
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 20,568 | closed | Added missing `test_tokenization_led` | # What does this PR do?
Added missing `test_tokenization_led`, was similar to Bart tokenizer made some changes by testing it in local environment
@sgugger
| 12-03-2022 18:54:44 | 12-03-2022 18:54:44 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@ydshieh Can you give some more points of what exactly is to be done?
As per the points given by you, I need to first create 2 texts let's say `A long paragraph for summarization.` and `Another paragraph for`, and then encode them as `tokenizer.encode_plus("Another paragraph for", padding=False)` passing padding as False so that it doesn't apply padding to text, and then we have to create a list of `global_attention_mask` let's say [0,0,0,0,0], doing this for both the text and then pass encoded_inputs along with `global_attention_mask` to the `tokenizer._pad()`<|||||>@IMvision12 Yes, that's the idea :-). Only at the end, you can do `tokenizer.pad()` instead -> it will call `_pad` internally.<|||||>@ydshieh Also what I really need to check in `assertEqual`?<|||||>We need to check the outputs after padding contains the key `global_attention_mask` and its value is the same as the expected one, which is the `global_attention_mask` being padded. You will either have to take a quick look in ` _pad` or at least run one example to get a better idea (which should be easy enough) what it does :-)<|||||>@ydshieh can you take a quick look at this function
Is this expected to be done?
```
def test_global_attention(self):
text = ["A long paragraph for summarization.", "Another paragraph for summarization."]
tokenizer = self.default_tokenizer_fast()
input_1 = tokenizer.encode_plus(text[0], padding=False)
input_1['global_attention_mask'] = [0,0,0,0,0]
outputs_1 = tokenizer.pad(input_1)
self.assertEqual(outputs_1['global_attention_mask'],[0, 0, 0, 0, 0, -1, -1, -1, -1])
input_2 = tokenizer.encode_plus(text[1], padding=False)
input_2['global_attention_mask'] = [0,0,0,0]
outputs_2 = tokenizer.pad(input_2)
self.assertEqual(outputs_2['global_attention_mask'],[0, 0, 0, 0, -1])
```<|||||>@IMvision12
The idea is to encode the 2 texts together without padding, and send the encoded outputs with `global_attention_mask` (not padded neither) to `.pad`.
You code above pads each sequence, which won't have any padding. The padding only happens with multiple sequences where the length are different.<|||||>@ydshieh sorry for pinging you so many times
Also i have created this colab for understanding https://colab.research.google.com/drive/1jYwtsE41ouAeh5aNzfWZ2LNLizFOwvQr?usp=sharing
```
def test_global_attention_mask(self):
text = ["A long paragraph.", "Hi I am using huggingface transformers"]
tokenizer = self.default_tokenizer_fast()
inputs = tokenizer.encode_plus(text, padding=False)
inputs['global_attention_mask'] = [0,0,0,0,0,0,0,0]
outputs = tokenizer.pad(inputs)
self.assertEqual(outputs['global_attention_mask'],[0, 0, 0, 0, 0, 0, 0, 0, -1, -1, -1, -1, -1, -1, -1, -1])
```<|||||>Hi, hope the following explains it more clearly :-)
First, batch encoding
```python
text = ["A long paragraph.", "Hi I am using huggingface transformers"]
x = tokenizer(text, padding=False)
x
```
Add `global_attention_mask` that is not padded
```python
x['global_attention_mask'] = [[0] * len(y) for y in x["input_ids"]]
x
```
Pad the whole un-padded inputs
```
tokenizer.pad(x)
```<|||||>I am not sure why `tests_pipelines_tf` are failing<|||||>No need to worry about the TF pipeline test. I will take a look - it's probably irrelevant to this PR.<|||||>Could you update your local main branch , and rebase your working branch on local `main`?<|||||>@ydshieh Done! any more changes?<|||||>@ydshieh Thanks for a concise explanation of `global_attention_mask` and guidance!! |
transformers | 20,567 | closed | Whether to use 'logits' or 'loss' in LabelSmoother | ### System Info
- 'transformers' version: 4.24.0
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
it is in "transformers/trainer.py"

it is in "transformers/trainer_pt_utils.py"

### Expected behavior
In fact, it is not a bug problem! I just have doubts about the variable used in a function
In "transformers/trainer_pt_utils.py", the class "LabelSmoother \__call\__" function, I noticed that it uses the **'logits'** value, but **'output [0]'** is selected under 'else' condition, if I am not mistaken, **'output[0]'** should represent loss(I use the **_BartForConditionalGeneration_**) . So is there any problem here? | 12-03-2022 16:47:41 | 12-03-2022 16:47:41 | Please use the [forums](https://discuss.huggingface.co/) to ask such questions, as we keep issues for bugs and feature requests only. The labels are popped when we use label smoothing, so the loss is not included in the ouputs/<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,566 | closed | Spanish translation of the file debugging.mdx | # What does this PR do?
Fixes #[15947](https://github.com/huggingface/transformers/issues/15947)
Adds the Spanish version of [debugging.mdx](https://github.com/huggingface/transformers/blob/master/docs/source/en/debugging.mdx) to [transformers/docs/source/es](https://github.com/huggingface/transformers/tree/main/docs/source/es)
Also found one typo error in the original doc, so I fixed it also.
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
## Who can review?
@omarespejel @osanseviero @sgugger | 12-03-2022 15:40:35 | 12-03-2022 15:40:35 | Can you just add the new file to the TOC of the Spanish doc? (in `transformers/docs/source/es/_toctree.yml`)<|||||>@sgugger like that is fine? Tried to mimic the eng TOC creating the same section "Rendimiento y escalabilidad"<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>All good, thanks! |
transformers | 20,564 | closed | make states contiguous for past_key_values | Add contiguous for key and value states.
If someone uses past_key_values, it seems to raise the following exception:
`
RuntimeError: view size is not compatible with input tensor‘s size and stride ...
`
since bart executes torch.cat in BartAttention class:
`
key_states = torch.cat([past_key_value[0], key_states], dim=2)
`
`
value_states = torch.cat([past_key_value[1], value_states], dim=2)
`
Thus, we should make key_states and value_states contiguous.
@patrickvonplaten
---
More, bart cannot correctly process the length of attention_mask when the item of past_key_values is added.
| 12-03-2022 03:23:07 | 12-03-2022 03:23:07 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,563 | closed | Model bart cannot correctly process the length of attention_mask when the item of past_key_values is added. | ### System Info
- `transformers` version: 4.18.0
- Platform: Linux-5.4.0-109-generic-x86_64-with-glibc2.31
- Python version: 3.9.12
- Huggingface_hub version: 0.2.1
- PyTorch version (GPU?): 1.11.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@patil-sura
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
execute the code:
`
outputs = self.bart(input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
labels=labels)
`
Model bart cannot correctly process the length of attention_mask when the item of past_key_values is added.
Additionally,
If someone uses past_key_values, it seems to raise the following exception:
`
RuntimeError: view size is not compatible with input tensor‘s size and stride ...
`
since bart executes torch.cat in BartAttention class:
`
key_states = torch.cat([past_key_value[0], key_states], dim=2)
`
`
value_states = torch.cat([past_key_value[1], value_states], dim=2)
`
Thus, we should make key_states and value_states contiguous.
@patrickvonplaten
---
### Expected behavior
It will run correctly. | 12-03-2022 03:05:41 | 12-03-2022 03:05:41 | cc @ArthurZucker
@xyjigsaw could you please add a complete reproducible code snippet here though?
We cannot run:
```python
outputs = self.bart(input_ids=input_ids, attention_mask=attention_mask, past_key_values=past_key_values, labels=labels)
```
because we don't know what `input_ids`, etc... is.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,562 | closed | Clip floating point constants to bf16 range to avoid inf conversion | When running HuggingFace BERT (any size) fine-tuning tutorial with transformers version >= 4.21.0 and using XLA_USE_BF16=1 or XLA_DOWNCAST_BF16=1, I see NaNs in the loss after the first step.
# What does this PR do?
This PR addresses the issue where the model code passes a value that is out of range for XLA_USE_BF16=1 or XLA_DOWNCAST_BF16=1, so the conversion would cast it to -inf.
The NaNs likely come from the transformers library change: https://github.com/huggingface/transformers/pull/17306 . This PR replaced many lines which used to be -float(inf) (or other small constants) with torch.finfo().min. For torch.float32 the min value is -3.4028234663852886e+38 which is smaller than the bfloat16 minimum of -3.3895313892515355e+38. So the problem is that torch.finfo(torch.float32).min = -3.4028234663852886e+38 gets converted to -inf. When the original encoder_extended_attention_mask is 1, then encoder_extended_attention_mask becomes (1.0 - 1.0 ) * -inf which becomes NaN (via IEEE rule Inf * 0.0 = NaN).
This PR ensures torch.finfo(torch.bfloat16).min = -3.3895313892515355e+38 and not -inf. Then the results would not have Nans.
The following lines checks for XLA_USE_BF16 or XLA_DOWNCAST_BF16 environment variable and sets the dtype accordingly:
```
if is_torch_tpu_available():
if os.environ.get("XLA_USE_BF16"):
return torch.bfloat16
if os.environ.get("XLA_DOWNCAST_BF16"):
if t.dtype == torch.float:
return torch.bfloat16
if t.dtype == torch.double:
return torch.float32
```
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 12-02-2022 23:51:54 | 12-02-2022 23:51:54 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Oh, looks like something went wrong in your rebase (see the diff showing lots of files). You can either force-push a commit (with --force) to repare the history for git, or close this PR and open a fresh one. |
transformers | 20,561 | closed | Fix code sample in preprocess | This PR fixes the code sample to use the new `ImageProcessor` in the code sample for preprocessing an image. | 12-02-2022 23:34:22 | 12-02-2022 23:34:22 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,560 | closed | Fix link to table transformer detection microsoft model | # What does this PR do?
Similar to #20558 the linking to the `microsoft/table-transformer-detection` model seems to be outdated or it has a typo and redirects to a 404. | 12-02-2022 20:16:18 | 12-02-2022 20:16:18 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,559 | closed | Split autoclasses on modality | This PR groups `AutoModel`, `TFAutoModel` and `FlaxAutoModel` by modality to make them easier to discover. | 12-02-2022 19:50:15 | 12-02-2022 19:50:15 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,558 | closed | Fix link to swin transformers v2 microsoft model | # What does this PR do?
The link `https://huggingface.co/microsoft/swinv2_tiny_patch4_windows8_256/` redirects to a 404. The actual link is https://huggingface.co/microsoft/swinv2-tiny-patch4-window8-256.
At the same time, loading the configuration using
```python3
from transformers import AutoConfig
config = AutoConfig.from_pretrained("microsoft/swinv2_tiny_patch4_windows8_256")
```
Returns
```
HTTPError: 401 Client Error: Unauthorized for url:
https://huggingface.co/microsoft/swinv2_tiny_patch4_windows8_256/resolve/main/config.json
```
As the link is not valid, this change fixes it. | 12-02-2022 19:25:56 | 12-02-2022 19:25:56 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,557 | closed | Fix link to Swin Model contributor novice03 | # What does this PR do?
Fixes `>` typo in `https://huggingface.co/novice03>` link that redirects to 404 not found site.
| 12-02-2022 19:09:02 | 12-02-2022 19:09:02 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,556 | closed | Fix flax GPT-J-6B linking model in tests | # What does this PR do?
Fixes the loading of the model `EleutherAI/gpt-j-6B` as the current code links `EleutherAI/gptj-6B` which does not exist and ends up failing the test. | 12-02-2022 18:46:52 | 12-02-2022 18:46:52 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,555 | closed | flan-t5.mdx: fix link to large model | ## Before submitting
- [*] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
Documentation: @sgugger | 12-02-2022 17:28:46 | 12-02-2022 17:28:46 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,554 | closed | Cleanup config attrs | # What does this PR do?
These are vision models, and they don't form encoder-decoder themselves (unlike some text models like `Bart`).
Furthermore, the current default value (specified in each config class `__init__`) for these configs are `False`, which is the same as the default value in `PretrainedConfig`. So we can just remove it from the parameters, and rely on `**kwargs` in the call to `super.__init__` .
| 12-02-2022 17:11:03 | 12-02-2022 17:11:03 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,553 | closed | exclude jit time from the speed metric calculation of evaluation and … | …prediction
Signed-off-by: Wang, Yi A <[email protected]>
| 12-02-2022 13:11:35 | 12-02-2022 13:11:35 | @sgugger @jianan-gu please have a review<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger done, please have a review of it. |
transformers | 20,552 | closed | `TrainingArguments` `lr_scheduler_type="cosine_with_restarts"` can/does not pass a `num_cycles` argument to `get_cosine_with_hard_restarts_schedule_with_warmup()` | ### System Info
- `transformers` version: 4.24.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.12
- Huggingface_hub version: 0.11.0
- PyTorch version (GPU?): 1.12.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I paste some dummy code but I think the explanation is more important (unless I have overlooked something): The `lr_scheduler_type="cosine_with_restarts"` that I pass to the `TrainingArguments` is used to call `get_scheduler()` in `optimization.py`. There it's mapped to `get_cosine_with_hard_restarts_schedule_with_warmup()`, but without a `num_cycles` argument, defaulting to `1`, i.e. it behaves like the `cosine` option.
Probably I could build the scheduler myself and pass it to the `Trainer`, but then I need to calculate the `num_trainings_steps` myself, correct? If true, would `len(train_dataset) * num_epochs // batch_size // gradient_accumulation_steps` be a decent approximation?
```python
args = TrainingArguments(
output_dir="./checkpoints",
per_device_train_batch_size=128,
per_device_eval_batch_size=128,
evaluation_strategy="steps",
eval_steps=1_000,
logging_steps=1_000,
gradient_accumulation_steps=8,
num_train_epochs=50,
weight_decay=0.1,
warmup_steps=5_000,
lr_scheduler_type="cosine_with_restarts", # that's actually the only relevant line
learning_rate=5e-4,
save_steps=1_000,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_data["train"],
eval_dataset=tokenized_data["validation"],
)
trainer.train()
```
### Expected behavior
Passing `lr_scheduler_type="cosine_with_restarts"` should allow for an additional parameter `num_cycles` in `TrainingArguments` which should then be passed on to `get_cosine_with_hard_restarts_schedule_with_warmup()`. | 12-02-2022 12:47:09 | 12-02-2022 12:47:09 | Yes, there is no argument to pass that information, so in this instance you should either build the scheduler yourself and pass it, or subclass the `Trainer` to override the `create_scheduler` method, whichever you prefer.
In both cases the formula you passed should give the good number of training steps!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I believe this should be fixed at a certain point! |
transformers | 20,551 | closed | Add entries to `FEATURE_EXTRACTOR_MAPPING_NAMES` | # What does this PR do?
Add entries to `FEATURE_EXTRACTOR_MAPPING_NAMES`
Not sure if there was any reason not to add these entries in `FEATURE_EXTRACTOR_MAPPING_NAMES`.
Furthermore, without these entries, we get some test failures for the (WIP) improved pipeline tests, because we now can generate tiny models for these config classes with the corresponding tokenizer/processor. (Previously these couldn't be generated).
The failures are because this line
https://github.com/huggingface/transformers/blob/cc3d0e1b017dbb8dcbba1eb01be77aef7bacee1a/tests/pipelines/test_pipelines_feature_extraction.py#L182
is not able to skip relevant tests for these configs/models.
**Remark: I am going to add them to `TOKENIZER_MAPPING_NAMES` too**
| 12-02-2022 11:32:08 | 12-02-2022 11:32:08 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,550 | closed | Add BiT + ViT hybrid | # What does this PR do?
This PR adds ViT hybrid to the library. As ViT hybrid uses BiT as backbone, this PR also adds BiT as a standalone model.
BiT itself is very similar to a ResNetv2, except that it replaces batch norm layers by group norm and uses "weight standardized" convolutional layers.
To do:
- [x] add image processors
- [ ] add tests for image processors (cc @amyeroberts can I directly add test_modeling_image_processor_xxx.py ?)
- [ ] transfer all checkpoints
- [x] add integration tests | 12-02-2022 09:48:26 | 12-02-2022 09:48:26 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks so much @sgugger for your review !
I should have updated everything and the main models are now up:
- https://huggingface.co/google/vit-hybrid-base-bit-384
- https://huggingface.co/google/bit-50 |
transformers | 20,549 | closed | processor.model_input_names doesn't work as it should be | ### System Info
Transformers, main branch
### Who can help?
@SaulLu
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Currently, processors like CLIPProcessor have a model_input_names attribute, but it doesn't have any effect on which keys are outputted in the BatchEncoding.
To reproduce:
```
# install transformers from my branch, see https://github.com/huggingface/transformers/pull/20295
from PIL import Image
import requests
from transformers import GITProcessor
processor = GITProcessor.from_pretrained("nielsr/git-base")
print(processor.model_input_names)
# this prints ['input_ids', 'attention_mask', 'pixel_values']
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
for key, value in inputs.items():
print(key, value.shape)
```
This prints:
```
input_ids torch.Size([2, 7])
token_type_ids torch.Size([2, 7])
attention_mask torch.Size([2, 7])
pixel_values torch.Size([1, 3, 224, 224])
```
=> as can be seen, token_type_ids are included here, which shouldn't be the case.
