
repo
stringlengths 26
115
| file
stringlengths 54
212
| language
stringclasses 2
values | license
stringclasses 16
values | content
stringlengths 19
1.07M
|
|---|---|---|---|---|
https://github.com/LDemetrios/Typst4Gradle | https://raw.githubusercontent.com/LDemetrios/Typst4Gradle/master/Changelog.md | markdown | # Change log
## 0.2.0
Breaking: ... Change almost everything. Add dependency on `Typst4k`.
# 0.1.0
Publish beta version of the library |
|
https://github.com/Isaac-Fate/booxtyp | https://raw.githubusercontent.com/Isaac-Fate/booxtyp/master/src/theorems/exercise.typ | typst | Apache License 2.0 | #import "new-plain-template.typ": new-plain-template
#import "../counters.typ": exercise-counter
#let exercise = new-plain-template(
"Exercise",
title-prefix: emoji.hand.write,
template-counter: exercise-counter,
)
|
https://github.com/lucannez64/Notes | https://raw.githubusercontent.com/lucannez64/Notes/master/ES_DM_2_14_02_2024.typ | typst | #import "template.typ": *
// Take a look at the file `template.typ` in the file panel
// to customize this template and discover how it works.
#show: project.with(
title: "ES DM 2 14 02 2024",
authors: (
"<NAME>",
),
date: "14 Février, 2024",
)
#set heading(numbering: "1.1.")
== #emph[Montrer que le terme "naturel", souvent associé à un champ
lexical positif, peut être un argument trompeur.]
<montrer-que-le-terme-naturel-souvent-associé-à-un-champ-lexical-positif-peut-être-un-argument-trompeur.>
L’omniprésence du terme "naturel" dans notre société incite à la
réflexion. Qu’il s’agisse de produits alimentaires, de cosmétiques ou de
pratiques de santé, l’adjectif "naturel" semble souvent synonyme de
qualité, de sécurité et d’authenticité. Mais que recouvre réellement ce
terme ? L’opposition entre "naturel" et "artificiel" est-elle aussi
binaire et simpliste qu’elle n’y paraît ? En déconstruisant les idées
reçues liées à la notion de "naturel", nous pouvons mieux appréhender la
complexité de la réalité et adopter une approche plus raisonnée face aux
choix qui s’offrent à nous. En quoi le terme "naturel" peut-il être
trompeur ?
En premier lieu, on peut relever le fait que le terme "nature" est
polysémique et sa signification peut varier selon le contexte. Ce qui
est considéré comme "naturel" dans un contexte donné peut ne pas l’être
dans un autre. Prenons l’exemple du sucre : s’il est naturel lorsqu’il
est présent dans un fruit, il ne les plus lorsqu’il est ajouté à un
aliment transformé. De plus, la perception de ce qui est "naturel" est
subjective et dépend des cultures, des époques et des individus.
L’idée reçue selon laquelle un produit "naturel" est nécessairement bon
pour la santé est erronée. En effet, de nombreux produits naturels
peuvent être dangereux, comme les plantes toxiques ou certains
champignons. À l’inverse, des produits artificiels peuvent être
bénéfiques pour la santé, comme certains médicaments ou vaccins. Comme
le dit le document, "c’est très souvent la dose qui fait le poison" être
exposé en excès à tout type d’espèce peut-être nocif qu’elle soit
naturelle ou artificielle. Il y a aussi le cas de la radioactivité
relevé dans un des documents en effet, la radioactivité provient de deux
types de sources : naturelles, dans les aliments, minéraux, rayons
cosmiques, eau et artificielles dans les appareils médicaux, déchets,
essais nucléaires. En réalité, l’exposition artificielle est si faible
qu’elle n’est pas nocive, car un individu est exposé à 35 % de
radioactivité de source artificielle en moyenne annuelle.
La réalité est bien plus complexe que l’opposition binaire entre
"naturel" et "artificiel". De nombreux produits et pratiques relèvent
d’une hybridation entre les deux. Un yaourt "naturel" peut contenir des
additifs artificiels, tout comme un médicament "artificiel" peut être
issu de substances naturelles.
Finalement l’idée que l’être humain est en opposition à la nature est
une vision anthropocentrée et erronée. L’être humain fait partie
intégrante de la nature et ses activités ont toujours eu un impact sur
son environnement. Par exemple dans l’alimentation : le lait maternel
est naturel, mais le lait maternisé ne l’est pas, bien que les deux
nourrissent les bébés.
Toutefois, les documents fournis ont plusieurs limites. Tout d’abord,
leurs sources ne sont pas indiquées ; de plus, ils n’offrent qu’une
vision partielle du terme "naturel".
En conclusion, l’adjectif "naturel" n’est pas un argument suffisant pour
indiquer la bienfaisance d’une substance. Nous devons nous informer sur
les propriétés et les effets de cette substance avant de hâtivement
juger cette pratique comme bonne ou mauvaise. De plus, il faut être
vigilante face aux personnes ou aux marques abusant de ce terme et
l’utilisé dans chaque contexte.
|
|
https://github.com/pluttan/shem | https://raw.githubusercontent.com/pluttan/shem/main/lab4/lab4.typ | typst | #import "@docs/bmstu:1.0.0":*
#import "@preview/tablex:0.0.8": tablex, rowspanx, colspanx, cellx
#show: student_work.with(
caf_name: "Компьютерные системы и сети",
faculty_name: "Информатика и системы управления",
work_type: "лабораторной работе",
work_num: "4",
discipline_name: "Схемотехника",
theme: "Синхронные одноступенчатые триггеры со статическим",
themecol2: "и динамическим управлением записью",
author: (group: "ИУ6-42Б", nwa: "<NAME>"),
adviser: (nwa: "<NAME>"),
city: "Москва",
table_of_contents: true,
)
#let xb = $op("x", limits: #true)^"__"$
#let ab = $op("a", limits: #true)^"__"$
#let bb = $op("b", limits: #true)^"__"$
#let Rb = $op("R", limits: #true)^"___"$
#let Sb = $op("S", limits: #true)^"___"$
#let Qb = $op("Q", limits: #true)^"___"$
#let Cb = $op("C", limits: #true)^"___"$
#let Db = $op("D", limits: #true)^"___"$
#let nt(a,b) = $op((#a), limits: #true)^#b$
= Исследовать работу асинхронного RS-триггера с инверсными входами в статическом режиме
== Таблица переходов
#align(center)[
#tablex(
columns: 4,
inset: 10pt,
align: center + horizon,
$ Rb $,$ Sb $,$Q_t$,$Q_"t+1"$,
$0$,$0$,$0$,$✘$,
$0$,$0$,$1$,$✘$,
$0$,$1$,$0$,$0$,
$0$,$1$,$1$,$0$,
$1$,$0$,$0$,$1$,
$1$,$0$,$1$,$1$,
$1$,$1$,$0$,$0$,
$1$,$1$,$1$,$1$,
)]
Как видно по таблице, чтобы удерживать текущее состояние необходимо просто подавать 0 в R и S. Сигнал будет меняться, если подать логическую единицу на один из этих входов, но не на оба сразу. Если подаем 1 на R то текущее значение становится 0, если на S -- 1.
== Функция переходов
$ Q_"t+1" = Qb_t Rb S or Q_t Rb S or Q_t Rb Sb $
#pagebreak()
== Схема
#img(image("1.png", width: 100%), [Схема асинхронного RS-триггера])
= Исследовать работу синхронного RS-триггера в статическом режиме
== Таблица переходов
#align(center)[
#tablex(
columns: 5,
inset: 10pt,
align: center + horizon,
$C$, $R$, $S$, $Q_t$, $Q_"t+1"$,
$0$, $0$, $0$, $0$, $0$,
$0$, $0$, $0$, $1$, $1$,
$0$, $0$, $1$, $0$, $0$,
$0$, $0$, $1$, $1$, $1$,
$0$, $1$, $0$, $0$, $0$,
$0$, $1$, $0$, $1$, $1$,
$0$, $1$, $1$, $0$, $0$,
$0$, $1$, $1$, $1$, $1$,
$1$, $0$, $0$, $0$, $0$,
$1$, $0$, $0$, $1$, $1$,
$1$, $0$, $1$, $0$, $1$,
$1$, $0$, $1$, $1$, $1$,
$1$, $1$, $0$, $0$, $0$,
$1$, $1$, $0$, $1$, $0$,
$1$, $1$, $1$, $0$, $✘$,
$1$, $1$, $1$, $1$, $✘$,
)]
Как видно из таблицы, в данном случае ситуация схожа с заданием 1, но появляется синхронизирующий бит, если его значение равно 0, то при любых R и S триггер не изменит своего состояния.
== Функция переходов
$ Q_"t+1" = Cb Q_t or C(Qb_t Rb S or Q_t Rb S or Q_t Rb Sb) $
== Схема
#img(image("2.png", width: 100%), [Схема синхронного RS-триггера])
= Исследовать работу синхронного D триггера в статическом режиме
== Таблица переходов
#align(center)[
#tablex(
columns: 4,
inset: 10pt,
align: center + horizon,
$C$, $D$, $Q_t$, $Q_"t+1"$,
$0$, $0$, $0$, $0$,
$0$, $0$, $1$, $1$,
$0$, $1$, $0$, $0$,
$0$, $1$, $1$, $1$,
$1$, $0$, $0$, $0$,
$1$, $0$, $1$, $0$,
$1$, $1$, $0$, $1$,
$1$, $1$, $1$, $1$,
)]
Как видно из таблицы, если бит C равен 1, то значение триггера равно D, иначе сохраняется предыдущее.
== Функция переходов
$ Q_"t+1" = Cb Db Q_t or Cb D Q_t or C D Qb_t or C D Q_t = Cb Q_t or C D $
#pagebreak()
== Схема
#img(image("3.png", width: 100%), [Схема синхронного D-триггера])
= Исследовать схему синхронного D-триггера с динамическим управлением записью в статическом режиме
== Таблица переходов
#align(center)[
#tablex(
columns: 4,
inset: 10pt,
align: center + horizon,
$C$, $D$, $Q_t$, $Q_"t+1"$,
$0$, $✘$, $0$, $0$,
$0$, $✘$, $1$, $1$,
$0 arrow 1$, $1$, $✘$, $1$,
$0 arrow 1$, $0$, $✘$, $0$,
$1 arrow 0$, $✘$, $0$, $0$,
$1 arrow 0$, $✘$, $1$, $1$,
)]
C меняется динамически, если меняется в 1, то записываем значение D в триггер, если меняется на 0 значение в D не записывается.
== Схема
#img(image("7.png", width: 100%), [Схема с динамическими сигналами])
#pagebreak()
== Временная диаграмма
#img(image("6.png", width: 100%), [Временная диаграмма])
= Исследовать работу ассинхронного T-триггера
== Таблица переходов
#align(center)[
#tablex(
columns: 5,
inset: 10pt,
align: center + horizon,
$R$, $S$, $T$, $Q_t$, $Q_"t+1"$,
$0$, $0$, $0$, $0$, $0$,
$0$, $0$, $0$, $1$, $1$,
$0$, $0$, $1$, $0$, $1$,
$0$, $0$, $1$, $1$, $0$,
$0$, $1$, $✘$, $✘$, $1$,
$1$, $0$, $✘$, $✘$, $0$,
$1$, $1$, $✘$, $✘$, $✘$,
)]
Таблица переходов похожа на таблицу обычного инвертора, но с некоторой памятью: если T равен 1, то триггер инвертирует предыдущее значение.
#pagebreak()
== Схема
#img(image("8.png", width: 100%), [Схема T триггера])
|
|
https://github.com/MasterTemple/typst-bible-plugin | https://raw.githubusercontent.com/MasterTemple/typst-bible-plugin/main/test.typ | typst | #import "bible.typ": bible_footnote, bible_quote, bible_quote_fmt
#import "conf.typ": conf
#show: doc => conf(doc)
// create short-hands
#let ul = underline
#let fn = footnote
= Theology of Money
== Work for it
#bible_quote("Ephesians 4:28")
#bible_quote("1 Thessalonians 4:11-12")
#bible_quote("2 Thessalonians 3:10")
== What is its purpose?
The best way to approach this is to ask, what does the Scripture say? #fn("As you should ask with everything.")
#bible_quote("Ephesians 4:28")
We see that
we are #ul[to acquire possessions],
to do so #ul[in a lawful manner],
so that we can #ul[share with those who are in need].
#image("./test.excalidraw.svg")
== Giving
// Usage example:
// #bible_quote_fmt(bible_quote("Ephesians 4:28"), "Let the")
// #bible_quote("Ephesians 4:28")
// #bible_quote_fmt("Ephesians 4:28", hl: "thief", b: "so", ul: "anyone", it: "in need")
// #bible_quote_fmt("Ephesians 4:28", hl: "thief", b: "no", ul: "steal", c: "rather let", fmt: highlight.with(fill: red))
// #bible_quote_fmt("Ephesians 4:28", hl: "thief", b: "no", ul: "steal", c: "rather let ", fmt: text.with(size: 0em, ))
#bible_quote_fmt("Ephesians 4:28", omit: "^.+?with")
// #bible_quote_fmt("Ephesians 4:28")
// #bible_quote_fmt("Ephesians 4:28")
// #bible_quote_fmt("Ephesians 4:28")
// #let bible_footnote_regex = regex("\^ ?(\w+) (\d+).(\d+-?\d+)?")
// #show bible_footnote_regex: it => {
// let (book, chapter, verse) = it.text.match(bible_footnote_regex).captures
// [#h(1pt) #bible_footnote(book + " " + chapter + ":" + verse)]
// }
// #let bible_quote_regex = regex("> ?(\w+) (\d+).(\d+-?\d+)?")
// #show bible_quote_regex: it => {
// let (book, chapter, verse) = it.text.match(bible_quote_regex).captures
// [#bible_quote(book + " " + chapter + ":" + verse)]
// }
God loves the world ^ John 3.15
God loves the world ^ John 3.16-17
> John 3.1-3
#bible_quote("Song of Solomon 1:1")
#show regex("((\d+).(\d+))"): (m) => [
#m #m
]
> Song of Solomon 1:1-2
> Song of Solomon 1.1-2
== Hospitality
// #bible_quote("1 Thessalonians 4:11-12")
// #bible_quote("Matthew 25:31-46")
// #bible_quote("Luke 12:33")
// #bible_quote("Romans 12:13")
// #bible_quote("Hebrews 13:2")
// #bible_quote("1 Peter 4:9")
// #bible_quote("Hebrews 13:16")
// #bible_quote("1 John 3:17")
// #bible_quote("James 2:15-17")
// #bible_quote("Psalm 24:1")
// #bible_quote("Proverbs 3:9-10")
// #bible_quote("Malachi 3:10") |
|
https://github.com/mumblingdrunkard/mscs-thesis | https://raw.githubusercontent.com/mumblingdrunkard/mscs-thesis/master/src/utils/config.typ | typst | #let authors = (
(name: "<NAME>", email: "<EMAIL>"),
(name: "<NAME> (Advisor)", email: "<EMAIL>"),
(name: "<NAME> (Advisor)", email: "<EMAIL>"),
)
#let course = (
code: "TDT4900",
name: "Computer Science, Master's Thesis"
)
#let department = "Computer Science"
#let project = (
name: "Doppelganger Loads in the \n Berkeley Out-of-Order Machine"
)
#let font = "New Computer Modern"
|
|
https://github.com/sses7757/sustech-graduated-thesis | https://raw.githubusercontent.com/sses7757/sustech-graduated-thesis/main/sustech-graduated-thesis/pages/outline-page.typ | typst | Apache License 2.0 | #import "@preview/outrageous:0.1.0"
#import "../utils/page-break.typ": page-break
#import "../utils/custom-heading.typ": heading-display, active-heading, current-heading
#import "../utils/style.typ": 字号, 字体
#let _outline-end = state("outline-end", "outline")
#let outline-pagenum() = (footer:
context [
#set align(center)
#set text(字号.五号)
#counter(page).display(
"I of I",
both: false,
)
]
)
#let outline-final(name, twoside: true) = {
_outline-end.update(_ => name)
context if _outline-end.final() == name {
page-break(twoside: twoside)
}
}
// 目录生成
#let outline-page(
// documentclass 传入参数
twoside: false,
fonts: (:),
// 其他参数
depth: 3,
title: "目 录",
outlined: false,
title-vspace: 0pt,
title-text-args: auto,
// 引用页数的字体,这里用于显示 Times New Roman
reference-font: auto,
reference-size: 字号.小四,
// 字体与字号
font: auto,
size: (字号.小四, ),
// 垂直间距
vspace: (25pt, 14pt),
indent: (0pt, 1em, 1em),
// 全都显示点号
fill: (auto,),
..args,
) = {
// 1. 默认参数
fonts = 字体 + fonts
if (title-text-args == auto) {
title-text-args = (font: fonts.黑体, size: 字号.三号)
}
// 引用页数的字体,这里用于显示 Times New Roman
if (reference-font == auto) {
reference-font = fonts.宋体
}
// 字体与字号
if (font == auto) {
font = (fonts.黑体, fonts.宋体)
}
// 2. 正式渲染
set page(..outline-pagenum())
page-break(twoside: twoside)
counter(page).update(1)
// 默认显示的字体
set text(font: reference-font, size: reference-size)
heading(level: 1, numbering: none, outlined: outlined, title)
v(title-vspace)
show outline.entry: outrageous.show-entry.with(
// 保留 Typst 基础样式
..outrageous.presets.typst,
body-transform: (level, it) => {
// 设置字体和字号
set text(
font: font.at(calc.min(level, font.len()) - 1),
size: size.at(calc.min(level, size.len()) - 1),
)
// 计算缩进
let indent-list = indent + range(level - indent.len()).map((it) => indent.last())
let indent-length = indent-list.slice(0, count: level).sum()
h(indent-length) + it
},
vspace: vspace,
fill: fill,
..args,
)
// 显示目录
outline(title: none, depth: depth)
outline-final("outline", twoside: twoside)
} |
https://github.com/fenjalien/mdbook-typst-doc | https://raw.githubusercontent.com/fenjalien/mdbook-typst-doc/main/example/data.typ | typst | Apache License 2.0 | #let a = [Hello from another file!] |
https://github.com/MitchellAcoustics/quarto-lapreprint | https://raw.githubusercontent.com/MitchellAcoustics/quarto-lapreprint/main/_extensions/lapreprint/typst-show.typ | typst | // Typst custom formats typically consist of a 'typst-template.typ' (which is
// the source code for a typst template) and a 'typst-show.typ' which calls the
// template's function (forwarding Pandoc metadata values as required)
//
// This is an example 'typst-show.typ' file (based on the default template
// that ships with Quarto). It calls the typst function named 'article' which
// is defined in the 'typst-template.typ' file.
//
// If you are creating or packaging a custom typst template you will likely
// want to replace this file and 'typst-template.typ' entirely. You can find
// documentation on creating typst templates here and some examples here:
// - https://typst.app/docs/tutorial/making-a-template/
// - https://github.com/typst/templates
#show: doc => template(
$if(title)$
title: [$title$],
$endif$
$if(subtitle)$
subtitle: "$subtitle$",
$endif$
$if(shorttitle)$
short-title: "$shorttitle$",
$endif$
$if(venue)$
venue: [$venue$],
$endif$
$if(by-author)$
authors: (
$for(by-author)$
$if(it.name.literal)$
( name: "$it.name.literal$",
$if(it.affiliations)$
affiliations: "$for(it.affiliations)$$it.name$$sep$, $endfor$",
$endif$
$if(it.email)$
email: [$it.email$],
$endif$
$if(it.orcid)$
orcid: "$it.orcid$",
$endif$
),
$endif$
$endfor$
),
$endif$
$if(affils)$
affiliations: (
$for(affils)$
( $if(it.name)$name: "$it.name$", $endif$
$if(it.id)$id: "$it.id$", $endif$
),
$endfor$
),
$endif$
$if(logo)$
logo: "$logo$",
$endif$
$if(doi)$
doi: "$doi$",
$endif$
$if(theme)$
theme: $theme$,
$endif$
$if(kind)$
kind: "$kind$",
$endif$
// $if(date)$
// date: [$date$],
// $endif$
$if(dates)$
date: (
$for(dates)$
( title: "$it.title$",
date: datetime(year: $it.year$, month: $it.month$, day: $it.day$)),
$endfor$
),
$endif$
$if(lang)$
lang: "$lang$",
$endif$
$if(region)$
region: "$region$",
$endif$
$if(abstract)$
abstract: [$abstract$],
$endif$
$if(keywords)$
keywords: ($for(keywords)$"$it$", $endfor$),
$endif$
$if(margins)$
margin: (
$for(margins)$ (
title: "$it.title$",
content: [$it.content$],
),
$endfor$
),
$endif$
$if(open-access)$
open-access: $open-access$,
$endif$
$if(margin)$
margin: ($for(margin/pairs)$$margin.key$: $margin.value$,$endfor$),
$endif$
$if(papersize)$
paper: "$papersize$",
$endif$
$if(mainfont)$
font: ("$mainfont$",),
$endif$
$if(fontsize)$
fontsize: $fontsize$,
$endif$
$if(section-numbering)$
sectionnumbering: "$section-numbering$",
$endif$
$if(toc)$
toc: $toc$,
$endif$
$if(bibliography-file)$
bibliography-file: "$bibliography-file$",
$endif$
$if(bibliography-style)$
bibliography-style: "$bibliography-style$",
$endif$
doc,
)
|
|
https://github.com/WinstonMDP/math | https://raw.githubusercontent.com/WinstonMDP/math/main/exers/k.typ | typst | #import "../cfg.typ": *
#show: cfg
$
"Prove that"
b_n =_(n -> oo) o(1/n) ->
ex({a_n}): sum_(n = 1)^oo a_n "converges" and b_n =_(n -> oo) o(a_n)
$
$b_n = (n b_n)/(-1)^(n + 1) (-1)^(n + 1)/n$
$sum_(n = 1)^oo (-1)^(n + 1)/n$ converges
$(n b_n)/(-1)^(n + 1) =_(n -> oo) (o(1))/(-1)^(n + 1) ->_(x -> oo) 0$
$qed$
|
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/chronos/0.1.0/src/diagram.typ | typst | Apache License 2.0 | #import "utils.typ": get-group-span, fit-canvas
#import "renderer.typ": render
#import "participant.typ" as participant: _par, PAR-SPECIALS
#let _gap(size: 20) = {
return ((
type: "gap",
size: size
),)
}
#let _evt(participant, event) = {
return ((
type: "evt",
participant: participant,
event: event,
lifeline-style: auto
),)
}
#let diagram(elements, width: auto) = {
if elements == none {
return
}
let participants = ()
let elmts = elements
let i = 0
// Flatten groups
while i < elmts.len() {
let elmt = elmts.at(i)
if elmt.type == "grp" {
let grp-elmts = elmt.elmts
elmt.elmts = elmt.elmts.map(e => {
if e.type == "seq" {
if e.p1 == "?" {
e.p1 = "?" + e.p2
} else if e.p2 == "?" {
e.p2 = e.p1 + "?"
}
}
e
})
elmts.at(i) = elmt
elmts = (
elmts.slice(0, i + 1) +
grp-elmts +
((
type: "grp-end"
),) +
elmts.slice(i+1)
)
}
i += 1
}
// List participants
let linked = ()
let last-seq = none
let last-note = none
for (i, elmt) in elmts.enumerate() {
if elmt.type == "par" {
participants.push(elmt)
} else if elmt.type == "seq" {
if not participant._exists(participants, elmt.p1) {
participants.push(_par(elmt.p1).first())
}
if not participant._exists(participants, elmt.p2) {
let par = _par(elmt.p2, from-start: not elmt.create-dst).first()
participants.push(par)
} else if elmt.create-dst {
let i = participants.position(p => p.name == elmt.p2)
participants.at(i).from-start = false
}
let p1 = elmt.p1
let p2 = elmt.p2
if elmt.p1 == "?" {
p1 = "?" + elmt.p2
}
if elmt.p2 == "?" {
p2 = elmt.p1 + "?"
}
linked.push(p1)
linked.push(p2)
last-seq = (
elmt: elmt,
i: i,
p1: p1,
p2: p2
)
} else if elmt.type == "note" {
elmt.insert("linked", elmt.pos == none and elmt.side != "across")
if elmt.pos == none and elmt.side != "across" {
let names = participants.map(p => p.name)
let i1 = names.position(n => n == last-seq.p1)
let i2 = names.position(n => n == last-seq.p2)
let pars = ((i1, last-seq.p1), (i2, last-seq.p2)).sorted(key: p => p.first())
if elmt.side == "left" {
elmt.pos = pars.first().last()
} else if elmt.side == "right" {
elmt.pos = pars.last().last()
}
let seq = last-seq.elmt
seq.insert("linked-note", elmt)
elmts.at(last-seq.i) = seq
}
if elmt.aligned {
let n = last-note.elmt
n.aligned-with = elmt
elmts.at(last-note.i) = n
}
elmts.at(i) = elmt
if elmt.side == "left" {
linked.push("[")
} else if elmt.side == "right" {
linked.push("]")
}
last-note = (
elmt: elmt,
i: i
)
} else if elmt.type == "evt" {
let par = elmt.participant
if not participant._exists(participants, par) {
let p = _par(par, from-start: elmt.event != "create").first()
participants.push(p)
} else if elmt.event == "create" {
let i = participants.position(p => p.name == par)
participants.at(i).from-start = false
}
}
}
linked = linked.dedup()
let pars = participants
participants = ()
if "[" in linked {
participants.push(_par("[", invisible: true).first())
}
for (i, p) in pars.enumerate() {
let before = _par("?" + p.name, invisible: true).first()
let after = _par(p.name + "?", invisible: true).first()
if before.name in linked {
if participants.len() == 0 or not participants.last().name.ends-with("?") {
participants.push(before)
} else {
participants.insert(-1, before)
}
}
participants.push(p)
if after.name in linked {
participants.push(after)
}
}
if "]" in linked {
participants.push(_par("]", invisible: true).first())
}
// Add index to participant
for (i, p) in participants.enumerate() {
p.insert("i", i)
participants.at(i) = p
}
// Compute groups spans (horizontal)
for (i, elmt) in elmts.enumerate() {
if elmt.type == "grp" {
let (min-i, max-i) = get-group-span(participants, elmt)
elmts.at(i).insert("min-i", min-i)
elmts.at(i).insert("max-i", max-i)
} else if elmt.type == "seq" {
if elmt.p1 == "?" {
elmts.at(i).p1 = "?" + elmt.p2
} else if elmt.p2 == "?" {
elmts.at(i).p2 = elmt.p1 + "?"
}
}
}
set text(font: "Source Sans 3")
let canvas = render(participants, elmts)
fit-canvas(canvas, width: width)
}
#let from-plantuml(code) = {
let code = code.text
} |
https://github.com/dainbow/FunctionalAnalysis2 | https://raw.githubusercontent.com/dainbow/FunctionalAnalysis2/main/themes/8.typ | typst | #import "../conf.typ": *
= Производная Фурье и свёртка в пространствах $L_1(RR)$ и $L_2(RR)$
== Определения и основные свойства. Формула умножения. Преобразование Фурье свёртки.
#definition[
Пусть $f in L_1(RR)$. Тогда *преобразованием Фурье* функции $f$ называется
функция, заданная следующим образом:
#eq[
$hat(f)(y) = F[f](y) := integral_RR f(x)e^(-i x y)dif mu(x)$
]
]
#proposition[
Преобразование Фурье отображает функции из $L_1(RR)$ в $B(RR)$ -- множество
ограниченных функций.
]
#proof[
#eq[
$abs(F[f](y)) <= integral_RR abs(f(x))dot 1 dif mu(x) = norm(f)_L_1 => norm(F[f])_L_oo <= norm(f)_L_1$
]
]
#proposition[
Преобразование Фурье отображает функции из $L_1(RR)$ в $C_0(RR)$ -- множество
непрерывных функций, стремящеся к нулю на бесконечности.
]
#proof[
Рассмотрим преобразование Фурье индикатора отрезка:
#eq[
$hat(II_[a,b])(y) = (e^(-i a y) - e^(-i b y)) / (i y) in C_0(RR)$
]
А как мы знаем, любая функция из $L_1(RR)$ приближается ступенчатыми.
Значит преобразование Фурье любой ступенчатой функции лежит в $C_0(RR)$. Более
того, $F$ -- непрерывный оператор, и поэтому образы будут равеномерно сходится.
]
#proposition(
"Формула умножения",
)[
Пусть $f, g in L_1(RR)$. Тогда
#eq[
$integral_RR f(y)hat(g)(y) dif mu(y) = integral_RR hat(f)(y)g(y) dif mu(y)$
]
]
#note[
Для применения теоремы Фубини (о перестановке интегралов), мы должны доказать,
что хотя бы один из повторных интегралов конечен.
]
#proof[
Распишем преобразование Фурье по определению:
#eq[
$abs(integral_RR f(y)hat(g)(y) dif mu(y)) &<= integral.double_(RR times RR) abs(f(y)g(x)e^(- i x y))dif mu(x) dif mu(y) = \ integral.double_(RR times RR) abs(f(y)g(x))dif mu(x) dif mu(y) &<= norm(g)_L_1 integral_RR abs(f(y)) dif mu(y) <= norm(f)_L_1norm(g)_L_1 < +oo$
]
]
#definition[
Пусть $f, g in L_1(RR)$. Тогда *свёрткой функций* $f$ и $g$ называется функция:
#eq[
$(f * g)(x) = integral_RR f(y)f(x - y)dif mu(y)$
]
]
#proposition[
Свёртка функций $f, g in L_1(RR)$ тоже лежит в пространстве $L_1(RR)$.
]
#proof[
Докажем, что ограничен интеграл от модуля свёртки:
#eq[
$integral.double_(RR times RR) abs(f(y)g(x - y))dif mu(y) dif mu(x) &attach(=, t: "Фубини") integral.double_(RR times RR) abs(f(y)g(x - y))dif mu(x) dif mu(y) = \
integral_RR abs(f(y))integral_RR abs(g(x - y)) dif mu(x) dif mu(y) &= integral_RR abs(f(y))integral_RR abs(g(x - y)) dif mu(x - y) dif mu(y) = \
integral_RR abs(f(y)) dif mu(y) integral_RR abs(g(t)) dif mu(t) &= norm(f)_L_1norm(g)_L_1 < +oo$
]
]
#proposition("Преобразование Фурье свёртки")[
Пусть $f, g in L_1(RR)$. Тогда верна формула:
#eq[
$hat(f * g) = hat(f)dot hat(g)$
]
]
#proof[
Распишем преобразование Фурье от свёртки:
#eq[
$hat(f * g)(y) = integral_RR (f * g)(x) e^(-i x y) dif mu(x) = integral.double_(RR times RR) f(xi)g(x - xi)e^(-i x y) dif mu(xi) dif mu(x)$
]
Выше мы уже доказали, что свёртка "хороших" функций лежит в $L_1(RR)$, а значит
мы можем применить теорему Фубини. Итак:
#eq[
$hat(f * g)(y) = integral_RR f(xi)integral_RR g(x - xi) e^(- i x y) dif mu(x) dif mu(xi) attach(=, t: 1 = e^(i xi y)e^(- i xi y)) \
integral_RR f(xi) e^(-i xi y) integral_RR g(x - xi) e^(-i(x - xi) y) dif mu(x - xi) dif mu(xi) = hat(f)(y)dot hat(g)(y)$
]
]
#definition[
*Пространством Шварца* $S subset L_1(RR) sect L_2(RR)$ называется множество
бесконечно дифференцируеых функций, которые вместе со всеми своими производными
убывают на бесконечности быстрее любой степени:
#eq[
$S = {f in C^oo(RR) | forall n in NN union {0}, m in NN : space lim_(x -> oo) x^m f^((n))(x) = 0 }$
]
]
#proposition[
Если $f in L_1(RR)$ и $forall p in NN : x^p f(x) in L_1(RR)$, то преобразование
фурье $g = F[f]$ дифференцируемо бесконечное число раз на $RR$.
]
#proof[
Функции пространства Шварца можно описать эквивалентным образом:
#eq[
$forall f in S : exists C_(n,m) in RR_+ : space forall x in RR : abs(x^m f^((n))(x)) <= C_(n,m)$
]
Покажем, что из этого факта следует $x^p f(x) in L_1(RR)$ при любом $p in NN$.
Действительно, можно написать следующее:
#eq[
$forall m in NN : exists C_(0, m + 2) in R_+ : space forall x in RR : abs(x^m f(x)) <= C_(0, m + 2) / x^2$
]
Отсюда тривиальным образом получаем абсолютную интегрируемость. Стало быть,
преобразование Фурье $g = F[f]$ обладает всеми производными.
Чтобы доказать, что они тоже являются функциями из пространства Шварца,
воспользуемся следующим равенством:
#eq[
$(i y)^q g^((m))(y) = (-i)^q F[(x^m f(x))^((q))](y)$
]
Из непрерывности преобразования Фурье, требуемое установлено.
]
#proposition[
Преобразование Фурье на $S$ обладает следующими свойствами:
+ $F : S -> S$ -- биекция
+ $F : S -> S$ -- изометрия
+ $F^4 = I$ (Более того, $F^2[f](x) = f(-x)$)
]
#proof[
+ Достаточно показать, что для любой $g in S$ найдётся прообраз по преобразованию
Фурье. Посмотрим на образ:
#eq[
$f^*(x) = 1 / sqrt(2 pi) integral_RR g(y) e^(- i y x) dif mu(y)$
]
Положим $f(x) = f^*(-x)$. Из уже доказанного, $f^* in S$, а значит и $f in S$.
