
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# How to contribute to Diffusers 🧨
We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out, and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕. <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=Discord&logoColor=white"></a>
Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
## Overview
You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
the core library.
In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose).
* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues).
* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples).
* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
As said before, **all contributions are valuable to the community**.
In the following, we will explain each contribution a bit more in detail.
For all contributions 4-9, you will need to open a PR. It is explained in detail how to do so in [Opening a pull request](#how-to-open-a-pr).
### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
- Reports of training or inference experiments in an attempt to share knowledge
- Presentation of personal projects
- Questions to non-official training examples
- Project proposals
- General feedback
- Paper summaries
- Asking for help on personal projects that build on top of the Diffusers library
- General questions
- Ethical questions regarding diffusion models
- ...
Every question that is asked on the forum or on Discord actively encourages the community to publicly
share knowledge and might very well help a beginner in the future that has the same question you're
having. Please do pose any questions you might have.
In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
**Please** keep in mind that the more effort you put into asking or answering a question, the higher
the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accessible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
**NOTE about channels**:
[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
In addition, questions and answers posted in the forum can easily be linked to.
In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
While it will most likely take less time for you to get an answer to your question on Discord, your
question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
### 2. Opening new issues on the GitHub issues tab
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
the problems they encounter. So thank you for reporting an issue.
Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
**Please consider the following guidelines when opening a new issue**:
- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
- Please never report a new issue on another (related) issue. If another issue is highly related, please
open a new issue nevertheless and link to the related issue.
- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
New issues usually include the following.
#### 2.1. Reproducible, minimal bug reports
A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
This means in more detail:
- Narrow the bug down as much as you can, **do not just dump your whole code file**.
- Format your code.
- Do not include any external libraries except for Diffusers depending on them.
- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&projects=&template=bug-report.yml).
#### 2.2. Feature requests
A world-class feature request addresses the following points:
1. Motivation first:
* Is it related to a problem/frustration with the library? If so, please explain
why. Providing a code snippet that demonstrates the problem is best.
* Is it related to something you would need for a project? We'd love to hear
about it!
* Is it something you worked on and think could benefit the community?
Awesome! Tell us what problem it solved for you.
2. Write a *full paragraph* describing the feature;
3. Provide a **code snippet** that demonstrates its future use;
4. In case this is related to a paper, please attach a link;
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
#### 2.3 Feedback
Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
#### 2.4 Technical questions
Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
why this part of the code is difficult to understand.
You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
#### 2.5 Proposal to add a new model, scheduler, or pipeline
If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
* Link to any of its open-source implementation.
* Link to the model weights if they are available.
If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
### 3. Answering issues on the GitHub issues tab
Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
Some tips to give a high-quality answer to an issue:
- Be as concise and minimal as possible.
- Stay on topic. An answer to the issue should concern the issue and only the issue.
- Provide links to code, papers, or other sources that prove or encourage your point.
- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
help to the maintainers if you can answer such issues, encouraging the author of the issue to be
more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
If you have verified that the issued bug report is correct and requires a correction in the source code,
please have a look at the next sections.
For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull request](#how-to-open-a-pr) section.
### 4. Fixing a "Good first issue"
*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
explains how a potential solution should look so that it is easier to fix.
If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
### 5. Contribute to the documentation
A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
valuable contribution**.
Contributing to the library can have many forms:
- Correcting spelling or grammatical errors.
- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
- Correct the shape or dimensions of a docstring input or output tensor.
- Clarify documentation that is hard to understand or incorrect.
- Update outdated code examples.
- Translating the documentation to another language.
Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
### 6. Contribute a community pipeline
[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models/overview) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
We support two types of pipelines:
- Official Pipelines
- Community Pipelines
Both official and community pipelines follow the same design and consist of the same type of components.
Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
Officially released diffusion pipelines,
such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
high quality of maintenance, no backward-breaking code changes, and testing.
More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
To add a community pipeline, one should add a <name-of-the-community>.py file to [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and adapt the [examples/community/README.md](https://github.com/huggingface/diffusers/tree/main/examples/community/README.md) to include an example of the new pipeline.
An example can be seen [here](https://github.com/huggingface/diffusers/pull/2400).
Community pipeline PRs are only checked at a superficial level and ideally they should be maintained by their original authors.
Contributing a community pipeline is a great way to understand how Diffusers models and schedulers work. Having contributed a community pipeline is usually the first stepping stone to contributing an official pipeline to the
core package.
### 7. Contribute to training examples
Diffusers examples are a collection of training scripts that reside in [examples](https://github.com/huggingface/diffusers/tree/main/examples).
We support two types of training examples:
- Official training examples
- Research training examples
Research training examples are located in [examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) whereas official training examples include all folders under [examples](https://github.com/huggingface/diffusers/tree/main/examples) except the `research_projects` and `community` folders.
The official training examples are maintained by the Diffusers' core maintainers whereas the research training examples are maintained by the community.
This is because of the same reasons put forward in [6. Contribute a community pipeline](#6-contribute-a-community-pipeline) for official pipelines vs. community pipelines: It is not feasible for the core maintainers to maintain all possible training methods for diffusion models.
If the Diffusers core maintainers and the community consider a certain training paradigm to be too experimental or not popular enough, the corresponding training code should be put in the `research_projects` folder and maintained by the author.
Both official training and research examples consist of a directory that contains one or more training scripts, a requirements.txt file, and a README.md file. In order for the user to make use of the
training examples, it is required to clone the repository:
```bash
git clone https://github.com/huggingface/diffusers
```
as well as to install all additional dependencies required for training:
```bash
pip install -r /examples/<your-example-folder>/requirements.txt
```
Therefore when adding an example, the `requirements.txt` file shall define all pip dependencies required for your training example so that once all those are installed, the user can run the example's training script. See, for example, the [DreamBooth `requirements.txt` file](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt).
Training examples of the Diffusers library should adhere to the following philosophy:
- All the code necessary to run the examples should be found in a single Python file.
- One should be able to run the example from the command line with `python <your-example>.py --args`.
- Examples should be kept simple and serve as **an example** on how to use Diffusers for training. The purpose of example scripts is **not** to create state-of-the-art diffusion models, but rather to reproduce known training schemes without adding too much custom logic. As a byproduct of this point, our examples also strive to serve as good educational materials.
To contribute an example, it is highly recommended to look at already existing examples such as [dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) to get an idea of how they should look like.
We strongly advise contributors to make use of the [Accelerate library](https://github.com/huggingface/accelerate) as it's tightly integrated
with Diffusers.
Once an example script works, please make sure to add a comprehensive `README.md` that states how to use the example exactly. This README should include:
- An example command on how to run the example script as shown [here e.g.](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch).
- A link to some training results (logs, models, ...) that show what the user can expect as shown [here e.g.](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5).
- If you are adding a non-official/research training example, **please don't forget** to add a sentence that you are maintaining this training example which includes your git handle as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations).
If you are contributing to the official training examples, please also make sure to add a test to [examples/test_examples.py](https://github.com/huggingface/diffusers/blob/main/examples/test_examples.py). This is not necessary for non-official training examples.
### 8. Fixing a "Good second issue"
*Good second issues* are marked by the [Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) label. Good second issues are
usually more complicated to solve than [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
The issue description usually gives less guidance on how to fix the issue and requires
a decent understanding of the library by the interested contributor.
If you are interested in tackling a good second issue, feel free to open a PR to fix it and link the PR to the issue. If you see that a PR has already been opened for this issue but did not get merged, have a look to understand why it wasn't merged and try to open an improved PR.
Good second issues are usually more difficult to get merged compared to good first issues, so don't hesitate to ask for help from the core maintainers. If your PR is almost finished the core maintainers can also jump into your PR and commit to it in order to get it merged.
### 9. Adding pipelines, models, schedulers
Pipelines, models, and schedulers are the most important pieces of the Diffusers library.
They provide easy access to state-of-the-art diffusion technologies and thus allow the community to
build powerful generative AI applications.
By adding a new model, pipeline, or scheduler you might enable a new powerful use case for any of the user interfaces relying on Diffusers which can be of immense value for the whole generative AI ecosystem.
Diffusers has a couple of open feature requests for all three components - feel free to gloss over them
if you don't know yet what specific component you would like to add:
- [Model or pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
- [Scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
Before adding any of the three components, it is strongly recommended that you give the [Philosophy guide](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md) a read to better understand the design of any of the three components. Please be aware that
we cannot merge model, scheduler, or pipeline additions that strongly diverge from our design philosophy
as it will lead to API inconsistencies. If you fundamentally disagree with a design choice, please
open a [Feedback issue](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=) instead so that it can be discussed whether a certain design
pattern/design choice shall be changed everywhere in the library and whether we shall update our design philosophy. Consistency across the library is very important for us.
Please make sure to add links to the original codebase/paper to the PR and ideally also ping the
original author directly on the PR so that they can follow the progress and potentially help with questions.
If you are unsure or stuck in the PR, don't hesitate to leave a message to ask for a first review or help.
## How to write a good issue
**The better your issue is written, the higher the chances that it will be quickly resolved.**
1. Make sure that you've used the correct template for your issue. You can pick between *Bug Report*, *Feature Request*, *Feedback about API Design*, *New model/pipeline/scheduler addition*, *Forum*, or a blank issue. Make sure to pick the correct one when opening [a new issue](https://github.com/huggingface/diffusers/issues/new/choose).
2. **Be precise**: Give your issue a fitting title. Try to formulate your issue description as simple as possible. The more precise you are when submitting an issue, the less time it takes to understand the issue and potentially solve it. Make sure to open an issue for one issue only and not for multiple issues. If you found multiple issues, simply open multiple issues. If your issue is a bug, try to be as precise as possible about what bug it is - you should not just write "Error in diffusers".
3. **Reproducibility**: No reproducible code snippet == no solution. If you encounter a bug, maintainers **have to be able to reproduce** it. Make sure that you include a code snippet that can be copy-pasted into a Python interpreter to reproduce the issue. Make sure that your code snippet works, *i.e.* that there are no missing imports or missing links to images, ... Your issue should contain an error message **and** a code snippet that can be copy-pasted without any changes to reproduce the exact same error message. If your issue is using local model weights or local data that cannot be accessed by the reader, the issue cannot be solved. If you cannot share your data or model, try to make a dummy model or dummy data.
4. **Minimalistic**: Try to help the reader as much as you can to understand the issue as quickly as possible by staying as concise as possible. Remove all code / all information that is irrelevant to the issue. If you have found a bug, try to create the easiest code example you can to demonstrate your issue, do not just dump your whole workflow into the issue as soon as you have found a bug. E.g., if you train a model and get an error at some point during the training, you should first try to understand what part of the training code is responsible for the error and try to reproduce it with a couple of lines. Try to use dummy data instead of full datasets.
5. Add links. If you are referring to a certain naming, method, or model make sure to provide a link so that the reader can better understand what you mean. If you are referring to a specific PR or issue, make sure to link it to your issue. Do not assume that the reader knows what you are talking about. The more links you add to your issue the better.
6. Formatting. Make sure to nicely format your issue by formatting code into Python code syntax, and error messages into normal code syntax. See the [official GitHub formatting docs](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for more information.
7. Think of your issue not as a ticket to be solved, but rather as a beautiful entry to a well-written encyclopedia. Every added issue is a contribution to publicly available knowledge. By adding a nicely written issue you not only make it easier for maintainers to solve your issue, but you are helping the whole community to better understand a certain aspect of the library.
## How to write a good PR
1. Be a chameleon. Understand existing design patterns and syntax and make sure your code additions flow seamlessly into the existing code base. Pull requests that significantly diverge from existing design patterns or user interfaces will not be merged.
2. Be laser focused. A pull request should solve one problem and one problem only. Make sure to not fall into the trap of "also fixing another problem while we're adding it". It is much more difficult to review pull requests that solve multiple, unrelated problems at once.
3. If helpful, try to add a code snippet that displays an example of how your addition can be used.
4. The title of your pull request should be a summary of its contribution.
5. If your pull request addresses an issue, please mention the issue number in
the pull request description to make sure they are linked (and people
consulting the issue know you are working on it);
6. To indicate a work in progress please prefix the title with `[WIP]`. These
are useful to avoid duplicated work, and to differentiate it from PRs ready
to be merged;
7. Try to formulate and format your text as explained in [How to write a good issue](#how-to-write-a-good-issue).
8. Make sure existing tests pass;
9. Add high-coverage tests. No quality testing = no merge.
- If you are adding new `@slow` tests, make sure they pass using
`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
CircleCI does not run the slow tests, but GitHub Actions does every night!
10. All public methods must have informative docstrings that work nicely with markdown. See [`pipeline_latent_diffusion.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py) for an example.
11. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
[`hf-internal-testing`](https://huggingface.co/hf-internal-testing) or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images) to place these files.
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## How to open a PR
Before writing code, we strongly advise you to search through the existing PRs or
issues to make sure that nobody is already working on the same thing. If you are
unsure, it is always a good idea to open an issue to get some feedback.
You will need basic `git` proficiency to be able to contribute to
🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
Git](https://git-scm.com/book/en/v2) is a very good reference.
Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L265)):
1. Fork the [repository](https://github.com/huggingface/diffusers) by
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
$ git clone [email protected]:<your GitHub handle>/diffusers.git
$ cd diffusers
$ git remote add upstream https://github.com/huggingface/diffusers.git
```
3. Create a new branch to hold your development changes:
```bash
$ git checkout -b a-descriptive-name-for-my-changes
```
**Do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
$ pip install -e ".[dev]"
```
If you have already cloned the repo, you might need to `git pull` to get the most recent changes in the
library.
5. Develop the features on your branch.
As you work on the features, you should make sure that the test suite
passes. You should run the tests impacted by your changes like this:
```bash
$ pytest tests/<TEST_TO_RUN>.py
```
Before you run the tests, please make sure you install the dependencies required for testing. You can do so
with this command:
```bash
$ pip install -e ".[test]"
```
You can also run the full test suite with the following command, but it takes
a beefy machine to produce a result in a decent amount of time now that
Diffusers has grown a lot. Here is the command for it:
```bash
$ make test
```
🧨 Diffusers relies on `ruff` and `isort` to format its source code
consistently. After you make changes, apply automatic style corrections and code verifications
that can't be automated in one go with:
```bash
$ make style
```
🧨 Diffusers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
control runs in CI, however, you can also run the same checks with:
```bash
$ make quality
```
Once you're happy with your changes, add changed files using `git add` and
make a commit with `git commit` to record your changes locally:
```bash
$ git add modified_file.py
$ git commit -m "A descriptive message about your changes."
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
$ git pull upstream main
```
Push the changes to your account using:
```bash
$ git push -u origin a-descriptive-name-for-my-changes
```
6. Once you are satisfied, go to the
webpage of your fork on GitHub. Click on 'Pull request' to send your changes
to the project maintainers for review.
7. It's ok if maintainers ask you for changes. It happens to core contributors
too! So everyone can see the changes in the Pull request, work in your local
branch and push the changes to your fork. They will automatically appear in
the pull request.
### Tests
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
repository, here's how to run tests with `pytest` for the library:
```bash
$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
```
In fact, that's how `make test` is implemented!
You can specify a smaller set of tests in order to test only the feature
you're working on.
By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
`yes` to run them. This will download many gigabytes of models — make sure you
have enough disk space and a good Internet connection, or a lot of patience!
```bash
$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
```
`unittest` is fully supported, here's how to run tests with it:
```bash
$ python -m unittest discover -s tests -t . -v
$ python -m unittest discover -s examples -t examples -v
```
### Syncing forked main with upstream (HuggingFace) main
To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
when syncing the main branch of a forked repository, please, follow these steps:
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash
$ git checkout -b your-branch-for-syncing
$ git pull --squash --no-commit upstream main
$ git commit -m '<your message without GitHub references>'
$ git push --set-upstream origin your-branch-for-syncing
```
### Style guide
For documentation strings, 🧨 Diffusers follows the [Google style](https://google.github.io/styleguide/pyguide.html).
| huggingface/diffusers/blob/main/CONTRIBUTING.md |
从 Google Sheets 创建实时仪表盘
Tags: TABULAR, DASHBOARD, PLOTS
[Google Sheets](https://www.google.com/sheets/about/) 是一种以电子表格形式存储表格数据的简便方法。借助 Gradio 和 pandas,可以轻松从公共或私有 Google Sheets 读取数据,然后显示数据或绘制数据。在本博文中,我们将构建一个小型 _real-time_ 仪表盘,该仪表盘在 Google Sheets 中的数据更新时进行更新。
构建仪表盘本身只需要使用 Gradio 的 9 行 Python 代码,我们的最终仪表盘如下所示:
<gradio-app space="gradio/line-plot"></gradio-app>
**先决条件**:本指南使用[Gradio Blocks](../quickstart/#blocks-more-flexibility-and-control),因此请确保您熟悉 Blocks 类。
具体步骤略有不同,具体取决于您是使用公开访问还是私有 Google Sheet。我们将分别介绍这两种情况,所以让我们开始吧!
## Public Google Sheets
由于[`pandas` 库](https://pandas.pydata.org/)的存在,从公共 Google Sheet 构建仪表盘非常简单:
1. 获取要使用的 Google Sheets 的网址。为此,只需进入 Google Sheets,单击右上角的“共享”按钮,然后单击“获取可共享链接”按钮。这将给您一个类似于以下示例的网址:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
```
2. 现在,修改此网址并使用它从 Google Sheets 读取数据到 Pandas DataFrame 中。 (在下面的代码中,用您的公开 Google Sheet 的网址替换 `URL` 变量):
```python
import pandas as pd
URL = "https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0"csv_url = URL.replace('/edit#gid=', '/export?format=csv&gid=')
def get_data():
return pd.read_csv(csv_url)
```
3. 数据查询是一个函数,这意味着可以使用 `gr.DataFrame` 组件实时显示或使用 `gr.LinePlot` 组件实时绘制数据(当然,根据数据的不同,可能需要不同的绘图方法)。只需将函数传递给相应的组件,并根据组件刷新的频率(以秒为单位)设置 `every` 参数。以下是 Gradio 代码:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=5)
with gr.Column():
gr.LinePlot(get_data, every=5, x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
到此为止!您现在拥有一个仪表盘,每 5 秒刷新一次,从 Google Sheets 中获取数据。
## 私有 Google Sheets
对于私有 Google Sheets,流程需要更多的工作量,但并不多!关键区别在于,现在您必须经过身份验证,以授权访问私有 Google Sheets。
### 身份验证
要进行身份验证,需从 Google Cloud 获取凭据。以下是[如何设置 Google Cloud 凭据](https://developers.google.com/workspace/guides/create-credentials):
1. 首先,登录您的 Google Cloud 帐户并转到 Google Cloud 控制台(https://console.cloud.google.com/)
2. 在 Cloud 控制台中,单击左上角的汉堡菜单,然后从菜单中选择“API 和服务”。如果您没有现有项目,则需要创建一个。
3. 然后,点击“+ 启用的 API 和服务”按钮,允许您为项目启用特定的服务。搜索“Google Sheets API”,点击它,然后单击“启用”按钮。如果看到“管理”按钮,则表示 Google Sheets 已启用,并且您已准备就绪。
4. 在 API 和服务菜单中,点击“凭据”选项卡,然后点击“创建凭据”按钮。
5. 在“创建凭据”对话框中,选择“服务帐号密钥”作为要创建的凭据类型,并为其命名。**记下服务帐号的电子邮件地址**
6. 在选择服务帐号之后,选择“JSON”密钥类型,然后点击“创建”按钮。这将下载包含您凭据的 JSON 密钥文件到您的计算机。文件类似于以下示例:
```json
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
### 查询
在获得凭据的 `.json` 文件后,可以按照以下步骤查询您的 Google Sheet:
1. 单击 Google Sheet 右上角的“共享”按钮。使用身份验证子部分第 5 步的服务的电子邮件地址共享 Google Sheets(此步骤很重要!)。然后单击“获取可共享链接”按钮。这将给您一个类似于以下示例的网址:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
```
2. 安装 [`gspread` 库](https://docs.gspread.org/en/v5.7.0/),通过在终端运行以下命令使 Python 中使用 [Google Sheets API](https://developers.google.com/sheets/api/guides/concepts) 更加简单:`pip install gspread`
3. 编写一个函数来从 Google Sheet 中加载数据,如下所示(用您的私有 Google Sheet 的 URL 替换 `URL` 变量):
```python
import gspreadimport pandas as pd
# 与 Google 进行身份验证并获取表格URL = 'https://docs.google.com/spreadsheets/d/1_91Vps76SKOdDQ8cFxZQdgjTJiz23375sAT7vPvaj4k/edit#gid=0'
gc = gspread.service_account("path/to/key.json")sh = gc.open_by_url(URL)worksheet = sh.sheet1
def get_data():
values = worksheet.get_all_values()
df = pd.DataFrame(values[1:], columns=values[0])
return df
```
4\. 数据查询是一个函数,这意味着可以使用 `gr.DataFrame` 组件实时显示数据,或使用 `gr.LinePlot` 组件实时绘制数据(当然,根据数据的不同,可能需要使用不同的图表)。要实现这一点,只需将函数传递给相应的组件,并根据需要设置 `every` 参数来确定组件刷新的频率(以秒为单位)。以下是 Gradio 代码:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 📈 实时折线图")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=5)
with gr.Column():
gr.LinePlot(get_data, every=5, x="日期", y="销售额", y_title="销售额(百万美元)", overlay_point=True, width=500, height=500)
demo.queue().launch() # 启动带有排队功能的演示
```
现在你有一个每 5 秒刷新一次的仪表盘,可以从你的 Google 表格中获取数据。
## 结论
就是这样!只需几行代码,你就可以使用 `gradio` 和其他库从公共或私有的 Google 表格中读取数据,然后在实时仪表盘中显示和绘制数据。
| gradio-app/gradio/blob/main/guides/cn/05_tabular-data-science-and-plots/creating-a-realtime-dashboard-from-google-sheets.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convolutional Vision Transformer (CvT)
## Overview
The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
The abstract from the paper is the following:
*We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT)
in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through
two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer
block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs)
to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention,
global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves
state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition,
performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on
ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding,
a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks.*
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
## Usage tips
- CvT models are regular Vision Transformers, but trained with convolutions. They outperform the [original model (ViT)](vit) when fine-tuned on ImageNet-1K and CIFAR-100.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoImageProcessor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
images and 1,000 classes).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CvT.
<PipelineTag pipeline="image-classification"/>
- [`CvtForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## CvtConfig
[[autodoc]] CvtConfig
<frameworkcontent>
<pt>
## CvtModel
[[autodoc]] CvtModel
- forward
## CvtForImageClassification
[[autodoc]] CvtForImageClassification
- forward
</pt>
<tf>
## TFCvtModel
[[autodoc]] TFCvtModel
- call
## TFCvtForImageClassification
[[autodoc]] TFCvtForImageClassification
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/cvt.md |
@gradio/radio
## 0.3.7
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.6
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.5
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.4
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.3
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.2
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.1
### Fixes
- [#6262](https://github.com/gradio-app/gradio/pull/6262) [`afb72bd19`](https://github.com/gradio-app/gradio/commit/afb72bd1970e6c43ddba0638fe9861330bdabb64) - Fix bug where radio.select passes the previous value to the function instead of the selected value. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6249](https://github.com/gradio-app/gradio/pull/6249) [`2cffcf3c3`](https://github.com/gradio-app/gradio/commit/2cffcf3c39acd782f314f8a406100ae22e0809b7) - ensure radios have different names. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Remove duplicate `elem_ids` from components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#6152](https://github.com/gradio-app/gradio/pull/6152) [`982bff2fd`](https://github.com/gradio-app/gradio/commit/982bff2fdd938b798c400fb90d1cf0caf7278894) - Remove duplicate `elem_ids` from components. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6026](https://github.com/gradio-app/gradio/pull/6026) [`338969af2`](https://github.com/gradio-app/gradio/commit/338969af290de032f9cdc204dab8a50be3bf3cc5) - V4: Single-file implementation of form components. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.1
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0
### Features
- [#5384](https://github.com/gradio-app/gradio/pull/5384) [`ddc02268`](https://github.com/gradio-app/gradio/commit/ddc02268f731bd2ed04b7a5854accf3383f9a0da) - Allows the `gr.Dropdown` to have separate names and values, as well as enables `allow_custom_value` for multiselect dropdown. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5232](https://github.com/gradio-app/gradio/pull/5232) [`c57d4c23`](https://github.com/gradio-app/gradio/commit/c57d4c232a97e03b4671f9e9edc3af456438fe89) - `gr.Radio` and `gr.CheckboxGroup` can now accept different names and values. Thanks [@abidlabs](https://github.com/abidlabs)!
| gradio-app/gradio/blob/main/js/radio/CHANGELOG.md |
Convert weights to safetensors
PyTorch model weights are commonly saved and stored as `.bin` files with Python's [`pickle`](https://docs.python.org/3/library/pickle.html) utility. To save and store your model weights in the more secure `safetensor` format, we recommend converting your weights to `.safetensors`.
The easiest way to convert your model weights is to use the [Convert Space](https://huggingface.co/spaces/diffusers/convert), given your model weights are already stored on the Hub. The Convert Space downloads the pickled weights, converts them, and opens a Pull Request to upload the newly converted `.safetensors` file to your repository.
<Tip warning={true}>
For larger models, the Space may be a bit slower because its resources are tied up in converting other models. You can also try running the [convert.py](https://github.com/huggingface/safetensors/blob/main/bindings/python/convert.py) script (this is what the Space is running) locally to convert your weights.
Feel free to ping [@Narsil](https://huggingface.co/Narsil) for any issues with the Space.
</Tip>
| huggingface/safetensors/blob/main/docs/source/convert-weights.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Sequence-to-Sequence Training and Evaluation
This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
For deprecated `bertabs` instructions, see [`bertabs/README.md`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/bertabs/README.md).
### Supported Architectures
- `BartForConditionalGeneration`
- `MarianMTModel`
- `PegasusForConditionalGeneration`
- `MBartForConditionalGeneration`
- `FSMTForConditionalGeneration`
- `T5ForConditionalGeneration`
### Download the Datasets
#### XSUM
```bash
cd examples/legacy/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
tar -xzvf xsum.tar.gz
export XSUM_DIR=${PWD}/xsum
```
this should make a directory called `xsum/` with files like `test.source`.
To use your own data, copy that files format. Each article to be summarized is on its own line.
#### CNN/DailyMail
```bash
cd examples/legacy/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
mv cnn_cln cnn_dm
export CNN_DIR=${PWD}/cnn_dm
```
this should make a directory called `cnn_dm/` with 6 files.
#### WMT16 English-Romanian Translation Data
download with this command:
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
export ENRO_DIR=${PWD}/wmt_en_ro
```
this should make a directory called `wmt_en_ro/` with 6 files.
#### WMT English-German
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
tar -xzvf wmt_en_de.tgz
export DATA_DIR=${PWD}/wmt_en_de
```
#### FSMT datasets (wmt)
Refer to the scripts starting with `eval_` under:
https://github.com/huggingface/transformers/tree/main/scripts/fsmt
#### Pegasus (multiple datasets)
Multiple eval datasets are available for download from:
https://github.com/stas00/porting/tree/master/datasets/pegasus
#### Your Data
If you are using your own data, it must be formatted as one directory with 6 files:
```
train.source
train.target
val.source
val.target
test.source
test.target
```
The `.source` files are the input, the `.target` files are the desired output.
### Potential issues
- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.7.1. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
### Tips and Tricks
General Tips:
- since you need to run from `examples/legacy/seq2seq`, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
- `fp16_opt_level=O1` (the default works best).
- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
- This warning can be safely ignored:
> "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
- Read scripts before you run them!
Summarization Tips:
- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
**Update 2018-07-18**
Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
Future work/help wanted: A new dataset to support multilingual tasks.
### Fine-tuning using Seq2SeqTrainer
To use `Seq2SeqTrainer` for fine-tuning you should use the `finetune_trainer.py` script. It subclasses `Trainer` to extend it for seq2seq training. Except the `Trainer`-related `TrainingArguments`, it shares the same argument names as that of `finetune.py` file. One notable difference is that calculating generative metrics (BLEU, ROUGE) is optional and is controlled using the `--predict_with_generate` argument.
With PyTorch 1.6+ it'll automatically use `native AMP` when `--fp16` is set.
To see all the possible command line options, run:
```bash
python finetune_trainer.py --help
```
For multi-gpu training use `torch.distributed.launch`, e.g. with 2 gpus:
```bash
torchrun --nproc_per_node=2 finetune_trainer.py ...
```
**At the moment, `Seq2SeqTrainer` does not support *with teacher* distillation.**
All `Seq2SeqTrainer`-based fine-tuning scripts are included in the `builtin_trainer` directory.
#### TPU Training
`Seq2SeqTrainer` supports TPU training with few caveats
1. As `generate` method does not work on TPU at the moment, `predict_with_generate` cannot be used. You should use `--prediction_loss_only` to only calculate loss, and do not set `--do_predict` and `--predict_with_generate`.
2. All sequences should be padded to be of equal length to avoid extremely slow training. (`finetune_trainer.py` does this automatically when running on TPU.)
We provide a very simple launcher script named `xla_spawn.py` that lets you run our example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for `torch.distributed`).
`builtin_trainer/finetune_tpu.sh` script provides minimal arguments needed for TPU training.
The following command fine-tunes `sshleifer/student_marian_en_ro_6_3` on TPU V3-8 and should complete one epoch in ~5-6 mins.
```bash
./builtin_trainer/train_distil_marian_enro_tpu.sh
```
## Evaluation Commands
To create summaries for each article in dataset, we use `run_eval.py`, here are a few commands that run eval for different tasks and models.
If 'translation' is in your task name, the computed metric will be BLEU. Otherwise, ROUGE will be used.
For t5, you need to specify --task translation_{src}_to_{tgt} as follows:
```bash
export DATA_DIR=wmt_en_ro
./run_eval.py t5-base \
$DATA_DIR/val.source t5_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation_en_to_ro \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
This command works for MBART, although the BLEU score is suspiciously low.
```bash
export DATA_DIR=wmt_en_ro
./run_eval.py facebook/mbart-large-en-ro $DATA_DIR/val.source mbart_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
Summarization (xsum will be very similar):
```bash
export DATA_DIR=cnn_dm
./run_eval.py sshleifer/distilbart-cnn-12-6 $DATA_DIR/val.source dbart_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path cnn_rouge.json \
--task summarization \
--n_obs 100 \
th 56 \
--fp16 \
--bs 32
```
### Multi-GPU Evaluation
here is a command to run xsum evaluation on 8 GPUS. It is more than linearly faster than run_eval.py in some cases
because it uses SortishSampler to minimize padding. You can also use it on 1 GPU. `data_dir` must have
`{type_path}.source` and `{type_path}.target`. Run `./run_distributed_eval.py --help` for all clargs.
```bash
torchrun --nproc_per_node=8 run_distributed_eval.py \
--model_name sshleifer/distilbart-large-xsum-12-3 \
--save_dir xsum_generations \
--data_dir xsum \
--fp16 # you can pass generate kwargs like num_beams here, just like run_eval.py
```
Contributions that implement this command for other distributed hardware setups are welcome!
#### Single-GPU Eval: Tips and Tricks
When using `run_eval.py`, the following features can be useful:
* if you running the script multiple times and want to make it easier to track what arguments produced that output, use `--dump-args`. Along with the results it will also dump any custom params that were passed to the script. For example if you used: `--num_beams 8 --early_stopping true`, the output will be:
```
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True}
```
`--info` is an additional argument available for the same purpose of tracking the conditions of the experiment. It's useful to pass things that weren't in the argument list, e.g. a language pair `--info "lang:en-ru"`. But also if you pass `--info` without a value it will fallback to the current date/time string, e.g. `2020-09-13 18:44:43`.
If using `--dump-args --info`, the output will be:
```
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': '2020-09-13 18:44:43'}
```
If using `--dump-args --info "pair:en-ru chkpt=best`, the output will be:
```
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': 'pair=en-ru chkpt=best'}
```
* if you need to perform a parametric search in order to find the best ones that lead to the highest BLEU score, let `run_eval_search.py` to do the searching for you.
The script accepts the exact same arguments as `run_eval.py`, plus an additional argument `--search`. The value of `--search` is parsed, reformatted and fed to ``run_eval.py`` as additional args.
The format for the `--search` value is a simple string with hparams and colon separated values to try, e.g.:
```
--search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
```
which will generate `12` `(2*3*2)` searches for a product of each hparam. For example the example that was just used will invoke `run_eval.py` repeatedly with:
```
--num_beams 5 --length_penalty 0.8 --early_stopping true
--num_beams 5 --length_penalty 0.8 --early_stopping false
[...]
--num_beams 10 --length_penalty 1.2 --early_stopping false
```
On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
```
bleu | num_beams | length_penalty | early_stopping
----- | --------- | -------------- | --------------
26.71 | 5 | 1.1 | 1
26.66 | 5 | 0.9 | 1
26.66 | 5 | 0.9 | 0
26.41 | 5 | 1.1 | 0
21.94 | 1 | 0.9 | 1
21.94 | 1 | 0.9 | 0
21.94 | 1 | 1.1 | 1
21.94 | 1 | 1.1 | 0
Best score args:
stas/wmt19-en-ru data/en-ru/val.source data/en-ru/test_translations.txt --reference_path data/en-ru/val.target --score_path data/en-ru/test_bleu.json --bs 8 --task translation --num_beams 5 --length_penalty 1.1 --early_stopping True
```
If you pass `--info "some experiment-specific info"` it will get printed before the results table - this is useful for scripting and multiple runs, so one can tell the different sets of results from each other.
### Contributing
- follow the standard contributing guidelines and code of conduct.
- add tests to `test_seq2seq_examples.py`
- To run only the seq2seq tests, you must be in the root of the repository and run:
```bash
pytest examples/seq2seq/
```
### Converting pytorch-lightning checkpoints
pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
This should be done for you, with a file called `{save_dir}/best_tfmr`.
If that file doesn't exist but you have a lightning `.ckpt` file, you can run
```bash
python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
```
Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
# Experimental Features
These features are harder to use and not always useful.
### Dynamic Batch Size for MT
`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
This feature can only be used:
- with fairseq installed
- on 1 GPU
- without sortish sampler
- after calling `./save_len_file.py $tok $data_dir`
For example,
```bash
./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
```
splits `wmt_en_ro/train` into 11,197 uneven lengthed batches and can finish 1 epoch in 8 minutes on a v100.
For comparison,
```bash
./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
```
uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
The feature is still experimental, because:
+ we can make it much more robust if we have memory mapped/preprocessed datasets.
+ The speedup over sortish sampler is not that large at the moment.
| huggingface/transformers/blob/main/examples/legacy/seq2seq/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# NLLB-MOE
## Overview
The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
The abstract of the paper is the following:
*Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today.
However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the
200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by
first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed
at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of
Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training
improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using
a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/facebookresearch/fairseq).
## Usage tips
- M2M100ForConditionalGeneration is the base model for both NLLB and NLLB MoE
- The NLLB-MoE is very similar to the NLLB model, but it's feed forward layer is based on the implementation of SwitchTransformers.
- The tokenizer is the same as the NLLB models.
## Implementation differences with SwitchTransformers
The biggest difference is the way the tokens are routed. NLLB-MoE uses a `top-2-gate` which means that for each input, only the top two experts are selected based on the
highest predicted probabilities from the gating network, and the remaining experts are ignored. In `SwitchTransformers`, only the top-1 probabilities are computed,
which means that tokens have less probability of being forwarded. Moreover, if a token is not routed to any expert, `SwitchTransformers` still adds its unmodified hidden
states (kind of like a residual connection) while they are masked in `NLLB`'s top-2 routing mechanism.
## Generating with NLLB-MoE
The available checkpoints require around 350GB of storage. Make sure to use `accelerate` if you do not have enough RAM on your machine.
While generating the target text set the `forced_bos_token_id` to the target language id. The following
example shows how to translate English to French using the *facebook/nllb-200-distilled-600M* model.
Note that we're using the BCP-47 code for French `fra_Latn`. See [here](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
for the list of all BCP-47 in the Flores 200 dataset.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
>>> article = "Previously, Ring's CEO, Jamie Siminoff, remarked the company started when his doorbell wasn't audible from his shop in his garage."
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["fra_Latn"], max_length=50
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
"Auparavant, le PDG de Ring, Jamie Siminoff, a fait remarquer que la société avait commencé lorsque sa sonnette n'était pas audible depuis son magasin dans son garage."
```
### Generating from any other language than English
English (`eng_Latn`) is set as the default language from which to translate. In order to specify that you'd like to translate from a different language,
you should specify the BCP-47 code in the `src_lang` keyword argument of the tokenizer initialization.
See example below for a translation from romanian to german:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b", src_lang="ron_Latn")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## NllbMoeConfig
[[autodoc]] NllbMoeConfig
## NllbMoeTop2Router
[[autodoc]] NllbMoeTop2Router
- route_tokens
- forward
## NllbMoeSparseMLP
[[autodoc]] NllbMoeSparseMLP
- forward
## NllbMoeModel
[[autodoc]] NllbMoeModel
- forward
## NllbMoeForConditionalGeneration
[[autodoc]] NllbMoeForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/nllb-moe.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DPMSolverSinglestepScheduler
`DPMSolverSinglestepScheduler` is a single step scheduler from [DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps](https://huggingface.co/papers/2206.00927) and [DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models](https://huggingface.co/papers/2211.01095) by Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu.
DPMSolver (and the improved version DPMSolver++) is a fast dedicated high-order solver for diffusion ODEs with convergence order guarantee. Empirically, DPMSolver sampling with only 20 steps can generate high-quality
samples, and it can generate quite good samples even in 10 steps.
The original implementation can be found at [LuChengTHU/dpm-solver](https://github.com/LuChengTHU/dpm-solver).
## Tips
It is recommended to set `solver_order` to 2 for guide sampling, and `solver_order=3` for unconditional sampling.
Dynamic thresholding from [Imagen](https://huggingface.co/papers/2205.11487) is supported, and for pixel-space
diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use dynamic
thresholding. This thresholding method is unsuitable for latent-space diffusion models such as
Stable Diffusion.
## DPMSolverSinglestepScheduler
[[autodoc]] DPMSolverSinglestepScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/singlestep_dpm_solver.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Prior Transformer
The Prior Transformer was originally introduced in [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://huggingface.co/papers/2204.06125) by Ramesh et al. It is used to predict CLIP image embeddings from CLIP text embeddings; image embeddings are predicted through a denoising diffusion process.
The abstract from the paper is:
*Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style. To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.*
## PriorTransformer
[[autodoc]] PriorTransformer
## PriorTransformerOutput
[[autodoc]] models.prior_transformer.PriorTransformerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/prior_transformer.md |
Gradio Demo: markdown_example
```
!pip install -q gradio
```
```
import gradio as gr
css = (
"footer {display: none !important;} .gradio-container {min-height: 0px !important;}"
)
# sample md stolen from https://dillinger.io/
md = """# Dillinger
## _The Last Markdown Editor, Ever_
This is some `inline code`, it is good.
[](https://travis-ci.org/joemccann/dillinger)
Dillinger is a cloud-enabled, mobile-ready, offline-storage compatible,
AngularJS-powered HTML5 Markdown editor.
- Type some Markdown on the left
- See HTML in the right
- ✨Magic ✨
## Features
- Import a HTML file and watch it magically convert to Markdown
- Drag and drop images (requires your Dropbox account be linked)
- Import and save files from GitHub, Dropbox, Google Drive and One Drive
- Drag and drop markdown and HTML files into Dillinger
- Export documents as Markdown, HTML and PDF
Markdown is a lightweight markup language based on the formatting conventions
that people naturally use in email.
As [John Gruber] writes on the [Markdown site][df1]
> The overriding design goal for Markdown's
> formatting syntax is to make it as readable
> as possible. The idea is that a
> Markdown-formatted document should be
> publishable as-is, as plain text, without
> looking like it's been marked up with tags
> or formatting instructions.
This text you see here is *actually- written in Markdown! To get a feel
for Markdown's syntax, type some text into the left window and
watch the results in the right.
## Tech
Dillinger uses a number of open source projects to work properly:
- [AngularJS] - HTML enhanced for web apps!
- [Ace Editor] - awesome web-based text editor
- [markdown-it] - Markdown parser done right. Fast and easy to extend.
- [Twitter Bootstrap] - great UI boilerplate for modern web apps
- [node.js] - evented I/O for the backend
- [Express] - fast node.js network app framework [@tjholowaychuk]
- [Gulp] - the streaming build system
- [Breakdance](https://breakdance.github.io/breakdance/) - HTML
to Markdown converter
- [jQuery] - duh
And of course Dillinger itself is open source with a [public repository][dill]
on GitHub.
## Installation
Dillinger requires [Node.js](https://nodejs.org/) v10+ to run.
Install the dependencies and devDependencies and start the server.
```bash
cd dillinger
npm i
node app
```
For production environments...
```bash
npm install --production
NODE_ENV=production node app
```
## Plugins
Dillinger is currently extended with the following plugins.
Instructions on how to use them in your own application are linked below.
| Plugin | README |
| ------ | ------ |
| Dropbox | [plugins/dropbox/README.md][PlDb] |
| GitHub | [plugins/github/README.md][PlGh] |
| Google Drive | [plugins/googledrive/README.md][PlGd] |
| OneDrive | [plugins/onedrive/README.md][PlOd] |
| Medium | [plugins/medium/README.md][PlMe] |
| Google Analytics | [plugins/googleanalytics/README.md][PlGa] |
## Development
Want to contribute? Great!
Dillinger uses Gulp + Webpack for fast developing.
Make a change in your file and instantaneously see your updates!
Open your favorite Terminal and run these commands.
First Tab:
```bash
node app
```
Second Tab:
```bash
gulp watch
```
(optional) Third:
```bash
karma test
```
#### Building for source
For production release:
```bash
gulp build --prod
```
Generating pre-built zip archives for distribution:
```bash
gulp build dist --prod
```
## Docker
Dillinger is very easy to install and deploy in a Docker container.
By default, the Docker will expose port 8080, so change this within the
Dockerfile if necessary. When ready, simply use the Dockerfile to
build the image.
```bash
cd dillinger
docker build -t <youruser>/dillinger:${package.json.version} .
```
This will create the dillinger image and pull in the necessary dependencies.
Be sure to swap out `${package.json.version}` with the actual
version of Dillinger.
Once done, run the Docker image and map the port to whatever you wish on
your host. In this example, we simply map port 8000 of the host to
port 8080 of the Docker (or whatever port was exposed in the Dockerfile):
```bash
docker run -d -p 8000:8080 --restart=always --cap-add=SYS_ADMIN --name=dillinger <youruser>/dillinger:${package.json.version}
```
> Note: `--capt-add=SYS-ADMIN` is required for PDF rendering.
Verify the deployment by navigating to your server address in
your preferred browser.
```bash
127.0.0.1:8000
```
```python
import gradio as gr
gr.Blocks() as demo:
gr.Markdown(value=md)
demo.launch()
```
```js
function fancyAlert(arg) {
if(arg) {
$.facebox({div:'#foo'})
}
}
```
## License
MIT
**Free Software, Hell Yeah!**
[//]: # (These are reference links used in the body of this note and get stripped out when the markdown processor does its job. There is no need to format nicely because it shouldn't be seen. Thanks SO - http://stackoverflow.com/questions/4823468/store-comments-in-markdown-syntax)
[dill]: <https://github.com/joemccann/dillinger>
[git-repo-url]: <https://github.com/joemccann/dillinger.git>
[john gruber]: <http://daringfireball.net>
[df1]: <http://daringfireball.net/projects/markdown/>
[markdown-it]: <https://github.com/markdown-it/markdown-it>
[Ace Editor]: <http://ace.ajax.org>
[node.js]: <http://nodejs.org>
[Twitter Bootstrap]: <http://twitter.github.com/bootstrap/>
[jQuery]: <http://jquery.com>
[@tjholowaychuk]: <http://twitter.com/tjholowaychuk>
[express]: <http://expressjs.com>
[AngularJS]: <http://angularjs.org>
[Gulp]: <http://gulpjs.com>
[PlDb]: <https://github.com/joemccann/dillinger/tree/master/plugins/dropbox/README.md>
[PlGh]: <https://github.com/joemccann/dillinger/tree/master/plugins/github/README.md>
[PlGd]: <https://github.com/joemccann/dillinger/tree/master/plugins/googledrive/README.md>
[PlOd]: <https://github.com/joemccann/dillinger/tree/master/plugins/onedrive/README.md>
[PlMe]: <https://github.com/joemccann/dillinger/tree/master/plugins/medium/README.md>
[PlGa]: <https://github.com/RahulHP/dillinger/blob/master/plugins/googleanalytics/README.md>
"""
with gr.Blocks(css=css) as demo:
gr.Markdown(value=md, header_links=True)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/markdown_example/run.ipynb |
--
title: SQuAD
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
This metric wrap the official scoring script for version 1 of the Stanford Question Answering Dataset (SQuAD).
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by
crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span,
from the corresponding reading passage, or the question might be unanswerable.
---
# Metric Card for SQuAD
## Metric description
This metric wraps the official scoring script for version 1 of the [Stanford Question Answering Dataset (SQuAD)](https://huggingface.co/datasets/squad).
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
## How to use
The metric takes two files or two lists of question-answers dictionaries as inputs : one with the predictions of the model and the other with the references to be compared to:
```python
from evaluate import load
squad_metric = load("squad")
results = squad_metric.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with two values: the average exact match score and the average [F1 score](https://huggingface.co/metrics/f1).
```
{'exact_match': 100.0, 'f1': 100.0}
```
The range of `exact_match` is 0-100, where 0.0 means no answers were matched and 100.0 means all answers were matched.
The range of `f1` is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall.
### Values from popular papers
The [original SQuAD paper](https://nlp.stanford.edu/pubs/rajpurkar2016squad.pdf) reported an F1 score of 51.0% and an Exact Match score of 40.0%. They also report that human performance on the dataset represents an F1 score of 90.5% and an Exact Match score of 80.3%.
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/squad).
## Examples
Maximal values for both exact match and F1 (perfect match):
```python
from evaluate import load
squad_metric = load("squad")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_metric.compute(predictions=predictions, references=references)
results
{'exact_match': 100.0, 'f1': 100.0}
```
Minimal values for both exact match and F1 (no match):
```python
from evaluate import load
squad_metric = load("squad")
predictions = [{'prediction_text': '1999', 'id': '56e10a3be3433e1400422b22'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_metric.compute(predictions=predictions, references=references)
results
{'exact_match': 0.0, 'f1': 0.0}
```
Partial match (2 out of 3 answers correct) :
```python
from evaluate import load
squad_metric = load("squad")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}, {'prediction_text': 'Beyonce', 'id': '56d2051ce7d4791d0090260b'}, {'prediction_text': 'climate change', 'id': '5733b5344776f419006610e1'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}, {'answers': {'answer_start': [233], 'text': ['Beyoncé and Bruno Mars']}, 'id': '56d2051ce7d4791d0090260b'}, {'answers': {'answer_start': [891], 'text': ['climate change']}, 'id': '5733b5344776f419006610e1'}]
results = squad_metric.compute(predictions=predictions, references=references)
results
{'exact_match': 66.66666666666667, 'f1': 66.66666666666667}
```
## Limitations and bias
This metric works only with datasets that have the same format as [SQuAD v.1 dataset](https://huggingface.co/datasets/squad).
The SQuAD dataset does contain a certain amount of noise, such as duplicate questions as well as missing answers, but these represent a minority of the 100,000 question-answer pairs. Also, neither exact match nor F1 score reflect whether models do better on certain types of questions (e.g. who questions) or those that cover a certain gender or geographical area -- carrying out more in-depth error analysis can complement these numbers.
## Citation
@inproceedings{Rajpurkar2016SQuAD10,
title={SQuAD: 100, 000+ Questions for Machine Comprehension of Text},
author={Pranav Rajpurkar and Jian Zhang and Konstantin Lopyrev and Percy Liang},
booktitle={EMNLP},
year={2016}
}
## Further References
- [The Stanford Question Answering Dataset: Background, Challenges, Progress (blog post)](https://rajpurkar.github.io/mlx/qa-and-squad/)
- [Hugging Face Course -- Question Answering](https://huggingface.co/course/chapter7/7)
| huggingface/evaluate/blob/main/metrics/squad/README.md |
Integrate your library with the Hub
The Hugging Face Hub aims to facilitate sharing machine learning models, checkpoints, and artifacts. This endeavor includes integrating the Hub into many of the amazing third-party libraries in the community. Some of the ones already integrated include [spaCy](https://spacy.io/usage/projects#huggingface_hub), [AllenNLP](https://allennlp.org/), and [timm](https://rwightman.github.io/pytorch-image-models/), among many others. Integration means users can download and upload files to the Hub directly from your library. We hope you will integrate your library and join us in democratizing artificial intelligence for everyone.
Integrating the Hub with your library provides many benefits, including:
- Free model hosting for you and your users.
- Built-in file versioning - even for huge files - made possible by [Git-LFS](https://git-lfs.github.com/).
- All public models are powered by the [Inference API](https://huggingface.co/docs/api-inference/index).
- In-browser widgets allow users to interact with your hosted models directly.
This tutorial will help you integrate the Hub into your library so your users can benefit from all the features offered by the Hub.
Before you begin, we recommend you create a [Hugging Face account](https://huggingface.co/join) from which you can manage your repositories and files.
If you need help with the integration, feel free to open an [issue](https://github.com/huggingface/huggingface_hub/issues/new/choose), and we would be more than happy to help you.
## Installation
1. Install the `huggingface_hub` library with pip in your environment:
```bash
python -m pip install huggingface_hub
```
2. Once you have successfully installed the `huggingface_hub` library, log in to your Hugging Face account:
```bash
huggingface-cli login
```
```bash
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
Username:
Password:
```
3. Alternatively, if you prefer working from a Jupyter or Colaboratory notebook, login with `notebook_login`:
```python
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
`notebook_login` will launch a widget in your notebook from which you can enter your Hugging Face credentials.
## Download files from the Hub
Integration allows users to download your hosted files directly from the Hub using your library.
Use the `hf_hub_download` function to retrieve a URL and download files from your repository. Downloaded files are stored in your cache: `~/.cache/huggingface/hub`. You don't have to re-download the file the next time you use it, and for larger files, this can save a lot of time. Furthermore, if the repository is updated with a new version of the file, `huggingface_hub` will automatically download the latest version and store it in the cache for you. Users don't have to worry about updating their files.
For example, download the `config.json` file from the [lysandre/arxiv-nlp](https://huggingface.co/lysandre/arxiv-nlp) repository:
```python
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")
```
Download a specific version of the file by specifying the `revision` parameter. The `revision` parameter can be a branch name, tag, or commit hash.
The commit hash must be a full-length hash instead of the shorter 7-character commit hash:
```python
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json", revision="877b84a8f93f2d619faa2a6e514a32beef88ab0a")
```
Use the `cache_dir` parameter to change where a file is stored:
```python
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json", cache_dir="/home/lysandre/test")
```
### Code sample
We recommend adding a code snippet to explain how to use a model in your downstream library.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/code_snippet.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/code_snippet-dark.png"/>
</div>
First, register your library by editing [model-libaries.ts](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/model-libraries.ts).
Then, add a code snippet by updating the [library-ui-elements](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/library-ui-elements.ts) file with instructions for your model. For example, the [Asteroid](https://huggingface.co/asteroid-team) integration includes a brief code snippet for how to load and use an Asteroid model:
```typescript
const asteroid = (model: ModelData) =>
`from asteroid.models import BaseModel
model = BaseModel.from_pretrained("${model.id}")`;
```
Doing so will also add a tag to your model so users can quickly identify models from your library.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-tags.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-tags-dark.png"/>
</div>
## Upload files to the Hub
You might also want to provide a method for creating model repositories and uploading files to the Hub directly from your library. The `huggingface_hub` library offers two ways to assist you with creating repositories and uploading files:
- `create_repo` creates a repository on the Hub.
- `upload_file` directly uploads files to a repository on the Hub.
### `create_repo`
The `create_repo` method creates a repository on the Hub. Use the `name` parameter to provide a name for your repository:
```python
>>> from huggingface_hub import create_repo
>>> create_repo(repo_id="test-model")
'https://huggingface.co/lysandre/test-model'
```
When you check your Hugging Face account, you should now see a `test-model` repository under your namespace.
### `upload_file`
The `upload_file` method uploads files to the Hub. This method requires the following:
- A path to the file to upload.
- The final path in the repository.
- The repository you wish to push the files to.
For example:
```python
>>> from huggingface_hub import upload_file
>>> upload_file(
... path_or_fileobj="/home/lysandre/dummy-test/README.md",
... path_in_repo="README.md",
... repo_id="lysandre/test-model"
... )
'https://huggingface.co/lysandre/test-model/blob/main/README.md'
```
If you need to upload more than one file, look at the [utilities offered by the `Repository` class](https://huggingface.co/docs/huggingface_hub/package_reference/repository).
Once again, if you check your Hugging Face account, you should see the file inside your repository.
Lastly, it is important to add a model card so users understand how to use your model. See [here](./model-cards) for more details about how to create a model card.
## Set up the Inference API
Our Inference API powers models uploaded to the Hub through your library.
### Create an Inference API Docker image
All third-party libraries are Dockerized, so you can install the dependencies you'll need for your library to work correctly. Add your library to the existing Docker images by navigating to the [Docker images folder](https://github.com/huggingface/api-inference-community/tree/main/docker_images).
1. Copy the `common` folder and rename it with the name of your library (e.g. `docker/common` to `docker/your-awesome-library`).
2. There are four files you need to edit:
* List the packages required for your library to work in `requirements.txt`.
* Update `app/main.py` with the tasks supported by your model (see [here](https://github.com/huggingface/api-inference-community) for a complete list of available tasks). Look out for the `IMPLEMENT_THIS` flag to add your supported task.
```python
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"token-classification": TokenClassificationPipeline
}
```
* For each task your library supports, modify the `app/pipelines/task_name.py` files accordingly. We have also added an `IMPLEMENT_THIS` flag in the pipeline files to guide you. If there isn't a pipeline that supports your task, feel free to add one. Open an [issue](https://github.com/huggingface/huggingface.js/issues/new) here, and we will be happy to help you.
* Add your model and task to the `tests/test_api.py` file. For example, if you have a text generation model:
```python
TESTABLE_MODELS: Dict[str,str] = {
"text-generation": "my-gpt2-model"
}
```
3. Finally, run the following test to ensure everything works as expected:
```bash
pytest -sv --rootdir docker_images/your-awesome-library/docker_images/your-awesome-library/
```
### Register your libraries supported tasks on the hub
To register the tasks supported by your library on the hub you'll need to add a mapping from your library name to its supported tasks in [library-to-tasks.ts file](https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/library-to-tasks.ts). This will ensure the inference API is registered for tasks supported by your model. This file is automatically generated as part of a [GitHub Action](https://github.com/huggingface/api-inference-community/actions/workflows/python-api-export-tasks.yaml) in the [
api-inference-community repository](https://github.com/huggingface/api-inference-community) repository. You can see an example of this [here](https://github.com/huggingface/api-inference-community/actions/runs/5126874210/jobs/9221890853#step:5:8).
With these simple but powerful methods, you brought the full functionality of the Hub into your library. Users can download files stored on the Hub from your library with `hf_hub_download`, create repositories with `create_repo`, and upload files with `upload_file`. You also set up Inference API with your library, allowing users to interact with your models on the Hub from inside a browser.
## Document your library
Finally, you can add your library to the Hub's documentation. Check for example the [Setfit PR](https://github.com/huggingface/hub-docs/pull/1150) that added [SetFit](./setfit) to the documentation.
| huggingface/hub-docs/blob/main/docs/hub/models-adding-libraries.md |
gradio_client
## 0.7.3
### Fixes
- [#6693](https://github.com/gradio-app/gradio/pull/6693) [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0) - Python client properly handles hearbeat and log messages. Also handles responses longer than 65k. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.7.2
### Features
- [#6598](https://github.com/gradio-app/gradio/pull/6598) [`7cbf96e`](https://github.com/gradio-app/gradio/commit/7cbf96e0bdd12db7ecac7bf99694df0a912e5864) - Issue 5245: consolidate usage of requests and httpx. Thanks [@cswamy](https://github.com/cswamy)!
- [#6704](https://github.com/gradio-app/gradio/pull/6704) [`24e0481`](https://github.com/gradio-app/gradio/commit/24e048196e8f7bd309ef5c597d4ffc6ca4ed55d0) - Hotfix: update `huggingface_hub` dependency version. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#6543](https://github.com/gradio-app/gradio/pull/6543) [`8a70e83`](https://github.com/gradio-app/gradio/commit/8a70e83db9c7751b46058cdd2514e6bddeef6210) - switch from black to ruff formatter. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
### Fixes
- [#6556](https://github.com/gradio-app/gradio/pull/6556) [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70) - Fix api event drops. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.7.1
### Fixes
- [#6602](https://github.com/gradio-app/gradio/pull/6602) [`b8034a1`](https://github.com/gradio-app/gradio/commit/b8034a1e72c3aac649ee0ad9178ffdbaaa60fc61) - Fix: Gradio Client work with private Spaces. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.7.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Add json schema unit tests. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Swap websockets for SSE. Thanks [@pngwn](https://github.com/pngwn)!
## 0.7.0-beta.2
### Features
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6069](https://github.com/gradio-app/gradio/pull/6069) [`bf127e124`](https://github.com/gradio-app/gradio/commit/bf127e1241a41401e144874ea468dff8474eb505) - Swap websockets for SSE. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.7.0-beta.1
### Features
- [#6082](https://github.com/gradio-app/gradio/pull/6082) [`037e5af33`](https://github.com/gradio-app/gradio/commit/037e5af3363c5b321b95efc955ee8d6ec0f4504e) - WIP: Fix docs. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5970](https://github.com/gradio-app/gradio/pull/5970) [`0c571c044`](https://github.com/gradio-app/gradio/commit/0c571c044035989d6fe33fc01fee63d1780635cb) - Add json schema unit tests. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6073](https://github.com/gradio-app/gradio/pull/6073) [`abff6fb75`](https://github.com/gradio-app/gradio/commit/abff6fb758bd310053a23c938bf1dd8fbdc5d333) - Fix remaining xfail tests in backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.7.0-beta.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Simplify how files are handled in components in 4.0. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Rename gradio_component to gradio component. Thanks [@pngwn](https://github.com/pngwn)!
## 0.6.1
### Fixes
- [#5811](https://github.com/gradio-app/gradio/pull/5811) [`1d5b15a2d`](https://github.com/gradio-app/gradio/commit/1d5b15a2d24387154f2cfb40a36de25b331471d3) - Assert refactor in external.py. Thanks [@harry-urek](https://github.com/harry-urek)!
## 0.6.0
### Highlights
#### new `FileExplorer` component ([#5672](https://github.com/gradio-app/gradio/pull/5672) [`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e))
Thanks to a new capability that allows components to communicate directly with the server _without_ passing data via the value, we have created a new `FileExplorer` component.
This component allows you to populate the explorer by passing a glob, but only provides the selected file(s) in your prediction function.
Users can then navigate the virtual filesystem and select files which will be accessible in your predict function. This component will allow developers to build more complex spaces, with more flexible input options.

For more information check the [`FileExplorer` documentation](https://gradio.app/docs/fileexplorer).
Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.5.3
### Features
- [#5721](https://github.com/gradio-app/gradio/pull/5721) [`84e03fe50`](https://github.com/gradio-app/gradio/commit/84e03fe506e08f1f81bac6d504c9fba7924f2d93) - Adds copy buttons to website, and better descriptions to API Docs. Thanks [@aliabd](https://github.com/aliabd)!
## 0.5.2
### Features
- [#5653](https://github.com/gradio-app/gradio/pull/5653) [`ea0e00b20`](https://github.com/gradio-app/gradio/commit/ea0e00b207b4b90a10e9d054c4202d4e705a29ba) - Prevent Clients from accessing API endpoints that set `api_name=False`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.5.1
### Features
- [#5514](https://github.com/gradio-app/gradio/pull/5514) [`52f783175`](https://github.com/gradio-app/gradio/commit/52f7831751b432411e109bd41add4ab286023a8e) - refactor: Use package.json for version management. Thanks [@DarhkVoyd](https://github.com/DarhkVoyd)!
## 0.5.0
### Highlights
#### Enable streaming audio in python client ([#5248](https://github.com/gradio-app/gradio/pull/5248) [`390624d8`](https://github.com/gradio-app/gradio/commit/390624d8ad2b1308a5bf8384435fd0db98d8e29e))
The `gradio_client` now supports streaming file outputs 🌊
No new syntax! Connect to a gradio demo that supports streaming file outputs and call `predict` or `submit` as you normally would.
```python
import gradio_client as grc
client = grc.Client("gradio/stream_audio_out")
# Get the entire generated audio as a local file
client.predict("/Users/freddy/Pictures/bark_demo.mp4", api_name="/predict")
job = client.submit("/Users/freddy/Pictures/bark_demo.mp4", api_name="/predict")
# Get the entire generated audio as a local file
job.result()
# Each individual chunk
job.outputs()
```
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#5295](https://github.com/gradio-app/gradio/pull/5295) [`7b8fa8aa`](https://github.com/gradio-app/gradio/commit/7b8fa8aa58f95f5046b9add64b40368bd3f1b700) - Allow caching examples with streamed output. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.4.0
### Highlights
#### Client.predict will now return the final output for streaming endpoints ([#5057](https://github.com/gradio-app/gradio/pull/5057) [`35856f8b`](https://github.com/gradio-app/gradio/commit/35856f8b54548cae7bd3b8d6a4de69e1748283b2))
### This is a breaking change (for gradio_client only)!
Previously, `Client.predict` would only return the first output of an endpoint that streamed results. This was causing confusion for developers that wanted to call these streaming demos via the client.
We realize that developers using the client don't know the internals of whether a demo streams or not, so we're changing the behavior of predict to match developer expectations.
Using `Client.predict` will now return the final output of a streaming endpoint. This will make it even easier to use gradio apps via the client.
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Features
- [#5076](https://github.com/gradio-app/gradio/pull/5076) [`2745075a`](https://github.com/gradio-app/gradio/commit/2745075a26f80e0e16863d483401ff1b6c5ada7a) - Add deploy_discord to docs. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#5061](https://github.com/gradio-app/gradio/pull/5061) [`136adc9c`](https://github.com/gradio-app/gradio/commit/136adc9ccb23e5cb4d02d2e88f23f0b850041f98) - Ensure `gradio_client` is backwards compatible with `gradio==3.24.1`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.0
### Highlights
#### Create Discord Bots from Gradio Apps 🤖 ([#4960](https://github.com/gradio-app/gradio/pull/4960) [`46e4ef67`](https://github.com/gradio-app/gradio/commit/46e4ef67d287dd68a91473b73172b29cbad064bc))
We're excited to announce that Gradio can now automatically create a discord bot from any `gr.ChatInterface` app.
It's as easy as importing `gradio_client`, connecting to the app, and calling `deploy_discord`!
_🦙 Turning Llama 2 70b into a discord bot 🦙_
```python
import gradio_client as grc
grc.Client("ysharma/Explore_llamav2_with_TGI").deploy_discord(to_id="llama2-70b-discord-bot")
```
<img src="https://gradio-builds.s3.amazonaws.com/demo-files/discordbots/guide/llama_chat.gif">
#### Getting started with template spaces
To help get you started, we have created an organization on Hugging Face called [gradio-discord-bots](https://huggingface.co/gradio-discord-bots) with template spaces you can use to turn state of the art LLMs powered by Gradio to discord bots.
Currently we have template spaces for:
- [Llama-2-70b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-70b-chat-hf) powered by a FREE Hugging Face Inference Endpoint!
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-13b-chat-hf) powered by Hugging Face Inference Endpoints.
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/llama-2-13b-chat-transformers) powered by Hugging Face transformers.
- [falcon-7b-instruct](https://huggingface.co/spaces/gradio-discord-bots/falcon-7b-instruct) powered by Hugging Face Inference Endpoints.
- [gpt-3.5-turbo](https://huggingface.co/spaces/gradio-discord-bots/gpt-35-turbo), powered by openai. Requires an OpenAI key.
But once again, you can deploy ANY `gr.ChatInterface` app exposed on the internet! So don't hesitate to try it on your own Chatbots.
❗️ Additional Note ❗️: Technically, any gradio app that exposes an api route that takes in a single string and outputs a single string can be deployed to discord. But `gr.ChatInterface` apps naturally lend themselves to discord's chat functionality so we suggest you start with those.
Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### New Features:
- Endpoints that return layout components are now properly handled in the `submit` and `view_api` methods. Output layout components are not returned by the API but all other components are (excluding `gr.State`). By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4871](https://github.com/gradio-app/gradio/pull/4871)
### Bug Fixes:
No changes to highlight
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.9
### New Features:
No changes to highlight
### Bug Fixes:
- Fix bug determining the api name when a demo has `api_name=False` by [@freddyboulton](https://github.com/freddyaboulton) in [PR 4886](https://github.com/gradio-app/gradio/pull/4886)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
- Pinned dependencies to major versions to reduce the likelihood of a broken `gradio_client` due to changes in downstream dependencies by [@abidlabs](https://github.com/abidlabs) in [PR 4885](https://github.com/gradio-app/gradio/pull/4885)
# 0.2.8
### New Features:
- Support loading gradio apps where `api_name=False` by [@abidlabs](https://github.com/abidlabs) in [PR 4683](https://github.com/gradio-app/gradio/pull/4683)
### Bug Fixes:
- Fix bug where space duplication would error if the demo has cpu-basic hardware by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4583](https://github.com/gradio-app/gradio/pull/4583)
- Fixes and optimizations to URL/download functions by [@akx](https://github.com/akx) in [PR 4695](https://github.com/gradio-app/gradio/pull/4695)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.7
### New Features:
- The output directory for files downloaded via the Client can now be set by the `output_dir` parameter in `Client` by [@abidlabs](https://github.com/abidlabs) in [PR 4501](https://github.com/gradio-app/gradio/pull/4501)
### Bug Fixes:
- The output directory for files downloaded via the Client are now set to a temporary directory by default (instead of the working directory in some cases) by [@abidlabs](https://github.com/abidlabs) in [PR 4501](https://github.com/gradio-app/gradio/pull/4501)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.6
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixed bug file deserialization didn't preserve all file extensions by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4440](https://github.com/gradio-app/gradio/pull/4440)
- Fixed bug where mounted apps could not be called via the client by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4435](https://github.com/gradio-app/gradio/pull/4435)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.5
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixes parameter names not showing underscores by [@abidlabs](https://github.com/abidlabs) in [PR 4230](https://github.com/gradio-app/gradio/pull/4230)
- Fixes issue in which state was not handled correctly if `serialize=False` by [@abidlabs](https://github.com/abidlabs) in [PR 4230](https://github.com/gradio-app/gradio/pull/4230)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
# 0.2.4
### Bug Fixes:
- Fixes missing serialization classes for several components: `Barplot`, `Lineplot`, `Scatterplot`, `AnnotatedImage`, `Interpretation` by [@abidlabs](https://github.com/abidlabs) in [PR 4167](https://github.com/gradio-app/gradio/pull/4167)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.2.3
### New Features:
No changes to highlight.
### Bug Fixes:
- Fix example inputs for `gr.File(file_count='multiple')` output components by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4153](https://github.com/gradio-app/gradio/pull/4153)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.2.2
### New Features:
No changes to highlight.
### Bug Fixes:
- Only send request to `/info` route if demo version is above `3.28.3` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4109](https://github.com/gradio-app/gradio/pull/4109)
### Other Changes:
- Fix bug in test from gradio 3.29.0 refactor by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 4138](https://github.com/gradio-app/gradio/pull/4138)
### Breaking Changes:
No changes to highlight.
# 0.2.1
### New Features:
No changes to highlight.
### Bug Fixes:
Removes extraneous `State` component info from the `Client.view_api()` method by [@abidlabs](https://github.com/freddyaboulton) in [PR 4107](https://github.com/gradio-app/gradio/pull/4107)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
Separates flaky tests from non-flaky tests by [@abidlabs](https://github.com/freddyaboulton) in [PR 4107](https://github.com/gradio-app/gradio/pull/4107)
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.1.4
### New Features:
- Progress Updates from `gr.Progress()` can be accessed via `job.status().progress_data` by @freddyaboulton](https://github.com/freddyaboulton) in [PR 3924](https://github.com/gradio-app/gradio/pull/3924)
### Bug Fixes:
- Fixed bug where unnamed routes where displayed with `api_name` instead of `fn_index` in `view_api` by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3972](https://github.com/gradio-app/gradio/pull/3972)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.1.3
### New Features:
No changes to highlight.
### Bug Fixes:
- Fixed bug where `Video` components in latest gradio were not able to be deserialized by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3860](https://github.com/gradio-app/gradio/pull/3860)
### Documentation Changes:
No changes to highlight.
### Testing and Infrastructure Changes:
No changes to highlight.
### Breaking Changes:
No changes to highlight.
### Full Changelog:
No changes to highlight.
### Contributors Shoutout:
No changes to highlight.
# 0.1.2
First public release of the Gradio Client library! The `gradio_client` Python library that makes it very easy to use any Gradio app as an API.
As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.

Using the `gradio_client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```python
from gradio_client import Client
client = Client("abidlabs/whisper")
client.predict("audio_sample.wav")
>> "This is a test of the whisper speech recognition model."
```
Read more about how to use the `gradio_client` library here: https://gradio.app/getting-started-with-the-python-client/ | gradio-app/gradio/blob/main/client/python/gradio_client/CHANGELOG.md |
Gradio Demo: blocks_form
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
error_box = gr.Textbox(label="Error", visible=False)
name_box = gr.Textbox(label="Name")
age_box = gr.Number(label="Age", minimum=0, maximum=100)
symptoms_box = gr.CheckboxGroup(["Cough", "Fever", "Runny Nose"])
submit_btn = gr.Button("Submit")
with gr.Column(visible=False) as output_col:
diagnosis_box = gr.Textbox(label="Diagnosis")
patient_summary_box = gr.Textbox(label="Patient Summary")
def submit(name, age, symptoms):
if len(name) == 0:
return {error_box: gr.Textbox(value="Enter name", visible=True)}
return {
output_col: gr.Column(visible=True),
diagnosis_box: "covid" if "Cough" in symptoms else "flu",
patient_summary_box: f"{name}, {age} y/o",
}
submit_btn.click(
submit,
[name_box, age_box, symptoms_box],
[error_box, diagnosis_box, patient_summary_box, output_col],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_form/run.ipynb |
he tokenization pipeline involves several steps that convert raw text into numbers. In this video, we will see what happens during the pre-tokenization step. The pre-tokenization operation is the operation performed after the normalization of the text and before the application of the tokenization algorithm. This step consists in applying rules that do not need to be learned to perform a first division of the text. Let's look at how several tokenizers pre_tokenize this example. The gpt 2 pretokenization divides the text on spaces and some punctuation - but the apostrophe is not a division criterion for example. We also notice that spaces have been replaced by a capital G with a dot above. Albert's pre-tokenization divides the text at the level of spaces, adds a space at the beginning of the sentence and replaces spaces with a special underscore. Finally, Bert's pre-tokenization divides the text at the level of punctuation and spaces. Unlike the previous tokenizers, spaces are not transformed and integrated to the tokens produced with this pre-tokenizer. Through these 3 examples, we could observe the two main types of operations brought by the pre-tokenization: some changes on the text and the division of the string into tokens that can be associated to words. Finally, the "backend_tokenizer" of the fast tokenizers also allows to test the pre-tokenization operation very easily thanks to its "pre_tokenize_str" method. We notice that the output of this operation is composed of both tokens and offsets which allow to link the token to its position in the text given in input of the method. This operation defines the largest tokens that can be produced by the tokenization or in other words the barriers of the sub-tokens which will be produced then. | huggingface/course/blob/main/subtitles/en/raw/chapter6/05b_pre-tokenization.md |
--
title: "What's going on with the Open LLM Leaderboard?"
thumbnail: /blog/assets/evaluating-mmlu-leaderboard/thumbnail.png
authors:
- user: clefourrier
- user: SaylorTwift
- user: slippylolo
- user: thomwolf
---
# What's going on with the Open LLM Leaderboard?
Recently an interesting discussion arose on Twitter following the release of [**Falcon 🦅**](https://huggingface.co/tiiuae/falcon-40b) and its addition to the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), a public leaderboard comparing open access large language models.
The discussion centered around one of the four evaluations displayed on the leaderboard: a benchmark for measuring [Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300) (shortname: MMLU).
The community was surprised that MMLU evaluation numbers of the current top model on the leaderboard, the [**LLaMA model 🦙**](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/), were significantly lower than the numbers in the [published LLaMa paper](https://arxiv.org/abs/2302.13971).
So we decided to dive in a rabbit hole to understand what was going on and how to fix it 🕳🐇
In our quest, we discussed with both the great [@javier-m](https://huggingface.co/javier-m) who collaborated on the evaluations of LLaMA and the amazing [@slippylolo](https://huggingface.co/slippylolo) from the Falcon team. This being said, all the errors in the below should be attributed to us rather than them of course!
Along this journey with us you’ll learn a lot about the ways you can evaluate a model on a single evaluation and whether or not to believe the numbers you see online and in papers.
Ready? Then buckle up, we’re taking off 🚀.
## What's the Open LLM Leaderboard?
First, note that the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) is actually just a wrapper running the open-source benchmarking library [Eleuther AI LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) created by the [EleutherAI non-profit AI research lab](https://www.eleuther.ai/) famous for creating [The Pile](https://pile.eleuther.ai/) and training [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6b), [GPT-Neo-X 20B](https://huggingface.co/EleutherAI/gpt-neox-20b), and [Pythia](https://github.com/EleutherAI/pythia). A team with serious credentials in the AI space!
This wrapper runs evaluations using the Eleuther AI harness on the spare cycles of Hugging Face’s compute cluster, and stores the results in a dataset on the hub that are then displayed on the [leaderboard online space](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
For the LLaMA models, the MMLU numbers obtained with the [Eleuther AI LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) significantly differ from the MMLU numbers reported in the LLaMa paper.
Why is that the case?
## 1001 flavors of MMLU
Well it turns out that the LLaMA team adapted another code implementation available online: the evaluation code proposed by the original UC Berkeley team which developed the MMLU benchmark available at https://github.com/hendrycks/test and that we will call here the **"Original implementation"**.
When diving further, we found yet another interesting implementation for evaluating on the very same MMLU dataset: the evalution code provided in Stanford’s [CRFM](https://crfm.stanford.edu/) very comprehensive evaluation benchmark [Holistic Evaluation of Language Models](https://crfm.stanford.edu/helm/latest/) that we will call here the **HELM implementation**.
Both the EleutherAI Harness and Stanford HELM benchmarks are interesting because they gather many evaluations in a single codebase (including MMLU), and thus give a wide view of a model’s performance. This is the reason the Open LLM Leaderboard is wrapping such “holistic” benchmarks instead of using individual code bases for each evaluation.
To settle the case, we decided to run these three possible implementations of the same MMLU evaluation on a set of models to rank them according to these results:
- the Harness implementation ([commit e47e01b](https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4))
- the HELM implementation ([commit cab5d89](https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec))
- the Original implementation (with Hugging Face integration by the amazing [@olmer](https://huggingface.co/olmer) at https://github.com/hendrycks/test/pull/13)
(Note that the Harness implementation has been recently updated - more in this at the end of our post)
The results are surprising:

You can find the full evaluation numbers at the end of the post.
These different implementations of the same benchmark give widely different numbers and even change the ranking order of the models on the leaderboard!
Let’s try to understand where this discrepancy comes from 🕵️But first, let’s briefly understand how we can automatically evaluate behaviors in modern LLMs.
## How we automatically evaluate a model in today’s LLM world
MMLU is a multiple choice question test, so a rather simple benchmark (versus open-ended questions) but as we’ll see, this still leaves a lot of room for implementation details and differences. The benchmark consists of questions with four possible answers covering 57 general knowledge domains grouped in coarse grained categories: “Humanities”, “Social Sciences”, “STEM”, etc
For each question, only one of the provided answers is the correct one. Here is an example:
```
Question: Glucose is transported into the muscle cell:
Choices:
A. via protein transporters called GLUT4.
B. only in the presence of insulin.
C. via hexokinase.
D. via monocarbylic acid transporters.
Correct answer: A
```
Note: you can very easily explore more of this dataset [in the dataset viewer](https://huggingface.co/datasets/cais/mmlu/viewer/college_medicine/dev?row=0) on the hub.
Large language models are simple models in the AI model zoo. They take a *string of text* as input (called a “prompt”), which is cut into tokens (words, sub-words or characters, depending on how the model is built) and fed in the model. From this input, they generate a distribution of probability for the next token, over all the tokens they know (so called the “vocabulary” of the model): you can therefore get how `probable’ any token is as a continuation of the input prompt.
We can use these probabilities to choose a token, for instance the most probable (or we can introduce some slight noise with a sampling to avoid having “too mechanical” answers). Adding our selected token to the prompt and feeding it back to the model allows to generate another token and so on until whole sentences are created as continuations of the input prompt:

This is how ChatGPT or Hugging Chat generate answers.
In summary, we have two main ways to get information out of a model to evaluate it:
1. get the **probabilities** that some specific tokens groups are continuations of the prompt – and **compare these probabilities together** for our predefined possible choices;
2. get a **text generation** from the model (by repeatedly selecting tokens as we’ve seen) – and **compare these text generations** to the texts of various predefined possible choices.
Armed with this knowledge, let's dive into our three implementations of MMLU, to find out what input is sent to models, what is expected as outputs, and how these outputs are compared.
## MMLU comes in all shapes and sizes: Looking at the prompts
Let’s compare an example of prompt each benchmark sends to the models by each implementation for the same MMLU dataset example:
<div>
<table><p>
<tbody>
<tr style="text-align: left;">
<td>Original implementation <a href="https://github.com/hendrycks/test/pull/13">Ollmer PR</a></td>
<td>HELM <a href="https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec">commit cab5d89</a> </td>
<td>AI Harness <a href="https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4">commit e47e01b</a></td>
</tr>
<tr style=" vertical-align: top;">
<td>The following are multiple choice questions (with answers) about us foreign policy. <br>
How did the 2008 financial crisis affect America's international reputation? <br>
A. It damaged support for the US model of political economy and capitalism <br>
B. It created anger at the United States for exaggerating the crisis <br>
C. It increased support for American global leadership under President Obama <br>
D. It reduced global use of the US dollar <br>
Answer:
</td>
<td>The following are multiple choice questions (with answers) about us foreign policy. <br>
<br>
Question: How did the 2008 financial crisis affect America's international reputation? <br>
A. It damaged support for the US model of political economy and capitalism <br>
B. It created anger at the United States for exaggerating the crisis <br>
C. It increased support for American global leadership under President Obama <br>
D. It reduced global use of the US dollar <br>
Answer:
</td>
<td>Question: How did the 2008 financial crisis affect America's international reputation? <br>
Choices: <br>
A. It damaged support for the US model of political economy and capitalism <br>
B. It created anger at the United States for exaggerating the crisis <br>
C. It increased support for American global leadership under President Obama <br>
D. It reduced global use of the US dollar <br>
Answer:
</td>
</tr>
</tbody>
</table><p>
</div>
The differences between them can seem small, did you spot them all? Here they are:
- First sentence, instruction, and topic: Few differences. HELM adds an extra space, and the Eleuther LM Harness does not include the topic line
- Question: HELM and the LM Harness add a “Question:” prefix
- Choices: Eleuther LM Harness prepends them with the keyword “Choices”
## Now how do we evaluate the model from these prompts?
Let’s start with how the [original MMLU implementation](https://github.com/hendrycks/test/pull/13) extracts the predictions of the model. In the original implementation we compare the probabilities predicted by the model, on the four answers only:

This can be beneficial for the model in some case, for instance, as you can see here:

In this case, the model got a +1 score for ranking the correct answer highest among the 4 options. But if we take a look at the full vocabulary it would have rather generated a word outside of our four options: the word “Zygote” (this is more of an example than a real use case 🙂)
How can we make sure that the model does as few as possible of these types of errors?
We can use a “**few shots**” approach in which we provide the model with one or several examples in the prompt, with their expected answers as well. Here is how it looks:

Here, the model has one example of the expected behavior and is thus less likely to predict answers outside of the expected range of answers.
Since this improves performance, MMLU is typically evaluated in 5 shots (prepending 5 examples to each prompt) in all our evaluations: the original implementation, EleutherAI LM Harness and HELM. (Note: Across benchmarks, though the same 5 examples are used, their order of introduction to the model can vary, which is also a possible source of difference, that we will not investigate here. You also obviously have to pay attention to avoid leaking some answers in the few shot examples you use…)
**HELM:** Let’s now turn to the [HELM implementation](https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec). While the few-shot prompt is generally similar, the way the model is evaluated is quite different from the original implementation we’ve just seen: we use the next token output probabilities from the model to select a text generation and we compare it to the text of the expected answer as displayed here:

In this case, if our "Zygote" token was instead the highest probability one (as we’ve seen above), the model answer ("Zygote") would be wrong and the model would not score any points for this question:

**Harness:** Now we finally turn to the - [EleutherAI Harness implementation as of January 2023](https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4) which was used to compute the first numbers for the leaderboard. As we will see, we’ve got here yet another way to compute a score for the model on the very same evaluation dataset (note that this implementation has been recently updated - more on this at the end).
In this case, we are using the probabilities again but this time the probabilities of the full answer sequence, with the letter followed by the text of the answer, for instance “C. The second pharyngeal arch”. To compute the probability for a full answer we get the probability for each token (like we saw above) and gather them. For numerical stability we gather them by summing the logarithm of the probabilities and we can decide (or not) to compute a normalization in which we divide the sum by the number of tokens to avoid giving too much advantage to longer answers (more on this later). Here is how it looks like:

Here is a table summary of the answers provided and generated by the model to summarize what we’ve seen up to now:
<div>
<table><p>
<tbody>
<tr style="text-align: left;">
<td>Original implementation</td>
<td>HELM</td>
<td>AI Harness (as of Jan 2023)</td>
</tr>
<tr style=" vertical-align: top;">
<td> We compare the probabilities of the following letter answers:
</td>
<td>The model is expected to generate as text the following letter answer:
</td>
<td>We compare the probabilities of the following full answers:
</td>
</tr>
<tr style=" vertical-align: top;">
<td> A <br>
B <br>
C <br>
D
</td>
<td>A
</td>
<td> A. It damaged support for the US model of political economy and capitalism <br>
B. It created anger at the United States for exaggerating the crisis <br>
C. It increased support for American global leadership under President Obama <br>
D. It reduced global use of the US dollar
</td>
</tr>
</tbody>
</table><p>
</div>
We’ve covered them all!
Now let’s compare the model scores on these three possible ways to evaluate the models:
| | MMLU (HELM) | MMLU (Harness) | MMLU (Original) |
|:------------------------------------------|------------:|---------------:|----------------:|
| llama-65b | **0.637** | 0.488 | **0.636** |
| tiiuae/falcon-40b | 0.571 | **0.527** | 0.558 |
| llama-30b | 0.583 | 0.457 | 0.584 |
| EleutherAI/gpt-neox-20b | 0.256 | 0.333 | 0.262 |
| llama-13b | 0.471 | 0.377 | 0.47 |
| llama-7b | 0.339 | 0.342 | 0.351 |
| tiiuae/falcon-7b | 0.278 | 0.35 | 0.254 |
| togethercomputer/RedPajama-INCITE-7B-Base | 0.275 | 0.34 | 0.269 |
We can see that for the same dataset, both absolute scores and model rankings (see the first figure) are very sensitive to the evaluation method we decide to use.
Let's say you've trained yourself a perfect reproduction of the LLaMA 65B model and evaluated it with the harness (score 0.488, see above). You're now comparing it to the published number (evaluated on the original MMLU implementation so with a score 0.637). With such a 30% difference in score you're probably thinking: "Oh gosh, I have completly messed up my training 😱". But nothing could be further from the truth, these are just numbers which are not at all comparable even if they're both labelled as "MMLU score" (and evaluated on the very same MMLU dataset).
Now, is there a "best way" to evaluate a model among all the ones we've seen? It's a tricky question. Different models may fare differently when evaluated one way or another as we see above when the rankings change. To keep this as fair as possible, one may be tempted to select an implementation where the average score for all tested models is the highest so that we "unlock" as many capabilities as possible from the models. In our case, that would mean using the log-likelihood option of the original implementation. But as we saw above, using the log-likelihood is also giving some indications to the model in some way by restricting the scope of possible answers, and thus is helping the less powerful models maybe too much. Also log-likelihood is easy to access for open-source models but is not always exposed for closed source API models.
And you, reader, what do you think? This blog post is already long so it's time to open the discussion and invite your comments. Please come discuss this topic in the following discussion thread of the Open LLM Leaderboard: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard/discussions/82
## Conclusion
A key takeaway lesson from our journey is that evaluations are strongly tied to their implementations–down to minute details such as prompts and tokenization. The mere indication of "MMLU results" gives you little to no information about how you can compare these numbers to others you evaluated on another library.
This is why open, standardized, and reproducible benchmarks such as the [EleutherAI Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness/) or [Stanford HELM](https://github.com/stanford-crfm/helm/) are invaluable to the community. Without them, comparing results across models and papers would be impossible, stifling research on improving LLMs.
**Post scriptum**: In the case of the Open LLM Leaderboard we’ve decided to stick to using community maintained evaluation libraries. Thankfully during the writing of this blog post, the amazing community around the EleutherAI Harness, and in particular [ollmer](https://github.com/EleutherAI/lm-evaluation-harness/issues/475)
have done an amazing work updating the evaluation of MMLU in the harness to make it similar to the original implementation and match these numbers.
We are currently updating the full leaderboard with the updated version of the [EleutherAI Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness/), so expect to see scores coming from the Eleuther Harness v2 coming up in the next few weeks! (Running all the models again will take some time, stay tuned :hugs:)
## Acknowledgements:
We are very grateful to Xavier Martinet, Aurélien Rodriguez and Sharan Narang from the LLaMA team for helpful suggestions in this blog post as well as having answered all our questions.
## Reproducibility hashes:
Here are the commit hashes of the various code implementations used in this blog post.
- EleutherAI LM harness implementation commit e47e01b: https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4
- HELM implementation commit cab5d89: https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec
- Original MMLU implementation (with Hugging Face integration by the amazing [@olmer](https://huggingface.co/olmer)): https://github.com/hendrycks/test/pull/13
| huggingface/blog/blob/main/evaluating-mmlu-leaderboard.md |
``python
import argparse
import gc
import hashlib
import itertools
import logging
import math
import os
import threading
import warnings
from pathlib import Path
from typing import Optional
import psutil
import json
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
from torch.utils.data import Dataset
import datasets
import diffusers
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
from diffusers import DDPMScheduler, PNDMScheduler, StableDiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version
from diffusers.utils.import_utils import is_xformers_available
from huggingface_hub import HfFolder, Repository, whoami
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig, CLIPFeatureExtractor
from peft import PeftModel, LoraConfig, get_peft_model_state_dict, set_peft_model_state_dict
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.10.0.dev0")
logger = get_logger(__name__)
MODEL_NAME = "CompVis/stable-diffusion-v1-4" # "stabilityai/stable-diffusion-2-1-base"
INSTANCE_PROMPT = "a photo of sks dog"
base_path = "/home/sourab/temp/"
```
```python
def get_lora_sd_pipeline(
ckpt_dir, base_model_name_or_path=None, dtype=torch.float16, device="cuda", adapter_name="default"
):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
if os.path.exists(text_encoder_sub_dir) and base_model_name_or_path is None:
config = LoraConfig.from_pretrained(text_encoder_sub_dir)
base_model_name_or_path = config.base_model_name_or_path
if base_model_name_or_path is None:
raise ValueError("Please specify the base model name or path")
pipe = StableDiffusionPipeline.from_pretrained(
base_model_name_or_path, torch_dtype=dtype, requires_safety_checker=False
).to(device)
pipe.unet = PeftModel.from_pretrained(pipe.unet, unet_sub_dir, adapter_name=adapter_name)
if os.path.exists(text_encoder_sub_dir):
pipe.text_encoder = PeftModel.from_pretrained(
pipe.text_encoder, text_encoder_sub_dir, adapter_name=adapter_name
)
if dtype in (torch.float16, torch.bfloat16):
pipe.unet.half()
pipe.text_encoder.half()
pipe.to(device)
return pipe
def load_adapter(pipe, ckpt_dir, adapter_name):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
pipe.unet.load_adapter(unet_sub_dir, adapter_name=adapter_name)
if os.path.exists(text_encoder_sub_dir):
pipe.text_encoder.load_adapter(text_encoder_sub_dir, adapter_name=adapter_name)
def set_adapter(pipe, adapter_name):
pipe.unet.set_adapter(adapter_name)
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.set_adapter(adapter_name)
def merging_lora_with_base(pipe, ckpt_dir, adapter_name="default"):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
if isinstance(pipe.unet, PeftModel):
pipe.unet.set_adapter(adapter_name)
else:
pipe.unet = PeftModel.from_pretrained(pipe.unet, unet_sub_dir, adapter_name=adapter_name)
pipe.unet = pipe.unet.merge_and_unload()
if os.path.exists(text_encoder_sub_dir):
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.set_adapter(adapter_name)
else:
pipe.text_encoder = PeftModel.from_pretrained(
pipe.text_encoder, text_encoder_sub_dir, adapter_name=adapter_name
)
pipe.text_encoder = pipe.text_encoder.merge_and_unload()
return pipe
def create_weighted_lora_adapter(pipe, adapters, weights, adapter_name="default"):
pipe.unet.add_weighted_adapter(adapters, weights, adapter_name)
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.add_weighted_adapter(adapters, weights, adapter_name)
return pipe
```
```python
%%time
pipe = get_lora_sd_pipeline(os.path.join(base_path, "dog_dreambooth_updated"), adapter_name="dog")
```
```python
%%time
load_adapter(pipe, os.path.join(base_path, "toy_dreambooth"), adapter_name="toy")
```
```python
pipe = create_weighted_lora_adapter(pipe, ["toy", "dog"], [1.0, 1.05], adapter_name="toy_dog")
```
```python
%%time
set_adapter(pipe, adapter_name="dog")
```
```python
prompt = "sks dog playing fetch in the park"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
```python
%%time
set_adapter(pipe, adapter_name="toy")
```
```python
prompt = "narendra modi rendered in the style of <1>"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
```python
set_adapter(pipe, adapter_name="dog")
prompt = "sks dog in a big red bucket"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
```python
set_adapter(pipe, adapter_name="toy")
prompt = "superman rendered in the style of <1>, close up potrait"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
```python
set_adapter(pipe, adapter_name="toy_dog")
prompt = "sks dog rendered in the style of <1>, close up potrait, 4K HD"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
| huggingface/peft/blob/main/examples/lora_dreambooth/lora_dreambooth_inference.ipynb |
Aim on Spaces
**Aim** is an easy-to-use & supercharged open-source experiment tracker. Aim logs your training runs and enables a beautiful UI to compare them and an API to query them programmatically.
ML engineers and researchers use Aim explorers to compare 1000s of training runs in a few clicks.
Check out the [Aim docs](https://aimstack.readthedocs.io/en/latest/) to learn more about Aim.
If you have an idea for a new feature or have noticed a bug, feel free to [open a feature request or report a bug](https://github.com/aimhubio/aim/issues/new/choose).
In the following sections, you'll learn how to deploy Aim on the Hugging Face Hub Spaces and explore your training runs directly from the Hub.
## Deploy Aim on Spaces
You can deploy Aim on Spaces with a single click!
<a href="https://huggingface.co/new-space?template=aimstack/aim">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg" />
</a>
Once you have created the Space, you'll see the `Building` status, and once it becomes `Running,` your Space is ready to go!
<img src="https://user-images.githubusercontent.com/23078323/231592155-869148a0-9a92-475f-8ebe-34d4deb2abc2.png" alt="Creating an Aim Space" width=800 />
Now, when you navigate to your Space's **App** section, you can access the Aim UI.
## Compare your experiments with Aim on Spaces
Let's use a quick example of a PyTorch CNN trained on MNIST to demonstrate end-to-end Aim on Spaces deployment.
The full example is in the [Aim repo examples folder](https://github.com/aimhubio/aim/blob/main/examples/pytorch_track.py).
```python
from aim import Run
from aim.pytorch import track_gradients_dists, track_params_dists
# Initialize a new Run
aim_run = Run()
...
items = {'accuracy': acc, 'loss': loss}
aim_run.track(items, epoch=epoch, context={'subset': 'train'})
# Track weights and gradients distributions
track_params_dists(model, aim_run)
track_gradients_dists(model, aim_run)
```
The experiments tracked by Aim are stored in the `.aim` folder. **To display the logs with the Aim UI in your Space, you need to compress the `.aim` folder to a `tar.gz` file and upload it to your Space using `git` or the Files and Versions sections of your Space.**
Here's a bash command for that:
```bash
tar -czvf aim_repo.tar.gz .aim
```
That’s it! Now open the App section of your Space and the Aim UI is available with your logs.
Here is what to expect:
Filter your runs using Aim’s Pythonic search. You can write pythonic [queries against](https://aimstack.readthedocs.io/en/latest/using/search.html) EVERYTHING you have tracked - metrics, hyperparams etc. Check out some [examples](https://huggingface.co/aimstack) on HF Hub Spaces.
<Tip>
Note that if your logs are in TensorBoard format, you can easily convert <a href="https://aimstack.readthedocs.io/en/latest/quick_start/convert_data.html#show-tensorboard-logs-in-aim">them to Aim with one command</a> and use the many advanced and high-performant training run comparison features available.
</Tip>
## More on HF Spaces
- [HF Docker spaces](https://huggingface.co/docs/hub/spaces-sdks-docker)
- [HF Docker space examples](https://huggingface.co/docs/hub/spaces-sdks-docker-examples)
## Feedback and Support
If you have improvement suggestions or need support, please open an issue on [Aim GitHub repo](https://github.com/aimhubio/aim).
The [Aim community Discord](https://github.com/aimhubio/aim#-community) is also available for community discussions.
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-aim.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Webhooks Server
Webhooks are a foundation for MLOps-related features. They allow you to listen for new changes on specific repos or to
all repos belonging to particular users/organizations you're interested in following. This guide will explain how to
leverage `huggingface_hub` to create a server listening to webhooks and deploy it to a Space. It assumes you are
familiar with the concept of webhooks on the Huggingface Hub. To learn more about webhooks themselves, you can read
this [guide](https://huggingface.co/docs/hub/webhooks) first.
The base class that we will use in this guide is [`WebhooksServer`]. It is a class for easily configuring a server that
can receive webhooks from the Huggingface Hub. The server is based on a [Gradio](https://gradio.app/) app. It has a UI
to display instructions for you or your users and an API to listen to webhooks.
<Tip>
To see a running example of a webhook server, check out the [Spaces CI Bot](https://huggingface.co/spaces/spaces-ci-bot/webhook)
one. It is a Space that launches ephemeral environments when a PR is opened on a Space.
</Tip>
<Tip warning={true}>
This is an [experimental feature](../package_reference/environment_variables#hfhubdisableexperimentalwarning). This
means that we are still working on improving the API. Breaking changes might be introduced in the future without prior
notice. Make sure to pin the version of `huggingface_hub` in your requirements.
</Tip>
## Create an endpoint
Implementing a webhook endpoint is as simple as decorating a function. Let's see a first example to explain the main
concepts:
```python
# app.py
from huggingface_hub import webhook_endpoint, WebhookPayload
@webhook_endpoint
async def trigger_training(payload: WebhookPayload) -> None:
if payload.repo.type == "dataset" and payload.event.action == "update":
# Trigger a training job if a dataset is updated
...
```
Save this snippet in a file called `'app.py'` and run it with `'python app.py'`. You should see a message like this:
```text
Webhook secret is not defined. This means your webhook endpoints will be open to everyone.
To add a secret, set `WEBHOOK_SECRET` as environment variable or pass it at initialization:
`app = WebhooksServer(webhook_secret='my_secret', ...)`
For more details about webhook secrets, please refer to https://huggingface.co/docs/hub/webhooks#webhook-secret.
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://1fadb0f52d8bf825fc.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
Webhooks are correctly setup and ready to use:
- POST https://1fadb0f52d8bf825fc.gradio.live/webhooks/trigger_training
Go to https://huggingface.co/settings/webhooks to setup your webhooks.
```
Good job! You just launched a webhook server! Let's break down what happened exactly:
1. By decorating a function with [`webhook_endpoint`], a [`WebhooksServer`] object has been created in the background.
As you can see, this server is a Gradio app running on http://127.0.0.1:7860. If you open this URL in your browser, you
will see a landing page with instructions about the registered webhooks.
2. A Gradio app is a FastAPI server under the hood. A new POST route `/webhooks/trigger_training` has been added to it.
This is the route that will listen to webhooks and run the `trigger_training` function when triggered. FastAPI will
automatically parse the payload and pass it to the function as a [`WebhookPayload`] object. This is a `pydantic` object
that contains all the information about the event that triggered the webhook.
3. The Gradio app also opened a tunnel to receive requests from the internet. This is the interesting part: you can
configure a Webhook on https://huggingface.co/settings/webhooks pointing to your local machine. This is useful for
debugging your webhook server and quickly iterating before deploying it to a Space.
4. Finally, the logs also tell you that your server is currently not secured by a secret. This is not problematic for
local debugging but is to keep in mind for later.
<Tip warning={true}>
By default, the server is started at the end of your script. If you are running it in a notebook, you can start the
server manually by calling `decorated_function.run()`. Since a unique server is used, you only have to start the server
once even if you have multiple endpoints.
</Tip>
## Configure a Webhook
Now that you have a webhook server running, you want to configure a Webhook to start receiving messages.
Go to https://huggingface.co/settings/webhooks, click on "Add a new webhook" and configure your Webhook. Set the target
repositories you want to watch and the Webhook URL, here `https://1fadb0f52d8bf825fc.gradio.live/webhooks/trigger_training`.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/configure_webhook.png"/>
</div>
And that's it! You can now trigger that webhook by updating the target repository (e.g. push a commit). Check the
Activity tab of your Webhook to see the events that have been triggered. Now that you have a working setup, you can
test it and quickly iterate. If you modify your code and restart the server, your public URL might change. Make sure
to update the webhook configuration on the Hub if needed.
## Deploy to a Space
Now that you have a working webhook server, the goal is to deploy it to a Space. Go to https://huggingface.co/new-space
to create a Space. Give it a name, select the Gradio SDK and click on "Create Space". Upload your code to the Space
in a file called `app.py`. Your Space will start automatically! For more details about Spaces, please refer to this
[guide](https://huggingface.co/docs/hub/spaces-overview).
Your webhook server is now running on a public Space. If most cases, you will want to secure it with a secret. Go to
your Space settings > Section "Repository secrets" > "Add a secret". Set the `WEBHOOK_SECRET` environment variable to
the value of your choice. Go back to the [Webhooks settings](https://huggingface.co/settings/webhooks) and set the
secret in the webhook configuration. Now, only requests with the correct secret will be accepted by your server.
And this is it! Your Space is now ready to receive webhooks from the Hub. Please keep in mind that if you run the Space
on a free 'cpu-basic' hardware, it will be shut down after 48 hours of inactivity. If you need a permanent Space, you
should consider setting to an [upgraded hardware](https://huggingface.co/docs/hub/spaces-gpus#hardware-specs).
## Advanced usage
The guide above explained the quickest way to setup a [`WebhooksServer`]. In this section, we will see how to customize
it further.
### Multiple endpoints
You can register multiple endpoints on the same server. For example, you might want to have one endpoint to trigger
a training job and another one to trigger a model evaluation. You can do this by adding multiple `@webhook_endpoint`
decorators:
```python
# app.py
from huggingface_hub import webhook_endpoint, WebhookPayload
@webhook_endpoint
async def trigger_training(payload: WebhookPayload) -> None:
if payload.repo.type == "dataset" and payload.event.action == "update":
# Trigger a training job if a dataset is updated
...
@webhook_endpoint
async def trigger_evaluation(payload: WebhookPayload) -> None:
if payload.repo.type == "model" and payload.event.action == "update":
# Trigger an evaluation job if a model is updated
...
```
Which will create two endpoints:
```text
(...)
Webhooks are correctly setup and ready to use:
- POST https://1fadb0f52d8bf825fc.gradio.live/webhooks/trigger_training
- POST https://1fadb0f52d8bf825fc.gradio.live/webhooks/trigger_evaluation
```
### Custom server
To get more flexibility, you can also create a [`WebhooksServer`] object directly. This is useful if you want to
customize the landing page of your server. You can do this by passing a [Gradio UI](https://gradio.app/docs/#blocks)
that will overwrite the default one. For example, you can add instructions for your users or add a form to manually
trigger the webhooks. When creating a [`WebhooksServer`], you can register new webhooks using the
[`~WebhooksServer.add_webhook`] decorator.
Here is a complete example:
```python
import gradio as gr
from fastapi import Request
from huggingface_hub import WebhooksServer, WebhookPayload
# 1. Define UI
with gr.Blocks() as ui:
...
# 2. Create WebhooksServer with custom UI and secret
app = WebhooksServer(ui=ui, webhook_secret="my_secret_key")
# 3. Register webhook with explicit name
@app.add_webhook("/say_hello")
async def hello(payload: WebhookPayload):
return {"message": "hello"}
# 4. Register webhook with implicit name
@app.add_webhook
async def goodbye(payload: WebhookPayload):
return {"message": "goodbye"}
# 5. Start server (optional)
app.run()
```
1. We define a custom UI using Gradio blocks. This UI will be displayed on the landing page of the server.
2. We create a [`WebhooksServer`] object with a custom UI and a secret. The secret is optional and can be set with
the `WEBHOOK_SECRET` environment variable.
3. We register a webhook with an explicit name. This will create an endpoint at `/webhooks/say_hello`.
4. We register a webhook with an implicit name. This will create an endpoint at `/webhooks/goodbye`.
5. We start the server. This is optional as your server will automatically be started at the end of the script. | huggingface/huggingface_hub/blob/main/docs/source/en/guides/webhooks_server.md |
Overview
The how-to guides offer a more comprehensive overview of all the tools 🤗 Datasets offers and how to use them. This will help you tackle messier real-world datasets where you may need to manipulate the dataset structure or content to get it ready for training.
The guides assume you are familiar and comfortable with the 🤗 Datasets basics. We recommend newer users check out our [tutorials](tutorial) first.
<Tip>
Interested in learning more? Take a look at [Chapter 5](https://huggingface.co/course/chapter5/1?fw=pt) of the Hugging Face course!
</Tip>
The guides are organized into six sections:
- <span class="underline decoration-sky-400 decoration-2 font-semibold">General usage</span>: Functions for general dataset loading and processing. The functions shown in this section are applicable across all dataset modalities.
- <span class="underline decoration-pink-400 decoration-2 font-semibold">Audio</span>: How to load, process, and share audio datasets.
- <span class="underline decoration-yellow-400 decoration-2 font-semibold">Vision</span>: How to load, process, and share image datasets.
- <span class="underline decoration-green-400 decoration-2 font-semibold">Text</span>: How to load, process, and share text datasets.
- <span class="underline decoration-orange-400 decoration-2 font-semibold">Tabular</span>: How to load, process, and share tabular datasets.
- <span class="underline decoration-indigo-400 decoration-2 font-semibold">Dataset repository</span>: How to share and upload a dataset to the <a href="https://huggingface.co/datasets">Hub</a>.
If you have any questions about 🤗 Datasets, feel free to join and ask the community on our [forum](https://discuss.huggingface.co/c/datasets/10).
| huggingface/datasets/blob/main/docs/source/how_to.md |
--
title: "The Technology Behind BLOOM Training"
thumbnail: /blog/assets/86_bloom_megatron_deepspeed/thumbnail.png
authors:
- user: stas
---
# The Technology Behind BLOOM Training
In recent years, training ever larger language models has become the norm. While the issues of those models' not being released for further study is frequently discussed, the hidden knowledge about how to train such models rarely gets any attention. This article aims to change this by shedding some light on the technology and engineering behind training such models both in terms of hardware and software on the example of the 176B parameter language model [BLOOM](https://huggingface.co/bigscience/bloom).
But first we would like to thank the companies and key people and groups that made the amazing feat of training a 176 Billion parameter model by a small group of dedicated people possible.
Then the hardware setup and main technological components will be discussed.

Here's a quick summary of project:
| | |
| :----- | :------------- |
| Hardware | 384 80GB A100 GPUs |
| Software | Megatron-DeepSpeed |
| Architecture | GPT3 w/ extras |
| Dataset | 350B tokens of 59 Languages |
| Training time | 3.5 months |
## People
The project was conceived by Thomas Wolf (co-founder and CSO - Hugging Face), who dared to compete with the huge corporations not only to train one of the largest multilingual models, but also to make the final result accessible to all people, thus making what was but a dream to most people a reality.
This article focuses specifically on the engineering side of the training of the model. The most important part of the technology behind BLOOM were the people and companies who shared their expertise and helped us with coding and training.
There are 6 main groups of people to thank:
1. The HuggingFace's BigScience team who dedicated more than half a dozen full time employees to figure out and run the training from inception to the finishing line and provided and paid for all the infrastructure beyond the Jean Zay's compute.
2. The Microsoft DeepSpeed team, who developed DeepSpeed and later integrated it with Megatron-LM, and whose developers spent many weeks working on the needs of the project and provided lots of awesome practical experiential advice before and during the training.
3. The NVIDIA Megatron-LM team, who developed Megatron-LM and who were super helpful answering our numerous questions and providing first class experiential advice.
4. The IDRIS / GENCI team managing the Jean Zay supercomputer, who donated to the project an insane amount of compute and great system administration support.
5. The PyTorch team who created a super powerful framework, on which the rest of the software was based, and who were very supportive to us during the preparation for the training, fixing multiple bugs and improving the usability of the PyTorch components we relied on during the training.
6. The volunteers in the BigScience Engineering workgroup
It'd be very difficult to name all the amazing people who contributed to the engineering side of the project, so I will just name a few key people outside of Hugging Face who were the engineering foundation of this project for the last 14 months:
Olatunji Ruwase, Deepak Narayanan, Jeff Rasley, Jared Casper, Samyam Rajbhandari and Rémi Lacroix
Also we are grateful to all the companies who allowed their employees to contribute to this project.
## Overview
BLOOM's architecture is very similar to [GPT3](https://en.wikipedia.org/wiki/GPT-3) with a few added improvements as will be discussed later in this article.
The model was trained on [Jean Zay](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html), the French government-funded super computer that is managed by GENCI and installed at [IDRIS](http://www.idris.fr/), the national computing center for the French National Center for Scientific Research (CNRS). The compute was generously donated to the project by GENCI (grant 2021-A0101012475).
The following hardware was used during the training:
- GPUs: 384 NVIDIA A100 80GB GPUs (48 nodes) + 32 spare gpus
- 8 GPUs per node Using NVLink 4 inter-gpu connects, 4 OmniPath links
- CPU: AMD EPYC 7543 32-Core Processor
- CPU memory: 512GB per node
- GPU memory: 640GB per node
- Inter-node connect: Omni-Path Architecture (OPA) w/ non-blocking fat tree
- NCCL-communications network: a fully dedicated subnet
- Disc IO network: GPFS shared with other nodes and users
Checkpoints:
- [main checkpoints](https://huggingface.co/bigscience/bloom)
- each checkpoint with fp32 optim states and bf16+fp32 weights is 2.3TB - just the bf16 weights are 329GB.
Datasets:
- 46 Languages in 1.5TB of deduplicated massively cleaned up text, converted into 350B unique tokens
- Vocabulary size of the model is 250,680 tokens
- For full details please see [The BigScience Corpus A 1.6TB Composite Multilingual Dataset](https://openreview.net/forum?id=UoEw6KigkUn)
The training of the 176B BLOOM model occurred over Mar-Jul 2022 and took about 3.5 months to complete (approximately 1M compute hours).
## Megatron-DeepSpeed
The 176B BLOOM model has been trained using [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is a combination of 2 main technologies:
* [DeepSpeed](https://github.com/microsoft/DeepSpeed) is a deep learning optimization library that makes distributed training easy, efficient, and effective.
* [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) is a large, powerful transformer model framework developed by the Applied Deep Learning Research team at NVIDIA.
The DeepSpeed team developed a 3D parallelism based implementation by combining ZeRO sharding and pipeline parallelism from the DeepSpeed library with Tensor Parallelism from Megatron-LM. More details about each component can be seen in the table below.
Please note that the BigScience's [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed) is a fork of the original [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) repository, to which we added multiple additions.
Here is a table of which components were provided by which framework to train BLOOM:
| Component | DeepSpeed | Megatron-LM |
| :---- | :---- | :---- |
| [ZeRO Data Parallelism](#zero-data-parallelism) | V | |
| [Tensor Parallelism](#tensor-parallelism) | | V |
| [Pipeline Parallelism](#pipeline-parallelism) | V | |
| [BF16Optimizer](#bf16optimizer) | V | |
| [Fused CUDA Kernels](#fused-cuda-kernels) | | V |
| [DataLoader](#datasets) | | V |
Please note that both Megatron-LM and DeepSpeed have Pipeline Parallelism and BF16 Optimizer implementations, but we used the ones from DeepSpeed as they are integrated with ZeRO.
Megatron-DeepSpeed implements 3D Parallelism to allow huge models to train in a very efficient way. Let’s briefly discuss the 3D components.
1. **DataParallel (DP)** - the same setup is replicated multiple times, and each being fed a slice of the data. The processing is done in parallel and all setups are synchronized at the end of each training step.
2. **TensorParallel (TP)** - each tensor is split up into multiple chunks, so instead of having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. During processing each shard gets processed separately and in parallel on different GPUs and the results are synced at the end of the step. This is what one may call horizontal parallelism, as the splitting happens on a horizontal level.
3. **PipelineParallel (PP)** - the model is split up vertically (layer-level) across multiple GPUs, so that only one or several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline and works on a small chunk of the batch.
4. **Zero Redundancy Optimizer (ZeRO)** - also performs sharding of the tensors somewhat similar to TP, except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need to be modified. It also supports various offloading techniques to compensate for limited GPU memory.
## Data Parallelism
Most users with just a few GPUs are likely to be familiar with `DistributedDataParallel` (DDP) [PyTorch documentation](https://pytorch.org/docs/master/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel). In this method the model is fully replicated to each GPU and then after each iteration all the models synchronize their states with each other. This approach allows training speed up but throwing more resources at the problem, but it only works if the model can fit onto a single GPU.
### ZeRO Data Parallelism
ZeRO-powered data parallelism (ZeRO-DP) is described on the following diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)

It can be difficult to wrap one's head around it, but in reality, the concept is quite simple. This is just the usual DDP, except, instead of replicating the full model params, gradients and optimizer states, each GPU stores only a slice of it. And then at run-time when the full layer params are needed just for the given layer, all GPUs synchronize to give each other parts that they miss - this is it.
This component is implemented by DeepSpeed.
## Tensor Parallelism
In Tensor Parallelism (TP) each GPU processes only a slice of a tensor and only aggregates the full tensor for operations that require the whole thing.
In this section we use concepts and diagrams from the [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) paper: [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
The main building block of any transformer is a fully connected `nn.Linear` followed by a nonlinear activation `GeLU`.
Following the Megatron paper's notation, we can write the dot-product part of it as `Y = GeLU(XA)`, where `X` and `Y` are the input and output vectors, and `A` is the weight matrix.
If we look at the computation in matrix form, it's easy to see how the matrix multiplication can be split between multiple GPUs:

If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel, then we will end up with `N` output vectors `Y_1, Y_2, ..., Y_n` which can be fed into `GeLU` independently:
. Notice with the Y matrix split along the columns, we can split the second GEMM along its rows so that it takes the output of the GeLU directly without any extra communication.
Using this principle, we can update an MLP of arbitrary depth, while synchronizing the GPUs after each row-column sequence. The Megatron-LM paper authors provide a helpful illustration for that:

Here `f` is an identity operator in the forward pass and all reduce in the backward pass while `g` is an all reduce in the forward pass and identity in the backward pass.
Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having multiple independent heads!

Special considerations: Due to the two all reduces per layer in both the forward and backward passes, TP requires a very fast interconnect between devices. Therefore it's not advisable to do TP across more than one node, unless you have a very fast network. In our case the inter-node was much slower than PCIe. Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use nodes that have at least 8 GPUs.
This component is implemented by Megatron-LM. Megatron-LM has recently expanded tensor parallelism to include sequence parallelism that splits the operations that cannot be split as above, such as LayerNorm, along the sequence dimension. The paper [Reducing Activation Recomputation in Large Transformer Models](https://arxiv.org/abs/2205.05198) provides details for this technique. Sequence parallelism was developed after BLOOM was trained so not used in the BLOOM training.
## Pipeline Parallelism
Naive Pipeline Parallelism (naive PP) is where one spreads groups of model layers across multiple GPUs and simply moves data along from GPU to GPU as if it were one large composite GPU. The mechanism is relatively simple - switch the desired layers `.to()` the desired devices and now whenever the data goes in and out those layers switch the data to the same device as the layer and leave the rest unmodified.
This performs a vertical model parallelism, because if you remember how most models are drawn, we slice the layers vertically. For example, if the following diagram shows an 8-layer model:
```
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
```
we just sliced it in 2 vertically, placing layers 0-3 onto GPU0 and 4-7 to GPU1.
Now while data travels from layer 0 to 1, 1 to 2 and 2 to 3 this is just like the forward pass of a normal model on a single GPU. But when data needs to pass from layer 3 to layer 4 it needs to travel from GPU0 to GPU1 which introduces a communication overhead. If the participating GPUs are on the same compute node (e.g. same physical machine) this copying is pretty fast, but if the GPUs are located on different compute nodes (e.g. multiple machines) the communication overhead could be significantly larger.
Then layers 4 to 5 to 6 to 7 are as a normal model would have and when the 7th layer completes we often need to send the data back to layer 0 where the labels are (or alternatively send the labels to the last layer). Now the loss can be computed and the optimizer can do its work.
Problems:
- the main deficiency and why this one is called "naive" PP, is that all but one GPU is idle at any given moment. So if 4 GPUs are used, it's almost identical to quadrupling the amount of memory of a single GPU, and ignoring the rest of the hardware. Plus there is the overhead of copying the data between devices. So 4x 6GB cards will be able to accommodate the same size as 1x 24GB card using naive PP, except the latter will complete the training faster, since it doesn't have the data copying overhead. But, say, if you have 40GB cards and need to fit a 45GB model you can with 4x 40GB cards (but barely because of the gradient and optimizer states).
- shared embeddings may need to get copied back and forth between GPUs.
Pipeline Parallelism (PP) is almost identical to a naive PP described above, but it solves the GPU idling problem, by chunking the incoming batch into micro-batches and artificially creating a pipeline, which allows different GPUs to concurrently participate in the computation process.
The following illustration from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html) shows the naive PP on the top, and PP on the bottom:

It's easy to see from the bottom diagram how PP has fewer dead zones, where GPUs are idle. The idle parts are referred to as the "bubble".
Both parts of the diagram show parallelism that is of degree 4. That is 4 GPUs are participating in the pipeline. So there is the forward path of 4 pipe stages F0, F1, F2 and F3 and then the return reverse order backward path of B3, B2, B1 and B0.
PP introduces a new hyper-parameter to tune that is called `chunks`. It defines how many chunks of data are sent in a sequence through the same pipe stage. For example, in the bottom diagram, you can see that `chunks=4`. GPU0 performs the same forward path on chunk 0, 1, 2 and 3 (F0,0, F0,1, F0,2, F0,3) and then it waits for other GPUs to do their work and only when their work is starting to be complete, does GPU0 start to work again doing the backward path for chunks 3, 2, 1 and 0 (B0,3, B0,2, B0,1, B0,0).
Note that conceptually this is the same concept as gradient accumulation steps (GAS). PyTorch uses `chunks`, whereas DeepSpeed refers to the same hyper-parameter as GAS.
Because of the chunks, PP introduces the concept of micro-batches (MBS). DP splits the global data batch size into mini-batches, so if you have a DP degree of 4, a global batch size of 1024 gets split up into 4 mini-batches of 256 each (1024/4). And if the number of `chunks` (or GAS) is 32 we end up with a micro-batch size of 8 (256/32). Each Pipeline stage works with a single micro-batch at a time.
To calculate the global batch size of the DP + PP setup we then do: `mbs*chunks*dp_degree` (`8*32*4=1024`).
Let's go back to the diagram.
With `chunks=1` you end up with the naive PP, which is very inefficient. With a very large `chunks` value you end up with tiny micro-batch sizes which could be not very efficient either. So one has to experiment to find the value that leads to the highest efficient utilization of the GPUs.
While the diagram shows that there is a bubble of "dead" time that can't be parallelized because the last `forward` stage has to wait for `backward` to complete the pipeline, the purpose of finding the best value for `chunks` is to enable a high concurrent GPU utilization across all participating GPUs which translates to minimizing the size of the bubble.
This scheduling mechanism is known as `all forward all backward`. Some other alternatives are [one forward one backward](https://www.microsoft.com/en-us/research/publication/pipedream-generalized-pipeline-parallelism-for-dnn-training/) and [interleaved one forward one backward](https://arxiv.org/abs/2104.04473).
While both Megatron-LM and DeepSpeed have their own implementation of the PP protocol, Megatron-DeepSpeed uses the DeepSpeed implementation as it's integrated with other aspects of DeepSpeed.
One other important issue here is the size of the word embedding matrix. While normally a word embedding matrix consumes less memory than the transformer block, in our case with a huge 250k vocabulary, the embedding layer needed 7.2GB in bf16 weights and the transformer block is just 4.9GB. Therefore, we had to instruct Megatron-Deepspeed to consider the embedding layer as a transformer block. So we had a pipeline of 72 layers, 2 of which were dedicated to the embedding (first and last). This allowed to balance out the GPU memory consumption. If we didn't do it, we would have had the first and the last stages consume most of the GPU memory, and 95% of GPUs would be using much less memory and thus the training would be far from being efficient.
## DP+PP
The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates how one combines DP with PP.

Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there are just GPUs 0 and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP. And GPU1 does the same by enlisting GPU3 to its aid.
Since each dimension requires at least 2 GPUs, here you'd need at least 4 GPUs.
## DP+PP+TP
To get an even more efficient training PP is combined with TP and DP which is called 3D parallelism. This can be seen in the following diagram.

This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
Since each dimension requires at least 2 GPUs, here you'd need at least 8 GPUs for full 3D parallelism.
## ZeRO DP+PP+TP
One of the main features of DeepSpeed is ZeRO, which is a super-scalable extension of DP. It has already been discussed in [ZeRO Data Parallelism](#zero-data-parallelism). Normally it's a standalone feature that doesn't require PP or TP. But it can be combined with PP and TP.
When ZeRO-DP is combined with PP (and optionally TP) it typically enables only ZeRO stage 1, which shards only optimizer states. ZeRO stage 2 additionally shards gradients, and stage 3 also shards the model weights.
While it's theoretically possible to use ZeRO stage 2 with Pipeline Parallelism, it will have bad performance impacts. There would need to be an additional reduce-scatter collective for every micro-batch to aggregate the gradients before sharding, which adds a potentially significant communication overhead. By nature of Pipeline Parallelism, small micro-batches are used and instead the focus is on trying to balance arithmetic intensity (micro-batch size) with minimizing the Pipeline bubble (number of micro-batches). Therefore those communication costs are going to hurt.
In addition, there are already fewer layers than normal due to PP and so the memory savings won't be huge. PP already reduces gradient size by ``1/PP``, and so gradient sharding savings on top of that are less significant than pure DP.
ZeRO stage 3 can also be used to train models at this scale, however, it requires more communication than the DeepSpeed 3D parallel implementation. After careful evaluation in our environment which happened a year ago we found Megatron-DeepSpeed 3D parallelism performed best. Since then ZeRO stage 3 performance has dramatically improved and if we were to evaluate it today perhaps we would have chosen stage 3 instead.
## BF16Optimizer
Training huge LLM models in FP16 is a no-no.
We have proved it to ourselves by spending several months [training a 104B model](https://github.com/bigscience-workshop/bigscience/tree/master/train/tr8-104B-wide) which as you can tell from the [tensorboard](https://huggingface.co/bigscience/tr8-104B-logs/tensorboard) was but a complete failure. We learned a lot of things while fighting the ever diverging lm-loss:

and we also got the same advice from the Megatron-LM and DeepSpeed teams after they trained the [530B model](https://arxiv.org/abs/2201.11990). The recent release of [OPT-175B](https://arxiv.org/abs/2205.01068) too reported that they had a very difficult time training in FP16.
So back in January as we knew we would be training on A100s which support the BF16 format Olatunji Ruwase developed a `BF16Optimizer` which we used to train BLOOM.
If you are not familiar with this data format, please have a look [at the bits layout]( https://en.wikipedia.org/wiki/Bfloat16_floating-point_format#bfloat16_floating-point_format). The key to BF16 format is that it has the same exponent as FP32 and thus doesn't suffer from overflow FP16 suffers from a lot! With FP16, which has a max numerical range of 64k, you can only multiply small numbers. e.g. you can do `250*250=62500`, but if you were to try `255*255=65025` you got yourself an overflow, which is what causes the main problems during training. This means your weights have to remain tiny. A technique called loss scaling can help with this problem, but the limited range of FP16 is still an issue when models become very large.
BF16 has no such problem, you can easily do `10_000*10_000=100_000_000` and it's no problem.
Of course, since BF16 and FP16 have the same size of 2 bytes, one doesn't get a free lunch and one pays with really bad precision when using BF16. However, if you remember the training using stochastic gradient descent and its variations is a sort of stumbling walk, so if you don't get the perfect direction immediately it's no problem, you will correct yourself in the next steps.
Regardless of whether one uses BF16 or FP16 there is also a copy of weights which is always in FP32 - this is what gets updated by the optimizer. So the 16-bit formats are only used for the computation, the optimizer updates the FP32 weights with full precision and then casts them into the 16-bit format for the next iteration.
All PyTorch components have been updated to ensure that they perform any accumulation in FP32, so no loss happening there.
One crucial issue is gradient accumulation, and it's one of the main features of pipeline parallelism as the gradients from each microbatch processing get accumulated. It's crucial to implement gradient accumulation in FP32 to keep the training precise, and this is what `BF16Optimizer` does.
Besides other improvements we believe that using BF16 mixed precision training turned a potential nightmare into a relatively smooth process which can be observed from the following lm loss graph:

## Fused CUDA Kernels
The GPU performs two things. It can copy data to/from memory and perform computations on that data. While the GPU is busy copying the GPU's computations units idle. If we want to efficiently utilize the GPU we want to minimize the idle time.
A kernel is a set of instructions that implements a specific PyTorch operation. For example, when you call `torch.add`, it goes through a [PyTorch dispatcher](http://blog.ezyang.com/2020/09/lets-talk-about-the-pytorch-dispatcher/) which looks at the input tensor(s) and various other things and decides which code it should run, and then runs it. A CUDA kernel is a specific implementation that uses the CUDA API library and can only run on NVIDIA GPUs.
Now, when instructing the GPU to compute `c = torch.add(a, b); e = torch.max([c,d])`, a naive approach, and what PyTorch will do unless instructed otherwise, is to launch two separate kernels, one to perform the addition of `a` and `b` and another to find the maximum value between `c` and `d`. In this case, the GPU fetches from its memory `a` and `b`, performs the addition, and then copies the result back into the memory. It then fetches `c` and `d` and performs the `max` operation and again copies the result back into the memory.
If we were to fuse these two operations, i.e. put them into a single "fused kernel", and just launch that one kernel we won't copy the intermediary result `c` to the memory, but leave it in the GPU registers and only need to fetch `d` to complete the last computation. This saves a lot of overhead and prevents GPU idling and makes the whole operation much more efficient.
Fused kernels are just that. Primarily they replace multiple discrete computations and data movements to/from memory into fused computations that have very few memory movements. Additionally, some fused kernels rewrite the math so that certain groups of computations can be performed faster.
To train BLOOM fast and efficiently it was necessary to use several custom fused CUDA kernels provided by Megatron-LM. In particular there is an optimized kernel to perform LayerNorm as well as kernels to fuse various combinations of the scaling, masking, and softmax operations. The addition of a bias term is also fused with the GeLU operation using PyTorch's JIT functionality. These operations are all memory bound, so it is important to fuse them to maximize the amount of computation done once a value has been retrieved from memory. So, for example, adding the bias term while already doing the memory bound GeLU operation adds no additional time. These kernels are all available in the [Megatron-LM repository](https://github.com/NVIDIA/Megatron-LM).
## Datasets
Another important feature from Megatron-LM is the efficient data loader. During start up of the initial training each data set is split into samples of the requested sequence length (2048 for BLOOM) and index is created to number each sample. Based on the training parameters the number of epochs for a dataset is calculated and an ordering for that many epochs is created and then shuffled. For example, if a dataset has 10 samples and should be gone through twice, the system first lays out the samples indices in order `[0, ..., 9, 0, ..., 9]` and then shuffles that order to create the final global order for the dataset. Notice that this means that training will not simply go through the entire dataset and then repeat, it is possible to see the same sample twice before seeing another sample at all, but at the end of training the model will have seen each sample twice. This helps ensure a smooth training curve through the entire training process. These indices, including the offsets into the base dataset of each sample, are saved to a file to avoid recomputing them each time a training process is started. Several of these datasets can then be blended with varying weights into the final data seen by the training process.
## Embedding LayerNorm
While we were fighting with trying to stop 104B from diverging we discovered that adding an additional LayerNorm right after the first word embedding made the training much more stable.
This insight came from experimenting with [bitsandbytes](https://github.com/facebookresearch/bitsandbytes) which contains a `StableEmbedding` which is a normal Embedding with layernorm and it uses a uniform xavier initialization.
## Positional Encoding
We also replaced the usual positional embedding with an AliBi - based on the paper: [Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation](https://arxiv.org/abs/2108.12409), which allows to extrapolate for longer input sequences than the ones the model was trained on. So even though we train on sequences with length 2048 the model can also deal with much longer sequences during inference.
## Training Difficulties
With the architecture, hardware and software in place we were able to start training in early March 2022. However, it was not just smooth sailing from there. In this section we discuss some of the main hurdles we encountered.
There were a lot of issues to figure out before the training started. In particular we found several issues that manifested themselves only once we started training on 48 nodes, and won't appear at small scale. E.g., `CUDA_LAUNCH_BLOCKING=1` was needed to prevent the framework from hanging, and we needed to split the optimizer groups into smaller groups, otherwise the framework would again hang. You can read about those in detail in the [training prequel chronicles](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr11-176B-ml/chronicles-prequel.md).
The main type of issue encountered during training were hardware failures. As this was a new cluster with about 400 GPUs, on average we were getting 1-2 GPU failures a week. We were saving a checkpoint every 3h (100 iterations) so on average we would lose 1.5h of training on hardware crash. The Jean Zay sysadmins would then replace the faulty GPUs and bring the node back up. Meanwhile we had backup nodes to use instead.
We have run into a variety of other problems that led to 5-10h downtime several times, some related to a deadlock bug in PyTorch, others due to running out of disk space. If you are curious about specific details please see [training chronicles](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr11-176B-ml/chronicles.md).
We were planning for all these downtimes when deciding on the feasibility of training this model - we chose the size of the model to match that feasibility and the amount of data we wanted the model to consume. With all the downtimes we managed to finish the training in our estimated time. As mentioned earlier it took about 1M compute hours to complete.
One other issue was that SLURM wasn't designed to be used by a team of people. A SLURM job is owned by a single user and if they aren't around, the other members of the group can't do anything to the running job. We developed a kill-switch workaround that allowed other users in the group to kill the current process without requiring the user who started the process to be present. This worked well in 90% of the issues. If SLURM designers read this - please add a concept of Unix groups, so that a SLURM job can be owned by a group.
As the training was happening 24/7 we needed someone to be on call - but since we had people both in Europe and West Coast Canada overall there was no need for someone to carry a pager, we would just overlap nicely. Of course, someone had to watch the training on the weekends as well. We automated most things, including recovery from hardware crashes, but sometimes a human intervention was needed as well.
## Conclusion
The most difficult and intense part of the training was the 2 months leading to the start of the training. We were under a lot of pressure to start training ASAP, since the resources allocation was limited in time and we didn't have access to A100s until the very last moment. So it was a very difficult time, considering that the `BF16Optimizer` was written in the last moment and we needed to debug it and fix various bugs. And as explained in the previous section we discovered new problems that manifested themselves only once we started training on 48 nodes, and won't appear at small scale.
But once we sorted those out, the training itself was surprisingly smooth and without major problems. Most of the time we had one person monitoring the training and only a few times several people were involved to troubleshoot. We enjoyed great support from Jean Zay's administration who quickly addressed most needs that emerged during the training.
Overall it was a super-intense but very rewarding experience.
Training large language models is still a challenging task, but we hope by building and sharing this technology in the open others can build on top of our experience.
## Resources
### Important links
- [main training document](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr11-176B-ml/README.md)
- [tensorboard](https://huggingface.co/bigscience/tr11-176B-ml-logs/tensorboard)
- [training slurm script](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr11-176B-ml/tr11-176B-ml.slurm)
- [training chronicles](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr11-176B-ml/chronicles.md)
### Papers and Articles
We couldn't have possibly explained everything in detail in this article, so if the technology presented here piqued your curiosity and you'd like to know more here are the papers to read:
Megatron-LM:
- [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
- [Reducing Activation Recomputation in Large Transformer Models](https://arxiv.org/abs/2205.05198)
DeepSpeed:
- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054)
- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)
- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)
- [DeepSpeed: Extreme-scale model training for everyone](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)
Joint Megatron-LM and Deepspeeed:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](https://arxiv.org/abs/2201.11990).
ALiBi:
- [Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation](https://arxiv.org/abs/2108.12409)
- [What Language Model to Train if You Have One Million GPU Hours?](https://openreview.net/forum?id=rI7BL3fHIZq) - there you will find the experiments that lead to us choosing ALiBi.
BitsNBytes:
- [8-bit Optimizers via Block-wise Quantization](https://arxiv.org/abs/2110.02861) (in the context of Embedding LayerNorm but the rest of the paper and the technology is amazing - the only reason were weren't using the 8-bit optimizer is because we were already saving the optimizer memory with DeepSpeed-ZeRO).
## Blog credits
Huge thanks to the following kind folks who asked good questions and helped improve the readability of the article (listed in alphabetical order):
Britney Muller,
Douwe Kiela,
Jared Casper,
Jeff Rasley,
Julien Launay,
Leandro von Werra,
Omar Sanseviero,
Stefan Schweter and
Thomas Wang.
The main graphics was created by Chunte Lee.
| huggingface/blog/blob/main/bloom-megatron-deepspeed.md |
Gradio Demo: tictactoe
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
turn = gr.Textbox("X", interactive=False, label="Turn")
board = gr.Dataframe(value=[["", "", ""]] * 3, interactive=False, type="array")
def place(board, turn, evt: gr.SelectData):
if evt.value:
return board, turn
board[evt.index[0]][evt.index[1]] = turn
turn = "O" if turn == "X" else "X"
return board, turn
board.select(place, [board, turn], [board, turn], show_progress="hidden")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/tictactoe/run.ipynb |
Gradio Demo: fake_gan_2
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/fake_gan_2/files/cheetah1.jpg
!wget -q -O files/elephant.jpg https://github.com/gradio-app/gradio/raw/main/demo/fake_gan_2/files/elephant.jpg
!wget -q -O files/tiger.jpg https://github.com/gradio-app/gradio/raw/main/demo/fake_gan_2/files/tiger.jpg
!wget -q -O files/zebra.jpg https://github.com/gradio-app/gradio/raw/main/demo/fake_gan_2/files/zebra.jpg
```
```
# This demo needs to be run from the repo folder.
# python demo/fake_gan/run.py
import random
import time
import gradio as gr
def fake_gan(desc):
if desc == "NSFW":
raise gr.Error("NSFW - banned content.")
if desc == "error":
raise ValueError("error")
time.sleep(9)
image = random.choice(
[
"files/cheetah1.jpg",
"files/elephant.jpg",
"files/tiger.jpg",
"files/zebra.jpg",
]
)
return image
demo = gr.Interface(
fn=fake_gan,
inputs=gr.Textbox(),
outputs=gr.Image(label="Generated Image"),
title="FD-GAN",
description="This is a fake demo of a GAN. In reality, the images are randomly chosen from Unsplash.",
)
demo.queue(max_size=3)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/fake_gan_2/run.ipynb |
simple dashboard ranking spaces by number of likes. | gradio-app/gradio/blob/main/demo/leaderboard/DESCRIPTION.md |
Metric Card for SacreBLEU
## Metric Description
SacreBLEU provides hassle-free computation of shareable, comparable, and reproducible BLEU scores. Inspired by Rico Sennrich's `multi-bleu-detok.perl`, it produces the official Workshop on Machine Translation (WMT) scores but works with plain text. It also knows all the standard test sets and handles downloading, processing, and tokenization.
See the [README.md] file at https://github.com/mjpost/sacreBLEU for more information.
## How to Use
This metric takes a set of predictions and a set of references as input, along with various optional parameters.
```python
>>> predictions = ["hello there general kenobi", "foo bar foobar"]
>>> references = [["hello there general kenobi", "hello there !"],
... ["foo bar foobar", "foo bar foobar"]]
>>> sacrebleu = datasets.load_metric("sacrebleu")
>>> results = sacrebleu.compute(predictions=predictions,
... references=references)
>>> print(list(results.keys()))
['score', 'counts', 'totals', 'precisions', 'bp', 'sys_len', 'ref_len']
>>> print(round(results["score"], 1))
100.0
```
### Inputs
- **`predictions`** (`list` of `str`): list of translations to score. Each translation should be tokenized into a list of tokens.
- **`references`** (`list` of `list` of `str`): A list of lists of references. The contents of the first sub-list are the references for the first prediction, the contents of the second sub-list are for the second prediction, etc. Note that there must be the same number of references for each prediction (i.e. all sub-lists must be of the same length).
- **`smooth_method`** (`str`): The smoothing method to use, defaults to `'exp'`. Possible values are:
- `'none'`: no smoothing
- `'floor'`: increment zero counts
- `'add-k'`: increment num/denom by k for n>1
- `'exp'`: exponential decay
- **`smooth_value`** (`float`): The smoothing value. Only valid when `smooth_method='floor'` (in which case `smooth_value` defaults to `0.1`) or `smooth_method='add-k'` (in which case `smooth_value` defaults to `1`).
- **`tokenize`** (`str`): Tokenization method to use for BLEU. If not provided, defaults to `'zh'` for Chinese, `'ja-mecab'` for Japanese and `'13a'` (mteval) otherwise. Possible values are:
- `'none'`: No tokenization.
- `'zh'`: Chinese tokenization.
- `'13a'`: mimics the `mteval-v13a` script from Moses.
- `'intl'`: International tokenization, mimics the `mteval-v14` script from Moses
- `'char'`: Language-agnostic character-level tokenization.
- `'ja-mecab'`: Japanese tokenization. Uses the [MeCab tokenizer](https://pypi.org/project/mecab-python3).
- **`lowercase`** (`bool`): If `True`, lowercases the input, enabling case-insensitivity. Defaults to `False`.
- **`force`** (`bool`): If `True`, insists that your tokenized input is actually detokenized. Defaults to `False`.
- **`use_effective_order`** (`bool`): If `True`, stops including n-gram orders for which precision is 0. This should be `True`, if sentence-level BLEU will be computed. Defaults to `False`.
### Output Values
- `score`: BLEU score
- `counts`: Counts
- `totals`: Totals
- `precisions`: Precisions
- `bp`: Brevity penalty
- `sys_len`: predictions length
- `ref_len`: reference length
The output is in the following format:
```python
{'score': 39.76353643835252, 'counts': [6, 4, 2, 1], 'totals': [10, 8, 6, 4], 'precisions': [60.0, 50.0, 33.333333333333336, 25.0], 'bp': 1.0, 'sys_len': 10, 'ref_len': 7}
```
The score can take any value between `0.0` and `100.0`, inclusive.
#### Values from Popular Papers
### Examples
```python
>>> predictions = ["hello there general kenobi",
... "on our way to ankh morpork"]
>>> references = [["hello there general kenobi", "hello there !"],
... ["goodbye ankh morpork", "ankh morpork"]]
>>> sacrebleu = datasets.load_metric("sacrebleu")
>>> results = sacrebleu.compute(predictions=predictions,
... references=references)
>>> print(list(results.keys()))
['score', 'counts', 'totals', 'precisions', 'bp', 'sys_len', 'ref_len']
>>> print(round(results["score"], 1))
39.8
```
## Limitations and Bias
Because what this metric calculates is BLEU scores, it has the same limitations as that metric, except that sacreBLEU is more easily reproducible.
## Citation
```bibtex
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
```
## Further References
- See the [sacreBLEU README.md file](https://github.com/mjpost/sacreBLEU) for more information. | huggingface/datasets/blob/main/metrics/sacrebleu/README.md |
--
title: "Happy 1st anniversary 🤗 Diffusers!"
thumbnail: /blog/assets/diffusers-turns-1/diffusers-turns-1.png
authors:
- user: stevhliu
- user: sayakpaul
- user: pcuenq
---
# Happy 1st anniversary 🤗 Diffusers!
🤗 Diffusers is happy to celebrate its first anniversary! It has been an exciting year, and we're proud and grateful for how far we've come thanks to our community and open-source contributors. Last year, text-to-image models like DALL-E 2, Imagen, and Stable Diffusion captured the world's attention with their ability to generate stunningly photorealistic images from text, sparking a massive surge of interest and development in generative AI. But access to these powerful models was limited.
At Hugging Face, our mission is to democratize good machine learning by collaborating and helping each other build an open and ethical AI future together. Our mission motivated us to create the 🤗 Diffusers library so *everyone* can experiment, research, or simply play with text-to-image models. That’s why we designed the library as a modular toolbox, so you can customize a diffusion model’s components or just start using it out-of-the-box.
As 🤗 Diffusers turns 1, here’s an overview of some of the most notable features we’ve added to the library with the help of our community. We are proud and immensely grateful for being part of an engaged community that promotes accessible usage, pushes diffusion models beyond just text-to-image generation, and is an all-around inspiration.
**Table of Contents**
* [Striving for photorealism](#striving-for-photorealism)
* [Video pipelines](#video-pipelines)
* [Text-to-3D models](#text-to-3d-models)
* [Image editing pipelines](#image-editing-pipelines)
* [Faster diffusion models](#faster-diffusion-models)
* [Ethics and safety](#ethics-and-safety)
* [Support for LoRA](#support-for-lora)
* [Torch 2.0 optimizations](#torch-20-optimizations)
* [Community highlights](#community-highlights)
* [Building products with 🤗 Diffusers](#building-products-with-🤗-diffusers)
* [Looking forward](#looking-forward)
## Striving for photorealism
Generative AI models are known for creating photorealistic images, but if you look closely, you may notice certain things that don't look right, like generating extra fingers on a hand. This year, the DeepFloyd IF and Stability AI SDXL models made a splash by improving the quality of generated images to be even more photorealistic.
[DeepFloyd IF](https://stability.ai/blog/deepfloyd-if-text-to-image-model) - A modular diffusion model that includes different processes for generating an image (for example, an image is upscaled 3x to produce a higher resolution image). Unlike Stable Diffusion, the IF model works directly on the pixel level, and it uses a large language model to encode text.
[Stable Diffusion XL (SDXL)](https://stability.ai/blog/sdxl-09-stable-diffusion) - The latest Stable Diffusion model from Stability AI, with significantly more parameters than its predecessor Stable Diffusion 2. It generates hyper-realistic images, leveraging a base model for close adherence to the prompt, and a refiner model specialized in the fine details and high-frequency content.
Head over to the DeepFloyd IF [docs](https://huggingface.co/docs/diffusers/v0.18.2/en/api/pipelines/if#texttoimage-generation) and the SDXL [docs](https://huggingface.co/docs/diffusers/v0.18.2/en/api/pipelines/stable_diffusion/stable_diffusion_xl) today to learn how to start generating your own images!
## Video pipelines
Text-to-image pipelines are cool, but text-to-video is even cooler! We currently support two text-to-video pipelines, [VideoFusion](https://huggingface.co/docs/diffusers/main/en/api/pipelines/text_to_video) and [Text2Video-Zero](https://huggingface.co/docs/diffusers/main/en/api/pipelines/text_to_video_zero).
If you’re already familiar with text-to-image pipelines, using a text-to-video pipeline is very similar:
```py
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_576w", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "Darth Vader surfing a wave"
video_frames = pipe(prompt, num_frames=24).frames
video_path = export_to_video(video_frames)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/darthvader_cerpense.gif" alt="Generated video of Darth Vader surfing."/>
</div>
We expect text-to-video to go through a revolution during 🤗 Diffusers second year, and we are excited to see what the community builds on top of these to push the boundaries of video generation from language!
## Text-to-3D models
In addition to text-to-video, we also have text-to-3D generation now thanks to OpenAI’s [Shap-E](https://hf.co/papers/2305.02463) model. Shap-E is trained by encoding a large dataset of 3D-text pairs, and a diffusion model is conditioned on the encoder’s outputs. You can design 3D assets for video games, interior design, and architecture.
Try it out today with the [`ShapEPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/shap_e#diffusers.ShapEPipeline) and [`ShapEImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/shap_e#diffusers.ShapEImg2ImgPipeline).
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/shap_e/cake_out.gif" alt="3D render of a birthday cupcake generated using SHAP-E."/>
</div>
## Image editing pipelines
Image editing is one of the most practical use cases in fashion, material design, and photography. With diffusion models, the possibilities of image editing continue to expand.
We have many [pipelines](https://huggingface.co/docs/diffusers/main/en/using-diffusers/controlling_generation) in 🤗 Diffusers to support image editing. There are image editing pipelines that allow you to describe your desired edit as a prompt, removing concepts from an image, and even a pipeline that unifies multiple generation methods to create high-quality images like panoramas. With 🤗 Diffusers, you can experiment with the future of photo editing now!
## Faster diffusion models
Diffusion models are known to be time-intensive because of their iterative steps. With OpenAI’s [Consistency Models](https://huggingface.co/papers/2303.01469), the image generation process is significantly faster. Generating a single 256x256 resolution image only takes 3/4 of a second on a modern CPU! You can try this out in 🤗 Diffusers with the [`ConsistencyModelPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/consistency_models).
On top of speedier diffusion models, we also offer many optimization techniques for faster inference like [PyTorch 2.0’s `scaled_dot_product_attention()` (SDPA) and `torch.compile()`](https://pytorch.org/blog/accelerated-diffusers-pt-20), sliced attention, feed-forward chunking, VAE tiling, CPU and model offloading, and more. These optimizations save memory, which translates to faster generation, and allow you to run inference on consumer GPUs. When you distribute a model with 🤗 Diffusers, all of these optimizations are immediately supported!
In addition to that, we also support specific hardware and formats like ONNX, the `mps` PyTorch device for Apple Silicon computers, Core ML, and others.
To learn more about how we optimize inference with 🤗 Diffusers, check out the [docs](https://huggingface.co/docs/diffusers/optimization/opt_overview)!
## Ethics and safety
Generative models are cool, but they also have the ability to produce harmful and NSFW content. To help users interact with these models responsibly and ethically, we’ve added a [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) component that flags inappropriate content generated during inference. Model creators can choose to incorporate this component into their models if they want.
In addition, generative models can also be used to produce disinformation. Earlier this year, the [Balenciaga Pope](https://www.theverge.com/2023/3/27/23657927/ai-pope-image-fake-midjourney-computer-generated-aesthetic) went viral for how realistic the image was despite it being fake. This underscores the importance and need for a mechanism to distinguish between generated and human content. That’s why we’ve added an invisible watermark for images generated by the SDXL model, which helps users be better informed.
The development of these features is guided by our [ethical charter](https://huggingface.co/docs/diffusers/main/en/conceptual/ethical_guidelines), which you can find in our documentation.
## Support for LoRA
Fine-tuning diffusion models is expensive and out of reach for most consumer GPUs. We added the Low-Rank Adaptation ([LoRA](https://huggingface.co/papers/2106.09685)) technique to close this gap. With LoRA, which is a method for parameter-efficient fine-tuning, you can fine-tune large diffusion models faster and consume less memory. The resulting model weights are also very lightweight compared to the original model, so you can easily share your custom models. If you want to learn more, [our documentation](https://huggingface.co/docs/diffusers/main/en/training/lora) shows how to perform fine-tuning and inference on Stable Diffusion with LoRA.
In addition to LoRA, we support other [training techniques](https://huggingface.co/docs/diffusers/main/en/training/overview) for personalized generation, including DreamBooth, textual inversion, custom diffusion, and more!
## Torch 2.0 optimizations
PyTorch 2.0 [introduced support](https://pytorch.org/get-started/pytorch-2.0/#pytorch-2x-faster-more-pythonic-and-as-dynamic-as-ever) for `torch.compile()`and `scaled_dot_product_attention()`, a more efficient implementation of the attention mechanism. 🤗 Diffusers [provides first-class support](https://huggingface.co/docs/diffusers/optimization/torch2.0) for these features resulting in massive speedups in inference latency, which can sometimes be more than twice as fast!
In addition to visual content (images, videos, 3D assets, etc.), we also added support for audio! Check out [the documentation](https://huggingface.co/docs/diffusers/using-diffusers/audio) to learn more.
## Community highlights
One of the most gratifying experiences of the past year has been seeing how the community is incorporating 🤗 Diffusers into their projects. From adapting Low-rank adaptation (LoRA) for faster training of text-to-image models to building a state-of-the-art inpainting tool, here are a few of our favorite projects:
<div class="mx-auto max-w-screen-xl py-8">
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">We built Core ML Stable Diffusion to make it easier for developers to add state-of-the-art generative AI capabilities in their iOS, iPadOS and macOS apps with the highest efficiency on Apple Silicon. We built on top of 🤗 Diffusers instead of from scratch as 🤗 Diffusers consistently stays on top of a rapidly evolving field and promotes much needed interoperability of new and old ideas.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/10639145?s=200&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">Atila Orhon</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">🤗 Diffusers has been absolutely developer-friendly for me to dive right into stable diffusion models. Main differentiating factor clearly being that 🤗 Diffusers implementation is often not some code from research lab, that are mostly focused on high velocity driven. While research codes are often poorly written and difficult to understand (lack of typing, assertions, inconsistent design patterns and conventions), 🤗 Diffusers was a breeze to use for me to hack my ideas within couple of hours. Without it, I would have needed to invest significantly more amount of time to start hacking. Well-written documentations and examples are extremely helpful as well.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/35953539?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">Simo</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">BentoML is the unified framework for for building, shipping, and scaling production-ready AI applications incorporating traditional ML, pre-trained AI models, Generative and Large Language Models. All Hugging Face Diffuser models and pipelines can be seamlessly integrated into BentoML applications, enabling the running of models on the most suitable hardware and independent scaling based on usage.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/49176046?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">BentoML</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">Invoke AI is an open-source Generative AI tool built to empower professional creatives, from game designers and photographers to architects and product designers. Invoke recently launched their hosted offering at invoke.ai, allowing users to generate assets from any computer, powered by the latest research in open-source.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/113954515?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">InvokeAI</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">TaskMatrix connects Large Language Model and a series of Visual Models to enable sending and receiving images during chatting.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/6154722?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">Chenfei Wu</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">Lama Cleaner is a powerful image inpainting tool that uses Stable Diffusion technology to remove unwanted objects, defects, or people from your pictures. It can also erase and replace anything in your images with ease.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://github.com/Sanster/lama-cleaner/raw/main/assets/logo.png" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">Qing</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">Grounded-SAM combines a powerful Zero-Shot detector Grounding-DINO and Segment-Anything-Model (SAM) to build a strong pipeline to detect and segment everything with text inputs. When combined with 🤗 Diffusers inpainting models, Grounded-SAM can do highly controllable image editing tasks, including replacing specific objects, inpainting the background, etc.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/113572103?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">Tianhe Ren</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">Stable-Dreamfusion leverages the convenient implementations of 2D diffusion models in 🤗 Diffusers to replicate recent text-to-3D and image-to-3D methods.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/25863658?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">kiui</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">MMagic (Multimodal Advanced, Generative, and Intelligent Creation) is an advanced and comprehensive Generative AI toolbox that provides state-of-the-art AI models (e.g., diffusion models powered by 🤗 Diffusers and GAN) to synthesize, edit and enhance images and videos. In MMagic, users can use rich components to customize their own models like playing with Legos and manage the training loop easily.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/10245193?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">mmagic</p>
</div>
</div>
</div>
<div class="mb-8 sm:break-inside-avoid">
<blockquote class="rounded-xl !mb-0 bg-gray-50 p-6 shadow dark:bg-gray-800">
<p class="leading-relaxed text-gray-700">Tune-A-Video, developed by Jay Zhangjie Wu and his team at Show Lab, is the first to fine-tune a pre-trained text-to-image diffusion model using a single text-video pair and enables changing video content while preserving motion.</p>
</blockquote>
<div class="flex items-center gap-4">
<img src="https://avatars.githubusercontent.com/u/101181824?s=48&v=4" class="h-12 w-12 rounded-full object-cover" />
<div class="text-sm">
<p class="font-medium">Jay Zhangjie Wu</p>
</div>
</div>
</div>
</div>
We also collaborated with Google Cloud (who generously provided the compute) to provide technical guidance and mentorship to help the community train diffusion models with TPUs (check out a summary of the event [here](https://opensource.googleblog.com/2023/06/controlling-stable-diffusion-with-jax-diffusers-and-cloud-tpus.html)). There were many cool models such as this [demo](https://huggingface.co/spaces/mfidabel/controlnet-segment-anything) that combines ControlNet with Segment Anything.
<div class="flex justify-center">
<img src="https://github.com/mfidabel/JAX_SPRINT_2023/blob/8632f0fde7388d7a4fc57225c96ef3b8411b3648/EX_1.gif?raw=true" alt="ControlNet and SegmentAnything demo of a hot air balloon in various styles">
</div>
Finally, we were delighted to receive contributions to our codebase from over 300 contributors, which allowed us to collaborate together in the most open way possible. Here are just a few of the contributions from our community:
- [Model editing](https://github.com/huggingface/diffusers/pull/2721) by [@bahjat-kawar](https://github.com/bahjat-kawar), a pipeline for editing a model’s implicit assumptions
- [LDM3D](https://github.com/huggingface/diffusers/pull/3668) by [@estelleafl](https://github.com/estelleafl), a diffusion model for 3D images
- [DPMSolver](https://github.com/huggingface/diffusers/pull/3314) by [@LuChengTHU](https://github.com/LuChengTHU), improvements for significantly improving inference speed
- [Custom Diffusion](https://github.com/huggingface/diffusers/pull/3031) by [@nupurkmr9](https://github.com/nupurkmr9), a technique for generating personalized images with only a few images of a subject
Besides these, a heartfelt shoutout to the following contributors who helped us ship some of the most powerful features of Diffusers (in no particular order):
* [@takuma104](https://github.com/huggingface/diffusers/commits?author=takuma104)
* [@nipunjindal](https://github.com/huggingface/diffusers/commits?author=nipunjindal)
* [@isamu-isozaki](https://github.com/huggingface/diffusers/commits?author=isamu-isozaki)
* [@piEsposito](https://github.com/huggingface/diffusers/commits?author=piEsposito)
* [@Birch-san](https://github.com/huggingface/diffusers/commits?author=Birch-san)
* [@LuChengTHU](https://github.com/huggingface/diffusers/commits?author=LuChengTHU)
* [@duongna21](https://github.com/huggingface/diffusers/commits?author=duongna21)
* [@clarencechen](https://github.com/huggingface/diffusers/commits?author=clarencechen)
* [@dg845](https://github.com/huggingface/diffusers/commits?author=dg845)
* [@Abhinay1997](https://github.com/huggingface/diffusers/commits?author=Abhinay1997)
* [@camenduru](https://github.com/huggingface/diffusers/commits?author=camenduru)
* [@ayushtues](https://github.com/huggingface/diffusers/commits?author=ayushtues)
## Building products with 🤗 Diffusers
Over the last year, we also saw many companies choosing to build their products on top of 🤗 Diffusers. Here are a couple of products that have caught our attention:
- [PlaiDay](http://plailabs.com/): “PlaiDay is a Generative AI experience where people collaborate, create, and connect. Our platform unlocks the limitless creativity of the human mind, and provides a safe, fun social canvas for expression.”
- [Previs One](https://previs.framer.wiki/): “Previs One is a diffuser pipeline for cinematic storyboarding and previsualization — it understands film and television compositional rules just as a director would speak them.”
- [Zust.AI](https://zust.ai/): “We leverage Generative AI to create studio-quality product photos for brands and marketing agencies.”
- [Dashtoon](https://dashtoon.com/): “Dashtoon is building a platform to create and consume visual content. We have multiple pipelines that load multiple LORAs, multiple control-nets and even multiple models powered by diffusers. Diffusers has made the gap between a product engineer and a ML engineer super low allowing dashtoon to ship user value faster and better.”
- [Virtual Staging AI](https://www.virtualstagingai.app/): "Filling empty rooms with beautiful furniture using generative models.”
- [Hexo.AI](https://www.hexo.ai/): “Hexo AI helps brands get higher ROI on marketing spends through Personalized Marketing at Scale. Hexo is building a proprietary campaign generation engine which ingests customer data and generates brand compliant personalized creatives.”
If you’re building products on top of 🤗 Diffusers, we’d love to chat to understand how we can make the library better together! Feel free to reach out to [email protected] or [email protected].
## Looking forward
As we celebrate our first anniversary, we're grateful to our community and open-source contributors who have helped us come so far in such a short time. We're happy to share that we'll be presenting a 🤗 Diffusers demo at ICCV 2023 this fall – if you're attending, do come and see us! We'll continue to develop and improve our library, making it easier for everyone to use. We're also excited to see what the community will create next with our tools and resources. Thank you for being a part of our journey so far, and we look forward to continuing to democratize good machine learning together! 🥳
❤️ Diffusers team
---
**Acknowledgements**: Thank you to [Omar Sanseviero](https://huggingface.co/osanseviero), [Patrick von Platen](https://huggingface.co/patrickvonplaten), [Giada Pistilli](https://huggingface.co/giadap) for their reviews, and [Chunte Lee](https://huggingface.co/Chunte) for designing the thumbnail.
| huggingface/blog/blob/main/diffusers-turns-1.md |
Installation
Before you start, you'll need to setup your environment and install the appropriate packages. `timm` is tested on **Python 3+**.
## Virtual Environment
You should install `timm` in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep things tidy and avoid dependency conflicts.
1. Create and navigate to your project directory:
```bash
mkdir ~/my-project
cd ~/my-project
```
2. Start a virtual environment inside your directory:
```bash
python -m venv .env
```
3. Activate and deactivate the virtual environment with the following commands:
```bash
# Activate the virtual environment
source .env/bin/activate
# Deactivate the virtual environment
source .env/bin/deactivate
```
`
Once you've created your virtual environment, you can install `timm` in it.
## Using pip
The most straightforward way to install `timm` is with pip:
```bash
pip install timm
```
Alternatively, you can install `timm` from GitHub directly to get the latest, bleeding-edge version:
```bash
pip install git+https://github.com/rwightman/pytorch-image-models.git
```
Run the following command to check if `timm` has been properly installed:
```bash
python -c "from timm import list_models; print(list_models(pretrained=True)[:5])"
```
This command lists the first five pretrained models available in `timm` (which are sorted alphebetically). You should see the following output:
```python
['adv_inception_v3', 'bat_resnext26ts', 'beit_base_patch16_224', 'beit_base_patch16_224_in22k', 'beit_base_patch16_384']
```
## From Source
Building `timm` from source lets you make changes to the code base. To install from the source, clone the repository and install with the following commands:
```bash
git clone https://github.com/rwightman/pytorch-image-models.git
cd timm
pip install -e .
```
Again, you can check if `timm` was properly installed with the following command:
```bash
python -c "from timm import list_models; print(list_models(pretrained=True)[:5])"
```
| huggingface/pytorch-image-models/blob/main/hfdocs/source/installation.mdx |
Results
CSV files containing an ImageNet-1K and out-of-distribution (OOD) test set validation results for all models with pretrained weights is located in the repository [results folder](https://github.com/rwightman/pytorch-image-models/tree/master/results).
## Self-trained Weights
The table below includes ImageNet-1k validation results of model weights that I've trained myself. It is not updated as frequently as the csv results outputs linked above.
|Model | Acc@1 (Err) | Acc@5 (Err) | Param # (M) | Interpolation | Image Size |
|---|---|---|---|---|---|
| efficientnet_b3a | 82.242 (17.758) | 96.114 (3.886) | 12.23 | bicubic | 320 (1.0 crop) |
| efficientnet_b3 | 82.076 (17.924) | 96.020 (3.980) | 12.23 | bicubic | 300 |
| regnet_32 | 82.002 (17.998) | 95.906 (4.094) | 19.44 | bicubic | 224 |
| skresnext50d_32x4d | 81.278 (18.722) | 95.366 (4.634) | 27.5 | bicubic | 288 (1.0 crop) |
| seresnext50d_32x4d | 81.266 (18.734) | 95.620 (4.380) | 27.6 | bicubic | 224 |
| efficientnet_b2a | 80.608 (19.392) | 95.310 (4.690) | 9.11 | bicubic | 288 (1.0 crop) |
| resnet50d | 80.530 (19.470) | 95.160 (4.840) | 25.6 | bicubic | 224 |
| mixnet_xl | 80.478 (19.522) | 94.932 (5.068) | 11.90 | bicubic | 224 |
| efficientnet_b2 | 80.402 (19.598) | 95.076 (4.924) | 9.11 | bicubic | 260 |
| seresnet50 | 80.274 (19.726) | 95.070 (4.930) | 28.1 | bicubic | 224 |
| skresnext50d_32x4d | 80.156 (19.844) | 94.642 (5.358) | 27.5 | bicubic | 224 |
| cspdarknet53 | 80.058 (19.942) | 95.084 (4.916) | 27.6 | bicubic | 256 |
| cspresnext50 | 80.040 (19.960) | 94.944 (5.056) | 20.6 | bicubic | 224 |
| resnext50_32x4d | 79.762 (20.238) | 94.600 (5.400) | 25 | bicubic | 224 |
| resnext50d_32x4d | 79.674 (20.326) | 94.868 (5.132) | 25.1 | bicubic | 224 |
| cspresnet50 | 79.574 (20.426) | 94.712 (5.288) | 21.6 | bicubic | 256 |
| ese_vovnet39b | 79.320 (20.680) | 94.710 (5.290) | 24.6 | bicubic | 224 |
| resnetblur50 | 79.290 (20.710) | 94.632 (5.368) | 25.6 | bicubic | 224 |
| dpn68b | 79.216 (20.784) | 94.414 (5.586) | 12.6 | bicubic | 224 |
| resnet50 | 79.038 (20.962) | 94.390 (5.610) | 25.6 | bicubic | 224 |
| mixnet_l | 78.976 (21.024 | 94.184 (5.816) | 7.33 | bicubic | 224 |
| efficientnet_b1 | 78.692 (21.308) | 94.086 (5.914) | 7.79 | bicubic | 240 |
| efficientnet_es | 78.066 (21.934) | 93.926 (6.074) | 5.44 | bicubic | 224 |
| seresnext26t_32x4d | 77.998 (22.002) | 93.708 (6.292) | 16.8 | bicubic | 224 |
| seresnext26tn_32x4d | 77.986 (22.014) | 93.746 (6.254) | 16.8 | bicubic | 224 |
| efficientnet_b0 | 77.698 (22.302) | 93.532 (6.468) | 5.29 | bicubic | 224 |
| seresnext26d_32x4d | 77.602 (22.398) | 93.608 (6.392) | 16.8 | bicubic | 224 |
| mobilenetv2_120d | 77.294 (22.706 | 93.502 (6.498) | 5.8 | bicubic | 224 |
| mixnet_m | 77.256 (22.744) | 93.418 (6.582) | 5.01 | bicubic | 224 |
| resnet34d | 77.116 (22.884) | 93.382 (6.618) | 21.8 | bicubic | 224 |
| seresnext26_32x4d | 77.104 (22.896) | 93.316 (6.684) | 16.8 | bicubic | 224 |
| skresnet34 | 76.912 (23.088) | 93.322 (6.678) | 22.2 | bicubic | 224 |
| ese_vovnet19b_dw | 76.798 (23.202) | 93.268 (6.732) | 6.5 | bicubic | 224 |
| resnet26d | 76.68 (23.32) | 93.166 (6.834) | 16 | bicubic | 224 |
| densenetblur121d | 76.576 (23.424) | 93.190 (6.810) | 8.0 | bicubic | 224 |
| mobilenetv2_140 | 76.524 (23.476) | 92.990 (7.010) | 6.1 | bicubic | 224 |
| mixnet_s | 75.988 (24.012) | 92.794 (7.206) | 4.13 | bicubic | 224 |
| mobilenetv3_large_100 | 75.766 (24.234) | 92.542 (7.458) | 5.5 | bicubic | 224 |
| mobilenetv3_rw | 75.634 (24.366) | 92.708 (7.292) | 5.5 | bicubic | 224 |
| mnasnet_a1 | 75.448 (24.552) | 92.604 (7.396) | 3.89 | bicubic | 224 |
| resnet26 | 75.292 (24.708) | 92.57 (7.43) | 16 | bicubic | 224 |
| fbnetc_100 | 75.124 (24.876) | 92.386 (7.614) | 5.6 | bilinear | 224 |
| resnet34 | 75.110 (24.890) | 92.284 (7.716) | 22 | bilinear | 224 |
| mobilenetv2_110d | 75.052 (24.948) | 92.180 (7.820) | 4.5 | bicubic | 224 |
| seresnet34 | 74.808 (25.192) | 92.124 (7.876) | 22 | bilinear | 224 |
| mnasnet_b1 | 74.658 (25.342) | 92.114 (7.886) | 4.38 | bicubic | 224 |
| spnasnet_100 | 74.084 (25.916) | 91.818 (8.182) | 4.42 | bilinear | 224 |
| skresnet18 | 73.038 (26.962) | 91.168 (8.832) | 11.9 | bicubic | 224 |
| mobilenetv2_100 | 72.978 (27.022) | 91.016 (8.984) | 3.5 | bicubic | 224 |
| resnet18d | 72.260 (27.740) | 90.696 (9.304) | 11.7 | bicubic | 224 |
| seresnet18 | 71.742 (28.258) | 90.334 (9.666) | 11.8 | bicubic | 224 |
## Ported and Other Weights
For weights ported from other deep learning frameworks (Tensorflow, MXNet GluonCV) or copied from other PyTorch sources, please see the full results tables for ImageNet and various OOD test sets at in the [results tables](https://github.com/rwightman/pytorch-image-models/tree/master/results).
Model code .py files contain links to original sources of models and weights.
| huggingface/pytorch-image-models/blob/main/docs/results.md |
# Model `license:other` challenge
Related to https://github.com/huggingface/hub-docs/issues/985.
## Context
The Hugging Face Hub hosts hundreds of thousands of public models and datasets. Public doesn't necessarily mean open-source without any limitations. Authors can define which license applies to the work they share (e.g. [MIT](https://opensource.org/license/mit/), [Apache2.0](https://www.apache.org/licenses/LICENSE-2.0), [OpenRAIL](https://huggingface.co/blog/open_rail), etc.). All users must be able to quickly know which license applies to which model and even to list models with a specific license (e.g. [Apache2.0](https://huggingface.co/models?license=license:apache-2.0&sort=trending)). The Hub relies on the [Model Card](https://huggingface.co/docs/hub/model-cards) to do so. A Model Card is a file attached to a model providing handy information. They are essential for discoverability, reproducibility and sharing. In our case, we will focus on the [metadata](https://huggingface.co/docs/hub/model-cards#model-card-metadata) section of the Model Card. This metadata contains valuable information, including a `license` tag.
In this challenge, we will focus on models that have the license `"other"`. This means that the model has a custom license defined by the author. For example, models from Coqui have their own [coqui-public-model-license](https://coqui.ai/cpml). Historically, this information was not available in the model card metadata. This is now possible by adding the license name and a URL to it:
```yaml
# Example from https://huggingface.co/coqui/XTTS-v1
---
license: other
license_name: coqui-public-model-license
license_link: https://coqui.ai/cpml
---
```
which display on the Hub as

This challenge aims to improve the completeness of this metadata on the Hub, which will ultimately benefit all users.
In other cases, the license was previously set as `other` but given the popularity of the models, the Hugging Face Hub started to support the license officially. This is especially the case of Llama 2 models for which the `license:llama2` is now a supported license. In this case, it's best to set it directly in the Model Card metadata:
```yaml
# Example from https://huggingface.co/codellama/CodeLlama-34b-hf
---
license: llama2
---
```
## How to contribute?
How to do it in practice? That's simple! We have listed models below that have `license:other` in their metadata and contain a LICENSE file in the repo. Those models require an update in their metadata to describe which license is attached.
For each model, the workflow looks like this:
1. Choose a model in the list below. We suggest focusing on the most downloaded or liked models first.
2. **Check that the model doesn't already have a PR to update the license**. Maybe another contributor already checked it!
3. Find the corresponding license. URLs to the LICENSE file(s) in the repo is provided to ease the search.
1. Note: the table suggests the name/URL for Llama models. It doesn't mean that the suggestion is accurate. It is to be double-checked correctly.
4. Check which license applies to the model. Attributes are:
1. `license_name` (short, lowercase, without spaces). Example: `"coqui-public-model-license"`
2. `license_link`. If possible, a URL owned by the author is better (for example: `"https://coqui.ai/cpml"`). Otherwise, linking to the LICENSE file in the repo is also fine.
3. **NOTE:** special case if it's a Llama 2 model. In this case, the card metadata should be `license: llama2` instead of `license: other` and `license_name`/`license_link` are not needed.
5. Open a PR on the Hub, describing the intent and suggesting a modification to the repo author. Here are 2 example for [XTTS-v1](https://huggingface.co/coqui/XTTS-v1/discussions/10/files) and [stable-diffusion-xl-base-0.9](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/discussions/58) models.
6. Once done, open a PR on GitHub to update the table below. Once merged, this will count as a Hacktoberfest contribution! In the PR, add the `pr_url` (the one on the Hub) and a status (opened, merged, closed).
## F.A.Q.
### What if the model has 2 licenses?
This use case can happen when a model is finetuned from another model. Usually this is manually described in the model card. As we don't have a good way to classify multi-license models, it's best to simply keep `license:other`. If that's the case, you can open a PR to add a "multi-license" status to the table below.
### How do I choose `license_name`?
There is no clear answer for that. You can either check other related models, discuss with the repo owner or suggest a name that make sense in your opinion. The name should be short, lowercase and without spaces (for example `"coqui-public-model-license"`).
### Can I use a script to automate the process?
Yes, it's perfectly possible to use a script to automate things! But don't forget that in the end, only **some of the process** can be automated. The PRs you open will be manually reviewed. It's important to refrain from polluting the repo owners with unchecked information.
To help with the programmatic approach, we've also exported the list [as CSV](./model_license_other.csv). This CSV will not be updated with the latest information on this page.
## Model list
Here is the list of models with `license:other` and a LICENSE file in the repo.
|status|pr_url |model_id|nb_downloads|nb_likes |suggested_license_name |suggested_license_link |license_url |license_url_2 |license_url_3 |
|------|----------------------------------------------------------------------------|--------|------------|-------------------------|----------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
|Opened|[Hub PR](https://huggingface.co/decapoda-research/llama-7b-hf/discussions/130)|[decapoda-research/llama-7b-hf](https://huggingface.co/decapoda-research/llama-7b-hf)|379224 |1223 |llama-license |https://huggingface.co/decapoda-research/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-7b-hf/blob/main/LICENSE) | | |
|Opened|[HUB_PR](https://huggingface.co/huggyllama/llama-7b/discussions/7)|[huggyllama/llama-7b](https://huggingface.co/huggyllama/llama-7b)|319220 |200 |llama-license |https://huggingface.co/huggyllama/llama-7b/blob/main/LICENSE |[LICENSE](https://huggingface.co/huggyllama/llama-7b/blob/main/LICENSE) | | |
| | |[TheBloke/MythoMax-L2-13B-GPTQ](https://huggingface.co/TheBloke/MythoMax-L2-13B-GPTQ)|183096 |69 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoMax-L2-13B-GPTQ/blob/main/LICENSE.txt) | | |
|Opened|[hub_pr](https://huggingface.co/elinas/chronos-13b-v2/discussions/3) |[elinas/chronos-13b-v2](https://huggingface.co/elinas/chronos-13b-v2)|35941 |16 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/elinas/chronos-13b-v2/blob/main/LICENSE.txt) | | |
|Opened|[HUB_PR](https://huggingface.co/huggyllama/llama-65b/discussions/1) |[huggyllama/llama-65b](https://huggingface.co/huggyllama/llama-65b)|25299 |64 |llama-license |https://huggingface.co/huggyllama/llama-65b/blob/main/LICENSE |[LICENSE](https://huggingface.co/huggyllama/llama-65b/blob/main/LICENSE) | | |
|Opened|[HUB_PR](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GPTQ/discussions/3) |[TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GPTQ](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GPTQ)|21192 |17 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GPTQ/blob/main/LICENSE.txt)| | |
|Opened|[HUB_PR](https://huggingface.co/defog/sqlcoder/discussions/16) |[defog/sqlcoder](https://huggingface.co/defog/sqlcoder)|13695 |211 |cc-attribution-sharealike-4.0-international-license | |[LICENSE](https://huggingface.co/defog/sqlcoder/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-13b-hf](https://huggingface.co/decapoda-research/llama-13b-hf)|13476 |346 |llama-license |https://huggingface.co/decapoda-research/llama-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-13b-hf/blob/main/LICENSE) | | |
| | |[aipicasso/picasso-diffusion-1-1](https://huggingface.co/aipicasso/picasso-diffusion-1-1)|12239 |37 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/picasso-diffusion-1-1/blob/main/MODEL-LICENSE) | | |
| | |[huggyllama/llama-13b](https://huggingface.co/huggyllama/llama-13b)|12174 |117 |llama-license |https://huggingface.co/huggyllama/llama-13b/blob/main/LICENSE |[LICENSE](https://huggingface.co/huggyllama/llama-13b/blob/main/LICENSE) | | |
| | |[huggyllama/llama-30b](https://huggingface.co/huggyllama/llama-30b)|11268 |37 |llama-license |https://huggingface.co/huggyllama/llama-30b/blob/main/LICENSE |[LICENSE](https://huggingface.co/huggyllama/llama-30b/blob/main/LICENSE) | | |
| | |[TheBloke/Llama-2-70B-fp16](https://huggingface.co/TheBloke/Llama-2-70B-fp16)|10430 |38 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama-2-70B-fp16/blob/main/LICENSE.txt) | | |
| | |[sambanovasystems/BLOOMChat-176B-v1](https://huggingface.co/sambanovasystems/BLOOMChat-176B-v1)|10075 |352 | | |[LICENSE](https://huggingface.co/sambanovasystems/BLOOMChat-176B-v1/blob/main/LICENSE) | | |
|Opened|[HUB_PR](https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/discussions/33) |[TheBloke/Llama-2-7B-Chat-GGML](https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML)|7835 |560 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/blob/main/LICENSE) | | |
|Merged|[HUB_PR](https://huggingface.co/TheBloke/Llama-2-70B-fp16/discussions/4) |[TheBloke/Llama-2-70B-fp16](https://huggingface.co/TheBloke/Llama-2-70B-fp16)|10430 |38 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama-2-70B-fp16/blob/main/LICENSE.txt) | | |
|Opened|[HUB_PR](https://huggingface.co/huggyllama/llama-30b/discussions/1) |[huggyllama/llama-30b](https://huggingface.co/huggyllama/llama-30b)|11268 |37 |llama-license |https://huggingface.co/huggyllama/llama-30b/blob/main/LICENSE |[LICENSE](https://huggingface.co/huggyllama/llama-30b/blob/main/LICENSE) | | |
|Opened|[HUB_PR](https://huggingface.co/huggyllama/llama-13b/discussions/2) |[huggyllama/llama-13b](https://huggingface.co/huggyllama/llama-13b)|12174 |117 |llama-license |https://huggingface.co/huggyllama/llama-13b/blob/main/LICENSE |[LICENSE](https://huggingface.co/huggyllama/llama-13b/blob/main/LICENSE) | | |
|Opened|[HUB_PR](https://huggingface.co/sambanovasystems/BLOOMChat-176B-v1/discussions/9) |[sambanovasystems/BLOOMChat-176B-v1](https://huggingface.co/sambanovasystems/BLOOMChat-176B-v1)|10075 |352 | bloomchat-v1.0 | |[LICENSE](https://huggingface.co/sambanovasystems/BLOOMChat-176B-v1/blob/main/LICENSE) | | |
| | |[TheBloke/Llama-2-7B-Chat-GGML](https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML)|7835 |560 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-30b-hf](https://huggingface.co/decapoda-research/llama-30b-hf)|7450 |133 |llama-license |https://huggingface.co/decapoda-research/llama-30b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-30b-hf/blob/main/LICENSE) | | |
| | |[shibing624/chinese-alpaca-plus-13b-hf](https://huggingface.co/shibing624/chinese-alpaca-plus-13b-hf)|6889 |31 |llama-license |https://huggingface.co/shibing624/chinese-alpaca-plus-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/shibing624/chinese-alpaca-plus-13b-hf/blob/main/LICENSE) | | |
| | |[georgesung/llama2_7b_chat_uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)|6672 |145 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/georgesung/llama2_7b_chat_uncensored/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Llama-2-70B-Chat-fp16](https://huggingface.co/TheBloke/Llama-2-70B-Chat-fp16)|4380 |39 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama-2-70B-Chat-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/llama2_7b_chat_uncensored-GPTQ](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ)|4206 |50 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ/blob/main/LICENSE.txt)| | |
| | |[stabilityai/japanese-stablelm-instruct-alpha-7b](https://huggingface.co/stabilityai/japanese-stablelm-instruct-alpha-7b)|3885 |80 | | |[LICENSE](https://huggingface.co/stabilityai/japanese-stablelm-instruct-alpha-7b/blob/main/LICENSE)| | |
| | |[TheBloke/orca_mini_v3_7B-GPTQ](https://huggingface.co/TheBloke/orca_mini_v3_7B-GPTQ)|3592 |8 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[stabilityai/japanese-instructblip-alpha](https://huggingface.co/stabilityai/japanese-instructblip-alpha)|3508 |43 | | |[LICENSE](https://huggingface.co/stabilityai/japanese-instructblip-alpha/blob/main/LICENSE) | | |
| | |[TheBloke/llama-2-70b-Guanaco-QLoRA-fp16](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-fp16)|3395 |52 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-fp16/blob/main/LICENSE.txt)| | |
| | |[jondurbin/airoboros-l2-7b-gpt4-1.4.1](https://huggingface.co/jondurbin/airoboros-l2-7b-gpt4-1.4.1)|2798 |10 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/jondurbin/airoboros-l2-7b-gpt4-1.4.1/blob/main/LICENSE.txt) | | |
| | |[shibing624/chinese-alpaca-plus-7b-hf](https://huggingface.co/shibing624/chinese-alpaca-plus-7b-hf)|2768 |44 |llama-license |https://huggingface.co/shibing624/chinese-alpaca-plus-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/shibing624/chinese-alpaca-plus-7b-hf/blob/main/LICENSE) | | |
| | |[TheBloke/VicUnlocked-alpaca-65B-QLoRA-fp16](https://huggingface.co/TheBloke/VicUnlocked-alpaca-65B-QLoRA-fp16)|2748 |9 |llama-license |https://huggingface.co/TheBloke/VicUnlocked-alpaca-65B-QLoRA-fp16/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/VicUnlocked-alpaca-65B-QLoRA-fp16/blob/main/LICENSE) | | |
| | |[h2oai/h2ogpt-research-oig-oasst1-512-30b](https://huggingface.co/h2oai/h2ogpt-research-oig-oasst1-512-30b)|2741 |2 |llama-license |https://huggingface.co/h2oai/h2ogpt-research-oig-oasst1-512-30b/blob/main/LICENSE |[LICENSE](https://huggingface.co/h2oai/h2ogpt-research-oig-oasst1-512-30b/blob/main/LICENSE) | | |
| | |[shibing624/chinese-llama-plus-13b-hf](https://huggingface.co/shibing624/chinese-llama-plus-13b-hf)|2719 |17 |llama-license |https://huggingface.co/shibing624/chinese-llama-plus-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/shibing624/chinese-llama-plus-13b-hf/blob/main/LICENSE) | | |
| | |[TheBloke/Kimiko-13B-fp16](https://huggingface.co/TheBloke/Kimiko-13B-fp16)|2705 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kimiko-13B-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-30B-fp16](https://huggingface.co/TheBloke/tulu-30B-fp16)|2673 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-30B-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-13B-fp16](https://huggingface.co/TheBloke/tulu-13B-fp16)|2664 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-13B-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-7B-fp16](https://huggingface.co/TheBloke/tulu-7B-fp16)|2663 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-7B-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Llama-2-13B-chat-GGML](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML)|2607 |595 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-65b-hf](https://huggingface.co/decapoda-research/llama-65b-hf)|2380 |281 |llama-license |https://huggingface.co/decapoda-research/llama-65b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-65b-hf/blob/main/LICENSE) | | |
| | |[valurank/MiniLM-L6-Keyword-Extraction](https://huggingface.co/valurank/MiniLM-L6-Keyword-Extraction)|2251 |6 | | |[LICENSE](https://huggingface.co/valurank/MiniLM-L6-Keyword-Extraction/blob/main/LICENSE) | | |
| | |[TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ)|1646 |35 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ/blob/main/LICENSE.txt)| | |
| | |[Enoch/llama-65b-hf](https://huggingface.co/Enoch/llama-65b-hf)|1630 |3 |llama-license |https://huggingface.co/Enoch/llama-65b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Enoch/llama-65b-hf/blob/main/LICENSE) | | |
| | |[luodian/llama-7b-hf](https://huggingface.co/luodian/llama-7b-hf)|1136 |14 |llama-license |https://huggingface.co/luodian/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/luodian/llama-7b-hf/blob/main/LICENSE) | | |
| | |[TheBloke/LLaMA-7b-GPTQ](https://huggingface.co/TheBloke/LLaMA-7b-GPTQ)|1112 |2 |llama-license |https://huggingface.co/TheBloke/LLaMA-7b-GPTQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-7b-GPTQ/blob/main/LICENSE) | | |
| | |[Mitsua/mitsua-diffusion-one](https://huggingface.co/Mitsua/mitsua-diffusion-one)|1095 |66 | | |[MODEL-LICENSE](https://huggingface.co/Mitsua/mitsua-diffusion-one/blob/main/MODEL-LICENSE) | | |
| | |[4bit/Llama-2-7b-Chat-GPTQ](https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ)|1087 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/4bit/Llama-2-7b-Chat-GPTQ/blob/main/LICENSE) | | |
| | |[learnanything/llama-7b-huggingface](https://huggingface.co/learnanything/llama-7b-huggingface)|962 |3 |llama-license |https://huggingface.co/learnanything/llama-7b-huggingface/blob/main/LICENSE |[LICENSE](https://huggingface.co/learnanything/llama-7b-huggingface/blob/main/LICENSE) | | |
| | |[TheBloke/LLaMA-30b-GPTQ](https://huggingface.co/TheBloke/LLaMA-30b-GPTQ)|828 |4 |llama-license |https://huggingface.co/TheBloke/LLaMA-30b-GPTQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-30b-GPTQ/blob/main/LICENSE) | | |
| | |[aipicasso/cool-japan-diffusion-2-1-1-1](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-1-1)|796 |3 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-1-1/blob/main/MODEL-LICENSE)| | |
| | |[aipicasso/cool-japan-diffusion-2-1-2-beta](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-2-beta)|703 |2 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-2-beta/blob/main/MODEL-LICENSE)| | |
| | |[waylandy/phosformer](https://huggingface.co/waylandy/phosformer)|690 |0 | | |[LICENSE](https://huggingface.co/waylandy/phosformer/blob/main/LICENSE) | | |
| | |[TheBloke/llama-2-70b-Guanaco-QLoRA-GPTQ](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-GPTQ)|618 |35 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-GPTQ/blob/main/LICENSE.txt)| | |
| | |[aipicasso/cool-japan-diffusion-2-1-0-beta](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-0-beta)|605 |30 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-0-beta/blob/main/MODEL-LICENSE)| | |
| | |[TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ)|575 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ/blob/main/LICENSE.txt)| | |
| | |[aipicasso/cool-japan-diffusion-2-1-1](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-1)|556 |20 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-1/blob/main/MODEL-LICENSE)| | |
| | |[TheBloke/MythoMix-L2-13B-GPTQ](https://huggingface.co/TheBloke/MythoMix-L2-13B-GPTQ)|534 |14 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoMix-L2-13B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[aipicasso/manga-diffusion-poc](https://huggingface.co/aipicasso/manga-diffusion-poc)|532 |2 | | |[LICENSE](https://huggingface.co/aipicasso/manga-diffusion-poc/blob/main/LICENSE) | | |
| | |[aipicasso/cool-japan-diffusion-2-1-1-beta](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-1-beta)|529 |10 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-1-beta/blob/main/MODEL-LICENSE)| | |
| | |[TheBloke/airoboros-l2-13b-gpt4-2.0-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-2.0-GPTQ)|519 |15 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-2.0-GPTQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Zarablend-L2-7B-GPTQ](https://huggingface.co/TheBloke/Zarablend-L2-7B-GPTQ)|475 |9 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarablend-L2-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/airoboros-l2-13B-gpt4-1.4.1-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-13B-gpt4-1.4.1-GPTQ)|450 |23 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13B-gpt4-1.4.1-GPTQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-13b-gpt4-m2.0-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-m2.0-GPTQ)|403 |26 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-m2.0-GPTQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Llama-2-70B-Chat-GGML](https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML)|370 |150 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML/blob/main/LICENSE.txt) | | |
| | |[shalomma/llama-7b-embeddings](https://huggingface.co/shalomma/llama-7b-embeddings)|363 |21 |llama-license |https://huggingface.co/shalomma/llama-7b-embeddings/blob/main/LICENSE |[LICENSE](https://huggingface.co/shalomma/llama-7b-embeddings/blob/main/LICENSE) | | |
| | |[aipicasso/cool-japan-diffusion-2-1-2](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-2)|360 |12 | | |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-2/blob/main/MODEL-LICENSE)| | |
| | |[TheBloke/orca_mini_v3_70B-GPTQ](https://huggingface.co/TheBloke/orca_mini_v3_70B-GPTQ)|334 |9 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_70B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[aipicasso/cool-japan-diffusion-2-1-0](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-0)|330 |63 | | |[LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-0/blob/main/LICENSE) |[MODEL-LICENSE](https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-0/blob/main/MODEL-LICENSE) | |
| | |[TheBloke/orca_mini_v3_13B-GPTQ](https://huggingface.co/TheBloke/orca_mini_v3_13B-GPTQ)|266 |9 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_13B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Airoboros-L2-70B-GPT4-m2.0-GPTQ](https://huggingface.co/TheBloke/Airoboros-L2-70B-GPT4-m2.0-GPTQ)|256 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Airoboros-L2-70B-GPT4-m2.0-GPTQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-7B-gpt4-2.0-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-2.0-GPTQ)|254 |7 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-2.0-GPTQ/blob/main/LICENSE.txt) | | |
| | |[valurank/finetuned-distilbert-news-article-categorization](https://huggingface.co/valurank/finetuned-distilbert-news-article-categorization)|253 |0 | | |[LICENSE](https://huggingface.co/valurank/finetuned-distilbert-news-article-categorization/blob/main/LICENSE)| | |
| | |[valurank/distilroberta-propaganda-2class](https://huggingface.co/valurank/distilroberta-propaganda-2class)|248 |3 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-propaganda-2class/blob/main/LICENSE) | | |
| | |[TheBloke/Llama-2-70B-GGML](https://huggingface.co/TheBloke/Llama-2-70B-GGML)|237 |69 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama-2-70B-GGML/blob/main/LICENSE.txt) | | |
| | |[valurank/distilroberta-clickbait](https://huggingface.co/valurank/distilroberta-clickbait)|237 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-clickbait/blob/main/LICENSE) | | |
| | |[valurank/distilroberta-bias](https://huggingface.co/valurank/distilroberta-bias)|223 |1 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-bias/blob/main/LICENSE) | | |
| | |[TheBloke/OpenChat_v3.2-GPTQ](https://huggingface.co/TheBloke/OpenChat_v3.2-GPTQ)|220 |12 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenChat_v3.2-GPTQ/blob/main/LICENSE.txt) | | |
| | |[valurank/distilroberta-news-small](https://huggingface.co/valurank/distilroberta-news-small)|214 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-news-small/blob/main/LICENSE) | | |
| | |[TheBloke/airoboros-l2-7B-gpt4-m2.0-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-m2.0-GPTQ)|210 |6 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-m2.0-GPTQ/blob/main/LICENSE.txt)| | |
| | |[valurank/distilroberta-proppy](https://huggingface.co/valurank/distilroberta-proppy)|209 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-proppy/blob/main/LICENSE) | | |
| | |[valurank/distilroberta-hatespeech](https://huggingface.co/valurank/distilroberta-hatespeech)|208 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-hatespeech/blob/main/LICENSE) | | |
| | |[valurank/distilroberta-offensive](https://huggingface.co/valurank/distilroberta-offensive)|208 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-offensive/blob/main/LICENSE) | | |
| | |[valurank/distilroberta-current](https://huggingface.co/valurank/distilroberta-current)|203 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-current/blob/main/LICENSE) | | |
| | |[TheBloke/Kuchiki-L2-7B-GGUF](https://huggingface.co/TheBloke/Kuchiki-L2-7B-GGUF)|192 |7 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kuchiki-L2-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarafusionex-1.1-L2-7B-GPTQ](https://huggingface.co/TheBloke/Zarafusionex-1.1-L2-7B-GPTQ)|187 |4 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarafusionex-1.1-L2-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/llama2_7b_chat_uncensored-GGML](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGML)|179 |89 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGML/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-70B-gpt4-1.4.1-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-70B-gpt4-1.4.1-GPTQ)|171 |55 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-70B-gpt4-1.4.1-GPTQ/blob/main/LICENSE.txt)| | |
| | |[Mitsua/vroid-diffusion-test](https://huggingface.co/Mitsua/vroid-diffusion-test)|170 |0 | | |[MODEL-LICENSE](https://huggingface.co/Mitsua/vroid-diffusion-test/blob/main/MODEL-LICENSE) | | |
| | |[Neko-Institute-of-Science/LLaMA-7B-HF](https://huggingface.co/Neko-Institute-of-Science/LLaMA-7B-HF)|167 |22 |llama-license |https://huggingface.co/Neko-Institute-of-Science/LLaMA-7B-HF/blob/main/LICENSE |[LICENSE](https://huggingface.co/Neko-Institute-of-Science/LLaMA-7B-HF/blob/main/LICENSE) | | |
| | |[TheBloke/Kuchiki-L2-7B-GPTQ](https://huggingface.co/TheBloke/Kuchiki-L2-7B-GPTQ)|162 |4 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kuchiki-L2-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[aleksickx/llama-7b-hf](https://huggingface.co/aleksickx/llama-7b-hf)|144 |10 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/aleksickx/llama-7b-hf/blob/main/LICENSE.txt) | | |
| | |[TheBloke/LLaMA-65B-GPTQ](https://huggingface.co/TheBloke/LLaMA-65B-GPTQ)|139 |4 |llama-license |https://huggingface.co/TheBloke/LLaMA-65B-GPTQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-65B-GPTQ/blob/main/LICENSE) | | |
| | |[TheBloke/MythoMax-L2-13B-AWQ](https://huggingface.co/TheBloke/MythoMax-L2-13B-AWQ)|135 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoMax-L2-13B-AWQ/blob/main/LICENSE.txt) | | |
| | |[OAOA/DifFace](https://huggingface.co/OAOA/DifFace)|124 |1 | | |[LICENSE](https://huggingface.co/OAOA/DifFace/blob/main/LICENSE) | | |
| | |[Enoch/llama-7b-hf](https://huggingface.co/Enoch/llama-7b-hf)|123 |0 |llama-license |https://huggingface.co/Enoch/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Enoch/llama-7b-hf/blob/main/LICENSE) | | |
| | |[TheBloke/MythoMax-L2-13B-GGUF](https://huggingface.co/TheBloke/MythoMax-L2-13B-GGUF)|119 |9 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoMax-L2-13B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/airoboros-l2-70B-GPT4-2.0-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-70B-GPT4-2.0-GPTQ)|116 |15 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-70B-GPT4-2.0-GPTQ/blob/main/LICENSE.txt)| | |
| | |[valurank/distilbert-quality](https://huggingface.co/valurank/distilbert-quality)|113 |0 | | |[LICENSE](https://huggingface.co/valurank/distilbert-quality/blob/main/LICENSE) | | |
| | |[TheBloke/HermesLimaRP-L2-7B-GPTQ](https://huggingface.co/TheBloke/HermesLimaRP-L2-7B-GPTQ)|112 |7 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/HermesLimaRP-L2-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/llama-2-70b-Guanaco-QLoRA-AWQ](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-AWQ)|102 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-AWQ/blob/main/LICENSE.txt) | | |
| | |[Neko-Institute-of-Science/LLaMA-65B-HF](https://huggingface.co/Neko-Institute-of-Science/LLaMA-65B-HF)|77 |6 |llama-license |https://huggingface.co/Neko-Institute-of-Science/LLaMA-65B-HF/blob/main/LICENSE |[LICENSE](https://huggingface.co/Neko-Institute-of-Science/LLaMA-65B-HF/blob/main/LICENSE) | | |
| | |[TheBloke/Llama2-22B-Daydreamer-v3-GPTQ](https://huggingface.co/TheBloke/Llama2-22B-Daydreamer-v3-GPTQ)|77 |7 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama2-22B-Daydreamer-v3-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarablend-L2-7B-GGUF](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF)|76 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarablend-L2-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[nenkoru/llama-7b-onnx-merged-fp16](https://huggingface.co/nenkoru/llama-7b-onnx-merged-fp16)|69 |6 |llama-license |https://huggingface.co/nenkoru/llama-7b-onnx-merged-fp16/blob/main/LICENSE |[LICENSE](https://huggingface.co/nenkoru/llama-7b-onnx-merged-fp16/blob/main/LICENSE) | | |
| | |[valurank/finetuned-distilbert-adult-content-detection](https://huggingface.co/valurank/finetuned-distilbert-adult-content-detection)|62 |0 | | |[LICENSE](https://huggingface.co/valurank/finetuned-distilbert-adult-content-detection/blob/main/LICENSE)| | |
| | |[TheBloke/LLaMA-13b-GPTQ](https://huggingface.co/TheBloke/LLaMA-13b-GPTQ)|56 |4 |llama-license |https://huggingface.co/TheBloke/LLaMA-13b-GPTQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-13b-GPTQ/blob/main/LICENSE) | | |
| | |[coqui/XTTS-v1](https://huggingface.co/coqui/XTTS-v1)|54 |218 | | |[LICENSE](https://huggingface.co/coqui/XTTS-v1/blob/main/LICENSE) | | |
| | |[coreml-projects/Llama-2-7b-chat-coreml](https://huggingface.co/coreml-projects/Llama-2-7b-chat-coreml)|46 |72 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/coreml-projects/Llama-2-7b-chat-coreml/blob/main/LICENSE.txt) | | |
| | |[elinas/chronos-13b-v2-GPTQ](https://huggingface.co/elinas/chronos-13b-v2-GPTQ)|45 |6 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/elinas/chronos-13b-v2-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/HermesLimaRP-L2-7B-GGUF](https://huggingface.co/TheBloke/HermesLimaRP-L2-7B-GGUF)|45 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/HermesLimaRP-L2-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/LLaMA-7b-AWQ](https://huggingface.co/TheBloke/LLaMA-7b-AWQ)|43 |0 |llama-license |https://huggingface.co/TheBloke/LLaMA-7b-AWQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-7b-AWQ/blob/main/LICENSE) | | |
| | |[arogov/llama2_13b_chat_uncensored](https://huggingface.co/arogov/llama2_13b_chat_uncensored)|42 |13 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/arogov/llama2_13b_chat_uncensored/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-30B-GPTQ](https://huggingface.co/TheBloke/tulu-30B-GPTQ)|42 |10 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-30B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[dfurman/llama-7b](https://huggingface.co/dfurman/llama-7b)|39 |0 |llama-license |https://huggingface.co/dfurman/llama-7b/blob/main/LICENSE |[LICENSE](https://huggingface.co/dfurman/llama-7b/blob/main/LICENSE) | | |
| | |[TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GGUF](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GGUF)|39 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-13b-gpt4-m2.0-AWQ](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-m2.0-AWQ)|38 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-m2.0-AWQ/blob/main/LICENSE.txt)| | |
| | |[alfredplpl/unlimited-replicant](https://huggingface.co/alfredplpl/unlimited-replicant)|37 |18 | | |[MODEL-LICENSE](https://huggingface.co/alfredplpl/unlimited-replicant/blob/main/MODEL-LICENSE) | | |
| | |[TheBloke/airoboros-l2-7b-gpt4-1.4.1-GPTQ](https://huggingface.co/TheBloke/airoboros-l2-7b-gpt4-1.4.1-GPTQ)|36 |9 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7b-gpt4-1.4.1-GPTQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-70B-GPT4-2.0-AWQ](https://huggingface.co/TheBloke/airoboros-l2-70B-GPT4-2.0-AWQ)|35 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-70B-GPT4-2.0-AWQ/blob/main/LICENSE.txt) | | |
| | |[Mitsua/vroid-diffusion-test-unconditional](https://huggingface.co/Mitsua/vroid-diffusion-test-unconditional)|33 |0 | | |[MODEL-LICENSE](https://huggingface.co/Mitsua/vroid-diffusion-test-unconditional/blob/main/MODEL-LICENSE)| | |
| | |[dfurman/llama-13b](https://huggingface.co/dfurman/llama-13b)|31 |0 |llama-license |https://huggingface.co/dfurman/llama-13b/blob/main/LICENSE |[LICENSE](https://huggingface.co/dfurman/llama-13b/blob/main/LICENSE) | | |
| | |[TheBloke/MythoLogic-Mini-7B-GPTQ](https://huggingface.co/TheBloke/MythoLogic-Mini-7B-GPTQ)|31 |10 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoLogic-Mini-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[massh3dpotato/Llama-2-7B-chat-GGML](https://huggingface.co/massh3dpotato/Llama-2-7B-chat-GGML)|30 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/massh3dpotato/Llama-2-7B-chat-GGML/blob/main/LICENSE.txt) | | |
| | |[Neko-Institute-of-Science/LLaMA-13B-HF](https://huggingface.co/Neko-Institute-of-Science/LLaMA-13B-HF)|30 |13 |llama-license |https://huggingface.co/Neko-Institute-of-Science/LLaMA-13B-HF/blob/main/LICENSE |[LICENSE](https://huggingface.co/Neko-Institute-of-Science/LLaMA-13B-HF/blob/main/LICENSE) | | |
| | |[TheBloke/orca_mini_v3_7B-GGUF](https://huggingface.co/TheBloke/orca_mini_v3_7B-GGUF)|30 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[Xilabs/Llama-2-7b-Sharded](https://huggingface.co/Xilabs/Llama-2-7b-Sharded)|30 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/Xilabs/Llama-2-7b-Sharded/blob/main/LICENSE.txt) | | |
| | |[ehartford/samantha-falcon-7b](https://huggingface.co/ehartford/samantha-falcon-7b)|29 |22 | | |[LICENSE.txt](https://huggingface.co/ehartford/samantha-falcon-7b/blob/main/LICENSE.txt) | | |
| | |[tawfikgh/llama2-ggml](https://huggingface.co/tawfikgh/llama2-ggml)|29 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/tawfikgh/llama2-ggml/blob/main/LICENSE) | | |
| | |[TheBloke/MythoMix-L2-13B-GGUF](https://huggingface.co/TheBloke/MythoMix-L2-13B-GGUF)|29 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoMix-L2-13B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarafusionex-1.1-L2-7B-GGUF](https://huggingface.co/TheBloke/Zarafusionex-1.1-L2-7B-GGUF)|29 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarafusionex-1.1-L2-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/qCammel-13-GPTQ](https://huggingface.co/TheBloke/qCammel-13-GPTQ)|26 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/qCammel-13-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/CodeFuse-CodeLlama-34B-GPTQ](https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-GPTQ)|25 |4 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-13B-GPTQ](https://huggingface.co/TheBloke/tulu-13B-GPTQ)|25 |7 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-13B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/NewHope-GPTQ](https://huggingface.co/TheBloke/NewHope-GPTQ)|24 |23 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/NewHope-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/qCammel-70-x-GPTQ](https://huggingface.co/TheBloke/qCammel-70-x-GPTQ)|24 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/qCammel-70-x-GPTQ/blob/main/LICENSE.txt) | | |
| | |[deerslab/llama-7b-embeddings](https://huggingface.co/deerslab/llama-7b-embeddings)|23 |5 |llama-license |https://huggingface.co/deerslab/llama-7b-embeddings/blob/main/LICENSE |[LICENSE](https://huggingface.co/deerslab/llama-7b-embeddings/blob/main/LICENSE) | | |
| | |[TheBloke/llama2_7b_chat_uncensored-GGUF](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGUF)|22 |6 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGUF/blob/main/LICENSE.txt)| | |
| | |[lyogavin/Anima33B-merged](https://huggingface.co/lyogavin/Anima33B-merged)|20 |22 |llama-license |https://huggingface.co/lyogavin/Anima33B-merged/blob/main/LICENSE |[LICENSE](https://huggingface.co/lyogavin/Anima33B-merged/blob/main/LICENSE) | | |
| | |[TheBloke/airoboros-l2-7B-gpt4-2.0-AWQ](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-2.0-AWQ)|20 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-2.0-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/LLaMA-30b-AWQ](https://huggingface.co/TheBloke/LLaMA-30b-AWQ)|20 |1 |llama-license |https://huggingface.co/TheBloke/LLaMA-30b-AWQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-30b-AWQ/blob/main/LICENSE) | | |
| | |[valurank/distilroberta-mbfc-bias](https://huggingface.co/valurank/distilroberta-mbfc-bias)|18 |2 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-mbfc-bias/blob/main/LICENSE) | | |
| | |[TheBloke/llama-2-70b-Guanaco-QLoRA-GGUF](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-GGUF)|15 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-GGUF/blob/main/LICENSE.txt)| | |
| | |[camelids/llama-7b-fp16-safetensors](https://huggingface.co/camelids/llama-7b-fp16-safetensors)|14 |1 |llama-license |https://huggingface.co/camelids/llama-7b-fp16-safetensors/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-7b-fp16-safetensors/blob/main/LICENSE) | | |
| | |[massh3dpotato/Llama-2-13B-chat-GGML](https://huggingface.co/massh3dpotato/Llama-2-13B-chat-GGML)|14 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/massh3dpotato/Llama-2-13B-chat-GGML/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Llama2-13B-MegaCode2-OASST-GPTQ](https://huggingface.co/TheBloke/Llama2-13B-MegaCode2-OASST-GPTQ)|14 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama2-13B-MegaCode2-OASST-GPTQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/orca_mini_v3_70B-GGUF](https://huggingface.co/TheBloke/orca_mini_v3_70B-GGUF)|14 |4 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_70B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/orca_mini_v3_7B-AWQ](https://huggingface.co/TheBloke/orca_mini_v3_7B-AWQ)|14 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/airoboros-l2-7B-gpt4-m2.0-AWQ](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-m2.0-AWQ)|13 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-m2.0-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/CodeFuse-CodeLlama-34B-AWQ](https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-AWQ)|13 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/CodeFuse-CodeLlama-34B-GGUF](https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-GGUF)|13 |8 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-GGUF/blob/main/LICENSE.txt) | | |
| | |[alfredplpl/unlimited-1-0](https://huggingface.co/alfredplpl/unlimited-1-0)|12 |0 | | |[MODEL-LICENSE](https://huggingface.co/alfredplpl/unlimited-1-0/blob/main/MODEL-LICENSE) | | |
| | |[ibm/roberta-large-vira-intents](https://huggingface.co/ibm/roberta-large-vira-intents)|12 |1 | | |[LICENSE](https://huggingface.co/ibm/roberta-large-vira-intents/blob/main/LICENSE) | | |
| | |[TheBloke/sqlcoder-GPTQ](https://huggingface.co/TheBloke/sqlcoder-GPTQ)|12 |2 | | |[LICENSE](https://huggingface.co/TheBloke/sqlcoder-GPTQ/blob/main/LICENSE) | | |
| | |[TheBloke/airoboros-l2-7B-gpt4-m2.0-GGUF](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-m2.0-GGUF)|11 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-m2.0-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Kuchiki-1.1-L2-7B-GPTQ](https://huggingface.co/TheBloke/Kuchiki-1.1-L2-7B-GPTQ)|11 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kuchiki-1.1-L2-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/llama2-22B-daydreamer-v2-GPTQ](https://huggingface.co/TheBloke/llama2-22B-daydreamer-v2-GPTQ)|11 |8 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2-22B-daydreamer-v2-GPTQ/blob/main/LICENSE.txt) | | |
| | |[yswill/llama-13b-hf](https://huggingface.co/yswill/llama-13b-hf)|11 |4 |llama-license |https://huggingface.co/yswill/llama-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/yswill/llama-13b-hf/blob/main/LICENSE) | | |
| | |[Enoch/llama-30b-hf](https://huggingface.co/Enoch/llama-30b-hf)|10 |0 |llama-license |https://huggingface.co/Enoch/llama-30b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Enoch/llama-30b-hf/blob/main/LICENSE) | | |
| | |[luodian/llama-13b-hf](https://huggingface.co/luodian/llama-13b-hf)|9 |3 |llama-license |https://huggingface.co/luodian/llama-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/luodian/llama-13b-hf/blob/main/LICENSE) | | |
| | |[TheBloke/OpenOrcaxOpenChat-Preview2-13B-GGML](https://huggingface.co/TheBloke/OpenOrcaxOpenChat-Preview2-13B-GGML)|9 |27 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenOrcaxOpenChat-Preview2-13B-GGML/blob/main/LICENSE.txt)| | |
| | |[nonlinearshimada/llama-13b](https://huggingface.co/nonlinearshimada/llama-13b)|8 |1 |llama-license |https://huggingface.co/nonlinearshimada/llama-13b/blob/main/LICENSE |[LICENSE](https://huggingface.co/nonlinearshimada/llama-13b/blob/main/LICENSE) | | |
| | |[TheBloke/MythoLogic-L2-13B-GPTQ](https://huggingface.co/TheBloke/MythoLogic-L2-13B-GPTQ)|7 |8 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoLogic-L2-13B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[turboderp/Llama2-70B-exl2](https://huggingface.co/turboderp/Llama2-70B-exl2)|7 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/turboderp/Llama2-70B-exl2/blob/main/LICENSE.txt) | | |
| | |[nenkoru/llama-7b-onnx-fp32](https://huggingface.co/nenkoru/llama-7b-onnx-fp32)|6 |0 |llama-license |https://huggingface.co/nenkoru/llama-7b-onnx-fp32/blob/main/LICENSE |[LICENSE](https://huggingface.co/nenkoru/llama-7b-onnx-fp32/blob/main/LICENSE) | | |
| | |[TheBloke/Chronohermes-Grad-L2-13B-GPTQ](https://huggingface.co/TheBloke/Chronohermes-Grad-L2-13B-GPTQ)|6 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Chronohermes-Grad-L2-13B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Llama2-22B-Daydreamer-v3-GGUF](https://huggingface.co/TheBloke/Llama2-22B-Daydreamer-v3-GGUF)|6 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama2-22B-Daydreamer-v3-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/llama2_7b_chat_uncensored-AWQ](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-AWQ)|6 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-AWQ/blob/main/LICENSE.txt) | | |
| | |[valurank/t5-paraphraser](https://huggingface.co/valurank/t5-paraphraser)|6 |2 | | |[LICENSE](https://huggingface.co/valurank/t5-paraphraser/blob/main/LICENSE) | | |
| | |[4bit/llama-13b-4bit-hf](https://huggingface.co/4bit/llama-13b-4bit-hf)|5 |2 |llama-license |https://huggingface.co/4bit/llama-13b-4bit-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/4bit/llama-13b-4bit-hf/blob/main/LICENSE) | | |
| | |[gsaivinay/Llama-2-7b-Chat-GPTQ](https://huggingface.co/gsaivinay/Llama-2-7b-Chat-GPTQ)|5 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/gsaivinay/Llama-2-7b-Chat-GPTQ/blob/main/LICENSE) | | |
| | |[TheBloke/MythoLogic-Mini-7B-GGUF](https://huggingface.co/TheBloke/MythoLogic-Mini-7B-GGUF)|5 |4 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoLogic-Mini-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/PuddleJumper-13B-V2-GPTQ](https://huggingface.co/TheBloke/PuddleJumper-13B-V2-GPTQ)|5 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/PuddleJumper-13B-V2-GPTQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-7B-GPTQ](https://huggingface.co/TheBloke/tulu-7B-GPTQ)|5 |9 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[valurank/pegasus-multi_news-headline](https://huggingface.co/valurank/pegasus-multi_news-headline)|5 |1 | | |[LICENSE](https://huggingface.co/valurank/pegasus-multi_news-headline/blob/main/LICENSE) | | |
| | |[zohaib99k/Nous-Hermes-Llama2-8bit-GPTQ](https://huggingface.co/zohaib99k/Nous-Hermes-Llama2-8bit-GPTQ)|5 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/zohaib99k/Nous-Hermes-Llama2-8bit-GPTQ/blob/main/LICENSE.txt) | | |
| | |[Jsevisal/ft-distilbert-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/ft-distilbert-gest-pred-seqeval-partialmatch)|4 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/ft-distilbert-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[pankaj-munde/llama-2-13b-chat-gptq](https://huggingface.co/pankaj-munde/llama-2-13b-chat-gptq)|4 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/pankaj-munde/llama-2-13b-chat-gptq/blob/main/LICENSE) | | |
| | |[TheBloke/Airoboros-L2-70B-GPT4-m2.0-AWQ](https://huggingface.co/TheBloke/Airoboros-L2-70B-GPT4-m2.0-AWQ)|4 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Airoboros-L2-70B-GPT4-m2.0-AWQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Llama2-13B-MegaCode2-OASST-AWQ](https://huggingface.co/TheBloke/Llama2-13B-MegaCode2-OASST-AWQ)|4 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama2-13B-MegaCode2-OASST-AWQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Llama2-13B-MegaCode2-OASST-GGUF](https://huggingface.co/TheBloke/Llama2-13B-MegaCode2-OASST-GGUF)|4 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama2-13B-MegaCode2-OASST-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/MythoMix-L2-13B-AWQ](https://huggingface.co/TheBloke/MythoMix-L2-13B-AWQ)|4 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoMix-L2-13B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/PuddleJumper-13B-V2-AWQ](https://huggingface.co/TheBloke/PuddleJumper-13B-V2-AWQ)|4 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/PuddleJumper-13B-V2-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Tulu-30B-SuperHOT-8K-GPTQ](https://huggingface.co/TheBloke/Tulu-30B-SuperHOT-8K-GPTQ)|4 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Tulu-30B-SuperHOT-8K-GPTQ/blob/main/LICENSE.txt) | | |
| | |[unoooo/llama-7b-hf](https://huggingface.co/unoooo/llama-7b-hf)|4 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/unoooo/llama-7b-hf/blob/main/LICENSE.txt) | | |
| | |[TheBloke/airoboros-l2-13b-gpt4-m2.0-GGUF](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-m2.0-GGUF)|3 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-m2.0-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-7B-gpt4-2.0-GGUF](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-2.0-GGUF)|3 |4 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7B-gpt4-2.0-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/MythoLogic-L2-13B-GGUF](https://huggingface.co/TheBloke/MythoLogic-L2-13B-GGUF)|3 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoLogic-L2-13B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/NewHope-GGML](https://huggingface.co/TheBloke/NewHope-GGML)|3 |37 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/NewHope-GGML/blob/main/LICENSE.txt) | | |
| | |[TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GGML](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GGML)|3 |11 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-v2-8K-3166-GGML/blob/main/LICENSE.txt)| | |
| | |[TheBloke/orca_mini_v3_13B-GGUF](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF)|3 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_13B-GGUF/blob/main/LICENSE.txt) | | |
| | |[valurank/distilroberta-mbfc-bias-4class](https://huggingface.co/valurank/distilroberta-mbfc-bias-4class)|3 |0 | | |[LICENSE](https://huggingface.co/valurank/distilroberta-mbfc-bias-4class/blob/main/LICENSE) | | |
| | |[Jsevisal/balanced-augmented-ft-roberta-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/balanced-augmented-ft-roberta-gest-pred-seqeval-partialmatch)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-ft-roberta-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-ft-roberta-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-ft-roberta-gest-pred-seqeval-partialmatch-2)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-ft-roberta-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-roberta-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/balanced-augmented-roberta-gest-pred-seqeval-partialmatch)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-roberta-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-roberta-large-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-roberta-large-gest-pred-seqeval-partialmatch-2)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-roberta-large-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Jsevisal/bert-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/bert-gest-pred-seqeval-partialmatch)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/bert-gest-pred-seqeval-partialmatch/blob/main/LICENSE) | | |
| | |[Jsevisal/ft-roberta-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/ft-roberta-gest-pred-seqeval-partialmatch)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/ft-roberta-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/roberta-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/roberta-gest-pred-seqeval-partialmatch)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/roberta-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/roberta-large-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/roberta-large-gest-pred-seqeval-partialmatch)|2 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/roberta-large-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Kamelowy/Nous-Hermes-Llama2-13b-Kimiko-GPTQ](https://huggingface.co/Kamelowy/Nous-Hermes-Llama2-13b-Kimiko-GPTQ)|2 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/Kamelowy/Nous-Hermes-Llama2-13b-Kimiko-GPTQ/blob/main/LICENSE.txt)| | |
| | |[nenkoru/alpaca-lora-7b-onnx-fp16-with-past](https://huggingface.co/nenkoru/alpaca-lora-7b-onnx-fp16-with-past)|2 |3 |llama-license |https://huggingface.co/nenkoru/alpaca-lora-7b-onnx-fp16-with-past/blob/main/LICENSE |[LICENSE](https://huggingface.co/nenkoru/alpaca-lora-7b-onnx-fp16-with-past/blob/main/LICENSE) | | |
| | |[nonlinearshimada/llama-65b](https://huggingface.co/nonlinearshimada/llama-65b)|2 |0 |llama-license |https://huggingface.co/nonlinearshimada/llama-65b/blob/main/LICENSE |[LICENSE](https://huggingface.co/nonlinearshimada/llama-65b/blob/main/LICENSE) | | |
| | |[research-rabbit/llama-7b-embeddings](https://huggingface.co/research-rabbit/llama-7b-embeddings)|2 |0 |llama-license |https://huggingface.co/research-rabbit/llama-7b-embeddings/blob/main/LICENSE |[LICENSE](https://huggingface.co/research-rabbit/llama-7b-embeddings/blob/main/LICENSE) | | |
| | |[TheBloke/airoboros-l2-7b-gpt4-1.4.1-GGUF](https://huggingface.co/TheBloke/airoboros-l2-7b-gpt4-1.4.1-GGUF)|2 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7b-gpt4-1.4.1-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Kimiko-7B-fp16](https://huggingface.co/TheBloke/Kimiko-7B-fp16)|2 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kimiko-7B-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Kuchiki-1.1-L2-7B-GGUF](https://huggingface.co/TheBloke/Kuchiki-1.1-L2-7B-GGUF)|2 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kuchiki-1.1-L2-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/OpenChat_v3.2-GGML](https://huggingface.co/TheBloke/OpenChat_v3.2-GGML)|2 |12 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/OpenChat_v3.2-GGML/blob/main/LICENSE.txt) | | |
| | |[TheBloke/orca_mini_v3_70B-AWQ](https://huggingface.co/TheBloke/orca_mini_v3_70B-AWQ)|2 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_70B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/qCammel-13-AWQ](https://huggingface.co/TheBloke/qCammel-13-AWQ)|2 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/qCammel-13-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarablend-MX-L2-7B-GPTQ](https://huggingface.co/TheBloke/Zarablend-MX-L2-7B-GPTQ)|2 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarablend-MX-L2-7B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[valurank/distilbert-allsides](https://huggingface.co/valurank/distilbert-allsides)|2 |0 | | |[LICENSE](https://huggingface.co/valurank/distilbert-allsides/blob/main/LICENSE) | | |
| | |[zohaib99k/Llama-2-13B-chat-8bit-GPTQ](https://huggingface.co/zohaib99k/Llama-2-13B-chat-8bit-GPTQ)|2 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/zohaib99k/Llama-2-13B-chat-8bit-GPTQ/blob/main/LICENSE.txt) | | |
| | |[Agtian/llama-65b-int4](https://huggingface.co/Agtian/llama-65b-int4)|1 |5 |llama-license |https://huggingface.co/Agtian/llama-65b-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/Agtian/llama-65b-int4/blob/main/LICENSE) | | |
| | |[Cartinoe5930/orca_mini_v3-13b-GPTQ](https://huggingface.co/Cartinoe5930/orca_mini_v3-13b-GPTQ)|1 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/Cartinoe5930/orca_mini_v3-13b-GPTQ/blob/main/LICENSE.txt) | | |
| | |[Jsevisal/balanced-augmented-ft-bert-large-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-ft-bert-large-gest-pred-seqeval-partialmatch-2)|1 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-ft-bert-large-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Mintrz/Loobe-3](https://huggingface.co/Mintrz/Loobe-3)|1 |0 |llama-license |https://huggingface.co/Mintrz/Loobe-3/blob/main/LICENSE |[LICENSE](https://huggingface.co/Mintrz/Loobe-3/blob/main/LICENSE) | | |
| | |[Neko-Institute-of-Science/LLaMA-30B-HF](https://huggingface.co/Neko-Institute-of-Science/LLaMA-30B-HF)|1 |4 |llama-license |https://huggingface.co/Neko-Institute-of-Science/LLaMA-30B-HF/blob/main/LICENSE |[LICENSE](https://huggingface.co/Neko-Institute-of-Science/LLaMA-30B-HF/blob/main/LICENSE) | | |
| | |[nenkoru/llama-7b-onnx-fp16](https://huggingface.co/nenkoru/llama-7b-onnx-fp16)|1 |0 |llama-license |https://huggingface.co/nenkoru/llama-7b-onnx-fp16/blob/main/LICENSE |[LICENSE](https://huggingface.co/nenkoru/llama-7b-onnx-fp16/blob/main/LICENSE) | | |
| | |[shekharchatterjee/temp-model-174](https://huggingface.co/shekharchatterjee/temp-model-174)|1 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/shekharchatterjee/temp-model-174/blob/main/LICENSE.txt) | | |
| | |[TheBloke/airoboros-l2-13B-gpt4-1.4.1-GGUF](https://huggingface.co/TheBloke/airoboros-l2-13B-gpt4-1.4.1-GGUF)|1 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13B-gpt4-1.4.1-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-13b-gpt4-2.0-AWQ](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-2.0-AWQ)|1 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-2.0-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/airoboros-l2-70B-GPT4-2.0-GGUF](https://huggingface.co/TheBloke/airoboros-l2-70B-GPT4-2.0-GGUF)|1 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-70B-GPT4-2.0-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Chronohermes-Grad-L2-13B-GGUF](https://huggingface.co/TheBloke/Chronohermes-Grad-L2-13B-GGUF)|1 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Chronohermes-Grad-L2-13B-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/llama2-22B-daydreamer-v2-GGUF](https://huggingface.co/TheBloke/llama2-22B-daydreamer-v2-GGUF)|1 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2-22B-daydreamer-v2-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Llama2-22B-Daydreamer-v3-AWQ](https://huggingface.co/TheBloke/Llama2-22B-Daydreamer-v3-AWQ)|1 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Llama2-22B-Daydreamer-v3-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/qCammel-13-GGUF](https://huggingface.co/TheBloke/qCammel-13-GGUF)|1 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/qCammel-13-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Tulu-30B-SuperHOT-8K-fp16](https://huggingface.co/TheBloke/Tulu-30B-SuperHOT-8K-fp16)|1 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Tulu-30B-SuperHOT-8K-fp16/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarablend-MX-L2-7B-GGUF](https://huggingface.co/TheBloke/Zarablend-MX-L2-7B-GGUF)|1 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarablend-MX-L2-7B-GGUF/blob/main/LICENSE.txt) | | |
| | |[4bit/Redmond-Puffin-13B-GPTQ](https://huggingface.co/4bit/Redmond-Puffin-13B-GPTQ)|0 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/4bit/Redmond-Puffin-13B-GPTQ/blob/main/LICENSE) | | |
| | |[Abzu/llama-7b-hf](https://huggingface.co/Abzu/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/Abzu/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Abzu/llama-7b-hf/blob/main/LICENSE) | | |
| | |[agonh/Llama-2-13B-GPT](https://huggingface.co/agonh/Llama-2-13B-GPT)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/agonh/Llama-2-13B-GPT/blob/main/LICENSE.txt) | | |
| | |[agonh/StableBeluga-13B-GPT](https://huggingface.co/agonh/StableBeluga-13B-GPT)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/agonh/StableBeluga-13B-GPT/blob/main/LICENSE.txt) | | |
| | |[Agtian/llama-30b-int4](https://huggingface.co/Agtian/llama-30b-int4)|0 |1 |llama-license |https://huggingface.co/Agtian/llama-30b-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/Agtian/llama-30b-int4/blob/main/LICENSE) | | |
| | |[AI-Engine/Llama2-7B-Chat-GGUF](https://huggingface.co/AI-Engine/Llama2-7B-Chat-GGUF)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/AI-Engine/Llama2-7B-Chat-GGUF/blob/main/LICENSE.txt) | | |
| | |[AI-Engine/MythoMax-L2-13B-GGUF](https://huggingface.co/AI-Engine/MythoMax-L2-13B-GGUF)|0 |0 | | |[LICENSE.txt](https://huggingface.co/AI-Engine/MythoMax-L2-13B-GGUF/blob/main/LICENSE.txt) | | |
| | |[alfredplpl/untitled](https://huggingface.co/alfredplpl/untitled)|0 |26 | | |[MODEL-LICENSE](https://huggingface.co/alfredplpl/untitled/blob/main/MODEL-LICENSE) | | |
| | |[alfredplpl/untitled-replicant](https://huggingface.co/alfredplpl/untitled-replicant)|0 |17 | | |[MODEL-LICENSE](https://huggingface.co/alfredplpl/untitled-replicant/blob/main/MODEL-LICENSE) | | |
| | |[amayprro552/jssml-000004](https://huggingface.co/amayprro552/jssml-000004)|0 |0 | | |[LICENSE](https://huggingface.co/amayprro552/jssml-000004/blob/main/LICENSE) | | |
| | |[amdnsr/llama-7b-hf](https://huggingface.co/amdnsr/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/amdnsr/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/amdnsr/llama-7b-hf/blob/main/LICENSE) | | |
| | |[Amerbarhoush/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ](https://huggingface.co/Amerbarhoush/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/Amerbarhoush/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ/blob/main/LICENSE.txt)| | |
| | |[aoyoo/llama-7b-hf](https://huggingface.co/aoyoo/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/aoyoo/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/aoyoo/llama-7b-hf/blob/main/LICENSE) | | |
| | |[aoyoo/llama-7b-hf-int4](https://huggingface.co/aoyoo/llama-7b-hf-int4)|0 |0 |llama-license |https://huggingface.co/aoyoo/llama-7b-hf-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/aoyoo/llama-7b-hf-int4/blob/main/LICENSE) | | |
| | |[ashi-ta/japanese-pretrained-ckpts](https://huggingface.co/ashi-ta/japanese-pretrained-ckpts)|0 |0 | | |[LICENSE](https://huggingface.co/ashi-ta/japanese-pretrained-ckpts/blob/main/LICENSE) | | |
| | |[baffo32/decapoda-research-llama-7B-hf](https://huggingface.co/baffo32/decapoda-research-llama-7B-hf)|0 |0 |llama-license |https://huggingface.co/baffo32/decapoda-research-llama-7B-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/baffo32/decapoda-research-llama-7B-hf/blob/main/LICENSE) | | |
| | |[baffo32/llama-7B-sparsetest-c4-25pct-128blksz](https://huggingface.co/baffo32/llama-7B-sparsetest-c4-25pct-128blksz)|0 |0 |llama-license |https://huggingface.co/baffo32/llama-7B-sparsetest-c4-25pct-128blksz/blob/main/LICENSE |[LICENSE](https://huggingface.co/baffo32/llama-7B-sparsetest-c4-25pct-128blksz/blob/main/LICENSE) | | |
| | |[baffo32/llama-7B-sparsetest-c4-75pct-128blksz](https://huggingface.co/baffo32/llama-7B-sparsetest-c4-75pct-128blksz)|0 |0 |llama-license |https://huggingface.co/baffo32/llama-7B-sparsetest-c4-75pct-128blksz/blob/main/LICENSE |[LICENSE](https://huggingface.co/baffo32/llama-7B-sparsetest-c4-75pct-128blksz/blob/main/LICENSE) | | |
| | |[bluefoxcreation/Codeformer-ONNX](https://huggingface.co/bluefoxcreation/Codeformer-ONNX)|0 |3 | | |[LICENSE.txt](https://huggingface.co/bluefoxcreation/Codeformer-ONNX/blob/main/LICENSE.txt) | | |
| | |[camelids/alpacino-13b-ggml-f16](https://huggingface.co/camelids/alpacino-13b-ggml-f16)|0 |0 | | |[LICENSE](https://huggingface.co/camelids/alpacino-13b-ggml-f16/blob/main/LICENSE) | | |
| | |[camelids/alpacino-13b-ggml-q5_1](https://huggingface.co/camelids/alpacino-13b-ggml-q5_1)|0 |2 | | |[LICENSE](https://huggingface.co/camelids/alpacino-13b-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/alpacino-33b-ggml-q5_1](https://huggingface.co/camelids/alpacino-33b-ggml-q5_1)|0 |1 | | |[LICENSE](https://huggingface.co/camelids/alpacino-33b-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/llama-13b-fp16-safetensors](https://huggingface.co/camelids/llama-13b-fp16-safetensors)|0 |0 |llama-license |https://huggingface.co/camelids/llama-13b-fp16-safetensors/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-13b-fp16-safetensors/blob/main/LICENSE) | | |
| | |[camelids/llama-13b-ggml-f16](https://huggingface.co/camelids/llama-13b-ggml-f16)|0 |0 |llama-license |https://huggingface.co/camelids/llama-13b-ggml-f16/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-13b-ggml-f16/blob/main/LICENSE) | | |
| | |[camelids/llama-13b-ggml-q5_1](https://huggingface.co/camelids/llama-13b-ggml-q5_1)|0 |1 |llama-license |https://huggingface.co/camelids/llama-13b-ggml-q5_1/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-13b-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/llama-13b-int4-gptq-groupsize128-safetensors](https://huggingface.co/camelids/llama-13b-int4-gptq-groupsize128-safetensors)|0 |2 |llama-license |https://huggingface.co/camelids/llama-13b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE|[LICENSE](https://huggingface.co/camelids/llama-13b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE)| | |
| | |[camelids/llama-13b-supercot-ggml-f16](https://huggingface.co/camelids/llama-13b-supercot-ggml-f16)|0 |0 |llama-license |https://huggingface.co/camelids/llama-13b-supercot-ggml-f16/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-13b-supercot-ggml-f16/blob/main/LICENSE) | | |
| | |[camelids/llama-13b-supercot-ggml-q5_1](https://huggingface.co/camelids/llama-13b-supercot-ggml-q5_1)|0 |1 |llama-license |https://huggingface.co/camelids/llama-13b-supercot-ggml-q5_1/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-13b-supercot-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/llama-33b-fp16-safetensors](https://huggingface.co/camelids/llama-33b-fp16-safetensors)|0 |0 |llama-license |https://huggingface.co/camelids/llama-33b-fp16-safetensors/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-33b-fp16-safetensors/blob/main/LICENSE) | | |
| | |[camelids/llama-33b-ggml-q5_1](https://huggingface.co/camelids/llama-33b-ggml-q5_1)|0 |0 |llama-license |https://huggingface.co/camelids/llama-33b-ggml-q5_1/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-33b-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/llama-33b-int4-gptq-groupsize128-safetensors](https://huggingface.co/camelids/llama-33b-int4-gptq-groupsize128-safetensors)|0 |2 |llama-license |https://huggingface.co/camelids/llama-33b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE|[LICENSE](https://huggingface.co/camelids/llama-33b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE)| | |
| | |[camelids/llama-33b-supercot-ggml-q5_1](https://huggingface.co/camelids/llama-33b-supercot-ggml-q5_1)|0 |5 |llama-license |https://huggingface.co/camelids/llama-33b-supercot-ggml-q5_1/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-33b-supercot-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/llama-65b-fp16-safetensors](https://huggingface.co/camelids/llama-65b-fp16-safetensors)|0 |1 |llama-license |https://huggingface.co/camelids/llama-65b-fp16-safetensors/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-65b-fp16-safetensors/blob/main/LICENSE) | | |
| | |[camelids/llama-65b-int4-gptq-groupsize128-safetensors](https://huggingface.co/camelids/llama-65b-int4-gptq-groupsize128-safetensors)|0 |1 |llama-license |https://huggingface.co/camelids/llama-65b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE|[LICENSE](https://huggingface.co/camelids/llama-65b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE)| | |
| | |[camelids/llama-7b-ggml-f16](https://huggingface.co/camelids/llama-7b-ggml-f16)|0 |0 |llama-license |https://huggingface.co/camelids/llama-7b-ggml-f16/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-7b-ggml-f16/blob/main/LICENSE) | | |
| | |[camelids/llama-7b-ggml-q5_1](https://huggingface.co/camelids/llama-7b-ggml-q5_1)|0 |1 |llama-license |https://huggingface.co/camelids/llama-7b-ggml-q5_1/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-7b-ggml-q5_1/blob/main/LICENSE) | | |
| | |[camelids/llama-7b-int4-gptq-groupsize128-safetensors](https://huggingface.co/camelids/llama-7b-int4-gptq-groupsize128-safetensors)|0 |0 |llama-license |https://huggingface.co/camelids/llama-7b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE |[LICENSE](https://huggingface.co/camelids/llama-7b-int4-gptq-groupsize128-safetensors/blob/main/LICENSE)| | |
| | |[camenduru/XTTS-v1](https://huggingface.co/camenduru/XTTS-v1)|0 |2 | | |[LICENSE](https://huggingface.co/camenduru/XTTS-v1/blob/main/LICENSE) | | |
| | |[cekal/LLaMA-7B](https://huggingface.co/cekal/LLaMA-7B)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/cekal/LLaMA-7B/blob/main/LICENSE.txt) | | |
| | |[coyotte508/bergere-enchantee](https://huggingface.co/coyotte508/bergere-enchantee)|0 |2 | | |[LICENSE](https://huggingface.co/coyotte508/bergere-enchantee/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-13b-hf-int4](https://huggingface.co/decapoda-research/llama-13b-hf-int4)|0 |75 |llama-license |https://huggingface.co/decapoda-research/llama-13b-hf-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-13b-hf-int4/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-30b-hf-int4](https://huggingface.co/decapoda-research/llama-30b-hf-int4)|0 |22 |llama-license |https://huggingface.co/decapoda-research/llama-30b-hf-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-30b-hf-int4/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-65b-hf-int4](https://huggingface.co/decapoda-research/llama-65b-hf-int4)|0 |29 |llama-license |https://huggingface.co/decapoda-research/llama-65b-hf-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-65b-hf-int4/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-7b-hf-int4](https://huggingface.co/decapoda-research/llama-7b-hf-int4)|0 |74 |llama-license |https://huggingface.co/decapoda-research/llama-7b-hf-int4/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-7b-hf-int4/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-7b-hf-int8](https://huggingface.co/decapoda-research/llama-7b-hf-int8)|0 |20 |llama-license |https://huggingface.co/decapoda-research/llama-7b-hf-int8/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-7b-hf-int8/blob/main/LICENSE) | | |
| | |[decapoda-research/llama-smallint-pt](https://huggingface.co/decapoda-research/llama-smallint-pt)|0 |34 |llama-license |https://huggingface.co/decapoda-research/llama-smallint-pt/blob/main/LICENSE |[LICENSE](https://huggingface.co/decapoda-research/llama-smallint-pt/blob/main/LICENSE) | | |
| | |[deepsbn/llama-2-13b-chat-ggml](https://huggingface.co/deepsbn/llama-2-13b-chat-ggml)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/deepsbn/llama-2-13b-chat-ggml/blob/main/LICENSE) | | |
| | |[Delcos/12bL](https://huggingface.co/Delcos/12bL)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/Delcos/12bL/blob/main/LICENSE.txt) | | |
| | |[dontito/llama-7b-hf-v0](https://huggingface.co/dontito/llama-7b-hf-v0)|0 |0 |llama-license |https://huggingface.co/dontito/llama-7b-hf-v0/blob/main/LICENSE |[LICENSE](https://huggingface.co/dontito/llama-7b-hf-v0/blob/main/LICENSE) | | |
| | |[Enoch/llama-13b-hf](https://huggingface.co/Enoch/llama-13b-hf)|0 |0 |llama-license |https://huggingface.co/Enoch/llama-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Enoch/llama-13b-hf/blob/main/LICENSE) | | |
| | |[fragro/llama-7b-hf](https://huggingface.co/fragro/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/fragro/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/fragro/llama-7b-hf/blob/main/LICENSE) | | |
| | |[GamerUntouch/LLaMa-Storytelling-4Bit](https://huggingface.co/GamerUntouch/LLaMa-Storytelling-4Bit)|0 |25 |llama-license |https://huggingface.co/GamerUntouch/LLaMa-Storytelling-4Bit/blob/main/LICENSE |[LICENSE](https://huggingface.co/GamerUntouch/LLaMa-Storytelling-4Bit/blob/main/LICENSE) | | |
| | |[heegyu/LIMA-13b](https://huggingface.co/heegyu/LIMA-13b)|0 |0 |llama-license |https://huggingface.co/heegyu/LIMA-13b/blob/main/LICENSE |[LICENSE](https://huggingface.co/heegyu/LIMA-13b/blob/main/LICENSE) | | |
| | |[Jamessjunk/AKGamer](https://huggingface.co/Jamessjunk/AKGamer)|0 |0 | | |[LICENSE](https://huggingface.co/Jamessjunk/AKGamer/blob/main/LICENSE) | | |
| | |[Jsevisal/balanced-augmented-bert-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/balanced-augmented-bert-gest-pred-seqeval-partialmatch)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-bert-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-bert-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-bert-gest-pred-seqeval-partialmatch-2)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-bert-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-bert-large-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/balanced-augmented-bert-large-gest-pred-seqeval-partialmatch)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-bert-large-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-bert-large-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-bert-large-gest-pred-seqeval-partialmatch-2)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-bert-large-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-distilbert-base-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/balanced-augmented-distilbert-base-gest-pred-seqeval-partialmatch)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-distilbert-base-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-distilbert-base-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-distilbert-base-gest-pred-seqeval-partialmatch-2)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-distilbert-base-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-ft-distilbert-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/balanced-augmented-ft-distilbert-gest-pred-seqeval-partialmatch)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-ft-distilbert-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/balanced-augmented-ft-distilbert-gest-pred-seqeval-partialmatch-2](https://huggingface.co/Jsevisal/balanced-augmented-ft-distilbert-gest-pred-seqeval-partialmatch-2)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/balanced-augmented-ft-distilbert-gest-pred-seqeval-partialmatch-2/blob/main/LICENSE)| | |
| | |[Jsevisal/bert-large-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/bert-large-gest-pred-seqeval-partialmatch)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/bert-large-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[Jsevisal/distilbert-base-gest-pred-seqeval-partialmatch](https://huggingface.co/Jsevisal/distilbert-base-gest-pred-seqeval-partialmatch)|0 |0 | | |[LICENSE](https://huggingface.co/Jsevisal/distilbert-base-gest-pred-seqeval-partialmatch/blob/main/LICENSE)| | |
| | |[keyfan/vicuna-chinese-replication-beta](https://huggingface.co/keyfan/vicuna-chinese-replication-beta)|0 |6 |llama-license |https://huggingface.co/keyfan/vicuna-chinese-replication-beta/blob/main/LICENSE |[LICENSE](https://huggingface.co/keyfan/vicuna-chinese-replication-beta/blob/main/LICENSE) | | |
| | |[khachdallak/llama-13b-hf-new-tok](https://huggingface.co/khachdallak/llama-13b-hf-new-tok)|0 |0 |llama-license |https://huggingface.co/khachdallak/llama-13b-hf-new-tok/blob/main/LICENSE |[LICENSE](https://huggingface.co/khachdallak/llama-13b-hf-new-tok/blob/main/LICENSE) | | |
| | |[khachdallak/llama-7b-hf-new-tok](https://huggingface.co/khachdallak/llama-7b-hf-new-tok)|0 |0 |llama-license |https://huggingface.co/khachdallak/llama-7b-hf-new-tok/blob/main/LICENSE |[LICENSE](https://huggingface.co/khachdallak/llama-7b-hf-new-tok/blob/main/LICENSE) | | |
| | |[linhvu/decapoda-research-llama-7b-hf](https://huggingface.co/linhvu/decapoda-research-llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/linhvu/decapoda-research-llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/linhvu/decapoda-research-llama-7b-hf/blob/main/LICENSE) | | |
| | |[lyogavin/Anima33B-DPO-Belle-1k-merged](https://huggingface.co/lyogavin/Anima33B-DPO-Belle-1k-merged)|0 |5 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/lyogavin/Anima33B-DPO-Belle-1k-merged/blob/main/LICENSE.txt) | | |
| | |[Mithilss/llama-7b-hf](https://huggingface.co/Mithilss/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/Mithilss/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Mithilss/llama-7b-hf/blob/main/LICENSE) | | |
| | |[muneerhanif7/Llama-2-13B-GPTQ](https://huggingface.co/muneerhanif7/Llama-2-13B-GPTQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/muneerhanif7/Llama-2-13B-GPTQ/blob/main/LICENSE.txt) | | |
| | |[nenkoru/llama-7b-onnx-merged-fp32](https://huggingface.co/nenkoru/llama-7b-onnx-merged-fp32)|0 |1 |llama-license |https://huggingface.co/nenkoru/llama-7b-onnx-merged-fp32/blob/main/LICENSE |[LICENSE](https://huggingface.co/nenkoru/llama-7b-onnx-merged-fp32/blob/main/LICENSE) | | |
| | |[nonlinearshimada/llama-30b](https://huggingface.co/nonlinearshimada/llama-30b)|0 |0 |llama-license |https://huggingface.co/nonlinearshimada/llama-30b/blob/main/LICENSE |[LICENSE](https://huggingface.co/nonlinearshimada/llama-30b/blob/main/LICENSE) | | |
| | |[nonlinearshimada/llama-7b](https://huggingface.co/nonlinearshimada/llama-7b)|0 |0 |llama-license |https://huggingface.co/nonlinearshimada/llama-7b/blob/main/LICENSE |[LICENSE](https://huggingface.co/nonlinearshimada/llama-7b/blob/main/LICENSE) | | |
| | |[openerotica/Llama-2-7B-GPTQ](https://huggingface.co/openerotica/Llama-2-7B-GPTQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/openerotica/Llama-2-7B-GPTQ/blob/main/LICENSE) | | |
| | |[openerotica/Qwen-7b](https://huggingface.co/openerotica/Qwen-7b)|0 |0 | | |[LICENSE](https://huggingface.co/openerotica/Qwen-7b/blob/main/LICENSE) | | |
| | |[perfectlyunreal/lora](https://huggingface.co/perfectlyunreal/lora)|0 |0 | | |[LICENSE](https://huggingface.co/perfectlyunreal/lora/blob/main/LICENSE) | | |
| | |[preemo/alpaca-lora-30b-gpt4-en-zh](https://huggingface.co/preemo/alpaca-lora-30b-gpt4-en-zh)|0 |3 | | |[LICENSE](https://huggingface.co/preemo/alpaca-lora-30b-gpt4-en-zh/blob/main/LICENSE) | | |
| | |[prodm93/llama_30b_corr](https://huggingface.co/prodm93/llama_30b_corr)|0 |0 |llama-license |https://huggingface.co/prodm93/llama_30b_corr/blob/main/LICENSE |[LICENSE](https://huggingface.co/prodm93/llama_30b_corr/blob/main/LICENSE) | | |
| | |[prodm93/llama_65b_corr](https://huggingface.co/prodm93/llama_65b_corr)|0 |0 |llama-license |https://huggingface.co/prodm93/llama_65b_corr/blob/main/LICENSE |[LICENSE](https://huggingface.co/prodm93/llama_65b_corr/blob/main/LICENSE) | | |
| | |[prodm93/llama_7b_corr](https://huggingface.co/prodm93/llama_7b_corr)|0 |0 |llama-license |https://huggingface.co/prodm93/llama_7b_corr/blob/main/LICENSE |[LICENSE](https://huggingface.co/prodm93/llama_7b_corr/blob/main/LICENSE) | | |
| | |[Robin021/llama-7b-hf](https://huggingface.co/Robin021/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/Robin021/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/Robin021/llama-7b-hf/blob/main/LICENSE) | | |
| | |[ruibin-wang/llama-13b-hf](https://huggingface.co/ruibin-wang/llama-13b-hf)|0 |0 |llama-license |https://huggingface.co/ruibin-wang/llama-13b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/ruibin-wang/llama-13b-hf/blob/main/LICENSE) | | |
| | |[ruibin-wang/llama-7b-hf](https://huggingface.co/ruibin-wang/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/ruibin-wang/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/ruibin-wang/llama-7b-hf/blob/main/LICENSE) | | |
| | |[SerrasKowalsky/LLM-7b](https://huggingface.co/SerrasKowalsky/LLM-7b)|0 |0 |llama-license |https://huggingface.co/SerrasKowalsky/LLM-7b/blob/main/LICENSE |[LICENSE](https://huggingface.co/SerrasKowalsky/LLM-7b/blob/main/LICENSE) | | |
| | |[Shashashasha/Yoshi-rvc](https://huggingface.co/Shashashasha/Yoshi-rvc)|0 |0 | | |[LICENSE](https://huggingface.co/Shashashasha/Yoshi-rvc/blob/main/LICENSE) | | |
| | |[shekharchatterjee/temp-model-278](https://huggingface.co/shekharchatterjee/temp-model-278)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/shekharchatterjee/temp-model-278/blob/main/LICENSE.txt) | | |
| | |[shibing624/chinese-alpaca-plus-13b-pth](https://huggingface.co/shibing624/chinese-alpaca-plus-13b-pth)|0 |6 | | |[LICENSE](https://huggingface.co/shibing624/chinese-alpaca-plus-13b-pth/blob/main/LICENSE) | | |
| | |[shirayu/sd-tohoku-v3b](https://huggingface.co/shirayu/sd-tohoku-v3b)|0 |0 | | |[LICENSE](https://huggingface.co/shirayu/sd-tohoku-v3b/blob/main/LICENSE) | | |
| | |[TheBloke/airoboros-l2-13B-gpt4-1.4.1-AWQ](https://huggingface.co/TheBloke/airoboros-l2-13B-gpt4-1.4.1-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13B-gpt4-1.4.1-AWQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-13b-gpt4-2.0-GGUF](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-2.0-GGUF)|0 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-13b-gpt4-2.0-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-70B-gpt4-1.4.1-AWQ](https://huggingface.co/TheBloke/airoboros-l2-70B-gpt4-1.4.1-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-70B-gpt4-1.4.1-AWQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-70B-gpt4-1.4.1-GGUF](https://huggingface.co/TheBloke/airoboros-l2-70B-gpt4-1.4.1-GGUF)|0 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-70B-gpt4-1.4.1-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Airoboros-L2-70B-GPT4-m2.0-GGUF](https://huggingface.co/TheBloke/Airoboros-L2-70B-GPT4-m2.0-GGUF)|0 |2 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Airoboros-L2-70B-GPT4-m2.0-GGUF/blob/main/LICENSE.txt)| | |
| | |[TheBloke/airoboros-l2-7b-gpt4-1.4.1-AWQ](https://huggingface.co/TheBloke/airoboros-l2-7b-gpt4-1.4.1-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/airoboros-l2-7b-gpt4-1.4.1-AWQ/blob/main/LICENSE.txt)| | |
| | |[TheBloke/Chronohermes-Grad-L2-13B-AWQ](https://huggingface.co/TheBloke/Chronohermes-Grad-L2-13B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Chronohermes-Grad-L2-13B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/HermesLimaRP-L2-7B-AWQ](https://huggingface.co/TheBloke/HermesLimaRP-L2-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/HermesLimaRP-L2-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Kuchiki-1.1-L2-7B-AWQ](https://huggingface.co/TheBloke/Kuchiki-1.1-L2-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kuchiki-1.1-L2-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Kuchiki-L2-7B-AWQ](https://huggingface.co/TheBloke/Kuchiki-L2-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Kuchiki-L2-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/LLaMA-13b-AWQ](https://huggingface.co/TheBloke/LLaMA-13b-AWQ)|0 |1 |llama-license |https://huggingface.co/TheBloke/LLaMA-13b-AWQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-13b-AWQ/blob/main/LICENSE) | | |
| | |[TheBloke/LLaMA-65B-AWQ](https://huggingface.co/TheBloke/LLaMA-65B-AWQ)|0 |0 |llama-license |https://huggingface.co/TheBloke/LLaMA-65B-AWQ/blob/main/LICENSE |[LICENSE](https://huggingface.co/TheBloke/LLaMA-65B-AWQ/blob/main/LICENSE) | | |
| | |[TheBloke/llama2-22B-daydreamer-v2-AWQ](https://huggingface.co/TheBloke/llama2-22B-daydreamer-v2-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/llama2-22B-daydreamer-v2-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/MythoLogic-L2-13B-AWQ](https://huggingface.co/TheBloke/MythoLogic-L2-13B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoLogic-L2-13B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/MythoLogic-Mini-7B-AWQ](https://huggingface.co/TheBloke/MythoLogic-Mini-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/MythoLogic-Mini-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/orca_mini_v3_13B-AWQ](https://huggingface.co/TheBloke/orca_mini_v3_13B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/orca_mini_v3_13B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/PuddleJumper-13B-V2-GGUF](https://huggingface.co/TheBloke/PuddleJumper-13B-V2-GGUF)|0 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/PuddleJumper-13B-V2-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/qCammel-70-x-AWQ](https://huggingface.co/TheBloke/qCammel-70-x-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/qCammel-70-x-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/qCammel-70-x-GGUF](https://huggingface.co/TheBloke/qCammel-70-x-GGUF)|0 |3 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/qCammel-70-x-GGUF/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-13B-AWQ](https://huggingface.co/TheBloke/tulu-13B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-13B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-13B-GGML](https://huggingface.co/TheBloke/tulu-13B-GGML)|0 |6 | | |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-13B-GGML/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-30B-AWQ](https://huggingface.co/TheBloke/tulu-30B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-30B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-7B-AWQ](https://huggingface.co/TheBloke/tulu-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/tulu-7B-GGML](https://huggingface.co/TheBloke/tulu-7B-GGML)|0 |5 | | |[LICENSE.txt](https://huggingface.co/TheBloke/tulu-7B-GGML/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarablend-L2-7B-AWQ](https://huggingface.co/TheBloke/Zarablend-L2-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarablend-L2-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarablend-MX-L2-7B-AWQ](https://huggingface.co/TheBloke/Zarablend-MX-L2-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarablend-MX-L2-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[TheBloke/Zarafusionex-1.1-L2-7B-AWQ](https://huggingface.co/TheBloke/Zarafusionex-1.1-L2-7B-AWQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/TheBloke/Zarafusionex-1.1-L2-7B-AWQ/blob/main/LICENSE.txt) | | |
| | |[Thireus/Vicuna13B-v1.1-8bit-128g](https://huggingface.co/Thireus/Vicuna13B-v1.1-8bit-128g)|0 |16 |llama-license |https://huggingface.co/Thireus/Vicuna13B-v1.1-8bit-128g/blob/main/LICENSE |[LICENSE](https://huggingface.co/Thireus/Vicuna13B-v1.1-8bit-128g/blob/main/LICENSE) | | |
| | |[Tobias/llama-7b-hf-corrected-config](https://huggingface.co/Tobias/llama-7b-hf-corrected-config)|0 |0 |llama-license |https://huggingface.co/Tobias/llama-7b-hf-corrected-config/blob/main/LICENSE |[LICENSE](https://huggingface.co/Tobias/llama-7b-hf-corrected-config/blob/main/LICENSE) | | |
| | |[universonic/llama-7b-hf](https://huggingface.co/universonic/llama-7b-hf)|0 |0 |llama-license |https://huggingface.co/universonic/llama-7b-hf/blob/main/LICENSE |[LICENSE](https://huggingface.co/universonic/llama-7b-hf/blob/main/LICENSE) | | |
| | |[usamakenway/llama2_7b_chat_uncensored-AutoGPTQ_Wizard_Vicuna](https://huggingface.co/usamakenway/llama2_7b_chat_uncensored-AutoGPTQ_Wizard_Vicuna)|0 |1 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/usamakenway/llama2_7b_chat_uncensored-AutoGPTQ_Wizard_Vicuna/blob/main/LICENSE.txt)| | |
| | |[valurank/paraphrase-mpnet-base-v2-offensive](https://huggingface.co/valurank/paraphrase-mpnet-base-v2-offensive)|0 |0 | | |[LICENSE](https://huggingface.co/valurank/paraphrase-mpnet-base-v2-offensive/blob/main/LICENSE) | | |
| | |[vishnu-vs/llama](https://huggingface.co/vishnu-vs/llama)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE](https://huggingface.co/vishnu-vs/llama/blob/main/LICENSE) | | |
| | |[Zhejian/llama-7b](https://huggingface.co/Zhejian/llama-7b)|0 |0 |llama-license |https://huggingface.co/Zhejian/llama-7b/blob/main/LICENSE |[LICENSE](https://huggingface.co/Zhejian/llama-7b/blob/main/LICENSE) | | |
| | |[Zhejian/llama-7b-fork](https://huggingface.co/Zhejian/llama-7b-fork)|0 |0 |llama-license |https://huggingface.co/Zhejian/llama-7b-fork/blob/main/LICENSE |[LICENSE](https://huggingface.co/Zhejian/llama-7b-fork/blob/main/LICENSE) | | |
| | |[zib16/llama_adapted](https://huggingface.co/zib16/llama_adapted)|0 |0 |llama-license |https://huggingface.co/zib16/llama_adapted/blob/main/LICENSE |[LICENSE](https://huggingface.co/zib16/llama_adapted/blob/main/LICENSE) | | |
| | |[zohaib99k/Llama-2-7b-Chat-64g-GPTQ](https://huggingface.co/zohaib99k/Llama-2-7b-Chat-64g-GPTQ)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/zohaib99k/Llama-2-7b-Chat-64g-GPTQ/blob/main/LICENSE.txt) | | |
| | |[zohaib99k/QnA_model_training](https://huggingface.co/zohaib99k/QnA_model_training)|0 |0 |llama-2-community-license |https://ai.meta.com/llama/license/ |[LICENSE.txt](https://huggingface.co/zohaib99k/QnA_model_training/blob/main/LICENSE.txt) | | |
| huggingface/hub-docs/blob/main/hacktoberfest_challenges/model_license_other.md |
@gradio/json
## 0.1.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.5
### Patch Changes
- Updated dependencies [[`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.4
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#5944](https://github.com/gradio-app/gradio/pull/5944) [`465f58957`](https://github.com/gradio-app/gradio/commit/465f58957f70c7cf3e894beef8a117b28339e3c1) - Show empty JSON icon when `value` is `null`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.0.5
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.4
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.0.3
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.2
### Patch Changes
- Updated dependencies []:
- @gradio/[email protected]
| gradio-app/gradio/blob/main/js/json/CHANGELOG.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FNet
## Overview
The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
accuracy of BERT counterparts on GLUE benchmark, and trains much faster than the BERT model. The abstract from the
paper is the following:
*We show that Transformer encoder architectures can be sped up, with limited accuracy costs, by replacing the
self-attention sublayers with simple linear transformations that "mix" input tokens. These linear mixers, along with
standard nonlinearities in feed-forward layers, prove competent at modeling semantic relationships in several text
classification tasks. Most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder
with a standard, unparameterized Fourier Transform achieves 92-97% of the accuracy of BERT counterparts on the GLUE
benchmark, but trains 80% faster on GPUs and 70% faster on TPUs at standard 512 input lengths. At longer input lengths,
our FNet model is significantly faster: when compared to the "efficient" Transformers on the Long Range Arena
benchmark, FNet matches the accuracy of the most accurate models, while outpacing the fastest models across all
sequence lengths on GPUs (and across relatively shorter lengths on TPUs). Finally, FNet has a light memory footprint
and is particularly efficient at smaller model sizes; for a fixed speed and accuracy budget, small FNet models
outperform Transformer counterparts.*
This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/google-research/google-research/tree/master/f_net).
## Usage tips
The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
sequence length for fine-tuning and inference.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## FNetConfig
[[autodoc]] FNetConfig
## FNetTokenizer
[[autodoc]] FNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## FNetTokenizerFast
[[autodoc]] FNetTokenizerFast
## FNetModel
[[autodoc]] FNetModel
- forward
## FNetForPreTraining
[[autodoc]] FNetForPreTraining
- forward
## FNetForMaskedLM
[[autodoc]] FNetForMaskedLM
- forward
## FNetForNextSentencePrediction
[[autodoc]] FNetForNextSentencePrediction
- forward
## FNetForSequenceClassification
[[autodoc]] FNetForSequenceClassification
- forward
## FNetForMultipleChoice
[[autodoc]] FNetForMultipleChoice
- forward
## FNetForTokenClassification
[[autodoc]] FNetForTokenClassification
- forward
## FNetForQuestionAnswering
[[autodoc]] FNetForQuestionAnswering
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/fnet.md |
ChatUI on Spaces
**Hugging Chat** is an open-source interface enabling everyone to try open-source large language models such as Falcon, StarCoder, and BLOOM. Thanks to an official Docker template called ChatUI, you can deploy your own Hugging Chat based on a model of your choice with a few clicks using Hugging Face's infrastructure.
## Deploy your own Chat UI
To get started, simply head [here](https://huggingface.co/new-space?template=huggingchat/chat-ui-template). In the backend of this application, [text-generation-inference](https://github.com/huggingface/text-generation-inference) is used for better optimized model inference. Since these models can't run on CPUs, you can select the GPU depending on your choice of model.
<a href="https://huggingface.co/new-space?template=huggingchat/chat-ui-template">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/huggingface.co_spaces_docker_chatui_landing.png" />
</a>
You should provide a MongoDB endpoint where your chats will be written. If you leave this section blank, your logs will be persisted to a database inside the Space. Note that Hugging Face does not have access to your chats. You can configure the name and the theme of the Space by providing the application name and application color parameters.
Below this, you can select the Hugging Face Hub ID of the model you wish to serve. You can also change the generation hyperparameters in the dictionary below in JSON format.
_Note_: If you'd like to deploy a model with gated access or a model in a private repository, you can simply provide `HUGGING_FACE_HUB_TOKEN` in repository secrets. You need to set its value to an access token you can get from [here](https://huggingface.co/settings/tokens).
<a href="Parameters">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/huggingface.co_spaces_docker_chatui_params.png" />
</a>
Once the creation is complete, you will see `Building` on your Space. Once built, you can try your own HuggingChat!
<a href="Hugging Chat Landing UI">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/huggingface.co_spaces_docker_chatui_ui.png" />
</a>
Start chatting!
<a href="Hugging Chat">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/huggingface.co_spaces_docker_chatui_chat.png" />
</a>
## Read more
- [HF Docker Spaces](https://huggingface.co/docs/hub/spaces-sdks-docker)
- [chat-ui GitHub Repository](https://github.com/huggingface/chat-ui)
- [text-generation-inference GitHub repository](https://github.com/huggingface/text-generation-inference)
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-chatui.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Reward Functions
🤗 Simulate provides a system to define simple and complex reward functions. This is achieved through the combination of "leaf" reward
functions, such as Sparse and Dense rewards functions, and predicate reward functions.
(LINK TO REWARD PREDICATE DIAGRAM)
Reward functions can be parameterized with a variety of distance metrics. Currently "euclidean", "cosine" and "best_euclidean" are supported.
Through the combination of predicates and leaf rewards, complex reward functions can be created. A good example of the is the
[Move Boxes](https://github.com/huggingface/simulate/blob/main/examples/rl/sb3_move_boxes.py) example.
The following "leaf" rewards are available in Simulate:
- "dense": A reward that is non-zero at every time-step.
- "sparse": A reward that is triggered by the proximity of another object.
- "timeout": A timeout reward that is triggered after a certain number of time-steps.
- "see": Triggered when an object is in the field of view of an Actor.
- "angle_to": Triggered when the angle between two objects and a certain direction is less that a threshold.
The "leaf" reward functions can be combined in a tree structure with the following predicate functions:
- "not": Triggers when a reward is not triggered.
- "and": Triggers when both children of this node are returning a positive reward.
- "or": Triggers when one or both of the children of this node are returning a positive reward.
- "xor": Triggers when only one of the children of this node are returning a positive reward.
[[autodoc]] RewardFunction
| huggingface/simulate/blob/main/docs/source/api/reward_functions.mdx |
`gradio/model3d`
```html
<script>
import {BaseModel3D, BaseModel3DUpload, BaseExample } from `@gradio/model3d`;
</script>
```
BaseModel3D
```javascript
export let value: FileData | null;
export let clear_color: [number, number, number, number] = [0, 0, 0, 0];
export let label = "";
export let show_label: boolean;
export let i18n: I18nFormatter;
export let zoom_speed = 1;
// alpha, beta, radius
export let camera_position: [number | null, number | null, number | null] = [
null,
null,
null
];
```
BaseModel3DUpload
```javascript
export let value: null | FileData;
export let clear_color: [number, number, number, number] = [0, 0, 0, 0];
export let label = "";
export let show_label: boolean;
export let root: string;
export let i18n: I18nFormatter;
export let zoom_speed = 1;
// alpha, beta, radius
export let camera_position: [number | null, number | null, number | null] = [
null,
null,
null
];
```
BaseExample
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
``` | gradio-app/gradio/blob/main/js/model3D/README.md |
@gradio/theme
## 0.2.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0-beta.2
### Features
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.2.0
### Highlights
#### new `FileExplorer` component ([#5672](https://github.com/gradio-app/gradio/pull/5672) [`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e))
Thanks to a new capability that allows components to communicate directly with the server _without_ passing data via the value, we have created a new `FileExplorer` component.
This component allows you to populate the explorer by passing a glob, but only provides the selected file(s) in your prediction function.
Users can then navigate the virtual filesystem and select files which will be accessible in your predict function. This component will allow developers to build more complex spaces, with more flexible input options.