In addition, it seems model_input_names doesn't get reflected when pushing a tokenizer to the hub and reloading. To reproduce:
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(tokenizer.model_input_names)
# update model input names (let's say we don't want token type ids)
tokenizer.model_input_names = ['input_ids', 'attention_mask']
tokenizer.push_to_hub("nielsr/test")
# reload
tokenizer = AutoTokenizer.from_pretrained("nielsr/test")
print(tokenizer.model_input_names)
```
### Expected behavior
model_input_names should work appropriately for both tokenizers and processors, making sure only keys which are in this list are included in the BatchEncoding. | 12-02-2022 09:08:54 | 12-02-2022 09:08:54 | Also cc'ing @sgugger and @amyeroberts here<|||||>There is no generic call method of the processors, like there is for the tokenizers, so to enforce that `model_input_names` only returns the keys you want, it's up to you to have the call method of your processor filter those outputs.
As for the second point, `model_input_names` are linked to an architecture, and as such they are a class variable. They are not supposed to be changed by a user, and it's completely natural that saving/reloading does not save that change.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>@amyeroberts would you like to add this functionality at some point? Also shouldn't `tokenizer.model_input_names` for instance work after re-instantiating from the hub?<|||||>I am not sure what was unclear in my comment above. This functionality cannot exist since there is no generic call method for the processor mixin. |
transformers | 20,548 | closed | Maked Patch in ViT and VilT | ### System Info
Hi,
I did check in vit docs from this link thttps://huggingface.co/transformers/v4.6.0/model_doc/vit.html
It said "The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
Not sure, Is there a mask function for image patch for ViT? If not, can you add this function in ViT or VilT?
It would be gratefully. Many thanks
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https://github.com/lucidrains/vit-pytorch/issues/97
mpp_trainer = MPP(
transformer=model,
patch_size=32,
dim=1024,
mask_prob=0.15, # probability of using token in masked prediction task
random_patch_prob=0.30, # probability of randomly replacing a token being used for mpp
replace_prob=0.50, # probability of replacing a token being used for mpp with the mask token
)
### Expected behavior
Hope add this masked patch function in ViT and VilT | 12-02-2022 06:47:40 | 12-02-2022 06:47:40 | Hi,
This comment is actually outdated as currently, self-supervised pre-training beats supervised pre-training, with models like [BEiT](https://huggingface.co/docs/transformers/model_doc/beit), [MAE](https://huggingface.co/docs/transformers/model_doc/vit_mae) as well as SimMIM.
All 3 are based on masking patches for ViT. We do provide a [ViTForMaskedImageModeling](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTForMaskedImageModeling) class exactly for this purpose. It also comes with a pre-training script, allowing you to pre-train a model for masked image modeling yourself on custom data: https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining.
We should update that comment ;) feel free to open a PR<|||||>Thank you very much for your answer. Can I use ViTForMaskedImageModeling in VilT as well?
appreciate for your valuable answer.<|||||>> Hi,
>
> This comment is actually outdated as currently, self-supervised pre-training beats supervised pre-training, with models like [BEiT](https://huggingface.co/docs/transformers/model_doc/beit), [MAE](https://huggingface.co/docs/transformers/model_doc/vit_mae) as well as SimMIM.
>
> All 3 are based on masking patches for ViT. We do provide a [ViTForMaskedImageModeling](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTForMaskedImageModeling) class exactly for this purpose. It also comes with a pre-training script, allowing you to pre-train a model for masked image modeling yourself on custom data: https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining.
>
> We should update that comment ;) feel free to open a PR
Hi Niels Rogge,
Thanks for replying. Appreciate for your valuable feedback.
So another problem is:
Can you add this function ViTForMaskedImageModeling in VilT as well? Not sure if it is ok.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @guanhdrmq, ViLT has its own pre-training objectives, which are different from `ViTForMaskedImageModeling`. Hence this would require a new `ViltForPreTraining` class which includes all heads used during the pre-training of ViLT. |
transformers | 20,547 | closed | Replace `set-output` by `$GITHUB_OUTPUT` | # What does this PR do?
Apply the suggestion in [GitHub Actions: Deprecating save-state and set-output commands](https://github.blog/changelog/2022-10-11-github-actions-deprecating-save-state-and-set-output-commands/) to avoid deprecated actions. | 12-02-2022 06:27:08 | 12-02-2022 06:27:08 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,546 | closed | Install natten with CUDA version | # What does this PR do?
The PR #20511 install `natten`, but on GPU machines, we need install it with CUDA supported versions. | 12-02-2022 06:24:39 | 12-02-2022 06:24:39 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,545 | open | add MeMViT model | ### Model description
[MeMViT, CVPR 2022](https://arxiv.org/abs/2201.08383) is the most efficient transformer-based video understanding model, and META AI released it. Its efficient online attention calculation mechanism decreases computation by 30 times compared to SOTA video classification models.
It would be an excellent addition to the `transformers` library considering it is the current SOTA on AVA, EPIC-Kitchens-100 action classification, and action anticipation datasets.
### Your contribution
I want to work on adding this architecture to the HuggingFace.
### Open source status
- [x] The model implementation is available
- [x] The model weights are available
### Provide useful links for the implementation
Source code: https://github.com/facebookresearch/MeMViT
Weight files: https://github.com/facebookresearch/MeMViT#model-checkpoints
cc: @NielsRogge @alaradirik | 12-02-2022 06:04:56 | 12-02-2022 06:04:56 | Hi @fcakyon, MeMViT definitely seems interesting and we would be happy to see it added to transformers!
If you haven't done so, you can start by taking a look at our [existing video classification models](https://huggingface.co/models?pipeline_tag=video-classification&sort=downloads) to see if there are any re-usable components you can copy paste and use for MeMViT (preprocessing, model modules, etc.).
The best way to add a new model is to start with the `transformers-cli add-new-model` or `transformers-cli add-new-model-like` command, which initializes all the model files and ensures the new model can be properly imported. You can learn more about it over [here.](https://huggingface.co/docs/transformers/add_new_model)
Feel free to ping me or @NielsRogge if you get stuck or have questions :)
<|||||>Thank you for the response @alaradirik. Just covered up the timesformer pr: https://github.com/huggingface/transformers/pull/18908
I will be starting the MeMViT implementation late this week 👍 <|||||>I am sorry that I won't be able to work on such a PR in the short future due to my time not allowing it. I have a lot of work to do for my Ph.D. If anyone else is willing to work on it, he/she is free to do 👍 <|||||>Hello, I would like to work upon adding this model<|||||>@fcakyon no problem at all :)
@Sandstorm831 sure, please feel free to start working on it, you can ping me or @NielsRogge if you run into issues or have questions about the library in general.<|||||>Hi @alaradirik I would like to contribute to this model.<|||||>Hi @alaradirik I and @Sandstorm831 are working together towards contributing to this model. |
transformers | 20,544 | closed | ESM openfold_utils type hints | # What does this PR do?
This PR generally adds type hints for the files located at `src/transformers/models/esm/openfold_utils/`.
0. add function/method parameter type hints where missing; add type info on collections
1. export `dict_multimap`, `flatten_final_dims`, `permute_final_dims` in `__init__.py` since these functions are currently duplicated in [src/transformers/models/esm/modeling_esmfold.py](https://github.com/huggingface/transformers/blob/2e17db8a8626baeea7efd6f2700be863f026699c/src/transformers/models/esm/modeling_esmfold.py#L218-L238); exporting these from `openfold_utils` should allow us to remove these duplicates
2. refactor `type(x) is y` to use the builtin `isinstance(x, y)`
3. refactor to avoid reassignment to the same variable with a different type (this is frowned upon by type checkers) by using multiple variables / combining expressions to avoid reassignment
4. add `assert` statements to to narrow types
5. add a `FIXME` statement at an apparent bug in [`protein.py`](https://github.com/huggingface/transformers/pull/20544/files#diff-b7388405b8a9b1877a3eeb6b6941091f68e321717beec3abb7727cd3114115bfR84) in which string mutation is attempted
6. various minor refactors
<!-- Remove if not applicable -->
Related: https://github.com/huggingface/transformers/issues/16059
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@Rocketknight1
| 12-02-2022 05:31:51 | 12-02-2022 05:31:51 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Wow, this is really comprehensive! All of your edits seem good, and thanks for catching those duplicate functions!
The code is failing some of our code style checks, but I believe I can fix that for you, hang on!<|||||>I think the other issues are just old issues with our repo - they'll be fixed if you pull from upstream on your fork's `main` branch in the GitHub UI and then rebase your branch onto that, followed by a force push<|||||>@ringohoffman Looks good to me now! Are you okay with me merging it?<|||||>> @ringohoffman Looks good to me now! Are you okay with me merging it?
I'm good if you are! |
transformers | 20,543 | closed | CLIPProcessor.from_pretrained is None | ### System Info
transformers version: 4.20.1
### Who can help?
@patil-suraj
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
### Expected behavior
returned processor without `TypeError: 'NoneType' object is not callable`. | 12-02-2022 02:51:08 | 12-02-2022 02:51:08 | Could you try:
- updating Transforemrs to the latest version
- make sure you have all optional dependencies necessary for CLIP (PILlow mainly)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,542 | closed | cannot import name 'ReduceOp' from 'torch.distributed' | ### System Info
Transformers version: 4.21.2
Platform: NVIDIA Jetson Xavier NX
Python version: 3.8.10
PyTorch version: '1.13.0a0+936e9305.nv22.11'
Errors out when trying to import SegformerForSemanticSegmentation, came back to test my code after not using it for a long while, changed nothing about the environment (didn't even turn the machine on) and it no longer works. Been trying to figure out what the problem is but finally gave up and decided to check if anyone else was having the problem, didn't see anything so I'm sure I'm just doing something stupid.
`from transformers import SegformerForSemanticSegmentation`
```
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 1002, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/usr/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 848, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/usr/local/lib/python3.8/dist-packages/transformers/models/segformer/modeling_segformer.py", line 28, in <module>
from ...modeling_utils import PreTrainedModel
File "/usr/local/lib/python3.8/dist-packages/transformers/modeling_utils.py", line 79, in <module>
from accelerate import dispatch_model, infer_auto_device_map, init_empty_weights
File "/usr/local/lib/python3.8/dist-packages/accelerate/__init__.py", line 7, in <module>
from .accelerator import Accelerator
File "/usr/local/lib/python3.8/dist-packages/accelerate/accelerator.py", line 27, in <module>
from .checkpointing import load_accelerator_state, load_custom_state, save_accelerator_state, save_custom_state
File "/usr/local/lib/python3.8/dist-packages/accelerate/checkpointing.py", line 24, in <module>
from .utils import (
File "/usr/local/lib/python3.8/dist-packages/accelerate/utils/__init__.py", line 68, in <module>
from .operations import (
File "/usr/local/lib/python3.8/dist-packages/accelerate/utils/operations.py", line 25, in <module>
from torch.distributed import ReduceOp
ImportError: cannot import name 'ReduceOp' from 'torch.distributed' (/usr/local/lib/python3.8/dist-packages/torch/distributed/__init__.py)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<frozen importlib._bootstrap>", line 1039, in _handle_fromlist
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 993, in __getattr__
value = getattr(module, name)
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 992, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 1004, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.models.segformer.modeling_segformer because of the following error (look up to see its traceback):
cannot import name 'ReduceOp' from 'torch.distributed' (/usr/local/lib/python3.8/dist-packages/torch/distributed/__init__.py)
```
### Who can help?
@LysandreJik SegformerForSemanticSegmentation
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
`from transformers import SegformerForSemanticSegmentation`
### Expected behavior
I would expect to be able to import SegformerForSemanticSegmentation and use the class to load my already existing Segformer model. My script used to work but now errors out at the import after not touching the machine for at least a month (didn't even turn it on) | 12-02-2022 01:38:03 | 12-02-2022 01:38:03 | Changed from using SegformerForSemanticSegmentation to using AutoModelForSemanticSegmentation, the import now works fine but loading the pretrained model does not.
```
from transformers import AutoFeatureExtractor, AutoModelForSemanticSegmentation
feature_extractor = AutoFeatureExtractor.from_pretrained("nvidia/segformer-b4-finetuned-ade-512-512")
segment_model = AutoModelForSemanticSegmentation.from_pretrained("segments-tobias/segformer-b0-finetuned-segments-sidewalk")
```
Same error, stack trace pasted below
```
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 1002, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/usr/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 848, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/usr/local/lib/python3.8/dist-packages/transformers/models/segformer/modeling_segformer.py", line 28, in <module>
from ...modeling_utils import PreTrainedModel
File "/usr/local/lib/python3.8/dist-packages/transformers/modeling_utils.py", line 79, in <module>
from accelerate import dispatch_model, infer_auto_device_map, init_empty_weights
File "/usr/local/lib/python3.8/dist-packages/accelerate/__init__.py", line 7, in <module>
from .accelerator import Accelerator
File "/usr/local/lib/python3.8/dist-packages/accelerate/accelerator.py", line 27, in <module>
from .checkpointing import load_accelerator_state, load_custom_state, save_accelerator_state, save_custom_state
File "/usr/local/lib/python3.8/dist-packages/accelerate/checkpointing.py", line 24, in <module>
from .utils import (
File "/usr/local/lib/python3.8/dist-packages/accelerate/utils/__init__.py", line 68, in <module>
from .operations import (
File "/usr/local/lib/python3.8/dist-packages/accelerate/utils/operations.py", line 25, in <module>
from torch.distributed import ReduceOp
ImportError: cannot import name 'ReduceOp' from 'torch.distributed' (/usr/local/lib/python3.8/dist-packages/torch/distributed/__init__.py)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/transformers/models/auto/auto_factory.py", line 445, in from_pretrained
model_class = _get_model_class(config, cls._model_mapping)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/auto/auto_factory.py", line 359, in _get_model_class
supported_models = model_mapping[type(config)]
File "/usr/local/lib/python3.8/dist-packages/transformers/models/auto/auto_factory.py", line 564, in __getitem__
return self._load_attr_from_module(model_type, model_name)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/auto/auto_factory.py", line 578, in _load_attr_from_module
return getattribute_from_module(self._modules[module_name], attr)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/auto/auto_factory.py", line 534, in getattribute_from_module
if hasattr(module, attr):
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 992, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/usr/local/lib/python3.8/dist-packages/transformers/utils/import_utils.py", line 1004, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.models.segformer.modeling_segformer because of the following error (look up to see its traceback):
cannot import name 'ReduceOp' from 'torch.distributed' (/usr/local/lib/python3.8/dist-packages/torch/distributed/__init__.py)
```<|||||>Solved by upgrading the PyTorch version 1.13.0, had to build from source with USE_DISTRIBUTED=1<|||||>You ever think a problem is solved but then you later figure out that your problem actually isn't solved? Yea I didn't get the same error as last time because the new PyTorch build didn't have CUDA enabled, when using a proper CUDA enabled PyTorch install I do still get this error. Gonna drop the ping once more as this likely would have gotten lost (sorry for the mess) @LysandreJik <|||||>Reverting to PyTorch 1.11.0 resolved this problem but gives the following warning:
```
/usr/local/lib/python3.8/dist-packages/transformers/models/segformer/image_processing_segformer.py:102: FutureWarning: The `reduce_labels` parameter is deprecated and will be removed in a future version. Please use `do_reduce_labels` instead.
```
I presume the Segformer model in Transformers simply relies on a portion of PyTorch that was deprecated starting at PyTorch version 1.12.0?<|||||>No this deprecation comes from the Transformers library, you should use the argument indicated.<|||||>But the error happens just when trying to initialize a Segformer model, would the solution be to update Transformers?<|||||>Error persists on Transformers 4.25.1<|||||>It's not an error, just a warning or are you still having the original issue?<|||||>I get the original issue on PyTorch 1.12.0+, it works fine on PyTorch 1.11.0<|||||>Any idea if the SegformerForSemanticSegmentation will be updated to support PyTorch 1.12 or has it been abandoned?<|||||>There is nothing wrong with segformer, the problem stems from your PyTorch install. We have tried to reproduce your issue with @muellerzr but with all versions of PyTorch from 1.11 to 1.13 there is nothing wrong with the import that fails on your setup.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I still have the same issue with :
pyTorch : 2.0.0+cpu
python : 3.9.1
transformers : 4.25.1
I found this issue by trying this clothes segmentation :
https://huggingface.co/mattmdjaga/segformer_b2_clothes
Error :
```
/lib/python3.9/site-packages/transformers/models/segformer/image_processing_segformer.py:102: FutureWarning: The `reduce_labels` parameter is deprecated and will be removed in a future version. Please use `do_reduce_labels` instead.
warnings.warn(
```
Okay it is a warning, but the pipe seems broken at the end. |
transformers | 20,541 | closed | Pretraing T5 model with run_t5_mlm_flax.py script does not support distributed training with deepspeed | ### System Info
- `transformers` version: 4.24.0.dev0
- Platform: Linux-3.10.0-1127.18.2.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.13
- Huggingface_hub version: 0.10.1
- PyTorch version (GPU?): 1.8.2+cu111
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): 0.6.1
- Jax version: 0.3.25
- JaxLib version: 0.3.25
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@patil-suraj
@patrickvonplaten
@stas
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
sh file to pretrain T5 model
deepspeed --hostfile hostfile \
--master_port <fill in> \
run_t5_mlm_flax.py \
--deepspeed deepspeed_configs.json \
--train_file <fill in> \
--output_dir <fill in> \
--model_name_or_path=t5-small \
--do_train \
--max_seq_length="512" \
--num_train_epochs=1 \
--save_steps=100 \
--per_device_train_batch_size=4 \
--warmup_steps=100 \
--logging_steps=100 \
--overwrite_output_dir
```
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--local_rank=0']
```
### Expected behavior
It seems run_t5_mlm_flax.py uses its own TrainingArguments file which does not define "local_rank" and "deepspeed"attributes (unlike transformers.TrainingArguments which defined these variables).
run_t5_mlm_flax.py should be configured for these attributes in order to train in a distributed manner. | 12-02-2022 01:37:27 | 12-02-2022 01:37:27 | @ArthurZucker could you take a look? :-) <|||||>DeepSpeed only supports PyTorch and the script you mention is for Flax. I don't think there is anything that can be done ;-)<|||||>Thanks for letting me know. Is there anything for distributed training on Flax models |
transformers | 20,540 | closed | run_speech_recognition_seq2seq.py: add `cache_dir` to load_dataset() | null | 12-01-2022 20:28:23 | 12-01-2022 20:28:23 | _The documentation is not available anymore as the PR was closed or merged._<|||||>cc @sanchit-gandhi |
transformers | 20,539 | closed | Support token suppression, forced tokens (besides eos and bos), and decoder prompting for flax generation | ### Feature request
Add logits processors for token suppression and forced tokens at specific indices.
