
hexsha
stringlengths 40
40
| size
int64 1
1.03M
| ext
stringclasses 10
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
239
| max_stars_repo_name
stringlengths 5
130
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
10
| max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
239
| max_issues_repo_name
stringlengths 5
130
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
10
| max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
239
| max_forks_repo_name
stringlengths 5
130
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
10
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 1
1.03M
| avg_line_length
float64 1
958k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a1f80a558ba7a87ac89b838f3c88c7881e9ecf2 | 2,594 | py | Python | tcconfig/_capabilities.py | phljcb/tcconfig | 78d6adb35f08201bac589d6b16f22b73d4cb951d | [
"MIT"
] | 1 | 2020-07-17T10:00:59.000Z | 2020-07-17T10:00:59.000Z | tcconfig/_capabilities.py | daifeilail/tcconfig | ef85bc4347daf2367a68aa59aa3407789e3a89bf | [
"MIT"
] | null | null | null | tcconfig/_capabilities.py | daifeilail/tcconfig | ef85bc4347daf2367a68aa59aa3407789e3a89bf | [
"MIT"
] | null | null | null | # encoding: utf-8
"""
.. codeauthor:: Tsuyoshi Hombashi <>
"""
from __future__ import absolute_import, unicode_literals
import errno
import os
import re
import sys
import subprocrunner as spr
from ._common import find_bin_path
from ._logger import logger
def get_required_capabilities(command):
required_capabilities_map = {
"tc": ["cap_net_admin"],
"ip": ["cap_net_raw", "cap_net_admin"],
"iptables": ["cap_net_raw", "cap_net_admin"],
}
return required_capabilities_map[command]
def get_permission_error_message(command):
PERMISSION_ERROR_MSG_FORMAT = "\n".join(
[
"Permission denied: you must be root or set Linux capabilities to execute the command.",
" How to setup Linux capabilities for the {command:s} command:",
" $ sudo setcap {capabilities:s}+ep {bin_path:s}",
]
)
return PERMISSION_ERROR_MSG_FORMAT.format(
command=command,
capabilities=",".join(get_required_capabilities(command)),
bin_path=find_bin_path(command),
)
def _has_capabilies(bin_path, capabilities):
getcap_bin_path = find_bin_path("getcap")
if not getcap_bin_path:
logger.error("command not found: getcap")
return False
bin_path = os.path.realpath(bin_path)
proc = spr.SubprocessRunner("{:s} {:s}".format(getcap_bin_path, bin_path))
if proc.run() != 0:
logger.error(proc.stderr)
sys.exit(proc.returncode)
getcap_output = proc.stdout
has_capabilies = True
for capability in capabilities:
if re.search(capability, getcap_output):
logger.debug("{:s} has {:s} capability".format(bin_path, capability))
else:
logger.debug("{:s} has no {:s} capability".format(bin_path, capability))
has_capabilies = False
capability = "+ep"
if re.search(re.escape(capability), getcap_output):
logger.debug("{:s} has {:s} capability".format(bin_path, capability))
else:
logger.debug("{:s} has no {:s} capability".format(bin_path, capability))
has_capabilies = False
return has_capabilies
def has_execution_authority(command):
from ._common import check_command_installation
check_command_installation(command)
if os.getuid() == 0:
return True
return _has_capabilies(find_bin_path(command), get_required_capabilities(command))
def check_execution_authority(command):
if has_execution_authority(command):
return
logger.error(get_permission_error_message(command))
sys.exit(errno.EPERM)
| 27.305263 | 100 | 0.677718 |
4a1f80c230fa3e7c278925aca58938fc9ca5b898 | 8,197 | py | Python | lib/gui/groupeditor.py | frontinc-ayau/dsce | 39051752f8f2e75f912903b0b07f7ad0aba680d8 | [
"Apache-2.0"
] | null | null | null | lib/gui/groupeditor.py | frontinc-ayau/dsce | 39051752f8f2e75f912903b0b07f7ad0aba680d8 | [
"Apache-2.0"
] | null | null | null | lib/gui/groupeditor.py | frontinc-ayau/dsce | 39051752f8f2e75f912903b0b07f7ad0aba680d8 | [
"Apache-2.0"
] | null | null | null | # This file is part of the DomainSharedContactsEditor (DSCE) application.
#
# DSCE is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# DSCE is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with DSCE. If not, see <http://www.gnu.org/licenses/>.
#
# Copyright (c) 2012 Klaus Melcher ([email protected])
import wx
import xrcl
import logging as log
import sys
import domaindata
import observer
from observer import pmsg
# list control configuration
COLIDX_NAME = 0
COLIDX_TYPE = 1
LABEL_NAME = "Group Name"
LABEL_TYPE = "Editable"
TYPE_TXT_PRI = "Yes"
TYPE_TXT_SYS = "No"
LABEL_ADD = "Add"
LABEL_UPD = "Update"
LABEL_DEL = "Delete"
class GroupName(object):
def __init__(self, name):
self.current = name
self.previous = None
self.flag = None # pmsg.GROUP_UPDATED, pmsg.GROUP_ADDED, pmsg.GROUP_DELETED or None
def update(self, new_name):
if self.current == new_name:
return
if not self.flag:
self.previous = self.current
self.current = new_name
self.flag = pmsg.GROUP_UPDATED
else:
if self.previous == new_name: # means step back to previous name
self.current = self.previous
self.previous = None
if self.flag != pmsg.GROUP_ADDED:
self.clearFlag()
else:
self.previous = self.current
self.current = new_name
if self.flag != pmsg.GROUP_ADDED: # added should remain added
self.flag = pmsg.GROUP_UPDATED
def delete(self):
self.flag = pmsg.GROUP_DELETED
def new(self):
self.flag = pmsg.GROUP_ADDED
def clearFlag(self):
self.flag = None
class Groups(object):
def __init__(self, names):
self.groups = []
if type(names) != list:
raise Exception("Groups needs a list to initialize!")
for n in names:
if type(n) == str or type(n) == unicode:
self.groups.append(GroupName(n))
else:
raise Exception("Cannot initialize GroupName from type %s" % str(type(n)))
def groupExists(self, name):
for g in self.groups:
if g.current == name:
return True
return False
def add(self, name):
if self.groupExists(name):
raise Exception("Group %s already exists" % name)
else:
g=GroupName(name)
g.new()
self.groups.append(g)
def delete(self, name):
for g in self.groups:
if g.current == name:
g.delete()
return
raise Exception("Cannot delete private group '%s' because it does not exist" % name)
def update(self, old, new):
for g in self.groups:
if g.current == old:
g.update(new)
def get(self):
return self.groups
def publishChanges(self):
for g in self.groups:
if g.flag:
observer.send_message(g.flag, data=g)
g.clearFlag()
log.debug("Published %s %s" % (str(g.flag), g.current))
class GroupEditDialog(wx.Dialog):
def __init__(self, parent, ID=-1, title="Manage Groups"):
wx.Dialog.__init__(self, parent, ID, title,
style=wx.DEFAULT_DIALOG_STYLE
#| wx.RESIZE_BORDER
)
self.idx = -1
# s = system groups, p = private groups
s, p = domaindata.get_group_names()
self.sg = Groups(s)
self.pg = Groups(p)
self.panel = xrcl.loadPanel(self, "groupeditor.xrc", "groupeditor")
self.glc = xrcl.getControl(self.panel, "grplstctrl")
self.gnc = xrcl.getControl(self.panel, "grpname")
self.uab = xrcl.getControl(self.panel, "upaddbutton")
self.uab.SetLabel(LABEL_ADD)
self.deb = xrcl.getControl(self.panel, "delbutton")
self.deb.SetLabel(LABEL_DEL)
self.populateForm()
space = 5
self.topSizer = wx.BoxSizer(wx.VERTICAL)
self.topSizer.Add(self.panel, 1, wx.EXPAND, space)
self.SetSizer(self.topSizer)
self.topSizer.Fit(self)
self.binEvents()
self.ShowModal()
def populateForm(self):
"""Fills tha form with existing data if any."""
self.glc.InsertColumn(COLIDX_NAME, LABEL_NAME)
self.glc.InsertColumn(COLIDX_TYPE, LABEL_TYPE)
for g in self.sg.get():
self.appendGroup(g.current, TYPE_TXT_SYS)
for g in self.pg.get():
self.appendGroup(g.current, TYPE_TXT_PRI)
def binEvents(self):
xrcl.getControl(self.panel, "wxID_OK").Bind(wx.EVT_BUTTON, self.onOk)
self.Bind(wx.EVT_LIST_ITEM_SELECTED, self.onItemSelected, self.glc)
self.Bind(wx.EVT_LIST_ITEM_DESELECTED, self.onItemDeselected, self.glc)
self.Bind(wx.EVT_BUTTON, self.onAddOrUpdate, self.uab)
self.Bind(wx.EVT_BUTTON, self.onDelete, self.deb)
def isSystemGroup(self, idx):
if idx < 0 or (self.glc.GetItem(idx, COLIDX_TYPE).GetText() != TYPE_TXT_SYS):
return False
else:
return True
def onItemSelected(self, event):
self.idx = event.GetIndex()
self._setDelButton()
if self.isSystemGroup(self.idx) == False:
self.gnc.SetValue(self.glc.GetItem(self.idx, COLIDX_NAME).GetText())
self._setUAButton()
def clearForm(self):
self.idx = -1
self.gnc.SetValue("")
self._setDelButton()
self._setUAButton()
def onDelete(self, event):
if self.idx >= 0:
name = self.gnc.GetValue().strip()
try:
self.pg.delete(name)
self.glc.DeleteItem(self.idx)
except Exception, e:
observer.send_message(pmsg.ALERT, data=str(e))
self.clearForm()
def onAddOrUpdate(self, event):
name = self.gnc.GetValue().strip()
if len(name) == 0: return
if self.idx < 0:
try:
self.pg.add(name)
self.appendGroup( name, TYPE_TXT_PRI)
except Exception, e:
observer.send_message(pmsg.ALERT, data=str(e))
self.clearForm()
else:
self.updateGroup( self.idx, name, TYPE_TXT_PRI)
def onItemDeselected(self, event):
self.clearForm()
def _setDelButton(self):
if self.idx >= 0 and self.isSystemGroup(self.idx) == False:
self.deb.Enable()
else:
self.deb.Disable()
def _setUAButton(self):
if self.idx < 0:
self.uab.SetLabel(LABEL_ADD)
else:
self.uab.SetLabel(LABEL_UPD)
def saveChanges(self):
self.pg.publishChanges()
def appendGroup(self, name, gtype=TYPE_TXT_PRI):
idx = self.glc.InsertStringItem(sys.maxint, name)
self.glc.SetStringItem(idx, COLIDX_TYPE, gtype)
def updateGroup(self, idx, name, gtype=TYPE_TXT_PRI):
oldname = self.glc.GetItem(idx, COLIDX_NAME).GetText()
self.glc.SetStringItem(idx, COLIDX_NAME, name)
self.glc.SetStringItem(idx, COLIDX_TYPE, gtype)
self.pg.update(oldname, name)
def onOk(self, event):
log.debug("Save changes in groups")
self.saveChanges()
self.Destroy()
| 30.700375 | 93 | 0.570575 |
4a1f827820d56563096365b83cc2f945495efd7d | 1,898 | py | Python | image/download/direct_io.py | hybrid-storage-dev/cinder-fs-111t-hybrid-cherry | 86eb7e8b71c26bc39164fa18a9faa1065e4c1fc1 | [
"Apache-2.0"
] | null | null | null | image/download/direct_io.py | hybrid-storage-dev/cinder-fs-111t-hybrid-cherry | 86eb7e8b71c26bc39164fa18a9faa1065e4c1fc1 | [
"Apache-2.0"
] | null | null | null | image/download/direct_io.py | hybrid-storage-dev/cinder-fs-111t-hybrid-cherry | 86eb7e8b71c26bc39164fa18a9faa1065e4c1fc1 | [
"Apache-2.0"
] | null | null | null | import mmap
import os
import time
import hashlib
from cinder.i18n import _
import logging
LOG = logging.getLogger(__name__)
def write(filename, data, chunk_size=1024 * 1024):
"""
Write the data into a file in the way of DirectIO.
filename : destination file name
data : data to write to filename, must be chunkable
chunk_size: size of data returned by data each time. must be several times of 4K
"""
LOG.debug(_('start write file %(dst_file)s using direct io mode') %
{'dst_file': filename})
try:
fp = os.open(filename, os.O_WRONLY|os.O_DIRECT|os.O_CREAT)
m = mmap.mmap(-1, chunk_size)
# Firstly, write most chunks with direct IO method.
tail = ''
size = 0
for chunk in data:
c_size = len(chunk)
free_size = chunk_size - size % chunk_size
size += c_size
if c_size < free_size:
m.write(chunk)
else:
m.write(chunk[:free_size])
writed_size = free_size
os.write(fp, m)
m.seek(0)
while (c_size - writed_size) / chunk_size:
m.write(chunk[writed_size:writed_size + chunk_size])
os.write(fp, m)
m.seek(0)
writed_size += chunk_size
m.write(chunk[writed_size:])
#sleep to let in other green-thread tasks
time.sleep(0)
finally:
m.seek(0)
tail = m.read(size % chunk_size)
if 'fp' in locals():
os.close(fp)
if 'm' in locals():
m.close()
# Then, add the last chunk with ordinary method.
if tail:
with open(filename, "a") as f:
f.write(tail)
LOG.debug('write file :%s successfully, the size is :%s' % (filename, size))
return size
| 31.114754 | 84 | 0.546365 |
4a1f84fe437b343a01966c6b03a7fac26569377f | 234 | py | Python | Chapter10/example1.py | KrisNguyen135/Advanced-Python-Programming-Second-Edition | e5d473e3efc5f6590028cb3f318e1f4aeb0aadd1 | [
"MIT"
] | null | null | null | Chapter10/example1.py | KrisNguyen135/Advanced-Python-Programming-Second-Edition | e5d473e3efc5f6590028cb3f318e1f4aeb0aadd1 | [
"MIT"
] | null | null | null | Chapter10/example1.py | KrisNguyen135/Advanced-Python-Programming-Second-Edition | e5d473e3efc5f6590028cb3f318e1f4aeb0aadd1 | [
"MIT"
] | null | null | null | import cv2
im = cv2.imread('input/ship.jpg')
cv2.imshow('Test', im)
cv2.waitKey(0) # press any key to move forward here
print(im)
print('Type:', type(im))
print('Shape:', im.shape)
print('Top-left pixel:', im[0, 0])
print('Done.')
| 18 | 51 | 0.662393 |
4a1f85e9c8ba56428e8ee4d452fce326b7b7aa5c | 4,604 | py | Python | examples/simpleflight.py | team-204/uas-control | 0820c95fe22af0507df398c71e61a6ca49a5a490 | [
"MIT"
] | 1 | 2019-03-17T12:33:21.000Z | 2019-03-17T12:33:21.000Z | examples/simpleflight.py | team-204/uas-control | 0820c95fe22af0507df398c71e61a6ca49a5a490 | [
"MIT"
] | 4 | 2018-03-12T03:39:37.000Z | 2018-03-27T22:08:13.000Z | examples/simpleflight.py | team-204/uas-control | 0820c95fe22af0507df398c71e61a6ca49a5a490 | [
"MIT"
] | 5 | 2018-02-27T17:55:20.000Z | 2019-03-09T15:36:07.000Z | """Flies the drone in a "+" shape formation.
Uses the ttyO4 connection (UART4) on the beaglebone. Installing the appropriate
service file (also located in examples) allows for this to start on boot. A 1
minute delay exists in order to allow the user to setup the and secure the
device before attempting flight. You better be clear after 1 minute.
This can also be ran as a simulation by appending SIMULATION as a command line
argument. This allows you to test the functionality easily.
"""
import logging
import sys
import time
from control.controller import Controller
from control.gps import get_location_offset, get_distance
from control.helper import location_global_relative_to_gps_reading, gps_reading_to_location_global
def main(target_altitude, radius):
"""Takes the drone up and then lands."""
# Setup logging
logger = logging.getLogger('control')
logger.setLevel(logging.DEBUG)
filehandler = logging.FileHandler('simpleflight.log')
filehandler.setLevel(logging.DEBUG)
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
filehandler.setFormatter(formatter)
console.setFormatter(formatter)
logger.addHandler(filehandler)
logger.addHandler(console)
# Connect to the drone
logger.debug("Starting program, attempting connection to flight controller.")
vehicle_control = Controller(CONNECTION_STRING, baud=57600)
# Sleep to avoid immediate takeoff on boot
if not SIMULATION:
time.sleep(60)
# Arm and takeoff
logger.debug("Arming...")
vehicle_control.arm()
vehicle_control.takeoff(target_altitude)
# Create points
home_gps = location_global_relative_to_gps_reading(vehicle_control.home)
north_gps = get_location_offset(home_gps, radius, 0)
south_gps = get_location_offset(home_gps, -1*radius, 0)
east_gps = get_location_offset(home_gps, 0, radius)
west_gps = get_location_offset(home_gps, 0, -1*radius)
points = [north_gps, south_gps, east_gps, west_gps, home_gps]
# Transform GpsReading to LocationGlobalRelative
for index, point in enumerate(points):
points[index] = gps_reading_to_location_global(point)
logger.debug("Destination {}: {}".format(index, points[index]))
# Go to the points
if vehicle_control.vehicle.mode.name == "GUIDED":
logger.debug("Flying to points...")
for point in points:
if vehicle_control.vehicle.mode.name != "GUIDED":
break
vehicle_control.goto(point)
# Wait for vehicle to reach destination before updating the point
for sleep_time in range(10):
if vehicle_control.vehicle.mode.name != "GUIDED":
break
vehicle_control.log_flight_info(point)
# Don't let the vehicle go too far (could be stricter if get_distance
# improved and if gps was more accurate. Also note that altitude
# is looser here to avoid false landings (since gps altitude not
# accurate at all).
vehicle_control.check_geofence(radius*2, target_altitude+20)
current = vehicle_control.vehicle.location.global_relative_frame
current_reading = location_global_relative_to_gps_reading(current)
point_reading = location_global_relative_to_gps_reading(point)
distance = get_distance(current_reading, point_reading)
if distance < 1:
logger.debug('Destination Reached')
time.sleep(3)
break
time.sleep(3)
# Land if still in guided mode (i.e. no user takeover, no flight controller failure)
if vehicle_control.vehicle.mode.name == "GUIDED":
logger.debug("Landing...")
vehicle_control.land()
# Always keep the programming running and logging until the vehicle is disarmed
while vehicle_control.vehicle.armed:
vehicle_control.log_flight_info()
time.sleep(3)
logger.debug("Finshed program.")
sys.exit(0)
if __name__ == "__main__":
time.sleep(15) # Sleep just a little to make sure serial is available on system
SIMULATION = False
SITL = None
CONNECTION_STRING = '/dev/ttyO4'
if 'SIMULATION' in sys.argv:
# This is a simulation
SIMULATION = True
import dronekit_sitl
SITL = dronekit_sitl.start_default()
CONNECTION_STRING = SITL.connection_string()
main(10, 10)
| 41.107143 | 98 | 0.686577 |
4a1f85ef49d034a61725fa8e06aceb5a4bb905d7 | 1,203 | py | Python | apps/message/models/models.py | wangyuhuiever/sanic-tailor | 8be2c855a737803a431e87068bada8489930c425 | [
"MIT"
] | null | null | null | apps/message/models/models.py | wangyuhuiever/sanic-tailor | 8be2c855a737803a431e87068bada8489930c425 | [
"MIT"
] | null | null | null | apps/message/models/models.py | wangyuhuiever/sanic-tailor | 8be2c855a737803a431e87068bada8489930c425 | [
"MIT"
] | null | null | null | # -*- coding: utf-8 -*-
from utils.orm.db import BaseModel, Base
from sqlalchemy import BigInteger, Column, Boolean, ForeignKey, String, DateTime, select
from sqlalchemy.orm import relationship, backref
class Message(BaseModel):
__tablename__ = 'messages'
content_id = Column(BigInteger(), ForeignKey('message_contents.id'), nullable=False)
receiver_id = Column(BigInteger(), ForeignKey('users.id')) # if message public, receiver_id is null
room_id = Column(BigInteger(), ForeignKey('message_rooms.id'))
read = Column(Boolean())
class MessageContent(BaseModel):
__tablename__ = 'message_contents'
content = Column(String(), nullable=False)
class MessageRoomUser(Base):
__tablename__ = "message_room_users"
user_id = Column(BigInteger(), ForeignKey("users.id"), primary_key=True)
room_id = Column(BigInteger(), ForeignKey("message_rooms.id"), primary_key=True)
class MessageRoom(BaseModel):
__tablename__ = 'message_rooms'
name = Column(String(), nullable=False)
description = Column(String())
code = Column(String(), nullable=False)
user_ids = relationship("utils.orm.db.User", secondary='message_room_users', backref="room_ids")
| 33.416667 | 104 | 0.729842 |
4a1f86aa3ea8ecb2df6dabdc8b3aa202f82a647d | 2,062 | py | Python | Additional_File/14_HypeSquadChanger/hypesquadchanger.py | Tominous/Discord-All-Tools-In-One | a2199b2b02242d6b9c07337960754c5c15feac9b | [
"MIT"
] | 1 | 2021-11-13T18:21:06.000Z | 2021-11-13T18:21:06.000Z | Additional_File/14_HypeSquadChanger/hypesquadchanger.py | FriXeee/Discord-All-Tools-In-One | b88ff7d56a8c0921b7c45539683e9d2f696fe03c | [
"MIT"
] | null | null | null | Additional_File/14_HypeSquadChanger/hypesquadchanger.py | FriXeee/Discord-All-Tools-In-One | b88ff7d56a8c0921b7c45539683e9d2f696fe03c | [
"MIT"
] | 1 | 2021-12-01T18:44:25.000Z | 2021-12-01T18:44:25.000Z | import os
import requests
from colorama import Fore
def hypesquadchanger():
os.system('cls')
hypesquadchangertitle()
print(f"""{y}[{b}#{y}]{w} Which house do you want to be part of: \n\n""")
print(f""" {y}[{w}01{y}]{w} Bravery\n""")
print(f""" {y}[{w}02{y}]{w} Brilliance\n""")
print(f""" {y}[{w}03{y}]{w} Balance\n\n\n""")
print(f"""{y}[{w}+{y}]{w} Enter your House choice : """)
house = str(input(f"""{y}[{b}#{y}]{w} Choice: """))
print(f"""\n{y}[{w}+{y}]{w} Enter the token of the account you want to change HypeSquad House : """)
token = str(input(f"""{y}[{b}#{y}]{w} Token: """))
headers = {'Authorization': token, 'Content-Type': 'application/json'}
r = requests.get('https://discord.com/api/v8/users/@me', headers=headers)
if r.status_code == 200:
headers = {
'Authorization': token,
'Content-Type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) discord/0.0.305 Chrome/69.0.3497.128 Electron/4.0.8 Safari/537.36'
}
if house == "1" or house == "01":
payload = {'house_id': 1}
elif house == "2" or house == "02":
payload = {'house_id': 2}
elif house == "3" or house == "03":
payload = {'house_id': 3}
else:
print(f""" {y}[{Fore.LIGHTRED_EX }#{y}]{w} Invalid Choice""")
input(f"""\n{y}[{b}#{y}]{w} Press ENTER to exit""")
main()
r = requests.post('https://discordapp.com/api/v6/hypesquad/online', headers=headers, json=payload, timeout=10)
if r.status_code == 204:
print(f""" \n{y}[{Fore.LIGHTGREEN_EX }!{y}]{w} Hypesquad House changed""")
input(f"""\n{y}[{b}#{y}]{w} Press ENTER to exit""")
main()
else:
print(f""" {y}[{Fore.LIGHTRED_EX }#{y}]{w} Invalid token""")
input(f"""\n{y}[{b}#{y}]{w} Press ENTER to exit""")
main()
hypesquadchanger()
| 44.826087 | 170 | 0.520369 |
4a1f874455e07d1580d6b2dc78c884a54c8ce03c | 6,788 | py | Python | tests/forte/data/entry_data_structures_test.py | yishen734/forte | a061dde4e39a8149a73f015c36641af80066f196 | [
"Apache-2.0"
] | 2 | 2021-01-01T12:07:27.000Z | 2021-09-10T03:57:18.000Z | tests/forte/data/entry_data_structures_test.py | ha-lins/forte | 4594f65f41a8dbfc822573d12fb9af58c37a83a4 | [
"Apache-2.0"
] | null | null | null | tests/forte/data/entry_data_structures_test.py | ha-lins/forte | 4594f65f41a8dbfc822573d12fb9af58c37a83a4 | [
"Apache-2.0"
] | null | null | null | import unittest
from dataclasses import dataclass
from typing import Optional, List, Any, Iterator
from forte.data.data_pack import DataPack
from forte.data.multi_pack import MultiPack
from forte.data.ontology import Generics, MultiPackGeneric, Annotation
from forte.data.ontology.core import FList, FDict, MpPointer, Pointer
from forte.data.readers.base_reader import PackReader, MultiPackReader
from forte.pack_manager import PackManager
from forte.pipeline import Pipeline
from forte.processors.base import PackProcessor, MultiPackProcessor
from ft.onto.base_ontology import EntityMention
@dataclass
class ExampleEntry(Generics):
secret_number: Optional[int] = None
def __init__(self, pack: DataPack):
super().__init__(pack)
@dataclass
class DifferentEntry(Generics):
secret_number: Optional[int] = None
def __init__(self, pack: DataPack):
super().__init__(pack)
@dataclass
class ExampleMPEntry(MultiPackGeneric):
refer_entry: Optional[ExampleEntry] = None
def __init__(self, pack: MultiPack):
super().__init__(pack)
@dataclass
class EntryWithList(Generics):
"""
Test whether entries are stored correctly as a List using FList.
"""
entries: FList[ExampleEntry] = None
def __init__(self, pack: MultiPack):
super().__init__(pack)
self.entries = FList[ExampleEntry](self)
class EntryWithDict(Generics):
"""
Test whether entries are stored correctly as a Dict using FDict.
"""
entries: FDict[int, ExampleEntry] = None
def __init__(self, pack: DataPack):
super().__init__(pack)
self.entries = FDict[int, ExampleEntry](self)
class EntryAsAttribute(Generics):
"""
Test whether entries are stored correctly in the entry.
"""
att_entry: Optional[ExampleEntry] = None
def __init__(self, pack: DataPack):
super().__init__(pack)
class EmptyReader(PackReader):
def _collect(self, names: List[str]) -> Iterator[Any]:
yield from names
def _parse_pack(self, name: str) -> Iterator[DataPack]:
p = self.new_pack()
p.pack_name = name
yield p
class EntryAnnotator(PackProcessor):
def _process(self, input_pack: DataPack):
# Add a EntryWithList
le: EntryWithList = EntryWithList(input_pack)
# Add a couple entry to the list.
for i in range(10):
e = ExampleEntry(input_pack)
e.secret_number = i
le.entries.append(e)
# Add a EntryWithDict
de: EntryWithDict = EntryWithDict(input_pack)
for i in range(10, 20):
e = ExampleEntry(input_pack)
e.secret_number = i
de.entries[i] = e
# Add a EntryWithEntry
e_with_a: EntryAsAttribute = EntryAsAttribute(input_pack)
ee = ExampleEntry(input_pack)
e_with_a.att_entry = ee
ee.secret_number = 27
class EmptyMultiReader(MultiPackReader):
def _collect(self, names: List[str]) -> Iterator[Any]:
yield from names
def _parse_pack(self, name: str) -> Iterator[MultiPack]:
p = self.new_pack()
p.pack_name = name
yield p
class MultiPackEntryAnnotator(MultiPackProcessor):
def _process(self, multi_pack: MultiPack):
# Add a pack.
p1 = multi_pack.add_pack('pack1')
p2 = multi_pack.add_pack('pack2')
# Add some entries into one pack.
e1: ExampleEntry = p1.add_entry(ExampleEntry(p1))
e1.secret_number = 1
p2.add_entry(ExampleEntry(p2))
# Add the multi pack entry.
mp_entry = ExampleMPEntry(multi_pack)
mp_entry.refer_entry = e1
class MultiEntryStructure(unittest.TestCase):
def setUp(self):
p: Pipeline[MultiPack] = Pipeline[MultiPack]()
p.set_reader(EmptyMultiReader())
p.add(MultiPackEntryAnnotator())
p.initialize()
self.pack: MultiPack = p.process(['doc1', 'doc2'])
def test_entry_attribute(self):
mpe: ExampleMPEntry = self.pack.get_single(ExampleMPEntry)
self.assertIsInstance(mpe.refer_entry, ExampleEntry)
self.assertIsInstance(mpe.__dict__['refer_entry'], MpPointer)
def test_wrong_attribute(self):
manager = PackManager()
input_pack = MultiPack(manager)
mp_entry = ExampleMPEntry(input_pack)
p1 = input_pack.add_pack('pack1')
e1: DifferentEntry = p1.add_entry(DifferentEntry(p1))
with self.assertRaises(TypeError):
mp_entry.refer_entry = e1
mp_entry.regret_creation()
class EntryDataStructure(unittest.TestCase):
def setUp(self):
p: Pipeline = Pipeline()
p.set_reader(EmptyReader())
p.add(EntryAnnotator())
p.initialize()
self.pack: DataPack = p.process(['doc1', 'doc2'])
def test_entry_attribute(self):
entry_with_attr: EntryAsAttribute = self.pack.get_single(
EntryAsAttribute)
# Make sure we can get the entry of correct type and data.
self.assertIsInstance(entry_with_attr.att_entry, ExampleEntry)
self.assertEqual(entry_with_attr.att_entry.secret_number, 27)
self.assertIsInstance(entry_with_attr.__dict__['att_entry'], Pointer)
def test_entry_list(self):
list_entry: EntryWithList = self.pack.get_single(EntryWithList)
# Make sure the list data types are correct.
for e in list_entry.entries:
self.assertIsInstance(e, ExampleEntry)
# Check size.
self.assertEqual(len(list_entry.entries), 10)
# Make sure we stored index instead of raw data in list.
for v in list_entry.entries.__dict__['_FList__data']:
self.assertIsInstance(v, Pointer)
def test_entry_dict(self):
dict_entry: EntryWithDict = self.pack.get_single(EntryWithDict)
# Make sure the dict data types are correct.
for e in dict_entry.entries.values():
self.assertTrue(isinstance(e, ExampleEntry))
self.assertEqual(len(dict_entry.entries), 10)
# Make sure we stored index (pointers) instead of raw data in dict.
for v in dict_entry.entries.__dict__['_FDict__data'].values():
self.assertTrue(isinstance(v, Pointer))
class NotHashingTest(unittest.TestCase):
def setUp(self):
manager = PackManager()
self.pack: DataPack = DataPack(manager)
self.pack.set_text("Some text to test annotations on.")
def test_not_hashable(self):
anno: Annotation = Annotation(self.pack, 0, 5)
with self.assertRaises(TypeError):
hash(anno)
anno.regret_creation()
anno1: EntityMention = EntityMention(self.pack, 0, 2)
with self.assertRaises(TypeError):
hash(anno1)
anno1.regret_creation()
| 31.137615 | 77 | 0.670301 |
4a1f876131c31beddcdf2d9d4d545800041f8845 | 1,471 | py | Python | www/mooc8.py | Renzhw/python3 | e83bc40325d78e7a64432a4304a18436cc2d0867 | [
"Apache-2.0"
] | null | null | null | www/mooc8.py | Renzhw/python3 | e83bc40325d78e7a64432a4304a18436cc2d0867 | [
"Apache-2.0"
] | null | null | null | www/mooc8.py | Renzhw/python3 | e83bc40325d78e7a64432a4304a18436cc2d0867 | [
"Apache-2.0"
] | null | null | null | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
#jiandan-meizitu,并保存至本地
import requests
import os
import re
a = 2426
print('开始爬取煎蛋网美女图片')
allpicurl=[]
def getHTMLText(url):
try:
headers = { "Accept":"text/html,application/xhtml+xml,application/xml;",
"Accept-Encoding":"gzip",
"Accept-Language":"zh-CN,zh;q=0.8",
"Referer":"http://www.example.com/",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36"
}
r = requests.get(url, timeout=30,headers=headers)
r.raise_for_status()
return r.text
except:
return ""
def foo(lst,a):
return[a+str(i) for i in lst]
def LoadPic(picurl,path):
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(picurl)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已保存")
except:
print("爬取失败")
def main():
infoList = []
rex = r'href="//w[xw][1-4].sinaimg.cn/large.*?.[jpg,png,gif]"'
plt = re.findall(rex,getHTMLText(url))
for i in range(len(plt)):
picurl = eval(plt[i].split('=')[1])
infoList.append(picurl)
picfile = foo(infoList,'http:')
for i in picfile:
path = root+url.split('page-')[1]+i.split('/')[-1]
LoadPic(i,path)
while a > 2424:
print(a)
b=str(a)
root = "./pic/"+b+"/"
url = 'http://jandan.net/ooxx/page-'+str(a)
main()
a=a-1
| 21.955224 | 135 | 0.605031 |
4a1f88341dcb229e81a53bf0e8d4a6c973e1c5eb | 1,712 | py | Python | model_utils.py | aghie/hpac | 1182b5f8e8378b4a5506f8f68c19fd4c08120f92 | [
"MIT"
] | 5 | 2019-05-21T22:40:06.000Z | 2021-05-27T11:56:32.000Z | model_utils.py | aghie/hpac | 1182b5f8e8378b4a5506f8f68c19fd4c08120f92 | [
"MIT"
] | null | null | null | model_utils.py | aghie/hpac | 1182b5f8e8378b4a5506f8f68c19fd4c08120f92 | [
"MIT"
] | 1 | 2021-10-04T16:31:35.000Z | 2021-10-04T16:31:35.000Z | import codecs
import numpy as np
import random
from collections import Counter
def _read_embedding_file(file_embedding):
if file_embedding is not None:
external_embedding_fp = open(file_embedding,'r')
line = external_embedding_fp.readline()
esize = len(line.split()) -1
pad_element_vector = [0.]*esize
unk_element_vector = [0.]*esize
vectors = [pad_element_vector,unk_element_vector]
iembeddings = {}
# line = external_embedding_fp.readline()
iline = 1
while line != '':
vector = [float(f) for f in line.strip('\n').split(' ')[1:]]
word = line.split(' ')[0]
vectors.append(vector)
iembeddings[word] = iline
iline+=1
line = external_embedding_fp.readline()
external_embedding_fp.close()
lookup = np.array(vectors)
return iembeddings, lookup, esize
else:
raise ValueError("Path in file_embedding: ", file_embedding," does not exist.")
def load_data(path, path_spells, train=True, d_l=None):
if train:
d_l = {}
with codecs.open(path_spells) as f:
labels = ["_".join(l.strip().upper().split())
for i,l in enumerate(f.readlines()) ]
words = []
labels = set([])
with codecs.open(path) as f:
l = f.readline()
while l != '':
ls = l.split('\t')
labels.add(ls[1])
for w in ls[2].split():
words.append(w)
l = f.readline()
word_counter = Counter(words)
return word_counter, labels
| 27.174603 | 87 | 0.540304 |
4a1f883e3a704a80ad359546bc41dd9a9781ad0d | 14,470 | py | Python | pyfiles/buy.py | Russell-A/course-design | 1a0c5954e5a7ca7835739ce59baf17771e62b74f | [
"MIT"
] | 4 | 2020-06-07T07:45:43.000Z | 2020-07-01T10:53:47.000Z | pyfiles/buy.py | Russell-A/course-design | 1a0c5954e5a7ca7835739ce59baf17771e62b74f | [
"MIT"
] | null | null | null | pyfiles/buy.py | Russell-A/course-design | 1a0c5954e5a7ca7835739ce59baf17771e62b74f | [
"MIT"
] | 3 | 2020-05-18T13:06:47.000Z | 2020-07-02T13:29:45.000Z | # -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'buy.ui'
#
# Created by: PyQt5 UI code generator 5.13.0
#
# WARNING! All changes made in this file will be lost!
from PyQt5 import QtCore, QtGui, QtWidgets
import jump_buy as jpb
class Ui_main(object):
def setupUi(self, main):
main.setObjectName("main")
main.resize(1271, 852)
icon = QtGui.QIcon()
icon.addPixmap(QtGui.QPixmap("../icon/flight.png"), QtGui.QIcon.Normal, QtGui.QIcon.Off)
Dialog.setWindowIcon(icon)
self.centralwidget = QtWidgets.QWidget(main)
self.centralwidget.setObjectName("centralwidget")
self.gridLayout = QtWidgets.QGridLayout(self.centralwidget)
self.gridLayout.setObjectName("gridLayout")
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.verticalLayout = QtWidgets.QVBoxLayout()
self.verticalLayout.setObjectName("verticalLayout")
self.horizontalLayout_2 = QtWidgets.QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.label_departure = QtWidgets.QLabel(self.centralwidget)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_departure.sizePolicy().hasHeightForWidth())
self.label_departure.setSizePolicy(sizePolicy)
self.label_departure.setAlignment(QtCore.Qt.AlignCenter)
self.label_departure.setObjectName("label_departure")
self.horizontalLayout_2.addWidget(self.label_departure)
self.comboBox_departure = QtWidgets.QComboBox(self.centralwidget)
self.comboBox_departure.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.comboBox_departure.sizePolicy().hasHeightForWidth())
self.comboBox_departure.setSizePolicy(sizePolicy)
self.comboBox_departure.setEditable(False)
self.comboBox_departure.setObjectName("comboBox_departure")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.comboBox_departure.addItem("")
self.horizontalLayout_2.addWidget(self.comboBox_departure)
self.label_destination = QtWidgets.QLabel(self.centralwidget)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_destination.sizePolicy().hasHeightForWidth())
self.label_destination.setSizePolicy(sizePolicy)
self.label_destination.setAlignment(QtCore.Qt.AlignCenter)
self.label_destination.setObjectName("label_destination")
self.horizontalLayout_2.addWidget(self.label_destination)
self.comboBox_destination = QtWidgets.QComboBox(self.centralwidget)
self.comboBox_destination.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.comboBox_destination.sizePolicy().hasHeightForWidth())
self.comboBox_destination.setSizePolicy(sizePolicy)
self.comboBox_destination.setEditable(False)
self.comboBox_destination.setObjectName("comboBox_destination")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.comboBox_destination.addItem("")
self.horizontalLayout_2.addWidget(self.comboBox_destination)
self.verticalLayout.addLayout(self.horizontalLayout_2)
self.horizontalLayout_4 = QtWidgets.QHBoxLayout()
self.horizontalLayout_4.setObjectName("horizontalLayout_4")
self.label_date = QtWidgets.QLabel(self.centralwidget)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_date.sizePolicy().hasHeightForWidth())
self.label_date.setSizePolicy(sizePolicy)
self.label_date.setAlignment(QtCore.Qt.AlignCenter)
self.label_date.setObjectName("label_date")
self.horizontalLayout_4.addWidget(self.label_date)
self.dateEdit = QtWidgets.QDateEdit(self.centralwidget)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.dateEdit.sizePolicy().hasHeightForWidth())
self.dateEdit.setSizePolicy(sizePolicy)
self.dateEdit.setDateTime(QtCore.QDateTime(QtCore.QDate(2019, 1, 1), QtCore.QTime(0, 0, 0)))
self.dateEdit.setMaximumDateTime(QtCore.QDateTime(QtCore.QDate(2019, 12, 31), QtCore.QTime(23, 59, 59)))
self.dateEdit.setMinimumDateTime(QtCore.QDateTime(QtCore.QDate(2019, 1, 1), QtCore.QTime(0, 0, 0)))
self.dateEdit.setObjectName("dateEdit")
self.horizontalLayout_4.addWidget(self.dateEdit)
self.verticalLayout.addLayout(self.horizontalLayout_4)
self.horizontalLayout_5 = QtWidgets.QHBoxLayout()
self.horizontalLayout_5.setObjectName("horizontalLayout_5")
self.label_class = QtWidgets.QLabel(self.centralwidget)
self.label_class.setAlignment(QtCore.Qt.AlignCenter)
self.label_class.setObjectName("label_class")
self.horizontalLayout_5.addWidget(self.label_class)
self.comboBox_class = QtWidgets.QComboBox(self.centralwidget)
self.comboBox_class.setObjectName("comboBox_class")
self.comboBox_class.addItem("")
self.comboBox_class.addItem("")
self.comboBox_class.addItem("")
self.horizontalLayout_5.addWidget(self.comboBox_class)
self.verticalLayout.addLayout(self.horizontalLayout_5)
self.Search = QtWidgets.QPushButton(self.centralwidget)
self.Search.setObjectName("Search")
self.verticalLayout.addWidget(self.Search)
self.buybutton = QtWidgets.QPushButton(self.centralwidget)
self.buybutton.setObjectName("buybutton")
self.verticalLayout.addWidget(self.buybutton)
self.horizontalLayout.addLayout(self.verticalLayout)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.horizontalLayout.addItem(spacerItem)
self.result = QtWidgets.QTableWidget(self.centralwidget)
self.result.setObjectName("result")
self.result.setColumnCount(6)
self.result.setRowCount(0)
item = QtWidgets.QTableWidgetItem()
self.result.setHorizontalHeaderItem(0, item)
item = QtWidgets.QTableWidgetItem()
self.result.setHorizontalHeaderItem(1, item)
item = QtWidgets.QTableWidgetItem()
self.result.setHorizontalHeaderItem(2, item)
item = QtWidgets.QTableWidgetItem()
self.result.setHorizontalHeaderItem(3, item)
item = QtWidgets.QTableWidgetItem()
self.result.setHorizontalHeaderItem(4, item)
item = QtWidgets.QTableWidgetItem()
self.result.setHorizontalHeaderItem(5, item)
self.horizontalLayout.addWidget(self.result)
self.gridLayout.addLayout(self.horizontalLayout, 0, 0, 1, 1)
main.setCentralWidget(self.centralwidget)
self.menubar = QtWidgets.QMenuBar(main)
self.menubar.setGeometry(QtCore.QRect(0, 0, 1271, 26))
self.menubar.setObjectName("menubar")
self.menu = QtWidgets.QMenu(self.menubar)
self.menu.setObjectName("menu")
self.menu_2 = QtWidgets.QMenu(self.menubar)
self.menu_2.setObjectName("menu_2")
self.menu_3 = QtWidgets.QMenu(self.menu_2)
self.menu_3.setObjectName("menu_3")
self.menu_4 = QtWidgets.QMenu(self.menu_2)
self.menu_4.setObjectName("menu_4")
main.setMenuBar(self.menubar)
self.toolBar = QtWidgets.QToolBar(main)
self.toolBar.setObjectName("toolBar")
main.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar)
self.toolBar_2 = QtWidgets.QToolBar(main)
self.toolBar_2.setObjectName("toolBar_2")
main.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar_2)
self.toolBar_3 = QtWidgets.QToolBar(main)
self.toolBar_3.setObjectName("toolBar_3")
main.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar_3)
self.statusBar = QtWidgets.QStatusBar(main)
self.statusBar.setObjectName("statusBar")
main.setStatusBar(self.statusBar)
self.actionregister = QtWidgets.QAction(main)
self.actionregister.setObjectName("actionregister")
self.actionbuy = QtWidgets.QAction(main)
self.actionbuy.setObjectName("actionbuy")
self.action1 = QtWidgets.QAction(main)
self.action1.setObjectName("action1")
self.actionds = QtWidgets.QAction(main)
self.actionds.setObjectName("actionds")
self.actionkj = QtWidgets.QAction(main)
self.actionkj.setObjectName("actionkj")
self.menu.addAction(self.actionregister)
self.menu_3.addAction(self.action1)
self.menu_3.addAction(self.actionds)
self.menu_4.addAction(self.actionkj)
self.menu_2.addAction(self.menu_3.menuAction())
self.menu_2.addAction(self.menu_4.menuAction())
self.menubar.addAction(self.menu.menuAction())
self.menubar.addAction(self.menu_2.menuAction())
self.retranslateUi(main)
QtCore.QMetaObject.connectSlotsByName(main)
def retranslateUi(self, main):
_translate = QtCore.QCoreApplication.translate
main.setWindowTitle(_translate("main", "MainWindow"))
self.label_departure.setText(_translate("main", "Departure"))
self.comboBox_departure.setCurrentText(_translate("main", "北京"))
self.comboBox_departure.setItemText(0, _translate("main", "北京"))
self.comboBox_departure.setItemText(1, _translate("main", "成都"))
self.comboBox_departure.setItemText(2, _translate("main", "香港"))
self.comboBox_departure.setItemText(3, _translate("main", "哈尔滨"))
self.comboBox_departure.setItemText(4, _translate("main", "海南"))
self.comboBox_departure.setItemText(5, _translate("main", "上海"))
self.comboBox_departure.setItemText(6, _translate("main", "长春"))
self.comboBox_departure.setItemText(7, _translate("main", "兰州"))
self.comboBox_departure.setItemText(8, _translate("main", "广州"))
self.comboBox_departure.setItemText(9, _translate("main", "长沙"))
self.comboBox_departure.setItemText(10, _translate("main", "南昌"))
self.label_destination.setText(_translate("main", "Destination"))
self.comboBox_destination.setItemText(0, _translate("main", "北京"))
self.comboBox_destination.setItemText(1, _translate("main", "成都"))
self.comboBox_destination.setItemText(2, _translate("main", "香港"))
self.comboBox_destination.setItemText(3, _translate("main", "哈尔滨"))
self.comboBox_destination.setItemText(4, _translate("main", "海南"))
self.comboBox_destination.setItemText(5, _translate("main", "上海"))
self.comboBox_destination.setItemText(6, _translate("main", "长春"))
self.comboBox_destination.setItemText(7, _translate("main", "兰州"))
self.comboBox_destination.setItemText(8, _translate("main", "广州"))
self.comboBox_destination.setItemText(9, _translate("main", "长沙"))
self.comboBox_destination.setItemText(10, _translate("main", "南昌"))
self.label_date.setText(_translate("main", "DATE"))
self.label_class.setText(_translate("main", "Class"))
self.comboBox_class.setItemText(0, _translate("main", "头等舱"))
self.comboBox_class.setItemText(1, _translate("main", "商务舱"))
self.comboBox_class.setItemText(2, _translate("main", "经济舱"))
self.Search.setText(_translate("main", "Search"))
self.buybutton.setText(_translate("main", "Buy"))
item = self.result.horizontalHeaderItem(0)
item.setText(_translate("main", "航班号"))
item = self.result.horizontalHeaderItem(1)
item.setText(_translate("main", "出发时间"))
item = self.result.horizontalHeaderItem(2)
item.setText(_translate("main", "出发机场"))
item = self.result.horizontalHeaderItem(3)
item.setText(_translate("main", "到达时间"))
item = self.result.horizontalHeaderItem(4)
item.setText(_translate("main", "到达机场"))
item = self.result.horizontalHeaderItem(5)
item.setText(_translate("main", "描述"))
self.menu.setTitle(_translate("main", "注册"))
self.menu_2.setTitle(_translate("main", "功能"))
self.menu_3.setTitle(_translate("main", "用户"))
self.menu_4.setTitle(_translate("main", "管理员"))
self.toolBar.setWindowTitle(_translate("main", "toolBar"))
self.toolBar_2.setWindowTitle(_translate("main", "toolBar_2"))
self.toolBar_3.setWindowTitle(_translate("main", "toolBar_3"))
self.actionregister.setText(_translate("main", "用户注册"))
self.actionbuy.setText(_translate("main", "机票购买"))
self.action1.setText(_translate("main", "机票购买"))
self.actionds.setText(_translate("main", "我的机票"))
self.actionkj.setText(_translate("main", "添加数据"))
| 55.229008 | 114 | 0.709468 |
4a1f88919752fee44e79ac3c7ccab21602a42a5e | 181 | py | Python | galaxy_ml/externals/selene_sdk/predict/__init__.py | bgruening/Galaxy-ML-1 | 47514940c7ac39d6ca1d595b58b5d1311b3f3840 | [
"MIT"
] | null | null | null | galaxy_ml/externals/selene_sdk/predict/__init__.py | bgruening/Galaxy-ML-1 | 47514940c7ac39d6ca1d595b58b5d1311b3f3840 | [
"MIT"
] | null | null | null | galaxy_ml/externals/selene_sdk/predict/__init__.py | bgruening/Galaxy-ML-1 | 47514940c7ac39d6ca1d595b58b5d1311b3f3840 | [
"MIT"
] | null | null | null | """
This module contains classes and methods for making and analyzing
predictions with models that have already been trained.
"""
from . import _common, _variant_effect_prediction
| 25.857143 | 65 | 0.80663 |
4a1f889fa6edb6979b8ef28d63f9eab2fb2896e3 | 628 | py | Python | examples/sklearn_model/start_service.py | geffy/ebonite | 2d85eeca44ac1799e743bafe333887712e325060 | [
"Apache-2.0"
] | 1 | 2019-11-27T14:33:45.000Z | 2019-11-27T14:33:45.000Z | examples/sklearn_model/start_service.py | geffy/ebonite | 2d85eeca44ac1799e743bafe333887712e325060 | [
"Apache-2.0"
] | null | null | null | examples/sklearn_model/start_service.py | geffy/ebonite | 2d85eeca44ac1799e743bafe333887712e325060 | [
"Apache-2.0"
] | null | null | null | """This example shows how you can use ebonite to wrap your sklearn model into flask service"""
from ebonite import Ebonite
from ebonite.runtime import run_model_server
def main():
# create local ebonite client. This client stores metadata and artifacts on local fs.
ebnt = Ebonite.local()
model = ebnt.get_model(project='my_project', task='regression_is_my_profession', model_name='mymodel')
# run flask service with this model
run_model_server(model)
# now you can use client.py to call this service or go to http://localhost:9000/apidocs to view swagger ui
if __name__ == '__main__':
main()
| 33.052632 | 110 | 0.740446 |
4a1f89a826c124af875e9afda090d136dfe629d4 | 739 | py | Python | jsonclasses/validators/min_validator.py | katrina799/jsonclasses | 7648d2c1dbef8a001975013f24e49dd6421099ba | [
"MIT"
] | null | null | null | jsonclasses/validators/min_validator.py | katrina799/jsonclasses | 7648d2c1dbef8a001975013f24e49dd6421099ba | [
"MIT"
] | null | null | null | jsonclasses/validators/min_validator.py | katrina799/jsonclasses | 7648d2c1dbef8a001975013f24e49dd6421099ba | [
"MIT"
] | null | null | null | """module for min validator."""
from typing import Union
from ..exceptions import ValidationException
from .validator import Validator
from ..contexts import ValidatingContext
class MinValidator(Validator):
"""Min validator validates value against min value."""
def __init__(self, min_value: Union[int, float]):
self.min_value = min_value
def validate(self, context: ValidatingContext) -> None:
if context.value is None:
return
if context.value < self.min_value:
raise ValidationException(
{context.keypath_root: f'Value \'{context.value}\' at \'{context.keypath_root}\' should not be less than {self.min_value}.'},
context.root
)
| 33.590909 | 141 | 0.664411 |
4a1f8b8544c98cf17015e9a1dad8f06fe3bfabc1 | 3,663 | py | Python | data/data_analysis/others/clf_models.py | mcpeixoto/Sentrade | 55f65508d6b565b99840c9ce5d757185f5027164 | [
"MIT"
] | 4 | 2020-09-28T18:40:47.000Z | 2021-12-01T08:29:29.000Z | data/data_analysis/others/clf_models.py | ZiyouZhang/Sentrade | c88d20a858de6d05649f99230ca2b44f4c76cd3c | [
"MIT"
] | null | null | null | data/data_analysis/others/clf_models.py | ZiyouZhang/Sentrade | c88d20a858de6d05649f99230ca2b44f4c76cd3c | [
"MIT"
] | 2 | 2021-08-10T22:32:52.000Z | 2022-02-03T21:28:47.000Z | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import joblib
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
__author__ = "Fengming Liu, Longzhen Li, Shaomiao Yin"
__status__ = "Development"
def classifier_run(clf, name, x_train, x_test, y_train, y_test):
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
return [accuracy_score(y_test, y_pred), confusion_matrix(y_test, y_pred), clf]
#company_list = ["apple", "amazon", "facebook", "google", "microsoft", "netflix", "tesla"]
features_list = [["relative_day", "past_3_days_senti_avg"],
["relative_day", "past_7_days_senti_avg"],
["relative_day", "1_day_sentiment_score"],
["1_day_sentiment_score"],
["past_3_days_senti_avg"],
["past_7_days_senti_avg"],
["1_day_news_count"],
["1_day_overall_sentiment_score"],
["1_day_sentiment_score","1_day_news_count"],
["1_day_sentiment_score","1_day_news_count","past_3_days_senti_avg"],
["1_day_sentiment_score","1_day_news_count","past_3_days_senti_avg","past_7_days_senti_avg"],
["1_day_sentiment_score","company_apple","company_amazon", "company_facebook", "company_google", "company_microsoft", "company_netflix", "company_tesla"],
["1_day_sentiment_score","1_day_news_count","company_apple","company_amazon", "company_facebook", "company_google", "company_microsoft", "company_netflix", "company_tesla"],
["1_day_sentiment_score","1_day_news_count","past_3_days_senti_avg","past_7_days_senti_avg","company_apple","company_amazon", "company_facebook", "company_google", "company_microsoft", "company_netflix", "company_tesla"],
]
response_list = ["up_cat"]
result = open("./results/clf_results.csv", "w")
alg_dict = {"KNN": KNeighborsClassifier(),
"DecisionTree": DecisionTreeClassifier(criterion='entropy'),
"SVM": SVC(gamma='auto'),
}
for response in response_list:
for features in features_list:
# write info
result.write("features:,")
for feat in features:
result.write(feat + ',')
result.write('\n')
result.write("response:," + response + '\n')
result.write(" ,")
for alg_name, clf in alg_dict.items():
result.write(alg_name + ',')
result.write('\n')
# do ML
###############################
total_df = pd.read_csv("./total_clf.csv")
x_train, x_test, y_train, y_test = train_test_split(total_df[features].to_numpy(),
total_df[response],
test_size=0.3,
shuffle=True,
random_state=500)
result.write(' ,')
for alg_name, clf in alg_dict.items():
print(features, response, alg_name)
[accuracy, cm, clf] = classifier_run(clf, alg_name, x_train, x_test, y_train, y_test)
joblib.dump(clf, "./models/" + alg_name + "_model.joblib")
print(cm)
result.write(str(accuracy) + ',')
result.write('\n')
result.write('\n')
result.write('\n')
result.close()
| 45.7875 | 238 | 0.598963 |
4a1f8ba75d0160522791bcc79393f032ce947dbc | 3,780 | py | Python | blog/settings.py | xuzhiguo2000cn/blog | c74d4c7e10212a036bdda22a6bc26e9c62d6d28f | [
"MIT"
] | null | null | null | blog/settings.py | xuzhiguo2000cn/blog | c74d4c7e10212a036bdda22a6bc26e9c62d6d28f | [
"MIT"
] | null | null | null | blog/settings.py | xuzhiguo2000cn/blog | c74d4c7e10212a036bdda22a6bc26e9c62d6d28f | [
"MIT"
] | null | null | null | """
Django settings for blog project.
Generated by 'django-admin startproject' using Django 3.0.6.
For more information on this file, see
https://docs.djangoproject.com/en/3.0/topics/settings/
For the full list of settings and their values, see
https://docs.djangoproject.com/en/3.0/ref/settings/
"""
import os
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/3.0/howto/deployment/checklist/
# SECURITY WARNING: keep the secret key used in production secret!
SECRET_KEY = '+c-+_n3q=no4@wb4v0yc_rifw12z5jmw1@ld5j-^ksiv(vjr5e'
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = True
ALLOWED_HOSTS = []
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'blog.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')]
,
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = 'blog.wsgi.application'
# Database
# https://docs.djangoproject.com/en/3.0/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'HOST': '127.0.0.1',
'PORT': 3306,
'USER': 'frank',
'PASSWORD': '123456',
'NAME': 'myblog',
}
}
# Password validation
# https://docs.djangoproject.com/en/3.0/ref/settings/#auth-password-validators
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
# Internationalization
# https://docs.djangoproject.com/en/3.0/topics/i18n/
LANGUAGE_CODE = 'en-us'
TIME_ZONE = 'UTC'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/3.0/howto/static-files/
STATIC_URL = '/static/'
#redis的配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
},
"session": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
#session由数据库存储改为redis存储
SESSION_ENGINE = "django.contrib.sessions.backends.cache"
SESSION_CACHE_ALIAS = "session" | 25.714286 | 91 | 0.669577 |
4a1f8cc7da2f4f0dac53ca8c851571620c85ddbe | 1,839 | py | Python | unittests/testdbuploader.py | rj79/lapmaster | edf12f7685df572f6022b50a808651ef5b0404d7 | [
"BSD-3-Clause"
] | null | null | null | unittests/testdbuploader.py | rj79/lapmaster | edf12f7685df572f6022b50a808651ef5b0404d7 | [
"BSD-3-Clause"
] | null | null | null | unittests/testdbuploader.py | rj79/lapmaster | edf12f7685df572f6022b50a808651ef5b0404d7 | [
"BSD-3-Clause"
] | null | null | null | import unittest
import os
from db_utils import Uploader
TEST_FILE_NAME = '/tmp/db_utils_unittest.csv'
class TestFile:
def __init__(self, filename):
self.FileName = filename
with open(self.FileName, 'w'):
pass
def writeline(self, text):
with open(self.FileName, 'a') as f:
f.write(text + os.linesep)
def __str__(self):
text = ""
for line in open(self.FileName, 'r'):
text += line
return text
class FakeDB:
def __init__(self):
self.Data = ""
def UploadData(self, data):
self.Data = data
return {"deleted": 0, "added": [{"bib": 101, "passage": 59}], "messages": []}
class TestDbUpload(unittest.TestCase):
def setUp(self):
self.File = TestFile(TEST_FILE_NAME)
def tearDown(self):
os.unlink(TEST_FILE_NAME)
def test_simple(self):
self.File.writeline('1408987100.0,start all');
self.File.writeline('1408987200.0,101');
self.File.writeline('1408987300.0,102');
db = FakeDB()
uploader = Uploader(db, TEST_FILE_NAME, 10)
uploader._upload()
self.assertEqual("1408987100\tall\n" +
"1408987200\t101\n" +
"1408987300\t102",
db.Data)
def test_missing_bib(self):
self.File.writeline('1408987100.0,start all');
self.File.writeline('1408987200.0,101');
self.File.writeline('1408987300.0,!!!!');
self.File.writeline('1408987400.0,102');
db = FakeDB()
uploader = Uploader(db, TEST_FILE_NAME, 10)
uploader._upload()
self.assertEqual("1408987100\tall\n" +
"1408987200\t101\n" +
"1408987400\t102",
db.Data)
| 28.734375 | 85 | 0.555193 |
4a1f8cf6284aa9f598ab2734a44cc8daa909a1e8 | 347 | py | Python | tests/test_users.py | tyeum/users | cf319fde3e6c07aea7c0130c201897f11a86b761 | [
"MIT"
] | null | null | null | tests/test_users.py | tyeum/users | cf319fde3e6c07aea7c0130c201897f11a86b761 | [
"MIT"
] | null | null | null | tests/test_users.py | tyeum/users | cf319fde3e6c07aea7c0130c201897f11a86b761 | [
"MIT"
] | 1 | 2018-03-03T00:00:11.000Z | 2018-03-03T00:00:11.000Z | from testinfra.utils.ansible_runner import AnsibleRunner
testinfra_hosts = AnsibleRunner('.molecule/ansible_inventory').get_hosts('all')
def test_users(Command, Ansible, Sudo):
with Sudo():
assert Command('''ssh dummy@localhost sudo whoami''').stdout == 'root'
def test_users_prune(Command):
assert Command('id prune').rc > 0
| 26.692308 | 79 | 0.731988 |
4a1f8e3119348246bb417da1157779315284cb59 | 7,996 | py | Python | tests/integration/scheduler/test_error.py | sypets/salt | 6ceb5fc73875c37b52408c4bef8deb409d836e8a | [
"Apache-2.0"
] | null | null | null | tests/integration/scheduler/test_error.py | sypets/salt | 6ceb5fc73875c37b52408c4bef8deb409d836e8a | [
"Apache-2.0"
] | null | null | null | tests/integration/scheduler/test_error.py | sypets/salt | 6ceb5fc73875c37b52408c4bef8deb409d836e8a | [
"Apache-2.0"
] | null | null | null | # -*- coding: utf-8 -*-
# Import Python libs
from __future__ import absolute_import
import copy
import logging
import os
import dateutil.parser as dateutil_parser
# Import Salt Testing libs
from tests.support.case import ModuleCase
from tests.support.mixins import SaltReturnAssertsMixin
from tests.support.mock import MagicMock, patch
from tests.support.unit import skipIf
from tests.support.runtests import RUNTIME_VARS
# Import Salt libs
import salt.utils.schedule
from salt.modules.test import ping as ping
try:
import croniter # pylint: disable=W0611
HAS_CRONITER = True
except ImportError:
HAS_CRONITER = False
log = logging.getLogger(__name__)
ROOT_DIR = os.path.join(RUNTIME_VARS.TMP, 'schedule-unit-tests')
SOCK_DIR = os.path.join(ROOT_DIR, 'test-socks')
DEFAULT_CONFIG = salt.config.minion_config(None)
DEFAULT_CONFIG['conf_dir'] = ROOT_DIR
DEFAULT_CONFIG['root_dir'] = ROOT_DIR
DEFAULT_CONFIG['sock_dir'] = SOCK_DIR
DEFAULT_CONFIG['pki_dir'] = os.path.join(ROOT_DIR, 'pki')
DEFAULT_CONFIG['cachedir'] = os.path.join(ROOT_DIR, 'cache')
class SchedulerErrorTest(ModuleCase, SaltReturnAssertsMixin):
'''
Validate the pkg module
'''
def setUp(self):
with patch('salt.utils.schedule.clean_proc_dir', MagicMock(return_value=None)):
functions = {'test.ping': ping}
self.schedule = salt.utils.schedule.Schedule(copy.deepcopy(DEFAULT_CONFIG), functions, returners={})
self.schedule.opts['loop_interval'] = 1
self.schedule.opts['grains']['whens'] = {'tea time': '11/29/2017 12:00pm'}
def tearDown(self):
self.schedule.reset()
@skipIf(not HAS_CRONITER, 'Cannot find croniter python module')
def test_eval_cron_invalid(self):
'''
verify that scheduled job runs
'''
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'cron': '0 16 29 13 *'
}
}
}
# Add the job to the scheduler
self.schedule.opts.update(job)
run_time = dateutil_parser.parse('11/29/2017 4:00pm')
with patch('croniter.croniter.get_next', MagicMock(return_value=run_time)):
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
self.assertEqual(ret['_error'],
'Invalid cron string. Ignoring job job1.')
def test_eval_when_invalid_date(self):
'''
verify that scheduled job does not run
and returns the right error
'''
run_time = dateutil_parser.parse('11/29/2017 4:00pm')
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'when': '13/29/2017 1:00pm',
}
}
}
# Add the job to the scheduler
self.schedule.opts.update(job)
# Evaluate 1 second before the run time
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
self.assertEqual(ret['_error'],
'Invalid date string 13/29/2017 1:00pm. Ignoring job job1.')
def test_eval_whens_grain_not_dict(self):
'''
verify that scheduled job does not run
and returns the right error
'''
run_time = dateutil_parser.parse('11/29/2017 4:00pm')
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'when': 'tea time',
}
}
}
self.schedule.opts['grains']['whens'] = ['tea time']
# Add the job to the scheduler
self.schedule.opts.update(job)
# Evaluate 1 second before the run time
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
self.assertEqual(ret['_error'],
'Grain "whens" must be a dict. Ignoring job job1.')
def test_eval_once_invalid_datestring(self):
'''
verify that scheduled job does not run
and returns the right error
'''
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'once': '2017-13-13T13:00:00',
}
}
}
run_time = dateutil_parser.parse('12/13/2017 1:00pm')
# Add the job to the scheduler
self.schedule.opts.update(job)
# Evaluate 1 second at the run time
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
_expected = ('Date string could not be parsed: '
'2017-13-13T13:00:00, %Y-%m-%dT%H:%M:%S. '
'Ignoring job job1.')
self.assertEqual(ret['_error'], _expected)
def test_eval_skip_during_range_invalid_date(self):
'''
verify that scheduled job does not run
and returns the right error
'''
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'hours': 1,
'skip_during_range': {'start': '1:00pm', 'end': '25:00pm'}
}
}
}
# Add the job to the scheduler
self.schedule.opts.update(job)
# eval at 3:00pm to prime, simulate minion start up.
run_time = dateutil_parser.parse('11/29/2017 3:00pm')
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
# eval at 4:00pm to prime
run_time = dateutil_parser.parse('11/29/2017 4:00pm')
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
_expected = ('Invalid date string for end in '
'skip_during_range. Ignoring '
'job job1.')
self.assertEqual(ret['_error'], _expected)
def test_eval_skip_during_range_end_before_start(self):
'''
verify that scheduled job does not run
and returns the right error
'''
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'hours': 1,
'skip_during_range': {'start': '1:00pm', 'end': '12:00pm'}
}
}
}
# Add the job to the scheduler
self.schedule.opts.update(job)
# eval at 3:00pm to prime, simulate minion start up.
run_time = dateutil_parser.parse('11/29/2017 3:00pm')
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
# eval at 4:00pm to prime
run_time = dateutil_parser.parse('11/29/2017 4:00pm')
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
_expected = ('schedule.handle_func: Invalid '
'range, end must be larger than '
'start. Ignoring job job1.')
self.assertEqual(ret['_error'], _expected)
def test_eval_skip_during_range_not_dict(self):
'''
verify that scheduled job does not run
and returns the right error
'''
job = {
'schedule': {
'job1': {
'function': 'test.ping',
'hours': 1,
'skip_during_range': ['start', '1:00pm', 'end', '12:00pm']
}
}
}
# Add the job to the scheduler
self.schedule.opts.update(job)
# eval at 3:00pm to prime, simulate minion start up.
run_time = dateutil_parser.parse('11/29/2017 3:00pm')
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
# eval at 4:00pm to prime
run_time = dateutil_parser.parse('11/29/2017 4:00pm')
self.schedule.eval(now=run_time)
ret = self.schedule.job_status('job1')
_expected = ('schedule.handle_func: Invalid, '
'range must be specified as a '
'dictionary. Ignoring job job1.')
self.assertEqual(ret['_error'], _expected)
| 30.753846 | 112 | 0.571411 |
4a1f8ee067914205060958dfd11e3c93e3704414 | 4,189 | py | Python | ucsmsdk/mometa/fabric/FabricFcSan.py | Kego/ucsmsdk | 244f283a5c295cf746110bb96686d079b19927ce | [
"Apache-2.0"
] | 78 | 2015-11-30T14:10:05.000Z | 2022-02-13T00:29:08.000Z | ucsmsdk/mometa/fabric/FabricFcSan.py | Kego/ucsmsdk | 244f283a5c295cf746110bb96686d079b19927ce | [
"Apache-2.0"
] | 113 | 2015-11-20T09:42:46.000Z | 2022-03-16T16:53:29.000Z | ucsmsdk/mometa/fabric/FabricFcSan.py | Kego/ucsmsdk | 244f283a5c295cf746110bb96686d079b19927ce | [
"Apache-2.0"
] | 86 | 2015-12-12T08:22:18.000Z | 2022-01-23T03:56:34.000Z | """This module contains the general information for FabricFcSan ManagedObject."""
from ...ucsmo import ManagedObject
from ...ucscoremeta import MoPropertyMeta, MoMeta
from ...ucsmeta import VersionMeta
class FabricFcSanConsts:
ID_A = "A"
ID_B = "B"
ID_NONE = "NONE"
UPLINK_TRUNKING_DISABLED = "disabled"
UPLINK_TRUNKING_ENABLED = "enabled"
class FabricFcSan(ManagedObject):
"""This is FabricFcSan class."""
consts = FabricFcSanConsts()
naming_props = set(['id'])
mo_meta = MoMeta("FabricFcSan", "fabricFcSan", "[id]", VersionMeta.Version101e, "InputOutput", 0xff, [], ["admin", "ext-san-config", "ext-san-policy"], ['fabricSanCloud'], ['fabricFcSanEp', 'fabricFcSanPc', 'fabricFcoeSanEp', 'fabricFcoeSanPc', 'fabricSubGroup', 'fabricVsan', 'faultInst'], ["Get", "Set"])
prop_meta = {
"child_action": MoPropertyMeta("child_action", "childAction", "string", VersionMeta.Version101e, MoPropertyMeta.INTERNAL, 0x2, None, None, r"""((deleteAll|ignore|deleteNonPresent),){0,2}(deleteAll|ignore|deleteNonPresent){0,1}""", [], []),
"config_qualifier": MoPropertyMeta("config_qualifier", "configQualifier", "string", VersionMeta.Version311e, MoPropertyMeta.READ_ONLY, None, None, None, r"""((defaultValue|not-applicable|vsan-count-exceeds-limit),){0,2}(defaultValue|not-applicable|vsan-count-exceeds-limit){0,1}""", [], []),
"dn": MoPropertyMeta("dn", "dn", "string", VersionMeta.Version101e, MoPropertyMeta.READ_ONLY, 0x4, 0, 256, None, [], []),
"id": MoPropertyMeta("id", "id", "string", VersionMeta.Version101e, MoPropertyMeta.NAMING, 0x8, None, None, None, ["A", "B", "NONE"], []),
"locale": MoPropertyMeta("locale", "locale", "string", VersionMeta.Version101e, MoPropertyMeta.READ_ONLY, None, None, None, r"""((defaultValue|unknown|server|chassis|internal|external),){0,5}(defaultValue|unknown|server|chassis|internal|external){0,1}""", [], []),
"name": MoPropertyMeta("name", "name", "string", VersionMeta.Version101e, MoPropertyMeta.CREATE_ONLY, 0x10, None, None, r"""[\-\.:_a-zA-Z0-9]{0,16}""", [], []),
"rn": MoPropertyMeta("rn", "rn", "string", VersionMeta.Version101e, MoPropertyMeta.READ_ONLY, 0x20, 0, 256, None, [], []),
"sacl": MoPropertyMeta("sacl", "sacl", "string", VersionMeta.Version302c, MoPropertyMeta.READ_ONLY, None, None, None, r"""((none|del|mod|addchild|cascade),){0,4}(none|del|mod|addchild|cascade){0,1}""", [], []),
"status": MoPropertyMeta("status", "status", "string", VersionMeta.Version101e, MoPropertyMeta.READ_WRITE, 0x40, None, None, r"""((removed|created|modified|deleted),){0,3}(removed|created|modified|deleted){0,1}""", [], []),
"transport": MoPropertyMeta("transport", "transport", "string", VersionMeta.Version101e, MoPropertyMeta.READ_ONLY, None, None, None, r"""((defaultValue|unknown|ether|dce|fc),){0,4}(defaultValue|unknown|ether|dce|fc){0,1}""", [], []),
"type": MoPropertyMeta("type", "type", "string", VersionMeta.Version101e, MoPropertyMeta.READ_ONLY, None, None, None, r"""((defaultValue|unknown|lan|san|ipc),){0,4}(defaultValue|unknown|lan|san|ipc){0,1}""", [], []),
"uplink_trunking": MoPropertyMeta("uplink_trunking", "uplinkTrunking", "string", VersionMeta.Version141i, MoPropertyMeta.READ_WRITE, 0x80, None, None, None, ["disabled", "enabled"], []),
}
prop_map = {
"childAction": "child_action",
"configQualifier": "config_qualifier",
"dn": "dn",
"id": "id",
"locale": "locale",
"name": "name",
"rn": "rn",
"sacl": "sacl",
"status": "status",
"transport": "transport",
"type": "type",
"uplinkTrunking": "uplink_trunking",
}
def __init__(self, parent_mo_or_dn, id, **kwargs):
self._dirty_mask = 0
self.id = id
self.child_action = None
self.config_qualifier = None
self.locale = None
self.name = None
self.sacl = None
self.status = None
self.transport = None
self.type = None
self.uplink_trunking = None
ManagedObject.__init__(self, "FabricFcSan", parent_mo_or_dn, **kwargs)
| 61.602941 | 310 | 0.650991 |
4a1f8f4e5b555453fc3513a151d40314efa382c4 | 300 | py | Python | src/main.py | SleepL1/IAssistant | adcc786e7beb3c216dfbeed939606954e47f6da2 | [
"MIT"
] | null | null | null | src/main.py | SleepL1/IAssistant | adcc786e7beb3c216dfbeed939606954e47f6da2 | [
"MIT"
] | null | null | null | src/main.py | SleepL1/IAssistant | adcc786e7beb3c216dfbeed939606954e47f6da2 | [
"MIT"
] | null | null | null | from src.assistant import GenericAssistant
import src.handler.intents as intents
import os
mappings = {'exit-program': intents.stop_assistant}
assistant = GenericAssistant(intent_methods=mappings)
assistant.train_model()
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
while True:
assistant.tick()
| 20 | 53 | 0.79 |
4a1f8f5967114900dcc748e1295ca725229d2d18 | 1,024 | py | Python | cloudshell/cli/service/cli.py | test-gh-org-workflow/probable-garbanzo | c6b8a0dbc573a2a0073b5ab7c8619c4d0baf7088 | [
"Apache-2.0"
] | 4 | 2017-01-31T14:05:19.000Z | 2019-04-10T16:35:44.000Z | cloudshell/cli/service/cli.py | test-gh-org-workflow/probable-garbanzo | c6b8a0dbc573a2a0073b5ab7c8619c4d0baf7088 | [
"Apache-2.0"
] | 89 | 2016-05-25T14:17:38.000Z | 2022-03-17T13:09:59.000Z | cloudshell/cli/service/cli.py | test-gh-org-workflow/probable-garbanzo | c6b8a0dbc573a2a0073b5ab7c8619c4d0baf7088 | [
"Apache-2.0"
] | 6 | 2016-07-21T12:24:10.000Z | 2022-02-21T06:33:18.000Z | import logging
from cloudshell.cli.service.session_pool_context_manager import (
SessionPoolContextManager,
)
from cloudshell.cli.service.session_pool_manager import SessionPoolManager
class CLI(object):
def __init__(self, session_pool=SessionPoolManager()):
self._session_pool = session_pool
def get_session(self, defined_sessions, command_mode, logger=None):
"""Get session from the pool or create new.
:param collections.Iterable defined_sessions:
:param cloudshell.cli.command_mode.CommandMode command_mode:
:param logging.Logger logger:
:rtype: cloudshell.cli.service.session_pool_context_manager.SessionPoolContextManager # noqa: E501
"""
if not isinstance(defined_sessions, list):
defined_sessions = [defined_sessions]
if not logger:
logger = logging.getLogger("cloudshell_cli")
return SessionPoolContextManager(
self._session_pool, defined_sessions, command_mode, logger
)
| 35.310345 | 107 | 0.72168 |
4a1f901b8fa17d5dfc200290f90de0b449e36d39 | 16,492 | py | Python | ross/api_report.py | micanica/ross | 7d827093b20088ec3409786da8403edb8e63eaa9 | [
"MIT"
] | 1 | 2019-09-07T17:10:25.000Z | 2019-09-07T17:10:25.000Z | ross/api_report.py | micanica/ross | 7d827093b20088ec3409786da8403edb8e63eaa9 | [
"MIT"
] | null | null | null | ross/api_report.py | micanica/ross | 7d827093b20088ec3409786da8403edb8e63eaa9 | [
"MIT"
] | null | null | null | import numpy as np
from scipy.signal import argrelextrema
from ross.rotor_assembly import Rotor, rotor_example
import ross as rs
import bokeh.palettes as bp
from bokeh.plotting import figure
from bokeh.models import (
ColumnDataSource,
HoverTool,
Span,
Label,
)
# set bokeh palette of colors
bokeh_colors = bp.RdGy[11]
class Report:
def __init__(
self,
rotor,
minspeed,
maxspeed,
speed_units="rpm",
):
"""Report according to standard analysis.
- Perform Stability_level1 analysis
- Apply Level 1 Screening Criteria
- Perform Stability_level2 analysis
Parameters
----------
rotor : object
A rotor built from rotor_assembly.
maxspeed : float
Maximum operation speed.
minspeed : float
Minimum operation speed.
speed_units : str
String defining the unit for rotor speed.
Default is "rpm".
Return
------
Example
-------
>>> rotor = rotor_example()
>>> report = Report(rotor=rotor,
... minspeed=400,
... maxspeed=1000,
... speed_units="rad/s")
"""
self.rotor = rotor
self.speed_units = speed_units
if speed_units == "rpm":
minspeed = minspeed * np.pi / 30
maxspeed = maxspeed * np.pi / 30
self.maxspeed = maxspeed
self.minspeed = minspeed
@classmethod
def from_saved_rotors(cls, path):
rotor = rs.Rotor.load(path)
return cls(rotor)
def static_forces(self):
"""
Method to calculate the bearing reaction forces.
Returns
-------
Fb : list
Bearing reaction forces.
Example
-------
>>> rotor = rotor_example()
>>> report = Report(rotor=rotor,
... minspeed=400,
... maxspeed=1000,
... speed_units="rad/s")
>>> report.static_forces()
array([44.09320349, 44.09320349])
"""
# get reaction forces on bearings
Fb = self.rotor.run_static().force_data['Bearings Reaction Forces']
Fb = np.array(Fb) / 9.8065
return Fb
def unbalance_forces(self, mode):
"""
Method to calculate the unbalance forces.
Parameters
----------
mode : int
n'th mode shape.
Returns
-------
U : list
Unbalancing forces.
Example
-------
>>> rotor = rotor_example()
>>> report = Report(rotor=rotor,
... minspeed=400,
... maxspeed=1000,
... speed_units="rad/s")
>>> report.unbalance_forces(mode=0)
[234.5654171598467]
"""
N = 60 * self.maxspeed / (2 * np.pi)
# get reaction forces on bearings
Fb = self.static_forces()
if mode == 0 or mode == 1:
U = [4 * max(6350 * np.sum(Fb) / N, 250e-3 * np.sum(Fb))]
if mode == 2 or mode == 3:
U = 4 * max(6350 * Fb / N, 250e-3 * Fb)
# get disk masses
W3 = 0
for disk in self.rotor.disk_elements:
if disk.n > self.rotor.df_bearings['n'].iloc[-1]:
W3 += disk.m
U = [6350 * W3 / N]
return U
def unbalance_response(
self,
clearances,
mode,
):
"""Evaluates the unbalance response for the rotor.
This analysis takes the critical speeds of interest, calculates the
position and weight of the required unbalance and performs the analysis
including:
- Check if vibration at MCS is below the limit with the applied weight;
- Check if the clearances are ok if the vibration deteriorate to the
limit level;
Parameters
----------
clearances : dict
Dict mapping between node and its clearance in meters.
(e.g. clearances = dict(3=0.001, 5=0.002...)
mode : int
n'th mode shape.
Returns
-------
mag_plot : bokeh axes
Bokeh axes with unbalance response plot.
Example
-------
"""
"""
>>> rotor = rotor_example()
>>> report = Report(rotor=rotor,
... minspeed=400,
... maxspeed=1000,
... speed_units="rad/s")
>>> clearances = {3:0.001, 5:0.002}
>>> report.unbalance_response(clearances=clearances, mode=0)
Figure(id='1372', ...)
"""
maxspeed = self.maxspeed
minspeed = self.minspeed
freq_range = np.linspace(0, 1.25 * maxspeed, 201)
# returns de nodes where forces will be applied
node_min, node_max = self.mode_shape(mode)
nodes = [int(node) for sub_nodes in [node_min, node_max] for node in sub_nodes]
force = self.unbalance_forces(mode)
phase = []
for node in nodes:
phase.append(np.pi)
response = self.rotor.unbalance_response(nodes, force, phase, freq_range)
mag = response.magnitude
for node in nodes:
dof = 4 * node + 1
mag_plot = response.plot_magnitude_bokeh(dof)
magnitude = mag[dof]
idx_max = argrelextrema(magnitude, np.greater)[0].tolist()
wn = freq_range[idx_max]
AF_table = []
SM_table = []
SM_ref_table = []
for i, peak in enumerate(magnitude[idx_max]):
peak_n = 0.707 * peak
peak_aux = np.linspace(peak_n, peak_n, len(freq_range))
idx = np.argwhere(
np.diff(np.sign(peak_aux - magnitude))
).flatten()
idx = np.sort(np.append(idx, idx_max[i]))
# if speed range is not long enough to catch the magnitudes
try:
idx_aux = [
list(idx).index(idx_max[i]) - 1,
list(idx).index(idx_max[i]) + 1,
]
idx = idx[idx_aux]
except IndexError:
idx = [
list(idx).index(idx_max[i]) - 1,
len(freq_range) - 1
]
# Amplification Factor (AF) - API684 - SP6.8.2.1
AF = wn[i] / (
freq_range[idx[1]] - freq_range[idx[0]]
)
# Separation Margin (SM) - API684 - SP6.8.2.10
if AF > 2.5 and wn[i] < minspeed:
SM = min([16, 17 * (1 - 1 / (AF - 1.5))]) / 100
SMspeed = wn[i] * (1 + SM)
SM_ref = (minspeed - wn[i]) / wn[i]
source = ColumnDataSource(
dict(
top=[max(magnitude[idx_max])],
bottom=[0],
left=[wn[i]],
right=[SMspeed],
tag1=[wn[i]],
tag2=[SMspeed],
)
)
mag_plot.quad(
top="top",
bottom="bottom",
left="left",
right="right",
source=source,
line_color=bokeh_colors[8],
line_width=0.8,
fill_alpha=0.2,
fill_color=bokeh_colors[8],
legend="Separation Margin",
name="SM2",
)
hover = HoverTool(names=["SM2"])
hover.tooltips = [
("Critical Speed :", "@tag1"),
("Speed at 0.707 x peak amplitude :", "@tag2"),
]
mag_plot.add_tools(hover)
elif AF > 2.5 and wn[i] > maxspeed:
SM = min([26, 10 + 17 * (1 - 1 / (AF - 1.5))]) / 100
SMspeed = wn[i] * (1 - SM)
SM_ref = (wn[i] - maxspeed) / maxspeed
source = ColumnDataSource(
dict(
top=[max(magnitude[idx_max])],
bottom=[0],
left=[SMspeed],
right=[wn[i]],
tag1=[wn[i]],
tag2=[SMspeed],
)
)
mag_plot.quad(
top="top",
bottom="bottom",
left="left",
right="right",
source=source,
line_color=bokeh_colors[8],
line_width=0.8,
fill_alpha=0.2,
fill_color=bokeh_colors[8],
legend="Separation Margin",
name="SM2",
)
hover = HoverTool(names=["SM2"])
hover.tooltips = [
("Critical Speed :", "@tag1"),
("Speed at 0.707 x peak amplitude :", "@tag2"),
]
mag_plot.add_tools(hover)
else:
SM = None
SM_ref = None
SMspeed = None
# amplitude limit in micrometers (A1) - API684 - SP6.8.2.11
A1 = 25.4 * np.sqrt(12000 / (30 * maxspeed / np.pi))
# amplitude from mode shape analysis
Amax = max(mag[dof])
# Scale Factor (Scc) - API684 - SP6.8.2.11 / API617 - 4.8.2.11
Scc = max(A1 / Amax, 0.5)
Scc = min(Scc, 6.0)
mag_plot.quad(
top=max(mag[dof]),
bottom=0,
left=minspeed,
right=maxspeed,
line_color="green",
line_width=0.8,
fill_alpha=0.2,
fill_color="green",
legend="Operation Speed Range",
)
source = ColumnDataSource(dict(x=freq_range, y=mag[dof]))
mag_plot.line(
x="x",
y="y",
source=source,
line_color=bokeh_colors[0],
line_alpha=1.0,
line_width=3,
)
mag_plot.line(
x=[minspeed, maxspeed],
y=[A1, A1],
line_dash="dotdash",
line_width=2.0,
line_color=bokeh_colors[1],
legend="Av1 - Mechanical test vibration limit",
)
mag_plot.add_layout(
Label(
x=(minspeed+maxspeed)/2,
y=A1,
angle=0,
text="Av1",
text_font_style="bold",
text_font_size="12pt",
text_baseline="top",
text_align="center",
y_offset=20,
)
)
mag_plot.width = 1280
mag_plot.height = 720
mag_plot.title.text_font_size = "14pt"
return mag_plot
def mode_shape(self, mode):
"""Evaluates the mode shapes for the rotor.
This analysis presents the vibration mode for each critical speed.
The importance is to locate the critical node, where the displacement
is the greatest, then apply loads for unbalance response (stability
level 1)
Parameters
----------
mode : int
the n'th vibration mode
Returns
-------
node_min, node_max : list
List with nodes where the largest absolute displacements occur
Example
-------
>>> rotor = rotor_example()
>>> report = Report(rotor=rotor,
... minspeed=400,
... maxspeed=1000,
... speed_units="rad/s")
>>> report.mode_shape(mode=0)
([], array([3.]))
"""
nodes_pos = self.rotor.nodes_pos
xn, yn, zn, xc, yc, zc_pos, nn = self.rotor.run_mode_shapes().calc_mode_shape(mode=mode)
# reduce 3D view to 2D view
vn = np.zeros(len(zn))
for i in range(len(zn)):
theta = np.arctan(xn[i] / yn[i])
vn[i] = xn[i] * np.sin(theta) + yn[i] * np.cos(theta)
# remove repetitive values from zn and vn
idx_remove = []
for i in range(1, len(zn)):
if zn[i] == zn[i-1]:
idx_remove.append(i)
zn = np.delete(zn, idx_remove)
vn = np.delete(vn, idx_remove)
aux_idx_max = argrelextrema(vn, np.greater)[0].tolist()
aux_idx_min = argrelextrema(vn, np.less)[0].tolist()
node_min = []
node_max = []
# verification of rigid modes
if len(aux_idx_max) == 0 and len(aux_idx_min) == 0:
idx_max = np.argmax(vn)
idx_min = np.argmin(vn)
# corrects the index by the removed points
for i in idx_remove:
if idx_min > i:
idx_min += 1
if idx_max > i:
idx_max += 1
node_max = np.round(np.array(idx_max) / nn)
node_min = np.round(np.array(idx_min) / nn)
if len(aux_idx_min) != 0:
idx_min = np.where(vn == min(vn[aux_idx_min]))[0].tolist()
# corrects the index by the removed points
for i in idx_remove:
if idx_min[0] > i:
idx_min[0] += 1
node_min = np.round(np.array(idx_min) / nn)
if len(aux_idx_max) != 0:
idx_max = np.where(vn == max(vn[aux_idx_max]))[0].tolist()
# corrects the index by the removed points
for i in idx_remove:
if idx_max[0] > i:
idx_max[0] += 1
node_max = np.round(np.array(idx_max) / nn)
TOOLS = "pan,wheel_zoom,box_zoom,reset,save,box_select"
plot = figure(
tools=TOOLS,
width=1400,
height=700,
title="Static Analysis",
x_axis_label="shaft lenght",
y_axis_label="lateral displacement",
)
nodes_pos = np.array(nodes_pos)
plot.line(zn, vn, line_width=4, line_color="red")
plot.line(
x=nodes_pos,
y=np.zeros(len(nodes_pos)),
line_dash="dotdash",
line_width=4.0,
line_color='black'
)
plot.circle(
x=nodes_pos[self.rotor.df_bearings['n'].tolist()],
y=np.zeros(len(self.rotor.df_bearings)),
size=12,
fill_color='black'
)
plot.add_layout(
Label(
x=np.mean(nodes_pos[self.rotor.df_bearings['n'].tolist()]),
y=0,
angle=0,
text="Bearing Span",
text_font_style="bold",
text_font_size="12pt",
text_baseline="top",
text_align="center",
y_offset=20,
)
)
for node in nodes_pos[self.rotor.df_bearings['n'].tolist()]:
plot.add_layout(
Span(
location=node,
dimension='height',
line_color='green',
line_dash='dashed',
line_width=3,
)
)
return node_min, node_max
def stability_level_1(self):
"""Stability analysis level 1.
This analysis consider a anticipated cross coupling QA based on
conditions at the normal operating point and the cross-coupling
required to produce a zero log decrement, Q0.
Components such as seals and impellers are not considered in this
analysis.
Parameters
----------
(Check what we need to calculate the applied cross coupling and list
them as parameters)
"""
pass
def stability_level_2(self):
"""Stability analysis level 2.