For more information check the [`FileExplorer` documentation](https://gradio.app/docs/fileexplorer).
Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.1.0
### Features
- [#5342](https://github.com/gradio-app/gradio/pull/5342) [`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912) - significantly improve the performance of `gr.Dataframe` for large datasets. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.3
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.2
### Fixes
- [#4997](https://github.com/gradio-app/gradio/pull/4997) [`41c83070`](https://github.com/gradio-app/gradio/commit/41c83070b01632084e7d29123048a96c1e261407) - Add CSS resets and specifiers to play nice with HF blog. Thanks [@aliabid94](https://github.com/aliabid94)! | gradio-app/gradio/blob/main/js/theme/CHANGELOG.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Activation functions
Customized activation functions for supporting various models in 🤗 Diffusers.
## GELU
[[autodoc]] models.activations.GELU
## GEGLU
[[autodoc]] models.activations.GEGLU
## ApproximateGELU
[[autodoc]] models.activations.ApproximateGELU
| huggingface/diffusers/blob/main/docs/source/en/api/activations.md |
Conclusion [[Conclusion]]
That’s all for today. Congrats on finishing this unit and the tutorial!
The best way to learn is to practice and try stuff. **Why not improve the implementation to handle frames as input?**.
See you on second part of this Unit 🔥
## Keep Learning, Stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit8/conclusion.mdx |
Cloud storage
🤗 Datasets supports access to cloud storage providers through a `fsspec` FileSystem implementations.
You can save and load datasets from any cloud storage in a Pythonic way.
Take a look at the following table for some example of supported cloud storage providers:
| Storage provider | Filesystem implementation |
|----------------------|---------------------------------------------------------------|
| Amazon S3 | [s3fs](https://s3fs.readthedocs.io/en/latest/) |
| Google Cloud Storage | [gcsfs](https://gcsfs.readthedocs.io/en/latest/) |
| Azure Blob/DataLake | [adlfs](https://github.com/fsspec/adlfs) |
| Dropbox | [dropboxdrivefs](https://github.com/MarineChap/dropboxdrivefs)|
| Google Drive | [gdrivefs](https://github.com/intake/gdrivefs) |
| Oracle Cloud Storage | [ocifs](https://ocifs.readthedocs.io/en/latest/) |
This guide will show you how to save and load datasets with any cloud storage.
Here are examples for S3, Google Cloud Storage, Azure Blob Storage, and Oracle Cloud Object Storage.
## Set up your cloud storage FileSystem
### Amazon S3
1. Install the S3 FileSystem implementation:
```
>>> pip install s3fs
```
2. Define your credentials
To use an anonymous connection, use `anon=True`.
Otherwise, include your `aws_access_key_id` and `aws_secret_access_key` whenever you are interacting with a private S3 bucket.
```py
>>> storage_options = {"anon": True} # for anonymous connection
# or use your credentials
>>> storage_options = {"key": aws_access_key_id, "secret": aws_secret_access_key} # for private buckets
# or use a botocore session
>>> import aiobotocore.session
>>> s3_session = aiobotocore.session.AioSession(profile="my_profile_name")
>>> storage_options = {"session": s3_session}
```
3. Create your FileSystem instance
```py
>>> import s3fs
>>> fs = s3fs.S3FileSystem(**storage_options)
```
### Google Cloud Storage
1. Install the Google Cloud Storage implementation:
```
>>> conda install -c conda-forge gcsfs
# or install with pip
>>> pip install gcsfs
```
2. Define your credentials
```py
>>> storage_options={"token": "anon"} # for anonymous connection
# or use your credentials of your default gcloud credentials or from the google metadata service
>>> storage_options={"project": "my-google-project"}
# or use your credentials from elsewhere, see the documentation at https://gcsfs.readthedocs.io/
>>> storage_options={"project": "my-google-project", "token": TOKEN}
```
3. Create your FileSystem instance
```py
>>> import gcsfs
>>> fs = gcsfs.GCSFileSystem(**storage_options)
```
### Azure Blob Storage
1. Install the Azure Blob Storage implementation:
```
>>> conda install -c conda-forge adlfs
# or install with pip
>>> pip install adlfs
```
2. Define your credentials
```py
>>> storage_options = {"anon": True} # for anonymous connection
# or use your credentials
>>> storage_options = {"account_name": ACCOUNT_NAME, "account_key": ACCOUNT_KEY} # gen 2 filesystem
# or use your credentials with the gen 1 filesystem
>>> storage_options={"tenant_id": TENANT_ID, "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET}
```
3. Create your FileSystem instance
```py
>>> import adlfs
>>> fs = adlfs.AzureBlobFileSystem(**storage_options)
```
### Oracle Cloud Object Storage
1. Install the OCI FileSystem implementation:
```
>>> pip install ocifs
```
2. Define your credentials
```py
>>> storage_options = {"config": "~/.oci/config", "region": "us-ashburn-1"}
```
3. Create your FileSystem instance
```py
>>> import ocifs
>>> fs = ocifs.OCIFileSystem(**storage_options)
```
## Load and Save your datasets using your cloud storage FileSystem
### Download and prepare a dataset into a cloud storage
You can download and prepare a dataset into your cloud storage by specifying a remote `output_dir` in `download_and_prepare`.
Don't forget to use the previously defined `storage_options` containing your credentials to write into a private cloud storage.
The `download_and_prepare` method works in two steps:
1. it first downloads the raw data files (if any) in your local cache. You can set your cache directory by passing `cache_dir` to [`load_dataset_builder`]
2. then it generates the dataset in Arrow or Parquet format in your cloud storage by iterating over the raw data files.
Load a dataset builder from the Hugging Face Hub (see [how to load from the Hugging Face Hub](./loading#hugging-face-hub)):
```py
>>> output_dir = "s3://my-bucket/imdb"
>>> builder = load_dataset_builder("imdb")
>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet")
```
Load a dataset builder using a loading script (see [how to load a local loading script](./loading#local-loading-script)):
```py
>>> output_dir = "s3://my-bucket/imdb"
>>> builder = load_dataset_builder("path/to/local/loading_script/loading_script.py")
>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet")
```
Use your own data files (see [how to load local and remote files](./loading#local-and-remote-files)):
```py
>>> data_files = {"train": ["path/to/train.csv"]}
>>> output_dir = "s3://my-bucket/imdb"
>>> builder = load_dataset_builder("csv", data_files=data_files)
>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet")
```
It is highly recommended to save the files as compressed Parquet files to optimize I/O by specifying `file_format="parquet"`.
Otherwise the dataset is saved as an uncompressed Arrow file.
You can also specify the size of the shards using `max_shard_size` (default is 500MB):
```py
>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet", max_shard_size="1GB")
```
#### Dask
Dask is a parallel computing library and it has a pandas-like API for working with larger than memory Parquet datasets in parallel.
Dask can use multiple threads or processes on a single machine, or a cluster of machines to process data in parallel.
Dask supports local data but also data from a cloud storage.
Therefore you can load a dataset saved as sharded Parquet files in Dask with
```py
import dask.dataframe as dd
df = dd.read_parquet(output_dir, storage_options=storage_options)
# or if your dataset is split into train/valid/test
df_train = dd.read_parquet(output_dir + f"/{builder.name}-train-*.parquet", storage_options=storage_options)
df_valid = dd.read_parquet(output_dir + f"/{builder.name}-validation-*.parquet", storage_options=storage_options)
df_test = dd.read_parquet(output_dir + f"/{builder.name}-test-*.parquet", storage_options=storage_options)
```
You can find more about dask dataframes in their [documentation](https://docs.dask.org/en/stable/dataframe.html).
## Saving serialized datasets
After you have processed your dataset, you can save it to your cloud storage with [`Dataset.save_to_disk`]:
```py
# saves encoded_dataset to amazon s3
>>> encoded_dataset.save_to_disk("s3://my-private-datasets/imdb/train", storage_options=storage_options)
# saves encoded_dataset to google cloud storage
>>> encoded_dataset.save_to_disk("gcs://my-private-datasets/imdb/train", storage_options=storage_options)
# saves encoded_dataset to microsoft azure blob/datalake
>>> encoded_dataset.save_to_disk("adl://my-private-datasets/imdb/train", storage_options=storage_options)
```
<Tip>
Remember to define your credentials in your [FileSystem instance](#set-up-your-cloud-storage-filesystem) `fs` whenever you are interacting with a private cloud storage.
</Tip>
## Listing serialized datasets
List files from a cloud storage with your FileSystem instance `fs`, using `fs.ls`:
```py
>>> fs.ls("my-private-datasets/imdb/train", detail=False)
["dataset_info.json.json","dataset.arrow","state.json"]
```
### Load serialized datasets
When you are ready to use your dataset again, reload it with [`Dataset.load_from_disk`]:
```py
>>> from datasets import load_from_disk
# load encoded_dataset from cloud storage
>>> dataset = load_from_disk("s3://a-public-datasets/imdb/train", storage_options=storage_options)
>>> print(len(dataset))
25000
```
| huggingface/datasets/blob/main/docs/source/filesystems.mdx |
Gradio Demo: automatic-speech-recognition
### Automatic speech recognition English. Record from your microphone and the app will transcribe the audio.
```
!pip install -q gradio
```
```
import gradio as gr
import os
# save your HF API token from https:/hf.co/settings/tokens as an env variable to avoid rate limiting
hf_token = os.getenv("hf_token")
# automatically load the interface from a HF model
# you can remove the hf_token parameter if you don't care about rate limiting.
demo = gr.load(
"huggingface/facebook/wav2vec2-base-960h",
title="Speech-to-text",
inputs="mic",
description="Let me try to guess what you're saying!",
hf_token=hf_token
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/automatic-speech-recognition/run.ipynb |
Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a machine translation is to a professional human translation, the better it is" – this is the central idea behind BLEU. BLEU was one of the first metrics to claim a high correlation with human judgements of quality, and remains one of the most popular automated and inexpensive metrics.
Scores are calculated for individual translated segments—generally sentences—by comparing them with a set of good quality reference translations. Those scores are then averaged over the whole corpus to reach an estimate of the translation's overall quality. Neither intelligibility nor grammatical correctness are not taken into account.
## Intended Uses
BLEU and BLEU-derived metrics are most often used for machine translation.
## How to Use
This metric takes as input lists of predicted sentences and reference sentences:
```python
>>> predictions = [
... ["hello", "there", "general", "kenobi"],
... ["foo", "bar", "foobar"]
... ]
>>> references = [
... [["hello", "there", "general", "kenobi"]],
... [["foo", "bar", "foobar"]]
... ]
>>> bleu = datasets.load_metric("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 7, 'reference_length': 7}
```
### Inputs
- **predictions** (`list`): Translations to score. Each translation should be tokenized into a list of tokens.
- **references** (`list` of `list`s): references for each translation. Each reference should be tokenized into a list of tokens.
- **max_order** (`int`): Maximum n-gram order to use when computing BLEU score. Defaults to `4`.
- **smooth** (`boolean`): Whether or not to apply Lin et al. 2004 smoothing. Defaults to `False`.
### Output Values
- **bleu** (`float`): bleu score
- **precisions** (`list` of `float`s): geometric mean of n-gram precisions,
- **brevity_penalty** (`float`): brevity penalty,
- **length_ratio** (`float`): ratio of lengths,
- **translation_length** (`int`): translation_length,
- **reference_length** (`int`): reference_length
Output Example:
```python
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.167, 'translation_length': 7, 'reference_length': 6}
```
BLEU's output is always a number between 0 and 1. This value indicates how similar the candidate text is to the reference texts, with values closer to 1 representing more similar texts. Few human translations will attain a score of 1, since this would indicate that the candidate is identical to one of the reference translations. For this reason, it is not necessary to attain a score of 1. Because there are more opportunities to match, adding additional reference translations will increase the BLEU score.
#### Values from Popular Papers
The [original BLEU paper](https://aclanthology.org/P02-1040/) (Papineni et al. 2002) compares BLEU scores of five different models on the same 500-sentence corpus. These scores ranged from 0.0527 to 0.2571.
The [Attention is All you Need paper](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) (Vaswani et al. 2017) got a BLEU score of 0.284 on the WMT 2014 English-to-German translation task, and 0.41 on the WMT 2014 English-to-French translation task.
### Examples
Example where each sample has 1 reference:
```python
>>> predictions = [
... ["hello", "there", "general", "kenobi"],
... ["foo", "bar", "foobar"]
... ]
>>> references = [
... [["hello", "there", "general", "kenobi"]],
... [["foo", "bar", "foobar"]]
... ]
>>> bleu = datasets.load_metric("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 7, 'reference_length': 7}
```
Example where the first sample has 2 references:
```python
>>> predictions = [
... ["hello", "there", "general", "kenobi"],
... ["foo", "bar", "foobar"]
... ]
>>> references = [
... [["hello", "there", "general", "kenobi"], ["hello", "there", "!"]],
... [["foo", "bar", "foobar"]]
... ]
>>> bleu = datasets.load_metric("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6}
```
## Limitations and Bias
This metric hase multiple known limitations and biases:
- BLEU compares overlap in tokens from the predictions and references, instead of comparing meaning. This can lead to discrepencies between BLEU scores and human ratings.
- BLEU scores are not comparable across different datasets, nor are they comparable across different languages.
- BLEU scores can vary greatly depending on which parameters are used to generate the scores, especially when different tokenization and normalization techniques are used. It is therefore not possible to compare BLEU scores generated using different parameters, or when these parameters are unknown.
- Shorter predicted translations achieve higher scores than longer ones, simply due to how the score is calculated. A brevity penalty is introduced to attempt to counteract this.
## Citation
```bibtex
@INPROCEEDINGS{Papineni02bleu:a,
author = {Kishore Papineni and Salim Roukos and Todd Ward and Wei-jing Zhu},
title = {BLEU: a Method for Automatic Evaluation of Machine Translation},
booktitle = {},
year = {2002},
pages = {311--318}
}
@inproceedings{lin-och-2004-orange,
title = "{ORANGE}: a Method for Evaluating Automatic Evaluation Metrics for Machine Translation",
author = "Lin, Chin-Yew and
Och, Franz Josef",
booktitle = "{COLING} 2004: Proceedings of the 20th International Conference on Computational Linguistics",
month = "aug 23{--}aug 27",
year = "2004",
address = "Geneva, Switzerland",
publisher = "COLING",
url = "https://www.aclweb.org/anthology/C04-1072",
pages = "501--507",
}
```
## Further References
- This Hugging Face implementation uses [this Tensorflow implementation](https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py)
| huggingface/datasets/blob/main/metrics/bleu/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Load community pipelines and components
[[open-in-colab]]
## Community pipelines
Community pipelines are any [`DiffusionPipeline`] class that are different from the original implementation as specified in their paper (for example, the [`StableDiffusionControlNetPipeline`] corresponds to the [Text-to-Image Generation with ControlNet Conditioning](https://arxiv.org/abs/2302.05543) paper). They provide additional functionality or extend the original implementation of a pipeline.
There are many cool community pipelines like [Speech to Image](https://github.com/huggingface/diffusers/tree/main/examples/community#speech-to-image) or [Composable Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#composable-stable-diffusion), and you can find all the official community pipelines [here](https://github.com/huggingface/diffusers/tree/main/examples/community).
To load any community pipeline on the Hub, pass the repository id of the community pipeline to the `custom_pipeline` argument and the model repository where you'd like to load the pipeline weights and components from. For example, the example below loads a dummy pipeline from [`hf-internal-testing/diffusers-dummy-pipeline`](https://huggingface.co/hf-internal-testing/diffusers-dummy-pipeline/blob/main/pipeline.py) and the pipeline weights and components from [`google/ddpm-cifar10-32`](https://huggingface.co/google/ddpm-cifar10-32):
<Tip warning={true}>
🔒 By loading a community pipeline from the Hugging Face Hub, you are trusting that the code you are loading is safe. Make sure to inspect the code online before loading and running it automatically!
</Tip>
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline", use_safetensors=True
)
```
Loading an official community pipeline is similar, but you can mix loading weights from an official repository id and pass pipeline components directly. The example below loads the community [CLIP Guided Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#clip-guided-stable-diffusion) pipeline, and you can pass the CLIP model components directly to it:
```py
from diffusers import DiffusionPipeline
from transformers import CLIPImageProcessor, CLIPModel
clip_model_id = "laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
feature_extractor = CLIPImageProcessor.from_pretrained(clip_model_id)
clip_model = CLIPModel.from_pretrained(clip_model_id)
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
custom_pipeline="clip_guided_stable_diffusion",
clip_model=clip_model,
feature_extractor=feature_extractor,
use_safetensors=True,
)
```
For more information about community pipelines, take a look at the [Community pipelines](custom_pipeline_examples) guide for how to use them and if you're interested in adding a community pipeline check out the [How to contribute a community pipeline](contribute_pipeline) guide!
## Community components
Community components allow users to build pipelines that may have customized components that are not a part of Diffusers. If your pipeline has custom components that Diffusers doesn't already support, you need to provide their implementations as Python modules. These customized components could be a VAE, UNet, and scheduler. In most cases, the text encoder is imported from the Transformers library. The pipeline code itself can also be customized.
This section shows how users should use community components to build a community pipeline.
You'll use the [showlab/show-1-base](https://huggingface.co/showlab/show-1-base) pipeline checkpoint as an example. So, let's start loading the components:
1. Import and load the text encoder from Transformers:
```python
from transformers import T5Tokenizer, T5EncoderModel
pipe_id = "showlab/show-1-base"
tokenizer = T5Tokenizer.from_pretrained(pipe_id, subfolder="tokenizer")
text_encoder = T5EncoderModel.from_pretrained(pipe_id, subfolder="text_encoder")
```
2. Load a scheduler:
```python
from diffusers import DPMSolverMultistepScheduler
scheduler = DPMSolverMultistepScheduler.from_pretrained(pipe_id, subfolder="scheduler")
```
3. Load an image processor:
```python
from transformers import CLIPFeatureExtractor
feature_extractor = CLIPFeatureExtractor.from_pretrained(pipe_id, subfolder="feature_extractor")
```
<Tip warning={true}>
In steps 4 and 5, the custom [UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py) and [pipeline](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) implementation must match the format shown in their files for this example to work.
</Tip>
4. Now you'll load a [custom UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py), which in this example, has already been implemented in the `showone_unet_3d_condition.py` [script](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) for your convenience. You'll notice the `UNet3DConditionModel` class name is changed to `ShowOneUNet3DConditionModel` because [`UNet3DConditionModel`] already exists in Diffusers. Any components needed for the `ShowOneUNet3DConditionModel` class should be placed in the `showone_unet_3d_condition.py` script.
Once this is done, you can initialize the UNet:
```python
from showone_unet_3d_condition import ShowOneUNet3DConditionModel
unet = ShowOneUNet3DConditionModel.from_pretrained(pipe_id, subfolder="unet")
```
5. Finally, you'll load the custom pipeline code. For this example, it has already been created for you in the `pipeline_t2v_base_pixel.py` [script](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/pipeline_t2v_base_pixel.py). This script contains a custom `TextToVideoIFPipeline` class for generating videos from text. Just like the custom UNet, any code needed for the custom pipeline to work should go in the `pipeline_t2v_base_pixel.py` script.
Once everything is in place, you can initialize the `TextToVideoIFPipeline` with the `ShowOneUNet3DConditionModel`:
```python
from pipeline_t2v_base_pixel import TextToVideoIFPipeline
import torch
pipeline = TextToVideoIFPipeline(
unet=unet,
text_encoder=text_encoder,
tokenizer=tokenizer,
scheduler=scheduler,
feature_extractor=feature_extractor
)
pipeline = pipeline.to(device="cuda")
pipeline.torch_dtype = torch.float16
```
Push the pipeline to the Hub to share with the community!
```python
pipeline.push_to_hub("custom-t2v-pipeline")
```
After the pipeline is successfully pushed, you need a couple of changes:
1. Change the `_class_name` attribute in [`model_index.json`](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/model_index.json#L2) to `"pipeline_t2v_base_pixel"` and `"TextToVideoIFPipeline"`.
2. Upload `showone_unet_3d_condition.py` to the `unet` [directory](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py).
3. Upload `pipeline_t2v_base_pixel.py` to the pipeline base [directory](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py).
To run inference, simply add the `trust_remote_code` argument while initializing the pipeline to handle all the "magic" behind the scenes.
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"<change-username>/<change-id>", trust_remote_code=True, torch_dtype=torch.float16
).to("cuda")
prompt = "hello"
# Text embeds
prompt_embeds, negative_embeds = pipeline.encode_prompt(prompt)
# Keyframes generation (8x64x40, 2fps)
video_frames = pipeline(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
num_frames=8,
height=40,
width=64,
num_inference_steps=2,
guidance_scale=9.0,
output_type="pt"
).frames
```
As an additional reference example, you can refer to the repository structure of [stabilityai/japanese-stable-diffusion-xl](https://huggingface.co/stabilityai/japanese-stable-diffusion-xl/), that makes use of the `trust_remote_code` feature:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/japanese-stable-diffusion-xl", trust_remote_code=True
)
pipeline.to("cuda")
# if using torch < 2.0
# pipeline.enable_xformers_memory_efficient_attention()
prompt = "柴犬、カラフルアート"
image = pipeline(prompt=prompt).images[0]
``` | huggingface/diffusers/blob/main/docs/source/en/using-diffusers/custom_pipeline_overview.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MusicGen
## Overview
The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned
on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a
sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*,
conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec,
to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of
the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g.
hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
The abstract from the paper is the following:
*We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates
over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised
of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for
cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen
can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better
controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human
studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark.
Through ablation studies, we shed light over the importance of each of the components comprising MusicGen.*
This model was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found
[here](https://github.com/facebookresearch/audiocraft). The pre-trained checkpoints can be found on the
[Hugging Face Hub](https://huggingface.co/models?sort=downloads&search=facebook%2Fmusicgen-).
## Usage tips
- After downloading the original checkpoints from [here](https://github.com/facebookresearch/audiocraft/blob/main/docs/MUSICGEN.md#importing--exporting-models) , you can convert them using the **conversion script** available at
`src/transformers/models/musicgen/convert_musicgen_transformers.py` with the following command:
```bash
python src/transformers/models/musicgen/convert_musicgen_transformers.py \
--checkpoint small --pytorch_dump_folder /output/path --safe_serialization
```
## Generation
MusicGen is compatible with two generation modes: greedy and sampling. In practice, sampling leads to significantly
better results than greedy, thus we encourage sampling mode to be used where possible. Sampling is enabled by default,
and can be explicitly specified by setting `do_sample=True` in the call to [`MusicgenForConditionalGeneration.generate`],
or by overriding the model's generation config (see below).
Generation is limited by the sinusoidal positional embeddings to 30 second inputs. Meaning, MusicGen cannot generate more
than 30 seconds of audio (1503 tokens), and input audio passed by Audio-Prompted Generation contributes to this limit so,
given an input of 20 seconds of audio, MusicGen cannot generate more than 10 seconds of additional audio.
Transformers supports both mono (1-channel) and stereo (2-channel) variants of MusicGen. The mono channel versions
generate a single set of codebooks. The stereo versions generate 2 sets of codebooks, 1 for each channel (left/right),
and each set of codebooks is decoded independently through the audio compression model. The audio streams for each
channel are combined to give the final stereo output.
### Unconditional Generation
The inputs for unconditional (or 'null') generation can be obtained through the method
[`MusicgenForConditionalGeneration.get_unconditional_inputs`]:
```python
>>> from transformers import MusicgenForConditionalGeneration
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> unconditional_inputs = model.get_unconditional_inputs(num_samples=1)
>>> audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
```
The audio outputs are a three-dimensional Torch tensor of shape `(batch_size, num_channels, sequence_length)`. To listen
to the generated audio samples, you can either play them in an ipynb notebook:
```python
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0].numpy(), rate=sampling_rate)
```
Or save them as a `.wav` file using a third-party library, e.g. `scipy`:
```python
>>> import scipy
>>> sampling_rate = model.config.audio_encoder.sampling_rate
>>> scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy())
```
### Text-Conditional Generation
The model can generate an audio sample conditioned on a text prompt through use of the [`MusicgenProcessor`] to pre-process
the inputs:
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> inputs = processor(
... text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
... padding=True,
... return_tensors="pt",
... )
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
```
The `guidance_scale` is used in classifier free guidance (CFG), setting the weighting between the conditional logits
(which are predicted from the text prompts) and the unconditional logits (which are predicted from an unconditional or
'null' prompt). Higher guidance scale encourages the model to generate samples that are more closely linked to the input
prompt, usually at the expense of poorer audio quality. CFG is enabled by setting `guidance_scale > 1`. For best results,
use `guidance_scale=3` (default).
### Audio-Prompted Generation
The same [`MusicgenProcessor`] can be used to pre-process an audio prompt that is used for audio continuation. In the
following example, we load an audio file using the 🤗 Datasets library, which can be pip installed through the command
below:
```
pip install --upgrade pip
pip install datasets[audio]
```
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
>>> from datasets import load_dataset
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
>>> sample = next(iter(dataset))["audio"]
>>> # take the first half of the audio sample
>>> sample["array"] = sample["array"][: len(sample["array"]) // 2]
>>> inputs = processor(
... audio=sample["array"],
... sampling_rate=sample["sampling_rate"],
... text=["80s blues track with groovy saxophone"],
... padding=True,
... return_tensors="pt",
... )
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
```
For batched audio-prompted generation, the generated `audio_values` can be post-processed to remove padding by using the
[`MusicgenProcessor`] class:
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
>>> from datasets import load_dataset
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
>>> sample = next(iter(dataset))["audio"]
>>> # take the first quarter of the audio sample
>>> sample_1 = sample["array"][: len(sample["array"]) // 4]
>>> # take the first half of the audio sample
>>> sample_2 = sample["array"][: len(sample["array"]) // 2]
>>> inputs = processor(
... audio=[sample_1, sample_2],
... sampling_rate=sample["sampling_rate"],
... text=["80s blues track with groovy saxophone", "90s rock song with loud guitars and heavy drums"],
... padding=True,
... return_tensors="pt",
... )
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
>>> # post-process to remove padding from the batched audio
>>> audio_values = processor.batch_decode(audio_values, padding_mask=inputs.padding_mask)
```
### Generation Configuration
The default parameters that control the generation process, such as sampling, guidance scale and number of generated
tokens, can be found in the model's generation config, and updated as desired:
```python
>>> from transformers import MusicgenForConditionalGeneration
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> # inspect the default generation config
>>> model.generation_config
>>> # increase the guidance scale to 4.0
>>> model.generation_config.guidance_scale = 4.0
>>> # decrease the max length to 256 tokens
>>> model.generation_config.max_length = 256
```
Note that any arguments passed to the generate method will **supersede** those in the generation config, so setting
`do_sample=False` in the call to generate will supersede the setting of `model.generation_config.do_sample` in the
generation config.
## Model Structure
The MusicGen model can be de-composed into three distinct stages:
1. Text encoder: maps the text inputs to a sequence of hidden-state representations. The pre-trained MusicGen models use a frozen text encoder from either T5 or Flan-T5
2. MusicGen decoder: a language model (LM) that auto-regressively generates audio tokens (or codes) conditional on the encoder hidden-state representations
3. Audio encoder/decoder: used to encode an audio prompt to use as prompt tokens, and recover the audio waveform from the audio tokens predicted by the decoder
Thus, the MusicGen model can either be used as a standalone decoder model, corresponding to the class [`MusicgenForCausalLM`],
or as a composite model that includes the text encoder and audio encoder/decoder, corresponding to the class
[`MusicgenForConditionalGeneration`]. If only the decoder needs to be loaded from the pre-trained checkpoint, it can be loaded by first
specifying the correct config, or be accessed through the `.decoder` attribute of the composite model:
```python
>>> from transformers import AutoConfig, MusicgenForCausalLM, MusicgenForConditionalGeneration
>>> # Option 1: get decoder config and pass to `.from_pretrained`
>>> decoder_config = AutoConfig.from_pretrained("facebook/musicgen-small").decoder
>>> decoder = MusicgenForCausalLM.from_pretrained("facebook/musicgen-small", **decoder_config)
>>> # Option 2: load the entire composite model, but only return the decoder
>>> decoder = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small").decoder
```
Since the text encoder and audio encoder/decoder models are frozen during training, the MusicGen decoder [`MusicgenForCausalLM`]
can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can
be combined with the frozen text encoder and audio encoder/decoders to recover the composite [`MusicgenForConditionalGeneration`]
model.
Tips:
* MusicGen is trained on the 32kHz checkpoint of Encodec. You should ensure you use a compatible version of the Encodec model.
* Sampling mode tends to deliver better results than greedy - you can toggle sampling with the variable `do_sample` in the call to [`MusicgenForConditionalGeneration.generate`]
## MusicgenDecoderConfig
[[autodoc]] MusicgenDecoderConfig
## MusicgenConfig
[[autodoc]] MusicgenConfig
## MusicgenProcessor
[[autodoc]] MusicgenProcessor
## MusicgenModel
[[autodoc]] MusicgenModel
- forward
## MusicgenForCausalLM
[[autodoc]] MusicgenForCausalLM
- forward
## MusicgenForConditionalGeneration
[[autodoc]] MusicgenForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/musicgen.md |
Datasets server SSE API
> Server-sent events API for the Datasets server. It's used to update the Hub's backend cache.
## Configuration
The service can be configured using environment variables. They are grouped by scope.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
## Endpoints
See https://huggingface.co/docs/datasets-server
- /healthcheck: Ensure the app is running
- /metrics: Return a list of metrics in the Prometheus format
- /hub-cache: Return a dataset information as a Server-Sent Event (SSE) when a dataset is updated. If `?all=true` is passed in the parameters, and if the cache already has some entries, one SSE per cached dataset is sent to the client. Then, a SSE is sent when a dataset is inserted, modified or deleted. The event data is a JSON with the following structure. The `hub_cache` field is null for deleted entries, or when the response is an error. The `num_rows` value is `0` if it could not be determined.
```typescript
{
dataset: string;
hub_cache: null | {
preview: boolean;
viewer: boolean;
partial: boolean;
num_rows: int;
};
}
```
| huggingface/datasets-server/blob/main/services/sse-api/README.md |
(Tensorflow) MobileNet v3
**MobileNetV3** is a convolutional neural network that is designed for mobile phone CPUs. The network design includes the use of a [hard swish activation](https://paperswithcode.com/method/hard-swish) and [squeeze-and-excitation](https://paperswithcode.com/method/squeeze-and-excitation-block) modules in the [MBConv blocks](https://paperswithcode.com/method/inverted-residual-block).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tf_mobilenetv3_large_075', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_mobilenetv3_large_075`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tf_mobilenetv3_large_075', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-02244,
author = {Andrew Howard and
Mark Sandler and
Grace Chu and
Liang{-}Chieh Chen and
Bo Chen and
Mingxing Tan and
Weijun Wang and
Yukun Zhu and
Ruoming Pang and
Vijay Vasudevan and
Quoc V. Le and
Hartwig Adam},
title = {Searching for MobileNetV3},
journal = {CoRR},
volume = {abs/1905.02244},
year = {2019},
url = {http://arxiv.org/abs/1905.02244},
archivePrefix = {arXiv},
eprint = {1905.02244},
timestamp = {Tue, 12 Jan 2021 15:30:06 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-02244.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: TF MobileNet V3
Paper:
Title: Searching for MobileNetV3
URL: https://paperswithcode.com/paper/searching-for-mobilenetv3
Models:
- Name: tf_mobilenetv3_large_075
In Collection: TF MobileNet V3
Metadata:
FLOPs: 194323712
Parameters: 3990000
File Size: 16097377
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: tf_mobilenetv3_large_075
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L394
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_075-150ee8b0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.45%
Top 5 Accuracy: 91.34%
- Name: tf_mobilenetv3_large_100
In Collection: TF MobileNet V3
Metadata:
FLOPs: 274535288
Parameters: 5480000
File Size: 22076649
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: tf_mobilenetv3_large_100
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L403
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_100-427764d5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.51%
Top 5 Accuracy: 92.61%
- Name: tf_mobilenetv3_large_minimal_100
In Collection: TF MobileNet V3
Metadata:
FLOPs: 267216928
Parameters: 3920000
File Size: 15836368
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x4 TPU Pod
ID: tf_mobilenetv3_large_minimal_100
LR: 0.1
Dropout: 0.8
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L412
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_minimal_100-8596ae28.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.24%
Top 5 Accuracy: 90.64%
- Name: tf_mobilenetv3_small_075
In Collection: TF MobileNet V3
Metadata:
FLOPs: 48457664
Parameters: 2040000
File Size: 8242701
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: tf_mobilenetv3_small_075
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bilinear
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L421
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_075-da427f52.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 65.72%
Top 5 Accuracy: 86.13%
- Name: tf_mobilenetv3_small_100
In Collection: TF MobileNet V3
Metadata:
FLOPs: 65450600
Parameters: 2540000
File Size: 10256398
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: tf_mobilenetv3_small_100
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bilinear
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L430
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_100-37f49e2b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 67.92%
Top 5 Accuracy: 87.68%
- Name: tf_mobilenetv3_small_minimal_100
In Collection: TF MobileNet V3
Metadata:
FLOPs: 60827936
Parameters: 2040000
File Size: 8258083
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Dropout
- Global Average Pooling
- Hard Swish
- Inverted Residual Block
- ReLU
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 16x GPUs
ID: tf_mobilenetv3_small_minimal_100
LR: 0.045
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 4096
Image Size: '224'
Weight Decay: 4.0e-05
Interpolation: bilinear
RMSProp Decay: 0.9
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/mobilenetv3.py#L439
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_minimal_100-922a7843.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 62.91%
Top 5 Accuracy: 84.24%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/tf-mobilenet-v3.mdx |
--
title: "Getting Started with Hugging Face Transformers for IPUs with Optimum"
thumbnail: /blog/assets/38_getting_started_graphcore/graphcore_1.png
authors:
- user: internetoftim
guest: true
- user: juliensimon
---
# Getting Started with Hugging Face Transformers for IPUs with Optimum
Transformer models have proven to be extremely efficient on a wide range of machine learning tasks, such as natural language processing, audio processing, and computer vision. However, the prediction speed of these large models can make them impractical for latency-sensitive use cases like conversational applications or search. Furthermore, optimizing their performance in the real world requires considerable time, effort and skills that are beyond the reach of many companies and organizations.
Luckily, Hugging Face has introduced [Optimum](https://huggingface.co/hardware), an open source library which makes it much easier to reduce the prediction latency of Transformer models on a variety of hardware platforms. In this blog post, you will learn how to accelerate Transformer models for the Graphcore [Intelligence Processing Unit](https://www.graphcore.ai/products/ipu) (IPU), a highly flexible, easy-to-use parallel processor designed from the ground up for AI workloads.
### Optimum Meets Graphcore IPU
Through this partnership between Graphcore and Hugging Face, we are now introducing BERT as the first IPU-optimized model. We will be introducing many more of these IPU-optimized models in the coming months, spanning applications such as vision, speech, translation and text generation.
Graphcore engineers have implemented and optimized BERT for our IPU systems using Hugging Face transformers to help developers easily train, fine-tune and accelerate their state-of-the-art models.
### Getting started with IPUs and Optimum
Let’s use BERT as an example to help you get started with using Optimum and IPUs.
In this guide, we will use an [IPU-POD16](https://www.graphcore.ai/products/mk2/ipu-pod16) system in Graphcloud, Graphcore’s cloud-based machine learning platform and follow PyTorch setup instructions found in [Getting Started with Graphcloud](https://docs.graphcore.ai/projects/graphcloud-getting-started/en/latest/index.html).
Graphcore’s [Poplar SDK](https://www.graphcore.ai/developer) is already installed on the Graphcloud server. If you have a different setup, you can find the instructions that apply to your system in the [PyTorch for the IPU: User Guide](https://docs.graphcore.ai/projects/poptorch-user-guide/en/latest/intro.html).
#### Set up the Poplar SDK Environment
You will need to run the following commands to set several environment variables that enable Graphcore tools and Poplar libraries. On the latest system running Poplar SDK version 2.3 on Ubuntu 18.04, you can find <sdk-path> in the folder ```/opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/```.
You would need to run both enable scripts for Poplar and PopART (Poplar Advanced Runtime) to use PyTorch:
```
$ cd /opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/
$ source poplar-ubuntu_18_04-2.3.0+774-b47c577c2a/enable.sh
$ source popart-ubuntu_18_04-2.3.0+774-b47c577c2a/enable.sh
```
#### Set up PopTorch for the IPU
PopTorch is part of the Poplar SDK. It provides functions that allow PyTorch models to run on the IPU with minimal code changes. You can create and activate a PopTorch environment following the guide [Setting up PyTorch for the IPU](https://docs.graphcore.ai/projects/graphcloud-pytorch-quick-start/en/latest/pytorch_setup.html):
```
$ virtualenv -p python3 ~/workspace/poptorch_env
$ source ~/workspace/poptorch_env/bin/activate
$ pip3 install -U pip
$ pip3 install /opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/poptorch-<sdk-version>.whl
```
#### Install Optimum Graphcore
Now that your environment has all the Graphcore Poplar and PopTorch libraries available, you need to install the latest 🤗 Optimum Graphcore package in this environment. This will be the interface between the 🤗 Transformers library and Graphcore IPUs.
Please make sure that the PopTorch virtual environment you created in the previous step is activated. Your terminal should have a prefix showing the name of the poptorch environment like below:
```
(poptorch_env) user@host:~/workspace/poptorch_env$ pip3 install optimum[graphcore] optuna
```
#### Clone Optimum Graphcore Repository
The Optimum Graphcore repository contains the sample code for using Optimum models in IPU. You should clone the repository and change the directory to the ```example/question-answering``` folder which contains the IPU implementation of BERT.
```
$ git clone https://github.com/huggingface/optimum-graphcore.git
$ cd optimum-graphcore/examples/question-answering
```
Now, we will use ```run_qa.py``` to fine-tune the IPU implementation of [BERT](https://huggingface.co/bert-large-uncased) on the SQUAD1.1 dataset.
#### Run a sample to fine-tune BERT on SQuAD1.1
The ```run_qa.py``` script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library), as it uses special features of those tokenizers. This is the case for our [BERT](https://huggingface.co/bert-large-uncased) model, and you should pass its name as the input argument to ```--model_name_or_path```. In order to use the IPU, Optimum will look for the ```ipu_config.json``` file from the path passed to the argument ```--ipu_config_name```.
```
$ python3 run_qa.py \
--ipu_config_name=./ \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--output_dir output \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 6e-5 \
--num_train_epochs 3 \
--max_seq_length 384 \
--doc_stride 128 \
--seed 1984 \
--lr_scheduler_type linear \
--loss_scaling 64 \
--weight_decay 0.01 \
--warmup_ratio 0.1 \
--output_dir /tmp/debug_squad/
```
### A closer look at Optimum-Graphcore
#### Getting the data
A very simple way to get datasets is to use the Hugging Face [Datasets library](https://github.com/huggingface/datasets), which makes it easy for developers to download and share datasets on the Hugging Face hub. It also has pre-built data versioning based on git and git-lfs, so you can iterate on updated versions of the data by just pointing to the same repo.
Here, the dataset comes with the training and validation files, and dataset configs to help facilitate which inputs to use in each model execution phase. The argument ```--dataset_name==squad``` points to [SQuAD v1.1](https://huggingface.co/datasets/squad) on the Hugging Face Hub. You could also provide your own CSV/JSON/TXT training and evaluation files as long as they follow the same format as the SQuAD dataset or another question-answering dataset in Datasets library.
#### Loading the pretrained model and tokenizer
To turn words into tokens, this script will require a fast tokenizer. It will show an error if you didn't pass one. For reference, here's the [list](https://huggingface.co/transformers/index.html#supported-frameworks) of supported tokenizers.
```
# Tokenizer check: this script requires a fast tokenizer.
if not isinstance(tokenizer, PreTrainedTokenizerFast):
raise ValueError("This example script only works for models that have a fast tokenizer. Checkout the big table of models
"at https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet this "
"requirement"
)
```
The argument ```--model_name_or_path==bert-base-uncased`` loads the [bert-base-uncased](https://huggingface.co/bert-base-uncased) model implementation available in the Hugging Face Hub.
From the Hugging Face Hub description:
"*BERT base model (uncased): Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is uncased: it does not make a difference between english and English.*"
#### Training and Validation
You can now use the ```IPUTrainer``` class available in Optimum to leverage the entire Graphcore software and hardware stack, and train your models in IPUs with minimal code changes. Thanks to Optimum, you can plug-and-play state of the art hardware to train your state of the art models.
<kbd>
<img src="assets/38_getting_started_graphcore/graphcore_1.png">
</kbd>
In order to train and validate the BERT model, you can pass the arguments ```--do_train``` and ```--do_eval``` to the ```run_qa.py``` script. After executing the script with the hyper-parameters above, you should see the following training and validation results:
```
"epoch": 3.0,
"train_loss": 0.9465060763888888,
"train_runtime": 368.4015,
"train_samples": 88524,
"train_samples_per_second": 720.877,
"train_steps_per_second": 2.809
The validation step yields the following results:
***** eval metrics *****
epoch = 3.0
eval_exact_match = 80.6623
eval_f1 = 88.2757
eval_samples = 10784
```
You can see the rest of the IPU BERT implementation in the [Optimum-Graphcore: SQuAD Examples](https://github.com/huggingface/optimum-graphcore/tree/main/examples/question-answering).
### Resources for Optimum Transformers on IPU Systems
* [Optimum-Graphcore: SQuAD Examples](https://github.com/huggingface/optimum-graphcore/tree/main/examples/question-answering)
* [Graphcore Hugging Face Models & Datasets](https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/tut_finetuning_bert#tutorial-on-bert-fine-tuning-on-ipu)
* GitHub Tutorial: [BERT Fine-tuning on IPU using Hugging Face transformers](https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/tut_finetuning_bert#tutorial-on-bert-fine-tuning-on-ipu)
* [Graphcore Developer Portal](https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/tut_finetuning_bert#tutorial-on-bert-fine-tuning-on-ipu)
* [Graphcore GitHub](https://github.com/graphcore)
* [Graphcore SDK Containers on Docker Hub](https://hub.docker.com/u/graphcore)
| huggingface/blog/blob/main/graphcore-getting-started.md |
Gradio Demo: event_trigger
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('img')
!wget -q -O img/a.jpg https://github.com/gradio-app/gradio/raw/main/demo/event_trigger/img/a.jpg
!wget -q -O img/b.jpg https://github.com/gradio-app/gradio/raw/main/demo/event_trigger/img/b.jpg
os.mkdir('mp4')
!wget -q -O mp4/a.mp4 https://github.com/gradio-app/gradio/raw/main/demo/event_trigger/mp4/a.mp4
!wget -q -O mp4/b.mp4 https://github.com/gradio-app/gradio/raw/main/demo/event_trigger/mp4/b.mp4
```
```
# %%
import gradio as gr
TEST_VIDEO_A = "mp4/a.mp4"
TEST_VIDEO_B = "mp4/b.mp4"
TEST_IMAGE_A = "img/a.jpg"
TEST_IMAGE_B = "img/b.jpg"
def alert_change(component, value):
print(f"Detected {component} change, {type(value)}")
if type(value) == list or type(value) == str:
print(value)
def change_interactive(state):
return gr.Video(interactive=not state), not state
with gr.Blocks() as demo:
with gr.Tab(label="Text change"):
with gr.Row():
with gr.Column():
textbox1 = gr.Textbox()
textbox2 = gr.Textbox(interactive=True)
with gr.Column():
btn = gr.Button()
def btn_click(state):
return state
def text_change(value):
print("text_change", value)
btn.click(fn=btn_click, inputs=textbox1, outputs=textbox2)
textbox2.change(fn=alert_change, inputs=[gr.State("Text"), textbox2])
with gr.Tab(label="Video change, play, pause"):
with gr.Row():
with gr.Column():
radio1 = gr.Radio(
choices=[TEST_VIDEO_A, TEST_VIDEO_B],
interactive=True,
type="index",
)
video_btn = gr.Button("Change interactive")
with gr.Column():
video1 = gr.Video(value=TEST_VIDEO_A, interactive=False)
video1_interactive = gr.State(value=False)
def change_video(index):
if index == 0:
return TEST_VIDEO_A
elif index == 1:
return TEST_VIDEO_B
def video_play():
print("video_play")
def video_pause():
print("video_pause")
def video_stop():
print("video_stop")
def video_end():
print("video_end")
video1.play(fn=video_play)
video1.pause(fn=video_pause)
video1.stop(fn=video_stop)
video1.end(fn=video_end)
radio1.change(fn=change_video, inputs=radio1, outputs=video1)
video1.change(fn=alert_change, inputs=[gr.State("Video"), video1])
video_btn.click(
fn=change_interactive,
inputs=video1_interactive,
outputs=[video1, video1_interactive],
)
with gr.Tab(label="Image change"):
with gr.Row():
with gr.Column():
radio2 = gr.Radio(
choices=[TEST_IMAGE_A, TEST_IMAGE_B],
interactive=True,
type="index",
)
with gr.Column():
image1 = gr.Image(value=TEST_IMAGE_A, interactive=True)
def change_image(index):
if index == 0:
return TEST_IMAGE_A
elif index == 1:
return TEST_IMAGE_B
radio2.change(fn=change_image, inputs=radio2, outputs=image1)
image1.change(fn=alert_change, inputs=[gr.State("Image"), image1])
with gr.Tab(label="File"):
with gr.Row():
with gr.Column():
radio3 = gr.Radio(
choices=["A", "B", "AB"],
interactive=True,
type="index",
)
file_btn = gr.Button("Change interactive")
with gr.Column():
file1 = gr.File(
value=[TEST_IMAGE_A, TEST_IMAGE_B],
interactive=False,
file_count="multiple",
)
file1_interactive = gr.State(value=False)
def change_file(index):
if index == 0:
return [TEST_IMAGE_A]
elif index == 1:
return [TEST_IMAGE_A]
elif index == 2:
return [TEST_IMAGE_A, TEST_IMAGE_B]
radio3.change(fn=change_file, inputs=radio3, outputs=file1)
file1.change(fn=alert_change, inputs=[gr.State("File"), file1])
file_btn.click(
fn=change_interactive,
inputs=file1_interactive,
outputs=[file1, file1_interactive],
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/event_trigger/run.ipynb |
`@gradio/button`
```html
<script>
import { BaseChatBot } from "@gradio/chatbot";
</script>
```
BaseChatBot
```javascript
export let value:
| [
string | { file: FileData; alt_text: string | null } | null,
string | { file: FileData; alt_text: string | null } | null
][]
| null;
let old_value:
| [
string | { file: FileData; alt_text: string | null } | null,
string | { file: FileData; alt_text: string | null } | null
][]
| null = null;
export let latex_delimiters: {
left: string;
right: string;
display: boolean;
}[];
export let pending_message = false;
export let selectable = false;
export let likeable = false;
export let show_share_button = false;
export let rtl = false;
export let show_copy_button = false;
export let avatar_images: [string | null, string | null] = [null, null];
export let sanitize_html = true;
export let bubble_full_width = true;
export let render_markdown = true;
export let line_breaks = true;
export let root: string;
export let root_url: null | string;
export let i18n: I18nFormatter;
export let layout: "bubble" | "panel" = "bubble";
``` | gradio-app/gradio/blob/main/js/chatbot/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation
Each framework has a generate method for text generation implemented in their respective `GenerationMixin` class:
- PyTorch [`~generation.GenerationMixin.generate`] is implemented in [`~generation.GenerationMixin`].
- TensorFlow [`~generation.TFGenerationMixin.generate`] is implemented in [`~generation.TFGenerationMixin`].
- Flax/JAX [`~generation.FlaxGenerationMixin.generate`] is implemented in [`~generation.FlaxGenerationMixin`].
Regardless of your framework of choice, you can parameterize the generate method with a [`~generation.GenerationConfig`]
class instance. Please refer to this class for the complete list of generation parameters, which control the behavior
of the generation method.
To learn how to inspect a model's generation configuration, what are the defaults, how to change the parameters ad hoc,
and how to create and save a customized generation configuration, refer to the
[text generation strategies guide](../generation_strategies). The guide also explains how to use related features,
like token streaming.
## GenerationConfig
[[autodoc]] generation.GenerationConfig
- from_pretrained
- from_model_config
- save_pretrained
## GenerationMixin
[[autodoc]] generation.GenerationMixin
- generate
- compute_transition_scores
- greedy_search
- sample
- beam_search
- beam_sample
- contrastive_search
- group_beam_search
- constrained_beam_search
## TFGenerationMixin
[[autodoc]] generation.TFGenerationMixin
- generate
- compute_transition_scores
## FlaxGenerationMixin
[[autodoc]] generation.FlaxGenerationMixin
- generate
| huggingface/transformers/blob/main/docs/source/en/main_classes/text_generation.md |
et's see how to preprocess a dataset for summarization. This is the task of well summarizing a long document. This video will focus on how to preprocess your dataset once you have managed to put it in the following format: one column for the long documents, and one for the summaries. Here is how we can achieve this with the Datasets library on the XSUM dataset. As long as you manage to have your data look like this, you should be able to follow the same steps. For once, our labels are not integers corresponding to some classes, but plain text. We will thus need to tokenize them, like our inputs. There is a small trap there though, as we need to tokenize our targets inside the as_target_tokenzier context manager. This is because the special tokens we add might be slightly different for the inputs and the targets, so the tokenizer has to know which one it is processing. Processing the whole dataset is then super easy with the map function. Since the summaries are usually much shorter than the documents, you should definitely pick different maximum lengths for the inputs and targets. You can choose to pad at this stage to that maximum length by setting padding=max_length. Here we will show you how to pad dynamically as it requires one more step. Your inputs and targets are all sentence of various lengths. We will pad the inputs and targets separately as the maximum length of the inputs and targets are completely different. Then we pad the inputs to the maximum lengths among the inputs, and same for the targets. We pad the inputs with the pad token and the targets with the -100 index, to make sure they are not taken into account in the loss computation. The Transformers library provides us with a data collator to do this all automatically. You can then pass it to the Trainer with your datasets, or use it in the to_tf_dataset method before using model.fit(). | huggingface/course/blob/main/subtitles/en/raw/chapter7/05a_summarization-processing.md |
Diving deeper into policy-gradient methods
## Getting the big picture
We just learned that policy-gradient methods aim to find parameters \\( \theta \\) that **maximize the expected return**.
The idea is that we have a *parameterized stochastic policy*. In our case, a neural network outputs a probability distribution over actions. The probability of taking each action is also called the *action preference*.
If we take the example of CartPole-v1:
- As input, we have a state.
- As output, we have a probability distribution over actions at that state.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_based.png" alt="Policy based" />
Our goal with policy-gradient is to **control the probability distribution of actions** by tuning the policy such that **good actions (that maximize the return) are sampled more frequently in the future.**
Each time the agent interacts with the environment, we tweak the parameters such that good actions will be sampled more likely in the future.
But **how are we going to optimize the weights using the expected return**?
The idea is that we're going to **let the agent interact during an episode**. And if we win the episode, we consider that each action taken was good and must be more sampled in the future
since they lead to win.
So for each state-action pair, we want to increase the \\(P(a|s)\\): the probability of taking that action at that state. Or decrease if we lost.
The Policy-gradient algorithm (simplified) looks like this:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/pg_bigpicture.jpg" alt="Policy Gradient Big Picture"/>
</figure>
Now that we got the big picture, let's dive deeper into policy-gradient methods.
## Diving deeper into policy-gradient methods
We have our stochastic policy \\(\pi\\) which has a parameter \\(\theta\\). This \\(\pi\\), given a state, **outputs a probability distribution of actions**.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/stochastic_policy.png" alt="Policy"/>
</figure>
Where \\(\pi_\theta(a_t|s_t)\\) is the probability of the agent selecting action \\(a_t\\) from state \\(s_t\\) given our policy.
**But how do we know if our policy is good?** We need to have a way to measure it. To know that, we define a score/objective function called \\(J(\theta)\\).
### The objective function
The *objective function* gives us the **performance of the agent** given a trajectory (state action sequence without considering reward (contrary to an episode)), and it outputs the *expected cumulative reward*.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/objective.jpg" alt="Return"/>
Let's give some more details on this formula:
- The *expected return* (also called expected cumulative reward), is the weighted average (where the weights are given by \\(P(\tau;\theta)\\) of all possible values that the return \\(R(\tau)\\) can take).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/expected_reward.png" alt="Return"/>
- \\(R(\tau)\\) : Return from an arbitrary trajectory. To take this quantity and use it to calculate the expected return, we need to multiply it by the probability of each possible trajectory.
- \\(P(\tau;\theta)\\) : Probability of each possible trajectory \\(\tau\\) (that probability depends on \\( \theta\\) since it defines the policy that it uses to select the actions of the trajectory which has an impact of the states visited).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/probability.png" alt="Probability"/>
- \\(J(\theta)\\) : Expected return, we calculate it by summing for all trajectories, the probability of taking that trajectory given \\(\theta \\) multiplied by the return of this trajectory.
Our objective then is to maximize the expected cumulative reward by finding the \\(\theta \\) that will output the best action probability distributions:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/max_objective.png" alt="Max objective"/>
## Gradient Ascent and the Policy-gradient Theorem
Policy-gradient is an optimization problem: we want to find the values of \\(\theta\\) that maximize our objective function \\(J(\theta)\\), so we need to use **gradient-ascent**. It's the inverse of *gradient-descent* since it gives the direction of the steepest increase of \\(J(\theta)\\).
(If you need a refresher on the difference between gradient descent and gradient ascent [check this](https://www.baeldung.com/cs/gradient-descent-vs-ascent) and [this](https://stats.stackexchange.com/questions/258721/gradient-ascent-vs-gradient-descent-in-logistic-regression)).
Our update step for gradient-ascent is:
\\( \theta \leftarrow \theta + \alpha * \nabla_\theta J(\theta) \\)
We can repeatedly apply this update in the hopes that \\(\theta \\) converges to the value that maximizes \\(J(\theta)\\).
However, there are two problems with computing the derivative of \\(J(\theta)\\):
1. We can't calculate the true gradient of the objective function since it requires calculating the probability of each possible trajectory, which is computationally super expensive.
So we want to **calculate a gradient estimation with a sample-based estimate (collect some trajectories)**.
2. We have another problem that I explain in the next optional section. To differentiate this objective function, we need to differentiate the state distribution, called the Markov Decision Process dynamics. This is attached to the environment. It gives us the probability of the environment going into the next state, given the current state and the action taken by the agent. The problem is that we can't differentiate it because we might not know about it.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/probability.png" alt="Probability"/>
Fortunately we're going to use a solution called the Policy Gradient Theorem that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_gradient_theorem.png" alt="Policy Gradient"/>
If you want to understand how we derive this formula for approximating the gradient, check out the next (optional) section.
## The Reinforce algorithm (Monte Carlo Reinforce)
The Reinforce algorithm, also called Monte-Carlo policy-gradient, is a policy-gradient algorithm that **uses an estimated return from an entire episode to update the policy parameter** \\(\theta\\):
In a loop:
- Use the policy \\(\pi_\theta\\) to collect an episode \\(\tau\\)
- Use the episode to estimate the gradient \\(\hat{g} = \nabla_\theta J(\theta)\\)
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_gradient_one.png" alt="Policy Gradient"/>
</figure>
- Update the weights of the policy: \\(\theta \leftarrow \theta + \alpha \hat{g}\\)
We can interpret this update as follows:
- \\(\nabla_\theta log \pi_\theta(a_t|s_t)\\) is the direction of **steepest increase of the (log) probability** of selecting action at from state st.
This tells us **how we should change the weights of policy** if we want to increase/decrease the log probability of selecting action \\(a_t\\) at state \\(s_t\\).
- \\(R(\tau)\\): is the scoring function:
- If the return is high, it will **push up the probabilities** of the (state, action) combinations.
- Otherwise, if the return is low, it will **push down the probabilities** of the (state, action) combinations.
We can also **collect multiple episodes (trajectories)** to estimate the gradient:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_gradient_multiple.png" alt="Policy Gradient"/>
</figure>
| huggingface/deep-rl-class/blob/main/units/en/unit4/policy-gradient.mdx |
Big Transfer (BiT)
**Big Transfer (BiT)** is a type of pretraining recipe that pre-trains on a large supervised source dataset, and fine-tunes the weights on the target task. Models are trained on the JFT-300M dataset. The finetuned models contained in this collection are finetuned on ImageNet.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('resnetv2_101x1_bitm', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `resnetv2_101x1_bitm`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('resnetv2_101x1_bitm', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{kolesnikov2020big,
title={Big Transfer (BiT): General Visual Representation Learning},
author={Alexander Kolesnikov and Lucas Beyer and Xiaohua Zhai and Joan Puigcerver and Jessica Yung and Sylvain Gelly and Neil Houlsby},
year={2020},
eprint={1912.11370},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Big Transfer
Paper:
Title: 'Big Transfer (BiT): General Visual Representation Learning'
URL: https://paperswithcode.com/paper/large-scale-learning-of-general-visual
Models:
- Name: resnetv2_101x1_bitm
In Collection: Big Transfer
Metadata:
FLOPs: 5330896
Parameters: 44540000
File Size: 178256468
Architecture:
- 1x1 Convolution
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Group Normalization
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Weight Standardization
Tasks:
- Image Classification
Training Techniques:
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPUv3-512
ID: resnetv2_101x1_bitm
LR: 0.03
Epochs: 90
Layers: 101
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 4096
Image Size: '480'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/resnetv2.py#L444
Weights: https://storage.googleapis.com/bit_models/BiT-M-R101x1-ILSVRC2012.npz
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.21%
Top 5 Accuracy: 96.47%
- Name: resnetv2_101x3_bitm
In Collection: Big Transfer
Metadata:
FLOPs: 15988688
Parameters: 387930000
File Size: 1551830100
Architecture:
- 1x1 Convolution
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Group Normalization
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Weight Standardization
Tasks:
- Image Classification
Training Techniques:
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPUv3-512
ID: resnetv2_101x3_bitm
LR: 0.03
Epochs: 90
Layers: 101
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 4096
Image Size: '480'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/resnetv2.py#L451
Weights: https://storage.googleapis.com/bit_models/BiT-M-R101x3-ILSVRC2012.npz
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.38%
Top 5 Accuracy: 97.37%
- Name: resnetv2_152x2_bitm
In Collection: Big Transfer
Metadata:
FLOPs: 10659792
Parameters: 236340000
File Size: 945476668
Architecture:
- 1x1 Convolution
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Group Normalization
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Weight Standardization
Tasks:
- Image Classification
Training Techniques:
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
ID: resnetv2_152x2_bitm
Crop Pct: '1.0'
Image Size: '480'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/resnetv2.py#L458
Weights: https://storage.googleapis.com/bit_models/BiT-M-R152x2-ILSVRC2012.npz
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.4%
Top 5 Accuracy: 97.43%
- Name: resnetv2_152x4_bitm
In Collection: Big Transfer
Metadata:
FLOPs: 21317584
Parameters: 936530000
File Size: 3746270104
Architecture:
- 1x1 Convolution
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Group Normalization
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Weight Standardization
Tasks:
- Image Classification
Training Techniques:
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPUv3-512
ID: resnetv2_152x4_bitm
Crop Pct: '1.0'
Image Size: '480'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/resnetv2.py#L465
Weights: https://storage.googleapis.com/bit_models/BiT-M-R152x4-ILSVRC2012.npz
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.95%
Top 5 Accuracy: 97.45%
- Name: resnetv2_50x1_bitm
In Collection: Big Transfer
Metadata:
FLOPs: 5330896
Parameters: 25550000
File Size: 102242668
Architecture:
- 1x1 Convolution
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Group Normalization
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Weight Standardization
Tasks:
- Image Classification
Training Techniques:
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPUv3-512
ID: resnetv2_50x1_bitm
LR: 0.03
Epochs: 90
Layers: 50
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 4096
Image Size: '480'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/resnetv2.py#L430
Weights: https://storage.googleapis.com/bit_models/BiT-M-R50x1-ILSVRC2012.npz
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.19%
Top 5 Accuracy: 95.63%
- Name: resnetv2_50x3_bitm
In Collection: Big Transfer
Metadata:
FLOPs: 15988688
Parameters: 217320000
File Size: 869321580
Architecture:
- 1x1 Convolution
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Group Normalization
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Weight Standardization
Tasks:
- Image Classification
Training Techniques:
- Mixup
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: Cloud TPUv3-512
ID: resnetv2_50x3_bitm
LR: 0.03
Epochs: 90
Layers: 50
Crop Pct: '1.0'
Momentum: 0.9
Batch Size: 4096
Image Size: '480'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/resnetv2.py#L437
Weights: https://storage.googleapis.com/bit_models/BiT-M-R50x3-ILSVRC2012.npz
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.75%
Top 5 Accuracy: 97.12%
--> | huggingface/pytorch-image-models/blob/main/docs/models/big-transfer.md |
Instagram ResNeXt WSL
A **ResNeXt** repeats a [building block](https://paperswithcode.com/method/resnext-block) that aggregates a set of transformations with the same topology. Compared to a [ResNet](https://paperswithcode.com/method/resnet), it exposes a new dimension, *cardinality* (the size of the set of transformations) $C$, as an essential factor in addition to the dimensions of depth and width.
This model was trained on billions of Instagram images using thousands of distinct hashtags as labels exhibit excellent transfer learning performance.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('ig_resnext101_32x16d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ig_resnext101_32x16d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('ig_resnext101_32x16d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{mahajan2018exploring,
title={Exploring the Limits of Weakly Supervised Pretraining},
author={Dhruv Mahajan and Ross Girshick and Vignesh Ramanathan and Kaiming He and Manohar Paluri and Yixuan Li and Ashwin Bharambe and Laurens van der Maaten},
year={2018},
eprint={1805.00932},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: IG ResNeXt
Paper:
Title: Exploring the Limits of Weakly Supervised Pretraining
URL: https://paperswithcode.com/paper/exploring-the-limits-of-weakly-supervised
Models:
- Name: ig_resnext101_32x16d
In Collection: IG ResNeXt
Metadata:
FLOPs: 46623691776
Parameters: 194030000
File Size: 777518664
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x16d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L874
Weights: https://download.pytorch.org/models/ig_resnext101_32x16-c6f796b0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.16%
Top 5 Accuracy: 97.19%
- Name: ig_resnext101_32x32d
In Collection: IG ResNeXt
Metadata:
FLOPs: 112225170432
Parameters: 468530000
File Size: 1876573776
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x32d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Minibatch Size: 8064
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L885
Weights: https://download.pytorch.org/models/ig_resnext101_32x32-e4b90b00.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.09%
Top 5 Accuracy: 97.44%
- Name: ig_resnext101_32x48d
In Collection: IG ResNeXt
Metadata:
FLOPs: 197446554624
Parameters: 828410000
File Size: 3317136976
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x48d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L896
Weights: https://download.pytorch.org/models/ig_resnext101_32x48-3e41cc8a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.42%
Top 5 Accuracy: 97.58%
- Name: ig_resnext101_32x8d
In Collection: IG ResNeXt
Metadata:
FLOPs: 21180417024
Parameters: 88790000
File Size: 356056638
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- IG-3.5B-17k
- ImageNet
Training Resources: 336x GPUs
ID: ig_resnext101_32x8d
Epochs: 100
Layers: 101
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 8064
Image Size: '224'
Weight Decay: 0.001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L863
Weights: https://download.pytorch.org/models/ig_resnext101_32x8-c38310e5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.7%
Top 5 Accuracy: 96.64%
--> | huggingface/pytorch-image-models/blob/main/docs/models/ig-resnext.md |
div align="center">
[<img src="readme_files/gradio.svg" alt="gradio" width=400>](https://gradio.app)<br>
[](https://github.com/gradio-app/gradio/actions/workflows/backend.yml)
[](https://github.com/gradio-app/gradio/actions/workflows/ui.yml)
[](https://pypi.org/project/gradio/)
[](https://pypi.org/project/gradio/)

[](https://twitter.com/gradio)
[Website](https://gradio.app)
| [Documentation](https://gradio.app/docs/)
| [Guides](https://gradio.app/guides/)
| [Getting Started](https://gradio.app/getting_started/)
| [Examples](demo/)
| [中文](readme_files/zh-cn#readme)
</div>
# Gradio: Build Machine Learning Web Apps — in Python
$getting_started
## Questions?
If you'd like to report a bug or have a feature request, please create an [issue on GitHub](https://github.com/gradio-app/gradio/issues/new/choose). For general questions about usage, we are available on [our Discord server](https://discord.com/invite/feTf9x3ZSB) and happy to help.
If you like Gradio, please leave us a ⭐ on GitHub!
## Open Source Stack
Gradio is built on top of many wonderful open-source libraries!
[<img src="readme_files/huggingface_mini.svg" alt="huggingface" height=40>](https://huggingface.co)
[<img src="readme_files/python.svg" alt="python" height=40>](https://www.python.org)
[<img src="readme_files/fastapi.svg" alt="fastapi" height=40>](https://fastapi.tiangolo.com)
[<img src="readme_files/encode.svg" alt="encode" height=40>](https://www.encode.io)
[<img src="readme_files/svelte.svg" alt="svelte" height=40>](https://svelte.dev)
[<img src="readme_files/vite.svg" alt="vite" height=40>](https://vitejs.dev)
[<img src="readme_files/pnpm.svg" alt="pnpm" height=40>](https://pnpm.io)
[<img src="readme_files/tailwind.svg" alt="tailwind" height=40>](https://tailwindcss.com)
[<img src="readme_files/storybook.svg" alt="storybook" height=40>](https://storybook.js.org/)
[<img src="readme_files/chromatic.svg" alt="chromatic" height=40>](https://www.chromatic.com/)
## License
Gradio is licensed under the Apache License 2.0 found in the [LICENSE](LICENSE) file in the root directory of this repository.
## Citation
Also check out the paper _[Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild](https://arxiv.org/abs/1906.02569), ICML HILL 2019_, and please cite it if you use Gradio in your work.
```
@article{abid2019gradio,
title = {Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild},
author = {Abid, Abubakar and Abdalla, Ali and Abid, Ali and Khan, Dawood and Alfozan, Abdulrahman and Zou, James},
journal = {arXiv preprint arXiv:1906.02569},
year = {2019},
}
```
| gradio-app/gradio/blob/main/readme_template.md |
libapi
A Python library for the API services
## Configuration
The APIs can be configured using environment variables. They are grouped by scope.
### API service
Set environment variables to configure the application (`API_` prefix):
- `API_HF_AUTH_PATH`: the path of the external authentication service, on the hub (see `HF_ENDPOINT`). The string must contain `%s` which will be replaced with the dataset name. The external authentication service must return 200, 401, 403 or 404. Defaults to "/api/datasets/%s/auth-check".
- `API_HF_JWT_PUBLIC_KEY_URL`: the URL where the "Hub JWT public key" is published. The "Hub JWT public key" must be in JWK format. It helps to decode a JWT sent by the Hugging Face Hub, for example, to bypass the external authentication check (JWT in the 'Authorization' header). If not set, the JWT is ignored. Defaults to empty.
- `API_HF_JWT_ADDITIONAL_PUBLIC_KEYS`: a comma-separated list of additional public keys to use to decode the JWT sent by the Hugging Face Hub. The public keys must be in PEM format and include "\n" for line breaks ("-----BEGIN PUBLIC KEY-----\n....\n-----END PUBLIC KEY-----\n"). Defaults to empty.
- `API_HF_JWT_ALGORITHM`: the algorithm used to encode the JWT. Defaults to `"EdDSA"`.
- `API_HF_TIMEOUT_SECONDS`: the timeout in seconds for the requests to the Hugging Face Hub. Defaults to `0.2` (200 ms).
- `API_HF_WEBHOOK_SECRET`: a shared secret sent by the Hub in the "X-Webhook-Secret" header of POST requests sent to /webhook, to authenticate the originator and bypass some validation of the content (avoiding roundtrip to the Hub). If not set, all the validations are done. Defaults to empty.
- `API_MAX_AGE_LONG`: number of seconds to set in the `max-age` header on data endpoints. Defaults to `120` (2 minutes).
- `API_MAX_AGE_SHORT`: number of seconds to set in the `max-age` header on technical endpoints. Defaults to `10` (10 seconds).
### Uvicorn
The following environment variables are used to configure the Uvicorn server (`API_UVICORN_` prefix):
- `API_UVICORN_HOSTNAME`: the hostname. Defaults to `"localhost"`.
- `API_UVICORN_NUM_WORKERS`: the number of uvicorn workers. Defaults to `2`.
- `API_UVICORN_PORT`: the port. Defaults to `8000`.
### Prometheus
- `PROMETHEUS_MULTIPROC_DIR`: the directory where the uvicorn workers share their prometheus metrics. See https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn. Defaults to empty, in which case every worker manages its own metrics, and the /metrics endpoint returns the metrics of a random worker.
| huggingface/datasets-server/blob/main/libs/libapi/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Load pretrained instances with an AutoClass
With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an `AutoClass` automatically infers and loads the correct architecture from a given checkpoint. The `from_pretrained()` method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
<Tip>
Remember, architecture refers to the skeleton of the model and checkpoints are the weights for a given architecture. For example, [BERT](https://huggingface.co/bert-base-uncased) is an architecture, while `bert-base-uncased` is a checkpoint. Model is a general term that can mean either architecture or checkpoint.
</Tip>
In this tutorial, learn to:
* Load a pretrained tokenizer.
* Load a pretrained image processor
* Load a pretrained feature extractor.
* Load a pretrained processor.
* Load a pretrained model.
* Load a model as a backbone.
## AutoTokenizer
Nearly every NLP task begins with a tokenizer. A tokenizer converts your input into a format that can be processed by the model.
Load a tokenizer with [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
Then tokenize your input as shown below:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoImageProcessor
For vision tasks, an image processor processes the image into the correct input format.
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
## AutoFeatureExtractor
For audio tasks, a feature extractor processes the audio signal the correct input format.
Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires an image processor to handle images and a tokenizer to handle text; a processor combines both of them.
Load a processor with [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
The `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Easily reuse the same checkpoint to load an architecture for a different task:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
<Tip warning={true}>
For PyTorch models, the `from_pretrained()` method uses `torch.load()` which internally uses `pickle` and is known to be insecure. In general, never load a model that could have come from an untrusted source, or that could have been tampered with. This security risk is partially mitigated for public models hosted on the Hugging Face Hub, which are [scanned for malware](https://huggingface.co/docs/hub/security-malware) at each commit. See the [Hub documentation](https://huggingface.co/docs/hub/security) for best practices like [signed commit verification](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg) with GPG.
TensorFlow and Flax checkpoints are not affected, and can be loaded within PyTorch architectures using the `from_tf` and `from_flax` kwargs for the `from_pretrained` method to circumvent this issue.
</Tip>
Generally, we recommend using the `AutoTokenizer` class and the `AutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
</pt>
<tf>
Finally, the `TFAutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`TFAutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Easily reuse the same checkpoint to load an architecture for a different task:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
</tf>
</frameworkcontent>
## AutoBackbone
`AutoBackbone` lets you use pretrained models as backbones and get feature maps as outputs from different stages of the models. Below you can see how to get feature maps from a [Swin](model_doc/swin) checkpoint.
```py
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(0,))
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_maps
>>> list(feature_maps[-1].shape)
[1, 96, 56, 56]
```
| huggingface/transformers/blob/main/docs/source/en/autoclass_tutorial.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Masked language modeling
[[open-in-colab]]
<Youtube id="mqElG5QJWUg"/>
Masked language modeling predicts a masked token in a sequence, and the model can attend to tokens bidirectionally. This
means the model has full access to the tokens on the left and right. Masked language modeling is great for tasks that
require a good contextual understanding of an entire sequence. BERT is an example of a masked language model.
This guide will show you how to:
1. Finetune [DistilRoBERTa](https://huggingface.co/distilroberta-base) on the [r/askscience](https://www.reddit.com/r/askscience/) subset of the [ELI5](https://huggingface.co/datasets/eli5) dataset.
2. Use your finetuned model for inference.
<Tip>
You can finetune other architectures for masked language modeling following the same steps in this guide.
Choose one of the following architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [CamemBERT](../model_doc/camembert), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ESM](../model_doc/esm), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [Perceiver](../model_doc/perceiver), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [TAPAS](../model_doc/tapas), [Wav2Vec2](../model_doc/wav2vec2), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load ELI5 dataset
Start by loading a smaller subset of the r/askscience subset of the ELI5 dataset from the 🤗 Datasets library. This'll
give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
```
Split the dataset's `train_asks` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
```py
>>> eli5 = eli5.train_test_split(test_size=0.2)
```
Then take a look at an example:
```py
>>> eli5["train"][0]
{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
'score': [6, 3],
'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
'answers_urls': {'url': []},
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls': {'url': []}}
```
While this may look like a lot, you're only really interested in the `text` field. What's cool about language modeling tasks is you don't need labels (also known as an unsupervised task) because the next word *is* the label.
## Preprocess
<Youtube id="8PmhEIXhBvI"/>
For masked language modeling, the next step is to load a DistilRoBERTa tokenizer to process the `text` subfield:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to e
xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'answers.a_id': ['c3d1aib', 'c3d4lya'],
'answers.score': [6, 3],
'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
'answers_urls.url': [],
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls.url': []}
```
Each subfield is now a separate column as indicated by the `answers` prefix, and the `text` field is a list now. Instead
of tokenizing each sentence separately, convert the list to a string so you can jointly tokenize them.
Here is a first preprocessing function to join the list of strings for each example and tokenize the result:
```py
>>> def preprocess_function(examples):
... return tokenizer([" ".join(x) for x in examples["answers.text"]])
```
To apply this preprocessing function over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once, and increasing the number of processes with `num_proc`. Remove any columns you don't need:
```py
>>> tokenized_eli5 = eli5.map(
... preprocess_function,
... batched=True,
... num_proc=4,
... remove_columns=eli5["train"].column_names,
... )
```
This dataset contains the token sequences, but some of these are longer than the maximum input length for the model.
You can now use a second preprocessing function to
- concatenate all the sequences
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
```py
>>> block_size = 128
>>> def group_texts(examples):
... # Concatenate all texts.
... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
... total_length = len(concatenated_examples[list(examples.keys())[0]])
... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
... # customize this part to your needs.
... if total_length >= block_size:
... total_length = (total_length // block_size) * block_size
... # Split by chunks of block_size.
... result = {
... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
... for k, t in concatenated_examples.items()
... }
... return result
```
Apply the `group_texts` function over the entire dataset:
```py
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
```
Now create a batch of examples using [`DataCollatorForLanguageModeling`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
<frameworkcontent>
<pt>
Use the end-of-sequence token as the padding token and specify `mlm_probability` to randomly mask tokens each time you iterate over the data:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
```
</pt>
<tf>
Use the end-of-sequence token as the padding token and specify `mlm_probability` to randomly mask tokens each time you iterate over the data:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load DistilRoBERTa with [`AutoModelForMaskedLM`]:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("distilroberta-base")
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_eli5_mlm_model",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... num_train_epochs=3,
... weight_decay=0.01,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=lm_dataset["train"],
... eval_dataset=lm_dataset["test"],
... data_collator=data_collator,
... )
>>> trainer.train()
```
Once training is completed, use the [`~transformers.Trainer.evaluate`] method to evaluate your model and get its perplexity:
```py
>>> import math
>>> eval_results = trainer.evaluate()
>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 8.76
```
Then share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Then you can load DistilRoBERTa with [`TFAutoModelForMaskedLM`]:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("distilroberta-base")
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... lm_dataset["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = model.prepare_tf_dataset(
... lm_dataset["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
... output_dir="my_awesome_eli5_mlm_model",
... tokenizer=tokenizer,
... )
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for masked language modeling, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text you'd like the model to fill in the blank with, and use the special `<mask>` token to indicate the blank:
```py
>>> text = "The Milky Way is a <mask> galaxy."
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for fill-mask with your model, and pass your text to it. If you like, you can use the `top_k` parameter to specify how many predictions to return:
```py
>>> from transformers import pipeline
>>> mask_filler = pipeline("fill-mask", "stevhliu/my_awesome_eli5_mlm_model")
>>> mask_filler(text, top_k=3)
[{'score': 0.5150994658470154,
'token': 21300,
'token_str': ' spiral',
'sequence': 'The Milky Way is a spiral galaxy.'},
{'score': 0.07087188959121704,
'token': 2232,
'token_str': ' massive',
'sequence': 'The Milky Way is a massive galaxy.'},
{'score': 0.06434620916843414,
'token': 650,
'token_str': ' small',
'sequence': 'The Milky Way is a small galaxy.'}]
```
<frameworkcontent>
<pt>
Tokenize the text and return the `input_ids` as PyTorch tensors. You'll also need to specify the position of the `<mask>` token:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="pt")
>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
```
Pass your inputs to the model and return the `logits` of the masked token:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
```
Then return the three masked tokens with the highest probability and print them out:
```py
>>> top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
>>> for token in top_3_tokens:
... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
```
</pt>
<tf>
Tokenize the text and return the `input_ids` as TensorFlow tensors. You'll also need to specify the position of the `<mask>` token:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="tf")
>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
```
Pass your inputs to the model and return the `logits` of the masked token:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
```
Then return the three masked tokens with the highest probability and print them out:
```py
>>> top_3_tokens = tf.math.top_k(mask_token_logits, 3).indices.numpy()
>>> for token in top_3_tokens:
... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
```
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/tasks/masked_language_modeling.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UL2
## Overview
The T5 model was presented in [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
The abstract from the paper is the following:
*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
## Usage tips
- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
<Tip>
As UL2 has the same architecture as T5v1.1, refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
</Tip>
| huggingface/transformers/blob/main/docs/source/en/model_doc/ul2.md |
Gradio Demo: theme_new_step_3
```
!pip install -q gradio
```
```
from __future__ import annotations
from typing import Iterable
import gradio as gr
from gradio.themes.base import Base
from gradio.themes.utils import colors, fonts, sizes
import time
class Seafoam(Base):
def __init__(
self,
*,
primary_hue: colors.Color | str = colors.emerald,
secondary_hue: colors.Color | str = colors.blue,
neutral_hue: colors.Color | str = colors.blue,
spacing_size: sizes.Size | str = sizes.spacing_md,
radius_size: sizes.Size | str = sizes.radius_md,
text_size: sizes.Size | str = sizes.text_lg,
font: fonts.Font
| str
| Iterable[fonts.Font | str] = (
fonts.GoogleFont("Quicksand"),
"ui-sans-serif",
"sans-serif",
),
font_mono: fonts.Font
| str
| Iterable[fonts.Font | str] = (
fonts.GoogleFont("IBM Plex Mono"),
"ui-monospace",
"monospace",
),
):
super().__init__(
primary_hue=primary_hue,
secondary_hue=secondary_hue,
neutral_hue=neutral_hue,
spacing_size=spacing_size,
radius_size=radius_size,
text_size=text_size,
font=font,
font_mono=font_mono,
)
super().set(
body_background_fill="repeating-linear-gradient(45deg, *primary_200, *primary_200 10px, *primary_50 10px, *primary_50 20px)",
body_background_fill_dark="repeating-linear-gradient(45deg, *primary_800, *primary_800 10px, *primary_900 10px, *primary_900 20px)",
button_primary_background_fill="linear-gradient(90deg, *primary_300, *secondary_400)",
button_primary_background_fill_hover="linear-gradient(90deg, *primary_200, *secondary_300)",
button_primary_text_color="white",
button_primary_background_fill_dark="linear-gradient(90deg, *primary_600, *secondary_800)",
slider_color="*secondary_300",
slider_color_dark="*secondary_600",
block_title_text_weight="600",
block_border_width="3px",
block_shadow="*shadow_drop_lg",
button_shadow="*shadow_drop_lg",
button_large_padding="32px",
)
seafoam = Seafoam()
with gr.Blocks(theme=seafoam) as demo:
textbox = gr.Textbox(label="Name")
slider = gr.Slider(label="Count", minimum=0, maximum=100, step=1)
with gr.Row():
button = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Output")
def repeat(name, count):
time.sleep(3)
return name * count
button.click(repeat, [textbox, slider], output)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/theme_new_step_3/run.ipynb |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Testing
Let's take a look at how 🤗 Transformers models are tested and how you can write new tests and improve the existing ones.
There are 2 test suites in the repository:
1. `tests` -- tests for the general API
2. `examples` -- tests primarily for various applications that aren't part of the API
## How transformers are tested
1. Once a PR is submitted it gets tested with 9 CircleCi jobs. Every new commit to that PR gets retested. These jobs
are defined in this [config file](https://github.com/huggingface/transformers/tree/main/.circleci/config.yml), so that if needed you can reproduce the same
environment on your machine.
These CI jobs don't run `@slow` tests.
2. There are 3 jobs run by [github actions](https://github.com/huggingface/transformers/actions):
- [torch hub integration](https://github.com/huggingface/transformers/tree/main/.github/workflows/github-torch-hub.yml): checks whether torch hub
integration works.
- [self-hosted (push)](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-push.yml): runs fast tests on GPU only on commits on
`main`. It only runs if a commit on `main` has updated the code in one of the following folders: `src`,
`tests`, `.github` (to prevent running on added model cards, notebooks, etc.)
- [self-hosted runner](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-scheduled.yml): runs normal and slow tests on GPU in
`tests` and `examples`:
```bash
RUN_SLOW=1 pytest tests/
RUN_SLOW=1 pytest examples/
```
The results can be observed [here](https://github.com/huggingface/transformers/actions).
## Running tests
### Choosing which tests to run
This document goes into many details of how tests can be run. If after reading everything, you need even more details
you will find them [here](https://docs.pytest.org/en/latest/usage.html).
Here are some most useful ways of running tests.
Run all:
```console
pytest
```
or:
```bash
make test
```
Note that the latter is defined as:
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/
```
which tells pytest to:
- run as many test processes as they are CPU cores (which could be too many if you don't have a ton of RAM!)
- ensure that all tests from the same file will be run by the same test process
- do not capture output
- run in verbose mode
### Getting the list of all tests
All tests of the test suite:
```bash
pytest --collect-only -q
```
All tests of a given test file:
```bash
pytest tests/test_optimization.py --collect-only -q
```
### Run a specific test module
To run an individual test module:
```bash
pytest tests/utils/test_logging.py
```
### Run specific tests
Since unittest is used inside most of the tests, to run specific subtests you need to know the name of the unittest
class containing those tests. For example, it could be:
```bash
pytest tests/test_optimization.py::OptimizationTest::test_adam_w
```
Here:
- `tests/test_optimization.py` - the file with tests
- `OptimizationTest` - the name of the class
- `test_adam_w` - the name of the specific test function
If the file contains multiple classes, you can choose to run only tests of a given class. For example:
```bash
pytest tests/test_optimization.py::OptimizationTest
```
will run all the tests inside that class.
As mentioned earlier you can see what tests are contained inside the `OptimizationTest` class by running:
```bash
pytest tests/test_optimization.py::OptimizationTest --collect-only -q
```
You can run tests by keyword expressions.
To run only tests whose name contains `adam`:
```bash
pytest -k adam tests/test_optimization.py
```
Logical `and` and `or` can be used to indicate whether all keywords should match or either. `not` can be used to
negate.
To run all tests except those whose name contains `adam`:
```bash
pytest -k "not adam" tests/test_optimization.py
```
And you can combine the two patterns in one:
```bash
pytest -k "ada and not adam" tests/test_optimization.py
```
For example to run both `test_adafactor` and `test_adam_w` you can use:
```bash
pytest -k "test_adam_w or test_adam_w" tests/test_optimization.py
```
Note that we use `or` here, since we want either of the keywords to match to include both.
If you want to include only tests that include both patterns, `and` is to be used:
```bash
pytest -k "test and ada" tests/test_optimization.py
```
### Run `accelerate` tests
Sometimes you need to run `accelerate` tests on your models. For that you can just add `-m accelerate_tests` to your command, if let's say you want to run these tests on `OPT` run:
```bash
RUN_SLOW=1 pytest -m accelerate_tests tests/models/opt/test_modeling_opt.py
```
### Run documentation tests
In order to test whether the documentation examples are correct, you should check that the `doctests` are passing.
As an example, let's use [`WhisperModel.forward`'s docstring](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py#L1017-L1035):
```python
r"""
Returns:
Example:
```python
>>> import torch
>>> from transformers import WhisperModel, WhisperFeatureExtractor
>>> from datasets import load_dataset
>>> model = WhisperModel.from_pretrained("openai/whisper-base")
>>> feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-base")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
>>> input_features = inputs.input_features
>>> decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
>>> last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
>>> list(last_hidden_state.shape)
[1, 2, 512]
```"""
```
Just run the following line to automatically test every docstring example in the desired file:
```bash
pytest --doctest-modules <path_to_file_or_dir>
```
If the file has a markdown extention, you should add the `--doctest-glob="*.md"` argument.
### Run only modified tests
You can run the tests related to the unstaged files or the current branch (according to Git) by using [pytest-picked](https://github.com/anapaulagomes/pytest-picked). This is a great way of quickly testing your changes didn't break
anything, since it won't run the tests related to files you didn't touch.
```bash
pip install pytest-picked
```
```bash
pytest --picked
```
All tests will be run from files and folders which are modified, but not yet committed.
### Automatically rerun failed tests on source modification
[pytest-xdist](https://github.com/pytest-dev/pytest-xdist) provides a very useful feature of detecting all failed
tests, and then waiting for you to modify files and continuously re-rerun those failing tests until they pass while you
fix them. So that you don't need to re start pytest after you made the fix. This is repeated until all tests pass after
which again a full run is performed.
```bash
pip install pytest-xdist
```
To enter the mode: `pytest -f` or `pytest --looponfail`
File changes are detected by looking at `looponfailroots` root directories and all of their contents (recursively).
If the default for this value does not work for you, you can change it in your project by setting a configuration
option in `setup.cfg`:
```ini
[tool:pytest]
looponfailroots = transformers tests
```
or `pytest.ini`/``tox.ini`` files:
```ini
[pytest]
looponfailroots = transformers tests
```
This would lead to only looking for file changes in the respective directories, specified relatively to the ini-file’s
directory.
[pytest-watch](https://github.com/joeyespo/pytest-watch) is an alternative implementation of this functionality.
### Skip a test module
If you want to run all test modules, except a few you can exclude them by giving an explicit list of tests to run. For
example, to run all except `test_modeling_*.py` tests:
```bash
pytest *ls -1 tests/*py | grep -v test_modeling*
```
### Clearing state
CI builds and when isolation is important (against speed), cache should be cleared:
```bash
pytest --cache-clear tests
```
### Running tests in parallel
As mentioned earlier `make test` runs tests in parallel via `pytest-xdist` plugin (`-n X` argument, e.g. `-n 2`
to run 2 parallel jobs).
`pytest-xdist`'s `--dist=` option allows one to control how the tests are grouped. `--dist=loadfile` puts the
tests located in one file onto the same process.
Since the order of executed tests is different and unpredictable, if running the test suite with `pytest-xdist`
produces failures (meaning we have some undetected coupled tests), use [pytest-replay](https://github.com/ESSS/pytest-replay) to replay the tests in the same order, which should help with then somehow
reducing that failing sequence to a minimum.
### Test order and repetition
It's good to repeat the tests several times, in sequence, randomly, or in sets, to detect any potential
inter-dependency and state-related bugs (tear down). And the straightforward multiple repetition is just good to detect
some problems that get uncovered by randomness of DL.
#### Repeat tests
- [pytest-flakefinder](https://github.com/dropbox/pytest-flakefinder):
```bash
pip install pytest-flakefinder
```
And then run every test multiple times (50 by default):
```bash
pytest --flake-finder --flake-runs=5 tests/test_failing_test.py
```
<Tip>
This plugin doesn't work with `-n` flag from `pytest-xdist`.
</Tip>
<Tip>
There is another plugin `pytest-repeat`, but it doesn't work with `unittest`.
</Tip>
#### Run tests in a random order
```bash
pip install pytest-random-order
```
Important: the presence of `pytest-random-order` will automatically randomize tests, no configuration change or
command line options is required.
As explained earlier this allows detection of coupled tests - where one test's state affects the state of another. When
`pytest-random-order` is installed it will print the random seed it used for that session, e.g:
```bash
pytest tests
[...]
Using --random-order-bucket=module
Using --random-order-seed=573663
```
So that if the given particular sequence fails, you can reproduce it by adding that exact seed, e.g.:
```bash
pytest --random-order-seed=573663
[...]
Using --random-order-bucket=module
Using --random-order-seed=573663
```
It will only reproduce the exact order if you use the exact same list of tests (or no list at all). Once you start to
manually narrowing down the list you can no longer rely on the seed, but have to list them manually in the exact order
they failed and tell pytest to not randomize them instead using `--random-order-bucket=none`, e.g.:
```bash
pytest --random-order-bucket=none tests/test_a.py tests/test_c.py tests/test_b.py
```
To disable the shuffling for all tests:
```bash
pytest --random-order-bucket=none
```
By default `--random-order-bucket=module` is implied, which will shuffle the files on the module levels. It can also
shuffle on `class`, `package`, `global` and `none` levels. For the complete details please see its
[documentation](https://github.com/jbasko/pytest-random-order).
Another randomization alternative is: [`pytest-randomly`](https://github.com/pytest-dev/pytest-randomly). This
module has a very similar functionality/interface, but it doesn't have the bucket modes available in
`pytest-random-order`. It has the same problem of imposing itself once installed.
### Look and feel variations
#### pytest-sugar
[pytest-sugar](https://github.com/Frozenball/pytest-sugar) is a plugin that improves the look-n-feel, adds a
progressbar, and show tests that fail and the assert instantly. It gets activated automatically upon installation.
```bash
pip install pytest-sugar
```
To run tests without it, run:
```bash
pytest -p no:sugar
```
or uninstall it.
#### Report each sub-test name and its progress
For a single or a group of tests via `pytest` (after `pip install pytest-pspec`):
```bash
pytest --pspec tests/test_optimization.py
```
#### Instantly shows failed tests
[pytest-instafail](https://github.com/pytest-dev/pytest-instafail) shows failures and errors instantly instead of
waiting until the end of test session.
```bash
pip install pytest-instafail
```
```bash
pytest --instafail
```
### To GPU or not to GPU
On a GPU-enabled setup, to test in CPU-only mode add `CUDA_VISIBLE_DEVICES=""`:
```bash
CUDA_VISIBLE_DEVICES="" pytest tests/utils/test_logging.py
```
or if you have multiple gpus, you can specify which one is to be used by `pytest`. For example, to use only the
second gpu if you have gpus `0` and `1`, you can run:
```bash
CUDA_VISIBLE_DEVICES="1" pytest tests/utils/test_logging.py
```
This is handy when you want to run different tasks on different GPUs.
Some tests must be run on CPU-only, others on either CPU or GPU or TPU, yet others on multiple-GPUs. The following skip
decorators are used to set the requirements of tests CPU/GPU/TPU-wise:
- `require_torch` - this test will run only under torch
- `require_torch_gpu` - as `require_torch` plus requires at least 1 GPU
- `require_torch_multi_gpu` - as `require_torch` plus requires at least 2 GPUs
- `require_torch_non_multi_gpu` - as `require_torch` plus requires 0 or 1 GPUs
- `require_torch_up_to_2_gpus` - as `require_torch` plus requires 0 or 1 or 2 GPUs
- `require_torch_tpu` - as `require_torch` plus requires at least 1 TPU
Let's depict the GPU requirements in the following table:
| n gpus | decorator |
|--------+--------------------------------|
| `>= 0` | `@require_torch` |
| `>= 1` | `@require_torch_gpu` |
| `>= 2` | `@require_torch_multi_gpu` |
| `< 2` | `@require_torch_non_multi_gpu` |
| `< 3` | `@require_torch_up_to_2_gpus` |
For example, here is a test that must be run only when there are 2 or more GPUs available and pytorch is installed:
```python no-style
@require_torch_multi_gpu
def test_example_with_multi_gpu():
```
If a test requires `tensorflow` use the `require_tf` decorator. For example:
```python no-style
@require_tf
def test_tf_thing_with_tensorflow():
```
These decorators can be stacked. For example, if a test is slow and requires at least one GPU under pytorch, here is
how to set it up:
```python no-style
@require_torch_gpu
@slow
def test_example_slow_on_gpu():
```
Some decorators like `@parametrized` rewrite test names, therefore `@require_*` skip decorators have to be listed
last for them to work correctly. Here is an example of the correct usage:
```python no-style
@parameterized.expand(...)
@require_torch_multi_gpu
def test_integration_foo():
```
This order problem doesn't exist with `@pytest.mark.parametrize`, you can put it first or last and it will still
work. But it only works with non-unittests.
Inside tests:
- How many GPUs are available:
```python
from transformers.testing_utils import get_gpu_count
n_gpu = get_gpu_count() # works with torch and tf
```
### Testing with a specific PyTorch backend or device
To run the test suite on a specific torch device add `TRANSFORMERS_TEST_DEVICE="$device"` where `$device` is the target backend. For example, to test on CPU only:
```bash
TRANSFORMERS_TEST_DEVICE="cpu" pytest tests/utils/test_logging.py
```
This variable is useful for testing custom or less common PyTorch backends such as `mps`. It can also be used to achieve the same effect as `CUDA_VISIBLE_DEVICES` by targeting specific GPUs or testing in CPU-only mode.
Certain devices will require an additional import after importing `torch` for the first time. This can be specified using the environment variable `TRANSFORMERS_TEST_BACKEND`:
```bash
TRANSFORMERS_TEST_BACKEND="torch_npu" pytest tests/utils/test_logging.py
```
Alternative backends may also require the replacement of device-specific functions. For example `torch.cuda.manual_seed` may need to be replaced with a device-specific seed setter like `torch.npu.manual_seed` to correctly set a random seed on the device. To specify a new backend with backend-specific device functions when running the test suite, create a Python device specification file in the format:
```
import torch
import torch_npu
# !! Further additional imports can be added here !!
# Specify the device name (eg. 'cuda', 'cpu', 'npu')
DEVICE_NAME = 'npu'
# Specify device-specific backends to dispatch to.
# If not specified, will fallback to 'default' in 'testing_utils.py`
MANUAL_SEED_FN = torch.npu.manual_seed
EMPTY_CACHE_FN = torch.npu.empty_cache
DEVICE_COUNT_FN = torch.npu.device_count
```
This format also allows for specification of any additional imports required. To use this file to replace equivalent methods in the test suite, set the environment variable `TRANSFORMERS_TEST_DEVICE_SPEC` to the path of the spec file.
Currently, only `MANUAL_SEED_FN`, `EMPTY_CACHE_FN` and `DEVICE_COUNT_FN` are supported for device-specific dispatch.
### Distributed training
`pytest` can't deal with distributed training directly. If this is attempted - the sub-processes don't do the right
thing and end up thinking they are `pytest` and start running the test suite in loops. It works, however, if one
spawns a normal process that then spawns off multiple workers and manages the IO pipes.
Here are some tests that use it:
- [test_trainer_distributed.py](https://github.com/huggingface/transformers/tree/main/tests/trainer/test_trainer_distributed.py)
- [test_deepspeed.py](https://github.com/huggingface/transformers/tree/main/tests/deepspeed/test_deepspeed.py)
To jump right into the execution point, search for the `execute_subprocess_async` call in those tests.
You will need at least 2 GPUs to see these tests in action:
```bash
CUDA_VISIBLE_DEVICES=0,1 RUN_SLOW=1 pytest -sv tests/test_trainer_distributed.py
```
### Output capture
During test execution any output sent to `stdout` and `stderr` is captured. If a test or a setup method fails, its
according captured output will usually be shown along with the failure traceback.
To disable output capturing and to get the `stdout` and `stderr` normally, use `-s` or `--capture=no`:
```bash
pytest -s tests/utils/test_logging.py
```
To send test results to JUnit format output:
```bash
py.test tests --junitxml=result.xml
```
### Color control
To have no color (e.g., yellow on white background is not readable):
```bash
pytest --color=no tests/utils/test_logging.py
```
### Sending test report to online pastebin service
Creating a URL for each test failure:
```bash
pytest --pastebin=failed tests/utils/test_logging.py
```
This will submit test run information to a remote Paste service and provide a URL for each failure. You may select
tests as usual or add for example -x if you only want to send one particular failure.
Creating a URL for a whole test session log:
```bash
pytest --pastebin=all tests/utils/test_logging.py
```
## Writing tests
🤗 transformers tests are based on `unittest`, but run by `pytest`, so most of the time features from both systems
can be used.
You can read [here](https://docs.pytest.org/en/stable/unittest.html) which features are supported, but the important
thing to remember is that most `pytest` fixtures don't work. Neither parametrization, but we use the module
`parameterized` that works in a similar way.
### Parametrization
Often, there is a need to run the same test multiple times, but with different arguments. It could be done from within
the test, but then there is no way of running that test for just one set of arguments.
```python
# test_this1.py
import unittest
from parameterized import parameterized
class TestMathUnitTest(unittest.TestCase):
@parameterized.expand(
[
("negative", -1.5, -2.0),
("integer", 1, 1.0),
("large fraction", 1.6, 1),
]
)
def test_floor(self, name, input, expected):
assert_equal(math.floor(input), expected)
```
Now, by default this test will be run 3 times, each time with the last 3 arguments of `test_floor` being assigned the
corresponding arguments in the parameter list.
and you could run just the `negative` and `integer` sets of params with:
```bash
pytest -k "negative and integer" tests/test_mytest.py
```
or all but `negative` sub-tests, with:
```bash
pytest -k "not negative" tests/test_mytest.py
```
Besides using the `-k` filter that was just mentioned, you can find out the exact name of each sub-test and run any
or all of them using their exact names.
```bash
pytest test_this1.py --collect-only -q
```
and it will list:
```bash
test_this1.py::TestMathUnitTest::test_floor_0_negative
test_this1.py::TestMathUnitTest::test_floor_1_integer
test_this1.py::TestMathUnitTest::test_floor_2_large_fraction
```
So now you can run just 2 specific sub-tests:
```bash
pytest test_this1.py::TestMathUnitTest::test_floor_0_negative test_this1.py::TestMathUnitTest::test_floor_1_integer
```
The module [parameterized](https://pypi.org/project/parameterized/) which is already in the developer dependencies
of `transformers` works for both: `unittests` and `pytest` tests.
If, however, the test is not a `unittest`, you may use `pytest.mark.parametrize` (or you may see it being used in
some existing tests, mostly under `examples`).
Here is the same example, this time using `pytest`'s `parametrize` marker:
```python
# test_this2.py
import pytest
@pytest.mark.parametrize(
"name, input, expected",
[
("negative", -1.5, -2.0),
("integer", 1, 1.0),
("large fraction", 1.6, 1),
],
)
def test_floor(name, input, expected):
assert_equal(math.floor(input), expected)
```
Same as with `parameterized`, with `pytest.mark.parametrize` you can have a fine control over which sub-tests are
run, if the `-k` filter doesn't do the job. Except, this parametrization function creates a slightly different set of
names for the sub-tests. Here is what they look like:
```bash
pytest test_this2.py --collect-only -q
```
and it will list:
```bash
test_this2.py::test_floor[integer-1-1.0]
test_this2.py::test_floor[negative--1.5--2.0]
test_this2.py::test_floor[large fraction-1.6-1]
```
So now you can run just the specific test:
```bash
pytest test_this2.py::test_floor[negative--1.5--2.0] test_this2.py::test_floor[integer-1-1.0]
```
as in the previous example.
### Files and directories
In tests often we need to know where things are relative to the current test file, and it's not trivial since the test
could be invoked from more than one directory or could reside in sub-directories with different depths. A helper class
`transformers.test_utils.TestCasePlus` solves this problem by sorting out all the basic paths and provides easy
accessors to them:
- `pathlib` objects (all fully resolved):
- `test_file_path` - the current test file path, i.e. `__file__`
- `test_file_dir` - the directory containing the current test file
- `tests_dir` - the directory of the `tests` test suite
- `examples_dir` - the directory of the `examples` test suite
- `repo_root_dir` - the directory of the repository
- `src_dir` - the directory of `src` (i.e. where the `transformers` sub-dir resides)
- stringified paths---same as above but these return paths as strings, rather than `pathlib` objects:
- `test_file_path_str`
- `test_file_dir_str`
- `tests_dir_str`
- `examples_dir_str`
- `repo_root_dir_str`
- `src_dir_str`
To start using those all you need is to make sure that the test resides in a subclass of
`transformers.test_utils.TestCasePlus`. For example:
```python
from transformers.testing_utils import TestCasePlus
class PathExampleTest(TestCasePlus):
def test_something_involving_local_locations(self):
data_dir = self.tests_dir / "fixtures/tests_samples/wmt_en_ro"
```
If you don't need to manipulate paths via `pathlib` or you just need a path as a string, you can always invoked
`str()` on the `pathlib` object or use the accessors ending with `_str`. For example:
```python
from transformers.testing_utils import TestCasePlus
class PathExampleTest(TestCasePlus):
def test_something_involving_stringified_locations(self):
examples_dir = self.examples_dir_str
```
### Temporary files and directories
Using unique temporary files and directories are essential for parallel test running, so that the tests won't overwrite
each other's data. Also we want to get the temporary files and directories removed at the end of each test that created
them. Therefore, using packages like `tempfile`, which address these needs is essential.
However, when debugging tests, you need to be able to see what goes into the temporary file or directory and you want
to know it's exact path and not having it randomized on every test re-run.
A helper class `transformers.test_utils.TestCasePlus` is best used for such purposes. It's a sub-class of
`unittest.TestCase`, so we can easily inherit from it in the test modules.
Here is an example of its usage:
```python
from transformers.testing_utils import TestCasePlus
class ExamplesTests(TestCasePlus):
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir()
```
This code creates a unique temporary directory, and sets `tmp_dir` to its location.
- Create a unique temporary dir:
```python
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir()
```
`tmp_dir` will contain the path to the created temporary dir. It will be automatically removed at the end of the
test.
- Create a temporary dir of my choice, ensure it's empty before the test starts and don't empty it after the test.
```python
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir("./xxx")
```
This is useful for debug when you want to monitor a specific directory and want to make sure the previous tests didn't
leave any data in there.
- You can override the default behavior by directly overriding the `before` and `after` args, leading to one of the
following behaviors:
- `before=True`: the temporary dir will always be cleared at the beginning of the test.
- `before=False`: if the temporary dir already existed, any existing files will remain there.
- `after=True`: the temporary dir will always be deleted at the end of the test.
- `after=False`: the temporary dir will always be left intact at the end of the test.
<Tip>
In order to run the equivalent of `rm -r` safely, only subdirs of the project repository checkout are allowed if
an explicit `tmp_dir` is used, so that by mistake no `/tmp` or similar important part of the filesystem will
get nuked. i.e. please always pass paths that start with `./`.
</Tip>
<Tip>
Each test can register multiple temporary directories and they all will get auto-removed, unless requested
otherwise.
</Tip>
### Temporary sys.path override
If you need to temporary override `sys.path` to import from another test for example, you can use the
`ExtendSysPath` context manager. Example:
```python
import os
from transformers.testing_utils import ExtendSysPath
bindir = os.path.abspath(os.path.dirname(__file__))
with ExtendSysPath(f"{bindir}/.."):
from test_trainer import TrainerIntegrationCommon # noqa
```
### Skipping tests
This is useful when a bug is found and a new test is written, yet the bug is not fixed yet. In order to be able to
commit it to the main repository we need make sure it's skipped during `make test`.
Methods:
- A **skip** means that you expect your test to pass only if some conditions are met, otherwise pytest should skip
running the test altogether. Common examples are skipping windows-only tests on non-windows platforms, or skipping
tests that depend on an external resource which is not available at the moment (for example a database).
- A **xfail** means that you expect a test to fail for some reason. A common example is a test for a feature not yet
implemented, or a bug not yet fixed. When a test passes despite being expected to fail (marked with
pytest.mark.xfail), it’s an xpass and will be reported in the test summary.
One of the important differences between the two is that `skip` doesn't run the test, and `xfail` does. So if the
code that's buggy causes some bad state that will affect other tests, do not use `xfail`.
#### Implementation
- Here is how to skip whole test unconditionally:
```python no-style
@unittest.skip("this bug needs to be fixed")
def test_feature_x():
```
or via pytest:
```python no-style
@pytest.mark.skip(reason="this bug needs to be fixed")
```
or the `xfail` way:
```python no-style
@pytest.mark.xfail
def test_feature_x():
```
Here's how to skip a test based on internal checks within the test:
```python
def test_feature_x():
if not has_something():
pytest.skip("unsupported configuration")
```
or the whole module:
```python
import pytest
if not pytest.config.getoption("--custom-flag"):
pytest.skip("--custom-flag is missing, skipping tests", allow_module_level=True)
```
or the `xfail` way:
```python
def test_feature_x():
pytest.xfail("expected to fail until bug XYZ is fixed")
```
- Here is how to skip all tests in a module if some import is missing:
```python
docutils = pytest.importorskip("docutils", minversion="0.3")
```
- Skip a test based on a condition:
```python no-style
@pytest.mark.skipif(sys.version_info < (3,6), reason="requires python3.6 or higher")
def test_feature_x():
```
or:
```python no-style
@unittest.skipIf(torch_device == "cpu", "Can't do half precision")
def test_feature_x():
```
or skip the whole module:
```python no-style
@pytest.mark.skipif(sys.platform == 'win32', reason="does not run on windows")
class TestClass():
def test_feature_x(self):
```
More details, example and ways are [here](https://docs.pytest.org/en/latest/skipping.html).
### Slow tests
The library of tests is ever-growing, and some of the tests take minutes to run, therefore we can't afford waiting for
an hour for the test suite to complete on CI. Therefore, with some exceptions for essential tests, slow tests should be
marked as in the example below:
```python no-style
from transformers.testing_utils import slow
@slow
def test_integration_foo():
```
Once a test is marked as `@slow`, to run such tests set `RUN_SLOW=1` env var, e.g.:
```bash
RUN_SLOW=1 pytest tests
```
Some decorators like `@parameterized` rewrite test names, therefore `@slow` and the rest of the skip decorators
`@require_*` have to be listed last for them to work correctly. Here is an example of the correct usage:
```python no-style
@parameteriz ed.expand(...)
@slow
def test_integration_foo():
```
As explained at the beginning of this document, slow tests get to run on a scheduled basis, rather than in PRs CI
checks. So it's possible that some problems will be missed during a PR submission and get merged. Such problems will
get caught during the next scheduled CI job. But it also means that it's important to run the slow tests on your
machine before submitting the PR.
Here is a rough decision making mechanism for choosing which tests should be marked as slow:
If the test is focused on one of the library's internal components (e.g., modeling files, tokenization files,
pipelines), then we should run that test in the non-slow test suite. If it's focused on an other aspect of the library,
such as the documentation or the examples, then we should run these tests in the slow test suite. And then, to refine
this approach we should have exceptions:
- All tests that need to download a heavy set of weights or a dataset that is larger than ~50MB (e.g., model or
tokenizer integration tests, pipeline integration tests) should be set to slow. If you're adding a new model, you
should create and upload to the hub a tiny version of it (with random weights) for integration tests. This is
discussed in the following paragraphs.
- All tests that need to do a training not specifically optimized to be fast should be set to slow.
- We can introduce exceptions if some of these should-be-non-slow tests are excruciatingly slow, and set them to
`@slow`. Auto-modeling tests, which save and load large files to disk, are a good example of tests that are marked
as `@slow`.
- If a test completes under 1 second on CI (including downloads if any) then it should be a normal test regardless.
Collectively, all the non-slow tests need to cover entirely the different internals, while remaining fast. For example,
a significant coverage can be achieved by testing with specially created tiny models with random weights. Such models
have the very minimal number of layers (e.g., 2), vocab size (e.g., 1000), etc. Then the `@slow` tests can use large
slow models to do qualitative testing. To see the use of these simply look for *tiny* models with:
```bash
grep tiny tests examples
```
Here is a an example of a [script](https://github.com/huggingface/transformers/tree/main/scripts/fsmt/fsmt-make-tiny-model.py) that created the tiny model
[stas/tiny-wmt19-en-de](https://huggingface.co/stas/tiny-wmt19-en-de). You can easily adjust it to your specific
model's architecture.
It's easy to measure the run-time incorrectly if for example there is an overheard of downloading a huge model, but if
you test it locally the downloaded files would be cached and thus the download time not measured. Hence check the
execution speed report in CI logs instead (the output of `pytest --durations=0 tests`).
That report is also useful to find slow outliers that aren't marked as such, or which need to be re-written to be fast.
If you notice that the test suite starts getting slow on CI, the top listing of this report will show the slowest
tests.
### Testing the stdout/stderr output
In order to test functions that write to `stdout` and/or `stderr`, the test can access those streams using the
`pytest`'s [capsys system](https://docs.pytest.org/en/latest/capture.html). Here is how this is accomplished:
```python
import sys
def print_to_stdout(s):
print(s)
def print_to_stderr(s):
sys.stderr.write(s)
def test_result_and_stdout(capsys):
msg = "Hello"
print_to_stdout(msg)
print_to_stderr(msg)
out, err = capsys.readouterr() # consume the captured output streams
# optional: if you want to replay the consumed streams:
sys.stdout.write(out)
sys.stderr.write(err)
# test:
assert msg in out
assert msg in err
```
And, of course, most of the time, `stderr` will come as a part of an exception, so try/except has to be used in such
a case:
```python
def raise_exception(msg):
raise ValueError(msg)
def test_something_exception():
msg = "Not a good value"
error = ""
try:
raise_exception(msg)
except Exception as e:
error = str(e)
assert msg in error, f"{msg} is in the exception:\n{error}"
```
Another approach to capturing stdout is via `contextlib.redirect_stdout`:
```python
from io import StringIO
from contextlib import redirect_stdout
def print_to_stdout(s):
print(s)
def test_result_and_stdout():
msg = "Hello"
buffer = StringIO()
with redirect_stdout(buffer):
print_to_stdout(msg)
out = buffer.getvalue()
# optional: if you want to replay the consumed streams:
sys.stdout.write(out)
# test:
assert msg in out
```
An important potential issue with capturing stdout is that it may contain `\r` characters that in normal `print`
reset everything that has been printed so far. There is no problem with `pytest`, but with `pytest -s` these
characters get included in the buffer, so to be able to have the test run with and without `-s`, you have to make an
extra cleanup to the captured output, using `re.sub(r'~.*\r', '', buf, 0, re.M)`.
But, then we have a helper context manager wrapper to automatically take care of it all, regardless of whether it has
some `\r`'s in it or not, so it's a simple:
```python
from transformers.testing_utils import CaptureStdout
with CaptureStdout() as cs:
function_that_writes_to_stdout()
print(cs.out)
```
Here is a full test example:
```python
from transformers.testing_utils import CaptureStdout
msg = "Secret message\r"
final = "Hello World"
with CaptureStdout() as cs:
print(msg + final)
assert cs.out == final + "\n", f"captured: {cs.out}, expecting {final}"
```
If you'd like to capture `stderr` use the `CaptureStderr` class instead:
```python
from transformers.testing_utils import CaptureStderr
with CaptureStderr() as cs:
function_that_writes_to_stderr()
print(cs.err)
```
If you need to capture both streams at once, use the parent `CaptureStd` class:
```python
from transformers.testing_utils import CaptureStd
with CaptureStd() as cs:
function_that_writes_to_stdout_and_stderr()
print(cs.err, cs.out)
```
Also, to aid debugging test issues, by default these context managers automatically replay the captured streams on exit
from the context.
### Capturing logger stream
If you need to validate the output of a logger, you can use `CaptureLogger`:
```python
from transformers import logging
from transformers.testing_utils import CaptureLogger
msg = "Testing 1, 2, 3"
logging.set_verbosity_info()
logger = logging.get_logger("transformers.models.bart.tokenization_bart")
with CaptureLogger(logger) as cl:
logger.info(msg)
assert cl.out, msg + "\n"
```
### Testing with environment variables
If you want to test the impact of environment variables for a specific test you can use a helper decorator
`transformers.testing_utils.mockenv`
```python
from transformers.testing_utils import mockenv
class HfArgumentParserTest(unittest.TestCase):
@mockenv(TRANSFORMERS_VERBOSITY="error")
def test_env_override(self):
env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None)
```
At times an external program needs to be called, which requires setting `PYTHONPATH` in `os.environ` to include
multiple local paths. A helper class `transformers.test_utils.TestCasePlus` comes to help:
```python
from transformers.testing_utils import TestCasePlus
class EnvExampleTest(TestCasePlus):
def test_external_prog(self):
env = self.get_env()
# now call the external program, passing `env` to it
```
Depending on whether the test file was under the `tests` test suite or `examples` it'll correctly set up
`env[PYTHONPATH]` to include one of these two directories, and also the `src` directory to ensure the testing is
done against the current repo, and finally with whatever `env[PYTHONPATH]` was already set to before the test was
called if anything.
This helper method creates a copy of the `os.environ` object, so the original remains intact.
### Getting reproducible results
In some situations you may want to remove randomness for your tests. To get identical reproducible results set, you
will need to fix the seed:
```python
seed = 42
# python RNG
import random
random.seed(seed)
# pytorch RNGs
import torch
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
# numpy RNG
import numpy as np
np.random.seed(seed)
# tf RNG
tf.random.set_seed(seed)
```
### Debugging tests
To start a debugger at the point of the warning, do this:
```bash
pytest tests/utils/test_logging.py -W error::UserWarning --pdb
```
## Working with github actions workflows
To trigger a self-push workflow CI job, you must:
1. Create a new branch on `transformers` origin (not a fork!).
2. The branch name has to start with either `ci_` or `ci-` (`main` triggers it too, but we can't do PRs on
`main`). It also gets triggered only for specific paths - you can find the up-to-date definition in case it
changed since this document has been written [here](https://github.com/huggingface/transformers/blob/main/.github/workflows/self-push.yml) under *push:*
3. Create a PR from this branch.
4. Then you can see the job appear [here](https://github.com/huggingface/transformers/actions/workflows/self-push.yml). It may not run right away if there
is a backlog.
## Testing Experimental CI Features
Testing CI features can be potentially problematic as it can interfere with the normal CI functioning. Therefore if a
new CI feature is to be added, it should be done as following.
1. Create a new dedicated job that tests what needs to be tested
2. The new job must always succeed so that it gives us a green ✓ (details below).
3. Let it run for some days to see that a variety of different PR types get to run on it (user fork branches,
non-forked branches, branches originating from github.com UI direct file edit, various forced pushes, etc. - there
are so many) while monitoring the experimental job's logs (not the overall job green as it's purposefully always
green)
4. When it's clear that everything is solid, then merge the new changes into existing jobs.
That way experiments on CI functionality itself won't interfere with the normal workflow.
Now how can we make the job always succeed while the new CI feature is being developed?
Some CIs, like TravisCI support ignore-step-failure and will report the overall job as successful, but CircleCI and
Github Actions as of this writing don't support that.
So the following workaround can be used:
1. `set +euo pipefail` at the beginning of the run command to suppress most potential failures in the bash script.
2. the last command must be a success: `echo "done"` or just `true` will do
Here is an example:
```yaml
- run:
name: run CI experiment
command: |
set +euo pipefail
echo "setting run-all-despite-any-errors-mode"
this_command_will_fail
echo "but bash continues to run"
# emulate another failure
false
# but the last command must be a success
echo "during experiment do not remove: reporting success to CI, even if there were failures"
```
For simple commands you could also do:
```bash
cmd_that_may_fail || true
```
Of course, once satisfied with the results, integrate the experimental step or job with the rest of the normal jobs,
while removing `set +euo pipefail` or any other things you may have added to ensure that the experimental job doesn't
interfere with the normal CI functioning.
This whole process would have been much easier if we only could set something like `allow-failure` for the
experimental step, and let it fail without impacting the overall status of PRs. But as mentioned earlier CircleCI and
Github Actions don't support it at the moment.
You can vote for this feature and see where it is at these CI-specific threads:
- [Github Actions:](https://github.com/actions/toolkit/issues/399)
- [CircleCI:](https://ideas.circleci.com/ideas/CCI-I-344)
| huggingface/transformers/blob/main/docs/source/en/testing.md |
Gradio Demo: dataframe_datatype
```
!pip install -q gradio
```
```
import gradio as gr
import pandas as pd
import numpy as np
def make_dataframe(n_periods):
return pd.DataFrame({"date_1": pd.date_range("2021-01-01", periods=n_periods),
"date_2": pd.date_range("2022-02-15", periods=n_periods).strftime('%B %d, %Y, %r'),
"number": np.random.random(n_periods).astype(np.float64),
"number_2": np.random.randint(0, 100, n_periods).astype(np.int32),
"bool": [True] * n_periods,
"markdown": ["# Hello"] * n_periods})
demo = gr.Interface(make_dataframe,
gr.Number(precision=0),
gr.Dataframe(datatype=["date", "date", "number", "number", "bool", "markdown"]))
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/dataframe_datatype/run.ipynb |
--
title: Recall
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Recall is the fraction of the positive examples that were correctly labeled by the model as positive. It can be computed with the equation:
Recall = TP / (TP + FN)
Where TP is the true positives and FN is the false negatives.
---
# Metric Card for Recall
## Metric Description
Recall is the fraction of the positive examples that were correctly labeled by the model as positive. It can be computed with the equation:
Recall = TP / (TP + FN)
Where TP is the number of true positives and FN is the number of false negatives.
## How to Use
At minimum, this metric takes as input two `list`s, each containing `int`s: predictions and references.
```python
>>> recall_metric = evaluate.load('recall')
>>> results = recall_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
["{'recall': 1.0}"]
```
### Inputs
- **predictions** (`list` of `int`): The predicted labels.
- **references** (`list` of `int`): The ground truth labels.
- **labels** (`list` of `int`): The set of labels to include when `average` is not set to `binary`, and their order when average is `None`. Labels present in the data can be excluded in this input, for example to calculate a multiclass average ignoring a majority negative class, while labels not present in the data will result in 0 components in a macro average. For multilabel targets, labels are column indices. By default, all labels in y_true and y_pred are used in sorted order. Defaults to None.
- **pos_label** (`int`): The class label to use as the 'positive class' when calculating the recall. Defaults to `1`.
- **average** (`string`): This parameter is required for multiclass/multilabel targets. If None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data. Defaults to `'binary'`.
- `'binary'`: Only report results for the class specified by `pos_label`. This is applicable only if the target labels and predictions are binary.
- `'micro'`: Calculate metrics globally by counting the total true positives, false negatives, and false positives.
- `'macro'`: Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- `'weighted'`: Calculate metrics for each label, and find their average weighted by support (the number of true instances for each label). This alters `'macro'` to account for label imbalance. Note that it can result in an F-score that is not between precision and recall.
- `'samples'`: Calculate metrics for each instance, and find their average (only meaningful for multilabel classification).
- **sample_weight** (`list` of `float`): Sample weights Defaults to `None`.
- **zero_division** (): Sets the value to return when there is a zero division. Defaults to .
- `'warn'`: If there is a zero division, the return value is `0`, but warnings are also raised.
- `0`: If there is a zero division, the return value is `0`.
- `1`: If there is a zero division, the return value is `1`.
### Output Values
- **recall**(`float`, or `array` of `float`, for multiclass targets): Either the general recall score, or the recall scores for individual classes, depending on the values input to `labels` and `average`. Minimum possible value is 0. Maximum possible value is 1. A higher recall means that more of the positive examples have been labeled correctly. Therefore, a higher recall is generally considered better.
Output Example(s):
```python
{'recall': 1.0}
```
```python
{'recall': array([1., 0., 0.])}
```
This metric outputs a dictionary with one entry, `'recall'`.
#### Values from Popular Papers
### Examples
Example 1-A simple example with some errors
```python
>>> recall_metric = evaluate.load('recall')
>>> results = recall_metric.compute(references=[0, 0, 1, 1, 1], predictions=[0, 1, 0, 1, 1])
>>> print(results)
{'recall': 0.6666666666666666}
```
Example 2-The same example as Example 1, but with `pos_label=0` instead of the default `pos_label=1`.
```python
>>> recall_metric = evaluate.load('recall')
>>> results = recall_metric.compute(references=[0, 0, 1, 1, 1], predictions=[0, 1, 0, 1, 1], pos_label=0)
>>> print(results)
{'recall': 0.5}
```
Example 3-The same example as Example 1, but with `sample_weight` included.
```python
>>> recall_metric = evaluate.load('recall')
>>> sample_weight = [0.9, 0.2, 0.9, 0.3, 0.8]
>>> results = recall_metric.compute(references=[0, 0, 1, 1, 1], predictions=[0, 1, 0, 1, 1], sample_weight=sample_weight)
>>> print(results)
{'recall': 0.55}
```
Example 4-A multiclass example, using different averages.
```python
>>> recall_metric = evaluate.load('recall')
>>> predictions = [0, 2, 1, 0, 0, 1]
>>> references = [0, 1, 2, 0, 1, 2]
>>> results = recall_metric.compute(predictions=predictions, references=references, average='macro')
>>> print(results)
{'recall': 0.3333333333333333}
>>> results = recall_metric.compute(predictions=predictions, references=references, average='micro')
>>> print(results)
{'recall': 0.3333333333333333}
>>> results = recall_metric.compute(predictions=predictions, references=references, average='weighted')
>>> print(results)
{'recall': 0.3333333333333333}
>>> results = recall_metric.compute(predictions=predictions, references=references, average=None)
>>> print(results)
{'recall': array([1., 0., 0.])}
```
## Limitations and Bias
## Citation(s)
```bibtex
@article{scikit-learn, title={Scikit-learn: Machine Learning in {P}ython}, author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.}, journal={Journal of Machine Learning Research}, volume={12}, pages={2825--2830}, year={2011}
```
## Further References
| huggingface/evaluate/blob/main/metrics/recall/README.md |
Create an image dataset
There are two methods for creating and sharing an image dataset. This guide will show you how to:
* Create an image dataset with `ImageFolder` and some metadata. This is a no-code solution for quickly creating an image dataset with several thousand images.
* Create an image dataset by writing a loading script. This method is a bit more involved, but you have greater flexibility over how a dataset is defined, downloaded, and generated which can be useful for more complex or large scale image datasets.
<Tip>
You can control access to your dataset by requiring users to share their contact information first. Check out the [Gated datasets](https://huggingface.co/docs/hub/datasets-gated) guide for more information about how to enable this feature on the Hub.
</Tip>
## ImageFolder
The `ImageFolder` is a dataset builder designed to quickly load an image dataset with several thousand images without requiring you to write any code.
<Tip>
💡 Take a look at the [Split pattern hierarchy](repository_structure#split-pattern-hierarchy) to learn more about how `ImageFolder` creates dataset splits based on your dataset repository structure.
</Tip>
`ImageFolder` automatically infers the class labels of your dataset based on the directory name. Store your dataset in a directory structure like:
```
folder/train/dog/golden_retriever.png
folder/train/dog/german_shepherd.png
folder/train/dog/chihuahua.png
folder/train/cat/maine_coon.png
folder/train/cat/bengal.png
folder/train/cat/birman.png
```
Then users can load your dataset by specifying `imagefolder` in [`load_dataset`] and the directory in `data_dir`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("imagefolder", data_dir="/path/to/folder")
```
You can also use `imagefolder` to load datasets involving multiple splits. To do so, your dataset directory should have the following structure:
```
folder/train/dog/golden_retriever.png
folder/train/cat/maine_coon.png
folder/test/dog/german_shepherd.png
folder/test/cat/bengal.png
```
<Tip warning={true}>
If all image files are contained in a single directory or if they are not on the same level of directory structure, `label` column won't be added automatically. If you need it, set `drop_labels=False` explicitly.
</Tip>
If there is additional information you'd like to include about your dataset, like text captions or bounding boxes, add it as a `metadata.csv` file in your folder. This lets you quickly create datasets for different computer vision tasks like text captioning or object detection. You can also use a JSONL file `metadata.jsonl`.
```
folder/train/metadata.csv
folder/train/0001.png
folder/train/0002.png
folder/train/0003.png
```
You can also zip your images:
```
folder/metadata.csv
folder/train.zip
folder/test.zip
folder/valid.zip
```
Your `metadata.csv` file must have a `file_name` column which links image files with their metadata:
```csv
file_name,additional_feature
0001.png,This is a first value of a text feature you added to your images
0002.png,This is a second value of a text feature you added to your images
0003.png,This is a third value of a text feature you added to your images
```
or using `metadata.jsonl`:
```jsonl
{"file_name": "0001.png", "additional_feature": "This is a first value of a text feature you added to your images"}
{"file_name": "0002.png", "additional_feature": "This is a second value of a text feature you added to your images"}
{"file_name": "0003.png", "additional_feature": "This is a third value of a text feature you added to your images"}
```
<Tip>
If metadata files are present, the inferred labels based on the directory name are dropped by default. To include those labels, set `drop_labels=False` in `load_dataset`.
</Tip>
### Image captioning
Image captioning datasets have text describing an image. An example `metadata.csv` may look like:
```csv
file_name,text
0001.png,This is a golden retriever playing with a ball
0002.png,A german shepherd
0003.png,One chihuahua
```
Load the dataset with `ImageFolder`, and it will create a `text` column for the image captions:
```py
>>> dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
>>> dataset[0]["text"]
"This is a golden retriever playing with a ball"
```
### Object detection
Object detection datasets have bounding boxes and categories identifying objects in an image. An example `metadata.jsonl` may look like:
```jsonl
{"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}}
{"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1]}}
{"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "categories": [2, 2]}}
```
Load the dataset with `ImageFolder`, and it will create a `objects` column with the bounding boxes and the categories:
```py
>>> dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
>>> dataset[0]["objects"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
```
### Upload dataset to the Hub
Once you've created a dataset, you can share it to the Hub with the [`~datasets.DatasetDict.push_to_hub`] method. Make sure you have the [huggingface_hub](https://huggingface.co/docs/huggingface_hub/index) library installed and you're logged in to your Hugging Face account (see the [Upload with Python tutorial](upload_dataset#upload-with-python) for more details).
Upload your dataset with [`~datasets.DatasetDict.push_to_hub`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
>>> dataset.push_to_hub("stevhliu/my-image-captioning-dataset")
```
## WebDataset
The [WebDataset](https://github.com/webdataset/webdataset) format is based on TAR archives and is suitable for big image datasets.
Indeed you can group your images in TAR archives (e.g. 1GB of images per TAR archive) and have thousands of TAR archives:
```
folder/train/00000.tar
folder/train/00001.tar
folder/train/00002.tar
...
```
In the archives, each example is made of files sharing the same prefix:
```
e39871fd9fd74f55.jpg
e39871fd9fd74f55.json
f18b91585c4d3f3e.jpg
f18b91585c4d3f3e.json
ede6e66b2fb59aab.jpg
ede6e66b2fb59aab.json
ed600d57fcee4f94.jpg
ed600d57fcee4f94.json
...
```
You can put your images labels/captions/bounding boxes using JSON or text files for example.
For more details on the WebDataset format and the python library, please check the [WebDataset documentation](https://webdataset.github.io/webdataset).
Load your WebDataset and it will create on column per file suffix (here "jpg" and "json"):
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("webdataset", data_dir="/path/to/folder", split="train")
>>> dataset[0]["json"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
```
## Loading script
Write a dataset loading script to share a dataset. It defines a dataset's splits and configurations, and handles downloading and generating a dataset. The script is located in the same folder or repository as the dataset and should have the same name.
```
my_dataset/
├── README.md
├── my_dataset.py
└── data/ # optional, may contain your images or TAR archives
```
This structure allows your dataset to be loaded in one line:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("path/to/my_dataset")
```
This guide will show you how to create a dataset loading script for image datasets, which is a bit different from <a class="underline decoration-green-400 decoration-2 font-semibold" href="./dataset_script">creating a loading script for text datasets</a>. You'll learn how to:
* Create a dataset builder class.
* Create dataset configurations.
* Add dataset metadata.
* Download and define the dataset splits.
* Generate the dataset.
* Generate the dataset metadata (optional).
* Upload the dataset to the Hub.
The best way to learn is to open up an existing image dataset loading script, like [Food-101](https://huggingface.co/datasets/food101/blob/main/food101.py), and follow along!
<Tip>
To help you get started, we created a loading script [template](https://github.com/huggingface/datasets/blob/main/templates/new_dataset_script.py) you can copy and use as a starting point!
</Tip>
### Create a dataset builder class
[`GeneratorBasedBuilder`] is the base class for datasets generated from a dictionary generator. Within this class, there are three methods to help create your dataset:
* `info` stores information about your dataset like its description, license, and features.
* `split_generators` downloads the dataset and defines its splits.
* `generate_examples` generates the images and labels for each split.
Start by creating your dataset class as a subclass of [`GeneratorBasedBuilder`] and add the three methods. Don't worry about filling in each of these methods yet, you'll develop those over the next few sections:
```py
class Food101(datasets.GeneratorBasedBuilder):
"""Food-101 Images dataset"""
def _info(self):
def _split_generators(self, dl_manager):
def _generate_examples(self, images, metadata_path):
```
#### Multiple configurations
In some cases, a dataset may have more than one configuration. For example, if you check out the [Imagenette dataset](https://huggingface.co/datasets/frgfm/imagenette), you'll notice there are three subsets.
To create different configurations, use the [`BuilderConfig`] class to create a subclass for your dataset. Provide the links to download the images and labels in `data_url` and `metadata_urls`:
```py
class Food101Config(datasets.BuilderConfig):
"""Builder Config for Food-101"""
def __init__(self, data_url, metadata_urls, **kwargs):
"""BuilderConfig for Food-101.
Args:
data_url: `string`, url to download the zip file from.
metadata_urls: dictionary with keys 'train' and 'validation' containing the archive metadata URLs
**kwargs: keyword arguments forwarded to super.
"""
super(Food101Config, self).__init__(version=datasets.Version("1.0.0"), **kwargs)
self.data_url = data_url
self.metadata_urls = metadata_urls
```
Now you can define your subsets at the top of [`GeneratorBasedBuilder`]. Imagine you want to create two subsets in the Food-101 dataset based on whether it is a breakfast or dinner food.
1. Define your subsets with `Food101Config` in a list in `BUILDER_CONFIGS`.
2. For each configuration, provide a name, description, and where to download the images and labels from.
```py
class Food101(datasets.GeneratorBasedBuilder):
"""Food-101 Images dataset"""
BUILDER_CONFIGS = [
Food101Config(
name="breakfast",
description="Food types commonly eaten during breakfast.",
data_url="https://link-to-breakfast-foods.zip",
metadata_urls={
"train": "https://link-to-breakfast-foods-train.txt",
"validation": "https://link-to-breakfast-foods-validation.txt"
},
,
Food101Config(
name="dinner",
description="Food types commonly eaten during dinner.",
data_url="https://link-to-dinner-foods.zip",
metadata_urls={
"train": "https://link-to-dinner-foods-train.txt",
"validation": "https://link-to-dinner-foods-validation.txt"
},
)...
]
```
Now if users want to load the `breakfast` configuration, they can use the configuration name:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset("food101", "breakfast", split="train")
```
### Add dataset metadata
Adding information about your dataset is useful for users to learn more about it. This information is stored in the [`DatasetInfo`] class which is returned by the `info` method. Users can access this information by:
```py
>>> from datasets import load_dataset_builder
>>> ds_builder = load_dataset_builder("food101")
>>> ds_builder.info
```
There is a lot of information you can specify about your dataset, but some important ones to include are:
1. `description` provides a concise description of the dataset.
2. `features` specify the dataset column types. Since you're creating an image loading script, you'll need to include the [`Image`] feature.
3. `supervised_keys` specify the input feature and label.
4. `homepage` provides a link to the dataset homepage.
5. `citation` is a BibTeX citation of the dataset.
6. `license` states the dataset's license.
<Tip>
You'll notice a lot of the dataset information is defined earlier in the loading script which makes it easier to read. There are also other [`~Datasets.Features`] you can input, so be sure to check out the full list for more details.
</Tip>
```py
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=datasets.Features(
{
"image": datasets.Image(),
"label": datasets.ClassLabel(names=_NAMES),
}
),
supervised_keys=("image", "label"),
homepage=_HOMEPAGE,
citation=_CITATION,
license=_LICENSE,
task_templates=[ImageClassification(image_column="image", label_column="label")],
)
```
### Download and define the dataset splits
Now that you've added some information about your dataset, the next step is to download the dataset and generate the splits.
1. Use the [`DownloadManager.download`] method to download the dataset and any other metadata you'd like to associate with it. This method accepts:
* a name to a file inside a Hub dataset repository (in other words, the `data/` folder)
* a URL to a file hosted somewhere else
* a list or dictionary of file names or URLs
In the Food-101 loading script, you'll notice again the URLs are defined earlier in the script.
2. After you've downloaded the dataset, use the [`SplitGenerator`] to organize the images and labels in each split. Name each split with a standard name like: `Split.TRAIN`, `Split.TEST`, and `SPLIT.Validation`.
In the `gen_kwargs` parameter, specify the file paths to the `images` to iterate over and load. If necessary, you can use [`DownloadManager.iter_archive`] to iterate over images in TAR archives. You can also specify the associated labels in the `metadata_path`. The `images` and `metadata_path` are actually passed onto the next step where you'll actually generate the dataset.
<Tip warning={true}>
To stream a TAR archive file, you need to use [`DownloadManager.iter_archive`]! The [`DownloadManager.download_and_extract`] function does not support TAR archives in streaming mode.
</Tip>
```py
def _split_generators(self, dl_manager):
archive_path = dl_manager.download(_BASE_URL)
split_metadata_paths = dl_manager.download(_METADATA_URLS)
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
gen_kwargs={
"images": dl_manager.iter_archive(archive_path),
"metadata_path": split_metadata_paths["train"],
},
),
datasets.SplitGenerator(
name=datasets.Split.VALIDATION,
gen_kwargs={
"images": dl_manager.iter_archive(archive_path),
"metadata_path": split_metadata_paths["test"],
},
),
]
```
### Generate the dataset
The last method in the [`GeneratorBasedBuilder`] class actually generates the images and labels in the dataset. It yields a dataset according to the stucture specified in `features` from the `info` method. As you can see, `generate_examples` accepts the `images` and `metadata_path` from the previous method as arguments.
<Tip warning={true}>
To stream a TAR archive file, the `metadata_path` needs to be opened and read first. TAR files are accessed and yielded sequentially. This means you need to have the metadata information in hand first so you can yield it with its corresponding image.
</Tip>
Now you can write a function for opening and loading examples from the dataset:
```py
def _generate_examples(self, images, metadata_path):
"""Generate images and labels for splits."""
with open(metadata_path, encoding="utf-8") as f:
files_to_keep = set(f.read().split("\n"))
for file_path, file_obj in images:
if file_path.startswith(_IMAGES_DIR):
if file_path[len(_IMAGES_DIR) : -len(".jpg")] in files_to_keep:
label = file_path.split("/")[2]
yield file_path, {
"image": {"path": file_path, "bytes": file_obj.read()},
"label": label,
}
```
### Generate the dataset metadata (optional)
The dataset metadata can be generated and stored in the dataset card (`README.md` file).
Run the following command to generate your dataset metadata in `README.md` and make sure your new loading script works correctly:
```bash
datasets-cli test path/to/<your-dataset-loading-script> --save_info --all_configs
```
If your loading script passed the test, you should now have the `dataset_info` YAML fields in the header of the `README.md` file in your dataset folder.
### Upload the dataset to the Hub
Once your script is ready, [create a dataset card](./dataset_card) and [upload it to the Hub](./share).
Congratulations, you can now load your dataset from the Hub! 🥳
```py
>>> from datasets import load_dataset
>>> load_dataset("<username>/my_dataset")
```
| huggingface/datasets/blob/main/docs/source/image_dataset.mdx |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeepSpeed
[DeepSpeed](https://www.deepspeed.ai/) is a library designed for speed and scale for distributed training of large models with billions of parameters. At its core is the Zero Redundancy Optimizer (ZeRO) that shards optimizer states (ZeRO-1), gradients (ZeRO-2), and parameters (ZeRO-3) across data parallel processes. This drastically reduces memory usage, allowing you to scale your training to billion parameter models. To unlock even more memory efficiency, ZeRO-Offload reduces GPU compute and memory by leveraging CPU resources during optimization.
Both of these features are supported in 🤗 Accelerate, and you can use them with 🤗 PEFT. This guide will help you learn how to use our DeepSpeed [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You'll configure the script to train a large model for conditional generation with ZeRO-3 and ZeRO-Offload.
<Tip>
💡 To help you get started, check out our example training scripts for [causal language modeling](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_ds_zero3_offload.py) and [conditional generation](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You can adapt these scripts for your own applications or even use them out of the box if your task is similar to the one in the scripts.
</Tip>
## Configuration
Start by running the following command to [create a DeepSpeed configuration file](https://huggingface.co/docs/accelerate/quicktour#launching-your-distributed-script) with 🤗 Accelerate. The `--config_file` flag allows you to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
The configuration file is used to set the default options when you launch the training script.
```bash
accelerate config --config_file ds_zero3_cpu.yaml
```
You'll be asked a few questions about your setup, and configure the following arguments. In this example, you'll use ZeRO-3 and ZeRO-Offload so make sure you pick those options.
```bash
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them.
`gradient_clipping`: Enable gradient clipping with value.
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2.
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3.
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3.
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3.
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training.
```
An example [configuration file](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/accelerate_ds_zero3_cpu_offload_config.yaml) might look like the following. The most important thing to notice is that `zero_stage` is set to `3`, and `offload_optimizer_device` and `offload_param_device` are set to the `cpu`.
```yml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
```
## The important parts
Let's dive a little deeper into the script so you can see what's going on, and understand how it works.
Within the [`main`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py#L103) function, the script creates an [`~accelerate.Accelerator`] class to initialize all the necessary requirements for distributed training.
<Tip>
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
</Tip>
The script also creates a configuration for the 🤗 PEFT method you're using, which in this case, is LoRA. The [`LoraConfig`] specifies the task type and important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, make sure you replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
```diff
def main():
+ accelerator = Accelerator()
model_name_or_path = "facebook/bart-large"
dataset_name = "twitter_complaints"
+ peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
```
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
The [`get_peft_model`] function takes a base model and the [`peft_config`] you prepared earlier to create a [`PeftModel`]:
```diff
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
```
Pass all the relevant training objects to 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] which makes sure everything is ready for training:
```py
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler
)
```
The next bit of code checks whether the DeepSpeed plugin is used in the `Accelerator`, and if the plugin exists, then the `Accelerator` uses ZeRO-3 as specified in the configuration file:
```py
is_ds_zero_3 = False
if getattr(accelerator.state, "deepspeed_plugin", None):
is_ds_zero_3 = accelerator.state.deepspeed_plugin.zero_stage == 3
```
Inside the training loop, the usual `loss.backward()` is replaced by 🤗 Accelerate's [`~accelerate.Accelerator.backward`] which uses the correct `backward()` method based on your configuration:
```diff
for epoch in range(num_epochs):
with TorchTracemalloc() as tracemalloc:
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
```
That is all! The rest of the script handles the training loop, evaluation, and even pushes it to the Hub for you.
## Train
Run the following command to launch the training script. Earlier, you saved the configuration file to `ds_zero3_cpu.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
```bash
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
```
You'll see some output logs that track memory usage during training, and once it's completed, the script returns the accuracy and compares the predictions to the labels:
```bash
GPU Memory before entering the train : 1916
GPU Memory consumed at the end of the train (end-begin): 66
GPU Peak Memory consumed during the train (max-begin): 7488
GPU Total Peak Memory consumed during the train (max): 9404
CPU Memory before entering the train : 19411
CPU Memory consumed at the end of the train (end-begin): 0
CPU Peak Memory consumed during the train (max-begin): 0
CPU Total Peak Memory consumed during the train (max): 19411
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
GPU Memory before entering the eval : 1982
GPU Memory consumed at the end of the eval (end-begin): -66
GPU Peak Memory consumed during the eval (max-begin): 672
GPU Total Peak Memory consumed during the eval (max): 2654
CPU Memory before entering the eval : 19411
CPU Memory consumed at the end of the eval (end-begin): 0
CPU Peak Memory consumed during the eval (max-begin): 0
CPU Total Peak Memory consumed during the eval (max): 19411
accuracy=100.0
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
``` | huggingface/peft/blob/main/docs/source/accelerate/deepspeed-zero3-offload.md |
Create a dataset card
Each dataset should have a dataset card to promote responsible usage and inform users of any potential biases within the dataset.
This idea was inspired by the Model Cards proposed by [Mitchell, 2018](https://arxiv.org/abs/1810.03993).
Dataset cards help users understand a dataset's contents, the context for using the dataset, how it was created, and any other considerations a user should be aware of.
Creating a dataset card is easy and can be done in a just a few steps:
1. Go to your dataset repository on the [Hub](https://hf.co/new-dataset) and click on **Create Dataset Card** to create a new `README.md` file in your repository.
2. Use the **Metadata UI** to select the tags that describe your dataset. You can add a license, language, pretty_name, the task_categories, size_categories, and any other tags that you think are relevant. These tags help users discover and find your dataset on the Hub.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-metadata-ui.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-metadata-ui-dark.png"/>
</div>
<Tip>
For a complete, but not required, set of tag options you can also look at the [Dataset Card specifications](https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1). This'll have a few more tag options like `multilinguality` and `language_creators` which are useful but not absolutely necessary.
</Tip>
3. Click on the **Import dataset card template** link to automatically create a template with all the relevant fields to complete. Fill out the template sections to the best of your ability. Take a look at the [Dataset Card Creation Guide](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md) for more detailed information about what to include in each section of the card. For fields you are unable to complete, you can write **[More Information Needed]**.
4. Once you're done, commit the changes to the `README.md` file and you'll see the completed dataset card on your repository.
YAML also allows you to customize the way your dataset is loaded by [defining splits and/or configurations](./repository_structure#define-your-splits-and-subsets-in-yaml) without the need to write any code.
Feel free to take a look at the [SNLI](https://huggingface.co/datasets/snli), [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail), and [Allociné](https://huggingface.co/datasets/allocine) dataset cards as examples to help you get started.
| huggingface/datasets/blob/main/docs/source/dataset_card.mdx |
Process
🤗 Datasets provides many tools for modifying the structure and content of a dataset. These tools are important for tidying up a dataset, creating additional columns, converting between features and formats, and much more.
This guide will show you how to:
- Reorder rows and split the dataset.
- Rename and remove columns, and other common column operations.
- Apply processing functions to each example in a dataset.
- Concatenate datasets.
- Apply a custom formatting transform.
- Save and export processed datasets.
For more details specific to processing other dataset modalities, take a look at the <a class="underline decoration-pink-400 decoration-2 font-semibold" href="./audio_process">process audio dataset guide</a>, the <a class="underline decoration-yellow-400 decoration-2 font-semibold" href="./image_process">process image dataset guide</a>, or the <a class="underline decoration-green-400 decoration-2 font-semibold" href="./nlp_process">process text dataset guide</a>.
The examples in this guide use the MRPC dataset, but feel free to load any dataset of your choice and follow along!
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("glue", "mrpc", split="train")
```
<Tip warning={true}>
All processing methods in this guide return a new [`Dataset`] object. Modification is not done in-place. Be careful about overriding your previous dataset!
</Tip>
## Sort, shuffle, select, split, and shard
There are several functions for rearranging the structure of a dataset.
These functions are useful for selecting only the rows you want, creating train and test splits, and sharding very large datasets into smaller chunks.
### Sort
Use [`~Dataset.sort`] to sort column values according to their numerical values. The provided column must be NumPy compatible.
```py
>>> dataset["label"][:10]
[1, 0, 1, 0, 1, 1, 0, 1, 0, 0]
>>> sorted_dataset = dataset.sort("label")
>>> sorted_dataset["label"][:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>>> sorted_dataset["label"][-10:]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
Under the hood, this creates a list of indices that is sorted according to values of the column.
This indices mapping is then used to access the right rows in the underlying Arrow table.
### Shuffle
The [`~Dataset.shuffle`] function randomly rearranges the column values. You can specify the `generator` parameter in this function to use a different `numpy.random.Generator` if you want more control over the algorithm used to shuffle the dataset.
```py
>>> shuffled_dataset = sorted_dataset.shuffle(seed=42)
>>> shuffled_dataset["label"][:10]
[1, 1, 1, 0, 1, 1, 1, 1, 1, 0]
```
Shuffling takes the list of indices `[0:len(my_dataset)]` and shuffles it to create an indices mapping.
However as soon as your [`Dataset`] has an indices mapping, the speed can become 10x slower.
This is because there is an extra step to get the row index to read using the indices mapping, and most importantly, you aren't reading contiguous chunks of data anymore.
To restore the speed, you'd need to rewrite the entire dataset on your disk again using [`Dataset.flatten_indices`], which removes the indices mapping.
Alternatively, you can switch to an [`IterableDataset`] and leverage its fast approximate shuffling [`IterableDataset.shuffle`]:
```py
>>> iterable_dataset = dataset.to_iterable_dataset(num_shards=128)
>>> shuffled_iterable_dataset = iterable_dataset.shuffle(seed=42, buffer_size=1000)
```
### Select and Filter
There are two options for filtering rows in a dataset: [`~Dataset.select`] and [`~Dataset.filter`].
- [`~Dataset.select`] returns rows according to a list of indices:
```py
>>> small_dataset = dataset.select([0, 10, 20, 30, 40, 50])
>>> len(small_dataset)
6
```
- [`~Dataset.filter`] returns rows that match a specified condition:
```py
>>> start_with_ar = dataset.filter(lambda example: example["sentence1"].startswith("Ar"))
>>> len(start_with_ar)
6
>>> start_with_ar["sentence1"]
['Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
'Arison said Mann may have been one of the pioneers of the world music movement and he had a deep love of Brazilian music .',
'Arts helped coach the youth on an eighth-grade football team at Lombardi Middle School in Green Bay .',
'Around 9 : 00 a.m. EDT ( 1300 GMT ) , the euro was at $ 1.1566 against the dollar , up 0.07 percent on the day .',
"Arguing that the case was an isolated example , Canada has threatened a trade backlash if Tokyo 's ban is not justified on scientific grounds .",
'Artists are worried the plan would harm those who need help most - performers who have a difficult time lining up shows .'
]
```
[`~Dataset.filter`] can also filter by indices if you set `with_indices=True`:
```py
>>> even_dataset = dataset.filter(lambda example, idx: idx % 2 == 0, with_indices=True)
>>> len(even_dataset)
1834
>>> len(dataset) / 2
1834.0
```
Unless the list of indices to keep is contiguous, those methods also create an indices mapping under the hood.
### Split
The [`~Dataset.train_test_split`] function creates train and test splits if your dataset doesn't already have them. This allows you to adjust the relative proportions or an absolute number of samples in each split. In the example below, use the `test_size` parameter to create a test split that is 10% of the original dataset:
```py
>>> dataset.train_test_split(test_size=0.1)
{'train': Dataset(schema: {'sentence1': 'string', 'sentence2': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 3301),
'test': Dataset(schema: {'sentence1': 'string', 'sentence2': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 367)}
>>> 0.1 * len(dataset)
366.8
```
The splits are shuffled by default, but you can set `shuffle=False` to prevent shuffling.
### Shard
🤗 Datasets supports sharding to divide a very large dataset into a predefined number of chunks. Specify the `num_shards` parameter in [`~Dataset.shard`] to determine the number of shards to split the dataset into. You'll also need to provide the shard you want to return with the `index` parameter.
For example, the [imdb](https://huggingface.co/datasets/imdb) dataset has 25000 examples:
```py
>>> from datasets import load_dataset
>>> datasets = load_dataset("imdb", split="train")
>>> print(dataset)
Dataset({
features: ['text', 'label'],
num_rows: 25000
})
```
After sharding the dataset into four chunks, the first shard will only have 6250 examples:
```py
>>> dataset.shard(num_shards=4, index=0)
Dataset({
features: ['text', 'label'],
num_rows: 6250
})
>>> print(25000/4)
6250.0
```
## Rename, remove, cast, and flatten
The following functions allow you to modify the columns of a dataset. These functions are useful for renaming or removing columns, changing columns to a new set of features, and flattening nested column structures.
### Rename
Use [`~Dataset.rename_column`] when you need to rename a column in your dataset. Features associated with the original column are actually moved under the new column name, instead of just replacing the original column in-place.
Provide [`~Dataset.rename_column`] with the name of the original column, and the new column name:
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.rename_column("sentence1", "sentenceA")
>>> dataset = dataset.rename_column("sentence2", "sentenceB")
>>> dataset
Dataset({
features: ['sentenceA', 'sentenceB', 'label', 'idx'],
num_rows: 3668
})
```
### Remove
When you need to remove one or more columns, provide the column name to remove to the [`~Dataset.remove_columns`] function. Remove more than one column by providing a list of column names:
```py
>>> dataset = dataset.remove_columns("label")
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.remove_columns(["sentence1", "sentence2"])
>>> dataset
Dataset({
features: ['idx'],
num_rows: 3668
})
```
Conversely, [`~Dataset.select_columns`] selects one or more columns to keep and removes the rest. This function takes either one or a list of column names:
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.select_columns(['sentence1', 'sentence2', 'idx'])
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.select_columns('idx')
>>> dataset
Dataset({
features: ['idx'],
num_rows: 3668
})
```
### Cast
The [`~Dataset.cast`] function transforms the feature type of one or more columns. This function accepts your new [`Features`] as its argument. The example below demonstrates how to change the [`ClassLabel`] and [`Value`] features:
```py
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
>>> from datasets import ClassLabel, Value
>>> new_features = dataset.features.copy()
>>> new_features["label"] = ClassLabel(names=["negative", "positive"])
>>> new_features["idx"] = Value("int64")
>>> dataset = dataset.cast(new_features)
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['negative', 'positive'], names_file=None, id=None),
'idx': Value(dtype='int64', id=None)}
```
<Tip>
Casting only works if the original feature type and new feature type are compatible. For example, you can cast a column with the feature type `Value("int32")` to `Value("bool")` if the original column only contains ones and zeros.
</Tip>
Use the [`~Dataset.cast_column`] function to change the feature type of a single column. Pass the column name and its new feature type as arguments:
```py
>>> dataset.features
{'audio': Audio(sampling_rate=44100, mono=True, id=None)}
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> dataset.features
{'audio': Audio(sampling_rate=16000, mono=True, id=None)}
```
### Flatten
Sometimes a column can be a nested structure of several types. Take a look at the nested structure below from the SQuAD dataset:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("squad", split="train")
>>> dataset.features
{'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None),
'context': Value(dtype='string', id=None),
'id': Value(dtype='string', id=None),
'question': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None)}
```
The `answers` field contains two subfields: `text` and `answer_start`. Use the [`~Dataset.flatten`] function to extract the subfields into their own separate columns:
```py
>>> flat_dataset = dataset.flatten()
>>> flat_dataset
Dataset({
features: ['id', 'title', 'context', 'question', 'answers.text', 'answers.answer_start'],
num_rows: 87599
})
```
Notice how the subfields are now their own independent columns: `answers.text` and `answers.answer_start`.
## Map
Some of the more powerful applications of 🤗 Datasets come from using the [`~Dataset.map`] function. The primary purpose of [`~Dataset.map`] is to speed up processing functions. It allows you to apply a processing function to each example in a dataset, independently or in batches. This function can even create new rows and columns.
In the following example, prefix each `sentence1` value in the dataset with `'My sentence: '`.
Start by creating a function that adds `'My sentence: '` to the beginning of each sentence. The function needs to accept and output a `dict`:
```py
>>> def add_prefix(example):
... example["sentence1"] = 'My sentence: ' + example["sentence1"]
... return example
```
Now use [`~Dataset.map`] to apply the `add_prefix` function to the entire dataset:
```py
>>> updated_dataset = small_dataset.map(add_prefix)
>>> updated_dataset["sentence1"][:5]
['My sentence: Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"My sentence: Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'My sentence: They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .',
'My sentence: Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
]
```
Let's take a look at another example, except this time, you'll remove a column with [`~Dataset.map`]. When you remove a column, it is only removed after the example has been provided to the mapped function. This allows the mapped function to use the content of the columns before they are removed.
Specify the column to remove with the `remove_columns` parameter in [`~Dataset.map`]:
```py
>>> updated_dataset = dataset.map(lambda example: {"new_sentence": example["sentence1"]}, remove_columns=["sentence1"])
>>> updated_dataset.column_names
['sentence2', 'label', 'idx', 'new_sentence']
```
<Tip>
🤗 Datasets also has a [`~Dataset.remove_columns`] function which is faster because it doesn't copy the data of the remaining columns.
</Tip>
You can also use [`~Dataset.map`] with indices if you set `with_indices=True`. The example below adds the index to the beginning of each sentence:
```py
>>> updated_dataset = dataset.map(lambda example, idx: {"sentence2": f"{idx}: " + example["sentence2"]}, with_indices=True)
>>> updated_dataset["sentence2"][:5]
['0: Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
"1: Yucaipa bought Dominick 's in 1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in 1998 .",
"2: On June 10 , the ship 's owners had published an advertisement on the Internet , offering the explosives for sale .",
'3: Tab shares jumped 20 cents , or 4.6 % , to set a record closing high at A $ 4.57 .',
'4: PG & E Corp. shares jumped $ 1.63 or 8 percent to $ 21.03 on the New York Stock Exchange on Friday .'
]
```
### Multiprocessing
Multiprocessing significantly speeds up processing by parallelizing processes on the CPU. Set the `num_proc` parameter in [`~Dataset.map`] to set the number of processes to use:
```py
>>> updated_dataset = dataset.map(lambda example, idx: {"sentence2": f"{idx}: " + example["sentence2"]}, num_proc=4)
```
The [`~Dataset.map`] also works with the rank of the process if you set `with_rank=True`. This is analogous to the `with_indices` parameter. The `with_rank` parameter in the mapped function goes after the `index` one if it is already present.
```py
>>> from multiprocess import set_start_method
>>> import torch
>>> import os
>>>
>>> for i in range(torch.cuda.device_count()): # send model to every GPU
... model.to(f"cuda:{i}")
>>>
>>> def gpu_computation(example, rank):
... torch.cuda.set_device(f"cuda:{rank}") # use one GPU
... # Your big GPU call goes here, for example
... inputs = tokenizer(texts, truncation=True, return_tensors="pt").to(f"cuda:{rank}")
... outputs = model.generate(**inputs)
... example["generated_text"] = tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)
... return example
>>>
>>> if __name__ == "__main__":
... set_start_method("spawn")
... updated_dataset = dataset.map(gpu_computation, with_rank=True, num_proc=torch.cuda.device_count())
```
The main use-case for rank is to parallelize computation across several GPUs. This requires setting `multiprocess.set_start_method("spawn")`. If you don't you'll receive the following CUDA error:
```bash
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method.
```
### Batch processing
The [`~Dataset.map`] function supports working with batches of examples. Operate on batches by setting `batched=True`. The default batch size is 1000, but you can adjust it with the `batch_size` parameter. Batch processing enables interesting applications such as splitting long sentences into shorter chunks and data augmentation.
#### Split long examples
When examples are too long, you may want to split them into several smaller chunks. Begin by creating a function that:
1. Splits the `sentence1` field into chunks of 50 characters.
2. Stacks all the chunks together to create the new dataset.
```py
>>> def chunk_examples(examples):
... chunks = []
... for sentence in examples["sentence1"]:
... chunks += [sentence[i:i + 50] for i in range(0, len(sentence), 50)]
... return {"chunks": chunks}
```
Apply the function with [`~Dataset.map`]:
```py
>>> chunked_dataset = dataset.map(chunk_examples, batched=True, remove_columns=dataset.column_names)
>>> chunked_dataset[:10]
{'chunks': ['Amrozi accused his brother , whom he called " the ',
'witness " , of deliberately distorting his evidenc',
'e .',
"Yucaipa owned Dominick 's before selling the chain",
' to Safeway in 1998 for $ 2.5 billion .',
'They had published an advertisement on the Interne',
't on June 10 , offering the cargo for sale , he ad',
'ded .',
'Around 0335 GMT , Tab shares were up 19 cents , or',
' 4.4 % , at A $ 4.56 , having earlier set a record']}
```
Notice how the sentences are split into shorter chunks now, and there are more rows in the dataset.
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> chunked_dataset
Dataset(schema: {'chunks': 'string'}, num_rows: 10470)
```
#### Data augmentation
The [`~Dataset.map`] function could also be used for data augmentation. The following example generates additional words for a masked token in a sentence.
Load and use the [RoBERTA](https://huggingface.co/roberta-base) model in 🤗 Transformers' [FillMaskPipeline](https://huggingface.co/transformers/main_classes/pipelines#transformers.FillMaskPipeline):
```py
>>> from random import randint
>>> from transformers import pipeline
>>> fillmask = pipeline("fill-mask", model="roberta-base")
>>> mask_token = fillmask.tokenizer.mask_token
>>> smaller_dataset = dataset.filter(lambda e, i: i<100, with_indices=True)
```
Create a function to randomly select a word to mask in the sentence. The function should also return the original sentence and the top two replacements generated by RoBERTA.
```py
>>> def augment_data(examples):
... outputs = []
... for sentence in examples["sentence1"]:
... words = sentence.split(' ')
... K = randint(1, len(words)-1)
... masked_sentence = " ".join(words[:K] + [mask_token] + words[K+1:])
... predictions = fillmask(masked_sentence)
... augmented_sequences = [predictions[i]["sequence"] for i in range(3)]
... outputs += [sentence] + augmented_sequences
...
... return {"data": outputs}
```
Use [`~Dataset.map`] to apply the function over the whole dataset:
```py
>>> augmented_dataset = smaller_dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, batch_size=8)
>>> augmented_dataset[:9]["data"]
['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'Amrozi accused his brother, whom he called " the witness ", of deliberately withholding his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately suppressing his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately destroying his evidence.',
"Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'Yucaipa owned Dominick Stores before selling the chain to Safeway in 1998 for $ 2.5 billion.',
"Yucaipa owned Dominick's before selling the chain to Safeway in 1998 for $ 2.5 billion.",
'Yucaipa owned Dominick Pizza before selling the chain to Safeway in 1998 for $ 2.5 billion.'
]
```
For each original sentence, RoBERTA augmented a random word with three alternatives. The original word `distorting` is supplemented by `withholding`, `suppressing`, and `destroying`.
### Process multiple splits
Many datasets have splits that can be processed simultaneously with [`DatasetDict.map`]. For example, tokenize the `sentence1` field in the train and test split by:
```py
>>> from datasets import load_dataset
# load all the splits
>>> dataset = load_dataset('glue', 'mrpc')
>>> encoded_dataset = dataset.map(lambda examples: tokenizer(examples["sentence1"]), batched=True)
>>> encoded_dataset["train"][0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0,
'input_ids': [ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
```
### Distributed usage
When you use [`~Dataset.map`] in a distributed setting, you should also use [torch.distributed.barrier](https://pytorch.org/docs/stable/distributed?highlight=barrier#torch.distributed.barrier). This ensures the main process performs the mapping, while the other processes load the results, thereby avoiding duplicate work.
The following example shows how you can use `torch.distributed.barrier` to synchronize the processes:
```py
>>> from datasets import Dataset
>>> import torch.distributed
>>> dataset1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> if training_args.local_rank > 0:
... print("Waiting for main process to perform the mapping")
... torch.distributed.barrier()
>>> dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})
>>> if training_args.local_rank == 0:
... print("Loading results from main process")
... torch.distributed.barrier()
```
## Concatenate
Separate datasets can be concatenated if they share the same column types. Concatenate datasets with [`concatenate_datasets`]:
```py
>>> from datasets import concatenate_datasets, load_dataset
>>> bookcorpus = load_dataset("bookcorpus", split="train")
>>> wiki = load_dataset("wikipedia", "20220301.en", split="train")
>>> wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
>>> assert bookcorpus.features.type == wiki.features.type
>>> bert_dataset = concatenate_datasets([bookcorpus, wiki])
```
You can also concatenate two datasets horizontally by setting `axis=1` as long as the datasets have the same number of rows:
```py
>>> from datasets import Dataset
>>> bookcorpus_ids = Dataset.from_dict({"ids": list(range(len(bookcorpus)))})
>>> bookcorpus_with_ids = concatenate_datasets([bookcorpus, bookcorpus_ids], axis=1)
```
### Interleave
You can also mix several datasets together by taking alternating examples from each one to create a new dataset. This is known as *interleaving*, which is enabled by the [`interleave_datasets`] function. Both [`interleave_datasets`] and [`concatenate_datasets`] work with regular [`Dataset`] and [`IterableDataset`] objects.
Refer to the [Stream](./stream#interleave) guide for an example of how to interleave [`IterableDataset`] objects.
You can define sampling probabilities for each of the original datasets to specify how to interleave the datasets.
In this case, the new dataset is constructed by getting examples one by one from a random dataset until one of the datasets runs out of samples.
```py
>>> seed = 42
>>> probabilities = [0.3, 0.5, 0.2]
>>> d1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
>>> d3 = Dataset.from_dict({"a": [20, 21, 22]})
>>> dataset = interleave_datasets([d1, d2, d3], probabilities=probabilities, seed=seed)
>>> dataset["a"]
[10, 11, 20, 12, 0, 21, 13]
```
You can also specify the `stopping_strategy`. The default strategy, `first_exhausted`, is a subsampling strategy, i.e the dataset construction is stopped as soon one of the dataset runs out of samples.
You can specify `stopping_strategy=all_exhausted` to execute an oversampling strategy. In this case, the dataset construction is stopped as soon as every samples in every dataset has been added at least once. In practice, it means that if a dataset is exhausted, it will return to the beginning of this dataset until the stop criterion has been reached.
Note that if no sampling probabilities are specified, the new dataset will have `max_length_datasets*nb_dataset samples`.
```py
>>> d1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
>>> d3 = Dataset.from_dict({"a": [20, 21, 22]})
>>> dataset = interleave_datasets([d1, d2, d3], stopping_strategy="all_exhausted")
>>> dataset["a"]
[0, 10, 20, 1, 11, 21, 2, 12, 22, 0, 13, 20]
```
## Format
The [`~Dataset.set_format`] function changes the format of a column to be compatible with some common data formats. Specify the output you'd like in the `type` parameter and the columns you want to format. Formatting is applied on-the-fly.
For example, create PyTorch tensors by setting `type="torch"`:
```py
>>> import torch
>>> dataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
```
The [`~Dataset.with_format`] function also changes the format of a column, except it returns a new [`Dataset`] object:
```py
>>> dataset = dataset.with_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
```
<Tip>
🤗 Datasets also provides support for other common data formats such as NumPy, Pandas, and JAX. Check out the [Using Datasets with TensorFlow](https://huggingface.co/docs/datasets/master/en/use_with_tensorflow#using-totfdataset) guide for more details on how to efficiently create a TensorFlow dataset.
</Tip>
If you need to reset the dataset to its original format, use the [`~Dataset.reset_format`] function:
```py
>>> dataset.format
{'type': 'torch', 'format_kwargs': {}, 'columns': ['label'], 'output_all_columns': False}
>>> dataset.reset_format()
>>> dataset.format
{'type': 'python', 'format_kwargs': {}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
```
### Format transform
The [`~Dataset.set_transform`] function applies a custom formatting transform on-the-fly. This function replaces any previously specified format. For example, you can use this function to tokenize and pad tokens on-the-fly. Tokenization is only applied when examples are accessed:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> def encode(batch):
... return tokenizer(batch["sentence1"], padding="longest", truncation=True, max_length=512, return_tensors="pt")
>>> dataset.set_transform(encode)
>>> dataset.format
{'type': 'custom', 'format_kwargs': {'transform': <function __main__.encode(batch)>}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
```
You can also use the [`~Dataset.set_transform`] function to decode formats not supported by [`Features`]. For example, the [`Audio`] feature uses [`soundfile`](https://python-soundfile.readthedocs.io/en/0.11.0/) - a fast and simple library to install - but it does not provide support for less common audio formats. Here is where you can use [`~Dataset.set_transform`] to apply a custom decoding transform on the fly. You're free to use any library you like to decode the audio files.
The example below uses the [`pydub`](http://pydub.com/) package to open an audio format not supported by `soundfile`:
```py
>>> import numpy as np
>>> from pydub import AudioSegment
>>> audio_dataset_amr = Dataset.from_dict({"audio": ["audio_samples/audio.amr"]})
>>> def decode_audio_with_pydub(batch, sampling_rate=16_000):
... def pydub_decode_file(audio_path):
... sound = AudioSegment.from_file(audio_path)
... if sound.frame_rate != sampling_rate:
... sound = sound.set_frame_rate(sampling_rate)
... channel_sounds = sound.split_to_mono()
... samples = [s.get_array_of_samples() for s in channel_sounds]
... fp_arr = np.array(samples).T.astype(np.float32)
... fp_arr /= np.iinfo(samples[0].typecode).max
... return fp_arr
...
... batch["audio"] = [pydub_decode_file(audio_path) for audio_path in batch["audio"]]
... return batch
>>> audio_dataset_amr.set_transform(decode_audio_with_pydub)
```
## Save
Once you are done processing your dataset, you can save and reuse it later with [`~Dataset.save_to_disk`].
Save your dataset by providing the path to the directory you wish to save it to:
```py
>>> encoded_dataset.save_to_disk("path/of/my/dataset/directory")
```
Use the [`load_from_disk`] function to reload the dataset:
```py
>>> from datasets import load_from_disk
>>> reloaded_dataset = load_from_disk("path/of/my/dataset/directory")
```
<Tip>
Want to save your dataset to a cloud storage provider? Read our [Cloud Storage](./filesystems) guide to learn how to save your dataset to AWS or Google Cloud Storage.
</Tip>
## Export
🤗 Datasets supports exporting as well so you can work with your dataset in other applications. The following table shows currently supported file formats you can export to:
| File type | Export method |
|-------------------------|----------------------------------------------------------------|
| CSV | [`Dataset.to_csv`] |
| JSON | [`Dataset.to_json`] |
| Parquet | [`Dataset.to_parquet`] |
| SQL | [`Dataset.to_sql`] |
| In-memory Python object | [`Dataset.to_pandas`] or [`Dataset.to_dict`] |
For example, export your dataset to a CSV file like this:
```py
>>> encoded_dataset.to_csv("path/of/my/dataset.csv")
```
| huggingface/datasets/blob/main/docs/source/process.mdx |
Metric Card for SQuAD v2
## Metric description
This metric wraps the official scoring script for version 2 of the [Stanford Question Answering Dataset (SQuAD)](https://huggingface.co/datasets/squad_v2).
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
SQuAD 2.0 combines the 100,000 questions in SQuAD 1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
## How to use
The metric takes two files or two lists - one representing model predictions and the other the references to compare them to.
*Predictions* : List of triple for question-answers to score with the following key-value pairs:
* `'id'`: the question-answer identification field of the question and answer pair
* `'prediction_text'` : the text of the answer
* `'no_answer_probability'` : the probability that the question has no answer
*References*: List of question-answers dictionaries with the following key-value pairs:
* `'id'`: id of the question-answer pair (see above),
* `'answers'`: a list of Dict {'text': text of the answer as a string}
* `'no_answer_threshold'`: the probability threshold to decide that a question has no answer.
```python
from datasets import load_metric
squad_metric = load_metric("squad_v2")
results = squad_metric.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with 13 values:
* `'exact'`: Exact match (the normalized answer exactly match the gold answer) (see the `exact_match` metric (forthcoming))
* `'f1'`: The average F1-score of predicted tokens versus the gold answer (see the [F1 score](https://huggingface.co/metrics/f1) metric)
* `'total'`: Number of scores considered
* `'HasAns_exact'`: Exact match (the normalized answer exactly match the gold answer)
* `'HasAns_f1'`: The F-score of predicted tokens versus the gold answer
* `'HasAns_total'`: How many of the questions have answers
* `'NoAns_exact'`: Exact match (the normalized answer exactly match the gold answer)
* `'NoAns_f1'`: The F-score of predicted tokens versus the gold answer
* `'NoAns_total'`: How many of the questions have no answers
* `'best_exact'` : Best exact match (with varying threshold)
* `'best_exact_thresh'`: No-answer probability threshold associated to the best exact match
* `'best_f1'`: Best F1 score (with varying threshold)
* `'best_f1_thresh'`: No-answer probability threshold associated to the best F1
The range of `exact_match` is 0-100, where 0.0 means no answers were matched and 100.0 means all answers were matched.
The range of `f1` is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall.
The range of `total` depends on the length of predictions/references: its minimal value is 0, and maximal value is the total number of questions in the predictions and references.
### Values from popular papers
The [SQuAD v2 paper](https://arxiv.org/pdf/1806.03822.pdf) reported an F1 score of 66.3% and an Exact Match score of 63.4%.
They also report that human performance on the dataset represents an F1 score of 89.5% and an Exact Match score of 86.9%.
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/squad).
## Examples
Maximal values for both exact match and F1 (perfect match):
```python
from datasets import load_metric
squad_v2_ metric = load_metric("squad_v2")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22', 'no_answer_probability': 0.}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_v2_metric.compute(predictions=predictions, references=references)
results
{'exact': 100.0, 'f1': 100.0, 'total': 1, 'HasAns_exact': 100.0, 'HasAns_f1': 100.0, 'HasAns_total': 1, 'best_exact': 100.0, 'best_exact_thresh': 0.0, 'best_f1': 100.0, 'best_f1_thresh': 0.0}
```
Minimal values for both exact match and F1 (no match):
```python
from datasets import load_metric
squad_metric = load_metric("squad_v2")
predictions = [{'prediction_text': '1999', 'id': '56e10a3be3433e1400422b22', 'no_answer_probability': 0.}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_v2_metric.compute(predictions=predictions, references=references)
results
{'exact': 0.0, 'f1': 0.0, 'total': 1, 'HasAns_exact': 0.0, 'HasAns_f1': 0.0, 'HasAns_total': 1, 'best_exact': 0.0, 'best_exact_thresh': 0.0, 'best_f1': 0.0, 'best_f1_thresh': 0.0}
```
Partial match (2 out of 3 answers correct) :
```python
from datasets import load_metric
squad_metric = load_metric("squad_v2")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22', 'no_answer_probability': 0.}, {'prediction_text': 'Beyonce', 'id': '56d2051ce7d4791d0090260b', 'no_answer_probability': 0.}, {'prediction_text': 'climate change', 'id': '5733b5344776f419006610e1', 'no_answer_probability': 0.}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}, {'answers': {'answer_start': [233], 'text': ['Beyoncé and Bruno Mars']}, 'id': '56d2051ce7d4791d0090260b'}, {'answers': {'answer_start': [891], 'text': ['climate change']}, 'id': '5733b5344776f419006610e1'}]
results = squad_v2_metric.compute(predictions=predictions, references=references)
results
{'exact': 66.66666666666667, 'f1': 66.66666666666667, 'total': 3, 'HasAns_exact': 66.66666666666667, 'HasAns_f1': 66.66666666666667, 'HasAns_total': 3, 'best_exact': 66.66666666666667, 'best_exact_thresh': 0.0, 'best_f1': 66.66666666666667, 'best_f1_thresh': 0.0}
```
## Limitations and bias
This metric works only with the datasets in the same format as the [SQuAD v.2 dataset](https://huggingface.co/datasets/squad_v2).
The SQuAD datasets do contain a certain amount of noise, such as duplicate questions as well as missing answers, but these represent a minority of the 100,000 question-answer pairs. Also, neither exact match nor F1 score reflect whether models do better on certain types of questions (e.g. who questions) or those that cover a certain gender or geographical area -- carrying out more in-depth error analysis can complement these numbers.
## Citation
```bibtex
@inproceedings{Rajpurkar2018SQuAD2,
title={Know What You Don't Know: Unanswerable Questions for SQuAD},
author={Pranav Rajpurkar and Jian Zhang and Percy Liang},
booktitle={ACL 2018},
year={2018}
}
```
## Further References
- [The Stanford Question Answering Dataset: Background, Challenges, Progress (blog post)](https://rajpurkar.github.io/mlx/qa-and-squad/)
- [Hugging Face Course -- Question Answering](https://huggingface.co/course/chapter7/7)
| huggingface/datasets/blob/main/metrics/squad_v2/README.md |
Gradio Demo: Echocardiogram-Segmentation
```
!pip install -q gradio -f https://download.pytorch.org/whl/torch_stable.html numpy matplotlib wget torch torchvision
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/Echocardiogram-Segmentation/img1.jpg
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/Echocardiogram-Segmentation/img2.jpg
```
```
import os
import numpy as np
import torch
import torchvision
import wget
destination_folder = "output"
destination_for_weights = "weights"
if os.path.exists(destination_for_weights):
print("The weights are at", destination_for_weights)
else:
print("Creating folder at ", destination_for_weights, " to store weights")
os.mkdir(destination_for_weights)
segmentationWeightsURL = 'https://github.com/douyang/EchoNetDynamic/releases/download/v1.0.0/deeplabv3_resnet50_random.pt'
if not os.path.exists(os.path.join(destination_for_weights, os.path.basename(segmentationWeightsURL))):
print("Downloading Segmentation Weights, ", segmentationWeightsURL," to ",os.path.join(destination_for_weights, os.path.basename(segmentationWeightsURL)))
filename = wget.download(segmentationWeightsURL, out = destination_for_weights)
else:
print("Segmentation Weights already present")
torch.cuda.empty_cache()
def collate_fn(x):
x, f = zip(*x)
i = list(map(lambda t: t.shape[1], x))
x = torch.as_tensor(np.swapaxes(np.concatenate(x, 1), 0, 1))
return x, f, i
model = torchvision.models.segmentation.deeplabv3_resnet50(pretrained=False, aux_loss=False)
model.classifier[-1] = torch.nn.Conv2d(model.classifier[-1].in_channels, 1, kernel_size=model.classifier[-1].kernel_size)
print("loading weights from ", os.path.join(destination_for_weights, "deeplabv3_resnet50_random"))
if torch.cuda.is_available():
print("cuda is available, original weights")
device = torch.device("cuda")
model = torch.nn.DataParallel(model)
model.to(device)
checkpoint = torch.load(os.path.join(destination_for_weights, os.path.basename(segmentationWeightsURL)))
model.load_state_dict(checkpoint['state_dict'])
else:
print("cuda is not available, cpu weights")
device = torch.device("cpu")
checkpoint = torch.load(os.path.join(destination_for_weights, os.path.basename(segmentationWeightsURL)), map_location = "cpu")
state_dict_cpu = {k[7:]: v for (k, v) in checkpoint['state_dict'].items()}
model.load_state_dict(state_dict_cpu)
model.eval()
def segment(input):
inp = input
x = inp.transpose([2, 0, 1]) # channels-first
x = np.expand_dims(x, axis=0) # adding a batch dimension
mean = x.mean(axis=(0, 2, 3))
std = x.std(axis=(0, 2, 3))
x = x - mean.reshape(1, 3, 1, 1)
x = x / std.reshape(1, 3, 1, 1)
with torch.no_grad():
x = torch.from_numpy(x).type('torch.FloatTensor').to(device)
output = model(x)
y = output['out'].numpy()
y = y.squeeze()
out = y>0
mask = inp.copy()
mask[out] = np.array([0, 0, 255])
return mask
import gradio as gr
i = gr.Image(label="Echocardiogram")
o = gr.Image(label="Segmentation Mask")
examples = [["img1.jpg"], ["img2.jpg"]]
title = None #"Left Ventricle Segmentation"
description = "This semantic segmentation model identifies the left ventricle in echocardiogram images."
# videos. Accurate evaluation of the motion and size of the left ventricle is crucial for the assessment of cardiac function and ejection fraction. In this interface, the user inputs apical-4-chamber images from echocardiography videos and the model will output a prediction of the localization of the left ventricle in blue. This model was trained on the publicly released EchoNet-Dynamic dataset of 10k echocardiogram videos with 20k expert annotations of the left ventricle and published as part of ‘Video-based AI for beat-to-beat assessment of cardiac function’ by Ouyang et al. in Nature, 2020."
thumbnail = "https://raw.githubusercontent.com/gradio-app/hub-echonet/master/thumbnail.png"
gr.Interface(segment, i, o, examples=examples, analytics_enabled=False, thumbnail=thumbnail, cache_examples=False).launch()
```
| gradio-app/gradio/blob/main/demo/Echocardiogram-Segmentation/run.ipynb |
he post-processing step in a question answering task. When doing question answering, the processing of the initial dataset implies splitting examples in several features, which may or may not contain the answer. Passing those features through the model will give us logits for the start and end positions, since our labels are the indices of the tokens that correspond to the start and end the answer. We must then somehow convert those logits into an answer, and then pick one of the various answers each feature gives to be THE answer for a given example. For the processing step, you should refer to the video linked below. It's not very different for validation, we just need to add a few lines to keep track of two things: instead of discarding the offset mapping, we keep them, and also include in them the information of where the context is by setting the offsets of the special tokens and the question to None. Then we also keep track of the example ID for each feature, to be able to map back feature to the examples that they originated from. If you don't want to compute the validation loss, you won't need to include all the special code that we used to create the labels. With this done, we can apply that preprocessing function using the map method. We take the SQUAD dataset like in the preprocessing for question-answering video. Once this is done, the next step is to create our model. We use the default model behind the question-answering pipeline here, but you should use any model you want to evaluate. With the to_tf_dataset method, we can just sent our processed dataset to model.predict, and we directly get our start and end logits for the whole dataset as NumPy arrays. With this done, we can really dive into the post-processing. We will need a map from examples to features, which we can create like this. Now, for the main part of the post-processing, let's see how to extract an answer from the logits. We could just take the best index for the start and end logits and be done, but if our model predicts something impossible, like tokens in the question, we will look at more of the logits. Note that in the question-answering pipeline, we attributed score to each answer based on the probabilities, which we did not compute here. In terms of logits, the multiplication we had in the scores becomes an addition. To go fast, we don't look at all possible start and end logits, but the twenty best ones. We ignore the logits that spawn impossible answers or answer that are too long. As we saw in the preprocessing, the labels (0, 0) correspond to no answer, otherwise we use the offsets to get the answer inside the context. Let's have a look at the predicted answer for the first feature, which is the answer with the best score (or the best logit score since the SoftMax is an increasing function). The model got it right! Next we just have to loop this for every example, picking for each the answer with the best logit score in all the features the example generated. Now you know how to get answers from your model predictions! | huggingface/course/blob/main/subtitles/en/raw/chapter7/07b_question-answering-post-processing-tf.md |
--
title: Deprecation of Git Authentication using password
thumbnail: /blog/assets/password-git-deprecation/thumbnail.png
authors:
- user: Sylvestre
- user: pierric
- user: sbrandeis
---
# Hugging Face Hub: Important Git Authentication Changes
Because we are committed to improving the security of our services, we are making changes to the way you authenticate when interacting with the Hugging Face Hub through Git.
Starting from **October 1st, 2023**, we will no longer accept passwords as a way to authenticate your command-line Git operations. Instead, we recommend using more secure authentication methods, such as replacing the password with a personal access token or using an SSH key.
## Background
In recent months, we have implemented various security enhancements, including sign-in alerts and support for SSH keys in Git. However, users have still been able to authenticate Git operations using their username and password. To further improve security, we are now transitioning to token-based or SSH key authentication.
Token-based and SSH key authentication offer several advantages over traditional password authentication, including unique, revocable, and random features that enhance security and control.
## Action Required Today
If you currently use your HF account password to authenticate with Git, please switch to using a personal access token or SSH keys before **October 1st, 2023**.
### Switching to personal access token
You will need to generate an access token for your account; you can follow https://huggingface.co/docs/hub/security-tokens#user-access-tokens to generate one.
After generating your access token, you can update your Git repository using the following commands:
```bash
$: git remote set-url origin https://<user_name>:<token>@huggingface.co/<repo_path>
$: git pull origin
```
where `<repo_path>` is in the form of:
- `<user_name>/<repo_name>` for models
- `datasets/<user_name>/<repo_name>` for datasets
- `spaces/<user_name>/<repo_name>` for Spaces
If you clone a new repo, you can just input a token in place of your password when your Git credential manager asks you for your authentication credentials.
### Switching to SSH keys
Follow our guide to generate an SSH key and add it to your account: https://huggingface.co/docs/hub/security-git-ssh
Then you'll be able to update your Git repository using:
```bash
$: git remote set-url origin [email protected]:<repo_path> # see above for the format of the repo path
```
## Timeline
Here's what you can expect in the coming weeks:
- Today: Users relying on passwords for Git authentication may receive emails urging them to update their authentication method.
- October 1st: Personal access tokens or SSH keys will be mandatory for all Git operations.
For more details, reach out to HF Support to address any questions or concerns at [email protected]
| huggingface/blog/blob/main/password-git-deprecation.md |
`@gradio/button`
```javascript
<script>
import { BaseButton } from "@gradio/button";
import { createEventDispatcher, tick, getContext } from "svelte";
const dispatch = createEventDispatcher();
</script>
<BaseButton
{value}
{variant}
{elem_id}
{elem_classes}
{size}
{scale}
{link}
{icon}
{min_width}
{visible}
{root}
{root_url}
on:click={() => dispatch("click")}
>
{"My Button"}
</Button>
```
| gradio-app/gradio/blob/main/js/button/README.md |
(Gluon) Xception
**Xception** is a convolutional neural network architecture that relies solely on [depthwise separable convolution](https://paperswithcode.com/method/depthwise-separable-convolution) layers.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('gluon_xception65', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_xception65`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('gluon_xception65', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{chollet2017xception,
title={Xception: Deep Learning with Depthwise Separable Convolutions},
author={François Chollet},
year={2017},
eprint={1610.02357},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun Xception
Paper:
Title: 'Xception: Deep Learning with Depthwise Separable Convolutions'
URL: https://paperswithcode.com/paper/xception-deep-learning-with-depthwise
Models:
- Name: gluon_xception65
In Collection: Gloun Xception
Metadata:
FLOPs: 17594889728
Parameters: 39920000
File Size: 160551306
Architecture:
- 1x1 Convolution
- Convolution
- Dense Connections
- Depthwise Separable Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_xception65
Crop Pct: '0.903'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_xception.py#L241
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/gluon_xception-7015a15c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.7%
Top 5 Accuracy: 94.87%
--> | huggingface/pytorch-image-models/blob/main/docs/models/gloun-xception.md |
--
title: "Finetune Stable Diffusion Models with DDPO via TRL"
thumbnail: /blog/assets/166_trl_ddpo/thumbnail.png
authors:
- user: metric-space
guest: true
- user: sayakpaul
- user: kashif
- user: lvwerra
---
# Finetune Stable Diffusion Models with DDPO via TRL
## Introduction
Diffusion models (e.g., DALL-E 2, Stable Diffusion) are a class of generative models that are widely successful at generating images most notably of the photorealistic kind. However, the images generated by these models may not always be on par with human preference or human intention. Thus arises the alignment problem i.e. how does one go about making sure that the outputs of a model are aligned with human preferences like “quality” or that outputs are aligned with intent that is hard to express via prompts? This is where Reinforcement Learning comes into the picture.
In the world of Large Language Models (LLMs), Reinforcement learning (RL) has proven to become a very effective tool for aligning said models to human preferences. It’s one of the main recipes behind the superior performance of systems like ChatGPT. More precisely, RL is the critical ingredient of Reinforcement Learning from Human Feedback (RLHF), which makes ChatGPT chat like human beings.
In [Training Diffusion Models with Reinforcement Learning, Black](https://arxiv.org/abs/2305.13301) et al. show how to augment diffusion models to leverage RL to fine-tune them with respect to an objective function via a method named Denoising Diffusion Policy Optimization (DDPO).
In this blog post, we discuss how DDPO came to be, a brief description of how it works, and how DDPO can be incorporated into an RLHF workflow to achieve model outputs more aligned with the human aesthetics. We then quickly switch gears to talk about how you can apply DDPO to your models with the newly integrated `DDPOTrainer` from the `trl` library and discuss our findings from running DDPO on Stable Diffusion.
## The Advantages of DDPO
DDPO is not the only working answer to the question of how to attempt to fine-tune diffusion models with RL.
Before diving in, there are two key points to remember when it comes to understanding the advantages of one RL solution over the other
1. Computational efficiency is key. The more complicated your data distribution gets, the higher your computational costs get.
2. Approximations are nice, but because approximations are not the real thing, associated errors stack up.
Before DDPO, Reward-weighted regression (RWR) was an established way of using Reinforcement Learning to fine-tune diffusion models. RWR reuses the denoising loss function of the diffusion model along with training data sampled from the model itself and per-sample loss weighting that depends on the reward associated with the final samples. This algorithm ignores the intermediate denoising steps/samples. While this works, two things should be noted:
1. Optimizing by weighing the associated loss, which is a maximum likelihood objective, is an approximate optimization
2. The associated loss is not an exact maximum likelihood objective but an approximation that is derived from a reweighed variational bound
The two orders of approximation have a significant impact on both performance and the ability to handle complex objectives.
DDPO uses this method as a starting point. Rather than viewing the denoising step as a single step by only focusing on the final sample, DDPO frames the whole denoising process as a multistep Markov Decision Process (MDP) where the reward is received at the very end. This formulation in addition to using a fixed sampler paves the way for the agent policy to become an isotropic Gaussian as opposed to an arbitrarily complicated distribution. So instead of using the approximate likelihood of the final sample (which is the path RWR takes), here the exact likelihood of each denoising step which is extremely easy to compute ( \\( \ell(\mu, \sigma^2; x) = -\frac{n}{2} \log(2\pi) - \frac{n}{2} \log(\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^n (x_i - \mu)^2 \\) ).
If you’re interested in learning more details about DDPO, we encourage you to check out the [original paper](https://arxiv.org/abs/2305.13301) and the [accompanying blog post](https://bair.berkeley.edu/blog/2023/07/14/ddpo/).
## DDPO algorithm briefly
Given the MDP framework used to model the sequential nature of the denoising process and the rest of the considerations that follow, the tool of choice to tackle the optimization problem is a policy gradient method. Specifically Proximal Policy Optimization (PPO). The whole DDPO algorithm is pretty much the same as Proximal Policy Optimization (PPO) but as a side, the portion that stands out as highly customized is the trajectory collection portion of PPO
Here’s a diagram to summarize the flow:

## DDPO and RLHF: a mix to enforce aestheticness
The general training aspect of [RLHF](https://huggingface.co/blog/rlhf) can roughly be broken down into the following steps:
1. Supervised fine-tuning a “base” model learns to the distribution of some new data
2. Gathering preference data and training a reward model using it.
3. Fine-tuning the model with reinforcement learning using the reward model as a signal.
It should be noted that preference data is the primary source for capturing human feedback in the context of RLHF.
When we add DDPO to the mix, the workflow gets morphed to the following:
1. Starting with a pretrained Diffusion Model
2. Gathering preference data and training a reward model using it.
3. Fine-tuning the model with DDPO using the reward model as a signal
Notice that step 3 from the general RLHF workflow is missing in the latter list of steps and this is because empirically it has been shown (as you will get to see yourself) that this is not needed.
To get on with our venture to get a diffusion model to output images more in line with the human perceived notion of what it means to be aesthetic, we follow these steps:
1. Starting with a pretrained Stable Diffusion (SD) Model
2. Training a frozen [CLIP](https://huggingface.co/openai/clip-vit-large-patch14) model with a trainable regression head on the [Aesthetic Visual Analysis](http://refbase.cvc.uab.es/files/MMP2012a.pdf) (AVA) dataset to predict how much people like an input image on average
3. Fine-tuning the SD model with DDPO using the aesthetic predictor model as the reward signaller
We keep these steps in mind while moving on to actually getting these running which is described in the following sections.
## Training Stable Diffusion with DDPO
### Setup
To get started, when it comes to the hardware side of things and this implementation of DDPO, at the very least access to an A100 NVIDIA GPU is required for successful training. Anything below this GPU type will soon run into Out-of-memory issues.
Use pip to install the `trl` library
```bash
pip install trl[diffusers]
```
This should get the main library installed. The following dependencies are for tracking and image logging. After getting `wandb` installed, be sure to login to save the results to a personal account
```bash
pip install wandb torchvision
```
Note: you could choose to use `tensorboard` rather than `wandb` for which you’d want to install the `tensorboard` package via `pip`.
### A Walkthrough
The main classes within the `trl` library responsible for DDPO training are the `DDPOTrainer` and `DDPOConfig` classes. See [docs](https://huggingface.co/docs/trl/ddpo_trainer#getting-started-with-examplesscriptsstablediffusiontuningpy) for more general info on the `DDPOTrainer` and `DDPOConfig`. There is an [example training script](https://github.com/huggingface/trl/blob/main/examples/scripts/ddpo.py) in the `trl` repo. It uses both of these classes in tandem with default implementations of required inputs and default parameters to finetune a default pretrained Stable Diffusion Model from `RunwayML` .
This example script uses `wandb` for logging and uses an aesthetic reward model whose weights are read from a public facing HuggingFace repo (so gathering data and training the aesthetic reward model is already done for you). The default prompt dataset used is a list of animal names.
There is only one commandline flag argument that is required of the user to get things up and running. Additionally, the user is expected to have a [huggingface user access token](https://huggingface.co/docs/hub/security-tokens) that will be used to upload the model post finetuning to HuggingFace hub.
The following bash command gets things running:
```python
python stable_diffusion_tuning.py --hf_user_access_token <token>
```
The following table contains key hyperparameters that are directly correlated with positive results:
| Parameter | Description | Recommended value for single GPU training (as of now) |
| --- | --- | --- |
| `num_epochs` | The number of epochs to train for | 200 |
| `train_batch_size` | The batch size to use for training | 3 |
| `sample_batch_size` | The batch size to use for sampling | 6 |
| `gradient_accumulation_steps` | The number of accelerator based gradient accumulation steps to use | 1 |
| `sample_num_steps` | The number of steps to sample for | 50 |
| `sample_num_batches_per_epoch` | The number of batches to sample per epoch | 4 |
| `per_prompt_stat_tracking` | Whether to track stats per prompt. If false, advantages will be calculated using the mean and std of the entire batch as opposed to tracking per prompt | `True` |
| `per_prompt_stat_tracking_buffer_size` | The size of the buffer to use for tracking stats per prompt | 32 |
| `mixed_precision` | Mixed precision training | `True` |
| `train_learning_rate` | Learning rate | 3e-4 |
The provided script is merely a starting point. Feel free to adjust the hyperparameters or even overhaul the script to accommodate different objective functions. For instance, one could integrate a function that gauges JPEG compressibility or [one that evaluates visual-text alignment using a multi-modal model](https://github.com/kvablack/ddpo-pytorch/blob/main/ddpo_pytorch/rewards.py#L45), among other possibilities.
## Lessons learned
1. The results seem to generalize over a wide variety of prompts despite the minimally sized training prompts size. This has been thoroughly verified for the objective function that rewards aesthetics
2. Attempts to try to explicitly generalize at least for the aesthetic objective function by increasing the training prompt size and varying the prompts seem to slow down the convergence rate for barely noticeable learned general behavior if at all this exists
3. While LoRA is recommended and is tried and tested multiple times, the non-LoRA is something to consider, among other reasons from empirical evidence, non-Lora does seem to produce relatively more intricate images than LoRA. However, getting the right hyperparameters for a stable non-LoRA run is significantly more challenging.
4. Recommendations for the config parameters for non-Lora are: set the learning rate relatively low, something around `1e-5` should do the trick and set `mixed_precision` to `None`
## Results
The following are pre-finetuned (left) and post-finetuned (right) outputs for the prompts `bear`, `heaven` and `dune` (each row is for the outputs of a single prompt):
| pre-finetuned | post-finetuned |
|:-------------------------:|:-------------------------:|
|  |  |
|  |  |
|  |  |
## Limitations
1. Right now `trl`'s DDPOTrainer is limited to finetuning vanilla SD models;
2. In our experiments we primarily focused on LoRA which works very well. We did a few experiments with full training which can lead to better quality but finding the right hyperparameters is more challenging.
## Conclusion
Diffusion models like Stable Diffusion, when fine-tuned using DDPO, can offer significant improvements in the quality of generated images as perceived by humans or any other metric once properly conceptualized as an objective function
The computational efficiency of DDPO and its ability to optimize without relying on approximations, especially over earlier methods to achieve the same goal of fine-tuning diffusion models, make it a suitable candidate for fine-tuning diffusion models like Stable Diffusion
`trl` library's `DDPOTrainer` implements DDPO for finetuning SD models.
Our experimental findings underline the strength of DDPO in generalizing across a broad range of prompts, although attempts at explicit generalization through varying prompts had mixed results. The difficulty of finding the right hyperparameters for non-LoRA setups also emerged as an important learning.
DDPO is a promising technique to align diffusion models with any reward function and we hope that with the release in TRL we can make it more accessible to the community!
## Acknowledgements
Thanks to Chunte Lee for the thumbnail of this blog post.
| huggingface/blog/blob/main/trl-ddpo.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# VQDiffusionScheduler
`VQDiffusionScheduler` converts the transformer model's output into a sample for the unnoised image at the previous diffusion timestep. It was introduced in [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://huggingface.co/papers/2111.14822) by Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, Baining Guo.
The abstract from the paper is:
*We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.*
## VQDiffusionScheduler
[[autodoc]] VQDiffusionScheduler
## VQDiffusionSchedulerOutput
[[autodoc]] schedulers.scheduling_vq_diffusion.VQDiffusionSchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/vq_diffusion.md |
Gradio Demo: reverse_audio_2
```
!pip install -q gradio numpy
```
```
import gradio as gr
import numpy as np
def reverse_audio(audio):
sr, data = audio
return (sr, np.flipud(data))
demo = gr.Interface(fn=reverse_audio,
inputs="microphone",
outputs="audio")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/reverse_audio_2/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
🤗 Optimum handles the export of PyTorch or TensorFlow models to ONNX in the `exporters.onnx` module. It provides classes, functions, and a command line interface to perform the export easily.
Supported architectures from [🤗 Transformers](https://huggingface.co/docs/transformers/index):
- AST
- Audio Spectrogram Transformer
- Albert
- Bart
- Beit
- Bert
- BlenderBot
- BlenderBotSmall
- Bloom
- Camembert
- CLIP
- CodeGen
- ConvBert
- ConvNext
- ConvNextV2
- Data2VecAudio
- Data2VecText
- Data2VecVision
- Deberta
- Deberta-v2
- Deit
- Detr
- DistilBert
- Donut-Swin
- Electra
- Encoder Decoder
- ESM
- Falcon
- Flaubert
- GPT-2
- GPT-BigCode
- GPT-J
- GPT-Neo
- GPT-NeoX
- OPT
- GroupVit
- Hubert
- IBert
- LayoutLM
- LayoutLM-v3
- Lilt
- Levit
- LongT5
- Llama
- M2-M100
- Marian
- MBart
- Mistral
- MobileBert
- MobileVit
- MobileNet v1
- MobileNet v2
- MPNet
- MT5
- Nystromformer
- OWL-ViT
- Pegasus
- Perceiver
- Phi
- Pix2Struct
- PoolFormer
- RegNet
- ResNet
- Roberta
- Roformer
- SAM
- Segformer
- SEW
- SEW-D
- Speech2Text
- SpeechT5
- Splinter
- SqueezeBert
- Swin
- T5
- TROCR
- UniSpeech
- UniSpeech SAT
- Vision Encoder Decoder
- Vit
- Wav2Vec2
- Wav2Vec2 Conformer
- WavLM
- Whisper
- XLM
- XLM-Roberta
- Yolos
Supported architectures from [🤗 Diffusers](https://huggingface.co/docs/diffusers/index):
- Stable Diffusion
Supported architectures from [🤗 Timm](https://huggingface.co/docs/timm/index):
- Adversarial Inception v3
- AdvProp (EfficientNet)
- Big Transfer (BiT)
- CSP-DarkNet
- CSP-ResNet
- CSP-ResNeXt
- DenseNet
- Deep Layer Aggregation
- Dual Path Network (DPN)
- ECA-ResNet
- EfficientNet
- EfficientNet (Knapsack Pruned)
- Ensemble Adversarial Inception ResNet v2
- FBNet
- (Gluon) Inception v3
- (Gluon) ResNet
- (Gluon) ResNeXt
- (Gluon) SENet
- (Gluon) SE-ResNeXt
- (Gluon) Xception
- HRNet
- Instagram ResNeXt WSL
- Inception ResNet v2
- Inception v3
- Inception v4
- (Legacy) SE-ResNet
- (Legacy) SE-ResNeXt
- (Legacy) SENet
- MixNet
- MnasNet
- MobileNet v2
- MobileNet v3
- NASNet
- Noisy Student (EfficientNet)
- PNASNet
- RegNetX
- RegNetY
- Res2Net
- Res2NeXt
- ResNeSt
- ResNet
- ResNet-D
- ResNeXt
- RexNet
- SE-ResNet
- SelecSLS
- SE-ResNeXt
- SK-ResNet
- SK-ResNeXt
- SPNASNet
- SSL ResNet
- SWSL ResNet
- SWSL ResNeXt
- (Tensorflow) EfficientNet
- (Tensorflow) EfficientNet CondConv
- (Tensorflow) EfficientNet Lite
- (Tensorflow) Inception v3
- (Tensorflow) MixNet
- (Tensorflow) MobileNet v3
- TResNet
- Wide ResNet
- Xception
Supported architectures from [Sentence Transformers](https://github.com/UKPLab/sentence-transformers):
- All Transformer and CLIP-based models.
| huggingface/optimum/blob/main/docs/source/exporters/onnx/overview.mdx |
--
title: "Fine-Tune Whisper For Multilingual ASR with 🤗 Transformers"
thumbnail: /blog/assets/111_fine_tune_whisper/thumbnail.jpg
authors:
- user: sanchit-gandhi
---
# Fine-Tune Whisper For Multilingual ASR with 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/fine_tune_whisper.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In this blog, we present a step-by-step guide on fine-tuning Whisper
for any multilingual ASR dataset using Hugging Face 🤗 Transformers. This blog
provides in-depth explanations of the Whisper model, the Common Voice dataset and
the theory behind fine-tuning, with accompanying code cells to execute the data
preparation and fine-tuning steps. For a more streamlined version of the notebook
with fewer explanations but all the code, see the accompanying [Google Colab](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/fine_tune_whisper.ipynb).
## Table of Contents
1. [Introduction](#introduction)
2. [Fine-tuning Whisper in a Google Colab](#fine-tuning-whisper-in-a-google-colab)
1. [Prepare Environment](#prepare-environment)
2. [Load Dataset](#load-dataset)
3. [Prepare Feature Extractor, Tokenizer and Data](#prepare-feature-extractor-tokenizer-and-data)
4. [Training and Evaluation](#training-and-evaluation)
5. [Building a Demo](#building-a-demo)
3. [Closing Remarks](#closing-remarks)
## Introduction
Whisper is a pre-trained model for automatic speech recognition (ASR)
published in [September 2022](https://openai.com/blog/whisper/) by the authors
Alec Radford et al. from OpenAI. Unlike many of its predecessors, such as
[Wav2Vec 2.0](https://arxiv.org/abs/2006.11477), which are pre-trained
on un-labelled audio data, Whisper is pre-trained on a vast quantity of
**labelled** audio-transcription data, 680,000 hours to be precise.
This is an order of magnitude more data than the un-labelled audio data used
to train Wav2Vec 2.0 (60,000 hours). What is more, 117,000 hours of this
pre-training data is multilingual ASR data. This results in checkpoints
that can be applied to over 96 languages, many of which are considered
_low-resource_.
This quantity of labelled data enables Whisper to be pre-trained directly on the
_supervised_ task of speech recognition, learning a speech-to-text mapping from
the labelled audio-transcription pre-training data \\({}^1\\). As a consequence,
Whisper requires little additional fine-tuning to yield a performant ASR model.
This is in contrast to Wav2Vec 2.0, which is pre-trained on the _unsupervised_
task of masked prediction. Here, the model is trained to learn an intermediate
mapping from speech to hidden states from un-labelled audio only data.
While unsupervised pre-training yields high-quality representations of speech,
it does **not** learn a speech-to-text mapping. This mapping is only learned
during fine-tuning, thus requiring more fine-tuning to yield competitive
performance.
When scaled to 680,000 hours of labelled pre-training data, Whisper models
demonstrate a strong ability to generalise to many datasets and domains.
The pre-trained checkpoints achieve competitive results to state-of-the-art
ASR systems, with near 3% word error rate (WER) on the test-clean subset of
LibriSpeech ASR and a new state-of-the-art on TED-LIUM with 4.7% WER (_c.f._
Table 8 of the [Whisper paper](https://cdn.openai.com/papers/whisper.pdf)).
The extensive multilingual ASR knowledge acquired by Whisper during pre-training
can be leveraged for other low-resource languages; through fine-tuning, the
pre-trained checkpoints can be adapted for specific datasets and languages
to further improve upon these results.
Whisper is a Transformer based encoder-decoder model,
also referred to as a _sequence-to-sequence_ model. It maps a _sequence_
of audio spectrogram features to a _sequence_ of text tokens. First,
the raw audio inputs are converted to a log-Mel spectrogram by action of
the feature extractor. The Transformer encoder then encodes the spectrogram
to form a sequence of encoder hidden states. Finally, the decoder
autoregressively predicts text tokens, conditional on both the previous tokens
and the encoder hidden states. Figure 1 summarises the Whisper model.
<figure>
<img src="assets/111_fine_tune_whisper/whisper_architecture.svg" alt="Trulli" style="width:100%">
<figcaption align = "center"><b>Figure 1:</b> Whisper model. The architecture
follows the standard Transformer-based encoder-decoder model. A
log-Mel spectrogram is input to the encoder. The last encoder
hidden states are input to the decoder via cross-attention mechanisms. The
decoder autoregressively predicts text tokens, jointly conditional on the
encoder hidden states and previously predicted tokens. Figure source:
<a href="https://openai.com/blog/whisper/">OpenAI Whisper Blog</a>.</figcaption>
</figure>
In a sequence-to-sequence model, the encoder transforms the audio inputs
into a set of hidden state representations, extracting important features
from the spoken speech. The decoder plays the role of a language model,
processing the hidden state representations and generating the corresponding
text transcriptions. Incorporating a language model **internally** in the
system architecture is termed _deep fusion_. This is in contrast to
_shallow fusion_, where a language model is combined **externally** with
an encoder, such as with CTC + \\(n\\)-gram (_c.f._ [Internal Language Model Estimation](https://arxiv.org/pdf/2011.01991.pdf)).
With deep fusion, the entire system can be trained end-to-end with the
same training data and loss function, giving greater flexibility and generally
superior performance (_c.f._ [ESB Benchmark](https://arxiv.org/abs/2210.13352)).
Whisper is pre-trained and fine-tuned using the cross-entropy objective function,
a standard objective function for training sequence-to-sequence systems on classification tasks.
Here, the system is trained to correctly classify the target text token from a pre-defined
vocabulary of text tokens.
The Whisper checkpoints come in five configurations of varying model sizes.
The smallest four are trained on either English-only or multilingual data.
The largest checkpoint is multilingual only. All nine of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Layers | Width | Heads | Parameters | English-only | Multilingual |
|--------|--------|-------|-------|------------|------------------------------------------------------|---------------------------------------------------|
| tiny | 4 | 384 | 6 | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny.) |
| base | 6 | 512 | 8 | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 12 | 768 | 12 | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 24 | 1024 | 16 | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 32 | 1280 | 20 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
For demonstration purposes, we'll fine-tune the multilingual version of the
[`small`](https://huggingface.co/openai/whisper-small) checkpoint with 244M params (~= 1GB).
As for our data, we'll train and evaluate our system on a low-resource language
taken from the [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0)
dataset. We'll show that with as little as 8 hours of fine-tuning data, we can achieve
strong performance in this language.
------------------------------------------------------------------------
\\({}^1\\) The name Whisper follows from the acronym “WSPSR”, which stands for “Web-scale Supervised Pre-training for Speech Recognition”.
## Fine-tuning Whisper in a Google Colab
### Prepare Environment
We'll employ several popular Python packages to fine-tune the Whisper model.
We'll use `datasets` to download and prepare our training data, alongside
`transformers` and `accelerate` to load and train our Whisper model.
We'll also require the `soundfile` package to pre-process audio files,
`evaluate` and `jiwer` to assess the performance of our model, and
`tensorboard` to log our metrics. Finally, we'll use `gradio` to build a
flashy demo of our fine-tuned model.
```bash
!pip install --upgrade pip
!pip install --upgrade datasets transformers accelerate soundfile librosa evaluate jiwer tensorboard gradio
```
We strongly advise you to upload model checkpoints directly the [Hugging Face Hub](https://huggingface.co/)
whilst training. The Hub provides:
- Integrated version control: you can be sure that no model checkpoint is lost during training.
- Tensorboard logs: track important metrics over the course of training.
- Model cards: document what a model does and its intended use cases.
- Community: an easy way to share and collaborate with the community!
Linking the notebook to the Hub is straightforward - it simply requires entering your
Hub authentication token when prompted. Find your Hub authentication token [here](https://huggingface.co/settings/tokens):
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Print Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
```
### Load Dataset
Common Voice is a series of crowd-sourced datasets where speakers
record text from Wikipedia in various languages. We'll use the latest edition
of the Common Voice dataset ([version 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0)).
As for our language, we'll fine-tune our model on
[_Hindi_](https://en.wikipedia.org/wiki/Hindi), an Indo-Aryan language
spoken in northern, central, eastern, and western India. Common Voice 11.0
contains approximately 12 hours of labelled Hindi data, 4 of which are
held-out test data.
Let's head to the Hub and view the dataset page for Common Voice: [mozilla-foundation/common_voice_11_0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0).
The first time we view this page, we'll be asked to accept the
terms of use. After that, we'll be given full access to the dataset.
Once we've provided authentication to use the dataset, we'll be presented with the
dataset preview. The dataset preview shows us the first 100 samples
of the dataset. What's more, it's loaded up with audio samples ready for us
to listen to in real time. We can select the Hindi subset of Common Voice by
setting the subset to `hi` using the dropdown menu (`hi` being the language
identifier code for Hindi):
<figure>
<img src="assets/111_fine_tune_whisper/select_hi.jpg" alt="Trulli" style="width:100%">
</figure>
If we hit the play button on the first sample, we can listen to the audio and
see the corresponding text. Have a scroll through the samples for the train
and test sets to get a better feel for the audio and text data that we're
dealing with. You can tell from the intonation and style that the recordings
are taken from narrated speech. You'll also likely notice the large variation in
speakers and recording quality, a common trait of crowd-sourced data.
Using 🤗 Datasets, downloading and preparing data is extremely simple.
We can download and prepare the Common Voice splits in just one line of code.
Since Hindi is very low-resource, we'll combine the `train` and `validation`
splits to give approximately 8 hours of training data. We'll use the 4 hours
of `test` data as our held-out test set:
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "hi", split="test", use_auth_token=True)
print(common_voice)
```
**Print Output:**
```
DatasetDict({
train: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment'],
num_rows: 6540
})
test: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment'],
num_rows: 2894
})
})
```
Most ASR datasets only provide input audio samples (`audio`) and the
corresponding transcribed text (`sentence`). Common Voice contains additional
metadata information, such as `accent` and `locale`, which we can disregard for ASR.
Keeping the notebook as general as possible, we only consider the input audio and
transcribed text for fine-tuning, discarding the additional metadata information:
```python
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
```
Common Voice is but one multilingual ASR dataset that we can download from the Hub -
there are plenty more available to us! To view the range of datasets available for speech recognition,
follow the link: [ASR Datasets on the Hub](https://huggingface.co/datasets?task_categories=task_categories:automatic-speech-recognition&sort=downloads).
### Prepare Feature Extractor, Tokenizer and Data
The ASR pipeline can be de-composed into three components:
1) A feature extractor which pre-processes the raw audio-inputs
2) The model which performs the sequence-to-sequence mapping
3) A tokenizer which post-processes the model outputs to text format
In 🤗 Transformers, the Whisper model has an associated feature extractor and tokenizer,
called [WhisperFeatureExtractor](https://huggingface.co/docs/transformers/main/model_doc/whisper#transformers.WhisperFeatureExtractor)
and [WhisperTokenizer](https://huggingface.co/docs/transformers/main/model_doc/whisper#transformers.WhisperTokenizer)
respectively.
We'll go through details of the feature extractor and tokenizer one-by-one!
### Load WhisperFeatureExtractor
Speech is represented by a 1-dimensional array that varies with time.
The value of the array at any given time step is the signal's _amplitude_
at that point. From the amplitude information alone, we can reconstruct the
frequency spectrum of the audio and recover all acoustic features.
Since speech is continuous, it contains an infinite number of amplitude values.
This poses problems for computer devices which expect finite arrays. Thus, we
discretise our speech signal by _sampling_ values from our signal at fixed time steps.
The interval with which we sample our audio is known as the _sampling rate_
and is usually measured in samples/sec or _Hertz (Hz)_. Sampling with a higher
sampling rate results in a better approximation of the continuous speech signal,
but also requires storing more values per second.
It is crucial that we match the sampling rate of our audio inputs to the sampling
rate expected by our model, as audio signals with different sampling rates have very
different distributions. Audio samples should only ever be processed with the
correct sampling rate. Failing to do so can lead to unexpected results!
For instance, taking an audio sample with a sampling rate of 16kHz and listening
to it with a sampling rate of 8kHz will make the audio sound as though it's in half-speed.
In the same way, passing audio with the wrong sampling rate can falter an ASR model
that expects one sampling rate and receives another. The Whisper
feature extractor expects audio inputs with a sampling rate of 16kHz, so we need to
match our inputs to this value. We don't want to inadvertently train an ASR
system on slow-motion speech!
The Whisper feature extractor performs two operations. It first pads/truncates a batch of audio samples
such that all samples have an input length of 30s. Samples shorter than 30s are padded to 30s
by appending zeros to the end of the sequence (zeros in an audio signal corresponding to no signal
or silence). Samples longer than 30s are truncated to 30s. Since all elements
in the batch are padded/truncated to a maximum length in the input space, we don't require
an attention mask when forwarding the audio inputs to the Whisper model.
Whisper is unique in this regard - with most audio models, you can expect to provide
an attention mask that details where sequences have been padded, and thus where they
should be ignored in the self-attention mechanism. Whisper is trained to operate without
an attention mask and infer directly from the speech signals where to ignore the inputs.
The second operation that the Whisper feature extractor performs is converting the
padded audio arrays to log-Mel spectrograms. These spectrograms are
a visual representation of the frequencies of a signal, rather like a Fourier transform.
An example spectrogram is shown in Figure 2. Along the \\(y\\)-axis are the Mel channels,
which correspond to particular frequency bins. Along the \\(x\\)-axis is time. The colour of
each pixel corresponds to the log-intensity of that frequency bin at a given time. The
log-Mel spectrogram is the form of input expected by the Whisper model.
The Mel channels (frequency bins) are standard in speech processing and chosen to approximate
the human auditory range. All we need to know for Whisper fine-tuning is that
the spectrogram is a visual representation of the frequencies in the speech signal. For more detail
on Mel channels, refer to [Mel-frequency cepstrum](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum).
<figure>
<img src="assets/111_fine_tune_whisper/spectrogram.jpg" alt="Trulli" style="width:100%">
<figcaption align = "center"><b>Figure 2:</b> Conversion of sampled audio array to log-Mel spectrogram.
Left: sampled 1-dimensional audio signal. Right: corresponding log-Mel spectrogram. Figure source:
<a href="https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html">Google SpecAugment Blog</a>.
</figcaption>
</figure>
Luckily for us, the 🤗 Transformers Whisper feature extractor performs both the
padding and spectrogram conversion in just one line of code! Let's go ahead
and load the feature extractor from the pre-trained checkpoint to have ready
for our audio data:
```python
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
```
### Load WhisperTokenizer
Now let's look at how to load a Whisper tokenizer. The Whisper model outputs
text tokens that indicate the _index_ of the predicted text among the dictionary
of vocabulary items. The tokenizer maps a sequence of text tokens to the actual
text string (e.g. [1169, 3797, 3332] -> "the cat sat").
Traditionally, when using encoder-only models for ASR, we decode using
[_Connectionist Temporal Classification (CTC)_](https://distill.pub/2017/ctc/).
Here we are required to train a CTC tokenizer for each dataset we use.
One of the advantages of using an encoder-decoder architecture is that
we can directly leverage the tokenizer from the pre-trained model.
The Whisper tokenizer is pre-trained on the transcriptions for the 96 pre-training languages.
Consequently, it has an extensive [byte-pair](https://huggingface.co/course/chapter6/5?fw=pt#bytepair-encoding-tokenization)
that is appropriate for almost all multilingual ASR applications.
For Hindi, we can load the tokenizer and use it for fine-tuning without
any further modifications. We simply have to specify the target language
and the task. These arguments inform the tokenizer to prefix the language
and task tokens to the start of encoded label sequences:
```python
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")
```
> **Tip:** the blog post can be adapted for *speech translation* by setting the task to `"translate"` and the language to the target text language in the above line. This will prepend the relevant task and language tokens for speech translation when the dataset is pre-processed.
We can verify that the tokenizer correctly encodes Hindi characters by
encoding and decoding the first sample of the Common Voice dataset. When
encoding the transcriptions, the tokenizer appends 'special tokens' to the
start and end of the sequence, including the start/end of transcript tokens, the
language token and the task tokens (as specified by the arguments in the previous step).
When decoding the label ids, we have the option of 'skipping' these special
tokens, allowing us to return a string in the original input form:
```python
input_str = common_voice["train"][0]["sentence"]
labels = tokenizer(input_str).input_ids
decoded_with_special = tokenizer.decode(labels, skip_special_tokens=False)
decoded_str = tokenizer.decode(labels, skip_special_tokens=True)
print(f"Input: {input_str}")
print(f"Decoded w/ special: {decoded_with_special}")
print(f"Decoded w/out special: {decoded_str}")
print(f"Are equal: {input_str == decoded_str}")
```
**Print Output:**
```bash
Input: खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई
Decoded w/ special: <|startoftranscript|><|hi|><|transcribe|><|notimestamps|>खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई<|endoftext|>
Decoded w/out special: खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई
Are equal: True
```
### Combine To Create A WhisperProcessor
To simplify using the feature extractor and tokenizer, we can _wrap_
both into a single `WhisperProcessor` class. This processor object
inherits from the `WhisperFeatureExtractor` and `WhisperProcessor`
and can be used on the audio inputs and model predictions as required.
In doing so, we only need to keep track of two objects during training:
the `processor` and the `model`:
```python
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="Hindi", task="transcribe")
```
### Prepare Data
Let's print the first example of the Common Voice dataset to see
what form the data is in:
```python
print(common_voice["train"][0])
```
**Print Output:**
```python
{'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/607848c7e74a89a3b5225c0fa5ffb9470e39b7f11112db614962076a847f3abf/cv-corpus-11.0-2022-09-21/hi/clips/common_voice_hi_25998259.mp3',
'array': array([0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 9.6724887e-07,
1.5334779e-06, 1.0415988e-06], dtype=float32),
'sampling_rate': 48000},
'sentence': 'खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई'}
```
We can see that we've got a 1-dimensional input audio array and the
corresponding target transcription. We've spoken heavily about the
importance of the sampling rate and the fact that we need to match the
sampling rate of our audio to that of the Whisper model (16kHz). Since
our input audio is sampled at 48kHz, we need to _downsample_ it to
16kHz before passing it to the Whisper feature extractor.
We'll set the audio inputs to the correct sampling rate using dataset's
[`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column)
method. This operation does not change the audio in-place,
but rather signals to `datasets` to resample audio samples _on the fly_ the
first time that they are loaded:
```python
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
```
Re-loading the first audio sample in the Common Voice dataset will resample
it to the desired sampling rate:
```python
print(common_voice["train"][0])
```
**Print Output:**
```python
{'audio': {'path': '/home/sanchit_huggingface_co/.cache/huggingface/datasets/downloads/extracted/607848c7e74a89a3b5225c0fa5ffb9470e39b7f11112db614962076a847f3abf/cv-corpus-11.0-2022-09-21/hi/clips/common_voice_hi_25998259.mp3',
'array': array([ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, ...,
-3.4206650e-07, 3.2979898e-07, 1.0042874e-06], dtype=float32),
'sampling_rate': 16000},
'sentence': 'खीर की मिठास पर गरमाई बिहार की सियासत, कुशवाहा ने दी सफाई'}
```
Great! We can see that the sampling rate has been downsampled to 16kHz. The
array values are also different, as we've now only got approximately one amplitude value
for every three we had before.
Now we can write a function to prepare our data ready for the model:
1. We load and resample the audio data by calling `batch["audio"]`. As explained above, 🤗 Datasets performs any necessary resampling operations on the fly.
2. We use the feature extractor to compute the log-Mel spectrogram input features from our 1-dimensional audio array.
3. We encode the transcriptions to label ids through the use of the tokenizer.
```python
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
```
We can apply the data preparation function to all of our training examples using dataset's `.map` method:
```python
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=4)
```
Alright! With that we have our data fully prepared for training!
Let's continue and take a look at how we can use this data to
fine-tune Whisper.
**Note**: Currently `datasets` makes use of both [`torchaudio`](https://pytorch.org/audio/stable/index.html)
and [`librosa`](https://librosa.org/doc/latest/index.html) for audio loading and resampling.
If you wish to implement your own customised data loading/sampling, you can use the `"path"`
column to obtain the audio file path and disregard the `"audio"` column.
## Training and Evaluation
Now that we've prepared our data, we're ready to dive into the training pipeline.
The [🤗 Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer)
will do much of the heavy lifting for us. All we have to do is:
- Define a data collator: the data collator takes our pre-processed data and prepares PyTorch tensors ready for the model.
- Evaluation metrics: during evaluation, we want to evaluate the model using the [word error rate (WER)](https://huggingface.co/metrics/wer) metric. We need to define a `compute_metrics` function that handles this computation.
- Load a pre-trained checkpoint: we need to load a pre-trained checkpoint and configure it correctly for training.
- Define the training arguments: these will be used by the 🤗 Trainer in constructing the training schedule.
Once we've fine-tuned the model, we will evaluate it on the test data to verify that we have correctly trained it
to transcribe speech in Hindi.
### Define a Data Collator
The data collator for a sequence-to-sequence speech model is unique in the sense that it
treats the `input_features` and `labels` independently: the `input_features` must be
handled by the feature extractor and the `labels` by the tokenizer.
The `input_features` are already padded to 30s and converted to a log-Mel spectrogram
of fixed dimension, so all we have to do is convert them to batched PyTorch tensors. We do this
using the feature extractor's `.pad` method with `return_tensors=pt`. Note that no additional
padding is applied here since the inputs are of fixed dimension,
the `input_features` are simply converted to PyTorch tensors.
On the other hand, the `labels` are un-padded. We first pad the sequences
to the maximum length in the batch using the tokenizer's `.pad` method. The padding tokens
are then replaced by `-100` so that these tokens are **not** taken into account when
computing the loss. We then cut the start of transcript token from the beginning of the label sequence as we
append it later during training.
We can leverage the `WhisperProcessor` we defined earlier to perform both the
feature extractor and the tokenizer operations:
```python
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
```
Let's initialise the data collator we've just defined:
```python
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
```
### Evaluation Metrics
Next, we define the evaluation metric we'll use on our evaluation
set. We'll use the Word Error Rate (WER) metric, the 'de-facto' metric for assessing
ASR systems. For more information, refer to the WER [docs](https://huggingface.co/metrics/wer).
We'll load the WER metric from 🤗 Evaluate:
```python
import evaluate
metric = evaluate.load("wer")
```
We then simply have to define a function that takes our model
predictions and returns the WER metric. This function, called
`compute_metrics`, first replaces `-100` with the `pad_token_id`
in the `label_ids` (undoing the step we applied in the
data collator to ignore padded tokens correctly in the loss).
It then decodes the predicted and label ids to strings. Finally,
it computes the WER between the predictions and reference labels:
```python
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
wer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
### Load a Pre-Trained Checkpoint
Now let's load the pre-trained Whisper `small` checkpoint. Again, this
is trivial through use of 🤗 Transformers!
```python
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
```
The Whisper model has token ids that are forced as model outputs before
autoregressive generation is started ([`forced_decoder_ids`](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate.forced_decoder_ids)).
These token ids control the transcription language and task for zero-shot ASR. For fine-tuning,
we'll set these ids to `None`, as we'll train the model to predict the correct language (Hindi)
and task (transcription). There are also tokens that are completely suppressed during generation
([`suppress_tokens`](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate.suppress_tokens)).
These tokens have their log probabilities set to `-inf`, such that they are never sampled.
We'll override these tokens to an empty list, meaning no tokens are suppressed:
```python
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
```
### Define the Training Arguments
In the final step, we define all the parameters related to training. A subset of parameters are
explained below:
- `output_dir`: local directory in which to save the model weights. This will also be the repository name on the [Hugging Face Hub](https://huggingface.co/).
- `generation_max_length`: maximum number of tokens to autoregressively generate during evaluation.
- `save_steps`: during training, intermediate checkpoints will be saved and uploaded asynchronously to the Hub every `save_steps` training steps.
- `eval_steps`: during training, evaluation of intermediate checkpoints will be performed every `eval_steps` training steps.
- `report_to`: where to save training logs. Supported platforms are `"azure_ml"`, `"comet_ml"`, `"mlflow"`, `"neptune"`, `"tensorboard"` and `"wandb"`. Pick your favourite or leave as `"tensorboard"` to log to the Hub.
For more detail on the other training arguments, refer to the Seq2SeqTrainingArguments [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments).
```python
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-hi", # change to a repo name of your choice
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
predict_with_generate=True,
generation_max_length=225,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
```
**Note**: if one does not want to upload the model checkpoints to the Hub,
set `push_to_hub=False`.
We can forward the training arguments to the 🤗 Trainer along with our model,
dataset, data collator and `compute_metrics` function:
```python
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor.feature_extractor,
)
```
And with that, we're ready to start training!
### Training
To launch training, simply execute:
```python
trainer.train()
```
Training will take approximately 5-10 hours depending on your GPU or the one
allocated to the Google Colab. Depending on your GPU, it is possible
that you will encounter a CUDA `"out-of-memory"` error when you start training. In this case,
you can reduce the `per_device_train_batch_size` incrementally by factors of 2
and employ [`gradient_accumulation_steps`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments.gradient_accumulation_steps)
to compensate.
**Print Output:**
| Step | Training Loss | Epoch | Validation Loss | WER |
|:----:|:-------------:|:-----:|:---------------:|:-----:|
| 1000 | 0.1011 | 2.44 | 0.3075 | 34.63 |
| 2000 | 0.0264 | 4.89 | 0.3558 | 33.13 |
| 3000 | 0.0025 | 7.33 | 0.4214 | 32.59 |
| 4000 | 0.0006 | 9.78 | 0.4519 | 32.01 |
| 5000 | 0.0002 | 12.22 | 0.4679 | 32.10 |
Our best WER is 32.0% - not bad for 8h of training data! The big question is how this
compares to other ASR systems. For that, we can view the [`hf-speech-bench`](https://huggingface.co/spaces/huggingface/hf-speech-bench),
a leaderboard that categorises models by language and dataset, and subsequently ranks
them according to their WER.
<figure>
<img src="assets/111_fine_tune_whisper/hf_speech_bench.jpg" alt="Trulli" style="width:100%">
</figure>
Our fine-tuned model significantly improves upon the zero-shot performance of the Whisper
`small` checkpoint, highlighting the strong transfer learning capabilities of Whisper.
We can automatically submit our checkpoint to the leaderboard when we
push the training results to the Hub - we simply have to set the appropriate key-word
arguments (kwargs). You can change these values to match your dataset, language and
model name accordingly:
```python
kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_11_0",
"dataset": "Common Voice 11.0", # a 'pretty' name for the training dataset
"dataset_args": "config: hi, split: test",
"language": "hi",
"model_name": "Whisper Small Hi - Sanchit Gandhi", # a 'pretty' name for your model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
"tags": "hf-asr-leaderboard",
}
```
The training results can now be uploaded to the Hub. To do so, execute the `push_to_hub` command:
```python
trainer.push_to_hub(**kwargs)
```
You can now share this model with anyone using the link on the Hub. They can also
load it with the identifier `"your-username/the-name-you-picked"`, for instance:
```python
from transformers import WhisperForConditionalGeneration, WhisperProcessor
model = WhisperForConditionalGeneration.from_pretrained("sanchit-gandhi/whisper-small-hi")
processor = WhisperProcessor.from_pretrained("sanchit-gandhi/whisper-small-hi")
```
While the fine-tuned model yields satisfactory results on the Common
Voice Hindi test data, it is by no means optimal. The purpose of this
notebook is to demonstrate how the pre-trained Whisper checkpoints can
be fine-tuned on any multilingual ASR dataset. The results could likely
be improved by optimising the training hyperparameters, such as
_learning rate_ and _dropout_, and using a larger pre-trained
checkpoint (`medium` or `large`).
### Building a Demo
Now that we've fine-tuned our model, we can build a demo to show
off its ASR capabilities! We'll use 🤗 Transformers
`pipeline`, which will take care of the entire ASR pipeline,
right from pre-processing the audio inputs to decoding the
model predictions. We'll build our interactive demo with [Gradio](https://www.gradio.app).
Gradio is arguably the most straightforward way of building
machine learning demos; with Gradio, we can build a demo in
just a matter of minutes!
Running the example below will generate a Gradio demo where we
can record speech through the microphone of our computer and input it to
our fine-tuned Whisper model to transcribe the corresponding text:
```python
from transformers import pipeline
import gradio as gr
pipe = pipeline(model="sanchit-gandhi/whisper-small-hi") # change to "your-username/the-name-you-picked"
def transcribe(audio):
text = pipe(audio)["text"]
return text
iface = gr.Interface(
fn=transcribe,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs="text",
title="Whisper Small Hindi",
description="Realtime demo for Hindi speech recognition using a fine-tuned Whisper small model.",
)
iface.launch()
```
## Closing Remarks
In this blog, we covered a step-by-step guide on fine-tuning Whisper for multilingual ASR
using 🤗 Datasets, Transformers and the Hugging Face Hub. Refer to the [Google Colab](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/fine_tune_whisper.ipynb)
should you wish to try fine-tuning for yourself. If you're interested in fine-tuning other
Transformers models, both for English and multilingual ASR, be sure to check out the
examples scripts at [examples/pytorch/speech-recognition](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
| huggingface/blog/blob/main/fine-tune-whisper.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DPT
## Overview
The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
The abstract from the paper is the following:
*We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dpt_architecture.jpg"
alt="drawing" width="600"/>
<small> DPT architecture. Taken from the <a href="https://arxiv.org/abs/2103.13413" target="_blank">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
## Usage tips
DPT is compatible with the [`AutoBackbone`] class. This allows to use the DPT framework with various computer vision backbones available in the library, such as [`VitDetBackbone`] or [`Dinov2Backbone`]. One can create it as follows:
```python
from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
# initialize with a Transformer-based backbone such as DINOv2
# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
config = DPTConfig(backbone_config=backbone_config)
model = DPTForDepthEstimation(config=config)
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
- Demo notebooks for [`DPTForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DPTConfig
[[autodoc]] DPTConfig
## DPTFeatureExtractor
[[autodoc]] DPTFeatureExtractor
- __call__
- post_process_semantic_segmentation
## DPTImageProcessor
[[autodoc]] DPTImageProcessor
- preprocess
- post_process_semantic_segmentation
## DPTModel
[[autodoc]] DPTModel
- forward
## DPTForDepthEstimation
[[autodoc]] DPTForDepthEstimation
- forward
## DPTForSemanticSegmentation
[[autodoc]] DPTForSemanticSegmentation
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/dpt.md |
Gradio Demo: model3d_component_events
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_3d = gr.Model3D(label="Input Model3D")
with gr.Column():
output_3d = gr.Model3D(label="Output Model3D")
with gr.Column():
num_change = gr.Number(label="# Change Events", value=0)
num_load = gr.Number(label="# Upload Events", value=0)
num_clear = gr.Number(label="# Clear Events", value=0)
clear_value = gr.Textbox(label="Clear Value", value="")
input_3d.upload(lambda s, n: (s, n + 1), [input_3d, num_load], [output_3d, num_load])
input_3d.change(lambda n: n + 1, num_change, num_change)
input_3d.clear(lambda s, n: (s, n + 1), [input_3d, num_clear], [clear_value, num_clear])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/model3d_component_events/run.ipynb |
Additional Readings [[additional-readings]]
## Bias-variance tradeoff in Reinforcement Learning
If you want to dive deeper into the question of variance and bias tradeoff in Deep Reinforcement Learning, you can check out these two articles:
- [Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning](https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565)
- [Bias-variance Tradeoff in Reinforcement Learning](https://www.endtoend.ai/blog/bias-variance-tradeoff-in-reinforcement-learning/)
## Advantage Functions
- [Advantage Functions, SpinningUp RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html?highlight=advantage%20functio#advantage-functions)
## Actor Critic
- [Foundations of Deep RL Series, L3 Policy Gradients and Advantage Estimation by Pieter Abbeel](https://www.youtube.com/watch?v=AKbX1Zvo7r8)
- [A2C Paper: Asynchronous Methods for Deep Reinforcement Learning](https://arxiv.org/abs/1602.01783v2)
| huggingface/deep-rl-class/blob/main/units/en/unit6/additional-readings.mdx |
This guideline is very much a work-in-progress.*
Contributions to `timm` for code, documentation, tests are more than welcome!
There haven't been any formal guidelines to date so please bear with me, and feel free to add to this guide.
# Coding style
Code linting and auto-format (black) are not currently in place but open to consideration. In the meantime, the style to follow is (mostly) aligned with Google's guide: https://google.github.io/styleguide/pyguide.html.
A few specific differences from Google style (or black)
1. Line length is 120 char. Going over is okay in some cases (e.g. I prefer not to break URL across lines).
2. Hanging indents are always prefered, please avoid aligning arguments with closing brackets or braces.
Example, from Google guide, but this is a NO here:
```
# Aligned with opening delimiter.
foo = long_function_name(var_one, var_two,
var_three, var_four)
meal = (spam,
beans)
# Aligned with opening delimiter in a dictionary.
foo = {
'long_dictionary_key': value1 +
value2,
...
}
```
This is YES:
```
# 4-space hanging indent; nothing on first line,
# closing parenthesis on a new line.
foo = long_function_name(
var_one, var_two, var_three,
var_four
)
meal = (
spam,
beans,
)
# 4-space hanging indent in a dictionary.
foo = {
'long_dictionary_key':
long_dictionary_value,
...
}
```
When there is discrepancy in a given source file (there are many origins for various bits of code and not all have been updated to what I consider current goal), please follow the style in a given file.
In general, if you add new code, formatting it with black using the following options should result in a style that is compatible with the rest of the code base:
```
black --skip-string-normalization --line-length 120 <path-to-file>
```
Avoid formatting code that is unrelated to your PR though.
PR with pure formatting / style fixes will be accepted but only in isolation from functional changes, best to ask before starting such a change.
# Documentation
As with code style, docstrings style based on the Google guide: guide: https://google.github.io/styleguide/pyguide.html
The goal for the code is to eventually move to have all major functions and `__init__` methods use PEP484 type annotations.
When type annotations are used for a function, as per the Google pyguide, they should **NOT** be duplicated in the docstrings, please leave annotations as the one source of truth re typing.
There are a LOT of gaps in current documentation relative to the functionality in timm, please, document away!
# Installation
Create a Python virtual environment using Python 3.10. Inside the environment, install torch` and `torchvision` using the instructions matching your system as listed on the [PyTorch website](https://pytorch.org/).
Then install the remaining dependencies:
```
python -m pip install -r requirements.txt
python -m pip install -r requirements-dev.txt # for testing
python -m pip install -e .
```
## Unit tests
Run the tests using:
```
pytest tests/
```
Since the whole test suite takes a lot of time to run locally (a few hours), you may want to select a subset of tests relating to the changes you made by using the `-k` option of [`pytest`](https://docs.pytest.org/en/7.1.x/example/markers.html#using-k-expr-to-select-tests-based-on-their-name). Moreover, running tests in parallel (in this example 4 processes) with the `-n` option may help:
```
pytest -k "substring-to-match" -n 4 tests/
```
## Building documentation
Please refer to [this document](https://github.com/huggingface/pytorch-image-models/tree/main/hfdocs).
# Questions
If you have any questions about contribution, where / how to contribute, please ask in the [Discussions](https://github.com/huggingface/pytorch-image-models/discussions/categories/contributing) (there is a `Contributing` topic).
| huggingface/pytorch-image-models/blob/main/CONTRIBUTING.md |
Gradio Demo: sentence_builder
```
!pip install -q gradio
```
```
import gradio as gr
def sentence_builder(quantity, animal, countries, place, activity_list, morning):
return f"""The {quantity} {animal}s from {" and ".join(countries)} went to the {place} where they {" and ".join(activity_list)} until the {"morning" if morning else "night"}"""
demo = gr.Interface(
sentence_builder,
[
gr.Slider(2, 20, value=4, label="Count", info="Choose between 2 and 20"),
gr.Dropdown(
["cat", "dog", "bird"], label="Animal", info="Will add more animals later!"
),
gr.CheckboxGroup(["USA", "Japan", "Pakistan"], label="Countries", info="Where are they from?"),
gr.Radio(["park", "zoo", "road"], label="Location", info="Where did they go?"),
gr.Dropdown(
["ran", "swam", "ate", "slept"], value=["swam", "slept"], multiselect=True, label="Activity", info="Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed auctor, nisl eget ultricies aliquam, nunc nisl aliquet nunc, eget aliquam nisl nunc vel nisl."
),
gr.Checkbox(label="Morning", info="Did they do it in the morning?"),
],
"text",
examples=[
[2, "cat", ["Japan", "Pakistan"], "park", ["ate", "swam"], True],
[4, "dog", ["Japan"], "zoo", ["ate", "swam"], False],
[10, "bird", ["USA", "Pakistan"], "road", ["ran"], False],
[8, "cat", ["Pakistan"], "zoo", ["ate"], True],
]
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/sentence_builder/run.ipynb |
Awesome projects built with Transformers
This page lists awesome projects built on top of Transformers. Transformers is more than a toolkit to use pretrained
models: it's a community of projects built around it and the Hugging Face Hub. We want Transformers to enable
developers, researchers, students, professors, engineers, and anyone else to build their dream projects.
In this list, we showcase incredibly impactful and novel projects that have pushed the field forward. We celebrate
100 of these projects as we reach the milestone of 100k stars as a community; but we're very open to pull requests
adding other projects to the list. If you believe a project should be here and it's not, then please, open a PR
to add it.
## [gpt4all](https://github.com/nomic-ai/gpt4all)
[gpt4all](https://github.com/nomic-ai/gpt4all) is an ecosystem of open-source chatbots trained on massive collections of clean assistant data including code, stories and dialogue. It offers open-source, large language models such as LLaMA and GPT-J trained in an assistant-style.
Keywords: Open-source, LLaMa, GPT-J, instruction, assistant
## [recommenders](https://github.com/microsoft/recommenders)
This repository contains examples and best practices for building recommendation systems, provided as Jupyter notebooks. It goes over several aspects required to build efficient recommendation systems: data preparation, modeling, evaluation, model selection & optimization, as well as operationalization
Keywords: Recommender systems, AzureML
## [lama-cleaner](https://github.com/Sanster/lama-cleaner)
Image inpainting tool powered by Stable Diffusion. Remove any unwanted object, defect, people from your pictures or erase and replace anything on your pictures.
Keywords: inpainting, SD, Stable Diffusion
## [flair](https://github.com/flairNLP/flair)
FLAIR is a powerful PyTorch NLP framework, convering several important tasks: NER, sentiment-analysis, part-of-speech tagging, text and document embeddings, among other things.
Keywords: NLP, text embedding, document embedding, biomedical, NER, PoS, sentiment-analysis
## [mindsdb](https://github.com/mindsdb/mindsdb)
MindsDB is a low-code ML platform, which automates and integrates several ML frameworks into the data stack as "AI Tables" to streamline the integration of AI into applications, making it accessible to developers of all skill levels.
Keywords: Database, low-code, AI table
## [langchain](https://github.com/hwchase17/langchain)
[langchain](https://github.com/hwchase17/langchain) is aimed at assisting in the development of apps merging both LLMs and other sources of knowledge. The library allows chaining calls to applications, creating a sequence across many tools.
Keywords: LLMs, Large Language Models, Agents, Chains
## [LlamaIndex](https://github.com/jerryjliu/llama_index)
[LlamaIndex](https://github.com/jerryjliu/llama_index) is a project that provides a central interface to connect your LLM's with external data. It provides various kinds of indices and retreival mechanisms to perform different LLM tasks and obtain knowledge-augmented results.
Keywords: LLMs, Large Language Models, Data Retrieval, Indices, Knowledge Augmentation
## [ParlAI](https://github.com/facebookresearch/ParlAI)
[ParlAI](https://github.com/facebookresearch/ParlAI) is a python framework for sharing, training and testing dialogue models, from open-domain chitchat, to task-oriented dialogue, to visual question answering. It provides more than 100 datasets under the same API, a large zoo of pretrained models, a set of agents, and has several integrations.
Keywords: Dialogue, Chatbots, VQA, Datasets, Agents
## [sentence-transformers](https://github.com/UKPLab/sentence-transformers)
This framework provides an easy method to compute dense vector representations for sentences, paragraphs, and images. The models are based on transformer networks like BERT / RoBERTa / XLM-RoBERTa etc. and achieve state-of-the-art performance in various task. Text is embedding in vector space such that similar text is close and can efficiently be found using cosine similarity.
Keywords: Dense vector representations, Text embeddings, Sentence embeddings
## [ludwig](https://github.com/ludwig-ai/ludwig)
Ludwig is a declarative machine learning framework that makes it easy to define machine learning pipelines using a simple and flexible data-driven configuration system. Ludwig is targeted at a wide variety of AI tasks. It provides a data-driven configuration system, training, prediction, and evaluation scripts, as well as a programmatic API.
Keywords: Declarative, Data-driven, ML Framework
## [InvokeAI](https://github.com/invoke-ai/InvokeAI)
[InvokeAI](https://github.com/invoke-ai/InvokeAI) is an engine for Stable Diffusion models, aimed at professionals, artists, and enthusiasts. It leverages the latest AI-driven technologies through CLI as well as a WebUI.
Keywords: Stable-Diffusion, WebUI, CLI
## [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)
[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP) is an easy-to-use and powerful NLP library particularly targeted at the Chinese languages. It has support for multiple pre-trained model zoos, and supports a wide-range of NLP tasks from research to industrial applications.
Keywords: NLP, Chinese, Research, Industry
## [stanza](https://github.com/stanfordnlp/stanza)
The Stanford NLP Group's official Python NLP library. It contains support for running various accurate natural language processing tools on 60+ languages and for accessing the Java Stanford CoreNLP software from Python.
Keywords: NLP, Multilingual, CoreNLP
## [DeepPavlov](https://github.com/deeppavlov/DeepPavlov)
[DeepPavlov](https://github.com/deeppavlov/DeepPavlov) is an open-source conversational AI library. It is designed for the development of production ready chat-bots and complex conversational systems, as well as research in the area of NLP and, particularly, of dialog systems.
Keywords: Conversational, Chatbot, Dialog
## [alpaca-lora](https://github.com/tloen/alpaca-lora)
Alpaca-lora contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). The repository provides training (fine-tuning) as well as generation scripts.
Keywords: LoRA, Parameter-efficient fine-tuning
## [imagen-pytorch](https://github.com/lucidrains/imagen-pytorch)
An open-source Implementation of Imagen, Google's closed-source Text-to-Image Neural Network that beats DALL-E2. As of release, it is the new SOTA for text-to-image synthesis.
Keywords: Imagen, Text-to-image
## [adapter-transformers](https://github.com/adapter-hub/adapter-transformers)
[adapter-transformers](https://github.com/adapter-hub/adapter-transformers) is an extension of HuggingFace's Transformers library, integrating adapters into state-of-the-art language models by incorporating AdapterHub, a central repository for pre-trained adapter modules. It is a drop-in replacement for transformers, which is regularly updated to stay up-to-date with the developments of transformers.
Keywords: Adapters, LoRA, Parameter-efficient fine-tuning, Hub
## [NeMo](https://github.com/NVIDIA/NeMo)
NVIDIA [NeMo](https://github.com/NVIDIA/NeMo) is a conversational AI toolkit built for researchers working on automatic speech recognition (ASR), text-to-speech synthesis (TTS), large language models (LLMs), and natural language processing (NLP). The primary objective of [NeMo](https://github.com/NVIDIA/NeMo) is to help researchers from industry and academia to reuse prior work (code and pretrained models) and make it easier to create new https://developer.nvidia.com/conversational-ai#started.
Keywords: Conversational, ASR, TTS, LLMs, NLP
## [Runhouse](https://github.com/run-house/runhouse)
[Runhouse](https://github.com/run-house/runhouse) allows to send code and data to any of your compute or data infra, all in Python, and continue to interact with them normally from your existing code and environment. Runhouse developers mention:
> Think of it as an expansion pack to your Python interpreter that lets it take detours to remote machines or manipulate remote data.
Keywords: MLOps, Infrastructure, Data storage, Modeling
## [MONAI](https://github.com/Project-MONAI/MONAI)
[MONAI](https://github.com/Project-MONAI/MONAI) is a PyTorch-based, open-source framework for deep learning in healthcare imaging, part of PyTorch Ecosystem. Its ambitions are:
- developing a community of academic, industrial and clinical researchers collaborating on a common foundation;
- creating state-of-the-art, end-to-end training workflows for healthcare imaging;
- providing researchers with the optimized and standardized way to create and evaluate deep learning models.
Keywords: Healthcare imaging, Training, Evaluation
## [simpletransformers](https://github.com/ThilinaRajapakse/simpletransformers)
Simple Transformers lets you quickly train and evaluate Transformer models. Only 3 lines of code are needed to initialize, train, and evaluate a model. It supports a wide variety of NLP tasks.
Keywords: Framework, simplicity, NLP
## [JARVIS](https://github.com/microsoft/JARVIS)
[JARVIS](https://github.com/microsoft/JARVIS) is a system attempting to merge LLMs such as GPT-4 with the rest of the open-source ML community: leveraging up to 60 downstream models in order to perform tasks identified by the LLM.
Keywords: LLM, Agents, HF Hub
## [transformers.js](https://xenova.github.io/transformers.js/)
[transformers.js](https://xenova.github.io/transformers.js/) is a JavaScript library targeted at running models from transformers directly within the browser.
Keywords: Transformers, JavaScript, browser
## [bumblebee](https://github.com/elixir-nx/bumblebee)
Bumblebee provides pre-trained Neural Network models on top of Axon, a neural networks library for the Elixir language. It includes integration with 🤗 Models, allowing anyone to download and perform Machine Learning tasks with few lines of code.
Keywords: Elixir, Axon
## [argilla](https://github.com/argilla-io/argilla)
Argilla is an open-source platform providing advanced NLP labeling, monitoring, and workspaces. It is compatible with many open source ecosystems such as Hugging Face, Stanza, FLAIR, and others.
Keywords: NLP, Labeling, Monitoring, Workspaces
## [haystack](https://github.com/deepset-ai/haystack)
Haystack is an open source NLP framework to interact with your data using Transformer models and LLMs. It offers production-ready tools to quickly build complex decision making, question answering, semantic search, text generation applications, and more.
Keywords: NLP, Framework, LLM
## [spaCy](https://github.com/explosion/spaCy)
[spaCy](https://github.com/explosion/spaCy) is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest research, and was designed from day one to be used in real products. It offers support for transformers models through its third party package, spacy-transformers.
Keywords: NLP, Framework
## [speechbrain](https://github.com/speechbrain/speechbrain)
SpeechBrain is an open-source and all-in-one conversational AI toolkit based on PyTorch.
The goal is to create a single, flexible, and user-friendly toolkit that can be used to easily develop state-of-the-art speech technologies, including systems for speech recognition, speaker recognition, speech enhancement, speech separation, language identification, multi-microphone signal processing, and many others.
Keywords: Conversational, Speech
## [skorch](https://github.com/skorch-dev/skorch)
Skorch is a scikit-learn compatible neural network library that wraps PyTorch. It has support for models within transformers, and tokenizers from tokenizers.
Keywords: Scikit-Learn, PyTorch
## [bertviz](https://github.com/jessevig/bertviz)
BertViz is an interactive tool for visualizing attention in Transformer language models such as BERT, GPT2, or T5. It can be run inside a Jupyter or Colab notebook through a simple Python API that supports most Huggingface models.
Keywords: Visualization, Transformers
## [mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax)
[mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax) is a haiku library using the xmap/pjit operators in JAX for model parallelism of transformers. This library is designed for scalability up to approximately 40B parameters on TPUv3s. It was the library used to train the GPT-J model.
Keywords: Haiku, Model parallelism, LLM, TPU
## [deepchem](https://github.com/deepchem/deepchem)
DeepChem aims to provide a high quality open-source toolchain that democratizes the use of deep-learning in drug discovery, materials science, quantum chemistry, and biology.
Keywords: Drug discovery, Materials Science, Quantum Chemistry, Biology
## [OpenNRE](https://github.com/thunlp/OpenNRE)
An Open-Source Package for Neural Relation Extraction (NRE). It is targeted at a wide range of users, from newcomers to relation extraction, to developers, researchers, or students.
Keywords: Neural Relation Extraction, Framework
## [pycorrector](https://github.com/shibing624/pycorrector)
PyCorrector is a Chinese Text Error Correction Tool. It uses a language model to detect errors, pinyin feature and shape feature to correct Chinese text errors. it can be used for Chinese Pinyin and stroke input method.
Keywords: Chinese, Error correction tool, Language model, Pinyin
## [nlpaug](https://github.com/makcedward/nlpaug)
This python library helps you with augmenting nlp for machine learning projects. It is a lightweight library featuring synthetic data generation for improving model performance, support for audio and text, and compatibility with several ecosystems (scikit-learn, pytorch, tensorflow).
Keywords: Data augmentation, Synthetic data generation, Audio, NLP
## [dream-textures](https://github.com/carson-katri/dream-textures)
[dream-textures](https://github.com/carson-katri/dream-textures) is a library targeted at bringing stable-diffusion support within Blender. It supports several use-cases, such as image generation, texture projection, inpainting/outpainting, ControlNet, and upscaling.
Keywords: Stable-Diffusion, Blender
## [seldon-core](https://github.com/SeldonIO/seldon-core)
Seldon core converts your ML models (Tensorflow, Pytorch, H2o, etc.) or language wrappers (Python, Java, etc.) into production REST/GRPC microservices.
Seldon handles scaling to thousands of production machine learning models and provides advanced machine learning capabilities out of the box including Advanced Metrics, Request Logging, Explainers, Outlier Detectors, A/B Tests, Canaries and more.
Keywords: Microservices, Modeling, Language wrappers
## [open_model_zoo](https://github.com/openvinotoolkit/open_model_zoo)
This repository includes optimized deep learning models and a set of demos to expedite development of high-performance deep learning inference applications. Use these free pre-trained models instead of training your own models to speed-up the development and production deployment process.
Keywords: Optimized models, Demos
## [ml-stable-diffusion](https://github.com/apple/ml-stable-diffusion)
ML-Stable-Diffusion is a repository by Apple bringing Stable Diffusion support to Core ML, on Apple Silicon devices. It supports stable diffusion checkpoints hosted on the Hugging Face Hub.
Keywords: Stable Diffusion, Apple Silicon, Core ML
## [stable-dreamfusion](https://github.com/ashawkey/stable-dreamfusion)
Stable-Dreamfusion is a pytorch implementation of the text-to-3D model Dreamfusion, powered by the Stable Diffusion text-to-2D model.
Keywords: Text-to-3D, Stable Diffusion
## [txtai](https://github.com/neuml/txtai)
[txtai](https://github.com/neuml/txtai) is an open-source platform for semantic search and workflows powered by language models. txtai builds embeddings databases, which are a union of vector indexes and relational databases enabling similarity search with SQL. Semantic workflows connect language models together into unified applications.
Keywords: Semantic search, LLM
## [djl](https://github.com/deepjavalibrary/djl)
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. DJL is designed to be easy to get started with and simple to use for developers. DJL provides a native Java development experience and functions like any other regular Java library. DJL offers [a Java binding](https://github.com/deepjavalibrary/djl/tree/master/extensions/tokenizers) for HuggingFace Tokenizers and easy conversion toolkit for HuggingFace model to deploy in Java.
Keywords: Java, Framework
## [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness/)
This project provides a unified framework to test generative language models on a large number of different evaluation tasks. It has support for more than 200 tasks, and supports different ecosystems: HF Transformers, GPT-NeoX, DeepSpeed, as well as the OpenAI API.
Keywords: LLM, Evaluation, Few-shot
## [gpt-neox](https://github.com/EleutherAI/gpt-neox)
This repository records EleutherAI's library for training large-scale language models on GPUs. The framework is based on NVIDIA's Megatron Language Model and has been augmented with techniques from DeepSpeed as well as some novel optimizations. It is focused on training multi-billion-parameter models.
Keywords: Training, LLM, Megatron, DeepSpeed
## [muzic](https://github.com/microsoft/muzic)
Muzic is a research project on AI music that empowers music understanding and generation with deep learning and artificial intelligence. Muzic was created by researchers from Microsoft Research Asia.
Keywords: Music understanding, Music generation
## [dalle-flow](https://github.com/jina-ai/dalle-flow)
DALL·E Flow is an interactive workflow for generating high-definition images from a text prompt. Itt leverages DALL·E-Mega, GLID-3 XL, and Stable Diffusion to generate image candidates, and then calls CLIP-as-service to rank the candidates w.r.t. the prompt.
The preferred candidate is fed to GLID-3 XL for diffusion, which often enriches the texture and background. Finally, the candidate is upscaled to 1024x1024 via SwinIR.
Keywords: High-definition image generation, Stable Diffusion, DALL-E Mega, GLID-3 XL, CLIP, SwinIR
## [lightseq](https://github.com/bytedance/lightseq)
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP and CV models such as BERT, GPT, Transformer, etc. It is therefore best useful for machine translation, text generation, image classification, and other sequence related tasks.
Keywords: Training, Inference, Sequence Processing, Sequence Generation
## [LaTeX-OCR](https://github.com/lukas-blecher/LaTeX-OCR)
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
Keywords: OCR, LaTeX, Math formula
## [open_clip](https://github.com/mlfoundations/open_clip)
OpenCLIP is an open source implementation of OpenAI's CLIP.
The goal of this repository is to enable training models with contrastive image-text supervision, and to investigate their properties such as robustness to distribution shift.
The starting point is an implementation of CLIP that matches the accuracy of the original CLIP models when trained on the same dataset.
Specifically, a ResNet-50 model trained with this codebase on OpenAI's 15 million image subset of YFCC achieves 32.7% top-1 accuracy on ImageNet.
Keywords: CLIP, Open-source, Contrastive, Image-text
## [dalle-playground](https://github.com/saharmor/dalle-playground)
A playground to generate images from any text prompt using Stable Diffusion and Dall-E mini.
Keywords: WebUI, Stable Diffusion, Dall-E mini
## [FedML](https://github.com/FedML-AI/FedML)
[FedML](https://github.com/FedML-AI/FedML) is a federated learning and analytics library enabling secure and collaborative machine learning on decentralized data anywhere at any scale.
It supports large-scale cross-silo federated learning, and cross-device federated learning on smartphones/IoTs, and research simulation.
Keywords: Federated Learning, Analytics, Collaborative ML, Decentralized
## [gpt-code-clippy](https://github.com/CodedotAl/gpt-code-clippy)
GPT-Code-Clippy (GPT-CC) is an open source version of GitHub Copilot, a language model -- based on GPT-3, called GPT-Codex -- that is fine-tuned on publicly available code from GitHub.
Keywords: LLM, Code
## [TextAttack](https://github.com/QData/TextAttack)
[TextAttack](https://github.com/QData/TextAttack) 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP.
Keywords: Adversarial attacks, Data augmentation, NLP
## [OpenPrompt](https://github.com/thunlp/OpenPrompt)
Prompt-learning is a paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modify the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. [OpenPrompt](https://github.com/thunlp/OpenPrompt) supports loading PLMs directly from https://github.com/huggingface/transformers.
## [text-generation-webui](https://github.com/oobabooga/text-generation-webui/)
[text-generation-webui](https://github.com/oobabooga/text-generation-webui/) is a Gradio Web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA.
Keywords: LLM, WebUI
## [libra](https://github.com/Palashio/libra)
An ergonomic machine learning [libra](https://github.com/Palashio/libra)ry for non-technical users. It focuses on ergonomics and on ensuring that training a model is as simple as it can be.
Keywords: Ergonomic, Non-technical
## [alibi](https://github.com/SeldonIO/alibi)
Alibi is an open source Python library aimed at machine learning model inspection and interpretation. The focus of the library is to provide high-quality implementations of black-box, white-box, local and global explanation methods for classification and regression models.
Keywords: Model inspection, Model interpretation, Black-box, White-box
## [tortoise-tts](https://github.com/neonbjb/tortoise-tts)
Tortoise is a text-to-speech program built with the following priorities: strong multi-voice capabilities, and highly realistic prosody and intonation.
Keywords: Text-to-speech
## [flower](https://github.com/adap/flower)
Flower (flwr) is a framework for building federated learning systems. The design of Flower is based on a few guiding principles: customizability, extendability, framework agnosticity, and ease-of-use.
Keywords: Federated learning systems, Customizable, Extendable, Framework-agnostic, Simplicity
## [fast-bert](https://github.com/utterworks/fast-bert)
Fast-Bert is a deep learning library that allows developers and data scientists to train and deploy BERT and XLNet based models for natural language processing tasks beginning with Text Classification. It is aimed at simplicity.
Keywords: Deployment, BERT, XLNet
## [towhee](https://github.com/towhee-io/towhee)
Towhee makes it easy to build neural data processing pipelines for AI applications. We provide hundreds of models, algorithms, and transformations that can be used as standard pipeline building blocks. Users can use Towhee's Pythonic API to build a prototype of their pipeline and automatically optimize it for production-ready environments.
Keywords: Data processing pipeline, Optimization
## [alibi-detect](https://github.com/SeldonIO/alibi-detect)
Alibi Detect is an open source Python library focused on outlier, adversarial and drift detection. The package aims to cover both online and offline detectors for tabular data, text, images and time series. Both TensorFlow and PyTorch backends are supported for drift detection.
Keywords: Adversarial, Outlier, Drift detection
## [FARM](https://github.com/deepset-ai/FARM)
[FARM](https://github.com/deepset-ai/FARM) makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built upon transformers and provides additional features to simplify the life of developers: Parallelized preprocessing, highly modular design, multi-task learning, experiment tracking, easy debugging and close integration with AWS SageMaker.
Keywords: Transfer Learning, Modular design, Multi-task learning, Experiment tracking
## [aitextgen](https://github.com/minimaxir/aitextgen)
A robust Python tool for text-based AI training and generation using OpenAI's GPT-2 and EleutherAI's GPT Neo/GPT-3 architecture.
[aitextgen](https://github.com/minimaxir/aitextgen) is a Python package that leverages PyTorch, Hugging Face Transformers and pytorch-lightning with specific optimizations for text generation using GPT-2, plus many added features.
Keywords: Training, Generation
## [diffgram](https://github.com/diffgram/diffgram)
Diffgram aims to integrate human supervision into platforms. We support your team programmatically changing the UI (Schema, layout, etc.) like in Streamlit. This means that you can collect and annotate timely data from users. In other words, we are the platform behind your platform, an integrated part of your application, to ship new & better AI products faster.
Keywords: Human supervision, Platform
## [ecco](https://github.com/jalammar/ecco)
Explain, analyze, and visualize NLP language models. Ecco creates interactive visualizations directly in Jupyter notebooks explaining the behavior of Transformer-based language models (like GPT2, BERT, RoBERTA, T5, and T0).
Keywords: Model explainability
## [s3prl](https://github.com/s3prl/s3prl)
[s3prl](https://github.com/s3prl/s3prl) stands for Self-Supervised Speech Pre-training and Representation Learning. Self-supervised speech pre-trained models are called upstream in this toolkit, and are utilized in various downstream tasks.
Keywords: Speech, Training
## [ru-dalle](https://github.com/ai-forever/ru-dalle)
RuDALL-E aims to be similar to DALL-E, targeted to Russian.
Keywords: DALL-E, Russian
## [DeepKE](https://github.com/zjunlp/DeepKE)
[DeepKE](https://github.com/zjunlp/DeepKE) is a knowledge extraction toolkit for knowledge graph construction supporting cnSchema,low-resource, document-level and multimodal scenarios for entity, relation and attribute extraction.
Keywords: Knowledge Extraction, Knowledge Graphs
## [Nebuly](https://github.com/nebuly-ai/nebuly)
Nebuly is the next-generation platform to monitor and optimize your AI costs in one place. The platform connects to all your AI cost sources (compute, API providers, AI software licenses, etc) and centralizes them in one place to give you full visibility on a model basis. The platform also provides optimization recommendations and a co-pilot model that can guide during the optimization process. The platform builds on top of the open-source tools allowing you to optimize the different steps of your AI stack to squeeze out the best possible cost performances.
Keywords: Optimization, Performance, Monitoring
## [imaginAIry](https://github.com/brycedrennan/imaginAIry)
Offers a CLI and a Python API to generate images with Stable Diffusion. It has support for many tools, like image structure control (controlnet), instruction-based image edits (InstructPix2Pix), prompt-based masking (clipseg), among others.
Keywords: Stable Diffusion, CLI, Python API
## [sparseml](https://github.com/neuralmagic/sparseml)
SparseML is an open-source model optimization toolkit that enables you to create inference-optimized sparse models using pruning, quantization, and distillation algorithms. Models optimized with SparseML can then be exported to the ONNX and deployed with DeepSparse for GPU-class performance on CPU hardware.
Keywords: Model optimization, Pruning, Quantization, Distillation
## [opacus](https://github.com/pytorch/opacus)
Opacus is a library that enables training PyTorch models with differential privacy. It supports training with minimal code changes required on the client, has little impact on training performance, and allows the client to online track the privacy budget expended at any given moment.
Keywords: Differential privacy
## [LAVIS](https://github.com/salesforce/LAVIS)
[LAVIS](https://github.com/salesforce/LAVIS) is a Python deep learning library for LAnguage-and-VISion intelligence research and applications. This library aims to provide engineers and researchers with a one-stop solution to rapidly develop models for their specific multimodal scenarios, and benchmark them across standard and customized datasets. It features a unified interface design to access
Keywords: Multimodal, NLP, Vision
## [buzz](https://github.com/chidiwilliams/buzz)
Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAI's Whisper.
Keywords: Audio transcription, Translation
## [rust-bert](https://github.com/guillaume-be/rust-bert)
Rust-native state-of-the-art Natural Language Processing models and pipelines. Port of Hugging Face's Transformers library, using the tch-rs crate and pre-processing from rust-tokenizers. Supports multi-threaded tokenization and GPU inference. This repository exposes the model base architecture, task-specific heads and ready-to-use pipelines.
Keywords: Rust, BERT, Inference
## [EasyNLP](https://github.com/alibaba/EasyNLP)
[EasyNLP](https://github.com/alibaba/EasyNLP) is an easy-to-use NLP development and application toolkit in PyTorch, first released inside Alibaba in 2021. It is built with scalable distributed training strategies and supports a comprehensive suite of NLP algorithms for various NLP applications. [EasyNLP](https://github.com/alibaba/EasyNLP) integrates knowledge distillation and few-shot learning for landing large pre-trained models, together with various popular multi-modality pre-trained models. It provides a unified framework of model training, inference, and deployment for real-world applications.
Keywords: NLP, Knowledge distillation, Few-shot learning, Multi-modality, Training, Inference, Deployment
## [TurboTransformers](https://github.com/Tencent/TurboTransformers)
A fast and user-friendly runtime for transformer inference (Bert, Albert, GPT2, Decoders, etc) on CPU and GPU.
Keywords: Optimization, Performance
## [hivemind](https://github.com/learning-at-home/hivemind)
Hivemind is a PyTorch library for decentralized deep learning across the Internet. Its intended usage is training one large model on hundreds of computers from different universities, companies, and volunteers.
Keywords: Decentralized training
## [docquery](https://github.com/impira/docquery)
DocQuery is a library and command-line tool that makes it easy to analyze semi-structured and unstructured documents (PDFs, scanned images, etc.) using large language models (LLMs). You simply point DocQuery at one or more documents and specify a question you want to ask. DocQuery is created by the team at Impira.
Keywords: Semi-structured documents, Unstructured documents, LLM, Document Question Answering
## [CodeGeeX](https://github.com/THUDM/CodeGeeX)
[CodeGeeX](https://github.com/THUDM/CodeGeeX) is a large-scale multilingual code generation model with 13 billion parameters, pre-trained on a large code corpus of more than 20 programming languages. It has several unique features:
- Multilingual code generation
- Crosslingual code translation
- Is a customizable programming assistant
Keywords: Code Generation Model
## [ktrain](https://github.com/amaiya/ktrain)
[ktrain](https://github.com/amaiya/ktrain) is a lightweight wrapper for the deep learning library TensorFlow Keras (and other libraries) to help build, train, and deploy neural networks and other machine learning models. Inspired by ML framework extensions like fastai and ludwig, [ktrain](https://github.com/amaiya/ktrain) is designed to make deep learning and AI more accessible and easier to apply for both newcomers and experienced practitioners.
Keywords: Keras wrapper, Model building, Training, Deployment
## [FastDeploy](https://github.com/PaddlePaddle/FastDeploy)
[FastDeploy](https://github.com/PaddlePaddle/FastDeploy) is an Easy-to-use and High Performance AI model deployment toolkit for Cloud, Mobile and Edge with packageout-of-the-box and unified experience, endend-to-end optimization for over fire160+ Text, Vision, Speech and Cross-modal AI models. Including image classification, object detection, OCR, face detection, matting, pp-tracking, NLP, stable diffusion, TTS and other tasks to meet developers' industrial deployment needs for multi-scenario, multi-hardware and multi-platform.
Keywords: Model deployment, CLoud, Mobile, Edge
## [underthesea](https://github.com/undertheseanlp/underthesea)
[underthesea](https://github.com/undertheseanlp/underthesea) is a Vietnamese NLP toolkit. Underthesea is a suite of open source Python modules data sets and tutorials supporting research and development in Vietnamese Natural Language Processing. We provides extremely easy API to quickly apply pretrained NLP models to your Vietnamese text, such as word segmentation, part-of-speech tagging (PoS), named entity recognition (NER), text classification and dependency parsing.
Keywords: Vietnamese, NLP
## [hasktorch](https://github.com/hasktorch/hasktorch)
Hasktorch is a library for tensors and neural networks in Haskell. It is an independent open source community project which leverages the core C++ libraries shared by PyTorch.
Keywords: Haskell, Neural Networks
## [donut](https://github.com/clovaai/donut)
Donut, or Document understanding transformer, is a new method of document understanding that utilizes an OCR-free end-to-end Transformer model.
Donut does not require off-the-shelf OCR engines/APIs, yet it shows state-of-the-art performances on various visual document understanding tasks, such as visual document classification or information extraction (a.k.a. document parsing).
Keywords: Document Understanding
## [transformers-interpret](https://github.com/cdpierse/transformers-interpret)
Transformers Interpret is a model explainability tool designed to work exclusively with the transformers package.
In line with the philosophy of the Transformers package Transformers Interpret allows any transformers model to be explained in just two lines. Explainers are available for both text and computer vision models. Visualizations are also available in notebooks and as savable png and html files
Keywords: Model interpretation, Visualization
## [mlrun](https://github.com/mlrun/mlrun)
MLRun is an open MLOps platform for quickly building and managing continuous ML applications across their lifecycle. MLRun integrates into your development and CI/CD environment and automates the delivery of production data, ML pipelines, and online applications, significantly reducing engineering efforts, time to production, and computation resources. With MLRun, you can choose any IDE on your local machine or on the cloud. MLRun breaks the silos between data, ML, software, and DevOps/MLOps teams, enabling collaboration and fast continuous improvements.
Keywords: MLOps
## [FederatedScope](https://github.com/alibaba/FederatedScope)
[FederatedScope](https://github.com/alibaba/FederatedScope) is a comprehensive federated learning platform that provides convenient usage and flexible customization for various federated learning tasks in both academia and industry. Based on an event-driven architecture, [FederatedScope](https://github.com/alibaba/FederatedScope) integrates rich collections of functionalities to satisfy the burgeoning demands from federated learning, and aims to build up an easy-to-use platform for promoting learning safely and effectively.
Keywords: Federated learning, Event-driven
## [pythainlp](https://github.com/PyThaiNLP/pythainlp)
PyThaiNLP is a Python package for text processing and linguistic analysis, similar to NLTK with focus on Thai language.
Keywords: Thai, NLP, NLTK
## [FlagAI](https://github.com/FlagAI-Open/FlagAI)
[FlagAI](https://github.com/FlagAI-Open/FlagAI) (Fast LArge-scale General AI models) is a fast, easy-to-use and extensible toolkit for large-scale model. Our goal is to support training, fine-tuning, and deployment of large-scale models on various downstream tasks with multi-modality.
Keywords: Large models, Training, Fine-tuning, Deployment, Multi-modal
## [pyserini](https://github.com/castorini/pyserini)
[pyserini](https://github.com/castorini/pyserini) is a Python toolkit for reproducible information retrieval research with sparse and dense representations. Retrieval using sparse representations is provided via integration with the group's Anserini IR toolkit. Retrieval using dense representations is provided via integration with Facebook's Faiss library.
Keywords: IR, Information Retrieval, Dense, Sparse
## [baal](https://github.com/baal-org/baal)
[baal](https://github.com/baal-org/baal) is an active learning library that supports both industrial applications and research usecases. [baal](https://github.com/baal-org/baal) currently supports Monte-Carlo Dropout, MCDropConnect, deep ensembles, and semi-supervised learning.
Keywords: Active Learning, Research, Labeling
## [cleanlab](https://github.com/cleanlab/cleanlab)
[cleanlab](https://github.com/cleanlab/cleanlab) is the standard data-centric AI package for data quality and machine learning with messy, real-world data and labels. For text, image, tabular, audio (among others) datasets, you can use cleanlab to automatically: detect data issues (outliers, label errors, near duplicates, etc), train robust ML models, infer consensus + annotator-quality for multi-annotator data, suggest data to (re)label next (active learning).
Keywords: Data-Centric AI, Data Quality, Noisy Labels, Outlier Detection, Active Learning
## [BentoML](https://github.com/bentoml/BentoML)
[BentoML](https://github.com/bentoml) is the unified framework for for building, shipping, and scaling production-ready AI applications incorporating traditional ML, pre-trained AI models, Generative and Large Language Models.
All Hugging Face models and pipelines can be seamlessly integrated into BentoML applications, enabling the running of models on the most suitable hardware and independent scaling based on usage.
Keywords: BentoML, Framework, Deployment, AI Applications
## [LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning)
[LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning) offers a user-friendly fine-tuning framework that incorporates PEFT. The repository includes training(fine-tuning) and inference examples for LLaMA-2, BLOOM, Falcon, Baichuan, Qwen, and other LLMs. A ChatGLM version is also available in [ChatGLM-Efficient-Tuning](https://github.com/hiyouga/ChatGLM-Efficient-Tuning).
Keywords: PEFT, fine-tuning, LLaMA-2, ChatGLM, Qwen
| huggingface/transformers/blob/main/awesome-transformers.md |
--
title: "Let's talk about biases in machine learning! Ethics and Society Newsletter #2"
thumbnail: /blog/assets/122_ethics_soc_2/thumbnail-solstice.png
authors:
- user: yjernite
---
# Machine Learning in development: Let's talk about bias!
_Bias in ML is ubiquitous, and Bias in ML is complex; so complex in fact that no single technical intervention is likely to meaningfully address the problems it engenders. ML models, as sociotechnical systems, amplify social trends that may exacerbate inequities and harmful biases in ways that depend on their deployment context and are constantly evolving._
_This means that developing ML systems with care requires vigilance and responding to feedback from those deployment contexts, which in turn we can facilitate by sharing lessons across contexts and developing tools to analyze signs of bias at every level of ML development._
_This blog post from the [Ethics and Society regulars @🤗](https://huggingface.co/blog/ethics-soc-1) shares some of the lessons we have learned along with tools we have developed to support ourselves and others in our community’s efforts to better address bias in Machine Learning. The first part is a broader reflection on bias and its context. If you’ve already read it and are coming back specifically for the tools, feel free to jump to the [datasets](#i-am-curatingpicking-a-dataset-for-my-ml-system-how-can-i-address-bias) or [models](#i-am-trainingselecting-a-model-for-my-ml-system-how-can-i-address-bias)
section!_
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img1.jpg" alt="Selection of tools developed by HF team members to address bias in ML" />
<em>Selection of tools developed by 🤗 team members to address bias in ML</em>
</p>
**<span style="text-decoration:underline;">Table of contents:</span>**
* **<span style="text-decoration:underline;">On Machine Biases</span>**
* [Machine Bias: from ML Systems to Risks](#machine-bias-from-ml-systems-to-personal-and-social-risks)
* [Putting Bias in Context](#putting-bias-in-context)
* **<span style="text-decoration:underline;">Tools and Recommendations</span>**
* [Addressing Bias throughout ML Development](#addressing-bias-throughout-the-ml-development-cycle)
* [Task Definition](#i-am-defining-the-task-of-my-ml-system-how-can-i-address-bias)
* [Dataset Curation](#i-am-curatingpicking-a-dataset-for-my-ml-system-how-can-i-address-bias)
* [Model Training](#i-am-trainingselecting-a-model-for-my-ml-system-how-can-i-address-bias)
* [Overview of 🤗 Bias Tools](#conclusion-and-overview-of-bias-analysis-and-documentation-tools-from-)
## _Machine Bias:_ from ML Systems to Personal and Social Risks
ML systems allow us to automate complex tasks at a scale never seen before as they are deployed in more sectors and use cases. When the technology works at its best, it can help smooth interactions between people and technical systems, remove the need for highly repetitive work, or unlock new ways of processing information to support research.
These same systems are also likely to reproduce discriminatory and abusive behaviors represented in their training data, especially when the data encodes human behaviors.
The technology then has the potential to make these issues significantly worse. Automation and deployment at scale can indeed:
1. **lock in** behaviors in time and hinder social progress [from being reflected in technology](https://dl.acm.org/doi/10.1145/3442188.3445922),
2. **spread** harmful behaviors [beyond the context](https://arxiv.org/abs/2203.07785) of the original training data,
3. **amplify** inequities by [overfocusing on stereotypical associations](https://arxiv.org/abs/2010.03058) when making predictions,
4. **remove possibilities for recourse** by hiding biases [inside “black-box” systems](https://pubmed.ncbi.nlm.nih.gov/33737318/).
In order to better understand and address these risks, ML researchers and developers have started studying _machine bias_ or _algorithmic bias_, mechanisms that might lead systems to, for example, encode **negative stereotypes or associations** or to have **disparate performance** for different population groups in their deployment context.
**These issues are deeply personal** for many of us ML researchers and developers at Hugging Face and in the broader ML community. Hugging Face is [an international company](https://twitter.com/osanseviero/status/1587444072901492737), with many of us existing between countries and cultures. It is hard to fully express our sense of urgency when we see the technology we work on developed [without sufficient concern](https://dl.acm.org/doi/10.1145/3461702.3462624) for protecting people like us; especially when these systems lead to discriminatory [wrongful arrests](https://incidentdatabase.ai/cite/72/) or undue [financial distress](https://racismandtechnology.center/2021/10/29/amnestys-grim-warning-against-another-toeslagenaffaire/) and are being [increasingly sold](https://www.oecd.org/migration/mig/EMN-OECD-INFORM-FEB-2022-The-use-of-Digitalisation-and-AI-in-Migration-Management.pdf) to immigration and law enforcement services around the world. Similarly, seeing our identities routinely [suppressed in training datasets](https://aclanthology.org/2021.emnlp-main.98/) or [underrepresented in the outputs](https://huggingface.co/spaces/sasha/StableDiffusionBiasExplorer) of “generative AI” [systems ](https://twitter.com/willie_agnew/status/1592829238889283585)connects these concerns to our daily lived experiences in ways that are [simultaneously enlightening and taxing](https://www.technologyreview.com/2022/10/28/1062332/responsible-ai-has-a-burnout-problem/).
While our own experiences do not come close to covering the myriad ways in which ML-mediated discrimination can disproportionately harm people whose experiences differ from ours, they provide an entry point into considerations of the trade-offs inherent in the technology. We work on these systems because we **strongly believe in ML’s potential — we think it can shine as a valuable tool as long as it is developed with care and input from people in its deployment context**, rather than as a one-size-fits-all panacea. In particular, enabling this care requires developing a better understanding of the mechanisms of machine bias across the ML development process, and developing tools that support people [with all levels of technical knowledge of these systems in participating in the necessary conversations](https://www.vice.com/en/article/bvm35w/this-tool-lets-anyone-see-the-bias-in-ai-image-generators) about how their benefits and harms are distributed.
The present blog post from the Hugging Face [Ethics and Society regulars](https://huggingface.co/blog/ethics-soc-1) provides an overview of how we have worked, are working, or recommend users of the HF ecosystem of libraries may work to address bias at the various stages of the ML development process, and the tools we develop to support this process. We hope you will find it a useful resource to guide concrete considerations of the social impact of your work and can leverage the tools referenced here to help mitigate these issues when they arise.
## Putting Bias in Context
The first and maybe most important concept to consider when dealing with machine bias is **context**. In their foundational work on [bias in NLP](https://aclanthology.org/2020.acl-main.485.pdf), Su Lin Blodgett et al. point out that: _“[T]he majority of [academic works on machine bias] fail to engage critically with what constitutes “bias” in the first place”_, including by building their work on top of _“unstated assumptions about what kinds of system behaviors are harmful, in what ways, to whom, and why”_.
This may not come as much of a surprise given the ML research community’s [focus on the value of “generalization”](https://dl.acm.org/doi/10.1145/3531146.3533083) — the most cited motivation for work in the field after “performance”. However, while tools for bias assessment that apply to a wide range of settings are valuable to **enable a broader analysis of common trends** in model behaviors, their ability to target the mechanisms that lead to discrimination in **concrete use cases is inherently limited**. Using them to guide specific decisions within the ML development cycle usually requires an extra step or two to take the system’s specific use context and affected people into consideration.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img_foresight.png" alt="Excerpt on considerations of ML uses context and people from the Model Card Guidebook" />
<em>Excerpt on considerations of ML uses context and people from the <a href="https://huggingface.co/docs/hub/model-cards">Model Card Guidebook</a></em>
</p>
Now let’s dive deeper into the issue of linking biases in stand-alone/context-less ML artifacts to specific harms. It can be useful to think of **machine biases as risk factors for discrimination-based harms**. Take the example of a text-to-image model that over-represents light skin tones when prompted to create a picture of a person in a professional setting, but produces darker skin tones [when the prompts mention criminality](https://arxiv.org/abs/2211.03759). These tendencies would be what we call _machine biases at the model level_. Now let’s think about a few systems that use such a text-to-image model:
1. <span style="text-decoration:underline;">The model is integrated into a website creation service</span> (e.g. SquareSpace, Wix) to help users generate backgrounds for their pages. The model explicitly disables images of people in the generated background.
* In this case, the machine bias “risk factor” does not lead to discrimination harm because the focus of the bias (images of people) is absent from the use case.
* Further risk mitigation is not required for machine biases, although developers should be aware of ongoing discussions about the legality of integrating systems trained on scraped data in commercial systems.
2. <span style="text-decoration:underline;">The model is integrated into a stock images website</span> to provide users with synthetic images of people (e.g. in professional settings) that they can use with fewer privacy concerns, for example, to serve as illustrations for Wikipedia articles
* In this case, machine bias acts to **lock in** and **amplify** existing social biases. It reinforces stereotypes about people (“CEOs are all white men”) that then feed back into complex social systems where increased bias leads to increased discrimination in many different ways (such as reinforcing [implicit bias](https://philpapers.org/rec/BEEAIT-2) in the workplace).
* Mitigation strategies may include educating the stock image users about these biases, or the stock image website may curate generated images to intentionally propose a more diverse set of representations.
3. <span style="text-decoration:underline;">The model is integrated into a “virtual sketch artist” software</span> marketed to police departments that will use it to generate pictures of suspects based on verbal testimony
* In this case, the machine biases directly cause discrimination by systematically directing police departments to darker-skinned people, putting them at increased risk of harm including physical injury and unlawful imprisonment.
* In cases like this one, there may be no level of bias mitigation that makes the risk acceptable. In particular, such a use case would be closely related to face recognition in the context of law enforcement, where [similar bias issues](https://www.law.georgetown.edu/privacy-technology-center/publications/a-forensic-without-the-science-face-recognition-in-u-s-criminal-investigations/) have led several commercial entities and legislatures to adopt moratoria pausing or banning its use across the board.
So, who’s on the hook for machine biases in ML? These three cases illustrate one of the reasons why discussions about the responsibility of ML developers in addressing bias can get so complicated: depending on decisions made at other points in the ML system development process by other people, the biases in an ML dataset or model may land anywhere between being irrelevant to the application settings and directly leading to grievous harm. However, in all of these cases, **stronger biases in the model/dataset increase the risk of negative outcomes**. The European Union has started to develop frameworks that address this phenomenon in [recent regulatory efforts](https://ec.europa.eu/info/business-economy-euro/doing-business-eu/contract-rules/digital-contracts/liability-rules-artificial-intelligence_en): in short, a company that deploys an AI system based on a measurably biased model is liable for harm caused by the system.
Conceptualizing bias as a risk factor then allows us to better understand the **shared responsibility** for machine biases between developers at all stages. Bias can never be fully removed, not least because the definitions of social biases and the power dynamics that tie them to discrimination vary vastly across social contexts. However:
1. Each stage of the development process, from task specification, dataset curation, and model training, to model integration and system deployment, can take steps to minimize the aspects of machine bias** that most directly depend on its choices** and technical decisions, and
2. Clear communication and **information flow between the various ML development stages** can make the difference between making choices that build on top of each other to attenuate the negative potential of bias (multipronged approach to bias mitigation, as in deployment scenario 1 above) _versus_ making choices that compound this negative potential to exacerbate the risk of harm (as in deployment scenario 3).
In the next section, we review these various stages along with some of the tools that can help us address machine bias at each of them.
## Addressing Bias throughout the ML Development Cycle
Ready for some practical advice yet? Here we go 🤗
There is no one single way to develop ML systems; which steps happen in what order depends on a number of factors including the development setting (university, large company, startup, grassroots organization, etc…), the modality (text, tabular data, images, etc…), and the preeminence or scarcity of publicly available ML resources. However, we can identify three common stages of particular interest in addressing bias. These are the task definition, the data curation, and the model training. Let’s have a look at how bias handling may differ across these various stages.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img_pipeline.png" alt="The Bias ML Pipeline by Meg" width="500" />
<em>The Bias ML Pipeline by <a href="https://huggingface.co/meg">Meg</a></em>
</p>
### I am <span style="text-decoration:underline;">defining the task</span> of my ML system, how can I address bias?
Whether and to what extent bias in the system concretely affects people ultimately depends on what the system is used for. As such, the first place developers can work to mitigate bias is when deciding how ML fits in their system, e.g., by deciding what optimization objective it will use.
For example, let’s go back to one of the first highly-publicized cases of a Machine Learning system used in production for algorithmic content recommendation. From 2006 to 2009, Netflix ran the [Netflix Prize](https://www.cs.uic.edu/~liub/KDD-cup-2007/proceedings/The-Netflix-Prize-Bennett.pdf), a competition with a 1M$ cash prize challenging teams around the world to develop ML systems to accurately predict a user’s rating for a new movie based on their past ratings. The [winning submission](https://www.asc.ohio-state.edu/statistics/dmsl/GrandPrize2009_BPC_BigChaos.pdf) improved the RMSE (Root-mean-square-error) of predictions on unseen user-movie pairs by over 10% over Netflix’s own CineMatch algorithm, meaning it got much better at predicting how users would rate a new movie based on their history. This approach opened the door for much of modern algorithmic content recommendation by bringing the role of ML in modeling user preferences in recommender systems to public awareness.
So what does this have to do with bias? Doesn’t showing people content that they’re likely to enjoy sound like a good service from a content platform? Well, it turns out that showing people more examples of **what they’ve liked in the past** ends up [reducing the diversity of the media they consume](https://dl.acm.org/doi/10.1145/3391403.3399532). Not only does it lead users to be [less satisfied in the long term](https://dl.acm.org/doi/abs/10.1145/3366423.3380281), but it also means that any biases or stereotypes captured by the initial models — such as when modeling [the preferences of Black American users](https://www.marieclaire.com/culture/a18817/netflix-algorithms-black-movies/) or [dynamics that systematically disadvantage](https://dl.acm.org/doi/10.1145/3269206.3272027) some artists — are likely to be reinforced if the model is [further trained on ongoing ML-mediated](https://arxiv.org/abs/2209.03942) user interactions. This reflects two of the types of bias-related concerns we’ve mentioned above: the training objective acts as a **risk factor** for bias-related harms as it makes pre-existing biases much more likely to show up in predictions, and the task framing has the effect of **locking in** and exacerbating past biases.
A promising bias mitigation strategy at this stage has been to reframe the task to explicitly [model both engagement and diversity](https://dl.acm.org/doi/10.1145/3437963.3441775) when applying ML to algorithmic content recommendation. Users are likely to get more long-term satisfaction and the risk of exacerbating biases as outlined above is reduced!
This example serves to illustrate that the impact of machine biases in an ML-supported product depends not just on where we decide to leverage ML, but also on how ML techniques are integrated into the broader technical system, and with what objective. When first investigating how ML can fit into a product or a use case you are interested in, we first recommend looking for the failure modes of the system through the lens of bias before even diving into the available models or datasets - which behaviors of existing systems in the space will be particularly harmful or more likely to occur if bias is exacerbated by ML predictions?
We built a [tool](https://huggingface.co/spaces/hf-task-exploration/ExploreACMnaacl) to take users through these questions in another case of algorithmic content management: [hate speech detection in automatic content moderation](https://aclanthology.org/2022.hcinlp-1.2/). We found for example that looking through news and scientific articles that didn’t particularly focus on the ML part of the technology was already a great way to get a sense of where bias is already at play. Definitely go have a look for an example of how the models and datasets fit with the deployment context and how they can relate to known bias-related harms!
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img2.png" alt="Selection of tools developed by HF team members to address bias in ML" />
<em><a href="https://huggingface.co/spaces/hf-task-exploration/ExploreACMnaacl">ACM Task Exploration tool</a> by <a href="https://huggingface.co/aymm">Angie</a>, <a href="https://huggingface.co/paullada">Amandalynne</a>, and <a href="https://huggingface.co/yjernite">Yacine</a></em>
</p>
#### Task definition: recommendations
There are as many ways for the ML task definition and deployment to affect the risk of bias-related harms as there are applications for ML systems. As in the examples above, some common steps that may help decide whether and how to apply ML in a way that minimizes bias-related risk include:
* Investigate:
* Reports of bias in the field pre-ML
* At-risk demographic categories for your specific use case
* Examine:
* The impact of your optimization objective on reinforcing biases
* Alternative objectives that favor diversity and positive long-term impacts
### I am <span style="text-decoration:underline;">curating/picking a dataset</span> for my ML system, how can I address bias?
While training datasets are [not the sole source of bias](https://www.cell.com/patterns/fulltext/S2666-3899(21)00061-1) in the ML development cycle, they do play a significant role. Does your [dataset disproportionately associate](https://aclanthology.org/2020.emnlp-main.23/) biographies of women with life events but those of men with achievements? Those **stereotypes** are probably going to show up in your full ML system! Does your voice recognition dataset only feature specific accents? Not a good sign for [the inclusivity of technology](https://www.scientificamerican.com/article/speech-recognition-tech-is-yet-another-example-of-bias/) you build with it in terms of **disparate performance**! Whether you’re curating a dataset for ML applications or selecting a dataset to train an ML model, finding out, mitigating, and [communicating](https://dl.acm.org/doi/10.1145/3479582) to what extent the data exhibits these phenomena are all necessary steps to reducing bias-related risks.
You can usually get a pretty good sense of likely biases in a dataset by reflecting on where it comes from, who are the people represented on the data, and what the curation process was. Several frameworks for this reflection and documentation have been proposed such as [Data Statements for NLP](https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00041/43452/Data-Statements-for-Natural-Language-Processing) or [Datasheets for Datasets](https://dl.acm.org/doi/10.1145/3458723). The Hugging Face Hub includes a Dataset Card [template](https://github.com/huggingface/datasets/blob/main/templates/README.md) and [guide](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#dataset-card-creation-guide) inspired by these works; the section on [considerations for using the data](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#considerations-for-using-the-data) is usually a good place to look for information about notable biases if you’re browsing datasets, or to write a paragraph sharing your insights on the topic if you’re sharing a new one. And if you’re looking for more inspiration on what to put there, check out these sections written by Hub users in the [BigLAM organization](https://huggingface.co/biglam) for historical datasets of [legal proceedings](https://huggingface.co/datasets/biglam/old_bailey_proceedings#social-impact-of-dataset), [image classification](https://huggingface.co/datasets/biglam/brill_iconclass#social-impact-of-dataset), and [newspapers](https://huggingface.co/datasets/biglam/bnl_newspapers1841-1879#social-impact-of-dataset).
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img3.png" alt="HF Dataset Card guide for the Social Impact and Bias Sections" />
<em><a href="https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#social-impact-of-dataset">HF Dataset Card guide</a> for the Social Impact and Bias Sections</em>
</p>
While describing the origin and context of a dataset is always a good starting point to understand the biases at play, [quantitatively measuring phenomena](https://arxiv.org/abs/2212.05129) that encode those biases can be just as helpful. If you’re choosing between two different datasets for a given task or choosing between two ML models trained on different datasets, knowing which one better represents the demographic makeup of your ML system’s user base can help you make an informed decision to minimize bias-related risks. If you’re curating a dataset iteratively by filtering data points from a source or selecting new sources of data to add, measuring how these choices affect the diversity and biases present in your overall dataset can make it safer to use in general.
We’ve recently released two tools you can leverage to measure your data through a bias-informed lens. The [disaggregators🤗 library](https://github.com/huggingface/disaggregators) provides utilities to quantify the composition of your dataset, using either metadata or leveraging models to infer properties of data points. This can be particularly useful to minimize risks of bias-related **[representation harms](https://aclanthology.org/P16-2096/)** or **disparate performances** of trained models. Look at the [demo](https://huggingface.co/spaces/society-ethics/disaggregators) to see it applied to the LAION, MedMCQA, and The Stack datasets!
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img4.png" alt="Disaggregators tool by Nima" />
<em><a href="https://huggingface.co/spaces/society-ethics/disaggregators">Disaggregator tool</a> by <a href="https://huggingface.co/NimaBoscarino">Nima</a></em>
</p>
Once you have some helpful statistics about the composition of your dataset, you’ll also want to look at associations between features in your data items, particularly at associations that may encode derogatory or otherwise negative stereotypes. The Data Measurements Tool we [originally introduced](https://huggingface.co/blog/data-measurements-tool#comparison-statistics) last year allows you to do this by looking at the [normalized Pointwise Mutual Information (nPMI)](https://dl.acm.org/doi/10.1145/3461702.3462557) between terms in your text-based dataset; particularly associations between gendered pronouns that may denote gendered stereotypes. [Run it yourself](https://github.com/huggingface/data-measurements-tool) or [try it here](https://huggingface.co/spaces/huggingface/data-measurements-tool) on a few pre-computed datasets!
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img5.png" alt="Data Measurements tool by Meg, Sasha, Bibi, and the Gradio team" />
<em><a href="https://huggingface.co/spaces/huggingface/data-measurements-tool">Data Measurements tool</a> by <a href="https://huggingface.co/meg">Meg</a>, <a href="https://huggingface.co/sasha">Sasha</a>, <a href="https://huggingface.co/Bibss">Bibi</a>, and the <a href="https://gradio.app/">Gradio team</a></em>
</p>
#### Dataset selection/curation: recommendations
These tools aren’t full solutions by themselves, rather, they are designed to support critical examination and improvement of datasets through several lenses, including the lens of bias and bias-related risks. In general, we encourage you to keep the following steps in mind when leveraging these and other tools to mitigate bias risks at the dataset curation/selection stage:
* Identify:
* Aspects of the dataset creation that may exacerbate specific biases
* Demographic categories and social variables that are particularly important to the dataset’s task and domain
* Measure:
* The demographic distribution in your dataset
* Pre-identified negative stereotypes represented
* Document:
* Share what you’ve Identified and Measured in your Dataset Card so it can benefit other users, developers, and otherwise affected people
* Adapt:
* By choosing the dataset least likely to cause bias-related harms
* By iteratively improving your dataset in ways that reduce bias risks
### I am <span style="text-decoration:underline;">training/selecting a model</span> for my ML system, how can I address bias?
Similar to the dataset curation/selection step, documenting and measuring bias-related phenomena in models can help both ML developers who are selecting a model to use as-is or to finetune and ML developers who want to train their own models. For the latter, measures of bias-related phenomena in the model can help them learn from what has worked or what hasn’t for other models and serve as a signal to guide their own development choices.
Model cards were originally proposed by [(Mitchell et al., 2019)](https://dl.acm.org/doi/10.1145/3287560.3287596) and provide a framework for model reporting that showcases information relevant to bias risks, including broad ethical considerations, disaggregated evaluation, and use case recommendation. The Hugging Face Hub provides even more tools for model documentation, with a [model card guidebook](https://huggingface.co/docs/hub/model-cards) in the Hub documentation, and an [app that lets you create extensive model cards](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool) easily for your new model.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img6.png" alt="Model Card writing tool by Ezi, Marissa, and Meg" />
<em><a href="https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool">Model Card writing tool</a> by <a href="https://huggingface.co/Ezi">Ezi</a>, <a href="https://huggingface.co/Marissa">Marissa</a>, and <a href="https://huggingface.co/meg">Meg</a></em>
</p>
Documentation is a great first step for sharing general insights about a model’s behavior, but it is usually static and presents the same information to all users. In many cases, especially for generative models that can generate outputs to approximate the distribution of their training data, we can gain a more contextual understanding of bias-related phenomena and **negative stereotypes** by visualizing and contrasting model outputs. Access to model generations can help users bring [intersectional issues in the model behavior](https://www.technologyreview.com/2022/12/12/1064751/the-viral-ai-avatar-app-lensa-undressed-me-without-my-consent/) corresponding to their lived experience, and evaluate to what extent a model reproduces [gendered stereotypes for different adjectives](https://www.vice.com/en/article/bvm35w/this-tool-lets-anyone-see-the-bias-in-ai-image-generators). To facilitate this process, we built a tool that lets you compare generations not just across a set of adjectives and professions, but also across different models! [Go try it out](https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer) to get a sense of which model might carry the least bias risks in your use case.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img7.png" alt="Visualize Adjective and Occupation Biases in Image Generation by Sasha" />
<br>
<em><a href="https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer">Visualize Adjective and Occupation Biases in Image Generation</a> by <a href="https://huggingface.co/sasha">Sasha</a></em>
</p>
Visualization of model outputs isn’t just for generative models though! For classification models, we also want to look out for bias-related harms caused by a model’s **disparate performance** on different demographics. If you know what protected classes are most at risk of discrimination and have those annotated in an evaluation set, then you can report disaggregated performance over the different categories in [your model card](https://dl.acm.org/doi/10.1145/3287560.3287596) as mentioned above, so users can make informed decisions. If however, you are worried that you haven’t identified all populations at risk of bias-related harms, or if you do not have access to annotated test examples to measure the biases you suspect, that’s where interactive visualizations of where and how the model fails come in handy! To help you with this, the [SEAL app](https://huggingface.co/spaces/nazneen/seal) groups similar mistakes by your model and shows you some common features in each cluster. If you want to go further, you can even combine it with the [disaggregators library](https://github.com/huggingface/disaggregators) we introduced in the datasets section to find clusters that are indicative of bias-related failure modes!
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img8.png" alt="Systematic Error Analysis and Labeling (SEAL) by Nazneen" />
<em><a href="https://huggingface.co/spaces/nazneen/seal">Systematic Error Analysis and Labeling (SEAL)</a> by <a href="https://huggingface.co/nazneen">Nazneen</a></em>
</p>
Finally, a few benchmarks exist that can measure bias-related phenomena in models. For language models, benchmarks such as [BOLD](https://github.com/amazon-science/bold), [HONEST](https://aclanthology.org/2021.naacl-main.191.pdf), or [WinoBias](https://aclanthology.org/N18-2003/) provide quantitative evaluations of targeted behaviors that are indicative of biases in the models. While the benchmarks have their [limitations](https://aclanthology.org/2021.acl-long.81/), they do provide a limited view into some pre-identified bias risks that can help describe how the models function or choose between different models. You can find these evaluations pre-computed on a range of common language models [in this exploration Space](https://huggingface.co/spaces/sasha/BiasDetection) to get a first sense of how they compare!
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img9.png" alt="Language Model Bias Detection by Sasha" />
<em><a href="https://huggingface.co/spaces/sasha/BiasDetection">Language Model Bias Detection</a> by <a href="https://huggingface.co/sasha">Sasha</a></em>
</p>
Even with access to a benchmark for the models you are considering, you might find that running evaluations of the larger language models you are considering can be prohibitively expensive or otherwise technically impossible with your own computing resources. The <a href="https://huggingface.co/spaces/autoevaluate/model-evaluator">Evaluation on the Hub</a> tool we released this year can help with that: not only will it run the evaluations for you, but it will also help connect them to the model documentation so the results are available once and for all — so everyone can see, for example, that size <a href="https://huggingface.co/blog/zero-shot-eval-on-the-hub">measurably increases bias risks in models like OPT</a>!
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/ethics_soc_2/img_winobias.png" alt="Large model WinoBias scores computed with Evaluation on the Hub by Helen, Tristan, Abhishek, Lewis, and Douwe" />
<em><a href="https://huggingface.co/spaces/sasha/BiasDetection"><a href="https://huggingface.co/blog/zero-shot-eval-on-the-hub">Large model WinoBias scores computed with Evaluation on the Hub</a> by <a href="https://huggingface.co/mathemakitten">Helen</a>, <a href="https://huggingface.co/Tristan">Tristan</a>, <a href="https://huggingface.co/abhishek">Abhishek</a>, <a href="https://huggingface.co/lewtun">Lewis</a>, and <a href="https://huggingface.co/douwekiela">Douwe</a></em>
</p>
#### Model selection/development: recommendations
For models just as for datasets, different tools for documentation and evaluation will provide different views of bias risks in a model which all have a part to play in helping developers choose, develop, or understand ML systems.
* Visualize
* Generative model: visualize how the model’s outputs may reflect stereotypes
* Classification model: visualize model errors to identify failure modes that could lead to disparate performance
* Evaluate
* When possible, evaluate models on relevant benchmarks
* Document
* Share your learnings from visualization and qualitative evaluation
* Report your model’s disaggregated performance and results on applicable fairness benchmarks
## Conclusion and Overview of Bias Analysis and Documentation Tools from 🤗
As we learn to leverage ML systems in more and more applications, reaping their benefits equitably will depend on our ability to actively mitigate the risks of bias-related harms associated with the technology. While there is no single answer to the question of how this should best be done in any possible setting, we can support each other in this effort by sharing lessons, tools, and methodologies to mitigate and document those risks. The present blog post outlines some of the ways Hugging Face team members have addressed this question of bias along with supporting tools, we hope that you will find them helpful and encourage you to develop and share your own!
Summary of linked tools:
* Tasks:
* Explore our directory of [ML Tasks](https://huggingface.co/tasks) to understand what technical framings and resources are available to choose from
* Use tools to explore the [full development lifecycle](https://huggingface.co/spaces/hf-task-exploration/ExploreACMnaacl) of specific tasks
* Datasets:
* Make use of and contribute to [Dataset Cards](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#social-impact-of-dataset) to share relevant insights on biases in datasets.
* Use [Disaggregator](https://github.com/huggingface/disaggregators) to look for [possible disparate performance](https://huggingface.co/spaces/society-ethics/disaggregators)
* Look at aggregated [measurements of your dataset](https://huggingface.co/spaces/huggingface/data-measurements-tool) including nPMI to surface possible stereotypical associations
* Models:
* Make use of and contribute to [Model Cards](https://huggingface.co/docs/hub/model-cards) to share relevant insights on biases in models.
* Use [Interactive Model Cards](https://huggingface.co/spaces/nazneen/interactive-model-cards) to visualize performance discrepancies
* Look at [systematic model errors](https://huggingface.co/spaces/nazneen/seal) and look out for known social biases
* Use [Evaluate](https://github.com/huggingface/evaluate) and [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator) to explore [language model biases](https://huggingface.co/blog/evaluating-llm-bias) including in [large models](https://huggingface.co/blog/zero-shot-eval-on-the-hub)
* Use a [Text-to-image bias explorer](https://huggingface.co/spaces/sasha/StableDiffusionBiasExplorer) to compare image generation models’ biases
* Compare LM models with Bias [Score Card](https://huggingface.co/spaces/sasha/BiasDetection)
Thanks for reading! 🤗
~ Yacine, on behalf of the Ethics and Society regulars
If you want to cite this blog post, please use the following:
```
@inproceedings{hf_ethics_soc_blog_2,
author = {Yacine Jernite and
Alexandra Sasha Luccioni and
Irene Solaiman and
Giada Pistilli and
Nathan Lambert and
Ezi Ozoani and
Brigitte Toussignant and
Margaret Mitchell},
title = {Hugging Face Ethics and Society Newsletter 2: Let's Talk about Bias!},
booktitle = {Hugging Face Blog},
year = {2022},
url = {https://doi.org/10.57967/hf/0214},
doi = {10.57967/hf/0214}
}
```
| huggingface/blog/blob/main/ethics-soc-2.md |
Deep Layer Aggregation
Extending “shallow” skip connections, **Dense Layer Aggregation (DLA)** incorporates more depth and sharing. The authors introduce two structures for deep layer aggregation (DLA): iterative deep aggregation (IDA) and hierarchical deep aggregation (HDA). These structures are expressed through an architectural framework, independent of the choice of backbone, for compatibility with current and future networks.
IDA focuses on fusing resolutions and scales while HDA focuses on merging features from all modules and channels. IDA follows the base hierarchy to refine resolution and aggregate scale stage-bystage. HDA assembles its own hierarchy of tree-structured connections that cross and merge stages to aggregate different levels of representation.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('dla102', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `dla102`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('dla102', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{yu2019deep,
title={Deep Layer Aggregation},
author={Fisher Yu and Dequan Wang and Evan Shelhamer and Trevor Darrell},
year={2019},
eprint={1707.06484},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: DLA
Paper:
Title: Deep Layer Aggregation
URL: https://paperswithcode.com/paper/deep-layer-aggregation
Models:
- Name: dla102
In Collection: DLA
Metadata:
FLOPs: 7192952808
Parameters: 33270000
File Size: 135290579
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla102
LR: 0.1
Epochs: 120
Layers: 102
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L410
Weights: http://dl.yf.io/dla/models/imagenet/dla102-d94d9790.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.03%
Top 5 Accuracy: 93.95%
- Name: dla102x
In Collection: DLA
Metadata:
FLOPs: 5886821352
Parameters: 26310000
File Size: 107552695
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla102x
LR: 0.1
Epochs: 120
Layers: 102
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L418
Weights: http://dl.yf.io/dla/models/imagenet/dla102x-ad62be81.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.51%
Top 5 Accuracy: 94.23%
- Name: dla102x2
In Collection: DLA
Metadata:
FLOPs: 9343847400
Parameters: 41280000
File Size: 167645295
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla102x2
LR: 0.1
Epochs: 120
Layers: 102
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L426
Weights: http://dl.yf.io/dla/models/imagenet/dla102x2-262837b6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.44%
Top 5 Accuracy: 94.65%
- Name: dla169
In Collection: DLA
Metadata:
FLOPs: 11598004200
Parameters: 53390000
File Size: 216547113
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: dla169
LR: 0.1
Epochs: 120
Layers: 169
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L434
Weights: http://dl.yf.io/dla/models/imagenet/dla169-0914e092.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.69%
Top 5 Accuracy: 94.33%
- Name: dla34
In Collection: DLA
Metadata:
FLOPs: 3070105576
Parameters: 15740000
File Size: 63228658
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla34
LR: 0.1
Epochs: 120
Layers: 32
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L362
Weights: http://dl.yf.io/dla/models/imagenet/dla34-ba72cf86.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.62%
Top 5 Accuracy: 92.06%
- Name: dla46_c
In Collection: DLA
Metadata:
FLOPs: 583277288
Parameters: 1300000
File Size: 5307963
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla46_c
LR: 0.1
Epochs: 120
Layers: 46
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L369
Weights: http://dl.yf.io/dla/models/imagenet/dla46_c-2bfd52c3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 64.87%
Top 5 Accuracy: 86.29%
- Name: dla46x_c
In Collection: DLA
Metadata:
FLOPs: 544052200
Parameters: 1070000
File Size: 4387641
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla46x_c
LR: 0.1
Epochs: 120
Layers: 46
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L378
Weights: http://dl.yf.io/dla/models/imagenet/dla46x_c-d761bae7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 65.98%
Top 5 Accuracy: 86.99%
- Name: dla60
In Collection: DLA
Metadata:
FLOPs: 4256251880
Parameters: 22040000
File Size: 89560235
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60
LR: 0.1
Epochs: 120
Layers: 60
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L394
Weights: http://dl.yf.io/dla/models/imagenet/dla60-24839fc4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.04%
Top 5 Accuracy: 93.32%
- Name: dla60_res2net
In Collection: DLA
Metadata:
FLOPs: 4147578504
Parameters: 20850000
File Size: 84886593
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60_res2net
Layers: 60
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L346
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net_dla60_4s-d88db7f9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.46%
Top 5 Accuracy: 94.21%
- Name: dla60_res2next
In Collection: DLA
Metadata:
FLOPs: 3485335272
Parameters: 17030000
File Size: 69639245
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60_res2next
Layers: 60
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L354
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2next_dla60_4s-d327927b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.44%
Top 5 Accuracy: 94.16%
- Name: dla60x
In Collection: DLA
Metadata:
FLOPs: 3544204264
Parameters: 17350000
File Size: 70883139
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60x
LR: 0.1
Epochs: 120
Layers: 60
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L402
Weights: http://dl.yf.io/dla/models/imagenet/dla60x-d15cacda.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.25%
Top 5 Accuracy: 94.02%
- Name: dla60x_c
In Collection: DLA
Metadata:
FLOPs: 593325032
Parameters: 1320000
File Size: 5454396
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- DLA Bottleneck Residual Block
- DLA Residual Block
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: dla60x_c
LR: 0.1
Epochs: 120
Layers: 60
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/dla.py#L386
Weights: http://dl.yf.io/dla/models/imagenet/dla60x_c-b870c45c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 67.91%
Top 5 Accuracy: 88.42%
--> | huggingface/pytorch-image-models/blob/main/docs/models/dla.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Habana Gaudi
🤗 Diffusers is compatible with Habana Gaudi through 🤗 [Optimum](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion). Follow the [installation](https://docs.habana.ai/en/latest/Installation_Guide/index.html) guide to install the SynapseAI and Gaudi drivers, and then install Optimum Habana:
```bash
python -m pip install --upgrade-strategy eager optimum[habana]
```
To generate images with Stable Diffusion 1 and 2 on Gaudi, you need to instantiate two instances:
- [`~optimum.habana.diffusers.GaudiStableDiffusionPipeline`], a pipeline for text-to-image generation.
- [`~optimum.habana.diffusers.GaudiDDIMScheduler`], a Gaudi-optimized scheduler.
When you initialize the pipeline, you have to specify `use_habana=True` to deploy it on HPUs and to get the fastest possible generation, you should enable **HPU graphs** with `use_hpu_graphs=True`.
Finally, specify a [`~optimum.habana.GaudiConfig`] which can be downloaded from the [Habana](https://huggingface.co/Habana) organization on the Hub.
```python
from optimum.habana import GaudiConfig
from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
model_name = "stabilityai/stable-diffusion-2-base"
scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
pipeline = GaudiStableDiffusionPipeline.from_pretrained(
model_name,
scheduler=scheduler,
use_habana=True,
use_hpu_graphs=True,
gaudi_config="Habana/stable-diffusion-2",
)
```
Now you can call the pipeline to generate images by batches from one or several prompts:
```python
outputs = pipeline(
prompt=[
"High quality photo of an astronaut riding a horse in space",
"Face of a yellow cat, high resolution, sitting on a park bench",
],
num_images_per_prompt=10,
batch_size=4,
)
```
For more information, check out 🤗 Optimum Habana's [documentation](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion) and the [example](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) provided in the official GitHub repository.
## Benchmark
We benchmarked Habana's first-generation Gaudi and Gaudi2 with the [Habana/stable-diffusion](https://huggingface.co/Habana/stable-diffusion) and [Habana/stable-diffusion-2](https://huggingface.co/Habana/stable-diffusion-2) Gaudi configurations (mixed precision bf16/fp32) to demonstrate their performance.
For [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) on 512x512 images:
| | Latency (batch size = 1) | Throughput |
| ---------------------- |:------------------------:|:---------------------------:|
| first-generation Gaudi | 3.80s | 0.308 images/s (batch size = 8) |
| Gaudi2 | 1.33s | 1.081 images/s (batch size = 8) |
For [Stable Diffusion v2.1](https://huggingface.co/stabilityai/stable-diffusion-2-1) on 768x768 images:
| | Latency (batch size = 1) | Throughput |
| ---------------------- |:------------------------:|:-------------------------------:|
| first-generation Gaudi | 10.2s | 0.108 images/s (batch size = 4) |
| Gaudi2 | 3.17s | 0.379 images/s (batch size = 8) |
| huggingface/diffusers/blob/main/docs/source/en/optimization/habana.md |
--
title: 'Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker'
thumbnail: /blog/assets/19_sagemaker_distributed_training_seq2seq/thumbnail.png
authors:
- user: philschmid
---
# Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker
<a target="_blank" href="https://github.com/huggingface/notebooks/blob/master/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb">
<img src="https://badgen.net/badge/Github/Open/black?icon=github" alt="Open on Github"/>
</a>
In case you missed it: on March 25th [we announced a collaboration with Amazon SageMaker](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face) to make it easier to create State-of-the-Art Machine Learning models, and ship cutting-edge NLP features faster.
Together with the SageMaker team, we built 🤗 Transformers optimized [Deep Learning Containers](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers) to accelerate training of Transformers-based models. Thanks AWS friends!🤗 🚀
With the new HuggingFace estimator in the [SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/), you can start training with a single line of code.