Осталось произвести замену переменной:
#eq[
$g(y) = 1 / sqrt(2 pi) integral_RR f^*(x)e^(i x y) = integral_RR f(x)e^(- i x y) dif mu(x) = F[f](y)$
]
+ Распишем скалярное произведение с использованием формулы обращения (без
доказательства):
#eq[
$(f, g) = integral_RR f(x)overline(g(x)) dif mu(x) = integral_RR f(x) overline(1 / sqrt(2 pi) integral_RR hat(g)(y) e^(i x y) dif mu (y)) dif mu(x) = \
1 / sqrt(2 pi) integral.double_(RR times RR) f(x)overline(hat(g)(y))e^(-i x y)dif mu(x)dif mu(y) = integral_RR overline(hat(g)(y)) 1 / sqrt(2 pi) integral_RR f(x) e^(-i x y) dif mu(x) dif mu(y) = (hat(f), hat(g))$
]
+ Заметим, что
#eq[
$F[f](y) = F^(-1)[f](-y)$
]
Так как преобразование Фурье биективно, можно применить его к полученному
равенству и получить требуемое.
]
#note[
Замыкание $S$ -- это пространство $L_2(RR)$.
]
#proposition[
Преобразование Фурье продолжается на $L_2(RR)$. Более того, $F[L_2(RR)] subset.eq L_2(RR)$
]
#proof[
Как известно из предыдущего семестра, линейный ограниченный оператор,
определённый на линейном многообразии, продолжается на его замыкание с
сохранением нормы. Именно это тут и происходит.
]
== Операторы Гильберта-Шмидта
#definition[
*Оператором Гильберта-Шмидта* называется частный случай оператора Фредгольма в $L_2[a, b]$:
#eq[
$(A f)(x) = integral_a^b K(x, t) f(t) dif mu(t), quad K in L_2([a, b]^2) $
]
]
#proposition[
Оператор Гильберта-Шмидта отображает в $L_2[a,b]$
]
#proof[
Раз $K in L_2([a, b]^2)$, то как функция по одному из своих аргументов, она тоже
будет из $L_2[a, b]$:
#eq[
$abs((A f)(x))^2 = abs(integral_a^b K(x, t)f(t) dif mu(t))^2 = abs((K(k, t), f(t)))^2 attach(<=, t: "КБШ") norm(f)^2_L_2 norm(K(x, dot))^2_L_2 < oo $
]
]
#theorem[
Оператор Гильберта-Шмидта является компактным оператором на $L_2[a, b]$.
]
#proof[
$L_2[a, b]$ -- сепарабельное гильбертово пространство, поэтому в нём есть
ортонормированный базис $seq(phi)$.
Идея состоит в том, чтобы найти последовательность компактных операторов $seq(idx: N, A)$,
которые сходятся по норме к $A$.
Итак, можно разложить ядро $K$ по вышеупомянутому базису:
#eq[
$K(x, t) = sum_(n,m = 1)^oo c_(n,m)phi_n (x)phi_m (t)$
]
Возьмём за отдельные ядра -- "срезки" от ряда выше:
#eq[
$K_N(x, t) = sum_(n, m = 1)^N c_(n, m)phi_n (x) phi_m (t)$
]
Тогда, тривиальным образом, $A_N f(x) = integral_a^b K_N(x, t)f(t) dif mu(t)$,
который является компактным из-за конечномерности образа.
Осталось вспомнить, что норма оператора Фредгольма оценивается сверху 2-нормой
ядра, а значит:
#eq[
$norm(A - A_n) <= norm(K - K_n) ->_(N -> oo) 0$
]
]
#definition[
Пусть $H$ -- гильбертово пространство, $seq(e)$ -- его базис. *Классом
операторов Гильберта-Шмидта* называется следующее множество операторов $A in seq(L)(H)$ таких,
что
#eq[
$sum_(n = 1)^oo norm(A e_n)^2 < +oo$
]
]
|
|
https://github.com/kdog3682/typkit | https://raw.githubusercontent.com/kdog3682/typkit/main/0.1.0/src/validation.typ | typst | #import "is.typ": *
// #import "str-utils.typ": test
#let exists(x) = { x != none and x != false }
#let empty(x) = { x == none }
#let not-none(x) = { x != none }
#let is-content-wrapper(c) = {
return c.fields().at("body", default: none) != none
}
#let has(x, key) = {
if is-object(x) {
return key in x
}
}
#let is-divisible(a, b) = {
return calc.rem(a, b) == 0
}
|
|
https://github.com/pluttan/os | https://raw.githubusercontent.com/pluttan/os/main/lab6/lab6.typ | typst | #import "@docs/bmstu:1.0.0":*
#import "@preview/tablex:0.0.8": tablex, rowspanx, colspanx, cellx
#show: student_work.with(
caf_name: "Компьютерные системы и сети",
faculty_name: "Информатика и системы управления",
work_type: "лабораторной работе",
work_num: 6,
study_field: "09.03.01 Информатика и вычислительная техника",
discipline_name: "Операционные системы",
theme: "Исследование методов защиты операционных систем и данных",
author: (group: "ИУ6-52Б", nwa: "<NAME>"),
adviser: (nwa: "<NAME>"),
city: "Москва",
table_of_contents: true,
)
= Введение
== Цель работы
Исследование методов защиты информации в Linux.
== Задание
Предположим, в вашей организации в нескольких подразделениях стоят
сканеры, пользователи сканируют на них документы и записывают на сервер.
На сервере работает программа, которая распознаёт файлы из одного
каталога и записывает файлы с распознанным текстом в другой каталог.
Пользователи загружают распознанные тексты документов в систему
документооборота, кроме документов «для служебного пользования»,
которые записывают в специальный каталог. К этому каталогу имеют доступ
только определённая группа пользователей.
Задача: С помощью команд:
- Создать несколько пользователей, включая пользователя от имени которого работает сервис распознавания.
- Для каждого пользователя создать каталоги:
- in — для файлов, предназначенных для распознавания
- out — для распознанных файлов\ #h(-13%)Пользователи не должны иметь доступ к файлам других пользователей.\ #h(-13%) Не забудьте дать права сервису распознавания.
- Создать каталог, в который выкладывают файлы пользователи группы «DSP». Только пользователи этой группы должны иметь к нему доступ.
- Создать файл протокола, в который записывает сообщения сервис распознавания. Все пользователи должны иметь права на чтение этого файла.
= Выполнение
== Создать несколько пользователей, включая пользователя от имени которого работает сервис распознавания.
При помощи комманды ```sh useradd``` добавим 4 пользователей:
- `user1`, `user2` -- пользователи группы «DSP»
- `user3` -- обычный пользователь
- `recognition_service` -- пользователь-сервер, который обрабатывает все запросы
#img(image("img/1.png", width:70%), [```sh useradd -m -s /bin/bash/ user1```])
После создания первого пользователя сразу же зададим его пароль при помощи утилиты ```sh passwd```.
#img(image("img/2.png", width:70%), [```sh passwd user1```])
#img(image("img/4.png", width:70%), [```sh useradd -m -s /bin/bash/ user2```])
#img(image("img/5.png", width:70%), [```sh useradd -m -s /bin/bash/ user3```])
#img(image("img/6.png", width:70%), [```sh useradd -m -s /bin/bash/ recognition_service```, ```sh passwd user2```, ```sh passwd user3```, ```sh passwd recognition_service```])
Сразу создадим группу пользователей, которые будут иметь доступ к каталогу «DSP». Добавим наших пользователей в группу.
#img(image("img/8.png", width:70%), [```sh groupadd DSP```, ```sh usermod -aG DSP user1```, ```sh usermod -aG DSP user1```])
== Для каждого пользователя создать каталоги in, out
С помощью утилиты ```sh mkdir``` создадим для каждого пользователя каталоги `in`, `out`.
```sh
mkdir -p /home/user1/in /home/user1/out
mkdir -p /home/user2/in /home/user2/out
mkdir -p /home/user3/in /home/user3/out
mkdir -p /home/recognition_service/in /home/recognition_service/out
```
#img(image("img/9.png", width:70%), [Добавляем каталоги])
С помощью утилит ```sh chown``` и ```sh chmod``` выдадим разрешение на чтение и запись разным пользователям.
```sh
chown user1:user1 /home/user1/in /home/user1/out
chmod 700 /home/user1/in /home/user1/out
chown user2:user2 /home/user2/in /home/user2/out
chmod 700 /home/user2/in /home/user2/out
chown user3:user3 /home/user3/in /home/user3/out
chmod 700 /home/user3/in /home/user3/out
chown recognition_service:recognition_service /home/recognition_service/in /home/recognition_service/out
chmod 700 /home/recognition_service/in /home/recognition_service/out
```
#img(image("img/11.png", width:70%), [```sh chown``` и ```sh chmod```])
#img(image("img/12.png", width:70%), [```sh chown``` и ```sh chmod```])
== Создать каталог, в который выкладывают файлы пользователи группы «DSP». Только пользователи этой группы должны иметь к нему доступ.
С помощью ```sh mkdir``` создадим данный каталог, с помощью ```sh chown``` и ```sh chmod``` зададим доступ только определенной группе пользовалетей на чтение и запись.
```sh
mkdir /srv/dsp_files
chown :DSP /srv/dsp_files
chmod 770 /srv/dsp_files
```
#img(image("img/13.png", width:70%), [```sh mkdir```, ```sh chown``` и ```sh chmod```])
== Создать файл протокола, в который записывает сообщения сервис распознавания. Все пользователи должны иметь права на чтение этого файла.
При помощи ```sh touch``` создадим файл для сервиса, с помошью ```sh chmod``` зададим права на чтение файла для всех.
```sh
touch /var/log/logfile.log
chmod 644 /var/log/logfile.log
```
#img(image("img/14.png", width:70%), [Создаем файл])
== Проверка
Проверим все созданные каталоги и файл на права доступа:
```sh ls -ld /home/user1/in /home/user1/out /home/user2/in /home/user2/out /home/user3/in /home/user3/out /home/recognition_service/in /home/recognition_service/out /srv/dsp_files /var/log/logfile.log```
#img(image("img/16.png", width:65%), [```sh ls```])
Видим что все директории принадлежат правитьным пользователям.
При помощи комманды ```sh groups``` посмотрим все группы, в которых состоят созданные пользователи:
```sh groups user1
groups user2
groups user3
groups recognition_service
```
#img(image("img/17.png", width:65%), [```sh groups```])
Зайдем под разными пользователями и проверим их права:
#img(image("img/18.png", width:70%), [`user1`])
#img(image("img/19.png", width:70%), [`user2`])
#img(image("img/20.png", width:70%), [`user3`])
|
|
https://github.com/hemmrich/CV_typst | https://raw.githubusercontent.com/hemmrich/CV_typst/master/template/lib.typ | typst | /*
* Entry point for the package
*/
/* Packages */
#import "./template.typ": *
#import "./styles.typ": overwriteFonts
/* Layout */
#let cv(
metadata,
profilePhoto: image("../src/avatar.png"),
doc) = {
// Non Latin Logic
let lang = metadata.language
let fontList = latinFontList
let headerFont = latinHeaderFont
fontList = overwriteFonts(metadata, latinFontList, latinHeaderFont).regularFonts
headerFont = overwriteFonts(metadata, latinFontList, latinHeaderFont).headerFont
// Page layout
set text(font: fontList, weight: "regular", size: 9pt)
set align(left)
set page(
paper: "a4",
margin: (left: 1.4cm, right: 1.4cm, top: .8cm, bottom: .5cm),
)
_cvHeader(metadata, profilePhoto, headerFont, regularColors, awesomeColors)
doc
_cvFooter(metadata)
} |
|
https://github.com/dvdvgt/typst-letter | https://raw.githubusercontent.com/dvdvgt/typst-letter/main/din5008-letter.typ | typst | MIT License |
#let default_address = [
Name\
Street, Street number\
ZIP, City
]
#let default_stroke = 0.75pt
#let mk_header(
name,
address,
contact,
accent
) = {
set block(spacing: 0.64em)
grid(
columns: (1fr, 1fr),
rows: 2,
align(top + left)[
#text(16pt, fill: accent, strong(name))\
#address
],
align(bottom + right, contact)
)
line(length: 100%, stroke: accent + default_stroke)
}
#let letter(
sender_address: [],
sender_contact: none,
sender_name: none,
receiver: none,
date: none,
subject: none,
greeting: none,
valediction: none,
attachments: none,
postal: false,
accent: black,
duplex: true,
content
) = {
set text(12pt)
set page(
paper: "a4",
margin: (top: 4.5cm, bottom: 2.5cm, left: 2.5cm, right: 2cm),
header: locate(loc => {
if loc.page() == 1 {
mk_header(sender_name, sender_address, sender_contact, accent)
} else {
set text(size: 9pt)
set block(spacing: 0.64em)
[#sender_name #h(1fr) #date]
line(length: 100%, stroke: default_stroke)
}}),
numbering: "1/1",
// set up fold line if it is a postal letter
background: locate(loc =>
if postal and (duplex or calc.mod(loc.page(), 2) != 0) {
place(top + left, line(start: (0mm, 105mm), length: 5mm))
place(top + left, line(start: (0mm, 210mm), length: 5mm))
})
)
let without_breaks = sender_address.children.filter(elem => elem != [ ] and elem != linebreak())
// Address fields
// change height if content is too large. Standard is 5.5cm
block(height: if postal { 4.5cm } else { 2.5cm })[
#set block(spacing: 0mm)
#if postal {
block(
width: 100%,
height: 17.7mm,
underline(text(size: 9pt, sender_name + " • " + without_breaks.join(" • ")))
)
}
#move(dx: 5mm, align(top + left, receiver))
]
// date
align(right)[#date]
// subject
linebreak()
strong(text(fill: accent, subject))
// greeting
linebreak()
linebreak()
greeting
// content
{
set par(justify: true)
content
}
// end
{
valediction
v(1.5em)
sender_name
}
// attachement
if attachments != none {
v(1fr)
set text(9pt)
[
*Attachments*:
#attachments
]
}
}
|
https://github.com/Toniolo-Marco/git-for-dummies | https://raw.githubusercontent.com/Toniolo-Marco/git-for-dummies/main/book/cover.typ | typst | #{
set page(fill: gradient.linear(..color.map.crest), margin: (left: 2in), numbering: none)
line(start: (0%, 5%), end: (8.5in, 5%), stroke: (thickness: 2pt))
align(horizon + left)[
#text(size: 24pt, [Git for Dummies])
<NAME>, <NAME>
]
align(bottom + left)[University of Trento, Advanced Programming course]
// #align(bottom + left)[#datetime.today().display()]
} |
|
https://github.com/jgm/typst-hs | https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/text/features-12.typ | typst | Other | // Error: 21-35 expected string, found boolean
#set text(features: ("tag", false))
|
https://github.com/ufodauge/typst-algomod | https://raw.githubusercontent.com/ufodauge/typst-algomod/main/readme.md | markdown | MIT License | # Algorithm for Typst
inspired by [typst-theorems](https://github.com/sahasatvik/typst-theorems).
## Example
```typ
#import "../algomod.typ": algomod, algomodLink
#import "../algomod_statements.typ": *
#let algorithm = algomod()
#algorithm(
title: [algorithm_title],
label: <label>,
lines: (
Function("func_name", $a, b$),
Let($"array" <- {1, 2, 3}$),
While($"array.length" < 10$),
$"array.push"("array.last" + 1)$,
End(),
ForAll("val", "array"),
If($"val" > b$),
$a <- a + "val"$,
Else(),
Return($a + b$),
End(),
End(),
Return($a + b$),
End(),
)
)
You can place link to #algomodLink(<label>)
#let customedAlgorithm = algomod(
// Change indent size
indentSize: 1.2em,
// Change format
format: (title, lines) => [
#block(
fill: rgb("#EBEEF5"),
radius: 8pt,
pad(
x: 2em,
y: 1em,
)[
#title
#v(.4em)
#enum(..lines)
]
)
]
)
// Customize statement
// preIndent: make indent in the current line
// postIndent: make indent in the next line
#let Comment(comment) = {
return createStatement(
preIndent: 0.5,
postIndent: -0.5,
[`//` #raw(comment)],
)
}
// Override default statement
// You can (de)indent w/o displaying any lines like this
#let End() = {
return createStatement(
preIndent: -1,
none,
)
}
#customedAlgorithm(title: [algorithm_title], lines: (
Comment("comment"),
Function($"func_name"$, $a, b$),
Let($"array" <- {1, 2, 3}$),
ForAll($"val"$, $"array"$),
If($"val" > b$),
$a <- a + "val"$,
End(),
End(),
Repeat(),
$a <- a + b$,
Until($a + b < 10$),
Return($a + b$),
End(),
))
```

|
https://github.com/levinion/typst-dlut-templates | https://raw.githubusercontent.com/levinion/typst-dlut-templates/main/examples/translate/translate.typ | typst | MIT License | #import "../../templates/translate/main.typ":translate
#show: translate.with(
chinese_title: "外文的中文题目",
english_title: "The title of foreign language",
author: "author",
workplace: "工作单位",
faculty: "",
major: "",
name: "",
id: "",
sup: "",
date: "",
intro: [这里是引言],
abstract: [要求忠于原文,语意流畅],
keywords: ("关键词1","关键词2","关键词3"),
)
= 第一章
== 第一节
正文内容
|
https://github.com/TypstApp-team/typst | https://raw.githubusercontent.com/TypstApp-team/typst/master/tests/typ/math/syntax.typ | typst | Apache License 2.0 | // Test math syntax.
---
// Test Unicode math.
$ ∑_(i=0)^ℕ a ∘ b = \u{2211}_(i=0)^NN a compose b $
---
// Test a few shorthands.
$ underline(f' : NN -> RR) \
n |-> cases(
[|1|] &"if" n >>> 10,
2 * 3 &"if" n != 5,
1 - 0 thick &...,
) $
---
// Test common symbols.
$ dot \ dots \ ast \ tilde \ star $
---
// Error: 1-2 unclosed delimiter
$a
|
https://github.com/xsro/typst-lsp | https://raw.githubusercontent.com/xsro/typst-lsp/xsro/dev/README.md | markdown | MIT License | # Typst LSP
A brand-new language server for [Typst](https://typst.app/).
## Features
- Syntax highlighting, error reporting, code completion, and function signature
help
- Compiles to PDF on save (configurable to as-you-type, or can be disabled)
This repo consists of:
- an LSP server, written in Rust
- [a corresponding VS Code(ium) extension](https://github.com/nvarner/typst-lsp/tree/master/addons/vscode).
The extension is available on the [VS Code Marketplace](https://marketplace.visualstudio.com/items?itemName=nvarner.typst-lsp)
and [OpenVSX](https://open-vsx.org/extension/nvarner/typst-lsp).
## Near future goals
- Improved preview (e.g. built-in PDF viewer, render to image for speed)
- Support for more editors
## Development guide
### Prerequisites
Install:
- [Rust](https://www.rust-lang.org/) for the LSP itself
- [Rust Analyzer](https://rust-analyzer.github.io/) an extension for Rust LSP for VS Code
- [node](https://nodejs.org/en) for the VS Code extension; it may be easiest to
install via [fnm](https://github.com/Schniz/fnm)
### First time setup
1. Clone this repository locally
2. Open it in VS Code; it's needed to run the extension
3. In the `addons/vscode` subdirectory:
1. Run `npm install` to install extension dependencies
2. Run `npm run compile` to build the extension
4. Run through the development cycle once to initialize and test everything
5. (Optional: install the dev version of the extension): Press <kbd>Ctrl</kbd>+<kbd>Shift</kbd>+<kbd>P</kbd>,
and choose `Developer: Install Extension from Location...` and choose
the directory for the extension, `addons/vscode/`. There will not be any messages, but
the extension can be found in the Extensions `@installed` list.
### Development cycle
1. Make any changes
2. Run `cargo install --path .`; at present, the VS Code extension just invokes
the `typst-lsp` command to start the LSP, and this command will compile and
replace that binary with the latest version
- If modifying the extension, keep `npm run watch` running, or `npm run compile`
after changes
3. Press <kbd>Ctrl</kbd>+<kbd>F5</kbd> to launch the "Extension Development Host"; if it's already
running, invoke "Developer: Reload Window" from the command palette in the
Extension Development Host
4. Within the Extension Development Host, the extension will be active and ready
for testing
|
https://github.com/typst-jp/typst-jp.github.io | https://raw.githubusercontent.com/typst-jp/typst-jp.github.io/main/docs/guides/tables.md | markdown | Apache License 2.0 | ---
description: |
Not sure how to change table strokes? Need to rotate a table? This guide
explains all you need to know about tables in Typst.
---
# Table guide
Tables are a great way to present data to your readers in an easily readable,
compact, and organized manner. They are not only used for numerical values, but
also survey responses, task planning, schedules, and more. Because of this wide
set of possible applications, there is no single best way to lay out a table.
Instead, think about the data you want to highlight, your document's overarching
design, and ultimately how your table can best serve your readers.
Typst can help you with your tables by automating styling, importing data from
other applications, and more! This guide takes you through a few of the most
common questions you may have when adding a table to your document with Typst.
Feel free to skip to the section most relevant to you – we designed this guide
to be read out of order.
If you want to look up a detail of how tables work, you should also [check out
their reference page]($table). And if you are looking for a table of contents
rather than a normal table, the reference page of the [`outline`
function]($outline) is the right place to learn more.
## How to create a basic table? { #basic-tables }
In order to create a table in Typst, use the [`table` function]($table). For a
basic table, you need to tell the table function two things:
- The number of columns
- The content for each of the table cells
So, let's say you want to create a table with two columns describing the
ingredients for a cookie recipe:
```example
#table(
columns: 2,
[*Amount*], [*Ingredient*],
[360g], [Baking flour],
[250g], [Butter (room temp.)],
[150g], [Brown sugar],
[100g], [Cane sugar],
[100g], [70% cocoa chocolate],
[100g], [35-40% cocoa chocolate],
[2], [Eggs],
[Pinch], [Salt],
[Drizzle], [Vanilla extract],
)
```
This example shows how to call, configure, and populate a table. Both the column
count and cell contents are passed to the table as arguments. The [argument
list]($function) is surrounded by round parentheses. In it, we first pass the
column count as a named argument. Then, we pass multiple [content
blocks]($content) as positional arguments. Each content block contains the
contents for a single cell.
To make the example more legible, we have placed two content block arguments on
each line, mimicking how they would appear in the table. You could also write
each cell on its own line. Typst does not care on which line you place the
arguments. Instead, Typst will place the content cells from left to right (or
right to left, if that is the writing direction of your language) and then from
top to bottom. It will automatically add enough rows to your table so that it
fits all of your content.
It is best to wrap the header row of your table in the [`table.header`
function]($table.header). This clarifies your intent and will also allow future
versions of Typst to make the output more accessible to users with a screen
reader:
```example
#table(
columns: 2,
table.header[*Amount*][*Ingredient*],
[360g], [Baking flour],
<<< // ... the remaining cells
>>> [250g], [Butter (room temp.)],
>>> [150g], [Brown sugar],
>>> [100g], [Cane sugar],
>>> [100g], [70% cocoa chocolate],
>>> [100g], [35-40% cocoa chocolate],
>>> [2], [Eggs],
>>> [Pinch], [Salt],
>>> [Drizzle], [Vanilla extract],
)
```
You could also write a show rule that automatically [strongly
emphasizes]($strong) the contents of the first cells for all tables. This
quickly becomes useful if your document contains multiple tables!
```example
#show table.cell.where(y: 0): strong
#table(
columns: 2,
table.header[Amount][Ingredient],
[360g], [Baking flour],
<<< // ... the remaining cells
>>> [250g], [Butter (room temp.)],
>>> [150g], [Brown sugar],
>>> [100g], [Cane sugar],
>>> [100g], [70% cocoa chocolate],
>>> [100g], [35-40% cocoa chocolate],
>>> [2], [Eggs],
>>> [Pinch], [Salt],
>>> [Drizzle], [Vanilla extract],
)
```
We are using a show rule with a selector for cell coordinates here instead of
applying our styles directly to `table.header`. This is due to a current
limitation of Typst that will be fixed in a future release.
Congratulations, you have created your first table! Now you can proceed to
[change column sizes](#column-sizes), [adjust the strokes](#strokes), [add
striped rows](#fills), and more!
## How to change the column sizes? { #column-sizes }
If you create a table and specify the number of columns, Typst will make each
column large enough to fit its largest cell. Often, you want something
different, for example, to make a table span the whole width of the page. You
can provide a list, specifying how wide you want each column to be, through the
`columns` argument. There are a few different ways to specify column widths:
- First, there is `{auto}`. This is the default behavior and tells Typst to grow
the column to fit its contents. If there is not enough space, Typst will try
its best to distribute the space among the `{auto}`-sized columns.
- [Lengths]($length) like `{6cm}`, `{0.7in}`, or `{120pt}`. As usual, you can
also use the font-dependent `em` unit. This is a multiple of your current font
size. It's useful if you want to size your table so that it always fits
about the same amount of text, independent of font size.
- A [ratio in percent]($ratio) such as `{40%}`. This will make the column take
up 40% of the total horizontal space available to the table, so either the
inner width of the page or the table's container. You can also mix ratios and
lengths into [relative lengths]($relative). Be mindful that even if you
specify a list of column widths that sum up to 100%, your table could still
become larger than its container. This is because there can be
[gutter]($table.gutter) between columns that is not included in the column
widths. If you want to make a table fill the page, the next option is often
very useful.
- A [fractional part of the free space]($fraction) using the `fr` unit, such as
`1fr`. This unit allows you to distribute the available space to columns. It
works as follows: First, Typst sums up the lengths of all columns that do not
use `fr`s. Then, it determines how much horizontal space is left. This
horizontal space then gets distributed to all columns denominated in `fr`s.
During this process, a `2fr` column will become twice as wide as a `1fr`
column. This is where the name comes from: The width of the column is its
fraction of the total fractionally sized columns.
Let's put this to use with a table that contains the dates, numbers, and
descriptions of some routine checks. The first two columns are `auto`-sized and
the last column is `1fr` wide as to fill the whole page.
```example
#table(
columns: (auto, auto, 1fr),
table.header[Date][°No][Description],
[24/01/03], [813], [Filtered participant pool],
[24/01/03], [477], [Transitioned to sec. regimen],
[24/01/11], [051], [Cycled treatment substrate],
)
```
Here, we have passed our list of column lengths as an [array], enclosed in round
parentheses, with its elements separated by commas. The first two columns are
automatically sized, so that they take on the size of their content and the
third column is sized as `{1fr}` so that it fills up the remainder of the space
on the page. If you wanted to instead change the second column to be a bit more
spacious, you could replace its entry in the `columns` array with a value like
`{6em}`.
## How to caption and reference my table? { #captions-and-references }
A table is just as valuable as the information your readers draw from it. You
can enhance the effectiveness of both your prose and your table by making a
clear connection between the two with a cross-reference. Typst can help you with
automatic [references]($ref) and the [`figure` function]($figure).
Just like with images, wrapping a table in the `figure` function allows you to
add a caption and a label, so you can reference the figure elsewhere. Wrapping
your table in a figure also lets you use the figure's `placement` parameter to
float it to the top or bottom of a page.
Let's take a look at a captioned table and how to reference it in prose:
```example
>>> #set page(width: 14cm)
#show table.cell.where(y: 0): set text(weight: "bold")
#figure(
table(
columns: 4,
stroke: none,
table.header[Test Item][Specification][Test Result][Compliance],
[Voltage], [220V ± 5%], [218V], [Pass],
[Current], [5A ± 0.5A], [4.2A], [Fail],
),
caption: [Probe results for design A],
) <probe-a>
The results from @probe-a show that the design is not yet optimal.
We will show how its performance can be improved in this section.
```
The example shows how to wrap a table in a figure, set a caption and a label,
and how to reference that label. We start by using the `figure` function. It
expects the contents of the figure as a positional argument. We just put the
table function call in its argument list, omitting the `#` character because it
is only needed when calling a function in markup mode. We also add the caption
as a named argument (above or below) the table.
After the figure call, we put a label in angle brackets (`[<probe-a>]`). This
tells Typst to remember this element and make it referenceable under this name
throughout your document. We can then reference it in prose by using the at sign
and the label name `[@probe-a]`. Typst will print a nicely formatted reference
and automatically update the label if the table's number changes.
## How to get a striped table? { #fills }
Many tables use striped rows or columns instead of strokes to differentiate
between rows and columns. This effect is often called _zebra stripes._ Tables
with zebra stripes are popular in Business and commercial Data Analytics
applications, while academic applications tend to use strokes instead.
To add zebra stripes to a table, we use the `table` function's `fill` argument.
It can take three kinds of arguments:
- A single color (this can also be a gradient or a pattern) to fill all cells
with. Because we want some cells to have another color, this is not useful if
we want to build zebra tables.
- An array with colors which Typst cycles through for each column. We can use an
array with two elements to get striped columns.
- A function that takes the horizontal coordinate `x` and the vertical
coordinate `y` of a cell and returns its fill. We can use this to create
horizontal stripes or [checkerboard patterns]($grid.cell).
Let's start with an example of a horizontally striped table:
```example
>>> #set page(width: 16cm)
#set text(font: "IBM Plex Sans")
// Medium bold table header.
#show table.cell.where(y: 0): set text(weight: "medium")
// Bold titles.
#show table.cell.where(x: 1): set text(weight: "bold")
// See the strokes section for details on this!
#let frame(stroke) = (x, y) => (
left: if x > 0 { 0pt } else { stroke },
right: stroke,
top: if y < 2 { stroke } else { 0pt },
bottom: stroke,
)
#set table(
fill: (rgb("EAF2F5"), none),
stroke: frame(rgb("21222C")),
)
#table(
columns: (0.4fr, 1fr, 1fr, 1fr),
table.header[Month][Title][Author][Genre],
[January], [The Great Gatsby], [<NAME>], [Classic],
[February], [To Kill a Mockingbird], [<NAME>], [Drama],
[March], [1984], [George Orwell], [Dystopian],
[April], [The Catcher in the Rye], [<NAME>], [Coming-of-Age],
)
```
This example shows a book club reading list. The line `{fill: (rgb("EAF2F5"),
none)}` in `table`'s set rule is all that is needed to add striped columns. It
tells Typst to alternate between coloring columns with a light blue (in the
[`rgb`]($color.rgb) function call) and nothing (`{none}`). Note that we
extracted all of our styling from the `table` function call itself into set and
show rules, so that we can automatically reuse it for multiple tables.
Because setting the stripes itself is easy we also added some other styles to
make it look nice. The other code in the example provides a dark blue
[stroke](#stroke-functions) around the table and below the first line and
emboldens the first row and the column with the book title. See the
[strokes](#strokes) section for details on how we achieved this stroke
configuration.
Let's next take a look at how we can change only the set rule to achieve
horizontal stripes instead:
```example
>>> #set page(width: 16cm)
>>> #set text(font: "IBM Plex Sans")
>>> #show table.cell.where(x: 1): set text(weight: "medium")
>>> #show table.cell.where(y: 0): set text(weight: "bold")
>>>
>>> #let frame(stroke) = (x, y) => (
>>> left: if x > 0 { 0pt } else { stroke },
>>> right: stroke,
>>> top: if y < 2 { stroke } else { 0pt },
>>> bottom: stroke,
>>> )
>>>
#set table(
fill: (_, y) => if calc.odd(y) { rgb("EAF2F5") },
stroke: frame(rgb("21222C")),
)
>>>
>>> #table(
>>> columns: (0.4fr, 1fr, 1fr, 1fr),
>>>
>>> table.header[Month][Title][Author][Genre],
>>> [January], [The Great Gatsby],
>>> [<NAME>], [Classic],
>>> [February], [To Kill a Mockingbird],
>>> [<NAME>], [Drama],
>>> [March], [1984],
>>> [<NAME>], [Dystopian],
>>> [April], [The Catcher in the Rye],
>>> [<NAME>], [Coming-of-Age],
>>> )
```
We just need to replace the set rule from the previous example with this one and
get horizontal stripes instead. Here, we are passing a function to `fill`. It
discards the horizontal coordinate with an underscore and then checks if the
vertical coordinate `y` of the cell is odd. If so, the cell gets a light blue
fill, otherwise, no fill is returned.
Of course, you can make this function arbitrarily complex. For example, if you
want to stripe the rows with a light and darker shade of blue, you could do
something like this:
```example
>>> #set page(width: 16cm)
>>> #set text(font: "IBM Plex Sans")
>>> #show table.cell.where(x: 1): set text(weight: "medium")
>>> #show table.cell.where(y: 0): set text(weight: "bold")
>>>
>>> #let frame(stroke) = (x, y) => (
>>> left: if x > 0 { 0pt } else { stroke },
>>> right: stroke,
>>> top: if y < 2 { stroke } else { 0pt },
>>> bottom: stroke,
>>> )
>>>
#set table(
fill: (_, y) => (none, rgb("EAF2F5"), rgb("DDEAEF")).at(calc.rem(y, 3)),
stroke: frame(rgb("21222C")),
)
>>>
>>> #table(
>>> columns: (0.4fr, 1fr, 1fr, 1fr),
>>>
>>> table.header[Month][Title][Author][Genre],
>>> [January], [The Great Gatsby],
>>> [<NAME>], [Classic],
>>> [February], [To Kill a Mockingbird],
>>> [<NAME>], [Drama],
>>> [March], [1984],
>>> [<NAME>], [Dystopian],
>>> [April], [The Catcher in the Rye],
>>> [<NAME>], [Coming-of-Age],
>>> )
```
This example shows an alternative approach to write our fill function. The
function uses an array with three colors and then cycles between its values for
each row by indexing the array with the remainder of `y` divided by 3.