For the level 2 stability analysis additional sources that contribute
to the rotor stability shall be considered such as:
a) labyrinth seals;
b) damper seals;
c) impeller/blade flow aerodynamic effects;
d) internal friction.
Parameters
----------
(Check what we need to calculate the applied cross coupling and list
them as parameters)
"""
| 30.484288 | 96 | 0.473805 |
4a1f9028b007109383474eed542386605c635bdf | 305 | py | Python | semester-6/Python Practice/numpyPractice/program36.py | saranshbht/bsc-codes | 7386c09cc986de9c84947f7dea7db3dc42219a35 | [
"MIT"
] | 3 | 2021-03-22T12:07:14.000Z | 2021-08-30T17:28:23.000Z | semester-6/Python Practice/numpyPractice/program36.py | saranshbht/bsc-codes | 7386c09cc986de9c84947f7dea7db3dc42219a35 | [
"MIT"
] | null | null | null | semester-6/Python Practice/numpyPractice/program36.py | saranshbht/bsc-codes | 7386c09cc986de9c84947f7dea7db3dc42219a35 | [
"MIT"
] | null | null | null | import numpy as np
import os
x = np.arange(10)
y = np.arange(11, 20)
print("Original arrays:")
print(x)
print(y)
np.savez('temp_arra.npz', x=x, y=y)
print("Load arrays from the 'temp_arra.npz' file:")
with np.load('temp_arra.npz') as data:
x2 = data['x']
y2 = data['y']
print(x2)
print(y2) | 21.785714 | 51 | 0.639344 |
4a1f934ee1737c76931aed9736f023f76ae2983e | 1,193 | py | Python | pypy/module/cpyext/test/test_misc.py | olliemath/pypy | 8b873bd0b8bf76075aba3d915c260789f26f5788 | [
"Apache-2.0",
"OpenSSL"
] | 1 | 2021-06-02T23:02:09.000Z | 2021-06-02T23:02:09.000Z | pypy/module/cpyext/test/test_misc.py | olliemath/pypy | 8b873bd0b8bf76075aba3d915c260789f26f5788 | [
"Apache-2.0",
"OpenSSL"
] | 1 | 2021-03-30T18:08:41.000Z | 2021-03-30T18:08:41.000Z | pypy/module/cpyext/test/test_misc.py | olliemath/pypy | 8b873bd0b8bf76075aba3d915c260789f26f5788 | [
"Apache-2.0",
"OpenSSL"
] | 1 | 2022-03-30T11:42:37.000Z | 2022-03-30T11:42:37.000Z | from pypy.module.cpyext.test.test_cpyext import AppTestCpythonExtensionBase
class AppTestMisc(AppTestCpythonExtensionBase):
def test_pyos_inputhook(self):
module = self.import_extension('foo', [
("set_pyos_inputhook", "METH_NOARGS",
'''
PyOS_InputHook = &my_callback;
Py_RETURN_NONE;
'''),
("fetch_value", "METH_NOARGS",
'''
return PyLong_FromLong(my_flag);
'''),
], prologue='''
static long my_flag = 0;
static int my_callback(void) { return ++my_flag; }
''')
try:
import __pypy__
except ImportError:
skip("only runs on top of pypy")
assert module.fetch_value() == 0
__pypy__.pyos_inputhook()
assert module.fetch_value() == 0
module.set_pyos_inputhook() # <= set
assert module.fetch_value() == 0
__pypy__.pyos_inputhook()
assert module.fetch_value() == 1
__pypy__.pyos_inputhook()
assert module.fetch_value() == 2
assert module.fetch_value() == 2
| 33.138889 | 75 | 0.537301 |
4a1f93eb7d3fbcaeba411249f0ddf0e40a39a7a1 | 7,112 | py | Python | examples/libtest/DictTest.py | takipsizad/pyjs | 54db0ba6747aca744f9f3c3e985a17e913dfb951 | [
"ECL-2.0",
"Apache-2.0"
] | 739 | 2015-01-01T02:05:11.000Z | 2022-03-30T15:26:16.000Z | examples/libtest/DictTest.py | takipsizad/pyjs | 54db0ba6747aca744f9f3c3e985a17e913dfb951 | [
"ECL-2.0",
"Apache-2.0"
] | 33 | 2015-03-25T23:17:04.000Z | 2021-08-19T08:25:22.000Z | examples/libtest/DictTest.py | takipsizad/pyjs | 54db0ba6747aca744f9f3c3e985a17e913dfb951 | [
"ECL-2.0",
"Apache-2.0"
] | 167 | 2015-01-01T22:27:47.000Z | 2022-03-17T13:29:19.000Z | from UnitTest import UnitTest
class Foo:
pass
class DictTest(UnitTest):
def testStringKeys(self):
d = {'a':1, 'b':2, '3':3, 3:4}
self.assertEqual(d['a'], 1)
self.assertEqual(d['b'], 2)
# XXX: the length here is 3 because we have the same keys for "3"
# and 3
#self.assertEqual(len(d), 4)
# XXX: we have to have constant handling in the translator in
# order to distinguish ints and strings, so the lines below do
# not work
#self.assertEqual(d['3'], 3)
#self.assertEqual(d[3], 4)
try:
x = d['notthere']
self.fail('__getitem__ must raise KeyError')
except KeyError, e:
self.assertEqual(e.__class__.__name__, 'KeyError')
self.assertEqual(str(e), "'notthere'")
d = {}
self.assertEqual(1, d.setdefault('foo', 1))
self.assertEqual(1, d.setdefault('foo', 2))
self.assertEqual(1, d.get('foo', 2))
self.assertEqual(2, d.get('bar', 2))
self.assertEqual(3, d.setdefault('bar', 3))
d = {}
d.update({1:1})
d.update({2:2}, a='a')
self.assertEqual(d, {1:1, 2:2, 'a':'a'})
self.assertRaises(TypeError, getattr(d, 'update'), {}, {})
def testTupleKeys(self):
d = {}
d[1] = 1
d[(2,)] = 3
d[(1,1)] = 4
d[1,2] = 5
v = {(1, 2): 5, 1: 1, (1, 1): 4, (2,): 3}
self.assertTrue(d == v, "%r == %r" % (d, v))
d = {}
d[1] = 1
d[1,] = 2
v = {1: 1, (1,): 2}
self.assertEqual(d, v, "%r == %r bug #273" % (d, v))
def testObjectKeys(self):
f1 = Foo()
f2 = Foo()
f3 = Foo()
d = {f1:1, f2:2}
self.assertEqual(d[f1], 1)
self.assertEqual(d[f2], 2)
# keys's result has no implied order, so sort explicitly
keys = d.keys()
keys.sort()
expected = [f1, f2]
expected.sort()
self.assertEqual(keys, expected)
# values's result has no implied order, so sort explicitly
values = d.values()
values.sort()
# already sorted
expected = [1, 2]
self.assertEqual(values, expected)
self.failUnless(f1 in d)
self.failUnless(f2 in d)
self.failIf(f3 in d)
self.assertEqual(None, d.get(f3))
self.assertEqual(1, d.get(f3, 1))
d.update({f3:3})
self.failUnless(f3 in d)
self.assertEqual(d[f3], 3)
self.assertEqual(3, len(d))
dd = d.copy()
self.assertEqual(dd[f3], 3)
self.failIf(dd is d)
def testConstructor(self):
d = dict(([1, 1], [2,2]))
self.assertEqual(d[1], 1)
self.assertEqual(d[2], 2)
# XXX: the other constructors handle javascript objets only,
# we need the other constructors too, like:
# d = dict({1:1, 2:2})
d = dict(a=1, b=2)
self.assertEqual(d['a'], 1)
self.assertEqual(d['b'], 2)
d = dict([(1, 1), (2,2)], a=1, b=2)
self.assertEqual(d[1], 1)
self.assertEqual(d[2], 2)
self.assertEqual(d['a'], 1)
self.assertEqual(d['b'], 2)
def testIter(self):
d = {1: [1,2,3], 2: {'a': 1, 'b': 2, 'c': 3}}
a = 0
for k in d:
a += k
self.assertEqual(a, 3)
a = 0
for k in d[1]:
a += k
self.assertEqual(a, 6)
a = 0
for k in d[1][1:]:
a += k
self.assertEqual(a, 5)
a = 0
for k in d[2]:
a += d[2][k]
self.assertEqual(a, 6)
def testEnumerate(self):
d = {1: [1,2,3], 2: {'a': 1, 'b': 2, 'c': 3}}
sum_i = 0
sum_k = 0
for i, k in enumerate(d):
sum_i += i
sum_k += k
self.assertEqual(sum_i, 1)
self.assertEqual(sum_k, 3)
a = 0
for i, k in enumerate(sorted(d)):
self.assertEqual(i+1, k)
a += k
self.assertEqual(a, 3)
def testPop(self):
d = {'a': 1, 'b': 2, 'c': 3}
item = d.pop('d', 4)
self.assertEqual(item, 4)
try:
item = d.pop('d')
self.fail("Failed to raise KeyError on d.pop('d')")
except KeyError, e:
self.assertEqual(e[0], "d")
item = d.pop('b')
self.assertEqual(item, 2)
item = d.popitem()
self.assertTrue(item == ('a',1) or item == ('c',3), "popped invalid item %s" % str(item))
item = d.popitem()
try:
item = d.popitem()
except KeyError, e:
self.assertEqual(e[0], "popitem(): dictionary is empty")
def testCmp(self):
self.assertEqual(cmp({}, {}), 0)
self.assertEqual(cmp({},{'1':1}), -1)
self.assertEqual(cmp({'1':1}, {'1':1}), 0)
self.assertEqual(cmp({'1':1}, {'1':2}), -1)
self.assertEqual(cmp({'1':1}, {'1':0}), 1)
self.assertEqual(cmp({'1':1, '2':2}, {'1':0}), 1)
self.assertEqual(cmp({'1':1, '2':2}, {'1':2}), 1)
self.assertEqual(cmp({'1':1, '2':2}, {'2':2, '1':1}), 0)
def testEq(self):
self.failUnlessEqual({}, {})
self.failUnlessEqual({'1':1}, {'1':1})
self.failIfEqual({},{'1':1})
self.failIfEqual({'1':1},{'1':2})
# test for bug 362
try:
self.failIfEqual({'1':1}, [1,2], "Test for Bug 362")
except TypeError:
self.fail("Bug 362 - comparison between dict and non-dict")
class DICT(dict): pass
self.failUnlessEqual(DICT(), {})
self.failUnlessEqual({}, DICT())
self.failUnlessEqual(DICT(a=1), dict(a=1))
def testFromkeys(self):
d1 = {'a':1, 'b':1}
d2 = {'a':None, 'b':None}
self.assertEqual(dict.fromkeys(d1), d2)
self.assertEqual(dict.fromkeys(d1, None), d2)
self.assertEqual(dict.fromkeys(d1, 1), d1)
self.assertEqual(d1.fromkeys(d1), d2)
self.assertEqual(d1.fromkeys(d1, None), d2)
self.assertEqual(d1.fromkeys(d1, 1), d1)
self.assertEqual(dict.fromkeys('ab'), d2)
def testIteritems(self):
d1 = {1:2,3:4}
a,b = 0,0
for x,y in d1.iteritems():
a += x
b += y
self.assertEqual((a,b),(4,6))
class DICT(dict): pass
d2 = DICT({1:2,3:4})
a,b = 0,0
for x,y in d2.iteritems():
a += x
b += y
self.assertEqual((a,b),(4,6))
d3 = dict()
a,b = 0,0
for x,y in d3.iteritems():
a += x
b += y
self.assertEqual((a,b),(0,0))
def testUpdate(self):
d1 = {1:2,3:4}
d1.update({3:5,7:9})
self.assertEqual(d1[3],5)
try:
d1.update(((3,6),(9,12)))
self.assertEqual(d1[3],6)
except TypeError:
self.fail("Couldn't dict.update(...) with a tuple of pairs.")
def testOverrideDict(self):
dict = 1
self.assertEqual(dict, 1)
x = dict
self.assertEqual(x, 1)
| 28.222222 | 97 | 0.478346 |
4a1f943f930a0e149c07bebc75a8fd7171a9b872 | 1,277 | py | Python | geometry/test_point_in_polygon.py | nulano/osm-map-viewer | 1a4a4f3473cb83ce714fe3de370c7a0e904a5ea9 | [
"Apache-2.0"
] | null | null | null | geometry/test_point_in_polygon.py | nulano/osm-map-viewer | 1a4a4f3473cb83ce714fe3de370c7a0e904a5ea9 | [
"Apache-2.0"
] | null | null | null | geometry/test_point_in_polygon.py | nulano/osm-map-viewer | 1a4a4f3473cb83ce714fe3de370c7a0e904a5ea9 | [
"Apache-2.0"
] | null | null | null | import geometry
print('testing geometry.point_in_polygon')
test_count = 0
correct_tests = 0
failure = None
with open('testdata/point_in.in', 'r') as f:
count = int(f.readline())
for i in range(count):
node_count = int(f.readline())
polygon = []
for j in range(node_count):
x, y = map(float, f.readline().split())
polygon.append((x, y))
query_count = int(f.readline())
for j in range(query_count):
x, y, exp = map(float, f.readline().split())
expected = exp == 1
result = geometry.point_in_polygon((x, y), polygon)
fail = None
if not isinstance(result, bool):
fail = 'expected bool, got {}'.format(type(result))
elif result != expected:
fail = 'expected {}, got {}'.format(expected, result)
else:
correct_tests += 1
test_count += 1
if failure is None and fail is not None:
failure = 'for polygon:\n{}\n and point {}: {}'.format(polygon, (x, y), fail)
f.readline()
print('{} out of {} test cases correct.'.format(correct_tests, test_count))
if failure is not None:
print('First failed test: {}'.format(failure))
| 35.472222 | 93 | 0.550509 |
4a1f94ff3334e29ff50278a5f2cb11491735bd4c | 53,262 | py | Python | tensorflow/python/tpu/tpu_embedding.py | rvinas/tensorflow | 75d8b63cc2253a4e6c413cbd0a4c9d2d87c0a18b | [
"Apache-2.0"
] | 2 | 2019-05-08T10:02:57.000Z | 2019-05-08T10:02:59.000Z | tensorflow/python/tpu/tpu_embedding.py | rvinas/tensorflow | 75d8b63cc2253a4e6c413cbd0a4c9d2d87c0a18b | [
"Apache-2.0"
] | null | null | null | tensorflow/python/tpu/tpu_embedding.py | rvinas/tensorflow | 75d8b63cc2253a4e6c413cbd0a4c9d2d87c0a18b | [
"Apache-2.0"
] | null | null | null | # Copyright 2018 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""TPU embedding APIs."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import copy
import math
import re
import six
from tensorflow.core.protobuf.tpu import optimization_parameters_pb2
from tensorflow.core.protobuf.tpu import tpu_embedding_configuration_pb2 as elc
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import ops
from tensorflow.python.ops import array_ops
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.ops import init_ops
from tensorflow.python.ops import partitioned_variables
from tensorflow.python.ops import state_ops
from tensorflow.python.ops import variable_scope
from tensorflow.python.tpu import tpu_system_metadata as tpu_system_metadata_lib
from tensorflow.python.tpu.ops import tpu_ops
TRAINING = elc.TPUEmbeddingConfiguration.TRAINING
INFERENCE = elc.TPUEmbeddingConfiguration.INFERENCE
class TableConfig(
collections.namedtuple(
'TableConfig',
['vocabulary_size', 'dimension', 'initializer', 'combiner'])):
"""Embedding table configuration."""
def __new__(cls,
vocabulary_size,
dimension,
initializer=None,
combiner='mean'):
"""Embedding table configuration.
Args:
vocabulary_size: Number of vocabulary (/rows) in the table.
dimension: The embedding dimension.
initializer: A variable initializer function to be used in embedding
variable initialization. If not specified, defaults to
`tf.compat.v1.truncated_normal_initializer` with mean `0.0` and standard
deviation `1/sqrt(dimension)`.
combiner: A string specifying how to reduce if there are multiple entries
in a single row. Currently 'mean', 'sqrtn', 'sum' and None are
supported, with 'mean' the default. 'sqrtn' often achieves good
accuracy, in particular with bag-of-words columns. For more information,
see `tf.nn.embedding_lookup_sparse`. None is only valid for dense rather
than sparse tensors.
Returns:
`TableConfig`.
Raises:
ValueError: if `vocabulary_size` is not positive integer.
ValueError: if `dimension` is not positive integer.
ValueError: if `initializer` is specified and is not callable.
ValueError: if `combiner` is not supported.
"""
if not isinstance(vocabulary_size, int) or vocabulary_size < 1:
raise ValueError('Invalid vocabulary_size {}.'.format(vocabulary_size))
if not isinstance(dimension, int) or dimension < 1:
raise ValueError('Invalid dimension {}.'.format(dimension))
if (initializer is not None) and (not callable(initializer)):
raise ValueError('initializer must be callable if specified.')
if initializer is None:
initializer = init_ops.truncated_normal_initializer(
mean=0.0, stddev=1 / math.sqrt(dimension))
if combiner not in ('mean', 'sum', 'sqrtn', None):
raise ValueError('Invalid combiner {}'.format(combiner))
return super(TableConfig, cls).__new__(cls, vocabulary_size, dimension,
initializer, combiner)
class FeatureConfig(
collections.namedtuple(
'FeatureConfig',
['table_id', 'max_sequence_length'])):
"""Feature configuration."""
def __new__(cls,
table_id,
max_sequence_length=0):
"""Feature configuration.
Args:
table_id: Which table the feature is uses for embedding lookups.
max_sequence_length: If positive, the feature is a sequence feature with
the corresponding maximum sequence length. If the sequence is longer
than this, it will be truncated. If 0, the feature is not a sequence
feature.
Returns:
`FeatureConfig`.
Raises:
ValueError: if `max_sequence_length` non-negative.
"""
if not isinstance(max_sequence_length, int) or max_sequence_length < 0:
raise ValueError('Invalid max_sequence_length {}.'.format(
max_sequence_length))
return super(FeatureConfig, cls).__new__(cls, table_id, max_sequence_length)
class EnqueueData(
collections.namedtuple(
'EnqueueData',
['embedding_indices', 'sample_indices', 'aggregation_weights'])):
"""Data to be enqueued through generate_enqueue_ops()."""
def __new__(cls,
embedding_indices,
sample_indices=None,
aggregation_weights=None):
"""Data to be enqueued through generate_enqueue_ops().
Args:
embedding_indices: A rank 1 Tensors, indices into the embedding tables. It
corresponds to sp_ids.values in embedding_lookup_sparse(). Both int32
and int64 are allowed and will be converted to int32 internally.
sample_indices: A rank 2 Tensors specifying the training example to which
the corresponding embedding_indices and aggregation_weights values
belong. It corresponds to sp_ids.indices in embedding_lookup_sparse().
If it is None, we assume each embedding_indices belongs to a different
sample. Both int32 and int64 are allowed and will be converted to int32
internally.
aggregation_weights: A rank 1 Tensors containing per training example
aggregation weights. It corresponds to sp_weights.values in
embedding_lookup_sparse(). If it is None, we assume all weights are 1.
Both float32 and float64 are allowed and will be converted to float32
internally.
Returns:
An EnqueueData tuple.
"""
return super(EnqueueData, cls).__new__(cls, embedding_indices,
sample_indices, aggregation_weights)
@staticmethod
def from_sparse_tensor(sp_tensor, weights=None):
return EnqueueData(
sp_tensor.values,
sp_tensor.indices,
aggregation_weights=weights.values if weights is not None else None)
def get_enqueue_datas_list_from_sparse_tensors_list(sp_tensors_list):
"""Convenient function for generate_enqueue_ops().
Args:
sp_tensors_list: a list of dictionary mapping from string of feature names
to SparseTensor. Each dictionary is for one TPU core. Dictionaries for the
same host should be contiguous on the list.
Returns:
enqueue_datas_list: a list of dictionary mapping from string
of feature names to EnqueueData. Each dictionary is for one
TPU core. Dictionaries for the same host should be contiguous
on the list.
"""
enqueue_datas_list = []
for sp_tensors in sp_tensors_list:
enqueue_datas = collections.OrderedDict(
(k, EnqueueData.from_sparse_tensor(v))
for k, v in six.iteritems(sp_tensors))
enqueue_datas_list.append(enqueue_datas)
return enqueue_datas_list
AdamSlotVariableNames = collections.namedtuple(
'AdamSlotVariableNames', ['m', 'v'])
AdagradSlotVariableName = collections.namedtuple(
'AdagradSlotVariableName', ['accumulator'])
AdamSlotVariables = collections.namedtuple(
'AdamSlotVariables', ['m', 'v'])
AdagradSlotVariable = collections.namedtuple(
'AdagradSlotVariable', ['accumulator'])
VariablesAndOps = collections.namedtuple(
'VariablesAndOps',
['embedding_variables_by_table', 'slot_variables_by_table',
'load_ops', 'retrieve_ops']
)
class _OptimizationParameters(object):
"""Parameters common to all optimizations."""
def __init__(self, learning_rate, use_gradient_accumulation,
clip_weight_min, clip_weight_max):
self.learning_rate = learning_rate
self.use_gradient_accumulation = use_gradient_accumulation
self.clip_weight_min = clip_weight_min
self.clip_weight_max = clip_weight_max
class AdagradParameters(_OptimizationParameters):
"""Optimization parameters for Adagrad."""
def __init__(self,
learning_rate,
initial_accumulator=0.1,
use_gradient_accumulation=True,
clip_weight_min=None,
clip_weight_max=None):
"""Optimization parameters for Adagrad.
Args:
learning_rate: used for updating embedding table.
initial_accumulator: initial accumulator for Adagrad.
use_gradient_accumulation: setting this to `False` makes embedding
gradients calculation less accurate but faster. Please see
`optimization_parameters.proto` for details.
for details.
clip_weight_min: the minimum value to clip by; None means -infinity.
clip_weight_max: the maximum value to clip by; None means +infinity.
"""
super(AdagradParameters,
self).__init__(learning_rate, use_gradient_accumulation,
clip_weight_min, clip_weight_max)
if initial_accumulator <= 0:
raise ValueError('Adagrad initial_accumulator must be positive')
self.initial_accumulator = initial_accumulator
class AdamParameters(_OptimizationParameters):
"""Optimization parameters for Adam."""
def __init__(self,
learning_rate,
beta1=0.9,
beta2=0.999,
epsilon=1e-08,
lazy_adam=True,
sum_inside_sqrt=True,
use_gradient_accumulation=True,
clip_weight_min=None,
clip_weight_max=None):
"""Optimization parameters for Adam.
Args:
learning_rate: a floating point value. The learning rate.
beta1: A float value.
The exponential decay rate for the 1st moment estimates.
beta2: A float value.
The exponential decay rate for the 2nd moment estimates.
epsilon: A small constant for numerical stability.
lazy_adam: Use lazy Adam instead of Adam. Lazy Adam trains faster.
Please see `optimization_parameters.proto` for details.
sum_inside_sqrt: This improves training speed. Please see
`optimization_parameters.proto` for details.
use_gradient_accumulation: setting this to `False` makes embedding
gradients calculation less accurate but faster. Please see
`optimization_parameters.proto` for details.
for details.
clip_weight_min: the minimum value to clip by; None means -infinity.
clip_weight_max: the maximum value to clip by; None means +infinity.
"""
super(AdamParameters,
self).__init__(learning_rate, use_gradient_accumulation,
clip_weight_min, clip_weight_max)
if beta1 < 0. or beta1 >= 1.:
raise ValueError('beta1 must be between 0. and 1; got {}.'.format(beta1))
if beta2 < 0. or beta2 >= 1.:
raise ValueError('beta2 must be between 0. and 1; got {}.'.format(beta2))
if epsilon <= 0.:
raise ValueError('epsilon must be positive; got {}.'.format(epsilon))
if not use_gradient_accumulation and not lazy_adam:
raise ValueError(
'When disabling Lazy Adam, gradient accumulation must be used.')
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.lazy_adam = lazy_adam
self.sum_inside_sqrt = sum_inside_sqrt
class StochasticGradientDescentParameters(_OptimizationParameters):
"""Optimization parameters for stochastic gradient descent."""
def __init__(self, learning_rate, clip_weight_min=None,
clip_weight_max=None):
"""Optimization parameters for stochastic gradient descent.
Args:
learning_rate: a floating point value. The learning rate.
clip_weight_min: the minimum value to clip by; None means -infinity.
clip_weight_max: the maximum value to clip by; None means +infinity.
"""
super(StochasticGradientDescentParameters,
self).__init__(learning_rate, False, clip_weight_min, clip_weight_max)
DeviceConfig = collections.namedtuple('DeviceConfig',
['num_hosts', 'num_cores', 'job_name'])
class TPUEmbedding(object):
"""API for using TPU for embedding.
Example:
```
table_config_user = tpu_embedding.TableConfig(
vocabulary_size=4, dimension=2,
initializer=initializer, combiner='mean')
table_to_config_dict = {'video': table_config_video,
'user': table_config_user}
feature_to_config_dict = {'watched': tpu_embedding.FeatureConfig('video'),
'favorited': tpu_embedding.FeatureConfig('video'),
'friends': tpu_embedding.FeatureConfig('user')}
batch_size = 4
num_hosts = 1
optimization_parameters = tpu_embedding.AdagradParameters(1., 1.)
mode = tpu_embedding.TRAINING
embedding = tpu_embedding.TPUEmbedding(
table_to_config_dict, feature_to_config_dict,
batch_size, num_hosts, mode, optimization_parameters)
batch_size_per_core = embedding.batch_size_per_core
sparse_features_list = []
for host in hosts:
with ops.device(host):
for _ in range(embedding.num_cores_per_host):
sparse_features = {}
sparse_features['watched'] = sparse_tensor.SparseTensor(...)
sparse_features['favorited'] = sparse_tensor.SparseTensor(...)
sparse_features['friends'] = sparse_tensor.SparseTensor(...)
sparse_features_list.append(sparse_features)
enqueue_ops = embedding.generate_enqueue_ops(sparse_features_list)
embedding_variables_and_ops = embedding.create_variables_and_ops()
def computation():
activations = embedding.get_activations()
loss = compute_loss(activations)
base_optimizer = gradient_descent.GradientDescentOptimizer(
learning_rate=1)
cross_shard_optimizer = tpu_optimizer.CrossShardOptimizer(
base_optimizer)
train_op = cross_shard_optimizer.minimize(loss)
gradients = (
tpu_embedding_gradient.get_gradients_through_compute_gradients(
cross_shard_optimizer, loss, activations)
send_gradients_op = embedding.generate_send_gradients_op(gradients)
with ops.control_dependencies([train_op, send_gradients_op]):
loss = array_ops.identity(loss)
loss = tpu.shard(computation,
num_shards=embedding.num_cores)
with self.test_session() as sess:
sess.run(tpu.initialize_system(embedding_config=
embedding.config_proto))
sess.run(variables.global_variables_initializer())
sess.run(embedding_variables_and_ops.load_ops())
sess.run(enqueue_ops)
loss_val = sess.run(loss)
```
"""
# TODO(shizhiw): Consider addign a field to FeatureConfig that indicates that
# the feature should not be used to update embedding table (cr/204852758,
# cr/204940540). Also, this can support different combiners for different
# features within the same table.
# TODO(shizhiw, b/118512626): Remove `batch_size` from `__init__` and move it
# to `FeatureConfig`?
# TODO(shizhiw): will it be cleaner to make `table_to_config_dict` and
# `feature_to_config_dict` lists of `TableSpec` and `FeatureSpec`
# respectively?
# TODO(shizhiw): Consider adding `input_fn` as an option to remove boilerplate
# for-loops around construction of inputs.
# `optimization_parameter` applies to all tables. If the need arises,
# we can add `optimization_parameters` to `TableConfig` to override this
# global setting.
def __init__(self,
table_to_config_dict,
feature_to_config_dict,
batch_size,
mode,
master=None,
optimization_parameters=None,
cluster_def=None,
pipeline_execution_with_tensor_core=False,
partition_strategy='div',
device_config=None):
"""API for using TPU for embedding lookups.
Args:
table_to_config_dict: A dictionary mapping from string of table name to
`TableConfig`. Table refers to an embedding table, e.g. `params`
argument to `tf.nn.embedding_lookup_sparse()`.
feature_to_config_dict: A dictionary mapping from string of feature name
to `FeatureConfig`. Feature refers to ids to lookup in embedding table,
e.g. `sp_ids` argument to `tf.nn.embedding_lookup_sparse()`.
batch_size: An `int` representing the global batch size.
mode: `TRAINING` or `INFERENCE`.
master: A `string` representing the TensorFlow master to use.
optimization_parameters: `AdagradParameters`, `AdamParameters`,
`Stochasticgradientdescentparameters`. Must be set in training and must
be `None` in inference.
cluster_def: A ClusterDef object describing the TPU cluster.
pipeline_execution_with_tensor_core: setting this to `True` makes training
faster, but trained model will be different if step N and step N+1
involve the same set of embedding IDs. Please see
`tpu_embedding_configuration.proto` for details.
partition_strategy: A string, either 'mod' or 'div', specifying how to map
the lookup id to the embedding tensor. For more information see
`tf.nn.embedding_lookup_sparse`.
device_config: A DeviceConfig instance, used when `master` and
`cluster_def` are both `None`.
Raises:
ValueError: if any input is invalid.
"""
if partition_strategy not in ('div', 'mod'):
raise ValueError(
'Invalid partition_strategy {}'.format(partition_strategy))
self._partition_strategy = partition_strategy
_validate_table_to_config_dict(table_to_config_dict)
# Avoid nondeterminism from `Dict` iteration order by using `OrderedDict`.
self._table_to_config_dict = _create_ordered_dict(table_to_config_dict)
_validate_feature_to_config_dict(table_to_config_dict,
feature_to_config_dict)
self._feature_to_config_dict = _create_ordered_dict(feature_to_config_dict)
self._table_to_features_dict, self._table_to_num_features_dict = (
_create_table_to_features_and_num_features_dicts(
self._feature_to_config_dict))
self._combiners = _create_combiners(self._table_to_config_dict,
self._table_to_features_dict)
self._batch_size = batch_size
if master is None and cluster_def is None:
if device_config is None:
raise ValueError('When master and cluster_def are both None,'
'device_config must be set but is not.')
if device_config.num_cores % device_config.num_hosts:
raise ValueError('num_hosts ({}) should divide num_cores ({}) '
'but does not.'.format(device_config.num_cores,
device_config.num_hosts))
self._num_hosts = device_config.num_hosts
self._num_cores = device_config.num_cores
self._num_cores_per_host = self._num_cores // self._num_hosts
self._hosts = [
'{}/replica:0/task:{}/device:CPU:0'.format(device_config.job_name, i)
for i in range(self._num_hosts)
]
else:
tpu_system_metadata = (
tpu_system_metadata_lib._query_tpu_system_metadata( # pylint: disable=protected-access
master,
cluster_def=cluster_def))
if tpu_system_metadata.num_cores == 0:
raise ValueError('TPUEmbedding needs TPUs, but master {} does not have '
'TPUs.'.format(master))
self._num_hosts = tpu_system_metadata.num_hosts
master_job_name = tpu_system_metadata_lib.master_job(master, cluster_def)
self._hosts = []
for device in tpu_system_metadata.devices:
if 'device:CPU:' in device.name and (
master_job_name is None or master_job_name in device.name):
self._hosts.append(device.name)
self._num_cores_per_host = tpu_system_metadata.num_of_cores_per_host
self._num_cores = tpu_system_metadata.num_cores
_validate_batch_size(self._batch_size, self._num_cores)
self._batch_size_per_core = self._batch_size // self._num_cores
# TODO(shizhiw): remove `mode`?
if mode == TRAINING:
_validate_optimization_parameters(optimization_parameters)
self._optimization_parameters = optimization_parameters
elif mode == INFERENCE:
if optimization_parameters is not None:
raise ValueError('`optimization_parameters` should be `None` '
'for inference mode.')
self._optimization_parameters = (
StochasticGradientDescentParameters(1.))
else:
raise ValueError('`mode` only supports {} and {}; got {}.'
.format(TRAINING, INFERENCE, mode))
self._mode = mode
# TODO(shizhiw): move `optimization_parameters` into `_optimizer_handler`
# and create special handler for inference that inherits from
# StochasticGradientDescentHandler with more user-friendly error message
# on get_slot().
self._optimizer_handler = _get_optimization_handler(
self._optimization_parameters)
self._pipeline_execution_with_tensor_core = (
pipeline_execution_with_tensor_core)
self._config_proto = self._create_config_proto()
@property
def hosts(self):
"""A list of device names for CPU hosts.
Returns:
A list of device names for CPU hosts.
"""
return copy.copy(self._hosts)
# TODO(shizhiw): change to num_tensor_cores_per_host to be more explicit and
# to be consistent with `tpu_embedding_configuration.proto`.
@property
def num_cores_per_host(self):
"""Number of TPU cores on a CPU host.
Returns:
Number of TPU cores on a CPU host.
"""
return self._num_cores_per_host
@property
def num_cores(self):
"""Total number of TPU cores on all hosts.
Returns:
Total number of TPU cores on all hosts.
"""
return self._num_cores
@property
def batch_size_per_core(self):
"""Batch size for each TPU core.
The sparse tensors in `sparse_features_list` to `generate_enqueue_ops`
must have batch dimension equal to this.
Returns:
Batch size for each TPU core.
"""
return self._batch_size_per_core
@property
def config_proto(self):
"""Create embedding config proto for `tpu.initialize_system()`.
Returns:
an `TPUEmbeddingConfiguration` proto describing the desired
configuration of the hardware embedding lookup tables, which
is passed to `tpu.initialize_system()`.
"""
return self._config_proto
@property
def table_to_config_dict(self):
return copy.copy(self._table_to_config_dict)
@property
def feature_to_config_dict(self):
return copy.copy(self._feature_to_config_dict)
@property
def table_to_features_dict(self):
return copy.copy(self._table_to_features_dict)
@property
def optimization_parameters(self):
return self._optimization_parameters
def _create_config_proto(self):
"""Create `TPUEmbeddingConfiguration`."""
config_proto = elc.TPUEmbeddingConfiguration()
for table in self._table_to_config_dict:
table_descriptor = config_proto.table_descriptor.add()
table_descriptor.name = table
table_config = self._table_to_config_dict[table]
table_descriptor.vocabulary_size = table_config.vocabulary_size
table_descriptor.dimension = table_config.dimension
table_descriptor.num_features = self._table_to_num_features_dict[table]
table_descriptor.optimization_parameters.learning_rate.constant = (
self._optimization_parameters.learning_rate)
table_descriptor.optimization_parameters.gradient_accumulation_status = (
optimization_parameters_pb2.GradientAccumulationStatus.ENABLED
if self._optimization_parameters.use_gradient_accumulation else
optimization_parameters_pb2.GradientAccumulationStatus.DISABLED)
if self._optimization_parameters.clip_weight_min is not None:
table_descriptor.optimization_parameters.clipping_limits.lower.value = (
self._optimization_parameters.clip_weight_min)
if self._optimization_parameters.clip_weight_max is not None:
table_descriptor.optimization_parameters.clipping_limits.upper.value = (
self._optimization_parameters.clip_weight_max)
self._optimizer_handler.set_optimization_parameters(table_descriptor)
config_proto.mode = self._mode
config_proto.batch_size_per_tensor_core = self._batch_size_per_core
config_proto.num_hosts = self._num_hosts
config_proto.num_tensor_cores = self._num_cores
config_proto.sharding_strategy = (
elc.TPUEmbeddingConfiguration.DIV_DEFAULT
if self._partition_strategy == 'div' else
elc.TPUEmbeddingConfiguration.MOD)
config_proto.pipeline_execution_with_tensor_core = (
self._pipeline_execution_with_tensor_core)
return config_proto
def create_variables_and_ops(self, embedding_variable_name_by_table=None,
slot_variable_names_by_table=None):
"""Create embedding and slot variables, with ops to load and retrieve them.
Args:
embedding_variable_name_by_table: A dictionary mapping from string of
table name to string of embedding variable name. If `None`,
defaults from `get_default_slot_variable_names()` will be used.
slot_variable_names_by_table: A dictionary mapping from string of table
name to `AdamSlotVariableNames`, `AdagradSlotVariableNames` etc. If
`None`, defaults from `get_default_slot_variable_names()` will be used.
Returns:
`tpu_embedding.VariablesAndOps` with:
A dictionary mapping from string of table name to embedding variables,
A dictionary mapping from string of table name to AdagradSlotVariable,
AdamSlotVariables etc with slot variables,
A function which returns a list of ops to load embedding and slot
variables from TPU to CPU.
A function which returns a list of ops to retrieve embedding and slot
variables from TPU to CPU.
"""
embedding_variables_by_table = {}
slot_variables_by_table = {}
load_op_fns = []
retrieve_op_fns = []
for table in self._table_to_config_dict:
if embedding_variable_name_by_table:
embedding_variable_name = embedding_variable_name_by_table[table]
else:
embedding_variable_name = table
if slot_variable_names_by_table:
slot_variable_names = slot_variable_names_by_table[table]
else:
slot_variable_names = (
self._optimizer_handler.get_default_slot_variable_names(table))
device_fn = _create_device_fn(self._hosts)
with ops.device(device_fn):
table_variables = _create_partitioned_variables(
name=embedding_variable_name,
num_hosts=self._num_hosts,
vocabulary_size=self._table_to_config_dict[table].vocabulary_size,
embedding_dimension=self._table_to_config_dict[table].dimension,
initializer=self._table_to_config_dict[table].initializer,
collections=[ops.GraphKeys.GLOBAL_VARIABLES])
embedding_variables_by_table[table] = table_variables
slot_variables_for_table, load_ops_fn, retrieve_ops_fn = (
self._optimizer_handler.create_variables_and_ops(
table, slot_variable_names, self._num_hosts,
self._table_to_config_dict[table], table_variables)
)
slot_variables_by_table[table] = slot_variables_for_table
load_op_fns.append(load_ops_fn)
retrieve_op_fns.append(retrieve_ops_fn)
def load_ops():
"""Calls and returns the load ops for each embedding table.
Returns:
A list of ops to load embedding and slot variables from CPU to TPU.
"""
load_ops_list = []
for load_op_fn in load_op_fns:
load_ops_list.extend(load_op_fn())
return load_ops_list
def retrieve_ops():
"""Calls and returns the retrieve ops for each embedding table.
Returns:
A list of ops to retrieve embedding and slot variables from TPU to CPU.
"""
retrieve_ops_list = []
for retrieve_op_fn in retrieve_op_fns:
retrieve_ops_list.extend(retrieve_op_fn())
return retrieve_ops_list
return VariablesAndOps(embedding_variables_by_table,
slot_variables_by_table,
load_ops, retrieve_ops)
def generate_enqueue_ops(self, enqueue_datas_list):
"""Generate enqueue ops.
Args:
enqueue_datas_list: a list of dictionary mapping from string
of feature names to EnqueueData. Each dictionary is for one
TPU core. Dictionaries for the same host should be contiguous
on the list.
Returns:
Ops to enqueue to TPU for embedding.
"""
self._validate_generate_enqueue_ops_enqueue_datas_list(enqueue_datas_list)
return [
self._generate_enqueue_op(
enqueue_datas, device_ordinal=i % self._num_cores_per_host)
for i, enqueue_datas in enumerate(enqueue_datas_list)
]
def _validate_generate_enqueue_ops_enqueue_datas_list(self,
enqueue_datas_list):
"""Validate `enqueue_datas_list`."""
feature_set = set(self._feature_to_config_dict.keys())
contiguous_device = None
for i, enqueue_datas in enumerate(enqueue_datas_list):
used_feature_set = set(enqueue_datas.keys())
# Check features are valid.
missing_feature_set = feature_set - used_feature_set
if missing_feature_set:
raise ValueError('`enqueue_datas_list[{}]` misses a feature that is '
'in `feature_to_config_dict`: {}.'.format(
i, missing_feature_set))
extra_feature_set = used_feature_set - feature_set
if extra_feature_set:
raise ValueError('`enqueue_datas_list[{}]` has a feature that is not '
'in `feature_to_config_dict`: {}.'.format(
i, extra_feature_set))
device = None
device_feature = None
for feature, enqueue_data in six.iteritems(enqueue_datas):
combiner = self._table_to_config_dict[
self._feature_to_config_dict[feature].table_id].combiner
if not isinstance(enqueue_data, EnqueueData):
raise ValueError('`enqueue_datas_list[{}]` has a feature that is '
'not mapped to `EnqueueData`. `feature`: {}'.format(
i, feature))
if enqueue_data.sample_indices is None and combiner:
raise ValueError('`enqueue_datas_list[{}]` has a feature that has '
'neither `EnqueueData` or `combiner`.'
'`feature`: {}, combiner: {}.'.format(
i, feature, combiner))
if (enqueue_data.sample_indices is not None and
enqueue_data.sample_indices.op.device !=
enqueue_data.embedding_indices.op.device):
raise ValueError(
'Device of sample_indices does not agree with '
'that of emebdding_indices for feature {}.'.format(feature))
if (enqueue_data.aggregation_weights is not None and
enqueue_data.aggregation_weights.op.device !=
enqueue_data.embedding_indices.op.device):
raise ValueError(
'Device of aggregation_weights does not agree with '
'that of emebdding_indices for feature {}.'.format(feature))
# Check all features are on the same device.
if device is None:
device = enqueue_data.embedding_indices.op.device
device_feature = feature
else:
if device != enqueue_data.embedding_indices.op.device:
raise ValueError('Devices are different between features in '
'`enqueue_datas_list[{}]`; '
'devices: {}, {}; features: {}, {}.'.format(
i, device,
enqueue_data.embedding_indices.op.device,
feature, device_feature))
if i % self._num_cores_per_host:
if device != contiguous_device:
raise ValueError('We expect the `enqueue_datas` which are on the '
'same host to be contiguous in '
'`enqueue_datas_list`, '
'`enqueue_datas_list[{}]` is on device {}, '
'but is expected to be on device {}.'.format(
i, device, contiguous_device))
else:
contiguous_device = device
def _generate_enqueue_op(self, enqueue_datas, device_ordinal):
enqueue_data0 = list(enqueue_datas.values())[0]
with ops.colocate_with(enqueue_data0.embedding_indices):
(sample_indices_list, embedding_indices_list, aggregation_weights_list,
table_ids, max_sequence_lengths) = (
self._format_for_tpu_embedding_sparse_tensor_batch(enqueue_datas))
return tpu_ops.enqueue_tpu_embedding_sparse_tensor_batch(
sample_indices_list,
embedding_indices_list,
aggregation_weights_list,
table_ids,
device_ordinal=device_ordinal,
combiners=self._combiners,
max_sequence_lengths=max_sequence_lengths)
def _format_for_tpu_embedding_sparse_tensor_batch(self, enqueue_datas):
"""Format sparse features for `enqueue_tpu_embedding_sparse_tensor_batch()`.
Args:
enqueue_datas: a `Dict` of tensors for embedding. Can be sparse or
dense.
Returns:
Arguments for `enqueue_tpu_embedding_sparse_tensor_batch()`.
"""
(sample_indices_list, embedding_indices_list, aggregation_weights_list,
table_ids, max_sequence_lengths) = [], [], [], [], []
for table_id, table in enumerate(self._table_to_features_dict):
features = self._table_to_features_dict[table]
for feature in features:
enqueue_data = enqueue_datas[feature]
sample_indices = (
enqueue_data.sample_indices
if enqueue_data.sample_indices is not None else array_ops.zeros(
(0,), dtype=dtypes.int32))
sample_indices_list.append(sample_indices)
aggregation_weights = (
enqueue_data.aggregation_weights if
enqueue_data.aggregation_weights is not None else array_ops.zeros(
(0,), dtype=dtypes.float32))
aggregation_weights_list.append(aggregation_weights)
embedding_indices_list.append(enqueue_data.embedding_indices)
table_ids.append(table_id)
max_sequence_lengths.append(
self._feature_to_config_dict[feature].max_sequence_length)
return (sample_indices_list, embedding_indices_list,
aggregation_weights_list, table_ids, max_sequence_lengths)
def get_activations(self):
"""Get activations for features.
This should be called within `computation` that is passed to
`tpu.replicate` and friends.
Returns:
A dictionary mapping from `String` of feature name to `Tensor`
of activation.
"""
recv_activations = tpu_ops.recv_tpu_embedding_activations(
num_outputs=len(self._table_to_config_dict),
config=self._config_proto.SerializeToString())
activations = collections.OrderedDict()
for table_id, table in enumerate(self._table_to_features_dict):
features = self._table_to_features_dict[table]
num_features = self._table_to_num_features_dict[table]
feature_index = 0
table_activations = array_ops.reshape(
recv_activations[table_id],
[self.batch_size_per_core, num_features, -1])
for feature in features:
seq_length = self._feature_to_config_dict[feature].max_sequence_length
if not seq_length:
activations[feature] = table_activations[:, feature_index, :]
feature_index = feature_index + 1
else:
activations[feature] = (
table_activations[:, feature_index:(feature_index+seq_length), :])
feature_index = feature_index + seq_length
return activations
def generate_send_gradients_op(self, feature_to_gradient_dict):
"""Send gradient to TPU embedding.
Args:
feature_to_gradient_dict: dict mapping feature names to gradient wrt
activations.
Returns:
SendTPUEmbeddingGradients Op.
Raises:
RuntimeError: If `mode` is not `TRAINING`.
"""
if self._mode != TRAINING:
raise RuntimeError('Only in training mode gradients need to '
'be sent to TPU embedding; got mode {}.'
.format(self._mode))
gradients = []
for table in self._table_to_features_dict:
features = self._table_to_features_dict[table]
table_gradients = []
for feature in features:
gradient = feature_to_gradient_dict[feature]
# Expand dims for non-sequence feature to match sequence features.
if gradient.shape.ndims == 2:
gradient = array_ops.expand_dims(gradient, 1)
table_gradients.append(gradient)
interleaved_table_grads = array_ops.reshape(
array_ops.concat(table_gradients, axis=1),
[-1, array_ops.shape(table_gradients[0])[-1]])
gradients.append(interleaved_table_grads)
return tpu_ops.send_tpu_embedding_gradients(
inputs=gradients, config=self.config_proto.SerializeToString())
def _validate_table_to_config_dict(table_to_config_dict):
"""Validate `table_to_config_dict`."""
for k, v in six.iteritems(table_to_config_dict):
if not isinstance(v, TableConfig):
raise ValueError('Value of `table_to_config_dict` must be of type '
'`TableConfig`, got {} for {}.'.format(type(v), k))
def _validate_feature_to_config_dict(table_to_config_dict,
feature_to_config_dict):
"""Validate `feature_to_config_dict`."""
used_table_set = set([feature.table_id
for feature in feature_to_config_dict.values()])
table_set = set(table_to_config_dict.keys())
unused_table_set = table_set - used_table_set
if unused_table_set:
raise ValueError('`table_to_config_dict` specifies table that is not '
'used in `feature_to_config_dict`: {}.'
.format(unused_table_set))
extra_table_set = used_table_set - table_set
if extra_table_set:
raise ValueError('`feature_to_config_dict` refers to a table that is not '
'specified in `table_to_config_dict`: {}.'
.format(extra_table_set))
def _validate_batch_size(batch_size, num_cores):
if batch_size % num_cores:
raise ValueError('`batch_size` is not a multiple of number of '
'cores. `batch_size`={}, `_num_cores`={}.'.format(
batch_size, num_cores))
def _validate_optimization_parameters(optimization_parameters):
if not isinstance(optimization_parameters, _OptimizationParameters):
raise ValueError('`optimization_parameters` must inherit from '
'`_OptimizationPramaters`. '
'`type(optimization_parameters)`={}'.format(
type(optimization_parameters)))
class _OptimizerHandler(object):
"""Interface class for handling optimizer specific logic."""
def __init__(self, optimization_parameters):
self._optimization_parameters = optimization_parameters
def set_optimization_parameters(self, table_descriptor):
raise NotImplementedError()
def get_default_slot_variable_names(self, table):
raise NotImplementedError()
def create_variables_and_ops(self, table, slot_variable_names, num_hosts,
table_config, table_variables):
raise NotImplementedError()
class _AdagradHandler(_OptimizerHandler):
"""Handles Adagrad specific logic."""
def __init__(self, optimization_parameters):
super(_AdagradHandler, self).__init__(optimization_parameters)
self._table_to_accumulator_variables_dict = {}
def set_optimization_parameters(self, table_descriptor):
table_descriptor.optimization_parameters.adagrad.SetInParent()
def get_default_slot_variable_names(self, table):
return AdagradSlotVariableName('{}/{}'.format(table, 'Adagrad'))
def create_variables_and_ops(self, table, slot_variable_names, num_hosts,
table_config, table_variables):
accumulator_initializer = init_ops.constant_initializer(
self._optimization_parameters.initial_accumulator)
accumulator_variables = _create_partitioned_variables(
name=slot_variable_names.accumulator,
num_hosts=num_hosts,
vocabulary_size=table_config.vocabulary_size,
embedding_dimension=table_config.dimension,
collections=[ops.GraphKeys.GLOBAL_VARIABLES],
initializer=accumulator_initializer)
slot_variables = AdagradSlotVariable(accumulator_variables)
def load_ops_fn():
"""Returns the retrieve ops for AdaGrad embedding tables.
Returns:
A list of ops to load embedding and slot variables from CPU to TPU.
"""
load_op_list = []
for host_id, table_variable, accumulator_variable in (zip(
range(num_hosts), table_variables, accumulator_variables)):
with ops.colocate_with(table_variable):
load_parameters_op = (
tpu_ops.load_tpu_embedding_adagrad_parameters(
parameters=table_variable,
accumulators=accumulator_variable,
table_name=table,
num_shards=num_hosts,
shard_id=host_id))
load_op_list.append(load_parameters_op)
return load_op_list
def retrieve_ops_fn():
"""Returns the retrieve ops for AdaGrad embedding tables.
Returns:
A list of ops to retrieve embedding and slot variables from TPU to CPU.
"""
retrieve_op_list = []
for host_id, table_variable, accumulator_variable in (zip(
range(num_hosts), table_variables, accumulator_variables)):
with ops.colocate_with(table_variable):
retrieved_table, retrieved_accumulator = (
tpu_ops.retrieve_tpu_embedding_adagrad_parameters(
table_name=table,
num_shards=num_hosts,
shard_id=host_id))
retrieve_parameters_op = control_flow_ops.group(
state_ops.assign(table_variable, retrieved_table),
state_ops.assign(accumulator_variable, retrieved_accumulator))
retrieve_op_list.append(retrieve_parameters_op)
return retrieve_op_list
return slot_variables, load_ops_fn, retrieve_ops_fn
class _AdamHandler(_OptimizerHandler):
"""Handles Adam specific logic."""
def __init__(self, optimization_parameters):
super(_AdamHandler, self).__init__(optimization_parameters)
self._table_to_m_variables_dict = {}
self._table_to_v_variables_dict = {}
def set_optimization_parameters(self, table_descriptor):
table_descriptor.optimization_parameters.adam.beta1 = (
self._optimization_parameters.beta1)
table_descriptor.optimization_parameters.adam.beta2 = (
self._optimization_parameters.beta2)
table_descriptor.optimization_parameters.adam.epsilon = (
self._optimization_parameters.epsilon)
table_descriptor.optimization_parameters.adam.use_non_lazy_adam = (
not self._optimization_parameters.lazy_adam)
table_descriptor.optimization_parameters.adam.use_sum_inside_sqrt = (
self._optimization_parameters.sum_inside_sqrt)
def get_default_slot_variable_names(self, table):
return AdamSlotVariableNames('{}/{}/m'.format(table, 'Adam'),
'{}/{}/v'.format(table, 'Adam'))
def create_variables_and_ops(self, table, slot_variable_names, num_hosts,
table_config, table_variables):
m_initializer = init_ops.zeros_initializer()
m_variables = _create_partitioned_variables(
name=slot_variable_names.m,
num_hosts=num_hosts,
vocabulary_size=table_config.vocabulary_size,
embedding_dimension=table_config.dimension,
collections=[ops.GraphKeys.GLOBAL_VARIABLES],
initializer=m_initializer)
v_initializer = init_ops.zeros_initializer()
v_variables = _create_partitioned_variables(
name=slot_variable_names.v,
num_hosts=num_hosts,
vocabulary_size=table_config.vocabulary_size,
embedding_dimension=table_config.dimension,
collections=[ops.GraphKeys.GLOBAL_VARIABLES],
initializer=v_initializer)
slot_variables = AdamSlotVariables(m_variables, v_variables)
def load_ops_fn():
"""Returns the retrieve ops for AdaGrad embedding tables.
Returns:
A list of ops to load embedding and slot variables from CPU to TPU.
"""
load_op_list = []
for host_id, table_variable, m_variable, v_variable in (zip(
range(num_hosts), table_variables,
m_variables, v_variables)):
with ops.colocate_with(table_variable):
load_parameters_op = (
tpu_ops.load_tpu_embedding_adam_parameters(
parameters=table_variable,
momenta=m_variable,
velocities=v_variable,
table_name=table,
num_shards=num_hosts,
shard_id=host_id))
load_op_list.append(load_parameters_op)
return load_op_list
def retrieve_ops_fn():
"""Returns the retrieve ops for Adam embedding tables.
Returns:
A list of ops to retrieve embedding and slot variables from TPU to CPU.
"""
retrieve_op_list = []
for host_id, table_variable, m_variable, v_variable in (zip(
range(num_hosts), table_variables,
m_variables, v_variables)):
with ops.colocate_with(table_variable):
retrieved_table, retrieved_m, retrieved_v = (
tpu_ops.retrieve_tpu_embedding_adam_parameters(
table_name=table,
num_shards=num_hosts,
shard_id=host_id))
retrieve_parameters_op = control_flow_ops.group(
state_ops.assign(table_variable, retrieved_table),
state_ops.assign(m_variable, retrieved_m),
state_ops.assign(v_variable, retrieved_v))
retrieve_op_list.append(retrieve_parameters_op)
return retrieve_op_list
return slot_variables, load_ops_fn, retrieve_ops_fn
class _StochasticGradientDescentHandler(_OptimizerHandler):
"""Handles stochastic gradient descent specific logic."""
def set_optimization_parameters(self, table_descriptor):
(table_descriptor.optimization_parameters.stochastic_gradient_descent
.SetInParent())
def get_default_slot_variable_names(self, table):
return None
def create_variables_and_ops(self, table, slot_variable_names, num_hosts,
table_config, table_variables):
del table_config
def load_ops_fn():
"""Returns the retrieve ops for AdaGrad embedding tables.
Returns:
A list of ops to load embedding and slot variables from CPU to TPU.
"""
load_op_list = []
for host_id, table_variable in (zip(
range(num_hosts), table_variables)):
with ops.colocate_with(table_variable):
load_parameters_op = (
tpu_ops
.load_tpu_embedding_stochastic_gradient_descent_parameters(
parameters=table_variable,
table_name=table,
num_shards=num_hosts,
shard_id=host_id))
load_op_list.append(load_parameters_op)
return load_op_list
def retrieve_ops_fn():
"""Returns the retrieve ops for SGD embedding tables.
Returns:
A list of ops to retrieve embedding and slot variables from TPU to CPU.
"""
retrieve_op_list = []
for host_id, table_variable in (zip(
range(num_hosts), table_variables)):
with ops.colocate_with(table_variable):
retrieved_table = (
tpu_ops
.retrieve_tpu_embedding_stochastic_gradient_descent_parameters(
table_name=table,
num_shards=num_hosts,
shard_id=host_id))
retrieve_parameters_op = control_flow_ops.group(
state_ops.assign(table_variable, retrieved_table))
retrieve_op_list.append(retrieve_parameters_op)
return retrieve_op_list
return None, load_ops_fn, retrieve_ops_fn
def _get_optimization_handler(optimization_parameters):
if isinstance(optimization_parameters, AdagradParameters):
return _AdagradHandler(optimization_parameters)
elif isinstance(optimization_parameters, AdamParameters):
return _AdamHandler(optimization_parameters)
elif isinstance(optimization_parameters, StochasticGradientDescentParameters):
return _StochasticGradientDescentHandler(optimization_parameters)
else:
return NotImplementedError()
def _create_ordered_dict(d):
"""Create an OrderedDict from Dict."""
return collections.OrderedDict((k, d[k]) for k in sorted(d))
def _create_combiners(table_to_config_dict, table_to_features_dict):
"""Create a per feature list of combiners, ordered by table."""
combiners = []
for table in table_to_config_dict:
combiner = table_to_config_dict[table].combiner or 'sum'
combiners.extend([combiner] * len(table_to_features_dict[table]))
return combiners
def _create_table_to_features_and_num_features_dicts(feature_to_config_dict):
"""Create mapping from table to a list of its features."""
table_to_features_dict_tmp = {}
table_to_num_features_dict_tmp = {}
for feature, feature_config in six.iteritems(feature_to_config_dict):
if feature_config.table_id in table_to_features_dict_tmp:
table_to_features_dict_tmp[feature_config.table_id].append(feature)
else:
table_to_features_dict_tmp[feature_config.table_id] = [feature]
table_to_num_features_dict_tmp[feature_config.table_id] = 0
if feature_config.max_sequence_length == 0:
table_to_num_features_dict_tmp[feature_config.table_id] = (
table_to_num_features_dict_tmp[feature_config.table_id] + 1)
else:
table_to_num_features_dict_tmp[feature_config.table_id] = (
table_to_num_features_dict_tmp[feature_config.table_id] +
feature_config.max_sequence_length)
table_to_features_dict = collections.OrderedDict()
table_to_num_features_dict = collections.OrderedDict()
for table in sorted(table_to_features_dict_tmp):
table_to_features_dict[table] = sorted(table_to_features_dict_tmp[table])
table_to_num_features_dict[table] = table_to_num_features_dict_tmp[table]
return table_to_features_dict, table_to_num_features_dict
def _create_device_fn(hosts):
"""Create device_fn() to use with _create_partitioned_variables()."""
def device_fn(op):
"""Returns the `device` for `op`."""
part_match = re.match(r'.*/part_(\d+)(/|$)', op.name)
if part_match:
idx = int(part_match.group(1))
else:
raise RuntimeError('Internal Error: '
'Expected %s to contain /part_*.' % op.name)
device = hosts[idx]
return device
return device_fn
def _create_partitioned_variables(name,
num_hosts,
vocabulary_size,
embedding_dimension,
initializer,
collections=None): # pylint: disable=redefined-outer-name
"""Creates ParitionedVariables based on `num_hosts` for `table`."""
# TODO(shizhiw): automatically place embedding lookup elsewhere?
if vocabulary_size < num_hosts:
raise ValueError('`vocabulary_size`({}) is smaller than `num_hosts`({}). '
'As TPU embedding is not optimized for small tables, '
'please consider other ways for this embedding lookup.')
return list(variable_scope.get_variable(
name,
shape=(vocabulary_size, embedding_dimension),
partitioner=partitioned_variables.fixed_size_partitioner(num_hosts),
dtype=dtypes.float32,
initializer=initializer,
collections=collections,
trainable=False))
| 40.503422 | 97 | 0.689854 |
4a1f958a5aea262fd68456ecfaf022d37b53f832 | 712 | py | Python | gym/mountaincar_experiment.py | watate/spinningup | f05f04f6319e3972212448ccec080d4cac426884 | [
"MIT"
] | null | null | null | gym/mountaincar_experiment.py | watate/spinningup | f05f04f6319e3972212448ccec080d4cac426884 | [
"MIT"
] | null | null | null | gym/mountaincar_experiment.py | watate/spinningup | f05f04f6319e3972212448ccec080d4cac426884 | [
"MIT"
] | null | null | null | #MountainCarContinuous-v0
from spinup.utils.run_utils import ExperimentGrid
from spinup import td3
import tensorflow as tf
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--cpu', type=int, default=4)
parser.add_argument('--num_runs', type=int, default=3)
args = parser.parse_args()
eg = ExperimentGrid(name='ppo-bench')
eg.add('env_name', 'CartPole-v0', '', True)
eg.add('seed', [10*i for i in range(args.num_runs)])
eg.add('epochs', 10)
eg.add('steps_per_epoch', 4000)
eg.add('ac_kwargs:hidden_sizes', [(32,), (64,64)], 'hid')
eg.add('ac_kwargs:activation', [tf.nn.relu], '')
eg.run(ppo, num_cpu=args.cpu) | 33.904762 | 61 | 0.672753 |
4a1f967811f2c3083c556c3b73ae13c7505f139e | 2,652 | py | Python | fireworks_thinking.py | Bustedblah/fireworks | b7d8974a965a866e3e4b97f31124c11b14cb71e8 | [
"MIT"
] | 1 | 2020-05-14T01:23:20.000Z | 2020-05-14T01:23:20.000Z | fireworks_thinking.py | Bustedblah/fireworks | b7d8974a965a866e3e4b97f31124c11b14cb71e8 | [
"MIT"
] | null | null | null | fireworks_thinking.py | Bustedblah/fireworks | b7d8974a965a866e3e4b97f31124c11b14cb71e8 | [
"MIT"
] | null | null | null | #!/opt/local/bin/python
visible_cards_in_hands = []
visible_cards_in_discard_deck = []
top_cards_on_board = []
player_hand_knowledge = []
# Start
# Figure out who's turn it is
q = 'MATCH (t:Token {name: "Player_Turn" }), (p:Player) WHERE (t)-[:IS]->(p) RETURN p.name'
results = db.query(q, returns=(str))
active_player_name = results[0][0]
################ LOOK AT ALL POSSIBLE ATTAINABLE INFORMATION ################
# He looks at all the player's cards
q = 'MATCH (p:Player {name: "' + active_player_name +'" }), (c:Card) WHERE (p)-[:CAN_SEE]->(c) RETURN c.value, c.position, c.color, p.name'
results = db.query(q, returns=(int, int, str, str))
for r in results:
visible_cards_in_hands.extend([r[0],r[1],r[2],r[3]])
# He looks at what's been discarded
q = 'MATCH (d:Deck {name: "Discard_Deck" }), (c:Card) WHERE (d)-[:CONTAINS]->(c) RETURN c.value, c.color'
results = db.query(q, returns=(str))
for r in results:
visible_cards_in_discard_deck.extend([r[0],r[1]])
# He looks at the game board
q = 'MATCH (c:Card {c.column_order: "Top") RETURN c.value, c.color'
results = db.query(q, returns=(str))
for r in results:
top_cards_on_board.extend([r[0],r[1]])
# He thinks about the cards he has
q = 'MATCH (p:Player {name: "' + active_player_name +'" }), (ci:Card) WHERE (p)-[:KNOWS]->(ci) RETURN ci.value, ci.color, ci.name'
results = db.query(q, returns=(int, int, str, str))
for r in results:
player_hand_knowledge.extend([r[0],r[1],r[2]])
# See how many Info Tokens are available
q = 'MATCH (t:Token {type: "Info", }) WHERE t.used == False RETURN t.name'
results = db.query(q, returns=(str))
active_player_name = results[0][0]
################ THE PLAYER THINKS !!!!! ################
# Actions: 1) Gives information, 2) plays card
weight_give_info = 0
weight_play_card = 0
################ ASSESS THE NEED OF ALL THE OTHER CARDS TO BE PLAYED !!!!! ################
if strategy_look_at_card_hand_order == 1:
# Check the thing out ...
#
#
#
# He crunches through a couple of agreed to philosophies
# {Expanse of effort}
# He decides to throw a card away, put a card down, or to give advice
# He organizes his/her own card order if he/she picked up a card
# Next player Go & Repeat
# Game is done when either 1) there is one more round after draw deck = 0, 2) all the columns are done, or 3) there are 3 failures to put down.
# Strategies:
# Only observe X players
# Information means playable or don't play
# Complete knowledge first, before playing
# A player never gives info for a dead color
# A player can give info for a dead color if he should not throw out the next couple of cards. | 34.441558 | 143 | 0.660633 |
4a1f96991975823af2247e2359a8f815952a3e24 | 2,438 | py | Python | RaspCode/motors/movement.py | TamuAlex/RC_TankBot | 58da179f89c97d69a594cedc56a3300c99a00dd0 | [
"Apache-2.0"
] | null | null | null | RaspCode/motors/movement.py | TamuAlex/RC_TankBot | 58da179f89c97d69a594cedc56a3300c99a00dd0 | [
"Apache-2.0"
] | 23 | 2021-11-04T10:50:45.000Z | 2021-12-13T09:28:33.000Z | RaspCode/motors/movement.py | TamuAlex/RC_TankBot | 58da179f89c97d69a594cedc56a3300c99a00dd0 | [
"Apache-2.0"
] | null | null | null | import motors
'''
Authors:
Alejandro Ortega Martinez: [email protected]
Juan Luis Garcia Gonzalez: [email protected]
'''
'''
Wrap class to define functions for moving the motors,
given the desired direction
It uses the motors library to iteract with the motors
at lower level
'''
class Movement:
def __init__(self):
pass
'''
Function that makes the robot move forward
'''
def forward(self):
#First both motors are enabled
motors.GPIOSet(motors.ENA)
motors.GPIOSet(motors.ENB)
#Then the direction is stablished
motors.GPIOSet(motors.IN1)
motors.GPIOClr(motors.IN2)
motors.GPIOSet(motors.IN3)
motors.GPIOClr(motors.IN4)
'''
Function that makes the robot move backward
'''
def back(self):
#First both motors are enabled
motors.GPIOSet(motors.ENA)
motors.GPIOSet(motors.ENB)
#Then the direction is stablished
motors.GPIOClr(motors.IN1)
motors.GPIOSet(motors.IN2)
motors.GPIOClr(motors.IN3)
motors.GPIOSet(motors.IN4)
'''
Function that makes the robot turn left
'''
def left(self):
#First only the right motor is enabled
motors.GPIOSet(motors.ENA)
motors.GPIOSet(motors.ENB)
#Then the direction is stablished
motors.GPIOSet(motors.IN1)
motors.GPIOClr(motors.IN2)
motors.GPIOClr(motors.IN3)
motors.GPIOSet(motors.IN4)
'''
Function that makes the robot turn right
'''
def right(self):
#First only the left motor is enabled
motors.GPIOSet(motors.ENA)
motors.GPIOSet(motors.ENB)
#Then the direction is stablished
motors.GPIOClr(motors.IN1)
motors.GPIOSet(motors.IN2)
motors.GPIOSet(motors.IN3)
motors.GPIOClr(motors.IN4)
'''
Function that makes the robot stop
'''
def stop(self):
#First both motors are disabled
motors.GPIOClr(motors.ENA)
motors.GPIOClr(motors.ENB)
#Then the direction is disabled
motors.GPIOClr(motors.IN1)
motors.GPIOClr(motors.IN2)
motors.GPIOClr(motors.IN3)
motors.GPIOClr(motors.IN4)
def setSpeed(self, speed):
motors.setSpeed(speed)
def getSpeed():
return motors.getSpeed() | 25.663158 | 60 | 0.611157 |
4a1f96b05c411192ba7f31908baaeca076432642 | 1,652 | py | Python | src/common/dynamiccode/dynamiccode.py | catarinaacsilva/security_auction | f0b76ad47ca8cc211fd90712c2090b8e5ff934a5 | [
"MIT"
] | null | null | null | src/common/dynamiccode/dynamiccode.py | catarinaacsilva/security_auction | f0b76ad47ca8cc211fd90712c2090b8e5ff934a5 | [
"MIT"
] | 1 | 2021-06-01T23:30:44.000Z | 2021-06-01T23:30:44.000Z | src/common/dynamiccode/dynamiccode.py | catarinaacsilva/security_auction | f0b76ad47ca8cc211fd90712c2090b8e5ff934a5 | [
"MIT"
] | null | null | null | import sys
import logging
from RestrictedPython import compile_restricted
from RestrictedPython import safe_builtins
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger('DC')
logger.setLevel(logging.DEBUG)
class DynamicCode:
@staticmethod
def run_dynamic(identity, value, times, prev_value, code):
'''
Runs dynamic code with the given values, returns boolean result
'''
result = DynamicCode.run(identity, value, times, prev_value, code)
return True if result[0] and result[1] else False
@staticmethod
def check_code(code):
'''
Checks dynamic code syntax and runs it with an example.
returns tuple (result, message)
result - the code passed or not
message - error message when result is False
'''
result = DynamicCode.run(12345678, 20, 2, 10, code)
return result
@staticmethod
def run(identity, value, times, prev_value, code):
'''
Runs code on safe sandbox
'''
logger.debug('%d %d %d %d', identity, value, times, prev_value)
func = "def test(identity, value, times, prev_value): \n"
end = "r = test(%d, %d, %d, %d)" % (identity, value, times, prev_value)
code = func + code + "\n" + end
try:
loc = {}
c = compile_restricted(code, "dyncode", 'exec')
exec(c, {'__builtins__': safe_builtins}, loc)
return (True, loc['r'])
except Exception as e:
return (False, e)
| 30.036364 | 103 | 0.592615 |
4a1f96cf491ede58daa20b1d366630a1f73d6d30 | 2,568 | py | Python | data/cirq_new/cirq_program/startCirq_noisy933.py | UCLA-SEAL/QDiff | d968cbc47fe926b7f88b4adf10490f1edd6f8819 | [
"BSD-3-Clause"
] | null | null | null | data/cirq_new/cirq_program/startCirq_noisy933.py | UCLA-SEAL/QDiff | d968cbc47fe926b7f88b4adf10490f1edd6f8819 | [
"BSD-3-Clause"
] | null | null | null | data/cirq_new/cirq_program/startCirq_noisy933.py | UCLA-SEAL/QDiff | d968cbc47fe926b7f88b4adf10490f1edd6f8819 | [
"BSD-3-Clause"
] | null | null | null | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 5/15/20 4:49 PM
# @File : grover.py
# qubit number=4
# total number=24
import cirq
import cirq.google as cg
from typing import Optional
import sys
from math import log2
import numpy as np
#thatsNoCode
def make_circuit(n: int, input_qubit):
c = cirq.Circuit() # circuit begin
c.append(cirq.H.on(input_qubit[0])) # number=1
c.append(cirq.H.on(input_qubit[1])) # number=2
c.append(cirq.H.on(input_qubit[1])) # number=7
c.append(cirq.H.on(input_qubit[2])) # number=3
c.append(cirq.H.on(input_qubit[3])) # number=4
c.append(cirq.H.on(input_qubit[0])) # number=21
c.append(cirq.CZ.on(input_qubit[3],input_qubit[0])) # number=22
c.append(cirq.H.on(input_qubit[0])) # number=23
c.append(cirq.H.on(input_qubit[0])) # number=16
c.append(cirq.CZ.on(input_qubit[3],input_qubit[0])) # number=17
c.append(cirq.H.on(input_qubit[0])) # number=18
c.append(cirq.SWAP.on(input_qubit[1],input_qubit[0])) # number=8
c.append(cirq.SWAP.on(input_qubit[1],input_qubit[0])) # number=9
c.append(cirq.SWAP.on(input_qubit[1],input_qubit[0])) # number=10
c.append(cirq.SWAP.on(input_qubit[1],input_qubit[0])) # number=11
c.append(cirq.SWAP.on(input_qubit[1],input_qubit[0])) # number=12
c.append(cirq.SWAP.on(input_qubit[1],input_qubit[0])) # number=13
c.append(cirq.SWAP.on(input_qubit[3],input_qubit[0])) # number=14
c.append(cirq.SWAP.on(input_qubit[3],input_qubit[0])) # number=15
c.append(cirq.SWAP.on(input_qubit[3],input_qubit[0])) # number=19
c.append(cirq.SWAP.on(input_qubit[3],input_qubit[0])) # number=20
# circuit end
c.append(cirq.measure(*input_qubit, key='result'))
return c
def bitstring(bits):
return ''.join(str(int(b)) for b in bits)
if __name__ == '__main__':
qubit_count = 4
input_qubits = [cirq.GridQubit(i, 0) for i in range(qubit_count)]
circuit = make_circuit(qubit_count,input_qubits)
circuit = cg.optimized_for_sycamore(circuit, optimizer_type='sqrt_iswap')
circuit_sample_count =2820
circuit = circuit.with_noise(cirq.depolarize(p=0.01))
simulator = cirq.Simulator()
result = simulator.run(circuit, repetitions=circuit_sample_count)
frequencies = result.histogram(key='result', fold_func=bitstring)
writefile = open("../data/startCirq_noisy933.csv","w+")
print(format(frequencies),file=writefile)
print("results end", file=writefile)
print(circuit.__len__(), file=writefile)
print(circuit,file=writefile)
writefile.close() | 35.178082 | 77 | 0.689642 |
4a1f986dc3ccae0e464c9a708c380174afd1b538 | 43,102 | py | Python | tests/test_views.py | conformist-mw/aldryn-accounts | e4bd60354547945a8e80cc692c0080582dd0d846 | [
"MIT"
] | null | null | null | tests/test_views.py | conformist-mw/aldryn-accounts | e4bd60354547945a8e80cc692c0080582dd0d846 | [
"MIT"
] | 1 | 2019-05-29T03:49:39.000Z | 2019-05-29T09:40:04.000Z | tests/test_views.py | conformist-mw/aldryn-accounts | e4bd60354547945a8e80cc692c0080582dd0d846 | [
"MIT"
] | 6 | 2019-03-05T15:19:26.000Z | 2021-12-16T20:50:21.000Z | # -*- coding: utf-8 -*-
from __future__ import unicode_literals
import datetime
from django.contrib.auth.models import User
from django.contrib.auth import SESSION_KEY
from django.contrib.messages import get_messages
from django.core import mail
from django.test import override_settings
from django.core.urlresolvers import reverse
from django.utils import unittest
from django.utils.translation import override
from aldryn_accounts.models import SignupCode, EmailConfirmation, EmailAddress
# use aldryn account patched settings
from aldryn_accounts.conf import settings
from .base import AllAccountsApphooksTestCase
class GetViewUrlMixin(object):
view_name = ''
def get_view_url(self, view_name=None, **kwargs):
if view_name is None:
view_name = self.view_name
with override('en'):
view_url = reverse(view_name, kwargs=kwargs)
return view_url
class ViewsAssertionsMixin(object):
def assertMessagesContains(self, response, text):
"""
Test if provided text is in response messages.
"""
storage = get_messages(response.wsgi_request)
messages = [msg.message for msg in storage]
self.assertIn(text, messages)
# session engine is hardcoded in djangocms-helper (atm v0.9.4), so override
# per test case
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class SignupViewTestCase(GetViewUrlMixin, AllAccountsApphooksTestCase):
view_name = "accounts_signup"
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=True)
def test_get_not_logged_in_no_code(self):
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertContains(response, 'New? Register now')
self.assertRedirects()
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=False)
def test_get_not_logged_in_no_code(self):
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertContains(response, 'Signup is currently closed')
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=False)
def test_get_not_logged_with_not_valid_code(self):
data = {
'code': 'not valid code',
}
view_url = self.get_view_url()
response = self.client.get(view_url, data=data)
self.assertContains(response, 'Signup is currently closed')
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=False)
def test_get_not_logged_with_valid_code(self):
random_code = self.rand_str()
new_code = SignupCode.create(code=random_code)
new_code.save()
data = {
'code': new_code.code,
}
view_url = self.get_view_url()
response = self.client.get(view_url, data=data)
self.assertContains(response, 'New? Register now')
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=False)
def test_post_with_not_valid_code(self):
data = {
'code': 'not valid code',
'email': '[email protected]',
}
view_url = self.get_view_url()
response = self.client.post(view_url, data=data)
self.assertContains(response, 'Signup is currently closed')
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=False)
def test_get_with_valid_code(self):
# ensure there is no users
self.assertEqual(User.objects.count(), 0)
random_code = self.rand_str()
new_code = SignupCode.create(code=random_code)
new_code.save()
data = {
'code': new_code.code,
'email': '[email protected]',
}
view_url = self.get_view_url()
response = self.client.post(view_url, data=data)
self.assertEqual(User.objects.count(), 1)
@override_settings(ALDRYN_ACCOUNTS_OPEN_SIGNUP=False)
def test_get_with_logged_in_user(self):
user = self.get_standard_user()
view_url = self.get_view_url()
self.client.login(username='standard', password='standard')
response = self.client.get(view_url, follow=True)
# ensure we had a redirect, redirect_chain will look like
# [('http://testserver/', 302), ('http://testserver/en/', 302)]
root_url = self.root_page.get_absolute_url()
self.assertRedirects(response, root_url)
class SignupEmailResendConfirmationViewTestCase(GetViewUrlMixin,
AllAccountsApphooksTestCase):
view_name = "aldryn_accounts:accounts_signup_email_resend_confirmation"
def test_get_with_not_existing_email_in_get_params(self):
"""
Tests get content with email present in get params, but email doesn't
exists
"""
# TODO: Check the desired behavior, adjust accordingly
# should we redirect or 404 if email does not exists or display the
# form anyway and validate only on post requests?
view_url = self.get_view_url()
data = {
'email': '[email protected]'
}
response = self.client.get(view_url, data=data)
# check the text from template
expected_string = 'confirmation email to {email} again'.format(**data)
self.assertContains(
response, expected_string)
# and button
self.assertContains(
response, 'Yes, send me the confirmation email again')
def test_post_with_invalid_email(self):
data = {
'email': '[email protected]',
}
mail.outbox = []
view_url = self.get_view_url()
response = self.client.post(view_url, data=data)
self.assertEqual(response.status_code, 302)
self.assertEqual(len(mail.outbox), 0)
def test_post_with_valid_email(self):
user = self.get_standard_user()
test_email = '[email protected]'
new_confirmation = EmailConfirmation.objects.request(
user=user,
email=test_email,
)
mail.outbox = []
data = {
'email': new_confirmation.email,
}
view_url = self.get_view_url()
response = self.client.post(view_url, data=data)
self.assertEqual(len(mail.outbox), 1)
self.assertEqual(response.status_code, 302)
class SignupEmailConfirmationSentViewTestCase(GetViewUrlMixin,
AllAccountsApphooksTestCase):
view_name = 'aldryn_accounts:accounts_signup_email_confirmation_sent'
def test_get_no_email(self):
# TODO: Check the desired behavior, adjust accordingly
# should we redirect or 404 if the email is not present?
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertContains(response, 'We have sent you an email to')
def test_getwith_email(self):
test_email = '[email protected]'
data = {
'email': test_email,
}
lookup_string = 'We have sent you an email to <b>{0}</b>'
view_url = self.get_view_url()
response = self.client.get(view_url, data=data)
self.assertContains(response, lookup_string.format(test_email))
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class LoginLogoutViewsTestCase(AllAccountsApphooksTestCase):
def login(self, username='standard', password='standard'):
with override('en'):
login_url = reverse('login')
response = self.client.post(login_url, {
'username': username,
'password': password,
})
self.assertIn(SESSION_KEY, self.client.session)
return response
def test_login_view_get(self):
with override('en'):
login_url = reverse('login')
response = self.client.get(login_url)
self.assertEqual(response.status_code, 200)
def test_login_view_logins(self):
self.get_standard_user()
self.login()
def test_logout_get_not_logged_in_user(self):
self.get_standard_user()
with override('en'):
logout_url = reverse('logout')
response = self.client.get(logout_url)
self.assertEqual(response.status_code, 302)
self.assertNotIn(SESSION_KEY, self.client.session)
def test_logout_get_logged_in_user(self):
self.get_standard_user()
self.login()
# test logout
with override('en'):
logout_url = reverse('logout')
response = self.client.get(logout_url)
self.assertEqual(response.status_code, 200)
self.assertIn(SESSION_KEY, self.client.session)
def test_logout_post(self):
self.get_standard_user()
self.login()
# test logout
with override('en'):
logout_url = reverse('logout')
response = self.client.post(logout_url)
self.assertEqual(response.status_code, 302)
self.assertNotIn(SESSION_KEY, self.client.session)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class PasswordResetViewsTestCase(GetViewUrlMixin, AllAccountsApphooksTestCase):
view_name = 'accounts_password_reset_recover'
def test_get(self):
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertContains(response, 'Recover my password')
def test_post_with_not_valid_username(self):
view_url = self.get_view_url()
data = {
'username_or_email': 'not_existing'
}
mail.outbox = []
response = self.client.post(view_url, data=data)
# check that no email were sent
self.assertEqual(len(mail.outbox), 0)
# check that there is a validation error message
# original message "Sorry, this user doesn't exist.", but ' is escaped
self.assertContains(response, "Sorry, this user doesn't exist.")
def test_post_with_valid_username_no_primary_email(self):
# Since we cant blindly trust not confirmed emails, we need to ensure
# that emails with recovery are not sent to not confirmed emails.
user = self.get_standard_user()
view_url = self.get_view_url()
data = {
'username_or_email': user.username,
}
mail.outbox = []
response = self.client.post(view_url, data=data, follow=True)
# check that email was not sent
self.assertEqual(len(mail.outbox), 0)
expected_msg = "Sorry, this user doesn't have any verified email."
self.assertContains(response, expected_msg)
@override_settings(
ALDRYN_ACCOUNTS_RESTORE_PASSWORD_RAISE_VALIDATION_ERROR=False)
def test_post_with_valid_email_no_primary_email(self):
# Since we cant blindly trust not confirmed emails, we need to ensure
# that emails with recovery are not sent to not confirmed emails.
user = self.get_standard_user()
view_url = self.get_view_url()
data = {
'username_or_email': user.email,
}
mail.outbox = []
response = self.client.post(view_url, data=data, follow=True)
# check that email was not sent
self.assertEqual(len(mail.outbox), 0)
# ensure there was a redirect
self.assertGreater(len(response.redirect_chain), 0)
expected_message = 'An email was sent'.format(
user.email)
self.assertContains(response, expected_message)
@override_settings(
ALDRYN_ACCOUNTS_RESTORE_PASSWORD_RAISE_VALIDATION_ERROR=True)
def test_post_with_valid_email_no_primary_email_check_validation(self):
# Since we cant blindly trust not confirmed emails, we need to ensure
# that emails with recovery are not sent to not confirmed emails.
user = self.get_standard_user()
view_url = self.get_view_url()
data = {
'username_or_email': user.email,
}
mail.outbox = []
response = self.client.post(view_url, data=data, follow=True)
# check that email was not sent
self.assertEqual(len(mail.outbox), 0)
expected_msg = "Sorry, this user doesn't have any verified email."
self.assertContains(response, expected_msg)
@override_settings(
ALDRYN_ACCOUNTS_RESTORE_PASSWORD_RAISE_VALIDATION_ERROR=True)
def test_post_with_old_user_email_and_existing_primary(self):
# Since we cant blindly trust not confirmed emails, we need to ensure
# that emails with recovery are to confirmed emails.
user = self.get_standard_user()
primary_email = '[email protected]'
old_email = user.email
EmailAddress.objects.add_email(
user=user,
email=primary_email,
make_primary=True
)
view_url = self.get_view_url()
data = {
'username_or_email': old_email,
}
mail.outbox = []
response = self.client.post(view_url, data=data, follow=True)
# check that email was not sent
self.assertEqual(len(mail.outbox), 0)
# ensure there were no redirect
self.assertEqual(len(response.redirect_chain), 0)
expected_message = "Sorry, this user doesn't exist."
self.assertContains(response, expected_message)
@override_settings(
ALDRYN_ACCOUNTS_RESTORE_PASSWORD_RAISE_VALIDATION_ERROR=True)
def test_post_with_valid_email_and_primary_email_for_primary_email(self):
# Since we cant blindly trust not confirmed emails, we need to ensure
# that emails with recovery are to confirmed emails.
user = self.get_standard_user()
primary_email = '[email protected]'
email = EmailAddress.objects.add_email(
user=user,
email=primary_email,
make_primary=True
)
view_url = self.get_view_url()
data = {
'username_or_email': primary_email,
}
mail.outbox = []
response = self.client.post(view_url, data=data, follow=True)
# check that email was not sent
self.assertEqual(len(mail.outbox), 1)
# ensure there was a redirect
self.assertGreater(len(response.redirect_chain), 0)
# expect that email was sent to primary address
self.assertContains(response, primary_email)
msg = mail.outbox[0]
self.assertEqual(msg.to, [primary_email])
# ensure template text
expected_message = "An email was sent"
self.assertContains(response, expected_message)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ConfirmEmailViewTestCase(GetViewUrlMixin,
ViewsAssertionsMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_confirm_email'
def setUp(self):
super(ConfirmEmailViewTestCase, self).setUp()
# create user but don't make him active
self.user = self.get_standard_user()
self.user.is_active = False
self.user.save()
self.confirmation_object = EmailConfirmation.objects.request(
user=self.user, email='[email protected]', send=True)
# reset the outbox
mail.outbox = []
def test_get_not_existing_key(self):
view_url = self.get_view_url(key='notExistingKey')
response = self.client.get(view_url)
self.assertEqual(response.status_code, 404)
def test_get_valid_key(self):
view_url = self.get_view_url(key=self.confirmation_object.key)
response = self.client.get(view_url)
self.assertContains(response, 'confirm and login')
def test_post_with_not_valid_key(self):
view_url = self.get_view_url(key='notExistingKey')
response = self.client.post(view_url)
self.assertEqual(response.status_code, 404)
# check that login and user are not affected
self.assertNotIn(SESSION_KEY, self.client.session)
self.user = User.objects.get(pk=self.user.pk)
self.assertFalse(self.user.is_active)
def test_post_with_valid_key(self):
view_url = self.get_view_url(key=self.confirmation_object.key)
# ensure user was not logged in
self.assertNotIn(SESSION_KEY, self.client.session)
response = self.client.post(view_url, follow=True)
# test that success messages is present in response
self.assertMessagesContains(response,
'You have confirmed [email protected].')
self.assertGreater(len(response.redirect_chain), 0)
expected_url = self.page_profile_email_settings.get_absolute_url('en')
self.assertRedirects(response, expected_url)
# ensure user has been logged in after success
self.assertIn(SESSION_KEY, self.client.session)
# refresh user from db
self.user = User.objects.get(pk=self.user.pk)
self.assertTrue(self.user.is_active)
def test_post_with_verified_email_no_delete(self):
view_url = self.get_view_url(key=self.confirmation_object.key)
# ensure user was not logged in
self.assertNotIn(SESSION_KEY, self.client.session)
# confirm email, but leave the item
self.confirmation_object.confirm(delete=False)
mail.outbox = []
response = self.client.post(view_url, follow=True)
self.assertMessagesContains(
response,
'This email has already been verified with an other account.')
# ensure user was not logged in and not affected
self.assertNotIn(SESSION_KEY, self.client.session)
self.user = User.objects.get(pk=self.user.pk)
self.assertFalse(self.user.is_active)
def test_post_with_verified_email_returns404(self):
view_url = self.get_view_url(key=self.confirmation_object.key)
self.confirmation_object.confirm()
response = self.client.post(view_url)
self.assertEqual(response.status_code, 404)
def test_post_with_expired_key(self):
view_url = self.get_view_url(key=self.confirmation_object.key)
# ensure user was not logged in
self.assertNotIn(SESSION_KEY, self.client.session)
# expire the key
expire_days = getattr(
settings,
'ALDRYN_ACCOUNTS_EMAIL_CONFIRMATION_EXPIRE_DAYS', 5)
expire_days_delta = datetime.timedelta(days=expire_days + 1)
self.confirmation_object.sent_at -= expire_days_delta
self.confirmation_object.save()
mail.outbox = []
response = self.client.post(view_url, follow=True)
self.assertMessagesContains(response, 'The activation key has expired.')
