
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 17,455 | closed | ProphetNet inconsistent with changing batch ordering | ### System Info
```shell
- `transformers` version: 4.15.0
- Platform: Windows-10-10.0.19044-SP0
- Python version: 3.9.7
- PyTorch version (GPU?): 1.10.1+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@patrickvonplaten
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
``` python
from transformers import ProphetNetForConditionalGeneration, ProphetNetTokenizer
model = ProphetNetForConditionalGeneration.from_pretrained('microsoft/prophetnet-large-uncased')
tokenizer = ProphetNetTokenizer.from_pretrained('microsoft/prophetnet-large-uncased')
input_string = ['Hello, my dog is cute', 'I have a cat that is not cute']
labels = ['My dog is cute', 'My cat is not cute']
inputs = tokenizer(input_string, return_tensors="pt", padding=True, truncation=True)
targets = tokenizer(labels, return_tensors="pt", padding=True, truncation=True)
# Inverse the ordering of the input and labels using [::-1]
inputs_inv = tokenizer(input_string[::-1], return_tensors="pt", padding=True, truncation=True)
targets_inv = tokenizer(labels[::-1], return_tensors="pt", padding=True, truncation=True)
output = model(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, labels=targets.input_ids)
output_inv = model(input_ids=inputs_inv.input_ids, attention_mask=inputs_inv.attention_mask, labels=targets_inv.input_ids)
print(output.loss.item())
print(output_inv.loss.item())
```
Given two different forward passes, where one of them is the inverse of the other, the two losses are different.
output.loss.item() = 5.023777484893799
output_inv.loss.item() = 6.5036540031433105
When comparing their encoder output (last hidden states), they are again not equal
```Python
enc_output = model.prophetnet.encoder(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask)
enc_output_inv = model.prophetnet.encoder(input_ids=inputs_inv.input_ids, attention_mask=inputs_inv.attention_mask)
# We flip the inverse encoder output to have the same order
print((enc_output.last_hidden_state == enc_output_inv.last_hidden_state.flip(0)).all())
```
Also equals `False`
### Expected behavior
```shell
I expect the order of the batch to not have an influence on the model output (aside from the ordering of the output)
```
**Edit** The issue persistent regardless of padding and also causes model.generate to generate two different sets of text.
| 05-27-2022 09:29:17 | 05-27-2022 09:29:17 | Hey @mikkelfo,
This indeed seems like a bug! I sadly won't be able to look into this any time soon - I'll mark the issue as a "good second issue" in case someone wants to give it a try :-). Also cc @patil-suraj <|||||>Thanks for the answer @patrickvonplaten. I suspected so, although I did question my sanity for a moment. I might have some time to look into this myself as I'm using it for my thesis.
I've done a little digging and the issue appears to start during the self-attention of the encoder, more specifically after [line 700](https://github.com/huggingface/transformers/blob/v4.19.2/src/transformers/models/prophetnet/modeling_prophetnet.py#L700). It appears to me that the reshaping into the attention heads (with `.view(*proj_shape)`)causes the issue, as I am unable to invert things back to the original form after that point. <|||||>Sorry for confusing you with this. To be honest, we've ported a relatively messy Prophetnet implementation and never fully tested it. If you have some time to dive into it, I'd suggest to add a test that ensures that changing the order of sequences in a batch still gives the same results (that's a great test btw) and then trying to correct this test while making sure that all other tests run correctly.
Happy to help you if you're stuck. Note the original implementation is here:
- https://github.com/microsoft/ProphetNet
The original author is @qiweizhen I think, we could maybe also ask him if you run into problems :-) <|||||>After some more digging, the issue appears to be centered around ProphetNetAttention and ProphetNetNgramSelfAttention (so both the encoder and the decoder suffers from this). The fix essentially boils down to changing the `proj_shape = (batch_size * self.num_attn_heads, -1, self.head_dim)` to `proj_shape = (batch_size, self.num_attn_heads, -1, self.head_dim)` and adapting the rest of the code to fit this. Keeping the dimensions seperate is also utilised in other transformer models (Took inspiration from BERT) and avoids potential mishaps with reshapes.
For the encoder, this is relatively simple as it only constitues changing the ProphetNetAttention [forward pass](https://github.com/huggingface/transformers/blob/v4.19.2/src/transformers/models/prophetnet/modeling_prophetnet.py#L655) and adapting the [attention mask](https://github.com/huggingface/transformers/blob/v4.19.2/src/transformers/models/prophetnet/modeling_prophetnet.py#L1317) to these new dimensions. I have done this, but it is only a fix for the encoder, so I don't know if that's worthy of a PR @patrickvonplaten? It greatly reduces the inconsistency to a few decimals (for this particular example), from a difference of 1.5 to 0.06.
I am trying to do the same for the decoder part (ProphetNetNgramSelfAttention), but it is quite a bit more cumbersome. I'll keep trying for a bit, otherwise I'll simply offer my encoder fix for now. <|||||>Hello again. I believe I have managed to fix both the encoder and decoder part, such that the hidden states are consistent. However, the loss computations of `ProphetNetForConditionalGeneration` and `ProphetNetForCasualLM` still differs (with a very slight amount).
When the log_softmax is taken ([line 2014](https://github.com/huggingface/transformers/blob/6e535425feae20ca61a8b10ae5e8a7fab4d394ba/src/transformers/models/prophetnet/modeling_prophetnet.py#L2014)) the logits are equal when inversed, but the probabilities are not.
```
# logits = (n_gram, batch_size, seq_length, vocab_size)
print((logits == logits_inv.flip(1)).all()) # True (Flip on batch_size)
lprobs = torch.nn.functional.log_softmax(logits.view(-1, logits.size(-1)),dim=-1,dtype=torch.float32,)
lprobs_inv = torch.nn.functional.log_softmax(logits_inv.view(-1, logits.size(-1)),dim=-1,dtype=torch.float32,)
print(lprobs - lprobs_inv) # -4.7684e-07
```
I believe the .view part is cause the issue due to the collapsing of dimensions. As for the case of the other fixes, merging dimensions are most likely the cause, so seperating from (n_gram\*batch_size\*tokens) to (batch_size, n_gram\*tokens) should fix the issue. It requires a bit more than changing `logits.view(-1, logits.size(-1))` to `logits.view(2, -1, logits.size(-1))`. I'm currently stuck on this, but I'm wondering if any of you can be of help? @patrickvonplaten @patil-suraj @qiweizhen
It is only these 3 lines that are left to fix. How can this be computed while keeping the batch dimension intact?
```
# [batch_size, n_gram, tokens, vocab_size] -> # [n_gram, batch_size, tokens, vocab_size]
logits = logits.transpose(0, 1).contiguous()
lprobs = nn.functional.log_softmax(
logits.view(-1, logits.size(-1)),
dim=-1,
dtype=torch.float32,
)
loss = nn.functional.nll_loss(lprobs, expend_targets.view(-1), reduction="mean")
```<|||||>the difference of `-4.7684e-07` is very small so IMO it can be ignored. `1e-4` is the threshold that we use in `Transformers`. So if the difference is less than that it should be fine I think. wdyt @patrickvonplaten <|||||>I checked a bit further (with my implemented fixes).
Given two model outputs, where one is a batch and the other is single element (i.e. the first element in input_string), we expect that the first element of the batched output is equal to the single element output. Below is a code snippet of how it would look.
```
outputs = model(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, labels=labels, output_hidden_states=True)
batch_size = inputs.input_ids.shape[0]
for i in range(batch_size):
single_outputs = model(input_ids=inputs.input_ids[i:i+1], attention_mask=inputs.attention_mask[i:i+1], labels=labels[i:i+1], output_hidden_states=True)
print((single_outputs.encoder_last_hidden_state - outputs.encoder_last_hidden_state[i:i+1]).abs().mean())
print((single_outputs.decoder_hidden_states[-1] - outputs.decoder_hidden_states[-1][i:i+1]).abs().mean())
```
We expect the differences between the two outputs to be 0, but there is a difference between `1e-6` to `1e-7` for each element in the hidden_states (was `1e` to `1e-1` previously) when using some examples from the CNN/DailyMail dataset. My previous example had equal hidden states, but a slight variation in loss, whereas this example does not have equal hidden states. As @patil-suraj mentioned, it is within the threshold used.
I don't have time to look into this anymore, but I am happy to create a pull request for now. While I dont believe the problem is fully fixed, my fixes makes the differences significantly less. If this is enough for a pull request, let me know and I'll create one @patrickvonplaten.
<|||||>Hi @patil-suraj , @patrickvonplaten.
If it's ok I would like to help and try to solve this issue.<|||||>If you want @kiansierra, here's a [link](https://github.com/mikkelfo/multi-document-abstractive-summarization/blob/main/src/models/prophetnet_fixes.py#L9) for my ad-hoc fixes I did.
I basically copy-pasted the source code and implemented the fixes, so you must figure out yourself where they are if you want. The function [prophetnet_fixes](https://github.com/mikkelfo/multi-document-abstractive-summarization/blob/main/src/models/prophetnet_fixes.py#L9) updates the affected functions for both the encoder and the decoder. |
transformers | 17,454 | closed | XLM-Roberta offset mapping is off by one in case of whitespace-subwords | ### System Info
```shell
- `transformers` version: 4.19.2
- Platform: Linux-5.4.0-94-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): 2.9.1 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
@LysandreJik @SaulLu
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained('xlm-roberta-large', use_fast=True)
>>> tokenizer.tokenize('Quality of work is sufficient')
['▁Quality', '▁of', '▁work', '▁is', '▁', 'sufficient']
>>> tokenizer.encode_plus('Quality of work is sufficient', return_offsets_mapping=True)
{'input_ids': [0, 124604, 111, 4488, 83, 6, 129980, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 7), (8, 10), (11, 15), (16, 18), (19, 20), (19, 29), (0, 0)]}
### Expected behavior
```shell
The third-last offset-tuple (19,20) overlaps with the second-last offset-tuple(19,29). I believe that this should be (18,19), and thus refer to the whitespace.
```
| 05-27-2022 09:25:59 | 05-27-2022 09:25:59 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I think @robvanderg is right (with my intuitive understanding). Since `return_offsets_mapping` is only for fast tokenizer, let me kindly tag @Narsil here
The results should be like
`... (18, 19), (19, 29) ...`
I think.<|||||>I agree with you @ydshieh, to solve it it might be best to open an issue on the [tokenizers](https://github.com/huggingface/tokenizers) library as this is where the offsets are computed :blush: <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,453 | closed | gpt-neo-1-3B large memory increase during training even with a small training dataset | ### System Info
```shell
- `transformers` version: 4.19.2
- Platform: Linux-5.4.0-1075-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.10
- Huggingface_hub version: 0.5.1
- PyTorch version (GPU?): 1.8.1+cu111 (True)
- Tensorflow version (GPU?): 2.8.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: NO
- Using distributed or parallel set-up in script?: NO
```
### Who can help?
@patil-suraj
Training the gpt-neo-1-3B model with a training dataset of 100 sentences (about 75 words max for each sentence, say about 100 tokens), there is jump of close to 29GB in memory consumption during the training. Tried batch sizes of 8/4/2 showing similar increase. Is that expected, or does this memory increase needs further investigation? Model is loaded without setting any of return_dict, output_attentions or output_hidden_states to True.
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Simple training loop as shown in code example in
https://towardsdatascience.com/how-to-fine-tune-gpt-2-for-text-generation-ae2ea53bc272
Use gpt-neo-1-3b and 100 entries for training.
Doing training for 1 epoch itself and the memory jumps by about 29G.
%memit model = train(dataset, model, tokenizer, epochs=1, gpt2_type="gpt_neo_1_3B")
peak memory: 36634.16 MiB, increment: 29428.80 MiB
### Expected behavior
```shell
Not sure if there is some issue with code or this kind of memory jump is expected.
```
| 05-27-2022 09:03:10 | 05-27-2022 09:03:10 | Hi @sandeeppagey !
Could you post a simple code-snippet here, with more details such as the GPU memory, the `dtype` for training.
Also note that, the model weights in fp32 are about 5GB and Adam takes 3x more memory, so this alone is about ~20GB and then there's more memory to store the activations and gradients. <|||||>Hi @patil-suraj
Thanks for the explanation. I am not running on GPU. I am running
on CPU just to check the memory increase. I have not changed the dtype so I guess it is fp32.
I agree with your calculations that the model training will require about 20G of memory. Please close
the issue.
The relevant code snippet is as follows.
model = GPTNeoForCausalLM.from_pretrained('/home1/pretrained_models/gpt_neo_1_3B')
optimizer = AdamW(model.parameters(), lr=2e-5)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=200, num_training_steps=-1
)
train_dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
loss=0
accumulating_batch_count = 0
input_tensor = None
for epoch in range(1):
print(f"Training epoch {epoch}")
print(f"Loss before: {loss}")
for idx, entry in tqdm(enumerate(train_dataloader)):
input_tensor = entry #tokenization has already been done
outputs = model(input_tensor, labels=input_tensor)
#print(isinstance(outputs, dict))
#print(type(outputs))
loss = outputs[0]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad() |
transformers | 17,452 | closed | NaN in GPT NeoX model (generation) | ### System Info
```shell
- `transformers` version: 4.20.0.dev0
- Platform: Linux-4.15.0-140-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- Huggingface_hub version: 0.7.0
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
@LysandreJik (NeoX)
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Script to run:
```
import torch
from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
from accelerate import init_empty_weights, infer_auto_device_map, load_checkpoint_and_dispatch
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, AutoModelForSeq2SeqLM
weights_path = "EleutherAI/gpt-neox-20b"
config = AutoConfig.from_pretrained(weights_path)
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config)
tokenizer = AutoTokenizer.from_pretrained(weights_path)
device_map = infer_auto_device_map(model, no_split_module_classes=["GPTNeoXLayer"])
load_checkpoint_and_dispatch(
model,
weights_path,
device_map=device_map,
offload_folder=None,
offload_state_dict=True
)
prompt = 'Huggingface is'
input_tokenized = tokenizer(prompt, return_tensors="pt")
output = model.generate(input_tokenized["input_ids"].to(0), do_sample=True)
output_text = tokenizer.decode(output[0].tolist())
```
Script is crashing with the traceback:
```
Traceback (most recent call last):
File "run.py", line 24, in <module>
output = model.generate(input_tokenized["input_ids"].to(0), do_sample=True)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/generation_utils.py", line 1316, in generate
return self.sample(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/generation_utils.py", line 1934, in sample
outputs = self(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/accelerate/hooks.py", line 148, in new_forward
output = old_forward(*args, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 596, in forward
outputs = self.gpt_neox(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 488, in forward
outputs = layer(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/accelerate/hooks.py", line 148, in new_forward
output = old_forward(*args, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 296, in forward
attention_layer_outputs = self.attention(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 148, in forward
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 208, in _attn
raise RuntimeError()
RuntimeError
```
The problem was also mentioned here:
https://github.com/huggingface/transformers/issues/15642#issuecomment-1133067212
https://github.com/huggingface/transformers/issues/15642#issuecomment-1133828254
The problem seems to be that `torch.einsum` returns `inf` (fp16 overflow) which leads to `nan` when calculating the softmax.
### Expected behavior
```shell
Code should run.
```
| 05-27-2022 08:56:37 | 05-27-2022 08:56:37 | cc @zphang do you have an idea of what might be happening there?
Also happening here: https://github.com/huggingface/accelerate/issues/404<|||||>Also cc @sgugger as it's leveraging the auto map.<|||||>I don't think it comes from the auto map, some weights are Nan and so an error is raised [here](https://github.com/huggingface/transformers/blob/5af38953bb05fe722c2ec5c345f54c2712ce4573/src/transformers/models/gpt_neox/modeling_gpt_neox.py#L208). (I did say that `RuntimeError` with no messages were not ideal @zphang ;-) )<|||||>Seems to be a float16 overflow problem after applying `torch.einsum`, fixable with
```
attn_scores = torch.einsum("bik,bjk->bij", query, key) / self.norm_factor
+ finfo = torch.finfo(attn_scores.dtype)
+ attn_scores = attn_scores.clamp(finfo.min, finfo.max)
```
Although after fixing this NaN problem, the generation is still not working correctly.
<|||||>Thanks @zomux, this works. I tried something similar (casting to FP32 and back) which gave the same error:
```
Traceback (most recent call last):
File "tt.py", line 24, in <module>
output = model.generate(input_tokenized["input_ids"].to(0), do_sample=True)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/generation_utils.py", line 1317, in generate
return self.sample(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/generation_utils.py", line 1937, in sample
outputs = self(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1112, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/accelerate/hooks.py", line 150, in new_forward
output = old_forward(*args, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 602, in forward
outputs = self.gpt_neox(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1112, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 493, in forward
outputs = layer(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1112, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/accelerate/hooks.py", line 150, in new_forward
output = old_forward(*args, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 299, in forward
attention_layer_outputs = self.attention(
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1112, in _call_impl
return forward_call(*input, **kwargs)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 150, in forward
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
File "/secondary/thies/anaconda3/envs/py38/lib/python3.8/site-packages/transformers/models/gpt_neox/modeling_gpt_neox.py", line 218, in _attn
attn_output = torch.matmul(attn_weights, value)
RuntimeError: Expected size for first two dimensions of batch2 tensor to be: [64, 5] but got: [64, 1]
```
I figured out that when setting use_cache=False generation runs without errors.
Change:
https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt_neox/modeling_gpt_neox.py#L642
```
- return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past}
+ return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past, "use_cache": False}
```
<|||||>> I don't think it comes from the auto map, some weights are Nan and so an error is raised [here](https://github.com/huggingface/transformers/blob/5af38953bb05fe722c2ec5c345f54c2712ce4573/src/transformers/models/gpt_neox/modeling_gpt_neox.py#L208). (I did say that `RuntimeError` with no messages were not ideal @zphang ;-) )
Ah, I thought I'd removed all the RuntimeErrors, I've submitted a PR here: https://github.com/huggingface/transformers/pull/17563
As for the NaN-ing, I've not figured that out either. I found (in very ad-hoc testing) that the einsum appears to be more stable than [the original approach](https://github.com/zphang/minimal-gpt-neox-20b/blob/1d485409c0c108d1c03831cb2498040a769e8460/minimal20b/model.py#L226-L232), but it looks like it hasn't fully solved the issue.<|||||>Hello @zphang,
the problem is that when the scaling factor is applied, the overflow has already happened.
Therefore I think the `self.norm_factor` should go into the matrix multiply (scale first and do the matrix multiply second):
```
- attn_scores = torch.einsum("bik,bjk->bij", query, key) / self.norm_factor
+ attn_scores = torch.einsum("bik,bjk->bij", query / self.norm_factor, key)
```
It seems to work fine:
```
Huggingface is a fast-growing Chinese company that is the leader in deep learning and natural language processing.
The company raised $75million from Tencent and Baidu.
Deep Voice is a Chinese startup that enables users to control various home appliances using simple commands issued with their voice alone.
```<|||||>@zphang Is there a clear release version where the issue is resolved?
I got `RuntimeError: probability tensor contains either `inf`, `nan` or element < 0` while deploying the gpt-neox model with half.
I can deploy it completely in full preciosion.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,451 | closed | May i just train a translation task with T5 from scratch without pretrain a language model? | ### Feature request
May i use bpe in preprocessing and train a translation model from scatch without pretrain a language model?
@patrickvonplaten
### Motivation
I want to distill a big model to T5 model and the T5 vocab should be the same as big model.
### Your contribution
I can verify the process. | 05-27-2022 08:35:39 | 05-27-2022 08:35:39 | Hey @520jefferson,
I understand your question as whether it's possible to fine-tune T5 from scratch and to **not** use a pretrained checkpoint.
Yes, this should definitely be possible, but I wouldn't really recommend it given the power of transfer learning.
Here also some very nice explanation by @sgugger on how powerful transfer learning is that might be interesting: https://huggingface.co/course/chapter1/4?fw=pt#transfer-learning
Why not fine-tune a pretrained T5 model on translation?<|||||>Hey @patrickvonplaten
I want to distill a big model (pytorch version) to t5 model (considering the FasterTransformer Backend
https://github.com/triton-inference-server/fastertransformer_backend has provide origin T5 (not t5.1) triton backend optimization , this reasoning optimizaiton will be conducive to carrying more online traffic) , why i don't use transformer as the student model because i haven't find the pytorch version transformer with reasoning optimization and combining with triton.
And the big model use bpe not sentencepiece, So the tokenizer should be load the bpe codes and the vocabs is differenct from the origin t5 model. Therefore i want to distill the big model to t5 model and use the vocab in the same time.
So I need to figure out two things:
1, whether the t5 can be train in dialogue without pretrain which treat the t5 like transformer without pretrain and i haven't find a relate case finetune from scratch.
2, how to set the tokenizer to just use bpe codes?
<|||||>Sorry I'm a bit lost here @520jefferson,
I don't fully understand what you want to do here, but I guess the target task is distillation? Should we maybe try to get help on the forum: https://discuss.huggingface.co/ for distillation? <|||||>@patrickvonplaten
I just need to finetune t5 from scratch without pretrain, and the tokenizer can just load vocab.txt (not json) or merges.txt (bpe codes).<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>the tokenizer can be built by hand. |
transformers | 17,450 | closed | attention_mask hold float values in [0,1] in T5 | ### Feature request
Hello Everybody,
I was wondering whether attention_mask input for T5 could be used as a float in [0,1] instead of an integer as in the documentation
`attention_mask (torch.FloatTensor of shape (batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in [0, 1]:
1 for tokens that are not masked,
0 for tokens that are masked. `
Would you think passing something like (I write tokens for clarity, but they would be tokens_ids)
`tokens = ['hello','how','are','you','pad','pad']
attention_mask = [0.5, 0.9, 0.2, 1, 0, 0] `
to attribute a particular emphasis on several tokens respect to the others (still keeping components 0 for Pad tokens) ?
Clearly the model requires a finetuning, but I wonder if this different usage of attention_mask could harm it in some way…
As far as I see from [transformers/modeling_t5.py at main · huggingface/transformers · GitHub](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
It is not really clear to me how the attention_masks act in the attention blocks (see here for instance [transformers/modeling_t5.py at 8f46ac98498dd47701971064617e00d7e723a98e · huggingface/transformers · GitHub](https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/t5/modeling_t5.py#L531)).
I was expecting some kind of “hard” attention, but as far as I see it’s a “soft” implementation shifting the position_bias. How this translates into the removal of ‘pad’ token contribution from the attention (is a shift of “1” as in the original attention_mask, enough to ensure a reasonable suppression of pads) ?
Any answer is very welcomed! Thank you!
### Motivation
This not-boolean usage of mask could offer important improvements over the model.
### Your contribution
I am not an expert, so before doing any development I would like to hear about the feasibility (or if it is already supported) from developers. | 05-27-2022 07:42:52 | 05-27-2022 07:42:52 | cc @ydshieh that has given some thought to this in the past, I believe<|||||>Well, as far as I can recall, I didn't have this idea before. This looks like @pretidav want to provide manual (float) attention mask.
- with the introduction of `dtype.min` in #17306 (or even with `-1e4` currently) as the large negative value for masking value, `0` will be replaced by `dtype.min`, but how about `0.5`? Use something like `0.5 * dtype.min` doesn't really make sense: if there is also a `1` in the (original) attention mask which is replaced by `0`, then `0.5 * dtype.min` won't get any attention, just like `dtype.min`. Use more complex transformation won't be good (potentially) for performance reason.
- The number of places to be changed would be quite large (if we decide to do it)
- In order to make the decision, I think it would be great if we can see this usage is proposed in some papers, or in some real world examples, that show the improvements (if we want to do it correctly)
- Finally, I am not sure how a user would provide meaningful float attention mask values. Just using some heuristic to get hard-coded values in advance? I kinda feel that these soft values is the role of the attention probability through training.
cc @patrickvonplaten @patil-suraj @sgugger
<|||||>Thanks for the answer @ydshieh !
Float attention values could be provided from another model or a human annotator. For instance, a human annotator can try to "force" the model to pay more attention to some part of the input document, or some specific entities. It's just a way to introduce some external control over the model attention other then its own attention probability obtained during the training.
Is there a way currently such a feature could be used in T5?
If I understand well, attn_mask is not the right feature to play with. <|||||>@pretidav There is currently no such feature. As mentioned previously, attention mask is not good for this purpose, as the range of the **final (processed)** attention mask is `[-inf, 0]`. The `-inf` means no attention at all (masked), and `0` means no mask (so attend to it).
The attention mask is combined with the attention scores (computed using `query` and `keys`), whose range is **NOT** a fixed interval.
So from these facts, there is no clear & meaningful values to provide extra attention values (before `softmax`), as far as I can tell.
A **manual** change, if one want to do it, could be done after the following line of attention probability computation (which has values between 0 and 1).
https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/t5/modeling_t5.py#L534-L536
However, it depends on how you would like to combine `attn_weights` with extra attention values.<|||||>Agree with what @ydshieh said!
This is an interesting question but to me it seems like a niche use-case and as @ydshieh said, this would require a lot of changes. IMO for this use-case one can just copy-paste the T5 model and tweak it to support this. The models in `Transformers` are designed in such a way that users could just take the modeling files and tweak it for their purpose rather than supporting everything in the framework. Thanks :) <|||||>Thank you very much for all the answers! I'll try to tweak the model. |
transformers | 17,449 | closed | Improve notrainer examples | # What does this PR do?
1. In no-trainer examples, `train_loss` being logged wasn't normalized and as such wasn't intuitive to understand. This also made it difficult to compare train loss between different tools such as comparing train loss from Trainer with that of Accelerate. This PR normalizes the train_loss per epoch to make is more intuitive and comparable.
2. Replaces HF AdamW with torch AdamW for NLP no-trainer examples. This prevents corresponding warning being displayed.
3. Fixing no-trainer examples so that tracker run is created only for the main process else wandb will create num_processes runs with no data.
4. converting `train_loss` from tensor to float so that it gets logged in tensorboard tracker
5. Fixing `run_ner_no_trainer.py` to correctly log `train_loss` in `all_results.json`
6. Adding `report_to` arg to enable users to specify preferred tracker instead of all available trackers which is default option. This prevents logging to the trackers that user doesn't want.
7. In many no-trainer NLP tasks one can train model from scratch, this means that user can bypass `model_name_or_path` arg. However, it is set as required for all scripts which throws error when it isn't specified. Setting this arg `required=False` in corresponding examples to resolve the error when training from scratch.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? | 05-27-2022 07:11:57 | 05-27-2022 07:11:57 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,448 | closed | ImportError: cannot import name 'OptionalDependencyNotAvailable' from 'transformers.utils' | ### System Info
```shell
Cannot import any models from transformers
# Name Version Build Channel
aiohttp 3.8.1 pypi_0 pypi
aiosignal 1.2.0 pypi_0 pypi
async-timeout 4.0.2 pypi_0 pypi
attrs 21.4.0 pypi_0 pypi
bzip2 1.0.8 he774522_0
ca-certificates 2022.4.26 haa95532_0
certifi 2022.5.18.1 py310haa95532_0
charset-normalizer 2.0.12 pypi_0 pypi
colorama 0.4.4 pypi_0 pypi
cudatoolkit 11.3.1 h59b6b97_2
datasets 2.2.2 pypi_0 pypi
dill 0.3.4 pypi_0 pypi
filelock 3.7.0 pypi_0 pypi
frozenlist 1.3.0 pypi_0 pypi
fsspec 2022.5.0 pypi_0 pypi
huggingface-hub 0.7.0 pypi_0 pypi
idna 3.3 pypi_0 pypi
libffi 3.4.2 h604cdb4_1
multidict 6.0.2 pypi_0 pypi
multiprocess 0.70.12.2 pypi_0 pypi
numpy 1.22.4 pypi_0 pypi
openssl 1.1.1o h2bbff1b_0
packaging 21.3 pypi_0 pypi
pandas 1.4.2 pypi_0 pypi
pip 21.2.4 py310haa95532_0
pyarrow 8.0.0 pypi_0 pypi
pyparsing 3.0.9 pypi_0 pypi
python 3.10.4 hbb2ffb3_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2022.1 pypi_0 pypi
pyyaml 6.0 pypi_0 pypi
regex 2022.4.24 pypi_0 pypi
requests 2.27.1 pypi_0 pypi
responses 0.18.0 pypi_0 pypi
sentencepiece 0.1.96 pypi_0 pypi
setuptools 61.2.0 py310haa95532_0
six 1.16.0 pypi_0 pypi
sqlite 3.38.3 h2bbff1b_0
tk 8.6.11 h2bbff1b_1
tokenizers 0.12.1 pypi_0 pypi
torch 1.11.0 pypi_0 pypi
tqdm 4.64.0 pypi_0 pypi
transformers 4.19.2 pypi_0 pypi
typing-extensions 4.2.0 pypi_0 pypi
tzdata 2022a hda174b7_0
urllib3 1.26.9 pypi_0 pypi
vc 14.2 h21ff451_1
vs2015_runtime 14.27.29016 h5e58377_2
wheel 0.37.1 pyhd3eb1b0_0
wincertstore 0.2 py310haa95532_2
xxhash 3.0.0 pypi_0 pypi
xz 5.2.5 h8cc25b3_1
yarl 1.7.2 pypi_0 pypi
zlib 1.2.12 h8cc25b3_2
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. from transformers import AutoTokenizer
### Expected behavior
```shell
Able to import without error.
```
| 05-27-2022 07:05:25 | 05-27-2022 07:05:25 | |
transformers | 17,447 | closed | More informative error message for DataCollatorForSeq2Seq | # What does this PR do?
I ran into an error related to an incorrect shape of inputs when using `DataCollatorForSeq2Seq`. I learned that it had to do with the `BatchEncoding` class. I did not find the error message particularly helpful as it does not mention anything about the input shape. Therefore I added the extra line on the error message to help guide anyone else who runs into this error.
Fixes #15505
@stas00
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 05-27-2022 01:08:28 | 05-27-2022 01:08:28 | @CakeCrusher, if it's programmable - won't it be better to actually validate the input shape explicitly, and assert if it's wrong - instead of piling up possible errors to an already long error message?<|||||>@stas00 agreed ill make a check for it<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @stas00 , is the pr ok?<|||||>This PR is waiting for your answer here: https://github.com/huggingface/transformers/pull/17447#discussion_r883964302
<|||||>@CakeCrusher, I think we lost each other here. Should we finish this PR?<|||||>@sgugger @stas00
Hi @stas00 sorry for the discontinuity, I am now able to focus and see this issue through.
Here is an example demonstrating successful and erring inputs:
https://colab.research.google.com/drive/16aLu6QrDSV_aUYRdpufl5E4iS08qkUGj?usp=sharing
I then made the following changes to overcome excessive nesting (a list containing a single item):
https://github.com/CakeCrusher/transformers/compare/main...lead_nesting_solution
I understand the changes are pretty fundamental, but they work. I have yet to add the assert statement, since the nesting fix does the job forcefully. I was hoping to do an overarching PR, involving the new error message (or assert) and the fix (possibly parametrized so that it is not forced). What are your thoughts?<|||||>This is an interesting idea, but I'm concerned it might be (1) not backward compatible (2) I think it's best for the user to apply this function themselves. Perhaps if it's a useful util function we can provide it and assert with a message to use it instead?
And to remind my initial suggestion was:
- check if shape is wrong and raise a specific assert if it is wrong (with possible hints at how to fix it)
e.g. the inputs shape is wrong, expecting a, but got b....
won't that be a clean solution?
we can then discuss with others if they feel your proposed util function would be a good match to add.<|||||>@stas00
> Perhaps if it's a useful util function we can provide it and assert with a message to use it instead?
That is an excellent idea.
I will have it ready early next week with a test.
Do you recommend I make a new PR for it or merge it to this one? <|||||>Hi @stas00 , I submitted a [new PR](https://github.com/huggingface/transformers/pull/18119) for the aforementioned fixes. I have yet to add the test and proper docs. As for what I have so far please let me know what you think.
(My git tree was a mess, so that was largely why it's a new PR sorry about that.)<|||||>Apologies for taking a long time to follow up, @CakeCrusher
As I suggested in the first place I think your suggestion to assert on invalid input nesting is great.
I see you tried to move the helper util to `datasets` and it's not being welcomed there, as it's really a user's responsibility to prepare the data correctly.
Perhaps we just stick to the assert part and trust the user to figure out how to fix it?
@sgugger, are you ok with the assertion part of this PR on the deeply nested input? I'd guess that you too might be against the 2nd part of adding a helper util to remove excessive nesting as it's not generic enough.<|||||>No worries @stas00,
Yeah.. I understand if I have to give up on introducing the helper function on this PR. I'll see what what [lhoestq](https://github.com/lhoestq) ends up thinking about the datasets alternative.
In the meantime, I'll keep the assert independent. And maybe open a new PR for the helper function.<|||||>I must admit I do not understand what the problem is, since the notebook linked executes without any issue.<|||||>Sorry about that @sgugger the notebook was organized in a weird way. Now [the notebook](https://colab.research.google.com/drive/16aLu6QrDSV_aUYRdpufl5E4iS08qkUGj?usp=sharing) will raise the error.<|||||>I see. I've pointed out in #18119 where that error message should be updated. |
transformers | 17,446 | closed | Train Transformer XL language modeling with padding | ### System Info
```shell
`transformers` version `4.19.2`, `python` version `3.9.12`
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
I'm using `DataCollatorForLanguageModeling` **and padding** to train Transformer XL with LM head from scratch.
I'm not sure if the error is intended, i.e. do HuggingFace support training with padding tokens?
I'm not sure because I had an error with padding, but the forward pass for LM head seems to consider padding?
```python
if labels is not None:
losses = softmax_output.view(bsz, tgt_len - 1)
# Avoids from incorporating padding (-100) tokens into loss value
loss = losses[losses != 0].mean()
```
I don't find much support for this. I checked [this issue](https://github.com/huggingface/transformers/issues/586).
And I don't think it's relevant in the notebook [language_modeling_from_scratch](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb) since all texts are concatenated.
Also, I'm using `n_clusters` == 0.
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
Traceback (most recent call last):
File "/Users/stefanhg/Documents/UMich/Research/Music with NLP/Symbolic-Music-Generation/musicnlp/trainer/train.py", line 407, in <module>
train_xl()
File "/Users/stefanhg/Documents/UMich/Research/Music with NLP/Symbolic-Music-Generation/musicnlp/trainer/train.py", line 406, in train_xl
trainer.train(ignore_keys_for_eval=ignore_keys_for_eval)
File "/Users/stefanhg/opt/anaconda3/envs/music-nlp/lib/python3.9/site-packages/transformers/trainer.py", line 1317, in train
return inner_training_loop(
File "/Users/stefanhg/opt/anaconda3/envs/music-nlp/lib/python3.9/site-packages/transformers/trainer.py", line 1554, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/Users/stefanhg/opt/anaconda3/envs/music-nlp/lib/python3.9/site-packages/transformers/trainer.py", line 2183, in training_step
loss = self.compute_loss(model, inputs)
File "/Users/stefanhg/Documents/UMich/Research/Music with NLP/Symbolic-Music-Generation/musicnlp/util/train/train_util_wrap.py", line 81, in compute_loss
outputs = model(**inputs)
File "/Users/stefanhg/opt/anaconda3/envs/music-nlp/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/stefanhg/Documents/UMich/Research/Music with NLP/Symbolic-Music-Generation/musicnlp/models/transformer_xl.py", line 189, in forward
softmax_output = self.crit(pred_hid, labels)
File "/Users/stefanhg/opt/anaconda3/envs/music-nlp/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/stefanhg/opt/anaconda3/envs/music-nlp/lib/python3.9/site-packages/transformers/models/transfo_xl/modeling_transfo_xl_utilities.py", line 112, in forward
out = -nn.functional.log_softmax(logit, dim=-1).gather(1, labels.unsqueeze(1)).squeeze(1)
RuntimeError: index -100 is out of bounds for dimension 1 with size 462
```
Here's my stack trace.
### Expected behavior
```shell
I hope the `ProjectedAdaptiveLogSoftmax` implementation can consider support ignoring padding tokens.
```
Looks like just filtering out the labels in adaptive softmax fixes it (and for this I need to ignore reshaping the `losses` in LM head forward
```python
if self.n_clusters == 0:
logit = self._compute_logit(hidden, self.out_layers[0].weight, self.out_layers[0].bias, self.out_projs[0])
if labels is not None:
# ========================== Begin of modified ==========================
out = -nn.functional.log_softmax(logit, dim=-1).gather(1, labels[labels != -100].unsqueeze(1)).squeeze(1)
# ========================== End of modified ==========================
else:
out = nn.functional.log_softmax(logit, dim=-1)
```
| 05-26-2022 23:55:20 | 05-26-2022 23:55:20 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,444 | open | [WIP] Warning when passing padded input ids but no attention mask | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
One of the most common mistake users make in Transformers IMO is that `input_ids` are padded, but no `attention_mask` is provided (we see many examples of this). As discussed multiple times, we **don't** want to infer the `attention_mask` automatically as this creates a lot of unmaintainable, "not-possible-to-deal-with" complexity.
A while ago, we discussed to throw a warning in this case, making sure it's done only once to not spam the user when calling the model multiple times. I'm not sure we found a good conclusion, but IMO it's important that we warn the user as too users (IMO) think the attention_mask is inferred from the padding tokens. This PR is tries to solve this and shows how it'd be implemented for just BERT. We would have to implement it for all other models then as well. Would very much like to hear your opinion here @sgugger @LysandreJik @patil-suraj . Note that this PR will touch a lot of important functions / files, so it'd be very important to make the warning as clear as possible.
I do however have a strong conviction that we should display such a warning.
No the warning function can display the following warning messages for a toy BERT example of passing just three input ids.
Possible warning messages:
1. Pad token present, no attention mask, eos, bos, sep all different from pad (that's **VERY** likely an error IMO):
**Displayed warning:**
```
The input IDs tensor([[0, 1, 1]]) contains the `pad_token_id` 0, but NO `attention_mask` is passed.
Padding the input IDs without passing an `attention_mask` leads to unexpected, possibly incorrect outputs.
```
2. Pad token present, no attention mask, eos or bos or sep same as pad:
**Displayed warning:**
```
The input IDs tensor([[0, 1, 1]]) contains the `pad_token_id` 0, but NO `attention_mask` is passed.
We strongly recommend passing an `attention_mask` to avoid possibly incorrectly computing the attention weights.
You can ignore this warning, if your `pad_token_id` 0 is identical to your `sep_token_id` 0 AND your input is NOT padded.
```
3. Pad token present, no attention mask, two or more of eos, bos, sep identical to pad (don't think this exists actually):
**Displayed warning:**
```
The input IDs tensor([[0, 1, 1]]) contains the `pad_token_id` 0, but NO `attention_mask` is passed.
We strongly recommend passing an `attention_mask` to avoid possibly incorrectly computing the attention weights.
You can ignore this warning, if your `pad_token_id` 0 is identical to your `bos_token_id` 0 AND your input is NOT padded.
We strongly recommend passing an `attention_mask` to avoid possibly incorrectly computing the attention weights.
You can ignore this warning, if your `pad_token_id` 0 is identical to your `sep_token_id` 0 AND your input is NOT padded.
```
4. Otherwise no warning.
Also note that the warning only appears at the first forward call.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-26-2022 18:33:01 | 05-26-2022 18:33:01 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17444). All of your documentation changes will be reflected on that endpoint.<|||||>Relevant issues:
https://github.com/huggingface/transformers/issues/4083
https://github.com/huggingface/transformers/issues/278
https://github.com/huggingface/transformers/issues/16136<|||||>I think the way you implemented it is clean and adds nice warnings. I agree with the idea behind it, and the better warnings we send, the better the models will perform for users.
I think handling it like it is done here based off of configuration attribute is not going to work very well across models, however. I feel like having the method be configurable by passing optional bos/eos tokens would likely make the method more versatile to the models which do not conform to the default approach.<|||||>> I think handling it like it is done here based off of configuration attribute is not going to work very well across models, however. I feel like having the method be configurable by passing optional bos/eos tokens would likely make the method more versatile to the models which do not conform to the default approach.
Hmm, don't really agree here. Note that `pad_token_id`, `bos_token_id`, `eos_token_id`, `sep_token_id` **must** be present in every model's config since it's in `configuration_utils.py`.
Also we never pass any of the above attributes through the forward method, so one would only ever pass `self.config.pad_token_id` to the method. Wdyt @LysandreJik ? Also very curious to hear @sgugger's opinion here<|||||>Sounds good, I'm likely worrying for nothing then. Good for me like this, very easy to add kwargs afterwards anyway!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I think this would be an impactful addition! @ydshieh, would you be interested in continuing this PR?<|||||>> I think this would be an impactful addition! @ydshieh, would you be interested in continuing this PR?
Sure. I will take a look and see if there is anything blocking. <|||||>You can search `elif input_ids is not None:` that is in the base model classes like `BertModel` (already done by @patrickvonplaten), `GPT2Model` etc.
You don't need to replace all of them - it would be super nice already for a few of the most used modes 🚀 Thank you! |
transformers | 17,443 | closed | Add CodeGen model | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adds [CodeGen](https://github.com/salesforce/codegen) PyTorch model.
