
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
sequencelengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
sequencelengths 0
25
| languages
sequencelengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
sequencelengths 0
352
| processed_texts
sequencelengths 1
353
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
f0bcb0f64866553125cf79c87621268a6535febd | # AutoTrain Dataset for project: climate-text-classification
## Dataset Descritpion
This dataset has been automatically processed by AutoTrain for project climate-text-classification.
### Languages
The BCP-47 code for the dataset's language is en.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "So the way our model has currently been built, we would look to pay down debt with our free cash flow generation that we're planning on generating this year, which is around $20 million to $30 million.",
"target": 0
},
{
"text": "So we don't see any big drama on the long-term FMPs as a result of this.",
"target": 0
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(num_classes=2, names=['0', '1'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 1919 |
| valid | 481 |
| prathap-reddy/autotrain-data-climate-text-classification | [
"task_categories:text-classification",
"language:en",
"region:us"
] | 2022-09-12T04:57:07+00:00 | {"language": ["en"], "task_categories": ["text-classification"]} | 2022-09-12T05:07:52+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-classification #language-English #region-us
| AutoTrain Dataset for project: climate-text-classification
==========================================================
Dataset Descritpion
-------------------
This dataset has been automatically processed by AutoTrain for project climate-text-classification.
### Languages
The BCP-47 code for the dataset's language is en.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] | [
"TAGS\n#task_categories-text-classification #language-English #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] |
b9860f54ee2427fb647f8950fb02018a485f0c94 | This dataset is not an official one, therefore should not be used without care! | Pakulski/ELI5-test | [
"region:us"
] | 2022-09-12T11:34:06+00:00 | {} | 2022-09-24T13:34:52+00:00 | [] | [] | TAGS
#region-us
| This dataset is not an official one, therefore should not be used without care! | [] | [
"TAGS\n#region-us \n"
] |
53b699798eb1ca8aa69f1fdcc8e9d8416ab00d86 |
# Datastet card for Encyclopaedia Britannica Illustrated
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://data.nls.uk/data/digitised-collections/encyclopaedia-britannica/](https://data.nls.uk/data/digitised-collections/encyclopaedia-britannica/)
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Citation Information
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| biglam/encyclopaedia_britannica_illustrated | [
"task_categories:image-classification",
"annotations_creators:expert-generated",
"size_categories:1K<n<10K",
"license:cc0-1.0",
"region:us"
] | 2022-09-12T16:40:02+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": [], "language": [], "license": ["cc0-1.0"], "multilinguality": [], "size_categories": ["1K<n<10K"], "source_datasets": [], "task_categories": ["image-classification"], "task_ids": [], "pretty_name": "Encyclopaedia Britannica Illustrated", "tags": []} | 2023-02-22T18:40:02+00:00 | [] | [] | TAGS
#task_categories-image-classification #annotations_creators-expert-generated #size_categories-1K<n<10K #license-cc0-1.0 #region-us
|
# Datastet card for Encyclopaedia Britannica Illustrated
## Table of Contents
- Dataset Card Creation Guide
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Initial Data Collection and Normalization
- Who are the source language producers?
- Annotations
- Annotation process
- Who are the annotators?
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
Thanks to @github-username for adding this dataset.
| [
"# Datastet card for Encyclopaedia Britannica Illustrated",
"## Table of Contents\n- Dataset Card Creation Guide\n - Table of Contents\n - Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n - Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n - Dataset Creation\n - Curation Rationale\n - Source Data\n - Initial Data Collection and Normalization\n - Who are the source language producers?\n - Annotations\n - Annotation process\n - Who are the annotators?\n - Personal and Sensitive Information\n - Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n - Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] | [
"TAGS\n#task_categories-image-classification #annotations_creators-expert-generated #size_categories-1K<n<10K #license-cc0-1.0 #region-us \n",
"# Datastet card for Encyclopaedia Britannica Illustrated",
"## Table of Contents\n- Dataset Card Creation Guide\n - Table of Contents\n - Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n - Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n - Dataset Creation\n - Curation Rationale\n - Source Data\n - Initial Data Collection and Normalization\n - Who are the source language producers?\n - Annotations\n - Annotation process\n - Who are the annotators?\n - Personal and Sensitive Information\n - Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n - Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] |
06928317703bcfa6099c7fc0f13e11bb295e7769 |
# LAION-Aesthetics :: CLIP → UMAP
This dataset is a CLIP (text) → UMAP embedding of the [LAION-Aesthetics dataset](https://laion.ai/blog/laion-aesthetics/) - specifically the [`improved_aesthetics_6plus` version](https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus), which filters the full dataset to images with scores of > 6 under the "aesthetic" filtering model.
Thanks LAION for this amazing corpus!
---
The dataset here includes coordinates for 3x separate UMAP fits using different values for the `n_neighbors` parameter - `10`, `30`, and `60` - which are broken out as separate columns with different suffixes:
- `n_neighbors=10` → (`x_nn10`, `y_nn10`)
- `n_neighbors=30` → (`x_nn30`, `y_nn30`)
- `n_neighbors=60` → (`x_nn60`, `y_nn60`)
### `nn10`

### `nn30`

### `nn60`
(The version from [Twitter](https://twitter.com/clured/status/1565399157606580224).)

## Pipeline
The script for producing this can be found here:
https://github.com/davidmcclure/loam-viz/blob/laion/laion.py
And is very simple - just using the `openai/clip-vit-base-patch32` model out-of-the-box to encode the text captions:
```python
@app.command()
def clip(
src: str,
dst: str,
text_col: str = 'TEXT',
limit: Optional[int] = typer.Option(None),
batch_size: int = typer.Option(512),
):
"""Embed with CLIP."""
df = pd.read_parquet(src)
if limit:
df = df.head(limit)
tokenizer = CLIPTokenizerFast.from_pretrained('openai/clip-vit-base-patch32')
model = CLIPTextModel.from_pretrained('openai/clip-vit-base-patch32')
model = model.to(device)
texts = df[text_col].tolist()
embeds = []
for batch in chunked_iter(tqdm(texts), batch_size):
enc = tokenizer(
batch,
return_tensors='pt',
padding=True,
truncation=True,
)
enc = enc.to(device)
with torch.no_grad():
res = model(**enc)
embeds.append(res.pooler_output.to('cpu'))
embeds = torch.cat(embeds).numpy()
np.save(dst, embeds)
print(embeds.shape)
```
Then using `cuml.GaussianRandomProjection` to do an initial squeeze to 64d (which gets the embedding tensor small enough to fit onto a single GPU for the UMAP) -
```python
@app.command()
def random_projection(src: str, dst: str, dim: int = 64):
"""Random projection on an embedding matrix."""
rmm.reinitialize(managed_memory=True)
embeds = np.load(src)
rp = cuml.GaussianRandomProjection(n_components=dim)
embeds = rp.fit_transform(embeds)
np.save(dst, embeds)
print(embeds.shape)
```
And then `cuml.UMAP` to get from 64d -> 2d -
```python
@app.command()
def umap(
df_src: str,
embeds_src: str,
dst: str,
n_neighbors: int = typer.Option(30),
n_epochs: int = typer.Option(1000),
negative_sample_rate: int = typer.Option(20),
):
"""UMAP to 2d."""
rmm.reinitialize(managed_memory=True)
df = pd.read_parquet(df_src)
embeds = np.load(embeds_src)
embeds = embeds.astype('float16')
print(embeds.shape)
print(embeds.dtype)
reducer = cuml.UMAP(
n_neighbors=n_neighbors,
n_epochs=n_epochs,
negative_sample_rate=negative_sample_rate,
verbose=True,
)
x = reducer.fit_transform(embeds)
df['x'] = x[:,0]
df['y'] = x[:,1]
df.to_parquet(dst)
print(df)
``` | dclure/laion-aesthetics-12m-umap | [
"language_creators:found",
"multilinguality:monolingual",
"language:en",
"license:mit",
"laion",
"stable-diffuson",
"text2img",
"region:us"
] | 2022-09-12T19:18:45+00:00 | {"annotations_creators": [], "language_creators": ["found"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": [], "source_datasets": [], "task_categories": [], "task_ids": [], "pretty_name": "laion-aesthetics-12m-umap", "tags": ["laion", "stable-diffuson", "text2img"]} | 2022-09-12T20:45:15+00:00 | [] | [
"en"
] | TAGS
#language_creators-found #multilinguality-monolingual #language-English #license-mit #laion #stable-diffuson #text2img #region-us
|
# LAION-Aesthetics :: CLIP → UMAP
This dataset is a CLIP (text) → UMAP embedding of the LAION-Aesthetics dataset - specifically the 'improved_aesthetics_6plus' version, which filters the full dataset to images with scores of > 6 under the "aesthetic" filtering model.
Thanks LAION for this amazing corpus!
---
The dataset here includes coordinates for 3x separate UMAP fits using different values for the 'n_neighbors' parameter - '10', '30', and '60' - which are broken out as separate columns with different suffixes:
- 'n_neighbors=10' → ('x_nn10', 'y_nn10')
- 'n_neighbors=30' → ('x_nn30', 'y_nn30')
- 'n_neighbors=60' → ('x_nn60', 'y_nn60')
### 'nn10'
!nn10
### 'nn30'
!nn30
### 'nn60'
(The version from Twitter.)
!nn60
## Pipeline
The script for producing this can be found here:
URL
And is very simple - just using the 'openai/clip-vit-base-patch32' model out-of-the-box to encode the text captions:
Then using 'cuml.GaussianRandomProjection' to do an initial squeeze to 64d (which gets the embedding tensor small enough to fit onto a single GPU for the UMAP) -
And then 'cuml.UMAP' to get from 64d -> 2d -
| [
"# LAION-Aesthetics :: CLIP → UMAP\n\nThis dataset is a CLIP (text) → UMAP embedding of the LAION-Aesthetics dataset - specifically the 'improved_aesthetics_6plus' version, which filters the full dataset to images with scores of > 6 under the \"aesthetic\" filtering model.\n\nThanks LAION for this amazing corpus!\n\n---\n\nThe dataset here includes coordinates for 3x separate UMAP fits using different values for the 'n_neighbors' parameter - '10', '30', and '60' - which are broken out as separate columns with different suffixes:\n\n- 'n_neighbors=10' → ('x_nn10', 'y_nn10')\n- 'n_neighbors=30' → ('x_nn30', 'y_nn30')\n- 'n_neighbors=60' → ('x_nn60', 'y_nn60')",
"### 'nn10'\n\n!nn10",
"### 'nn30'\n\n!nn30",
"### 'nn60'\n\n(The version from Twitter.)\n\n!nn60",
"## Pipeline\n\nThe script for producing this can be found here:\n\nURL\n\nAnd is very simple - just using the 'openai/clip-vit-base-patch32' model out-of-the-box to encode the text captions:\n\n\n\nThen using 'cuml.GaussianRandomProjection' to do an initial squeeze to 64d (which gets the embedding tensor small enough to fit onto a single GPU for the UMAP) -\n\n\n\nAnd then 'cuml.UMAP' to get from 64d -> 2d -"
] | [
"TAGS\n#language_creators-found #multilinguality-monolingual #language-English #license-mit #laion #stable-diffuson #text2img #region-us \n",
"# LAION-Aesthetics :: CLIP → UMAP\n\nThis dataset is a CLIP (text) → UMAP embedding of the LAION-Aesthetics dataset - specifically the 'improved_aesthetics_6plus' version, which filters the full dataset to images with scores of > 6 under the \"aesthetic\" filtering model.\n\nThanks LAION for this amazing corpus!\n\n---\n\nThe dataset here includes coordinates for 3x separate UMAP fits using different values for the 'n_neighbors' parameter - '10', '30', and '60' - which are broken out as separate columns with different suffixes:\n\n- 'n_neighbors=10' → ('x_nn10', 'y_nn10')\n- 'n_neighbors=30' → ('x_nn30', 'y_nn30')\n- 'n_neighbors=60' → ('x_nn60', 'y_nn60')",
"### 'nn10'\n\n!nn10",
"### 'nn30'\n\n!nn30",
"### 'nn60'\n\n(The version from Twitter.)\n\n!nn60",
"## Pipeline\n\nThe script for producing this can be found here:\n\nURL\n\nAnd is very simple - just using the 'openai/clip-vit-base-patch32' model out-of-the-box to encode the text captions:\n\n\n\nThen using 'cuml.GaussianRandomProjection' to do an initial squeeze to 64d (which gets the embedding tensor small enough to fit onto a single GPU for the UMAP) -\n\n\n\nAnd then 'cuml.UMAP' to get from 64d -> 2d -"
] |
5c8d08d69a9d54741c252ba8bdd8653ee32f52b6 |
# CARES - A Corpus of Anonymised Radiological Evidences in Spanish 📑🏥
CARES is a high-quality text resource manually labeled with ICD-10 codes and reviewed by radiologists. These types of resources are essential for developing automatic text classification tools as they are necessary for training and fine-tuning our computational systems.
The CARES corpus has been manually annotated using the ICD-10 ontology, which stands for for the 10th version of the International Classification of Diseases. For each radiological report, a minimum of one code and a maximum of 9 codes were assigned, while the average number of codes per text is 2.15 with the standard deviation of 1.12.
The corpus was additionally preprocessed in order to make its format coherent with the automatic text classification task. Considering the hierarchical structure of the ICD-10 ontology, each sub-code was mapped to its respective code and chapter, obtaining two new sets of labels for each report. The entire CARES collection contains 6,907 sub-code annotations among the 3,219 radiologic reports. There are 223 unique ICD-10 sub-codes within the annotations, which were mapped to 156 unique ICD-10 codes and 16 unique chapters of the cited ontology. | chizhikchi/CARES_random | [
"task_categories:text-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:es",
"license:afl-3.0",
"radiology",
"biomedicine",
"ICD-10",
"region:us"
] | 2022-09-13T09:32:00+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["es"], "license": ["afl-3.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "pretty_name": "CARES", "tags": ["radiology", "biomedicine", "ICD-10"]} | 2022-11-23T09:36:01+00:00 | [] | [
"es"
] | TAGS
#task_categories-text-classification #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Spanish #license-afl-3.0 #radiology #biomedicine #ICD-10 #region-us
|
# CARES - A Corpus of Anonymised Radiological Evidences in Spanish
CARES is a high-quality text resource manually labeled with ICD-10 codes and reviewed by radiologists. These types of resources are essential for developing automatic text classification tools as they are necessary for training and fine-tuning our computational systems.
The CARES corpus has been manually annotated using the ICD-10 ontology, which stands for for the 10th version of the International Classification of Diseases. For each radiological report, a minimum of one code and a maximum of 9 codes were assigned, while the average number of codes per text is 2.15 with the standard deviation of 1.12.
The corpus was additionally preprocessed in order to make its format coherent with the automatic text classification task. Considering the hierarchical structure of the ICD-10 ontology, each sub-code was mapped to its respective code and chapter, obtaining two new sets of labels for each report. The entire CARES collection contains 6,907 sub-code annotations among the 3,219 radiologic reports. There are 223 unique ICD-10 sub-codes within the annotations, which were mapped to 156 unique ICD-10 codes and 16 unique chapters of the cited ontology. | [
"# CARES - A Corpus of Anonymised Radiological Evidences in Spanish \n\nCARES is a high-quality text resource manually labeled with ICD-10 codes and reviewed by radiologists. These types of resources are essential for developing automatic text classification tools as they are necessary for training and fine-tuning our computational systems. \n\nThe CARES corpus has been manually annotated using the ICD-10 ontology, which stands for for the 10th version of the International Classification of Diseases. For each radiological report, a minimum of one code and a maximum of 9 codes were assigned, while the average number of codes per text is 2.15 with the standard deviation of 1.12.\n\nThe corpus was additionally preprocessed in order to make its format coherent with the automatic text classification task. Considering the hierarchical structure of the ICD-10 ontology, each sub-code was mapped to its respective code and chapter, obtaining two new sets of labels for each report. The entire CARES collection contains 6,907 sub-code annotations among the 3,219 radiologic reports. There are 223 unique ICD-10 sub-codes within the annotations, which were mapped to 156 unique ICD-10 codes and 16 unique chapters of the cited ontology."
] | [
"TAGS\n#task_categories-text-classification #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Spanish #license-afl-3.0 #radiology #biomedicine #ICD-10 #region-us \n",
"# CARES - A Corpus of Anonymised Radiological Evidences in Spanish \n\nCARES is a high-quality text resource manually labeled with ICD-10 codes and reviewed by radiologists. These types of resources are essential for developing automatic text classification tools as they are necessary for training and fine-tuning our computational systems. \n\nThe CARES corpus has been manually annotated using the ICD-10 ontology, which stands for for the 10th version of the International Classification of Diseases. For each radiological report, a minimum of one code and a maximum of 9 codes were assigned, while the average number of codes per text is 2.15 with the standard deviation of 1.12.\n\nThe corpus was additionally preprocessed in order to make its format coherent with the automatic text classification task. Considering the hierarchical structure of the ICD-10 ontology, each sub-code was mapped to its respective code and chapter, obtaining two new sets of labels for each report. The entire CARES collection contains 6,907 sub-code annotations among the 3,219 radiologic reports. There are 223 unique ICD-10 sub-codes within the annotations, which were mapped to 156 unique ICD-10 codes and 16 unique chapters of the cited ontology."
] |
e2e03c91c385e8d1a758389cdb20cf9c024f6cbf |
# Dataset Card for recycling-dataset
### Dataset Summary
This is a recycling dataset that can be used for image classification. It has 11 categories:
- aluminium
- batteries
- cardboard
- disposable plates
- glass
- hard plastic
- paper
- paper towel
- polystyrene
- soft plastics
- takeaway cups
It was scrapped from DuckDuckGo using this tool: https://pypi.org/project/jmd-imagescraper/
| viola77data/recycling-dataset | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:apache-2.0",
"recycling",
"image-classification",
"region:us"
] | 2022-09-13T11:43:15+00:00 | {"annotations_creators": [], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["image-classification"], "task_ids": ["multi-class-image-classification"], "pretty_name": "recycling-dataset", "tags": ["recycling", "image-classification"]} | 2022-09-13T12:17:15+00:00 | [] | [
"en"
] | TAGS
#task_categories-image-classification #task_ids-multi-class-image-classification #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-apache-2.0 #recycling #image-classification #region-us
|
# Dataset Card for recycling-dataset
### Dataset Summary
This is a recycling dataset that can be used for image classification. It has 11 categories:
- aluminium
- batteries
- cardboard
- disposable plates
- glass
- hard plastic
- paper
- paper towel
- polystyrene
- soft plastics
- takeaway cups
It was scrapped from DuckDuckGo using this tool: URL
| [
"# Dataset Card for recycling-dataset",
"### Dataset Summary\n\nThis is a recycling dataset that can be used for image classification. It has 11 categories:\n\n- aluminium\n- batteries\n- cardboard\n- disposable plates\n- glass\n- hard plastic\n- paper\n- paper towel\n- polystyrene\n- soft plastics\n- takeaway cups\n\nIt was scrapped from DuckDuckGo using this tool: URL"
] | [
"TAGS\n#task_categories-image-classification #task_ids-multi-class-image-classification #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-apache-2.0 #recycling #image-classification #region-us \n",
"# Dataset Card for recycling-dataset",
"### Dataset Summary\n\nThis is a recycling dataset that can be used for image classification. It has 11 categories:\n\n- aluminium\n- batteries\n- cardboard\n- disposable plates\n- glass\n- hard plastic\n- paper\n- paper towel\n- polystyrene\n- soft plastics\n- takeaway cups\n\nIt was scrapped from DuckDuckGo using this tool: URL"
] |
0443841c9c89d542de4ab68bce7686c988f00a12 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: JNK789/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-42ff1e-1454153801 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-13T17:00:38+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "JNK789/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-13T17:01:07+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Multi-class Text Classification
* Model: JNK789/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: JNK789/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: JNK789/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
e3054439375c30e9e0cf0308c274efed194a98c6 | # Dataset Card for CUAD
This is a modified version of original [CUAD](https://huggingface.co/datasets/cuad/blob/main/README.md) which trims the question to its label form.
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Contract Understanding Atticus Dataset](https://www.atticusprojectai.org/cuad)
- **Repository:** [Contract Understanding Atticus Dataset](https://github.com/TheAtticusProject/cuad/)
- **Paper:** [CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review](https://arxiv.org/abs/2103.06268)
- **Point of Contact:** [Atticus Project Team]([email protected])
### Dataset Summary
Contract Understanding Atticus Dataset (CUAD) v1 is a corpus of more than 13,000 labels in 510 commercial legal contracts that have been manually labeled to identify 41 categories of important clauses that lawyers look for when reviewing contracts in connection with corporate transactions.
CUAD is curated and maintained by The Atticus Project, Inc. to support NLP research and development in legal contract review. Analysis of CUAD can be found at https://arxiv.org/abs/2103.06268. Code for replicating the results and the trained model can be found at https://github.com/TheAtticusProject/cuad.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The dataset contains samples in English only.
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answers": {
"answer_start": [44],
"text": ['DISTRIBUTOR AGREEMENT']
},
"context": 'EXHIBIT 10.6\n\n DISTRIBUTOR AGREEMENT\n\n THIS DISTRIBUTOR AGREEMENT (the "Agreement") is made by and between Electric City Corp., a Delaware corporation ("Company") and Electric City of Illinois LLC ("Distributor") this 7th day of September, 1999...',
"id": "LIMEENERGYCO_09_09_1999-EX-10-DISTRIBUTOR AGREEMENT__Document Name_0",
"question": "Highlight the parts (if any) of this contract related to "Document Name" that should be reviewed by a lawyer. Details: The name of the contract",
"title": "LIMEENERGYCO_09_09_1999-EX-10-DISTRIBUTOR AGREEMENT"
}
```
### Data Fields
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `answer_start`: a `int32` feature.
### Data Splits
This dataset is split into train/test set. Number of samples in each set is given below:
| | Train | Test |
| ----- | ------ | ---- |
| CUAD | 22450 | 4182 |
## Dataset Creation
### Curation Rationale
A highly valuable specialized task without a public large-scale dataset is contract review, which costs humans substantial time, money, and attention. Many law firms spend approximately 50% of their time reviewing contracts (CEB, 2017). Due to the specialized training necessary to understand and interpret contracts, the billing rates for lawyers at large law firms are typically around $500-$900 per hour in the US. As a result, many transactions cost companies hundreds of thousands of dollars just so that lawyers can verify that there are no problematic obligations or requirements included in the contracts. Contract review can be a source of drudgery and, in comparison to other legal tasks, is widely considered to be especially boring.
Contract review costs also affect consumers. Since contract review costs are so prohibitive, contract review is not often performed outside corporate transactions. Small companies and individuals consequently often sign contracts without even reading them, which can result in predatory behavior that harms consumers. Automating contract review by openly releasing high-quality data and fine-tuned models can increase access to legal support for small businesses and individuals, so that legal support is not exclusively available to wealthy companies.
To reduce the disparate societal costs of contract review, and to study how well NLP models generalize to specialized domains, the authors introduced a new large-scale dataset for contract review. As part of The Atticus Project, a non-profit organization of legal experts, CUAD is introduced, the Contract Understanding Atticus Dataset. This dataset was created with a year-long effort pushed forward by dozens of law student annotators, lawyers, and machine learning researchers. The dataset includes more than 500 contracts and more than 13,000 expert annotations that span 41 label categories. For each of 41 different labels, models must learn to highlight the portions of a contract most salient to that label. This makes the task a matter of finding needles in a haystack.
### Source Data
#### Initial Data Collection and Normalization
The CUAD includes commercial contracts selected from 25 different types of contracts based on the contract names as shown below. Within each type, the creators randomly selected contracts based on the names of the filing companies across the alphabet.
Type of Contracts: # of Docs
Affiliate Agreement: 10
Agency Agreement: 13
Collaboration/Cooperation Agreement: 26
Co-Branding Agreement: 22
Consulting Agreement: 11
Development Agreement: 29
Distributor Agreement: 32
Endorsement Agreement: 24
Franchise Agreement: 15
Hosting Agreement: 20
IP Agreement: 17
Joint Venture Agreemen: 23
License Agreement: 33
Maintenance Agreement: 34
Manufacturing Agreement: 17
Marketing Agreement: 17
Non-Compete/No-Solicit/Non-Disparagement Agreement: 3
Outsourcing Agreement: 18
Promotion Agreement: 12
Reseller Agreement: 12
Service Agreement: 28
Sponsorship Agreement: 31
Supply Agreement: 18
Strategic Alliance Agreement: 32
Transportation Agreement: 13
TOTAL: 510
#### Who are the source language producers?
The contracts were sourced from EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system used at the U.S. Securities and Exchange Commission (SEC). Publicly traded companies in the United States are required to file certain contracts under the SEC rules. Access to these contracts is available to the public for free at https://www.sec.gov/edgar. Please read the Datasheet at https://www.atticusprojectai.org/ for information on the intended use and limitations of the CUAD.
### Annotations
#### Annotation process
The labeling process included multiple steps to ensure accuracy:
1. Law Student Training: law students attended training sessions on each of the categories that included a summary, video instructions by experienced attorneys, multiple quizzes and workshops. Students were then required to label sample contracts in eBrevia, an online contract review tool. The initial training took approximately 70-100 hours.
2. Law Student Label: law students conducted manual contract review and labeling in eBrevia.
3. Key Word Search: law students conducted keyword search in eBrevia to capture additional categories that have been missed during the “Student Label” step.
4. Category-by-Category Report Review: law students exported the labeled clauses into reports, review each clause category-by-category and highlight clauses that they believe are mislabeled.
5. Attorney Review: experienced attorneys reviewed the category-by-category report with students comments, provided comments and addressed student questions. When applicable, attorneys discussed such results with the students and reached consensus. Students made changes in eBrevia accordingly.
6. eBrevia Extras Review. Attorneys and students used eBrevia to generate a list of “extras”, which are clauses that eBrevia AI tool identified as responsive to a category but not labeled by human annotators. Attorneys and students reviewed all of the “extras” and added the correct ones. The process is repeated until all or substantially all of the “extras” are incorrect labels.
7. Final Report: The final report was exported into a CSV file. Volunteers manually added the “Yes/No” answer column to categories that do not contain an answer.
#### Who are the annotators?
Answered in above section.
### Personal and Sensitive Information
Some clauses in the files are redacted because the party submitting these contracts redacted them to protect confidentiality. Such redaction may show up as asterisks (\*\*\*) or underscores (\_\_\_) or blank spaces. The dataset and the answers reflect such redactions. For example, the answer for “January \_\_ 2020” would be “1/[]/2020”).
For any categories that require an answer of “Yes/No”, annotators include full sentences as text context in a contract. To maintain consistency and minimize inter-annotator disagreement, annotators select text for the full sentence, under the instruction of “from period to period”.
For the other categories, annotators selected segments of the text in the contract that are responsive to each such category. One category in a contract may include multiple labels. For example, “Parties” may include 4-10 separate text strings that are not continuous in a contract. The answer is presented in the unified format separated by semicolons of “Party A Inc. (“Party A”); Party B Corp. (“Party B”)”.
Some sentences in the files include confidential legends that are not part of the contracts. An example of such confidential legend is as follows:
THIS EXHIBIT HAS BEEN REDACTED AND IS THE SUBJECT OF A CONFIDENTIAL TREATMENT REQUEST. REDACTED MATERIAL IS MARKED WITH [* * *] AND HAS BEEN FILED SEPARATELY WITH THE SECURITIES AND EXCHANGE COMMISSION.
Some sentences in the files contain irrelevant information such as footers or page numbers. Some sentences may not be relevant to the corresponding category. Some sentences may correspond to a different category. Because many legal clauses are very long and contain various sub-parts, sometimes only a sub-part of a sentence is responsive to a category.
To address the foregoing limitations, annotators manually deleted the portion that is not responsive, replacing it with the symbol "<omitted>" to indicate that the two text segments do not appear immediately next to each other in the contracts. For example, if a “Termination for Convenience” clause starts with “Each Party may terminate this Agreement if” followed by three subparts “(a), (b) and (c)”, but only subpart (c) is responsive to this category, the authors manually deleted subparts (a) and (b) and replaced them with the symbol "<omitted>”. Another example is for “Effective Date”, the contract includes a sentence “This Agreement is effective as of the date written above” that appears after the date “January 1, 2010”. The annotation is as follows: “January 1, 2010 <omitted> This Agreement is effective as of the date written above.”
Because the contracts were converted from PDF into TXT files, the converted TXT files may not stay true to the format of the original PDF files. For example, some contracts contain inconsistent spacing between words, sentences and paragraphs. Table format is not maintained in the TXT files.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Attorney Advisors
Wei Chen, John Brockland, Kevin Chen, Jacky Fink, Spencer P. Goodson, Justin Haan, Alex Haskell, Kari Krusmark, Jenny Lin, Jonas Marson, Benjamin Petersen, Alexander Kwonji Rosenberg, William R. Sawyers, Brittany Schmeltz, Max Scott, Zhu Zhu
Law Student Leaders
John Batoha, Daisy Beckner, Lovina Consunji, Gina Diaz, Chris Gronseth, Calvin Hannagan, Joseph Kroon, Sheetal Sharma Saran
Law Student Contributors
Scott Aronin, Bryan Burgoon, Jigar Desai, Imani Haynes, Jeongsoo Kim, Margaret Lynch, Allison Melville, Felix Mendez-Burgos, Nicole Mirkazemi, David Myers, Emily Rissberger, Behrang Seraj, Sarahginy Valcin
Technical Advisors & Contributors
Dan Hendrycks, Collin Burns, Spencer Ball, Anya Chen
### Licensing Information
CUAD is licensed under the Creative Commons Attribution 4.0 (CC BY 4.0) license and free to the public for commercial and non-commercial use.
The creators make no representations or warranties regarding the license status of the underlying contracts, which are publicly available and downloadable from EDGAR.
Privacy Policy & Disclaimers
The categories or the contracts included in the dataset are not comprehensive or representative. The authors encourage the public to help improve them by sending them your comments and suggestions to [email protected]. Comments and suggestions will be reviewed by The Atticus Project at its discretion and will be included in future versions of Atticus categories once approved.
The use of CUAD is subject to their privacy policy https://www.atticusprojectai.org/privacy-policy and disclaimer https://www.atticusprojectai.org/disclaimer.
### Citation Information
```
@article{hendrycks2021cuad,
title={CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review},
author={Dan Hendrycks and Collin Burns and Anya Chen and Spencer Ball},
journal={arXiv preprint arXiv:2103.06268},
year={2021}
}
```
### Contributions
Thanks to [@bhavitvyamalik](https://github.com/bhavitvyamalik) for adding the original CUAD dataset. | chenghao/cuad_qa | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"task_ids:extractive-qa",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"arxiv:2103.06268",
"region:us"
] | 2022-09-13T23:01:15+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["closed-domain-qa", "extractive-qa"], "paperswithcode_id": "cuad", "pretty_name": "CUAD", "train-eval-index": [{"config": "default", "task": "question-answering", "task_id": "extractive_question_answering", "splits": {"train_split": "train", "eval_split": "test"}, "col_mapping": {"question": "question", "context": "context", "answers": {"text": "text", "answer_start": "answer_start"}}, "metrics": [{"type": "cuad", "name": "CUAD"}]}]} | 2022-09-14T15:15:12+00:00 | [
"2103.06268"
] | [
"en"
] | TAGS
#task_categories-question-answering #task_ids-closed-domain-qa #task_ids-extractive-qa #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-4.0 #arxiv-2103.06268 #region-us
| Dataset Card for CUAD
=====================
This is a modified version of original CUAD which trims the question to its label form.
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: Contract Understanding Atticus Dataset
* Repository: Contract Understanding Atticus Dataset
* Paper: CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review
* Point of Contact: Atticus Project Team
### Dataset Summary
Contract Understanding Atticus Dataset (CUAD) v1 is a corpus of more than 13,000 labels in 510 commercial legal contracts that have been manually labeled to identify 41 categories of important clauses that lawyers look for when reviewing contracts in connection with corporate transactions.
CUAD is curated and maintained by The Atticus Project, Inc. to support NLP research and development in legal contract review. Analysis of CUAD can be found at URL Code for replicating the results and the trained model can be found at URL
### Supported Tasks and Leaderboards
### Languages
The dataset contains samples in English only.
Dataset Structure
-----------------
### Data Instances
An example of 'train' looks as follows.
### Data Fields
* 'id': a 'string' feature.
* 'title': a 'string' feature.
* 'context': a 'string' feature.
* 'question': a 'string' feature.
* 'answers': a dictionary feature containing:
+ 'text': a 'string' feature.
+ 'answer\_start': a 'int32' feature.
### Data Splits
This dataset is split into train/test set. Number of samples in each set is given below:
Train: CUAD, Test: 22450
Dataset Creation
----------------
### Curation Rationale
A highly valuable specialized task without a public large-scale dataset is contract review, which costs humans substantial time, money, and attention. Many law firms spend approximately 50% of their time reviewing contracts (CEB, 2017). Due to the specialized training necessary to understand and interpret contracts, the billing rates for lawyers at large law firms are typically around $500-$900 per hour in the US. As a result, many transactions cost companies hundreds of thousands of dollars just so that lawyers can verify that there are no problematic obligations or requirements included in the contracts. Contract review can be a source of drudgery and, in comparison to other legal tasks, is widely considered to be especially boring.
Contract review costs also affect consumers. Since contract review costs are so prohibitive, contract review is not often performed outside corporate transactions. Small companies and individuals consequently often sign contracts without even reading them, which can result in predatory behavior that harms consumers. Automating contract review by openly releasing high-quality data and fine-tuned models can increase access to legal support for small businesses and individuals, so that legal support is not exclusively available to wealthy companies.
To reduce the disparate societal costs of contract review, and to study how well NLP models generalize to specialized domains, the authors introduced a new large-scale dataset for contract review. As part of The Atticus Project, a non-profit organization of legal experts, CUAD is introduced, the Contract Understanding Atticus Dataset. This dataset was created with a year-long effort pushed forward by dozens of law student annotators, lawyers, and machine learning researchers. The dataset includes more than 500 contracts and more than 13,000 expert annotations that span 41 label categories. For each of 41 different labels, models must learn to highlight the portions of a contract most salient to that label. This makes the task a matter of finding needles in a haystack.
### Source Data
#### Initial Data Collection and Normalization
The CUAD includes commercial contracts selected from 25 different types of contracts based on the contract names as shown below. Within each type, the creators randomly selected contracts based on the names of the filing companies across the alphabet.
Type of Contracts: # of Docs
Affiliate Agreement: 10
Agency Agreement: 13
Collaboration/Cooperation Agreement: 26
Co-Branding Agreement: 22
Consulting Agreement: 11
Development Agreement: 29
Distributor Agreement: 32
Endorsement Agreement: 24
Franchise Agreement: 15
Hosting Agreement: 20
IP Agreement: 17
Joint Venture Agreemen: 23
License Agreement: 33
Maintenance Agreement: 34
Manufacturing Agreement: 17
Marketing Agreement: 17
Non-Compete/No-Solicit/Non-Disparagement Agreement: 3
Outsourcing Agreement: 18
Promotion Agreement: 12
Reseller Agreement: 12
Service Agreement: 28
Sponsorship Agreement: 31
Supply Agreement: 18
Strategic Alliance Agreement: 32
Transportation Agreement: 13
TOTAL: 510
#### Who are the source language producers?
The contracts were sourced from EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system used at the U.S. Securities and Exchange Commission (SEC). Publicly traded companies in the United States are required to file certain contracts under the SEC rules. Access to these contracts is available to the public for free at URL Please read the Datasheet at URL for information on the intended use and limitations of the CUAD.
### Annotations
#### Annotation process
The labeling process included multiple steps to ensure accuracy:
1. Law Student Training: law students attended training sessions on each of the categories that included a summary, video instructions by experienced attorneys, multiple quizzes and workshops. Students were then required to label sample contracts in eBrevia, an online contract review tool. The initial training took approximately 70-100 hours.
2. Law Student Label: law students conducted manual contract review and labeling in eBrevia.
3. Key Word Search: law students conducted keyword search in eBrevia to capture additional categories that have been missed during the “Student Label” step.
4. Category-by-Category Report Review: law students exported the labeled clauses into reports, review each clause category-by-category and highlight clauses that they believe are mislabeled.
5. Attorney Review: experienced attorneys reviewed the category-by-category report with students comments, provided comments and addressed student questions. When applicable, attorneys discussed such results with the students and reached consensus. Students made changes in eBrevia accordingly.
6. eBrevia Extras Review. Attorneys and students used eBrevia to generate a list of “extras”, which are clauses that eBrevia AI tool identified as responsive to a category but not labeled by human annotators. Attorneys and students reviewed all of the “extras” and added the correct ones. The process is repeated until all or substantially all of the “extras” are incorrect labels.
7. Final Report: The final report was exported into a CSV file. Volunteers manually added the “Yes/No” answer column to categories that do not contain an answer.
#### Who are the annotators?
Answered in above section.
### Personal and Sensitive Information
Some clauses in the files are redacted because the party submitting these contracts redacted them to protect confidentiality. Such redaction may show up as asterisks (\*\*\*) or underscores (\_\_\_) or blank spaces. The dataset and the answers reflect such redactions. For example, the answer for “January \_\_ 2020” would be “1/[]/2020”).
For any categories that require an answer of “Yes/No”, annotators include full sentences as text context in a contract. To maintain consistency and minimize inter-annotator disagreement, annotators select text for the full sentence, under the instruction of “from period to period”.
For the other categories, annotators selected segments of the text in the contract that are responsive to each such category. One category in a contract may include multiple labels. For example, “Parties” may include 4-10 separate text strings that are not continuous in a contract. The answer is presented in the unified format separated by semicolons of “Party A Inc. (“Party A”); Party B Corp. (“Party B”)”.
Some sentences in the files include confidential legends that are not part of the contracts. An example of such confidential legend is as follows:
THIS EXHIBIT HAS BEEN REDACTED AND IS THE SUBJECT OF A CONFIDENTIAL TREATMENT REQUEST. REDACTED MATERIAL IS MARKED WITH [\* \* \*] AND HAS BEEN FILED SEPARATELY WITH THE SECURITIES AND EXCHANGE COMMISSION.
Some sentences in the files contain irrelevant information such as footers or page numbers. Some sentences may not be relevant to the corresponding category. Some sentences may correspond to a different category. Because many legal clauses are very long and contain various sub-parts, sometimes only a sub-part of a sentence is responsive to a category.
To address the foregoing limitations, annotators manually deleted the portion that is not responsive, replacing it with the symbol "" to indicate that the two text segments do not appear immediately next to each other in the contracts. For example, if a “Termination for Convenience” clause starts with “Each Party may terminate this Agreement if” followed by three subparts “(a), (b) and (c)”, but only subpart (c) is responsive to this category, the authors manually deleted subparts (a) and (b) and replaced them with the symbol "”. Another example is for “Effective Date”, the contract includes a sentence “This Agreement is effective as of the date written above” that appears after the date “January 1, 2010”. The annotation is as follows: “January 1, 2010 This Agreement is effective as of the date written above.”
Because the contracts were converted from PDF into TXT files, the converted TXT files may not stay true to the format of the original PDF files. For example, some contracts contain inconsistent spacing between words, sentences and paragraphs. Table format is not maintained in the TXT files.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
Attorney Advisors
Wei Chen, John Brockland, Kevin Chen, Jacky Fink, Spencer P. Goodson, Justin Haan, Alex Haskell, Kari Krusmark, Jenny Lin, Jonas Marson, Benjamin Petersen, Alexander Kwonji Rosenberg, William R. Sawyers, Brittany Schmeltz, Max Scott, Zhu Zhu
Law Student Leaders
John Batoha, Daisy Beckner, Lovina Consunji, Gina Diaz, Chris Gronseth, Calvin Hannagan, Joseph Kroon, Sheetal Sharma Saran
Law Student Contributors
Scott Aronin, Bryan Burgoon, Jigar Desai, Imani Haynes, Jeongsoo Kim, Margaret Lynch, Allison Melville, Felix Mendez-Burgos, Nicole Mirkazemi, David Myers, Emily Rissberger, Behrang Seraj, Sarahginy Valcin
Technical Advisors & Contributors
Dan Hendrycks, Collin Burns, Spencer Ball, Anya Chen
### Licensing Information
CUAD is licensed under the Creative Commons Attribution 4.0 (CC BY 4.0) license and free to the public for commercial and non-commercial use.
The creators make no representations or warranties regarding the license status of the underlying contracts, which are publicly available and downloadable from EDGAR.
Privacy Policy & Disclaimers
The categories or the contracts included in the dataset are not comprehensive or representative. The authors encourage the public to help improve them by sending them your comments and suggestions to info@URL. Comments and suggestions will be reviewed by The Atticus Project at its discretion and will be included in future versions of Atticus categories once approved.
