[[autodoc]] datasets.DownloadConfig
[[autodoc]] datasets.DownloadMode
## Verification
[[autodoc]] datasets.VerificationMode
## Splits
[[autodoc]] datasets.SplitGenerator
[[autodoc]] datasets.Split
[[autodoc]] datasets.NamedSplit
[[autodoc]] datasets.NamedSplitAll
[[autodoc]] datasets.ReadInstruction
## Version
[[autodoc]] datasets.utils.Version
| huggingface/datasets/blob/main/docs/source/package_reference/builder_classes.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PEFT configurations and models
The sheer size of today's large pretrained models - which commonly have billions of parameters - present a significant training challenge because they require more storage space and more computational power to crunch all those calculations. You'll need access to powerful GPUs or TPUs to train these large pretrained models which is expensive, not widely accessible to everyone, not environmentally friendly, and not very practical. PEFT methods address many of these challenges. There are several types of PEFT methods (soft prompting, matrix decomposition, adapters), but they all focus on the same thing, reduce the number of trainable parameters. This makes it more accessible to train and store large models on consumer hardware.
The PEFT library is designed to help you quickly train large models on free or low-cost GPUs, and in this tutorial, you'll learn how to setup a configuration to apply a PEFT method to a pretrained base model for training. Once the PEFT configuration is setup, you can use any training framework you like (Transformer's [`~transformers.Trainer`] class, [Accelerate](https://hf.co/docs/accelerate), a custom PyTorch training loop).
## PEFT configurations
<Tip>
Learn more about the parameters you can configure for each PEFT method in their respective API reference page.
</Tip>
A configuration stores important parameters that specify how a particular PEFT method should be applied.
For example, take a look at the following [`LoraConfig`](https://huggingface.co/ybelkada/opt-350m-lora/blob/main/adapter_config.json) for applying LoRA and [`PromptEncoderConfig`](https://huggingface.co/smangrul/roberta-large-peft-p-tuning/blob/main/adapter_config.json) for applying p-tuning (these configuration files are already JSON-serialized). Whenever you load a PEFT adapter, it is a good idea to check whether it has an associated adapter_config.json file which is required.
<hfoptions id="config">
<hfoption id="LoraConfig">
```json
{
"base_model_name_or_path": "facebook/opt-350m", #base model to apply LoRA to
"bias": "none",
"fan_in_fan_out": false,
"inference_mode": true,
"init_lora_weights": true,
"layers_pattern": null,
"layers_to_transform": null,
"lora_alpha": 32,
"lora_dropout": 0.05,
"modules_to_save": null,
"peft_type": "LORA", #PEFT method type
"r": 16,
"revision": null,
"target_modules": [
"q_proj", #model modules to apply LoRA to (query and value projection layers)
"v_proj"
],
"task_type": "CAUSAL_LM" #type of task to train model on
}
```
You can create your own configuration for training by initializing a [`LoraConfig`].
```py
from peft import LoraConfig, TaskType
lora_config = LoraConfig(
r=16,
target_modules=["q_proj", "v_proj"],
task_type=TaskType.CAUSAL_LM,
lora_alpha=32,
lora_dropout=0.05
)
```
</hfoption>
<hfoption id="PromptEncoderConfig">
```json
{
"base_model_name_or_path": "roberta-large", #base model to apply p-tuning to
"encoder_dropout": 0.0,
"encoder_hidden_size": 128,
"encoder_num_layers": 2,
"encoder_reparameterization_type": "MLP",
"inference_mode": true,
"num_attention_heads": 16,
"num_layers": 24,
"num_transformer_submodules": 1,
"num_virtual_tokens": 20,
"peft_type": "P_TUNING", #PEFT method type
"task_type": "SEQ_CLS", #type of task to train model on
"token_dim": 1024
}
```
You can create your own configuration for training by initializing a [`PromptEncoderConfig`].
```py
from peft import PromptEncoderConfig, TaskType
p_tuning_config = PromptEncoderConfig(
encoder_reprameterization_type="MLP",
encoder_hidden_size=128,
num_attention_heads=16,
num_layers=24,
num_transformer_submodules=1,
num_virtual_tokens=20,
token_dim=1024,
task_type=TaskType.SEQ_CLS
)
```
</hfoption>
</hfoptions>
## PEFT models
With a PEFT configuration in hand, you can now apply it to any pretrained model to create a [`PeftModel`]. Choose from any of the state-of-the-art models from the [Transformers](https://hf.co/docs/transformers) library, a custom model, and even new and unsupported transformer architectures.
For this tutorial, load a base [facebook/opt-350m](https://huggingface.co/facebook/opt-350m) model to finetune.
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
```
Use the [`get_peft_model`] function to create a [`PeftModel`] from the base facebook/opt-350m model and the `lora_config` you created earlier.
```py
from peft import get_peft_model
lora_model = get_peft_model(model, lora_config)
lora_model.print_trainable_parameters()
"trainable params: 1,572,864 || all params: 332,769,280 || trainable%: 0.472659014678278"
```
Now you can train the [`PeftModel`] with your preferred training framework! After training, you can save your model locally with [`~PeftModel.save_pretrained`] or upload it to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method.
```py
# save locally
lora_model.save_pretrained("your-name/opt-350m-lora")
# push to Hub
lora_model.push_to_hub("your-name/opt-350m-lora")
```
To load a [`PeftModel`] for inference, you'll need to provide the [`PeftConfig`] used to create it and the base model it was trained from.
```py
from peft import PeftModel, PeftConfig
config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
lora_model = PeftModel.from_pretrained(model, "ybelkada/opt-350m-lora")
```
<Tip>
By default, the [`PeftModel`] is set for inference, but if you'd like to train the adapter some more you can set `is_trainable=True`.
```py
lora_model = PeftModel.from_pretrained(model, "ybelkada/opt-350m-lora", is_trainable=True)
```
</Tip>
The [`PeftModel.from_pretrained`] method is the most flexible way to load a [`PeftModel`] because it doesn't matter what model framework was used (Transformers, timm, a generic PyTorch model). Other classes, like [`AutoPeftModel`], are just a convenient wrapper around the base [`PeftModel`], and makes it easier to load PEFT models directly from the Hub or locally where the PEFT weights are stored.
```py
from peft import AutoPeftModelForCausalLM
lora_model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
```
Take a look at the [AutoPeftModel](package_reference/auto_class) API reference to learn more about the [`AutoPeftModel`] classes.
## Next steps
With the appropriate [`PeftConfig`], you can apply it to any pretrained model to create a [`PeftModel`] and train large powerful models faster on freely available GPUs! To learn more about PEFT configurations and models, the following guide may be helpful:
* Learn how to configure a PEFT method for models that aren't from Transformers in the [Working with custom models](../developer_guides/custom_models) guide.
| huggingface/peft/blob/main/docs/source/tutorial/peft_model_config.md |
Plug and Play Language Models: a Simple Approach to Controlled Text Generation
Authors: [Sumanth Dathathri](https://dathath.github.io/), [Andrea Madotto](https://andreamad8.github.io/), Janice Lan, Jane Hung, Eric Frank, [Piero Molino](https://w4nderlu.st/), [Jason Yosinski](http://yosinski.com/), and [Rosanne Liu](http://www.rosanneliu.com/)
This folder contains the original code used to run the Plug and Play Language Model (PPLM).
Paper link: https://arxiv.org/abs/1912.02164
Blog link: https://eng.uber.com/pplm
Please check out the repo under uber-research for more information: https://github.com/uber-research/PPLM
# Note
⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
## Setup
```bash
git clone https://github.com/huggingface/transformers && cd transformers
pip install .
pip install nltk torchtext # additional requirements.
cd examples/research_projects/pplm
```
## PPLM-BoW
### Example command for bag-of-words control
```bash
python run_pplm.py -B military --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample
```
### Tuning hyperparameters for bag-of-words control
1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
2. If the language being generated is repetitive (For e.g. "science science experiment experiment"), there are several options to consider: </br>
a) Reduce the `--stepsize` </br>
b) Increase `--kl_scale` (the KL-loss coefficient) or decrease `--gm_scale` (the gm-scaling term) </br>
c) Add `--grad-length xx` where xx is an (integer <= length, e.g. `--grad-length 30`).</br>
## PPLM-Discrim
### Example command for discriminator based sentiment control
```bash
python run_pplm.py -D sentiment --class_label 2 --cond_text "My dog died" --length 50 --gamma 1.0 --num_iterations 10 --num_samples 10 --stepsize 0.04 --kl_scale 0.01 --gm_scale 0.95 --sample
```
### Tuning hyperparameters for discriminator control
1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
2. Use `--class_label 3` for negative, and `--class_label 2` for positive
| huggingface/transformers/blob/main/examples/research_projects/pplm/README.md |
--
title: "Supercharged Searching on the 🤗 Hub"
thumbnail: /blog/assets/48_hubsearch/thumbnail.png
authors:
- user: muellerzr
---
# Supercharged Searching on the Hugging Face Hub
<a target="_blank" href="https://colab.research.google.com/github/muellerzr/hf-blog-notebooks/blob/main/Searching-the-Hub.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
The `huggingface_hub` library is a lightweight interface that provides a programmatic approach to exploring the hosting endpoints Hugging Face provides: models, datasets, and Spaces.
Up until now, searching on the Hub through this interface was tricky to pull off, and there were many aspects of it a user had to "just know" and get accustomed to.
In this article, we will be looking at a few exciting new features added to `huggingface_hub` to help lower that bar and provide users with a friendly API to search for the models and datasets they want to use without leaving their Jupyter or Python interfaces.
> Before we begin, if you do not have the latest version of the `huggingface_hub` library on your system, please run the following cell:
```python
!pip install huggingface_hub -U
```
## Situating the Problem:
First, let's imagine the scenario you are in. You'd like to find all models hosted on the Hugging Face Hub for Text Classification, were trained on the GLUE dataset, and are compatible with PyTorch.
You may simply just open https://huggingface.co/models and use the widgets on there. But this requires leaving your IDE and scanning those results, all of which requires a few button clicks to get you the information you need.
What if there were a solution to this without having to leave your IDE? With a programmatic interface, it also could be easy to see this being integrated into workflows for exploring the Hub.
This is where the `huggingface_hub` comes in.
For those familiar with the library, you may already know that we can search for these type of models. However, getting the query right is a painful process of trial and error.
Could we simplify that? Let's find out!
## Finding what we need
First we'll import the `HfApi`, which is a class that helps us interact with the backend hosting for Hugging Face. We can interact with the models, datasets, and more through it. Along with this, we'll import a few helper classes: the `ModelFilter` and `ModelSearchArguments`
```python
from huggingface_hub import HfApi, ModelFilter, ModelSearchArguments
api = HfApi()
```
These two classes can help us frame a solution to our above problem. The `ModelSearchArguments` class is a namespace-like one that contains every single valid parameter we can search for!
Let's take a peek:
```python
>>> model_args = ModelSearchArguments()
>>> model_args
```
Available Attributes or Keys:
* author
* dataset
* language
* library
* license
* model_name
* pipeline_tag
We can see a variety of attributes available to us (more on how this magic is done later). If we were to categorize what we wanted, we could likely separate them out as:
- `pipeline_tag` (or task): Text Classification
- `dataset`: GLUE
- `library`: PyTorch
Given this separation, it would make sense that we would find them within our `model_args` we've declared:
```python
>>> model_args.pipeline_tag.TextClassification
```
'text-classification'
```python
>>> model_args.dataset.glue
```
'dataset:glue'
```python
>>> model_args.library.PyTorch
```
'pytorch'
What we begin to notice though is some of the convience wrapping we perform here. `ModelSearchArguments` (and the complimentary `DatasetSearchArguments`) have a human-readable interface with formatted outputs the API wants, such as how the GLUE dataset should be searched with `dataset:glue`.
This is key because without this "cheat sheet" of knowing how certain parameters should be written, you can very easily sit in frustration as you're trying to search for models with the API!
Now that we know what the right parameters are, we can search the API easily:
```python
>>> models = api.list_models(filter = (
>>> model_args.pipeline_tag.TextClassification,
>>> model_args.dataset.glue,
>>> model_args.library.PyTorch)
>>> )
>>> print(len(models))
```
```
140
```
We find that there were **140** matching models that fit our criteria! (at the time of writing this). And if we take a closer look at one, we can see that it does indeed look right:
```python
>>> models[0]
```
```
ModelInfo: {
modelId: Jiva/xlm-roberta-large-it-mnli
sha: c6e64469ec4aa17fedbd1b2522256f90a90b5b86
lastModified: 2021-12-10T14:56:38.000Z
tags: ['pytorch', 'xlm-roberta', 'text-classification', 'it', 'dataset:multi_nli', 'dataset:glue', 'arxiv:1911.02116', 'transformers', 'tensorflow', 'license:mit', 'zero-shot-classification']
pipeline_tag: zero-shot-classification
siblings: [ModelFile(rfilename='.gitattributes'), ModelFile(rfilename='README.md'), ModelFile(rfilename='config.json'), ModelFile(rfilename='pytorch_model.bin'), ModelFile(rfilename='sentencepiece.bpe.model'), ModelFile(rfilename='special_tokens_map.json'), ModelFile(rfilename='tokenizer.json'), ModelFile(rfilename='tokenizer_config.json')]
config: None
private: False
downloads: 680
library_name: transformers
likes: 1
}
```
It's a bit more readable, and there's no guessing involved with "Did I get this parameter right?"
> Did you know you can also get the information of this model programmatically with its model ID? Here's how you would do it:
> ```python
> api.model_info('Jiva/xlm-roberta-large-it-mnli')
> ```
## Taking it up a Notch
We saw how we could use the `ModelSearchArguments` and `DatasetSearchArguments` to remove the guesswork from when we want to search the Hub, but what about if we have a very complex, messy query?
Such as:
I want to search for all models trained for both `text-classification` and `zero-shot` classification, were trained on the Multi NLI and GLUE datasets, and are compatible with both PyTorch and TensorFlow (a more exact query to get the above model).
To setup this query, we'll make use of the `ModelFilter` class. It's designed to handle these types of situations, so we don't need to scratch our heads:
```python
>>> filt = ModelFilter(
>>> task = ["text-classification", "zero-shot-classification"],
>>> trained_dataset = [model_args.dataset.multi_nli, model_args.dataset.glue],
>>> library = ['pytorch', 'tensorflow']
>>> )
>>> api.list_models(filt)
```
```
[ModelInfo: {
modelId: Jiva/xlm-roberta-large-it-mnli
sha: c6e64469ec4aa17fedbd1b2522256f90a90b5b86
lastModified: 2021-12-10T14:56:38.000Z
tags: ['pytorch', 'xlm-roberta', 'text-classification', 'it', 'dataset:multi_nli', 'dataset:glue', 'arxiv:1911.02116', 'transformers', 'tensorflow', 'license:mit', 'zero-shot-classification']
pipeline_tag: zero-shot-classification
siblings: [ModelFile(rfilename='.gitattributes'), ModelFile(rfilename='README.md'), ModelFile(rfilename='config.json'), ModelFile(rfilename='pytorch_model.bin'), ModelFile(rfilename='sentencepiece.bpe.model'), ModelFile(rfilename='special_tokens_map.json'), ModelFile(rfilename='tokenizer.json'), ModelFile(rfilename='tokenizer_config.json')]
config: None
private: False
downloads: 680
library_name: transformers
likes: 1
}]
```
Very quickly we see that it's a much more coordinated approach for searching through the API, with no added headache for you!
## What is the magic?
Very briefly we'll talk about the underlying magic at play that gives us this enum-dictionary-like datatype, the `AttributeDictionary`.
Heavily inspired by the `AttrDict` class from the [fastcore](https://fastcore.fast.ai/basics.html#AttrDict) library, the general idea is we take a normal dictionary and supercharge it for *exploratory programming* by providing tab-completion for every key in the dictionary.
As we saw earlier, this gets even stronger when we have nested dictionaries we can explore through, such as `model_args.dataset.glue`!
> For those familiar with JavaScript, we mimic how the `object` class is working.
This simple utility class can provide a much more user-focused experience when exploring nested datatypes and trying to understand what is there, such as the return of an API request!
As mentioned before, we expand on the `AttrDict` in a few key ways:
- You can delete keys with `del model_args[key]` *or* with `del model_args.key`
- That clean `__repr__` we saw earlier
One very important concept to note though, is that if a key contains a number or special character it **must** be indexed as a dictionary, and *not* as an object.
```python
>>> from huggingface_hub.utils.endpoint_helpers import AttributeDictionary
```
A very brief example of this is if we have an `AttributeDictionary` with a key of `3_c`:
```python
>>> d = {"a":2, "b":3, "3_c":4}
>>> ad = AttributeDictionary(d)
```
```python
>>> # As an attribute
>>> ad.3_c
```
File "<ipython-input-6-c0fe109cf75d>", line 2
ad.3_c
^
SyntaxError: invalid token
```python
>>> # As a dictionary key
>>> ad["3_c"]
```
4
## Concluding thoughts
Hopefully by now you have a brief understanding of how this new searching API can directly impact your workflow and exploration of the Hub! Along with this, perhaps you know of a place in your code where the `AttributeDictionary` might be useful for you to use.
From here, make sure to check out the official documentation on [Searching the Hub Efficiently](https://huggingface.co/docs/huggingface_hub/searching-the-hub) and don't forget to give us a [star](https://github.com/huggingface/huggingface_hub)!
| huggingface/blog/blob/main/searching-the-hub.md |
--
title: "Optimization story: Bloom inference"
thumbnail: /blog/assets/bloom-inference-pytorch-scripts/thumbnail.png
authors:
- user: Narsil
---
# Optimization story: Bloom inference
This article gives you the behind-the-scenes of how we made an efficient inference server that powers bloom.
inference server that powers [https://huggingface.co/bigscience/bloom]().
We achieved a 5x latency reduction over several weeks (and 50x more throughput). We wanted to share all the struggles and epic wins we went through to achieve such speed improvements.
A lot of different people were involved at many stages so not everything will be covered here. And please bear with us, some of the content might be outdated or flat out wrong because
we're still learning how to optimize extremely large models and lots of new
hardware features and content keep coming out regularly.
If your favorite flavor of optimizations
is not discussed or improperly represented, we're sorry, please share it with us
we're more than happy to try out new stuff and correct our mistakes.
# Creating BLOOM
This goes without saying but without the large model being accessible in the first
place, there would be no real reasons to optimize inference for it. This was an
incredible effort led by many different people.
To maximize the GPU during training, several solutions were explored
and in the end, [Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed) was chosen to train the end model.
This meant that the code as-is wasn't necessarily compatible with the `transformers`
library.
# Porting to transformers
Because of the original training code, we set out to do something which we regularly
do: port an existing model to `transformers`. The goal was to extract from the
training code the relevant parts and implement it within `transformers`.
This effort was tackled by [Younes](/ybelkada).
This is by no means a small effort as it took almost a month and [200 commits](https://github.com/huggingface/transformers/pull/17474/commits) to get there.
There are several things to note that will come back later:
We needed to have smaller models [bigscience/bigscience-small-testing](https://huggingface.co/bigscience/bigscience-small-testing) and [bigscience/bloom-560m](https://huggingface.co/bigscience/bloom-560m).
This is extremely important because they are smaller, so everything is faster when
working with them.
First, you have to abandon all hope to have exactly the same logits at the end down
to the bytes. PyTorch versions can change the kernels and introduce subtle differences, and different hardware
might yield different results because of different architecture (and you probably
don't want to develop on a A100 GPU all the time for cost reasons).
***Getting a good strict test suite is really important for all models***
The best test we found was having a fixed set of prompts. You know the prompt,
you know the completion that needs to be deterministic so greedy.
If two generations are identical, you can basically ignore small logits differences
Whenever you see a drift, you need to investigate. It could be that your code
is not doing what it should OR that you are actually out of domain for that model
and therefore the model is more sensitive to noise. If you have several prompts
and long enough prompts, you're less likely to trigger that for all prompts by
accident. The more prompts the better, the longer the better.
The first model (small-testing) is in `bfloat16` like the big bloom so
everything should be very similar, but it wasn't trained a lot or just doesn't perform
well, so it highly fluctuates in outputs. That means we had issues with those generation
tests. The second model is more stable but was trained and saved in `float16` instead
of `bfloat16`. That's more room for error between the two.
To be perfectly fair `bfloat16` -> `float16` conversion seemed to be OK in inference
mode (`bfloat16` mostly exists to handle large gradients, which do not exist in inference).
During that step, one important tradeoff was discovered and implemented.
Because bloom was trained in a distributed setting, part of the code was doing
Tensor parallelism on a Linear layer meaning running the same operation as a single
operation on a single GPU was giving [different results](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bloom/modeling_bloom.py#L350).
This took a while to pinpoint and either we went for 100% compliance and the model
was much slower, or we would take a small difference in generation
but was much faster to run and simpler code. We opted for a configurable flag.
# First inference (PP + Accelerate)
```
Note: Pipeline Parallelism (PP) means in this context that each GPU will own
some layers so each GPU will work on a given chunk of data before handing
it off to the next GPU.
```
Now we have a workable `transformers` clean version of the start
working on running this.
Bloom is a 352GB (176B parameters in bf16) model, we need at least that much
GPU RAM to make it fit. We briefly explored offloading to CPU on smaller machines
but the inference speed was orders of magnitude slower so we discarded it.
Then we wanted to basically use the [pipeline](https://huggingface.co/docs/transformers/v4.22.2/en/pipeline_tutorial#pipeline-usage).
So it's dogfooding and this is what the API uses under the hood all the time.
However `pipelines` are not distributed aware (it's not their goal). After briefly
discussing options, we ended up using [accelerate](https://github.com/huggingface/accelerate/) newly
created `device_map="auto"` to manage the sharding of the model. We had to iron
out a few bugs, and fix the `transformers` code a bit to help `accelerate` do the right job.
It works by splitting the various layers of the transformers and giving part of
the model to each GPU. So GPU0 gets to work, then hands it over to GPU1 so on
and so forth.
In the end, with a small HTTP server on top, we could start serving bloom (the big model) !!
# Starting point
But we haven't even started discussing optimizations yet!
We actually have quite a bit, all this process is a castle of cards. During
optimizations we are going to make modifications to the underlying code, being
extra sure you're not killing the model in one way or the other is really important
and easier to do than you think.
So we are now at the very first step of optimizations and we need to start measuring
and keep measuring performance. So we need to consider what we care about.
For an open inference server supporting many options, we expect users to send
many queries with different parameters and what we care about are:
The number of users we can serve at the same time (throughput)
How long does it take for an average user to be served (latency)?
We made a testing script in [locust](https://locust.io/) which is exactly this:
```python
from locust import HttpUser, between, task
from random import randrange, random
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {"max_new_tokens": 20, "seed": random()},
},
)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {
"max_new_tokens": 20,
"do_sample": True,
"top_p": 0.9,
"seed": random(),
},
},
)
```
**Note: This is not the best nor the only load testing we used, but it was
always the first to be run so that it could compare fairly across approaches.
Being the best on this benchmark does NOT mean it is the best solution. Other
more complex scenarios had to be used in addition to actual real-world performance.
**
We wanted to observe the ramp-up for various implementations and also make sure
that underload the server properly circuit breaked. Circuit breaking means
that the server can answer (fast) that it will not answer your query because too
many people are trying to use it at the same time.
It's extremely important to avoid the hug of death.
On this benchmark the initial performance was (on 16xA100 40Go on GCP which is the machine used throughout):
Requests/s : 0.3 (throughput)
Latency: 350ms/token (latency)
Those numbers are not that great. Before getting to work let's estimate
the best we can imagine achieving.
The formula for amount of operations is `24Bsh^2 + 4𝐵s^2h24Bsh^2 + 4𝐵s^2h` where `B` is
the batch size, `s` the sequence length, and `h` the hidden dimension.
Let's do the math and we are getting `17 TFlop` for a single forward pass.
Looking at the [specs](https://www.nvidia.com/en-us/data-center/a100/) of A100 it claims `312 TFLOPS` for a single card.
That means a single GPU could potentially run at `17 / 312 = 54ms/token`. We're using 16 of those so `3ms/token` on the overall
machine. Take all these numbers with a big grain of salt, it's never possible to reach those numbers,
and real-life performance rarely matches the specs. Also if computation is not your limiting
factor then this is not the lowest you can get. It's just good practice to know how far you are from
your target. In this case, we're 2 orders of magnitude so pretty far. Also, this estimate puts
all the flops at the service of latency which means only a single request can go at a time (it's ok since you're maximizing your machine
so there's not much else to be done, but we can have higher latency and get throughput back through batching much more easily).
# Exploring many routes
```
Note: Tensor Parallelism (TP) means in this context that each GPU will own
part of the weights, so ALL gpus are active all the time and do less work.
Usually this comes with a very slight overhead that some work is duplicated
and more importantly that the GPUs regularly have to communicate to each other
their results to continue the computation
```
Now that we have a good understanding of where we stand it's time to get to work.
We tried many different things based on the people and our various knowledge.
ALL endeavors deserve their own blog post so I'll just list them, explain the
few final learnings and delve into the details of only what went into the current
server. Moving from Pipeline Parallelism (PP) to Tensor Parallelism (TP) is
one big interesting change for latency. Each GPU will own part of the parameters
and all will be working at the same time. So the latency should decrease drastically
but the price to pay is the communication overhead since they regularly need
to communicate with each other about their results.
It is to note that this is a very wide range of approaches and the intent
was deliberately to learn more about each tool and how it could fit in later
endeavors.
## Porting the code the JAX/Flax to run on TPUs:
- Expected to be easier to choose the type of parallelism. so TP should be
easier to test.
It's one of the perks of Jax's design.
- More constrained on hardware, performance on TPU likely superior
than GPU, and less vendor choice for TPU.
- Cons, another port is needed. But it would be welcome anyway in our libs.
Results:
- Porting was not an easy task as some conditions and kernels were hard to
reproduce correctly enough. Still manageable though.
- Parallelism was quite easy to get once ported
Kudos to Jax the claim is alive.
- Ray/communicating with TPU workers proved to be a real pain for us.
We don't know if its the tool, the network, or simply our lack of knowledge
but it slowed down experiments and work much more than we anticipated.
We would launch an experiment that takes 5mn to run, wait for 5mn nothing
had happened, 10mn later still nothing, turned out some worker was down/not responding
we had to manually get in, figure out what went on, fix it, restart something, and relaunch and we had just lost half an hour.
Repeat that enough times, and lost days add up quickly.
Let's emphasize that it's not necessarily a critique of the tools we used
but the subjective experience we had remains.
- No control over compilation
Once we had the thing running, we tried several settings to figure out which
suited best the inference we had in mind, and it turned out it was really hard
to guess from settings what would happen in the latency/throughput. For instance,
we had a 0.3 rps on batch_size=1 (so every request/user is on its own) with a latency of
15ms/token (Do not compare too much with other numbers in this article it's on a different machine with
a very different profile) which is great, but the overall throughput is not much better than
what we had with the old code. So we decided to add batching, and with BS=2 and the
latency went up 5 fold, with only 2 times the throughput... Upon further investigation,
it turned out that up to batch_size=16 every batch_size had the same latency profile.
So we could have 16x more throughput at a 5x latency cost. Not bad, but looking
at the numbers we really would have preferred a more fine-grained control.
The numbers we were aiming for stem from the [100ms, 1s, 10s, 1mn](https://www.nngroup.com/articles/response-times-3-important-limits/) rule.
## Using ONNX/TRT or other compiled approaches
- They are supposed to handle most of the optimization work
- Con, Usually parallelism needs to be handled manually.
Results:
- Turned out that to be able to trace/jit/export stuff we needed to
rework part of the PyTorch, so it easily fused with the pure PyTorch approach
And overall we figured out that we could have most of the optimizations we desired
by staying within PyTorch world, enabling us to keep flexibility without
having to make too much coding effort.
Another thing to note, since we're running on GPU and text-generation has many
forward passes going on, we need the tensors to stay on the GPU, and it is
sometimes hard to send your tensors to some lib, be given back the result, perform
the logits computation (like argmax or sampling) and feed it back again.
Putting the loop within the external lib means losing flexibility just like
Jax, so it was not envisioned in our use case.
## DeepSpeed
- This is the technology that powered training, it seemed only fair to use
it for inference
- Cons, it was never used/prepared for inference before.
Results:
- We had really impressive results fast which are roughly the same as
the last iteration we are currently running.
- We had to invent a way to put a webserver (so dealing with concurrency) on
top of DeepSpeed which also has several processes (one for each GPU). Since
there is an excellent library [Mii](https://github.com/microsoft/DeepSpeed-MII).
It doesn't fit the extremely flexible goals we had in mind, but we probably
would have started working on top of it now. (The current solution is discussed later).
- The biggest caveat we encountered with DeepSpeed, was the lack of stability.
We had issues when running it on CUDA 11.4 where the code was built for 11.6
And the long-standing issue we could never really fix is that there would
be regular kernel crashes (Cuda illegal access, dimensions mismatch, etc..).
We fixed a bunch of these but we could never quite achieve stability under stress
of our webserver. Despite, that I want to shout out to the Microsoft folks that
helped us, we had a really good conversation that improved our understanding
of what was happening, and gave us real insights to do some follow-up works.
- One of the pain points I feel is that our team is mostly in Europe, while
Microsoft is in California, so the collaboration was tricky timewise and we
probably lost a big chunk of time because of it. This has nothing to do
with the technical part, but it's good to acknowledge that the organizational
part of working together is also really important.
- Another thing to note, is that DeepSpeed relies on `transformers` to inject
its optimization, and since we were updating our code pretty much consistently
it made it hard for the DeepSpeed team to keep things working on our `main`
branch. We're sorry to have made it hard, I guess this is why it's called
bleeding edge.
## Webserver ideas
- Given that we are going to run a free server where users are going to
send long text, short text, want a few tokens, or a whole recipe each with
different parameters, something had to be done here.
Results:
- We recoded everything in `Rust` with the excellent bindings [tch-rs](https://github.com/LaurentMazare/tch-rs). Rust was not aimed at having performance gains but just
much more fine-grained control over parallelism (threads/processes) and playing
more fine-grained on the webserver concurrency and the PyTorch one.
Python is infamously hard to handle low-level details thanks to the [GIL](https://realpython.com/python-gil/).
- Turned out that most of the pain came from the port, and after that, the experimentation
was a breeze. And we figured that with enough control over the loops
we could have great performance for everyone even in the context of a very
wide array of requests with different properties. [Code](https://github.com/Narsil/bloomserver) for the curious, but it doesn't come with any support or nice docs.
- It became production for a few weeks because it was more lenient on the parallelism, we could use the GPUs more efficiently (using GPU0 for request 1
while GPU1 is treating request 0).
and we
went from 0.3 RPS to ~2.5 RPS with the same latency. The optimal case would have been to increase throughput by 16X but the numbers shown here
are real workloads measurements so this is not too bad.
## Pure PyTorch
- Purely modify the existing code to make it faster by removing operations
like `reshape`, using better-optimized kernels so on and so forth.
- Con, we have to code TP ourselves and we have a constraint that the code still fits our library (mostly).
Results
- Next chapter.
# Final route: PyTorch + TP + 1 custom kernel + torch.jit.script
## Writing more efficient PyTorch
The first item on the list was removing unnecessary operations in the first implementations
Some can be seen by just looking at the code and figuring out obvious flaws:
- Alibi is used in Bloom to add position embeddings and it was calculated in too
many places, we could only calculate it once and more efficiently.
The old code: [link](https://github.com/huggingface/transformers/blob/ca2a55e9dfb245527b5e1c954fec6ffbb7aef07b/src/transformers/models/bloom/modeling_bloom.py#L94-L132)
The new code: [link](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bloom/modeling_bloom.py#L86-L127)
This is a 10x speedup and the latest version includes padding too!
Since this step is only computed once, the actual speed is not important
but overall reducing the number of operations and tensor creation is a good direction.
Other parts come out more clearly when you start [profiling](https://pytorch.org/tutorials/recipes/recipes/profiler_recipe.html) and we used quite extensively the [tensorboard extension](https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html)
This provides this sort of image which give insights:
<img src="assets/bloom-inference-optimization/profiler_simple.png">
Attention takes a lot of time, careful this is a CPU view so the long
bars don't mean long, they mean the CPU is awaiting the GPU results of the
previous step.
<img src="assets/bloom-inference-optimization/profiler.png">
We see many `cat` operations before `baddbmm`.
Removing a lot of reshape/transpose, for instance, we figured out that:
- The attention is the hot path (it's expected but always good to verify).
- In the attention, a lot of kernels were actual copies due to the massive amount of reshapes
- We **could** remove the reshapes by reworking the weights themselves and the past.
This is a breaking change but it did improve performance quite a bit!
## Supporting TP
Ok, we have removed most of the low-hanging fruits now we went roughly from 350ms/token
latency to 300ms/token in PP. That's a 15% reduction in latency, but it actually provided
more than that, but we were not extremely rigorous in our measuring initially so let's stick to that figure.
Then we went on to provide a TP implementation. Turned out to be much faster
than we anticipated the implementation took half a day of a single (experienced) dev.
The result is [here](https://github.com/huggingface/transformers/tree/thomas/dirty_bloom_tp/src/transformers/models/bloom). We were also able to reuse code from other projects which helped.
The latency went directly from 300ms/token to 91ms/token which is a huge improvement in user experience.
A simple 20 tokens request went from 6s to 2s which went from a "slow" experience to slightly delayed.
Also, the throughput went up a lot to 10RPS. The throughput comes from the fact
that running a query in batch_size=1 takes the same time as batch_size=32
and throughput becomes essentially *free* in latency cost at this point.
## Low-hanging fruits
Now that we had a TP implementation, we could start profiling and optimizing again.
It's a significant enough shift that we had to start from scratch again.
The first thing that stood out, is that synchronization (ncclAllReduce) starts
to become a preponderant part of the load, which is expected, this is the synchronization
part and it **is** taking some time. We never tried to look and optimize this as it's
already using `nccl` but there might still be some room for improvement there.
We assumed it would be hard to do much better.
The second thing is that `Gelu` operator was launching many elementwise
kernels and overall it was taking a bigger share of compute than we expected.
We made the change from:
```python
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
```
to
```python
@torch.jit.script
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
```
This transforms the operations from multiple small element-wise kernels (and hence tensor copies)
to a single kernel operation!
This provided a 10% latency improvement from 91ms/token to 81ms/token, right there!
Be careful though, this is not some magic black box you can just throw everywhere,
the kernel fusion will not necessarily happen or the previously used operations
are already extremely efficient.
Places where we found it worked well:
- You have a lot of small/elementwise operations
- You have a hotspot with a few hard-to-remove reshape, copies in general
- When the fusion happens.
## Epic fail
We also had some points, during our testing periods, where we ended up seeing some consistent
25% lower latency for the Rust server compared to the Python one. This was rather
odd, but because it was consistently measured, and because removing kernels provided a speed
up, we were under the impression that maybe dropping the Python overhead could
provide a nice boost.
We started a 3-day job to reimplement the necessary parts of `torch.distributed`
To get up and running in the Rust world [nccl-rs](https://github.com/Narsil/nccl-rs).
We had the version working but something was off in the generations compared to its
Python counterpart. During the investigation of the issues, we figured...
**that we had forgotten to remove the profiler in the Pytorch measurements**...
That was the epic fail because removing it gave us back the 25% and then both
codes ran just as fast. This is what we initially expected, that python mustn't
be a performance hit, since it's mostly running torch cpp's code. In the end,
3 days is not the end of the world, and it might become useful sometime in the
future but still pretty bad.
This is quite common when doing optimizations to do wrong or misrepresentative
measurements which end up being disappointing or even detrimental to the overall
product. This is why doing it in small steps and having expectations about the
outcome as soon as possible helps contain that risk.
Another place where we had to be extra careful, was the initial forward pass (without
past) and the later forward passes (with past). If you optimize the first one,
you're most certainly going to be slowing down the later ones which are much more
important and account for most of the runtime.
Another pretty common culprit is measuring times which are CPU times, and not
actual CUDA times, so you need to `torch.cuda.synchronize()` when doing
runs to be sure that the kernels complete.
## Custom kernel
So far, we had achieved close to DeepSpeed performance without any custom code
outside of PyTorch! Pretty neat. We also didn't have to make any compromise
on the flexibility of the run time batch size!
But given the DeepSpeed experience, we wanted to try and write a custom kernel
to fuse a few operations in the hot path where `torch.jit.script` wasn't able to
do it for us. Essentially the following two lines:
```python
attn_weights = attention_scores.masked_fill_(attention_mask, torch.finfo(attention_scores.dtype).min)
attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
```
The first masked fill is creating a new tensor, which is here only to
say to the softmax operator to ignore those values. Also, the softmax needs to be calculated
on float32 (for stability) but within a custom kernel, we could limit the amount of
upcasting necessary so we limit them to the actual sums and accumulated needed.
Code can be found [here](https://github.com/huggingface/transformers/blob/thomas/add_custom_kernels/src/transformers/models/bloom/custom_kernels/fused_bloom_attention_cuda.cu).
Keep in mind we had a single GPU architecture to target so we could focus on this
and we are not experts (yet) at writing kernels, so there could be better ways
to do this.
This custom kernel provided yet another 10% latency increase moving down from
81ms/token to 71ms/token latency. All the while keeping our flexibility.
After that, we investigated and explored other things like fusing more operators
removing other reshapes, or putting them in other places. But no attempt ever made
a significant enough impact to make it to the final versions.
## Webserver part
Just like the Rust counterpart, we had to implement the batching of requests
with different parameters. Since we were in the `PyTorch` world, we have pretty
much full control of what's going on.
Since we're in Python, we have the limiting factor that the `torch.distributed`
needs to run on several processes instead of threads, which means it's slightly
harder to communicate between processes. In the end, we opted to communicate
raw strings over a Redis pub/sub to distribute the requests to all processes at once.
Since we are in different processes it's easier to do it that way than communicating
tensors (which are way bigger) for instance.
Then we had to drop the use [generate](https://huggingface.co/docs/transformers/v4.22.2/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate) since
this applies the parameters to all members of the batch, and we actually
want to apply a different set of parameters.
Thankfully, we can reuse lower-level items like the [LogitsProcessor](https://huggingface.co/docs/transformers/internal/generation_utils#transformers.LogitsProcessor)
to save us a lot of work.
So we reconstructed a `generate` function that takes a list of parameters
and applies them to each member of the batch.
Another really important aspect of the final UX is latency.
Since we have different parameter sets for different requests, we might have
1 request for 20 tokens and the other for 250 tokens. Since it takes
75ms/token latency one request takes 1.5s and the other 18s. If we were
batching all the way, we would be making the user that asked to wait for 18s
and making it appear to him as if we were running at 900ms/token which is quite slow!
Since we're in a PyTorch world with extreme flexibility, what we can do instead
is extract from the batch the first request as soon as we generated to first 20
tokens, and return to that user within the requested 1.5s! We also happen to save 230 tokens worth of computation.
So flexibility **is** important to get the best possible latency out there.
# Last notes and crazy ideas
Optimization is a never-ending job, and like any other project, 20% of work
will usually yield 80% of the results.
At some point, we started having a small testing strategy to figure out
potential yields of some idea we had, and if the tests didn't yield significant
results then we discarded the idea. 1 day for a 10% increase is valuable enough, 2 weeks for 10X
is valuable enough. 2 weeks for 10% is not so interesting.
## Have you tried ...?
Stuff we know exists and haven't used because of various reasons. It
could be it felt like it wasn't adapted to our use case, it was too much
work, the yields weren't promising enough, or even simply we had too many
options to try out from and discarded some for no particular reasons and just
lack of time. The following are in no particular order:
- [Cuda graphs](https://developer.nvidia.com/blog/cuda-graphs/)
- [nvFuser](https://pytorch.org/tutorials/intermediate/nvfuser_intro_tutorial.html) (This is what powers `torch.jit.script` so we did use it.)
- [FasterTransformer](https://github.com/NVIDIA/FasterTransformer)
- [Nvidia's Triton](https://developer.nvidia.com/nvidia-triton-inference-server)
- [XLA](https://www.tensorflow.org/xla) (Jax is using xla too !)
- [torch.fx](https://pytorch.org/docs/stable/fx.html)
- [TensorRT](https://developer.nvidia.com/blog/accelerating-inference-up-to-6x-faster-in-pytorch-with-torch-tensorrt/)
Please feel free to reach out if your favorite tool is missing from
here or if you think we missed out on something important that could
prove useful!
## [Flash attention](https://github.com/HazyResearch/flash-attention)
We have briefly looked at integrating flash attention, and while it performs extremely
well on the first forward pass (without `past_key_values`) it didn't yield as big improvements
when running when using `past_key_values`. Since we needed to adapt it to include the `alibi` tensor
in the calculation we decide to not do the work (at least not yet).
## [OpenAI Triton](https://openai.com/blog/triton/)
[Triton](https://github.com/openai/triton) is a great framework for building custom kernels
in Python. We want to get to use it more but we haven't so far. We would
be eager to see if it performs better than our Cuda kernel. Writing directly in
Cuda seemed like the shortest path for our goal when we considered our options
for that part.
## Padding and Reshapes
As mentioned throughout this article, every tensor copy has a cost and another
hidden cost of running production is padding. When two queries come in with very
different lengths, you have to pad (use a dummy token) to make them fit a square.
This leads to maybe a lot of unnecessary calculations. [More information](https://huggingface.co/docs/transformers/v4.22.2/en/main_classes/pipelines#pipeline-batching).
Ideally, we would be able to *not* do those calculations at all, and never have reshapes.
Tensorflow has the concept of [RaggedTensor](https://www.tensorflow.org/guide/ragged_tensor) and
Pytorch [Nested tensors](https://pytorch.org/docs/stable/nested.html). Both of these
seem not as streamlined as regular tensors but might enable us to do less computation
which is always a win.
In an ideal world, the entire inference would be written in CUDA or pure GPU implementation.
Considering the performance improvements yielded when we could fuse operations it looks desirable.
But to what extent this would deliver, we have no idea. If smarter GPU people have
ideas we are listening!
# Acknowledgments
All this work results of the collaboration of many HF team members. In no particular
order, [@ThomasWang](https://huggingface.co/TimeRobber) [@stas](https://huggingface.co/stas)
[@Nouamane](https://huggingface.co/nouamanetazi) [@Suraj](https://huggingface.co/valhalla)
[@Sanchit](https://huggingface.co/sanchit-gandhi) [@Patrick](https://huggingface.co/patrickvonplaten)
[@Younes](/ybelkada) [@Sylvain](https://huggingface.co/sgugger)
[@Jeff (Microsoft)](https://github.com/jeffra) [@Reza](https://github.com/RezaYazdaniAminabadi)
And all the [BigScience](https://huggingface.co/bigscience) organization.
| huggingface/blog/blob/main/bloom-inference-optimization.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for Image Processors
This page lists all the utility functions used by the image processors, mainly the functional
transformations used to process the images.
Most of those are only useful if you are studying the code of the image processors in the library.
## Image Transformations
[[autodoc]] image_transforms.center_crop
[[autodoc]] image_transforms.center_to_corners_format
[[autodoc]] image_transforms.corners_to_center_format
[[autodoc]] image_transforms.id_to_rgb
[[autodoc]] image_transforms.normalize
[[autodoc]] image_transforms.pad
[[autodoc]] image_transforms.rgb_to_id
[[autodoc]] image_transforms.rescale
[[autodoc]] image_transforms.resize
[[autodoc]] image_transforms.to_pil_image
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
| huggingface/transformers/blob/main/docs/source/en/internal/image_processing_utils.md |
p align="center">
<br/>
<img alt="huggingface_hub library logo" src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/huggingface_hub.svg" width="376" height="59" style="max-width: 100%;">
<br/>
</p>
<p align="center">
<i>공식 Huggingface Hub 파이썬 클라이언트</i>
</p>
<p align="center">
<a href="https://huggingface.co/docs/huggingface_hub/ko/index"><img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/huggingface_hub/index.svg?down_color=red&down_message=offline&up_message=online&label=doc"></a>
<a href="https://github.com/huggingface/huggingface_hub/releases"><img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/huggingface_hub.svg"></a>
<a href="https://github.com/huggingface/huggingface_hub"><img alt="PyPi version" src="https://img.shields.io/pypi/pyversions/huggingface_hub.svg"></a>
<a href="https://pypi.org/project/huggingface-hub"><img alt="downloads" src="https://static.pepy.tech/badge/huggingface_hub/month"></a>
<a href="https://codecov.io/gh/huggingface/huggingface_hub"><img alt="Code coverage" src="https://codecov.io/gh/huggingface/huggingface_hub/branch/main/graph/badge.svg?token=RXP95LE2XL"></a>
</p>
<h4 align="center">
<p>
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README.md">English</a> |
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README_de.md">Deutsch</a> |
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README_hi.md">हिंदी</a> |
<b>한국어</b>|
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README_cn.md">中文(简体)</a>
<p>
</h4>
---
**기술 문서**: <a href="https://hf.co/docs/huggingface_hub" target="_blank">https://hf.co/docs/huggingface_hub</a>
**소스 코드**: <a href="https://github.com/huggingface/huggingface_hub" target="_blank">https://github.com/huggingface/huggingface_hub</a>
---
## huggingface_hub 라이브러리 개요
`huggingface_hub` 라이브러리는 [Hugging Face Hub](https://huggingface.co/)와 상호작용할 수 있게 해줍니다. Hugging Face Hub는 창작자와 협업자를 위한 오픈소스 머신러닝 플랫폼입니다. 여러분의 프로젝트에 적합한 사전 훈련된 모델과 데이터셋을 발견하거나, Hub에 호스팅된 수천 개의 머신러닝 앱들을 사용해보세요. 또한, 여러분이 만든 모델, 데이터셋, 데모를 커뮤니티와 공유할 수도 있습니다. `huggingface_hub` 라이브러리는 파이썬으로 이 모든 것을 간단하게 할 수 있는 방법을 제공합니다.
## 주요 기능
- Hub에서 [파일을 다운로드](https://huggingface.co/docs/huggingface_hub/main/ko/guides/download)
- Hub에 [파일을 업로드](https://huggingface.co/docs/huggingface_hub/main/en/guides/upload) (영어)
- [레포지토리를 관리](https://huggingface.co/docs/huggingface_hub/main/en/guides/repository) (영어)
- 배포된 모델에 [추론을 실행](https://huggingface.co/docs/huggingface_hub/main/en/guides/inference) (영어)
- 모델, 데이터셋, Space를 [검색](https://huggingface.co/docs/huggingface_hub/main/en/guides/search) (영어)
- [모델 카드를 공유](https://huggingface.co/docs/huggingface_hub/main/en/guides/model-cards)하여 모델을 문서화 (영어)
- PR과 댓글을 통해 [커뮤니티와 소통](https://huggingface.co/docs/huggingface_hub/main/en/guides/community) (영어)
## 설치
[pip](https://pypi.org/project/huggingface-hub/)로 `huggingface_hub` 패키지를 설치하세요:
```bash
pip install huggingface_hub
```
원한다면 [conda](https://huggingface.co/docs/huggingface_hub/ko/installation#install-with-conda)를 이용하여 설치할 수도 있습니다.
기본 패키지를 작게 유지하기 위해 `huggingface_hub`는 유용한 의존성을 추가적으로 제공합니다. 추론과 관련된 기능을 원한다면, 아래를 실행하세요:
```bash
pip install huggingface_hub[inference]
```
설치와 선택적 의존성에 대해 더 알아보려면, [설치 가이드](https://huggingface.co/docs/huggingface_hub/ko/installation)를 참고하세요.
## 맛보기
### 파일 다운로드
파일 하나의 경우:
```py
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="tiiuae/falcon-7b-instruct", filename="config.json")
```
레포지토리 전체의 경우:
```py
from huggingface_hub import snapshot_download
snapshot_download("stabilityai/stable-diffusion-2-1")
```
파일은 로컬 캐시 폴더에 다운로드됩니다. 자세한 내용은 [이 가이드](https://huggingface.co/docs/huggingface_hub/ko/guides/manage-cache)를 참조하세요.
### 로그인
Hugging Face Hub는 토큰을 사용하여 애플리케이션을 인증합니다([문서](https://huggingface.co/docs/hub/security-tokens) 참조). 컴퓨터에서 로그인하려면 CLI를 사용하세요:
```bash
huggingface-cli login
# 또는 환경 변수로 지정해주세요
huggingface-cli login --token $HUGGINGFACE_TOKEN
```
### 레포지토리 생성
```py
from huggingface_hub import create_repo
create_repo(repo_id="super-cool-model")
```
### 파일 업로드
파일 하나의 경우:
```py
from huggingface_hub import upload_file
upload_file(
path_or_fileobj="/home/lysandre/dummy-test/README.md",
path_in_repo="README.md",
repo_id="lysandre/test-model",
)
```
레포지토리 전체의 경우:
```py
from huggingface_hub import upload_folder
upload_folder(
folder_path="/path/to/local/space",
repo_id="username/my-cool-space",
repo_type="space",
)
```
자세한 내용은 [업로드 가이드](https://huggingface.co/docs/huggingface_hub/ko/guides/upload)를 참조하세요.
## Hugging Face Hub와 함께 성장하기
저희는 멋진 오픈소스 ML 라이브러리들과 협력하여, 모델 호스팅과 버전 관리를 무료로 제공하고 있습니다. 이미 통합된 라이브러리들은 [여기](https://huggingface.co/docs/hub/libraries)서 확인할 수 있습니다.
이렇게 하면 다음과 같은 장점이 있습니다:
- 라이브러리 사용자들의 모델이나 데이터셋을 무료로 호스팅해줍니다.
- git을 기반으로 한 방식으로, 아주 큰 파일들도 버전을 관리할 수 있습니다.
- 공개된 모든 모델에 대해 추론 API를 호스팅해줍니다.
- 업로드된 모델들을 브라우저에서 쉽게 사용할 수 있는 위젯을 제공합니다.
- 누구나 여러분의 라이브러리에 새로운 모델을 업로드할 수 있습니다. 모델이 검색될 수 있도록 해당 태그만 추가하면 됩니다.
- 다운로드 속도가 매우 빠릅니다! 왜냐하면 Cloudfront (CDN)를 이용하여 전 세계 어디에서나 빠르게 다운로드할 수 있도록 지역적으로 복제해뒀기 때문입니다.
- 사용 통계와 더 많은 기능들을 제공합니다.
여러분의 라이브러리를 통합하고 싶다면, 이슈를 열어서 의견을 나눠주세요. 통합 과정을 안내하기 위해 ❤️을 담아 [단계별 가이드](https://huggingface.co/docs/hub/adding-a-library)를 작성했습니다.
## (기능 요청, 버그 패치 등의) 기여는 대환영입니다 💙💚💛💜🧡❤️
모든 분들의 기여를 환영하며, 소중히 생각합니다. 코드 작성만이 커뮤니티에 도움을 주는 유일한 방법이 아니에요.
질문에 답하거나, 다른 분들을 돕거나, 컨택하거나, 문서를 개선하는 것도 커뮤니티에 큰 도움이 됩니다.
지금 시작하려면 간단한 [기여 가이드](https://github.com/huggingface/huggingface_hub/blob/main/CONTRIBUTING.md)를 참조해주세요.
| huggingface/huggingface_hub/blob/main/README_ko.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Latent Consistency Model Multistep Scheduler
## Overview
Multistep and onestep scheduler (Algorithm 3) introduced alongside latent consistency models in the paper [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) by Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao.
This scheduler should be able to generate good samples from [`LatentConsistencyModelPipeline`] in 1-8 steps.
## LCMScheduler
[[autodoc]] LCMScheduler
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/lcm.md |
--
title: "Welcome spaCy to the Hugging Face Hub"
thumbnail: /blog/assets/23_spacy/thumbnail.png
authors:
- user: osanseviero
- user: ines
---
# Welcome spaCy to the Hugging Face Hub
[spaCy](https://github.com/explosion/spaCy) is a popular library for advanced Natural Language Processing used widely across industry. spaCy makes it easy to use and train pipelines for tasks like named entity recognition, text classification, part of speech tagging and more, and lets you build powerful applications to process and analyze large volumes of text.
Hugging Face makes it really easy to share your spaCy pipelines with the community! With a single command, you can upload any pipeline package, with a pretty model card and all required metadata auto-generated for you. The inference API currently supports NER out-of-the-box, and you can try out your pipeline interactively in your browser. You'll also get a live URL for your package that you can `pip install` from anywhere for a smooth path from prototype all the way to production!
### Finding models
Over 60 canonical models can be found in the [spaCy](https://hf.co/spacy) org. These models are from the [latest 3.1 release](https://explosion.ai/blog/spacy-v3-1), so you can try the latest realesed models right now! On top of this, you can find all spaCy models from the community here https://huggingface.co/models?filter=spacy.
### Widgets
This integration includes support for NER widgets, so all models with a NER component will have this out of the box! Coming soon there will be support for text classification and POS.
<div><a class="text-xs block mb-3 text-gray-300" href="/spacy/en_core_web_sm"><code>spacy/en_core_web_sm</code></a>
<div class="SVELTE_HYDRATER " data-props="{"apiUrl":"https://api-inference.huggingface.co","model":{"author":"spacy","autoArchitecture":"AutoModel","branch":"main","cardData":{"tags":["spacy","token-classification"],"language":["en"],"license":"MIT","model-index":[{"name":"en_core_web_sm","results":[{"tasks":{"name":"NER","type":"token-classification","metrics":[{"name":"Precision","type":"precision","value":0.8424355924},{"name":"Recall","type":"recall","value":0.8335336538},{"name":"F Score","type":"f_score","value":0.8379609817}]}},{"tasks":{"name":"POS","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9720712187}]}},{"tasks":{"name":"SENTER","type":"token-classification","metrics":[{"name":"Precision","type":"precision","value":0.9074955788},{"name":"Recall","type":"recall","value":0.8801372122},{"name":"F Score","type":"f_score","value":0.893607046}]}},{"tasks":{"name":"UNLABELED_DEPENDENCIES","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9185392711}]}},{"tasks":{"name":"LABELED_DEPENDENCIES","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9185392711}]}}]}]},"cardSource":true,"id":"spacy/en_core_web_sm","pipeline_tag":"token-classification","library_name":"spacy","modelId":"spacy/en_core_web_sm","private":false,"siblings":[{"rfilename":".gitattributes"},{"rfilename":"LICENSE"},{"rfilename":"LICENSES_SOURCES"},{"rfilename":"README.md"},{"rfilename":"accuracy.json"},{"rfilename":"config.cfg"},{"rfilename":"en_core_web_sm-any-py3-none-any.whl"},{"rfilename":"meta.json"},{"rfilename":"tokenizer"},{"rfilename":"attribute_ruler/patterns"},{"rfilename":"lemmatizer/lookups/lookups.bin"},{"rfilename":"ner/cfg"},{"rfilename":"ner/model"},{"rfilename":"ner/moves"},{"rfilename":"vocab/lookups.bin"},{"rfilename":"vocab/strings.json"},{"rfilename":"vocab/vectors"}],"tags":["en","spacy","token-classification","license:mit","model-index"],"tag_objs":[{"id":"token-classification","label":"Token Classification","type":"pipeline_tag"},{"id":"spacy","label":"spaCy","type":"library"},{"id":"en","label":"en","type":"language"},{"id":"license:mit","label":"mit","type":"license"},{"id":"model-index","label":"model-index","type":"other"}],"widgetData":[{"text":"My name is Wolfgang and I live in Berlin"},{"text":"My name is Sarah and I live in London"},{"text":"My name is Clara and I live in Berkeley, California."}]},"shouldUpdateUrl":true}" data-target="InferenceWidget"><div class="flex flex-col w-full max-w-full
"> <div class="font-semibold flex items-center mb-2"><div class="text-lg flex items-center"><svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24"><path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path></svg>
Hosted inference API</div> <a target="_blank" href="/docs"><svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path><path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path><path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path></svg></a></div> <div class="flex items-center text-sm text-gray-500 mb-1.5"><div class="inline-flex items-center"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 18 18"><path d="M11.075 10.1875H12.1625V11.275H11.075V10.1875Z"></path><path d="M15.425 9.10004H16.5125V10.1875H15.425V9.10004Z"></path><path d="M7.8125 3.66254H8.9V4.75004H7.8125V3.66254Z"></path><path d="M8.90001 12.3625H6.72501V9.09998C6.72472 8.81165 6.61005 8.5352 6.40617 8.33132C6.20228 8.12744 5.92584 8.01277 5.63751 8.01248H2.37501C2.08667 8.01277 1.81023 8.12744 1.60635 8.33132C1.40246 8.5352 1.28779 8.81165 1.28751 9.09998V12.3625C1.28779 12.6508 1.40246 12.9273 1.60635 13.1311C1.81023 13.335 2.08667 13.4497 2.37501 13.45H5.63751V15.625C5.63779 15.9133 5.75246 16.1898 5.95635 16.3936C6.16023 16.5975 6.43667 16.7122 6.72501 16.7125H8.90001C9.18834 16.7122 9.46478 16.5975 9.66867 16.3936C9.87255 16.1898 9.98722 15.9133 9.98751 15.625V13.45C9.98722 13.1616 9.87255 12.8852 9.66867 12.6813C9.46478 12.4774 9.18834 12.3628 8.90001 12.3625V12.3625ZM2.37501 12.3625V9.09998H5.63751V12.3625H2.37501ZM6.72501 15.625V13.45H8.90001V15.625H6.72501Z"></path><path d="M15.425 16.7125H13.25C12.9617 16.7122 12.6852 16.5976 12.4813 16.3937C12.2775 16.1898 12.1628 15.9134 12.1625 15.625V13.45C12.1628 13.1617 12.2775 12.8852 12.4813 12.6814C12.6852 12.4775 12.9617 12.3628 13.25 12.3625H15.425C15.7133 12.3628 15.9898 12.4775 16.1937 12.6814C16.3976 12.8852 16.5122 13.1617 16.5125 13.45V15.625C16.5122 15.9134 16.3976 16.1898 16.1937 16.3937C15.9898 16.5976 15.7133 16.7122 15.425 16.7125ZM13.25 13.45V15.625H15.425V13.45H13.25Z"></path><path d="M15.425 1.48752H12.1625C11.8742 1.48781 11.5977 1.60247 11.3938 1.80636C11.19 2.01024 11.0753 2.28668 11.075 2.57502V5.83752H9.98751C9.69917 5.83781 9.42273 5.95247 9.21885 6.15636C9.01496 6.36024 8.9003 6.63668 8.90001 6.92502V8.01252C8.9003 8.30085 9.01496 8.5773 9.21885 8.78118C9.42273 8.98506 9.69917 9.09973 9.98751 9.10002H11.075C11.3633 9.09973 11.6398 8.98506 11.8437 8.78118C12.0476 8.5773 12.1622 8.30085 12.1625 8.01252V6.92502H15.425C15.7133 6.92473 15.9898 6.81006 16.1937 6.60618C16.3976 6.4023 16.5122 6.12585 16.5125 5.83752V2.57502C16.5122 2.28668 16.3976 2.01024 16.1937 1.80636C15.9898 1.60247 15.7133 1.48781 15.425 1.48752ZM9.98751 8.01252V6.92502H11.075V8.01252H9.98751ZM12.1625 5.83752V2.57502H15.425V5.83752H12.1625Z"></path><path d="M4.55001 5.83752H2.37501C2.08667 5.83723 1.81023 5.72256 1.60635 5.51868C1.40246 5.3148 1.28779 5.03835 1.28751 4.75002V2.57502C1.28779 2.28668 1.40246 2.01024 1.60635 1.80636C1.81023 1.60247 2.08667 1.48781 2.37501 1.48752H4.55001C4.83834 1.48781 5.11478 1.60247 5.31867 1.80636C5.52255 2.01024 5.63722 2.28668 5.63751 2.57502V4.75002C5.63722 5.03835 5.52255 5.3148 5.31867 5.51868C5.11478 5.72256 4.83834 5.83723 4.55001 5.83752V5.83752ZM2.37501 2.57502V4.75002H4.55001V2.57502H2.37501Z"></path></svg> <span>Token Classification</span></div> <div class="ml-auto"></div></div> <form><div class="flex h-10"><input class="form-input-alt flex-1 rounded-r-none " placeholder="Your sentence here..." required="" type="text"> <button class="btn-widget w-24 h-10 px-5 rounded-l-none border-l-0 " type="submit">Compute</button></div></form> <div class="mt-1.5"><div class="text-gray-400 text-xs">This model is currently loaded and running on the Inference API.</div> </div> <div class="mt-auto pt-4 flex items-center text-xs text-gray-500"><button class="flex items-center cursor-not-allowed text-gray-300" disabled=""><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);"><path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path><path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path><path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path></svg>
JSON Output</button> <button class="flex items-center ml-auto"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path><path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path><path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path></svg>
Maximize</button></div> </div></div></div>
### Using existing models
All models from the Hub can be directly installed using `pip install`.
```bash
pip install https://huggingface.co/spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl
```
```python
# Using spacy.load().
import spacy
nlp = spacy.load("en_core_web_sm")
# Importing as module.
import en_core_web_sm
nlp = en_core_web_sm.load()
```
When you open a repository, you can click `Use in spaCy` and you will be given a working snippet that you can use to install and load the model!


You can even make HTTP requests to call the models from the Inference API, which is useful in production settings. Here is an example of a simple request:
```bash
curl -X POST --data '{"inputs": "Hello, this is Omar"}' https://api-inference.huggingface.co/models/spacy/en_core_web_sm
>>> [{"entity_group":"PERSON","word":"Omar","start":15,"end":19,"score":1.0}]
```
And for larger-scale use cases, you can click "Deploy > Accelerated Inference" and see how to do this with Python.