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? ==> Discussed with @lvwerra and @patil-suraj.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@lvwerra @patil-suraj @loubnabnl | 05-26-2022 17:29:17 | 05-26-2022 17:29:17 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hey @patil-suraj @rooa you should go fetch upstream on [your fork](https://github.com/rooa/transformers/tree/add_codegen). There were some test fixes that I think you are missing which is causing the red exes that no one likes to see. I actually would love to use this but I can't because this PR is not merged yet!<|||||>Merging now! Thanks a lot @rooa for working on this and being patient with the review and tests. |
transformers | 17,442 | closed | [Generate] Greedy Search, fix output scores from logits to scores | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
🚨🚨 **This PR can lead to silently changing values for users of `greedy_search` and `output_scores=True`. Please read the issue below** 🚨 🚨
Fixes https://github.com/huggingface/transformers/issues/17424
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-26-2022 15:53:35 | 05-26-2022 15:53:35 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@patil-suraj Will there be any support for raw logits instead logits that are processed? (see #17521 ) |
transformers | 17,441 | closed | [OPT] Fix bos token id default opt | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes https://github.com/huggingface/transformers/issues/17431
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-26-2022 15:30:59 | 05-26-2022 15:30:59 | Opening PRs for all OPT models online as well<|||||>CI errors are flaky |
transformers | 17,440 | closed | Pin protobouf that breaks TensorBoard in PyTorch | # What does this PR do?
The recent release of Protobuf (4.21) has broken TensorBoard in PyTorch and thus multiple tests. This PR pins protobuf to fix said tests. | 05-26-2022 13:27:58 | 05-26-2022 13:27:58 | Yes to rebuliding a docker image ASAP. I will merge this once all tests pass :-) <|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Python dependencies 🤦♀️ |
transformers | 17,439 | closed | Fix model parallelism test | # What does this PR do?
This fixes the model parallelism test for models whose config does not have a `num_hidden_layers` attribute, or if that attribute is a dict and not an int. | 05-26-2022 12:56:38 | 05-26-2022 12:56:38 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,438 | closed | [wip] testing doc-build | testing https://github.com/huggingface/doc-builder/pull/228 | 05-26-2022 08:57:07 | 05-26-2022 08:57:07 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,437 | closed | OPT - Fix Softmax NaN in half precision mode | # What does this PR do?
Fix overflow / unstable operation issues when using large OPT models in half precision
- As it is done in [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed/blob/908dc9cb4b9717707241eaf8b92a986b2e251218/megatron/model/fused_softmax.py#L205), for large models it appears that you will have to first upcast the input to float32 before applying the Softmax function to avoid unexpected NaNs. This is because we use very large values (eg `-3.24e+38`) to mask the padded tokens. EDIT: it seems to we use correct values to mask padded tokens
- Linked issue: #17433
- We'll probably need to re-compute the logits for slow tests but I am not sure
cc @patrickvonplaten @ArthurZucker @ydshieh @stas00 | 05-26-2022 08:31:38 | 05-26-2022 08:31:38 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @younesbelkada
```
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
```
So when running in `half precision`, `_expand_mask` will use `torch.finfo(dtype)` with `dtype = inputs_embeds.dtype = fp16` and the `min` is `-65536`.
Am I missing anything here?
Is `fp32.min` used unexpectedly instead of `fp16.min` in this particular issue?
I have a PR #17306 for related issue. If using `-65536` has issue, then I need to hold on that PR to investigate.<|||||>Hi @ydshieh !
I think that you are right, when running in half precision I have `-65530` and not `-3.24e+38` in the attention mask as I said. But even with this mask I get NaNs on the padded hidden states for opt-1.3b, and upcasting the input to fp32 and casting back to fp16 seems to solve the issue for now <|||||>> Hi @ydshieh ! I think that you are right, when running in half precision I have `-65530` and not `-3.24e+38` in the attention mask as I said. But even with this mask I get NaNs on the padded hidden states for opt-1.3b, and upcasting the input to fp32 and casting back to fp16 seems to solve the issue for now
Let me check - as if this is the case, the PR #17306 needs to find another way out 😢 <|||||>> I get NaNs on the padded hidden states for opt-1.3b,
@younesbelkada
- Could you point me which line in OPTModel you got `NaN for padded hidden states`?
- Did you use the generation script in the linked issue, or you just run the model with some input ids? If it is the later case, could you provide the code snippet 🙏 please?<|||||>- I got NaNs exactly here: https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/opt/modeling_opt.py#L217 - to fix it you can just do ` attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len).float() + attention_mask` [here](https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/opt/modeling_opt.py#L214) and then `attn_weights = nn.functional.softmax(attn_weights, dim=-1).half()` [here](https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/opt/modeling_opt.py#L217)
- Yes use the generation script provided in the issue, ie:
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# I have tested and the error happens to opt-1.3b, opt-2.7b, opt-6.7b, and opt-13b.
# opt-125m and opt-350m seems to work fine.
# I haven't tested opt-30b.
model_name = "facebook/opt-1.3b"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
tokenizer.padding_side = "left"
# It works when torch_dtype=torch.float32
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, use_cache=True)
model = model.eval().to("cuda")
batch = tokenizer(
["Who are you?", "Joe Biden is the president of"],
padding=True, return_tensors="pt"
)
# It produces NaN in the early layers for the first sequence.
# I check the pattern, and NaN first appears in the padded token position.
greedy_output = model.generate(
input_ids=batch["input_ids"].to("cuda"),
attention_mask=batch["attention_mask"].to("cuda"),
do_sample=False, top_k=0
)
```
Note also that everything works fine when `torch_dtype` is set to `torch.float32` or `torch.bfloat16` <|||||>@younesbelkada
The root cause is `-inf` is used here
https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/opt/modeling_opt.py#L64
Change it to `mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min)` **should** be fine.
(+/- inf * 0.0 will result NaN ).
### More details
With the above fix, there is still a minor issue. In
https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/models/opt/modeling_opt.py#L525
for batch index 0, we will see an `-inf`
```
tensor([[[[-65504., -inf, -65504., -65504., -65504., -65504., -65504.],
[-65504., -65504., -65504., -65504., -65504., -65504., -65504.],
[-65504., -65504., 0., -65504., -65504., -65504., -65504.],
[-65504., -65504., 0., 0., -65504., -65504., -65504.],
[-65504., -65504., 0., 0., 0., -65504., -65504.],
[-65504., -65504., 0., 0., 0., 0., -65504.],
[-65504., -65504., 0., 0., 0., 0., 0.]]],
```
This is because we have `-65504` for causal mask + `-65504` due to (left) padding.
Regarding this part, we need to discuss with the team.
In general, we shouldn't have or use `-inf` (the only safe place to use it is immediately before the softmax).
<|||||>Great! My suggestion is to mix both - we can force the attention mask to use -65504 for fp16 + upcast in fp32 and cast it back to fp16 after softmax for sanity check and avoid possible overflow issues. - Wdyt?<|||||>@stephenroller @suchenzang have you seen something similar in your training / inference runs?
Also cc @patil-suraj - see issue. Would be nice to hear your opinion here<|||||>FYI, it can happen that during training you never use padding tokens. I may be mistaken but I know that for Bloom we do not train on padded batch inputs but on truncated sequences instead.
Usually these issues can happen at inference time only!<|||||>Upcast to fp32 should never be required if masked tokens are masked with something that's not -inf. Upcast to fp32 is significant performance penalty. Single `-inf` value shouldn't be a problem as long as there are some non-zero values in the row, it would change output a little bit but that output is meaningless anyway, the whole row is masked out. <|||||>Great thank you all for your comments and help! Following your advice I have added the changes proposed by @ydshieh - let me know if this works for you!<|||||>[This change](https://github.com/huggingface/transformers/blob/77162b94bddd51bb57c712e973e23eed2cd39971/src/transformers/models/opt/modeling_opt.py#L64) is also in #17306, but I am fine for a quick fix for `OPTModel`.
I would still like to point out that, although it is not useful for real usage of the model, leaving non-zero large negative values mixed with `-inf` to mask a whole sequence is not good for testing/debugging purpose -> but this could be addressed in another PR.
<|||||>> [This change](https://github.com/huggingface/transformers/blob/77162b94bddd51bb57c712e973e23eed2cd39971/src/transformers/models/opt/modeling_opt.py#L64) is also in #17306, but I am fine for a quick fix for `OPTModel`.
>
> I would still like to point out that, although it is not useful for real usage of the model, leaving non-zero large negative values mixed with `-inf` to mask a whole sequence is not good for testing/debugging purpose -> but this could be addressed in another PR.
Forgot to say, with current change, it's still possible to get `[-inf, -inf, dtype.min, dtype.min ...]` or `[-inf, -inf, -inf]` etc. after summing with the `attn_weights` (as mentioned, this depends the values in `attn_weights`). I will try to implement some processing in #17306 today.<|||||>We perform the upcast in our code, though we do it with softmax(dtype=torch.float32). It's very important.<|||||>That's an excellent point, Stephen! Thank you for that crucial reminder.
Indeed, for pytorch ops that support accumulate dtype arg this approach makes things much more efficient than manual casting.
I remember I discovered that when optimizing the `LabelSmoother`:
https://github.com/huggingface/transformers/blob/7999ec125fc31428ed6879bf01bb013483daf704/src/transformers/trainer_pt_utils.py#L481
it made a huge difference.<|||||>> accumulate dtype arg this approach makes things much
For learning purpose, could you share why `using softmax(dtype=torch.float32)` is more efficient than explicit upcasting?<|||||>Because the op kernel does it automatically internally in a single operation by already accumulating in the correct dtype.
When you do it in 2 steps: `op(...).to(dtype=...)`, 2 additional memory copying operations have to happen to perform the casting.
@ngimel, did I explain that correctly? Thank you!
and it should be simple to benchmark the 2 cases to see the difference.<|||||>@Chillee, would `nvfuser` fuse explicit casting into the op's accumulate dtype automatically?
<|||||>My original understanding of the process is like:
```
attn_scores = attn_scores.to(torch.float32)
attn_prob = nn.functional.softmax(attn_scores)
```
So I think the correct way should be:
```
attn_prob = nn.functional.softmax(attn_scores, dtype=torch.float32)
```
right?
### Another question regarding dtype
After we get `attn_prob` in `float32`, should we cast it back to the target precision for the subsequential ops, like
```
attn_output = torch.bmm(attn_probs, value_states)
```
I am talking about the case where a user loads the models in fp16 and specify the inputs in fp16 too:
```
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)
```
- If we don't cast `attn_probs` back to the target type (here `fp16`)
- it will fail (if `value_states` is `fp16`) for some op like `torch.bmm`
- or will propagate the type fp32 for some simple ops (like `+`)
(I am not sure this is the correct/usual way to do inference in fp16, but this is what I see in the code snippet from the issue reporter)<|||||>I think the issue that this PR aims to address is not really about the upcast to float32. (@younesbelkada , right?)
It is mentioned in the PR description as a potential solution, but the original issue we want to address here comes from the fact that we get a sequence with all `-inf` as attention scores before `softmax`.
Maybe it it better to move the discussion(s) regarding the upcasting to another issue/PR page.<|||||>That's correct, the underlying issue is that for a row full of `-inf` softmax (by definition) produces `nan` (it's 0/0), and ideally that shouldn't be a problem because those fully masked row shouldn't participate in loss computation, but apparently they do and corrupt other values<|||||>> My original understanding of the process is like:
>
> ```
> attn_scores = attn_scores.to(torch.float32)
> attn_prob = nn.functional.softmax(attn_scores)
> ```
>
> So I think the correct way should be:
>
> ```
> attn_prob = nn.functional.softmax(attn_scores, dtype=torch.float32)
> ```
>
> right?
It's correct. Just be aware that not all ops support this.
> ### Another question regarding dtype
>
> After we get `attn_prob` in `float32`, should we cast it back to the target precision for the subsequential ops, like
>
> ```
> attn_output = torch.bmm(attn_probs, value_states)
> ```
>
> I am talking about the case where a user loads the models in fp16 and specify the inputs in fp16 too:
>
> ```
> model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)
> ```
>
> * If we don't cast `attn_probs` back to the target type (here `fp16`)
>
> * it will fail (if `value_states` is `fp16`) for some op like `torch.bmm`
> * or will propagate the type fp32 for some simple ops (like `+`)
>
>
> (I am not sure this is the correct/usual way to do inference in fp16, but this is what I see in the code snippet from the issue reporter)
Yes, you definitely need to adjust the dtype to the one you expect.
In some cases it's enough to turn autocast off locally to have the whole ensemble automatically done in the right precision w/o any additional casting back and forth. For example see this workaround proposed for the t5 arch:
https://github.com/huggingface/transformers/pull/10956/files
```
def forward(self, hidden_states):
# many t5/mt5 models are trained in bfloat16 and don't do well under mixed precision (fp16).
# It appears that it's enough to disable autocast for this FF layer to avoid inf/nan
# problems for the whole model
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
<|||||>Hi @ydshieh, I am down for both solutions. We can either merge this PR as a quick patch for OPT or wait for #17306 to be merged!
I can also open another PR to move the whole discussion around the upcasting issue (I think we need to address since it is done in the original OPT pipeline if I understood it right) - let me know what works best for you ;) ! <|||||>@younesbelkada #17306 still needs some more reviews. So let's just see which PR is approved earlier and merge as it is.<|||||>@younesbelkada
Since #17306 won't be merged at this moment, I guess you can try something like
(and see if the reviewers & pytorch experts like it 🙏 )
```
# change `-inf` to `dtype.min` to avoid `NaN` during `softmax`.
attn_scores = torch.max(attn_scores, torch.finfo(attn_scores.dtyte).min)
attn_prob = torch.nn.functional.softmax(attn_scores, ...)
```<|||||>Hi all,
I propose a fix in the latest commits as suggested by @ydshieh . To make it work I basically:
1- pre-process the att scores (suggestion by @ydshieh )
2- upcast the softmax in fp32 and cast it back to the original `dtype` (for consistency with what is done in the original implementation)
I also added a slow test to make sure these things do not happen in the future with OPT
I can also confirm that all slow test passes with this fix! Let me know what do you think ;)
cc @ydshieh @patrickvonplaten <|||||>@patil-suraj could you also take a quick look? :-)<|||||>Just a quick question before we merge. With this fix this issue here is solved: https://github.com/huggingface/transformers/issues/17433 ? What do the generations now give with this fix? Also I'm wondering a bit whether this is rather just because the model weights might be incorrect see: https://github.com/huggingface/transformers/issues/17653
Should we maybe rather wait with this one until we have #17653 resolved? Or could we maybe run the examples of #17653 with this fix and see if we get better results?<|||||>@patrickvonplaten I can confirm that this implementation fixes #17433 - I added a test to make sure that this will never be produced again. The generations gave `Who are you? What do you want? What do you want? What do you` with this fix instead of `Who are you? <\s> <\s> <\s> <\s>`
I think that we can merge this at least to fix this behavior + to make OPT implementation consistent with the one from Meta, since we do not upcast the softmax to float32 in our implementation.
I think the problems with #17653 are related with the TP merging strategy <|||||>Do we still need this fix @younesbelkada after having released the OPT fix ? Wondering because we do break the copy mechanism here which I'd like to avoid if possible - otherwise ok to merge I think<|||||>@patrickvonplaten I can confirm we are still observing this behaviour after the fix
<img width="877" alt="Screenshot 2022-06-22 at 11 46 22" src="https://user-images.githubusercontent.com/49240599/174999015-074152ad-78b2-4c7c-a0b0-ac564115d022.png">
Could you share what do you mean by breaking the copy mechanism? Maybe we can avoid that by just retrieving the previous `dtype`without copying the old `attn_weights` as we do now
<|||||>I can confirm the batched generations works fine now, can we merge?<|||||>Hi, as new code shows
```
if dtype_attn_weights == torch.float16:
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(dtype_attn_weights)
else:
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
```
in modeling_opt.py at line 219 to 222, I wondered if it's equivalent to change these lines to
```
attn_weights = attn_weights-attn_weights.max(-1, keepdim=True).values
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
```
In this case, we no longer need to upcast float16 to float32 and might speedup the training , and(or at leaest) the inference?<|||||>cc @younesbelkada here<|||||>hey!
Sorry for responding here late, indeed it seems to be equivalent, ie the slow test that verifiies this specific issue successfully pass with your proposed change.
Recall that the most crucial part to solve the issue is this line: `attn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))` (at least as in today) and we decided to keep the `nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32)` to make the implementation consistent with original OPT as mentioned above.
However, your proposed changes break 2 `torch.fx` tests and I did not dig further into that, maybe if you open a PR we could discuss that into more details
Thanks!
|
transformers | 17,436 | closed | improve no-trainer examples | # What does this PR do?
1. In no-trainer examples, `train_loss` being logged wasn't normalized and as such wasn't intuitive to understand. This also made it difficult to compare train loss between different tools such as comparing train loss from Trainer with that of Accelerate. This PR normalizes the train_loss per epoch to make is more intuitive and comparable.
2. Replaces HF AdamW with torch AdamW for NLP no-trainer examples. This prevents corresponding warning being displayed.
3. Fixing no-trainer examples so that tracker run is created only for the main process else wandb will create num_processes runs with no data.
4. converting `train_loss` from tensor to float so that it gets logged in tensorboard tracker
5. Fixing `run_ner_no_trainer.py` to correctly log `train_loss` in `all_results.json`
6. Adding `report_to` arg to enable users to specify preferred tracker instead of all available trackers which is default option. This prevents logging to the trackers that user doesn't want.
7. In many no-trainer NLP tasks one can train model from scratch, this means that user can bypass `model_name_or_path` arg. However, it is set as required for all scripts which throws error when it isn't specified. Setting this arg `required=False` in corresponding examples to resolve the error when training from scratch.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? | 05-26-2022 08:15:21 | 05-26-2022 08:15:21 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Opened a new PR on the branch of main repo instead of fork #17449 |
transformers | 17,435 | closed | Fix doc builder Dockerfile | # What does this PR do?
Fix the docker file in `transformers-doc-builder`.
~~(We don't need to run `doc-builder build` in the DockerFile, right? I think it is only for the CI runs.)~~
Currently, `Doc builder (Docker image build)` fails, see [this run](https://github.com/huggingface/transformers/actions/runs/2388105533). | 05-26-2022 08:10:36 | 05-26-2022 08:10:36 | _The documentation is not available anymore as the PR was closed or merged._<|||||>The goal of running it inside the dockerfile is to ensure it actually works before publishing the image, so that it doesn't fail at runtime. Do you know why it failed in the first place?<|||||>Thank you, I understand it better now. I will check why it fails inside docker build.<|||||>@LysandreJik
The problem comes from the fact that `$PR_NUMBER` is not defined in the docker image build (`doc-builder`). We can use `main` instead, right?
From `--help`, I saw
```
--version VERSION Version of the documentation to generate. Will default to the version of the package module (using `main` for a version containing dev).
```<|||||>Changed `pr_$PR_NUMBER` to `main`.<|||||>Changed to
```
RUN doc-builder build transformers transformers/docs/source/en --build_dir doc-build-dev --notebook_dir notebooks/transformers_doc --clean --version main
```
works.
Job run page
https://github.com/huggingface/transformers/runs/6775059643?check_suite_focus=true |
transformers | 17,434 | closed | Docker image build in parallel | # What does this PR do?
Remove `needs` in `.github/workflows/build-docker-images.yml`, as it can run in parallel now.
See this [run page](https://github.com/huggingface/transformers/actions/runs/2389099113) v.s. the [previous run page](https://github.com/huggingface/transformers/actions/runs/2388105533), with 14 mins. v.s. 40 mins. | 05-26-2022 07:44:54 | 05-26-2022 07:44:54 | _The documentation is not available anymore as the PR was closed or merged._<|||||>From the job run page, I saw
```
#18 exporting to image
#18 pushing layers 35.6s done
#18 pushing manifest for docker.io/huggingface/transformers-all-latest-gpu:latest@sha256:d8523684a112bff61a2899a69e06e05e26c507778df4754454b95c3dcf244012
#18 pushing manifest for docker.io/huggingface/transformers-all-latest-gpu:latest@sha256:d8523684a112bff61a2899a69e06e05e26c507778df4754454b95c3dcf244012 0.3s done
#18 DONE 289.9s
ImageID
sha256:08ed1b5cc8db313f116b58d86292b2e109f0552737088fba4a5c672012bca3ae
Digest
sha256:d8523684a112bff61a2899a69e06e05e26c507778df4754454b95c3dcf244012
```
so it looks fine to me. But I will run it again and verify the images on docker hub to make sure! |
transformers | 17,433 | closed | OPT produce NaN during batched generation | ### System Info
* transformers==4.19.2
* PyTorch (GPU?): 1.11.0+cu102 (True)
* GPUs: single V100
### Who can help?
@LysandreJik, @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# I have tested and the error happens to opt-1.3b, opt-2.7b, opt-6.7b, and opt-13b.
# opt-125m and opt-350m seems to work fine.
# I haven't tested opt-30b.
model_name = "facebook/opt-1.3b"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
tokenizer.padding_side = "left"
# It works when torch_dtype=torch.float32
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)
model = model.eval().to("cuda")
batch = tokenizer(
["Who are you?", "Joe Biden is the president of"],
padding=True, return_tensors="pt"
)
# It produces NaN in the early layers for the first sequence.
# I check the pattern, and NaN first appears in the padded token position.
model.generate(
input_ids=batch["input_ids"].to("cuda"),
attention_mask=batch["attention_mask"].to("cuda"),
do_sample=True, max_new_tokens=32
)
```
### Expected behavior
The generation under fp16 should be close to fp32.
| 05-26-2022 02:40:38 | 05-26-2022 02:40:38 | Hi @shijie-wu ! Thanks for pointing out the issue,
It appears that in our current implementation we use a naive Softmax function that is applied to the attention scores. When passing the attention scores combined with the attention mask we use very large values to mask padding tokens such as `torch.inf` or `-3.24e+38` on the softmax function. (EDIT: see #17437 - we use correct padding values and not `-3.24e+38`)
It seems that this sometimes leads to unstable operations and results in having NaNs when using half precision mode, but only for large models.
I think that the correct workaroud is to upcast the attention scores to float32 before summing it with the attention mask, apply the Softmax then cast it back to the input dtype as it is done in [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed/blob/908dc9cb4b9717707241eaf8b92a986b2e251218/megatron/model/fused_softmax.py#L204) for eg.
A proper fix will be addressed in #17437 but a quick and dirty solution would be to use `bfloat16` instead of `float16`. At least it worked with `opt-1.3b` but I don't know if it will work with larger models.
Let me know if this helps!<|||||>Hi @younesbelkada ! Thank you for the quick response! I will follow https://github.com/huggingface/transformers/pull/17437. A fix for fp16 would be great as only A100 class support bf16 AFAIK.
Out of curiosity, do you have any intuition on why it only impacts larger models but not smaller models? From https://github.com/huggingface/transformers/pull/17437, it seems to me that it would impact smaller models as well?<|||||>Thanks for the comment!
We will try to have a patch to fix that for fp16 asap I guess ;) Curious to know if the proposed PR will fix your issue (you can checkout the PR and build it from source if you have time)!
Regarding your second question - I totally agree with you - it should also not work on small models. It is just an intuition but possibly the number of heads and/or hidden dimension are impacting that (since it is the only thing that differs between `opt-125m` and `opt-1.3b` in the first layers). I would wait for the team's comments to see if they have better intuition on that! <|||||>Interesting! Thanks a lot for reporting this @shijie-wu
@shephenroller @suchenzang do you have any insight here maybe?
Also cc @patil-suraj, I remember we had a similar problem with GPT-Neo/GPT-J no? Was the solution to force the last computation of the logits to be in fp32?<|||||>Hi @shijie-wu !
After discussing with @ydshieh , it appears that this is completely independent from the model size but it just happened by luck that the logits before the softmax were negative only for large models - therefore causing an overflow that leaded to NaNs.
I am quoting his answer here:
> And back to your question about "why only large model":
This is about the weights and inputs. In the generation script provided in the issue, when I run it, in second time passing Attention Layer, there is some point we get [-16.x, -16.x, ....] as attn_weights , and attn_mask as [-65504, -65504, -inf, -inf, ...]
The 2 -65504 from left padding, -inf from causal mask .
However in fp16, -65504 + -16 = -inf . So we get a batch index with all -inf as input to softmax , and get outputs NaN`
Very interesting!<|||||>FYI (if you want to know more details)
https://github.com/huggingface/transformers/pull/17306#issuecomment-1138660341<|||||>> Also cc @patil-suraj, I remember we had a similar problem with GPT-Neo/GPT-J no? Was the solution to force the last computation of the logits to be in fp32?
@patrickvonplaten I dunno about GPT-Neo/GPT-J but can vouch for the fact that the same thing is happening with GPT-NeoX currently.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>The PR https://github.com/huggingface/transformers/pull/17437 has been merged, @shijie-wu could you confirm this fixed your issue?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,432 | closed | Make all configs nicely readable | ### Feature request
All configs nicely readable (tokenizers & feature extractor)
### Motivation
https://huggingface.co/facebook/opt-30b/discussions/1
### Your contribution
Happy to do it early next week - happy if someone else wants to take it over though! | 05-26-2022 02:37:47 | 05-26-2022 02:37:47 | in strong favor of this!<|||||>PR: https://github.com/huggingface/transformers/pull/17457 |
transformers | 17,431 | closed | Mismatch of special token ids between config and tokenizer config | ### System Info
```shell
main branch
```
### Who can help?
@SaulLu, @LysandreJik
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Example mismatch:
* OPT-* has `bos_token_id` set to 0 in `config.json` while `bos_token` set to `</s>` (which leads to `bos_token_id` as 2) in `tokenizer_config.json`. As a result, `model.config.bos_token_id != tokenizer.bos_token_id`. It might cause subtle bug during generation as the `.generate` load special token ids from `model.config` by default (I don't think it will cause bug for OPT but it might cause subtle bug if `eos_token` is mismatch)
https://github.com/huggingface/transformers/blob/8f46ac98498dd47701971064617e00d7e723a98e/src/transformers/generation_utils.py#L1123-L1134
* Others models might have similar issues.
### Expected behavior
Ideally we would have a single source of truth for special tokens id, if not, we might want to have some assertions to see if there's any mismatch or document this potential pitfall. I understand tokenizer and model are decoupled so it might be hard to introduce assertion in the library, and I am not sure how realistic to have some sort of unittests for mismatch for the model zoo. | 05-26-2022 00:32:53 | 05-26-2022 00:32:53 | Thanks for the report @shijie-wu ! That's indeed a bug in the model's config. Will update all of them now. The BOS token is identical to the EOS token and should therefore be 2 (=> the tokenizer has it correct here).<|||||>Also for the record, this is not a critical bug since in 99% of the times a user prompts OPT with something. This means the user passes a string through the tokenizer and then to the model:
```py
input_ids = tokenizer("some prompt", return_tensors="pt").input_ids
sequence = opt.generate(input_ids)
```
In this case the tokenizer **always** correctly prepends the EOS token. The only time when the model config would cause a bug is if the user would generate from an empty prompt:
```py
sequence = opt.generate()
```<|||||>Thanks for updating OPT!
I understand this won't cause bug in most cases. But hypothetically speaking, if users misconfig `eos_token` in `model.config` and it doesn't match `tokenizer.eos_token`, it would cause the generation to cut short silently. I understand having an assertion might not make sense but documenting it somewhere might be helpful?<|||||>> Also for the record, this is not a critical bug since in 99% of the times a user prompts OPT with something. This means the user passes a string through the tokenizer and then to the model:
>
> ```python
> input_ids = tokenizer("some prompt", return_tensors="pt").input_ids
> sequence = opt.generate(input_ids)
> ```
>
> In this case the tokenizer **always** correctly prepends the EOS token. The only time when the model config would cause a bug is if the user would generate from an empty prompt:
>
> ```python
> sequence = opt.generate()
> ```
Hi, @patrickvonplaten I notice that the tokenizer of OPT models uses `</s>` for `eos_token`, `bos_token` and `unk_token` in `special_tokens_map`. Is it intended?
```
# transformers 4.20.1
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('facebook/opt-1.3b') # all OPT models
print(tokenizer.special_tokens_map)
# {'bos_token': '</s>', 'eos_token': '</s>', 'unk_token': '</s>', 'pad_token': '<pad>'}
```
Another issue I found is the the vocab size in the tokenizer does not match the size of embedding module of OPT models. Tokenizer has vocab size 50265 while the embedding table in opt models has 50272.
```
# transformers 4.20.1
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('facebook/opt-1.3b') # all OPT models
print("Embedding table: " ,model.decode.embed_tokens.weight.shape[0])
# Embedding table: 50272
tokenizer = AutoTokenizer.from_pretrained('facebook/opt-1.3b') # all OPT models
print("Vocab size:", tokenizer.vocab_size)
# Vocab size: 50265
```
Just to confirm is it a bug or intended? Thanks.
<|||||>Hey @git-xp,
Yes OPT indeed uses the same token for both `bos_token` and `eos_token` being `</s>`.
The `unk_token` should actually never really be produced by the tokenizer, since the tokenizer iss based on byte-level Byte-Pair-Encoding and thus will always produce a valid token, no matter what the input (cc @SaulLu just to verify that's correct what I'm saying here)
Also note that OPT's tokenizer is fully based on GPT2's tokenizer which also uses the same token for all BOS, EOS and UNK.
Now regarding the 2nd question, yes it's expected that the OPT model has more vocab entries in the model entry than the tokenizer has tokens. The final tokens of the model are simply never used (they've just been added so that the model has a weight matrix that's a better "power of 2" matrix - *i.e.* 50272 is divisible by 2**5 whereas 50265 is not divisible by 2 at all)<|||||>Your explanation that a byte-level tokenizer has no use as an unknown token is perfect @patrickvonplaten ! :+1: |
transformers | 17,430 | closed | Logits size does not match vocabulary size when fine-tuning Hubert large with pyctcdecode | ### System Info
```shell
- `transformers` version: 4.18.0
- Platform: Linux-5.13.0-44-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.5.1
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@patrickvonplaten
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hello, I have a very similar issue [like this one](https://github.com/huggingface/transformers/issues/15392) for Hubert large. I got this logits size value error when fine-tuning Hubert model with pyctcdecode
Tried with the [previous comment on this issue](https://github.com/huggingface/transformers/issues/15392#issuecomment-1024905216). Setting both `eos_token` and `bos_token` did not work and returned the same error.
Here is the code snippet I used for a single audio file processing and debugging
```python
processor = Wav2Vec2Processor.from_pretrained(
"facebook/hubert-large-ls960-ft",
eos_token=None, bos_token=None)
tokenizer_vocab_dict = processor.tokenizer.get_vocab()
tokenizer_vocab_lowercase = {k.lower(): v for k,v in tokenizer_vocab_dict.items()}
with open("../vocab/vocab.json", "w", encoding="utf-8") as f:
f.write(json.dumps(tokenizer_vocab_lowercase, ensure_ascii=False))
processor.tokenizer = Wav2Vec2CTCTokenizer("../vocab/vocab.json")
processor.save_pretrained("../processor-lm")
ngram = 3
from pyctcdecode import build_ctcdecoder
from transformers import Wav2Vec2FeatureExtractor, Wav2Vec2CTCTokenizer, Wav2Vec2ProcessorWithLM
cus_processor = Wav2Vec2Processor.from_pretrained("facebook/hubert-large-ls960-ft")
vocab_dict = cus_processor.tokenizer.get_vocab()
sorted_vocab_dict = {
k.lower(): v for k, v in sorted(vocab_dict.items(), key=lambda item: item[1])}
decoder = build_ctcdecoder(
labels=list(sorted_vocab_dict.keys()),
kenlm_model_path=f"../{ngram}gram_correct.arpa",
)
processor = Wav2Vec2ProcessorWithLM(
feature_extractor=cus_processor.feature_extractor,
tokenizer=cus_processor.tokenizer,
decoder=decoder
)
model = AutoModelForCTC.from_pretrained(
"facebook/hubert-large-ls960-ft",
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id)
model.freeze_feature_encoder()
# test run
s = "sentence from audio file"
audio_input, sample_rate = sf.read("audio_loc")
inputs = processor(
audio_input, sampling_rate=sample_rate, return_tensors="pt")
with processor.as_target_processor():
labels = np.asarray(processor(s, padding=True).input_ids)
print(f"target processor logit shape: {labels.shape}")
with torch.no_grad():
logits = model(**inputs).logits
print(f"logit shape returned by the model: {logits.shape}")
transcription = processor.batch_decode(logits.numpy()).text[0]
text = processor.decode(labels)
```
### Expected behavior
```python
with processor.as_target_processor():
labels = np.asarray(processor(s, padding=True).input_ids)
```
`labels` should be a vector with size of 32, then it can be sent to the `map_to_result` and `compute_metrics' functions mentioned in [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) with some changes listed below.
```python
def map_to_result(batch):
"""
batchfy and map the hidden states into transcript
:param batch: _description_
:type batch: _type_
"""
#model.to("cuda")
inputs = processor(
batch["speech"],
sampling_rate=batch["sampling_rate"],
return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
batch["pred_str"] = processor.batch_decode(logits.numpy()).text[0]
batch["text"] = processor.decode(batch["labels"])
return batch
def compute_metrics(pred):
"""
batchfy and compute the WER metrics
:param pred: _description_
:type pred: _type_
:return: _description_
:rtype: _type_
"""
wer_metric = load_metric("wer")
transcription = processor.batch_decode(pred.predictions.numpy())
pred_str = transcription.text[0]
# we do not want to group tokens when computing the metrics
label_str = processor.decode(pred.label_ids.numpy())
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
But it returned a vector with size of 45, thus `text = processor.decode(np.asarray(labels))` got the ValueError for logits size unmatched. As results, `map_to_result` and `compute_metrics` also cannot be run during the fine-tuning process. I was wondering if it needs a similar fix as mentioned in [this issue](https://github.com/huggingface/transformers/issues/15392). If not, do you have any suggestions or commends on solving this issue? Thanks in advance.
| 05-26-2022 00:13:15 | 05-26-2022 00:13:15 | Hey @changyeli,
I sadly cannot rerun your code to reproduce the error. Could you try to send a **minimal**, **fully reproducible** code snippet?
E.g. I don't have access to `f"../{ngram}gram_correct.arpa"`<|||||>Hey @patrickvonplaten unfortunately it's a protected corpus so I can't upload the full file here. Will random/first 20 lines from this file work in this case?<|||||>Please don't upload the whole `corpus` - I can try to help, if it's just a some dummy examples. It would be amazing if you could try to make the reproducible code snippet to run as fast as possible and to be as short as possible<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,429 | closed | raise ValueError("You have to specify either input_ids or inputs_embeds") | ### System Info
Hi,
I keep getting this error:
raise ValueError("You have to specify either input_ids or inputs_embeds")
ValueError: You have to specify either input_ids or inputs_embeds
### Sample code :
```shell
# Initializing a ViT & BERT style configuration
config_encoder = ViTConfig()
config_decoder = BertConfig()
config = VisionEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
# Initializing a ViTBert model from a ViT & bert-base-uncased style configurations
model = VisionEncoderDecoderModel(config=config)
# Accessing the model configuration
config_encoder = model.config.encoder
config_decoder = model.config.decoder
# set decoder config to causal lm
config_decoder.is_decoder = True
config_decoder.add_cross_attention = True
# Saving the model, including its configuration
model.save_pretrained("my-model")
# loading model and config from pretrained folder
encoder_decoder_config = VisionEncoderDecoderConfig.from_pretrained("my-model")
model = VisionEncoderDecoderModel.from_pretrained("my-model", config=encoder_decoder_config)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
# load image from the IAM dataset
url = "https://fki.tic.heia-fr.ch/static/img/a01-122-02.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
code is above from the samples provided.
### Expected behavior
```shell
I get this error :
raise ValueError("You have to specify either input_ids or inputs_embeds")
ValueError: You have to specify either input_ids or inputs_embeds
```
| 05-25-2022 20:44:03 | 05-25-2022 20:44:03 | Thanks for reporting, I'll take a look at this<|||||>Hi, @Ngheissari
For `VisionEncoderDecoderModel`, we have to provide the following as the inputs
- `pixel_values`
- either `decoder_input_ids` or `labels`
In you code snippet, you only prepare `pixel_values`, that's why the error occurs. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Thanks for looking into this @ydshieh! Closing this issue. |
transformers | 17,428 | closed | Disk offload fix | # What does this PR do?
This PR fixes the disk offloading for pretrained models (requires latest accelerate main branch) and adds a test. The test passes locally for GPT-2, GPT-J, OPT and T5 (the only model where it's activated right now). | 05-25-2022 20:28:59 | 05-25-2022 20:28:59 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,427 | closed | Add TF ResNet model | Adds a tensorflow implementation of the ResNet model + associated tests.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR. | 05-25-2022 20:02:24 | 05-25-2022 20:02:24 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Swapping @sgugger and @LysandreJik as Lysandre's off and adding @Rocketknight1 for the TF side. <|||||>I'm seeing a failure in `test_keras_fit` - it looks like the outputs are different depending on whether the labels are passed in the input dict or separately. That might actually have nothing to do with the labels and instead be caused by some random differences in the model outputs, though - maybe the `training` flag isn't being passed correctly so layers like dropout are still being run in training mode during eval time? Alternatively, maybe the tolerances we use for NLP models are just too strict for this one?<|||||>Please also incorporate the updates made in #17731 <|||||>> I'm seeing a failure in test_keras_fit - it looks like the outputs are different depending on whether the labels are passed in the input dict or separately. That might actually have nothing to do with the labels and instead be caused by some random differences in the model outputs, though - maybe the training flag isn't being passed correctly so layers like dropout are still being run in training mode during eval time? Alternatively, maybe the tolerances we use for NLP models are just too strict for this one?
@Rocketknight1 Digging into this - I believe this is because of the batch norm layers. Every time the layer is called it updates its `moving_mean` and `moving_variance` parameters. During training, the batches are normalised based on the batch stats, which will be exactly the same for both fit calls, because the data isn't shuffled. And we see this - the training loss for the two histories in `test_keras_fit` are exactly the same. However, at inference the batches are normalised based on the `moving_mean` and `moving_var` params. I'm not really sure how to address this. @ydshieh have we handled anything like this with tests before?
Weirdly, the test was passing before. I'm guessing just a fluke? <|||||>Ahhh, of course! I had thought that running a single iteration of training with a learning rate of 0 would leave the weights unchanged, but that isn't true for `BatchNorm`, because `BatchNorm` weights aren't updated by gradient descent. The test was broken and we only got away with it because NLP models generally don't use `BatchNorm`. I'll fix it tomorrow!<|||||>@sgugger Sorry - I didn't mean to re-request for you as you'd already approved! <|||||>@NielsRogge @Rocketknight1 friendly nudge - let me know if there's any other changes or if I'm good to merge :) |
transformers | 17,426 | closed | TF: GPT-2 generation supports left-padding | # What does this PR do?
This PR does two things:
1. Enables left-padding with GPT-2 generation.
- It was working before only with XLA and was left as a TODO;
- 🚨 Naturally, tests had to be changed. In the batched tests, the shortest sequence is now different, as a consequence of the correct processing of the left-padding;
- Because we now have non-XLA left-padding, the XLA/non-XLA equivalence tests for GPT-2 now have two entries with different lengths;
- An additional test was added, to ensure the output is the same regardless of left-padding.
2. Fix minor issues and TODOs in TF generate. In particular, I'd highlight the following:
- All generated arrays are initialized with the `pad_token_id`, as opposed to with `0`. This was already present in `beam_search`, as one test caught it there;
- Corrects the number of iterations in greedy search and sample -- it was one iteration short and resulting in outputs with `max_length-1` when length was the constraint (also an argument in favor by contradiction: if this change resulted in too many iterations, we would be attempting to write out of bounds of the `TensorArray`, which isn't the case)
___________________
Locally run slow tests: GPT-2, T5, BART, RAG, Encoder_Decoder, Vision_Encoder_Decoder, Speech2Text | 05-25-2022 19:48:15 | 05-25-2022 19:48:15 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@patrickvonplaten made the changes we talked about 👍 ~~There are a couple of tests failing, but I don't think they are related to these changes (like torch tests)~~ <|||||>Cool ! Looks good to me, if possible it'd be great if @sgugger could take a quick look here since the discussed logic of how to handle "automatic creation" of the `attention_mask` is a bit universal in Transformers.<|||||>@sgugger, in short we have the following situation for the automatic attention mask creation.
We **never** do this in the forward pass, but since a long time we have such a feature implementation implemented in PyTorch's generate: https://github.com/huggingface/transformers/blob/d156898f3b9b2c990e5963f5030a7143d57921a2/src/transformers/generation_utils.py#L490
So we won't be able to change that back in PyTorch (except for a major version). For now we do the following in PyTorch which handles the attention_mask creation correctly in 99% of the cases:
- If user doesn't provide the attention_mask **and** the padding token is in the input_ids **and** the padding token is not equal to the EOS token, we create an attention_mask automatically
This doesn't cover the edge-case where the user forwards both padding tokens and eos tokens + they are the same. Think the edge-case is really an edge case, but overall we should nudge the user to **always** provide an attention_mask if doing generate in batches.
=> As a conclusion, we've now copied the PT logic 1-to-1 to TF generate & added a warning. After this PR is merged we should also add this warning to PT IMO.