The use of CUAD is subject to their privacy policy URL and disclaimer URL
### Contributions
Thanks to @bhavitvyamalik for adding the original CUAD dataset.
| [
"### Dataset Summary\n\n\nContract Understanding Atticus Dataset (CUAD) v1 is a corpus of more than 13,000 labels in 510 commercial legal contracts that have been manually labeled to identify 41 categories of important clauses that lawyers look for when reviewing contracts in connection with corporate transactions.\nCUAD is curated and maintained by The Atticus Project, Inc. to support NLP research and development in legal contract review. Analysis of CUAD can be found at URL Code for replicating the results and the trained model can be found at URL",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nThe dataset contains samples in English only.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\n* 'id': a 'string' feature.\n* 'title': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.",
"### Data Splits\n\n\nThis dataset is split into train/test set. Number of samples in each set is given below:\n\n\nTrain: CUAD, Test: 22450\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nA highly valuable specialized task without a public large-scale dataset is contract review, which costs humans substantial time, money, and attention. Many law firms spend approximately 50% of their time reviewing contracts (CEB, 2017). Due to the specialized training necessary to understand and interpret contracts, the billing rates for lawyers at large law firms are typically around $500-$900 per hour in the US. As a result, many transactions cost companies hundreds of thousands of dollars just so that lawyers can verify that there are no problematic obligations or requirements included in the contracts. Contract review can be a source of drudgery and, in comparison to other legal tasks, is widely considered to be especially boring.\nContract review costs also affect consumers. Since contract review costs are so prohibitive, contract review is not often performed outside corporate transactions. Small companies and individuals consequently often sign contracts without even reading them, which can result in predatory behavior that harms consumers. Automating contract review by openly releasing high-quality data and fine-tuned models can increase access to legal support for small businesses and individuals, so that legal support is not exclusively available to wealthy companies.\nTo reduce the disparate societal costs of contract review, and to study how well NLP models generalize to specialized domains, the authors introduced a new large-scale dataset for contract review. As part of The Atticus Project, a non-profit organization of legal experts, CUAD is introduced, the Contract Understanding Atticus Dataset. This dataset was created with a year-long effort pushed forward by dozens of law student annotators, lawyers, and machine learning researchers. The dataset includes more than 500 contracts and more than 13,000 expert annotations that span 41 label categories. For each of 41 different labels, models must learn to highlight the portions of a contract most salient to that label. This makes the task a matter of finding needles in a haystack.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe CUAD includes commercial contracts selected from 25 different types of contracts based on the contract names as shown below. Within each type, the creators randomly selected contracts based on the names of the filing companies across the alphabet.\nType of Contracts: # of Docs\nAffiliate Agreement: 10\nAgency Agreement: 13\nCollaboration/Cooperation Agreement: 26\nCo-Branding Agreement: 22\nConsulting Agreement: 11\nDevelopment Agreement: 29\nDistributor Agreement: 32\nEndorsement Agreement: 24\nFranchise Agreement: 15\nHosting Agreement: 20\nIP Agreement: 17\nJoint Venture Agreemen: 23\nLicense Agreement: 33\nMaintenance Agreement: 34\nManufacturing Agreement: 17\nMarketing Agreement: 17\nNon-Compete/No-Solicit/Non-Disparagement Agreement: 3\nOutsourcing Agreement: 18\nPromotion Agreement: 12\nReseller Agreement: 12\nService Agreement: 28\nSponsorship Agreement: 31\nSupply Agreement: 18\nStrategic Alliance Agreement: 32\nTransportation Agreement: 13\nTOTAL: 510",
"#### Who are the source language producers?\n\n\nThe contracts were sourced from EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system used at the U.S. Securities and Exchange Commission (SEC). Publicly traded companies in the United States are required to file certain contracts under the SEC rules. Access to these contracts is available to the public for free at URL Please read the Datasheet at URL for information on the intended use and limitations of the CUAD.",
"### Annotations",
"#### Annotation process\n\n\nThe labeling process included multiple steps to ensure accuracy:\n\n\n1. Law Student Training: law students attended training sessions on each of the categories that included a summary, video instructions by experienced attorneys, multiple quizzes and workshops. Students were then required to label sample contracts in eBrevia, an online contract review tool. The initial training took approximately 70-100 hours.\n2. Law Student Label: law students conducted manual contract review and labeling in eBrevia.\n3. Key Word Search: law students conducted keyword search in eBrevia to capture additional categories that have been missed during the “Student Label” step.\n4. Category-by-Category Report Review: law students exported the labeled clauses into reports, review each clause category-by-category and highlight clauses that they believe are mislabeled.\n5. Attorney Review: experienced attorneys reviewed the category-by-category report with students comments, provided comments and addressed student questions. When applicable, attorneys discussed such results with the students and reached consensus. Students made changes in eBrevia accordingly.\n6. eBrevia Extras Review. Attorneys and students used eBrevia to generate a list of “extras”, which are clauses that eBrevia AI tool identified as responsive to a category but not labeled by human annotators. Attorneys and students reviewed all of the “extras” and added the correct ones. The process is repeated until all or substantially all of the “extras” are incorrect labels.\n7. Final Report: The final report was exported into a CSV file. Volunteers manually added the “Yes/No” answer column to categories that do not contain an answer.",
"#### Who are the annotators?\n\n\nAnswered in above section.",
"### Personal and Sensitive Information\n\n\nSome clauses in the files are redacted because the party submitting these contracts redacted them to protect confidentiality. Such redaction may show up as asterisks (\\*\\*\\*) or underscores (\\_\\_\\_) or blank spaces. The dataset and the answers reflect such redactions. For example, the answer for “January \\_\\_ 2020” would be “1/[]/2020”).\nFor any categories that require an answer of “Yes/No”, annotators include full sentences as text context in a contract. To maintain consistency and minimize inter-annotator disagreement, annotators select text for the full sentence, under the instruction of “from period to period”.\nFor the other categories, annotators selected segments of the text in the contract that are responsive to each such category. One category in a contract may include multiple labels. For example, “Parties” may include 4-10 separate text strings that are not continuous in a contract. The answer is presented in the unified format separated by semicolons of “Party A Inc. (“Party A”); Party B Corp. (“Party B”)”.\nSome sentences in the files include confidential legends that are not part of the contracts. An example of such confidential legend is as follows:\nTHIS EXHIBIT HAS BEEN REDACTED AND IS THE SUBJECT OF A CONFIDENTIAL TREATMENT REQUEST. REDACTED MATERIAL IS MARKED WITH [\\* \\* \\*] AND HAS BEEN FILED SEPARATELY WITH THE SECURITIES AND EXCHANGE COMMISSION.\nSome sentences in the files contain irrelevant information such as footers or page numbers. Some sentences may not be relevant to the corresponding category. Some sentences may correspond to a different category. Because many legal clauses are very long and contain various sub-parts, sometimes only a sub-part of a sentence is responsive to a category.\nTo address the foregoing limitations, annotators manually deleted the portion that is not responsive, replacing it with the symbol \"\" to indicate that the two text segments do not appear immediately next to each other in the contracts. For example, if a “Termination for Convenience” clause starts with “Each Party may terminate this Agreement if” followed by three subparts “(a), (b) and (c)”, but only subpart (c) is responsive to this category, the authors manually deleted subparts (a) and (b) and replaced them with the symbol \"”. Another example is for “Effective Date”, the contract includes a sentence “This Agreement is effective as of the date written above” that appears after the date “January 1, 2010”. The annotation is as follows: “January 1, 2010 This Agreement is effective as of the date written above.”\nBecause the contracts were converted from PDF into TXT files, the converted TXT files may not stay true to the format of the original PDF files. For example, some contracts contain inconsistent spacing between words, sentences and paragraphs. Table format is not maintained in the TXT files.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nAttorney Advisors\nWei Chen, John Brockland, Kevin Chen, Jacky Fink, Spencer P. Goodson, Justin Haan, Alex Haskell, Kari Krusmark, Jenny Lin, Jonas Marson, Benjamin Petersen, Alexander Kwonji Rosenberg, William R. Sawyers, Brittany Schmeltz, Max Scott, Zhu Zhu\nLaw Student Leaders\nJohn Batoha, Daisy Beckner, Lovina Consunji, Gina Diaz, Chris Gronseth, Calvin Hannagan, Joseph Kroon, Sheetal Sharma Saran\nLaw Student Contributors\nScott Aronin, Bryan Burgoon, Jigar Desai, Imani Haynes, Jeongsoo Kim, Margaret Lynch, Allison Melville, Felix Mendez-Burgos, Nicole Mirkazemi, David Myers, Emily Rissberger, Behrang Seraj, Sarahginy Valcin\nTechnical Advisors & Contributors\nDan Hendrycks, Collin Burns, Spencer Ball, Anya Chen",
"### Licensing Information\n\n\nCUAD is licensed under the Creative Commons Attribution 4.0 (CC BY 4.0) license and free to the public for commercial and non-commercial use.\nThe creators make no representations or warranties regarding the license status of the underlying contracts, which are publicly available and downloadable from EDGAR.\nPrivacy Policy & Disclaimers\nThe categories or the contracts included in the dataset are not comprehensive or representative. The authors encourage the public to help improve them by sending them your comments and suggestions to info@URL. Comments and suggestions will be reviewed by The Atticus Project at its discretion and will be included in future versions of Atticus categories once approved.\nThe use of CUAD is subject to their privacy policy URL and disclaimer URL",
"### Contributions\n\n\nThanks to @bhavitvyamalik for adding the original CUAD dataset."
] | [
"TAGS\n#task_categories-question-answering #task_ids-closed-domain-qa #task_ids-extractive-qa #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-cc-by-4.0 #arxiv-2103.06268 #region-us \n",
"### Dataset Summary\n\n\nContract Understanding Atticus Dataset (CUAD) v1 is a corpus of more than 13,000 labels in 510 commercial legal contracts that have been manually labeled to identify 41 categories of important clauses that lawyers look for when reviewing contracts in connection with corporate transactions.\nCUAD is curated and maintained by The Atticus Project, Inc. to support NLP research and development in legal contract review. Analysis of CUAD can be found at URL Code for replicating the results and the trained model can be found at URL",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nThe dataset contains samples in English only.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\n* 'id': a 'string' feature.\n* 'title': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.",
"### Data Splits\n\n\nThis dataset is split into train/test set. Number of samples in each set is given below:\n\n\nTrain: CUAD, Test: 22450\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nA highly valuable specialized task without a public large-scale dataset is contract review, which costs humans substantial time, money, and attention. Many law firms spend approximately 50% of their time reviewing contracts (CEB, 2017). Due to the specialized training necessary to understand and interpret contracts, the billing rates for lawyers at large law firms are typically around $500-$900 per hour in the US. As a result, many transactions cost companies hundreds of thousands of dollars just so that lawyers can verify that there are no problematic obligations or requirements included in the contracts. Contract review can be a source of drudgery and, in comparison to other legal tasks, is widely considered to be especially boring.\nContract review costs also affect consumers. Since contract review costs are so prohibitive, contract review is not often performed outside corporate transactions. Small companies and individuals consequently often sign contracts without even reading them, which can result in predatory behavior that harms consumers. Automating contract review by openly releasing high-quality data and fine-tuned models can increase access to legal support for small businesses and individuals, so that legal support is not exclusively available to wealthy companies.\nTo reduce the disparate societal costs of contract review, and to study how well NLP models generalize to specialized domains, the authors introduced a new large-scale dataset for contract review. As part of The Atticus Project, a non-profit organization of legal experts, CUAD is introduced, the Contract Understanding Atticus Dataset. This dataset was created with a year-long effort pushed forward by dozens of law student annotators, lawyers, and machine learning researchers. The dataset includes more than 500 contracts and more than 13,000 expert annotations that span 41 label categories. For each of 41 different labels, models must learn to highlight the portions of a contract most salient to that label. This makes the task a matter of finding needles in a haystack.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe CUAD includes commercial contracts selected from 25 different types of contracts based on the contract names as shown below. Within each type, the creators randomly selected contracts based on the names of the filing companies across the alphabet.\nType of Contracts: # of Docs\nAffiliate Agreement: 10\nAgency Agreement: 13\nCollaboration/Cooperation Agreement: 26\nCo-Branding Agreement: 22\nConsulting Agreement: 11\nDevelopment Agreement: 29\nDistributor Agreement: 32\nEndorsement Agreement: 24\nFranchise Agreement: 15\nHosting Agreement: 20\nIP Agreement: 17\nJoint Venture Agreemen: 23\nLicense Agreement: 33\nMaintenance Agreement: 34\nManufacturing Agreement: 17\nMarketing Agreement: 17\nNon-Compete/No-Solicit/Non-Disparagement Agreement: 3\nOutsourcing Agreement: 18\nPromotion Agreement: 12\nReseller Agreement: 12\nService Agreement: 28\nSponsorship Agreement: 31\nSupply Agreement: 18\nStrategic Alliance Agreement: 32\nTransportation Agreement: 13\nTOTAL: 510",
"#### Who are the source language producers?\n\n\nThe contracts were sourced from EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system used at the U.S. Securities and Exchange Commission (SEC). Publicly traded companies in the United States are required to file certain contracts under the SEC rules. Access to these contracts is available to the public for free at URL Please read the Datasheet at URL for information on the intended use and limitations of the CUAD.",
"### Annotations",
"#### Annotation process\n\n\nThe labeling process included multiple steps to ensure accuracy:\n\n\n1. Law Student Training: law students attended training sessions on each of the categories that included a summary, video instructions by experienced attorneys, multiple quizzes and workshops. Students were then required to label sample contracts in eBrevia, an online contract review tool. The initial training took approximately 70-100 hours.\n2. Law Student Label: law students conducted manual contract review and labeling in eBrevia.\n3. Key Word Search: law students conducted keyword search in eBrevia to capture additional categories that have been missed during the “Student Label” step.\n4. Category-by-Category Report Review: law students exported the labeled clauses into reports, review each clause category-by-category and highlight clauses that they believe are mislabeled.\n5. Attorney Review: experienced attorneys reviewed the category-by-category report with students comments, provided comments and addressed student questions. When applicable, attorneys discussed such results with the students and reached consensus. Students made changes in eBrevia accordingly.\n6. eBrevia Extras Review. Attorneys and students used eBrevia to generate a list of “extras”, which are clauses that eBrevia AI tool identified as responsive to a category but not labeled by human annotators. Attorneys and students reviewed all of the “extras” and added the correct ones. The process is repeated until all or substantially all of the “extras” are incorrect labels.\n7. Final Report: The final report was exported into a CSV file. Volunteers manually added the “Yes/No” answer column to categories that do not contain an answer.",
"#### Who are the annotators?\n\n\nAnswered in above section.",
"### Personal and Sensitive Information\n\n\nSome clauses in the files are redacted because the party submitting these contracts redacted them to protect confidentiality. Such redaction may show up as asterisks (\\*\\*\\*) or underscores (\\_\\_\\_) or blank spaces. The dataset and the answers reflect such redactions. For example, the answer for “January \\_\\_ 2020” would be “1/[]/2020”).\nFor any categories that require an answer of “Yes/No”, annotators include full sentences as text context in a contract. To maintain consistency and minimize inter-annotator disagreement, annotators select text for the full sentence, under the instruction of “from period to period”.\nFor the other categories, annotators selected segments of the text in the contract that are responsive to each such category. One category in a contract may include multiple labels. For example, “Parties” may include 4-10 separate text strings that are not continuous in a contract. The answer is presented in the unified format separated by semicolons of “Party A Inc. (“Party A”); Party B Corp. (“Party B”)”.\nSome sentences in the files include confidential legends that are not part of the contracts. An example of such confidential legend is as follows:\nTHIS EXHIBIT HAS BEEN REDACTED AND IS THE SUBJECT OF A CONFIDENTIAL TREATMENT REQUEST. REDACTED MATERIAL IS MARKED WITH [\\* \\* \\*] AND HAS BEEN FILED SEPARATELY WITH THE SECURITIES AND EXCHANGE COMMISSION.\nSome sentences in the files contain irrelevant information such as footers or page numbers. Some sentences may not be relevant to the corresponding category. Some sentences may correspond to a different category. Because many legal clauses are very long and contain various sub-parts, sometimes only a sub-part of a sentence is responsive to a category.\nTo address the foregoing limitations, annotators manually deleted the portion that is not responsive, replacing it with the symbol \"\" to indicate that the two text segments do not appear immediately next to each other in the contracts. For example, if a “Termination for Convenience” clause starts with “Each Party may terminate this Agreement if” followed by three subparts “(a), (b) and (c)”, but only subpart (c) is responsive to this category, the authors manually deleted subparts (a) and (b) and replaced them with the symbol \"”. Another example is for “Effective Date”, the contract includes a sentence “This Agreement is effective as of the date written above” that appears after the date “January 1, 2010”. The annotation is as follows: “January 1, 2010 This Agreement is effective as of the date written above.”\nBecause the contracts were converted from PDF into TXT files, the converted TXT files may not stay true to the format of the original PDF files. For example, some contracts contain inconsistent spacing between words, sentences and paragraphs. Table format is not maintained in the TXT files.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nAttorney Advisors\nWei Chen, John Brockland, Kevin Chen, Jacky Fink, Spencer P. Goodson, Justin Haan, Alex Haskell, Kari Krusmark, Jenny Lin, Jonas Marson, Benjamin Petersen, Alexander Kwonji Rosenberg, William R. Sawyers, Brittany Schmeltz, Max Scott, Zhu Zhu\nLaw Student Leaders\nJohn Batoha, Daisy Beckner, Lovina Consunji, Gina Diaz, Chris Gronseth, Calvin Hannagan, Joseph Kroon, Sheetal Sharma Saran\nLaw Student Contributors\nScott Aronin, Bryan Burgoon, Jigar Desai, Imani Haynes, Jeongsoo Kim, Margaret Lynch, Allison Melville, Felix Mendez-Burgos, Nicole Mirkazemi, David Myers, Emily Rissberger, Behrang Seraj, Sarahginy Valcin\nTechnical Advisors & Contributors\nDan Hendrycks, Collin Burns, Spencer Ball, Anya Chen",
"### Licensing Information\n\n\nCUAD is licensed under the Creative Commons Attribution 4.0 (CC BY 4.0) license and free to the public for commercial and non-commercial use.\nThe creators make no representations or warranties regarding the license status of the underlying contracts, which are publicly available and downloadable from EDGAR.\nPrivacy Policy & Disclaimers\nThe categories or the contracts included in the dataset are not comprehensive or representative. The authors encourage the public to help improve them by sending them your comments and suggestions to info@URL. Comments and suggestions will be reviewed by The Atticus Project at its discretion and will be included in future versions of Atticus categories once approved.\nThe use of CUAD is subject to their privacy policy URL and disclaimer URL",
"### Contributions\n\n\nThanks to @bhavitvyamalik for adding the original CUAD dataset."
] |
5b7594b2d1e6a6a63df63bbc943409112acf0377 |
# CABank Japanese Sakura Corpus
- Susanne Miyata
- Department of Medical Sciences
- Aichi Shukotoku University
- [email protected]
- website: https://ca.talkbank.org/access/Sakura.html
## Important
This data set is a copy from the original one located at https://ca.talkbank.org/access/Sakura.html.
## Details
- Participants: 31
- Type of Study: xxx
- Location: Japan
- Media type: audio
- DOI: doi:10.21415/T5M90R
## Citation information
Some citation here.
In accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.
## Project Description
This corpus of 18 conversations is the product of six graduation theses on gender differences in students' group talk. Each conversation lasted between 12 and 35 minutes (avg. 25 minutes) resulting in an overall time of 7 hours and 30 minutes. 31 Students (19 female, 12 male) participated in the study (Table 1). The participants gathered in groups of 4 students, either of the same or the opposite sex (6 conversations with a group of 4 female students, 6 with 4 male students, and 6 conversations with 2 male and 2 female students), according to age (first and third year students) and affiliation (two academic departments). In addition, the participants of each conversation came from the same small-sized class and were well acquainted.
The participants were informed that their conversations may be transcribed and a video recorded for use in possible publication when recruited. Additionally, permission was asked once more after the transcription in cases where either private information had been displayed, or a misunderstanding concerning the nature and degree of the publication of the conversations became apparent during the conversation.
The recordings took place in a small conference room at the university between or after lectures. The participants were given a card with a conversation topic to start with, but were free to vary (topic 1 "What do you expect from an opposite sex friend?" [isee ni motomeru koto]; topic 2 "Are you a dog lover or a cat lover?" [inuha ka nekoha ka]; topic 3 "About part-time work" [arubaito ni tsuite]). The investigator was not present during the recording. The combination of participants, the topic, and the duration of the 18 conversations are given in Table 2.
The participants produced 15,449 utterances overall (female: 8,027 utterances, male: 7,422 utterances). All utterances were linked to video and transcribed in regular Japanese orthography and Latin script (Wakachi2002), and provided with morphological tags (JMOR04.1). Proper names were replaced by pseudonyms.
## Acknowledgements
Additional contributors: Banno, Kyoko; Konishi, Saya; Matsui, Ayumi; Matsumoto, Shiori; Oogi, Rie; Takahashi, Akane; Muraki, Kyoko.
| Fhrozen/CABankSakura | [
"task_categories:audio-classification",
"task_categories:automatic-speech-recognition",
"task_ids:speaker-identification",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:found",
"language:ja",
"license:cc",
"speech-recognition",
"region:us"
] | 2022-09-14T04:47:24+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["crowdsourced", "expert-generated"], "language": ["ja"], "license": ["cc"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["found"], "task_categories": ["audio-classification", "automatic-speech-recognition"], "task_ids": ["speaker-identification"], "pretty_name": "banksakura", "tags": ["speech-recognition"]} | 2022-12-03T03:26:50+00:00 | [] | [
"ja"
] | TAGS
#task_categories-audio-classification #task_categories-automatic-speech-recognition #task_ids-speaker-identification #annotations_creators-expert-generated #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-found #language-Japanese #license-cc #speech-recognition #region-us
|
# CABank Japanese Sakura Corpus
- Susanne Miyata
- Department of Medical Sciences
- Aichi Shukotoku University
- smiyata@URL
- website: URL
## Important
This data set is a copy from the original one located at URL
## Details
- Participants: 31
- Type of Study: xxx
- Location: Japan
- Media type: audio
- DOI: doi:10.21415/T5M90R
information
Some citation here.
In accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.
## Project Description
This corpus of 18 conversations is the product of six graduation theses on gender differences in students' group talk. Each conversation lasted between 12 and 35 minutes (avg. 25 minutes) resulting in an overall time of 7 hours and 30 minutes. 31 Students (19 female, 12 male) participated in the study (Table 1). The participants gathered in groups of 4 students, either of the same or the opposite sex (6 conversations with a group of 4 female students, 6 with 4 male students, and 6 conversations with 2 male and 2 female students), according to age (first and third year students) and affiliation (two academic departments). In addition, the participants of each conversation came from the same small-sized class and were well acquainted.
The participants were informed that their conversations may be transcribed and a video recorded for use in possible publication when recruited. Additionally, permission was asked once more after the transcription in cases where either private information had been displayed, or a misunderstanding concerning the nature and degree of the publication of the conversations became apparent during the conversation.
The recordings took place in a small conference room at the university between or after lectures. The participants were given a card with a conversation topic to start with, but were free to vary (topic 1 "What do you expect from an opposite sex friend?" [isee ni motomeru koto]; topic 2 "Are you a dog lover or a cat lover?" [inuha ka nekoha ka]; topic 3 "About part-time work" [arubaito ni tsuite]). The investigator was not present during the recording. The combination of participants, the topic, and the duration of the 18 conversations are given in Table 2.
The participants produced 15,449 utterances overall (female: 8,027 utterances, male: 7,422 utterances). All utterances were linked to video and transcribed in regular Japanese orthography and Latin script (Wakachi2002), and provided with morphological tags (JMOR04.1). Proper names were replaced by pseudonyms.
## Acknowledgements
Additional contributors: Banno, Kyoko; Konishi, Saya; Matsui, Ayumi; Matsumoto, Shiori; Oogi, Rie; Takahashi, Akane; Muraki, Kyoko.
| [
"# CABank Japanese Sakura Corpus\n\n- Susanne Miyata\n- Department of Medical Sciences\n- Aichi Shukotoku University\n- smiyata@URL\n- website: URL",
"## Important\n\nThis data set is a copy from the original one located at URL",
"## Details\n\n- Participants: 31\n- Type of Study: xxx\n- Location: Japan\n- Media type: audio\n- DOI: doi:10.21415/T5M90R\n\ninformation\n\nSome citation here.\nIn accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.",
"## Project Description\n\nThis corpus of 18 conversations is the product of six graduation theses on gender differences in students' group talk. Each conversation lasted between 12 and 35 minutes (avg. 25 minutes) resulting in an overall time of 7 hours and 30 minutes. 31 Students (19 female, 12 male) participated in the study (Table 1). The participants gathered in groups of 4 students, either of the same or the opposite sex (6 conversations with a group of 4 female students, 6 with 4 male students, and 6 conversations with 2 male and 2 female students), according to age (first and third year students) and affiliation (two academic departments). In addition, the participants of each conversation came from the same small-sized class and were well acquainted.\n\nThe participants were informed that their conversations may be transcribed and a video recorded for use in possible publication when recruited. Additionally, permission was asked once more after the transcription in cases where either private information had been displayed, or a misunderstanding concerning the nature and degree of the publication of the conversations became apparent during the conversation.\n\nThe recordings took place in a small conference room at the university between or after lectures. The participants were given a card with a conversation topic to start with, but were free to vary (topic 1 \"What do you expect from an opposite sex friend?\" [isee ni motomeru koto]; topic 2 \"Are you a dog lover or a cat lover?\" [inuha ka nekoha ka]; topic 3 \"About part-time work\" [arubaito ni tsuite]). The investigator was not present during the recording. The combination of participants, the topic, and the duration of the 18 conversations are given in Table 2.\n\nThe participants produced 15,449 utterances overall (female: 8,027 utterances, male: 7,422 utterances). All utterances were linked to video and transcribed in regular Japanese orthography and Latin script (Wakachi2002), and provided with morphological tags (JMOR04.1). Proper names were replaced by pseudonyms.",
"## Acknowledgements\n\nAdditional contributors: Banno, Kyoko; Konishi, Saya; Matsui, Ayumi; Matsumoto, Shiori; Oogi, Rie; Takahashi, Akane; Muraki, Kyoko."
] | [
"TAGS\n#task_categories-audio-classification #task_categories-automatic-speech-recognition #task_ids-speaker-identification #annotations_creators-expert-generated #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-found #language-Japanese #license-cc #speech-recognition #region-us \n",
"# CABank Japanese Sakura Corpus\n\n- Susanne Miyata\n- Department of Medical Sciences\n- Aichi Shukotoku University\n- smiyata@URL\n- website: URL",
"## Important\n\nThis data set is a copy from the original one located at URL",
"## Details\n\n- Participants: 31\n- Type of Study: xxx\n- Location: Japan\n- Media type: audio\n- DOI: doi:10.21415/T5M90R\n\ninformation\n\nSome citation here.\nIn accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.",
"## Project Description\n\nThis corpus of 18 conversations is the product of six graduation theses on gender differences in students' group talk. Each conversation lasted between 12 and 35 minutes (avg. 25 minutes) resulting in an overall time of 7 hours and 30 minutes. 31 Students (19 female, 12 male) participated in the study (Table 1). The participants gathered in groups of 4 students, either of the same or the opposite sex (6 conversations with a group of 4 female students, 6 with 4 male students, and 6 conversations with 2 male and 2 female students), according to age (first and third year students) and affiliation (two academic departments). In addition, the participants of each conversation came from the same small-sized class and were well acquainted.\n\nThe participants were informed that their conversations may be transcribed and a video recorded for use in possible publication when recruited. Additionally, permission was asked once more after the transcription in cases where either private information had been displayed, or a misunderstanding concerning the nature and degree of the publication of the conversations became apparent during the conversation.\n\nThe recordings took place in a small conference room at the university between or after lectures. The participants were given a card with a conversation topic to start with, but were free to vary (topic 1 \"What do you expect from an opposite sex friend?\" [isee ni motomeru koto]; topic 2 \"Are you a dog lover or a cat lover?\" [inuha ka nekoha ka]; topic 3 \"About part-time work\" [arubaito ni tsuite]). The investigator was not present during the recording. The combination of participants, the topic, and the duration of the 18 conversations are given in Table 2.\n\nThe participants produced 15,449 utterances overall (female: 8,027 utterances, male: 7,422 utterances). All utterances were linked to video and transcribed in regular Japanese orthography and Latin script (Wakachi2002), and provided with morphological tags (JMOR04.1). Proper names were replaced by pseudonyms.",
"## Acknowledgements\n\nAdditional contributors: Banno, Kyoko; Konishi, Saya; Matsui, Ayumi; Matsumoto, Shiori; Oogi, Rie; Takahashi, Akane; Muraki, Kyoko."
] |
208ae52187c393a222ee77605d94ec3e033d7e92 |
# CABank Japanese CallHome Corpus
- Participants: 120
- Type of Study: phone call
- Location: United States
- Media type: audio
- DOI: doi:10.21415/T5H59V
- Web: https://ca.talkbank.org/access/CallHome/jpn.html
## Citation information
Some citation here.
In accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.
## Project Description
This is the Japanese portion of CallHome.
Speakers were solicited by the LDC to participate in this telephone speech collection effort via the internet, publications (advertisements), and personal contacts. A total of 200 call originators were found, each of whom placed a telephone call via a toll-free robot operator maintained by the LDC. Access to the robot operator was possible via a unique Personal Identification Number (PIN) issued by the recruiting staff at the LDC when the caller enrolled in the project. The participants were made aware that their telephone call would be recorded, as were the call recipients. The call was allowed only if both parties agreed to being recorded. Each caller was allowed to talk up to 30 minutes. Upon successful completion of the call, the caller was paid $20 (in addition to making a free long-distance telephone call). Each caller was allowed to place only one telephone call.
Although the goal of the call collection effort was to have unique speakers in all calls, a handful of repeat speakers are included in the corpus. In all, 200 calls were transcribed. Of these, 80 have been designated as training calls, 20 as development test calls, and 100 as evaluation test calls. For each of the training and development test calls, a contiguous 10-minute region was selected for transcription; for the evaluation test calls, a 5-minute region was transcribed. For the present publication, only 20 of the evaluation test calls are being released; the remaining 80 test calls are being held in reserve for future LVCSR benchmark tests.
After a successful call was completed, a human audit of each telephone call was conducted to verify that the proper language was spoken, to check the quality of the recording, and to select and describe the region to be transcribed. The description of the transcribed region provides information about channel quality, number of speakers, their gender, and other attributes.
## Acknowledgements
Andrew Yankes reformatted this corpus into accord with current versions of CHAT.
| Fhrozen/CABankSakuraCHJP | [
"task_categories:audio-classification",
"task_categories:automatic-speech-recognition",
"task_ids:speaker-identification",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:found",
"language:ja",
"license:cc",
"speech-recognition",
"region:us"
] | 2022-09-14T04:48:24+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["crowdsourced", "expert-generated"], "language": ["ja"], "license": ["cc"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["found"], "task_categories": ["audio-classification", "automatic-speech-recognition"], "task_ids": ["speaker-identification"], "pretty_name": "banksakura", "tags": ["speech-recognition"]} | 2022-12-03T03:26:43+00:00 | [] | [
"ja"
] | TAGS
#task_categories-audio-classification #task_categories-automatic-speech-recognition #task_ids-speaker-identification #annotations_creators-expert-generated #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-found #language-Japanese #license-cc #speech-recognition #region-us
|
# CABank Japanese CallHome Corpus
- Participants: 120
- Type of Study: phone call
- Location: United States
- Media type: audio
- DOI: doi:10.21415/T5H59V
- Web: URL
information
Some citation here.
In accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.
## Project Description
This is the Japanese portion of CallHome.
Speakers were solicited by the LDC to participate in this telephone speech collection effort via the internet, publications (advertisements), and personal contacts. A total of 200 call originators were found, each of whom placed a telephone call via a toll-free robot operator maintained by the LDC. Access to the robot operator was possible via a unique Personal Identification Number (PIN) issued by the recruiting staff at the LDC when the caller enrolled in the project. The participants were made aware that their telephone call would be recorded, as were the call recipients. The call was allowed only if both parties agreed to being recorded. Each caller was allowed to talk up to 30 minutes. Upon successful completion of the call, the caller was paid $20 (in addition to making a free long-distance telephone call). Each caller was allowed to place only one telephone call.
Although the goal of the call collection effort was to have unique speakers in all calls, a handful of repeat speakers are included in the corpus. In all, 200 calls were transcribed. Of these, 80 have been designated as training calls, 20 as development test calls, and 100 as evaluation test calls. For each of the training and development test calls, a contiguous 10-minute region was selected for transcription; for the evaluation test calls, a 5-minute region was transcribed. For the present publication, only 20 of the evaluation test calls are being released; the remaining 80 test calls are being held in reserve for future LVCSR benchmark tests.
After a successful call was completed, a human audit of each telephone call was conducted to verify that the proper language was spoken, to check the quality of the recording, and to select and describe the region to be transcribed. The description of the transcribed region provides information about channel quality, number of speakers, their gender, and other attributes.
## Acknowledgements
Andrew Yankes reformatted this corpus into accord with current versions of CHAT.
| [
"# CABank Japanese CallHome Corpus\n\n- Participants: 120\n- Type of Study: phone call\n- Location: United States\n- Media type: audio\n- DOI: doi:10.21415/T5H59V\n\n- Web: URL\n\ninformation\n\nSome citation here.\nIn accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.",
"## Project Description\n\nThis is the Japanese portion of CallHome.\n\nSpeakers were solicited by the LDC to participate in this telephone speech collection effort via the internet, publications (advertisements), and personal contacts. A total of 200 call originators were found, each of whom placed a telephone call via a toll-free robot operator maintained by the LDC. Access to the robot operator was possible via a unique Personal Identification Number (PIN) issued by the recruiting staff at the LDC when the caller enrolled in the project. The participants were made aware that their telephone call would be recorded, as were the call recipients. The call was allowed only if both parties agreed to being recorded. Each caller was allowed to talk up to 30 minutes. Upon successful completion of the call, the caller was paid $20 (in addition to making a free long-distance telephone call). Each caller was allowed to place only one telephone call.\n\nAlthough the goal of the call collection effort was to have unique speakers in all calls, a handful of repeat speakers are included in the corpus. In all, 200 calls were transcribed. Of these, 80 have been designated as training calls, 20 as development test calls, and 100 as evaluation test calls. For each of the training and development test calls, a contiguous 10-minute region was selected for transcription; for the evaluation test calls, a 5-minute region was transcribed. For the present publication, only 20 of the evaluation test calls are being released; the remaining 80 test calls are being held in reserve for future LVCSR benchmark tests.\n\nAfter a successful call was completed, a human audit of each telephone call was conducted to verify that the proper language was spoken, to check the quality of the recording, and to select and describe the region to be transcribed. The description of the transcribed region provides information about channel quality, number of speakers, their gender, and other attributes.",
"## Acknowledgements\n\nAndrew Yankes reformatted this corpus into accord with current versions of CHAT."
] | [
"TAGS\n#task_categories-audio-classification #task_categories-automatic-speech-recognition #task_ids-speaker-identification #annotations_creators-expert-generated #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-found #language-Japanese #license-cc #speech-recognition #region-us \n",
"# CABank Japanese CallHome Corpus\n\n- Participants: 120\n- Type of Study: phone call\n- Location: United States\n- Media type: audio\n- DOI: doi:10.21415/T5H59V\n\n- Web: URL\n\ninformation\n\nSome citation here.\nIn accordance with TalkBank rules, any use of data from this corpus must be accompanied by at least one of the above references.",
"## Project Description\n\nThis is the Japanese portion of CallHome.\n\nSpeakers were solicited by the LDC to participate in this telephone speech collection effort via the internet, publications (advertisements), and personal contacts. A total of 200 call originators were found, each of whom placed a telephone call via a toll-free robot operator maintained by the LDC. Access to the robot operator was possible via a unique Personal Identification Number (PIN) issued by the recruiting staff at the LDC when the caller enrolled in the project. The participants were made aware that their telephone call would be recorded, as were the call recipients. The call was allowed only if both parties agreed to being recorded. Each caller was allowed to talk up to 30 minutes. Upon successful completion of the call, the caller was paid $20 (in addition to making a free long-distance telephone call). Each caller was allowed to place only one telephone call.\n\nAlthough the goal of the call collection effort was to have unique speakers in all calls, a handful of repeat speakers are included in the corpus. In all, 200 calls were transcribed. Of these, 80 have been designated as training calls, 20 as development test calls, and 100 as evaluation test calls. For each of the training and development test calls, a contiguous 10-minute region was selected for transcription; for the evaluation test calls, a 5-minute region was transcribed. For the present publication, only 20 of the evaluation test calls are being released; the remaining 80 test calls are being held in reserve for future LVCSR benchmark tests.\n\nAfter a successful call was completed, a human audit of each telephone call was conducted to verify that the proper language was spoken, to check the quality of the recording, and to select and describe the region to be transcribed. The description of the transcribed region provides information about channel quality, number of speakers, their gender, and other attributes.",
"## Acknowledgements\n\nAndrew Yankes reformatted this corpus into accord with current versions of CHAT."
] |
acac1e8a2f086619a3f86242e3485b3b6069d496 |
# FINN.no Slate Dataset for Recommender Systems
> Data and helper functions for FINN.no slate dataset containing both viewed items and clicks from the FINN.no second hand marketplace.
Note: The dataset is originally hosted at https://github.com/finn-no/recsys_slates_dataset and this is a copy of the readme until this repo is properly created "huggingface-style".
We release the *FINN.no slate dataset* to improve recommender systems research.
The dataset includes both search and recommendation interactions between users and the platform over a 30 day period.
The dataset has logged both exposures and clicks, *including interactions where the user did not click on any of the items in the slate*.
To our knowledge there exists no such large-scale dataset, and we hope this contribution can help researchers constructing improved models and improve offline evaluation metrics.

For each user u and interaction step t we recorded all items in the visible slate  ) (up to the scroll length ), and the user's click response .
The dataset consists of 37.4 million interactions, |U| ≈ 2.3) million users and |I| ≈ 1.3 million items that belong to one of G = 290 item groups. For a detailed description of the data please see the [paper](https://arxiv.org/abs/2104.15046).

FINN.no is the leading marketplace in the Norwegian classifieds market and provides users with a platform to buy and sell general merchandise, cars, real estate, as well as house rentals and job offerings.
For questions, email [email protected] or file an issue.
## Install
`pip install recsys_slates_dataset`
## How to use
To download the generic numpy data files:
```
from recsys_slates_dataset import data_helper
data_helper.download_data_files(data_dir="data")
```
Download and prepare data into ready-to-use PyTorch dataloaders:
``` python
from recsys_slates_dataset import dataset_torch
ind2val, itemattr, dataloaders = dataset_torch.load_dataloaders(data_dir="data")
```
## Organization
The repository is organized as follows:
- The dataset is placed in `data/` and stored using git-lfs. We also provide an automatic download function in the pip package (preferred usage).
- The code open sourced from the article ["Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling"](https://arxiv.org/abs/2104.15046) is found in (`code_eide_et_al21/`). However, we are in the process of making the data more generally available which makes the code incompatible with the current (newer) version of the data. Please use [the v1.0 release of the repository](https://github.com/finn-no/recsys-slates-dataset/tree/v1.0) for a compatible version of the code and dataset.
## Quickstart dataset [](https://colab.research.google.com/github/finn-no/recsys-slates-dataset/blob/main/examples/quickstart-finn-recsys-slate-data.ipynb)
We provide a quickstart Jupyter notebook that runs on Google Colab (quickstart-finn-recsys-slate-data.ipynb) which includes all necessary steps above.
It gives a quick introduction to how to use the dataset.
## Example training scripts
We provide an example training jupyter notebook that implements a matrix factorization model with categorical loss that can be found in `examples/`.
It is also runnable using Google Colab: [](https://colab.research.google.com/github/finn-no/recsys-slates-dataset/blob/main/examples/matrix_factorization.ipynb)
There is ongoing work in progress to build additional examples and use them as benchmarks for the dataset.
### Dataset files
The dataset `data.npz` contains the following fields:
- userId: The unique identifier of the user.
- click: The items the user clicked on in each of the 20 presented slates.
- click_idx: The index the clicked item was on in each of the 20 presented slates.
- slate_lengths: The length of the 20 presented slates.
- slate: All the items in each of the 20 presented slates.
- interaction_type: The recommendation slate can be the result of a search query (1), a recommendation (2) or can be undefined (0).
The dataset `itemattr.npz` contains the categories ranging from 0 to 290. Corresponding with the 290 unique groups that the items belong to. These 290 unique groups are constructed using a combination of categorical information and the geographical location.
The dataset `ind2val.json` contains the mapping between the indices and the values of the categories (e.g. `"287": "JOB, Rogaland"`) and interaction types (e.g. `"1": "search"`).
## Citations
This repository accompanies the paper ["Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling"](https://arxiv.org/abs/2104.15046) by Simen Eide, David S. Leslie and Arnoldo Frigessi.
The article is under review, and the preprint can be obtained [here](https://arxiv.org/abs/2104.15046).
If you use either the code, data or paper, please consider citing the paper.
```
Eide, S., Leslie, D.S. & Frigessi, A. Dynamic slate recommendation with gated recurrent units and Thompson sampling. Data Min Knowl Disc (2022). https://doi.org/10.1007/s10618-022-00849-w
```
---
license: apache-2.0
---
| simeneide/recsys_slates_dataset | [
"arxiv:2104.15046",
"region:us"
] | 2022-09-14T06:41:48+00:00 | {} | 2022-09-14T07:51:42+00:00 | [
"2104.15046"
] | [] | TAGS
#arxiv-2104.15046 #region-us
|
# URL Slate Dataset for Recommender Systems
> Data and helper functions for URL slate dataset containing both viewed items and clicks from the URL second hand marketplace.
Note: The dataset is originally hosted at URL and this is a copy of the readme until this repo is properly created "huggingface-style".
We release the *URL slate dataset* to improve recommender systems research.
The dataset includes both search and recommendation interactions between users and the platform over a 30 day period.
The dataset has logged both exposures and clicks, *including interactions where the user did not click on any of the items in the slate*.
To our knowledge there exists no such large-scale dataset, and we hope this contribution can help researchers constructing improved models and improve offline evaluation metrics.
!A visualization of a presented slate to the user on the frontpage of URL
For each user u and interaction step t we recorded all items in the visible slate !equ ) (up to the scroll length !equ), and the user's click response !equ.
The dataset consists of 37.4 million interactions, |U| ≈ 2.3) million users and |I| ≈ 1.3 million items that belong to one of G = 290 item groups. For a detailed description of the data please see the paper.
!A visualization of a presented slate to the user on the frontpage of URL
URL is the leading marketplace in the Norwegian classifieds market and provides users with a platform to buy and sell general merchandise, cars, real estate, as well as house rentals and job offerings.
For questions, email URL@URL or file an issue.
## Install
'pip install recsys_slates_dataset'
## How to use
To download the generic numpy data files:
Download and prepare data into ready-to-use PyTorch dataloaders:
## Organization
The repository is organized as follows:
- The dataset is placed in 'data/' and stored using git-lfs. We also provide an automatic download function in the pip package (preferred usage).
- The code open sourced from the article "Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling" is found in ('code_eide_et_al21/'). However, we are in the process of making the data more generally available which makes the code incompatible with the current (newer) version of the data. Please use the v1.0 release of the repository for a compatible version of the code and dataset.
## Quickstart dataset  which includes all necessary steps above.
It gives a quick introduction to how to use the dataset.
## Example training scripts
We provide an example training jupyter notebook that implements a matrix factorization model with categorical loss that can be found in 'examples/'.
It is also runnable using Google Colab: , a recommendation (2) or can be undefined (0).
The dataset 'URL' contains the categories ranging from 0 to 290. Corresponding with the 290 unique groups that the items belong to. These 290 unique groups are constructed using a combination of categorical information and the geographical location.
The dataset 'URL' contains the mapping between the indices and the values of the categories (e.g. '"287": "JOB, Rogaland"') and interaction types (e.g. '"1": "search"').
s
This repository accompanies the paper "Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling" by Simen Eide, David S. Leslie and Arnoldo Frigessi.
The article is under review, and the preprint can be obtained here.
If you use either the code, data or paper, please consider citing the paper.