### Sharing your models
But probably the coolest feature is that now you can very easily share your models with the `spacy-huggingface-hub` [library](https://github.com/explosion/spacy-huggingface-hub), which extends the `spaCy` CLI with a new command, `huggingface-hub push`.
```bash
huggingface-cli login
python -m spacy package ./en_ner_fashion ./output --build wheel
cd ./output/en_ner_fashion-0.0.0/dist
python -m spacy huggingface-hub push en_ner_fashion-0.0.0-py3-none-any.whl
```
In just a minute, you can get your packaged model in the Hub, try it out directly in the browser, and share it with the rest of the community. All the required metadata will be uploaded for you and you even get a cool model card.
Try it out and share your models with the community!
## Would you like to integrate your library to the Hub?
This integration is possible thanks to the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library which has all our widgets and the API for all our supported libraries. If you would like to integrate your library to the Hub, we have a [guide](https://huggingface.co/docs/hub/models-adding-libraries) for you!
| huggingface/blog/blob/main/spacy.md |
--
title: "Porting fairseq wmt19 translation system to transformers"
thumbnail: /blog/assets/07_porting_fsmt/thumbnail.png
authors:
- user: stas
guest: true
---
# Porting fairseq wmt19 translation system to transformers
##### A guest blog post by Stas Bekman
This article is an attempt to document how [fairseq wmt19 translation system](https://github.com/pytorch/fairseq/tree/master/examples/wmt19) was ported to [`transformers`](https://github.com/huggingface/transformers/).
I was looking for some interesting project to work on and [Sam Shleifer](https://github.com/sshleifer) suggested I work on [porting a high quality translator](https://github.com/huggingface/transformers/issues/5419).
I read the short paper: [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) that describes the original system and decided to give it a try.
Initially, I had no idea how to approach this complex project and Sam helped me to [break it down to smaller tasks](https://github.com/huggingface/transformers/issues/5419), which was of a great help.
I chose to work with the pre-trained `en-ru`/`ru-en` models during porting as I speak both languages. It'd have been much more difficult to work with `de-en`/`en-de` pairs as I don't speak German, and being able to evaluate the translation quality by just reading and making sense of the outputs at the advanced stages of the porting process saved me a lot of time.
Also, as I did the initial porting with the `en-ru`/`ru-en` models, I was totally unaware that the `de-en`/`en-de` models used a merged vocabulary, whereas the former used 2 separate vocabularies of different sizes. So once I did the more complicated work of supporting 2 separate vocabularies, it was trivial to get the merged vocabulary to work.
## Let's cheat
The first step was to cheat, of course. Why make a big effort when one can make a little one. So I wrote a [short notebook](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/nbs/cheat.ipynb) that in a few lines of code provided a proxy to `fairseq` and emulated `transformers` API.
If no other things, but basic translation, was required, this would have been enough. But, of course, we wanted to have the full porting, so after having this small victory, I moved onto much harder things.
## Preparations
For the sake of this article let's assume that we work under `~/porting`, and therefore let's create this directory:
```
mkdir ~/porting
cd ~/porting
```
We need to install a few things for this work:
```
# install fairseq
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install -e .
# install mosesdecoder under fairseq
git clone https://github.com/moses-smt/mosesdecoder
# install fastBPE under fairseq
git clone [email protected]:glample/fastBPE.git
cd fastBPE; g++ -std=c++11 -pthread -O3 fastBPE/main.cc -IfastBPE -o fast; cd -
cd -
# install transformers
git clone https://github.com/huggingface/transformers/
pip install -e .[dev]
```
## Files
As a quick overview, the following files needed to be created and written:
* [`src/transformers/configuration_fsmt.py`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/configuration_fsmt.py) - a short configuration class.
* [`src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py) - a complex conversion script.
* [`src/transformers/modeling_fsmt.py`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/modeling_fsmt.py) - this is where the model architecture is implemented.
* [`src/transformers/tokenization_fsmt.py`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/tokenization_fsmt.py) - a tokenizer code.
* [`tests/test_modeling_fsmt.py`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/tests/test_modeling_fsmt.py) - model tests.
* [`tests/test_tokenization_fsmt.py`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/tests/test_tokenization_fsmt.py) - tokenizer tests.
* [`docs/source/model_doc/fsmt.rst`](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/docs/source/model_doc/fsmt.rst) - a doc file.
There are other files that needed to be modified as well, we will talk about those towards the end.
## Conversion
One of the most important parts of the porting process is to create a script that will take all the available source data provided by the original developer of the model, which includes a checkpoint with pre-trained weights, model and training configuration, dictionaries and tokenizer support files, and convert them into a new set of model files supported by `transformers`. You will find the final conversion script here: [src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py)
I started this process by copying one of the existing conversion scripts `src/transformers/convert_bart_original_pytorch_checkpoint_to_pytorch.py`, gutted most of it out and then gradually added parts to it as I was progressing in the porting process.
During the development I was testing all my code against a local copy of the converted model files, and only at the very end when everything was ready I uploaded the files to 🤗 s3 and then continued testing against the online version.
## fairseq model and its support files
Let's first look at what data we get with the `fairseq` pre-trained model.
We are going to use the convenient `torch.hub` API, which makes it very easy to deploy models submitted to [that hub](https://pytorch.org/hub/):
```
import torch
torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru', checkpoint_file='model4.pt',
tokenizer='moses', bpe='fastbpe')
```
This code downloads the pre-trained model and its support files. I found this information at the page corresponding to [fairseq](https://pytorch.org/hub/pytorch_fairseq_translation/) on the pytorch hub.
To see what's inside the downloaded files, we have to first hunt down the right folder under `~/.cache`.
```
ls -1 ~/.cache/torch/hub/pytorch_fairseq/
```
shows:
```
15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9
15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9.json
```
You may have more than one entry there if you have been using the `hub` for other models.
Let's make a symlink so that we can easily refer to that obscure cache folder name down the road:
```
ln -s /code/data/cache/torch/hub/pytorch_fairseq/15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9 \
~/porting/pytorch_fairseq_model
```
Note: the path could be different when you try it yourself, since the hash value of the model could change. You will find the right one in `~/.cache/torch/hub/pytorch_fairseq/`
If we look inside that folder:
```
ls -l ~/porting/pytorch_fairseq_model/
total 13646584
-rw-rw-r-- 1 stas stas 532048 Sep 8 21:29 bpecodes
-rw-rw-r-- 1 stas stas 351706 Sep 8 21:29 dict.en.txt
-rw-rw-r-- 1 stas stas 515506 Sep 8 21:29 dict.ru.txt
-rw-rw-r-- 1 stas stas 3493170533 Sep 8 21:28 model1.pt
-rw-rw-r-- 1 stas stas 3493170532 Sep 8 21:28 model2.pt
-rw-rw-r-- 1 stas stas 3493170374 Sep 8 21:28 model3.pt
-rw-rw-r-- 1 stas stas 3493170386 Sep 8 21:29 model4.pt
```
we have:
1. `model*.pt` - 4 checkpoints (pytorch `state_dict` with all the pre-trained weights, and various other things)
2. `dict.*.txt` - source and target dictionaries
3. `bpecodes` - special map file used by the tokenizer
We are going to investigate each of these files in the following sections.
## How translation systems work
Here is a very brief introduction to how computers translate text nowadays.
Computers can't read text, but can only handle numbers. So when working with text we have to map one or more letters into numbers, and hand those to a computer program. When the program completes it too returns numbers, which we need to convert back into text.
Let's start with two sentences in Russian and English and assign a unique number to each word:
```
я люблю следовательно я существую
10 11 12 10 13
I love therefore I am
20 21 22 20 23
```
The numbers starting with 10 map Russian words to unique numbers. The numbers starting with 20 do the same for English words. If you don't speak Russian, you can still see that the word `я` (means 'I') repeats twice in the sentence and it gets the same number 10 associated with it. Same goes for `I` (20), which also repeats twice.
A translation system works in the following stages:
```
1. [я люблю следовательно я существую] # tokenize sentence into words
2. [10 11 12 10 13] # look up words in the input dictionary and convert to ids
3. [black box] # machine learning system magic
4. [20 21 22 20 23] # look up numbers in the output dictionary and convert to text
5. [I love therefore I am] # detokenize the tokens back into a sentence
```
If we combine the first two and the last two steps we get 3 stages:
1. **Encode input**: break input text into tokens, create a dictionary (vocab) of these tokens and remap each token into a unique id in that dictionary.
2. **Generate translation**: take input numbers, run them through a pre-trained machine learning model which predicts the best translation, and return output numbers.
3. **Decode output**: take output numbers, look them up in the target language dictionary, convert them back to text, and finally merge the converted tokens into the translated sentence.
The second stage may return one or several possible translations. In the case of the latter the caller then can choose the most suitable outcome. In this article I will refer to [the beam search algorithm](https://en.wikipedia.org/wiki/Beam_search), which is one of the ways multiple possible results are searched for. And the size of the beam refers to how many results are returned.
If there is only one result that's requested, the model will choose the one with the highest likelihood probability. If multiple results are requested it will return those results sorted by their probabilities.
Note that this same idea applies to the majority of NLP tasks, and not just translation.
## Tokenization
Early systems tokenized sentences into words and punctuation marks. But since many languages have hundreds of thousands of words, it is very taxing to work with huge vocabularies, as it dramatically increases the compute resource requirements and the length of time to complete the task.
As of 2020 there are quite a few different tokenizing methods, but most of the recent ones are based on sub-word tokenization - that is instead of breaking input text down into words, these modern tokenizers break the input text down into word segments and letters, using some kind of training to obtain the most optimal tokenization.
Let's see how this approach helps to reduce memory and computation requirements. If we have an input vocabulary of 6 common words: go, going, speak, speaking, sleep, sleeping - with word-level tokenization we end up with 6 tokens. However, if we break these down into: go, go-ing, speak, speak-ing, etc., then we have only 4 tokens in our vocabulary: go, speak, sleep, ing. This simple change made a 33% improvement! Except, the sub-word tokenizers don't use grammar rules, but they are trained on massive text inputs to find such splits. In this example I used a simple grammar rule as it's easy to understand.
Another important advantage of this approach is when dealing with input text words, that aren't in our vocabulary. For example, let's say our system encounters the word `grokking` (*), which can't be found in its vocabulary. If we split it into `grokk'-'ing', then the machine learning model might not know what to do with the first part of the word, but it gets a useful insight that 'ing' indicates a continuous tense, so it'll be able to produce a better translation. In such situation the tokenizer will split the unknown segments into segments it knows, in the worst case reducing them to individual letters.
* footnote: to grok was coined in 1961 by Robert A. Heinlein in "Stranger in a Strange Land": to understand (something) intuitively or by empathy.
There are many other nuances to why the modern tokenization approach is much more superior than simple word tokenization, which won't be covered in the scope of this article. Most of these systems are very complex to how they do the tokenization, as compared to the simple example of splitting `ing` endings that was just demonstrated, but the principle is similar.
## Tokenizer porting
The first step was to port the encoder part of the tokenizer, where text is converted to ids. The decoder part won't be needed until the very end.
### fairseq's tokenizer workings
Let's understand how `fairseq`'s tokenizer works.
`fairseq` (*) uses the [Byte Pair Encoding](https://en.wikipedia.org/wiki/Byte_pair_encoding) (BPE) algorithm for tokenization.
* footnote: from here on when I refer to `fairseq`, I refer [to this specific model implementation](https://github.com/pytorch/fairseq/tree/master/examples/wmt19) - the `fairseq` project itself has dozens of different implementations of different models.
Let's see what BPE does:
```
import torch
sentence = "Machine Learning is great"
checkpoint_file='model4.pt'
model = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru', checkpoint_file=checkpoint_file, tokenizer='moses', bpe='fastbpe')
# encode step by step
tokens = model.tokenize(sentence)
print("tokenize ", tokens)
bpe = model.apply_bpe(tokens)
print("apply_bpe: ", bpe)
bin = model.binarize(bpe)
print("binarize: ", len(bin), bin)
# compare to model.encode - should give us the same output
expected = model.encode(sentence)
print("encode: ", len(expected), expected)
```
gives us:
```
('tokenize ', 'Machine Learning is great')
('apply_bpe: ', 'Mach@@ ine Lear@@ ning is great')
('binarize: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
('encode: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
```
You can see that `model.encode` does `tokenize+apply_bpe+binarize` - as we get the same output.
The steps were:
1. `tokenize`: normally it'd escape apostrophes and do other pre-processing, in this example it just returned the input sentence without any changes
2. `apply_bpe`: BPE splits the input into words and sub-words according to its `bpecodes` file supplied by the tokenizer - we get 6 BPE chunks
3. `binarize`: this simply remaps the BPE chunks from the previous step into their corresponding ids in the vocabulary (which is also downloaded with the model)
You can refer to [this notebook](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/nbs/tokenizer.ipynb) to see more details.
This is a good time to look inside the `bpecodes` file. Here is the top of the file:
```
$ head -15 ~/porting/pytorch_fairseq_model/bpecodes
e n</w> 1423551864
e r 1300703664
e r</w> 1142368899
i n 1130674201
c h 933581741
a n 845658658
t h 811639783
e n 780050874
u n 661783167
s t 592856434
e i 579569900
a r 494774817
a l 444331573
o r 439176406
th e</w> 432025210
[...]
```
The top entries of this file include very frequent short 1-letter sequences. As we will see in a moment the bottom includes the most common multi-letter sub-words and even full long words.
A special token `</w>` indicates the end of the word. So in several lines quoted above we find:
```
e n</w> 1423551864
e r</w> 1142368899
th e</w> 432025210
```
If the second column doesn't include `</w>`, it means that this segment is found in the middle of the word and not at the end of it.
The last column declares the number of times this BPE code has been encountered while being trained. The `bpecodes` file is sorted by this column - so the most common BPE codes are on top.
By looking at the counts we now know that when this tokenizer was trained it encountered 1,423,551,864 words ending in `en`, 1,142,368,899 words ending in `er` and 432,025,210 words ending in `the`. For the latter it most likely means the actual word `the`, but it would also include words like `lathe`, `loathe`, `tithe`, etc.
These huge numbers also indicate to us that this tokenizer was trained on an enormous amount of text!
If we look at the bottom of the same file:
```
$ tail -10 ~/porting/pytorch_fairseq_model/bpecodes
4 x 109019
F ische</w> 109018
sal aries</w> 109012
e kt 108978
ver gewal 108978
Sten cils</w> 108977
Freiwilli ge</w> 108969
doub les</w> 108965
po ckets</w> 108953
Gö tz</w> 108943
```
we see complex combinations of sub-words which are still pretty frequent, e.g. `sal aries` for 109,012 times! So it got its own dedicated entry in the `bpecodes` map file.
How `apply_bpe` does its work? By looking up the various combinations of letters in the `bpecodes` map file and when finding the longest fitting entry it uses that.
Going back to our example, we saw that it split `Machine` into: `Mach@@` + `ine` - let's check:
```
$ grep -i ^mach ~/porting/pytorch_fairseq_model/bpecodes
mach ine</w> 463985
Mach t 376252
Mach ines</w> 374223
mach ines</w> 214050
Mach th 119438
```
You can see that it has `mach ine</w>`. We don't see `Mach ine` in there - so it must be handling lower cased look ups when normal case is not matching.
Now let's check: `Lear@@` + `ning`
```
$ grep -i ^lear ~/porting/pytorch_fairseq_model/bpecodes
lear n</w> 675290
lear ned</w> 505087
lear ning</w> 417623
```
We find `lear ning</w>` is there (again the case is not the same).
Thinking more about it, the case probably doesn't matter for tokenization, as long as there is a unique entry for `Mach`/`Lear` and `mach`/`lear` in the dictionary where it's very critical to have each case covered.
Hopefully, you can now see how this works.
One confusing thing is that if you remember the `apply_bpe` output was:
```
('apply_bpe: ', 6, ['Mach@@', 'ine', 'Lear@@', 'ning', 'is', 'great'])
```
Instead of marking endings of the words with `</w>`, it leaves those as is, but, instead, marks words that were not the endings with `@@`. This is probably so, because `fastBPE` implementation is used by `fairseq` and that's how it does things. I had to change this to fit the `transformers` implementation, which doesn't use `fastBPE`.
One last thing to check is the remapping of the BPE codes to vocabulary ids. To repeat, we had:
```
('apply_bpe: ', 'Mach@@ ine Lear@@ ning is great')
('binarize: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
```
`2` - the last token id is a `eos` (end of stream) token. It's used to indicate to the model the end of input.
And then `Mach@@` gets remapped to `10217`, and `ine` to `1419`.
Let's check that the dictionary file is in agreement:
```
$ grep ^Mach@@ ~/porting/pytorch_fairseq_model/dict.en.txt
Mach@@ 6410
$ grep "^ine " ~/porting/pytorch_fairseq_model/dict.en.txt
ine 88376
```
Wait a second - those aren't the ids that we got after `binarize`, which should be `10217` and `1419` correspondingly.
It took some investigating to find out that the vocab file ids aren't the ids used by the model and that internally it remaps them to new ids once the vocab file is loaded. Luckily, I didn't need to figure out how exactly it was done. Instead, I just used `fairseq.data.dictionary.Dictionary.load` to load the dictionary (*), which performed all the re-mappings, - and I then saved the final dictionary. I found out about that `Dictionary` class by stepping through `fairseq` code with debugger.
* footnote: the more I work on porting models and datasets, the more I realize that putting the original code to work for me, rather than trying to replicate it, is a huge time saver and most importantly that code has already been tested - it's too easy to miss something and down the road discover big problems! After all, at the end, none of this conversion code will matter, since only the data it generated will be used by `transformers` and its end users.
Here is the relevant part of the conversion script:
```
from fairseq.data.dictionary import Dictionary
def rewrite_dict_keys(d):
# (1) remove word breaking symbol
# (2) add word ending symbol where the word is not broken up,
# e.g.: d = {'le@@': 5, 'tt@@': 6, 'er': 7} => {'le': 5, 'tt': 6, 'er</w>': 7}
d2 = dict((re.sub(r"@@$", "", k), v) if k.endswith("@@") else (re.sub(r"$", "</w>", k), v) for k, v in d.items())
keep_keys = "<s> <pad> </s> <unk>".split()
# restore the special tokens
for k in keep_keys:
del d2[f"{k}</w>"]
d2[k] = d[k] # restore
return d2
src_dict_file = os.path.join(fsmt_folder_path, f"dict.{src_lang}.txt")
src_dict = Dictionary.load(src_dict_file)
src_vocab = rewrite_dict_keys(src_dict.indices)
src_vocab_size = len(src_vocab)
src_vocab_file = os.path.join(pytorch_dump_folder_path, "vocab-src.json")
print(f"Generating {src_vocab_file}")
with open(src_vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(src_vocab, ensure_ascii=False, indent=json_indent))
# we did the same for the target dict - omitted quoting it here
# and we also had to save `bpecodes`, it's called `merges.txt` in the transformers land
```
After running the conversion script, let's check the converted dictionary:
```
$ grep '"Mach"' /code/huggingface/transformers-fair-wmt/data/wmt19-en-ru/vocab-src.json
"Mach": 10217,
$ grep '"ine</w>":' /code/huggingface/transformers-fair-wmt/data/wmt19-en-ru/vocab-src.json
"ine</w>": 1419,
```
We have the correct ids in the `transformers` version of the vocab file.
As you can see I also had to re-write the vocabularies to match the `transformers` BPE implementation. We have to change:
```
['Mach@@', 'ine', 'Lear@@', 'ning', 'is', 'great']
```
to:
```
['Mach', 'ine</w>', 'Lear', 'ning</w>', 'is</w>', 'great</w>']
```
Instead of marking chunks that are segments of a word, with the exception of the last segment, we mark segments or words that are the final segment. One can easily go from one style of encoding to another and back.
This successfully completed the porting of the first part of the model files. You can see the final version of the code [here](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py#L128).
If you're curious to look deeper there are more tinkering bits in [this notebook](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/nbs/tokenizer-dev.ipynb).
### Porting tokenizer's encoder to transformers
`transformers` can't rely on [`fastBPE`](https://github.com/glample/fastBPE) since the latter requires a C-compiler, but luckily someone already implemented a python version of the same in [`tokenization_xlm.py`](https://github.com/huggingface/transformers/blob/master/src/transformers/tokenization_xlm.py).
So I just copied it to `src/transformers/tokenization_fsmt.py` and renamed the class names:
```
cp tokenization_xlm.py tokenization_fsmt.py
perl -pi -e 's|XLM|FSMT|ig; s|xlm|fsmt|g;' tokenization_fsmt.py
```
and with very few changes I had a working encoder part of the tokenizer. There was a lot of code that didn't apply to the languages I needed to support, so I removed that code.
Since I needed 2 different vocabularies, instead of one here in tokenizer and everywhere else I had to change the code to support both. So for example I had to override the super-class' methods:
```
def get_vocab(self) -> Dict[str, int]:
return self.get_src_vocab()
@property
def vocab_size(self) -> int:
return self.src_vocab_size
```
Since `fairseq` didn't use `bos` (beginning of stream) tokens, I also had to change the code to not include those (*):
```
- return bos + token_ids_0 + sep
- return bos + token_ids_0 + sep + token_ids_1 + sep
+ return token_ids_0 + sep
+ return token_ids_0 + sep + token_ids_1 + sep
```
* footnote: this is the output of `diff(1)` which shows the difference between two chunks of code - lines starting with `-` show what was removed, and with `+` what was added.
`fairseq` was also escaping characters and performing an aggressive dash splitting, so I had to also change:
```
- [...].tokenize(text, return_str=False, escape=False)
+ [...].tokenize(text, return_str=False, escape=True, aggressive_dash_splits=True)
```
If you're following along, and would like to see all the changes I did to the original `tokenization_xlm.py`, you can do:
```
cp tokenization_xlm.py tokenization_orig.py
perl -pi -e 's|XLM|FSMT|g; s|xlm|fsmt|g;' tokenization_orig.py
diff -u tokenization_orig.py tokenization_fsmt.py | less
```
Just make sure you're checking out the repository [around the time fsmt was released](https://github.com/huggingface/transformers/tree/129fdae04033fe4adfe013b734deaec6ec34ae2e), since the 2 files could have diverged since then.
The final stage was to run through a bunch of inputs and to ensure that the ported tokenizer produced the same ids as the original. You can see this is done in [this notebook](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/nbs/tokenizer.ipynb), which I was running repeatedly while trying to figure out how to make the outputs match.
This is how most of the porting process went, I'd take a small feature, run it the `fairseq`-way, get the outputs, do the same with the `transformers` code, try to make the outputs match - fiddle with the code until it did, then try a different kind of input make sure it produced the same outputs, and so on, until all inputs produced outputs that matched.
## Porting the core translation functionality
Having had a relatively quick success with porting the tokenizer (obviously, thanks to most of the code being there already), the next stage was much more complex. This is the `generate()` function which takes inputs ids, runs them through the model and returns output ids.
I had to break it down into multiple sub-tasks. I had to
1. port the model weights.
2. make `generate()` work for a single beam (i.e. return just one result).
3. and then multiple beams (i.e. return multiple results).
I first researched which of the existing architectures were the closest to my needs. It was BART that fit the closest, so I went ahead and did:
```
cp modeling_bart.py modeling_fsmt.py
perl -pi -e 's|Bart|FSMT|ig; s|bart|fsmt|g;' modeling_fsmt.py
```
This was my starting point that I needed to tweak to work with the model weights provided by `fairseq`.
### Porting weights and configuration
The first thing I did is to look at what was inside the publicly shared checkpoint. [This notebook](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/nbs/config.ipynb) shows what I did there.
I discovered that there were 4 checkpoints in there. I had no idea what to do about it, so I started with a simpler job of using just the first checkpoint. Later I discovered that `fairseq` used all 4 checkpoints in an ensemble to get the best predictions, and that `transformers` currently doesn't support that feature. When the porting was completed and I was able to measure the performance scores, I found out that the `model4.pt` checkpoint provided the best score. But during the porting performance didn't matter much. Since I was using only one checkpoint it was crucial that when I was comparing outputs, I had `fairseq` also use just one and the same checkpoint.
To accomplish that I used a slightly different `fairseq` API:
```
from fairseq import hub_utils
#checkpoint_file = 'model1.pt:model2.pt:model3.pt:model4.pt'
checkpoint_file = 'model1.pt'
model_name_or_path = 'transformer.wmt19.ru-en'
data_name_or_path = '.'
cls = fairseq.model_parallel.models.transformer.ModelParallelTransformerModel
models = cls.hub_models()
kwargs = {'bpe': 'fastbpe', 'tokenizer': 'moses'}
ru2en = hub_utils.from_pretrained(
model_name_or_path,
checkpoint_file,
data_name_or_path,
archive_map=models,
**kwargs
)
```
First I looked at the model:
```
print(ru2en["models"][0])
```
```
TransformerModel(
(encoder): TransformerEncoder(
(dropout_module): FairseqDropout()
(embed_tokens): Embedding(31232, 1024, padding_idx=1)
(embed_positions): SinusoidalPositionalEmbedding()
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
[...]
# the full output is in the notebook
```
which looked very similar to BART's architecture, with some slight differences in a few layers - some were added, others removed. So this was great news as I didn't have to re-invent the wheel, but to only tweak a well-working design.
Note that in the code sample above I'm not using `torch.load()` to load `state_dict`. This is what I initially did and the result was most puzzling - I was missing `self_attn.(k|q|v)_proj` weights and instead had a single `self_attn.in_proj`. When I tried loading the model using `fairseq` API, it fixed things up - apparently that model was old and was using an old architecture that had one set of weights for `k/q/v` and the newer architecture has them separate. When `fairseq` loads this old model, it rewrites the weights to match the modern architecture.
I also used [this notebook](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/nbs/visualize-models.ipynb) to compare the `state_dict`s visually. In that notebook you will also see that `fairseq` fetches a 2.2GB-worth of data in `last_optimizer_state`, which we can safely ignore, and have a 3 times leaner final model size.
In the conversion script I also had to remove some `state_dict` keys, which I wasn't going to use, e.g. `model.encoder.version`, `model.model` and a few others.
Next we look at the configuration args:
```
args = dict(vars(ru2en["args"]))
pprint(args)
```
```
'activation_dropout': 0.0,
'activation_fn': 'relu',
'adam_betas': '(0.9, 0.98)',
'adam_eps': 1e-08,
'adaptive_input': False,
'adaptive_softmax_cutoff': None,
'adaptive_softmax_dropout': 0,
'arch': 'transformer_wmt_en_de_big',
'attention_dropout': 0.1,
'bpe': 'fastbpe',
[... full output is in the notebook ...]
```
ok, we will copy those to configure the model. I had to rename some of the argument names, wherever `transformers` used different names for the corresponding configuration setting. So the re-mapping of configuration looks as following:
```
model_conf = {
"architectures": ["FSMTForConditionalGeneration"],
"model_type": "fsmt",
"activation_dropout": args["activation_dropout"],
"activation_function": "relu",
"attention_dropout": args["attention_dropout"],
"d_model": args["decoder_embed_dim"],
"dropout": args["dropout"],
"init_std": 0.02,
"max_position_embeddings": args["max_source_positions"],
"num_hidden_layers": args["encoder_layers"],
"src_vocab_size": src_vocab_size,
"tgt_vocab_size": tgt_vocab_size,
"langs": [src_lang, tgt_lang],
[...]
"bos_token_id": 0,
"pad_token_id": 1,
"eos_token_id": 2,
"is_encoder_decoder": True,
"scale_embedding": not args["no_scale_embedding"],
"tie_word_embeddings": args["share_all_embeddings"],
}
```
All that remains is to save the configuration into `config.json` and create a new `state_dict` dump into `pytorch.dump`:
```
print(f"Generating {fsmt_tokenizer_config_file}")
with open(fsmt_tokenizer_config_file, "w", encoding="utf-8") as f:
f.write(json.dumps(tokenizer_conf, ensure_ascii=False, indent=json_indent))
[...]
print(f"Generating {pytorch_weights_dump_path}")
torch.save(model_state_dict, pytorch_weights_dump_path)
```
We have the configuration and the model's `state_dict` ported - yay!
You will find the final conversion code [here](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py#L162).
### Porting the architecture code
Now that we have the model weights and the model configuration ported, we *just* need to adjust the code copied from `modeling_bart.py` to match `fairseq`'s functionality.
The first step was to take a sentence, encode it and then feed to the `generate` function - for `fairseq` and for `transformers`.
After a few very failing attempts to get somewhere (*) - I quickly realized that with the current level of complexity using `print` as debugging method will get me nowhere, and neither will the basic `pdb` debugger. In order to be efficient and to be able to watch multiple variables and have watches that are code-evaluations I needed a serious visual debugger. I spent a day trying all kinds of python debuggers and only when I tried `pycharm` I realized that it was the tool that I needed. It was my first time using `pycharm`, but I quickly figured out how to use it, as it was quite intuitive.
* footnote: the model was generating 'nononono' in Russian - that was fair and hilarious!
Over time I found a great feature in `pycharm` that allowed me to group breakpoints by functionality and I could turn whole groups on and off depending on what I was debugging. For example, here I have beam-search related break-points off and decoder ones on:

Now that I have used this debugger to port FSMT, I know that it would have taken me many times over to use pdb to do the same - I may have even given it up.
I started with 2 scripts:
* [fseq-translate](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fseq-translate.py)
* [fsmt-translate](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fsmt-translate.py)
(without the `decode` part first)
running both side by side, stepping through with debugger on each side and comparing values of relevant variables - until I found the first divergence. I then studied the code, made adjustments inside `modeling_fsmt.py`, restarted the debugger, quickly jumped to the point of divergence and re-checked the outputs. This cycle has been repeated multiple times until the outputs matched.
The first things I had to change was to remove a few layers that weren't used by `fairseq` and then add some new layers it was using instead. And then the rest was primarily figuring out when to switch to `src_vocab_size` and when to `tgt_vocab_size` - since in the core modules it's just `vocab_size`, which weren't accounting for a possible model that has 2 dictionaries. Finally, I discovered that a few hyperparameter configurations weren't the same, and so those were changed too.
I first did this process for the simpler no-beam search, and once the outputs were 100% matching I repeated it with the more complicated beam search. Here, for example, I discovered that `fairseq` was using the equivalent of `early_stopping=True`, whereas `transformers` has it as `False` by default. When early stopping is enabled it stops looking for new candidates as soon as there are as many candidates as the beam size, whereas when it's disabled, the algorithm stops searching only when it can't find higher probability candidates than what it already has. The `fairseq` paper mentions that a huge beam size of 50 was used, which compensates for using early stopping.
## Tokenizer decoder porting
Once I had the ported `generate` function produce pretty similar results to `fairseq`'s `generate` I next needed to complete the last stage of decoding the outputs into the human readable text. This allowed me to use my eyes for a quick comparison and the quality of translation - something I couldn't do with output ids.
Similar to the encoding process, this one was done in reverse.
The steps were:
1. convert output ids into text strings
2. remove BPE encodings
3. detokenize - handle escaped characters, etc.
After doing some more debugging here, I had to change the way BPE was dealt with from the original approach in `tokenization_xlm.py` and also run the outputs through the `moses` detokenizer.
```
def convert_tokens_to_string(self, tokens):
""" Converts a sequence of tokens (string) in a single string. """
- out_string = "".join(tokens).replace("</w>", " ").strip()
- return out_string
+ # remove BPE
+ tokens = [t.replace(" ", "").replace("</w>", " ") for t in tokens]
+ tokens = "".join(tokens).split()
+ # detokenize
+ text = self.moses_detokenize(tokens, self.tgt_lang)
+ return text
```
And all was good.
## Uploading models to s3
Once the conversion script did a complete job of porting all the required files to `transformers`, I uploaded the models to my 🤗 s3 account:
```
cd data
transformers-cli upload -y wmt19-ru-en
transformers-cli upload -y wmt19-en-ru
transformers-cli upload -y wmt19-de-en
transformers-cli upload -y wmt19-en-de
cd -
```
For the duration of testing I was using my 🤗 s3 account and once my PR with the complete changes was ready to be merged I asked in the PR to move the models to the `facebook` organization account, since these models belong there.
Several times I had to update just the config files, and I didn't want to re-upload the large models, so I wrote this little script that produces the right upload commands, which otherwise were too long to type and as a result were error-prone:
```
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] \
for map { "wmt19-$_" } ("en-ru", "ru-en", "de-en", "en-de")}' \
vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
```
So if, for example, I only needed to update all the `config.json` files, the script above gave me a convenient copy-n-paste:
```
transformers-cli upload -y wmt19-en-ru/config.json --filename wmt19-en-ru/config.json
transformers-cli upload -y wmt19-ru-en/config.json --filename wmt19-ru-en/config.json
transformers-cli upload -y wmt19-de-en/config.json --filename wmt19-de-en/config.json
transformers-cli upload -y wmt19-en-de/config.json --filename wmt19-en-de/config.json
```
Once the upload was completed, these models could be accessed as (*):
```
tokenizer = FSMTTokenizer.from_pretrained("stas/wmt19-en-ru")
```
* footnote:`stas` is my username at https://huggingface.co.
Before I made this upload I had to use the local path to the folder with the model files, e.g.:
```
tokenizer = FSMTTokenizer.from_pretrained("/code/huggingface/transformers-fair-wmt/data/wmt19-en-ru")
```
Important: If you update the model files, and re-upload them, you must be aware that due to CDN caching the uploaded model may be unavailable for up to 24 hours after the upload - i.e. the old cached model will be delivered. So the only way to start using the new model sooner is by either:
1. downloading it to a local path and using that path as an argument that gets passed to `from_pretrained()`.
2. or using: `from_pretrained(..., use_cdn=False)` everywhere for the next 24h - it's not enough to do it once.
## AutoConfig, AutoTokenizer, etc.
One other change I needed to do is to plug the newly ported model into the automated model `transformers` system. This is used primarily on the [models website](https://huggingface.co/models) to load the model configuration, tokenizer and the main class without providing any specific class names. For example, in the case of `FSMT` one can do:
```
from transformers import AutoTokenizer, AutoModelWithLMHead
mname = "facebook/wmt19-en-ru"
tokenizer = AutoTokenizer.from_pretrained(mname)
model = AutoModelWithLMHead.from_pretrained(mname)
```
There are 3 `*auto*` files that have mappings to enable that:
```
-rw-rw-r-- 1 stas stas 16K Sep 23 13:53 src/transformers/configuration_auto.py
-rw-rw-r-- 1 stas stas 65K Sep 23 13:53 src/transformers/modeling_auto.py
-rw-rw-r-- 1 stas stas 13K Sep 23 13:53 src/transformers/tokenization_auto.py
```
Then the are the pipelines, which completely hide all the NLP complexities from the end user and provide a very simple API to just pick a model and use it for a task at hand. For example, here is how one could perform a summarization task using `pipeline`:
```
summarizer = pipeline("summarization", model="t5-base", tokenizer="t5-base")
summary = summarizer("Some long document here", min_length=5, max_length=20)
print(summary)
```
The translation pipelines are a work in progress as of this writing, watch [this document](https://huggingface.co/transformers/main_classes/pipelines.html) for updates for when translation will be supported (currently only a few specific models/languages are supported).
Finally, there is `src/transforers/__init__.py` to edit so that one could do:
```
from transformers import FSMTTokenizer, FSMTForConditionalGeneration
```
instead of:
```
from transformers.tokenization_fsmt import FSMTTokenizer
from transformers.modeling_fsmt import FSMTForConditionalGeneration
```
but either way works.
To find all the places I needed to plug FSMT in, I mimicked `BartConfig`, `BartForConditionalGeneration` and `BartTokenizer`. I just `grep`ped which files had it and inserted corresponding entries for `FSMTConfig`, `FSMTForConditionalGeneration` and `FSMTTokenizer`.
```
$ egrep -l "(BartConfig|BartForConditionalGeneration|BartTokenizer)" src/transformers/*.py \
| egrep -v "(marian|bart|pegasus|rag|fsmt)"
src/transformers/configuration_auto.py
src/transformers/generation_utils.py
src/transformers/__init__.py
src/transformers/modeling_auto.py
src/transformers/pipelines.py
src/transformers/tokenization_auto.py
```
In the `grep` search I excluded the files that also include those classes.
## Manual testing
Until now I was primarily using my own scripts to do the testing.
Once I had the translator working, I converted the reversed `ru-en` model and then wrote two paraphrase scripts:
* [fseq-paraphrase](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fseq-paraphrase.py)
* [fsmt-paraphrase](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fsmt-paraphrase.py)
which took a sentence in the source language, translated it to another language and then translated the result of that back to the original language. This process usually results in a paraphrased outcome, due to differences in how different languages express similar things.
With the help of these scripts I found some more problems with the detokenizer, stepped through with the debugger and made the fsmt script produce the same results as the `fairseq` version.
At this stage no-beam search was producing mostly identical results, but there was still some divergence in the beam search. In order to identify the special cases, I wrote a [fsmt-port-validate.py](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fsmt-port-validate.py) script that used as inputs `sacrebleu` test data and it run that data through both `fairseq` and `transformers` translation and reported only mismatches. It quickly identified a few remaining problems and observing the patterns I was able to fix those issues as well.
## Porting other models
I next proceeded to port the `en-de` and `de-en` models.
I was surprised to discover that these weren't built in the same way. Each of these had a merged dictionary, so for a moment I felt frustration, since I thought I'd now have to do another huge change to support that. But, I didn't need to make any changes, as the merged dictionary fit in without needing any changes. I just used 2 identical dictionaries - one as a source and a copy of it as a target.
I wrote another script to test all ported models' basic functionality: [fsmt-test-all.py](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fsmt-test-all.py).
## Test Coverage
This next step was very important - I needed to prepare an extensive testing for the ported model.
In the `transformers` test suite most tests that deal with large models are marked as `@slow` and those don't get to run normally on CI (Continual Integration), as they are, well, slow. So I needed to also create a tiny model, that has the same structure as a normal pre-trained model, but it had to be very small and it could have random weights. This tiny model is then can be used to test the ported functionality. It just can't be used for quality testing, since it has just a few weights and thus can't really be trained to do anything practical. [fsmt-make-tiny-model.py](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fsmt-make-tiny-model.py) creates such a tiny model. The generated model with all of its dictionary and config files was just 3MB in size. I uploaded it to `s3` using `transformers-cli upload` and now I was able to use it in the test suite.
Just like with the code, I started by copying `tests/test_modeling_bart.py` and converting it to use `FSMT`, and then tweaking it to work with the new model.
I then converted a few of my scripts I used for manual testing into unit tests - that was easy.
`transformers` has a huge set of common tests that each model runs through - I had to do some more tweaks to make these tests work for `FSMT` (primarily to adjust for the 2 dictionary setup) and I had to override a few tests, that weren't possible to run due to the uniqueness of this model, in order to skip them. You can see the results [here](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/tests/test_tokenization_fsmt.py).
I added one more test that performs a light BLEU evaluation - I used just 8 text inputs for each of the 4 models and measured BLEU scores on those. Here is the [test](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/examples/seq2seq/test_fsmt_bleu_score.py) and the [script that generated data](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/examples/seq2seq/test_data/fsmt/build-eval-data.py).
## SinusoidalPositionalEmbedding
`fairseq` used a slightly different implementation of `SinusoidalPositionalEmbedding` than the one used by `transformers`. Initially I copied the `fairseq` implementation. But when trying to get the test suite to work I couldn't get the `torchscript` tests to pass. `SinusoidalPositionalEmbedding` was written so that it won't be part of `state_dict` and not get saved with the model weights - all the weights generated by this class are deterministic and are not trained. `fairseq` used a trick to make this work transparently by not making its weights a parameter or a buffer, and then during `forward` switching the weights to the correct device. `torchscript` wasn't taking this well, as it wanted all the weights to be on the correct device before the first `forward` call.
I had to rewrite the implementation to convert it to a normal `nn.Embedding` subclass and then add functionality to not save these weights during `save_pretrained()` and for `from_pretrained()` to not complain if it can't find those weights during the `state_dict` loading.
## Evaluation
I knew that the ported model was doing quite well based on my manual testing with a large body of text, but I didn't know how well the ported model performed comparatively to the original. So it was time to evaluate.
For the task of translation [BLEU score](https://en.wikipedia.org/wiki/BLEU) is used as an evaluation metric. `transformers`
has a script [run_eval.py](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/examples/seq2seq/run_eval.py`) to perform the evaluation.
Here is an evaluation for the `ru-en` pair
```
export PAIR=ru-en
export MODEL=facebook/wmt19-$PAIR
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
export LENGTH_PENALTY=1.1
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL \
$DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
--score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS \
--length_penalty $LENGTH_PENALTY --info $MODEL --dump-args
```
which took a few minutes to run and returned:
```
{'bleu': 39.0498, 'n_obs': 2000, 'runtime': 184, 'seconds_per_sample': 0.092,
'num_beams': 5, 'length_penalty': 1.1, 'info': 'ru-en'}
```
You can see that the BLEU score was `39.0498` and that it evaluated using 2000 test inputs, provided by `sacrebleu` using the `wmt19` dataset.
Remember, I couldn't use the model ensemble, so I next needed to find the best performing checkpoint. For that purpose I wrote a script [fsmt-bleu-eval-each-chkpt.py](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fsmt-bleu-eval-each-chkpt.sh) which converted each checkpoint, run the eval script and reported the best one. As a result I knew that `model4.pt` was delivering the best performance, out of the 4 available checkpoints.
I wasn't getting the same BLEU scores as the ones reported in the original paper, so I next needed to make sure that we were comparing the same data using the same tools. Through asking at the `fairseq` issue I was given the code that was used by `fairseq` developers to get their BLEU scores - you will find it [here](https://github.com/stas00/porting/tree/master/transformers/fairseq-wmt19/scripts/fseq-reproduce-bleu.sh). But, alas, their method was using a re-ranking approach which wasn't disclosed. Moreover, they evaled on outputs before detokenization and not the real output, which apparently scores better. Bottom line - we weren't scoring in the same way (*).
* footnote: the paper [A Call for Clarity in Reporting BLEU Scores](https://arxiv.org/abs/1804.08771) invites developers to start using the same method for calculating the metrics (tldr: use `sacrebleu`).
Currently, this ported model is slightly behind the original on the BLEU scores, because model ensemble is not used, but it's impossible to tell the exact difference until the same measuring method is used.
## Porting new models
After uploading the 4 `fairseq` models [here](https://huggingface.co/models?filter=facebook&tag=fsmt) it was then suggested to port 3 `wmt16` and 2 `wmt19` AllenAI models ([Jungo Kasai, et al](https://github.com/jungokasai/deep-shallow/)). The porting was a breeze, as I only had to figure out how to put all the source files together, since they were spread out through several unrelated archives. Once this was done the conversion worked without a hitch.
The only issue I discovered after porting is that I was getting a lower BLEU score than the original. Jungo Kasai, the creator of these models, was very helpful at suggesting that a custom hyper-parameter`length_penalty=0.6` was used, and once I plugged that in I was getting much better results.
This discovery lead me to write a new script: [run_eval_search.py](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/examples/seq2seq/run_eval_search.py`), which can be used to search various hyper-parameters that would lead to the best BLEU scores. Here is an example of its usage:
```
# search space
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=32
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py stas/wmt19-$PAIR \
$DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
--score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation \
--search="num_beams=5:8:11:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1 early_stopping=true:false"
```
Here it searches though all the possible combinations of `num_beams`, `length_penalty` and `early_stopping`.
Once finished executing it reports:
```
bleu | num_beams | length_penalty | early_stopping
----- | --------- | -------------- | --------------
39.20 | 15 | 1.1 | 0
39.13 | 11 | 1.1 | 0
39.05 | 5 | 1.1 | 0
39.05 | 8 | 1.1 | 0
39.03 | 15 | 1.0 | 0
39.00 | 11 | 1.0 | 0
38.93 | 8 | 1.0 | 0
38.92 | 15 | 1.1 | 1
[...]
```
You can see that in the case of `transformers` `early_stopping=False` performs better (`fairseq` uses the `early_stopping=True` equivalent).
So for the 5 new models I used this script to find the best default parameters and I used those when converting the models. User can still override these parameters, when invoking `generate()`, but why not provide the best defaults.
You will find the 5 ported AllenAI models [here](https://huggingface.co/models?filter=allenai&tag=fsmt).
## More scripts
As each ported group of models has its own nuances, I made dedicated scripts to each one of them, so that it will be easy to re-build things in the future or to create new scripts to convert new models. You will find all the conversion, evaluation, and other scripts [here](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/scripts/fsmt/).
### Model cards
One other important thing is that it's not enough to port a model and make it available to others. One needs to provide information on how to use it, nuances about hyper-parameters, sources of datasets, evaluation metrics, etc. This is all done by creating model cards, which is just a `README.md` file, that starts with some metadata that is used by [the models website](https://huggingface.co/models), followed by all the useful information that can be shared.
For example, let's take [the `facebook/wmt19-en-ru` model card](https://github.com/huggingface/transformers/tree/129fdae04033fe4adfe013b734deaec6ec34ae2e/model_cards/facebook/wmt19-en-ru/README.md). Here is its top:
```
---
language:
- en
- ru
thumbnail:
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of
[...]
```
As you can see we define the languages, tags, license, datasets, and metrics. There is a full guide for writing these at [Model sharing and uploading](https://huggingface.co/transformers/model_sharing.html#add-a-model-card). The rest is the markdown document describing the model and its nuances.
You can also try out the models directly from the model pages thanks to the Inference widgets. For example for English-to-russian translation: https://huggingface.co/facebook/wmt19-en-ru?text=My+name+is+Diego+and+I+live+in+Moscow.

## Documentation
Finally, the documentation needed to be added.
Luckily, most of the documentation is autogenerated from the docstrings in the module files.
As before, I copied `docs/source/model_doc/bart.rst` and adapted it to `FSMT`. When it was ready I linked to it by adding `fsmt` entry inside `docs/source/index.rst`
I used:
```
make docs
```
to test that the newly added document was building correctly. The file I needed to check after running that target was `docs/_build/html/model_doc/fsmt.html` - I just loaded in my browser and verified that it rendered correctly.
Here is the final source document [docs/source/model_doc/fsmt.rst](https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/docs/source/model_doc/fsmt.rst) and its [rendered version](https://huggingface.co/transformers/model_doc/fsmt.html).
## It's PR time
Once I felt my work was quite complete, I was ready to submit my PR.
Since this work involved many git commits, I wanted to make a clean PR, so I used the following technique to squash all the commits into one in a new branch. This kept all the initial commits in place if I wanted to access any of them later.
The branch I was developing on was called `fair-wmt`, and the new branch that I was going to submit the PR from I named `fair-wmt-clean`, so here is what I did:
```
git checkout master
git checkout -b fair-wmt-clean
git merge --squash fair-wmt
git commit -m "Ready for PR"
git push origin fair-wmt-clean
```
Then I went to github and submitted this [PR](https://github.com/huggingface/transformers/pull/6940) based on the `fair-wmt-clean` branch.
It took two weeks of several cycles of feedback, followed by modifications, and more such cycles. Eventually it was all satisfactory and the PR got merged.
While this process was going on, I was finding issues here and there, adding new tests, improving the documentation, etc., so it was time well spent.
I subsequently filed a few more PRs with changes after I improved and reworked a few features, adding various build scripts, models cards, etc.
Since the models I ported were belonging to `facebook` and `allenai` organizations, I had to ask Sam to move those model files from my account on `s3` to the corresponding organizations.
## Closing thoughts
- While I couldn't port the model ensemble as `transformers` doesn't support it, on the plus side the download size of the final `facebook/wmt19-*` models is 1.1GB and not 13GB as in the original. For some reason the original includes the optimizer state saved in the model - so it adds almost 9GB (4x2.2GB) of dead weight for those who just want to download the model to use it as is to translate text.
- While the job of porting looked very challenging at the beginning as I didn't know the internals of neither `transformers` nor `fairseq`, looking back it wasn't that difficult after all. This was primarily due to having most of the components already available to me in the various parts of `transformers` - I *just* needed to find parts that I needed, mostly borrowing heavily from other models, and then tweak them to do what I needed. This was true for both the code and the tests. Let's rephrase that - porting was difficult - but it'd have been much more difficult if I had to write it all from scratch. And finding the right parts wasn't easy.
## Appreciations
- Having [Sam Shleifer](https://github.com/sshleifer) mentor me through this process was of an extreme help to me, both thanks to his technical support and just as importantly for inspiring and encouraging me when I was getting stuck.
- The PR merging process took a good couple of weeks before it was accepted. During this stage, besides Sam, [Lysandre Debut](https://github.com/LysandreJik) and [Sylvain Gugger](https://github.com/sgugger) contributed a lot through their insights and suggestions, which I integrating into the codebase.
- I'm grateful to everybody who has contributed to the `transformers` codebase, which paved the way for my work.
## Notes
### Autoprint all in Jupyter Notebook
My jupyter notebook is configured to automatically print all expressions, so I don't have to explicitly `print()` them. The default behavior is to print only the last expression of each cell. So if you read the outputs in my notebooks they may not the be same as if you were to run them yourself, unless you have the same setup.
You can enable the print-all feature in your jupyter notebook setup by adding the following to `~/.ipython/profile_default/ipython_config.py` (create it if you don't have one):
```
c = get_config()
# Run all nodes interactively
c.InteractiveShell.ast_node_interactivity = "all"
# restore to the original behavior
# c.InteractiveShell.ast_node_interactivity = "last_expr"
```
and restarting your jupyter notebook server.
### Links to the github versions of files
In order to ensure that all links work if you read this article much later after it has been written, the links were made to a specific SHA version of the code and not necessarily the latest version. This is so that if files were renamed or removed you will still find the code this article is referring to. If you want to ensure you're looking at the latest version of the code, replace the hash code in the links with `master`. For example, a link:
```
https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/modeling_fsmt.py
```
becomes:
```
https://github.com/huggingface/transformers/blob/master/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
```
Thank you for reading!
| huggingface/blog/blob/main/porting-fsmt.md |
Stable Diffusion XL for JAX + TPUv5e
[TPU v5e](https://cloud.google.com/blog/products/compute/how-cloud-tpu-v5e-accelerates-large-scale-ai-inference) is a new generation of TPUs from Google Cloud. It is the most cost-effective, versatile, and scalable Cloud TPU to date. This makes them ideal for serving and scaling large diffusion models.
[JAX](https://github.com/google/jax) is a high-performance numerical computation library that is well-suited to develop and deploy diffusion models:
- **High performance**. All JAX operations are implemented in terms of operations in [XLA](https://www.tensorflow.org/xla/) - the Accelerated Linear Algebra compiler
- **Compilation**. JAX uses just-in-time (jit) compilation of JAX Python functions so it can be executed efficiently in XLA. In order to get the best performance, we must use static shapes for jitted functions, this is because JAX transforms work by tracing a function and to determine its effect on inputs of a specific shape and type. When a new shape is introduced to an already compiled function, it retriggers compilation on the new shape, which can greatly reduce performance. **Note**: JIT compilation is particularly well-suited for text-to-image generation because all inputs and outputs (image input / output sizes) are static.
- **Parallelization**. Workloads can be scaled across multiple devices using JAX's [pmap](https://jax.readthedocs.io/en/latest/_autosummary/jax.pmap.html), which expresses single-program multiple-data (SPMD) programs. Applying pmap to a function will compile a function with XLA, then execute in parallel on XLA devices. For text-to-image generation workloads this means that increasing the number of images rendered simultaneously is straightforward to implement and doesn't compromise performance.
👉 Try it out for yourself:
[](https://huggingface.co/spaces/google/sdxl)
## Stable Diffusion XL pipeline in JAX
Upon having access to a TPU VM (TPUs higher than version 3), you should first install
a TPU-compatible version of JAX:
```
pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
```
Next, we can install [flax](https://github.com/google/flax) and the diffusers library:
```
pip install flax diffusers transformers
```
In [sdxl_single.py](./sdxl_single.py) we give a simple example of how to write a text-to-image generation pipeline in JAX using [StabilityAI's Stable Diffusion XL](stabilityai/stable-diffusion-xl-base-1.0).
Let's explain it step-by-step:
**Imports and Setup**
```python
import jax
import jax.numpy as jnp
import numpy as np
from flax.jax_utils import replicate
from diffusers import FlaxStableDiffusionXLPipeline
from jax.experimental.compilation_cache import compilation_cache as cc
cc.initialize_cache("/tmp/sdxl_cache")
import time
NUM_DEVICES = jax.device_count()
```
First, we import the necessary libraries:
- `jax` is provides the primitives for TPU operations
- `flax.jax_utils` contains some useful utility functions for `Flax`, a neural network library built on top of JAX
- `diffusers` has all the code that is relevant for SDXL.
- We also initialize a cache to speed up the JAX model compilation.
- We automatically determine the number of available TPU devices.
**1. Downloading Model and Loading Pipeline**
```python
pipeline, params = FlaxStableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", revision="refs/pr/95", split_head_dim=True
)
```
Here, a pre-trained model `stable-diffusion-xl-base-1.0` from the namespace `stabilityai` is loaded. It returns a pipeline for inference and its parameters.
**2. Casting Parameter Types**
```python
scheduler_state = params.pop("scheduler")
params = jax.tree_util.tree_map(lambda x: x.astype(jnp.bfloat16), params)
params["scheduler"] = scheduler_state
```
This section adjusts the data types of the model parameters.
We convert all parameters to `bfloat16` to speed-up the computation with model weights.
**Note** that the scheduler parameters are **not** converted to `blfoat16` as the loss
in precision is degrading the pipeline's performance too significantly.
**3. Define Inputs to Pipeline**
```python
default_prompt = ...
default_neg_prompt = ...
default_seed = 33
default_guidance_scale = 5.0
default_num_steps = 25
```
Here, various default inputs for the pipeline are set, including the prompt, negative prompt, random seed, guidance scale, and the number of inference steps.
**4. Tokenizing Inputs**
```python
def tokenize_prompt(prompt, neg_prompt):
prompt_ids = pipeline.prepare_inputs(prompt)
neg_prompt_ids = pipeline.prepare_inputs(neg_prompt)
return prompt_ids, neg_prompt_ids
```
This function tokenizes the given prompts. It's essential because the text encoders of SDXL don't understand raw text; they work with numbers. Tokenization converts text to numbers.
**5. Parallelization and Replication**
```python
p_params = replicate(params)
def replicate_all(prompt_ids, neg_prompt_ids, seed):
...
```
To utilize JAX's parallel capabilities, the parameters and input tensors are duplicated across devices. The `replicate_all` function also ensures that every device produces a different image by creating a unique random seed for each device.
**6. Putting Everything Together**
```python
def generate(...):
...
```
This function integrates all the steps to produce the desired outputs from the model. It takes in prompts, tokenizes them, replicates them across devices, runs them through the pipeline, and converts the images to a format that's more interpretable (PIL format).
**7. Compilation Step**
```python
start = time.time()
print(f"Compiling ...")
generate(default_prompt, default_neg_prompt)
print(f"Compiled in {time.time() - start}")
```
The initial run of the `generate` function will be slow because JAX compiles the function during this call. By running it once here, subsequent calls will be much faster. This section measures and prints the compilation time.
**8. Fast Inference**
```python
start = time.time()
prompt = ...
neg_prompt = ...
images = generate(prompt, neg_prompt)
print(f"Inference in {time.time() - start}")
```
Now that the function is compiled, this section shows how to use it for fast inference. It measures and prints the inference time.
In summary, the code demonstrates how to load a pre-trained model using Flax and JAX, prepare it for inference, and run it efficiently using JAX's capabilities.
## Ahead of Time (AOT) Compilation
FlaxStableDiffusionXLPipeline takes care of parallelization across multiple devices using jit. Now let's build parallelization ourselves.
For this we will be using a JAX feature called [Ahead of Time](https://jax.readthedocs.io/en/latest/aot.html) (AOT) lowering and compilation. AOT allows to fully compile prior to execution time and have control over different parts of the compilation process.
In [sdxl_single_aot.py](./sdxl_single_aot.py) we give a simple example of how to write our own parallelization logic for text-to-image generation pipeline in JAX using [StabilityAI's Stable Diffusion XL](stabilityai/stable-diffusion-xl-base-1.0)
We add a `aot_compile` function that compiles the `pipeline._generate` function
telling JAX which input arguments are static, that is, arguments that
are known at compile time and won't change. In our case, it is num_inference_steps,
height, width and return_latents.
Once the function is compiled, these parameters are omitted from future calls and
cannot be changed without modifying the code and recompiling.
```python
def aot_compile(
prompt=default_prompt,
negative_prompt=default_neg_prompt,
seed=default_seed,
guidance_scale=default_guidance_scale,
num_inference_steps=default_num_steps
):
prompt_ids, neg_prompt_ids = tokenize_prompt(prompt, negative_prompt)
prompt_ids, neg_prompt_ids, rng = replicate_all(prompt_ids, neg_prompt_ids, seed)
g = jnp.array([guidance_scale] * prompt_ids.shape[0], dtype=jnp.float32)
g = g[:, None]
return pmap(
pipeline._generate,static_broadcasted_argnums=[3, 4, 5, 9]
).lower(
prompt_ids,
p_params,
rng,
num_inference_steps, # num_inference_steps
height, # height
width, # width
g,
None,
neg_prompt_ids,
False # return_latents
).compile()
````
Next we can compile the generate function by executing `aot_compile`.
```python
start = time.time()
print("Compiling ...")
p_generate = aot_compile()
print(f"Compiled in {time.time() - start}")
```
And again we put everything together in a `generate` function.
```python
def generate(
prompt,
negative_prompt,
seed=default_seed,
guidance_scale=default_guidance_scale
):
prompt_ids, neg_prompt_ids = tokenize_prompt(prompt, negative_prompt)
prompt_ids, neg_prompt_ids, rng = replicate_all(prompt_ids, neg_prompt_ids, seed)
g = jnp.array([guidance_scale] * prompt_ids.shape[0], dtype=jnp.float32)
g = g[:, None]
images = p_generate(
prompt_ids,
p_params,
rng,
g,
None,
neg_prompt_ids)
# convert the images to PIL
images = images.reshape((images.shape[0] * images.shape[1], ) + images.shape[-3:])
return pipeline.numpy_to_pil(np.array(images))
```
The first forward pass after AOT compilation still takes a while longer than
subsequent passes, this is because on the first pass, JAX uses Python dispatch, which
Fills the C++ dispatch cache.
When using jit, this extra step is done automatically, but when using AOT compilation,
it doesn't happen until the function call is made.
```python
start = time.time()
prompt = "photo of a rhino dressed suit and tie sitting at a table in a bar with a bar stools, award winning photography, Elke vogelsang"
neg_prompt = "cartoon, illustration, animation. face. male, female"
images = generate(prompt, neg_prompt)
print(f"First inference in {time.time() - start}")
```
From this point forward, any calls to generate should result in a faster inference
time and it won't change.
```python
start = time.time()
prompt = "photo of a rhino dressed suit and tie sitting at a table in a bar with a bar stools, award winning photography, Elke vogelsang"
neg_prompt = "cartoon, illustration, animation. face. male, female"
images = generate(prompt, neg_prompt)
print(f"Inference in {time.time() - start}")
```
| huggingface/diffusers/blob/main/examples/research_projects/sdxl_flax/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
## Language model training
Fine-tuning (or training from scratch) the library models for language modeling on a text dataset for GPT, GPT-2,
ALBERT, BERT, DistilBERT, RoBERTa, XLNet... GPT and GPT-2 are trained or fine-tuned using a causal language modeling
(CLM) loss while ALBERT, BERT, DistilBERT and RoBERTa are trained or fine-tuned using a masked language modeling (MLM)
loss. XLNet uses permutation language modeling (PLM), you can find more information about the differences between those
objectives in our [model summary](https://huggingface.co/transformers/model_summary.html).
There are two sets of scripts provided. The first set leverages the Trainer API. The second set with `no_trainer` in the suffix uses a custom training loop and leverages the 🤗 Accelerate library . Both sets use the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
**Note:** The old script `run_language_modeling.py` is still available [here](https://github.com/huggingface/transformers/blob/main/examples/legacy/run_language_modeling.py).
The following examples, will run on datasets hosted on our [hub](https://huggingface.co/datasets) or with your own
text files for training and validation. We give examples of both below.
### GPT-2/GPT and causal language modeling
The following example fine-tunes GPT-2 on WikiText-2. We're using the raw WikiText-2 (no tokens were replaced before
the tokenization). The loss here is that of causal language modeling.
```bash
python run_clm.py \
--model_name_or_path gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm
```
This takes about half an hour to train on a single K80 GPU and about one minute for the evaluation to run. It reaches
a score of ~20 perplexity once fine-tuned on the dataset.
To run on your own training and validation files, use the following command:
```bash
python run_clm.py \
--model_name_or_path gpt2 \
--train_file path_to_train_file \
--validation_file path_to_validation_file \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm
```
This uses the built in HuggingFace `Trainer` for training. If you want to use a custom training loop, you can utilize or adapt the `run_clm_no_trainer.py` script. Take a look at the script for a list of supported arguments. An example is shown below:
```bash
python run_clm_no_trainer.py \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--model_name_or_path gpt2 \
--output_dir /tmp/test-clm
```
### RoBERTa/BERT/DistilBERT and masked language modeling
The following example fine-tunes RoBERTa on WikiText-2. Here too, we're using the raw WikiText-2. The loss is different
as BERT/RoBERTa have a bidirectional mechanism; we're therefore using the same loss that was used during their
pre-training: masked language modeling.
In accordance to the RoBERTa paper, we use dynamic masking rather than static masking. The model may, therefore,
converge slightly slower (over-fitting takes more epochs).