Finally, here is a bonus example that uses the _stroke_ to achieve striped rows:
```example
>>> #set page(width: 16cm)
>>> #set text(font: "IBM Plex Sans")
>>> #show table.cell.where(x: 1): set text(weight: "medium")
>>> #show table.cell.where(y: 0): set text(weight: "bold")
>>>
>>> #let frame(stroke) = (x, y) => (
>>> left: if x > 0 { 0pt } else { stroke },
>>> right: stroke,
>>> top: if y < 2 { stroke } else { 0pt },
>>> bottom: stroke,
>>> )
>>>
#set table(
stroke: (x, y) => (
y: 1pt,
left: if x > 0 { 0pt } else if calc.even(y) { 1pt },
right: if calc.even(y) { 1pt },
),
)
>>>
>>> #table(
>>> columns: (0.4fr, 1fr, 1fr, 1fr),
>>>
>>> table.header[Month][Title][Author][Genre],
>>> [January], [The Great Gatsby],
>>> [<NAME>], [Classic],
>>> [February], [To Kill a Mockingbird],
>>> [<NAME>], [Drama],
>>> [March], [1984],
>>> [<NAME>], [Dystopian],
>>> [April], [The Catcher in the Rye],
>>> [<NAME>], [Coming-of-Age],
>>> )
```
### Manually overriding a cell's fill color { #fill-override }
Sometimes, the fill of a cell needs not to vary based on its position in the
table, but rather based on its contents. We can use the [`table.cell`
element]($table.cell) in the `table`'s parameter list to wrap a cell's content
and override its fill.
For example, here is a list of all German presidents, with the cell borders
colored in the color of their party.
```example
>>> #set page(width: 10cm)
#set text(font: "Roboto")
#let cdu(name) = ([CDU], table.cell(fill: black, text(fill: white, name)))
#let spd(name) = ([SPD], table.cell(fill: red, text(fill: white, name)))
#let fdp(name) = ([FDP], table.cell(fill: yellow, name))
#table(
columns: (auto, auto, 1fr),
stroke: (x: none),
table.header[Tenure][Party][President],
[1949-1959], ..fdp[<NAME>],
[1959-1969], ..cdu[<NAME>bke],
[1969-1974], ..spd[<NAME>],
[1974-1979], ..fdp[<NAME>],
[1979-1984], ..cdu[<NAME>],
[1984-1994], ..cdu[<NAME>],
[1994-1999], ..cdu[<NAME>],
[1999-2004], ..spd[<NAME>],
[2004-2010], ..cdu[<NAME>],
[2010-2012], ..cdu[<NAME>],
[2012-2017], [n/a], [<NAME>],
[2017-], ..spd[Frank-Walter-Steinmeier],
)
```
In this example, we make use of variables because there only have been a total
of three parties whose members have become president (and one unaffiliated
president). Their colors will repeat multiple times, so we store a function that
produces an array with their party's name and a table cell with that party's
color and the president's name (`cdu`, `spd`, and `fdp`). We then use these
functions in the `table` argument list instead of directly adding the name. We
use the [spread operator]($arguments/#spreading) `..` to turn the items of the
arrays into single cells. We could also write something like
`{[FDP], table.cell(fill: yellow)[Theodor Heuss]}` for each cell directly in the
`table`'s argument list, but that becomes unreadable, especially for the parties
whose colors are dark so that they require white text. We also delete vertical
strokes and set the font to Roboto.
The party column and the cell color in this example communicate redundant
information on purpose: Communicating important data using color only is a bad
accessibility practice. It disadvantages users with vision impairment and is in
violation of universal access standards, such as the
[WCAG 2.1 Success Criterion 1.4.1](https://www.w3.org/WAI/WCAG21/Understanding/use-of-color.html).
To improve this table, we added a column printing the party name. Alternatively,
you could have made sure to choose a color-blindness friendly palette and mark
up your cells with an additional label that screen readers can read out loud.
The latter feature is not currently supported by Typst, but will be added in a
future release. You can check how colors look for color-blind readers with
[this Chrome extension](https://chromewebstore.google.com/detail/colorblindly/floniaahmccleoclneebhhmnjgdfijgg),
[Photoshop](https://helpx.adobe.com/photoshop/using/proofing-colors.html), or
[GIMP](https://docs.gimp.org/2.10/en/gimp-display-filter-dialog.html).
## How to adjust the lines in a table? { #strokes }
By default, Typst adds strokes between each row and column of a table. You can
adjust these strokes in a variety of ways. Which one is the most practical,
depends on the modification you want to make and your intent:
- Do you want to style all tables in your document, irrespective of their size
and content? Use the `table` function's [stroke]($table.stroke) argument in a
set rule.
- Do you want to customize all lines in a single table? Use the `table`
function's [stroke]($table.stroke) argument when calling the table function.
- Do you want to change, add, or remove the stroke around a single cell? Use the
`table.cell` element in the argument list of your table call.
- Do you want to change, add, or remove a single horizontal or vertical stroke
in a single table? Use the [`table.hline`] and [`table.vline`] elements in the
argument list of your table call.
We will go over all of these options with examples next! First, we will tackle
the `table` function's [stroke]($table.stroke) argument. Here, you can adjust
both how the table's lines get drawn and configure which lines are drawn at all.
Let's start by modifying the color and thickness of the stroke:
```example
#table(
columns: 4,
stroke: 0.5pt + rgb("666675"),
[*Monday*], [11.5], [13.0], [4.0],
[*Tuesday*], [8.0], [14.5], [5.0],
[*Wednesday*], [9.0], [18.5], [13.0],
)
```
This makes the table lines a bit less wide and uses a bluish gray. You can see
that we added a width in point to a color to achieve our customized stroke. This
addition yields a value of the [stroke type]($stroke). Alternatively, you can
use the dictionary representation for strokes which allows you to access
advanced features such as dashed lines.
The previous example showed how to use the stroke argument in the table
function's invocation. Alternatively, you can specify the stroke argument in the
`table`'s set rule. This will have exactly the same effect on all subsequent
`table` calls as if the stroke argument was specified in the argument list. This
is useful if you are writing a template or want to style your whole document.
```typ
// Renders the exact same as the last example
#set table(stroke: 0.5pt + rgb("666675"))
#table(
columns: 4,
[*Monday*], [11.5], [13.0], [4.0],
[*Tuesday*], [8.0], [14.5], [5.0],
[*Wednesday*], [9.0], [18.5], [13.0],
)
```
For small tables, you sometimes want to suppress all strokes because they add
too much visual noise. To do this, just set the stroke argument to `{none}`:
```example
#table(
columns: 4,
stroke: none,
[*Monday*], [11.5], [13.0], [4.0],
[*Tuesday*], [8.0], [14.5], [5.0],
[*Wednesday*], [9.0], [18.5], [13.0],
)
```
If you want more fine-grained control of where lines get placed in your table,
you can also pass a dictionary with the keys `top`, `left`, `right`, `bottom`
(controlling the respective cell sides), `x`, `y` (controlling vertical and
horizontal strokes), and `rest` (covers all strokes not styled by other
dictionary entries). All keys are optional; omitted keys will be treated as if
their value was the default value. For example, to get a table with only
horizontal lines, you can do this:
```example
#table(
columns: 2,
stroke: (x: none),
align: horizon,
[☒], [Close cabin door],
[☐], [Start engines],
[☐], [Radio tower],
[☐], [Push back],
)
```
This turns off all vertical strokes and leaves the horizontal strokes in place.
To achieve the reverse effect (only horizontal strokes), set the stroke argument
to `{(y: none)}` instead.
[Further down in the guide](#stroke-functions), we cover how to use a function
in the stroke argument to customize all strokes individually. This is how you
achieve more complex stroking patterns.
### Adding individual lines in the table { #individual-lines }
If you want to add a single horizontal or vertical line in your table, for
example to separate a group of rows, you can use the [`table.hline`] and
[`table.vline`] elements for horizontal and vertical lines, respectively. Add
them to the argument list of the `table` function just like you would add
individual cells and a header.
Let's take a look at the following example from the reference:
```example
#set table.hline(stroke: 0.6pt)
#table(
stroke: none,
columns: (auto, 1fr),
// Morning schedule abridged.
[14:00], [Talk: Tracked Layout],
[15:00], [Talk: Automations],
[16:00], [Workshop: Tables],
table.hline(),
[19:00], [Day 1 Attendee Mixer],
)
```
In this example, you can see that we have placed a call to `table.hline` between
the cells, producing a horizontal line at that spot. We also used a set rule on
the element to reduce its stroke width to make it fit better with the weight of
the font.
By default, Typst places horizontal and vertical lines after the current row or
column, depending on their position in the argument list. You can also manually
move them to a different position by adding the `y` (for `hline`) or `x` (for
`vline`) argument. For example, the code below would produce the same result:
```typ
#set table.hline(stroke: 0.6pt)
#table(
stroke: none,
columns: (auto, 1fr),
// Morning schedule abridged.
table.hline(y: 3),
[14:00], [Talk: Tracked Layout],
[15:00], [Talk: Automations],
[16:00], [Workshop: Tables],
[19:00], [Day 1 Attendee Mixer],
)
```
Let's imagine you are working with a template that shows none of the table
strokes except for one between the first and second row. Now, since you have one
table that also has labels in the first column, you want to add an extra
vertical line to it. However, you do not want this vertical line to cross into
the top row. You can achieve this with the `start` argument:
```example
>>> #set page(width: 12cm)
>>> #show table.cell.where(y: 0): strong
>>> #set table(stroke: (_, y) => if y == 0 { (bottom: 1pt) })
// Base template already configured tables, but we need some
// extra configuration for this table.
#{
set table(align: (x, _) => if x == 0 { left } else { right })
show table.cell.where(x: 0): smallcaps
table(
columns: (auto, 1fr, 1fr, 1fr),
table.vline(x: 1, start: 1),
table.header[Trainset][Top Speed][Length][Weight],
[TGV Réseau], [320 km/h], [200m], [383t],
[ICE 403], [330 km/h], [201m], [409t],
[Shinkansen N700], [300 km/h], [405m], [700t],
)
}
```
In this example, we have added `table.vline` at the start of our positional
argument list. But because the line is not supposed to go to the left of the
first column, we specified the `x` argument as `{1}`. We also set the `start`
argument to `{1}` so that the line does only start after the first row.
The example also contains two more things: We use the align argument with a
function to right-align the data in all but the first column and use a show rule
to make the first column of table cells appear in small capitals. Because these
styles are specific to this one table, we put everything into a [code
block]($scripting/#blocks), so that the styling does not affect any further
tables.
### Overriding the strokes of a single cell { #stroke-override }
Imagine you want to change the stroke around a single cell. Maybe your cell is
very important and needs highlighting! For this scenario, there is the
[`table.cell` function]($table.cell). Instead of adding your content directly in
the argument list of the table, you wrap it in a `table.cell` call. Now, you can
use `table.cell`'s argument list to override the table properties, such as the
stroke, for this cell only.
Here's an example with a matrix of two of the Big Five personality factors, with
one intersection highlighted.
```example
>>> #set page(width: 16cm)
#table(
columns: 3,
stroke: (x: none),
[], [*High Neuroticism*], [*Low Neuroticism*],
[*High Agreeableness*],
table.cell(stroke: orange + 2pt)[
_Sensitive_ \ Prone to emotional distress but very empathetic.
],
[_Compassionate_ \ Caring and stable, often seen as a supportive figure.],
[*Low Agreeableness*],
[_Contentious_ \ Competitive and easily agitated.],
[_Detached_ \ Independent and calm, may appear aloof.],
)
```
Above, you can see that we used the `table.cell` element in the table's argument
list and passed the cell content to it. We have used its `stroke` argument to
set a wider orange stroke. Despite the fact that we disabled vertical strokes on
the table, the orange stroke appeared on all sides of the modified cell, showing
that the table's stroke configuration is overwritten.
### Complex document-wide stroke customization { #stroke-functions }
This section explains how to customize all lines at once in one or multiple
tables. This allows you to draw only the first horizontal line or omit the outer
lines, without knowing how many cells the table has. This is achieved by
providing a function to the table's `stroke` parameter. The function should
return a stroke given the zero-indexed x and y position of the current cell. You
should only need these functions if you are a template author, do not use a
template, or need to heavily customize your tables. Otherwise, your template
should set appropriate default table strokes.
For example, this is a set rule that draws all horizontal lines except for the
very first and last line.
```example
#show table.cell.where(x: 0): set text(style: "italic")
#show table.cell.where(y: 0): set text(style: "normal", weight: "bold")
#set table(stroke: (_, y) => if y > 0 { (top: 0.8pt) })
#table(
columns: 3,
align: center + horizon,
table.header[Technique][Advantage][Drawback],
[Diegetic], [Immersive], [May be contrived],
[Extradiegetic], [Breaks immersion], [Obtrusive],
[Omitted], [Fosters engagement], [May fracture audience],
)
```
In the set rule, we pass a function that receives two arguments, assigning the
vertical coordinate to `y` and discarding the horizontal coordinate. It then
returns a stroke dictionary with a `{0.8pt}` top stroke for all but the first
line. The cells in the first line instead implicitly receive `{none}` as the
return value. You can easily modify this function to just draw the inner
vertical lines instead as `{(x, _) => if x > 0 { (left: 0.8pt) }}`.
Let's try a few more stroking functions. The next function will only draw a line
below the first row:
```example
>>> #show table.cell: it => if it.x == 0 and it.y > 0 {
>>> set text(style: "italic")
>>> it
>>> } else {
>>> it
>>> }
>>>
>>> #show table.cell.where(y: 0): strong
#set table(stroke: (_, y) => if y == 0 { (bottom: 1pt) })
<<< // Table as seen above
>>> #table(
>>> columns: 3,
>>> align: center + horizon,
>>> table.header[Technique][Advantage][Drawback],
>>> [Diegetic], [Immersive], [May be contrived],
>>> [Extradiegetic], [Breaks immersion], [Obtrusive],
>>> [Omitted], [Fosters engagement], [May fracture audience],
>>> )
```
If you understood the first example, it becomes obvious what happens here. We
check if we are in the first row. If so, we return a bottom stroke. Otherwise,
we'll return `{none}` implicitly.
The next example shows how to draw all but the outer lines:
```example
>>> #show table.cell: it => if it.x == 0 and it.y > 0 {
>>> set text(style: "italic")
>>> it
>>> } else {
>>> it
>>> }
>>>
>>> #show table.cell.where(y: 0): strong
#set table(stroke: (x, y) => (
left: if x > 0 { 0.8pt },
top: if y > 0 { 0.8pt },
))
<<< // Table as seen above
>>> #table(
>>> columns: 3,
>>> align: center + horizon,
>>> table.header[Technique][Advantage][Drawback],
>>> [Diegetic], [Immersive], [May be contrived],
>>> [Extradiegetic], [Breaks immersion], [Obtrusive],
>>> [Omitted], [Fosters engagement], [May fracture audience],
>>> )
```
This example uses both the `x` and `y` coordinates. It omits the left stroke in
the first column and the top stroke in the first row. The right and bottom lines
are not drawn.
Finally, here is a table that draws all lines except for the vertical lines in
the first row and horizontal lines in the table body. It looks a bit like a
calendar.
```example
>>> #show table.cell: it => if it.x == 0 and it.y > 0 {
>>> set text(style: "italic")
>>> it
>>> } else {
>>> it
>>> }
>>>
>>> #show table.cell.where(y: 0): strong
#set table(stroke: (x, y) => (
left: if x == 0 or y > 0 { 1pt } else { 0pt },
right: 1pt,
top: if y <= 1 { 1pt } else { 0pt },
bottom: 1pt,
))
<<< // Table as seen above
>>> #table(
>>> columns: 3,
>>> align: center + horizon,
>>> table.header[Technique][Advantage][Drawback],
>>> [Diegetic], [Immersive], [May be contrived],
>>> [Extradiegetic], [Breaks immersion], [Obtrusive],
>>> [Omitted], [Fosters engagement], [May fracture audience],
>>> )
```
This example is a bit more complex. We start by drawing all the strokes on the
right of the cells. But this means that we have drawn strokes in the top row,
too, and we don't need those! We use the fact that `left` will override `right`
and only draw the left line if we are not in the first row or if we are in the
first column. In all other cases, we explicitly remove the left line. Finally,
we draw the horizontal lines by first setting the bottom line and then for the
first two rows with the `top` key, suppressing all other top lines. The last
line appears because there is no `top` line that could suppress it.
### How to achieve a double line? { #double-stroke }
Typst does not yet have a native way to draw double strokes, but there are
multiple ways to emulate them, for example with [patterns]($pattern). We will
show a different workaround in this section: Table gutters.
Tables can space their cells apart using the `gutter` argument. When a gutter is
applied, a stroke is drawn on each of the now separated cells. We can
selectively add gutter between the rows or columns for which we want to draw a
double line. The `row-gutter` and `column-gutter` arguments allow us to do this.
They accept arrays of gutter values. Let's take a look at an example:
```example
#table(
columns: 3,
stroke: (x: none),
row-gutter: (2.2pt, auto),
table.header[Date][Exercise Type][Calories Burned],
[2023-03-15], [Swimming], [400],
[2023-03-17], [Weightlifting], [250],
[2023-03-18], [Yoga], [200],
)
```
We can see that we used an array for `row-gutter` that specifies a `{2.2pt}` gap
between the first and second row. It then continues with `auto` (which is the
default, in this case `{0pt}` gutter) which will be the gutter between all other
rows, since it is the last entry in the array.
## How to align the contents of the cells in my table? { #alignment }
You can use multiple mechanisms to align the content in your table. You can
either use the `table` function's `align` argument to set the alignment for your
whole table (or use it in a set rule to set the alignment for tables throughout
your document) or the [`align`] function (or `table.cell`'s `align` argument) to
override the alignment of a single cell.
When using the `table` function's align argument, you can choose between three
methods to specify an [alignment]:
- Just specify a single alignment like `right` (aligns in the top-right corner)
or `center + horizon` (centers all cell content). This changes the alignment
of all cells.
- Provide an array. Typst will cycle through this array for each column.
- Provide a function that is passed the horizontal `x` and vertical `y`
coordinate of a cell and returns an alignment.
For example, this travel itinerary right-aligns the day column and left-aligns
everything else by providing an array in the `align` argument:
```example
>>> #set page(width: 12cm)
#set text(font: "IBM Plex Sans")
#show table.cell.where(y: 0): set text(weight: "bold")
#table(
columns: 4,
align: (right, left, left, left),
fill: (_, y) => if calc.odd(y) { green.lighten(90%) },
stroke: none,
table.header[Day][Location][Hotel or Apartment][Activities],
[1], [Paris, France], [Hotel de L'Europe], [Arrival, Evening River Cruise],
[2], [Paris, France], [Hotel de L'Europe], [Louvre Museum, Eiffel Tower],
[3], [Lyon, France], [Lyon City Hotel], [City Tour, Local Cuisine Tasting],
[4], [Geneva, Switzerland], [Lakeview Inn], [Lake Geneva, Red Cross Museum],
[5], [Zermatt, Switzerland], [Alpine Lodge], [Visit Matterhorn, Skiing],
)
```
However, this example does not yet look perfect — the header cells should be
bottom-aligned. Let's use a function instead to do so:
```example
>>> #set page(width: 12cm)
#set text(font: "IBM Plex Sans")
#show table.cell.where(y: 0): set text(weight: "bold")
#table(
columns: 4,
align: (x, y) =>
if x == 0 { right } else { left } +
if y == 0 { bottom } else { top },
fill: (_, y) => if calc.odd(y) { green.lighten(90%) },
stroke: none,
table.header[Day][Location][Hotel or Apartment][Activities],
[1], [Paris, France], [Hotel de L'Europe], [Arrival, Evening River Cruise],
[2], [Paris, France], [Hotel de L'Europe], [Louvre Museum, Eiffel Tower],
<<< // ... remaining days omitted
>>> [3], [Lyon, France], [Lyon City Hotel], [City Tour, Local Cuisine Tasting],
>>> [4], [Geneva, Switzerland], [Lakeview Inn], [Lake Geneva, Red Cross Museum],
>>> [5], [Zermatt, Switzerland], [Alpine Lodge], [Visit Matterhorn, Skiing],
)
```
In the function, we calculate a horizontal and vertical alignment based on
whether we are in the first column (`{x == 0}`) or the first row (`{y == 0}`).
We then make use of the fact that we can add horizontal and vertical alignments
with `+` to receive a single, two-dimensional alignment.
You can find an example of using `table.cell` to change a single cell's
alignment on [its reference page]($table.cell).
## How to merge cells? { #merge-cells }
When a table contains logical groupings or the same data in multiple adjacent
cells, merging multiple cells into a single, larger cell can be advantageous.
Another use case for cell groups are table headers with multiple rows: That way,
you can group for example a sales data table by quarter in the first row and by
months in the second row.
A merged cell spans multiple rows and/or columns. You can achieve it with the
[`table.cell`] function's `rowspan` and `colspan` arguments: Just specify how
many rows or columns you want your cell to span.
The example below contains an attendance calendar for an office with in-person
and remote days for each team member. To make the table more glanceable, we
merge adjacent cells with the same value:
```example
>>> #set page(width: 22cm)
#let ofi = [Office]
#let rem = [_Remote_]
#let lea = [*On leave*]
#show table.cell.where(y: 0): set text(
fill: white,
weight: "bold",
)
#table(
columns: 6 * (1fr,),
align: (x, y) => if x == 0 or y == 0 { left } else { center },
stroke: (x, y) => (
// Separate black cells with white strokes.
left: if y == 0 and x > 0 { white } else { black },
rest: black,
),
fill: (_, y) => if y == 0 { black },
table.header(
[Team member],
[Monday],
[Tuesday],
[Wednesday],
[Thursday],
[Friday]
),
[<NAME>],
table.cell(colspan: 2, ofi),
table.cell(colspan: 2, rem),
ofi,
[<NAME>],
table.cell(colspan: 5, lea),
[<NAME>],
rem,
table.cell(colspan: 2, ofi),
rem,
ofi,
)
```
In the example, we first define variables with "Office", "Remote", and "On
leave" so we don't have to write these labels out every time. We can then use
these variables in the table body either directly or in a `table.cell` call if
the team member spends multiple consecutive days in office, remote, or on leave.
The example also contains a black header (created with `table`'s `fill`
argument) with white strokes (`table`'s `stroke` argument) and white text (set
by the `table.cell` set rule). Finally, we align all the content of all table
cells in the body in the center. If you want to know more about the functions
passed to `align`, `stroke`, and `fill`, you can check out the sections on
[alignment], [strokes](#stroke-functions), and [striped
tables](#fills).
This table would be a great candidate for fully automated generation from an
external data source! Check out the [section about importing
data](#importing-data) to learn more about that.
## How to rotate a table? { #rotate-table }
When tables have many columns, a portrait paper orientation can quickly get
cramped. Hence, you'll sometimes want to switch your tables to landscape
orientation. There are two ways to accomplish this in Typst:
- If you want to rotate only the table but not the other content of the page and
the page itself, use the [`rotate` function]($rotate) with the `reflow`
argument set to `{true}`.
- If you want to rotate the whole page the table is on, you can use the [`page`
function]($page) with its `flipped` argument set to `{true}`. The header,
footer, and page number will now also appear on the long edge of the page.
This has the advantage that the table will appear right side up when read on a
computer, but it also means that a page in your document has different
dimensions than all the others, which can be jarring to your readers.
Below, we will demonstrate both techniques with a student grade book table.
First, we will rotate the table on the page. The example also places some text
on the right of the table.
```example
#set page("a5", columns: 2, numbering: "— 1 —")
>>> #set page(margin: auto)
#show table.cell.where(y: 0): set text(weight: "bold")
#rotate(
-90deg,
reflow: true,
table(
columns: (1fr,) + 5 * (auto,),
inset: (x: 0.6em,),
stroke: (_, y) => (
x: 1pt,
top: if y <= 1 { 1pt } else { 0pt },
bottom: 1pt,
),
align: (left, right, right, right, right, left),
table.header(
[Student Name],
[Assignment 1], [Assignment 2],
[Mid-term], [Final Exam],
[Total Grade],
),
[<NAME>], [78%], [82%], [75%], [80%], [B],
[<NAME>], [90%], [95%], [94%], [96%], [A+],
[<NAME>], [85%], [90%], [88%], [92%], [A],
[<NAME>], [88%], [84%], [89%], [85%], [B+],
[<NAME>], [93%], [89%], [90%], [91%], [A-],
[<NAME>], [96%], [91%], [74%], [69%], [B-],
),
)
#lorem(80)
```
What we have here is a two-column document on ISO A5 paper with page numbers on
the bottom. The table has six columns and contains a few customizations to
[stroke](#strokes), alignment and spacing. But the most important part is that
the table is wrapped in a call to the `rotate` function with the `reflow`
argument being `{true}`. This will make the table rotate 90 degrees
counterclockwise. The reflow argument is needed so that the table's rotation
affects the layout. If it was omitted, Typst would lay out the page as if the
table was not rotated (`{true}` might become the default in the future).
The example also shows how to produce many columns of the same size: To the
initial `{1fr}` column, we add an array with five `{auto}` items that we
create by multiplying an array with one `{auto}` item by five. Note that arrays
with just one item need a trailing comma to distinguish them from merely
parenthesized expressions.
The second example shows how to rotate the whole page, so that the table stays
upright:
```example
#set page("a5", numbering: "— 1 —")
>>> #set page(margin: auto)
#show table.cell.where(y: 0): set text(weight: "bold")
#page(flipped: true)[
#table(
columns: (1fr,) + 5 * (auto,),
inset: (x: 0.6em,),
stroke: (_, y) => (
x: 1pt,
top: if y <= 1 { 1pt } else { 0pt },
bottom: 1pt,
),
align: (left, right, right, right, right, left),
table.header(
[Student Name],
[Assignment 1], [Assignment 2],
[Mid-term], [Final Exam],
[Total Grade],
),
[<NAME>], [78%], [82%], [75%], [80%], [B],
[<NAME>], [90%], [95%], [94%], [96%], [A+],
[<NAME>], [85%], [90%], [88%], [92%], [A],
[<NAME>], [88%], [84%], [89%], [85%], [B+],
[<NAME>], [93%], [89%], [90%], [91%], [A-],
[<NAME>], [96%], [91%], [74%], [69%], [B-],
)
#pad(x: 15%, top: 1.5em)[
= Winter 2023/24 results
#lorem(80)
]
]
```
Here, we take the same table and the other content we want to set with it and
put it into a call to the [`page`] function while supplying `{true}` to the
`flipped` argument. This will instruct Typst to create new pages with width and
height swapped and place the contents of the function call onto a new page.
Notice how the page number is also on the long edge of the paper now. At the
bottom of the page, we use the [`pad`] function to constrain the width of the
paragraph to achieve a nice and legible line length.
## How to break a table across pages? { #table-across-pages }
It is best to contain a table on a single page. However, some tables just have
many rows, so breaking them across pages becomes unavoidable. Fortunately, Typst
supports breaking tables across pages out of the box. If you are using the
[`table.header`] and [`table.footer`] functions, their contents will be repeated
on each page as the first and last rows, respectively. If you want to disable
this behavior, you can set `repeat` to `{false}` on either of them.
If you have placed your table inside of a [figure], it becomes unable to break
across pages by default. However, you can change this behavior. Let's take a
look:
```example
#set page(width: 9cm, height: 6cm)
#show table.cell.where(y: 0): set text(weight: "bold")
#show figure: set block(breakable: true)
#figure(
caption: [Training regimen for Marathon],
table(
columns: 3,
fill: (_, y) => if y == 0 { gray.lighten(75%) },
table.header[Week][Distance (km)][Time (hh:mm:ss)],
[1], [5], [00:30:00],
[2], [7], [00:45:00],
[3], [10], [01:00:00],
[4], [12], [01:10:00],
[5], [15], [01:25:00],
[6], [18], [01:40:00],
[7], [20], [01:50:00],
[8], [22], [02:00:00],
[...], [...], [...],
table.footer[_Goal_][_42.195_][_02:45:00_],
)
)
```
A figure automatically produces a [block] which cannot break by default.
However, we can reconfigure the block of the figure using a show rule to make it
`breakable`. Now, the figure spans multiple pages with the headers and footers
repeating.
## How to import data into a table? { #importing-data }
Often, you need to put data that you obtained elsewhere into a table. Sometimes,
this is from Microsoft Excel or Google Sheets, sometimes it is from a dataset
on the web or from your experiment. Fortunately, Typst can load many [common
file formats]($category/data-loading), so you can use scripting to include their
data in a table.
The most common file format for tabular data is CSV. You can obtain a CSV file
from Excel by choosing "Save as" in the _File_ menu and choosing the file format
"CSV UTF-8 (Comma-delimited) (.csv)". Save the file and, if you are using the
web app, upload it to your project.
In our case, we will be building a table about Moore's Law. For this purpose, we
are using a statistic with [how many transistors the average microprocessor
consists of per year from Our World in
Data](https://ourworldindata.org/grapher/transistors-per-microprocessor). Let's
start by pressing the "Download" button to get a CSV file with the raw data.
Be sure to move the file to your project or somewhere Typst can see it, if you
are using the CLI. Once you did that, we can open the file to see how it is
structured:
```csv
Entity,Code,Year,Transistors per microprocessor
World,OWID_WRL,1971,2308.2417
World,OWID_WRL,1972,3554.5222
World,OWID_WRL,1974,6097.5625
```
The file starts with a header and contains four columns: Entity (which is to
whom the metric applies), Code, the year, and the number of transistors per
microprocessor. Only the last two columns change between each row, so we can
disregard "Entity" and "Code".
First, let's start by loading this file with the [`csv`] function. It accepts
the file name of the file we want to load as a string argument:
```typ
#let moore = csv("moore.csv")
```
We have loaded our file (assuming we named it `moore.csv`) and [bound
it]($scripting/#bindings) to the new variable `moore`. This will not produce any
output, so there's nothing to see yet. If we want to examine what Typst loaded,
we can either hover the name of the variable in the web app or print some items
from the array:
```example
#let moore = csv("moore.csv")
#moore.slice(0, 3)
```
With the arguments `{(0, 3)}`, the [`slice`]($array.slice) method returns the
first three items in the array (with the indices 0, 1, and 2). We can see that
each row is its own array with one item per cell.
Now, let's write a loop that will transform this data into an array of cells
that we can use with the table function.
```example
#let moore = csv("moore.csv")
#table(
columns: 2,
..for (.., year, count) in moore {
(year, count)
}
)
```
The example above uses a for loop that iterates over the rows in our CSV file
and returns an array for each iteration. We use the for loop's
[destructuring]($scripting/#bindings) capability to discard all but the last two
items of each row. We then create a new array with just these two. Because Typst
will concatenate the array results of all the loop iterations, we get a
one-dimensional array in which the year column and the number of transistors
alternate. We can then insert the array as cells. For this we use the [spread
operator]($arguments/#spreading) (`..`). By prefixing an array, or, in our case
an expression that yields an array, with two dots, we tell Typst that the
array's items should be used as positional arguments.
Alternatively, we can also use the [`map`]($array.map), [`slice`]($array.slice),
and [`flatten`]($array.flatten) array methods to write this in a more functional
style:
```typ
#let moore = csv("moore.csv")
#table(
columns: moore.first().len(),
..moore.map(m => m.slice(2)).flatten(),
)
```
This example renders the same as the previous one, but first uses the `map`
function to change each row of the data. We pass a function to map that gets run
on each row of the CSV and returns a new value to replace that row with. We use
it to discard the first two columns with `slice`. Then, we spread the data into
the `table` function. However, we need to pass a one-dimensional array and
`moore`'s value is two-dimensional (that means that each of its row values
contains an array with the cell data). That's why we call `flatten` which
converts it to a one-dimensional array. We also extract the number of columns
from the data itself.
Now that we have nice code for our table, we should try to also make the table
itself nice! The transistor counts go from millions in 1995 to trillions in 2021
and changes are difficult to see with so many digits. We could try to present
our data logarithmically to make it more digestible:
```example
#let moore = csv("moore.csv")
#let moore-log = moore.slice(1).map(m => {
let (.., year, count) = m
let log = calc.log(float(count))
let rounded = str(calc.round(log, digits: 2))
(year, rounded)
})
#show table.cell.where(x: 0): strong
#table(
columns: moore-log.first().len(),
align: right,
fill: (_, y) => if calc.odd(y) { rgb("D7D9E0") },
stroke: none,
table.header[Year][Transistor count ($log_10$)],
table.hline(stroke: rgb("4D4C5B")),
..moore-log.flatten(),
)
```
In this example, we first drop the header row from the data since we are adding
our own. Then, we discard all but the last two columns as above. We do this by
[destructuring]($scripting/#bindings) the array `m`, discarding all but the two
last items. We then convert the string in `count` to a floating point number,
calculate its logarithm and store it in the variable `log`. Finally, we round it
to two digits, convert it to a string, and store it in the variable `rounded`.