Enable prompting the decoder of encoder-decoder models with decoder_input_ids.
### Motivation
Currently, the flax generation utilities do not support token suppression, forcing specific tokens to be decoded at specific response indices, nor prompting the decoder (helpful for models like Whisper that support decoder prompts - Flax Whisper is implemented in #20479). Adding these would move the flax utilities closer to feature parity with the pytorch generation utilities. Adding these features would fully unlock a flax implementation of Whisper inference.
### Your contribution
I already have these features implemented in a branch of my fork - happy to open a PR! | 12-01-2022 19:22:10 | 12-01-2022 19:22:10 | @sanchit-gandhi @patil-suraj @gante <|||||>Did we decide to implement these features in the Flax Whisper PR in the end? cc @ArthurZucker<|||||>@sanchit-gandhi @ArthurZucker I just added these back into the Flax Whisper PR<|||||>Cool! Closing this issue in favour of the PR https://github.com/huggingface/transformers/pull/20479 |
transformers | 20,539 | closed | Support token suppression, forced tokens (besides eos and bos), and decoder prompting for flax generation | ### Feature request
Add logits processors for token suppression and forced tokens at specific indices.
Enable prompting the decoder of encoder-decoder models with decoder_input_ids.
### Motivation
Currently, the flax generation utilities do not support token suppression, forcing specific tokens to be decoded at specific response indices, nor prompting the decoder (helpful for models like Whisper that support decoder prompts - Flax Whisper is implemented in #20479). Adding these would move the flax utilities closer to feature parity with the pytorch generation utilities. Adding these features would fully unlock a flax implementation of Whisper inference.
### Your contribution
I already have these features implemented in a branch of my fork - happy to open a PR! | 12-01-2022 19:22:10 | 12-01-2022 19:22:10 | @sanchit-gandhi @patil-suraj @gante <|||||>Did we decide to implement these features in the Flax Whisper PR in the end? cc @ArthurZucker<|||||>@sanchit-gandhi @ArthurZucker I just added these back into the Flax Whisper PR<|||||>Cool! Closing this issue in favour of the PR https://github.com/huggingface/transformers/pull/20479 |
transformers | 20,538 | closed | cross platform from_pretrained | # What does this PR do?
Allows loading sharded checkpoints in TF models. Should fix #19965
- [x] `from_pt=True`
- [ ] `from_flax=True`
cc @sgugger just FYI | 12-01-2022 18:48:00 | 12-01-2022 18:48:00 | Works great for sharded `pytorch` since a utility was already implemented. Though we are not gonna push for `Flax`, would still help to have the support already!
```python
from transformers import TFT5ForConditionalGeneration
MODEL_NAME = "google/flan-t5-xl"
m = TFT5ForConditionalGeneration.from_pretrained(MODEL_NAME, from_pt=True)
```
<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Just need to remove the `# TODOs`
|
transformers | 20,537 | closed | Update some GH action versions | # What does this PR do?
(I am running part of the CI to make sure nothing is broken by this PR)
We get a lot of warnings on CI summary page
```bash
Node.js 12 actions are deprecated. For more information see: https://github.blog/changelog/2022-09-22-github-actions-all-actions-will-begin-running-on-node16-instead-of-node12/. Please update the following actions to use Node.js 16: ...
```
This PR tries to update some of them. The remaining ones include `set-output` command and another one - I will work on that in another PR.
| 12-01-2022 17:46:46 | 12-01-2022 17:46:46 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,536 | closed | [Vision] `.to` function for ImageProcessors | # What does this PR do?
PoC for adding `.to` support on ImageProcessors
related #20453
| 12-01-2022 17:23:35 | 12-01-2022 17:23:35 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Here is a quick v1, but I am afraid it's a bit too much in the sense that I am literally testing every possible combination
Also regarding tests, we can remove them or put them as slow. I checked with `deit`, `vit` & `vilt` (for multimodal setup) and the tests are green (the failing test for LayoutLM can be easily fixed)
May I ask you to have a quick look @sgugger @ydshieh ? Thanks!<|||||>You're looking at something too complicated: `to()` does all that work for you already. You can pass it a string, a device or a dtype.<|||||>Yes I was thinking of something very complicated where someone could set `.to(device, dtype)` let's maybe keep it even simpler and force the user to put only a single argument in `.to` ?
EDIT: it seems that there is a workaround for that<|||||>Thanks everyone for the feedback! Let me know if you think it's relevant to add the `test_cast_dtype` for all ImageProcessors as it may slow down our CI testing suite<|||||>Ahaha no worries! thanks for all the iterations 💪 |
transformers | 20,535 | closed | Add ESM contact prediction | This PR adds the `ContactPredictionHead` for ESM (both PT and TF). I also need to update some weights on our uploaded models to support this! | 12-01-2022 16:52:54 | 12-01-2022 16:52:54 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger All suggestions included! |
transformers | 20,534 | closed | [ResNet] Fix doctest | # What does this PR do?
This PR fixes the failing doctest for `ResNetBackbone`. | 12-01-2022 14:47:51 | 12-01-2022 14:47:51 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,533 | closed | Transformer XL training fails because of IndexError due to change in ModuleList for torch>1.11 | ### System Info
Transformer version- 4.24
Torch version> 1.11
Stacktrace:
```
venv/lib/python3.8/site-packages/transformers/models/transfo_xl/modeling_transfo_xl.py:1115: in forward
softmax_output = self.crit(pred_hid, labels)
venv/lib/python3.8/site-packages/torch/nn/modules/module.py:1190: in _call_impl
return forward_call(*input, **kwargs)
venv/lib/python3.8/site-packages/torch/nn/modules/module.py:1178: in _slow_forward
result = self.forward(*input, **kwargs)
venv/lib/python3.8/site-packages/transformers/models/transfo_xl/modeling_transfo_xl_utilities.py:134: in forward
head_weight, head_bias, head_proj = weights[0], biases[0], self.out_projs[0]
venv/lib/python3.8/site-packages/torch/nn/modules/container.py:282: in __getitem__
return self._modules[self._get_abs_string_index(idx)]
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = ModuleList(), idx = 0
def _get_abs_string_index(self, idx):
"""Get the absolute index for the list of modules"""
idx = operator.index(idx)
if not (-len(self) <= idx < len(self)):
> raise IndexError('index {} is out of range'.format(idx))
E IndexError: index 0 is out of range
venv/lib/python3.8/site-packages/torch/nn/modules/container.py:272: IndexError
```
Please do let me know if further info is required.
### Who can help?
@patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Use generic torch src_token as input with d_model=d_embed with torch>1.11
### Expected behavior
Should work with different torch versions | 12-01-2022 14:11:49 | 12-01-2022 14:11:49 | Thanks for reporting but could you give us a short reproducer as our CI didn't catch any regression here?<|||||>> Thanks for reporting but could you give us a short reproducer as our CI didn't catch any regression here?
I run it as a part of fairseq. This test case-https://github.com/facebookresearch/fairseq/blob/main/tests/test_binaries.py#L1319 also fails due to same reason. IIUC, in the fairseq case d_embed=d_model maybe this condition is required to reproduce the issue?<|||||>That's not exactly a small reproducer we can run on our side ;-)<|||||>Can you point me to the test case that tests the training of the transformer XL model in huggingface? Maybe I can tune the parameters accordingly to reproduce the issue<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>actually this is still a problem. Can you please try by setting the params d_embed and d_model iwith same value? <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,532 | closed | Add run_gsg.py and run_gsg_no_trainer.py pre-training scripts to examples | ### Feature request
Models such as Pegasus and LongT5 have been pretrained using Gap Sentences Generation (GSG) strategy rather the typical Masked Language Modelling (MLM).
This pre-training strategy leads to improved performance in certain language tasks such as [summarisation](https://arxiv.org/pdf/1912.08777.pdf). This request is to add run_gsg_.py and run_gsg_no_trainer.py files in the examples folder that would enable pre-training using the GSG strategy instead of or on top of MLM.
### Motivation
This will enable users to pre-train Pegasus or LongT5 models from scratch or to continue pre-training existing checkpoints on new datasets.
### Your contribution
I've started thinking about how to build this and am happy to contribute a PR if the HF team think this is valuable and can offer advice on the best ways to approach this. | 12-01-2022 12:33:04 | 12-01-2022 12:33:04 | We try to avoid having examples that are too specific in the maintained examples, as we don't have the bandwidth for too many of them. How about you host it in a repo of yourself and then link to it from the model pages in our doc as well as the community page?<|||||>Ah I see, not problem that seems like a good alternative. Where would be the best place for asking for help with road blocks if I stumble across any?<|||||>You can use this issue or the [forums](https://discuss.huggingface.co/) :-)<|||||>Thank you @sgugger. I've had to de-prioritise this for due to funding constraints that will delay when we can train a bigger version of LongT5 from scratch so I'll close this for now and if we pick this back up I'll post any qs in the forums. |
transformers | 20,531 | closed | Fix `ConditionalDetrForSegmentation` doc example | # What does this PR do?
Need this change after PR #20160. This was done for `DetrForSegmentation`, but we missed it for `ConditionalDetrForSegmentation` | 12-01-2022 11:32:42 | 12-01-2022 11:32:42 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,530 | closed | Doc-generate | # What does this PR do?
Adds documentation for the `generate`function. It superseeds #17873 opened previously. | 12-01-2022 10:56:31 | 12-01-2022 10:56:31 | |
transformers | 20,529 | closed | Change transformers.onnx to use optimum.exporters.onnx | # What does this PR do?
As the title say. The `transformers.onnx` command-line tool now uses the `optimum.exporters.onnx` command-line tool in the background, and redirects the user to use this tool directly for the next times (same in the documentation). | 12-01-2022 10:29:06 | 12-01-2022 10:29:06 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,528 | closed | Update `ZeroShotObjectDetectionPipeline` doc example | # What does this PR do?
As @amyeroberts mentioned in #20160, there is some tiny difference after that PR, and we need this update to pass the doctests. | 12-01-2022 10:20:01 | 12-01-2022 10:20:01 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,527 | closed | fix plbart doctest | # What does this PR do?
We need to update the expect output in doc example after PR #19980 | 12-01-2022 10:10:18 | 12-01-2022 10:10:18 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@ydshieh @sgugger I just want to know how this PR works and why was the doctests failing earlier? Thanks in advance!<|||||>As the PR description mentioned, PR #19980 changed `PLBartTokenizer`, and some expected outputs in the tests have to be updated.<|||||>@ydshieh got it. Thanks! |
transformers | 20,526 | closed | Crash on google colab | ### System Info
google colab
transformers==4.20.0
https://github.com/kpu/kenlm/archive/master.zip
pyctcdecode==0.4.0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
from transformers import Wav2Vec2ProcessorWithLM
from IPython.lib.display import Audio
import torchaudio
import torch
# Load model & processor
model_name = "nguyenvulebinh/wav2vec2-large-vi-vlsp2020"
model = SourceFileLoader("model", cached_path(hf_bucket_url(model_name,filename="model_handling.py"))).load_module().Wav2Vec2ForCTC.from_pretrained(model_name)
processor = Wav2Vec2ProcessorWithLM.from_pretrained(model_name)
# Load an example audio (16k)
audio, sample_rate = torchaudio.load(cached_path(hf_bucket_url(model_name, filename="t2_0000006682.wav")))
input_data = processor.feature_extractor(audio[0], sampling_rate=16000)
# Infer
output = model(**input_data)
# Output transcript without LM
print(processor.tokenizer.decode(output.logits.argmax(dim=-1)[0].detach().cpu().numpy()))
# Output transcript with LM
print(processor.decode(output.logits.cpu().detach().numpy()[0], beam_width=100).text)
```
### Expected behavior
When ever i run this code
input_data = processor.feature_extractor(audio[0], sampling_rate=16000)
google colab restart for unknown reason. I really dont know is that a conflict by cpu and gpu??? | 12-01-2022 10:02:44 | 12-01-2022 10:02:44 | cc @sanchit-gandhi <|||||>Hey @GoldDRoge! So the issue lies with the `processor.feature_extractor` call method?
Could you provide a Google Colab link / reproducible code snippet I can run to get this error?
Looks like you're using local audio data. For the shared Colab link / reproducible code snippet, you can use this audio sample:
```python
!pip install datasets
from datasets import load_dataset
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = librispeech_dummy[0]["audio"]
audio = sample["array"]
sampling_rate = sample["sampling_rate]
```<|||||>Thanks for quickly response here the link https://colab.research.google.com/drive/1UdedI76aBEMCqlLcj1uakIdRAoztrmg5?usp=sharing
ok let me try. thanks for your help
@sanchit-gandhi <|||||>i have try like u suggest but it still crash when ever i run
input_data = processor.feature_extractor(audio[0], sampling_rate=16000)
hmmm i really dont know what error is that.
@sanchit-gandhi <|||||>Hey @GoldDRoge! Sorry for the late reply! I was able to reproduce the error with your Google Colab. However, installing the latest version of transformers and pyctcdecode remedies the issue for me: https://colab.research.google.com/drive/1Za4340oWO5GMLlKvgEtvFO8vWVS4Fafy?usp=sharing
Could you try pip installing the latest version of transformers and pyctcdecode as highlighted? Let me know if the issue still persists!
There is a 'warning' that is presented when using your Wav2Vec2ProcessorWithLM that is **not** present with the 'official' processor from the [blog post](https://huggingface.co/blog/wav2vec2-with-ngram#1-decoding-audio-data-with-wav2vec2-and-a-language-model):
```
WARNING:pyctcdecode.language_model:Only 0 unigrams passed as vocabulary. Is this small or artificial data?
```
Could you double check that your KenLM is built correctly? It's quite strange behaviour for the `unigrams.txt` file to be empty in the KenLM! This means that only sub-word tokens form your LM. https://huggingface.co/nguyenvulebinh/wav2vec2-large-vi-vlsp2020/tree/main/language_model<|||||>Hey @GoldDRoge! Did updating to the latest version of transformers and pyctcdecode help with the issue?We should definitely verify that our KenLM is built correctly and is returning a non-zero list of unigrams! Let me know if you're encountering any problems running the updated code snippet, more than happy to help here! 🤗<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,525 | closed | [BT] add links to `optimum` docs | # What does this PR do?
This PR adds link to `BetterTransformer` documentation on `transformers` documentation
cc @ydshieh @michaelbenayoun @fxmarty
| 12-01-2022 09:58:30 | 12-01-2022 09:58:30 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,524 | closed | added docs to time series transformer's generate function | # What does this PR do?
Added docs to the time series transformer's generate function.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 12-01-2022 09:37:04 | 12-01-2022 09:37:04 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_20524). All of your documentation changes will be reflected on that endpoint. |
transformers | 20,523 | closed | Change doctests ci launch time | # What does this PR do?
Current doctests CI is launched at 0h (GTM+0), but the docker images are built at 1h (GTM+0), while modeling CI is at 2h (GTM+0).
It happens a few times that we change something in doctest docker image workflow file, expect the failed tests will pass in the next run, and turns out it is not - as the next run is launched 1 hour before the new image is built.
To avoid confusion, this PR **change the doctest launch time to be the same as the modeling CI time - which is after the docker image build CI**. | 12-01-2022 09:27:16 | 12-01-2022 09:27:16 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,522 | closed | QnA example: add speed metric | Examples:
@sgugger
| 12-01-2022 09:19:56 | 12-01-2022 09:19:56 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,521 | closed | Fix OwlViTFeatureExtractor.post_process_image_guided_detection device incompatibility issue | fixes https://github.com/huggingface/transformers/issues/20513 | 12-01-2022 08:34:46 | 12-01-2022 08:34:46 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thank you for the fast response! |
transformers | 20,520 | closed | Add RemBERT ONNX config | # What does this PR do?
Add RemBERT ONNX config (part of https://github.com/huggingface/transformers/issues/16308)
The max absolute difference between reference model and ONNX exported model is around `2e-05` in testings. I learned from other PRs that this discrepancy is within an acceptable range so I loosen the default atol.
Slow tests are passed (`RUN_SLOW=1 pytest tests/onnx/test_onnx_v2.py -k "rembert"`).
I'm new to contributing to Transformers. If anyone can help me understand what is lacking, it would be appreciated!