```bash
python run_mlm.py \
--model_name_or_path roberta-base \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-mlm
```
To run on your own training and validation files, use the following command:
```bash
python run_mlm.py \
--model_name_or_path roberta-base \
--train_file path_to_train_file \
--validation_file path_to_validation_file \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-mlm
```
If your dataset is organized with one sample per line, you can use the `--line_by_line` flag (otherwise the script
concatenates all texts and then splits them in blocks of the same length).
This uses the built in HuggingFace `Trainer` for training. If you want to use a custom training loop, you can utilize or adapt the `run_mlm_no_trainer.py` script. Take a look at the script for a list of supported arguments. An example is shown below:
```bash
python run_mlm_no_trainer.py \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--model_name_or_path roberta-base \
--output_dir /tmp/test-mlm
```
**Note:** On TPU, you should use the flag `--pad_to_max_length` in conjunction with the `--line_by_line` flag to make
sure all your batches have the same length.
### Whole word masking
This part was moved to `examples/research_projects/mlm_wwm`.
### XLNet and permutation language modeling
XLNet uses a different training objective, which is permutation language modeling. It is an autoregressive method
to learn bidirectional contexts by maximizing the expected likelihood over all permutations of the input
sequence factorization order.
We use the `--plm_probability` flag to define the ratio of length of a span of masked tokens to surrounding
context length for permutation language modeling.
The `--max_span_length` flag may also be used to limit the length of a span of masked tokens used
for permutation language modeling.
Here is how to fine-tune XLNet on wikitext-2:
```bash
python run_plm.py \
--model_name_or_path=xlnet-base-cased \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-plm
```
To fine-tune it on your own training and validation file, run:
```bash
python run_plm.py \
--model_name_or_path=xlnet-base-cased \
--train_file path_to_train_file \
--validation_file path_to_validation_file \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-plm
```
If your dataset is organized with one sample per line, you can use the `--line_by_line` flag (otherwise the script
concatenates all texts and then splits them in blocks of the same length).
**Note:** On TPU, you should use the flag `--pad_to_max_length` in conjunction with the `--line_by_line` flag to make
sure all your batches have the same length.
## Streaming
To use the streaming dataset mode which can be very useful for large datasets, add `--streaming` to the command line. This is currently supported by `run_mlm.py` and `run_clm.py`.
## Low Cpu Memory Usage
To use low cpu memory mode which can be very useful for LLM, add `--low_cpu_mem_usage` to the command line. This is currently supported by `run_clm.py`,`run_mlm.py`, `run_plm.py`,`run_mlm_no_trainer.py` and `run_clm_no_trainer.py`.
## Creating a model on the fly
When training a model from scratch, configuration values may be overridden with the help of `--config_overrides`:
```bash
python run_clm.py --model_type gpt2 --tokenizer_name gpt2 \ --config_overrides="n_embd=1024,n_head=16,n_layer=48,n_positions=102" \
[...]
```
This feature is only available in `run_clm.py`, `run_plm.py` and `run_mlm.py`.
| huggingface/transformers/blob/main/examples/pytorch/language-modeling/README.md |
Basic usage completed![[basic-usage-completed]]
<CourseFloatingBanner
chapter={2}
classNames="absolute z-10 right-0 top-0"
/>
Great job following the course up to here! To recap, in this chapter you:
- Learned the basic building blocks of a Transformer model.
- Learned what makes up a tokenization pipeline.
- Saw how to use a Transformer model in practice.
- Learned how to leverage a tokenizer to convert text to tensors that are understandable by the model.
- Set up a tokenizer and a model together to get from text to predictions.
- Learned the limitations of input IDs, and learned about attention masks.
- Played around with versatile and configurable tokenizer methods.
From now on, you should be able to freely navigate the 🤗 Transformers docs: the vocabulary will sound familiar, and you've already seen the methods that you'll use the majority of the time.
| huggingface/course/blob/main/chapters/en/chapter2/7.mdx |
--
title: "Understanding BigBird's Block Sparse Attention"
thumbnail: /blog/assets/18_big_bird/attn.png
authors:
- user: vasudevgupta
---
# Understanding BigBird's Block Sparse Attention
## Introduction
Transformer-based models have shown to be very useful for many NLP tasks. However, a major limitation of transformers-based models is its \\(O(n^2)\\) time & memory complexity (where \\(n\\) is sequence length). Hence, it's computationally very expensive to apply transformer-based models on long sequences \\(n > 512\\). Several recent papers, *e.g.* `Longformer`, `Performer`, `Reformer`, `Clustered attention` try to remedy this problem by approximating the full attention matrix. You can checkout 🤗's recent blog [post](https://huggingface.co/blog/long-range-transformers) in case you are unfamiliar with these models.
`BigBird` (introduced in [paper](https://arxiv.org/abs/2007.14062)) is one of such recent models to address this issue. `BigBird` relies on **block sparse attention** instead of normal attention (*i.e.* BERT's attention) and can handle sequences up to a length of **4096** at a much lower computational cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
**BigBird RoBERTa-like** model is now available in 🤗Transformers. The goal of this post is to give the reader an **in-depth** understanding of big bird implementation & ease one's life in using BigBird with 🤗Transformers. But, before going into more depth, it is important to remember that the `BigBird's` attention is an approximation of `BERT`'s full attention and therefore does not strive to be **better** than `BERT's` full attention, but rather to be more efficient. It simply allows to apply transformer-based models to much longer sequences since BERT's quadratic memory requirement quickly becomes unbearable. Simply put, if we would have \\(\infty\\) compute & \\(\infty\\) time, BERT's attention would be preferred over block sparse attention (which we are going to discuss in this post).
If you wonder why we need more compute when working with longer sequences, this blog post is just right for you!
---
Some of the main questions one might have when working with standard `BERT`-like attention include:
* Do all tokens really have to attend to all other tokens?
* Why not compute attention only over important tokens?
* How to decide what tokens are important?
* How to attend to just a few tokens in a very efficient way?
---
In this blog post, we will try to answer those questions.
### What tokens should be attended to?
We will give a practical example of how attention works by considering the sentence "BigBird is now available in HuggingFace for extractive question answering".
In `BERT`-like attention, every word would simply attend to all other tokens. Put mathematically, this would mean that each queried token \\( \text{query-token} \in \{\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering}\} \\),
would attend to the full list of \\( \text{key-tokens} = \left[\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering} \right]\\).
Let's think about a sensible choice of key tokens that a queried token actually only should attend to by writing some pseudo-code.
Will will assume that the token `available` is queried and build a sensible list of key tokens to attend to.
```python
>>> # let's consider following sentence as an example
>>> example = ['BigBird', 'is', 'now', 'available', 'in', 'HuggingFace', 'for', 'extractive', 'question', 'answering']
>>> # further let's assume, we're trying to understand the representation of 'available' i.e.
>>> query_token = 'available'
>>> # We will initialize an empty `set` and fill up the tokens of our interest as we proceed in this section.
>>> key_tokens = [] # => currently 'available' token doesn't have anything to attend
```
Nearby tokens should be important because, in a sentence (sequence of words), the current word is highly dependent on neighboring past & future tokens. This intuition is the idea behind the concept of `sliding attention`.
```python
>>> # considering `window_size = 3`, we will consider 1 token to left & 1 to right of 'available'
>>> # left token: 'now' ; right token: 'in'
>>> sliding_tokens = ["now", "available", "in"]
>>> # let's update our collection with the above tokens
>>> key_tokens.append(sliding_tokens)
```
**Long-range dependencies:** For some tasks, it is crucial to capture long-range relationships between tokens. *E.g.*, in `question-answering the model needs to compare each token of the context to the whole question to be able to figure out which part of the context is useful for a correct answer. If most of the context tokens would just attend to other context tokens, but not to the question, it becomes much harder for the model to filter important context tokens from less important context tokens.
Now, `BigBird` proposes two ways of allowing long-term attention dependencies while staying computationally efficient.
* **Global tokens:** Introduce some tokens which will attend to every token and which are attended by every token. Eg: *"HuggingFace is building nice libraries for easy NLP"*. Now, let's say *'building'* is defined as a global token, and the model needs to know the relation among *'NLP'* & *'HuggingFace'* for some task (Note: these 2 tokens are at two extremes); Now having *'building'* attend globally to all other tokens will probably help the model to associate *'NLP'* with *'HuggingFace'*.
```python
>>> # let's assume 1st & last token to be `global`, then
>>> global_tokens = ["BigBird", "answering"]
>>> # fill up global tokens in our key tokens collection
>>> key_tokens.append(global_tokens)
```
* **Random tokens:** Select some tokens randomly which will transfer information by transferring to other tokens which in turn can transfer to other tokens. This may reduce the cost of information travel from one token to other.
```python
>>> # now we can choose `r` token randomly from our example sentence
>>> # let's choose 'is' assuming `r=1`
>>> random_tokens = ["is"] # Note: it is chosen compleletly randomly; so it can be anything else also.
>>> # fill random tokens to our collection
>>> key_tokens.append(random_tokens)
>>> # it's time to see what tokens are in our `key_tokens` list
>>> key_tokens
{'now', 'is', 'in', 'answering', 'available', 'BigBird'}
# Now, 'available' (query we choose in our 1st step) will attend only these tokens instead of attending the complete sequence
```
This way, the query token attends only to a subset of all possible tokens while yielding a good approximation of full attention. The same approach will is used for all other queried tokens. But remember, the whole point here is to approximate `BERT`'s full attention as efficiently as possible. Simply making each queried token attend all key tokens as it's done for BERT can be computed very effectively as a sequence of matrix multiplication on modern hardware, like GPUs. However, a combination of sliding, global & random attention appears to imply sparse matrix multiplication, which is harder to implement efficiently on modern hardware.
One of the major contributions of `BigBird` is the proposition of a `block sparse` attention mechanism that allows computing sliding, global & random attention effectively. Let's look into it!
### Understanding the need for global, sliding, random keys with Graphs
First, let's get a better understanding of `global`, `sliding` & `random` attention using graphs and try to understand how the combination of these three attention mechanisms yields a very good approximation of standard `Bert-like` attention.
<img src="assets/18_big_bird/global.png" width=250 height=250>
<img src="assets/18_big_bird/sliding.png" width=250 height=250>
<img src="assets/18_big_bird/random.png" width=250 height=250> <br>
*The above figure shows `global` (left), `sliding` (middle) & `random` (right) connections respectively as a graph. Each node corresponds to a token and each line represents an attention score. If no connection is made between 2 tokens, then an attention score is assumed to 0.*

<img src="assets/18_big_bird/full.png" width=230 height=230>
**BigBird block sparse attention** is a combination of sliding, global & random connections (total 10 connections) as shown in `gif` in left. While a graph of **normal attention** (right) will have all 15 connections (note: total 6 nodes are present). You can simply think of normal attention as all the tokens attending globally \\( {}^1 \\).
**Normal attention:** Model can transfer information from one token to another token directly in a single layer since each token is queried over every other token and is attended by every other token. Let's consider an example similar to what is shown in the above figures. If the model needs to associate *'going'* with *'now'*, it can simply do that in a single layer since there is a direct connection joining both the tokens.
**Block sparse attention:** If the model needs to share information between two nodes (or tokens), information will have to travel across various other nodes in the path for some of the tokens; since all the nodes are not directly connected in a single layer.
*Eg.*, assuming model needs to associate *'going'* with *'now'*, then if only sliding attention is present the flow of information among those 2 tokens, is defined by the path: `going -> am -> i -> now` (i.e. it will have to travel over 2 other tokens). Hence, we may need multiple layers to capture the entire information of the sequence. Normal attention can capture this in a single layer. In an extreme case, this could mean that as many layers as input tokens are needed. If, however, we introduce some global tokens information can travel via the path: `going -> i -> now` (which is shorter). If we in addition introduce random connections it can travel via: `going -> am -> now`. With the help of random connections & global connections, information can travel very rapidly (with just a few layers) from one token to the next.
In case, we have many global tokens, then we may not need random connections since there will be multiple short paths through which information can travel. This is the idea behind keeping `num_random_tokens = 0` when working with a variant of BigBird, called ETC (more on this in later sections).
\\( {}^1 \\) In these graphics, we are assuming that the attention matrix is symmetric **i.e.** \\(\mathbf{A}_{ij} = \mathbf{A}_{ji}\\) since in a graph if some token **A** attends **B**, then **B** will also attend **A**. You can see from the figure of the attention matrix shown in the next section that this assumption holds for most tokens in BigBird
| Attention Type | `global_tokens` | `sliding_tokens` | `random_tokens` |
|-----------------|-------------------|------------------|------------------------------------|
| `original_full` | `n` | 0 | 0 |
| `block_sparse` | 2 x `block_size` | 3 x `block_size` | `num_random_blocks` x `block_size` |
*`original_full` represents `BERT`'s attention while `block_sparse` represents `BigBird`'s attention. Wondering what the `block_size` is? We will cover that in later sections. For now, consider it to be 1 for simplicity*
## BigBird block sparse attention
BigBird block sparse attention is just an efficient implementation of what we discussed above. Each token is attending some **global tokens**, **sliding tokens**, & **random tokens** instead of attending to **all** other tokens. The authors hardcoded the attention matrix for multiple query components separately; and used a cool trick to speed up training/inference on GPU and TPU.

*Note: on the top, we have 2 extra sentences. As you can notice, every token is just switched by one place in both sentences. This is how sliding attention is implemented. When `q[i]` is multiplied with `k[i,0:3]`, we will get a sliding attention score for `q[i]` (where `i` is index of element in sequence).*
You can find the actual implementation of `block_sparse` attention [here](https://github.com/vasudevgupta7/transformers/blob/5f2d6a0c93ca2017961199aa04a344b9b779d454/src/transformers/models/big_bird/modeling_big_bird.py#L513). This may look very scary 😨😨 now. But this article will surely ease your life in understanding the code.
### Global Attention
For global attention, each query is simply attending to all the other tokens in the sequence & is attended by every other token. Let's assume `Vasudev` (1st token) & `them` (last token) to be global (in the above figure). You can see that these tokens are directly connected to all other tokens (blue boxes).
```python
# pseudo code
Q -> Query martix (seq_length, head_dim)
K -> Key matrix (seq_length, head_dim)
# 1st & last token attends all other tokens
Q[0] x [K[0], K[1], K[2], ......, K[n-1]]
Q[n-1] x [K[0], K[1], K[2], ......, K[n-1]]
# 1st & last token getting attended by all other tokens
K[0] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
K[n-1] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
```
### Sliding Attention
The sequence of key tokens is copied 2 times with each element shifted to the right in one of the copies and to the left in the other copy. Now if we multiply query sequence vectors by these 3 sequence vectors, we will cover all the sliding tokens. Computational complexity is simply `O(3xn) = O(n)`. Referring to the above picture, the orange boxes represent the sliding attention. You can see 3 sequences at the top of the figure with 2 of them shifted by one token (1 to the left, 1 to the right).
```python
# what we want to do
Q[i] x [K[i-1], K[i], K[i+1]] for i = 1:-1
# efficient implementation in code (assume dot product multiplication 👇)
[Q[0], Q[1], Q[2], ......, Q[n-2], Q[n-1]] x [K[1], K[2], K[3], ......, K[n-1], K[0]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[n-1], K[0], K[1], ......, K[n-2]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[0], K[1], K[2], ......, K[n-1]]
# Each sequence is getting multiplied by only 3 sequences to keep `window_size = 3`.
# Some computations might be missing; this is just a rough idea.
```
### Random Attention
Random attention is ensuring that each query token will attend a few random tokens as well. For the actual implementation, this means that the model gathers some tokens randomly and computes their attention score.
```python
# r1, r2, r are some random indices; Note: r1, r2, r3 are different for each row 👇
Q[1] x [Q[r1], Q[r2], ......, Q[r]]
.
.
.
Q[n-2] x [Q[r1], Q[r2], ......, Q[r]]
# leaving 0th & (n-1)th token since they are already global
```
**Note:** The current implementation further divides sequence into blocks & each notation is defined w.r.to block instead of tokens. Let's discuss this in more detail in the next section.
### Implementation
**Recap:** In regular BERT attention, a sequence of tokens i.e. \\( X = x_1, x_2, ...., x_n \\) is projected through a dense layer into \\( Q,K,V \\) and the attention score \\( Z \\) is calculated as \\( Z=Softmax(QK^T) \\). In the case of BigBird block sparse attention, the same algorithm is used but only with some selected query & key vectors.
Let's have a look at how bigbird block sparse attention is implemented. To begin with, let's assume \\(b, r, s, g\\) represent `block_size`, `num_random_blocks`, `num_sliding_blocks`, `num_global_blocks`, respectively. Visually, we can illustrate the components of big bird's block sparse attention with \\(b=4, r=1, g=2, s=3, d=5\\) as follows:
<img src="assets/18_big_bird/intro.png" width=500 height=250>
Attention scores for \\({q}_{1}, {q}_{2}, {q}_{3:n-2}, {q}_{n-1}, {q}_{n}\\) are calculated separately as described below:
---
Attention score for \\(\mathbf{q}_{1}\\) represented by \\(a_1\\) where \\(a_1=Softmax(q_1 * K^T)\\), is nothing but attention score between all the tokens in 1st block with all the other tokens in the sequence.

\\(q_1\\) represents 1st block, \\(g_i\\) represents \\(i\\) block. We are simply performing normal attention operation between \\(q_1\\) & \\(g\\) (i.e. all the keys).
---
For calculating attention score for tokens in seconcd block, we are gathering the first three blocks, the last block, and the fifth block. Then we can compute \\(a_2 = Softmax(q_2 * concat(k_1, k_2, k_3, k_5, k_7)\\).

*I am representing tokens by \\(g, r, s\\) just to represent their nature explicitly (i.e. showing global, random, sliding tokens), else they are \\(k\\) only.*
---
For calculating attention score for \\({q}_{3:n-2}\\), we will gather global, sliding, random keys & will compute the normal attention operation over \\({q}_{3:n-2}\\) and the gathered keys. Note that sliding keys are gathered using the special shifting trick as discussed earlier in the sliding attention section.

---
For calculating attention score for tokens in previous to last block (i.e. \\({q}_{n-1}\\)), we are gathering the first block, last three blocks, and the third block. Then we can apply the formula \\({a}_{n-1} = Softmax({q}_{n-1} * concat(k_1, k_3, k_5, k_6, k_7))\\). This is very similar to what we did for \\(q_2\\).

---
Attention score for \\(\mathbf{q}_{n}\\) is represented by \\(a_n\\) where \\(a_n=Softmax(q_n * K^T)\\), and is nothing but attention score between all the tokens in the last block with all the other tokens in sequence. This is very similar to what we did for \\( q_1 \\) .

---
Let's combine the above matrices to get the final attention matrix. This attention matrix can be used to get a representation of all the tokens.

*`blue -> global blocks`, `red -> random blocks`, `orange -> sliding blocks` This attention matrix is just for illustration. During the forward pass, we aren't storing `white` blocks, but are computing a weighted value matrix (i.e. representation of each token) directly for each separated components as discussed above.*
Now, we have covered the hardest part of block sparse attention, i.e. its implementation. Hopefully, you now have a better background to understand the actual code. Feel free to dive into it and to connect each part of the code with one of the components above.
## Time & Memory complexity
| Attention Type | Sequence length | Time & Memory Complexity |
|-----------------|-----------------|--------------------------|
| `original_full` | 512 | `T` |
| | 1024 | 4 x `T` |
| | 4096 | 64 x `T` |
| `block_sparse` | 1024 | 2 x `T` |
| | 4096 | 8 x `T` |
*Comparison of time & space complexity of BERT attention and BigBird block sparse attention.*
<details>
<summary>Expand this snippet in case you wanna see the calculations</summary>
```md
BigBird time complexity = O(w x n + r x n + g x n)
BERT time complexity = O(n^2)
Assumptions:
w = 3 x 64
r = 3 x 64
g = 2 x 64
When seqlen = 512
=> **time complexity in BERT = 512^2**
When seqlen = 1024
=> time complexity in BERT = (2 x 512)^2
=> **time complexity in BERT = 4 x 512^2**
=> time complexity in BigBird = (8 x 64) x (2 x 512)
=> **time complexity in BigBird = 2 x 512^2**
When seqlen = 4096
=> time complexity in BERT = (8 x 512)^2
=> **time complexity in BERT = 64 x 512^2**
=> compute in BigBird = (8 x 64) x (8 x 512)
=> compute in BigBird = 8 x (512 x 512)
=> **time complexity in BigBird = 8 x 512^2**
```
</details>
## ITC vs ETC
The BigBird model can be trained using 2 different strategies: **ITC** & **ETC**. ITC (internal transformer construction) is simply what we discussed above. In ETC (extended transformer construction), some additional tokens are made global such that they will attend to / will be attended by all tokens.
ITC requires less compute since very few tokens are global while at the same time the model can capture sufficient global information (also with the help of random attention). On the other hand, ETC can be very helpful for tasks in which we need a lot of global tokens such as `question-answering for which the entire question should be attended to globally by the context to be able to relate the context correctly to the question.
***Note:** It is shown in the Big Bird paper that in many ETC experiments, the number of random blocks is set to 0. This is reasonable given our discussions above in the graph section.*
The table below summarizes ITC & ETC:
| | ITC | ETC |
|----------------------------------------------|---------------------------------------|--------------------------------------|
| Attention Matrix with global attention | \\( A = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} \\) | \\( B = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} \\) |
| `global_tokens` | 2 x `block_size` | `extra_tokens` + 2 x `block_size` |
| `random_tokens` | `num_random_blocks` x `block_size` | `num_random_blocks` x `block_size` |
| `sliding_tokens` | 3 x `block_size` | 3 x `block_size` |
## Using BigBird with 🤗Transformers
You can use `BigBirdModel` just like any other 🤗 model. Let's see some code below:
```python
from transformers import BigBirdModel
# loading bigbird from its pretrained checkpoint
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
# This will init the model with default configuration i.e. attention_type = "block_sparse" num_random_blocks = 3, block_size = 64.
# But You can freely change these arguments with any checkpoint. These 3 arguments will just change the number of tokens each query token is going to attend.
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", num_random_blocks=2, block_size=16)
# By setting attention_type to `original_full`, BigBird will be relying on the full attention of n^2 complexity. This way BigBird is 99.9 % similar to BERT.
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")
```
There are total **3 checkpoints** available in **🤗Hub** (at the point of writing this article): [`bigbird-roberta-base`](https://huggingface.co/google/bigbird-roberta-base), [`bigbird-roberta-large`](https://huggingface.co/google/bigbird-roberta-large), [`bigbird-base-trivia-itc`](https://huggingface.co/google/bigbird-base-trivia-itc). The first two checkpoints come from pretraining `BigBirdForPretraining` with `masked_lm loss`; while the last one corresponds to the checkpoint after finetuning `BigBirdForQuestionAnswering` on `trivia-qa` dataset.
Let's have a look at minimal code you can write (in case you like to use your PyTorch trainer), to use 🤗's BigBird model for fine-tuning your tasks.
```python
# let's consider our task to be question-answering as an example
from transformers import BigBirdForQuestionAnswering, BigBirdTokenizer
import torch
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# lets initialize bigbird model from pretrained weights with randomly initialized head on its top
model = BigBirdForQuestionAnswering.from_pretrained("google/bigbird-roberta-base", block_size=64, num_random_blocks=3)
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
model.to(device)
dataset = "torch.utils.data.DataLoader object"
optimizer = "torch.optim object"
epochs = ...
# very minimal training loop
for e in range(epochs):
for batch in dataset:
model.train()
batch = {k: batch[k].to(device) for k in batch}
# forward pass
output = model(**batch)
# back-propogation
output["loss"].backward()
optimizer.step()
optimizer.zero_grad()
# let's save final weights in a local directory
model.save_pretrained("<YOUR-WEIGHTS-DIR>")
# let's push our weights to 🤗Hub
from huggingface_hub import ModelHubMixin
ModelHubMixin.push_to_hub("<YOUR-WEIGHTS-DIR>", model_id="<YOUR-FINETUNED-ID>")
# using finetuned model for inference
question = ["How are you doing?", "How is life going?"]
context = ["<some big context having ans-1>", "<some big context having ans-2>"]
batch = tokenizer(question, context, return_tensors="pt")
batch = {k: batch[k].to(device) for k in batch}
model = BigBirdForQuestionAnswering.from_pretrained("<YOUR-FINETUNED-ID>")
model.to(device)
with torch.no_grad():
start_logits, end_logits = model(**batch).to_tuple()
# now decode start_logits, end_logits with what ever strategy you want.
# Note:
# This was very minimal code (in case you want to use raw PyTorch) just for showing how BigBird can be used very easily
# I would suggest using 🤗Trainer to have access for a lot of features
```
It's important to keep the following points in mind while working with big bird:
* Sequence length must be a multiple of block size i.e. `seqlen % block_size = 0`. You need not worry since 🤗Transformers will automatically `<pad>` (to smallest multiple of block size which is greater than sequence length) if batch sequence length is not a multiple of `block_size`.
* Currently, HuggingFace version **doesn't support ETC** and hence only 1st & last block will be global.
* Current implementation doesn't support `num_random_blocks = 0`.
* It's recommended by authors to set `attention_type = "original_full"` when sequence length < 1024.
* This must hold: `seq_length > global_token + random_tokens + sliding_tokens + buffer_tokens` where `global_tokens = 2 x block_size`, `sliding_tokens = 3 x block_size`, `random_tokens = num_random_blocks x block_size` & `buffer_tokens = num_random_blocks x block_size`. In case you fail to do that, 🤗Transformers will automatically switch `attention_type` to `original_full` with a warning.
* When using big bird as decoder (or using `BigBirdForCasualLM`), `attention_type` should be `original_full`. But you need not worry, 🤗Transformers will automatically switch `attention_type` to `original_full` in case you forget to do that.
## What's next?
[@patrickvonplaten](https://github.com/patrickvonplaten) has made a really cool [notebook](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) on how to evaluate `BigBirdForQuestionAnswering` on the `trivia-qa` dataset. Feel free to play with BigBird using that notebook.
You will soon find **BigBird Pegasus-like** model in the library for **long document summarization**💥.
## End Notes
The original implementation of **block sparse attention matrix** can be found [here](https://github.com/google-research/bigbird/blob/master/bigbird/core/attention.py). You can find 🤗's version [here](https://github.com/huggingface/transformers/tree/master/src/transformers/models/big_bird).
| huggingface/blog/blob/main/big-bird.md |
--
title: "Train your first Decision Transformer"
thumbnail: /blog/assets/101_train-decision-transformers/thumbnail.gif
authors:
- user: edbeeching
- user: ThomasSimonini
---
# Train your first Decision Transformer
In a [previous post](https://huggingface.co/blog/decision-transformers), we announced the launch of Decision Transformers in the transformers library. This new technique of **using a Transformer as a Decision-making model** is getting increasingly popular.
So today, **you’ll learn to train your first Offline Decision Transformer model from scratch to make a half-cheetah run.** We'll train it directly on a Google Colab that you can find here 👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb
<figure class="image table text-center m-0 w-full">
<video
alt="CheetahEd-expert"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/101_train-decision-transformers/replay.mp4" type="video/mp4">
</video>
</figure>
*An "expert" Decision Transformers model, learned using offline RL in the Gym HalfCheetah environment.*
Sounds exciting? Let's get started!
- [What are Decision Transformers?](#what-are-decision-transformers)
- [Training Decision Transformers](#training-decision-transformers)
- [Loading the dataset and building the Custom Data Collator](#loading-the-dataset-and-building-the-custom-data-collator)
- [Training the Decision Transformer model with a 🤗 transformers Trainer](#training-the-decision-transformer-model-with-a--transformers-trainer)
- [Conclusion](#conclusion)
- [What’s next?](#whats-next)
- [References](#references)
## What are Decision Transformers?
The Decision Transformer model was introduced by **[“Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345)**. It abstracts Reinforcement Learning as a **conditional-sequence modeling problem**.
The main idea is that instead of training a policy using RL methods, such as fitting a value function that will tell us what action to take to maximize the return (cumulative reward), **we use a sequence modeling algorithm (Transformer)** that, given the desired return, past states, and actions, will generate future actions to achieve this desired return. It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
**This is a complete shift in the Reinforcement Learning paradigm** since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. It means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
The process goes this way:
1. We feed **the last K timesteps** into the Decision Transformer with three inputs:
- Return-to-go
- State
- Action
2. **The tokens are embedded** either with a linear layer if the state is a vector or a CNN encoder if it’s frames.
3. **The inputs are processed by a GPT-2 model**, which predicts future actions via autoregressive modeling.

*Decision Transformer architecture. States, actions, and returns are fed into modality-specific linear embeddings, and a positional episodic timestep encoding is added. Tokens are fed into a GPT architecture which predicts actions autoregressively using a causal self-attention mask. Figure from [1].*
There are different types of Decision Transformers, but today, we’re going to train an offline Decision Transformer, meaning that we only use data collected from other agents or human demonstrations. **The agent does not interact with the environment**. If you want to know more about the difference between offline and online reinforcement learning, [check this article](https://huggingface.co/blog/decision-transformers).
Now that we understand the theory behind Offline Decision Transformers, **let’s see how we’re going to train one in practice.**
## Training Decision Transformers
In the previous post, we demonstrated how to use a transformers Decision Transformer model and load pretrained weights from the 🤗 hub.
In this part we will use 🤗 Trainer and a custom Data Collator to train a Decision Transformer model from scratch, using an Offline RL Dataset hosted on the 🤗 hub. You can find code for this tutorial in [this Colab notebook](https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb).
We will be performing offline RL to learn the following behavior in the [mujoco halfcheetah environment](https://www.gymlibrary.dev/environments/mujoco/half_cheetah/).
<figure class="image table text-center m-0 w-full">
<video
alt="CheetahEd-expert"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/101_train-decision-transformers/replay.mp4" type="video/mp4">
</video>
</figure>
*An "expert" Decision Transformers model, learned using offline RL in the Gym HalfCheetah environment.*
### Loading the dataset and building the Custom Data Collator
We host a number of Offline RL Datasets on the hub. Today we will be training with the halfcheetah “expert” dataset, hosted here on hub.
First we need to import the `load_dataset` function from the 🤗 datasets package and download the dataset to our machine.
```python
from datasets import load_dataset
dataset = load_dataset("edbeeching/decision_transformer_gym_replay", "halfcheetah-expert-v2")
```
While most datasets on the hub are ready to use out of the box, sometimes we wish to perform some additional processing or modification of the dataset. In this case [we wish to match the author's implementation](https://github.com/kzl/decision-transformer), that is we need to:
- Normalize each feature by subtracting the mean and dividing by the standard deviation.
- Pre-compute discounted returns for each trajectory.
- Scale the rewards and returns by a factor of 1000.
- Augment the dataset sampling distribution so it takes into account the length of the expert agent’s trajectories.
In order to perform this dataset preprocessing, we will use a custom 🤗 [Data Collator](https://huggingface.co/docs/transformers/main/en/main_classes/data_collator).
Now let’s get started on the Custom Data Collator for Offline Reinforcement Learning.
```python
@dataclass
class DecisionTransformerGymDataCollator:
return_tensors: str = "pt"
max_len: int = 20 #subsets of the episode we use for training
state_dim: int = 17 # size of state space
act_dim: int = 6 # size of action space
max_ep_len: int = 1000 # max episode length in the dataset
scale: float = 1000.0 # normalization of rewards/returns
state_mean: np.array = None # to store state means
state_std: np.array = None # to store state stds
p_sample: np.array = None # a distribution to take account trajectory lengths
n_traj: int = 0 # to store the number of trajectories in the dataset
def __init__(self, dataset) -> None:
self.act_dim = len(dataset[0]["actions"][0])
self.state_dim = len(dataset[0]["observations"][0])
self.dataset = dataset
# calculate dataset stats for normalization of states
states = []
traj_lens = []
for obs in dataset["observations"]:
states.extend(obs)
traj_lens.append(len(obs))
self.n_traj = len(traj_lens)
states = np.vstack(states)
self.state_mean, self.state_std = np.mean(states, axis=0), np.std(states, axis=0) + 1e-6
traj_lens = np.array(traj_lens)
self.p_sample = traj_lens / sum(traj_lens)
def _discount_cumsum(self, x, gamma):
discount_cumsum = np.zeros_like(x)
discount_cumsum[-1] = x[-1]
for t in reversed(range(x.shape[0] - 1)):
discount_cumsum[t] = x[t] + gamma * discount_cumsum[t + 1]
return discount_cumsum
def __call__(self, features):
batch_size = len(features)
# this is a bit of a hack to be able to sample of a non-uniform distribution
batch_inds = np.random.choice(
np.arange(self.n_traj),
size=batch_size,
replace=True,
p=self.p_sample, # reweights so we sample according to timesteps
)
# a batch of dataset features
s, a, r, d, rtg, timesteps, mask = [], [], [], [], [], [], []
for ind in batch_inds:
# for feature in features:
feature = self.dataset[int(ind)]
si = random.randint(0, len(feature["rewards"]) - 1)
# get sequences from dataset
s.append(np.array(feature["observations"][si : si + self.max_len]).reshape(1, -1, self.state_dim))
a.append(np.array(feature["actions"][si : si + self.max_len]).reshape(1, -1, self.act_dim))
r.append(np.array(feature["rewards"][si : si + self.max_len]).reshape(1, -1, 1))
d.append(np.array(feature["dones"][si : si + self.max_len]).reshape(1, -1))
timesteps.append(np.arange(si, si + s[-1].shape[1]).reshape(1, -1))
timesteps[-1][timesteps[-1] >= self.max_ep_len] = self.max_ep_len - 1 # padding cutoff
rtg.append(
self._discount_cumsum(np.array(feature["rewards"][si:]), gamma=1.0)[
: s[-1].shape[1] # TODO check the +1 removed here
].reshape(1, -1, 1)
)
if rtg[-1].shape[1] < s[-1].shape[1]:
print("if true")
rtg[-1] = np.concatenate([rtg[-1], np.zeros((1, 1, 1))], axis=1)
# padding and state + reward normalization
tlen = s[-1].shape[1]
s[-1] = np.concatenate([np.zeros((1, self.max_len - tlen, self.state_dim)), s[-1]], axis=1)
s[-1] = (s[-1] - self.state_mean) / self.state_std
a[-1] = np.concatenate(
[np.ones((1, self.max_len - tlen, self.act_dim)) * -10.0, a[-1]],
axis=1,
)
r[-1] = np.concatenate([np.zeros((1, self.max_len - tlen, 1)), r[-1]], axis=1)
d[-1] = np.concatenate([np.ones((1, self.max_len - tlen)) * 2, d[-1]], axis=1)
rtg[-1] = np.concatenate([np.zeros((1, self.max_len - tlen, 1)), rtg[-1]], axis=1) / self.scale
timesteps[-1] = np.concatenate([np.zeros((1, self.max_len - tlen)), timesteps[-1]], axis=1)
mask.append(np.concatenate([np.zeros((1, self.max_len - tlen)), np.ones((1, tlen))], axis=1))
s = torch.from_numpy(np.concatenate(s, axis=0)).float()
a = torch.from_numpy(np.concatenate(a, axis=0)).float()
r = torch.from_numpy(np.concatenate(r, axis=0)).float()
d = torch.from_numpy(np.concatenate(d, axis=0))
rtg = torch.from_numpy(np.concatenate(rtg, axis=0)).float()
timesteps = torch.from_numpy(np.concatenate(timesteps, axis=0)).long()
mask = torch.from_numpy(np.concatenate(mask, axis=0)).float()
return {
"states": s,
"actions": a,
"rewards": r,
"returns_to_go": rtg,
"timesteps": timesteps,
"attention_mask": mask,
}
```
That was a lot of code, the TLDR is that we defined a class that takes our dataset, performs the required preprocessing and will return us batches of **states**, **actions**, **rewards**, **returns**, **timesteps** and **masks.** These batches can be directly used to train a Decision Transformer model with a 🤗 transformers Trainer.
### Training the Decision Transformer model with a 🤗 transformers Trainer.
In order to train the model with the 🤗 [Trainer](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#trainer) class, we first need to ensure the dictionary it returns contains a loss, in this case [L-2 norm](https://en.wikipedia.org/wiki/Norm_(mathematics)#Euclidean_norm) of the models action predictions and the targets. We achieve this by making a TrainableDT class, which inherits from the Decision Transformer model.
```python
class TrainableDT(DecisionTransformerModel):
def __init__(self, config):
super().__init__(config)
def forward(self, **kwargs):
output = super().forward(**kwargs)
# add the DT loss
action_preds = output[1]
action_targets = kwargs["actions"]
attention_mask = kwargs["attention_mask"]
act_dim = action_preds.shape[2]
action_preds = action_preds.reshape(-1, act_dim)[attention_mask.reshape(-1) > 0]
action_targets = action_targets.reshape(-1, act_dim)[attention_mask.reshape(-1) > 0]
loss = torch.mean((action_preds - action_targets) ** 2)
return {"loss": loss}
def original_forward(self, **kwargs):
return super().forward(**kwargs)
```
The transformers Trainer class required a number of arguments, defined in the TrainingArguments class. We use the same hyperparameters are in the authors original implementation, but train for fewer iterations. This takes around 40 minutes to train in a Colab notebook, so grab a coffee or read the 🤗 [Annotated Diffusion](https://huggingface.co/blog/annotated-diffusion) blog post while you wait. The authors train for around 3 hours, so the results we get here will not be quite as good as theirs.
```python
training_args = TrainingArguments(
output_dir="output/",
remove_unused_columns=False,
num_train_epochs=120,
per_device_train_batch_size=64,
learning_rate=1e-4,
weight_decay=1e-4,
warmup_ratio=0.1,
optim="adamw_torch",
max_grad_norm=0.25,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
data_collator=collator,
)
trainer.train()
```
Now that we explained the theory behind Decision Transformer, the Trainer, and how to train it. **You're ready to train your first offline Decision Transformer model from scratch to make a half-cheetah run** 👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb
The Colab includes visualizations of the trained model, as well as how to save your model on the 🤗 hub.
## Conclusion
This post has demonstrated how to train the Decision Transformer on an offline RL dataset, hosted on [🤗 datasets](https://huggingface.co/docs/datasets/index). We have used a 🤗 transformers [Trainer](https://huggingface.co/docs/transformers/v4.21.3/en/model_doc/decision_transformer#overview) and a custom data collator.
In addition to Decision Transformers, **we want to support more use cases and tools from the Deep Reinforcement Learning community**. Therefore, it would be great to hear your feedback on the Decision Transformer model, and more generally anything we can build with you that would be useful for RL. Feel free to **[reach out to us](mailto:[email protected])**.
## What’s next?
In the coming weeks and months, **we plan on supporting other tools from the ecosystem**:
- Expanding our repository of Decision Transformer models with models trained or finetuned in an online setting [2]
- Integrating [sample-factory version 2.0](https://github.com/alex-petrenko/sample-factory)
The best way to keep in touch is to **[join our discord server](https://discord.gg/YRAq8fMnUG)** to exchange with us and with the community.
## References
[1] Chen, Lili, et al. "Decision transformer: Reinforcement learning via sequence modeling." *Advances in neural information processing systems* 34 (2021).
[2] Zheng, Qinqing and Zhang, Amy and Grover, Aditya “*Online Decision Transformer”* (arXiv preprint, 2022)
| huggingface/blog/blob/main/train-decision-transformers.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LoKr
Low-Rank Kronecker Product ([LoKr](https://hf.co/papers/2309.14859)), is a LoRA-variant method that approximates the large weight matrix with two low-rank matrices and combines them with the Kronecker product. LoKr also provides an optional third low-rank matrix to provide better control during fine-tuning.
## LoKrConfig
[[autodoc]] tuners.lokr.config.LoKrConfig
## LoKrModel
[[autodoc]] tuners.lokr.model.LoKrModel | huggingface/peft/blob/main/docs/source/package_reference/lokr.md |
et's study how to preprocess a dataset for question answering! Question answering is the task of finding answers to a question in some context. For our example, we will use the squad dataset, in which we remove columns we won't use and just extract the information we will need for the labels: the start and the end of the answer in the context. If you have your own dataset for question answering, just make sure you clean your data to get to the same point, with one column containing the questions, one column containing the contexts, one column for the index of the start and end character of the answer in the context. Note that the answer must be part of the context. If you want to perform generative question answering, look at one of the sequence to sequence videos linked below. Now if we have a look at the tokens we will feed our model we will see the answer lies somewhere inside the context. For very long context that answer may get truncated by the tokenizer. In this case, we wont have any proper labels for our model. So we should keep the truncated part as a separate feature instead of discarding it. The only thing we need to be careful with, is to allow some overlap between separate chunks so that the answer is not truncated, and that the feature containing the answer gets sufficient context to be able to predict it. Here is how it can be done by the tokenizer: we pass it the question, context, set the truncation for the context only and the padding to the maximum length. The stride argument is where we set the number of overlapping tokens, and the return_overflowing_tokens means we don't want to discard the truncated part. Lastly, we also return the offset mappings to be able to find the tokens corresponding to the answer start and end. We want those two tokens, because there will be the labels we pass to our model. In a one-hot encoded version, here is what they look like. If the context we have does not contain the answer, we set the two labels to the index of the CLS token. We also do this if the context only partially contains the answer. In terms of code, here is how we can do it: using the sequence IDs of an input, we can determine the beginning and the end of the context. Then we know if have to return the CLS position for the two labels or we determine the positions of the first and last tokens of the answer. We can check it works properly on our previous example. Putting it all together looks like this big function, which we can apply to our datasets. Since we applied padding during the tokenization, we can then use this directly in the Trainer or apply the to_tf_dataset method to use Keras.fit. | huggingface/course/blob/main/subtitles/en/raw/chapter7/07a_question-answering-processing.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Latent Consistency Model
Latent Consistency Models (LCM) enable quality image generation in typically 2-4 steps making it possible to use diffusion models in almost real-time settings.
From the [official website](https://latent-consistency-models.github.io/):
> LCMs can be distilled from any pre-trained Stable Diffusion (SD) in only 4,000 training steps (~32 A100 GPU Hours) for generating high quality 768 x 768 resolution images in 2~4 steps or even one step, significantly accelerating text-to-image generation. We employ LCM to distill the Dreamshaper-V7 version of SD in just 4,000 training iterations.
For a more technical overview of LCMs, refer to [the paper](https://huggingface.co/papers/2310.04378).
LCM distilled models are available for [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5), [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and the [SSD-1B](https://huggingface.co/segmind/SSD-1B) model. All the checkpoints can be found in this [collection](https://huggingface.co/collections/latent-consistency/latent-consistency-models-weights-654ce61a95edd6dffccef6a8).
This guide shows how to perform inference with LCMs for
- text-to-image
- image-to-image
- combined with style LoRAs
- ControlNet/T2I-Adapter
## Text-to-image
You'll use the [`StableDiffusionXLPipeline`] pipeline with the [`LCMScheduler`] and then load the LCM-LoRA. Together with the LCM-LoRA and the scheduler, the pipeline enables a fast inference workflow, overcoming the slow iterative nature of diffusion models.
```python
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, LCMScheduler
import torch
unet = UNet2DConditionModel.from_pretrained(
"latent-consistency/lcm-sdxl",
torch_dtype=torch.float16,
variant="fp16",
)
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", unet=unet, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt, num_inference_steps=4, generator=generator, guidance_scale=8.0
).images[0]
```

Notice that we use only 4 steps for generation which is way less than what's typically used for standard SDXL.
Some details to keep in mind:
* To perform classifier-free guidance, batch size is usually doubled inside the pipeline. LCM, however, applies guidance using guidance embeddings, so the batch size does not have to be doubled in this case. This leads to a faster inference time, with the drawback that negative prompts don't have any effect on the denoising process.
* The UNet was trained using the [3., 13.] guidance scale range. So, that is the ideal range for `guidance_scale`. However, disabling `guidance_scale` using a value of 1.0 is also effective in most cases.
## Image-to-image
LCMs can be applied to image-to-image tasks too. For this example, we'll use the [LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7) model, but the same steps can be applied to other LCM models as well.
```python
import torch
from diffusers import AutoPipelineForImage2Image, UNet2DConditionModel, LCMScheduler
from diffusers.utils import make_image_grid, load_image
unet = UNet2DConditionModel.from_pretrained(
"SimianLuo/LCM_Dreamshaper_v7",
subfolder="unet",
torch_dtype=torch.float16,
)
pipe = AutoPipelineForImage2Image.from_pretrained(
"Lykon/dreamshaper-7",
unet=unet,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronauts in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
generator = torch.manual_seed(0)
image = pipe(
prompt,
image=init_image,
num_inference_steps=4,
guidance_scale=7.5,
strength=0.5,
generator=generator
).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```

<Tip>
You can get different results based on your prompt and the image you provide. To get the best results, we recommend trying different values for `num_inference_steps`, `strength`, and `guidance_scale` parameters and choose the best one.
</Tip>
## Combine with style LoRAs
LCMs can be used with other styled LoRAs to generate styled-images in very few steps (4-8). In the following example, we'll use the [papercut LoRA](TheLastBen/Papercut_SDXL).
```python
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, LCMScheduler
import torch
unet = UNet2DConditionModel.from_pretrained(
"latent-consistency/lcm-sdxl",
torch_dtype=torch.float16,
variant="fp16",
)
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", unet=unet, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights("TheLastBen/Papercut_SDXL", weight_name="papercut.safetensors", adapter_name="papercut")
prompt = "papercut, a cute fox"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt, num_inference_steps=4, generator=generator, guidance_scale=8.0
).images[0]
image
```

## ControlNet/T2I-Adapter
Let's look at how we can perform inference with ControlNet/T2I-Adapter and a LCM.
### ControlNet
For this example, we'll use the [LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7) model with canny ControlNet, but the same steps can be applied to other LCM models as well.
```python
import torch
import cv2
import numpy as np
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, LCMScheduler
from diffusers.utils import load_image, make_image_grid
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
).resize((512, 512))
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"SimianLuo/LCM_Dreamshaper_v7",
controlnet=controlnet,
torch_dtype=torch.float16,
safety_checker=None,
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
generator = torch.manual_seed(0)
image = pipe(
"the mona lisa",
image=canny_image,
num_inference_steps=4,
generator=generator,
).images[0]
make_image_grid([canny_image, image], rows=1, cols=2)
```

<Tip>
The inference parameters in this example might not work for all examples, so we recommend trying different values for the `num_inference_steps`, `guidance_scale`, `controlnet_conditioning_scale`, and `cross_attention_kwargs` parameters and choosing the best one.
</Tip>
### T2I-Adapter
This example shows how to use the `lcm-sdxl` with the [Canny T2I-Adapter](TencentARC/t2i-adapter-canny-sdxl-1.0).
```python
import torch
import cv2
import numpy as np
from PIL import Image
from diffusers import StableDiffusionXLAdapterPipeline, UNet2DConditionModel, T2IAdapter, LCMScheduler
from diffusers.utils import load_image, make_image_grid
# Prepare image
# Detect the canny map in low resolution to avoid high-frequency details
image = load_image(
"https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_canny.jpg"
).resize((384, 384))
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image).resize((1024, 1216))
# load adapter
adapter = T2IAdapter.from_pretrained("TencentARC/t2i-adapter-canny-sdxl-1.0", torch_dtype=torch.float16, varient="fp16").to("cuda")
unet = UNet2DConditionModel.from_pretrained(
"latent-consistency/lcm-sdxl",
torch_dtype=torch.float16,
variant="fp16",
)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
unet=unet,
adapter=adapter,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
prompt = "Mystical fairy in real, magic, 4k picture, high quality"
negative_prompt = "extra digit, fewer digits, cropped, worst quality, low quality, glitch, deformed, mutated, ugly, disfigured"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=canny_image,
num_inference_steps=4,
guidance_scale=5,
adapter_conditioning_scale=0.8,
adapter_conditioning_factor=1,
generator=generator,
).images[0]
grid = make_image_grid([canny_image, image], rows=1, cols=2)
```

| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/inference_with_lcm.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Managing collections
Check out the [`HfApi`] documentation page for the reference of methods to manage your Space on the Hub.
- Get collection content: [`get_collection`]
- Create new collection: [`create_collection`]
- Update a collection: [`update_collection_metadata`]
- Delete a collection: [`delete_collection`]
- Add an item to a collection: [`add_collection_item`]
- Update an item in a collection: [`update_collection_item`]
- Remove an item from a collection: [`delete_collection_item`]
### Collection
[[autodoc]] Collection
### CollectionItem
[[autodoc]] CollectionItem | huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/collections.md |
## Translating the `huggingface_hub` documentation into your language
As part of our mission to democratize machine learning, we'd love to make the `huggingface_hub` library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
**🗞️ Open an issue**
To get started, navigate to the [Issues](https://github.com/huggingface/huggingface_hub/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "Translation template" from the "New issue" button.
Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
**🍴 Fork the repository**
First, you'll need to [fork the `huggingface_hub` repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
```bash
git clone https://github.com/YOUR-USERNAME/huggingface_hub.git
```
**📋 Copy-paste the English version with a new language code**
The documentation files are in one leading directory:
- [`docs/source`](https://github.com/huggingface/huggingface_hub/tree/main/docs/source): All the documentation materials are organized here by language.
You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/huggingface_hub/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
```bash
cd ~/path/to/huggingface_hub/docs
cp -r source/en source/LANG-ID
```
Here, `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
**✍️ Start translating**
The fun part comes - translating the text!
The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/LANG-ID/` directory!
The fields you should add are `local` (with the name of the file containing the translation; e.g. `guides/manage-spaces`), and `title` (with the title of the doc in your language; e.g. `Manage your Space`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/huggingface_hub/blob/main/docs/source/en/_toctree.yml):
```yaml
- title: "How-to guides" # Translate this!
sections:
- local: guides/manage-spaces # Do not change this! Use the same name for your .md file
title: Manage your Space # Translate this!
...
```
Once you have translated the `_toctree.yml` file, you can start translating the Markdown files associated with your docs chapter.
> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/huggingface_hub/issues) and tag @Wauplin. | huggingface/huggingface_hub/blob/main/docs/TRANSLATING.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# UniPCMultistepScheduler
`UniPCMultistepScheduler` is a training-free framework designed for fast sampling of diffusion models. It was introduced in [UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models](https://huggingface.co/papers/2302.04867) by Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, Jiwen Lu.
It consists of a corrector (UniC) and a predictor (UniP) that share a unified analytical form and support arbitrary orders.
UniPC is by design model-agnostic, supporting pixel-space/latent-space DPMs on unconditional/conditional sampling. It can also be applied to both noise prediction and data prediction models. The corrector UniC can be also applied after any off-the-shelf solvers to increase the order of accuracy.
The abstract from the paper is:
*Diffusion probabilistic models (DPMs) have demonstrated a very promising ability in high-resolution image synthesis. However, sampling from a pre-trained DPM is time-consuming due to the multiple evaluations of the denoising network, making it more and more important to accelerate the sampling of DPMs. Despite recent progress in designing fast samplers, existing methods still cannot generate satisfying images in many applications where fewer steps (e.g., <10) are favored. In this paper, we develop a unified corrector (UniC) that can be applied after any existing DPM sampler to increase the order of accuracy without extra model evaluations, and derive a unified predictor (UniP) that supports arbitrary order as a byproduct. Combining UniP and UniC, we propose a unified predictor-corrector framework called UniPC for the fast sampling of DPMs, which has a unified analytical form for any order and can significantly improve the sampling quality over previous methods, especially in extremely few steps. We evaluate our methods through extensive experiments including both unconditional and conditional sampling using pixel-space and latent-space DPMs. Our UniPC can achieve 3.87 FID on CIFAR10 (unconditional) and 7.51 FID on ImageNet 256×256 (conditional) with only 10 function evaluations. Code is available at [this https URL](https://github.com/wl-zhao/UniPC).*
## Tips
It is recommended to set `solver_order` to 2 for guide sampling, and `solver_order=3` for unconditional sampling.
Dynamic thresholding from [Imagen](https://huggingface.co/papers/2205.11487) is supported, and for pixel-space
diffusion models, you can set both `predict_x0=True` and `thresholding=True` to use dynamic thresholding. This thresholding method is unsuitable for latent-space diffusion models such as Stable Diffusion.
## UniPCMultistepScheduler
[[autodoc]] UniPCMultistepScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/unipc.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Models
[`PeftModel`] is the base model class for specifying the base Transformer model and configuration to apply a PEFT method to. The base `PeftModel` contains methods for loading and saving models from the Hub.
## PeftModel
[[autodoc]] PeftModel
- all
## PeftModelForSequenceClassification
A `PeftModel` for sequence classification tasks.
[[autodoc]] PeftModelForSequenceClassification
- all
## PeftModelForTokenClassification
A `PeftModel` for token classification tasks.
[[autodoc]] PeftModelForTokenClassification
- all
## PeftModelForCausalLM
A `PeftModel` for causal language modeling.
[[autodoc]] PeftModelForCausalLM
- all
## PeftModelForSeq2SeqLM
A `PeftModel` for sequence-to-sequence language modeling.
[[autodoc]] PeftModelForSeq2SeqLM
- all
## PeftModelForQuestionAnswering
A `PeftModel` for question answering.
[[autodoc]] PeftModelForQuestionAnswering
- all
## PeftModelForFeatureExtraction
A `PeftModel` for getting extracting features/embeddings from transformer models.
[[autodoc]] PeftModelForFeatureExtraction
- all
## Utilities
[[autodoc]] get_peft_model
[[autodoc]] utils.prepare_model_for_kbit_training | huggingface/peft/blob/main/docs/source/package_reference/peft_model.md |
Gradio Demo: fake_gan
### This is a fake GAN that shows how to create a text-to-image interface for image generation. Check out the Stable Diffusion demo for more: https://hf.co/spaces/stabilityai/stable-diffusion/
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/fake_gan/files/cheetah1.jpg
```
```
# This demo needs to be run from the repo folder.
# python demo/fake_gan/run.py
import random
import gradio as gr
def fake_gan():
images = [
(random.choice(
[
"http://www.marketingtool.online/en/face-generator/img/faces/avatar-1151ce9f4b2043de0d2e3b7826127998.jpg",
"http://www.marketingtool.online/en/face-generator/img/faces/avatar-116b5e92936b766b7fdfc242649337f7.jpg",
"http://www.marketingtool.online/en/face-generator/img/faces/avatar-1163530ca19b5cebe1b002b8ec67b6fc.jpg",
"http://www.marketingtool.online/en/face-generator/img/faces/avatar-1116395d6e6a6581eef8b8038f4c8e55.jpg",
"http://www.marketingtool.online/en/face-generator/img/faces/avatar-11319be65db395d0e8e6855d18ddcef0.jpg",
]
), f"label {i}")
for i in range(3)
]
return images
with gr.Blocks() as demo:
gallery = gr.Gallery(
label="Generated images", show_label=False, elem_id="gallery"
, columns=[3], rows=[1], object_fit="contain", height="auto")
btn = gr.Button("Generate images", scale=0)
btn.click(fake_gan, None, gallery)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/fake_gan/run.ipynb |
--
title: MAE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual
values.
---
# Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
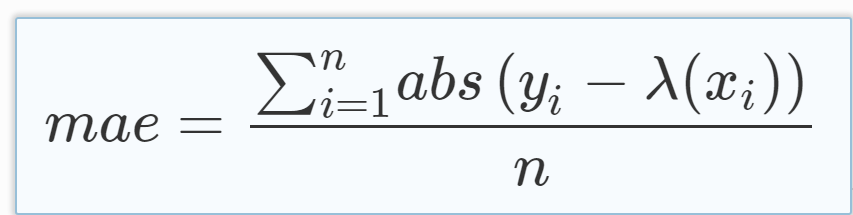
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mae_metric = evaluate.load("mae")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mae_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MAE `float` value ranges from `0.0` to `+inf`, with the best value being 0.0.
Output Example(s):
```python
{'mae': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mae': array([0.5, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> mae_metric = evaluate.load("mae")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mae_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mae': 0.5}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> mae_metric = evaluate.load("mae", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0, 2], [-1, 2], [8, -5]]
>>> results = mae_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mae': 0.75}
>>> results = mae_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mae': array([0.5, 1. ])}
```
## Limitations and Bias
One limitation of MAE is that the relative size of the error is not always obvious, meaning that it can be difficult to tell a big error from a smaller one -- metrics such as Mean Absolute Percentage Error (MAPE) have been proposed to calculate MAE in percentage terms.
Also, since it calculates the mean, MAE may underestimate the impact of big, but infrequent, errors -- metrics such as the Root Mean Square Error (RMSE) compensate for this by taking the root of error values.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{willmott2005advantages,
title={Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance},
author={Willmott, Cort J and Matsuura, Kenji},
journal={Climate research},
volume={30},
number={1},
pages={79--82},
year={2005}
}
```
## Further References
- [Mean Absolute Error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_error)
| huggingface/evaluate/blob/main/metrics/mae/README.md |
FrameworkSwitchCourse {fw} />
# Introduction[[introduction]]
<CourseFloatingBanner
chapter={7}
classNames="absolute z-10 right-0 top-0"
/>
In [Chapter 3](/course/chapter3), you saw how to fine-tune a model for text classification. In this chapter, we will tackle the following common NLP tasks:
- Token classification
- Masked language modeling (like BERT)
- Summarization
- Translation
- Causal language modeling pretraining (like GPT-2)
- Question answering
{#if fw === 'pt'}
To do this, you'll need to leverage everything you learned about the `Trainer` API and the 🤗 Accelerate library in [Chapter 3](/course/chapter3), the 🤗 Datasets library in [Chapter 5](/course/chapter5), and the 🤗 Tokenizers library in [Chapter 6](/course/chapter6). We'll also upload our results to the Model Hub, like we did in [Chapter 4](/course/chapter4), so this is really the chapter where everything comes together!
Each section can be read independently and will show you how to train a model with the `Trainer` API or with your own training loop, using 🤗 Accelerate. Feel free to skip either part and focus on the one that interests you the most: the `Trainer` API is great for fine-tuning or training your model without worrying about what's going on behind the scenes, while the training loop with `Accelerate` will let you customize any part you want more easily.
{:else}
To do this, you'll need to leverage everything you learned about training models with the Keras API in [Chapter 3](/course/chapter3), the 🤗 Datasets library in [Chapter 5](/course/chapter5), and the 🤗 Tokenizers library in [Chapter 6](/course/chapter6). We'll also upload our results to the Model Hub, like we did in [Chapter 4](/course/chapter4), so this is really the chapter where everything comes together!
Each section can be read independently.
{/if}
<Tip>
If you read the sections in sequence, you will notice that they have quite a bit of code and prose in common. The repetition is intentional, to allow you to dip in (or come back later) to any task that interests you and find a complete working example.
</Tip>
| huggingface/course/blob/main/chapters/en/chapter7/1.mdx |
# Requirements
In order to generate the documentation, it is necessary to have a Python environment with the
following:
```python
pip install sphinx sphinx_rtd_theme setuptools_rust
```
It is also necessary to have the `tokenizers` library in this same environment, for Sphinx to
generate all the API Reference and links properly. If you want to visualize the documentation with
some modifications made to the Python bindings, make sure you build it from source.
## Building the documentation
Once everything is setup, you can build the documentation automatically for all the languages
using the following command in the `/docs` folder:
```bash
make html_all
```
If you want to build only for a specific language, you can use:
```bash
make html O="-t python"
```
(Replacing `python` by the target language among `rust`, `node`, and `python`)
**NOTE**
If you are making any structural change to the documentation, it is recommended to clean the build
directory before rebuilding:
```bash
make clean && make html_all
```
| huggingface/tokenizers/blob/main/docs/README.md |
--
title: Goodbye cold boot - how we made LoRA Inference 300% faster
thumbnail: /blog/assets/171_load_lora_adapters/thumbnail3.png
authors:
- user: raphael-gl
---
# Goodbye cold boot - how we made LoRA Inference 300% faster
tl;dr: We swap the Stable Diffusion LoRA adapters per user request, while keeping the base model warm allowing fast LoRA inference across multiple users. You can experience this by browsing our [LoRA catalogue](https://huggingface.co/models?library=diffusers&other=lora) and playing with the inference widget.

In this blog we will go in detail over how we achieved that.
We've been able to drastically speed up inference in the Hub for public LoRAs based on public Diffusion models. This has allowed us to save compute resources and provide a faster and better user experience.
To perform inference on a given model, there are two steps:
1. Warm up phase - that consists in downloading the model and setting up the service (25s).
2. Then the inference job itself (10s).
With the improvements, we were able to reduce the warm up time from 25s to 3s. We are now able to serve inference for hundreds of distinct LoRAs, with less than 5 A10G GPUs, while the response time to user requests decreased from 35s to 13s.
Let's talk more about how we can leverage some recent features developed in the [Diffusers](https://github.com/huggingface/diffusers/) library to serve many distinct LoRAs in a dynamic fashion with one single service.
## LoRA
LoRA is a fine-tuning technique that belongs to the family of "parameter-efficient" (PEFT) methods, which try to reduce the number of trainable parameters affected by the fine-tuning process. It increases fine-tuning speed while reducing the size of fine-tuned checkpoints.
Instead of fine-tuning the model by performing tiny changes to all its weights, we freeze most of the layers and only train a few specific ones in the attention blocks. Furthermore, we avoid touching the parameters of those layers by adding the product of two smaller matrices to the original weights. Those small matrices are the ones whose weights are updated during the fine-tuning process, and then saved to disk. This means that all of the model original parameters are preserved, and we can load the LoRA weights on top using an adaptation method.