Then, we return an array with `year` and `rounded` that replaces the original
row. In our table, we have added our custom header that tells the reader that
we've applied a logarithm to the values. Then, we spread the flattened data as
above.
We also styled the table with [stripes](#fills), a
[horizontal line](#individual-lines) below the first row, [aligned](#alignment)
everything to the right, and emboldened the first column. Click on the links to
go to the relevant guide sections and see how it's done!
## What if I need the table function for something that isn't a table? { #table-and-grid }
Tabular layouts of content can be useful not only for matrices of closely
related data, like shown in the examples throughout this guide, but also for
presentational purposes. Typst differentiates between grids that are for layout
and presentational purposes only and tables, in which the arrangement of the
cells itself conveys information.
To make this difference clear to other software and allow templates to heavily
style tables, Typst has two functions for grid and table layout:
- The [`table`] function explained throughout this guide which is intended for
tabular data.
- The [`grid`] function which is intended for presentational purposes and page
layout.
Both elements work the same way and have the same arguments. You can apply
everything you have learned about tables in this guide to grids. There are only
three differences:
- You'll need to use the [`grid.cell`], [`grid.vline`], and [`grid.hline`]
elements instead of [`table.cell`], [`table.vline`], and [`table.hline`].
- The grid has different defaults: It draws no strokes by default and has no
spacing (`inset`) inside of its cells.
- Elements like `figure` do not react to grids since they are supposed to have
no semantical bearing on the document structure.
|
https://github.com/tingerrr/hydra | https://raw.githubusercontent.com/tingerrr/hydra/main/doc/manual.typ | typst | MIT License | #import "template.typ": project, raw-bg
#import "util.typ": package, bbox
#show: project.with(
package: package,
subtitle: [/ˈhaɪdrə/ \ Of headings and headers],
date: datetime.today(),
abstract: package.description,
)
#[
#show raw.where(block: false): bbox.with(fill: raw-bg)
= Introduction
#include "chapters/1-intro.typ"
= Features
#include "chapters/2-features.typ"
]
= Reference
#include "chapters/3-reference.typ"
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-16B00.typ | typst | Apache License 2.0 | #let data = (
("PAHAWH HMONG VOWEL KEEB", "Lo", 0),
("PAHAWH HMONG VOWEL KEEV", "Lo", 0),
("PAHAWH HMONG VOWEL KIB", "Lo", 0),
("PAHAWH HMONG VOWEL KIV", "Lo", 0),
("PAHAWH HMONG VOWEL KAUB", "Lo", 0),
("PAHAWH HMONG VOWEL KAUV", "Lo", 0),
("PAHAWH HMONG VOWEL KUB", "Lo", 0),
("PAHAWH HMONG VOWEL KUV", "Lo", 0),
("PAHAWH HMONG VOWEL KEB", "Lo", 0),
("PAHAWH HMONG VOWEL KEV", "Lo", 0),
("PAHAWH HMONG VOWEL KAIB", "Lo", 0),
("PAHAWH HMONG VOWEL KAIV", "Lo", 0),
("PAHAWH HMONG VOWEL KOOB", "Lo", 0),
("PAHAWH HMONG VOWEL KOOV", "Lo", 0),
("PAHAWH HMONG VOWEL KAWB", "Lo", 0),
("PAHAWH HMONG VOWEL KAWV", "Lo", 0),
("PAHAWH HMONG VOWEL KUAB", "Lo", 0),
("PAHAWH HMONG VOWEL KUAV", "Lo", 0),
("PAHAWH HMONG VOWEL KOB", "Lo", 0),
("PAHAWH HMONG VOWEL KOV", "Lo", 0),
("PAHAWH HMONG VOWEL KIAB", "Lo", 0),
("PAHAWH HMONG VOWEL KIAV", "Lo", 0),
("PAHAWH HMONG VOWEL KAB", "Lo", 0),
("PAHAWH HMONG VOWEL KAV", "Lo", 0),
("PAHAWH HMONG VOWEL KWB", "Lo", 0),
("PAHAWH HMONG VOWEL KWV", "Lo", 0),
("PAHAWH HMONG VOWEL KAAB", "Lo", 0),
("PAHAWH HMONG VOWEL KAAV", "Lo", 0),
("PAHAWH HMONG CONSONANT VAU", "Lo", 0),
("PAHAWH HMONG CONSONANT NTSAU", "Lo", 0),
("PAHAWH HMONG CONSONANT LAU", "Lo", 0),
("PAHAWH HMONG CONSONANT HAU", "Lo", 0),
("PAHAWH HMONG CONSONANT NLAU", "Lo", 0),
("PAHAWH HMONG CONSONANT RAU", "Lo", 0),
("PAHAWH HMONG CONSONANT NKAU", "Lo", 0),
("PAHAWH HMONG CONSONANT QHAU", "Lo", 0),
("PAHAWH HMONG CONSONANT YAU", "Lo", 0),
("PAHAWH HMONG CONSONANT HLAU", "Lo", 0),
("PAHAWH HMONG CONSONANT MAU", "Lo", 0),
("PAHAWH HMONG CONSONANT CHAU", "Lo", 0),
("PAHAWH HMONG CONSONANT NCHAU", "Lo", 0),
("PAHAWH HMONG CONSONANT HNAU", "Lo", 0),
("PAHAWH HMONG CONSONANT PLHAU", "Lo", 0),
("PAHAWH HMONG CONSONANT NTHAU", "Lo", 0),
("PAHAWH HMONG CONSONANT NAU", "Lo", 0),
("PAHAWH HMONG CONSONANT AU", "Lo", 0),
("PAHAWH HMONG CONSONANT XAU", "Lo", 0),
("PAHAWH HMONG CONSONANT CAU", "Lo", 0),
("PAHAWH HMONG MARK CIM TUB", "Mn", 230),
("PAHAWH HMONG MARK CIM SO", "Mn", 230),
("PAHAWH HMONG MARK CIM KES", "Mn", 230),
("PAHAWH HMONG MARK CIM KHAV", "Mn", 230),
("PAHAWH HMONG MARK CIM SUAM", "Mn", 230),
("PAHAWH HMONG MARK CIM HOM", "Mn", 230),
("PAHAWH HMONG MARK CIM TAUM", "Mn", 230),
("PAHAWH HMONG SIGN VOS THOM", "Po", 0),
("PAHAWH HMONG SIGN VOS TSHAB CEEB", "Po", 0),
("PAHAWH HMONG SIGN CIM CHEEM", "Po", 0),
("PAHAWH HMONG SIGN VOS THIAB", "Po", 0),
("PAHAWH HMONG SIGN VOS FEEM", "Po", 0),
("PAHAWH HMONG SIGN XYEEM NTXIV", "So", 0),
("PAHAWH HMONG SIGN XYEEM RHO", "So", 0),
("PAHAWH HMONG SIGN XYEEM TOV", "So", 0),
("PAHAWH HMONG SIGN XYEEM FAIB", "So", 0),
("PAHAWH HMONG SIGN VOS SEEV", "Lm", 0),
("PAHAWH HMONG SIGN MEEJ SUAB", "Lm", 0),
("PAHAWH HMONG SIGN VOS NRUA", "Lm", 0),
("PAHAWH HMONG SIGN IB YAM", "Lm", 0),
("PAHAWH HMONG SIGN XAUS", "Po", 0),
("PAHAWH HMONG SIGN CIM TSOV ROG", "So", 0),
(),
(),
(),
(),
(),
(),
(),
(),
(),
(),
("PAHAWH HMONG DIGIT ZERO", "Nd", 0),
("PAHAWH HMONG DIGIT ONE", "Nd", 0),
("PAHAWH HMONG DIGIT TWO", "Nd", 0),
("PAHAWH HMONG DIGIT THREE", "Nd", 0),
("PAHAWH HMONG DIGIT FOUR", "Nd", 0),
("PAHAWH HMONG DIGIT FIVE", "Nd", 0),
("PAHAWH HMONG DIGIT SIX", "Nd", 0),
("PAHAWH HMONG DIGIT SEVEN", "Nd", 0),
("PAHAWH HMONG DIGIT EIGHT", "Nd", 0),
("PAHAWH HMONG DIGIT NINE", "Nd", 0),
(),
("PAHAWH HMONG NUMBER TENS", "No", 0),
("PAHAWH HMONG NUMBER HUNDREDS", "No", 0),
("PAHAWH HMONG NUMBER TEN THOUSANDS", "No", 0),
("PAHAWH HMONG NUMBER MILLIONS", "No", 0),
("PAHAWH HMONG NUMBER HUNDRED MILLIONS", "No", 0),
("PAHAWH HMONG NUMBER TEN BILLIONS", "No", 0),
("PAHAWH HMONG NUMBER TRILLIONS", "No", 0),
(),
("PAHAWH HMONG SIGN VOS LUB", "Lo", 0),
("PAHAWH HMONG SIGN XYOO", "Lo", 0),
("PAHAWH HMONG SIGN HLI", "Lo", 0),
("PAHAWH HMONG SIGN THIRD-STAGE HLI", "Lo", 0),
("PAHAWH HMONG SIGN ZWJ THAJ", "Lo", 0),
("PAHAWH HMONG SIGN HNUB", "Lo", 0),
("PAHAWH HMONG SIGN NQIG", "Lo", 0),
("PAHAWH HMONG SIGN XIAB", "Lo", 0),
("PAHAWH HMONG SIGN NTUJ", "Lo", 0),
("PAHAWH HMONG SIGN AV", "Lo", 0),
("PAHAWH HMONG SIGN TXHEEJ CEEV", "Lo", 0),
("PAHAWH HMONG SIGN MEEJ TSEEB", "Lo", 0),
("PAHAWH HMONG SIGN TAU", "Lo", 0),
("PAHAWH HMONG SIGN LOS", "Lo", 0),
("PAHAWH HMONG SIGN MUS", "Lo", 0),
("PAHAWH HMONG SIGN CIM HAIS LUS NTOG NTOG", "Lo", 0),
("PAHAWH HMONG SIGN CIM CUAM TSHOOJ", "Lo", 0),
("PAHAWH HMONG SIGN CIM TXWV", "Lo", 0),
("PAHAWH HMONG SIGN CIM TXWV CHWV", "Lo", 0),
("PAHAWH HMONG SIGN CIM PUB DAWB", "Lo", 0),
("PAHAWH HMONG SIGN CIM NRES TOS", "Lo", 0),
(),
(),
(),
(),
(),
("PAHAWH HMONG CLAN SIGN TSHEEJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN YEEG", "Lo", 0),
("PAHAWH HMONG CLAN SIGN LIS", "Lo", 0),
("PAHAWH HMONG CLAN SIGN LAUJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN XYOOJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN KOO", "Lo", 0),
("PAHAWH HMONG CLAN SIGN HAWJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN MUAS", "Lo", 0),
("PAHAWH HMONG CLAN SIGN THOJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN TSAB", "Lo", 0),
("PAHAWH HMONG CLAN SIGN PHAB", "Lo", 0),
("PAHAWH HMONG CLAN SIGN KHAB", "Lo", 0),
("PAHAWH HMONG CLAN SIGN HAM", "Lo", 0),
("PAHAWH HMONG CLAN SIGN VAJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN FAJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN YAJ", "Lo", 0),
("PAHAWH HMONG CLAN SIGN TSWB", "Lo", 0),
("PAHAWH HMONG CLAN SIGN KWM", "Lo", 0),
("PAHAWH HMONG CLAN SIGN VWJ", "Lo", 0),
)
|
https://github.com/haxibami/haxipst | https://raw.githubusercontent.com/haxibami/haxipst/main/src/lib/better-heading.typ | typst | // Typst's default heading is a bit tight, so we'll make it a bit more
#let better-heading(
font: (
"sans-serif",
),
tight: false,
inset-y: none,
prefix: none,
body,
) = {
if tight {
inset-y = 0.5em
} else if inset-y == none {
inset-y = 0.75em
}
show heading: it => {
block(inset: (
y: inset-y,
))[
#text(
font: font,
weight: "bold",
size: 1em,
)[
#prefix
#if it.numbering != none {
counter(heading).display()
}
#it.body
]
]
}
body
}
|
|
https://github.com/HiiGHoVuTi/requin | https://raw.githubusercontent.com/HiiGHoVuTi/requin/main/glossary-pool.typ | typst | #import "@preview/gloss-awe:0.0.5": gls
// NOTE(Juliette): Dans l'ordre alphabétique !!
#let glossary-pool = (
Catégorie: (
description: [
#show figure.where(kind: "jkrb_glossary"): it => {it.body}
Une _catégorie_ $cal(C)$ est une #gls(entry: "Classe")[classe] de _morphismes_ $"mor"(cal(C))$ munie de
#align(center, grid(columns: (1fr, 1fr, 1fr),
[- une classe $"ob"(cal(C))$],
[- deux fonctions $"dom", "cod" : "mor"(cal(C)) -> "ob"(cal(C))$],
[- une loi de composition $compose$ associative unitaire \ \ ],
[- Si $"cod"f = "dom"g,$], [$g compose f$ est défini], [$"cod"(g compose f)="cod" g$ et\ $"dom"(g compose f) = "dom"f$]
))
On note $"Hom"(A, B) := {f in "mor"(cal(C)), "dom"f=A, "cod"f=B}$.
]
),
Classe: (
description: [
Le concept de _classe_ généralise celui d'ensemble. Une classe peut-être définie par une propriété logique, par induction, ...
Ce qui différenciera en pratique une classe d'un ensemble dans le _REQUIN_, c'est qu'une classe ne peut se trouver qu'à droite du symbole $in$.
]
),
"Classe combinatoire": (
description: [
Une _classe combinatoire_ est un ensemble $cal(C)$ muni d'une fonction $"taille" = |dot| : cal(C) --> NN$ telle que pour tout $n in NN$, $"taille"^(-1)(n)$ est un ensemble fini.
On la munit d'une suite $c_n := |"taille"^(-1)(n)|$ (lettre minuscule) et de la série formelle $C_n in CC((X))$ (lettre majuscule droite).
]
),
Demi-groupe: (
description: [
Un _demi-groupe_ $(S, +)$ est un magma associatif, c'est-à-dire que
#align(center, grid(columns: (1fr, 1fr),
[- $S$ est stable par $+$],
[- La loi $+$ est associative]))
]
),
Foncteur: (
description: [
#show figure.where(kind: "jkrb_glossary"): it => {it.body}
Un _foncteur_ est un morphisme de #gls(entry: "Catégorie")[catégories]. C'est-à-dire que si $F$ est un foncteur de $cal(C)$ dans $cal(D)$, $F("Ob"(cal(C))) subset "Ob"(cal(D))$, et
$F("mor"(cal(C))) subset "mor"(cal(D))$. De plus, $F(g compose f) = F g compose F f$ et $F"id" = "id"$.
]
),
Magma: (
description: [
Un magma $(A, +)$ est un ensemble muni d'une loi de composition interne.
]
),
Monoïde: (
description: [
#show figure.where(kind: "jkrb_glossary"): it => {it.body}
Un _monoïde_ est $(M, +)$ est un #gls(entry: "Magma")[magma] associatif unifère, c'est-à-dire un #gls(entry: "Demi-groupe")[demi-groupe] avec un élément neutre.
]
),
"Nombres de Catalan": (
description: [
// TODO(Juliette): do better
$ C_n = 1/(n+1)binom(2n, n) $
]
),
"Transformation naturelle": (
description: [
#show figure.where(kind: "jkrb_glossary"): it => {it.body}
Une _transformation naturelle_ $alpha$ entre un #gls(entry: "Foncteur")[foncteur] $F$ et un #gls(entry: "Foncteur")[foncteur] $G$ est une famille de fonctions telles que pour $x,y$ des types et $h : x -> y$, le diagramme suivant commute
#import "@preview/fletcher:0.5.1" as fletcher: diagram, node, edge
#align(center, diagram(
node((0, 0), $F(x)$),
node((0, 1), $G(x)$),
node((1, 0), $F(y)$),
node((1, 1), $G(y)$),
edge((0, 0), (0, 1), "->", $alpha_x$),
edge((1, 0), (1, 1), "->", $alpha_y$),
edge((0, 0), (1, 0), "->", $F(h)$),
edge((0, 1), (1, 1), "->", $G(h)$),
))
]
)
)
|
|
https://github.com/ClazyChen/Table-Tennis-Rankings | https://raw.githubusercontent.com/ClazyChen/Table-Tennis-Rankings/main/history/2004/MS-01.typ | typst |
#set text(font: ("Courier New", "NSimSun"))
#figure(
caption: "Men's Singles (1 - 32)",
table(
columns: 4,
[Ranking], [Player], [Country/Region], [Rating],
[1], [<NAME>], [CHN], [2567],
[2], [WANG Liqin], [CHN], [2471],
[3], [WANG Hao], [CHN], [2445],
[4], [CHUANG Chih-Yuan], [TPE], [2333],
[5], [<NAME>], [KOR], [2324],
[6], [KONG Linghui], [CHN], [2322],
[7], [KREANGA Kalinikos], [GRE], [2318],
[8], [HAO Shuai], [CHN], [2307],
[9], [CHEN Qi], [CHN], [2282],
[10], [<NAME>], [CHN], [2278],
[11], [OH Sangeun], [KOR], [2273],
[12], [JOO Saehyuk], [KOR], [2258],
[13], [SAMSONOV Vladimir], [BLR], [2221],
[14], [<NAME>], [GER], [2213],
[15], [<NAME>], [AUT], [2191],
[16], [LUNDQVIST Jens], [SWE], [2175],
[17], [KORBEL Petr], [CZE], [2170],
[18], [SMIRNOV Alexey], [RUS], [2162],
[19], [QIU Yike], [CHN], [2147],
[20], [WALDNER Jan-Ove], [SWE], [2128],
[21], [<NAME>], [CRO], [2118],
[22], [KARLSSON Peter], [SWE], [2113],
[23], [<NAME>], [AUT], [2105],
[24], [<NAME>], [KOR], [2084],
[25], [<NAME>], [BEL], [2079],
[26], [<NAME>], [SLO], [2072],
[27], [<NAME>], [KOR], [2066],
[28], [<NAME>], [CHN], [2056],
[29], [<NAME>], [DEN], [2043],
[30], [<NAME>], [HKG], [2043],
[31], [<NAME>-Lung], [TPE], [2041],
[32], [<NAME>], [NED], [2036],
)
)#pagebreak()
#set text(font: ("Courier New", "NSimSun"))
#figure(
caption: "Men's Singles (33 - 64)",
table(
columns: 4,
[Ranking], [Player], [Country/Region], [Rating],
[33], [HEISTER Danny], [NED], [2034],
[34], [<NAME>], [SWE], [2029],
[35], [#text(gray, "QIN Zhijian")], [CHN], [2021],
[36], [PAVELKA Tomas], [CZE], [2021],
[37], [ROSSKOPF Jorg], [GER], [2013],
[38], [KO Lai Chak], [HKG], [2012],
[39], [<NAME>], [RUS], [2010],
[40], [<NAME>], [ROU], [1992],
[41], [<NAME>chao], [CHN], [1986],
[42], [<NAME>], [CZE], [1986],
[43], [<NAME>], [SWE], [1973],
[44], [<NAME>], [GER], [1967],
[45], [<NAME>], [GER], [1964],
[46], [<NAME>], [ROU], [1958],
[47], [<NAME>], [TPE], [1949],
[48], [<NAME>], [CZE], [1946],
[49], [<NAME>], [FRA], [1946],
[50], [<NAME>], [GER], [1943],
[51], [<NAME>], [HKG], [1936],
[52], [<NAME>], [SWE], [1935],
[53], [MATSUSHITA Koji], [JPN], [1934],
[54], [<NAME>], [FRA], [1931],
[55], [<NAME>], [SWE], [1931],
[56], [#text(gray, "<NAME>")], [JPN], [1929],
[57], [TASAKI Toshio], [JPN], [1918],
[58], [BLASZCZYK Lucjan], [POL], [1917],
[59], [FRANZ Peter], [GER], [1911],
[60], [<NAME>], [CHN], [1911],
[61], [SHMYREV Maxim], [RUS], [1906],
[62], [<NAME>], [KOR], [1898],
[63], [TUGWELL Finn], [DEN], [1894],
[64], [<NAME>], [SRB], [1886],
)
)#pagebreak()
#set text(font: ("Courier New", "NSimSun"))
#figure(
caption: "Men's Singles (65 - 96)",
table(
columns: 4,
[Ranking], [Player], [Country/Region], [Rating],
[65], [CIOTI Constantin], [ROU], [1886],
[66], [<NAME>], [HKG], [1886],
[67], [<NAME>], [CAN], [1881],
[68], [<NAME>], [FRA], [1876],
[69], [<NAME>], [AUT], [1873],
[70], [<NAME>ianfeng], [NOR], [1873],
[71], [<NAME>], [DEN], [1873],
[72], [<NAME>], [ESP], [1871],
[73], [<NAME>], [HKG], [1870],
[74], [<NAME>], [FRA], [1865],
[75], [<NAME>], [SRB], [1862],
[76], [<NAME>], [NOR], [1861],
[77], [<NAME>], [SVK], [1852],
[78], [<NAME>], [DEN], [1848],
[79], [<NAME>], [POL], [1847],
[80], [<NAME>], [GRE], [1847],
[81], [<NAME>], [FRA], [1843],
[82], [PAPAGEORGIOU Konstantinos], [GRE], [1843],
[83], [<NAME>], [GER], [1841],
[84], [<NAME>], [CZE], [1836],
[85], [LENGEROV Kostadin], [AUT], [1833],
[86], [ZOOGLING Mikael], [SWE], [1824],
[87], [<NAME>], [FRA], [1824],
[88], [<NAME>], [SRB], [1823],
[89], [KOSOWSKI Jakub], [POL], [1820],
[90], [<NAME>], [GER], [1820],
[91], [<NAME>], [POL], [1817],
[92], [<NAME>], [GRE], [1813],
[93], [<NAME>], [KOR], [1811],
[94], [<NAME>], [CRO], [1810],
[95], [<NAME>], [DEN], [1806],
[96], [<NAME>], [RUS], [1805],
)
)#pagebreak()
#set text(font: ("Courier New", "NSimSun"))
#figure(
caption: "Men's Singles (97 - 128)",
table(
columns: 4,
[Ranking], [Player], [Country/Region], [Rating],
[97], [<NAME>], [FRA], [1804],
[98], [OLEJNIK Martin], [CZE], [1803],
[99], [<NAME>], [JPN], [1801],
[100], [YAN Sen], [CHN], [1801],
[101], [<NAME>], [GER], [1799],
[102], [<NAME>], [KOR], [1797],
[103], [<NAME>], [POL], [1793],
[104], [<NAME>], [HUN], [1793],
[105], [<NAME>], [FRA], [1791],
[106], [<NAME>], [JPN], [1791],
[107], [<NAME>], [FRA], [1789],
[108], [<NAME>], [BRA], [1788],
[109], [<NAME>], [JPN], [1785],
[110], [<NAME>], [ROU], [1782],
[111], [<NAME>], [NOR], [1778],
[112], [<NAME>], [BEL], [1768],
[113], [<NAME>], [AUT], [1765],
[114], [<NAME>], [NGR], [1765],
[115], [<NAME>], [SWE], [1758],
[116], [<NAME>], [USA], [1754],
[117], [<NAME>], [CRO], [1749],
[118], [<NAME>], [JPN], [1745],
[119], [<NAME>], [ITA], [1744],
[120], [<NAME>], [JPN], [1741],
[121], [KAYAMA Hyogo], [JPN], [1739],
[122], [KUSINSKI Marcin], [POL], [1737],
[123], [<NAME>], [BRA], [1736],
[124], [<NAME>], [SLO], [1735],
[125], [<NAME>], [BEL], [1733],
[126], [<NAME>], [BEL], [1729],
[127], [<NAME>], [HUN], [1726],
[128], [<NAME>], [JPN], [1725],
)
) |
|
https://github.com/htlwienwest/da-vorlage-typst | https://raw.githubusercontent.com/htlwienwest/da-vorlage-typst/main/lib/pages/eidesstattliche.typ | typst | MIT License | #let eidesstattliche(datum: none, persons: ()) = [
= Selbständigkeitserklärung
#set text(11pt)
Wir erklären, dass wir die vorliegende Diplomarbeit selbstständig und ohne fremde Hilfe verfasst, andere als die angegebenen Quellen und Hilfsmittel nicht benutzt und die den benutzten Quellen wörtlich und inhaltlich entnommenen Stellen als solche kenntlich gemacht haben.
#v(1cm)
#let signature(person) = {
set align(center)
stack(
spacing: 2mm,
line(length: 80%, stroke: 0.5pt),
person
)
}
Wien, am #datum
#v(4cm)
#grid(
columns: (1fr, 1fr, 1fr),
..persons.map(signature)
)
]
|
https://github.com/geek-space-hq/SchedulePrinter | https://raw.githubusercontent.com/geek-space-hq/SchedulePrinter/master/test.typ | typst | #import "@preview/tablex:0.0.7": *
#let www=12cm
#set page(
width: www,
height: 40cm,
)
#let title="aaaa"
#title
#pagebreak(
weak: true
) |
|
https://github.com/Myriad-Dreamin/typst.ts | https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/visualize/svg-text_00.typ | typst | Apache License 2.0 |
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
#set page(width: 250pt)
#figure(
image("/assets/files/diagram.svg"),
caption: [A textful diagram],
)
|
https://github.com/mem-courses/calculus | https://raw.githubusercontent.com/mem-courses/calculus/main/note-1/6.微积分的应用.typ | typst | #import "../template.typ": *
#show: project.with(
course: "Calculus I",
course_fullname: "Calculus (A) I",
course_code: "821T0150",
semester: "Autumn-Winter 2023",
title: "Note #6: 微积分的应用",
authors: (
(
name: "memset0",
email: "<EMAIL>",
id: "3230104585",
),
),
date: "January 7, 2024",
)
#let def(x) = text("【" + x + "】", weight: "bold")
#let deft(x) = text("【" + x + "】", weight: "bold", fill: rgb("#FFFFFF"))
= 微积分在几何中的应用
== 切线与法线
=== 切线方程
函数 $y=f(x)$ 在 $x=x_0$ 处的切线方程为:$y-y_0 = f'(x_0) (x-x_0)$。
=== 法线方程
函数 $y=f(x)$ 在 $x=x_0$ 处的法线方程为:$y-y_0 = display(-1/(f' (x_0))) (x-x_0)$。
若 $f'(x_0) = 0$,切线与 $x$ 轴平行,且称 $x_0$ 为驻点。
== 曲率
#definition[
设 $M,N$ 是曲线上邻近的两点,两者沿曲线的距离为 $r$,切线的转角为 $theta$,则将 $display(theta/r)$ 称为这两点的#bb[平均曲率]。
]
#definition[
曲线 $y=f(x)$ 在某点的#bb[曲率]为 $display(k = (|y''|)/((1+y'^2)^(3/2)))$。
]
#definition[
曲线 $y=f(x)$ 在某点的#bb[曲率圆半径] $R$ 是 $k$ 的倒数,即 $display(R=1/k)$。
]
== 平面图形面积
#theorem[
设 $y=f(x)$ 与直线 $x=a,sp x=b$ 及 $x$ 轴围成的曲边梯形的有向面积为 $A$,则
$ dif A = f(x) dif x sp ==> sp A = int_a^b f(x) dx $
]
#theorem[
当曲线方程由参数方程 $display(cases(x=phi(t),y=psi(t)))$ 给出时,面积公式可修改为
$
A = int_a^b psi(t) dif (phi(t)) = int_(t_1)^(t_2) psi(t) phi'(t) dt
$
这里 $a=phi(t_1)$,$b=phi(t_2)$。
]
#theorem[
设 $phi(theta) in C[alpha,beta],sp phi(theta)>=0$ 与射线 $theta=alpha,sp theta=beta$ 围成的面积 $A$,则在 $[alpha,beta]$ 上任取小区间 $[theta,dif theta]$ 将其近似为三角形可得
$
dif A= 1 / 2 phi^2(theta) dif theta sp ==> sp A = 1 / 2 int_alpha^beta phi^2(theta) dif theta
$
]
== 平面曲线的弧长
#definition[
若在弧 $A B$ 上任作内接折线,当折线段的最大边长 $lambda->0$ 时,折线的长度趋向于一个确定的极限,称为曲线弧 $A B$ 的#bb[弧长]。
]
#lemma[
任意的光滑(即 $f(x)$ 与 $f'(x)$ 均连续)曲线弧都是可求长的。
]
#lemma(name: "弧微分基本公式")[
$(dif s)^2 = (dx)^2 + (dy)^2$。这可以用于计算弧长。
]
#theorem[
曲线 $y=f(x) sp (a<=x<=b)$ 的弧长为
$
dif s = sqrt((dx)^2 + (dy)^2) = sqrt(1+y'^2) dx
sp ==> sp s=int_a^b sqrt(1+f'^2(x)) dx
$
]
#theorem[
曲线 $display(cases(x=phi(t),y=psi(t))) sp (alpha<=t<=beta)$ 的弧长为
$
dif s = sqrt((dx)^2 + (dy)^2) = sqrt(phi'^2(t) + psi'^2(t)) dt
sp ==> sp s=int_alpha^beta sqrt(phi'^2(t) + psi'^2(t)) dt
$
]
#theorem[
曲线 $r=r(theta) sp (alpha<=theta<=beta)$(令 $x(theta)=r(theta)cos theta,sp y(theta)=r(theta)sin theta$)的弧长为
$
dif s
=sqrt((x'(theta))^2 + (y'(theta))^2) dif theta
=sqrt(r^2(theta) + r'^2(theta)) dif theta
sp==> sp s
=int_alpha^beta sqrt(r^2(theta) + r'^2(theta)) dif theta
$
]
== 旋转体的体积
#theorem[
连续曲线段 $y=f(x) sp (a<=x<=b)$ 绕 $x$ 轴一圈围成的立体体积为:
$
V_x = int_a^b pi f^2(x) dx
$
]
#theorem(name: "柱壳法")[
平面图形 $D:sp 0<=y<=f(x),sp a<=x<=b$ 绕 $y$ 轴形成的旋转体的体积为:
$
V_y = 2 pi int_a^b x f(x) dx
$
]
== 旋转体的侧面积
#theorem[
连续曲线段 $y=f(x)$ 且 $f(x)>=0$ 绕 $x$ 旋转一周所得到的旋转体表面积为:
$
dif S = 2 pi y dif s
sp ==> sp
S = 2 pi int_a^b f(x) sqrt(1 + f'^2(x)) dx
$
] |
|
https://github.com/frectonz/the-pg-book | https://raw.githubusercontent.com/frectonz/the-pg-book/main/book/093.%20distraction.html.typ | typst | distraction.html
Disconnecting Distraction
Note: The strategy described at the end of this essay didn't work.
It would work for a while, and then I'd gradually find myself
using the Internet on my work computer. I'm trying other
strategies now, but I think this time I'll wait till I'm sure
they work before writing about them.May 2008Procrastination feeds on distractions. Most people find it
uncomfortable just to sit and do nothing; you avoid work by doing
something else.So one way to beat procrastination is to starve it of distractions.
But that's not as straightforward as it sounds, because there are
people working hard to distract you. Distraction is not a static
obstacle that you avoid like you might avoid a rock in the road.
Distraction seeks you out.Chesterfield described dirt as matter out of place. Distracting
is, similarly, desirable at the wrong time. And technology is
continually being refined to produce more and more desirable things.
Which means that as we learn to avoid one class of distractions,
new ones constantly appear, like drug-resistant bacteria.Television, for example, has after 50 years of refinement reached
the point where it's like visual crack. I realized when I was 13
that TV was addictive, so I stopped watching it. But I read recently
that the average American watches
4 hours
of TV a day. A quarter
of their life.TV is in decline now, but only because people have found even more
addictive ways of wasting time. And what's especially dangerous
is that many happen at your computer. This is no accident. An
ever larger percentage of office workers sit in front of computers
connected to the Internet, and distractions always evolve toward
the procrastinators.I remember when computers were, for me at least, exclusively for
work. I might occasionally dial up a server to get mail or ftp
files, but most of the time I was offline. All I could do was write
and program. Now I feel as if someone snuck a television onto my
desk. Terribly addictive things are just a click away. Run into
an obstacle in what you're working on? Hmm, I wonder what's new
online. Better check.After years of carefully avoiding classic time sinks like TV, games,
and Usenet, I still managed to fall prey to distraction, because
I didn't realize that it evolves. Something that used to be safe,
using the Internet, gradually became more and more dangerous. Some
days I'd wake up, get a cup of tea and check the news, then check
email, then check the news again, then answer a few emails, then
suddenly notice it was almost lunchtime and I hadn't gotten any real
work done. And this started to happen more and more often.It took me surprisingly long to realize how distracting the Internet
had become, because the problem was intermittent. I ignored it the
way you let yourself ignore a bug that only appears intermittently. When
I was in the middle of a project, distractions weren't really a
problem. It was when I'd finished one project and was deciding
what to do next that they always bit me.Another reason it was hard to notice the danger of this new type
of distraction was that social customs hadn't yet caught up with
it. If I'd spent a whole morning sitting on a sofa watching TV,
I'd have noticed very quickly. That's a known danger sign, like
drinking alone. But using the Internet still looked and felt a
lot like work.Eventually, though, it became clear that the Internet had become so much
more distracting that I had to start treating it differently.