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@lewtun & @ChainYo for ONNX and @Iwontbecreative for RemBERT.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 12-01-2022 08:26:04 | 12-01-2022 08:26:04 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> Hi @hchings, the PR looks excellent! Did you try to run tests locally?
>
> ```
> RUN_SLOW=1 pytest tests/onnx/test_onnx_v2.py -k "rembert"
> ```
>
> Could you also remove the `Fixes #...` before the link to the ONNX issue to avoid an auto-close from GitHub? Thanks a lot for your contribution!
Yes, all slow tests passed for PyTorch locally. Should we add TensorFlow tests as well? My understanding is TF tests are needed only when TF has parity with PyTorch implementations. But correct me if I'm wrong.
|
transformers | 20,519 | closed | 'WhisperTokenizer' object has no attribute 'set_prefix_tokens' | ### System Info
- `transformers` version: 4.24.0
- Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.27
- Python version: 3.9.15
- Huggingface_hub version: 0.11.0
- PyTorch version (GPU?): 1.13.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help?
@LysandreJik
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-medium", language="spanish", cache_dir="./pretrained_models")
tokenizer.set_prefix_tokens(language="english")
AttributeError: 'WhisperTokenizer' object has no attribute 'set_prefix_tokens'
### Expected behavior
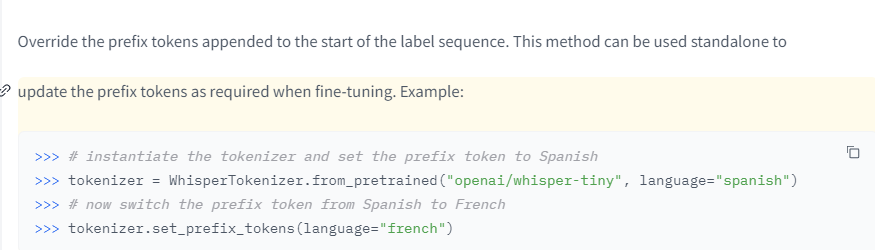
This method should exist according to the documentation | 12-01-2022 06:45:34 | 12-01-2022 06:45:34 | Hi @nethermanpro, I'm not a maintainer, but I think I know what is going on.
It seems that in `transformers 4.24.0`, the method `set_prefix_tokens` is not present in this version. You can find it in this repository in the main branch, if you want to use it, you will need to install transformers directly from this repository `pip install git+https://github.com/huggingface/transformers.git` or wait for the next stable release.
The documentation you are looking at seems to be https://huggingface.co/docs/transformers/main/en/model_doc/whisper which is the documentation of the main branch, to check the documentation of `4.24.0` you can
select it at the top left dropdown where it says `main`.
Here you have the link https://huggingface.co/docs/transformers/v4.24.0/en/model_doc/whisper#transformers.WhisperTokenizer
<|||||>Thanks, I think that solves my problem. |
transformers | 20,518 | closed | [WIP] Add Atlas - Retrieval Augmented Language Model | # What does this PR do?
Implements Atlas: Few-shot Learning with Retrieval Augmented Language Model as mentioned here
https://github.com/huggingface/transformers/issues/20503
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@patrickvonplaten, @lhoestq, @patil-suraj
cc @patrick-s-h-lewis and @gizacard
| 12-01-2022 05:34:14 | 12-01-2022 05:34:14 | This branch is very much a WIP currently, but for anyone interested here is roughly how I plan to structure things, aiming to roughly mesh the shape of the original implementation with Transformer's existing patterns. For the most part, I hope to make its usage as similar as possible to `T5ForConditionalGeneration`.
This is all new to me, so any feedback would be super helpful!
```python
class AtlasConfig():
pass
class AtlasTrainer(Trainer):
pass
class AtlasPreTrainedModel(PreTrainedModel):
pass
class AtlasModel(AtlasPreTrainedModel):
def __init__(self, queryPassageEncoder, reader, retriever):
self.queryPassageEncoder = queryPassageEncoder # UntiedDualEncoder
self.reader = reader # FiD
self.retriever = retriever # HFIndexBase
class FiD(T5ForConditionalGeneration):
def __init__(self):
self.encoder = FiDStack()
self.decoder = FiDStack()
class FiDStack(T5Stack):
pass
class UntiedDualEncoder(torch.nn.Module):
def __init__(self, query_contriever, passage_contriever):
self.query_contriever = query_contriever
self.passage_contriever = passage_contriever
class Contriever(BertModel):
pass
class HFIndexBase():
pass
class AtlasRetriever:
def __init__(self, index):
self.index = index # HFIndexBase
```
---
The existing RAG implementation makes its sub-models easily swappable, however, the inputs and outputs expected by 'reader' model (the name given to the T5 encoder/decoder in the original implementation) here are non-standard due to the fusion-in-decoder mechanism, so I don't plan to make these models as easily swappable as I think that would complicate things unnecessarily.
As I'm not doing this, it seems it may be best practice to copy implementation (w/ "Copied from" comments) of models like the BertModel and T5ForConditionalGeneration rather than import - if that's the case I'll switch these across once the PR's almost ready.
---
There is some complexity here in how we make the model trainable E2E within Huggingface's patterns, which I haven't yet looked into deeply. I wonder whether a `class AtlasTrainer(Trainer)` would make sense, which can implement the various continuous re-indexing strategies described in the original paper.
<|||||>Yes, please do use the approach of copying model code and adding `# Copied from` comments as it's more inline with the general approach in the library (RAG being an exception :-) )<|||||>cc @ArthurZucker <|||||>@ArthurZucker @ae99 let me know if you need help with anything - think this is a super cool addition! <|||||>> @ArthurZucker @ae99 let me know if you need help with anything - think this is a super cool addition!
Hey @patrickvonplaten and @ArthurZucker! I think the general structure of this model is mostly in place. I'd love to get an early review on the PR from you just to check if things are looking ok and confirm the major things are roughly fitting patterns correctly.
I have a few temporary notebooks `save_pretrained.ipynb`, `test_retriever.ipynb` and `test_model.ipynb` in place of actual tests at the moment if you would like to get a sense of usage. Like RAG I have a dedicated retriever, but I've cut this down to mostly be a small wrapper around a dataset+index for now. Documentation and tests haven't been touched at all yet, and everything is very WIP still!<|||||>Hi @ae99, I would also like to contribute. Let me know if there is something I can help you with.
<|||||>@ArthurZucker could you maybe take a look here? :-) Let me know if you need some help<|||||>@akashe feel free to give this PR a review as well if you'd like to help a bit :-) <|||||>Will review now 😉 <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hey @ae99 , are you still working on the integration? If not then let me know, I would be happy to continue from where you left.<|||||>> Hey @ae99 , are you still working on the integration? If not then let me know, I would be happy to continue from where you left.
Hey @akashe, that'd be perfect.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi!
This one would be really relevant for something that we are working on in my org.
What's the status on it? We may be able to chip in.<|||||>Hey! We have not really picked it up, if the community needs it we can probably come back to it, but I would advise to just put the model on the hub following this [tutorial](https://huggingface.co/docs/transformers/custom_models)! 🤗 |
transformers | 20,517 | closed | Fix link in pipeline device map | This PR fixes the broken link in the pipeline `device_map` parameter. | 12-01-2022 01:05:12 | 12-01-2022 01:05:12 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,516 | closed | Fix Hubert models in TFHubertModel and TFHubertForCTC documentation code | # What does this PR do?
This PR updates the used models in the `TFHubertModel` and `TFHubertModelForCTC` example codes to the same model used in `HubertModel` and `HubertModelForCTC` other examples in the same documentation as `"facebook/hubert-base-960h"` does not exist and the actual code doesn't run. | 12-01-2022 00:41:59 | 12-01-2022 00:41:59 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,515 | closed | Add some warning for Dynamo and enable TF32 when it's set | # What does this PR do?
This PR adds a warning when a user sets torchdynamo without an Ampere GPU (or higher) and also enables TF32 unless the user explicitly asked not it with `--no_tf32` to get the best performance. | 11-30-2022 20:23:43 | 11-30-2022 20:23:43 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,514 | closed | Why tflite model output shape is different than the original model converted from T5ForConditionalGeneration? | ### System Info
- `transformers` version: 4.24.0
- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.12.1+cu113 (True)
- Tensorflow version (GPU?): 2.9.2 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@patric @anton-l @sanchit-gandhi @Rocketknight1
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
**T5ForConditionalGeneration Model to translate English to German**
```
from transformers import T5TokenizerFast, T5ForConditionalGeneration
tokenizer = T5TokenizerFast.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
input_ids = tokenizer("translate English to German: the flowers are wonderful.", return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Output : Die Blumen sind wunderbar.
**Input Shape**
```
input_ids.shape
```
Output : torch.Size([1, 11])
**Output Shape**
```
outputs.shape
```
Output : torch.Size([1, 7])
**Save Pretrained model**
```
!mkdir /content/test
model.save_pretrained('/content/test')
```
**Load TFT5Model model from pretrained**
```
from transformers import TFT5Model
t5model = TFT5Model.from_pretrained('/content/test',from_pt=True)
!mkdir /content/test/t5
t5model.save('/content/test/t5')
```
**Convert TFT5Model to TFlite**
```
import tensorflow as tf
saved_model_dir = '/content/test/t5'
!mkdir /content/test/tflite
tflite_model_path = '/content/test/tflite/model.tflite'
# Convert the model
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.experimental_new_converter = True
converter.experimental_new_quantizer = True
converter.experimental_new_dynamic_range_quantizer = True
converter.allow_custom_ops=True
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TensorFlow Lite ops.
tf.lite.OpsSet.SELECT_TF_OPS # enable TensorFlow ops.
]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
#print(tflite_model)
print(type(tflite_model))
# Save the model
with open(tflite_model_path, 'wb') as f:
f.write(tflite_model)
```
**Load The TFLite model**
```
import numpy as np
import tensorflow as tf
tflite_model_path = '/content/test/tflite/model.tflite'
# Load the TFLite model and allocate tensors
interpreter = tf.lite.Interpreter(model_path=tflite_model_path)
interpreter.resize_tensor_input(0, [1,5], strict=True)
interpreter.resize_tensor_input(1, [1,5], strict=True)
interpreter.resize_tensor_input(2, [1,5], strict=True)
interpreter.resize_tensor_input(3, [1,5], strict=True)
interpreter.allocate_tensors()
# Get input and output tensors
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_shape = input_details[0]['shape']
#print the output
input_data = np.array(np.random.random_sample((input_shape)), dtype=np.int64)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
```
**Get The Output Shape**
```
print(output_data.shape)
```
### Expected behavior
`print(output_data.shape)`
results in
**Output : (1, 8, 5, 64)
Expected something like : (1, 7)**
Can someone let me know where am I going wrong ?
The output shape of the tflite model is completely different from the T5ForConditionalGeneration model
| 11-30-2022 18:37:23 | 11-30-2022 18:37:23 | You reloaded your model in a `TFT5Model`, which is not the same as `T5ForConditionalGeneration`: it's the base model without the decoder.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hello @sgugger ,
Thank you for the update.
Is there any way to convert T5ForConditionalGeneration to TFlite model taking the docs below into consideration ?
https://www.tensorflow.org/api_docs/python/tf/lite/TFLiteConverter<|||||>cc @gante @Rocketknight1 the TF experts might be able to help here!<|||||>Hey @generic-matrix 👋 you probably want to export the entire generation function (which wraps the model), not just the model itself. Look at this [test example](https://github.com/huggingface/transformers/blob/92ce53aab859012f7714dae6d6fce7a7d701e75f/tests/generation/test_tf_utils.py#L140) :)<|||||>@generic-matrix please see the sample [notebook](https://colab.research.google.com/github/usefulsensors/openai-whisper/blob/main/notebooks/generate_tflite_from_whisper.ipynb) converting from TFWhisperForConditionalGeneration to tflite
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,513 | closed | owlvit image guided detection does not work in gpu (cuda) | ### System Info
- `transformers` version: 4.25.0.dev0
- Platform: Linux-5.4.0-132-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.11.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@alaradirik @NielsRogge
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run this demo in gpu: https://huggingface.co/spaces/adirik/image-guided-owlvit
Get this error:
```bash
File ".../lib/python3.8/site-packages/transformers/models/owlvit/image_processing_owlvit.py", line 420, in post_process_image_guided_detection
target_boxes = target_boxes * scale_fct[:, None, :]
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
```
### Expected behavior
I have posted a possible fix in this comment: https://github.com/huggingface/transformers/pull/20160#discussion_r1036281555 | 11-30-2022 17:58:56 | 11-30-2022 17:58:56 | Hi @fcakyon, thanks for bringing this up! You can expect a fix PR shortly.
As a side note, we open new issues and PRs for bugs to make it easier to track improvements. You can directly include your fix suggestions in the issue.<|||||>I will try to open a PR, give me few mins 👍 <|||||>@alaradirik tried to open the related pr here: https://github.com/huggingface/transformers/pull/20521 |
transformers | 20,512 | closed | Update expected output in `AutomaticSpeechRecognitionPipeline` doc example | # What does this PR do?
The failed doc example uses `openai/whisper-base`. Maybe same reason in #20493, so I just updated the expected output.
| 11-30-2022 17:04:48 | 11-30-2022 17:04:48 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,511 | closed | Add `natten` in docker file | # What does this PR do?
So we can run the tests for `dinat` model. | 11-30-2022 16:38:26 | 11-30-2022 16:38:26 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,510 | closed | Fix Data2VecTextForCasualLM example code documentation | # What does this PR do?
Fixes documentation of Data2VecTextForCasualLM example code, as it is currently importing `Data2VecTextTokenizer`, which does not exist, and the tokenizer is actually `RobertaTokenizer`. At the same time, the model name `"data2vec-base"` does not exist, and it doesn't particularly say to create one locally (with the change, it aims to `"facebook/data2vec-text-base"`). | 11-30-2022 16:18:06 | 11-30-2022 16:18:06 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,509 | closed | Fix Typo in Docs for GPU | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes Typo in Docs for multi gpu training (https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 11-30-2022 15:25:39 | 11-30-2022 15:25:39 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,508 | closed | more_itertools required for Whisper normaliser | ### System Info
- `transformers` version: 4.25.0.dev0
- Platform: macOS-12.5-arm64-arm-64bit
- Python version: 3.8.9
- Huggingface_hub version: 0.10.0
- PyTorch version (GPU?): 1.11.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): 0.5.1 (cpu)
- Jax version: 0.3.6
- JaxLib version: 0.3.5
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
cc @ArthurZucker
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
The English normaliser for Whisper relies on the `more_itertools` package.
It is imported here:
https://github.com/huggingface/transformers/blob/761b3fad922310457003af2fea6c447768676c8d/src/transformers/models/whisper/english_normalizer.py#L23-L24
And used here:
https://github.com/huggingface/transformers/blob/761b3fad922310457003af2fea6c447768676c8d/src/transformers/models/whisper/english_normalizer.py#L243
Since we import `more_itertools` under the if statement `if is_more_itertools_available()`, the normaliser **fails** if `more_itertools` is **not** installed.
```python
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-tiny.en")
tokenizer._normalize("the cat")
```
```
File "/home/user/.local/lib/python3.8/site-packages/transformers/models/whisper/tokenization_whisper.py", line 485, in _normalize
return normalizer(text)
File "/home/user/.local/lib/python3.8/site-packages/transformers/models/whisper/english_normalizer.py", line 593, in __call__
s = self.standardize_numbers(s)
File "/home/user/.local/lib/python3.8/site-packages/transformers/models/whisper/english_normalizer.py", line 497, in __call__
s = " ".join(word for word in self.process_words(s.split()) if word is not None)
File "/home/user/.local/lib/python3.8/site-packages/transformers/models/whisper/english_normalizer.py", line 497, in
s = " ".join(word for word in self.process_words(s.split()) if word is not None)
File "/home/user/.local/lib/python3.8/site-packages/transformers/models/whisper/english_normalizer.py", line 243, in process_words
for prev, current, next in windowed([None] + words + [None], 3):
NameError: name 'windowed' is not defined
```
IMO this is a pretty cryptic error message for the user. Perhaps we can add a warning that `more_itertools` is required for the normaliser? Even better, we implement the `windowed` function ourselves to prevent an extra library dependency that we use for one function.
### Expected behavior
Good: warning that `more_itertools` is not installed
Better: implement the `windowed` function ourselves | 11-30-2022 14:48:11 | 11-30-2022 14:48:11 | Totally agree here! If we only use window and it is pretty short, makes sense to implement it! But IIRC it was a pretty long dependency. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>cc @Narsil do you want to take this over? <|||||>Done I think.<|||||>Thanks @Narsil! |
transformers | 20,507 | closed | Fix TF nightly tests | This PR fixes two issues with the TF tests:
1) `test_saved_model_creation` failed sometimes because the dict being passed to the saved model didn't match the inputs it was traced/compiled with. This should be fixed now.
2) Some of the tests for the new `TFGPT2Tokenizer` (cc @piEsposito) were using `is_tensorflow_text_available` or `requires_tensorflow_text`, but `TFGPT2Tokenizer` actually depends on `keras-nlp`. I made sure the requirements were changed and that `is_keras_nlp_available` is importable from the root. | 11-30-2022 13:50:10 | 11-30-2022 13:50:10 | Don't worry, it was a really small fix! Just making sure you saw this so you didn't get confused about why your code was being changed.<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,506 | closed | [modelcard] Update dataset tags | # What does this PR do?