The LoRA name (Low Rank Adaptation) comes from the small matrices we mentioned. For more information about the method, please refer to [this post](https://huggingface.co/blog/lora) or the [original paper](https://arxiv.org/abs/2106.09685).
<div id="diagram"></div>

The diagram above shows two smaller orange matrices that are saved as part of the LoRA adapter. We can later load the LoRA adapter and merge it with the blue base model to obtain the yellow fine-tuned model. Crucially, _unloading_ the adapter is also possible so we can revert back to the original base model at any point.
In other words, the LoRA adapter is like an add-on of a base model that can be added and removed on demand. And because of A and B smaller ranks, it is very light in comparison with the model size. Therefore, loading is much faster than loading the whole base model.
If you look, for example, inside the [Stable Diffusion XL Base 1.0 model repo](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main), which is widely used as a base model for many LoRA adapters, you can see that its size is around **7 GB**. However, typical LoRA adapters like [this one](https://huggingface.co/minimaxir/sdxl-wrong-lora/) take a mere **24 MB** of space !
There are far less blue base models than there are yellow ones on the Hub. If we can go quickly from the blue to yellow one and vice versa, then we have a way serve many distinct yellow models with only a few distinct blue deployments.
For a more exhaustive presentation on what LoRA is, please refer to the following blog post:[Using LoRA for Efficient Stable Diffusion Fine-Tuning](https://huggingface.co/blog/lora), or refer directly to the [original paper](https://arxiv.org/abs/2106.09685).
## Benefits
We have approximately **2500** distinct public LoRAs on the Hub. The vast majority (**~92%**) of them are LoRAs based on the [Stable Diffusion XL Base 1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) model.
Before this mutualization, this would have meant deploying a dedicated service for all of them (eg. for all the yellow merged matrices in the diagram above); releasing + reserving at least one new GPU. The time to spawn the service and have it ready to serve requests for a specific model is approximately **25s**, then on top of this you have the inference time (**~10s** for a 1024x1024 SDXL inference diffusion with 25 inference steps on an A10G). If an adapter is only occasionally requested, its service gets stopped to free resources preempted by others.
If you were requesting a LoRA that was not so popular, even if it was based on the SDXL model like the vast majority of adapters found on the Hub so far, it would have required **35s** to warm it up and get an answer on the first request (the following ones would have taken the inference time, eg. **10s**).
Now: request time has decreased from 35s to 13s since adapters will use only a few distinct "blue" base models (like 2 significant ones for Diffusion). Even if your adapter is not so popular, there is a good chance that its "blue" service is already warmed up. In other words, there is a good chance that you avoid the 25s warm up time, even if you do not request your model that often. The blue model is already downloaded and ready, all we have to do is unload the previous adapter and load the new one, which takes **3s** as we see [below](#loading-figures).
Overall, this requires less GPUs to serve all distinct models, even though we already had a way to share GPUs between deployments to maximize their compute usage. In a **2min** time frame, there are approximately **10** distinct LoRA weights that are requested. Instead of spawning 10 deployments, and keeping them warm, we simply serve all of them with 1 to 2 GPUs (or more if there is a request burst).
## Implementation
We implemented LoRA mutualization in the Inference API. When a request is performed on a model available in our platform, we first determine whether this is a LoRA or not. We then identify the base model for the LoRA and route the request to a common backend farm, with the ability to serve requests for the said model. Inference requests get served by keeping the base model warm and loading/unloading LoRAs on the fly. This way we can ultimately reuse the same compute resources to serve many distinct models at once.
### LoRA structure
In the Hub, LoRAs can be identified with two attributes:

A LoRA will have a ```base_model``` attribute. This is simply the model which the LoRA was built for and should be applied to when performing inference.
Because LoRAs are not the only models with such an attribute (any duplicated model will have one), a LoRA will also need a ```lora``` tag to be properly identified.
### Loading/Offloading LoRA for Diffusers 🧨
<div class="alert">
<p>
Note that there is a more seemless way to perform the same as what is presented in this section using the <a href="https://github.com/huggingface/peft">peft</a> library. Please refer to <a href="https://huggingface.co/docs/diffusers/main/en/tutorials/using_peft_for_inference">the documentation</a> for more details. The principle remains the same as below (going from/to the blue box to/from the yellow one in the <a href="#diagram">diagram</a> above)
</p>
</div>
</br>
4 functions are used in the Diffusers library to load and unload distinct LoRA weights:
```load_lora_weights``` and ```fuse_lora``` for loading and merging weights with the main layers. Note that merging weights with the main model before performing inference can decrease the inference time by 30%.
```unload_lora_weights``` and ```unfuse_lora``` for unloading.
We provide an example below on how one can leverage the Diffusers library to quickly load several LoRA weights on top of a base model:
```py
import torch
from diffusers import (
AutoencoderKL,
DiffusionPipeline,
)
import time
base = "stabilityai/stable-diffusion-xl-base-1.0"
adapter1 = 'nerijs/pixel-art-xl'
weightname1 = 'pixel-art-xl.safetensors'
adapter2 = 'minimaxir/sdxl-wrong-lora'
weightname2 = None
inputs = "elephant"
kwargs = {}
if torch.cuda.is_available():
kwargs["torch_dtype"] = torch.float16
start = time.time()
# Load VAE compatible with fp16 created by madebyollin
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16,
)
kwargs["vae"] = vae
kwargs["variant"] = "fp16"
model = DiffusionPipeline.from_pretrained(
base, **kwargs
)
if torch.cuda.is_available():
model.to("cuda")
elapsed = time.time() - start
print(f"Base model loaded, elapsed {elapsed:.2f} seconds")
def inference(adapter, weightname):
start = time.time()
model.load_lora_weights(adapter, weight_name=weightname)
# Fusing lora weights with the main layers improves inference time by 30 % !
model.fuse_lora()
elapsed = time.time() - start
print(f"LoRA adapter loaded and fused to main model, elapsed {elapsed:.2f} seconds")
start = time.time()
data = model(inputs, num_inference_steps=25).images[0]
elapsed = time.time() - start
print(f"Inference time, elapsed {elapsed:.2f} seconds")
start = time.time()
model.unfuse_lora()
model.unload_lora_weights()
elapsed = time.time() - start
print(f"LoRA adapter unfused/unloaded from base model, elapsed {elapsed:.2f} seconds")
inference(adapter1, weightname1)
inference(adapter2, weightname2)
```
## Loading figures
All numbers below are in seconds:
<table>
<tr>
<th>GPU</th>
<td>T4</td>
<td>A10G</td>
</tr>
<tr>
<th>Base model loading - not cached</th>
<td>20</td>
<td>20</td>
</tr>
<tr>
<th>Base model loading - cached</th>
<td>5.95</td>
<td>4.09</td>
</tr>
<tr>
<th>Adapter 1 loading</th>
<td>3.07</td>
<td>3.46</td>
</tr>
<tr>
<th>Adapter 1 unloading</th>
<td>0.52</td>
<td>0.28</td>
</tr>
<tr>
<th>Adapter 2 loading</th>
<td>1.44</td>
<td>2.71</td>
</tr>
<tr>
<th>Adapter 2 unloading</th>
<td>0.19</td>
<td>0.13</td>
</tr>
<tr>
<th>Inference time</th>
<td>20.7</td>
<td>8.5</td>
</tr>
</table>
With 2 to 4 additional seconds per inference, we can serve many distinct LoRAs. However, on an A10G GPU, the inference time decreases by a lot while the adapters loading time does not change much, so the LoRA's loading/unloading is relatively more expensive.
### Serving requests
To serve inference requests, we use [this open source community image](https://github.com/huggingface/api-inference-community/tree/main/docker_images/diffusers)
You can find the previously described mechanism used in the [TextToImagePipeline](https://github.com/huggingface/api-inference-community/blob/main/docker_images/diffusers/app/pipelines/text_to_image.py) class.
When a LoRA is requested, we'll look at the one that is loaded and change it only if required, then we perform inference as usual. This way, we are able to serve requests for the base model and many distinct adapters.
Below is an example on how you can test and request this image:
```
$ git clone https://github.com/huggingface/api-inference-community.git
$ cd api-inference-community/docker_images/diffusers
$ docker build -t test:1.0 -f Dockerfile .
$ cat > /tmp/env_file <<'EOF'
MODEL_ID=stabilityai/stable-diffusion-xl-base-1.0
TASK=text-to-image
HF_HUB_ENABLE_HF_TRANSFER=1
EOF
$ docker run --gpus all --rm --name test1 --env-file /tmp/env_file_minimal -p 8888:80 -it test:1.0
```
Then in another terminal perform requests to the base model and/or miscellaneous LoRA adapters to be found on the HF Hub.
```
# Request the base model
$ curl 0:8888 -d '{"inputs": "elephant", "parameters": {"num_inference_steps": 20}}' > /tmp/base.jpg
# Request one adapter
$ curl -H 'lora: minimaxir/sdxl-wrong-lora' 0:8888 -d '{"inputs": "elephant", "parameters": {"num_inference_steps": 20}}' > /tmp/adapter1.jpg
# Request another one
$ curl -H 'lora: nerijs/pixel-art-xl' 0:8888 -d '{"inputs": "elephant", "parameters": {"num_inference_steps": 20}}' > /tmp/adapter2.jpg
```
### What about batching ?
Recently a really interesting [paper](https://arxiv.org/abs/2311.03285) came out, that described how to increase the throughput by performing batched inference on LoRA models. In short, all inference requests would be gathered in a batch, the computation related to the common base model would be done all at once, then the remaining adapter-specific products would be computed. We did not implement such a technique (close to the approach adopted in [text-generation-inference](https://github.com/huggingface/text-generation-inference/) for LLMs). Instead, we stuck to single sequential inference requests. The reason is that we observed that batching was not interesting for diffusers: throughput does not increase significantly with batch size. On the simple image generation benchmark we performed, it only increased 25% for a batch size of 8, in exchange for 6 times increased latency! Comparatively, batching is far more interesting for LLMs because you get 8 times the sequential throughput with only a 10% latency increase. This is the reason why we did not implement batching for diffusers.
## Conclusion: **Time**!
Using dynamic LoRA loading, we were able to save compute resources and improve the user experience in the Hub Inference API. Despite the extra time added by the process of unloading the previously loaded adapter and loading the one we're interested in, the fact that the serving process is most often already up and running makes the inference time response on the whole much shorter.
Note that for a LoRA to benefit from this inference optimization on the Hub, it must both be public, non-gated and based on a non-gated public model. Please do let us know if you apply the same method to your deployment!
| huggingface/blog/blob/main/lora-adapters-dynamic-loading.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Create reproducible pipelines
[[open-in-colab]]
Reproducibility is important for testing, replicating results, and can even be used to [improve image quality](reusing_seeds). However, the randomness in diffusion models is a desired property because it allows the pipeline to generate different images every time it is run. While you can't expect to get the exact same results across platforms, you can expect results to be reproducible across releases and platforms within a certain tolerance range. Even then, tolerance varies depending on the diffusion pipeline and checkpoint.
This is why it's important to understand how to control sources of randomness in diffusion models or use deterministic algorithms.
<Tip>
💡 We strongly recommend reading PyTorch's [statement about reproducibility](https://pytorch.org/docs/stable/notes/randomness.html):
> Completely reproducible results are not guaranteed across PyTorch releases, individual commits, or different platforms. Furthermore, results may not be reproducible between CPU and GPU executions, even when using identical seeds.
</Tip>
## Control randomness
During inference, pipelines rely heavily on random sampling operations which include creating the
Gaussian noise tensors to denoise and adding noise to the scheduling step.
Take a look at the tensor values in the [`DDIMPipeline`] after two inference steps:
```python
from diffusers import DDIMPipeline
import numpy as np
model_id = "google/ddpm-cifar10-32"
# load model and scheduler
ddim = DDIMPipeline.from_pretrained(model_id, use_safetensors=True)
# run pipeline for just two steps and return numpy tensor
image = ddim(num_inference_steps=2, output_type="np").images
print(np.abs(image).sum())
```
Running the code above prints one value, but if you run it again you get a different value. What is going on here?
Every time the pipeline is run, [`torch.randn`](https://pytorch.org/docs/stable/generated/torch.randn.html) uses a different random seed to create Gaussian noise which is denoised stepwise. This leads to a different result each time it is run, which is great for diffusion pipelines since it generates a different random image each time.
But if you need to reliably generate the same image, that'll depend on whether you're running the pipeline on a CPU or GPU.
### CPU
To generate reproducible results on a CPU, you'll need to use a PyTorch [`Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) and set a seed:
```python
import torch
from diffusers import DDIMPipeline
import numpy as np
model_id = "google/ddpm-cifar10-32"
# load model and scheduler
ddim = DDIMPipeline.from_pretrained(model_id, use_safetensors=True)
# create a generator for reproducibility
generator = torch.Generator(device="cpu").manual_seed(0)
# run pipeline for just two steps and return numpy tensor
image = ddim(num_inference_steps=2, output_type="np", generator=generator).images
print(np.abs(image).sum())
```
Now when you run the code above, it always prints a value of `1491.1711` no matter what because the `Generator` object with the seed is passed to all the random functions of the pipeline.
If you run this code example on your specific hardware and PyTorch version, you should get a similar, if not the same, result.
<Tip>
💡 It might be a bit unintuitive at first to pass `Generator` objects to the pipeline instead of
just integer values representing the seed, but this is the recommended design when dealing with
probabilistic models in PyTorch, as `Generator`s are *random states* that can be
passed to multiple pipelines in a sequence.
</Tip>
### GPU
Writing a reproducible pipeline on a GPU is a bit trickier, and full reproducibility across different hardware is not guaranteed because matrix multiplication - which diffusion pipelines require a lot of - is less deterministic on a GPU than a CPU. For example, if you run the same code example above on a GPU:
```python
import torch
from diffusers import DDIMPipeline
import numpy as np
model_id = "google/ddpm-cifar10-32"
# load model and scheduler
ddim = DDIMPipeline.from_pretrained(model_id, use_safetensors=True)
ddim.to("cuda")
# create a generator for reproducibility
generator = torch.Generator(device="cuda").manual_seed(0)
# run pipeline for just two steps and return numpy tensor
image = ddim(num_inference_steps=2, output_type="np", generator=generator).images
print(np.abs(image).sum())
```
The result is not the same even though you're using an identical seed because the GPU uses a different random number generator than the CPU.
To circumvent this problem, 🧨 Diffusers has a [`~diffusers.utils.torch_utils.randn_tensor`] function for creating random noise on the CPU, and then moving the tensor to a GPU if necessary. The `randn_tensor` function is used everywhere inside the pipeline, allowing the user to **always** pass a CPU `Generator` even if the pipeline is run on a GPU.
You'll see the results are much closer now!
```python
import torch
from diffusers import DDIMPipeline
import numpy as np
model_id = "google/ddpm-cifar10-32"
# load model and scheduler
ddim = DDIMPipeline.from_pretrained(model_id, use_safetensors=True)
ddim.to("cuda")
# create a generator for reproducibility; notice you don't place it on the GPU!
generator = torch.manual_seed(0)
# run pipeline for just two steps and return numpy tensor
image = ddim(num_inference_steps=2, output_type="np", generator=generator).images
print(np.abs(image).sum())
```
<Tip>
💡 If reproducibility is important, we recommend always passing a CPU generator.
The performance loss is often neglectable, and you'll generate much more similar
values than if the pipeline had been run on a GPU.
</Tip>
Finally, for more complex pipelines such as [`UnCLIPPipeline`], these are often extremely
susceptible to precision error propagation. Don't expect similar results across
different GPU hardware or PyTorch versions. In this case, you'll need to run
exactly the same hardware and PyTorch version for full reproducibility.
## Deterministic algorithms
You can also configure PyTorch to use deterministic algorithms to create a reproducible pipeline. However, you should be aware that deterministic algorithms may be slower than nondeterministic ones and you may observe a decrease in performance. But if reproducibility is important to you, then this is the way to go!
Nondeterministic behavior occurs when operations are launched in more than one CUDA stream. To avoid this, set the environment variable [`CUBLAS_WORKSPACE_CONFIG`](https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility) to `:16:8` to only use one buffer size during runtime.
PyTorch typically benchmarks multiple algorithms to select the fastest one, but if you want reproducibility, you should disable this feature because the benchmark may select different algorithms each time. Lastly, pass `True` to [`torch.use_deterministic_algorithms`](https://pytorch.org/docs/stable/generated/torch.use_deterministic_algorithms.html) to enable deterministic algorithms.
```py
import os
import torch
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8"
torch.backends.cudnn.benchmark = False
torch.use_deterministic_algorithms(True)
```
Now when you run the same pipeline twice, you'll get identical results.
```py
import torch
from diffusers import DDIMScheduler, StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_safetensors=True).to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
g = torch.Generator(device="cuda")
prompt = "A bear is playing a guitar on Times Square"
g.manual_seed(0)
result1 = pipe(prompt=prompt, num_inference_steps=50, generator=g, output_type="latent").images
g.manual_seed(0)
result2 = pipe(prompt=prompt, num_inference_steps=50, generator=g, output_type="latent").images
print("L_inf dist =", abs(result1 - result2).max())
"L_inf dist = tensor(0., device='cuda:0')"
```
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/reproducibility.md |
hat happens inside the pipeline function? In this video, we will look at what actually happens when we use the pipeline function of the Transformers library. More specifically, we will look at the sentiment analysis pipeline, and how it went from the two following sentences to the positive labels with their respective scores. As we have seen in the pipeline presentation, there are three stages in the pipeline. First, we convert the raw texts to numbers the model can make sense of, using a tokenizer. Then, those numbers go through the model, which outputs logits. Finally, the post-processing steps transforms those logits into labels and scores. Let's look in detail at those three steps, and how to replicate them using the Transformers library, beginning with the first stage, tokenization. The tokenization process has several steps. First, the text is split into small chunks called tokens. They can be words, parts of words or punctuation symbols. Then the tokenizer will had some special tokens (if the model expect them). Here the model uses expects a CLS token at the beginning and a SEP token at the end of the sentence to classify. Lastly, the tokenizer matches each token to its unique ID in the vocabulary of the pretrained model. To load such a tokenizer, the Transformers library provides the AutoTokenizer API. The most important method of this class is from_pretrained, which will download and cache the configuration and the vocabulary associated to a given checkpoint. Here, the checkpoint used by default for the sentiment analysis pipeline is distilbert base uncased finetuned sst2 english. We instantiate a tokenizer associated with that checkpoint, then feed it the two sentences. Since those two sentences are not of the same size, we will need to pad the shortest one to be able to build an array. This is done by the tokenizer with the option padding=True. With truncation=True, we ensure that any sentence longer than the maximum the model can handle is truncated. Lastly, the return_tensors option tells the tokenizer to return a PyTorch tensor. Looking at the result, we see we have a dictionary with two keys. Input IDs contains the IDs of both sentences, with 0s where the padding is applied. The second key, attention mask, indicates where padding has been applied, so the model does not pay attention to it. This is all what is inside the tokenization step. Now let's have a look at the second step, the model. As for the tokenizer, there is an AutoModel API, with a from_pretrained method. It will download and cache the configuration of the model as well as the pretrained weights. However, the AutoModel API will only instantiate the body of the model, that is, the part of the model that is left once the pretraining head is removed. It will output a high-dimensional tensor that is a representation of the sentences passed, but which is not directly useful for our classification problem. Here the tensor has two sentences, each of sixteen tokens and the last dimension is the hidden size of our model 768. To get an output linked to our classification problem, we need to use the AutoModelForSequenceClassification class. It works exactly as the AutoModel class, except that it will build a model with a classification head. There is one auto class for each common NLP task in the Transformers library. Here, after giving our model the two sentences, we get a tensor of size two by two: one result for each sentence and for each possible label. Those outputs are not probabilities yet (we can see they don't sum to 1). This is because each model of the Transformers library returns logits. To make sense of those logits, we need to dig into the third and last step of the pipeline: post-processing. To convert logits into probabilities, we need to apply a SoftMax layer to them. As we can see, this transforms them into positive numbers that sum up to 1. The last step is to know which of those corresponds to the positive or the negative label. This is given by the id2label field of the model config. The first probabilities (index 0) correspond to the negative label, and the seconds (index 1) correspond to the positive label. This is how our classifier built with the pipeline function picked those labels and computed those scores. Now that you know how each steps works, you can easily tweak them to your needs. | huggingface/course/blob/main/subtitles/en/raw/chapter2/02_inside-pipeline-pt.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities
## Configure logging
The `huggingface_hub` package exposes a `logging` utility to control the logging level of the package itself.
You can import it as such:
```py
from huggingface_hub import logging
```
Then, you may define the verbosity in order to update the amount of logs you'll see:
```python
from huggingface_hub import logging
logging.set_verbosity_error()
logging.set_verbosity_warning()
logging.set_verbosity_info()
logging.set_verbosity_debug()
logging.set_verbosity(...)
```
The levels should be understood as follows:
- `error`: only show critical logs about usage which may result in an error or unexpected behavior.
- `warning`: show logs that aren't critical but usage may result in unintended behavior.
Additionally, important informative logs may be shown.
- `info`: show most logs, including some verbose logging regarding what is happening under the hood.
If something is behaving in an unexpected manner, we recommend switching the verbosity level to this in order
to get more information.
- `debug`: show all logs, including some internal logs which may be used to track exactly what's happening
under the hood.
[[autodoc]] logging.get_verbosity
[[autodoc]] logging.set_verbosity
[[autodoc]] logging.set_verbosity_info
[[autodoc]] logging.set_verbosity_debug
[[autodoc]] logging.set_verbosity_warning
[[autodoc]] logging.set_verbosity_error
[[autodoc]] logging.disable_propagation
[[autodoc]] logging.enable_propagation
### Repo-specific helper methods
The methods exposed below are relevant when modifying modules from the `huggingface_hub` library itself.
Using these shouldn't be necessary if you use `huggingface_hub` and you don't modify them.
[[autodoc]] logging.get_logger
## Configure progress bars
Progress bars are a useful tool to display information to the user while a long-running task is being executed (e.g.
when downloading or uploading files). `huggingface_hub` exposes a [`~utils.tqdm`] wrapper to display progress bars in a
consistent way across the library.
By default, progress bars are enabled. You can disable them globally by setting `HF_HUB_DISABLE_PROGRESS_BARS`
environment variable. You can also enable/disable them using [`~utils.enable_progress_bars`] and
[`~utils.disable_progress_bars`]. If set, the environment variable has priority on the helpers.
```py
>>> from huggingface_hub import snapshot_download
>>> from huggingface_hub.utils import are_progress_bars_disabled, disable_progress_bars, enable_progress_bars
>>> # Disable progress bars globally
>>> disable_progress_bars()
>>> # Progress bar will not be shown !
>>> snapshot_download("gpt2")
>>> are_progress_bars_disabled()
True
>>> # Re-enable progress bars globally
>>> enable_progress_bars()
```
### are_progress_bars_disabled
[[autodoc]] huggingface_hub.utils.are_progress_bars_disabled
### disable_progress_bars
[[autodoc]] huggingface_hub.utils.disable_progress_bars
### enable_progress_bars
[[autodoc]] huggingface_hub.utils.enable_progress_bars
## Configure HTTP backend
In some environments, you might want to configure how HTTP calls are made, for example if you are using a proxy.
`huggingface_hub` let you configure this globally using [`configure_http_backend`]. All requests made to the Hub will
then use your settings. Under the hood, `huggingface_hub` uses `requests.Session` so you might want to refer to the
[`requests` documentation](https://requests.readthedocs.io/en/latest/user/advanced) to learn more about the available
parameters.
Since `requests.Session` is not guaranteed to be thread-safe, `huggingface_hub` creates one session instance per thread.
Using sessions allows us to keep the connection open between HTTP calls and ultimately save time. If you are
integrating `huggingface_hub` in a third-party library and wants to make a custom call to the Hub, use [`get_session`]
to get a Session configured by your users (i.e. replace any `requests.get(...)` call by `get_session().get(...)`).
[[autodoc]] configure_http_backend
[[autodoc]] get_session
## Handle HTTP errors
`huggingface_hub` defines its own HTTP errors to refine the `HTTPError` raised by
`requests` with additional information sent back by the server.
### Raise for status
[`~utils.hf_raise_for_status`] is meant to be the central method to "raise for status" from any
request made to the Hub. It wraps the base `requests.raise_for_status` to provide
additional information. Any `HTTPError` thrown is converted into a `HfHubHTTPError`.
```py
import requests
from huggingface_hub.utils import hf_raise_for_status, HfHubHTTPError
response = requests.post(...)
try:
hf_raise_for_status(response)
except HfHubHTTPError as e:
print(str(e)) # formatted message
e.request_id, e.server_message # details returned by server
# Complete the error message with additional information once it's raised
e.append_to_message("\n`create_commit` expects the repository to exist.")
raise
```
[[autodoc]] huggingface_hub.utils.hf_raise_for_status
### HTTP errors
Here is a list of HTTP errors thrown in `huggingface_hub`.
#### HfHubHTTPError
`HfHubHTTPError` is the parent class for any HF Hub HTTP error. It takes care of parsing
the server response and format the error message to provide as much information to the
user as possible.
[[autodoc]] huggingface_hub.utils.HfHubHTTPError
#### RepositoryNotFoundError
[[autodoc]] huggingface_hub.utils.RepositoryNotFoundError
#### GatedRepoError
[[autodoc]] huggingface_hub.utils.GatedRepoError
#### RevisionNotFoundError
[[autodoc]] huggingface_hub.utils.RevisionNotFoundError
#### EntryNotFoundError
[[autodoc]] huggingface_hub.utils.EntryNotFoundError
#### BadRequestError
[[autodoc]] huggingface_hub.utils.BadRequestError
#### LocalEntryNotFoundError
[[autodoc]] huggingface_hub.utils.LocalEntryNotFoundError
#### OfflineModeIsEnabled
[[autodoc]] huggingface_hub.utils.OfflineModeIsEnabled
## Telemetry
`huggingface_hub` includes an helper to send telemetry data. This information helps us debug issues and prioritize new features.
Users can disable telemetry collection at any time by setting the `HF_HUB_DISABLE_TELEMETRY=1` environment variable.
Telemetry is also disabled in offline mode (i.e. when setting HF_HUB_OFFLINE=1).
If you are maintainer of a third-party library, sending telemetry data is as simple as making a call to [`send_telemetry`].
Data is sent in a separate thread to reduce as much as possible the impact for users.
[[autodoc]] utils.send_telemetry
## Validators
`huggingface_hub` includes custom validators to validate method arguments automatically.
Validation is inspired by the work done in [Pydantic](https://pydantic-docs.helpmanual.io/)
to validate type hints but with more limited features.
### Generic decorator
[`~utils.validate_hf_hub_args`] is a generic decorator to encapsulate
methods that have arguments following `huggingface_hub`'s naming. By default, all
arguments that has a validator implemented will be validated.
If an input is not valid, a [`~utils.HFValidationError`] is thrown. Only
the first non-valid value throws an error and stops the validation process.
Usage:
```py
>>> from huggingface_hub.utils import validate_hf_hub_args
>>> @validate_hf_hub_args
... def my_cool_method(repo_id: str):
... print(repo_id)
>>> my_cool_method(repo_id="valid_repo_id")
valid_repo_id
>>> my_cool_method("other..repo..id")
huggingface_hub.utils._validators.HFValidationError: Cannot have -- or .. in repo_id: 'other..repo..id'.
>>> my_cool_method(repo_id="other..repo..id")
huggingface_hub.utils._validators.HFValidationError: Cannot have -- or .. in repo_id: 'other..repo..id'.
>>> @validate_hf_hub_args
... def my_cool_auth_method(token: str):
... print(token)
>>> my_cool_auth_method(token="a token")
"a token"
>>> my_cool_auth_method(use_auth_token="a use_auth_token")
"a use_auth_token"
>>> my_cool_auth_method(token="a token", use_auth_token="a use_auth_token")
UserWarning: Both `token` and `use_auth_token` are passed (...). `use_auth_token` value will be ignored.
"a token"
```
#### validate_hf_hub_args
[[autodoc]] utils.validate_hf_hub_args
#### HFValidationError
[[autodoc]] utils.HFValidationError
### Argument validators
Validators can also be used individually. Here is a list of all arguments that can be
validated.
#### repo_id
[[autodoc]] utils.validate_repo_id
#### smoothly_deprecate_use_auth_token
Not exactly a validator, but ran as well.
[[autodoc]] utils.smoothly_deprecate_use_auth_token
| huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/utilities.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trajectory Transformer
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
The abstract from the paper is the following:
*Reinforcement learning (RL) is typically concerned with estimating stationary policies or single-step models,
leveraging the Markov property to factorize problems in time. However, we can also view RL as a generic sequence
modeling problem, with the goal being to produce a sequence of actions that leads to a sequence of high rewards.
Viewed in this way, it is tempting to consider whether high-capacity sequence prediction models that work well
in other domains, such as natural-language processing, can also provide effective solutions to the RL problem.
To this end, we explore how RL can be tackled with the tools of sequence modeling, using a Transformer architecture
to model distributions over trajectories and repurposing beam search as a planning algorithm. Framing RL as sequence
modeling problem simplifies a range of design decisions, allowing us to dispense with many of the components common
in offline RL algorithms. We demonstrate the flexibility of this approach across long-horizon dynamics prediction,
imitation learning, goal-conditioned RL, and offline RL. Further, we show that this approach can be combined with
existing model-free algorithms to yield a state-of-the-art planner in sparse-reward, long-horizon tasks.*
This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
## Usage tips
This Transformer is used for deep reinforcement learning. To use it, you need to create sequences from
actions, states and rewards from all previous timesteps. This model will treat all these elements together
as one big sequence (a trajectory).
## TrajectoryTransformerConfig
[[autodoc]] TrajectoryTransformerConfig
## TrajectoryTransformerModel
[[autodoc]] TrajectoryTransformerModel
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/trajectory_transformer.md |
he purpose of this directory is to showcase various attacks (and creating your own).
# Torch Arbitrary code execution
Try it out. This will create a seemingly innocuous `torch_ace.pt` file.
```
python torch_ace_create.py
python torch_ace_get_pwned.py
```
# PaddlePaddle Arbitrary code execution
Try it out. This will create a seemingly innocuous `paddle_ace.pdparams` file.
```
python paddle_ace_create.py
python paddle_ace_get_pwned.py
```
# Tensorflow (Keras) Arbitrary Code execution (does not affect `transformers`)
Try it out. This will create a seemingly innocuous `tf_ace.h5` file.
```
python tf_dos_create.py
python tf_dos_get_pwned.py
```
# Torch Denial of Service (OOM kills the running process)
Try it out. This will create a seemingly innocuous `torch_dos.pt` file.
```
python torch_dos_create.py
python torch_dos_get_pwned.py
```
# Numpy Denial of Service (OOM kills the running process)
Try it out. This will create a seemingly innocuous `numpy_dos.npz` file.
```
python numpy_dos_create.py
python numpy_dos_get_pwned.py
```
# Safetensors abuse attempts
In order to try and check the limits, we also try to abuse the current format.
Please send ideas!
A few things can be abused:
- Proposal 1: The initial 8 bytes, which could be too big with regards to the file. This crashes, and crashes early (Out of bounds) (Attempt #1).
- Proposal 2: The initial header is JSON, an attacker could use a 4Go JSON file to delay the loads. Debattable how much of an attack this is, but at least
it's impossible to "bomb" (like the DOS attacks above) where the files are vastly smaller than their expanded version (because of zip abuse).
Various "protections" could be put in place, like a header proportion cap (header should always be <<< of the size of the file). (Attempt #2)
- Proposal 3: The offsets could be negative, out of the file. This is all crashing by default.
- Proposal 4: The offsets could overlap. ~~This is actually OK.~~ This is NOT ok.
While testing Proposal 2, I realized that the tensors themselves where all allocated, and gave me an idea for a DOS exploit where you would have a relatively small
file a few megs tops, but defining many tensors on the same overlapping part of the file, it was essentially a DOS attack. The mitigation is rather simple, we sanitize the fact
that the offsets must be contiguous and non overlapping.
- Proposal 5: The offsets could mismatch the declared shapes + dtype. This validated against.
- Proposal 6: The file being mmaped could be modified while it's opened (attacker has access to your filesystem, seems like you're already pwned).
- Proposal 7: serde JSON deserialization abuse (nothing so far: https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=serde). It doesn't mean there isn't a flaw. Same goes for the actual rust compiled binary.
```
python safetensors_abuse_attempt_1.py
python safetensors_abuse_attempt_2.py
python safetensors_abuse_attempt_3.py
```
| huggingface/safetensors/blob/main/attacks/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
Then you need to install our special tool that builds the documentation:
```bash
pip install git+https://github.com/huggingface/doc-builder
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look before committing for instance). You don't have to commit the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages, you can generate the documentation by
typing the following command:
```bash
doc-builder build transformers docs/source/en/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
## Previewing the documentation
To preview the docs, first install the `watchdog` module with:
```bash
pip install watchdog
```
Then run the following command:
```bash
doc-builder preview {package_name} {path_to_docs}
```
For example:
```bash
doc-builder preview transformers docs/source/en/
```
The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
---
**NOTE**
The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course, if you moved it to another file, then:
```
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
For an example of a rich moved section set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
## Writing Documentation - Specification
The `huggingface/transformers` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or
four.
### Translating
When translating, refer to the guide at [./TRANSLATING.md](https://github.com/huggingface/transformers/blob/main/docs/TRANSLATING.md).
### Adding a new model
When adding a new model:
- Create a file `xxx.md` or under `./source/model_doc` (don't hesitate to copy an existing file as template).
- Link that file in `./source/_toctree.yml`.
- Write a short overview of the model:
- Overview with paper & authors
- Paper abstract
- Tips and tricks and how to use it best
- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
The order is generally:
- Configuration
- Tokenizer
- PyTorch base model
- PyTorch head models
- TensorFlow base model
- TensorFlow head models
- Flax base model
- Flax head models
These classes should be added using our Markdown syntax. Usually as follows:
```
## XXXConfig
[[autodoc]] XXXConfig
```
This will include every public method of the configuration that is documented. If for some reason you wish for a method
not to be displayed in the documentation, you can do so by specifying which methods should be in the docs:
```
## XXXTokenizer
[[autodoc]] XXXTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
```
If you just want to add a method that is not documented (for instance magic methods like `__call__` are not documented
by default) you can put the list of methods to add in a list that contains `all`:
```
## XXXTokenizer
[[autodoc]] XXXTokenizer
- all
- __call__
```
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None, or any strings should usually be put in `code`.
When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`utils.ModelOutput\`\]. This will be converted into a link with
`utils.ModelOutput` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~utils.ModelOutput\`\] will generate a link with `ModelOutput` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line, another indentation is necessary before writing the description
after the argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
[`~PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ...
a (`float`, *optional*, defaults to 1):
This argument is used to ...
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```
# first line of code
# second line
# etc
```
````
We follow the [doctest](https://docs.python.org/3/library/doctest.html) syntax for the examples to automatically test
the results to stay consistent with the library.
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example of a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example of a tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
#### Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## Styling the docstring
We have an automatic script running with the `make style` comment that will make sure that:
- the docstrings fully take advantage of the line width
- all code examples are formatted using black, like the code of the Transformers library
This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
recommended to commit your changes before running `make style`, so you can revert the changes done by that script
easily.
# Testing documentation examples
Good documentation often comes with an example of how a specific function or class should be used.
Each model class should contain at least one example showcasing
how to use this model class in inference. *E.g.* the class [Wav2Vec2ForCTC](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC)
includes an example of how to transcribe speech to text in the
[docstring of its forward function](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC.forward).
## Writing documentation examples
The syntax for Example docstrings can look as follows:
```
Example:
```python
>>> from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
```
```
The docstring should give a minimal, clear example of how the respective model
is to be used in inference and also include the expected (ideally sensible)
output.
Often, readers will try out the example before even going through the function
or class definitions. Therefore, it is of utmost importance that the example
works as expected.
## Docstring testing
To do so each example should be included in the doctests.
We use pytests' [doctest integration](https://docs.pytest.org/doctest.html) to verify that all of our examples run correctly.
For Transformers, the doctests are run on a daily basis via GitHub Actions as can be
seen [here](https://github.com/huggingface/transformers/actions/workflows/doctests.yml).
### For Python files
Run all the tests in the docstrings of a given file with the following command, here is how we test the modeling file of Wav2Vec2 for instance:
```bash
pytest --doctest-modules src/transformers/models/wav2vec2/modeling_wav2vec2.py -sv --doctest-continue-on-failure
```
If you want to isolate a specific docstring, just add `::` after the file name then type the whole path of the function/class/method whose docstring you want to test. For instance, here is how to just test the forward method of `Wav2Vec2ForCTC`:
```bash
pytest --doctest-modules src/transformers/models/wav2vec2/modeling_wav2vec2.py::transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForCTC.forward -sv --doctest-continue-on-failure
```
### For Markdown files
You can test locally a given file with this command (here testing the quicktour):
```bash
pytest --doctest-modules docs/source/quicktour.md -sv --doctest-continue-on-failure --doctest-glob="*.md"
```
### Writing doctests
Here are a few tips to help you debug the doctests and make them pass:
- The outputs of the code need to match the expected output **exactly**, so make sure you have the same outputs. In particular doctest will see a difference between single quotes and double quotes, or a missing parenthesis. The only exceptions to that rule are:
* whitespace: one give whitespace (space, tabulation, new line) is equivalent to any number of whitespace, so you can add new lines where there are spaces to make your output more readable.
* numerical values: you should never put more than 4 or 5 digits to expected results as different setups or library versions might get you slightly different results. `doctest` is configured to ignore any difference lower than the precision to which you wrote (so 1e-4 if you write 4 digits).
- Don't leave a block of code that is very long to execute. If you can't make it fast, you can either not use the doctest syntax on it (so that it's ignored), or if you want to use the doctest syntax to show the results, you can add a comment `# doctest: +SKIP` at the end of the lines of code too long to execute
- Each line of code that produces a result needs to have that result written below. You can ignore an output if you don't want to show it in your code example by adding a comment ` # doctest: +IGNORE_RESULT` at the end of the line of code producing it.
| huggingface/transformers/blob/main/docs/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Image-to-image
The Stable Diffusion model can also be applied to image-to-image generation by passing a text prompt and an initial image to condition the generation of new images.
The [`StableDiffusionImg2ImgPipeline`] uses the diffusion-denoising mechanism proposed in [SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations](https://huggingface.co/papers/2108.01073) by Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon.
The abstract from the paper is:
*Guided image synthesis enables everyday users to create and edit photo-realistic images with minimum effort. The key challenge is balancing faithfulness to the user input (e.g., hand-drawn colored strokes) and realism of the synthesized image. Existing GAN-based methods attempt to achieve such balance using either conditional GANs or GAN inversions, which are challenging and often require additional training data or loss functions for individual applications. To address these issues, we introduce a new image synthesis and editing method, Stochastic Differential Editing (SDEdit), based on a diffusion model generative prior, which synthesizes realistic images by iteratively denoising through a stochastic differential equation (SDE). Given an input image with user guide of any type, SDEdit first adds noise to the input, then subsequently denoises the resulting image through the SDE prior to increase its realism. SDEdit does not require task-specific training or inversions and can naturally achieve the balance between realism and faithfulness. SDEdit significantly outperforms state-of-the-art GAN-based methods by up to 98.09% on realism and 91.72% on overall satisfaction scores, according to a human perception study, on multiple tasks, including stroke-based image synthesis and editing as well as image compositing.*
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
</Tip>
## StableDiffusionImg2ImgPipeline
[[autodoc]] StableDiffusionImg2ImgPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
- load_textual_inversion
- from_single_file
- load_lora_weights
- save_lora_weights
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
## FlaxStableDiffusionImg2ImgPipeline
[[autodoc]] FlaxStableDiffusionImg2ImgPipeline
- all
- __call__
## FlaxStableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/img2img.md |
`tokenizers-linux-x64-gnu`
This is the **x86_64-unknown-linux-gnu** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/linux-x64-gnu/README.md |
如何使用 3D 模型组件
相关空间:https://huggingface.co/spaces/dawood/Model3D, https://huggingface.co/spaces/radames/PIFu-Clothed-Human-Digitization, https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-obj
标签:VISION, IMAGE
## 介绍
机器学习中的 3D 模型越来越受欢迎,并且是一些最有趣的演示实验。使用 `gradio`,您可以轻松构建您的 3D 图像模型的演示,并与任何人分享。Gradio 3D 模型组件接受 3 种文件类型,包括:_.obj_,_.glb_ 和 _.gltf_。
本指南将向您展示如何使用几行代码构建您的 3D 图像模型的演示;像下面这个示例一样。点击、拖拽和缩放来玩转 3D 对象:
<gradio-app space="dawood/Model3D"> </gradio-app>
### 先决条件
确保已经[安装](https://gradio.app/quickstart)了 `gradio` Python 包。
## 查看代码
让我们来看看如何创建上面的最简界面。在这种情况下,预测函数将只返回原始的 3D 模型网格,但您可以更改此函数以在您的机器学习模型上运行推理。我们将在下面看更复杂的示例。
```python
import gradio as gr
def load_mesh(mesh_file_name):
return mesh_file_name
demo = gr.Interface(
fn=load_mesh,
inputs=gr.Model3D(),
outputs=gr.Model3D(clear_color=[0.0, 0.0, 0.0, 0.0], label="3D Model"),
examples=[
["files/Bunny.obj"],
["files/Duck.glb"],
["files/Fox.gltf"],
["files/face.obj"],
],
cache_examples=True,
)
demo.launch()
```
让我们来解析上面的代码:
`load_mesh`:这是我们的“预测”函数,为简单起见,该函数将接收 3D 模型网格并返回它。
创建界面:
- `fn`:当用户点击提交时使用的预测函数。在我们的例子中,它是 `load_mesh` 函数。
- `inputs`:创建一个 model3D 输入组件。输入是一个上传的文件,作为{str}文件路径。
- `outputs`:创建一个 model3D 输出组件。输出组件也期望一个文件作为{str}文件路径。
- `clear_color`:这是 3D 模型画布的背景颜色。期望 RGBa 值。
- `label`:出现在组件左上角的标签。
- `examples`:3D 模型文件的列表。3D 模型组件可以接受*.obj*,*.glb*和*.gltf*文件类型。
- `cache_examples`:保存示例的预测输出,以节省推理时间。
## 探索更复杂的 Model3D 演示
下面是一个使用 DPT 模型预测图像深度,然后使用 3D 点云创建 3D 对象的演示。查看[code.py](https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-obj/blob/main/app.py)文件,了解代码和模型预测函数。
<gradio-app space="radames/dpt-depth-estimation-3d-obj"> </gradio-app>
下面是一个使用 PIFu 模型将穿着衣物的人的图像转换为 3D 数字化模型的演示。查看[spaces.py](https://huggingface.co/spaces/radames/PIFu-Clothed-Human-Digitization/blob/main/PIFu/spaces.py)文件,了解代码和模型预测函数。
<gradio-app space="radames/PIFu-Clothed-Human-Digitization"> </gradio-app>
---
搞定!这就是构建 Model3D 模型界面所需的所有代码。以下是一些您可能会发现有用的参考资料:
- Gradio 的[“入门指南”](https://gradio.app/getting_started/)
- 第一个[3D 模型演示](https://huggingface.co/spaces/dawood/Model3D)和[完整代码](https://huggingface.co/spaces/dawood/Model3D/tree/main)(在 Hugging Face Spaces 上)
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/how-to-use-3D-model-component.md |
@gradio/accordion
## 0.2.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.4
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
- [#6171](https://github.com/gradio-app/gradio/pull/6171) [`28322422c`](https://github.com/gradio-app/gradio/commit/28322422cb9d8d3e471e439ad602959662e79312) - strip dangling svelte imports. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.2
### Patch Changes
- Updated dependencies [[`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a), [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.2.0-beta.1
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0-beta.0
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.4
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.3
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.2
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
| gradio-app/gradio/blob/main/js/accordion/CHANGELOG.md |
Gradio Demo: highlightedtext_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.HighlightedText(
combine_adjacent=True,
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/highlightedtext_component/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Schedulers
[[open-in-colab]]
Diffusion pipelines are inherently a collection of diffusion models and schedulers that are partly independent from each other. This means that one is able to switch out parts of the pipeline to better customize
a pipeline to one's use case. The best example of this is the [Schedulers](../api/schedulers/overview).
Whereas diffusion models usually simply define the forward pass from noise to a less noisy sample,
schedulers define the whole denoising process, *i.e.*:
- How many denoising steps?
- Stochastic or deterministic?
- What algorithm to use to find the denoised sample?
They can be quite complex and often define a trade-off between **denoising speed** and **denoising quality**.
It is extremely difficult to measure quantitatively which scheduler works best for a given diffusion pipeline, so it is often recommended to simply try out which works best.
The following paragraphs show how to do so with the 🧨 Diffusers library.
## Load pipeline
Let's start by loading the [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) model in the [`DiffusionPipeline`]:
```python
from huggingface_hub import login
from diffusers import DiffusionPipeline
import torch
login()
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
```
Next, we move it to GPU:
```python
pipeline.to("cuda")
```
## Access the scheduler
The scheduler is always one of the components of the pipeline and is usually called `"scheduler"`.
So it can be accessed via the `"scheduler"` property.
```python
pipeline.scheduler
```
**Output**:
```
PNDMScheduler {
"_class_name": "PNDMScheduler",
"_diffusers_version": "0.21.4",
"beta_end": 0.012,
"beta_schedule": "scaled_linear",
"beta_start": 0.00085,
"clip_sample": false,
"num_train_timesteps": 1000,
"set_alpha_to_one": false,
"skip_prk_steps": true,
"steps_offset": 1,
"timestep_spacing": "leading",
"trained_betas": null
}
```
We can see that the scheduler is of type [`PNDMScheduler`].
Cool, now let's compare the scheduler in its performance to other schedulers.
First we define a prompt on which we will test all the different schedulers:
```python
prompt = "A photograph of an astronaut riding a horse on Mars, high resolution, high definition."
```
Next, we create a generator from a random seed that will ensure that we can generate similar images as well as run the pipeline:
```python
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_pndm.png" width="400"/>
<br>
</p>
## Changing the scheduler
Now we show how easy it is to change the scheduler of a pipeline. Every scheduler has a property [`~SchedulerMixin.compatibles`]
which defines all compatible schedulers. You can take a look at all available, compatible schedulers for the Stable Diffusion pipeline as follows.
```python
pipeline.scheduler.compatibles
```
**Output**:
```
[diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler]
```
Cool, lots of schedulers to look at. Feel free to have a look at their respective class definitions:
- [`EulerDiscreteScheduler`],
- [`LMSDiscreteScheduler`],
- [`DDIMScheduler`],
- [`DDPMScheduler`],
- [`HeunDiscreteScheduler`],
- [`DPMSolverMultistepScheduler`],
- [`DEISMultistepScheduler`],
- [`PNDMScheduler`],
- [`EulerAncestralDiscreteScheduler`],
- [`UniPCMultistepScheduler`],
- [`KDPM2DiscreteScheduler`],
- [`DPMSolverSinglestepScheduler`],
- [`KDPM2AncestralDiscreteScheduler`].
We will now compare the input prompt with all other schedulers. To change the scheduler of the pipeline you can make use of the
convenient [`~ConfigMixin.config`] property in combination with the [`~ConfigMixin.from_config`] function.
```python
pipeline.scheduler.config
```
returns a dictionary of the configuration of the scheduler:
**Output**:
```py
FrozenDict([('num_train_timesteps', 1000),
('beta_start', 0.00085),
('beta_end', 0.012),
('beta_schedule', 'scaled_linear'),
('trained_betas', None),
('skip_prk_steps', True),
('set_alpha_to_one', False),
('prediction_type', 'epsilon'),
('timestep_spacing', 'leading'),
('steps_offset', 1),
('_use_default_values', ['timestep_spacing', 'prediction_type']),
('_class_name', 'PNDMScheduler'),
('_diffusers_version', '0.21.4'),
('clip_sample', False)])
```
This configuration can then be used to instantiate a scheduler
of a different class that is compatible with the pipeline. Here,
we change the scheduler to the [`DDIMScheduler`].
```python
from diffusers import DDIMScheduler
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
```
Cool, now we can run the pipeline again to compare the generation quality.
```python
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_ddim.png" width="400"/>
<br>
</p>
If you are a JAX/Flax user, please check [this section](#changing-the-scheduler-in-flax) instead.
## Compare schedulers
So far we have tried running the stable diffusion pipeline with two schedulers: [`PNDMScheduler`] and [`DDIMScheduler`].
A number of better schedulers have been released that can be run with much fewer steps; let's compare them here:
[`LMSDiscreteScheduler`] usually leads to better results:
```python
from diffusers import LMSDiscreteScheduler
pipeline.scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_lms.png" width="400"/>
<br>
</p>
[`EulerDiscreteScheduler`] and [`EulerAncestralDiscreteScheduler`] can generate high quality results with as little as 30 steps.
```python
from diffusers import EulerDiscreteScheduler
pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator, num_inference_steps=30).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_euler_discrete.png" width="400"/>
<br>
</p>
and:
```python
from diffusers import EulerAncestralDiscreteScheduler
pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator, num_inference_steps=30).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_euler_ancestral.png" width="400"/>
<br>
</p>
[`DPMSolverMultistepScheduler`] gives a reasonable speed/quality trade-off and can be run with as little as 20 steps.
```python
from diffusers import DPMSolverMultistepScheduler
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cuda").manual_seed(8)
image = pipeline(prompt, generator=generator, num_inference_steps=20).images[0]
image
```
<p align="center">
<br>
<img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_dpm.png" width="400"/>
<br>
</p>
As you can see, most images look very similar and are arguably of very similar quality. It often really depends on the specific use case which scheduler to choose. A good approach is always to run multiple different
schedulers to compare results.
## Changing the Scheduler in Flax
If you are a JAX/Flax user, you can also change the default pipeline scheduler. This is a complete example of how to run inference using the Flax Stable Diffusion pipeline and the super-fast [DPM-Solver++ scheduler](../api/schedulers/multistep_dpm_solver):
```Python
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline, FlaxDPMSolverMultistepScheduler
model_id = "runwayml/stable-diffusion-v1-5"
scheduler, scheduler_state = FlaxDPMSolverMultistepScheduler.from_pretrained(
model_id,
subfolder="scheduler"
)
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
model_id,
scheduler=scheduler,
revision="bf16",
dtype=jax.numpy.bfloat16,
)
params["scheduler"] = scheduler_state
# Generate 1 image per parallel device (8 on TPUv2-8 or TPUv3-8)
prompt = "a photo of an astronaut riding a horse on mars"
num_samples = jax.device_count()
prompt_ids = pipeline.prepare_inputs([prompt] * num_samples)
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 25
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
```
<Tip warning={true}>
The following Flax schedulers are _not yet compatible_ with the Flax Stable Diffusion Pipeline:
- `FlaxLMSDiscreteScheduler`
- `FlaxDDPMScheduler`
</Tip>
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/schedulers.md |
et's see how to preprocess a dataset for translation. This is the task of well translating a sentence in another language. This video will focus on how to preprocess your dataset once you have managed to put it in the following format: one column for the input texts, and one for the target texts. Here is how we can achieve this with the Datasets library on the KDE4 dataset for English to French translation. As long as you manage to have your data look like this, you should be able to follow the same steps. For once, our labels are not integers corresponding to some classes, but plain text. We will thus need to tokenize them, like our inputs. There is a trap there though, as if you tokenize your targets like your inputs, you will hit a problem. Even if you don't speak French, you might notice some weird things in the tokenization of the targets: most of the words are tokenized in several subtokens, while "fish", one of the only English word, is tokenized as a single word. That's because our inputs have been tokenized as English. Since our model knows two languages, you have to warn it when tokenizing the targets, so it switches in French mode. This is done with the as_target_tokenizer context manager. You can see how it results in a more compact tokenization. Processing the whole dataset is then super easy with the map function. You can pick different maximum lengths for the input and targets, and choose to pad at this stage to that maximum length by setting padding=max_length. Here we will show you how to pad dynamically as it requires one more step. Your inputs and targets are all sentence of various lengths. We will pad the inputs and targets separately as the maximum length of the inputs and targets might be different. Then we pad the inputs with the pad token and the targets with the -100 index, to make sure they are not taken into account in the loss computation. Once this is done, batching inputs and targets become super easy! The Transformers library provides us with a data collator to do this all automatically. You can then pass it to the Trainer with your datasets, or use it in the to_tf_dataset method before using model.fit(). | huggingface/course/blob/main/subtitles/en/raw/chapter7/04a_translation-processing.md |
Gradio Demo: on_listener_decorator
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output Box")
greet_btn = gr.Button("Greet")
@gr.on(triggers=[name.submit, greet_btn.click], inputs=name, outputs=output)
def greet(name):
return "Hello " + name + "!"
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/on_listener_decorator/run.ipynb |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
## Language generation
Based on the script [`run_generation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py).
Conditional text generation using the auto-regressive models of the library: GPT, GPT-2, GPTJ, Transformer-XL, XLNet, CTRL, BLOOM, LLAMA, OPT.
A similar script is used for our official demo [Write With Transfomer](https://transformer.huggingface.co), where you
can try out the different models available in the library.
Example usage:
```bash
python run_generation.py \
--model_type=gpt2 \
--model_name_or_path=gpt2
```
| huggingface/transformers/blob/main/examples/pytorch/text-generation/README.md |
Type of tasks [[tasks]]
A task is an **instance** of a Reinforcement Learning problem. We can have two types of tasks: **episodic** and **continuing**.
## Episodic task [[episodic-task]]
In this case, we have a starting point and an ending point **(a terminal state). This creates an episode**: a list of States, Actions, Rewards, and new States.
For instance, think about Super Mario Bros: an episode begin at the launch of a new Mario Level and ends **when you’re killed or you reached the end of the level.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/mario.jpg" alt="Mario">
<figcaption>Beginning of a new episode.
</figcaption>
</figure>
## Continuing tasks [[continuing-tasks]]
These are tasks that continue forever (**no terminal state**). In this case, the agent must **learn how to choose the best actions and simultaneously interact with the environment.**
For instance, an agent that does automated stock trading. For this task, there is no starting point and terminal state. **The agent keeps running until we decide to stop it.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/stock.jpg" alt="Stock Market" width="100%">
To recap:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/tasks.jpg" alt="Tasks recap" width="100%">
| huggingface/deep-rl-class/blob/main/units/en/unit1/tasks.mdx |
--
title: "Open-Source Text Generation & LLM Ecosystem at Hugging Face"
thumbnail: /blog/assets/os_llms/thumbnail.png
authors:
- user: merve
---
# Open-Source Text Generation & LLM Ecosystem at Hugging Face
[Updated on July 24, 2023: Added Llama 2.]
Text generation and conversational technologies have been around for ages. Earlier challenges in working with these technologies were controlling both the coherence and diversity of the text through inference parameters and discriminative biases. More coherent outputs were less creative and closer to the original training data and sounded less human. Recent developments overcame these challenges, and user-friendly UIs enabled everyone to try these models out. Services like ChatGPT have recently put the spotlight on powerful models like GPT-4 and caused an explosion of open-source alternatives like Llama to go mainstream. We think these technologies will be around for a long time and become more and more integrated into everyday products.
This post is divided into the following sections:
1. [Brief background on text generation](#brief-background-on-text-generation)
2. [Licensing](#licensing)
3. [Tools in the Hugging Face Ecosystem for LLM Serving](#tools-in-the-hugging-face-ecosystem-for-llm-serving)
4. [Parameter Efficient Fine Tuning (PEFT)](#parameter-efficient-fine-tuning-peft)
## Brief Background on Text Generation
Text generation models are essentially trained with the objective of completing an incomplete text or generating text from scratch as a response to a given instruction or question. Models that complete incomplete text are called Causal Language Models, and famous examples are GPT-3 by OpenAI and [Llama](https://ai.meta.com/blog/large-language-model-Llama-meta-ai/) by Meta AI.

One concept you need to know before we move on is fine-tuning. This is the process of taking a very large model and transferring the knowledge contained in this base model to another use case, which we call _a downstream task_. These tasks can come in the form of instructions. As the model size grows, it can generalize better to instructions that do not exist in the pre-training data, but were learned during fine-tuning.
Causal language models are adapted using a process called reinforcement learning from human feedback (RLHF). This optimization is mainly made over how natural and coherent the text sounds rather than the validity of the answer. Explaining how RLHF works is outside the scope of this blog post, but you can find more information about this process [here](https://huggingface.co/blog/rlhf).
For example, GPT-3 is a causal language _base_ model, while the models in the backend of ChatGPT (which is the UI for GPT-series models) are fine-tuned through RLHF on prompts that can consist of conversations or instructions. It’s an important distinction to make between these models.
On the Hugging Face Hub, you can find both causal language models and causal language models fine-tuned on instructions (which we’ll give links to later in this blog post). Llama is one of the first open-source LLMs to have outperformed/matched closed-source ones. A research group led by Together has created a reproduction of Llama's dataset, called Red Pajama, and trained LLMs and instruction fine-tuned models on it. You can read more about it [here](https://www.together.xyz/blog/redpajama) and find [the model checkpoints on Hugging Face Hub](https://huggingface.co/models?sort=trending&search=togethercomputer%2Fredpajama). By the time this blog post is written, three of the largest causal language models with open-source licenses are [MPT-30B by MosaicML](https://huggingface.co/mosaicml/mpt-30b), [XGen by Salesforce](https://huggingface.co/Salesforce/xgen-7b-8k-base) and [Falcon by TII UAE](https://huggingface.co/tiiuae/falcon-40b), available completely open on Hugging Face Hub.
Recently, Meta released [Llama 2](https://ai.meta.com/Llama/), an open-access model with a license that allows commercial use. As of now, Llama 2 outperforms all of the other open-source large language models on different benchmarks. [Llama 2 checkpoints on Hugging Face Hub](https://huggingface.co/meta-Llama) are compatible with transformers, and the largest checkpoint is available for everyone to try at [HuggingChat](https://huggingface.co/chat/). You can read more about how to fine-tune, deploy and prompt with Llama 2 in [this blog post](https://huggingface.co/blog/llama2).
The second type of text generation model is commonly referred to as the text-to-text generation model. These models are trained on text pairs, which can be questions and answers or instructions and responses. The most popular ones are T5 and BART (which, as of now, aren’t state-of-the-art). Google has recently released the FLAN-T5 series of models. FLAN is a recent technique developed for instruction fine-tuning, and FLAN-T5 is essentially T5 fine-tuned using FLAN. As of now, the FLAN-T5 series of models are state-of-the-art and open-source, available on the [Hugging Face Hub](https://huggingface.co/models?search=google/flan). Note that these are different from instruction-tuned causal language models, although the input-output format might seem similar. Below you can see an illustration of how these models work.

Having more variation of open-source text generation models enables companies to keep their data private, to adapt models to their domains faster, and to cut costs for inference instead of relying on closed paid APIs. All open-source causal language models on Hugging Face Hub can be found [here](https://huggingface.co/models?pipeline_tag=text-generation), and text-to-text generation models can be found [here](https://huggingface.co/models?pipeline_tag=text2text-generation&sort=trending).
### Models created with love by Hugging Face with BigScience and BigCode 💗
Hugging Face has co-led two science initiatives, BigScience and BigCode. As a result of them, two large language models were created, [BLOOM](https://huggingface.co/bigscience/bloom) 🌸 and [StarCoder](https://huggingface.co/bigcode/starcoder) 🌟.
BLOOM is a causal language model trained on 46 languages and 13 programming languages. It is the first open-source model to have more parameters than GPT-3. You can find all the available checkpoints in the [BLOOM documentation](https://huggingface.co/docs/transformers/model_doc/bloom).
StarCoder is a language model trained on permissive code from GitHub (with 80+ programming languages 🤯) with a Fill-in-the-Middle objective. It’s not fine-tuned on instructions, and thus, it serves more as a coding assistant to complete a given code, e.g., translate Python to C++, explain concepts (what’s recursion), or act as a terminal. You can try all of the StarCoder checkpoints [in this application](https://huggingface.co/spaces/bigcode/bigcode-playground). It also comes with a [VSCode extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode).
Snippets to use all models mentioned in this blog post are given in either the model repository or the documentation page of that model type in Hugging Face.
## Licensing
Many text generation models are either closed-source or the license limits commercial use. Fortunately, open-source alternatives are starting to appear and being embraced by the community as building blocks for further development, fine-tuning, or integration with other projects. Below you can find a list of some of the large causal language models with fully open-source licenses:
- [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b)
- [XGen](https://huggingface.co/tiiuae/falcon-40b)
- [MPT-30B](https://huggingface.co/mosaicml/mpt-30b)
- [Pythia-12B](https://huggingface.co/EleutherAI/pythia-12b)
- [RedPajama-INCITE-7B](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base)
- [OpenAssistant (Falcon variant)](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226)
There are two code generation models, [StarCoder by BigCode](https://huggingface.co/models?sort=trending&search=bigcode%2Fstarcoder) and [Codegen by Salesforce](https://huggingface.co/models?sort=trending&search=salesforce%2Fcodegen). There are model checkpoints in different sizes and open-source or [open RAIL](https://huggingface.co/blog/open_rail) licenses for both, except for [Codegen fine-tuned on instruction](https://huggingface.co/Salesforce/codegen25-7b-instruct).
The Hugging Face Hub also hosts various models fine-tuned for instruction or chat use. They come in various styles and sizes depending on your needs.
- [MPT-30B-Chat](https://huggingface.co/mosaicml/mpt-30b-chat), by Mosaic ML, uses the CC-BY-NC-SA license, which does not allow commercial use. However, [MPT-30B-Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) uses CC-BY-SA 3.0, which can be used commercially.