Basically, I had to add a new application to my list of known time
sinks: Firefox.* * *The problem is a hard one to solve because most people still need
the Internet for some things. If you drink too much, you can solve
that problem by stopping entirely. But you can't solve the problem
of overeating by stopping eating. I couldn't simply avoid the
Internet entirely, as I'd done with previous time sinks.At first I tried rules. For example, I'd tell myself I was only
going to use the Internet twice a day. But these schemes never
worked for long. Eventually something would come up that required
me to use it more than that. And then I'd gradually slip back
into my old ways.Addictive things have to be treated as if they were sentient
adversaries—as if there were a little man in your head always
cooking up the most plausible arguments for doing whatever you're
trying to stop doing. If you leave a path to it, he'll find it.The key seems to be visibility. The biggest ingredient in most bad habits
is denial. So you have to make it so that you can't merely slip
into doing the thing you're trying to avoid. It has to set off
alarms.Maybe in the long term the right answer for dealing with Internet
distractions will be
software that watches and controls them. But
in the meantime I've found a more drastic solution that definitely
works: to set up a separate computer for using the Internet.I now leave wifi turned off on my main computer except when I need
to transfer a file or edit a web page, and I have a separate laptop
on the other side
of the room that I use to check mail or browse the web. (Irony of
ironies, it's the computer <NAME> wrote Reddit on. When
Steve and Alexis auctioned off their old laptops for charity, I
bought them for the Y Combinator museum.)My rule is that I can spend as much time online as I want, as long
as I do it on that computer. And this turns out to be enough. When
I have to sit on the other side of the room to check email or browse
the web, I become much more aware of it. Sufficiently aware, in
my case at least, that it's hard to spend more than about an hour
a day online.And my main computer is now freed for work. If you try this trick,
you'll probably be struck by how different it feels when your
computer is disconnected from the Internet. It was alarming to me
how foreign it felt to sit in front of a computer that could
only be used for work, because that showed how much time I must
have been wasting.Wow. All I can do at this computer is work. Ok, I better work
then.That's the good part. Your old bad habits now help you to work.
You're used to sitting in front of that computer for hours at a
time. But you can't browse the web or check email now. What are
you going to do? You can't just sit there. So you start working.Good and Bad ProcrastinationSpanish TranslationArabic TranslationCatalan TranslationRussian TranslationSpanish Translation
|
|
https://github.com/qujihan/toydb-book | https://raw.githubusercontent.com/qujihan/toydb-book/main/main.typ | typst | #import "typst-book-template/book.typ": *
#set text(lang: "zh")
#show: book.with(info:(
title: "从零开始的分布式数据库生活 \n (From Zero to Distributed Database)",
name: "Quhaha",
outline-depth: 3,
))
#set heading(supplement: "")
#show ref: it => {
if it.element.func() == heading {
link(it.target, "第" + it + "章" + it.element.body)
} else {
link(it.target, it)
}
}
#include "src/chapter1.typ"
#include "src/chapter2.typ"
#include "src/chapter3.typ"
#include "src/chapter4.typ"
#include "src/chapter5.typ"
#include "src/chapter6.typ"
#include "src/chapter7.typ" |
|
https://github.com/typst-community/valkyrie | https://raw.githubusercontent.com/typst-community/valkyrie/main/tests/types/color/test.typ | typst | Other | #import "/src/lib.typ" as z
#set page(height: 1cm, width: 1cm)
#{
_ = z.parse(rgb(0, 0, 0), z.color())
_ = z.parse(cmyk(0%, 0%, 0%, 0%), z.color())
//_ = z.parse(0, z.color())
//_ = z.parse(none, z.color())
}
|
https://github.com/Area-53-Robotics/53E-Notebook-Over-Under-2023-2024 | https://raw.githubusercontent.com/Area-53-Robotics/53E-Notebook-Over-Under-2023-2024/giga-notebook/entries/intake-rebuild/test.typ | typst | Creative Commons Attribution Share Alike 4.0 International | #import "/packages.typ": notebookinator
#import notebookinator: *
#import themes.radial.components: *
#import "/utils.typ": plot-from-csv
#show: create-body-entry.with(
title: "Test: Intake Rebuild",
type: "test",
date: datetime(year: 2024, month: 2, day: 24),
author: "<NAME>",
witness: "Violet Ridge",
)
#metadata(none) <test-intake>
Since the changes to the intake were mostly structural, we decided the most
important thing to test for would be friction, as this would tell us if our
design's construction was sound. We do this by collecting the power draw of the
motor while free spinning. A motor typically consumes around 1W of power under
ideal conditions while free spinning, so this is our target.
= Procedures
+ Download the program to the brain
```cpp
#ifdef LOGGING
logger.telemetry(
fmt::format("{},{},{}", LOGGING_INTAKE_ROUTE, motor->get_power(), motor->get_temperature()));
#endif
```
2. Connect to the robot with the Loginator
+ Make sure that the intake is not contacting anything, and can spin freely.
+ Run the code. This should spin the intake for exactly a minute.
= Results
== Before Tuning
#admonition(
type: "warning",
)[
We forgot to set Grafana to keep the data for a long enough time, so while data
was recorded for the full minute, about half of it was deleted, and could not be
recovered.
]
#let data = plot-from-csv(read("./Intake-data-2024-02-24_17_27_55.3850.csv"))
#plot(x-label: "Time (ms)", y-label: "Power Draw (Watts)", ..data)
As you can see from this data, the motors are consuming about 10W of power. This
is much higher than the desired 1W. Upon seeing this we began troubleshooting
the intake to see where the issue arose. We checked to make sure that the
structure and axles were square, and in doing so noticed that the holes in the
plastic sleds for the high strength axles were too small. We drilled them out,
and then ran the test again.
== After Tuning
After drilling out the holes we got much better results.
#let data = plot-from-csv(read("./Intake-data-2024-02-24_17_51_02.8800.csv"))
#plot(x-label: "Time (ms)", y-label: "Power Draw (Watts)", ..data)
The power draw has fallen to acceptable levels of error. Overall we're very
happy with how this redesign has gone, and are excited to compete with it at the
state championship.
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-1EC70.typ | typst | Apache License 2.0 | #let data = (
(),
("INDIC SIYAQ NUMBER ONE", "No", 0),
("INDIC SIYAQ NUMBER TWO", "No", 0),
("INDIC SIYAQ NUMBER THREE", "No", 0),
("INDIC SIYAQ NUMBER FOUR", "No", 0),
("INDIC SIYAQ NUMBER FIVE", "No", 0),
("INDIC SIYAQ NUMBER SIX", "No", 0),
("INDIC SIYAQ NUMBER SEVEN", "No", 0),
("INDIC SIYAQ NUMBER EIGHT", "No", 0),
("INDIC SIYAQ NUMBER NINE", "No", 0),
("INDIC SIYAQ NUMBER TEN", "No", 0),
("INDIC SIYAQ NUMBER TWENTY", "No", 0),
("INDIC SIYAQ NUMBER THIRTY", "No", 0),
("INDIC SIYAQ NUMBER FORTY", "No", 0),
("INDIC SIYAQ NUMBER FIFTY", "No", 0),
("INDIC SIYAQ NUMBER SIXTY", "No", 0),
("INDIC SIYAQ NUMBER SEVENTY", "No", 0),
("INDIC SIYAQ NUMBER EIGHTY", "No", 0),
("INDIC SIYAQ NUMBER NINETY", "No", 0),
("INDIC SIYAQ NUMBER ONE HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER TWO HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER THREE HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER FOUR HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER FIVE HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER SIX HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER SEVEN HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER EIGHT HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER NINE HUNDRED", "No", 0),
("INDIC SIYAQ NUMBER ONE THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER TWO THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER THREE THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER FOUR THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER FIVE THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER SIX THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER SEVEN THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER EIGHT THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER NINE THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER TEN THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER TWENTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER THIRTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER FORTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER FIFTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER SIXTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER SEVENTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER EIGHTY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER NINETY THOUSAND", "No", 0),
("INDIC SIYAQ NUMBER LAKH", "No", 0),
("INDIC SIYAQ NUMBER LAKHAN", "No", 0),
("INDIC SIYAQ LAKH MARK", "No", 0),
("INDIC SIYAQ NUMBER KAROR", "No", 0),
("INDIC SIYAQ NUMBER KARORAN", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED ONE", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED TWO", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED THREE", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED FOUR", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED FIVE", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED SIX", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED SEVEN", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED EIGHT", "No", 0),
("INDIC SIYAQ NUMBER PREFIXED NINE", "No", 0),
("INDIC SIYAQ PLACEHOLDER", "So", 0),
("INDIC SIYAQ FRACTION ONE QUARTER", "No", 0),
("INDIC SIYAQ FRACTION ONE HALF", "No", 0),
("INDIC SIYAQ FRACTION THREE QUARTERS", "No", 0),
("INDIC SIYAQ RUPEE MARK", "Sc", 0),
("INDIC SIYAQ NUMBER ALTERNATE ONE", "No", 0),
("INDIC SIYAQ NUMBER ALTERNATE TWO", "No", 0),
("INDIC SIYAQ NUMBER ALTERNATE TEN THOUSAND", "No", 0),
("INDIC SIYAQ ALTERNATE LAKH MARK", "No", 0),
)
|
https://github.com/pku-typst/ichigo | https://raw.githubusercontent.com/pku-typst/ichigo/main/doc/doc.typ | typst | MIT License | #import "@preview/numbly:0.1.0": numbly
#import "@preview/indenta:0.0.3": fix-indent
#import "@preview/codly:1.0.0": codly, codly-init
// Scripting
#let param-table(..docs) = {
let headers = ([参数], [类型], [默认值], [说明])
let items = docs
.pos()
.flatten()
.chunks(headers.len())
.map(((p, t, dv, dscr)) => (
strong(p),
t,
if dv == none [无(位置参数)] else {
dv
},
dscr,
))
.flatten()
figure({
set align(left)
table(
columns: (25%, 20%, 20%, 35%),
row-gutter: 0.6em,
stroke: none,
table.header(..headers),
table.hline(),
..items
)
})
}
#let dict-struct(..docs) = {
let headers = ([字段], [类型], [说明])
let items = docs
.pos()
.flatten()
.chunks(headers.len())
.map(((k, v, d)) => (
strong(k),
v,
d,
))
.flatten()
figure({
set align(left)
table(
columns: (30%, 30%, 40%),
row-gutter: 0.6em,
stroke: none,
table.header(..headers),
table.hline(),
..items
)
})
}
#let ichigo-meta = toml("../typst.toml")
// Layout
#set text(lang: "zh")
#set text(font: (
"New Computer Modern",
"Source Han Serif SC",
))
#show ref: underline
#show link: underline
#show ref: set text(fill: color.eastern)
#show link: set text(fill: color.eastern)
#show: codly-init.with()
#codly(languages: (
typ: (
name: "Typst",
color: rgb("#00beb4"),
),
))
#set heading(numbering: numbly("{1:一}、", "{2}.", "{2}.{3}."))
#set par(first-line-indent: 2em)
#show: fix-indent()
// Document
#align(center)[#text(size: 24pt)[Ichigo 作业模板v#ichigo-meta.package.version 文档]]
#outline(depth: 2, indent: 1em)
= 使用须知
ichigo 提供了一个功能库和一份文档模板, 对功能定制要求不高的用户可以直接修改模板使用.
功能库提供了 `config` 和 `prob` 两个函数, 前者用于处理文档内容, 后者用于产生统一形式的文档内容
= 接口文档
== `config`
=== 参数
// @typstyle off
#param-table(
`doc`, `content`, none, [文档内容],
`serial-str`, `str | none`, `none`, [作业编号(e.g. 第四周作业), 必须主动传入, 若希望留空请使用 `""`],
`theme-name`, `str`, `"simple"`, [主题名称, 可用主题见@available-themes],
`title-style`, `str | none`, `"whole-page"`, [标题样式, 可选值为 `"whole-page"`, `"simple"` 和 `none`],
`author-info`, `content`, `[]`, [作者信息, 默认为 `[]`],
`course-name`, `str`, `none`, [课程名称, 默认为 `none`, 必须主动传入, 若希望留空请使用 `""`],
`author-names`, `str | array`, `""`, [作者姓名(列表), 用于填入文档的 metadata, 默认为 `""`],
`heading-numberings`, `array`, `(none, none, "(1)", "a.")`, [标题编号格式, 默认为 `(none, none, "(1)", "a.")`, 具体格式参考 `numbly` 包的文档],
)
=== 使用方法
用于 `show` 语句中可将整个文档置于 `config` 的 `doc` 参数中, 结合 Typst 的 `.with` 语法, 给出以下示例:
```typ
#show: config.with(
course-name: "高等 Typst 学",
serial-str: "第一次作业",
author-names: "?sjfh",
author-info: [sjfh from PKU-Typst]
)
这里写作业内容
```
== `prob`
=== 参数
// @typstyle off
#param-table(
`question`, `content`, none, [题目内容],
`solution`, `content`, none, [解答内容],
`title`, `content | auto`, `auto`, [标题, 默认为自动生成编号],
)
=== 使用方法
示例:
```typ
#prob[
你好呀
][
爱用 Typst 的小朋友
]
#prob(title: [小试牛刀])[
请给出 Fibonacci 数列的第 25 项
][
#let f(n) = {
if n <= 2 {
return 1
}
return f(n - 1) + f(n - 2)
}
#f(25)
]
```
= 主题开发 <theme-dev>
== 现有可用主题
#import "../src/themes.typ": THEMES
#figure(
table(
columns: (15%, 60%),
table.header([主题名称], [预览图]),
..THEMES.map(t => (t, [暂无])).flatten()
),
caption: [可用主题],
) <available-themes>
== 主题开发
新建主题需要在 `/src/themes/{theme_name}/lib.typ` 文件中包含一个名为 `theme` 的函数, 其中 `{theme_name}` 为主题名称.
对 `theme` 函数的要求为:
- 接受一个位置参数 `meta`, 格式见 @struct-meta
- 返回一个 `theme`, 格式见 @struct-theme
并记得将该主题名称加入 `/src/themes.typ` 文件中的 `THEMES` 列表中.
== 特定数据结构
=== `meta` <struct-meta>
`dictionary` 类型, 包含以下字段:
// @typstyle off
#dict-struct(
`course-name`, `str`, [课程名称],
`serial-str`, `str`, [作业编号],
`author-info`, `content`, [作者信息],
`author-names`, `str | array`, [作者姓名(列表), 用于填入文档的 metadata],
)
=== `theme` <struct-theme>
`dictionary` 类型, 包含以下字段:
// @typstyle off
#dict-struct(
`title`, `dictionary`, [标题样式],
`page-setting`, `dictionary`, [页面设置],
`fonts`, `dictionary`, [字体设置],
)
其中 `title` 字段包含以下字段:
// @typstyle off
#dict-struct(
`whole-page`, `function`, [整页模式],
`simple`, `function`, [简易模式],
)
`page-setting` 字段包含以下字段:
// @typstyle off
#dict-struct(
`header`, `function`, [页眉],
`footer`, `function`, [页脚],
)
`fonts` 字段包含以下字段:
// @typstyle off
#dict-struct(
`heading`, link(<struct-font-schema>)[`font-schema`], [标题],
`text`, link(<struct-font-schema>)[`font-schema`], [正文],
`equation`, link(<struct-font-schema>)[`font-schema`], [公式],
)
=== `font-schema` <struct-font-schema>
`str` 或 `tuple` 类型
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/superb-pci/0.1.0/template/main.typ | typst | Apache License 2.0 | #import "@preview/superb-pci:0.1.0": *
#show: pci.with(
title: [Sample for the template, with quite a very long title],
abstract: [#lorem(200)],
authors: (
(
name: "<NAME>",
orcid: "0000-0000-0000-0001",
affiliations: "#,1"
),
(
name: "<NAME>",
orcid: "0000-0000-0000-0001",
affiliations: "#,2",
),
(
name: "<NAME>",
affiliations: "2",
),
(
name: "<NAME>",
orcid: "0000-0000-0000-0001",
affiliations: "3"
),
),
affiliations: (
(id: "1", name: "Rue sans aplomb, Paris, France"),
(id: "2", name: "Center for spiced radium experiments, United Kingdom"),
(id: "3", name: "Bruce's Bar and Grill, London (near Susan's)"),
(id: "#", name: "Equal contributions"),
),
doi: "https://doi.org/10.5802/fake.doi",
keywords: ("Scientific writing", "Typst", "PCI", "Example"),
correspondence: "<EMAIL>",
numbered_sections: false,
bibliography: bibliography("refs.bib"),
pcj: false,
)
= Example of a section, e.g. Introduction
#lorem(100)
= Example of a section, e.g. Material and methods
#lorem(100)
== First subsection
#lorem(100)
== Second subsection
#lorem(200)
== Third subsection
#lorem(100)
= Example of a section, e.g. Results
#lorem(100)
// how to rotate content
#pagebreak()
#rotate(-90deg, reflow: true)[
= Landscape section
#lorem(100)
#lorem(50)
#lorem(50)
]
#pagebreak()
= Example of a section, e.g. Discussion
#lorem(100)
- toto (see Appendix~sA and @eq:eq1)
- foo (see @fig:fig1)
- bar
== An other subsection
#lorem(100)
+ first item
+ second item
+ 2a<2a> item #link(<2a>)[2a]
+ item 2b (cf.~#cite(<Ivanov_curve-complex_1997>, form: "prose", supplement: [Thm.~3])
=== A subsubsection
#lorem(100)
This is an equation:
$
1 = 1
$ <eq:eq1>
A paragraph. #lorem(100)
$
exp(x) = 1 + x + frac(x^2, 2!) + frac(x^3, 3!) + frac(x^4, 4!) + frac(x^5, 5!) + frac(x^6, 6!) + frac(x^7, 7!) +frac(x^8, 8!) +frac(x^9, 9!) \
+ frac(x^10, 10!) + frac(x^11, 11!)+ frac(x^12, 12!) + frac(x^13, 13!) + frac(x^14, 14!) + frac(x^15, 15!) + frac(x^16, 16!) + o(n^16)
$
#figure(
image("pci-graph-small.png", width: 50%),
caption: [
This is the title of the figure. It also contains the legend of the figure, with some math to check everything is working: $log(frac(1, 2))$. The caption is different from the caption of the table (see @tab:tab1).
]
) <fig:fig1>
#lorem(100)
#figure(
[
#set table.hline(stroke: .6pt)
#table(
columns: 5,
table.hline(),
table.header(
[$n$], [1], [2], [3], [4],
),
table.hline(),
[$n^2$], [1], [4], [9], [16],
[$n^3$], [1], [4], [9], [18],
table.hline(),
)
#table_note[This is the note of the table if required. It is below the table to look nice. This can be done by using the template function `table_note` in the same block as the table. Compare with the figure caption above (see @fig:fig1).]
],
caption: [
This is the title of the table. It also contains the legend i.e. an explanation of what the table reveals about the problem at hand (typeset using the `caption` argument of figure()).
],
) <tab:tab1>
// Manually do proof at the moment
_Proof._ This is a proof that ends with a \verb+{align}+ type of equation. The last equation should be numbered, but \verb+\qedhere+ breaks it (yet it works in most other journals?)
$
x &= 1234596748613548534863 \
3x + y &= "some text" \
&1234864 + sum_(i=1)^(n) frac(1, i)
$ #math.qed
= Example of a section, e.g. Conclusion
#lorem(200)
// Appendix sections
#appendix()[
= Some other things
<sA>
// \appendix
// \section{Some other things}\label{sA}
If your appendices fit in less than 2 pages, add your appendices here.
If your appendices take more than 2 pages, please proceed as follows:
- deposit them in an open repository such as Zenodo
- add the DOI and the citation in the section “Data, scripts, code, and supplementary information availability”
- add the reference in the list of references
== Example of appendix subsection
#lorem(50)
] // end appendix
// post-sections, make sure to remove numbering
#set heading(numbering: none)
= Acknowledgements
This is your acknowledgments. Preprint version xxx[change to the correct number] of this article has been peer-reviewed and recommended by Peer Community In XYZ[change to the name of the PCI] (#link("https://doi.org/10.24072/pci.xxx")[https://doi.org/10.24072/pci.xxx] [replace by the doi of the recommendation]; #cite(<fake>, form: "prose") [replace by the citation of the recommendation]).
= Fundings
Declare your fundings. If your study has not been supported by particular
funding, please indicate "The authors declare that they have received no
specific funding for this study".
= Conflict of interest disclosure
The authors declare that they comply with the PCI rule of having no financial conflicts of interest in relation to the content of the article. [IF APPROPRIATE: The authors declare the following non-financial conflict of interest: XXX (if some of the authors are recommenders of a PCI, indicate it here)].
= Data, script, code, and supplementary information availability
Data are available online (#link("https://doi.org/10.24072/fake1")[https://doi.org/10.24072/fake1] [Replace by the DOI of the webpage hosting the data]; #cite(<CharleMar_independant-trace-su2_2012>, form: "prose") [Replace by the citation of the data])
Script and codes are available online (#link("https://doi.org/10.24072/fake2")[https://doi.org/10.24072/fake2] [Replace by the DOI of the webpage hosting the script and code]; #cite(<CharleMar_independant-trace-su2_2012>, form: "prose") [Replace by the citation of the script and code])
Supplementary information is available online (#link("https://doi.org/10.24072/fake3")[https://doi.org/10.24072/fake3] [Replace by the DOI of the webpage hosting the Supplementary information]; #cite(<CharleMar_independant-trace-su2_2012>, form: "prose") [Replace by the citation of the Supplementary information])
#v(1em)
The DOI hyperlinks should be active. They should also be present in the reference list and cited in the text.
For the reference section below, do not forget to add a doi for each reference (if available). Do not forget to add the reference of the recommendation, the reference of the data, scripts, code and supplementary material to your bib file, if appropriate.
|
https://github.com/Chasing1020/typst-cv-template | https://raw.githubusercontent.com/Chasing1020/typst-cv-template/main/README.md | markdown | Apache License 2.0 | # Typst CV template
This is a Typst template for a professional resume. The template is designed to be easy to customize and modify, allowing you to create a personalized and professional-looking resume in no time.
# Preview

# Features
- Clean and modern design
- Customizable text attributes
- Easy-to-use functions for formatting section content
- Responsive layout for printing and digital use.
# Usage
To use this template, you'll need to have Typst installed on your computer. Typst is available through several package managers:
```bash
# macOS
brew install typst
# Arch
pacman -S typst
```
Once you have Typst installed, you can use the typst command to generate a PDF file from the template:
```bash
# Use the command
typst resume.typ resume.pdf
# or just
make
```
# Customization
To customize the template for your own use, you can modify the following elements:
- Text attributes: Use the set text command to define the font, size, color, and other attributes for text elements.
- Icons: Use the let icon command to define custom icons for section headings. Currently this project uses [fontawesome](https://fontawesome.com/v4/license/).
- Section headings: Use the show heading command to format section headings.
- Section content: Use the set text command to format section content.
- Page layout: Use the set page command to define the paper size, margins, and other attributes of the resume.
# License
This template is released under the Apache License. See the [LICENSE](./LICENSE) file for more details.
# Credits
This template was created by [Chasing1020](https://github.com/Chasing1020). If you have any questions or feedback, please feel free to contact me at <EMAIL>.
|
https://github.com/Kasci/LiturgicalBooks | https://raw.githubusercontent.com/Kasci/LiturgicalBooks/master/RT/akatisty/akatistGojdic.typ | typst | #import "/style.typ": *
#import "../styleAkatist.typ": *
= Akatist k Presvätej Bohorodičke
#align(horizon + center)[#primText[
#text(40pt)[AKAFIST \
svjaščeno-\ mučenîkovî \
PAVLOVÎ PETROVÎ \
GOJĎIČOVÎ\
Prjašivskomu jepiskopovî ]
]]
#let akatist = (
(
"index": 1,
"kondak": [Ty uzriv svit v rodîňi Gojďičiv \* jak treťij syn pobožnych rodičiv \* - ňaňka Stefana i mamky Anny \* v seľi Rusky Pekľany. \* Zato, proslavlenyj vladyko, \* prosîme ťa tvojim rodnym jazykom: \* Vyprošaj od Hospoda zhory \* dar virnostî, ľubvî i pokory \* tym, što ľubľať tebe - archijereja svoho. \*\* Raduj sja, vladyko serdcja zlatoho! ],
"zvolanie": [Raduj sja, vladyko serdcja zlatoho! ],
"ikos": [Ty, vladyko, ďistav ľubov do daru \* od virnoho rodîčovskoho paru. \* Teper’ spomidži kryl anheľskych \* posmoť na našy pary manžeľsky \* i vypros’ jim mnoho blahodatî, \* naj znajuť ľubov rozdavatî. \* Naj znajuť plody ľubvi prijatî \* v manzeľskij čistoťi, bez potraťiv. \* Naj sja naroďať zdravy ďitî \* tym, što jich buduť od Boha prosîtî, \* žeby tak ďitî, jich ňaňko i matî \*\* mohlî ťa vjedno ospivovatî:],
"prosby": (
[Raduj sja, plode v ľubvi počatyj. ],
[Raduj sja, Božyj dare ľubo prijatyj.],
[Raduj sja, chlopče ľubvov plekanyj.],
[Raduj sja, synu Petrom nazvanyj.],
[Raduj sja, poticho od Boha dana.],
[Raduj sja, ďitîno svjato vychovana.],
[Raduj sja, prinošateľu Božoho blahoslovľiňa. ],
[Raduj sja, kvitko z rajskoho nasiňa.],
[Raduj sja, vladyko serdcja zlatoho.]