# ensure user was not logged in and not affected
self.assertNotIn(SESSION_KEY, self.client.session)
self.user = User.objects.get(pk=self.user.pk)
self.assertFalse(self.user.is_active)
class CreateChangePasswordCommonTestCasesMixin(object):
def setUp(self):
super(CreateChangePasswordCommonTestCasesMixin, self).setUp()
self.user = self.get_standard_user()
def test_get_not_authenticated(self):
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertEqual(response.status_code, 302)
def _view_get_with_valid_user_no_assert(self):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
response = self.client.get(view_url)
return response
def _view_get_with_not_usable_user_password(self):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
self.user.set_unusable_password()
self.user.save()
response = self.client.get(view_url, follow=True)
return response
def test_post_with_not_authenticated_user(self):
view_url = self.get_view_url()
response = self.client.post(view_url)
self.assertEqual(response.status_code, 302)
def _test_post_with_valid_data(self, set_unusable_password=False):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
if set_unusable_password:
self.user.set_unusable_password()
self.user.save()
response = self.client.post(view_url, data=self.valid_data, follow=True)
self.client.logout()
# check that we can login with new password
login_result = self.client.login(
username=self.user.username, password=self.new_password)
self.assertTrue(login_result)
return response
def test_post_with_valid_data_no_extra_settings(
self, set_unusable_password=False):
self._test_post_with_valid_data(
set_unusable_password=set_unusable_password)
@override_settings(ALDRYN_ACCOUNTS_NOTIFY_PASSWORD_CHANGE=False)
def test_post_with_valid_data_dont_send_email(self,
set_unusable_password=False):
mail.outbox = []
response = self._test_post_with_valid_data(
set_unusable_password=set_unusable_password)
expected_url = self.page_profile_index.get_absolute_url('en')
self.assertRedirects(response, expected_url)
self.assertMessagesContains(response, 'Password successfully changed.')
self.assertEqual(len(mail.outbox), 0)
@override_settings(ALDRYN_ACCOUNTS_NOTIFY_PASSWORD_CHANGE=True)
def test_post_with_valid_data_and_send_email(self,
set_unusable_password=False):
mail.outbox = []
response = self._test_post_with_valid_data(
set_unusable_password=set_unusable_password)
expected_url = self.page_profile_index.get_absolute_url('en')
self.assertRedirects(response, expected_url)
self.assertMessagesContains(response, 'Password successfully changed.')
self.assertEqual(len(mail.outbox), 1)
def test_post_with_not_valid_data(self, set_unusable_password=False):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
if set_unusable_password:
self.user.set_unusable_password()
self.user.save()
response = self.client.post(view_url, data=self.invalid_data,
follow=True)
self.client.logout()
# check that we can't login with new password
login_result = self.client.login(
username=self.user.username, password=self.new_password)
self.assertFalse(login_result)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ChangePasswordViewTestCase(GetViewUrlMixin,
ViewsAssertionsMixin,
CreateChangePasswordCommonTestCasesMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_change_password'
new_password = 'new_password'
valid_data = {
'password_current': 'standard',
'password_new': new_password,
}
invalid_data = {
'password_current': 'wrong_password',
'password_new': new_password,
}
def test_get_with_valid_user(self):
response = self._view_get_with_valid_user_no_assert()
self.assertContains(response, 'set new password')
def test_get_with_not_usable_user_password(self):
response = self._view_get_with_not_usable_user_password()
expected_url = self.get_view_url(view_name='accounts_create_password')
self.assertRedirects(response, expected_url)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class CreatePasswordViewTestCase(GetViewUrlMixin,
ViewsAssertionsMixin,
CreateChangePasswordCommonTestCasesMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_create_password'
new_password = 'new_password'
valid_data = {
'password_new': new_password,
}
invalid_data = {
'password_new': '',
}
def test_get_with_valid_user(self):
response = self._view_get_with_valid_user_no_assert()
self.assertEqual(response.status_code, 302)
def test_get_with_not_usable_user_password(self):
response = self._view_get_with_not_usable_user_password()
self.assertContains(response, 'set new password')
def test_post_with_valid_data_no_extra_settings(self,
set_unusable_password=True):
super(CreatePasswordViewTestCase,
self).test_post_with_valid_data_no_extra_settings(
set_unusable_password=set_unusable_password)
def test_post_with_valid_data_dont_send_email(self,
set_unusable_password=True):
super(CreatePasswordViewTestCase,
self).test_post_with_valid_data_dont_send_email(
set_unusable_password=set_unusable_password)
def test_post_with_not_valid_data(self, set_unusable_password=True):
super(CreatePasswordViewTestCase, self).test_post_with_not_valid_data(
set_unusable_password=set_unusable_password)
def test_post_with_valid_data_and_send_email(self,
set_unusable_password=True):
super(CreatePasswordViewTestCase,
self).test_post_with_valid_data_and_send_email(
set_unusable_password=set_unusable_password)
class ProfileViewsCommonMixin(object):
def setUp(self):
super(ProfileViewsCommonMixin, self).setUp()
self.user = self.get_standard_user()
def _view_get_logged_in(self):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
response = self.client.get(view_url)
return response
def _view_get_not_logged_in(self):
view_url = self.get_view_url()
response = self.client.get(view_url)
return response
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileViewTestCase(GetViewUrlMixin,
ProfileViewsCommonMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_profile'
def test_get_not_logged_in(self):
response = self._view_get_not_logged_in()
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
response = self._view_get_logged_in()
expected_username = 'username: {0}'.format(self.user.username)
expected_user_email = 'email: {0}'.format(self.user.email)
self.assertContains(response, expected_username)
self.assertContains(response, expected_user_email)
@unittest.skip("Since social auth is not working - don't run this test cases.")
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileAssociationsViewTestCase(GetViewUrlMixin,
ProfileViewsCommonMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_profile_associations'
def test_get_not_logged_in(self):
response = self._view_get_not_logged_in()
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
response = self._view_get_logged_in()
self.assertContains(response, 'Connected accounts')
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileEmailListViewTestCase(GetViewUrlMixin,
ProfileViewsCommonMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_email_list'
def test_get_not_logged_in(self):
response = self._view_get_not_logged_in()
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
response = self._view_get_logged_in()
self.assertContains(response, 'Email addresses')
self.assertContains(response, 'add')
def test_get_contains_only_user_owned_itmes(self):
# standard user email addresses and confirmation objects
user_email_address = EmailAddress(
user=self.user,
email='[email protected]',
is_primary=True,
)
user_email_address.save()
user_email_confirmtaion = EmailConfirmation.objects.request(
user=self.user, email='[email protected]', send=True)
# staff user email addresses and confirmations
staff_user = self.get_staff_user_with_std_permissions()
staff_email_address = EmailAddress(
user=staff_user,
email='[email protected]',
is_primary=True,
)
user_email_address.save()
staff_email_confirmtaion = EmailConfirmation.objects.request(
user=staff_user, email='[email protected]', send=True)
# get response for standard user
response = self._view_get_logged_in()
self.assertContains(response, user_email_address.email)
self.assertContains(response, user_email_confirmtaion.email)
# ensure that other user emails are not present
self.assertNotContains(response, staff_email_address.email)
self.assertNotContains(response, staff_email_confirmtaion.email)
def test_post_with_valid_new_email(self):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
data = {
'email': '[email protected]'
}
self.assertEqual(EmailConfirmation.objects.count(), 0)
response = self.client.post(view_url, data=data)
self.assertEqual(response.status_code, 302)
self.assertEqual(EmailConfirmation.objects.count(), 1)
def test_post_with_same_email_two_times(self):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
data = {
'email': '[email protected]'
}
self.assertEqual(EmailConfirmation.objects.count(), 0)
response = self.client.post(view_url, data=data, follow=True)
self.assertRedirects(response, view_url)
self.assertEqual(EmailConfirmation.objects.count(), 1)
# test second time
response = self.client.post(view_url, data=data, follow=True)
self.assertRedirects(response, view_url)
# ensure that another email confirmation object was created.
# the actual owner of email can only confirm the email
# redundant emails can be deleted on cleanup or other way.
self.assertEqual(EmailConfirmation.objects.count(), 2)
def test_post_if_email_objeselfct_exists(self):
view_url = self.get_view_url()
self.client.login(username=self.user.username, password='standard')
new_email = EmailAddress(
user=self.user,
email='[email protected]',
is_primary=True,
)
new_email.save()
data = {
'email': '[email protected]'
}
response = self.client.post(view_url, data=data)
self.assertContains(response, 'This email address is already in use')
class ProfileEmailConfirmationCommonMixin(object):
confirmation_email_addr = '[email protected]'
def setUp(self):
self.user = self.get_standard_user()
self.staff_user = self.get_staff_user_with_std_permissions()
super(ProfileEmailConfirmationCommonMixin, self).setUp()
self.client.login(username=self.user.username, password='standard')
def _get_not_logged_in(self, **kwargs):
self.client.logout()
view_url = self.get_view_url(**kwargs)
response = self.client.get(view_url)
return response
def _get_logged_in(self, **kwargs):
view_url = self.get_view_url(**kwargs)
response = self.client.get(view_url)
return response
def _get_logged_in_confirmation_for_another_user(self):
staff_user_confirmation = EmailConfirmation.objects.request(
user=self.staff_user, email='[email protected]', send=True)
mail.outbox = []
view_url = self.get_view_url(pk=staff_user_confirmation.pk)
response = self.client.get(view_url)
return response
def _post_with_valid_pk(self, **kwargs):
view_url = self.get_view_url(**kwargs)
self.assertEqual(len(mail.outbox), 0)
response = self.client.post(view_url)
return response
def _post_with_not_valid_pk(self, pk=42):
view_url = self.get_view_url(pk=pk)
self.assertEqual(len(mail.outbox), 0)
response = self.client.post(view_url)
return response
def _post(self, **kwargs):
view_url = self.get_view_url(**kwargs)
response = self.client.post(view_url)
return response
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileEmailConfirmationResendViewTestCase(
GetViewUrlMixin,
ProfileEmailConfirmationCommonMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_email_confirmation_resend'
def setUp(self):
super(ProfileEmailConfirmationResendViewTestCase, self).setUp()
self.confirmation = EmailConfirmation.objects.request(
user=self.user, email=self.confirmation_email_addr, send=True)
self.staff_user_confirmation = EmailConfirmation.objects.request(
user=self.staff_user, email='[email protected]', send=True)
mail.outbox = []
def test_get_not_logged_in(self):
response = self._get_not_logged_in(pk=self.confirmation.pk)
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
response = self._get_logged_in(pk=self.confirmation.pk)
self.assertContains(
response, 'Do you want to re-send the confirmation request')
def test_get_logged_in_confirmation_for_another_user(self):
response = self._get_logged_in_confirmation_for_another_user()
self.assertEqual(response.status_code, 404)
def test_post_with_valid_pk(self):
response = self._post_with_valid_pk(pk=self.confirmation.pk)
self.assertEqual(response.status_code, 302)
self.assertEqual(len(mail.outbox), 1)
def test_post_with_not_valid_pk(self):
response = self._post_with_not_valid_pk()
self.assertEqual(response.status_code, 404)
self.assertEqual(len(mail.outbox), 0)
def test_post_confirmation_for_another_user(self):
response = self._post(pk=self.staff_user_confirmation.pk)
self.assertEqual(response.status_code, 404)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileEmailConfirmationCancelViewTestCase(
GetViewUrlMixin,
ProfileEmailConfirmationCommonMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_email_confirmation_cancel'
def setUp(self):
super(ProfileEmailConfirmationCancelViewTestCase, self).setUp()
self.confirmation = EmailConfirmation.objects.request(
user=self.user, email=self.confirmation_email_addr, send=True)
self.staff_user_confirmation = EmailConfirmation.objects.request(
user=self.staff_user, email='[email protected]', send=True)
mail.outbox = []
def test_get_not_logged_in(self):
response = self._get_not_logged_in(pk=self.confirmation.pk)
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
response = self._get_logged_in(pk=self.confirmation.pk)
self.assertContains(
response,
'cancel the confirmation request for {0}'.format(
self.confirmation_email_addr))
def test_post_with_valid_pk(self):
confirmation_pk = self.confirmation.pk
response = self._post_with_valid_pk(pk=self.confirmation.pk)
self.assertFalse(
EmailConfirmation.objects.filter(pk=confirmation_pk).exists())
self.assertEqual(response.status_code, 302)
def test_post_with_not_valid_pk(self):
confirmation_pk = self.confirmation.pk
response = self._post_with_not_valid_pk()
self.assertTrue(
EmailConfirmation.objects.filter(pk=confirmation_pk).exists())
self.assertEqual(response.status_code, 404)
def test_post_confirmation_for_another_user(self):
staf_user_confirmation_pk = self.staff_user_confirmation.pk
response = self._post(pk=self.staff_user_confirmation.pk)
self.assertTrue(EmailConfirmation.objects.filter(
pk=staf_user_confirmation_pk).exists())
self.assertEqual(response.status_code, 404)
class ProfileEmailObjectsSetupMixin(object):
def setUp(self):
super(ProfileEmailObjectsSetupMixin, self).setUp()
# regular user
self.user_email_1 = EmailAddress.objects.add_email(
user=self.user,
email='[email protected]',
make_primary=True)
self.user_email_2 = EmailAddress.objects.add_email(
user=self.user,
email='[email protected]',
make_primary=False)
# staff user
self.staff_email_1 = EmailAddress.objects.add_email(
user=self.staff_user,
email='[email protected]',
make_primary=True)
self.staff_email_2 = EmailAddress.objects.add_email(
user=self.staff_user,
email='[email protected]',
make_primary=False)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileEmailMakePrimaryViewTestCase(
GetViewUrlMixin,
ProfileEmailConfirmationCommonMixin,
ProfileEmailObjectsSetupMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_email_make_primary'
def test_get_not_logged_in(self):
email_pk = self.user_email_1.pk
response = self._get_not_logged_in(pk=email_pk)
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
email_pk = self.user_email_2.pk
response = self._get_logged_in(pk=email_pk)
self.assertContains(
response,
'to make {0} your primary email'.format(
self.user_email_2.email))
def test_post_with_valid_pk(self):
email_1_pk = self.user_email_1.pk
email_2_pk = self.user_email_2.pk
response = self._post_with_valid_pk(pk=email_2_pk)
user_email_1 = EmailAddress.objects.get(pk=email_1_pk)
user_email_2 = EmailAddress.objects.get(pk=email_2_pk)
self.assertFalse(user_email_1.is_primary)
self.assertTrue(user_email_2.is_primary)
self.assertEqual(response.status_code, 302)
def test_post_with_not_valid_pk(self):
response = self._post_with_not_valid_pk()
user_email_1 = EmailAddress.objects.get(pk=self.user_email_1.pk)
self.assertTrue(user_email_1.is_primary)
self.assertEqual(response.status_code, 404)
def test_post_for_another_user(self):
staf_user_email_pk = self.staff_email_2.pk
response = self._post(pk=staf_user_email_pk)
self.assertTrue(EmailAddress.objects.filter(
pk=staf_user_email_pk).exists())
self.assertEqual(response.status_code, 404)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class ProfileEmailDeleteViewTestCase(
GetViewUrlMixin,
ProfileEmailConfirmationCommonMixin,
ProfileEmailObjectsSetupMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_email_delete'
def test_get_not_logged_in(self):
# we are using second email, because user shouldn't be able to delete
# the primary email
email_pk = self.user_email_2.pk
response = self._get_not_logged_in(pk=email_pk)
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
# we are using second email, because user shouldn't be able to delete
# the primary email
email_pk = self.user_email_2.pk
response = self._get_logged_in(pk=email_pk)
self.assertContains(
response,
'to remove {0} from your account'.format(
self.user_email_2.email))
def test_get_logged_in_for_another_user(self):
staf_user_email_pk = self.staff_email_2.pk
response = self._get_logged_in(pk=staf_user_email_pk)
self.assertEqual(response.status_code, 404)
def test_post_with_valid_pk(self):
email_1_pk = self.user_email_1.pk
email_2_pk = self.user_email_2.pk
response = self._post_with_valid_pk(pk=email_2_pk)
# first email exists
self.assertTrue(
EmailAddress.objects.filter(pk=email_1_pk).exists())
# second email does not exists
self.assertFalse(
EmailAddress.objects.filter(pk=email_2_pk).exists())
self.assertEqual(response.status_code, 302)
def test_post_with_not_valid_pk(self):
response = self._post_with_not_valid_pk()
user_email_1 = EmailAddress.objects.filter(pk=self.user_email_1.pk)
self.assertTrue(user_email_1.exists())
self.assertEqual(response.status_code, 404)
def test_post_with_primary_email_address(self):
primary_email_pk = self.user_email_1.pk
response = self._post_with_valid_pk(pk=primary_email_pk)
user_email_1 = EmailAddress.objects.filter(pk=primary_email_pk)
self.assertTrue(user_email_1.exists())
self.assertEqual(response.status_code, 404)
def test_post_for_another_user(self):
staf_user_email_pk = self.staff_email_2.pk
response = self._post(pk=staf_user_email_pk)
self.assertTrue(EmailAddress.objects.filter(
pk=staf_user_email_pk).exists())
self.assertEqual(response.status_code, 404)
@override_settings(SESSION_ENGINE='django.contrib.sessions.backends.cached_db')
class UserSettingsViewTestCase(GetViewUrlMixin,
AllAccountsApphooksTestCase):
view_name = 'accounts_settings'
def setUp(self):
self.user = self.get_standard_user()
self.staff_user = self.get_staff_user_with_std_permissions()
super(UserSettingsViewTestCase, self).setUp()
def test_get_not_logged_in(self):
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertEqual(response.status_code, 302)
def test_get_logged_in(self):
self.client.login(username=self.user.username, password='standard')
view_url = self.get_view_url()
response = self.client.get(view_url)
self.assertContains(response, 'Settings')
self.assertContains(response, 'save')
| 40.509398 | 80 | 0.678553 |
4a1f98b51a6a418192f10f5bdd2c9cb22302af3e | 3,362 | py | Python | apis/project_api/project_api/test/test_disagg.py | ucgmsim/gmhazard | d3d90b4c94b3d9605597a3efeccc8523a1e50c0e | [
"MIT"
] | null | null | null | apis/project_api/project_api/test/test_disagg.py | ucgmsim/gmhazard | d3d90b4c94b3d9605597a3efeccc8523a1e50c0e | [
"MIT"
] | 8 | 2021-10-13T02:33:23.000Z | 2022-03-29T21:01:08.000Z | apis/project_api/project_api/test/test_disagg.py | ucgmsim/gmhazard | d3d90b4c94b3d9605597a3efeccc8523a1e50c0e | [
"MIT"
] | null | null | null | import api_utils.test as tu
from project_api import constants
# Disagg Tests
def test_get_disagg_rps(config):
""" Tests the successful get request of a Disagg RP's"""
response = tu.send_test_request(
constants.PROJECT_DISAGG_RPS_ENDPOINT,
{"project_id": config["general"]["project_id"]},
api="PROJECT",
)
tu.response_checks(
response,
[
("rps", list),
],
[],
)
def test_get_disagg_rps_missing_parameter():
""" Tests the successful get request of a Disagg RP's"""
response = tu.send_test_request(
constants.PROJECT_DISAGG_RPS_ENDPOINT, {}, api="PROJECT"
)
tu.response_checks(
response, [("error", str)], [("error", tu.MISSING_PARAM_MSG.format("project_id"))], 400
)
def test_get_disagg(config):
""" Tests the successful get request of a Disagg"""
response = tu.send_test_request(
constants.PROJECT_DISAGG_ENDPOINT,
{**config["general"], **config["disagg"]},
api="PROJECT",
)
tu.response_checks(
response,
[
("disagg_data", dict),
(["disagg_data", "im"], str),
(["disagg_data", "im_value"], float),
(["disagg_data", "mean_values"], dict),
(["disagg_data", "station"], str),
(["disagg_data", "total_contribution"], dict),
("download_token", str),
("ensemble_id", str),
("extra_info", dict),
(["extra_info", "annual_rec_prob"], dict),
(["extra_info", "magnitude"], dict),
(["extra_info", "rrup"], dict),
(["extra_info", "rupture_name"], dict),
("im", str),
("station", str),
],
[
("ensemble_id", config["general"]["project_id"]),
("im", config["disagg"]["im"]),
(["disagg_data", "im"], config["disagg"]["im"]),
("station", config["general"]["station_id"]),
(["disagg_data", "station"], config["general"]["station_id"]),
],
)
def test_get_disagg_missing_parameter(config):
""" Tests the failed get request of a Disagg with missing parameters"""
response = tu.send_test_request(
constants.PROJECT_DISAGG_ENDPOINT, config["general"], api="PROJECT"
)
tu.response_checks(
response, [("error", str)], [("error", tu.MISSING_PARAM_MSG.format("im"))], 400
)
def test_get_disagg_download(config):
""" Tests the successful get request of a Disagg download"""
disagg_response = tu.send_test_request(
constants.PROJECT_DISAGG_ENDPOINT,
{**config["general"], **config["disagg"]},
api="PROJECT",
)
response = tu.send_test_request(
constants.PROJECT_DISAGG_DOWNLOAD_ENDPOINT,
{"disagg_token": disagg_response.json()["download_token"]},
api="PROJECT",
)
tu.response_checks(response, [], [], 200, "application/zip")
def test_get_disagg_download_missing_parameter():
""" Tests the failed get request of a Disagg download without the download token"""
response = tu.send_test_request(
constants.PROJECT_DISAGG_DOWNLOAD_ENDPOINT, api="PROJECT"
)
tu.response_checks(
response,
[("error", str)],
[("error", tu.MISSING_PARAM_MSG.format("disagg_token"))],
400,
)
| 32.326923 | 95 | 0.586853 |
4a1f9995000d679e7011c48c0022acdcb11b5620 | 11,166 | py | Python | Lib/site-packages/numarray/session.py | raychorn/svn_Python-2.5.1 | 425005b1b489ba44ec0bb989e077297e8953d9be | [
"PSF-2.0"
] | null | null | null | Lib/site-packages/numarray/session.py | raychorn/svn_Python-2.5.1 | 425005b1b489ba44ec0bb989e077297e8953d9be | [
"PSF-2.0"
] | null | null | null | Lib/site-packages/numarray/session.py | raychorn/svn_Python-2.5.1 | 425005b1b489ba44ec0bb989e077297e8953d9be | [
"PSF-2.0"
] | null | null | null | """ This module contains a "session saver" which saves the state of a
numarray session to a file. At a later time, a different Python
process can be started and the saved session can be restored using
load().
The session saver relies on the Python pickle protocol to save and
restore objects. Objects which are not themselves picklable (e.g.
modules) can sometimes be saved by "proxy", particularly when they
are global constants of some kind. If it's not known that proxying
will work, a warning is issued at save time. If a proxy fails to
reload properly (e.g. because it's not a global constant), a warning
is issued at reload time and that name is bound to a _ProxyFailure
instance which tries to identify what should have been restored.
First, some unfortunate (probably unnecessary) concessions to doctest
to keep the test run free of warnings.
>>> del _PROXY_ALLOWED
>>> del copy
>>> del __builtins__
By default, save() stores every variable in the caller's namespace:
>>> import numarray as na
>>> a = na.arange(10)
>>> save()
Alternately, save() can be passed a comma seperated string of variables:
>>> save("a,na")
Alternately, save() can be passed a dictionary, typically one you already
have lying around somewhere rather than created inline as shown here:
>>> save(dictionary={"a":a,"na":na})
If both variables and a dictionary are specified, the variables to be
saved are taken from the dictionary.
>>> save(variables="a,na",dictionary={"a":a,"na":na})
Remove names from the session namespace
>>> del a, na
By default, load() restores every variable/object in the session file
to the caller's namespace.
>>> load()
load() can be passed a comma seperated string of variables to be
restored from the session file to the caller's namespace:
>>> load("a,na")
load() can also be passed a dictionary to *restore to*:
>>> d = {}
>>> load(dictionary=d)
load can be passed both a list variables of variables to restore and a
dictionary to restore to:
>>> load(variables="a,na", dictionary=d)
>>> na.all(a == na.arange(10))
1
>>> na.__name__
'numarray'
NOTE: session saving is faked for modules using module proxy objects.
Saved modules are re-imported at load time but any "state" in the module
which is not restored by a simple import is lost.
"""
import copy
import sys
import pickle
SAVEFILE="session.dat"
VERBOSE = False # global import-time override
def _foo(): pass
_PROXY_ALLOWED = (type(sys), # module
type(_foo), # function
type(None)) # None
def _update_proxy_types():
"""Suppress warnings for known un-picklables with working proxies."""
global _PROXY_ALLOWED
try:
import numarray.ufunc as uf
_PROXY_ALLOWED += (type(uf.cos), type(uf.add), type(uf.add.reduce))
except ImportError:
pass
try:
import Numeric as nc
_PROXY_ALLOWED += (type(nc.add), type(nc.add.reduce))
except ImportError:
pass
def _unknown(_type):
"""returns True iff _type isn't known as OK to proxy"""
return (_type is not None) and (_type not in _PROXY_ALLOWED)
# caller() from the following article with one extra f_back added.
# from http://www.python.org/search/hypermail/python-1994q1/0506.html
# SUBJECT: import ( how to put a symbol into caller's namespace )
# SENDER: Steven D. Majewski ([email protected])
# DATE: Thu, 24 Mar 1994 15:38:53 -0500
def _caller():
"""caller() returns the frame object of the function's caller."""
try:
1 + '' # make an error happen
except: # and return the caller's caller's frame
return sys.exc_traceback.tb_frame.f_back.f_back.f_back
def _callers_globals():
"""callers_globals() returns the global dictionary of the caller."""
frame = _caller()
return frame.f_globals
def _callers_modules():
"""returns a list containing the names of all the modules in the caller's
global namespace."""
g = _callers_globals()
mods = []
for k,v in g.items():
if type(v) == type(sys):
mods.append(getattr(v,"__name__"))
return mods
def _errout(*args):
for a in args:
print >>sys.stderr, a,
print >>sys.stderr
def _verbose(*args):
if VERBOSE:
_errout(*args)
class _ProxyingFailure:
"""Object which is bound to a variable for a proxy pickle which failed to reload"""
def __init__(self, module, name, type=None):
self.module = module
self.name = name
self.type = type
def __repr__(self):
return "ProxyingFailure('%s','%s','%s')" % (self.module, self.name, self.type)
class _ModuleProxy(object):
"""Proxy object which fakes pickling a module"""
def __new__(_type, name, save=False):
if save:
_verbose("proxying module", name)
self = object.__new__(_type)
self.name = name
else:
_verbose("loading module proxy", name)
try:
self = _loadmodule(name)
except ImportError:
_errout("warning: module", name,"import failed.")
return self
def __getnewargs__(self):
return (self.name,)
def __getstate__(self):
return False
def _loadmodule(module):
if not sys.modules.has_key(module):
modules = module.split(".")
s = ""
for i in range(len(modules)):
s = ".".join(modules[:i+1])
exec "import " + s
return sys.modules[module]
class _ObjectProxy(object):
"""Proxy object which fakes pickling an arbitrary object. Only global
constants can really be proxied."""
def __new__(_type, module, name, _type2, save=False):
if save:
if _unknown(_type2):
_errout("warning: proxying object", module + "." + name,
"of type", _type2, "because it wouldn't pickle...",
"it may not reload later.")
else:
_verbose("proxying object", module, name)
self = object.__new__(_type)
self.module, self.name, self.type = module, name, str(_type2)
else:
_verbose("loading object proxy", module, name)
try:
m = _loadmodule(module)
except (ImportError, KeyError):
_errout("warning: loading object proxy", module + "." + name,
"module import failed.")
return _ProxyingFailure(module,name,_type2)
try:
self = getattr(m, name)
except AttributeError:
_errout("warning: object proxy", module + "." + name,
"wouldn't reload from", m)
return _ProxyingFailure(module,name,_type2)
return self
def __getnewargs__(self):
return (self.module, self.name, self.type)
def __getstate__(self):
return False
class _SaveSession(object):
"""Tag object which marks the end of a save session and holds the
saved session variable names as a list of strings in the same
order as the session pickles."""
def __new__(_type, keys, save=False):
if save:
_verbose("saving session", keys)
else:
_verbose("loading session", keys)
self = object.__new__(_type)
self.keys = keys
return self
def __getnewargs__(self):
return (self.keys,)
def __getstate__(self):
return False
class ObjectNotFound(RuntimeError):
pass
def _locate(modules, object):
for mname in modules:
m = sys.modules[mname]
if m:
for k,v in m.__dict__.items():
if v is object:
return m.__name__, k
else:
raise ObjectNotFound(k)
def save(variables=None, file=SAVEFILE, dictionary=None, verbose=False):
"""saves variables from a numarray session to a file. Variables
which won't pickle are "proxied" if possible.
'variables' a string of comma seperated variables: e.g. "a,b,c"
Defaults to dictionary.keys().
'file' a filename or file object for the session file.
'dictionary' the dictionary in which to look up the variables.
Defaults to the caller's globals()
'verbose' print additional debug output when True.
"""
global VERBOSE
VERBOSE = verbose
_update_proxy_types()
if isinstance(file, str):
file = open(file, "wb")
if dictionary is None:
dictionary = _callers_globals()
if variables is None:
keys = dictionary.keys()
else:
keys = variables.split(",")
source_modules = _callers_modules() + sys.modules.keys()
p = pickle.Pickler(file, protocol=2)
_verbose("variables:",keys)
for k in keys:
v = dictionary[k]
_verbose("saving", k, type(v))
try: # Try to write an ordinary pickle
p.dump(v)
_verbose("pickled", k)
except (pickle.PicklingError, TypeError, SystemError):
# Use proxies for stuff that won't pickle
if isinstance(v, type(sys)): # module
proxy = _ModuleProxy(v.__name__, save=True)
else:
try:
module, name = _locate(source_modules, v)
except ObjectNotFound:
_errout("warning: couldn't find object",k,
"in any module... skipping.")
continue
else:
proxy = _ObjectProxy(module, name, type(v), save=True)
p.dump(proxy)
o = _SaveSession(keys, save=True)
p.dump(o)
file.close()
def load(variables=None, file=SAVEFILE, dictionary=None, verbose=False):
"""load a numarray session from a file and store the specified
'variables' into 'dictionary'.
'variables' a string of comma seperated variables: e.g. "a,b,c"
Defaults to dictionary.keys().
'file' a filename or file object for the session file.
'dictionary' the dictionary in which to look up the variables.
Defaults to the caller's globals()
'verbose' print additional debug output when True.
"""
global VERBOSE
VERBOSE = verbose
if isinstance(file, str):
file = open(file, "rb")
if dictionary is None:
dictionary = _callers_globals()
values = []
p = pickle.Unpickler(file)
while 1:
o = p.load()
if isinstance(o, _SaveSession):
session = dict(zip(o.keys, values))
_verbose("updating dictionary with session variables.")
if variables is None:
keys = session.keys()
else:
keys = variables.split(",")
for k in keys:
dictionary[k] = session[k]
return None
else:
_verbose("unpickled object", str(o))
values.append(o)
def test():
import doctest, numarray.session
return doctest.testmod(numarray.session)
| 31.189944 | 87 | 0.612395 |
4a1f99e898a3f59102508fb5718f0ee51613eaee | 1,978 | py | Python | CoreModules/XMLConfigReader.py | QIB-Sheffield/WEASEL | e4dad345fd6f347cfac990708252844a7cbcd025 | [
"Apache-2.0"
] | 2 | 2021-02-10T09:07:15.000Z | 2021-03-16T17:05:24.000Z | CoreModules/XMLConfigReader.py | QIB-Sheffield/WEASEL | e4dad345fd6f347cfac990708252844a7cbcd025 | [
"Apache-2.0"
] | 102 | 2021-01-20T11:14:21.000Z | 2021-12-12T17:34:42.000Z | CoreModules/XMLConfigReader.py | QIB-Sheffield/WEASEL | e4dad345fd6f347cfac990708252844a7cbcd025 | [
"Apache-2.0"
] | 1 | 2021-01-29T09:28:05.000Z | 2021-01-29T09:28:05.000Z | """
Class for reading the Weasel XML configuration file `config.xml`.
"""
import os, sys
import xml.etree.cElementTree as ET
import logging
logger = logging.getLogger(__name__)
class XMLConfigReader:
def __init__(self):
try:
self.hasXMLFileParsedOK = True
self.fullFilePath = os.path.join(os.path.dirname(sys.argv[0]), "config.xml")
self.tree = ET.parse(self.fullFilePath)
self.root = self.tree.getroot()
logger.info('In module ' + __name__ + ' Created XML Reader Object')
except Exception as e:
print('Error in XMLConfigReader.__init__: ' + str(e))
logger.exception('Error in XMLConfigReader.__init__: ' + str(e))
def __repr__(self):
return '{}, {!r}'.format(
self.__class__.__name__,
self.fullFilePath)
def getMenuConfigFile(self):
"""This method gets the menu file name in the `<menu_config_file>` field."""
try:
menu = self.root.find('./menu_config_file')
if menu.text is None:
return None
else:
return menu.text
except Exception as e:
print('Error in XMLConfigReader.getMenuConfigFile: ' + str(e))
logger.exception('Error in XMLConfigReader.getMenuConfigFile: ' + str(e))
def getWeaselDataFolder(self):
"""This method gets the default DICOM data folder in the `<weasel_data_folder>` field."""
try:
folder = self.root.find('./weasel_data_folder')
if folder.text is None:
return os.path.dirname(sys.argv[0])
elif folder.text == '':
return os.path.dirname(sys.argv[0])
else:
return folder.text
except Exception as e:
print('Error in XMLConfigReader.getWeaselDataFolder: ' + str(e))
logger.exception('Error in XMLConfigReader.getWeaselDataFolder: ' + str(e))
| 35.321429 | 97 | 0.595551 |
4a1f9b408f068d4c3cf9bdc2d95dc0b3cc3e0496 | 541 | py | Python | Model Evaluation/creating-baseline-classification-model.py | WyckliffeAluga/data-chronicles | 5219fe9cdbafb9fd7be88727483952c4c13f2790 | [
"MIT"
] | null | null | null | Model Evaluation/creating-baseline-classification-model.py | WyckliffeAluga/data-chronicles | 5219fe9cdbafb9fd7be88727483952c4c13f2790 | [
"MIT"
] | null | null | null | Model Evaluation/creating-baseline-classification-model.py | WyckliffeAluga/data-chronicles | 5219fe9cdbafb9fd7be88727483952c4c13f2790 | [
"MIT"
] | 1 | 2021-02-09T12:22:55.000Z | 2021-02-09T12:22:55.000Z |
# load libraries
from sklearn.datasets import load_iris
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import train_test_split
# load data
iris = load_iris()
# create features and target
x , y = iris.data , iris.target
# split data into training and test set
x_train, x_test, y_train, y_test = train_test_split(x,y, random_state=0)
# create a dumy classifier
dummy = DummyClassifier(strategy='uniform', random_state=1)
# train model
dummy.fit(x_train, y_train)
# get accuracy score
dummy.score(x_test, y_test)
| 22.541667 | 72 | 0.781885 |
4a1f9be63440bb5afd887e139848fb34034767a7 | 2,335 | py | Python | test/test_notification_api.py | silencewwt/bitmex-swagger-client | 01403685eeb12eb27d53a0310d3bc7541793aa0f | [
"MIT"
] | 1 | 2018-08-04T15:05:43.000Z | 2018-08-04T15:05:43.000Z | test/test_notification_api.py | silencewwt/bitmex-swagger | 01403685eeb12eb27d53a0310d3bc7541793aa0f | [
"MIT"
] | null | null | null | test/test_notification_api.py | silencewwt/bitmex-swagger | 01403685eeb12eb27d53a0310d3bc7541793aa0f | [
"MIT"
] | null | null | null | # coding: utf-8
"""
BitMEX API
## REST API for the BitMEX Trading Platform [View Changelog](/app/apiChangelog) ---- #### Getting Started Base URI: [https://www.bitmex.com/api/v1](/api/v1) ##### Fetching Data All REST endpoints are documented below. You can try out any query right from this interface. Most table queries accept `count`, `start`, and `reverse` params. Set `reverse=true` to get rows newest-first. Additional documentation regarding filters, timestamps, and authentication is available in [the main API documentation](/app/restAPI). *All* table data is available via the [Websocket](/app/wsAPI). We highly recommend using the socket if you want to have the quickest possible data without being subject to ratelimits. ##### Return Types By default, all data is returned as JSON. Send `?_format=csv` to get CSV data or `?_format=xml` to get XML data. ##### Trade Data Queries *This is only a small subset of what is available, to get you started.* Fill in the parameters and click the `Try it out!` button to try any of these queries. * [Pricing Data](#!/Quote/Quote_get) * [Trade Data](#!/Trade/Trade_get) * [OrderBook Data](#!/OrderBook/OrderBook_getL2) * [Settlement Data](#!/Settlement/Settlement_get) * [Exchange Statistics](#!/Stats/Stats_history) Every function of the BitMEX.com platform is exposed here and documented. Many more functions are available. ##### Swagger Specification [⇩ Download Swagger JSON](swagger.json) ---- ## All API Endpoints Click to expand a section. # noqa: E501
OpenAPI spec version: 1.2.0
Contact: [email protected]
Generated by: https://github.com/swagger-api/swagger-codegen.git
"""
from __future__ import absolute_import
import unittest
import bitmex_swagger
from bitmex_swagger.api.notification_api import NotificationApi # noqa: E501
from bitmex_swagger.rest import ApiException
class TestNotificationApi(unittest.TestCase):
"""NotificationApi unit test stubs"""
def setUp(self):
self.api = bitmex_swagger.api.notification_api.NotificationApi() # noqa: E501
def tearDown(self):
pass
def test_notification_get(self):
"""Test case for notification_get
Get your current notifications. # noqa: E501
"""
pass
if __name__ == '__main__':
unittest.main()
| 55.595238 | 1,509 | 0.722056 |
4a1f9f58960abe6a839b4c15e8ef89db2244a5da | 2,898 | py | Python | src/layout/cards/settings/callbacks/colour_selection.py | rayanht/UK-Biobank-Visualisation | d4eb00f194b6452cbd2164d87b433e71ab1783f6 | [
"MIT"
] | 3 | 2021-03-03T20:11:04.000Z | 2021-12-20T12:38:47.000Z | src/layout/cards/settings/callbacks/colour_selection.py | rayanht/UK-Biobank-Visualisation | d4eb00f194b6452cbd2164d87b433e71ab1783f6 | [
"MIT"
] | 16 | 2020-10-28T16:08:47.000Z | 2022-02-13T23:46:09.000Z | src/layout/cards/settings/callbacks/colour_selection.py | rayanht/UK-Biobank-Visualisation | d4eb00f194b6452cbd2164d87b433e71ab1783f6 | [
"MIT"
] | 1 | 2021-01-07T01:43:11.000Z | 2021-01-07T01:43:11.000Z | import dash_html_components as html
from dash.dependencies import Input, Output, State
from src.dash_app import app
from src.graph_data import get_field_type
from src.tree.node_utils import get_field_id, get_option
from src.value_type import ValueType
from .variable_selection import (
get_dropdown_id as get_var_dropdown_id,
get_option_dropdown as get_dropdown,
)
def get_option_dropdown(arg):
return html.Div(
id="colour-selection-div",
children=[html.H6("Colour", className="mt-2"), get_dropdown("colour")],
style={"display": "none"},
)
def get_dropdown_id():
return get_var_dropdown_id("colour")
@app.callback(
[
Output(component_id="colour-selection-div", component_property="style"),
Output(component_id=get_dropdown_id(), component_property="options"),
Output(component_id=get_dropdown_id(), component_property="value"),
],
[Input(component_id="settings-graph-type-dropdown", component_property="value")],
[State(component_id="tree", component_property="selected_nodes")],
)
def update_colour_visible(graph_type, selected_nodes):
"""
Callback to update the visibility of the colour dropdown
:param graph_type: the type of graph that is currently being prepared.
(Violin, Pie, Scatter etc.)
:param selected_nodes: the data fields that are currently selected in the
tree
:return: a HTML div of the colour dropdown, potentially hidden.
"""
all_options, violin_options = [], []
for node in selected_nodes:
option = get_option(node)
is_all_colour, is_violin_colour = is_colour_option(node)
if is_all_colour:
all_options.append(option)
if is_violin_colour:
violin_options.append(option)
if (graph_type == 4) | (graph_type is None):
# Currently do not support colour for pie charts
return {"display": "none"}, {}, None
if graph_type == 1:
# Only categorical data can be used for violin plot colouring
return {"display": "block"}, violin_options, None
return {"display": "block"}, all_options, None
def is_colour_option(node):
"""
Determine whether or node a data field can be used to colour a plot.
:param node: the selected data field.
:return: Tuple(iff option can be used for general colouring,
iff option can be used for colouring violin plots)
"""
node_value_type = get_field_type(get_field_id(node))
return (
(
node_value_type == ValueType.INTEGER
or node_value_type == ValueType.CONT
or node_value_type == ValueType.CAT_SINGLE
or node_value_type == ValueType.CAT_MULT
),
(
node_value_type == ValueType.CAT_SINGLE
or node_value_type == ValueType.CAT_MULT
),
)
| 34.5 | 85 | 0.669427 |
4a1fa001b5ad304f86b3cbcb717ac1066dbc491f | 3,647 | py | Python | transcode/config/ebml/configelement.py | shersonb/python-transcode | db42e82f019ef4c3b7f59f34587576205e19eb96 | [
"MIT"
] | 1 | 2020-06-25T01:00:15.000Z | 2020-06-25T01:00:15.000Z | transcode/config/ebml/configelement.py | shersonb/python-transcode | db42e82f019ef4c3b7f59f34587576205e19eb96 | [
"MIT"
] | null | null | null | transcode/config/ebml/configelement.py | shersonb/python-transcode | db42e82f019ef4c3b7f59f34587576205e19eb96 | [
"MIT"
] | null | null | null | from ebml.base import EBMLProperty
import ebml.serialization
import pathlib
try:
import lzma
except ImportError:
lzma = None
try:
import bz2
except ImportError:
bz2 = None
try:
import gzip
except ImportError:
gzip = None
from ..obj import Config
from .inputfiles import InputFiles
from .filterchains import FilterChains
from .outputfiles import OutputFiles
class ConfigElement(ebml.serialization.Object):
constructor = Config
ebmlID = b'\x13\xce\x86\xc9'
__ebmlchildren__ = (
EBMLProperty("objID", ebml.serialization.ObjID, optional=True),
EBMLProperty("inputFiles", InputFiles),
EBMLProperty("filterChains", FilterChains, optional=True),
EBMLProperty("outputFiles", OutputFiles),
)
@classmethod
def _createElement(cls, constructor, args, environ, refs):
(path,) = args
environ["cwd"] = path.parent
self = cls.__new__(cls)
return self
def _saveState(self, state, environ, refs):
environ["module"] = "transcode.containers"
self.inputFiles = InputFiles.fromObj(
state.get("input_files"), environ, refs)
if state.get("filter_chains"):
environ["module"] = "transcode.filters"
self.filterChains = FilterChains.fromObj(
state.get("filter_chains"), environ, refs)
environ["module"] = "transcode.containers"
self.outputFiles = OutputFiles.fromObj(
state.pop("output_files"), environ, refs)
def _constructArgs(self, environ, refs):
configname = pathlib.Path(environ.get("configname", "untitled.ptc"))
environ["cwd"] = configname.parent
return (configname,)
def _restoreState(self, obj, environ, refs):
state = {}
environ["module"] = "transcode.containers"
state["input_files"] = self.inputFiles.toObj(environ, refs)
if self.filterChains:
environ["module"] = "transcode.filters"
state["filter_chains"] = self.filterChains.toObj(environ, refs)
environ["module"] = "transcode.containers"
state["output_files"] = self.outputFiles.toObj(environ, refs)
obj.__setstate__(state)
@classmethod
def load(cls, configname, file=None):
configname = pathlib.Path(configname)
if file is None:
if lzma and configname.suffix.upper() == ".XZ":
file = lzma.LZMAFile(configname, "r")
elif bz2 and configname.suffix.upper() == ".BZ2":
file = bz2.BZ2File(configname, "r")
elif gzip and configname.suffix.upper() == ".GZ":
file = gzip.GzipFile(configname, "r")
else:
file = open(configname, "rb")
self = cls.fromFile(file)
return self.toObj({"configname": configname})
@classmethod
def save(cls, config, configname=None, file=None):
if configname is not None:
config.configname = configname
self = cls.fromObj(config)
if file is None:
if lzma and config.configname.suffix.upper() == ".XZ":
file = lzma.LZMAFile(config.configname, "w",
preset=9 | lzma.PRESET_EXTREME)
elif bz2 and config.configname.suffix.upper() == ".BZ2":
file = bz2.BZ2File(config.configname, "w", compresslevel=9)
elif gzip and config.configname.suffix.upper() == ".GZ":
file = gzip.GzipFile(config.configname, "w", compresslevel=9)
else:
file = open(config.configname, "wb")
self.toFile(file)
| 30.140496 | 77 | 0.609542 |
4a1fa02186c4c752a3a5ead7c3107b0c801167aa | 1,214 | py | Python | setup.py | faust-streaming/python-rocksdb | e6bf958000e84c684e0625d45207b1003273acc3 | [
"BSD-3-Clause"
] | 7 | 2021-02-01T18:54:20.000Z | 2022-02-01T15:25:21.000Z | setup.py | hipacloud/python-rocksdb | 9190e3edb4818bec020b33a435410fd953b31fb4 | [
"BSD-3-Clause"
] | 2 | 2021-01-22T01:26:17.000Z | 2021-02-06T17:43:29.000Z | setup.py | hipacloud/python-rocksdb | 9190e3edb4818bec020b33a435410fd953b31fb4 | [
"BSD-3-Clause"
] | 1 | 2021-08-29T14:10:00.000Z | 2021-08-29T14:10:00.000Z | import platform
from setuptools import setup
from setuptools import find_packages
from setuptools import Extension
extra_compile_args = [
'-std=c++11',
'-O3',
'-Wall',
'-Wextra',
'-Wconversion',
'-fno-strict-aliasing',
'-fno-rtti',
]
if platform.system() == 'Darwin':
extra_compile_args += ['-mmacosx-version-min=10.7', '-stdlib=libc++']
setup(
name="faust-streaming-rocksdb",
version='0.8.0',
description="Python bindings for RocksDB",
keywords='rocksdb',
author='Ming Hsuan Tu',
author_email="[email protected]",
url="https://github.com/twmht/python-rocksdb",
license='BSD License',
setup_requires=['setuptools>=25', 'Cython>=0.20'],
install_requires=['setuptools>=25'],
package_dir={'rocksdb': 'rocksdb'},
packages=find_packages('.'),
ext_modules=[Extension(
'rocksdb._rocksdb',
['rocksdb/_rocksdb.pyx'],
extra_compile_args=extra_compile_args,
language='c++',
libraries=['rocksdb', 'snappy', 'bz2', 'z', 'lz4'],
)],
extras_require={
"doc": ['sphinx_rtd_theme', 'sphinx'],
"test": ['pytest'],
},
include_package_data=True,
zip_safe=False,
)
| 25.291667 | 73 | 0.622735 |
4a1fa0b6e2536b0b621ce73d17dcf02373276928 | 49,078 | py | Python | tools/eval_rcnn_afusg.py | jjn037/FusionAttack | 25646543b3008bd7f92760c8b0e6645450e79abf | [
"MIT"
] | null | null | null | tools/eval_rcnn_afusg.py | jjn037/FusionAttack | 25646543b3008bd7f92760c8b0e6645450e79abf | [
"MIT"
] | null | null | null | tools/eval_rcnn_afusg.py | jjn037/FusionAttack | 25646543b3008bd7f92760c8b0e6645450e79abf | [
"MIT"
] | null | null | null | import _init_path
import os
import numpy as np
import torch
from torch.utils.data import DataLoader
import torch.nn.functional as F
from lib.net.point_rcnn import PointRCNN
from lib.net.GAN_model import Generator_fusimg, Generator_fuspts
from lib.net.train_functions import reduce_sum
from lib.datasets.kitti_rcnn_dataset import KittiRCNNDataset
import tools.train_utils.train_utils as train_utils
from lib.utils.bbox_transform import decode_bbox_target
from tools.kitti_object_eval_python.evaluate import evaluate as kitti_evaluate
from lib.config import cfg, cfg_from_file, save_config_to_file, cfg_from_list
import argparse
import lib.utils.kitti_utils as kitti_utils
import lib.utils.iou3d.iou3d_utils as iou3d_utils
from datetime import datetime
import logging
import re
import glob
import time
from tensorboardX import SummaryWriter
import tqdm
np.random.seed(1024) # set the same seed
parser = argparse.ArgumentParser(description = "arg parser")
parser.add_argument('--cfg_file', type = str, default = 'cfgs/default.yml', help = 'specify the config for evaluation')
parser.add_argument("--eval_mode", type = str, default = 'rpn', required = True, help = "specify the evaluation mode")
parser.add_argument('--eval_all', action = 'store_true', default = False, help = 'whether to evaluate all checkpoints')
parser.add_argument('--test', action = 'store_true', default = False, help = 'evaluate without ground truth')
parser.add_argument("--ckpt", type = str, default = None, help = "specify a checkpoint to be evaluated")
parser.add_argument("--rpn_ckpt", type = str, default = None,
help = "specify the checkpoint of rpn if trained separated")
parser.add_argument("--rcnn_ckpt", type = str, default = None,
help = "specify the checkpoint of rcnn if trained separated")
parser.add_argument("--afus_ckpt_dir", type = str, default = None)
parser.add_argument("--afus_epoch", type = int, default = 1)
parser.add_argument("--afus_iter", type = int, default = 100)
parser.add_argument('--gen_pert', action = 'store_true', default = True)
parser.add_argument('--batch_size', type = int, default = 1, help = 'batch size for evaluation')
parser.add_argument('--workers', type = int, default = 4, help = 'number of workers for dataloader')
parser.add_argument("--extra_tag", type = str, default = 'default', help = "extra tag for multiple evaluation")
parser.add_argument('--output_dir', type = str, default = None, help = 'specify an output directory if needed')
parser.add_argument("--ckpt_dir", type = str, default = None,
help = "specify a ckpt directory to be evaluated if needed")
parser.add_argument('--save_result', action = 'store_true', default = False, help = 'save evaluation results to files')
parser.add_argument('--save_rpn_feature', action = 'store_true', default = False,
help = 'save features for separately rcnn training and evaluation')
parser.add_argument('--random_select', action = 'store_true', default = True,
help = 'sample to the same number of points')
parser.add_argument('--start_epoch', default = 0, type = int, help = 'ignore the checkpoint smaller than this epoch')
parser.add_argument('--max_waiting_mins', type=int, default=30, help='max waiting minutes')
parser.add_argument("--rcnn_eval_roi_dir", type = str, default = None,
help = 'specify the saved rois for rcnn evaluation when using rcnn_offline mode')
parser.add_argument("--rcnn_eval_feature_dir", type = str, default = None,
help = 'specify the saved features for rcnn evaluation when using rcnn_offline mode')
parser.add_argument('--set', dest = 'set_cfgs', default = None, nargs = argparse.REMAINDER,
help = 'set extra config keys if needed')
parser.add_argument('--model_type', type = str, default = 'base', help = 'model type')
args = parser.parse_args()
def create_logger(log_file):
log_format = '%(asctime)s %(levelname)5s %(message)s'
logging.basicConfig(level = logging.INFO, format = log_format, filename = log_file)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(logging.Formatter(log_format))
logging.getLogger(__name__).addHandler(console)
return logging.getLogger(__name__)
def save_kitti_format(sample_id, calib, bbox3d, kitti_output_dir, scores, img_shape):
corners3d = kitti_utils.boxes3d_to_corners3d(bbox3d)
img_boxes, _ = calib.corners3d_to_img_boxes(corners3d)
img_boxes[:, 0] = np.clip(img_boxes[:, 0], 0, img_shape[1] - 1)
img_boxes[:, 1] = np.clip(img_boxes[:, 1], 0, img_shape[0] - 1)
img_boxes[:, 2] = np.clip(img_boxes[:, 2], 0, img_shape[1] - 1)
img_boxes[:, 3] = np.clip(img_boxes[:, 3], 0, img_shape[0] - 1)
img_boxes_w = img_boxes[:, 2] - img_boxes[:, 0]
img_boxes_h = img_boxes[:, 3] - img_boxes[:, 1]
box_valid_mask = np.logical_and(img_boxes_w < img_shape[1] * 0.8, img_boxes_h < img_shape[0] * 0.8)
kitti_output_file = os.path.join(kitti_output_dir, '%06d.txt' % sample_id)
with open(kitti_output_file, 'w') as f:
for k in range(bbox3d.shape[0]):
if box_valid_mask[k] == 0:
continue
x, z, ry = bbox3d[k, 0], bbox3d[k, 2], bbox3d[k, 6]
beta = np.arctan2(z, x)
alpha = -np.sign(beta) * np.pi / 2 + beta + ry
print('%s -1 -1 %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f' %
(cfg.CLASSES, alpha, img_boxes[k, 0], img_boxes[k, 1], img_boxes[k, 2], img_boxes[k, 3],
bbox3d[k, 3], bbox3d[k, 4], bbox3d[k, 5], bbox3d[k, 0], bbox3d[k, 1], bbox3d[k, 2],
bbox3d[k, 6], scores[k]), file = f)
def save_rpn_features(seg_result, rpn_scores_raw, pts_features, backbone_xyz, backbone_features, kitti_features_dir,
sample_id):
pts_intensity = pts_features[:, 0]
output_file = os.path.join(kitti_features_dir, '%06d.npy' % sample_id)
xyz_file = os.path.join(kitti_features_dir, '%06d_xyz.npy' % sample_id)
seg_file = os.path.join(kitti_features_dir, '%06d_seg.npy' % sample_id)
intensity_file = os.path.join(kitti_features_dir, '%06d_intensity.npy' % sample_id)
np.save(output_file, backbone_features)
np.save(xyz_file, backbone_xyz)
np.save(seg_file, seg_result)
np.save(intensity_file, pts_intensity)
rpn_scores_raw_file = os.path.join(kitti_features_dir, '%06d_rawscore.npy' % sample_id)
np.save(rpn_scores_raw_file, rpn_scores_raw)
def eval_one_epoch_rpn(model, dataloader, epoch_id, result_dir, logger):
np.random.seed(1024)
mode = 'TEST' if args.test else 'EVAL'
if args.save_rpn_feature:
kitti_features_dir = os.path.join(result_dir, 'features')
os.makedirs(kitti_features_dir, exist_ok = True)
if args.save_result or args.save_rpn_feature:
kitti_output_dir = os.path.join(result_dir, 'detections', 'data')
seg_output_dir = os.path.join(result_dir, 'seg_result')
os.makedirs(kitti_output_dir, exist_ok = True)
os.makedirs(seg_output_dir, exist_ok = True)
logger.info('---- EPOCH %s RPN EVALUATION ----' % epoch_id)
model.eval()
thresh_list = [0.1, 0.3, 0.5, 0.7, 0.9]
total_recalled_bbox_list, total_gt_bbox = [0] * 5, 0
dataset = dataloader.dataset
cnt = max_num = rpn_iou_avg = 0
progress_bar = tqdm.tqdm(total = len(dataloader), leave = True, desc = 'eval')
for data in dataloader:
sample_id_list, pts_rect, pts_features, pts_input = \
data['sample_id'], data['pts_rect'], data['pts_features'], data['pts_input']
sample_id = sample_id_list[0]
cnt += len(sample_id_list)
if not args.test:
rpn_cls_label, rpn_reg_label = data['rpn_cls_label'], data['rpn_reg_label']
gt_boxes3d = data['gt_boxes3d']
rpn_cls_label = torch.from_numpy(rpn_cls_label).cuda(non_blocking = True).long()
if gt_boxes3d.shape[1] == 0: # (B, M, 7)
pass
# logger.info('%06d: No gt box' % sample_id)
else:
gt_boxes3d = torch.from_numpy(gt_boxes3d).cuda(non_blocking = True).float()
inputs = torch.from_numpy(pts_input).cuda(non_blocking = True).float()
input_data = { 'pts_input': inputs }
# img feature
if cfg.LI_FUSION.ENABLED:
pts_origin_xy, img = data['pts_origin_xy'], data['img']
pts_origin_xy = torch.from_numpy(pts_origin_xy).cuda(non_blocking = True).float()
img = torch.from_numpy(img).cuda(non_blocking = True).float().permute((0,3,1,2))
input_data['pts_origin_xy'] = pts_origin_xy
input_data['img'] = img
if cfg.RPN.USE_RGB or cfg.RCNN.USE_RGB:
pts_rgb=data['rgb']
pts_rgb=torch.from_numpy(pts_rgb).cuda(non_blocking = True).float()
input_data['pts_rgb']=pts_rgb
# model inference
ret_dict = model(input_data)
rpn_cls, rpn_reg = ret_dict['rpn_cls'], ret_dict['rpn_reg']
backbone_xyz, backbone_features = ret_dict['backbone_xyz'], ret_dict['backbone_features']
rpn_scores_raw = rpn_cls[:, :, 0]
rpn_scores = torch.sigmoid(rpn_scores_raw)
seg_result = (rpn_scores > cfg.RPN.SCORE_THRESH).long()
# proposal layer
rois, roi_scores_raw = model.rpn.proposal_layer(rpn_scores_raw, rpn_reg, backbone_xyz) # (B, M, 7)
batch_size = rois.shape[0]
# calculate recall and save results to file
for bs_idx in range(batch_size):
cur_sample_id = sample_id_list[bs_idx]
cur_scores_raw = roi_scores_raw[bs_idx] # (N)
cur_boxes3d = rois[bs_idx] # (N, 7)
cur_seg_result = seg_result[bs_idx]
cur_pts_rect = pts_rect[bs_idx]
# calculate recall
if not args.test:
cur_rpn_cls_label = rpn_cls_label[bs_idx]
cur_gt_boxes3d = gt_boxes3d[bs_idx]
k = cur_gt_boxes3d.__len__() - 1
while k > 0 and cur_gt_boxes3d[k].sum() == 0:
k -= 1
cur_gt_boxes3d = cur_gt_boxes3d[:k + 1]
recalled_num = 0
if cur_gt_boxes3d.shape[0] > 0:
iou3d = iou3d_utils.boxes_iou3d_gpu(cur_boxes3d, cur_gt_boxes3d[:, 0:7])
gt_max_iou, _ = iou3d.max(dim = 0)
for idx, thresh in enumerate(thresh_list):
total_recalled_bbox_list[idx] += (gt_max_iou > thresh).sum().item()
recalled_num = (gt_max_iou > 0.7).sum().item()
total_gt_bbox += cur_gt_boxes3d.__len__()
fg_mask = cur_rpn_cls_label > 0
correct = ((cur_seg_result == cur_rpn_cls_label) & fg_mask).sum().float()
union = fg_mask.sum().float() + (cur_seg_result > 0).sum().float() - correct
rpn_iou = correct / torch.clamp(union, min = 1.0)
rpn_iou_avg += rpn_iou.item()
# save result
if args.save_rpn_feature:
# save features to file
save_rpn_features(seg_result[bs_idx].float().cpu().numpy(),
rpn_scores_raw[bs_idx].float().cpu().numpy(),
pts_features[bs_idx],
backbone_xyz[bs_idx].cpu().numpy(),
backbone_features[bs_idx].cpu().numpy().transpose(1, 0),
kitti_features_dir, cur_sample_id)
if args.save_result or args.save_rpn_feature:
cur_pred_cls = cur_seg_result.cpu().numpy()
output_file = os.path.join(seg_output_dir, '%06d.npy' % cur_sample_id)
if not args.test:
cur_gt_cls = cur_rpn_cls_label.cpu().numpy()
output_data = np.concatenate(
(cur_pts_rect.reshape(-1, 3), cur_gt_cls.reshape(-1, 1), cur_pred_cls.reshape(-1, 1)),
axis = 1)
else:
output_data = np.concatenate((cur_pts_rect.reshape(-1, 3), cur_pred_cls.reshape(-1, 1)), axis = 1)
np.save(output_file, output_data.astype(np.float16))
# save as kitti format
calib = dataset.get_calib(cur_sample_id)
cur_boxes3d = cur_boxes3d.cpu().numpy()
image_shape = dataset.get_image_shape(cur_sample_id)
save_kitti_format(cur_sample_id, calib, cur_boxes3d, kitti_output_dir, cur_scores_raw, image_shape)
disp_dict = { 'mode' : mode, 'recall': '%d/%d' % (total_recalled_bbox_list[3], total_gt_bbox),
'rpn_iou': rpn_iou_avg / max(cnt, 1.0) }
progress_bar.set_postfix(disp_dict)
progress_bar.update()
progress_bar.close()
logger.info(str(datetime.now()))
logger.info('-------------------performance of epoch %s---------------------' % epoch_id)
logger.info('max number of objects: %d' % max_num)
logger.info('rpn iou avg: %f' % (rpn_iou_avg / max(cnt, 1.0)))
ret_dict = { 'max_obj_num': max_num, 'rpn_iou': rpn_iou_avg / cnt }
for idx, thresh in enumerate(thresh_list):
cur_recall = total_recalled_bbox_list[idx] / max(total_gt_bbox, 1.0)
logger.info('total bbox recall(thresh=%.3f): %d / %d = %f' % (thresh, total_recalled_bbox_list[idx],
total_gt_bbox, cur_recall))
ret_dict['rpn_recall(thresh=%.2f)' % thresh] = cur_recall
logger.info('result is saved to: %s' % result_dir)
return ret_dict
def eval_one_epoch_rcnn(model, dataloader, epoch_id, result_dir, logger):
np.random.seed(1024)
MEAN_SIZE = torch.from_numpy(cfg.CLS_MEAN_SIZE[0]).cuda()
mode = 'TEST' if args.test else 'EVAL'
final_output_dir = os.path.join(result_dir, 'final_result', 'data')
os.makedirs(final_output_dir, exist_ok = True)
if args.save_result:
roi_output_dir = os.path.join(result_dir, 'roi_result', 'data')
refine_output_dir = os.path.join(result_dir, 'refine_result', 'data')
os.makedirs(roi_output_dir, exist_ok = True)
os.makedirs(refine_output_dir, exist_ok = True)
logger.info('---- EPOCH %s RCNN EVALUATION ----' % epoch_id)
model.eval()
thresh_list = [0.1, 0.3, 0.5, 0.7, 0.9]
total_recalled_bbox_list, total_gt_bbox = [0] * 5, 0
total_roi_recalled_bbox_list = [0] * 5
dataset = dataloader.dataset
cnt = final_total = total_cls_acc = total_cls_acc_refined = 0
progress_bar = tqdm.tqdm(total = len(dataloader), leave = True, desc = 'eval')
for data in dataloader:
sample_id = data['sample_id']
cnt += 1
assert args.batch_size == 1, 'Only support bs=1 here'
input_data = { }
for key, val in data.items():
if key != 'sample_id':
input_data[key] = torch.from_numpy(val).contiguous().cuda(non_blocking = True).float()
roi_boxes3d = input_data['roi_boxes3d']
roi_scores = input_data['roi_scores']
if cfg.RCNN.ROI_SAMPLE_JIT:
for key, val in input_data.items():
if key in ['gt_iou', 'gt_boxes3d']:
continue
input_data[key] = input_data[key].unsqueeze(dim = 0)
else:
pts_input = torch.cat((input_data['pts_input'], input_data['pts_features']), dim = -1)
input_data['pts_input'] = pts_input
# img feature
if cfg.LI_FUSION.ENABLED:
pts_origin_xy, img = data['pts_origin_xy'], data['img']
pts_origin_xy = torch.from_numpy(pts_origin_xy).cuda(non_blocking = True).float()
img = torch.from_numpy(img).cuda(non_blocking = True).float().permute((0,3,1,2))
input_data['pts_origin_xy'] = pts_origin_xy
input_data['img'] = img
if cfg.RPN.USE_RGB or cfg.RCNN.USE_RGB:
pts_rgb=data['rgb']
pts_rgb=torch.from_numpy(pts_rgb).cuda(non_blocking = True).float()
input_data['pts_rgb']=pts_rgb
ret_dict = model(input_data)
rcnn_cls = ret_dict['rcnn_cls']
rcnn_reg = ret_dict['rcnn_reg']
# bounding box regression
anchor_size = MEAN_SIZE
if cfg.RCNN.SIZE_RES_ON_ROI:
roi_size = input_data['roi_size']
anchor_size = roi_size
pred_boxes3d = decode_bbox_target(roi_boxes3d, rcnn_reg,
anchor_size = anchor_size,
loc_scope = cfg.RCNN.LOC_SCOPE,
loc_bin_size = cfg.RCNN.LOC_BIN_SIZE,
num_head_bin = cfg.RCNN.NUM_HEAD_BIN,
get_xz_fine = True, get_y_by_bin = cfg.RCNN.LOC_Y_BY_BIN,
loc_y_scope = cfg.RCNN.LOC_Y_SCOPE, loc_y_bin_size = cfg.RCNN.LOC_Y_BIN_SIZE,
get_ry_fine = True)
# scoring
if rcnn_cls.shape[1] == 1:
raw_scores = rcnn_cls.view(-1)
norm_scores = torch.sigmoid(raw_scores)
pred_classes = (norm_scores > cfg.RCNN.SCORE_THRESH).long()
else:
pred_classes = torch.argmax(rcnn_cls, dim = 1).view(-1)
cls_norm_scores = F.softmax(rcnn_cls, dim = 1)
raw_scores = rcnn_cls[:, pred_classes]
norm_scores = cls_norm_scores[:, pred_classes]
# evaluation
disp_dict = { 'mode': mode }
if not args.test:
gt_boxes3d = input_data['gt_boxes3d']
gt_iou = input_data['gt_iou']
# calculate recall
gt_num = gt_boxes3d.shape[0]
if gt_num > 0:
iou3d = iou3d_utils.boxes_iou3d_gpu(pred_boxes3d, gt_boxes3d)
gt_max_iou, _ = iou3d.max(dim = 0)
refined_iou, _ = iou3d.max(dim = 1)
for idx, thresh in enumerate(thresh_list):
total_recalled_bbox_list[idx] += (gt_max_iou > thresh).sum().item()
recalled_num = (gt_max_iou > 0.7).sum().item()
total_gt_bbox += gt_num
iou3d_in = iou3d_utils.boxes_iou3d_gpu(roi_boxes3d, gt_boxes3d)
gt_max_iou_in, _ = iou3d_in.max(dim = 0)
for idx, thresh in enumerate(thresh_list):
total_roi_recalled_bbox_list[idx] += (gt_max_iou_in > thresh).sum().item()
# classification accuracy
cls_label = (gt_iou > cfg.RCNN.CLS_FG_THRESH).float()
cls_valid_mask = ((gt_iou >= cfg.RCNN.CLS_FG_THRESH) | (gt_iou <= cfg.RCNN.CLS_BG_THRESH)).float()
cls_acc = ((pred_classes == cls_label.long()).float() * cls_valid_mask).sum() / max(cls_valid_mask.sum(),
1.0)
iou_thresh = 0.7 if cfg.CLASSES == 'Car' else 0.5
cls_label_refined = (gt_iou >= iou_thresh).float()
cls_acc_refined = (pred_classes == cls_label_refined.long()).float().sum() / max(cls_label_refined.shape[0],
1.0)
total_cls_acc += cls_acc.item()
total_cls_acc_refined += cls_acc_refined.item()
disp_dict['recall'] = '%d/%d' % (total_recalled_bbox_list[3], total_gt_bbox)
disp_dict['cls_acc_refined'] = '%.2f' % cls_acc_refined.item()
progress_bar.set_postfix(disp_dict)
progress_bar.update()
image_shape = dataset.get_image_shape(sample_id)
if args.save_result:
# save roi and refine results
roi_boxes3d_np = roi_boxes3d.cpu().numpy()
pred_boxes3d_np = pred_boxes3d.cpu().numpy()
calib = dataset.get_calib(sample_id)
save_kitti_format(sample_id, calib, roi_boxes3d_np, roi_output_dir, roi_scores, image_shape)
save_kitti_format(sample_id, calib, pred_boxes3d_np, refine_output_dir, raw_scores.cpu().numpy(),
image_shape)
# NMS and scoring
# scores thresh
inds = norm_scores > cfg.RCNN.SCORE_THRESH
if inds.sum() == 0:
continue
pred_boxes3d_selected = pred_boxes3d[inds]
raw_scores_selected = raw_scores[inds]
# NMS thresh
boxes_bev_selected = kitti_utils.boxes3d_to_bev_torch(pred_boxes3d_selected)
keep_idx = iou3d_utils.nms_gpu(boxes_bev_selected, raw_scores_selected, cfg.RCNN.NMS_THRESH)
pred_boxes3d_selected = pred_boxes3d_selected[keep_idx]
scores_selected = raw_scores_selected[keep_idx]
pred_boxes3d_selected, scores_selected = pred_boxes3d_selected.cpu().numpy(), scores_selected.cpu().numpy()
calib = dataset.get_calib(sample_id)
final_total += pred_boxes3d_selected.shape[0]
save_kitti_format(sample_id, calib, pred_boxes3d_selected, final_output_dir, scores_selected, image_shape)
progress_bar.close()
# dump empty files
split_file = os.path.join(dataset.imageset_dir, '..', '..', 'ImageSets', dataset.split + '.txt')
split_file = os.path.abspath(split_file)
image_idx_list = [x.strip() for x in open(split_file).readlines()]
empty_cnt = 0
for k in range(image_idx_list.__len__()):
cur_file = os.path.join(final_output_dir, '%s.txt' % image_idx_list[k])
if not os.path.exists(cur_file):
with open(cur_file, 'w') as temp_f:
pass
empty_cnt += 1
logger.info('empty_cnt=%d: dump empty file %s' % (empty_cnt, cur_file))
ret_dict = { 'empty_cnt': empty_cnt }
logger.info('-------------------performance of epoch %s---------------------' % epoch_id)
logger.info(str(datetime.now()))
avg_cls_acc = (total_cls_acc / max(cnt, 1.0))
avg_cls_acc_refined = (total_cls_acc_refined / max(cnt, 1.0))
avg_det_num = (final_total / max(cnt, 1.0))
logger.info('final average detections: %.3f' % avg_det_num)
logger.info('final average cls acc: %.3f' % avg_cls_acc)
logger.info('final average cls acc refined: %.3f' % avg_cls_acc_refined)
ret_dict['rcnn_cls_acc'] = avg_cls_acc
ret_dict['rcnn_cls_acc_refined'] = avg_cls_acc_refined
ret_dict['rcnn_avg_num'] = avg_det_num
for idx, thresh in enumerate(thresh_list):
cur_roi_recall = total_roi_recalled_bbox_list[idx] / max(total_gt_bbox, 1.0)
logger.info('total roi bbox recall(thresh=%.3f): %d / %d = %f' % (thresh, total_roi_recalled_bbox_list[idx],
total_gt_bbox, cur_roi_recall))
ret_dict['rpn_recall(thresh=%.2f)' % thresh] = cur_roi_recall
for idx, thresh in enumerate(thresh_list):
cur_recall = total_recalled_bbox_list[idx] / max(total_gt_bbox, 1.0)
logger.info('total bbox recall(thresh=%.3f): %d / %d = %f' % (thresh, total_recalled_bbox_list[idx],
total_gt_bbox, cur_recall))
ret_dict['rcnn_recall(thresh=%.2f)' % thresh] = cur_recall
if cfg.TEST.SPLIT != 'test':
logger.info('Averate Precision:')
name_to_class = { 'Car': 0, 'Pedestrian': 1, 'Cyclist': 2 }
ap_result_str, ap_dict = kitti_evaluate(dataset.label_dir, final_output_dir, label_split_file = split_file,
current_class = name_to_class[cfg.CLASSES])
logger.info(ap_result_str)
ret_dict.update(ap_dict)
logger.info('result is saved to: %s' % result_dir)
return ret_dict
def eval_one_epoch_joint(model, generator_img, generator_pts, dataloader, epoch_id, result_dir, logger):
np.random.seed(666)
MEAN_SIZE = torch.from_numpy(cfg.CLS_MEAN_SIZE[0]).cuda()
mode = 'TEST' if args.test else 'EVAL'
final_output_dir = os.path.join(result_dir, 'final_result', 'data')
os.makedirs(final_output_dir, exist_ok = True)
if args.save_result:
roi_output_dir = os.path.join(result_dir, 'roi_result', 'data')
refine_output_dir = os.path.join(result_dir, 'refine_result', 'data')
rpn_output_dir = os.path.join(result_dir, 'rpn_result', 'data')
os.makedirs(rpn_output_dir, exist_ok = True)
os.makedirs(roi_output_dir, exist_ok = True)
os.makedirs(refine_output_dir, exist_ok = True)
logger.info('---- EPOCH %s JOINT EVALUATION ----' % epoch_id)
logger.info('==> Output file: %s' % result_dir)
model.eval()
generator_img.eval()
generator_pts.eval()
thresh_list = [0.1, 0.3, 0.5, 0.7, 0.9]
total_recalled_bbox_list, total_gt_bbox = [0] * 5, 0
total_roi_recalled_bbox_list = [0] * 5
dataset = dataloader.dataset
cnt = final_total = total_cls_acc = total_cls_acc_refined = total_rpn_iou = 0
pert_dist_img = 0
refined_dist_img = 0
pert_dist_pts = 0
progress_bar = tqdm.tqdm(total = len(dataloader), leave = True, desc = 'eval')
img_mean = np.array([0.485, 0.456, 0.406])
img_std = np.array([0.229, 0.224, 0.225])
clamp_max = (1. - img_mean) / img_std
clamp_min = - img_mean / img_std
for data in dataloader:
# input('Pause')
cnt += 1
sample_id, pts_rect, pts_features, pts_input = \
data['sample_id'], data['pts_rect'], data['pts_features'], data['pts_input']
batch_size = len(sample_id)
inputs = torch.from_numpy(pts_input).cuda(non_blocking = True).float()
input_data = {}
# img feature
if cfg.LI_FUSION.ENABLED:
pts_origin_xy, img = data['pts_origin_xy'], data['img']
pts_origin_xy = torch.from_numpy(pts_origin_xy).cuda(non_blocking = True).float()
img = torch.from_numpy(img).cuda(non_blocking = True).float().permute((0,3,1,2))
input_data['pts_origin_xy'] = pts_origin_xy
# input_data['img'] = img
img_pert, img_pert_fea = generator_img(img)
cur_dist_img = torch.mean(reduce_sum(img_pert ** 2))
pert_dist_img += cur_dist_img
input_data['img'] = img + img_pert
for j in range(3):
input_data['img'][:, j, :, :] = torch.clamp(input_data['img'][:, j, :, :],
min=clamp_min[j], max=clamp_max[j])
cur_dist_img_r = torch.mean(reduce_sum((input_data['img'] - img) ** 2))
refined_dist_img += cur_dist_img_r
if args.gen_pert:
pts_pert = generator_pts(inputs, img_pert_fea, pts_origin_xy)
input_data['pts_input'] = inputs + pts_pert
cur_dist_pts = torch.mean(reduce_sum(pts_pert ** 2))
else:
input_data['pts_input'] = generator_pts(inputs)
cur_dist_pts = torch.mean(reduce_sum((input_data['pts_input'] - inputs) ** 2))
pert_dist_pts += cur_dist_pts
if cfg.RPN.USE_RGB or cfg.RCNN.USE_RGB:
pts_rgb=data['rgb']
pts_rgb=torch.from_numpy(pts_rgb).cuda(non_blocking = True).float()
input_data['pts_rgb']=pts_rgb
# model inference
ret_dict = model(input_data)
roi_scores_raw = ret_dict['roi_scores_raw'] # (B, M)
roi_boxes3d = ret_dict['rois'] # (B, M, 7)
seg_result = ret_dict['seg_result'].long() # (B, N)
rcnn_cls = ret_dict['rcnn_cls'].view(batch_size, -1, ret_dict['rcnn_cls'].shape[1])
rcnn_reg = ret_dict['rcnn_reg'].view(batch_size, -1, ret_dict['rcnn_reg'].shape[1]) # (B, M, C)
if cfg.USE_IOU_BRANCH:
rcnn_iou_branch = ret_dict['rcnn_iou_branch'].view(batch_size, -1, ret_dict['rcnn_iou_branch'].shape[1]) ##########################TO
rcnn_iou_branch = torch.max(rcnn_iou_branch, rcnn_iou_branch.new().resize_(rcnn_iou_branch.shape).fill_(1e-4))
rcnn_cls = rcnn_iou_branch * rcnn_cls
# bounding box regression
anchor_size = MEAN_SIZE
if cfg.RCNN.SIZE_RES_ON_ROI:
assert False
pred_boxes3d = decode_bbox_target(roi_boxes3d.view(-1, 7), rcnn_reg.view(-1, rcnn_reg.shape[-1]),
anchor_size = anchor_size,
loc_scope = cfg.RCNN.LOC_SCOPE,
loc_bin_size = cfg.RCNN.LOC_BIN_SIZE,
num_head_bin = cfg.RCNN.NUM_HEAD_BIN,
get_xz_fine = True, get_y_by_bin = cfg.RCNN.LOC_Y_BY_BIN,
loc_y_scope = cfg.RCNN.LOC_Y_SCOPE, loc_y_bin_size = cfg.RCNN.LOC_Y_BIN_SIZE,
get_ry_fine = True).view(batch_size, -1, 7)
# scoring
if rcnn_cls.shape[2] == 1:
raw_scores = rcnn_cls # (B, M, 1)
norm_scores = torch.sigmoid(raw_scores)
pred_classes = (norm_scores > cfg.RCNN.SCORE_THRESH).long()
else:
pred_classes = torch.argmax(rcnn_cls, dim = 1).view(-1)
cls_norm_scores = F.softmax(rcnn_cls, dim = 1)
raw_scores = rcnn_cls[:, pred_classes]
norm_scores = cls_norm_scores[:, pred_classes]
# evaluation
recalled_num = gt_num = rpn_iou = 0
if not args.test:
if not cfg.RPN.FIXED:
rpn_cls_label, rpn_reg_label = data['rpn_cls_label'], data['rpn_reg_label']
rpn_cls_label = torch.from_numpy(rpn_cls_label).cuda(non_blocking = True).long()
gt_boxes3d = data['gt_boxes3d']
for k in range(batch_size):
# calculate recall
cur_gt_boxes3d = gt_boxes3d[k]
tmp_idx = cur_gt_boxes3d.__len__() - 1
while tmp_idx >= 0 and cur_gt_boxes3d[tmp_idx].sum() == 0:
tmp_idx -= 1
if tmp_idx >= 0:
cur_gt_boxes3d = cur_gt_boxes3d[:tmp_idx + 1]
cur_gt_boxes3d = torch.from_numpy(cur_gt_boxes3d).cuda(non_blocking = True).float()
iou3d = iou3d_utils.boxes_iou3d_gpu(pred_boxes3d[k], cur_gt_boxes3d)
gt_max_iou, _ = iou3d.max(dim = 0)
refined_iou, _ = iou3d.max(dim = 1)
for idx, thresh in enumerate(thresh_list):
total_recalled_bbox_list[idx] += (gt_max_iou > thresh).sum().item()
recalled_num += (gt_max_iou > 0.7).sum().item()
gt_num += cur_gt_boxes3d.shape[0]
total_gt_bbox += cur_gt_boxes3d.shape[0]
# original recall
iou3d_in = iou3d_utils.boxes_iou3d_gpu(roi_boxes3d[k], cur_gt_boxes3d)
gt_max_iou_in, _ = iou3d_in.max(dim = 0)
for idx, thresh in enumerate(thresh_list):
total_roi_recalled_bbox_list[idx] += (gt_max_iou_in > thresh).sum().item()
if not cfg.RPN.FIXED:
fg_mask = rpn_cls_label > 0
correct = ((seg_result == rpn_cls_label) & fg_mask).sum().float()
union = fg_mask.sum().float() + (seg_result > 0).sum().float() - correct
rpn_iou = correct / torch.clamp(union, min = 1.0)
total_rpn_iou += rpn_iou.item()
disp_dict = {'mode': mode, 'recall': '%d/%d' % (total_recalled_bbox_list[3], total_gt_bbox),
'img': cur_dist_img.item(), 'r_img': cur_dist_img_r.item(),
'pts': cur_dist_pts.item()}
progress_bar.set_postfix(disp_dict)
progress_bar.update()
if args.save_result:
# save roi and refine results
roi_boxes3d_np = roi_boxes3d.cpu().numpy()
pred_boxes3d_np = pred_boxes3d.cpu().numpy()
roi_scores_raw_np = roi_scores_raw.cpu().numpy()
raw_scores_np = raw_scores.cpu().numpy()
rpn_cls_np = ret_dict['rpn_cls'].cpu().numpy()
rpn_xyz_np = ret_dict['backbone_xyz'].cpu().numpy()
seg_result_np = seg_result.cpu().numpy()
output_data = np.concatenate((rpn_xyz_np, rpn_cls_np.reshape(batch_size, -1, 1),
seg_result_np.reshape(batch_size, -1, 1)), axis = 2)
for k in range(batch_size):
cur_sample_id = sample_id[k]
calib = dataset.get_calib(cur_sample_id)
image_shape = dataset.get_image_shape(cur_sample_id)
save_kitti_format(cur_sample_id, calib, roi_boxes3d_np[k], roi_output_dir,
roi_scores_raw_np[k], image_shape)
save_kitti_format(cur_sample_id, calib, pred_boxes3d_np[k], refine_output_dir,
raw_scores_np[k], image_shape)
output_file = os.path.join(rpn_output_dir, '%06d.npy' % cur_sample_id)
np.save(output_file, output_data.astype(np.float32))
# scores thresh
inds = norm_scores > cfg.RCNN.SCORE_THRESH
# print('cfg.RCNN.SCORE_THRESH:',cfg.RCNN.SCORE_THRESH)
# print('cfg.RCNN.NMS_THRESH:',cfg.RCNN.NMS_THRESH)
for k in range(batch_size):
cur_inds = inds[k].view(-1)
if cur_inds.sum() == 0:
continue
pred_boxes3d_selected = pred_boxes3d[k, cur_inds]
raw_scores_selected = raw_scores[k, cur_inds]
norm_scores_selected = norm_scores[k, cur_inds]
# NMS thresh
# rotated nms
boxes_bev_selected = kitti_utils.boxes3d_to_bev_torch(pred_boxes3d_selected)
keep_idx = iou3d_utils.nms_gpu(boxes_bev_selected, raw_scores_selected, cfg.RCNN.NMS_THRESH).view(-1)
pred_boxes3d_selected = pred_boxes3d_selected[keep_idx]
scores_selected = raw_scores_selected[keep_idx]
pred_boxes3d_selected, scores_selected = pred_boxes3d_selected.cpu().numpy(), scores_selected.cpu().numpy()
cur_sample_id = sample_id[k]
calib = dataset.get_calib(cur_sample_id)
final_total += pred_boxes3d_selected.shape[0]
image_shape = dataset.get_image_shape(cur_sample_id)
save_kitti_format(cur_sample_id, calib, pred_boxes3d_selected, final_output_dir, scores_selected,
image_shape)
progress_bar.close()
# dump empty files
split_file = os.path.join(dataset.imageset_dir, '..', '..', 'ImageSets', dataset.split + '.txt')
split_file = os.path.abspath(split_file)
image_idx_list = [x.strip() for x in open(split_file).readlines()]
empty_cnt = 0
for k in range(image_idx_list.__len__()):
cur_file = os.path.join(final_output_dir, '%s.txt' % image_idx_list[k])
if not os.path.exists(cur_file):
with open(cur_file, 'w') as temp_f:
pass
empty_cnt += 1
logger.info('empty_cnt=%d: dump empty file %s' % (empty_cnt, cur_file))
ret_dict = { 'empty_cnt': empty_cnt }
logger.info('-------------------performance of epoch %s---------------------' % epoch_id)
logger.info(str(datetime.now()))
avg_rpn_iou = (total_rpn_iou / max(cnt, 1.0))
avg_cls_acc = (total_cls_acc / max(cnt, 1.0))
avg_cls_acc_refined = (total_cls_acc_refined / max(cnt, 1.0))
avg_det_num = (final_total / max(len(dataset), 1.0))
avg_pimg_dist = (pert_dist_img / max(cnt, 1.0))
avg_refined_dist = (refined_dist_img / max(cnt, 1.0))
avg_ppts_dist = (pert_dist_pts / max(cnt, 1.0))
logger.info('final average detections: %.3f' % avg_det_num)
logger.info('final average rpn_iou refined: %.3f' % avg_rpn_iou)
logger.info('final average cls acc: %.3f' % avg_cls_acc)
logger.info('final average cls acc refined: %.3f' % avg_cls_acc_refined)
logger.info('final average pert img dist: %f' % avg_pimg_dist)
logger.info('final average pert img dist refined: %f' % avg_refined_dist)
logger.info('final average pert pts dist: %f' % avg_ppts_dist)
ret_dict['rpn_iou'] = avg_rpn_iou
ret_dict['rcnn_cls_acc'] = avg_cls_acc
ret_dict['rcnn_cls_acc_refined'] = avg_cls_acc_refined
ret_dict['rcnn_avg_num'] = avg_det_num
ret_dict['pimg_dist'] = avg_pimg_dist
ret_dict['pimg_dist_refined'] = avg_refined_dist
ret_dict['ppts_dist'] = avg_ppts_dist
for idx, thresh in enumerate(thresh_list):
cur_roi_recall = total_roi_recalled_bbox_list[idx] / max(total_gt_bbox, 1.0)
logger.info('total roi bbox recall(thresh=%.3f): %d / %d = %f' % (thresh, total_roi_recalled_bbox_list[idx],
total_gt_bbox, cur_roi_recall))
ret_dict['rpn_recall(thresh=%.2f)' % thresh] = cur_roi_recall
for idx, thresh in enumerate(thresh_list):
cur_recall = total_recalled_bbox_list[idx] / max(total_gt_bbox, 1.0)
logger.info('total bbox recall(thresh=%.3f): %d / %d = %f' % (thresh, total_recalled_bbox_list[idx],
total_gt_bbox, cur_recall))
ret_dict['rcnn_recall(thresh=%.2f)' % thresh] = cur_recall
if cfg.TEST.SPLIT != 'test':
logger.info('Averate Precision:')
name_to_class = { 'Car': 0, 'Pedestrian': 1, 'Cyclist': 2 }
ap_result_str, ap_dict = kitti_evaluate(dataset.label_dir, final_output_dir, label_split_file = split_file,
current_class = name_to_class[cfg.CLASSES])
logger.info(ap_result_str)
ret_dict.update(ap_dict)
logger.info('result is saved to: %s' % result_dir)
return ret_dict
def eval_one_epoch(model, generator_img, generator_pts, dataloader, epoch_id, result_dir, logger):
if cfg.RPN.ENABLED and not cfg.RCNN.ENABLED:
ret_dict = eval_one_epoch_rpn(model, dataloader, epoch_id, result_dir, logger)
elif not cfg.RPN.ENABLED and cfg.RCNN.ENABLED:
ret_dict = eval_one_epoch_rcnn(model, dataloader, epoch_id, result_dir, logger)
elif cfg.RPN.ENABLED and cfg.RCNN.ENABLED:
ret_dict = eval_one_epoch_joint(model, generator_img, generator_pts, dataloader, epoch_id, result_dir, logger)
else:
raise NotImplementedError
return ret_dict
def load_part_ckpt(model, filename, logger, total_keys = -1):
if os.path.isfile(filename):
logger.info("==> Loading part model from checkpoint '{}'".format(filename))
checkpoint = torch.load(filename)
model_state = checkpoint['model_state']
update_model_state = { key: val for key, val in model_state.items() if key in model.state_dict() }
state_dict = model.state_dict()
state_dict.update(update_model_state)
model.load_state_dict(state_dict)
update_keys = update_model_state.keys().__len__()
if update_keys == 0:
raise RuntimeError
logger.info("==> Done (loaded %d/%d)" % (update_keys, total_keys))
else:
raise FileNotFoundError
def load_ckpt_based_on_args(model, generator_img, generator_pts, logger):
if args.ckpt is not None:
train_utils.load_checkpoint(model, filename = args.ckpt, logger = logger)
if args.afus_ckpt_dir is not None:
logger.info("==> Loading generator")
aimg_ckpt = os.path.join(args.afus_ckpt_dir, 'checkpoint_Gimg_iter_%d.pth' % args.afus_iter)
checkpoint = torch.load(aimg_ckpt)
generator_img.load_state_dict(checkpoint['model_state'])
logger.info("==> Loading perturbation")
apts_ckpt = os.path.join(args.afus_ckpt_dir, 'checkpoint_Gpts_iter_%d.pth' % args.afus_iter)
checkpoint = torch.load(apts_ckpt)
generator_pts.load_state_dict(checkpoint['model_state'])
logger.info("==> Done")
total_keys = model.state_dict().keys().__len__()
if cfg.RPN.ENABLED and args.rpn_ckpt is not None:
load_part_ckpt(model, filename = args.rpn_ckpt, logger = logger, total_keys = total_keys)
if cfg.RCNN.ENABLED and args.rcnn_ckpt is not None:
load_part_ckpt(model, filename = args.rcnn_ckpt, logger = logger, total_keys = total_keys)
def eval_single_ckpt(root_result_dir):
root_result_dir = os.path.join(root_result_dir, 'eval')
# set epoch_id and output dir
num_list = re.findall(r'\d+', args.ckpt) if args.ckpt is not None else []
epoch_id = num_list[-1] if num_list.__len__() > 0 else 'no_number'
root_result_dir = os.path.join(root_result_dir, 'epoch_%s' % epoch_id, cfg.TEST.SPLIT)
if args.test:
root_result_dir = os.path.join(root_result_dir, 'test_mode')
if args.extra_tag != 'default':
root_result_dir = os.path.join(root_result_dir, args.extra_tag)
os.makedirs(root_result_dir, exist_ok = True)
log_file = os.path.join(root_result_dir, 'log_eval_one.txt')
logger = create_logger(log_file)
logger.info('**********************Start logging**********************')
for key, val in vars(args).items():
logger.info("{:16} {}".format(key, val))
save_config_to_file(cfg, logger = logger)
# create dataloader & network
test_loader = create_dataloader(logger)
# model = PointRCNN(num_classes=test_loader.dataset.num_class, use_xyz=True, mode='TEST')
if args.model_type == 'base':
model = PointRCNN(num_classes = test_loader.dataset.num_class, use_xyz = True, mode = 'TEST')
generator_img = Generator_fusimg(num_channels=3, ngf=100)
input_channels = int(cfg.RPN.USE_INTENSITY) + 3 * int(cfg.RPN.USE_RGB)
generator_pts = Generator_fuspts(input_channels=input_channels, use_xyz=True)
# elif args.model_type == 'rpn_mscale':
# model = PointRCNN_mScale(num_classes = test_loader.dataset.num_class, use_xyz = True, mode = 'TEST')
model.cuda()
generator_img.cuda()
generator_pts.cuda()
# copy important files to backup
# backup_dir = os.path.join(root_result_dir, 'backup_files')
# os.makedirs(backup_dir, exist_ok = True)
# os.system('cp *.py %s/' % backup_dir)
# os.system('cp ../lib/net/*.py %s/' % backup_dir)
# os.system('cp ../lib/datasets/kitti_rcnn_dataset.py %s/' % backup_dir)
# load checkpoint
load_ckpt_based_on_args(model, generator_img, generator_pts, logger)
# start evaluation
eval_one_epoch(model, generator_img, generator_pts, test_loader, epoch_id, root_result_dir, logger)
def get_no_evaluated_ckpt(ckpt_dir, ckpt_record_file):
ckpt_list = glob.glob(os.path.join(ckpt_dir, '*checkpoint_epoch_*.pth'))
ckpt_list.sort(key = os.path.getmtime)
evaluated_ckpt_list = [float(x.strip()) for x in open(ckpt_record_file, 'r').readlines()]
for cur_ckpt in ckpt_list:
num_list = re.findall('checkpoint_epoch_(.*).pth', cur_ckpt)
if num_list.__len__() == 0:
continue
epoch_id = num_list[-1]
if float(epoch_id) not in evaluated_ckpt_list and int(float(epoch_id)) >= args.start_epoch:
return epoch_id, cur_ckpt
return -1, None
def repeat_eval_ckpt(root_result_dir, ckpt_dir):
root_result_dir = os.path.join(root_result_dir, 'eval', 'eval_all_' + args.extra_tag)
os.makedirs(root_result_dir, exist_ok = True)
log_file = os.path.join(root_result_dir, 'log_eval_all_%s.txt' % cfg.TEST.SPLIT)
logger = create_logger(log_file)
logger.info('**********************Start logging**********************')
# save config
for key, val in vars(args).items():
logger.info("{:16} {}".format(key, val))
save_config_to_file(cfg, logger = logger)
# create dataloader & network
test_loader = create_dataloader(logger)
# model = PointRCNN(num_classes=test_loader.dataset.num_class, use_xyz=True, mode='TEST')
if args.model_type == 'base':
model = PointRCNN(num_classes = test_loader.dataset.num_class, use_xyz = True, mode = 'TEST')
# print(model)
# elif args.model_type == 'rpn_mscale':
# model = PointRCNN_mScale(num_classes = test_loader.dataset.num_class, use_xyz = True, mode = 'TEST')
model.cuda()
# copy important files to backup
backup_dir = os.path.join(root_result_dir, 'backup_files')
os.makedirs(backup_dir, exist_ok = True)
os.system('cp *.py %s/' % backup_dir)
os.system('cp ../lib/net/*.py %s/' % backup_dir)
os.system('cp ../lib/datasets/kitti_rcnn_dataset.py %s/' % backup_dir)
# evaluated ckpt record
ckpt_record_file = os.path.join(root_result_dir, 'eval_list_%s.txt' % cfg.TEST.SPLIT)
with open(ckpt_record_file, 'a'):
pass
# tensorboard log
tb_log = SummaryWriter(logdir = os.path.join(root_result_dir, 'tensorboard_%s' % cfg.TEST.SPLIT))
total_time = 0
first_eval = True
while True:
# check whether there is checkpoint which is not evaluated
cur_epoch_id, cur_ckpt = get_no_evaluated_ckpt(ckpt_dir, ckpt_record_file)
if cur_epoch_id == -1 or int(float(cur_epoch_id)) < args.start_epoch:
wait_second = 30
print('Wait %s second for next check: %s' % (wait_second, ckpt_dir))
time.sleep(wait_second)
total_time += 30
if total_time > args.max_waiting_mins * 60 and (first_eval is False):
break
continue
total_time = 0
first_eval = False
# load checkpoint
train_utils.load_checkpoint(model, filename = cur_ckpt)
# start evaluation
cur_result_dir = os.path.join(root_result_dir, 'epoch_%s' % cur_epoch_id, cfg.TEST.SPLIT)
tb_dict = eval_one_epoch(model, test_loader, cur_epoch_id, cur_result_dir, logger)
step = int(float(cur_epoch_id))
if step == float(cur_epoch_id):
for key, val in tb_dict.items():
tb_log.add_scalar(key, val, step)
# record this epoch which has been evaluated
with open(ckpt_record_file, 'a') as f:
print('%s' % cur_epoch_id, file = f)
logger.info('Epoch %s has been evaluated' % cur_epoch_id)
def create_dataloader(logger):
mode = 'TEST' if args.test else 'EVAL'
DATA_PATH = os.path.join('../', 'data')
# create dataloader
test_set = KittiRCNNDataset(root_dir = DATA_PATH, npoints = cfg.RPN.NUM_POINTS, split = cfg.TEST.SPLIT, mode = mode,
random_select = args.random_select,
rcnn_eval_roi_dir = args.rcnn_eval_roi_dir,
rcnn_eval_feature_dir = args.rcnn_eval_feature_dir,
classes = cfg.CLASSES,
logger = logger)
test_loader = DataLoader(test_set, batch_size = args.batch_size, shuffle = False, pin_memory = True,
num_workers = args.workers, collate_fn = test_set.collate_batch)
return test_loader
if __name__ == "__main__":
# merge config and log to file
if args.cfg_file is not None:
cfg_from_file(args.cfg_file)
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)
cfg.TAG = os.path.splitext(os.path.basename(args.cfg_file))[0]
if args.eval_mode == 'rpn':
cfg.RPN.ENABLED = True
cfg.RCNN.ENABLED = False
root_result_dir = os.path.join('../', 'output', 'rpn', cfg.TAG)
ckpt_dir = os.path.join('../', 'output', 'rpn', cfg.TAG, 'ckpt')
elif args.eval_mode == 'rcnn':
cfg.RCNN.ENABLED = True
cfg.RPN.ENABLED = cfg.RPN.FIXED = True
root_result_dir = os.path.join('../', 'output', 'rcnn', cfg.TAG)
ckpt_dir = os.path.join('../', 'output', 'rcnn', cfg.TAG, 'ckpt')
elif args.eval_mode == 'rcnn_online':
cfg.RCNN.ENABLED = True
cfg.RPN.ENABLED = True
cfg.RPN.FIXED = False
root_result_dir = os.path.join('../', 'output', 'rcnn', cfg.TAG)
ckpt_dir = os.path.join('../', 'output', 'rcnn', cfg.TAG, 'ckpt')
elif args.eval_mode == 'rcnn_offline':
cfg.RCNN.ENABLED = True
cfg.RPN.ENABLED = False
root_result_dir = os.path.join('../', 'output', 'rcnn', cfg.TAG)
ckpt_dir = os.path.join('../', 'output', 'rcnn', cfg.TAG, 'ckpt')
assert args.rcnn_eval_roi_dir is not None and args.rcnn_eval_feature_dir is not None
else:
raise NotImplementedError
if args.ckpt_dir is not None:
ckpt_dir = args.ckpt_dir
if args.output_dir is not None:
root_result_dir = args.output_dir
os.makedirs(root_result_dir, exist_ok = True)
with torch.no_grad():
if args.eval_all:
assert os.path.exists(ckpt_dir), '%s' % ckpt_dir
repeat_eval_ckpt(root_result_dir, ckpt_dir)
else:
eval_single_ckpt(root_result_dir)
| 46.78551 | 152 | 0.61875 |
4a1fa132fe0c2a60e27d81b52301195cfa6bb332 | 549 | py | Python | tests/test_rrt_star_reeds_shepp.py | yuokamoto/PythonRobotics | 754256d15e074f6091bc6c9b7e8e6499df865fb6 | [
"MIT"
] | 38 | 2019-12-08T12:26:04.000Z | 2022-03-06T11:29:08.000Z | tests/test_rrt_star_reeds_shepp.py | Kashyap95/PythonRobotics | ac066ee6049adc6315a859127344ee5de1e48b30 | [
"MIT"
] | null | null | null | tests/test_rrt_star_reeds_shepp.py | Kashyap95/PythonRobotics | ac066ee6049adc6315a859127344ee5de1e48b30 | [
"MIT"
] | 15 | 2020-02-12T15:57:28.000Z | 2021-08-28T07:39:18.000Z | from unittest import TestCase
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__))
+ "/../PathPlanning/RRTStarReedsShepp/")
sys.path.append(os.path.dirname(os.path.abspath(__file__))
+ "/../PathPlanning/ReedsSheppPath/")
try:
import rrt_star_reeds_shepp as m
except:
raise
print(__file__)
class Test(TestCase):
def test1(self):
m.show_animation = False
m.main(maxIter=5)
if __name__ == '__main__': # pragma: no cover
test = Test()
test.test1()
| 18.931034 | 58 | 0.652095 |
4a1fa13ee8dfc55fc6958a50a95b410e64e78649 | 17,070 | py | Python | saleor/graphql/checkout/types.py | Herbafill-HFG/saleor | 8206e407407cb711a669a28d0fcb03522e98b755 | [
"CC-BY-4.0"
] | 1 | 2022-02-19T13:27:40.000Z | 2022-02-19T13:27:40.000Z | saleor/graphql/checkout/types.py | Herbafill-HFG/saleor | 8206e407407cb711a669a28d0fcb03522e98b755 | [
"CC-BY-4.0"
] | 1 | 2019-04-05T17:22:52.000Z | 2019-04-05T17:22:52.000Z | saleor/graphql/checkout/types.py | Herbafill-HFG/saleor | 8206e407407cb711a669a28d0fcb03522e98b755 | [
"CC-BY-4.0"
] | 2 | 2021-12-03T16:59:37.000Z | 2022-02-19T13:05:42.000Z | import graphene
from promise import Promise
from ...checkout import calculations, models
from ...checkout.utils import get_valid_shipping_methods_for_checkout
from ...core.exceptions import PermissionDenied
from ...core.permissions import AccountPermissions
from ...core.taxes import zero_taxed_money
from ..account.dataloaders import AddressByIdLoader
from ..account.utils import requestor_has_access
from ..channel import ChannelContext
from ..channel.dataloaders import ChannelByCheckoutLineIDLoader, ChannelByIdLoader
from ..core.connection import CountableDjangoObjectType
from ..core.scalars import UUID
from ..core.types.money import TaxedMoney
from ..discount.dataloaders import DiscountsByDateTimeLoader
from ..giftcard.types import GiftCard
from ..meta.types import ObjectWithMetadata
from ..product.dataloaders import (
ProductTypeByProductIdLoader,
ProductTypeByVariantIdLoader,
ProductVariantByIdLoader,
)
from ..shipping.dataloaders import (
ShippingMethodByIdLoader,
ShippingMethodChannelListingByShippingMethodIdAndChannelSlugLoader,
)
from ..shipping.types import ShippingMethod
from ..utils import get_user_or_app_from_context
from .dataloaders import (
CheckoutByTokenLoader,
CheckoutInfoByCheckoutTokenLoader,
CheckoutLinesByCheckoutTokenLoader,
CheckoutLinesInfoByCheckoutTokenLoader,
)
class GatewayConfigLine(graphene.ObjectType):
field = graphene.String(required=True, description="Gateway config key.")
value = graphene.String(description="Gateway config value for key.")
class Meta:
description = "Payment gateway client configuration key and value pair."
class PaymentGateway(graphene.ObjectType):
name = graphene.String(required=True, description="Payment gateway name.")
id = graphene.ID(required=True, description="Payment gateway ID.")
config = graphene.List(
graphene.NonNull(GatewayConfigLine),
required=True,
description="Payment gateway client configuration.",
)
currencies = graphene.List(
graphene.String,
required=True,
description="Payment gateway supported currencies.",
)
class Meta:
description = (
"Available payment gateway backend with configuration "
"necessary to setup client."