Currently, the `model-index` portion of the model cards generated by Trainer reference the train dataset and omit the dataset split and config. This PR:
1. Uses the **eval dataset** to build the yaml data for the model card rather than the **train dataset** by default. Why? Because the yaml data is built on a trio of information of {task, dataset, metrics} (_c.f._ [modelcard.py#L446](https://github.com/huggingface/transformers/blob/d0c1ded5f36e27cd74728c0127add5afdf1f2afa/src/transformers/modelcard.py#L446)). Here, metrics is referring to the **eval dataset** metrics, so we should build the metadata information with the eval dataset name, config, split, etc. If the eval_dataset is None, we revert to the train_dataset.
2. Checks if `dataset_metadata` is None. If so, builds from the `one_dataset`.
The combined changes of 1 and 2 mean that model cards generated by Trainer will be compatible with the autoevaluate leaderboards! https://huggingface.co/spaces/autoevaluate/leaderboards
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 11-30-2022 10:56:06 | 11-30-2022 10:56:06 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Here's an example @lewtun
Before: https://huggingface.co/sanchit-gandhi/whisper-debug/blob/88128010f73114cc2274868938ccbf6c373b15c5/README.md#L11-L20
After: https://huggingface.co/sanchit-gandhi/whisper-debug/blob/3be9573cff0eb5af8877189481fd13d411171a86/README.md#L9-L20 (only used 8 samples for eval)<|||||>Will merge if you're happy with the changes @lewtun?<|||||>(merging to unblock testing for the Whisper fine-tuning event) |
transformers | 20,505 | closed | layerdrop in Wav2Vec2Adapter | ### System Info
Hi!
As mentioned in https://github.com/huggingface/transformers/issues/20451, the layer dropout in `Wav2Vec2Adapter` may produce outputs with different lengths.
I understand the use of layerdrop in transformer structure, but do we need it in CNNs (`Wav2Vec2Adapter`)?
https://github.com/huggingface/transformers/blob/61d3928bfb3029bceb5be3e68ca3d4bf8456758f/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L1006-L1009
### Who can help?
cc @anton-l @patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I copied the reproduction code of @OllieBroadhurst in https://github.com/huggingface/transformers/issues/20451
```python
from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("anton-l/wav2vec2-base-lang-id",
add_adapter=True,
adapter_stride=2,
adapter_kernel_size=3,
num_adapter_layers=2)
model.train() # NB
dummy_input = torch.randn((1, 16000))
expected_output_sequence_length = 13
for _ in range(200):
output_shape = model(input_values=dummy_input)[0].shape[1]
if output_shape != expected_output_sequence_length:
print(output_shape)
```
### Expected behavior
The above loop shouldn't print anything out. | 11-30-2022 07:25:11 | 11-30-2022 07:25:11 | @sanchit-gandhi could you take a look here? <|||||>Hey @bofenghuang! Thanks for opening this issue.
For context, we use the adapter layer when combining the Wav2Vec2 model in a sequence-to-sequence combination (see https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition#warm-started-speech-encoder-decoder-model). Here, the purpose of the adapter layer is to better match the time scale of the encoder with that of the decoder (see aforementioned doc).
In this respect, it's fine if the CNN downsamples the Wav2Vec2 output sequence at a stochastic rate for all training samples. This should add some 'robustness' to our text decoder which has to infer the correct target transcription from Wav2Vec2 output sequences of slightly varying length.
You can also disable layer drop by setting `layerdrop=0.0` in the config: https://huggingface.co/facebook/wav2vec2-base-960h/blob/main/config.json#L59<|||||>Thanks @sanchit-gandhi ! |
transformers | 20,504 | closed | fix ipex+fp32 jit trace model inference error in ipex 1.13 | error show like: “Currently the auto_kernel_selection does not support the grad mode! Please add torch.no_grad() before the inference runtime..” since jit mode only work in inference mode, it's safe to add such logic.
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
- trainer: @sgugger
| 11-30-2022 06:31:55 | 11-30-2022 06:31:55 | @jianan-gu <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,503 | open | Atlas: Few-shot Learning with Retrieval Augmented Language Model | ### Model description
Atlas is a retrieval-augmented seq2seq language model comprised of a Contriever retriever and fusion-in-decoder (FID) architecture (which uses T5), introduced in the paper [Atlas: Few-shot Learning with Retrieval Augmented Language Models](https://arxiv.org/pdf/2208.03299.pdf)
From the papers abstract:
> Large language models have shown impressive few-shot results on a wide range of tasks.
However, when knowledge is key for such results, as is the case for tasks such as question
answering and fact checking, massive parameter counts to store knowledge seem to be needed.
Retrieval augmented models are known to excel at knowledge intensive tasks without the
need for as many parameters, but it is unclear whether they work in few-shot settings. In this
work we present Atlas, a carefully designed and pre-trained retrieval augmented language
model able to learn knowledge intensive tasks with very few training examples. We perform
evaluations on a wide range of tasks, including MMLU, KILT and NaturalQuestions, and
study the impact of the content of the document index, showing that it can easily be updated.
Notably, Atlas reaches over 42% accuracy on Natural Questions using only 64 examples,
outperforming a 540B parameters model by 3% despite having 50x fewer parameters.
### Open source status
- [X] The model implementation is available https://github.com/facebookresearch/atlas
- [X] The model weights are available https://github.com/facebookresearch/atlas
### Provide useful links for the implementation
Open-sourced implementation from Meta https://github.com/facebookresearch/atlas, with weights available.
Authored by @patrick-s-h-lewis and @gizacard | 11-30-2022 02:56:08 | 11-30-2022 02:56:08 | Hi all!
Super appreciative of the authors for open-sourcing this model, really exciting stuff.
I'm planning on having a go at implementing this model here. Aware there are others who have been looking at similar models in the past (https://github.com/huggingface/transformers/issues/15387), so thought it good to get this ticket in early in case you are also interested in working on this!<|||||>go for it! it shouldnt be too hard to get inference working - training may be more involved - the way we do the distributed index might be a little painful to integrate gracefully.
good luck!
Please make sure that you provide links to the original repo prominently, and try to make sure the models are 1) capable of achieving the same accuracy that they do in our repo 2) mathematically preform the same computations.
<|||||>Hello, is ATLAS a part of huggingface now? |
transformers | 20,502 | closed | HTTPS request to model repo despite local_files_only=T | ### System Info
- `transformers` version: 4.9.2
- Platform: Linux-5.4.0-109-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.10.0a0+git36449ea (True)
- Tensorflow version (GPU?): 2.4.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: none
### Who can help?
@mrm8488
I am trying to to Q&A in a very large text so I chunk the text and do Q&A in smaller chunks.
I have a pipeline using this model embedded in a function that I call in a loop.
```
my_guru <- function(my_sents, my_topk, my_question) {
sequence_length <- lengths(gregexpr("\\W+", my_sents)) + 1
print(sequence_length)
assert("Sequence length < 4096", sequence_length < 4096)
text <- reticulate::import("tensorflow_text")
transformers <- reticulate::import("transformers")
torch <- reticulate::import("torch")
model <- transformers$AutoModelForQuestionAnswering$from_pretrained("mrm8488/longformer-base-4096-finetuned-squadv2",
#low_cpu_mem_usage=FALSE,
local_files_only=T)
tokenizer <- transformers$AutoTokenizer$from_pretrained("mrm8488/longformer-base-4096-finetuned-squadv2",
truncation = FALSE,
padding='max_length',
local_files_only=T)
guru <- transformers$pipeline("question-answering",
model=model,
tokenizer=tokenizer,
device=0L)
answers <- guru(context = my_sents, question = my_question, top_k = my_topk)
rm(tokenizer)
gc()
torch$cuda$empty_cache()
return(answers)
}
````
Since I am using local_files_only=T. I should expect it to run over the days and complete without going to internet. However after looping a few thousand times, It generates an error and crashes out
```
/usr/local/lib/python3.8/dist-packages/transformers/pipelines/question_answering.py:316: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:198.)
fw_args = {k: torch.tensor(v, device=self.device) for (k, v) in fw_args.items()}
Error in py_call_impl(callable, dots$args, dots$keywords) :
requests.exceptions.HTTPError: 504 Server Error: Gateway Time-out for url: https://huggingface.co/api/models/mrm8488/longformer-base-4096-finetuned-squadv2
```
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
set local files to TRUE
repeat the pipeline over thousands of times
### Expected behavior
The script should not send a request to huggingface when local files is set to TRUE | 11-30-2022 00:28:12 | 11-30-2022 00:28:12 | You need to upgrade your version of Transformers as it's pretty old and many bugs with the cache system have been fixed since then.<|||||>Thank you. Upgrade fixes the problem |
transformers | 20,501 | closed | Update doc examples feature extractor -> image processor | # What does this PR do?
Replaces vision feature extractor references with image processors throughout transformers documentation.
Places where changes didn't happen:
* Vision models which use a `Processor` class. Some processor classes still have `feature_extractor_class` property, to be removed in future.
* `examples/...` - required changes to code outside to scope of this PR and dependant on some changes to `Processor` class
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? | 11-29-2022 23:46:21 | 11-29-2022 23:46:21 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,500 | closed | Unstable generation results when using Top-p decoding | ### System Info
I trained a T5-base model for a translation task. I use Top-p decoding strategy to generate text.
Something is weird in the model; every time I ask the model to generate text for the given same input, it generates a different text. When I fix the random seed, the model starts to generate the exact text every time.
My question is, why the model generates different texts for the same input if the random seed is not fixed? Top-P decoding strategy has no randomness.
```
y = data['target_ids'].to(device, dtype=torch.long)
ids = data['source_ids'].to(device, dtype=torch.long)
mask = data['source_mask'].to(device, dtype=torch.long)
generated_ids = model.generate(input_ids=ids, attention_mask=mask, max_length=512, do_sample=True, top_p=0.9, top_k=0, num_return_sequences=1)
```
@patrickvonplaten
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I just trained the T5 model on a translation task and then generate text using the above code.
### Expected behavior
The model generates the same text even if I don't fix the random seed. | 11-29-2022 23:40:23 | 11-29-2022 23:40:23 | Gently pinging @gante here<|||||>Hi @bilalghanem 👋
Top-p has randomness -- when using `top_p=0.9`, `generate()` picks a token among the top candidate tokens, where the sum of the probability of those top candidates is >= 0.9. In other words, unless you model predicts a token with probability > 0.9 at each generation step, it will not be deterministic.
I'd recommend reading this blog post: https://github.com/huggingface/blog/blob/main/how-to-generate.md<|||||>>
Thanks @gante.
Can you clarify, how it won't be deterministic if we don't find a token that satisfies the P condition? <|||||>@bilalghanem It considers all tokens, from most to least likely, such that its summed probability is `top_p`, and samples (proportionally) from those tokens.
Consider the following logits array: `[0.5, 0.4, 0.1]`. If you run sampling with `top_p=0.9`, it will pick the first token `(0.5/0.9)*100 = 55.6%` of the times, the second token `(0.4/0.9)*100 = 44.4%` of the times, and the last token `0%` of the times.
If you want a deterministic behavior, use `do_sample=False`. Again, I'd recommend reading the following blog post, which explains all of this: https://github.com/huggingface/blog/blob/main/how-to-generate.md
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,499 | closed | ValueError: Expected input batch_size (8) to match target batch_size (1008). | ### System Info
- `transformers` version: 4.24.0
- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.12.1+cu113 (True)
- Tensorflow version (GPU?): 2.9.2 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@sgugger @lys
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am fine-tuning a custom model for multiclass classification. When I run the sixth cell of [this collab notebook](https://colab.research.google.com/drive/1NYk_RJcZ3GmwYQTv9X3kcG_FbHDjWvsd?usp=sharing), I get the following error:
```
ValueError Traceback (most recent call last)
[<ipython-input-17-f9d56f5f4088>](https://localhost:8080/#) in <module>
27 )
28
---> 29 trainer.train()
30
31 trainer.push_to_hub()
8 frames
[/usr/local/lib/python3.7/dist-packages/transformers/trainer.py](https://localhost:8080/#) in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1503 resume_from_checkpoint=resume_from_checkpoint,
1504 trial=trial,
-> 1505 ignore_keys_for_eval=ignore_keys_for_eval,
1506 )
1507
[/usr/local/lib/python3.7/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1747 tr_loss_step = self.training_step(model, inputs)
1748 else:
-> 1749 tr_loss_step = self.training_step(model, inputs)
1750
1751 if (
[/usr/local/lib/python3.7/dist-packages/transformers/trainer.py](https://localhost:8080/#) in training_step(self, model, inputs)
2506
2507 with self.compute_loss_context_manager():
-> 2508 loss = self.compute_loss(model, inputs)
2509
2510 if self.args.n_gpu > 1:
[/usr/local/lib/python3.7/dist-packages/transformers/trainer.py](https://localhost:8080/#) in compute_loss(self, model, inputs, return_outputs)
2538 else:
2539 labels = None
-> 2540 outputs = model(**inputs)
2541 # Save past state if it exists
2542 # TODO: this needs to be fixed and made cleaner later.
[/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
[/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py](https://localhost:8080/#) in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, output_attentions, output_hidden_states, return_dict)
1238 elif self.config.problem_type == "single_label_classification":
1239 loss_fct = CrossEntropyLoss()
-> 1240 loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
1241 elif self.config.problem_type == "multi_label_classification":
1242 loss_fct = BCEWithLogitsLoss()
[/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
[/usr/local/lib/python3.7/dist-packages/torch/nn/modules/loss.py](https://localhost:8080/#) in forward(self, input, target)
1164 return F.cross_entropy(input, target, weight=self.weight,
1165 ignore_index=self.ignore_index, reduction=self.reduction,
-> 1166 label_smoothing=self.label_smoothing)
1167
1168
[/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py](https://localhost:8080/#) in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction, label_smoothing)
3012 if size_average is not None or reduce is not None:
3013 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 3014 return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
3015
3016
ValueError: Expected input batch_size (8) to match target batch_size (1008).
```
### Expected behavior
I expected training to continue as usual. | 11-29-2022 21:33:21 | 11-29-2022 21:33:21 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Disabling one-hot encoding (`encoding['labels'] = [[stage] for stage in examples['Stage']]`) and the data collator (`# data_collator=data_collator`) seems to resolve this issue.
Not sure if labels should be sparsely encoded and what the data_collator does to create this error, maybe it 'collates' on the wrong axis? |
transformers | 20,498 | closed | Repurpose torchdynamo training args towards torch._dynamo | # What does this PR do?
This PR re-uses the current `torchdynamo` training argument to be compatible with the internal module of PyTorch (in the nightlies). This is slightly breaking but at the same time the torchdynamo package has migrated to PyTorch proper, and the integration was marked as experimental.
The "fx2trt-fp16" backend is not advertised by PyTorch, so I removed it. | 11-29-2022 19:53:53 | 11-29-2022 19:53:53 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,497 | closed | Fix disk offload for full safetensors checkpoints | # What does this PR do?
#20321 was only tested with safetensors checkpoints containing multiple shards. The code failed for full checkpoints, this PR fixes it. | 11-29-2022 19:16:45 | 11-29-2022 19:16:45 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,496 | closed | [modelcard] Set model name if empty | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
When building the model card, if the `model_name` is unspecified we set it to `training_args.output_dir`:
https://github.com/huggingface/transformers/blob/86e435bbb1e54f169351dbb798141afee7fa1b93/src/transformers/modelcard.py#L592-L593
This is typically the case during intermediate push to Hubs during training (when we don't specify any extra push to hub kwargs).
However, if we're fine-tuning from **within** a model repo, we set `--output_dir=./`. This means that `Path(trainer.args.output_dir).name=""`, and so `model_name=""`.
This causes a problem when we try and push the model card to the Hub: a model name of `""` registers as an **empty** model index name, meaning the push is rejected:
```bash
remote: ----------------------------------------------------------
remote: Sorry, your push was rejected during YAML metadata verification:
remote: - Error: "model-index[0].name" is not allowed to be empty
remote: ----------------------------------------------------------
remote: Please find the documentation at:
remote: https://huggingface.co/docs/hub/model-cards#model-card-metadata
remote: ----------------------------------------------------------
```
This PR sets the `model_name` to `finetuned_from` in the case that it is empty (`""`), meaning that the push to hub is allowed.
Unless there's a neater way of inferring the model repo id, this is probably the best way of preventing rejected push to Hubs?
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 11-29-2022 18:28:27 | 11-29-2022 18:28:27 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,495 | closed | [modelcard] Check for IterableDataset | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adds check for a HF IterableDataset (i.e. a HF dataset in streaming mode).
Required to build the model card when training models with streaming mode!