---
license: apache-2.0
---
| [
"# URL Slate Dataset for Recommender Systems\n> Data and helper functions for URL slate dataset containing both viewed items and clicks from the URL second hand marketplace.\n\nNote: The dataset is originally hosted at URL and this is a copy of the readme until this repo is properly created \"huggingface-style\".\n\nWe release the *URL slate dataset* to improve recommender systems research.\nThe dataset includes both search and recommendation interactions between users and the platform over a 30 day period.\nThe dataset has logged both exposures and clicks, *including interactions where the user did not click on any of the items in the slate*.\nTo our knowledge there exists no such large-scale dataset, and we hope this contribution can help researchers constructing improved models and improve offline evaluation metrics.\n\n!A visualization of a presented slate to the user on the frontpage of URL\n\nFor each user u and interaction step t we recorded all items in the visible slate !equ ) (up to the scroll length !equ), and the user's click response !equ.\nThe dataset consists of 37.4 million interactions, |U| ≈ 2.3) million users and |I| ≈ 1.3 million items that belong to one of G = 290 item groups. For a detailed description of the data please see the paper.\n\n!A visualization of a presented slate to the user on the frontpage of URL\n\nURL is the leading marketplace in the Norwegian classifieds market and provides users with a platform to buy and sell general merchandise, cars, real estate, as well as house rentals and job offerings.\nFor questions, email URL@URL or file an issue.",
"## Install\n\n'pip install recsys_slates_dataset'",
"## How to use\n\nTo download the generic numpy data files:\n\n\n\nDownload and prepare data into ready-to-use PyTorch dataloaders:",
"## Organization\nThe repository is organized as follows:\n- The dataset is placed in 'data/' and stored using git-lfs. We also provide an automatic download function in the pip package (preferred usage).\n- The code open sourced from the article \"Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling\" is found in ('code_eide_et_al21/'). However, we are in the process of making the data more generally available which makes the code incompatible with the current (newer) version of the data. Please use the v1.0 release of the repository for a compatible version of the code and dataset.",
"## Quickstart dataset  which includes all necessary steps above.\nIt gives a quick introduction to how to use the dataset.",
"## Example training scripts\nWe provide an example training jupyter notebook that implements a matrix factorization model with categorical loss that can be found in 'examples/'.\nIt is also runnable using Google Colab: , a recommendation (2) or can be undefined (0).\n\nThe dataset 'URL' contains the categories ranging from 0 to 290. Corresponding with the 290 unique groups that the items belong to. These 290 unique groups are constructed using a combination of categorical information and the geographical location. \n\nThe dataset 'URL' contains the mapping between the indices and the values of the categories (e.g. '\"287\": \"JOB, Rogaland\"') and interaction types (e.g. '\"1\": \"search\"'). \ns\nThis repository accompanies the paper \"Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling\" by Simen Eide, David S. Leslie and Arnoldo Frigessi.\nThe article is under review, and the preprint can be obtained here.\n\nIf you use either the code, data or paper, please consider citing the paper.\n\n\n\n---\nlicense: apache-2.0\n---"
] | [
"TAGS\n#arxiv-2104.15046 #region-us \n",
"# URL Slate Dataset for Recommender Systems\n> Data and helper functions for URL slate dataset containing both viewed items and clicks from the URL second hand marketplace.\n\nNote: The dataset is originally hosted at URL and this is a copy of the readme until this repo is properly created \"huggingface-style\".\n\nWe release the *URL slate dataset* to improve recommender systems research.\nThe dataset includes both search and recommendation interactions between users and the platform over a 30 day period.\nThe dataset has logged both exposures and clicks, *including interactions where the user did not click on any of the items in the slate*.\nTo our knowledge there exists no such large-scale dataset, and we hope this contribution can help researchers constructing improved models and improve offline evaluation metrics.\n\n!A visualization of a presented slate to the user on the frontpage of URL\n\nFor each user u and interaction step t we recorded all items in the visible slate !equ ) (up to the scroll length !equ), and the user's click response !equ.\nThe dataset consists of 37.4 million interactions, |U| ≈ 2.3) million users and |I| ≈ 1.3 million items that belong to one of G = 290 item groups. For a detailed description of the data please see the paper.\n\n!A visualization of a presented slate to the user on the frontpage of URL\n\nURL is the leading marketplace in the Norwegian classifieds market and provides users with a platform to buy and sell general merchandise, cars, real estate, as well as house rentals and job offerings.\nFor questions, email URL@URL or file an issue.",
"## Install\n\n'pip install recsys_slates_dataset'",
"## How to use\n\nTo download the generic numpy data files:\n\n\n\nDownload and prepare data into ready-to-use PyTorch dataloaders:",
"## Organization\nThe repository is organized as follows:\n- The dataset is placed in 'data/' and stored using git-lfs. We also provide an automatic download function in the pip package (preferred usage).\n- The code open sourced from the article \"Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling\" is found in ('code_eide_et_al21/'). However, we are in the process of making the data more generally available which makes the code incompatible with the current (newer) version of the data. Please use the v1.0 release of the repository for a compatible version of the code and dataset.",
"## Quickstart dataset  which includes all necessary steps above.\nIt gives a quick introduction to how to use the dataset.",
"## Example training scripts\nWe provide an example training jupyter notebook that implements a matrix factorization model with categorical loss that can be found in 'examples/'.\nIt is also runnable using Google Colab: , a recommendation (2) or can be undefined (0).\n\nThe dataset 'URL' contains the categories ranging from 0 to 290. Corresponding with the 290 unique groups that the items belong to. These 290 unique groups are constructed using a combination of categorical information and the geographical location. \n\nThe dataset 'URL' contains the mapping between the indices and the values of the categories (e.g. '\"287\": \"JOB, Rogaland\"') and interaction types (e.g. '\"1\": \"search\"'). \ns\nThis repository accompanies the paper \"Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling\" by Simen Eide, David S. Leslie and Arnoldo Frigessi.\nThe article is under review, and the preprint can be obtained here.\n\nIf you use either the code, data or paper, please consider citing the paper.\n\n\n\n---\nlicense: apache-2.0\n---"
] |
826870d287708d23f6828c7cd2405b715c4f1d29 | # MFQEv2 Dataset
For some video enhancement/restoration tasks, lossless reference videos are necessary.
We open-source the dataset used in our [MFQEv2 paper](https://arxiv.org/abs/1902.09707), which includes 108 lossless YUV videos for training and 18 test videos recommended by [ITU-T](https://ieeexplore.ieee.org/document/6317156).
## 1. Content
- 108 lossless YUV videos for training.
- 18 lossless YUV videos for test, recommended by ITU-T.
- An HEVC compression tool box.
43.1 GB in total.
## 2. Download Raw Videos
[[Dropbox]](https://www.dropbox.com/sh/tphdy1lmlpz7zq3/AABR4Qim-P-3xGtouWk6ohi5a?dl=0)
or [[百度网盘 (key: mfqe)]](https://pan.baidu.com/s/1oBZf75bFGRanLmQQLAg4Ew)
## 3. Compress Videos
We compress both training and test videos by [HM](https://hevc.hhi.fraunhofer.de/) 16.5 at low delay P (LDP) mode with QP=37. The video compression toolbox is provided at the dataset folder.
We will get:
```tex
MFQEv2_dataset/
├── train_108/
│ ├── raw/
│ └── HM16.5_LDP/
│ └── QP37/
├── test_18/
│ ├── raw/
│ └── HM16.5_LDP/
│ └── QP37/
├── video_compression/
│ └── ...
└── README.md
```
### Ubuntu
1. `cd video_compression/`
2. Edit `option.yml`.
3. `chmod +x TAppEncoderStatic`
4. `python unzip_n_compress.py`
### Windows
1. Unzip `train_108.zip` and `test_18.zip` manually!
2. `cd video_compression\`
3. Edit `option.yml` (e.g., `system: windows`).
4. `python unzip_n_compress.py`
## 4. Citation
If you find this helpful, please star and cite:
```tex
@article{2019xing,
doi = {10.1109/tpami.2019.2944806},
url = {https://doi.org/10.1109%2Ftpami.2019.2944806},
year = 2021,
month = {mar},
publisher = {Institute of Electrical and Electronics Engineers ({IEEE})},
volume = {43},
number = {3},
pages = {949--963},
author = {Zhenyu Guan and Qunliang Xing and Mai Xu and Ren Yang and Tie Liu and Zulin Wang},
title = {{MFQE} 2.0: A New Approach for Multi-Frame Quality Enhancement on Compressed Video},
journal = {{IEEE} Transactions on Pattern Analysis and Machine Intelligence}
}
```
| ryanxingql/MFQEv2 | [
"license:apache-2.0",
"arxiv:1902.09707",
"region:us"
] | 2022-09-14T07:46:59+00:00 | {"license": "apache-2.0"} | 2022-09-14T07:48:17+00:00 | [
"1902.09707"
] | [] | TAGS
#license-apache-2.0 #arxiv-1902.09707 #region-us
| # MFQEv2 Dataset
For some video enhancement/restoration tasks, lossless reference videos are necessary.
We open-source the dataset used in our MFQEv2 paper, which includes 108 lossless YUV videos for training and 18 test videos recommended by ITU-T.
## 1. Content
- 108 lossless YUV videos for training.
- 18 lossless YUV videos for test, recommended by ITU-T.
- An HEVC compression tool box.
43.1 GB in total.
## 2. Download Raw Videos
[[Dropbox]](URL
or [[百度网盘 (key: mfqe)]](URL
## 3. Compress Videos
We compress both training and test videos by HM 16.5 at low delay P (LDP) mode with QP=37. The video compression toolbox is provided at the dataset folder.
We will get:
### Ubuntu
1. 'cd video_compression/'
2. Edit 'URL'.
3. 'chmod +x TAppEncoderStatic'
4. 'python unzip_n_compress.py'
### Windows
1. Unzip 'train_108.zip' and 'test_18.zip' manually!
2. 'cd video_compression\'
3. Edit 'URL' (e.g., 'system: windows').
4. 'python unzip_n_compress.py'
## 4. Citation
If you find this helpful, please star and cite:
| [
"# MFQEv2 Dataset\n\nFor some video enhancement/restoration tasks, lossless reference videos are necessary.\n\nWe open-source the dataset used in our MFQEv2 paper, which includes 108 lossless YUV videos for training and 18 test videos recommended by ITU-T.",
"## 1. Content\n\n- 108 lossless YUV videos for training.\n- 18 lossless YUV videos for test, recommended by ITU-T.\n- An HEVC compression tool box.\n\n43.1 GB in total.",
"## 2. Download Raw Videos\n\n[[Dropbox]](URL\n\nor [[百度网盘 (key: mfqe)]](URL",
"## 3. Compress Videos\n\nWe compress both training and test videos by HM 16.5 at low delay P (LDP) mode with QP=37. The video compression toolbox is provided at the dataset folder.\n\nWe will get:",
"### Ubuntu\n\n1. 'cd video_compression/'\n2. Edit 'URL'.\n3. 'chmod +x TAppEncoderStatic'\n4. 'python unzip_n_compress.py'",
"### Windows\n\n1. Unzip 'train_108.zip' and 'test_18.zip' manually!\n2. 'cd video_compression\\'\n3. Edit 'URL' (e.g., 'system: windows').\n4. 'python unzip_n_compress.py'",
"## 4. Citation\n\nIf you find this helpful, please star and cite:"
] | [
"TAGS\n#license-apache-2.0 #arxiv-1902.09707 #region-us \n",
"# MFQEv2 Dataset\n\nFor some video enhancement/restoration tasks, lossless reference videos are necessary.\n\nWe open-source the dataset used in our MFQEv2 paper, which includes 108 lossless YUV videos for training and 18 test videos recommended by ITU-T.",
"## 1. Content\n\n- 108 lossless YUV videos for training.\n- 18 lossless YUV videos for test, recommended by ITU-T.\n- An HEVC compression tool box.\n\n43.1 GB in total.",
"## 2. Download Raw Videos\n\n[[Dropbox]](URL\n\nor [[百度网盘 (key: mfqe)]](URL",
"## 3. Compress Videos\n\nWe compress both training and test videos by HM 16.5 at low delay P (LDP) mode with QP=37. The video compression toolbox is provided at the dataset folder.\n\nWe will get:",
"### Ubuntu\n\n1. 'cd video_compression/'\n2. Edit 'URL'.\n3. 'chmod +x TAppEncoderStatic'\n4. 'python unzip_n_compress.py'",
"### Windows\n\n1. Unzip 'train_108.zip' and 'test_18.zip' manually!\n2. 'cd video_compression\\'\n3. Edit 'URL' (e.g., 'system: windows').\n4. 'python unzip_n_compress.py'",
"## 4. Citation\n\nIf you find this helpful, please star and cite:"
] |
d88018ac299bf2075e1860461d0165ed88e97d99 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: Emanuel/twitter-emotion-deberta-v3-base
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-2feb36-1456053837 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T08:15:54+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "Emanuel/twitter-emotion-deberta-v3-base", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-14T08:16:38+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Multi-class Text Classification
* Model: Emanuel/twitter-emotion-deberta-v3-base
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: Emanuel/twitter-emotion-deberta-v3-base\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: Emanuel/twitter-emotion-deberta-v3-base\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
3de4889cb01d4c83cff36d11aafd915429ac3488 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: ARTeLab/it5-summarization-fanpage
* Dataset: cnn_dailymail
* Config: 3.0.0
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@ehahaha](https://huggingface.co/ehahaha) for evaluating this model. | autoevaluate/autoeval-eval-cnn_dailymail-3.0.0-8ddaed-1457553860 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T08:18:38+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["cnn_dailymail"], "eval_info": {"task": "summarization", "model": "ARTeLab/it5-summarization-fanpage", "metrics": [], "dataset_name": "cnn_dailymail", "dataset_config": "3.0.0", "dataset_split": "train", "col_mapping": {"text": "article", "target": "highlights"}}} | 2022-09-14T12:30:24+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: ARTeLab/it5-summarization-fanpage
* Dataset: cnn_dailymail
* Config: 3.0.0
* Split: train
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @ehahaha for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: ARTeLab/it5-summarization-fanpage\n* Dataset: cnn_dailymail\n* Config: 3.0.0\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @ehahaha for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: ARTeLab/it5-summarization-fanpage\n* Dataset: cnn_dailymail\n* Config: 3.0.0\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @ehahaha for evaluating this model."
] |
8b762e1dac1b31d60e01ee8f08a9d8a232b59e17 |
# Dataset Card for Pokémon BLIP captions
_Dataset used to train [Pokémon text to image model](https://github.com/LambdaLabsML/examples/tree/main/stable-diffusion-finetuning)_
BLIP generated captions for Pokémon images from Few Shot Pokémon dataset introduced by _Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis_ (FastGAN). Original images were obtained from [FastGAN-pytorch](https://github.com/odegeasslbc/FastGAN-pytorch) and captioned with the [pre-trained BLIP model](https://github.com/salesforce/BLIP).
For each row the dataset contains `image` and `text` keys. `image` is a varying size PIL jpeg, and `text` is the accompanying text caption. Only a train split is provided.
## Examples

> a drawing of a green pokemon with red eyes

> a green and yellow toy with a red nose

> a red and white ball with an angry look on its face
## Citation
If you use this dataset, please cite it as:
```
@misc{pinkney2022pokemon,
author = {Pinkney, Justin N. M.},
title = {Pokemon BLIP captions},
year={2022},
howpublished= {\url{https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions/}}
}
``` | lambdalabs/pokemon-blip-captions | [
"task_categories:text-to-image",
"annotations_creators:machine-generated",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:huggan/few-shot-pokemon",
"language:en",
"license:cc-by-nc-sa-4.0",
"region:us"
] | 2022-09-14T11:04:50+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["other"], "language": ["en"], "license": "cc-by-nc-sa-4.0", "multilinguality": ["monolingual"], "size_categories": ["n<1K"], "source_datasets": ["huggan/few-shot-pokemon"], "task_categories": ["text-to-image"], "task_ids": [], "pretty_name": "Pok\u00e9mon BLIP captions", "tags": []} | 2022-09-21T09:38:05+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-to-image #annotations_creators-machine-generated #language_creators-other #multilinguality-monolingual #size_categories-n<1K #source_datasets-huggan/few-shot-pokemon #language-English #license-cc-by-nc-sa-4.0 #region-us
|
# Dataset Card for Pokémon BLIP captions
_Dataset used to train Pokémon text to image model_
BLIP generated captions for Pokémon images from Few Shot Pokémon dataset introduced by _Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis_ (FastGAN). Original images were obtained from FastGAN-pytorch and captioned with the pre-trained BLIP model.
For each row the dataset contains 'image' and 'text' keys. 'image' is a varying size PIL jpeg, and 'text' is the accompanying text caption. Only a train split is provided.
## Examples
!URL
> a drawing of a green pokemon with red eyes
!URL
> a green and yellow toy with a red nose
!URL
> a red and white ball with an angry look on its face
If you use this dataset, please cite it as:
| [
"# Dataset Card for Pokémon BLIP captions\n\n_Dataset used to train Pokémon text to image model_\n\nBLIP generated captions for Pokémon images from Few Shot Pokémon dataset introduced by _Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis_ (FastGAN). Original images were obtained from FastGAN-pytorch and captioned with the pre-trained BLIP model.\n\nFor each row the dataset contains 'image' and 'text' keys. 'image' is a varying size PIL jpeg, and 'text' is the accompanying text caption. Only a train split is provided.",
"## Examples\n\n\n!URL\n> a drawing of a green pokemon with red eyes\n\n!URL\n> a green and yellow toy with a red nose\n\n!URL\n> a red and white ball with an angry look on its face\n\nIf you use this dataset, please cite it as:"
] | [
"TAGS\n#task_categories-text-to-image #annotations_creators-machine-generated #language_creators-other #multilinguality-monolingual #size_categories-n<1K #source_datasets-huggan/few-shot-pokemon #language-English #license-cc-by-nc-sa-4.0 #region-us \n",
"# Dataset Card for Pokémon BLIP captions\n\n_Dataset used to train Pokémon text to image model_\n\nBLIP generated captions for Pokémon images from Few Shot Pokémon dataset introduced by _Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis_ (FastGAN). Original images were obtained from FastGAN-pytorch and captioned with the pre-trained BLIP model.\n\nFor each row the dataset contains 'image' and 'text' keys. 'image' is a varying size PIL jpeg, and 'text' is the accompanying text caption. Only a train split is provided.",
"## Examples\n\n\n!URL\n> a drawing of a green pokemon with red eyes\n\n!URL\n> a green and yellow toy with a red nose\n\n!URL\n> a red and white ball with an angry look on its face\n\nIf you use this dataset, please cite it as:"
] |
cb3553a29970018ebc7b305acf37b6ec5f66b505 |
This is a copy of the [Cochrane](https://huggingface.co/datasets/allenai/mslr2022) dataset, except the input source documents of its `validation` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `target` field of each example
- __corpus__: The union of all documents in the `train`, `validation` and `test` splits. A document is the concatenation of the `title` and `abstract`.
- __retriever__: BM25 via [PyTerrier](https://pyterrier.readthedocs.io/en/latest/) with default settings
- __top-k strategy__: `"max"`, i.e. the number of documents retrieved, `k`, is set as the maximum number of documents seen across examples in this dataset, in this case `k==25`
Retrieval results on the `train` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.7014 | 0.3841 | 0.1698 | 0.5471 |
Retrieval results on the `validation` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.7226 | 0.4023 | 0.1729 | 0.5676 |
Retrieval results on the `test` set:
N/A. Test set is blind so we do not have any queries. | allenai/cochrane_sparse_max | [
"task_categories:summarization",
"task_categories:text2text-generation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-MS^2",
"source_datasets:extended|other-Cochrane",
"language:en",
"license:apache-2.0",
"region:us"
] | 2022-09-14T12:15:14+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|other-MS^2", "extended|other-Cochrane"], "task_categories": ["summarization", "text2text-generation"], "paperswithcode_id": "multi-document-summarization", "pretty_name": "MSLR Shared Task"} | 2022-11-24T14:50:26+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_categories-text2text-generation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|other-MS^2 #source_datasets-extended|other-Cochrane #language-English #license-apache-2.0 #region-us
| This is a copy of the Cochrane dataset, except the input source documents of its 'validation' split have been replaced by a **sparse** retriever. The retrieval pipeline used:
* **query**: The 'target' field of each example
* **corpus**: The union of all documents in the 'train', 'validation' and 'test' splits. A document is the concatenation of the 'title' and 'abstract'.
* **retriever**: BM25 via PyTerrier with default settings
* **top-k strategy**: '"max"', i.e. the number of documents retrieved, 'k', is set as the maximum number of documents seen across examples in this dataset, in this case 'k==25'
Retrieval results on the 'train' set:
Retrieval results on the 'validation' set:
Retrieval results on the 'test' set:
N/A. Test set is blind so we do not have any queries.
| [] | [
"TAGS\n#task_categories-summarization #task_categories-text2text-generation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|other-MS^2 #source_datasets-extended|other-Cochrane #language-English #license-apache-2.0 #region-us \n"
] |
72ac00150e537264a866f5136f0a57c4c0e9be00 |
This is a copy of the [Cochrane](https://huggingface.co/datasets/allenai/mslr2022) dataset, except the input source documents of its `validation` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `target` field of each example
- __corpus__: The union of all documents in the `train`, `validation` and `test` splits. A document is the concatenation of the `title` and `abstract`.
- __retriever__: BM25 via [PyTerrier](https://pyterrier.readthedocs.io/en/latest/) with default settings
- __top-k strategy__: `"mean"`, i.e. the number of documents retrieved, `k`, is set as the mean number of documents seen across examples in this dataset, in this case `k==9`
Retrieval results on the `train` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.7014 | 0.3841 | 0.2976 | 0.4157 |
Retrieval results on the `validation` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.7226 | 0.4023 | 0.3095 | 0.4443 |
Retrieval results on the `test` set:
N/A. Test set is blind so we do not have any queries. | allenai/cochrane_sparse_mean | [
"task_categories:summarization",
"task_categories:text2text-generation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-MS^2",
"source_datasets:extended|other-Cochrane",
"language:en",
"license:apache-2.0",
"region:us"
] | 2022-09-14T12:15:44+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|other-MS^2", "extended|other-Cochrane"], "task_categories": ["summarization", "text2text-generation"], "paperswithcode_id": "multi-document-summarization", "pretty_name": "MSLR Shared Task"} | 2022-11-24T15:04:01+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_categories-text2text-generation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|other-MS^2 #source_datasets-extended|other-Cochrane #language-English #license-apache-2.0 #region-us
| This is a copy of the Cochrane dataset, except the input source documents of its 'validation' split have been replaced by a **sparse** retriever. The retrieval pipeline used:
* **query**: The 'target' field of each example
* **corpus**: The union of all documents in the 'train', 'validation' and 'test' splits. A document is the concatenation of the 'title' and 'abstract'.
* **retriever**: BM25 via PyTerrier with default settings
* **top-k strategy**: '"mean"', i.e. the number of documents retrieved, 'k', is set as the mean number of documents seen across examples in this dataset, in this case 'k==9'
Retrieval results on the 'train' set:
Retrieval results on the 'validation' set:
Retrieval results on the 'test' set:
N/A. Test set is blind so we do not have any queries.
| [] | [
"TAGS\n#task_categories-summarization #task_categories-text2text-generation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|other-MS^2 #source_datasets-extended|other-Cochrane #language-English #license-apache-2.0 #region-us \n"
] |
a12849702d4d495199ba73a295ff3393f600c82e |
This is a copy of the [Cochrane](https://huggingface.co/datasets/allenai/mslr2022) dataset, except the input source documents of its `validation` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `target` field of each example
- __corpus__: The union of all documents in the `train`, `validation` and `test` splits. A document is the concatenation of the `title` and `abstract`.
- __retriever__: BM25 via [PyTerrier](https://pyterrier.readthedocs.io/en/latest/) with default settings
- __top-k strategy__: `"oracle"`, i.e. the number of documents retrieved, `k`, is set as the original number of input documents for each example
Retrieval results on the `train` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.7014 | 0.3841 | 0.3841 | 0.3841 |
Retrieval results on the `validation` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.7226 | 0.4023 | 0.4023 | 0.4023 |
Retrieval results on the `test` set:
N/A. Test set is blind so we do not have any queries. | allenai/cochrane_sparse_oracle | [
"task_categories:summarization",
"task_categories:text2text-generation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-MS^2",
"source_datasets:extended|other-Cochrane",
"language:en",
"license:apache-2.0",
"region:us"
] | 2022-09-14T12:16:16+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|other-MS^2", "extended|other-Cochrane"], "task_categories": ["summarization", "text2text-generation"], "paperswithcode_id": "multi-document-summarization", "pretty_name": "MSLR Shared Task"} | 2022-11-24T14:54:01+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_categories-text2text-generation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|other-MS^2 #source_datasets-extended|other-Cochrane #language-English #license-apache-2.0 #region-us
| This is a copy of the Cochrane dataset, except the input source documents of its 'validation' split have been replaced by a **sparse** retriever. The retrieval pipeline used:
* **query**: The 'target' field of each example
* **corpus**: The union of all documents in the 'train', 'validation' and 'test' splits. A document is the concatenation of the 'title' and 'abstract'.
* **retriever**: BM25 via PyTerrier with default settings
* **top-k strategy**: '"oracle"', i.e. the number of documents retrieved, 'k', is set as the original number of input documents for each example
Retrieval results on the 'train' set:
Retrieval results on the 'validation' set:
Retrieval results on the 'test' set:
N/A. Test set is blind so we do not have any queries.
| [] | [
"TAGS\n#task_categories-summarization #task_categories-text2text-generation #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|other-MS^2 #source_datasets-extended|other-Cochrane #language-English #license-apache-2.0 #region-us \n"
] |
9d84b3ac8da24fbce401b98a178082e54a1bca8f |
This contains the datasets for the Trojan Detection Challenge NeurIPS 2022 competition. To learn more, please see the [competition website](http://trojandetection.ai/).
# **Trojan Detection**
##### Detect and Analyze Trojan attacks on deep neural networks that are designed to be difficult to detect.
### **Overview**
Neural Trojans are a growing concern for the security of ML systems, but little is known about the fundamental offense-defense balance of Trojan detection. Early work suggests that standard Trojan attacks may be easy to detect, but recently it has been shown that in simple cases one can design practically undetectable Trojans.
This repository contains code for the **Trojan Detection Challenge (TDC) NeurIPS 2022** [competition](https://trojandetection.ai/).
There are 3 main tracks for this competition:
- **Trojan Detection Track**: Given a dataset of Trojaned and clean networks spanning multiple data sources, build a Trojan detector that classifies a test set of networks with held-out labels (Trojan, clean). For more information, see here.
- **Trojan Analysis Track**: Given a dataset of Trojaned networks spanning multiple data sources, predict various properties of Trojaned networks on a test set with held-out labels. This track has two subtracks: (1) target label prediction, (2) trigger synthesis. For more information, see here.
- **Evasive Trojans Track**: Given a dataset of clean networks and a list of attack specifications, train a small set of Trojaned networks meeting the specifications and upload them to the evaluation server. The server will verify that the attack specifications are met, then train and evaluate a baseline Trojan detector using held-out clean networks and the submitted Trojaned networks. The task is to create Trojaned networks that are hard to detect. For more information, see here.
The competition has two rounds: In the primary round, participants will compete on the three main tracks. In the final round, the solution of the first-place team in the Evasive Trojans track will be used to train a new set of hard-to-detect Trojans, and participants will compete to detect these networks. For more information on the final round, see here.
### **Contents**
There are four folders corresponding to different tracks and subtracks: 1) Trojan Detection, 2) Trojan Analysis (Target Label Prediction), 3) Trojan Analysis (Trigger Synthesis), and 4) Evasive Trojans. We provide starter code for submitting baselines in ```example_submission.ipynb``` under each folder. The ```tdc_datasets``` folder is expected to be under the same parent directory as ```tdc-starter-kit```. The datasets are available [here](https://zenodo.org/record/6894041). You can download them from the Zenodo website or by running ```download_datasets.py```.
The ```utils.py``` file contains helper functions for loading new models, generating new attack specifications, and training clean/Trojaned networks. This is primarily used for the Evasive Trojans Track starter kit. It also contains the load_data function for loading data sources (CIFAR-10/100, GTSRB, MNIST), which may be of general use. To load GTSRB images, unzip ```gtsrb_preprocessed.zip``` in the data folder (NOTE: This folder is only for storing data sources. The network datasets are stored in tdc_datasets, which must be downloaded from Zenodo). You may need to adjust the paths in the load_data function depending on your working directory. The ```wrn.py``` file contains the definition of the Wide Residual Network class used for CIFAR-10 and CIFAR-100 models. When loading networks from the competition datasets, ```wrn.py``` must be in your path. See the example submission notebooks for details.
### **Data**
Unlike standard machine learning tasks, the datasets consist of neural networks. That is, rather than making predictions on input images, goal will be identifying hidden functionality in neural networks. Networks are trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. Variants of two standard Trojan attacks are used that are modified to be harder to detect. For the Detection Track, the training, validation, and test sets have 1,000 neural networks each. Networks are split evenly across all four data sources. Half of the networks are Trojaned, and there is a 50/50 split between the two attack types.
## How to Use
**Clone this repository, download the competition [datasets](https://huggingface.co/datasets/n1ghtf4l1/vigilant-fortnight/blob/main/tdc_datasets.zip) from my HuggingFace repository and unzip adjacent to the repository**. Ensure that Jupyter version is up-to-date (fairly recent). To avoid errors with model incompatibility, please use PyTorch version 1.11.0. Run one of the example notebooks or start building your own submission.
### **Additional Information**
#### **Model Architectures and Data Sources**
Networks have been trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. GTSRB images are resized to 32x32.
For MNIST, convolutional networks have been used. For CIFAR-10 and CIFAR-100, Wide Residual Networks have been used. For GTSRB, Vision Transformers have been used.
#### **Trojan Attacks**
Trojaned networks have been trained with patch and whole-image attacks. These attacks are variants of the foundational BadNets and blended attacks modified to be harder to detect. These modified attacks use a simple change to the standard Trojan training procedure. Instead of training Trojaned networks from scratch, they were fine-tuned from the starting parameters of clean networks and regularize them with various similarity losses such that they are similar to the distribution of clean networks. Additionally, the networks have been trained to have high specificity for the particular trigger pattern associated with the attack. In extensive experiments, baseline detectors have been verified obtain substantially lower performance on these hard-to-detect Trojans.
All patch attacks in datasets use random trigger patterns sampled from an independent Bernoulli 0/1 distribution for each pixel and color channel (for Trojan detection and target label prediction, patches are black-and-white; for trigger synthesis, patches are colored). Each patch attack uses a different location and size for its trigger mask. All blended attacks in our datasets use random trigger trigger patterns sampled from an independent Uniform(0,1) distribution for each pixel and color channel. All attacks are all-to-one with a random target label. For more details, please see the starter kit.
MNTD, Neural Cleanse, and ABS has been used as baseline Trojan detectors for participants to improve upon. These are well-known Trojan detectors from the academic literature, each with a distinct approach to Trojan detection. Also a specificity-based detector has been used as a baseline, since Trojan attacks with low specificity can be highly susceptible to such a detector. The specificity detector applies random triggers to inputs from a given data source, then runs these triggered inputs through the network in question. The negative entropy of the average posterior is used as a detection score. This leverages the fact that Trojan attacks without specificity are activated quite frequently by randomly sampled triggers. | n1ghtf4l1/vigilant-fortnight | [
"license:mit",
"region:us"
] | 2022-09-14T13:01:28+00:00 | {"license": "mit"} | 2022-11-01T06:59:48+00:00 | [] | [] | TAGS
#license-mit #region-us
|
This contains the datasets for the Trojan Detection Challenge NeurIPS 2022 competition. To learn more, please see the competition website.
# Trojan Detection
##### Detect and Analyze Trojan attacks on deep neural networks that are designed to be difficult to detect.
### Overview
Neural Trojans are a growing concern for the security of ML systems, but little is known about the fundamental offense-defense balance of Trojan detection. Early work suggests that standard Trojan attacks may be easy to detect, but recently it has been shown that in simple cases one can design practically undetectable Trojans.
This repository contains code for the Trojan Detection Challenge (TDC) NeurIPS 2022 competition.
There are 3 main tracks for this competition:
- Trojan Detection Track: Given a dataset of Trojaned and clean networks spanning multiple data sources, build a Trojan detector that classifies a test set of networks with held-out labels (Trojan, clean). For more information, see here.
- Trojan Analysis Track: Given a dataset of Trojaned networks spanning multiple data sources, predict various properties of Trojaned networks on a test set with held-out labels. This track has two subtracks: (1) target label prediction, (2) trigger synthesis. For more information, see here.
- Evasive Trojans Track: Given a dataset of clean networks and a list of attack specifications, train a small set of Trojaned networks meeting the specifications and upload them to the evaluation server. The server will verify that the attack specifications are met, then train and evaluate a baseline Trojan detector using held-out clean networks and the submitted Trojaned networks. The task is to create Trojaned networks that are hard to detect. For more information, see here.
The competition has two rounds: In the primary round, participants will compete on the three main tracks. In the final round, the solution of the first-place team in the Evasive Trojans track will be used to train a new set of hard-to-detect Trojans, and participants will compete to detect these networks. For more information on the final round, see here.
### Contents
There are four folders corresponding to different tracks and subtracks: 1) Trojan Detection, 2) Trojan Analysis (Target Label Prediction), 3) Trojan Analysis (Trigger Synthesis), and 4) Evasive Trojans. We provide starter code for submitting baselines in under each folder. The folder is expected to be under the same parent directory as . The datasets are available here. You can download them from the Zenodo website or by running .
The file contains helper functions for loading new models, generating new attack specifications, and training clean/Trojaned networks. This is primarily used for the Evasive Trojans Track starter kit. It also contains the load_data function for loading data sources (CIFAR-10/100, GTSRB, MNIST), which may be of general use. To load GTSRB images, unzip in the data folder (NOTE: This folder is only for storing data sources. The network datasets are stored in tdc_datasets, which must be downloaded from Zenodo). You may need to adjust the paths in the load_data function depending on your working directory. The file contains the definition of the Wide Residual Network class used for CIFAR-10 and CIFAR-100 models. When loading networks from the competition datasets, must be in your path. See the example submission notebooks for details.
### Data
Unlike standard machine learning tasks, the datasets consist of neural networks. That is, rather than making predictions on input images, goal will be identifying hidden functionality in neural networks. Networks are trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. Variants of two standard Trojan attacks are used that are modified to be harder to detect. For the Detection Track, the training, validation, and test sets have 1,000 neural networks each. Networks are split evenly across all four data sources. Half of the networks are Trojaned, and there is a 50/50 split between the two attack types.
## How to Use
Clone this repository, download the competition datasets from my HuggingFace repository and unzip adjacent to the repository. Ensure that Jupyter version is up-to-date (fairly recent). To avoid errors with model incompatibility, please use PyTorch version 1.11.0. Run one of the example notebooks or start building your own submission.
### Additional Information
#### Model Architectures and Data Sources
Networks have been trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. GTSRB images are resized to 32x32.
For MNIST, convolutional networks have been used. For CIFAR-10 and CIFAR-100, Wide Residual Networks have been used. For GTSRB, Vision Transformers have been used.
#### Trojan Attacks
Trojaned networks have been trained with patch and whole-image attacks. These attacks are variants of the foundational BadNets and blended attacks modified to be harder to detect. These modified attacks use a simple change to the standard Trojan training procedure. Instead of training Trojaned networks from scratch, they were fine-tuned from the starting parameters of clean networks and regularize them with various similarity losses such that they are similar to the distribution of clean networks. Additionally, the networks have been trained to have high specificity for the particular trigger pattern associated with the attack. In extensive experiments, baseline detectors have been verified obtain substantially lower performance on these hard-to-detect Trojans.
All patch attacks in datasets use random trigger patterns sampled from an independent Bernoulli 0/1 distribution for each pixel and color channel (for Trojan detection and target label prediction, patches are black-and-white; for trigger synthesis, patches are colored). Each patch attack uses a different location and size for its trigger mask. All blended attacks in our datasets use random trigger trigger patterns sampled from an independent Uniform(0,1) distribution for each pixel and color channel. All attacks are all-to-one with a random target label. For more details, please see the starter kit.
MNTD, Neural Cleanse, and ABS has been used as baseline Trojan detectors for participants to improve upon. These are well-known Trojan detectors from the academic literature, each with a distinct approach to Trojan detection. Also a specificity-based detector has been used as a baseline, since Trojan attacks with low specificity can be highly susceptible to such a detector. The specificity detector applies random triggers to inputs from a given data source, then runs these triggered inputs through the network in question. The negative entropy of the average posterior is used as a detection score. This leverages the fact that Trojan attacks without specificity are activated quite frequently by randomly sampled triggers. | [
"# Trojan Detection",
"##### Detect and Analyze Trojan attacks on deep neural networks that are designed to be difficult to detect.",
"### Overview\n\nNeural Trojans are a growing concern for the security of ML systems, but little is known about the fundamental offense-defense balance of Trojan detection. Early work suggests that standard Trojan attacks may be easy to detect, but recently it has been shown that in simple cases one can design practically undetectable Trojans.\n\nThis repository contains code for the Trojan Detection Challenge (TDC) NeurIPS 2022 competition.\n\nThere are 3 main tracks for this competition:\n- Trojan Detection Track: Given a dataset of Trojaned and clean networks spanning multiple data sources, build a Trojan detector that classifies a test set of networks with held-out labels (Trojan, clean). For more information, see here.\n\n- Trojan Analysis Track: Given a dataset of Trojaned networks spanning multiple data sources, predict various properties of Trojaned networks on a test set with held-out labels. This track has two subtracks: (1) target label prediction, (2) trigger synthesis. For more information, see here.\n\n- Evasive Trojans Track: Given a dataset of clean networks and a list of attack specifications, train a small set of Trojaned networks meeting the specifications and upload them to the evaluation server. The server will verify that the attack specifications are met, then train and evaluate a baseline Trojan detector using held-out clean networks and the submitted Trojaned networks. The task is to create Trojaned networks that are hard to detect. For more information, see here.\n\nThe competition has two rounds: In the primary round, participants will compete on the three main tracks. In the final round, the solution of the first-place team in the Evasive Trojans track will be used to train a new set of hard-to-detect Trojans, and participants will compete to detect these networks. For more information on the final round, see here.",
"### Contents\n\nThere are four folders corresponding to different tracks and subtracks: 1) Trojan Detection, 2) Trojan Analysis (Target Label Prediction), 3) Trojan Analysis (Trigger Synthesis), and 4) Evasive Trojans. We provide starter code for submitting baselines in under each folder. The folder is expected to be under the same parent directory as . The datasets are available here. You can download them from the Zenodo website or by running .\n\nThe file contains helper functions for loading new models, generating new attack specifications, and training clean/Trojaned networks. This is primarily used for the Evasive Trojans Track starter kit. It also contains the load_data function for loading data sources (CIFAR-10/100, GTSRB, MNIST), which may be of general use. To load GTSRB images, unzip in the data folder (NOTE: This folder is only for storing data sources. The network datasets are stored in tdc_datasets, which must be downloaded from Zenodo). You may need to adjust the paths in the load_data function depending on your working directory. The file contains the definition of the Wide Residual Network class used for CIFAR-10 and CIFAR-100 models. When loading networks from the competition datasets, must be in your path. See the example submission notebooks for details.",
"### Data\n\nUnlike standard machine learning tasks, the datasets consist of neural networks. That is, rather than making predictions on input images, goal will be identifying hidden functionality in neural networks. Networks are trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. Variants of two standard Trojan attacks are used that are modified to be harder to detect. For the Detection Track, the training, validation, and test sets have 1,000 neural networks each. Networks are split evenly across all four data sources. Half of the networks are Trojaned, and there is a 50/50 split between the two attack types.",
"## How to Use\n\nClone this repository, download the competition datasets from my HuggingFace repository and unzip adjacent to the repository. Ensure that Jupyter version is up-to-date (fairly recent). To avoid errors with model incompatibility, please use PyTorch version 1.11.0. Run one of the example notebooks or start building your own submission.",
"### Additional Information",
"#### Model Architectures and Data Sources\n\nNetworks have been trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. GTSRB images are resized to 32x32.\n\nFor MNIST, convolutional networks have been used. For CIFAR-10 and CIFAR-100, Wide Residual Networks have been used. For GTSRB, Vision Transformers have been used.",
"#### Trojan Attacks\n\nTrojaned networks have been trained with patch and whole-image attacks. These attacks are variants of the foundational BadNets and blended attacks modified to be harder to detect. These modified attacks use a simple change to the standard Trojan training procedure. Instead of training Trojaned networks from scratch, they were fine-tuned from the starting parameters of clean networks and regularize them with various similarity losses such that they are similar to the distribution of clean networks. Additionally, the networks have been trained to have high specificity for the particular trigger pattern associated with the attack. In extensive experiments, baseline detectors have been verified obtain substantially lower performance on these hard-to-detect Trojans.\n\nAll patch attacks in datasets use random trigger patterns sampled from an independent Bernoulli 0/1 distribution for each pixel and color channel (for Trojan detection and target label prediction, patches are black-and-white; for trigger synthesis, patches are colored). Each patch attack uses a different location and size for its trigger mask. All blended attacks in our datasets use random trigger trigger patterns sampled from an independent Uniform(0,1) distribution for each pixel and color channel. All attacks are all-to-one with a random target label. For more details, please see the starter kit. \n\nMNTD, Neural Cleanse, and ABS has been used as baseline Trojan detectors for participants to improve upon. These are well-known Trojan detectors from the academic literature, each with a distinct approach to Trojan detection. Also a specificity-based detector has been used as a baseline, since Trojan attacks with low specificity can be highly susceptible to such a detector. The specificity detector applies random triggers to inputs from a given data source, then runs these triggered inputs through the network in question. The negative entropy of the average posterior is used as a detection score. This leverages the fact that Trojan attacks without specificity are activated quite frequently by randomly sampled triggers."