)
class CheckoutLine(CountableDjangoObjectType):
total_price = graphene.Field(
TaxedMoney,
description="The sum of the checkout line price, taxes and discounts.",
)
requires_shipping = graphene.Boolean(
description="Indicates whether the item need to be delivered."
)
class Meta:
only_fields = ["id", "quantity", "variant"]
description = "Represents an item in the checkout."
interfaces = [graphene.relay.Node]
model = models.CheckoutLine
filter_fields = ["id"]
@staticmethod
def resolve_variant(root: models.CheckoutLine, info):
variant = ProductVariantByIdLoader(info.context).load(root.variant_id)
channel = ChannelByCheckoutLineIDLoader(info.context).load(root.id)
return Promise.all([variant, channel]).then(
lambda data: ChannelContext(node=data[0], channel_slug=data[1].slug)
)
@staticmethod
def resolve_total_price(root, info):
def with_checkout(checkout):
discounts = DiscountsByDateTimeLoader(info.context).load(
info.context.request_time
)
checkout_info = CheckoutInfoByCheckoutTokenLoader(info.context).load(
checkout.token
)
lines = CheckoutLinesInfoByCheckoutTokenLoader(info.context).load(
checkout.token
)
def calculate_line_total_price(data):
(
discounts,
checkout_info,
lines,
) = data
line_info = None
for line_info in lines:
if line_info.line.pk == root.pk:
address = (
checkout_info.shipping_address
or checkout_info.billing_address
)
return info.context.plugins.calculate_checkout_line_total(
checkout_info=checkout_info,
lines=lines,
checkout_line_info=line_info,
address=address,
discounts=discounts,
)
return None
return Promise.all(
[
discounts,
checkout_info,
lines,
]
).then(calculate_line_total_price)
return (
CheckoutByTokenLoader(info.context)
.load(root.checkout_id)
.then(with_checkout)
)
@staticmethod
def resolve_requires_shipping(root: models.CheckoutLine, info):
def is_shipping_required(product_type):
return product_type.is_shipping_required
return (
ProductTypeByVariantIdLoader(info.context)
.load(root.variant_id)
.then(is_shipping_required)
)
class Checkout(CountableDjangoObjectType):
available_shipping_methods = graphene.List(
ShippingMethod,
required=True,
description="Shipping methods that can be used with this order.",
)
available_payment_gateways = graphene.List(
graphene.NonNull(PaymentGateway),
description="List of available payment gateways.",
required=True,
)
email = graphene.String(description="Email of a customer.", required=True)
gift_cards = graphene.List(
GiftCard, description="List of gift cards associated with this checkout."
)
is_shipping_required = graphene.Boolean(
description="Returns True, if checkout requires shipping.", required=True
)
lines = graphene.List(
CheckoutLine,
description=(
"A list of checkout lines, each containing information about "
"an item in the checkout."
),
)
shipping_price = graphene.Field(
TaxedMoney,
description="The price of the shipping, with all the taxes included.",
)
shipping_method = graphene.Field(
ShippingMethod,
description="The shipping method related with checkout.",
)
subtotal_price = graphene.Field(
TaxedMoney,
description="The price of the checkout before shipping, with taxes included.",
)
token = graphene.Field(UUID, description="The checkout's token.", required=True)
total_price = graphene.Field(
TaxedMoney,
description=(
"The sum of the the checkout line prices, with all the taxes,"
"shipping costs, and discounts included."
),
)
class Meta:
only_fields = [
"billing_address",
"created",
"discount_name",
"gift_cards",
"is_shipping_required",
"last_change",
"channel",
"note",
"quantity",
"shipping_address",
"translated_discount_name",
"user",
"voucher_code",
"discount",
]
description = "Checkout object."
model = models.Checkout
interfaces = [graphene.relay.Node, ObjectWithMetadata]
filter_fields = ["token"]
@staticmethod
def resolve_shipping_address(root: models.Checkout, info):
if not root.shipping_address_id:
return
return AddressByIdLoader(info.context).load(root.shipping_address_id)
@staticmethod
def resolve_billing_address(root: models.Checkout, info):
if not root.billing_address_id:
return
return AddressByIdLoader(info.context).load(root.billing_address_id)
@staticmethod
def resolve_user(root: models.Checkout, info):
requestor = get_user_or_app_from_context(info.context)
if requestor_has_access(requestor, root.user, AccountPermissions.MANAGE_USERS):
return root.user
raise PermissionDenied()
@staticmethod
def resolve_email(root: models.Checkout, _info):
return root.get_customer_email()
@staticmethod
def resolve_shipping_method(root: models.Checkout, info):
if not root.shipping_method_id:
return None
def wrap_shipping_method_with_channel_context(data):
shipping_method, channel = data
return ChannelContext(node=shipping_method, channel_slug=channel.slug)
shipping_method = ShippingMethodByIdLoader(info.context).load(
root.shipping_method_id
)
channel = ChannelByIdLoader(info.context).load(root.channel_id)
return Promise.all([shipping_method, channel]).then(
wrap_shipping_method_with_channel_context
)
@staticmethod
# TODO: We should optimize it in/after PR#5819
def resolve_total_price(root: models.Checkout, info):
def calculate_total_price(data):
address, lines, checkout_info, discounts = data
taxed_total = (
calculations.checkout_total(
manager=info.context.plugins,
checkout_info=checkout_info,
lines=lines,
address=address,
discounts=discounts,
)
- root.get_total_gift_cards_balance()
)
return max(taxed_total, zero_taxed_money(root.currency))
address_id = root.shipping_address_id or root.billing_address_id
address = (
AddressByIdLoader(info.context).load(address_id) if address_id else None
)
lines = CheckoutLinesInfoByCheckoutTokenLoader(info.context).load(root.token)
checkout_info = CheckoutInfoByCheckoutTokenLoader(info.context).load(root.token)
discounts = DiscountsByDateTimeLoader(info.context).load(
info.context.request_time
)
return Promise.all([address, lines, checkout_info, discounts]).then(
calculate_total_price
)
@staticmethod
# TODO: We should optimize it in/after PR#5819
def resolve_subtotal_price(root: models.Checkout, info):
def calculate_subtotal_price(data):
address, lines, checkout_info, discounts = data
return calculations.checkout_subtotal(
manager=info.context.plugins,
checkout_info=checkout_info,
lines=lines,
address=address,
discounts=discounts,
)
address_id = root.shipping_address_id or root.billing_address_id
address = (
AddressByIdLoader(info.context).load(address_id) if address_id else None
)
lines = CheckoutLinesInfoByCheckoutTokenLoader(info.context).load(root.token)
checkout_info = CheckoutInfoByCheckoutTokenLoader(info.context).load(root.token)
discounts = DiscountsByDateTimeLoader(info.context).load(
info.context.request_time
)
return Promise.all([address, lines, checkout_info, discounts]).then(
calculate_subtotal_price
)
@staticmethod
# TODO: We should optimize it in/after PR#5819
def resolve_shipping_price(root: models.Checkout, info):
def calculate_shipping_price(data):
address, lines, checkout_info, discounts = data
return calculations.checkout_shipping_price(
manager=info.context.plugins,
checkout_info=checkout_info,
lines=lines,
address=address,
discounts=discounts,
)
address = (
AddressByIdLoader(info.context).load(root.shipping_address_id)
if root.shipping_address_id
else None
)
lines = CheckoutLinesInfoByCheckoutTokenLoader(info.context).load(root.token)
checkout_info = CheckoutInfoByCheckoutTokenLoader(info.context).load(root.token)
discounts = DiscountsByDateTimeLoader(info.context).load(
info.context.request_time
)
return Promise.all([address, lines, checkout_info, discounts]).then(
calculate_shipping_price
)
@staticmethod
def resolve_lines(root: models.Checkout, info):
return CheckoutLinesByCheckoutTokenLoader(info.context).load(root.token)
@staticmethod
# TODO: We should optimize it in/after PR#5819
def resolve_available_shipping_methods(root: models.Checkout, info):
def calculate_available_shipping_methods(data):
address, lines, checkout_info, discounts, channel = data
channel_slug = channel.slug
display_gross = info.context.site.settings.display_gross_prices
manager = info.context.plugins
subtotal = manager.calculate_checkout_subtotal(
checkout_info, lines, address, discounts
)
if not address:
return []
available = get_valid_shipping_methods_for_checkout(
checkout_info,
lines,
subtotal=subtotal,
country_code=address.country.code,
)
if available is None:
return []
available_ids = available.values_list("id", flat=True)
def map_shipping_method_with_channel(shippings):
def apply_price_to_shipping_method(channel_listings):
channel_listing_map = {
channel_listing.shipping_method_id: channel_listing
for channel_listing in channel_listings
}
available_with_channel_context = []
for shipping in shippings:
shipping_channel_listing = channel_listing_map[shipping.id]
taxed_price = info.context.plugins.apply_taxes_to_shipping(
shipping_channel_listing.price, address
)
if display_gross:
shipping.price = taxed_price.gross
else:
shipping.price = taxed_price.net
available_with_channel_context.append(
ChannelContext(node=shipping, channel_slug=channel_slug)
)
return available_with_channel_context
map_shipping_method_and_channel = (
(shipping_method_id, channel_slug)
for shipping_method_id in available_ids
)
return (
ShippingMethodChannelListingByShippingMethodIdAndChannelSlugLoader(
info.context
)
.load_many(map_shipping_method_and_channel)
.then(apply_price_to_shipping_method)
)
return (
ShippingMethodByIdLoader(info.context)
.load_many(available_ids)
.then(map_shipping_method_with_channel)
)
channel = ChannelByIdLoader(info.context).load(root.channel_id)
address = (
AddressByIdLoader(info.context).load(root.shipping_address_id)
if root.shipping_address_id
else None
)
lines = CheckoutLinesInfoByCheckoutTokenLoader(info.context).load(root.token)
checkout_info = CheckoutInfoByCheckoutTokenLoader(info.context).load(root.token)
discounts = DiscountsByDateTimeLoader(info.context).load(
info.context.request_time
)
return Promise.all([address, lines, checkout_info, discounts, channel]).then(
calculate_available_shipping_methods
)
@staticmethod
def resolve_available_payment_gateways(root: models.Checkout, info):
return info.context.plugins.list_payment_gateways(
currency=root.currency, checkout=root
)
@staticmethod
def resolve_gift_cards(root: models.Checkout, _info):
return root.gift_cards.all()
@staticmethod
def resolve_is_shipping_required(root: models.Checkout, info):
def is_shipping_required(lines):
product_ids = [line_info.product.id for line_info in lines]
def with_product_types(product_types):
return any([pt.is_shipping_required for pt in product_types])
return (
ProductTypeByProductIdLoader(info.context)
.load_many(product_ids)
.then(with_product_types)
)
return (
CheckoutLinesInfoByCheckoutTokenLoader(info.context)
.load(root.token)
.then(is_shipping_required)
)
| 37.516484 | 88 | 0.625425 |
4a1fa18953a2c9c9db15ba5a4ce17065fb8457ef | 1,542 | py | Python | tolqc-api/app/main/resource/__init__.py | sanger-tol/tolqc | 6ef535a0eb0028c5d9270ff18d95d38c6656cbdd | [
"MIT"
] | null | null | null | tolqc-api/app/main/resource/__init__.py | sanger-tol/tolqc | 6ef535a0eb0028c5d9270ff18d95d38c6656cbdd | [
"MIT"
] | null | null | null | tolqc-api/app/main/resource/__init__.py | sanger-tol/tolqc | 6ef535a0eb0028c5d9270ff18d95d38c6656cbdd | [
"MIT"
] | null | null | null | # SPDX-FileCopyrightText: 2021 Genome Research Ltd.
#
# SPDX-License-Identifier: MIT
from .sex import api_sex # noqa
from .allocation import api_allocation # noqa
from .centre import api_centre # noqa
from .environment import api_environment # noqa
from .library_type import api_library_type # noqa
from .library import api_library # noqa
from .platform import api_platform # noqa
from .project import api_project # noqa
from .run import api_run # noqa
from .sample import api_sample # noqa
from .species import api_species # noqa
from .specimen import api_specimen # noqa
from .user import api_user # noqa
from .software_version import api_software_version # noqa
from .status import api_status # noqa
from .file import api_file # noqa
from .accession_type_dict import api_accession_type_dict # noqa
from .accession import api_accession # noqa
from .assembly_component import api_assembly_component # noqa
from .status_dict import api_status_dict # noqa
from .qc_dict import api_qc_dict # noqa
from .milestone_dict import api_milestone_dict # noqa
from .pacbio_run_metrics import api_pacbio_run_metrics # noqa
from .data import api_data # noqa
from .dataset import api_dataset # noqa
from .set import api_set # noqa
from .busco_lineage import api_busco_lineage # noqa
from .assembly import api_assembly # noqa
from .assembly_metrics import api_assembly_metrics # noqa
from .merqury_metrics import api_merqury_metrics # noqa
from .busco_metrics import api_busco_metrics # noqa
from .genomescope_metrics import api_genomescope_metrics # noqa
| 41.675676 | 63 | 0.821012 |
4a1fa2c07d1bf8c418115f0c8314dec5b1080f6c | 1,980 | py | Python | pygeneratedata/dim_afd_militia.py | yeyuan-acmis2019/yy-paper2022 | d72e5843ef8253bfab18fac7ed1ea954ff40ad02 | [
"Apache-2.0"
] | null | null | null | pygeneratedata/dim_afd_militia.py | yeyuan-acmis2019/yy-paper2022 | d72e5843ef8253bfab18fac7ed1ea954ff40ad02 | [
"Apache-2.0"
] | null | null | null | pygeneratedata/dim_afd_militia.py | yeyuan-acmis2019/yy-paper2022 | d72e5843ef8253bfab18fac7ed1ea954ff40ad02 | [
"Apache-2.0"
] | null | null | null | from itertools import chain
import pymysql
from faker import Faker
import random
import datetime
from dim_ova_veteran import search_people
fake = Faker('zh_CN')
# 连接MySQL数据库
mysql_conn = pymysql.connect(host="192.168.101.105", user="root", password="123456", db="dim", port=3306,
charset='utf8')
cur = mysql_conn.cursor()
military_list = ""
def search_resident():
sql = "SELECT person_id FROM dim_hrssb_personal WHERE birth > DATE_SUB(CURDATE(),INTERVAL 35 YEAR)"
cur.execute(sql)
return list(chain.from_iterable(cur.fetchall()))
def insert_militia(person_id, person_name, military_class, political_status, nation, address, phone):
sql = "INSERT INTO dim_afd_militia() VALUES('{person_id}', '{person_name}', '{military_class}', " \
"'{political_status}', '{nation}', '{address}', '{phone}')"\
.format(person_id=person_id, person_name=person_name, military_class=military_class,
political_status=political_status, nation=nation, address=address, phone=phone)
print(sql)
cur.execute(sql)
mysql_conn.commit()
def is_veteran(person_id):
sql = "SELECT person_id FROM dim_ova_veteran WHERE person_id='{person_id}';".format(person_id=person_id)
cur.execute(sql)
return cur.fetchone() is not None
def generate_militia():
militia_list = search_resident()
random.shuffle(militia_list)
for i in range(10000):
people = search_people(militia_list[i])
person_id = people[0]
person_name = people[1]
age = datetime.datetime.now().year - int(person_id[6:10])
military_class = "基干民兵" if (age < 28) & is_veteran(person_id) else "普通民兵"
political_status = people[2]
nation = people[3]
phone = people[4]
address = people[5]
insert_militia(person_id, person_name, military_class, political_status, nation, address, phone)
if __name__ == '__main__':
generate_militia()
mysql_conn.close()
| 34.137931 | 108 | 0.687879 |
4a1fa2e32d0698c25e52bdd18741d179b91acd2c | 1,005 | py | Python | configs/textdet/bsnet_fcos/bsnet_fcos_test_cp8_CA_new.py | zzx0226/mmocr | 50354895244339a392b4f1af5a35963883923cca | [
"Apache-2.0"
] | null | null | null | configs/textdet/bsnet_fcos/bsnet_fcos_test_cp8_CA_new.py | zzx0226/mmocr | 50354895244339a392b4f1af5a35963883923cca | [
"Apache-2.0"
] | null | null | null | configs/textdet/bsnet_fcos/bsnet_fcos_test_cp8_CA_new.py | zzx0226/mmocr | 50354895244339a392b4f1af5a35963883923cca | [
"Apache-2.0"
] | null | null | null | _base_ = [
'../../_base_/runtime_10e.py', '../../_base_/schedules/schedule_sgd_1500e.py',
'../../_base_/det_models/bsnet_fcos_r50dcnv2_fpn_cp8_ca_new.py', '../../_base_/det_datasets/ctw1500.py',
'../../_base_/det_pipelines/bsnet_fcos_pipeline_cp8.py'
]
train_list = {{_base_.train_list}}
test_list = {{_base_.test_list}}
train_pipeline_ctw1500 = {{_base_.train_pipeline_ctw1500}}
test_pipeline_ctw1500 = {{_base_.test_pipeline_ctw1500}}
data = dict(samples_per_gpu=6,
workers_per_gpu=6,
val_dataloader=dict(samples_per_gpu=1),
test_dataloader=dict(samples_per_gpu=1),
train=dict(type='UniformConcatDataset', datasets=train_list, pipeline=train_pipeline_ctw1500),
val=dict(type='UniformConcatDataset', datasets=test_list, pipeline=test_pipeline_ctw1500),
test=dict(type='UniformConcatDataset', datasets=test_list, pipeline=test_pipeline_ctw1500))
evaluation = dict(interval=1500, metric='hmean-iou', save_best='auto')
| 45.681818 | 108 | 0.725373 |
4a1fa4149a77e3848b991cc7fefb1bff2877240b | 6,109 | py | Python | official/nlp/projects/bigbird/recomputing_dropout.py | hjkim-haga/TF-OD-API | 22ac477ff4dfb93fe7a32c94b5f0b1e74330902b | [
"Apache-2.0"
] | 1 | 2021-05-22T12:50:50.000Z | 2021-05-22T12:50:50.000Z | official/nlp/projects/bigbird/recomputing_dropout.py | DemonDamon/mask-detection-based-on-tf2odapi | 192ae544169c1230c21141c033800aa1bd94e9b6 | [
"MIT"
] | null | null | null | official/nlp/projects/bigbird/recomputing_dropout.py | DemonDamon/mask-detection-based-on-tf2odapi | 192ae544169c1230c21141c033800aa1bd94e9b6 | [
"MIT"
] | null | null | null | # Copyright 2021 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Keras dropout layer that is aware of `RecomputeContext`."""
import numpy as np
import tensorflow as tf
from official.nlp.projects.bigbird import recompute_grad as recompute_grad_lib
from official.nlp.projects.bigbird import stateless_dropout as stateless_dropout_lib
# Reimplements internal function
# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/framework/smart_cond.py.
def smart_cond(pred, true_fn=None, false_fn=None, name=None):
"""Return either `true_fn()` if predicate `pred` is true else `false_fn()`.
If `pred` is a bool or has a constant value, we return either `true_fn()`
or `false_fn()`, otherwise we use `tf.cond` to dynamically route to both.
Arguments:
pred: A scalar determining whether to return the result of `true_fn` or
`false_fn`.
true_fn: The callable to be performed if pred is true.
false_fn: The callable to be performed if pred is false.
name: Optional name prefix when using `tf.cond`.
Returns:
Tensors returned by the call to either `true_fn` or `false_fn`.
Raises:
TypeError: If `true_fn` or `false_fn` is not callable.
"""
if not callable(true_fn):
raise TypeError('`true_fn` must be callable.')
if not callable(false_fn):
raise TypeError('`false_fn` must be callable.')
pred_value = tf.get_static_value(pred)
if isinstance(pred, tf.Variable) or pred_value is None:
return tf.cond(
pred, true_fn=true_fn, false_fn=false_fn, name=name)
if pred_value:
return true_fn()
else:
return false_fn()
# See https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dropout.
class RecomputingDropout(tf.keras.layers.Layer):
"""`tf.keras.layers.Dropout` that supports `recompute_grad`."""
def __init__(self,
rate,
noise_shape=None,
seed=None,
force_recomputation=False,
**kwargs):
"""Initializes `RecomputingDropout`.
Args:
rate: Float between 0 and 1. Fraction of the input units to drop.
noise_shape: 1D integer tensor representing the shape of the binary
dropout mask that will be multiplied with the input. For instance, if
inputs have shape `(batch_size, timesteps, features)` and you want the
dropout mask to be the same for all timesteps, you can use
`noise_shape=(batch_size, 1, features)`.
seed: A Python integer to use as random seed.
force_recomputation: If `True`, then raises an error if called outside a
recompute context.
**kwargs: Keyword arguments for `tf.keras.layers.Layer`.
"""
super(RecomputingDropout, self).__init__(**kwargs)
self.rate = rate
self.noise_shape = noise_shape
self.seed = seed
self.force_recomputation = force_recomputation
self.supports_masking = True
# Create a layer-specific seed to combine with the global recompute seed.
self._recompute_seed = (
np.random.randint(-2**31, 2**31, dtype=np.int32)
if seed is None else seed)
def _get_noise_shape(self, inputs):
# Subclasses of `Dropout` may implement `_get_noise_shape(self, inputs)`,
# which will override `self.noise_shape`, and allows for custom noise
# shapes with dynamically sized inputs.
if self.noise_shape is None:
return None
concrete_inputs_shape = tf.shape(inputs)
noise_shape = []
for i, value in enumerate(self.noise_shape):
noise_shape.append(concrete_inputs_shape[i] if value is None else value)
return tf.convert_to_tensor(noise_shape)
def call(self, inputs, training=None):
"""Builds computation graph.
Args:
inputs: Input tensor (of any rank).
training: Python boolean indicating whether the layer should behave in
training mode (adding dropout) or in inference mode (doing nothing).
Returns:
`inputs` masked according to layer configuration.
Raises:
ValueError: If `force_recomputation` is `True` and called outside a
a recompute context.
"""
if training is None:
training = tf.keras.backend.learning_phase()
def dropped_inputs():
"""Randomly drops elements of `inputs` when `training=True`."""
recompute_context = recompute_grad_lib.get_recompute_context()
if recompute_context is None:
if self.force_recomputation:
raise ValueError(
'RecomputeContext is required when force_recomputation=True.')
return tf.nn.dropout(
inputs,
noise_shape=self._get_noise_shape(inputs),
seed=self.seed,
rate=self.rate)
seed = tf.stack([recompute_context.seed, self._recompute_seed])
return stateless_dropout_lib.stateless_dropout(
inputs,
rate=self.rate,
seed=seed,
noise_shape=self._get_noise_shape(inputs))
output = smart_cond(training, dropped_inputs, lambda: tf.identity(inputs))
return output
def compute_output_shape(self, input_shape):
return input_shape
def get_config(self):
config = {
'rate': self.rate,
'noise_shape': self.noise_shape,
'seed': self.seed,
'force_recomputation': self.force_recomputation,
}
base_config = super(RecomputingDropout, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
| 38.18125 | 98 | 0.678998 |
4a1fa50fe59043d8a82b775dbbd1541150ceacb4 | 511 | py | Python | exams/migrations/0019_examauthorization_exam_coupon.py | Wassaf-Shahzad/micromasters | b1340a8c233499b1d8d22872a6bc1fe7f49fd323 | [
"BSD-3-Clause"
] | 32 | 2016-03-25T01:03:13.000Z | 2022-01-15T19:35:42.000Z | exams/migrations/0019_examauthorization_exam_coupon.py | Wassaf-Shahzad/micromasters | b1340a8c233499b1d8d22872a6bc1fe7f49fd323 | [
"BSD-3-Clause"
] | 4,858 | 2016-03-03T13:48:30.000Z | 2022-03-29T22:09:51.000Z | exams/migrations/0019_examauthorization_exam_coupon.py | umarmughal824/micromasters | ea92d3bcea9be4601150fc497302ddacc1161622 | [
"BSD-3-Clause"
] | 20 | 2016-08-18T22:07:44.000Z | 2021-11-15T13:35:35.000Z | # Generated by Django 2.2.13 on 2021-02-25 17:53
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
dependencies = [
('exams', '0018_examruncoupon'),
]
operations = [
migrations.AddField(
model_name='examauthorization',
name='exam_coupon',
field=models.OneToOneField(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='exams.ExamRunCoupon'),
),
]
| 25.55 | 134 | 0.655577 |
4a1fa549de03ba7ad96a8ff2b17153a35182e0ba | 1,918 | py | Python | pipelines/PipelineScRnaseq.py | snsansom/xcell | 910e6c960b6f2cddca05c4d8c49c7d664eb171e6 | [
"MIT"
] | 2 | 2015-11-17T16:36:13.000Z | 2016-07-04T11:22:01.000Z | pipelines/PipelineScRnaseq.py | snsansom/xcell | 910e6c960b6f2cddca05c4d8c49c7d664eb171e6 | [
"MIT"
] | 7 | 2018-05-24T14:10:40.000Z | 2018-12-14T21:01:35.000Z | pipelines/PipelineScRnaseq.py | snsansom/xcell | 910e6c960b6f2cddca05c4d8c49c7d664eb171e6 | [
"MIT"
] | 2 | 2016-10-24T17:47:49.000Z | 2017-09-20T07:53:14.000Z | import sys
import os
import re
import sqlite3
import pandas as pd
import numpy as np
from cgatcore import experiment as E
from cgatcore import pipeline as P
# load options from the config file
PARAMS = P.get_parameters(
["%s/pipeline.yml" % os.path.splitext(__file__)[0],
"../pipeline.yml",
"pipeline.yml"])
# ########################################################################### #
# ####################### General functions ################################# #
# ########################################################################### #
def runCuffNorm(geneset, cxb_files, labels,
outdir, logFile,
library_type="fr-unstranded",
normalisation="classic-fpkm",
standards_file=None,
hits="total"):
'''
Run cuffnorm.
'''
total_mem = PARAMS["cufflinks_cuffnorm_total_mb_memory"]
job_threads = PARAMS["cufflinks_cuffnorm_threads"]
job_memory = str(int(total_mem) // int(job_threads)) + "M"
hits_method = "--%(hits)s-hits-norm" % locals()
if standards_file:
norm_standards = "--norm-standards-file=%(standards_file)s" % locals()
else:
norm_standards = ""
statement = ''' gtf=`mktemp -p %(local_tmpdir)s`;
checkpoint;
zcat %(geneset)s > $gtf;
checkpoint;
cuffnorm
--output-dir %(outdir)s
--num-threads=%(job_threads)s
--library-type %(library_type)s
%(hits_method)s
--library-norm-method %(normalisation)s
%(norm_standards)s
--labels %(labels)s
$gtf %(cxb_files)s > %(logFile)s;
checkpoint;
rm $gtf;
'''
P.run(statement)
| 30.935484 | 79 | 0.464546 |
4a1fa5a6dd7ea4421c09cc22f423dd244919b848 | 5,782 | py | Python | meta_mb/trainers/svg_trainer.py | iclavera/meta-mb | a1204e573c1415161129403cfb287bf120488fd0 | [
"MIT"
] | 4 | 2021-01-07T08:22:51.000Z | 2021-12-27T10:53:14.000Z | meta_mb/trainers/svg_trainer.py | iclavera/meta-mb | a1204e573c1415161129403cfb287bf120488fd0 | [
"MIT"
] | null | null | null | meta_mb/trainers/svg_trainer.py | iclavera/meta-mb | a1204e573c1415161129403cfb287bf120488fd0 | [
"MIT"
] | null | null | null | import tensorflow as tf
import time
from meta_mb.logger import logger
class Trainer(object):
"""
Performs steps for MAML
Args:
algo (Algo) :
env (Env) :
sampler (Sampler) :
sample_processor (SampleProcessor) :
baseline (Baseline) :
policy (Policy) :
n_itr (int) : Number of iterations to train for
start_itr (int) : Number of iterations policy has already trained for, if reloading
num_inner_grad_steps (int) : Number of inner steps per maml iteration
sess (tf.Session) : current tf session (if we loaded policy, for example)
"""
def __init__(
self,
algo,
env,
sampler,
sample_processor,
policy,
dynamics_model,
value_function,
n_itr,
start_itr=0,
initial_random_samples=True,
sess=None,
dynamics_model_max_epochs=200,
vfun_max_epochs=200,
):
self.algo = algo
self.env = env
self.sampler = sampler
self.sample_processor = sample_processor
self.dynamics_model = dynamics_model
self.value_function = value_function
self.policy = policy
self.n_itr = n_itr
self.start_itr = start_itr
self.dynamics_model_max_epochs = dynamics_model_max_epochs
self.vfun_max_epochs = vfun_max_epochs
self.initial_random_samples = initial_random_samples
if sess is None:
sess = tf.Session()
self.sess = sess
def train(self):
"""
Trains policy on env using algo
Pseudocode:
for itr in n_itr:
for step in num_inner_grad_steps:
sampler.sample()
algo.compute_updated_dists()
algo.optimize_policy()
sampler.update_goals()
"""
with self.sess.as_default() as sess:
# initialize uninitialized vars (only initialize vars that were not loaded)
uninit_vars = [var for var in tf.global_variables() if not sess.run(tf.is_variable_initialized(var))]
sess.run(tf.variables_initializer(uninit_vars))
start_time = time.time()
for itr in range(self.start_itr, self.n_itr):
itr_start_time = time.time()
logger.log("\n ---------------- Iteration %d ----------------" % itr)
time_env_sampling_start = time.time()
logger.log("Obtaining samples from the environment using the policy...")
env_paths = self.sampler.obtain_samples(log=True, log_prefix='')
logger.record_tabular('Time-EnvSampling', time.time() - time_env_sampling_start)
logger.log("Processing environment samples...")
# first processing just for logging purposes
time_env_samp_proc = time.time()
samples_data = self.sample_processor.process_samples(env_paths,
log=True,
log_prefix='EnvTrajs-')
logger.record_tabular('Time-EnvSampleProc', time.time() - time_env_samp_proc)
''' --------------- fit dynamics model --------------- '''
time_fit_start = time.time()
logger.log("Training dynamics model for %i epochs ..." % self.dynamics_model_max_epochs)
self.dynamics_model.fit(samples_data['observations'],
samples_data['actions'],
samples_data['next_observations'],
epochs=self.dynamics_model_max_epochs,
verbose=False, log_tabular=True,
early_stopping=True, compute_normalization=False)
logger.log("Training the value function for %i epochs ..." % self.vfun_max_epochs)
self.value_function.fit(samples_data['observations'],
samples_data['returns'],
epochs=self.vfun_max_epochs,
verbose=False, log_tabular=True, compute_normalization=False)
logger.log("Training the policy ...")
self.algo.optimize_policy(samples_data)
logger.record_tabular('Time-ModelFit', time.time() - time_fit_start)
""" ------------------- Logging Stuff --------------------------"""
logger.logkv('Itr', itr)
logger.logkv('n_timesteps', self.sampler.total_timesteps_sampled)
logger.logkv('Time', time.time() - start_time)
logger.logkv('ItrTime', time.time() - itr_start_time)
logger.log("Saving snapshot...")
params = self.get_itr_snapshot(itr)
self.log_diagnostics(env_paths, '')
logger.save_itr_params(itr, params)
logger.log("Saved")
logger.dumpkvs()
if itr == 0:
sess.graph.finalize()
logger.log("Training finished")
self.sess.close()
def get_itr_snapshot(self, itr):
"""
Gets the current policy and env for storage
"""
return dict(itr=itr, policy=self.policy, env=self.env,
dynamics_model=self.dynamics_model, value_function=self.value_function)
def log_diagnostics(self, paths, prefix):
self.env.log_diagnostics(paths, prefix)
self.policy.log_diagnostics(paths, prefix)
| 38.805369 | 113 | 0.539087 |
4a1fa5c33b9f09b51527bc9c65baa511c7774358 | 15,408 | py | Python | bootstrap/p1.5.0/src/cluster_info.py | apurwaj2/df-on-k8s | 1aecb0bc293d008c5a2384df32ad434bfcc51caa | [
"Apache-2.0"
] | null | null | null | bootstrap/p1.5.0/src/cluster_info.py | apurwaj2/df-on-k8s | 1aecb0bc293d008c5a2384df32ad434bfcc51caa | [
"Apache-2.0"
] | null | null | null | bootstrap/p1.5.0/src/cluster_info.py | apurwaj2/df-on-k8s | 1aecb0bc293d008c5a2384df32ad434bfcc51caa | [
"Apache-2.0"
] | null | null | null | import json
import os
import sys
import time
from common.mapr_exceptions.ex import MapRException
from common.mapr_logger.log import Log
from common.os_command import OSCommand
class ClusterInfo(object):
SYSTEM = "hpe-system"
SPARK = "hpe-spark-operator"
SPARK_OLD = "spark-operator"
LDAP = "hpe-ldap"
CSI = "hpe-csi"
ECP = "hpecp"
ECP_53 = "hpecp-falco"
NODE_SERVICE = "hpe-nodesvc"
MAPR_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + SYSTEM + "\")]}'"
SPARK_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + SPARK + "\")]}'"
SPARK_EXISTS_OLD = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + SPARK_OLD + "\")]}'"
LDAP_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + LDAP + "\")]}'"
CSI_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + CSI + "\")]}'"
ECP_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + ECP + "\")]}'"
ECP_53_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + ECP_53 + "\")]}'"
NODESVC_EXISTS = "kubectl get ns -o jsonpath='{.items[?(@.metadata.name == \"" + NODE_SERVICE + "\")]}'"
FAKE_LABEL = "kubectl get pod -n hpe-nodesvc -o jsonpath='{range .items[*]}{.spec.containers[*].env[*].name}{\"\\t\"}{.spec.containers[*].env[].value}{\"\\n\"}{end}' | grep FAKE_LABEL_NODES | cut -f 2 | head -n 1"
MASTER_TOLERATION = "kubectl get pods -n hpe-nodesvc -o jsonpath=\"{.items[].spec.tolerations}\""
CLUSTER_INFO = "kubectl get pods -n {0} -o json -l \"app={1}\""
LDAP_INFO = "kubectl get pods -n {0} -o json -l \"hpe.com/component={1}\""
SPARK_INFO = "kubectl get pods -n " + SPARK + " -o json -l \"app.kubernetes.io/name=sparkoperator\""
SPARK_INFO_OLD = "kubectl get pods -n " + SPARK_OLD + " -o json -l \"app.kubernetes.io/name=sparkoperator\""
SPARK_OLD_RUNNING_POD = "kubectl get pods --no-headers -o custom-columns=\":metadata.name\" --field-selector=status.phase=Running -n " + SPARK_OLD + " | head -n 1 | tr -d '\n'"
def __init__(self):
self._system_namespace_exists = None
self._spark_namespace_exists = None
self._spark_namespace_exists_old = None
self._ldap_namespace_exists = None
self._csi_namespace_exists = None
self._ecp_namespace_exists = None
self._nodesvc_namespace_exists = None
self._ecp_53_exists = None
self._cluster_op_json = None
self._tenant_op_json = None
self._spark_op_json = None
self._spark_op_json_old = None
self._ldap_op_json = None
self._csi_op_json = None
self.schedule_pods_on_master = False
self._fake_labels = False
def examine_cluster(self, wait_for_running):
print("")
Log.info("Gathering Data Fabric cluster information...", stdout=True)
Log.info("Checking namespaces...", stdout=True)
response, status = OSCommand.run2(ClusterInfo.MAPR_EXISTS)
self._system_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._system_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.SYSTEM))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.SYSTEM))
response, status = OSCommand.run2(ClusterInfo.SPARK_EXISTS)
self._spark_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._spark_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.SPARK))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.SPARK))
response, status = OSCommand.run2(ClusterInfo.SPARK_EXISTS_OLD)
self._spark_namespace_exists_old = True if status == 0 and response != "<no response>" else False
if not self._spark_namespace_exists_old:
Log.info("The " + ClusterInfo.SPARK_OLD + " namespace was not found on this Kubernetes cluster")
response, status = OSCommand.run2(ClusterInfo.LDAP_EXISTS)
self._ldap_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._ldap_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.LDAP))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.LDAP))
response, status = OSCommand.run2(ClusterInfo.CSI_EXISTS)
self._csi_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._csi_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.CSI))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.CSI))
response, status = OSCommand.run2(ClusterInfo.ECP_EXISTS)
self._ecp_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._ecp_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.ECP))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.ECP))
response, status = OSCommand.run2(ClusterInfo.NODESVC_EXISTS)
self._nodesvc_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._nodesvc_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.NODE_SERVICE))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.NODE_SERVICE))
Log.info("Checking if pods are enabled on master:", stdout=True)
try:
if self._nodesvc_namespace_exists:
response, status = OSCommand.run2(ClusterInfo.MASTER_TOLERATION)
json_response = json.loads(response)
for toleration in json_response:
if toleration["key"] == "node-role.kubernetes.io/master":
if toleration["effect"] == "NoSchedule" and toleration["operator"] == "Exists":
self.schedule_pods_on_master = True
break
if self.schedule_pods_on_master:
Log.info("Pod scheduling enabled on master.", stdout=True)
else:
Log.info("Pod scheduling disabled on master.", stdout=True)
response, status = OSCommand.run2(ClusterInfo.FAKE_LABEL)
if response != "<no response>":
Log.info("Got a response from getting fake label value of: {0}".format(response))
if response.strip("\n").lower() == "true":
Log.info("Setting fake labeler to true since it was found to be currently set on the nodeservice pods")
self._fake_labels = True
else:
Log.warn("Could not determine current fake labeler setting; assuming false")
except MapRException as me:
Log.error(me.value)
Log.info("Error during determining if master is enabled for DF pods scheduling.", stdout=True)
Log.info("Checking operators...", stdout=True)
try:
if self._system_namespace_exists:
self._cluster_op_json = self.check_operator(wait_for_running, ClusterInfo.CLUSTER_INFO.format(ClusterInfo.SYSTEM, "dataplatformoperator"), "dataplatformoperator")
if self._system_namespace_exists:
self._tenant_op_json = self.check_operator(wait_for_running, ClusterInfo.CLUSTER_INFO.format(ClusterInfo.SYSTEM, "tenantoperator"), "tenantoperator")
if self._spark_namespace_exists:
self._spark_op_json = self.check_operator(wait_for_running, ClusterInfo.SPARK_INFO, "sparkoperator")
if self._spark_namespace_exists_old:
self._spark_op_json_old = self.check_operator(wait_for_running, ClusterInfo.SPARK_INFO_OLD, "sparkoperator")
if self._ldap_namespace_exists:
self._ldap_op_json = self.check_operator(wait_for_running, ClusterInfo.LDAP_INFO.format(ClusterInfo.LDAP, "ldap"), "ldap")
if self._csi_namespace_exists:
self._csi_op_json = self.check_operator(wait_for_running, ClusterInfo.CLUSTER_INFO.format(ClusterInfo.CSI, "hpe-controller-kdf"), "hpe-controller-kdf")
except MapRException as me:
Log.error(me.value)
Log.info("Correct the above error and make sure that all pods are in a running state and try the operation again", stdout=True)
sys.exit(1)
@staticmethod
def check_operator(wait_for_running, cmd, pod_name):
json_val = None
for i in range(1, 20):
response, status = OSCommand.run2(cmd, truncate_response=200)
if status != 0:
Log.info("Could not gather {0} operator information".format(pod_name))
continue
json_val = ClusterInfo.get_json(response)
if json_val is None:
break
j = 0
for j in range(0, len(json_val["items"])):
job_label = json_val["items"][j]["metadata"]["labels"].get("job-name")
if job_label is None:
break
status = json_val["items"][j]["status"]["phase"].lower()
if not wait_for_running:
if status != "running":
raise MapRException("The {0} pod is in a {1} state; Expected running".format(pod_name, status))
break
if status == "running":
break
Log.info("Waiting for the {0} operator to become running (was {1})...".format(pod_name, status), stdout=True)
time.sleep(10)
json_val = None
if json_val is None and wait_for_running:
Log.warn("The {0} pod did not transition to a running state. The pod might still become running after waiting some more time".format(pod_name))
return json_val
@staticmethod
def get_json(json_str):
j = json.loads(json_str)
if j is None or len(j.get("items")) == 0:
Log.debug("Could not find 'items' in JSON: {0}".format(j))
return None
return j
def get_cluster_operator_json(self):
return self._cluster_op_json
def get_tenant_operator_json(self):
return self._tenant_op_json
def get_spark_operator_json(self):
return self._spark_op_json
def get_spark_operator_json_old(self):
return self._spark_op_json_old
def get_ldap_operator_json(self):
return self._ldap_op_json
def is_data_fabric_installed(self):
return self._system_namespace_exists and self._cluster_op_json is not None
def is_compute_installed(self):
return self._system_namespace_exists and self._tenant_op_json is not None
def is_ldap_installed(self):
return self._ldap_namespace_exists and self._ldap_op_json is not None
def is_spark_installed(self):
return self._spark_namespace_exists and self._spark_op_json is not None
def is_spark_installed_old(self):
return self._spark_namespace_exists_old and self._spark_op_json_old is not None
def is_csi_installed(self):
return self._csi_namespace_exists and self._csi_op_json is not None
def is_spark_old_ns_exists(self):
return self._spark_namespace_exists_old
def is_hpe_spark_in_old_ns(self):
response_pod_name, status_pod_name = OSCommand.run2(ClusterInfo.SPARK_OLD_RUNNING_POD)
response_hpe_spark_installed, status_hpe_spark_installed = OSCommand.run2("kubectl exec " + response_pod_name + " -n " + ClusterInfo.SPARK_OLD + " -- ls -la /opt/mapr/spark/sparkversion")
return status_hpe_spark_installed == 0
def is_ecp53(self):
response, status = OSCommand.run2(ClusterInfo.ECP_EXISTS)
self._ecp_namespace_exists = True if status == 0 and response != "<no response>" else False
if not self._ecp_namespace_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.ECP))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.ECP))
response, status = OSCommand.run2(ClusterInfo.ECP_53_EXISTS)
self._ecp_53_exists = True if status == 0 and response != "<no response>" else False
if not self._ecp_53_exists:
Log.info("The {0} namespace was not found on this Kubernetes cluster".format(ClusterInfo.ECP_53))
else:
Log.info("The {0} namespace was found on this Kubernetes cluster".format(ClusterInfo.ECP_53))
return self._ecp_namespace_exists and self._ecp_53_exists
@staticmethod
def _get_pod_info(json_obj, title):
index = 0
if json_obj is None:
return ""
items = json_obj.get("items")
if items is None or len(items) == 0:
Log.info("Pod JSON has no items")
pod_name = json_obj["items"][index]["metadata"]["name"]
create_time = json_obj["items"][index]["metadata"]["creationTimestamp"]
image_name = json_obj["items"][index]["spec"]["containers"][0]["image"]
image_name = image_name[image_name.rindex("/") + 1:]
status = json_obj["items"][index]["status"]["phase"]
return title + os.linesep + \
" Pod: {0}".format(pod_name) + os.linesep + \
" Image: {0}".format(image_name) + os.linesep + \
" Create Time: {0}".format(create_time) + os.linesep + \
" Status: {0}".format(status)
def __str__(self):
rslt = os.linesep + "data fabric installed: " + str(self.is_data_fabric_installed())
rslt += os.linesep + "compute installed: " + str(self.is_compute_installed())
rslt += os.linesep + "ldap installed: " + str(self.is_ldap_installed())
rslt += os.linesep + "spark installed: " + str(self.is_spark_installed())
rslt += os.linesep + "spark old installed: " + str(self.is_spark_installed_old())
rslt += os.linesep + "csi installed: " + str(self.is_csi_installed())
if self.is_data_fabric_installed():
rslt += os.linesep + ClusterInfo._get_pod_info(self._cluster_op_json, "Data Platform Operator:")
if self.is_compute_installed():
rslt += os.linesep + ClusterInfo._get_pod_info(self._tenant_op_json, "Tenant Operator:")
if self.is_ldap_installed():
rslt += os.linesep + ClusterInfo._get_pod_info(self._ldap_op_json, "LDAP Pod:")
if self._spark_op_json is not None:
for i in range(0, len(self._spark_op_json["items"])):
if self._spark_op_json["items"][i]["metadata"]["generateName"].find("sparkoperator-init-") == -1:
rslt += os.linesep + ClusterInfo._get_pod_info(self._spark_op_json, "Spark Operator:")
break
return rslt
| 51.704698 | 217 | 0.64486 |
4a1fa5f967656d92eaad346a341f2827035556c7 | 10,728 | py | Python | configs/stylegan2_finetune_config.py | bytedance/Hammer | 388ed20b3d9b34f33f5357d75f8fe5d726782ec8 | [
"MIT"
] | 97 | 2022-02-08T09:00:57.000Z | 2022-03-23T05:33:35.000Z | configs/stylegan2_finetune_config.py | bytedance/Hammer | 388ed20b3d9b34f33f5357d75f8fe5d726782ec8 | [
"MIT"
] | null | null | null | configs/stylegan2_finetune_config.py | bytedance/Hammer | 388ed20b3d9b34f33f5357d75f8fe5d726782ec8 | [
"MIT"
] | 7 | 2022-02-08T15:13:02.000Z | 2022-03-19T19:11:13.000Z | # python3.7
"""Configuration for fine-tuning StyleGAN2."""
from .stylegan2_config import StyleGAN2Config
__all__ = ['StyleGAN2FineTuneConfig']
class StyleGAN2FineTuneConfig(StyleGAN2Config):
"""Defines the configuration for fine-tuning StyleGAN2."""
name = 'stylegan2_finetune'
hint = 'Fine-tune a StyleGAN2 model by freezing selected parameters.'
info = '''
It is possible to fine-tune a StyleGAN2 model by partially freezing the
parameters of the generator and the discriminator. This trick is commonly used
when the training data is limited, to prevent overfitting.
For the generator, consisting of a mapping network and a synthesis network,
users can use `freeze_g_mapping_layers` and `freeze_g_synthesis_blocks` to
control the behavior of these two parts independently. As for a particular layer
in the synthesis network, it contains an affine layer (fully-connected layer) to
learn per-layer style, a convolutional layer, a noise modulation operation, and
a ToRGB layer (only after each block). Users can use `freeze_g_affine`,
`freeze_g_conv`, `freeze_g_noise`, `freeze_g_torgb` to control these four parts,
separately. Note that, the embedding layer for conditional synthesis, and the
learnable constant tensor for synthesis network, should be separately
configured.
For the discriminator, consisting of a backbone and a bi-classification head,
users can use `freeze_d_blocks` and `freeze_d_adv_head` to control the behavior
of these two parts independently. Note that, the embedding layer for conditional
synthesis, and the input layer of the backbone, should be separately configured.
'''
@classmethod
def get_options(cls):
options = super().get_options()
options['Generator fine-tuning settings'].extend([
cls.command_option(
'--freeze_g_embedding', type=cls.bool_type, default=False,
help='Whether to freeze the embedding layer in the generator '
'for conditional synthesis.'),
cls.command_option(
'--freeze_g_mapping_layers', type=cls.index_type, default=None,
help='Indices of layers in the mapping network to freeze. Use '
'comma to join multiple indices.'),
cls.command_option(
'--freeze_g_const', type=cls.bool_type, default=False,
help='Whether to freeze the initial learnable constant.'),
cls.command_option(
'--freeze_g_synthesis_blocks', type=cls.index_type,
default=None,
help='Indices of blocks in the synthesis network to freeze. '
'Use comma to join multiple indices.'),
cls.command_option(
'--freeze_g_affine', type=cls.bool_type, default=False,
help='Whether to freeze the style affine transformations.'),
cls.command_option(
'--freeze_g_conv', type=cls.bool_type, default=False,
help='Whether to freeze the convolution layers.'),
cls.command_option(
'--freeze_g_noise', type=cls.bool_type, default=False,
help='Whether to freeze the noise modulation parameters.'),
cls.command_option(
'--freeze_g_torgb_affine', type=cls.bool_type, default=False,
help='Whether to freeze the style affine transformations '
'within the ToRGB layers.'),
cls.command_option(
'--freeze_g_torgb', type=cls.bool_type, default=False,
help='Whether to freeze the ToRGB convolutional layers.'),
cls.command_option(
'--freeze_g_keywords', type=str, default=None,
help='Additional keywords used to select the parameters of the '
'generator that should be frozen. Use comma to join '
'multiple keys.')
])
options['Discriminator fine-tuning settings'].extend([
cls.command_option(
'--freeze_d_embedding', type=cls.bool_type, default=False,
help='Whether to freeze the embedding layer in the '
'discriminator for conditional synthesis.'),
cls.command_option(
'--freeze_d_mapping_layers', type=cls.index_type, default=None,
help='Indices of layers in the mapping network of the '
'discriminator to freeze. Use comma to join multiple '
'indices.'),
cls.command_option(
'--freeze_d_blocks', type=cls.index_type, default=None,
help='Indices of blocks in the discriminator to freeze. Use '
'comma to join multiple indices.'),
cls.command_option(
'--freeze_d_input', type=cls.bool_type, default=False,
help='Whether to freeze the input layer of the to-freeze'
'blocks of the discriminator backbone.'),
cls.command_option(
'--freeze_d_adv_head', type=cls.bool_type, default=False,
help='Whether to freeze the bi-classification task head.'),
cls.command_option(
'--freeze_d_keywords', type=str, default=None,
help='Additional keywords used to select the parameters of the '
'discriminator that should be frozen. Use comma to join '
'multiple keys.')
])
return options
@classmethod
def get_recommended_options(cls):
recommended_opts = super().get_recommended_options()
recommended_opts.extend([
'freeze_g_embedding', 'freeze_g_mapping_layers', 'freeze_g_const',
'freeze_g_synthesis_blocks', 'freeze_g_affine', 'freeze_g_conv',
'freeze_g_noise', 'freeze_g_torgb_affine', 'freeze_g_torgb',
'freeze_g_keywords', 'freeze_d_embedding',
'freeze_d_mapping_layers', 'freeze_d_blocks', 'freeze_d_input',
'freeze_d_adv_head', 'freeze_d_keywords'
])
return recommended_opts
def parse_options(self):
super().parse_options()
# Get parameters to freeze in generator.
freeze_g_embedding = self.args.pop('freeze_g_embedding')
freeze_g_mapping_layers = self.args.pop('freeze_g_mapping_layers')
freeze_g_const = self.args.pop('freeze_g_const')
freeze_g_synthesis_blocks = self.args.pop('freeze_g_synthesis_blocks')
freeze_g_affine = self.args.pop('freeze_g_affine')
freeze_g_conv = self.args.pop('freeze_g_conv')
freeze_g_noise = self.args.pop('freeze_g_noise')
freeze_g_torgb_affine = self.args.pop('freeze_g_torgb_affine')
freeze_g_torgb = self.args.pop('freeze_g_torgb')
freeze_g_keywords = self.args.pop('freeze_g_keywords')
g_freeze_param_list = []
# Categorical embedding.
if freeze_g_embedding:
g_freeze_param_list.append('mapping.embedding')
# Mapping network.
freeze_g_mapping_layers = freeze_g_mapping_layers or list()
for idx in freeze_g_mapping_layers:
g_freeze_param_list.append(f'mapping.dense{idx}.')
# Learnable constant tensor.
if freeze_g_const:
g_freeze_param_list.append('synthesis.early_layer.const')
# Synthesis network.
freeze_g_synthesis_blocks = freeze_g_synthesis_blocks or list()
for block_idx in freeze_g_synthesis_blocks:
# Handle each convolutional layer.
if block_idx != 0:
layer_indices = [block_idx * 2 - 1, block_idx * 2]
else:
layer_indices = [0]
for layer_idx in layer_indices:
if freeze_g_affine:
g_freeze_param_list.append(
f'synthesis.layer{layer_idx}.style')
if freeze_g_conv:
g_freeze_param_list.append(
f'synthesis.layer{layer_idx}.weight')
g_freeze_param_list.append(
f'synthesis.layer{layer_idx}.bias')
if freeze_g_noise:
g_freeze_param_list.append(
f'synthesis.layer{layer_idx}.noise_strength')
# Handle each residual layer.
if freeze_g_conv:
g_freeze_param_list.append(f'synthesis.residual{block_idx}.')
# Handle each ToRGB layers.
if freeze_g_torgb_affine:
g_freeze_param_list.append(f'synthesis.output{block_idx}.style')
if freeze_g_torgb:
g_freeze_param_list.append(
f'synthesis.output{block_idx}.weight')
g_freeze_param_list.append(f'synthesis.output{block_idx}.bias')
# Additional keywords.
if freeze_g_keywords:
for keyword in freeze_g_keywords.replace(' ', '').split(','):
g_freeze_param_list.append(keyword)
self.config.models.generator.update(
freeze_keywords=','.join(g_freeze_param_list)
)
# Get parameters to freeze in discriminator.
freeze_d_embedding = self.args.pop('freeze_d_embedding')
freeze_d_mapping_layers = self.args.pop('freeze_d_mapping_layers')
freeze_d_blocks = self.args.pop('freeze_d_blocks')
freeze_d_input = self.args.pop('freeze_d_input')
freeze_d_adv_head = self.args.pop('freeze_d_adv_head')
freeze_d_keywords = self.args.pop('freeze_d_keywords')
d_freeze_param_list = []
# Categorical embedding.
if freeze_d_embedding:
d_freeze_param_list.append('embedding')
# Mapping network.
freeze_d_mapping_layers = freeze_d_mapping_layers or list()
for idx in freeze_d_mapping_layers:
d_freeze_param_list.append(f'mapping{idx}.')
# Backbone.
freeze_d_blocks = freeze_d_blocks or list()
for block_idx in freeze_d_blocks:
if freeze_d_input:
d_freeze_param_list.append(f'input{block_idx}.')
d_freeze_param_list.append(f'layer{block_idx * 2}.')
d_freeze_param_list.append(f'layer{block_idx * 2 + 1}.')
d_freeze_param_list.append(f'residual{block_idx}')
if freeze_d_adv_head:
d_freeze_param_list.append('output.')
# Additional keywords.
if freeze_d_keywords:
for keyword in freeze_d_keywords.replace(' ', '').split(','):
d_freeze_param_list.append(keyword)
self.config.models.discriminator.update(
freeze_keywords=','.join(d_freeze_param_list)
)
| 48.324324 | 80 | 0.634135 |
4a1fa72f73e44c4d8ffcf930925bac99abff36b6 | 17,417 | py | Python | dev/Tools/build/waf-1.7.13/waflib/Configure.py | CJoriginal/cjlumberyard | 2e3184a7d8e59ba05e5707371b8cb6fe40b0ca60 | [
"AML"
] | 2 | 2019-05-13T22:21:28.000Z | 2019-05-24T22:52:01.000Z | dev/Tools/build/waf-1.7.13/waflib/Configure.py | CJoriginal/cjlumberyard | 2e3184a7d8e59ba05e5707371b8cb6fe40b0ca60 | [
"AML"
] | null | null | null | dev/Tools/build/waf-1.7.13/waflib/Configure.py | CJoriginal/cjlumberyard | 2e3184a7d8e59ba05e5707371b8cb6fe40b0ca60 | [
"AML"
] | 5 | 2020-08-27T20:44:18.000Z | 2021-08-21T22:54:11.000Z | #!/usr/bin/env python
# encoding: utf-8
# Thomas Nagy, 2005-2010 (ita)
"""
Configuration system
A :py:class:`waflib.Configure.ConfigurationContext` instance is created when ``waf configure`` is called, it is used to:
* create data dictionaries (ConfigSet instances)
* store the list of modules to import
* hold configuration routines such as ``find_program``, etc
"""
import os, shlex, sys, time
from waflib import ConfigSet, Utils, Options, Logs, Context, Build, Errors
try:
from urllib import request
except ImportError:
from urllib import urlopen
else:
urlopen = request.urlopen
BREAK = 'break'
"""In case of a configuration error, break"""
CONTINUE = 'continue'
"""In case of a configuration error, continue"""
WAF_CONFIG_LOG = 'config.log'
"""Name of the configuration log file"""
autoconfig = False
"""Execute the configuration automatically"""
conf_template = '''# project %(app)s configured on %(now)s by
# waf %(wafver)s (abi %(abi)s, python %(pyver)x on %(systype)s)
# using %(args)s
#'''
def download_check(node):
"""
Hook to check for the tools which are downloaded. Replace with your function if necessary.
"""
pass
def download_tool(tool, force=False, ctx=None):
"""
Download a Waf tool from the remote repository defined in :py:const:`waflib.Context.remote_repo`::
$ waf configure --download
"""
for x in Utils.to_list(Context.remote_repo):
for sub in Utils.to_list(Context.remote_locs):
url = '/'.join((x, sub, tool + '.py'))
try:
web = urlopen(url)
try:
if web.getcode() != 200:
continue
except AttributeError:
pass
except Exception:
# on python3 urlopen throws an exception
# python 2.3 does not have getcode and throws an exception to fail
continue
else:
tmp = ctx.root.make_node(os.sep.join((Context.waf_dir, 'waflib', 'extras', tool + '.py')))
tmp.write(web.read(), 'wb')
Logs.warn('Downloaded %s from %s' % (tool, url))
download_check(tmp)
try:
module = Context.load_tool(tool)
except Exception:
Logs.warn('The tool %s from %s is unusable' % (tool, url))
try:
tmp.delete()
except Exception:
pass
continue
return module
raise Errors.WafError('Could not load the Waf tool')
class ConfigurationContext(Context.Context):
'''configures the project'''
cmd = 'configure'
error_handlers = []
"""
Additional functions to handle configuration errors
"""
def __init__(self, **kw):
super(ConfigurationContext, self).__init__(**kw)
self.environ = dict(os.environ)
self.all_envs = {}
self.top_dir = None
self.out_dir = None
self.lock_dir = None
self.tools = [] # tools loaded in the configuration, and that will be loaded when building
self.hash = 0
self.files = []
self.tool_cache = []
self.setenv('')
def setenv(self, name, env=None):
"""
Set a new config set for conf.env. If a config set of that name already exists,
recall it without modification.
The name is the filename prefix to save to ``c4che/NAME_cache.py``, and it
is also used as *variants* by the build commands.
Though related to variants, whatever kind of data may be stored in the config set::
def configure(cfg):
cfg.env.ONE = 1
cfg.setenv('foo')
cfg.env.ONE = 2
def build(bld):
2 == bld.env_of_name('foo').ONE
:param name: name of the configuration set
:type name: string
:param env: ConfigSet to copy, or an empty ConfigSet is created
:type env: :py:class:`waflib.ConfigSet.ConfigSet`
"""
if name not in self.all_envs or env:
if not env:
env = ConfigSet.ConfigSet()
self.prepare_env(env)
else:
env = env.derive()
self.all_envs[name] = env
self.variant = name
def get_env(self):
"""Getter for the env property"""
return self.all_envs[self.variant]
def set_env(self, val):
"""Setter for the env property"""
self.all_envs[self.variant] = val
env = property(get_env, set_env)
def init_dirs(self):
"""
Initialize the project directory and the build directory
"""
top = self.top_dir
if not top:
top = Options.options.top
if not top:
top = getattr(Context.g_module, Context.TOP, None)
if not top:
top = self.path.abspath()
top = os.path.abspath(top)
self.srcnode = (os.path.isabs(top) and self.root or self.path).find_dir(top)
assert(self.srcnode)
out = self.out_dir
if not out:
out = Options.options.out
if not out:
out = getattr(Context.g_module, Context.OUT, None)
if not out:
out = Options.lockfile.replace('.lock-waf_%s_' % sys.platform, '').replace('.lock-waf', '')
self.bldnode = (os.path.isabs(out) and self.root or self.path).make_node(out)
self.bldnode.mkdir()
if not os.path.isdir(self.bldnode.abspath()):
conf.fatal('Could not create the build directory %s' % self.bldnode.abspath())
def execute(self):
"""
See :py:func:`waflib.Context.Context.execute`
"""
self.init_dirs()
Logs.info("[WAF] Executing 'configure'")
self.cachedir = self.bldnode.make_node(Build.CACHE_DIR)
self.cachedir.mkdir()
path = os.path.join(self.bldnode.abspath(), WAF_CONFIG_LOG)
self.logger = Logs.make_logger(path, 'cfg')
app = getattr(Context.g_module, 'APPNAME', '')
if app:
ver = getattr(Context.g_module, 'VERSION', '')
if ver:
app = "%s (%s)" % (app, ver)
now = time.ctime()
pyver = sys.hexversion
systype = sys.platform
args = " ".join(sys.argv)
wafver = Context.WAFVERSION
abi = Context.ABI
self.to_log(conf_template % vars())
if id(self.srcnode) == id(self.bldnode):
Logs.warn('Setting top == out (remember to use "update_outputs")')
elif id(self.path) != id(self.srcnode):
if self.srcnode.is_child_of(self.path):
Logs.warn('Are you certain that you do not want to set top="." ?')
super(ConfigurationContext, self).execute()
self.store()
Context.top_dir = self.srcnode.abspath()
Context.out_dir = self.bldnode.abspath()
# import waf branch spec
branch_spec_globals = Context.load_branch_spec(Context.top_dir)
Context.lock_dir = Context.run_dir + os.sep + branch_spec_globals['BINTEMP_FOLDER']
# this will write a configure lock so that subsequent builds will
# consider the current path as the root directory (see prepare_impl).
# to remove: use 'waf distclean'
env = ConfigSet.ConfigSet()
env['argv'] = sys.argv
env['options'] = Options.options.__dict__
env.run_dir = Context.run_dir
env.top_dir = Context.top_dir
env.out_dir = Context.out_dir
env.lock_dir = Context.lock_dir
# Add lmbr_waf.bat or lmbr_waf for dependency tracking
###############################################################################
waf_command = os.path.basename(sys.executable)
if waf_command.lower().startswith('python'):
waf_executable = self.engine_node.make_node('./Tools/build/waf-1.7.13/lmbr_waf')
else:
waf_executable = self.path.make_node(waf_command)
self.hash = hash((self.hash, waf_executable.read('rb')))
self.files.append(os.path.normpath(waf_executable.abspath()))
# conf.hash & conf.files hold wscript files paths and hash
# (used only by Configure.autoconfig)
env['hash'] = self.hash
env['files'] = self.files
env['environ'] = dict(self.environ)
env.store(Context.lock_dir + os.sep + Options.lockfile)
def prepare_env(self, env):
"""
Insert *PREFIX*, *BINDIR* and *LIBDIR* values into ``env``
:type env: :py:class:`waflib.ConfigSet.ConfigSet`
:param env: a ConfigSet, usually ``conf.env``
"""
if not env.PREFIX:
if Options.options.prefix or Utils.is_win32:
env.PREFIX = os.path.abspath(os.path.expanduser(Options.options.prefix))
else:
env.PREFIX = ''
if not env.BINDIR:
env.BINDIR = Utils.subst_vars('${PREFIX}/bin', env)
if not env.LIBDIR:
env.LIBDIR = Utils.subst_vars('${PREFIX}/lib', env)
def store(self):
"""Save the config results into the cache file"""
n = self.cachedir.make_node('build.config.py')
n.write('version = 0x%x\ntools = %r\n' % (Context.HEXVERSION, self.tools))
if not self.all_envs:
self.fatal('nothing to store in the configuration context!')
for key in self.all_envs:
tmpenv = self.all_envs[key]
tmpenv.store(os.path.join(self.cachedir.abspath(), key + Build.CACHE_SUFFIX))
def load(self, input, tooldir=None, funs=None, download=True):
"""
Load Waf tools, which will be imported whenever a build is started.
:param input: waf tools to import
:type input: list of string
:param tooldir: paths for the imports
:type tooldir: list of string
:param funs: functions to execute from the waf tools
:type funs: list of string
:param download: whether to download the tool from the waf repository
:type download: bool
"""
tools = Utils.to_list(input)
if tooldir:
tooldir = Utils.to_list(tooldir)
# Assume that whenever we specify a tooldir, we want to track those files
if os.path.isabs(tooldir[0]):
lmbr_waf_lib = self.root.make_node(tooldir).make_node(input + '.py')
else:
lmbr_waf_lib = self.path.make_node(tooldir).make_node(input + '.py')
self.hash = hash((self.hash, lmbr_waf_lib.read('rb')))
self.files.append(os.path.normpath(lmbr_waf_lib.abspath()))
for tool in tools:
# avoid loading the same tool more than once with the same functions
# used by composite projects
mag = (tool, id(self.env), funs)
if mag in self.tool_cache:
self.to_log('(tool %s is already loaded, skipping)' % tool)
continue
self.tool_cache.append(mag)
module = None
try:
module = Context.load_tool(tool, tooldir)
except ImportError as e:
if Options.options.download:
module = download_tool(tool, ctx=self)
if not module:
self.fatal('Could not load the Waf tool %r or download a suitable replacement from the repository (sys.path %r)\n%s' % (tool, sys.path, e))
else:
self.fatal('Could not load the Waf tool %r from %r (try the --download option?):\n%s' % (tool, sys.path, e))
except Exception as e:
self.to_log('imp %r (%r & %r)' % (tool, tooldir, funs))
self.to_log(Utils.ex_stack())
raise
if funs is not None:
self.eval_rules(funs)
else:
func = getattr(module, 'configure', None)
if func:
if type(func) is type(Utils.readf): func(self)
else: self.eval_rules(func)
self.tools.append({'tool':tool, 'tooldir':tooldir, 'funs':funs})
def post_recurse(self, node):
"""
Records the path and a hash of the scripts visited, see :py:meth:`waflib.Context.Context.post_recurse`
:param node: script
:type node: :py:class:`waflib.Node.Node`
"""
super(ConfigurationContext, self).post_recurse(node)
self.hash = hash((self.hash, node.read('rb')))
self.files.append(node.abspath())
if hasattr(self, 'addional_files_to_track'):
for file_node in self.addional_files_to_track:
#print 'found addional_files_to_track ', file_node
self.hash = hash((self.hash, file_node.read('rb')))
self.files.append(file_node.abspath())
self.addional_files_to_track = []
def eval_rules(self, rules):
"""
Execute the configuration tests. The method :py:meth:`waflib.Configure.ConfigurationContext.err_handler`
is used to process the eventual exceptions
:param rules: list of configuration method names
:type rules: list of string
"""
self.rules = Utils.to_list(rules)
for x in self.rules:
f = getattr(self, x)
if not f: self.fatal("No such method '%s'." % x)
try:
f()
except Exception as e:
ret = self.err_handler(x, e)
if ret == BREAK:
break
elif ret == CONTINUE:
continue
else:
raise
def err_handler(self, fun, error):
"""
Error handler for the configuration tests, the default is to let the exception raise
:param fun: configuration test
:type fun: method
:param error: exception
:type error: exception
"""
pass
def conf(f):
"""
Decorator: attach new configuration functions to :py:class:`waflib.Build.BuildContext` and
:py:class:`waflib.Configure.ConfigurationContext`. The methods bound will accept a parameter
named 'mandatory' to disable the configuration errors::
def configure(conf):
conf.find_program('abc', mandatory=False)
:param f: method to bind
:type f: function
"""
def fun(*k, **kw):
mandatory = True
if 'mandatory' in kw:
mandatory = kw['mandatory']
del kw['mandatory']
try:
return f(*k, **kw)
except Errors.ConfigurationError:
if mandatory:
raise
setattr(Options.OptionsContext, f.__name__, fun)
setattr(ConfigurationContext, f.__name__, fun)
setattr(Build.BuildContext, f.__name__, fun)
return f
@conf
def add_os_flags(self, var, dest=None):
"""
Import operating system environment values into ``conf.env`` dict::
def configure(conf):
conf.add_os_flags('CFLAGS')
:param var: variable to use
:type var: string
:param dest: destination variable, by default the same as var
:type dest: string
"""
# do not use 'get' to make certain the variable is not defined
try: self.env.append_value(dest or var, shlex.split(self.environ[var]))
except KeyError: pass
@conf
def cmd_to_list(self, cmd):
"""
Detect if a command is written in pseudo shell like ``ccache g++`` and return a list.
:param cmd: command
:type cmd: a string or a list of string
"""
if isinstance(cmd, str) and cmd.find(' '):
try:
os.stat(cmd)
except OSError:
return shlex.split(cmd)
else:
return [cmd]
return cmd
@conf
def check_waf_version(self, mini='1.6.99', maxi='1.8.0'):
"""
Raise a Configuration error if the Waf version does not strictly match the given bounds::
conf.check_waf_version(mini='1.7.0', maxi='1.8.0')
:type mini: number, tuple or string
:param mini: Minimum required version
:type maxi: number, tuple or string
:param maxi: Maximum allowed version
"""
self.start_msg('Checking for waf version in %s-%s' % (str(mini), str(maxi)))
ver = Context.HEXVERSION
if Utils.num2ver(mini) > ver:
self.fatal('waf version should be at least %r (%r found)' % (Utils.num2ver(mini), ver))
if Utils.num2ver(maxi) < ver:
self.fatal('waf version should be at most %r (%r found)' % (Utils.num2ver(maxi), ver))
self.end_msg('ok')
@conf
def find_file(self, filename, path_list=[]):
"""
Find a file in a list of paths
:param filename: name of the file to search for
:param path_list: list of directories to search
:return: the first occurrence filename or '' if filename could not be found
"""
for n in Utils.to_list(filename):
for d in Utils.to_list(path_list):
p = os.path.join(d, n)
if os.path.exists(p):
return p
self.fatal('Could not find %r' % filename)
@conf
def find_program(self, filename, **kw):
"""
Search for a program on the operating system
When var is used, you may set os.environ[var] to help find a specific program version, for example::
$ VALAC=/usr/bin/valac_test waf configure
:param path_list: paths to use for searching
:type param_list: list of string
:param var: store the result to conf.env[var], by default use filename.upper()
:type var: string
:param ext: list of extensions for the binary (do not add an extension for portability)
:type ext: list of string
"""
exts = kw.get('exts', Utils.is_win32 and '.exe,.com,.bat,.cmd' or ',.sh,.pl,.py')
environ = kw.get('environ', os.environ)
ret = ''
filename = Utils.to_list(filename)
var = kw.get('var', '')
if not var:
var = filename[0].upper()
if self.env[var]:
ret = self.env[var]
elif var in environ:
ret = environ[var]
path_list = kw.get('path_list', '')
if not ret:
if path_list:
path_list = Utils.to_list(path_list)
else:
path_list = environ.get('PATH', '').split(os.pathsep)
if not isinstance(filename, list):
filename = [filename]
for a in exts.split(','):
if ret:
break
for b in filename:
if ret:
break
for c in path_list:
if ret:
break
x = os.path.expanduser(os.path.join(c, b + a))
if os.path.isfile(x):
ret = x
if not ret and Utils.winreg:
ret = Utils.get_registry_app_path(Utils.winreg.HKEY_CURRENT_USER, filename)
if not ret and Utils.winreg:
ret = Utils.get_registry_app_path(Utils.winreg.HKEY_LOCAL_MACHINE, filename)
if not kw.get('silent_output'):
self.msg('Checking for program ' + ','.join(filename), ret or False)
self.to_log('find program=%r paths=%r var=%r -> %r' % (filename, path_list, var, ret))
if not ret:
self.fatal(kw.get('errmsg', '') or 'Could not find the program %s' % ','.join(filename))
if var:
self.env[var] = ret
return ret
@conf
def find_perl_program(self, filename, path_list=[], var=None, environ=None, exts=''):
"""
Search for a perl program on the operating system
:param filename: file to search for
:type filename: string
:param path_list: list of paths to look into
:type path_list: list of string
:param var: store the results into *conf.env.var*
:type var: string
:param environ: operating system environment to pass to :py:func:`waflib.Configure.find_program`
:type environ: dict
:param exts: extensions given to :py:func:`waflib.Configure.find_program`
:type exts: list
"""
try:
app = self.find_program(filename, path_list=path_list, var=var, environ=environ, exts=exts)
except Exception:
self.find_program('perl', var='PERL')
app = self.find_file(filename, os.environ['PATH'].split(os.pathsep))
if not app:
raise
if var:
self.env[var] = Utils.to_list(self.env['PERL']) + [app]
self.msg('Checking for %r' % filename, app)
| 28.980033 | 145 | 0.684733 |
4a1fa7cdeab6acca5a17d509a16ae0f01e96a9d2 | 7,206 | py | Python | backend/test_mobile_app_4_28824/settings.py | crowdbotics-apps/test-mobile-app-4-28824 | 05ef5ad9d4b3d54106fda9f874277abd25f83dcf | [
"FTL",
"AML",
"RSA-MD"
] | null | null | null | backend/test_mobile_app_4_28824/settings.py | crowdbotics-apps/test-mobile-app-4-28824 | 05ef5ad9d4b3d54106fda9f874277abd25f83dcf | [
"FTL",
"AML",
"RSA-MD"
] | null | null | null | backend/test_mobile_app_4_28824/settings.py | crowdbotics-apps/test-mobile-app-4-28824 | 05ef5ad9d4b3d54106fda9f874277abd25f83dcf | [
"FTL",
"AML",
"RSA-MD"
] | null | null | null | """
Django settings for test_mobile_app_4_28824 project.
Generated by 'django-admin startproject' using Django 2.2.2.