)
), (
"index": 2,
"kondak": [Peršy bukvy ty, vladyko, jak škoľar' stričav \* v bukvarju <NAME>. \* A jak jes' oddanyj do Božoj voľi \* uspišno zmaturovav v škoľi, \* poviv jes’ rodîčam i soklasnikam: \* Čuju poklîkaňa za svjaščenîka. \* Hospoď ňa čerez ľubov oslovľuje, \*\* poslucham i odpovim: Alîluja“ ],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [V škoľi ty, vladyko, byv dobrym študentom, \* od Boha obdarovanym talentom. \* Byv jes’ prikladom pro prîjateľiv, \* chvalîlî ťa učiteľi. \* Pros’ teper’ Ducha, što zyšov na apostoľiv, \* naj ďije v kazďij našij škoľi. \* Naj rozdavať svojich sim dariv \* i prosviščať našych škoľariv, \* bo onî vjedno z učîtelamî \*\* ospivujut’ ťa tyma slovamî:],
"prosby": (
[Raduj sja, vyznavateľu vičnoho Slova.],
[Raduj sja, prîklade pro každoho bohoslova.],
[Raduj sja, učenîku Velehrada.],
[Raduj sja, mudra ovečko Gorazdovoho stada.],
[Raduj sja, učiteľu pravdîvoj viry. ],
[Raduj sja, prîjateľu ochotnyj i ščiryj.],
[Raduj sja, ikono moralnostî. ],
[Raduj sja, knîho Solomonovoj mudrostî.],
[Radujsja, vladyko serdcja zlatoho],
)
), (
"index": 3,
"kondak": [ Svjaščenstvo ty prîjav v Priašivskij katedraľi, \* de ťa vysvjatîv svjatîteľ <NAME>ľij. \* A po časi tebe, molodoho dušpastyrja, \* prîjalî do Mukačevskoho monastyrja, \* a tak, zajedno z Božym planom, \* ty sja stav monachom-vasîlijanom. \* Tot čin monachiv zato Bohu ďakuje \*\* spivom anheľskoj pisňi: Alîluja. ],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Otče Petre, ty napovnenyj Božym strachom \* už jak svjaščenîk stav sja monachom. \* Teper' maš imena ver'chovnych apostoľiv, \* stojiš z nîma pri nebesňim prestoľi. \* Vypros' od Otcja všytkych otciv \* poklikaňa pro našych chlopciv, \* naj sja stanuť svjaščenîkamî i monachamî \*\* i tak ťa proslavľajuť vjedno z namî: ],
"prosby": (
[Raduj sja, slavo čina Vasîlijaňskoho.],
[Raduj sja, nasľidovnîku Vasîlija Velîkoho.],
[Raduj sja, natchnenyj misionarju.],
[Raduj sja, chvorych duš ľikarju.],
[Raduj sja, okraso vasîlijaňskych monastyriv.],
[Raduj sja, svitîlo našych duspastyriv.],
[Raduj sja, otče z nebom zvinčanyj.],
[Raduj sja, brate Pavlom nazvanyj.],
[Raduj sja, vladyko serdcja zlatoho! ],
)
), (
"index": 4,
"kondak": [V marci ťisjač devjaťsto dvadcjať semoho roku \* byv jes', otče, vysvjačenyj na vladyku \* jak virnyj syn našoho naroda, \* bo taka byla voľa Hospoda. \* Poťim namistnik Christa - otec' svjatyj \* tobi podarovav nahrudnyj krest zlatyj \* na znak kresťiv, kotryma ťa Hospoď obdaruje \*\* Ty ho prijav i ďakovav spivom: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [KMučenîku Pavle blahoslovlenyj, \* svjatym otcjom za vladyku ustanovlenyj \* pro svoju ľubov i dobrotu, \* prosîme ťa, vypovnî nam pros’bu totu:\* Vymoľ pro nas - grekokatolîkiv, \* tvojich dostojnych nastupnîkiv, \* kotry by za nas z ľubvov zastavali \*\* a vjedno z namî ťa tak ospivovalî: ],
"prosby": (
[Raduj sja, zlate serdce grekokatolîkiv.],
[Raduj sja, naďijo rodoľubnych virnîkiv.],
[Raduj sja, krasoto našoho obrjadu.],
[Raduj sja, perlo z nebesnoho pokladu.],
[Raduj sja, vladyko čistoho žyvota.],
[Raduj sja, chranîteľu svjatoho kivota.],
[Raduj sja, svjatîteľu virnyj Rîmu. ],
[Raduj sja, vjazňu bezbožnoho režimu.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 5,
"kondak": [Kolî ty, otče, stav sja vladykom, \* pomič podatî bylo tvojim zvykom. \* Ľuďom ubohym, no povnym doviry \* vse jes’ ščiro rozdavav ofiry, \* kolî ty chodîv na vizitaciji \* svojoj ľuboj Prjašivskoj eparchiji. \* Popros' Hospoda naj pomîluje \*\* tych, što i v nužďi spivajuť: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Tobi, vladyko, pomahala Prečista <NAME>, \* kotru ľubîv ty i tvoja eparchija. \* Ty jej prosîv za všytkych od velîka do mala, \* žeby každa parochija duchovno vzrostala. \* Pros', naj i nam pomože Boža Matî \*\* a my ťa budeme ospivovatî:],
"prosby": (
[Raduj sja, anhele našoho kraju.],
[Raduj sja, novočasnyj Nîkolaju.],
[Raduj sja, rossivateľu Božoj mîlostî.],
[Raduj sja, chranîteľu ľuďskoj dostojnostî.],
[Raduj sja, nasľidovnîku mîloserdnoho Samarijana.],
[Raduj sja, manno ščiro rozdavana.],
[Raduj sja, poťicho vdovic' i sirot.],
[Raduj sja, vladyko ľubîvšyj svij narod.],
[Raduj sja, vladyko serdcja zlatoho! ],
)
), (
"index": 6,
"kondak": [Kolî tu nastala „temna doba“ \* čekala ťa, vladyko, ťažka proba, \* bo tak ťi povilî zloslužyteľi zavzjaty: \* „Kiď chočeš archipastyrjom ostatî, \* ta zaveď svoji vivci do ľipšoho košara \* a svit'ska mic' sja o nîch i o tebe postarať.“ \* Ale ty poviv: „Ne nasľiduju Judu!“ \* A zato peredalî ťa, vladyko, sudu \* toty, što sja odreklî od Viruju, \*\* no ne znîščilî slavne: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Spovnîlo sja proroctvo Pija jedenadcjatoho \* - hotovľať kresty pro vladyku virnoho. \* Už sja i Čornyj orel ňimo čuduje \* tomu, što sja na Prjašivskim sobori rîchtuje, \* bo svit'ska mic' tam virnych grekokatolîkiv \* nasîlu vyholosîla za inšovirnîkiv. \* No ty sja, vladyko, ne dav zvestî \* zato ťa dnes' trîmame v čestî. \* Vypros' nam mnoho blahodatî, \* žeby s'me znalî viru utrîmatî, \* žeby s'me svoje vse sochraňalî \*\* a tobi z poďakov vse spivalî:],
"prosby": (
[Raduj sja, čiste sumľiňa Prjašivskoj eparchiji. ],
[Raduj sja, svitložaro vjazeňskoj keliji.],
[Raduj sja, svjatîteľu v oblečiňu vjazňa.],
[Raduj sja, žyva molîtvo prjazna.],
[Raduj sja, revo z Christovoho vînohradu.],
[Raduj sja, pastyrju virnyj svojomu stadu.],
[Raduj sja, baranku nemîloserdno strîženyj.],
[Raduj sja, vladyko strašno ponîženyj.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 7,
"kondak": [Na roskaz nasľidovnîkiv Pilata \* dalî ťa, vladyko, do ruk katam. \* Obvîňalî ťa, hanobîlî, \* mnohyma karami mukarîlî \* Ne dalî ťi odpočitî, \* ne perestavali ťa mučitî. \* No daremne bylo jich namahaňa, \* ne ďistalî tvoje nepravdîve prîznaňa, \* bo Hospoď Boh vse pidkripľuje tych, \*\* što virno spivajuť: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Do vjazňici v Prazi-Ruziňi \* zaperlî ťa, vladyko, ponevînňi. \* Tam mučiteľi-zloslužyteľi strohy \* vyprobovalî muky premnohy, \* žeby ťa mohlî usvidčitî \* i tverdyj rossudok vyholosîtî. \* No na jich bisidy pusty \* psalmy šeptali tvoji usta. \* Pomož i nam vyprosîtî \* dar vse prjazno sja molîtî, \* molîtvov Christa proslavľaťî \*\* a tebe tak ospivovatî:],
"prosby": (
[Raduj sja, vladyko mukamî pidkriplenyj.],
[Raduj sja, vjazňu pokorjanyj no nepokorenyj.],
[Raduj sja, tîchoholosnyj psalmospivče.],
[Raduj sja, ponevînňi uvjaznenyj dobroďijče.],
[Raduj sja, svidku dijavoľskoj zloby.],
[Raduj sja, obžalobo preťažkoj doby.],
[Raduj sja, vyterpiteľu nespravedlîvoj kary.],
[Raduj sja, bohoľubče v rukach varvariv.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 8,
"kondak": [Nespravedlîvyj rossudok sudu \* spečatîv tvoju krutu suďbu. \* „Bude vjazňom do kincja žyvota“- \* uznesla sja sudna porota. \* Tak jes', vladyko, začav u Valďicjach \* strastnu dorohu po vjazňicjach. \* No zo slovami: „Za svoju viru terpľu ja,“ \*\* chvalîv jes' Boha spivom: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Z Ruziňi, Valďic', Ilavy do Leopoldova \* perevažalî ťa, vladyko, v okovach. \* Zaznav jes' vysmich, ponîžovaňa,“ proklînaňa, opľuvaňa, znevažaňa. \* A choc' tak toptalî tvoji prava, \* ty svoje odpuščiňa všytkym davav \* a na totu velîku ľuďsku zlobu \* odpoviv jes' ľubvov až do hrobu. \* Pros' Boha, naj taku ľubov mame \* i my, što ťa tak pozdravľame:],
"prosby": (
[Raduj sja, žertvo sudciv besčestnych.],
[Raduj sja, prîjateľu ran bolestnych.],
[Raduj sja, novozavitnyj čestnyj Jove.],
[Raduj sja, blahe jahňatko Christove.],
[Raduj sja, pravdo krîvdov toptana.],
[Raduj sja, ľubov svitu rozdana.],
[Raduj sja, čašo strastej do dna vypîta.],
[Raduj sja, ružo v terňu roscvîta.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 9,
"kondak": [I v temnych vjazeňskych kelijach \* pidkripľala ťa, vladyko, presvjata Evcharistija. \* Daremny byli okovy i hroz'by -\* de byv ty, bylî peršochristijaňsky katakomby. \* Bo Christos vsjahdy navščivľuje \*\* tych, što v naďiji spivajuť: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Ty i vjazňiv vse pidkripľav rado \* duchovnym slovom dobrym prîkladom, \* a z velîkov ľubovjov \* hostîv jes' jich Božym ťilom i krovľov. \* Bo Christa ne zopruť stražny vežy \* anî micny kovany mrežy. \* Ty, vladyko, to dosvidčiv mnoho raz, \* prîhovor' sja u Hospoda i za nas, \* naj jak Bohu žyvy a hrichu mertvy \* tyž dostojny s'me toj bezkrovnoj žertvy, \* a kiď budeme joho Tajny prîčašcatî, \*\* ne zabudeme na ťa spomînatî:],
"prosby": (
[Raduj sja, sîlo z presvjatoj Evcharistiji.],
[Raduj sja, zvistovateľu naďiji.],
[Raduj sja, vjazňu čislo šisťsto visemdesjať jeden.],
[Raduj sja, stežko, što z tmy ku Svitlu vede. ],
[Raduj sja, vjazeňskyj Blahovistníku.],
[Raduj sja, Svitlonosnyj svičnîku.],
[Raduj sja, zlatoustyj propovidateľu.],
[Raduj sja, puťov pravdy sprovadžateľu.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 10,
"kondak": [Tvoja strastna puť, vladyko, u vjazňici skončila \* blaženym zasnuťom tvoho tila, \* bo ťi byla od našoho Hospoda \* dana tota velika blahodať, \* že jes' mih v spoviďi pľamy z dušy stertî \* poky jes' perešov branov smertî. \* A tak tvoja duša v Emavskij radostî, \* midži anhelamî u vičnostî \* svij deň narodžiňa oslavuje, \*\* ťišyť sja i sprvať: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Hospoď sobi cinîť smerť svojich prepodobnych - \* ľudej čestnych, virnych, pobožnych. \* I ty, vladyko, jak veľîkyj dobroďij, \* usnuv jes' blaženo v našim Hospodi \* čistyj, bez hrichovnoj provîny, \* v tot deň, kolî jes' mav narodeniny. \* Vymoľ i nam, perlo vasîlijaňskoho činu, \* blahu, pokijnu, bezhrišnu končinu, \* žeby s'me mohli čisty na Sud statî \* i my, kotry ťa trîmame v pamjatî:],
"prosby": (
[Raduj sja, vjazňu neskonavšyj nespoďivano.],
[Raduj sja, brate pomeršyj vyspovidano.],
[Raduj sja, rajska dušo blažena.],
[Raduj sja, ľubov boľom okrašena.],
[Raduj sja, virnyj sluho Carja Christa.],
[Raduj sja, mitro neoskvernena, čista.],
[Raduj sja, smilyj mužu terpiňa.],
[Raduj sja, svjateju z rusîňskoho koriňa.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 11,
"kondak": [Dva dňi po smertî, skoro rano, \* už bylo tvoje ťilo pochovane. \* Dali ťa jak zločincja do hrobu \* lem tak, bez dostojnoho pohrobu. \* Tak na ťim vjazeňskim cinterju v jami \* ležav jes', vladyko, midži zločincjami \* i čekav na „arimatejcja“ - otcja Marijana. \* A jak našij Cer'kvî byla sloboda dana, \* vin odviz tvoje ťilo na dostojne misce spokoja \* a poťim v dodži slyz zvučalo: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Vladyko, pochovalî ťa nedostojno, \* a to jak dezertera v časi vojny, \* choc' ty bojovatî ne perestav \* i nîgda jes' ne zyšov zo svoho kresta. \* Tabľičku z čislom ťi dalî na hrib a vece nîč, \* žeby jich ne strašylo imja Gojďič. \* No čerez zasluhu jeromonacha - vasîlijana, \* tvojomu mertvomu ťilu byla česť oddana, \* bo ono bylo z toho hroba vybrane \* a poťim v Prjašovi dostojno pochovane. \* My, virny, ťa tam, vladyko, navščivľame \*\* i vďačno ťi toto spivame:],
"prosby": (
[Raduj sja, archo ľubvî vorohamî oskvernena.],
[Raduj sja, tvar' svjatcja v mramori zvičnena.],
[Raduj sja, silo v sarkofagu katedraly.],
[Raduj sja, skalo z Petrovoj skaly.],
[Raduj sja, holose spravedlîvostî.],
[Raduj sja, žridlo bohobojnostî. ],
[Raduj sja, more čestnot premnohych.],
[Raduj sja, zorjo naďiji ubohych.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 12,
"kondak": [Vladyko Pavle v nebi oblažanyj \* ty už i na Zemľi zakonom opravdanyj \* a v Rimi, roku dva ťisjač peršoho, \* byv jes' vyhološenyj za blahoslovlenoho.\* Každyj grekokatolîk sja tomu raduje \*\* iz poďakov v serdci spivať: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": [Prečudesnyj je Hospoď v svojich svjatych! \* Vin ťi prîhotovîv nebesny komnaty \* a čerez stolec' <NAME> druhoho \* vyjavîv ťa svitu jak proslavlenoho. \* Vypros' i nam, blaženyj mučeníku, \* totu prepotrebnu ľubov velîku, \* naj sja čerez ňu v nebi radujeme \*\* i my, što ťa tak ospivujeme:],
"prosby": (
[Raduj sja, hordosť Kirila i Metoďija.],
[Raduj sja, vypovnîteľu Jevanhelija.],
[Raduj sja, luču slavy Spasîteľa. ],
[Raduj sja, žezlo Krestonosîteľa.],
[Raduj sja, molodnîku z rajskoho stroma.],
[Raduj sja, nasľidnîku novoho Edema.],
[Raduj sja, Žaro viry prejasna.],
[Raduj sja, naša zvizdo prekrasna.],
[Raduj sja, vladyko serdcja zlatoho!],
)
), (
"index": 13,
"kondak": [Čestnyj i virnyj synu našoho naroda, \* svojim žyvotom ty proslavîv Hospoda, \* bo ty od svojoj molodostî \* išov za holosom z vysokostî. \* Ty prîjav „ľube jar'mo“ Christa Boha \* a choc' ťa čekala strastna doroha, \* ty sja ne odrik od Apostoľskoho prestola, \* no podľa prîkladu Pavla apostola - \* dobri jes' bojovav, viru jes' utrîmav. \* Zato v slavi novoho Jerusalîma, \* vladyko Pavle, za mnohy terpiňa \* ďistav jes' vinec' proslavľiňa \* a ťišyš sja zo svitla v raju, \* de dušy svjatych perebyvajuť. \* Prîjmî našu poďaku z toho miscja svjatoho: \* Raduj sja, vladyko serdcja zlatoho \* i pros' Hospoda, kotryj vično carjuje, \*\* za tych, što vďačno spivajuť: Alîluja.],
"zvolanie": [Alîluja, alîluja, alîluja],
"ikos": none,
"prosby": none,
"velkost": 8pt,
"modlitba": "Dorohyj naš vladyko zlatoho serdcja, svitložaro grekokatolîkiv! Pronasľidovaňa, kotre ty zaznav v ťažkych časach neslobody, ne zlomîlî tvoju pevnu voľu. Ne padav jes' duchom a viru Christovu i našu Cer'kov ty smilo zastavav až do posľidňoho dychu svoho žyvota. Podľa rady našoho Hospoda ty položyv ruky na pluh a ne obzerav jes' sja nazad. Tvij bohobojnyj žyvot, starostlîvosť o tobi zvirene stado i ľubov ku všytkym ľuďom, nelem ku prîjateľam, no i ku neprijateľam, to je svitlo, kotre svitîlo ľuďom za tvoho žyvota, dnes' svitîť nam a bude svitîtî i budučim generacijam. Bo svitlo ľubvî je vične a nîjaka zlobna sîla temnoty ho ne zahasîť. Ľubyj naš svjaščenomučeniku Pavle, v tobi mame naďiju a čerez tebe prosime Hospoda o pomič v našych denno-denych trapľiňach, bolesťach, pokušiňach i pronasľidovaňach od lukavoho. Prosîme i o pomič pro našy christijaňsky rodîny, naj svitlo tvojoj dobroprîkladnostî prosvitîť serdcja všytkych tych našych braťiv i sester, kotry suť zatemneny nevirstvom, abo zyšlî z pravdîvoj dorohy do vičnostî. Pomož svojomu narodu a sochraňaj i utrîmaj ho pevnym v pravovirnostî, čerez čolovikoľubstvo jedînorodnoho Syna Božoho, kotromu zistav virnyj ty, a kotromu i my chočeme zistatî virny až do kincja našoho žyvota i naviky-vikiv."
)
);
#akatistGenerate(akatist)
|
|
https://github.com/LDemetrios/Typst4k | https://raw.githubusercontent.com/LDemetrios/Typst4k/master/src/test/resources/suite/text/edge.typ | typst | // Test top and bottom text edge.
--- text-edge ---
#set page(width: 160pt)
#set text(size: 8pt)
#let try(top, bottom) = rect(inset: 0pt, fill: conifer)[
// Warning: 19-34 unknown font family: ibm plex mono
#set text(font: "IBM Plex Mono", top-edge: top, bottom-edge: bottom)
From #top to #bottom
]
#let try-bounds(top, bottom) = rect(inset: 0pt, fill: conifer)[
// Warning: 19-34 unknown font family: ibm plex mono
#set text(font: "IBM Plex Mono", top-edge: top, bottom-edge: bottom)
#top to #bottom: "yay, Typst"
]
#try("ascender", "descender")
#try("ascender", "baseline")
#try("cap-height", "baseline")
#try("x-height", "baseline")
#try-bounds("cap-height", "baseline")
#try-bounds("bounds", "baseline")
#try-bounds("bounds", "bounds")
#try-bounds("x-height", "bounds")
#try(4pt, -2pt)
#try(1pt + 0.3em, -0.15em)
--- text-edge-bad-type ---
// Error: 21-23 expected "ascender", "cap-height", "x-height", "baseline", "bounds", or length, found array
#set text(top-edge: ())
--- text-edge-bad-value ---
// Error: 24-26 expected "baseline", "descender", "bounds", or length
#set text(bottom-edge: "")
--- text-edge-wrong-edge ---
// Error: 24-36 expected "baseline", "descender", "bounds", or length
#set text(bottom-edge: "cap-height")
|
|
https://github.com/sitandr/typst-examples-book | https://raw.githubusercontent.com/sitandr/typst-examples-book/main/src/packages/layout.md | markdown | MIT License | # Layouting
General useful things.
## Pinit: relative place by pins
The idea of [pinit](https://github.com/OrangeX4/typst-pinit) is pinning pins on the normal flow of the text, and then placing the content relative to pins.
```typ
#import "@preview/pinit:0.1.3": *
#set page(height: 6em, width: 20em)
#set text(size: 24pt)
A simple #pin(1)highlighted text#pin(2).
#pinit-highlight(1, 2)
#pinit-point-from(2)[It is simple.]
```
More complex example:
```typ
#import "@preview/pinit:0.1.3": *
// Pages
#set page(paper: "presentation-4-3")
#set text(size: 20pt)
#show heading: set text(weight: "regular")
#show heading: set block(above: 1.4em, below: 1em)
#show heading.where(level: 1): set text(size: 1.5em)
// Useful functions
#let crimson = rgb("#c00000")
#let greybox(..args, body) = rect(fill: luma(95%), stroke: 0.5pt, inset: 0pt, outset: 10pt, ..args, body)
#let redbold(body) = {
set text(fill: crimson, weight: "bold")
body
}
#let blueit(body) = {
set text(fill: blue)
body
}
// Main body
#block[
= Asymptotic Notation: $O$
Use #pin("h1")asymptotic notations#pin("h2") to describe asymptotic efficiency of algorithms.
(Ignore constant coefficients and lower-order terms.)
#greybox[
Given a function $g(n)$, we denote by $O(g(n))$ the following *set of functions*:
#redbold(${f(n): "exists" c > 0 "and" n_0 > 0, "such that" f(n) <= c dot g(n) "for all" n >= n_0}$)
]
#pinit-highlight("h1", "h2")
$f(n) = O(g(n))$: #pin(1)$f(n)$ is *asymptotically smaller* than $g(n)$.#pin(2)
$f(n) redbold(in) O(g(n))$: $f(n)$ is *asymptotically* #redbold[at most] $g(n)$.
#pinit-line(stroke: 3pt + crimson, start-dy: -0.25em, end-dy: -0.25em, 1, 2)
#block[Insertion Sort as an #pin("r1")example#pin("r2"):]
- Best Case: $T(n) approx c n + c' n - c''$ #pin(3)
- Worst case: $T(n) approx c n + (c' \/ 2) n^2 - c''$ #pin(4)
#pinit-rect("r1", "r2")
#pinit-place(3, dx: 15pt, dy: -15pt)[#redbold[$T(n) = O(n)$]]
#pinit-place(4, dx: 15pt, dy: -15pt)[#redbold[$T(n) = O(n)$]]
#blueit[Q: Is $n^(3) = O(n^2)$#pin("que")? How to prove your answer#pin("ans")?]
#pinit-point-to("que", fill: crimson, redbold[No.])
#pinit-point-from("ans", body-dx: -150pt)[
Show that the equation $(3/2)^n >= c$ \
has infinitely many solutions for $n$.
]
]
```
## Margin notes
```````typ
#import "@preview/drafting:0.1.1": *
#let (l-margin, r-margin) = (1in, 2in)
#set page(
margin: (left: l-margin, right: r-margin, rest: 0.1in),
)
#set-page-properties(margin-left: l-margin, margin-right: r-margin)
= Margin Notes
== Setup
Unfortunately `typst` doesn't expose margins to calling functions, so you'll need to set them explicitly. This is done using `set-page-properties` *before you place any content*:
// At the top of your source file
// Of course, you can substitute any margin numbers you prefer
// provided the page margins match what you pass to `set-page-properties`
== The basics
#lorem(20)
#margin-note(side: left)[Hello, world!]
#lorem(10)
#margin-note[Hello from the other side]
#lorem(25)
#margin-note[When notes are about to overlap, they're automatically shifted]
#margin-note(stroke: aqua + 3pt)[To avoid collision]
#lorem(25)
#let caution-rect = rect.with(inset: 1em, radius: 0.5em, fill: orange.lighten(80%))
#inline-note(rect: caution-rect)[
Be aware that notes will stop automatically avoiding collisions if 4 or more notes
overlap. This is because `typst` warns when the layout doesn't resolve after 5 attempts
(initial layout + adjustment for each note)
]
```````
```````typ
#import "@preview/drafting:0.1.1": *
#let (l-margin, r-margin) = (1in, 2in)
#set page(
margin: (left: l-margin, right: r-margin, rest: 0.1in),
)
#set-page-properties(margin-left: l-margin, margin-right: r-margin)
== Adjusting the default style
All function defaults are customizable through updating the module state:
#lorem(4) #margin-note(dy: -2em)[Default style]
#set-margin-note-defaults(stroke: orange, side: left)
#lorem(4) #margin-note[Updated style]
Even deeper customization is possible by overriding the default `rect`:
#import "@preview/colorful-boxes:1.1.0": stickybox
#let default-rect(stroke: none, fill: none, width: 0pt, content) = {
stickybox(rotation: 30deg, width: width/1.5, content)
}
#set-margin-note-defaults(rect: default-rect, stroke: none, side: right)
#lorem(20)
#margin-note(dy: -25pt)[Why not use sticky notes in the margin?]
// Undo changes from last example
#set-margin-note-defaults(rect: rect, stroke: red)
== Multiple document reviewers
#let reviewer-a = margin-note.with(stroke: blue)
#let reviewer-b = margin-note.with(stroke: purple)
#lorem(20)
#reviewer-a[Comment from reviewer A]
#lorem(15)
#reviewer-b(side: left)[Comment from reviewer B]
== Inline Notes
#lorem(10)
#inline-note[The default inline note will split the paragraph at its location]
#lorem(10)
/*
// Should work, but doesn't? Created an issue in repo.
#inline-note(par-break: false, stroke: (paint: orange, dash: "dashed"))[
But you can specify `par-break: false` to prevent this
]
*/
#lorem(10)
```````
```````typ
#import "@preview/drafting:0.1.1": *
#let (l-margin, r-margin) = (1in, 2in)
#set page(
margin: (left: l-margin, right: r-margin, rest: 0.1in),
)
#set-page-properties(margin-left: l-margin, margin-right: r-margin)
== Hiding notes for print preview
#set-margin-note-defaults(hidden: true)
#lorem(20)
#margin-note[This will respect the global "hidden" state]
#margin-note(hidden: false, dy: -2.5em)[This note will never be hidden]
= Positioning
== Precise placement: rule grid
Need to measure space for fine-tuned positioning? You can use `rule-grid` to cross-hatch
the page with rule lines:
#rule-grid(width: 10cm, height: 3cm, spacing: 20pt)
#place(
dx: 180pt,
dy: 40pt,
rect(fill: white, stroke: red, width: 1in, "This will originate at (180pt, 40pt)")
)
// Optionally specify divisions of the smallest dimension to automatically calculate
// spacing
#rule-grid(dx: 10cm + 3em, width: 3cm, height: 1.2cm, divisions: 5, square: true, stroke: green)
// The rule grid doesn't take up space, so add it explicitly
#v(3cm + 1em)
== Absolute positioning
What about absolutely positioning something regardless of margin and relative location? `absolute-place` is your friend. You can put content anywhere:
#context {
let (dx, dy) = (25%, here().position().y)
let content-str = (
"This absolutely-placed box will originate at (" + repr(dx) + ", " + repr(dy) + ")"
+ " in page coordinates"
)
absolute-place(
dx: dx, dy: dy,
rect(
fill: green.lighten(60%),
radius: 0.5em,
width: 2.5in,
height: 0.5in,
[#align(center + horizon, content-str)]
)
)
}
#v(1in)
The "rule-grid" also supports absolute placement at the top-left of the page by passing `relative: false`. This is helpful for "rule"-ing the whole page.
```````
## Dropped capitals
> Get more info [here](https://github.com/EpicEricEE/typst-plugins/tree/master/droplet)
### Basic usage
```typ
#import "@preview/droplet:0.1.0": dropcap
#dropcap(gap: -2pt, hanging-indent: 8pt)[
#lorem(42)
]
```
### Extended styling
```typ
#import "@preview/droplet:0.1.0": dropcap
#dropcap(
height: 2,
justify: true,
gap: 6pt,
transform: letter => style(styles => {
let height = measure(letter, styles).height
grid(columns: 2, gutter: 6pt,
align(center + horizon, text(blue, letter)),
// Use "place" to ignore the line's height when
// the font size is calculated later on.
place(horizon, line(
angle: 90deg,
length: height + 6pt,
stroke: blue.lighten(40%) + 1pt
)),
)
})
)[
#lorem(42)
]
```
## Headings for actual current chapter
> See [hydra](https://github.com/tingerrr/hydra)
```typ-nopreamble
#import "@preview/hydra:0.2.0": hydra
#set page(header: hydra() + line(length: 100%))
#set heading(numbering: "1.1")
#show heading.where(level: 1): it => pagebreak(weak: true) + it
= Introduction
#lorem(750)
= Content
== First Section
#lorem(500)
== Second Section
#lorem(250)
== Third Section
#lorem(500)
= Annex
#lorem(10)
``` |
https://github.com/OrangeX4/vscode-typst-sympy-calculator | https://raw.githubusercontent.com/OrangeX4/vscode-typst-sympy-calculator/main/README.md | markdown | MIT License | 
# Typst Sympy Calculator
## About
`Typst Sympy Calculator` parses **typst math expressions** and converts it into the equivalent **SymPy form**. Then, **calculate it** and convert to typst result.
It is designed for providing **people writing in typst** a ability to calculate something when writing math expression. It is based on `Python`, `Sympy` and [`typst-sympy-calculator`](https://github.com/OrangeX4/typst-sympy-calculator) module.
PS: If you want to install the extension, **PLEASE READ THE INSTALL DESCRIPTION!**
## Features
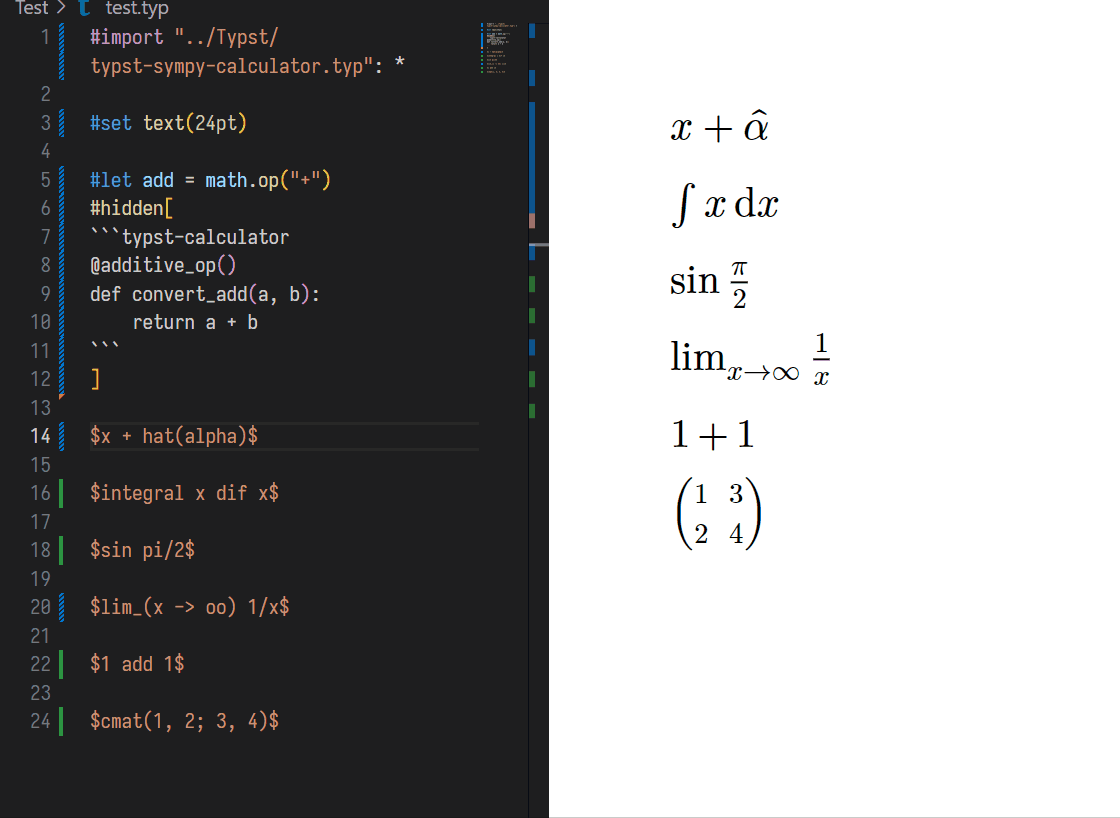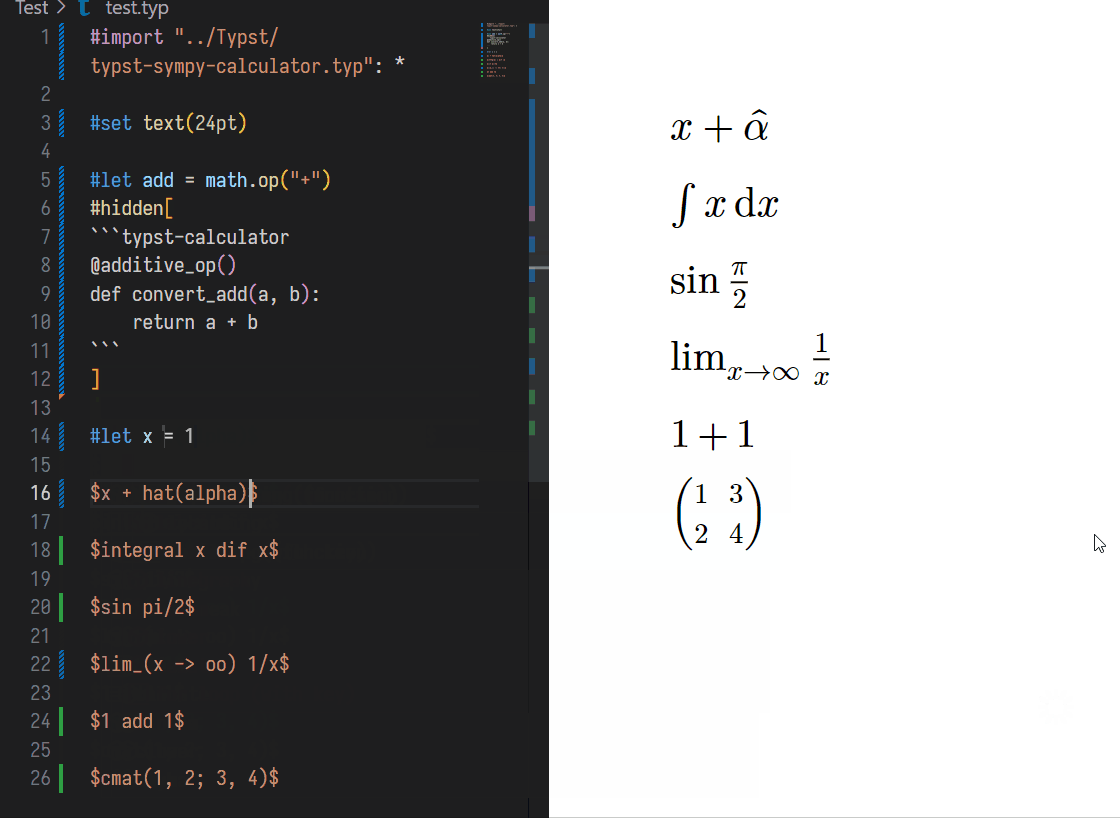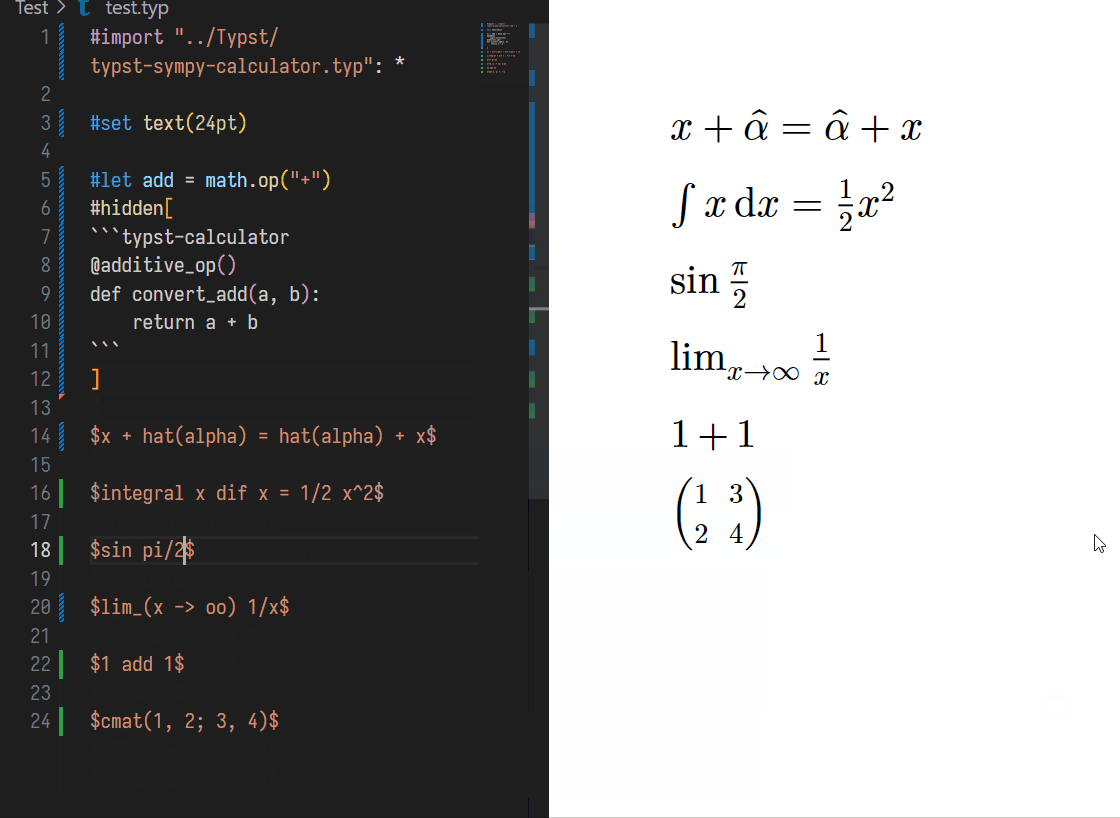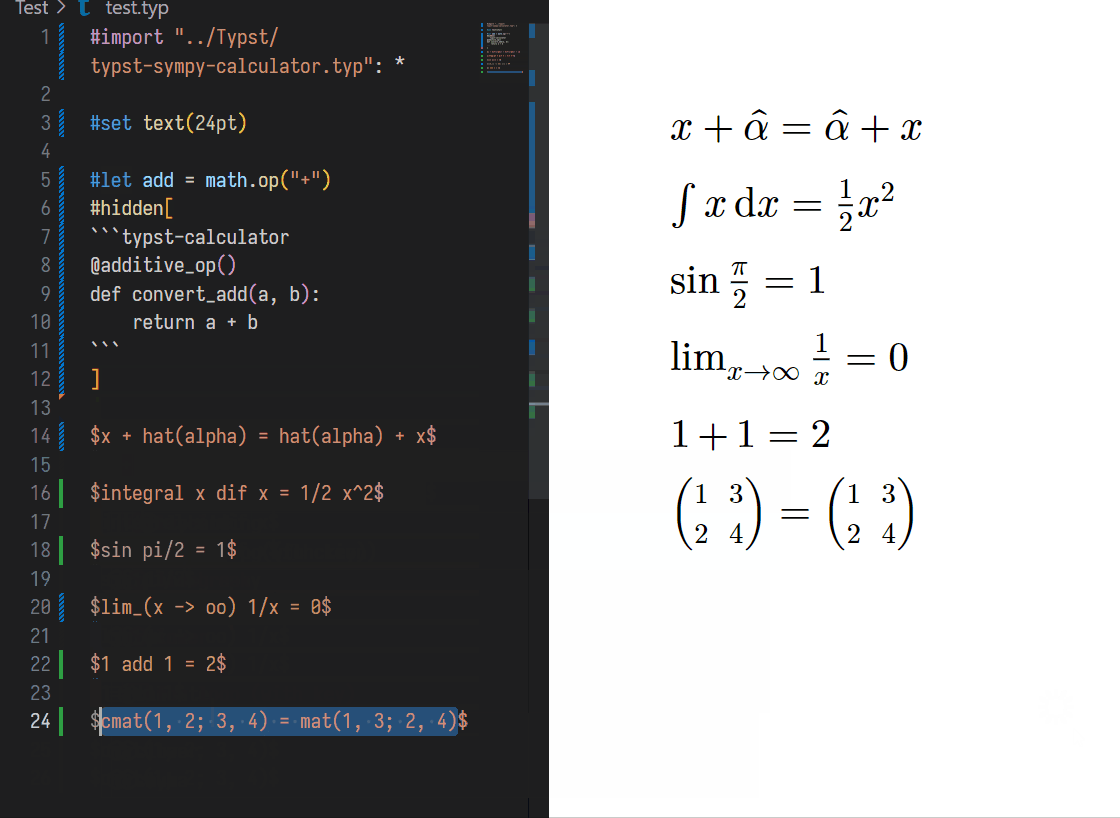
- **Default Math:**
- [x] **Arithmetic:** Add (`+`), Sub (`-`), Dot Mul (`dot`), Cross Mul (`times`), Frac (`/`), Power (`^`), Abs (`|x|`), Sqrt (`sqrt`), etc...