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 11-29-2022 18:14:27 | 11-29-2022 18:14:27 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,494 | closed | PyTorch training scripts freeze when preprocessing_num_workers > 1 | ### System Info
transformers 4.24.0
datasets 2.7.1
Dockerfile: https://github.com/aws/deep-learning-containers/blob/master/pytorch/training/docker/1.12/py3/cu113/Dockerfile.gpu
### Who can help?
@sgugger, @patil-sura
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
### Local Repro
`python3.8 run_mlm.py --dataloader_drop_last True --dataset_config_name wikitext-103-v1 --dataset_name wikitext --do_train True --fp16 True --max_seq_length 512 --model_name_or_path bert-base-uncased --num_train_epochs 16 --per_device_train_batch_size 32 --preprocessing_num_workers 12
`
### AWS Repro
`
!pip install sagemaker
from sagemaker.pytorch import PyTorch
PyTorch(
framework_version='1.12',
py_version="py38",
instance_type="ml.p4d.24xlarge",
distribution={"pytorchddp": {"enabled": True}},
source_dir="examples/pytorch/language-modeling",
entry_point="run_mlm.py",
hyperparameters={
'dataset_name': 'wikitext',
'dataset_config_name': 'wikitext-103-v1',
'do_train': True,
'fp16': True,
'model_name_or_path': 'bert-base-uncased',
'num_train_epochs': 10,
'per_device_train_batch_size': 32,
'preprocessing_num_workers': 12,
},
).fit()
`
### Expected behavior
Training to completion without stalls/freezes at data preprocessing.
Currently the training stalls with the last log line being:
```
Grouping texts in chunks of 512
``` | 11-29-2022 18:11:55 | 11-29-2022 18:11:55 | Any update here ?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,493 | closed | [CI, WHISPER] fix the latest failing test | # What does this PR do?
In a recent update, we followed the original code which changed some of the suppress tokens for better performances. This lead to a small change in the output of on particular case. Tested with the original code and we have the correct output now!
See [here](https://huggingface.co/openai/whisper-large/commit/ed97120f929257fb801f99587ada69be0daf5b0a) for the particular commit | 11-29-2022 18:02:20 | 11-29-2022 18:02:20 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,492 | closed | Support extraction of both train and eval XLA graphs | Neuron supports extraction of XLA graphs for compilation. However, when both do_train and do_eval options are enabled, sizes returned by tensor operator can be 0. To avoid INVALID_ARGUMENT error, we use inequality in the check whether a tensor needs padding or not.
# What does this PR do?
This PR reduces compilation time of Hugging Face training/evaluation on Trainium using Neuron SDK.
Neuron SDK enables Hugging Face training on Trainium. To reduce compilation time, we have an optional [parallel compilation step](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/frameworks/torch/torch-neuronx/api-reference-guide/training/pytorch-neuron-parallel-compile.html) which 1) extracts XLA HLO graphs by trial execution of the training script with stub graphs that output zeros only, 2) perform parallel compilations of the graphs, and 3) place compiled graphs into Neuron cache. Currently, this flow only works for do_train step in the [HF trainer API tutorial](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/frameworks/torch/torch-neuronx/tutorials/training/finetune_hftrainer.html#) by itself but encounters INVALID_ARGUMENT error when do_eval is included together with do_train.
The error during parallel compilation is due to code at https://github.com/huggingface/transformers/blob/61a51f5f23d7ce6b8acf61b5aa170e01d7658d74/src/transformers/trainer.py#L3147 that creates new tensor based on the shape of another tensor. The tensor is created but it values are zero (as opposed to the shape) during parallel compilation (trial execution of stub graphs that output zeros only).
This PR introduces an inequality in the check for whether a tensor needs padding or not. During normal execution on all platforms, the max_size is greater than or equal to the tensor size so in no cases should max_size be smaller than tensor size, except in our case where we do trial execution of stub graphs that output zeros only.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
| 11-29-2022 17:19:01 | 11-29-2022 17:19:01 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks so much @sgugger ! |
transformers | 20,491 | closed | Fix documentation code to import facebook/detr-resnet-50 model | # What does this PR do?
Changes example import line
`>>> model = DetrForObjectDetection.from_pretrained("facebook/resnet-50")`
to
`>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")`
As trying to import `"facebook/resnet-50"` raises:
```
OSError: facebook/resnet-50 is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
If this is a private repository, make sure to pass a token having permission to this repo with `use_auth_token` or log in with `huggingface-cli login` and pass `use_auth_token=True`.
```
| 11-29-2022 16:55:53 | 11-29-2022 16:55:53 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,490 | closed | fixed small typo | # What does this PR do?
This PR fixes a small typo in VAN model.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@NielsRogge
Models:
- van
| 11-29-2022 16:17:58 | 11-29-2022 16:17:58 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,489 | closed | Fix minimum version for device_map | # What does this PR do?
Turns out it all works fine with PyTorch 1.10 which contains `torch.cuda.mem_get_info` used by Accelerate (but this isn't in the documentation of PyTorch 1.10). | 11-29-2022 14:41:04 | 11-29-2022 14:41:04 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,488 | closed | remove truncation in whisper | # What does this PR do?
remove truncation in whisper | 11-29-2022 12:07:35 | 11-29-2022 12:07:35 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hey @ArthurZucker ,
Just got an error, seems related to this issue?
`RuntimeError: The size of tensor a (507) must match the size of tensor b (448) at non-singleton dimension 1`<|||||>@RK-BAKU This PR is not merged yet. Are you trying this PR instead of a stable release or the `main` branch?<|||||>Hey! @RK-BAKU Could you provide a reproducing script and open a separate issue ? |
transformers | 20,487 | closed | extract warnings in GH workflows | # What does this PR do?
This PR uses the change in #20474 to collect the warnings in our GH scheduled daily CI, and provide a button in the slack reports to access this information.
<img width="493" alt="image" src="https://user-images.githubusercontent.com/2521628/204501762-1ed46a7c-4a91-40ba-9b16-3288168f0dfc.png">
| 11-29-2022 10:15:51 | 11-29-2022 10:15:51 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,486 | closed | fix cuda OOM by using single Prior | # What does this PR do?
Fixes the OOM issue with the `5b` model and `fp16` sampling.
Also fixes the slow generation test by sending each prior to `cuda` only when they are actually used. | 11-29-2022 10:03:23 | 11-29-2022 10:03:23 | _The documentation is not available anymore as the PR was closed or merged._<|||||>This will require #20485 to be merged, otherwise the logits for `fp16_sampling` will differ. <|||||>I will wait the mentioned PR #20485 :-) then back to this one. Also see my comment in that PR 🙏 @ArthurZucker 🙏 <|||||>I'll just push to model to another repo and ping you back here! |
transformers | 20,485 | closed | [CORE] Use model prefix instead of cls | # What does this PR do?
This adresses a very particular bug found when `base_model_prefix` is specific to the instance.
The `JukeboxPrior` are defined by their level of generation. Thus to each level, the corresponding base model prefix : `priors.0`.
When load the checkpoints from a pretrained `JukeboxModel`, the `_load_pretrained_model` uses the `cls.base_model_prefix` while the `model.base_model_prefix` is also always available. This means that the weights will [not be properly loaded](https://github.com/huggingface/transformers/blob/main/src/transformers/modeling_utils.py#L472), but it will be silent.
This should adresse any current and futur model loading issues where the `base_model_prefix` is modified per instance. | 11-29-2022 09:46:15 | 11-29-2022 09:46:15 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @ArthurZucker
For this issue and the fix in the PR, it's would be very nice if you could provide a code snippet to demonstrate what is currently wrong to justify the fix. It will also help future developers (either inside HF or external contributors) to understand it much better and faster (if they ever track back to this PR for some reason).
Thank you, looking forward for it!
<|||||>Discussed internally with @ArthurZucker. I am very much against using a "dynamic" attribute instead of the class attribute.<|||||>Yep, closing this!
Snipper is impossible to provide as it is very specific to jukebox and an invisible bug! <|||||>Since you close the PR, I would not ask the code snippet. It's still somehow strange that it is impossible to give a code snippet. From the description, it looks like if we have a checkpoint, when loading it, we will get some weights not being loaded correctly.
One possible way is to create a model, save it, and reload it. Then point out which weights are not loaded correctly.
I might miss many details here, and things may not be so easy. But if you are able to find the invisible bug, it's no longer invisible @ArthurZucker .
And if it is completely different thing than I imagine, just ignore me :-)<|||||>No, the weights are not loaded correctly but the error is silent. Here is a snippet (but nothing will be outputed)
```python
>>> from transformers import JukeboxPrior, JukeboxModel
>>> model = JukeboxModel.from_pretrained("openai/jukebox-5b-lyrics").priors[0]
>>> prior = JukeboxPrior.from_pretrained("openai/jukebox-5b-lyrics")
>>> assert model.encoder.start_token == prior.encoder.start_token
```
There will be no `missing` or `unexpected keys` but the weights will not be loaded<|||||>OK, it's silent, but you speak for it so now it's clear 💯 ! |
transformers | 20,484 | closed | Error when getting the long-t5 model | ### System Info
When I get the relevant pipline or the corresponding model and tokenizer from this page, I get the `KeyError: 'longt5'`
### Who can help?
@patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https://huggingface.co/google/long-t5-tglobal-base
my code:
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/long-t5-tglobal-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/long-t5-tglobal-base")
```
Full error output:
```
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<command-440662132347528> in <module>
1 from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
2
----> 3 tokenizer = AutoTokenizer.from_pretrained("google/long-t5-tglobal-base")
4 model = AutoModelForSeq2SeqLM.from_pretrained("google/long-t5-tglobal-base")
/databricks/python/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py in from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs)
400 tokenizer_config = get_tokenizer_config("bert-base-uncased")
401 # This model does not have a tokenizer config so the result will be an empty dict.
--> 402 tokenizer_config = get_tokenizer_config("xlm-roberta-base")
403
404 # Save a pretrained tokenizer locally and you can reload its config
/databricks/python/lib/python3.8/site-packages/transformers/models/auto/configuration_auto.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
430 ("unispeech", "UniSpeech"),
431 ("unispeech-sat", "UniSpeechSat"),
--> 432 ("van", "VAN"),
433 ("videomae", "VideoMAE"),
434 ("vilt", "ViLT"),
KeyError: 'longt5'
```
Any kind of help is appreciated!
### Expected behavior
Correct import of models and corresponding piplines | 11-29-2022 09:08:34 | 11-29-2022 09:08:34 | Hi, what `transformers` version are you using?<|||||>> Hi, what `transformers` version are you using?
I am using `transformers==4.24.0`<|||||>@ArthurZucker could you take a look here? <|||||>Not really able to reproduce the code for now, but will have a look! I also used `transformers==4.24.0` and the import worked. It was added 6 month ago see [here](https://github.com/huggingface/transformers/pull/16792). Also can confirm that `("longt5", "LongT5"),` is [in the auto config](https://github.com/ArthurZucker/transformers/blob/main/src/transformers/models/auto/configuration_auto.py#L391).<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,483 | closed | [MaskFormer] Add support for ResNet backbone | # What does this PR do?
This PR is part 3 of 3 of the big #20204 PR.
This PR does 2 things:
1) it makes sure that ResNet is supported as backbone for MaskFormer, besides Swin. It leverages the `AutoBackbone` class for this.
2) <s> it makes sure that MaskFormer defaults to Swin as backbone, not relying on MaskFormerSwin, but just on plain Swin. For this, the argument `output_hidden_states_before_downsampling` is added to `SwinConfig`. </s> => `SwinBackbone` will be added in a separate PR
To do:
- [x] convert all remaining MaskFormer checkpoints | 11-29-2022 09:03:02 | 11-29-2022 09:03:02 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger feel free to approve, I'm currently uploading all checkpoints to the hub :) |
transformers | 20,482 | closed | How to reproduce the machine translation experiments in Attention is all you need. | ### Feature request
I want to reproduce the experiments described in _Attention is all you need_, which is a transformer base model from scratch. The model architecture is the same as _Attention is all you need_.
In other words, I am looking for a transformer base model to train from scratch with HuggingFace.
### Motivation
Reproduce the Transformer experiments in machine translation. I found that there are many pre-trained models (e.g., T5, BART, MariaMT), but I would like to train a transformer base model from scratch to compare different optimizers during pre-training.
### Your contribution
I found a previous issue here but not sure whether it is the right way to go. https://github.com/huggingface/transformers/issues/12386 | 11-29-2022 09:00:08 | 11-29-2022 09:00:08 | Hi,
I am trying to reproduce the performance of transformer-base (from attention is all you need) on WMT14.
I am using `FSMT` because I cannot find an implementation of the transformer.
I was wondering which dataset and tokenizer are the best choices.
1. `stas/wmt14-en-de-pre-processed` with `facebook/wmt19-en-de`
2. `wmt14` with `facebook/wmt19-en-de`
Especially, I do not know which tokenizer should be used.
Thanks in advance if you could provide some suggestions!
@patil-suraj @patrickvonplaten <|||||>Please use the [forums](https://discuss.huggingface.co/) to discuss such questions as we keep issues for bugs and feature requests only.<|||||>> Please use the [forums](https://discuss.huggingface.co/) to discuss such questions as we keep issues for bugs and feature requests only.
OK, sorry about this. |
transformers | 20,481 | closed | CLIP - Mismatch tokenizer_config.json of CLIPTokenizer.from_pretrained() and huggingface_hub | ### System Info
Model ID : `"openai/clip-vit-base-patch32"`
Transformer Version : 4.23.0
In the huggingface hub, the file https://huggingface.co/openai/clip-vit-base-patch32/blob/main/tokenizer_config.json doesn't have the parameter `model_max_length:77`.
On the contrary, if I use the following:
`tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")`
`tokenizer.save_pretrained('./test_tokenizer/')`
The tokenizer_config.json saved under **test_tokenizer** has the the parameter `model_max_length:77`.
So, when I load tokenizer from the downloaded files from https://huggingface.co/openai/clip-vit-base-patch32/tree/main , the `tokenizer.model_max_length` is different from the `CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")`.
The former one has a `model_max_length=1000000000000000019884624838656`
The later one has a `model_max_length=77`
### Who can help?
@patil-suraj , @SaulLu
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. Download the files directly from CLIP huggingface hub: https://huggingface.co/openai/clip-vit-base-patch32/tree/main and store them under a folder such as './hub_model_clip/'
2. Run the following code in a notebook
```
from transformers import CLIPTokenizer
tokenizer_1 = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")
tokenizer_2 = CLIPTokenizer.from_pretrained("./hub_model_clip/")
```
3. Check the following two:
```
print(tokenizer_1.model_max_length) # 77
print(tokenizer_2.model_max_length) # 1000000000000000019884624838656
```
### Expected behavior
Sync up the model_max_len from different source of the CLIP tokenizer | 11-29-2022 04:33:20 | 11-29-2022 04:33:20 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,480 | closed | Unexpected behavior when input ends with multiple newlines | ### System Info
- `transformers` version: 4.15.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.5
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): 2.5.1 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
@patrickvonplaten, @Narsil
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from transformers import GPTNeoForCausalLM, GPT2Tokenizer
model_name = "EleutherAI/gpt-neo-125M"
model = GPTNeoForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True, cache_dir='gpt_cache_dir', resume_download=True).half().to("cuda:0")
tokenizer = GPT2Tokenizer.from_pretrained(model_name, low_cpu_mem_usage=True, cache_dir='gpt_cache_dir', resume_download=True)
input_ids = tokenizer("This is a line 1\n\nThis is a line 2\n\nThis is a line 3\n\n", return_tensors="pt").input_ids.cuda()
gen_tokens = model.generate(input_ids, do_sample=True, temperature=0.01, max_length=40, min_length=1, repetition_penalty=1.0)
gen_text = "Output: \"" + tokenizer.batch_decode(gen_tokens[:, input_ids.shape[1]:])[0] + "\""
print(gen_text)
```
Actual behavior:
-If the input ends with 1 newline, generating multiple tokens works as expected, but generating just 1 token says the next token should be a newline by itself.
-If the input ends with 2 newlines, generate multiple tokens doesn't work as expected, and printing the next top score reveals the next token is some unexpected thing such as another newline or a token beginning with a space.
### Expected behavior
Expected behavior: If prompt ends in \n\n, generated text shouldn't start with \n.
Duplicate of https://github.com/huggingface/transformers/issues/17860 but it won't let me re-open | 11-29-2022 03:33:41 | 11-29-2022 03:33:41 | Stop telling the model what it should do: [quote](https://history.aip.org/exhibits/einstein/ae63.htm).
Joke aside, how do you know what the model should do ? It's a small model, so if it's less performant than expected or than the larger ones is completely normal.<|||||>> Stop telling the model what it should do: [quote](https://history.aip.org/exhibits/einstein/ae63.htm).
>
> Joke aside, how do you know what the model should do ? It's a small model, so if it's less performant than expected or than the larger ones is completely normal.
Please take a closer look; it is literally impossible for this discrepancy to be caused by model performance/accuracy. Otherwise I would not have reported this as a bug. Again: If you take away one or more of the "\n\n" at the end, it completes the expected "\n\n", followed by the expected sentence. But if you end with "\n\n" it predicts the next token is yet another "\n". That means at the point of the end of "\n\n" there were two different token predictions even though the input at that point was exactly the same in both cases.<|||||>You are talking about strings here, the model reasons in tokens.
So it's perfectly possible that your sentence ending with `\n\n` is chunked differently than without, yielding different tokens, and so different outputs.
Could you check the different tokenizations ?<|||||>Assuming what you say is true (which seems like the most likely explanation):
1. Isn't this still considered a bug during tokenization? Shouldn't the same input at each step lead to the same output?
2. Is there a possible workaround, other than making sure certain types of inputs never get passed in?<|||||>> Isn't this still considered a bug during tokenization? Shouldn't the same input at each step lead to the same output?