- [Falcon-40B-Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) and [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) both use the Apache 2.0 license, so commercial use is also permitted.
- Another popular family of models is OpenAssistant, some of which are built on Meta's Llama model using a custom instruction-tuning dataset. Since the original Llama model can only be used for research, the OpenAssistant checkpoints built on Llama don’t have full open-source licenses. However, there are OpenAssistant models built on open-source models like [Falcon](https://huggingface.co/models?search=openassistant/falcon) or [pythia](https://huggingface.co/models?search=openassistant/pythia) that use permissive licenses.
- [StarChat Beta](https://huggingface.co/HuggingFaceH4/starchat-beta) is the instruction fine-tuned version of StarCoder, and has BigCode Open RAIL-M v1 license, which allows commercial use. Instruction-tuned coding model of Salesforce, [XGen model](https://huggingface.co/Salesforce/xgen-7b-8k-inst), only allows research use.
If you're looking to fine-tune a model on an existing instruction dataset, you need to know how a dataset was compiled. Some of the existing instruction datasets are either crowd-sourced or use outputs of existing models (e.g., the models behind ChatGPT). [ALPACA](https://crfm.stanford.edu/2023/03/13/alpaca.html) dataset created by Stanford is created through the outputs of models behind ChatGPT. Moreover, there are various crowd-sourced instruction datasets with open-source licenses, like [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) (created by thousands of people voluntarily!) or [databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k). If you'd like to create a dataset yourself, you can check out [the dataset card of Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k#sources) on how to create an instruction dataset. Models fine-tuned on these datasets can be distributed.
You can find a comprehensive table of some open-source/open-access models below.
| Model | Dataset | License | Use |
|------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------|-------------------------|
| [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) | [Falcon RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | Apache-2.0 | Text Generation |
| [SalesForce XGen 7B](https://huggingface.co/Salesforce/xgen-7b-8k-base) | Mix of C4, RedPajama and more | Apache-2.0 | Text Generation |
| [MPT-30B](https://huggingface.co/mosaicml/mpt-30b) | Mix of C4, RedPajama and more | Apache-2.0 | Text Generation |
| [Pythia-12B](https://huggingface.co/EleutherAI/pythia-12b) | [Pile](https://huggingface.co/datasets/EleutherAI/pile) | Apache-2.0 | Text Generation |
| [RedPajama INCITE 7B](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) | [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-7B-Base) | Apache-2.0 | Text Generation |
| [OpenAssistant Falcon 40B](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226) | [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) and [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | Apache-2.0 | Text Generation |
| [StarCoder](https://huggingface.co/bigcode/starcoder) | [The Stack](https://huggingface.co/datasets/bigcode/the-stack-dedup) | BigCode OpenRAIL-M | Code Generation |
| [Salesforce CodeGen](https://huggingface.co/Salesforce/codegen25-7b-multi) | [Starcoder Data](https://huggingface.co/datasets/bigcode/starcoderdata) | Apache-2.0 | Code Generation |
| [FLAN-T5-XXL](https://huggingface.co/google/flan-t5-xxl) | [gsm8k](https://huggingface.co/datasets/gsm8k), [lambada](https://huggingface.co/datasets/lambada), and [esnli](https://huggingface.co/datasets/esnli) | Apache-2.0 | Text-to-text Generation |
| [MPT-30B Chat](https://huggingface.co/mosaicml/mpt-30b-chat) | [ShareGPT-Vicuna](https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered), [OpenAssistant Guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) and more | CC-By-NC-SA-4.0 | Chat |
| [MPT-30B Instruct](https://huggingface.co/mosaicml/mpt-30b-instruct) | [duorc](https://huggingface.co/datasets/duorc), [competition_math](https://huggingface.co/datasets/competition_math), [dolly_hhrlhf](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf) | CC-By-SA-3.0 | Instruction |
| [Falcon 40B Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) | [baize](https://github.com/project-baize/baize-chatbot) | Apache-2.0 | Instruction |
| [Dolly v2](https://huggingface.co/databricks/dolly-v2-12b) | [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | MIT | Text Generation |
| [StarChat-β](https://huggingface.co/HuggingFaceH4/starchat-beta) | [OpenAssistant Guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) | BigCode OpenRAIL-M | Code Instruction |
| [Llama 2](https://huggingface.co/meta-Llama/Llama-2-70b-hf) | Undisclosed dataset | Custom Meta License (Allows commercial use) | Text Generation |
## Tools in the Hugging Face Ecosystem for LLM Serving
### Text Generation Inference
Response time and latency for concurrent users are a big challenge for serving these large models. To tackle this problem, Hugging Face has released [text-generation-inference](https://github.com/huggingface/text-generation-inference) (TGI), an open-source serving solution for large language models built on Rust, Python, and gRPc. TGI is integrated into inference solutions of Hugging Face, [Inference Endpoints](https://huggingface.co/inference-endpoints), and [Inference API](https://huggingface.co/inference-api), so you can directly create an endpoint with optimized inference with few clicks, or simply send a request to Hugging Face's Inference API to benefit from it, instead of integrating TGI to your platform.

TGI currently powers [HuggingChat](https://huggingface.co/chat/), Hugging Face's open-source chat UI for LLMs. This service currently uses one of OpenAssistant's models as the backend model. You can chat as much as you want with HuggingChat and enable the Web search feature for responses that use elements from current Web pages. You can also give feedback to each response for model authors to train better models. The UI of HuggingChat is also [open-sourced](https://github.com/huggingface/chat-ui), and we are working on more features for HuggingChat to allow more functions, like generating images inside the chat.

Recently, a Docker template for HuggingChat was released for Hugging Face Spaces. This allows anyone to deploy their instance based on a large language model with only a few clicks and customize it. You can create your large language model instance [here](https://huggingface.co/new-space?template=huggingchat/chat-ui-template) based on various LLMs, including Llama 2.

### How to find the best model?
Hugging Face hosts an [LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). This leaderboard is created by evaluating community-submitted models on text generation benchmarks on Hugging Face’s clusters. If you can’t find the language or domain you’re looking for, you can filter them [here](https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads).

You can also check out the [LLM Performance leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), which aims to evaluate the latency and throughput of large language models available on Hugging Face Hub.
## Parameter Efficient Fine Tuning (PEFT)
If you’d like to fine-tune one of the existing large models on your instruction dataset, it is nearly impossible to do so on consumer hardware and later deploy them (since the instruction models are the same size as the original checkpoints that are used for fine-tuning). [PEFT](https://huggingface.co/docs/peft/index) is a library that allows you to do parameter-efficient fine-tuning techniques. This means that rather than training the whole model, you can train a very small number of additional parameters, enabling much faster training with very little performance degradation. With PEFT, you can do low-rank adaptation (LoRA), prefix tuning, prompt tuning, and p-tuning.
You can check out further resources for more information on text generation.
**Further Resources**
- Together with AWS we released TGI-based LLM deployment deep learning containers called LLM Inference Containers. Read about them [here](https://aws.amazon.com/tr/blogs/machine-learning/announcing-the-launch-of-new-hugging-face-llm-inference-containers-on-amazon-sagemaker/).
- [Text Generation task page](https://huggingface.co/tasks/text-generation) to find out more about the task itself.
- PEFT announcement [blog post](https://huggingface.co/blog/peft).
- Read about how Inference Endpoints use TGI [here](https://huggingface.co/blog/inference-endpoints-llm).
- Read about how to fine-tune Llama 2 transformers and PEFT, and prompt [here](https://huggingface.co/blog/llama2).
| huggingface/blog/blob/main/os-llms.md |
Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [0.13.2]
- Python only changes
## [0.13.1]
- [#1072] Fixing Roberta type ids.
## [0.13.0]
- [#1009] `unstable_wasm` feature to support building on Wasm (it's unstable !)
- [#1008] `Decoder` is now a composable trait, but without being backward incompatible
- [#1047, #1051, #1052] `Processor` is now a composable trait, but without being backward incompatible
Both trait changes warrant a "major" number since, despite best efforts to not break backward
compatibility, the code is different enough that we cannot be exactly sure.
## [0.12.1]
- [#938] **Reverted breaking change**. https://github.com/huggingface/transformers/issues/16520
## [0.12.0] YANKED
Bump minor version because of a breaking change.
- [#938] [REVERTED IN 0.12.1] **Breaking change**. Decoder trait is modified to be composable. This is only breaking if you are using decoders on their own. tokenizers should be error free.
- [#939] Making the regex in `ByteLevel` pre_tokenizer optional (necessary for BigScience)
- [#952] Fixed the vocabulary size of UnigramTrainer output (to respect added tokens)
- [#954] Fixed not being able to save vocabularies with holes in vocab (ConvBert). Yell warnings instead, but stop panicking.
- [#961] Added link for Ruby port of `tokenizers`
- [#960] Feature gate for `cli` and its `clap` dependency
## [0.11.3]
- [#919] Fixing single_word AddedToken. (regression from 0.11.2)
- [#916] Deserializing faster `added_tokens` by loading them in batch.
## [0.11.2]
- [#884] Fixing bad deserialization following inclusion of a default for Punctuation
## [0.11.1]
- [#882] Fixing Punctuation deserialize without argument.
- [#868] Fixing missing direction in TruncationParams
- [#860] Adding TruncationSide to TruncationParams
## [0.11.0]
### Fixed
- [#236]: Fix a bug with offsets being shifted when there are sub-sequences (Usually with
special tokens and/or added tokens in the sequence).
- [#286]: Fix various crash when training a BPE model
- [#309]: Fixed a few bugs related to additional vocabulary/tokens
- [#363]: Fix panic from unwrapping `File::open` in `count_words`
### Changed
- [#234]: Completely changed the alignement mappings available on `Encoding`. Previous mappings
were misleading and only providing offsets. New ones provide methods to easily convert between
`char` or `word` (input space) and `token` (output space)
- [#236]: `AddedToken` with special options like `rstrip` will keep the matched whitespaces
in the textual representation of the token, exposed in `tokens` on the `Encoding`. The ID stays
the same as usual. This fixes the offsets for said tokens.
- [#236]: Offsets are now converted back to the original referential before we merge the
sub-sequences together and then do the post-processing. This also fixes some offsets bugs.
- [#236]: ByteLevel PostProcessor now uses the `add_prefix_space` attribute to determine how to
trim offsets.
- Improved `TruncationError` to handle cases where provided max length is too low.
- [#249]: `encode` and `encode_batch` input has been greatly improved, and it now also accept
pre-tokenized inputs.
- Improved `TruncationError` to handle cases where provided max length is too low.
- [#276]: Improve BPE training speeds, by reading files sequentially, but parallelizing the
processing of each file
- [#280]: Use `onig` for byte-level pre-tokenization to remove all the differences with the original
implementation from GPT-2
- [#309]: Improved the management of the additional vocabulary. This introduces an option
`normalized`, controlling whether a token should be extracted from the normalized version of the
input text.
- [#330]: BertNormalizer now keeps the same behavior than the original implementation when
`strip_accents` is not specified.
- [#355]: Tokenizer does not use any dynamic dispatch anymore.
- [#377]: Use byte offsets everywhere (instead of the char offsets)
### Added
- [#236]: RobertaProcessing is now also taking care of trimming offsets, and works just as ByteLevel
on this front.
- [#272]: Serialization of the `Tokenizer` and all the parts (`PreTokenizer`, `Normalizer`, ...)
using serde. It is now easy to save/load an entire tokenizer.
- [#289]: Ability to pad to a multiple of a specified value. This is especially useful to ensure
activation of the Tensor Cores, while ensuring padding to a multiple of 8.
- [#298]: Ability to get the currently set truncation/padding params
- [#311]: Ability to enable/disable the parallelism using the `TOKENIZERS_PARALLELISM` environment
variable.
- [#403]: Add `TemplateProcessing` `PostProcessor`.
### How to migrate
- Replace any `XXX_to_YYY_offsets()` method call by any of the new ones.
- Specify the `add_prefix_space` and `trim_offsets` options on `RobertaProcessing` if you don't
want the offsets trimmed out.
- Any custom `PostProcessor` now handles offsets relative to the original string (as opposed to the
normalized one).
## [0.10.1]
### Fixed
- [#226]: Fix the word indexes when there are special tokens
## [0.10.0]
### Changed
- [#222]: All Tokenizer's subparts must now be `Send + Sync`
### Added
- [#208]: Ability to retrieve the vocabulary from the `Tokenizer` & `Model`
### Fixed
- [#205]: Trim the decoded string in `BPEDecoder`
- [b770f36]: Fix a bug with added tokens generated IDs
## [0.9.0]
### Changed
- Only one progress bar while reading files during training. This is better for use-cases with
a high number of files as it avoids having too many progress bars on screen. Also avoids reading the
size of each file before starting to actually read these files, as this process could take really
long.
- [#190]: Improved BPE and WordPiece builders
- [#193]: `encode` and `encode_batch` now take a new argument, specifying whether we should add the
special tokens
- [#197]: The `NormalizedString` has been removed from the `Encoding`. It is now possible to
retrieve it by calling `normalize` on the `Tokenizer`. This brings a reduction of 70% of the memory
footprint
- [#197]: The `NormalizedString` API has been improved. It is now possible to retrieve parts of both
strings using both "normalized" or "original" offsets
- [#197]: The offsets provided on `Encoding` are now relative to the original string, and not the
normalized one anymore
- `AddedToken` are now used for both `add_special_tokens` and `add_tokens`. Also, these AddedToken
have more options to allow various behaviors.
### Added
- [#188]: `impl PostProcessor for ByteLevel`: Handles trimming the offsets if activated. This avoids
the unintuitive inclusion of the whitespaces in the produced offsets, even if these whitespaces are
part of the actual token
- More alignment mappings on the `Encoding`.
- `post_process` can be called on the `Tokenizer`
### Fixed
- [#193]: Fix some issues with the offsets being wrong with the `ByteLevel` BPE:
- when `add_prefix_space` is activated
- [#156]: when a Unicode character gets split-up in multiple byte-level characters
- Fix a bug where offsets were wrong when there was any added tokens in the sequence being encoded.
- [#175]: Fix a bug that prevented the addition of more than a certain amount of tokens (even if not
advised, but that's not the question)
### How to migrate
- Add the `ByteLevel` `PostProcessor` to your byte-level BPE tokenizers if relevant.
## [0.8.0]
### Changed
- [#165]: Big improvements in speed for BPE (Both training and tokenization)
### Fixed
- [#163]: Do not open all files directly while training
- [#156]: There was a bug in ByteLevel PreTokenizer that caused offsets to be wrong if a char got
split up in multiple bytes
- [#174]: The `LongestFirst` truncation strategy had a bug
[#1072]: https://github.com/huggingface/tokenizers/pull/1072
[#956]: https://github.com/huggingface/tokenizers/pull/956
[#1008]: https://github.com/huggingface/tokenizers/pull/1008
[#1009]: https://github.com/huggingface/tokenizers/pull/1009
[#1047]: https://github.com/huggingface/tokenizers/pull/1047
[#1055]: https://github.com/huggingface/tokenizers/pull/1055
[#1051]: https://github.com/huggingface/tokenizers/pull/1051
[#1052]: https://github.com/huggingface/tokenizers/pull/1052
[#938]: https://github.com/huggingface/tokenizers/pull/938
[#939]: https://github.com/huggingface/tokenizers/pull/939
[#952]: https://github.com/huggingface/tokenizers/pull/952
[#954]: https://github.com/huggingface/tokenizers/pull/954
[#961]: https://github.com/huggingface/tokenizers/pull/961
[#960]: https://github.com/huggingface/tokenizers/pull/960
[#919]: https://github.com/huggingface/tokenizers/pull/919
[#916]: https://github.com/huggingface/tokenizers/pull/916
[#884]: https://github.com/huggingface/tokenizers/pull/884
[#882]: https://github.com/huggingface/tokenizers/pull/882
[#868]: https://github.com/huggingface/tokenizers/pull/868
[#860]: https://github.com/huggingface/tokenizers/pull/860
[#403]: https://github.com/huggingface/tokenizers/pull/403
[#377]: https://github.com/huggingface/tokenizers/pull/377
[#355]: https://github.com/huggingface/tokenizers/pull/355
[#363]: https://github.com/huggingface/tokenizers/pull/363
[#330]: https://github.com/huggingface/tokenizers/pull/330
[#311]: https://github.com/huggingface/tokenizers/pull/311
[#309]: https://github.com/huggingface/tokenizers/pull/309
[#298]: https://github.com/huggingface/tokenizers/pull/298
[#289]: https://github.com/huggingface/tokenizers/pull/289
[#286]: https://github.com/huggingface/tokenizers/pull/286
[#280]: https://github.com/huggingface/tokenizers/pull/280
[#276]: https://github.com/huggingface/tokenizers/pull/276
[#272]: https://github.com/huggingface/tokenizers/pull/272
[#249]: https://github.com/huggingface/tokenizers/pull/249
[b770f36]: https://github.com/huggingface/tokenizers/commit/b770f364280af33efeffea8f0003102cda8cf1b7
[#236]: https://github.com/huggingface/tokenizers/pull/236
[#234]: https://github.com/huggingface/tokenizers/pull/234
[#226]: https://github.com/huggingface/tokenizers/pull/226
[#222]: https://github.com/huggingface/tokenizers/pull/222
[#208]: https://github.com/huggingface/tokenizers/pull/208
[#205]: https://github.com/huggingface/tokenizers/issues/205
[#197]: https://github.com/huggingface/tokenizers/pull/197
[#193]: https://github.com/huggingface/tokenizers/pull/193
[#190]: https://github.com/huggingface/tokenizers/pull/190
[#188]: https://github.com/huggingface/tokenizers/pull/188
[#175]: https://github.com/huggingface/tokenizers/issues/175
[#174]: https://github.com/huggingface/tokenizers/issues/174
[#165]: https://github.com/huggingface/tokenizers/pull/165
[#163]: https://github.com/huggingface/tokenizers/issues/163
[#156]: https://github.com/huggingface/tokenizers/pull/156
| huggingface/tokenizers/blob/main/tokenizers/CHANGELOG.md |
The intuition behind PPO [[the-intuition-behind-ppo]]
The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large of a policy update.**
For two reasons:
- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
- A too-big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and taking a long time or even having no possibility to recover.**
<figure class="image table text-center m-0 w-full">
<img class="center" src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/cliff.jpg" alt="Policy Update cliff"/>
<figcaption>Taking smaller policy updates to improve the training stability</figcaption>
<figcaption>Modified version from RL — Proximal Policy Optimization (PPO) <a href="https://jonathan-hui.medium.com/rl-proximal-policy-optimization-ppo-explained-77f014ec3f12">Explained by Jonathan Hui</a></figcaption>
</figure>
**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
| huggingface/deep-rl-class/blob/main/units/en/unit8/intuition-behind-ppo.mdx |
Preview a dataset
Datasets Server provides a `/first-rows` endpoint for visualizing the first 100 rows of a dataset. This'll give you a good idea of the data types and example data contained in a dataset.

This guide shows you how to use Datasets Server's `/first-rows` endpoint to preview a dataset. Feel free to also try it out with [Postman](https://www.postman.com/huggingface/workspace/hugging-face-apis/request/23242779-32d6a8be-b800-446a-8cee-f6b5ca1710df), [RapidAPI](https://rapidapi.com/hugging-face-hugging-face-default/api/hugging-face-datasets-api), or [ReDoc](https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json#operation/listFirstRows).
The `/first-rows` endpoint accepts three query parameters:
- `dataset`: the dataset name, for example `glue` or `mozilla-foundation/common_voice_10_0`
- `config`: the configuration name, for example `cola`
- `split`: the split name, for example `train`
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/first-rows?dataset=duorc&config=SelfRC&split=train"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/first-rows?dataset=duorc&config=SelfRC&split=train",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/first-rows?dataset=duorc&config=SelfRC&split=train \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The endpoint response is a JSON containing two keys:
- The [`features`](https://huggingface.co/docs/datasets/about_dataset_features) of a dataset, including the column's name and data type.
- The first 100 `rows` of a dataset and the content contained in each column of a specific row.
For example, here are the `features` and the first 100 `rows` of the `duorc`/`SelfRC` train split:
```json
{
"dataset": "duorc",
"config": "SelfRC",
"split": "train",
"features": [
{
"feature_idx": 0,
"name": "plot_id",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 1,
"name": "plot",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 2,
"name": "title",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 3,
"name": "question_id",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 4,
"name": "question",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 5,
"name": "answers",
"type": {
"feature": { "dtype": "string", "_type": "Value" },
"_type": "Sequence"
}
},
{
"feature_idx": 6,
"name": "no_answer",
"type": { "dtype": "bool", "_type": "Value" }
}
],
"rows": [
{
"row_idx": 0,
"row": {
"plot_id": "/m/03vyhn",
"plot": "200 years in the future, Mars has been colonized by a high-tech company.\nMelanie Ballard (Natasha Henstridge) arrives by train to a Mars mining camp which has cut all communication links with the company headquarters. She's not alone, as she is with a group of fellow police officers. They find the mining camp deserted except for a person in the prison, Desolation Williams (Ice Cube), who seems to laugh about them because they are all going to die. They were supposed to take Desolation to headquarters, but decide to explore first to find out what happened.They find a man inside an encapsulated mining car, who tells them not to open it. However, they do and he tries to kill them. One of the cops witnesses strange men with deep scarred and heavily tattooed faces killing the remaining survivors. The cops realise they need to leave the place fast.Desolation explains that the miners opened a kind of Martian construction in the soil which unleashed red dust. Those who breathed that dust became violent psychopaths who started to build weapons and kill the uninfected. They changed genetically, becoming distorted but much stronger.The cops and Desolation leave the prison with difficulty, and devise a plan to kill all the genetically modified ex-miners on the way out. However, the plan goes awry, and only Melanie and Desolation reach headquarters alive. Melanie realises that her bosses won't ever believe her. However, the red dust eventually arrives to headquarters, and Melanie and Desolation need to fight once again.",
"title": "Ghosts of Mars",
"question_id": "b440de7d-9c3f-841c-eaec-a14bdff950d1",
"question": "How did the police arrive at the Mars mining camp?",
"answers": ["They arrived by train."],
"no_answer": false
},
"truncated_cells": []
},
{
"row_idx": 1,
"row": {
"plot_id": "/m/03vyhn",
"plot": "200 years in the future, Mars has been colonized by a high-tech company.\nMelanie Ballard (Natasha Henstridge) arrives by train to a Mars mining camp which has cut all communication links with the company headquarters. She's not alone, as she is with a group of fellow police officers. They find the mining camp deserted except for a person in the prison, Desolation Williams (Ice Cube), who seems to laugh about them because they are all going to die. They were supposed to take Desolation to headquarters, but decide to explore first to find out what happened.They find a man inside an encapsulated mining car, who tells them not to open it. However, they do and he tries to kill them. One of the cops witnesses strange men with deep scarred and heavily tattooed faces killing the remaining survivors. The cops realise they need to leave the place fast.Desolation explains that the miners opened a kind of Martian construction in the soil which unleashed red dust. Those who breathed that dust became violent psychopaths who started to build weapons and kill the uninfected. They changed genetically, becoming distorted but much stronger.The cops and Desolation leave the prison with difficulty, and devise a plan to kill all the genetically modified ex-miners on the way out. However, the plan goes awry, and only Melanie and Desolation reach headquarters alive. Melanie realises that her bosses won't ever believe her. However, the red dust eventually arrives to headquarters, and Melanie and Desolation need to fight once again.",
"title": "Ghosts of Mars",
"question_id": "a9f95c0d-121f-3ca9-1595-d497dc8bc56c",
"question": "Who has colonized Mars 200 years in the future?",
"answers": [
"A high-tech company has colonized Mars 200 years in the future."
],
"no_answer": false
},
"truncated_cells": []
}
...
],
"truncated": false
}
```
## Truncated responses
For some datasets, the response size from `/first-rows` may exceed 1MB, in which case the response is truncated until the size is under 1MB. This means you may not get 100 rows in your response because the rows are truncated, in which case the `truncated` field would be `true`.
In some cases, if even the first few rows generate a response that exceeds 1MB, some of the columns are truncated and converted to a string. You'll see these listed in the `truncated_cells` field.
For example, the [`ett`](https://datasets-server.huggingface.co/first-rows?dataset=ett&config=m2&split=test) dataset only returns 10 rows, and the `target` and `feat_dynamic_real` columns are truncated:
```json
...
"rows": [
{
"row_idx": 0,
"row": {
"start": "2016-07-01T00:00:00",
"target": "[38.6619987487793,38.222999572753906,37.34400177001953,37.124000549316406,37.124000549316406,36.9039",
"feat_static_cat": [0],
"feat_dynamic_real": "[[41.130001068115234,39.62200164794922,38.86800003051758,35.518001556396484,37.52799987792969,37.611",
"item_id": "OT"
},
"truncated_cells": ["target", "feat_dynamic_real"]
},
{
"row_idx": 1,
"row": {
"start": "2016-07-01T00:00:00",
"target": "[38.6619987487793,38.222999572753906,37.34400177001953,37.124000549316406,37.124000549316406,36.9039",
"feat_static_cat": [0],
"feat_dynamic_real": "[[41.130001068115234,39.62200164794922,38.86800003051758,35.518001556396484,37.52799987792969,37.611",
"item_id": "OT"
},
"truncated_cells": ["target", "feat_dynamic_real"]
},
...
],
truncated: true
```
| huggingface/datasets-server/blob/main/docs/source/first_rows.mdx |
# Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
Colab for training
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
Colab for inference
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run:
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Cat toy example
First, let's login so that we can upload the checkpoint to the Hub during training:
```bash
huggingface-cli login
```
Now let's get our dataset. For this example we will use some cat images: https://huggingface.co/datasets/diffusers/cat_toy_example .
Let's first download it locally:
```py
from huggingface_hub import snapshot_download
local_dir = "./cat"
snapshot_download("diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes")
```
This will be our training data.
Now we can launch the training using:
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="./cat"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--push_to_hub \
--output_dir="textual_inversion_cat"
```
A full training run takes ~1 hour on one V100 GPU.
**Note**: As described in [the official paper](https://arxiv.org/abs/2208.01618)
only one embedding vector is used for the placeholder token, *e.g.* `"<cat-toy>"`.
However, one can also add multiple embedding vectors for the placeholder token
to increase the number of fine-tuneable parameters. This can help the model to learn
more complex details. To use multiple embedding vectors, you should define `--num_vectors`
to a number larger than one, *e.g.*:
```bash
--num_vectors 5
```
The saved textual inversion vectors will then be larger in size compared to the default case.
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("cat-backpack.png")
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATA_DIR="path-to-dir-containing-images"
python textual_inversion_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--output_dir="textual_inversion_cat"
```
It should be at least 70% faster than the PyTorch script with the same configuration.
### Training with xformers:
You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
| huggingface/diffusers/blob/main/examples/textual_inversion/README.md |
FrameworkSwitchCourse {fw} />
# Fine-tuning, Check![[fine-tuning-check]]
<CourseFloatingBanner
chapter={3}
classNames="absolute z-10 right-0 top-0"
/>
That was fun! In the first two chapters you learned about models and tokenizers, and now you know how to fine-tune them for your own data. To recap, in this chapter you:
{#if fw === 'pt'}
* Learned about datasets in the [Hub](https://huggingface.co/datasets)
* Learned how to load and preprocess datasets, including using dynamic padding and collators
* Implemented your own fine-tuning and evaluation of a model
* Implemented a lower-level training loop
* Used 🤗 Accelerate to easily adapt your training loop so it works for multiple GPUs or TPUs
{:else}
* Learned about datasets in the [Hub](https://huggingface.co/datasets)
* Learned how to load and preprocess datasets
* Learned how to fine-tune and evaluate a model with Keras
* Implemented a custom metric
{/if}
| huggingface/course/blob/main/chapters/en/chapter3/5.mdx |
(Legacy) SE-ResNeXt
**SE ResNeXt** is a variant of a [ResNeXt](https://www.paperswithcode.com/method/resnext) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('legacy_seresnext101_32x4d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `legacy_seresnext101_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('legacy_seresnext101_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Legacy SE ResNeXt
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: legacy_seresnext101_32x4d
In Collection: Legacy SE ResNeXt
Metadata:
FLOPs: 10287698672
Parameters: 48960000
File Size: 196466866
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnext101_32x4d
LR: 0.6
Epochs: 100
Layers: 101
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L462
Weights: http://data.lip6.fr/cadene/pretrainedmodels/se_resnext101_32x4d-3b2fe3d8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.23%
Top 5 Accuracy: 95.02%
- Name: legacy_seresnext26_32x4d
In Collection: Legacy SE ResNeXt
Metadata:
FLOPs: 3187342304
Parameters: 16790000
File Size: 67346327
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnext26_32x4d
LR: 0.6
Epochs: 100
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L448
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext26_32x4d-65ebdb501.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.11%
Top 5 Accuracy: 93.31%
- Name: legacy_seresnext50_32x4d
In Collection: Legacy SE ResNeXt
Metadata:
FLOPs: 5459954352
Parameters: 27560000
File Size: 110559176
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnext50_32x4d
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L455
Weights: http://data.lip6.fr/cadene/pretrainedmodels/se_resnext50_32x4d-a260b3a4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.08%
Top 5 Accuracy: 94.43%
--> | huggingface/pytorch-image-models/blob/main/docs/models/legacy-se-resnext.md |
Gradio Demo: zip_files
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/titanic.csv https://github.com/gradio-app/gradio/raw/main/demo/zip_files/files/titanic.csv
```
```
import os
from zipfile import ZipFile
import gradio as gr
def zip_files(files):
with ZipFile("tmp.zip", "w") as zipObj:
for idx, file in enumerate(files):
zipObj.write(file.name, file.name.split("/")[-1])
return "tmp.zip"
demo = gr.Interface(
zip_files,
gr.File(file_count="multiple", file_types=["text", ".json", ".csv"]),
"file",
examples=[[[os.path.join(os.path.abspath(''),"files/titanic.csv"),
os.path.join(os.path.abspath(''),"files/titanic.csv"),
os.path.join(os.path.abspath(''),"files/titanic.csv")]]],
cache_examples=True
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/zip_files/run.ipynb |
Metrics
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
Metrics are important for evaluating a model's predictions. In the tutorial, you learned how to compute a metric over an entire evaluation set. You have also seen how to load a metric.
This guide will show you how to:
- Add predictions and references.
- Compute metrics using different methods.
- Write your own metric loading script.
## Add predictions and references
When you want to add model predictions and references to a [`Metric`] instance, you have two options:
- [`Metric.add`] adds a single `prediction` and `reference`.
- [`Metric.add_batch`] adds a batch of `predictions` and `references`.
Use [`Metric.add_batch`] by passing it your model predictions, and the references the model predictions should be evaluated against:
```py
>>> import datasets
>>> metric = datasets.load_metric('my_metric')
>>> for model_input, gold_references in evaluation_dataset:
... model_predictions = model(model_inputs)
... metric.add_batch(predictions=model_predictions, references=gold_references)
>>> final_score = metric.compute()
```
<Tip>
Metrics accepts various input formats (Python lists, NumPy arrays, PyTorch tensors, etc.) and converts them to an appropriate format for storage and computation.
</Tip>
## Compute scores
The most straightforward way to calculate a metric is to call [`Metric.compute`]. But some metrics have additional arguments that allow you to modify the metrics behavior.
Let's load the [SacreBLEU](https://huggingface.co/metrics/sacrebleu) metric, and compute it with a different smoothing method.
1. Load the SacreBLEU metric:
```py
>>> import datasets
>>> metric = datasets.load_metric('sacrebleu')
```
2. Inspect the different argument methods for computing the metric:
```py
>>> print(metric.inputs_description)
Produces BLEU scores along with its sufficient statistics
from a source against one or more references.
Args:
predictions: The system stream (a sequence of segments).
references: A list of one or more reference streams (each a sequence of segments).
smooth_method: The smoothing method to use. (Default: 'exp').
smooth_value: The smoothing value. Only valid for 'floor' and 'add-k'. (Defaults: floor: 0.1, add-k: 1).
tokenize: Tokenization method to use for BLEU. If not provided, defaults to 'zh' for Chinese, 'ja-mecab' for Japanese and '13a' (mteval) otherwise.
lowercase: Lowercase the data. If True, enables case-insensitivity. (Default: False).
force: Insist that your tokenized input is actually detokenized.
...
```
3. Compute the metric with the `floor` method, and a different `smooth_value`:
```py
>>> score = metric.compute(smooth_method="floor", smooth_value=0.2)
```
<a id='metric_script'></a>
## Custom metric loading script
Write a metric loading script to use your own custom metric (or one that is not on the Hub). Then you can load it as usual with [`load_metric`].
To help you get started, open the [SQuAD metric loading script](https://github.com/huggingface/datasets/blob/main/metrics/squad/squad.py) and follow along.
<Tip>
Get jump started with our metric loading script [template](https://github.com/huggingface/datasets/blob/f9713d2e23813142a02f1b0e965095f528785cff/templates/new_metric_script.py)!
</Tip>
### Add metric attributes
Start by adding some information about your metric in [`Metric._info`]. The most important attributes you should specify are:
1. [`MetricInfo.description`] provides a brief description about your metric.
2. [`MetricInfo.citation`] contains a BibTex citation for the metric.
3. [`MetricInfo.inputs_description`] describes the expected inputs and outputs. It may also provide an example usage of the metric.
4. [`MetricInfo.features`] defines the name and type of the predictions and references.
After you've filled out all these fields in the template, it should look like the following example from the SQuAD metric script:
```py
class Squad(datasets.Metric):
def _info(self):
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": {"id": datasets.Value("string"), "prediction_text": datasets.Value("string")},
"references": {
"id": datasets.Value("string"),
"answers": datasets.features.Sequence(
{
"text": datasets.Value("string"),
"answer_start": datasets.Value("int32"),
}
),
},
}
),
codebase_urls=["https://rajpurkar.github.io/SQuAD-explorer/"],
reference_urls=["https://rajpurkar.github.io/SQuAD-explorer/"],
)
```
### Download metric files
If your metric needs to download, or retrieve local files, you will need to use the [`Metric._download_and_prepare`] method. For this example, let's examine the [BLEURT metric loading script](https://github.com/huggingface/datasets/blob/main/metrics/bleurt/bleurt.py).
1. Provide a dictionary of URLs that point to the metric files:
```py
CHECKPOINT_URLS = {
"bleurt-tiny-128": "https://storage.googleapis.com/bleurt-oss/bleurt-tiny-128.zip",
"bleurt-tiny-512": "https://storage.googleapis.com/bleurt-oss/bleurt-tiny-512.zip",
"bleurt-base-128": "https://storage.googleapis.com/bleurt-oss/bleurt-base-128.zip",
"bleurt-base-512": "https://storage.googleapis.com/bleurt-oss/bleurt-base-512.zip",
"bleurt-large-128": "https://storage.googleapis.com/bleurt-oss/bleurt-large-128.zip",
"bleurt-large-512": "https://storage.googleapis.com/bleurt-oss/bleurt-large-512.zip",
}
```
<Tip>
If the files are stored locally, provide a dictionary of path(s) instead of URLs.
</Tip>
2. [`Metric._download_and_prepare`] will take the URLs and download the metric files specified:
```py
def _download_and_prepare(self, dl_manager):
# check that config name specifies a valid BLEURT model
if self.config_name == "default":
logger.warning(
"Using default BLEURT-Base checkpoint for sequence maximum length 128. "
"You can use a bigger model for better results with e.g.: datasets.load_metric('bleurt', 'bleurt-large-512')."
)
self.config_name = "bleurt-base-128"
if self.config_name not in CHECKPOINT_URLS.keys():
raise KeyError(
f"{self.config_name} model not found. You should supply the name of a model checkpoint for bleurt in {CHECKPOINT_URLS.keys()}"
)
# download the model checkpoint specified by self.config_name and set up the scorer
model_path = dl_manager.download_and_extract(CHECKPOINT_URLS[self.config_name])
self.scorer = score.BleurtScorer(os.path.join(model_path, self.config_name))
```
### Compute score
[`DatasetBuilder._compute`] provides the actual instructions for how to compute a metric given the predictions and references. Now let's take a look at the [GLUE metric loading script](https://github.com/huggingface/datasets/blob/main/metrics/glue/glue.py).
1. Provide the functions for [`DatasetBuilder._compute`] to calculate your metric:
```py
def simple_accuracy(preds, labels):
return (preds == labels).mean().item()
def acc_and_f1(preds, labels):
acc = simple_accuracy(preds, labels)
f1 = f1_score(y_true=labels, y_pred=preds).item()
return {
"accuracy": acc,
"f1": f1,
}
def pearson_and_spearman(preds, labels):
pearson_corr = pearsonr(preds, labels)[0].item()
spearman_corr = spearmanr(preds, labels)[0].item()
return {
"pearson": pearson_corr,
"spearmanr": spearman_corr,
}
```
2. Create [`DatasetBuilder._compute`] with instructions for what metric to calculate for each configuration:
```py
def _compute(self, predictions, references):
if self.config_name == "cola":
return {"matthews_correlation": matthews_corrcoef(references, predictions)}
elif self.config_name == "stsb":
return pearson_and_spearman(predictions, references)
elif self.config_name in ["mrpc", "qqp"]:
return acc_and_f1(predictions, references)
elif self.config_name in ["sst2", "mnli", "mnli_mismatched", "mnli_matched", "qnli", "rte", "wnli", "hans"]:
return {"accuracy": simple_accuracy(predictions, references)}
else:
raise KeyError(
"You should supply a configuration name selected in "
'["sst2", "mnli", "mnli_mismatched", "mnli_matched", '
'"cola", "stsb", "mrpc", "qqp", "qnli", "rte", "wnli", "hans"]'
)
```
### Test
Once you're finished writing your metric loading script, try to load it locally:
```py
>>> from datasets import load_metric
>>> metric = load_metric('PATH/TO/MY/SCRIPT.py')
```
| huggingface/datasets/blob/main/docs/source/how_to_metrics.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Lights
[[autodoc]] Light
Under construction 🚧. | huggingface/simulate/blob/main/docs/source/api/lights.mdx |
his demo uses a fake model to showcase iterative output. The Image output will update every time a generator is returned until the final image. | gradio-app/gradio/blob/main/demo/fake_diffusion/DESCRIPTION.md |
FrameworkSwitchCourse {fw} />
# Debugging the training pipeline[[debugging-the-training-pipeline]]
<CourseFloatingBanner chapter={8}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter8/section4_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter8/section4_tf.ipynb"},
]} />
You've written a beautiful script to train or fine-tune a model on a given task, dutifully following the advice from [Chapter 7](/course/chapter7). But when you launch the command `model.fit()`, something horrible happens: you get an error 😱! Or worse, everything seems to be fine and the training runs without error, but the resulting model is crappy. In this section, we will show you what you can do to debug these kinds of issues.
## Debugging the training pipeline[[debugging-the-training-pipeline]]
<Youtube id="N9kO52itd0Q"/>
The problem when you encounter an error in `model.fit()` is that it could come from multiple sources, as training usually brings together a lot of things that you've been working on up until that point. The problem could be something wrong in your dataset, or some issue when trying to batch elements of the datasets together. Or it could be something wrong in the model code, or your loss function or optimizer. And even if everything goes well for training, something could still go wrong during the evaluation if there is a problem with your metric.
The best way to debug an error that arises in `model.fit()` is to manually go through this whole pipeline to see where things went awry. The error is then often very easy to solve.
To demonstrate this, we will use the following script that (tries to) fine-tune a DistilBERT model on the [MNLI dataset](https://huggingface.co/datasets/glue):
```py
from datasets import load_dataset
import evaluate
from transformers import (
AutoTokenizer,
TFAutoModelForSequenceClassification,
)
raw_datasets = load_dataset("glue", "mnli")
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
train_dataset = tokenized_datasets["train"].to_tf_dataset(
columns=["input_ids", "labels"], batch_size=16, shuffle=True
)
validation_dataset = tokenized_datasets["validation_matched"].to_tf_dataset(
columns=["input_ids", "labels"], batch_size=16, shuffle=True
)
model = TFAutoModelForSequenceClassification.from_pretrained(model_checkpoint)
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
model.fit(train_dataset)
```
If you try to execute it, you might get some `VisibleDeprecationWarning`s when doing the dataset conversion -- this is a known UX issue we have, so please ignore it. If you're reading the course after, say, November 2021 and it's still happening, then send rage tweets at @carrigmat until he fixes it.
What's a more serious problem, though, is that we get an outright error. And it's really, terrifyingly long:
```python out
ValueError: No gradients provided for any variable: ['tf_distil_bert_for_sequence_classification/distilbert/embeddings/word_embeddings/weight:0', '...']
```
What does that mean? We tried to train on our data, but we got no gradient? This is pretty perplexing; how do we even begin to debug something like that? When the error you get doesn't immediately suggest where the problem is, the best solution is often to walk through things in sequence, making sure at each stage that everything looks right. And of course, the place to start is always to...
### Check your data[[check-your-data]]
This goes without saying, but if your data is corrupted, Keras is not going to be able to fix it for you. So first things first, you need to have a look at what is inside your training set.
Although it's tempting to look inside `raw_datasets` and `tokenized_datasets`, we highly recommend you go to the data right at the point where it's going to enter the model. That means reading an output from the `tf.data.Dataset` you created with the `to_tf_dataset()` function! So how do we do that? `tf.data.Dataset` objects give us whole batches at a time and don't support indexing, so we can't just ask for `train_dataset[0]`. We can, however, ask it politely for a batch:
```py
for batch in train_dataset:
break
```
`break` ends the loop after one iteration, so this grabs the first batch that comes out of `train_dataset` and saves it as `batch`. Now, let's take a look at what's inside:
```python out
{'attention_mask': <tf.Tensor: shape=(16, 76), dtype=int64, numpy=
array([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]])>,
'label': <tf.Tensor: shape=(16,), dtype=int64, numpy=array([0, 2, 1, 2, 1, 1, 2, 0, 0, 0, 1, 0, 1, 2, 2, 1])>,
'input_ids': <tf.Tensor: shape=(16, 76), dtype=int64, numpy=
array([[ 101, 2174, 1010, ..., 0, 0, 0],
[ 101, 3174, 2420, ..., 0, 0, 0],
[ 101, 2044, 2048, ..., 0, 0, 0],
...,
[ 101, 3398, 3398, ..., 2051, 2894, 102],
[ 101, 1996, 4124, ..., 0, 0, 0],
[ 101, 1999, 2070, ..., 0, 0, 0]])>}
```
This looks right, doesn't it? We're passing the `labels`, `attention_mask`, and `input_ids` to the model, which should be everything it needs to compute outputs and calculate the loss. So why don't we have a gradient? Look closer: we're passing a single dictionary as input, but a training batch is usually an input tensor or dictionary, plus a labels tensor. Our labels are just a key in our input dictionary.
Is this a problem? Not always, actually! But it's one of the most common issues you'll encounter when training Transformer models with TensorFlow. Our models can all compute loss internally, but to do that the labels need to be passed in the input dictionary. This is the loss that is used when we don't specify a loss value to `compile()`. Keras, on the other hand, usually expects labels to be passed separately from the input dictionary, and loss computations will usually fail if you don't do that.
The problem has now become clearer: we passed a `loss` argument, which means we're asking Keras to compute losses for us, but we passed our labels as inputs to the model, not as labels in the place Keras expects them! We need to choose one or the other: either we use the model's internal loss and keep the labels where they are, or we keep using Keras losses, but we move the labels to the place Keras expects them. For simplicity, let's take the first approach. Change the call to `compile()` to read:
```py
model.compile(optimizer="adam")
```
Now we'll use the model's internal loss, and this problem should be resolved!
<Tip>
✏️ **Your turn!** As an optional challenge after we've resolved the other issues, you can try coming back to this step and getting the model to work with the original Keras-computed loss instead of the internal loss. You'll need to add `"labels"` to the `label_cols` argument of `to_tf_dataset()` to ensure that the labels are correctly outputted, which will get you gradients -- but there's one more problem with the loss that we specified. Training will still run with this problem, but learning will be very slow and will plateau at a high training loss. Can you figure out what it is?
A ROT13-encoded hint, if you're stuck: Vs lbh ybbx ng gur bhgchgf bs FrdhraprPynffvsvpngvba zbqryf va Genafsbezref, gurve svefg bhgchg vf `ybtvgf`. Jung ner ybtvgf?
And a second hint: Jura lbh fcrpvsl bcgvzvmref, npgvingvbaf be ybffrf jvgu fgevatf, Xrenf frgf nyy gur nethzrag inyhrf gb gurve qrsnhygf. Jung nethzragf qbrf FcnefrPngrtbevpnyPebffragebcl unir, naq jung ner gurve qrsnhygf?
</Tip>
Now, let's try training. We should get gradients now, so hopefully (ominous music plays here) we can just call `model.fit()` and everything will work fine!
```python out
246/24543 [..............................] - ETA: 15:52 - loss: nan
```
Oh no.
`nan` is not a very encouraging loss value. Still, we've checked our data, and it looks pretty good. If that's not the problem, where can we go next? The obvious next step is to...
### Check your model[[check-your-model]]
`model.fit()` is a really great convenience function in Keras, but it does a lot of things for you, and that can make it trickier to find exactly where a problem has occurred. If you're debugging your model, one strategy that can really help is to pass just a single batch to the model, and look at the outputs for that one batch in detail. Another really helpful tip if the model is throwing errors is to `compile()` the model with `run_eagerly=True`. This will make it a lot slower, but it will make the error messages much more comprehensible, because they'll indicate exactly where in your model's code the problem occurred.
For now, though, we don't need `run_eagerly` just yet. Let's run the `batch` we got before through the model and see what the outputs look like:
```py
model(batch)
```
```python out
TFSequenceClassifierOutput(loss=<tf.Tensor: shape=(16,), dtype=float32, numpy=
array([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan], dtype=float32)>, logits=<tf.Tensor: shape=(16, 2), dtype=float32, numpy=
array([[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan],
[nan, nan]], dtype=float32)>, hidden_states=None, attentions=None)
```
Well, this is tricky. Everything is `nan`! But that's strange, isn't it? How would all our logits become `nan`? `nan` means "not a number." `nan` values often occur when you perform a forbidden operation, such as division by zero. But one thing that's very important to know about `nan` in machine learning is that this value tends to *propagate*. If you multiply a number by `nan`, the output is also `nan`. And if you get a `nan` anywhere in your output, your loss, or your gradient, then it will rapidly spread throughout your whole model -- because when that `nan` value is propagated back through your network, you'll get `nan` gradients, and when weight updates are computed with those gradients, you'll get `nan` weights, and those weights will compute even more `nan` outputs! Soon enough the whole network will just be one big block of `nan`s. Once that happens, it's pretty hard to see where the problem started. How can we isolate where `nan` first crept in?
The answer is to try *reinitializing* our model. Once we started training, we got a `nan` somewhere and it quickly propagated through the whole model. So, let's load the model from a checkpoint and not do any weight updates, and see where we get a `nan` value:
```py
model = TFAutoModelForSequenceClassification.from_pretrained(model_checkpoint)
model(batch)
```
When we run that, we get:
```py out
TFSequenceClassifierOutput(loss=<tf.Tensor: shape=(16,), dtype=float32, numpy=
array([0.6844486 , nan, nan, 0.67127866, 0.7068601 ,
nan, 0.69309855, nan, 0.65531296, nan,
nan, nan, 0.675402 , nan, nan,
0.69831556], dtype=float32)>, logits=<tf.Tensor: shape=(16, 2), dtype=float32, numpy=
array([[-0.04761693, -0.06509043],
[-0.0481936 , -0.04556257],
[-0.0040929 , -0.05848458],
[-0.02417453, -0.0684005 ],
[-0.02517801, -0.05241832],
[-0.04514256, -0.0757378 ],
[-0.02656011, -0.02646275],
[ 0.00766164, -0.04350497],
[ 0.02060014, -0.05655622],
[-0.02615328, -0.0447021 ],
[-0.05119278, -0.06928903],
[-0.02859691, -0.04879177],
[-0.02210129, -0.05791225],
[-0.02363213, -0.05962167],
[-0.05352269, -0.0481673 ],
[-0.08141848, -0.07110836]], dtype=float32)>, hidden_states=None, attentions=None)
```
*Now* we're getting somewhere! There are no `nan` values in our logits, which is reassuring. But we do see a few `nan` values in our loss! Is there something about those samples in particular that's causing this problem? Let's see which ones they are (note that if you run this code yourself, you may get different indices because the dataset has been shuffled):
```python
import numpy as np
loss = model(batch).loss.numpy()
indices = np.flatnonzero(np.isnan(loss))
indices
```
```python out
array([ 1, 2, 5, 7, 9, 10, 11, 13, 14])
```
Let's look at the samples these indices came from:
```python
input_ids = batch["input_ids"].numpy()
input_ids[indices]
```
```python out
array([[ 101, 2007, 2032, 2001, 1037, 16480, 3917, 2594, 4135,
23212, 3070, 2214, 10170, 1010, 2012, 4356, 1997, 3183,
6838, 12953, 2039, 2000, 1996, 6147, 1997, 2010, 2606,
1012, 102, 6838, 2001, 3294, 6625, 3773, 1996, 2214,
2158, 1012, 102, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 1998, 6814, 2016, 2234, 2461, 2153, 1998, 13322,
2009, 1012, 102, 2045, 1005, 1055, 2053, 3382, 2008,
2016, 1005, 2222, 3046, 8103, 2075, 2009, 2153, 1012,
102, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 1998, 2007, 1996, 3712, 4634, 1010, 2057, 8108,
2025, 3404, 2028, 1012, 1996, 2616, 18449, 2125, 1999,
1037, 9666, 1997, 4100, 8663, 11020, 6313, 2791, 1998,
2431, 1011, 4301, 1012, 102, 2028, 1005, 1055, 5177,
2110, 1998, 3977, 2000, 2832, 2106, 2025, 2689, 2104,
2122, 6214, 1012, 102, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 1045, 2001, 1999, 1037, 13090, 5948, 2007, 2048,
2308, 2006, 2026, 5001, 2043, 2026, 2171, 2001, 2170,
1012, 102, 1045, 2001, 3564, 1999, 2277, 1012, 102,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 2195, 4279, 2191, 2039, 1996, 2181, 2124, 2004,
1996, 2225, 7363, 1012, 102, 2045, 2003, 2069, 2028,
2451, 1999, 1996, 2225, 7363, 1012, 102, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 2061, 2008, 1045, 2123, 1005, 1056, 2113, 2065,
2009, 2428, 10654, 7347, 2030, 2009, 7126, 2256, 2495,
2291, 102, 2009, 2003, 5094, 2256, 2495, 2291, 2035,
2105, 1012, 102, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 2051, 1010, 2029, 3216, 2019, 2503, 3444, 1010,
6732, 1996, 2265, 2038, 19840, 2098, 2125, 9906, 1998,
2003, 2770, 2041, 1997, 4784, 1012, 102, 2051, 6732,
1996, 2265, 2003, 9525, 1998, 4569, 1012, 102, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 1996, 10556, 2140, 11515, 2058, 1010, 2010, 2162,
2252, 5689, 2013, 2010, 7223, 1012, 102, 2043, 1996,
10556, 2140, 11515, 2058, 1010, 2010, 2252, 3062, 2000,
1996, 2598, 1012, 102, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[ 101, 13543, 1999, 2049, 6143, 2933, 2443, 102, 2025,
13543, 1999, 6143, 2933, 2003, 2443, 102, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])
```
Well, there's a lot in here, but nothing stands out as unusual. Let's look at the labels:
```python out
labels = batch['labels'].numpy()
labels[indices]
```
```python out
array([2, 2, 2, 2, 2, 2, 2, 2, 2])
```
Ah! The `nan` samples all have the same label, and it's label 2. This is a very strong hint. The fact that we're only getting a loss of `nan` when our label is 2 suggests that this is a very good time to check the number of labels in our model:
```python
model.config.num_labels
```
```python out
2
```
Now we see the problem: the model thinks there are only two classes, but the labels go up to 2, which means there are in fact three classes (because 0 is also a class). This is how we got a `nan` -- by trying to compute the loss for a nonexistent class! Let's try changing that and fitting the model again:
```
model = TFAutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=3)
model.compile(optimizer='adam')
model.fit(train_dataset)
```
```python out
869/24543 [>.............................] - ETA: 15:29 - loss: 1.1032
```
We're training! No more `nan`s, and our loss is declining... sort of. If you watch it for a while, you might start to get a bit impatient, because the loss value stays stubbornly high. Let's stop training here and try to think about what could be causing this problem. At this point, we're pretty sure both the data and the model are okay, but our model isn't learning well. What else is left? It's time to...
### Check your hyperparameters[[check-your-hyperparameters]]
If you look back at the code above, you might not be able to see any hyperparameters at all, except perhaps the `batch_size`, and that doesn't seem like a likely culprit. Don't be fooled, though; there are always hyperparameters, and if you can't see them, it just means that you don't know what they're set to. In particular, remember a critical thing about Keras: if you set a loss, optimizer, or activation function with a string, _all of its arguments will be set to their default values_. This means that even though using strings for this is very convenient, you should be very careful when doing so, as it can easily hide critical things from you. (Anyone trying the optional challenge above should take careful note of this fact.)
In this case, where have we set an argument with a string? We were setting the loss with a string initially, but we're not doing that anymore. We are, however, setting the optimizer with a string. Could that be hiding anything from us? Let's take a look at [its arguments](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam).
Does anything stand out here? That's right -- the learning rate! When we just use the string `'adam'`, we're going to get the default learning rate, which is 0.001, or 1e-3. This is way too high for a Transformer model! In general, we recommend trying learning rates between 1e-5 and 1e-4 for your models; that's somewhere between 10X and 100X smaller than the value we're actually using here. That sounds like it might be a major problem, so let's try reducing it. To do that, we need to import the actual `optimizer` object. While we're at it, let's reinitialize the model from the checkpoint, in case training with the high learning rate damaged its weights:
```python
from tensorflow.keras.optimizers import Adam
model = TFAutoModelForSequenceClassification.from_pretrained(model_checkpoint)
model.compile(optimizer=Adam(5e-5))
```
<Tip>
💡 You can also import the `create_optimizer()` function from 🤗 Transformers, which will give you an AdamW optimizer with correct weight decay as well as learning rate warmup and decay. This optimizer will often produce slightly better results than the ones you get with the default Adam optimizer.
</Tip>
Now, we can try fitting the model with the new, improved learning rate:
```python
model.fit(train_dataset)
```
```python out
319/24543 [..............................] - ETA: 16:07 - loss: 0.9718
```
Now our loss is really going somewhere! Training finally looks like it's working. There's a lesson here: when your model is running but loss isn't declining, and you're sure your data is okay, it's a good idea to check hyperparameters like the learning rate and weight decay. Setting either of those too high is very likely to cause training to "stall" at a high loss value.
## Other potential issues[[other-potential-issues]]
We've covered the issues in the script above, but there are several other common errors you might face. Let's take a look at a (very incomplete) list.
### Dealing with out-of-memory errors[[dealing-with-out-of-memory-errors]]
The telltale sign of running out of memory is an error like "OOM when allocating tensor" -- OOM is short for "out of memory." This is a very common hazard when dealing with large language models. If you encounter this, a good strategy is to halve your batch size and try again. Bear in mind, though, that some models are *very* large. For example, the full-size GPT-2 has 1.5B parameters, which means you'll need 6 GB of memory just to store the model, and another 6 GB for its gradients! Training the full GPT-2 model will usually require over 20 GB of VRAM no matter what batch size you use, which only a few GPUs have. More lightweight models like `distilbert-base-cased` are much easier to run, and train much more quickly too.
<Tip>
In the next part of the course, we'll look at more advanced techniques that can help you reduce your memory footprint and let you fine-tune the biggest models.
</Tip>
### Hungry Hungry TensorFlow 🦛[[hungry-hungry-tensorflow]]
One particular quirk of TensorFlow that you should be aware of is that it allocates *all* of your GPU memory to itself as soon as you load a model or do any training, and then it divides up that memory as required. This is different from the behavior of other frameworks, like PyTorch, which allocate memory as required with CUDA rather than doing it internally. One advantage of the TensorFlow approach is that it can often give useful errors when you run out of memory, and it can recover from that state without crashing the whole CUDA kernel. But there's also an important downside: if you run two TensorFlow processes at once, then **you're going to have a bad time**.
If you're running on Colab you don't need to worry about this, but if you're running locally this is definitely something you should be careful about. In particular, be aware that closing a notebook tab does not necessarily shut that notebook down! You may need to select running notebooks (the ones with a green icon) and manually shut them down in the directory listing. Any running notebook that was using TensorFlow could still be holding on to a bunch of your GPU memory, and that means any new notebook you start may encounter some very odd issues.
If you start getting errors about CUDA, BLAS, or cuBLAS in code that worked before, this is very often the culprit. You can use a command like `nvidia-smi` to check -- when you shut down or restart your current notebook, is most of your memory free, or is it still in use? If it's still in use, something else is holding on to it!
### Check your data (again!)[[check-your-data-again]]
Your model will only learn something if it's actually possible to learn anything from your data. If there is a bug that corrupts the data or the labels are attributed randomly, it's very likely you won't get any model training on your dataset. One helpful tool here is `tokenizer.decode()`. This will turn `input_ids` back into strings, so you can view the data and see if your training data is teaching what you want it to teach. For example, after you get a `batch` from your `tf.data.Dataset` like we did above, you can decode the first element like so:
```py
input_ids = batch["input_ids"].numpy()
tokenizer.decode(input_ids[0])
```
Then you can compare it with the first label, like so:
```py
labels = batch["labels"].numpy()
label = labels[0]
```
Once you can view your data like this, you can ask yourself the following questions:
- Is the decoded data understandable?
- Do you agree with the labels?
- Is there one label that's more common than the others?
- What should the loss/metric be if the model predicted a random answer/always the same answer?
After looking at your data, go through a few of the model's predictions -- if your model outputs tokens, try decoding them too! If the model is always predicting the same thing it might be because your dataset is biased toward one category (for classification problems), so techniques like oversampling rare classes might help. Alternatively, this can also be caused by training issues like bad hyperparameter settings.
If the loss/metric you get on your initial model before any training is very different from the loss/metric you would expect for random predictions, double-check the way your loss or metric is computed, as there is probably a bug there. If you are using several losses that you add at the end, make sure they are of the same scale.
When you are sure your data is perfect, you can see if the model is capable of training on it with one simple test.
### Overfit your model on one batch[[overfit-your-model-on-one-batch]]
Overfitting is usually something we try to avoid when training, as it means the model is not learning to recognize the general features we want it to but is instead just memorizing the training samples. However, trying to train your model on one batch over and over again is a good test to check if the problem as you framed it can be solved by the model you are attempting to train. It will also help you see if your initial learning rate is too high.
Doing this once you have defined your `model` is really easy; just grab a batch of training data, then treat that `batch` as your entire dataset, fitting on it for a large number of epochs:
```py
for batch in train_dataset:
break
# Make sure you have run model.compile() and set your optimizer,
# and your loss/metrics if you're using them
model.fit(batch, epochs=20)
```
<Tip>
💡 If your training data is unbalanced, make sure to build a batch of training data containing all the labels.
</Tip>
The resulting model should have close-to-perfect results on the `batch`, with a loss declining quickly toward 0 (or the minimum value for the loss you're using).
If you don't manage to have your model obtain perfect results like this, it means there is something wrong with the way you framed the problem or your data, so you should fix that. Only when you manage to pass the overfitting test can you be sure that your model can actually learn something.
<Tip warning={true}>
⚠️ You will have to recreate your model and recompile after this overfitting test, as the model obtained probably won't be able to recover and learn something useful on your full dataset.
</Tip>
### Don't tune anything until you have a first baseline[[dont-tune-anything-until-you-have-a-first-baseline]]
Intense hyperparameter tuning is always emphasized as being the hardest part of machine learning, but it's just the last step to help you gain a little bit on the metric. *Very* bad values for your hyperparameters, like using the default Adam learning rate of 1e-3 with a Transformer model, will make learning proceed very slowly or completely stall, of course, but most of the time "reasonable" hyperparameters, like a learning rate from 1e-5 to 5e-5, will work just fine to give you good results. So, don't launch into a time-consuming and costly hyperparameter search until you have something that beats the baseline you have on your dataset.
Once you have a good enough model, you can start tweaking a bit. Don't try launching a thousand runs with different hyperparameters, but compare a couple of runs with different values for one hyperparameter to get an idea of which has the greatest impact.
If you are tweaking the model itself, keep it simple and don't try anything you can't reasonably justify. Always make sure you go back to the overfitting test to verify that your change hasn't had any unintended consequences.
### Ask for help[[ask-for-help]]
Hopefully you will have found some advice in this section that helped you solve your issue, but if that's not the case, remember you can always ask the community on the [forums](https://discuss.huggingface.co/).
Here are some additional resources that may prove helpful:
- ["Reproducibility as a vehicle for engineering best practices"](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p) by Joel Grus
- ["Checklist for debugging neural networks"](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21) by Cecelia Shao
- ["How to unit test machine learning code"](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765) by Chase Roberts
- ["A Recipe for Training Neural Networks"](http://karpathy.github.io/2019/04/25/recipe/) by Andrej Karpathy
Of course, not every problem you encounter when training neural nets is your own fault! If you encounter something in the 🤗 Transformers or 🤗 Datasets library that does not seem right, you may have encountered a bug. You should definitely tell us all about it, and in the next section we'll explain exactly how to do that.
| huggingface/course/blob/main/chapters/en/chapter8/4_tf.mdx |
Secrets Scanning
It is important to manage [your secrets (env variables) properly](./spaces-overview#managing-secrets-and-environment-variables). The most common way people expose their secrets to the outside world is by hard-coding their secrets in their `app.py` files directly, which makes it possible for a malicious user to utilize your secrets and services your secrets have access to.