- [x] **Alphabet:** `a - z`, `A - Z`, `alpha - omega`, Subscript (`x_1`), Accent Bar(`hat(x)`), etc...
- [x] **Common Functions:** `gcd`, `lcm`, `floor`, `ceil`, `max`, `min`, `log`, `ln`, `exp`, `sin`, `cos`, `tan`, `csc`, `sec`, `cot`, `arcsin`, `sinh`, `arsinh`, etc...
- [x] **Funcion Symbol:** `f(x)`, `f(x-1,)`, `g(x,y)`, etc...
- [x] **Calculous:** Limit `lim_(x -> oo) 1/x`, Integration `integral_1^2 x dif x`, etc...
- [x] **Calculous:** Derivation (`dif/(dif x) (x^2 + 1)` is not supported, but you can use `derivative(expr, var)` instead), etc...
- [x] **Reduce:** Sum `sum_(k=1)^oo (1/2)^k`, Product `product_(k=1)^oo (1/2)^k`, etc...
- [x] **Eval At:** Evalat `x^2 bar_(x = 2)`, `x^2 "|"_(x = 2)`, etc...
- [x] **Linear Algebra:** Matrix to raw echelon form `rref`, Determinant `det`, Transpose `^T`, Inverse `^(-1)`, etc...
- [x] **Relations:** `==`, `>`, `>=`, `<`, `<=`, etc...
- [x] **Solve Equation:** Single Equation `x + 1 = 2`, Multiple Equations `cases(x + y = 1, x - y = 2)`, etc...
- [ ] **Logical:** `and`, `or`, `not`, etc...
- [ ] **Set Theory:** `in`, `sect`, `union`, `subset`, etc...
- [x] **Other:** Binomial `binom(n, k)` ...
- **Custom Math (in typst file):**
- [x] **Define Accents:** `#let acc(x) = math.accent(x, math.grave)`
- [x] **Define Operators:** `#let add = math.op("add")`
- [x] **Define Symbols:** `#let xy = math.italic("xy")` or `#let mail = symbol("🖂", ("stamped", "🖃"),)`
- [x] **Define Functions:**
```py
# typst-calculator
@func()
def convert_add(a, b):
return a + b
```
- **Typst Math Printer:**
- [x] Complete `TypstMathPrinter` in `TypstConverter.py`
- [ ] Custom Printer for `TypstCalculator.py` and `TypstCalculatorServer.py`
- **VS Code Extension:**
- [x] Develop a VS Code Extension for `Typst Calculator`
## Install
**IT IS IMPORTANT!**
**IT IS IMPORTANT!**
**IT IS IMPORTANT!**
Before you use the extension, please install python and two python modules: `typst-sympy-calculator` and `Flask`.
Install **Python** in [Python.org](https://www.python.org/), and then install **NECESSARY modules** by running:
```sh
pip install typst-sympy-calculator
pip install Flask
```
Then import the typst template file [`typst-sympy-calculator.typ`](https://github.com/OrangeX4/typst-sympy-calculator.typ) into your typst file. It will be like:
```typst
#import "typst-sympy-calculator.typ": *
```
This step is not necessary, but it can provide you with examples of custom functions.
## Usage

### Typst to Typst
You can **SELECT** some text, and press `Shift + Ctrl + Alt + E` (equal) to get the result of the selected Typst text. It will be like:
```typst
// Before
$ integral x dif x $
// After
$ integral x dif x = 1/2 x^2 $
```
You can **SELECT** some text, and press `Shift + Ctrl + Alt + R` (replace) to get the result of the selected Typst text. It will be like:
```typst
// Before
$ integral x dif x $
// After
$ 1/2 x^2 $
```
### Factor and Expand
You can **SELECT** some text, and press `Shift + Ctrl + Alt + F` (factor) to get the factor of the selected Typst text. It will be like:
```typst
// Before
$ x^2 + 2 x y + y^2 $
// After
$ (x + y)^2 $
```
If you are using **windows**, the shortcut `Shift + Ctrl + Alt + F` may be invalid, you can set another shortcut for it.
You can **SELECT** some text, and press `Shift + Ctrl + Alt + X` (expand) to get the expand of the selected Typst text. It will be like:
```typst
// Before
$ (x + y)^2 $
// After
$ x^2 + 2 x y + y^2 $
```
### Typst to Numerical Result
You can **SELECT** some text, and press `Shift + Ctrl + Alt + N` (numerical) to get the numerical result of the selected Typst text. It will be like:
```typst
// Before
sqrt(2)
// After
1.41421356237310
```
### Solve Equations and Inequations
You can **SELECT** some text, and press `Shift + Ctrl + Alt + S` (solve) to solve the equations of the selected Typst text. It will be like:
```typst
// Before
x + y = 1
// After
y = 1 - x, x = 1 - y
// Before
cases(x + y = 1, x - y = 1)
// After
cases(x = 1, y = 0)
// Before
x + 3 < 1
// After
-oo < x and x < -2
```
### Variances
You can **ASSIGN** variance a value using same assignment form in typst:
```typst
#let x = 1
// Before
$ x $
// Shift + Ctrl + E
// After
$ x = 1 $
```
PS: You can use grammar like `y == x + 1` to describe the relation of equality.
If you want to see the bonding of variances, you can press `Shift + Ctrl + P`, and input `typst-sympy-calculator: Show Current variances`, then you will get data like:
```typst
y = x + 1
z = 2 x
```
### Functions
You can **DEFINE** a function using same form in typst:
```typst
#let f = math.op("f")
// Before
$ f(1) + f(1) $
// Shift + Ctrl + E
// After
$ f(1) + f(1) = 2 f(1) $
```
### Symbols
You can **DEFINE** a symbol using same form in typst:
```typst
#let xy = math.italic("xy")
#let email = symbol("🖂", ("stamped", "🖃"),)
$ xy + email + email.stamped $
```
### Accents
You can **DEFINE** a accent using same form in typst:
```typst
#let acc(x) = math.accent(x, math.grave)
$ acc(x) $
```
### Decorators for Operators
You can **DEFINE** a operator using same form in typst:
```typst
#let add = math.op("+")
'''typst-calculator
@additive_op()
def convert_add(a, b):
return a + b
'''
// Before
$ 1 add 1 $
// Shift + Ctrl + E
// After
$ 1 add 1 = 2 $
```
Or just use `'''typst-sympy-calculator` or `'''python \n # typst-calculator` to define a operator.
there are some decorators you can use:
- `@operator(type='ADDITIVE_OP', convert_ast=convert_ast, name=name, ast=False)`: Define a common operator;
- `@func()`: Define a function, receive args list;
- `@func_mat()`: Define a matrix function, receive single arg `matrix`;
- `@constant()`: Define a constant, receive no args but only return a constant value;
- `@relation_op()`: Define a relation operator, receive args `a` and `b`;
- `@additive_op()`: Define a additive operator, receive args `a` and `b`;
- `@mp_op()`: Define a multiplicative operator, receive args `a` and `b`;
- `@postfix_op()`: Define a postfix operator, receive args `a`;
- `@reduce_op()`: Define a reduce operator, receive args `expr` and `args = (symbol, sub, sup)`;
It is important that the function name MUST be `def convert_{operator_name}`, or you can use decorator arg `@func(name='operator_name')`, and the substring `_dot_` will be replaced by `.`.
There are some examples (from [DefaultTypstCalculator.py](https://github.com/OrangeX4/typst-sympy-calculator/blob/main/DefaultTypstCalculator.py)):
```python
# Functions
@func()
def convert_binom(n, k):
return sympy.binomial(n, k)
# Matrix
@func_mat()
def convert_mat(mat):
return sympy.Matrix(mat)
# Constants
@constant()
def convert_oo():
return sympy.oo
# Relation Operators
@relation_op()
def convert_eq(a, b):
return sympy.Eq(a, b)
# Additive Operators
@additive_op()
def convert_plus(a, b):
return a + b
# Mp Operators
@mp_op()
def convert_times(a, b):
return a * b
# Postfix Operators
@postfix_op()
def convert_degree(expr):
return expr / 180 * sympy.pi
# Reduces
@reduce_op()
def convert_sum(expr, args):
# symbol, sub, sup = args
return sympy.Sum(expr, args)
```
### Python
You can calculate a python expression by `Shift + Ctrl + Alt + P`.
**You can use all sympy expression in it.**
For example, you can get variances you assigned by:
``` python
# Before
typst(var['y'])
# After
typst(var['y']) = x + 1
```
Calculator the roots of the equation:
``` python
# Before
sympy.solve([2 * x - y - 3, 3 * x + y - 7],[x, y])
# After
sympy.solve([2 * x - y - 3, 3 * x + y - 7],[x, y]) = {x: 2, y: 1}
```
## Thanks
- [augustt198 / latex2sympy](https://github.com/augustt198/latex2sympy)
- [purdue-tlt / latex2sympy](https://github.com/purdue-tlt/latex2sympy)
- [ANTLR](https://www.antlr.org/)
- [Sympy](https://www.sympy.org/en/index.html)
## License
This project is licensed under the MIT License. |
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/circuiteria/0.1.0/src/gates.typ | typst | Apache License 2.0 | #import "elements/logic/gate.typ": gate
#import "elements/logic/and.typ": gate-and, gate-nand
#import "elements/logic/or.typ": gate-or, gate-nor
#import "elements/logic/xor.typ": gate-xor, gate-xnor
#import "elements/logic/buf.typ": gate-buf, gate-not |
https://github.com/YDX-2147483647/herglotz | https://raw.githubusercontent.com/YDX-2147483647/herglotz/main/README.md | markdown | # Herglotz Trick and more
## Compile
```shell
python -m pseudonym
typst compile herglotz.typ
typst compile cantor.typ
typst compile fourier.typ
```
`pseudonym/hashes.csv` and `fig/` are available at [the release][release].
[release]: https://github.com/YDX-2147483647/herglotz/releases/latest "Latest release"
## 补充
丁玖《[美丽而“无用”的莫比乌斯反演,解决了一类物理问题](https://mp.weixin.qq.com/s/S4Xv8_zJE_4DyrO5IKXo-A)》也介绍了Möbius反演等。与[`fourier.typ`](./fourier.typ)相比,这篇文章更单调,但也更丰富。
|
|
https://github.com/wildfire322/typst-x86_64-pc-windows-msvc | https://raw.githubusercontent.com/wildfire322/typst-x86_64-pc-windows-msvc/main/1.typ | typst | #set page(
paper:"a4",
margin:(
x:2cm,
y:2cm
),
header: align(center,text(30pt)[普物复习])
)
#set text(
size : 12pt,
font: "Times New Roman"
)
#set heading(numbering: "1.")
#set par(justify: true)
= math
== 基础
$ v=(dif x)/(dif t)=accent(x,.) $\
$ a=dot.double(x)=(dif v)/(dif t)=(dif^2 x)/(dif t^2) $\
== cross product:
$ A times (B plus C)=A times B+ A times C $\
$ (dif (A times B))/(dif t)=A (dif B)/(dif t)+B (dif A)/(dif t) $\
$ a times b=|a||b|sin(theta)hat(n) $\
#set math.mat(delim:"|")
could also be written as:$ mat(hat(i),hat(j),hat(k);a_1,a_2,a_3;b_1,b_2,b_3) $\
if $ a eq a_1 hat(i)+a_2 hat(j)+a_3 hat(k) $ #align(center)[while the same to b]
== 极坐标:
$ accent(r,hat),accent(phi.alt,hat) $\
== 三维平面
#figure(
image("2.png",width: 40%),
caption:[三维平面]
)\
$ r=(x,y,z) $
$ x&=r sin(theta) cos(phi) \
y&=r sin(theta) sin(phi) \
z&=r cos(theta) $
= 各种运动
\
\
#figure(
image("1.png",width: 40%),
caption:[PPT示例]
)\
$ l^2 =x^2 plus y^2 $
#align(center)[因为l是常量,所以有]
$ 2 x dif x plus 2 y dif y=0& \
(dif x)/(dif t) x+(dif y)/(dif t) y=0& \
v_x /v_y= -y/x =minus tan(theta) &
$\
#figure(
image("3.png",width: 60%),
caption:[圆周运动坐标系]
)\
#figure(
image("4.png",width: 60%),
caption:[非匀速的圆周运动加速度分析]
)\
\
\
\
圆锥摆:\
#figure(
image("5.png",width: 60%),
)\
$ I=integral r^2 dif m $此即转动惯量\
\
= 牛顿定律
== 惯性系(Inertial)与非惯性系 (Non-Inertial)
伽利略变换 :from Inertial to Non-Inertial\
$ arrow(r^')&=arrow(r)-arrow(v_0) dot t\
arrow(v^')&=arrow(v)-arrow(v_0)\
arrow(a^')&=arrow(a)\ $
== 流体阻力
低速下:$ F=-b v $\
高速下:$ F=-c v^2 $\
低速稳态解:$v_t"指"v_"terminal"$\
$ v_t=m g /b $
令$ tau=m /b=v_t/g $
则任意时刻速度为:$ v=v_t (1-e^(-t/tau)) $
$ a=(dif v)/(dif t)=g e^(-t/tau) $\
高速下:
#figure(
image("6.png",width: 60%),
)
例题一:
#figure(
image("9.png",width: 60%),
)
\
#figure(
image("8.png",width: 60%),
)
\
例题二:
#figure(
image("10.png",width: 60%),
)\
#figure(
image("11.png",width: 60%),
)\
== 功与动能
$ W=integral_(r_i)^r_f F dot dif r $\
== 机械能守恒
$ E=K+U="Constant" $\
稳定平衡(stable equilibrium)是系统能量的最小值点,也即$ (dif U)/(dif x)=0 "并且" (dif^2 U)/(dif x^2)>0 $\
同样,不稳定平衡(unstable equilibrium)是系统能量的最大点,也即$ (dif U)/(dif x)=0 "并且" (dif^2 U)/(dif x^2)<0 $\
== 势能
势能要求力是保守力(conservative),即力做的功与路径无关\
\
$ U=-integral F dot dif r $\
万有引力: \
$ &F=-G(m_1 m_2)/(r^2)=minus (dif U)/(dif r)\
&U=minus G(m_1 m_2)/r
$\
开普勒定律:Orbital period:$ T=2pi sqrt(a^3/(G(m_1+m_2))) $,i.e. $ T^2 prop a^3 $\
在距离地球中心为r的轨道稳定运行所具有的能量: $ E=minus G(m_1 m_2)/(2r) $\
Escaped speed: $ v=sqrt((2 G m_1)/r) $\
from:$ 1/2 m v^2 -(G M m) / r=0 $
火箭发射:$ v_f=v_i+u ln(M_i/M_f) $\
其中,$u$为燃料速度,$M_i$为初始质量,$M_f$为最终质量\
火箭的推力(thrust):$ F=(dif m)/(dif t) u $\
例题\
\
#figure(
image("30.png",width: 60%),
caption: "PPT例题"
)<\
\
== 动量
Impulse: $ I=integral_(t_i)^t_f arrow(F) dot dif t $\
$ arrow(p)=m arrow(v) $\
注意弹性碰撞和非弹性碰撞中动量与动能情况\
在两种碰撞中,动量均守恒,完全非弹性碰撞损失能量最多。对于完全弹性碰撞,如图:\
#figure(
image("12.png",width: 60%),
caption:[完全弹性碰撞]
)\
注意:每当两个相同质量的物体发生弹性碰撞且其中一个最初处于静止状态时,它们的最终速度总是彼此成直角。
\
== 转动
$ omega =(dif theta)/(dif t)\
alpha=(dif omega)/(dif t)=(dif^2theta)/(dif t^2) $
\
\
叉乘的右手定则\
\
方向:
#figure(
image("14.png",width: 60%),
)\
$ arrow(v)=arrow(r) times arrow(omega)\
arrow(tau)=arrow(r) times arrow(F)\
i.e.\
arrow(r) =I alpha hat(omega)\
tau =I alpha $\
$ W = integral_(theta_i)^theta_f tau dif theta=1/2 I omega_f^2-1/2 I omega_i^2
\
P=(dif W)/(dif t)=tau omega
$\
转动惯量:$ I= sum_(i) m_i r_(i)^2 $
$ K_R = 1/2 I omega^2 $
常用转动惯量:\
#set align(center)
#table(
columns: (auto,auto,auto),
inset: 10pt,
align: center,
[*几何体*],[*转动惯量*],[*图片*],
"实心圆柱体",$ I=1/2 M R^2 $ ,image("22.png",width: 40%),
"圆环",$ I=M R^2 $,"none",
"薄球壳",$ I=2/3 M R^2 $,image("17.png",width: 40%),
"实心球体",$ I=2/5 M R^2 $,image("18.png",width: 40%),
"棒绕中心点转动",$ I=1/12 M L^2 $,image("15.png",width: 40%),
"棒绕一端转动",$ I=1/3 M L^2 $,image("16.png",width: 40%),
"圆柱壳",$ I= M R^2 $,image("19.png",width: 40%),
"中空圆柱",$ I=1/2 M (R_1^2+R_2^2) $,image("20.png",width: 40%),
"矩形盘",$ I=1/12 M (a^2+b^2) $,image("21.png",width: 40%),
)
#set align(left)
== 角动量
$ tau =(dif L)/(dif t) $
$ arrow(L)&=arrow(r) times arrow(p)\
&=I arrow(omega) $\
P,W分别为功率与功
$ P=(dif W)/(dif t)=tau omega $\
$ W=tau theta $\
\
如果外力矩为零,则角动量守恒\
*注意:角动量的计算依赖于原点的选取*
\
== 例题
#figure(
image("25.png",width: 60%),
)\
#figure(
image("23.png",width: 60%),
)\
#figure(
image("24.png",width: 60%),
)\
another one \
#figure(
image("26.png",width: 60%),
)\
#figure(
image("27.png",width: 60%),
)\
#figure(
image("28.png",width: 60%),
)\
#figure(
image("29.png",width: 60%),
)\
== 质心
$ arrow(r_"CM")=1/M sum_(i) m_i arrow(r_i)=1/M integral r dif m $\
对于非均匀的物体,如图
#figure(
image("13.png",width: 60%)
)
\
\
$ arrow(v_"CM")=1/M sum_(i) m_i arrow(v_i) $\
$ K=K_"CM" plus K^'=1/2 M v_"CM"^2+1/2 sum_(i)m_i (arrow(v_i)-arrow(v_"CM"))^2 $\
平行轴定理:$ I=I_"CM"+M h^2 $\
= 简谐运动
$ x - x_0= A cos(omega t plus phi.alt), $where omega equals to $sqrt(k/m)$\
形如$ dot.double(x)+omega^2 x=0 $的解为:
$ x=A cos(omega t plus phi.alt) $\
= Waves
right moving wave: $ y(x,t)=A cos(x-v t) $\
left moving wave: $ y(x,t)=A cos(x+v t) $\
principle of superposition: $ y^' (x,t)=y_1(x,t)+y_2(x,t) $\
对于线性波(linear wave)
$ (diff^2 y)/(diff t^2)=v^2 (diff^2 y)/(diff x^2) $\
$ v = sqrt(T/mu) $v为波传播的速度,T为张力,$mu$为线密度\
= sinusoidal wave
$ y(x,t)=A cos(k x-omega t plus phi.alt) $\
$ v = omega/k =lambda /T $\
interference: $ y(x,t)=A cos(k x-omega t plus phi)+A cos(k x-omega t ) \
=2A cos(phi/2) sin(k x -omega t +phi/2) $\
相长:$ phi_1-phi_2=laplace phi=2pi n $\
相消:$ phi_1-phi_2=laplace phi=(2n+1)pi $\
Beat(频率不同的线性波的暂时干涉)\
$ lambda^' dash.wave (2pi v)/(laplace omega"/"2) $\
$ f_("beat") eq (laplace omega)/(2pi) $
== standing wave
$ y_1&=A sin(k x- omega t) \
y_2&=A sin(k x+ omega t) \
y&=y_1 plus y_2=A sin(k x) cos(omega t) \
$
nodes and antinodes
- node:波节,$ k x = n pi $
- antinode:波腹,$ k x = (2n+1) pi/2 $
== Sound Waves
Intensity: $ I=P/(4 pi r^2)=1/2 rho v omega^2 s_(m)^2 $\
for a wave:$ S(x,t)=S_m cos(k x-omega t) $\
Sound lever : $ beta=10 lg(I/I_0) $\
$ I_0=1 times 10^"-12" W"/"m^2 $
Doppler effect: $ f^' =f (v plus.minus v_s)/(v plus.minus v_r) $\
其中,$v_s$为观察者速度,$v_r$为声源速度,$v$为声速\
= 相对论
== 速度合成
在非相对论体系下,速度合成为:$ w =v plus u $\
其中,_w_可以当作是物体相对于地面的速度,_v_是物体相对于火车的速度,_u_是火车相对于地面的速度。\
但当速度接近光速时,速度合成公式为:$ w = (v plus u)/(1 plus (v u)/c^2) $\
|
|
https://github.com/mariunaise/HDA-Thesis | https://raw.githubusercontent.com/mariunaise/HDA-Thesis/master/graphics/plots/bach/help.typ | typst | #import "@preview/cetz:0.2.2": canvas, plot
#let data2 = csv("../../../data/errorrates/bach/errorrates2.csv")
#let ndata2 = data2.map(value => value.map(v => calc.log(float(v))))// fucking hell is that cursed
#let data4 = csv("../../../data/errorrates/bach/errorrates4.csv")
#let ndata4 = data4.map(value => value.map(v => calc.log(float(v))))
#let formatter(v) = [$10^#v$]
#let dashed = (stroke: (dash: "dashed"))
#canvas({
plot.plot(size: (10,5),
x-tick-step: none,
////x-ticks: ((0.04, [2]),(2, [100])),
y-label: $"Bit error rate"$,
x-label: $s$,
y-tick-step: none,
x-max: 1,
//y-ticks : (
// (-1.5, calc.exp(-1.5)),
//),
y-max: 1,
y-format: formatter,
axis-style: "left",
{
plot.add((ndata2), line: "spline", label: [2-bit BER])
plot.add((ndata4), line: "spline", label: [4-bit BER])
})
})
|
|
https://github.com/mem-courses/linear-algebra | https://raw.githubusercontent.com/mem-courses/linear-algebra/main/homework/linear-algebra-homework3.typ | typst | #import "../template.typ": *
#show: project.with(
title: "Linear Algebra Homework #3",
authors: (
(name: "<NAME> (#95)", email: "<EMAIL>", phone: "3230104585"),
),
date: "October 11, 2023",
)
= P36 习题二 12(3) #ac
#prob[
计算行列式的值:
$ mat(
2,0,dots.c,0,2;
-1,2,dots.c,0,2;
dots.v,dots.v,,dots.v,dots.v;
0,0,dots.c,2,2;
0,0,dots.c,-1,2;
)_n $
]
$
D
&= a_(1 n) A_(1 n) + a_(2 n) A_(2 n) + dots.c + a_(n n) A_(n n)\
&= 2 sum_(i=1)^n 2^(i-1) (-1)^(n-i) (-1)^(i+n)\
&= sum_(i=1)^n 2^i = 2^(n+1)-2
$
= P36 习题二 12(8) #ac
#prob[
计算行列式的值:
$ mat(
space x,y,0,dots.c,0,0 space;
space 0,x,y,dots.c,0,0 space;
space 0,0,x,dots.c,0,0 space;
space dots.v,dots.v,dots.v,,dots.v,dots.v space;
space 0,0,0,dots.c,x,y space;
space y,0,0,dots.c,0,x space;
)_n $
]
$
D_n
&= a_(11) A_(11) + a_(12) A_12\
&= (-1)^(1+1) x mat(
x,y,dots.c,0,0;
0,x,dots.c,0,0;
dots.v,dots.v,,dots.v,dots.v;
0,0,dots.c,x,y;
0,0,dots.c,0,x;
) + (-1)^(1+2) (-1)^(n-2) y mat(
y,0,dots.c,0,0;
x,y,dots.c,0,0;
dots.v,dots.v,,dots.v,dots.v;
0,0,dots.c,y,0;
0,0,dots.c,x,y;
) \
&= x^n + (-1)^(n-1) y^n
$
= P37 习题二 12(9) #ac
#prob[
计算行列式的值:
$ mat(
x,-1,0,dots.c,0,0;
0,x,-1,dots.c,0,0;
0,0,x,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
0,0,0,dots.c,x,-1;
a_n,a_(n-1),a_(n-2),dots.c,a_2,a_1+x;
) $
]
$
D_n
&= mat(
x,-1,0,dots.c,0,0;
0,x,-1,dots.c,0,0;
0,0,x,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
0,0,0,dots.c,x,-1;
0,0,0,dots.c,0,x;
) + mat(
x,-1,0,dots.c,0,0;
0,x,-1,dots.c,0,0;
0,0,x,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
0,0,0,dots.c,x,-1;
a_n,a_(n-1),a_(n-2),dots.c,a_2,a_1;
)\
&= x^n + sum_(i=1)^n a_i x^(n-i) (-1)^(i-1) (-1)^(n-i+1+n)\
&= x^n + sum_(i=1)^n a_i x^(n-i)
$
= P37 习题二 12(11) #ac
#prob[
计算行列式的值:
$ mat(
1,1,1,dots.c,1;
2,2^2,2^3,dots.c,2^n;
3,3^3,3^3,dots.c,3^n;
dots.v,dots.v,dots.v,,dots.v;
n,n^2,n^3,dots.c,n^n;
) $
]
令 $display(|bold(A')|=mat(
1,0,0,0,dots.c,0;
1,1,1,1,dots.c,1;
1,2,2^2,2^3,dots.c,2^n;
1,3,3^3,3^3,dots.c,3^n;
1,dots.v,dots.v,dots.v,,dots.v;
1,n,n^2,n^3,dots.c,n^n;
))$,有 $D'=(-1)^(1+1) a'_(11)A'_11=D$.
根据 Vandermonde 行列式,可以得到:
$
D_n
= product_(0<=i<j<=n) (j-i)
= product_(i=1)^n i^(n-i+1)
$
#note[也可以提出每一行的公因子,共 $n!$.剩下的恰为 Vandermonde 矩阵.]
= P37 习题二 13 #ac
#prob[
设 $display(D_n = mat(
1,2,3,dots.c,n-1,n;
1,1,0,dots.c,0,0;
1,0,1,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
1,0,0,dots.c,1,0;
1,0,0,dots.c,0,1;
))$,计算 $D_n$ 及 $t_1 A_(11) + t_2A_12 + dots.c + t_n A_(1 n)$,这里 $A_(i j)$ 为 $D_n$ 的第 $i$ 行第 $j$ 列元素的代数余子式.
]
$
D_n=product_(i=2)^n -(i-1) = (-1)^(n-1) dot (n-1)!
$
$
t_1 A_(11) + t_2A_12 + dots.c + t_n A_(1 n)
=& mat(
t_1,t_2,t_3,dots.c,t_(n-1),t_n;
1,1,0,dots.c,0,0;
1,0,1,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
1,0,0,dots.c,1,0;
1,0,0,dots.c,0,1;
)\
=& mat(
t_1-sum_(i=2)^n t_i,t_2,t_3,dots.c,t_(n-1),t_n;
0,1,0,dots.c,0,0;
0,0,1,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
0,0,0,dots.c,1,0;
0,0,0,dots.c,0,1;
)\
=& t_1-sum_(i=2)^n t_i
$
= P37 习题二 14 #pc
#prob[
计算行列式
$ mat(
1,1,dots.c,1,1;
x_1,x_2,dots.c,x_(n-1),x_n;
dots.v,dots.v,,dots.v,dots.v;
x_1^(n-2),x_2^(n-2),dots.c,x_(n-1)^(n-2),x_n^(n-2);
x_1^n,x_2^n,dots.c,x_(n-1)^n,x_n^n;
) $
]
$
D_n
=& sum_(k=1)^n x_k^n (-1)^(k+n) A_(k,n) \
=& sum_(k=1)^n x_k^n (-1)^(k+n) sum_(1<=i<j<=n\ i!=k and j != k) (x_j-x_i) \
=& (-1)^n sum_(1<=i<j<=n) (x_j-x_i) (sum_(k=1)^n (-1)^k x_k - (-1)^i x_i - (-1)^j x_j)
$
#warn[
考虑 $display(A_(n+1) = mat(
1,1,dots.c,1,1,1;
x_1,x_2,dots.c,x_(n-1),x_n,y;
dots.v,dots.v,,dots.v,dots.v,dots.v;
x_1^(n-2),x_2^(n-2),dots.c,x_(n-1)^(n-2),x_n^(n-2),y^(n-2);
x_1^(n-1),x_2^(n-1),dots.c,x_(n-1)^(n-1),x_n^(n-1),y^(n-1);
x_1^n,x_2^n,dots.c,x_(n-1)^n,x_n^n,y^n;
) = product_(i=1)^n (y-x_i) product_(1<=j<k<=n) (x_k-x_j))$.
题设行列式 $D_n$ 是 $A_(n+1)$ 中对应项的余子式.故:
$
(-1)^(n+n+1) D_n =
-sum_(i=1)^n x_i product_(1<=j<k<=n) (x_k-x_j)
$
所以 $display(D_n = sum_(i=1)^n product_(1<=j<k<=n) (x_k-x_j))$.
]
= P38 习题二 16(4) #ac
#prob[
利用 Laplace 定理计算行列式的值:
$ mat(
1,b,c,0,0,0;
0,0,3,0,0,0;
a_11,a_12,a_13,0,2,d;
a_21,a_22,a_23,0,0,1;
a_31,a_32,a_33,3,e,f;
0,2,g,0,0,0;
) $
]
$
mat(
1,b,c,0,0,0;
0,0,3,0,0,0;
a_11,a_12,a_13,0,2,d;
a_21,a_22,a_23,0,0,1;
a_31,a_32,a_33,3,e,f;
0,2,g,0,0,0;
) =& (-1)^3 mat(
1,b,c,0,0,0;
0,0,3,0,0,0;
0,2,g,0,0,0;
a_11,a_12,a_13,0,2,d;
a_21,a_22,a_23,0,0,1;
a_31,a_32,a_33,3,e,f;
)\ =& (-1)^3 (-1)^((3 times 2)/2) mat(
1,b,c;
0,0,3;
0,2,g;
) mat(
0,2,d;
0,0,1;
3,e,f;
)\ =& 36
$
= P39 习题二 24 #ac
#prob[
问 $a,b,c$ 满足什么条件时,线性方程组
$ cases(
x &&+y &&+z &&=a+b+c,
a x &&+b y &&+c z &&=a^2+b^2+c^2,
b c x&&+a c y&&+a b z&&=3a b c,
) $
有唯一解,并求出该解.
]
求线性方程组的系数矩阵的行列式:
$
|bold(D)|
=& mat(
1,1,1;
a,b,c;
b c,a c,a b;
) = mat(
1,1,1;
0,b-a,c-a;
0,-c(b-a),-b(c-a);
)\ =& mat(
1,1,1;
0,b-a,c-a;
0,0,(c-b)(c-a);
)\ =& (b-a)(c-a)(c-b)
$
根据 Cramer 法则,当且仅当 $a,b,c$ 互异时,原线性方程组有唯一解.