Does this sound good to you? <|||||>Related: https://github.com/huggingface/transformers/pull/17444<|||||>Sounds good to me @patrickvonplaten !<|||||>Feel free to merge whenever @gante !<|||||>@gante King of TF `generate`! |
transformers | 17,425 | closed | The tokenizer config for OPT-30B is missing a pad token | ### System Info
```shell
Version 4.20.0.dev0, built from source
Issue is in https://huggingface.co/facebook/opt-30b/blob/main/tokenizer_config.json
```
### Who can help?
@patrickvonplaten has his name in the code :)
Discovered when testing the OPT models on various datasets.
https://huggingface.co/facebook/opt-30b/blob/main/tokenizer_config.json is missing a padding token
https://huggingface.co/facebook/opt-13b/blob/main/tokenizer_config.json looks to have the real config for opt-13b?
https://huggingface.co/facebook/opt-13b/blob/main/tokenizer_config.json
{"errors": "replace", "unk_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "bos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "eos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "pad_token": {"content": "<pad>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "add_prefix_space": false, "add_bos_token": true, "special_tokens_map_file": null, "name_or_path": "patrickvonplaten/opt-30b", "tokenizer_class": "GPT2Tokenizer"}
https://huggingface.co/facebook/opt-30b/blob/main/tokenizer_config.json
{"errors": "replace", "bos_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "eos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "add_prefix_space": false, "special_tokens_map_file": null, "name_or_path": "patrickvonplaten/opt_gpt2_tokenizer", "tokenizer_class": "GPT2Tokenizer"}
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run the following code snippet
```
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="validation")
dataset = [s['text'] for s in dataset if s['text'] != '']
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-30b", use_fast=False)
encoded = tokenizer(dataset,
return_tensors="pt",
padding=True)
```
You will see an error because the tokenizer lacks a padding token.
### Expected behavior
```shell
The OPT-30B tokenizer has a padding token and pads the input.
```
| 05-25-2022 19:45:55 | 05-25-2022 19:45:55 | That's an important bug and completely on me! Thanks a mille for spotting it @aninrusimha !<|||||>Fixed it - https://huggingface.co/facebook/opt-30b/discussions/1 |
transformers | 17,424 | closed | Inconsistent behavior in generate when output_scores=True | ### System Info
main branch
### Who can help?
@patrickvonplaten, @Narsil, @gante
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
In `generate` when `output_scores=True`, the behavior is inconsistent. In `greedy_search` mode, the scores are raw logits https://github.com/huggingface/transformers/blob/740a1574f1d95fb81f063bdda9f4c27abea7f04b/src/transformers/generation_utils.py#L1690-L1695
but in `sample` mode (and various beam search modes), the scores are processed logits https://github.com/huggingface/transformers/blob/740a1574f1d95fb81f063bdda9f4c27abea7f04b/src/transformers/generation_utils.py#L1945-L1954
### Expected behavior
In `generate` when `output_scores=True`, the returned scores should be consistent. It could either be raw logits or the processed logits. While for my usecase, I only need raw logits. There might be some usecases which require the processed logits. So there're multiple options:
1. Return raw logits when `output_scores=True`
2. Return processed logits when `output_scores=True`
3. Return processed logits when `output_scores=True`, and raw logits when `output_raw_scores=True`
| 05-25-2022 19:33:40 | 05-25-2022 19:33:40 | Great find @shijie-wu,
We've settled on outputting the processed scores since those are the ones that determine the next token, e.g. argmax and sample is taken on those scores. Given the name of the flag (`output_scores`), I think this makes the most sense.
Will open a PR to fix `greedy_search` here.
It's a good point that people might need the "raw scores" though. I think it's sensible to output the output logits of the model in this case as this would be the most understandable & consistent across generation methods. E.g. every LM model outputs logits which is the "rawest" score, so I'd be fine with adding a `output_logits=True/False` flag for this.
What do you think @patil-suraj @gante @shijie-wu ?<|||||>@patrickvonplaten regarding flag for the logits: on paper yes... but we are starting to get many boolean flags to control the output of internal variables (related issue: https://github.com/huggingface/transformers/issues/17016, where it is requested the output of past key values). I wonder whether there is a better way to collect and expose the internals of generate for advanced uses 🤔 <|||||>For testing purpose, especially for PT/TF generation equivalence test, I think it would be better to be able to return the raw scores from the models --> so we can identify which parts get wrong if any test failure occur.
(But I understand that we have a lot of flags in `generate` already.)<|||||>Having `output_logits=True/False` flag for raw logits sounds good. In terms of too many flags in `generate`, we could have something like `output_flags: Set[ModelInternal]=set(["logits", "scores"])`?<|||||>Just a general comment that may seem obvious to some but I feel like it's always good to restate common options when dealing with such issues (rampant too many options + enabling users to do powerful things),
I don't intend to say that any idea should be applied, just those are my go to options when dealing with such issues, and might provide insights to you on how to deal with this !
#Idea number 1:
- If you have too many arguments, usually some combinations do no make any sense. For instance here ( output_logits=True with output_scores=False, don't make any sense, you're not outputting scores so why `output_logits` value would be of any interest). Having invalid, bogus combinations is a great place for fusing two arguments into 1 that's an enum. For instance `output_scores: ["none", "logits", "scores"] (and keep False, None, True for BC) `. Now you can see that there's no way to express the previous bogus combination.
#Idea number 2:
- Grouping arguments is a good option too, since users are usually likely to touch more some arguments than others. Some users are really interested in looking at the scores, while some are much more interested in the generation options like `top_k` or `decoder_input_ids`. Having some form of groups makes things easier: `generate(input_ids, logits_options, model_options,return_options )`.It's super important to be sure that the groups are extremely clear (so users don't have to question where option X lives). Even better options for power users is exposing directly some objects like `LogitsProcessor` or `StoppingCriteria` (enables full freedom).
#Idea number 3:
In general for power users wanting to access internals, I think, enabling tons of options to flag what needs to be outputted is just asking for general computing as parameters. Exposing the internals seem like a better option.
For instance one could add a `LogitsProcessor` so see the raw models scores (and at each step at that !) and manually save them himself. It **is** a bit of work, but then the user is empowered to save exactly what he wants without relying on our code to enable his option.
#Idea number 4:
It's OK to say no, more is not always better.<|||||>Thank you for sharing the options! Option 3 seems to be the fastest way to enable returning raw logits without any code change. However, I just go though the relevant path. It seems the user provided `logits_processor` is appended to an new instance of `LogitsProcessorList`. As a result, user cannot get the raw logits using the current implementation even with a custom `LogitsProcessor`. I might be missing something.
IMO, callbacks like custom `LogitsProcessor` seems to be the best way to enable advance usage while keeping the main `generate` code clean. |
transformers | 17,423 | closed | Wav2vec2 finetuning shared file system | # What does this PR do?
Make wav2vec2 fine-tuning script more robust when dealing with multi-node / shared file systems (interesting edge case :sweat_smile: )
Fixes #17412
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-25-2022 19:26:17 | 05-25-2022 19:26:17 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,422 | closed | XGLM onnx support | ### Feature request
I am trying to convert an XGLM based model using the following command, but am receiving an error that onnx does not support an XGLM based model:
```
./venv/bin/python -m transformers.onnx --model=facebook/incoder-1B onnx/
```
Error:
```
KeyError: "xglm is not supported yet. Only ['albert', 'bart', 'beit', 'bert', 'big-bird', 'bigbird-pegasus', 'blenderbot', 'blenderbot-small', 'camembert', 'convbert', 'data2vec-text', 'deit', 'distilbert', 'electra', 'flaubert', 'gpt2', 'gptj', 'gpt-neo', 'ibert', 'layoutlm', 'marian', 'mbart', 'mobilebert', 'm2m-100', 'roberta', 'roformer', 't5', 'vit', 'xlm-roberta'] are supported. If you want to support xglm please propose a PR or open up an issue."
``` | 05-25-2022 19:06:28 | 05-25-2022 19:06:28 | cc @lewtun<|||||>Hey @FrankHeijden, indeed this architecture is not yet supported in the ONNX exporter. If you'd like to have a go at it yourself, you can follow [this guide](https://huggingface.co/docs/transformers/v4.19.2/en/serialization#exporting-a-model-for-an-unsupported-architecture) and use the `BartOnxxConfig` as a template to work from (I think this model should be similar)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,421 | closed | Add link to Hub PR docs in model cards | # What does this PR do?
This PR update the model card guide to point to the new Hub PR feature. I couldn't find the docs on https://huggingface.co/docs/hub/main so decided to link to the raw file for now.
| 05-25-2022 18:15:02 | 05-25-2022 18:15:02 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,420 | closed | Add Gated-SiLU to T5 | # What does this PR do?
Adds gated SiLU to the t5 model in order to support recently the released UL2 model: https://github.com/google-research/google-research/tree/master/ul2
@patrickvonplaten, @patil-suraj
| 05-25-2022 18:11:12 | 05-25-2022 18:11:12 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hmm, yeah so I think I understand what you want to do, but I really don't understand why.
for back compatibility we want:
- non-gated activation function if you specify `feed_forward_proj='relu'`
- gated activation function if you specify `feed_forward_proj='gated-gelu'`
Both my current version and with your modifications this is handled correctly.
For new activation functions:
my version:
- you get the activation function you specify in `feed_forward_proj`
- you get a gated activation function if you specify `is_gated=True`
your version:
- you always get a gated activation function if you specify `dense_act_fn`
I don't see why it's better to 1. change the parameter name where you specify the activation function 2. not support new non-gated activation functions.
<|||||>```
- you always get a gated activation function if you specify dense_act_fn
```
no that was not the logic. The logic was to only get a "gated" feed forward when you specify `feed_forward_proj="gated-gelu"`, but maybe that's too complicated then here actually.
New (better) idea maybe:
How about we just add a new `feed_forward_proj="gated-silu"` and then you extract if the model should be gated or not with:
```py
is_gated = feed_forward_proj.split("-")[0] == "gated"
```
and the activation function with:
```py
act_fn = feed_forward_proj.split("-")[-1]
```
maybe that's the cleanest actually<|||||>This way no dup code, no need for an additional config attribute and it's fairly clean<|||||>Alright, should be mostly in order now. I do agree that it's a bit cleaner to not introduce more new parameters.
Getting a few (as far as I can tell) unrelated tests erroring out, with protobuff problems:
```
E TypeError: Descriptors cannot not be created directly.
E If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
E If you cannot immediately regenerate your protos, some other possible workarounds are:
E 1. Downgrade the protobuf package to 3.20.x or lower.
E 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
```
But otherwise I guess things are ok. <|||||>@DanielHesslow - great the solution works well for me - thanks for making the changes. Left 1 suggestion to improve the error message a bit, but besides that all good to me.<|||||>@DanielHesslow,
The failing CI tests are because of TF releasing a new protobuffer version which broke our CI. You could solve this by rebasing your branch to main (or just pull main into your branch).
Once your branch is up to date, the CI tests should work again :-)
```
git pull origin main
git push
```
Thanks a lot for your work here!<|||||>Okay, fixed the error message and rebased onto main, so all should be good now I believe. <|||||>Merging now |
transformers | 17,419 | closed | fix link in performance docs | This PR fixes the link from `perf_train_gpu_single` to `perf_train_gpu_one ` in `performance.mdx` doc.
Thanks for reporting @stas00! | 05-25-2022 15:44:48 | 05-25-2022 15:44:48 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,418 | closed | DEIT -Some weights of the model checkpoint at facebook/deit-base-patch16-224 were not used when initializing DeiTMode | ### System Info
```shell
Nvidia 3080
Windows 11
```
### Who can help?
@NielsRogge
The warning I get is this and a big list of layers
You are using a model of type vit to instantiate a model of type deit. This is not supported for all configurations of models and can yield errors.
Some weights of the model checkpoint at facebook/deit-base-patch16-224 were not used when initializing DeiTModel:
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I did the following
from transformers import DeiTFeatureExtractor, DeiTModel
feature_extractor = DeiTFeatureExtractor.from_pretrained("facebook/deit-base-patch16-224")
model = DeiTModel.from_pretrained("facebook/deit-base-patch16-224")
inputs_ref = feature_extractor(images=im_ref, return_tensors="pt")
with torch.no_grad():
outputs_ref = model(**inputs_ref)
last_hidden_states_ref = outputs_ref.last_hidden_state
The warning I get is this and a big list of layers
You are using a model of type vit to instantiate a model of type deit. This is not supported for all configurations of models and can yield errors.
Some weights of the model checkpoint at facebook/deit-base-patch16-224 were not used when initializing DeiTModel:
The images are simple scenes only.
### Expected behavior
```shell
Is this warning something I should take seriously. I need only weights from a pre trained model to use.
The warning is 'You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference'
I am new to Hugging face community and I appreciate any help. I tried to follow the guidelines, please revert to me in case of more information
```
| 05-25-2022 15:02:15 | 05-25-2022 15:02:15 | Hi,
That's because the checkpoint you are loading ([facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224)) needs to be loaded in a `ViTModel`/`ViTForImageClassification` rather than a `DeiTModel`. As explained in the [docs](https://huggingface.co/docs/transformers/model_doc/deit) of DeiT, the authors also trained more efficient ViT models:
> The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into [ViTModel](https://huggingface.co/docs/transformers/v4.19.2/en/model_doc/vit#transformers.ViTModel) or [ViTForImageClassification](https://huggingface.co/docs/transformers/v4.19.2/en/model_doc/vit#transformers.ViTForImageClassification). Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset (while only using ImageNet-1k for pre-training). There are 4 variants available (in 3 different sizes): facebook/deit-tiny-patch16-224, facebook/deit-small-patch16-224, facebook/deit-base-patch16-224 and facebook/deit-base-patch16-384. Note that one should use [DeiTFeatureExtractor](https://huggingface.co/docs/transformers/v4.19.2/en/model_doc/deit#transformers.DeiTFeatureExtractor) in order to prepare images for the model.<|||||>@NielsRogge
Thank you very much for responding and I have got my mistake but still I have a confusion. Because Initially I started with 'facebook/deit-base-distilled-patch16-224' from the tutorial mentioned
https://huggingface.co/docs/transformers/v4.19.2/en/model_doc/deit#transformers.DeiTFeatureExtractor
Still I get this issue. I understand I am not doing any classification so I get some warning but still I am not able to comprehend this. Any direction will be appreciated. Thanks in advance
Some weights of the model checkpoint at facebook/deit-base-distilled-patch16-224 were not used when initializing DeiTModel: ['distillation_classifier.bias', 'cls_classifier.weight', 'distillation_classifier.weight', 'cls_classifier.bias']
- This IS expected if you are initializing DeiTModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DeiTModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DeiTModel were not initialized from the model checkpoint at facebook/deit-base-distilled-patch16-224 and are newly initialized: ['deit.pooler.dense.weight', 'deit.pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi,
When initializing a `DeiTModel`, it won't include the heads on top. For that, you'll need to instantiate a `DeiTForImageClassification` or `DeiTForImageClassificationWithTeacher` model. |
transformers | 17,417 | closed | Use latest stable PyTorch/DeepSpeed for Push & Scheduled CI | # What does this PR do?
(**As there are a few PRs waiting for review, feel free to postpone the review for this PR if things get confusing at this moment**)
Currently:
- scheduled CI uses latest stable PyTorch (OK) + nightly DeepSpeed (Not OK)
- push CI uses PyTorch 1.9 (Not OK) + latest stable DeepSpeed (OK)
This PR fix it by using latest stable PyTorch + DeepSpeed, for both push/scheduled CIs
(**Let me run a dummy test before merge** 🙏 ) | 05-25-2022 14:33:30 | 05-25-2022 14:33:30 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@stas00
Regarding `transformers-pytorch-gpu`:
https://github.com/huggingface/transformers/blob/7e46ec71371b5e705522821e741d7c0dac910859/docker/transformers-pytorch-gpu/Dockerfile#L17
Here we only upgrade `torch`, but not `torchvision` and `torcuaudio`. Those two are installed in a previous step
https://github.com/huggingface/transformers/blob/7e46ec71371b5e705522821e741d7c0dac910859/docker/transformers-pytorch-gpu/Dockerfile#L12
I am not sure if we need to upgrade all 3 modules at the same time. PyTorch installation instructions always install these 3 at the same time, so I guess yes ??
<|||||>Yes, usually it's the easiest to always handle all 3 packages as a single package to avoid incompatibility conflicts down the road.
I first tried to "optimize" and only install the other 2 when it was needed, but later I switched to always installing the 3 together. the other 2 are tiny compared to the main package.<|||||>> Yes, usually it's the easiest to always handle all 3 packages as a single package to avoid incompatibility conflicts down the road.
>
> I first tried to "optimize" and only install the other 2 when it was needed, but later I switched to always installing the 3 together. the other 2 are tiny compared to the main package.
OK, I will try to get it done. A bit not easy as here we have using an argument `$PYTORCH` so we can specify torch version.
(although we only use the default value to get the latest stable version for now.)<|||||>[Just FYI] an update:
I am running the tests before merge. So far only a subset of tests is run. I got some issues
PyTorch pipelines (single-gpu)]
https://github.com/huggingface/transformers/runs/6728867682?check_suite_focus=true
Torch CUDA test (multi GPUs)
https://github.com/huggingface/transformers/runs/6728868779?check_suite_focus=true
I will try to re-run them later, also will wait the scheduled CIs during this weekend in order to compare.
<|||||>Feel free to also spawn dummy machines to help you out if it helps getting it merged quicker<|||||>I am going to merge now.
----------------------------------
@stas00
- `intel_extension_for_pytorch` is added
- the version still uses the approach so far `$(python3 -c "from torch import version; print(version.__version__.split('+')[0])")`
- I have to remove `pip uninstall -y` that was in your original patch. The whole line wasn't working.
For the versions, let's discuss in #17586
----------------------------------
@stas00
I observed with the latest stable PyTorch/DeepSpeed, `test_can_resume_training_normal_zero2_fp16` takes quite long to run the first time: (On push CI, it will timeout)
First Run
```
63.46s call tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero2_fp16
10.97s call tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero3_fp16
```
Second Run
```
18.17s call tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero2_fp16
11.01s call tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero3_fp16
```
With previous setting (PyTorch 1.9 + DeepSpeed Recompiled)
```
6.16s call tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero2_fp16
2.83s call tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero3_fp16
```
<|||||>> I observed with the latest stable PyTorch/DeepSpeed, test_can_resume_training_normal_zero2_fp16 takes quite long to run the first time: (On push CI, it will timeout)
The very first deepspeed test using deepspeed JIT install will have the overhead of building deepspeed, which takes about 1min - depending on the hardware.
This doesn't happen if deepspeed was prebuilt before tests were run.
Is it possible that this test happens to be the first one to run?<|||||>@stas00
(This is for the stable release of `DeepSpeed` + `PyTorch`)
Here is the job run page
https://github.com/huggingface/transformers/runs/6761224960?check_suite_focus=true
The tests are ran in the following order
```
# The following 3 are OK
tests/deepspeed/test_deepspeed.py::CoreIntegrationDeepSpeed::test_init_zero3_fp16
tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_errors_zero2_fp16
tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_errors_zero3_fp16
# This one timed out
tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero2_fp16
# This one is OK
tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_can_resume_training_normal_zero3_fp16
tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_config_object
...
```
Dumb question: Is stable release of `DeepSpeed` == pre-built ?<|||||>You can see that it was indeed building deepspeed during that test's run, see: https://github.com/huggingface/transformers/runs/6761224960?check_suite_focus=true#step:6:334
so need to either have a longer timeout or always prebuild deepspeed.
> Dumb question: Is stable release of DeepSpeed == pre-built ?
Hope the following makes the whole situation loud and clear:
### What is being built:
* stable release install: `pip install deepspeed==0.6.5`
* bleed/master install: `pip install git+https://github.com/microsoft/DeepSpeed` (or `git clone ...; pip install -e .`)
### How is it being built:
* `pip install deepspeed` JIT build - this will build deepspeed the first time it's used. pip just installs the source files here.
* `DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option="build_ext" --global-option="-j8"` - this is the prebuiding - so that the first time it's used it's already ready to use<|||||>Thank you @stas00 , thankfully I get better understanding of the terminology now!
I will pre-build `DeepSpeed` so it will be indeed ready to be speedy! |
transformers | 17,416 | closed | Update AutoTokenizer.from_pretrained documentation examples | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #17391
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@SaulLu
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-25-2022 13:31:54 | 05-25-2022 13:31:54 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,415 | closed | Fix a typo in `Trainer` (remove parenthesis) | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-25-2022 13:26:56 | 05-25-2022 13:26:56 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,414 | closed | Different behaviours for `tf/flax` and `pt` on `generate(max_length = len of input id)` | ### System Info
```shell
- `transformers` version: 4.20.0.dev0
- Platform: macOS-12.4-arm64-arm-64bit
- Python version: 3.9.12
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.13.0.dev20220521 (False)
- Tensorflow version (GPU?): 2.9.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.4.2 (cpu)
- Jax version: 0.3.6
- JaxLib version: 0.3.5
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
@patrickvonplaten @LysandreJik
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Simply try the `generate` function in the pytorch model and the the `tf` model. Stumbled up upon that issue when I was working on the OPT model tests. In pytorch, even if the `max_length` argument is smaller than the length of the input sequence, a token is still generated.
The following example using GPT2 is quite clear. The source of the bug is from [generation_utils](https://github.com/huggingface/transformers/blob/56b35ce3ebeb1edb53ef98b3ad3557f79ce788e2/src/transformers/generation_utils.py#L1217) which only throws a warning in `pytorch` while throwing an error in both Flax and TF.
Not sure how this should be approached, but IMO we should probably adapt the `tf/flax` code to throw the same warning (if it generates a single token like in pytorch).
```python
>>> from transformers import GPT2LMHeadModel, TFGPT2LMHeadModel, GPT2Tokenizer
>>> pt_model = GPT2LMHeadModel.from_pretrained('gpt2')
>>> tf_model = TFGPT2LMHeadModel.from_pretrained('gpt2')
>>> tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
>>> text = "Today is a beautiful day and I want to thank"
>>> pt_input_ids = tokenizer(text,return_tensors = 'pt').input_ids
>>> tf_input_ids = tokenizer(text,return_tensors = 'tf').input_ids
>>> pt_output = model.generate(pt_input_ids,max_length = 10)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Input length of input_ids is 10, but ``max_length`` is set to 10. This can lead to unexpected behavior. You should consider increasing ``config.max_length`` or ``max_length``.
>>> tokenizer.batch_decode(pt_output,skip_special_tokens = True)
["Today is a beautiful day and I want to thank everyone"]
>>> tf_output = model.generate(tf_input_ids,max_length = 10)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "transformers/src/transformers/generation_tf_utils.py", line 569, in generate
return self._generate(
File "transformers/src/transformers/generation_tf_utils.py", line 1543, in _generate
raise ValueError(
ValueError: The context has 10 number of tokens, but `max_length` is only 10. Please make sure that `max_length` is bigger than the number of tokens, by setting either `generate(max_length=...,...)` or `config.max_length = ...`
```
### Expected behavior
```shell
Input length of input_ids is 10, but ``max_length`` is set to 10. This can lead to unexpected behavior. You should consider increasing ``config.max_length`` or ``max_length``.
```
| 05-25-2022 13:18:09 | 05-25-2022 13:18:09 | @ArthurZucker small tip, it's nicer to show code + error message as follows:
```py
>>> from transformers import GPT2LMHeadModel, TFGPT2LMHeadModel, GPT2Tokenizer
>>> pt_model = GPT2LMHeadModel.from_pretrained('gpt2')
>>> tf_model = TFGPT2LMHeadModel.from_pretrained('gpt2')
>>> tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
>>> text = "Today is a beautiful day and I want to thank"
>>> pt_input_ids = tokenizer(text,return_tensors = 'pt').input_ids
>>> tf_input_ids = tokenizer(text,return_tensors = 'tf').input_ids
>>> pt_output = model.generate(pt_input_ids,max_length = 10)
```
```
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Input length of input_ids is 10, but ``max_length`` is set to 10. This can lead to unexpected behavior. You should consider increasing ``config.max_length`` or ``max_length``.
```
```py
>>> tokenizer.batch_decode(pt_output,skip_special_tokens = True)
```
```
["Today is a beautiful day and I want to thank everyone"]
```
```py
>>> tf_output = model.generate(tf_input_ids,max_length = 10)
```
```
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "transformers/src/transformers/generation_tf_utils.py", line 569, in generate
return self._generate(
File "transformers/src/transformers/generation_tf_utils.py", line 1543, in _generate
raise ValueError(
ValueError: The context has 10 number of tokens, but `max_length` is only 10. Please make sure that `max_length` is bigger than the number of tokens, by setting either `generate(max_length=...,...)` or `config.max_length = ...`
```
<|||||>cc @patil-suraj @gante @Narsil
Think we should discuss on how to correct this. Currently we see a different behavior between PyTorch and Tensorflow.
@patil-suraj @gante any ideas on how to go about it (without breaking backwards comp?)<|||||>Hi there! [Tensorflow](https://github.com/huggingface/transformers/blob/main/src/transformers/generation_tf_utils.py#L1980) (and [FLAX](https://github.com/huggingface/transformers/blob/main/src/transformers/generation_flax_utils.py#L439)) have to pre-allocate the output arrays with length=`max_length`, to be compatible with XLA. That implies that even if the exception above didn't exist, it would fail when writing into these arrays if we allow it to enter the generation loop.
I see three options:
1. Do nothing: annoying because of the different outputs;
2. Upgrade the severity of PT from a warning to an exception: annoying because API/pipeline users might start getting exceptions where things were running before;
3. On the three frameworks, return the first `max_length` tokens when the input is longer than `max_length`: not fully backward compatible, but probably the most correct exception-free behavior, as the request is for a output with length=`max_length`.
WDYT?<|||||>Think we can follow 2. and go from warning to deprecation warning stating that it'll lead to an error in future versions (it is indeed a weird PT behavior). @patil-suraj what do you think?<|||||>> Upgrade the severity of PT from a warning to an exception: annoying because API/pipeline users might start getting exceptions where things were running before;
`max_length` is impossible to use for pipelines users because there is no way they can know how many tokens are being used by their `string`. The option that's actually controllable is `max_new_tokens` since it means the same thing in both the case of `encoder-decoder` and `decoder-only`, AND it means something similar for all models (ByT5 does require more new tokens than GPT2 for same string length but at least it does not depend on the string users send).
Maybe `pipeline` could absorb the cost if it makes more sense (personally I think `max_length` is always hard to deal with in `generate` but it has been here for a long time, so probably not going away It's just that `max_length = max_new_tokens_length + input_ids.shape[0] if decoder_only else max_length = max_new_tokens + decoder_start_ids` and that knowledge is not trivial to understand)
For instance `gpt2` has max_length =50 which is quite small compared to its `512` capacity: https://huggingface.co/gpt2/blob/main/config.json. So enforcing an error is likely to trigger issues (making `max_length=512` is not ideal either tbh).
tldr; I would like to propose option 4:
4- Move away from `max_length` and towards `max_new_tokens` (`max_length` can take precendence because of BC). That makes arguments orthogonal in terms of catching exceptions. `max_new_tokens<=0` raises exception regardless of input. Allocation can still be done correctly See `max_length` calculation from `input_ids` or `deocder_input_ids`.
Basically we discard the entire class of error since now the arguments don't depend on each other like `max_length` and `input_ids` do. We can still raise an warning if `max_new_tokens + input_ids.shape[0] > max_model_length` and simply truncate the command.<|||||>Thanks a lot for all the important background info here @Narsil !
Think it'll be impossible to replace `max_length` with `max_new_tokens` and change the `max_length` default (it's been 20 since a long time in `configuration_utils.py` and changing any of this behavior would be a massive backward breaking behavior).
However, I think what we could do is to give `max_new_tokens` priority over `max_length` if it's passed. Maybe we could then add a safeguard in pipelines that checks if `input_ids.shape[0] >= max_length` then `max_new_tokens = input_ids.shape[0] + 1` is passed with a warning and then `max_new_tokens` is being given priority over `max_length` (maybe we need to do this also slowly with warning and then change).
However, I feel like this should be handled by the pipelines. What do you think @Narsil ?
I very much don't like how it's currently done in PyTorch's `generate`, which silently adds +1 to `max_length` instead of throwing an error -> it should really throw an error IMO. So I'd like to escalate this to a nice error message sometime soon (the latest in v5) (option 2. of @gante)
What do you think @gante @Narsil @patil-suraj <|||||>> However, I feel like this should be handled by the pipelines. What do you think @Narsil ?
As I said, yes `pipeline` can very much swallow the difference. It's really important for pipeline because users don't even have access to their current length.
> Think it'll be impossible to replace max_length with max_new_tokens and change the max_length default (it's been 20 since a long time in configuration_utils.py and changing any of this behavior would be a massive backward breaking behavior).
I know, we can't break BC, I just want to emphasize that some pipeline usage would break (and possibly `generate` usage too) instead of working if we upgrade that to a hard error.
I was merely trying to point out another option which was trying to avoid hard errors at all.
If you're OK with moving on hard error, I will make the necessary adjustements on `pipeline` (which might be already done actually I don't remember)<|||||>It's an important error, maybe let's jump on a quick offline call for it. @patil-suraj @gante - also curious to hear your thoughts on it here<|||||>> However, I think what we could do is to give `max_new_tokens` priority over `max_length` if it's passed.
I like this idea! There would be no change for existing users, and new users could benefit from a clearer argument. However, we should be aware that `max_new_tokens` can be sneaky and result in more tokens than what the model can handle if `input_ids` is large enough -- we should build proper exceptions from the start.
As for the original issue (`input_ids.shape[0] >= max_length`), we can start with a warning and then move it into an exception, pointing at the `max_new_tokens` argument.<|||||>Just had a call with @Narsil .
We agreed on the following:
- 1. TF, Flax, PT should have the same behavior regarding `max_length` and `max_new_tokens`
- 2. `max_new_tokens` should be favored over `max_length` meaning that if both are provided then `max_new_tokens` should be used
- 3. PT should escalate the warning when `input_ids.shape[0] >= max_length` to a `"This will lead to an error in a future version"` warning
- 4. generation pipelines should absorb the case when `input_ids.shape[0]` >= max_length` by just passing `max
What do you think @gante @patil-suraj - good for you?
This leads to a couple of PRs we should open:
1. @gante could you maybe add `max_new_tokens` logic to Flax and TF generate?
2. Escalate the warning in PT and add a deprecation warning -> @gante could you maybe also open a PR for this?
3. I could take care of changing the docs to advertise `max_new_tokens` instead of `max_length`.
4. @Narsil could you maybe make sure that the PT pipelines correctly absorb the use case when `input_ids.shape[0] >= max_length`?
Would this work for you?<|||||>> @Narsil could you maybe make sure that the PT pipelines correctly absorb the use case when input_ids.shape[0] >= max_length?
Yes !<|||||>Sounds good 👍 <|||||>Cool! I'll take care of the docs then :-)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi, is this issue still exists guys? <|||||>With the recent merge of #18018, it should not exist anymore. 😉 <|||||>Let's close the issue then, |
transformers | 17,413 | closed | [WIP]Add splinter test tokenization file | # What does this PR do?
This PR adds test tokenization file for Splinter. It inherits from BERT Tokenizer.
Contributes fixes to issue https://github.com/huggingface/transformers/issues/16627
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@LysandreJik
@SaulLu | 05-25-2022 11:44:06 | 05-25-2022 11:44:06 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @farahdian , thank you very much for your contribution. I see that several tests have failed, is this still a work in progress? <|||||>> Hi @farahdian , thank you very much for your contribution. I see that several tests have failed, is this still a work in progress?
Yup a work in progress, but will appreciate some guidance and will be inspecting the failed tests. Sorry for any confusion!<|||||>Ok top! I'd be happy to give you a hand.
I think in your case it would be great if the title of the PR started with `[WIP]` and a first failing test that you can fix is style of the files by running the `make fixup` command locally (cf the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests)).
For the rest of the tests that fail, could you tell me more about what is obscure for you?<|||||>Many thanks. I've tried to run ```make fixup``` but this error keeps coming up:
```
make : The term 'make' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included, verify that the path is correct and try again.
At line:1 char:1
+ make fixup
+ ~~~~
+ CategoryInfo : ObjectNotFound: (make:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
```
I've tried using ```python -m``` alongside but then it returns this:
```
usage: __main__.py [-h] {project,get} ...
__main__.py: error: invalid choice: 'fixup' (choose from 'project', 'get')
```
Think this may be related to why I've been having some issues running tests locally... appreciate you having a look!<|||||>From your error message, what I understand is that you don't have the `make` command installed on your computer.
([source](https://www.computerhope.com/unix/umake.htm))
> On Unix-like operating systems, make is a utility for building and maintaining groups of programs (and other types of files) from source code.
Depending on your OS, you'll probably have an alternative to install it. For example on [Windows you can use WSL.](https://github.com/Microsoft/WSL/issues/2073)<|||||>Hi @farahdian ,
Just a quick message to see how you're doing with adding the tests on your end. :relaxed: <|||||>> Hi @farahdian ,
>
> Just a quick message to see how you're doing with adding the tests on your end. ☺️
Thanks for checking up on me!
I'm struggling a bit with this and I'm not sure how to proceed... I've been trying to use WSL and it seems like I'm coming close but this error appears.
```make: *** No rule to make target 'fixup'. Stop.```<|||||>Hi @farahdian ,
Thanks for the update. What is your working directory when you run the `make fixup` command?<|||||>> Hi @farahdian ,
>
> Thanks for the update. What is your working directory when you run the `make fixup` command?
```transformers/tests/splinter```<|||||>I see, you need to run it from the root repository `transformers/` where the [Makefile](https://github.com/huggingface/transformers/blob/main/Makefile) lives :blush: <|||||>> I see, you need to run it from the root repository `transformers/` where the [Makefile](https://github.com/huggingface/transformers/blob/main/Makefile) lives 😊
Unfortunately, when I run '''make fixup''' from the root repo this error then comes up:
```
make: python: Command not found
No library .py files were modified
python utils/custom_init_isort.py
make: python: Command not found
make: *** [Makefile:56: extra_style_checks] Error 127
```<|||||>This error suggests that `python` isn't installed. I guess that you'll get the same error if you run `python --version` (which isn't specific to `transformers`)<|||||>Hi @farahdian,
How things are going for you? :slightly_smiling_face: <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Sorry for the delay, think I reached beyond my capabilities with this one. Hope this can be passed on to another contributer<|||||>Thank you for keeping us informed |
transformers | 17,412 | closed | wav2vec2 multi-node training problems in a shared file system | ### System Info
```shell
- `transformers` version: 4.18.0
- Platform: Linux-4.18.0-147.8.1.el8_1.x86_64-x86_64-with-centos-8.1.1911-Core
- Python version: 3.7.4
- Huggingface_hub version: 0.1.2
- PyTorch version (GPU?): 1.9.0+rocm4.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: distributed
```
### Who can help?
@patrickvonplaten, @anton-l, @lhoestq
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Steps to produce the behavior:
1. clone [this huggingface model](https://huggingface.co/PereLluis13/wav2vec2-xls-r-300m-ca-lm) in order to run the custom `run_speech_recognition_ctc.py` script
2. Setup the `venv` according to the requirements of the model file plus `datasets==2.0.0`, `transformers==4.18.0` and `torch==1.9.0`
3. Launch the runner in a distributed environment which has a shared file system for two nodes, preferably with SLURM. Example [here](https://gist.github.com/gullabi/3f66094caa8db1c1e615dd35bd67ec71)
The processes fail with the error:
```
Traceback (most recent call last):
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 816, in <module>
main()
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 560, in main
os.remove(vocab_file)
FileNotFoundError: [Errno 2] No such file or directory: 'wav2vec2-xls-r-300m-ca_dist/vocab.json'
```
as both nodes are seeing the `vocab_file` and trying to delete it at the same time, but since nodes are on a shared file system, the training fails.
As further information, when the `os.remove` is escaped via
```
with training_args.main_process_first():
if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
try:
os.remove(vocab_file)
except Exception as e:
logger.info(e)
```
the runner trains the model successfully until the first checkpoint. However, during the evaluation just before saving the checkpoint to the file system this error occurs:
```
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/
run_speech_recognition_ctc.py", line 819, in <module>
main()
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/
run_speech_recognition_ctc.py", line 770, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/
lib/python3.7/site-packages/transformers/trainer.py", line 1497, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch,
ignore_keys_for_eval)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/
lib/python3.7/site-packages/transformers/trainer.py", line 1624, in
_maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/
lib/python3.7/site-packages/transformers/trainer.py", line 2291, in evaluate
metric_key_prefix=metric_key_prefix,
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/
lib/python3.7/site-packages/transformers/trainer.py", line 2535, in
evaluation_loop
metrics = self.compute_metrics(EvalPrediction(predictions=all_preds,
label_ids=all_labels))
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/
run_speech_recognition_ctc.py", line 720, in compute_metrics
metrics = {k: v.compute(predictions=pred_str, references=label_str) for k,
v in eval_metrics.items()}
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/
run_speech_recognition_ctc.py", line 720, in <dictcomp>
metrics = {k: v.compute(predictions=pred_str, references=label_str) for k,
v in eval_metrics.items()}
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/
lib/python3.7/site-packages/datasets/metric.py", line 444, in compute
os.remove(file_path)
FileNotFoundError: [Errno 2] No such file or directory: '/home/bsc88/bsc88474
/.cache/huggingface/metrics/wer/default/default_experiment-1-0.arrow'
```
This is presumably the metric evaluation is done on all nodes, but since they are in a shared file system removal of the cached evaluation files creates a conflict.
In principle, transformers library has a context `main_process_first` which in the case `local=False` is passed only the main node of the multi-node executes the tasks. The metric calculation is not within this context and we are not sure whether (apart from the `os.remove(vocab.json)` problem) the solution is to add the context [here](https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L659).
Since this issue is also related to the filelock processes within the `datasets` library we also included `@lhoestq` as a person who can help.
### Expected behavior
```shell
The training process runs successfully without producing any errors concerning the write/delete process conflicts or any other error related to the file locks.
```
| 05-25-2022 10:45:58 | 05-25-2022 10:45:58 | When instantiating a metric in a distributed setup, you need to specify it:
```python
load_metric(..., process_id=rank, num_process=total_world_size)
```
this way there will be no collision on the files used to store the predictions and references used to compute the metric.
(and this makes me think one should rename `num_process` to `num_processes` or something like that)<|||||>Thank you for the quick responses and fixes.
Although you have closed the issue, I want to document the results. With the changes I did in the `load_metric` the processes errored out with the message:
```
ValueError: Error in _init_writer: another metric instance is already using the local cache file at /home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/default_experiment-8-rdv.lock. Please specify an experiment_id (currently: default_experiment) to avoid collision between distributed metric instances.
```
I understand that `experiment_id` is a string and it can be anything. I just made the change but I won't get the results for a while since I am in the job queue.<|||||>Should we maybe move this (still open) issue to datasets @gullabi @lhoestq ?<|||||>It might be a good idea but let me check the results of the experiment. If it is working as intended there is no reason to move it I think. But if we notice any problem, I will let you know and we can move the discussion to datasets. thanks!<|||||>So I am back, with more problems. Now might be a good idea to move the issue to datasets. I am still running into problems. I am continuing here but you will let me know if I need to do something.
Here are the changes I did to the `run_speech_recognition_ctc.py`
```
process_id=int(os.environ["RANK"])
num_process=int(os.environ["WORLD_SIZE"])
eval_metrics = {metric: load_metric(metric,
process_id=process_id,
num_process=num_process,
experiment_id="slurm")
for metric in data_args.eval_metrics}
```
For the test I am executing the world size is 4, with 2 GPUs in 2 nodes. However the process is not finding the necessary lock files
```
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 841, in <module>
main()
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 792, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/trainer.py", line 1497, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/trainer.py", line 1624, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/trainer.py", line 2291, in evaluate
metric_key_prefix=metric_key_prefix,
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/trainer.py", line 2535, in evaluation_loop
metrics = self.compute_metrics(EvalPrediction(predictions=all_preds, label_ids=all_labels))
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 742, in compute_metrics
metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 742, in <dictcomp>
metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/datasets/metric.py", line 419, in compute
self.add_batch(**inputs)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/datasets/metric.py", line 465, in add_batch
self._init_writer()
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/datasets/metric.py", line 552, in _init_writer
self._check_rendez_vous() # wait for master to be ready and to let everyone go
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/datasets/metric.py", line 342, in _check_rendez_vous
) from None
ValueError: Expected to find locked file /home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-0.arrow.lock from process 3 but it doesn't exist.
```
When I look at the cache directory, I can see all the lock files in principle:
```
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-0.arrow
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-0.arrow.lock
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-1.arrow
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-1.arrow.lock
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-2.arrow
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-2.arrow.lock
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-3.arrow
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-3.arrow.lock
/home/bsc88/bsc88474/.cache/huggingface/metrics/wer/default/slurm-4-rdv.lock
```
I appreciate any help regarding this, thanks! @lhoestq <|||||>After fixing the parts related to `datasets` we ran into another problem with the `run_speech_recognition_ctc.py` script. Maybe a question for @patrickvonplaten sorry to bother you with a mention.