For more information on this file, see
https://docs.djangoproject.com/en/2.2/topics/settings/
For the full list of settings and their values, see
https://docs.djangoproject.com/en/2.2/ref/settings/
"""
import os
import environ
import logging
from modules.manifest import get_modules
env = environ.Env()
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = env.bool("DEBUG", default=False)
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/2.2/howto/deployment/checklist/
# SECURITY WARNING: keep the secret key used in production secret!
SECRET_KEY = env.str("SECRET_KEY")
ALLOWED_HOSTS = env.list("HOST", default=["*"])
SITE_ID = 1
SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
SECURE_SSL_REDIRECT = env.bool("SECURE_REDIRECT", default=False)
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django.contrib.sites'
]
LOCAL_APPS = [
'home',
'users.apps.UsersConfig',
]
THIRD_PARTY_APPS = [
'rest_framework',
'rest_framework.authtoken',
'rest_auth',
'rest_auth.registration',
'bootstrap4',
'allauth',
'allauth.account',
'allauth.socialaccount',
'allauth.socialaccount.providers.google',
'django_extensions',
'drf_yasg',
'storages',
# start fcm_django push notifications
'fcm_django',
# end fcm_django push notifications
]
MODULES_APPS = get_modules()
INSTALLED_APPS += LOCAL_APPS + THIRD_PARTY_APPS + MODULES_APPS
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'test_mobile_app_4_28824.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'web_build')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = 'test_mobile_app_4_28824.wsgi.application'
# Database
# https://docs.djangoproject.com/en/2.2/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
if env.str("DATABASE_URL", default=None):
DATABASES = {
'default': env.db()
}
# Password validation
# https://docs.djangoproject.com/en/2.2/ref/settings/#auth-password-validators
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
# Internationalization
# https://docs.djangoproject.com/en/2.2/topics/i18n/
LANGUAGE_CODE = 'en-us'
TIME_ZONE = 'UTC'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/2.2/howto/static-files/
STATIC_URL = '/static/'
MIDDLEWARE += ['whitenoise.middleware.WhiteNoiseMiddleware']
AUTHENTICATION_BACKENDS = (
'django.contrib.auth.backends.ModelBackend',
'allauth.account.auth_backends.AuthenticationBackend'
)
STATIC_ROOT = os.path.join(BASE_DIR, "staticfiles")
STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static'), os.path.join(BASE_DIR, 'web_build/static')]
STATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'
# allauth / users
ACCOUNT_EMAIL_REQUIRED = True
ACCOUNT_AUTHENTICATION_METHOD = 'email'
ACCOUNT_USERNAME_REQUIRED = False
ACCOUNT_EMAIL_VERIFICATION = "optional"
ACCOUNT_CONFIRM_EMAIL_ON_GET = True
ACCOUNT_LOGIN_ON_EMAIL_CONFIRMATION = True
ACCOUNT_UNIQUE_EMAIL = True
LOGIN_REDIRECT_URL = "users:redirect"
ACCOUNT_ADAPTER = "users.adapters.AccountAdapter"
SOCIALACCOUNT_ADAPTER = "users.adapters.SocialAccountAdapter"
ACCOUNT_ALLOW_REGISTRATION = env.bool("ACCOUNT_ALLOW_REGISTRATION", True)
SOCIALACCOUNT_ALLOW_REGISTRATION = env.bool("SOCIALACCOUNT_ALLOW_REGISTRATION", True)
REST_AUTH_SERIALIZERS = {
# Replace password reset serializer to fix 500 error
"PASSWORD_RESET_SERIALIZER": "home.api.v1.serializers.PasswordSerializer",
}
REST_AUTH_REGISTER_SERIALIZERS = {
# Use custom serializer that has no username and matches web signup
"REGISTER_SERIALIZER": "home.api.v1.serializers.SignupSerializer",
}
# Custom user model
AUTH_USER_MODEL = "users.User"
EMAIL_HOST = env.str("EMAIL_HOST", "smtp.sendgrid.net")
EMAIL_HOST_USER = env.str("SENDGRID_USERNAME", "")
EMAIL_HOST_PASSWORD = env.str("SENDGRID_PASSWORD", "")
EMAIL_PORT = 587
EMAIL_USE_TLS = True
# AWS S3 config
AWS_ACCESS_KEY_ID = env.str("AWS_ACCESS_KEY_ID", "")
AWS_SECRET_ACCESS_KEY = env.str("AWS_SECRET_ACCESS_KEY", "")
AWS_STORAGE_BUCKET_NAME = env.str("AWS_STORAGE_BUCKET_NAME", "")
AWS_STORAGE_REGION = env.str("AWS_STORAGE_REGION", "")
USE_S3 = (
AWS_ACCESS_KEY_ID and
AWS_SECRET_ACCESS_KEY and
AWS_STORAGE_BUCKET_NAME and
AWS_STORAGE_REGION
)
if USE_S3:
AWS_S3_CUSTOM_DOMAIN = env.str("AWS_S3_CUSTOM_DOMAIN", "")
AWS_S3_OBJECT_PARAMETERS = {"CacheControl": "max-age=86400"}
AWS_DEFAULT_ACL = env.str("AWS_DEFAULT_ACL", "public-read")
AWS_MEDIA_LOCATION = env.str("AWS_MEDIA_LOCATION", "media")
AWS_AUTO_CREATE_BUCKET = env.bool("AWS_AUTO_CREATE_BUCKET", True)
DEFAULT_FILE_STORAGE = env.str(
"DEFAULT_FILE_STORAGE", "home.storage_backends.MediaStorage"
)
MEDIA_URL = '/mediafiles/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'mediafiles')
# start fcm_django push notifications
FCM_DJANGO_SETTINGS = {
"FCM_SERVER_KEY": env.str("FCM_SERVER_KEY", "")
}
# end fcm_django push notifications
# Swagger settings for api docs
SWAGGER_SETTINGS = {
"DEFAULT_INFO": f"{ROOT_URLCONF}.api_info",
}
if DEBUG or not (EMAIL_HOST_USER and EMAIL_HOST_PASSWORD):
# output email to console instead of sending
if not DEBUG:
logging.warning("You should setup `SENDGRID_USERNAME` and `SENDGRID_PASSWORD` env vars to send emails.")
EMAIL_BACKEND = "django.core.mail.backends.console.EmailBackend"
| 29.056452 | 112 | 0.731474 |
4a1fa8285669d5820828e9a41add44de8202a9ed | 2,616 | py | Python | raiden_contracts/tests/fixtures/contracts.py | weilbith/raiden-contracts | 91dc2e5aae2f36916c88ed3c719d93e29da69b78 | [
"MIT"
] | 49 | 2018-03-18T07:25:46.000Z | 2022-03-11T14:07:18.000Z | raiden_contracts/tests/fixtures/contracts.py | weilbith/raiden-contracts | 91dc2e5aae2f36916c88ed3c719d93e29da69b78 | [
"MIT"
] | 1,378 | 2018-03-13T03:41:06.000Z | 2022-03-28T23:19:12.000Z | raiden_contracts/tests/fixtures/contracts.py | weilbith/raiden-contracts | 91dc2e5aae2f36916c88ed3c719d93e29da69b78 | [
"MIT"
] | 55 | 2018-03-21T14:37:27.000Z | 2022-02-07T10:31:59.000Z | import logging
from typing import Any, Callable, Tuple
import pytest
from eth_tester.exceptions import TransactionFailed
from eth_typing import HexAddress
from web3 import Web3
from web3.contract import Contract
from raiden_contracts.contract_manager import ContractManager
from raiden_contracts.tests.utils.blockchain import mine_blocks
from raiden_contracts.tests.utils.constants import DEPLOYER_ADDRESS
log = logging.getLogger(__name__)
def deploy_contract_txhash(
web3: Web3,
contracts_manager: ContractManager,
deployer_address: HexAddress,
contract_name: str,
**kwargs: Any,
) -> Tuple[HexAddress, Contract]:
json_contract = contracts_manager.get_contract(contract_name)
abi = json_contract["abi"]
bytecode = json_contract["bin"]
bytecode_runtime = None
if bytecode_runtime is not None:
contract = web3.eth.contract(abi=abi, bytecode=bytecode, bytecode_runtime=bytecode_runtime)
else:
contract = web3.eth.contract(abi=abi, bytecode=bytecode)
mine_blocks(web3, 3)
# Failure does not fire an exception. Check the receipt for status.
txhash = contract.constructor(**kwargs).transact({"from": deployer_address})
mine_blocks(web3, 1)
receipt = web3.eth.get_transaction_receipt(txhash)
if receipt["status"] != 1:
raise TransactionFailed("deployment failed")
return txhash, contract(receipt["contractAddress"])
@pytest.fixture
def deploy_tester_contract_txhash(web3: Web3, contracts_manager: ContractManager) -> Callable:
"""Returns a function that can be used to deploy a named contract,
but returning txhash only"""
def f(
contract_name: str,
deployer_address: HexAddress = DEPLOYER_ADDRESS,
**kwargs: Any,
) -> HexAddress:
txhash, _ = deploy_contract_txhash(
web3,
contracts_manager,
deployer_address,
contract_name,
**kwargs,
)
return txhash
return f
@pytest.fixture(scope="session")
def deploy_tester_contract(web3: Web3, contracts_manager: ContractManager) -> Callable:
"""Returns a function that can be used to deploy a named contract,
using contract manager to compile the bytecode and get the ABI"""
def f(
contract_name: str,
deployer_address: HexAddress = DEPLOYER_ADDRESS,
**kwargs: Any,
) -> Contract:
_, contract = deploy_contract_txhash(
web3,
contracts_manager,
deployer_address,
contract_name,
**kwargs,
)
return contract
return f
| 29.727273 | 99 | 0.69419 |
4a1fa864d82ec0c699213a2f0bfa000a658bdc79 | 76,882 | py | Python | Lib/fontTools/ufoLib/__init__.py | twardoch/fonttools-py27 | 75b852d3f59fc0d03c6e78581530597d4c6368a1 | [
"MIT",
"BSD-3-Clause"
] | 240 | 2021-01-11T14:49:24.000Z | 2022-03-29T22:33:49.000Z | Lib/fontTools/ufoLib/__init__.py | twardoch/fonttools-py27 | 75b852d3f59fc0d03c6e78581530597d4c6368a1 | [
"MIT",
"BSD-3-Clause"
] | 77 | 2021-01-12T20:23:30.000Z | 2022-03-28T12:14:34.000Z | Lib/fontTools/ufoLib/__init__.py | twardoch/fonttools-py27 | 75b852d3f59fc0d03c6e78581530597d4c6368a1 | [
"MIT",
"BSD-3-Clause"
] | 28 | 2021-01-17T05:44:11.000Z | 2022-01-11T19:58:46.000Z | from __future__ import absolute_import, unicode_literals
import sys
import os
from copy import deepcopy
import logging
import zipfile
import enum
from collections import OrderedDict
import fs
import fs.base
import fs.subfs
import fs.errors
import fs.copy
import fs.osfs
import fs.zipfs
import fs.tempfs
import fs.tools
from fontTools.misc.py23 import basestring, unicode, tounicode
from fontTools.misc import plistlib
from fontTools.ufoLib.validators import *
from fontTools.ufoLib.filenames import userNameToFileName
from fontTools.ufoLib.converters import convertUFO1OrUFO2KerningToUFO3Kerning
from fontTools.ufoLib.errors import UFOLibError
from fontTools.ufoLib.utils import datetimeAsTimestamp, fsdecode, numberTypes
"""
A library for importing .ufo files and their descendants.
Refer to http://unifiedfontobject.com for the UFO specification.
The UFOReader and UFOWriter classes support versions 1, 2 and 3
of the specification.
Sets that list the font info attribute names for the fontinfo.plist
formats are available for external use. These are:
fontInfoAttributesVersion1
fontInfoAttributesVersion2
fontInfoAttributesVersion3
A set listing the fontinfo.plist attributes that were deprecated
in version 2 is available for external use:
deprecatedFontInfoAttributesVersion2
Functions that do basic validation on values for fontinfo.plist
are available for external use. These are
validateFontInfoVersion2ValueForAttribute
validateFontInfoVersion3ValueForAttribute
Value conversion functions are available for converting
fontinfo.plist values between the possible format versions.
convertFontInfoValueForAttributeFromVersion1ToVersion2
convertFontInfoValueForAttributeFromVersion2ToVersion1
convertFontInfoValueForAttributeFromVersion2ToVersion3
convertFontInfoValueForAttributeFromVersion3ToVersion2
"""
__all__ = [
"makeUFOPath",
"UFOLibError",
"UFOReader",
"UFOWriter",
"UFOReaderWriter",
"UFOFileStructure",
"fontInfoAttributesVersion1",
"fontInfoAttributesVersion2",
"fontInfoAttributesVersion3",
"deprecatedFontInfoAttributesVersion2",
"validateFontInfoVersion2ValueForAttribute",
"validateFontInfoVersion3ValueForAttribute",
"convertFontInfoValueForAttributeFromVersion1ToVersion2",
"convertFontInfoValueForAttributeFromVersion2ToVersion1"
]
__version__ = "3.0.0"
logger = logging.getLogger(__name__)
# ---------
# Constants
# ---------
DEFAULT_GLYPHS_DIRNAME = "glyphs"
DATA_DIRNAME = "data"
IMAGES_DIRNAME = "images"
METAINFO_FILENAME = "metainfo.plist"
FONTINFO_FILENAME = "fontinfo.plist"
LIB_FILENAME = "lib.plist"
GROUPS_FILENAME = "groups.plist"
KERNING_FILENAME = "kerning.plist"
FEATURES_FILENAME = "features.fea"
LAYERCONTENTS_FILENAME = "layercontents.plist"
LAYERINFO_FILENAME = "layerinfo.plist"
DEFAULT_LAYER_NAME = "public.default"
supportedUFOFormatVersions = [1, 2, 3]
class UFOFileStructure(enum.Enum):
ZIP = "zip"
PACKAGE = "package"
# --------------
# Shared Methods
# --------------
class _UFOBaseIO(object):
def getFileModificationTime(self, path):
"""
Returns the modification time for the file at the given path, as a
floating point number giving the number of seconds since the epoch.
The path must be relative to the UFO path.
Returns None if the file does not exist.
"""
try:
dt = self.fs.getinfo(fsdecode(path), namespaces=["details"]).modified
except (fs.errors.MissingInfoNamespace, fs.errors.ResourceNotFound):
return None
else:
return datetimeAsTimestamp(dt)
def _getPlist(self, fileName, default=None):
"""
Read a property list relative to the UFO filesystem's root.
Raises UFOLibError if the file is missing and default is None,
otherwise default is returned.
The errors that could be raised during the reading of a plist are
unpredictable and/or too large to list, so, a blind try: except:
is done. If an exception occurs, a UFOLibError will be raised.
"""
try:
with self.fs.open(fileName, "rb") as f:
return plistlib.load(f)
except fs.errors.ResourceNotFound:
if default is None:
raise UFOLibError(
"'%s' is missing on %s. This file is required"
% (fileName, self.fs)
)
else:
return default
except Exception as e:
# TODO(anthrotype): try to narrow this down a little
raise UFOLibError(
"'%s' could not be read on %s: %s" % (fileName, self.fs, e)
)
def _writePlist(self, fileName, obj):
"""
Write a property list to a file relative to the UFO filesystem's root.
Do this sort of atomically, making it harder to corrupt existing files,
for example when plistlib encounters an error halfway during write.
This also checks to see if text matches the text that is already in the
file at path. If so, the file is not rewritten so that the modification
date is preserved.
The errors that could be raised during the writing of a plist are
unpredictable and/or too large to list, so, a blind try: except: is done.
If an exception occurs, a UFOLibError will be raised.
"""
if self._havePreviousFile:
try:
data = plistlib.dumps(obj)
except Exception as e:
raise UFOLibError(
"'%s' could not be written on %s because "
"the data is not properly formatted: %s"
% (fileName, self.fs, e)
)
if self.fs.exists(fileName) and data == self.fs.readbytes(fileName):
return
self.fs.writebytes(fileName, data)
else:
with self.fs.openbin(fileName, mode="w") as fp:
try:
plistlib.dump(obj, fp)
except Exception as e:
raise UFOLibError(
"'%s' could not be written on %s because "
"the data is not properly formatted: %s"
% (fileName, self.fs, e)
)
# ----------
# UFO Reader
# ----------
class UFOReader(_UFOBaseIO):
"""
Read the various components of the .ufo.
By default read data is validated. Set ``validate`` to
``False`` to not validate the data.
"""
def __init__(self, path, validate=True):
if hasattr(path, "__fspath__"): # support os.PathLike objects
path = path.__fspath__()
if isinstance(path, basestring):
structure = _sniffFileStructure(path)
try:
if structure is UFOFileStructure.ZIP:
parentFS = fs.zipfs.ZipFS(path, write=False, encoding="utf-8")
else:
parentFS = fs.osfs.OSFS(path)
except fs.errors.CreateFailed as e:
raise UFOLibError("unable to open '%s': %s" % (path, e))
if structure is UFOFileStructure.ZIP:
# .ufoz zip files must contain a single root directory, with arbitrary
# name, containing all the UFO files
rootDirs = [
p.name for p in parentFS.scandir("/")
# exclude macOS metadata contained in zip file
if p.is_dir and p.name != "__MACOSX"
]
if len(rootDirs) == 1:
# 'ClosingSubFS' ensures that the parent zip file is closed when
# its root subdirectory is closed
self.fs = parentFS.opendir(
rootDirs[0], factory=fs.subfs.ClosingSubFS
)
else:
raise UFOLibError(
"Expected exactly 1 root directory, found %d" % len(rootDirs)
)
else:
# normal UFO 'packages' are just a single folder
self.fs = parentFS
# when passed a path string, we make sure we close the newly opened fs
# upon calling UFOReader.close method or context manager's __exit__
self._shouldClose = True
self._fileStructure = structure
elif isinstance(path, fs.base.FS):
filesystem = path
try:
filesystem.check()
except fs.errors.FilesystemClosed:
raise UFOLibError("the filesystem '%s' is closed" % path)
else:
self.fs = filesystem
try:
path = filesystem.getsyspath("/")
except fs.errors.NoSysPath:
# network or in-memory FS may not map to the local one
path = unicode(filesystem)
# when user passed an already initialized fs instance, it is her
# responsibility to close it, thus UFOReader.close/__exit__ are no-op
self._shouldClose = False
# default to a 'package' structure
self._fileStructure = UFOFileStructure.PACKAGE
else:
raise TypeError(
"Expected a path string or fs.base.FS object, found '%s'"
% type(path).__name__
)
self._path = fsdecode(path)
self._validate = validate
self.readMetaInfo(validate=validate)
self._upConvertedKerningData = None
# properties
def _get_path(self):
import warnings
warnings.warn(
"The 'path' attribute is deprecated; use the 'fs' attribute instead",
DeprecationWarning,
stacklevel=2,
)
return self._path
path = property(_get_path, doc="The path of the UFO (DEPRECATED).")
def _get_formatVersion(self):
return self._formatVersion
formatVersion = property(_get_formatVersion, doc="The format version of the UFO. This is determined by reading metainfo.plist during __init__.")
def _get_fileStructure(self):
return self._fileStructure
fileStructure = property(
_get_fileStructure,
doc=(
"The file structure of the UFO: "
"either UFOFileStructure.ZIP or UFOFileStructure.PACKAGE"
)
)
# up conversion
def _upConvertKerning(self, validate):
"""
Up convert kerning and groups in UFO 1 and 2.
The data will be held internally until each bit of data
has been retrieved. The conversion of both must be done
at once, so the raw data is cached and an error is raised
if one bit of data becomes obsolete before it is called.
``validate`` will validate the data.
"""
if self._upConvertedKerningData:
testKerning = self._readKerning()
if testKerning != self._upConvertedKerningData["originalKerning"]:
raise UFOLibError("The data in kerning.plist has been modified since it was converted to UFO 3 format.")
testGroups = self._readGroups()
if testGroups != self._upConvertedKerningData["originalGroups"]:
raise UFOLibError("The data in groups.plist has been modified since it was converted to UFO 3 format.")
else:
groups = self._readGroups()
if validate:
invalidFormatMessage = "groups.plist is not properly formatted."
if not isinstance(groups, dict):
raise UFOLibError(invalidFormatMessage)
for groupName, glyphList in groups.items():
if not isinstance(groupName, basestring):
raise UFOLibError(invalidFormatMessage)
elif not isinstance(glyphList, list):
raise UFOLibError(invalidFormatMessage)
for glyphName in glyphList:
if not isinstance(glyphName, basestring):
raise UFOLibError(invalidFormatMessage)
self._upConvertedKerningData = dict(
kerning={},
originalKerning=self._readKerning(),
groups={},
originalGroups=groups
)
# convert kerning and groups
kerning, groups, conversionMaps = convertUFO1OrUFO2KerningToUFO3Kerning(
self._upConvertedKerningData["originalKerning"],
deepcopy(self._upConvertedKerningData["originalGroups"])
)
# store
self._upConvertedKerningData["kerning"] = kerning
self._upConvertedKerningData["groups"] = groups
self._upConvertedKerningData["groupRenameMaps"] = conversionMaps
# support methods
def readBytesFromPath(self, path):
"""
Returns the bytes in the file at the given path.
The path must be relative to the UFO's filesystem root.
Returns None if the file does not exist.
"""
try:
return self.fs.readbytes(fsdecode(path))
except fs.errors.ResourceNotFound:
return None
def getReadFileForPath(self, path, encoding=None):
"""
Returns a file (or file-like) object for the file at the given path.
The path must be relative to the UFO path.
Returns None if the file does not exist.
By default the file is opened in binary mode (reads bytes).
If encoding is passed, the file is opened in text mode (reads unicode).
Note: The caller is responsible for closing the open file.
"""
path = fsdecode(path)
try:
if encoding is None:
return self.fs.openbin(path)
else:
return self.fs.open(path, mode="r", encoding=encoding)
except fs.errors.ResourceNotFound:
return None
# metainfo.plist
def readMetaInfo(self, validate=None):
"""
Read metainfo.plist. Only used for internal operations.
``validate`` will validate the read data, by default it is set
to the class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
data = self._getPlist(METAINFO_FILENAME)
if validate and not isinstance(data, dict):
raise UFOLibError("metainfo.plist is not properly formatted.")
formatVersion = data["formatVersion"]
if validate:
if not isinstance(formatVersion, int):
raise UFOLibError(
"formatVersion must be specified as an integer in '%s' on %s"
% (METAINFO_FILENAME, self.fs)
)
if formatVersion not in supportedUFOFormatVersions:
raise UFOLibError(
"Unsupported UFO format (%d) in '%s' on %s"
% (formatVersion, METAINFO_FILENAME, self.fs)
)
self._formatVersion = formatVersion
# groups.plist
def _readGroups(self):
return self._getPlist(GROUPS_FILENAME, {})
def readGroups(self, validate=None):
"""
Read groups.plist. Returns a dict.
``validate`` will validate the read data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
# handle up conversion
if self._formatVersion < 3:
self._upConvertKerning(validate)
groups = self._upConvertedKerningData["groups"]
# normal
else:
groups = self._readGroups()
if validate:
valid, message = groupsValidator(groups)
if not valid:
raise UFOLibError(message)
return groups
def getKerningGroupConversionRenameMaps(self, validate=None):
"""
Get maps defining the renaming that was done during any
needed kerning group conversion. This method returns a
dictionary of this form:
{
"side1" : {"old group name" : "new group name"},
"side2" : {"old group name" : "new group name"}
}
When no conversion has been performed, the side1 and side2
dictionaries will be empty.
``validate`` will validate the groups, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
if self._formatVersion >= 3:
return dict(side1={}, side2={})
# use the public group reader to force the load and
# conversion of the data if it hasn't happened yet.
self.readGroups(validate=validate)
return self._upConvertedKerningData["groupRenameMaps"]
# fontinfo.plist
def _readInfo(self, validate):
data = self._getPlist(FONTINFO_FILENAME, {})
if validate and not isinstance(data, dict):
raise UFOLibError("fontinfo.plist is not properly formatted.")
return data
def readInfo(self, info, validate=None):
"""
Read fontinfo.plist. It requires an object that allows
setting attributes with names that follow the fontinfo.plist
version 3 specification. This will write the attributes
defined in the file into the object.
``validate`` will validate the read data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
infoDict = self._readInfo(validate)
infoDataToSet = {}
# version 1
if self._formatVersion == 1:
for attr in fontInfoAttributesVersion1:
value = infoDict.get(attr)
if value is not None:
infoDataToSet[attr] = value
infoDataToSet = _convertFontInfoDataVersion1ToVersion2(infoDataToSet)
infoDataToSet = _convertFontInfoDataVersion2ToVersion3(infoDataToSet)
# version 2
elif self._formatVersion == 2:
for attr, dataValidationDict in list(fontInfoAttributesVersion2ValueData.items()):
value = infoDict.get(attr)
if value is None:
continue
infoDataToSet[attr] = value
infoDataToSet = _convertFontInfoDataVersion2ToVersion3(infoDataToSet)
# version 3
elif self._formatVersion == 3:
for attr, dataValidationDict in list(fontInfoAttributesVersion3ValueData.items()):
value = infoDict.get(attr)
if value is None:
continue
infoDataToSet[attr] = value
# unsupported version
else:
raise NotImplementedError
# validate data
if validate:
infoDataToSet = validateInfoVersion3Data(infoDataToSet)
# populate the object
for attr, value in list(infoDataToSet.items()):
try:
setattr(info, attr, value)
except AttributeError:
raise UFOLibError("The supplied info object does not support setting a necessary attribute (%s)." % attr)
# kerning.plist
def _readKerning(self):
data = self._getPlist(KERNING_FILENAME, {})
return data
def readKerning(self, validate=None):
"""
Read kerning.plist. Returns a dict.
``validate`` will validate the kerning data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
# handle up conversion
if self._formatVersion < 3:
self._upConvertKerning(validate)
kerningNested = self._upConvertedKerningData["kerning"]
# normal
else:
kerningNested = self._readKerning()
if validate:
valid, message = kerningValidator(kerningNested)
if not valid:
raise UFOLibError(message)
# flatten
kerning = {}
for left in kerningNested:
for right in kerningNested[left]:
value = kerningNested[left][right]
kerning[left, right] = value
return kerning
# lib.plist
def readLib(self, validate=None):
"""
Read lib.plist. Returns a dict.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
data = self._getPlist(LIB_FILENAME, {})
if validate:
valid, message = fontLibValidator(data)
if not valid:
raise UFOLibError(message)
return data
# features.fea
def readFeatures(self):
"""
Read features.fea. Return a unicode string.
The returned string is empty if the file is missing.
"""
try:
with self.fs.open(FEATURES_FILENAME, "r", encoding="utf-8") as f:
return f.read()
except fs.errors.ResourceNotFound:
return ""
# glyph sets & layers
def _readLayerContents(self, validate):
"""
Rebuild the layer contents list by checking what glyphsets
are available on disk.
``validate`` will validate the layer contents.
"""
if self._formatVersion < 3:
return [(DEFAULT_LAYER_NAME, DEFAULT_GLYPHS_DIRNAME)]
contents = self._getPlist(LAYERCONTENTS_FILENAME)
if validate:
valid, error = layerContentsValidator(contents, self.fs)
if not valid:
raise UFOLibError(error)
return contents
def getLayerNames(self, validate=None):
"""
Get the ordered layer names from layercontents.plist.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
layerContents = self._readLayerContents(validate)
layerNames = [layerName for layerName, directoryName in layerContents]
return layerNames
def getDefaultLayerName(self, validate=None):
"""
Get the default layer name from layercontents.plist.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
layerContents = self._readLayerContents(validate)
for layerName, layerDirectory in layerContents:
if layerDirectory == DEFAULT_GLYPHS_DIRNAME:
return layerName
# this will already have been raised during __init__
raise UFOLibError("The default layer is not defined in layercontents.plist.")
def getGlyphSet(self, layerName=None, validateRead=None, validateWrite=None):
"""
Return the GlyphSet associated with the
glyphs directory mapped to layerName
in the UFO. If layerName is not provided,
the name retrieved with getDefaultLayerName
will be used.
``validateRead`` will validate the read data, by default it is set to the
class's validate value, can be overridden.
``validateWrte`` will validate the written data, by default it is set to the
class's validate value, can be overridden.
"""
from fontTools.ufoLib.glifLib import GlyphSet
if validateRead is None:
validateRead = self._validate
if validateWrite is None:
validateWrite = self._validate
if layerName is None:
layerName = self.getDefaultLayerName(validate=validateRead)
directory = None
layerContents = self._readLayerContents(validateRead)
for storedLayerName, storedLayerDirectory in layerContents:
if layerName == storedLayerName:
directory = storedLayerDirectory
break
if directory is None:
raise UFOLibError("No glyphs directory is mapped to \"%s\"." % layerName)
try:
glyphSubFS = self.fs.opendir(directory)
except fs.errors.ResourceNotFound:
raise UFOLibError(
"No '%s' directory for layer '%s'" % (directory, layerName)
)
return GlyphSet(
glyphSubFS,
ufoFormatVersion=self._formatVersion,
validateRead=validateRead,
validateWrite=validateWrite,
)
def getCharacterMapping(self, layerName=None, validate=None):
"""
Return a dictionary that maps unicode values (ints) to
lists of glyph names.
"""
if validate is None:
validate = self._validate
glyphSet = self.getGlyphSet(layerName, validateRead=validate, validateWrite=True)
allUnicodes = glyphSet.getUnicodes()
cmap = {}
for glyphName, unicodes in allUnicodes.items():
for code in unicodes:
if code in cmap:
cmap[code].append(glyphName)
else:
cmap[code] = [glyphName]
return cmap
# /data
def getDataDirectoryListing(self):
"""
Returns a list of all files in the data directory.
The returned paths will be relative to the UFO.
This will not list directory names, only file names.
Thus, empty directories will be skipped.
"""
try:
self._dataFS = self.fs.opendir(DATA_DIRNAME)
except fs.errors.ResourceNotFound:
return []
except fs.errors.DirectoryExpected:
raise UFOLibError("The UFO contains a \"data\" file instead of a directory.")
try:
# fs Walker.files method returns "absolute" paths (in terms of the
# root of the 'data' SubFS), so we strip the leading '/' to make
# them relative
return [
p.lstrip("/") for p in self._dataFS.walk.files()
]
except fs.errors.ResourceError:
return []
def getImageDirectoryListing(self, validate=None):
"""
Returns a list of all image file names in
the images directory. Each of the images will
have been verified to have the PNG signature.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if self._formatVersion < 3:
return []
if validate is None:
validate = self._validate
try:
self._imagesFS = imagesFS = self.fs.opendir(IMAGES_DIRNAME)
except fs.errors.ResourceNotFound:
return []
except fs.errors.DirectoryExpected:
raise UFOLibError("The UFO contains an \"images\" file instead of a directory.")
result = []
for path in imagesFS.scandir("/"):
if path.is_dir:
# silently skip this as version control
# systems often have hidden directories
continue
if validate:
with imagesFS.openbin(path.name) as fp:
valid, error = pngValidator(fileObj=fp)
if valid:
result.append(path.name)
else:
result.append(path.name)
return result
def readData(self, fileName):
"""
Return bytes for the file named 'fileName' inside the 'data/' directory.
"""
fileName = fsdecode(fileName)
try:
try:
dataFS = self._dataFS
except AttributeError:
# in case readData is called before getDataDirectoryListing
dataFS = self.fs.opendir(DATA_DIRNAME)
data = dataFS.readbytes(fileName)
except fs.errors.ResourceNotFound:
raise UFOLibError("No data file named '%s' on %s" % (fileName, self.fs))
return data
def readImage(self, fileName, validate=None):
"""
Return image data for the file named fileName.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
if self._formatVersion < 3:
raise UFOLibError("Reading images is not allowed in UFO %d." % self._formatVersion)
fileName = fsdecode(fileName)
try:
try:
imagesFS = self._imagesFS
except AttributeError:
# in case readImage is called before getImageDirectoryListing
imagesFS = self.fs.opendir(IMAGES_DIRNAME)
data = imagesFS.readbytes(fileName)
except fs.errors.ResourceNotFound:
raise UFOLibError("No image file named '%s' on %s" % (fileName, self.fs))
if validate:
valid, error = pngValidator(data=data)
if not valid:
raise UFOLibError(error)
return data
def close(self):
if self._shouldClose:
self.fs.close()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, exc_tb):
self.close()
# ----------
# UFO Writer
# ----------
class UFOWriter(UFOReader):
"""
Write the various components of the .ufo.
By default, the written data will be validated before writing. Set ``validate`` to
``False`` if you do not want to validate the data. Validation can also be overriden
on a per method level if desired.
"""
def __init__(
self,
path,
formatVersion=3,
fileCreator="com.github.fonttools.ufoLib",
structure=None,
validate=True,
):
if formatVersion not in supportedUFOFormatVersions:
raise UFOLibError("Unsupported UFO format (%d)." % formatVersion)
if hasattr(path, "__fspath__"): # support os.PathLike objects
path = path.__fspath__()
if isinstance(path, basestring):
# normalize path by removing trailing or double slashes
path = os.path.normpath(path)
havePreviousFile = os.path.exists(path)
if havePreviousFile:
# ensure we use the same structure as the destination
existingStructure = _sniffFileStructure(path)
if structure is not None:
try:
structure = UFOFileStructure(structure)
except ValueError:
raise UFOLibError(
"Invalid or unsupported structure: '%s'" % structure
)
if structure is not existingStructure:
raise UFOLibError(
"A UFO with a different structure (%s) already exists "
"at the given path: '%s'" % (existingStructure, path)
)
else:
structure = existingStructure
else:
# if not exists, default to 'package' structure
if structure is None:
structure = UFOFileStructure.PACKAGE
dirName = os.path.dirname(path)
if dirName and not os.path.isdir(dirName):
raise UFOLibError(
"Cannot write to '%s': directory does not exist" % path
)
if structure is UFOFileStructure.ZIP:
if havePreviousFile:
# we can't write a zip in-place, so we have to copy its
# contents to a temporary location and work from there, then
# upon closing UFOWriter we create the final zip file
parentFS = fs.tempfs.TempFS()
with fs.zipfs.ZipFS(path, encoding="utf-8") as origFS:
fs.copy.copy_fs(origFS, parentFS)
# if output path is an existing zip, we require that it contains
# one, and only one, root directory (with arbitrary name), in turn
# containing all the existing UFO contents
rootDirs = [
p.name for p in parentFS.scandir("/")
# exclude macOS metadata contained in zip file
if p.is_dir and p.name != "__MACOSX"
]
if len(rootDirs) != 1:
raise UFOLibError(
"Expected exactly 1 root directory, found %d" % len(rootDirs)
)
else:
# 'ClosingSubFS' ensures that the parent filesystem is closed
# when its root subdirectory is closed
self.fs = parentFS.opendir(
rootDirs[0], factory=fs.subfs.ClosingSubFS
)
else:
# if the output zip file didn't exist, we create the root folder;
# we name it the same as input 'path', but with '.ufo' extension
rootDir = os.path.splitext(os.path.basename(path))[0] + ".ufo"
parentFS = fs.zipfs.ZipFS(path, write=True, encoding="utf-8")
parentFS.makedir(rootDir)
self.fs = parentFS.opendir(rootDir, factory=fs.subfs.ClosingSubFS)
else:
self.fs = fs.osfs.OSFS(path, create=True)
self._fileStructure = structure
self._havePreviousFile = havePreviousFile
self._shouldClose = True
elif isinstance(path, fs.base.FS):
filesystem = path
try:
filesystem.check()
except fs.errors.FilesystemClosed:
raise UFOLibError("the filesystem '%s' is closed" % path)
else:
self.fs = filesystem
try:
path = filesystem.getsyspath("/")
except fs.errors.NoSysPath:
# network or in-memory FS may not map to the local one
path = unicode(filesystem)
# if passed an FS object, always use 'package' structure
if structure and structure is not UFOFileStructure.PACKAGE:
import warnings
warnings.warn(
"The 'structure' argument is not used when input is an FS object",
UserWarning,
stacklevel=2,
)
self._fileStructure = UFOFileStructure.PACKAGE
# if FS contains a "metainfo.plist", we consider it non-empty
self._havePreviousFile = filesystem.exists(METAINFO_FILENAME)
# the user is responsible for closing the FS object
self._shouldClose = False
else:
raise TypeError(
"Expected a path string or fs object, found %s"
% type(path).__name__
)
# establish some basic stuff
self._path = fsdecode(path)
self._formatVersion = formatVersion
self._fileCreator = fileCreator
self._downConversionKerningData = None
self._validate = validate
# if the file already exists, get the format version.
# this will be needed for up and down conversion.
previousFormatVersion = None
if self._havePreviousFile:
metaInfo = self._getPlist(METAINFO_FILENAME)
previousFormatVersion = metaInfo.get("formatVersion")
try:
previousFormatVersion = int(previousFormatVersion)
except (ValueError, TypeError):
self.fs.close()
raise UFOLibError("The existing metainfo.plist is not properly formatted.")
if previousFormatVersion not in supportedUFOFormatVersions:
self.fs.close()
raise UFOLibError("Unsupported UFO format (%d)." % formatVersion)
# catch down conversion
if previousFormatVersion is not None and previousFormatVersion > formatVersion:
raise UFOLibError("The UFO located at this path is a higher version (%d) than the version (%d) that is trying to be written. This is not supported." % (previousFormatVersion, formatVersion))
# handle the layer contents
self.layerContents = {}
if previousFormatVersion is not None and previousFormatVersion >= 3:
# already exists
self.layerContents = OrderedDict(self._readLayerContents(validate))
else:
# previous < 3
# imply the layer contents
if self.fs.exists(DEFAULT_GLYPHS_DIRNAME):
self.layerContents = {DEFAULT_LAYER_NAME : DEFAULT_GLYPHS_DIRNAME}
# write the new metainfo
self._writeMetaInfo()
# properties
def _get_fileCreator(self):
return self._fileCreator
fileCreator = property(_get_fileCreator, doc="The file creator of the UFO. This is set into metainfo.plist during __init__.")
# support methods for file system interaction
def copyFromReader(self, reader, sourcePath, destPath):
"""
Copy the sourcePath in the provided UFOReader to destPath
in this writer. The paths must be relative. This works with
both individual files and directories.
"""
if not isinstance(reader, UFOReader):
raise UFOLibError("The reader must be an instance of UFOReader.")
sourcePath = fsdecode(sourcePath)
destPath = fsdecode(destPath)
if not reader.fs.exists(sourcePath):
raise UFOLibError("The reader does not have data located at \"%s\"." % sourcePath)
if self.fs.exists(destPath):
raise UFOLibError("A file named \"%s\" already exists." % destPath)
# create the destination directory if it doesn't exist
self.fs.makedirs(fs.path.dirname(destPath), recreate=True)
if reader.fs.isdir(sourcePath):
fs.copy.copy_dir(reader.fs, sourcePath, self.fs, destPath)
else:
fs.copy.copy_file(reader.fs, sourcePath, self.fs, destPath)
def writeBytesToPath(self, path, data):
"""
Write bytes to a path relative to the UFO filesystem's root.
If writing to an existing UFO, check to see if data matches the data
that is already in the file at path; if so, the file is not rewritten
so that the modification date is preserved.
If needed, the directory tree for the given path will be built.
"""
path = fsdecode(path)
if self._havePreviousFile:
if self.fs.isfile(path) and data == self.fs.readbytes(path):
return
try:
self.fs.writebytes(path, data)
except fs.errors.FileExpected:
raise UFOLibError("A directory exists at '%s'" % path)
except fs.errors.ResourceNotFound:
self.fs.makedirs(fs.path.dirname(path), recreate=True)
self.fs.writebytes(path, data)
def getFileObjectForPath(self, path, mode="w", encoding=None):
"""
Returns a file (or file-like) object for the
file at the given path. The path must be relative
to the UFO path. Returns None if the file does
not exist and the mode is "r" or "rb.
An encoding may be passed if the file is opened in text mode.
Note: The caller is responsible for closing the open file.
"""
path = fsdecode(path)
try:
return self.fs.open(path, mode=mode, encoding=encoding)
except fs.errors.ResourceNotFound as e:
m = mode[0]
if m == "r":
# XXX I think we should just let it raise. The docstring,
# however, says that this returns None if mode is 'r'
return None
elif m == "w" or m == "a" or m == "x":
self.fs.makedirs(fs.path.dirname(path), recreate=True)
return self.fs.open(path, mode=mode, encoding=encoding)
except fs.errors.ResourceError as e:
return UFOLibError(
"unable to open '%s' on %s: %s" % (path, self.fs, e)
)
def removePath(self, path, force=False, removeEmptyParents=True):
"""
Remove the file (or directory) at path. The path
must be relative to the UFO.
Raises UFOLibError if the path doesn't exist.
If force=True, ignore non-existent paths.
If the directory where 'path' is located becomes empty, it will
be automatically removed, unless 'removeEmptyParents' is False.
"""
path = fsdecode(path)
try:
self.fs.remove(path)
except fs.errors.FileExpected:
self.fs.removetree(path)
except fs.errors.ResourceNotFound:
if not force:
raise UFOLibError(
"'%s' does not exist on %s" % (path, self.fs)
)
if removeEmptyParents:
parent = fs.path.dirname(path)
if parent:
fs.tools.remove_empty(self.fs, parent)
# alias kept for backward compatibility with old API
removeFileForPath = removePath
# UFO mod time
def setModificationTime(self):
"""
Set the UFO modification time to the current time.
This is never called automatically. It is up to the
caller to call this when finished working on the UFO.
"""
path = self._path
if path is not None and os.path.exists(path):
try:
# this may fail on some filesystems (e.g. SMB servers)
os.utime(path, None)
except OSError as e:
logger.warning("Failed to set modified time: %s", e)
# metainfo.plist
def _writeMetaInfo(self):
metaInfo = dict(
creator=self._fileCreator,
formatVersion=self._formatVersion
)
self._writePlist(METAINFO_FILENAME, metaInfo)
# groups.plist
def setKerningGroupConversionRenameMaps(self, maps):
"""
Set maps defining the renaming that should be done
when writing groups and kerning in UFO 1 and UFO 2.
This will effectively undo the conversion done when
UFOReader reads this data. The dictionary should have
this form:
{
"side1" : {"group name to use when writing" : "group name in data"},
"side2" : {"group name to use when writing" : "group name in data"}
}
This is the same form returned by UFOReader's
getKerningGroupConversionRenameMaps method.
"""
if self._formatVersion >= 3:
return # XXX raise an error here
# flip the dictionaries
remap = {}
for side in ("side1", "side2"):
for writeName, dataName in list(maps[side].items()):
remap[dataName] = writeName
self._downConversionKerningData = dict(groupRenameMap=remap)
def writeGroups(self, groups, validate=None):
"""
Write groups.plist. This method requires a
dict of glyph groups as an argument.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
# validate the data structure
if validate:
valid, message = groupsValidator(groups)
if not valid:
raise UFOLibError(message)
# down convert
if self._formatVersion < 3 and self._downConversionKerningData is not None:
remap = self._downConversionKerningData["groupRenameMap"]
remappedGroups = {}
# there are some edge cases here that are ignored:
# 1. if a group is being renamed to a name that
# already exists, the existing group is always
# overwritten. (this is why there are two loops
# below.) there doesn't seem to be a logical
# solution to groups mismatching and overwriting
# with the specifiecd group seems like a better
# solution than throwing an error.
# 2. if side 1 and side 2 groups are being renamed
# to the same group name there is no check to
# ensure that the contents are identical. that
# is left up to the caller.
for name, contents in list(groups.items()):
if name in remap:
continue
remappedGroups[name] = contents
for name, contents in list(groups.items()):
if name not in remap:
continue
name = remap[name]
remappedGroups[name] = contents
groups = remappedGroups
# pack and write
groupsNew = {}
for key, value in groups.items():
groupsNew[key] = list(value)
if groupsNew:
self._writePlist(GROUPS_FILENAME, groupsNew)
elif self._havePreviousFile:
self.removePath(GROUPS_FILENAME, force=True, removeEmptyParents=False)
# fontinfo.plist
def writeInfo(self, info, validate=None):
"""
Write info.plist. This method requires an object
that supports getting attributes that follow the
fontinfo.plist version 2 specification. Attributes
will be taken from the given object and written
into the file.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
# gather version 3 data
infoData = {}
for attr in list(fontInfoAttributesVersion3ValueData.keys()):
if hasattr(info, attr):
try:
value = getattr(info, attr)
except AttributeError:
raise UFOLibError("The supplied info object does not support getting a necessary attribute (%s)." % attr)
if value is None:
continue
infoData[attr] = value
# down convert data if necessary and validate
if self._formatVersion == 3:
if validate:
infoData = validateInfoVersion3Data(infoData)
elif self._formatVersion == 2:
infoData = _convertFontInfoDataVersion3ToVersion2(infoData)
if validate:
infoData = validateInfoVersion2Data(infoData)
elif self._formatVersion == 1:
infoData = _convertFontInfoDataVersion3ToVersion2(infoData)
if validate:
infoData = validateInfoVersion2Data(infoData)
infoData = _convertFontInfoDataVersion2ToVersion1(infoData)
# write file
self._writePlist(FONTINFO_FILENAME, infoData)
# kerning.plist
def writeKerning(self, kerning, validate=None):
"""
Write kerning.plist. This method requires a
dict of kerning pairs as an argument.
This performs basic structural validation of the kerning,
but it does not check for compliance with the spec in
regards to conflicting pairs. The assumption is that the
kerning data being passed is standards compliant.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
# validate the data structure
if validate:
invalidFormatMessage = "The kerning is not properly formatted."
if not isDictEnough(kerning):
raise UFOLibError(invalidFormatMessage)
for pair, value in list(kerning.items()):
if not isinstance(pair, (list, tuple)):
raise UFOLibError(invalidFormatMessage)
if not len(pair) == 2:
raise UFOLibError(invalidFormatMessage)
if not isinstance(pair[0], basestring):
raise UFOLibError(invalidFormatMessage)
if not isinstance(pair[1], basestring):
raise UFOLibError(invalidFormatMessage)
if not isinstance(value, numberTypes):
raise UFOLibError(invalidFormatMessage)
# down convert
if self._formatVersion < 3 and self._downConversionKerningData is not None:
remap = self._downConversionKerningData["groupRenameMap"]
remappedKerning = {}
for (side1, side2), value in list(kerning.items()):
side1 = remap.get(side1, side1)
side2 = remap.get(side2, side2)
remappedKerning[side1, side2] = value
kerning = remappedKerning
# pack and write
kerningDict = {}
for left, right in kerning.keys():
value = kerning[left, right]
if left not in kerningDict:
kerningDict[left] = {}
kerningDict[left][right] = value
if kerningDict:
self._writePlist(KERNING_FILENAME, kerningDict)
elif self._havePreviousFile:
self.removePath(KERNING_FILENAME, force=True, removeEmptyParents=False)
# lib.plist
def writeLib(self, libDict, validate=None):
"""
Write lib.plist. This method requires a
lib dict as an argument.
``validate`` will validate the data, by default it is set to the
class's validate value, can be overridden.
"""
if validate is None:
validate = self._validate
if validate:
valid, message = fontLibValidator(libDict)
if not valid:
raise UFOLibError(message)
if libDict:
self._writePlist(LIB_FILENAME, libDict)
elif self._havePreviousFile:
self.removePath(LIB_FILENAME, force=True, removeEmptyParents=False)
# features.fea
def writeFeatures(self, features, validate=None):
"""
Write features.fea. This method requires a
features string as an argument.
"""
if validate is None:
validate = self._validate
if self._formatVersion == 1:
raise UFOLibError("features.fea is not allowed in UFO Format Version 1.")
if validate:
if not isinstance(features, basestring):
raise UFOLibError("The features are not text.")
if features:
self.writeBytesToPath(FEATURES_FILENAME, features.encode("utf8"))
elif self._havePreviousFile:
self.removePath(FEATURES_FILENAME, force=True, removeEmptyParents=False)
# glyph sets & layers
def writeLayerContents(self, layerOrder=None, validate=None):
"""
Write the layercontents.plist file. This method *must* be called
after all glyph sets have been written.
"""
if validate is None:
validate = self._validate
if self.formatVersion < 3:
return
if layerOrder is not None:
newOrder = []
for layerName in layerOrder:
if layerName is None:
layerName = DEFAULT_LAYER_NAME
else:
layerName = tounicode(layerName)
newOrder.append(layerName)
layerOrder = newOrder
else:
layerOrder = list(self.layerContents.keys())
if validate and set(layerOrder) != set(self.layerContents.keys()):
raise UFOLibError("The layer order content does not match the glyph sets that have been created.")
layerContents = [(layerName, self.layerContents[layerName]) for layerName in layerOrder]
self._writePlist(LAYERCONTENTS_FILENAME, layerContents)
def _findDirectoryForLayerName(self, layerName):
foundDirectory = None
for existingLayerName, directoryName in list(self.layerContents.items()):
if layerName is None and directoryName == DEFAULT_GLYPHS_DIRNAME:
foundDirectory = directoryName
break
elif existingLayerName == layerName:
foundDirectory = directoryName
break
if not foundDirectory:
raise UFOLibError("Could not locate a glyph set directory for the layer named %s." % layerName)
return foundDirectory
def getGlyphSet(self, layerName=None, defaultLayer=True, glyphNameToFileNameFunc=None, validateRead=None, validateWrite=None):
"""
Return the GlyphSet object associated with the
appropriate glyph directory in the .ufo.
If layerName is None, the default glyph set
will be used. The defaultLayer flag indictes
that the layer should be saved into the default
glyphs directory.
``validateRead`` will validate the read data, by default it is set to the
class's validate value, can be overridden.
``validateWrte`` will validate the written data, by default it is set to the
class's validate value, can be overridden.
"""
if validateRead is None:
validateRead = self._validate
if validateWrite is None:
validateWrite = self._validate
# only default can be written in < 3
if self._formatVersion < 3 and (not defaultLayer or layerName is not None):
raise UFOLibError("Only the default layer can be writen in UFO %d." % self.formatVersion)
# locate a layer name when None has been given
if layerName is None and defaultLayer:
for existingLayerName, directory in self.layerContents.items():
if directory == DEFAULT_GLYPHS_DIRNAME:
layerName = existingLayerName
if layerName is None:
layerName = DEFAULT_LAYER_NAME
elif layerName is None and not defaultLayer:
raise UFOLibError("A layer name must be provided for non-default layers.")
# move along to format specific writing
if self.formatVersion == 1:
return self._getGlyphSetFormatVersion1(validateRead, validateWrite, glyphNameToFileNameFunc=glyphNameToFileNameFunc)
elif self.formatVersion == 2:
return self._getGlyphSetFormatVersion2(validateRead, validateWrite, glyphNameToFileNameFunc=glyphNameToFileNameFunc)
elif self.formatVersion == 3:
return self._getGlyphSetFormatVersion3(validateRead, validateWrite, layerName=layerName, defaultLayer=defaultLayer, glyphNameToFileNameFunc=glyphNameToFileNameFunc)
else:
raise AssertionError(self.formatVersion)
def _getGlyphSetFormatVersion1(self, validateRead, validateWrite, glyphNameToFileNameFunc=None):
from fontTools.ufoLib.glifLib import GlyphSet
glyphSubFS = self.fs.makedir(DEFAULT_GLYPHS_DIRNAME, recreate=True)
return GlyphSet(
glyphSubFS,
glyphNameToFileNameFunc=glyphNameToFileNameFunc,
ufoFormatVersion=1,
validateRead=validateRead,
validateWrite=validateWrite,
)
def _getGlyphSetFormatVersion2(self, validateRead, validateWrite, glyphNameToFileNameFunc=None):
from fontTools.ufoLib.glifLib import GlyphSet
glyphSubFS = self.fs.makedir(DEFAULT_GLYPHS_DIRNAME, recreate=True)
return GlyphSet(
glyphSubFS,
glyphNameToFileNameFunc=glyphNameToFileNameFunc,
ufoFormatVersion=2,
validateRead=validateRead,
validateWrite=validateWrite,
)
def _getGlyphSetFormatVersion3(self, validateRead, validateWrite, layerName=None, defaultLayer=True, glyphNameToFileNameFunc=None):
from fontTools.ufoLib.glifLib import GlyphSet
# if the default flag is on, make sure that the default in the file
# matches the default being written. also make sure that this layer
# name is not already linked to a non-default layer.
if defaultLayer:
for existingLayerName, directory in self.layerContents.items():
if directory == DEFAULT_GLYPHS_DIRNAME:
if existingLayerName != layerName:
raise UFOLibError(
"Another layer ('%s') is already mapped to the default directory."
% existingLayerName
)
elif existingLayerName == layerName:
raise UFOLibError("The layer name is already mapped to a non-default layer.")
# get an existing directory name
if layerName in self.layerContents:
directory = self.layerContents[layerName]
# get a new directory name
else:
if defaultLayer:
directory = DEFAULT_GLYPHS_DIRNAME
else:
# not caching this could be slightly expensive,
# but caching it will be cumbersome
existing = {d.lower() for d in self.layerContents.values()}
if not isinstance(layerName, unicode):
try:
layerName = unicode(layerName)
except UnicodeDecodeError:
raise UFOLibError("The specified layer name is not a Unicode string.")
directory = userNameToFileName(layerName, existing=existing, prefix="glyphs.")
# make the directory
glyphSubFS = self.fs.makedir(directory, recreate=True)
# store the mapping
self.layerContents[layerName] = directory
# load the glyph set
return GlyphSet(
glyphSubFS,
glyphNameToFileNameFunc=glyphNameToFileNameFunc,
ufoFormatVersion=3,
validateRead=validateRead,
validateWrite=validateWrite,
)
def renameGlyphSet(self, layerName, newLayerName, defaultLayer=False):
"""
Rename a glyph set.
Note: if a GlyphSet object has already been retrieved for
layerName, it is up to the caller to inform that object that
the directory it represents has changed.
"""
if self._formatVersion < 3:
# ignore renaming glyph sets for UFO1 UFO2
# just write the data from the default layer
return
# the new and old names can be the same
# as long as the default is being switched
if layerName == newLayerName:
# if the default is off and the layer is already not the default, skip
if self.layerContents[layerName] != DEFAULT_GLYPHS_DIRNAME and not defaultLayer:
return
# if the default is on and the layer is already the default, skip
if self.layerContents[layerName] == DEFAULT_GLYPHS_DIRNAME and defaultLayer:
return
else:
# make sure the new layer name doesn't already exist
if newLayerName is None:
newLayerName = DEFAULT_LAYER_NAME
if newLayerName in self.layerContents:
raise UFOLibError("A layer named %s already exists." % newLayerName)
# make sure the default layer doesn't already exist
if defaultLayer and DEFAULT_GLYPHS_DIRNAME in self.layerContents.values():
raise UFOLibError("A default layer already exists.")
# get the paths
oldDirectory = self._findDirectoryForLayerName(layerName)
if defaultLayer:
newDirectory = DEFAULT_GLYPHS_DIRNAME
else:
existing = {name.lower() for name in self.layerContents.values()}
newDirectory = userNameToFileName(newLayerName, existing=existing, prefix="glyphs.")
# update the internal mapping
del self.layerContents[layerName]
self.layerContents[newLayerName] = newDirectory
# do the file system copy
self.fs.movedir(oldDirectory, newDirectory, create=True)
def deleteGlyphSet(self, layerName):
"""
Remove the glyph set matching layerName.
"""
if self._formatVersion < 3:
# ignore deleting glyph sets for UFO1 UFO2 as there are no layers
# just write the data from the default layer
return
foundDirectory = self._findDirectoryForLayerName(layerName)
self.removePath(foundDirectory, removeEmptyParents=False)
del self.layerContents[layerName]
def writeData(self, fileName, data):
"""
Write data to fileName in the 'data' directory.
The data must be a bytes string.
"""
self.writeBytesToPath("%s/%s" % (DATA_DIRNAME, fsdecode(fileName)), data)
def removeData(self, fileName):
"""
Remove the file named fileName from the data directory.
"""
self.removePath("%s/%s" % (DATA_DIRNAME, fsdecode(fileName)))
# /images
def writeImage(self, fileName, data, validate=None):
"""
Write data to fileName in the images directory.
The data must be a valid PNG.
"""
if validate is None:
validate = self._validate
if self._formatVersion < 3:
raise UFOLibError("Images are not allowed in UFO %d." % self._formatVersion)
fileName = fsdecode(fileName)
if validate:
valid, error = pngValidator(data=data)
if not valid:
raise UFOLibError(error)
self.writeBytesToPath("%s/%s" % (IMAGES_DIRNAME, fileName), data)
def removeImage(self, fileName, validate=None): # XXX remove unused 'validate'?
"""
Remove the file named fileName from the
images directory.
"""
if self._formatVersion < 3:
raise UFOLibError("Images are not allowed in UFO %d." % self._formatVersion)
self.removePath("%s/%s" % (IMAGES_DIRNAME, fsdecode(fileName)))
def copyImageFromReader(self, reader, sourceFileName, destFileName, validate=None):
"""
Copy the sourceFileName in the provided UFOReader to destFileName
in this writer. This uses the most memory efficient method possible
for copying the data possible.
"""
if validate is None:
validate = self._validate
if self._formatVersion < 3:
raise UFOLibError("Images are not allowed in UFO %d." % self._formatVersion)
sourcePath = "%s/%s" % (IMAGES_DIRNAME, fsdecode(sourceFileName))
destPath = "%s/%s" % (IMAGES_DIRNAME, fsdecode(destFileName))
self.copyFromReader(reader, sourcePath, destPath)
def close(self):
if self._havePreviousFile and self._fileStructure is UFOFileStructure.ZIP:
# if we are updating an existing zip file, we can now compress the
# contents of the temporary filesystem in the destination path
rootDir = os.path.splitext(os.path.basename(self._path))[0] + ".ufo"
with fs.zipfs.ZipFS(self._path, write=True, encoding="utf-8") as destFS:
fs.copy.copy_fs(self.fs, destFS.makedir(rootDir))
super(UFOWriter, self).close()
# just an alias, makes it more explicit
UFOReaderWriter = UFOWriter
# ----------------
# Helper Functions
# ----------------
def _sniffFileStructure(ufo_path):
"""Return UFOFileStructure.ZIP if the UFO at path 'ufo_path' (basestring)
is a zip file, else return UFOFileStructure.PACKAGE if 'ufo_path' is a
directory.
Raise UFOLibError if it is a file with unknown structure, or if the path
does not exist.
"""
if zipfile.is_zipfile(ufo_path):
return UFOFileStructure.ZIP
elif os.path.isdir(ufo_path):
return UFOFileStructure.PACKAGE
elif os.path.isfile(ufo_path):
raise UFOLibError(
"The specified UFO does not have a known structure: '%s'" % ufo_path
)
else:
raise UFOLibError("No such file or directory: '%s'" % ufo_path)
def makeUFOPath(path):
"""
Return a .ufo pathname.
>>> makeUFOPath("directory/something.ext") == (
... os.path.join('directory', 'something.ufo'))
True
>>> makeUFOPath("directory/something.another.thing.ext") == (
... os.path.join('directory', 'something.another.thing.ufo'))
True
"""
dir, name = os.path.split(path)
name = ".".join([".".join(name.split(".")[:-1]), "ufo"])
return os.path.join(dir, name)
# ----------------------
# fontinfo.plist Support
# ----------------------
# Version Validators
# There is no version 1 validator and there shouldn't be.
# The version 1 spec was very loose and there were numerous
# cases of invalid values.
def validateFontInfoVersion2ValueForAttribute(attr, value):
"""
This performs very basic validation of the value for attribute
following the UFO 2 fontinfo.plist specification. The results
of this should not be interpretted as *correct* for the font
that they are part of. This merely indicates that the value
is of the proper type and, where the specification defines
a set range of possible values for an attribute, that the
value is in the accepted range.
"""
dataValidationDict = fontInfoAttributesVersion2ValueData[attr]
valueType = dataValidationDict.get("type")
validator = dataValidationDict.get("valueValidator")
valueOptions = dataValidationDict.get("valueOptions")
# have specific options for the validator
if valueOptions is not None:
isValidValue = validator(value, valueOptions)
# no specific options
else:
if validator == genericTypeValidator:
isValidValue = validator(value, valueType)
else:
isValidValue = validator(value)
return isValidValue
def validateInfoVersion2Data(infoData):
"""
This performs very basic validation of the value for infoData
following the UFO 2 fontinfo.plist specification. The results
of this should not be interpretted as *correct* for the font
that they are part of. This merely indicates that the values
are of the proper type and, where the specification defines
a set range of possible values for an attribute, that the
value is in the accepted range.
"""
validInfoData = {}
for attr, value in list(infoData.items()):
isValidValue = validateFontInfoVersion2ValueForAttribute(attr, value)
if not isValidValue:
raise UFOLibError("Invalid value for attribute %s (%s)." % (attr, repr(value)))
else:
validInfoData[attr] = value
return validInfoData
def validateFontInfoVersion3ValueForAttribute(attr, value):
"""
This performs very basic validation of the value for attribute
following the UFO 3 fontinfo.plist specification. The results
of this should not be interpretted as *correct* for the font
that they are part of. This merely indicates that the value
is of the proper type and, where the specification defines
a set range of possible values for an attribute, that the
value is in the accepted range.
"""
dataValidationDict = fontInfoAttributesVersion3ValueData[attr]
valueType = dataValidationDict.get("type")
validator = dataValidationDict.get("valueValidator")
valueOptions = dataValidationDict.get("valueOptions")
# have specific options for the validator
if valueOptions is not None:
isValidValue = validator(value, valueOptions)
# no specific options
else:
if validator == genericTypeValidator:
isValidValue = validator(value, valueType)
else:
isValidValue = validator(value)
return isValidValue
def validateInfoVersion3Data(infoData):
"""
This performs very basic validation of the value for infoData
following the UFO 3 fontinfo.plist specification. The results
of this should not be interpretted as *correct* for the font
that they are part of. This merely indicates that the values
are of the proper type and, where the specification defines
a set range of possible values for an attribute, that the
value is in the accepted range.
"""
validInfoData = {}
for attr, value in list(infoData.items()):
isValidValue = validateFontInfoVersion3ValueForAttribute(attr, value)
if not isValidValue:
raise UFOLibError("Invalid value for attribute %s (%s)." % (attr, repr(value)))
else:
validInfoData[attr] = value
return validInfoData
# Value Options
fontInfoOpenTypeHeadFlagsOptions = list(range(0, 15))
fontInfoOpenTypeOS2SelectionOptions = [1, 2, 3, 4, 7, 8, 9]
fontInfoOpenTypeOS2UnicodeRangesOptions = list(range(0, 128))
fontInfoOpenTypeOS2CodePageRangesOptions = list(range(0, 64))
fontInfoOpenTypeOS2TypeOptions = [0, 1, 2, 3, 8, 9]
# Version Attribute Definitions
# This defines the attributes, types and, in some
# cases the possible values, that can exist is
# fontinfo.plist.
fontInfoAttributesVersion1 = set([
"familyName",
"styleName",
"fullName",
"fontName",
"menuName",
"fontStyle",
"note",
"versionMajor",
"versionMinor",
"year",
"copyright",
"notice",
"trademark",
"license",
"licenseURL",
"createdBy",
"designer",
"designerURL",
"vendorURL",
"unitsPerEm",
"ascender",
"descender",
"capHeight",
"xHeight",
"defaultWidth",
"slantAngle",
"italicAngle",
"widthName",
"weightName",
"weightValue",
"fondName",
"otFamilyName",
"otStyleName",
"otMacName",
"msCharSet",
"fondID",
"uniqueID",
"ttVendor",
"ttUniqueID",
"ttVersion",
])
fontInfoAttributesVersion2ValueData = {
"familyName" : dict(type=basestring),
"styleName" : dict(type=basestring),
"styleMapFamilyName" : dict(type=basestring),
"styleMapStyleName" : dict(type=basestring, valueValidator=fontInfoStyleMapStyleNameValidator),
"versionMajor" : dict(type=int),
"versionMinor" : dict(type=int),
"year" : dict(type=int),
"copyright" : dict(type=basestring),
"trademark" : dict(type=basestring),
"unitsPerEm" : dict(type=(int, float)),
"descender" : dict(type=(int, float)),
"xHeight" : dict(type=(int, float)),
"capHeight" : dict(type=(int, float)),
"ascender" : dict(type=(int, float)),
"italicAngle" : dict(type=(float, int)),
"note" : dict(type=basestring),
"openTypeHeadCreated" : dict(type=basestring, valueValidator=fontInfoOpenTypeHeadCreatedValidator),
"openTypeHeadLowestRecPPEM" : dict(type=(int, float)),
"openTypeHeadFlags" : dict(type="integerList", valueValidator=genericIntListValidator, valueOptions=fontInfoOpenTypeHeadFlagsOptions),
"openTypeHheaAscender" : dict(type=(int, float)),
"openTypeHheaDescender" : dict(type=(int, float)),
"openTypeHheaLineGap" : dict(type=(int, float)),
"openTypeHheaCaretSlopeRise" : dict(type=int),
"openTypeHheaCaretSlopeRun" : dict(type=int),
"openTypeHheaCaretOffset" : dict(type=(int, float)),
"openTypeNameDesigner" : dict(type=basestring),
"openTypeNameDesignerURL" : dict(type=basestring),
"openTypeNameManufacturer" : dict(type=basestring),
"openTypeNameManufacturerURL" : dict(type=basestring),
"openTypeNameLicense" : dict(type=basestring),
"openTypeNameLicenseURL" : dict(type=basestring),
"openTypeNameVersion" : dict(type=basestring),
"openTypeNameUniqueID" : dict(type=basestring),
"openTypeNameDescription" : dict(type=basestring),
"openTypeNamePreferredFamilyName" : dict(type=basestring),
"openTypeNamePreferredSubfamilyName" : dict(type=basestring),
"openTypeNameCompatibleFullName" : dict(type=basestring),
"openTypeNameSampleText" : dict(type=basestring),
"openTypeNameWWSFamilyName" : dict(type=basestring),
"openTypeNameWWSSubfamilyName" : dict(type=basestring),
"openTypeOS2WidthClass" : dict(type=int, valueValidator=fontInfoOpenTypeOS2WidthClassValidator),
"openTypeOS2WeightClass" : dict(type=int, valueValidator=fontInfoOpenTypeOS2WeightClassValidator),
"openTypeOS2Selection" : dict(type="integerList", valueValidator=genericIntListValidator, valueOptions=fontInfoOpenTypeOS2SelectionOptions),
"openTypeOS2VendorID" : dict(type=basestring),
"openTypeOS2Panose" : dict(type="integerList", valueValidator=fontInfoVersion2OpenTypeOS2PanoseValidator),
"openTypeOS2FamilyClass" : dict(type="integerList", valueValidator=fontInfoOpenTypeOS2FamilyClassValidator),
"openTypeOS2UnicodeRanges" : dict(type="integerList", valueValidator=genericIntListValidator, valueOptions=fontInfoOpenTypeOS2UnicodeRangesOptions),
"openTypeOS2CodePageRanges" : dict(type="integerList", valueValidator=genericIntListValidator, valueOptions=fontInfoOpenTypeOS2CodePageRangesOptions),
"openTypeOS2TypoAscender" : dict(type=(int, float)),
"openTypeOS2TypoDescender" : dict(type=(int, float)),
"openTypeOS2TypoLineGap" : dict(type=(int, float)),
"openTypeOS2WinAscent" : dict(type=(int, float)),
"openTypeOS2WinDescent" : dict(type=(int, float)),
"openTypeOS2Type" : dict(type="integerList", valueValidator=genericIntListValidator, valueOptions=fontInfoOpenTypeOS2TypeOptions),
"openTypeOS2SubscriptXSize" : dict(type=(int, float)),
"openTypeOS2SubscriptYSize" : dict(type=(int, float)),
"openTypeOS2SubscriptXOffset" : dict(type=(int, float)),
"openTypeOS2SubscriptYOffset" : dict(type=(int, float)),
"openTypeOS2SuperscriptXSize" : dict(type=(int, float)),
"openTypeOS2SuperscriptYSize" : dict(type=(int, float)),
"openTypeOS2SuperscriptXOffset" : dict(type=(int, float)),
"openTypeOS2SuperscriptYOffset" : dict(type=(int, float)),
"openTypeOS2StrikeoutSize" : dict(type=(int, float)),
"openTypeOS2StrikeoutPosition" : dict(type=(int, float)),
"openTypeVheaVertTypoAscender" : dict(type=(int, float)),
"openTypeVheaVertTypoDescender" : dict(type=(int, float)),
"openTypeVheaVertTypoLineGap" : dict(type=(int, float)),
"openTypeVheaCaretSlopeRise" : dict(type=int),
"openTypeVheaCaretSlopeRun" : dict(type=int),
"openTypeVheaCaretOffset" : dict(type=(int, float)),
"postscriptFontName" : dict(type=basestring),
"postscriptFullName" : dict(type=basestring),
"postscriptSlantAngle" : dict(type=(float, int)),
"postscriptUniqueID" : dict(type=int),
"postscriptUnderlineThickness" : dict(type=(int, float)),
"postscriptUnderlinePosition" : dict(type=(int, float)),
"postscriptIsFixedPitch" : dict(type=bool),
"postscriptBlueValues" : dict(type="integerList", valueValidator=fontInfoPostscriptBluesValidator),
"postscriptOtherBlues" : dict(type="integerList", valueValidator=fontInfoPostscriptOtherBluesValidator),
"postscriptFamilyBlues" : dict(type="integerList", valueValidator=fontInfoPostscriptBluesValidator),
"postscriptFamilyOtherBlues" : dict(type="integerList", valueValidator=fontInfoPostscriptOtherBluesValidator),
"postscriptStemSnapH" : dict(type="integerList", valueValidator=fontInfoPostscriptStemsValidator),
"postscriptStemSnapV" : dict(type="integerList", valueValidator=fontInfoPostscriptStemsValidator),
"postscriptBlueFuzz" : dict(type=(int, float)),
"postscriptBlueShift" : dict(type=(int, float)),
"postscriptBlueScale" : dict(type=(float, int)),
"postscriptForceBold" : dict(type=bool),
"postscriptDefaultWidthX" : dict(type=(int, float)),
"postscriptNominalWidthX" : dict(type=(int, float)),
"postscriptWeightName" : dict(type=basestring),
"postscriptDefaultCharacter" : dict(type=basestring),
"postscriptWindowsCharacterSet" : dict(type=int, valueValidator=fontInfoPostscriptWindowsCharacterSetValidator),
"macintoshFONDFamilyID" : dict(type=int),
"macintoshFONDName" : dict(type=basestring),
}
fontInfoAttributesVersion2 = set(fontInfoAttributesVersion2ValueData.keys())
fontInfoAttributesVersion3ValueData = deepcopy(fontInfoAttributesVersion2ValueData)
fontInfoAttributesVersion3ValueData.update({
"versionMinor" : dict(type=int, valueValidator=genericNonNegativeIntValidator),
"unitsPerEm" : dict(type=(int, float), valueValidator=genericNonNegativeNumberValidator),
"openTypeHeadLowestRecPPEM" : dict(type=int, valueValidator=genericNonNegativeNumberValidator),
"openTypeHheaAscender" : dict(type=int),
"openTypeHheaDescender" : dict(type=int),
"openTypeHheaLineGap" : dict(type=int),
"openTypeHheaCaretOffset" : dict(type=int),
"openTypeOS2Panose" : dict(type="integerList", valueValidator=fontInfoVersion3OpenTypeOS2PanoseValidator),
"openTypeOS2TypoAscender" : dict(type=int),
"openTypeOS2TypoDescender" : dict(type=int),
"openTypeOS2TypoLineGap" : dict(type=int),
"openTypeOS2WinAscent" : dict(type=int, valueValidator=genericNonNegativeNumberValidator),
"openTypeOS2WinDescent" : dict(type=int, valueValidator=genericNonNegativeNumberValidator),
"openTypeOS2SubscriptXSize" : dict(type=int),
"openTypeOS2SubscriptYSize" : dict(type=int),
"openTypeOS2SubscriptXOffset" : dict(type=int),
"openTypeOS2SubscriptYOffset" : dict(type=int),
"openTypeOS2SuperscriptXSize" : dict(type=int),
"openTypeOS2SuperscriptYSize" : dict(type=int),
"openTypeOS2SuperscriptXOffset" : dict(type=int),
"openTypeOS2SuperscriptYOffset" : dict(type=int),
"openTypeOS2StrikeoutSize" : dict(type=int),
"openTypeOS2StrikeoutPosition" : dict(type=int),
"openTypeGaspRangeRecords" : dict(type="dictList", valueValidator=fontInfoOpenTypeGaspRangeRecordsValidator),
"openTypeNameRecords" : dict(type="dictList", valueValidator=fontInfoOpenTypeNameRecordsValidator),
"openTypeVheaVertTypoAscender" : dict(type=int),
"openTypeVheaVertTypoDescender" : dict(type=int),
"openTypeVheaVertTypoLineGap" : dict(type=int),
"openTypeVheaCaretOffset" : dict(type=int),
"woffMajorVersion" : dict(type=int, valueValidator=genericNonNegativeIntValidator),
"woffMinorVersion" : dict(type=int, valueValidator=genericNonNegativeIntValidator),
"woffMetadataUniqueID" : dict(type=dict, valueValidator=fontInfoWOFFMetadataUniqueIDValidator),
"woffMetadataVendor" : dict(type=dict, valueValidator=fontInfoWOFFMetadataVendorValidator),
"woffMetadataCredits" : dict(type=dict, valueValidator=fontInfoWOFFMetadataCreditsValidator),
"woffMetadataDescription" : dict(type=dict, valueValidator=fontInfoWOFFMetadataDescriptionValidator),
"woffMetadataLicense" : dict(type=dict, valueValidator=fontInfoWOFFMetadataLicenseValidator),
"woffMetadataCopyright" : dict(type=dict, valueValidator=fontInfoWOFFMetadataCopyrightValidator),
"woffMetadataTrademark" : dict(type=dict, valueValidator=fontInfoWOFFMetadataTrademarkValidator),
"woffMetadataLicensee" : dict(type=dict, valueValidator=fontInfoWOFFMetadataLicenseeValidator),
"woffMetadataExtensions" : dict(type=list, valueValidator=fontInfoWOFFMetadataExtensionsValidator),
"guidelines" : dict(type=list, valueValidator=guidelinesValidator)
})
fontInfoAttributesVersion3 = set(fontInfoAttributesVersion3ValueData.keys())
# insert the type validator for all attrs that
# have no defined validator.
for attr, dataDict in list(fontInfoAttributesVersion2ValueData.items()):
if "valueValidator" not in dataDict:
dataDict["valueValidator"] = genericTypeValidator
for attr, dataDict in list(fontInfoAttributesVersion3ValueData.items()):
if "valueValidator" not in dataDict:
dataDict["valueValidator"] = genericTypeValidator
# Version Conversion Support
# These are used from converting from version 1
# to version 2 or vice-versa.
def _flipDict(d):
flipped = {}
for key, value in list(d.items()):
flipped[value] = key
return flipped
fontInfoAttributesVersion1To2 = {
"menuName" : "styleMapFamilyName",
"designer" : "openTypeNameDesigner",
"designerURL" : "openTypeNameDesignerURL",
"createdBy" : "openTypeNameManufacturer",
"vendorURL" : "openTypeNameManufacturerURL",
"license" : "openTypeNameLicense",
"licenseURL" : "openTypeNameLicenseURL",
"ttVersion" : "openTypeNameVersion",
"ttUniqueID" : "openTypeNameUniqueID",
"notice" : "openTypeNameDescription",
"otFamilyName" : "openTypeNamePreferredFamilyName",
"otStyleName" : "openTypeNamePreferredSubfamilyName",
"otMacName" : "openTypeNameCompatibleFullName",
"weightName" : "postscriptWeightName",
"weightValue" : "openTypeOS2WeightClass",
"ttVendor" : "openTypeOS2VendorID",
"uniqueID" : "postscriptUniqueID",
"fontName" : "postscriptFontName",
"fondID" : "macintoshFONDFamilyID",
"fondName" : "macintoshFONDName",
"defaultWidth" : "postscriptDefaultWidthX",
"slantAngle" : "postscriptSlantAngle",
"fullName" : "postscriptFullName",
# require special value conversion
"fontStyle" : "styleMapStyleName",
"widthName" : "openTypeOS2WidthClass",
"msCharSet" : "postscriptWindowsCharacterSet"
}
fontInfoAttributesVersion2To1 = _flipDict(fontInfoAttributesVersion1To2)
deprecatedFontInfoAttributesVersion2 = set(fontInfoAttributesVersion1To2.keys())
_fontStyle1To2 = {
64 : "regular",
1 : "italic",
32 : "bold",
33 : "bold italic"
}
_fontStyle2To1 = _flipDict(_fontStyle1To2)
# Some UFO 1 files have 0
_fontStyle1To2[0] = "regular"
_widthName1To2 = {
"Ultra-condensed" : 1,
"Extra-condensed" : 2,
"Condensed" : 3,
"Semi-condensed" : 4,
"Medium (normal)" : 5,
"Semi-expanded" : 6,
"Expanded" : 7,
"Extra-expanded" : 8,
"Ultra-expanded" : 9
}
_widthName2To1 = _flipDict(_widthName1To2)
# FontLab's default width value is "Normal".
# Many format version 1 UFOs will have this.
_widthName1To2["Normal"] = 5
# FontLab has an "All" width value. In UFO 1
# move this up to "Normal".
_widthName1To2["All"] = 5
# "medium" appears in a lot of UFO 1 files.
_widthName1To2["medium"] = 5
# "Medium" appears in a lot of UFO 1 files.
_widthName1To2["Medium"] = 5
_msCharSet1To2 = {
0 : 1,
1 : 2,
2 : 3,
77 : 4,
128 : 5,
129 : 6,
130 : 7,
134 : 8,
136 : 9,
161 : 10,
162 : 11,
163 : 12,
177 : 13,
178 : 14,
186 : 15,
200 : 16,
204 : 17,
222 : 18,
238 : 19,
255 : 20
}
_msCharSet2To1 = _flipDict(_msCharSet1To2)
# 1 <-> 2
def convertFontInfoValueForAttributeFromVersion1ToVersion2(attr, value):
"""
Convert value from version 1 to version 2 format.
Returns the new attribute name and the converted value.
If the value is None, None will be returned for the new value.
"""
# convert floats to ints if possible
if isinstance(value, float):
if int(value) == value:
value = int(value)
if value is not None:
if attr == "fontStyle":
v = _fontStyle1To2.get(value)
if v is None:
raise UFOLibError("Cannot convert value (%s) for attribute %s." % (repr(value), attr))
value = v
elif attr == "widthName":
v = _widthName1To2.get(value)
if v is None:
raise UFOLibError("Cannot convert value (%s) for attribute %s." % (repr(value), attr))
value = v
elif attr == "msCharSet":
v = _msCharSet1To2.get(value)
if v is None:
raise UFOLibError("Cannot convert value (%s) for attribute %s." % (repr(value), attr))
value = v
attr = fontInfoAttributesVersion1To2.get(attr, attr)
return attr, value
def convertFontInfoValueForAttributeFromVersion2ToVersion1(attr, value):
"""
Convert value from version 2 to version 1 format.
Returns the new attribute name and the converted value.
If the value is None, None will be returned for the new value.
"""
if value is not None:
if attr == "styleMapStyleName":
value = _fontStyle2To1.get(value)
elif attr == "openTypeOS2WidthClass":
value = _widthName2To1.get(value)
elif attr == "postscriptWindowsCharacterSet":
value = _msCharSet2To1.get(value)
attr = fontInfoAttributesVersion2To1.get(attr, attr)
return attr, value
def _convertFontInfoDataVersion1ToVersion2(data):
converted = {}
for attr, value in list(data.items()):
# FontLab gives -1 for the weightValue
# for fonts wil no defined value. Many
# format version 1 UFOs will have this.
if attr == "weightValue" and value == -1:
continue
newAttr, newValue = convertFontInfoValueForAttributeFromVersion1ToVersion2(attr, value)
# skip if the attribute is not part of version 2
if newAttr not in fontInfoAttributesVersion2:
continue
# catch values that can't be converted
if value is None:
raise UFOLibError("Cannot convert value (%s) for attribute %s." % (repr(value), newAttr))
# store
converted[newAttr] = newValue
return converted
def _convertFontInfoDataVersion2ToVersion1(data):
converted = {}
for attr, value in list(data.items()):
newAttr, newValue = convertFontInfoValueForAttributeFromVersion2ToVersion1(attr, value)
# only take attributes that are registered for version 1
if newAttr not in fontInfoAttributesVersion1:
continue
# catch values that can't be converted
if value is None:
raise UFOLibError("Cannot convert value (%s) for attribute %s." % (repr(value), newAttr))
# store
converted[newAttr] = newValue
return converted
# 2 <-> 3
_ufo2To3NonNegativeInt = set((
"versionMinor",
"openTypeHeadLowestRecPPEM",
"openTypeOS2WinAscent",
"openTypeOS2WinDescent"
))
_ufo2To3NonNegativeIntOrFloat = set((
"unitsPerEm"
))
_ufo2To3FloatToInt = set(((
"openTypeHeadLowestRecPPEM",
"openTypeHheaAscender",
"openTypeHheaDescender",
"openTypeHheaLineGap",
"openTypeHheaCaretOffset",
"openTypeOS2TypoAscender",
"openTypeOS2TypoDescender",
"openTypeOS2TypoLineGap",
"openTypeOS2WinAscent",
"openTypeOS2WinDescent",
"openTypeOS2SubscriptXSize",
"openTypeOS2SubscriptYSize",
"openTypeOS2SubscriptXOffset",
"openTypeOS2SubscriptYOffset",
"openTypeOS2SuperscriptXSize",
"openTypeOS2SuperscriptYSize",
"openTypeOS2SuperscriptXOffset",
"openTypeOS2SuperscriptYOffset",
"openTypeOS2StrikeoutSize",
"openTypeOS2StrikeoutPosition",
"openTypeVheaVertTypoAscender",
"openTypeVheaVertTypoDescender",
"openTypeVheaVertTypoLineGap",
"openTypeVheaCaretOffset"
)))
def convertFontInfoValueForAttributeFromVersion2ToVersion3(attr, value):
"""
Convert value from version 2 to version 3 format.
Returns the new attribute name and the converted value.
If the value is None, None will be returned for the new value.
"""
if attr in _ufo2To3FloatToInt:
try:
v = int(round(value))
except (ValueError, TypeError):
raise UFOLibError("Could not convert value for %s." % attr)
if v != value:
value = v
if attr in _ufo2To3NonNegativeInt:
try:
v = int(abs(value))
except (ValueError, TypeError):
raise UFOLibError("Could not convert value for %s." % attr)
if v != value:
value = v
elif attr in _ufo2To3NonNegativeIntOrFloat:
try:
v = float(abs(value))
except (ValueError, TypeError):
raise UFOLibError("Could not convert value for %s." % attr)
if v == int(v):
v = int(v)
if v != value:
value = v
return attr, value
def convertFontInfoValueForAttributeFromVersion3ToVersion2(attr, value):
"""
Convert value from version 3 to version 2 format.
Returns the new attribute name and the converted value.
If the value is None, None will be returned for the new value.
"""
return attr, value
def _convertFontInfoDataVersion3ToVersion2(data):
converted = {}
for attr, value in list(data.items()):
newAttr, newValue = convertFontInfoValueForAttributeFromVersion3ToVersion2(attr, value)
if newAttr not in fontInfoAttributesVersion2:
continue
converted[newAttr] = newValue
return converted
def _convertFontInfoDataVersion2ToVersion3(data):
converted = {}
for attr, value in list(data.items()):
attr, value = convertFontInfoValueForAttributeFromVersion2ToVersion3(attr, value)
converted[attr] = value
return converted
if __name__ == "__main__":
import doctest
doctest.testmod()
| 34.851315 | 193 | 0.733032 |
4a1fa94cecbc7a9a7f261cd1aa95ce7b0ee5507f | 541 | py | Python | eyed/api/common/response.py | ThousandMileEye/Eye | b0eca371fed5e01353ebddf7e4c400927decf0d2 | [
"Apache-2.0"
] | null | null | null | eyed/api/common/response.py | ThousandMileEye/Eye | b0eca371fed5e01353ebddf7e4c400927decf0d2 | [
"Apache-2.0"
] | 55 | 2017-12-21T15:20:36.000Z | 2019-01-20T02:49:41.000Z | eyed/api/common/response.py | ThousandMileEye/Eye | b0eca371fed5e01353ebddf7e4c400927decf0d2 | [
"Apache-2.0"
] | 3 | 2018-05-18T09:02:36.000Z | 2019-12-29T10:27:44.000Z | #!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyramid.httpexceptions import HTTPFound, HTTPOk
from pyramid.httpexceptions import HTTPNotFound, HTTPBadRequest, HTTPRequestTimeout
#
# リクエスト成功時の処理
#
def OK(value = None):
return HTTPOk(json_body = {
'ok' : True,
'data' : value,
}, headers = [{
'Access-Control-Allow-Origin', '*'
}])
#
# リクエスト失敗時の処理
#
def Error(message):
return HTTPBadRequest(json_body = {
'ok' : False,
'error' : {
'message' : message
}
}, headers = [{
'Access-Control-Allow-Origin', '*'
}])
| 18.033333 | 83 | 0.64695 |
4a1fa9d9058e6215fc09c3c55b9ba8a19b4a5058 | 172 | py | Python | qlib/rl/utils/__init__.py | SunsetWolf/qlib | 89972f6c6f9fa629b4f74093d4ba1e93c9f7a5e5 | [
"MIT"
] | 1 | 2021-12-14T13:48:38.000Z | 2021-12-14T13:48:38.000Z | qlib/rl/utils/__init__.py | SunsetWolf/qlib | 89972f6c6f9fa629b4f74093d4ba1e93c9f7a5e5 | [
"MIT"
] | null | null | null | qlib/rl/utils/__init__.py | SunsetWolf/qlib | 89972f6c6f9fa629b4f74093d4ba1e93c9f7a5e5 | [
"MIT"
] | null | null | null | # Copyright (c) Microsoft Corporation.
# Licensed under the MIT License.
from .data_queue import *
from .env_wrapper import *
from .finite_env import *
from .log import *
| 21.5 | 38 | 0.755814 |
4a1fa9e9d69e139cc63a7a6370a2bd0c36650de2 | 4,859 | py | Python | hrp/researches/urls.py | ken-mathenge/health_research_portal | e7e5ac8109c002a2d666c27ad076bbe040e00e5f | [
"MIT"
] | 1 | 2020-01-21T10:27:35.000Z | 2020-01-21T10:27:35.000Z | hrp/researches/urls.py | ken-mathenge/health_research_portal | e7e5ac8109c002a2d666c27ad076bbe040e00e5f | [
"MIT"
] | 13 | 2020-03-23T09:25:15.000Z | 2020-07-14T12:41:14.000Z | hrp/researches/urls.py | KennethMathenge/health_research_portal | e7e5ac8109c002a2d666c27ad076bbe040e00e5f | [
"MIT"
] | null | null | null | """Researches app urls."""
from django.urls import path
from . import views
app_name = "researches"
urlpatterns = [
path(
"",
views.Index.as_view(),
name="index",
),
path("signup/", views.SignUp.as_view(), name="signup"),
path(
"discussions/<int:pk>",
views.DiscussionCreateView.as_view(),
name="discussions",
),
path(
"discussions/replies_to_discussions/<int:pk>",
views.DiscussionReplyCreateView.as_view(),
name="replies_to_discussions",
),
path(
"recommend/<int:pk>/",
views.RecommendsRedirectView.as_view(),
name="recommends",
),
path(
"my_recommends/",
views.ReccomendedReasearchListView.as_view(),
name="my_recommends",
),
path(
"<int:pk>/", views.ResearchDetailView.as_view(), name="research-detail"
),
path(
"reviews/<int:pk>",
views.ReviewCreateView.as_view(),
name="reviews",
),
path(
"search/",
views.Search.as_view(),
name="search",
),
path(
"cancer/",
views.CancerTemplateView.as_view(),
name="cancer",
),
path(
"cancer/diagnosis/",
views.CancerDiagnosisListView.as_view(),
name="cancer_diagnosis",
),
path(
"cancer/treatment/",
views.CancerTreatmentListView.as_view(),
name="cancer_treatment",
),
path(
"cancer/location/",
views.CancerLocationListView.as_view(),
name="cancer_location",
),
path(
"malaria/",
views.MalariaTemplateView.as_view(),
name="malaria",
),
path(
"malaria/diagnosis/",
views.MalariaDiagnosisListView.as_view(),
name="malaria_diagnosis",
),
path(
"malaria/treatment/",
views.MalariaTreatmentListView.as_view(),
name="malaria_treatment",
),
path(
"malaria/location/",
views.MalariaLocationListView.as_view(),
name="malaria_location",
),
path(
"cholera/",
views.CholeraTemplateView.as_view(),
name="cholera",
),
path(
"cholera/treatment/",
views.CholeraTreatmentListView.as_view(),
name="cholera_treatment",
),
path(
"cholera/diagnosis/",
views.CholeraDiagnosisListView.as_view(),
name="cholera_diagnosis",
),
path(
"cholera/county/",
views.CholeraLocationListView.as_view(),
name="cholera_county",
),
path(
"typhoid/",
views.TyphoidTemplateView.as_view(),
name="typhoid",
),
path(
"typhoid/treatment/",
views.TyphoidTreatmentListView.as_view(),
name="typhoid_treatment",
),
path(
"typhoid/location/",
views.TyphoidLocationListView.as_view(),
name="typhoid_location",
),
path(
"TB/",
views.TBTemplateView.as_view(),
name="TB",
),
path(
"TB/treatment/",
views.TBTreatmentListView.as_view(),
name="TB_treatment",
),
path(
"TB/diagnosis/",
views.TBDiagnosisListView.as_view(),
name="TB_diagnosis",
),
path(
"TB/county-based/",
views.TBCountyListView.as_view(),
name="TB_county",
),
path(
"measles/",
views.MeaslesTemplateView.as_view(),
name="measles",
),
path(
"measles/location/",
views.MeaslesLocationListView.as_view(),
name="measles_location",
),
path(
"diabetes/",
views.DiabetesTemplateView.as_view(),
name="diabetes",
),
path(
"diabetes/diagnosis/",
views.DiabetesDiagnosisListView.as_view(),
name="diabetes_diagnosis",
),
path(
"diabetes/treatment/",
views.DiabetesTreatmentListView.as_view(),
name="diabetes_treatment",
),
path(
"pneumonia/",
views.PneumoniaTemplateView.as_view(),
name="pneumonia",
),
path(
"pneumonia/diagnosis/",
views.PneumoniaDiagnosisListView.as_view(),
name="pneumonia_diagnosis",
),
path(
"malnutrition/",
views.MalnutritionTemplateView.as_view(),
name="malnutrition",
),
path(
"malnutrition/treatment/",
views.MalnutritionTreatmentListView.as_view(),
name="malnutrition_treatment",
),
path(
"malnutrition/location/",
views.MalnutritionLocationListView.as_view(),
name="malnutrition_location",
),
path(
"covid-19/information/",
views.Covid19TemplateView.as_view(),
name="covid-19",
),
path(
"covid/",
views.CovidTemplateView.as_view(),
name="covid",
),
]
| 23.935961 | 79 | 0.557934 |
4a1fac5f696af66179a02751793cc524817901cd | 14,129 | py | Python | markdown/preprocessors.py | jackoalan/Python-Markdown | 77d4150614f39de82d5a63fa47fa15f87e44cb13 | [
"BSD-3-Clause"
] | 1 | 2018-07-15T14:50:44.000Z | 2018-07-15T14:50:44.000Z | pythonlib/markdown/preprocessors.py | Jumpscale/web | 8e8ec2ce01f3105c7647ee8a0c90af09311cbbeb | [
"Apache-2.0"
] | null | null | null | pythonlib/markdown/preprocessors.py | Jumpscale/web | 8e8ec2ce01f3105c7647ee8a0c90af09311cbbeb | [
"Apache-2.0"
] | 3 | 2018-10-29T07:39:49.000Z | 2021-07-16T17:45:34.000Z | """
PRE-PROCESSORS
=============================================================================
Preprocessors work on source text before we start doing anything too
complicated.