For example, this is what a compromised `app.py` file might look like:
```py
import numpy as np
import scipy as sp
api_key = "sw-xyz1234567891213"
def call_inference(prompt: str) -> str:
result = call_api(prompt, api_key)
return result
```
To prevent this issue, we run an automated bot (Spaces Secrets Scanner) that scans for hard-coded secrets and opens a discussion (in case hard-coded secrets are found) about the exposed secrets & how to handle this problem.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/token-scanner-light.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/token-scanner-dark.png"/>
</div>
| huggingface/hub-docs/blob/main/docs/hub/security-secrets.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 快速入门
[Hugging Face Hub](https://huggingface.co/)是分享机器学习模型、演示、数据集和指标的首选平台`huggingface_hub`库帮助你在不离开开发环境的情况下与 Hub 进行交互。你可以轻松地创建和管理仓库,下载和上传文件,并从 Hub 获取有用的模型和数据集元数据
## 安装
要开始使用,请安装`huggingface_hub`库:
```bash
pip install --upgrade huggingface_hub
```
更多详细信息,请查看[安装指南](installation)
## 下载文件
Hugging Face 平台上的存储库是使用 git 版本控制的,用户可以下载单个文件或整个存储库。您可以使用 [`hf_hub_download`] 函数下载文件。该函数将下载并将文件缓存在您的本地磁盘上。下次您需要该文件时,它将从您的缓存中加载,因此您无需重新下载它
您将需要填写存储库 ID 和您要下载的文件的文件名。例如,要下载[Pegasus](https://huggingface.co/google/pegasus-xsum)模型配置文件,请运行以下代码:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="google/pegasus-xsum", filename="config.json")
repo_id: 仓库的 ID 或路径,这里使用了 "google/pegasus-xsum"
filename: 要下载的文件名,这里是 "config.json"
```
要下载文件的特定版本,请使用`revision`参数指定分支名称、标签或提交哈希。如果您选择使用提交哈希,它必须是完整长度的哈希,而不是较短的7个字符的提交哈希:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(
... repo_id="google/pegasus-xsum",
... filename="config.json",
... revision="4d33b01d79672f27f001f6abade33f22d993b151"
... )
```
有关更多详细信息和选项,请参阅 [`hf_hub_download`] 的 API 参考文档
## 登录
在许多情况下,您必须使用 Hugging Face 帐户进行登录后才能与 Hugging Face 模型库进行交互,例如下载私有存储库、上传文件、创建 PR 等。如果您还没有帐户,请[创建一个](https://huggingface.co/join),然后登录以获取您的 [用户访问令牌](https://huggingface.co/docs/hub/security-tokens),security-tokens从您的[设置页面](https://huggingface.co/settings/tokens)进入设置,用户访问令牌用于向模型库进行身份验证
运行以下代码,这将使用您的用户访问令牌登录到Hugging Face模型库
```bash
huggingface-cli login
huggingface-cli login --token $HUGGINGFACE_TOKEN
```
或者,你可以在笔记本电脑或脚本中使用 [`login`] 来进行程序化登录,请运行以下代码:
```py
>>> from huggingface_hub import login
>>> login()
```
您还可以直接将令牌传递给 [`login`],如下所示:`login(token="hf_xxx")`。这将使用您的用户访问令牌登录到 Hugging Face 模型库,而无需您输入任何内容。但是,如果您这样做,请在共享源代码时要小心。最好从安全保管库中加载令牌,而不是在代码库/笔记本中显式保存它
您一次只能登录一个帐户。如果您使用另一个帐户登录您的机器,您将会从之前的帐户注销。请确保使用命令 `huggingface-cli whoami`来检查您当前使用的是哪个帐户。如果您想在同一个脚本中处理多个帐户,您可以在调用每个方法时提供您的令牌。这对于您不想在您的机器上存储任何令牌也很有用
<Tip warning={true}>
一旦您登录了,所有对模型库的请求(即使是不需要认证的方法)都将默认使用您的访问令牌。如果您想禁用对令牌的隐式使用,您应该设置`HF_HUB_DISABLE_IMPLICIT_TOKEN`环境变量
</Tip>
## 创建存储库
一旦您注册并登录,请使用 [`create_repo`] 函数创建存储库:
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> api.create_repo(repo_id="super-cool-model")
```
如果您想将存储库设置为私有,请按照以下步骤操作:
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> api.create_repo(repo_id="super-cool-model", private=True)
```
私有存储库将不会对任何人可见,除了您自己
<Tip>
创建存储库或将内容推送到 Hub 时,必须提供具有`写入`权限的用户访问令牌。您可以在创建令牌时在您的[设置页面](https://huggingface.co/settings/tokens)中选择权限
</Tip>
## 上传文件
您可以使用 [`upload_file`] 函数将文件添加到您新创建的存储库。您需要指定:
1. 要上传的文件的路径
2. 文件在存储库中的位置
3. 您要将文件添加到的存储库的 ID
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> api.upload_file(
... path_or_fileobj="/home/lysandre/dummy-test/README.md"
... path_in_repo="README.md"
... repo_id="lysandre/test-model"
... )
```
要一次上传多个文件,请查看[上传指南](./guides/upload) ,该指南将向您介绍几种上传文件的方法(有或没有 git)。
## 下一步
`huggingface_hub`库为用户提供了一种使用Python与Hub 进行交互的简单方法。要了解有关如何在Hub上管理文件和存储库的更多信息,我们建议您阅读我们的[操作方法指南](./guides/overview):
- [管理您的存储库](./guides/repository)
- [从Hub下载文件](./guides/download)
- [将文件上传到Hub](./guides/upload)
- [在Hub中搜索您的所需模型或数据集](./guides/search)
- [了解如何使用 Inference API 进行快速推理](./guides/inference)
| huggingface/huggingface_hub/blob/main/docs/source/cn/quick-start.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Quicktour
Diffusion models are trained to denoise random Gaussian noise step-by-step to generate a sample of interest, such as an image or audio. This has sparked a tremendous amount of interest in generative AI, and you have probably seen examples of diffusion generated images on the internet. 🧨 Diffusers is a library aimed at making diffusion models widely accessible to everyone.
Whether you're a developer or an everyday user, this quicktour will introduce you to 🧨 Diffusers and help you get up and generating quickly! There are three main components of the library to know about:
* The [`DiffusionPipeline`] is a high-level end-to-end class designed to rapidly generate samples from pretrained diffusion models for inference.
* Popular pretrained [model](./api/models) architectures and modules that can be used as building blocks for creating diffusion systems.
* Many different [schedulers](./api/schedulers/overview) - algorithms that control how noise is added for training, and how to generate denoised images during inference.
The quicktour will show you how to use the [`DiffusionPipeline`] for inference, and then walk you through how to combine a model and scheduler to replicate what's happening inside the [`DiffusionPipeline`].
<Tip>
The quicktour is a simplified version of the introductory 🧨 Diffusers [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) to help you get started quickly. If you want to learn more about 🧨 Diffusers' goal, design philosophy, and additional details about its core API, check out the notebook!
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install --upgrade diffusers accelerate transformers
```
- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) speeds up model loading for inference and training.
- [🤗 Transformers](https://huggingface.co/docs/transformers/index) is required to run the most popular diffusion models, such as [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
## DiffusionPipeline
The [`DiffusionPipeline`] is the easiest way to use a pretrained diffusion system for inference. It is an end-to-end system containing the model and the scheduler. You can use the [`DiffusionPipeline`] out-of-the-box for many tasks. Take a look at the table below for some supported tasks, and for a complete list of supported tasks, check out the [🧨 Diffusers Summary](./api/pipelines/overview#diffusers-summary) table.
| **Task** | **Description** | **Pipeline**
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
| Unconditional Image Generation | generate an image from Gaussian noise | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
| Text-Guided Image Generation | generate an image given a text prompt | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
| Text-Guided Image-to-Image Translation | adapt an image guided by a text prompt | [img2img](./using-diffusers/img2img) |
| Text-Guided Image-Inpainting | fill the masked part of an image given the image, the mask and a text prompt | [inpaint](./using-diffusers/inpaint) |
| Text-Guided Depth-to-Image Translation | adapt parts of an image guided by a text prompt while preserving structure via depth estimation | [depth2img](./using-diffusers/depth2img) |
Start by creating an instance of a [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
You can use the [`DiffusionPipeline`] for any [checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads) stored on the Hugging Face Hub.
In this quicktour, you'll load the [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint for text-to-image generation.
<Tip warning={true}>
For [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) models, please carefully read the [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) first before running the model. 🧨 Diffusers implements a [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) to prevent offensive or harmful content, but the model's improved image generation capabilities can still produce potentially harmful content.
</Tip>
Load the model with the [`~DiffusionPipeline.from_pretrained`] method:
```python
>>> from diffusers import DiffusionPipeline
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
```
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components. You'll see that the Stable Diffusion pipeline is composed of the [`UNet2DConditionModel`] and [`PNDMScheduler`] among other things:
```py
>>> pipeline
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.21.4",
...,
"scheduler": [
"diffusers",
"PNDMScheduler"
],
...,
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
We strongly recommend running the pipeline on a GPU because the model consists of roughly 1.4 billion parameters.
You can move the generator object to a GPU, just like you would in PyTorch:
```python
>>> pipeline.to("cuda")
```
Now you can pass a text prompt to the `pipeline` to generate an image, and then access the denoised image. By default, the image output is wrapped in a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) object.
```python
>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png"/>
</div>
Save the image by calling `save`:
```python
>>> image.save("image_of_squirrel_painting.png")
```
### Local pipeline
You can also use the pipeline locally. The only difference is you need to download the weights first:
```bash
!git lfs install
!git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
```
Then load the saved weights into the pipeline:
```python
>>> pipeline = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5", use_safetensors=True)
```
Now, you can run the pipeline as you would in the section above.
### Swapping schedulers
Different schedulers come with different denoising speeds and quality trade-offs. The best way to find out which one works best for you is to try them out! One of the main features of 🧨 Diffusers is to allow you to easily switch between schedulers. For example, to replace the default [`PNDMScheduler`] with the [`EulerDiscreteScheduler`], load it with the [`~diffusers.ConfigMixin.from_config`] method:
```py
>>> from diffusers import EulerDiscreteScheduler
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
```
Try generating an image with the new scheduler and see if you notice a difference!
In the next section, you'll take a closer look at the components - the model and scheduler - that make up the [`DiffusionPipeline`] and learn how to use these components to generate an image of a cat.
## Models
Most models take a noisy sample, and at each timestep it predicts the *noise residual* (other models learn to predict the previous sample directly or the velocity or [`v-prediction`](https://github.com/huggingface/diffusers/blob/5e5ce13e2f89ac45a0066cb3f369462a3cf1d9ef/src/diffusers/schedulers/scheduling_ddim.py#L110)), the difference between a less noisy image and the input image. You can mix and match models to create other diffusion systems.
Models are initiated with the [`~ModelMixin.from_pretrained`] method which also locally caches the model weights so it is faster the next time you load the model. For the quicktour, you'll load the [`UNet2DModel`], a basic unconditional image generation model with a checkpoint trained on cat images:
```py
>>> from diffusers import UNet2DModel
>>> repo_id = "google/ddpm-cat-256"
>>> model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)
```
To access the model parameters, call `model.config`:
```py
>>> model.config
```
The model configuration is a 🧊 frozen 🧊 dictionary, which means those parameters can't be changed after the model is created. This is intentional and ensures that the parameters used to define the model architecture at the start remain the same, while other parameters can still be adjusted during inference.
Some of the most important parameters are:
* `sample_size`: the height and width dimension of the input sample.
* `in_channels`: the number of input channels of the input sample.
* `down_block_types` and `up_block_types`: the type of down- and upsampling blocks used to create the UNet architecture.
* `block_out_channels`: the number of output channels of the downsampling blocks; also used in reverse order for the number of input channels of the upsampling blocks.
* `layers_per_block`: the number of ResNet blocks present in each UNet block.
To use the model for inference, create the image shape with random Gaussian noise. It should have a `batch` axis because the model can receive multiple random noises, a `channel` axis corresponding to the number of input channels, and a `sample_size` axis for the height and width of the image:
```py
>>> import torch
>>> torch.manual_seed(0)
>>> noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
>>> noisy_sample.shape
torch.Size([1, 3, 256, 256])
```
For inference, pass the noisy image and a `timestep` to the model. The `timestep` indicates how noisy the input image is, with more noise at the beginning and less at the end. This helps the model determine its position in the diffusion process, whether it is closer to the start or the end. Use the `sample` method to get the model output:
```py
>>> with torch.no_grad():
... noisy_residual = model(sample=noisy_sample, timestep=2).sample
```
To generate actual examples though, you'll need a scheduler to guide the denoising process. In the next section, you'll learn how to couple a model with a scheduler.
## Schedulers
Schedulers manage going from a noisy sample to a less noisy sample given the model output - in this case, it is the `noisy_residual`.
<Tip>
🧨 Diffusers is a toolbox for building diffusion systems. While the [`DiffusionPipeline`] is a convenient way to get started with a pre-built diffusion system, you can also choose your own model and scheduler components separately to build a custom diffusion system.
</Tip>
For the quicktour, you'll instantiate the [`DDPMScheduler`] with its [`~diffusers.ConfigMixin.from_config`] method:
```py
>>> from diffusers import DDPMScheduler
>>> scheduler = DDPMScheduler.from_pretrained(repo_id)
>>> scheduler
DDPMScheduler {
"_class_name": "DDPMScheduler",
"_diffusers_version": "0.21.4",
"beta_end": 0.02,
"beta_schedule": "linear",
"beta_start": 0.0001,
"clip_sample": true,
"clip_sample_range": 1.0,
"dynamic_thresholding_ratio": 0.995,
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"sample_max_value": 1.0,
"steps_offset": 0,
"thresholding": false,
"timestep_spacing": "leading",
"trained_betas": null,
"variance_type": "fixed_small"
}
```
<Tip>
💡 Unlike a model, a scheduler does not have trainable weights and is parameter-free!
</Tip>
Some of the most important parameters are:
* `num_train_timesteps`: the length of the denoising process or, in other words, the number of timesteps required to process random Gaussian noise into a data sample.
* `beta_schedule`: the type of noise schedule to use for inference and training.
* `beta_start` and `beta_end`: the start and end noise values for the noise schedule.
To predict a slightly less noisy image, pass the following to the scheduler's [`~diffusers.DDPMScheduler.step`] method: model output, `timestep`, and current `sample`.
```py
>>> less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
>>> less_noisy_sample.shape
torch.Size([1, 3, 256, 256])
```
The `less_noisy_sample` can be passed to the next `timestep` where it'll get even less noisy! Let's bring it all together now and visualize the entire denoising process.
First, create a function that postprocesses and displays the denoised image as a `PIL.Image`:
```py
>>> import PIL.Image
>>> import numpy as np
>>> def display_sample(sample, i):
... image_processed = sample.cpu().permute(0, 2, 3, 1)
... image_processed = (image_processed + 1.0) * 127.5
... image_processed = image_processed.numpy().astype(np.uint8)
... image_pil = PIL.Image.fromarray(image_processed[0])
... display(f"Image at step {i}")
... display(image_pil)
```
To speed up the denoising process, move the input and model to a GPU:
```py
>>> model.to("cuda")
>>> noisy_sample = noisy_sample.to("cuda")
```
Now create a denoising loop that predicts the residual of the less noisy sample, and computes the less noisy sample with the scheduler:
```py
>>> import tqdm
>>> sample = noisy_sample
>>> for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
... # 1. predict noise residual
... with torch.no_grad():
... residual = model(sample, t).sample
... # 2. compute less noisy image and set x_t -> x_t-1
... sample = scheduler.step(residual, t, sample).prev_sample
... # 3. optionally look at image
... if (i + 1) % 50 == 0:
... display_sample(sample, i + 1)
```
Sit back and watch as a cat is generated from nothing but noise! 😻
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusion-quicktour.png"/>
</div>
## Next steps
Hopefully, you generated some cool images with 🧨 Diffusers in this quicktour! For your next steps, you can:
* Train or finetune a model to generate your own images in the [training](./tutorials/basic_training) tutorial.
* See example official and community [training or finetuning scripts](https://github.com/huggingface/diffusers/tree/main/examples#-diffusers-examples) for a variety of use cases.
* Learn more about loading, accessing, changing, and comparing schedulers in the [Using different Schedulers](./using-diffusers/schedulers) guide.
* Explore prompt engineering, speed and memory optimizations, and tips and tricks for generating higher-quality images with the [Stable Diffusion](./stable_diffusion) guide.
* Dive deeper into speeding up 🧨 Diffusers with guides on [optimized PyTorch on a GPU](./optimization/fp16), and inference guides for running [Stable Diffusion on Apple Silicon (M1/M2)](./optimization/mps) and [ONNX Runtime](./optimization/onnx).
| huggingface/diffusers/blob/main/docs/source/en/quicktour.md |
🧨 Diffusers Pipelines
Pipelines provide a simple way to run state-of-the-art diffusion models in inference.
Most diffusion systems consist of multiple independently-trained models and highly adaptable scheduler
components - all of which are needed to have a functioning end-to-end diffusion system.
As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
- [Autoencoder](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/models/vae.py#L392)
- [Conditional Unet](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/models/unet_2d_condition.py#L12)
- [CLIP text encoder](https://huggingface.co/docs/transformers/main/en/model_doc/clip#transformers.CLIPTextModel)
- a scheduler component, [scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py),
- a [CLIPImageProcessor](https://huggingface.co/docs/transformers/main/en/model_doc/clip#transformers.CLIPImageProcessor),
- as well as a [safety checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py).
All of these components are necessary to run stable diffusion in inference even though they were trained
or created independently from each other.
To that end, we strive to offer all open-sourced, state-of-the-art diffusion system under a unified API.
More specifically, we strive to provide pipelines that
- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LDMTextToImagePipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)),
- 2. have a simple user interface to run the model in inference (see the [Pipelines API](#pipelines-api) section),
- 3. are easy to understand with code that is self-explanatory and can be read along-side the official paper (see [Pipelines summary](#pipelines-summary)),
- 4. can easily be contributed by the community (see the [Contribution](#contribution) section).
**Note** that pipelines do not (and should not) offer any training functionality.
If you are looking for *official* training examples, please have a look at [examples](https://github.com/huggingface/diffusers/tree/main/examples).
## Pipelines Summary
The following table summarizes all officially supported pipelines, their corresponding paper, and if
available a colab notebook to directly try them out.
| Pipeline | Source | Tasks | Colab
|-------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------|:---:|:---:|
| [dance diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/Harmonai-org/sample-generator) | *Unconditional Audio Generation* |
| [ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | *Unconditional Image Generation* |
| [ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | *Unconditional Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
| [latent_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | *Text-to-Image Generation* |
| [latent_diffusion_uncond](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | *Unconditional Image Generation* |
| [pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | *Unconditional Image Generation* |
| [score_sde_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | *Unconditional Image Generation* |
| [score_sde_vp](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | *Unconditional Image Generation* |
| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb)
| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
| [stochastic_karras_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | *Unconditional Image Generation* |
**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
However, most of them can be adapted to use different scheduler components or even different model components. Some pipeline examples are shown in the [Examples](#examples) below.
## Pipelines API
Diffusion models often consist of multiple independently-trained models or other previously existing components.
Each model has been trained independently on a different task and the scheduler can easily be swapped out and replaced with a different one.
During inference, we however want to be able to easily load all components and use them in inference - even if one component, *e.g.* CLIP's text encoder, originates from a different library, such as [Transformers](https://github.com/huggingface/transformers). To that end, all pipelines provide the following functionality:
- [`from_pretrained` method](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L139) that accepts a Hugging Face Hub repository id, *e.g.* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) or a path to a local directory, *e.g.*
"./stable-diffusion". To correctly retrieve which models and components should be loaded, one has to provide a `model_index.json` file, *e.g.* [runwayml/stable-diffusion-v1-5/model_index.json](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), which defines all components that should be
loaded into the pipelines. More specifically, for each model/component one needs to define the format `<name>: ["<library>", "<class name>"]`. `<name>` is the attribute name given to the loaded instance of `<class name>` which can be found in the library or pipeline folder called `"<library>"`.
- [`save_pretrained`](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L90) that accepts a local path, *e.g.* `./stable-diffusion` under which all models/components of the pipeline will be saved. For each component/model a folder is created inside the local path that is named after the given attribute name, *e.g.* `./stable_diffusion/unet`.
In addition, a `model_index.json` file is created at the root of the local path, *e.g.* `./stable_diffusion/model_index.json` so that the complete pipeline can again be instantiated
from the local path.
- [`to`](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L118) which accepts a `string` or `torch.device` to move all models that are of type `torch.nn.Module` to the passed device. The behavior is fully analogous to [PyTorch's `to` method](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.to).
- [`__call__`] method to use the pipeline in inference. `__call__` defines inference logic of the pipeline and should ideally encompass all aspects of it, from pre-processing to forwarding tensors to the different models and schedulers, as well as post-processing. The API of the `__call__` method can strongly vary from pipeline to pipeline. *E.g.* a text-to-image pipeline, such as [`StableDiffusionPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) should accept among other things the text prompt to generate the image. A pure image generation pipeline, such as [DDPMPipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/ddpm) on the other hand can be run without providing any inputs. To better understand what inputs can be adapted for
each pipeline, one should look directly into the respective pipeline.
**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community)
## Contribution
We are more than happy about any contribution to the officially supported pipelines 🤗. We aspire
all of our pipelines to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
- **Self-contained**: A pipeline shall be as self-contained as possible. More specifically, this means that all functionality should be either directly defined in the pipeline file itself, should be inherited from (and only from) the [`DiffusionPipeline` class](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L56) or be directly attached to the model and scheduler components of the pipeline.
- **Easy-to-use**: Pipelines should be extremely easy to use - one should be able to load the pipeline and
use it for its designated task, *e.g.* text-to-image generation, in just a couple of lines of code. Most
logic including pre-processing, an unrolled diffusion loop, and post-processing should all happen inside the `__call__` method.
- **Easy-to-tweak**: Certain pipelines will not be able to handle all use cases and tasks that you might like them to. If you want to use a certain pipeline for a specific use case that is not yet supported, you might have to copy the pipeline file and tweak the code to your needs. We try to make the pipeline code as readable as possible so that each part –from pre-processing to diffusing to post-processing– can easily be adapted. If you would like the community to benefit from your customized pipeline, we would love to see a contribution to our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community). If you feel that an important pipeline should be part of the official pipelines but isn't, a contribution to the [official pipelines](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines) would be even better.
- **One-purpose-only**: Pipelines should be used for one task and one task only. Even if two tasks are very similar from a modeling point of view, *e.g.* image2image translation and in-painting, pipelines shall be used for one task only to keep them *easy-to-tweak* and *readable*.
## Examples
### Text-to-Image generation with Stable Diffusion
```python
# make sure you're logged in with `huggingface-cli login`
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
### Image-to-Image text-guided generation with Stable Diffusion
The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
```python
import requests
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionImg2ImgPipeline
# load the pipeline
device = "cuda"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
).to(device)
# let's download an initial image
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((768, 512))
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
images[0].save("fantasy_landscape.png")
```
You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
### Tweak prompts reusing seeds and latents
You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb).
### In-painting using Stable Diffusion
The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
```python
import PIL
import requests
import torch
from io import BytesIO
from diffusers import StableDiffusionInpaintPipeline
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
```
You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
| huggingface/diffusers/blob/main/src/diffusers/pipelines/README.md |
Gradio Demo: color_picker
```
!pip install -q gradio Pillow
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/color_picker/rabbit.png
```
```
import gradio as gr
import numpy as np
import os
from PIL import Image, ImageColor
def change_color(icon, color):
"""
Function that given an icon in .png format changes its color
Args:
icon: Icon whose color needs to be changed.
color: Chosen color with which to edit the input icon.
Returns:
edited_image: Edited icon.
"""
img = icon.convert("LA")
img = img.convert("RGBA")
image_np = np.array(icon)
_, _, _, alpha = image_np.T
mask = alpha > 0
image_np[..., :-1][mask.T] = ImageColor.getcolor(color, "RGB")
edited_image = Image.fromarray(image_np)
return edited_image
inputs = [
gr.Image(label="icon", type="pil", image_mode="RGBA"),
gr.ColorPicker(label="color"),
]
outputs = gr.Image(label="colored icon")
demo = gr.Interface(
fn=change_color,
inputs=inputs,
outputs=outputs,
examples=[
[os.path.join(os.path.abspath(''), "rabbit.png"), "#ff0000"],
[os.path.join(os.path.abspath(''), "rabbit.png"), "#0000FF"],
],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/color_picker/run.ipynb |
The Bellman Equation: simplify our value estimation [[bellman-equation]]
The Bellman equation **simplifies our state value or state-action value calculation.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman.jpg" alt="Bellman equation"/>
With what we have learned so far, we know that if we calculate \\(V(S_t)\\) (the value of a state), we need to calculate the return starting at that state and then follow the policy forever after. **(The policy we defined in the following example is a Greedy Policy; for simplification, we don't discount the reward).**
So to calculate \\(V(S_t)\\), we need to calculate the sum of the expected rewards. Hence:
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman2.jpg" alt="Bellman equation"/>
<figcaption>To calculate the value of State 1: the sum of rewards if the agent started in that state and then followed the greedy policy (taking actions that leads to the best states values) for all the time steps.</figcaption>
</figure>
Then, to calculate the \\(V(S_{t+1})\\), we need to calculate the return starting at that state \\(S_{t+1}\\).
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman3.jpg" alt="Bellman equation"/>
<figcaption>To calculate the value of State 2: the sum of rewards <b>if the agent started in that state</b>, and then followed the <b>policy for all the time steps.</b></figcaption>
</figure>
So you may have noticed, we're repeating the computation of the value of different states, which can be tedious if you need to do it for each state value or state-action value.
Instead of calculating the expected return for each state or each state-action pair, **we can use the Bellman equation.** (hint: if you know what Dynamic Programming is, this is very similar! if you don't know what it is, no worries!)
The Bellman equation is a recursive equation that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as:
**The immediate reward \\(R_{t+1}\\) + the discounted value of the state that follows ( \\(gamma * V(S_{t+1}) \\) ) .**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman4.jpg" alt="Bellman equation"/>
</figure>
If we go back to our example, we can say that the value of State 1 is equal to the expected cumulative return if we start at that state.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman2.jpg" alt="Bellman equation"/>
To calculate the value of State 1: the sum of rewards **if the agent started in that state 1** and then followed the **policy for all the time steps.**
This is equivalent to \\(V(S_{t})\\) = Immediate reward \\(R_{t+1}\\) + Discounted value of the next state \\(\gamma * V(S_{t+1})\\)
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/bellman6.jpg" alt="Bellman equation"/>
<figcaption>For simplification, here we don’t discount so gamma = 1.</figcaption>
</figure>
In the interest of simplicity, here we don't discount, so gamma = 1.
But you'll study an example with gamma = 0.99 in the Q-Learning section of this unit.
- The value of \\(V(S_{t+1}) \\) = Immediate reward \\(R_{t+2}\\) + Discounted value of the next state ( \\(gamma * V(S_{t+2})\\) ).
- And so on.
To recap, the idea of the Bellman equation is that instead of calculating each value as the sum of the expected return, **which is a long process**, we calculate the value as **the sum of immediate reward + the discounted value of the state that follows.**
Before going to the next section, think about the role of gamma in the Bellman equation. What happens if the value of gamma is very low (e.g. 0.1 or even 0)? What happens if the value is 1? What happens if the value is very high, such as a million?
| huggingface/deep-rl-class/blob/main/units/en/unit2/bellman-equation.mdx |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
Processors can mean two different things in the Transformers library:
- the objects that pre-process inputs for multi-modal models such as [Wav2Vec2](../model_doc/wav2vec2) (speech and text)
or [CLIP](../model_doc/clip) (text and vision)
- deprecated objects that were used in older versions of the library to preprocess data for GLUE or SQUAD.
## Multi-modal processors
Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
vision and audio). This is handled by objects called processors, which group together two or more processing objects
such as tokenizers (for the text modality), image processors (for vision) and feature extractors (for audio).
Those processors inherit from the following base class that implements the saving and loading functionality:
[[autodoc]] ProcessorMixin
## Deprecated processors
All processors follow the same architecture which is that of the
[`~data.processors.utils.DataProcessor`]. The processor returns a list of
[`~data.processors.utils.InputExample`]. These
[`~data.processors.utils.InputExample`] can be converted to
[`~data.processors.utils.InputFeatures`] in order to be fed to the model.
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) is a benchmark that evaluates the
performance of models across a diverse set of existing NLU tasks. It was released together with the paper [GLUE: A
multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7)
This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
QQP, QNLI, RTE and WNLI.
Those processors are:
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
Additionally, the following method can be used to load values from a data file and convert them to a list of
[`~data.processors.utils.InputExample`].
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[The Cross-Lingual NLI Corpus (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) is a benchmark that evaluates the
quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
different languages (including both high-resource language such as English and low-resource languages such as Swahili).
It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
This library hosts the processor to load the XNLI data:
- [`~data.processors.utils.XnliProcessor`]
Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) script.
## SQuAD
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
This library hosts a processor for each of the two versions:
### Processors
Those processors are:
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
They both inherit from the abstract class [`~data.processors.utils.SquadProcessor`]
[[autodoc]] data.processors.squad.SquadProcessor
- all
Additionally, the following method can be used to convert SQuAD examples into
[`~data.processors.utils.SquadFeatures`] that can be used as model inputs.
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
These processors as well as the aforementioned method can be used with files containing the data as well as with the
*tensorflow_datasets* package. Examples are given below.
### Example usage
Here is an example using the processors as well as the conversion method using data files:
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
Using *tensorflow_datasets* is as easy as using a data file:
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
Another example using these processors is given in the [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) script.
| huggingface/transformers/blob/main/docs/source/en/main_classes/processors.md |
SE-ResNeXt
**SE ResNeXt** is a variant of a [ResNext](https://www.paperswithcode.com/method/resneXt) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('seresnext26d_32x4d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `seresnext26d_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('seresnext26d_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SEResNeXt
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: seresnext26d_32x4d
In Collection: SEResNeXt
Metadata:
FLOPs: 3507053024
Parameters: 16810000
File Size: 67425193
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnext26d_32x4d
LR: 0.6
Epochs: 100
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1234
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext26d_32x4d-80fa48a3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.59%
Top 5 Accuracy: 93.61%
- Name: seresnext26t_32x4d
In Collection: SEResNeXt
Metadata:
FLOPs: 3466436448
Parameters: 16820000
File Size: 67414838
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnext26t_32x4d
LR: 0.6
Epochs: 100
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1246
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext26tn_32x4d-569cb627.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.99%
Top 5 Accuracy: 93.73%
- Name: seresnext50_32x4d
In Collection: SEResNeXt
Metadata:
FLOPs: 5475179184
Parameters: 27560000
File Size: 110569859
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnext50_32x4d
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1267
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext50_32x4d_racm-a304a460.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.27%
Top 5 Accuracy: 95.62%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/seresnext.mdx |
--
title: "Deploying Hugging Face Models with BentoML: DeepFloyd IF in Action"
thumbnail: /blog/assets/deploy-deepfloydif-using-bentoml/thumbnail.png
authors:
- user: Sherlockk
guest: true
- user: larme
guest: true
---
# Deploying Hugging Face Models with BentoML: DeepFloyd IF in Action
Hugging Face provides a Hub platform that allows you to upload, share, and deploy your models with ease. It saves developers the time and computational resources required to train models from scratch. However, deploying models in a real-world production environment or in a cloud-native way can still present challenges.
This is where BentoML comes into the picture. BentoML is an open-source platform for machine learning model serving and deployment. It is a unified framework for building, shipping, and scaling production-ready AI applications incorporating traditional, pre-trained, and generative models as well as Large Language Models. Here is how you use the BentoML framework from a high-level perspective:
1. **Define a model**: Before you can use BentoML, you need a machine learning model (or multiple models). This model can be trained using a machine learning library such as TensorFlow and PyTorch.
2. **Save the model**: Once you have a trained model, save it to the BentoML local Model Store, which is used for managing all your trained models locally as well as accessing them for serving.
3. **Create a BentoML Service**: You create a `service.py` file to wrap the model and define the serving logic. It specifies [Runners](https://docs.bentoml.org/en/latest/concepts/runner.html) for models to run model inference at scale and exposes APIs to define how to process inputs and outputs.
4. **Build a Bento**: By creating a configuration YAML file, you package all the models and the [Service](https://docs.bentoml.org/en/latest/concepts/service.html) into a [Bento](https://docs.bentoml.org/en/latest/concepts/bento.html), a deployable artifact containing all the code and dependencies.
5. **Deploy the Bento**: Once the Bento is ready, you can containerize the Bento to create a Docker image and run it on Kubernetes. Alternatively, deploy the Bento directly to Yatai, an open-source, end-to-end solution for automating and running machine learning deployments on Kubernetes at scale.
In this blog post, we will demonstrate how to integrate [DeepFloyd IF](https://huggingface.co/docs/diffusers/api/pipelines/if) with BentoML by following the above workflow.
## Table of contents
- [A brief introduction to DeepFloyd IF](#a-brief-introduction-to-deepfloyd-if)
- [Preparing the environment](#preparing-the-environment)
- [Downloading the model to the BentoML Model Store](#downloading-the-model-to-the-bentoml-model-store)
- [Starting a BentoML Service](#starting-a-bentoml-service)
- [Building and serving a Bento](#building-and-serving-a-bento)
- [Testing the server](#testing-the-server)
- [What's next](#whats-next)
## A brief introduction to DeepFloyd IF
DeepFloyd IF is a state-of-the-art, open-source text-to-image model. It stands apart from latent diffusion models like Stable Diffusion due to its distinct operational strategy and architecture.
DeepFloyd IF delivers a high degree of photorealism and sophisticated language understanding. Unlike Stable Diffusion, DeepFloyd IF works directly in pixel space, leveraging a modular structure that encompasses a frozen text encoder and three cascaded pixel diffusion modules. Each module plays a unique role in the process: Stage 1 is responsible for the creation of a base 64x64 px image, which is then progressively upscaled to 1024x1024 px across Stage 2 and Stage 3. Another critical aspect of DeepFloyd IF’s uniqueness is its integration of a Large Language Model (T5-XXL-1.1) to encode prompts, which offers superior understanding of complex prompts. For more information, see this [Stability AI blog post about DeepFloyd IF](https://stability.ai/blog/deepfloyd-if-text-to-image-model).
To make sure your DeepFloyd IF application runs in high performance in production, you may want to allocate and manage your resources wisely. In this respect, BentoML allows you to scale the Runners independently for each Stage. For example, you can use more Pods for your Stage 1 Runners or allocate more powerful GPU servers to them.
## Preparing the environment
[This GitHub repository](https://github.com/bentoml/IF-multi-GPUs-demo) stores all necessary files for this project. To run this project locally, make sure you have the following:
- Python 3.8+
- `pip` installed
- At least 2x16GB VRAM GPU or 1x40 VRAM GPU. For this project, we used a machine of type `n1-standard-16` from Google Cloud plus 64 GB of RAM and 2 NVIDIA T4 GPUs. Note that while it is possible to run IF on a single T4, it is not recommended for production-grade serving
Once the prerequisites are met, clone the project repository to your local machine and navigate to the target directory.
```bash
git clone https://github.com/bentoml/IF-multi-GPUs-demo.git
cd IF-multi-GPUs-demo
```
Before building the application, let’s briefly explore the key files within this directory:
- `import_models.py`: Defines the models for each stage of the [`IFPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/if). You use this file to download all the models to your local machine so that you can package them into a single Bento.
- `requirements.txt`: Defines all the packages and dependencies required for this project.
- `service.py`: Defines a BentoML Service, which contains three Runners created using the `to_runner` method and exposes an API for generating images. The API takes a JSON object as input (i.e. prompts and negative prompts) and returns an image as output by using a sequence of models.
- `start-server.py`: Starts a BentoML HTTP server through the Service defined in `service.py` and creates a Gradio web interface for users to enter prompts to generate images.
- `bentofile.yaml`: Defines the metadata of the Bento to be built, including the Service, Python packages, and models.
We recommend you create a Virtual Environment for dependency isolation. For example, run the following command to activate `myenv`:
```bash
python -m venv venv
source venv/bin/activate
```
Install the required dependencies:
```bash
pip install -r requirements.txt
```
If you haven’t previously downloaded models from Hugging Face using the command line, you must log in first:
```bash
pip install -U huggingface_hub
huggingface-cli login
```
## Downloading the model to the BentoML Model Store
As mentioned above, you need to download all the models used by each DeepFloyd IF stage. Once you have set up the environment, run the following command to download models to your local Model store. The process may take some time.
```bash
python import_models.py
```
Once the downloads are complete, view the models in the Model store.
```bash
$ bentoml models list
Tag Module Size Creation Time
sd-upscaler:bb2ckpa3uoypynry bentoml.diffusers 16.29 GiB 2023-07-06 10:15:53
if-stage2:v1.0 bentoml.diffusers 13.63 GiB 2023-07-06 09:55:49
if-stage1:v1.0 bentoml.diffusers 19.33 GiB 2023-07-06 09:37:59
```
## Starting a BentoML Service
You can directly run the BentoML HTTP server with a web UI powered by Gradio using the `start-server.py` file, which is the entry point of this application. It provides various options for customizing the execution and managing GPU allocation among different Stages. You may use different commands depending on your GPU setup:
- For a GPU with over 40GB VRAM, run all models on the same GPU.
```bash
python start-server.py
```
- For two Tesla T4 with 15GB VRAM each, assign the Stage 1 model to the first GPU, and the Stage 2 and Stage 3 models to the second GPU.
```bash
python start-server.py --stage1-gpu=0 --stage2-gpu=1 --stage3-gpu=1
```
- For one Tesla T4 with 15GB VRAM and two additional GPUs with smaller VRAM size, assign the Stage 1 model to T4, and Stage 2 and Stage 3 models to the second and third GPUs respectively.
```bash
python start-server.py --stage1-gpu=0 --stage2-gpu=1 --stage3-gpu=2
```
To see all customizable options (like the server’s port), run:
```bash
python start-server.py --help
```
## Testing the server
Once the server starts, you can visit the web UI at http://localhost:7860. The BentoML API endpoint is also accessible at http://localhost:3000. Here is an example of a prompt and a negative prompt.
Prompt:
> orange and black, head shot of a woman standing under street lights, dark theme, Frank Miller, cinema, ultra realistic, ambiance, insanely detailed and intricate, hyper realistic, 8k resolution, photorealistic, highly textured, intricate details
Negative prompt:
> tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, blurred, text, watermark, grainy
Result:

## Building and serving a Bento
Now that you have successfully run DeepFloyd IF locally, you can package it into a Bento by running the following command in the project directory.
```bash
$ bentoml build
Converting 'IF-stage1' to lowercase: 'if-stage1'.
Converting 'IF-stage2' to lowercase: 'if-stage2'.
Converting DeepFloyd-IF to lowercase: deepfloyd-if.
Building BentoML service "deepfloyd-if:6ufnybq3vwszgnry" from build context "/Users/xxx/Documents/github/IF-multi-GPUs-demo".
Packing model "sd-upscaler:bb2ckpa3uoypynry"
Packing model "if-stage1:v1.0"
Packing model "if-stage2:v1.0"
Locking PyPI package versions.
██████╗░███████╗███╗░░██╗████████╗░█████╗░███╗░░░███╗██╗░░░░░
██╔══██╗██╔════╝████╗░██║╚══██╔══╝██╔══██╗████╗░████║██║░░░░░
██████╦╝█████╗░░██╔██╗██║░░░██║░░░██║░░██║██╔████╔██║██║░░░░░
██╔══██╗██╔══╝░░██║╚████║░░░██║░░░██║░░██║██║╚██╔╝██║██║░░░░░
██████╦╝███████╗██║░╚███║░░░██║░░░╚█████╔╝██║░╚═╝░██║███████╗
╚═════╝░╚══════╝╚═╝░░╚══╝░░░╚═╝░░░░╚════╝░╚═╝░░░░░╚═╝╚══════╝
Successfully built Bento(tag="deepfloyd-if:6ufnybq3vwszgnry").
```
View the Bento in the local Bento Store.
```bash
$ bentoml list
Tag Size Creation Time
deepfloyd-if:6ufnybq3vwszgnry 49.25 GiB 2023-07-06 11:34:52
```
The Bento is now ready for serving in production.
```bash
bentoml serve deepfloyd-if:6ufnybq3vwszgnry
```
To deploy the Bento in a more cloud-native way, generate a Docker image by running the following command:
```bash
bentoml containerize deepfloyd-if:6ufnybq3vwszgnry
```
You can then deploy the model on Kubernetes.
## What’s next?
[BentoML](https://github.com/bentoml/BentoML) provides a powerful and straightforward way to deploy Hugging Face models for production. With its support for a wide range of ML frameworks and easy-to-use APIs, you can ship your model to production in no time. Whether you’re working with the DeepFloyd IF model or any other model on the Hugging Face Model Hub, BentoML can help you bring your models to life.
Check out the following resources to see what you can build with BentoML and its ecosystem tools, and stay tuned for more information about BentoML.
- [OpenLLM](https://github.com/bentoml/OpenLLM) - An open platform for operating Large Language Models (LLMs) in production.
- [StableDiffusion](https://github.com/bentoml/stable-diffusion-bentoml) - Create your own text-to-image service with any diffusion models.
- [Transformer NLP Service](https://github.com/bentoml/transformers-nlp-service) - Online inference API for Transformer NLP models.
- Join the [BentoML community on Slack](https://l.bentoml.com/join-slack).
- Follow us on [Twitter](https://twitter.com/bentomlai) and [LinkedIn](https://www.linkedin.com/company/bentoml/). | huggingface/blog/blob/main/deploy-deepfloydif-using-bentoml.md |
Metric Card for MAUVE
## Metric description
MAUVE is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the eponymous MAUVE measure. It summarizes both Type I and Type II errors measured softly using [Kullback–Leibler (KL) divergences](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence).
This metric is a wrapper around the [official implementation](https://github.com/krishnap25/mauve) of MAUVE.
For more details, consult the [MAUVE paper](https://arxiv.org/abs/2102.01454).
## How to use
The metric takes two lists of strings of tokens separated by spaces: one representing `predictions` (i.e. the text generated by the model) and the second representing `references` (a reference text for each prediction):
```python
from datasets import load_metric
mauve = load_metric('mauve')
predictions = ["hello world", "goodnight moon"]
references = ["hello world", "goodnight moon"]
mauve_results = mauve.compute(predictions=predictions, references=references)
```
It also has several optional arguments:
`num_buckets`: the size of the histogram to quantize P and Q. Options: `auto` (default) or an integer.
`pca_max_data`: the number data points to use for PCA dimensionality reduction prior to clustering. If -1, use all the data. The default is `-1`.
`kmeans_explained_var`: amount of variance of the data to keep in dimensionality reduction by PCA. The default is `0.9`.
`kmeans_num_redo`: number of times to redo k-means clustering (the best objective is kept). The default is `5`.
`kmeans_max_iter`: maximum number of k-means iterations. The default is `500`.
`featurize_model_name`: name of the model from which features are obtained, from one of the following: `gpt2`, `gpt2-medium`, `gpt2-large`, `gpt2-xl`. The default is `gpt2-large`.
`device_id`: Device for featurization. Supply a GPU id (e.g. `0` or `3`) to use GPU. If no GPU with this id is found, the metric will use CPU.
`max_text_length`: maximum number of tokens to consider. The default is `1024`.
`divergence_curve_discretization_size` Number of points to consider on the divergence curve. The default is `25`.
`mauve_scaling_factor`: Hyperparameter for scaling. The default is `5`.
`verbose`: If `True` (default), running the metric will print running time updates.
`seed`: random seed to initialize k-means cluster assignments, randomly assigned by default.
## Output values
This metric outputs a dictionary with 5 key-value pairs:
`mauve`: MAUVE score, which ranges between 0 and 1. **Larger** values indicate that P and Q are closer.
`frontier_integral`: Frontier Integral, which ranges between 0 and 1. **Smaller** values indicate that P and Q are closer.
`divergence_curve`: a numpy.ndarray of shape (m, 2); plot it with `matplotlib` to view the divergence curve.
`p_hist`: a discrete distribution, which is a quantized version of the text distribution `p_text`.
`q_hist`: same as above, but with `q_text`.
### Values from popular papers
The [original MAUVE paper](https://arxiv.org/abs/2102.01454) reported values ranging from 0.88 to 0.94 for open-ended text generation using a text completion task in the web text domain. The authors found that bigger models resulted in higher MAUVE scores, and that MAUVE is correlated with human judgments.
## Examples
Perfect match between prediction and reference:
```python
from datasets import load_metric
mauve = load_metric('mauve')
predictions = ["hello world", "goodnight moon"]
references = ["hello world", "goodnight moon"]
mauve_results = mauve.compute(predictions=predictions, references=references)
print(mauve_results.mauve)
1.0
```
Partial match between prediction and reference:
```python
from datasets import load_metric
mauve = load_metric('mauve')
predictions = ["hello world", "goodnight moon"]
references = ["hello there", "general kenobi"]
mauve_results = mauve.compute(predictions=predictions, references=references)
print(mauve_results.mauve)
0.27811372536724027
```
## Limitations and bias
The [original MAUVE paper](https://arxiv.org/abs/2102.01454) did not analyze the inductive biases present in different embedding models, but related work has shown different kinds of biases exist in many popular generative language models including GPT-2 (see [Kirk et al., 2021](https://arxiv.org/pdf/2102.04130.pdf), [Abid et al., 2021](https://arxiv.org/abs/2101.05783)). The extent to which these biases can impact the MAUVE score has not been quantified.
Also, calculating the MAUVE metric involves downloading the model from which features are obtained -- the default model, `gpt2-large`, takes over 3GB of storage space and downloading it can take a significant amount of time depending on the speed of your internet connection. If this is an issue, choose a smaller model; for instance `gpt` is 523MB.
## Citation
```bibtex
@inproceedings{pillutla-etal:mauve:neurips2021,
title={MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers},
author={Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid},
booktitle = {NeurIPS},
year = {2021}
}
```
## Further References
- [Official MAUVE implementation](https://github.com/krishnap25/mauve)
- [Hugging Face Tasks - Text Generation](https://huggingface.co/tasks/text-generation)
| huggingface/datasets/blob/main/metrics/mauve/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# BROS
## Overview
The BROS model was proposed in [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
BROS stands for *BERT Relying On Spatiality*. It is an encoder-only Transformer model that takes a sequence of tokens and their bounding boxes as inputs and outputs a sequence of hidden states. BROS encode relative spatial information instead of using absolute spatial information.
It is pre-trained with two objectives: a token-masked language modeling objective (TMLM) used in BERT, and a novel area-masked language modeling objective (AMLM)
In TMLM, tokens are randomly masked, and the model predicts the masked tokens using spatial information and other unmasked tokens.
AMLM is a 2D version of TMLM. It randomly masks text tokens and predicts with the same information as TMLM, but it masks text blocks (areas).
`BrosForTokenClassification` has a simple linear layer on top of BrosModel. It predicts the label of each token.
`BrosSpadeEEForTokenClassification` has an `initial_token_classifier` and `subsequent_token_classifier` on top of BrosModel. `initial_token_classifier` is used to predict the first token of each entity, and `subsequent_token_classifier` is used to predict the next token of within entity. `BrosSpadeELForTokenClassification` has an `entity_linker` on top of BrosModel. `entity_linker` is used to predict the relation between two entities.
`BrosForTokenClassification` and `BrosSpadeEEForTokenClassification` essentially perform the same job. However, `BrosForTokenClassification` assumes input tokens are perfectly serialized (which is very challenging task since they exist in a 2D space), while `BrosSpadeEEForTokenClassification` allows for more flexibility in handling serialization errors as it predicts next connection tokens from one token.
`BrosSpadeELForTokenClassification` perform the intra-entity linking task. It predicts relation from one token (of one entity) to another token (of another entity) if these two entities share some relation.
BROS achieves comparable or better result on Key Information Extraction (KIE) benchmarks such as FUNSD, SROIE, CORD and SciTSR, without relying on explicit visual features.
The abstract from the paper is the following:
*Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-trained language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks-(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples-and demonstrates the superiority of BROS over previous methods.*
This model was contributed by [jinho8345](https://huggingface.co/jinho8345). The original code can be found [here](https://github.com/clovaai/bros).
## Usage tips and examples
- [`~transformers.BrosModel.forward`] requires `input_ids` and `bbox` (bounding box). Each bounding box should be in (x0, y0, x1, y1) format (top-left corner, bottom-right corner). Obtaining of Bounding boxes depends on external OCR system. The `x` coordinate should be normalized by document image width, and the `y` coordinate should be normalized by document image height.
```python
def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
# here, bboxes are numpy array
# Normalize bbox -> 0 ~ 1
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
```
- [`~transformers.BrosForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`] require not only `input_ids` and `bbox` but also `box_first_token_mask` for loss calculation. It is a mask to filter out non-first tokens of each box. You can obtain this mask by saving start token indices of bounding boxes when creating `input_ids` from words. You can make `box_first_token_mask` with following code,
```python
def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
# encode(tokenize) each word from words (List[str])
input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
# get the length of each box
tokens_length_list: List[int] = [len(l) for l in input_ids_list]
box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
# filter out the indices that are out of max_seq_length
box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
if len(box_start_token_indices) > len(box_end_token_indices):
box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
# set box_start_token_indices to True
box_first_token_mask[box_start_token_indices] = True
return box_first_token_mask
```
## Resources
- Demo scripts can be found [here](https://github.com/clovaai/bros).
## BrosConfig
[[autodoc]] BrosConfig
## BrosProcessor
[[autodoc]] BrosProcessor
- __call__
## BrosModel
[[autodoc]] BrosModel
- forward
## BrosForTokenClassification
[[autodoc]] BrosForTokenClassification
- forward
## BrosSpadeEEForTokenClassification
[[autodoc]] BrosSpadeEEForTokenClassification
- forward
## BrosSpadeELForTokenClassification
[[autodoc]] BrosSpadeELForTokenClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/bros.md |
Conclusion
That's all for today. Congrats on finishing this Unit and the tutorial! ⭐️
Now that you've successfully trained your Doom agent, why not try deathmatch? Remember, that's a much more complex level than the one you've just trained, **but it's a nice experiment and I advise you to try it.**
If you do it, don't hesitate to share your model in the `#rl-i-made-this` channel in our [discord server](https://www.hf.co/join/discord).
This concludes the last unit, but we are not finished yet! 🤗 The following **bonus unit includes some of the most interesting, advanced, and cutting edge work in Deep Reinforcement Learning**.
See you next time 🔥
## Keep Learning, Stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit8/conclusion-sf.mdx |
Gradio Demo: tax_calculator
### Calculate taxes using Textbox, Radio, and Dataframe components
```
!pip install -q gradio
```
```
import gradio as gr
def tax_calculator(income, marital_status, assets):
tax_brackets = [(10, 0), (25, 8), (60, 12), (120, 20), (250, 30)]
total_deductible = sum(assets["Cost"])
taxable_income = income - total_deductible
total_tax = 0
for bracket, rate in tax_brackets:
if taxable_income > bracket:
total_tax += (taxable_income - bracket) * rate / 100
if marital_status == "Married":
total_tax *= 0.75
elif marital_status == "Divorced":
total_tax *= 0.8
return round(total_tax)
demo = gr.Interface(
tax_calculator,
[
"number",
gr.Radio(["Single", "Married", "Divorced"]),
gr.Dataframe(
headers=["Item", "Cost"],
datatype=["str", "number"],
label="Assets Purchased this Year",
),
],
"number",
examples=[
[10000, "Married", [["Suit", 5000], ["Laptop", 800], ["Car", 1800]]],
[80000, "Single", [["Suit", 800], ["Watch", 1800], ["Car", 800]]],
],
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/tax_calculator/run.ipynb |
FrameworkSwitchCourse {fw} />
# Debugging the training pipeline[[debugging-the-training-pipeline]]
<CourseFloatingBanner chapter={8}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter8/section4.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter8/section4.ipynb"},
]} />
You've written a beautiful script to train or fine-tune a model on a given task, dutifully following the advice from [Chapter 7](/course/chapter7). But when you launch the command `trainer.train()`, something horrible happens: you get an error 😱! Or worse, everything seems to be fine and the training runs without error, but the resulting model is crappy. In this section, we will show you what you can do to debug these kinds of issues.
## Debugging the training pipeline[[debugging-the-training-pipeline]]
<Youtube id="L-WSwUWde1U"/>
The problem when you encounter an error in `trainer.train()` is that it could come from multiple sources, as the `Trainer` usually puts together lots of things. It converts datasets to dataloaders, so the problem could be something wrong in your dataset, or some issue when trying to batch elements of the datasets together. Then it takes a batch of data and feeds it to the model, so the problem could be in the model code. After that, it computes the gradients and performs the optimization step, so the problem could also be in your optimizer. And even if everything goes well for training, something could still go wrong during the evaluation if there is a problem with your metric.
The best way to debug an error that arises in `trainer.train()` is to manually go through this whole pipeline to see where things went awry. The error is then often very easy to solve.
To demonstrate this, we will use the following script that (tries to) fine-tune a DistilBERT model on the [MNLI dataset](https://huggingface.co/datasets/glue):
```py
from datasets import load_dataset
import evaluate
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
)
raw_datasets = load_dataset("glue", "mnli")
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
args = TrainingArguments(
f"distilbert-finetuned-mnli",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
)
metric = evaluate.load("glue", "mnli")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model,
args,
train_dataset=raw_datasets["train"],
eval_dataset=raw_datasets["validation_matched"],
compute_metrics=compute_metrics,
)
trainer.train()
```
If you try to execute it, you will be met with a rather cryptic error:
```python out
'ValueError: You have to specify either input_ids or inputs_embeds'
```
### Check your data[[check-your-data]]
This goes without saying, but if your data is corrupted, the `Trainer` is not going to be able to form batches, let alone train your model. So first things first, you need to have a look at what is inside your training set.
To avoid countless hours spent trying to fix something that is not the source of the bug, we recommend you use `trainer.train_dataset` for your checks and nothing else. So let's do that here:
```py
trainer.train_dataset[0]
```
```python out
{'hypothesis': 'Product and geography are what make cream skimming work. ',
'idx': 0,
'label': 1,
'premise': 'Conceptually cream skimming has two basic dimensions - product and geography.'}
```
Do you notice something wrong? This, in conjunction with the error message about `input_ids` missing, should make you realize those are texts, not numbers the model can make sense of. Here, the original error is very misleading because the `Trainer` automatically removes the columns that don't match the model signature (that is, the arguments expected by the model). That means here, everything apart from the labels was discarded. There was thus no issue with creating batches and then sending them to the model, which in turn complained it didn't receive the proper input.
Why wasn't the data processed? We did use the `Dataset.map()` method on the datasets to apply the tokenizer on each sample. But if you look closely at the code, you will see that we made a mistake when passing the training and evaluation sets to the `Trainer`. Instead of using `tokenized_datasets` here, we used `raw_datasets` 🤦. So let's fix this!
```py
from datasets import load_dataset
import evaluate
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
)
raw_datasets = load_dataset("glue", "mnli")
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
args = TrainingArguments(
f"distilbert-finetuned-mnli",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
)
metric = evaluate.load("glue", "mnli")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation_matched"],
compute_metrics=compute_metrics,
)
trainer.train()
```
This new code will now give a different error (progress!):
```python out
'ValueError: expected sequence of length 43 at dim 1 (got 37)'
```
Looking at the traceback, we can see the error happens in the data collation step:
```python out
~/git/transformers/src/transformers/data/data_collator.py in torch_default_data_collator(features)
105 batch[k] = torch.stack([f[k] for f in features])
106 else:
--> 107 batch[k] = torch.tensor([f[k] for f in features])
108
109 return batch
```
So, we should move to that. Before we do, however, let's finish inspecting our data, just to be 100% sure it's correct.
One thing you should always do when debugging a training session is have a look at the decoded inputs of your model. We can't make sense of the numbers that we feed it directly, so we should look at what those numbers represent. In computer vision, for example, that means looking at the decoded pictures of the pixels you pass, in speech it means listening to the decoded audio samples, and for our NLP example here it means using our tokenizer to decode the inputs:
```py
tokenizer.decode(trainer.train_dataset[0]["input_ids"])
```
```python out
'[CLS] conceptually cream skimming has two basic dimensions - product and geography. [SEP] product and geography are what make cream skimming work. [SEP]'
```
So that seems correct. You should do this for all the keys in the inputs:
```py
trainer.train_dataset[0].keys()
```
```python out
dict_keys(['attention_mask', 'hypothesis', 'idx', 'input_ids', 'label', 'premise'])
```
Note that the keys that don't correspond to inputs accepted by the model will be automatically discarded, so here we will only keep `input_ids`, `attention_mask`, and `label` (which will be renamed `labels`). To double-check the model signature, you can print the class of your model, then go check its documentation:
```py
type(trainer.model)
```
```python out
transformers.models.distilbert.modeling_distilbert.DistilBertForSequenceClassification
```
So in our case, we can check the parameters accepted on [this page](https://huggingface.co/transformers/model_doc/distilbert.html#distilbertforsequenceclassification). The `Trainer` will also log the columns it's discarding.
We have checked that the input IDs are correct by decoding them. Next is the `attention_mask`:
```py
trainer.train_dataset[0]["attention_mask"]
```
```python out
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
Since we didn't apply padding in our preprocessing, this seems perfectly natural. To be sure there is no issue with that attention mask, let's check it is the same length as our input IDs:
```py
len(trainer.train_dataset[0]["attention_mask"]) == len(
trainer.train_dataset[0]["input_ids"]
)
```
```python out
True
```
That's good! Lastly, let's check our label:
```py
trainer.train_dataset[0]["label"]
```
```python out
1
```
Like the input IDs, this is a number that doesn't really make sense on its own. As we saw before, the map between integers and label names is stored inside the `names` attribute of the corresponding *feature* of the dataset:
```py
trainer.train_dataset.features["label"].names
```
```python out
['entailment', 'neutral', 'contradiction']
```
So `1` means `neutral`, which means the two sentences we saw above are not in contradiction, and the first one does not imply the second one. That seems correct!
We don't have token type IDs here, since DistilBERT does not expect them; if you have some in your model, you should also make sure that they properly match where the first and second sentences are in the input.
<Tip>
✏️ **Your turn!** Check that everything seems correct with the second element of the training dataset.
</Tip>
We are only doing the check on the training set here, but you should of course double-check the validation and test sets the same way.
Now that we know our datasets look good, it's time to check the next step of the training pipeline.
### From datasets to dataloaders[[from-datasets-to-dataloaders]]
The next thing that can go wrong in the training pipeline is when the `Trainer` tries to form batches from the training or validation set. Once you are sure the `Trainer`'s datasets are correct, you can try to manually form a batch by executing the following (replace `train` with `eval` for the validation dataloader):
```py
for batch in trainer.get_train_dataloader():
break
```
This code creates the training dataloader, then iterates through it, stopping at the first iteration. If the code executes without error, you have the first training batch that you can inspect, and if the code errors out, you know for sure the problem is in the dataloader, as is the case here:
```python out
~/git/transformers/src/transformers/data/data_collator.py in torch_default_data_collator(features)
105 batch[k] = torch.stack([f[k] for f in features])
106 else:
--> 107 batch[k] = torch.tensor([f[k] for f in features])
108
109 return batch
ValueError: expected sequence of length 45 at dim 1 (got 76)
```
Inspecting the last frame of the traceback should be enough to give you a clue, but let's do a bit more digging. Most of the problems during batch creation arise because of the collation of examples into a single batch, so the first thing to check when in doubt is what `collate_fn` your `DataLoader` is using:
```py
data_collator = trainer.get_train_dataloader().collate_fn
data_collator
```
```python out
<function transformers.data.data_collator.default_data_collator(features: List[InputDataClass], return_tensors='pt') -> Dict[str, Any]>
```
So this is the `default_data_collator`, but that's not what we want in this case. We want to pad our examples to the longest sentence in the batch, which is done by the `DataCollatorWithPadding` collator. And this data collator is supposed to be used by default by the `Trainer`, so why is it not used here?
The answer is because we did not pass the `tokenizer` to the `Trainer`, so it couldn't create the `DataCollatorWithPadding` we want. In practice, you should never hesitate to explicitly pass along the data collator you want to use, to make sure you avoid these kinds of errors. Let's adapt our code to do exactly that:
```py
from datasets import load_dataset
import evaluate
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
DataCollatorWithPadding,
TrainingArguments,
Trainer,
)
raw_datasets = load_dataset("glue", "mnli")
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
args = TrainingArguments(
f"distilbert-finetuned-mnli",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
)
metric = evaluate.load("glue", "mnli")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=predictions, references=labels)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation_matched"],
compute_metrics=compute_metrics,
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
```
The good news? We don't get the same error as before, which is definitely progress. The bad news? We get an infamous CUDA error instead:
```python out
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
```
This is bad because CUDA errors are extremely hard to debug in general. We will see in a minute how to solve this, but first let's finish our analysis of batch creation.