When we increase the number of nodes, we are getting a `JSONDecodeError` for `preprocessor_config.json`. Checking the file, we see that it is fine. We suspect that the nodes are trying to read a file that is currently being written. In order to solve the problem we put `local=False` to the `main_process_first` contexts, but it didn't help. We are putting the snippet which we think is causing the problem, plus the logs in the end
```
with training_args.main_process_first(local=False, desc="dataset map preprocessing"):
vectorized_datasets = raw_datasets.map(
prepare_dataset,
remove_columns=next(iter(raw_datasets.values())).column_names,
num_proc=num_workers,
desc="preprocess datasets",
)
def is_audio_in_length_range(length):
return length > min_input_length and length < max_input_length
# filter data that is shorter than min_input_length
vectorized_datasets = vectorized_datasets.filter(
is_audio_in_length_range,
num_proc=num_workers,
input_columns=["input_length"],
)
```
and the log (sorry it's a jumbled mess since many nodes are writing at the same time):
```
^Mpreprocess datasets #11: 0%| | 0/12020 [00:00<?, ?ex/s]ESC[AESC[AESC[AESC[AESC[AESC[AESC[AESC[AESC[AESC[AESC[AFeature extractor saved in wav2vec2-xls-r-300m-ca_new/preprocessor_con
fig.json
Special tokens file saved in wav2vec2-xls-r-300m-ca_new/special_tokens_map.json
added tokens file saved in wav2vec2-xls-r-300m-ca_new/added_tokens.json
tokenizer config file saved in wav2vec2-xls-r-300m-ca_new/tokenizer_config.json
Special tokens file saved in wav2vec2-xls-r-300m-ca_new/special_tokens_map.json
Configuration saved in wav2vec2-xls-r-300m-ca_new/config.json
/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py:761: FutureWarning: Loading a processor from a feature extractor config that does not include a `processo
r_class` attribute is deprecated and will be removed in v5. Please add the following attribute to your `preprocessor_config.json` file to suppress this warning: `'processor_class': 'Wav2Vec2P
rocessor'`
FutureWarning,
/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py:761: FutureWarning: Loading a processor from a feature extractor config that does not include a `processo
r_class` attribute is deprecated and will be removed in v5. Please add the following attribute to your `preprocessor_config.json` file to suppress this warning: `'processor_class': 'Wav2Vec2P
rocessor'`
FutureWarning,
/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py:58: FutureWarning: Loading a tokenizer inside
Wav2Vec2Processor from a config that does not include a `tokenizer_class` attribute is deprecated and will be removed in v5. Please add `'tokenizer_class': 'Wav2Vec2CTCTokenizer'` attribute to
either your `config.json` or `tokenizer_config.json` file to suppress this warning:
FutureWarning,
/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py:58: FutureWarning: Loading a tokenizer inside
Wav2Vec2Processor from a config that does not include a `tokenizer_class` attribute is deprecated and will be removed in v5. Please add `'tokenizer_class': 'Wav2Vec2CTCTokenizer'` attribute to
either your `config.json` or `tokenizer_config.json` file to suppress this warning:
FutureWarning,
Traceback (most recent call last):
Traceback (most recent call last):
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/feature_extraction_utils.py", line 454, in get_feature_extractor_dict
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/feature_extraction_utils.py", line 454, in get_feature_extractor_dict
Feature extractor saved in wav2vec2-xls-r-300m-ca_new/preprocessor_config.json
feature_extractor_dict = json.loads(text)
feature_extractor_dict = json.loads(text) File "/apps/PYTHON/3.7.4/INTEL/lib/python3.7/json/__init__.py", line 348, in loads
File "/apps/PYTHON/3.7.4/INTEL/lib/python3.7/json/__init__.py", line 348, in loads
return _default_decoder.decode(s)
File "/apps/PYTHON/3.7.4/INTEL/lib/python3.7/json/decoder.py", line 337, in decode
return _default_decoder.decode(s)
File "/apps/PYTHON/3.7.4/INTEL/lib/python3.7/json/decoder.py", line 337, in decode
added tokens file saved in wav2vec2-xls-r-300m-ca_new/added_tokens.json
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/apps/PYTHON/3.7.4/INTEL/lib/python3.7/json/decoder.py", line 355, in raw_decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/apps/PYTHON/3.7.4/INTEL/lib/python3.7/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 841, in <module>
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 841, in <module>
^Mpreprocess datasets #5: 3%|▎ | 414/12021 [00:01<00:23, 495.45ex/s]ESC[AESC[AESC[AESC[AESC[A
main()
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 763, in main
main()
File "/gpfs/projects/bsc88/speech/asr/wav2vec2-xls-r-300m-ca-lm/run_speech_recognition_ctc.py", line 763, in main
processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py", line 61, in from_pretrained
processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py", line 61, in from_pretrained
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/feature_extraction_utils.py", line 308, in from_pretrained
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/feature_extraction_utils.py", line 308, in from_pretrained
feature_extractor_dict, kwargs = cls.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/feature_extraction_utils.py", line 458, in get_feature_extractor_dict
feature_extractor_dict, kwargs = cls.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
File "/gpfs/projects/bsc88/projects/speech-tech-resources/venv_amd_speech/lib/python3.7/site-packages/transformers/feature_extraction_utils.py", line 458, in get_feature_extractor_dict
f"It looks like the config file at '{resolved_feature_extractor_file}' is not a valid JSON file."
OSError: It looks like the config file at 'wav2vec2-xls-r-300m-ca_new/preprocessor_config.json' is not a valid JSON file.
tokenizer config file saved in wav2vec2-xls-r-300m-ca_new/tokenizer_config.json
f"It looks like the config file at '{resolved_feature_extractor_file}' is not a valid JSON file."
OSError: It looks like the config file at 'wav2vec2-xls-r-300m-ca_new/preprocessor_config.json' is not a valid JSON file.
Feature extractor saved in wav2vec2-xls-r-300m-ca_new/preprocessor_config.json
Configuration saved in wav2vec2-xls-r-300m-ca_new/config.json
Special tokens file saved in wav2vec2-xls-r-300m-ca_new/special_tokens_map.json
tokenizer config file saved in wav2vec2-xls-r-300m-ca_new/tokenizer_config.json
added tokens file saved in wav2vec2-xls-r-300m-ca_new/added_tokens.json
loading feature extractor configuration file wav2vec2-xls-r-300m-ca_new/preprocessor_config.json
loading configuration file wav2vec2-xls-r-300m-ca_new/config.json
```<|||||>Hmm, the file should not be written - I guess what might happen here is that one node is much much faster then another node and already wants read a file that has not been created in the previous step yet.
Could you do the following:
- Simply run the script on one node to correctly write the tokenizer and feature processor config jsons
- Then pass all those files to the script on multi-node so that the in multi-node no config is being written at all? <|||||>Thanks Patrick. For the second step, do I need to skip the data preprocessing also? If so is there a way to load the preprocessed files directly from the cache?
A bit ashamed to say but, I have been looking at the script to try to skip the data preprocessing phase, and did not manage to do it. In the output I see warnings saying that the preprocessed data is being loaded from the cache (for various steps), but I see the tdqm process task bar and the process takes a long time, so I am assuming at least some nodes are doing the preprocessing. I don"t know if this is the usual behavior. <|||||>In principle I have avoided this error by putting a sleep, after the preprocessing and before loading the feature processing config json, not the most elegant solution.
Afterwards we have ran into other unrelated problems but in principle for now the script seems to be working. I am giving feedback just in case it is useful for someone else. <|||||>Hey @gullabi,
Exactly in the second step, you should be able to fully skip the dataset processing. In short, I'd strongly advise to create the whole tokenizer file before doing the multi-node run and then this `if-branch`: https://github.com/huggingface/transformers/blob/da27c4b398e607c161451f335367ad666de08497/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L500 should never be run which means that no files sholud be written **and** read at the same time.
However if `sleep` works for you, I think that's also totally fine. So far we've never had a case where multi-node + shared file-system was used for the examples, so this issue here serves as a great readme guide for future such use cases :-)<|||||>Thanks for the suggestion and I am glad that it the issue is useful for something. For the sake of completeness, I would like to give feedback. Although your suggestion sped up the preprocessing (I used the `--tokenizer_name_or_path` cli parameter), it does not directly solve the problem we were facing.
The problem was at the step where the feature extractor, config and the tokenizer files are written, and just before the training starts. The errors were pointing out specifically to loading the feature extractor config right before the training. Realizing that the problem is simultaneous reading and writing going by multiple nodes to the same file systems, the problematic write was here:
https://github.com/huggingface/transformers/blob/da27c4b398e607c161451f335367ad666de08497/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L675
So I put a sleep right after writing this `if is_main_process` block. |
transformers | 17,411 | closed | can't run (TF)BartForConditionalGeneration.generation on GPU, it's speed very very very slow | ### System Info
```shell
transformers==4.19
tensorflow-gpu==2.3
torch==1.11
```
### Who can help?
@patil-suraj@patrickvonplaten, @Narsil, @gante@Rocketknight1
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from transformers import BertTokenizer, TFBartForConditionalGeneration
tokenizer = BertTokenizer.from_pretrained("fnlp/bart-base-chinese")
model = TFBartForConditionalGeneration.from_pretrained("fnlp/bart-base-chinese", from_pt=True)
batch_data = ['北京是[MASK]的首都']*64
for i in range(20):
batch_dict = tokenizer.batch_encode_plus(batch_data, return_token_type_ids=False, return_tensors='tf')
result = model.generate(**batch_dict, max_length=20)
result = tokenizer.batch_decode(result, skip_special_tokens=True)
print(result)
### Expected behavior
```shell
1 . when I run CUDA_VISIBLE_DEVICES=1 python test.py, GPU's memory is used,GPU utilization is almost zero,and generate speed is very very very slow, cpu utilization is 100%.
2. when i replace TFBartForConditionalGeneration with BartForConditionalGeneration, GPU's memory is used,
GPU utilization is almost zero,cpu utilization greater than 100%,speed is normal,but it mean that, generate is on cpu not GPU.
```
| 05-25-2022 08:02:49 | 05-25-2022 08:02:49 | Hey @TheHonestBob 👋 We are aware of the generate speed problems with TensorFlow, and will be releasing an update very soon. It is not a bug, but rather how Eager Execution works, sadly. Stay tuned 🤞 <|||||>> Hey @TheHonestBob 👋 We are aware of the generate speed problems with TensorFlow, and will be releasing an update very soon. It is not a bug, but rather how Eager Execution works, sadly. Stay tuned 🤞
thanks for your reply,what can I do before update to solve it.<|||||>My advice would be to go with the PyTorch version, if performance is a bottleneck to you and you need something working in the next ~2 weeks. If you can afford to wait ~2 weeks, then you can have a look at the guides we are writing up at the moment :) <|||||>> My advice would be to go with the PyTorch version, if performance is a bottleneck to you and you need something working in the next ~2 weeks. If you can afford to wait ~2 weeks, then you can have a look at the guides we are writing up at the moment :)
OK, I will continue to pay attention no it<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>@TheHonestBob -- some of the functionality to speed up has been merged recently. If you try running a modified version of your script and you have a GPU, you will see it is much much faster.
```python
import tensorflow as tf
from transformers import BertTokenizer, TFBartForConditionalGeneration
tokenizer = BertTokenizer.from_pretrained("fnlp/bart-base-chinese")
model = TFBartForConditionalGeneration.from_pretrained("fnlp/bart-base-chinese", from_pt=True)
batch_data = ['北京是[MASK]的首都']*64
xla_generate = tf.function(model.generate, jit_compile=True)
for i in range(20):
batch_dict = tokenizer.batch_encode_plus(batch_data, return_token_type_ids=False, return_tensors='tf')
result = xla_generate(**batch_dict, max_length=20, no_repeat_ngram_size=0, num_beams=1)
result = tokenizer.batch_decode(result, skip_special_tokens=True)
print(result)
```
To enable bigger values of `num_beams`, which should increase the quality of the generation, [this PR](https://github.com/huggingface/transformers/pull/17857) has to be merged first :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>@TheHonestBob The newest release (v4.21) fixes this issue. Check our recent blog post -- https://huggingface.co/blog/tf-xla-generate<|||||>> @TheHonestBob The newest release (v4.21) fixes this issue. Check our recent blog post -- https://huggingface.co/blog/tf-xla-generate
thanks a lot, I'll try it |
transformers | 17,410 | closed | TFBartForConditionalGeneration.generate is very very slow,but not BartForConditionalGeneration.generate。 | when I use TFBartForConditionalGeneration.generate so slow, but BartForConditionalGeneration.generate is ok, here is some suggestion for me, thinks a lot. | 05-25-2022 05:13:40 | 05-25-2022 05:13:40 | |
transformers | 17,409 | closed | fix layoutlmv2 doc page | # What does this PR do?
Quick follow up PR to #17168 to address @NielsRogge 's comments
Clarify that the `torchvision` and `tesseract` packages are optional dependencies for LayoutLMv2.
## Who can review?
@sgugger @NielsRogge
| 05-25-2022 02:50:53 | 05-25-2022 02:50:53 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17409). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,408 | closed | Make check_init script more robust and clean inits | # What does this PR do?
This PR was triggered by the inits deactivating the formatter (see `wav2_vec2_with_lm` below) which was a bit sad. In one line, `check_inits.py` was unable to parse `_import_structure` initialized in one line, this PR addresses that and cleans many model inits.
HuBERT also contained some reference to Wav2Vec2FeatureExtractor, which should not be the case. This PR cleans that up as well.
| 05-24-2022 21:51:34 | 05-24-2022 21:51:34 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,407 | closed | Fix README localizer script | # What does this PR do?
Currently, the script that updates the localized READMEs does not remove duplicates. This PR fixes that. | 05-24-2022 20:42:52 | 05-24-2022 20:42:52 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,406 | closed | NotebookProgressCallback doesn't work in databricks notebooks properly--should either be fixed or removed from trainer automatically if it is a databricks runtime | https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/utils/notebook.py#L269
Hey all,
Using databricks for training, the default Trainer behavior will automatically add NotebookProgressCallback for databricks notebooks, but the databricks UI currently does not display the output properly. It just prints a bunch of text saying `<IPython.core.display.HTML object>` over and over. This is likely an issue on Databricks' end, so I recommend not adding this callback if the transformers library can detect it is a databricks runtime not a jupyter/google collab notebook. I think there should also be an easier way to delete specific callbacks--it took a long time to trace this issue and reading source code to figure out what the source cause is. I am circumventing the issue for now by popping the callback from the trainer callback handlers list but that is not a good pattern.
Thanks! | 05-24-2022 20:39:23 | 05-24-2022 20:39:23 | Do you know which test we could do to easily detect if we are in a `Databrick` runtime?<|||||>> Do you know which test we could do to easily detect if we are in a `Databrick` runtime?
From stackoverflow:
```
def isRunningInDatabricks(): Boolean =
sys.env.contains("DATABRICKS_RUNTIME_VERSION")
```
<|||||>`sys.env` is not something that exists. Did you mean `os.environ`?<|||||>Could you try if the PR mentioned above does solve your problem?<|||||>Hi, just want to add, since I experienced the same issue in the past.
I believe the reason why the HTML produced by `NotebookProgressCallback` is not displayed properly is because Databricks (with runtime version prior to 11.0) is not using IPython kernel to execute the Python code.
There was a guide how to set Databricks to use IPython kernel. And in my experience, when this is set, the evaluation result table produced by `NotebookProgressCallback` is displayed properly.
https://web.archive.org/web/20211227103927/https://docs.microsoft.com/en-us/azure/databricks/notebooks/ipython-kernel
Most users, however, I believe will use the default setting i.e. not overriding Databricks default setting to specifically use IPython kernel. Therefore, the changes in this [commit](https://github.com/huggingface/transformers/pull/17496) looks good.
However, in the most recent Databricks runtime version 11.0, IPython kernel is now the default Python code execution engine. Therefore, the HTML produced by `NotebookProgressCallback` I believe can be displayed **correctly** by default in Databricks runtime 11.x
https://docs.microsoft.com/en-us/azure/databricks/notebooks/ipython-kernel
I suggest, in addition to checking if this environment variable `DATABRICKS_RUNTIME_VERSION` is set, we should also check the version. If the version is 11.x, I believe it is ok to use the `NotebookProgressCallback`. It can show the table HTML output properly in my test.
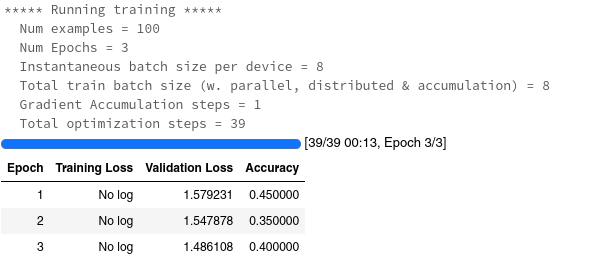
<|||||>If you want to make a PR with the adjustment, I'll be happy to look at it!<|||||>> If you want to make a PR with the adjustment, I'll be happy to look at it!
https://github.com/huggingface/transformers/pull/17988
Thanks |
transformers | 17,405 | closed | Unable to instantiate ImageGPTFeatureExtractor | ### System Info
```shell
- `transformers` version: 4.19.2
- Platform: macOS-12.3.1-arm64-arm-64bit
- Python version: 3.9.9
- Huggingface_hub version: 0.4.0
- PyTorch version (GPU?): 1.11.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@NielsRogge @sgugger
Looks like the `ImageGPTFeatureExtractor` is among the feature extractors supported at the moment but I cannot resolve it with the latest version available on Pip.
I can see it's available here: https://github.com/huggingface/transformers/blob/main/src/transformers/models/auto/feature_extraction_auto.py#L53
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Code:
```
extractor = AutoFeatureExtractor.from_pretrained("openai/imagegpt-small")
```
Stacktrace:
```
feature_extractor_class = feature_extractor_class_from_name(feature_extractor_class)
> return feature_extractor_class.from_dict(config_dict, **kwargs)
E AttributeError: 'NoneType' object has no attribute 'from_dict'
```
### Expected behavior
```shell
Loads feature extractor without any exception.
```
| 05-24-2022 20:34:08 | 05-24-2022 20:34:08 | This is because you do not have `Pillow` installed. We have fixed the error message in #17289 (will be in the next release but is not in 4.19.2) to let you know explicitly you should do `pip install pillow`.<|||||>Thanks @sgugger but unfortunately installing Pillow didn't fix it for me. While debugging, I can see that the method `feature_extractor_class_from_name` fails to return the correct class and returns `None` instead.
I guess it's because in my local installation `FEATURE_EXTRACTOR_MAPPING_NAMES` is defined as follows:
```python
FEATURE_EXTRACTOR_MAPPING_NAMES = OrderedDict(
[
("beit", "BeitFeatureExtractor"),
("detr", "DetrFeatureExtractor"),
("deit", "DeiTFeatureExtractor"),
("hubert", "Wav2Vec2FeatureExtractor"),
("speech_to_text", "Speech2TextFeatureExtractor"),
("vit", "ViTFeatureExtractor"),
("wav2vec2", "Wav2Vec2FeatureExtractor"),
("detr", "DetrFeatureExtractor"),
("layoutlmv2", "LayoutLMv2FeatureExtractor"),
("clip", "CLIPFeatureExtractor"),
("flava", "FlavaFeatureExtractor"),
("perceiver", "PerceiverFeatureExtractor"),
("swin", "ViTFeatureExtractor"),
("vit_mae", "ViTFeatureExtractor"),
("segformer", "SegformerFeatureExtractor"),
("convnext", "ConvNextFeatureExtractor"),
("van", "ConvNextFeatureExtractor"),
("resnet", "ConvNextFeatureExtractor"),
("regnet", "ConvNextFeatureExtractor"),
("poolformer", "PoolFormerFeatureExtractor"),
("maskformer", "MaskFormerFeatureExtractor"),
("data2vec-audio", "Wav2Vec2FeatureExtractor"),
("data2vec-vision", "BeitFeatureExtractor"),
("dpt", "DPTFeatureExtractor"),
("glpn", "GLPNFeatureExtractor"),
("yolos", "YolosFeatureExtractor"),
]
)
```
So it's clearly missing `imagegpt` and this justifies the fail. Any ideas?
I verified that my version of Transformers is the following:
```
Name: transformers
Version: 4.19.2
Summary: State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow
Home-page: https://github.com/huggingface/transformers
Author: The Hugging Face team (past and future) with the help of all our contributors (https://github.com/huggingface/transformers/graphs/contributors)
Author-email: [email protected]
License: Apache
Location: /Users/as2180/workspace/perceptual-simulator/.venv/lib/python3.9/site-packages
Requires: filelock, huggingface-hub, numpy, packaging, pyyaml, regex, requests, tokenizers, tqdm
```
Instead if I install the version from Github, I can get the correct file. Is the wheel on pip up to date?<|||||>Hi,
This was fixed yesterday (#16871) so you need to install Transformers from source:
```
pip install git+https://github.com/huggingface/transformers.git
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,404 | closed | No 'Translation template' | Hi!
Following the [TRANSLATING guide](https://github.com/huggingface/transformers/blob/main/docs/TRANSLATING.md), I realised that there is no 'Translation template' when I try to open an issue.
I would like to try to fix the bug myself by creating the template from: [#15947](https://github.com/huggingface/transformers/issues/15947) and [#16824](https://github.com/huggingface/transformers/issues/16824), unless the file with the template already exists and is simply in some other folder. | 05-24-2022 20:04:09 | 05-24-2022 20:04:09 | Hi @mfumanelli! Thank you for your issue 🤗. Would the translation be for Italian? @sgugger @osanseviero, would this be a step we would wish to pursue?
If that is the case, @mfumanelli, you can use the format in issues #15947 and #16824. Particularly:
- Use informal language.
- Use inclusive language; eg. not letting know any gender and rather talking about "the people".
<|||||>Yes @omarespejel, in case it would be for Italian. Perfect for the two suggestions ☺️.
Then I'll wait to see if it's something you want to pursue at the moment or not, thanks!<|||||>Yes! Let's do this for Italian and any other language the community would like to help translating :fire:
@omarespejel, do we have a smaller list of documents that need to get translated that are higher priority? I think Get Started section + Tutorial section is the most important, but I might be wrong<|||||>@osanseviero I agree that we can start with `Get Started` + `Tutorial` sections.
@mfumanelli then we can go ahead with opening an issue for Italian following #15947 and #16824 🚀. Thank you for opening this venue. Do you know Italian-speaking communities or individuals interested in collaborating?
These would be the first docs to translate:
### Get Started section
- [] [quicktour.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/quicktour.mdx).
- [] [installation.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/installation.mdx).
### Tutorial section
- [] [pipeline_tutorial.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/pipeline_tutorial.mdx)
- [] [autoclass_tutorial.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/autoclass_tutorial.mdx)
- [] [preprocessing.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/preprocessing.mdx)
- [] [training.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/training.mdx)
- [] [accelerate.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/accelerate.mdx)
- [] [model_sharing.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/model_sharing.mdx)
- [] [multilingual.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/multilingual.mdx) <|||||>If you agree as a first step I will shortly make a PR to add the file "Translation template" to the transformers/.github/ISSUE_TEMPLATE folder. So that anyone who wants to translate into other languages can follow the [TRANSLATING guide](https://github.com/huggingface/transformers/blob/main/docs/TRANSLATING.md), and select the "Translation template" from the "New issue" button 🤗.
I will then open a dedicated issue for Italian so that other people can collaborate. I will ask among my contacts if others want to help with the translation 🌈 <|||||>Thank you @mfumanelli! That's a great idea. We were actually reviewing the translation template in this issue #17028. It's a great time to discuss it further if we want to allow the community to translate into different languages. WDYT @sgugger?
I think that in the meantime we can start with the Italian question. WDYT @mfumanelli? While we discuss in #17028.
Wow reaching your contacts would be amazing! Also, count on our support to reach for Italian-speaking contributors in our community 🤗
<|||||>Perfect, we can proceed with the opening of the issue in Italian then. Thanks! 🤗🌈🌈
can I proceed or would you prefer to open it? I don't know if I open it if others can edit it over time to add the various contributors<|||||>Sure @mfumanelli you can open it! Thank you 🤗
I can edit it if when necessary, no problem with that. Also please let me know if you have any doubt 🚀<|||||>Thanks @omarespejel! I created it, you can find it here [#17459](https://github.com/huggingface/transformers/issues/17459). If you agree we can close this issue 🌈<|||||>Agreed! Thank you @mfumanelli 🤗. On Monday I will send a tweet directed to the Italian-speaking community that wants to contribute to #17459 🇮🇹. I will let you know, |
transformers | 17,403 | closed | Error in TAPAS Tokenizer | ### System Info
```shell
Google Colab CPU
```
### Who can help?
@SaulLu @NielsRogge
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
# TODO: should this be in the base class?
https://github.com/huggingface/transformers/blob/3f936df66287f557c6528912a9a68d7850913b9b/src/transformers/tokenization_utils.py#L507
Giving Error in the above function , though the code should not be called
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
import re
import regex
import pandas as pd # library for data analysis
import requests # library to handle requests
from bs4 import BeautifulSoup # library to parse HTML documents
import numpy as np
from transformers import TapasTokenizer, TapasModel
import pandas as pd
tokenizer = TapasTokenizer.from_pretrained("google/tapas-base")
model = TapasModel.from_pretrained("google/tapas-base")
table_class="wikitable sortable jquery-tablesorter"
response=requests.get("https://en.wikipedia.org/wiki/2017_EFL_Trophy_Final")
soup = BeautifulSoup(response.text, 'html.parser')
indiatable=soup.find('table',{'class':"wikitable"})
if indiatable:
count +=1
df=pd.read_html(str(indiatable))
df=pd.DataFrame(df[0])
df = df.astype(str, errors='ignore')
queries=["2017 EFL Trophy Final"]
inputs = tokenizer(table=df, queries=queries, do_lower_case=False, do_basic_tokenize=False, padding="max_length",
return_tensors="pt", truncation = True)
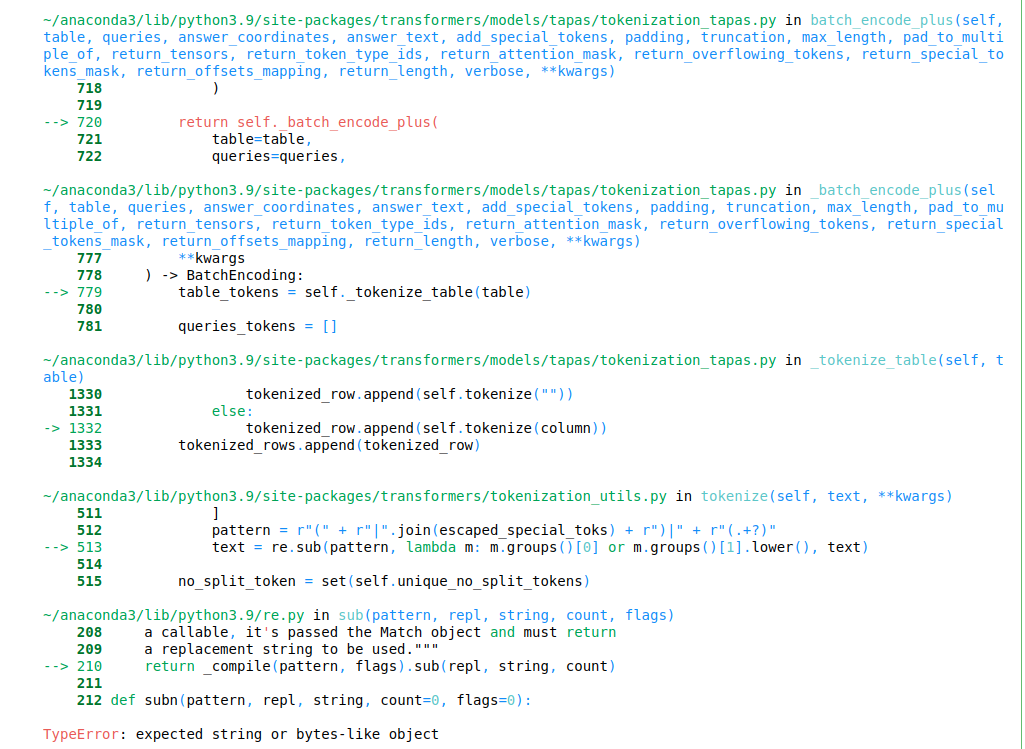
### Expected behavior
```shell
This attribute is set false explicitly, thus should not be called
```
| 05-24-2022 17:51:56 | 05-24-2022 17:51:56 | Hello @shivangibithel,
You are entering the following loop:
https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/tokenization_utils.py#L508-L514
because `do_lower_case` is a paramer that need to be filled in when initializing the tokenizer (or redefined in `from_pretrained`) but not in the `__call__` method. I'm also taking this opportunity to highlight that `do_basic_tokenize` is also a parameter that can't be changed in the `__call__` method.
I hope this will help you! :relaxed:
I also take this opportunity to share [some tips](https://github.com/huggingface/transformers/blob/main/ISSUES.md#the-github-issues) that would help us a lot to read quickly your issue :slightly_smiling_face: . <|||||>Closing this issue due to inactivity :slightly_smiling_face: |
transformers | 17,402 | closed | illegal hardware instruction | ### System Info
```shell
i use macbookpro, and pip install transformers, but i get this error:
>>> from transformers import DistilBertConfig
zsh: illegal hardware instruction python
could you help me?
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
zsh: illegal hardware instruction python
### Expected behavior
```shell
zsh: illegal hardware instruction python
```
| 05-24-2022 17:39:08 | 05-24-2022 17:39:08 | I think this is due to you installation of tensorflow and not necessarily the library .
Did you try installing with
```
conda install -c apple tensorflow-deps
python -m pip install tensorflow-macos
python -m pip install tensorflow-metal
```
Also it is recommended to install using [MiniForge](https://github.com/conda-forge/miniforge#miniforge3)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I'm having the same issue. It happened with the same code recently after installing Big Sur. |
transformers | 17,401 | closed | Add test for new model parallelism features | # What does this PR do?
This PR adds common tests for the new model parallelism/CPU offload features. Those are activated for models having a `_no_split_modules` attribute, so for now GPT-2, GPT-J, OPT and T5. The tests are only run on GPU and multi-GPU (so the CI won't catch any failure on the PR) but they all pass locally for me.
In passing I hit two blockers which this PR fixes:
- the ability to pass `max_memory` directly into `from_pretrained` to limit the memory used in `device_map="auto"`
- the CPU offload wasn't working with T5 because of some `device` taken from the model parameters instead of the input. | 05-24-2022 17:32:58 | 05-24-2022 17:32:58 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,400 | closed | Bump tensorflow from 2.8.0 to 2.8.1 in /examples/research_projects/decision_transformer | Bumps [tensorflow](https://github.com/tensorflow/tensorflow) from 2.8.0 to 2.8.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/tensorflow/tensorflow/releases">tensorflow's releases</a>.</em></p>
<blockquote>
<h2>TensorFlow 2.8.1</h2>
<h1>Release 2.8.1</h1>
<p>This releases introduces several vulnerability fixes:</p>
<ul>
<li>Fixes a code injection in <code>saved_model_cli</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29216">CVE-2022-29216</a>)</li>
<li>Fixes a missing validation which causes <code>TensorSummaryV2</code> to crash (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29193">CVE-2022-29193</a>)</li>
<li>Fixes a missing validation which crashes <code>QuantizeAndDequantizeV4Grad</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29192">CVE-2022-29192</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>DeleteSessionTensor</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29194">CVE-2022-29194</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>GetSessionTensor</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29191">CVE-2022-29191</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>StagePeek</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29195">CVE-2022-29195</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>UnsortedSegmentJoin</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29197">CVE-2022-29197</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>LoadAndRemapMatrix</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29199">CVE-2022-29199</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>SparseTensorToCSRSparseMatrix</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29198">CVE-2022-29198</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>LSTMBlockCell</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29200">CVE-2022-29200</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>Conv3DBackpropFilterV2</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29196">CVE-2022-29196</a>)</li>
<li>Fixes a <code>CHECK</code> failure in depthwise ops via overflows (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-41197">CVE-2021-41197</a>)</li>
<li>Fixes issues arising from undefined behavior stemming from users supplying invalid resource handles (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29207">CVE-2022-29207</a>)</li>
<li>Fixes a segfault due to missing support for quantized types (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29205">CVE-2022-29205</a>)</li>
<li>Fixes a missing validation which results in undefined behavior in <code>SparseTensorDenseAdd</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29206">CVE-2022-29206</a>)</li>
<li>Fixes a missing validation which results in undefined behavior in <code>QuantizedConv2D</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29201">CVE-2022-29201</a>)</li>
<li>Fixes an integer overflow in <code>SpaceToBatchND</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29203">CVE-2022-29203</a>)</li>
<li>Fixes a segfault and OOB write due to incomplete validation in <code>EditDistance</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29208">CVE-2022-29208</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>Conv3DBackpropFilterV2</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29204">CVE-2022-29204</a>)</li>
<li>Fixes a denial of service in <code>tf.ragged.constant</code> due to lack of validation (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29202">CVE-2022-29202</a>)</li>
<li>Fixes a segfault when <code>tf.histogram_fixed_width</code> is called with NaN values (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29211">CVE-2022-29211</a>)</li>
<li>Fixes a core dump when loading TFLite models with quantization (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29212">CVE-2022-29212</a>)</li>
<li>Fixes crashes stemming from incomplete validation in signal ops (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29213">CVE-2022-29213</a>)</li>
<li>Fixes a type confusion leading to <code>CHECK</code>-failure based denial of service (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29209">CVE-2022-29209</a>)</li>
<li>Fixes a heap buffer overflow due to incorrect hash function (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29210">CVE-2022-29210</a>)</li>
<li>Updates <code>curl</code> to <code>7.83.1</code> to handle (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-22576">CVE-2022-22576</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27774">CVE-2022-27774</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27775">CVE-2022-27775</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27776">CVE-2022-27776</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27778">CVE-2022-27778</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27779">CVE-2022-27779</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27780">CVE-2022-27780</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27781">CVE-2022-27781</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27782">CVE-2022-27782</a> and (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-30115">CVE-2022-30115</a></li>
<li>Updates <code>zlib</code> to <code>1.2.12</code> after <code>1.2.11</code> was pulled due to <a href="https://www.openwall.com/lists/oss-security/2022/03/28/1">security issue</a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/tensorflow/tensorflow/blob/master/RELEASE.md">tensorflow's changelog</a>.</em></p>
<blockquote>
<h1>Release 2.8.1</h1>
<p>This releases introduces several vulnerability fixes:</p>
<ul>
<li>Fixes a code injection in <code>saved_model_cli</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29216">CVE-2022-29216</a>)</li>
<li>Fixes a missing validation which causes <code>TensorSummaryV2</code> to crash (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29193">CVE-2022-29193</a>)</li>
<li>Fixes a missing validation which crashes <code>QuantizeAndDequantizeV4Grad</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29192">CVE-2022-29192</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>DeleteSessionTensor</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29194">CVE-2022-29194</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>GetSessionTensor</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29191">CVE-2022-29191</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>StagePeek</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29195">CVE-2022-29195</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>UnsortedSegmentJoin</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29197">CVE-2022-29197</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>LoadAndRemapMatrix</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29199">CVE-2022-29199</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>SparseTensorToCSRSparseMatrix</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29198">CVE-2022-29198</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>LSTMBlockCell</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29200">CVE-2022-29200</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>Conv3DBackpropFilterV2</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29196">CVE-2022-29196</a>)</li>
<li>Fixes a <code>CHECK</code> failure in depthwise ops via overflows (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-41197">CVE-2021-41197</a>)</li>
<li>Fixes issues arising from undefined behavior stemming from users supplying invalid resource handles (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29207">CVE-2022-29207</a>)</li>
<li>Fixes a segfault due to missing support for quantized types (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29205">CVE-2022-29205</a>)</li>
<li>Fixes a missing validation which results in undefined behavior in <code>SparseTensorDenseAdd</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29206">CVE-2022-29206</a>)</li>
<li>Fixes a missing validation which results in undefined behavior in <code>QuantizedConv2D</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29201">CVE-2022-29201</a>)</li>
<li>Fixes an integer overflow in <code>SpaceToBatchND</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29203">CVE-2022-29203</a>)</li>
<li>Fixes a segfault and OOB write due to incomplete validation in <code>EditDistance</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29208">CVE-2022-29208</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>Conv3DBackpropFilterV2</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29204">CVE-2022-29204</a>)</li>
<li>Fixes a denial of service in <code>tf.ragged.constant</code> due to lack of validation (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29202">CVE-2022-29202</a>)</li>
<li>Fixes a segfault when <code>tf.histogram_fixed_width</code> is called with NaN values (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29211">CVE-2022-29211</a>)</li>
<li>Fixes a core dump when loading TFLite models with quantization (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29212">CVE-2022-29212</a>)</li>
<li>Fixes crashes stemming from incomplete validation in signal ops (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29213">CVE-2022-29213</a>)</li>
<li>Fixes a type confusion leading to <code>CHECK</code>-failure based denial of service (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29209">CVE-2022-29209</a>)</li>
<li>Fixes a heap buffer overflow due to incorrect hash function (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29210">CVE-2022-29210</a>)</li>
<li>Updates <code>curl</code> to <code>7.83.1</code> to handle (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-22576">CVE-2022-22576</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27774">CVE-2022-27774</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27775">CVE-2022-27775</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27776">CVE-2022-27776</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27778">CVE-2022-27778</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27779">CVE-2022-27779</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27780">CVE-2022-27780</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27781">CVE-2022-27781</a>, (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-27782">CVE-2022-27782</a> and (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=VE-2022-30115">CVE-2022-30115</a></li>
<li>Updates <code>zlib</code> to <code>1.2.12</code> after <code>1.2.11</code> was pulled due to <a href="https://www.openwall.com/lists/oss-security/2022/03/28/1">security issue</a></li>
</ul>
<h1>Release 2.7.2</h1>
<p>This releases introduces several vulnerability fixes:</p>
<ul>
<li>Fixes a code injection in <code>saved_model_cli</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29216">CVE-2022-29216</a>)</li>
<li>Fixes a missing validation which causes <code>TensorSummaryV2</code> to crash (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29193">CVE-2022-29193</a>)</li>
<li>Fixes a missing validation which crashes <code>QuantizeAndDequantizeV4Grad</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29192">CVE-2022-29192</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>DeleteSessionTensor</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29194">CVE-2022-29194</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>GetSessionTensor</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29191">CVE-2022-29191</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>StagePeek</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29195">CVE-2022-29195</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>UnsortedSegmentJoin</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29197">CVE-2022-29197</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>LoadAndRemapMatrix</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29199">CVE-2022-29199</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>SparseTensorToCSRSparseMatrix</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29198">CVE-2022-29198</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>LSTMBlockCell</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29200">CVE-2022-29200</a>)</li>
<li>Fixes a missing validation which causes denial of service via <code>Conv3DBackpropFilterV2</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29196">CVE-2022-29196</a>)</li>
<li>Fixes a <code>CHECK</code> failure in depthwise ops via overflows (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-41197">CVE-2021-41197</a>)</li>
<li>Fixes issues arising from undefined behavior stemming from users supplying invalid resource handles (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29207">CVE-2022-29207</a>)</li>
<li>Fixes a segfault due to missing support for quantized types (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29205">CVE-2022-29205</a>)</li>
<li>Fixes a missing validation which results in undefined behavior in <code>SparseTensorDenseAdd</code> (<a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-29206">CVE-2022-29206</a>)</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/tensorflow/tensorflow/commit/0516d4d8bced506cae97dc3cb45dbd2fe4311f26"><code>0516d4d</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/tensorflow/tensorflow/issues/56035">#56035</a> from tensorflow-jenkins/relnotes-2.8.1-4205</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/25faa9f51698b743af7f66304efa2d412a15427a"><code>25faa9f</code></a> Update RELEASE.md</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/0d75d6ad32402c939ca29b73de47ea2b2b3a03d2"><code>0d75d6a</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/tensorflow/tensorflow/issues/56074">#56074</a> from tensorflow/fix-r2.8-build</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/b82dff5267ac2b6bac124d24929b2b4a891338a8"><code>b82dff5</code></a> Install dep as user</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/1e7468765d5aac6208b3df06dea8747aea2dd7d5"><code>1e74687</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/tensorflow/tensorflow/issues/56071">#56071</a> from tensorflow/fix-r2.8-build</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/86bbc7004f0631a194ae1ea48f8f6b69811cdb84"><code>86bbc70</code></a> Another attempt at fixing <a href="https://github-redirect.dependabot.com/pypa/setuptools/issues/3293">pypa/setuptools#3293</a></li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/fd5fbebf32a09030ea30f2324ed2276b104e3c9c"><code>fd5fbeb</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/tensorflow/tensorflow/issues/56068">#56068</a> from tensorflow/mm-cp-52488e5072f6fe44411d70c6af09e...</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/bdb80bc3de2f412cf27747f9e68d93f5a69283ce"><code>bdb80bc</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/tensorflow/tensorflow/issues/56060">#56060</a> from yongtang:curl-7.83.1</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/3f8784c87c7647b11683e8b7a21b355e03a570b4"><code>3f8784c</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/tensorflow/tensorflow/issues/56064">#56064</a> from tensorflow/mihaimaruseac-patch-1</li>
<li><a href="https://github.com/tensorflow/tensorflow/commit/0da453f218b4ed7c53fa2b5a0fcb5b272944fbb3"><code>0da453f</code></a> Fix pip install ordering</li>
<li>Additional commits viewable in <a href="https://github.com/tensorflow/tensorflow/compare/v2.8.0...v2.8.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
- `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language
- `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language
- `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language
- `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/huggingface/transformers/network/alerts).