"""
from __future__ import absolute_import
from __future__ import unicode_literals
from . import util
from . import odict
import re
def build_preprocessors(md_instance, **kwargs):
""" Build the default set of preprocessors used by Markdown. """
preprocessors = odict.OrderedDict()
preprocessors['normalize_whitespace'] = NormalizeWhitespace(md_instance)
if md_instance.safeMode != 'escape':
preprocessors["html_block"] = HtmlBlockPreprocessor(md_instance)
preprocessors["reference"] = ReferencePreprocessor(md_instance)
return preprocessors
class Preprocessor(util.Processor):
"""
Preprocessors are run after the text is broken into lines.
Each preprocessor implements a "run" method that takes a pointer to a
list of lines of the document, modifies it as necessary and returns
either the same pointer or a pointer to a new list.
Preprocessors must extend markdown.Preprocessor.
"""
def run(self, lines):
"""
Each subclass of Preprocessor should override the `run` method, which
takes the document as a list of strings split by newlines and returns
the (possibly modified) list of lines.
"""
pass #pragma: no cover
class NormalizeWhitespace(Preprocessor):
""" Normalize whitespace for consistant parsing. """
def run(self, lines):
source = '\n'.join(lines)
source = source.replace(util.STX, "").replace(util.ETX, "")
source = source.replace("\r\n", "\n").replace("\r", "\n") + "\n\n"
source = source.expandtabs(self.markdown.tab_length)
source = re.sub(r'(?<=\n) +\n', '\n', source)
return source.split('\n')
class HtmlBlockPreprocessor(Preprocessor):
"""Remove html blocks from the text and store them for later retrieval."""
right_tag_patterns = ["</%s>", "%s>"]
attrs_pattern = r"""
\s+(?P<attr>[^>"'/= ]+)=(?P<q>['"])(?P<value>.*?)(?P=q) # attr="value"
| # OR
\s+(?P<attr1>[^>"'/= ]+)=(?P<value1>[^> ]+) # attr=value
| # OR
\s+(?P<attr2>[^>"'/= ]+) # attr
"""
left_tag_pattern = r'^\<(?P<tag>[^> ]+)(?P<attrs>(%s)*)\s*\/?\>?' % attrs_pattern
attrs_re = re.compile(attrs_pattern, re.VERBOSE)
left_tag_re = re.compile(left_tag_pattern, re.VERBOSE)
markdown_in_raw = False
def _get_left_tag(self, block):
m = self.left_tag_re.match(block)
if m:
tag = m.group('tag')
raw_attrs = m.group('attrs')
attrs = {}
if raw_attrs:
for ma in self.attrs_re.finditer(raw_attrs):
if ma.group('attr'):
if ma.group('value'):
attrs[ma.group('attr').strip()] = ma.group('value')
else:
attrs[ma.group('attr').strip()] = ""
elif ma.group('attr1'):
if ma.group('value1'):
attrs[ma.group('attr1').strip()] = ma.group('value1')
else:
attrs[ma.group('attr1').strip()] = ""
elif ma.group('attr2'):
attrs[ma.group('attr2').strip()] = ""
return tag, len(m.group(0)), attrs
else:
tag = block[1:].split(">", 1)[0].lower()
return tag, len(tag)+2, {}
def _recursive_tagfind(self, ltag, rtag, start_index, block):
while 1:
i = block.find(rtag, start_index)
if i == -1:
return -1
j = block.find(ltag, start_index)
# if no ltag, or rtag found before another ltag, return index
if (j > i or j == -1):
return i + len(rtag)
# another ltag found before rtag, use end of ltag as starting
# point and search again
j = block.find('>', j)
start_index = self._recursive_tagfind(ltag, rtag, j + 1, block)
if start_index == -1:
# HTML potentially malformed- ltag has no corresponding
# rtag
return -1
def _get_right_tag(self, left_tag, left_index, block):
for p in self.right_tag_patterns:
tag = p % left_tag
i = self._recursive_tagfind("<%s" % left_tag, tag, left_index, block)
if i > 2:
return tag.lstrip("<").rstrip(">"), i
return block.rstrip()[-left_index:-1].lower(), len(block)
def _equal_tags(self, left_tag, right_tag):
if left_tag[0] in ['?', '@', '%']: # handle PHP, etc.
return True
if ("/" + left_tag) == right_tag:
return True
if (right_tag == "--" and left_tag == "--"):
return True
elif left_tag == right_tag[1:] \
and right_tag[0] == "/":
return True
else:
return False
def _is_oneliner(self, tag):
return (tag in ['hr', 'hr/'])
def _stringindex_to_listindex(self, stringindex, items):
"""
Same effect as concatenating the strings in items,
finding the character to which stringindex refers in that string,
and returning the index of the item in which that character resides.
"""
items.append('dummy')
i, count = 0, 0
while count <= stringindex:
count += len(items[i])
i += 1
return i - 1
def _nested_markdown_in_html(self, items):
"""Find and process html child elements of the given element block."""
for i, item in enumerate(items):
if self.left_tag_re.match(item):
left_tag, left_index, attrs = \
self._get_left_tag(''.join(items[i:]))
right_tag, data_index = self._get_right_tag(
left_tag, left_index, ''.join(items[i:]))
right_listindex = \
self._stringindex_to_listindex(data_index, items[i:]) + i
if 'markdown' in attrs.keys():
items[i] = items[i][left_index:] # remove opening tag
placeholder = self.markdown.htmlStash.store_tag(
left_tag, attrs, i + 1, right_listindex + 1)
items.insert(i, placeholder)
if len(items) - right_listindex <= 1: # last nest, no tail
right_listindex -= 1
items[right_listindex] = items[right_listindex][
:-len(right_tag) - 2] # remove closing tag
else: # raw html
if len(items) - right_listindex <= 1: # last element
right_listindex -= 1
placeholder = self.markdown.htmlStash.store('\n\n'.join(
items[i:right_listindex + 1]))
del items[i:right_listindex + 1]
items.insert(i, placeholder)
return items
def run(self, lines):
text = "\n".join(lines)
new_blocks = []
text = text.rsplit("\n\n")
items = []
left_tag = ''
right_tag = ''
in_tag = False # flag
while text:
block = text[0]
if block.startswith("\n"):
block = block[1:]
text = text[1:]
if block.startswith("\n"):
block = block[1:]
if not in_tag:
if block.startswith("<") and len(block.strip()) > 1:
if block[1:4] == "!--":
# is a comment block
left_tag, left_index, attrs = "--", 2, {}
else:
left_tag, left_index, attrs = self._get_left_tag(block)
right_tag, data_index = self._get_right_tag(left_tag,
left_index,
block)
# keep checking conditions below and maybe just append
if data_index < len(block) \
and (util.isBlockLevel(left_tag)
or left_tag == '--'):
text.insert(0, block[data_index:])
block = block[:data_index]
if not (util.isBlockLevel(left_tag) \
or block[1] in ["!", "?", "@", "%"]):
new_blocks.append(block)
continue
if self._is_oneliner(left_tag):
new_blocks.append(block.strip())
continue
if block.rstrip().endswith(">") \
and self._equal_tags(left_tag, right_tag):
if self.markdown_in_raw and 'markdown' in attrs.keys():
block = block[left_index:-len(right_tag) - 2]
new_blocks.append(self.markdown.htmlStash.
store_tag(left_tag, attrs, 0, 2))
new_blocks.extend([block])
else:
new_blocks.append(
self.markdown.htmlStash.store(block.strip()))
continue
else:
# if is block level tag and is not complete
if (not self._equal_tags(left_tag, right_tag)) and \
(util.isBlockLevel(left_tag) or left_tag == "--"):
items.append(block.strip())
in_tag = True
else:
new_blocks.append(
self.markdown.htmlStash.store(block.strip()))
continue
else:
new_blocks.append(block)
else:
items.append(block)
right_tag, data_index = self._get_right_tag(left_tag, 0, block)
if self._equal_tags(left_tag, right_tag):
# if find closing tag
if data_index < len(block):
# we have more text after right_tag
items[-1] = block[:data_index]
text.insert(0, block[data_index:])
in_tag = False
if self.markdown_in_raw and 'markdown' in attrs.keys():
items[0] = items[0][left_index:]
items[-1] = items[-1][:-len(right_tag) - 2]
if items[len(items) - 1]: # not a newline/empty string
right_index = len(items) + 3
else:
right_index = len(items) + 2
new_blocks.append(self.markdown.htmlStash.store_tag(
left_tag, attrs, 0, right_index))
placeholderslen = len(self.markdown.htmlStash.tag_data)
new_blocks.extend(
self._nested_markdown_in_html(items))
nests = len(self.markdown.htmlStash.tag_data) - \
placeholderslen
self.markdown.htmlStash.tag_data[-1 - nests][
'right_index'] += nests - 2
else:
new_blocks.append(
self.markdown.htmlStash.store('\n\n'.join(items)))
items = []
if items:
if self.markdown_in_raw and 'markdown' in attrs.keys():
items[0] = items[0][left_index:]
items[-1] = items[-1][:-len(right_tag) - 2]
if items[len(items) - 1]: # not a newline/empty string
right_index = len(items) + 3
else:
right_index = len(items) + 2
new_blocks.append(
self.markdown.htmlStash.store_tag(
left_tag, attrs, 0, right_index))
placeholderslen = len(self.markdown.htmlStash.tag_data)
new_blocks.extend(self._nested_markdown_in_html(items))
nests = len(self.markdown.htmlStash.tag_data) - placeholderslen
self.markdown.htmlStash.tag_data[-1 - nests][
'right_index'] += nests - 2
else:
new_blocks.append(
self.markdown.htmlStash.store('\n\n'.join(items)))
new_blocks.append('\n')
new_text = "\n\n".join(new_blocks)
return new_text.split("\n")
class ReferencePreprocessor(Preprocessor):
""" Remove reference definitions from text and store for later use. """
TITLE = r'[ ]*(\"(.*)\"|\'(.*)\'|\((.*)\))[ ]*'
RE = re.compile(r'^[ ]{0,3}\[([^\]]*)\]:\s*([^ ]*)[ ]*(%s)?$' % TITLE, re.DOTALL)
TITLE_RE = re.compile(r'^%s$' % TITLE)
def run (self, lines):
new_text = [];
while lines:
line = lines.pop(0)
m = self.RE.match(line)
if m:
id = m.group(1).strip().lower()
link = m.group(2).lstrip('<').rstrip('>')
t = m.group(5) or m.group(6) or m.group(7)
if not t:
# Check next line for title
tm = self.TITLE_RE.match(lines[0])
if tm:
lines.pop(0)
t = tm.group(2) or tm.group(3) or tm.group(4)
self.markdown.references[id] = (link, t)
else:
new_text.append(line)
return new_text #+ "\n"
| 41.312865 | 85 | 0.478378 |
4a1facb5926679b16c68f43b61f6cfa93af97cd3 | 529 | py | Python | mp_sort/virtenv/lib/python3.6/site-packages/transcrypt/development/automated_tests/transcrypt/tuple_assignment/__init__.py | ang-jason/fip_powerx_mini_projects-foxtrot | 37e3671969b516369e2d1c7cab5890b75c489f56 | [
"MIT"
] | 2,200 | 2016-10-12T16:47:13.000Z | 2022-03-30T16:40:35.000Z | mp_sort/virtenv/lib/python3.6/site-packages/transcrypt/development/automated_tests/transcrypt/tuple_assignment/__init__.py | ang-jason/fip_powerx_mini_projects-foxtrot | 37e3671969b516369e2d1c7cab5890b75c489f56 | [
"MIT"
] | 672 | 2016-10-12T16:36:48.000Z | 2022-03-25T00:57:04.000Z | mp_sort/virtenv/lib/python3.6/site-packages/transcrypt/development/automated_tests/transcrypt/tuple_assignment/__init__.py | ang-jason/fip_powerx_mini_projects-foxtrot | 37e3671969b516369e2d1c7cab5890b75c489f56 | [
"MIT"
] | 230 | 2016-10-20T14:31:40.000Z | 2022-03-16T15:57:15.000Z | def run (autoTester):
((a, b), santa, [c, d], e) = ((1, 2), 'santa-claus', {3, 4}, 5)
autoTester.check (a, b, c, d, e, santa)
for i, x in enumerate ((0.5, 1.5, 2.5, 3.5)):
autoTester.check (i, x)
e, pi = 3.14, 2.74
e, pi = pi, e
autoTester.check (e, pi)
def f ():
return [(i, 2 * i) for i in range (7000, 10000, 1000)]
def g ():
return f
[k, l], [m, n], (o, p) = g () ()
autoTester.check (k, l, m, n, o, p)
| 25.190476 | 68 | 0.408318 |
4a1fad368adb67392f8067b65679f12b09515251 | 1,400 | py | Python | zq/__init__.py | prakhar-zipha/py-service-sdk | dcef97e8080689071b6e1e9aecec654f0ec38562 | [
"MIT"
] | null | null | null | zq/__init__.py | prakhar-zipha/py-service-sdk | dcef97e8080689071b6e1e9aecec654f0ec38562 | [
"MIT"
] | null | null | null | zq/__init__.py | prakhar-zipha/py-service-sdk | dcef97e8080689071b6e1e9aecec654f0ec38562 | [
"MIT"
] | 2 | 2020-09-27T11:23:38.000Z | 2020-12-12T08:20:24.000Z | import yaml
import os
MAX_CONNECTIONS_COUNT = os.environ['MAX_CONNECTIONS_COUNT']
MIN_CONNECTIONS_COUNT = os.environ['MIN_CONNECTIONS_COUNT']
MONGO_HOST = os.environ['MONGO_HOST']
MONGO_PORT =os.environ['MONGO_PORT']
MONGO_USER = os.environ['MONGO_USER']
MONGO_PASS = os.environ['MONGO_PASS']
MONGO_DB= os.environ['MONGO_DB']
API_V1_STR = os.environ['API_V1_STR']
JWT_TOKEN_PREFIX = os.environ['JWT_TOKEN_PREFIX']
PROJECT_NAME = os.environ["PROJECT_NAME"]
ALLOWED_HOSTS = ["*"]
KAFKA_URL = os.environ["KAFKA_URL"]
REDIS_PORT = os.environ["REDIS_PORT"]
REDIS_HOST = os.environ["REDIS_HOST"]
# with open("config.yml", "r") as ymlfile:
# cfg = yaml.load(ymlfile)
# if cfg['db']:
# db = cfg['db']
# MAX_CONNECTIONS_COUNT = db['MAX_CONNECTIONS_COUNT']
# MIN_CONNECTIONS_COUNT = db['MIN_CONNECTIONS_COUNT']
# MONGO_HOST = db['MONGO_HOST']
# MONGO_PORT = db['MONGO_PORT']
# MONGO_USER = db['MONGO_USER']
# MONGO_PASS = db['MONGO_PASS']
# MONGO_DB = db['MONGO_DB']
# if cfg['project']:
# project = cfg['project']
# API_V1_STR = project['API_V1_STR']
# JWT_TOKEN_PREFIX = project['JWT_TOKEN_PREFIX']
# PROJECT_NAME = project["PROJECT_NAME"]
# ALLOWED_HOSTS = project["ALLOWED_HOSTS"]
# if cfg['kafka']:
# kafka = cfg['kafka']
# KAFKA_URL = kafka['KAFKA_URL']
# if cfg['redis']:
# redis = cfg['redis']
# REDIS_PORT=redis['REDIS_PORT']
# REDIS_HOST = redis['REDIS_HOST'] | 28.571429 | 59 | 0.709286 |
4a1fad517a24fd3108a3de9af13774a31ebffefa | 14,378 | py | Python | tests/test_io.py | arianpasquali/textacy | b08b1585237154b95e1dfb3e07e830eddb45d1a4 | [
"Apache-2.0"
] | null | null | null | tests/test_io.py | arianpasquali/textacy | b08b1585237154b95e1dfb3e07e830eddb45d1a4 | [
"Apache-2.0"
] | null | null | null | tests/test_io.py | arianpasquali/textacy | b08b1585237154b95e1dfb3e07e830eddb45d1a4 | [
"Apache-2.0"
] | null | null | null | # -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
import os
import numpy as np
import pytest
from scipy import sparse as sp
from textacy import cache, compat, io
TEXT = (
"The year was 2081, and everybody was finally equal. "
"They weren't only equal before God and the law. "
"They were equal every which way."
)
TESTS_DIR = os.path.split(__file__)[0]
@pytest.fixture(scope="module")
def spacy_doc():
spacy_lang = cache.load_spacy_lang("en")
spacy_doc = spacy_lang(TEXT)
return spacy_doc
class TestTextIO(object):
def test_read_write_bytes(self, tmpdir):
expected = compat.to_bytes(TEXT)
for ext in (".txt", ".gz", ".bz2", ".xz"):
filepath = str(tmpdir.join("test_read_write_file_bytes" + ext))
if compat.PY2 is True and ext == ".xz":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wb", encoding="utf-8", make_dirs=True)
else:
io.write_text(expected, filepath, mode="wb", make_dirs=True)
observed = next(io.read_text(filepath, mode="rb"))
assert observed == expected
def test_read_write_unicode(self, tmpdir):
expected = TEXT
for ext in (".txt", ".gz", ".bz2", ".xz"):
filepath = str(tmpdir.join("test_read_write_file_unicode" + ext))
if compat.PY2 is True and ext != ".txt":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wt", encoding="utf-8", make_dirs=True)
else:
io.write_text(expected, filepath, mode="wt", make_dirs=True)
observed = next(io.read_text(filepath, mode="rt"))
assert observed == expected
def test_read_write_bytes_lines(self, tmpdir, spacy_doc):
expected = [compat.to_bytes(sent.text) for sent in spacy_doc.sents]
for ext in (".txt", ".gz", ".bz2", ".xz"):
filepath = str(tmpdir.join("test_read_write_file_lines_bytes" + ext))
if compat.PY2 is True and ext == ".xz":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wb", encoding="utf-8", make_dirs=True)
else:
io.write_text(expected, filepath, mode="wb", make_dirs=True, lines=True)
observed = [
line.strip() for line in io.read_text(filepath, mode="rb", lines=True)
]
assert observed == expected
def test_read_write_unicode_lines(self, tmpdir, spacy_doc):
expected = [sent.text for sent in spacy_doc.sents]
for ext in (".txt", ".gz", ".bz2", ".xz"):
filepath = str(tmpdir.join("test_read_write_file_lines_unicode" + ext))
if compat.PY2 is True and ext != ".txt":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wt", encoding=None, make_dirs=True)
else:
io.write_text(expected, filepath, mode="wt", make_dirs=True, lines=True)
observed = [
line.strip() for line in io.read_text(filepath, mode="rt", lines=True)
]
assert observed == expected
class TestJSONIO(object):
def test_read_write_bytes(self, tmpdir, spacy_doc):
expected = [{"idx": i, "sent": sent.text} for i, sent in enumerate(spacy_doc.sents)]
for ext in (".json", ".json.gz", ".json.bz2", ".json.xz"):
filepath = str(tmpdir.join("test_read_write_json_bytes" + ext))
if compat.PY2 is True:
if ext == ".json.xz":
with pytest.raises(ValueError):
io.open_sesame(
filepath, mode="wb", encoding="utf-8", make_dirs=True
)
else:
io.write_json(expected, filepath, mode="wb", make_dirs=True)
observed = next(io.read_json(filepath, mode="rb", lines=False))
assert observed == expected
else:
with pytest.raises(TypeError):
io.write_json(expected, filepath, "wb", make_dirs=True)
def test_read_write_unicode(self, tmpdir, spacy_doc):
expected = [{"idx": i, "sent": sent.text} for i, sent in enumerate(spacy_doc.sents)]
for ext in (".json", ".json.gz", ".json.bz2", ".json.xz"):
filepath = str(tmpdir.join("test_read_write_json_unicode" + ext))
if compat.PY2 is True and ext != ".json":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wt", encoding=None, make_dirs=True)
else:
io.write_json(expected, filepath, mode="wt", make_dirs=True)
observed = next(io.read_json(filepath, mode="rt", lines=False))
assert observed == expected
def test_read_write_bytes_lines(self, tmpdir, spacy_doc):
expected = [{"idx": i, "sent": sent.text} for i, sent in enumerate(spacy_doc.sents)]
for ext in (".json", ".json.gz", ".json.bz2", ".json.xz"):
filepath = str(tmpdir.join("test_read_write_json_lines_bytes" + ext))
if compat.PY2 is True:
if ext == ".json.xz":
with pytest.raises(ValueError):
io.open_sesame(
filepath, mode="wb", encoding="utf-8", make_dirs=True
)
else:
io.write_json(expected, filepath, mode="wb", make_dirs=True, lines=True)
observed = list(io.read_json(filepath, mode="rb", lines=True))
assert observed == expected
else:
with pytest.raises(TypeError):
io.write_json(
expected,
filepath,
mode="wb",
encoding=None,
make_dirs=True,
lines=True,
)
def test_read_write_unicode_lines(self, tmpdir, spacy_doc):
expected = [{"idx": i, "sent": sent.text} for i, sent in enumerate(spacy_doc.sents)]
for ext in (".json", ".json.gz", ".json.bz2", ".json.xz"):
filepath = str(tmpdir.join("test_read_write_json_lines_unicode" + ext))
if compat.PY2 is True and ext != ".json":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wt", encoding=None, make_dirs=True)
else:
io.write_json(expected, filepath, mode="wt", make_dirs=True, lines=True)
observed = list(io.read_json(filepath, mode="rt", lines=True))
assert observed == expected
class TestCSVIO(object):
def test_read_write_compressed(self, tmpdir):
expected = [
["this is some text", "scandal", 42.0],
["here's some more text: boom!", "escándalo", 1.0],
]
for ext in (".csv", ".csv.gz", ".csv.bz2", ".csv.xz"):
filepath = str(tmpdir.join("test_read_write_csv" + ext))
if compat.PY2 is True and ext != ".csv":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wt", encoding=None, make_dirs=True)
else:
io.write_csv(expected, filepath, make_dirs=True)
observed = list(io.read_csv(filepath))
assert observed == expected
def test_read_write_delimiters(self, tmpdir):
expected = [
["this is some text", "scandal", 42.0],
["here's some more text: boom!", "escándalo", 1.0],
]
for delimiter in (",", "\t", "|", ":"):
filepath = str(tmpdir.join("test_read_write_csv.csv"))
io.write_csv(expected, filepath, delimiter=delimiter, make_dirs=True)
observed = list(io.read_csv(filepath, delimiter=delimiter))
assert observed == expected
def test_read_write_dialect(self, tmpdir):
expected = [
["this is some text", "scandal", 42.0],
["here's some more text: boom!", "escándalo", 1.0],
]
filepath = str(tmpdir.join("test_read_write_csv.csv"))
io.write_csv(expected, filepath, dialect="excel", make_dirs=True)
observed = list(io.read_csv(filepath, dialect="infer"))
assert observed == expected
def test_read_write_dict(self, tmpdir):
expected = [
{"text": "this is some text", "kind": "scandal", "number": 42.0},
{"text": "here's some more text: boom!", "kind": "escándalo", "number": 1.0},
]
filepath = str(tmpdir.join("test_read_write_csv_dict.csv"))
io.write_csv(
expected,
filepath,
dialect="excel",
make_dirs=True,
fieldnames=["text", "kind", "number"],
)
observed = [
dict(item)
for item in io.read_csv(
filepath, dialect="excel", fieldnames=["text", "kind", "number"]
)
]
assert observed == expected
class TestSpacyIO(object):
def test_read_write_docs(self, tmpdir, spacy_doc):
expected = [tok.lower_ for tok in spacy_doc]
for ext in (".pkl", ".pkl.gz", ".pkl.bz2", ".pkl.xz"):
filepath = str(tmpdir.join("test_read_write_spacy_docs" + ext))
if compat.PY2 is True and ext == ".pkl.xz":
with pytest.raises(ValueError):
io.open_sesame(filepath, mode="wb", encoding=None, make_dirs=True)
else:
io.write_spacy_docs(spacy_doc, filepath, True)
observed = [
tok.lower_ for doc in io.read_spacy_docs(filepath) for tok in doc
]
assert observed == expected
def test_read_write_docs_binary(self, tmpdir, spacy_doc):
expected = [tok.lower_ for tok in spacy_doc]
filepath = str(tmpdir.join("test_read_write_spacy_docs_binary.bin"))
io.write_spacy_docs(spacy_doc, filepath, True, format="binary")
with pytest.raises(ValueError):
next(io.read_spacy_docs(filepath, format="binary", lang=None))
observed = [
tok.lower_
for doc in io.read_spacy_docs(filepath, format="binary", lang="en")
for tok in doc
]
assert observed == expected
def test_read_write_docs_binary_exclude(self, tmpdir, spacy_doc):
expected = [tok.lower_ for tok in spacy_doc]
filepath = str(tmpdir.join("test_read_write_spacy_docs_binary_exclude.bin"))
io.write_spacy_docs(
spacy_doc, filepath, True,
format="binary", exclude=["sentiment", "user_data"],
)
observed = [
tok.lower_
for doc in io.read_spacy_docs(filepath, format="binary", lang="en")
for tok in doc
]
assert observed == expected
class TestMatrixIO(object):
def test_read_write_sparse_csr(self, tmpdir):
expected = sp.csr_matrix(
(
np.array([1, 2, 3, 4, 5, 6]),
(np.array([0, 0, 1, 2, 2, 2]), np.array([0, 2, 2, 0, 1, 2])),
),
shape=(3, 3),
)
filepath = str(tmpdir.join("test_read_write_sparse_matrix_csr.npz"))
io.write_sparse_matrix(expected, filepath, compressed=False)
observed = io.read_sparse_matrix(filepath, kind="csr")
assert abs(observed - expected).nnz == 0
def test_read_write_sparse_csr_compressed(self, tmpdir):
expected = sp.csr_matrix(
(
np.array([1, 2, 3, 4, 5, 6]),
(np.array([0, 0, 1, 2, 2, 2]), np.array([0, 2, 2, 0, 1, 2])),
),
shape=(3, 3),
)
filepath = str(tmpdir.join("test_read_write_sparse_matrix_csr_compressed.npz"))
io.write_sparse_matrix(expected, filepath, compressed=True)
observed = io.read_sparse_matrix(filepath, kind="csr")
assert abs(observed - expected).nnz == 0
def test_read_write_sparse_csc(self, tmpdir):
expected = sp.csc_matrix(
(
np.array([1, 2, 3, 4, 5, 6]),
(np.array([0, 0, 1, 2, 2, 2]), np.array([0, 2, 2, 0, 1, 2])),
),
shape=(3, 3),
)
filepath = str(tmpdir.join("test_read_write_sparse_matrix_csc.npz"))
io.write_sparse_matrix(expected, filepath, compressed=False)
observed = io.read_sparse_matrix(filepath, kind="csc")
assert abs(observed - expected).nnz == 0
def test_read_write_sparse_csc_compressed(self, tmpdir):
expected = sp.csc_matrix(
(
np.array([1, 2, 3, 4, 5, 6]),
(np.array([0, 0, 1, 2, 2, 2]), np.array([0, 2, 2, 0, 1, 2])),
),
shape=(3, 3),
)
filepath = str(tmpdir.join("test_read_write_sparse_matrix_csc_compressed.npz"))
io.write_sparse_matrix(expected, filepath, compressed=True)
observed = io.read_sparse_matrix(filepath, kind="csc")
assert abs(observed - expected).nnz == 0
class TestIOUtils(object):
def test_get_filepaths(self):
expected = sorted(
os.path.join(TESTS_DIR, fname)
for fname in os.listdir(TESTS_DIR)
if os.path.isfile(os.path.join(TESTS_DIR, fname))
)
observed = sorted(
io.get_filepaths(TESTS_DIR, ignore_invisible=False, recursive=False)
)
assert observed == expected
def test_get_filepaths_ignore_invisible(self):
dirpath = os.path.dirname(os.path.abspath(__file__))
assert len(list(io.get_filepaths(dirpath, ignore_invisible=True))) <= len(
list(io.get_filepaths(dirpath, ignore_invisible=False))
)
def test_get_filepaths_ignore_regex(self):
assert (
len(
list(
io.get_filepaths(TESTS_DIR, ignore_regex="test_", ignore_invisible=True)
)
)
== 0
)
def test_get_filepaths_match_regex(self):
assert (
len(list(io.get_filepaths(TESTS_DIR, match_regex="io", extension=".py"))) == 1
)
| 41.796512 | 92 | 0.559049 |
4a1faf2932cce5c9474cebd70113268933c1ed23 | 563 | py | Python | monitor/scheduler/scheduler.py | davepuchyr/cosmos-voter | ae33dac3b68389e36db204fd6ab27bf5db8a20ff | [
"MIT"
] | 1 | 2018-09-13T01:27:27.000Z | 2018-09-13T01:27:27.000Z | monitor/scheduler/scheduler.py | davepuchyr/cosmos-voter | ae33dac3b68389e36db204fd6ab27bf5db8a20ff | [
"MIT"
] | null | null | null | monitor/scheduler/scheduler.py | davepuchyr/cosmos-voter | ae33dac3b68389e36db204fd6ab27bf5db8a20ff | [
"MIT"
] | 1 | 2019-03-28T22:44:29.000Z | 2019-03-28T22:44:29.000Z | import time
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.triggers.cron import CronTrigger
# very simple cron scheduler
class Scheduler:
def __init__(self, strategy, cron):
self.strategy = strategy
self.scheduler = BlockingScheduler()
self.cron = cron
def _func(self):
self.strategy.run()
def start(self):
self.scheduler.add_job(self._func, CronTrigger.from_crontab(self.cron))
self.scheduler.start()
def stop(self):
self.scheduler.shutdown(wait=False)
| 25.590909 | 79 | 0.699822 |
4a1faf3ccece404dfd4a5c4292afae36cd9b34d6 | 27,589 | py | Python | src/aioextensions/__init__.py | kamadorueda/aioextensions | 1e4a953c0b0be3d7e98a975177599d34e3f26369 | [
"MIT"
] | 5 | 2020-08-18T02:44:33.000Z | 2021-05-21T16:54:40.000Z | src/aioextensions/__init__.py | fluidattacks/aioextensions | 2ee63716fb4c03a114cd7f24fa6ac3a5843ae325 | [
"MIT"
] | 1 | 2020-11-19T05:24:21.000Z | 2020-11-20T01:47:17.000Z | src/aioextensions/__init__.py | fluidattacks/aioextensions | 2ee63716fb4c03a114cd7f24fa6ac3a5843ae325 | [
"MIT"
] | 1 | 2021-07-27T04:10:57.000Z | 2021-07-27T04:10:57.000Z | """High performance functions to work with the async IO.
[](
https://pypi.org/project/aioextensions)
[](
https://fluidattacks.github.io/aioextensions/)
[](
https://pypi.org/project/aioextensions)
[](
https://pypi.org/project/aioextensions)
[](
https://fluidattacks.github.io/aioextensions/)
[](
https://github.com/fluidattacks/aioextensions/blob/latest/LICENSE.md)
# Rationale
Modern services deal with a bunch of different tasks to perform:
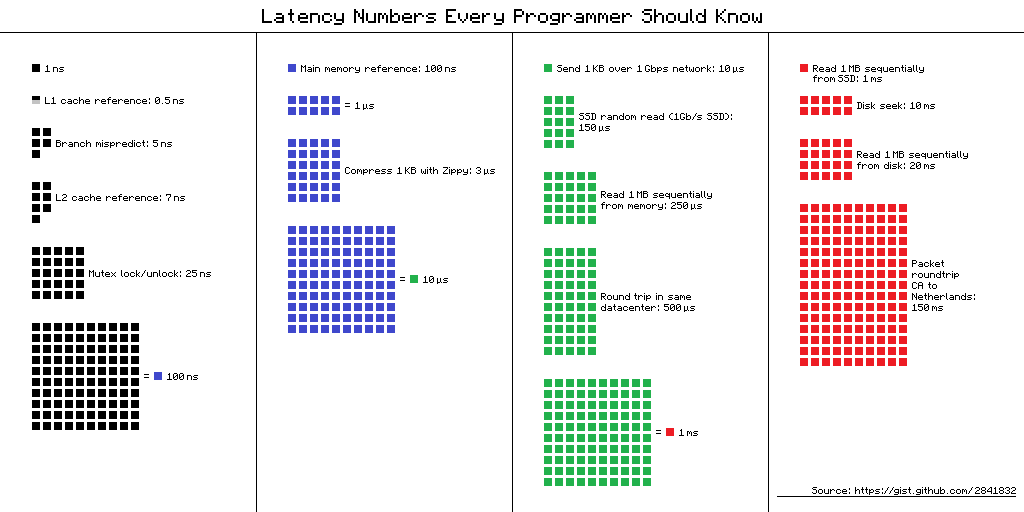
The important thing to note is that tasks can be categorized in two groups:
## CPU bound tasks
Those that happen inside the CPU, with very low latency and exploit the full
potential of the hardware in the computer.

Examples of these tasks include:
| Task | Latency in seconds |
|----------------------|-------------------:|
| CPU computation | 0.000000001 |
| Memory access | 0.0000001 |
| CPU Processing (1KB) | 0.000003 |
| Memory read (1MB) | 0.00025 |
## IO bound tasks
Those that happen over a wire that transports data, with very high latencies
and do not exploit the full potential of the hardware because the only thing to
do is waiting until the data gets to the other end and comes back (round-trip).

Examples of these tasks include:
| Task | Latency in seconds |
|----------------------|-------------------:|
| Disk access | 0.00015 |
| HTTP to localhost | 0.0005 |
| Disk read (1MB) | 0.02 |
| HTTP to internet | 0.15 |
# Speed and costs matter
At the end of the day, we want to minimize the amount of cost per user served
by the program, server, or service while maximizing the user perception of
speed.
In order to achieve this we need a model that allows us to exploit all CPU
cores and installed hardware in the machine, while maintaining the ability to
query large amounts of high-latency external services over the network:
databases, caches, storage, distributed queues, or input from multiple users.
# Concurrency model
Python's Async IO has a concurrency model based on an **event loop**, which
is responsible for executing the code, collecting and processing what's needed.
This event-loop executes in the main thread of the Python interpreter and
therefore it's limited by the [GIL](https://realpython.com/python-gil), so it's
alone unable to exploit all hardware installed in the host.
However:
- CPU intensive work can be sent to a pool of processes, far from the
event-loop and thus being able to bypass the
[GIL](https://realpython.com/python-gil), exploiting many CPU cores in
the machine, and leaving the event-loop schedule and coordinate incoming
requests.
- IO intensive work can be sent to a pool of threads, far from the event-loop
and thus being able to wait for high-latency operations without
interrupting the event-loop work.
There is an important difference:
- Work done by a pool of processes is executed in parallel: all CPU cores are
being used.
- Work done by a pool of threads is done concurrently: tasks execution is
overlapping, but not necessarily parallel: only 1 task can use the CPU
while the remaining ones are waiting the
[GIL](https://realpython.com/python-gil).
## Solving CPU bound tasks efficiently
The optimal way to perform CPU bound tasks is to send them to separate
processses in order to bypass the [GIL](https://realpython.com/python-gil).
Usage:
>>> from aioextensions import collect, in_process, run
>>> def cpu_bound_task(id: str):
print(f'doing: {id}')
# Imagine here something that uses a lot the CPU
# For example: this complex mathematical operation
for _ in range(10): 3**20000000
print(f'returning: {id}')
return id
>>> async def main():
results = await collect([
# in_process sends the task to a pool of processes
in_process(cpu_bound_task, id)
# Let's solve 5 of those tasks in parallel!
for id in range(5)
])
print(f'results: {results}')
>>> run(main())
# I have 4 CPU cores in my machine
doing: 0
doing: 1
doing: 2
doing: 3
returning: 1
doing: 4
returning: 2
returning: 3
returning: 0
returning: 4
results: (0, 1, 2, 3, 4)
As expected, all CPU cores were used and we were hardware-efficient!
## Solving IO bound tasks efficiently
The optimal way to perform IO bound tasks is to send them to separate
threads. This does not bypass the [GIL](https://realpython.com/python-gil).
However, threads will be in idle state most of the time, waiting high-latency
operations to complete.
Usage:
>>> from aioextensions import collect, in_thread, run
>>> from time import sleep, time
>>> def io_bound_task(id: str):
print(f'time: {time()}, doing: {id}')
# Imagine here something with high latency
# For example: a call to the database, or this sleep
sleep(1)
print(f'time: {time()}, returning: {id}')
return id
>>> async def main():
results = await collect([
# in_thread sends the task to a pool of threads
in_thread(io_bound_task, id)
# Let's solve 5 of those tasks concurrently!
for id in range(5)
])
print(f'time: {time()}, results: {results}')
>>> run(main)
time: 1597623831, doing: 0
time: 1597623831, doing: 1
time: 1597623831, doing: 2
time: 1597623831, doing: 3
time: 1597623831, doing: 4
time: 1597623832, returning: 0
time: 1597623832, returning: 4
time: 1597623832, returning: 3
time: 1597623832, returning: 2
time: 1597623832, returning: 1
time: 1597623832, results: (0, 1, 2, 3, 4)
As expected, all tasks were executed concurrently. This means that instead of
waiting five seconds for five tasks (serially) we just waited one second for
all of them.
# Installing
$ pip install aioextensions
# Optionally if you want uvloop support (not available on Windows)
$ pip install aioextensions[full]
# Using
>>> from aioextensions import * # to import everything
Please read the documentation bellow for more details about every function.
"""
# Standard library
import asyncio
from collections import (
deque,
)
from concurrent.futures import (
Executor,
ProcessPoolExecutor,
ThreadPoolExecutor,
)
from contextlib import (
asynccontextmanager,
suppress,
)
from functools import (
partial,
wraps,
)
from itertools import (
tee,
)
from os import (
cpu_count,
)
from typing import (
Any,
AsyncGenerator,
AsyncIterator,
Awaitable,
Callable,
cast,
Deque,
Dict,
Generator,
Iterable,
Optional,
Tuple,
Type,
TypeVar,
Union,
)
# Third party libraries
try:
# Attempt to install uvloop (optional dependency)
import uvloop
UVLOOP = uvloop
except ImportError:
UVLOOP = None
# Constants
F = TypeVar("F", bound=Callable[..., Any]) # pylint: disable=invalid-name
S = TypeVar("S") # pylint: disable=invalid-name
T = TypeVar("T") # pylint: disable=invalid-name
Y = TypeVar("Y") # pylint: disable=invalid-name
# Linters
# pylint: disable=unsubscriptable-object
def run(coroutine: Awaitable[T], *, debug: bool = False) -> T:
"""Execute an asynchronous function synchronously and return its result.
Usage:
>>> async def do(a, b=0):
await something
return a + b
>>> run(do(1, b=2))
>>> 3
This function acts as a drop-in replacement of asyncio.run and
installs `uvloop` (the fastest event-loop implementation out there) if
available.
.. tip::
Use this as the entrypoint for your program.
"""
if UVLOOP is not None:
UVLOOP.install()
return asyncio.run(coroutine, debug=debug)
async def in_thread(
function: Callable[..., T],
*args: Any,
**kwargs: Any,
) -> T:
"""Execute `function(*args, **kwargs)` in the configured thread pool.
This is the most performant wrapper for IO bound and high-latency tasks.
Every task will be assigned at most one thread, if there are more tasks
than threads in the pool the excess will be executed in FIFO order.
Spawning a million IO bound tasks with this function has a very small
memory footprint.
.. warning::
Executing CPU intensive work here is a bad idea because of the
limitations that the [GIL](https://realpython.com/python-gil) imposes.
See `in_process` for a CPU performant alternative.
"""
_ensure_thread_pool_is_initialized()
return await asyncio.get_running_loop().run_in_executor(
THREAD_POOL.pool,
partial(function, *args, **kwargs),
)
async def in_process(
function: Callable[..., T],
*args: Any,
**kwargs: Any,
) -> T:
"""Execute `function(*args, **kwargs)` in the configured process pool.
This is the most performant wrapper for CPU bound and low-latency tasks.
Tasks executed in a process pool bypass the
[GIL](https://realpython.com/python-gil) and can consume all CPU cores
available in the host if needed.
Every task will be assigned at most one process, if there are more tasks
than processes in the pool the excess will be executed in FIFO order.
.. warning::
Executing IO intensive work here is possible, but spawning a process
has some overhead that can be avoided using threads at no performance
expense.
See `in_thread` for an IO performant alternative.
"""
_ensure_process_pool_is_initialized()
return await asyncio.get_running_loop().run_in_executor(
PROCESS_POOL.pool,
partial(function, *args, **kwargs),
)
def rate_limited(
*,
max_calls: int,
max_calls_period: Union[float, int],
min_seconds_between_calls: Union[float, int] = 0,
) -> Callable[[F], F]:
"""Decorator to turn an asynchronous function into a rate limited one.
The decorated function won't be able to execute more than `max_calls` times
over a period of `max_calls_period` seconds. The excess will be queued in
FIFO mode.
Aditionally, it's guaranteed that no successive calls can be performed
faster than `min_seconds_between_calls` seconds.
Usage:
If you want to perform at most 2 calls to a database per second:
>>> @rate_limited(
max_calls=2,
max_calls_period=1,
min_seconds_between_calls=0.2,
)
async def query(n):
await something
print(f'time: {time()}, doing: {n}')
>>> await collect(map(query, range(10)))
Output:
```
time: 1597706698.0, doing: 0
time: 1597706698.2, doing: 1
time: 1597706699.0, doing: 2
time: 1597706699.2, doing: 3
time: 1597706700.0, doing: 4
time: 1597706700.2, doing: 5
time: 1597706701.0, doing: 6
time: 1597706701.2, doing: 7
time: 1597706702.0, doing: 8
time: 1597706702.2, doing: 9
```
.. tip::
Use `min_seconds_between_calls` as an anti-burst system. This can, for
instance, lower your bill in DynamoDB or prevent a cooldown period
(also know as ban) by a firewall.
This decorator creates a `max_calls` sized data structure.
"""
if max_calls < 1:
raise ValueError("max_calls must be >= 1")
if max_calls_period <= 0:
raise ValueError("max_calls_period must be > 0")
if min_seconds_between_calls < 0:
raise ValueError("min_seconds_between_calls must be >= 0")
def decorator(function: F) -> F:
lock = None
waits: Deque[float] = deque()
@wraps(function)
async def wrapper(*args: Any, **kwargs: Any) -> Any:
nonlocal lock
lock = lock or asyncio.Lock()
loop = asyncio.get_event_loop()
async with lock:
if waits:
# Anti burst control system:
# wait until the difference between the most recent call
# and the current call is >= min_seconds_between_calls
await asyncio.sleep(
waits[-1] + min_seconds_between_calls - loop.time()
)
while len(waits) >= max_calls:
# Rate limit control system:
# wait until the least recent call and the current call
# is >= max_calls_period
await asyncio.sleep(
waits.popleft() + max_calls_period - loop.time()
)
waits.append(loop.time())
return await function(*args, **kwargs)
return cast(F, wrapper)
return decorator
async def collect(
awaitables: Iterable[Awaitable[T]],
*,
workers: int = 1024,
) -> Tuple[T, ...]:
"""Resolve concurrently the input stream and return back in the same order.
At any point in time there will be at most _number of `workers`_
tasks being resolved concurrently.
Aditionally, the algorithm makes sure that at any point in time every
worker is busy.
Args:
awaitables: An iterable (generator, list, tuple, set, etc) of
awaitables (coroutine, asyncio.Task, or asyncio.Future).
workers: The number of independent workers that will be processing
the input stream.
Returns:
A tuple with the results of executing each awaitable in the event loop.
Results are returned in the same order of the input stream.
Usage:
>>> async def do(n):
print(f'running: {n}')
await sleep(1)
print(f'returning: {n}')
return n
>>> iterable = map(do, range(5))
>>> results = await collect(iterable, workers=2)
>>> print(f'results: {results}')
Output:
```
running: 0
running: 1
returning: 0
returning: 1
running: 2
running: 3
returning: 2
returning: 3
running: 4
returning: 4
results: (0, 1, 2, 3, 4)
```
.. tip::
This is similar to asyncio.as_completed. However results are returned
in order and allows you to control how much resources are consumed
throughout the execution, for instance:
- How many open files will be opened at the same time
- How many HTTP requests will be performed to a service (rate limit)
- How many sockets will be opened concurrently
- Etc
This is useful for finite resources, for instance: the number
of sockets provided by the operative system is limited; going beyond it
would make the kernel to kill the program abruptly.
If awaitables is an instance of Sized (has `__len__` prototype).
This function will launch at most `len(awaitables)` workers.
"""
return tuple(
[
await elem
for elem in resolve(
awaitables,
workers=workers,
worker_greediness=0,
)
]
)
def resolve( # noqa: mccabe
awaitables: Iterable[Awaitable[T]],
*,
workers: int = 1024,
worker_greediness: int = 0,
) -> Iterable[Awaitable[T]]:
"""Resolve concurrently the input stream and yield back in the same order.
At any point in time there will be at most _number of `workers`_
tasks being resolved concurrently.
Aditionally, the algorithm makes sure that at any point in time every
worker is busy (if greediness allow them).
Args:
awaitables: An iterable (generator, list, tuple, set, etc) of
awaitables (coroutine, asyncio.Task, or asyncio.Future).
workers: The number of independent workers that will be processing
the input stream.
worker_greediness: How much tasks can a worker process before waiting
for you to retrieve its results. 0 means unlimited. Set to non-zero
in order to upper-bound memory usage throughout the execution.
Yields:
A future with the result of the next ready task. Futures are yielded in
the same order of the input stream.
Usage:
>>> async def do(n):
print(f'running: {n}')
await asyncio.sleep(1)
print(f'returning: {n}')
return n
>>> iterable = map(do, range(5))
>>> for next in resolve(iterable, workers=2):
try:
print(f'got resolved result: {await next}')
except:
pass # Handle possible exceptions
Output:
```
running: 0
running: 1
returning: 0
returning: 1
got resolved result: 0
got resolved result: 1
running: 2
running: 3
returning: 2
returning: 3
got resolved result: 2
got resolved result: 3
running: 4
returning: 4
got resolved result: 4
```
.. tip::
This is similar to asyncio.as_completed. However results are returned
in order and allows you to control how much resources are consumed
throughout the execution, for instance:
- How many open files will be opened at the same time
- How many HTTP requests will be performed to a service (rate limit)
- How many sockets will be opened concurrently
- Etc
This is useful for finite resources, for instance: the number
of sockets provided by the operative system is limited; going beyond it
would make the kernel to kill the program abruptly.
If awaitables is an instance of Sized (has `__len__` prototype).
This function will launch at most `len(awaitables)` workers.
"""
if workers < 1:
raise ValueError("workers must be >= 1")
if worker_greediness < 0:
raise ValueError("worker_greediness must be >= 0")
if hasattr(awaitables, "__len__"):
workers = min(workers, len(awaitables)) # type: ignore
loop = asyncio.get_event_loop()
store: Dict[int, asyncio.Queue] = {}
stream, stream_copy = tee(enumerate(awaitables))
stream_finished = asyncio.Event()
workers_up = asyncio.Event()
workers_tasks: Dict[int, asyncio.Task] = {}
async def worker() -> None:
done: asyncio.Queue = asyncio.Queue(worker_greediness)
for index, awaitable in stream:
store[index] = done
future = loop.create_future()
future.set_result(await schedule(awaitable, loop=loop))
await done.put(future)
workers_up.set()
workers_up.set()
stream_finished.set()
async def start_workers() -> None:
for index in range(workers):
if stream_finished.is_set():
break
workers_tasks[index] = asyncio.create_task(worker())
await force_loop_cycle()
await workers_up.wait()
async def get_one(index: int) -> Awaitable[T]:
if not workers_tasks:
await start_workers()
awaitable = await store.pop(index).get()
result: Awaitable[T] = (await awaitable).result()
return result
for index, _ in stream_copy:
yield cast(Awaitable[T], get_one(index))
async def force_loop_cycle() -> None:
"""Force the event loop to perform one cycle.
This can be used to suspend the execution of the current coroutine and
yield control back to the event-loop until the next cycle.
Can be seen as a forceful switch of control between threads.
Useful for cooperative initialization.
Usage:
>>> await forceforce_loop_cycle()
"""
await asyncio.sleep(0)
async def generate_in_thread(
generator_func: Callable[..., Generator[Y, S, None]],
*args: Any,
**kwargs: Any,
) -> AsyncGenerator[Y, S]:
"""Mimic `generator_func(*args, **kwargs)` in the configured thread pool.
Note that `generator_func(*args, **kwargs)` may return a generator or an
interator and both cases are handled rightfully.
Usage:
>>> from os import scandir
>>> async for entry in generate_in_thread(scandir, '.'):
print(entry.name)
Output:
```
.gitignore
LICENSE.md
README.md
...
```
Calls to the generator are done serially and not concurrently.
The benefit of wrapping a generator with this function is that the
event-loop is free to schedule and wait another tasks in the mean time.
For instance, in a web server.
"""
gen: Generator[Y, S, None] = generator_func(*args, **kwargs)
gen_sent: Any = None
def gen_next(val: S) -> Y:
with suppress(StopIteration):
return gen.send(val) if hasattr(gen, "send") else next(gen)
raise StopAsyncIteration()
while True:
try:
gen_sent = yield await in_thread(gen_next, gen_sent)
except StopAsyncIteration:
return
def schedule(
awaitable: Awaitable[T],
*,
loop: Optional[asyncio.AbstractEventLoop] = None,
) -> "Awaitable[asyncio.Future[T]]":
"""Schedule an awaitable in the event loop and return a wrapper for it.
Usage:
>>> async def do(n):
print(f'running: {n}')
await sleep(1)
print(f'returning: {n}')
>>> task = schedule(do(3)) # Task is executing in the background now
>>> print('other work is being done here')
>>> task_result = await task # Wait until the task is ready
>>> print(f'result: {task_result.result()}') # may rise if do() raised
Output:
```
other work is being done here
doing: 3
returning: 3
3
```
This works very similar to asyncio.create_task. The main difference is that
the result (or exception) can be accessed via exception() or result()
methods.
If an exception was raised by the awaitable, it will be propagated only at
the moment result() is called and never otherwise.
"""
wrapper = (loop or asyncio.get_event_loop()).create_future()
def _done_callback(future: asyncio.Future) -> None:
if not wrapper.done(): # pragma: no cover
wrapper.set_result(future)
asyncio.create_task(awaitable).add_done_callback(_done_callback)
return wrapper
class Semaphore(asyncio.Semaphore):
"""Same as `asyncio.Semaphore` plus some useful methods."""
@asynccontextmanager
async def acquire_many(self, times: int) -> AsyncIterator[None]:
"""Acquire a semaphore many times, and release on exit.
Usage:
>>> async with semaphore.acquire_many(5):
# Work with shared resource
...
"""
if times <= 0:
raise ValueError("times must be >= 1")
try:
await collect([self.acquire() for _ in range(times)])
yield
finally:
for _ in range(times):
self.release()
class BoundedSemaphore(Semaphore, asyncio.BoundedSemaphore):
"""Same as `asyncio.BoundedSemaphore` plus some useful methods."""
def _ensure_process_pool_is_initialized() -> None:
if not PROCESS_POOL.initialized:
PROCESS_POOL.initialize(max_workers=CPU_CORES)
def _ensure_thread_pool_is_initialized() -> None:
if not THREAD_POOL.initialized:
THREAD_POOL.initialize(max_workers=10 * CPU_CORES)
class ExecutorPool:
"""Object representing a pool of Processes or Threads.
The actual pool is created at `initialization` time
and it is empty until that.
"""
def __init__(
self,
cls: Union[
Type[ProcessPoolExecutor],
Type[ThreadPoolExecutor],
],
) -> None:
self._cls = cls
self._pool: Optional[Executor] = None
def initialize(self, *, max_workers: Optional[int] = None) -> None:
"""Initialize the executor with a cap of at most `max_workers`.
Workers are created on-demand as needed or never created at all
if never needed.
"""
if self._pool is not None:
self._pool.shutdown(wait=False)
self._pool = self._cls(max_workers=max_workers)
def shutdown(self, *, wait: bool) -> None:
"""Shut down the executor and (optionally) waits for workers to finish."""
if self._pool is not None:
self._pool.shutdown(wait=wait)
self._pool = None
@property
def pool(self) -> Executor:
"""Low level pool of workers held by the executor, may be None."""
if self._pool is None:
raise RuntimeError("Must call initialize first")
return self._pool
@property
def initialized(self) -> bool:
"""Return true if the executor is initialized and ready to process."""
return self._pool is not None
def run_decorator(function: F) -> F:
"""Decorator to turn an asynchronous function into a synchronous one.
Usage:
>>> @run_decorator
async def do(a, b=0):
return a + b
>>> do(1, b=2)
Output:
```
3
```
This can be used as a bridge between synchronous and asynchronous code.
We use it mostly in tests for its convenience over pytest-asyncio plugin.
"""
@wraps(function)
def wrapper(*args: Any, **kwargs: Any) -> Any:
return run(function(*args, **kwargs))
return cast(F, wrapper)
# Constants
CPU_CORES: int = cpu_count() or 1
"""Number of CPU cores in the host system."""
PROCESS_POOL: ExecutorPool = ExecutorPool(ProcessPoolExecutor)
"""Process pool used by `in_process` function to execute work.
Preconfigured to launch at most `CPU_CORES` processes (if needed).
Proceses are created on the first `in_process` call, one by one as needed
or never launched otherwise.
"""
THREAD_POOL: ExecutorPool = ExecutorPool(ThreadPoolExecutor)
"""Thread pool used by `in_thread` function to execute work.
Preconfigured to launch at most 10 * `CPU_CORES` threads (if needed).
Threads are created on the first `in_thread` call, one by one as needed,
or never launched otherwise.
"""
| 30.586475 | 103 | 0.632716 |
4a1faf70b288692cdf6fc818b0648e5a338d0303 | 6,457 | py | Python | env/Lib/site-packages/plotly/express/trendline_functions/__init__.py | andresgreen-byte/Laboratorio-1--Inversion-de-Capital | 8a4707301d19c3826c31026c4077930bcd6a8182 | [
"MIT"
] | 11,750 | 2015-10-12T07:03:39.000Z | 2022-03-31T20:43:15.000Z | packages/python/plotly/plotly/express/trendline_functions/__init__.py | jiangrongbo/plotly.py | df19fc702b309586cc24e25373b87e8bdbb3ff60 | [
"MIT"
] | 2,951 | 2015-10-12T00:41:25.000Z | 2022-03-31T22:19:26.000Z | packages/python/plotly/plotly/express/trendline_functions/__init__.py | jiangrongbo/plotly.py | df19fc702b309586cc24e25373b87e8bdbb3ff60 | [
"MIT"
] | 2,623 | 2015-10-15T14:40:27.000Z | 2022-03-28T16:05:50.000Z | """
The `trendline_functions` module contains functions which are called by Plotly Express
when the `trendline` argument is used. Valid values for `trendline` are the names of the
functions in this module, and the value of the `trendline_options` argument to PX
functions is passed in as the first argument to these functions when called.
Note that the functions in this module are not meant to be called directly, and are
exposed as part of the public API for documentation purposes.
"""
import pandas as pd
import numpy as np
__all__ = ["ols", "lowess", "rolling", "ewm", "expanding"]
def ols(trendline_options, x_raw, x, y, x_label, y_label, non_missing):
"""Ordinary Least Squares (OLS) trendline function
Requires `statsmodels` to be installed.
This trendline function causes fit results to be stored within the figure,
accessible via the `plotly.express.get_trendline_results` function. The fit results
are the output of the `statsmodels.api.OLS` function.
Valid keys for the `trendline_options` dict are:
- `add_constant` (`bool`, default `True`): if `False`, the trendline passes through
the origin but if `True` a y-intercept is fitted.
- `log_x` and `log_y` (`bool`, default `False`): if `True` the OLS is computed with
respect to the base 10 logarithm of the input. Note that this means no zeros can
be present in the input.
"""
valid_options = ["add_constant", "log_x", "log_y"]
for k in trendline_options.keys():
if k not in valid_options:
raise ValueError(
"OLS trendline_options keys must be one of [%s] but got '%s'"
% (", ".join(valid_options), k)
)
import statsmodels.api as sm
add_constant = trendline_options.get("add_constant", True)
log_x = trendline_options.get("log_x", False)
log_y = trendline_options.get("log_y", False)
if log_y:
if np.any(y <= 0):
raise ValueError(
"Can't do OLS trendline with `log_y=True` when `y` contains non-positive values."
)
y = np.log10(y)
y_label = "log10(%s)" % y_label
if log_x:
if np.any(x <= 0):
raise ValueError(
"Can't do OLS trendline with `log_x=True` when `x` contains non-positive values."
)
x = np.log10(x)
x_label = "log10(%s)" % x_label
if add_constant:
x = sm.add_constant(x)
fit_results = sm.OLS(y, x, missing="drop").fit()
y_out = fit_results.predict()
if log_y:
y_out = np.power(10, y_out)
hover_header = "<b>OLS trendline</b><br>"
if len(fit_results.params) == 2:
hover_header += "%s = %g * %s + %g<br>" % (
y_label,
fit_results.params[1],
x_label,
fit_results.params[0],
)
elif not add_constant:
hover_header += "%s = %g * %s<br>" % (y_label, fit_results.params[0], x_label)
else:
hover_header += "%s = %g<br>" % (y_label, fit_results.params[0])
hover_header += "R<sup>2</sup>=%f<br><br>" % fit_results.rsquared
return y_out, hover_header, fit_results
def lowess(trendline_options, x_raw, x, y, x_label, y_label, non_missing):
"""LOcally WEighted Scatterplot Smoothing (LOWESS) trendline function
Requires `statsmodels` to be installed.
Valid keys for the `trendline_options` dict are:
- `frac` (`float`, default `0.6666666`): the `frac` parameter from the
`statsmodels.api.nonparametric.lowess` function
"""
valid_options = ["frac"]
for k in trendline_options.keys():
if k not in valid_options:
raise ValueError(
"LOWESS trendline_options keys must be one of [%s] but got '%s'"
% (", ".join(valid_options), k)
)
import statsmodels.api as sm
frac = trendline_options.get("frac", 0.6666666)
y_out = sm.nonparametric.lowess(y, x, missing="drop", frac=frac)[:, 1]
hover_header = "<b>LOWESS trendline</b><br><br>"
return y_out, hover_header, None
def _pandas(mode, trendline_options, x_raw, y, non_missing):
modes = dict(rolling="Rolling", ewm="Exponentially Weighted", expanding="Expanding")
trendline_options = trendline_options.copy()
function_name = trendline_options.pop("function", "mean")
function_args = trendline_options.pop("function_args", dict())
series = pd.Series(y, index=x_raw)
agg = getattr(series, mode) # e.g. series.rolling
agg_obj = agg(**trendline_options) # e.g. series.rolling(**opts)
function = getattr(agg_obj, function_name) # e.g. series.rolling(**opts).mean
y_out = function(**function_args) # e.g. series.rolling(**opts).mean(**opts)
y_out = y_out[non_missing]
hover_header = "<b>%s %s trendline</b><br><br>" % (modes[mode], function_name)
return y_out, hover_header, None
def rolling(trendline_options, x_raw, x, y, x_label, y_label, non_missing):
"""Rolling trendline function
The value of the `function` key of the `trendline_options` dict is the function to
use (defaults to `mean`) and the value of the `function_args` key are taken to be
its arguments as a dict. The remainder of the `trendline_options` dict is passed as
keyword arguments into the `pandas.Series.rolling` function.
"""
return _pandas("rolling", trendline_options, x_raw, y, non_missing)
def expanding(trendline_options, x_raw, x, y, x_label, y_label, non_missing):
"""Expanding trendline function
The value of the `function` key of the `trendline_options` dict is the function to
use (defaults to `mean`) and the value of the `function_args` key are taken to be
its arguments as a dict. The remainder of the `trendline_options` dict is passed as
keyword arguments into the `pandas.Series.expanding` function.
"""
return _pandas("expanding", trendline_options, x_raw, y, non_missing)
def ewm(trendline_options, x_raw, x, y, x_label, y_label, non_missing):
"""Exponentially Weighted Moment (EWM) trendline function
The value of the `function` key of the `trendline_options` dict is the function to
use (defaults to `mean`) and the value of the `function_args` key are taken to be
its arguments as a dict. The remainder of the `trendline_options` dict is passed as
keyword arguments into the `pandas.Series.ewm` function.
"""
return _pandas("ewm", trendline_options, x_raw, y, non_missing)
| 40.867089 | 98 | 0.666409 |
4a1faf7a532b3c33e75db80860bef559a2a47879 | 1,144 | py | Python | test/Task/Image/ConvertTextureTaskTest.py | paulondc/chilopoda | 046dbb0c1b4ff20ea5f2e1679f8d89f3089b6aa4 | [
"MIT"
] | 2 | 2019-09-24T18:56:27.000Z | 2021-02-07T04:58:49.000Z | test/Task/Image/ConvertTextureTaskTest.py | paulondc/kombi | 046dbb0c1b4ff20ea5f2e1679f8d89f3089b6aa4 | [
"MIT"
] | 20 | 2019-02-16T04:21:13.000Z | 2019-03-09T21:21:21.000Z | test/Task/Image/ConvertTextureTaskTest.py | paulondc/kombi | 046dbb0c1b4ff20ea5f2e1679f8d89f3089b6aa4 | [
"MIT"
] | 3 | 2019-11-15T05:16:32.000Z | 2021-09-28T21:28:29.000Z | import os
import unittest
from ...BaseTestCase import BaseTestCase
from kombi.Task import Task
from kombi.Crawler.Fs import FsCrawler
class ConvertTextureTaskTest(BaseTestCase):
"""
Test ConvertTexture task.
"""
__sourcePath = os.path.join(BaseTestCase.dataTestsDirectory(), "test.png")
__targetPath = os.path.join(BaseTestCase.tempDirectory(), "testToDelete.tx")
def testConvertTexture(self):
"""
Test that the ConvertTexture task works properly.
"""
crawler = FsCrawler.createFromPath(self.__sourcePath)
convertTask = Task.create('convertTexture')
convertTask.setOption('maketxArgs', '-u --unpremult --oiio')
convertTask.add(crawler, self.__targetPath)
result = convertTask.output()
self.assertEqual(len(result), 1)
self.assertEqual(result[0].var('filePath'), self.__targetPath)
self.assertTrue(os.path.exists(self.__targetPath))
@classmethod
def tearDownClass(cls):
"""
Remove the file that was copied.
"""
os.remove(cls.__targetPath)
if __name__ == "__main__":
unittest.main()
| 29.333333 | 80 | 0.673077 |
4a1faf8b27a9beb333fc4db5f84f4180c885ba94 | 3,650 | py | Python | fmfexporter/adapters/polarion/fmf_adapter_polarion.py | rh-messaging-qe/fmfexporter | a2db70bf5d3e89d418063b1890924e6ec7cbeed6 | [
"Apache-2.0"
] | 4 | 2019-02-15T11:44:01.000Z | 2021-08-20T16:46:30.000Z | fmfexporter/adapters/polarion/fmf_adapter_polarion.py | rh-messaging-qe/fmfexporter | a2db70bf5d3e89d418063b1890924e6ec7cbeed6 | [
"Apache-2.0"
] | 14 | 2019-02-14T18:51:04.000Z | 2020-01-16T14:12:45.000Z | fmfexporter/adapters/polarion/fmf_adapter_polarion.py | rh-messaging-qe/fmfexporter | a2db70bf5d3e89d418063b1890924e6ec7cbeed6 | [
"Apache-2.0"
] | 2 | 2019-02-25T10:06:54.000Z | 2019-05-06T20:26:16.000Z | import logging
from fmfexporter.adapters.polarion.args.polarion_args_parser import PolarionArgParser
from fmfexporter import FMFTestCase
from fmfexporter.adapters.polarion.connectors.jira.fmf_jira import FMFJiraPopulator
from fmfexporter.adapters.polarion.polarion_reporter import PolarionReporter
from fmfexporter.adapters.polarion.polarion_test_case import PolarionTestCase
from fmfexporter.fmf_adapter import FMFAdapter, FMFAdapterArgParser
"""
FMF Adapter for the Polarion ALM tool.
"""
# Constants
ADAPTER_ID = "polarion"
LOGGER = logging.getLogger(__name__)
class FMFAdapterPolarion(FMFAdapter):
"""
FMF Adapter implementation for the Polarion ALM tool.
"""
def __init__(self, fmf_tree_path: str = '.'):
super(FMFAdapterPolarion, self).__init__(fmf_tree_path)
# If the config file has been parsed, create a reporter...
self._reporter = None
if PolarionArgParser.CONFIG_FILE:
self._reporter: PolarionReporter = PolarionReporter(PolarionArgParser.CONFIG_FILE)
@staticmethod
def adapter_id() -> str:
return ADAPTER_ID
@staticmethod
def get_args_parser() -> FMFAdapterArgParser:
return PolarionArgParser()
def convert_from(self, fmf_testcase: FMFTestCase):
return PolarionTestCase.from_fmf_testcase(fmf_testcase)
def submit_testcase(self, fmf_testcase: FMFTestCase):
ptc = self.convert_from(fmf_testcase)
#
# If config file has been parsed (and there is a reporter available)
# and --submit has been given, submit. Otherwise simply prints the tc.
#
if self._reporter and PolarionArgParser.SUBMIT:
LOGGER.info("Submitting test case: %s" % ptc.id)
tc = self._reporter.submit_testcase(ptc, PolarionArgParser.POPUL_TC)
self.populate_jira(tc)
return ptc
else:
print("Dumping test case: %s\n%s\n" % (ptc.id, ptc.to_xml()))
def submit_testcases(self, fmf_testcases: list):
submitted_tc = []
polarion_test_cases = []
for fmf_testcase in fmf_testcases:
polarion_test_cases.append(self.convert_from(fmf_testcase))
#
# If config file has been parsed (and there is a reporter available)
# and --submit has been given, submit. Otherwise simply prints the tc.
#
if self._reporter and PolarionArgParser.SUBMIT:
if PolarionArgParser.ONE_BY_ONE:
for ptc in polarion_test_cases:
LOGGER.info("Submitting test case: %s" % ptc.id)
submitted_tc.append(self._reporter.submit_testcase(ptc, PolarionArgParser.POPUL_TC))
else:
for ptc in polarion_test_cases:
LOGGER.info("Submitting test case: %s" % ptc.id)
submitted_tc.extend(self._reporter.submit_testcases(polarion_test_cases, PolarionArgParser.POPUL_TC))
else:
if PolarionArgParser.ONE_BY_ONE:
for ptc in polarion_test_cases:
print("Dumping test case: %s\n%s\n" % (ptc.id, ptc.to_xml()))
else:
print("Dumping test cases: \n%s\n" % (PolarionReporter.to_xml(polarion_test_cases)))
self.populate_jira(submitted_tc)
def populate_jira(self, submitted_testcases: list):
# Linking Test Case Work items in jira
if PolarionArgParser.JIRA_CONFIG is not None:
jira_pop = FMFJiraPopulator(PolarionArgParser.JIRA_CONFIG)
jira_pop.populate_testcases(submitted_testcases)
else:
LOGGER.warning("Jira configuration not provided") | 40.10989 | 117 | 0.677534 |
4a1fb1562bd9da3951ba4ea4b9863e1a82ca3713 | 959 | py | Python | Examples/PVA-water/pva.py | tamaswells/pysimm | 2586679a9eacdf1046baa2312c8f92c9247ac5be | [
"MIT"
] | null | null | null | Examples/PVA-water/pva.py | tamaswells/pysimm | 2586679a9eacdf1046baa2312c8f92c9247ac5be | [
"MIT"
] | null | null | null | Examples/PVA-water/pva.py | tamaswells/pysimm | 2586679a9eacdf1046baa2312c8f92c9247ac5be | [
"MIT"
] | null | null | null | from pysimm import system, lmps, forcefield
from pysimm.apps.random_walk import random_walk
def monomer():
s = system.read_pubchem_smiles('CCO')
f = forcefield.Gaff2()
s.apply_forcefield(f)
c1 = s.particles[2]
c1.linker = 'tail'
c2 = s.particles[3]
c2.linker = 'head'
for b in c1.bonds:
if b.a.elem == 'H' or b.b.elem == 'H':
pb = b.a if b.b is c1 else b.b
s.particles.remove(pb.tag, update=False)
break
for b in c2.bonds:
if b.a.elem == 'H' or b.b.elem == 'H':
pb = b.a if b.b is c2 else b.b
s.particles.remove(pb.tag, update=False)
break
s.remove_spare_bonding()
lmps.quick_min(s, min_style='fire')
s.add_particle_bonding()
return s
def polymer_chain(length):
mon = monomer()
polym = random_walk(mon, length, forcefield=forcefield.Gaff2())
return polym | 25.918919 | 67 | 0.565172 |
4a1fb16660a0734aecad20c392e5c5322302a337 | 14,084 | py | Python | sandbox/settings.py | waltparkman/oscar | 9c34ba3d9f5d9ce591c5e0a9f26c5c83daec3c36 | [
"BSD-3-Clause"
] | null | null | null | sandbox/settings.py | waltparkman/oscar | 9c34ba3d9f5d9ce591c5e0a9f26c5c83daec3c36 | [
"BSD-3-Clause"
] | 9 | 2022-01-01T11:09:59.000Z | 2022-03-01T11:05:48.000Z | sandbox/settings.py | waltparkman/oscar | 9c34ba3d9f5d9ce591c5e0a9f26c5c83daec3c36 | [
"BSD-3-Clause"
] | null | null | null | import os
import environ
import oscar
from oscar.defaults import *
from settings import * # noqa
#DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.postgresql_psycopg2',
# 'NAME': 'oscar_travis',
# 'USER': 'travis',
# 'PASSWORD': '',
# 'HOST': '127.0.0.1',
# 'PORT': '',
# }
#}
env = environ.Env()
# Path helper
location = lambda x: os.path.join(
os.path.dirname(os.path.realpath(__file__)), x)
DEBUG = env.bool('DEBUG', default=True)
ALLOWED_HOSTS = env.list('ALLOWED_HOSTS', default=['161.35.236.66', 'parkmanpython.com'])
EMAIL_SUBJECT_PREFIX = '[Oscar sandbox] '
EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'
# Use a Sqlite database by default
# DATABASES = {
# 'default': {
# 'ENGINE': os.environ.get('DATABASE_ENGINE', 'django.db.backends.sqlite3'),
# 'NAME': os.environ.get('DATABASE_NAME', location('db.sqlite3')),
# 'USER': os.environ.get('DATABASE_USER', None),
# 'PASSWORD': os.environ.get('DATABASE_PASSWORD', None),
# 'HOST': os.environ.get('DATABASE_HOST', None),
# 'PORT': os.environ.get('DATABASE_PORT', None),
# 'ATOMIC_REQUESTS': True
# }
# }
#Postgres configuration
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'oscar',
'USER': 'oscar',
'PASSWORD': 'Another-Fence-Chief-Literature-1',
'HOST': '127.0.0.1',
'PORT': '',
}
}
CACHES = {
'default': env.cache(default='locmemcache://'),
}
# Local time zone for this installation. Choices can be found here:
# http://en.wikipedia.org/wiki/List_of_tz_zones_by_name
# although not all choices may be available on all operating systems.
# On Unix systems, a value of None will cause Django to use the same
# timezone as the operating system.
USE_TZ = True
TIME_ZONE = 'Europe/London'
TEST_RUNNER = 'django.test.runner.DiscoverRunner'
# Language code for this installation. All choices can be found here:
# http://www.i18nguy.com/unicode/language-identifiers.html
LANGUAGE_CODE = 'en-gb'
# Includes all languages that have >50% coverage in Transifex
# Taken from Django's default setting for LANGUAGES
gettext_noop = lambda s: s
LANGUAGES = (
('ar', gettext_noop('Arabic')),
('ca', gettext_noop('Catalan')),
('cs', gettext_noop('Czech')),
('da', gettext_noop('Danish')),
('de', gettext_noop('German')),
('en-gb', gettext_noop('British English')),
('el', gettext_noop('Greek')),
('es', gettext_noop('Spanish')),
('fi', gettext_noop('Finnish')),
('fr', gettext_noop('French')),
('it', gettext_noop('Italian')),
('ko', gettext_noop('Korean')),
('nl', gettext_noop('Dutch')),
('pl', gettext_noop('Polish')),
('pt', gettext_noop('Portuguese')),
('pt-br', gettext_noop('Brazilian Portuguese')),
('ro', gettext_noop('Romanian')),
('ru', gettext_noop('Russian')),
('sk', gettext_noop('Slovak')),
('uk', gettext_noop('Ukrainian')),
('zh-cn', gettext_noop('Simplified Chinese')),
)
SITE_ID = 1
# If you set this to False, Django will make some optimizations so as not
# to load the internationalization machinery.
USE_I18N = True
# If you set this to False, Django will not format dates, numbers and
# calendars according to the current locale
USE_L10N = True
# Absolute path to the directory that holds media.
# Example: "/home/media/media.lawrence.com/"
MEDIA_ROOT = location("public/media")
# URL that handles the media served from MEDIA_ROOT. Make sure to use a
# trailing slash if there is a path component (optional in other cases).
# Examples: "http://media.lawrence.com", "http://example.com/media/"
MEDIA_URL = '/media/'
STATIC_URL = '/static/'
STATIC_ROOT = location('public/static')
STATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'
STATICFILES_DIRS = (
location('static/'),
)
STATICFILES_FINDERS = (
'django.contrib.staticfiles.finders.FileSystemFinder',
'django.contrib.staticfiles.finders.AppDirectoriesFinder',
)
# Default primary key field type
# https://docs.djangoproject.com/en/dev/ref/settings/#default-auto-field
DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
# Make this unique, and don't share it with anybody.
SECRET_KEY = env.str('SECRET_KEY', default='UajFCuyjDKmWHe29neauXzHi9eZoRXr6RMbT5JyAdPiACBP6Cra2')
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
location('templates'),
],
'OPTIONS': {
'loaders': [
'django.template.loaders.filesystem.Loader',
'django.template.loaders.app_directories.Loader',
],
'context_processors': [
'django.contrib.auth.context_processors.auth',
'django.template.context_processors.request',
'django.template.context_processors.debug',
'django.template.context_processors.i18n',
'django.template.context_processors.media',
'django.template.context_processors.static',
'django.contrib.messages.context_processors.messages',
# Oscar specific
'oscar.apps.search.context_processors.search_form',
'oscar.apps.communication.notifications.context_processors.notifications',
'oscar.apps.checkout.context_processors.checkout',
'oscar.core.context_processors.metadata',
],
'debug': DEBUG,
}
}
]
MIDDLEWARE = [
'debug_toolbar.middleware.DebugToolbarMiddleware',
'django.middleware.security.SecurityMiddleware',
'whitenoise.middleware.WhiteNoiseMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware',
# Allow languages to be selected
'django.middleware.locale.LocaleMiddleware',
'django.middleware.http.ConditionalGetMiddleware',
'django.middleware.common.CommonMiddleware',
# Ensure a valid basket is added to the request instance for every request
'oscar.apps.basket.middleware.BasketMiddleware',
]
ROOT_URLCONF = 'urls'
# A sample logging configuration. The only tangible logging
# performed by this configuration is to send an email to
# the site admins on every HTTP 500 error.
# See http://docs.djangoproject.com/en/dev/topics/logging for
# more details on how to customize your logging configuration.
LOGGING = {
'version': 1,
'disable_existing_loggers': True,
'formatters': {
'verbose': {
'format': '%(levelname)s %(asctime)s %(module)s %(message)s',
},
'simple': {
'format': '[%(asctime)s] %(message)s'
},
},
'root': {
'level': 'DEBUG',
'handlers': ['console'],
},
'handlers': {
'null': {
'level': 'DEBUG',
'class': 'logging.NullHandler',
},
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
},
'loggers': {
'oscar': {
'level': 'DEBUG',
'propagate': True,
},
'oscar.catalogue.import': {
'handlers': ['console'],
'level': 'INFO',
'propagate': False,
},
'oscar.alerts': {
'handlers': ['null'],
'level': 'INFO',
'propagate': False,
},
# Django loggers
'django': {
'handlers': ['null'],
'propagate': True,
'level': 'INFO',
},
'django.request': {
'handlers': ['console'],
'level': 'ERROR',
'propagate': True,
},
'django.db.backends': {
'level': 'WARNING',
'propagate': True,
},
'django.security.DisallowedHost': {
'handlers': ['null'],
'propagate': False,
},
# Third party
'raven': {
'level': 'DEBUG',
'handlers': ['console'],
'propagate': False,
},
'sorl.thumbnail': {
'handlers': ['console'],
'propagate': True,
'level': 'INFO',
},
}
}
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django.contrib.sites',
'django.contrib.flatpages',
'oscar.config.Shop',
'oscar.apps.analytics.apps.AnalyticsConfig',
'oscar.apps.checkout.apps.CheckoutConfig',
'oscar.apps.address.apps.AddressConfig',
'oscar.apps.shipping.apps.ShippingConfig',
'oscar.apps.catalogue.apps.CatalogueConfig',
'oscar.apps.catalogue.reviews.apps.CatalogueReviewsConfig',
'oscar.apps.communication.apps.CommunicationConfig',
'oscar.apps.partner.apps.PartnerConfig',
'oscar.apps.basket.apps.BasketConfig',
'oscar.apps.payment.apps.PaymentConfig',
'oscar.apps.offer.apps.OfferConfig',
'oscar.apps.order.apps.OrderConfig',
'oscar.apps.customer.apps.CustomerConfig',
'oscar.apps.search.apps.SearchConfig',
'oscar.apps.voucher.apps.VoucherConfig',
'oscar.apps.wishlists.apps.WishlistsConfig',
'oscar.apps.dashboard.apps.DashboardConfig',
'oscar.apps.dashboard.reports.apps.ReportsDashboardConfig',
'oscar.apps.dashboard.users.apps.UsersDashboardConfig',
'oscar.apps.dashboard.orders.apps.OrdersDashboardConfig',
'oscar.apps.dashboard.catalogue.apps.CatalogueDashboardConfig',
'oscar.apps.dashboard.offers.apps.OffersDashboardConfig',
'oscar.apps.dashboard.partners.apps.PartnersDashboardConfig',
'oscar.apps.dashboard.pages.apps.PagesDashboardConfig',
'oscar.apps.dashboard.ranges.apps.RangesDashboardConfig',
'oscar.apps.dashboard.reviews.apps.ReviewsDashboardConfig',
'oscar.apps.dashboard.vouchers.apps.VouchersDashboardConfig',
'oscar.apps.dashboard.communications.apps.CommunicationsDashboardConfig',
'oscar.apps.dashboard.shipping.apps.ShippingDashboardConfig',
# 3rd-party apps that Oscar depends on
'widget_tweaks',
'haystack',
'treebeard',
'sorl.thumbnail',
'easy_thumbnails',
'django_tables2',
# Django apps that the sandbox depends on
'django.contrib.sitemaps',
# 3rd-party apps that the sandbox depends on
'django_extensions',
'debug_toolbar',
]
# Add Oscar's custom auth backend so users can sign in using their email
# address.
AUTHENTICATION_BACKENDS = (
'oscar.apps.customer.auth_backends.EmailBackend',
'django.contrib.auth.backends.ModelBackend',
)
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
'OPTIONS': {
'min_length': 9,
}
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
]
LOGIN_REDIRECT_URL = '/'
APPEND_SLASH = True
# ====================
# Messages contrib app
# ====================
from django.contrib.messages import constants as messages
MESSAGE_TAGS = {
messages.ERROR: 'danger'
}
# Haystack settings
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'PATH': location('whoosh_index'),
},
}
# Here's a sample Haystack config for Solr 6.x (which is recommended)
# HAYSTACK_CONNECTIONS = {
# 'default': {
# 'ENGINE': 'haystack.backends.solr_backend.SolrEngine',
# 'URL': 'http://127.0.0.1:8983/solr/sandbox',
# 'ADMIN_URL': 'http://127.0.0.1:8983/solr/admin/cores',
# 'INCLUDE_SPELLING': True,
# }
# }
# =============
# Debug Toolbar
# =============
INTERNAL_IPS = ['127.0.0.1', '::1']
# ==============
# Oscar settings
# ==============
#from oscar.defaults import *
# Meta
# ====
OSCAR_SHOP_NAME = 'Nucamp Books'
OSCAR_SHOP_TAGLINE = 'Using PostgreSQL'
OSCAR_RECENTLY_VIEWED_PRODUCTS = 20
OSCAR_ALLOW_ANON_CHECKOUT = True
# Order processing
# ================
# Sample order/line status settings. This is quite simplistic. It's like you'll
# want to override the set_status method on the order object to do more
# sophisticated things.
OSCAR_INITIAL_ORDER_STATUS = 'Pending'
OSCAR_INITIAL_LINE_STATUS = 'Pending'
# This dict defines the new order statuses than an order can move to
OSCAR_ORDER_STATUS_PIPELINE = {
'Pending': ('Being processed', 'Cancelled',),
'Being processed': ('Complete', 'Cancelled',),
'Cancelled': (),
'Complete': (),
}
# This dict defines the line statuses that will be set when an order's status
# is changed
OSCAR_ORDER_STATUS_CASCADE = {
'Being processed': 'Being processed',
'Cancelled': 'Cancelled',
'Complete': 'Shipped',
}
# Sorl
# ====
THUMBNAIL_DEBUG = DEBUG
THUMBNAIL_KEY_PREFIX = 'oscar-sandbox'
THUMBNAIL_KVSTORE = env(
'THUMBNAIL_KVSTORE',
default='sorl.thumbnail.kvstores.cached_db_kvstore.KVStore')
THUMBNAIL_REDIS_URL = env('THUMBNAIL_REDIS_URL', default=None)
# Django 1.6 has switched to JSON serializing for security reasons, but it does not
# serialize Models. We should resolve this by extending the
# django/core/serializers/json.Serializer to have the `dumps` function. Also
# in tests/config.py
SESSION_SERIALIZER = 'django.contrib.sessions.serializers.JSONSerializer'
# Security
SECURE_SSL_REDIRECT = env.bool('SECURE_SSL_REDIRECT', default=False)
SECURE_HSTS_SECONDS = env.int('SECURE_HSTS_SECONDS', default=0)
SECURE_CONTENT_TYPE_NOSNIFF = True
SECURE_BROWSER_XSS_FILTER = True
# Try and import local settings which can be used to override any of the above.
try:
from settings_local import *
except ImportError:
pass
| 30.684096 | 98 | 0.649176 |
4a1fb1a14912efecafb4c4d771e4255e4e7648b0 | 113 | py | Python | PopulationSampling/simplerandom.py | Ra654/Stats-Calculator | 039ecaba3f8bb3ef69bb29e27f9c32d0fe2096b0 | [
"MIT"
] | null | null | null | PopulationSampling/simplerandom.py | Ra654/Stats-Calculator | 039ecaba3f8bb3ef69bb29e27f9c32d0fe2096b0 | [
"MIT"
] | null | null | null | PopulationSampling/simplerandom.py | Ra654/Stats-Calculator | 039ecaba3f8bb3ef69bb29e27f9c32d0fe2096b0 | [
"MIT"
] | null | null | null | from random import sample
def ran_sample(n):
list1 = [1, 2, 3, 4, 5]
n = sample(list1, 3)
return n
| 14.125 | 27 | 0.584071 |
4a1fb33aa8819cc49de6b304253fb9969d72449b | 3,445 | py | Python | monitor.py | Dexter-Maine/Eeveaem | ba9b551971d64274a7e5dd5ac87f820a96ab5060 | [
"MIT"
] | null | null | null | monitor.py | Dexter-Maine/Eeveaem | ba9b551971d64274a7e5dd5ac87f820a96ab5060 | [
"MIT"
] | null | null | null | monitor.py | Dexter-Maine/Eeveaem | ba9b551971d64274a7e5dd5ac87f820a96ab5060 | [
"MIT"
] | null | null | null | #!/usr/bin/python3
# Vivian Ethereum Address Monitor System Example.
import time
import os
from vweb3 import *
balance = web3.eth.getBalance
transactions = web3.eth.getTransactionCount
counter = 0
Menu = True
Monitor = False
address = ''
def _balance(address):
bal = balance(address)
return bal
def _transactionCount(address):
tranCount = transactions(address)
return tranCount
def _setAddress():
global address
global Menu
global Monitor
print('Please Input The Address You Are Watching.')
address = input('>>: ')
if len(address) != 42:
print('You Need To Use A Proper Ethereum Address Please.')
_setAddress()
for i in address:
if i not in Allowed_Address_Characters:
print('[{}] Is Not Allowed Within A Ethereum Address.'.format(i))
print('Watching [{}] For Transactions And Balance Difference.'.format(address))
try:
AddressMap = pickle.load(open('AddressMap.vnm','rb'))
if address not in AddressMap:
AddressMap[address] = dict()
AddressMap[address]['Checks'] = 0
AddressMap[address]['Previous Balance'] = _balance(address)
AddressMap[address]['Previous Transaction Count'] = _transactionCount(address)
pickle.dump(AddressMap,open('AddressMap.vnm','wb'))
Menu = False
Monitor = True
else:
AddressMap[address]['Checks'] += 1
if _balance(address) != AddressMap[address]['Previous Balance']:
AddressMap[address]['Previous Balance'] = _balance(address)
if _transactionCount(address) != AddressMap[address]['Previous Transaction Count']:
AddressMap[address]['Previous Transaction Count'] = _transactionCount(address)
pickle.dump(AddressMap,open('AddressMap.vnm','wb'))
Menu = False
except Exception as File_Needed:
AddressMap[address] = dict()
AddressMap[address]['Checks'] = 0
AddressMap[address]['Previous Balance'] = _balance(address)
AddressMap[address]['Previous Transaction Count'] = _transactionCount(address)
pickle.dump(AddressMap,open('AddressMap.vnm','wb'))
Menu = False
Monitor = True
while Menu:
print('Welcome To The Eeveaem Address Auto Monitoring System.')
_setAddress()
while Monitor:
time.sleep(INTERVAL)
print('Watching [{}] For Transactions And Balance Difference.'.format(address))
try:
AddressMap = pickle.load(open('AddressMap.vnm','rb'))
if address not in AddressMap:
AddressMap[address] = dict()
AddressMap[address]['Checks'] = 0
AddressMap[address]['Previous Balance'] = _balance(address)
AddressMap[address]['Previous Transaction Count'] = _transactionCount(address)
pickle.dump(AddressMap,open('AddressMap.vnm','wb'))
Menu = False
Monitor = True
else:
AddressMap[address]['Checks'] += 1
if _balance(address) != AddressMap[address]['Previous Balance']:
AddressMap[address]['Previous Balance'] = _balance(address)
if _transactionCount(address) != AddressMap[address]['Previous Transaction Count']:
AddressMap[address]['Previous Transaction Count'] = _transactionCount(address)
pickle.dump(AddressMap,open('AddressMap.vnm','wb'))
Menu = False
except Exception as File_Needed:
AddressMap[address] = dict()
AddressMap[address]['Checks'] = 0
AddressMap[address]['Previous Balance'] = _balance(address)
AddressMap[address]['Previous Transaction Count'] = _transactionCount(address)
pickle.dump(AddressMap,open('AddressMap.vnm','wb'))
Menu = False
Monitor = True
| 35.515464 | 87 | 0.709724 |
4a1fb35f7da6c0748c77929e8499e520e9861c5d | 5,301 | bzl | Python | struct2tensor/struct2tensor.bzl | KendallPark/struct2tensor | 7e42ed9938dfb88aa451f07b943b6308cd758411 | [
"Apache-2.0"
] | null | null | null | struct2tensor/struct2tensor.bzl | KendallPark/struct2tensor | 7e42ed9938dfb88aa451f07b943b6308cd758411 | [
"Apache-2.0"
] | null | null | null | struct2tensor/struct2tensor.bzl | KendallPark/struct2tensor | 7e42ed9938dfb88aa451f07b943b6308cd758411 | [
"Apache-2.0"
] | null | null | null | # Copyright 2019 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Bazel macros used in OSS."""
load("@com_google_protobuf//:protobuf.bzl", "cc_proto_library", "py_proto_library")
def s2t_pytype_library(
name,
srcs = [],
deps = [],
srcs_version = "PY2AND3",
testonly = False):
native.py_library(name = name, srcs = srcs, deps = deps, testonly = testonly)
def s2t_proto_library(
name,
srcs = [],
has_services = False,
deps = [],
visibility = None,
testonly = 0,
cc_grpc_version = None,
cc_api_version = 2):
"""Opensource proto_library.