If you are sure your data collator is the right one, you should try to apply it on a couple of samples of your dataset:
```py
data_collator = trainer.get_train_dataloader().collate_fn
batch = data_collator([trainer.train_dataset[i] for i in range(4)])
```
This code will fail because the `train_dataset` contains string columns, which the `Trainer` usually removes. You can remove them manually, or if you want to replicate exactly what the `Trainer` is doing behind the scenes, you can call the private `Trainer._remove_unused_columns()` method that does that:
```py
data_collator = trainer.get_train_dataloader().collate_fn
actual_train_set = trainer._remove_unused_columns(trainer.train_dataset)
batch = data_collator([actual_train_set[i] for i in range(4)])
```
You should then be able to manually debug what happens inside the data collator if the error persists.
Now that we've debugged the batch creation process, it's time to pass one through the model!
### Going through the model[[going-through-the-model]]
You should be able to get a batch by executing the following command:
```py
for batch in trainer.get_train_dataloader():
break
```
If you're running this code in a notebook, you may get a CUDA error that's similar to the one we saw earlier, in which case you need to restart your notebook and reexecute the last snippet without the `trainer.train()` line. That's the second most annoying thing about CUDA errors: they irremediably break your kernel. The most annoying thing about them is the fact that they are hard to debug.
Why is that? It has to do with the way GPUs work. They are extremely efficient at executing a lot of operations in parallel, but the drawback is that when one of those instructions results in an error, you don't know it instantly. It's only when the program calls a synchronization of the multiple processes on the GPU that it will realize something went wrong, so the error is actually raised at a place that has nothing to do with what created it. For instance, if we look at our previous traceback, the error was raised during the backward pass, but we will see in a minute that it actually stems from something in the forward pass.
So how do we debug those errors? The answer is easy: we don't. Unless your CUDA error is an out-of-memory error (which means there is not enough memory in your GPU), you should always go back to the CPU to debug it.
To do this in our case, we just have to put the model back on the CPU and call it on our batch -- the batch returned by the `DataLoader` has not been moved to the GPU yet:
```python
outputs = trainer.model.cpu()(**batch)
```
```python out
~/.pyenv/versions/3.7.9/envs/base/lib/python3.7/site-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce, reduction)
2386 )
2387 if dim == 2:
-> 2388 ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
2389 elif dim == 4:
2390 ret = torch._C._nn.nll_loss2d(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
IndexError: Target 2 is out of bounds.
```
So, the picture is getting clearer. Instead of having a CUDA error, we now have an `IndexError` in the loss computation (so nothing to do with the backward pass, as we said earlier). More precisely, we can see that it's target 2 that creates the error, so this is a very good moment to check the number of labels of our model:
```python
trainer.model.config.num_labels
```
```python out
2
```
With two labels, only 0s and 1s are allowed as targets, but according to the error message we got a 2. Getting a 2 is actually normal: if we remember the label names we extracted earlier, there were three, so we have indices 0, 1, and 2 in our dataset. The problem is that we didn't tell that to our model, which should have been created with three labels. So let's fix that!
```py
from datasets import load_dataset
import evaluate
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
DataCollatorWithPadding,
TrainingArguments,
Trainer,
)
raw_datasets = load_dataset("glue", "mnli")
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=3)
args = TrainingArguments(
f"distilbert-finetuned-mnli",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
)
metric = evaluate.load("glue", "mnli")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=predictions, references=labels)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation_matched"],
compute_metrics=compute_metrics,
data_collator=data_collator,
tokenizer=tokenizer,
)
```
We aren't including the `trainer.train()` line yet, to take the time to check that everything looks good. If we request a batch and pass it to our model, it now works without error!
```py
for batch in trainer.get_train_dataloader():
break
outputs = trainer.model.cpu()(**batch)
```
The next step is then to move back to the GPU and check that everything still works:
```py
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
batch = {k: v.to(device) for k, v in batch.items()}
outputs = trainer.model.to(device)(**batch)
```
If you still get an error, make sure you restart your notebook and only execute the last version of the script.
### Performing one optimization step[[performing-one-optimization-step]]
Now that we know that we can build batches that actually go through the model, we are ready for the next step of the training pipeline: computing the gradients and performing an optimization step.
The first part is just a matter of calling the `backward()` method on the loss:
```py
loss = outputs.loss
loss.backward()
```
It's pretty rare to get an error at this stage, but if you do get one, make sure to go back to the CPU to get a helpful error message.
To perform the optimization step, we just need to create the `optimizer` and call its `step()` method:
```py
trainer.create_optimizer()
trainer.optimizer.step()
```
Again, if you're using the default optimizer in the `Trainer`, you shouldn't get an error at this stage, but if you have a custom optimizer, there might be some problems to debug here. Don't forget to go back to the CPU if you get a weird CUDA error at this stage. Speaking of CUDA errors, earlier we mentioned a special case. Let's have a look at that now.
### Dealing with CUDA out-of-memory errors[[dealing-with-cuda-out-of-memory-errors]]
Whenever you get an error message that starts with `RuntimeError: CUDA out of memory`, this indicates that you are out of GPU memory. This is not directly linked to your code, and it can happen with a script that runs perfectly fine. This error means that you tried to put too many things in the internal memory of your GPU, and that resulted in an error. Like with other CUDA errors, you will need to restart your kernel to be in a spot where you can run your training again.
To solve this issue, you just need to use less GPU space -- something that is often easier said than done. First, make sure you don't have two models on the GPU at the same time (unless that's required for your problem, of course). Then, you should probably reduce your batch size, as it directly affects the sizes of all the intermediate outputs of the model and their gradients. If the problem persists, consider using a smaller version of your model.
<Tip>
In the next part of the course, we'll look at more advanced techniques that can help you reduce your memory footprint and let you fine-tune the biggest models.
</Tip>
### Evaluating the model[[evaluating-the-model]]
Now that we've solved all the issues with our code, everything is perfect and the training should run smoothly, right? Not so fast! If you run the `trainer.train()` command, everything will look good at first, but after a while you will get the following:
```py
# This will take a long time and error out, so you shouldn't run this cell
trainer.train()
```
```python out
TypeError: only size-1 arrays can be converted to Python scalars
```
You will realize this error appears during the evaluation phase, so this is the last thing we will need to debug.
You can run the evaluation loop of the `Trainer` independently form the training like this:
```py
trainer.evaluate()
```
```python out
TypeError: only size-1 arrays can be converted to Python scalars
```
<Tip>
💡 You should always make sure you can run `trainer.evaluate()` before launching `trainer.train()`, to avoid wasting lots of compute resources before hitting an error.
</Tip>
Before attempting to debug a problem in the evaluation loop, you should first make sure that you've had a look at the data, are able to form a batch properly, and can run your model on it. We've completed all of those steps, so the following code can be executed without error:
```py
for batch in trainer.get_eval_dataloader():
break
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = trainer.model(**batch)
```
The error comes later, at the end of the evaluation phase, and if we look at the traceback we see this:
```python trace
~/git/datasets/src/datasets/metric.py in add_batch(self, predictions, references)
431 """
432 batch = {"predictions": predictions, "references": references}
--> 433 batch = self.info.features.encode_batch(batch)
434 if self.writer is None:
435 self._init_writer()
```
This tells us that the error originates in the `datasets/metric.py` module -- so this is a problem with our `compute_metrics()` function. It takes a tuple with the logits and the labels as NumPy arrays, so let's try to feed it that:
```py
predictions = outputs.logits.cpu().numpy()
labels = batch["labels"].cpu().numpy()
compute_metrics((predictions, labels))
```
```python out
TypeError: only size-1 arrays can be converted to Python scalars
```
We get the same error, so the problem definitely lies with that function. If we look back at its code, we see it's just forwarding the `predictions` and the `labels` to `metric.compute()`. So is there a problem with that method? Not really. Let's have a quick look at the shapes:
```py
predictions.shape, labels.shape
```
```python out
((8, 3), (8,))
```
Our predictions are still logits, not the actual predictions, which is why the metric is returning this (somewhat obscure) error. The fix is pretty easy; we just have to add an argmax in the `compute_metrics()` function:
```py
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels)
compute_metrics((predictions, labels))
```
```python out
{'accuracy': 0.625}
```
Now our error is fixed! This was the last one, so our script will now train a model properly.
For reference, here is the completely fixed script:
```py
import numpy as np
from datasets import load_dataset
import evaluate
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
DataCollatorWithPadding,
TrainingArguments,
Trainer,
)
raw_datasets = load_dataset("glue", "mnli")
model_checkpoint = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
def preprocess_function(examples):
return tokenizer(examples["premise"], examples["hypothesis"], truncation=True)
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=3)
args = TrainingArguments(
f"distilbert-finetuned-mnli",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
)
metric = evaluate.load("glue", "mnli")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation_matched"],
compute_metrics=compute_metrics,
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
```
In this instance, there are no more problems, and our script will fine-tune a model that should give reasonable results. But what can we do when the training proceeds without any error, and the model trained does not perform well at all? That's the hardest part of machine learning, and we'll show you a few techniques that can help.
<Tip>
💡 If you're using a manual training loop, the same steps apply to debug your training pipeline, but it's easier to separate them. Make sure you have not forgotten the `model.eval()` or `model.train()` at the right places, or the `zero_grad()` at each step, however!
</Tip>
## Debugging silent errors during training[[debugging-silent-errors-during-training]]
What can we do to debug a training that completes without error but doesn't get good results? We'll give you some pointers here, but be aware that this kind of debugging is the hardest part of machine learning, and there is no magical answer.
### Check your data (again!)[[check-your-data-again]]
Your model will only learn something if it's actually possible to learn anything from your data. If there is a bug that corrupts the data or the labels are attributed randomly, it's very likely you won't get any model training on your dataset. So always start by double-checking your decoded inputs and labels, and ask yourself the following questions:
- Is the decoded data understandable?
- Do you agree with the labels?
- Is there one label that's more common than the others?
- What should the loss/metric be if the model predicted a random answer/always the same answer?
<Tip warning={true}>
⚠️ If you are doing distributed training, print samples of your dataset in each process and triple-check that you get the same thing. One common bug is to have some source of randomness in the data creation that makes each process have a different version of the dataset.
</Tip>
After looking at your data, go through a few of the model's predictions and decode them too. If the model is always predicting the same thing, it might be because your dataset is biased toward one category (for classification problems); techniques like oversampling rare classes might help.
If the loss/metric you get on your initial model is very different from the loss/metric you would expect for random predictions, double-check the way your loss or metric is computed, as there is probably a bug there. If you are using several losses that you add at the end, make sure they are of the same scale.
When you are sure your data is perfect, you can see if the model is capable of training on it with one simple test.
### Overfit your model on one batch[[overfit-your-model-on-one-batch]]
Overfitting is usually something we try to avoid when training, as it means the model is not learning to recognize the general features we want it to but is instead just memorizing the training samples. However, trying to train your model on one batch over and over again is a good test to check if the problem as you framed it can be solved by the model you are attempting to train. It will also help you see if your initial learning rate is too high.
Doing this once you have defined your `Trainer` is really easy; just grab a batch of training data, then run a small manual training loop only using that batch for something like 20 steps:
```py
for batch in trainer.get_train_dataloader():
break
batch = {k: v.to(device) for k, v in batch.items()}
trainer.create_optimizer()
for _ in range(20):
outputs = trainer.model(**batch)
loss = outputs.loss
loss.backward()
trainer.optimizer.step()
trainer.optimizer.zero_grad()
```
<Tip>
💡 If your training data is unbalanced, make sure to build a batch of training data containing all the labels.
</Tip>
The resulting model should have close-to-perfect results on the same `batch`. Let's compute the metric on the resulting predictions:
```py
with torch.no_grad():
outputs = trainer.model(**batch)
preds = outputs.logits
labels = batch["labels"]
compute_metrics((preds.cpu().numpy(), labels.cpu().numpy()))
```
```python out
{'accuracy': 1.0}
```
100% accuracy, now this is a nice example of overfitting (meaning that if you try your model on any other sentence, it will very likely give you a wrong answer)!
If you don't manage to have your model obtain perfect results like this, it means there is something wrong with the way you framed the problem or your data, so you should fix that. Only when you manage to pass the overfitting test can you be sure that your model can actually learn something.
<Tip warning={true}>
⚠️ You will have to recreate your model and your `Trainer` after this test, as the model obtained probably won't be able to recover and learn something useful on your full dataset.
</Tip>
### Don't tune anything until you have a first baseline[[dont-tune-anything-until-you-have-a-first-baseline]]
Hyperparameter tuning is always emphasized as being the hardest part of machine learning, but it's just the last step to help you gain a little bit on the metric. Most of the time, the default hyperparameters of the `Trainer` will work just fine to give you good results, so don't launch into a time-consuming and costly hyperparameter search until you have something that beats the baseline you have on your dataset.
Once you have a good enough model, you can start tweaking a bit. Don't try launching a thousand runs with different hyperparameters, but compare a couple of runs with different values for one hyperparameter to get an idea of which has the greatest impact.
If you are tweaking the model itself, keep it simple and don't try anything you can't reasonably justify. Always make sure you go back to the overfitting test to verify that your change hasn't had any unintended consequences.
### Ask for help[[ask-for-help]]
Hopefully you will have found some advice in this section that helped you solve your issue, but if that's not the case, remember you can always ask the community on the [forums](https://discuss.huggingface.co/).
Here are some additional resources that may prove helpful:
- ["Reproducibility as a vehicle for engineering best practices"](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p) by Joel Grus
- ["Checklist for debugging neural networks"](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21) by Cecelia Shao
- ["How to unit test machine learning code"](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765) by Chase Roberts
- ["A Recipe for Training Neural Networks"](http://karpathy.github.io/2019/04/25/recipe/) by Andrej Karpathy
Of course, not every problem you encounter when training neural nets is your own fault! If you encounter something in the 🤗 Transformers or 🤗 Datasets library that does not seem right, you may have encountered a bug. You should definitely tell us all about it, and in the next section we'll explain exactly how to do that.
| huggingface/course/blob/main/chapters/en/chapter8/4.mdx |
Fine-tune FLAN-T5 using `bitsandbytes`, `peft` & `transformers` 🤗
In this notebook we will see how to properly use `peft` , `transformers` & `bitsandbytes` to fine-tune `flan-t5-large` in a google colab!
We will finetune the model on [`financial_phrasebank`](https://huggingface.co/datasets/financial_phrasebank) dataset, that consists of pairs of text-labels to classify financial-related sentences, if they are either `positive`, `neutral` or `negative`.
Note that you could use the same notebook to fine-tune `flan-t5-xl` as well, but you would need to shard the models first to avoid CPU RAM issues on Google Colab, check [these weights](https://huggingface.co/ybelkada/flan-t5-xl-sharded-bf16).
## Install requirements
```python
!pip install -q bitsandbytes datasets accelerate
!pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git@main
```
## Import model and tokenizer
```python
# Select CUDA device index
import os
import torch
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from datasets import load_dataset
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "google/flan-t5-large"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name, load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## Prepare model for training
Some pre-processing needs to be done before training such an int8 model using `peft`, therefore let's import an utiliy function `prepare_model_for_int8_training` that will:
- Casts all the non `int8` modules to full precision (`fp32`) for stability
- Add a `forward_hook` to the input embedding layer to enable gradient computation of the input hidden states
- Enable gradient checkpointing for more memory-efficient training
```python
from peft import prepare_model_for_int8_training
model = prepare_model_for_int8_training(model)
```
## Load your `PeftModel`
Here we will use LoRA (Low-Rank Adaptators) to train our model
```python
from peft import LoraConfig, get_peft_model, TaskType
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
lora_config = LoraConfig(
r=16, lora_alpha=32, target_modules=["q", "v"], lora_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
)
model = get_peft_model(model, lora_config)
print_trainable_parameters(model)
```
As you can see, here we are only training 0.6% of the parameters of the model! This is a huge memory gain that will enable us to fine-tune the model without any memory issue.
## Load and process data
Here we will use [`financial_phrasebank`](https://huggingface.co/datasets/financial_phrasebank) dataset to fine-tune our model on sentiment classification on financial sentences. We will load the split `sentences_allagree`, which corresponds according to the model card to the split where there is a 100% annotator agreement.
```python
# loading dataset
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["label"]]},
batched=True,
num_proc=1,
)
```
Let's also apply some pre-processing of the input data, the labels needs to be pre-processed, the tokens corresponding to `pad_token_id` needs to be set to `-100` so that the `CrossEntropy` loss associated with the model will correctly ignore these tokens.
```python
# data preprocessing
text_column = "sentence"
label_column = "text_label"
max_length = 128
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
```
## Train our model!
Let's now train our model, run the cells below.
Note that for T5 since some layers are kept in `float32` for stability purposes there is no need to call autocast on the trainer.
```python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
"temp",
evaluation_strategy="epoch",
learning_rate=1e-3,
gradient_accumulation_steps=1,
auto_find_batch_size=True,
num_train_epochs=1,
save_steps=100,
save_total_limit=8,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
```
```python
trainer.train()
```
## Qualitatively test our model
Let's have a quick qualitative evaluation of the model, by taking a sample from the dataset that corresponds to a positive label. Run your generation similarly as you were running your model from `transformers`:
```python
model.eval()
input_text = "In January-September 2009 , the Group 's net interest income increased to EUR 112.4 mn from EUR 74.3 mn in January-September 2008 ."
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print("input sentence: ", input_text)
print(" output prediction: ", tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
## Share your adapters on 🤗 Hub
Once you have trained your adapter, you can easily share it on the Hub using the method `push_to_hub` . Note that only the adapter weights and config will be pushed
```python
from huggingface_hub import notebook_login
notebook_login()
```
```python
model.push_to_hub("ybelkada/flan-t5-large-financial-phrasebank-lora", use_auth_token=True)
```
## Load your adapter from the Hub
You can load the model together with the adapter with few lines of code! Check the snippet below to load the adapter from the Hub and run the example evaluation!
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
peft_model_id = "ybelkada/flan-t5-large-financial-phrasebank-lora"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_id)
```
```python
model.eval()
input_text = "In January-September 2009 , the Group 's net interest income increased to EUR 112.4 mn from EUR 74.3 mn in January-September 2008 ."
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print("input sentence: ", input_text)
print(" output prediction: ", tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
| huggingface/peft/blob/main/examples/int8_training/Finetune_flan_t5_large_bnb_peft.ipynb |
Customizing your demo with CSS and Javascript
Gradio allows you to customize your demo in several ways. You can customize the layout of your demo, add custom HTML, and add custom theming as well. This tutorial will go beyond that and walk you through how to add custom CSS and JavaScript code to your demo in order to add custom styling, animations, custom UI functionality, analytics, and more.
## Adding custom CSS to your demo
Gradio themes are the easiest way to customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Blocks` constructor. For example:
```python
with gr.Blocks(theme=gr.themes.Glass()):
...
```
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. You can extend these themes or create your own themes from scratch - see the [Theming guide](/guides/theming-guide) for more details.
For additional styling ability, you can pass any CSS to your app using the `css=` kwarg. You can either the filepath to a CSS file, or a string of CSS code.
**Warning**: The use of query selectors in custom JS and CSS is _not_ guaranteed to work across Gradio versions as the Gradio HTML DOM may change. We recommend using query selectors sparingly.
The base class for the Gradio app is `gradio-container`, so here's an example that changes the background color of the Gradio app:
```python
with gr.Blocks(css=".gradio-container {background-color: red}") as demo:
...
```
If you'd like to reference external files in your css, preface the file path (which can be a relative or absolute path) with `"file="`, for example:
```python
with gr.Blocks(css=".gradio-container {background: url('file=clouds.jpg')}") as demo:
...
```
Note: By default, files in the host machine are not accessible to users running the Gradio app. As a result, you should make sure that any referenced files (such as `clouds.jpg` here) are either URLs or allowed via the `allow_list` parameter in `launch()`. Read more in our [section on Security and File Access](/guides/sharing-your-app#security-and-file-access).
## The `elem_id` and `elem_classes` Arguments
You can `elem_id` to add an HTML element `id` to any component, and `elem_classes` to add a class or list of classes. This will allow you to select elements more easily with CSS. This approach is also more likely to be stable across Gradio versions as built-in class names or ids may change (however, as mentioned in the warning above, we cannot guarantee complete compatibility between Gradio versions if you use custom CSS as the DOM elements may themselves change).
```python
css = """
#warning {background-color: #FFCCCB}
.feedback textarea {font-size: 24px !important}
"""
with gr.Blocks(css=css) as demo:
box1 = gr.Textbox(value="Good Job", elem_classes="feedback")
box2 = gr.Textbox(value="Failure", elem_id="warning", elem_classes="feedback")
```
The CSS `#warning` ruleset will only target the second Textbox, while the `.feedback` ruleset will target both. Note that when targeting classes, you might need to put the `!important` selector to override the default Gradio styles.
## Adding custom JavaScript to your demo
There are 3 ways to add javascript code to your Gradio demo:
1. You can add JavaScript code as a string or as a filepath to the `js` parameter of the `Blocks` or `Interface` initializer. This will run the JavaScript code when the demo is first loaded.
Below is an example of adding custom js to show an animated welcome message when the demo first loads.
$code_blocks_js_load
$demo_blocks_js_load
Note: You can also supply your custom js code as a file path. For example, if you have a file called `custom.js` in the same directory as your Python script, you can add it to your demo like so: `with gr.Blocks(js="custom.js") as demo:`. Same goes for `Interface` (ex: `gr.Interface(..., js="custom.js")`).
2. When using `Blocks` and event listeners, events have a `js` argument that can take a JavaScript function as a string and treat it just like a Python event listener function. You can pass both a JavaScript function and a Python function (in which case the JavaScript function is run first) or only Javascript (and set the Python `fn` to `None`). Take a look at the code below:
$code_blocks_js_methods
$demo_blocks_js_methods
1. Lastly, you can add JavaScript code to the `head` param of the `Blocks` initializer. This will add the code to the head of the HTML document. For example, you can add Google Analytics to your demo like so:
```python
head = f"""
<script async src="https://www.googletagmanager.com/gtag/js?id={google_analytics_tracking_id}"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){{dataLayer.push(arguments);}}
gtag('js', new Date());
gtag('config', '{google_analytics_tracking_id}');
</script>
"""
with gr.Blocks(head=head) as demo:
...demo code...
```
Note: The `head` parameter accepts any HTML tags you would normally insert into the `<head>` of a page. For example, you can also include `<meta>` tags to `head`.
| gradio-app/gradio/blob/main/guides/03_building-with-blocks/04_custom-CSS-and-JS.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PEGASUS-X
## Overview
The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
PEGASUS-X (PEGASUS eXtended) extends the PEGASUS models for long input summarization through additional long input pretraining and using staggered block-local attention with global tokens in the encoder.
The abstract from the paper is the following:
*While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train.*
This model was contributed by [zphang](<https://huggingface.co/zphang). The original code can be found [here](https://github.com/google-research/pegasus).
## Documentation resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
<Tip>
PEGASUS-X uses the same tokenizer as [PEGASUS](pegasus).
</Tip>
## PegasusXConfig
[[autodoc]] PegasusXConfig
## PegasusXModel
[[autodoc]] PegasusXModel
- forward
## PegasusXForConditionalGeneration
[[autodoc]] PegasusXForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/pegasus_x.md |
--
title: "Deep Q-Learning with Space Invaders"
thumbnail: /blog/assets/78_deep_rl_dqn/thumbnail.gif
authors:
- user: ThomasSimonini
---
# Deep Q-Learning with Space Invaders
<h2>Unit 3, of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit3/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/78_deep_rl_dqn/thumbnail.gif" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit3/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
[In the last unit](https://huggingface.co/blog/deep-rl-q-part2), we learned our first reinforcement learning algorithm: Q-Learning, **implemented it from scratch**, and trained it in two environments, FrozenLake-v1 ☃️ and Taxi-v3 🚕.
We got excellent results with this simple algorithm. But these environments were relatively simple because the **State Space was discrete and small** (14 different states for FrozenLake-v1 and 500 for Taxi-v3).
But as we'll see, producing and updating a **Q-table can become ineffective in large state space environments.**
So today, **we'll study our first Deep Reinforcement Learning agent**: Deep Q-Learning. Instead of using a Q-table, Deep Q-Learning uses a Neural Network that takes a state and approximates Q-values for each action based on that state.
And **we'll train it to play Space Invaders and other Atari environments using [RL-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**, a training framework for RL using Stable-Baselines that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results, and recording videos.
<figure class="image table text-center m-0 w-full">
<img src="assets/78_deep_rl_dqn/atari-envs.gif" alt="Environments"/>
</figure>
So let’s get started! 🚀
To be able to understand this unit, **you need to understand [Q-Learning](https://huggingface.co/blog/deep-rl-q-part2) first.**
- [From Q-Learning to Deep Q-Learning](#from-q-learning-to-deep-q-learning)
- [The Deep Q Network](#the-deep-q-network-dqn)
- [Preprocessing the input and temporal limitation](#preprocessing-the-input-and-temporal-limitation)
- [The Deep Q-Learning Algorithm](#the-deep-q-learning-algorithm)
- [Experience Replay to make more efficient use of experiences](#experience-replay-to-make-more-efficient-use-of-experiences)
- [Fixed Q-Target to stabilize the training](#fixed-q-target-to-stabilize-the-training)
- [Double DQN](#double-dqn)
## From Q-Learning to Deep Q-Learning
We learned that **Q-Learning is an algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
<figure class="image table text-center m-0 w-full"> <img src="assets/73_deep_rl_q_part2/Q-function.jpg" alt="Q-function"/> <figcaption>Given a state and action, our Q Function outputs a state-action value (also called Q-value)</figcaption> </figure>
The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
The problem is that Q-Learning is a *tabular method*. Aka, a problem in which the state and actions spaces **are small enough to approximate value functions to be represented as arrays and tables**. And this is **not scalable**.
Q-Learning was working well with small state space environments like:
- FrozenLake, we had 14 states.
- Taxi-v3, we had 500 states.
But think of what we're going to do today: we will train an agent to learn to play Space Invaders using the frames as input.
As **[Nikita Melkozerov mentioned](https://twitter.com/meln1k), Atari environments** have an observation space with a shape of (210, 160, 3), containing values ranging from 0 to 255 so that gives us 256^(210x160x3) = 256^100800 (for comparison, we have approximately 10^80 atoms in the observable universe).
<img src="assets/78_deep_rl_dqn/atari.jpg" alt="Atari State Space"/>
Therefore, the state space is gigantic; hence creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values instead of a Q-table using a parametrized Q-function \\(Q_{\theta}(s,a)\\) .
This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that's exactly what Deep Q-Learning does.
<img src="assets/63_deep_rl_intro/deep.jpg" alt="Deep Q Learning"/>
Now that we understand Deep Q-Learning, let's dive deeper into the Deep Q-Network.
## The Deep Q-Network (DQN)
This is the architecture of our Deep Q-Learning network:
<img src="assets/78_deep_rl_dqn/deep-q-network.jpg" alt="Deep Q Network"/>
As input, we take a **stack of 4 frames** passed through the network as a state and output a **vector of Q-values for each possible action at that state**. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
When the Neural Network is initialized, **the Q-value estimation is terrible**. But during training, our Deep Q-Network agent will associate a situation with appropriate action and **learn to play the game well**.
### Preprocessing the input and temporal limitation
We mentioned that we **preprocess the input**. It’s an essential step since we want to reduce the complexity of our state to reduce the computation time needed for training.
So what we do is **reduce the state space to 84x84 and grayscale it** (since the colors in Atari environments don't add important information).
This is an essential saving since we **reduce our three color channels (RGB) to 1**.
We can also **crop a part of the screen in some games** if it does not contain important information.
Then we stack four frames together.
<img src="assets/78_deep_rl_dqn/preprocessing.jpg" alt="Preprocessing"/>
Why do we stack four frames together?
We stack frames together because it helps us **handle the problem of temporal limitation**. Let’s take an example with the game of Pong. When you see this frame:
<img src="assets/78_deep_rl_dqn/temporal-limitation.jpg" alt="Temporal Limitation"/>
Can you tell me where the ball is going?
No, because one frame is not enough to have a sense of motion! But what if I add three more frames? **Here you can see that the ball is going to the right**.
<img src="assets/78_deep_rl_dqn/temporal-limitation-2.jpg" alt="Temporal Limitation"/>
That’s why, to capture temporal information, we stack four frames together.
Then, the stacked frames are processed by three convolutional layers. These layers **allow us to capture and exploit spatial relationships in images**. But also, because frames are stacked together, **you can exploit some spatial properties across those frames**.
Finally, we have a couple of fully connected layers that output a Q-value for each possible action at that state.
<img src="assets/78_deep_rl_dqn/deep-q-network.jpg" alt="Deep Q Network"/>
So, we see that Deep Q-Learning is using a neural network to approximate, given a state, the different Q-values for each possible action at that state. Let’s now study the Deep Q-Learning algorithm.
## The Deep Q-Learning Algorithm
We learned that Deep Q-Learning **uses a deep neural network to approximate the different Q-values for each possible action at a state** (value-function estimation).
The difference is that, during the training phase, instead of updating the Q-value of a state-action pair directly as we have done with Q-Learning:
<img src="https://huggingface.co/blog/assets/73_deep_rl_q_part2/q-ex-5.jpg" alt="Q Loss"/>
In Deep Q-Learning, we create a **Loss function between our Q-value prediction and the Q-target and use Gradient Descent to update the weights of our Deep Q-Network to approximate our Q-values better**.
<img src="assets/78_deep_rl_dqn/Q-target.jpg" alt="Q-target"/>
The Deep Q-Learning training algorithm has *two phases*:
- **Sampling**: we perform actions and **store the observed experiences tuples in a replay memory**.
- **Training**: Select the **small batch of tuple randomly and learn from it using a gradient descent update step**.
<img src="assets/78_deep_rl_dqn/sampling-training.jpg" alt="Sampling Training"/>
But, this is not the only change compared with Q-Learning. Deep Q-Learning training **might suffer from instability**, mainly because of combining a non-linear Q-value function (Neural Network) and bootstrapping (when we update targets with existing estimates and not an actual complete return).
To help us stabilize the training, we implement three different solutions:
1. *Experience Replay*, to make more **efficient use of experiences**.
2. *Fixed Q-Target* **to stabilize the training**.
3. *Double Deep Q-Learning*, to **handle the problem of the overestimation of Q-values**.
<!--- We'll see these three solutions in the pseudocode. --->
### Experience Replay to make more efficient use of experiences
Why do we create a replay memory?
Experience Replay in Deep Q-Learning has two functions:
1. **Make more efficient use of the experiences during the training**.
- Experience replay helps us **make more efficient use of the experiences during the training.** Usually, in online reinforcement learning, we interact in the environment, get experiences (state, action, reward, and next state), learn from them (update the neural network) and discard them.
- But with experience replay, we create a replay buffer that saves experience samples **that we can reuse during the training.**
<img src="assets/78_deep_rl_dqn/experience-replay.jpg" alt="Experience Replay"/>
⇒ This allows us to **learn from individual experiences multiple times**.
2. **Avoid forgetting previous experiences and reduce the correlation between experiences**.
- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget **the previous experiences as it overwrites new experiences.** For instance, if we are in the first level and then the second, which is different, our agent can forget how to behave and play in the first level.
The solution is to create a Replay Buffer that stores experience tuples while interacting with the environment and then sample a small batch of tuples. This prevents **the network from only learning about what it has immediately done.**
Experience replay also has other benefits. By randomly sampling the experiences, we remove correlation in the observation sequences and avoid **action values from oscillating or diverging catastrophically.**
In the Deep Q-Learning pseudocode, we see that we **initialize a replay memory buffer D from capacity N** (N is an hyperparameter that you can define). We then store experiences in the memory and sample a minibatch of experiences to feed the Deep Q-Network during the training phase.
<img src="assets/78_deep_rl_dqn/experience-replay-pseudocode.jpg" alt="Experience Replay Pseudocode"/>
### Fixed Q-Target to stabilize the training
When we want to calculate the TD error (aka the loss), we calculate the **difference between the TD target (Q-Target) and the current Q-value (estimation of Q)**.
But we **don’t have any idea of the real TD target**. We need to estimate it. Using the Bellman equation, we saw that the TD target is just the reward of taking that action at that state plus the discounted highest Q value for the next state.
<img src="assets/78_deep_rl_dqn/Q-target.jpg" alt="Q-target"/>
However, the problem is that we are using the same parameters (weights) for estimating the TD target **and** the Q value. Consequently, there is a significant correlation between the TD target and the parameters we are changing.
Therefore, it means that at every step of training, **our Q values shift but also the target value shifts.** So, we’re getting closer to our target, but the target is also moving. It’s like chasing a moving target! This led to a significant oscillation in training.
It’s like if you were a cowboy (the Q estimation) and you want to catch the cow (the Q-target), you must get closer (reduce the error).
<img src="assets/78_deep_rl_dqn/qtarget-1.jpg" alt="Q-target"/>
At each time step, you’re trying to approach the cow, which also moves at each time step (because you use the same parameters).
<img src="assets/78_deep_rl_dqn/qtarget-2.jpg" alt="Q-target"/>
<img src="assets/78_deep_rl_dqn/qtarget-3.jpg" alt="Q-target"/>
This leads to a bizarre path of chasing (a significant oscillation in training).
<img src="assets/78_deep_rl_dqn/qtarget-4.jpg" alt="Q-target"/>
Instead, what we see in the pseudo-code is that we:
- Use a **separate network with a fixed parameter** for estimating the TD Target
- **Copy the parameters from our Deep Q-Network at every C step** to update the target network.
<img src="assets/78_deep_rl_dqn/fixed-q-target-pseudocode.jpg" alt="Fixed Q-target Pseudocode"/>
### Double DQN
Double DQNs, or Double Learning, were introduced [by Hado van Hasselt](https://papers.nips.cc/paper/3964-double-q-learning). This method **handles the problem of the overestimation of Q-values.**
To understand this problem, remember how we calculate the TD Target:
We face a simple problem by calculating the TD target: how are we sure that **the best action for the next state is the action with the highest Q-value?**
We know that the accuracy of Q values depends on what action we tried **and** what neighboring states we explored.
Consequently, we don’t have enough information about the best action to take at the beginning of the training. Therefore, taking the maximum Q value (which is noisy) as the best action to take can lead to false positives. If non-optimal actions are regularly **given a higher Q value than the optimal best action, the learning will be complicated.**
The solution is: when we compute the Q target, we use two networks to decouple the action selection from the target Q value generation. We:
<!---<img src="assets/78_deep_rl_dqn/double-dqn-pseudocode.jpg" alt="Double DQN Pseudocode"/>--->
- Use our **DQN network** to select the best action to take for the next state (the action with the highest Q value).
- Use our **Target network** to calculate the target Q value of taking that action at the next state.
Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
Since these three improvements in Deep Q-Learning, many have been added such as Prioritized Experience Replay, Dueling Deep Q-Learning. They’re out of the scope of this course but if you’re interested, check the links we put in the reading list. 👉 **[https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md](https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md)**
Now that you've studied the theory behind Deep Q-Learning, **you’re ready to train your Deep Q-Learning agent to play Atari Games**. We'll start with Space Invaders, but you'll be able to use any Atari game you want 🔥
We're using the RL-Baselines-3 Zoo integration, a vanilla version of Deep Q-Learning with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.
Start the tutorial here 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit3/unit3.ipynb
The leaderboard to compare your results with your classmates 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
<figure class="image table text-center m-0 w-full">
<img src="assets/78_deep_rl_dqn/atari-envs.gif" alt="Environments"/>
</figure>
---
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
That’s **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
Take time to really grasp the material before continuing.
Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
We published additional readings in the syllabus if you want to go deeper 👉 **[https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md](https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md)**
In the next unit, we’re going to learn about Policy Gradients methods.
And don't forget to share with your friends who want to learn 🤗 !
Finally, we want **to improve and update the course iteratively with your feedback**. If you have some, please fill this form 👉 **[https://forms.gle/3HgA7bEHwAmmLfwh9](https://forms.gle/3HgA7bEHwAmmLfwh9)**
### **Keep learning, stay awesome,**
| huggingface/blog/blob/main/deep-rl-dqn.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RWKV
## Overview
The RWKV model was proposed in [this repo](https://github.com/BlinkDL/RWKV-LM)
It suggests a tweak in the traditional Transformer attention to make it linear. This way, the model can be used as recurrent network: passing inputs for timestamp 0 and timestamp 1 together is the same as passing inputs at timestamp 0, then inputs at timestamp 1 along with the state of timestamp 0 (see example below).
This can be more efficient than a regular Transformer and can deal with sentence of any length (even if the model uses a fixed context length for training).
This model was contributed by [sgugger](https://huggingface.co/sgugger).
The original code can be found [here](https://github.com/BlinkDL/RWKV-LM).
## Usage example
```py
import torch
from transformers import AutoTokenizer, RwkvConfig, RwkvModel
model = RwkvModel.from_pretrained("sgugger/rwkv-430M-pile")
tokenizer = AutoTokenizer.from_pretrained("sgugger/rwkv-430M-pile")
inputs = tokenizer("This is an example.", return_tensors="pt")
# Feed everything to the model
outputs = model(inputs["input_ids"])
output_whole = outputs.last_hidden_state
outputs = model(inputs["input_ids"][:, :2])
output_one = outputs.last_hidden_state
# Using the state computed on the first inputs, we will get the same output
outputs = model(inputs["input_ids"][:, 2:], state=outputs.state)
output_two = outputs.last_hidden_state
torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5)
```
If you want to make sure the model stops generating when `'\n\n'` is detected, we recommend using the following stopping criteria:
```python
from transformers import StoppingCriteria
class RwkvStoppingCriteria(StoppingCriteria):
def __init__(self, eos_sequence = [187,187], eos_token_id = 537):
self.eos_sequence = eos_sequence
self.eos_token_id = eos_token_id
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
last_2_ids = input_ids[:,-2:].tolist()
return self.eos_sequence in last_2_ids
output = model.generate(inputs["input_ids"], max_new_tokens=64, stopping_criteria = [RwkvStoppingCriteria()])
```
## RwkvConfig
[[autodoc]] RwkvConfig
## RwkvModel
[[autodoc]] RwkvModel
- forward
## RwkvLMHeadModel
[[autodoc]] RwkvForCausalLM
- forward
## Rwkv attention and the recurrent formulas
In a traditional auto-regressive Transformer, attention is written as
$$O = \hbox{softmax}(QK^{T} / \sqrt{d}) V$$
with \\(Q\\), \\(K\\) and \\(V\\) are matrices of shape `seq_len x hidden_size` named query, key and value (they are actually bigger matrices with a batch dimension and an attention head dimension but we're only interested in the last two, which is where the matrix product is taken, so for the sake of simplicity we only consider those two). The product \\(QK^{T}\\) then has shape `seq_len x seq_len` and we can take the maxtrix product with \\(V\\) to get the output \\(O\\) of the same shape as the others.
Replacing the softmax by its value gives:
$$O_{i} = \frac{\sum_{j=1}^{i} e^{Q_{i} K_{j}^{T} / \sqrt{d}} V_{j}}{\sum_{j=1}^{i} e^{Q_{i} K_{j}^{T} / \sqrt{d}}}$$
Note that the entries in \\(QK^{T}\\) corresponding to \\(j > i\\) are masked (the sum stops at j) because the attention is not allowed to look at future tokens (only past ones).
In comparison, the RWKV attention is given by
$$O_{i} = \sigma(R_{i}) \frac{\sum_{j=1}^{i} e^{W_{i-j} + K_{j}} V_{j}}{\sum_{j=1}^{i} e^{W_{i-j} + K_{j}}}$$
where \\(R\\) is a new matrix called receptance by the author, \\(K\\) and \\(V\\) are still the key and value (\\(\sigma\\) here is the sigmoid function). \\(W\\) is a new vector that represents the position of the token and is given by
$$W_{0} = u \hbox{ and } W_{k} = (k-1)w \hbox{ for } k \geq 1$$
with \\(u\\) and \\(w\\) learnable parameters called in the code `time_first` and `time_decay` respectively. The numerator and denominator can both be expressed recursively. Naming them \\(N_{i}\\) and \\(D_{i}\\) we have:
$$N_{i} = e^{u + K_{i}} V_{i} + \hat{N}_{i} \hbox{ where } \hat{N}_{i} = e^{K_{i-1}} V_{i-1} + e^{w + K_{i-2}} V_{i-2} \cdots + e^{(i-2)w + K_{1}} V_{1}$$
so \\(\hat{N}_{i}\\) (called `numerator_state` in the code) satistfies
$$\hat{N}_{0} = 0 \hbox{ and } \hat{N}_{j+1} = e^{K_{j}} V_{j} + e^{w} \hat{N}_{j}$$
and
$$D_{i} = e^{u + K_{i}} + \hat{D}_{i} \hbox{ where } \hat{D}_{i} = e^{K_{i-1}} + e^{w + K_{i-2}} \cdots + e^{(i-2)w + K_{1}}$$
so \\(\hat{D}_{i}\\) (called `denominator_state` in the code) satistfies
$$\hat{D}_{0} = 0 \hbox{ and } \hat{D}_{j+1} = e^{K_{j}} + e^{w} \hat{D}_{j}$$
The actual recurrent formula used are a tiny bit more complex, as for numerical stability we don't want to compute exponentials of big numbers. Usually the softmax is not computed as is, but the exponential of the maximum term is divided of the numerator and denominator:
$$\frac{e^{x_{i}}}{\sum_{j=1}^{n} e^{x_{j}}} = \frac{e^{x_{i} - M}}{\sum_{j=1}^{n} e^{x_{j} - M}}$$
with \\(M\\) the maximum of all \\(x_{j}\\). So here on top of saving the numerator state (\\(\hat{N}\\)) and the denominator state (\\(\hat{D}\\)) we also keep track of the maximum of all terms encountered in the exponentials. So we actually use
$$\tilde{N}_{i} = e^{-M_{i}} \hat{N}_{i} \hbox{ and } \tilde{D}_{i} = e^{-M_{i}} \hat{D}_{i}$$
defined by the following recurrent formulas:
$$\tilde{N}_{0} = 0 \hbox{ and } \tilde{N}_{j+1} = e^{K_{j} - q} V_{j} + e^{w + M_{j} - q} \tilde{N}_{j} \hbox{ where } q = \max(K_{j}, w + M_{j})$$
and
$$\tilde{D}_{0} = 0 \hbox{ and } \tilde{D}_{j+1} = e^{K_{j} - q} + e^{w + M_{j} - q} \tilde{D}_{j} \hbox{ where } q = \max(K_{j}, w + M_{j})$$
and \\(M_{j+1} = q\\). With those, we can then compute
$$N_{i} = e^{u + K_{i} - q} V_{i} + e^{M_{i}} \tilde{N}_{i} \hbox{ where } q = \max(u + K_{i}, M_{i})$$
and
$$D_{i} = e^{u + K_{i} - q} + e^{M_{i}} \tilde{D}_{i} \hbox{ where } q = \max(u + K_{i}, M_{i})$$
which finally gives us
$$O_{i} = \sigma(R_{i}) \frac{N_{i}}{D_{i}}$$ | huggingface/transformers/blob/main/docs/source/en/model_doc/rwkv.md |
Distillation for quantization on Textual Inversion models to personalize text2image
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images._By using just 3-5 images new concepts can be taught to Stable Diffusion and the model personalized on your own images_
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
We have enabled distillation for quantization in `textual_inversion.py` to do quantization aware training as well as distillation on the model generated by Textual Inversion method.
## Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -r requirements.txt
```
## Prepare Datasets
One picture which is from the huggingface datasets [sd-concepts-library/dicoo2](https://huggingface.co/sd-concepts-library/dicoo2) is needed, and save it to the `./dicoo` directory. The picture is shown below:
<a href="https://huggingface.co/sd-concepts-library/dicoo2/blob/main/concept_images/1.jpeg">
<img src="https://huggingface.co/sd-concepts-library/dicoo2/resolve/main/concept_images/1.jpeg" width = "300" height="300">
</a>
## Get a FP32 Textual Inversion model
Use the following command to fine-tune the Stable Diffusion model on the above dataset to obtain the FP32 Textual Inversion model.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATA_DIR="./dicoo"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="dicoo_model"
```
## Do distillation for quantization
Distillation for quantization is a method that combines [intermediate layer knowledge distillation](https://github.com/intel/neural-compressor/blob/master/docs/source/distillation.md#intermediate-layer-knowledge-distillation) and [quantization aware training](https://github.com/intel/neural-compressor/blob/master/docs/source/quantization.md#quantization-aware-training) in the same training process to improve the performance of the quantized model. Provided a FP32 model, the distillation for quantization approach will take this model itself as the teacher model and transfer the knowledges of the specified layers to the student model, i.e. quantized version of the FP32 model, during the quantization aware training process.
Once you have the FP32 Textual Inversion model, the following command will take the FP32 Textual Inversion model as input to do distillation for quantization and generate the INT8 Textual Inversion model.
```bash
export FP32_MODEL_NAME="./dicoo_model"
export DATA_DIR="./dicoo"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$FP32_MODEL_NAME \
--train_data_dir=$DATA_DIR \
--use_ema --learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=300 \
--learning_rate=5.0e-04 --max_grad_norm=3 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="int8_model" \
--do_quantization --do_distillation --verify_loading
```
After the distillation for quantization process, the quantized UNet would be 4 times smaller (3279MB -> 827MB).
## Inference
Once you have trained a INT8 model with the above command, the inference can be done simply using the `text2images.py` script. Make sure to include the `placeholder_token` in your prompt.
```bash
export INT8_MODEL_NAME="./int8_model"
python text2images.py \
--pretrained_model_name_or_path=$INT8_MODEL_NAME \
--caption "a lovely <dicoo> in red dress and hat, in the snowly and brightly night, with many brighly buildings." \
--images_num 4
```
Here is the comparison of images generated by the FP32 model (left) and INT8 model (right) respectively:
<p float="left">
<img src="https://huggingface.co/datasets/Intel/textual_inversion_dicoo_dfq/resolve/main/FP32.png" width = "300" height = "300" alt="FP32" align=center />
<img src="https://huggingface.co/datasets/Intel/textual_inversion_dicoo_dfq/resolve/main/INT8.png" width = "300" height = "300" alt="INT8" align=center />
</p>
| huggingface/diffusers/blob/main/examples/research_projects/intel_opts/textual_inversion_dfq/README.md |
`tokenizers-win32-arm64-msvc`
This is the **aarch64-pc-windows-msvc** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/win32-arm64-msvc/README.md |
Search text in a dataset
Datasets Server provides a `/search` endpoint for searching words in a dataset.
<Tip warning={true}>
Currently, only <a href="./parquet">datasets with Parquet exports</a>
are supported so Datasets Server can index the contents and run the search without
downloading the whole dataset.
</Tip>
This guide shows you how to use Datasets Server's `/search` endpoint to search for a query string.
Feel free to also try it out with [ReDoc](https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json#operation/searchRows).
The text is searched in the columns of type `string`, even if the values are nested in a dictionary.
The `/search` endpoint accepts five query parameters:
- `dataset`: the dataset name, for example `glue` or `mozilla-foundation/common_voice_10_0`
- `config`: the configuration name, for example `cola`
- `split`: the split name, for example `train`
- `query`: the text to search
- `offset`: the offset of the slice, for example `150`
- `length`: the length of the slice, for example `10` (maximum: `100`)
For example, let's search for the text `"dog"` in the `train` split of the `SelfRC` configuration of the `duorc` dataset, restricting the results to the slice 150-151:
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/search?dataset=duorc&config=SelfRC&split=train&query=dog&offset=150&length=2"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/search?dataset=duorc&config=SelfRC&split=train&query=dog&offset=150&length=2",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/search?dataset=duorc&config=SelfRC&split=train&query=dog&offset=150&length=2 \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The endpoint response is a JSON containing two keys (same format as [`/rows`](./rows)):
- The [`features`](https://huggingface.co/docs/datasets/about_dataset_features) of a dataset, including the column's name and data type.
- The slice of `rows` of a dataset and the content contained in each column of a specific row.
The rows are ordered by the row index, and the text strings matching the query are not highlighted.
For example, here are the `features` and the slice 150-151 of matching `rows` of the `duorc`/`SelfRC` train split for the query `dog`:
```json
{
"features": [
{
"feature_idx": 0,
"name": "plot_id",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 1,
"name": "plot",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 2,
"name": "title",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 3,
"name": "question_id",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 4,
"name": "question",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 5,
"name": "answers",
"type": {
"feature": { "dtype": "string", "_type": "Value" },
"_type": "Sequence"
}
},
{
"feature_idx": 6,
"name": "no_answer",
"type": { "dtype": "bool", "_type": "Value" }
}
],
"rows": [
{
"row_idx": 1561,
"row": {
"plot_id": "/m/014bjk",
"plot": "The film begins with clips that track a telephone call between London and Geneva, where a university student and part-time model, Valentine Dussault (Irène Jacob), is talking to her emotionally infantile and possessive boyfriend. During her work as a model she poses for a chewing-gum campaign and during the photo shoot the photographer asks her to look very sad. While walking back home, Auguste, a neighbour of Valentine's, drops a set of books, notices that a particular chapter of the Criminal Code opened at random, and concentrates on that passage. As she drives back to her apartment, Valentine is distracted while adjusting the radio and accidentally hits a dog. She tracks down the owner, a reclusive retired judge, Joseph Kern (Jean-Louis Trintignant). He seems unconcerned by the accident or the injuries sustained by Rita, his dog. Valentine takes Rita to a veterinarian, where she learns that Rita is pregnant. Valentine takes the dog home. Later, money is delivered to her apartment from an unnamed sender.\nWhilst Valentine is walking Rita the next day the dog runs away and Valentine eventually finds her back at Kern's house. She asks and he confirms that the money sent to her came from him, for the vet bill. He then tells Valentine she can have the dog. A short time later Valentine finds Kern eavesdropping on his neighbours' private telephone conversations. The judge challenges Valentine to go tell the neighbours and initially she goes to do so. She visits the neighbours' house, which appears, on the surface, to contain a contented nuclear family, causing her to change her mind about exposing their secrets. She returns to Kern's house and Kern tells her that it would make no difference if she denounced him for his spying because the people's lives he listens to would eventually turn into hell anyway. She leaves saying that she feels nothing but pity for him.\nWhilst visiting Kern, Valentine hears a phone conversation between her (unbeknownst to her) neighbour, Auguste, and his girlfriend, Karin (Frederique Feder). They discuss if they should go bowling. Valentine covers her ears but from the very little she hears she concludes that they love each other. Kern disagrees. That evening Valentine is alone at home and hopes that her boyfriend will call, but it is the photographer who calls, saying that her billboard was set up that evening and asks her to join them bowling to celebrate. Later, Auguste takes his exam and passes it and becomes a judge. Karin asks if he was asked any questions regarding the article that was open when he dropped his books. Auguste says yes. Karin gives him a fancy fountain pen as a gift and he wonders what the first judgment he signs with it will be. That evening, Kern writes a series of letters to his neighbours and the court confessing his activities, and the community files a class action. Later, at the law courts, he sees Karin make the acquaintance of and begin to flirt with another man. Earlier, Auguste had missed a call from Karin and tried to call her back but got no answer.\nValentine reads the news about a retired judge who spied on his neighbours and rushes to Kern's house to tell him that she did not report on him. He confesses that he turned himself in, just to see what she would do. He asks her in and shows her that Rita has had seven puppies. He tells her that in their last conversation when she spoke about pity he later realized that she really meant disgust. He ponders about the reasons why people obey laws and concludes that often it is more on selfish grounds and from fear than about obeying the law or being decent. It is his birthday and he offers her pear brandy for a toast. During their conversation he reminisces about a sailor he acquitted a long time ago, only later realizing he had made a mistake, and that the man was guilty. However, the man later married, had children and grandchildren and lives peacefully and happy. Valentine says that he did what he had to do, but Kern wonders how many other people that he acquitted or condemned might have seen a different life had he decided otherwise. Valentine tells Kern about her intended trip to England for a modeling job and to visit her boyfriend. Kern suggests that she take the ferry.\nAuguste has been unable to reach Karin since graduation so he goes to her place and sees her having sex with another man. Distraught, he leaves. Later, Auguste sees Karin and her new boyfriend in a restaurant. He gets her attention by tapping on the restaurant window with the pen she gave him. But when she rushes outside, he hides from her. In a temper, he ties his dog by a quayside and abandons him.\nKarin runs a service providing personalised weather information to travelers by telephone. Kern calls and enquires about the weather in the English Channel for the time when Valentine will be traveling to England. Karin states that she expects the weather to be perfect and reveals that she is about to take a trip there (with her new boyfriend who owns a yacht).\nThe day before Valentine leaves, she invites Kern to a fashion show where she is modeling. After the show they speak about the dream Kern had about her, where he saw her at the age of 50 and happy with an unidentified man. The conversation then turns to Kern and the reasons why he disliked Karin. Kern reveals that before becoming a judge, he was in love with a woman very much like Karin, who betrayed him for another man. While preparing for his exam, he once went to the same theatre where the fashion show took place and he accidentally dropped one of his books. When he picked it up, Kern studied the chapter where the book accidentally opened, which turned out to be the crucial question at his examination. After his girlfriend left him, he followed her across the English Channel but never saw her again, because she died in an accident. Later, he was assigned to judge a case where the defendant was the same man who took his girlfriend from him. Despite this connection, Kern did not recuse himself from the case and found the man guilty. He tells Valentine the judgment was entirely legal but also that he subsequently requested early retirement.\nValentine boards the ferry to England. Auguste is also on the ferry, clutching the dog he had temporarily abandoned. Although living in the same neighborhood and nearly crossing paths many times, the two have still never met. Suddenly a storm rises and sinks both the ferry and the boat with Karin and her boyfriend. Only seven survivors are pulled from the ferry: the main characters from the first two films of the trilogy, Julie and Olivier from Blue, Karol and Dominique from White, and Valentine and Auguste, who meet for the first time, as well as an English bartender named Stephen Killian. As in the previous films, the film's final sequence shows a character crying - in this case, the judge - but the final image replicates the iconic chewing-gum poster of Valentine, but this time with real emotion showing on her face.",
"title": "Three Colors: Red",
"question_id": "7c583513-0b7f-ddb3-be43-64befc7e90cc",
"question": "Where is Valentine going on her trip?",
"answers": ["England."],
"no_answer": false
},
"truncated_cells": []
},
{
"row_idx": 1562,
"row": {
"plot_id": "/m/014bjk",
"plot": "The film begins with clips that track a telephone call between London and Geneva, where a university student and part-time model, Valentine Dussault (Irène Jacob), is talking to her emotionally infantile and possessive boyfriend. During her work as a model she poses for a chewing-gum campaign and during the photo shoot the photographer asks her to look very sad. While walking back home, Auguste, a neighbour of Valentine's, drops a set of books, notices that a particular chapter of the Criminal Code opened at random, and concentrates on that passage. As she drives back to her apartment, Valentine is distracted while adjusting the radio and accidentally hits a dog. She tracks down the owner, a reclusive retired judge, Joseph Kern (Jean-Louis Trintignant). He seems unconcerned by the accident or the injuries sustained by Rita, his dog. Valentine takes Rita to a veterinarian, where she learns that Rita is pregnant. Valentine takes the dog home. Later, money is delivered to her apartment from an unnamed sender.\nWhilst Valentine is walking Rita the next day the dog runs away and Valentine eventually finds her back at Kern's house. She asks and he confirms that the money sent to her came from him, for the vet bill. He then tells Valentine she can have the dog. A short time later Valentine finds Kern eavesdropping on his neighbours' private telephone conversations. The judge challenges Valentine to go tell the neighbours and initially she goes to do so. She visits the neighbours' house, which appears, on the surface, to contain a contented nuclear family, causing her to change her mind about exposing their secrets. She returns to Kern's house and Kern tells her that it would make no difference if she denounced him for his spying because the people's lives he listens to would eventually turn into hell anyway. She leaves saying that she feels nothing but pity for him.\nWhilst visiting Kern, Valentine hears a phone conversation between her (unbeknownst to her) neighbour, Auguste, and his girlfriend, Karin (Frederique Feder). They discuss if they should go bowling. Valentine covers her ears but from the very little she hears she concludes that they love each other. Kern disagrees. That evening Valentine is alone at home and hopes that her boyfriend will call, but it is the photographer who calls, saying that her billboard was set up that evening and asks her to join them bowling to celebrate. Later, Auguste takes his exam and passes it and becomes a judge. Karin asks if he was asked any questions regarding the article that was open when he dropped his books. Auguste says yes. Karin gives him a fancy fountain pen as a gift and he wonders what the first judgment he signs with it will be. That evening, Kern writes a series of letters to his neighbours and the court confessing his activities, and the community files a class action. Later, at the law courts, he sees Karin make the acquaintance of and begin to flirt with another man. Earlier, Auguste had missed a call from Karin and tried to call her back but got no answer.\nValentine reads the news about a retired judge who spied on his neighbours and rushes to Kern's house to tell him that she did not report on him. He confesses that he turned himself in, just to see what she would do. He asks her in and shows her that Rita has had seven puppies. He tells her that in their last conversation when she spoke about pity he later realized that she really meant disgust. He ponders about the reasons why people obey laws and concludes that often it is more on selfish grounds and from fear than about obeying the law or being decent. It is his birthday and he offers her pear brandy for a toast. During their conversation he reminisces about a sailor he acquitted a long time ago, only later realizing he had made a mistake, and that the man was guilty. However, the man later married, had children and grandchildren and lives peacefully and happy. Valentine says that he did what he had to do, but Kern wonders how many other people that he acquitted or condemned might have seen a different life had he decided otherwise. Valentine tells Kern about her intended trip to England for a modeling job and to visit her boyfriend. Kern suggests that she take the ferry.\nAuguste has been unable to reach Karin since graduation so he goes to her place and sees her having sex with another man. Distraught, he leaves. Later, Auguste sees Karin and her new boyfriend in a restaurant. He gets her attention by tapping on the restaurant window with the pen she gave him. But when she rushes outside, he hides from her. In a temper, he ties his dog by a quayside and abandons him.\nKarin runs a service providing personalised weather information to travelers by telephone. Kern calls and enquires about the weather in the English Channel for the time when Valentine will be traveling to England. Karin states that she expects the weather to be perfect and reveals that she is about to take a trip there (with her new boyfriend who owns a yacht).\nThe day before Valentine leaves, she invites Kern to a fashion show where she is modeling. After the show they speak about the dream Kern had about her, where he saw her at the age of 50 and happy with an unidentified man. The conversation then turns to Kern and the reasons why he disliked Karin. Kern reveals that before becoming a judge, he was in love with a woman very much like Karin, who betrayed him for another man. While preparing for his exam, he once went to the same theatre where the fashion show took place and he accidentally dropped one of his books. When he picked it up, Kern studied the chapter where the book accidentally opened, which turned out to be the crucial question at his examination. After his girlfriend left him, he followed her across the English Channel but never saw her again, because she died in an accident. Later, he was assigned to judge a case where the defendant was the same man who took his girlfriend from him. Despite this connection, Kern did not recuse himself from the case and found the man guilty. He tells Valentine the judgment was entirely legal but also that he subsequently requested early retirement.\nValentine boards the ferry to England. Auguste is also on the ferry, clutching the dog he had temporarily abandoned. Although living in the same neighborhood and nearly crossing paths many times, the two have still never met. Suddenly a storm rises and sinks both the ferry and the boat with Karin and her boyfriend. Only seven survivors are pulled from the ferry: the main characters from the first two films of the trilogy, Julie and Olivier from Blue, Karol and Dominique from White, and Valentine and Auguste, who meet for the first time, as well as an English bartender named Stephen Killian. As in the previous films, the film's final sequence shows a character crying - in this case, the judge - but the final image replicates the iconic chewing-gum poster of Valentine, but this time with real emotion showing on her face.",
"title": "Three Colors: Red",
"question_id": "80becb22-908d-84bc-3a5f-00b620d551bc",
"question": "What was the profession of the dog's owner?",
"answers": ["Retired Judge"],
"no_answer": false
},
"truncated_cells": []
}
],
"num_rows_total": 5247,
"num_rows_per_page": 100,
"partial": false
}
```
If the result has `partial: true` it means that the search couldn't be run on the full dataset because it's too big.
Indeed, the indexing for `/search` can be partial if the dataset is bigger than 5GB. In that case, it only uses the first 5GB.
## Truncated responses
Unlike `/first-rows`, there is currently no truncation in `/search`.
The `truncated_cells` field is still there but is always empty.
| huggingface/datasets-server/blob/main/docs/source/search.mdx |
The `Interface` class
As mentioned in the [Quickstart](/main/guides/quickstart), the `gr.Interface` class is a high-level abstraction in Gradio that allows you to quickly create a demo for any Python function simply by specifying the input types and the output types. Revisiting our first demo:
$code_hello_world_4
We see that the `Interface` class is initialized with three required parameters:
- `fn`: the function to wrap a user interface (UI) around
- `inputs`: which Gradio component(s) to use for the input. The number of components should match the number of arguments in your function.
- `outputs`: which Gradio component(s) to use for the output. The number of components should match the number of return values from your function.
Let's take a closer look at these components used to provide input and output.
## Components Attributes
We used the default versions of the `gr.Textbox` and `gr.Slider`, but what if you want to change how the UI components look or behave?
Let's say you want to customize the slider to have values from 1 to 10, with a default of 2. And you wanted to customize the output text field — you want it to be larger and have a label.
If you use the actual class for `gr.Textbox` and `gr.Slider` instead of using the string shortcut, you have access to much more customizability through component attributes.
$code_hello_world_2
$demo_hello_world_2
## Multiple Input and Output Components
Suppose you had a more complex function, with multiple outputs as well. In the example below, we define a function that takes a string, boolean, and number, and returns a string and number.