</details> | 05-24-2022 17:31:36 | 05-24-2022 17:31:36 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,399 | open | [RFC] Scan & Gradient checkpointing in Flax | ### Feature request
We should add scan and remat (gradient checkpointing) to the most important Flax/JAX models (BERT, GPT2, OPT, T5, BART, Wav2Vec2).
### Motivation
Scan allows for much faster compilation and memory savings and `remat` is the equivalent of `gradient_checkpointing` in PyTorch.
@sanchit-gandhi already uses both features in the Flax Seq2Seq Speech project - see: https://github.com/sanchit-gandhi/seq2seq-speech so it'd be quite trivial to get them working.
**Implementation details:**
Given that both `scan` and `remat` are not related to the model architecture, they should IMO **not** be in the model's config (We've done this mistake in PyTorch and don't want to repeat it here).
I would advocate for the following API:
```python
model = FlaxBertForMaskedLM.from_pretrained("bert-base-cased")
model.scan() # or model.scan_enable()
model.unscan() # or model.scan_disable()
```
and
```python
model = FlaxBertForMaskedLM.from_pretrained("bert-base-cased")
model.gradient_checkpoint_enable()
model.gradient_checkpoint_disable()
```
As can be seen here: https://github.com/sanchit-gandhi/seq2seq-speech/blob/b28d0c25c8fad0f9ffa6707f91f7aba320d44a4b/models/modeling_flax_wav2vec2.py#L504
We'll need to re-initialize the `flax.linen.module` inside the model. However this should be fine since it just means that we do
```
self.module = self.module_class(config=config, dtype=dtype, use_scan=True, **kwargs)
self. _is_scan_enabled = True
```
similar to this line: https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py#L868
We can see along the PR how much logic can reside in `modeling_flax_utils.py` and how much would go into the specific models, *e.g.* `modeling_flax_wav2vec2.py`.
The same API / logic could be used for the `gradient_checkpointing`.
### Your contribution
Happy to give this implementation a shot with @sanchit-gandhi and @patil-suraj .
Also would love to hear feedback from @borisdayma @marcvanzee about the API | 05-24-2022 15:53:36 | 05-24-2022 15:53:36 | I'm not sure you would need both versions within a same script (scan and unscanned, or with and without checkpointing which affects only training anyway).
Then maybe you could just add it directly as an arg to `model.from_pretrained(..., scan=False, gradient_checkpointing=False)`
You would just have to use some naming conventions on your params to see if you need to scan/unscan when loading a checkpoint.<|||||>Suppose you have a training script, it would be useful to be able to use `scan` and `remat` during training for faster compile times and larger batch sizes, and then switch to `unscan` and no `remat` during eval for faster inference?<|||||>I'm not sure it would be worth it:
* Most of the time evaluation is relatively fast
* You would have to reformat your parameters each time between eval and train, potentially leading to memory fragmentation<|||||>Hey @patrickvonplaten, I'm keen to get gradient checkpointing working in JAX for [long-t5](https://huggingface.co/google/long-t5-tglobal-xl/tree/main). If this is not on the cards to be added soon happy to work on a PR for it if that works with you all?<|||||>Hey @KMFODA! There's a PR that is close to being merged: https://github.com/huggingface/transformers/pull/17843 I'll let you know once it's complete, and you can copy the logic across to Flax T5 in a new PR if that sounds good to you! |
transformers | 17,398 | closed | typo IBERT in __repr__ quant_mode |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #17397
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-24-2022 14:37:08 | 05-24-2022 14:37:08 | @LysandreJik @kssteven418 <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,397 | closed | typo IBERT in `__repr__` | should be `quant_mode: {self.quant_mode}` in here
https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/models/ibert/quant_modules.py#L150-L155 | 05-24-2022 14:34:12 | 05-24-2022 14:34:12 | |
transformers | 17,396 | closed | check min version | ### System Info
```shell
Hi, in transformers/examples/pytorch/text-classification/run_glue.py in line 50, there is a line of code :
'''
check_min_version("4.20.0.dev0")
'''
and there is no 4.20.0 version so I think it should be corrected.
```
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
python transformers/examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--train_file ./train.csv \
--validation_file ./test.csv \
--do_train \
--do_eval \
--evaluation_strategy epoch \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 5e-5 \
--max_seq_length 128 \
--num_train_epochs 2 \
--seed 2021\
--output_dir /yazdani/tmp/imdb/
### Expected behavior
```shell
change this part to
'''
check_min_version("4.18.0.dev0")
'''
```
| 05-24-2022 14:01:10 | 05-24-2022 14:01:10 | Hello! The `4.20.dev0` version means that it's the current `main` branch. The recommended way to run these examples is to clone the repository.
See the following note: https://github.com/huggingface/transformers/tree/main/examples#important-note<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,395 | closed | Fix expected value for OPT test `test_inference_no_head` | # What does this PR do?
- Update the expected value in the test `OPTModelIntegrationTests.test_inference_no_head` to have more precisions
- Lower atol to `5e-5`
On GPU VM, the test has to be run with TF32 disabled (or without TF32 support).
See: https://pytorch.org/docs/stable/notes/cuda.html
Related discussion: #16588 | 05-24-2022 13:39:40 | 05-24-2022 13:39:40 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,394 | closed | Inconsistency multiple mask in fill-mask | ### System Info
```shell
- `transformers` version: 4.14.1
- Platform: Darwin-21.5.0-x86_64-i386-64bit
- Python version: 3.6.13
- PyTorch version (GPU?): 1.10.2 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
```
### Who can help?
@Narsil
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
pipe = pipeline("fill-mask", top_k=1)
pipe("It is <mask>.")
=> [{..., 'sequence': 'It is true.'}]
pipe("It is <mask> <mask>.")
=> [[{..., 'sequence': '<s>It is very<mask>.</s>'}], [{..., 'sequence': '<s>It is<mask>orable.</s>'}]]
```
### Expected behavior
I would expect that the "sequence" does not include `<s>` and `</s>` tokens. It also seems to remove whitespace before the `<mask>` tokens left in the result, but I believe that does not make a difference for the tokenizer.
What I would expect:
```shell
pipe = pipeline("fill-mask", top_k=1)
pipe("It is <mask>.")
=> [{..., 'sequence': 'It is true.'}]
pipe("It is <mask><mask>.")
=> [[{..., 'sequence': 'It is very <mask>.'}], [{..., 'sequence': 'It is <mask>orable.'}]]
```
| 05-24-2022 13:12:20 | 05-24-2022 13:12:20 | nvm it seems deliberate https://github.com/huggingface/transformers/blob/374a2f693f75305eded1a2bb7a7e452f0ab33fad/src/transformers/pipelines/fill_mask.py#L137-L140 |
transformers | 17,393 | closed | Fx support for multiple model architectures | # What does this PR do?
This PR adds support torch.fx tracing for the following model architectures:
- BART
- mBART
- Marian
- M2M100
- Blenderbot
- Blenderbot Small
- Pegasus
- PLBart
- XGLM
- Speech2Text
- Speech2Text2
- OPT
- CLIP
- TrOCR | 05-24-2022 12:28:03 | 05-24-2022 12:28:03 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@michaelbenayoun
```
import inspect
import transformers.utils.fx as fx
from transformers import *
model = LayoutLMForMaskedLM(LayoutLMConfig())
input_names = model.dummy_inputs.keys()
sig = inspect.signature(model.forward)
concrete_args = {p.name: p.default for p in sig.parameters.values() if p.name not in input_names}
hf_tracer = fx.HFTracer()
hf_tracer.trace(model, concrete_args=concrete_args)
```
```
Traceback (most recent call last):
File "/Users/pbelevich/PycharmProjects/PiPPy/test/hf_test3.py", line 14, in <module>
hf_tracer.trace(model, concrete_args=concrete_args)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/utils/fx.py", line 877, in trace
self.graph = super().trace(root, concrete_args=concrete_args)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 587, in trace
self.create_node('output', 'output', (self.create_arg(fn(*args)),), {},
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/models/layoutlm/modeling_layoutlm.py", line 935, in forward
outputs = self.layoutlm(
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 577, in module_call_wrapper
return self.call_module(mod, forward, args, kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/utils/fx.py", line 834, in call_module
return super().call_module(m, forward, args, kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 372, in call_module
return forward(*args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 573, in forward
return _orig_module_call(mod, *args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/models/layoutlm/modeling_layoutlm.py", line 803, in forward
bbox = torch.zeros(tuple(list(input_shape) + [4]), dtype=torch.long, device=device)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/proxy.py", line 260, in __iter__
return self.tracer.iter(self)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/proxy.py", line 169, in iter
raise TraceError('Proxy object cannot be iterated. This can be '
torch.fx.proxy.TraceError: Proxy object cannot be iterated. This can be attempted when the Proxy is used in a loop or as a *args or **kwargs function argument. See the torch.fx docs on pytorch.org for a more detailed explanation of what types of control flow can be traced, and check out the Proxy docstring for help troubleshooting Proxy iteration errors
Process finished with exit code 1
```<|||||>@michaelbenayoun
```
import inspect
import transformers.utils.fx as fx
from transformers import *
model = Speech2TextForConditionalGeneration(Speech2TextConfig())
input_names = model.dummy_inputs.keys()
sig = inspect.signature(model.forward)
concrete_args = {p.name: p.default for p in sig.parameters.values() if p.name not in input_names}
hf_tracer = fx.HFTracer()
hf_tracer.trace(model, concrete_args=concrete_args)
```
```
Traceback (most recent call last):
File "/Users/pbelevich/PycharmProjects/PiPPy/test/hf_test4.py", line 14, in <module>
hf_tracer.trace(model, concrete_args=concrete_args)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/utils/fx.py", line 877, in trace
self.graph = super().trace(root, concrete_args=concrete_args)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 587, in trace
self.create_node('output', 'output', (self.create_arg(fn(*args)),), {},
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/models/speech_to_text/modeling_speech_to_text.py", line 1349, in forward
outputs = self.model(
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 577, in module_call_wrapper
return self.call_module(mod, forward, args, kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/utils/fx.py", line 834, in call_module
return super().call_module(m, forward, args, kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 372, in call_module
return forward(*args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 573, in forward
return _orig_module_call(mod, *args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/models/speech_to_text/modeling_speech_to_text.py", line 1193, in forward
encoder_outputs = self.encoder(
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 577, in module_call_wrapper
return self.call_module(mod, forward, args, kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/utils/fx.py", line 834, in call_module
return super().call_module(m, forward, args, kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 372, in call_module
return forward(*args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 573, in forward
return _orig_module_call(mod, *args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/models/speech_to_text/modeling_speech_to_text.py", line 770, in forward
inputs_embeds = self.conv(input_features)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 577, in module_call_wrapper
return self.call_module(mod, forward, args, kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/utils/fx.py", line 834, in call_module
return super().call_module(m, forward, args, kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 372, in call_module
return forward(*args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 573, in forward
return _orig_module_call(mod, *args, **kwargs)
File "/Users/pbelevich/miniconda3/envs/PiPPy/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/Users/pbelevich/PycharmProjects/pbelevich-transformers/src/transformers/models/speech_to_text/modeling_speech_to_text.py", line 124, in forward
hidden_states = input_features.transpose(1, 2).contiguous() # -> B x (C x D) x T
AttributeError: 'NoneType' object has no attribute 'transpose'
Process finished with exit code 1
```<|||||>@pbelevich Thanks for raising those issues!
- About LayoutLM, I just pushed a fix that should solve the issue.
- About Speech2Text, I don't think that this is an issue, it's just that the dummy inputs for this model are wrong... it creates `input_ids` but it should create something else since this model does not have `input_ids` as inputs... I added a check in the `symbolic_trace` function (and not `HFTracer.trace`), that will test if the `input_names` passed are correct for the model we want to trace. |
transformers | 17,392 | closed | [Deepspeed alternative] PatrickStar | ### Feature request
https://github.com/Tencent/PatrickStar
Adding PatrickStar as alternative to deepspeed
### Motivation
I think it could be interesting to benchmark with deepspeed.
In their Readme they are writing it's faster then deepspeed zero 3.
But they are also writing, gradient accumulation is not possible with the library.
pinging @stas00 for interest ?
### Your contribution
I could give it a try integrating it into the trainer | 05-24-2022 12:06:13 | 05-24-2022 12:06:13 | @flozi00,
Thank you for the heads up about this framework.
I read the overview https://github.com/Tencent/PatrickStar/blob/master/INSIDE.md and it looks like they are trying to solve problems that have been solved in Deepspeed many moons ago - perhaps they started working on this project long time ago and are referring to a really old deepspeed version? e.g. param offload has been implemented long time ago there. And of course CPU offload implements prefetching, which happens in parallel with compute.
I will try to find time to read their paper: https://arxiv.org/abs/2108.05818 to understand what innovation it has proposed with the chunked memory management.
Before doing an integration probably the first good step would be to try to reproduce their benchmarks and the current deepspeed side by side to compare the performance and see if it's indeed offering an improvement.<|||||>To update - after you shared this a few weeks ago I've requested with the deepspeed devs to look into PatrickStar and see if they could Match the performance - that way we don't need to add a complicated support for another framework. Let's see what unfolds. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>@flozi00 @stas00 Thanks for your attention on PatrickStar.
I would like to clarify that the comparison results of PatrickStar and DeepSpeed is repeatly verified by many users.
The results in the paper are still valid in May 2022 with the latest version DeepSpeed at that time.
Also, the PatrickStar idea has already been integrated into ColossalAI and played a key role.
I strongly believe that PatrickStar's design, or part of it, will inherently accelerate the training of large models. I'm open to any help with using Patrickstar, either integrated into DeepSpeed or huggingface transformers.<|||||>Thank you for your commentary and willingness to contribute, @feifeibear
> I strongly believe that PatrickStar's design, or part of it, will inherently accelerate the training of large models. I'm open to any help with using Patrickstar, either integrated into DeepSpeed or huggingface transformers.
I think it'd be amazing to have it integrated into Deepspeed. I'm tagging @tjruwase (Deepspeed) on this suggestion. Perhaps let's start a new DS-specific thread at https://github.com/microsoft/DeepSpeed/issues?
> Also, the PatrickStar idea has already been integrated into ColossalAI and played a key role.
Indeed, we are discussing the CAI integration here: https://github.com/huggingface/transformers/issues/18624
<|||||>Thanks! I will keep an eye on the CAI issue! And feel free to contact me if I can help! |
transformers | 17,391 | closed | AutoTokenizer _batch_encode_plus method don't have add_prefix_space argument | ### System Info
```shell
- `transformers` version: 4.20.0.dev0
- Platform: macOS-12.3.1-arm64-arm-64bit
- Python version: 3.8.12
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.11.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
```
### Who can help?
@SaulLu @LysandreJik
Hi, im just noticed that `AutoTokenizer._batch_encode_plus` method don't have `add_prefix_space` argument if I init it as `roberta-base` model.
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
tokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base')
input_ids = tokenizer('test string', add_prefix_space=True).data["input_ids"]
# Output: TypeError: _batch_encode_plus() got an unexpected keyword argument 'add_prefix_space'
```
### Expected behavior
```shell
tokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base')
input_ids = tokenizer('test string', add_prefix_space=True).data["input_ids"]
# Output: >>> input_ids [0, 1296, 6755, 2]
```
| 05-24-2022 11:19:44 | 05-24-2022 11:19:44 | Hi @c00k1ez ,
I think I can guess a little confusion, this argument must be specified during the initialization of the tokenizer or redefined when using `from_pretrained` but it won't work in the `__call__` method.
If any documentation has misled you, I would be very grateful if you would share it with us! :pray: (and even better that you propose an improvement in PR :smile: )
Here is the snippet which will give what you expect:
```python
tokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base', add_prefix_space=True)
input_ids = tokenizer('test string').data["input_ids"]
```<|||||>Thank you for your answer, it becomes much clearer!
I think it seems great to add smth like
```python
>>> # Download vocabulary from huggingface.co and define model-specific arguments
>>> tokenizer = AutoTokenizer.from_pretrained("roberta-base", add_prefix_space=True)
```
to
https://github.com/huggingface/transformers/blob/71e602725b90f63f404109bae9f72cbdf755477b/src/transformers/models/auto/tokenization_auto.py#L476
What do u think?<|||||>It makes sense to me! Do you want to open a PR with this proposal?<|||||>Yeah, no problem<|||||>> Hi @c00k1ez ,
>
> I think I can guess a little confusion, this argument must be specified during the initialization of the tokenizer or redefined when using `from_pretrained` but it won't work in the `__call__` method.
>
> If any documentation has misled you, I would be very grateful if you would share it with us! 🙏 (and even better that you propose an improvement in PR 😄 )
>
> Here is the snippet which will give what you expect:
>
> ```python
> tokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base', add_prefix_space=True)
> input_ids = tokenizer('test string').data["input_ids"]
> ```
Hi @SaulLu, some documentation which I found misleading in relation to this: https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.bad_words_ids(List[List[int]],
Huggingface Docs > Transformers > Text Generation > GenerationConfig > Params > bad_words_ids
"**bad_words_ids**(List[List[int]], optional) — List of token ids that are not allowed to be generated. In order to get the token ids of the words that should not appear in the generated text, use tokenizer(bad_words, add_prefix_space=True, add_special_tokens=False).input_ids."
Here, it seems like the docs are telling us to use add_prefix_space=True in the `__call__` method.<|||||>Thanks for your feedback! Let me ping @ArthurZucker who is now the person supervising the tokenizers in transformers. |
transformers | 17,390 | closed | Allow creation of tokenizer from a vocab dictionary | ### Feature request
Tokenizers that need a vocab.json file are expected to be created in this manner:
`transformers.Wav2Vec2CTCTokenizer(vocab_file="path/to/vocab.json")`
With the file read with a `json.load` statement.
I'm suggesting an optional `vocab` parameter that could be passed instead.
```
vocab= {"a":0, "b":1,......}
tokenizer = transformers.Wav2Vec2CTCTokenizer(vocab=vocab)
# Would also be possible
transformers.Wav2Vec2CTCTokenizer(vocab_file="path/to/vocab.json")
````
### Motivation
Remove the necesity to clutter the disk with a vocab file and allow a dynamic vocab creation process
### Your contribution
I could implement this if it seems like a good addition | 05-24-2022 08:40:21 | 05-24-2022 08:40:21 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,389 | closed | OPT-350M Throws Error On Load after Finetuning | ### System Info
```shell
- `transformers` version: 4.19.0
- Platform: macOS-12.3.1-arm64-i386-64bit
- Python version: 3.8.13
- Huggingface_hub version: 0.2.1
- PyTorch version (GPU?): 1.10.2 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
## 🐛 Bug
When the OPT-350M variant is fine-tuned via huggingface, the resulting model will give the following error when loaded
```
model = OPTForCausalLM.from_pretrained(model path)
RuntimeError: Error(s) in loading state_dict for OPTForCausalLM:
size mismatch for lm_head.weight: copying a param with shape torch.Size([50272, 512]) from checkpoint, the shape in current model is torch.Size([50272, 1024]).
```
##Code to load model
```
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed, OPTForCausalLM
import torch
def generate_text(model, tokenizer, prompt):
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, do_sample=True, num_return_sequences=5, max_length=10)
texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
return texts
path = "facebook/opt-350m"
path = "opt/model_ckpts"
model = OPTForCausalLM.from_pretrained(path)
tokenizer = AutoTokenizer.from_pretrained(path, use_fast=False)
prompt = "The woman worked as a"
print(generate_text(model, tokenizer, prompt))
```
##Training Code
```
import torch as th
from dataset import get_examples, GSMDataset
from transformers import GPT2Tokenizer, GPT2LMHeadModel
from transformers import GPT2Config, AdamW
from transformers import get_scheduler
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer, OPTModel, OPTConfig, OPTForCausalLM
import torch
model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m", use_fast=False)
try:
model = OPTForCausalLM.from_pretrained("model_ckpts")
print("model loaded")
except Exception as e:
print(e)
train_examples = get_examples("train")
train_dset = GSMDataset(tokenizer, train_examples)
device = th.device("cuda")
model.to(device)
model.train()
train_loader = DataLoader(train_dset, batch_size=4, shuffle=True)
optim = AdamW(model.parameters(), lr=1e-5)
num_epochs = 10
num_training_steps = num_epochs * len(train_loader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optim,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
pbar = tqdm(range(num_training_steps))
for epoch in range(num_epochs):
for batch in train_loader:
optim.zero_grad()
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch, labels=batch["input_ids"])
loss = outputs[0]
loss.backward()
optim.step()
lr_scheduler.step()
pbar.update(1)
pbar.set_description(f"train_loss: {loss.item():.5f}")
model.save_pretrained("model_ckpts/")
```
##Dataset module
```import json
import os
import re
import torch as th
def read_jsonl(path: str):
with open(path) as fh:
return [json.loads(line) for line in fh.readlines() if line]
def get_examples(split):
path = os.path.join("data/", f"{split}.jsonl")
examples = read_jsonl(path)
#examples = examples[0:100]
for ex in examples:
ex.update(question=ex["question"] + "\n")
ex.update(answer=ex["answer"] + "<|endoftext|>")
print(f"{len(examples)} {split} examples")
return examples
ANS_RE = re.compile(r"#### (\-?[0-9\.\,]+)")
INVALID_ANS = "[invalid]"
def extract_answer(completion):
match = ANS_RE.search(completion)
if match:
match_str = match.group(1).strip()
match_str = match_str.replace(",", "")
return match_str
else:
return INVALID_ANS
def is_correct(model_completion, gt_example):
gt_answer = extract_answer(gt_example["answer"])
assert gt_answer != INVALID_ANS
return extract_answer(model_completion) == gt_answer
class GSMDataset(th.utils.data.Dataset):
def __init__(self, tokenizer, examples, loss_on_prefix=True):
self.examples = examples
self.qns = [ex["question"] for ex in self.examples]
self.ans = [ex["answer"] for ex in self.examples]
self.qns = tokenizer(self.qns, padding=False)
self.ans = tokenizer(self.ans, padding=False)
self.loss_on_prefix = loss_on_prefix
self.max_len = max(
[
len(self.qns["input_ids"][i]) + len(self.ans["input_ids"][i])
for i in range(len(self.examples))
]
)
print(f"Max tokens: {self.max_len}")
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
qn_tokens = self.qns["input_ids"][idx]
ans_tokens = self.ans["input_ids"][idx]
pad_tokens = [0] * (self.max_len - len(qn_tokens) - len(ans_tokens))
tokens = qn_tokens + ans_tokens + pad_tokens
mask = (
([int(self.loss_on_prefix)] * len(qn_tokens))
+ ([1] * len(ans_tokens))
+ ([0] * len(pad_tokens))
)
tokens = th.tensor(tokens)
mask = th.tensor(mask)
return dict(input_ids=tokens, attention_mask=mask)```
### Expected behavior
```shell
Expected model to load
```
| 05-24-2022 07:52:21 | 05-24-2022 07:52:21 | facing same error, unable to load after finetuning. Any update ?<|||||>Ping @patrickvonplaten , but also cc @younesbelkada and @ArthurZucker .<|||||>On it 👍<|||||>@Leli1024 @omerarshad If you don't mind and have some time, maybe you can try with the latest dev build?
If you clone the repo, you can do it like `pip install --upgrade -e .[dev]`.
(There are some minor fixes since then, I didn't check if they are related)<|||||>Not sure if it is related but It is possible that you have used a version of transformers before merging this PR #17225 <|||||>> @Leli1024 @omerarshad If you don't mind and have some time, maybe you can try with the latest dev build?
>
> If you clone the repo, you can do it like `pip install --upgrade -e .[dev]`. (There are some minor fixes since then, I didn't check if they are related)
This totally worked thank you!!!
Also not to be pedantic but I needed to remove '[dev]' from the command to run it. Just thought I should let anyone else having trouble with it know<|||||>> > @Leli1024 @omerarshad If you don't mind and have some time, maybe you can try with the latest dev build?
> > If you clone the repo, you can do it like `pip install --upgrade -e .[dev]`. (There are some minor fixes since then, I didn't check if they are related)
>
> This totally worked thank you!!!
Great!<|||||>So building from source worked? or is the patch released?<|||||>> So building from source worked? or is the patch released?
Building from source<|||||>I'm experiencing this issue when I try to use the Inference API to test a `facebook/opt-350m` model fine tuned using transformers 4.19.3, 4.19.4, or 4.20.0, and even when I install directly from git like this:
```sh
python -m pip install git+https://github.com/huggingface/transformers
```
The error I'm seeing is identical to above:
> Error(s) in loading state_dict for OPTForCausalLM: size mismatch for lm_head.weight: copying a param with shape torch.Size([50272, 512]) from checkpoint, the shape in current model is torch.Size([50272, 1024]).
If I download the model to my machine and run it using a pipeline, then it works - it just seems to be an issue for the Inference API.
Here are the package versions I'm using:
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1<|||||>Hey, could you provide an example script to help us reproduce the error? <|||||>This seems to be able to reproduce it for me:
```python
import pathlib
from datasets import DatasetDict
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
default_data_collator,
Trainer,
TrainingArguments,
)
HUGGINGFACE_API_KEY = "..."
if __name__ == "__main__":
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
training_args = TrainingArguments(
output_dir="/tmp/model",
overwrite_output_dir=True,
num_train_epochs=1,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
push_to_hub=True,
hub_strategy="end",
hub_model_id="17389",
hub_token=HUGGINGFACE_API_KEY,
)
path = pathlib.Path("/tmp/data/dataset.txt")
path.parent.mkdir(exist_ok=True)
with path.open("w") as fp:
for _ in range(10):
fp.write("Hello, world\n")
def encode(batch):
encodings = tokenizer(batch["text"], padding="max_length", truncation=True)
encodings["labels"] = encodings["input_ids"].copy()
return encodings
dataset = DatasetDict.from_text(
{"train": path.as_posix(), "validation": path.as_posix()}
).map(
encode,
remove_columns="text",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
data_collator=default_data_collator,
)
trainer.train()
trainer.save_model()
```
Just ran this on my machine and the resulting model is here: https://huggingface.co/dhorgan/17389<|||||>Hi @ArthurZucker, have you had any luck with this? I tried running the example code above again today with v4.20.1 after #17785 was merged, but nothing seems to have changed. The new model is here, if you're interested: https://huggingface.co/dhorgan/17389-test-fix<|||||>Hey! Yeah I know where the bug is from! The inference API is not up to date with the main branch of transformers! @Narsil is the one handling that but he is in holiday! Gotta wait for a bit 😀
<|||||>Hi @donaghhorgan ,
You are not including the `tokenizer` in your `Trainer` so it is **not** saved in your model: https://huggingface.co/dhorgan/17389-test-fix/tree/main
You can fix this by simply doing `tokenizer.save_pretrained('....')` and uploading it or doing `Trainer(tokenizer=tokenizer)` (I think, I don't use `Trainer` that often personnally but I have seen that being suggested and working).
Anyhow, you can check the failure by doing.
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dhorgan/17389-test-fix")
```
It should crash (becuase no tokenizer files are there)<|||||>That's great, thanks @Narsil! It's all working for me here now. |
transformers | 17,388 | closed | Opt in flax and tf | # What does this PR do?
Adds support for OPT in both Flax and TF
## Who can review?
@patrickvonplaten, @LysandreJik @younesbelkada @patil-suraj @sgugger
| 05-24-2022 07:47:26 | 05-24-2022 07:47:26 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Should we close the other PR? Let me know once it's ready for a review :-)<|||||>Superseeds https://github.com/huggingface/transformers/pull/17227 and https://github.com/huggingface/transformers/pull/17226<|||||>Cool, very nice job @ArthurZucker !
Could you as a final safety guard also add TFOPT and FlaxOPT to the documentation test suite?
See: https://github.com/huggingface/transformers/tree/main/docs#docstring-testing<|||||>Can I merge @LysandreJik @sgugger ? (failing test are not related to OPT) <|||||>@patil-suraj could you quickly check Flax and maybe @gante go over TF OPT?<|||||>Thanks all for the reviews 😄 🥳 |
transformers | 17,387 | open | Add Google's Trillson Audio Classification Model | # What does this PR do?
Add Google's Trillson Audio Classification Model #17339
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten
| 05-24-2022 03:15:57 | 05-24-2022 03:15:57 | Still WIP (maybe we can link the google colab here if you want @vumichien :-) )<|||||>Thanks @patrickvonplaten, This is the current link of colab notebook I am working on https://colab.research.google.com/drive/1lFGDVNgtXXyuvM4J-pBmsPj43LW9VlpQ#scrollTo=t-icrfOL60dT to load all TF weights of trillsson3 into Efficientnetv2bS PyTorch model
Current process:
- Check the output of each layer between the original TF and PT model
<|||||>Hey @vumichien,
Sorry to have dropped the ball here. I will be off for the two weeks ahead, but will take a look at the PR once I'm back!<|||||>Hi @patrickvonplaten,
I am swamped finishing my job this month before the summer holiday.
I just want to update the current process, I have successfully loaded the TF trillson weight to PyTorch model (you can check in the notebook here https://colab.research.google.com/drive/1lFGDVNgtXXyuvM4J-pBmsPj43LW9VlpQ#scrollTo=M4k3zhZcypUH)
In the next step, I think I will write the script in the correct format of the Transformers library. However if possible, could you describe in detail or give necessary notes for the next step?<|||||>Very cool @vumichien !
I'd suggest to copy-paste the PyTorch model and preprocessing as defined in your colab to `modeling_trillson_efficient.py` in Transformers and in a first step add a couple slow integration tests to make sure that when refactoring your code the outputs stay correct.
More specifically, it'd be very useful to add a couple of those tests: https://github.com/huggingface/transformers/blob/e54a1b49aa6268c484625c6374f952f318914743/tests/models/bert/test_modeling_bert.py#L585 (maybe 2 or 3 given that the model is relatively complex)
Once this works we have a safety mechanism that we can always fall back to that ensures the model works correctly.
Then the refactor starts.
- 1) Move the pre-processing out into a new file `feature_extraction_trillson_efficient.py` and make the model code pretty.
Making the code pretty means that it should adhere to Transformers style (e.g. the model should inherit from a `PretrainedModel` class, the naming should be similar to, e.g. BERT.) You can find more information about this here: https://huggingface.co/docs/transformers/add_new_model#stepbystep-recipe-to-add-a-model-to-transformers
- 2) Then the next step is to improve the weight names and to write a conversion script that automatically converts the old checkpoint names to the new PyTorch ones (Point 6. here: https://huggingface.co/docs/transformers/add_new_model#stepbystep-recipe-to-add-a-model-to-transformers)
- 3) Once that works it's again a bit more refactoring and then we're good to go #18511
- 4) If you want I can also allocate you with a GPU to run some fine-tuning experiments
Overall, really amazing work & really sorry that I was so unavailable to help you. But now that the most difficult part is solved I think the rest is easy :-)
Generally, I'd suggest to just adapt this PR to include the newest version of your model + tests and then I'm more than happy to also directly comment in the PR
<|||||>Hi @patrickvonplaten, I just upload the new version of Trillsson model, would you mind checking on it?<|||||>> Hi @patrickvonplaten, I just upload the new version of Trillsson model, would you mind checking on it?
Very cool! Does it work just like the original model? In this case should we try fine-tuning it on emotion recognition? <|||||>I have checked the embedding outputs, they are the same as the TF model in the original repo. I think we could try fine-tuning with emotion recognition by adding one dense classifier layer on top of embedding outputs. Do you have any suggestions which dataset we could use for fine-tuning?
Can I leverage the Trainer for the fine-tuning? I don't know whether the current version code of Trillsson_efficient is good enough to use with Trainer.<|||||>Hey @vumichien,
That's a very nice idea! Could we try to set up this fine-tuning example for key word spotting with trillson?
https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification#single-gpu
I think you only need to add one head layer for it.
Let me know if you need access to a GPU (think google colab pro should be enough though) or help with how to start training! Think you can just follow the example :-) <|||||>I have started fine-tuning the classifier Trillsson model, it works on the CPU. However, when I tried to fine-tune on GPU, it threw the error `RuntimeError: CUDA error: unspecified launch failure`. I have checked the whole process, I think it's because of the data loader but it's hard to debug. Do you have any experience in dealing with this error? This is the script I used to fine-tune https://github.com/vumichien/transformers/blob/add_trillson_effecient/src/transformers/models/trillsson_efficient/run_audio_classification.py<|||||>Hmm usually datasets should not be related in any way to the GPU. Are you fine-tuning on Google Colab? We could try to debug together on Google colab :-) <|||||>@patrickvonplaten
I made the notebook in Colab for fine-tuning Trillsson models here https://colab.research.google.com/drive/1q51cxmpa_MtCd6LG6Jj4rLrvFIyj9uDq#scrollTo=8qcyuhPkShQd. It would be great if you have time to check it.<|||||>Hey @vumichien,
The notebook looks very nice! Does it work? Can you train it in a google colab? Otherwise happy to give you access to a GPU for a week if you'd like :-) <|||||>Sorry, It still doesn't work on GPU. When I try to fine-tune the model on GPU it throws the error `RuntimeError: CUDA error: unspecified launch failure`. It works on CPU and shows the warning `E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NOT_INITIALIZED: initialization error` but I didn't figure out where it came from yet.<|||||>This is the result after training 5 epochs on CPU, the eval loss reduces but eval accuracy doesn't change as much. I think we should do more experiments with different hyperparameters like learning_rate and batch_size https://huggingface.co/vumichien/trillsson3-ft-keyword-spotting<|||||>Hi @patrickvonplaten
I think I can solve the problem of training with GPU. The problem is with the dataloader multiprocess (the error is CUDA cannot be initialized), CUDA is initialized beforehand so the dataloader cannot reinitialize CUDA in multiprocess (I think because the TensorFlow code part did it) so I have to set the dataloader_num_workers to 0 to solve this problem.
The result is this (https://huggingface.co/vumichien/trillsson3-ft-keyword-spotting-6/tensorboard). The eval accuracy is low (0.62) and unchanged after training with 20 epochs. I think training with Colab is good enough and I will try with other learning rates and max_length_seconds.
Do you have any suggestions? <|||||>Very cool that training now works! Hmm, not 100% sure what could help the training here - the training curves looks very smooth. Gently nudging/pinging the author here (cc @joel-shor) - any ideas what could help the training? Do the training curves look reasonable?<|||||>I have found and fixed the bug when transposing the shape of the input audio array after preprocessing. Now the results look very good, we could achieve around 91% accuracy after 5 epochs. I have done several training experiments, and the results are here https://wandb.ai/chienvu/trillsson-finetune-emotion. <|||||>Hey @vumichien,
Great job - that's very cool! I think we can now just make the tests green and merge the model then :-)
Also cc @ArthurZucker @sanchit-gandhi could you maybe help @vumichien with the final steps to merge this PR?
If possible it would be great if we could add an example code to https://github.com/huggingface/transformers/blob/main/examples/pytorch/audio-classification/README.md that showcases how to train the trillson audio classification model for emotion recognition! >90% is def better than any model we have so far so we should feature this prominently :-) <|||||>Hey @sanchit-gandhi @ArthurZucker. Thank you very much for helping me.
However, when I try to use the feature extractor code from Whisper, the results are not the same.
The first one is mel_filter from [Whisper](https://github.com/huggingface/transformers/blob/0d4c45c585fadd0d9339061feda0f22fce04c57d/src/transformers/models/whisper/feature_extraction_whisper.py#L86)
and [Trillsson](https://github.com/vumichien/transformers/blob/caa21806add107b6e8acab737a8d35ce74a6e0cf/src/transformers/models/trillsson_efficient/feature_extraction_trillsson_efficient.py#L166-L172) are not the same. I have tried with sr=16000, n_mels=80, max_mel=7500.0, and min_mel=125.0. I think I should implement the original code from Tensorflow in Numpy (pls correct me if my assumption is wrong)
https://github.com/tensorflow/tensorflow/blob/359c3cdfc5fabac82b3c70b3b6de2b0a8c16874f/tensorflow/python/ops/signal/mel_ops.py#L89-L215
The second one is the STFT features from [Whisper](https://github.com/huggingface/transformers/blob/0d4c45c585fadd0d9339061feda0f22fce04c57d/src/transformers/models/whisper/feature_extraction_whisper.py#L207) and from [Trillsson](https://github.com/vumichien/transformers/blob/caa21806add107b6e8acab737a8d35ce74a6e0cf/src/transformers/models/trillsson_efficient/feature_extraction_trillsson_efficient.py#L157) are also not the same. I have tried with n_fft = 512, sampling_rate = 16000, n_mels=80, and window_length = 400, hop_length =160, the shape output from Whisper is (400, 257) compared to TF is (398, 257).
<|||||>Hey @vumichien! If the implementations of the Mel-filter and STFT are _inherently_ different between the NumPy Whisper code and the Tensorflow Trillsson code, then you are entirely correct in that we should re-implement it. Have you managed to determine _where_ in the code the two implementations deviate? Perhaps if you pin it down we could assert whether it's a configuration issue, or inherent implementation difference. If it's the former, we won't have to re-implement. If it's the latter, we will!
Maybe one other thing you could try is using the PyTorch implementation of the log-Mel feature extractor from Speech2Text: https://github.com/huggingface/transformers/blob/c3a93d8d821bc1df3601ba858e7385eada8db3a5/src/transformers/models/speech_to_text/feature_extraction_speech_to_text.py#L80
If we've got a PyTorch model, having a PyTorch dependency in the feature extractor is ok IMO. However, we'll have to re-implement it in NumPy though should someone wish to add the TF/JAX port of Trillsson later down the line.<|||||>BTW since I took care of the Mel and STFT with whisper, I will try having a look 🤗<|||||>Maybe @ArthurZucker you could share the reasoning behind why you opted for a **NumPy** feature extractor for Whisper rather than a **PyTorch** one as we have in Speech2Text? We can then decide whether we need a NumPy / PyTorch one for Trillsson. IMO a NumPy one is more "future proof" should we wish to add TF / JAX implementations of Trillsson, and consequently this would be my preference.<|||||>Hey @ArthurZucker! If you get the chance it would be awesome to hear your thoughts with regards to a PyTorch feature extractor (see above 👆)<|||||>Hey! Sorry for the late reply!
It's mostly to remove the dependency on `PyTorch` as we were sure that the `tf` model would be implemented.
I guess that it's not that hard of a constraint. I'll have a look ! Sorry for the long wait 🙇<|||||>Great! So I guess it boils down to the question of whether we anticipate this model will be added in TF or Flax? I probably stand-by my previously stated preference from NumPy in this regard - given the performance of this model for audio classification, I don't see any reason why this model won't be added in either of the other frameworks in due course!<|||||>Hey @vumichien,
I'm going back on my previous comment! My advice would be to try using the PyTorch feature extractor from speech-to-text:
https://github.com/huggingface/transformers/blob/cbbeca3d1733aa7c9b443af5ff231a5affcd8a1e/src/transformers/models/speech_to_text/feature_extraction_speech_to_text.py#L33
If this PyTorch feature extractor matches the current TF one, we can just use a PyTorch feature extractor for purpose of this PR. If in due course we add the TF or Flax model, we can switch it out for a NumPy one. This should be much faster for you than implementing in NumPy from scratch.
If, however, the PyTorch feature extractor does not match the current TF one, we can implement the feature extractor in NumPy from the get-go with the help of @ArthurZucker!
You can check quickly if the implementations match just by importing the Speech2TextFeatureExtractor:
```python
from transformers import Speech2TextFeatureExtractor
feature_extractor = Speech2TextFeatureExtractor.from_pretrained("facebook/s2t-small-librispeech-asr")
inputs = ...
input_features = feature_extractor(inputs).input_features[0]
```
then check `input_features` against your current TF implementation<|||||>Hi @sanchit-gandhi, thank you for your advice.
I will test PyTorch feature extractor from speech-to-text<|||||>Hey @sanchit-gandhi @ArthurZucker
I have tested the Speech2TextFeatureExtractor and the output is not the same as the Trillsson TF feature extractor (it's much closer to WhisperFeatureExtractor but we need to modify it a bit)
In order to implement the Trillsson TF feature extractor in NumPy, we need to implement two functions: [tf.signal.linear_to_mel_weight_matrix](https://www.tensorflow.org/api_docs/python/tf/signal/linear_to_mel_weight_matrix) (This function follows the [Hidden Markov Model Toolkit (HTK)](http://htk.eng.cam.ac.uk/) convention) and [tf.signal.stft](https://www.tensorflow.org/api_docs/python/tf/signal/stft). It's not a hard task but it takes time to check everything carefully.<|||||>Okay! Tell me if I can be of help or if you are stuck! <|||||>Sounds good! Keep us posted with progress / questions, more than happy to help 🤗<|||||>Hey @sanchit-gandhi @ArthurZucker. I have implemented the function to compute STFT from Tensorflow into Numpy. I also checked the training result after changing the feature extractor and the [result](https://huggingface.co/vumichien/trillsson3-ft-keyword-spotting-15/tensorboard) was almost the same as before. But the CircleCI tests are still red, would you mind helping me?<|||||>Hey! So first thing first, you should run `make fix-copies`. Then try solving whatever error you get when running `make fixup`. This should solve at least a few issues and clean a bit.
Seems like you have naming errors regarding :
```python
AttributeError: module transformers.models.trillsson_efficient has no attribute Trillsson_efficientFeatureExtractor
```
So `make fix-copies` will help a lot. <|||||>Hi @ArthurZucker @sanchit-gandhi, could you help me fix this CI/CD test.