The [announcement blog post](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face) provides all the information you need to know about the integration, including a "Getting Started" example and links to documentation, examples, and features.
listed again here:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
If you're not familiar with Amazon SageMaker: *"Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models." [[REF](https://aws.amazon.com/sagemaker/faqs/)]*
---
# Tutorial
We will use the new [Hugging Face DLCs](https://github.com/aws/deep-learning-containers/tree/master/huggingface) and [Amazon SageMaker extension](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/sagemaker.huggingface.html#huggingface-estimator) to train a distributed Seq2Seq-transformer model on the `summarization` task using the `transformers` and `datasets` libraries, and then upload the model to [huggingface.co](http://huggingface.co) and test it.
As [distributed training strategy](https://huggingface.co/transformers/sagemaker.html#distributed-training-data-parallel) we are going to use [SageMaker Data Parallelism](https://aws.amazon.com/blogs/aws/managed-data-parallelism-in-amazon-sagemaker-simplifies-training-on-large-datasets/), which has been built into the [Trainer](https://huggingface.co/transformers/main_classes/trainer.html) API. To use data-parallelism we only have to define the `distribution` parameter in our `HuggingFace` estimator.
```python
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
```
In this tutorial, we will use an Amazon SageMaker Notebook Instance for running our training job. You can learn [here how to set up a Notebook Instance](https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html).
**What are we going to do:**
- Set up a development environment and install sagemaker
- Choose 🤗 Transformers `examples/` script
- Configure distributed training and hyperparameters
- Create a `HuggingFace` estimator and start training
- Upload the fine-tuned model to [huggingface.co](http://huggingface.co)
- Test inference
### Model and Dataset
We are going to fine-tune [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the [samsum](https://huggingface.co/datasets/samsum) dataset. *"BART is sequence-to-sequence model trained with denoising as pretraining objective."* [[REF](https://github.com/pytorch/fairseq/blob/master/examples/bart/README.md)]
The `samsum` dataset contains about 16k messenger-like conversations with summaries.
```json
{"id": "13818513",
"summary": "Amanda baked cookies and will bring Jerry some tomorrow.",
"dialogue": "Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I'll bring you tomorrow :-)"}
```
---
## Set up a development environment and install sagemaker
After our SageMaker Notebook Instance is running we can select either Jupyer Notebook or JupyterLab and create a new Notebook with the `conda_pytorch_p36 kernel`.
_**Note:** The use of Jupyter is optional: We could also launch SageMaker Training jobs from anywhere we have an SDK installed, connectivity to the cloud and appropriate permissions, such as a Laptop, another IDE or a task scheduler like Airflow or AWS Step Functions._
After that we can install the required dependencies
```bash
!pip install transformers "datasets[s3]" sagemaker --upgrade
```
[install](https://github.com/git-lfs/git-lfs/wiki/Installation) `git-lfs` for model upload.
```bash
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
!sudo yum install git-lfs -y
!git lfs install
```
To run training on SageMaker we need to create a sagemaker Session and provide an IAM role with the right permission. This IAM role will be later attached to the `TrainingJob` enabling it to download data, e.g. from Amazon S3.
```python
import sagemaker
sess = sagemaker.Session()
role = sagemaker.get_execution_role()
print(f"IAM role arn used for running training: {role}")
print(f"S3 bucket used for storing artifacts: {sess.default_bucket()}")
```
---
# Choose 🤗 Transformers `examples/` script
The [🤗 Transformers repository](https://github.com/huggingface/transformers/tree/master/examples) contains several `examples/`scripts for fine-tuning models on tasks from `language-modeling` to `token-classification`. In our case, we are using the `run_summarization.py` from the `seq2seq/` examples.
***Note**: you can use this tutorial as-is to train your model on a different examples script.*
Since the `HuggingFace` Estimator has git support built-in, we can specify a [training script stored in a GitHub repository](https://sagemaker.readthedocs.io/en/stable/overview.html#use-scripts-stored-in-a-git-repository) as `entry_point` and `source_dir`.
We are going to use the `transformers 4.4.2` DLC which means we need to configure the `v4.4.2` as the branch to pull the compatible example scripts.
```python
#git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'} # v4.4.2 is referring to the `transformers_version you use in the estimator.
# used due an missing package in v4.4.2
git_config = {'repo': 'https://github.com/philschmid/transformers.git','branch': 'master'} # v4.4.2 is referring to the `transformers_version you use in the estimator.
```
---
## Configure distributed training and hyperparameters
Next, we will define our `hyperparameters` and configure our distributed training strategy. As hyperparameter, we can define any [Seq2SeqTrainingArguments](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainingarguments) and the ones defined in [run_summarization.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/seq2seq#sequence-to-sequence-training-and-evaluation).
```python
# hyperparameters, which are passed into the training job
hyperparameters={
'per_device_train_batch_size': 4,
'per_device_eval_batch_size': 4,
'model_name_or_path':'facebook/bart-large-cnn',
'dataset_name':'samsum',
'do_train':True,
'do_predict': True,
'predict_with_generate': True,
'output_dir':'/opt/ml/model',
'num_train_epochs': 3,
'learning_rate': 5e-5,
'seed': 7,
'fp16': True,
}
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
```
Since, we are using [SageMaker Data Parallelism](https://aws.amazon.com/blogs/aws/managed-data-parallelism-in-amazon-sagemaker-simplifies-training-on-large-datasets/) our `total_batch_size` will be `per_device_train_batch_size` * `n_gpus`.
---
## Create a `HuggingFace` estimator and start training
The last step before training is creating a `HuggingFace` estimator. The Estimator handles the end-to-end Amazon SageMaker training. We define which fine-tuning script should be used as `entry_point`, which `instance_type` should be used, and which `hyperparameters` are passed in.
```python
from sagemaker.huggingface import HuggingFace
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_summarization.py', # script
source_dir='./examples/seq2seq', # relative path to example
git_config=git_config,
instance_type='ml.p3dn.24xlarge',
instance_count=2,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
role=role,
hyperparameters = hyperparameters,
distribution = distribution
)
```
As `instance_type` we are using `ml.p3dn.24xlarge`, which contains 8x NVIDIA A100 with an `instance_count` of 2. This means we are going to run training on 16 GPUs and a `total_batch_size` of 16*4=64. We are going to train a 400 Million Parameter model with a `total_batch_size` of 64, which is just wow.
To start our training we call the `.fit()` method.
```python
# starting the training job
huggingface_estimator.fit()
```
```bash
2021-04-01 13:00:35 Starting - Starting the training job...
2021-04-01 13:01:03 Starting - Launching requested ML instancesProfilerReport-1617282031: InProgress
2021-04-01 13:02:23 Starting - Preparing the instances for training......
2021-04-01 13:03:25 Downloading - Downloading input data...
2021-04-01 13:04:04 Training - Downloading the training image...............
2021-04-01 13:06:33 Training - Training image download completed. Training in progress
....
....
2021-04-01 13:16:47 Uploading - Uploading generated training model
2021-04-01 13:27:49 Completed - Training job completed
Training seconds: 2882
Billable seconds: 2882
```
The training seconds are 2882 because they are multiplied by the number of instances. If we calculate 2882/2=1441 is it the duration from "Downloading the training image" to "Training job completed".
Converted to real money, our training on 16 NVIDIA Tesla V100-GPU for a State-of-the-Art summarization model comes down to ~28$.
---
## Upload the fine-tuned model to [huggingface.co](http://huggingface.co)
Since our model achieved a pretty good score we are going to upload it to [huggingface.co](http://huggingface.co), create a `model_card` and test it with the Hosted Inference widget. To upload a model you need to [create an account here](https://huggingface.co/join).
We can download our model from Amazon S3 and unzip it using the following snippet.
```python
import os
import tarfile
from sagemaker.s3 import S3Downloader
local_path = 'my_bart_model'
os.makedirs(local_path, exist_ok = True)
# download model from S3
S3Downloader.download(
s3_uri=huggingface_estimator.model_data, # s3 uri where the trained model is located
local_path=local_path, # local path where *.tar.gz will be saved
sagemaker_session=sess # sagemaker session used for training the model
)
# unzip model
tar = tarfile.open(f"{local_path}/model.tar.gz", "r:gz")
tar.extractall(path=local_path)
tar.close()
os.remove(f"{local_path}/model.tar.gz")
```
Before we are going to upload our model to [huggingface.co](http://huggingface.co) we need to create a `model_card`. The `model_card` describes the model and includes hyperparameters, results, and specifies which dataset was used for training. To create a `model_card` we create a `README.md` in our `local_path`
```python
# read eval and test results
with open(f"{local_path}/eval_results.json") as f:
eval_results_raw = json.load(f)
eval_results={}
eval_results["eval_rouge1"] = eval_results_raw["eval_rouge1"]
eval_results["eval_rouge2"] = eval_results_raw["eval_rouge2"]
eval_results["eval_rougeL"] = eval_results_raw["eval_rougeL"]
eval_results["eval_rougeLsum"] = eval_results_raw["eval_rougeLsum"]
with open(f"{local_path}/test_results.json") as f:
test_results_raw = json.load(f)
test_results={}
test_results["test_rouge1"] = test_results_raw["test_rouge1"]
test_results["test_rouge2"] = test_results_raw["test_rouge2"]
test_results["test_rougeL"] = test_results_raw["test_rougeL"]
test_results["test_rougeLsum"] = test_results_raw["test_rougeLsum"]
```
After we extract all the metrics we want to include we are going to create our `README.md`. Additionally to the automated generation of the results table we add the metrics manually to the `metadata` of our model card under `model-index`
```python
import json
MODEL_CARD_TEMPLATE = """
---
language: en
tags:
- sagemaker
- bart
- summarization
license: apache-2.0
datasets:
- samsum
model-index:
- name: {model_name}
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization"
type: samsum
metrics:
- name: Validation ROGUE-1
type: rogue-1
value: 42.621
- name: Validation ROGUE-2
type: rogue-2
value: 21.9825
- name: Validation ROGUE-L
type: rogue-l
value: 33.034
- name: Test ROGUE-1
type: rogue-1
value: 41.3174
- name: Test ROGUE-2
type: rogue-2
value: 20.8716
- name: Test ROGUE-L
type: rogue-l
value: 32.1337
widget:
- text: |
Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
---
## `{model_name}`
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container.
For more information look at:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
## Hyperparameters
{hyperparameters}
## Usage
from transformers import pipeline
summarizer = pipeline("summarization", model="philschmid/{model_name}")
conversation = '''Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
'''
nlp(conversation)
## Results
| key | value |
| --- | ----- |
{eval_table}
{test_table}
"""
# Generate model card (todo: add more data from Trainer)
model_card = MODEL_CARD_TEMPLATE.format(
model_name=f"{hyperparameters['model_name_or_path'].split('/')[1]}-{hyperparameters['dataset_name']}",
hyperparameters=json.dumps(hyperparameters, indent=4, sort_keys=True),
eval_table="\n".join(f"| {k} | {v} |" for k, v in eval_results.items()),
test_table="\n".join(f"| {k} | {v} |" for k, v in test_results.items()),
)
with open(f"{local_path}/README.md", "w") as f:
f.write(model_card)
```
After we have our unzipped model and model card located in `my_bart_model` we can use the either `huggingface_hub` SDK to create a repository and upload it to [huggingface.co](https://huggingface.co) – or just to https://huggingface.co/new an create a new repository and upload it.
```python
from getpass import getpass
from huggingface_hub import HfApi, Repository
hf_username = "philschmid" # your username on huggingface.co
hf_email = "[email protected]" # email used for commit
repository_name = f"{hyperparameters['model_name_or_path'].split('/')[1]}-{hyperparameters['dataset_name']}" # repository name on huggingface.co
password = getpass("Enter your password:") # creates a prompt for entering password
# get hf token
token = HfApi().login(username=hf_username, password=password)
# create repository
repo_url = HfApi().create_repo(token=token, name=repository_name, exist_ok=True)
# create a Repository instance
model_repo = Repository(use_auth_token=token,
clone_from=repo_url,
local_dir=local_path,
git_user=hf_username,
git_email=hf_email)
# push model to the hub
model_repo.push_to_hub()
```
---
## Test inference
After we uploaded our model we can access it at `https://huggingface.co/{hf_username}/{repository_name}`
```python
print(f"https://huggingface.co/{hf_username}/{repository_name}")
```
And use the "Hosted Inference API" widget to test it.
[https://huggingface.co/philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum)