] | [
"TAGS\n#license-mit #region-us \n",
"# Trojan Detection",
"##### Detect and Analyze Trojan attacks on deep neural networks that are designed to be difficult to detect.",
"### Overview\n\nNeural Trojans are a growing concern for the security of ML systems, but little is known about the fundamental offense-defense balance of Trojan detection. Early work suggests that standard Trojan attacks may be easy to detect, but recently it has been shown that in simple cases one can design practically undetectable Trojans.\n\nThis repository contains code for the Trojan Detection Challenge (TDC) NeurIPS 2022 competition.\n\nThere are 3 main tracks for this competition:\n- Trojan Detection Track: Given a dataset of Trojaned and clean networks spanning multiple data sources, build a Trojan detector that classifies a test set of networks with held-out labels (Trojan, clean). For more information, see here.\n\n- Trojan Analysis Track: Given a dataset of Trojaned networks spanning multiple data sources, predict various properties of Trojaned networks on a test set with held-out labels. This track has two subtracks: (1) target label prediction, (2) trigger synthesis. For more information, see here.\n\n- Evasive Trojans Track: Given a dataset of clean networks and a list of attack specifications, train a small set of Trojaned networks meeting the specifications and upload them to the evaluation server. The server will verify that the attack specifications are met, then train and evaluate a baseline Trojan detector using held-out clean networks and the submitted Trojaned networks. The task is to create Trojaned networks that are hard to detect. For more information, see here.\n\nThe competition has two rounds: In the primary round, participants will compete on the three main tracks. In the final round, the solution of the first-place team in the Evasive Trojans track will be used to train a new set of hard-to-detect Trojans, and participants will compete to detect these networks. For more information on the final round, see here.",
"### Contents\n\nThere are four folders corresponding to different tracks and subtracks: 1) Trojan Detection, 2) Trojan Analysis (Target Label Prediction), 3) Trojan Analysis (Trigger Synthesis), and 4) Evasive Trojans. We provide starter code for submitting baselines in under each folder. The folder is expected to be under the same parent directory as . The datasets are available here. You can download them from the Zenodo website or by running .\n\nThe file contains helper functions for loading new models, generating new attack specifications, and training clean/Trojaned networks. This is primarily used for the Evasive Trojans Track starter kit. It also contains the load_data function for loading data sources (CIFAR-10/100, GTSRB, MNIST), which may be of general use. To load GTSRB images, unzip in the data folder (NOTE: This folder is only for storing data sources. The network datasets are stored in tdc_datasets, which must be downloaded from Zenodo). You may need to adjust the paths in the load_data function depending on your working directory. The file contains the definition of the Wide Residual Network class used for CIFAR-10 and CIFAR-100 models. When loading networks from the competition datasets, must be in your path. See the example submission notebooks for details.",
"### Data\n\nUnlike standard machine learning tasks, the datasets consist of neural networks. That is, rather than making predictions on input images, goal will be identifying hidden functionality in neural networks. Networks are trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. Variants of two standard Trojan attacks are used that are modified to be harder to detect. For the Detection Track, the training, validation, and test sets have 1,000 neural networks each. Networks are split evenly across all four data sources. Half of the networks are Trojaned, and there is a 50/50 split between the two attack types.",
"## How to Use\n\nClone this repository, download the competition datasets from my HuggingFace repository and unzip adjacent to the repository. Ensure that Jupyter version is up-to-date (fairly recent). To avoid errors with model incompatibility, please use PyTorch version 1.11.0. Run one of the example notebooks or start building your own submission.",
"### Additional Information",
"#### Model Architectures and Data Sources\n\nNetworks have been trained on four standard data sources: MNIST, CIFAR-10, CIFAR-100, and GTSRB. GTSRB images are resized to 32x32.\n\nFor MNIST, convolutional networks have been used. For CIFAR-10 and CIFAR-100, Wide Residual Networks have been used. For GTSRB, Vision Transformers have been used.",
"#### Trojan Attacks\n\nTrojaned networks have been trained with patch and whole-image attacks. These attacks are variants of the foundational BadNets and blended attacks modified to be harder to detect. These modified attacks use a simple change to the standard Trojan training procedure. Instead of training Trojaned networks from scratch, they were fine-tuned from the starting parameters of clean networks and regularize them with various similarity losses such that they are similar to the distribution of clean networks. Additionally, the networks have been trained to have high specificity for the particular trigger pattern associated with the attack. In extensive experiments, baseline detectors have been verified obtain substantially lower performance on these hard-to-detect Trojans.\n\nAll patch attacks in datasets use random trigger patterns sampled from an independent Bernoulli 0/1 distribution for each pixel and color channel (for Trojan detection and target label prediction, patches are black-and-white; for trigger synthesis, patches are colored). Each patch attack uses a different location and size for its trigger mask. All blended attacks in our datasets use random trigger trigger patterns sampled from an independent Uniform(0,1) distribution for each pixel and color channel. All attacks are all-to-one with a random target label. For more details, please see the starter kit. \n\nMNTD, Neural Cleanse, and ABS has been used as baseline Trojan detectors for participants to improve upon. These are well-known Trojan detectors from the academic literature, each with a distinct approach to Trojan detection. Also a specificity-based detector has been used as a baseline, since Trojan attacks with low specificity can be highly susceptible to such a detector. The specificity detector applies random triggers to inputs from a given data source, then runs these triggered inputs through the network in question. The negative entropy of the average posterior is used as a detection score. This leverages the fact that Trojan attacks without specificity are activated quite frequently by randomly sampled triggers."
] |
6dd53ddc97b18d6fc7c29252712ff261543e0fea |
Dataset Contain sentimen for Indonesia Communication Industry. Source from Twitter and manually annotated in prodigy spacy
| dwisaji/indonesia-telecomunication-sentiment-dataset | [
"license:mit",
"region:us"
] | 2022-09-14T13:25:03+00:00 | {"license": "mit"} | 2022-09-16T10:36:02+00:00 | [] | [] | TAGS
#license-mit #region-us
|
Dataset Contain sentimen for Indonesia Communication Industry. Source from Twitter and manually annotated in prodigy spacy
| [] | [
"TAGS\n#license-mit #region-us \n"
] |
c66d38584e94865e84e2295385fd18b39e721d79 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: t5-base
* Dataset: HadiPourmousa/TextSummarization
* Config: HadiPourmousa--TextSummarization
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@marcmaxmeister](https://huggingface.co/marcmaxmeister) for evaluating this model. | autoevaluate/autoeval-eval-HadiPourmousa__TextSummarization-HadiPourmousa__TextSum-31dfb4-1463253931 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T15:05:10+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["HadiPourmousa/TextSummarization"], "eval_info": {"task": "summarization", "model": "t5-base", "metrics": [], "dataset_name": "HadiPourmousa/TextSummarization", "dataset_config": "HadiPourmousa--TextSummarization", "dataset_split": "train", "col_mapping": {"text": "Text", "target": "Title"}}} | 2022-09-14T15:06:24+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: t5-base
* Dataset: HadiPourmousa/TextSummarization
* Config: HadiPourmousa--TextSummarization
* Split: train
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @marcmaxmeister for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: t5-base\n* Dataset: HadiPourmousa/TextSummarization\n* Config: HadiPourmousa--TextSummarization\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @marcmaxmeister for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: t5-base\n* Dataset: HadiPourmousa/TextSummarization\n* Config: HadiPourmousa--TextSummarization\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @marcmaxmeister for evaluating this model."
] |
2a8b1b48cf1266ce9417abd61b51e004491e6e5d | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: shivaniNK8/t5-small-finetuned-cnn-news
* Dataset: HadiPourmousa/TextSummarization
* Config: HadiPourmousa--TextSummarization
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@marcmaxmeister](https://huggingface.co/marcmaxmeister) for evaluating this model. | autoevaluate/autoeval-eval-HadiPourmousa__TextSummarization-HadiPourmousa__TextSum-31dfb4-1463253932 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T15:05:14+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["HadiPourmousa/TextSummarization"], "eval_info": {"task": "summarization", "model": "shivaniNK8/t5-small-finetuned-cnn-news", "metrics": [], "dataset_name": "HadiPourmousa/TextSummarization", "dataset_config": "HadiPourmousa--TextSummarization", "dataset_split": "train", "col_mapping": {"text": "Text", "target": "Title"}}} | 2022-09-14T15:05:51+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: shivaniNK8/t5-small-finetuned-cnn-news
* Dataset: HadiPourmousa/TextSummarization
* Config: HadiPourmousa--TextSummarization
* Split: train
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @marcmaxmeister for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: shivaniNK8/t5-small-finetuned-cnn-news\n* Dataset: HadiPourmousa/TextSummarization\n* Config: HadiPourmousa--TextSummarization\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @marcmaxmeister for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: shivaniNK8/t5-small-finetuned-cnn-news\n* Dataset: HadiPourmousa/TextSummarization\n* Config: HadiPourmousa--TextSummarization\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @marcmaxmeister for evaluating this model."
] |
46db0397e01c802cd02a14c954cc3e60a4f929a3 |
# Şalom Ladino articles text corpus
Text corpus compiled from 397 articles from the Judeo-Espanyol section of [Şalom newspaper](https://www.salom.com.tr/haberler/17/judeo-espanyol). Original sentences and articles belong to Şalom.
Size: 176,843 words
[Offical link](https://data.sefarad.com.tr/dataset/salom-ladino-articles-text-corpus)
Paper on [ArXiv](https://arxiv.org/abs/2205.15599)
Citation:
```
Preparing an endangered language for the digital age: The Case of Judeo-Spanish. Alp Öktem, Rodolfo Zevallos, Yasmin Moslem, Güneş Öztürk, Karen Şarhon.
Workshop on Resources and Technologies for Indigenous, Endangered and Lesser-resourced Languages in Eurasia (EURALI) @ LREC 2022. Marseille, France. 20 June 2022
```
This dataset is created as part of project "Judeo-Spanish: Connecting the two ends of the Mediterranean" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union. | collectivat/salom-ladino-articles | [
"task_categories:text-generation",
"task_ids:language-modeling",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:lad",
"license:cc-by-4.0",
"arxiv:2205.15599",
"region:us"
] | 2022-09-14T15:30:48+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["lad"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["text-generation"], "task_ids": ["language-modeling"]} | 2022-10-25T10:46:20+00:00 | [
"2205.15599"
] | [
"lad"
] | TAGS
#task_categories-text-generation #task_ids-language-modeling #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Ladino #license-cc-by-4.0 #arxiv-2205.15599 #region-us
|
# Şalom Ladino articles text corpus
Text corpus compiled from 397 articles from the Judeo-Espanyol section of Şalom newspaper. Original sentences and articles belong to Şalom.
Size: 176,843 words
Offical link
Paper on ArXiv
Citation:
This dataset is created as part of project "Judeo-Spanish: Connecting the two ends of the Mediterranean" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union. | [
"# Şalom Ladino articles text corpus \n\nText corpus compiled from 397 articles from the Judeo-Espanyol section of Şalom newspaper. Original sentences and articles belong to Şalom. \n\nSize: 176,843 words\n\nOffical link\n\nPaper on ArXiv\n\nCitation:\n\n\n\nThis dataset is created as part of project \"Judeo-Spanish: Connecting the two ends of the Mediterranean\" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union."
] | [
"TAGS\n#task_categories-text-generation #task_ids-language-modeling #annotations_creators-found #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Ladino #license-cc-by-4.0 #arxiv-2205.15599 #region-us \n",
"# Şalom Ladino articles text corpus \n\nText corpus compiled from 397 articles from the Judeo-Espanyol section of Şalom newspaper. Original sentences and articles belong to Şalom. \n\nSize: 176,843 words\n\nOffical link\n\nPaper on ArXiv\n\nCitation:\n\n\n\nThis dataset is created as part of project \"Judeo-Spanish: Connecting the two ends of the Mediterranean\" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union."
] |
a91c62f46e6e69eb7ab019798e5913c135d061f8 |
# Una fraza al diya
Ladino language learning sentences prepared by Karen Sarhon of Sephardic Center of Istanbul. Each sentence has translations in Turkish, English, Spanish. Includes audio and image. 307 sentences in total.
Source: https://sefarad.com.tr/judeo-espanyolladino/frazadeldia/
Images and audio: http://collectivat.cat/share/judeoespanyol_audio_image.zip
[Offical link on Ladino Data Hub](https://data.sefarad.com.tr/dataset/una-fraza-al-diya-skad)
Paper on [ArXiv](https://arxiv.org/abs/2205.15599)
Citation:
```
Preparing an endangered language for the digital age: The Case of Judeo-Spanish. Alp Öktem, Rodolfo Zevallos, Yasmin Moslem, Güneş Öztürk, Karen Şarhon.
Workshop on Resources and Technologies for Indigenous, Endangered and Lesser-resourced Languages in Eurasia (EURALI) @ LREC 2022. Marseille, France. 20 June 2022
```
This dataset is created as part of project "Judeo-Spanish: Connecting the two ends of the Mediterranean" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union.
| collectivat/una-fraza-al-diya | [
"task_categories:text-generation",
"task_categories:translation",
"task_ids:language-modeling",
"annotations_creators:found",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:lad",
"language:es",
"language:tr",
"language:en",
"license:cc-by-4.0",
"arxiv:2205.15599",
"region:us"
] | 2022-09-14T15:46:46+00:00 | {"annotations_creators": ["found"], "language_creators": ["found"], "language": ["lad", "es", "tr", "en"], "license": "cc-by-4.0", "multilinguality": ["multilingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["text-generation", "translation"], "task_ids": ["language-modeling"]} | 2022-10-25T10:46:11+00:00 | [
"2205.15599"
] | [
"lad",
"es",
"tr",
"en"
] | TAGS
#task_categories-text-generation #task_categories-translation #task_ids-language-modeling #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-100K<n<1M #source_datasets-original #language-Ladino #language-Spanish #language-Turkish #language-English #license-cc-by-4.0 #arxiv-2205.15599 #region-us
|
# Una fraza al diya
Ladino language learning sentences prepared by Karen Sarhon of Sephardic Center of Istanbul. Each sentence has translations in Turkish, English, Spanish. Includes audio and image. 307 sentences in total.
Source: URL
Images and audio: URL
Offical link on Ladino Data Hub
Paper on ArXiv
Citation:
This dataset is created as part of project "Judeo-Spanish: Connecting the two ends of the Mediterranean" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union.
| [
"# Una fraza al diya\n\nLadino language learning sentences prepared by Karen Sarhon of Sephardic Center of Istanbul. Each sentence has translations in Turkish, English, Spanish. Includes audio and image. 307 sentences in total.\n\nSource: URL\n\nImages and audio: URL \n\nOffical link on Ladino Data Hub\n\nPaper on ArXiv\n\nCitation:\n\n\n\nThis dataset is created as part of project \"Judeo-Spanish: Connecting the two ends of the Mediterranean\" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union."
] | [
"TAGS\n#task_categories-text-generation #task_categories-translation #task_ids-language-modeling #annotations_creators-found #language_creators-found #multilinguality-multilingual #size_categories-100K<n<1M #source_datasets-original #language-Ladino #language-Spanish #language-Turkish #language-English #license-cc-by-4.0 #arxiv-2205.15599 #region-us \n",
"# Una fraza al diya\n\nLadino language learning sentences prepared by Karen Sarhon of Sephardic Center of Istanbul. Each sentence has translations in Turkish, English, Spanish. Includes audio and image. 307 sentences in total.\n\nSource: URL\n\nImages and audio: URL \n\nOffical link on Ladino Data Hub\n\nPaper on ArXiv\n\nCitation:\n\n\n\nThis dataset is created as part of project \"Judeo-Spanish: Connecting the two ends of the Mediterranean\" carried out by Col·lectivaT and Sephardic Center of Istanbul within the framework of the “Grant Scheme for Common Cultural Heritage: Preservation and Dialogue between Turkey and the EU–II (CCH-II)” implemented by the Ministry of Culture and Tourism of the Republic of Turkey with the financial support of the European Union. The content of this website is the sole responsibility of Col·lectivaT and does not necessarily reflect the views of the European Union."
] |
fbc749f1c537e5c3834e93b15784302e331debe2 |
## Dataset Description
- **Repository:** https://conala-corpus.github.io/
- **Paper:** [Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow](https://arxiv.org/pdf/1805.08949.pdf)
### Dataset Summary
[CoNaLa](https://conala-corpus.github.io/) is a benchmark of code and natural language pairs, for the evaluation of code generation tasks. The dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators, split into 2,379 training and 500 test examples. The automatically mined dataset is also available with almost 600k examples.
### Supported Tasks and Leaderboards
This dataset is used to evaluate code generations.
### Languages
English - Python code.
## Dataset Structure
```python
dataset_curated = load_dataset("neulab/conala")
DatasetDict({
train: Dataset({
features: ['question_id', 'intent', 'rewritten_intent', 'snippet'],
num_rows: 2379
})
test: Dataset({
features: ['question_id', 'intent', 'rewritten_intent', 'snippet'],
num_rows: 500
})
})
dataset_mined = load_dataset("neulab/conala", "mined")
DatasetDict({
train: Dataset({
features: ['question_id', 'parent_answer_post_id', 'prob', 'snippet', 'intent', 'id'],
num_rows: 593891
})
})
```
### Data Instances
#### CoNaLa - curated
This is the curated dataset by annotators
```
{
'question_id': 41067960,
'intent': 'How to convert a list of multiple integers into a single integer?',
'rewritten_intent': "Concatenate elements of a list 'x' of multiple integers to a single integer",
'snippet': 'sum(d * 10 ** i for i, d in enumerate(x[::-1]))'
}
```
#### CoNaLa - mined
This is the automatically mined dataset before curation
```
{
'question_id': 34705205,
'parent_answer_post_id': 34705233,
'prob': 0.8690001442846342,
'snippet': 'sorted(l, key=lambda x: (-int(x[1]), x[0]))',
'intent': 'Sort a nested list by two elements',
'id': '34705205_34705233_0'
}
```
### Data Fields
Curated:
|Field|Type|Description|
|---|---|---|
|question_id|int64|Id of the Stack Overflow question|
|intent|string|Natural Language intent (i.e., the title of a Stack Overflow question)|
|rewritten_intent|string|Crowdsourced revised intents that try to better reflect the full meaning of the code|
|snippet|string| Code snippet that implements the intent|
Mined:
|Field|Type|Description|
|---|---|---|
|question_id|int64|Id of the Stack Overflow question|
|parent_answer_post_id|int64|Id of the answer post from which the candidate snippet is extracted|
|intent|string|Natural Language intent (i.e., the title of a Stack Overflow question)|
|snippet|string| Code snippet that implements the intent|
|id|string|Unique id for this intent/snippet pair|
|prob|float64|Probability given by the mining model|
### Data Splits
There are two version of the dataset (curated and mined), mined only has a train split and curated has two splits: train and test.
## Dataset Creation
The dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators. For more details, please refer to the original [paper](https://arxiv.org/pdf/1805.08949.pdf)
### Citation Information
```
@inproceedings{yin2018learning,
title={Learning to mine aligned code and natural language pairs from stack overflow},
author={Yin, Pengcheng and Deng, Bowen and Chen, Edgar and Vasilescu, Bogdan and Neubig, Graham},
booktitle={2018 IEEE/ACM 15th international conference on mining software repositories (MSR)},
pages={476--486},
year={2018},
organization={IEEE}
}
``` | neulab/conala | [
"task_categories:text2text-generation",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"language:code",
"license:mit",
"code-generation",
"arxiv:1805.08949",
"region:us"
] | 2022-09-14T18:31:08+00:00 | {"annotations_creators": [], "language_creators": ["crowdsourced", "expert-generated"], "language": ["code"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["original"], "task_categories": ["text2text-generation"], "task_ids": [], "pretty_name": "CoNaLa", "tags": ["code-generation"]} | 2022-10-20T19:25:00+00:00 | [
"1805.08949"
] | [
"code"
] | TAGS
#task_categories-text2text-generation #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-unknown #source_datasets-original #language-code #license-mit #code-generation #arxiv-1805.08949 #region-us
| Dataset Description
-------------------
* Repository: URL
* Paper: Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow
### Dataset Summary
CoNaLa is a benchmark of code and natural language pairs, for the evaluation of code generation tasks. The dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators, split into 2,379 training and 500 test examples. The automatically mined dataset is also available with almost 600k examples.
### Supported Tasks and Leaderboards
This dataset is used to evaluate code generations.
### Languages
English - Python code.
Dataset Structure
-----------------
### Data Instances
#### CoNaLa - curated
This is the curated dataset by annotators
#### CoNaLa - mined
This is the automatically mined dataset before curation
### Data Fields
Curated:
Field: question\_id, Type: int64, Description: Id of the Stack Overflow question
Field: intent, Type: string, Description: Natural Language intent (i.e., the title of a Stack Overflow question)
Field: rewritten\_intent, Type: string, Description: Crowdsourced revised intents that try to better reflect the full meaning of the code
Field: snippet, Type: string, Description: Code snippet that implements the intent
Mined:
Field: question\_id, Type: int64, Description: Id of the Stack Overflow question
Field: parent\_answer\_post\_id, Type: int64, Description: Id of the answer post from which the candidate snippet is extracted
Field: intent, Type: string, Description: Natural Language intent (i.e., the title of a Stack Overflow question)
Field: snippet, Type: string, Description: Code snippet that implements the intent
Field: id, Type: string, Description: Unique id for this intent/snippet pair
Field: prob, Type: float64, Description: Probability given by the mining model
### Data Splits
There are two version of the dataset (curated and mined), mined only has a train split and curated has two splits: train and test.
Dataset Creation
----------------
The dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators. For more details, please refer to the original paper
| [
"### Dataset Summary\n\n\nCoNaLa is a benchmark of code and natural language pairs, for the evaluation of code generation tasks. The dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators, split into 2,379 training and 500 test examples. The automatically mined dataset is also available with almost 600k examples.",
"### Supported Tasks and Leaderboards\n\n\nThis dataset is used to evaluate code generations.",
"### Languages\n\n\nEnglish - Python code.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### CoNaLa - curated\n\n\nThis is the curated dataset by annotators",
"#### CoNaLa - mined\n\n\nThis is the automatically mined dataset before curation",
"### Data Fields\n\n\nCurated:\n\n\nField: question\\_id, Type: int64, Description: Id of the Stack Overflow question\nField: intent, Type: string, Description: Natural Language intent (i.e., the title of a Stack Overflow question)\nField: rewritten\\_intent, Type: string, Description: Crowdsourced revised intents that try to better reflect the full meaning of the code\nField: snippet, Type: string, Description: Code snippet that implements the intent\n\n\nMined:\n\n\nField: question\\_id, Type: int64, Description: Id of the Stack Overflow question\nField: parent\\_answer\\_post\\_id, Type: int64, Description: Id of the answer post from which the candidate snippet is extracted\nField: intent, Type: string, Description: Natural Language intent (i.e., the title of a Stack Overflow question)\nField: snippet, Type: string, Description: Code snippet that implements the intent\nField: id, Type: string, Description: Unique id for this intent/snippet pair\nField: prob, Type: float64, Description: Probability given by the mining model",
"### Data Splits\n\n\nThere are two version of the dataset (curated and mined), mined only has a train split and curated has two splits: train and test.\n\n\nDataset Creation\n----------------\n\n\nThe dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators. For more details, please refer to the original paper"
] | [
"TAGS\n#task_categories-text2text-generation #language_creators-crowdsourced #language_creators-expert-generated #multilinguality-monolingual #size_categories-unknown #source_datasets-original #language-code #license-mit #code-generation #arxiv-1805.08949 #region-us \n",
"### Dataset Summary\n\n\nCoNaLa is a benchmark of code and natural language pairs, for the evaluation of code generation tasks. The dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators, split into 2,379 training and 500 test examples. The automatically mined dataset is also available with almost 600k examples.",
"### Supported Tasks and Leaderboards\n\n\nThis dataset is used to evaluate code generations.",
"### Languages\n\n\nEnglish - Python code.\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### CoNaLa - curated\n\n\nThis is the curated dataset by annotators",
"#### CoNaLa - mined\n\n\nThis is the automatically mined dataset before curation",
"### Data Fields\n\n\nCurated:\n\n\nField: question\\_id, Type: int64, Description: Id of the Stack Overflow question\nField: intent, Type: string, Description: Natural Language intent (i.e., the title of a Stack Overflow question)\nField: rewritten\\_intent, Type: string, Description: Crowdsourced revised intents that try to better reflect the full meaning of the code\nField: snippet, Type: string, Description: Code snippet that implements the intent\n\n\nMined:\n\n\nField: question\\_id, Type: int64, Description: Id of the Stack Overflow question\nField: parent\\_answer\\_post\\_id, Type: int64, Description: Id of the answer post from which the candidate snippet is extracted\nField: intent, Type: string, Description: Natural Language intent (i.e., the title of a Stack Overflow question)\nField: snippet, Type: string, Description: Code snippet that implements the intent\nField: id, Type: string, Description: Unique id for this intent/snippet pair\nField: prob, Type: float64, Description: Probability given by the mining model",
"### Data Splits\n\n\nThere are two version of the dataset (curated and mined), mined only has a train split and curated has two splits: train and test.\n\n\nDataset Creation\n----------------\n\n\nThe dataset was crawled from Stack Overflow, automatically filtered, then curated by annotators. For more details, please refer to the original paper"
] |
e5eaccf06c04cd1fcedf0d73d67d51d7bd23693b |
This is a copy of the [WCEP-10](https://huggingface.co/datasets/ccdv/WCEP-10) dataset, except the input source documents of its `test` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `summary` field of each example
- __corpus__: The union of all documents in the `train`, `validation` and `test` splits
- __retriever__: BM25 via [PyTerrier](https://pyterrier.readthedocs.io/en/latest/) with default settings
- __top-k strategy__: `"max"`, i.e. the number of documents retrieved, `k`, is set as the maximum number of documents seen across examples in this dataset, in this case `k==10`
Retrieval results on the `train` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8753 | 0.6443 | 0.5919 | 0.6588 |
Retrieval results on the `validation` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8706 | 0.6280 | 0.5988 | 0.6346 |
Retrieval results on the `test` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8836 | 0.6658 | 0.6296 | 0.6746 | | allenai/wcep_sparse_max | [
"task_categories:summarization",
"task_ids:news-articles-summarization",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:other",
"region:us"
] | 2022-09-14T19:36:21+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["summarization"], "task_ids": ["news-articles-summarization"], "paperswithcode_id": "wcep", "pretty_name": "WCEP-10", "train-eval-index": [{"config": "default", "task": "summarization", "task_id": "summarization", "splits": {"train_split": "train", "eval_split": "test"}, "col_mapping": {"document": "text", "summary": "target"}, "metrics": [{"type": "rouge", "name": "Rouge"}]}]} | 2022-11-24T15:03:54+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-other #region-us
| This is a copy of the WCEP-10 dataset, except the input source documents of its 'test' split have been replaced by a **sparse** retriever. The retrieval pipeline used:
* **query**: The 'summary' field of each example
* **corpus**: The union of all documents in the 'train', 'validation' and 'test' splits
* **retriever**: BM25 via PyTerrier with default settings
* **top-k strategy**: '"max"', i.e. the number of documents retrieved, 'k', is set as the maximum number of documents seen across examples in this dataset, in this case 'k==10'
Retrieval results on the 'train' set:
Retrieval results on the 'validation' set:
Retrieval results on the 'test' set:
| [] | [
"TAGS\n#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-other #region-us \n"
] |
4099112870faebab587478313df6acecff54008f |
This is a copy of the [WCEP-10](https://huggingface.co/datasets/ccdv/WCEP-10) dataset, except the input source documents of its `test` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `summary` field of each example
- __corpus__: The union of all documents in the `train`, `validation` and `test` splits
- __retriever__: BM25 via [PyTerrier](https://pyterrier.readthedocs.io/en/latest/) with default settings
- __top-k strategy__: `"mean"`, i.e. the number of documents retrieved, `k`, is set as the mean number of documents seen across examples in this dataset, in this case `k==9`
Retrieval results on the `train` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8753 | 0.6443 | 0.6196 | 0.6237 |
Retrieval results on the `validation` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8706 | 0.6280 | 0.6260 | 0.5989 |
Retrieval results on the `test` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8836 | 0.6658 | 0.6601 | 0.6388 | | allenai/wcep_sparse_mean | [
"task_categories:summarization",
"task_ids:news-articles-summarization",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:other",
"region:us"
] | 2022-09-14T19:36:44+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["summarization"], "task_ids": ["news-articles-summarization"], "paperswithcode_id": "wcep", "pretty_name": "WCEP-10", "train-eval-index": [{"config": "default", "task": "summarization", "task_id": "summarization", "splits": {"train_split": "train", "eval_split": "test"}, "col_mapping": {"document": "text", "summary": "target"}, "metrics": [{"type": "rouge", "name": "Rouge"}]}]} | 2022-11-24T15:10:48+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-other #region-us
| This is a copy of the WCEP-10 dataset, except the input source documents of its 'test' split have been replaced by a **sparse** retriever. The retrieval pipeline used:
* **query**: The 'summary' field of each example
* **corpus**: The union of all documents in the 'train', 'validation' and 'test' splits
* **retriever**: BM25 via PyTerrier with default settings
* **top-k strategy**: '"mean"', i.e. the number of documents retrieved, 'k', is set as the mean number of documents seen across examples in this dataset, in this case 'k==9'
Retrieval results on the 'train' set:
Retrieval results on the 'validation' set:
Retrieval results on the 'test' set:
| [] | [
"TAGS\n#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-other #region-us \n"
] |
d21df471d1b06e5d95571001a44995a368c13c19 |
This is a copy of the [WCEP-10](https://huggingface.co/datasets/ccdv/WCEP-10) dataset, except the input source documents of its `test` split have been replaced by a __sparse__ retriever. The retrieval pipeline used:
- __query__: The `summary` field of each example
- __corpus__: The union of all documents in the `train`, `validation` and `test` splits
- __retriever__: BM25 via [PyTerrier](https://pyterrier.readthedocs.io/en/latest/) with default settings
- __top-k strategy__: `"oracle"`, i.e. the number of documents retrieved, `k`, is set as the original number of input documents for each example
Retrieval results on the `train` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8753 | 0.6443 | 0.6443 | 0.6443 |
Retrieval results on the `validation` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8706 | 0.6280 | 0.6280 | 0.6280 |
Retrieval results on the `test` set:
| Recall@100 | Rprec | Precision@k | Recall@k |
| ----------- | ----------- | ----------- | ----------- |
| 0.8836 | 0.6658 | 0.6658 | 0.6658 | | allenai/wcep_sparse_oracle | [
"task_categories:summarization",
"task_ids:news-articles-summarization",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:other",
"region:us"
] | 2022-09-14T19:37:12+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["summarization"], "task_ids": ["news-articles-summarization"], "paperswithcode_id": "wcep", "pretty_name": "WCEP-10", "train-eval-index": [{"config": "default", "task": "summarization", "task_id": "summarization", "splits": {"train_split": "train", "eval_split": "test"}, "col_mapping": {"document": "text", "summary": "target"}, "metrics": [{"type": "rouge", "name": "Rouge"}]}]} | 2022-11-24T15:58:43+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-other #region-us
| This is a copy of the WCEP-10 dataset, except the input source documents of its 'test' split have been replaced by a **sparse** retriever. The retrieval pipeline used:
* **query**: The 'summary' field of each example
* **corpus**: The union of all documents in the 'train', 'validation' and 'test' splits
* **retriever**: BM25 via PyTerrier with default settings
* **top-k strategy**: '"oracle"', i.e. the number of documents retrieved, 'k', is set as the original number of input documents for each example
Retrieval results on the 'train' set:
Retrieval results on the 'validation' set:
Retrieval results on the 'test' set:
| [] | [
"TAGS\n#task_categories-summarization #task_ids-news-articles-summarization #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-English #license-other #region-us \n"
] |
afc723a840ee4e71596d0c4970dec294f1d4eea8 |
Dataset of titles of the top 1000 posts from the top 250 subreddits scraped using [PRAW](https://praw.readthedocs.io/en/stable/index.html).
For steps to create the dataset check out the [dataset](https://github.com/daspartho/predict-subreddit/blob/main/dataset.py) script in the GitHub repo. | daspartho/subreddit-posts | [
"license:apache-2.0",
"region:us"
] | 2022-09-14T20:19:16+00:00 | {"license": "apache-2.0"} | 2022-12-23T20:52:04+00:00 | [] | [] | TAGS
#license-apache-2.0 #region-us
|
Dataset of titles of the top 1000 posts from the top 250 subreddits scraped using PRAW.
For steps to create the dataset check out the dataset script in the GitHub repo. | [] | [
"TAGS\n#license-apache-2.0 #region-us \n"
] |
554b062213e9b94c22c98dea9a72b1c451db1785 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_sum
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelfipps123](https://huggingface.co/samuelfipps123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-5abc44-1464853958 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T20:23:28+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "test", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-14T20:32:43+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_sum
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @samuelfipps123 for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_sum\n* Dataset: samsum\n* Config: samsum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelfipps123 for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_sum\n* Dataset: samsum\n* Config: samsum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelfipps123 for evaluating this model."
] |
b707596946d87b12e0b9c3fdfb92280c73505003 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: cnn_dailymail
* Config: 3.0.0
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-cnn_dailymail-3.0.0-fb0535-1465153964 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T22:24:31+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["cnn_dailymail"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "cnn_dailymail", "dataset_config": "3.0.0", "dataset_split": "test", "col_mapping": {"text": "article", "target": "highlights"}}} | 2022-09-16T05:49:48+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: cnn_dailymail
* Config: 3.0.0
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: cnn_dailymail\n* Config: 3.0.0\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: cnn_dailymail\n* Config: 3.0.0\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
b03bcdf81535a6550ece72d65a15f8a9132a5177 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: big_patent
* Config: y
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-big_patent-y-3c6f0a-1465253965 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T22:24:36+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["big_patent"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "big_patent", "dataset_config": "y", "dataset_split": "test", "col_mapping": {"text": "description", "target": "abstract"}}} | 2022-09-16T08:16:49+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: big_patent
* Config: y
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: big_patent\n* Config: y\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: big_patent\n* Config: y\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
574d5679836e0858757a0d3a15f6e88d52a8b12d | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: billsum
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-billsum-default-a34c3f-1465353966 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T22:51:59+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["billsum"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "billsum", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "summary"}}} | 2022-09-15T12:21:49+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: billsum
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: billsum\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: billsum\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
e802fcbc2e19103618b1e7afd9c0835d85642bc9 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-89ef9c-1465453967 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T23:20:56+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "test", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-14T23:39:49+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: samsum\n* Config: samsum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: samsum\n* Config: samsum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
3739d09f05f0116bde477fbc5e9b4c8346db847d | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: launch/gov_report
* Config: plain_text
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-launch__gov_report-plain_text-c8c9c8-1465553968 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T23:20:59+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["launch/gov_report"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "launch/gov_report", "dataset_config": "plain_text", "dataset_split": "test", "col_mapping": {"text": "document", "target": "summary"}}} | 2022-09-15T04:53:11+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: launch/gov_report
* Config: plain_text
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: launch/gov_report\n* Config: plain_text\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: launch/gov_report\n* Config: plain_text\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
f6b8ab257df3565fbb66b5aa490535371936aa04 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: Blaise-g/PubMed_summ
* Config: Blaise-g--PubMed_summ
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-Blaise-g__PubMed_summ-Blaise-g__PubMed_summ-0234b8-1465653969 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T23:21:04+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["Blaise-g/PubMed_summ"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "Blaise-g/PubMed_summ", "dataset_config": "Blaise-g--PubMed_summ", "dataset_split": "test", "col_mapping": {"text": "article", "target": "abstract"}}} | 2022-09-16T05:40:02+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: Blaise-g/PubMed_summ
* Config: Blaise-g--PubMed_summ
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: Blaise-g/PubMed_summ\n* Config: Blaise-g--PubMed_summ\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: Blaise-g/PubMed_summ\n* Config: Blaise-g--PubMed_summ\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
ea5404aecf4e9eecb11b8a4e655b959ae298648c | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: ccdv/arxiv-summarization
* Config: document
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-ccdv__arxiv-summarization-document-47d12e-1465753970 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-14T23:21:10+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["ccdv/arxiv-summarization"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "ccdv/arxiv-summarization", "dataset_config": "document", "dataset_split": "test", "col_mapping": {"text": "article", "target": "abstract"}}} | 2022-09-16T04:46:07+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: ccdv/arxiv-summarization
* Config: document
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: ccdv/arxiv-summarization\n* Config: document\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: ccdv/arxiv-summarization\n* Config: document\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
df25b0c51d06c4aef5f462ac1bcd0d0e37eeac82 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-kmfoda__booksum-kmfoda__booksum-228ea1-1466053986 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T00:38:01+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["kmfoda/booksum"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-base-16384-booksum-V12", "metrics": [], "dataset_name": "kmfoda/booksum", "dataset_config": "kmfoda--booksum", "dataset_split": "test", "col_mapping": {"text": "chapter", "target": "summary_text"}}} | 2022-09-15T10:16:52+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: kmfoda/booksum\n* Config: kmfoda--booksum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12\n* Dataset: kmfoda/booksum\n* Config: kmfoda--booksum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
f8322d1772f53552a45d61d20fb69ecc61562e33 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP13
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-kmfoda__booksum-kmfoda__booksum-1006ec-1466153987 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T00:38:06+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["kmfoda/booksum"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP13", "metrics": [], "dataset_name": "kmfoda/booksum", "dataset_config": "kmfoda--booksum", "dataset_split": "test", "col_mapping": {"text": "chapter", "target": "summary_text"}}} | 2022-09-16T06:13:52+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP13
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP13\n* Dataset: kmfoda/booksum\n* Config: kmfoda--booksum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP13\n* Dataset: kmfoda/booksum\n* Config: kmfoda--booksum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
5049442efa4cb3d9d27987be83961addba9d6ea4 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP11
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model. | autoevaluate/autoeval-eval-kmfoda__booksum-kmfoda__booksum-1006ec-1466153988 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T00:38:11+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["kmfoda/booksum"], "eval_info": {"task": "summarization", "model": "pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP11", "metrics": [], "dataset_name": "kmfoda/booksum", "dataset_config": "kmfoda--booksum", "dataset_split": "test", "col_mapping": {"text": "chapter", "target": "summary_text"}}} | 2022-09-16T05:16:26+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP11
* Dataset: kmfoda/booksum
* Config: kmfoda--booksum
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @pszemraj for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP11\n* Dataset: kmfoda/booksum\n* Config: kmfoda--booksum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP11\n* Dataset: kmfoda/booksum\n* Config: kmfoda--booksum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @pszemraj for evaluating this model."
] |
570d90ae4f7b64fe4fdd5f42fc9f9279b8c9fd9d |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset. | ai4bharat/IndicQA | [
"task_categories:question-answering",
"task_ids:closed-domain-qa",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:n<1K",
"source_datasets:original",
"language:as",
"language:bn",
"language:gu",
"language:hi",
"language:kn",
"language:ml",
"language:mr",
"language:or",
"language:pa",
"language:ta",
"language:te",
"license:cc-by-4.0",
"region:us"
] | 2022-09-15T03:52:16+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["as", "bn", "gu", "hi", "kn", "ml", "mr", "or", "pa", "ta", "te"], "license": ["cc-by-4.0"], "multilinguality": ["multilingual"], "size_categories": ["n<1K"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": ["closed-domain-qa"], "pretty_name": "IndicQA", "tags": []} | 2023-06-20T02:03:32+00:00 | [] | [
"as",
"bn",
"gu",
"hi",
"kn",
"ml",
"mr",
"or",
"pa",
"ta",
"te"
] | TAGS
#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-expert-generated #language_creators-found #multilinguality-multilingual #size_categories-n<1K #source_datasets-original #language-Assamese #language-Bengali #language-Gujarati #language-Hindi #language-Kannada #language-Malayalam #language-Marathi #language-Oriya (macrolanguage) #language-Panjabi #language-Tamil #language-Telugu #license-cc-by-4.0 #region-us
|
# Dataset Card for [Dataset Name]
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
Thanks to @github-username for adding this dataset. | [
"# Dataset Card for [Dataset Name]",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] | [
"TAGS\n#task_categories-question-answering #task_ids-closed-domain-qa #annotations_creators-expert-generated #language_creators-found #multilinguality-multilingual #size_categories-n<1K #source_datasets-original #language-Assamese #language-Bengali #language-Gujarati #language-Hindi #language-Kannada #language-Malayalam #language-Marathi #language-Oriya (macrolanguage) #language-Panjabi #language-Tamil #language-Telugu #license-cc-by-4.0 #region-us \n",
"# Dataset Card for [Dataset Name]",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage:\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions\n\nThanks to @github-username for adding this dataset."
] |
7d2f6a1445c3337a06a50a82775c613abe7cf508 |
# Dataset Card for Unannotated Spanish 3 Billion Words Corpora
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Source Data](#source-data)
- [Data Subset](#data-subset)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Repository:** https://github.com/josecannete/spanish-corpora
- **Paper:** https://users.dcc.uchile.cl/~jperez/papers/pml4dc2020.pdf
### Dataset Summary
* Number of lines: 300904000 (300M)
* Number of tokens: 2996016962 (3B)
* Number of chars: 18431160978 (18.4B)
### Languages
* Spanish
### Source Data
* Available to download here: [Zenodo](https://doi.org/10.5281/zenodo.3247731)
### Data Subset
* Spanish Wikis: Wich include Wikipedia, Wikinews, Wikiquotes and more. These were first processed with wikiextractor (https://github.com/josecannete/wikiextractorforBERT) using the wikis dump of 20/04/2019.
* ParaCrawl: Spanish portion of ParaCrawl (http://opus.nlpl.eu/ParaCrawl.php)
* EUBookshop: Spanish portion of EUBookshop (http://opus.nlpl.eu/EUbookshop.php)
* MultiUN: Spanish portion of MultiUN (http://opus.nlpl.eu/MultiUN.php)
* OpenSubtitles: Spanish portion of OpenSubtitles2018 (http://opus.nlpl.eu/OpenSubtitles-v2018.php)
* DGC: Spanish portion of DGT (http://opus.nlpl.eu/DGT.php)
* DOGC: Spanish portion of DOGC (http://opus.nlpl.eu/DOGC.php)
* ECB: Spanish portion of ECB (http://opus.nlpl.eu/ECB.php)
* EMEA: Spanish portion of EMEA (http://opus.nlpl.eu/EMEA.php)
* Europarl: Spanish portion of Europarl (http://opus.nlpl.eu/Europarl.php)
* GlobalVoices: Spanish portion of GlobalVoices (http://opus.nlpl.eu/GlobalVoices.php)
* JRC: Spanish portion of JRC (http://opus.nlpl.eu/JRC-Acquis.php)
* News-Commentary11: Spanish portion of NCv11 (http://opus.nlpl.eu/News-Commentary-v11.php)
* TED: Spanish portion of TED (http://opus.nlpl.eu/TED2013.php)
* UN: Spanish portion of UN (http://opus.nlpl.eu/UN.php)
## Additional Information
### Licensing Information
* [MIT Licence](https://github.com/josecannete/spanish-corpora/blob/master/LICENSE)
### Citation Information
```
@dataset{jose_canete_2019_3247731,
author = {José Cañete},
title = {Compilation of Large Spanish Unannotated Corpora},
month = may,
year = 2019,
publisher = {Zenodo},
doi = {10.5281/zenodo.3247731},
url = {https://doi.org/10.5281/zenodo.3247731}
}
@inproceedings{CaneteCFP2020,
title={Spanish Pre-Trained BERT Model and Evaluation Data},
author={Cañete, José and Chaperon, Gabriel and Fuentes, Rodrigo and Ho, Jou-Hui and Kang, Hojin and Pérez, Jorge},
booktitle={PML4DC at ICLR 2020},
year={2020}
}
``` | vialibre/splittedspanish3bwc | [
"multilinguality:monolingual",
"language:es",
"license:mit",
"region:us"
] | 2022-09-15T04:48:02+00:00 | {"language": ["es"], "license": ["mit"], "multilinguality": ["monolingual"], "pretty_name": "Unannotated Spanish 3 Billion Words Corpora"} | 2023-01-24T18:17:47+00:00 | [] | [
"es"
] | TAGS
#multilinguality-monolingual #language-Spanish #license-mit #region-us
|
# Dataset Card for Unannotated Spanish 3 Billion Words Corpora
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Languages
- Source Data
- Data Subset
- Additional Information
- Licensing Information
- Citation Information
## Dataset Description
- Repository: URL
- Paper: URL
### Dataset Summary
* Number of lines: 300904000 (300M)
* Number of tokens: 2996016962 (3B)
* Number of chars: 18431160978 (18.4B)
### Languages
* Spanish
### Source Data
* Available to download here: Zenodo
### Data Subset
* Spanish Wikis: Wich include Wikipedia, Wikinews, Wikiquotes and more. These were first processed with wikiextractor (URL using the wikis dump of 20/04/2019.