I can run the test file on a local machine by this syntax
```python
RUN_SLOW=1 pytest -sv tests/models/trillsson_efficient/test_modeling_trillsson_efficient.py
````
and all the test cases were passed. But the CI/CD test show that's error
```python
AttributeError: module transformers.models.trillsson_efficient has no attribute Trillsson_efficientFeatureExtractor
```
However, the test_torch in CI/CD was passed. So in my case, how could I fix it?<|||||>Hey, let me have a look ! I think it should be a typo or small nit we forgot! <|||||>@ArthurZucker I have applied your suggestion but It still didn't pass the test :smiling_face_with_tear: <|||||>The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17387). All of your documentation changes will be reflected on that endpoint.<|||||>Thanks, @ArthurZucker. I think it's fine now. Do you need me to revise or do something before merging?<|||||>@ArthurZucker Thank you for your review. I have made some changes as per your kind suggestion. Could you please check again and let me know if I need to revise something?<|||||>Hey! Will have a look again 😉 You can also try to pull from main to fix the two `README` issues !<|||||>Hi @ArthurZucker, I have solved these conflict README files. However, I want to ask you about the [post init here](https://github.com/vumichien/transformers/blob/2f056b886bf43febc3615fb8988eab68cc0f7b66/src/transformers/models/trillsson_efficientnet/modeling_trillsson_efficientnet.py#L611), when I try to init weight of base model of TrillssonEfficientNetForSequenceClassification like this
```python
from transformers import (
AutoConfig,
TrillssonEfficientNetForSequenceClassification,
)
config = AutoConfig.from_pretrained(
"vumichien/nonsemantic-speech-trillsson3", finetuning_task="audio-classification", use_auth_token=False
)
model = TrillssonEfficientNetForSequenceClassification.from_pretrained(
"vumichien/nonsemantic-speech-trillsson3",
from_tf=False,
config=config,
use_auth_token=True,
)
```
It fails and shows the error message
```python
Some weights of the model checkpoint at vumichien/nonsemantic-speech-trillsson3 were not used when initializing TrillssonEfficientNetForSequenceClassification: ['block.10.expand_bn.weight', 'block.33.expand_bn.weight', 'block.29.project_bn.bias', 'block.23.se.se_expand.bias', 'block.5.project_conv.weight', 'block.39.expand_bn.weight', 'block.39.expand_bn.num_batches_tracked', 'block.33.bn.bias', 'block.13.se.se_expand.bias', 'block.26.expand_bn.weight', 'block.18.se.se_expand.bias', 'block.36.project_bn.running_var', 'block.33.project_bn.running_var', 'block.11.bn.num_batches_tracked', 'block.22.bn.running_var', 'block.35.project_bn.running_mean', 'block.10.expand_conv.weight', 'block.11.project_bn.num_batches_tracked', 'block.21.bn.running_var', 'block.31.project_bn.running_mean', 'block.16.bn.bias', 'block.11.bn.running_var', 'block.2.expand_conv.weight', 'block.26.expand_bn.running_mean', 'block.38.expand_bn.weight', 'block.20.dwconv2.weight', 'block.14.expand_conv.weight', 'block.27.project_bn.bias', 'block.20.bn.num_batches_tracked', 'block.34.project_conv.weight', 'block.12.se.se_expand.bias', 'block.32.expand_bn.running_mean', 'block.37.bn.weight', 'block.6.expand_bn.bias', 'block.23.expand_bn.num_batches_tracked', 'block.26.expand_conv.weight', 'block.13.project_bn.weight', 'top.top_bn.num_batches_tracked', 'block.24.project_bn.running_mean', 'block.28.project_bn.bias', 'block.16.se.se_reduce.bias', 'block.6.project_bn.weight', 'block.16.project_bn.running_mean', 'block.28.bn.running_mean', 'block.10.project_bn.bias', 'block.16.expand_bn.weight', 'block.17.bn.weight', 'block.1.project_bn.running_mean', 'block.11.expand_bn.weight', 'block.9.expand_bn.bias', 'block.22.dwconv2.weight', 'block.16.bn.weight', 'block.37.se.se_expand.bias', 'block.16.project_bn.weight', 'block.20.se.se_expand.weight', 'block.23.bn.bias', 'block.22.expand_bn.running_mean', 'block.32.expand_conv.weight', 'block.14.project_conv.weight', 'block.13.project_bn.bias', 'block.14.project_bn.running_mean', 'block.31.expand_bn.weight', 'block.25.bn.weight', 'block.33.project_conv.weight', 'block.29.expand_bn.num_batches_tracked', 'block.11.expand_bn.running_mean', 'block.39.bn.running_var', 'block.15.bn.weight', 'block.33.se.se_reduce.weight', 'block.36.expand_bn.bias', 'block.14.expand_bn.weight', 'block.13.se.se_expand.weight', 'block.21.project_bn.running_var', 'block.32.dwconv2.weight', 'block.30.bn.running_var', 'block.25.project_bn.num_batches_tracked', 'block.26.bn.num_batches_tracked', 'block.30.expand_bn.weight', 'block.33.expand_bn.bias', 'block.25.project_bn.running_var', 'block.36.bn.num_batches_tracked', 'block.7.project_conv.weight', 'block.33.bn.num_batches_tracked', 'block.3.project_bn.weight', 'block.14.project_bn.running_var', 'block.38.se.se_expand.bias', 'block.13.expand_bn.bias', 'block.27.expand_bn.num_batches_tracked', 'block.14.se.se_reduce.weight', 'block.32.project_bn.bias', 'block.22.expand_conv.weight', 'block.27.dwconv2.weight', 'block.13.project_bn.running_mean', 'block.16.bn.running_mean', 'block.23.se.se_reduce.bias', 'block.29.se.se_expand.weight', 'block.39.se.se_reduce.weight', 'block.29.project_bn.running_mean', 'block.33.expand_bn.num_batches_tracked', 'block.9.project_bn.running_var', 'block.38.bn.bias', 'block.21.project_bn.num_batches_tracked', 'block.21.bn.running_mean', 'block.21.dwconv2.weight', 'block.39.bn.running_mean', 'block.10.expand_bn.num_batches_tracked', 'block.19.project_bn.running_mean', 'block.28.project_bn.num_batches_tracked', 'block.37.se.se_expand.weight', 'block.20.se.se_reduce.bias', 'block.20.bn.running_var', 'block.18.expand_conv.weight', 'block.25.project_bn.running_mean', 'block.28.project_bn.running_var', 'block.28.bn.num_batches_tracked', 'block.17.bn.running_var', 'block.8.project_bn.bias', 'block.27.bn.running_mean', 'block.26.project_bn.num_batches_tracked', 'block.10.expand_bn.running_mean', 'block.24.bn.num_batches_tracked', 'block.26.se.se_expand.weight', 'block.35.expand_bn.num_batches_tracked', 'block.17.se.se_reduce.bias', 'block.23.project_conv.weight', 'block.7.project_bn.running_mean', 'block.17.project_bn.num_batches_tracked', 'block.31.project_bn.bias', 'block.19.dwconv2.weight', 'block.32.se.se_reduce.weight', 'block.19.expand_conv.weight', 'block.29.project_bn.running_var', 'block.29.expand_bn.running_var', 'top.top_bn.running_var', 'block.27.project_bn.weight', 'block.20.se.se_expand.bias', 'block.28.se.se_expand.weight', 'block.37.expand_conv.weight', 'block.25.expand_bn.running_mean', 'block.28.bn.running_var', 'block.7.project_bn.running_var', 'block.19.expand_bn.weight', 'block.28.expand_bn.bias', 'block.9.expand_conv.weight', 'block.18.project_bn.running_mean', 'block.22.expand_bn.weight', 'block.23.bn.weight', 'block.39.expand_bn.running_var', 'block.21.project_bn.weight', 'block.32.project_bn.num_batches_tracked', 'block.11.expand_conv.weight', 'block.31.se.se_expand.bias', 'block.13.project_bn.running_var', 'block.14.bn.num_batches_tracked', 'block.14.expand_bn.num_batches_tracked', 'block.15.project_bn.bias', 'block.26.se.se_expand.bias', 'block.15.project_bn.running_var', 'block.26.bn.bias', 'block.35.dwconv2.weight', 'block.28.project_bn.running_mean', 'block.32.expand_bn.running_var', 'block.36.project_bn.running_mean', 'stem.stem_bn.running_mean', 'block.22.se.se_reduce.weight', 'block.15.project_conv.weight', 'block.18.bn.weight', 'block.30.se.se_reduce.weight', 'block.6.project_bn.running_var', 'block.19.expand_bn.running_mean', 'block.8.expand_bn.bias', 'block.26.project_bn.running_mean', 'block.33.expand_conv.weight', 'block.10.expand_bn.running_var', 'block.22.expand_bn.bias', 'block.21.project_bn.running_mean', 'block.25.bn.num_batches_tracked', 'block.35.expand_bn.bias', 'block.4.project_bn.running_mean', 'block.11.project_bn.running_var', 'block.38.project_bn.weight', 'block.39.se.se_reduce.bias', 'block.10.project_conv.weight', 'block.5.project_bn.running_var', 'top.top_bn.bias', 'block.21.expand_bn.weight', 'block.5.expand_bn.num_batches_tracked', 'block.6.expand_bn.num_batches_tracked', 'block.18.bn.bias', 'block.28.expand_bn.running_mean', 'block.13.bn.num_batches_tracked', 'block.36.expand_bn.num_batches_tracked', 'block.37.project_bn.running_var', 'block.27.se.se_expand.weight', 'block.13.bn.running_var', 'block.33.se.se_expand.bias', 'block.5.expand_bn.running_mean', 'block.36.project_conv.weight', 'block.31.bn.running_mean', 'block.12.expand_bn.running_var', 'block.39.bn.bias', 'block.15.se.se_expand.weight', 'top.top_conv.weight', 'block.3.project_conv.weight', 'block.25.se.se_reduce.bias', 'block.32.expand_bn.num_batches_tracked', 'block.12.project_bn.bias', 'block.34.project_bn.num_batches_tracked', 'block.34.expand_conv.weight', 'block.16.expand_bn.bias', 'block.15.bn.num_batches_tracked', 'block.8.expand_conv.weight', 'block.24.se.se_expand.bias', 'stem.stem_conv.weight', 'block.23.bn.num_batches_tracked', 'block.16.se.se_reduce.weight', 'block.5.project_bn.weight', 'block.9.project_bn.weight', 'block.13.expand_conv.weight', 'block.3.expand_bn.num_batches_tracked', 'block.31.se.se_expand.weight', 'block.38.dwconv2.weight', 'block.7.expand_bn.num_batches_tracked', 'block.11.dwconv2.weight', 'block.20.bn.weight', 'block.34.expand_bn.bias', 'block.16.project_bn.bias', 'block.29.expand_conv.weight', 'block.12.bn.num_batches_tracked', 'block.13.expand_bn.running_var', 'block.29.expand_bn.weight', 'block.12.expand_bn.num_batches_tracked', 'block.19.bn.weight', 'block.39.project_bn.weight', 'block.18.project_bn.running_var', 'block.13.expand_bn.running_mean', 'block.32.project_bn.weight', 'block.12.bn.running_mean', 'block.33.se.se_expand.weight', 'block.12.expand_conv.weight', 'block.25.bn.running_var', 'block.3.project_bn.running_mean', 'block.2.expand_bn.weight', 'block.12.bn.weight', 'block.18.expand_bn.num_batches_tracked', 'block.21.expand_bn.num_batches_tracked', 'block.36.expand_conv.weight', 'block.11.expand_bn.num_batches_tracked', 'block.36.se.se_expand.weight', 'block.2.project_bn.bias', 'block.28.project_conv.weight', 'block.9.expand_bn.running_var', 'block.18.se.se_expand.weight', 'block.15.project_bn.weight', 'block.15.expand_conv.weight', 'block.5.project_bn.bias', 'block.37.expand_bn.num_batches_tracked', 'block.1.project_bn.num_batches_tracked', 'block.36.project_bn.num_batches_tracked', 'block.31.project_bn.num_batches_tracked', 'block.36.se.se_reduce.bias', 'block.26.bn.running_var', 'block.24.bn.weight', 'block.9.project_bn.running_mean', 'block.5.expand_bn.weight', 'block.38.project_bn.running_var', 'block.22.expand_bn.num_batches_tracked', 'block.18.expand_bn.running_mean', 'block.39.bn.num_batches_tracked', 'block.4.expand_bn.running_var', 'block.37.bn.num_batches_tracked', 'block.30.bn.bias', 'block.31.project_conv.weight', 'block.17.expand_bn.running_var', 'block.35.project_bn.bias', 'block.39.project_bn.num_batches_tracked', 'block.22.project_conv.weight', 'block.35.expand_conv.weight', 'block.11.bn.running_mean', 'block.16.project_bn.num_batches_tracked', 'block.24.expand_bn.running_mean', 'block.31.bn.bias', 'block.12.project_bn.weight', 'block.18.project_bn.weight', 'block.3.expand_bn.running_var', 'block.4.project_bn.weight', 'block.6.project_bn.bias', 'block.16.se.se_expand.bias', 'block.20.expand_bn.running_var', 'block.2.expand_bn.running_mean', 'block.37.dwconv2.weight', 'block.39.project_bn.bias', 'block.32.bn.running_var', 'block.36.expand_bn.weight', 'block.16.project_bn.running_var', 'stem.stem_bn.running_var', 'block.6.expand_bn.weight', 'block.15.se.se_reduce.bias', 'block.10.bn.weight', 'block.17.expand_bn.num_batches_tracked', 'block.18.bn.running_var', 'block.20.project_bn.running_var', 'block.15.expand_bn.bias', 'block.25.dwconv2.weight', 'block.7.project_bn.weight', 'block.14.bn.running_var', 'block.17.expand_bn.running_mean', 'block.28.project_bn.weight', 'block.33.bn.running_mean', 'block.22.bn.bias', 'block.28.expand_bn.running_var', 'block.28.dwconv2.weight', 'block.30.expand_bn.running_var', 'block.37.bn.running_var', 'block.17.expand_bn.bias', 'block.2.expand_bn.num_batches_tracked', 'block.19.expand_bn.bias', 'block.25.expand_bn.bias', 'block.34.expand_bn.running_mean', 'block.3.project_bn.running_var', 'block.38.bn.weight', 'block.37.expand_bn.weight', 'block.15.project_bn.num_batches_tracked', 'block.20.project_bn.weight', 'block.29.expand_bn.running_mean', 'block.24.project_bn.num_batches_tracked', 'block.25.project_bn.bias', 'block.32.project_conv.weight', 'block.39.expand_bn.bias', 'block.12.se.se_reduce.weight', 'block.20.project_bn.bias', 'block.33.bn.weight', 'block.10.project_bn.running_mean', 'block.34.bn.num_batches_tracked', 'block.10.se.se_expand.bias', 'block.22.bn.num_batches_tracked', 'block.15.expand_bn.weight', 'block.38.expand_bn.bias', 'block.16.expand_conv.weight', 'block.4.project_bn.bias', 'block.8.project_bn.num_batches_tracked', 'block.34.se.se_reduce.weight', 'block.24.expand_bn.running_var', 'block.4.project_bn.running_var', 'block.10.project_bn.running_var', 'block.25.expand_bn.num_batches_tracked', 'block.26.project_bn.bias', 'block.37.expand_bn.running_var', 'block.22.bn.running_mean', 'block.33.project_bn.running_mean', 'block.15.dwconv2.weight', 'block.39.se.se_expand.weight', 'block.13.expand_bn.weight', 'block.8.expand_bn.running_mean', 'block.2.expand_bn.bias', 'block.33.expand_bn.running_var', 'block.27.bn.num_batches_tracked', 'block.35.bn.num_batches_tracked', 'block.32.se.se_expand.weight', 'block.31.se.se_reduce.bias', 'block.7.expand_bn.weight', 'block.18.bn.running_mean', 'block.34.bn.running_mean', 'block.32.project_bn.running_var', 'block.5.project_bn.num_batches_tracked', 'block.31.project_bn.weight', 'block.25.bn.running_mean', 'block.27.se.se_expand.bias', 'block.38.bn.running_mean', 'block.30.expand_bn.running_mean', 'block.29.se.se_reduce.bias', 'block.20.expand_conv.weight', 'block.8.project_bn.weight', 'block.0.project_bn.bias', 'block.18.project_conv.weight', 'block.7.expand_bn.running_mean', 'block.26.project_bn.running_var', 'block.38.project_bn.num_batches_tracked', 'block.12.project_conv.weight', 'block.12.project_bn.running_mean', 'block.33.dwconv2.weight', 'block.38.bn.running_var', 'block.12.project_bn.running_var', 'block.21.se.se_reduce.bias', 'block.15.project_bn.running_mean', 'block.19.project_bn.running_var', 'block.34.project_bn.running_mean', 'block.24.se.se_expand.weight', 'block.36.bn.weight', 'block.35.project_bn.num_batches_tracked', 'block.26.se.se_reduce.bias', 'block.29.bn.bias', 'block.3.expand_bn.running_mean', 'block.24.se.se_reduce.bias', 'block.27.expand_bn.bias', 'block.27.se.se_reduce.weight', 'block.31.expand_bn.bias', 'block.21.se.se_expand.bias', 'block.37.se.se_reduce.bias', 'block.19.se.se_expand.weight', 'block.11.se.se_expand.bias', 'block.14.bn.bias', 'block.37.project_bn.running_mean', 'block.14.project_bn.bias', 'block.21.se.se_expand.weight', 'block.32.bn.bias', 'block.12.dwconv2.weight', 'block.23.project_bn.bias', 'block.19.project_bn.bias', 'block.30.bn.num_batches_tracked', 'block.27.project_conv.weight', 'block.12.expand_bn.weight', 'block.35.expand_bn.running_mean', 'block.34.bn.running_var', 'block.24.expand_conv.weight', 'block.36.bn.running_var', 'block.34.expand_bn.weight', 'block.29.expand_bn.bias', 'block.10.se.se_expand.weight', 'block.35.project_conv.weight', 'block.35.se.se_reduce.bias', 'block.14.se.se_expand.bias', 'block.17.se.se_expand.weight', 'block.30.project_bn.weight', 'block.24.bn.running_mean', 'block.20.expand_bn.num_batches_tracked', 'block.18.se.se_reduce.weight', 'block.16.expand_bn.running_mean', 'block.35.expand_bn.running_var', 'block.8.project_bn.running_var', 'block.36.bn.bias', 'block.32.expand_bn.weight', 'block.3.expand_bn.weight', 'block.23.project_bn.running_mean', 'block.22.se.se_expand.weight', 'block.13.bn.running_mean', 'block.31.expand_bn.running_mean', 'block.14.expand_bn.running_var', 'block.23.expand_bn.bias', 'block.24.project_bn.weight', 'block.29.dwconv2.weight', 'block.15.se.se_reduce.weight', 'block.23.expand_bn.running_mean', 'block.11.se.se_expand.weight', 'block.30.se.se_expand.weight', 'block.34.expand_bn.num_batches_tracked', 'block.38.se.se_expand.weight', 'block.39.project_bn.running_var', 'block.37.bn.running_mean', 'block.22.expand_bn.running_var', 'block.9.expand_bn.running_mean', 'block.33.project_bn.num_batches_tracked', 'block.10.project_bn.num_batches_tracked', 'block.19.project_bn.num_batches_tracked', 'block.1.project_conv.weight', 'block.19.expand_bn.running_var', 'block.21.expand_conv.weight', 'block.24.expand_bn.num_batches_tracked', 'block.29.se.se_expand.bias', 'block.8.expand_bn.weight', 'block.36.project_bn.weight', 'block.38.se.se_reduce.bias', 'block.6.project_conv.weight', 'block.36.dwconv2.weight', 'block.0.project_conv.weight', 'block.32.project_bn.running_mean', 'top.top_bn.weight', 'block.31.dwconv2.weight', 'block.36.expand_bn.running_mean', 'block.19.bn.num_batches_tracked', 'block.20.project_conv.weight', 'block.8.expand_bn.running_var', 'block.19.se.se_expand.bias', 'block.5.project_bn.running_mean', 'block.28.se.se_reduce.bias', 'block.29.project_bn.num_batches_tracked', 'block.2.project_bn.running_var', 'block.11.se.se_reduce.bias', 'block.23.bn.running_mean', 'block.10.se.se_reduce.weight', 'block.31.se.se_reduce.weight', 'block.30.project_bn.num_batches_tracked', 'block.7.expand_bn.bias', 'block.38.project_bn.bias', 'block.22.project_bn.bias', 'block.32.bn.running_mean', 'block.28.bn.bias', 'block.15.se.se_expand.bias', 'block.25.se.se_reduce.weight', 'block.17.bn.running_mean', 'block.8.project_conv.weight', 'block.35.project_bn.weight', 'block.11.project_bn.running_mean', 'block.4.project_bn.num_batches_tracked', 'block.6.expand_conv.weight', 'block.18.project_bn.bias', 'block.35.se.se_expand.weight', 'block.18.bn.num_batches_tracked', 'block.28.se.se_reduce.weight', 'block.18.dwconv2.weight', 'block.17.project_conv.weight', 'block.4.expand_bn.bias', 'block.22.project_bn.num_batches_tracked', 'block.30.expand_conv.weight', 'top.top_bn.running_mean', 'block.2.project_bn.weight', 'block.30.project_bn.running_var', 'block.14.se.se_reduce.bias', 'block.35.bn.running_var', 'block.5.expand_conv.weight', 'block.19.bn.running_mean', 'block.31.bn.weight', 'block.6.expand_bn.running_mean', 'block.32.bn.num_batches_tracked', 'block.34.se.se_expand.bias', 'block.16.expand_bn.num_batches_tracked', 'block.3.expand_bn.bias', 'block.25.se.se_expand.bias', 'block.0.project_bn.weight', 'block.8.project_bn.running_mean', 'block.36.se.se_reduce.weight', 'block.20.se.se_reduce.weight', 'block.24.project_bn.bias', 'block.39.se.se_expand.bias', 'block.11.bn.bias', 'block.14.project_bn.weight', 'block.9.expand_bn.num_batches_tracked', 'block.5.expand_bn.running_var', 'block.19.project_conv.weight', 'block.26.expand_bn.bias', 'block.34.se.se_expand.weight', 'block.15.expand_bn.num_batches_tracked', 'block.29.bn.weight', 'block.26.project_bn.weight', 'block.38.expand_bn.running_mean', 'block.39.bn.weight', 'block.19.bn.bias', 'block.15.bn.running_mean', 'block.21.project_bn.bias', 'block.34.bn.weight', 'block.29.bn.running_var', 'block.16.bn.num_batches_tracked', 'block.36.se.se_expand.bias', 'block.39.project_conv.weight', 'block.2.expand_bn.running_var', 'block.22.project_bn.weight', 'block.11.expand_bn.running_var', 'block.34.dwconv2.weight', 'block.23.dwconv2.weight', 'block.27.bn.weight', 'block.4.project_conv.weight', 'block.21.expand_bn.running_mean', 'block.25.se.se_expand.weight', 'block.38.project_conv.weight', 'block.12.expand_bn.bias', 'block.27.project_bn.running_var', 'block.13.se.se_reduce.bias', 'block.30.expand_bn.bias', 'block.27.expand_bn.running_mean', 'block.31.expand_conv.weight', 'block.6.project_bn.running_mean', 'block.4.expand_bn.num_batches_tracked', 'block.20.bn.running_mean', 'block.30.dwconv2.weight', 'block.17.project_bn.weight', 'block.17.expand_bn.weight', 'block.17.expand_conv.weight', 'block.35.project_bn.running_var', 'block.16.dwconv2.weight', 'block.32.se.se_expand.bias', 'block.21.bn.bias', 'block.34.se.se_reduce.bias', 'block.28.bn.weight', 'block.7.project_bn.bias', 'block.29.bn.running_mean', 'block.29.se.se_reduce.weight', 'block.11.project_conv.weight', 'block.38.expand_bn.running_var', 'block.10.bn.running_var', 'block.3.project_bn.num_batches_tracked', 'block.30.bn.weight', 'block.37.expand_bn.running_mean', 'block.1.project_bn.bias', 'block.26.se.se_reduce.weight', 'block.24.project_conv.weight', 'block.19.se.se_reduce.bias', 'block.33.bn.running_var', 'block.14.project_bn.num_batches_tracked', 'block.19.se.se_reduce.weight', 'block.23.expand_conv.weight', 'block.35.expand_bn.weight', 'block.32.expand_bn.bias', 'block.17.se.se_expand.bias', 'block.25.bn.bias', 'block.17.bn.bias', 'block.30.se.se_reduce.bias', 'block.31.bn.num_batches_tracked', 'block.21.expand_bn.running_var', 'block.26.bn.running_mean', 'block.27.expand_bn.weight', 'block.25.expand_bn.running_var', 'block.22.se.se_expand.bias', 'block.18.expand_bn.bias', 'block.12.se.se_reduce.bias', 'block.22.se.se_reduce.bias', 'block.5.expand_bn.bias', 'block.21.expand_bn.bias', 'block.1.project_bn.weight', 'block.17.project_bn.running_mean', 'block.25.project_conv.weight', 'block.29.project_conv.weight', 'block.30.project_bn.bias', 'block.13.expand_bn.num_batches_tracked', 'block.12.bn.running_var', 'block.22.project_bn.running_mean', 'block.23.se.se_expand.weight', 'block.29.project_bn.weight', 'block.23.expand_bn.running_var', 'block.28.se.se_expand.bias', 'block.25.project_bn.weight', 'block.17.project_bn.bias', 'block.33.project_bn.weight', 'block.20.project_bn.num_batches_tracked', 'block.28.expand_bn.weight', 'block.15.bn.bias', 'block.13.se.se_reduce.weight', 'block.11.se.se_reduce.weight', 'block.24.project_bn.running_var', 'block.27.expand_conv.weight', 'block.26.dwconv2.weight', 'block.3.project_bn.bias', 'block.18.expand_bn.running_var', 'block.38.bn.num_batches_tracked', 'block.24.dwconv2.weight', 'block.20.project_bn.running_mean', 'block.30.se.se_expand.bias', 'block.37.project_bn.num_batches_tracked', 'block.31.expand_bn.num_batches_tracked', 'block.4.expand_bn.weight', 'block.26.expand_bn.num_batches_tracked', 'block.15.bn.running_var', 'block.38.project_bn.running_mean', 'block.28.expand_bn.num_batches_tracked', 'block.30.bn.running_mean', 'block.13.dwconv2.weight', 'block.22.bn.weight', 'dense.weight', 'block.16.project_conv.weight', 'block.19.bn.running_var', 'block.27.expand_bn.running_var', 'block.21.se.se_reduce.weight', 'block.27.bn.bias', 'block.11.expand_bn.bias', 'block.23.project_bn.num_batches_tracked', 'block.37.se.se_reduce.weight', 'block.25.expand_conv.weight', 'block.26.expand_bn.running_var', 'block.7.project_bn.num_batches_tracked', 'block.14.se.se_expand.weight', 'block.39.dwconv2.weight', 'block.0.project_bn.running_var', 'block.21.bn.num_batches_tracked', 'block.2.project_bn.running_mean', 'block.37.project_bn.weight', 'block.4.expand_conv.weight', 'block.38.expand_conv.weight', 'block.14.dwconv2.weight', 'block.37.expand_bn.bias', 'block.11.project_bn.weight', 'block.29.bn.num_batches_tracked', 'block.23.bn.running_var', 'block.9.expand_bn.weight', 'block.24.bn.bias', 'block.32.se.se_reduce.bias', 'block.37.project_conv.weight', 'block.23.se.se_reduce.weight', 'block.14.bn.weight', 'block.14.bn.running_mean', 'stem.stem_bn.num_batches_tracked', 'block.14.expand_bn.bias', 'block.39.expand_conv.weight', 'block.24.bn.running_var', 'block.1.project_bn.running_var', 'block.3.expand_conv.weight', 'block.12.se.se_expand.weight', 'block.27.bn.running_var', 'block.23.expand_bn.weight', 'block.13.project_bn.num_batches_tracked', 'block.24.expand_bn.weight', 'block.27.se.se_reduce.bias', 'block.35.bn.weight', 'block.12.bn.bias', 'block.4.expand_bn.running_mean', 'block.34.project_bn.bias', 'block.16.bn.running_var', 'block.8.expand_bn.num_batches_tracked', 'block.17.bn.num_batches_tracked', 'block.16.expand_bn.running_var', 'block.6.project_bn.num_batches_tracked', 'block.6.expand_bn.running_var', 'block.26.project_conv.weight', 'block.20.bn.bias', 'block.13.bn.weight', 'dense.bias', 'block.12.project_bn.num_batches_tracked', 'block.33.project_bn.bias', 'block.11.bn.weight', 'block.15.expand_bn.running_mean', 'block.0.project_bn.running_mean', 'block.10.se.se_reduce.bias', 'block.17.project_bn.running_var', 'block.27.project_bn.running_mean', 'block.9.project_bn.num_batches_tracked', 'block.14.expand_bn.running_mean', 'block.25.expand_bn.weight', 'block.18.expand_bn.weight', 'block.34.project_bn.running_var', 'block.15.expand_bn.running_var', 'block.7.expand_bn.running_var', 'block.27.project_bn.num_batches_tracked', 'block.20.expand_bn.running_mean', 'block.35.se.se_reduce.weight', 'block.7.expand_conv.weight', 'block.19.project_bn.weight', 'block.18.se.se_reduce.bias', 'block.23.project_bn.running_var', 'block.13.project_conv.weight', 'block.10.bn.running_mean', 'block.9.project_conv.weight', 'block.17.dwconv2.weight', 'block.18.project_bn.num_batches_tracked', 'block.17.se.se_reduce.weight', 'block.22.project_bn.running_var', 'block.37.project_bn.bias', 'block.20.expand_bn.bias', 'block.21.bn.weight', 'block.24.se.se_reduce.weight', 'block.10.bn.num_batches_tracked', 'block.16.se.se_expand.weight', 'stem.stem_bn.weight', 'block.9.project_bn.bias', 'block.10.project_bn.weight', 'block.24.expand_bn.bias', 'block.26.bn.weight', 'block.2.project_conv.weight', 'block.0.project_bn.num_batches_tracked', 'block.30.expand_bn.num_batches_tracked', 'block.35.bn.bias', 'block.35.se.se_expand.bias', 'block.31.bn.running_var', 'block.31.expand_bn.running_var', 'block.30.project_conv.weight', 'block.13.bn.bias', 'block.2.project_bn.num_batches_tracked', 'block.12.expand_bn.running_mean', 'block.10.dwconv2.weight', 'block.34.expand_bn.running_var', 'block.28.expand_conv.weight', 'block.30.project_bn.running_mean', 'block.31.project_bn.running_var', 'block.33.se.se_reduce.bias', 'block.21.project_conv.weight', 'block.35.bn.running_mean', 'block.38.expand_bn.num_batches_tracked', 'block.39.project_bn.running_mean', 'block.20.expand_bn.weight', 'stem.stem_bn.bias', 'block.34.bn.bias', 'block.36.bn.running_mean', 'block.23.project_bn.weight', 'block.10.expand_bn.bias', 'block.33.expand_bn.running_mean', 'block.32.bn.weight', 'block.38.se.se_reduce.weight', 'block.39.expand_bn.running_mean', 'block.37.bn.bias', 'block.36.project_bn.bias', 'block.36.expand_bn.running_var', 'block.19.expand_bn.num_batches_tracked', 'block.34.project_bn.weight', 'block.11.project_bn.bias', 'block.10.bn.bias']
- This IS expected if you are initializing TrillssonEfficientNetForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TrillssonEfficientNetForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of TrillssonEfficientNetForSequenceClassification were not initialized from the model checkpoint at vumichien/nonsemantic-speech-trillsson3 and are newly initialized: ['trillsson.block.39.expand_conv.weight', 'trillsson.block.37.project_conv.weight', 'trillsson.block.11.se.se_expand.bias', 'trillsson.block.34.expand_bn.num_batches_tracked', 'trillsson.block.18.expand_bn.bias', 'trillsson.block.8.expand_bn.weight', 'trillsson.block.31.bn.running_var', 'trillsson.block.5.expand_conv.weight', 'trillsson.block.36.expand_bn.running_mean', 'trillsson.block.18.se.se_reduce.weight', 'trillsson.block.28.se.se_reduce.weight', 'trillsson.block.24.expand_bn.bias', 'trillsson.block.29.se.se_reduce.bias', 'trillsson.block.16.bn.bias', 'trillsson.block.37.se.se_reduce.weight', 'trillsson.block.37.bn.running_mean', 'trillsson.block.33.bn.weight', 'trillsson.block.19.se.se_expand.weight', 'trillsson.block.36.bn.num_batches_tracked', 'classifier.bias', 'trillsson.block.35.project_bn.weight', 'trillsson.block.28.bn.num_batches_tracked', 'trillsson.block.37.se.se_expand.bias', 'trillsson.block.37.project_bn.running_mean', 'trillsson.block.19.se.se_reduce.weight', 'trillsson.block.26.bn.running_mean', 'trillsson.block.22.dwconv2.weight', 'trillsson.block.23.bn.num_batches_tracked', 'trillsson.block.26.project_bn.running_mean', 'trillsson.block.18.project_conv.weight', 'trillsson.block.18.bn.bias', 'trillsson.block.6.project_bn.bias', 'trillsson.block.3.project_bn.running_mean', 'trillsson.block.25.project_bn.weight', 'trillsson.block.19.project_conv.weight', 'trillsson.block.29.expand_bn.running_var', 'trillsson.block.29.project_bn.running_var', 'trillsson.block.2.expand_bn.weight', 'trillsson.block.16.se.se_reduce.bias', 'trillsson.block.31.bn.bias', 'trillsson.block.10.bn.running_var', 'trillsson.block.17.se.se_reduce.bias', 'trillsson.block.38.bn.running_var', 'trillsson.block.20.se.se_expand.weight', 'trillsson.block.14.bn.running_var', 'trillsson.block.20.bn.running_var', 'trillsson.block.13.project_bn.num_batches_tracked', 'trillsson.block.16.project_conv.weight', 'trillsson.block.16.bn.running_mean', 'trillsson.block.37.bn.running_var', 'trillsson.block.21.project_bn.num_batches_tracked', 'trillsson.block.13.bn.running_mean', 'trillsson.block.16.dwconv2.weight', 'trillsson.block.26.bn.num_batches_tracked', 'trillsson.block.15.expand_conv.weight', 'trillsson.block.10.bn.num_batches_tracked', 'trillsson.block.22.project_bn.num_batches_tracked', 'trillsson.block.32.bn.weight', 'trillsson.block.27.se.se_expand.bias', 'trillsson.block.26.se.se_expand.bias', 'trillsson.block.10.project_bn.bias', 'trillsson.block.20.project_bn.num_batches_tracked', 'trillsson.block.29.expand_bn.weight', 'trillsson.block.36.project_conv.weight', 'trillsson.block.25.expand_bn.weight', 'trillsson.block.14.bn.weight', 'trillsson.block.13.bn.weight', 'trillsson.block.0.project_conv.weight', 'trillsson.block.2.expand_bn.running_var', 'trillsson.block.27.bn.running_var', 'trillsson.block.28.se.se_reduce.bias', 'trillsson.block.11.expand_conv.weight', 'trillsson.block.28.bn.running_mean', 'trillsson.block.20.expand_bn.weight', 'trillsson.block.26.se.se_reduce.weight', 'trillsson.block.21.se.se_expand.bias', 'trillsson.block.13.expand_bn.running_var', 'trillsson.block.9.project_bn.bias', 'trillsson.block.21.expand_bn.running_var', 'trillsson.block.10.project_bn.num_batches_tracked', 'trillsson.block.15.project_bn.num_batches_tracked', 'trillsson.block.38.bn.bias', 'trillsson.block.15.project_conv.weight', 'trillsson.block.9.expand_bn.weight', 'trillsson.block.14.bn.num_batches_tracked', 'trillsson.block.14.se.se_expand.bias', 'trillsson.block.39.project_bn.num_batches_tracked', 'trillsson.block.9.project_bn.running_mean', 'trillsson.block.10.expand_bn.running_mean', 'trillsson.block.20.project_bn.bias', 'trillsson.block.19.expand_bn.running_var', 'trillsson.block.12.expand_conv.weight', 'trillsson.block.33.se.se_expand.bias', 'trillsson.block.37.expand_bn.running_mean', 'trillsson.block.31.project_bn.num_batches_tracked', 'trillsson.block.26.project_conv.weight', 'trillsson.block.38.bn.running_mean', 'trillsson.block.21.project_bn.weight', 'trillsson.block.19.bn.running_var', 'trillsson.block.24.project_bn.running_mean', 'trillsson.block.38.expand_bn.bias', 'trillsson.block.4.expand_bn.bias', 'trillsson.block.20.project_bn.running_var', 'trillsson.block.10.project_conv.weight', 'trillsson.block.0.project_bn.num_batches_tracked', 'trillsson.block.26.dwconv2.weight', 'trillsson.block.22.expand_bn.weight', 'trillsson.block.34.bn.weight', 'trillsson.block.6.expand_conv.weight', 'trillsson.top.top_bn.running_mean', 'trillsson.block.11.bn.weight', 'trillsson.block.10.se.se_expand.bias', 'trillsson.block.23.project_bn.running_mean', 'trillsson.block.15.bn.bias', 'trillsson.block.25.project_bn.bias', 'trillsson.block.14.project_bn.running_mean', 'trillsson.block.8.project_bn.num_batches_tracked', 'trillsson.block.39.bn.weight', 'trillsson.block.28.expand_bn.bias', 'trillsson.block.4.project_bn.num_batches_tracked', 'trillsson.block.18.dwconv2.weight', 'trillsson.block.32.expand_bn.weight', 'trillsson.block.22.se.se_expand.weight', 'trillsson.block.1.project_bn.num_batches_tracked', 'trillsson.block.30.project_bn.running_mean', 'trillsson.block.19.bn.num_batches_tracked', 'trillsson.block.5.project_bn.bias', 'trillsson.block.2.expand_bn.bias', 'trillsson.block.36.expand_conv.weight', 'trillsson.block.21.bn.num_batches_tracked', 'trillsson.block.32.project_conv.weight', 'trillsson.block.9.expand_bn.running_mean', 'trillsson.block.18.expand_bn.weight', 'trillsson.block.24.expand_bn.weight', 'trillsson.block.7.project_bn.bias', 'trillsson.block.19.bn.bias', 'trillsson.block.17.bn.running_var', 'trillsson.block.4.expand_bn.weight', 'trillsson.block.15.project_bn.weight', 'trillsson.block.21.bn.bias', 'trillsson.block.32.expand_bn.running_mean', 'trillsson.block.8.expand_bn.bias', 'trillsson.block.26.expand_bn.running_mean', 'trillsson.block.10.project_bn.running_var', 'trillsson.block.29.dwconv2.weight', 'trillsson.block.22.project_bn.weight', 'trillsson.block.34.project_bn.num_batches_tracked', 'trillsson.block.39.expand_bn.bias', 'trillsson.block.16.se.se_expand.weight', 'trillsson.block.17.dwconv2.weight', 'trillsson.block.26.expand_bn.weight', 'trillsson.block.22.expand_bn.num_batches_tracked', 'trillsson.block.17.se.se_expand.bias', 'trillsson.block.35.se.se_expand.weight', 'trillsson.block.16.project_bn.weight', 'trillsson.block.31.se.se_reduce.bias', 'trillsson.block.29.expand_conv.weight', 'trillsson.block.38.project_bn.num_batches_tracked', 'trillsson.block.37.bn.weight', 'trillsson.block.3.expand_bn.running_mean', 'trillsson.block.27.project_bn.num_batches_tracked', 'trillsson.block.25.expand_bn.num_batches_tracked', 'trillsson.block.10.se.se_reduce.weight', 'trillsson.block.12.project_conv.weight', 'trillsson.block.23.expand_bn.num_batches_tracked', 'trillsson.block.7.project_bn.running_var', 'trillsson.block.28.project_bn.bias', 'trillsson.block.39.se.se_expand.weight', 'trillsson.block.21.expand_bn.bias', 'trillsson.block.38.expand_bn.weight', 'trillsson.block.38.dwconv2.weight', 'trillsson.block.8.expand_conv.weight', 'trillsson.block.21.expand_bn.num_batches_tracked', 'trillsson.block.24.project_bn.running_var', 'trillsson.block.35.se.se_expand.bias', 'trillsson.block.11.project_bn.weight', 'trillsson.block.16.project_bn.running_mean', 'trillsson.block.17.expand_conv.weight', 'trillsson.block.34.bn.running_var', 'trillsson.block.36.bn.weight', 'trillsson.block.20.se.se_reduce.bias', 'trillsson.block.7.expand_bn.running_mean', 'trillsson.block.7.project_bn.weight', 'trillsson.block.31.bn.num_batches_tracked', 'trillsson.block.12.se.se_expand.bias', 'trillsson.block.25.bn.weight', 'trillsson.block.4.project_bn.running_mean', 'trillsson.block.28.project_bn.running_mean', 'trillsson.block.28.project_bn.num_batches_tracked', 'trillsson.block.20.project_bn.running_mean', 'trillsson.block.26.project_bn.num_batches_tracked', 'trillsson.block.9.expand_bn.bias', 'trillsson.block.31.dwconv2.weight', 'trillsson.block.6.expand_bn.running_var', 'trillsson.block.4.expand_conv.weight', 'trillsson.block.25.se.se_reduce.weight', 'trillsson.block.12.expand_bn.running_mean', 'trillsson.block.36.bn.bias', 'trillsson.block.22.bn.bias', 'trillsson.block.35.expand_bn.weight', 'trillsson.block.29.se.se_expand.weight', 'trillsson.block.39.bn.running_mean', 'trillsson.block.5.project_conv.weight', 'trillsson.block.37.bn.num_batches_tracked', 'trillsson.block.33.dwconv2.weight', 'trillsson.block.7.expand_bn.weight', 'trillsson.block.18.bn.weight', 'trillsson.block.29.project_bn.weight', 'trillsson.block.6.project_bn.running_var', 'trillsson.block.33.bn.running_var', 'trillsson.block.6.project_bn.num_batches_tracked', 'trillsson.block.13.project_bn.running_mean', 'trillsson.block.25.project_conv.weight', 'trillsson.block.30.expand_bn.running_mean', 'trillsson.block.32.bn.bias', 'trillsson.block.35.bn.weight', 'trillsson.block.12.project_bn.running_mean', 'trillsson.block.20.expand_bn.running_var', 'trillsson.block.22.project_bn.running_var', 'trillsson.block.17.expand_bn.num_batches_tracked', 'trillsson.block.27.expand_bn.weight', 'trillsson.block.17.se.se_expand.weight', 'trillsson.block.28.bn.running_var', 'trillsson.block.11.bn.num_batches_tracked', 'trillsson.block.23.expand_conv.weight', 'trillsson.block.36.se.se_expand.weight', 'trillsson.block.37.project_bn.running_var', 'trillsson.block.9.expand_bn.num_batches_tracked', 'trillsson.block.23.se.se_expand.bias', 'trillsson.block.5.expand_bn.weight', 'trillsson.block.20.bn.bias', 'trillsson.block.30.project_bn.running_var', 'trillsson.block.14.expand_bn.bias', 'trillsson.block.19.project_bn.running_var', 'trillsson.block.18.se.se_expand.weight', 'trillsson.block.2.project_bn.bias', 