$code_hello_world_3
$demo_hello_world_3
Just as each component in the `inputs` list corresponds to one of the parameters of the function, in order, each component in the `outputs` list corresponds to one of the values returned by the function, in order.
## An Image Example
Gradio supports many types of components, such as `Image`, `DataFrame`, `Video`, or `Label`. Let's try an image-to-image function to get a feel for these!
$code_sepia_filter
$demo_sepia_filter
When using the `Image` component as input, your function will receive a NumPy array with the shape `(height, width, 3)`, where the last dimension represents the RGB values. We'll return an image as well in the form of a NumPy array.
You can also set the datatype used by the component with the `type=` keyword argument. For example, if you wanted your function to take a file path to an image instead of a NumPy array, the input `Image` component could be written as:
```python
gr.Image(type="filepath", shape=...)
```
Also note that our input `Image` component comes with an edit button 🖉, which allows for cropping and zooming into images. Manipulating images in this way can help reveal biases or hidden flaws in a machine learning model!
You can read more about the many components and how to use them in the [Gradio docs](https://gradio.app/docs).
## Example Inputs
You can provide example data that a user can easily load into `Interface`. This can be helpful to demonstrate the types of inputs the model expects, as well as to provide a way to explore your dataset in conjunction with your model. To load example data, you can provide a **nested list** to the `examples=` keyword argument of the Interface constructor. Each sublist within the outer list represents a data sample, and each element within the sublist represents an input for each input component. The format of example data for each component is specified in the [Docs](https://gradio.app/docs#components).
$code_calculator
$demo_calculator
You can load a large dataset into the examples to browse and interact with the dataset through Gradio. The examples will be automatically paginated (you can configure this through the `examples_per_page` argument of `Interface`).
Continue learning about examples in the [More On Examples](https://gradio.app/guides/more-on-examples) guide.
## Descriptive Content
In the previous example, you may have noticed the `title=` and `description=` keyword arguments in the `Interface` constructor that helps users understand your app.
There are three arguments in the `Interface` constructor to specify where this content should go:
- `title`: which accepts text and can display it at the very top of interface, and also becomes the page title.
- `description`: which accepts text, markdown or HTML and places it right under the title.
- `article`: which also accepts text, markdown or HTML and places it below the interface.

If you're using the `Blocks` API instead, you can insert text, markdown, or HTML anywhere using the `gr.Markdown(...)` or `gr.HTML(...)` components, with descriptive content inside the `Component` constructor.
Another useful keyword argument is `label=`, which is present in every `Component`. This modifies the label text at the top of each `Component`. You can also add the `info=` keyword argument to form elements like `Textbox` or `Radio` to provide further information on their usage.
```python
gr.Number(label='Age', info='In years, must be greater than 0')
```
## Flagging
By default, an `Interface` will have "Flag" button. When a user testing your `Interface` sees input with interesting output, such as erroneous or unexpected model behaviour, they can flag the input for you to review. Within the directory provided by the `flagging_dir=` argument to the `Interface` constructor, a CSV file will log the flagged inputs. If the interface involves file data, such as for Image and Audio components, folders will be created to store those flagged data as well.
For example, with the calculator interface shown above, we would have the flagged data stored in the flagged directory shown below:
```directory
+-- calculator.py
+-- flagged/
| +-- logs.csv
```
_flagged/logs.csv_
```csv
num1,operation,num2,Output
5,add,7,12
6,subtract,1.5,4.5
```
With the sepia interface shown earlier, we would have the flagged data stored in the flagged directory shown below:
```directory
+-- sepia.py
+-- flagged/
| +-- logs.csv
| +-- im/
| | +-- 0.png
| | +-- 1.png
| +-- Output/
| | +-- 0.png
| | +-- 1.png
```
_flagged/logs.csv_
```csv
im,Output
im/0.png,Output/0.png
im/1.png,Output/1.png
```
If you wish for the user to provide a reason for flagging, you can pass a list of strings to the `flagging_options` argument of Interface. Users will have to select one of the strings when flagging, which will be saved as an additional column to the CSV.
| gradio-app/gradio/blob/main/guides/02_building-interfaces/00_the-interface-class.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OneFormer
## Overview
The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/oneformer_teaser.png"/>
The abstract from the paper is the following:
*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/oneformer_architecture.png"/>
This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
## Usage tips
- OneFormer requires two inputs during inference: *image* and *task token*.
- During training, OneFormer only uses panoptic annotations.
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `OneFormerLoss` class of `modeling_oneformer.py`. When training on multiple nodes, this should be
set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/SHI-Labs/OneFormer/blob/33ebb56ed34f970a30ae103e786c0cb64c653d9a/oneformer/modeling/criterion.py#L287).
- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneformerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OneFormer.
- Demo notebooks regarding inference + fine-tuning on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OneFormer).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## OneFormer specific outputs
[[autodoc]] models.oneformer.modeling_oneformer.OneFormerModelOutput
[[autodoc]] models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput
## OneFormerConfig
[[autodoc]] OneFormerConfig
## OneFormerImageProcessor
[[autodoc]] OneFormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## OneFormerProcessor
[[autodoc]] OneFormerProcessor
## OneFormerModel
[[autodoc]] OneFormerModel
- forward
## OneFormerForUniversalSegmentation
[[autodoc]] OneFormerForUniversalSegmentation
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/oneformer.md |
--
title: "Deep Dive: Vision Transformers On Hugging Face Optimum Graphcore"
thumbnail: /blog/assets/97_vision_transformers/thumbnail.png
authors:
- user: juliensimon
---
# Deep Dive: Vision Transformers On Hugging Face Optimum Graphcore
This blog post will show how easy it is to fine-tune pre-trained Transformer models for your dataset using the Hugging Face Optimum library on Graphcore Intelligence Processing Units (IPUs). As an example, we will show a step-by-step guide and provide a notebook that takes a large, widely-used chest X-ray dataset and trains a vision transformer (ViT) model.
<h2>Introducing vision transformer (ViT) models</h2>
<p>In 2017 a group of Google AI researchers published a paper introducing the transformer model architecture. Characterised by a novel self-attention mechanism, transformers were proposed as a new and efficient group of models for language applications. Indeed, in the last five years, transformers have seen explosive popularity and are now accepted as the de facto standard for natural language processing (NLP).</p>
<p>Transformers for language are perhaps most notably represented by the rapidly evolving GPT and BERT model families. Both can run easily and efficiently on Graphcore IPUs as part of the growing <a href="/posts/getting-started-with-hugging-face-transformers-for-ipus-with-optimum" rel="noopener" target="_blank">Hugging Face Optimum Graphcore library</a>).</p>
<p><img src="https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=1024&name=transformers_chrono.png" alt="transformers_chrono" loading="lazy" style="width: 1024px; margin-left: auto; margin-right: auto; display: block;" width="1024" srcset="https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=512&name=transformers_chrono.png 512w, https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=1024&name=transformers_chrono.png 1024w, https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=1536&name=transformers_chrono.png 1536w, https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=2048&name=transformers_chrono.png 2048w, https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=2560&name=transformers_chrono.png 2560w, https://www.graphcore.ai/hs-fs/hubfs/transformers_chrono.png?width=3072&name=transformers_chrono.png 3072w" sizes="(max-width: 1024px) 100vw, 1024px"></p>
<div class="blog-caption" style="max-height: 100%; max-width: 90%; margin-left: auto; margin-right: auto; line-height: 1.4;">
<p>A timeline showing releases of prominent transformer language models (credit: Hugging Face)</p>
</div>
<p>An in-depth explainer about the transformer model architecture (with a focus on NLP) can be found <a href="https://huggingface.co/course/chapter1/4?fw=pt" rel="noopener" target="_blank">on the Hugging Face website</a>.</p>
<p>While transformers have seen initial success in language, they are extremely versatile and can be used for a range of other purposes including computer vision (CV), as we will cover in this blog post.</p>
<p>CV is an area where convolutional neural networks (CNNs) are without doubt the most popular architecture. However, the vision transformer (ViT) architecture, first introduced in a <a href="https://arxiv.org/abs/2010.11929" rel="noopener" target="_blank">2021 paper</a> from Google Research, represents a breakthrough in image recognition and uses the same self-attention mechanism as BERT and GPT as its main component.</p>
<p>Whereas BERT and other transformer-based language processing models take a sentence (i.e., a list of words) as input, ViT models divide an input image into several small patches, equivalent to individual words in language processing. Each patch is linearly encoded by the transformer model into a vector representation that can be processed individually. This approach of splitting images into patches, or visual tokens, stands in contrast to the pixel arrays used by CNNs.</p>
<p>Thanks to pre-training, the ViT model learns an inner representation of images that can then be used to extract visual features useful for downstream tasks. For instance, you can train a classifier on a new dataset of labelled images by placing a linear layer on top of the pre-trained visual encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.</p>
<p><img src="https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=1024&name=vit%20diag.png" alt="vit diag" loading="lazy" style="width: 1024px; margin-left: auto; margin-right: auto; display: block;" width="1024" srcset="https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=512&name=vit%20diag.png 512w, https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=1024&name=vit%20diag.png 1024w, https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=1536&name=vit%20diag.png 1536w, https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=2048&name=vit%20diag.png 2048w, https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=2560&name=vit%20diag.png 2560w, https://www.graphcore.ai/hs-fs/hubfs/vit%20diag.png?width=3072&name=vit%20diag.png 3072w" sizes="(max-width: 1024px) 100vw, 1024px"></p>
<div class="blog-caption" style="max-height: 100%; max-width: 90%; margin-left: auto; margin-right: auto; line-height: 1.4;">
<p>An overview of the ViT model structure as introduced in <a href="https://arxiv.org/abs/2010.11929" rel="noopener" target="_blank">Google Research’s original 2021 paper</a></p>
</div>
<p>Compared to CNNs, ViT models have displayed higher recognition accuracy with lower computational cost, and are applied to a range of applications including image classification, object detection, and segmentation. Use cases in the healthcare domain alone include detection and classification for <a href="https://www.mdpi.com/1660-4601/18/21/11086/pdf" rel="noopener" target="_blank">COVID-19</a>, <a href="https://towardsdatascience.com/vision-transformers-for-femur-fracture-classification-480d62f87252" rel="noopener" target="_blank">femur fractures</a>, <a href="https://iopscience.iop.org/article/10.1088/1361-6560/ac3dc8/meta" rel="noopener" target="_blank">emphysema</a>, <a href="https://arxiv.org/abs/2110.14731" rel="noopener" target="_blank">breast cancer</a>, and <a href="https://www.biorxiv.org/content/10.1101/2021.11.27.470184v2.full" rel="noopener" target="_blank">Alzheimer’s disease</a>—among many others.</p>
<h2>ViT models – a perfect fit for IPU</h2>
<p>Graphcore IPUs are particularly well-suited to ViT models due to their ability to parallelise training using a combination of data pipelining and model parallelism. Accelerating this massively parallel process is made possible through IPU’s MIMD architecture and its scale-out solution centred on the IPU-Fabric.</p>
<p>By introducing pipeline parallelism, the batch size that can be processed per instance of data parallelism is increased, the access efficiency of the memory area handled by one IPU is improved, and the communication time of parameter aggregation for data parallel learning is reduced.</p>
<p>Thanks to the addition of a range of pre-optimized transformer models to the open-source Hugging Face Optimum Graphcore library, it’s incredibly easy to achieve a high degree of performance and efficiency when running and fine-tuning models such as ViT on IPUs.</p>
<p>Through Hugging Face Optimum, Graphcore has released ready-to-use IPU-trained model checkpoints and configuration files to make it easy to train models with maximum efficiency. This is particularly helpful since ViT models generally require pre-training on a large amount of data. This integration lets you use the checkpoints released by the original authors themselves within the Hugging Face model hub, so you won’t have to train them yourself. By letting users plug and play any public dataset, Optimum shortens the overall development lifecycle of AI models and allows seamless integration to Graphcore’s state-of-the-art hardware, giving a quicker time-to-value.</p>
<p>For this blog post, we will use a ViT model pre-trained on ImageNet-21k, based on the paper <a href="https://arxiv.org/abs/2010.11929" rel="noopener" target="_blank">An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale</a> by Dosovitskiy et al. As an example, we will show you the process of using Optimum to fine-tune ViT on the <a href="https://paperswithcode.com/dataset/chestx-ray14" rel="noopener" target="_blank">ChestX-ray14 Dataset</a>.</p>
<h2>The value of ViT models for X-ray classification</h2>
<p>As with all medical imaging tasks, radiologists spend many years learning reliably and efficiently detect problems and make tentative diagnoses on the basis of X-ray images. To a large degree, this difficulty arises from the very minute differences and spatial limitations of the images, which is why computer aided detection and diagnosis (CAD) techniques have shown such great potential for impact in improving clinician workflows and patient outcomes.</p>
<p>At the same time, developing any model for X-ray classification (ViT or otherwise) will entail its fair share of challenges:</p>
<ul>
<li>Training a model from scratch takes an enormous amount of labeled data;</li>
<li>The high resolution and volume requirements mean powerful compute is necessary to train such models; and</li>
<li>The complexity of multi-class and multi-label problems such as pulmonary diagnosis is exponentially compounded due to the number of disease categories.</li>
</ul>
<p>As mentioned above, for the purpose of our demonstration using Hugging Face Optimum, we don’t need to train ViT from scratch. Instead, we will use model weights hosted in the <a href="https://huggingface.co/google/vit-base-patch16-224-in21k" rel="noopener" target="_blank">Hugging Face model hub</a>.</p>
<p>As an X-ray image can have multiple diseases, we will work with a multi-label classification model. The model in question uses <a href="https://huggingface.co/google/vit-base-patch16-224-in21k" rel="noopener" target="_blank">google/vit-base-patch16-224-in21k</a> checkpoints. It has been converted from the <a href="https://github.com/rwightman/pytorch-image-models" rel="noopener" target="_blank">TIMM repository</a> and pre-trained on 14 million images from ImageNet-21k. In order to parallelise and optimise the job for IPU, the configuration has been made available through the <a href="https://huggingface.co/Graphcore/vit-base-ipu" rel="noopener" target="_blank">Graphcore-ViT model card</a>.</p>
<p>If this is your first time using IPUs, read the <a href="https://docs.graphcore.ai/projects/ipu-programmers-guide/en/latest/" rel="noopener" target="_blank">IPU Programmer's Guide</a> to learn the basic concepts. To run your own PyTorch model on the IPU see the <a href="https://github.com/graphcore/tutorials/blob/master/tutorials/pytorch/basics" rel="noopener" target="_blank">Pytorch basics tutorial</a>, and learn how to use Optimum through our <a href="https://github.com/huggingface/optimum-graphcore/tree/main/notebooks" rel="noopener" target="_blank">Hugging Face Optimum Notebooks</a>.</p>
<h2>Training ViT on the ChestXRay-14 dataset</h2>
<p>First, we need to download the National Institutes of Health (NIH) Clinical Center’s <a href="http://nihcc.app.box.com/v/ChestXray-NIHCC" rel="noopener" target="_blank">Chest X-ray dataset</a>. This dataset contains 112,120 deidentified frontal view X-rays from 30,805 patients over a period from 1992 to 2015. The dataset covers a range of 14 common diseases based on labels mined from the text of radiology reports using NLP techniques.</p>
<p><img src="https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=700&name=chest%20x-ray%20examples.png" alt="chest x-ray examples" loading="lazy" style="width: 700px; margin-left: auto; margin-right: auto; display: block;" width="700" srcset="https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=350&name=chest%20x-ray%20examples.png 350w, https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=700&name=chest%20x-ray%20examples.png 700w, https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=1050&name=chest%20x-ray%20examples.png 1050w, https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=1400&name=chest%20x-ray%20examples.png 1400w, https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=1750&name=chest%20x-ray%20examples.png 1750w, https://www.graphcore.ai/hs-fs/hubfs/chest%20x-ray%20examples.png?width=2100&name=chest%20x-ray%20examples.png 2100w" sizes="(max-width: 700px) 100vw, 700px"></p>
<div class="blog-caption" style="max-height: 100%; max-width: 90%; margin-left: auto; margin-right: auto; line-height: 1.4;">
<p>Eight visual examples of common thorax diseases (Credit: NIC)</p>
</div>
<h2>Setting up the environment</h2>
<p>Here are the requirements to run this walkthrough:</p>
<ul>
<li>A Jupyter Notebook server with the latest Poplar SDK and PopTorch environment enabled (see our <a href="https://github.com/graphcore/tutorials/blob/master/tutorials/standard_tools/using_jupyter/README.md" rel="noopener" target="_blank">guide on using IPUs from Jupyter notebooks</a>)</li>
<li>The ViT Training Notebook from the <a href="https://github.com/graphcore/tutorials" rel="noopener" target="_blank">Graphcore Tutorials repo</a></li>
</ul>
<p>The Graphcore Tutorials repository contains the step-by-step tutorial notebook and Python script discussed in this guide. Clone the repository and launch the walkthrough.ipynb notebook found in <code><a href="https://github.com/graphcore/tutorials" rel="noopener" target="_blank">tutorials</a>/<a href="https://github.com/graphcore/tutorials/tree/master/tutorials" rel="noopener" target="_blank">tutorials</a>/<a href="https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch" rel="noopener" target="_blank">pytorch</a>/vit_model_training/</code>.</p>
<p style="font-weight: bold;">We’ve even made it easier and created the HF Optimum Gradient so you can launch the getting started tutorial in Free IPUs. <a href="http://paperspace.com/graphcore" rel="noopener" target="_blank">Sign up</a> and launch the runtime:<br><a href="https://console.paperspace.com/github/gradient-ai/Graphcore-HuggingFace?machine=Free-IPU-POD16&container=graphcore%2Fpytorch-jupyter%3A2.6.0-ubuntu-20.04-20220804&file=%2Fget-started%2Fwalkthrough.ipynb" rel="noopener" target="_blank"><img src="https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=200&name=gradient-badge-gradient-05-d-05.png" alt="run on Gradient" loading="lazy" style="width: 200px; float: left;" width="200" srcset="https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=100&name=gradient-badge-gradient-05-d-05.png 100w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=200&name=gradient-badge-gradient-05-d-05.png 200w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=300&name=gradient-badge-gradient-05-d-05.png 300w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=400&name=gradient-badge-gradient-05-d-05.png 400w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=500&name=gradient-badge-gradient-05-d-05.png 500w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=600&name=gradient-badge-gradient-05-d-05.png 600w" sizes="(max-width: 200px) 100vw, 200px"></a></p>
<p> </p>
<p> </p>
<h2>Getting the dataset</h2>
<a id="getting-the-dataset" data-hs-anchor="true"></a>
<p>Download the <a href="http://nihcc.app.box.com/v/ChestXray-NIHCC" rel="noopener" target="_blank">dataset's</a> <code>/images</code> directory. You can use <code>bash</code> to extract the files: <code>for f in images*.tar.gz; do tar xfz "$f"; done</code>.</p>
<p>Next, download the <code>Data_Entry_2017_v2020.csv</code> file, which contains the labels. By default, the tutorial expects the <code>/images</code> folder and .csv file to be in the same folder as the script being run.</p>
<p>Once your Jupyter environment has the datasets, you need to install and import the latest Hugging Face Optimum Graphcore package and other dependencies in <code><a href="https://github.com/graphcore/tutorials/blob/master/tutorials/pytorch/vit_model_training/requirements.txt" rel="noopener" target="_blank">requirements.txt</a></code>:</p>
<p><span style="color: #6b7a8c;"><code>%pip install -r requirements.txt </code></span></p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/24206176ff0ae6c1780dc47893997b80.js"></script>
</div>
<p><span style="color: #6b7a8c;"><code></code></span><code><span style="color: #6b7a8c;"></span></code></p>
<p>The examinations contained in the Chest X-ray dataset consist of X-ray images (greyscale, 224x224 pixels) with corresponding metadata: <code>Finding Labels, Follow-up #,Patient ID, Patient Age, Patient Gender, View Position, OriginalImage[Width Height] and OriginalImagePixelSpacing[x y]</code>.</p>
<p>Next, we define the locations of the downloaded images and the file with the labels to be downloaded in <a href="#getting-the-dataset" rel="noopener">Getting the dataset</a>:</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/cbcf9b59e7d3dfb02221dfafba8d8e10.js"></script>
</div>
<p>We are going to train the Graphcore Optimum ViT model to predict diseases (defined by "Finding Label") from the images. "Finding Label" can be any number of 14 diseases or a "No Finding" label, which indicates that no disease was detected. To be compatible with the Hugging Face library, the text labels need to be transformed to N-hot encoded arrays representing the multiple labels which are needed to classify each image. An N-hot encoded array represents the labels as a list of booleans, true if the label corresponds to the image and false if not.</p>
<p>First we identify the unique labels in the dataset.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/832eea2e60f94fb5ac6bb14f112a10ad.js"></script>
</div>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/7783093c436e570d0f7b1ed619771ae6.js"></script>
</div>
<p>Now we transform the labels into N-hot encoded arrays:</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/cf9fc70bee43b51ffd38c2046ee4380e.js"></script>
</div>
<p>When loading data using the <code>datasets.load_dataset</code> function, labels can be provided either by having folders for each of the labels (see "<a href="https://huggingface.co/docs/datasets/v2.3.2/en/image_process%22%20/l%20%22imagefolder" rel="noopener" target="_blank">ImageFolder</a>" documentation) or by having a <code>metadata.jsonl</code> file (see "<a href="https://huggingface.co/docs/datasets/v2.3.2/en/image_process%22%20/l%20%22imagefolder-with-metadata" rel="noopener" target="_blank">ImageFolder with metadata</a>" documentation). As the images in this dataset can have multiple labels, we have chosen to use a <code>metadata.jsonl file</code>. We write the image file names and their associated labels to the <code>metadata.jsonl</code> file.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/b59866219a4ec051da2e31fca6eb7e4d.js"></script>
</div>
<h2>Creating the dataset</h2>
<p>We are now ready to create the PyTorch dataset and split it into training and validation sets. This step converts the dataset to the <a href="https://arrow.apache.org/" rel="noopener" target="_blank">Arrow file format</a> which allows data to be loaded quickly during training and validation (<a href="https://huggingface.co/docs/datasets/v2.3.2/en/about_arrow" rel="noopener" target="_blank">about Arrow and Hugging Face</a>). Because the entire dataset is being loaded and pre-processed it can take a few minutes.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/6d2e26d5c1ad3df6ba966567086f8413.js"></script>
</div>
<p>We are going to import the ViT model from the checkpoint <code>google/vit-base-patch16-224-in21k</code>. The checkpoint is a standard model hosted by Hugging Face and is not managed by Graphcore.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/1df44cf80f72e1132441e539e3c3df84.js"></script>
</div>
<p>To fine-tune a pre-trained model, the new dataset must have the same properties as the original dataset used for pre-training. In Hugging Face, the original dataset information is provided in a config file loaded using the <code>AutoImageProcessor</code>. For this model, the X-ray images are resized to the correct resolution (224x224), converted from grayscale to RGB, and normalized across the RGB channels with a mean (0.5, 0.5, 0.5) and a standard deviation (0.5, 0.5, 0.5).</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/15c3fa337c2fd7e0b3cad23c421c3d28.js"></script>
</div>
<p>For the model to run efficiently, images need to be batched. To do this, we define the <code>vit_data_collator</code> function that returns batches of images and labels in a dictionary, following the <code>default_data_collator</code> pattern in <a href="https://huggingface.co/docs/transformers/main_classes/data_collator" rel="noopener" target="_blank">Transformers Data Collator</a>.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/a8af618ee4032b5984917ac8fe129cf5.js"></script>
</div>
<h2>Visualising the dataset</h2>
<p>To examine the dataset, we display the first 10 rows of metadata.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/f00def295657886e166e93394077d6cd.js"></script>
</div>
<p>Let's also plot some images from the validation set with their associated labels.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/20752216ae9ab314563d87cb3d6aeb94.js"></script>
</div>
<p><img src="https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=1024&name=x-ray%20images%20transformed.jpg" alt="x-ray images transformed" loading="lazy" style="width: 1024px; margin-left: auto; margin-right: auto; display: block;" width="1024" srcset="https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=512&name=x-ray%20images%20transformed.jpg 512w, https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=1024&name=x-ray%20images%20transformed.jpg 1024w, https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=1536&name=x-ray%20images%20transformed.jpg 1536w, https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=2048&name=x-ray%20images%20transformed.jpg 2048w, https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=2560&name=x-ray%20images%20transformed.jpg 2560w, https://www.graphcore.ai/hs-fs/hubfs/x-ray%20images%20transformed.jpg?width=3072&name=x-ray%20images%20transformed.jpg 3072w" sizes="(max-width: 1024px) 100vw, 1024px"></p>
<div class="blog-caption" style="max-height: 100%; max-width: 90%; margin-left: auto; margin-right: auto; line-height: 1.4;">
<p>The images are chest X-rays with labels of lung diseases the patient was diagnosed with. Here, we show the transformed images.</p>
</div>
<p>Our dataset is now ready to be used.</p>
<h2>Preparing the model</h2>
<p>To train a model on the IPU we need to import it from Hugging Face Hub and define a trainer using the IPUTrainer class. The IPUTrainer class takes the same arguments as the original <a href="https://huggingface.co/docs/transformers/main_classes/trainer" rel="noopener" target="_blank">Transformer Trainer</a> and works in tandem with the IPUConfig object which specifies the behaviour for compilation and execution on the IPU.</p>
<p>Now we import the ViT model from Hugging Face.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/dd026fd7056bbe918f7086f42c4e58e3.js"></script>
</div>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/68664b599cfe39b633a8853364b81008.js"></script>
</div>
<p>To use this model on the IPU we need to load the IPU configuration, <code>IPUConfig</code>, which gives control to all the parameters specific to Graphcore IPUs (existing IPU configs <a href="https://huggingface.co/Graphcore" rel="noopener" target="_blank">can be found here</a>). We are going to use <code>Graphcore/vit-base-ipu</code>.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/3759d2f899ff75e61383b2cc54593179.js"></script>
</div>
<p>Let's set our training hyperparameters using <code>IPUTrainingArguments</code>. This subclasses the Hugging Face <code>TrainingArguments</code> class, adding parameters specific to the IPU and its execution characteristics.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/aaad87d4b2560cc288913b9ec85ed312.js"></script>
</div>
<h2>Implementing a custom performance metric for evaluation</h2>
<p>The performance of multi-label classification models can be assessed using the area under the ROC (receiver operating characteristic) curve (AUC_ROC). The AUC_ROC is a plot of the true positive rate (TPR) against the false positive rate (FPR) of different classes and at different threshold values. This is a commonly used performance metric for multi-label classification tasks because it is insensitive to class imbalance and easy to interpret.</p>
<p>For this dataset, the AUC_ROC represents the ability of the model to separate the different diseases. A score of 0.5 means that it is 50% likely to get the correct disease and a score of 1 means that it can perfectly separate the diseases. This metric is not available in Datasets, hence we need to implement it ourselves. HuggingFace Datasets package allows custom metric calculation through the <code>load_metric()</code> function. We define a <code>compute_metrics</code> function and expose it to Transformer’s evaluation function just like the other supported metrics through the datasets package. The <code>compute_metrics</code> function takes the labels predicted by the ViT model and computes the area under the ROC curve. The <code>compute_metrics</code> function takes an <code>EvalPrediction</code> object (a named tuple with a <code>predictions</code> and <code>label_ids</code> field), and has to return a dictionary string to float.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/1924be9dc0aeb17e301936c5566b4de2.js"></script>
</div>
<p>To train the model, we define a trainer using the <code>IPUTrainer</code> class which takes care of compiling the model to run on IPUs, and of performing training and evaluation. The <code>IPUTrainer</code> class works just like the Hugging Face Trainer class, but takes the additional <code>ipu_config</code> argument.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/0b273df36666ceb85763e3210c39d5f6.js"></script>
</div>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/c94c59a6aed6165b0519af24e168139b.js"></script>
</div>
<h2>Running the training</h2>
<p>To accelerate training we will load the last checkpoint if it exists.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/6033ce6f471af9f2136cf45002db97ab.js"></script>
</div>
<p>Now we are ready to train.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/e203649cd06809ecf52821efbbdac7f6.js"></script>
</div>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/cc5e9367cfd1f8c295d016c35b552620.js"></script>
</div>
<h2>Plotting convergence</h2>
<p>Now that we have completed the training, we can format and plot the trainer output to evaluate the training behaviour.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/05fbef22532f22c64572e9a62d9f219b.js"></script>
</div>
<p>We plot the training loss and the learning rate.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/3f124ca1d9362c51c6ebd7573019133d.js"></script>
</div>
<p><img src="https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=1024&name=vit%20output.png" alt="vit output" loading="lazy" style="width: 1024px; margin-left: auto; margin-right: auto; display: block;" width="1024" srcset="https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=512&name=vit%20output.png 512w, https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=1024&name=vit%20output.png 1024w, https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=1536&name=vit%20output.png 1536w, https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=2048&name=vit%20output.png 2048w, https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=2560&name=vit%20output.png 2560w, https://www.graphcore.ai/hs-fs/hubfs/vit%20output.png?width=3072&name=vit%20output.png 3072w" sizes="(max-width: 1024px) 100vw, 1024px">The loss curve shows a rapid reduction in the loss at the start of training before stabilising around 0.1, showing that the model is learning. The learning rate increases through the warm-up of 25% of the training period, before following a cosine decay.</p>
<h2>Running the evaluation</h2>
<p>Now that we have trained the model, we can evaluate its ability to predict the labels of unseen data using the validation dataset.</p>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/bd946bc17558c3045662262da31890b3.js"></script>
</div>
<div style="font-size: 14px; line-height: 1.3;">
<script src="https://gist.github.com/nickmaxfield/562ceec321a9f4ac16483c11cb3694c2.js"></script>
</div>
<p>The metrics show the validation AUC_ROC score the tutorial achieves after 3 epochs.</p>
<p>There are several directions to explore to improve the accuracy of the model including longer training. The validation performance might also be improved through changing optimisers, learning rate, learning rate schedule, loss scaling, or using auto-loss scaling.</p>
<h2>Try Hugging Face Optimum on IPUs for free</h2>
<p>In this post, we have introduced ViT models and have provided a tutorial for training a Hugging Face Optimum model on the IPU using a local dataset.</p>
<p>The entire process outlined above can now be run end-to-end within minutes for free, thanks to Graphcore’s <a href="/posts/paperspace-graphcore-partner-free-ipus-developers" rel="noopener" target="_blank" style="font-weight: bold;">new partnership with Paperspace</a>. Launching today, the service will provide access to a selection of Hugging Face Optimum models powered by Graphcore IPUs within Gradient—Paperspace’s web-based Jupyter notebooks.</p>
<p><a href="https://console.paperspace.com/github/gradient-ai/Graphcore-HuggingFace?machine=Free-IPU-POD16&container=graphcore%2Fpytorch-jupyter%3A2.6.0-ubuntu-20.04-20220804&file=%2Fget-started%2Fwalkthrough.ipynb" rel="noopener" target="_blank"><img src="https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=200&name=gradient-badge-gradient-05-d-05.png" alt="run on Gradient" loading="lazy" style="width: 200px; float: left;" width="200" srcset="https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=100&name=gradient-badge-gradient-05-d-05.png 100w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=200&name=gradient-badge-gradient-05-d-05.png 200w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=300&name=gradient-badge-gradient-05-d-05.png 300w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=400&name=gradient-badge-gradient-05-d-05.png 400w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=500&name=gradient-badge-gradient-05-d-05.png 500w, https://www.graphcore.ai/hs-fs/hubfs/gradient-badge-gradient-05-d-05.png?width=600&name=gradient-badge-gradient-05-d-05.png 600w" sizes="(max-width: 200px) 100vw, 200px"></a></p>
<p> </p>
<p> </p>
<p>If you’re interested in trying Hugging Face Optimum with IPUs on Paperspace Gradient including ViT, BERT, RoBERTa and more, you can <a href="https://www.paperspace.com/graphcore" rel="noopener" target="_blank" style="font-weight: bold;">sign up here</a> and find a getting started guide <a href="/posts/getting-started-with-ipus-on-paperspace" rel="noopener" target="_blank" style="font-weight: bold;">here</a>.</p>
<h2>More Resources for Hugging Face Optimum on IPUs</h2>
<ul>
<li><a href="https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/vit_model_training" rel="noopener" target="_blank">ViT Optimum tutorial code on Graphcore GitHub</a></li>
<li><a href="https://huggingface.co/Graphcore" rel="noopener" target="_blank">Graphcore Hugging Face Models & Datasets</a></li>
<li><a href="https://github.com/huggingface/optimum-graphcore" rel="noopener" target="_blank">Optimum Graphcore on GitHub</a></li>
</ul>
<p>This deep dive would not have been possible without extensive support, guidance, and insights from Eva Woodbridge, James Briggs, Jinchen Ge, Alexandre Payot, Thorin Farnsworth, and all others contributing from Graphcore, as well as Jeff Boudier, Julien Simon, and Michael Benayoun from Hugging Face.</p></span>
</div>
</article>
| huggingface/blog/blob/main/vision-transformers.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Multiple Choice
## Fine-tuning on SWAG with the Trainer
`run_swag` allows you to fine-tune any model from our [hub](https://huggingface.co/models) (as long as its architecture as a `ForMultipleChoice` version in the library) on the SWAG dataset or your own csv/jsonlines files as long as they are structured the same way. To make it works on another dataset, you will need to tweak the `preprocess_function` inside the script.
```bash
python examples/multiple-choice/run_swag.py \
--model_name_or_path roberta-base \
--do_train \
--do_eval \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/swag_base \
--per_device_eval_batch_size=16 \
--per_device_train_batch_size=16 \
--overwrite_output
```
Training with the defined hyper-parameters yields the following results:
```
***** Eval results *****
eval_acc = 0.8338998300509847
eval_loss = 0.44457291918821606
```
## With Accelerate
Based on the script [run_swag_no_trainer.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/multiple-choice/run_swag_no_trainer.py).
Like `run_swag.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) (as long as its architecture as a `ForMultipleChoice` version in the library) on
the SWAG dataset or your own data in a csv or a JSON file. The main difference is that this
script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
It offers less options than the script with `Trainer` (but you can easily change the options for the optimizer
or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then
```bash
export DATASET_NAME=swag
python run_swag_no_trainer.py \
--model_name_or_path bert-base-cased \
--dataset_name $DATASET_NAME \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$DATASET_NAME/
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
export DATASET_NAME=swag
accelerate launch run_swag_no_trainer.py \
--model_name_or_path bert-base-cased \
--dataset_name $DATASET_NAME \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$DATASET_NAME/
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| huggingface/transformers/blob/main/examples/pytorch/multiple-choice/README.md |
Gradio Demo: variable_outputs
```
!pip install -q gradio
```
```
import gradio as gr
max_textboxes = 10
def variable_outputs(k):
k = int(k)
return [gr.Textbox(visible=True)]*k + [gr.Textbox(visible=False)]*(max_textboxes-k)
with gr.Blocks() as demo:
s = gr.Slider(1, max_textboxes, value=max_textboxes, step=1, label="How many textboxes to show:")
textboxes = []
for i in range(max_textboxes):
t = gr.Textbox(f"Textbox {i}")
textboxes.append(t)
s.change(variable_outputs, s, textboxes)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/variable_outputs/run.ipynb |
Downloading datasets
## Integrated libraries
If a dataset on the Hub is tied to a [supported library](./datasets-libraries), loading the dataset can be done in just a few lines. For information on accessing the dataset, you can click on the "Use in dataset library" button on the dataset page to see how to do so. For example, [`samsum`](https://huggingface.co/datasets/samsum?library=true) shows how to do so with 🤗 Datasets below.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-usage.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-usage-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-usage-modal.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-usage-modal-dark.png"/>
</div>
## Using the Hugging Face Client Library
You can use the [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub) library to create, delete, update and retrieve information from repos. You can also download files from repos or integrate them into your library! For example, you can quickly load a CSV dataset with a few lines using Pandas.
```py
from huggingface_hub import hf_hub_download
import pandas as pd
REPO_ID = "YOUR_REPO_ID"
FILENAME = "data.csv"
dataset = pd.read_csv(
hf_hub_download(repo_id=REPO_ID, filename=FILENAME, repo_type="dataset")
)
```
## Using Git
Since all datasets on the Hub are Git repositories, you can clone the datasets locally by running:
```bash
git lfs install
git clone [email protected]:datasets/<dataset ID> # example: git clone [email protected]:datasets/allenai/c4
```
If you have write-access to the particular dataset repo, you'll also have the ability to commit and push revisions to the dataset.
Add your SSH public key to [your user settings](https://huggingface.co/settings/keys) to push changes and/or access private repos.
| huggingface/hub-docs/blob/main/docs/hub/datasets-downloading.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Templates for Chat Models
## Introduction
An increasingly common use case for LLMs is **chat**. In a chat context, rather than continuing a single string
of text (as is the case with a standard language model), the model instead continues a conversation that consists
of one or more **messages**, each of which includes a **role**, like "user" or "assistant", as well as message text.
Much like tokenization, different models expect very different input formats for chat. This is the reason we added
**chat templates** as a feature. Chat templates are part of the tokenizer. They specify how to convert conversations,
represented as lists of messages, into a single tokenizable string in the format that the model expects.
Let's make this concrete with a quick example using the `BlenderBot` model. BlenderBot has an extremely simple default
template, which mostly just adds whitespace between rounds of dialogue:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
```
Notice how the entire chat is condensed into a single string. If we use `tokenize=True`, which is the default setting,
that string will also be tokenized for us. To see a more complex template in action, though, let's use the
`mistralai/Mistral-7B-Instruct-v0.1` model.
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
"<s>[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today?</s> [INST] I'd like to show off how chat templating works! [/INST]"
```
Note that this time, the tokenizer has added the control tokens [INST] and [/INST] to indicate the start and end of
user messages (but not assistant messages!). Mistral-instruct was trained with these tokens, but BlenderBot was not.
## How do I use chat templates?
As you can see in the example above, chat templates are easy to use. Simply build a list of messages, with `role`
and `content` keys, and then pass it to the [`~PreTrainedTokenizer.apply_chat_template`] method. Once you do that,
you'll get output that's ready to go! When using chat templates as input for model generation, it's also a good idea
to use `add_generation_prompt=True` to add a [generation prompt](#what-are-generation-prompts).
Here's an example of preparing input for `model.generate()`, using the `Zephyr` assistant model:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
```
This will yield a string in the input format that Zephyr expects.
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
```
Now that our input is formatted correctly for Zephyr, we can use the model to generate a response to the user's question:
```python
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
```
This will yield:
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
```
Arr, 'twas easy after all!
## Is there an automated pipeline for chat?
Yes, there is: [`ConversationalPipeline`]. This pipeline is designed to make it easy to use chat models. Let's try
the `Zephyr` example again, but this time using the pipeline:
```python
from transformers import pipeline
pipe = pipeline("conversational", "HuggingFaceH4/zephyr-7b-beta")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
print(pipe(messages))
```
```text
Conversation id: 76d886a0-74bd-454e-9804-0467041a63dc
system: You are a friendly chatbot who always responds in the style of a pirate
user: How many helicopters can a human eat in one sitting?
assistant: Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
```
[`ConversationalPipeline`] will take care of all the details of tokenization and calling `apply_chat_template` for you -
once the model has a chat template, all you need to do is initialize the pipeline and pass it the list of messages!
## What are "generation prompts"?
You may have noticed that the `apply_chat_template` method has an `add_generation_prompt` argument. This argument tells
the template to add tokens that indicate the start of a bot response. For example, consider the following chat:
```python
messages = [
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "Can I ask a question?"}
]
```
Here's what this will look like without a generation prompt, using the ChatML template we saw in the Zephyr example:
```python
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
"""
```
And here's what it looks like **with** a generation prompt:
```python
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
"""
```
Note that this time, we've added the tokens that indicate the start of a bot response. This ensures that when the model
generates text it will write a bot response instead of doing something unexpected, like continuing the user's
message. Remember, chat models are still just language models - they're trained to continue text, and chat is just a
special kind of text to them! You need to guide them with the appropriate control tokens so they know what they're
supposed to be doing.
Not all models require generation prompts. Some models, like BlenderBot and LLaMA, don't have any
special tokens before bot responses. In these cases, the `add_generation_prompt` argument will have no effect. The exact
effect that `add_generation_prompt` has will depend on the template being used.
## Can I use chat templates in training?
Yes! We recommend that you apply the chat template as a preprocessing step for your dataset. After this, you
can simply continue like any other language model training task. When training, you should usually set
`add_generation_prompt=False`, because the added tokens to prompt an assistant response will not be helpful during
training. Let's see an example:
```python
from transformers import AutoTokenizer
from datasets import Dataset
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
chat1 = [
{"role": "user", "content": "Which is bigger, the moon or the sun?"},
{"role": "assistant", "content": "The sun."}
]
chat2 = [
{"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
{"role": "assistant", "content": "A bacterium."}
]
dataset = Dataset.from_dict({"chat": [chat1, chat2]})
dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
print(dataset['formatted_chat'][0])
```
And we get:
```text
<|user|>
Which is bigger, the moon or the sun?</s>
<|assistant|>
The sun.</s>
```
From here, just continue training like you would with a standard language modelling task, using the `formatted_chat` column.
## Advanced: How do chat templates work?
The chat template for a model is stored on the `tokenizer.chat_template` attribute. If no chat template is set, the
default template for that model class is used instead. Let's take a look at the template for `BlenderBot`:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> tokenizer.default_chat_template
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
```
That's kind of intimidating. Let's add some newlines and indentation to make it more readable. Note that the first
newline after each block as well as any preceding whitespace before a block are ignored by default, using the
Jinja `trim_blocks` and `lstrip_blocks` flags. However, be cautious - although leading whitespace on each
line is stripped, spaces between blocks on the same line are not. We strongly recommend checking that your template
isn't printing extra spaces where it shouldn't be!
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ ' ' }}
{% endif %}
{{ message['content'] }}
{% if not loop.last %}
{{ ' ' }}
{% endif %}
{% endfor %}
{{ eos_token }}
```
If you've never seen one of these before, this is a [Jinja template](https://jinja.palletsprojects.com/en/3.1.x/templates/).
Jinja is a templating language that allows you to write simple code that generates text. In many ways, the code and
syntax resembles Python. In pure Python, this template would look something like this:
```python
for idx, message in enumerate(messages):
if message['role'] == 'user':
print(' ')
print(message['content'])
if not idx == len(messages) - 1: # Check for the last message in the conversation
print(' ')
print(eos_token)
```
Effectively, the template does three things:
1. For each message, if the message is a user message, add a blank space before it, otherwise print nothing.
2. Add the message content
3. If the message is not the last message, add two spaces after it. After the final message, print the EOS token.
This is a pretty simple template - it doesn't add any control tokens, and it doesn't support "system" messages, which
are a common way to give the model directives about how it should behave in the subsequent conversation.
But Jinja gives you a lot of flexibility to do those things! Let's see a Jinja template that can format inputs
similarly to the way LLaMA formats them (note that the real LLaMA template includes handling for default system
messages and slightly different system message handling in general - don't use this one in your actual code!)
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ ' ' + message['content'] + ' ' + eos_token }}
{% endif %}
{% endfor %}
```
Hopefully if you stare at this for a little bit you can see what this template is doing - it adds specific tokens based
on the "role" of each message, which represents who sent it. User, assistant and system messages are clearly
distinguishable to the model because of the tokens they're wrapped in.
## Advanced: Adding and editing chat templates
### How do I create a chat template?
Simple, just write a jinja template and set `tokenizer.chat_template`. You may find it easier to start with an
existing template from another model and simply edit it for your needs! For example, we could take the LLaMA template
above and add "[ASST]" and "[/ASST]" to assistant messages:
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'].strip() + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
{% endif %}
{% endfor %}
```
Now, simply set the `tokenizer.chat_template` attribute. Next time you use [`~PreTrainedTokenizer.apply_chat_template`], it will
use your new template! This attribute will be saved in the `tokenizer_config.json` file, so you can use
[`~utils.PushToHubMixin.push_to_hub`] to upload your new template to the Hub and make sure everyone's using the right
template for your model!
```python
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
```
The method [`~PreTrainedTokenizer.apply_chat_template`] which uses your chat template is called by the [`ConversationalPipeline`] class, so
once you set the correct chat template, your model will automatically become compatible with [`ConversationalPipeline`].
### What are "default" templates?
Before the introduction of chat templates, chat handling was hardcoded at the model class level. For backwards
compatibility, we have retained this class-specific handling as default templates, also set at the class level. If a
model does not have a chat template set, but there is a default template for its model class, the `ConversationalPipeline`
class and methods like `apply_chat_template` will use the class template instead. You can find out what the default
template for your tokenizer is by checking the `tokenizer.default_chat_template` attribute.
This is something we do purely for backward compatibility reasons, to avoid breaking any existing workflows. Even when
the class template is appropriate for your model, we strongly recommend overriding the default template by
setting the `chat_template` attribute explicitly to make it clear to users that your model has been correctly configured
for chat, and to future-proof in case the default templates are ever altered or deprecated.
### What template should I use?
When setting the template for a model that's already been trained for chat, you should ensure that the template
exactly matches the message formatting that the model saw during training, or else you will probably experience
performance degradation. This is true even if you're training the model further - you will probably get the best
performance if you keep the chat tokens constant. This is very analogous to tokenization - you generally get the
best performance for inference or fine-tuning when you precisely match the tokenization used during training.
If you're training a model from scratch, or fine-tuning a base language model for chat, on the other hand,
you have a lot of freedom to choose an appropriate template! LLMs are smart enough to learn to handle lots of different
input formats. Our default template for models that don't have a class-specific template follows the
[ChatML format](https://github.com/openai/openai-python/blob/main/chatml.md), and this is a good, flexible choice for many use-cases. It looks like this:
```
{% for message in messages %}
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
```
If you like this one, here it is in one-liner form, ready to copy into your code. The one-liner also includes
handy support for [generation prompts](#what-are-generation-prompts), but note that it doesn't add BOS or EOS tokens!
If your model expects those, they won't be added automatically by `apply_chat_template` - in other words, the
text will be tokenized with `add_special_tokens=False`. This is to avoid potential conflicts between the template and
the `add_special_tokens` logic. If your model expects special tokens, make sure to add them to the template!
```
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
```
This template wraps each message in `<|im_start|>` and `<|im_end|>` tokens, and simply writes the role as a string, which
allows for flexibility in the roles you train with. The output looks like this:
```text
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm doing great!<|im_end|>
```
The "user", "system" and "assistant" roles are the standard for chat, and we recommend using them when it makes sense,
particularly if you want your model to operate well with [`ConversationalPipeline`]. However, you are not limited
to these roles - templating is extremely flexible, and any string can be a role.
### I want to add some chat templates! How should I get started?
If you have any chat models, you should set their `tokenizer.chat_template` attribute and test it using
[`~PreTrainedTokenizer.apply_chat_template`], then push the updated tokenizer to the Hub. This applies even if you're
not the model owner - if you're using a model with an empty chat template, or one that's still using the default class
template, please open a [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to the model repository so that this attribute can be set properly!
Once the attribute is set, that's it, you're done! `tokenizer.apply_chat_template` will now work correctly for that
model, which means it is also automatically supported in places like `ConversationalPipeline`!
By ensuring that models have this attribute, we can make sure that the whole community gets to use the full power of
open-source models. Formatting mismatches have been haunting the field and silently harming performance for too long -
it's time to put an end to them!
## Advanced: Template writing tips
If you're unfamiliar with Jinja, we generally find that the easiest way to write a chat template is to first
write a short Python script that formats messages the way you want, and then convert that script into a template.
Remember that the template handler will receive the conversation history as a variable called `messages`. Each
message is a dictionary with two keys, `role` and `content`. You will be able to access `messages` in your template
just like you can in Python, which means you can loop over it with `{% for message in messages %}` or access
individual messages with, for example, `{{ messages[0] }}`.
You can also use the following tips to convert your code to Jinja:
### For loops
For loops in Jinja look like this:
```
{% for message in messages %}
{{ message['content'] }}
{% endfor %}
```
Note that whatever's inside the {{ expression block }} will be printed to the output. You can use operators like
`+` to combine strings inside expression blocks.
### If statements
If statements in Jinja look like this:
```
{% if message['role'] == 'user' %}
{{ message['content'] }}
{% endif %}
```
Note how where Python uses whitespace to mark the beginnings and ends of `for` and `if` blocks, Jinja requires you
to explicitly end them with `{% endfor %}` and `{% endif %}`.
### Special variables
Inside your template, you will have access to the list of `messages`, but you can also access several other special
variables. These include special tokens like `bos_token` and `eos_token`, as well as the `add_generation_prompt`
variable that we discussed above. You can also use the `loop` variable to access information about the current loop
iteration, for example using `{% if loop.last %}` to check if the current message is the last message in the
conversation. Here's an example that puts these ideas together to add a generation prompt at the end of the
conversation if add_generation_prompt is `True`:
```
{% if loop.last and add_generation_prompt %}
{{ bos_token + 'Assistant:\n' }}
{% endif %}
```
### Notes on whitespace
As much as possible, we've tried to get Jinja to ignore whitespace outside of {{ expressions }}. However, be aware
that Jinja is a general-purpose templating engine, and it may treat whitespace between blocks on the same line
as significant and print it to the output. We **strongly** recommend checking that your template isn't printing extra
spaces where it shouldn't be before you upload it! | huggingface/transformers/blob/main/docs/source/en/chat_templating.md |
``python
import argparse
import os
import torch
from torch.optim import AdamW
from torch.utils.data import DataLoader
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
PeftType,
PrefixTuningConfig,
PromptEncoderConfig,
PromptTuningConfig,
)
import evaluate
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from tqdm import tqdm
```
```python
batch_size = 32
model_name_or_path = "roberta-large"
task = "mrpc"
peft_type = PeftType.PROMPT_TUNING
device = "cuda"
num_epochs = 20
```
```python
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
lr = 1e-3
```
```python
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
datasets = load_dataset("glue", task)
metric = evaluate.load("glue", task)
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
return tokenizer.pad(examples, padding="longest", return_tensors="pt")
# Instantiate dataloaders.
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size
)
```
```python
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
```
```python
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0.06 * (len(train_dataloader) * num_epochs),
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
model.to(device)
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(tqdm(train_dataloader)):
batch.to(device)
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(f"epoch {epoch}:", eval_metric)
```
## Share adapters on the 🤗 Hub
```python
model.push_to_hub("smangrul/roberta-large-peft-prompt-tuning", use_auth_token=True)
```
## Load adapters from the Hub
You can also directly load adapters from the Hub using the commands below:
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "smangrul/roberta-large-peft-prompt-tuning"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
inference_model = PeftModel.from_pretrained(inference_model, peft_model_id)
inference_model.to(device)
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(device)
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric)
```
| huggingface/peft/blob/main/examples/sequence_classification/Prompt_Tuning.ipynb |
--
title: "Nyströmformer: Approximating self-attention in linear time and memory via the Nyström method"
thumbnail: /blog/assets/86_nystromformer/thumbnail.png
authors:
- user: asi
guest: true
---
# Nyströmformer: Approximating self-attention in linear time and memory via the Nyström method
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## Introduction
Transformers have exhibited remarkable performance on various Natural Language Processing and Computer Vision tasks. Their success can be attributed to the self-attention mechanism, which captures the pairwise interactions between all the tokens in an input. However, the standard self-attention mechanism has a time and memory complexity of \\(O(n^2)\\) (where \\(n\\) is the length of the input sequence), making it expensive to train on long input sequences.
The [Nyströmformer](https://arxiv.org/abs/2102.03902) is one of many efficient Transformer models that approximates standard self-attention with \\(O(n)\\) complexity. Nyströmformer exhibits competitive performance on various downstream NLP and CV tasks while improving upon the efficiency of standard self-attention. The aim of this blog post is to give readers an overview of the Nyström method and how it can be adapted to approximate self-attention.
## Nyström method for matrix approximation
At the heart of Nyströmformer is the Nyström method for matrix approximation. It allows us to approximate a matrix by sampling some of its rows and columns. Let's consider a matrix \\(P^{n \times n}\\), which is expensive to compute in its entirety. So, instead, we approximate it using the Nyström method. We start by sampling \\(m\\) rows and columns from \\(P\\). We can then arrange the sampled rows and columns as follows:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Representing P as a block matrix" src="assets/86_nystromformer/p_block.png"></medium-zoom>
<figcaption>Representing P as a block matrix</figcaption>
</figure>
We now have four submatrices: \\(A_P, B_P, F_P,\\) and \\(C_P\\), with sizes \\(m \times m, m \times (n - m), (n - m) \times m\\) and
\\((n - m) \times (n - m)\\) respectively. The \\(m\\) sampled columns are contained in \\(A_P\\) and \\(F_P\\), whereas the \\(m\\) sampled rows are contained in \\(A_P\\) and \\(B_P\\). So, the entries of \\(A_P, B_P,\\) and \\(F_P\\) are known to us, and we will estimate \\(C_P\\). According to the Nyström method, \\(C_P\\) is given by:
$$C_P = F_P A_P^+ B_P$$
Here, \\(+\\) denotes the Moore-Penrose inverse (or pseudoinverse).
Thus, the Nyström approximation of \\(P, \hat{P}\\) can be written as:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Nyström approximation of P" src="assets/86_nystromformer/p_hat.png"></medium-zoom>
<figcaption>Nyström approximation of P</figcaption>
</figure>
As shown in the second line, \\(\hat{P}\\) can be expressed as a product of three matrices. The reason for doing so will become clear later.
## Can we approximate self-attention with the Nyström method?
Our goal is to ultimately approximate the softmax matrix in standard self attention: S = softmax \\( \frac{QK^T}{\sqrt{d}} \\)
Here, \\(Q\\) and \\(K\\) denote the queries and keys respectively. Following the procedure discussed above, we would sample \\(m\\) rows and columns from \\(S\\), form four submatrices, and obtain \\(\hat{S}\\):
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Nyström approximation of S" src="assets/86_nystromformer/s_hat.png"></medium-zoom>
<figcaption>Nyström approximation of S</figcaption>
</figure>
But, what does it mean to sample a column from \\(S\\)? It means we select one element from each row. Recall how S is calculated: the final operation is a row-wise softmax. To find a single entry in a row, we must access all other entries (for the denominator in softmax). So, sampling one column requires us to know all other columns in the matrix. Therefore, we cannot directly apply the Nyström method to approximate the softmax matrix.
## How can we adapt the Nyström method to approximate self-attention?
Instead of sampling from \\(S\\), the authors propose to sample landmarks (or Nyström points) from queries and keys. We denote the query landmarks and key landmarks as \\(\tilde{Q}\\) and \\(\tilde{K}\\) respectively. \\(\tilde{Q}\\) and \\(\tilde{K}\\) can be used to construct three matrices corresponding to those in the Nyström approximation of \\(S\\). We define the following matrices:
$$\tilde{F} = softmax(\frac{Q\tilde{K}^T}{\sqrt{d}}) \hspace{40pt} \tilde{A} = softmax(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d}})^+ \hspace{40pt} \tilde{B} = softmax(\frac{\tilde{Q}K^T}{\sqrt{d}})$$
The sizes of \\(\tilde{F}\\), \\(\tilde{A}\\), and \\(\tilde{B}) are \\(n \times m, m \times m,\\) and \\(m \times n\\) respectively.
We replace the three matrices in the Nyström approximation of \\(S\\) with the new matrices we have defined to obtain an alternative Nyström approximation:
$$\begin{aligned}\hat{S} &= \tilde{F} \tilde{A} \tilde{B} \\ &= softmax(\frac{Q\tilde{K}^T}{\sqrt{d}}) softmax(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d}})^+ softmax(\frac{\tilde{Q}K^T}{\sqrt{d}}) \end{aligned}$$
This is the Nyström approximation of the softmax matrix in the self-attention mechanism. We multiply this matrix with the values ( \\(V\\)) to obtain a linear approximation of self-attention. Note that we never calculated the product \\(QK^T\\), avoiding the \\(O(n^2)\\) complexity.
## How do we select landmarks?
Instead of sampling \\(m\\) rows from \\(Q\\) and \\(K\\), the authors propose to construct \\(\tilde{Q}\\) and \\(\tilde{K}\\)
using segment means. In this procedure, \\(n\\) tokens are grouped into \\(m\\) segments, and the mean of each segment is computed. Ideally, \\(m\\) is much smaller than \\(n\\). According to experiments from the paper, selecting just \\(32\\) or \\(64\\) landmarks produces competetive performance compared to standard self-attention and other efficient attention mechanisms, even for long sequences lengths ( \\(n=4096\\) or \\(8192\\)).
The overall algorithm is summarised by the following figure from the paper:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Efficient self-attention with the Nyström method" src="assets/86_nystromformer/paper_figure.png"></medium-zoom>
<figcaption>Efficient self-attention with the Nyström method</figcaption>
</figure>
The three orange matrices above correspond to the three matrices we constructed using the key and query landmarks. Also, notice that there is a DConv box. This corresponds to a skip connection added to the values using a 1D depthwise convolution.
## How is Nyströmformer implemented?
The original implementation of Nyströmformer can be found [here](https://github.com/mlpen/Nystromformer) and the HuggingFace implementation can be found [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/nystromformer/modeling_nystromformer.py). Let's take a look at a few lines of code (with some comments added) from the HuggingFace implementation. Note that some details such as normalization, attention masking, and depthwise convolution are avoided for simplicity.
```python
key_layer = self.transpose_for_scores(self.key(hidden_states)) # K
value_layer = self.transpose_for_scores(self.value(hidden_states)) # V
query_layer = self.transpose_for_scores(mixed_query_layer) # Q
q_landmarks = query_layer.reshape(
-1,
self.num_attention_heads,
self.num_landmarks,
self.seq_len // self.num_landmarks,
self.attention_head_size,
).mean(dim=-2) # \tilde{Q}
k_landmarks = key_layer.reshape(
-1,
self.num_attention_heads,
self.num_landmarks,
self.seq_len // self.num_landmarks,
self.attention_head_size,
).mean(dim=-2) # \tilde{K}
kernel_1 = torch.nn.functional.softmax(torch.matmul(query_layer, k_landmarks.transpose(-1, -2)), dim=-1) # \tilde{F}
kernel_2 = torch.nn.functional.softmax(torch.matmul(q_landmarks, k_landmarks.transpose(-1, -2)), dim=-1) # \tilde{A} before pseudo-inverse
attention_scores = torch.matmul(q_landmarks, key_layer.transpose(-1, -2)) # \tilde{B} before softmax
kernel_3 = nn.functional.softmax(attention_scores, dim=-1) # \tilde{B}
attention_probs = torch.matmul(kernel_1, self.iterative_inv(kernel_2)) # \tilde{F} * \tilde{A}
new_value_layer = torch.matmul(kernel_3, value_layer) # \tilde{B} * V
context_layer = torch.matmul(attention_probs, new_value_layer) # \tilde{F} * \tilde{A} * \tilde{B} * V
```
## Using Nyströmformer with HuggingFace
Nyströmformer for Masked Language Modeling (MLM) is available on HuggingFace. Currently, there are 4 checkpoints, corresponding to various sequence lengths: [`nystromformer-512`](https://huggingface.co/uw-madison/nystromformer-512), [`nystromformer-1024`](https://huggingface.co/uw-madison/nystromformer-1024), [`nystromformer-2048`](https://huggingface.co/uw-madison/nystromformer-2048), and [`nystromformer-4096`](https://huggingface.co/uw-madison/nystromformer-4096). The number of landmarks, \\(m\\), can be controlled using the `num_landmarks` parameter in the [`NystromformerConfig`](https://huggingface.co/docs/transformers/v4.18.0/en/model_doc/nystromformer#transformers.NystromformerConfig). Let's take a look at a minimal example of Nyströmformer for MLM:
```python
from transformers import AutoTokenizer, NystromformerForMaskedLM
import torch
tokenizer = AutoTokenizer.from_pretrained("uw-madison/nystromformer-512")
model = NystromformerForMaskedLM.from_pretrained("uw-madison/nystromformer-512")
inputs = tokenizer("Paris is the [MASK] of France.", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# retrieve index of [MASK]
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
tokenizer.decode(predicted_token_id)
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
capital
</div>
Alternatively, we can use the [pipeline API](https://huggingface.co/docs/transformers/main_classes/pipelines) (which handles all the complexity for us):
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='uw-madison/nystromformer-512')
unmasker("Paris is the [MASK] of France.")
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
[{'score': 0.829957902431488,
'token': 1030,
'token_str': 'capital',
'sequence': 'paris is the capital of france.'},
{'score': 0.022157637402415276,
'token': 16081,
'token_str': 'birthplace',
'sequence': 'paris is the birthplace of france.'},
{'score': 0.01904447190463543,
'token': 197,
'token_str': 'name',
'sequence': 'paris is the name of france.'},
{'score': 0.017583081498742104,
'token': 1107,
'token_str': 'kingdom',
'sequence': 'paris is the kingdom of france.'},
{'score': 0.005948934704065323,
'token': 148,
'token_str': 'city',
'sequence': 'paris is the city of france.'}]
</div>
## Conclusion
Nyströmformer offers an efficient approximation to the standard self-attention mechanism, while outperforming other linear self-attention schemes. In this blog post, we went over a high-level overview of the Nyström method and how it can be leveraged for self-attention. Readers interested in deploying or fine-tuning Nyströmformer for downstream tasks can find the HuggingFace documentation [here](https://huggingface.co/docs/transformers/model_doc/nystromformer).
| huggingface/blog/blob/main/nystromformer.md |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.