* ParaCrawl: Spanish portion of ParaCrawl (URL
* EUBookshop: Spanish portion of EUBookshop (URL
* MultiUN: Spanish portion of MultiUN (URL
* OpenSubtitles: Spanish portion of OpenSubtitles2018 (URL
* DGC: Spanish portion of DGT (URL
* DOGC: Spanish portion of DOGC (URL
* ECB: Spanish portion of ECB (URL
* EMEA: Spanish portion of EMEA (URL
* Europarl: Spanish portion of Europarl (URL
* GlobalVoices: Spanish portion of GlobalVoices (URL
* JRC: Spanish portion of JRC (URL
* News-Commentary11: Spanish portion of NCv11 (URL
* TED: Spanish portion of TED (URL
* UN: Spanish portion of UN (URL
## Additional Information
### Licensing Information
* MIT Licence
| [
"# Dataset Card for Unannotated Spanish 3 Billion Words Corpora",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n - Source Data\n - Data Subset\n- Additional Information\n - Licensing Information\n - Citation Information",
"## Dataset Description\n- Repository: URL\n- Paper: URL",
"### Dataset Summary\n* Number of lines: 300904000 (300M)\n* Number of tokens: 2996016962 (3B)\n* Number of chars: 18431160978 (18.4B)",
"### Languages\n* Spanish",
"### Source Data\n* Available to download here: Zenodo",
"### Data Subset\n* Spanish Wikis: Wich include Wikipedia, Wikinews, Wikiquotes and more. These were first processed with wikiextractor (URL using the wikis dump of 20/04/2019.\n* ParaCrawl: Spanish portion of ParaCrawl (URL\n* EUBookshop: Spanish portion of EUBookshop (URL\n* MultiUN: Spanish portion of MultiUN (URL\n* OpenSubtitles: Spanish portion of OpenSubtitles2018 (URL\n* DGC: Spanish portion of DGT (URL\n* DOGC: Spanish portion of DOGC (URL\n* ECB: Spanish portion of ECB (URL\n* EMEA: Spanish portion of EMEA (URL\n* Europarl: Spanish portion of Europarl (URL\n* GlobalVoices: Spanish portion of GlobalVoices (URL\n* JRC: Spanish portion of JRC (URL\n* News-Commentary11: Spanish portion of NCv11 (URL\n* TED: Spanish portion of TED (URL\n* UN: Spanish portion of UN (URL",
"## Additional Information",
"### Licensing Information\n\n* MIT Licence"
] | [
"TAGS\n#multilinguality-monolingual #language-Spanish #license-mit #region-us \n",
"# Dataset Card for Unannotated Spanish 3 Billion Words Corpora",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n - Source Data\n - Data Subset\n- Additional Information\n - Licensing Information\n - Citation Information",
"## Dataset Description\n- Repository: URL\n- Paper: URL",
"### Dataset Summary\n* Number of lines: 300904000 (300M)\n* Number of tokens: 2996016962 (3B)\n* Number of chars: 18431160978 (18.4B)",
"### Languages\n* Spanish",
"### Source Data\n* Available to download here: Zenodo",
"### Data Subset\n* Spanish Wikis: Wich include Wikipedia, Wikinews, Wikiquotes and more. These were first processed with wikiextractor (URL using the wikis dump of 20/04/2019.\n* ParaCrawl: Spanish portion of ParaCrawl (URL\n* EUBookshop: Spanish portion of EUBookshop (URL\n* MultiUN: Spanish portion of MultiUN (URL\n* OpenSubtitles: Spanish portion of OpenSubtitles2018 (URL\n* DGC: Spanish portion of DGT (URL\n* DOGC: Spanish portion of DOGC (URL\n* ECB: Spanish portion of ECB (URL\n* EMEA: Spanish portion of EMEA (URL\n* Europarl: Spanish portion of Europarl (URL\n* GlobalVoices: Spanish portion of GlobalVoices (URL\n* JRC: Spanish portion of JRC (URL\n* News-Commentary11: Spanish portion of NCv11 (URL\n* TED: Spanish portion of TED (URL\n* UN: Spanish portion of UN (URL",
"## Additional Information",
"### Licensing Information\n\n* MIT Licence"
] |
ceea7758a71df239a2aec65d28e54c5207f3e5b2 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: Adrian/distilbert-base-uncased-finetuned-squad-colab
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-c76793-16626245 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:51:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "Adrian/distilbert-base-uncased-finetuned-squad-colab", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T04:55:06+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: Adrian/distilbert-base-uncased-finetuned-squad-colab
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Adrian/distilbert-base-uncased-finetuned-squad-colab\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Adrian/distilbert-base-uncased-finetuned-squad-colab\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
cc9a1b600ae3a78649cb2aed244118c15eccadc4 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: 21iridescent/distilbert-base-uncased-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-c76793-16626243 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:51:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "21iridescent/distilbert-base-uncased-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T04:55:06+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: 21iridescent/distilbert-base-uncased-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: 21iridescent/distilbert-base-uncased-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: 21iridescent/distilbert-base-uncased-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
15a694a839c2cac55ecb0a6dc6a7ff1dfc395b2c | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: Akari/albert-base-v2-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-c76793-16626246 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:51:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "Akari/albert-base-v2-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T04:57:19+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: Akari/albert-base-v2-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Akari/albert-base-v2-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Akari/albert-base-v2-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
3ff4b745deb79d6834359d9e3d9d38fbecad9a80 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: 21iridescent/distilroberta-base-finetuned-squad2-lwt
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-c76793-16626244 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:51:49+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "21iridescent/distilroberta-base-finetuned-squad2-lwt", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T04:55:14+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: 21iridescent/distilroberta-base-finetuned-squad2-lwt
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: 21iridescent/distilroberta-base-finetuned-squad2-lwt\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: 21iridescent/distilroberta-base-finetuned-squad2-lwt\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
57b74ba8affbdcd36661fcd37b7b315f83c3cb31 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: Akihiro2/bert-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-c76793-16626247 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:57:00+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "Akihiro2/bert-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T05:01:39+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: Akihiro2/bert-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Akihiro2/bert-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Akihiro2/bert-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
307626be4df7c25e14c9e122770bea7b5c4b0a6d | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: AyushPJ/test-squad-trained-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-c76793-16626248 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:59:32+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "AyushPJ/test-squad-trained-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T05:02:49+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: AyushPJ/test-squad-trained-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: AyushPJ/test-squad-trained-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: AyushPJ/test-squad-trained-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
c036789ee389f8b75efc172316b8153ead77708e | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: haritzpuerto/MiniLM-L12-H384-uncased-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@timbmg](https://huggingface.co/timbmg) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-07bda3-16636249 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T04:59:33+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "haritzpuerto/MiniLM-L12-H384-uncased-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T05:03:24+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: haritzpuerto/MiniLM-L12-H384-uncased-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @timbmg for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: haritzpuerto/MiniLM-L12-H384-uncased-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @timbmg for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: haritzpuerto/MiniLM-L12-H384-uncased-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @timbmg for evaluating this model."
] |
14c2a7d0daa831f77cf485eda29f3b92bf5a9cb9 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: mrm8488/longformer-base-4096-finetuned-squadv2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Liam-Scott-Russell](https://huggingface.co/Liam-Scott-Russell) for evaluating this model. | autoevaluate/autoeval-staging-eval-squad_v2-squad_v2-972433-16666252 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T05:05:57+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "mrm8488/longformer-base-4096-finetuned-squadv2", "metrics": ["bertscore"], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-15T06:07:27+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: mrm8488/longformer-base-4096-finetuned-squadv2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @Liam-Scott-Russell for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: mrm8488/longformer-base-4096-finetuned-squadv2\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @Liam-Scott-Russell for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: mrm8488/longformer-base-4096-finetuned-squadv2\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @Liam-Scott-Russell for evaluating this model."
] |
4b1a960c1331c8bf2a9114b9bb8d895a0a317b64 |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Genes_Proteins_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
| Timofey/Genes_Proteins_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T08:38:09+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:01:38+00:00 | [
"2007.15779"
] | [] | TAGS
#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us
|
A PubMed-based dataset, used for the fine-tuning of the BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace card of the fine-tuned model.<br>
GitHub link with a notebooks, for the fine-tuning and application of the model.
| [] | [
"TAGS\n#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us \n"
] |
12a67fa2b064a06d7c22d3e32b223f484d2f3a57 |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Diseases_Side-Effects_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
--- | Timofey/Diseases_Side-Effects_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T08:48:34+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:01:08+00:00 | [
"2007.15779"
] | [] | TAGS
#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us
|
A PubMed-based dataset, used for the fine-tuning of the BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace card of the fine-tuned model.<br>
GitHub link with a notebooks, for the fine-tuning and application of the model.
--- | [] | [
"TAGS\n#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us \n"
] |
fc4e15ea42bdae5e66a3df41a9f047acda875ebf |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Pathways_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model. | Timofey/Pathways_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T08:55:55+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:02:39+00:00 | [
"2007.15779"
] | [] | TAGS
#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us
|
A PubMed-based dataset, used for the fine-tuning of the BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace card of the fine-tuned model.<br>
GitHub link with a notebooks, for the fine-tuning and application of the model. | [] | [
"TAGS\n#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us \n"
] |
a8d0fb879ef9b12fd3f2ceb910a25af0bfbea10f |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Cell_Components_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
| Timofey/Cell_Components_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T10:26:27+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:02:12+00:00 | [
"2007.15779"
] | [] | TAGS
#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us
|
A PubMed-based dataset, used for the fine-tuning of the BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace card of the fine-tuned model.<br>
GitHub link with a notebooks, for the fine-tuning and application of the model.
| [] | [
"TAGS\n#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us \n"
] |
86daa918401d71f6df102d24db7ed4bc60d39caa |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Drugs_Metabolites_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
| Timofey/Drugs_Metabolites_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T10:35:21+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:00:35+00:00 | [
"2007.15779"
] | [] | TAGS
#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us
|
A PubMed-based dataset, used for the fine-tuning of the BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace card of the fine-tuned model.<br>
GitHub link with a notebooks, for the fine-tuning and application of the model.
| [] | [
"TAGS\n#ANDDigest #ANDSystem #PubMed #arxiv-2007.15779 #region-us \n"
] |
dd7d748ed3c8e00fd078e625a01c2d9addff358b |
# Data card for Internet Archive historic book pages unlabelled.
- `10,844,387` unlabelled pages from historical books from the internet archive.
- Intended to be used for:
- pre-training computer vision models in an unsupervised manner
- using weak supervision to generate labels | ImageIN/IA_unlabelled | [
"region:us"
] | 2022-09-15T12:52:19+00:00 | {"annotations_creators": [], "language_creators": [], "language": [], "license": [], "multilinguality": [], "size_categories": [], "source_datasets": [], "task_categories": [], "task_ids": [], "pretty_name": "Internet Archive historic book pages unlabelled.", "tags": []} | 2022-10-21T13:38:12+00:00 | [] | [] | TAGS
#region-us
|
# Data card for Internet Archive historic book pages unlabelled.
- '10,844,387' unlabelled pages from historical books from the internet archive.
- Intended to be used for:
- pre-training computer vision models in an unsupervised manner
- using weak supervision to generate labels | [
"# Data card for Internet Archive historic book pages unlabelled.\n\n\n- '10,844,387' unlabelled pages from historical books from the internet archive.\n- Intended to be used for:\n - pre-training computer vision models in an unsupervised manner\n - using weak supervision to generate labels"
] | [
"TAGS\n#region-us \n",
"# Data card for Internet Archive historic book pages unlabelled.\n\n\n- '10,844,387' unlabelled pages from historical books from the internet archive.\n- Intended to be used for:\n - pre-training computer vision models in an unsupervised manner\n - using weak supervision to generate labels"
] |
e0aa6f54740139a2bde073beac5f93403ed2e990 | annotations_creators:
- no-annotation
languages:
-English
All data pulled from Gene Expression Omnibus website. tab separated file with GSE number followed by title and abstract text. | spiccolo/gene_expression_omnibus_nlp | [
"region:us"
] | 2022-09-15T14:53:44+00:00 | {} | 2022-10-13T15:34:55+00:00 | [] | [] | TAGS
#region-us
| annotations_creators:
- no-annotation
languages:
-English
All data pulled from Gene Expression Omnibus website. tab separated file with GSE number followed by title and abstract text. | [] | [
"TAGS\n#region-us \n"
] |
7b976142cd87d9b99c4e9841a3c579e99eee09ed | # AutoTrain Dataset for project: ratnakar_1000_sample_curated
## Dataset Description
This dataset has been automatically processed by AutoTrain for project ratnakar_1000_sample_curated.
### Languages
The BCP-47 code for the dataset's language is en.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"tokens": [
"INTRADAY",
"NAHARINDUS",
" ABOVE ",
"128",
" - 129 SL ",
"126",
" TARGET ",
"140",
" "
],
"tags": [
8,
10,
0,
3,
0,
9,
0,
5,
0
]
},
{
"tokens": [
"INTRADAY",
"ASTRON",
" ABV ",
"39",
" SL ",
"37.50",
" TARGET ",
"45",
" "
],
"tags": [
8,
10,
0,
3,
0,
9,
0,
5,
0
]
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"tokens": "Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)",
"tags": "Sequence(feature=ClassLabel(num_classes=12, names=['NANA', 'btst', 'delivery', 'enter', 'entry_momentum', 'exit', 'exit2', 'exit3', 'intraday', 'sl', 'symbol', 'touched'], id=None), length=-1, id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 726 |
| valid | 259 |
# GitHub Link to this project : [Telegram Trade Msg Backtest ML](https://github.com/hemangjoshi37a/TelegramTradeMsgBacktestML)
# Need custom model for your application? : Place a order on hjLabs.in : [Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning](https://hjlabs.in/product/custom-token-classification-or-named-entity-recognition-ner-model-as-in-natural-language-processing-nlp-machine-learning/)
## What this repository contains? :
1. Label data using LabelStudio NER(Named Entity Recognition or Token Classification) tool.
 convert to 
2. Convert LabelStudio CSV or JSON to HuggingFace-autoTrain dataset conversion script

3. Train NER model on Hugginface-autoTrain.

4. Use Hugginface-autoTrain model to predict labels on new data in LabelStudio using LabelStudio-ML-Backend.



5. Define python function to predict labels using Hugginface-autoTrain model.


6. Only label new data from newly predicted-labels-dataset that has falsified labels.

7. Backtest Truely labelled dataset against real historical data of the stock using zerodha kiteconnect and jugaad_trader.
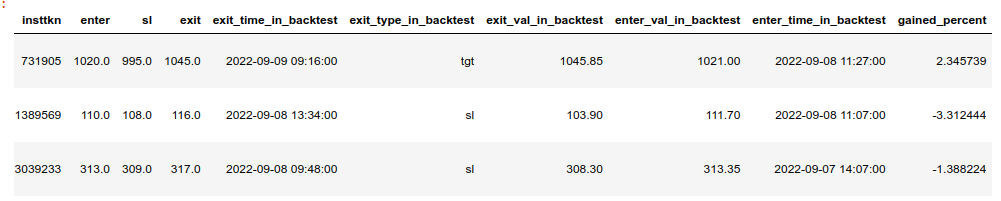
8. Evaluate total gained percentage since inception summation-wise and compounded and plot.

9. Listen to telegram channel for new LIVE messages using telegram API for algotrading.

10. Serve the app as flask web API for web request and respond to it as labelled tokens.
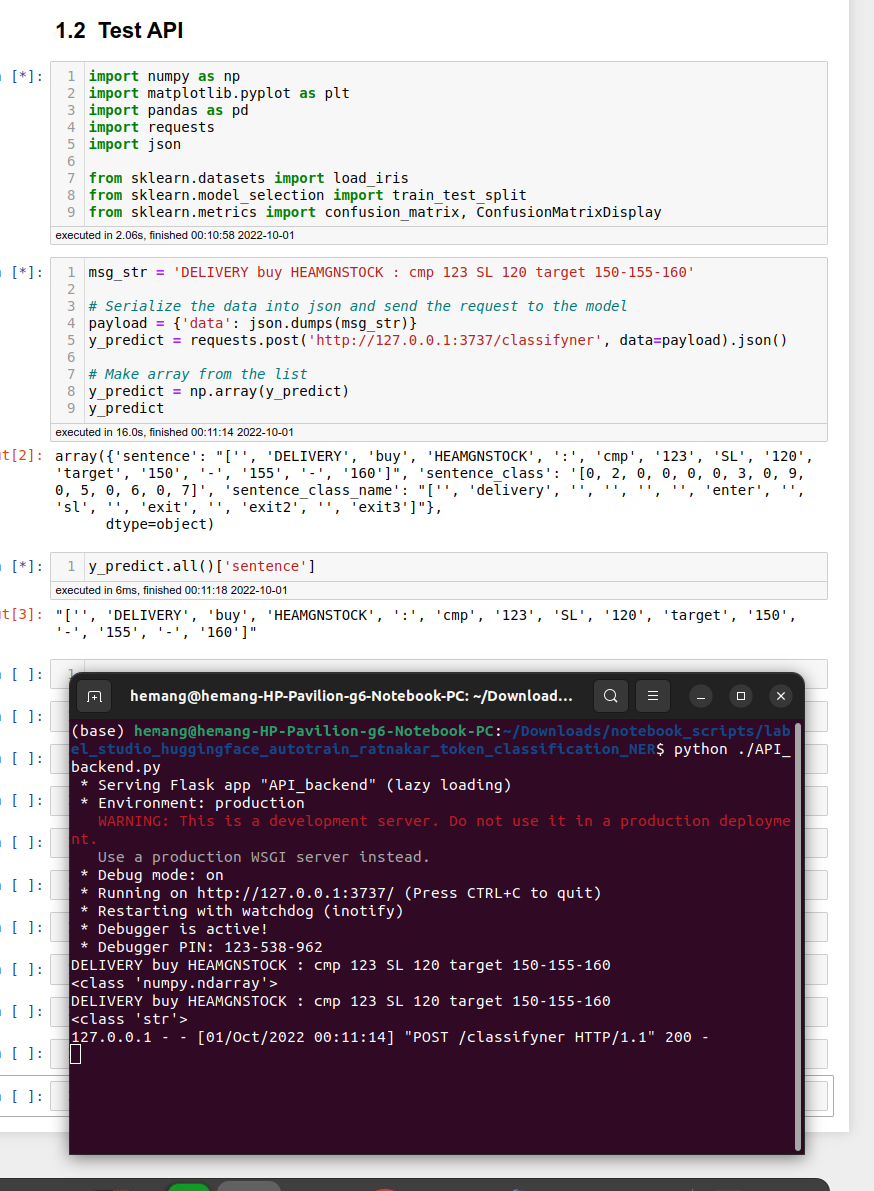
11. Outperforming or underperforming results of the telegram channel tips against exchange index by percentage.
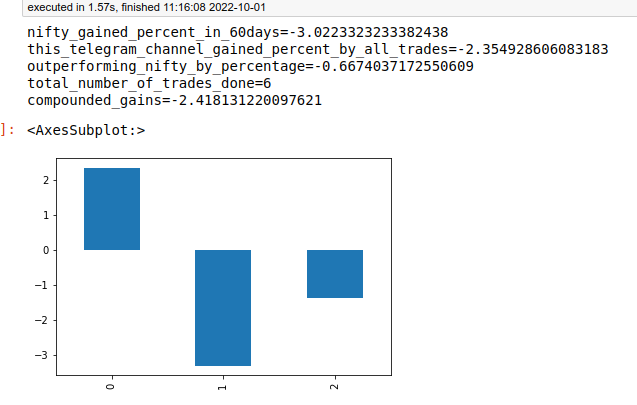
Place a custom order on hjLabs.in : [https://hjLabs.in](https://hjlabs.in/?product=custom-algotrading-software-for-zerodha-and-angel-w-source-code)
----------------------------------------------------------------------
### Contact us
Mobile : [+917016525813](tel:+917016525813)
Whatsapp & Telegram : [+919409077371](tel:+919409077371)
Email : [[email protected]](mailto:[email protected])
Place a custom order on hjLabs.in : [https://hjLabs.in](https://hjlabs.in/)
Please contribute your suggestions and corections to support our efforts.
Thank you.
Buy us a coffee for $5 on PayPal ?
[](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=5JXC8VRCSUZWJ)
----------------------------------------------------------------------
### Checkout Our Other Repositories
- [pyPortMan](https://github.com/hemangjoshi37a/pyPortMan)
- [transformers_stock_prediction](https://github.com/hemangjoshi37a/transformers_stock_prediction)
- [TrendMaster](https://github.com/hemangjoshi37a/TrendMaster)
- [hjAlgos_notebooks](https://github.com/hemangjoshi37a/hjAlgos_notebooks)
- [AutoCut](https://github.com/hemangjoshi37a/AutoCut)
- [My_Projects](https://github.com/hemangjoshi37a/My_Projects)
- [Cool Arduino and ESP8266 or NodeMCU Projects](https://github.com/hemangjoshi37a/my_Arduino)
- [Telegram Trade Msg Backtest ML](https://github.com/hemangjoshi37a/TelegramTradeMsgBacktestML)
### Checkout Our Other Products
- [WiFi IoT LED Matrix Display](https://hjlabs.in/product/wifi-iot-led-display)
- [SWiBoard WiFi Switch Board IoT Device](https://hjlabs.in/product/swiboard-wifi-switch-board-iot-device)
- [Electric Bicycle](https://hjlabs.in/product/electric-bicycle)
- [Product 3D Design Service with Solidworks](https://hjlabs.in/product/product-3d-design-with-solidworks/)
- [AutoCut : Automatic Wire Cutter Machine](https://hjlabs.in/product/automatic-wire-cutter-machine/)
- [Custom AlgoTrading Software Coding Services](https://hjlabs.in/product/custom-algotrading-software-for-zerodha-and-angel-w-source-code//)
- [SWiBoard :Tasmota MQTT Control App](https://play.google.com/store/apps/details?id=in.hjlabs.swiboard)
- [Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning](https://hjlabs.in/product/custom-token-classification-or-named-entity-recognition-ner-model-as-in-natural-language-processing-nlp-machine-learning/)
## Some Cool Arduino and ESP8266 (or NodeMCU) IoT projects:
- [IoT_LED_over_ESP8266_NodeMCU : Turn LED on and off using web server hosted on a nodemcu or esp8266](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_LED_over_ESP8266_NodeMCU)
- [ESP8266_NodeMCU_BasicOTA : Simple OTA (Over The Air) upload code from Arduino IDE using WiFi to NodeMCU or ESP8266](https://github.com/hemangjoshi37a/my_Arduino/tree/master/ESP8266_NodeMCU_BasicOTA)
- [IoT_CSV_SD : Read analog value of Voltage and Current and write it to SD Card in CSV format for Arduino, ESP8266, NodeMCU etc](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_CSV_SD)
- [Honeywell_I2C_Datalogger : Log data in A SD Card from a Honeywell I2C HIH8000 or HIH6000 series sensor having external I2C RTC clock](https://github.com/hemangjoshi37a/my_Arduino/tree/master/Honeywell_I2C_Datalogger)
- [IoT_Load_Cell_using_ESP8266_NodeMC : Read ADC value from High Precision 12bit ADS1015 ADC Sensor and Display on SSD1306 SPI Display as progress bar for Arduino or ESP8266 or NodeMCU](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_Load_Cell_using_ESP8266_NodeMC)
- [IoT_SSD1306_ESP8266_NodeMCU : Read from High Precision 12bit ADC seonsor ADS1015 and display to SSD1306 SPI as progress bar in ESP8266 or NodeMCU or Arduino](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_SSD1306_ESP8266_NodeMCU)
## Checkout Our Awesome 3D GrabCAD Models:
- [AutoCut : Automatic Wire Cutter Machine](https://grabcad.com/library/automatic-wire-cutter-machine-1)
- [ESP Matrix Display 5mm Acrylic Box](https://grabcad.com/library/esp-matrix-display-5mm-acrylic-box-1)
- [Arcylic Bending Machine w/ Hot Air Gun](https://grabcad.com/library/arcylic-bending-machine-w-hot-air-gun-1)
- [Automatic Wire Cutter/Stripper](https://grabcad.com/library/automatic-wire-cutter-stripper-1)
## Our HuggingFace Models :
- [hemangjoshi37a/autotrain-ratnakar_1000_sample_curated-1474454086 : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.](https://huggingface.co/hemangjoshi37a/autotrain-ratnakar_1000_sample_curated-1474454086)
## Our HuggingFace Datasets :
- [hemangjoshi37a/autotrain-data-ratnakar_1000_sample_curated : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.](https://huggingface.co/datasets/hemangjoshi37a/autotrain-data-ratnakar_1000_sample_curated)
## We sell Gigs on Fiverr :
- [code android and ios app for you using flutter firebase software stack](https://business.fiverr.com/share/3v14pr)
- [code custom algotrading software for zerodha or angel broking](https://business.fiverr.com/share/kzkvEy)
## Awesome Fiverr. Gigs:
- [develop machine learning ner model as in nlp using python](https://www.fiverr.com/share/9YNabx)
- [train custom chatgpt question answering model](https://www.fiverr.com/share/rwx6r7)
- [build algotrading, backtesting and stock monitoring tools using python](https://www.fiverr.com/share/A7Y14q)
- [tutor you in your science problems](https://www.fiverr.com/share/zPzmlz)
- [make apps for you crossplatform ](https://www.fiverr.com/share/BGw12l)
| hemangjoshi37a/autotrain-data-ratnakar_1000_sample_curated | [
"language:en",
"region:us"
] | 2022-09-15T16:35:58+00:00 | {"language": ["en"]} | 2023-02-16T12:45:39+00:00 | [] | [
"en"
] | TAGS
#language-English #region-us
| AutoTrain Dataset for project: ratnakar\_1000\_sample\_curated
==============================================================
Dataset Description
-------------------
This dataset has been automatically processed by AutoTrain for project ratnakar\_1000\_sample\_curated.
### Languages
The BCP-47 code for the dataset's language is en.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
GitHub Link to this project : Telegram Trade Msg Backtest ML
============================================================
Need custom model for your application? : Place a order on URL : Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning
=============================================================================================================================================================================================
What this repository contains? :
--------------------------------
1. Label data using LabelStudio NER(Named Entity Recognition or Token Classification) tool.
!Screenshot from 2022-09-30 12-28-50 convert to !Screenshot from 2022-09-30 18-59-14
2. Convert LabelStudio CSV or JSON to HuggingFace-autoTrain dataset conversion script
!Screenshot from 2022-10-01 10-36-03
3. Train NER model on Hugginface-autoTrain.
!Screenshot from 2022-10-01 10-38-24
4. Use Hugginface-autoTrain model to predict labels on new data in LabelStudio using LabelStudio-ML-Backend.
!Screenshot from 2022-10-01 10-41-07
!Screenshot from 2022-10-01 10-42-36
!Screenshot from 2022-10-01 10-44-56
5. Define python function to predict labels using Hugginface-autoTrain model.
!Screenshot from 2022-10-01 10-47-08
!Screenshot from 2022-10-01 10-47-25
6. Only label new data from newly predicted-labels-dataset that has falsified labels.
!Screenshot from 2022-09-30 22-47-23
7. Backtest Truely labelled dataset against real historical data of the stock using zerodha kiteconnect and jugaad\_trader.
!Screenshot from 2022-10-01 00-05-55
8. Evaluate total gained percentage since inception summation-wise and compounded and plot.
!Screenshot from 2022-10-01 00-06-59
9. Listen to telegram channel for new LIVE messages using telegram API for algotrading.
!Screenshot from 2022-10-01 00-09-29
10. Serve the app as flask web API for web request and respond to it as labelled tokens.
!Screenshot from 2022-10-01 00-12-12
11. Outperforming or underperforming results of the telegram channel tips against exchange index by percentage.
!Screenshot from 2022-10-01 11-16-27
Place a custom order on URL : URL
---
### Contact us
Mobile : +917016525813
Whatsapp & Telegram : +919409077371
Email : hemangjoshi37a@URL
Place a custom order on URL : URL
Please contribute your suggestions and corections to support our efforts.
Thank you.
Buy us a coffee for $5 on PayPal ?
 model as in Natural Language Processing (NLP) Machine Learning
Some Cool Arduino and ESP8266 (or NodeMCU) IoT projects:
--------------------------------------------------------
* IoT\_LED\_over\_ESP8266\_NodeMCU : Turn LED on and off using web server hosted on a nodemcu or esp8266
* ESP8266\_NodeMCU\_BasicOTA : Simple OTA (Over The Air) upload code from Arduino IDE using WiFi to NodeMCU or ESP8266
* IoT\_CSV\_SD : Read analog value of Voltage and Current and write it to SD Card in CSV format for Arduino, ESP8266, NodeMCU etc
* Honeywell\_I2C\_Datalogger : Log data in A SD Card from a Honeywell I2C HIH8000 or HIH6000 series sensor having external I2C RTC clock
* IoT\_Load\_Cell\_using\_ESP8266\_NodeMC : Read ADC value from High Precision 12bit ADS1015 ADC Sensor and Display on SSD1306 SPI Display as progress bar for Arduino or ESP8266 or NodeMCU
* IoT\_SSD1306\_ESP8266\_NodeMCU : Read from High Precision 12bit ADC seonsor ADS1015 and display to SSD1306 SPI as progress bar in ESP8266 or NodeMCU or Arduino
Checkout Our Awesome 3D GrabCAD Models:
---------------------------------------
* AutoCut : Automatic Wire Cutter Machine
* ESP Matrix Display 5mm Acrylic Box
* Arcylic Bending Machine w/ Hot Air Gun
* Automatic Wire Cutter/Stripper
Our HuggingFace Models :
------------------------
* hemangjoshi37a/autotrain-ratnakar\_1000\_sample\_curated-1474454086 : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.
Our HuggingFace Datasets :
--------------------------
* hemangjoshi37a/autotrain-data-ratnakar\_1000\_sample\_curated : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.
We sell Gigs on Fiverr :
------------------------
* code android and ios app for you using flutter firebase software stack
* code custom algotrading software for zerodha or angel broking
Awesome Fiverr. Gigs:
---------------------
* develop machine learning ner model as in nlp using python
* train custom chatgpt question answering model
* build algotrading, backtesting and stock monitoring tools using python
* tutor you in your science problems
* make apps for you crossplatform
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:\n\n\n\nGitHub Link to this project : Telegram Trade Msg Backtest ML\n============================================================\n\n\nNeed custom model for your application? : Place a order on URL : Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning\n=============================================================================================================================================================================================\n\n\nWhat this repository contains? :\n--------------------------------\n\n\n1. Label data using LabelStudio NER(Named Entity Recognition or Token Classification) tool.\n!Screenshot from 2022-09-30 12-28-50 convert to !Screenshot from 2022-09-30 18-59-14\n2. Convert LabelStudio CSV or JSON to HuggingFace-autoTrain dataset conversion script\n!Screenshot from 2022-10-01 10-36-03\n3. Train NER model on Hugginface-autoTrain.\n!Screenshot from 2022-10-01 10-38-24\n4. Use Hugginface-autoTrain model to predict labels on new data in LabelStudio using LabelStudio-ML-Backend.\n!Screenshot from 2022-10-01 10-41-07\n!Screenshot from 2022-10-01 10-42-36\n!Screenshot from 2022-10-01 10-44-56\n5. Define python function to predict labels using Hugginface-autoTrain model.\n!Screenshot from 2022-10-01 10-47-08\n!Screenshot from 2022-10-01 10-47-25\n6. Only label new data from newly predicted-labels-dataset that has falsified labels.\n!Screenshot from 2022-09-30 22-47-23\n7. Backtest Truely labelled dataset against real historical data of the stock using zerodha kiteconnect and jugaad\\_trader.\n!Screenshot from 2022-10-01 00-05-55\n8. Evaluate total gained percentage since inception summation-wise and compounded and plot.\n!Screenshot from 2022-10-01 00-06-59\n9. Listen to telegram channel for new LIVE messages using telegram API for algotrading.\n!Screenshot from 2022-10-01 00-09-29\n10. Serve the app as flask web API for web request and respond to it as labelled tokens.\n!Screenshot from 2022-10-01 00-12-12\n11. Outperforming or underperforming results of the telegram channel tips against exchange index by percentage.\n!Screenshot from 2022-10-01 11-16-27\n\n\nPlace a custom order on URL : URL\n\n\n\n\n---",
"### Contact us\n\n\nMobile : +917016525813\nWhatsapp & Telegram : +919409077371\n\n\nEmail : hemangjoshi37a@URL\n\n\nPlace a custom order on URL : URL\n\n\nPlease contribute your suggestions and corections to support our efforts.\n\n\nThank you.\n\n\nBuy us a coffee for $5 on PayPal ?\n\n\n model as in Natural Language Processing (NLP) Machine Learning\n\n\nSome Cool Arduino and ESP8266 (or NodeMCU) IoT projects:\n--------------------------------------------------------\n\n\n* IoT\\_LED\\_over\\_ESP8266\\_NodeMCU : Turn LED on and off using web server hosted on a nodemcu or esp8266\n* ESP8266\\_NodeMCU\\_BasicOTA : Simple OTA (Over The Air) upload code from Arduino IDE using WiFi to NodeMCU or ESP8266\n* IoT\\_CSV\\_SD : Read analog value of Voltage and Current and write it to SD Card in CSV format for Arduino, ESP8266, NodeMCU etc\n* Honeywell\\_I2C\\_Datalogger : Log data in A SD Card from a Honeywell I2C HIH8000 or HIH6000 series sensor having external I2C RTC clock\n* IoT\\_Load\\_Cell\\_using\\_ESP8266\\_NodeMC : Read ADC value from High Precision 12bit ADS1015 ADC Sensor and Display on SSD1306 SPI Display as progress bar for Arduino or ESP8266 or NodeMCU\n* IoT\\_SSD1306\\_ESP8266\\_NodeMCU : Read from High Precision 12bit ADC seonsor ADS1015 and display to SSD1306 SPI as progress bar in ESP8266 or NodeMCU or Arduino\n\n\nCheckout Our Awesome 3D GrabCAD Models:\n---------------------------------------\n\n\n* AutoCut : Automatic Wire Cutter Machine\n* ESP Matrix Display 5mm Acrylic Box\n* Arcylic Bending Machine w/ Hot Air Gun\n* Automatic Wire Cutter/Stripper\n\n\nOur HuggingFace Models :\n------------------------\n\n\n* hemangjoshi37a/autotrain-ratnakar\\_1000\\_sample\\_curated-1474454086 : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.\n\n\nOur HuggingFace Datasets :\n--------------------------\n\n\n* hemangjoshi37a/autotrain-data-ratnakar\\_1000\\_sample\\_curated : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.\n\n\nWe sell Gigs on Fiverr :\n------------------------\n\n\n* code android and ios app for you using flutter firebase software stack\n* code custom algotrading software for zerodha or angel broking\n\n\nAwesome Fiverr. Gigs:\n---------------------\n\n\n* develop machine learning ner model as in nlp using python\n* train custom chatgpt question answering model\n* build algotrading, backtesting and stock monitoring tools using python\n* tutor you in your science problems\n* make apps for you crossplatform"
] | [
"TAGS\n#language-English #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:\n\n\n\nGitHub Link to this project : Telegram Trade Msg Backtest ML\n============================================================\n\n\nNeed custom model for your application? : Place a order on URL : Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning\n=============================================================================================================================================================================================\n\n\nWhat this repository contains? :\n--------------------------------\n\n\n1. Label data using LabelStudio NER(Named Entity Recognition or Token Classification) tool.\n!Screenshot from 2022-09-30 12-28-50 convert to !Screenshot from 2022-09-30 18-59-14\n2. Convert LabelStudio CSV or JSON to HuggingFace-autoTrain dataset conversion script\n!Screenshot from 2022-10-01 10-36-03\n3. Train NER model on Hugginface-autoTrain.\n!Screenshot from 2022-10-01 10-38-24\n4. Use Hugginface-autoTrain model to predict labels on new data in LabelStudio using LabelStudio-ML-Backend.\n!Screenshot from 2022-10-01 10-41-07\n!Screenshot from 2022-10-01 10-42-36\n!Screenshot from 2022-10-01 10-44-56\n5. Define python function to predict labels using Hugginface-autoTrain model.\n!Screenshot from 2022-10-01 10-47-08\n!Screenshot from 2022-10-01 10-47-25\n6. Only label new data from newly predicted-labels-dataset that has falsified labels.\n!Screenshot from 2022-09-30 22-47-23\n7. Backtest Truely labelled dataset against real historical data of the stock using zerodha kiteconnect and jugaad\\_trader.\n!Screenshot from 2022-10-01 00-05-55\n8. Evaluate total gained percentage since inception summation-wise and compounded and plot.\n!Screenshot from 2022-10-01 00-06-59\n9. Listen to telegram channel for new LIVE messages using telegram API for algotrading.\n!Screenshot from 2022-10-01 00-09-29\n10. Serve the app as flask web API for web request and respond to it as labelled tokens.\n!Screenshot from 2022-10-01 00-12-12\n11. Outperforming or underperforming results of the telegram channel tips against exchange index by percentage.\n!Screenshot from 2022-10-01 11-16-27\n\n\nPlace a custom order on URL : URL\n\n\n\n\n---",
"### Contact us\n\n\nMobile : +917016525813\nWhatsapp & Telegram : +919409077371\n\n\nEmail : hemangjoshi37a@URL\n\n\nPlace a custom order on URL : URL\n\n\nPlease contribute your suggestions and corections to support our efforts.\n\n\nThank you.\n\n\nBuy us a coffee for $5 on PayPal ?\n\n\n model as in Natural Language Processing (NLP) Machine Learning\n\n\nSome Cool Arduino and ESP8266 (or NodeMCU) IoT projects:\n--------------------------------------------------------\n\n\n* IoT\\_LED\\_over\\_ESP8266\\_NodeMCU : Turn LED on and off using web server hosted on a nodemcu or esp8266\n* ESP8266\\_NodeMCU\\_BasicOTA : Simple OTA (Over The Air) upload code from Arduino IDE using WiFi to NodeMCU or ESP8266\n* IoT\\_CSV\\_SD : Read analog value of Voltage and Current and write it to SD Card in CSV format for Arduino, ESP8266, NodeMCU etc\n* Honeywell\\_I2C\\_Datalogger : Log data in A SD Card from a Honeywell I2C HIH8000 or HIH6000 series sensor having external I2C RTC clock\n* IoT\\_Load\\_Cell\\_using\\_ESP8266\\_NodeMC : Read ADC value from High Precision 12bit ADS1015 ADC Sensor and Display on SSD1306 SPI Display as progress bar for Arduino or ESP8266 or NodeMCU\n* IoT\\_SSD1306\\_ESP8266\\_NodeMCU : Read from High Precision 12bit ADC seonsor ADS1015 and display to SSD1306 SPI as progress bar in ESP8266 or NodeMCU or Arduino\n\n\nCheckout Our Awesome 3D GrabCAD Models:\n---------------------------------------\n\n\n* AutoCut : Automatic Wire Cutter Machine\n* ESP Matrix Display 5mm Acrylic Box\n* Arcylic Bending Machine w/ Hot Air Gun\n* Automatic Wire Cutter/Stripper\n\n\nOur HuggingFace Models :\n------------------------\n\n\n* hemangjoshi37a/autotrain-ratnakar\\_1000\\_sample\\_curated-1474454086 : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.\n\n\nOur HuggingFace Datasets :\n--------------------------\n\n\n* hemangjoshi37a/autotrain-data-ratnakar\\_1000\\_sample\\_curated : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.\n\n\nWe sell Gigs on Fiverr :\n------------------------\n\n\n* code android and ios app for you using flutter firebase software stack\n* code custom algotrading software for zerodha or angel broking\n\n\nAwesome Fiverr. Gigs:\n---------------------\n\n\n* develop machine learning ner model as in nlp using python\n* train custom chatgpt question answering model\n* build algotrading, backtesting and stock monitoring tools using python\n* tutor you in your science problems\n* make apps for you crossplatform"
] |
f5295abf41f24f8fc5b9790311a2484400dcdf00 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-autoevaluate__zero-shot-classification-sample-autoevalu-acab52-16766274 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T17:06:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["autoevaluate/zero-shot-classification-sample"], "eval_info": {"task": "text_zero_shot_classification", "model": "autoevaluate/zero-shot-classification", "metrics": [], "dataset_name": "autoevaluate/zero-shot-classification-sample", "dataset_config": "autoevaluate--zero-shot-classification-sample", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-15T18:13:14+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: autoevaluate/zero-shot-classification\n* Dataset: autoevaluate/zero-shot-classification-sample\n* Config: autoevaluate--zero-shot-classification-sample\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: autoevaluate/zero-shot-classification\n* Dataset: autoevaluate/zero-shot-classification-sample\n* Config: autoevaluate--zero-shot-classification-sample\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
be8e467ab348721baeae3c5e8761e120f1b9e341 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: Tristan/zero_shot_classification_test
* Config: Tristan--zero_shot_classification_test
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Tristan](https://huggingface.co/Tristan) for evaluating this model. | autoevaluate/autoeval-staging-eval-Tristan__zero_shot_classification_test-Tristan__zero_sh-997db8-16786276 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T18:25:59+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["Tristan/zero_shot_classification_test"], "eval_info": {"task": "text_zero_shot_classification", "model": "autoevaluate/zero-shot-classification", "metrics": [], "dataset_name": "Tristan/zero_shot_classification_test", "dataset_config": "Tristan--zero_shot_classification_test", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-15T18:26:29+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: Tristan/zero_shot_classification_test
* Config: Tristan--zero_shot_classification_test
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @Tristan for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: autoevaluate/zero-shot-classification\n* Dataset: Tristan/zero_shot_classification_test\n* Config: Tristan--zero_shot_classification_test\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @Tristan for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: autoevaluate/zero-shot-classification\n* Dataset: Tristan/zero_shot_classification_test\n* Config: Tristan--zero_shot_classification_test\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @Tristan for evaluating this model."