'trillsson.block.15.se.se_reduce.bias', 'trillsson.block.25.expand_bn.bias', 'trillsson.block.25.project_bn.running_var', 'trillsson.block.31.project_conv.weight', 'trillsson.block.34.dwconv2.weight', 'trillsson.block.25.se.se_expand.bias', 'trillsson.block.11.project_bn.running_mean', 'trillsson.block.39.se.se_reduce.weight', 'trillsson.block.29.project_conv.weight', 'trillsson.block.28.dwconv2.weight', 'trillsson.block.19.bn.running_mean', 'trillsson.block.11.project_bn.num_batches_tracked', 'trillsson.block.38.project_bn.running_mean', 'trillsson.block.26.project_bn.running_var', 'trillsson.block.6.expand_bn.bias', 'trillsson.block.22.expand_bn.running_var', 'trillsson.block.12.bn.num_batches_tracked', 'trillsson.block.32.expand_bn.bias', 'trillsson.block.25.bn.running_mean', 'trillsson.block.37.expand_bn.running_var', 'trillsson.block.27.bn.weight', 'trillsson.block.23.bn.weight', 'trillsson.block.39.expand_bn.running_mean', 'trillsson.block.26.expand_bn.running_var', 'trillsson.block.17.expand_bn.running_var', 'trillsson.block.29.project_bn.running_mean', 'trillsson.block.38.project_bn.running_var', 'trillsson.block.36.bn.running_mean', 'trillsson.block.13.bn.num_batches_tracked', 'trillsson.block.14.dwconv2.weight', 'trillsson.block.38.se.se_reduce.bias', 'trillsson.stem.stem_bn.num_batches_tracked', 'trillsson.block.2.project_bn.running_mean', 'trillsson.block.32.dwconv2.weight', 'trillsson.block.36.expand_bn.bias', 'trillsson.block.33.expand_bn.num_batches_tracked', 'trillsson.block.27.project_bn.running_mean', 'trillsson.block.19.project_bn.bias', 'trillsson.block.5.project_bn.weight', 'trillsson.block.17.bn.num_batches_tracked', 'trillsson.block.31.project_bn.bias', 'trillsson.block.36.se.se_reduce.weight', 'trillsson.block.23.dwconv2.weight', 'trillsson.stem.stem_conv.weight', 'trillsson.block.13.expand_bn.num_batches_tracked', 'trillsson.block.20.expand_conv.weight', 'trillsson.block.35.se.se_reduce.weight', 'trillsson.block.18.expand_bn.num_batches_tracked', 'trillsson.block.33.expand_bn.bias', 'trillsson.block.10.expand_bn.num_batches_tracked', 'trillsson.block.25.expand_conv.weight', 'trillsson.block.32.expand_bn.num_batches_tracked', 'trillsson.block.39.expand_bn.running_var', 'trillsson.block.2.project_bn.running_var', 'trillsson.block.8.expand_bn.running_var', 'trillsson.block.16.se.se_reduce.weight', 'trillsson.block.33.project_bn.weight', 'trillsson.block.29.expand_bn.num_batches_tracked', 'trillsson.block.29.bn.bias', 'trillsson.block.39.project_bn.running_var', 'trillsson.block.3.project_bn.num_batches_tracked', 'trillsson.block.17.bn.bias', 'trillsson.block.3.expand_bn.weight', 'trillsson.block.27.bn.bias', 'trillsson.block.27.bn.num_batches_tracked', 'trillsson.block.6.expand_bn.running_mean', 'trillsson.block.11.dwconv2.weight', 'trillsson.block.22.se.se_reduce.bias', 'trillsson.block.34.expand_conv.weight', 'trillsson.block.12.bn.bias', 'trillsson.block.13.se.se_expand.weight', 'trillsson.block.8.project_conv.weight', 'trillsson.dense.bias', 'trillsson.block.24.bn.bias', 'trillsson.block.35.expand_bn.running_mean', 'trillsson.block.23.expand_bn.bias', 'trillsson.block.11.project_conv.weight', 'trillsson.block.38.bn.weight', 'trillsson.block.29.project_bn.bias', 'trillsson.block.5.expand_bn.running_var', 'trillsson.block.20.expand_bn.num_batches_tracked', 'trillsson.block.33.project_conv.weight', 'trillsson.block.27.bn.running_mean', 'trillsson.block.2.expand_bn.running_mean', 'trillsson.block.18.expand_bn.running_mean', 'trillsson.block.32.bn.running_mean', 'trillsson.block.33.bn.num_batches_tracked', 'trillsson.block.24.project_bn.weight', 'trillsson.block.34.expand_bn.weight', 'trillsson.block.9.expand_bn.running_var', 'trillsson.block.1.project_bn.running_mean', 'trillsson.block.4.project_bn.bias', 'trillsson.block.32.se.se_reduce.weight', 'trillsson.block.10.expand_bn.bias', 'trillsson.block.37.expand_bn.weight', 'trillsson.block.23.bn.bias', 'trillsson.block.26.se.se_reduce.bias', 'trillsson.block.19.project_bn.num_batches_tracked', 'trillsson.block.10.dwconv2.weight', 'trillsson.block.16.expand_bn.weight', 'trillsson.block.36.expand_bn.num_batches_tracked', 'trillsson.block.16.expand_bn.running_var', 'trillsson.block.7.expand_conv.weight', 'trillsson.block.26.bn.weight', 'trillsson.block.28.bn.weight', 'classifier.weight', 'trillsson.block.28.expand_bn.weight', 'trillsson.block.15.expand_bn.running_var', 'trillsson.block.25.bn.bias', 'trillsson.block.13.project_bn.weight', 'trillsson.block.10.project_bn.weight', 'trillsson.block.15.bn.running_mean', 'trillsson.block.19.se.se_expand.bias', 'trillsson.block.24.se.se_reduce.bias', 'trillsson.block.3.project_conv.weight', 'trillsson.block.35.bn.running_mean', 'trillsson.block.11.expand_bn.weight', 'trillsson.block.0.project_bn.weight', 'trillsson.block.4.expand_bn.running_var', 'trillsson.block.15.dwconv2.weight', 'trillsson.block.22.expand_bn.running_mean', 'trillsson.block.31.expand_bn.num_batches_tracked', 'trillsson.block.16.se.se_expand.bias', 'trillsson.block.35.project_bn.running_var', 'trillsson.block.14.bn.running_mean', 'trillsson.block.4.expand_bn.num_batches_tracked', 'trillsson.block.1.project_bn.running_var', 'trillsson.block.23.project_bn.num_batches_tracked', 'trillsson.block.20.expand_bn.bias', 'trillsson.block.8.project_bn.running_mean', 'trillsson.block.12.se.se_reduce.bias', 'trillsson.block.36.project_bn.running_var', 'trillsson.block.1.project_conv.weight', 'trillsson.block.31.se.se_expand.bias', 'trillsson.block.18.project_bn.bias', 'trillsson.block.22.bn.running_mean', 'trillsson.block.5.project_bn.num_batches_tracked', 'trillsson.block.36.project_bn.num_batches_tracked', 'trillsson.block.24.se.se_reduce.weight', 'trillsson.block.29.project_bn.num_batches_tracked', 'trillsson.block.16.expand_bn.bias', 'trillsson.block.18.project_bn.running_mean', 'trillsson.block.21.se.se_expand.weight', 'trillsson.block.17.bn.weight', 'trillsson.block.27.project_conv.weight', 'trillsson.block.33.se.se_expand.weight', 'trillsson.block.30.bn.num_batches_tracked', 'trillsson.block.21.expand_bn.weight', 'trillsson.block.21.project_bn.running_var', 'trillsson.block.30.bn.running_mean', 'trillsson.block.30.project_bn.num_batches_tracked', 'trillsson.block.26.bn.running_var', 'trillsson.block.31.expand_bn.weight', 'trillsson.block.25.expand_bn.running_var', 'trillsson.block.14.project_bn.num_batches_tracked', 'trillsson.block.17.project_bn.running_mean', 'trillsson.block.26.expand_bn.bias', 'trillsson.block.24.expand_bn.num_batches_tracked', 'trillsson.block.34.se.se_reduce.bias', 'trillsson.block.10.se.se_expand.weight', 'trillsson.block.27.dwconv2.weight', 'trillsson.block.37.se.se_reduce.bias', 'trillsson.block.20.se.se_expand.bias', 'trillsson.block.29.bn.running_var', 'trillsson.block.28.project_bn.running_var', 'trillsson.block.39.bn.num_batches_tracked', 'trillsson.block.31.project_bn.running_var', 'trillsson.block.13.expand_bn.running_mean', 'trillsson.block.14.expand_bn.weight', 'trillsson.block.27.project_bn.bias', 'trillsson.block.38.bn.num_batches_tracked', 'trillsson.block.15.expand_bn.num_batches_tracked', 'trillsson.block.39.project_bn.bias', 'trillsson.block.12.bn.weight', 'trillsson.block.36.project_bn.bias', 'trillsson.block.11.expand_bn.bias', 'trillsson.block.30.se.se_reduce.bias', 'trillsson.block.15.expand_bn.bias', 'trillsson.stem.stem_bn.running_var', 'trillsson.block.27.project_bn.running_var', 'trillsson.block.4.project_bn.weight', 'trillsson.block.31.se.se_reduce.weight', 'trillsson.block.17.project_bn.running_var', 'trillsson.block.15.se.se_reduce.weight', 'trillsson.block.16.project_bn.running_var', 'trillsson.block.17.expand_bn.weight', 'trillsson.block.23.expand_bn.weight', 'trillsson.block.6.project_bn.weight', 'trillsson.block.21.bn.weight', 'trillsson.block.8.expand_bn.num_batches_tracked', 'trillsson.block.31.expand_bn.bias', 'trillsson.block.35.se.se_reduce.bias', 'trillsson.stem.stem_bn.weight', 'trillsson.block.22.se.se_reduce.weight', 'trillsson.block.27.expand_bn.running_mean', 'trillsson.block.3.project_bn.running_var', 'trillsson.block.36.se.se_expand.bias', 'trillsson.block.13.se.se_expand.bias', 'trillsson.block.38.se.se_expand.weight', 'trillsson.block.35.project_bn.bias', 'trillsson.block.39.bn.running_var', 'trillsson.block.29.expand_bn.bias', 'trillsson.block.34.project_bn.bias', 'trillsson.block.16.expand_conv.weight', 'trillsson.block.32.se.se_reduce.bias', 'trillsson.block.32.project_bn.running_mean', 'trillsson.block.9.expand_conv.weight', 'trillsson.block.39.expand_bn.num_batches_tracked', 'trillsson.block.30.se.se_reduce.weight', 'trillsson.block.5.expand_bn.bias', 'trillsson.block.11.bn.bias', 'trillsson.block.18.project_bn.running_var', 'trillsson.block.39.se.se_reduce.bias', 'trillsson.block.33.bn.bias', 'trillsson.block.10.bn.running_mean', 'trillsson.block.33.expand_bn.running_var', 'trillsson.block.10.expand_bn.weight', 'trillsson.block.28.project_conv.weight', 'trillsson.block.12.expand_bn.weight', 'trillsson.block.3.project_bn.weight', 'trillsson.block.25.project_bn.num_batches_tracked', 'trillsson.block.10.bn.weight', 'trillsson.block.23.project_bn.bias', 'trillsson.block.32.project_bn.num_batches_tracked', 'trillsson.block.11.bn.running_var', 'trillsson.block.31.bn.weight', 'trillsson.block.38.expand_conv.weight', 'trillsson.block.18.project_bn.num_batches_tracked', 'trillsson.stem.stem_bn.bias', 'trillsson.block.15.se.se_expand.weight', 'trillsson.block.15.bn.num_batches_tracked', 'trillsson.block.24.expand_bn.running_mean', 'trillsson.block.36.dwconv2.weight', 'trillsson.block.33.bn.running_mean', 'trillsson.block.33.se.se_reduce.weight', 'trillsson.block.27.expand_conv.weight', 'trillsson.block.3.expand_bn.bias', 'trillsson.block.30.expand_bn.bias', 'trillsson.block.37.expand_conv.weight', 'trillsson.block.22.project_bn.bias', 'trillsson.block.2.project_conv.weight', 'trillsson.block.38.se.se_expand.bias', 'trillsson.block.32.project_bn.bias', 'trillsson.block.17.se.se_reduce.weight', 'trillsson.block.18.bn.running_mean', 'trillsson.block.18.expand_conv.weight', 'trillsson.block.38.project_conv.weight', 'trillsson.block.25.project_bn.running_mean', 'trillsson.block.16.bn.num_batches_tracked', 'trillsson.block.29.bn.running_mean', 'trillsson.block.30.project_conv.weight', 'trillsson.block.20.bn.num_batches_tracked', 'trillsson.block.0.project_bn.running_var', 'trillsson.block.9.project_bn.num_batches_tracked', 'trillsson.block.4.expand_bn.running_mean', 'trillsson.block.24.bn.running_var', 'trillsson.block.7.project_conv.weight', 'trillsson.block.35.project_conv.weight', 'trillsson.block.20.dwconv2.weight', 'trillsson.block.18.bn.num_batches_tracked', 'trillsson.block.30.expand_bn.running_var', 'trillsson.block.37.bn.bias', 'trillsson.block.34.bn.bias', 'trillsson.block.2.project_bn.num_batches_tracked', 'trillsson.top.top_conv.weight', 'trillsson.block.0.project_bn.bias', 'trillsson.block.32.project_bn.running_var', 'trillsson.block.15.project_bn.running_var', 'trillsson.block.2.expand_bn.num_batches_tracked', 'trillsson.block.13.dwconv2.weight', 'trillsson.block.26.project_bn.bias', 'trillsson.block.35.expand_bn.bias', 'trillsson.block.8.expand_bn.running_mean', 'trillsson.block.35.project_bn.num_batches_tracked', 'trillsson.block.2.expand_conv.weight', 'trillsson.block.17.project_bn.weight', 'trillsson.block.22.bn.num_batches_tracked', 'trillsson.block.24.bn.running_mean', 'trillsson.block.3.expand_bn.running_var', 'trillsson.block.34.expand_bn.bias', 'trillsson.block.15.project_bn.bias', 'trillsson.block.5.project_bn.running_mean', 'trillsson.block.28.expand_bn.num_batches_tracked', 'trillsson.block.21.expand_bn.running_mean', 'trillsson.block.26.bn.bias', 'trillsson.block.30.project_bn.bias', 'trillsson.block.35.expand_bn.running_var', 'trillsson.block.27.project_bn.weight', 'trillsson.block.12.project_bn.num_batches_tracked', 'trillsson.block.23.project_conv.weight', 'trillsson.block.34.bn.running_mean', 'trillsson.block.17.project_bn.num_batches_tracked', 'trillsson.block.12.expand_bn.bias', 'trillsson.block.17.project_conv.weight', 'trillsson.block.39.expand_bn.weight', 'trillsson.block.16.project_bn.num_batches_tracked', 'trillsson.block.33.expand_bn.weight', 'trillsson.block.12.project_bn.weight', 'trillsson.block.26.expand_bn.num_batches_tracked', 'trillsson.block.39.dwconv2.weight', 'trillsson.block.39.project_conv.weight', 'trillsson.block.14.project_bn.bias', 'trillsson.block.31.project_bn.weight', 'trillsson.block.33.project_bn.bias', 'trillsson.block.27.se.se_reduce.bias', 'trillsson.block.14.bn.bias', 'trillsson.block.28.expand_bn.running_mean', 'trillsson.block.32.bn.num_batches_tracked', 'trillsson.block.2.project_bn.weight', 'trillsson.block.11.bn.running_mean', 'trillsson.block.23.bn.running_var', 'trillsson.block.37.expand_bn.bias', 'trillsson.block.33.project_bn.num_batches_tracked', 'trillsson.block.36.project_bn.weight', 'trillsson.block.38.project_bn.weight', 'trillsson.block.24.expand_bn.running_var', 'trillsson.block.36.expand_bn.weight', 'trillsson.block.13.bn.bias', 'trillsson.block.5.project_bn.running_var', 'trillsson.block.28.bn.bias', 'trillsson.block.16.bn.running_var', 'trillsson.block.30.expand_bn.num_batches_tracked', 'trillsson.block.28.project_bn.weight', 'trillsson.block.3.expand_conv.weight', 'trillsson.block.39.project_bn.running_mean', 'trillsson.block.9.project_conv.weight', 'trillsson.block.38.expand_bn.running_var', 'trillsson.block.8.project_bn.bias', 'trillsson.block.17.expand_bn.bias', 'trillsson.block.23.se.se_reduce.weight', 'trillsson.block.24.bn.num_batches_tracked', 'trillsson.block.13.expand_bn.weight', 'trillsson.block.19.se.se_reduce.bias', 'trillsson.block.27.se.se_reduce.weight', 'trillsson.block.6.project_bn.running_mean', 'trillsson.block.21.expand_conv.weight', 'trillsson.block.39.se.se_expand.bias', 'trillsson.block.34.project_bn.running_mean', 'trillsson.block.29.bn.num_batches_tracked', 'trillsson.block.7.expand_bn.num_batches_tracked', 'trillsson.block.21.bn.running_var', 'trillsson.block.13.se.se_reduce.weight', 'trillsson.block.35.expand_conv.weight', 'trillsson.block.14.se.se_expand.weight', 'trillsson.block.20.bn.weight', 'trillsson.block.21.project_bn.running_mean', 'trillsson.block.4.project_conv.weight', 'trillsson.block.26.se.se_expand.weight', 'trillsson.block.16.project_bn.bias', 'trillsson.top.top_bn.bias', 'trillsson.block.39.bn.bias', 'trillsson.block.11.expand_bn.num_batches_tracked', 'trillsson.block.38.project_bn.bias', 'trillsson.block.7.expand_bn.bias', 'trillsson.block.33.project_bn.running_var', 'trillsson.block.4.project_bn.running_var', 'trillsson.block.20.bn.running_mean', 'trillsson.block.30.dwconv2.weight', 'trillsson.block.3.expand_bn.num_batches_tracked', 'trillsson.block.21.dwconv2.weight', 'trillsson.block.22.se.se_expand.bias', 'trillsson.block.11.se.se_reduce.weight', 'trillsson.block.37.project_bn.weight', 'trillsson.block.30.se.se_expand.weight', 'trillsson.block.33.project_bn.running_mean', 'trillsson.block.15.se.se_expand.bias', 'trillsson.block.34.se.se_reduce.weight', 'trillsson.block.13.project_bn.bias', 'trillsson.block.22.project_bn.running_mean', 'trillsson.block.31.project_bn.running_mean', 'trillsson.block.5.expand_bn.running_mean', 'trillsson.block.32.se.se_expand.bias', 'trillsson.block.34.project_conv.weight', 'trillsson.block.13.bn.running_var', 'trillsson.block.24.se.se_expand.bias', 'trillsson.block.25.expand_bn.running_mean', 'trillsson.block.27.expand_bn.num_batches_tracked', 'trillsson.block.12.project_bn.bias', 'trillsson.block.12.bn.running_mean', 'trillsson.block.3.project_bn.bias', 'trillsson.block.11.expand_bn.running_var', 'trillsson.block.11.se.se_expand.weight', 'trillsson.block.12.se.se_reduce.weight', 'trillsson.block.28.expand_conv.weight', 'trillsson.block.30.bn.running_var', 'trillsson.block.18.project_bn.weight', 'trillsson.block.10.se.se_reduce.bias', 'trillsson.block.7.project_bn.running_mean', 'trillsson.block.29.bn.weight', 'trillsson.block.34.project_bn.weight', 'trillsson.block.16.expand_bn.num_batches_tracked', 'trillsson.block.33.se.se_reduce.bias', 'trillsson.block.12.expand_bn.running_var', 'trillsson.block.23.project_bn.running_var', 'trillsson.block.24.project_bn.bias', 'trillsson.block.20.project_conv.weight', 'trillsson.block.15.project_bn.running_mean', 'trillsson.block.11.expand_bn.running_mean', 'trillsson.block.15.bn.running_var', 'trillsson.block.12.dwconv2.weight', 'trillsson.block.39.project_bn.weight', 'trillsson.block.27.expand_bn.running_var', 'trillsson.block.6.expand_bn.num_batches_tracked', 'trillsson.block.16.bn.weight', 'trillsson.block.22.bn.running_var', 'trillsson.block.22.bn.weight', 'trillsson.block.34.expand_bn.running_mean', 'trillsson.block.22.expand_bn.bias', 'trillsson.block.20.se.se_reduce.weight', 'trillsson.block.21.bn.running_mean', 'trillsson.block.14.project_bn.running_var', 'trillsson.block.19.dwconv2.weight', 'trillsson.block.24.expand_conv.weight', 'trillsson.block.28.expand_bn.running_var', 'trillsson.dense.weight', 'trillsson.block.9.project_bn.weight', 'trillsson.block.19.expand_bn.bias', 'trillsson.block.12.project_bn.running_var', 'trillsson.block.21.se.se_reduce.bias', 'trillsson.block.23.bn.running_mean', 'trillsson.block.11.project_bn.running_var', 'trillsson.block.25.se.se_expand.weight', 'trillsson.block.14.se.se_reduce.weight', 'trillsson.block.14.expand_bn.running_mean', 'trillsson.block.34.se.se_expand.weight', 'trillsson.block.17.bn.running_mean', 'trillsson.block.31.expand_conv.weight', 'trillsson.block.36.project_bn.running_mean', 'trillsson.block.14.expand_conv.weight', 'trillsson.block.27.expand_bn.bias', 'trillsson.block.6.expand_bn.weight', 'trillsson.block.37.project_bn.bias', 'trillsson.block.27.se.se_expand.weight', 'trillsson.block.30.project_bn.weight', 'trillsson.block.6.project_conv.weight', 'trillsson.block.8.project_bn.weight', 'trillsson.block.22.project_conv.weight', 'trillsson.block.11.se.se_reduce.bias', 'trillsson.block.17.expand_bn.running_mean', 'trillsson.block.17.project_bn.bias', 'trillsson.stem.stem_bn.running_mean', 'trillsson.block.29.se.se_reduce.weight', 'trillsson.block.37.se.se_expand.weight', 'trillsson.block.32.project_bn.weight', 'trillsson.block.8.project_bn.running_var', 'trillsson.block.37.dwconv2.weight', 'trillsson.block.19.project_bn.weight', 'trillsson.block.30.expand_conv.weight', 'trillsson.block.19.bn.weight', 'trillsson.block.13.expand_conv.weight', 'trillsson.block.30.expand_bn.weight', 'trillsson.block.36.expand_bn.running_var', 'trillsson.block.37.expand_bn.num_batches_tracked', 'trillsson.block.21.se.se_reduce.weight', 'trillsson.block.19.project_bn.running_mean', 'trillsson.block.29.expand_bn.running_mean', 'trillsson.block.13.expand_bn.bias', 'trillsson.block.14.project_conv.weight', 'trillsson.block.31.se.se_expand.weight', 'trillsson.top.top_bn.running_var', 'trillsson.block.19.expand_bn.running_mean', 'trillsson.block.30.bn.bias', 'trillsson.block.16.expand_bn.running_mean', 'trillsson.block.35.dwconv2.weight', 'trillsson.block.28.se.se_expand.weight', 'trillsson.block.15.expand_bn.running_mean', 'trillsson.block.7.expand_bn.running_var', 'trillsson.block.26.expand_conv.weight', 'trillsson.block.14.expand_bn.num_batches_tracked', 'trillsson.block.24.bn.weight', 'trillsson.block.19.expand_bn.weight', 'trillsson.top.top_bn.num_batches_tracked', 'trillsson.block.21.project_bn.bias', 'trillsson.block.23.se.se_expand.weight', 'trillsson.block.18.bn.running_var', 'trillsson.block.10.expand_conv.weight', 'trillsson.block.12.bn.running_var', 'trillsson.block.25.se.se_reduce.bias', 'trillsson.block.24.project_conv.weight', 'trillsson.block.38.expand_bn.running_mean', 'trillsson.block.23.project_bn.weight', 'trillsson.block.13.project_conv.weight', 'trillsson.block.13.se.se_reduce.bias', 'trillsson.block.31.expand_bn.running_mean', 'trillsson.block.24.se.se_expand.weight', 'trillsson.block.19.expand_bn.num_batches_tracked', 'trillsson.block.23.se.se_reduce.bias', 'trillsson.block.15.bn.weight', 'trillsson.block.24.project_bn.num_batches_tracked', 'trillsson.block.38.se.se_reduce.weight', 'trillsson.block.25.bn.num_batches_tracked', 'trillsson.block.10.expand_bn.running_var', 'trillsson.block.5.expand_bn.num_batches_tracked', 'trillsson.block.20.expand_bn.running_mean', 'trillsson.block.24.dwconv2.weight', 'trillsson.block.34.se.se_expand.bias', 'trillsson.block.7.project_bn.num_batches_tracked', 'trillsson.block.35.bn.running_var', 'trillsson.block.10.bn.bias', 'trillsson.block.30.bn.weight', 'trillsson.block.12.se.se_expand.weight', 'trillsson.block.20.project_bn.weight', 'trillsson.top.top_bn.weight', 'trillsson.block.1.project_bn.bias', 'trillsson.block.14.project_bn.weight', 'trillsson.block.9.project_bn.running_var', 'trillsson.block.34.bn.num_batches_tracked', 'trillsson.block.13.project_bn.running_var', 'trillsson.block.29.se.se_expand.bias', 'trillsson.block.32.bn.running_var', 'trillsson.block.1.project_bn.weight', 'trillsson.block.33.expand_bn.running_mean', 'trillsson.block.34.expand_bn.running_var', 'trillsson.block.0.project_bn.running_mean', 'trillsson.block.35.expand_bn.num_batches_tracked', 'trillsson.block.12.expand_bn.num_batches_tracked', 'trillsson.block.32.expand_conv.weight', 'trillsson.block.14.expand_bn.running_var', 'trillsson.block.35.bn.num_batches_tracked', 'trillsson.block.31.expand_bn.running_var', 'trillsson.block.25.bn.running_var', 'trillsson.block.23.expand_bn.running_mean', 'trillsson.block.32.se.se_expand.weight', 'trillsson.block.18.expand_bn.running_var', 'trillsson.block.33.expand_conv.weight', 'trillsson.block.18.se.se_expand.bias', 'trillsson.block.10.project_bn.running_mean', 'trillsson.block.14.se.se_reduce.bias', 'trillsson.block.21.project_conv.weight', 'trillsson.block.22.expand_conv.weight', 'trillsson.block.32.expand_bn.running_var', 'trillsson.block.36.se.se_reduce.bias', 'trillsson.block.35.bn.bias', 'trillsson.block.26.project_bn.weight', 'trillsson.block.25.dwconv2.weight', 'trillsson.block.36.bn.running_var', 'trillsson.block.19.expand_conv.weight', 'trillsson.block.23.expand_bn.running_var', 'trillsson.block.11.project_bn.bias', 'trillsson.block.30.se.se_expand.bias', 'trillsson.block.35.project_bn.running_mean', 'trillsson.block.37.project_bn.num_batches_tracked', 'trillsson.block.15.expand_bn.weight', 'trillsson.block.28.se.se_expand.bias', 'trillsson.block.31.bn.running_mean', 'trillsson.block.18.se.se_reduce.bias', 'trillsson.block.34.project_bn.running_var', 'trillsson.block.38.expand_bn.num_batches_tracked']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
Do you have any ideas how to fix this problem?<|||||>OKay! Will have a look at that with my review 😉 <|||||>Also I think we should probably specify which architecture is actually being implemented here as TRILLsson introduced 3 student networks, and I am mostly seing 2 variations in architectures here. (so which one gives Resnetish or efficient net). Correct me if I am wrong!
- Audio Spectrogram Transformer (AST) is already included in HF, but we could probably convert the checkpoints of this model and add it to the hub easily ! (the config should be enough to change the depths and widths)
<|||||>Thank you very much for reviewing my code :heart: . I will check all of them<|||||>Sorry for the late response and thanks again for reviewing my code @ArthurZucker. I revised it as per your suggestion. Regarding your question, Trillsson has 3 different student architectures but here I just implement only one, efficientnetv2. After that, we can expand to other variants in the future.<|||||>Feel free to ping me again for a review<|||||>@ArthurZucker can you review it again <|||||>Update: I am really sorry, but EfficientNet has been merged to transformers! SOrry because it means some of your hard work goes to the drain (a little bit)! But should ease the addition of your models! See this [PR](https://github.com/huggingface/transformers/pull/21563/). You can use this implementation by relying on `# copied from` to get the efficien net code in your code! <|||||>@ArthurZucker Thank you for letting me know. I think I need a bit of time to investigate the structure of merged EfficientNet to load weight correctly. |
transformers | 17,386 | closed | Add FP16 Support for SageMaker Model Parallel |
(This PR is still pending some changes/fixes)
This PR adds support for SageMaker Model Parallel with FP16.
- To Enable fp16 with SMMP, user needs to add `fp16: True` to `SM_HP_MP_PARAMETERS`, when there's mismatch between `SM_HP_MP_PARAMETERS` and trainer args, a warning log would be printed and `SM_HP_MP_PARAMETERS` will be used as truth.
- Remove amp related stuff for SMMP as SMMP manages it's own half precision.
- Added `clip_master_grads` for grad clipping
- Some minor fixes
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 05-23-2022 23:46:00 | 05-23-2022 23:46:00 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@philschmid Please review or suggest review, thanks!<|||||>Can you just run `make style` on your branch to fix the code quality issue? Thanks! |
transformers | 17,385 | closed | Same sequence gets different token probabilities depending on whether it's generated from sampling or beam search | ### System Info
```shell
- `transformers` version: 4.20.0.dev0
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.11.0+cu113 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?:No
```
### Who can help?
@patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I first generate a sequence using beam search with T5. I then generate a sequence using sampling set to a particular seed that happens to get the same sequence as the beam search decoding. I then calculate the token probabilities for both sequences and find that they differ despite being the same sequences.
This colab reproduces the behavior:
https://colab.research.google.com/drive/1vLmUfqYdKVo1z2Ztv2V2sQ29nDCYNbFK?usp=sharing
### Expected behavior
```shell
A sequence generated from a model using beam search and the same sequence generated from the same model from sampling should have the same token probabilities provided that they have the same hyperparameters (e.g., the length penalty should be the same for both).
```
| 05-23-2022 21:07:44 | 05-23-2022 21:07:44 | Heey @hacobe,
I'm not sure this is a bug. Note that beam_search is very much different from sample, see: https://huggingface.co/blog/how-to-generate
Why should they give the same probabilities?<|||||>Hi @patrickvonplaten,
The probability for a token is the output of the softmax layer for that token conditioning on the sequence generated so far. The way we generate a sequence changes if we use beam search instead of sampling, but the definition of the probability does not change. The probability is a function of the model you're using and the sequence generated so far. If you're using the same model and you've happened to generate the same sequence (and hyperparameters like length penalty are the same), then the probabilities should be the same.
Take the example under the "Beam search" heading in that blog post. The top beam search sequence is ("The", "dog", "has"). It starts with the prompt "The". The token "dog" has a probability of 0.4 conditional on the sequence ("The"). The token "has" has a probability of 0.9 conditional on the sequence ("The", "dog").
Now suppose we sample from the same model starting with the prompt "The". What is the probability of the selecting the token "dog" at this step? It still has a probability of 0.4, because we're using the same model and conditioning on the same sequence ("The"). Suppose we happen to sample "dog". Then the sequence is ("The", "dog"). What is the probability of selecting the token "has" at this step? Again, the token "has" will have a probability of 0.9, because we're using the same model and conditioning on the same sequence ("The", "dog").
By the way, thanks for all your work on the token probabilities! I think it's an important feature (both OpenAI and fairseq return token probabilities in their APIs). It's a key input for uncertainty estimation and error detection.<|||||>Hey @hacobe,
Note that for beam search we sample from `current_beam_scores + log_prob_of_token` whereas for sampling we just sample from prob_of_token.
For beam search see here:
https://github.com/huggingface/transformers/blob/5c17918fe4cda80dae5b7ec8f0b2d23a813c4a05/src/transformers/generation_utils.py#L2225
For sampling see here:
https://github.com/huggingface/transformers/blob/5c17918fe4cda80dae5b7ec8f0b2d23a813c4a05/src/transformers/generation_utils.py#L1974<|||||>Hi @patrickvonplaten,
By "for beam search we sample from `current_beam_scores + log_prob_of_token`", do you mean that beam search selects sequences based on `current_beam_scores + log_prob_of_token`? Beam search is deterministic. It does not involve sampling. `current_beam_scores + log_prob_of_token` is the log sequence probability used to select the top k sequences at each step in beam search. I'm comparing the transition beam scores given by `compute_transition_beam_scores`, which I interpret as the log token (not sequence) probabilities, to the log token (not sequence) probabilities from sampling. If you think I'm still missing something, I can dig into the code when I get some time. Thanks for your help!<|||||>Hi @patrickvonplaten,
I didn't realize top_k is set to 50 by default. When I change top_k = 0, then I get the same probabilities as expected. |
transformers | 17,384 | closed | Print more library versions in CI | # What does this PR do?
- Print more library versions in CI jobs
- `transformers`, `PyTorch`, `TensorFlow`, `DeepSpeed`, etc.
- easier to access without the need to open several tabs
| 05-23-2022 19:55:40 | 05-23-2022 19:55:40 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@stas00 OK for me to use a script, on it!<|||||>@stas00
Just pushed a quick version. It is now named `utils/print_env.py`, which tries to print information if a library could be imported.
Probably need a better job name than `GPU visibility`, but it shows something like
<img width="512" alt="Screenshot 2022-05-24 215339" src="https://user-images.githubusercontent.com/2521628/170120952-2be2f4d4-9061-43a4-9d51-8ebdb92650b2.png">
<|||||>Looks great, @ydshieh
Perhaps let's just turn warnings off to keep the SNR high? |
transformers | 17,383 | closed | Add FP16 Support for SageMaker Model Parallel | # What does this PR do?
(This PR is still pending some changes/fixes)
This PR adds support for SageMaker Model Parallel with FP16.
- To Enable fp16 with SMMP, user needs to add `fp16: True` to `SM_HP_MP_PARAMETERS`, when there's mismatch between `SM_HP_MP_PARAMETERS` and trainer args, a warning log would be printed and `SM_HP_MP_PARAMETERS` will be used as truth.
- Only do `uncale_` for `pp_rank` 0 in the beginning, as `scaler._scale `would be None at first for `pp_rank` > 0.
- Added `clip_master_grads` for grad clipping
- Some minor fixes
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
| 05-23-2022 19:55:29 | 05-23-2022 19:55:29 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,382 | closed | Add support for `device_map="auto"` to OPT | # What does this PR do?
I forgot to have OPT in the initial list of models supporting `device_map="auto"` (along side GPT-J, GPT-2 and T5). This PR takes care of it. | 05-23-2022 19:24:21 | 05-23-2022 19:24:21 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17382). All of your documentation changes will be reflected on that endpoint. |
transformers | 17,381 | closed | Fix Comet ML integration |
# What does this PR do?
This PR fixes an issue where the callback function `on_train_end` crashed if Comet ML integration was used but `experiment` was `None` after training (e.g. because the environment variable `COMET_MODE` was set to `DISABLE`).
Python snippet for testing (crashes before fix is applied):
```python
import os
from datasets import Dataset
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, Trainer, TrainingArguments
# disable comet_ml logging
os.environ['COMET_MODE'] = 'DISABLE'
# create dummy dataset for training
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
inputs = tokenizer(["Who likes Pizza?"], ["Dave likes pizza"])
inputs['start_positions'] = [[6]]
inputs['end_positions'] = [[6]]
dataset = Dataset.from_dict(inputs)
# create trainer
trainer = Trainer(model=AutoModelForQuestionAnswering.from_pretrained('bert-base-uncased'), args=TrainingArguments(output_dir='tmp', max_steps=1), train_dataset=dataset)
trainer.train()
```
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-23-2022 13:52:09 | 05-23-2022 13:52:09 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,380 | closed | Clean up CLIP tests | # What does this PR do?
This PR cleans up some tests of CLIP. See #17024 for more info. | 05-23-2022 09:33:21 | 05-23-2022 09:33:21 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,379 | closed | Add missing comment quotes | # What does this PR do?
This minor fix adds missing quote marks round some explanatory comments in the "new model" tokenizer cookiecutter template.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
`blame` suggests @LysandreJik | 05-23-2022 07:00:29 | 05-23-2022 07:00:29 | _The documentation is not available anymore as the PR was closed or merged._<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Sorry for letting this fall through the cracks, just merged it! |
transformers | 17,378 | closed | TF: Correct XLA generation with GPT-2 and T5 | # What does this PR do?
(WIP) | 05-21-2022 13:18:37 | 05-21-2022 13:18:37 | For future reference: the most recent commit, where T5 was adapted to discard padded past values (similarly to the FLAX implementation), works correctly numerically. However, when compiling to XLA, we get the following `NotImplementedError`:
<img width="1511" alt="Screenshot 2022-05-21 at 14 17 40" src="https://user-images.githubusercontent.com/12240844/169653445-25892c4b-3380-475b-ae24-861e840a9f05.png">
Because of that, I'll try a new strategy: the model receives as input the sliced past, without padding.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>The previous commit had a different approach (feed to the model the unpadded past), but resulted in the exact same exception. Both are related to a dynamic-size slicing of the past.<|||||>superceded by https://github.com/huggingface/transformers/pull/17426, which grabbed the good changes from this PR. T5 needs further 🔍 |
transformers | 17,377 | closed | Fix the wrong sample-rate of random tokens | # What does this PR do?
Fix the wrong sample-rate of random tokens from `0.1` to `0.5` in the `DataCollatorForLanguageModeling` and `DataCollatorForWholeWordMask`. | 05-21-2022 07:33:56 | 05-21-2022 07:33:56 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17377). All of your documentation changes will be reflected on that endpoint.<|||||>Hello! Why is it wrong?<|||||>> Hello! Why is it wrong?
Sorry for late! we should replace 10% masked input tokens with random word, but the code means replacing 10% from the remaining tokens not replaced with [MASK] token. So, we only replace 0.2 * 0.1 tokens, it should be 0.2 * 0.5 ?!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,376 | closed | Fix the wrong sample-rate of random tokens | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-21-2022 06:28:56 | 05-21-2022 06:28:56 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,375 | closed | 'lm_head.weight' is improperly not initialized when loading BART weights into BartForCausalLM | ### System Info
```shell
- `transformers` version: 4.19.2
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.11.0+cu113 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
```
### Who can help?
@patrickvonplaten
@patil-suraj
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Input: `bart = BartForCausalLM.from_pretrained('facebook/bart-base')`
Output: `Some weights of BartForCausalLM were not initialized from the model checkpoint at facebook/bart-base and are newly initialized: ['lm_head.weight']`
Input: `bart2 = BartForConditionalGeneration.from_pretrained('facebook/bart-base')`
Result: The LM Head for the encoder decoder model is properly initialized from the Bart-Base checkpoint
### Expected behavior
For both model configurations using `facebook/bart-base`, the LM Head layer has the same dimensions (`(lm_head): Linear(in_features=768, out_features=50265, bias=False)`). However, for BartForCausalLM, the LM head is randomly initialized, while for BartForConditionalGeneration, the LM is properly instantiated from the `facebook/bart-base` checkpoint.