Not really, all models usually have the basic ASCII chars, so the model is free to generate `t` + `h` + `e` which most likley will be in its vocabulary as `the`. Now this is usually not the case (since the model was usually not trained to output individual letters like here. But it's definitely not a guarantee. Some models actually DO train on such irregular tokenizations, and this is called tokenization `dropout`. Benefits in general seems mitigated (some says it's super important, some that it negatively impacts final performance. I personnally don't have any opinion on this).
> Is there a possible workaround, other than making sure certain types of inputs never get passed in?
You could do that. This is what is done under the hood for GPT-3 for instance, where you have these "START" and "STOP" sequence which are inserted for you as tokens, which avoids letting the tokenizer doing it on its own. For Bloom, we also had the same issue, where prompt perform better when it doesn't end with a trailing space (so removing trailing spaces from prompts help the perceived quality of free text users).
As far as I know, there is no "FIX" for it entirely.
If you could stick to using tokens, things would make more sense maybe, but it depends on the use case and how the model was trained really.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,479 | closed | add flax whisper implementation | Adds Flax whisper implementations, and adjusts flax generation utils to support it.
@ydshieh @ArthurZucker
See discussion in #19512 | 11-28-2022 22:15:54 | 11-28-2022 22:15:54 | @andyehrenberg
Thank you for the PR. However, a pull request should focus on a single objective/goal, rather than changing multiple things at the same time which are not absolutely coupled.
Please
- follow the pytorch implementation regarding the `past_key_values`
- revert the changes on the flax generation utils
(You may want to have a backup branch to save these changes for future pull requests.)
The goal of this PR is to add Flax implementation of Whisper. For other changes, it's better to open issue tickets, and if we all agree with the proposals, a PR could proceed :-)
Thank you!<|||||>I see a few other instances in this repo where the pytorch implementation computes `past_key_values_length` while the flax implementation uses `position_ids` (BART, OPT, etc) - to me, keeping consistency among the APIs of the flax models is something we should strive for. What do you think @ydshieh @patrickvonplaten ?
Happy to remove the changes to the generation stuff and open a separate PR for that - will definitely do this to make flax Whisper generation work!<|||||>I wasn't aware of that inconsistency, thank you for pointing out. This is a good question! But I don't think that's a very serious problem so far - the most important thing is the different frameworks produce the same outputs when feeding the same (supported) inputs + the API on the top model levels being consistent.
(The internal computation could be somehow different - if there is good reason)
In any case, this could be discussed in an issue and we can proceed with a PR once decided :-) <|||||>BTW, there is some issue for triggering CircleCI. The message is
```bash
Could not find a usable config.yml, you may have revoked the CircleCI OAuth app.
Please sign out of CircleCI and log back in with your VCS before triggering a new pipeline.
```
Do you use some IDE to push the commits? Could you try to push the commit with a commandline tool or some git GUI tools instead?<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Also cc @sanchit-gandhi <|||||>Hey! Thanks for opening the follow PR 🤗
I don't think I agree with @ydshieh here, adding the `flax_generation_utils` along with whisper totally makes sense as it was done for `pytorch` and `tf`, and is required to add the `generation` tests which are currently missing!
Regarding the `past_key_values`, we don't really strive to match `transformers` with other APIs, rather I think we prefer consistency within our own library, and code clarity.
However you can still open an issue and we can discuss whether we should refactor the design of `past_key_values` for our `flax` model!
Will have a look at the PR 😉 <|||||>You are right! I am not aware of those generation features are introduced when you added Whisper @ArthurZucker . Sorry about that, @andyehrenberg !
<|||||>Super excited by this PR! 🚀 Feel free to tag me with questions / review requests as well @andyehrenberg 🤗<|||||>Hey @andyehrenberg! Looks like you found my old PR for implementing scan with Flax `nn.Modules` and copied the logic across https://github.com/huggingface/transformers/pull/18341
I'm happy to answer @ArthurZucker's questions regarding scan here. In the end, we decided not to pursue with adding scan in Transformers - this is why you haven't seen the PR merged or scan in any of our Flax models.
The reason for this is that scan adds **a lot** of complexity to the modelling code. Whilst it does give faster compile times for training, it is actually **slower** for inference. On balance, it's not worth the myriad of extra code for a small speed-up to compile time for training. We prefer readability and ease of understanding over highly optimised code in Transformers. Because of this, unfortunately scan is not a good fit.
Note: since Whisper pads/truncates the audio inputs to 30s, the inputs to Whisper are **always** of fixed dimension. This means that you only ever need 1 compile step! So the compilation time is entirely amortised by the subsequent compiled times during training/inference. For this reason, I advise that you stick to the regular way of implementing unrolled Flax `nn.Modules` for Whisper.
Happy to answer any questions regarding scan and why we don't include it in our modelling code!
The optimum library might be a better place for highly optimised Flax code: https://github.com/huggingface/optimum<|||||>Hey @ydshieh! Is there a way of enabling the Flax CI in this PR? Before merging it'd be awesome to verify that the Flax CI is ✅<|||||>cc @sanchit-gandhi @sgugger for a final review here maybe :-) <|||||>@andyehrenberg thanks for the changes in the last commit <3
Green light for this PR on my end [generate]<|||||>Mmmm, before merging this PR, there is something wrong going on with the tests: only one of the tests job is actually run (no tests_flax/tests_tf etc...)
Will investigate later today unless someone beats me to it.<|||||>It looks like running under the wrong CircleCI project (on the PR author one, not on `huggingface/transformers`), and it got
> Resource class docker for xlarge is not available for your project, or is not a valid resource class. This message will often appear if the pricing plan for this project does not support docker use.
See https://app.circleci.com/pipelines/github/andyehrenberg/transformers?branch=flax_whisper<|||||>@andyehrenberg
Could you follow the instruction mentioned [here](https://support.circleci.com/hc/en-us/articles/360008097173-Troubleshooting-why-pull-requests-are-not-triggering-jobs-on-my-organization-), and see if it fixes the CI issue?
> If you're following the fork instead of the upstream repo
A user who submits a pull request to your repository from a fork, but no pipeline is triggered with the pull request. This can happen when the user is following the project fork on their personal account rather than the project itself on CircleCI.
> This will cause the jobs to trigger under the user's personal account. If the user is following a fork of the repository on CircleCI, we will only build on that fork and not the parent, so the parent’s PR will not get status updates.
> In these cases, the user unfollows their fork of the project on CircleCI. This will trigger their jobs to run under the organization when they submit pull requests. Those users can optionally follow the source project if they wish to see the pipelines.<|||||>
> Mmmm, before merging this PR, there is something wrong going on with the tests: only one of the tests job is actually run (no tests_flax/tests_tf etc...)
>
> Will investigate later today unless someone beats me to it.
@sgugger Fixed, and all tests are passing now (had to override some tests due to `input_features` being different from its usual shape in the tests)<|||||>Thanks @andyehrenberg !
@sanchit-gandhi Can you have one final look?<|||||>@sanchit-gandhi - How can I rerun the checks without further commits? The error looks like an account limit overshoot and doesn't seem to do with the two newer commits.<|||||>@andyehrenberg We can re-run the failed tests on the job run page
<img width="1063" alt="Screenshot 2023-01-16 202103" src="https://user-images.githubusercontent.com/2521628/212752381-4bce24af-697c-4c4f-ab30-457b2b7a6b4a.png">
But I think only HF members can do that - I will launch it.<|||||>@sanchit-gandhi I think it's ready for another look by you! The torch tests it's failing current seem unrelated to the PR, so rerunning CI may give all passes<|||||>Also sorry! We just modified Whisper quit a bit 😅 <|||||>> Also sorry! We just modified Whisper quit a bit 😅
@ArthurZucker - Doesn't actually look too bad to catch up with those changes! Can do that soon-ish. I already have a jax timestamp processor that's compilable.<|||||>Oh no - sorry you have to iterate again here @andyehrenberg! Feel free to ping me with any questions / discussions - more than happy to help with the final sprint of the integration! Otherwise super excited to review a final time before merge! 🚀<|||||>@sanchit-gandhi - I think this is ready for another look - the recent commits (I think) get us to feature parity with the torch version.<|||||>@sanchit-gandhi Bump<|||||>@sanchit-gandhi @ArthurZucker - Addressed Arthur's comments and cleaned up the timestamp logits processor a bit. Hopefully we're close to getting this merged!<|||||>> Very nice @andyehrenberg! Thanks for iterating here - reviewed the new changes and the PR is looking super clean. Last request from me is if we can avoid defining the `if_true()` functions if possible and just add the code explicitly! Good for merge otherwise :)
For sure, made those changes :) |
transformers | 20,478 | closed | Replace assert statements with raise exceptions | # What does this PR do?
Fixes an instance of https://github.com/huggingface/transformers/issues/12789.
Replaces 4 assert statements with ValueError exception in `src/transformers/data/metrics/squad_metrics.py`
Co-author: @mollerup23
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 11-28-2022 21:05:35 | 11-28-2022 21:05:35 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger Appreciate the feedback! I've addressed and made the necessary changes. |
transformers | 20,477 | closed | Fix init import_structure sorting | # What does this PR do?
The custom script we have that sorts the imports in our inits was broken since a while ago. This PR fixes it. | 11-28-2022 19:42:29 | 11-28-2022 19:42:29 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 20,476 | closed | Trainer Eval loop fails to handle COCO formatted data | ### System Info
- `transformers` version: 4.23.1
- Platform: Linux-4.14.294-220.533.amzn2.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.13
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: YES
- Using distributed or parallel set-up in script?: NO
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Download and format (into Dataset object) a COCO vision dataset with the following features:
```
features = Features(
{
"pixel_mask": Sequence(Sequence(Sequence(Value(dtype="float32")))),
'labels': [{
'boxes': Sequence(Sequence(Value(dtype="float32"))),
'class_labels': Sequence(ClassLabel(names=label_list)),
'image_id': Sequence(Value(dtype="int64")),
'area': Sequence(Value(dtype="float32")),
'iscrowd': Sequence(Value(dtype="int64")),
'orig_size': Sequence(Value(dtype="int64")),
'size': Sequence(Value(dtype="int64"))
}],
'carrier': Value(dtype='string'),
'pixel_values': Array3D(dtype="float32", shape=(3, 1049, 800))
}
)
```
3. Load the DETR model
```
def model_init():
return DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101-dc5',
id2label=id2label,
label2id=label2id,
ignore_mismatched_sizes=True)
```
4. Create custom collator function
```
def collate_fn(batch):
pixel_values = torch.cat([item["pixel_values"].unsqueeze(dim=0) for item in batch])
encoding = feature_extractor.pad_and_create_pixel_mask(
pixel_values, return_tensors="pt"
)
labels = [item["labels"][0] for item in batch]
batch = {}
batch['pixel_values'] = pixel_values
batch["pixel_mask"] = encoding["pixel_mask"]
batch["labels"] = labels
return batch
```
5. Instantiate Trainer
```
training_args = transformers.TrainingArguments(
output_dir=output_dir,
logging_dir=logging_dir,
max_steps=1000,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
learning_rate=1e-5,
evaluation_strategy="steps",
eval_steps=100,
save_strategy='steps',
save_steps=100,
report_to="tensorboard",
logging_strategy='steps',
logging_steps=50,
seed=42
)
trainer = Trainer(
model_init=model_init,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=collate_fn,
compute_metrics=compute_metrics
# callbacks=[tensorboard_callback]
)
```
6. Call trainer.prediction_step
`loss, logits, labels = trainer.prediction_step(model, example, False, ignore_keys=True)`
7. Receive error message:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In [86], line 1
----> 1 loss, logits, labels = trainer.prediction_step(model, example, False, ignore_keys=True)
File /opt/conda/lib/python3.8/site-packages/transformers/trainer.py:3166, in Trainer.prediction_step(self, model, inputs, prediction_loss_only, ignore_keys)
3164 # labels may be popped when computing the loss (label smoothing for instance) so we grab them first.
3165 if has_labels:
-> 3166 labels = nested_detach(tuple(inputs.get(name) for name in self.label_names))
3167 if len(labels) == 1:
3168 labels = labels[0]
File /opt/conda/lib/python3.8/site-packages/transformers/trainer_pt_utils.py:158, in nested_detach(tensors)
156 "Detach `tensors` (even if it's a nested list/tuple of tensors)."
157 if isinstance(tensors, (list, tuple)):
--> 158 return type(tensors)(nested_detach(t) for t in tensors)
159 return tensors.detach()
File /opt/conda/lib/python3.8/site-packages/transformers/trainer_pt_utils.py:158, in <genexpr>(.0)
156 "Detach `tensors` (even if it's a nested list/tuple of tensors)."
157 if isinstance(tensors, (list, tuple)):
--> 158 return type(tensors)(nested_detach(t) for t in tensors)
159 return tensors.detach()
File /opt/conda/lib/python3.8/site-packages/transformers/trainer_pt_utils.py:159, in nested_detach(tensors)
157 if isinstance(tensors, (list, tuple)):
158 return type(tensors)(nested_detach(t) for t in tensors)
--> 159 return tensors.detach()
AttributeError: 'dict' object has no attribute 'detach'
### Expected behavior
The function should return the loss, logits, labels as expected. | 11-28-2022 16:52:17 | 11-28-2022 16:52:17 | This has been fixed by #19455, you should upgrade to the latest version of Transformers to have the fix. |
transformers | 20,475 | closed | Fix torch meshgrid warnings | # What does this PR do?
This PR fixes unwanted warnings due in `torch.meshgrid`:
```
/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/torch/functional.py:478:
UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing
argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2894.)
>>> ys = torch.linspace(-5, 5, steps=100)
```
Passing `indexing="ij"` is necessary to keep the current behavior, see https://pytorch.org/docs/stable/generated/torch.meshgrid.html and https://github.com/pytorch/pytorch/issues/50276
```python
import torch
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
grid_x, grid_y = torch.meshgrid(x, y, indexing="ij") # vs indexing="xy"
print(grid_x)
print(grid_y)
```
## Before submitting
- [x] This PR fixes a typo
## Who can review?
any core maintainer to approve
| 11-28-2022 16:49:10 | 11-28-2022 16:49:10 | From a quick search in the PyTorch doc, this argument is only accepted starting in PyTorch 1.10, so this PR will break the corresponding models for older versions. You should add a `meshgrid` function the pytorch utils that passes the argument or not depending on the PyTorch version, then use this util in the modeling code.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger Thank you, hopefully fixed!
edit: will fix the CI tomorrow<|||||>@sgugger the CI is good at last!<|||||>Arf my comment from yesterday never went through :sweat_smile: |
transformers | 20,474 | closed | Extract warnings from CI artifacts | # What does this PR do?
The default behavior is to extract the `DeprecationWarning`, but it could be changed by specifying `--targets`.
Currently, I don't use this script in our CI workflow file. If it is desired, we can add an extra job in our CI workflow to generate this report at the end, but this could be done in a separate PR if you allow me :-) | 11-28-2022 16:48:06 | 11-28-2022 16:48:06 | _The documentation is not available anymore as the PR was closed or merged._<|||||>This is the current list of `DeprecationWarning`. I could NOT find any thing from torch/TF/accelerate. Hope I don't miss anything here.