| huggingface/blog/blob/main/sagemaker-distributed-training-seq2seq.md |
Metric Card for Perplexity
## Metric Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence. This can be used in two main ways:
1. to evaluate how well the model has learned the distribution of the text it was trained on
- In this case, the model input should be the trained model to be evaluated, and the input texts should be the text that the model was trained on.
2. to evaluate how well a selection of text matches the distribution of text that the input model was trained on
- In this case, the model input should be a trained model, and the input texts should be the text to be evaluated.
## Intended Uses
Any language generation task.
## How to Use
The metric takes a list of text as input, as well as the name of the model used to compute the metric:
```python
from datasets import load_metric
perplexity = load_metric("perplexity")
results = perplexity.compute(input_texts=input_texts, model_id='gpt2')
```
### Inputs
- **model_id** (str): model used for calculating Perplexity. NOTE: Perplexity can only be calculated for causal language models.
- This includes models such as gpt2, causal variations of bert, causal versions of t5, and more (the full list can be found in the AutoModelForCausalLM documentation here: https://huggingface.co/docs/transformers/master/en/model_doc/auto#transformers.AutoModelForCausalLM )
- **input_texts** (list of str): input text, each separate text snippet is one list entry.
- **batch_size** (int): the batch size to run texts through the model. Defaults to 16.
- **add_start_token** (bool): whether to add the start token to the texts, so the perplexity can include the probability of the first word. Defaults to True.
- **device** (str): device to run on, defaults to 'cuda' when available
### Output Values
This metric outputs a dictionary with the perplexity scores for the text input in the list, and the average perplexity.
If one of the input texts is longer than the max input length of the model, then it is truncated to the max length for the perplexity computation.
```
{'perplexities': [8.182524681091309, 33.42122268676758, 27.012239456176758], 'mean_perplexity': 22.871995608011883}
```
This metric's range is 0 and up. A lower score is better.
#### Values from Popular Papers
### Examples
Calculating perplexity on input_texts defined here:
```python
perplexity = datasets.load_metric("perplexity")
input_texts = ["lorem ipsum", "Happy Birthday!", "Bienvenue"]
results = perplexity.compute(model_id='gpt2',
add_start_token=False,
input_texts=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>78.22
print(round(results["perplexities"][0], 2))
>>>11.11
```
Calculating perplexity on input_texts loaded in from a dataset:
```python
perplexity = datasets.load_metric("perplexity")
input_texts = datasets.load_dataset("wikitext",
"wikitext-2-raw-v1",
split="test")["text"][:50]
input_texts = [s for s in input_texts if s!='']
results = perplexity.compute(model_id='gpt2',
input_texts=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>60.35
print(round(results["perplexities"][0], 2))
>>>81.12
```
## Limitations and Bias
Note that the output value is based heavily on what text the model was trained on. This means that perplexity scores are not comparable between models or datasets.
## Citation
```bibtex
@article{jelinek1977perplexity,
title={Perplexity—a measure of the difficulty of speech recognition tasks},
author={Jelinek, Fred and Mercer, Robert L and Bahl, Lalit R and Baker, James K},
journal={The Journal of the Acoustical Society of America},
volume={62},
number={S1},
pages={S63--S63},
year={1977},
publisher={Acoustical Society of America}
}
```
## Further References
- [Hugging Face Perplexity Blog Post](https://huggingface.co/docs/transformers/perplexity)
| huggingface/datasets/blob/main/metrics/perplexity/README.md |
--
title: BERT Score
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
BERTScore leverages the pre-trained contextual embeddings from BERT and matches words in candidate and reference
sentences by cosine similarity.
It has been shown to correlate with human judgment on sentence-level and system-level evaluation.
Moreover, BERTScore computes precision, recall, and F1 measure, which can be useful for evaluating different language
generation tasks.
See the project's README at https://github.com/Tiiiger/bert_score#readme for more information.
---
# Metric Card for BERT Score
## Metric description
BERTScore is an automatic evaluation metric for text generation that computes a similarity score for each token in the candidate sentence with each token in the reference sentence. It leverages the pre-trained contextual embeddings from [BERT](https://huggingface.co/bert-base-uncased) models and matches words in candidate and reference sentences by cosine similarity.
Moreover, BERTScore computes precision, recall, and F1 measure, which can be useful for evaluating different language generation tasks.
## How to use
BERTScore takes 3 mandatory arguments : `predictions` (a list of string of candidate sentences), `references` (a list of strings or list of list of strings of reference sentences) and either `lang` (a string of two letters indicating the language of the sentences, in [ISO 639-1 format](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes)) or `model_type` (a string specififying which model to use, according to the BERT specification). The default behavior of the metric is to use the suggested model for the target language when one is specified, otherwise to use the `model_type` indicated.
```python
from evaluate import load
bertscore = load("bertscore")
predictions = ["hello there", "general kenobi"]
references = ["hello there", "general kenobi"]
results = bertscore.compute(predictions=predictions, references=references, lang="en")
```
BERTScore also accepts multiple optional arguments:
`num_layers` (int): The layer of representation to use. The default is the number of layers tuned on WMT16 correlation data, which depends on the `model_type` used.
`verbose` (bool): Turn on intermediate status update. The default value is `False`.
`idf` (bool or dict): Use idf weighting; can also be a precomputed idf_dict.
`device` (str): On which the contextual embedding model will be allocated on. If this argument is `None`, the model lives on `cuda:0` if cuda is available.
`nthreads` (int): Number of threads used for computation. The default value is `4`.
`rescale_with_baseline` (bool): Rescale BERTScore with the pre-computed baseline. The default value is `False`.
`batch_size` (int): BERTScore processing batch size, at least one of `model_type` or `lang`. `lang` needs to be specified when `rescale_with_baseline` is `True`.
`baseline_path` (str): Customized baseline file.
`use_fast_tokenizer` (bool): `use_fast` parameter passed to HF tokenizer. The default value is `False`.
## Output values
BERTScore outputs a dictionary with the following values:
`precision`: The [precision](https://huggingface.co/metrics/precision) for each sentence from the `predictions` + `references` lists, which ranges from 0.0 to 1.0.
`recall`: The [recall](https://huggingface.co/metrics/recall) for each sentence from the `predictions` + `references` lists, which ranges from 0.0 to 1.0.
`f1`: The [F1 score](https://huggingface.co/metrics/f1) for each sentence from the `predictions` + `references` lists, which ranges from 0.0 to 1.0.
`hashcode:` The hashcode of the library.
### Values from popular papers
The [original BERTScore paper](https://openreview.net/pdf?id=SkeHuCVFDr) reported average model selection accuracies (Hits@1) on WMT18 hybrid systems for different language pairs, which ranged from 0.004 for `en<->tr` to 0.824 for `en<->de`.
For more recent model performance, see the [metric leaderboard](https://paperswithcode.com/paper/bertscore-evaluating-text-generation-with).
## Examples
Maximal values with the `distilbert-base-uncased` model:
```python
from evaluate import load
bertscore = load("bertscore")
predictions = ["hello world", "general kenobi"]
references = ["hello world", "general kenobi"]
results = bertscore.compute(predictions=predictions, references=references, model_type="distilbert-base-uncased")
print(results)
{'precision': [1.0, 1.0], 'recall': [1.0, 1.0], 'f1': [1.0, 1.0], 'hashcode': 'distilbert-base-uncased_L5_no-idf_version=0.3.10(hug_trans=4.10.3)'}
```
Partial match with the `distilbert-base-uncased` model:
```python
from evaluate import load
bertscore = load("bertscore")
predictions = ["hello world", "general kenobi"]
references = ["goodnight moon", "the sun is shining"]
results = bertscore.compute(predictions=predictions, references=references, model_type="distilbert-base-uncased")
print(results)
{'precision': [0.7380737066268921, 0.5584042072296143], 'recall': [0.7380737066268921, 0.5889028906822205], 'f1': [0.7380737066268921, 0.5732481479644775], 'hashcode': 'bert-base-uncased_L5_no-idf_version=0.3.10(hug_trans=4.10.3)'}
```
## Limitations and bias
The [original BERTScore paper](https://openreview.net/pdf?id=SkeHuCVFDr) showed that BERTScore correlates well with human judgment on sentence-level and system-level evaluation, but this depends on the model and language pair selected.
Furthermore, not all languages are supported by the metric -- see the [BERTScore supported language list](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages) for more information.
Finally, calculating the BERTScore metric involves downloading the BERT model that is used to compute the score-- the default model for `en`, `roberta-large`, takes over 1.4GB of storage space and downloading it can take a significant amount of time depending on the speed of your internet connection. If this is an issue, choose a smaller model; for instance `distilbert-base-uncased` is 268MB. A full list of compatible models can be found [here](https://docs.google.com/spreadsheets/d/1RKOVpselB98Nnh_EOC4A2BYn8_201tmPODpNWu4w7xI/edit#gid=0).
## Citation
```bibtex
@inproceedings{bert-score,
title={BERTScore: Evaluating Text Generation with BERT},
author={Tianyi Zhang* and Varsha Kishore* and Felix Wu* and Kilian Q. Weinberger and Yoav Artzi},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://openreview.net/forum?id=SkeHuCVFDr}
}
```
## Further References
- [BERTScore Project README](https://github.com/Tiiiger/bert_score#readme)
- [BERTScore ICLR 2020 Poster Presentation](https://iclr.cc/virtual_2020/poster_SkeHuCVFDr.html)
| huggingface/evaluate/blob/main/metrics/bertscore/README.md |
Model Cards
<Tip>
[New! Try our experimental Model Card Creator App](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool)
</Tip>
## What are Model Cards?
Model cards are files that accompany the models and provide handy information. Under the hood, model cards are simple Markdown files with additional metadata. Model cards are essential for discoverability, reproducibility, and sharing! You can find a model card as the `README.md` file in any model repo.
The model card should describe:
- the model
- its intended uses & potential limitations, including biases and ethical considerations as detailed in [Mitchell, 2018](https://arxiv.org/abs/1810.03993)
- the training params and experimental info (you can embed or link to an experiment tracking platform for reference)
- which datasets were used to train your model
- your evaluation results
The model card template is available [here](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md).
## Model card metadata
A model repo will render its `README.md` as a model card. The model card is a [Markdown](https://en.wikipedia.org/wiki/Markdown) file, with a [YAML](https://en.wikipedia.org/wiki/YAML) section at the top that contains metadata about the model.
The metadata you add to the model card supports discovery and easier use of your model. For example:
* Allowing users to filter models at https://huggingface.co/models.
* Displaying the model's license.
* Adding datasets to the metadata will add a message reading `Datasets used to train:` to your model card and link the relevant datasets, if they're available on the Hub.
Dataset, metric, and language identifiers are those listed on the [Datasets](https://huggingface.co/datasets), [Metrics](https://huggingface.co/metrics) and [Languages](https://huggingface.co/languages) pages.
### Adding metadata to your model card
There are a few different ways to add metadata to your model card including:
- Using the metadata UI
- Directly editing the YAML section of the `README.md` file
- Via the [`huggingface_hub`](https://huggingface.co/docs/huggingface_hub) Python library, see the [docs](https://huggingface.co/docs/huggingface_hub/guides/model-cards#update-metadata) for more details.
Many libraries with [Hub integration](./models-libraries) will automatically add metadata to the model card when you upload a model.
#### Using the metadata UI
You can add metadata to your model card using the metadata UI. To access the metadata UI, go to the model page and click on the `Edit model card` button in the top right corner of the model card. This will open an editor showing the model card `README.md` file, as well as a UI for editing the metadata.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/metadata-ui-editor.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/metadata-ui-editor-dark.png"/>
</div>
This UI will allow you to add key metadata to your model card and many of the fields will autocomplete based on the information you provide. Using the UI is the easiest way to add metadata to your model card, but it doesn't support all of the metadata fields. If you want to add metadata that isn't supported by the UI, you can edit the YAML section of the `README.md` file directly.
#### Editing the YAML section of the `README.md` file
You can also directly edit the YAML section of the `README.md` file. If the model card doesn't already have a YAML section, you can add one by adding three `---` at the top of the file, then include all of the relevant metadata, and close the section with another group of `---` like the example below:
```yaml
---
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
base_model: "base model Hub identifier"
---
```
You can find the detailed model card metadata specification <a href="https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1" target="_blank">here</a>.
### Specifying a library
You can specify the supported libraries in the model card metadata section. Find more about our supported libraries [here](./models-libraries). The library will be specified in the following order of priority:
1. Specifying `library_name` in the model card (recommended if your model is not a `transformers` model). This information can be added via the metadata UI or directly in the model card YAML section:
```yaml
library_name: flair
```
2. Having a tag with the name of a library that is supported
```yaml
tags:
- flair
```
If it's not specified, the Hub will try to automatically detect the library type. Unless your model is from `transformers`, this approach is discouraged and repo creators should use the explicit `library_name` as much as possible.
1. By looking into the presence of files such as `*.nemo` or `*saved_model.pb*`, the Hub can determine if a model is from NeMo or Keras.
2. If nothing is detected and there is a `config.json` file, it's assumed the library is `transformers`.
### Specifying a base model
If your model is a fine-tune or adapter of a base model, you can specify the base model in the model card metadata section. This information can also be used to indicate if your model is a merge of multiple existing models. The `base_model` field can either be a single model ID, or a list of one or more base_models (specified by their Hub identifier).
```yaml
base_model: HuggingFaceH4/zephyr-7b-beta
```
This metadata will be used to display the base model on the model page. Users can also use this information to filter models by base model or find models that are fine-tuned from a specific base model.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/base-model-ui.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/base-model-ui-dark.png"/>
</div>
### Specifying a dataset
You can specify the datasets used to train your model in the model card metadata section. The datasets will be displayed on the model page and users will be able to filter models by dataset. You should use the Hub dataset identifier, which is the same as the dataset's repo name as the identifier:
```yaml
datasets:
- imdb
- HuggingFaceH4/no_robots
```
### Specifying a task (`pipeline_tag`)
You can specify the `pipeline_tag` in the model card metadata. The `pipeline_tag` indicates the type of task the model is intended for. This tag will be displayed on the model page and users can filter models on the Hub by task. This tag is also used to determine which [widget](./models-widgets.md#enabling-a-widget) to use for the model and which APIs to use under the hood.
For `transformers` models, the pipeline tag is automatically inferred from the model's `config.json` file but you can override it in the model card metadata if required. Editing this field in the metadata UI will ensure that the pipeline tag is valid. Some other libraries with Hub integration will also automatically add the pipeline tag to the model card metadata.
### Specifying a license
You can specify the license in the model card metadata section. The license will be displayed on the model page and users will be able to filter models by license. Using the metadata UI, you will see a dropdown of the most common licenses.
If required, you can also specify a custom license by adding `other` as the license value and specifying the name and a link to the license in the metadata.
```yaml
# Example from https://huggingface.co/coqui/XTTS-v1
---
license: other
license_name: coqui-public-model-license
license_link: https://coqui.ai/cpml
---
```
If the license is not available via a URL you can link to a LICENSE stored in the model repo.
### Evaluation Results
You can specify your **model's evaluation results** in a structured way in the model card metadata. Results are parsed by the Hub and displayed in a widget on the model page. Here is an example on how it looks like for the [bigcode/starcoder](https://huggingface.co/bigcode/starcoder) model:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/eval-results-v2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/eval-results-v2-dark.png"/>
</div>
The metadata spec was based on Papers with code's [model-index specification](https://github.com/paperswithcode/model-index). This allow us to directly index the results into Papers with code's leaderboards when appropriate. You can also link the source from where the eval results has been computed.
Here is a partial example to describe [01-ai/Yi-34B](https://huggingface.co/01-ai/Yi-34B)'s score on the ARC benchmark. The result comes from the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) which is defined as the `source`:
```yaml
---
model-index:
- name: Yi-34B
results:
- task:
type: text-generation
dataset:
name: ai2_arc
type: ai2_arc
metrics:
- name: AI2 Reasoning Challenge (25-Shot)
type: AI2 Reasoning Challenge (25-Shot)
value: 64.59
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
---
```
For more details on how to format this data, check out the [Model Card specifications](https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1).
### CO2 Emissions
The model card is also a great place to show information about the CO<sub>2</sub> impact of your model. Visit our [guide on tracking and reporting CO<sub>2</sub> emissions](./model-cards-co2) to learn more.
### Linking a Paper
If the model card includes a link to a paper on arXiv, the Hugging Face Hub will extract the arXiv ID and include it in the model tags with the format `arxiv:<PAPER ID>`. Clicking on the tag will let you:
* Visit the Paper page
* Filter for other models on the Hub that cite the same paper.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-arxiv.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-arxiv-dark.png"/>
</div>
Read more about Paper pages [here](./paper-pages).
## FAQ
### How are model tags determined?
Each model page lists all the model's tags in the page header, below the model name. These are primarily computed from the model card metadata, although some are added automatically, as described in [Creating a Widget](./models-widgets#creating-a-widget).
### Can I add custom tags to my model?
Yes, you can add custom tags to your model by adding them to the `tags` field in the model card metadata. The metadata UI will suggest some popular tags, but you can add any tag you want. For example, you could indicate that your model is focused on finance by adding a `finance` tag.
### How can I indicate that my model is not suitable for all audiences
You can add a `not-for-all-audience` tag to your model card metadata. When this tag is present, a message will be displayed on the model page indicating that the model is not for all audiences. Users can click through this message to view the model card.
### Can I write LaTeX in my model card?
Yes! The Hub uses the [KaTeX](https://katex.org/) math typesetting library to render math formulas server-side before parsing the Markdown.
You have to use the following delimiters:
- `$$ ... $$` for display mode
- `\\(...\\)` for inline mode (no space between the slashes and the parenthesis).
Then you'll be able to write:
$$
\LaTeX
$$
$$
\mathrm{MSE} = \left(\frac{1}{n}\right)\sum_{i=1}^{n}(y_{i} - x_{i})^{2}
$$
$$ E=mc^2 $$
| huggingface/hub-docs/blob/main/docs/hub/model-cards.md |
A full training[[a-full-training]]
<CourseFloatingBanner chapter={3}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter3/section4.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter3/section4.ipynb"},
]} />
<Youtube id="Dh9CL8fyG80"/>
Now we'll see how to achieve the same results as we did in the last section without using the `Trainer` class. Again, we assume you have done the data processing in section 2. Here is a short summary covering everything you will need:
```py
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
### Prepare for training[[prepare-for-training]]
Before actually writing our training loop, we will need to define a few objects. The first ones are the dataloaders we will use to iterate over batches. But before we can define those dataloaders, we need to apply a bit of postprocessing to our `tokenized_datasets`, to take care of some things that the `Trainer` did for us automatically. Specifically, we need to:
- Remove the columns corresponding to values the model does not expect (like the `sentence1` and `sentence2` columns).
- Rename the column `label` to `labels` (because the model expects the argument to be named `labels`).
- Set the format of the datasets so they return PyTorch tensors instead of lists.
Our `tokenized_datasets` has one method for each of those steps:
```py
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
tokenized_datasets["train"].column_names
```
We can then check that the result only has columns that our model will accept:
```python
["attention_mask", "input_ids", "labels", "token_type_ids"]
```
Now that this is done, we can easily define our dataloaders:
```py
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)
```
To quickly check there is no mistake in the data processing, we can inspect a batch like this:
```py
for batch in train_dataloader:
break
{k: v.shape for k, v in batch.items()}
```
```python out
{'attention_mask': torch.Size([8, 65]),
'input_ids': torch.Size([8, 65]),
'labels': torch.Size([8]),
'token_type_ids': torch.Size([8, 65])}
```
Note that the actual shapes will probably be slightly different for you since we set `shuffle=True` for the training dataloader and we are padding to the maximum length inside the batch.
Now that we're completely finished with data preprocessing (a satisfying yet elusive goal for any ML practitioner), let's turn to the model. We instantiate it exactly as we did in the previous section:
```py
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
To make sure that everything will go smoothly during training, we pass our batch to this model:
```py
outputs = model(**batch)
print(outputs.loss, outputs.logits.shape)
```
```python out
tensor(0.5441, grad_fn=<NllLossBackward>) torch.Size([8, 2])
```
All 🤗 Transformers models will return the loss when `labels` are provided, and we also get the logits (two for each input in our batch, so a tensor of size 8 x 2).
We're almost ready to write our training loop! We're just missing two things: an optimizer and a learning rate scheduler. Since we are trying to replicate what the `Trainer` was doing by hand, we will use the same defaults. The optimizer used by the `Trainer` is `AdamW`, which is the same as Adam, but with a twist for weight decay regularization (see ["Decoupled Weight Decay Regularization"](https://arxiv.org/abs/1711.05101) by Ilya Loshchilov and Frank Hutter):
```py
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
```
Finally, the learning rate scheduler used by default is just a linear decay from the maximum value (5e-5) to 0. To properly define it, we need to know the number of training steps we will take, which is the number of epochs we want to run multiplied by the number of training batches (which is the length of our training dataloader). The `Trainer` uses three epochs by default, so we will follow that:
```py
from transformers import get_scheduler
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
print(num_training_steps)
```
```python out
1377
```
### The training loop[[the-training-loop]]
One last thing: we will want to use the GPU if we have access to one (on a CPU, training might take several hours instead of a couple of minutes). To do this, we define a `device` we will put our model and our batches on:
```py
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
device
```
```python out
device(type='cuda')
```
We are now ready to train! To get some sense of when training will be finished, we add a progress bar over our number of training steps, using the `tqdm` library:
```py
from tqdm.auto import tqdm
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
You can see that the core of the training loop looks a lot like the one in the introduction. We didn't ask for any reporting, so this training loop will not tell us anything about how the model fares. We need to add an evaluation loop for that.
### The evaluation loop[[the-evaluation-loop]]
As we did earlier, we will use a metric provided by the 🤗 Evaluate library. We've already seen the `metric.compute()` method, but metrics can actually accumulate batches for us as we go over the prediction loop with the method `add_batch()`. Once we have accumulated all the batches, we can get the final result with `metric.compute()`. Here's how to implement all of this in an evaluation loop:
```py
import evaluate
metric = evaluate.load("glue", "mrpc")
model.eval()
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
metric.compute()
```
```python out
{'accuracy': 0.8431372549019608, 'f1': 0.8907849829351535}
```
Again, your results will be slightly different because of the randomness in the model head initialization and the data shuffling, but they should be in the same ballpark.
<Tip>
✏️ **Try it out!** Modify the previous training loop to fine-tune your model on the SST-2 dataset.
</Tip>
### Supercharge your training loop with 🤗 Accelerate[[supercharge-your-training-loop-with-accelerate]]
<Youtube id="s7dy8QRgjJ0" />
The training loop we defined earlier works fine on a single CPU or GPU. But using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library, with just a few adjustments we can enable distributed training on multiple GPUs or TPUs. Starting from the creation of the training and validation dataloaders, here is what our manual training loop looks like:
```py
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
And here are the changes:
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
The first line to add is the import line. The second line instantiates an `Accelerator` object that will look at the environment and initialize the proper distributed setup. 🤗 Accelerate handles the device placement for you, so you can remove the lines that put the model on the device (or, if you prefer, change them to use `accelerator.device` instead of `device`).
Then the main bulk of the work is done in the line that sends the dataloaders, the model, and the optimizer to `accelerator.prepare()`. This will wrap those objects in the proper container to make sure your distributed training works as intended. The remaining changes to make are removing the line that puts the batch on the `device` (again, if you want to keep this you can just change it to use `accelerator.device`) and replacing `loss.backward()` with `accelerator.backward(loss)`.
<Tip>
⚠️ In order to benefit from the speed-up offered by Cloud TPUs, we recommend padding your samples to a fixed length with the `padding="max_length"` and `max_length` arguments of the tokenizer.
</Tip>
If you'd like to copy and paste it to play around, here's what the complete training loop looks like with 🤗 Accelerate:
```py
from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
train_dl, eval_dl, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
num_epochs = 3
num_training_steps = num_epochs * len(train_dl)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dl:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
Putting this in a `train.py` script will make that script runnable on any kind of distributed setup. To try it out in your distributed setup, run the command:
```bash
accelerate config
```
which will prompt you to answer a few questions and dump your answers in a configuration file used by this command:
```
accelerate launch train.py
```
which will launch the distributed training.
If you want to try this in a Notebook (for instance, to test it with TPUs on Colab), just paste the code in a `training_function()` and run a last cell with:
```python
from accelerate import notebook_launcher
notebook_launcher(training_function)
```
You can find more examples in the [🤗 Accelerate repo](https://github.com/huggingface/accelerate/tree/main/examples).
| huggingface/course/blob/main/chapters/en/chapter3/4.mdx |
--
title: "SetFitABSA: Few-Shot Aspect Based Sentiment Analysis using SetFit"
thumbnail: /blog/assets/setfit-absa/intel_hf_logo_2.png
authors:
- user: ronenlap
guest: true
- user: tomaarsen
- user: lewtun
- user: dkorat
guest: true
- user: orenpereg
guest: true
- user: moshew
guest: true
---
# SetFitABSA: Few-Shot Aspect Based Sentiment Analysis using SetFit
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/method.png" width=500>
</p>
<p align="center">
<em>SetFitABSA is an efficient technique to detect the sentiment towards specific aspects within the text.</em>
</p>
Aspect-Based Sentiment Analysis (ABSA) is the task of detecting the sentiment towards specific aspects within the text. For example, in the sentence, "This phone has a great screen, but its battery is too small", the _aspect_ terms are "screen" and "battery" and the sentiment polarities towards them are Positive and Negative, respectively.
ABSA is widely used by organizations for extracting valuable insights by analyzing customer feedback towards aspects of products or services in various domains. However, labeling training data for ABSA is a tedious task because of the fine-grained nature (token level) of manually identifying aspects within the training samples.
Intel Labs and Hugging Face are excited to introduce SetFitABSA, a framework for few-shot training of domain-specific ABSA models; SetFitABSA is competitive and even outperforms generative models such as Llama2 and T5 in few-shot scenarios.
Compared to LLM based methods, SetFitABSA has two unique advantages:
<p>🗣 <strong>No prompts needed:</strong> few-shot in-context learning with LLMs requires handcrafted prompts which make the results brittle, sensitive to phrasing and dependent on user expertise. SetFitABSA dispenses with prompts altogether by generating rich embeddings directly from a small number of labeled text examples.</p>
<p>🏎 <strong>Fast to train:</strong> SetFitABSA requires only a handful of labeled training samples; in addition, it uses a simple training data format, eliminating the need for specialized tagging tools. This makes the data labeling process fast and easy.</p>
In this blog post, we'll explain how SetFitABSA works and how to train your very own models using the [SetFit library](https://github.com/huggingface/setfit). Let's dive in!
## How does it work?
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/method.png" width=700>
</p>
<p align="center">
<em>SetFitABSA's three-stage training process</em>
</p>
SetFitABSA is comprised of three steps. The first step extracts aspect candidates from the text, the second one yields the aspects by classifying the aspect candidates as aspects or non-aspects, and the final step associates a sentiment polarity to each extracted aspect. Steps two and three are based on SetFit models.
### Training
**1. Aspect candidate extraction**
In this work we assume that aspects, which are usually features of products and services, are mostly nouns or noun compounds (strings of consecutive nouns). We use [spaCy](https://spacy.io/) to tokenize and extract nouns/noun compounds from the sentences in the (few-shot) training set. Since not all extracted nouns/noun compounds are aspects, we refer to them as aspect candidates.
**2. Aspect/Non-aspect classification**
Now that we have aspect candidates, we need to train a model to be able to distinguish between nouns that are aspects and nouns that are non-aspects. For this purpose, we need training samples with aspect/no-aspect labels. This is done by considering aspects in the training set as `True` aspects, while other non-overlapping candidate aspects are considered non-aspects and therefore labeled as `False`:
* **Training sentence:** "Waiters aren't friendly but the cream pasta is out of this world."
* **Tokenized:** [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
* **Extracted aspect candidates:** [<strong style="color:orange">Waiters</strong>, are, n't, friendly, but, the, <strong style="color:orange">cream</strong>, <strong style="color:orange">pasta</strong>, is, out, of, this, <strong style="color:orange">world</strong>, .]
* **Gold labels from training set, in [BIO format](https://en.wikipedia.org/wiki/Inside–outside–beginning_(tagging)):** [B-ASP, O, O, O, O, O, B-ASP, I-ASP, O, O, O, O, O, .]
* **Generated aspect/non-aspect Labels:** [<strong style="color:green">Waiters</strong>, are, n't, friendly, but, the, <strong style="color:green">cream</strong>, <strong style="color:green">pasta</strong>, is, out, of, this, <strong style="color:red">world</strong>, .]
Now that we have all the aspect candidates labeled, how do we use it to train the candidate aspect classification model? In other words, how do we use SetFit, a sentence classification framework, to classify individual tokens? Well, this is the trick: each aspect candidate is concatenated with the entire training sentence to create a training instance using the following template:
```
aspect_candidate:training_sentence
```
Applying the template to the example above will generate 3 training instances – two with `True` labels representing aspect training instances, and one with `False` label representing non-aspect training instance:
| Text | Label |
|:------------------------------------------------------------------------------|:------|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| world:Waiters aren't friendly but the cream pasta is out of this world. | 0 |
| ... | ... |
After generating the training instances, we are ready to use the power of SetFit to train a few-shot domain-specific binary classifier to extract aspects from an input text review. This will be our first fine-tuned SetFit model.
**3. Sentiment polarity classification**
Once the system extracts the aspects from the text, it needs to associate a sentiment polarity (e.g., positive, negative or neutral) to each aspect. For this purpose, we use a 2nd SetFit model and train it in a similar fashion to the aspect extraction model as illustrated in the following example:
* **Training sentence:** "Waiters aren't friendly but the cream pasta is out of this world."
* **Tokenized:** [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
* **Gold labels from training set:** [NEG, O, O, O, O, O, POS, POS, O, O, O, O, O, .]
| Text | Label |
|:------------------------------------------------------------------------------|:------|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | NEG |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | POS |
| ... | ... |
Note that as opposed to the aspect extraction model, we don't include non-aspects in this training set because the goal is to classify the sentiment polarity towards real aspects.
## Running inference
At inference time, the test sentence passes through the spaCy aspect candidate extraction phase, resulting in test instances using the template `aspect_candidate:test_sentence`. Next, non-aspects are filtered by the aspect/non-aspect classifier. Finally, the extracted aspects are fed to the sentiment polarity classifier that predicts the sentiment polarity per aspect.
In practice, this means the model can receive normal text as input, and output aspects and their sentiments:
**Model Input:**
```
"their dinner specials are fantastic."
```
**Model Output:**
```
[{'span': 'dinner specials', 'polarity': 'positive'}]
```
## Benchmarking
SetFitABSA was benchmarked against the recent state-of-the-art work by [AWS AI Labs](https://arxiv.org/pdf/2210.06629.pdf) and [Salesforce AI Research](https://arxiv.org/pdf/2204.05356.pdf) that finetune T5 and GPT2 using prompts. To get a more complete picture, we also compare our model to the Llama-2-chat model using in-context learning.
We use the popular Laptop14 and Restaurant14 ABSA [datasets](https://huggingface.co/datasets/alexcadillon/SemEval2014Task4) from the Semantic Evaluation Challenge 2014 ([SemEval14](https://aclanthology.org/S14-2004.pdf)).
SetFitABSA is evaluated both on the intermediate task of aspect term extraction (SB1) and on the full ABSA task of aspect extraction along with their sentiment polarity predictions (SB1+SB2).
### Model size comparison
| Model | Size (params) |
|:------------------:|:-------------:|
| Llama-2-chat | 7B |
| T5-base | 220M |
| GPT2-base | 124M |
| GPT2-medium | 355M |
| **SetFit (MPNet)** | 2x 110M |
Note that for the SB1 task, SetFitABSA is 110M parameters, for SB2 it is 110M parameters, and for SB1+SB2 SetFitABSA consists of 220M parameters.
### Performance comparison
We see a clear advantage of SetFitABSA when the number of training instances is low, despite being 2x smaller than T5 and x3 smaller than GPT2-medium. Even when compared to Llama 2, which is x64 larger, the performance is on par or better.
**SetFitABSA vs GPT2**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_GPT2.png" width=700>
</p>
**SetFitABSA vs T5**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_T5.png" width=700>
</p>
Note that for fair comparison, we conducted comparisons with SetFitABSA against exactly the dataset splits used by the various baselines (GPT2, T5, etc.).
**SetFitABSA vs Llama2**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_Llama2.png" width=700>
</p>
We notice that increasing the number of in-context training samples for Llama2 did not result in improved performance. This phenomenon [has been shown for ChatGPT before](https://www.analyticsvidhya.com/blog/2023/09/power-of-llms-zero-shot-and-few-shot-prompting/), and we think it should be further investigated.
## Training your own model
SetFitABSA is part of the SetFit framework. To train an ABSA model, start by installing `setfit` with the `absa` option enabled:
```shell
python -m pip install -U "setfit[absa]"
```
Additionally, we must install the `en_core_web_lg` spaCy model:
```shell
python -m spacy download en_core_web_lg
```
We continue by preparing the training set. The format of the training set is a `Dataset` with the columns `text`, `span`, `label`, `ordinal`:
* **text**: The full sentence or text containing the aspects.
* **span**: An aspect from the full sentence. Can be multiple words. For example: "food".
* **label**: The (polarity) label corresponding to the aspect span. For example: "positive". The label names can be chosen arbitrarily when tagging the collected training data.
* **ordinal**: If the aspect span occurs multiple times in the text, then this ordinal represents the index of those occurrences. Often this is just 0, as each aspect usually appears only once in the input text.
For example, the training text "Restaurant with wonderful food but worst service I ever seen" contains two aspects, so will add two lines to the training set table:
| Text | Span | Label | Ordinal |
|:-------------------------------------------------------------|:--------|:---------|:--------|
| Restaurant with wonderful food but worst service I ever seen | food | positive | 0 |
| Restaurant with wonderful food but worst service I ever seen | service | negative | 0 |
| ... | ... | ... | ... |
Once we have the training dataset ready we can create an ABSA trainer and execute the training. SetFit models are fairly efficient to train, but as SetFitABSA involves two models trained sequentially, it is recommended to use a GPU for training to keep the training time low. For example, the following training script trains a full SetFitABSA model in about 10 minutes with the free Google Colab T4 GPU.
```python
from datasets import load_dataset
from setfit import AbsaTrainer, AbsaModel
# Create a training dataset as above
# For convenience we will use an already prepared dataset here
train_dataset = load_dataset("tomaarsen/setfit-absa-semeval-restaurants", split="train[:128]")
# Create a model with a chosen sentence transformer from the Hub
model = AbsaModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create a trainer:
trainer = AbsaTrainer(model, train_dataset=train_dataset)
# Execute training:
trainer.train()
```
That's it! We have trained a domain-specific ABSA model. We can save our trained model to disk or upload it to the Hugging Face hub. Bear in mind that the model contains two submodels, so each is given its own path:
```python
model.save_pretrained(
"models/setfit-absa-model-aspect",
"models/setfit-absa-model-polarity"
)
# or
model.push_to_hub(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
```
Now we can use our trained model for inference. We start by loading the model:
```python
from setfit import AbsaModel
model = AbsaModel.from_pretrained(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
```
Then, we use the predict API to run inference. The input is a list of strings, each representing a textual review:
```python
preds = model.predict([
"Best pizza outside of Italy and really tasty.",
"The food variations are great and the prices are absolutely fair.",
"Unfortunately, you have to expect some waiting time and get a note with a waiting number if it should be very full."
])
print(preds)
# [
# [{'span': 'pizza', 'polarity': 'positive'}],
# [{'span': 'food variations', 'polarity': 'positive'}, {'span': 'prices', 'polarity': 'positive'}],
# [{'span': 'waiting time', 'polarity': 'neutral'}, {'span': 'waiting number', 'polarity': 'neutral'}]
# ]
```
For more details on training options, saving and loading models, and inference see the SetFit [docs](https://huggingface.co/docs/setfit/how_to/absa).
## References
* Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, and Suresh Manandhar. 2014. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35.
* Siddharth Varia, Shuai Wang, Kishaloy Halder, Robert Vacareanu, Miguel Ballesteros, Yassine Benajiba, Neha Anna John, Rishita Anubhai, Smaranda Muresan, Dan Roth, 2023 "Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis". https://arxiv.org/abs/2210.06629
* Ehsan Hosseini-Asl, Wenhao Liu, Caiming Xiong, 2022. "A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis". https://arxiv.org/abs/2204.05356
* Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. "Efficient Few-Shot Learning Without Prompts". https://arxiv.org/abs/2209.11055 | huggingface/blog/blob/main/setfit-absa.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-light.svg">
<img alt="Hugging Face Transformers Library" src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-light.svg" width="352" height="59" style="max-width: 100%;">
</picture>
<br/>
<br/>
</p>
<p align="center">
<a href="https://circleci.com/gh/huggingface/transformers">
<img alt="Build" src="https://img.shields.io/circleci/build/github/huggingface/transformers/main">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/transformers.svg?color=blue">
</a>
<a href="https://huggingface.co/docs/transformers/index">
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/transformers/index.svg?down_color=red&down_message=offline&up_message=online">
</a>
<a href="https://github.com/huggingface/transformers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/transformers.svg">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-v2.0%20adopted-ff69b4.svg">
</a>
<a href="https://zenodo.org/badge/latestdoi/155220641"><img src="https://zenodo.org/badge/155220641.svg" alt="DOI"></a>
</p>
<h4 align="center">
<p>
<b>English</b> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hans.md">简体中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hant.md">繁體中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ko.md">한국어</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_es.md">Español</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ja.md">日本語</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_hd.md">हिन्दी</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ru.md">Русский</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_pt-br.md">Рortuguês</a> |
<a href="https://github.com/huggingface/transformers//blob/main/README_te.md">తెలుగు</a> |
</p>
</h4>
<h3 align="center">
<p>Aprendizado de máquina de última geração para JAX, PyTorch e TensorFlow</p>
</h3>
<h3 align="center">
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
</h3>
A biblioteca 🤗 Transformers oferece milhares de modelos pré-treinados para executar tarefas em diferentes modalidades, como texto, visão e áudio.
Esses modelos podem ser aplicados a:
* 📝 Texto, para tarefas como classificação de texto, extração de informações, resposta a perguntas, sumarização, tradução, geração de texto, em mais de 100 idiomas.
* 🖼️ Imagens, para tarefas como classificação de imagens, detecção de objetos e segmentação.
* 🗣️ Áudio, para tarefas como reconhecimento de fala e classificação de áudio.
Os modelos Transformer também podem executar tarefas em diversas modalidades combinadas, como responder a perguntas em tabelas, reconhecimento óptico de caracteres, extração de informações de documentos digitalizados, classificação de vídeo e resposta a perguntas visuais.
A biblioteca 🤗 Transformers oferece APIs para baixar e usar rapidamente esses modelos pré-treinados em um texto específico, ajustá-los em seus próprios conjuntos de dados e, em seguida, compartilhá-los com a comunidade em nosso [model hub](https://huggingface.co/models). Ao mesmo tempo, cada módulo Python que define uma arquitetura é totalmente independente e pode ser modificado para permitir experimentos de pesquisa rápidos.
A biblioteca 🤗 Transformers é respaldada pelas três bibliotecas de aprendizado profundo mais populares — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) e [TensorFlow](https://www.tensorflow.org/) — com uma integração perfeita entre elas. É simples treinar seus modelos com uma delas antes de carregá-los para inferência com a outra
## Demonstração Online
Você pode testar a maioria de nossos modelos diretamente em suas páginas a partir do [model hub](https://huggingface.co/models). Também oferecemos [hospedagem de modelos privados, versionamento e uma API de inferência](https://huggingface.co/pricing)
para modelos públicos e privados.
Aqui estão alguns exemplos:
Em Processamento de Linguagem Natural:
- [Completar palavra mascarada com BERT](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
- [Reconhecimento de Entidades Nomeadas com Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
- [Geração de texto com GPT-2](https://huggingface.co/gpt2?text=A+long+time+ago%2C)
- [Inferência de Linguagem Natural com RoBERTa](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
- [Sumarização com BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
- [Resposta a perguntas com DistilBERT](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
- [Tradução com T5](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
Em Visão Computacional:
- [Classificação de Imagens com ViT](https://huggingface.co/google/vit-base-patch16-224)
- [Detecção de Objetos com DETR](https://huggingface.co/facebook/detr-resnet-50)
- [Segmentação Semântica com SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [Segmentação Panóptica com MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
- [Estimativa de Profundidade com DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
- [Classificação de Vídeo com VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
- [Segmentação Universal com OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
Em Áudio:
- [Reconhecimento Automático de Fala com Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
- [Detecção de Palavras-Chave com Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
- [Classificação de Áudio com Transformer de Espectrograma de Áudio](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
Em Tarefas Multimodais:
- [Respostas de Perguntas em Tabelas com TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
- [Respostas de Perguntas Visuais com ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
- [Classificação de Imagens sem Anotação com CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
- [Respostas de Perguntas em Documentos com LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
- [Classificação de Vídeo sem Anotação com X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
## 100 Projetos Usando Transformers
Transformers é mais do que um conjunto de ferramentas para usar modelos pré-treinados: é uma comunidade de projetos construídos ao seu redor e o Hugging Face Hub. Queremos que o Transformers permita que desenvolvedores, pesquisadores, estudantes, professores, engenheiros e qualquer outra pessoa construa seus projetos dos sonhos.
Para celebrar as 100.000 estrelas do Transformers, decidimos destacar a comunidade e criamos a página [awesome-transformers](./awesome-transformers.md), que lista 100 projetos incríveis construídos nas proximidades dos Transformers.
Se você possui ou utiliza um projeto que acredita que deveria fazer parte da lista, abra um PR para adicioná-lo!
## Se você está procurando suporte personalizado da equipe Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a><br>
## Tour Rápido
Para usar imediatamente um modelo em uma entrada específica (texto, imagem, áudio, ...), oferecemos a API `pipeline`. Os pipelines agrupam um modelo pré-treinado com o pré-processamento que foi usado durante o treinamento desse modelo. Aqui está como usar rapidamente um pipeline para classificar textos como positivos ou negativos:
```python
from transformers import pipeline
# Carregue o pipeline de classificação de texto
>>> classifier = pipeline("sentiment-analysis")
# Classifique o texto como positivo ou negativo
>>> classifier("Estamos muito felizes em apresentar o pipeline no repositório dos transformers.")
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
```
A segunda linha de código baixa e armazena em cache o modelo pré-treinado usado pelo pipeline, enquanto a terceira linha o avalia no texto fornecido. Neste exemplo, a resposta é "positiva" com uma confiança de 99,97%.
Muitas tarefas têm um `pipeline` pré-treinado pronto para uso, não apenas em PNL, mas também em visão computacional e processamento de áudio. Por exemplo, podemos facilmente extrair objetos detectados em uma imagem:
``` python
>>> import requests
>>> from PIL import Image
>>> from transformers import pipeline
# Download an image with cute cats
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
>>> image_data = requests.get(url, stream=True).raw
>>> image = Image.open(image_data)
# Allocate a pipeline for object detection
>>> object_detector = pipeline('object-detection')
>>> object_detector(image)
[{'score': 0.9982201457023621,
'label': 'remote',
'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
{'score': 0.9960021376609802,
'label': 'remote',
'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
{'score': 0.9954745173454285,
'label': 'couch',
'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
{'score': 0.9988006353378296,
'label': 'cat',
'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
{'score': 0.9986783862113953,
'label': 'cat',
'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
```
Aqui obtemos uma lista de objetos detectados na imagem, com uma caixa envolvendo o objeto e uma pontuação de confiança. Aqui está a imagem original à esquerda, com as previsões exibidas à direita:
<h3 align="center">
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png" width="400"></a>
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample_post_processed.png" width="400"></a>
</h3>
Você pode aprender mais sobre as tarefas suportadas pela API `pipeline` em [este tutorial](https://huggingface.co/docs/transformers/task_summary).
Além do `pipeline`, para baixar e usar qualquer um dos modelos pré-treinados em sua tarefa específica, tudo o que é necessário são três linhas de código. Aqui está a versão em PyTorch:
```python
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)
```
E aqui está o código equivalente para TensorFlow:
```python
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
>>> outputs = model(**inputs)
```
O tokenizador é responsável por todo o pré-processamento que o modelo pré-treinado espera, e pode ser chamado diretamente em uma única string (como nos exemplos acima) ou em uma lista. Ele produzirá um dicionário que você pode usar no código subsequente ou simplesmente passar diretamente para o seu modelo usando o operador de descompactação de argumentos **.
O modelo em si é um [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou um [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)(dependendo do seu back-end) que você pode usar como de costume. [Este tutorial](https://huggingface.co/docs/transformers/training) explica como integrar esse modelo em um ciclo de treinamento clássico do PyTorch ou TensorFlow, ou como usar nossa API `Trainer` para ajuste fino rápido em um novo conjunto de dados.
## Por que devo usar transformers?
1. Modelos state-of-the-art fáceis de usar:
- Alto desempenho em compreensão e geração de linguagem natural, visão computacional e tarefas de áudio.
- Barreira de entrada baixa para educadores e profissionais.
- Poucas abstrações visíveis para o usuário, com apenas três classes para aprender.
- Uma API unificada para usar todos os nossos modelos pré-treinados.
1. Menores custos de computação, menor pegada de carbono:
- Pesquisadores podem compartilhar modelos treinados em vez de treinar sempre do zero.
- Profissionais podem reduzir o tempo de computação e os custos de produção.
- Dezenas de arquiteturas com mais de 60.000 modelos pré-treinados em todas as modalidades.
1. Escolha o framework certo para cada parte da vida de um modelo:
- Treine modelos state-of-the-art em 3 linhas de código.
- Mova um único modelo entre frameworks TF2.0/PyTorch/JAX à vontade.
- Escolha o framework certo de forma contínua para treinamento, avaliação e produção.
1. Personalize facilmente um modelo ou um exemplo para atender às suas necessidades:
- Fornecemos exemplos para cada arquitetura para reproduzir os resultados publicados pelos autores originais.
- Os detalhes internos do modelo são expostos de maneira consistente.
- Os arquivos do modelo podem ser usados de forma independente da biblioteca para experimentos rápidos.
## Por que não devo usar transformers?
- Esta biblioteca não é uma caixa de ferramentas modular para construir redes neurais. O código nos arquivos do modelo não é refatorado com abstrações adicionais de propósito, para que os pesquisadores possam iterar rapidamente em cada um dos modelos sem se aprofundar em abstrações/arquivos adicionais.
- A API de treinamento não é projetada para funcionar com qualquer modelo, mas é otimizada para funcionar com os modelos fornecidos pela biblioteca. Para loops de aprendizado de máquina genéricos, você deve usar outra biblioteca (possivelmente, [Accelerate](https://huggingface.co/docs/accelerate)).
- Embora nos esforcemos para apresentar o maior número possível de casos de uso, os scripts em nossa [pasta de exemplos](https://github.com/huggingface/transformers/tree/main/examples) são apenas isso: exemplos. É esperado que eles não funcionem prontos para uso em seu problema específico e que seja necessário modificar algumas linhas de código para adaptá-los às suas necessidades.
### Com pip
Este repositório é testado no Python 3.8+, Flax 0.4.1+, PyTorch 1.10+ e TensorFlow 2.6+.
Você deve instalar o 🤗 Transformers em um [ambiente virtual](https://docs.python.org/3/library/venv.html). Se você não está familiarizado com ambientes virtuais em Python, confira o [guia do usuário](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Primeiro, crie um ambiente virtual com a versão do Python que você vai usar e ative-o.
Em seguida, você precisará instalar pelo menos um dos back-ends Flax, PyTorch ou TensorFlow.
Consulte a [página de instalação do TensorFlow](https://www.tensorflow.org/install/), a [página de instalação do PyTorch](https://pytorch.org/get-started/locally/#start-locally) e/ou [Flax](https://github.com/google/flax#quick-install) e [Jax](https://github.com/google/jax#installation) páginas de instalação para obter o comando de instalação específico para a sua plataforma.
Quando um desses back-ends estiver instalado, o 🤗 Transformers pode ser instalado usando pip da seguinte forma:
```bash
pip install transformers
```
Se você deseja experimentar com os exemplos ou precisa da versão mais recente do código e não pode esperar por um novo lançamento, você deve instalar a [biblioteca a partir do código-fonte](https://huggingface.co/docs/transformers/installation#installing-from-source).
### Com conda
Desde a versão v4.0.0 do Transformers, agora temos um canal conda: `huggingface`.
O 🤗 Transformers pode ser instalado com conda da seguinte forma:
```bash
conda install -c huggingface transformers
```
Siga as páginas de instalação do Flax, PyTorch ou TensorFlow para ver como instalá-los com conda.
Siga as páginas de instalação do Flax, PyTorch ou TensorFlow para ver como instalá-los com o conda.
> **_NOTA:_** No Windows, você pode ser solicitado a ativar o Modo de Desenvolvedor para aproveitar o cache. Se isso não for uma opção para você, por favor nos avise [neste problema](https://github.com/huggingface/huggingface_hub/issues/1062).
## Arquiteturas de Modelos
**[Todos os pontos de verificação de modelo](https://huggingface.co/models)** fornecidos pelo 🤗 Transformers são integrados de forma transparente do [model hub](https://huggingface.co/models) do huggingface.co, onde são carregados diretamente por [usuários](https://huggingface.co/users) e [organizações](https://huggingface.co/organizations).
Número atual de pontos de verificação: 
🤗 Transformers atualmente fornece as seguintes arquiteturas (veja [aqui](https://huggingface.co/docs/transformers/model_summary) para um resumo de alto nível de cada uma delas):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (from NAVER CLOVA) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (from Meta/USC/CMU/SJTU) released with the paper [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (from HUST-VL) rreleased with the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (from Meta AI) released with the paper [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng,
Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
1. Quer contribuir com um novo modelo? Adicionamos um **guia detalhado e modelos de exemplo** para orientar você no processo de adição de um novo modelo. Você pode encontrá-los na pasta [`templates`](./templates) do repositório. Certifique-se de verificar as [diretrizes de contribuição](./CONTRIBUTING.md) e entrar em contato com os mantenedores ou abrir uma issue para coletar feedback antes de iniciar sua PR.
Para verificar se cada modelo tem uma implementação em Flax, PyTorch ou TensorFlow, ou possui um tokenizador associado com a biblioteca 🤗 Tokenizers, consulte [esta tabela](https://huggingface.co/docs/transformers/index#supported-frameworks).
Essas implementações foram testadas em vários conjuntos de dados (veja os scripts de exemplo) e devem corresponder ao desempenho das implementações originais. Você pode encontrar mais detalhes sobre o desempenho na seção de Exemplos da [documentação](https://github.com/huggingface/transformers/tree/main/examples).
## Saiba mais
| Seção | Descrição |
|-|-|
| [Documentação](https://huggingface.co/docs/transformers/) | Documentação completa da API e tutoriais |
| [Resumo de Tarefas](https://huggingface.co/docs/transformers/task_summary) | Tarefas suportadas pelo 🤗 Transformers |
| [Tutorial de Pré-processamento](https://huggingface.co/docs/transformers/preprocessing) | Usando a classe `Tokenizer` para preparar dados para os modelos |
| [Treinamento e Ajuste Fino](https://huggingface.co/docs/transformers/training) | Usando os modelos fornecidos pelo 🤗 Transformers em um loop de treinamento PyTorch/TensorFlow e a API `Trainer` |
| [Tour Rápido: Scripts de Ajuste Fino/Utilização](https://github.com/huggingface/transformers/tree/main/examples) | Scripts de exemplo para ajuste fino de modelos em uma ampla gama de tarefas |
| [Compartilhamento e Envio de Modelos](https://huggingface.co/docs/transformers/model_sharing) | Envie e compartilhe seus modelos ajustados com a comunidade |
## Citação
Agora temos um [artigo](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) que você pode citar para a biblioteca 🤗 Transformers:
```bibtex
@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = out,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}
```
| huggingface/transformers/blob/main/README_pt-br.md |
--
title: "Boosting Wav2Vec2 with n-grams in 🤗 Transformers"
thumbnail: /blog/assets/44_boost_wav2vec2_ngram/wav2vec2_ngram.png
authors:
- user: patrickvonplaten
---
# Boosting Wav2Vec2 with n-grams in 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Boosting_Wav2Vec2_with_n_grams_in_Transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Wav2Vec2** is a popular pre-trained model for speech recognition.
Released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
by Meta AI Research, the novel architecture catalyzed progress in
self-supervised pretraining for speech recognition, *e.g.* [*G. Ng et
al.*, 2021](https://arxiv.org/pdf/2104.03416.pdf), [*Chen et al*,
2021](https://arxiv.org/abs/2110.13900), [*Hsu et al.*,
2021](https://arxiv.org/abs/2106.07447) and [*Babu et al.*,
2021](https://arxiv.org/abs/2111.09296). On the Hugging Face Hub,
Wav2Vec2's most popular pre-trained checkpoint currently amounts to
over [**250,000** monthly
downloads](https://huggingface.co/facebook/wav2vec2-base-960h).
Using Connectionist Temporal Classification (CTC), pre-trained
Wav2Vec2-like checkpoints are extremely easy to fine-tune on downstream
speech recognition tasks. In a nutshell, fine-tuning pre-trained
Wav2Vec2 checkpoints works as follows:
A single randomly initialized linear layer is stacked on top of the
pre-trained checkpoint and trained to classify raw audio input to a
sequence of letters. It does so by:
1. extracting audio representations from the raw audio (using CNN
layers),
2. processing the sequence of audio representations with a stack of
transformer layers, and,
3. classifying the processed audio representations into a sequence of
output letters.
Previously audio classification models required an additional language
model (LM) and a dictionary to transform the sequence of classified audio
frames to a coherent transcription. Wav2Vec2's architecture is based on
transformer layers, thus giving each processed audio representation
context from all other audio representations. In addition, Wav2Vec2
leverages the [CTC algorithm](https://distill.pub/2017/ctc/) for
fine-tuning, which solves the problem of alignment between a varying
"input audio length"-to-"output text length" ratio.
Having contextualized audio classifications and no alignment problems,
Wav2Vec2 does not require an external language model or dictionary to
yield acceptable audio transcriptions.
As can be seen in Appendix C of the [official
paper](https://arxiv.org/abs/2006.11477), Wav2Vec2 gives impressive
downstream performances on [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) without using a language model at
all. However, from the appendix, it also becomes clear that using Wav2Vec2
in combination with a language model can yield a significant
improvement, especially when the model was trained on only 10 minutes of
transcribed audio.
Until recently, the 🤗 Transformers library did not offer a simple user
interface to decode audio files with a fine-tuned Wav2Vec2 **and** a
language model. This has thankfully changed. 🤗 Transformers now offers
an easy-to-use integration with *Kensho Technologies'* [pyctcdecode
library](https://github.com/kensho-technologies/pyctcdecode). This blog
post is a step-by-step **technical** guide to explain how one can create
an **n-gram** language model and combine it with an existing fine-tuned
Wav2Vec2 checkpoint using 🤗 Datasets and 🤗 Transformers.
We start by:
1. How does decoding audio with an LM differ from decoding audio
without an LM?
2. How to get suitable data for a language model?
3. How to build an *n-gram* with KenLM?
4. How to combine the *n-gram* with a fine-tuned Wav2Vec2 checkpoint?
For a deep dive into how Wav2Vec2 functions - which is not necessary for
this blog post - the reader is advised to consult the following
material:
- [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations](https://arxiv.org/abs/2006.11477)
- [Fine-Tune Wav2Vec2 for English ASR with 🤗
Transformers](https://huggingface.co/blog/fine-tune-wav2vec2-english)
- [An Illustrated Tour of Wav2vec
2.0](https://jonathanbgn.com/2021/09/30/illustrated-wav2vec-2.html)
## **1. Decoding audio data with Wav2Vec2 and a language model**
As shown in 🤗 Transformers [exemple docs of
Wav2Vec2](https://huggingface.co/docs/transformers/master/en/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC),
audio can be transcribed as follows.
First, we install `datasets` and `transformers`.
```bash
pip install datasets transformers
```
Let's load a small excerpt of the [Librispeech
dataset](https://huggingface.co/datasets/librispeech_asr) to demonstrate
Wav2Vec2's speech transcription capabilities.
```python
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset
```
**Output:**
```bash
Reusing dataset librispeech_asr (/root/.cache/huggingface/datasets/hf-internal-testing___librispeech_asr/clean/2.1.0/f2c70a4d03ab4410954901bde48c54b85ca1b7f9bf7d616e7e2a72b5ee6ddbfc)
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
```
We can pick one of the 73 audio samples and listen to it.
```python
audio_sample = dataset[2]
audio_sample["text"].lower()
```
**Output:**
```bash
he tells us that at this festive season of the year with christmas and roast beef looming before us similes drawn from eating and its results occur most readily to the mind
```
Having chosen a data sample, we now load the fine-tuned model and
processor.
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-100h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-100h")
```
Next, we process the data
```python
inputs = processor(audio_sample["audio"]["array"], sampling_rate=audio_sample["audio"]["sampling_rate"], return_tensors="pt")
```
forward it to the model
```python
import torch
with torch.no_grad():
logits = model(**inputs).logits
```
and decode it
```python
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
transcription[0].lower()
```
**Output:**
```bash
'he tells us that at this festive season of the year with christmaus and rose beef looming before us simalyis drawn from eating and its results occur most readily to the mind'
```
Comparing the transcription to the target transcription above, we can
see that some words *sound* correct, but are not *spelled* correctly,
*e.g.*:
- *christmaus* vs. *christmas*
- *rose* vs. *roast*
- *simalyis* vs. *similes*
Let's see whether combining Wav2Vec2 with an ***n-gram*** lnguage model
can help here.
First, we need to install `pyctcdecode` and `kenlm`.
```bash
pip install https://github.com/kpu/kenlm/archive/master.zip pyctcdecode
```
For demonstration purposes, we have prepared a new model repository
[patrickvonplaten/wav2vec2-base-100h-with-lm](https://huggingface.co/patrickvonplaten/wav2vec2-base-100h-with-lm)
which contains the same Wav2Vec2 checkpoint but has an additional
**4-gram** language model for English.
Instead of using `Wav2Vec2Processor`, this time we use
`Wav2Vec2ProcessorWithLM` to load the **4-gram** model in addition to
the feature extractor and tokenizer.
```python
from transformers import Wav2Vec2ProcessorWithLM
processor = Wav2Vec2ProcessorWithLM.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
```
In constrast to decoding the audio without language model, the processor
now directly receives the model's output `logits` instead of the
`argmax(logits)` (called `predicted_ids`) above. The reason is that when
decoding with a language model, at each time step, the processor takes
the probabilities of all possible output characters into account. Let's
take a look at the dimension of the `logits` output.
```python
logits.shape
```
**Output:**
```bash
torch.Size([1, 624, 32])
```
We can see that the `logits` correspond to a sequence of 624 vectors
each having 32 entries. Each of the 32 entries thereby stands for the
logit probability of one of the 32 possible output characters of the
model:
```python
" ".join(sorted(processor.tokenizer.get_vocab()))
```
**Output:**
```bash
"' </s> <pad> <s> <unk> A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |"
```
Intuitively, one can understand the decoding process of
`Wav2Vec2ProcessorWithLM` as applying beam search through a matrix of
size 624 $\times$ 32 probabilities while leveraging the probabilities of
the next letters as given by the *n-gram* language model.
OK, let's run the decoding step again. `pyctcdecode` language model
decoder does not automatically convert `torch` tensors to `numpy` so
we'll have to convert them ourselves before.
```python
transcription = processor.batch_decode(logits.numpy()).text
transcription[0].lower()
```
**Output:**
```bash
'he tells us that at this festive season of the year with christmas and rose beef looming before us similes drawn from eating and its results occur most readily to the mind'
```
Cool! Recalling the words `facebook/wav2vec2-base-100h` without a
language model transcribed incorrectly previously, *e.g.*,
> - *christmaus* vs. *christmas*
> - *rose* vs. *roast*
> - *simalyis* vs. *similes*
we can take another look at the transcription of
`facebook/wav2vec2-base-100h` **with** a 4-gram language model. 2 out of
3 errors are corrected; *christmas* and *similes* have been correctly
transcribed.
Interestingly, the incorrect transcription of *rose* persists. However,
this should not surprise us very much. Decoding audio without a language
model is much more prone to yield spelling mistakes, such as
*christmaus* or *similes* (those words don't exist in the English
language as far as I know). This is because the speech recognition
system almost solely bases its prediction on the acoustic input it was
given and not really on the language modeling context of previous and
successive predicted letters \\( {}^1 \\). If on the other hand, we add a
language model, we can be fairly sure that the speech recognition
system will heavily reduce spelling errors since a well-trained *n-gram*
model will surely not predict a word that has spelling errors. But the
word *rose* is a valid English word and therefore the 4-gram will
predict this word with a probability that is not insignificant.
The language model on its own most likely does favor the correct word
*roast* since the word sequence *roast beef* is much more common in
English than *rose beef*. Because the final transcription is derived
from a weighted combination of `facebook/wav2vec2-base-100h` output
probabilities and those of the *n-gram* language model, it is quite
common to see incorrectly transcribed words such as *rose*.
For more information on how you can tweak different parameters when
decoding with `Wav2Vec2ProcessorWithLM`, please take a look at the
official documentation
[here](https://huggingface.co/docs/transformers/master/en/model_doc/wav2vec2#transformers.Wav2Vec2ProcessorWithLM.batch_decode).
------------------------------------------------------------------------
\\({}^1 \\) Some research shows that a model such as
`facebook/wav2vec2-base-100h` - when sufficiently large and trained on
enough data - can learn language modeling dependencies between
intermediate audio representations similar to a language model.
Great, now that you have seen the advantages adding an *n-gram* language
model can bring, let's dive into how to create an *n-gram* and
`Wav2Vec2ProcessorWithLM` from scratch.
## **2. Getting data for your language model**
A language model that is useful for a speech recognition system should
support the acoustic model, *e.g.* Wav2Vec2, in predicting the next word
(or token, letter) and therefore model the following distribution:
\\( \mathbf{P}(w_n | \mathbf{w}_0^{t-1}) \\) with \\( w_n \\) being the next word
and \\( \mathbf{w}_0^{t-1} \\) being the sequence of all previous words since
the beginning of the utterance. Simply said, the language model should
be good at predicting the next word given all previously transcribed
words regardless of the audio input given to the speech recognition
system.
As always a language model is only as good as the data it is trained on.
In the case of speech recognition, we should therefore ask ourselves for
what kind of data, the speech recognition will be used for:
*conversations*, *audiobooks*, *movies*, *speeches*, *, etc*, \...?
The language model should be good at modeling language that corresponds
to the target transcriptions of the speech recognition system. For
demonstration purposes, we assume here that we have fine-tuned a
pre-trained
[`facebook/wav2vec2-xls-r-300m`](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
on [Common Voice
7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0)
in Swedish. The fine-tuned checkpoint can be found
[here](https://huggingface.co/hf-test/xls-r-300m-sv). Common Voice 7 is
a relatively crowd-sourced read-out audio dataset and we will evaluate
the model on its test data.
Let's now look for suitable text data on the Hugging Face Hub. We
search all datasets for those [that contain Swedish
data](https://huggingface.co/datasets?languages=languages:sv&sort=downloads).
Browsing a bit through the datasets, we are looking for a dataset that
is similar to Common Voice's read-out audio data. The obvious choices
of [oscar](https://huggingface.co/datasets/oscar) and
[mc4](https://huggingface.co/datasets/mc4) might not be the most
suitable here because they:
- are generated from crawling the web, which might not be very
clean and correspond well to spoken language
- require a lot of pre-processing
- are very large which is not ideal for demonstration purposes
here 😉
A dataset that seems sensible here and which is relatively clean and
easy to pre-process is
[europarl_bilingual](https://huggingface.co/datasets/europarl_bilingual)
as it's a dataset that is based on discussions and talks of the
European parliament. It should therefore be relatively clean and
correspond well to read-out audio data. The dataset is originally designed
for machine translation and can therefore only be accessed in
translation pairs. We will only extract the text of the target
language, Swedish (`sv`), from the *English-to-Swedish* translations.
```python
target_lang="sv" # change to your target lang
```
Let's download the data.
```python
from datasets import load_dataset
dataset = load_dataset("europarl_bilingual", lang1="en", lang2=target_lang, split="train")
```
We see that the data is quite large - it has over a million
translations. Since it's only text data, it should be relatively easy
to process though.
Next, let's look at how the data was preprocessed when training the
fine-tuned *XLS-R* checkpoint in Swedish. Looking at the [`run.sh`
file](https://huggingface.co/hf-test/xls-r-300m-sv/blob/main/run.sh), we
can see that the following characters were removed from the official
transcriptions:
```python
chars_to_ignore_regex = '[,?.!\-\;\:"“%‘”�—’…–]' # change to the ignored characters of your fine-tuned model
```
Let's do the same here so that the alphabet of our language model
matches the one of the fine-tuned acoustic checkpoints.
We can write a single map function to extract the Swedish text and
process it right away.
```python
import re
def extract_text(batch):
text = batch["translation"][target_lang]
batch["text"] = re.sub(chars_to_ignore_regex, "", text.lower())
return batch
```
Let's apply the `.map()` function. This should take roughly 5 minutes.
```python
dataset = dataset.map(extract_text, remove_columns=dataset.column_names)
```
Great. Let's upload it to the Hub so
that we can inspect and reuse it better.
You can log in by executing the following cell.
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
```
Next, we call 🤗 Hugging Face's
[`push_to_hub`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=push#datasets.Dataset.push_to_hub)
method to upload the dataset to the repo
`"sv_corpora_parliament_processed"`.
```python
dataset.push_to_hub(f"{target_lang}_corpora_parliament_processed", split="train")
```
That was easy! The dataset viewer is automatically enabled when
uploading a new dataset, which is very convenient. You can now directly
inspect the dataset online.
Feel free to look through our preprocessed dataset directly on
[`hf-test/sv_corpora_parliament_processed`](https://huggingface.co/datasets/hf-test/sv_corpora_parliament_processed).
Even if we are not a native speaker in Swedish, we can see that the data
is well processed and seems clean.
Next, let's use the data to build a language model.
## **3. Build an *n-gram* with KenLM**
While large language models based on the [Transformer architecture](https://jalammar.github.io/illustrated-transformer/) have become the standard in NLP, it is still very common to use an ***n-gram*** LM to boost speech recognition systems - as shown in Section 1.
Looking again at Table 9 of Appendix C of the [official Wav2Vec2 paper](https://arxiv.org/abs/2006.11477), it can be noticed that using a *Transformer*-based LM for decoding clearly yields better results than using an *n-gram* model, but the difference between *n-gram* and *Transformer*-based LM is much less significant than the difference between *n-gram* and no LM.
*E.g.*, for the large Wav2Vec2 checkpoint that was fine-tuned on 10min only, an *n-gram* reduces the word error rate (WER) compared to no LM by *ca.* 80% while a *Transformer*-based LM *only* reduces the WER by another 23% compared to the *n-gram*. This relative WER reduction becomes less, the more data the acoustic model has been trained on. *E.g.*, for the large checkpoint a *Transformer*-based LM reduces the WER by merely 8% compared to an *n-gram* LM whereas the *n-gram* still yields a 21% WER reduction compared to no language model.
The reason why an *n-gram* is preferred over a *Transformer*-based LM is that *n-grams* come at a significantly smaller computational cost. For an *n-gram*, retrieving the probability of a word given previous words is almost only as computationally expensive as querying a look-up table or tree-like data storage - *i.e.* it's very fast compared to modern *Transformer*-based language models that would require a full forward pass to retrieve the next word probabilities.
For more information on how *n-grams* function and why they are (still) so useful for speech recognition, the reader is advised to take a look at [this excellent summary](https://web.stanford.edu/~jurafsky/slp3/3.pdf) from Stanford.
Great, let's see step-by-step how to build an *n-gram*. We will use the
popular [KenLM library](https://github.com/kpu/kenlm) to do so. Let's
start by installing the Ubuntu library prerequisites:
```bash
sudo apt install build-essential cmake libboost-system-dev libboost-thread-dev libboost-program-options-dev libboost-test-dev libeigen3-dev zlib1g-dev libbz2-dev liblzma-dev
```
before downloading and unpacking the KenLM repo.
```bash
wget -O - https://kheafield.com/code/kenlm.tar.gz | tar xz
```
KenLM is written in C++, so we'll make use of `cmake` to build the
binaries.
```bash
mkdir kenlm/build && cd kenlm/build && cmake .. && make -j2
ls kenlm/build/bin
```
Great, as we can see, the executable functions have successfully
been built under `kenlm/build/bin/`.
KenLM by default computes an *n-gram* with [Kneser-Ney
smooting](https://en.wikipedia.org/wiki/Kneser%E2%80%93Ney_smoothing).
All text data used to create the *n-gram* is expected to be stored in a
text file. We download our dataset and save it as a `.txt` file.
```python
from datasets import load_dataset
username = "hf-test" # change to your username
dataset = load_dataset(f"{username}/{target_lang}_corpora_parliament_processed", split="train")
with open("text.txt", "w") as file:
file.write(" ".join(dataset["text"]))
```
Now, we just have to run KenLM's `lmplz` command to build our *n-gram*,
called `"5gram.arpa"`. As it's relatively common in speech recognition,
we build a *5-gram* by passing the `-o 5` parameter.
For more information on the different *n-gram* LM that can be built
with KenLM, one can take a look at the [official website of KenLM](https://kheafield.com/code/kenlm/).
Executing the command below might take a minute or so.
```bash
kenlm/build/bin/lmplz -o 5 <"text.txt" > "5gram.arpa"
```
**Output:**
```bash
=== 1/5 Counting and sorting n-grams ===
Reading /content/swedish_text.txt
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
tcmalloc: large alloc 1918697472 bytes == 0x55d40d0f0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b28c51e 0x55d40b26b2eb 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 8953896960 bytes == 0x55d47f6c0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26b308 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
****************************************************************************************************
Unigram tokens 42153890 types 360209
=== 2/5 Calculating and sorting adjusted counts ===
Chain sizes: 1:4322508 2:1062772928 3:1992699264 4:3188318720 5:4649631744
tcmalloc: large alloc 4649631744 bytes == 0x55d40d0f0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26b8d7 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 1992704000 bytes == 0x55d561ce0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26bcdd 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 3188326400 bytes == 0x55d695a86000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26bcdd 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
Statistics:
1 360208 D1=0.686222 D2=1.01595 D3+=1.33685
2 5476741 D1=0.761523 D2=1.06735 D3+=1.32559
3 18177681 D1=0.839918 D2=1.12061 D3+=1.33794
4 30374983 D1=0.909146 D2=1.20496 D3+=1.37235
5 37231651 D1=0.944104 D2=1.25164 D3+=1.344
Memory estimate for binary LM:
type MB
probing 1884 assuming -p 1.5
probing 2195 assuming -r models -p 1.5
trie 922 without quantization
trie 518 assuming -q 8 -b 8 quantization
trie 806 assuming -a 22 array pointer compression
trie 401 assuming -a 22 -q 8 -b 8 array pointer compression and quantization
=== 3/5 Calculating and sorting initial probabilities ===
Chain sizes: 1:4322496 2:87627856 3:363553620 4:728999592 5:1042486228
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
####################################################################################################
=== 4/5 Calculating and writing order-interpolated probabilities ===
Chain sizes: 1:4322496 2:87627856 3:363553620 4:728999592 5:1042486228
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
####################################################################################################
=== 5/5 Writing ARPA model ===
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
Name:lmplz VmPeak:14181536 kB VmRSS:2199260 kB RSSMax:4160328 kB user:120.598 sys:26.6659 CPU:147.264 real:136.344
```
Great, we have built a *5-gram* LM! Let's inspect the first couple of
lines.
```bash
head -20 5gram.arpa
```
**Output:**
```bash
\data\
ngram 1=360208
ngram 2=5476741
ngram 3=18177681
ngram 4=30374983
ngram 5=37231651
\1-grams:
-6.770219 <unk> 0
0 <s> -0.11831701
-4.6095004 återupptagande -1.2174699
-2.2361007 av -0.79668784
-4.8163533 sessionen -0.37327805
-2.2251768 jag -1.4205662
-4.181505 förklarar -0.56261665
-3.5790775 europaparlamentets -0.63611007
-4.771945 session -0.3647111
-5.8043895 återupptagen -0.3058712
-2.8580177 efter -0.7557702
-5.199537 avbrottet -0.43322718
```
There is a small problem that 🤗 Transformers will not be happy about
later on. The *5-gram* correctly includes a "Unknown" or `<unk>`, as
well as a *begin-of-sentence*, `<s>` token, but no *end-of-sentence*,
`</s>` token. This sadly has to be corrected currently after the build.
We can simply add the *end-of-sentence* token by adding the line
`0 </s> -0.11831701` below the *begin-of-sentence* token and increasing
the `ngram 1` count by 1. Because the file has roughly 100 million
lines, this command will take *ca.* 2 minutes.
```python
with open("5gram.arpa", "r") as read_file, open("5gram_correct.arpa", "w") as write_file:
has_added_eos = False
for line in read_file:
if not has_added_eos and "ngram 1=" in line:
count=line.strip().split("=")[-1]
write_file.write(line.replace(f"{count}", f"{int(count)+1}"))
elif not has_added_eos and "<s>" in line:
write_file.write(line)
write_file.write(line.replace("<s>", "</s>"))
has_added_eos = True
else:
write_file.write(line)
```
Let's now inspect the corrected *5-gram*.
```bash
head -20 5gram_correct.arpa
```
**Output:**
```bash
\data\
ngram 1=360209
ngram 2=5476741
ngram 3=18177681
ngram 4=30374983
ngram 5=37231651
\1-grams:
-6.770219 <unk> 0
0 <s> -0.11831701
0 </s> -0.11831701
-4.6095004 återupptagande -1.2174699
-2.2361007 av -0.79668784
-4.8163533 sessionen -0.37327805
-2.2251768 jag -1.4205662
-4.181505 förklarar -0.56261665
-3.5790775 europaparlamentets -0.63611007
-4.771945 session -0.3647111
-5.8043895 återupptagen -0.3058712
-2.8580177 efter -0.7557702
```
Great, this looks better! We're done at this point and all that is left
to do is to correctly integrate the `"ngram"` with
[`pyctcdecode`](https://github.com/kensho-technologies/pyctcdecode) and
🤗 Transformers.
## **4. Combine an *n-gram* with Wav2Vec2**
In a final step, we want to wrap the *5-gram* into a
`Wav2Vec2ProcessorWithLM` object to make the *5-gram* boosted decoding
as seamless as shown in Section 1. We start by downloading the currently
"LM-less" processor of
[`xls-r-300m-sv`](https://huggingface.co/hf-test/xls-r-300m-sv).
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("hf-test/xls-r-300m-sv")
```
Next, we extract the vocabulary of its tokenizer as it represents the
`"labels"` of `pyctcdecode`'s `BeamSearchDecoder` class.
```python
vocab_dict = processor.tokenizer.get_vocab()
sorted_vocab_dict = {k.lower(): v for k, v in sorted(vocab_dict.items(), key=lambda item: item[1])}
```
The `"labels"` and the previously built `5gram_correct.arpa` file is all
that's needed to build the decoder.
```python
from pyctcdecode import build_ctcdecoder
decoder = build_ctcdecoder(
labels=list(sorted_vocab_dict.keys()),
kenlm_model_path="5gram_correct.arpa",
)
```
**Output:**
```bash
Found entries of length > 1 in alphabet. This is unusual unless style is BPE, but the alphabet was not recognized as BPE type. Is this correct?
Unigrams and labels don't seem to agree.
```
We can safely ignore the warning and all that is left to do now is to
wrap the just created `decoder`, together with the processor's
`tokenizer` and `feature_extractor` into a `Wav2Vec2ProcessorWithLM`
class.
```python
from transformers import Wav2Vec2ProcessorWithLM
processor_with_lm = Wav2Vec2ProcessorWithLM(
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
decoder=decoder
)
```
We want to directly upload the LM-boosted processor into the model
folder of
[`xls-r-300m-sv`](https://huggingface.co/hf-test/xls-r-300m-sv) to have
all relevant files in one place.
Let's clone the repo, add the new decoder files and upload them
afterward. First, we need to install `git-lfs`.
```bash
sudo apt-get install git-lfs tree
```
Cloning and uploading of modeling files can be done conveniently with
the `huggingface_hub`'s `Repository` class.
More information on how to use the `huggingface_hub` to upload any
files, please take a look at the [official
docs](https://huggingface.co/docs/huggingface_hub/how-to-upstream).
```python
from huggingface_hub import Repository
repo = Repository(local_dir="xls-r-300m-sv", clone_from="hf-test/xls-r-300m-sv")
```
**Output:**
```bash
Cloning https://huggingface.co/hf-test/xls-r-300m-sv into local empty directory.
```
Having cloned `xls-r-300m-sv`, let's save the new processor with LM
into it.
```python
processor_with_lm.save_pretrained("xls-r-300m-sv")
```
Let's inspect the local repository. The `tree` command conveniently can
also show the size of the different files.
```bash
tree -h xls-r-300m-sv/
```
**Output:**
```bash
xls-r-300m-sv/
├── [ 23] added_tokens.json
├── [ 401] all_results.json
├── [ 253] alphabet.json
├── [2.0K] config.json
├── [ 304] emissions.csv
├── [ 226] eval_results.json
├── [4.0K] language_model
│ ├── [4.1G] 5gram_correct.arpa
│ ├── [ 78] attrs.json
│ └── [4.9M] unigrams.txt
├── [ 240] preprocessor_config.json
├── [1.2G] pytorch_model.bin
├── [3.5K] README.md
├── [4.0K] runs
│ └── [4.0K] Jan09_22-00-50_brutasse
│ ├── [4.0K] 1641765760.8871996
│ │ └── [4.6K] events.out.tfevents.1641765760.brutasse.31164.1
│ ├── [ 42K] events.out.tfevents.1641765760.brutasse.31164.0
│ └── [ 364] events.out.tfevents.1641794162.brutasse.31164.2
├── [1.2K] run.sh
├── [ 30K] run_speech_recognition_ctc.py
├── [ 502] special_tokens_map.json
├── [ 279] tokenizer_config.json
├── [ 29K] trainer_state.json
├── [2.9K] training_args.bin
├── [ 196] train_results.json
├── [ 319] vocab.json
└── [4.0K] wandb
├── [ 52] debug-internal.log -> run-20220109_220240-1g372i3v/logs/debug-internal.log
├── [ 43] debug.log -> run-20220109_220240-1g372i3v/logs/debug.log
├── [ 28] latest-run -> run-20220109_220240-1g372i3v
└── [4.0K] run-20220109_220240-1g372i3v
├── [4.0K] files
│ ├── [8.8K] conda-environment.yaml
│ ├── [140K] config.yaml
│ ├── [4.7M] output.log
│ ├── [5.4K] requirements.txt
│ ├── [2.1K] wandb-metadata.json
│ └── [653K] wandb-summary.json
├── [4.0K] logs
│ ├── [3.4M] debug-internal.log
│ └── [8.2K] debug.log
└── [113M] run-1g372i3v.wandb
9 directories, 34 files
```
As can be seen the *5-gram* LM is quite large - it amounts to more than
4 GB. To reduce the size of the *n-gram* and make loading faster,
`kenLM` allows converting `.arpa` files to binary ones using the
`build_binary` executable.
Let's make use of it here.
```bash
kenlm/build/bin/build_binary xls-r-300m-sv/language_model/5gram_correct.arpa xls-r-300m-sv/language_model/5gram.bin
```
**Output:**
```bash
Reading xls-r-300m-sv/language_model/5gram_correct.arpa
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
SUCCESS
```
Great, it worked! Let's remove the `.arpa` file and check the size of
the binary *5-gram* LM.
```bash
rm xls-r-300m-sv/language_model/5gram_correct.arpa && tree -h xls-r-300m-sv/
```
**Output:**
```bash
xls-r-300m-sv/
├── [ 23] added_tokens.json
├── [ 401] all_results.json
├── [ 253] alphabet.json
├── [2.0K] config.json
├── [ 304] emissions.csv
├── [ 226] eval_results.json
├── [4.0K] language_model
│ ├── [1.8G] 5gram.bin
│ ├── [ 78] attrs.json
│ └── [4.9M] unigrams.txt
├── [ 240] preprocessor_config.json
├── [1.2G] pytorch_model.bin
├── [3.5K] README.md
├── [4.0K] runs
│ └── [4.0K] Jan09_22-00-50_brutasse
│ ├── [4.0K] 1641765760.8871996
│ │ └── [4.6K] events.out.tfevents.1641765760.brutasse.31164.1
│ ├── [ 42K] events.out.tfevents.1641765760.brutasse.31164.0
│ └── [ 364] events.out.tfevents.1641794162.brutasse.31164.2
├── [1.2K] run.sh
├── [ 30K] run_speech_recognition_ctc.py
├── [ 502] special_tokens_map.json
├── [ 279] tokenizer_config.json
├── [ 29K] trainer_state.json
├── [2.9K] training_args.bin
├── [ 196] train_results.json
├── [ 319] vocab.json
└── [4.0K] wandb
├── [ 52] debug-internal.log -> run-20220109_220240-1g372i3v/logs/debug-internal.log
├── [ 43] debug.log -> run-20220109_220240-1g372i3v/logs/debug.log
├── [ 28] latest-run -> run-20220109_220240-1g372i3v
└── [4.0K] run-20220109_220240-1g372i3v
├── [4.0K] files
│ ├── [8.8K] conda-environment.yaml
│ ├── [140K] config.yaml
│ ├── [4.7M] output.log
│ ├── [5.4K] requirements.txt
│ ├── [2.1K] wandb-metadata.json
│ └── [653K] wandb-summary.json
├── [4.0K] logs
│ ├── [3.4M] debug-internal.log
│ └── [8.2K] debug.log
└── [113M] run-1g372i3v.wandb
9 directories, 34 files
```
Nice, we reduced the *n-gram* by more than half to less than 2GB now. In
the final step, let's upload all files.
```python
repo.push_to_hub(commit_message="Upload lm-boosted decoder")
```
**Output:**
```bash
Git LFS: (1 of 1 files) 1.85 GB / 1.85 GB
Counting objects: 9, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 1.23 MiB | 1.92 MiB/s, done.
Total 9 (delta 3), reused 0 (delta 0)
To https://huggingface.co/hf-test/xls-r-300m-sv
27d0c57..5a191e2 main -> main
```
That's it. Now you should be able to use the *5gram* for LM-boosted
decoding as shown in Section 1.
As can be seen on [`xls-r-300m-sv`'s model
card](https://huggingface.co/hf-test/xls-r-300m-sv#inference-with-lm)
our *5gram* LM-boosted decoder yields a WER of 18.85% on Common Voice's 7
test set which is a relative performance of *ca.* 30% 🔥.
| huggingface/blog/blob/main/wav2vec2-with-ngram.md |
DreamBooth training example for Stable Diffusion XL (SDXL)
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_sdxl.py` script shows how to implement the training procedure and adapt it for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952).
> 💡 **Note**: For now, we only allow DreamBooth fine-tuning of the SDXL UNet via LoRA. LoRA is a parameter-efficient fine-tuning technique introduced in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/dreambooth` folder and run
```bash
pip install -r requirements_sdxl.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.6.0` installed in your environment.
### Dog toy example
Now let's get our dataset. For this example we will use some dog images: https://huggingface.co/datasets/diffusers/dog-example.
Let's first download it locally:
```python
from huggingface_hub import snapshot_download
local_dir = "./dog"
snapshot_download(
"diffusers/dog-example",
local_dir=local_dir, repo_type="dataset",
ignore_patterns=".gitattributes",
)
```
This will also allow us to push the trained LoRA parameters to the Hugging Face Hub platform.
Now, we can launch training using:
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export INSTANCE_DIR="dog"
export OUTPUT_DIR="lora-trained-xl"
export VAE_PATH="madebyollin/sdxl-vae-fp16-fix"
accelerate launch train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--pretrained_vae_model_name_or_path=$VAE_PATH \
--output_dir=$OUTPUT_DIR \
--mixed_precision="fp16" \
--instance_prompt="a photo of sks dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a bucket" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
```
To better track our training experiments, we're using the following flags in the command above:
* `report_to="wandb` will ensure the training runs are tracked on Weights and Biases. To use it, be sure to install `wandb` with `pip install wandb`.
* `validation_prompt` and `validation_epochs` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
Our experiments were conducted on a single 40GB A100 GPU.
### Dog toy example with < 16GB VRAM
By making use of [`gradient_checkpointing`](https://pytorch.org/docs/stable/checkpoint.html) (which is natively supported in Diffusers), [`xformers`](https://github.com/facebookresearch/xformers), and [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) libraries, you can train SDXL LoRAs with less than 16GB of VRAM by adding the following flags to your accelerate launch command:
```diff
+ --enable_xformers_memory_efficient_attention \
+ --gradient_checkpointing \
+ --use_8bit_adam \
+ --mixed_precision="fp16" \
```
and making sure that you have the following libraries installed:
```
bitsandbytes>=0.40.0
xformers>=0.0.20
```
### Inference
Once training is done, we can perform inference like so:
```python
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline
import torch
lora_model_id = <"lora-sdxl-dreambooth-id">
card = RepoCard.load(lora_model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
pipe.load_lora_weights(lora_model_id)
image = pipe("A picture of a sks dog in a bucket", num_inference_steps=25).images[0]
image.save("sks_dog.png")
```
We can further refine the outputs with the [Refiner](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0):
```python
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline, StableDiffusionXLImg2ImgPipeline
import torch
lora_model_id = <"lora-sdxl-dreambooth-id">
card = RepoCard.load(lora_model_id)
base_model_id = card.data.to_dict()["base_model"]
# Load the base pipeline and load the LoRA parameters into it.
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
pipe.load_lora_weights(lora_model_id)
# Load the refiner.
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
)
refiner.to("cuda")
prompt = "A picture of a sks dog in a bucket"
generator = torch.Generator("cuda").manual_seed(0)
# Run inference.
image = pipe(prompt=prompt, output_type="latent", generator=generator).images[0]
image = refiner(prompt=prompt, image=image[None, :], generator=generator).images[0]
image.save("refined_sks_dog.png")
```
Here's a side-by-side comparison of the with and without Refiner pipeline outputs:
| Without Refiner | With Refiner |
|---|---|
|  |  |
### Training with text encoder(s)
Alongside the UNet, LoRA fine-tuning of the text encoders is also supported. To do so, just specify `--train_text_encoder` while launching training. Please keep the following points in mind:
* SDXL has two text encoders. So, we fine-tune both using LoRA.
* When not fine-tuning the text encoders, we ALWAYS precompute the text embeddings to save memory.
### Specifying a better VAE
SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
## Notes
In our experiments, we found that SDXL yields good initial results without extensive hyperparameter tuning. For example, without fine-tuning the text encoders and without using prior-preservation, we observed decent results. We didn't explore further hyper-parameter tuning experiments, but we do encourage the community to explore this avenue further and share their results with us 🤗
## Results
You can explore the results from a couple of our internal experiments by checking out this link: [https://wandb.ai/sayakpaul/dreambooth-lora-sd-xl](https://wandb.ai/sayakpaul/dreambooth-lora-sd-xl). Specifically, we used the same script with the exact same hyperparameters on the following datasets:
* [Dogs](https://huggingface.co/datasets/diffusers/dog-example)
* [Starbucks logo](https://huggingface.co/datasets/diffusers/starbucks-example)
* [Mr. Potato Head](https://huggingface.co/datasets/diffusers/potato-head-example)
* [Keramer face](https://huggingface.co/datasets/diffusers/keramer-face-example)
## Running on a free-tier Colab Notebook
Check out [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/SDXL_DreamBooth_LoRA_.ipynb).
| huggingface/diffusers/blob/main/examples/dreambooth/README_sdxl.md |
--
title: Competition MATH
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
This metric is used to assess performance on the Mathematics Aptitude Test of Heuristics (MATH) dataset.
It first canonicalizes the inputs (e.g., converting "1/2" to "\frac{1}{2}") and then computes accuracy.
---
# Metric Card for Competition MATH
## Metric description
This metric is used to assess performance on the [Mathematics Aptitude Test of Heuristics (MATH) dataset](https://huggingface.co/datasets/competition_math).
It first canonicalizes the inputs (e.g., converting `1/2` to `\\frac{1}{2}`) and then computes accuracy.
## How to use
This metric takes two arguments:
`predictions`: a list of predictions to score. Each prediction is a string that contains natural language and LaTeX.
`references`: list of reference for each prediction. Each reference is a string that contains natural language and LaTeX.
```python
>>> from evaluate import load
>>> math = load("competition_math")
>>> references = ["\\frac{1}{2}"]
>>> predictions = ["1/2"]
>>> results = math.compute(references=references, predictions=predictions)
```
N.B. To be able to use Competition MATH, you need to install the `math_equivalence` dependency using `pip install git+https://github.com/hendrycks/math.git`.
## Output values
This metric returns a dictionary that contains the [accuracy](https://huggingface.co/metrics/accuracy) after canonicalizing inputs, on a scale between 0.0 and 1.0.
### Values from popular papers
The [original MATH dataset paper](https://arxiv.org/abs/2103.03874) reported accuracies ranging from 3.0% to 6.9% by different large language models.
More recent progress on the dataset can be found on the [dataset leaderboard](https://paperswithcode.com/sota/math-word-problem-solving-on-math).
## Examples
Maximal values (full match):
```python
>>> from evaluate import load
>>> math = load("competition_math")
>>> references = ["\\frac{1}{2}"]
>>> predictions = ["1/2"]
>>> results = math.compute(references=references, predictions=predictions)
>>> print(results)
{'accuracy': 1.0}
```
Minimal values (no match):
```python
>>> from evaluate import load
>>> math = load("competition_math")
>>> references = ["\\frac{1}{2}"]
>>> predictions = ["3/4"]
>>> results = math.compute(references=references, predictions=predictions)
>>> print(results)
{'accuracy': 0.0}
```
Partial match:
```python
>>> from evaluate import load
>>> math = load("competition_math")
>>> references = ["\\frac{1}{2}","\\frac{3}{4}"]
>>> predictions = ["1/5", "3/4"]
>>> results = math.compute(references=references, predictions=predictions)
>>> print(results)
{'accuracy': 0.5}
```
## Limitations and bias
This metric is limited to datasets with the same format as the [Mathematics Aptitude Test of Heuristics (MATH) dataset](https://huggingface.co/datasets/competition_math), and is meant to evaluate the performance of large language models at solving mathematical problems.
N.B. The MATH dataset also assigns levels of difficulty to different problems, so disagregating model performance by difficulty level (similarly to what was done in the [original paper](https://arxiv.org/abs/2103.03874) can give a better indication of how a given model does on a given difficulty of math problem, compared to overall accuracy.
## Citation
```bibtex
@article{hendrycksmath2021,
title={Measuring Mathematical Problem Solving With the MATH Dataset},
author={Dan Hendrycks
and Collin Burns
and Saurav Kadavath
and Akul Arora
and Steven Basart
and Eric Tang
and Dawn Song
and Jacob Steinhardt},
journal={arXiv preprint arXiv:2103.03874},
year={2021}
}
```
## Further References
- [MATH dataset](https://huggingface.co/datasets/competition_math)
- [MATH leaderboard](https://paperswithcode.com/sota/math-word-problem-solving-on-math)
- [MATH paper](https://arxiv.org/abs/2103.03874) | huggingface/evaluate/blob/main/metrics/competition_math/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Load safetensors
[[open-in-colab]]
[safetensors](https://github.com/huggingface/safetensors) is a safe and fast file format for storing and loading tensors. Typically, PyTorch model weights are saved or *pickled* into a `.bin` file with Python's [`pickle`](https://docs.python.org/3/library/pickle.html) utility. However, `pickle` is not secure and pickled files may contain malicious code that can be executed. safetensors is a secure alternative to `pickle`, making it ideal for sharing model weights.
This guide will show you how you load `.safetensor` files, and how to convert Stable Diffusion model weights stored in other formats to `.safetensor`. Before you start, make sure you have safetensors installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install safetensors
```
If you look at the [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main) repository, you'll see weights inside the `text_encoder`, `unet` and `vae` subfolders are stored in the `.safetensors` format. By default, 🤗 Diffusers automatically loads these `.safetensors` files from their subfolders if they're available in the model repository.
For more explicit control, you can optionally set `use_safetensors=True` (if `safetensors` is not installed, you'll get an error message asking you to install it):
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
```
However, model weights are not necessarily stored in separate subfolders like in the example above. Sometimes, all the weights are stored in a single `.safetensors` file. In this case, if the weights are Stable Diffusion weights, you can load the file directly with the [`~diffusers.loaders.FromSingleFileMixin.from_single_file`] method:
```py
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_single_file(
"https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix/AbyssOrangeMix.safetensors"
)
```
## Convert to safetensors
Not all weights on the Hub are available in the `.safetensors` format, and you may encounter weights stored as `.bin`. In this case, use the [Convert Space](https://huggingface.co/spaces/diffusers/convert) to convert the weights to `.safetensors`. The Convert Space downloads the pickled weights, converts them, and opens a Pull Request to upload the newly converted `.safetensors` file on the Hub. This way, if there is any malicious code contained in the pickled files, they're uploaded to the Hub - which has a [security scanner](https://huggingface.co/docs/hub/security-pickle#hubs-security-scanner) to detect unsafe files and suspicious pickle imports - instead of your computer.
You can use the model with the new `.safetensors` weights by specifying the reference to the Pull Request in the `revision` parameter (you can also test it in this [Check PR](https://huggingface.co/spaces/diffusers/check_pr) Space on the Hub), for example `refs/pr/22`:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", revision="refs/pr/22", use_safetensors=True
)
```
## Why use safetensors?
There are several reasons for using safetensors:
- Safety is the number one reason for using safetensors. As open-source and model distribution grows, it is important to be able to trust the model weights you downloaded don't contain any malicious code. The current size of the header in safetensors prevents parsing extremely large JSON files.
- Loading speed between switching models is another reason to use safetensors, which performs zero-copy of the tensors. It is especially fast compared to `pickle` if you're loading the weights to CPU (the default case), and just as fast if not faster when directly loading the weights to GPU. You'll only notice the performance difference if the model is already loaded, and not if you're downloading the weights or loading the model for the first time.
The time it takes to load the entire pipeline:
```py
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", use_safetensors=True)
"Loaded in safetensors 0:00:02.033658"
"Loaded in PyTorch 0:00:02.663379"
```
But the actual time it takes to load 500MB of the model weights is only:
```bash
safetensors: 3.4873ms
PyTorch: 172.7537ms
```
- Lazy loading is also supported in safetensors, which is useful in distributed settings to only load some of the tensors. This format allowed the [BLOOM](https://huggingface.co/bigscience/bloom) model to be loaded in 45 seconds on 8 GPUs instead of 10 minutes with regular PyTorch weights.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/using_safetensors.md |
--
title: "Hugging Face Machine Learning Demos on arXiv"
thumbnail: /blog/assets/arxiv/thumbnail.png
authors:
- user: abidlabs
- user: osanseviero
- user: pcuenq
---
# Hugging Face Machine Learning Demos on arXiv
We’re very excited to announce that Hugging Face has collaborated with arXiv to make papers more accessible, discoverable, and fun! Starting today, [Hugging Face Spaces](https://huggingface.co/spaces) is integrated with arXivLabs through a Demo tab that includes links to demos created by the community or the authors themselves. By going to the Demos tab of your favorite paper, you can find links to open-source demos and try them out immediately 🔥
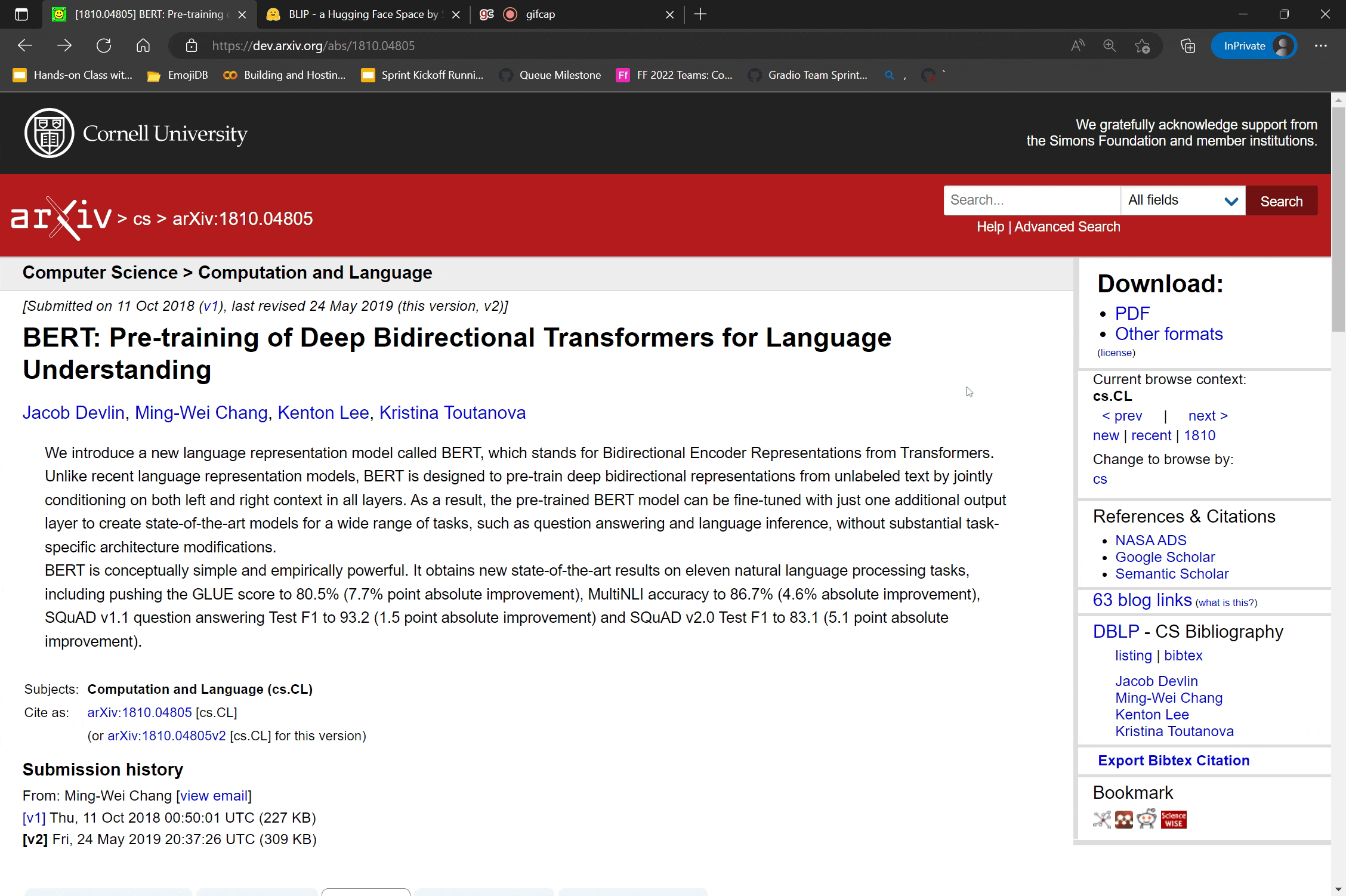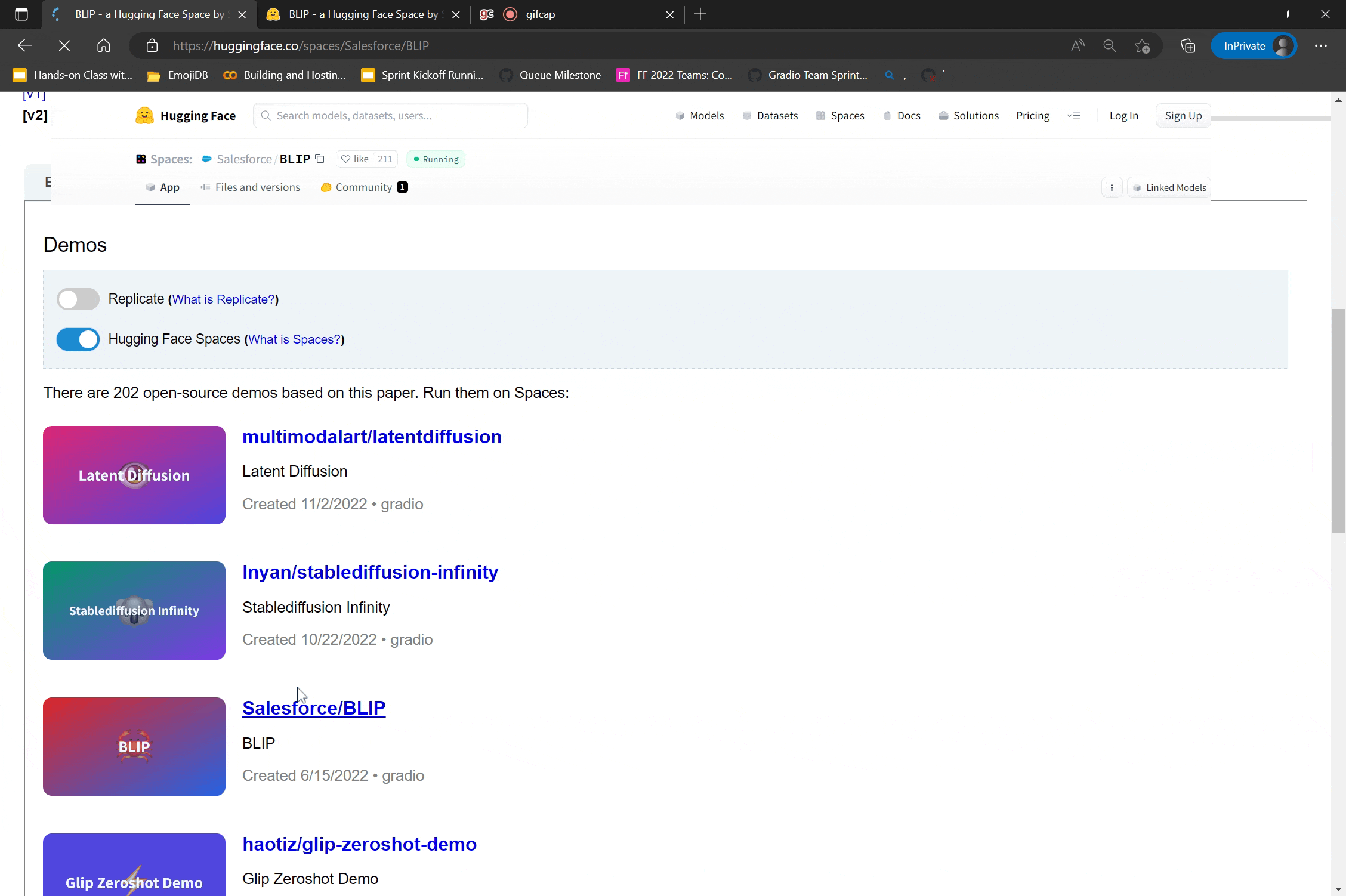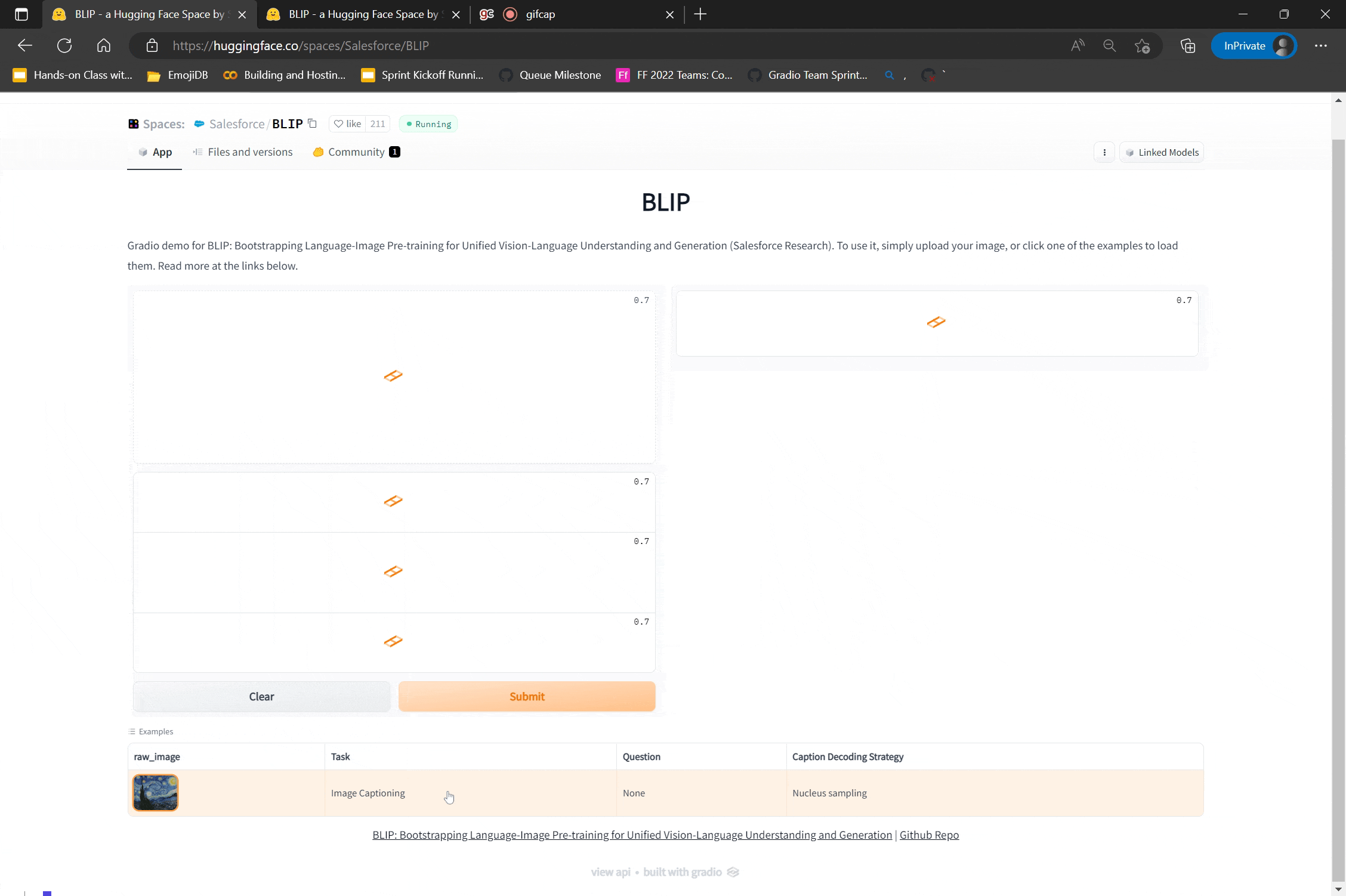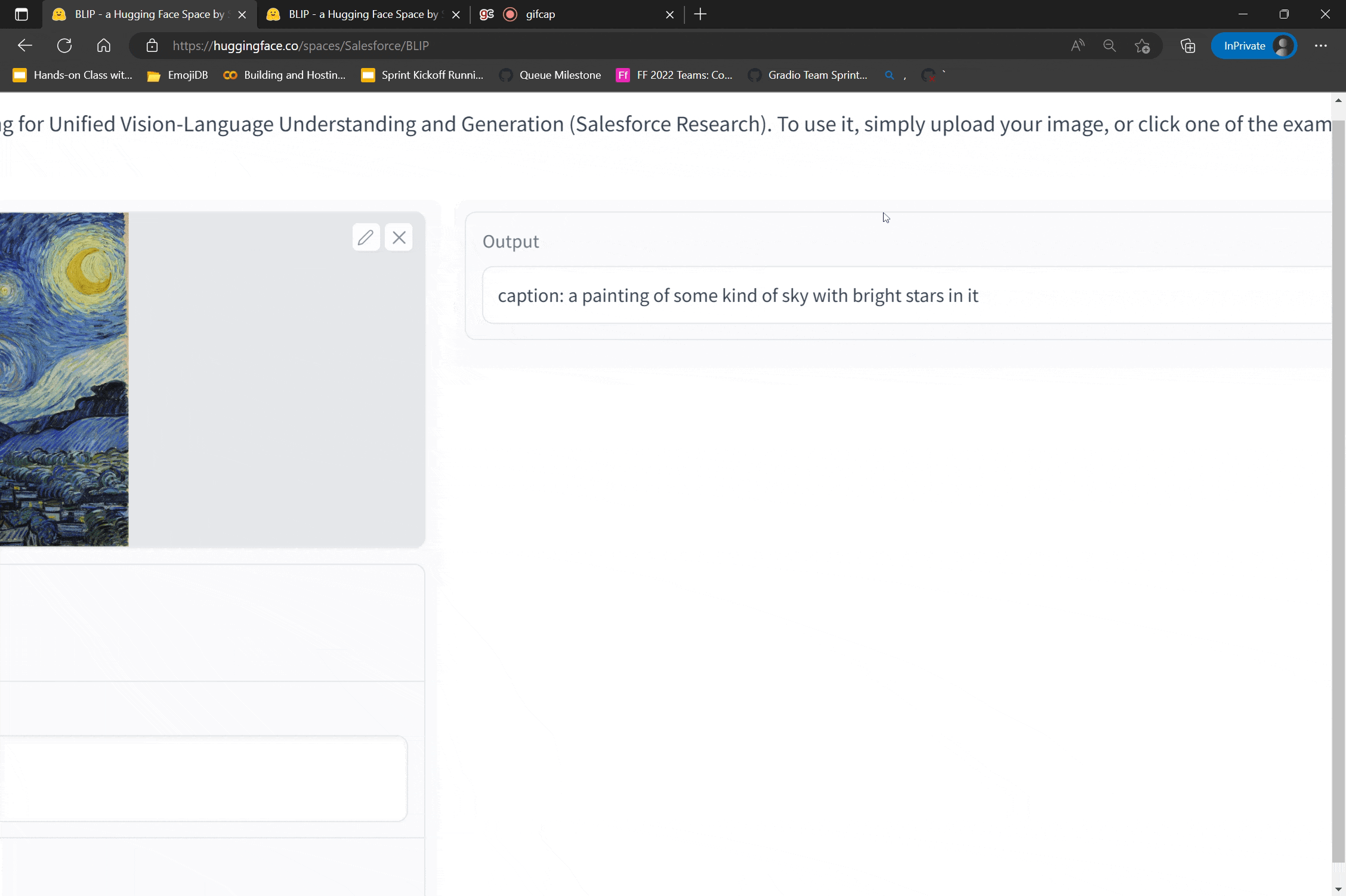
Since its launch in October 2021, Hugging Face Spaces has been used to build and share over 12,000 open-source machine learning demos crafted by the community. With Spaces, Hugging Face users can share, explore, discuss models, and build interactive applications that enable anyone with a browser to try them out without having to run any code. These demos are built using open-source tools such as the Gradio and Streamlit Python libraries, and leverage models and datasets available on the Hugging Face Hub.
Thanks to the latest arXiv integration, users can now find the most popular demos for a paper on its arXiv abstract page. For example, if you want to try out demos of the BERT language model, you can go to the BERT paper’s [arXiv page](https://arxiv.org/abs/1810.04805), and navigate to the demo tab. You will see more than 200 demos built by the open-source community -- some demos simply showcase the BERT model, while others showcase related applications that modify or use BERT as part of larger pipelines, such as the demo shown above.
Demos allow a much wider audience to explore machine learning as well as other fields in which computational models are built, such as biology, chemistry, astronomy, and economics. They help increase the awareness and understanding of how models work, amplify the visibility of researchers' work, and allow a more diverse audience to identify and debug biases and other issues. The demos increase the reproducibility of research by enabling others to explore the paper's results without having to write a single line of code! We are thrilled about this integration with arXiv and can’t wait to see how the research community will use it to improve communication, dissemination and interpretability.
| huggingface/blog/blob/main/arxiv.md |
@gradio/audio
## 0.6.3
### Fixes
- [#6766](https://github.com/gradio-app/gradio/pull/6766) [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144) - Improve source selection UX. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.6.2
### Fixes
- [#6799](https://github.com/gradio-app/gradio/pull/6799) [`c352811`](https://github.com/gradio-app/gradio/commit/c352811f76d4126613ece0a584f8c552fdd8d1f6) - Adds docstrings for `gr.WaveformOptions`, `gr.Brush`, and `gr.Eraser`, fixes examples for `ImageEditor`, and allows individual images to be used as the initial `value` for `ImageEditor`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.6.1
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.6.0
### Features
- [#6398](https://github.com/gradio-app/gradio/pull/6398) [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0) - Lite v4. Thanks [@whitphx](https://github.com/whitphx)!
- [#6745](https://github.com/gradio-app/gradio/pull/6745) [`3240d04`](https://github.com/gradio-app/gradio/commit/3240d042e907a3f2f679c2310c0dc6a688d2c07e) - Add `editable` parameter to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.5
### Fixes
- [#6551](https://github.com/gradio-app/gradio/pull/6551) [`8fc562a`](https://github.com/gradio-app/gradio/commit/8fc562a8abc0932fc312ac33bcc015f6cf2700f6) - Add `show_recording_waveform` to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.4
### Fixes
- [#6546](https://github.com/gradio-app/gradio/pull/6546) [`a424fdbb2`](https://github.com/gradio-app/gradio/commit/a424fdbb2389219661b9a73197f4cc095a08cfe9) - Ensure audio waveform `autoplay` updates. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.5.2
### Features
- [#6419](https://github.com/gradio-app/gradio/pull/6419) [`1959471a8`](https://github.com/gradio-app/gradio/commit/1959471a8d939275c7b9184913a5a6f92e567604) - Add download tests for audio/video. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6454](https://github.com/gradio-app/gradio/pull/6454) [`2777f326e`](https://github.com/gradio-app/gradio/commit/2777f326e595541fbec8ce14f56340b9e740f1da) - Ensure Audio ouput events are dispatched. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6254](https://github.com/gradio-app/gradio/pull/6254) [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a) - Add volume control to Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.1
### Fixes
- [#6382](https://github.com/gradio-app/gradio/pull/6382) [`2090aad73`](https://github.com/gradio-app/gradio/commit/2090aad731b186ef0a3f63ec2b4d1a6e3acb1754) - Move wavesurfer dep to js/audio. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.5.0
### Features
- [#6343](https://github.com/gradio-app/gradio/pull/6343) [`37dd335e5`](https://github.com/gradio-app/gradio/commit/37dd335e5f04a8e689dd7f23ae24ad1934ea08d8) - Fix audio streaming output issues in 4.0. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.4.3
### Fixes
- [#6317](https://github.com/gradio-app/gradio/pull/6317) [`19af2806a`](https://github.com/gradio-app/gradio/commit/19af2806a58419cc551d2d1d6d8987df0db91ccb) - Add autoplay to `waveform_settings`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6279](https://github.com/gradio-app/gradio/pull/6279) [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780) - Ensure source selection does not get hidden in overflow. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.4.2
### Fixes
- [#6234](https://github.com/gradio-app/gradio/pull/6234) [`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e) - Video/Audio fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.4.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Improve Audio Component. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.9
### Features
- [#6153](https://github.com/gradio-app/gradio/pull/6153) [`1162ed621`](https://github.com/gradio-app/gradio/commit/1162ed6217fe58d66a1923834c390150599ad81f) - Remove `show_edit_button` param in Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6124](https://github.com/gradio-app/gradio/pull/6124) [`a7435ba9e`](https://github.com/gradio-app/gradio/commit/a7435ba9e6f8b88a838e80893eb8fedf60ccda67) - Fix static issues with Lite on v4. Thanks [@aliabd](https://github.com/aliabd)!
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6142](https://github.com/gradio-app/gradio/pull/6142) [`103416d17`](https://github.com/gradio-app/gradio/commit/103416d17f021c82f5ff0583dcc2d80906ad279e) - JS READMEs and Storybook on Docs. Thanks [@aliabd](https://github.com/aliabd)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.8
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5966](https://github.com/gradio-app/gradio/pull/5966) [`9cad2127b`](https://github.com/gradio-app/gradio/commit/9cad2127b965023687470b3abfe620e188a9da6e) - Improve Audio Component. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.7
### Patch Changes
- Updated dependencies [[`174b73619`](https://github.com/gradio-app/gradio/commit/174b736194756e23f51bbaf6f850bac5f1ca95b5), [`5fbda0bd2`](https://github.com/gradio-app/gradio/commit/5fbda0bd2b2bbb2282249b8875d54acf87cd7e84)]:
- @gradio/[email protected]
## 0.4.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Fix deployed demos on v4 branch. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0
### Features
- [#5627](https://github.com/gradio-app/gradio/pull/5627) [`b67115e8e`](https://github.com/gradio-app/gradio/commit/b67115e8e6e489fffd5271ea830211863241ddc5) - Lite: Make the Examples component display media files using pseudo HTTP requests to the Wasm server. Thanks [@whitphx](https://github.com/whitphx)!
- [#5934](https://github.com/gradio-app/gradio/pull/5934) [`8d909624f`](https://github.com/gradio-app/gradio/commit/8d909624f61a49536e3c0f71cb2d9efe91216219) - Fix styling issues with Audio, Image and Video components. Thanks [@aliabd](https://github.com/aliabd)!
## 0.3.7
### Fixes
- [#5794](https://github.com/gradio-app/gradio/pull/5794) [`f096c3ae1`](https://github.com/gradio-app/gradio/commit/f096c3ae168c0df00f90fe131c1e48c572e0574b) - Throw helpful error when media devices are not found. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.6
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.5
### Patch Changes
- Updated dependencies [[`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423)]:
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.4
### Fixes
- [#5587](https://github.com/gradio-app/gradio/pull/5587) [`e0d61b8ba`](https://github.com/gradio-app/gradio/commit/e0d61b8baa0f6293f53b9bdb1647d42f9ae2583a) - Fix `.clear()` events for audio and image. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.3.3
### Fixes
- [#5459](https://github.com/gradio-app/gradio/pull/5459) [`bd2fda77`](https://github.com/gradio-app/gradio/commit/bd2fda77fc98d815f4fb670f535af453ebee9b80) - Dispatch `stop_recording` event in Audio. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.3.1
### Features
- [#5370](https://github.com/gradio-app/gradio/pull/5370) [`61803c65`](https://github.com/gradio-app/gradio/commit/61803c6545e73fce47e8740bd46721ab9bb0ba5c) - chore(deps): update dependency extendable-media-recorder to v9. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.3.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5264](https://github.com/gradio-app/gradio/pull/5264) [`46a2b600`](https://github.com/gradio-app/gradio/commit/46a2b600a7ff030a9ea1560b882b3bf3ad266bbc) - ensure translations for audio work correctly. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0
### Features
- [#5149](https://github.com/gradio-app/gradio/pull/5149) [`144df459`](https://github.com/gradio-app/gradio/commit/144df459a3b7895e524defcfc4c03fbb8b083aca) - Add `show_edit_button` param to `gr.Audio`. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5023](https://github.com/gradio-app/gradio/pull/5023) [`e6317d77`](https://github.com/gradio-app/gradio/commit/e6317d77f87d3dad638acca3dbc4a9228570e63c) - Update dependency extendable-media-recorder to v8. Thanks [@renovate](https://github.com/apps/renovate)!
- [#5085](https://github.com/gradio-app/gradio/pull/5085) [`13e47835`](https://github.com/gradio-app/gradio/commit/13e478353532c4af18cfa50772f8b6fb3c6c9818) - chore(deps): update dependency extendable-media-recorder to v8. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.1.0
### Features
- [#4993](https://github.com/gradio-app/gradio/pull/4993) [`dc07a9f9`](https://github.com/gradio-app/gradio/commit/dc07a9f947de44b419d8384987a02dcf94977851) - Bringing back the "Add download button for audio" PR by [@leuryr](https://github.com/leuryr). Thanks [@abidlabs](https://github.com/abidlabs)! | gradio-app/gradio/blob/main/js/audio/CHANGELOG.md |
--
title: "Illustrating Reinforcement Learning from Human Feedback (RLHF)"
thumbnail: /blog/assets/120_rlhf/thumbnail.png
authors:
- user: natolambert
- user: LouisCastricato
guest: true
- user: lvwerra
- user: Dahoas
guest: true
---
# Illustrating Reinforcement Learning from Human Feedback (RLHF)
_This article has been translated to Chinese [简体中文](https://huggingface.co/blog/zh/rlhf) and Vietnamese [đọc tiếng việt](https://trituenhantao.io/kien-thuc/minh-hoa-rlhf-vu-khi-dang-sau-gpt/)_.
Language models have shown impressive capabilities in the past few years by generating diverse and compelling text from human input prompts. However, what makes a "good" text is inherently hard to define as it is subjective and context dependent. There are many applications such as writing stories where you want creativity, pieces of informative text which should be truthful, or code snippets that we want to be executable.
Writing a loss function to capture these attributes seems intractable and most language models are still trained with a simple next token prediction loss (e.g. cross entropy). To compensate for the shortcomings of the loss itself people define metrics that are designed to better capture human preferences such as [BLEU](https://en.wikipedia.org/wiki/BLEU) or [ROUGE](https://en.wikipedia.org/wiki/ROUGE_(metric)). While being better suited than the loss function itself at measuring performance these metrics simply compare generated text to references with simple rules and are thus also limited. Wouldn't it be great if we use human feedback for generated text as a measure of performance or go even one step further and use that feedback as a loss to optimize the model? That's the idea of Reinforcement Learning from Human Feedback (RLHF); use methods from reinforcement learning to directly optimize a language model with human feedback. RLHF has enabled language models to begin to align a model trained on a general corpus of text data to that of complex human values.
RLHF's most recent success was its use in [ChatGPT](https://openai.com/blog/chatgpt/). Given ChatGPT's impressive abilities, we asked it to explain RLHF for us:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/chatgpt-explains.png" width="500" />
</p>
It does surprisingly well, but doesn't quite cover everything. We'll fill in those gaps!
# RLHF: Let’s take it step by step
Reinforcement learning from Human Feedback (also referenced as RL from human preferences) is a challenging concept because it involves a multiple-model training process and different stages of deployment. In this blog post, we’ll break down the training process into three core steps:
1. Pretraining a language model (LM),
2. gathering data and training a reward model, and
3. fine-tuning the LM with reinforcement learning.
To start, we'll look at how language models are pretrained.
### Pretraining language models
As a starting point RLHF use a language model that has already been pretrained with the classical pretraining objectives (see this [blog post](https://huggingface.co/blog/how-to-train) for more details). OpenAI used a smaller version of GPT-3 for its first popular RLHF model, [InstructGPT](https://openai.com/blog/instruction-following/). In their shared papers, Anthropic used transformer models from 10 million to 52 billion parameters trained for this task. DeepMind has documented using up to their 280 billion parameter model [Gopher](https://arxiv.org/abs/2112.11446). It is likely that all these companies use much larger models in their RLHF-powered products.
This initial model *can* also be fine-tuned on additional text or conditions, but does not necessarily need to be. For example, OpenAI fine-tuned on human-generated text that was “preferable” and Anthropic generated their initial LM for RLHF by distilling an original LM on context clues for their “helpful, honest, and harmless” criteria. These are both sources of what we refer to as expensive, *augmented* data, but it is not a required technique to understand RLHF. Core to starting the RLHF process is having a _model that responds well to diverse instructions_.
In general, there is not a clear answer on “which model” is the best for the starting point of RLHF. This will be a common theme in this blog – the design space of options in RLHF training are not thoroughly explored.
Next, with a language model, one needs to generate data to train a **reward model**, which is how human preferences are integrated into the system.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/pretraining.png" width="500" />
</p>
### Reward model training
Generating a reward model (RM, also referred to as a preference model) calibrated with human preferences is where the relatively new research in RLHF begins. The underlying goal is to get a model or system that takes in a sequence of text, and returns a scalar reward which should numerically represent the human preference. The system can be an end-to-end LM, or a modular system outputting a reward (e.g. a model ranks outputs, and the ranking is converted to reward). The output being a **scalar** **reward** is crucial for existing RL algorithms being integrated seamlessly later in the RLHF process.
These LMs for reward modeling can be both another fine-tuned LM or a LM trained from scratch on the preference data. For example, Anthropic has used a specialized method of fine-tuning to initialize these models after pretraining (preference model pretraining, PMP) because they found it to be more sample efficient than fine-tuning, but no one base model is considered the clear best choice for reward models.
The training dataset of prompt-generation pairs for the RM is generated by sampling a set of prompts from a predefined dataset (Anthropic’s data generated primarily with a chat tool on Amazon Mechanical Turk is [available](https://huggingface.co/datasets/Anthropic/hh-rlhf) on the Hub, and OpenAI used prompts submitted by users to the GPT API). The prompts are passed through the initial language model to generate new text.
Human annotators are used to rank the generated text outputs from the LM. One may initially think that humans should apply a scalar score directly to each piece of text in order to generate a reward model, but this is difficult to do in practice. The differing values of humans cause these scores to be uncalibrated and noisy. Instead, rankings are used to compare the outputs of multiple models and create a much better regularized dataset.
There are multiple methods for ranking the text. One method that has been successful is to have users compare generated text from two language models conditioned on the same prompt. By comparing model outputs in head-to-head matchups, an [Elo](https://en.wikipedia.org/wiki/Elo_rating_system) system can be used to generate a ranking of the models and outputs relative to each-other. These different methods of ranking are normalized into a scalar reward signal for training.
An interesting artifact of this process is that the successful RLHF systems to date have used reward language models with varying sizes relative to the text generation (e.g. OpenAI 175B LM, 6B reward model, Anthropic used LM and reward models from 10B to 52B, DeepMind uses 70B Chinchilla models for both LM and reward). An intuition would be that these preference models need to have similar capacity to understand the text given to them as a model would need in order to generate said text.
At this point in the RLHF system, we have an initial language model that can be used to generate text and a preference model that takes in any text and assigns it a score of how well humans perceive it. Next, we use **reinforcement learning (RL)** to optimize the original language model with respect to the reward model.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/reward-model.png" width="600" />
</p>
### Fine-tuning with RL
Training a language model with reinforcement learning was, for a long time, something that people would have thought as impossible both for engineering and algorithmic reasons.
What multiple organizations seem to have gotten to work is fine-tuning some or all of the parameters of a **copy of the initial LM** with a policy-gradient RL algorithm, Proximal Policy Optimization (PPO).
Some parameters of the LM are frozen because fine-tuning an entire 10B or 100B+ parameter model is prohibitively expensive (for more, see Low-Rank Adaptation ([LoRA](https://arxiv.org/abs/2106.09685)) for LMs or the [Sparrow](https://arxiv.org/abs/2209.14375) LM from DeepMind) -- depending on the scale of the model and infrastructure being used. The exact dynamics of how many parameters to freeze, or not, is considered an open research problem.
PPO has been around for a relatively long time – there are [tons](https://spinningup.openai.com/en/latest/algorithms/ppo.html) of [guides](https://huggingface.co/blog/deep-rl-ppo) on how it works. The relative maturity of this method made it a favorable choice for scaling up to the new application of distributed training for RLHF. It turns out that many of the core RL advancements to do RLHF have been figuring out how to update such a large model with a familiar algorithm (more on that later).
Let's first formulate this fine-tuning task as a RL problem. First, the **policy** is a language model that takes in a prompt and returns a sequence of text (or just probability distributions over text). The **action space** of this policy is all the tokens corresponding to the vocabulary of the language model (often on the order of 50k tokens) and the **observation space** is the distribution of possible input token sequences, which is also quite large given previous uses of RL (the dimension is approximately the size of vocabulary ^ length of the input token sequence). The **reward function** is a combination of the preference model and a constraint on policy shift.
The reward function is where the system combines all of the models we have discussed into one RLHF process. Given a prompt, *x*, from the dataset, the text *y* is generated by the current iteration of the fine-tuned policy. Concatenated with the original prompt, that text is passed to the preference model, which returns a scalar notion of “preferability”, \\( r_\theta \\). In addition, per-token probability distributions from the RL policy are compared to the ones from the initial model to compute a penalty on the difference between them. In multiple papers from OpenAI, Anthropic, and DeepMind, this penalty has been designed as a scaled version of the Kullback–Leibler [(KL) divergence](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) between these sequences of distributions over tokens, \\( r_\text{KL} \\). The KL divergence term penalizes the RL policy from moving substantially away from the initial pretrained model with each training batch, which can be useful to make sure the model outputs reasonably coherent text snippets. Without this penalty the optimization can start to generate text that is gibberish but fools the reward model to give a high reward. In practice, the KL divergence is approximated via sampling from both distributions (explained by John Schulman [here](http://joschu.net/blog/kl-approx.html)). The final reward sent to the RL update rule is \\( r = r_\theta - \lambda r_\text{KL} \\).
Some RLHF systems have added additional terms to the reward function. For example, OpenAI experimented successfully on InstructGPT by mixing in additional pre-training gradients (from the human annotation set) into the update rule for PPO. It is likely as RLHF is further investigated, the formulation of this reward function will continue to evolve.
Finally, the **update rule** is the parameter update from PPO that maximizes the reward metrics in the current batch of data (PPO is on-policy, which means the parameters are only updated with the current batch of prompt-generation pairs). PPO is a trust region optimization algorithm that uses constraints on the gradient to ensure the update step does not destabilize the learning process. DeepMind used a similar reward setup for Gopher but used [synchronous advantage actor-critic](http://proceedings.mlr.press/v48/mniha16.html?ref=https://githubhelp.com) (A2C) to optimize the gradients, which is notably different but has not been reproduced externally.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/rlhf.png" width="650" />
</p>
_Technical detail note: The above diagram makes it look like both models generate different responses for the same prompt, but what really happens is that the RL policy generates text, and that text is fed into the initial model to produce its relative probabilities for the KL penalty. This initial model is untouched by gradient updates during training_.
Optionally, RLHF can continue from this point by iteratively updating the reward model and the policy together. As the RL policy updates, users can continue ranking these outputs versus the model's earlier versions. Most papers have yet to discuss implementing this operation, as the deployment mode needed to collect this type of data only works for dialogue agents with access to an engaged user base. Anthropic discusses this option as *Iterated Online RLHF* (see the original [paper](https://arxiv.org/abs/2204.05862)), where iterations of the policy are included in the ELO ranking system across models. This introduces complex dynamics of the policy and reward model evolving, which represents a complex and open research question.
# Open-source tools for RLHF
The first [code](https://github.com/openai/lm-human-preferences) released to perform RLHF on LMs was from OpenAI in TensorFlow in 2019.
Today, there are already a few active repositories for RLHF in PyTorch that grew out of this. The primary repositories are Transformers Reinforcement Learning ([TRL](https://github.com/lvwerra/trl)), [TRLX](https://github.com/CarperAI/trlx) which originated as a fork of TRL, and Reinforcement Learning for Language models ([RL4LMs](https://github.com/allenai/RL4LMs)).
TRL is designed to fine-tune pretrained LMs in the Hugging Face ecosystem with PPO. TRLX is an expanded fork of TRL built by [CarperAI](https://carper.ai/) to handle larger models for online and offline training. At the moment, TRLX has an API capable of production-ready RLHF with PPO and Implicit Language Q-Learning [ILQL](https://sea-snell.github.io/ILQL_site/) at the scales required for LLM deployment (e.g. 33 billion parameters). Future versions of TRLX will allow for language models up to 200B parameters. As such, interfacing with TRLX is optimized for machine learning engineers with experience at this scale.
[RL4LMs](https://github.com/allenai/RL4LMs) offers building blocks for fine-tuning and evaluating LLMs with a wide variety of RL algorithms (PPO, NLPO, A2C and TRPO), reward functions and metrics. Moreover, the library is easily customizable, which allows training of any encoder-decoder or encoder transformer-based LM on any arbitrary user-specified reward function. Notably, it is well-tested and benchmarked on a broad range of tasks in [recent work](https://arxiv.org/abs/2210.01241) amounting up to 2000 experiments highlighting several practical insights on data budget comparison (expert demonstrations vs. reward modeling), handling reward hacking and training instabilities, etc.
RL4LMs current plans include distributed training of larger models and new RL algorithms.
Both TRLX and RL4LMs are under heavy further development, so expect more features beyond these soon.
There is a large [dataset](https://huggingface.co/datasets/Anthropic/hh-rlhf) created by Anthropic available on the Hub.
# What’s next for RLHF?
While these techniques are extremely promising and impactful and have caught the attention of the biggest research labs in AI, there are still clear limitations. The models, while better, can still output harmful or factually inaccurate text without any uncertainty. This imperfection represents a long-term challenge and motivation for RLHF – operating in an inherently human problem domain means there will never be a clear final line to cross for the model to be labeled as *complete*.
When deploying a system using RLHF, gathering the human preference data is quite expensive due to the direct integration of other human workers outside the training loop. RLHF performance is only as good as the quality of its human annotations, which takes on two varieties: human-generated text, such as fine-tuning the initial LM in InstructGPT, and labels of human preferences between model outputs.
Generating well-written human text answering specific prompts is very costly, as it often requires hiring part-time staff (rather than being able to rely on product users or crowdsourcing). Thankfully, the scale of data used in training the reward model for most applications of RLHF (~50k labeled preference samples) is not as expensive. However, it is still a higher cost than academic labs would likely be able to afford. Currently, there only exists one large-scale dataset for RLHF on a general language model (from [Anthropic](https://huggingface.co/datasets/Anthropic/hh-rlhf)) and a couple of smaller-scale task-specific datasets (such as summarization data from [OpenAI](https://github.com/openai/summarize-from-feedback)). The second challenge of data for RLHF is that human annotators can often disagree, adding a substantial potential variance to the training data without ground truth.
With these limitations, huge swaths of unexplored design options could still enable RLHF to take substantial strides. Many of these fall within the domain of improving the RL optimizer. PPO is a relatively old algorithm, but there are no structural reasons that other algorithms could not offer benefits and permutations on the existing RLHF workflow. One large cost of the feedback portion of fine-tuning the LM policy is that every generated piece of text from the policy needs to be evaluated on the reward model (as it acts like part of the environment in the standard RL framework). To avoid these costly forward passes of a large model, offline RL could be used as a policy optimizer. Recently, new algorithms have emerged, such as [implicit language Q-learning](https://arxiv.org/abs/2206.11871) (ILQL) [[Talk](https://youtu.be/fGq4np3brbs) on ILQL at CarperAI], that fit particularly well with this type of optimization. Other core trade-offs in the RL process, like exploration-exploitation balance, have also not been documented. Exploring these directions would at least develop a substantial understanding of how RLHF functions and, if not, provide improved performance.
We hosted a lecture on Tuesday 13 December 2022 that expanded on this post; you can watch it [here](https://www.youtube.com/watch?v=2MBJOuVq380&feature=youtu.be)!
### Further reading
Here is a list of the most prevalent papers on RLHF to date. The field was recently popularized with the emergence of DeepRL (around 2017) and has grown into a broader study of the applications of LLMs from many large technology companies.
Here are some papers on RLHF that pre-date the LM focus:
- [TAMER: Training an Agent Manually via Evaluative Reinforcement](https://www.cs.utexas.edu/~pstone/Papers/bib2html-links/ICDL08-knox.pdf) (Knox and Stone 2008): Proposed a learned agent where humans provided scores on the actions taken iteratively to learn a reward model.
- [Interactive Learning from Policy-Dependent Human Feedback](http://proceedings.mlr.press/v70/macglashan17a/macglashan17a.pdf) (MacGlashan et al. 2017): Proposed an actor-critic algorithm, COACH, where human feedback (both positive and negative) is used to tune the advantage function.
- [Deep Reinforcement Learning from Human Preferences](https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html) (Christiano et al. 2017): RLHF applied on preferences between Atari trajectories.
- [Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces](https://ojs.aaai.org/index.php/AAAI/article/view/11485) (Warnell et al. 2018): Extends the TAMER framework where a deep neural network is used to model the reward prediction.
- [A Survey of Preference-based Reinforcement Learning Methods](https://www.jmlr.org/papers/volume18/16-634/16-634.pdf) (Wirth et al. 2017): Summarizes efforts above with many, many more references.
And here is a snapshot of the growing set of "key" papers that show RLHF's performance for LMs:
- [Fine-Tuning Language Models from Human Preferences](https://arxiv.org/abs/1909.08593) (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
- [Learning to summarize with human feedback](https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html) (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, [Recursively Summarizing Books with Human Feedback](https://arxiv.org/abs/2109.10862) (OpenAI Alignment Team 2021), follow on work summarizing books.
- [WebGPT: Browser-assisted question-answering with human feedback](https://arxiv.org/abs/2112.09332) (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
- InstructGPT: [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155) (OpenAI Alignment Team 2022): RLHF applied to a general language model [[Blog post](https://openai.com/blog/instruction-following/) on InstructGPT].
- GopherCite: [Teaching language models to support answers with verified quotes](https://www.deepmind.com/publications/gophercite-teaching-language-models-to-support-answers-with-verified-quotes) (Menick et al. 2022): Train a LM with RLHF to return answers with specific citations.
- Sparrow: [Improving alignment of dialogue agents via targeted human judgements](https://arxiv.org/abs/2209.14375) (Glaese et al. 2022): Fine-tuning a dialogue agent with RLHF
- [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/) (OpenAI 2022): Training a LM with RLHF for suitable use as an all-purpose chat bot.
- [Scaling Laws for Reward Model Overoptimization](https://arxiv.org/abs/2210.10760) (Gao et al. 2022): studies the scaling properties of the learned preference model in RLHF.
- [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) (Anthropic, 2022): A detailed documentation of training a LM assistant with RLHF.
- [Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned](https://arxiv.org/abs/2209.07858) (Ganguli et al. 2022): A detailed documentation of efforts to “discover, measure, and attempt to reduce [language models] potentially harmful outputs.”
- [Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning](https://arxiv.org/abs/2208.02294) (Cohen at al. 2022): Using RL to enhance the conversational skill of an open-ended dialogue agent.
- [Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization](https://arxiv.org/abs/2210.01241) (Ramamurthy and Ammanabrolu et al. 2022): Discusses the design space of open-source tools in RLHF and proposes a new algorithm NLPO (Natural Language Policy Optimization) as an alternative to PPO.
- [Llama 2](https://arxiv.org/abs/2307.09288) (Touvron et al. 2023): Impactful open-access model with substantial RLHF details.
The field is the convergence of multiple fields, so you can also find resources in other areas:
* Continual learning of instructions ([Kojima et al. 2021](https://arxiv.org/abs/2108.04812), [Suhr and Artzi 2022](https://arxiv.org/abs/2212.09710)) or bandit learning from user feedback ([Sokolov et al. 2016](https://arxiv.org/abs/1601.04468), [Gao et al. 2022](https://arxiv.org/abs/2203.10079))
* Earlier history on using other RL algorithms for text generation (not all with human preferences), such as with recurrent neural networks ([Ranzato et al. 2015](https://arxiv.org/abs/1511.06732)), an actor-critic algorithm for text prediction ([Bahdanau et al. 2016](https://arxiv.org/abs/1607.07086)), or an early work adding human preferences to this framework ([Nguyen et al. 2017](https://arxiv.org/abs/1707.07402)).
**Citation:**
If you found this useful for your academic work, please consider citing our work, in text:
```
Lambert, et al., "Illustrating Reinforcement Learning from Human Feedback (RLHF)", Hugging Face Blog, 2022.
```
BibTeX citation:
```
@article{lambert2022illustrating,
author = {Lambert, Nathan and Castricato, Louis and von Werra, Leandro and Havrilla, Alex},
title = {Illustrating Reinforcement Learning from Human Feedback (RLHF)},
journal = {Hugging Face Blog},
year = {2022},
note = {https://huggingface.co/blog/rlhf},
}
```
*Thanks to [Robert Kirk](https://robertkirk.github.io/) for fixing some factual errors regarding specific implementations of RLHF. Thanks to Stas Bekman for fixing some typos or confusing phrases Thanks to [Peter Stone](https://www.cs.utexas.edu/~pstone/), [Khanh X. Nguyen](https://machineslearner.com/) and [Yoav Artzi](https://yoavartzi.com/) for helping expand the related works further into history. Thanks to [Igor Kotenkov](https://www.linkedin.com/in/seeall/) for pointing out a technical error in the KL-penalty term of the RLHF procedure, its diagram, and textual description.* | huggingface/blog/blob/main/rlhf.md |
Gradio Demo: waveform
```
!pip install -q gradio
```
```
import gradio as gr
import random
COLORS = [
["#ff0000", "#00ff00"],
["#00ff00", "#0000ff"],
["#0000ff", "#ff0000"],
]
def audio_waveform(audio, image):
return (
audio,
gr.make_waveform(audio),
gr.make_waveform(audio, animate=True),
gr.make_waveform(audio, bg_image=image, bars_color=random.choice(COLORS)),
)
gr.Interface(
audio_waveform,
inputs=[gr.Audio(), gr.Image(type="filepath")],
outputs=[
gr.Audio(),
gr.Video(),
gr.Video(),
gr.Video(),
],
).launch()
```
| gradio-app/gradio/blob/main/demo/waveform/run.ipynb |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.