] |
c2a2bfe23d23992408295e0dcaa40e1d06fbacc9 |
# openwebtext_20p
## Dataset Description
- **Origin:** [openwebtext](https://huggingface.co/datasets/openwebtext)
- **Download Size** 4.60 GiB
- **Generated Size** 7.48 GiB
- **Total Size** 12.08 GiB
first 20% of [openwebtext](https://huggingface.co/datasets/openwebtext) | Bingsu/openwebtext_20p | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:extended|openwebtext",
"language:en",
"license:cc0-1.0",
"region:us"
] | 2022-09-16T01:15:16+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["found"], "language": ["en"], "license": ["cc0-1.0"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["extended|openwebtext"], "task_categories": ["text-generation", "fill-mask"], "task_ids": ["language-modeling", "masked-language-modeling"], "paperswithcode_id": "openwebtext", "pretty_name": "openwebtext_20p"} | 2022-09-16T01:36:38+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-generation #task_categories-fill-mask #task_ids-language-modeling #task_ids-masked-language-modeling #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-1M<n<10M #source_datasets-extended|openwebtext #language-English #license-cc0-1.0 #region-us
|
# openwebtext_20p
## Dataset Description
- Origin: openwebtext
- Download Size 4.60 GiB
- Generated Size 7.48 GiB
- Total Size 12.08 GiB
first 20% of openwebtext | [
"# openwebtext_20p",
"## Dataset Description\n- Origin: openwebtext\n- Download Size 4.60 GiB\n- Generated Size 7.48 GiB\n- Total Size 12.08 GiB\n\nfirst 20% of openwebtext"
] | [
"TAGS\n#task_categories-text-generation #task_categories-fill-mask #task_ids-language-modeling #task_ids-masked-language-modeling #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-1M<n<10M #source_datasets-extended|openwebtext #language-English #license-cc0-1.0 #region-us \n",
"# openwebtext_20p",
"## Dataset Description\n- Origin: openwebtext\n- Download Size 4.60 GiB\n- Generated Size 7.48 GiB\n- Total Size 12.08 GiB\n\nfirst 20% of openwebtext"
] |
a99cdd9ebcda07905cf2d6c5cdf58b70c43cce8e |
# Dataset Card for Kelly
Keywords for Language Learning for Young and adults alike
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://spraakbanken.gu.se/en/resources/kelly
- **Paper:** https://link.springer.com/article/10.1007/s10579-013-9251-2
### Dataset Summary
The Swedish Kelly list is a freely available frequency-based vocabulary list
that comprises general-purpose language of modern Swedish. The list was
generated from a large web-acquired corpus (SweWaC) of 114 million words
dating from the 2010s. It is adapted to the needs of language learners and
contains 8,425 most frequent lemmas that cover 80% of SweWaC.
### Languages
Swedish (sv-SE)
## Dataset Structure
### Data Instances
Here is a sample of the data:
```python
{
'id': 190,
'raw_frequency': 117835.0,
'relative_frequency': 1033.61,
'cefr_level': 'A1',
'source': 'SweWaC',
'marker': 'en',
'lemma': 'dag',
'pos': 'noun-en',
'examples': 'e.g. god dag'
}
```
This can be understood as:
> The common noun "dag" ("day") has a rank of 190 in the list. It was used 117,835
times in SweWaC, meaning it occured 1033.61 times per million words. This word
is among the most important vocabulary words for Swedish language learners and
should be learned at the A1 CEFR level. An example usage of this word is the
phrase "god dag" ("good day").
### Data Fields
- `id`: The row number for the data entry, starting at 1. Generally corresponds
to the rank of the word.
- `raw_frequency`: The raw frequency of the word.
- `relative_frequency`: The relative frequency of the word measured in
number of occurences per million words.
- `cefr_level`: The CEFR level (A1, A2, B1, B2, C1, C2) of the word.
- `source`: Whether the word came from SweWaC, translation lists (T2), or
was manually added (manual).
- `marker`: The grammatical marker of the word, if any, such as an article or
infinitive marker.
- `lemma`: The lemma of the word, sometimes provided with its spelling or
stylistic variants.
- `pos`: The word's part-of-speech.
- `examples`: Usage examples and comments. Only available for some of the words.
Manual entries were prepended to the list, giving them a higher rank than they
might otherwise have had. For example, the manual entry "Göteborg ("Gothenberg")
has a rank of 20, while the first non-manual entry "och" ("and") has a rank of
87. However, a conjunction and common stopword is far more likely to occur than
the name of a city.
### Data Splits
There is a single split, `train`.
## Dataset Creation
Please refer to the article [Corpus-based approaches for the creation of a frequency
based vocabulary list in the EU project KELLY – issues on reliability, validity and
coverage](https://gup.ub.gu.se/publication/148533?lang=en) for information about how
the original dataset was created and considerations for using the data.
**The following changes have been made to the original dataset**:
- Changed header names.
- Normalized the large web-acquired corpus name to "SweWac" in the `source` field.
- Set the relative frequency of manual entries to null rather than 1000000.
## Additional Information
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0)
### Citation Information
Please cite the authors if you use this dataset in your work:
```bibtex
@article{Kilgarriff2013,
doi = {10.1007/s10579-013-9251-2},
url = {https://doi.org/10.1007/s10579-013-9251-2},
year = {2013},
month = sep,
publisher = {Springer Science and Business Media {LLC}},
volume = {48},
number = {1},
pages = {121--163},
author = {Adam Kilgarriff and Frieda Charalabopoulou and Maria Gavrilidou and Janne Bondi Johannessen and Saussan Khalil and Sofie Johansson Kokkinakis and Robert Lew and Serge Sharoff and Ravikiran Vadlapudi and Elena Volodina},
title = {Corpus-based vocabulary lists for language learners for nine languages},
journal = {Language Resources and Evaluation}
}
```
### Contributions
Thanks to [@spraakbanken](https://github.com/spraakbanken) for creating this dataset
and to [@codesue](https://github.com/codesue) for adding it.
| codesue/kelly | [
"task_categories:text-classification",
"task_ids:text-scoring",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:sv",
"license:cc-by-4.0",
"lexicon",
"swedish",
"CEFR",
"region:us"
] | 2022-09-16T01:18:16+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["sv"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": [], "task_categories": ["text-classification"], "task_ids": ["text-scoring"], "pretty_name": "kelly", "tags": ["lexicon", "swedish", "CEFR"]} | 2022-12-18T22:06:55+00:00 | [] | [
"sv"
] | TAGS
#task_categories-text-classification #task_ids-text-scoring #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #language-Swedish #license-cc-by-4.0 #lexicon #swedish #CEFR #region-us
|
# Dataset Card for Kelly
Keywords for Language Learning for Young and adults alike
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Additional Information
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Paper: URL
### Dataset Summary
The Swedish Kelly list is a freely available frequency-based vocabulary list
that comprises general-purpose language of modern Swedish. The list was
generated from a large web-acquired corpus (SweWaC) of 114 million words
dating from the 2010s. It is adapted to the needs of language learners and
contains 8,425 most frequent lemmas that cover 80% of SweWaC.
### Languages
Swedish (sv-SE)
## Dataset Structure
### Data Instances
Here is a sample of the data:
This can be understood as:
> The common noun "dag" ("day") has a rank of 190 in the list. It was used 117,835
times in SweWaC, meaning it occured 1033.61 times per million words. This word
is among the most important vocabulary words for Swedish language learners and
should be learned at the A1 CEFR level. An example usage of this word is the
phrase "god dag" ("good day").
### Data Fields
- 'id': The row number for the data entry, starting at 1. Generally corresponds
to the rank of the word.
- 'raw_frequency': The raw frequency of the word.
- 'relative_frequency': The relative frequency of the word measured in
number of occurences per million words.
- 'cefr_level': The CEFR level (A1, A2, B1, B2, C1, C2) of the word.
- 'source': Whether the word came from SweWaC, translation lists (T2), or
was manually added (manual).
- 'marker': The grammatical marker of the word, if any, such as an article or
infinitive marker.
- 'lemma': The lemma of the word, sometimes provided with its spelling or
stylistic variants.
- 'pos': The word's part-of-speech.
- 'examples': Usage examples and comments. Only available for some of the words.
Manual entries were prepended to the list, giving them a higher rank than they
might otherwise have had. For example, the manual entry "Göteborg ("Gothenberg")
has a rank of 20, while the first non-manual entry "och" ("and") has a rank of
87. However, a conjunction and common stopword is far more likely to occur than
the name of a city.
### Data Splits
There is a single split, 'train'.
## Dataset Creation
Please refer to the article Corpus-based approaches for the creation of a frequency
based vocabulary list in the EU project KELLY – issues on reliability, validity and
coverage for information about how
the original dataset was created and considerations for using the data.
The following changes have been made to the original dataset:
- Changed header names.
- Normalized the large web-acquired corpus name to "SweWac" in the 'source' field.
- Set the relative frequency of manual entries to null rather than 1000000.
## Additional Information
### Licensing Information
CC BY 4.0
Please cite the authors if you use this dataset in your work:
### Contributions
Thanks to @spraakbanken for creating this dataset
and to @codesue for adding it.
| [
"# Dataset Card for Kelly\n\nKeywords for Language Learning for Young and adults alike",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n- Additional Information\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Paper: URL",
"### Dataset Summary\n\nThe Swedish Kelly list is a freely available frequency-based vocabulary list\nthat comprises general-purpose language of modern Swedish. The list was\ngenerated from a large web-acquired corpus (SweWaC) of 114 million words\ndating from the 2010s. It is adapted to the needs of language learners and\ncontains 8,425 most frequent lemmas that cover 80% of SweWaC.",
"### Languages\n\nSwedish (sv-SE)",
"## Dataset Structure",
"### Data Instances\n\nHere is a sample of the data:\n\n\n\nThis can be understood as:\n\n> The common noun \"dag\" (\"day\") has a rank of 190 in the list. It was used 117,835\ntimes in SweWaC, meaning it occured 1033.61 times per million words. This word\nis among the most important vocabulary words for Swedish language learners and\nshould be learned at the A1 CEFR level. An example usage of this word is the\nphrase \"god dag\" (\"good day\").",
"### Data Fields\n\n- 'id': The row number for the data entry, starting at 1. Generally corresponds\n to the rank of the word.\n- 'raw_frequency': The raw frequency of the word.\n- 'relative_frequency': The relative frequency of the word measured in\n number of occurences per million words.\n- 'cefr_level': The CEFR level (A1, A2, B1, B2, C1, C2) of the word.\n- 'source': Whether the word came from SweWaC, translation lists (T2), or\n was manually added (manual).\n- 'marker': The grammatical marker of the word, if any, such as an article or\n infinitive marker.\n- 'lemma': The lemma of the word, sometimes provided with its spelling or\n stylistic variants.\n- 'pos': The word's part-of-speech.\n- 'examples': Usage examples and comments. Only available for some of the words.\n\nManual entries were prepended to the list, giving them a higher rank than they\nmight otherwise have had. For example, the manual entry \"Göteborg (\"Gothenberg\")\nhas a rank of 20, while the first non-manual entry \"och\" (\"and\") has a rank of\n87. However, a conjunction and common stopword is far more likely to occur than\nthe name of a city.",
"### Data Splits\n\nThere is a single split, 'train'.",
"## Dataset Creation\n\nPlease refer to the article Corpus-based approaches for the creation of a frequency\nbased vocabulary list in the EU project KELLY – issues on reliability, validity and\ncoverage for information about how\nthe original dataset was created and considerations for using the data.\n\nThe following changes have been made to the original dataset:\n\n- Changed header names.\n- Normalized the large web-acquired corpus name to \"SweWac\" in the 'source' field.\n- Set the relative frequency of manual entries to null rather than 1000000.",
"## Additional Information",
"### Licensing Information\n\nCC BY 4.0\n\n\n\nPlease cite the authors if you use this dataset in your work:",
"### Contributions\n\nThanks to @spraakbanken for creating this dataset\nand to @codesue for adding it."
] | [
"TAGS\n#task_categories-text-classification #task_ids-text-scoring #annotations_creators-expert-generated #language_creators-expert-generated #multilinguality-monolingual #size_categories-1K<n<10K #language-Swedish #license-cc-by-4.0 #lexicon #swedish #CEFR #region-us \n",
"# Dataset Card for Kelly\n\nKeywords for Language Learning for Young and adults alike",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n- Additional Information\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Paper: URL",
"### Dataset Summary\n\nThe Swedish Kelly list is a freely available frequency-based vocabulary list\nthat comprises general-purpose language of modern Swedish. The list was\ngenerated from a large web-acquired corpus (SweWaC) of 114 million words\ndating from the 2010s. It is adapted to the needs of language learners and\ncontains 8,425 most frequent lemmas that cover 80% of SweWaC.",
"### Languages\n\nSwedish (sv-SE)",
"## Dataset Structure",
"### Data Instances\n\nHere is a sample of the data:\n\n\n\nThis can be understood as:\n\n> The common noun \"dag\" (\"day\") has a rank of 190 in the list. It was used 117,835\ntimes in SweWaC, meaning it occured 1033.61 times per million words. This word\nis among the most important vocabulary words for Swedish language learners and\nshould be learned at the A1 CEFR level. An example usage of this word is the\nphrase \"god dag\" (\"good day\").",
"### Data Fields\n\n- 'id': The row number for the data entry, starting at 1. Generally corresponds\n to the rank of the word.\n- 'raw_frequency': The raw frequency of the word.\n- 'relative_frequency': The relative frequency of the word measured in\n number of occurences per million words.\n- 'cefr_level': The CEFR level (A1, A2, B1, B2, C1, C2) of the word.\n- 'source': Whether the word came from SweWaC, translation lists (T2), or\n was manually added (manual).\n- 'marker': The grammatical marker of the word, if any, such as an article or\n infinitive marker.\n- 'lemma': The lemma of the word, sometimes provided with its spelling or\n stylistic variants.\n- 'pos': The word's part-of-speech.\n- 'examples': Usage examples and comments. Only available for some of the words.\n\nManual entries were prepended to the list, giving them a higher rank than they\nmight otherwise have had. For example, the manual entry \"Göteborg (\"Gothenberg\")\nhas a rank of 20, while the first non-manual entry \"och\" (\"and\") has a rank of\n87. However, a conjunction and common stopword is far more likely to occur than\nthe name of a city.",
"### Data Splits\n\nThere is a single split, 'train'.",
"## Dataset Creation\n\nPlease refer to the article Corpus-based approaches for the creation of a frequency\nbased vocabulary list in the EU project KELLY – issues on reliability, validity and\ncoverage for information about how\nthe original dataset was created and considerations for using the data.\n\nThe following changes have been made to the original dataset:\n\n- Changed header names.\n- Normalized the large web-acquired corpus name to \"SweWac\" in the 'source' field.\n- Set the relative frequency of manual entries to null rather than 1000000.",
"## Additional Information",
"### Licensing Information\n\nCC BY 4.0\n\n\n\nPlease cite the authors if you use this dataset in your work:",
"### Contributions\n\nThanks to @spraakbanken for creating this dataset\nand to @codesue for adding it."
] |
dc137a6a976f6b5bb8768e9bb51ec58df930ccd1 |
# Dataset Card for "privy-english"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy](https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy)
### Dataset Summary
A synthetic PII dataset generated using [Privy](https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy), a tool which parses OpenAPI specifications and generates synthetic request payloads, searching for keywords in API schema definitions to select appropriate data providers. Generated API payloads are converted to various protocol trace formats like JSON and SQL to approximate the data developers might encounter while debugging applications.
This labelled PII dataset consists of protocol traces (JSON, SQL (PostgreSQL, MySQL), HTML, and XML) generated from OpenAPI specifications and includes 60+ PII types.
### Supported Tasks and Leaderboards
Named Entity Recognition (NER) and PII classification.
### Label Scheme
<details>
<summary>View label scheme (26 labels for 60 PII data providers)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `PERSON`, `LOCATION`, `NRP`, `DATE_TIME`, `CREDIT_CARD`, `URL`, `IBAN_CODE`, `US_BANK_NUMBER`, `PHONE_NUMBER`, `US_SSN`, `US_PASSPORT`, `US_DRIVER_LICENSE`, `IP_ADDRESS`, `US_ITIN`, `EMAIL_ADDRESS`, `ORGANIZATION`, `TITLE`, `COORDINATE`, `IMEI`, `PASSWORD`, `LICENSE_PLATE`, `CURRENCY`, `ROUTING_NUMBER`, `SWIFT_CODE`, `MAC_ADDRESS`, `AGE` |
</details>
### Languages
English
## Dataset Structure
### Data Instances
A sample:
```
{
"full_text": "{\"full_name_female\": \"Bethany Williams\", \"NewServerCertificateName\": \"\", \"NewPath\": \"\", \"ServerCertificateName\": \"dCwMNqR\", \"Action\": \"\", \"Version\": \"u zNS zNS\"}",
"masked": "{\"full_name_female\": \"{{name_female}}\", \"NewServerCertificateName\": \"{{string}}\", \"NewPath\": \"{{string}}\", \"ServerCertificateName\": \"{{string}}\", \"Action\": \"{{string}}\", \"Version\": \"{{string}}\"}",
"spans": [
{
"entity_type": "PERSON",
"entity_value": "Bethany Williams",
"start_position": 22,
"end_position": 38
}
],
"template_id": 51889,
"metadata": null
}
```
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@online{WinNT,
author = {Benjamin Kilimnik},
title = {{Privy} Synthetic PII Protocol Trace Dataset},
year = 2022,
url = {https://huggingface.co/datasets/beki/privy},
}
```
### Contributions
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | beki/privy | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"size_categories:100K<n<200K",
"size_categories:300K<n<400K",
"language:en",
"license:mit",
"pii-detection",
"region:us"
] | 2022-09-16T03:41:28+00:00 | {"language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<200K", "300K<n<400K"], "task_categories": ["token-classification"], "task_ids": ["named-entity-recognition"], "pretty_name": "Privy English", "tags": ["pii-detection"], "train-eval-index": [{"config": "privy-small", "task": "token-classification", "task_id": "entity_extraction", "splits": {"train_split": "train", "eval_split": "test"}, "metrics": [{"type": "seqeval", "name": "seqeval"}]}]} | 2023-04-25T20:45:06+00:00 | [] | [
"en"
] | TAGS
#task_categories-token-classification #task_ids-named-entity-recognition #multilinguality-monolingual #size_categories-100K<n<200K #size_categories-300K<n<400K #language-English #license-mit #pii-detection #region-us
| Dataset Card for "privy-english"
================================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
### Dataset Summary
A synthetic PII dataset generated using Privy, a tool which parses OpenAPI specifications and generates synthetic request payloads, searching for keywords in API schema definitions to select appropriate data providers. Generated API payloads are converted to various protocol trace formats like JSON and SQL to approximate the data developers might encounter while debugging applications.
This labelled PII dataset consists of protocol traces (JSON, SQL (PostgreSQL, MySQL), HTML, and XML) generated from OpenAPI specifications and includes 60+ PII types.
### Supported Tasks and Leaderboards
Named Entity Recognition (NER) and PII classification.
### Label Scheme
View label scheme (26 labels for 60 PII data providers)
### Languages
English
Dataset Structure
-----------------
### Data Instances
A sample:
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
### Contributions
| [
"### Dataset Summary\n\n\nA synthetic PII dataset generated using Privy, a tool which parses OpenAPI specifications and generates synthetic request payloads, searching for keywords in API schema definitions to select appropriate data providers. Generated API payloads are converted to various protocol trace formats like JSON and SQL to approximate the data developers might encounter while debugging applications.\n\n\nThis labelled PII dataset consists of protocol traces (JSON, SQL (PostgreSQL, MySQL), HTML, and XML) generated from OpenAPI specifications and includes 60+ PII types.",
"### Supported Tasks and Leaderboards\n\n\nNamed Entity Recognition (NER) and PII classification.",
"### Label Scheme\n\n\n\nView label scheme (26 labels for 60 PII data providers)",
"### Languages\n\n\nEnglish\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample:\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] | [
"TAGS\n#task_categories-token-classification #task_ids-named-entity-recognition #multilinguality-monolingual #size_categories-100K<n<200K #size_categories-300K<n<400K #language-English #license-mit #pii-detection #region-us \n",
"### Dataset Summary\n\n\nA synthetic PII dataset generated using Privy, a tool which parses OpenAPI specifications and generates synthetic request payloads, searching for keywords in API schema definitions to select appropriate data providers. Generated API payloads are converted to various protocol trace formats like JSON and SQL to approximate the data developers might encounter while debugging applications.\n\n\nThis labelled PII dataset consists of protocol traces (JSON, SQL (PostgreSQL, MySQL), HTML, and XML) generated from OpenAPI specifications and includes 60+ PII types.",
"### Supported Tasks and Leaderboards\n\n\nNamed Entity Recognition (NER) and PII classification.",
"### Label Scheme\n\n\n\nView label scheme (26 labels for 60 PII data providers)",
"### Languages\n\n\nEnglish\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample:\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
ffe47778949ab10a9d142c9156da20cceae5488e |
# Dataset Card for Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/77?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The data were recorded by 700 Mandarin speakers, 65% of whom were women. There is no pre-made text, and speakers makes phone calls in a natural way while recording the contents of the calls. This data mainly labels the near-end speech, and the speech content is naturally colloquial.
For more details, please refer to the link: https://www.nexdata.ai/datasets/77?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Mandarin
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commercial License
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone | [
"task_categories:automatic-speech-recognition",
"language:zh",
"region:us"
] | 2022-09-16T09:10:40+00:00 | {"language": ["zh"], "task_categories": ["automatic-speech-recognition"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-22T09:44:03+00:00 | [] | [
"zh"
] | TAGS
#task_categories-automatic-speech-recognition #language-Chinese #region-us
|
# Dataset Card for Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
The data were recorded by 700 Mandarin speakers, 65% of whom were women. There is no pre-made text, and speakers makes phone calls in a natural way while recording the contents of the calls. This data mainly labels the near-end speech, and the speech content is naturally colloquial.
For more details, please refer to the link: URL
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Mandarin
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
Commercial License
### Contributions | [
"# Dataset Card for Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThe data were recorded by 700 Mandarin speakers, 65% of whom were women. There is no pre-made text, and speakers makes phone calls in a natural way while recording the contents of the calls. This data mainly labels the near-end speech, and the speech content is naturally colloquial.\n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nMandarin",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommercial License",
"### Contributions"
] | [
"TAGS\n#task_categories-automatic-speech-recognition #language-Chinese #region-us \n",
"# Dataset Card for Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nThe data were recorded by 700 Mandarin speakers, 65% of whom were women. There is no pre-made text, and speakers makes phone calls in a natural way while recording the contents of the calls. This data mainly labels the near-end speech, and the speech content is naturally colloquial.\n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nMandarin",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommercial License",
"### Contributions"
] |
2751c683885849b771797fec13e146fe59811180 |
# Dataset Card for Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1103?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
About 700 Korean speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1103?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Korean
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commercial License
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone | [
"task_categories:conversational",
"language:ko",
"region:us"
] | 2022-09-16T09:13:43+00:00 | {"language": ["ko"], "task_categories": ["conversational"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-22T09:43:54+00:00 | [] | [
"ko"
] | TAGS
#task_categories-conversational #language-Korean #region-us
|
# Dataset Card for Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
About 700 Korean speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: URL
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Korean
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
Commercial License
### Contributions | [
"# Dataset Card for Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nAbout 700 Korean speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nKorean",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommercial License",
"### Contributions"
] | [
"TAGS\n#task_categories-conversational #language-Korean #region-us \n",
"# Dataset Card for Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nAbout 700 Korean speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nKorean",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommercial License",
"### Contributions"
] |
466e1bbc26e58600d32cfdab7779aea4be5f6c78 |
# Dataset Card for Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1166?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
About 1000 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1166?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Japanese
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commercial License
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone | [
"task_categories:conversational",
"language:ja",
"region:us"
] | 2022-09-16T09:14:35+00:00 | {"language": ["ja"], "task_categories": ["conversational"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-22T09:44:24+00:00 | [] | [
"ja"
] | TAGS
#task_categories-conversational #language-Japanese #region-us
|
# Dataset Card for Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage: URL
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
About 1000 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: URL
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Japanese
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
Commercial License
### Contributions | [
"# Dataset Card for Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nAbout 1000 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nJapanese",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommercial License",
"### Contributions"
] | [
"TAGS\n#task_categories-conversational #language-Japanese #region-us \n",
"# Dataset Card for Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: URL\n- Repository:\n- Paper:\n- Leaderboard:\n- Point of Contact:",
"### Dataset Summary\n\nAbout 1000 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy. \n \nFor more details, please refer to the link: URL",
"### Supported Tasks and Leaderboards\n\nautomatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).",
"### Languages\n\nJapanese",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information\n\nCommercial License",
"### Contributions"
] |
9d53d40614e2466e905a48c39d3593ad4ed52b81 |
# Dataset Card for Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone
## Description
About 700 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1178?source=Huggingface
## Format
16kHz, 16bit, uncompressed wav, mono channel;
## Recording Environment
quiet indoor environment, without echo;
## Recording content
dozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed;
## Demographics
About 700 people.
## Annotation
annotating for the transcription text, speaker identification and gender
## Device
Android mobile phone, iPhone;
## Language
Italian
## Application scenarios
speech recognition; voiceprint recognition;
## Accuracy rate
the word accuracy rate is not less than 98%
# Licensing Information
Commercial License
| Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone | [
"task_categories:conversational",
"language:it",
"region:us"
] | 2022-09-16T09:15:32+00:00 | {"language": ["it"], "task_categories": ["conversational"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-10T07:48:10+00:00 | [] | [
"it"
] | TAGS
#task_categories-conversational #language-Italian #region-us
|
# Dataset Card for Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone
## Description
About 700 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: URL
## Format
16kHz, 16bit, uncompressed wav, mono channel;
## Recording Environment
quiet indoor environment, without echo;
## Recording content
dozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed;
## Demographics
About 700 people.
## Annotation
annotating for the transcription text, speaker identification and gender
## Device
Android mobile phone, iPhone;
## Language
Italian
## Application scenarios
speech recognition; voiceprint recognition;
## Accuracy rate
the word accuracy rate is not less than 98%
# Licensing Information
Commercial License
| [
"# Dataset Card for Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone",
"## Description\nAbout 700 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.\n\nFor more details, please refer to the link: URL",
"## Format\n16kHz, 16bit, uncompressed wav, mono channel;",
"## Recording Environment\nquiet indoor environment, without echo;",
"## Recording content\ndozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed;",
"## Demographics\nAbout 700 people.",
"## Annotation\nannotating for the transcription text, speaker identification and gender",
"## Device\nAndroid mobile phone, iPhone;",
"## Language\nItalian",
"## Application scenarios\nspeech recognition; voiceprint recognition;",
"## Accuracy rate\nthe word accuracy rate is not less than 98%",
"# Licensing Information\nCommercial License"
] | [
"TAGS\n#task_categories-conversational #language-Italian #region-us \n",
"# Dataset Card for Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone",
"## Description\nAbout 700 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.\n\nFor more details, please refer to the link: URL",
"## Format\n16kHz, 16bit, uncompressed wav, mono channel;",
"## Recording Environment\nquiet indoor environment, without echo;",
"## Recording content\ndozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed;",
"## Demographics\nAbout 700 people.",
"## Annotation\nannotating for the transcription text, speaker identification and gender",
"## Device\nAndroid mobile phone, iPhone;",
"## Language\nItalian",
"## Application scenarios\nspeech recognition; voiceprint recognition;",
"## Accuracy rate\nthe word accuracy rate is not less than 98%",
"# Licensing Information\nCommercial License"
] |
b96e3be1f0db925f88558b78d9092a1269c814e0 |
NLI를 위한 한국어 속담 데이터셋입니다.
'question'은 속담의 의미와 보기(5지선다)가 표시되어 있으며,
'label'에는 정답의 번호(0-4)가 표시되어 있습니다.
licence: cc-by-sa-2.0-kr (원본 출처:국립국어원 표준국어대사전)
|Model| psyche/korean_idioms |
|:------:|:---:|
|klue/bert-base|0.7646| | psyche/korean_idioms | [
"task_categories:text-classification",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:ko",
"region:us"
] | 2022-09-16T10:31:37+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["ko"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "pretty_name": "psyche/korean_idioms", "tags": []} | 2022-10-23T03:02:44+00:00 | [] | [
"ko"
] | TAGS
#task_categories-text-classification #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Korean #region-us
| NLI를 위한 한국어 속담 데이터셋입니다.
'question'은 속담의 의미와 보기(5지선다)가 표시되어 있으며,
'label'에는 정답의 번호(0-4)가 표시되어 있습니다.
licence: cc-by-sa-2.0-kr (원본 출처:국립국어원 표준국어대사전)
| [] | [
"TAGS\n#task_categories-text-classification #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Korean #region-us \n"
] |
28fb0d7e0d32c1ac7b6dd09f8d9a4e283212e1c0 |
|Model| psyche/bool_sentence (10k) |
|:------:|:---:|
|klue/bert-base|0.9335|
licence: cc-by-sa-2.0-kr (원본 출처:국립국어원 표준국어대사전) | psyche/bool_sentence | [
"task_categories:text-classification",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:ko",
"region:us"
] | 2022-09-16T11:30:21+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["ko"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": [], "pretty_name": "psyche/bool_sentence", "tags": []} | 2022-10-23T01:52:40+00:00 | [] | [
"ko"
] | TAGS
#task_categories-text-classification #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Korean #region-us
|
licence: cc-by-sa-2.0-kr (원본 출처:국립국어원 표준국어대사전)
| [] | [
"TAGS\n#task_categories-text-classification #annotations_creators-machine-generated #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-Korean #region-us \n"
] |
7dfaa5ab1015d802d08b5ca624675a53d4502bda |
```sh
git clone https://github.com/natir/br.git
git clone https://github.com/natir/pcon
git clone https://github.com/natir/yacrd
git clone https://github.com/natir/rasusa
git clone https://github.com/natir/fpa
git clone https://github.com/natir/kmrf
rm -f RustBioGPT-train.csv && for i in `find . -name "*.rs"`;do paste -d "," <(echo $i|perl -pe "s/\.\/(\w+)\/.+/\"\1\"/g") <(echo $i|perl -pe "s/(.+)/\"\1\"/g") <(perl -pe "s/\n/\\\n/g" $i|perl -pe s"/\"/\'/g" |perl -pe "s/(.+)/\"\1\"/g") <(echo "mit"|perl -pe "s/(.+)/\"\1\"/g") >> RustBioGPT-train.csv; done
sed -i '1i "repo_name","path","content","license"' RustBioGPT-train.csv
``` | jelber2/RustBioGPT | [
"license:mit",
"region:us"
] | 2022-09-16T11:59:39+00:00 | {"license": "mit"} | 2022-09-27T11:02:09+00:00 | [] | [] | TAGS
#license-mit #region-us
| [] | [
"TAGS\n#license-mit #region-us \n"
] |
|
6ca3d7b3c4711e6f9df5d73ee70958c2750f925c |
# WNLI-es
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Website:** https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html
- **Point of Contact:** [Carlos Rodríguez-Penagos]([email protected]) and [Carme Armentano-Oller]([email protected])
### Dataset Summary
"A Winograd schema is a pair of sentences that differ in only one or two words and that contain an ambiguity that is resolved in opposite ways in the two sentences and requires the use of world knowledge and reasoning for its resolution. The schema takes its name from Terry Winograd." Source: [The Winograd Schema Challenge](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html).
The [Winograd NLI dataset](https://dl.fbaipublicfiles.com/glue/data/WNLI.zip) presents 855 sentence pairs, in which the first sentence contains an ambiguity and the second one a possible interpretation of it. The label indicates if the interpretation is correct (1) or not (0).
This dataset is a professional translation into Spanish of [Winograd NLI dataset](https://dl.fbaipublicfiles.com/glue/data/WNLI.zip) as published in [GLUE Benchmark](https://gluebenchmark.com/tasks).
Both the original dataset and this translation are licenced under a [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/).
### Supported Tasks and Leaderboards
Textual entailment, Text classification, Language Model.
### Languages
* Spanish (es)
## Dataset Structure
### Data Instances
Three tsv files.
### Data Fields
- index
- sentence 1: first sentence of the pair
- sentence 2: second sentence of the pair
- label: relation between the two sentences:
* 0: the second sentence does not entail a correct interpretation of the first one (neutral)
* 1: the second sentence entails a correct interpretation of the first one (entailment)
### Data Splits
- wnli-train-es.csv: 636 sentence pairs
- wnli-dev-es.csv: 72 sentence pairs
- wnli-test-shuffled-es.csv: 147 sentence pairs
## Dataset Creation
### Curation Rationale
We translated this dataset to contribute to the development of language models in Spanish.
### Source Data
- [GLUE Benchmark site](https://gluebenchmark.com)
#### Initial Data Collection and Normalization
This is a professional translation of [WNLI dataset](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html) into Spanish, commissioned by [BSC TeMU](https://temu.bsc.es/) within the the framework of the [Plan-TL](https://plantl.mineco.gob.es/Paginas/index.aspx).
For more information on how the Winograd NLI dataset was created, visit the webpage [The Winograd Schema Challenge](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html).
#### Who are the source language producers?
For more information on how the Winograd NLI dataset was created, visit the webpage [The Winograd Schema Challenge](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html).
### Annotations
#### Annotation process
We comissioned a professional translation of [WNLI dataset](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html) into Spanish.
#### Who are the annotators?
Translation was commisioned to a professional translation agency.
### Personal and Sensitive Information
No personal or sensitive information included.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset contributes to the development of language models in Spanish.
### Discussion of Biases
[N/A]
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center ([email protected]).
For further information, send an email to ([email protected]).
This work was funded by the [Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA)](https://avancedigital.mineco.gob.es/en-us/Paginas/index.aspx) within the framework of the [Plan-TL](https://plantl.mineco.gob.es/Paginas/index.aspx).
### Licensing information
This work is licensed under [CC Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/) License.
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Contributions
[N/A]
| PlanTL-GOB-ES/wnli-es | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:extended|glue",
"language:es",
"license:cc-by-4.0",
"region:us"
] | 2022-09-16T12:51:45+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["es"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["extended|glue"], "task_categories": ["text-classification"], "task_ids": ["natural-language-inference"], "pretty_name": "wnli-es"} | 2022-11-18T12:03:25+00:00 | [] | [
"es"
] | TAGS
#task_categories-text-classification #task_ids-natural-language-inference #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-extended|glue #language-Spanish #license-cc-by-4.0 #region-us
|
# WNLI-es
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Website: URL
- Point of Contact: Carlos Rodríguez-Penagos and Carme Armentano-Oller
### Dataset Summary
"A Winograd schema is a pair of sentences that differ in only one or two words and that contain an ambiguity that is resolved in opposite ways in the two sentences and requires the use of world knowledge and reasoning for its resolution. The schema takes its name from Terry Winograd." Source: The Winograd Schema Challenge.
The Winograd NLI dataset presents 855 sentence pairs, in which the first sentence contains an ambiguity and the second one a possible interpretation of it. The label indicates if the interpretation is correct (1) or not (0).
This dataset is a professional translation into Spanish of Winograd NLI dataset as published in GLUE Benchmark.
Both the original dataset and this translation are licenced under a Creative Commons Attribution 4.0 International License.
### Supported Tasks and Leaderboards
Textual entailment, Text classification, Language Model.
### Languages
* Spanish (es)
## Dataset Structure
### Data Instances
Three tsv files.
### Data Fields
- index
- sentence 1: first sentence of the pair
- sentence 2: second sentence of the pair
- label: relation between the two sentences:
* 0: the second sentence does not entail a correct interpretation of the first one (neutral)
* 1: the second sentence entails a correct interpretation of the first one (entailment)
### Data Splits
- URL: 636 sentence pairs
- URL: 72 sentence pairs
- URL: 147 sentence pairs
## Dataset Creation
### Curation Rationale
We translated this dataset to contribute to the development of language models in Spanish.
### Source Data
- GLUE Benchmark site
#### Initial Data Collection and Normalization
This is a professional translation of WNLI dataset into Spanish, commissioned by BSC TeMU within the the framework of the Plan-TL.
For more information on how the Winograd NLI dataset was created, visit the webpage The Winograd Schema Challenge.
#### Who are the source language producers?
For more information on how the Winograd NLI dataset was created, visit the webpage The Winograd Schema Challenge.
### Annotations
#### Annotation process
We comissioned a professional translation of WNLI dataset into Spanish.
#### Who are the annotators?
Translation was commisioned to a professional translation agency.
### Personal and Sensitive Information
No personal or sensitive information included.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset contributes to the development of language models in Spanish.
### Discussion of Biases
[N/A]
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@URL).
For further information, send an email to (plantl-gob-es@URL).
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
### Licensing information
This work is licensed under CC Attribution 4.0 International License.
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Contributions
[N/A]
| [
"# WNLI-es",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n- Website: URL\n- Point of Contact: Carlos Rodríguez-Penagos and Carme Armentano-Oller",
"### Dataset Summary\n\n\"A Winograd schema is a pair of sentences that differ in only one or two words and that contain an ambiguity that is resolved in opposite ways in the two sentences and requires the use of world knowledge and reasoning for its resolution. The schema takes its name from Terry Winograd.\" Source: The Winograd Schema Challenge.\n\nThe Winograd NLI dataset presents 855 sentence pairs, in which the first sentence contains an ambiguity and the second one a possible interpretation of it. The label indicates if the interpretation is correct (1) or not (0).\n\nThis dataset is a professional translation into Spanish of Winograd NLI dataset as published in GLUE Benchmark.\n\nBoth the original dataset and this translation are licenced under a Creative Commons Attribution 4.0 International License.",
"### Supported Tasks and Leaderboards\n\nTextual entailment, Text classification, Language Model.",
"### Languages\n\n* Spanish (es)",
"## Dataset Structure",
"### Data Instances\n\nThree tsv files.",
"### Data Fields\n\n- index\n- sentence 1: first sentence of the pair\n- sentence 2: second sentence of the pair\n- label: relation between the two sentences:\n * 0: the second sentence does not entail a correct interpretation of the first one (neutral)\n * 1: the second sentence entails a correct interpretation of the first one (entailment)",
"### Data Splits\n\n- URL: 636 sentence pairs\n- URL: 72 sentence pairs\n- URL: 147 sentence pairs",
"## Dataset Creation",
"### Curation Rationale\n\nWe translated this dataset to contribute to the development of language models in Spanish.",
"### Source Data\n\n- GLUE Benchmark site",
"#### Initial Data Collection and Normalization\n\nThis is a professional translation of WNLI dataset into Spanish, commissioned by BSC TeMU within the the framework of the Plan-TL.\n\nFor more information on how the Winograd NLI dataset was created, visit the webpage The Winograd Schema Challenge.",
"#### Who are the source language producers?\n\nFor more information on how the Winograd NLI dataset was created, visit the webpage The Winograd Schema Challenge.",
"### Annotations",
"#### Annotation process\n\nWe comissioned a professional translation of WNLI dataset into Spanish.",
"#### Who are the annotators?\n\nTranslation was commisioned to a professional translation agency.",
"### Personal and Sensitive Information\n\nNo personal or sensitive information included.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThis dataset contributes to the development of language models in Spanish.",
"### Discussion of Biases\n\n[N/A]",
"### Other Known Limitations\n\n[N/A]",
"## Additional Information",
"### Dataset Curators \nText Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@URL). \n\nFor further information, send an email to (plantl-gob-es@URL).\n\nThis work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.",
"### Licensing information\nThis work is licensed under CC Attribution 4.0 International License.\n\nCopyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)",
"### Contributions\n[N/A]"
] | [
"TAGS\n#task_categories-text-classification #task_ids-natural-language-inference #annotations_creators-expert-generated #language_creators-found #multilinguality-monolingual #size_categories-unknown #source_datasets-extended|glue #language-Spanish #license-cc-by-4.0 #region-us \n",
"# WNLI-es",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n- Website: URL\n- Point of Contact: Carlos Rodríguez-Penagos and Carme Armentano-Oller",
"### Dataset Summary\n\n\"A Winograd schema is a pair of sentences that differ in only one or two words and that contain an ambiguity that is resolved in opposite ways in the two sentences and requires the use of world knowledge and reasoning for its resolution. The schema takes its name from Terry Winograd.\" Source: The Winograd Schema Challenge.\n\nThe Winograd NLI dataset presents 855 sentence pairs, in which the first sentence contains an ambiguity and the second one a possible interpretation of it. The label indicates if the interpretation is correct (1) or not (0).\n\nThis dataset is a professional translation into Spanish of Winograd NLI dataset as published in GLUE Benchmark.\n\nBoth the original dataset and this translation are licenced under a Creative Commons Attribution 4.0 International License.",
"### Supported Tasks and Leaderboards\n\nTextual entailment, Text classification, Language Model.",
"### Languages\n\n* Spanish (es)",
"## Dataset Structure",
"### Data Instances\n\nThree tsv files.",
"### Data Fields\n\n- index\n- sentence 1: first sentence of the pair\n- sentence 2: second sentence of the pair\n- label: relation between the two sentences:\n * 0: the second sentence does not entail a correct interpretation of the first one (neutral)\n * 1: the second sentence entails a correct interpretation of the first one (entailment)",
"### Data Splits\n\n- URL: 636 sentence pairs\n- URL: 72 sentence pairs\n- URL: 147 sentence pairs",
"## Dataset Creation",
"### Curation Rationale\n\nWe translated this dataset to contribute to the development of language models in Spanish.",
"### Source Data\n\n- GLUE Benchmark site",
"#### Initial Data Collection and Normalization\n\nThis is a professional translation of WNLI dataset into Spanish, commissioned by BSC TeMU within the the framework of the Plan-TL.\n\nFor more information on how the Winograd NLI dataset was created, visit the webpage The Winograd Schema Challenge.",
"#### Who are the source language producers?\n\nFor more information on how the Winograd NLI dataset was created, visit the webpage The Winograd Schema Challenge.",
"### Annotations",
"#### Annotation process\n\nWe comissioned a professional translation of WNLI dataset into Spanish.",
"#### Who are the annotators?\n\nTranslation was commisioned to a professional translation agency.",
"### Personal and Sensitive Information\n\nNo personal or sensitive information included.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThis dataset contributes to the development of language models in Spanish.",
"### Discussion of Biases\n\n[N/A]",
"### Other Known Limitations\n\n[N/A]",
"## Additional Information",
"### Dataset Curators \nText Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@URL). \n\nFor further information, send an email to (plantl-gob-es@URL).\n\nThis work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.",
"### Licensing information\nThis work is licensed under CC Attribution 4.0 International License.\n\nCopyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)",
"### Contributions\n[N/A]"
] |
4a15933dcd0acf4d468b13e12f601a4e456deeb6 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-squad_v2-squad_v2-e15d25-1483654271 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T15:14:24+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-16T15:19:11+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
dd8b911a18f8578bdc3a4009ce27af553ff6dd62 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: MYX4567/distilbert-base-uncased-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-squad_v2-squad_v2-e15d25-1483654272 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T15:14:27+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "MYX4567/distilbert-base-uncased-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-16T15:16:56+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Question Answering
* Model: MYX4567/distilbert-base-uncased-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: MYX4567/distilbert-base-uncased-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Question Answering\n* Model: MYX4567/distilbert-base-uncased-finetuned-squad\n* Dataset: squad_v2\n* Config: squad_v2\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
ecd209ffe06e918e4c7e7ce8684640434697e830 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: mathemakitten/opt-125m
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mathemakitten](https://huggingface.co/mathemakitten) for evaluating this model. | autoevaluate/autoeval-eval-autoevaluate__zero-shot-classification-sample-autoevalu-912bbb-1484454284 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T16:55:47+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["autoevaluate/zero-shot-classification-sample"], "eval_info": {"task": "text_zero_shot_classification", "model": "mathemakitten/opt-125m", "metrics": [], "dataset_name": "autoevaluate/zero-shot-classification-sample", "dataset_config": "autoevaluate--zero-shot-classification-sample", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-16T16:56:15+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: mathemakitten/opt-125m
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @mathemakitten for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: mathemakitten/opt-125m\n* Dataset: autoevaluate/zero-shot-classification-sample\n* Config: autoevaluate--zero-shot-classification-sample\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @mathemakitten for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: mathemakitten/opt-125m\n* Dataset: autoevaluate/zero-shot-classification-sample\n* Config: autoevaluate--zero-shot-classification-sample\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @mathemakitten for evaluating this model."