```bash
[
"/opt/conda/lib/python3.8/site-packages/sklearn/utils/multiclass.py:14: DeprecationWarning: Please use `spmatrix` from the `scipy.sparse` namespace, the `scipy.sparse.base` namespace is deprecated.\nfrom scipy.sparse.base import spmatrix",
"/transformers/src/transformers/commands/add_new_model_like.py:1079: DeprecationWarning: invalid escape sequence \\s\ncontent = re.sub(\"<!--\\s*Copyright (\\d+)\\s\", f\"<!--Copyright {CURRENT_YEAR} \", content)",
"/transformers/src/transformers/commands/add_new_model_like.py:1105: DeprecationWarning: invalid escape sequence \\s\nelif re.search(\"^#\\s+\\S+\", block) is not None:",
"/transformers/src/transformers/commands/add_new_model_like.py:1117: DeprecationWarning: invalid escape sequence \\s\nblock_class = re.search(\"^#+\\s+(\\S.*)$\", block_title).groups()[0]",
"/transformers/src/transformers/commands/add_new_model_like.py:126: DeprecationWarning: invalid escape sequence \\s\nsearch = re.search(\"^(\\s*)(?:\\S|$)\", line)",
"/transformers/src/transformers/commands/add_new_model_like.py:427: DeprecationWarning: invalid escape sequence \\d\ncontent = re.sub(\"# Copyright (\\d+)\\s\", f\"# Copyright {CURRENT_YEAR} \", content)",
"/transformers/src/transformers/commands/add_new_model_like.py:476: DeprecationWarning: invalid escape sequence \\s\nhas_copied_from = re.search(\"^#\\s+Copied from\", obj, flags=re.MULTILINE) is not None",
"/transformers/src/transformers/commands/add_new_model_like.py:568: DeprecationWarning: invalid escape sequence \\s\n_re_checkpoint_for_doc = re.compile(\"^_CHECKPOINT_FOR_DOC\\s+=\\s+(\\S*)\\s*$\", flags=re.MULTILINE)",
"/transformers/src/transformers/commands/add_new_model_like.py:811: DeprecationWarning: invalid escape sequence \\s\nre.search('^\\s*\"(tokenization|processing|feature_extraction)', lines[idx]) is None",
"/transformers/src/transformers/commands/add_new_model_like.py:812: DeprecationWarning: invalid escape sequence \\s\nand re.search(\"^\\s*from .(tokenization|processing|feature_extraction)\", lines[idx]) is None",
"/transformers/src/transformers/models/deformable_detr/modeling_deformable_detr.py:1796: DeprecationWarning: invalid escape sequence \\.\n_keys_to_ignore_on_load_missing = [\"bbox_embed\\.[1-9]\\d*\", \"class_embed\\.[1-9]\\d*\"]",
"/transformers/src/transformers/models/deit/image_processing_deit.py:117: DeprecationWarning: BICUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BICUBIC instead.\nresample: PILImageResampling = PIL.Image.BICUBIC,",
"/transformers/src/transformers/models/deit/image_processing_deit.py:86: DeprecationWarning: BICUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BICUBIC instead.\nresample: PILImageResampling = PIL.Image.BICUBIC,",
"/transformers/src/transformers/models/glpn/modeling_glpn.py:637: DeprecationWarning: invalid escape sequence \\s\n\"\"\"",
"/transformers/src/transformers/models/jukebox/tokenization_jukebox.py:152: DeprecationWarning: invalid escape sequence \\-\noov = \"[^A-Za-z0-9.,:;!?\\-'\\\"()\\[\\] \\t\\n]+\"",
"/transformers/src/transformers/models/jukebox/tokenization_jukebox.py:155: DeprecationWarning: invalid escape sequence \\-\noov = oov.replace(\"\\-'\", \"\\-+'\")",
"/transformers/src/transformers/models/jukebox/tokenization_jukebox.py:234: DeprecationWarning: invalid escape sequence \\-\nself.out_of_vocab = regex.compile(\"[^A-Za-z0-9.,:;!?\\-'\\\"()\\[\\] \\t\\n]+\")",
"/transformers/src/transformers/models/jukebox/tokenization_jukebox.py:243: DeprecationWarning: invalid escape sequence \\-\nself.out_of_vocab = regex.compile(\"[^A-Za-z0-9.,:;!?\\-+'\\\"()\\[\\] \\t\\n]+\")",
"/transformers/src/transformers/models/maskformer/feature_extraction_maskformer.py:313: DeprecationWarning: NEAREST is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.NEAREST or Dither.NONE instead.\ntarget = self.resize(target, size=size, resample=Image.NEAREST)",
"/transformers/src/transformers/models/maskformer/modeling_maskformer.py:2066: DeprecationWarning: invalid escape sequence \\e\n\"\"\"",
"/transformers/src/transformers/models/mobilevit/image_processing_mobilevit.py:141: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\nresample: PILImageResampling = PIL.Image.BILINEAR,",
"/transformers/src/transformers/models/perceiver/image_processing_perceiver.py:156: DeprecationWarning: BICUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BICUBIC instead.\nresample: PILImageResampling = PIL.Image.BICUBIC,",
"/transformers/src/transformers/models/segformer/image_processing_segformer.py:304: DeprecationWarning: NEAREST is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.NEAREST or Dither.NONE instead.\nresample=PIL.Image.NEAREST,",
"/transformers/src/transformers/models/segformer/image_processing_segformer.py:441: DeprecationWarning: NEAREST is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.NEAREST or Dither.NONE instead.\nresample=PIL.Image.NEAREST,",
"/transformers/src/transformers/models/t5/tokenization_t5.py:217: DeprecationWarning: invalid escape sequence \\d\nset(filter(lambda x: bool(re.search(\"<extra_id_\\d+>\", x)) is not None, self.additional_special_tokens))",
"/transformers/src/transformers/models/t5/tokenization_t5_fast.py:240: DeprecationWarning: invalid escape sequence \\d\nset(filter(lambda x: bool(re.search(\"<extra_id_\\d+>\", x)) is not None, self.additional_special_tokens))",
"/transformers/src/transformers/models/transfo_xl/modeling_transfo_xl.py:1018: DeprecationWarning: The output of TransfoXL will be updated in v5 to support a single loss as first argument. In orderto use that updated output, please specify `trainer_compatible=True` as your configuration attribute.\nwarnings.warn(",
"/transformers/tests/models/maskformer/test_feature_extraction_maskformer.py:407: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(inputs[\"mask_labels\"][0].sum().item(), 41527.0)",
"/transformers/tests/models/maskformer/test_feature_extraction_maskformer.py:408: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(inputs[\"mask_labels\"][1].sum().item(), 26259.0)",
"/transformers/tests/models/maskformer/test_feature_extraction_maskformer.py:449: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(inputs[\"mask_labels\"][0].sum().item(), 170200.0)",
"/transformers/tests/models/maskformer/test_feature_extraction_maskformer.py:450: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(inputs[\"mask_labels\"][1].sum().item(), 257036.0)",
"/transformers/tests/models/maskformer/test_feature_extraction_maskformer.py:514: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(inputs[\"mask_labels\"][0].sum().item(), 315193.0)",
"/transformers/tests/models/maskformer/test_feature_extraction_maskformer.py:515: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(inputs[\"mask_labels\"][1].sum().item(), 350747.0)",
"/transformers/tests/models/realm/test_modeling_realm.py:394: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.\nDeprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\ndtype=np.object,",
"/transformers/tests/models/realm/test_retrieval_realm.py:103: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.\nDeprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\ndtype=np.object,",
"/transformers/tests/models/realm/test_retrieval_realm.py:119: DeprecationWarning: `np.long` is a deprecated alias for `np.compat.long`. To silence this warning, use `np.compat.long` by itself. In the likely event your code does not need to work on Python 2 you can use the builtin `int` for which `np.compat.long` is itself an alias. Doing this will not modify any behaviour and is safe. When replacing `np.long`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.\nDeprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\nretrieved_block_ids = np.array([0, 3], dtype=np.long)",
"/transformers/tests/models/realm/test_retrieval_realm.py:154: DeprecationWarning: `np.long` is a deprecated alias for `np.compat.long`. To silence this warning, use `np.compat.long` by itself. In the likely event your code does not need to work on Python 2 you can use the builtin `int` for which `np.compat.long` is itself an alias. Doing this will not modify any behaviour and is safe. When replacing `np.long`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.\nDeprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\nretrieved_block_ids = np.array([0, 3, 5], dtype=np.long)",
"/transformers/tests/models/t5/test_tokenization_t5.py:387: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(len(sentinel_tokens), 10)",
"/transformers/tests/models/t5/test_tokenization_t5.py:389: DeprecationWarning: invalid escape sequence \\d\nself.assertTrue([re.search(\"<extra_id_\\d+>\", token) is not None for token in sentinel_tokens])",
"/transformers/tests/models/t5/test_tokenization_t5.py:398: DeprecationWarning: Please use assertEqual instead.\nself.assertEquals(len(sentinel_tokens), 10)",
"/transformers/tests/models/t5/test_tokenization_t5.py:400: DeprecationWarning: invalid escape sequence \\d\nself.assertTrue([re.search(\"<extra_id_\\d+>\", token) is not None for token in sentinel_tokens])",
"/transformers/tests/sagemaker/conftest.py:36: DeprecationWarning: invalid escape sequence \\D\n{\"Name\": \"train_runtime\", \"Regex\": \"train_runtime.*=\\D*(.*?)$\"},",
"/transformers/tests/sagemaker/conftest.py:37: DeprecationWarning: invalid escape sequence \\D\n{\"Name\": \"eval_accuracy\", \"Regex\": \"eval_accuracy.*=\\D*(.*?)$\"},",
"/transformers/tests/sagemaker/conftest.py:38: DeprecationWarning: invalid escape sequence \\D\n{\"Name\": \"eval_loss\", \"Regex\": \"eval_loss.*=\\D*(.*?)$\"},",
"/transformers/tests/sagemaker/conftest.py:42: DeprecationWarning: invalid escape sequence \\D\n{\"Name\": \"train_runtime\", \"Regex\": \"train_runtime.*=\\D*(.*?)$\"},",
"/transformers/tests/sagemaker/conftest.py:43: DeprecationWarning: invalid escape sequence \\D\n{\"Name\": \"eval_accuracy\", \"Regex\": \"loss.*=\\D*(.*?)]?$\"},",
"/transformers/tests/sagemaker/conftest.py:44: DeprecationWarning: invalid escape sequence \\D\n{\"Name\": \"eval_loss\", \"Regex\": \"sparse_categorical_accuracy.*=\\D*(.*?)]?$\"},",
"/transformers/tests/utils/test_add_new_model_like.py:156: DeprecationWarning: invalid escape sequence \\s\nself.assertEqual(add_content_to_text(test_text, line, add_before=re.compile('^\\s*\"bert\":')), expected)",
"/transformers/tests/utils/test_add_new_model_like.py:163: DeprecationWarning: invalid escape sequence \\s\nself.assertEqual(add_content_to_text(test_text, line, add_after=re.compile('^\\s*\"gpt\":')), expected)",
"/transformers/tests/utils/test_add_new_model_like.py:196: DeprecationWarning: invalid escape sequence \\s\nadd_content_to_file(file_name, line, add_before=re.compile('^\\s*\"bert\":'))",
"/transformers/tests/utils/test_add_new_model_like.py:212: DeprecationWarning: invalid escape sequence \\s\nadd_content_to_file(file_name, line, add_after=re.compile('^\\s*\"gpt\":'))",
"/usr/local/lib/python3.8/dist-packages/detectron2/data/transforms/augmentation_impl.py:113: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\ndef __init__(self, shape, interp=Image.BILINEAR):",
"/usr/local/lib/python3.8/dist-packages/detectron2/data/transforms/augmentation_impl.py:140: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\nself, short_edge_length, max_size=sys.maxsize, sample_style=\"range\", interp=Image.BILINEAR",
"/usr/local/lib/python3.8/dist-packages/detectron2/data/transforms/augmentation_impl.py:214: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\ninterp: int = Image.BILINEAR,",
"/usr/local/lib/python3.8/dist-packages/detectron2/data/transforms/augmentation_impl.py:635: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\ndef __init__(self, shape_list, interp=Image.BILINEAR):",
"/usr/local/lib/python3.8/dist-packages/detectron2/data/transforms/transform.py:46: DeprecationWarning: LINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\ndef __init__(self, src_rect, output_size, interp=Image.LINEAR, fill=0):",
"/usr/local/lib/python3.8/dist-packages/tf2onnx/tf_utils.py:58: DeprecationWarning: `np.str` is a deprecated alias for the builtin `str`. To silence this warning, use `str` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.str_` here.\nDeprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\nnp_data = np_data.astype(np.str).astype(object)",
"/workspace/transformers/src/transformers/models/t5/tokenization_t5.py:217: DeprecationWarning: invalid escape sequence \\d\nset(filter(lambda x: bool(re.search(\"<extra_id_\\d+>\", x)) is not None, self.additional_special_tokens))",
"/workspace/transformers/src/transformers/models/t5/tokenization_t5_fast.py:240: DeprecationWarning: invalid escape sequence \\d\nset(filter(lambda x: bool(re.search(\"<extra_id_\\d+>\", x)) is not None, self.additional_special_tokens))"
]
```
|
transformers | 20,473 | closed | Fix Swin ONNX export warnings | # What does this PR do?
This PR fixes uninformative warnings in the ONNX export for Swin as reported in https://github.com/huggingface/transformers/issues/19780 , namely
```
UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently
rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use
torch.div(a, b, rounding_mode='floor').
```
Since `torch.jit.trace` assumes expressions like `tensor.size(0)`, `tensor.size()[1]`, `tensor.shape[2]` are tensors in tracing mode ([reference](https://ppwwyyxx.com/blog/2022/TorchScript-Tracing-vs-Scripting/)), the warning is raised.
## Before submitting
- [x] This PR fixes a typo
## Who can review?
@lewtun | 11-28-2022 16:35:37 | 11-28-2022 16:35:37 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Note that this will only work in recent versions of PyTorch. As was done for the [int div](https://github.com/huggingface/transformers/blob/321ef388fe041f630e65abc26a3be8580d7e858b/src/transformers/pytorch_utils.py#LL35C3-L35C3), you should create a util function in the PyTorch utils that works across PyTorch versions<|||||>Good to know, thanks a lot! I think there are other models having the issue of using `torch.div` then, I'll fix as well. I'm a bit skeptic about readability (including this PR), trying to support tracing overall makes the code less readable I feel.<|||||>Just realized that the warning above is not shown anymore in PyTorch 1.13. Seem to be https://github.com/pytorch/pytorch/pull/78411
Refer to the release notes: `Updated torch.floor_divide to perform floor division` https://github.com/pytorch/pytorch/releases
This is fine since it influences only negative numbers. I'll close this PR. |
transformers | 20,472 | closed | Added TFBartForSequenceClassification | # What does this PR do?
Fixes: #19653
| 11-28-2022 15:25:34 | 11-28-2022 15:25:34 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger I have tested locally, not sure why tests are failing<|||||>@IMvision12 the common tests do not pass for the model you have added, you can run them with `pytest tests/models/bart/test_modeling_tf_bart.py`.
Also the equivalence test PyTorch/TensorFlow does not pas either.<|||||>@sgugger I've looked at some SequenceClassification models and the tests that have been written but none of them have TFSeq2SeqSequenceClassification or tests for it, so I'm not sure how to add a test for that. Need little help<|||||>@ydshieh Still the tests are failing<|||||>This issue has been solved in this PR here #20570 so i am closing this PR
|
transformers | 20,471 | closed | ImportError: cannot import name 'CommitOperationAdd' from 'huggingface_hub' | ### System Info
PS C:\Users\46213> transformers-cli env
Traceback (most recent call last):
File "C:\Users\46213\anaconda3\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\46213\anaconda3\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\46213\anaconda3\Scripts\transformers-cli.exe\__main__.py", line 4, in <module>
File "C:\Users\46213\anaconda3\lib\site-packages\transformers\__init__.py", line 30, in <module>
from . import dependency_versions_check
File "C:\Users\46213\anaconda3\lib\site-packages\transformers\dependency_versions_check.py", line 17, in <module>
from .utils.versions import require_version, require_version_core
File "C:\Users\46213\anaconda3\lib\site-packages\transformers\utils\__init__.py", line 48, in <module>
from .hub import (
File "C:\Users\46213\anaconda3\lib\site-packages\transformers\utils\hub.py", line 32, in <module>
from huggingface_hub import (
ImportError: cannot import name 'CommitOperationAdd' from 'huggingface_hub' (C:\Users\46213\anaconda3\lib\site-packages\huggingface_hub\__init__.py)
### Who can help?
@LysandreJik
@sgugger
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
PS C:\Users\46213> pip show huggingface_hub
Name: huggingface-hub
Version: 0.10.1
Summary: Client library to download and publish models, datasets and other repos on the huggingface.co hub
Home-page: https://github.com/huggingface/huggingface_hub
Author: Hugging Face, Inc.
Author-email: [email protected]
License: Apache
Location: c:\users\46213\anaconda3\lib\site-packages
Requires: requests, typing-extensions, tqdm, pyyaml, packaging, filelock
Required-by: transformers, ltp, evaluate, datasets
### Expected behavior
my transformer don‘t run ,please help me | 11-28-2022 13:44:20 | 11-28-2022 13:44:20 | There seems to be an installation problem with `huggingface_hub`. You should try to uninstall and re-install it in your environment.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,470 | closed | Standardize expected input shapes for audio models | ### Feature request
Hi, it seems some audio models expect `(batch_size, feature_size, n_frames)` (e.g. whisper) while others expect `(batch_size, sequence_length)` (e.g. wavlm, wav2vec2). Could this be standardized? It seems like the naming follows `input_features` vs `input_values` (but wav2vec2 feature extractor returns input_values!)
It seems to be the difference between models taking raw audio as an input vs MEL-spectrogram / STFT.
### Motivation
I ask because I am wondering if for models handling stereo I should pass inputs as `(batch_size, 2, n_frames)`. And if so, why not be able to pass `(batch_size, 1, n_frames)` for mono? Is not raw audio a feature as well?
Related https://github.com/huggingface/transformers/issues/16564
Preliminar internal discussion at https://huggingface.slack.com/archives/C02G13FEMDH/p1669637602417809
### Your contribution
/ | 11-28-2022 12:40:42 | 11-28-2022 12:40:42 | It's not possible to standardize this across all models, since some models naturally work on raw audio while others use various types of spectrograms.
However, I feel that we should make the FeatureExtractors more flexible in the type of inputs they accept.
For example, right now, the Wav2Vec2FeatureExtractor expects the input to be mono and 16 kHz. It would be nicer if you could pass in a tensor of shape `(batch_size, num_channels, num_samples)` and an arbitrary sampling rate.
If the model requires mono input, the FeatureExtractor can automatically downmix stereo to mono. If the sampling rate does not match what the model expects, the FeatureExtractor can automatically resample the data. It's more convenient to do this in the FeatureExtractor than having the user do this themselves.
This is analogous to what the ImageProcessors do in vision models: if the image is not the expected size, it will be resized (= resampled). If the number of color channels is wrong, the ImageProcessor fixes this.
These operations are optional, so if the user already has a pipeline where they put the data in the correct format, they can choose to skip the resampling / downmixing stages.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 20,469 | closed | fix both failing RoCBert tests | # What does this PR do?
Fixes two failing test :
- tokenization test did not take into account that the dummy tokenizer's `pad_token_id = 2` and `bos_token_id = 1`. The values used were `102, 101`.
- on of the modeling test used `assertEqual` on tensors and not list, which is ambigus.
| 11-28-2022 12:08:48 | 11-28-2022 12:08:48 | The two tests no pass locally (which was not the case before) <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.