Isn't this incorrect?
| 05-21-2022 00:53:33 | 05-21-2022 00:53:33 | Hey @nbravulapalli,
Thanks for the report. The model is actually correctly initialized, the reason you see this error message is simply because these lines:
https://github.com/huggingface/transformers/blob/56f50590d5a9ac881db9ee1753f4642cf3d33d28/src/transformers/models/bart/modeling_bart.py#L1275
are preset for `BartForConditionalGeneration` but not for `BartForCausalLM`
https://github.com/huggingface/transformers/blob/56f50590d5a9ac881db9ee1753f4642cf3d33d28/src/transformers/models/bart/modeling_bart.py#L1700
The model should however be correctly initialized.
Do you mind opening a PR to fix it? :-)
<|||||>Thank you for your reply @patrickvonplaten! I will take a shot at the PR, but I have two clarifying questions:
1) If I understand correctly, the LM head is properly initialized for both BartForConditionalGeneration and BartForCausalLM, but with BartForConditionalGeneration the error message is suppressed?
This is a separate question:
2) When I evaluate `bartMod.config.add_cross_attention` (a BartForCausalLM object) I get `False`. However, the model structure for `bartMod` includes
`(encoder_attn): BartAttention(`
`(k_proj): Linear(in_features=768, out_features=768, bias=True)`
`(v_proj): Linear(in_features=768, out_features=768, bias=True)`
`(q_proj): Linear(in_features=768, out_features=768, bias=True)`
`(out_proj): Linear(in_features=768, out_features=768, bias=True))`
which I assumed was the cross-attention layer designed for the decoder query matrix and the encoder key, value matrices.
a) Is this cross-attention layer not actually present in the CausalLM model, and this layer is improperly displayed? If so, does this mean that the CausalLM model doesn't actually work out of the box (since the built-in cross-attention layers are removed), and requires finetuning to be used for CausalLM?
b) If this cross-attention layer is actually present in the CausalLM model (and this layer is properly displayed), then how is this cross-attention layer still working even without being able to receive the encoder key, value matrices at inference time?<|||||>1. Yes, note it's a warning message that is suppressed not a error message
a) Yes BartForCausalLM won't work out of the box exactly because the cross attention layers are removed
b) It's not present in BartForCausalLM :-)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,374 | closed | fill-mask target for full words not enabled? | ### System Info
```shell
- `transformers` version: 4.19.2
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.11.0+cu113 (False)
- Tensorflow version (GPU?): 2.8.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
@Narsil and @LysandreJik (?)
How can one use Roberta for fill-mask to get the **full** word candidate and its "full" score for Roberta-large? Open to workaround solutions.
My example:
`sentence = f"Nitzsch argues against the doctrine of the annihilation of the wicked, regards the teaching of Scripture about eternal {nlp.tokenizer.mask_token} as hypothetical."`
Notebook [here](https://colab.research.google.com/drive/12QrU5SC7kHsM0gekzjLXDJXptAkdSnuq?usp=sharing).
Using pipeline, the output I get is:
`The specified target token ` damnation` does not exist in the model vocabulary. Replacing with `Ġdamn`.`
Thanks.
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
See notebook above.
### Expected behavior
```shell
I expect to see "damnation" with its score.
```
| 05-20-2022 23:12:58 | 05-20-2022 23:12:58 | hi @i-am-neo ,
Fill-mask works at a token level, not words, so you cannot use targets which are multi token. Since `damnation` seems to no exist directly in your vocabulary, it uses the closes `1-token` element it finds `damn`. You cannot unfortunately have `fill-mask` work with varying number of holes/tokens. You could use 2 masks instead of one for instance, but then you will need to logic "fuse" those two tokens which might not correspond to a single word.<|||||>Thanks @Narsil . I had thought so. No plans to allow full words and regex in your roadmap?<|||||>It's not something that fits the current `pipeline` model (at least in the default settings).
`pipeline` is aimed to make ML model usable without any ML specific knowledge, BUT never hiding any complexities it induces.
In this particular part, `fill-mask` model, do work on a token level, and trying to do `word-level` really requires some custom strategies (how many tokens is your word? Do you want to handle multiple size of tokens ?). How to resolve in case of multi tokens (since multi tokens will give you independent token probabilities, and not grouped probabilities).
Since it is a non trivial problem, we decide to not do it on behalf of users and give an output that is much closer to what the original model does. If simple strategies can be implemented maybe we can add them as opt-in parameters, but so far nothing is being worked on as far as I know. PRs are more than welcome.
If you want more background for instance, this PR might be valuable to read (and the linked PRs too); https://github.com/huggingface/transformers/pull/10222
I would like to point out `zero-shot-classification` which although not being the same pipeline we have seen being used in a similar fashion, which might suit your needs.
side note: An easy start solution for regexp is to fetch all tokens in the vocabulary that start with your prefix and use them as targets `targets=[word for word in tokenizer.get_vocab() if word.startswith("X")]` for instance. It's not all possible english words, but at least all possible elements of the vocabulary that will work.<|||||>I hear you @Narsil, it sure is non-trivial.
In my case, I would like a large-enough LM (for example, Roberta-large) to generate word candidates to start with, given some regex as hints/constraints, _without knowing in advance what the best candidates are, except for those hints_. My thinking is that the candidates the LM generates would more or less already fit into the context given to the model. Multiple candidates would be ranked post-fill by their scores.
Re `zero-shot-classification`, the trouble is without knowing in advance what the correct/best candidates are, it's more difficult to work it in.<|||||>> In my case, I would like a large-enough LM (for example, Roberta-large) to generate word candidates to start with, given some regex as hints/constraints, without knowing in advance what the best candidates are, except for those hints.
I think there would be a **lot of value** to be able to do that, but AFAIK there's no simple way to do that with bert-like models. I think the biggest culprit is that models are trained to give independant probabilities, and not joint ones. Solving it might require an entire new training objective.
`This house is <mask> and <mask>`:
Disjoint probabilities: (big: 50%, red: 50) (big: 50%, red: 50%)
Joint probabilities: ( (big, red, 50%) , (red, big, 50%) ) . (Btu then (big, big = 0% for instance, which is allowed in disjoint probabilities)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,373 | open | [WIP] [deepspeed] from_pretrained deal with ignore_mismatched_sizes | An attempt to fix the issue reported https://github.com/huggingface/transformers/issues/17336
Fixes: https://github.com/huggingface/transformers/issues/17336 | 05-20-2022 21:00:58 | 05-20-2022 21:00:58 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17373). All of your documentation changes will be reflected on that endpoint.<|||||>After creating a test I discovered it breaks on tied variables since they get ignored in `model.named_parameters` - so back to the drawing table. |
transformers | 17,372 | closed | Text2TextGeneration Pipeline : Batch size and num_return_sequences are not working together | ### System Info
```shell
- `transformers` version: 4.16.2
- Platform: Linux-5.13.0-40-generic-x86_64-with-glibc2.31
- Python version: 3.9.12
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
```
### Who can help?
Hello @Narsil,
When using a pipeline I wanted to speed up the generation and thus use the `batch_size` parameter.
In a `Text2TextGenerationPipeline`, with `num_return_sequences` of 1 everything works fine and I have a x3 speedup when using a `batch_size` of 8 !
However, I would like to use `num_return_sequences > 1`. Setting this still leads to the same amount of output utterances of input (and not twice as much (2 per input utterance if `num_return_sequences` is =2 )) and after investigation, I realized that the Text2TextPipeline has a `__call__` method with `[res[0] for res in results]` so I decided to remove it (with a custom class) to be able to have the "num_return_sequences * input_len".
```python
class MultipleText2TextGenerationPipeline(Text2TextGenerationPipeline):
def __call__(self, *args, **kwargs) -> list[str]:
result: list[list[dict[Literal["generated_text"], str]]] = super(Text2TextGenerationPipeline, self).__call__(*args, **kwargs)
flatten_results: list[str] = []
for result_list in result:
for result_dict in result_list:
flatten_results.append(result_dict["generated_text"].replace("question: ", ""))
return flatten_results
```
When, using `batch_size` with `num_return_sequences > 1` lead to weird output like having 24 outputs with `batch_size = 8` and `num_return_sequences=3`.... When using `num_return_sequences=1` I have the good output meaning 60 sentences if I places 20 uttrances as input with `num_return_sequences=3` but not for `batch_size>1`
Thanks in advance for any help,
Have a great day.
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from time import perf_counter
from torch import bfloat16
from transformers import Text2TextGenerationPipeline
from transformers.modeling_utils import PreTrainedModel
from transformers.models.auto.modeling_auto import AutoModelForSeq2SeqLM
from transformers.models.auto.tokenization_auto import AutoTokenizer
from transformers.tokenization_utils import PreTrainedTokenizer
class MultipleText2TextGenerationPipeline(Text2TextGenerationPipeline):
def __call__(self, *args, **kwargs) -> list[str]:
result: list[list[dict[Literal["generated_text"], str]]] = super(Text2TextGenerationPipeline, self).__call__(*args, **kwargs)
flatten_results: list[str] = []
for result_list in result:
for result_dict in result_list:
flatten_results.append(result_dict["generated_text"].replace("question: ", ""))
return flatten_results
tokenizer: PreTrainedTokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-question-generation-ap")
model: PreTrainedModel = AutoModelForSeq2SeqLM.from_pretrained("mrm8488/t5-base-finetuned-question-generation-ap")
pipeline = MultipleText2TextGenerationPipeline(model=model,tokenizer=tokenizer, device=0)
input_texts = [f"answer: {ans} context: I like to eat bananas in the morning" for ans in ['I', 'bananas', 'morning', 'yes', 'no']]
DEFAULT_GENERATOR_OPTIONS = {
"max_length": 128,
"min_length": 2,
"early_stopping": True,
"num_beams": 3,
"temperature": 1.0,
"top_k": 0,
"top_p": 0.92,
"repetition_penalty": 2.0,
"length_penalty": 1.0,
}
start=perf_counter()
print(len(input_texts))
print(f"expecting {len(input_texts)} got : ", end=" ")
print(len(pipeline(input_texts, **DEFAULT_GENERATOR_OPTIONS, num_return_sequences=1))) # 20
print(perf_counter()-start)
start=perf_counter()
print(len(input_texts))
print(f"expecting {len(input_texts)*3} got : ", end=" ")
print(len(pipeline(input_texts, **DEFAULT_GENERATOR_OPTIONS, num_return_sequences=3))) # 60
print(perf_counter()-start)
start=perf_counter()
print(len(input_texts))
print(f"expecting {len(input_texts)*3} got : ", end=" ")
print(len(pipeline(input_texts, **DEFAULT_GENERATOR_OPTIONS, num_return_sequences=3, batch_size=8))) # 24
print(perf_counter()-start)
```
### Expected behavior
```shell
If setting the number of return sequence of a list of string, return a list of len(list)*num_return_sequences
```
| 05-20-2022 20:30:45 | 05-20-2022 20:30:45 | Solved with huggingface 4.19.2.
Sorry for all the fuss. Maybe it will help someone someday. |
transformers | 17,371 | closed | tokenizer object incorrectly modified in PreTrainedTokenizerFast.train_new_from_iterator() | ### System Info
```shell
- `transformers` version: 4.19.2
- Platform: Linux-5.10.16.3-microsoft-standard-WSL2-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.6.0
- PyTorch version (GPU?): 1.11.0+cu102 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
```
### Who can help?
@SaulLu
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Steps to reproduce this behavior:
1) Create a tokenizer object from `tokenizers.implementations.ByteLevelBPETokenizer()`
2) Instanciate a PreTrainedTokenizer with it (`PreTrainedTokenizerFast.__init__(tokenizer_object=tokenizer)`)
3) Train the model using `PreTrainedTokenizer.train_new_from_iterator()`
4) Encode a token not found in the training set
5) Notice that the tokenized string has a unk token (or nothing) instead of the token
See this example:
```
import tokenizers
import transformers
tokenizer = tokenizers.implementations.ByteLevelBPETokenizer()
tokenizer_fast = transformers.PreTrainedTokenizerFast(tokenizer_object=tokenizer).train_new_from_iterator(text_iterator=["a" for _ in range(1000)], length=1000, vocab_size=5000)
## {'input_ids': [0], 'token_type_ids': [0], 'attention_mask': [1]}
print(tokenizer_fast("ab"))
```
This is because in `tokenization_utils_fast.py`, in `PreTrainedTokenizer.train_new_from_iterator`, the following code snippet ignores the class of the tokenizer_object that was passed inside the `__init__`:
```
print(type(self._tokenizer)) # <class 'tokenizers.implementations.byte_level_bpe.ByteLevelBPETokenizer'>
tokenizer = TokenizerFast.from_str(json.dumps(tokenizer_json))
print(type(tokenizer)) # <class 'tokenizers.Tokenizer'
```
And the `ByteLevelBPETokenizer` has a custom `train_from_iterator` which provides an initial_alphabet.
This issue does not arise if using only the `tokenizers` library for training:
```
import tokenizers
import transformers
tokenizer = tokenizers.implementations.ByteLevelBPETokenizer()
tokenizer.train_from_iterator(iterator=["a" for _ in range(1000)], length=1000, vocab_size=5000)
tokenizer_fast = transformers.PreTrainedTokenizerFast(tokenizer_object=tokenizer)
## {'input_ids': [64, 65], 'token_type_ids': [0, 0], 'attention_mask': [1, 1]}
print(tokenizer_fast("ab"))
```
### Expected behavior
I would expect the transformer library to use the tokenizer_object's train_from_iterator, even if that object is from a specific implementation. This is currently fixable on my side by providing **kwargs to train_new_from_iterator to emulate what the `ByteLevelBPETokenizer` is doing, but is something I expect the library to handle by itself. | 05-20-2022 17:41:59 | 05-20-2022 17:41:59 | Maybe also cc @Narsil |
transformers | 17,370 | closed | `_fast_init` overwrites weights passed to custom model | ### System Info
```shell
Transformers > 4.6.0
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Copy-pasting an issue from https://github.com/huggingface/transformers/pull/11471#issuecomment-1132324119 into a new issue to make it more visible as multiple people could have this problem.
When abstracting a `transformers` model and passing custom layers to the init method, the initialization can show strange behavior.
Consider the following case (taken from @josh-heyer ):
```python
from torch.nn import Linear
from transformers import BertModel
class MyCustomModel(BertModel):
def __init__(self, config, custom_layer=None):
super().__init__(config)
if custom_layer is not None:
self.custom_layer = custom_layer
else:
self.custom_layer = Linear(1024, 1024)
if __name__ == "__main__":
import transformers
print(transformers.__version__)
layer = Linear(1024, 1024)
print(layer.weight.sum())
custom_model = MyCustomModel.from_pretrained('bert-base-uncased', custom_layer=layer)
# used to be the same as the layer above, but it is "re-initialized" in the from_pretrained method
print(custom_model.custom_layer.weight.sum())
```
What will happen here since `_fast_init` was introduced in 4.6.0: https://github.com/huggingface/transformers/pull/11471 is that the weights of the custom layer will be overriden.
### Expected behavior
It might be reasonable to state that the custom layer should **not** be overriden.
| 05-20-2022 15:20:42 | 05-20-2022 15:20:42 | To describe what happens here:
If `_fast_init=True` (which is set by default) the following happens. All weight names of the `state_dict` loaded from `bert-base-uncased` are compared with all weight names of a random `state_dict` that is generated when calling `MyCustomModel()`.
Inside `from_pretrained(...)` at this point: https://github.com/huggingface/transformers/blob/7213a40bd914776a6dcebcc96353c4cf8c8c6668/src/transformers/modeling_utils.py#L2284 `custom_layer` is considered a missing layer because it cannot be found in the `state_dict` loaded from `bert-base-uncased` and thus will be randomly initialized, which happens **after** `self.custom_layer` has been set to the passed `layer` weight meaning `self.custom_layer` will be overridden.
This seems unexpected from the outside, but after having looked a bit into the internals of `from_pretrained(...)`, we sadly cannot really change this behavior and also don't consider it a bug.
In our opinion the problems rather lies in the following:
- 1. We **never** abstract `nn.Module` model classes that have an `__init__(...)` method except for the most basic `PretrainedModel` class which has an absolute minimal `__init__(...)` method (see [here](https://github.com/huggingface/transformers/blob/7213a40bd914776a6dcebcc96353c4cf8c8c6668/src/transformers/modeling_utils.py#L980) that just sets the config.
In the whole code base of `transformers`, models, such as `BertModel`, only abstract from their respective `...PretrainedModel` class, *e.g.* `BertModel` abstracts from `BertPretrainedModel`, but those classes don't have an `__init__` method, see [here]( https://github.com/huggingface/transformers/blob/3fd7de49f4d53832621ef67cfd1825b000323250/src/transformers/models/bert/modeling_bert.py#L733).
This way we can be sure that the only `__init__(...)` method that matters is the one of `BertModel`. Now this is broken here. `MyCustomModel` abstracts away `BertModel` which is exactly not what we want.
In short, we **always** favor **modularization over abstraction**. In our opinion, it is less error-prone and easier to understand.
- 2. We never have want to allow passing layers, such as `nn.Linear` into the `__init__` for the outer-most `nn.Module` classes, not even conditionally. The reason is that, if we allow / recommend this design, it would also mean that one could / should pass a trainable layer through `from_pretrained(...)`. We definitely don't want this as it breaks the assumption that a model is **always** self-contained a single checkpoint, *e.g.* `bert-base-cased` and would therefore make `from_pretrained(...)` very complex. So we never want users to pass trainable layers through `from_pretrained(...)`.
<|||||>To solve the problem above, we recommend to instead of using abstraction, to just use modularization:
```python
from torch.nn import Linear
from transformers import BertPreTrainedModel, BertModel
class MyCustomModel(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.custom_layer = Linear(1024, 1024)
def forward(self, ...):
self.bert(....)
def set_custom_layer(self, linear_embed):
self.custom_layer = linear_embed
```
Note that this is also exactly how we coded up `BertForMaskedLM`: https://github.com/huggingface/transformers/blob/3fd7de49f4d53832621ef67cfd1825b000323250/src/transformers/models/bert/modeling_bert.py#L1292<|||||>Thanks @patrickvonplaten - btw you tagged "josh-heyer" rather than "john"* haha. I'll take a deeper look and see how we can change our model initialization.<|||||>Ups sorry :sweat_smile: <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,369 | closed | Try to make push CI less noisy on commit pages. | # What does this PR do?
Try to make push CI less noisy on commit pages.
(Current commit page shows all push CI jobs (more than 256 now) status, which is noisy to check which tests failed.)
### Idea
1. push to `main` -> trigger a workflow, that push to another branch `push-ci`
2. push to `push-ci` -> trigger the actual push CI
~~- **TODO**: try to get failures in `2`, and add them to `1`. Fail the job if there is any failure.~~
Example run
[caller workflow run] https://github.com/huggingface/transformers/actions/runs/2358695597
[actual push CI run] https://github.com/huggingface/transformers/actions/runs/2358698408
| 05-20-2022 14:11:41 | 05-20-2022 14:11:41 | @LysandreJik This is still in WIP (just need to add back the failure report in the caller), but I think you can review it already :).
I follow [this guide](https://medium.com/prompt/trigger-another-github-workflow-without-using-a-personal-access-token-f594c21373ef) to add 2 keys in our `Settings`.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger Is it necessary to show the push CI (non Circle CI ones) results (simplified version) on the commit history page?
The current approach needs to find a way to wait (on a GitHub hosted CPU machine) the `actual push CI` run finish and get back the results. This is not obvious, as the 2 workflow are somehow `independent`. I will try in this week if this is necessary.<|||||>Since those are reported on slack, I don't think so. Just having the circle CI results (since those are not on slack) is good IMO.<|||||>Hi @sgugger , @LysandreJik
Sorry, I should have checked the results after this PR being merged.
It turns out that **the whole push CI jobs are still shown** in the dropdown menu when we click the green/red check/cross icons, see
https://github.com/huggingface/transformers/commit/39e146146b5545c89d3bc3cd5a0befd491757473
- It seems to me this check status **relies on the commit SHA**, rather than the branches where that workflow is triggered.
- We can use **on: workflow_run**, but we will lose important information in the workflow run page, see https://github.com/huggingface/accelerate/actions/workflows/on-merge.yml
- Changing the workflow/job names won't alter the order in the check status list
I will come back to this after the nightly PyTorch CI and past CI tasks, if it is OK for @sgugger .
<|||||>I think it's more important to have something less noisy to debug when a break happened, personally.<|||||>It's indeed important to make debugging easier. But could you let me know which following works for you 🙏
- changing the (push CI) trigger event to `on: workflow_run`: so we can see clearly on commit history page (for CircleCI tests) what go wrong, and we don't really care the push CI workflow run pages (less informative) - we rely on Slack push CI report
- this could be done quickly (if everything is working fine)
- We should keep `on: push`, but try to run the whole tests as a single job
- this will take more time - as we also like to keep the Slack report as the current format
- so the question becomes if I should work on the past CI first, which is already delayed for a few month now.
And one remark: it seems to me that the `ci/circleci` checks are always at the end - after all Github Actions check status<|||||>The first option is what I asked for at the beginning :-). It's impossible to even see the full title of the GitHub Action failing jobs, so seeing their failures in the commit is completely useless IMO. The slack CI reports are great and more than enough for those failures.
> And one remark: it seems to me that the ci/circleci checks are always at the end - after all Github Actions check status
Yes, you still have to scroll through 200 checks on several commits when trying to debug where the break happened, so leaving as is is not a viable solution. |
transformers | 17,368 | closed | Pin dill to fix examples | # What does this PR do?
This PR addresses the recent failures in the examples by pinning dill to exclude the latest version. | 05-20-2022 13:44:59 | 05-20-2022 13:44:59 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Merging to fix the example test failures on main |
transformers | 17,367 | closed | Fix cvt docstrings | # What does this PR do?
This PR does the following:
1. Remove the error in `README.md` where `CvT` description was copy of `CTRL`
2. Fix `size` of image for `feature extractor` which was set to `224`.
3. fix the input docstring for forward classes of `CvtModel` and `CvtForImageClassification` (head mask etc not needed).
@NielsRogge | 05-20-2022 11:03:41 | 05-20-2022 11:03:41 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Will merge as soon as it's green!<|||||>@LysandreJik @NielsRogge You can merge it now. Thanks for review! 😊 |
transformers | 17,366 | closed | Fix a typo `relative_postion_if_large` -> `relative_position_if_large` | # What does this PR do?
This PR fixes a minor typo in `T5` and `WavLM` model codes.
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@patil-suraj | 05-20-2022 10:42:16 | 05-20-2022 10:42:16 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,365 | closed | Export Generated Text 1 Token at a Time | ### Feature request
When using the text-generation pipeline. We would like to be able export each token as it is generated. Currently we have to wait for the generation to be completed to view the results.
### Motivation
Using text-generation in a production environment, this would greatly improve the user experience. Users currently have to wait for text to be generated. If we are able to implement this they could read text as it is generated by the models.
### Your contribution
I would be able to bug check this feature if it was added! | 05-20-2022 10:03:50 | 05-20-2022 10:03:50 | WDYT of such a feature @Narsil?<|||||>I like the idea.
How would that look like though code wise ?
```python
pipe = pipeline('text-generation")
# Regular usage
generated = pipe("This is my prompt")
for out in pipe("This is my prompt", continuous=True):
# out = [{"generated_text": " and"}]
#
```
The biggest caveat with this idea is this parameters will probably be hard to cumulate with things like `batch_size` and `num_beams`. We can disable some options if some combinations of arguments are provided, but in general I prefer when all combinations of parameters are available.
Other idea would be to somehow add a callback within `generate` to receive the ids also as they come in.
What I don't like, is callback (not easy to work with and debug), but it could be much easier to implement, since we're just injecting something within `generate`.
```python
def intermediate_results(out):
print(out)
pipe = pipeline("text-generation")
out = pipe("This is my prompt", continous_fn=print_intermediate_results))
```
Pinging @patrickvonplaten to see if you have ideas to get continuous tokens within `generate`.<|||||>@gante @patil-suraj could you take a look here?<|||||>As @Narsil said, in greedy search/sample generation, we can loop over and call generation with one new token at a time. The performance penalty is not that big, a bit over 2x ([on colab](https://colab.research.google.com/drive/1BQgO3HBRs7sYpKCGFs4LpXvmZFJ0QWEp?usp=sharing), the penalty probably grows with sequence length), and is trivial to implement.
For beam search generation, either there is some channel to push sequences as they are generated, or the whole generation logic is somehow exposed to correctly keep track of running sequences/scores. The latter seems unfeasible, the former could be done e.g. with some form of asynchronous queue (one thread runs generate and pushes to the queue, another reads from the queue).
I'm not experienced in these matters, but... the cost/benefit ratio doesn't seem good (for beam search) 😅 <|||||>I like the idea, but I think it won't be trivial to implement given the current complexity of `generate`. Even for greedy search/sampling, simply calling `generate` for one token at a time will be very slow, as it won't be able to take advantage of caching.
Adding callback seems a good idea IMO as it won't clutter `generate` a lot. wdyt @patrickvonplaten @gante <|||||>Both can leverage the current `generate` and do NOT call `generate` 1 step at a time in my mind.
Both would use a callback within `generate` but the idea is to understand how a user would use those results.
I was merely asking how it should look live from a pipeline user perspective.<|||||>As a user OpenAI deal with this quite well.
They use server sent events to send over partial completions - aka the JavaScript EventSource library
See “stream”
https://beta.openai.com/docs/api-reference/completions/create<|||||>To be honest, I'm not in favor of adding this to `generate` - it's too much of a nice-to-have feature and would unnecessarily increase maintenance and make `generate` much harder to understand than it already is<|||||>If it's possible to make it easy and clean with a general `callbacks: Optional[GenerationCallback] = None` function arg I think I'd be fine with it though, but would need to see a PR for it<|||||>Then inside `generate()` ideally we only have one `if callbacks is not None: then call all callbacks` code<|||||>```python
from transformers import pipeline
import torch
import threading
from transformers.generation_stopping_criteria import StoppingCriteria, StoppingCriteriaList
from queue import Queue
pipe = pipeline(model="hf-internal-testing/tiny-random-gpt2", task="text-generation", device=0)
class Stream(StoppingCriteria):
def __init__(self, q):
self.q = q
def __call__(self, input_ids, scores) -> bool:
self.q.put(input_ids)
return False
queue = Queue()
def gen():
pipe.model.generate(
torch.LongTensor([[0, 1, 2]]).cuda(),
stopping_criteria=StoppingCriteriaList([Stream(queue)]),
max_new_tokens=10,
)
print("Finished generation")
queue.put(False)
threading.Thread(target=gen).start()
while True:
i = queue.get()
if i is False:
break
else:
print("Got i", pipe.tokenizer.decode(i[0]))
```
What do you think about this ?
I thought this would be an elegant solution to the problem.
Basically send generate to another thread and wait for results as they are coming.
The main drawback for pipelines as I said, is the other parameters combinations + backward compatibility support. (+ Threads are a nightmare and if users are already using pipelines within thread/async/multiprocessing bad things might happen)<|||||>I'd be fine with this design - think it's nice! Think we should maybe put it under a new class though, called `Callback` instead of `StoppingCriteria` ?<|||||>> Think we should maybe put it under a new class though, called Callback instead of StoppingCriteria ?
Yes for sure, this was the minimal code, definitely not fit for merge.
Again, lots of caveats too with this approach, but at least it could be implemented relatively fast.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Has there been any progress on this since last year?
I am interested in generating one token at a time for an interactive text generation web UI. But simply calling `model.generate` with `max_new_tokens=1` multiple times is a lot slower (about 2x) than generating all the tokens at once.<|||||>@oobabooga no progress, but I have it in my backlog for exploration. Very unlikely that it will see the light of day in the next ~6 months, though :)<|||||>FYI, I made a streaming generation service for Hugging Face [transformers](https://github.com/huggingface/transformers) that is fully compatible with the OpenAI API: https://github.com/hyperonym/basaran |
transformers | 17,364 | closed | Nana123 | Savings | 05-20-2022 09:08:46 | 05-20-2022 09:08:46 | Savings 💰 can be a real issue, but it does not seem to be a `transformers` issue :) |
transformers | 17,363 | closed | TFGenerationMixin.generate should support a parameter such as logit_mask | ### Feature request
when i use encoder-decoder model for relation extract task, I make sure the decoder output must in encoder input text. so a parameter such logit_mask should be necessary.
### Motivation
when I use prompt finetuning a encoder-decoder to extract spo, I make sure the decoder output must in encoder input text. I try so many ways to Implement model constraint generation,but I filed,bad_world_ids parameter is not enough.
### Your contribution
I think TFGenerationMixin.generate should support a parameter such as logit_mask to mask next tokens score. | 05-20-2022 05:34:15 | 05-20-2022 05:34:15 | Hey @TheHonestBob 👋 If your task is not TensorFlow-dependent, would the constraints-related arguments in the more complete pytorch version help? ([docs here](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin))<|||||>> Hey @TheHonestBob 👋 If your task is not TensorFlow-dependent, would the constraints-related arguments in the more complete pytorch version help? ([docs here](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin))
thanks for your reply, I read this docs,in pytorch generation_utils.py logits_processor parameter maybe I want,but not in tensorflow-dependent,I always use tf to code. on the other hand,I found that in the TFPreTrainedModel's subclass call func always return TFSeq2SeqLMOutput class, it's very python nice, but TFPreTrainedModel don't Implement fit() func, there will be two problem in my opinion,1. if I inherit TFPreTrainedModel to Implement my model ,I can't use fit() func, because fit func require call() func return fixed format, 2. if I use tf.keras.model.Model to Implement my model, I can't use generate func, as well as inherit TFGenerationMixin also can't solve it.<|||||>`TFPreTrainedModel` is not meant to be a stand-alone model, but something your model inherits from :) See [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_tf_t5.py#L1260) for an example. When built this way, `fit()` will work as usual with Keras, and the model will have `generate()` support. However, it is quite complex to build, as you might notice -- I'd recommend starting from an existing model.
As for the original logit masking feature, I'm going to tag @patil-suraj and @patrickvonplaten -- do we have some functionality related to this feature request? (see issue at the top)<|||||>We have `bad_token_word_ids` which should do exactly this:
https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate.bad_words_ids(List[List[int]],
Could you try this @TheHonestBob ?<|||||>> `TFPreTrainedModel` is not meant to be a stand-alone model, but something your model inherits from :) See [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_tf_t5.py#L1260) for an example. When built this way, `fit()` will work as usual with Keras, and the model will have `generate()` support. However, it is quite complex to build, as you might notice -- I'd recommend starting from an existing model.
>
> As for the original logit masking feature, I'm going to tag @patil-suraj and @patrickvonplaten -- do we have some functionality related to this feature request? (see issue at the top)
thanks for your reply,I view lastest Bart source code, in my opinion,transformers overwrite so many tensorflow func, such as train_step compile, I haven't done more experiments to verify whether the latest code is more compatible with tensorflow, I feel that the transformers library is too integrated, and seems to lack the flexibility of tensorflow. If I need more flexible requirements, I may have to write more code. The transformers library looks more and more like an AI framework based on tensorflow, rather than an easy-to-use pre training model library, because the transformers library has its own entire training and prediction logic, Maybe the above is just that I don't know much about the transformers library.
<|||||>> We have `bad_token_word_ids` which should do exactly this: [https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate.bad_words_ids(List[List[int]]](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate.bad_words_ids(List%5BList%5Bint%5D%5D),
>
> Could you try this @TheHonestBob ?
thanks for your reply, I try this, in my opinion,this parameter not python nice,if bad word more than 20000,or each batch data have different bad word,I think this parameter will work not well.<|||||>> `TFPreTrainedModel` is not meant to be a stand-alone model, but something your model inherits from :) See [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_tf_t5.py#L1260) for an example. When built this way, `fit()` will work as usual with Keras, and the model will have `generate()` support. However, it is quite complex to build, as you might notice -- I'd recommend starting from an existing model.
>
> As for the original logit masking feature, I'm going to tag @patil-suraj and @patrickvonplaten -- do we have some functionality related to this feature request? (see issue at the top)
thanks for your reply,I view lastest Bart source code, in my opinion,transformers overwrite so many tensorflow func, such as train_step compile, I haven't done more experiments to verify whether the latest code is more compatible with tensorflow, I feel that the transformers library is too integrated, and seems to lack the flexibility of tensorflow. If I need more flexible requirements, I may have to write more code. The transformers library looks more and more like an AI framework based on tensorflow, rather than an easy-to-use pre training model library, because the transformers library has its own entire training and prediction logic, Maybe the above is just that I don't know much about the transformers library.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,362 | closed | About model loading without parameter | https://github.com/huggingface/transformers/blob/6e535425feae20ca61a8b10ae5e8a7fab4d394ba/src/transformers/models/vilt/modeling_vilt.py#L1175
Hello, I want to use vilt in other fields through from_ Can Pretrain only load models without loading model parameters. Because the coco dataset is very different from my domain dataset. I don't know if there is any way. | 05-20-2022 02:21:07 | 05-20-2022 02:21:07 | To initialize a model without any pretrained weights, you can just load it with a configuration:
```
from transformers import ViltConfig, ViltForImageAndTextRetrieval
config = ViltConfig()
model = ViltForImageAndTextRetrieval(config)
```
All weights will be randomly initialized.<|||||>Closing this issue, as I believe I've answered it. Feel free to re-open. |
transformers | 17,361 | closed | Remove/ablating particular head in a Transformer model | ### System Info
```shell
I am currently working on some research in which I am to analyze the important heads, which is similar to the work done in the paper "Are Sixteen Heads Really Better than One?". Basically, what they did is to iteratively ablate each head of each layer one by one, and then observe the size of the reduction in the final model prediction performance.
If the prediction metric value obtained after ablating a head is much lower than the original model in that all heads are used, it means that the ablated head is important.
The approach they used is to time 0 to the output of the ablated head and time 1 to the rest of the considered heads.
I am wondering if the Transformer models in huggingface could do something similar to this to evaluate the importance of each head?
(Sorry to raise this as a bug. If I should not raise this question as bug, please advise and I will convert this from Bug to others.)
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
No reproduction for this, maybe link to the paper's repo: https://github.com/pmichel31415/are-16-heads-really-better-than-1
### Expected behavior
```shell
Hope someone can give me indication how to evaluate which head is relatively more important in a Transformer model.
Thanks
```
| 05-19-2022 23:03:26 | 05-19-2022 23:03:26 | I resolved this problem. Refer to Issue 850. https://github.com/huggingface/transformers/issues/850
Thanks |
transformers | 17,360 | closed | VisualBERT: Low accuracy on VQA v2 | I use the exact code from visual bert demo, but only got about 46% accuracy on VQA v2 validation data. Has anyone had the same issue? | 05-19-2022 21:52:04 | 05-19-2022 21:52:04 | Has anyone found a problem solution?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 17,359 | closed | [Test OPT] Add batch generation test opt | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Just adds a test to make sure that generation in batches works correctly.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 05-19-2022 21:18:13 | 05-19-2022 21:18:13 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,358 | closed | wip: testing https://github.com/huggingface/doc-builder/pull/214 | wip: testing https://github.com/huggingface/doc-builder/pull/214 | 05-19-2022 21:15:47 | 05-19-2022 21:15:47 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 17,357 | closed | Example of TFMarianMTModel is not working very well | Hello, I copied the TFMarianMTModel example code from [https://huggingface.co/docs/transformers/v4.19.2/en/model_doc/marian#transformers.TFMarianMTModel](url) and compiled in Tensorflow 2.4.1. But it turned out the output length of "model.generate(**batch)" is always 512.
```python
from transformers import MarianTokenizer, TFMarianMTModel
from typing import List
src = "fr" # source language
trg = "en" # target language
sample_text = "où est l'arrêt de bus ?"
model_name = f"Helsinki-NLP/opus-mt-{src}-{trg}"
model = TFMarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
batch = tokenizer([sample_text], return_tensors="tf")
gen = model.generate(**batch)
tokenizer.batch_decode(gen, skip_special_tokens=True)
```
Could you help with it?
@patrickvonplaten | 05-19-2022 20:45:49 | 05-19-2022 20:45:49 | Hey @Zhenzi-Weng,
When I execute the code above, I'm getting an error. I'm assuming you want to execute the following:
```python
from transformers import MarianTokenizer, TFMarianMTModel
from typing import List
src = "fr" # source language
trg = "en" # target language
sample_text = "où est l'arrêt de bus ?"
model_name = f"Helsinki-NLP/opus-mt-{src}-{trg}"
model = TFMarianMTModel.from_pretrained(model_name, from_pt=True)
tokenizer = MarianTokenizer.from_pretrained(model_name)
batch = tokenizer([sample_text], return_tensors="tf")
gen = model.generate(**batch)
tokenizer.batch_decode(gen, skip_special_tokens=True)
```
<|||||>When executing the above code, I'm getting a pretty reasonable answer:
```
["Where's the bus stop?"]
```
=> What is the problem here exactly?
<|||||>> When executing the above code, I'm getting a pretty reasonable answer:
>
> ```
> ["Where's the bus stop?"]
> ```
>
> => What is the problem here exactly?
Hello @patrickvonplaten , thanks for your reply. I tried your code and it did output a reasonable translation, but I believe your code is for Pytorch. I‘m using Tensorflow and the problem is the output will contain many invalid characters. Would you mind to try the following code again? Many thanks. My Tensorflow version is 2.4.1 and I installed transformers v4.19.0.
`from transformers import MarianTokenizer, TFMarianMTModel
src = "en" # source language
trg = "zh" # target language
model_name = f"Helsinki-NLP/opus-mt-{src}-{trg}"
model = TFMarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
sample_text = "My name is Wolfgang and I live in Berlin"
batch = tokenizer([sample_text], return_tensors="tf")
generated_ids = model.generate(**batch)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)`<|||||>Hey @Zhenzi-Weng,
Note that my codesnippet above is for Tensorflow, the model is loaded into a `TFMarianMTModel` class. We just need to have PyTorch installed to convert the PT weights to TF before <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @patrickvonplaten, related to this question, why is it that the TF version of MarianMTModel much slower than the PT version? Maybe it has something to do with the length of generating output?<|||||>TF is generally much slower in eager mode than PyTorch - you could try to compile the generate method in Tensorflow which should speed things up :-)
cc @gante <|||||>@jamie0725 correct, TF (eager execution) is much slower than PyTorch. However, with XLA, it should be much faster. Have a look at [this blog post](https://huggingface.co/blog/tf-xla-generate)! |
transformers | 17,356 | closed | Fixes #17128 . | # What does this PR do?
Finalize changes as per this [PR](https://github.com/huggingface/transformers/pull/17277).
Sorry. I messed up changes during merge and hence this new PR.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #17128
## Before submitting
- [N/A] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Here's the [link](https://github.com/huggingface/transformers/issues/17128)
- [N/A] Did you make sure to update the documentation with your changes?
- [ ] Did you write any new necessary tests? I didn't write a custom test. Ran the following commands run to ensure local tests pass
1. `RUN_PIPELINE_TESTS=yes python -m unittest discover -s tests/pipelines -p "test_pipelines_question_answering.py" -t . -v -f `
2. `python -m unittest discover -s . -p "test_tokenization_wav2vec2.py" -t . -v -f`
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik
@Narsil | 05-19-2022 19:42:10 | 05-19-2022 19:42:10 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thank you for your contribution, @mygithubid1! |
transformers | 17,355 | closed | [BigBird] random attention in FlaxBigBird is not random | ### System Info
```shell
NOT NEEDED
```
### Who can help?
@patrickvonplaten
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
`numpy.random` is getting used everywhere in `FlaxBigBird` for fetching random indices for computing attention over random tokens. This is wrong as these indices would be cached during jit compilation. Hence, bigbird would attend similar random tokens (i.e same indices) in every step
This can be fixed if random indices are prepared in datacollator and passed to `model.__call__` during training.
https://github.com/huggingface/transformers/blob/ee393c009a243bbb86fa11d2efa771a1704d85cf/src/transformers/models/big_bird/modeling_flax_big_bird.py#L975
| 05-19-2022 17:48:29 | 05-19-2022 17:48:29 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I see, thanks for putting up this issue here!
Think the easiest fix in this case would be to use transition from `numpy.random` to `jax.random`: https://jax.readthedocs.io/en/latest/jax.random.html no? This way the user can always pass a PRNG key to the forward which would define the random attention mask?
What do you think @vasudevgupta7 ?<|||||>Hello @patrickvonplaten,
sorry for the late reply. I missed your comment somehow.
> Think the easiest fix in this case would be to use transition from numpy.random to jax.random: https://jax.readthedocs.io/en/latest/jax.random.html no? This way the user can always pass a PRNG key to the forward which would define the random attention mask?
Yes, this should be the best way to go. But then Jax implementation will diverge from PyTorch implementation in case of block sparse attention right?? and some tests would fail ig.<|||||>Thanks for the reply @vasudevgupta7!
Leaving this as a "second good issue" now as I won't find the time to dig into it in the near future. @community Please ping me here if you'd like this to be fixed soon<|||||>Hi @patrickvonplaten @thevasudevgupta - is this still a problem? If so I would love to pick it up to have some work on the Christmas break :)<|||||>This would be great @Bearnardd :-) <|||||>@thevasudevgupta this issue can be closed as the fix is merged :)<|||||>Very cool to know that! |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.