] |
63a9e740124aeaed97c6cc48ed107b95833d7121 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: mathemakitten/opt-125m
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mathemakitten](https://huggingface.co/mathemakitten) for evaluating this model. | autoevaluate/autoeval-eval-autoevaluate__zero-shot-classification-sample-autoevalu-c3526e-1484354283 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T16:55:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["autoevaluate/zero-shot-classification-sample"], "eval_info": {"task": "text_zero_shot_classification", "model": "mathemakitten/opt-125m", "metrics": [], "dataset_name": "autoevaluate/zero-shot-classification-sample", "dataset_config": "autoevaluate--zero-shot-classification-sample", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-16T16:56:15+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: mathemakitten/opt-125m
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @mathemakitten for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: mathemakitten/opt-125m\n* Dataset: autoevaluate/zero-shot-classification-sample\n* Config: autoevaluate--zero-shot-classification-sample\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @mathemakitten for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: mathemakitten/opt-125m\n* Dataset: autoevaluate/zero-shot-classification-sample\n* Config: autoevaluate--zero-shot-classification-sample\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @mathemakitten for evaluating this model."
] |
4f7cf75267bc4b751a03ed9f668350be69d9ce4a | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: chandrasutrisnotjhong/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554291 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:31+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "chandrasutrisnotjhong/bert-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:22:45+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Token Classification
* Model: chandrasutrisnotjhong/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: chandrasutrisnotjhong/bert-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: chandrasutrisnotjhong/bert-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
c816be36bf214a2b8ed525580d849ac7df0d2634 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: baptiste/deberta-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554292 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:37+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "baptiste/deberta-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:02+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Token Classification
* Model: baptiste/deberta-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: baptiste/deberta-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: baptiste/deberta-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
4c2a0ee535002890fffbd6b6a0fe8afc5bc2f6cf | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: mariolinml/roberta_large-ner-conll2003_0818_v0
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554294 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:47+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "mariolinml/roberta_large-ner-conll2003_0818_v0", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:36+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Token Classification
* Model: mariolinml/roberta_large-ner-conll2003_0818_v0
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: mariolinml/roberta_large-ner-conll2003_0818_v0\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: mariolinml/roberta_large-ner-conll2003_0818_v0\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
5e2e4e90132c48d0b3e0afa6337a75225510eb8a | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: jjglilleberg/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554295 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:53+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "jjglilleberg/bert-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:06+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Token Classification
* Model: jjglilleberg/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: jjglilleberg/bert-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: jjglilleberg/bert-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
2105a9d5dd2b3d9ca6f7a7d51c60455a31a40e2a | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: Yv/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554297 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:05+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "Yv/bert-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:19+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Token Classification
* Model: Yv/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: Yv/bert-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Token Classification\n* Model: Yv/bert-finetuned-ner\n* Dataset: conll2003\n* Config: conll2003\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
6d4a3c8d5c40bf818348fcef1f6147e947481fef | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: armandnlp/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-fe1aa0-1485654301 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:29+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "armandnlp/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-16T19:22:59+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Multi-class Text Classification
* Model: armandnlp/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: armandnlp/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: armandnlp/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
f009dc448491e5daf234a5e867b3fb012e366dc9 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: andreaschandra/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-fe1aa0-1485654303 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:41+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "andreaschandra/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-16T19:23:06+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Multi-class Text Classification
* Model: andreaschandra/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: andreaschandra/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: andreaschandra/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
b42408bed4845eabbde9ec840f2c77be1ce455ae | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: bousejin/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-fe1aa0-1485654304 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "bousejin/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-16T19:23:15+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Multi-class Text Classification
* Model: bousejin/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @lewtun for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: bousejin/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Multi-class Text Classification\n* Model: bousejin/distilbert-base-uncased-finetuned-emotion\n* Dataset: emotion\n* Config: default\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @lewtun for evaluating this model."
] |
8f69a50e60bac11a0b2f12e5354f0678281aaf50 | # AutoTrain Dataset for project: consbert
## Dataset Description
This dataset has been automatically processed by AutoTrain for project consbert.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "DECLARATION OF PERFORMANCE fermacell Screws 1. unique identification code of the product type 2. purpose of use 3. manufacturer 5. system(s) for assessment and verification of constancy of performance 6. harmonised standard Notified body(ies) 7. Declared performance Essential feature Reaction to fire Tensile strength Length Corrosion protection (Reis oeueelt Nr. FC-0103 A FC-0103 A Drywall screws type TSN for fastening gypsum fibreboards James Hardie Europe GmbH Bennigsen- Platz 1 D-40474 Disseldorf Tel. +49 800 3864001 E-Mail fermacell jameshardie.de System 4 DIN EN 14566:2008+A1:2009 Stichting Hout Research (2590) Performance Al fulfilled <63mm Phosphated - Class 48 The performance of the above product corresponds to the declared performance(s). The manufacturer mentioned aboveis solely responsible for the preparation of the declaration of performancein accordance with Regulation (EU) No. 305/2011. Signed for the manufacturer and on behalf of the manufacturerof: Dusseldorf, 01.01.2020 2020 James Hardie Europe GmbH. and designate registered and incorporated trademarks of James Hardie Technology Limited Dr. J\u00e9rg Brinkmann (CEO) AESTUVER Seite 1/1 ",
"target": 1
},
{
"text": "DERBIGUM\u201d MAKING BUILDINGS SMART 9 - Performances d\u00e9clar\u00e9es selon EN 13707 : 2004 + A2: 2009 Caract\u00e9ristiques essentielles Performances Unit\u00e9s R\u00e9sistance a un feu ext\u00e9rieur (Note 1) FRoof (t3) - R\u00e9action au feu F - Etanch\u00e9it\u00e9 a l\u2019eau Conforme - Propri\u00e9t\u00e9s en traction : R\u00e9sistance en traction LxT* 900 x 700(+4 20%) N/50 mm Allongement LxT* 45 x 45 (+ 15) % R\u00e9sistance aux racines NPD** - R\u00e9sistance au poinconnementstatique (A) 20 kg R\u00e9sistance au choc (A et B) NPD** mm R\u00e9sistance a la d\u00e9chirure LxT* 200 x 200 (+ 20%) N R\u00e9sistance des jonctions: R\u00e9sistance au pelage NPD** N/50 mm R\u00e9sistance au cisaillement NPD** N/50 mm Durabilit\u00e9 : Sous UV, eau et chaleur Conforme - Pliabilit\u00e9 a froid apr\u00e9s vieillissement a la -10 (+ 5) \u00b0C chaleur Pliabilit\u00e9 a froid -18 \u00b0C Substances dangereuses (Note 2) - * L signifie la direction longitudinale, T signifie la direction transversale **NPD signifie Performance Non D\u00e9termin\u00e9e Note 1: Aucune performance ne peut \u00e9tre donn\u00e9e pourle produit seul, la performance de r\u00e9sistance a un feu ext\u00e9rieur d\u2019une toiture d\u00e9pend du syst\u00e9me complet Note 2: En l\u2019absence de norme d\u2019essai europ\u00e9enne harmonis\u00e9e, aucune performanceli\u00e9e au comportementa la lixiviation ne peut \u00e9tre d\u00e9clar\u00e9e, la d\u00e9claration doit \u00e9tre \u00e9tablie selon les dispositions nationales en vigueur. 10 - Les performances du produit identifi\u00e9 aux points 1 et 2 ci-dessus sont conformes aux performances d\u00e9clar\u00e9es indiqu\u00e9es au point 9. La pr\u00e9sente d\u00e9claration des performances est \u00e9tablie sous la seule responsabilit\u00e9 du fabricant identifi\u00e9 au point 4 Sign\u00e9 pourle fabricant et en son nom par: Mr Steve Geubels, Group Operations Director Perwez ,30/09/2016 Page 2 of 2 ",
"target": 8
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(num_classes=9, names=['0', '1', '2', '3', '4', '5', '6', '7', '8'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 59 |
| valid | 18 |
| Chemsseddine/autotrain-data-consbert | [
"task_categories:text-classification",
"region:us"
] | 2022-09-16T20:00:22+00:00 | {"task_categories": ["text-classification"]} | 2022-09-16T20:03:18+00:00 | [] | [] | TAGS
#task_categories-text-classification #region-us
| AutoTrain Dataset for project: consbert
=======================================
Dataset Description
-------------------
This dataset has been automatically processed by AutoTrain for project consbert.
### Languages
The BCP-47 code for the dataset's language is unk.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is unk.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] | [
"TAGS\n#task_categories-text-classification #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is unk.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] |
55c4e0884053ad905c6ceccdff7e02e8a0d9c7b8 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: Tristan/zero-shot-classification-large-test
* Config: Tristan--zero-shot-classification-large-test
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Tristan](https://huggingface.co/Tristan) for evaluating this model. | autoevaluate/autoeval-eval-Tristan__zero-shot-classification-large-test-Tristan__z-7873ce-1486054319 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T22:52:59+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["Tristan/zero-shot-classification-large-test"], "eval_info": {"task": "text_zero_shot_classification", "model": "autoevaluate/zero-shot-classification", "metrics": [], "dataset_name": "Tristan/zero-shot-classification-large-test", "dataset_config": "Tristan--zero-shot-classification-large-test", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-16T23:43:54+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: Tristan/zero-shot-classification-large-test
* Config: Tristan--zero-shot-classification-large-test
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @Tristan for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: autoevaluate/zero-shot-classification\n* Dataset: Tristan/zero-shot-classification-large-test\n* Config: Tristan--zero-shot-classification-large-test\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @Tristan for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Zero-Shot Text Classification\n* Model: autoevaluate/zero-shot-classification\n* Dataset: Tristan/zero-shot-classification-large-test\n* Config: Tristan--zero-shot-classification-large-test\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @Tristan for evaluating this model."
] |
35d2e5d9f41feed5ca053572780ad7263b060d96 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelfipps123](https://huggingface.co/samuelfipps123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-7cb0ac-1486354325 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-17T00:56:39+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "test", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-17T01:01:53+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @samuelfipps123 for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum\n* Dataset: samsum\n* Config: samsum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelfipps123 for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum\n* Dataset: samsum\n* Config: samsum\n* Split: test\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelfipps123 for evaluating this model."
] |
834a9ec3ad3d01d96e9371cce33ce5a28a721102 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelallen123](https://huggingface.co/samuelallen123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-2c3c14-1486454326 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-17T00:56:42+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "train", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-17T01:46:32+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: train
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @samuelallen123 for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum\n* Dataset: samsum\n* Config: samsum\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelallen123 for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum\n* Dataset: samsum\n* Config: samsum\n* Split: train\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelallen123 for evaluating this model."
] |
7f5976b44f8b7f02b192b65fd7163c1a5a969940 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelallen123](https://huggingface.co/samuelallen123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-1bb2ba-1486554327 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-17T00:56:47+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "validation", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-17T01:02:01+00:00 | [] | [] | TAGS
#autotrain #evaluation #region-us
| # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by AutoTrain for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: validation
To run new evaluation jobs, visit Hugging Face's automatic model evaluator.
## Contributions
Thanks to @samuelallen123 for evaluating this model. | [
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum\n* Dataset: samsum\n* Config: samsum\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelallen123 for evaluating this model."
] | [
"TAGS\n#autotrain #evaluation #region-us \n",
"# Dataset Card for AutoTrain Evaluator\n\nThis repository contains model predictions generated by AutoTrain for the following task and dataset:\n\n* Task: Summarization\n* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum\n* Dataset: samsum\n* Config: samsum\n* Split: validation\n\nTo run new evaluation jobs, visit Hugging Face's automatic model evaluator.",
"## Contributions\n\nThanks to @samuelallen123 for evaluating this model."
] |
a26e48dc333aa4403237068028ac612fe2e9581f | # AutoTrain Dataset for project: opus-mt-en-zh_hanz
## Dataset Description
This dataset has been automatically processed by AutoTrain for project opus-mt-en-zh_hanz.
### Languages
The BCP-47 code for the dataset's language is en2zh.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"source": "And then I hear something.",
"target": "\u63a5\u7740\u542c\u5230\u4ec0\u4e48\u52a8\u9759\u3002",
"feat_en_length": 26,
"feat_zh_length": 9
},
{
"source": "A ghostly iron whistle blows through the tunnels.",
"target": "\u9b3c\u9b45\u7684\u54e8\u58f0\u5439\u8fc7\u96a7\u9053\u3002",
"feat_en_length": 49,
"feat_zh_length": 10
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"source": "Value(dtype='string', id=None)",
"target": "Value(dtype='string', id=None)",
"feat_en_length": "Value(dtype='int64', id=None)",
"feat_zh_length": "Value(dtype='int64', id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 16350 |
| valid | 4088 |
| darcy01/autotrain-data-opus-mt-en-zh_hanz | [
"task_categories:translation",
"language:en",
"language:zh",
"region:us"
] | 2022-09-17T07:52:21+00:00 | {"language": ["en", "zh"], "task_categories": ["translation"]} | 2022-09-17T10:36:03+00:00 | [] | [
"en",
"zh"
] | TAGS
#task_categories-translation #language-English #language-Chinese #region-us
| AutoTrain Dataset for project: opus-mt-en-zh\_hanz
==================================================
Dataset Description
-------------------
This dataset has been automatically processed by AutoTrain for project opus-mt-en-zh\_hanz.
### Languages
The BCP-47 code for the dataset's language is en2zh.
Dataset Structure
-----------------
### Data Instances
A sample from this dataset looks as follows:
### Dataset Fields
The dataset has the following fields (also called "features"):
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| [
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en2zh.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] | [
"TAGS\n#task_categories-translation #language-English #language-Chinese #region-us \n",
"### Languages\n\n\nThe BCP-47 code for the dataset's language is en2zh.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nA sample from this dataset looks as follows:",
"### Dataset Fields\n\n\nThe dataset has the following fields (also called \"features\"):",
"### Dataset Splits\n\n\nThis dataset is split into a train and validation split. The split sizes are as follow:"
] |
f8d2cc4cbdeb4b666ef8342830bcb6525ba09fbb |
# Dataset Card for **slone/myv_ru_2022**
## Dataset Description
- **Repository:** https://github.com/slone-nlp/myv-nmt
- **Paper:**: https://arxiv.org/abs/2209.09368
- **Point of Contact:** @cointegrated
### Dataset Summary
This is a corpus of parallel Erzya-Russian words, phrases and sentences, collected in the paper [The first neural machine translation system for the Erzya language](https://arxiv.org/abs/2209.09368).
Erzya (`myv`) is a language from the Uralic family. It is spoken primarily in the Republic of Mordovia and some other regions of Russia and other post-Soviet countries. We use the Cyrillic version of its script.
The corpus consists of the following parts:
| name | size | composition |
| -----| ---- | -------|
|train | 74503 | parallel words, phrases and sentences, mined from dictionaries, books and web texts |
| dev | 1500 | parallel sentences mined from books and web texts |
| test | 1500 | parallel sentences mined from books and web texts |
| mono | 333651| Erzya sentences mined from books and web texts, translated to Russian by a neural model |
The dev and test splits contain sentences from the following sources
| name | size | description|
| ---------------|----| -------|
|wiki |600 | Aligned sentences from linked Erzya and Russian Wikipedia articles |
|bible |400 | Paired verses from the Bible (https://finugorbib.com) |
|games |250 | Aligned sentences from the book *"Сказовые формы мордовской литературы", И.И. Шеянова, 2017, НИИ гуманитарых наук при Правительстве Республики Мордовия, Саранск* |
|tales |100 | Aligned sentences from the book *"Мордовские народные игры", В.С. Брыжинский, 2009, Мордовское книжное издательство, Саранск* |
|fiction |100 | Aligned sentences from modern Erzya prose and poetry (https://rus4all.ru/myv) |
|constitution | 50 | Aligned sentences from the Soviet 1938 constitution |
To load the first three parts (train, validation and test), use the code:
```Python
from datasets import load_dataset
data = load_dataset('slone/myv_ru_2022')
```
To load all four parts (included the back-translated data), please specify the data files explicitly:
```Python
from datasets import load_dataset
data_extended = load_dataset(
'slone/myv_ru_2022',
data_files={'train':'train.jsonl', 'validation': 'dev.jsonl', 'test': 'test.jsonl', 'mono': 'back_translated.jsonl'}
)
```
### Supported Tasks and Leaderboards
- `translation`: the dataset may be used to train `ru-myv` translation models. There are no specific leaderboards for it yet, but if you feel like discussing it, welcome to the comments!
### Languages
The main part of the dataset (`train`, `dev` and `test`) consists of "natural" Erzya (Cyrillic) and Russian sentences, translated to the other language by humans. There is also a larger Erzya-only part of the corpus (`mono`), translated to Russian automatically.
## Dataset Structure
### Data Instances
All data instances have three string fields: `myv`, `ru` and `src` (the last one is currently meaningful only for dev and test splits), for example:
```
{'myv': 'Сюкпря Пазонтень, кие кирвазтизе Титэнь седейс тынк кисэ секе жо бажамонть, кона палы минек седейсэяк!',
'ru': 'Благодарение Богу, вложившему в сердце Титово такое усердие к вам.',
'src': 'bible'}
```
### Data Fields
- `myv`: the Erzya text (word, phrase, or sentence)
- `ru`: the corresponding Russian text
- `src`: the source of data (only for dev and test splits)
### Data Splits
- train: parallel sentences, words and phrases, collected from various sources. Most of them are aligned automatically. Noisy.
- dev: 1500 parallel sentences, selected from the 6 most reliable and diverse sources.
- test: same as dev.
- mono: Erzya sentences collected from various sources, with the Russian counterpart generated by a neural machine translation model.
## Dataset Creation
### Curation Rationale
This is, as far as we know, the first publicly available parallel Russian-Erzya corpus, and the first medium-sized translation corpus for Erzya.
We hope that it sets a meaningful baseline for Erzya machine translation.
### Source Data
#### Initial Data Collection and Normalization
The dataset was collected from various sources (see below).
The texts were spit in sentences using the [razdel]() package.
For some sources, sentences were filtered by language using the [slone/fastText-LID-323](https://huggingface.co/slone/fastText-LID-323) model.
For most of the sources, `myv` and `ru` sentences were aligned automatically using the [slone/LaBSE-en-ru-myv-v1](https://huggingface.co/slone/LaBSE-en-ru-myv-v1) sentence encoder
and the code from [the paper repository](https://github.com/slone-nlp/myv-nmt).
#### Who are the source language producers?
The dataset comprises parallel `myv-ru` and monolingual `myv` texts from diverse sources:
- 12K parallel sentences from the Bible (http://finugorbib.com);
- 3K parallel Wikimedia sentences from OPUS;
- 42K parallel words or short phrases collected from various online dictionaries ();
- the Erzya Wikipedia and the corresponding articles from the Russian Wikipedia;
- 18 books, including 3 books with Erzya-Russian bitexts (http://lib.e-mordovia.ru);
- Soviet-time books and periodicals (https://fennougrica.kansalliskirjasto.fi);
- The Erzya part of Wikisource (https://wikisource.org/wiki/Main_Page/?oldid=895127);
- Short texts by modern Erzya authors (https://rus4all.ru/myv/);
- News articles from the Erzya Pravda website (http://erziapr.ru);
- Texts found in LiveJournal (https://www.livejournal.com) by searching with the 100 most frequent Erzya words.
### Annotations
No human annotation was involved in the data collection.
### Personal and Sensitive Information
All data was collected from public sources, so no sensitive information is expected in them.
However, some sentences collected, for example, from news articles or LiveJournal posts, can contain personal data.
## Considerations for Using the Data
### Social Impact of Dataset
Publication of this dataset may attract some attention to the endangered Erzya language.
### Discussion of Biases
Most of the dataset has been collected by automatical means, so it may contain errors and noise.
Some types of these errors are systemic: for example, the words for "Erzya" and "Russian" are often aligned together,
because they appear in the corresponding Wikipedias on similar positions.
### Other Known Limitations
The dataset is noisy: some texts in it may be ungrammatical, in a wrong language, or poorly aligned.
## Additional Information
### Dataset Curators
The data was collected by David Dale (https://huggingface.co/cointegrated).
### Licensing Information
The status of the dataset is not final, but after we check everything, we hope to be able to distribute it under the [CC-BY-SA license](http://creativecommons.org/licenses/by-sa/4.0/).
### Citation Information
[TBD]
| slone/myv_ru_2022 | [
"task_categories:translation",
"annotations_creators:found",
"annotations_creators:machine-generated",
"language_creators:found",
"language_creators:machine-generated",
"multilinguality:translation",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:myv",
"language:ru",
"license:cc-by-sa-4.0",
"erzya",
"mordovian",
"arxiv:2209.09368",
"region:us"
] | 2022-09-17T12:53:23+00:00 | {"annotations_creators": ["found", "machine-generated"], "language_creators": ["found", "machine-generated"], "language": ["myv", "ru"], "license": ["cc-by-sa-4.0"], "multilinguality": ["translation"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["translation"], "task_ids": [], "pretty_name": "Erzya-Russian parallel corpus", "tags": ["erzya", "mordovian"]} | 2022-09-28T18:38:26+00:00 | [
"2209.09368"
] | [
"myv",
"ru"
] | TAGS
#task_categories-translation #annotations_creators-found #annotations_creators-machine-generated #language_creators-found #language_creators-machine-generated #multilinguality-translation #size_categories-10K<n<100K #source_datasets-original #language-Erzya #language-Russian #license-cc-by-sa-4.0 #erzya #mordovian #arxiv-2209.09368 #region-us
| Dataset Card for slone/myv\_ru\_2022
====================================
Dataset Description
-------------------
* Repository: URL
* Paper:: URL
* Point of Contact: @cointegrated
### Dataset Summary
This is a corpus of parallel Erzya-Russian words, phrases and sentences, collected in the paper The first neural machine translation system for the Erzya language.
Erzya ('myv') is a language from the Uralic family. It is spoken primarily in the Republic of Mordovia and some other regions of Russia and other post-Soviet countries. We use the Cyrillic version of its script.
The corpus consists of the following parts:
name: train, size: 74503, composition: parallel words, phrases and sentences, mined from dictionaries, books and web texts
name: dev, size: 1500, composition: parallel sentences mined from books and web texts
name: test, size: 1500, composition: parallel sentences mined from books and web texts
name: mono, size: 333651, composition: Erzya sentences mined from books and web texts, translated to Russian by a neural model
The dev and test splits contain sentences from the following sources
name: wiki, size: 600, description: Aligned sentences from linked Erzya and Russian Wikipedia articles
name: bible, size: 400, description: Paired verses from the Bible (URL)
name: games, size: 250, description: Aligned sentences from the book *"Сказовые формы мордовской литературы", И.И. Шеянова, 2017, НИИ гуманитарых наук при Правительстве Республики Мордовия, Саранск*
name: tales, size: 100, description: Aligned sentences from the book *"Мордовские народные игры", В.С. Брыжинский, 2009, Мордовское книжное издательство, Саранск*
name: fiction, size: 100, description: Aligned sentences from modern Erzya prose and poetry (URL
name: constitution, size: 50, description: Aligned sentences from the Soviet 1938 constitution
To load the first three parts (train, validation and test), use the code:
To load all four parts (included the back-translated data), please specify the data files explicitly:
### Supported Tasks and Leaderboards
* 'translation': the dataset may be used to train 'ru-myv' translation models. There are no specific leaderboards for it yet, but if you feel like discussing it, welcome to the comments!
### Languages
The main part of the dataset ('train', 'dev' and 'test') consists of "natural" Erzya (Cyrillic) and Russian sentences, translated to the other language by humans. There is also a larger Erzya-only part of the corpus ('mono'), translated to Russian automatically.
Dataset Structure
-----------------
### Data Instances
All data instances have three string fields: 'myv', 'ru' and 'src' (the last one is currently meaningful only for dev and test splits), for example:
### Data Fields
* 'myv': the Erzya text (word, phrase, or sentence)
* 'ru': the corresponding Russian text
* 'src': the source of data (only for dev and test splits)
### Data Splits
* train: parallel sentences, words and phrases, collected from various sources. Most of them are aligned automatically. Noisy.
* dev: 1500 parallel sentences, selected from the 6 most reliable and diverse sources.
* test: same as dev.
* mono: Erzya sentences collected from various sources, with the Russian counterpart generated by a neural machine translation model.
Dataset Creation
----------------
### Curation Rationale
This is, as far as we know, the first publicly available parallel Russian-Erzya corpus, and the first medium-sized translation corpus for Erzya.
We hope that it sets a meaningful baseline for Erzya machine translation.
### Source Data
#### Initial Data Collection and Normalization
The dataset was collected from various sources (see below).
The texts were spit in sentences using the razdel package.
For some sources, sentences were filtered by language using the slone/fastText-LID-323 model.
For most of the sources, 'myv' and 'ru' sentences were aligned automatically using the slone/LaBSE-en-ru-myv-v1 sentence encoder
and the code from the paper repository.
#### Who are the source language producers?
The dataset comprises parallel 'myv-ru' and monolingual 'myv' texts from diverse sources:
* 12K parallel sentences from the Bible (URL);
* 3K parallel Wikimedia sentences from OPUS;
* 42K parallel words or short phrases collected from various online dictionaries ();
* the Erzya Wikipedia and the corresponding articles from the Russian Wikipedia;
* 18 books, including 3 books with Erzya-Russian bitexts (URL);
* Soviet-time books and periodicals (URL);
* The Erzya part of Wikisource (URL
* Short texts by modern Erzya authors (URL
* News articles from the Erzya Pravda website (URL);
* Texts found in LiveJournal (URL) by searching with the 100 most frequent Erzya words.
### Annotations
No human annotation was involved in the data collection.
### Personal and Sensitive Information
All data was collected from public sources, so no sensitive information is expected in them.
However, some sentences collected, for example, from news articles or LiveJournal posts, can contain personal data.
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
Publication of this dataset may attract some attention to the endangered Erzya language.
### Discussion of Biases
Most of the dataset has been collected by automatical means, so it may contain errors and noise.
Some types of these errors are systemic: for example, the words for "Erzya" and "Russian" are often aligned together,
because they appear in the corresponding Wikipedias on similar positions.
### Other Known Limitations
The dataset is noisy: some texts in it may be ungrammatical, in a wrong language, or poorly aligned.
Additional Information
----------------------
### Dataset Curators
The data was collected by David Dale (URL
### Licensing Information
The status of the dataset is not final, but after we check everything, we hope to be able to distribute it under the CC-BY-SA license.
[TBD]
| [
"### Dataset Summary\n\n\nThis is a corpus of parallel Erzya-Russian words, phrases and sentences, collected in the paper The first neural machine translation system for the Erzya language.\n\n\nErzya ('myv') is a language from the Uralic family. It is spoken primarily in the Republic of Mordovia and some other regions of Russia and other post-Soviet countries. We use the Cyrillic version of its script.\n\n\nThe corpus consists of the following parts:\n\n\nname: train, size: 74503, composition: parallel words, phrases and sentences, mined from dictionaries, books and web texts\nname: dev, size: 1500, composition: parallel sentences mined from books and web texts\nname: test, size: 1500, composition: parallel sentences mined from books and web texts\nname: mono, size: 333651, composition: Erzya sentences mined from books and web texts, translated to Russian by a neural model\n\n\nThe dev and test splits contain sentences from the following sources\n\n\nname: wiki, size: 600, description: Aligned sentences from linked Erzya and Russian Wikipedia articles\nname: bible, size: 400, description: Paired verses from the Bible (URL)\nname: games, size: 250, description: Aligned sentences from the book *\"Сказовые формы мордовской литературы\", И.И. Шеянова, 2017, НИИ гуманитарых наук при Правительстве Республики Мордовия, Саранск*\nname: tales, size: 100, description: Aligned sentences from the book *\"Мордовские народные игры\", В.С. Брыжинский, 2009, Мордовское книжное издательство, Саранск*\nname: fiction, size: 100, description: Aligned sentences from modern Erzya prose and poetry (URL\nname: constitution, size: 50, description: Aligned sentences from the Soviet 1938 constitution\n\n\nTo load the first three parts (train, validation and test), use the code:\n\n\nTo load all four parts (included the back-translated data), please specify the data files explicitly:",
"### Supported Tasks and Leaderboards\n\n\n* 'translation': the dataset may be used to train 'ru-myv' translation models. There are no specific leaderboards for it yet, but if you feel like discussing it, welcome to the comments!",
"### Languages\n\n\nThe main part of the dataset ('train', 'dev' and 'test') consists of \"natural\" Erzya (Cyrillic) and Russian sentences, translated to the other language by humans. There is also a larger Erzya-only part of the corpus ('mono'), translated to Russian automatically.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAll data instances have three string fields: 'myv', 'ru' and 'src' (the last one is currently meaningful only for dev and test splits), for example:",
"### Data Fields\n\n\n* 'myv': the Erzya text (word, phrase, or sentence)\n* 'ru': the corresponding Russian text\n* 'src': the source of data (only for dev and test splits)",
"### Data Splits\n\n\n* train: parallel sentences, words and phrases, collected from various sources. Most of them are aligned automatically. Noisy.\n* dev: 1500 parallel sentences, selected from the 6 most reliable and diverse sources.\n* test: same as dev.\n* mono: Erzya sentences collected from various sources, with the Russian counterpart generated by a neural machine translation model.\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThis is, as far as we know, the first publicly available parallel Russian-Erzya corpus, and the first medium-sized translation corpus for Erzya.\nWe hope that it sets a meaningful baseline for Erzya machine translation.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe dataset was collected from various sources (see below).\n\n\nThe texts were spit in sentences using the razdel package.\nFor some sources, sentences were filtered by language using the slone/fastText-LID-323 model.\nFor most of the sources, 'myv' and 'ru' sentences were aligned automatically using the slone/LaBSE-en-ru-myv-v1 sentence encoder\nand the code from the paper repository.",
"#### Who are the source language producers?\n\n\nThe dataset comprises parallel 'myv-ru' and monolingual 'myv' texts from diverse sources:\n\n\n* 12K parallel sentences from the Bible (URL);\n* 3K parallel Wikimedia sentences from OPUS;\n* 42K parallel words or short phrases collected from various online dictionaries ();\n* the Erzya Wikipedia and the corresponding articles from the Russian Wikipedia;\n* 18 books, including 3 books with Erzya-Russian bitexts (URL);\n* Soviet-time books and periodicals (URL);\n* The Erzya part of Wikisource (URL\n* Short texts by modern Erzya authors (URL\n* News articles from the Erzya Pravda website (URL);\n* Texts found in LiveJournal (URL) by searching with the 100 most frequent Erzya words.",
"### Annotations\n\n\nNo human annotation was involved in the data collection.",
"### Personal and Sensitive Information\n\n\nAll data was collected from public sources, so no sensitive information is expected in them.\nHowever, some sentences collected, for example, from news articles or LiveJournal posts, can contain personal data.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nPublication of this dataset may attract some attention to the endangered Erzya language.",
"### Discussion of Biases\n\n\nMost of the dataset has been collected by automatical means, so it may contain errors and noise.\nSome types of these errors are systemic: for example, the words for \"Erzya\" and \"Russian\" are often aligned together,\nbecause they appear in the corresponding Wikipedias on similar positions.",
"### Other Known Limitations\n\n\nThe dataset is noisy: some texts in it may be ungrammatical, in a wrong language, or poorly aligned.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe data was collected by David Dale (URL",
"### Licensing Information\n\n\nThe status of the dataset is not final, but after we check everything, we hope to be able to distribute it under the CC-BY-SA license.\n\n\n[TBD]"
] | [
"TAGS\n#task_categories-translation #annotations_creators-found #annotations_creators-machine-generated #language_creators-found #language_creators-machine-generated #multilinguality-translation #size_categories-10K<n<100K #source_datasets-original #language-Erzya #language-Russian #license-cc-by-sa-4.0 #erzya #mordovian #arxiv-2209.09368 #region-us \n",
"### Dataset Summary\n\n\nThis is a corpus of parallel Erzya-Russian words, phrases and sentences, collected in the paper The first neural machine translation system for the Erzya language.\n\n\nErzya ('myv') is a language from the Uralic family. It is spoken primarily in the Republic of Mordovia and some other regions of Russia and other post-Soviet countries. We use the Cyrillic version of its script.\n\n\nThe corpus consists of the following parts:\n\n\nname: train, size: 74503, composition: parallel words, phrases and sentences, mined from dictionaries, books and web texts\nname: dev, size: 1500, composition: parallel sentences mined from books and web texts\nname: test, size: 1500, composition: parallel sentences mined from books and web texts\nname: mono, size: 333651, composition: Erzya sentences mined from books and web texts, translated to Russian by a neural model\n\n\nThe dev and test splits contain sentences from the following sources\n\n\nname: wiki, size: 600, description: Aligned sentences from linked Erzya and Russian Wikipedia articles\nname: bible, size: 400, description: Paired verses from the Bible (URL)\nname: games, size: 250, description: Aligned sentences from the book *\"Сказовые формы мордовской литературы\", И.И. Шеянова, 2017, НИИ гуманитарых наук при Правительстве Республики Мордовия, Саранск*\nname: tales, size: 100, description: Aligned sentences from the book *\"Мордовские народные игры\", В.С. Брыжинский, 2009, Мордовское книжное издательство, Саранск*\nname: fiction, size: 100, description: Aligned sentences from modern Erzya prose and poetry (URL\nname: constitution, size: 50, description: Aligned sentences from the Soviet 1938 constitution\n\n\nTo load the first three parts (train, validation and test), use the code:\n\n\nTo load all four parts (included the back-translated data), please specify the data files explicitly:",
"### Supported Tasks and Leaderboards\n\n\n* 'translation': the dataset may be used to train 'ru-myv' translation models. There are no specific leaderboards for it yet, but if you feel like discussing it, welcome to the comments!",
"### Languages\n\n\nThe main part of the dataset ('train', 'dev' and 'test') consists of \"natural\" Erzya (Cyrillic) and Russian sentences, translated to the other language by humans. There is also a larger Erzya-only part of the corpus ('mono'), translated to Russian automatically.\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAll data instances have three string fields: 'myv', 'ru' and 'src' (the last one is currently meaningful only for dev and test splits), for example:",
"### Data Fields\n\n\n* 'myv': the Erzya text (word, phrase, or sentence)\n* 'ru': the corresponding Russian text\n* 'src': the source of data (only for dev and test splits)",
"### Data Splits\n\n\n* train: parallel sentences, words and phrases, collected from various sources. Most of them are aligned automatically. Noisy.\n* dev: 1500 parallel sentences, selected from the 6 most reliable and diverse sources.\n* test: same as dev.\n* mono: Erzya sentences collected from various sources, with the Russian counterpart generated by a neural machine translation model.\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThis is, as far as we know, the first publicly available parallel Russian-Erzya corpus, and the first medium-sized translation corpus for Erzya.\nWe hope that it sets a meaningful baseline for Erzya machine translation.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nThe dataset was collected from various sources (see below).\n\n\nThe texts were spit in sentences using the razdel package.\nFor some sources, sentences were filtered by language using the slone/fastText-LID-323 model.\nFor most of the sources, 'myv' and 'ru' sentences were aligned automatically using the slone/LaBSE-en-ru-myv-v1 sentence encoder\nand the code from the paper repository.",
"#### Who are the source language producers?\n\n\nThe dataset comprises parallel 'myv-ru' and monolingual 'myv' texts from diverse sources:\n\n\n* 12K parallel sentences from the Bible (URL);\n* 3K parallel Wikimedia sentences from OPUS;\n* 42K parallel words or short phrases collected from various online dictionaries ();\n* the Erzya Wikipedia and the corresponding articles from the Russian Wikipedia;\n* 18 books, including 3 books with Erzya-Russian bitexts (URL);\n* Soviet-time books and periodicals (URL);\n* The Erzya part of Wikisource (URL\n* Short texts by modern Erzya authors (URL\n* News articles from the Erzya Pravda website (URL);\n* Texts found in LiveJournal (URL) by searching with the 100 most frequent Erzya words.",
"### Annotations\n\n\nNo human annotation was involved in the data collection.",
"### Personal and Sensitive Information\n\n\nAll data was collected from public sources, so no sensitive information is expected in them.\nHowever, some sentences collected, for example, from news articles or LiveJournal posts, can contain personal data.\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset\n\n\nPublication of this dataset may attract some attention to the endangered Erzya language.",
"### Discussion of Biases\n\n\nMost of the dataset has been collected by automatical means, so it may contain errors and noise.\nSome types of these errors are systemic: for example, the words for \"Erzya\" and \"Russian\" are often aligned together,\nbecause they appear in the corresponding Wikipedias on similar positions.",
"### Other Known Limitations\n\n\nThe dataset is noisy: some texts in it may be ungrammatical, in a wrong language, or poorly aligned.\n\n\nAdditional Information\n----------------------",
"### Dataset Curators\n\n\nThe data was collected by David Dale (URL",
"### Licensing Information\n\n\nThe status of the dataset is not final, but after we check everything, we hope to be able to distribute it under the CC-BY-SA license.\n\n\n[TBD]"
] |
dbfe82d9d01c08ca01e402d466e1ac817bdbb182 | 256x256 mel spectrograms of 5 second samples of instrumental Hip Hop. The code to convert from audio to spectrogram and vice versa can be found in https://github.com/teticio/audio-diffusion along with scripts to train and run inference using De-noising Diffusion Probabilistic Models.
```
x_res = 256
y_res = 256
sample_rate = 22050
n_fft = 2048
hop_length = 512
``` | teticio/audio-diffusion-instrumental-hiphop-256 | [
"task_categories:image-to-image",
"size_categories:10K<n<100K",
"audio",
"spectrograms",
"region:us"
] | 2022-09-17T13:06:30+00:00 | {"annotations_creators": [], "language_creators": [], "language": [], "license": [], "multilinguality": [], "size_categories": ["10K<n<100K"], "source_datasets": [], "task_categories": ["image-to-image"], "task_ids": [], "pretty_name": "Mel spectrograms of instrumental Hip Hop music", "tags": ["audio", "spectrograms"]} | 2022-11-09T10:50:58+00:00 | [] | [] | TAGS
#task_categories-image-to-image #size_categories-10K<n<100K #audio #spectrograms #region-us
| 256x256 mel spectrograms of 5 second samples of instrumental Hip Hop. The code to convert from audio to spectrogram and vice versa can be found in URL along with scripts to train and run inference using De-noising Diffusion Probabilistic Models.
| [] | [
"TAGS\n#task_categories-image-to-image #size_categories-10K<n<100K #audio #spectrograms #region-us \n"
] |
9f7a6cacd22203e821ffdb3470f1575eb71eedc5 |
# Korpus-frazennou-brezhonek
Corpus de 4532 phrases bilingues (français-breton) alignées et libres de droits provenant de l'Office Public de la Langue Bretonne.
Plus d'informations [ici](https://www.fr.brezhoneg.bzh/212-donnees-libres-de-droits.htm)
# Usage
```
from datasets import load_dataset
dataset = load_dataset("bzh-dataset/Korpus-frazennou-brezhonek", sep=";")
```
| bzh-dataset/Korpus-frazennou-brezhonek | [
"language:fr",
"language:br",
"license:unknown",
"region:us"
] | 2022-09-17T19:58:22+00:00 | {"language": ["fr", "br"], "license": "unknown"} | 2022-09-17T20:26:30+00:00 | [] | [
"fr",
"br"
] | TAGS
#language-French #language-Breton #license-unknown #region-us
|
# Korpus-frazennou-brezhonek
Corpus de 4532 phrases bilingues (français-breton) alignées et libres de droits provenant de l'Office Public de la Langue Bretonne.
Plus d'informations ici
# Usage
| [
"# Korpus-frazennou-brezhonek \n\nCorpus de 4532 phrases bilingues (français-breton) alignées et libres de droits provenant de l'Office Public de la Langue Bretonne.\nPlus d'informations ici",
"# Usage"
] | [
"TAGS\n#language-French #language-Breton #license-unknown #region-us \n",
"# Korpus-frazennou-brezhonek \n\nCorpus de 4532 phrases bilingues (français-breton) alignées et libres de droits provenant de l'Office Public de la Langue Bretonne.\nPlus d'informations ici",
"# Usage"
] |
493d1d86e7977892b60f8eeb901a10fe84fd1fc7 |
## Dataset Description
FBAnimeHQ is a dataset with high-quality full-body anime girl images in a resolution of 1024 × 512.
### Dataset Summary
The dataset contains 112,806 images.
All images are on white background
### Collection Method
#### v1.0
Collect from danbooru website.
Use yolov5 to detect and clip image.
Use anime-segmentation to remove background.
Use deepdanbooru to filter image.
Finally clean the dataset manually.
#### v2.0
Base on v1.0, use Novelai image-to-image to enhance and expand the dataset.
### Contributions
Thanks to [@SkyTNT](https://github.com/SkyTNT) for adding this dataset. | skytnt/fbanimehq | [
"task_categories:unconditional-image-generation",
"size_categories:100K<n<1M",
"source_datasets:original",
"license:cc0-1.0",
"region:us"
] | 2022-09-18T00:01:43+00:00 | {"annotations_creators": [], "language_creators": [], "language": [], "license": ["cc0-1.0"], "multilinguality": [], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["unconditional-image-generation"], "task_ids": [], "pretty_name": "Full Body Anime HQ", "tags": []} | 2022-10-23T13:02:23+00:00 | [] | [] | TAGS
#task_categories-unconditional-image-generation #size_categories-100K<n<1M #source_datasets-original #license-cc0-1.0 #region-us
|
## Dataset Description
FBAnimeHQ is a dataset with high-quality full-body anime girl images in a resolution of 1024 × 512.
### Dataset Summary
The dataset contains 112,806 images.
All images are on white background
### Collection Method
#### v1.0
Collect from danbooru website.
Use yolov5 to detect and clip image.
Use anime-segmentation to remove background.
Use deepdanbooru to filter image.
Finally clean the dataset manually.
#### v2.0
Base on v1.0, use Novelai image-to-image to enhance and expand the dataset.
### Contributions
Thanks to @SkyTNT for adding this dataset. | [
"## Dataset Description\n\nFBAnimeHQ is a dataset with high-quality full-body anime girl images in a resolution of 1024 × 512.",
"### Dataset Summary\n\nThe dataset contains 112,806 images.\n\nAll images are on white background",
"### Collection Method",
"#### v1.0\nCollect from danbooru website.\n\nUse yolov5 to detect and clip image.\n\nUse anime-segmentation to remove background.\n\nUse deepdanbooru to filter image.\n\nFinally clean the dataset manually.",
"#### v2.0\n\nBase on v1.0, use Novelai image-to-image to enhance and expand the dataset.",
"### Contributions\n\nThanks to @SkyTNT for adding this dataset."
] | [
"TAGS\n#task_categories-unconditional-image-generation #size_categories-100K<n<1M #source_datasets-original #license-cc0-1.0 #region-us \n",
"## Dataset Description\n\nFBAnimeHQ is a dataset with high-quality full-body anime girl images in a resolution of 1024 × 512.",
"### Dataset Summary\n\nThe dataset contains 112,806 images.\n\nAll images are on white background",
"### Collection Method",
"#### v1.0\nCollect from danbooru website.\n\nUse yolov5 to detect and clip image.\n\nUse anime-segmentation to remove background.\n\nUse deepdanbooru to filter image.\n\nFinally clean the dataset manually.",
"#### v2.0\n\nBase on v1.0, use Novelai image-to-image to enhance and expand the dataset.",
"### Contributions\n\nThanks to @SkyTNT for adding this dataset."