Args:
name: the name of the build target.
srcs: .proto file sources.
has_services: no effect
deps: dependencies
visibility: visibility constraints
testonly: if true, only use in tests.
cc_grpc_version: If set, use grpc plugin.
cc_api_version: The version of the API in C++.
"""
_ignore = [has_services]
native.filegroup(
name = name + "_proto_srcs",
srcs = srcs,
testonly = testonly,
)
use_grpc_plugin = None
if cc_grpc_version:
use_grpc_plugin = True
# TODO(martinz): replace with proto_library, when that works.
cc_proto_library(
name = name,
srcs = srcs,
deps = deps,
#cc_api_version = cc_api_version,
cc_libs = ["@com_google_protobuf//:protobuf"],
protoc = "@com_google_protobuf//:protoc",
default_runtime = "@com_google_protobuf//:protobuf",
testonly = testonly,
visibility = visibility,
)
DYNAMIC_COPTS = [
"-pthread",
"-std=c++11",
"-D_GLIBCXX_USE_CXX11_ABI=0",
]
DYNAMIC_DEPS = ["@local_config_tf//:libtensorflow_framework", "@local_config_tf//:tf_header_lib"]
def s2t_dynamic_binary(name, deps):
"""Creates a .so file intended for linking with tensorflow_framework.so."""
native.cc_binary(
name = name,
copts = DYNAMIC_COPTS,
linkshared = 1,
deps = deps + DYNAMIC_DEPS,
)
def s2t_dynamic_library(
name,
srcs,
deps = None):
"""Creates a static library intended for linking with tensorflow_framework.so."""
true_deps = [] if deps == None else deps
native.cc_library(
name = name,
srcs = srcs,
copts = DYNAMIC_COPTS,
deps = true_deps + DYNAMIC_DEPS,
)
def s2t_gen_op_wrapper_py(
name,
out,
static_library,
dynamic_library):
"""Applies gen_op_wrapper_py externally.
Instead of a static library, links to a dynamic library.
Instead of generating a file, one is provided.
Args:
name: name of the target
out: a file that must be provided. Included as source.
static_library: a static library (ignored).
dynamic_library: a dynamic library included as data.
"""
native.py_library(
name = name,
srcs = ([
out,
]),
data = [
dynamic_library,
],
srcs_version = "PY2AND3",
)
def s2t_proto_library_cc(
name,
srcs = [],
has_services = False,
deps = [],
visibility = None,
testonly = 0,
cc_grpc_version = None):
"""Opensource cc_proto_library.
Args:
name: name of library
srcs: .proto sources
has_services: no effect
deps: dependencies
visibility: visibility constraints
testonly: if true, can only be used in tests.
cc_grpc_version: if set, use_grpc_version is True.
"""
_ignore = [has_services]
native.filegroup(
name = name + "_proto_srcs",
srcs = srcs,
testonly = testonly,
)
use_grpc_plugin = None
if cc_grpc_version:
use_grpc_plugin = True
cc_proto_library(
name = name,
srcs = srcs,
deps = deps,
cc_libs = ["@com_google_protobuf//:protobuf"],
protoc = "@com_google_protobuf//:protoc",
default_runtime = "@com_google_protobuf//:protobuf",
use_grpc_plugin = use_grpc_plugin,
testonly = testonly,
visibility = visibility,
)
def s2t_proto_library_py(name, proto_library, srcs = [], deps = [], oss_deps = [], visibility = None, testonly = 0, api_version = None):
"""Opensource py_proto_library."""
_ignore = [proto_library, api_version]
py_proto_library(
name = name,
srcs = srcs,
srcs_version = "PY2AND3",
deps = ["@com_google_protobuf//:protobuf_python"] + oss_deps,
default_runtime = "@com_google_protobuf//:protobuf_python",
protoc = "@com_google_protobuf//:protoc",
visibility = visibility,
testonly = testonly,
)
| 28.967213 | 136 | 0.616676 |
4a1fb4cba5386f4d2ddb73e3c7f8c3c575ce5c3e | 317 | py | Python | RealAppAnalysis/test dump/browsers/mozilla/mozilla_performance_analyzer_test.py | benjaminy/Charcoal | a4117a5e373faff839a78afc5183906ae2a81445 | [
"MIT"
] | 4 | 2016-01-16T02:45:24.000Z | 2017-07-19T18:14:18.000Z | RealAppAnalysis/test dump/browsers/mozilla/mozilla_performance_analyzer_test.py | benjaminy/Charcoal | a4117a5e373faff839a78afc5183906ae2a81445 | [
"MIT"
] | null | null | null | RealAppAnalysis/test dump/browsers/mozilla/mozilla_performance_analyzer_test.py | benjaminy/Charcoal | a4117a5e373faff839a78afc5183906ae2a81445 | [
"MIT"
] | null | null | null | import datautil
import os
getKeyManually = False;
trace_profile = datautil.getJSONDataFromFile();
print(trace_profile.keys());
if(getKeyManually):
key = input("Key: ");
datautil.toTxt(trace_profile[key], "out_" + key);
else:
key = "meta"
datautil.toTxt(trace_profile[key], "out_" + key); | 24.384615 | 54 | 0.671924 |
4a1fb66bfc39465cc927b123c4b99501a170fc77 | 7,205 | py | Python | Stage 1/get_metadata.py | diegommezp28/NLP_202110 | 0ffb15245a0b2afb568ddf5a621f29a5d0318d7a | [
"MIT"
] | null | null | null | Stage 1/get_metadata.py | diegommezp28/NLP_202110 | 0ffb15245a0b2afb568ddf5a621f29a5d0318d7a | [
"MIT"
] | null | null | null | Stage 1/get_metadata.py | diegommezp28/NLP_202110 | 0ffb15245a0b2afb568ddf5a621f29a5d0318d7a | [
"MIT"
] | 1 | 2021-05-30T01:09:44.000Z | 2021-05-30T01:09:44.000Z | #!/usr/bin/python
# -*- coding: utf-8 -*-
#
# /$$$$$$ /$$ /$$ /$$ /$$ /$$$$$$$$
# /$$__ $$| $$$ /$$$| $$$ /$$$|__ $$__/
# | $$ \__/| $$$$ /$$$$| $$$$ /$$$$ | $$
# | $$$$$$ | $$ $$/$$ $$| $$ $$/$$ $$ | $$
# \____ $$| $$ $$$| $$| $$ $$$| $$ | $$
# /$$ \ $$| $$\ $ | $$| $$\ $ | $$ | $$
# | $$$$$$/| $$ \/ | $$| $$ \/ | $$ | $$
# \______/ |__/ |__/|__/ |__/ |__/
#
#
# Developed during Biomedical Hackathon 6 - http://blah6.linkedannotation.org/
# Authors: Ramya Tekumalla, Javad Asl, Juan M. Banda
# Contributors: Kevin B. Cohen, Joanthan Lucero
import tweepy
import json
import math
import glob
import csv
import zipfile
import zlib
import argparse
import os
import os.path as osp
import pandas as pd
from tweepy import TweepError
from time import sleep
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-o", "--outputfile", help="Output file name with extension")
parser.add_argument("-i", "--inputfile", help="Input file name with extension")
parser.add_argument("-k", "--keyfile", help="Json api key file name")
parser.add_argument("-c", "--idcolumn", help="tweet id column in the input file, string name")
parser.add_argument("-m", "--mode", help="Enter e for extended mode ; else the program would consider default compatible mode")
args = parser.parse_args()
if args.inputfile is None or args.outputfile is None:
parser.error("please add necessary arguments")
if args.keyfile is None:
parser.error("please add a keyfile argument")
with open(args.keyfile) as f:
keys = json.load(f)
auth = tweepy.OAuthHandler(keys['consumer_key'], keys['consumer_secret'])
auth.set_access_token(keys['access_token'], keys['access_token_secret'])
api = tweepy.API(auth, wait_on_rate_limit=True, retry_delay=60*3, retry_count=5,retry_errors=set([401, 404, 500, 503]), wait_on_rate_limit_notify=True)
if api.verify_credentials() == False:
print("Your twitter api credentials are invalid")
sys.exit()
else:
print("Your twitter api credentials are valid.")
output_file = args.outputfile
hydration_mode = args.mode
output_file_noformat = output_file.split(".",maxsplit=1)[0]
print(output_file)
output_file = '{}'.format(output_file)
output_file_short = '{}_short.json'.format(output_file_noformat)
compression = zipfile.ZIP_DEFLATED
ids = []
if '.tsv' in args.inputfile:
inputfile_data = pd.read_csv(args.inputfile, sep='\t')
print('tab seperated file, using \\t delimiter')
elif '.csv' in args.inputfile:
inputfile_data = pd.read_csv(args.inputfile)
elif '.txt' in args.inputfile:
inputfile_data = pd.read_csv(args.inputfile, sep='\n', header=None, names= ['tweet_id'] )
print(inputfile_data)
if not isinstance(args.idcolumn, type(None)):
inputfile_data = inputfile_data.set_index(args.idcolumn)
else:
inputfile_data = inputfile_data.set_index('tweet_id')
ids = list(inputfile_data.index)
print('total ids: {}'.format(len(ids)))
start = 0
end = 100
limit = len(ids)
i = int(math.ceil(float(limit) / 100))
last_tweet = None
if osp.isfile(args.outputfile) and osp.getsize(args.outputfile) > 0:
with open(output_file, 'rb') as f:
#may be a large file, seeking without iterating
f.seek(-2, os.SEEK_END)
while f.read(1) != b'\n':
f.seek(-2, os.SEEK_CUR)
last_line = f.readline().decode()
last_tweet = json.loads(last_line)
start = ids.index(last_tweet['id'])
end = start+100
i = int(math.ceil(float(limit-start) / 100))
print('metadata collection complete')
print('creating master json file')
try:
with open(output_file, 'a') as outfile:
for go in range(i):
print('currently getting {} - {}'.format(start, end))
sleep(6) # needed to prevent hitting API rate limit
id_batch = ids[start:end]
start += 100
end += 100
backOffCounter = 1
while True:
try:
if hydration_mode == "e":
tweets = api.statuses_lookup(id_batch,tweet_mode = "extended")
else:
tweets = api.statuses_lookup(id_batch)
break
except tweepy.TweepError as ex:
print('Caught the TweepError exception:\n %s' % ex)
sleep(30*backOffCounter) # sleep a bit to see if connection Error is resolved before retrying
backOffCounter += 1 # increase backoff
continue
for tweet in tweets:
json.dump(tweet._json, outfile)
outfile.write('\n')
except:
print('exception: continuing to zip the file')
print('creating ziped master json file')
zf = zipfile.ZipFile('{}.zip'.format(output_file_noformat), mode='w')
zf.write(output_file, compress_type=compression)
zf.close()
def is_retweet(entry):
return 'retweeted_status' in entry.keys()
def get_source(entry):
if '<' in entry["source"]:
return entry["source"].split('>')[1].split('<')[0]
else:
return entry["source"]
print('creating minimized json master file')
with open(output_file_short, 'w') as outfile:
with open(output_file) as json_data:
for tweet in json_data:
data = json.loads(tweet)
if hydration_mode == "e":
text = data["full_text"]
else:
text = data["text"]
t = {
"created_at": data["created_at"],
"text": text,
"in_reply_to_screen_name": data["in_reply_to_screen_name"],
"retweet_count": data["retweet_count"],
"favorite_count": data["favorite_count"],
"source": get_source(data),
"id_str": data["id_str"],
"is_retweet": is_retweet(data)
}
json.dump(t, outfile)
outfile.write('\n')
f = csv.writer(open('{}.csv'.format(output_file_noformat), 'w'))
print('creating CSV version of minimized json master file')
fields = ["favorite_count", "source", "text", "in_reply_to_screen_name", "is_retweet", "created_at", "retweet_count", "id_str"]
f.writerow(fields)
with open(output_file_short) as master_file:
for tweet in master_file:
data = json.loads(tweet)
f.writerow([data["favorite_count"], data["source"], data["text"].encode('utf-8'), data["in_reply_to_screen_name"], data["is_retweet"], data["created_at"], data["retweet_count"], data["id_str"].encode('utf-8')])
# main invoked here
main()
| 38.529412 | 222 | 0.559056 |
4a1fb6766ee592caea078ad40016aa4a9a9c8264 | 43 | py | Python | hyperion/deprec/keras1/__init__.py | jsalt2019-diadet/hyperion | 14a11436d62f3c15cd9b1f70bcce3eafbea2f753 | [
"Apache-2.0"
] | 9 | 2019-09-22T05:19:59.000Z | 2022-03-05T18:03:37.000Z | hyperion/deprec/keras1/__init__.py | jsalt2019-diadet/hyperion | 14a11436d62f3c15cd9b1f70bcce3eafbea2f753 | [
"Apache-2.0"
] | null | null | null | hyperion/deprec/keras1/__init__.py | jsalt2019-diadet/hyperion | 14a11436d62f3c15cd9b1f70bcce3eafbea2f753 | [
"Apache-2.0"
] | 4 | 2019-10-10T06:34:05.000Z | 2022-03-05T18:03:56.000Z | from __future__ import absolute_import
| 7.166667 | 38 | 0.813953 |
4a1fb716dc2f911df12cc57dbdb176deeca4d523 | 12,879 | py | Python | manila/share/drivers/zfssa/restclient.py | nidhimittalhada/access_group_repo | 62f3365bc5fb728fcca692a9b3977690fabcd78f | [
"Apache-2.0"
] | 1 | 2020-12-04T02:46:42.000Z | 2020-12-04T02:46:42.000Z | manila/share/drivers/zfssa/restclient.py | nidhimittalhada/access_group_repo | 62f3365bc5fb728fcca692a9b3977690fabcd78f | [
"Apache-2.0"
] | 5 | 2015-08-13T15:17:28.000Z | 2016-08-02T02:55:01.000Z | manila/share/drivers/zfssa/restclient.py | nidhimittalhada/access_group_repo | 62f3365bc5fb728fcca692a9b3977690fabcd78f | [
"Apache-2.0"
] | 3 | 2019-05-03T12:32:47.000Z | 2021-01-30T20:26:19.000Z | # Copyright (c) 2014, Oracle and/or its affiliates. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
"""
ZFS Storage Appliance REST API Client Programmatic Interface
TODO(diemtran): this module needs to be placed in a library common to OpenStack
services. When this happens, the file should be removed from Manila code
base and imported from the relevant library.
"""
import time
from oslo_serialization import jsonutils
import six
from six.moves import http_client
# pylint: disable=E0611,F0401
from six.moves.urllib import error as urlerror
from six.moves.urllib import request as urlrequest
def log_debug_msg(obj, message):
if obj.log_function:
obj.log_function(message)
class Status(object):
"""Result HTTP Status."""
#: Request return OK
OK = http_client.OK # pylint: disable=invalid-name
#: New resource created successfully
CREATED = http_client.CREATED
#: Command accepted
ACCEPTED = http_client.ACCEPTED
#: Command returned OK but no data will be returned
NO_CONTENT = http_client.NO_CONTENT
#: Bad Request
BAD_REQUEST = http_client.BAD_REQUEST
#: User is not authorized
UNAUTHORIZED = http_client.UNAUTHORIZED
#: The request is not allowed
FORBIDDEN = http_client.FORBIDDEN
#: The requested resource was not found
NOT_FOUND = http_client.NOT_FOUND
#: The request is not allowed
NOT_ALLOWED = http_client.METHOD_NOT_ALLOWED
#: Request timed out
TIMEOUT = http_client.REQUEST_TIMEOUT
#: Invalid request
CONFLICT = http_client.CONFLICT
#: Service Unavailable
BUSY = http_client.SERVICE_UNAVAILABLE
class RestResult(object):
"""Result from a REST API operation."""
def __init__(self, logfunc=None, response=None, err=None):
"""Initialize a RestResult containing the results from a REST call.
:param logfunc: debug log function.
:param response: HTTP response.
:param err: HTTP error.
"""
self.response = response
self.log_function = logfunc
self.error = err
self.data = ""
self.status = 0
if self.response:
self.status = self.response.getcode()
result = self.response.read()
while result:
self.data += result
result = self.response.read()
if self.error:
self.status = self.error.code
self.data = http_client.responses[self.status]
log_debug_msg(self, 'Response code: %s' % self.status)
log_debug_msg(self, 'Response data: %s' % self.data)
def get_header(self, name):
"""Get an HTTP header with the given name from the results.
:param name: HTTP header name.
:return: The header value or None if no value is found.
"""
if self.response is None:
return None
info = self.response.info()
return info.getheader(name)
class RestClientError(Exception):
"""Exception for ZFS REST API client errors."""
def __init__(self, status, name="ERR_INTERNAL", message=None):
"""Create a REST Response exception.
:param status: HTTP response status.
:param name: The name of the REST API error type.
:param message: Descriptive error message returned from REST call.
"""
super(RestClientError, self).__init__(message)
self.code = status
self.name = name
self.msg = message
if status in http_client.responses:
self.msg = http_client.responses[status]
def __str__(self):
return "%d %s %s" % (self.code, self.name, self.msg)
class RestClientURL(object): # pylint: disable=R0902
"""ZFSSA urllib client."""
def __init__(self, url, logfunc=None, **kwargs):
"""Initialize a REST client.
:param url: The ZFSSA REST API URL.
:key session: HTTP Cookie value of x-auth-session obtained from a
normal BUI login.
:key timeout: Time in seconds to wait for command to complete.
(Default is 60 seconds).
"""
self.url = url
self.log_function = logfunc
self.local = kwargs.get("local", False)
self.base_path = kwargs.get("base_path", "/api")
self.timeout = kwargs.get("timeout", 60)
self.headers = None
if kwargs.get('session'):
self.headers['x-auth-session'] = kwargs.get('session')
self.headers = {"content-type": "application/json"}
self.do_logout = False
self.auth_str = None
def _path(self, path, base_path=None):
"""Build rest url path."""
if path.startswith("http://") or path.startswith("https://"):
return path
if base_path is None:
base_path = self.base_path
if not path.startswith(base_path) and not (
self.local and ("/api" + path).startswith(base_path)):
path = "%s%s" % (base_path, path)
if self.local and path.startswith("/api"):
path = path[4:]
return self.url + path
def _authorize(self):
"""Performs authorization setting x-auth-session."""
self.headers['authorization'] = 'Basic %s' % self.auth_str
if 'x-auth-session' in self.headers:
del self.headers['x-auth-session']
try:
result = self.post("/access/v1")
del self.headers['authorization']
if result.status == http_client.CREATED:
self.headers['x-auth-session'] = \
result.get_header('x-auth-session')
self.do_logout = True
log_debug_msg(self, ('ZFSSA version: %s')
% result.get_header('x-zfssa-version'))
elif result.status == http_client.NOT_FOUND:
raise RestClientError(result.status, name="ERR_RESTError",
message=("REST Not Available:"
"Please Upgrade"))
except RestClientError as err:
del self.headers['authorization']
raise err
def login(self, auth_str):
"""Login to an appliance using a user name and password.
Start a session like what is done logging into the BUI. This is not a
requirement to run REST commands, since the protocol is stateless.
What is does is set up a cookie session so that some server side
caching can be done. If login is used remember to call logout when
finished.
:param auth_str: Authorization string (base64).
"""
self.auth_str = auth_str
self._authorize()
def logout(self):
"""Logout of an appliance."""
result = None
try:
result = self.delete("/access/v1", base_path="/api")
except RestClientError:
pass
self.headers.clear()
self.do_logout = False
return result
def islogin(self):
"""return if client is login."""
return self.do_logout
@staticmethod
def mkpath(*args, **kwargs):
"""Make a path?query string for making a REST request.
:cmd_params args: The path part.
:cmd_params kwargs: The query part.
"""
buf = six.StringIO()
query = "?"
for arg in args:
buf.write("/")
buf.write(arg)
for k in kwargs:
buf.write(query)
if query == "?":
query = "&"
buf.write(k)
buf.write("=")
buf.write(kwargs[k])
return buf.getvalue()
# pylint: disable=R0912
def request(self, path, request, body=None, **kwargs):
"""Make an HTTP request and return the results.
:param path: Path used with the initialized URL to make a request.
:param request: HTTP request type (GET, POST, PUT, DELETE).
:param body: HTTP body of request.
:key accept: Set HTTP 'Accept' header with this value.
:key base_path: Override the base_path for this request.
:key content: Set HTTP 'Content-Type' header with this value.
"""
out_hdrs = dict.copy(self.headers)
if kwargs.get("accept"):
out_hdrs['accept'] = kwargs.get("accept")
if body:
if isinstance(body, dict):
body = six.text_type(jsonutils.dumps(body))
if body and len(body):
out_hdrs['content-length'] = len(body)
zfssaurl = self._path(path, kwargs.get("base_path"))
req = urlrequest.Request(zfssaurl, body, out_hdrs)
req.get_method = lambda: request
maxreqretries = kwargs.get("maxreqretries", 10)
retry = 0
response = None
log_debug_msg(self, 'Request: %s %s' % (request, zfssaurl))
log_debug_msg(self, 'Out headers: %s' % out_hdrs)
if body and body != '':
log_debug_msg(self, 'Body: %s' % body)
while retry < maxreqretries:
try:
response = urlrequest.urlopen(req, timeout=self.timeout)
except urlerror.HTTPError as err:
if err.code == http_client.NOT_FOUND:
log_debug_msg(self, 'REST Not Found: %s' % err.code)
else:
log_debug_msg(self, ('REST Not Available: %s') % err.code)
if (err.code == http_client.SERVICE_UNAVAILABLE and
retry < maxreqretries):
retry += 1
time.sleep(1)
log_debug_msg(self, ('Server Busy retry request: %s')
% retry)
continue
if ((err.code == http_client.UNAUTHORIZED or
err.code == http_client.INTERNAL_SERVER_ERROR) and
'/access/v1' not in zfssaurl):
try:
log_debug_msg(self, ('Authorizing request: '
'%(zfssaurl)s'
'retry: %(retry)d .')
% {'zfssaurl': zfssaurl,
'retry': retry})
self._authorize()
req.add_header('x-auth-session',
self.headers['x-auth-session'])
except RestClientError:
log_debug_msg(self, ('Cannot authorize.'))
retry += 1
time.sleep(1)
continue
return RestResult(self.log_function, err=err)
except urlerror.URLError as err:
log_debug_msg(self, ('URLError: %s') % err.reason)
raise RestClientError(-1, name="ERR_URLError",
message=err.reason)
break
if ((response and
response.getcode() == http_client.SERVICE_UNAVAILABLE) and
retry >= maxreqretries):
raise RestClientError(response.getcode(), name="ERR_HTTPError",
message="REST Not Available: Disabled")
return RestResult(self.log_function, response=response)
def get(self, path, **kwargs):
"""Make an HTTP GET request.
:param path: Path to resource.
"""
return self.request(path, "GET", **kwargs)
def post(self, path, body="", **kwargs):
"""Make an HTTP POST request.
:param path: Path to resource.
:param body: Post data content.
"""
return self.request(path, "POST", body, **kwargs)
def put(self, path, body="", **kwargs):
"""Make an HTTP PUT request.
:param path: Path to resource.
:param body: Put data content.
"""
return self.request(path, "PUT", body, **kwargs)
def delete(self, path, **kwargs):
"""Make an HTTP DELETE request.
:param path: Path to resource that will be deleted.
"""
return self.request(path, "DELETE", **kwargs)
def head(self, path, **kwargs):
"""Make an HTTP HEAD request.
:param path: Path to resource.
"""
return self.request(path, "HEAD", **kwargs)
| 34.808108 | 79 | 0.57388 |
4a1fb720c221e2a8d606329d400989605fd57c72 | 1,570 | py | Python | st2common/st2common/models/db/timer.py | magiceses/st2 | a048ba92a8a1a5d272f277bf8fab0951df903306 | [
"Apache-2.0"
] | null | null | null | st2common/st2common/models/db/timer.py | magiceses/st2 | a048ba92a8a1a5d272f277bf8fab0951df903306 | [
"Apache-2.0"
] | 2 | 2020-03-04T08:33:36.000Z | 2020-03-04T08:34:14.000Z | st2common/st2common/models/db/timer.py | magiceses/st2 | a048ba92a8a1a5d272f277bf8fab0951df903306 | [
"Apache-2.0"
] | null | null | null | # Licensed to the StackStorm, Inc ('StackStorm') under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import mongoengine as me
from st2common.models.db import stormbase
from st2common.constants.types import ResourceType
class TimerDB(stormbase.StormFoundationDB, stormbase.UIDFieldMixin):
"""
Note: Right now timer is a meta model which is not persisted in the database (it's only used
for RBAC purposes).
Attribute:
name: Timer name - maps to the URL path (e.g. st2/ or my/webhook/one).
"""
RESOURCE_TYPE = ResourceType.TIMER
UID_FIELDS = ['pack', 'name']
name = me.StringField(required=True)
pack = me.StringField(required=True, unique_with='name')
type = me.StringField()
parameters = me.DictField()
def __init__(self, *args, **values):
super(TimerDB, self).__init__(*args, **values)
self.uid = self.get_uid()
| 37.380952 | 96 | 0.729299 |
4a1fb77e7008dafe265634d583cd39d9cfb89725 | 2,522 | py | Python | Project 3 - ROBDD/main.py | YC-Vertex/VLSI-EDA-Projects | ab3ff2d57d1ad0960c736758182d657d655f8b3e | [
"MIT"
] | 3 | 2020-12-08T18:32:08.000Z | 2021-01-10T16:31:29.000Z | Project 3 - ROBDD/main.py | YC-Vertex/VLSI-EDA-Projects | ab3ff2d57d1ad0960c736758182d657d655f8b3e | [
"MIT"
] | null | null | null | Project 3 - ROBDD/main.py | YC-Vertex/VLSI-EDA-Projects | ab3ff2d57d1ad0960c736758182d657d655f8b3e | [
"MIT"
] | null | null | null | import sys
from prj3_robdd import *
def Project3(argc, argv):
if argc >= 2:
infile = open(argv[1], 'r')
dummy = infile.readline()
count = int(infile.readline())
varSeq = infile.readline().split()
for i in range(len(varSeq)):
varSeq[i] = varSeq[i].strip()
R = ROBDD(varSeq)
for i in range(count):
instr = infile.readline()
Xstr = instr.split('=')[0].strip()
iteParam = instr.split('(')[1].split(')')[0].split(',')
for i in range(len(iteParam)):
iteParam[i] = iteParam[i].strip()
p = iteParam[i]
if '+' in p:
Fstr, var = str.split(p, '+')
R.addCofFormula(Fstr, var, '+')
elif '-' in p:
Fstr, var = str.split(p, '-')
R.addCofFormula(Fstr, var, '-')
R.addIteFormula(Xstr, iteParam[0], iteParam[1], iteParam[2])
R.showFormula(Xstr)
print('---------- Print ----------')
while True:
instr = infile.readline()
if len(instr.split()) < 2:
break
Xstr = instr.split()[1].strip()
R.showFormula(Xstr)
print('---------------------------')
else:
dummy = input()
count = int(input())
varSeq = input().split()
for i in range(len(varSeq)):
varSeq[i] = varSeq[i].strip()
R = ROBDD(varSeq)
for i in range(count):
instr = input()
Xstr = instr.split('=')[0].strip()
iteParam = instr.split('(')[1].split(')')[0].split(',')
for i in range(len(iteParam)):
iteParam[i] = iteParam[i].strip()
p = iteParam[i]
if '+' in p:
Fstr, var = str.split(p, '+')
R.addCofFormula(Fstr, var, '+')
elif '-' in p:
Fstr, var = str.split(p, '-')
R.addCofFormula(Fstr, var, '-')
R.addIteFormula(Xstr, iteParam[0], iteParam[1], iteParam[2])
R.showFormula(Xstr)
print('---------- Print ----------')
while True:
instr = input()
if len(instr.split()) < 2:
break
Xstr = instr.split()[1].strip()
R.showFormula(Xstr)
print('---------------------------')
if __name__ == '__main__':
Project3(len(sys.argv), sys.argv) | 33.626667 | 72 | 0.428628 |
4a1fb8540b6ee96ce02db73703cf678c812de175 | 2,024 | py | Python | 01_02_using_bgd/01_using_bgd.py | rubio/pygame-tutorials | 9e6269f8a4ac7650921bab53daca056e44607a64 | [
"Apache-2.0"
] | null | null | null | 01_02_using_bgd/01_using_bgd.py | rubio/pygame-tutorials | 9e6269f8a4ac7650921bab53daca056e44607a64 | [
"Apache-2.0"
] | null | null | null | 01_02_using_bgd/01_using_bgd.py | rubio/pygame-tutorials | 9e6269f8a4ac7650921bab53daca056e44607a64 | [
"Apache-2.0"
] | null | null | null | #!/usr/bin/env python
#
#
#
#
#
# documentation string of this module
"""
tutorial 01: first blit
"""
# some informational variables
__author__ = "$Author: DR0ID $"
__version__ = "$Revision: 109 $"
__date__ = "$Date: 2007-04-03 18:00:40 +0200 (Di, 03 Apr 2007) $"
__license__ = 'public domain'
__copyright__ = "DR0ID (c) 2007 http://mypage.bluewin.ch/DR0ID"
#----------------------------- actual code --------------------------------
# import the pygame module, so you can use it
import pygame
# define a main function
def main():
# initialize the pygame module
pygame.init()
# load and set the logo
logo = pygame.image.load("logo32x32.png")
pygame.display.set_icon(logo)
pygame.display.set_caption("using a background")
# create a surface on screen that has the size of 240 x 180
screen = pygame.display.set_mode((240,180))
# load image (it is in same directory)
image = pygame.image.load("01_image.png")
bgd_image = pygame.image.load("background.png")
# blit image(s) to screen
screen.blit(bgd_image,(0,0)) # first background
# instead of blitting the background image you could fill it
# (uncomment the next line to do so)
#screen.fill((255,0,0))
screen.blit(image, (50,50))
# update the screen to make the changes visible (fullscreen update)
pygame.display.flip()
# define a variable to control the main loop
running = True
# main loop
while running:
# event handling, gets all event from the eventqueue
for event in pygame.event.get():
# only do something if the event if of type QUIT
if event.type == pygame.QUIT:
# change the value to False, to exit the main loop
running = False
# run the main function only if this module is executed as the main script
# (if you import this as a module then nothing is executed)
if __name__=="__main__":
# call the main function
main() | 28.914286 | 75 | 0.626482 |
4a1fb8733a5a35879ef0b9f205ec71fb90e7a8c5 | 10,558 | py | Python | openedx_webhooks/utils.py | stvstnfrd/openedx-webhooks | c12aede9eb87ae67bc3d3c9fb9ebe4879f668ba5 | [
"Apache-2.0"
] | 9 | 2016-12-20T04:18:46.000Z | 2021-09-09T10:50:03.000Z | openedx_webhooks/utils.py | stvstnfrd/openedx-webhooks | c12aede9eb87ae67bc3d3c9fb9ebe4879f668ba5 | [
"Apache-2.0"
] | 119 | 2015-01-20T12:01:28.000Z | 2021-12-17T18:50:46.000Z | openedx_webhooks/utils.py | stvstnfrd/openedx-webhooks | c12aede9eb87ae67bc3d3c9fb9ebe4879f668ba5 | [
"Apache-2.0"
] | 19 | 2015-01-20T11:58:43.000Z | 2021-11-01T09:38:32.000Z | """
Generic utilities.
"""
import functools
import hmac
import os
import sys
import time
from functools import wraps
from hashlib import sha1
from time import sleep as retry_sleep # so that we can patch it for tests.
from typing import Optional
import cachetools.func
import requests
from flask import request, Response
from flask_dance.contrib.jira import jira
from urlobject import URLObject
from openedx_webhooks import logger
from openedx_webhooks.oauth import jira_get
from openedx_webhooks.types import JiraDict
def environ_get(name: str, default=None) -> str:
"""
Get an environment variable, raising an error if it's missing.
"""
val = os.environ.get(name, default)
if val is None:
raise Exception(f"Required environment variable {name!r} is missing")
return val
def _check_auth(username, password):
"""
Checks if a username / password combination is valid.
"""
return (
username == os.environ.get('HTTP_BASIC_AUTH_USERNAME') and
password == os.environ.get('HTTP_BASIC_AUTH_PASSWORD')
)
def _authenticate():
"""
Sends a 401 response that enables basic auth
"""
return Response(
'Could not verify your access level for that URL.\n'
'You have to login with proper credentials', 401,
{'WWW-Authenticate': 'Basic realm="Login Required"'}
)
def requires_auth(f):
@wraps(f)
def decorated(*args, **kwargs):
auth = request.authorization
if not auth or not _check_auth(auth.username, auth.password):
return _authenticate()
return f(*args, **kwargs)
return decorated
def log_check_response(response, raise_for_status=True):
"""
Logs HTTP request and response at debug level and checks if it succeeded.
Arguments:
response (requests.Response)
raise_for_status (bool): if True, call raise_for_status on the response
also.
"""
msg = "Request: {0.method} {0.url}: {0.body!r}".format(response.request)
logger.debug(msg)
msg = "Response: {0.status_code} {0.reason!r} for {0.url}: {0.content!r}".format(response)
logger.debug(msg)
if raise_for_status:
response.raise_for_status()
def is_valid_payload(secret: str, signature: str, payload: bytes) -> bool:
"""
Ensure payload is valid according to signature.
Make sure the payload hashes to the signature as calculated using
the shared secret.
Arguments:
secret (str): The shared secret
signature (str): Signature as calculated by the server, sent in
the request
payload (bytes): The request payload
Returns:
bool: Is the payload legit?
"""
mac = hmac.new(secret.encode(), msg=payload, digestmod=sha1)
digest = 'sha1=' + mac.hexdigest()
return hmac.compare_digest(digest.encode(), signature.encode())
def text_summary(text, length=40):
"""
Make a summary of `text`, at most `length` chars long.
The middle will be elided if needed.
"""
if len(text) <= length:
return text
else:
start = (length - 3) // 2
end = (length - 3 - start)
return text[:start] + "..." + text[-end:]
def retry_get(session, url, **kwargs):
"""
Get a URL, but retry if it returns a 404.
GitHub has been known to send us a pull request event, and then return a
404 when we ask for the comments on the pull request. This will retry
with a pause to get the real answer.
"""
tries = 10
while True:
resp = session.get(url, **kwargs)
if resp.status_code == 404:
tries -= 1
if tries == 0:
break
retry_sleep(.5)
continue
else:
break
return resp
def paginated_get(url, session=None, limit=None, per_page=100, callback=None, **kwargs):
"""
Retrieve all objects from a paginated API.
Assumes that the pagination is specified in the "link" header, like
Github's v3 API.
The `limit` describes how many results you'd like returned. You might get
more than this, but you won't make more requests to the server once this
limit has been exceeded. For example, paginating by 100, if you set a
limit of 250, three requests will be made, and you'll get 300 objects.
"""
url = URLObject(url).set_query_param('per_page', str(per_page))
limit = limit or 999999999
session = session or requests.Session()
returned = 0
while url:
resp = retry_get(session, url, **kwargs)
if callable(callback):
callback(resp)
result = resp.json()
if not resp.ok:
msg = "{code} error for url {url}: {message}".format(
code=resp.status_code,
url=resp.url,
message=result["message"]
)
raise requests.exceptions.HTTPError(msg, response=resp)
for item in result:
yield item
returned += 1
url = None
if resp.links and returned < limit:
url = resp.links.get("next", {}).get("url", "")
def jira_paginated_get(url, session=None,
start=0, start_param="startAt", obj_name=None,
retries=3, debug=False, **fields):
"""
Like ``paginated_get``, but uses JIRA's conventions for a paginated API, which
are different from Github's conventions.
"""
session = session or requests.Session()
url = URLObject(url)
more_results = True
while more_results:
result_url = (
url.set_query_param(start_param, str(start))
.set_query_params(**fields)
)
for _ in range(retries):
try:
if debug:
print(result_url, file=sys.stderr)
result_resp = session.get(result_url)
result = result_resp.json()
break
except ValueError:
continue
result_resp.raise_for_status()
result = result_resp.json()
if not result:
break
if obj_name:
objs = result[obj_name]
else:
objs = result
for obj in objs:
yield obj
# are we done yet?
if isinstance(result, dict):
returned = len(objs)
total = result["total"]
if start + returned < total:
start += returned
else:
more_results = False
else:
# `result` is a list
start += len(result)
more_results = True # just keep going until there are no more results.
# A list of all the memoized functions, so that `clear_memoized_values` can
# clear them all.
_memoized_functions = []
def memoize(func):
"""Cache the value returned by a function call forever."""
func = functools.lru_cache()(func)
_memoized_functions.append(func)
return func
def memoize_timed(minutes):
"""Cache the value of a function for `minutes` minutes."""
def _timed(func):
# We use time.time as the timer so that freezegun can test it, and in a
# new function so that freezegun's patching will work. Freezegun doesn't
# patch time.monotonic, and we aren't that picky about the time anyway.
def patchable_timer():
return time.time()
func = cachetools.func.ttl_cache(ttl=60 * minutes, timer=patchable_timer)(func)
_memoized_functions.append(func)
return func
return _timed
def clear_memoized_values():
"""Clear all the values saved by @memoize and @memoize_timed, to ensure isolated tests."""
for func in _memoized_functions:
func.cache_clear()
def minimal_wsgi_environ():
values = {
"HTTP_HOST", "SERVER_NAME", "SERVER_PORT", "REQUEST_METHOD",
"SCRIPT_NAME", "PATH_INFO", "QUERY_STRING", "wsgi.url_scheme",
}
return {key: value for key, value in request.environ.items()
if key in values}
def sentry_extra_context(data_dict):
"""Apply the keys and values from data_dict to the Sentry extra context."""
from sentry_sdk import configure_scope
with configure_scope() as scope:
for key, value in data_dict.items():
scope.set_extra(key, value)
@memoize_timed(minutes=30)
def get_jira_custom_fields(session=None):
"""
Return a name-to-id mapping for the custom fields on JIRA.
"""
session = session or jira
field_resp = session.get("/rest/api/2/field")
field_resp.raise_for_status()
fields = field_resp.json()
return {f["name"]: f["id"] for f in fields if f["custom"]}
def get_jira_issue(key: str, missing_ok: bool = False) -> Optional[JiraDict]:
"""
Get the dictionary for a Jira issue, from its key.
Args:
key: the Jira id of the issue to find.
missing_ok: True if this function should return None for missing issue.
Returns:
A dict of Jira information, or None if missing_ok is True, and the issue
is missing.
"""
resp = jira_get("/rest/api/2/issue/{key}".format(key=key))
if resp.status_code == 404 and missing_ok:
return None
log_check_response(resp)
return resp.json()
def github_pr_repo(issue):
custom_fields = get_jira_custom_fields()
pr_repo = issue["fields"].get(custom_fields["Repo"])
parent_ref = issue["fields"].get("parent")
if not pr_repo and parent_ref:
parent = get_jira_issue(parent_ref["key"])
pr_repo = parent["fields"].get(custom_fields["Repo"])
return pr_repo
def github_pr_num(issue):
custom_fields = get_jira_custom_fields()
pr_num = issue["fields"].get(custom_fields["PR Number"])
parent_ref = issue["fields"].get("parent")
if not pr_num and parent_ref:
parent = get_jira_issue(parent_ref["key"])
pr_num = parent["fields"].get(custom_fields["PR Number"])
try:
return int(pr_num)
except Exception: # pylint: disable=broad-except
return None
def github_pr_url(issue):
"""
Return the pull request URL for the given JIRA issue,
or raise an exception if they can't be determined.
"""
pr_repo = github_pr_repo(issue)
pr_num = github_pr_num(issue)
if not pr_repo or not pr_num:
issue_key = issue["key"]
fail_msg = '{key} is missing "Repo" or "PR Number" fields'.format(key=issue_key)
raise Exception(fail_msg)
return "/repos/{repo}/pulls/{num}".format(repo=pr_repo, num=pr_num)
| 31.236686 | 94 | 0.630328 |
4a1fba55fdffb831af66da830d216353fdb16b0b | 7,236 | py | Python | python_msx_sdk/model/workflow_footer.py | CiscoDevNet/python-msx-sdk | d7e0a08c656504b4f4551d263e67c671a2a04b3f | [
"MIT"
] | null | null | null | python_msx_sdk/model/workflow_footer.py | CiscoDevNet/python-msx-sdk | d7e0a08c656504b4f4551d263e67c671a2a04b3f | [
"MIT"
] | null | null | null | python_msx_sdk/model/workflow_footer.py | CiscoDevNet/python-msx-sdk | d7e0a08c656504b4f4551d263e67c671a2a04b3f | [
"MIT"
] | null | null | null | """
MSX SDK
MSX SDK client. # noqa: E501
The version of the OpenAPI document: 1.0.9
Generated by: https://openapi-generator.tech
"""
import re # noqa: F401
import sys # noqa: F401
from python_msx_sdk.model_utils import ( # noqa: F401
ApiTypeError,
ModelComposed,
ModelNormal,
ModelSimple,
cached_property,
change_keys_js_to_python,
convert_js_args_to_python_args,
date,
datetime,
file_type,
none_type,
validate_get_composed_info,
)
class WorkflowFooter(ModelNormal):
"""NOTE: This class is auto generated by OpenAPI Generator.
Ref: https://openapi-generator.tech
Do not edit the class manually.
Attributes:
allowed_values (dict): The key is the tuple path to the attribute
and the for var_name this is (var_name,). The value is a dict
with a capitalized key describing the allowed value and an allowed
value. These dicts store the allowed enum values.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
discriminator_value_class_map (dict): A dict to go from the discriminator
variable value to the discriminator class name.
validations (dict): The key is the tuple path to the attribute
and the for var_name this is (var_name,). The value is a dict
that stores validations for max_length, min_length, max_items,
min_items, exclusive_maximum, inclusive_maximum, exclusive_minimum,
inclusive_minimum, and regex.
additional_properties_type (tuple): A tuple of classes accepted
as additional properties values.
"""
allowed_values = {
}
validations = {
}
additional_properties_type = None
_nullable = False
@cached_property
def openapi_types():
"""
This must be a method because a model may have properties that are
of type self, this must run after the class is loaded
Returns
openapi_types (dict): The key is attribute name
and the value is attribute type.
"""
return {
'created_on': (str,), # noqa: E501
'created_by': (str,), # noqa: E501
'updated_on': (str,), # noqa: E501
'updated_by': (str, none_type,), # noqa: E501
'owner': (str, none_type,), # noqa: E501
'unique_name': (str, none_type,), # noqa: E501
}
@cached_property
def discriminator():
return None
attribute_map = {
'created_on': 'created_on', # noqa: E501
'created_by': 'created_by', # noqa: E501
'updated_on': 'updated_on', # noqa: E501
'updated_by': 'updated_by', # noqa: E501
'owner': 'owner', # noqa: E501
'unique_name': 'unique_name', # noqa: E501
}
_composed_schemas = {}
required_properties = set([
'_data_store',
'_check_type',
'_spec_property_naming',
'_path_to_item',
'_configuration',
'_visited_composed_classes',
])
@convert_js_args_to_python_args
def __init__(self, *args, **kwargs): # noqa: E501
"""WorkflowFooter - a model defined in OpenAPI
Keyword Args:
_check_type (bool): if True, values for parameters in openapi_types
will be type checked and a TypeError will be
raised if the wrong type is input.
Defaults to True
_path_to_item (tuple/list): This is a list of keys or values to
drill down to the model in received_data
when deserializing a response
_spec_property_naming (bool): True if the variable names in the input data
are serialized names, as specified in the OpenAPI document.
False if the variable names in the input data
are pythonic names, e.g. snake case (default)
_configuration (Configuration): the instance to use when
deserializing a file_type parameter.
If passed, type conversion is attempted
If omitted no type conversion is done.
_visited_composed_classes (tuple): This stores a tuple of
classes that we have traveled through so that
if we see that class again we will not use its
discriminator again.
When traveling through a discriminator, the
composed schema that is
is traveled through is added to this set.
For example if Animal has a discriminator
petType and we pass in "Dog", and the class Dog
allOf includes Animal, we move through Animal
once using the discriminator, and pick Dog.
Then in Dog, we will make an instance of the
Animal class but this time we won't travel
through its discriminator because we passed in
_visited_composed_classes = (Animal,)
created_on (str): [optional] # noqa: E501
created_by (str): [optional] # noqa: E501
updated_on (str): [optional] # noqa: E501
updated_by (str, none_type): [optional] # noqa: E501
owner (str, none_type): [optional] # noqa: E501
unique_name (str, none_type): [optional] # noqa: E501
"""
_check_type = kwargs.pop('_check_type', True)
_spec_property_naming = kwargs.pop('_spec_property_naming', False)
_path_to_item = kwargs.pop('_path_to_item', ())
_configuration = kwargs.pop('_configuration', None)
_visited_composed_classes = kwargs.pop('_visited_composed_classes', ())
if args:
raise ApiTypeError(
"Invalid positional arguments=%s passed to %s. Remove those invalid positional arguments." % (
args,
self.__class__.__name__,
),
path_to_item=_path_to_item,
valid_classes=(self.__class__,),
)
self._data_store = {}
self._check_type = _check_type
self._spec_property_naming = _spec_property_naming
self._path_to_item = _path_to_item
self._configuration = _configuration
self._visited_composed_classes = _visited_composed_classes + (self.__class__,)
for var_name, var_value in kwargs.items():
if var_name not in self.attribute_map and \
self._configuration is not None and \
self._configuration.discard_unknown_keys and \
self.additional_properties_type is None:
# discard variable.
continue
setattr(self, var_name, var_value)
| 39.758242 | 110 | 0.574489 |
4a1fbb75653d28c99c1feb6fb5a7c8ed0b019980 | 986 | py | Python | home/migrations/0007_ourteam.py | mukesh2505/restoproject | 8336804690026a285cc913fea93959fa5d2c2ae5 | [
"Apache-2.0"
] | null | null | null | home/migrations/0007_ourteam.py | mukesh2505/restoproject | 8336804690026a285cc913fea93959fa5d2c2ae5 | [
"Apache-2.0"
] | null | null | null | home/migrations/0007_ourteam.py | mukesh2505/restoproject | 8336804690026a285cc913fea93959fa5d2c2ae5 | [
"Apache-2.0"
] | null | null | null | # Generated by Django 3.1.6 on 2021-02-19 12:48
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('home', '0006_auto_20210219_1215'),
]
operations = [
migrations.CreateModel(
name='OurTeam',
fields=[
('id', models.AutoField(primary_key=True, serialize=False)),
('name', models.CharField(max_length=255)),
('designation', models.CharField(default=None, max_length=50, null=True)),
('profile_pic', models.CharField(max_length=1000, null=True)),
('facebook_url', models.CharField(max_length=1000, null=True)),
('tweet_url', models.CharField(max_length=1000, null=True)),
('created_date', models.DateTimeField(auto_now_add=True)),
],
options={
'db_table': 'our_team',
'managed': True,
},
),
]
| 32.866667 | 90 | 0.554767 |
4a1fbcbb53db90c47aae2c0d2eb7e6e701b71677 | 3,531 | py | Python | tests/test_generator.py | GrayUnit/pyqt3wrapper | 4c6b742e1a9055c85b72c3a3f1b904a6f7fa3474 | [
"MIT"
] | null | null | null | tests/test_generator.py | GrayUnit/pyqt3wrapper | 4c6b742e1a9055c85b72c3a3f1b904a6f7fa3474 | [
"MIT"
] | null | null | null | tests/test_generator.py | GrayUnit/pyqt3wrapper | 4c6b742e1a9055c85b72c3a3f1b904a6f7fa3474 | [
"MIT"
] | null | null | null | #!/usr/bin/env python
import io
import os
import unittest
import tempfile
import subprocess
from pyqt3wrapper.pyuic_pyqt3wrapper import (IndentPrinter,
pyqt3wrapper_generator)
class IndentPrinterTestCase(unittest.TestCase):
def test_indent(self):
with open(os.path.join("tests", "output", "indent_test1")) as f:
expected_output = f.readlines()
print("expected_output: %s" % expected_output)
with io.BytesIO() as fileinput:
with IndentPrinter(fileinput) as f:
f.write("class Foo(object):\n")
with f:
f.write("def bar(self):\n")
with f:
f.write("pass\n")
f.write("\n")
with f:
f.write("def haha(self):\n")
with f:
f.write("self.setupUi(self)\n")
fileinput.seek(0)
assert expected_output == fileinput.readlines()
class PyQt3WrapperTestCase(unittest.TestCase):
_subprocess_args = {"shell": False, "close_fds": True}
_exec_name = "pyuic_pyqt3wrapper.py"
def test_wrapper(self):
with tempfile.NamedTemporaryFile(delete=False) as outputfile:
fileinputname = open(os.path.join("tests", "ui", "test1.ui"))
expected_output = open(
os.path.join("tests", "output", "test_wrapper")).readlines()
pyqt3wrapper_generator(fileinputname, outputfile)
outputfile.seek(0)
outresult = outputfile.readlines()
assert(outresult == expected_output)
def _test_call_pyqt3wrapper(self, expected_output_filename, cmd):
with open(expected_output_filename, "r") as f:
output_expected = f.readlines()
with tempfile.NamedTemporaryFile(delete=False) as outputfile:
cmd += [outputfile.name, ]
assert subprocess.call(cmd, **self._subprocess_args) == 0
outputfile = self._strip(outputfile)
with outputfile as f:
outresult = f.readlines()
assert(outresult == output_expected)
def test_generate(self):
self._test_call_pyqt3wrapper(
os.path.join("tests/output/test_pyuicwrapper"),
[self._exec_name, "-f",
os.path.join("tests", "ui", "test1.ui"), "-o"])
def test_pyuicargs(self):
self._test_call_pyqt3wrapper(
os.path.join("tests/output/test_pyuicexecute"),
[self._exec_name, "-f", "-x", "-d",
os.path.join("tests", "ui", "test1.ui"), "-o"])
def test_fileopen(self):
subprocess.call([
self._exec_name,
os.path.join("tests", "ui", "test1.ui"),
"-o",
os.path.join("tests", "output", "test_pyuicwrapper")],
**self._subprocess_args)
assert SystemExit(2)
def _strip(self, outputfile):
tmpout = tempfile.NamedTemporaryFile(delete=False)
with outputfile as fin:
with tmpout as fout:
fin.seek(0)
for line in fin.readlines():
if line.startswith("# Created"):
fout.write("# Created: stripped\n")
elif line.startswith("# by:"):
fout.write("# by: PyQt\n")
else:
fout.write(line)
os.unlink(outputfile.name)
return open(fout.name, "r")
| 37.56383 | 76 | 0.549419 |
4a1fbcd27e942acf73dfb1dc2734ef96cf9077a8 | 38,306 | py | Python | src/sqlfluff/rules/L003.py | kiri1701/sqlfluff | 93d109d87f327037efe6fa30f2f7eea8d44f7e91 | [
"MIT"
] | null | null | null | src/sqlfluff/rules/L003.py | kiri1701/sqlfluff | 93d109d87f327037efe6fa30f2f7eea8d44f7e91 | [
"MIT"
] | null | null | null | src/sqlfluff/rules/L003.py | kiri1701/sqlfluff | 93d109d87f327037efe6fa30f2f7eea8d44f7e91 | [
"MIT"
] | null | null | null | """Implementation of Rule L003."""
import dataclasses
import itertools
from typing import Dict, Iterable, List, Optional, Sequence, Set, Tuple
from sqlfluff.core.parser import WhitespaceSegment
from sqlfluff.core.parser.segments import BaseSegment
from sqlfluff.core.rules.functional import rsp, sp, Segments
from sqlfluff.core.rules.base import BaseRule, LintResult, LintFix, RuleContext
from sqlfluff.core.rules.doc_decorators import (
document_fix_compatible,
document_configuration,
)
from sqlfluff.core.templaters import TemplatedFile
from sqlfluff.core.templaters.base import RawFileSlice
@dataclasses.dataclass
class _LineSummary:
"""A dataobject to represent a line.
A _LineSummary is created and then filled with elements,
before calling self.finalise to generate a final
representation.
"""
line_no: int = 0
line_buffer: List[BaseSegment] = dataclasses.field(default_factory=list)
indent_buffer: List[BaseSegment] = dataclasses.field(default_factory=list)
# As of end of line
indent_balance: int = 0
# As it was as of the "Anchor" / first code elem
anchor_indent_balance: int = 0
line_anchor: Optional[BaseSegment] = None
# Fixed calculated values
templated_line: Optional[int] = None
hanging_indent: Optional[int] = None
indent_size: int = 1
clean_indent: bool = True
templated_line_type: Optional[str] = None
is_comment_line: bool = False
is_empty_line: bool = False
has_code_segment: bool = False
line_indent_stack: List[int] = dataclasses.field(default_factory=list)
hanger_pos: Optional[int] = None
def __repr__(self) -> str:
"""Printable Summary without Segments."""
keys_to_strip = (
"line_buffer",
"indent_buffer",
"as_of_anchor",
)
print_dict: Dict = {
key: value
for key, value in self.__dict__.copy().items()
if key not in keys_to_strip
}
print_dict["raw_line"] = self.template_content
return print_dict.__repr__()
@property
def template_content(self): # pragma: no cover
return "".join(
seg.raw or getattr(seg, "source_str", "") for seg in self.line_buffer
)
def finalise(self, line_no: int, templated_file: Optional[TemplatedFile]):
"""Create a final summary from a memo/marker line."""
copied_line_buffer = self.line_buffer[:]
# Generate our final line summary based on the current state
is_comment_line = all(
seg.is_type(
"whitespace", "comment", "indent" # dedent is a subtype of indent
)
for seg in copied_line_buffer
)
has_code_segment = any(elem.is_code for elem in copied_line_buffer)
has_placeholder = any(
elem.is_type("placeholder") for elem in copied_line_buffer
)
is_empty_line = not has_code_segment and not has_placeholder
line_summary = self.__class__(
line_no=line_no,
templated_line=self.templated_line,
line_buffer=copied_line_buffer,
indent_buffer=self.indent_buffer,
indent_size=self.indent_size,
indent_balance=self.indent_balance,
anchor_indent_balance=self.anchor_indent_balance,
hanging_indent=self.hanger_pos if self.line_indent_stack else None,
# Clean indent is true if the line *ends* with an indent
# or has an indent in the initial whitespace.
clean_indent=self.clean_indent,
# Solidify expensive immutable characteristics
templated_line_type=_get_template_block_type(
copied_line_buffer, templated_file
),
is_comment_line=is_comment_line,
is_empty_line=is_empty_line,
has_code_segment=has_code_segment,
)
return line_summary
def _set_line_anchor(
line: _LineSummary,
anchor: Optional[BaseSegment],
tab_space_size: int,
):
"""Create a Line state of this line upon reaching the anchor."""
line.anchor_indent_balance = line.indent_balance
line.indent_size = _indent_size(
line.indent_buffer,
tab_space_size=tab_space_size,
)
line.line_anchor = anchor
return line
def _is_clean_indent(prev_line_buffer: List[BaseSegment]):
"""Check the previous line to see if the current state is a clean indent."""
# Assume an unclean indent, but if the last line
# ended with an indent then we might be ok.
# Was there an indent after the last code element of the previous line?
for search_elem in reversed(prev_line_buffer):
is_meta = search_elem.is_meta
if not search_elem.is_code and not is_meta:
continue
if is_meta and search_elem.indent_val > 0: # type: ignore
return True
break
return False
@dataclasses.dataclass
class _Memory:
problem_lines: Set[int] = dataclasses.field(default_factory=set)
# hanging_lines keeps track of hanging lines so that we don't
# compare to them when assessing indent.
hanging_lines: Set[int] = dataclasses.field(default_factory=set)
comment_lines: Set[int] = dataclasses.field(default_factory=set)
line_summaries: Dict[int, _LineSummary] = dataclasses.field(default_factory=dict)
in_indent: bool = True
trigger: Optional[BaseSegment] = None
line_no: int = dataclasses.field(default=1)
start_process_raw_idx: int = dataclasses.field(default=0)
@property
def noncomparable_lines(self):
return self.hanging_lines.union(self.problem_lines)
@document_fix_compatible
@document_configuration
class Rule_L003(BaseRule):
"""Indentation not consistent with previous lines.
**Anti-pattern**
The ``•`` character represents a space.
In this example, the third line contains five spaces instead of four.
.. code-block:: sql
:force:
SELECT
••••a,
•••••b
FROM foo
**Best practice**
Change the indentation to use a multiple of four spaces.
.. code-block:: sql
:force:
SELECT
••••a,
••••b
FROM foo
"""
groups = ("all", "core")
targets_templated = True
_works_on_unparsable = False
needs_raw_stack = True
_adjust_anchors = True
_ignore_types: List[str] = ["script_content"]
config_keywords = ["tab_space_size", "indent_unit", "hanging_indents"]
@staticmethod
def _make_indent(
num: int = 1, tab_space_size: int = 4, indent_unit: str = "space"
) -> str:
if indent_unit == "tab":
return "\t" * num
if indent_unit == "space":
return " " * tab_space_size * num
raise ValueError(
f"Parameter indent_unit has unexpected value: `{indent_unit}`. Expected"
" `tab` or `space`."
)
@staticmethod
def _indent_size(segments: Sequence[BaseSegment], tab_space_size: int = 4) -> int:
return _indent_size(segments, tab_space_size)
@classmethod
def _process_raw_stack(
cls,
raw_stack: Tuple[BaseSegment, ...],
memory: _Memory,
tab_space_size: int = 4,
templated_file: Optional[TemplatedFile] = None,
) -> Dict[int, _LineSummary]:
"""Take the raw stack, split into lines and evaluate some stats."""
result_buffer: Dict[int, _LineSummary] = memory.line_summaries
cached_line_count = len(result_buffer)
starting_indent_balance = 0
if cached_line_count:
starting_indent_balance = result_buffer[cached_line_count].indent_balance
working_state = _LineSummary(indent_balance=starting_indent_balance)
line_no = memory.line_no
target_line_no = cached_line_count + 1
for idx, elem in enumerate(raw_stack[memory.start_process_raw_idx :]):
is_newline = elem.is_type("newline")
if line_no < target_line_no:
if is_newline:
line_no += 1
if line_no == target_line_no:
memory.start_process_raw_idx += idx + 1
memory.line_no = line_no
continue
working_state.line_buffer.append(elem)
# Pin indent_balance to above zero
if working_state.indent_balance < 0:
working_state.indent_balance = 0
if is_newline:
result_buffer[line_no] = working_state.finalise(line_no, templated_file)
# Set the "templated_line" if the newline that ended the *current* line
# was in templated space. Reason: We want to ignore indentation of lines
# not present in the raw (pre-templated) code.
working_state = _LineSummary(
indent_balance=working_state.indent_balance,
clean_indent=_is_clean_indent(working_state.line_buffer),
templated_line=elem.is_templated,
)
line_no += 1
continue
if working_state.line_anchor is None:
working_state = cls._process_pre_anchor(
elem, working_state, tab_space_size
)
# If we hit the trigger element, stop processing.
if elem is memory.trigger:
break
continue
if elem.is_meta and elem.indent_val != 0: # type: ignore
working_state = cls._process_line_indents(
elem, working_state, tab_space_size
)
continue
elif elem.is_code and working_state.hanger_pos is None:
working_state.hanger_pos = cls._indent_size(
working_state.line_buffer[:-1], tab_space_size=tab_space_size
)
# If we get to the end, and still have a buffer, add it on
if working_state.line_buffer:
result_buffer[line_no] = working_state.finalise(
line_no,
templated_file,
)
return result_buffer
@classmethod
def _process_line_indents(
cls,
elem: BaseSegment,
working_state: _LineSummary,
tab_space_size: int,
) -> _LineSummary:
working_state.indent_balance += elem.indent_val # type: ignore
if elem.indent_val > 0: # type: ignore
# Keep track of the indent at the last ... indent
working_state.line_indent_stack.append(
cls._indent_size(
working_state.line_buffer, tab_space_size=tab_space_size
)
)
working_state.hanger_pos = None
return working_state
# this is a dedent, we could still have a hanging indent,
# but only if there's enough on the stack
if working_state.line_indent_stack:
working_state.line_indent_stack.pop()
return working_state
@classmethod
def _process_pre_anchor(
cls,
elem: BaseSegment,
working_state: _LineSummary,
tab_space_size: int,
) -> _LineSummary:
if elem.is_whitespace:
working_state.indent_buffer.append(elem)
return working_state
if elem.is_meta and elem.indent_val != 0: # type: ignore
working_state.indent_balance += elem.indent_val # type: ignore
if elem.indent_val > 0: # type: ignore
# a "clean" indent is one where it contains
# an increase in indentation? Can't quite
# remember the logic here. Let's go with that.
working_state.clean_indent = True
return working_state
return _set_line_anchor(working_state, elem, tab_space_size)
def _coerce_indent_to(
self,
desired_indent: str,
current_indent_buffer: List[BaseSegment],
current_anchor: BaseSegment,
) -> List[LintFix]:
"""Generate fixes to make an indent a certain size."""
# In all cases we empty the existing buffer
# except for our indent markers
fixes = [
LintFix.delete(elem)
for elem in current_indent_buffer
if not elem.is_type("indent")
]
if len(desired_indent) == 0:
# If there shouldn't be an indent at all, just delete.
return fixes
# Anything other than 0 create a fresh buffer
return [
LintFix.create_before(
current_anchor,
[
WhitespaceSegment(
raw=desired_indent,
),
],
),
*fixes,
]
def _eval(self, context: RuleContext) -> Optional[LintResult]:
"""Indentation not consistent with previous lines.
To set the default tab size, set the `tab_space_size` value
in the appropriate configuration.
We compare each line (first non-whitespace element of the
line), with the indentation of previous lines. The presence
(or lack) of indent or dedent meta-characters indicate whether
the indent is appropriate.
- Any line is assessed by the indent level at the first non
whitespace element.
- Any increase in indentation may be _up to_ the number of
indent characters.
- Any line must be in line with the previous line which had
the same indent balance at its start.
- Apart from "whole" indents, a "hanging" indent is possible
if the line starts in line with either the indent of the
previous line or if it starts at the same indent as the *last*
indent meta segment in the previous line.
"""
# Config type hints
self.tab_space_size: int
self.indent_unit: str
self.hanging_indents: bool
segment = context.segment
memory: _Memory = context.memory or _Memory()
raw_stack: Tuple[BaseSegment, ...] = context.raw_stack
if raw_stack and raw_stack[-1] is not context.segment:
raw_stack = raw_stack + (segment,)
is_ignorable = any(
el.is_type(*self._ignore_types) for el in context.parent_stack + (segment,)
)
if is_ignorable:
return LintResult(memory=memory)
if segment.is_type("newline"):
memory.in_indent = True
elif memory.in_indent:
has_children = bool(segment.segments)
is_placeholder = segment.is_meta and segment.indent_val != 0 # type: ignore
if not (segment.is_whitespace or has_children or is_placeholder):
memory.in_indent = False
# First non-whitespace element is our trigger
memory.trigger = segment
is_last = context.segment is context.final_segment
if not segment.is_type("newline") and not is_last:
# Process on line ends or file end
return LintResult(memory=memory)
line_summaries = self._process_raw_stack(
raw_stack=raw_stack,
memory=memory,
tab_space_size=self.tab_space_size,
templated_file=context.templated_file,
)
memory.line_summaries = line_summaries
trigger_segment = memory.trigger
memory.trigger = None
if line_summaries and trigger_segment:
last_line_no = max(line_summaries.keys())
this_line = line_summaries[last_line_no]
result = self._process_working_state(memory, trigger_segment)
# Template lines don't need fixes
# However we do need the mutations from the processing.
if not this_line.templated_line:
return result
return LintResult(memory=memory)
def _process_working_state(
self,
memory: _Memory,
trigger_segment: BaseSegment,
) -> LintResult:
"""Checks indentation of one line of code, returning a LintResult.
The _eval() function calls it for the current line of code:
- When passed a newline segment (thus ending a line)
- When passed the *final* segment in the entire parse tree (which may
not be a newline)
"""
line_summaries = memory.line_summaries
this_line_no = max(line_summaries.keys())
this_line: _LineSummary = line_summaries.pop(this_line_no)
self.logger.debug(
"Evaluating line #%s. %s",
this_line_no,
this_line,
)
if this_line.is_comment_line:
# Comment line, deal with it later.
memory.comment_lines.add(this_line_no)
self.logger.debug(" Comment Line. #%s", this_line_no)
return LintResult(memory=memory)
previous_line_numbers = sorted(line_summaries.keys(), reverse=True)
# we will iterate this more than once
previous_lines = list(map(lambda k: line_summaries[k], previous_line_numbers))
# handle hanging indents if allowed
hanger_res = self.hanging_indents and self._handle_hanging_indents(
this_line, previous_lines, memory
)
if hanger_res:
return hanger_res
# Is this an indented first line?
if this_line.line_no == 1 and this_line.indent_size > 0:
self.logger.debug(" Indented First Line. #%s", this_line_no)
return LintResult(
anchor=trigger_segment,
memory=memory,
description="First line has unexpected indent",
fixes=[LintFix.delete(elem) for elem in this_line.indent_buffer],
)
# Special handling for template end blocks on a line by themselves.
if this_line.templated_line_type == "end":
return self._handle_template_blocks(
this_line=this_line,
trigger_segment=trigger_segment,
previous_lines=previous_lines,
memory=memory,
)
# Assuming it's not a hanger, let's compare it to the other previous
# lines. We do it in reverse so that closer lines are more relevant.
prev_line = _find_previous_line(
this_line,
previous_lines,
memory.noncomparable_lines,
)
if not prev_line:
return LintResult(memory=memory)
prev_line_no = prev_line.line_no
indent_diff = this_line.anchor_indent_balance - prev_line.anchor_indent_balance
this_indent_num = this_line.indent_size // self.tab_space_size
comp_indent_num = prev_line.indent_size // self.tab_space_size
# Is the indent balance the same?
if indent_diff == 0:
self.logger.debug(
" [same indent balance] Comparing to #%s",
prev_line_no,
)
if this_line.indent_size != prev_line.indent_size:
# Indents don't match even though balance is the same...
memory.problem_lines.add(this_line_no)
# Work out desired indent
desired_indent = self._make_indent(
indent_unit=self.indent_unit,
tab_space_size=self.tab_space_size,
num=comp_indent_num,
)
fixes = self._coerce_indent_to(
desired_indent=desired_indent,
current_indent_buffer=this_line.indent_buffer,
current_anchor=trigger_segment,
)
self.logger.debug(
" !! Indentation does not match #%s. Fixes: %s",
prev_line_no,
fixes,
)
return LintResult(
anchor=trigger_segment,
memory=memory,
description=_Desc(
expected=comp_indent_num,
found=this_indent_num,
compared_to=prev_line.line_no,
),
fixes=fixes,
)
# Are we at a deeper indent?
elif indent_diff > 0:
self.logger.debug(
" [deeper indent balance] Comparing to #%s",
prev_line_no,
)
# NB: We shouldn't need to deal with correct hanging indents
# here, they should already have been dealt with before. We
# may still need to deal with *creating* hanging indents if
# appropriate.
self.logger.debug(" Comparison Line: %s", prev_line)
# Check to see if we've got a whole number of multiples. If
# we do then record the number for later, otherwise raise
# an error. We do the comparison here so we have a reference
# point to do the repairs. We need a sensible previous line
# to base the repairs off. If there's no indent at all, then
# we should also take this route because there SHOULD be one.
if this_line.indent_size % self.tab_space_size != 0:
memory.problem_lines.add(this_line_no)
# The default indent is the one just reconstructs it from
# the indent size.
desired_indent = self._make_indent(
indent_unit=self.indent_unit,
tab_space_size=self.tab_space_size,
num=indent_diff + this_indent_num,
)
# If we have the option of a hanging indent then use it.
if self.hanging_indents and prev_line.hanging_indent:
self.logger.debug(" Use hanging indent.")
desired_indent = " " * prev_line.hanging_indent
fixes = self._coerce_indent_to(
desired_indent=desired_indent,
current_indent_buffer=this_line.indent_buffer,
current_anchor=trigger_segment,
)
return LintResult(
anchor=trigger_segment,
memory=memory,
description=_Desc(
expected=len(desired_indent) // self.tab_space_size,
found=this_indent_num,
compared_to=prev_line.line_no,
),
fixes=fixes,
)
# The indent number should be at least 1, and can be UP TO
# and including the difference in the indent balance.
if comp_indent_num == this_indent_num:
# We have two lines indented the same, but with a different starting
# indent balance. This is either a problem OR a sign that one of the
# opening indents wasn't used. We account for the latter and then
# have a violation if that wasn't the case.
# Does the comparison line have enough unused indent to get us back
# to where we need to be? NB: This should only be applied if this is
# a CLOSING bracket.
# First work out if we have some closing brackets, and if so, how
# many.
b_num = 0
for elem in this_line.line_buffer:
if not elem.is_code:
continue
if elem.is_type("end_bracket", "end_square_bracket"):
b_num += 1
continue
break # pragma: no cover
if b_num < indent_diff:
# It doesn't. That means we *should* have an indent when
# compared to this line and we DON'T.
memory.problem_lines.add(this_line_no)
return LintResult(
anchor=trigger_segment,
memory=memory,
description=_Desc(
expected=this_indent_num + 1,
found=this_indent_num,
compared_to=prev_line.line_no,
),
# Add in an extra bit of whitespace for the indent
fixes=[
LintFix.create_before(
trigger_segment,
[
WhitespaceSegment(
raw=self._make_indent(
indent_unit=self.indent_unit,
tab_space_size=self.tab_space_size,
),
),
],
),
],
)
elif (
this_indent_num < comp_indent_num
or this_indent_num > comp_indent_num + indent_diff
):
memory.problem_lines.add(this_line_no)
desired_indent = self._make_indent(
num=comp_indent_num,
indent_unit=self.indent_unit,
tab_space_size=self.tab_space_size,
)
fixes = self._coerce_indent_to(
desired_indent=desired_indent,
current_indent_buffer=this_line.indent_buffer,
current_anchor=trigger_segment,
)
return LintResult(
anchor=trigger_segment,
memory=memory,
description=_Desc(
expected=comp_indent_num,
found=this_indent_num,
compared_to=prev_line.line_no,
),
fixes=fixes,
)
# This was a valid comparison, so if it doesn't flag then
# we can assume that we're ok.
self.logger.debug(" Indent deemed ok comparing to #%s", prev_line_no)
comment_fix = self._calculate_comment_fixes(
memory, previous_line_numbers, this_line
)
return comment_fix or LintResult(memory=memory)
def _calculate_comment_fixes(
self, memory: _Memory, previous_line_numbers: List[int], this_line: _LineSummary
) -> Optional[LintResult]:
# Given that this line is ok, consider if the preceding lines are
# comments. If they are, lint the indentation of the comment(s).
fixes: List[LintFix] = []
anchor: Optional[BaseSegment] = None
for n in previous_line_numbers:
if n not in memory.comment_lines:
break
# The previous line WAS a comment.
prev_line = memory.line_summaries[n]
if this_line.indent_size != prev_line.indent_size:
# It's not aligned.
# Find the anchor first.
for seg in prev_line.line_buffer:
if seg.is_type("comment"):
anchor = seg
break
if not anchor: # pragma: no cover
continue
fixes += self._coerce_indent_to(
desired_indent="".join(
elem.raw for elem in this_line.indent_buffer
),
current_indent_buffer=prev_line.indent_buffer,
current_anchor=anchor,
)
memory.problem_lines.add(n)
if not fixes:
return None
return LintResult(
anchor=anchor,
memory=memory,
description="Comment not aligned with following line.",
fixes=fixes,
)
def _handle_hanging_indents(
self,
this_line: _LineSummary,
previous_lines: List[_LineSummary],
memory: _Memory,
) -> Optional[LintResult]:
if len(previous_lines) == 0:
return None
last_line = _find_last_meaningful_line(previous_lines)
if not last_line:
return None
# Handle Hanging Indents
is_anchor_indent_match = (
this_line.anchor_indent_balance == last_line.anchor_indent_balance
)
is_end_indent_match = this_line.indent_size == last_line.indent_size
is_known_hanging_line = last_line.line_no in memory.hanging_lines
# There MUST also be a non-zero indent. Otherwise we're just on the
# baseline.
if this_line.indent_size <= 0:
return None
# NB: Hangers are only allowed if there was content after the last
# indent on the previous line. Otherwise it's just an indent.
is_hanging_match = this_line.indent_size == last_line.hanging_indent
# Or they're if the indent balance is the same and the indent is the
# same AND the previous line was a hanger
is_matching_previous = (
is_anchor_indent_match and is_end_indent_match and is_known_hanging_line
)
if not is_matching_previous and not is_hanging_match:
return None
memory.hanging_lines.add(this_line.line_no)
self.logger.debug(" Hanger Line. #%s", this_line.line_no)
self.logger.debug(" Last Line: %s", last_line)
return LintResult(memory=memory)
def _handle_template_blocks(
self,
this_line: _LineSummary,
trigger_segment: BaseSegment,
previous_lines: List[_LineSummary],
memory: _Memory,
):
# For a template block end on a line by itself, search for a
# matching block start on a line by itself. If there is one, match
# its indentation. Question: Could we avoid treating this as a
# special case? It has some similarities to the non-templated test
# case test/fixtures/linter/indentation_error_contained.sql, in tha
# both have lines where anchor_indent_balance drops 2 levels from one line
# to the next, making it a bit unclear how to indent that line.
template_line = _find_matching_start_line(previous_lines)
# In rare circumstances there may be disbalanced pairs
if not template_line:
return LintResult(memory=memory)
if template_line.line_no in memory.noncomparable_lines:
return LintResult(memory=memory)
self.logger.debug(
" [template block end] Comparing to #%s", template_line.line_no
)
if this_line.indent_size == template_line.indent_size:
return LintResult(memory=memory)
memory.problem_lines.add(this_line.line_no)
# The previous indent.
desired_indent = "".join(elem.raw for elem in template_line.indent_buffer)
first_non_indent_i = len(this_line.indent_buffer)
current_anchor = this_line.line_buffer[first_non_indent_i]
fixes = self._coerce_indent_to(
desired_indent=desired_indent,
current_indent_buffer=this_line.indent_buffer,
current_anchor=current_anchor,
)
self.logger.debug(
" !! Indentation does not match #%s. Fixes: %s",
template_line.line_no,
fixes,
)
return LintResult(
anchor=trigger_segment,
memory=memory,
description=_Desc(
len(desired_indent) // self.tab_space_size,
this_line.indent_size,
template_line.line_no,
),
fixes=fixes,
)
class _TemplateLineInterpreter:
start_blocks = (
("placeholder", "block_start"),
("placeholder", "compound"),
("placeholder", "literal"),
("placeholder", "block_mid"),
)
indent_types = (
("indent", None),
("newline", None),
)
valid_start_combos = list(
itertools.product(
start_blocks,
indent_types,
)
)
dedent_types = (("dedent", None),)
end_block = (
("placeholder", "block_end"),
("placeholder", "compound"),
("placeholder", "block_mid"),
)
valid_end_combos = list(
itertools.product(
dedent_types,
end_block,
)
)
def __init__(
self,
working_state: List[BaseSegment],
templated_file: Optional[TemplatedFile],
) -> None:
self.working_state = [el for el in working_state if not el.is_whitespace]
self.templated_file = templated_file
self._adjacent_pairs: Optional[
List[Tuple[Tuple[str, Optional[str]], Tuple[str, Optional[str]]]]
] = None
def is_single_placeholder_line(self):
count_placeholder = 0
for seg in self.working_state:
if seg.is_code:
return False
elif seg.is_type("placeholder"):
count_placeholder += 1
return count_placeholder == 1
def list_segment_and_raw_segment_types(self) -> Iterable[Tuple[str, Optional[str]]]:
"""Yields the tuple of seg type and underlying type were applicable."""
for seg in self.working_state:
raw_seg = self.get_raw_slices(seg)
raw_str = raw_seg[0].slice_type if raw_seg else None
yield (seg.type, raw_str)
def get_adjacent_type_pairs(self):
"""Produce a list of pairs of each sequenctial combo of two."""
if self._adjacent_pairs:
return self._adjacent_pairs
iterable = self.list_segment_and_raw_segment_types()
a, b = itertools.tee(iterable)
# consume the first item in b
next(b, None)
self._adjacent_pairs = list(zip(a, b))
return self._adjacent_pairs
def is_block_start(self):
return any(
pair in self.valid_start_combos for pair in self.get_adjacent_type_pairs()
)
def is_block_end(self):
return any(
pair in self.valid_end_combos for pair in self.get_adjacent_type_pairs()
)
def block_type(self) -> Optional[str]:
"""Return a block_type enum."""
if not self.templated_file:
return None
if not self.is_single_placeholder_line():
return None
if self.is_block_end():
return "end"
if self.is_block_start():
return "start"
return None
def get_raw_slices(self, elem: BaseSegment) -> Optional[List[RawFileSlice]]:
if not self.templated_file: # pragma: no cover
return None
if not elem.is_type("placeholder"):
return None
assert elem.pos_marker, "TypeGuard"
slices = self.templated_file.raw_slices_spanning_source_slice(
elem.pos_marker.source_slice
)
return slices or None
def _get_template_block_type(
line_buffer: List[BaseSegment],
templated_file: Optional[TemplatedFile] = None,
):
"""Convenience fn for getting 'start', 'end' etc of a placeholder line."""
template_info = _TemplateLineInterpreter(line_buffer, templated_file)
return template_info.block_type()
def _segment_length(elem: BaseSegment, tab_space_size: int):
# Start by assuming the typical case, where we need not consider slices
# or templating.
raw = elem.raw
# If it's whitespace, it might be a mixture of literal and templated
# whitespace. Check for this.
if elem.is_type("whitespace") and elem.is_templated:
# Templated case: Find the leading *literal* whitespace.
assert elem.pos_marker
templated_file = elem.pos_marker.templated_file
# Extract the leading literal whitespace, slice by slice.
raw = ""
for raw_slice in Segments(
elem, templated_file=templated_file
).raw_slices.select(loop_while=rsp.is_slice_type("literal")):
# Compute and append raw_slice's contribution.
raw += sp.raw_slice(elem, raw_slice)
# convert to spaces for convenience (and hanging indents)
return raw.replace("\t", " " * tab_space_size)
def _indent_size(segments: Sequence[BaseSegment], tab_space_size: int = 4) -> int:
indent_size = 0
for elem in segments:
raw = _segment_length(elem, tab_space_size)
indent_size += len(raw)
return indent_size
def _find_last_meaningful_line(
previous_lines: List[_LineSummary],
) -> Optional[_LineSummary]:
# Find last meaningful line indent.
for line in previous_lines:
if line.has_code_segment:
return line
return None
def _find_previous_line(
this_line: _LineSummary,
previous_lines: List[_LineSummary],
ignoreable_lines: Set[int],
) -> Optional[_LineSummary]:
for prev_line in previous_lines:
should_ignore = prev_line.line_no in ignoreable_lines
if should_ignore or prev_line.is_empty_line:
continue
# Work out the difference in indent
indent_diff = this_line.anchor_indent_balance - prev_line.anchor_indent_balance
# If we're comparing to a previous, more deeply indented line,
# then skip and keep looking.
if indent_diff < 0:
continue
return prev_line
return None
def _find_matching_start_line(
previous_lines: List[_LineSummary],
) -> Optional[_LineSummary]:
template_block_level = -1
for template_line in previous_lines:
if not template_line.templated_line_type:
continue
if template_line.templated_line_type == "end":
template_block_level -= 1
else:
template_block_level += 1
if template_block_level != 0:
continue
return template_line
return None # pragma: no cover
def _Desc(
expected: int,
found: int,
compared_to: int,
) -> str:
return (
f"Expected {expected} indentations,"
f" found {found} [compared to line {compared_to:02}]"
)
| 37.190291 | 88 | 0.595338 |
4a1fbf1ef1944e406c062f79b5093ef78326e940 | 52,451 | py | Python | rl_coach/agents/agent.py | crr0004/coach | b601441eb594ae7c12e5f3106bc0537f39bbd7b8 | [
"Apache-2.0"
] | null | null | null | rl_coach/agents/agent.py | crr0004/coach | b601441eb594ae7c12e5f3106bc0537f39bbd7b8 | [
"Apache-2.0"
] | null | null | null | rl_coach/agents/agent.py | crr0004/coach | b601441eb594ae7c12e5f3106bc0537f39bbd7b8 | [
"Apache-2.0"
] | null | null | null | #
# Copyright (c) 2017 Intel Corporation
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import copy
import random
from collections import OrderedDict
from typing import Dict, List, Union, Tuple
import numpy as np
from six.moves import range
from rl_coach.agents.agent_interface import AgentInterface
from rl_coach.architectures.network_wrapper import NetworkWrapper
from rl_coach.base_parameters import AgentParameters, Device, DeviceType, DistributedTaskParameters, Frameworks
from rl_coach.core_types import RunPhase, PredictionType, EnvironmentEpisodes, ActionType, Batch, Episode, StateType
from rl_coach.core_types import Transition, ActionInfo, TrainingSteps, EnvironmentSteps, EnvResponse
from rl_coach.logger import screen, Logger, EpisodeLogger
from rl_coach.memories.episodic.episodic_experience_replay import EpisodicExperienceReplay
from rl_coach.saver import SaverCollection
from rl_coach.spaces import SpacesDefinition, VectorObservationSpace, GoalsSpace, AttentionActionSpace
from rl_coach.utils import Signal, force_list
from rl_coach.utils import dynamic_import_and_instantiate_module_from_params
from rl_coach.memories.backend.memory_impl import get_memory_backend
class Agent(AgentInterface):
def __init__(self, agent_parameters: AgentParameters, parent: Union['LevelManager', 'CompositeAgent']=None):
"""
:param agent_parameters: A AgentParameters class instance with all the agent parameters
"""
super().__init__()
self.ap = agent_parameters
self.task_id = self.ap.task_parameters.task_index
self.is_chief = self.task_id == 0
self.shared_memory = type(agent_parameters.task_parameters) == DistributedTaskParameters \
and self.ap.memory.shared_memory
if self.shared_memory:
self.shared_memory_scratchpad = self.ap.task_parameters.shared_memory_scratchpad
self.name = agent_parameters.name
self.parent = parent
self.parent_level_manager = None
self.full_name_id = agent_parameters.full_name_id = self.name
if type(agent_parameters.task_parameters) == DistributedTaskParameters:
screen.log_title("Creating agent - name: {} task id: {} (may take up to 30 seconds due to "
"tensorflow wake up time)".format(self.full_name_id, self.task_id))
else:
screen.log_title("Creating agent - name: {}".format(self.full_name_id))
self.imitation = False
self.agent_logger = Logger()
self.agent_episode_logger = EpisodeLogger()
# get the memory
# - distributed training + shared memory:
# * is chief? -> create the memory and add it to the scratchpad
# * not chief? -> wait for the chief to create the memory and then fetch it
# - non distributed training / not shared memory:
# * create memory
memory_name = self.ap.memory.path.split(':')[1]
self.memory_lookup_name = self.full_name_id + '.' + memory_name
if self.shared_memory and not self.is_chief:
self.memory = self.shared_memory_scratchpad.get(self.memory_lookup_name)
else:
# modules
self.memory = dynamic_import_and_instantiate_module_from_params(self.ap.memory)
if hasattr(self.ap.memory, 'memory_backend_params'):
self.memory_backend = get_memory_backend(self.ap.memory.memory_backend_params)
if self.ap.memory.memory_backend_params.run_type != 'trainer':
self.memory.set_memory_backend(self.memory_backend)
if agent_parameters.memory.load_memory_from_file_path:
screen.log_title("Loading replay buffer from pickle. Pickle path: {}"
.format(agent_parameters.memory.load_memory_from_file_path))
self.memory.load(agent_parameters.memory.load_memory_from_file_path)
if self.shared_memory and self.is_chief:
self.shared_memory_scratchpad.add(self.memory_lookup_name, self.memory)
# set devices
if type(agent_parameters.task_parameters) == DistributedTaskParameters:
self.has_global = True
self.replicated_device = agent_parameters.task_parameters.device
self.worker_device = "/job:worker/task:{}".format(self.task_id)
if agent_parameters.task_parameters.use_cpu:
self.worker_device += "/cpu:0"
else:
self.worker_device += "/device:GPU:0"
else:
self.has_global = False
self.replicated_device = None
if agent_parameters.task_parameters.use_cpu:
self.worker_device = Device(DeviceType.CPU)
else:
self.worker_device = [Device(DeviceType.GPU, i)
for i in range(agent_parameters.task_parameters.num_gpu)]
# filters
self.input_filter = self.ap.input_filter
self.input_filter.set_name('input_filter')
self.output_filter = self.ap.output_filter
self.output_filter.set_name('output_filter')
self.pre_network_filter = self.ap.pre_network_filter
self.pre_network_filter.set_name('pre_network_filter')
device = self.replicated_device if self.replicated_device else self.worker_device
# TODO-REMOVE This is a temporary flow dividing to 3 modes. To be converged to a single flow once distributed tf
# is removed, and Redis is used for sharing data between local workers.
# Filters MoW will be split between different configurations
# 1. Distributed coach synchrnization type (=distributed across multiple nodes) - Redis based data sharing + numpy arithmetic backend
# 2. Distributed TF (=distributed on a single node, using distributed TF) - TF for both data sharing and arithmetic backend
# 3. Single worker (=both TF and Mxnet) - no data sharing needed + numpy arithmetic backend
if hasattr(self.ap.memory, 'memory_backend_params') and self.ap.algorithm.distributed_coach_synchronization_type:
self.input_filter.set_device(device, memory_backend_params=self.ap.memory.memory_backend_params, mode='numpy')
self.output_filter.set_device(device, memory_backend_params=self.ap.memory.memory_backend_params, mode='numpy')
self.pre_network_filter.set_device(device, memory_backend_params=self.ap.memory.memory_backend_params, mode='numpy')
elif (type(agent_parameters.task_parameters) == DistributedTaskParameters and
agent_parameters.task_parameters.framework_type == Frameworks.tensorflow):
self.input_filter.set_device(device, mode='tf')
self.output_filter.set_device(device, mode='tf')
self.pre_network_filter.set_device(device, mode='tf')
else:
self.input_filter.set_device(device, mode='numpy')
self.output_filter.set_device(device, mode='numpy')
self.pre_network_filter.set_device(device, mode='numpy')
# initialize all internal variables
self._phase = RunPhase.HEATUP
self.total_shaped_reward_in_current_episode = 0
self.total_reward_in_current_episode = 0
self.total_steps_counter = 0
self.running_reward = None
self.training_iteration = 0
self.last_target_network_update_step = 0
self.last_training_phase_step = 0
self.current_episode = self.ap.current_episode = 0
self.curr_state = {}
self.current_hrl_goal = None
self.current_episode_steps_counter = 0
self.episode_running_info = {}
self.last_episode_evaluation_ran = 0
self.running_observations = []
self.agent_logger.set_current_time(self.current_episode)
self.exploration_policy = None
self.networks = {}
self.last_action_info = None
self.running_observation_stats = None
self.running_reward_stats = None
self.accumulated_rewards_across_evaluation_episodes = 0
self.accumulated_shaped_rewards_across_evaluation_episodes = 0
self.num_successes_across_evaluation_episodes = 0
self.num_evaluation_episodes_completed = 0
self.current_episode_buffer = Episode(discount=self.ap.algorithm.discount, n_step=self.ap.algorithm.n_step)
# TODO: add agents observation rendering for debugging purposes (not the same as the environment rendering)
# environment parameters
self.spaces = None
self.in_action_space = self.ap.algorithm.in_action_space
# signals
self.episode_signals = []
self.step_signals = []
self.loss = self.register_signal('Loss')
self.curr_learning_rate = self.register_signal('Learning Rate')
self.unclipped_grads = self.register_signal('Grads (unclipped)')
self.reward = self.register_signal('Reward', dump_one_value_per_episode=False, dump_one_value_per_step=True)
self.shaped_reward = self.register_signal('Shaped Reward', dump_one_value_per_episode=False, dump_one_value_per_step=True)
self.discounted_return = self.register_signal('Discounted Return')
if isinstance(self.in_action_space, GoalsSpace):
self.distance_from_goal = self.register_signal('Distance From Goal', dump_one_value_per_step=True)
# use seed
if self.ap.task_parameters.seed is not None:
random.seed(self.ap.task_parameters.seed)
np.random.seed(self.ap.task_parameters.seed)
else:
# we need to seed the RNG since the different processes are initialized with the same parent seed
random.seed()
np.random.seed()
@property
def parent(self) -> 'LevelManager':
"""
Get the parent class of the agent
:return: the current phase
"""
return self._parent
@parent.setter
def parent(self, val) -> None:
"""
Change the parent class of the agent.