] |
4199328f25c6d3de0e783797426affa11dbbf348 |
# Please cite as
```
@InProceedings{Spinde2021f,
title = "Neural Media Bias Detection Using Distant Supervision With {BABE} - Bias Annotations By Experts",
author = "Spinde, Timo and
Plank, Manuel and
Krieger, Jan-David and
Ruas, Terry and
Gipp, Bela and
Aizawa, Akiko",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.101",
doi = "10.18653/v1/2021.findings-emnlp.101",
pages = "1166--1177",
}
``` | mediabiasgroup/BABE | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | 2022-09-18T02:18:38+00:00 | {"license": "cc-by-nc-sa-4.0"} | 2023-08-23T04:24:17+00:00 | [] | [] | TAGS
#license-cc-by-nc-sa-4.0 #region-us
|
# Please cite as
| [
"# Please cite as"
] | [
"TAGS\n#license-cc-by-nc-sa-4.0 #region-us \n",
"# Please cite as"
] |
6b1af94c41e300f43a41ec578499df68033f6b14 | prem | premhuggingface/prem | [
"region:us"
] | 2022-09-18T07:49:31+00:00 | {} | 2022-09-18T07:50:31+00:00 | [] | [] | TAGS
#region-us
| prem | [] | [
"TAGS\n#region-us \n"
] |
d816d4a05cb89bde39dd99284c459801e1e7e69a |
# Stable Diffusion Dataset
This is a set of about 80,000 prompts filtered and extracted from the image finder for Stable Diffusion: "[Lexica.art](https://lexica.art/)". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare.
If you want to test the model with a demo, you can go to: "[spaces/Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion)".
If you want to see the model, go to: "[Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusion)". | Gustavosta/Stable-Diffusion-Prompts | [
"annotations_creators:no-annotation",
"language_creators:found",
"source_datasets:original",
"language:en",
"license:unknown",
"region:us"
] | 2022-09-18T11:13:15+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["found"], "language": ["en"], "license": ["unknown"], "source_datasets": ["original"]} | 2022-09-18T21:38:59+00:00 | [] | [
"en"
] | TAGS
#annotations_creators-no-annotation #language_creators-found #source_datasets-original #language-English #license-unknown #region-us
|
# Stable Diffusion Dataset
This is a set of about 80,000 prompts filtered and extracted from the image finder for Stable Diffusion: "URL". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare.
If you want to test the model with a demo, you can go to: "spaces/Gustavosta/MagicPrompt-Stable-Diffusion".
If you want to see the model, go to: "Gustavosta/MagicPrompt-Stable-Diffusion". | [
"# Stable Diffusion Dataset\n\nThis is a set of about 80,000 prompts filtered and extracted from the image finder for Stable Diffusion: \"URL\". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare.\n\nIf you want to test the model with a demo, you can go to: \"spaces/Gustavosta/MagicPrompt-Stable-Diffusion\".\n\nIf you want to see the model, go to: \"Gustavosta/MagicPrompt-Stable-Diffusion\"."
] | [
"TAGS\n#annotations_creators-no-annotation #language_creators-found #source_datasets-original #language-English #license-unknown #region-us \n",
"# Stable Diffusion Dataset\n\nThis is a set of about 80,000 prompts filtered and extracted from the image finder for Stable Diffusion: \"URL\". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare.\n\nIf you want to test the model with a demo, you can go to: \"spaces/Gustavosta/MagicPrompt-Stable-Diffusion\".\n\nIf you want to see the model, go to: \"Gustavosta/MagicPrompt-Stable-Diffusion\"."
] |
61a5b55d423a65338145f63a0247e2d1c0552cd0 | A sampled version of the [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix) dataset for the English-Romanian pair, containing 1M train entries.
Please refer to the original for more info. | din0s/ccmatrix_en-ro | [
"task_categories:translation",
"multilinguality:translation",
"size_categories:100K<n<1M",
"language:en",
"language:ro",
"region:us"
] | 2022-09-18T11:44:19+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en", "ro"], "license": [], "multilinguality": ["translation"], "size_categories": ["100K<n<1M"], "source_datasets": [], "task_categories": ["translation"], "task_ids": [], "pretty_name": "CCMatrix (en-ro)", "tags": []} | 2022-09-19T21:42:56+00:00 | [] | [
"en",
"ro"
] | TAGS
#task_categories-translation #multilinguality-translation #size_categories-100K<n<1M #language-English #language-Romanian #region-us
| A sampled version of the CCMatrix dataset for the English-Romanian pair, containing 1M train entries.
Please refer to the original for more info. | [] | [
"TAGS\n#task_categories-translation #multilinguality-translation #size_categories-100K<n<1M #language-English #language-Romanian #region-us \n"
] |
4a08d21e2e71ce0106721aa1c3bca936049fccf6 | The Victoria electricity demand dataset from the [MAPIE github repository](https://github.com/scikit-learn-contrib/MAPIE/tree/master/examples/data).
It consists of hourly electricity demand (in GW)
of the Victoria state in Australia together with the temperature
(in Celsius degrees).
| rajistics/electricity_demand | [
"task_categories:time-series-forecasting",
"region:us"
] | 2022-09-18T18:06:12+00:00 | {"task_categories": ["time-series-forecasting"]} | 2022-10-19T20:03:02+00:00 | [] | [] | TAGS
#task_categories-time-series-forecasting #region-us
| The Victoria electricity demand dataset from the MAPIE github repository.
It consists of hourly electricity demand (in GW)
of the Victoria state in Australia together with the temperature
(in Celsius degrees).
| [] | [
"TAGS\n#task_categories-time-series-forecasting #region-us \n"
] |
c53dad48e14e0df066905a4e4bd5893b9e790e49 |
# Mario Maker 2 levels
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 levels dataset consists of 26.6 million levels from Nintendo's online service totaling around 100GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 levels dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_level", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 3000004,
'name': 'カベキック',
'description': 'カベキックをとにかくするコースです。',
'uploaded': 1561644329,
'created': 1561674240,
'gamestyle': 4,
'theme': 0,
'difficulty': 0,
'tag1': 7,
'tag2': 10,
'game_version': 1,
'world_record': 8049,
'upload_time': 193540,
'upload_attempts': 1,
'num_comments': 60,
'clear_condition': 0,
'clear_condition_magnitude': 0,
'timer': 300,
'autoscroll_speed': 0,
'clears': 1646,
'attempts': 3168,
'clear_rate': 51.957070707070706,
'plays': 1704,
'versus_matches': 80,
'coop_matches': 27,
'likes': 152,
'boos': 118,
'unique_players_and_versus': 1391,
'weekly_likes': 0,
'weekly_plays': 1,
'uploader_pid': '5218390885570355093',
'first_completer_pid': '16824392528839047213',
'record_holder_pid': '5411258160547085075',
'level_data': [some binary data],
'unk2': 0,
'unk3': [some binary data],
'unk9': 3,
'unk10': 4,
'unk11': 1,
'unk12': 1
}
```
Level data is a binary blob describing the actual level and is equivalent to the level format Nintendo uses in-game. It is gzip compressed and needs to be decompressed to be read. To read it you only need to use the provided `level.ksy` kaitai struct file and install the kaitai struct runtime to parse it into an object:
```python
from datasets import load_dataset
from kaitaistruct import KaitaiStream
from io import BytesIO
from level import Level
import zlib
ds = load_dataset("TheGreatRambler/mm2_level", streaming=True, split="train")
level_data = next(iter(ds))["level_data"]
level = Level(KaitaiStream(BytesIO(zlib.decompress(level_data))))
# NOTE level.overworld.objects is a fixed size (limitation of Kaitai struct)
# must iterate by object_count or null objects will be included
for i in range(level.overworld.object_count):
obj = level.overworld.objects[i]
print("X: %d Y: %d ID: %s" % (obj.x, obj.y, obj.id))
#OUTPUT:
X: 1200 Y: 400 ID: ObjId.block
X: 1360 Y: 400 ID: ObjId.block
X: 1360 Y: 240 ID: ObjId.block
X: 1520 Y: 240 ID: ObjId.block
X: 1680 Y: 240 ID: ObjId.block
X: 1680 Y: 400 ID: ObjId.block
X: 1840 Y: 400 ID: ObjId.block
X: 2000 Y: 400 ID: ObjId.block
X: 2160 Y: 400 ID: ObjId.block
X: 2320 Y: 400 ID: ObjId.block
X: 2480 Y: 560 ID: ObjId.block
X: 2480 Y: 720 ID: ObjId.block
X: 2480 Y: 880 ID: ObjId.block
X: 2160 Y: 880 ID: ObjId.block
```
Rendering the level data into an image can be done using [Toost](https://github.com/TheGreatRambler/toost) if desired.
You can also download the full dataset. Note that this will download ~100GB:
```python
ds = load_dataset("TheGreatRambler/mm2_level", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 3000004,
'name': 'カベキック',
'description': 'カベキックをとにかくするコースです。',
'uploaded': 1561644329,
'created': 1561674240,
'gamestyle': 4,
'theme': 0,
'difficulty': 0,
'tag1': 7,
'tag2': 10,
'game_version': 1,
'world_record': 8049,
'upload_time': 193540,
'upload_attempts': 1,
'num_comments': 60,
'clear_condition': 0,
'clear_condition_magnitude': 0,
'timer': 300,
'autoscroll_speed': 0,
'clears': 1646,
'attempts': 3168,
'clear_rate': 51.957070707070706,
'plays': 1704,
'versus_matches': 80,
'coop_matches': 27,
'likes': 152,
'boos': 118,
'unique_players_and_versus': 1391,
'weekly_likes': 0,
'weekly_plays': 1,
'uploader_pid': '5218390885570355093',
'first_completer_pid': '16824392528839047213',
'record_holder_pid': '5411258160547085075',
'level_data': [some binary data],
'unk2': 0,
'unk3': [some binary data],
'unk9': 3,
'unk10': 4,
'unk11': 1,
'unk12': 1
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|Data IDs are unique identifiers, gaps in the table are due to levels deleted by users or Nintendo|
|name|string|Course name|
|description|string|Course description|
|uploaded|int|UTC timestamp for when the level was uploaded|
|created|int|Local timestamp for when the level was created|
|gamestyle|int|Gamestyle, enum below|
|theme|int|Theme, enum below|
|difficulty|int|Difficulty, enum below|
|tag1|int|The first tag, if it exists, enum below|
|tag2|int|The second tag, if it exists, enum below|
|game_version|int|The version of the game this level was made on|
|world_record|int|The world record in milliseconds|
|upload_time|int|The upload time in milliseconds|
|upload_attempts|int|The number of attempts it took the uploader to upload|
|num_comments|int|Number of comments, may not reflect the archived comments if there were more than 1000 comments|
|clear_condition|int|Clear condition, enum below|
|clear_condition_magnitude|int|If applicable, the magnitude of the clear condition|
|timer|int|The timer of the level|
|autoscroll_speed|int|A unit of how fast the configured autoscroll speed is for the level|
|clears|int|Course clears|
|attempts|int|Course attempts|
|clear_rate|float|Course clear rate as a float between 0 and 1|
|plays|int|Course plays, or "footprints"|
|versus_matches|int|Course versus matches|
|coop_matches|int|Course coop matches|
|likes|int|Course likes|
|boos|int|Course boos|
|unique_players_and_versus|int|All unique players that have ever played this level, including the number of versus matches|
|weekly_likes|int|The weekly likes on this course|
|weekly_plays|int|The weekly plays on this course|
|uploader_pid|string|The player ID of the uploader|
|first_completer_pid|string|The player ID of the user who first cleared this course|
|record_holder_pid|string|The player ID of the user who held the world record at time of archival |
|level_data|bytes|The GZIP compressed decrypted level data, kaitai struct file is provided for reading|
|unk2|int|Unknown|
|unk3|bytes|Unknown|
|unk9|int|Unknown|
|unk10|int|Unknown|
|unk11|int|Unknown|
|unk12|int|Unknown|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
GameStyles = {
0: "SMB1",
1: "SMB3",
2: "SMW",
3: "NSMBU",
4: "SM3DW"
}
Difficulties = {
0: "Easy",
1: "Normal",
2: "Expert",
3: "Super expert"
}
CourseThemes = {
0: "Overworld",
1: "Underground",
2: "Castle",
3: "Airship",
4: "Underwater",
5: "Ghost house",
6: "Snow",
7: "Desert",
8: "Sky",
9: "Forest"
}
TagNames = {
0: "None",
1: "Standard",
2: "Puzzle solving",
3: "Speedrun",
4: "Autoscroll",
5: "Auto mario",
6: "Short and sweet",
7: "Multiplayer versus",
8: "Themed",
9: "Music",
10: "Art",
11: "Technical",
12: "Shooter",
13: "Boss battle",
14: "Single player",
15: "Link"
}
ClearConditions = {
137525990: "Reach the goal without landing after leaving the ground.",
199585683: "Reach the goal after defeating at least/all (n) Mechakoopa(s).",
272349836: "Reach the goal after defeating at least/all (n) Cheep Cheep(s).",
375673178: "Reach the goal without taking damage.",
426197923: "Reach the goal as Boomerang Mario.",
436833616: "Reach the goal while wearing a Shoe.",
713979835: "Reach the goal as Fire Mario.",
744927294: "Reach the goal as Frog Mario.",
751004331: "Reach the goal after defeating at least/all (n) Larry(s).",
900050759: "Reach the goal as Raccoon Mario.",
947659466: "Reach the goal after defeating at least/all (n) Blooper(s).",
976173462: "Reach the goal as Propeller Mario.",
994686866: "Reach the goal while wearing a Propeller Box.",
998904081: "Reach the goal after defeating at least/all (n) Spike(s).",
1008094897: "Reach the goal after defeating at least/all (n) Boom Boom(s).",
1051433633: "Reach the goal while holding a Koopa Shell.",
1061233896: "Reach the goal after defeating at least/all (n) Porcupuffer(s).",
1062253843: "Reach the goal after defeating at least/all (n) Charvaargh(s).",
1079889509: "Reach the goal after defeating at least/all (n) Bullet Bill(s).",
1080535886: "Reach the goal after defeating at least/all (n) Bully/Bullies.",
1151250770: "Reach the goal while wearing a Goomba Mask.",
1182464856: "Reach the goal after defeating at least/all (n) Hop-Chops.",
1219761531: "Reach the goal while holding a Red POW Block. OR Reach the goal after activating at least/all (n) Red POW Block(s).",
1221661152: "Reach the goal after defeating at least/all (n) Bob-omb(s).",
1259427138: "Reach the goal after defeating at least/all (n) Spiny/Spinies.",
1268255615: "Reach the goal after defeating at least/all (n) Bowser(s)/Meowser(s).",
1279580818: "Reach the goal after defeating at least/all (n) Ant Trooper(s).",
1283945123: "Reach the goal on a Lakitu's Cloud.",
1344044032: "Reach the goal after defeating at least/all (n) Boo(s).",
1425973877: "Reach the goal after defeating at least/all (n) Roy(s).",
1429902736: "Reach the goal while holding a Trampoline.",
1431944825: "Reach the goal after defeating at least/all (n) Morton(s).",
1446467058: "Reach the goal after defeating at least/all (n) Fish Bone(s).",
1510495760: "Reach the goal after defeating at least/all (n) Monty Mole(s).",
1656179347: "Reach the goal after picking up at least/all (n) 1-Up Mushroom(s).",
1665820273: "Reach the goal after defeating at least/all (n) Hammer Bro(s.).",
1676924210: "Reach the goal after hitting at least/all (n) P Switch(es). OR Reach the goal while holding a P Switch.",
1715960804: "Reach the goal after activating at least/all (n) POW Block(s). OR Reach the goal while holding a POW Block.",
1724036958: "Reach the goal after defeating at least/all (n) Angry Sun(s).",
1730095541: "Reach the goal after defeating at least/all (n) Pokey(s).",
1780278293: "Reach the goal as Superball Mario.",
1839897151: "Reach the goal after defeating at least/all (n) Pom Pom(s).",
1969299694: "Reach the goal after defeating at least/all (n) Peepa(s).",
2035052211: "Reach the goal after defeating at least/all (n) Lakitu(s).",
2038503215: "Reach the goal after defeating at least/all (n) Lemmy(s).",
2048033177: "Reach the goal after defeating at least/all (n) Lava Bubble(s).",
2076496776: "Reach the goal while wearing a Bullet Bill Mask.",
2089161429: "Reach the goal as Big Mario.",
2111528319: "Reach the goal as Cat Mario.",
2131209407: "Reach the goal after defeating at least/all (n) Goomba(s)/Galoomba(s).",
2139645066: "Reach the goal after defeating at least/all (n) Thwomp(s).",
2259346429: "Reach the goal after defeating at least/all (n) Iggy(s).",
2549654281: "Reach the goal while wearing a Dry Bones Shell.",
2694559007: "Reach the goal after defeating at least/all (n) Sledge Bro(s.).",
2746139466: "Reach the goal after defeating at least/all (n) Rocky Wrench(es).",
2749601092: "Reach the goal after grabbing at least/all (n) 50-Coin(s).",
2855236681: "Reach the goal as Flying Squirrel Mario.",
3036298571: "Reach the goal as Buzzy Mario.",
3074433106: "Reach the goal as Builder Mario.",
3146932243: "Reach the goal as Cape Mario.",
3174413484: "Reach the goal after defeating at least/all (n) Wendy(s).",
3206222275: "Reach the goal while wearing a Cannon Box.",
3314955857: "Reach the goal as Link.",
3342591980: "Reach the goal while you have Super Star invincibility.",
3346433512: "Reach the goal after defeating at least/all (n) Goombrat(s)/Goombud(s).",
3348058176: "Reach the goal after grabbing at least/all (n) 10-Coin(s).",
3353006607: "Reach the goal after defeating at least/all (n) Buzzy Beetle(s).",
3392229961: "Reach the goal after defeating at least/all (n) Bowser Jr.(s).",
3437308486: "Reach the goal after defeating at least/all (n) Koopa Troopa(s).",
3459144213: "Reach the goal after defeating at least/all (n) Chain Chomp(s).",
3466227835: "Reach the goal after defeating at least/all (n) Muncher(s).",
3481362698: "Reach the goal after defeating at least/all (n) Wiggler(s).",
3513732174: "Reach the goal as SMB2 Mario.",
3649647177: "Reach the goal in a Koopa Clown Car/Junior Clown Car.",
3725246406: "Reach the goal as Spiny Mario.",
3730243509: "Reach the goal in a Koopa Troopa Car.",
3748075486: "Reach the goal after defeating at least/all (n) Piranha Plant(s)/Jumping Piranha Plant(s).",
3797704544: "Reach the goal after defeating at least/all (n) Dry Bones.",
3824561269: "Reach the goal after defeating at least/all (n) Stingby/Stingbies.",
3833342952: "Reach the goal after defeating at least/all (n) Piranha Creeper(s).",
3842179831: "Reach the goal after defeating at least/all (n) Fire Piranha Plant(s).",
3874680510: "Reach the goal after breaking at least/all (n) Crates(s).",
3974581191: "Reach the goal after defeating at least/all (n) Ludwig(s).",
3977257962: "Reach the goal as Super Mario.",
4042480826: "Reach the goal after defeating at least/all (n) Skipsqueak(s).",
4116396131: "Reach the goal after grabbing at least/all (n) Coin(s).",
4117878280: "Reach the goal after defeating at least/all (n) Magikoopa(s).",
4122555074: "Reach the goal after grabbing at least/all (n) 30-Coin(s).",
4153835197: "Reach the goal as Balloon Mario.",
4172105156: "Reach the goal while wearing a Red POW Box.",
4209535561: "Reach the Goal while riding Yoshi.",
4269094462: "Reach the goal after defeating at least/all (n) Spike Top(s).",
4293354249: "Reach the goal after defeating at least/all (n) Banzai Bill(s)."
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset consists of levels from many different Mario Maker 2 players globally and as such their titles and descriptions could contain harmful language. Harmful depictions could also be present in the level data, should you choose to render it.
| TheGreatRambler/mm2_level | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:15:00+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 levels", "tags": ["text-mining"]} | 2022-11-11T08:07:34+00:00 | [] | [
"multilingual"
] | TAGS
#task_categories-other #task_categories-object-detection #task_categories-text-retrieval #task_categories-token-classification #task_categories-text-generation #multilinguality-multilingual #size_categories-10M<n<100M #source_datasets-original #language-multilingual #license-cc-by-nc-sa-4.0 #text-mining #region-us
| Mario Maker 2 levels
====================
Part of the Mario Maker 2 Dataset Collection
Dataset Description
-------------------
The Mario Maker 2 levels dataset consists of 26.6 million levels from Nintendo's online service totaling around 100GB of data. The dataset was created using the self-hosted Mario Maker 2 api over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 levels dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of 'datasets'. You can load and iterate through the dataset with the following code:
Level data is a binary blob describing the actual level and is equivalent to the level format Nintendo uses in-game. It is gzip compressed and needs to be decompressed to be read. To read it you only need to use the provided 'URL' kaitai struct file and install the kaitai struct runtime to parse it into an object:
Rendering the level data into an image can be done using Toost if desired.
You can also download the full dataset. Note that this will download ~100GB:
Data Structure
--------------
### Data Instances
### Data Fields
Field: data\_id, Type: int, Description: Data IDs are unique identifiers, gaps in the table are due to levels deleted by users or Nintendo
Field: name, Type: string, Description: Course name
Field: description, Type: string, Description: Course description
Field: uploaded, Type: int, Description: UTC timestamp for when the level was uploaded
Field: created, Type: int, Description: Local timestamp for when the level was created
Field: gamestyle, Type: int, Description: Gamestyle, enum below
Field: theme, Type: int, Description: Theme, enum below
Field: difficulty, Type: int, Description: Difficulty, enum below
Field: tag1, Type: int, Description: The first tag, if it exists, enum below
Field: tag2, Type: int, Description: The second tag, if it exists, enum below
Field: game\_version, Type: int, Description: The version of the game this level was made on
Field: world\_record, Type: int, Description: The world record in milliseconds
Field: upload\_time, Type: int, Description: The upload time in milliseconds
Field: upload\_attempts, Type: int, Description: The number of attempts it took the uploader to upload
Field: num\_comments, Type: int, Description: Number of comments, may not reflect the archived comments if there were more than 1000 comments
Field: clear\_condition, Type: int, Description: Clear condition, enum below
Field: clear\_condition\_magnitude, Type: int, Description: If applicable, the magnitude of the clear condition
Field: timer, Type: int, Description: The timer of the level
Field: autoscroll\_speed, Type: int, Description: A unit of how fast the configured autoscroll speed is for the level
Field: clears, Type: int, Description: Course clears
Field: attempts, Type: int, Description: Course attempts
Field: clear\_rate, Type: float, Description: Course clear rate as a float between 0 and 1
Field: plays, Type: int, Description: Course plays, or "footprints"
Field: versus\_matches, Type: int, Description: Course versus matches
Field: coop\_matches, Type: int, Description: Course coop matches
Field: likes, Type: int, Description: Course likes
Field: boos, Type: int, Description: Course boos
Field: unique\_players\_and\_versus, Type: int, Description: All unique players that have ever played this level, including the number of versus matches
Field: weekly\_likes, Type: int, Description: The weekly likes on this course
Field: weekly\_plays, Type: int, Description: The weekly plays on this course
Field: uploader\_pid, Type: string, Description: The player ID of the uploader
Field: first\_completer\_pid, Type: string, Description: The player ID of the user who first cleared this course
Field: record\_holder\_pid, Type: string, Description: The player ID of the user who held the world record at time of archival
Field: level\_data, Type: bytes, Description: The GZIP compressed decrypted level data, kaitai struct file is provided for reading
Field: unk2, Type: int, Description: Unknown
Field: unk3, Type: bytes, Description: Unknown
Field: unk9, Type: int, Description: Unknown
Field: unk10, Type: int, Description: Unknown
Field: unk11, Type: int, Description: Unknown
Field: unk12, Type: int, Description: Unknown
### Data Splits
The dataset only contains a train split.
Enums
-----
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
Dataset Creation
----------------
The dataset was created over a little more than a month in Febuary 2022 using the self hosted Mario Maker 2 api. As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
Considerations for Using the Data
---------------------------------
The dataset consists of levels from many different Mario Maker 2 players globally and as such their titles and descriptions could contain harmful language. Harmful depictions could also be present in the level data, should you choose to render it.
| [
"### How to use it\n\n\nThe Mario Maker 2 levels dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of 'datasets'. You can load and iterate through the dataset with the following code:\n\n\nLevel data is a binary blob describing the actual level and is equivalent to the level format Nintendo uses in-game. It is gzip compressed and needs to be decompressed to be read. To read it you only need to use the provided 'URL' kaitai struct file and install the kaitai struct runtime to parse it into an object:\n\n\nRendering the level data into an image can be done using Toost if desired.\n\n\nYou can also download the full dataset. Note that this will download ~100GB:\n\n\nData Structure\n--------------",
"### Data Instances",
"### Data Fields\n\n\nField: data\\_id, Type: int, Description: Data IDs are unique identifiers, gaps in the table are due to levels deleted by users or Nintendo\nField: name, Type: string, Description: Course name\nField: description, Type: string, Description: Course description\nField: uploaded, Type: int, Description: UTC timestamp for when the level was uploaded\nField: created, Type: int, Description: Local timestamp for when the level was created\nField: gamestyle, Type: int, Description: Gamestyle, enum below\nField: theme, Type: int, Description: Theme, enum below\nField: difficulty, Type: int, Description: Difficulty, enum below\nField: tag1, Type: int, Description: The first tag, if it exists, enum below\nField: tag2, Type: int, Description: The second tag, if it exists, enum below\nField: game\\_version, Type: int, Description: The version of the game this level was made on\nField: world\\_record, Type: int, Description: The world record in milliseconds\nField: upload\\_time, Type: int, Description: The upload time in milliseconds\nField: upload\\_attempts, Type: int, Description: The number of attempts it took the uploader to upload\nField: num\\_comments, Type: int, Description: Number of comments, may not reflect the archived comments if there were more than 1000 comments\nField: clear\\_condition, Type: int, Description: Clear condition, enum below\nField: clear\\_condition\\_magnitude, Type: int, Description: If applicable, the magnitude of the clear condition\nField: timer, Type: int, Description: The timer of the level\nField: autoscroll\\_speed, Type: int, Description: A unit of how fast the configured autoscroll speed is for the level\nField: clears, Type: int, Description: Course clears\nField: attempts, Type: int, Description: Course attempts\nField: clear\\_rate, Type: float, Description: Course clear rate as a float between 0 and 1\nField: plays, Type: int, Description: Course plays, or \"footprints\"\nField: versus\\_matches, Type: int, Description: Course versus matches\nField: coop\\_matches, Type: int, Description: Course coop matches\nField: likes, Type: int, Description: Course likes\nField: boos, Type: int, Description: Course boos\nField: unique\\_players\\_and\\_versus, Type: int, Description: All unique players that have ever played this level, including the number of versus matches\nField: weekly\\_likes, Type: int, Description: The weekly likes on this course\nField: weekly\\_plays, Type: int, Description: The weekly plays on this course\nField: uploader\\_pid, Type: string, Description: The player ID of the uploader\nField: first\\_completer\\_pid, Type: string, Description: The player ID of the user who first cleared this course\nField: record\\_holder\\_pid, Type: string, Description: The player ID of the user who held the world record at time of archival\nField: level\\_data, Type: bytes, Description: The GZIP compressed decrypted level data, kaitai struct file is provided for reading\nField: unk2, Type: int, Description: Unknown\nField: unk3, Type: bytes, Description: Unknown\nField: unk9, Type: int, Description: Unknown\nField: unk10, Type: int, Description: Unknown\nField: unk11, Type: int, Description: Unknown\nField: unk12, Type: int, Description: Unknown",
"### Data Splits\n\n\nThe dataset only contains a train split.\n\n\nEnums\n-----\n\n\nThe dataset contains some enum integer fields. This can be used to convert back to their string equivalents:\n\n\nDataset Creation\n----------------\n\n\nThe dataset was created over a little more than a month in Febuary 2022 using the self hosted Mario Maker 2 api. As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nThe dataset consists of levels from many different Mario Maker 2 players globally and as such their titles and descriptions could contain harmful language. Harmful depictions could also be present in the level data, should you choose to render it."
] | [
"TAGS\n#task_categories-other #task_categories-object-detection #task_categories-text-retrieval #task_categories-token-classification #task_categories-text-generation #multilinguality-multilingual #size_categories-10M<n<100M #source_datasets-original #language-multilingual #license-cc-by-nc-sa-4.0 #text-mining #region-us \n",
"### How to use it\n\n\nThe Mario Maker 2 levels dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of 'datasets'. You can load and iterate through the dataset with the following code:\n\n\nLevel data is a binary blob describing the actual level and is equivalent to the level format Nintendo uses in-game. It is gzip compressed and needs to be decompressed to be read. To read it you only need to use the provided 'URL' kaitai struct file and install the kaitai struct runtime to parse it into an object:\n\n\nRendering the level data into an image can be done using Toost if desired.\n\n\nYou can also download the full dataset. Note that this will download ~100GB:\n\n\nData Structure\n--------------",
"### Data Instances",
"### Data Fields\n\n\nField: data\\_id, Type: int, Description: Data IDs are unique identifiers, gaps in the table are due to levels deleted by users or Nintendo\nField: name, Type: string, Description: Course name\nField: description, Type: string, Description: Course description\nField: uploaded, Type: int, Description: UTC timestamp for when the level was uploaded\nField: created, Type: int, Description: Local timestamp for when the level was created\nField: gamestyle, Type: int, Description: Gamestyle, enum below\nField: theme, Type: int, Description: Theme, enum below\nField: difficulty, Type: int, Description: Difficulty, enum below\nField: tag1, Type: int, Description: The first tag, if it exists, enum below\nField: tag2, Type: int, Description: The second tag, if it exists, enum below\nField: game\\_version, Type: int, Description: The version of the game this level was made on\nField: world\\_record, Type: int, Description: The world record in milliseconds\nField: upload\\_time, Type: int, Description: The upload time in milliseconds\nField: upload\\_attempts, Type: int, Description: The number of attempts it took the uploader to upload\nField: num\\_comments, Type: int, Description: Number of comments, may not reflect the archived comments if there were more than 1000 comments\nField: clear\\_condition, Type: int, Description: Clear condition, enum below\nField: clear\\_condition\\_magnitude, Type: int, Description: If applicable, the magnitude of the clear condition\nField: timer, Type: int, Description: The timer of the level\nField: autoscroll\\_speed, Type: int, Description: A unit of how fast the configured autoscroll speed is for the level\nField: clears, Type: int, Description: Course clears\nField: attempts, Type: int, Description: Course attempts\nField: clear\\_rate, Type: float, Description: Course clear rate as a float between 0 and 1\nField: plays, Type: int, Description: Course plays, or \"footprints\"\nField: versus\\_matches, Type: int, Description: Course versus matches\nField: coop\\_matches, Type: int, Description: Course coop matches\nField: likes, Type: int, Description: Course likes\nField: boos, Type: int, Description: Course boos\nField: unique\\_players\\_and\\_versus, Type: int, Description: All unique players that have ever played this level, including the number of versus matches\nField: weekly\\_likes, Type: int, Description: The weekly likes on this course\nField: weekly\\_plays, Type: int, Description: The weekly plays on this course\nField: uploader\\_pid, Type: string, Description: The player ID of the uploader\nField: first\\_completer\\_pid, Type: string, Description: The player ID of the user who first cleared this course\nField: record\\_holder\\_pid, Type: string, Description: The player ID of the user who held the world record at time of archival\nField: level\\_data, Type: bytes, Description: The GZIP compressed decrypted level data, kaitai struct file is provided for reading\nField: unk2, Type: int, Description: Unknown\nField: unk3, Type: bytes, Description: Unknown\nField: unk9, Type: int, Description: Unknown\nField: unk10, Type: int, Description: Unknown\nField: unk11, Type: int, Description: Unknown\nField: unk12, Type: int, Description: Unknown",
"### Data Splits\n\n\nThe dataset only contains a train split.\n\n\nEnums\n-----\n\n\nThe dataset contains some enum integer fields. This can be used to convert back to their string equivalents:\n\n\nDataset Creation\n----------------\n\n\nThe dataset was created over a little more than a month in Febuary 2022 using the self hosted Mario Maker 2 api. As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nThe dataset consists of levels from many different Mario Maker 2 players globally and as such their titles and descriptions could contain harmful language. Harmful depictions could also be present in the level data, should you choose to render it."
] |
e1ded9a5fb0f1d052d0a7a44ec46f79a4b27903a |
# Mario Maker 2 level comments
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 level comment dataset consists of 31.9 million level comments from Nintendo's online service totaling around 20GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 level comment dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_level_comments", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 3000006,
'comment_id': '20200430072710528979_302de3722145c7a2_2dc6c6',
'type': 2,
'pid': '3471680967096518562',
'posted': 1561652887,
'clear_required': 0,
'text': '',
'reaction_image_id': 10,
'custom_image': [some binary data],
'has_beaten': 0,
'x': 557,
'y': 64,
'reaction_face': 0,
'unk8': 0,
'unk10': 0,
'unk12': 0,
'unk14': [some binary data],
'unk17': 0
}
```
Comments can be one of three types: text, reaction image or custom image. `type` can be used with the enum below to identify different kinds of comments. Custom images are binary PNGs.
You can also download the full dataset. Note that this will download ~20GB:
```python
ds = load_dataset("TheGreatRambler/mm2_level_comments", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 3000006,
'comment_id': '20200430072710528979_302de3722145c7a2_2dc6c6',
'type': 2,
'pid': '3471680967096518562',
'posted': 1561652887,
'clear_required': 0,
'text': '',
'reaction_image_id': 10,
'custom_image': [some binary data],
'has_beaten': 0,
'x': 557,
'y': 64,
'reaction_face': 0,
'unk8': 0,
'unk10': 0,
'unk12': 0,
'unk14': [some binary data],
'unk17': 0
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|The data ID of the level this comment appears on|
|comment_id|string|Comment ID|
|type|int|Type of comment, enum below|
|pid|string|Player ID of the comment creator|
|posted|int|UTC timestamp of when this comment was created|
|clear_required|bool|Whether this comment requires a clear to view|
|text|string|If the comment type is text, the text of the comment|
|reaction_image_id|int|If this comment is a reaction image, the id of the reaction image, enum below|
|custom_image|bytes|If this comment is a custom drawing, the custom drawing as a PNG binary|
|has_beaten|int|Whether the user had beaten the level when they created the comment|
|x|int|The X position of the comment in game|
|y|int|The Y position of the comment in game|
|reaction_face|int|The reaction face of the mii of this user, enum below|
|unk8|int|Unknown|
|unk10|int|Unknown|
|unk12|int|Unknown|
|unk14|bytes|Unknown|
|unk17|int|Unknown|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
CommentType = {
0: "Custom Image",
1: "Text",
2: "Reaction Image"
}
CommentReactionImage = {
0: "Nice!",
1: "Good stuff!",
2: "So tough...",
3: "EASY",
4: "Seriously?!",
5: "Wow!",
6: "Cool idea!",
7: "SPEEDRUN!",
8: "How?!",
9: "Be careful!",
10: "So close!",
11: "Beat it!"
}
CommentReactionFace = {
0: "Normal",
16: "Wink",
1: "Happy",
4: "Surprised",
18: "Scared",
3: "Confused"
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset consists of comments from many different Mario Maker 2 players globally and as such their text could contain harmful language. Harmful depictions could also be present in the custom images.
| TheGreatRambler/mm2_level_comments | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:15:48+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 level comments", "tags": ["text-mining"]} | 2022-11-11T08:06:48+00:00 | [] | [
"multilingual"
] | TAGS
#task_categories-other #task_categories-object-detection #task_categories-text-retrieval #task_categories-token-classification #task_categories-text-generation #multilinguality-multilingual #size_categories-10M<n<100M #source_datasets-original #language-multilingual #license-cc-by-nc-sa-4.0 #text-mining #region-us
| Mario Maker 2 level comments
============================
Part of the Mario Maker 2 Dataset Collection
Dataset Description
-------------------
The Mario Maker 2 level comment dataset consists of 31.9 million level comments from Nintendo's online service totaling around 20GB of data. The dataset was created using the self-hosted Mario Maker 2 api over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 level comment dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of 'datasets'. You can load and iterate through the dataset with the following code:
Comments can be one of three types: text, reaction image or custom image. 'type' can be used with the enum below to identify different kinds of comments. Custom images are binary PNGs.
You can also download the full dataset. Note that this will download ~20GB:
Data Structure
--------------
### Data Instances
### Data Fields
Field: data\_id, Type: int, Description: The data ID of the level this comment appears on
Field: comment\_id, Type: string, Description: Comment ID
Field: type, Type: int, Description: Type of comment, enum below
Field: pid, Type: string, Description: Player ID of the comment creator
Field: posted, Type: int, Description: UTC timestamp of when this comment was created
Field: clear\_required, Type: bool, Description: Whether this comment requires a clear to view
Field: text, Type: string, Description: If the comment type is text, the text of the comment
Field: reaction\_image\_id, Type: int, Description: If this comment is a reaction image, the id of the reaction image, enum below
Field: custom\_image, Type: bytes, Description: If this comment is a custom drawing, the custom drawing as a PNG binary
Field: has\_beaten, Type: int, Description: Whether the user had beaten the level when they created the comment
Field: x, Type: int, Description: The X position of the comment in game
Field: y, Type: int, Description: The Y position of the comment in game
Field: reaction\_face, Type: int, Description: The reaction face of the mii of this user, enum below
Field: unk8, Type: int, Description: Unknown
Field: unk10, Type: int, Description: Unknown
Field: unk12, Type: int, Description: Unknown
Field: unk14, Type: bytes, Description: Unknown
Field: unk17, Type: int, Description: Unknown
### Data Splits
The dataset only contains a train split.
Enums
-----
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
Dataset Creation
----------------
The dataset was created over a little more than a month in Febuary 2022 using the self hosted Mario Maker 2 api. As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
Considerations for Using the Data
---------------------------------
The dataset consists of comments from many different Mario Maker 2 players globally and as such their text could contain harmful language. Harmful depictions could also be present in the custom images.
| [
"### How to use it\n\n\nThe Mario Maker 2 level comment dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of 'datasets'. You can load and iterate through the dataset with the following code:\n\n\nComments can be one of three types: text, reaction image or custom image. 'type' can be used with the enum below to identify different kinds of comments. Custom images are binary PNGs.\n\n\nYou can also download the full dataset. Note that this will download ~20GB:\n\n\nData Structure\n--------------",
"### Data Instances",
"### Data Fields\n\n\nField: data\\_id, Type: int, Description: The data ID of the level this comment appears on\nField: comment\\_id, Type: string, Description: Comment ID\nField: type, Type: int, Description: Type of comment, enum below\nField: pid, Type: string, Description: Player ID of the comment creator\nField: posted, Type: int, Description: UTC timestamp of when this comment was created\nField: clear\\_required, Type: bool, Description: Whether this comment requires a clear to view\nField: text, Type: string, Description: If the comment type is text, the text of the comment\nField: reaction\\_image\\_id, Type: int, Description: If this comment is a reaction image, the id of the reaction image, enum below\nField: custom\\_image, Type: bytes, Description: If this comment is a custom drawing, the custom drawing as a PNG binary\nField: has\\_beaten, Type: int, Description: Whether the user had beaten the level when they created the comment\nField: x, Type: int, Description: The X position of the comment in game\nField: y, Type: int, Description: The Y position of the comment in game\nField: reaction\\_face, Type: int, Description: The reaction face of the mii of this user, enum below\nField: unk8, Type: int, Description: Unknown\nField: unk10, Type: int, Description: Unknown\nField: unk12, Type: int, Description: Unknown\nField: unk14, Type: bytes, Description: Unknown\nField: unk17, Type: int, Description: Unknown",
"### Data Splits\n\n\nThe dataset only contains a train split.\n\n\nEnums\n-----\n\n\nThe dataset contains some enum integer fields. This can be used to convert back to their string equivalents:\n\n\nDataset Creation\n----------------\n\n\nThe dataset was created over a little more than a month in Febuary 2022 using the self hosted Mario Maker 2 api. As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nThe dataset consists of comments from many different Mario Maker 2 players globally and as such their text could contain harmful language. Harmful depictions could also be present in the custom images."
] | [
"TAGS\n#task_categories-other #task_categories-object-detection #task_categories-text-retrieval #task_categories-token-classification #task_categories-text-generation #multilinguality-multilingual #size_categories-10M<n<100M #source_datasets-original #language-multilingual #license-cc-by-nc-sa-4.0 #text-mining #region-us \n",
"### How to use it\n\n\nThe Mario Maker 2 level comment dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of 'datasets'. You can load and iterate through the dataset with the following code:\n\n\nComments can be one of three types: text, reaction image or custom image. 'type' can be used with the enum below to identify different kinds of comments. Custom images are binary PNGs.\n\n\nYou can also download the full dataset. Note that this will download ~20GB:\n\n\nData Structure\n--------------",
"### Data Instances",
"### Data Fields\n\n\nField: data\\_id, Type: int, Description: The data ID of the level this comment appears on\nField: comment\\_id, Type: string, Description: Comment ID\nField: type, Type: int, Description: Type of comment, enum below\nField: pid, Type: string, Description: Player ID of the comment creator\nField: posted, Type: int, Description: UTC timestamp of when this comment was created\nField: clear\\_required, Type: bool, Description: Whether this comment requires a clear to view\nField: text, Type: string, Description: If the comment type is text, the text of the comment\nField: reaction\\_image\\_id, Type: int, Description: If this comment is a reaction image, the id of the reaction image, enum below\nField: custom\\_image, Type: bytes, Description: If this comment is a custom drawing, the custom drawing as a PNG binary\nField: has\\_beaten, Type: int, Description: Whether the user had beaten the level when they created the comment\nField: x, Type: int, Description: The X position of the comment in game\nField: y, Type: int, Description: The Y position of the comment in game\nField: reaction\\_face, Type: int, Description: The reaction face of the mii of this user, enum below\nField: unk8, Type: int, Description: Unknown\nField: unk10, Type: int, Description: Unknown\nField: unk12, Type: int, Description: Unknown\nField: unk14, Type: bytes, Description: Unknown\nField: unk17, Type: int, Description: Unknown",
"### Data Splits\n\n\nThe dataset only contains a train split.\n\n\nEnums\n-----\n\n\nThe dataset contains some enum integer fields. This can be used to convert back to their string equivalents:\n\n\nDataset Creation\n----------------\n\n\nThe dataset was created over a little more than a month in Febuary 2022 using the self hosted Mario Maker 2 api. As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nThe dataset consists of comments from many different Mario Maker 2 players globally and as such their text could contain harmful language. Harmful depictions could also be present in the custom images."
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.