Additionally, updates the full name of the agent
:param val: the new parent
:return: None
"""
self._parent = val
if self._parent is not None:
if not hasattr(self._parent, 'name'):
raise ValueError("The parent of an agent must have a name")
self.full_name_id = self.ap.full_name_id = "{}/{}".format(self._parent.name, self.name)
def setup_logger(self) -> None:
"""
Setup the logger for the agent
:return: None
"""
# dump documentation
logger_prefix = "{graph_name}.{level_name}.{agent_full_id}".\
format(graph_name=self.parent_level_manager.parent_graph_manager.name,
level_name=self.parent_level_manager.name,
agent_full_id='.'.join(self.full_name_id.split('/')))
self.agent_logger.set_logger_filenames(self.ap.task_parameters.experiment_path, logger_prefix=logger_prefix,
add_timestamp=True, task_id=self.task_id)
if self.ap.visualization.dump_in_episode_signals:
self.agent_episode_logger.set_logger_filenames(self.ap.task_parameters.experiment_path,
logger_prefix=logger_prefix,
add_timestamp=True, task_id=self.task_id)
def set_session(self, sess) -> None:
"""
Set the deep learning framework session for all the agents in the composite agent
:return: None
"""
self.input_filter.set_session(sess)
self.output_filter.set_session(sess)
self.pre_network_filter.set_session(sess)
[network.set_session(sess) for network in self.networks.values()]
def register_signal(self, signal_name: str, dump_one_value_per_episode: bool=True,
dump_one_value_per_step: bool=False) -> Signal:
"""
Register a signal such that its statistics will be dumped and be viewable through dashboard
:param signal_name: the name of the signal as it will appear in dashboard
:param dump_one_value_per_episode: should the signal value be written for each episode?
:param dump_one_value_per_step: should the signal value be written for each step?
:return: the created signal
"""
signal = Signal(signal_name)
if dump_one_value_per_episode:
self.episode_signals.append(signal)
if dump_one_value_per_step:
self.step_signals.append(signal)
return signal
def set_environment_parameters(self, spaces: SpacesDefinition):
"""
Sets the parameters that are environment dependent. As a side effect, initializes all the components that are
dependent on those values, by calling init_environment_dependent_modules
:param spaces: the environment spaces definition
:return: None
"""
self.spaces = copy.deepcopy(spaces)
if self.ap.algorithm.use_accumulated_reward_as_measurement:
if 'measurements' in self.spaces.state.sub_spaces:
self.spaces.state['measurements'].shape += 1
self.spaces.state['measurements'].measurements_names += ['accumulated_reward']
else:
self.spaces.state['measurements'] = VectorObservationSpace(1, measurements_names=['accumulated_reward'])
for observation_name in self.spaces.state.sub_spaces.keys():
self.spaces.state[observation_name] = \
self.pre_network_filter.get_filtered_observation_space(observation_name,
self.input_filter.get_filtered_observation_space(observation_name,
self.spaces.state[observation_name]))
self.spaces.reward = self.pre_network_filter.get_filtered_reward_space(
self.input_filter.get_filtered_reward_space(self.spaces.reward))
self.spaces.action = self.output_filter.get_unfiltered_action_space(self.spaces.action)
if isinstance(self.in_action_space, GoalsSpace):
# TODO: what if the goal type is an embedding / embedding change?
self.spaces.goal = self.in_action_space
self.spaces.goal.set_target_space(self.spaces.state[self.spaces.goal.goal_name])
self.init_environment_dependent_modules()
def create_networks(self) -> Dict[str, NetworkWrapper]:
"""
Create all the networks of the agent.
The network creation will be done after setting the environment parameters for the agent, since they are needed
for creating the network.
:return: A list containing all the networks
"""
networks = {}
for network_name in sorted(self.ap.network_wrappers.keys()):
networks[network_name] = NetworkWrapper(name=network_name,
agent_parameters=self.ap,
has_target=self.ap.network_wrappers[network_name].create_target_network,
has_global=self.has_global,
spaces=self.spaces,
replicated_device=self.replicated_device,
worker_device=self.worker_device)
if self.ap.visualization.print_networks_summary:
print(networks[network_name])
return networks
def init_environment_dependent_modules(self) -> None:
"""
Initialize any modules that depend on knowing information about the environment such as the action space or
the observation space
:return: None
"""
# initialize exploration policy
if isinstance(self.ap.exploration, dict):
if self.spaces.action.__class__ in self.ap.exploration.keys():
self.ap.exploration = self.ap.exploration[self.spaces.action.__class__]
else:
raise ValueError("The exploration parameters were defined as a mapping between action space types and "
"exploration types, but the action space used by the environment ({}) was not part of "
"the exploration parameters dictionary keys ({})"
.format(self.spaces.action.__class__, list(self.ap.exploration.keys())))
self.ap.exploration.action_space = self.spaces.action
self.exploration_policy = dynamic_import_and_instantiate_module_from_params(self.ap.exploration)
# create all the networks of the agent
self.networks = self.create_networks()
@property
def phase(self) -> RunPhase:
"""
The current running phase of the agent
:return: RunPhase
"""
return self._phase
@phase.setter
def phase(self, val: RunPhase) -> None:
"""
Change the phase of the run for the agent and all the sub components
:param val: the new run phase (TRAIN, TEST, etc.)
:return: None
"""
self.reset_evaluation_state(val)
self._phase = val
self.exploration_policy.change_phase(val)
def reset_evaluation_state(self, val: RunPhase) -> None:
"""
Perform accumulators initialization when entering an evaluation phase, and signal dumping when exiting an
evaluation phase. Entering or exiting the evaluation phase is determined according to the new phase given
by val, and by the current phase set in self.phase.
:param val: The new phase to change to
:return: None
"""
starting_evaluation = (val == RunPhase.TEST)
ending_evaluation = (self.phase == RunPhase.TEST)
if starting_evaluation:
self.accumulated_rewards_across_evaluation_episodes = 0
self.accumulated_shaped_rewards_across_evaluation_episodes = 0
self.num_successes_across_evaluation_episodes = 0
self.num_evaluation_episodes_completed = 0
if self.ap.is_a_highest_level_agent or self.ap.task_parameters.verbosity == "high":
screen.log_title("{}: Starting evaluation phase".format(self.name))
elif ending_evaluation:
# we write to the next episode, because it could be that the current episode was already written
# to disk and then we won't write it again
self.agent_logger.set_current_time(self.current_episode + 1)
evaluation_reward = self.accumulated_rewards_across_evaluation_episodes / self.num_evaluation_episodes_completed
self.agent_logger.create_signal_value(
'Evaluation Reward', evaluation_reward)
self.agent_logger.create_signal_value(
'Shaped Evaluation Reward',
self.accumulated_shaped_rewards_across_evaluation_episodes / self.num_evaluation_episodes_completed)
success_rate = self.num_successes_across_evaluation_episodes / self.num_evaluation_episodes_completed
self.agent_logger.create_signal_value(
"Success Rate",
success_rate
)
if self.ap.is_a_highest_level_agent or self.ap.task_parameters.verbosity == "high":
screen.log_title("{}: Finished evaluation phase. Success rate = {}, Avg Total Reward = {}"
.format(self.name, np.round(success_rate, 2), np.round(evaluation_reward, 2)))
def call_memory(self, func, args=()):
"""
This function is a wrapper to allow having the same calls for shared or unshared memories.
It should be used instead of calling the memory directly in order to allow different algorithms to work
both with a shared and a local memory.
:param func: the name of the memory function to call
:param args: the arguments to supply to the function
:return: the return value of the function
"""
if self.shared_memory:
result = self.shared_memory_scratchpad.internal_call(self.memory_lookup_name, func, args)
else:
if type(args) != tuple:
args = (args,)
result = getattr(self.memory, func)(*args)
return result
def log_to_screen(self) -> None:
"""
Write an episode summary line to the terminal
:return: None
"""
# log to screen
log = OrderedDict()
log["Name"] = self.full_name_id
if self.task_id is not None:
log["Worker"] = self.task_id
log["Episode"] = self.current_episode
log["Total reward"] = np.round(self.total_reward_in_current_episode, 2)
log["Exploration"] = np.round(self.exploration_policy.get_control_param(), 2)
log["Steps"] = self.total_steps_counter
log["Training iteration"] = self.training_iteration
screen.log_dict(log, prefix=self.phase.value)
def update_step_in_episode_log(self) -> None:
"""
Updates the in-episode log file with all the signal values from the most recent step.
:return: None
"""
# log all the signals to file
self.agent_episode_logger.set_current_time(self.current_episode_steps_counter)
self.agent_episode_logger.create_signal_value('Training Iter', self.training_iteration)
self.agent_episode_logger.create_signal_value('In Heatup', int(self._phase == RunPhase.HEATUP))
self.agent_episode_logger.create_signal_value('ER #Transitions', self.call_memory('num_transitions'))
self.agent_episode_logger.create_signal_value('ER #Episodes', self.call_memory('length'))
self.agent_episode_logger.create_signal_value('Total steps', self.total_steps_counter)
self.agent_episode_logger.create_signal_value("Epsilon", self.exploration_policy.get_control_param())
self.agent_episode_logger.create_signal_value("Shaped Accumulated Reward", self.total_shaped_reward_in_current_episode)
self.agent_episode_logger.create_signal_value('Update Target Network', 0, overwrite=False)
self.agent_episode_logger.update_wall_clock_time(self.current_episode_steps_counter)
for signal in self.step_signals:
self.agent_episode_logger.create_signal_value(signal.name, signal.get_last_value())
# dump
self.agent_episode_logger.dump_output_csv()
def update_log(self) -> None:
"""
Updates the episodic log file with all the signal values from the most recent episode.
Additional signals for logging can be set by the creating a new signal using self.register_signal,
and then updating it with some internal agent values.
:return: None
"""
# log all the signals to file
self.agent_logger.set_current_time(self.current_episode)
self.agent_logger.create_signal_value('Training Iter', self.training_iteration)
self.agent_logger.create_signal_value('In Heatup', int(self._phase == RunPhase.HEATUP))
self.agent_logger.create_signal_value('ER #Transitions', self.call_memory('num_transitions'))
self.agent_logger.create_signal_value('ER #Episodes', self.call_memory('length'))
self.agent_logger.create_signal_value('Episode Length', self.current_episode_steps_counter)
self.agent_logger.create_signal_value('Total steps', self.total_steps_counter)
self.agent_logger.create_signal_value("Epsilon", np.mean(self.exploration_policy.get_control_param()))
self.agent_logger.create_signal_value("Shaped Training Reward", self.total_shaped_reward_in_current_episode
if self._phase == RunPhase.TRAIN else np.nan)
self.agent_logger.create_signal_value("Training Reward", self.total_reward_in_current_episode
if self._phase == RunPhase.TRAIN else np.nan)
self.agent_logger.create_signal_value('Update Target Network', 0, overwrite=False)
self.agent_logger.update_wall_clock_time(self.current_episode)
if self._phase != RunPhase.TEST:
self.agent_logger.create_signal_value('Evaluation Reward', np.nan, overwrite=False)
self.agent_logger.create_signal_value('Shaped Evaluation Reward', np.nan, overwrite=False)
self.agent_logger.create_signal_value('Success Rate', np.nan, overwrite=False)
for signal in self.episode_signals:
self.agent_logger.create_signal_value("{}/Mean".format(signal.name), signal.get_mean())
self.agent_logger.create_signal_value("{}/Stdev".format(signal.name), signal.get_stdev())
self.agent_logger.create_signal_value("{}/Max".format(signal.name), signal.get_max())
self.agent_logger.create_signal_value("{}/Min".format(signal.name), signal.get_min())
# dump
if self.current_episode % self.ap.visualization.dump_signals_to_csv_every_x_episodes == 0 \
and self.current_episode > 0:
self.agent_logger.dump_output_csv()
def handle_episode_ended(self) -> None:
"""
Make any changes needed when each episode is ended.
This includes incrementing counters, updating full episode dependent values, updating logs, etc.
This function is called right after each episode is ended.
:return: None
"""
self.current_episode_buffer.is_complete = True
self.current_episode_buffer.update_transitions_rewards_and_bootstrap_data()
for transition in self.current_episode_buffer.transitions:
self.discounted_return.add_sample(transition.n_step_discounted_rewards)
if self.phase != RunPhase.TEST or self.ap.task_parameters.evaluate_only:
self.current_episode += 1
if self.phase != RunPhase.TEST:
if isinstance(self.memory, EpisodicExperienceReplay):
self.call_memory('store_episode', self.current_episode_buffer)
elif self.ap.algorithm.store_transitions_only_when_episodes_are_terminated:
for transition in self.current_episode_buffer.transitions:
self.call_memory('store', transition)
if self.phase == RunPhase.TEST:
self.accumulated_rewards_across_evaluation_episodes += self.total_reward_in_current_episode
self.accumulated_shaped_rewards_across_evaluation_episodes += self.total_shaped_reward_in_current_episode
self.num_evaluation_episodes_completed += 1
if self.spaces.reward.reward_success_threshold and \
self.total_reward_in_current_episode >= self.spaces.reward.reward_success_threshold:
self.num_successes_across_evaluation_episodes += 1
if self.ap.visualization.dump_csv:
self.update_log()
if self.ap.is_a_highest_level_agent or self.ap.task_parameters.verbosity == "high":
self.log_to_screen()
def reset_internal_state(self) -> None:
"""
Reset all the episodic parameters. This function is called right before each episode starts.
:return: None
"""
for signal in self.episode_signals:
signal.reset()
for signal in self.step_signals:
signal.reset()
self.agent_episode_logger.set_episode_idx(self.current_episode)
self.total_shaped_reward_in_current_episode = 0
self.total_reward_in_current_episode = 0
self.curr_state = {}
self.current_episode_steps_counter = 0
self.episode_running_info = {}
self.current_episode_buffer = Episode(discount=self.ap.algorithm.discount, n_step=self.ap.algorithm.n_step)
if self.exploration_policy:
self.exploration_policy.reset()
self.input_filter.reset()
self.output_filter.reset()
self.pre_network_filter.reset()
if isinstance(self.memory, EpisodicExperienceReplay):
self.call_memory('verify_last_episode_is_closed')
for network in self.networks.values():
network.online_network.reset_internal_memory()
def learn_from_batch(self, batch) -> Tuple[float, List, List]:
"""
Given a batch of transitions, calculates their target values and updates the network.
:param batch: A list of transitions
:return: The total loss of the training, the loss per head and the unclipped gradients
"""
return 0, [], []
def _should_update_online_weights_to_target(self):
"""
Determine if online weights should be copied to the target.
:return: boolean: True if the online weights should be copied to the target.
"""
# update the target network of every network that has a target network
step_method = self.ap.algorithm.num_steps_between_copying_online_weights_to_target
if step_method.__class__ == TrainingSteps:
should_update = (self.training_iteration - self.last_target_network_update_step) >= step_method.num_steps
if should_update:
self.last_target_network_update_step = self.training_iteration
elif step_method.__class__ == EnvironmentSteps:
should_update = (self.total_steps_counter - self.last_target_network_update_step) >= step_method.num_steps
if should_update:
self.last_target_network_update_step = self.total_steps_counter
else:
raise ValueError("The num_steps_between_copying_online_weights_to_target parameter should be either "
"EnvironmentSteps or TrainingSteps. Instead it is {}".format(step_method.__class__))
return should_update
def _should_train(self):
"""
Determine if we should start a training phase according to the number of steps passed since the last training
:return: boolean: True if we should start a training phase
"""
should_update = self._should_update()
steps = self.ap.algorithm.num_consecutive_playing_steps
if should_update:
if steps.__class__ == EnvironmentEpisodes:
self.last_training_phase_step = self.current_episode
if steps.__class__ == EnvironmentSteps:
self.last_training_phase_step = self.total_steps_counter
return should_update
def _should_update(self):
wait_for_full_episode = self.ap.algorithm.act_for_full_episodes
steps = self.ap.algorithm.num_consecutive_playing_steps
if steps.__class__ == EnvironmentEpisodes:
should_update = (self.current_episode - self.last_training_phase_step) >= steps.num_steps
should_update = should_update and self.call_memory('length') > 0
elif steps.__class__ == EnvironmentSteps:
should_update = (self.total_steps_counter - self.last_training_phase_step) >= steps.num_steps
should_update = should_update and self.call_memory('num_transitions') > 0
if wait_for_full_episode:
should_update = should_update and self.current_episode_buffer.is_complete
else:
raise ValueError("The num_consecutive_playing_steps parameter should be either "
"EnvironmentSteps or Episodes. Instead it is {}".format(steps.__class__))
return should_update
def train(self) -> float:
"""
Check if a training phase should be done as configured by num_consecutive_playing_steps.
If it should, then do several training steps as configured by num_consecutive_training_steps.
A single training iteration: Sample a batch, train on it and update target networks.
:return: The total training loss during the training iterations.
"""
loss = 0
if self._should_train():
for network in self.networks.values():
network.set_is_training(True)
for training_step in range(self.ap.algorithm.num_consecutive_training_steps):
# TODO: this should be network dependent
network_parameters = list(self.ap.network_wrappers.values())[0]
# update counters
self.training_iteration += 1
# sample a batch and train on it
batch = self.call_memory('sample', network_parameters.batch_size)
if self.pre_network_filter is not None:
batch = self.pre_network_filter.filter(batch, update_internal_state=False, deep_copy=False)
# if the batch returned empty then there are not enough samples in the replay buffer -> skip
# training step
if len(batch) > 0:
# train
batch = Batch(batch)
total_loss, losses, unclipped_grads = self.learn_from_batch(batch)
loss += total_loss
self.unclipped_grads.add_sample(unclipped_grads)
# TODO: the learning rate decay should be done through the network instead of here
# decay learning rate
if network_parameters.learning_rate_decay_rate != 0:
self.curr_learning_rate.add_sample(self.networks['main'].sess.run(
self.networks['main'].online_network.current_learning_rate))
else:
self.curr_learning_rate.add_sample(network_parameters.learning_rate)
if any([network.has_target for network in self.networks.values()]) \
and self._should_update_online_weights_to_target():
for network in self.networks.values():
network.update_target_network(self.ap.algorithm.rate_for_copying_weights_to_target)
self.agent_logger.create_signal_value('Update Target Network', 1)
else:
self.agent_logger.create_signal_value('Update Target Network', 0, overwrite=False)
self.loss.add_sample(loss)
if self.imitation:
self.log_to_screen()
for network in self.networks.values():
network.set_is_training(False)
# run additional commands after the training is done
self.post_training_commands()
return loss
def choose_action(self, curr_state):
"""
choose an action to act with in the current episode being played. Different behavior might be exhibited when
training or testing.
:param curr_state: the current state to act upon.
:return: chosen action, some action value describing the action (q-value, probability, etc)
"""
pass
def prepare_batch_for_inference(self, states: Union[Dict[str, np.ndarray], List[Dict[str, np.ndarray]]],
network_name: str) -> Dict[str, np.array]:
"""
Convert curr_state into input tensors tensorflow is expecting. i.e. if we have several inputs states, stack all
observations together, measurements together, etc.
:param states: A list of environment states, where each one is a dict mapping from an observation name to its
corresponding observation
:param network_name: The agent network name to prepare the batch for. this is needed in order to extract only
the observation relevant for the network from the states.
:return: A dictionary containing a list of values from all the given states for each of the observations
"""
# convert to batch so we can run it through the network
states = force_list(states)
batches_dict = {}
for key in self.ap.network_wrappers[network_name].input_embedders_parameters.keys():
# there are cases (e.g. ddpg) where the state does not contain all the information needed for running
# through the network and this has to be added externally (e.g. ddpg where the action needs to be given in
# addition to the current_state, so that all the inputs of the network will be filled)
if key in states[0].keys():
batches_dict[key] = np.array([np.array(state[key]) for state in states])
return batches_dict
def act(self) -> ActionInfo:
"""
Given the agents current knowledge, decide on the next action to apply to the environment
:return: An ActionInfo object, which contains the action and any additional info from the action decision process
"""
if self.phase == RunPhase.TRAIN and self.ap.algorithm.num_consecutive_playing_steps.num_steps == 0:
# This agent never plays while training (e.g. behavioral cloning)
return None
# count steps (only when training or if we are in the evaluation worker)
if self.phase != RunPhase.TEST or self.ap.task_parameters.evaluate_only:
self.total_steps_counter += 1
self.current_episode_steps_counter += 1
# decide on the action
if self.phase == RunPhase.HEATUP and not self.ap.algorithm.heatup_using_network_decisions:
# random action
self.last_action_info = self.spaces.action.sample_with_info()
else:
# informed action
if self.pre_network_filter is not None:
# before choosing an action, first use the pre_network_filter to filter out the current state
update_filter_internal_state = self.phase is not RunPhase.TEST
curr_state = self.run_pre_network_filter_for_inference(self.curr_state, update_filter_internal_state)
else:
curr_state = self.curr_state
self.last_action_info = self.choose_action(curr_state)
filtered_action_info = self.output_filter.filter(self.last_action_info)
return filtered_action_info
def run_pre_network_filter_for_inference(self, state: StateType, update_filter_internal_state: bool=True)\
-> StateType:
"""
Run filters which where defined for being applied right before using the state for inference.
:param state: The state to run the filters on
:param update_filter_internal_state: Should update the filter's internal state - should not update when evaluating
:return: The filtered state
"""
dummy_env_response = EnvResponse(next_state=state, reward=0, game_over=False)
return self.pre_network_filter.filter(dummy_env_response,
update_internal_state=update_filter_internal_state)[0].next_state
def get_state_embedding(self, state: dict) -> np.ndarray:
"""
Given a state, get the corresponding state embedding from the main network
:param state: a state dict
:return: a numpy embedding vector
"""
# TODO: this won't work anymore
# TODO: instead of the state embedding (which contains the goal) we should use the observation embedding
embedding = self.networks['main'].online_network.predict(
self.prepare_batch_for_inference(state, "main"),
outputs=self.networks['main'].online_network.state_embedding)
return embedding
def update_transition_before_adding_to_replay_buffer(self, transition: Transition) -> Transition:
"""
Allows agents to update the transition just before adding it to the replay buffer.
Can be useful for agents that want to tweak the reward, termination signal, etc.
:param transition: the transition to update
:return: the updated transition
"""
return transition
def observe(self, env_response: EnvResponse) -> bool:
"""
Given a response from the environment, distill the observation from it and store it for later use.
The response should be a dictionary containing the performed action, the new observation and measurements,
the reward, a game over flag and any additional information necessary.
:param env_response: result of call from environment.step(action)
:return: a boolean value which determines if the agent has decided to terminate the episode after seeing the
given observation
"""
# filter the env_response
filtered_env_response = self.input_filter.filter(env_response)[0]
# inject agent collected statistics, if required
if self.ap.algorithm.use_accumulated_reward_as_measurement:
if 'measurements' in filtered_env_response.next_state:
filtered_env_response.next_state['measurements'] = np.append(filtered_env_response.next_state['measurements'],
self.total_shaped_reward_in_current_episode)
else:
filtered_env_response.next_state['measurements'] = np.array([self.total_shaped_reward_in_current_episode])
# if we are in the first step in the episode, then we don't have a a next state and a reward and thus no
# transition yet, and therefore we don't need to store anything in the memory.
# also we did not reach the goal yet.
if self.current_episode_steps_counter == 0:
# initialize the current state
self.curr_state = filtered_env_response.next_state
return env_response.game_over
else:
transition = Transition(state=copy.copy(self.curr_state), action=self.last_action_info.action,
reward=filtered_env_response.reward, next_state=filtered_env_response.next_state,
game_over=filtered_env_response.game_over, info=filtered_env_response.info)
# now that we have formed a basic transition - the next state progresses to be the current state
self.curr_state = filtered_env_response.next_state
# make agent specific changes to the transition if needed
transition = self.update_transition_before_adding_to_replay_buffer(transition)
# merge the intrinsic reward in
if self.ap.algorithm.scale_external_reward_by_intrinsic_reward_value:
transition.reward = transition.reward * (1 + self.last_action_info.action_intrinsic_reward)
else:
transition.reward = transition.reward + self.last_action_info.action_intrinsic_reward
# sum up the total shaped reward
self.total_shaped_reward_in_current_episode += transition.reward
self.total_reward_in_current_episode += env_response.reward
self.shaped_reward.add_sample(transition.reward)
self.reward.add_sample(env_response.reward)
# add action info to transition
if type(self.parent).__name__ == 'CompositeAgent':
transition.add_info(self.parent.last_action_info.__dict__)
else:
transition.add_info(self.last_action_info.__dict__)
# create and store the transition
if self.phase in [RunPhase.TRAIN, RunPhase.HEATUP]:
# for episodic memories we keep the transitions in a local buffer until the episode is ended.
# for regular memories we insert the transitions directly to the memory
self.current_episode_buffer.insert(transition)
if not isinstance(self.memory, EpisodicExperienceReplay) \
and not self.ap.algorithm.store_transitions_only_when_episodes_are_terminated:
self.call_memory('store', transition)
if self.ap.visualization.dump_in_episode_signals:
self.update_step_in_episode_log()
return transition.game_over
def post_training_commands(self) -> None:
"""
A function which allows adding any functionality that is required to run right after the training phase ends.
:return: None
"""
pass
def get_predictions(self, states: List[Dict[str, np.ndarray]], prediction_type: PredictionType):
"""
Get a prediction from the agent with regard to the requested prediction_type.
If the agent cannot predict this type of prediction_type, or if there is more than possible way to do so,
raise a ValueException.
:param states: The states to get a prediction for
:param prediction_type: The type of prediction to get for the states. For example, the state-value prediction.
:return: the predicted values
"""
predictions = self.networks['main'].online_network.predict_with_prediction_type(
# states=self.dict_state_to_batches_dict(states, 'main'), prediction_type=prediction_type)
states=states, prediction_type=prediction_type)
if len(predictions.keys()) != 1:
raise ValueError("The network has more than one component {} matching the requested prediction_type {}. ".
format(list(predictions.keys()), prediction_type))
return list(predictions.values())[0]
def set_incoming_directive(self, action: ActionType) -> None:
"""
Allows setting a directive for the agent to follow. This is useful in hierarchy structures, where the agent
has another master agent that is controlling it. In such cases, the master agent can define the goals for the
slave agent, define it's observation, possible actions, etc. The directive type is defined by the agent
in-action-space.
:param action: The action that should be set as the directive
:return:
"""
if isinstance(self.in_action_space, GoalsSpace):
self.current_hrl_goal = action
elif isinstance(self.in_action_space, AttentionActionSpace):
self.input_filter.observation_filters['attention'].crop_low = action[0]
self.input_filter.observation_filters['attention'].crop_high = action[1]
self.output_filter.action_filters['masking'].set_masking(action[0], action[1])
def save_checkpoint(self, checkpoint_prefix: str) -> None:
"""
Allows agents to store additional information when saving checkpoints.
:param checkpoint_prefix: The prefix of the checkpoint file to save
:return: None
"""
checkpoint_dir = self.ap.task_parameters.checkpoint_save_dir
checkpoint_prefix = '.'.join([checkpoint_prefix] + self.full_name_id.split('/')) # adds both level name and agent name
self.input_filter.save_state_to_checkpoint(checkpoint_dir, checkpoint_prefix)
self.output_filter.save_state_to_checkpoint(checkpoint_dir, checkpoint_prefix)
self.pre_network_filter.save_state_to_checkpoint(checkpoint_dir, checkpoint_prefix)
def restore_checkpoint(self, checkpoint_dir: str) -> None:
"""
Allows agents to store additional information when saving checkpoints.
:param checkpoint_dir: The checkpoint dir to restore from
:return: None
"""
checkpoint_prefix = '.'.join(self.full_name_id.split('/')) # adds both level name and agent name
self.input_filter.restore_state_from_checkpoint(checkpoint_dir, checkpoint_prefix)
self.pre_network_filter.restore_state_from_checkpoint(checkpoint_dir, checkpoint_prefix)
# no output filters currently have an internal state to restore
# self.output_filter.restore_state_from_checkpoint(checkpoint_dir)
def sync(self) -> None:
"""
Sync the global network parameters to local networks
:return: None
"""
for network in self.networks.values():
network.sync()
# TODO-remove - this is a temporary flow, used by the trainer worker, duplicated from observe() - need to create
# an external trainer flow reusing the existing flow and methods [e.g. observe(), step(), act()]
def emulate_observe_on_trainer(self, transition: Transition) -> bool:
"""
This emulates the observe using the transition obtained from the rollout worker on the training worker
in case of distributed training.
Given a response from the environment, distill the observation from it and store it for later use.
The response should be a dictionary containing the performed action, the new observation and measurements,
the reward, a game over flag and any additional information necessary.
:return:
"""
# sum up the total shaped reward
self.total_shaped_reward_in_current_episode += transition.reward
self.total_reward_in_current_episode += transition.reward
self.shaped_reward.add_sample(transition.reward)
self.reward.add_sample(transition.reward)
# create and store the transition
if self.phase in [RunPhase.TRAIN, RunPhase.HEATUP]:
# for episodic memories we keep the transitions in a local buffer until the episode is ended.
# for regular memories we insert the transitions directly to the memory
self.current_episode_buffer.insert(transition)
if not isinstance(self.memory, EpisodicExperienceReplay) \
and not self.ap.algorithm.store_transitions_only_when_episodes_are_terminated:
self.call_memory('store', transition)
if self.ap.visualization.dump_in_episode_signals:
self.update_step_in_episode_log()
return transition.game_over
# TODO-remove - this is a temporary flow, used by the trainer worker, duplicated from observe() - need to create
# an external trainer flow reusing the existing flow and methods [e.g. observe(), step(), act()]
def emulate_act_on_trainer(self, transition: Transition) -> ActionInfo:
"""
This emulates the act using the transition obtained from the rollout worker on the training worker
in case of distributed training.
Given the agents current knowledge, decide on the next action to apply to the environment
:return: an action and a dictionary containing any additional info from the action decision process
"""
if self.phase == RunPhase.TRAIN and self.ap.algorithm.num_consecutive_playing_steps.num_steps == 0:
# This agent never plays while training (e.g. behavioral cloning)
return None
# count steps (only when training or if we are in the evaluation worker)
if self.phase != RunPhase.TEST or self.ap.task_parameters.evaluate_only:
self.total_steps_counter += 1
self.current_episode_steps_counter += 1
self.last_action_info = transition.action
return self.last_action_info
def get_success_rate(self) -> float:
return self.num_successes_across_evaluation_episodes / self.num_evaluation_episodes_completed
def collect_savers(self, parent_path_suffix: str) -> SaverCollection:
"""
Collect all of agent's network savers
:param parent_path_suffix: path suffix of the parent of the agent
(could be name of level manager or composite agent)
:return: collection of all agent savers
"""
parent_path_suffix = "{}.{}".format(parent_path_suffix, self.name)
savers = SaverCollection()
for network in self.networks.values():
savers.update(network.collect_savers(parent_path_suffix))
return savers
| 50.579556 | 141 | 0.672037 |
4a1fc04ff8265fd2357572022865fcefce9b8377 | 7,601 | py | Python | torchmetrics/functional/__init__.py | walidbou6/metrics | 44b049cb57ccbf3904f4db16c818c3cdc566788e | [
"Apache-2.0"
] | 1 | 2022-03-22T08:49:04.000Z | 2022-03-22T08:49:04.000Z | torchmetrics/functional/__init__.py | walidbou6/metrics | 44b049cb57ccbf3904f4db16c818c3cdc566788e | [
"Apache-2.0"
] | null | null | null | torchmetrics/functional/__init__.py | walidbou6/metrics | 44b049cb57ccbf3904f4db16c818c3cdc566788e | [
"Apache-2.0"
] | null | null | null | # Copyright The PyTorch Lightning team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from torchmetrics.functional.audio.pit import permutation_invariant_training, pit_permutate
from torchmetrics.functional.audio.sdr import scale_invariant_signal_distortion_ratio, signal_distortion_ratio
from torchmetrics.functional.audio.snr import scale_invariant_signal_noise_ratio, signal_noise_ratio
from torchmetrics.functional.classification.accuracy import accuracy
from torchmetrics.functional.classification.auc import auc
from torchmetrics.functional.classification.auroc import auroc
from torchmetrics.functional.classification.average_precision import average_precision
from torchmetrics.functional.classification.calibration_error import calibration_error
from torchmetrics.functional.classification.cohen_kappa import cohen_kappa
from torchmetrics.functional.classification.confusion_matrix import confusion_matrix
from torchmetrics.functional.classification.dice import dice_score
from torchmetrics.functional.classification.f_beta import f1_score, fbeta_score
from torchmetrics.functional.classification.hamming import hamming_distance
from torchmetrics.functional.classification.hinge import hinge_loss
from torchmetrics.functional.classification.jaccard import jaccard_index
from torchmetrics.functional.classification.kl_divergence import kl_divergence
from torchmetrics.functional.classification.matthews_corrcoef import matthews_corrcoef
from torchmetrics.functional.classification.precision_recall import precision, precision_recall, recall
from torchmetrics.functional.classification.precision_recall_curve import precision_recall_curve
from torchmetrics.functional.classification.ranking import (
coverage_error,
label_ranking_average_precision,
label_ranking_loss,
)
from torchmetrics.functional.classification.roc import roc
from torchmetrics.functional.classification.specificity import specificity
from torchmetrics.functional.classification.stat_scores import stat_scores
from torchmetrics.functional.image.gradients import image_gradients
from torchmetrics.functional.image.psnr import peak_signal_noise_ratio
from torchmetrics.functional.image.sam import spectral_angle_mapper
from torchmetrics.functional.image.ssim import (
multiscale_structural_similarity_index_measure,
structural_similarity_index_measure,
)
from torchmetrics.functional.image.uqi import universal_image_quality_index
from torchmetrics.functional.pairwise.cosine import pairwise_cosine_similarity
from torchmetrics.functional.pairwise.euclidean import pairwise_euclidean_distance
from torchmetrics.functional.pairwise.linear import pairwise_linear_similarity
from torchmetrics.functional.pairwise.manhattan import pairwise_manhattan_distance
from torchmetrics.functional.regression.cosine_similarity import cosine_similarity
from torchmetrics.functional.regression.explained_variance import explained_variance
from torchmetrics.functional.regression.log_mse import mean_squared_log_error
from torchmetrics.functional.regression.mae import mean_absolute_error
from torchmetrics.functional.regression.mape import mean_absolute_percentage_error
from torchmetrics.functional.regression.mse import mean_squared_error
from torchmetrics.functional.regression.pearson import pearson_corrcoef
from torchmetrics.functional.regression.r2 import r2_score
from torchmetrics.functional.regression.spearman import spearman_corrcoef
from torchmetrics.functional.regression.symmetric_mape import symmetric_mean_absolute_percentage_error
from torchmetrics.functional.regression.tweedie_deviance import tweedie_deviance_score
from torchmetrics.functional.retrieval.average_precision import retrieval_average_precision
from torchmetrics.functional.retrieval.fall_out import retrieval_fall_out
from torchmetrics.functional.retrieval.hit_rate import retrieval_hit_rate
from torchmetrics.functional.retrieval.ndcg import retrieval_normalized_dcg
from torchmetrics.functional.retrieval.precision import retrieval_precision
from torchmetrics.functional.retrieval.r_precision import retrieval_r_precision
from torchmetrics.functional.retrieval.recall import retrieval_recall
from torchmetrics.functional.retrieval.reciprocal_rank import retrieval_reciprocal_rank
from torchmetrics.functional.text.bleu import bleu_score
from torchmetrics.functional.text.cer import char_error_rate
from torchmetrics.functional.text.chrf import chrf_score
from torchmetrics.functional.text.eed import extended_edit_distance
from torchmetrics.functional.text.mer import match_error_rate
from torchmetrics.functional.text.rouge import rouge_score
from torchmetrics.functional.text.sacre_bleu import sacre_bleu_score
from torchmetrics.functional.text.squad import squad
from torchmetrics.functional.text.ter import translation_edit_rate
from torchmetrics.functional.text.wer import word_error_rate
from torchmetrics.functional.text.wil import word_information_lost
from torchmetrics.functional.text.wip import word_information_preserved
from torchmetrics.utilities.imports import _TRANSFORMERS_AUTO_AVAILABLE
if _TRANSFORMERS_AUTO_AVAILABLE:
from torchmetrics.functional.text.bert import bert_score # noqa: F401
__all__ = [
"accuracy",
"auc",
"auroc",
"average_precision",
"bleu_score",
"calibration_error",
"chrf_score",
"cohen_kappa",
"confusion_matrix",
"cosine_similarity",
"coverage_error",
"tweedie_deviance_score",
"dice_score",
"explained_variance",
"extended_edit_distance",
"f1_score",
"fbeta_score",
"hamming_distance",
"hinge_loss",
"image_gradients",
"jaccard_index",
"kl_divergence",
"label_ranking_average_precision",
"label_ranking_loss",
"matthews_corrcoef",
"mean_absolute_error",
"mean_absolute_percentage_error",
"mean_squared_error",
"mean_squared_log_error",
"multiscale_structural_similarity_index_measure",
"pairwise_cosine_similarity",
"pairwise_euclidean_distance",
"pairwise_linear_similarity",
"pairwise_manhattan_distance",
"pearson_corrcoef",
"permutation_invariant_training",
"pit_permutate",
"precision",
"precision_recall",
"precision_recall_curve",
"peak_signal_noise_ratio",
"r2_score",
"recall",
"retrieval_average_precision",
"retrieval_fall_out",
"retrieval_hit_rate",
"retrieval_normalized_dcg",
"retrieval_precision",
"retrieval_r_precision",
"retrieval_recall",
"retrieval_reciprocal_rank",
"roc",
"rouge_score",
"sacre_bleu_score",
"signal_distortion_ratio",
"scale_invariant_signal_distortion_ratio",
"scale_invariant_signal_noise_ratio",
"signal_noise_ratio",
"spearman_corrcoef",
"specificity",
"squad",
"structural_similarity_index_measure",
"stat_scores",
"symmetric_mean_absolute_percentage_error",
"translation_edit_rate",
"universal_image_quality_index",
"spectral_angle_mapper",
"word_error_rate",
"char_error_rate",
"match_error_rate",
"word_information_lost",
"word_information_preserved",
]
| 46.631902 | 110 | 0.837127 |
4a1fc0ac81b1f56a29d803303c0fcd62df854fae | 1,991 | py | Python | src/Testing/ZopeTestCase/__init__.py | lukenowak/Zope | c9002f06a5a94841d2cbf6b51d366d3b7f633297 | [
"ZPL-2.1"
] | 1 | 2018-11-30T12:39:27.000Z | 2018-11-30T12:39:27.000Z | src/Testing/ZopeTestCase/__init__.py | lukenowak/Zope | c9002f06a5a94841d2cbf6b51d366d3b7f633297 | [
"ZPL-2.1"
] | null | null | null | src/Testing/ZopeTestCase/__init__.py | lukenowak/Zope | c9002f06a5a94841d2cbf6b51d366d3b7f633297 | [
"ZPL-2.1"
] | 1 | 2018-11-30T12:39:34.000Z | 2018-11-30T12:39:34.000Z | ##############################################################################
#
# Copyright (c) 2005 Zope Foundation and Contributors.
#
# This software is subject to the provisions of the Zope Public License,
# Version 2.1 (ZPL). A copy of the ZPL should accompany this distribution.
# THIS SOFTWARE IS PROVIDED "AS IS" AND ANY AND ALL EXPRESS OR IMPLIED
# WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
# WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND FITNESS
# FOR A PARTICULAR PURPOSE.
#
##############################################################################
"""Names exported by the ZopeTestCase package
"""
from . import ZopeLite as Zope2
from . import utils # NOQA
from . import layer # NOQA
from .ZopeLite import hasProduct # NOQA
from .ZopeLite import installProduct # NOQA
from .ZopeLite import hasPackage # NOQA
from .ZopeLite import installPackage # NOQA
from .ZopeLite import _print # NOQA
from .ZopeTestCase import folder_name # NOQA
from .ZopeTestCase import user_name # NOQA
from .ZopeTestCase import user_password # NOQA
from .ZopeTestCase import user_role # NOQA
from .ZopeTestCase import standard_permissions # NOQA
from .ZopeTestCase import ZopeTestCase # NOQA
from .ZopeTestCase import FunctionalTestCase # NOQA
from .PortalTestCase import portal_name # NOQA
from .PortalTestCase import PortalTestCase # NOQA
from .sandbox import Sandboxed # NOQA
from .functional import Functional # NOQA
from .base import TestCase # NOQA
from .base import app # NOQA
from .base import close # NOQA
from .warnhook import WarningsHook # NOQA
from unittest import main # NOQA
from .zopedoctest import ZopeDocTestSuite # NOQA
from .zopedoctest import ZopeDocFileSuite # NOQA
from .zopedoctest import FunctionalDocTestSuite # NOQA
from .zopedoctest import FunctionalDocFileSuite # NOQA
from . import zopedoctest as doctest # NOQA
import transaction # NOQA
from . import placeless # NOQA
Zope = Zope2
| 34.929825 | 78 | 0.716223 |
4a1fc0c1db5ff11e4ff9158e332adf615ca3fcac | 1,254 | py | Python | tools/format/formatters/tests/python_test.py | ChrisCummins/format | d42b4dafcd7c4b187311473f1b446e0ca1988b12 | [
"Apache-2.0"
] | null | null | null | tools/format/formatters/tests/python_test.py | ChrisCummins/format | d42b4dafcd7c4b187311473f1b446e0ca1988b12 | [
"Apache-2.0"
] | 12 | 2020-01-12T11:55:03.000Z | 2020-01-17T01:00:23.000Z | tools/format/formatters/tests/python_test.py | ChrisCummins/format | d42b4dafcd7c4b187311473f1b446e0ca1988b12 | [
"Apache-2.0"
] | null | null | null | # Copyright 2020 Chris Cummins <[email protected]>.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Unit tests for //tools/format/formatters:python."""
from labm8.py import test
from tools.format.formatters import python
FLAGS = test.FLAGS
def test_empty_python_program():
assert python.FormatPython.Format("") == ""
def test_small_python_program():
"""Test pre-processing a small C++ program."""
text = python.FormatPython.Format(
"""
def foo():
print('hi')
"""
)
print(text)
assert (
text
== """\
def foo():
print("hi")
"""
)
def test_malformed_python_program():
with test.Raises(python.FormatPython.FormatError):
python.FormatPython.Format("invalid syntax")
if __name__ == "__main__":
test.Main()
| 25.08 | 74 | 0.715311 |
4a1fc1ae85dc86f97dc86188b74126e1ddbcd932 | 1,476 | py | Python | src/test/bctest.py | yankpay/yank | 33237ce209d782730b9159d6f138d8c767882044 | [
"MIT"
] | 1 | 2018-02-11T23:14:22.000Z | 2018-02-11T23:14:22.000Z | src/test/bctest.py | yankpay/yank | 33237ce209d782730b9159d6f138d8c767882044 | [
"MIT"
] | 1 | 2018-01-29T09:30:51.000Z | 2020-05-13T13:29:26.000Z | src/test/bctest.py | yankpay/yank | 33237ce209d782730b9159d6f138d8c767882044 | [
"MIT"
] | 7 | 2017-12-23T19:24:36.000Z | 2020-10-24T16:19:59.000Z | # Copyright 2014 BitPay, Inc.
# Distributed under the MIT/X13 software license, see the accompanying
# file COPYING or http://www.opensource.org/licenses/mit-license.php.
import subprocess
import os
import json
import sys
def bctest(testDir, testObj, exeext):
execprog = testObj['exec'] + exeext
execargs = testObj['args']
execrun = [execprog] + execargs
stdinCfg = None
inputData = None
if "input" in testObj:
filename = testDir + "/" + testObj['input']
inputData = open(filename).read()
stdinCfg = subprocess.PIPE
outputFn = None
outputData = None
if "output_cmp" in testObj:
outputFn = testObj['output_cmp']
outputData = open(testDir + "/" + outputFn).read()
proc = subprocess.Popen(execrun, stdin=stdinCfg, stdout=subprocess.PIPE, stderr=subprocess.PIPE,universal_newlines=True)
try:
outs = proc.communicate(input=inputData)
except OSError:
print("OSError, Failed to execute " + execprog)
sys.exit(1)
if outputData and (outs[0] != outputData):
print("Output data mismatch for " + outputFn)
sys.exit(1)
wantRC = 0
if "return_code" in testObj:
wantRC = testObj['return_code']
if proc.returncode != wantRC:
print("Return code mismatch for " + outputFn)
sys.exit(1)
def bctester(testDir, input_basename, buildenv):
input_filename = testDir + "/" + input_basename
raw_data = open(input_filename).read()
input_data = json.loads(raw_data)
for testObj in input_data:
bctest(testDir, testObj, buildenv.exeext)
sys.exit(0)
| 26.836364 | 121 | 0.72561 |
4a1fc1c435178907462c3c54be8c5e0e63a7a10b | 7,660 | py | Python | sanic_openapi/openapi.py | matsurihime/fork-sanic-openapi | b0558fa788459983723e80775f3ef06895ae4e82 | [
"MIT"
] | null | null | null | sanic_openapi/openapi.py | matsurihime/fork-sanic-openapi | b0558fa788459983723e80775f3ef06895ae4e82 | [
"MIT"
] | 1 | 2018-05-30T05:09:22.000Z | 2018-05-30T05:09:22.000Z | sanic_openapi/openapi.py | matsurihime/fork-sanic-openapi | b0558fa788459983723e80775f3ef06895ae4e82 | [
"MIT"
] | null | null | null | import re
from itertools import repeat
from sanic.blueprints import Blueprint
from sanic.response import json
from sanic.views import CompositionView
from .doc import excluded_paths, definitions, route_specs, serialize_schema
from .doc import RouteSpec
blueprint = Blueprint('openapi', url_prefix='openapi')
_spec = {}
# Removes all null values from a dictionary
def remove_nulls(dictionary, deep=True):
return {
k: remove_nulls(v, deep) if deep and type(v) is dict else v
for k, v in dictionary.items()
if v is not None
}
@blueprint.listener('before_server_start')
def build_spec(app, loop):
_spec['swagger'] = '2.0'
_spec['info'] = {
"version": getattr(app.config, 'API_VERSION', '1.0.0'),
"title": getattr(app.config, 'API_TITLE', 'API'),
"description": getattr(app.config, 'API_DESCRIPTION', ''),
"termsOfService": getattr(app.config, 'API_TERMS_OF_SERVICE', ''),
"contact": {
"email": getattr(app.config, 'API_CONTACT_EMAIL', None),
},
"license": {
"name": getattr(app.config, 'API_LICENSE_NAME', None),
"url": getattr(app.config, 'API_LICENSE_URL', None),
}
}
_spec['schemes'] = getattr(app.config, 'API_SCHEMES', ['http'])
# --------------------------------------------------------------- #
# Blueprint Tags
# --------------------------------------------------------------- #
for blueprint in app.blueprints.values():
if hasattr(blueprint, 'routes'):
for route in blueprint.routes:
route_spec = route_specs[route.handler]
route_spec.blueprint = blueprint
if not route_spec.tags:
route_spec.tags.append(blueprint.name)
paths = {}
for uri, route in app.router.routes_all.items():
if uri.startswith("/swagger") or uri.startswith("/openapi") \
or '<file_uri' in uri:
# TODO: add static flag in sanic routes
continue
if any(uri.startswith(path) for path in excluded_paths):
continue
# --------------------------------------------------------------- #
# Methods
# --------------------------------------------------------------- #
# Build list of methods and their handler functions
handler_type = type(route.handler)
if handler_type is CompositionView:
view = route.handler
method_handlers = view.handlers.items()
else:
method_handlers = zip(route.methods, repeat(route.handler))
methods = {}
for _method, _handler in method_handlers:
_methods = {
'GET': lambda: _handler.view_class.get,
'POST': lambda: _handler.view_class.post,
'PUT': lambda: _handler.view_class.put,
'PATCH': lambda: _handler.view_class.patch,
'DELETE': lambda: _handler.view_class.delete,
}
if 'view_class' in dir(_handler):
route_spec = route_specs.get(_methods.get(_method)()) or RouteSpec()
else:
route_spec = route_specs.get(_handler) or RouteSpec()
if _method == 'OPTIONS' or route_spec.exclude:
continue
consumes_content_types = route_spec.consumes_content_type or \
getattr(app.config, 'API_CONSUMES_CONTENT_TYPES', ['application/json'])
produces_content_types = route_spec.produces_content_type or \
getattr(app.config, 'API_PRODUCES_CONTENT_TYPES', ['application/json'])
# Parameters - Path & Query String
route_parameters = []
for parameter in route.parameters:
param_description = route_spec.path_parameters[parameter.name] \
if parameter.name in route_spec.path_parameters.keys() else ''
route_parameters.append({
**serialize_schema(parameter.cast),
'required': True,
'in': 'path',
'name': parameter.name,
'description': param_description,
})
for consumer in route_spec.consumes:
spec = serialize_schema(consumer.field)
if 'properties' in spec:
for name, prop_spec in spec['properties'].items():
route_param = {
**prop_spec,
'required': consumer.required,
'in': consumer.location,
'name': name,
'description': consumer.description,
}
else:
route_param = {
**spec,
'required': consumer.required,
'in': consumer.location,
'name': consumer.field.name if hasattr(consumer.field, 'name') else 'body',
'description': consumer.description,
}
if '$ref' in route_param:
route_param["schema"] = {'$ref': route_param['$ref']}
del route_param['$ref']
route_parameters.append(route_param)
responses = {
'200': {
'schema': serialize_schema(route_spec.produces.field) if route_spec.produces else None,
'description': route_spec.produces.description if route_spec.produces else None,
}
}
for (status_code, route_field) in route_spec.responses:
if route_field.override_default:
del responses['200']
responses[str(status_code)] = {
'schema': serialize_schema(route_field.field),
'description': route_field.description,
}
endpoint = remove_nulls({
'operationId': route_spec.operation or route.name,
'summary': route_spec.summary,
'description': route_spec.description,
'consumes': consumes_content_types,
'produces': produces_content_types,
'tags': route_spec.tags or None,
'parameters': route_parameters,
'responses': responses,
})
methods[_method.lower()] = endpoint
uri_parsed = uri
for parameter in route.parameters:
uri_parsed = re.sub('<'+parameter.name+'.*?>', '{'+parameter.name+'}', uri_parsed)
paths[uri_parsed] = methods
# --------------------------------------------------------------- #
# Definitions
# --------------------------------------------------------------- #
_spec['definitions'] = {obj.object_name: definition for cls, (obj, definition) in definitions.items()}
# --------------------------------------------------------------- #
# Tags
# --------------------------------------------------------------- #
# TODO: figure out how to get descriptions in these
tags = {}
for route_spec in route_specs.values():
if route_spec.blueprint and route_spec.blueprint.name in ('swagger', 'openapi'):
# TODO: add static flag in sanic routes
continue
for tag in route_spec.tags:
tags[tag] = True
_spec['tags'] = [{"name": name} for name in tags.keys()]
_spec['paths'] = paths
@blueprint.route('/spec.json')
def spec(_):
return json(_spec)
| 38.492462 | 107 | 0.511749 |
4a1fc1d6c454a1ab3e77649b72d6ec57730300c5 | 608 | py | Python | tests/conftest.py | pgjones/quart-db | 975351507f4a83678a6b8799dc94b103915afebc | [
"MIT"
] | null | null | null | tests/conftest.py | pgjones/quart-db | 975351507f4a83678a6b8799dc94b103915afebc | [
"MIT"
] | null | null | null | tests/conftest.py | pgjones/quart-db | 975351507f4a83678a6b8799dc94b103915afebc | [
"MIT"
] | null | null | null | import os
from typing import AsyncGenerator
import pytest
from quart import Quart
from quart_db import Connection, QuartDB
from .utils import Options
@pytest.fixture(name="connection")
async def _connection() -> AsyncGenerator[Connection, None]:
db = QuartDB(Quart(__name__), url=os.environ["DATABASE_URL"])
await db.migrate()
db.set_converter("options_t", lambda type_: type_.value, Options)
await db.before_serving()
async with db.connection() as connection:
async with connection.transaction(force_rollback=True):
yield connection
await db.after_serving()
| 27.636364 | 69 | 0.740132 |
4a1fc1d9a9b10a2738a508c7440bb63a32d4e89c | 12,106 | py | Python | tensorflow/python/kernel_tests/slice_op_test.py | Zwysilence/tensorflow | b55001be83da044bb21d539d433dec6231eaec55 | [
"Apache-2.0"
] | 8 | 2017-03-20T12:04:21.000Z | 2021-06-24T20:34:30.000Z | tensorflow/python/kernel_tests/slice_op_test.py | Zwysilence/tensorflow | b55001be83da044bb21d539d433dec6231eaec55 | [
"Apache-2.0"
] | 1 | 2018-09-04T07:44:56.000Z | 2018-09-04T07:44:56.000Z | tensorflow/python/kernel_tests/slice_op_test.py | Zwysilence/tensorflow | b55001be83da044bb21d539d433dec6231eaec55 | [
"Apache-2.0"
] | 2 | 2017-03-20T12:10:56.000Z | 2017-11-12T00:15:54.000Z | # Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functional tests for slice op."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
from six.moves import xrange # pylint: disable=redefined-builtin
from tensorflow.python.framework import constant_op
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import errors_impl
from tensorflow.python.ops import array_ops
from tensorflow.python.ops import gradients_impl
from tensorflow.python.platform import test
class SliceTest(test.TestCase):
def testEmpty(self):
inp = np.random.rand(4, 4).astype("f")
for k in xrange(4):
with self.test_session(use_gpu=True):
a = constant_op.constant(inp, shape=[4, 4], dtype=dtypes.float32)
slice_t = a[2, k:k]
slice_val = slice_t.eval()
self.assertAllEqual(slice_val, inp[2, k:k])
def testInt32(self):
inp = np.random.rand(4, 4).astype("i")
for k in xrange(4):
with self.test_session(use_gpu=True):
a = constant_op.constant(inp, shape=[4, 4], dtype=dtypes.int32)
slice_t = a[2, k:k]
slice_val = slice_t.eval()
self.assertAllEqual(slice_val, inp[2, k:k])
def testInt64Slicing(self):
with self.test_session(use_gpu=True):
a = constant_op.constant([0, 1, 2], dtype=dtypes.int64)
# Slice using int64 Tensor.
i = constant_op.constant(1, dtype=dtypes.int64)
slice_t = a[i]
slice_val = slice_t.eval()
self.assertAllEqual(1, slice_val)
slice_t = a[i:i+1]
slice_val = slice_t.eval()
self.assertAllEqual([1], slice_val)
# Slice using int64 integer.
i = np.asarray(1).astype(np.int64)
slice_t = a[i]
slice_val = slice_t.eval()
self.assertAllEqual(1, slice_val)
slice_t = a[i:i+1]
slice_val = slice_t.eval()
self.assertAllEqual([1], slice_val)
def testSelectAll(self):
for _ in range(10):
with self.test_session(use_gpu=True):
inp = np.random.rand(4, 4, 4, 4).astype("f")
a = constant_op.constant(inp, shape=[4, 4, 4, 4], dtype=dtypes.float32)
slice_explicit_t = array_ops.slice(a, [0, 0, 0, 0], [-1, -1, -1, -1])
slice_implicit_t = a[:, :, :, :]
self.assertAllEqual(inp, slice_explicit_t.eval())
self.assertAllEqual(inp, slice_implicit_t.eval())
self.assertEqual(inp.shape, slice_explicit_t.get_shape())
self.assertEqual(inp.shape, slice_implicit_t.get_shape())
def testSingleDimension(self):
for _ in range(10):
with self.test_session(use_gpu=True):
inp = np.random.rand(10).astype("f")
a = constant_op.constant(inp, shape=[10], dtype=dtypes.float32)
hi = np.random.randint(0, 9)
scalar_t = a[hi]
scalar_val = scalar_t.eval()
self.assertAllEqual(scalar_val, inp[hi])
if hi > 0:
lo = np.random.randint(0, hi)
else:
lo = 0
slice_t = a[lo:hi]
slice_val = slice_t.eval()
self.assertAllEqual(slice_val, inp[lo:hi])
def testScalarInput(self):
input_val = 0
with self.test_session() as sess:
# Test with constant input; shape inference fails.
with self.assertRaisesWithPredicateMatch(ValueError, "out of range"):
constant_op.constant(input_val)[:].get_shape()
# Test evaluating with non-constant input; kernel execution fails.
input_t = array_ops.placeholder(dtypes.int32)
slice_t = input_t[:]
with self.assertRaisesWithPredicateMatch(errors_impl.InvalidArgumentError,
"out of range"):
sess.run([slice_t], feed_dict={input_t: input_val})
def testInvalidIndex(self):
input_val = [1, 2]
with self.test_session() as sess:
# Test with constant input; shape inference fails.
with self.assertRaisesWithPredicateMatch(ValueError, "out of range"):
constant_op.constant(input_val)[1:, 1:].get_shape()
# Test evaluating with non-constant input; kernel execution fails.
input_t = array_ops.placeholder(dtypes.int32)
slice_t = input_t[1:, 1:]
with self.assertRaisesWithPredicateMatch(errors_impl.InvalidArgumentError,
"out of range"):
sess.run([slice_t], feed_dict={input_t: input_val})
def _testSliceMatrixDim0(self, x, begin, size):
with self.test_session(use_gpu=True):
tf_ans = array_ops.slice(x, [begin, 0], [size, x.shape[1]]).eval()
np_ans = x[begin:begin + size, :]
self.assertAllEqual(tf_ans, np_ans)
def testSliceMatrixDim0(self):
x = np.random.rand(8, 4).astype("f")
self._testSliceMatrixDim0(x, 1, 2)
self._testSliceMatrixDim0(x, 3, 3)
y = np.random.rand(8, 7).astype("f") # 7 * sizeof(float) is not aligned
self._testSliceMatrixDim0(y, 1, 2)
self._testSliceMatrixDim0(y, 3, 3)
def testSingleElementAll(self):
for _ in range(10):
with self.test_session(use_gpu=True):
inp = np.random.rand(4, 4).astype("f")
a = constant_op.constant(inp, shape=[4, 4], dtype=dtypes.float32)
x, y = np.random.randint(0, 3, size=2).tolist()
slice_t = a[x, 0:y]
slice_val = slice_t.eval()
self.assertAllEqual(slice_val, inp[x, 0:y])
def testSimple(self):
with self.test_session(use_gpu=True) as sess:
inp = np.random.rand(4, 4).astype("f")
a = constant_op.constant(
[float(x) for x in inp.ravel(order="C")],
shape=[4, 4],
dtype=dtypes.float32)
slice_t = array_ops.slice(a, [0, 0], [2, 2])
slice2_t = a[:2, :2]
slice_val, slice2_val = sess.run([slice_t, slice2_t])
self.assertAllEqual(slice_val, inp[:2, :2])
self.assertAllEqual(slice2_val, inp[:2, :2])
self.assertEqual(slice_val.shape, slice_t.get_shape())
self.assertEqual(slice2_val.shape, slice2_t.get_shape())
def testComplex(self):
with self.test_session(use_gpu=True):
inp = np.random.rand(4, 10, 10, 4).astype("f")
a = constant_op.constant(inp, dtype=dtypes.float32)
x = np.random.randint(0, 9)
z = np.random.randint(0, 9)
if z > 0:
y = np.random.randint(0, z)
else:
y = 0
slice_t = a[:, x, y:z, :]
self.assertAllEqual(slice_t.eval(), inp[:, x, y:z, :])
def testRandom(self):
# Random dims of rank 6
input_shape = np.random.randint(0, 20, size=6)
inp = np.random.rand(*input_shape).astype("f")
with self.test_session(use_gpu=True) as sess:
a = constant_op.constant(
[float(x) for x in inp.ravel(order="C")],
shape=input_shape,
dtype=dtypes.float32)
indices = [0 if x == 0 else np.random.randint(x) for x in input_shape]
sizes = [
np.random.randint(0, input_shape[i] - indices[i] + 1)
for i in range(6)
]
slice_t = array_ops.slice(a, indices, sizes)
slice2_t = a[indices[0]:indices[0] + sizes[0], indices[1]:indices[
1] + sizes[1], indices[2]:indices[2] + sizes[2], indices[3]:indices[3]
+ sizes[3], indices[4]:indices[4] + sizes[4], indices[5]:
indices[5] + sizes[5]]
slice_val, slice2_val = sess.run([slice_t, slice2_t])
expected_val = inp[indices[0]:indices[0] + sizes[0], indices[1]:indices[
1] + sizes[1], indices[2]:indices[2] + sizes[2], indices[3]:indices[
3] + sizes[3], indices[4]:indices[4] + sizes[4], indices[5]:indices[
5] + sizes[5]]
self.assertAllEqual(slice_val, expected_val)
self.assertAllEqual(slice2_val, expected_val)
self.assertEqual(expected_val.shape, slice_t.get_shape())
self.assertEqual(expected_val.shape, slice2_t.get_shape())
def testPartialShapeInference(self):
z = array_ops.zeros((1, 2, 3))
self.assertAllEqual(z.get_shape().as_list(), [1, 2, 3])
m1 = array_ops.slice(z, [0, 0, 0], [-1, -1, -1])
self.assertAllEqual(m1.get_shape().as_list(), [1, 2, 3])
m2 = array_ops.slice(z, [0, 0, 0], [constant_op.constant(1) + 0, 2, -1])
self.assertAllEqual(m2.get_shape().as_list(), [1, 2, 3])
def _testGradientSlice(self, input_shape, slice_begin, slice_size):
with self.test_session(use_gpu=True):
num_inputs = np.prod(input_shape)
num_grads = np.prod(slice_size)
inp = np.random.rand(num_inputs).astype("f").reshape(input_shape)
a = constant_op.constant(
[float(x) for x in inp.ravel(order="C")],
shape=input_shape,
dtype=dtypes.float32)
slice_t = array_ops.slice(a, slice_begin, slice_size)
grads = np.random.rand(num_grads).astype("f").reshape(slice_size)
grad_tensor = constant_op.constant(grads)
grad = gradients_impl.gradients(slice_t, [a], grad_tensor)[0]
result = grad.eval()
# Create a zero tensor of the input shape ane place
# the grads into the right location to compare against TensorFlow.
np_ans = np.zeros(input_shape)
slices = []
for i in xrange(len(input_shape)):
slices.append(slice(slice_begin[i], slice_begin[i] + slice_size[i]))
np_ans[slices] = grads
self.assertAllClose(np_ans, result)
def _testGradientVariableSize(self):
with self.test_session(use_gpu=True):
inp = constant_op.constant([1.0, 2.0, 3.0], name="in")
out = array_ops.slice(inp, [1], [-1])
grad_actual = gradients_impl.gradients(out, inp)[0].eval()
self.assertAllClose([0., 1., 1.], grad_actual)
def testGradientsAll(self):
# Slice the middle square out of a 4x4 input
self._testGradientSlice([4, 4], [1, 1], [2, 2])
# Slice the upper left square out of a 4x4 input
self._testGradientSlice([4, 4], [0, 0], [2, 2])
# Slice a non-square input starting from (2,1)
self._testGradientSlice([4, 4], [2, 1], [1, 2])
# Slice a 3D tensor
self._testGradientSlice([3, 3, 3], [0, 1, 0], [2, 1, 1])
# Use -1 as a slice dimension.
self._testGradientVariableSize()
def testNotIterable(self):
# NOTE(mrry): If we register __getitem__ as an overloaded
# operator, Python will valiantly attempt to iterate over the
# Tensor from 0 to infinity. This test ensures that this
# unintended behavior is prevented.
c = constant_op.constant(5.0)
with self.assertRaisesWithPredicateMatch(
TypeError, lambda e: "Tensor objects are only iterable" in str(e)):
for _ in c:
pass
def testComputedShape(self):
# NOTE(mrry): We cannot currently handle partially-known values,
# because `tf.slice()` uses -1 to specify a wildcard size, and
# this can't be handled using the
# `tensor_util.constant_value_as_shape()` trick.
a = constant_op.constant([[1, 2, 3], [4, 5, 6]])
begin = constant_op.constant(0)
size = constant_op.constant(1)
b = array_ops.slice(a, [begin, 0], [size, 2])
self.assertEqual([1, 2], b.get_shape())
begin = array_ops.placeholder(dtypes.int32, shape=())
c = array_ops.slice(a, [begin, 0], [-1, 2])
self.assertEqual([None, 2], c.get_shape().as_list())
def testSliceOfSlice(self):
with self.test_session(use_gpu=True):
a = constant_op.constant([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
b = a[1:, :]
c = b[:-1, :]
d = c[1, :]
res = 2 * d - c[1, :] + a[2, :] - 2 * b[-2, :]
self.assertAllEqual([0, 0, 0], res.eval())
if __name__ == "__main__":
test.main()
| 38.189274 | 80 | 0.635718 |
4a1fc2ec2bfe78e2876fea693082918fac6ed809 | 4,199 | py | Python | synapse/rest/__init__.py | ewaf1/synapse | 77661ce81a799a375317dff9e4c8696da528984c | [
"Apache-2.0"
] | 2 | 2020-04-30T18:38:02.000Z | 2020-07-08T21:38:28.000Z | synapse/rest/__init__.py | ewaf1/synapse | 77661ce81a799a375317dff9e4c8696da528984c | [
"Apache-2.0"
] | null | null | null | synapse/rest/__init__.py | ewaf1/synapse | 77661ce81a799a375317dff9e4c8696da528984c | [
"Apache-2.0"
] | 2 | 2020-03-03T18:34:52.000Z | 2022-03-31T11:06:18.000Z | # -*- coding: utf-8 -*-
# Copyright 2014-2016 OpenMarket Ltd
# Copyright 2018 New Vector Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import synapse.rest.admin
from synapse.http.server import JsonResource
from synapse.rest.client import versions
from synapse.rest.client.v1 import (
directory,
events,
initial_sync,
login as v1_login,
logout,
presence,
profile,
push_rule,
pusher,
room,
voip,
)
from synapse.rest.client.v2_alpha import (
account,
account_data,
account_validity,
auth,
capabilities,
devices,
filter,
groups,
keys,
notifications,
openid,
read_marker,
receipts,
register,
relations,
report_event,
room_keys,
room_upgrade_rest_servlet,
sendtodevice,
sync,
tags,
thirdparty,
tokenrefresh,
user_directory,
)
class ClientRestResource(JsonResource):
"""Matrix Client API REST resource.
This gets mounted at various points under /_matrix/client, including:
* /_matrix/client/r0
* /_matrix/client/api/v1
* /_matrix/client/unstable
* etc
"""
def __init__(self, hs):
JsonResource.__init__(self, hs, canonical_json=False)
self.register_servlets(self, hs)
@staticmethod
def register_servlets(client_resource, hs):
versions.register_servlets(hs, client_resource)
# Deprecated in r0
initial_sync.register_servlets(hs, client_resource)
room.register_deprecated_servlets(hs, client_resource)
# Partially deprecated in r0
events.register_servlets(hs, client_resource)
# "v1" + "r0"
room.register_servlets(hs, client_resource)
v1_login.register_servlets(hs, client_resource)
profile.register_servlets(hs, client_resource)
presence.register_servlets(hs, client_resource)
directory.register_servlets(hs, client_resource)
voip.register_servlets(hs, client_resource)
pusher.register_servlets(hs, client_resource)
push_rule.register_servlets(hs, client_resource)
logout.register_servlets(hs, client_resource)
# "v2"
sync.register_servlets(hs, client_resource)
filter.register_servlets(hs, client_resource)
account.register_servlets(hs, client_resource)
register.register_servlets(hs, client_resource)
auth.register_servlets(hs, client_resource)
receipts.register_servlets(hs, client_resource)
read_marker.register_servlets(hs, client_resource)
room_keys.register_servlets(hs, client_resource)
keys.register_servlets(hs, client_resource)
tokenrefresh.register_servlets(hs, client_resource)
tags.register_servlets(hs, client_resource)
account_data.register_servlets(hs, client_resource)
report_event.register_servlets(hs, client_resource)
openid.register_servlets(hs, client_resource)
notifications.register_servlets(hs, client_resource)
devices.register_servlets(hs, client_resource)
thirdparty.register_servlets(hs, client_resource)
sendtodevice.register_servlets(hs, client_resource)
user_directory.register_servlets(hs, client_resource)
groups.register_servlets(hs, client_resource)
room_upgrade_rest_servlet.register_servlets(hs, client_resource)
capabilities.register_servlets(hs, client_resource)
account_validity.register_servlets(hs, client_resource)
relations.register_servlets(hs, client_resource)
# moving to /_synapse/admin
synapse.rest.admin.register_servlets_for_client_rest_resource(
hs, client_resource
)
| 33.325397 | 74 | 0.714932 |
4a1fc41a8fccf69b8a044b78cb0ec3a06c82c65f | 2,182 | py | Python | 23-trie/python/0211-add-and-search-word-data-structure-design-3.py | agnes-yang/LeetCode-Solutions-in-Good-Style | acc8661338cc7c1ae067915fb16079a9e3e66847 | [
"Apache-2.0"
] | 461 | 2019-06-27T03:15:28.000Z | 2019-12-17T15:17:42.000Z | 23-trie/python/0211-add-and-search-word-data-structure-design-3.py | dahui888/LeetCode-Solutions-in-Good-Style | acc8661338cc7c1ae067915fb16079a9e3e66847 | [
"Apache-2.0"
] | 62 | 2019-07-09T05:27:33.000Z | 2019-10-12T07:10:48.000Z | 23-trie/python/0211-add-and-search-word-data-structure-design-3.py | dahui888/LeetCode-Solutions-in-Good-Style | acc8661338cc7c1ae067915fb16079a9e3e66847 | [
"Apache-2.0"
] | 47 | 2019-06-27T08:34:18.000Z | 2019-12-17T03:14:46.000Z | class WordDictionary:
class Node:
def __init__(self):
self.is_word = False
self.next = [None for _ in range(26)]
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = WordDictionary.Node()
def addWord(self, word: str) -> None:
"""
Adds a word into the data structure.
"""
size = len(word)
cur_node = self.root
for i in range(size):
alpha = word[i]
next = cur_node.next[ord(alpha) - ord('a')]
if next is None:
cur_node.next[ord(alpha) - ord('a')] = WordDictionary.Node()
cur_node = cur_node.next[ord(alpha) - ord('a')]
if not cur_node.is_word:
cur_node.is_word = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter.
"""
return self.__match(word, self.root, 0)
def __match(self, word, node, start):
if start == len(word):
return node.is_word
alpha = word[start]
# 关键在这里,如果当前字母是 "." ,每一个分支都要走一遍
if alpha == '.':
# print(node.next)
for i in range(26):
if node.next[i] and self.__match(word, node.next[i], start + 1):
return True
return False
else:
if not node.next[ord(alpha)-ord('a')]:
return False
return self.__match(word, node.next[ord(alpha) - ord('a')], start + 1)
# Your WordDictionary object will be instantiated and called as such:
# obj = WordDictionary()
# obj.addWord(word)
# param_2 = obj.search(word)
if __name__ == '__main__':
wd = WordDictionary()
wd.addWord("bad")
wd.addWord("dad")
wd.addWord("mad")
# search("pad") -> false
# search("bad") -> true
# search(".ad") -> true
# search("b..") -> true
#
res1 = wd.search("pad")
res2 = wd.search("bad")
res3 = wd.search(".ad")
res4 = wd.search("b..")
print(res1)
print(res2)
print(res3)
print(res4)
| 27.974359 | 125 | 0.531622 |
4a1fc46f8498eb7bcd63851f854c5b9fb8dc1fed | 3,694 | py | Python | tests/schema/product/mutation/product/conftest.py | simonsobs/acondbs | 6ca11c2889d827ecdb2b54d0cf3b94b8cdd281e6 | [
"MIT"
] | null | null | null | tests/schema/product/mutation/product/conftest.py | simonsobs/acondbs | 6ca11c2889d827ecdb2b54d0cf3b94b8cdd281e6 | [
"MIT"
] | 24 | 2020-04-02T19:29:07.000Z | 2022-03-08T03:05:43.000Z | tests/schema/product/mutation/product/conftest.py | simonsobs/acondbs | 6ca11c2889d827ecdb2b54d0cf3b94b8cdd281e6 | [
"MIT"
] | 1 | 2020-04-08T15:48:28.000Z | 2020-04-08T15:48:28.000Z | import pytest
import datetime
from acondbs.db.sa import sa
from acondbs.models import (
GitHubUser,
GitHubToken,
)
from acondbs import ops
##__________________________________________________________________||
@pytest.fixture
def app(app_empty):
y = app_empty
user1 = GitHubUser(login="user1", git_hub_id="04:User1")
token1 = GitHubToken(
token="39d86487d76a84087f1da599c872dac4473e5f07", scope="", user=user1
)
with y.app_context():
sa.session.add(user1)
sa.session.add(token1)
sa.session.commit()
# map1 -> beam1
# | |
# +--------+---> beam2
#
# map2
# map3
with y.app_context():
ops.create_product_relation_type(
type_={
"type_id": 1,
"name": "parent",
},
reverse={
"type_id": 2,
"name": "child",
},
)
ops.commit()
with y.app_context():
ops.create_field(
field_id=1,
name="contact",
type_=ops.FieldType.UnicodeText,
)
ops.create_field(
field_id=2,
name="produced_by",
type_=ops.FieldType.UnicodeText,
)
ops.create_field(
field_id=3,
name="date_produced",
type_=ops.FieldType.Date,
)
ops.commit()
with y.app_context():
ops.create_product_type(
type_id=1,
name="map",
field_ids=[1, 2, 3],
)
ops.create_product_type(
type_id=2,
name="beam",
field_ids=[1, 2, 3],
)
ops.commit()
with y.app_context():
ops.create_product(
type_id=1,
product_id=1,
name="map1",
date_produced=datetime.date(2020, 2, 1),
attributes={3: datetime.date(2020, 2, 1)},
paths=["site1:/path/to/map1", "site2:/another/way/map1"],
)
ops.create_product(
type_id=1,
product_id=2,
name="map2",
date_produced=datetime.date(2020, 2, 10),
attributes={3: datetime.date(2020, 2, 10)},
paths=["site1:/path/to/map2"],
)
ops.create_product(
type_id=1,
product_id=3,
name="map3",
date_produced=datetime.date(2020, 3, 19),
attributes={3: datetime.date(2020, 3, 19)},
paths=["site1:/path/to/map3", "site2:/another/way/map3"],
)
ops.create_product(
type_id=2,
product_id=4,
name="beam1",
date_produced=datetime.date(2020, 2, 5),
attributes={3: datetime.date(2020, 2, 5)},
paths=["site1:/path/to/beam1", "site2:/another/way/beam1"],
)
ops.create_product(
type_id=2,
product_id=5,
name="beam2",
date_produced=datetime.date(2020, 3, 4),
attributes={3: datetime.date(2020, 3, 4)},
paths=["site1:/path/to/beam2"],
)
ops.commit()
with y.app_context():
ops.create_product_relation(
type_id=1,
self_product_id=4,
other_product_id=1,
)
ops.create_product_relation(
type_id=1,
self_product_id=5,
other_product_id=1,
)
ops.create_product_relation(
type_id=1,
self_product_id=5,
other_product_id=4,
)
ops.commit()
yield y
##__________________________________________________________________||
| 25.30137 | 78 | 0.507851 |
4a1fc4bf12a187e91b9fbba3c919d386004f6a9d | 1,672 | py | Python | extract.py | vndee/offline-CROHME | 0e09cbdbe7e549ee3b7fcb9ef8548906bcf6947d | [
"MIT"
] | 35 | 2019-06-26T09:24:32.000Z | 2022-01-13T07:15:55.000Z | extract.py | vndee/offline-CROHME | 0e09cbdbe7e549ee3b7fcb9ef8548906bcf6947d | [
"MIT"
] | null | null | null | extract.py | vndee/offline-CROHME | 0e09cbdbe7e549ee3b7fcb9ef8548906bcf6947d | [
"MIT"
] | 5 | 2019-07-06T07:20:03.000Z | 2021-09-11T11:27:06.000Z | import shutil
import glob
import os
import inkml2img
from datetime import datetime
dataPath = 'CROHME_labeled_2016/'
dataMergedPath = 'data_merged/'
targetFolder = 'data_processed/'
logger = open('log.txt', 'w+')
def writeLog(message):
logger.write("[" + datetime.now().strftime('%Y-%m-%d %H:%M:%S') + "] " + str(message) + "\n")
def createDirectory(dirPath):
if not os.path.exists(dirPath):
os.mkdir(dirPath)
writeLog("Create " + dirPath)
if __name__ == "__main__":
writeLog("Start processing.")
filesPath = glob.glob(dataPath + '*/*.inkml')
writeLog("There are " + str(len(filesPath)) + " files in " + dataPath)
createDirectory(dataMergedPath)
cnt = 0
for fileName in filesPath:
cnt = cnt + 1
print("Copying %d/%d" % (cnt, len(filesPath)))
writeLog("Copied " + fileName + " --> " + dataMergedPath + fileName)
shutil.copy2(fileName, dataMergedPath)
createDirectory(targetFolder)
listFiles = glob.glob(dataMergedPath + '*.inkml')
numberOfFile = len(listFiles)
writeLog("There are " + str(numberOfFile) + " files in " + dataMergedPath)
cnt = 0
for fileInkml in listFiles:
cnt = cnt + 1
fileName = fileInkml.split('/')[1]
print("Processing %s [%d/%d]" % (fileName, cnt, numberOfFile))
writeLog("[" + str(cnt) + "/" + str(numberOfFile) + "]" + "Processed " + fileInkml + " --> " + targetFolder + fileName + ".png")
try:
inkml2img.inkml2img(fileInkml, targetFolder + fileName + '.png')
except:
writeLog("Failed!")
print("An error occured!")
writeLog("Successful!")
| 31.54717 | 136 | 0.608254 |
4a1fc5c4045de93cfd0a61fd0bea6e1f8a164413 | 12,655 | py | Python | pybind/slxos/v16r_1_00b/overlay/access_list/type/vxlan/extended/__init__.py | shivharis/pybind | 4e1c6d54b9fd722ccec25546ba2413d79ce337e6 | [
"Apache-2.0"
] | null | null | null | pybind/slxos/v16r_1_00b/overlay/access_list/type/vxlan/extended/__init__.py | shivharis/pybind | 4e1c6d54b9fd722ccec25546ba2413d79ce337e6 | [
"Apache-2.0"
] | null | null | null | pybind/slxos/v16r_1_00b/overlay/access_list/type/vxlan/extended/__init__.py | shivharis/pybind | 4e1c6d54b9fd722ccec25546ba2413d79ce337e6 | [
"Apache-2.0"
] | 1 | 2021-11-05T22:15:42.000Z | 2021-11-05T22:15:42.000Z |
from operator import attrgetter
import pyangbind.lib.xpathhelper as xpathhelper
from pyangbind.lib.yangtypes import RestrictedPrecisionDecimalType, RestrictedClassType, TypedListType
from pyangbind.lib.yangtypes import YANGBool, YANGListType, YANGDynClass, ReferenceType
from pyangbind.lib.base import PybindBase
from decimal import Decimal
from bitarray import bitarray
import __builtin__
import ext_seq
class extended(PybindBase):
"""
This class was auto-generated by the PythonClass plugin for PYANG
from YANG module brocade-vxlan-visibility - based on the path /overlay/access-list/type/vxlan/extended. Each member element of
the container is represented as a class variable - with a specific
YANG type.
"""
__slots__ = ('_pybind_generated_by', '_path_helper', '_yang_name', '_rest_name', '_extmethods', '__ext_user_acl_name','__ext_seq',)
_yang_name = 'extended'
_rest_name = 'extended'
_pybind_generated_by = 'container'
def __init__(self, *args, **kwargs):
path_helper_ = kwargs.pop("path_helper", None)
if path_helper_ is False:
self._path_helper = False
elif path_helper_ is not None and isinstance(path_helper_, xpathhelper.YANGPathHelper):
self._path_helper = path_helper_
elif hasattr(self, "_parent"):
path_helper_ = getattr(self._parent, "_path_helper", False)
self._path_helper = path_helper_
else:
self._path_helper = False
extmethods = kwargs.pop("extmethods", None)
if extmethods is False:
self._extmethods = False
elif extmethods is not None and isinstance(extmethods, dict):
self._extmethods = extmethods
elif hasattr(self, "_parent"):
extmethods = getattr(self._parent, "_extmethods", None)
self._extmethods = extmethods
else:
self._extmethods = False
self.__ext_seq = YANGDynClass(base=YANGListType("ext_seq_num",ext_seq.ext_seq, yang_name="ext-seq", rest_name="seq", parent=self, is_container='list', user_ordered=False, path_helper=self._path_helper, yang_keys='ext-seq-num', extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}), is_container='list', yang_name="ext-seq", rest_name="seq", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='list', is_config=True)
self.__ext_user_acl_name = YANGDynClass(base=RestrictedClassType(base_type=unicode, restriction_dict={'pattern': u'[a-zA-Z]{1}([-a-zA-Z0-9_]{0,62})'}), is_leaf=True, yang_name="ext-user-acl-name", rest_name="ext-user-acl-name", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'Access List Name (Max 63)'}}, is_keyval=True, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='user-acl-name-type', is_config=True)
load = kwargs.pop("load", None)
if args:
if len(args) > 1:
raise TypeError("cannot create a YANG container with >1 argument")
all_attr = True
for e in self._pyangbind_elements:
if not hasattr(args[0], e):
all_attr = False
break
if not all_attr:
raise ValueError("Supplied object did not have the correct attributes")
for e in self._pyangbind_elements:
nobj = getattr(args[0], e)
if nobj._changed() is False:
continue
setmethod = getattr(self, "_set_%s" % e)
if load is None:
setmethod(getattr(args[0], e))
else:
setmethod(getattr(args[0], e), load=load)
def _path(self):
if hasattr(self, "_parent"):
return self._parent._path()+[self._yang_name]
else:
return [u'overlay', u'access-list', u'type', u'vxlan', u'extended']
def _rest_path(self):
if hasattr(self, "_parent"):
if self._rest_name:
return self._parent._rest_path()+[self._rest_name]
else:
return self._parent._rest_path()
else:
return [u'overlay', u'access-list', u'type', u'vxlan', u'extended']
def _get_ext_user_acl_name(self):
"""
Getter method for ext_user_acl_name, mapped from YANG variable /overlay/access_list/type/vxlan/extended/ext_user_acl_name (user-acl-name-type)
"""
return self.__ext_user_acl_name
def _set_ext_user_acl_name(self, v, load=False):
"""
Setter method for ext_user_acl_name, mapped from YANG variable /overlay/access_list/type/vxlan/extended/ext_user_acl_name (user-acl-name-type)
If this variable is read-only (config: false) in the
source YANG file, then _set_ext_user_acl_name is considered as a private
method. Backends looking to populate this variable should
do so via calling thisObj._set_ext_user_acl_name() directly.
"""
parent = getattr(self, "_parent", None)
if parent is not None and load is False:
raise AttributeError("Cannot set keys directly when" +
" within an instantiated list")
if hasattr(v, "_utype"):
v = v._utype(v)
try:
t = YANGDynClass(v,base=RestrictedClassType(base_type=unicode, restriction_dict={'pattern': u'[a-zA-Z]{1}([-a-zA-Z0-9_]{0,62})'}), is_leaf=True, yang_name="ext-user-acl-name", rest_name="ext-user-acl-name", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'Access List Name (Max 63)'}}, is_keyval=True, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='user-acl-name-type', is_config=True)
except (TypeError, ValueError):
raise ValueError({
'error-string': """ext_user_acl_name must be of a type compatible with user-acl-name-type""",
'defined-type': "brocade-vxlan-visibility:user-acl-name-type",
'generated-type': """YANGDynClass(base=RestrictedClassType(base_type=unicode, restriction_dict={'pattern': u'[a-zA-Z]{1}([-a-zA-Z0-9_]{0,62})'}), is_leaf=True, yang_name="ext-user-acl-name", rest_name="ext-user-acl-name", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'Access List Name (Max 63)'}}, is_keyval=True, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='user-acl-name-type', is_config=True)""",
})
self.__ext_user_acl_name = t
if hasattr(self, '_set'):
self._set()
def _unset_ext_user_acl_name(self):
self.__ext_user_acl_name = YANGDynClass(base=RestrictedClassType(base_type=unicode, restriction_dict={'pattern': u'[a-zA-Z]{1}([-a-zA-Z0-9_]{0,62})'}), is_leaf=True, yang_name="ext-user-acl-name", rest_name="ext-user-acl-name", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'Access List Name (Max 63)'}}, is_keyval=True, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='user-acl-name-type', is_config=True)
def _get_ext_seq(self):
"""
Getter method for ext_seq, mapped from YANG variable /overlay/access_list/type/vxlan/extended/ext_seq (list)
"""
return self.__ext_seq
def _set_ext_seq(self, v, load=False):
"""
Setter method for ext_seq, mapped from YANG variable /overlay/access_list/type/vxlan/extended/ext_seq (list)
If this variable is read-only (config: false) in the
source YANG file, then _set_ext_seq is considered as a private
method. Backends looking to populate this variable should
do so via calling thisObj._set_ext_seq() directly.
"""
if hasattr(v, "_utype"):
v = v._utype(v)
try:
t = YANGDynClass(v,base=YANGListType("ext_seq_num",ext_seq.ext_seq, yang_name="ext-seq", rest_name="seq", parent=self, is_container='list', user_ordered=False, path_helper=self._path_helper, yang_keys='ext-seq-num', extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}), is_container='list', yang_name="ext-seq", rest_name="seq", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='list', is_config=True)
except (TypeError, ValueError):
raise ValueError({
'error-string': """ext_seq must be of a type compatible with list""",
'defined-type': "list",
'generated-type': """YANGDynClass(base=YANGListType("ext_seq_num",ext_seq.ext_seq, yang_name="ext-seq", rest_name="seq", parent=self, is_container='list', user_ordered=False, path_helper=self._path_helper, yang_keys='ext-seq-num', extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}), is_container='list', yang_name="ext-seq", rest_name="seq", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='list', is_config=True)""",
})
self.__ext_seq = t
if hasattr(self, '_set'):
self._set()
def _unset_ext_seq(self):
self.__ext_seq = YANGDynClass(base=YANGListType("ext_seq_num",ext_seq.ext_seq, yang_name="ext-seq", rest_name="seq", parent=self, is_container='list', user_ordered=False, path_helper=self._path_helper, yang_keys='ext-seq-num', extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}), is_container='list', yang_name="ext-seq", rest_name="seq", parent=self, path_helper=self._path_helper, extmethods=self._extmethods, register_paths=True, extensions={u'tailf-common': {u'info': u'seq <seq-num>', u'cli-suppress-mode': None, u'callpoint': u'VxlanVisibilityExtendedSeqCallpoint', u'cli-suppress-list-no': None, u'cli-full-no': None, u'cli-compact-syntax': None, u'cli-sequence-commands': None, u'cli-suppress-key-abbreviation': None, u'cli-incomplete-command': None, u'alt-name': u'seq'}}, namespace='urn:brocade.com:mgmt:brocade-vxlan-visibility', defining_module='brocade-vxlan-visibility', yang_type='list', is_config=True)
ext_user_acl_name = __builtin__.property(_get_ext_user_acl_name, _set_ext_user_acl_name)
ext_seq = __builtin__.property(_get_ext_seq, _set_ext_seq)
_pyangbind_elements = {'ext_user_acl_name': ext_user_acl_name, 'ext_seq': ext_seq, }
| 77.164634 | 1,233 | 0.724299 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.