对原线性方程组的系数矩阵的增广矩阵应用初等行变换得
#set math.mat(delim: "(")
$
bold(A) &= mat(
1,1,1,a+b+c;
a,b,c,a^2+b^2+c^2;
b c,a c,a b,3a b c;
)\ &xarrow(R_2-a R_1\ R_3-b c R_1) mat(
1,1,1,a+b+c;
0,b-a,c-a,b^2+c^2-a b-a c;
0,c(a-b),b(a-c),2a b c-b^2 c-b c^2;
)\ &xarrow(R_3+c R_2) mat(
1,1,1,a+b+c;
0,b-a,c-a,(b-a)b+(c-a)c;
0,0,(c-a)(c-b),(c-a)(c-b)c
)
$
#set math.mat(delim: "|")
解得 $display(cases(
x_1 = a,
x_2 = b,
x_3 = c,
))$ 是原线性方程组的唯一解.
#note[由于解唯一,可以直接把 $x_1=a,sp x_2=b,sp x_3=c$ 代入验证,而不必要将系数矩阵化为阶梯形.]
= P39 习题二 26 #wa
#prob[
已知 $n$ 阶行列式 $D_n=|a_(i j)|_n!=0$,证明:线性方程组
$ cases(
a_11 x_1 + a_12 x_2 + &&dots.c + a_(1,n-1) x_(n-1) = a_(1 n),
a_21 x_1 + a_22 x_2 + &&dots.c + a_(2,n-1) x_(n-1) = a_(2 n),
&&dots.c,
a_(n 1) x_1 + a_(n 2) x_2 + &&dots.c + a_(n,n-1) x_(n-1) = a_(n n),
) $
无解.
]
取前 $n-1$ 个线性方程组,由于 $|a_(i j)|_n!=0$,那么 $D_(n-1)=|a_(i j)|_(n-1)!=0$.根据 Cramer 法则,只考虑前 $n-1$ 个线性方程组时,有唯一解.
先假设线性方程组有解,我们有 $forall k in [1,n)$,$display(x_k=((-1)^(n-k-1) M_(n,k))/(D_(n-1)) = -A_(n,k)/D_(n-1) = -A_(n,k)/A_(n,n))$.
将其代入原线性方程组的最后一个方程得:
$
-(a_(n,1) A_(n,1))/A_(n,n)-(a_(n,2) A_(n,2))/A_(n,n)-dots.c-(a_(n,n-1) A_(n,n-1))/A_(n,n)=a_(n,n)
$
即:
$
a_(n,1)A_(n,1)+a_(n,2)A_(n,2)+dots.c+a_(n,n)A_(n,n)=D_n=0
$
与题设矛盾,前 $n-1$ 个线性方程的解不符合第 $n$ 个方程,即原线性方程组无解.
#warn[
注意到 $r(bold(A)) <= n-1$;而根据 Vandermonde 行列式,$|bold(A)| = D_n != 0$,故 $r(overline(bold(A))) = n$.所以有 $r(bold(A)) != r(bold(overline(A)))$,故无解.
]
= P40 补充题二 3(1) #pc
#prob[
试计算行列式的值:
$ mat(
x,a,a,dots.c,a,a;
b,x,a,dots.c,a,a;
b,b,x,dots.c,a,a;
dots.v,dots.v,dots.v,,dots.v,dots.v;
b,b,b,dots.c,x,a;
b,b,b,dots.c,b,x;
)_n $
]
$
D_n =& mat(
x,a,a,dots.c,a,0+a;
b,x,a,dots.c,a,0+a;
b,b,x,dots.c,a,0+a;
dots.v,dots.v,dots.v,,dots.v,dots.v;
b,b,b,dots.c,x,0+a;
b,b,b,dots.c,b,(x-b)+b;
) = mat(
x,a,a,dots.c,a,0;
b,x,a,dots.c,a,0;
b,b,x,dots.c,a,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
b,b,b,dots.c,x,0;
b,b,b,dots.c,b,x-b;
) + mat(
x,a,a,dots.c,a,a;
b,x,a,dots.c,a,a;
b,b,x,dots.c,a,a;
dots.v,dots.v,dots.v,,dots.v,dots.v;
b,b,b,dots.c,x,a;
b,b,b,dots.c,b,b;
)\ =& (x-b) D_(n-1) + mat(
x-a,0,0,dots.c,0,a;
b-a,x-a,0,dots.c,0,a;
b-a,b-a,x-a,dots.c,0,a;
dots.v,dots.v,dots.v,,dots.v,dots.v;
b-a,b-a,b-a,dots.c,x-a,a;
0,0,0,dots.c,0,b;
)\ =& (x-b) D_(n-1) + b (x-a)^(n-1)
$
对转置后的矩阵应用同理可得 $D_n = (x-a) D_(n-1) + a (x-b)^(n-1)$.
$ cases(
(x-a)D_n &= (x-a)(x-b) D_(n-1) + b(x-a)^n,
(x-b)D_n &= (x-a)(x-b) D_(n-1) + a(x-b)^n,
) $
两式相减得:$ D_n &= (b(x-a)^n - a(x-b)^n)/(b-a) $
#warn[
要分 $a=b$ 和 $a!=b$ 两种情况讨论.
]
= P40 补充题二 3(5) #ac
#prob[
试计算行列式的值:
$ mat(
a_0+a_1,a_1,0,dots.c,0,0;
a_1,a_1+a_2,a_2,dots.c,0,0;
0,a_2,a_2+a_3,dots.c,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v;
0,0,0,dots.c,a_(n-2)+a_(n-1),a_(n-1);
0,0,0,dots.c,a_(n-1),a_(n-1)+a_n;
) $
]
$
D_n =& (a_(n-1) + a_n) (-1)^(2n) A_(n,n) + a_(n-1) (-1)^(2n-1) A_(n-1,n)\
=& (a_(n-1) + a_n) D_(n-1) - a_(n-1)^2 D_(n-2)
$
下归纳证明:$display(D_n=sum_(i=1)^n 1/a_i product_(i=1)^n a_i)$.
- 当 $n=1$ 时,$D_1 = a_0+a_1$,合法;
- 当 $n=2$ 时,$display(D_2 = (a_0+a_1)(a_1+a_2-(a_1^2)/(a_0+a_1))) = a_0a_1+a_0a_2+a_1a_2$,合法;
- 下证 $n=k-1$ 和 $n=k-2$ 时均成立,则 $n=k$ 也成立:
$
D_k =& (a_(k-1)+a_k) sum_(i=1)^(k-1) 1/a_i product_(i=1)^(k-1) a_i - a_(k-1)^2 sum_(i=1)^(k-2) 1/a_i product_(i=1)^(k-2) a_i\
=& (1+a_(k-1)/a_k) sum_(i=1)^(k-1) 1/a_i product_(i=1)^k a_i - a_(k-1)/a_k sum_(i=1)^(k-2) 1/a_i product_(i=1)^k a_i\
=& sum_(i=1)^(k-1) 1/a_i product_(i=1)^k a_i - a_(k-1)/a_k dot 1/a_(k-1)product_(i=1)^k a_i\
=& sum_(i=1)^k 1/a_i product_(i=1)^k a_i\
$
得证.
= P41 补充题二 3(6) #pc
#prob[
试计算行列式的值:
$ mat(
2^n-2,2^(n-1)-2,2^(n-2)-2,dots.c,2^2-2;
3^n-3,3^(n-1)-3,3^(n-2)-3,dots.c,3^2-3;
4^n-4,4^(n-1)-4,4^(n-2)-4,dots.c,4^2-4;
dots.v,dots.v,dots.v,,dots.v;
n^n-n,n^(n-1)-n,n^(n-2)-n,dots.c,n^2-n;
) $
]
$
|bold(D)| &= product_(k=2)^n k(k-1) mat(
sum_(i=0)^(n-2) 2^i,sum_(i=0)^(n-3) 2^i,dots.c,2^2+2+1,2+1,1;
sum_(i=0)^(n-2) 3^i,sum_(i=0)^(n-3) 3^i,dots.c,3^2+3+1,3+1,1;
dots.v,dots.v,,dots.v,dots.v;
sum_(i=0)^(n-2) n^i,sum_(i=0)^(n-3) n^i,dots.c,n^2+n+1,n+1,1;
)\ &= product_(k=2)^n k(k-1) mat(
sum_(i=0)^(n-2) 2^i,sum_(i=0)^(n-3) 2^i,dots.c,2^2+2+1,2+1,1;
sum_(i=0)^(n-2) 3^i,sum_(i=0)^(n-3) 3^i,dots.c,3^2+3+1,3+1,1;
dots.v,dots.v,,dots.v,dots.v;
sum_(i=0)^(n-2) n^i,sum_(i=0)^(n-3) n^i,dots.c,n^2+n+1,n+1,1;
)\ &= product_(k=2)^n k(k-1) mat(
2^(n-2),2^(n-3),dots.c,2^2,2,1;
3^(n-2),3^(n-3),dots.c,3^2,3,1;
dots.v,dots.v,,dots.v,dots.v;
n^(n-2),n^(n-3),dots.c,n^2,n,1;
)\
&= n! (n-1)! product_(1<=i<j<=(n-1)) ((j+1)-(i+1)) \
&= n! (n-1)! product_(i=1)^(n-2) i^(n-1-i)
$
#warn[
倒数第三行的方阵并不是 Vandermonde 矩阵,需要将其左右翻转.故行列式还需要乘以系数 $(-1)^(n(n-1)/2)$.
]
= P41 补充题二 4 #ac
#prob[
设 $n space (n>1)$ 阶行列式 $D=|a_(i j)|_n=4$,且 $D$ 中各列元素之和均为 $3$,并记元素 $a_(i j)$ 的代数余子式为 $A_(i j)$,试求 $display(sum_(i=1)^n sum_(j=1)^n A_(i j))$.
]
一方面,
$
sum_(i=1)^n sum_(j=1)^n a_(i,j) sum_(k=1)^n A_(k,j)
= sum_(k=1)^n sum_(j=1)^n A_(k,j) sum_(i=1)^n a_(i,j)
= 3 sum_(k=1)^n sum_(j=1)^n A_(k,j)
$
另一方面,
$
sum_(i=1)^n sum_(j=1)^n a_(i,j) sum_(k=1)^n A_(k,j)
= sum_(i=1)^n sum_(k=1)^n [i=k] sum_(j=1)^n a_(i,j) A_(k,j)
= sum_(i=1)^n sum_(j=1)^n a_(i,j) A_(i,j) = n D = 4n
$
故:$display(sum_(i=1)^n sum_(j=1)^n A_(i j) = (4n)/3)$.
#warn[也可以把每一列都累加到第一行去,此时第一行全为 $3$.利用 Laplace 展开可以得到 $display(D = 3 sum_(j=1)^n A_(1 j) = 4)$.对 $i=1,2,dots,n$ 分别做这个过程,也可以得到答案.]
= P41 补充题二 5 #ac
#prob[
已知 $a!=pm b$,试证明线性方程组
$ cases(
a x_1 + b x_(2n) &= 1,
a x_2 + b x_(2n-1) &= 1,
&dots.c,
a x_n + b x_(n+1) &= 1,
b x_n + a x_(n+1) &= 1,
&dots.c,
b x_2 + a x_(2n-1) &= 1,
b x_1 + a x_(2n) &= 1,
) $
有唯一解,并求该解.
]
考虑线性方程组的系数矩阵的行列式:
$
D_n =& mat(
a,0,0,dots.c,0,0,dots.c,0,0,b;
0,a,0,dots.c,0,0,dots.c,0,b,0;
0,0,a,dots.c,0,0,dots.c,b,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v,,dots.v,dots.v,dots.v;
0,0,0,dots.c,a,b,dots.c,0,0,0;
0,0,0,dots.c,b,a,dots.c,0,0,0;
dots.v,dots.v,dots.v,,dots.v,dots.v,,dots.v,dots.v,dots.v;
0,0,b,dots.c,0,0,dots.c,a,0,0;
0,b,0,dots.c,0,0,dots.c,0,a,0;
b,0,0,dots.c,0,0,dots.c,0,0,a;
)_(2n)\
=& a (-1)^(1+1) A_(1,1) + b (-1)^(1+2n) A_(1,2n)\
=& a (-1)^(1+1) dot a (-1)^((2n-1)+(2n-1)) dot D_(n-1) + b (-1)^(1+2n) dot b (-1)^(1+(2n-1)) dot D_(n-1)\
=& (a^2 - b^2) D_(n-1)\
=& (a^2 - b^2)^n
$
由于 $a!=pm b$,故 $D_n!=0$.根据 Cramer 法则,原线性方程组有唯一解.
猜想该解为 $x_1=x_2=dots.c=x_(2n)=display(1/(a+b))$,容易验证合法.由于原线性方程组的解只有一个,故这就是其唯一解.
= P41 补充题二 9 #ac
#prob[
设 $a,b,c$ 均不为零,且互异,试证明平面上的 $3$ 条不同直线
$
l_1 &: &space a x &+ b y &+ c &= 0\
l_2 &: &space b x &+ c y &+ a &= 0\
l_3 &: &space c x &+ a y &+ b &= 0\
$
相交于一点的充分必要条件为 $a+b+c=0$.
]
相交于一点的充分必要条件是三条直线方程构成的线性方程组有唯一解.
求线性方程组的系数矩阵的行列式:
$
D_3 =& a mat(c,a;a,b) - b mat(b,a;c,b) + c mat(b,c;c,a)\
=& a(b c - a^2) - b (b^2 - a c) + c(a b - c^2)\
=& 3 a b c -a^3 - b^3 - c^3\
=& (a+b+c)(a^2+b^2+c^2-a b-a c-b c)\
=& 1/2(a+b+c)((a-b)^2+(a-c)^2+(b-c)^2)\
$
根据 Cramer 法则,线性方程组有唯一解的充分必要条件是 $D_3=0$ .由于 $a,b,c$ 互异,故当且仅当 $a+b+c=0$ 时成立,得证. |
|
https://github.com/mizlan/typst-resume-sans | https://raw.githubusercontent.com/mizlan/typst-resume-sans/main/README.md | markdown | Sans-serif Typst resume template, heavily inspired by
[this](https://github.com/skyzh/chicv).
Depends on the fonts [Inter](https://rsms.me/inter/) and
[General Sans](https://www.fontshare.com/fonts/general-sans).
**Directions**: Edit `resume.typ` and compile it either locally or in your [browser](https://typst.app/).
Want to customize but don't know how? Learn how to use Typst effectively by
reading the [documentation](https://typst.app/docs/).

|
|
https://github.com/jonaspleyer/peace-of-posters | https://raw.githubusercontent.com/jonaspleyer/peace-of-posters/main/lib.typ | typst | MIT License | #import "boxes.typ": *
#import "layouts.typ": *
#import "themes.typ": *
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-E000.typ | typst | Apache License 2.0 | #let data = (
"0": ("<Private Use, First>", "Co", 0),
"18ff": ("<Private Use, Last>", "Co", 0),
)
|
https://github.com/Dav1com/resume | https://raw.githubusercontent.com/Dav1com/resume/main/modules/professional.typ | typst | Apache License 2.0 | #import "../brilliant-CV/template.typ": *
#cvSection("Professional Experience")
#cvEntry(
title: [Software Developer],
society: [t14 Consulting],
//logo: "../src/logos/xyz_corp.png",
date: [Feb 2023 - Present],
location: [Remote work],
description: list(
[Design and implementation of custom made software, primarly in Java.],
[*FACT*: Design and implementation of batched requests for high throughput in Apache Camel.],
[*Levers NetChange*: Optimization of Snowflake requests, analyze and transform SQL queries to minimize DB requests.]
),
logo: "../img/t14.jpg",
tags: ("Java", "Apache Camel", "Apache Kafka", "Snowflake", "AWS", "Spring", "Gradle")
)
#cvEntry(
title: [Supervised Project],
society: [University of Chile],
date: [Ago 2024 - Dec 2024],
location: [Santiago, Chile],
description: list(
[Design of abstractions for including gradual typing techniques into static analyses with abstract interpretation.],
[Helping into the design, and implementation, of analyses on top of the developed abstractions.],
[Code done in Scala using the framework Sturdy],
[Working under the supervision of <NAME> and <NAME>.],
),
logo: "../img/uchile.svg",
tags: ("Scala", "Static Analysis")
)
#cvEntry(
title: [Teaching Assistant],
society: [University of Chile],
date: [Mar 2024 - Dec 2024],
location: [Santiago, Chile],
logo: "../img/uchile.svg",
description: list(
[*CC4101 Programming Languages*: Grading evaluations.]
)
)
#cvEntry(
title: [Teaching Assistant],
society: [University of Chile],
//logo: "../src/logos/abc_company.png",
date: [Jul 2022 - Dec 2022],
location: [Santiago, Chile],
logo: "../img/uchile.svg",
description: list(
[*CC4005 Competitive Programming*: Giving lessons, grading, and designing evaluations],
),
tags: ("C/C++", "GDB")
)
#cvEntry(
title: [Full-Stack Intern],
society: [Simple Data Corp.],
//logo: "../src/logos/pqr_corp.png",
date: [Summer 2019],
location: [Santiago, Chile],
logo: "../img/simple_data_corp.jpg",
description: list(
[Design and implementation of new features to existing dynamic forms module.],
[*Technologies*: PHP, CodeIgniter 3, JQuery, RabbitMQ, Postman, Linux tools.]
)
) |
https://github.com/Myriad-Dreamin/tinymist | https://raw.githubusercontent.com/Myriad-Dreamin/tinymist/main/syntaxes/textmate/tests/unit/bugs/link.typ | typst | Apache License 2.0 | ("https://github.com/Myriad-Dreamin/tinymist/tree/main/editors/vscode#symbol-view")[integrating]
("https://github.com/istudyatuni/sublimelsp-LSP/blob/40ea8ea01af19b8719b0e2e827dbfb8651261199/docs/src/language_servers.md#tinymist")[] |
https://github.com/Thumuss/utpm | https://raw.githubusercontent.com/Thumuss/utpm/dev/TODO.md | markdown | MIT License | # TODO list
## V2:
- [x] Reimpl errors
- [x] Last typst version
- [x] More commands:
- [x] Unlink
- [x] List
- [x] Create `typst.toml` by asking questions
- [x] use semver
- [x] Use custom packages namespace (e.g "@custom/example:1.0.1")
- [x] Fix typo
## V2.1:
- [X] ""pre-export"" package by giving them what they need
- [ ] Documentation for developpers
- [ ] utils.rs
- [ ] main.rs
- [ ] commands.rs → remake it?
- [ ] commands/create.rs
- [ ] commands/link.rs
- [ ] commands/list.rs
- [ ] commands/unlink.rs
- [ ] commands/install.rs
- [x] Download packages from unofficial repos, see #3
- [x] git2-rs
- [x] Dependencies managed
- [x] use utpm namespace to use libs (or portable so without any links) → It wouldn't be as good as it sounds, typst can't use package outside the data folder
- [x] Maybe a launchable version from utpm to link packages?
- [x] Portable version and only installable version
- [x] Integrate install
- [x] And all of todos from above with #3
- [ ] New commands for install:
- [ ] Info.rs
- [ ] Update, (using semver)
- [x] Bulk delete
- [ ] Clean?
- [ ] Maybe a listing dependencies system? -> Track every dependencies to delete when they aren't used -> Not for now
- [ ] Templates (first impl) -> Not now → V3
- [ ] JSON only mode
## V3
This update will introduce documentations, a better handling error system, JSON and some commands.
- [x] Better handling errors (json, string, toml maybe)
- [ ] Maybe a listing dependencies system? -> Track every dependencies to delete when they aren't used
- [ ] Create a global and local configuration instead of using typst.toml file. It can become harder to
- [x] JSON only mode
- [x] Remake clap
- [ ] Documentation for developpers and users
- [ ] utils.rs
- [ ] main.rs
- [ ] commands.rs → remake it?
- [ ] commands/create.rs
- [ ] commands/link.rs
- [ ] commands/list.rs
- [ ] commands/unlink.rs
- [ ] commands/install.rs
- [ ] New commands for install:
- [ ] Info.rs -> Partial impl for now
- [ ] Update, (using semver) → \w listing dependencies
- [ ] Clean?
## V4 (2024.03.10)
> Last update: 05.06.2024
As of today (2024.03.10), a new version of typst has been released (`v0.11.0-rc1 (fe94bd85)`) with a new template system.
For now on, this version of utpm will focus on both adapting the new system and being compatible with the previous system.
If time isn't running out, I'll add quality of life improvements such as a `Context` system, new commands to go along with the `typst init` command and Dockerise everything (kubernetes included).
The main focus will be :
- [ ] Add templates in `utpm` (transfer to [typst-project](https://github.com/tingerrr/typst-project))
- [X] Struct
- [ ] Implementation
- [ ] Compatibility with older version of typst
- [ ] Use `tracing-subscriber` as a logger (thanks @frozolotl)
- [X] Improve `README`: add more example, an explanation, ... (thanks @Pachi)
- [ ] Add `utpm publish` command, like [this repository](https://github.com/tingerrr/alabaster) (thanks @tingerrr)
Optional, not needed in this PR but will be added in the future :
- [ ] Docker, Compose and Kubernetes files (and examples)
- [ ] ENV compatible.
- [ ] get along with `typst init`
- [x] tree and list for `list` commands
- [ ] Transform "portable" to "CI" binary
#### Appendix
- [Typst package](https://github.com/typst/packages/tree/0a5370faafd3b0662310255c4f827f9f2f1425cb)
If you have any ideas to improve utpm, I will gladly accept them into account <3 |
https://github.com/Ttajika/class | https://raw.githubusercontent.com/Ttajika/class/main/seminar2024/main.typ | typst | #import "quiz_bank.typ":*
#show heading: set text(font: "<NAME>", fill: gradient.linear(..color.map.crest))
#set heading(numbering: "1.")
#set page(numbering: "1")
#set text(font: "<NAME>", lang:"ja")
#show raw: set text(font: ("Roboto Mono", "<NAME>"), lang: "ja")
#set par(leading: 1em, first-line-indent: 1em)
#show math.equation: set text(font: "TeX Gyre Pagella Math")
#set par(linebreaks: "optimized")
#show enum: set block(breakable: true)
#show strong: set text(fill:maroon.darken(30%))
#show strong: set text(font: "<NAME>")
#let kuran_count = counter("kuran_counter")
#show link: set text(fill: eastern.darken(30%))
#show: codly-init.with()
#codly(
languages: (
R: (
name: "",
icon: box(image("img/R_logo.svg",width:9pt, height:7pt)),
color: white
),
)
)
//問題自体は[quiz_bank.typ]に格納する.
#align(center)[ #text(size:18pt,font: "<NAME>", weight: "bold", fill: gradient.linear(..color.map.crest))[ゲーム理論・練習問題集]\
多鹿 智哉 \@ 日本大学 経済学部
教科書:上條・矢内 (2023)『Rで学ぶゲーム理論』朝倉書店
]
//問題の具体的なsourceはquiz_bank.typを参照すること
= 問題
#tests_gen(Quiz,style:"Q", numbering-style: "number", subgroups:("Q11", "Q3"), question-style: test-question-style-no-space, answer-style: test-answer-style)
#pagebreak()
= ヒント
コードを読む時の注意:
- `l`は小文字のエル,`I`は大文字のアイ, `1`は数字の1
- `0`は数字のゼロ, `o`はアルファベット小文字のオー,`O`は大文字オー
#tests_gen(Quiz,style:"Q", numbering-style: "number", subgroups:("Q11", "Q3"), question-style: commentary_pick)
|
|
https://github.com/JakMobius/courses | https://raw.githubusercontent.com/JakMobius/courses/main/mipt-os-basic-2024/sem07/utils.typ | typst |
#import "../theme/theme.typ": *
#import "@preview/cetz:0.2.2"
#let cell-color(base-color) = {
if base-color == none {
base-color = blue
}
let background-color = color.mix((base-color, 20%), (white, 80%))
let stroke-color = color.mix((base-color, 50%), (black, 50%))
(
base-color: base-color, background-color: background-color, stroke-color: stroke-color,
)
}
|
|
https://github.com/lphoogenboom/typstThesisDCSC | https://raw.githubusercontent.com/lphoogenboom/typstThesisDCSC/master/acronymList.typ | typst | // Dictionary with acronyms
#let acronyms = (
TUD: "Technisch Universiteit Delft",
DCSC: "Delft Center for Systems and Control",
API: "Application programmable interface",
)
|
|
https://github.com/frectonz/the-pg-book | https://raw.githubusercontent.com/frectonz/the-pg-book/main/book/210.%20heresy.html.typ | typst | heresy.html
Heresy
April 2022One of the most surprising things I've witnessed in my lifetime is
the rebirth of the concept of heresy.In his excellent biography of Newton, <NAME> writes about the
moment when he was elected a fellow of Trinity College:
Supported comfortably, Newton was free to devote himself wholly
to whatever he chose. To remain on, he had only to avoid the three
unforgivable sins: crime, heresy, and marriage.
[1]
The first time I read that, in the 1990s, it sounded amusingly
medieval. How strange, to have to avoid committing heresy. But when
I reread it 20 years later it sounded like a description of
contemporary employment.There are an ever-increasing number of opinions you can be fired
for. Those doing the firing don't use the word "heresy" to describe
them, but structurally they're equivalent. Structurally there are
two distinctive things about heresy: (1) that it takes priority
over the question of truth or falsity, and (2) that it outweighs
everything else the speaker has done.For example, when someone calls a statement "x-ist," they're also
implicitly saying that this is the end of the discussion. They do
not, having said this, go on to consider whether the statement is
true or not. Using such labels is the conversational equivalent of
signalling an exception. That's one of the reasons they're used:
to end a discussion.If you find yourself talking to someone who uses these labels a
lot, it might be worthwhile to ask them explicitly if they believe
any babies are being thrown out with the bathwater. Can a statement
be x-ist, for whatever value of x, and also true? If the answer is
yes, then they're admitting to banning the truth. That's obvious
enough that I'd guess most would answer no. But if they answer no,
it's easy to show that they're mistaken, and that in practice such
labels are applied to statements regardless of their truth or
falsity.The clearest evidence of this is that whether a statement is
considered x-ist often depends on who said it. Truth doesn't work
that way. The same statement can't be true when one person says it,
but x-ist, and therefore false, when another person does.
[2]The other distinctive thing about heresies, compared to ordinary
opinions, is that the public expression of them outweighs everything
else the speaker has done. In ordinary matters, like knowledge of
history, or taste in music, you're judged by the average of your
opinions. A heresy is qualitatively different. It's like dropping
a chunk of uranium onto the scale.Back in the day (and still, in some places) the punishment for
heresy was death. You could have led a life of exemplary goodness,
but if you publicly doubted, say, the divinity of Christ, you were
going to burn. Nowadays, in civilized countries, heretics only get
fired in the metaphorical sense, by losing their jobs. But the
structure of the situation is the same: the heresy
outweighs everything else. You could have spent the last ten years
saving children's lives, but if you express certain opinions, you're
automatically fired.It's much the same as if you committed a crime. No matter how
virtuously you've lived, if you commit a crime, you must still
suffer the penalty of the law. Having lived a previously blameless
life might mitigate the punishment, but it doesn't affect whether
you're guilty or not.A heresy is an opinion whose expression is treated like a crime —
one that makes some people feel not merely that you're mistaken,
but that you should be punished. Indeed, their desire to see you
punished is often stronger than it would be if you'd committed an
actual crime. There are many on the far left who believe
strongly in the reintegration of felons (as I do myself), and yet
seem to feel that anyone guilty of certain heresies should never
work again.There are always some heresies — some opinions you'd be punished
for expressing. But there are a lot more now than there were a few
decades ago, and even those who are happy about this would have to
agree that it's so.Why? Why has this antiquated-sounding religious concept come back
in a secular form? And why now?You need two ingredients for a wave of intolerance: intolerant
people, and an ideology to guide them. The intolerant people are
always there. They exist in every sufficiently large society. That's
why waves of intolerance can arise so suddenly; all they need is
something to set them off.I've already written an essay
describing the aggressively
conventional-minded. The short version is that people can be
classified in two dimensions according to (1) how independent- or
conventional-minded they are, and (2) how aggressive they are about
it. The aggressively conventional-minded are the enforcers of
orthodoxy.Normally they're only locally visible. They're the grumpy, censorious
people in a group — the ones who are always first to complain when
something violates the current rules of propriety. But occasionally,
like a vector field whose elements become aligned, a large number
of aggressively conventional-minded people unite behind some ideology
all at once. Then they become much more of a problem, because a mob
dynamic takes over, where the enthusiasm of each participant is
increased by the enthusiasm of the others.The most notorious 20th century case may have been the Cultural
Revolution. Though initiated by Mao to undermine his rivals, the
Cultural Revolution was otherwise mostly a grass-roots phenomenon.
Mao said in essence: There are heretics among us. Seek them out and
punish them. And that's all the aggressively conventional-minded
ever need to hear. They went at it with the delight of dogs chasing
squirrels.To unite the conventional-minded, an ideology must have many of the
features of a religion. In particular it must have strict and
arbitrary rules that adherents can demonstrate their
purity
by obeying, and its adherents must believe that anyone who obeys these
rules is ipso facto morally superior to anyone who doesn't.
[3]In the late 1980s a new ideology of this type appeared in US
universities. It had a very strong component of moral purity, and
the aggressively conventional-minded seized upon it with their usual
eagerness — all the more because the relaxation of social norms
in the preceding decades meant there had been less and less to
forbid. The resulting wave of intolerance has been eerily similar
in form to the Cultural Revolution, though fortunately much smaller
in magnitude.
[4]I've deliberately avoided mentioning any specific heresies here.
Partly because one of the universal tactics of heretic hunters, now
as in the past, is to accuse those who disapprove of the way in
which they suppress ideas of being heretics themselves. Indeed,
this tactic is so consistent that you could use it as a way of
detecting witch hunts in any era.And that's the second reason I've avoided mentioning any specific
heresies. I want this essay to work in the future, not just now.
And unfortunately it probably will. The aggressively conventional-minded
will always be among us, looking for things to forbid. All they
need is an ideology to tell them what. And it's unlikely the current
one will be the last.There are aggressively conventional-minded people on both the right
and the left. The reason the current wave of intolerance comes from
the left is simply because the new unifying ideology happened to
come from the left. The next one might come from the right. Imagine
what that would be like.Fortunately in western countries the suppression of heresies is
nothing like as bad as it used to be. Though the window of opinions
you can express publicly has narrowed in the last decade, it's still
much wider than it was a few hundred years ago. The problem is the
derivative. Up till about 1985 the window had been growing ever
wider. Anyone looking into the future in 1985 would have expected
freedom of expression to continue to increase. Instead it has
decreased.
[5]The situation is similar to what's happened with infectious diseases
like measles. Anyone looking into the future in 2010 would have
expected the number of measles cases in the US to continue to
decrease. Instead, thanks to anti-vaxxers, it has increased. The
absolute number is still not that high. The problem is the derivative.
[6]In both cases it's hard to know how much to worry. Is it really
dangerous to society as a whole if a handful of extremists refuse
to get their kids vaccinated, or shout down speakers at universities?
The point to start worrying is presumably when their efforts start
to spill over into everyone else's lives. And in both cases that
does seem to be happening.So it's probably worth spending some amount of effort on pushing
back to keep open the window of free expression. My hope is that
this essay will help form social antibodies not just against current
efforts to suppress ideas, but against the concept of heresy in
general. That's the real prize. How do you disable the concept of
heresy? Since the Enlightenment, western societies have discovered
many techniques for doing that, but there are surely more to be
discovered.Overall I'm optimistic. Though the trend in freedom of expression
has been bad over the last decade, it's been good over the longer
term. And there are signs that the current wave of intolerance is
peaking. Independent-minded people I talk to seem more confident
than they did a few years ago. On the other side, even some of the
leaders are starting to wonder if things have
gone too far. And popular culture among the young has already moved on.
All we have
to do is keep pushing back, and the wave collapses. And then we'll
be net ahead, because as well as having defeated this wave, we'll
also have developed new tactics for resisting the next one.Notes[1]
Or more accurately, biographies of Newton, since Westfall wrote
two: a long version called Never at Rest, and a shorter one called
The Life of <NAME>. Both are great. The short version moves
faster, but the long one is full of interesting and often very funny
details. This passage is the same in both.[2]
Another more subtle but equally damning bit of evidence is
that claims of x-ism are never qualified. You never hear anyone say
that a statement is "probably x-ist" or "almost certainly y-ist."
If claims of x-ism were actually claims about truth, you'd expect
to see "probably" in front of "x-ist" as often as you see it in
front of "fallacious."[3]
The rules must be strict, but they need not be demanding. So
the most effective type of rules are those about superficial matters,
like doctrinal minutiae, or the precise words adherents must use.
Such rules can be made extremely complicated, and yet don't repel
potential converts by requiring significant sacrifice.The superficial demands of orthodoxy make it an inexpensive substitute
for virtue. And that in turn is one of the reasons orthodoxy is so
attractive to bad people. You could be a horrible person, and yet
as long as you're orthodox, you're better than everyone who isn't.[4]
Arguably there were two. The first had died down somewhat by
2000, but was followed by a second in the 2010s, probably caused
by social media.[5]
Fortunately most of those trying to suppress ideas today still
respect Enlightenment principles enough to pay lip service to them.
They know they're not supposed to ban ideas per se, so they have
to recast the ideas as causing "harm," which sounds like something
that can be banned. The more extreme try to claim speech itself is
violence, or even that silence is. But strange as it may sound,
such gymnastics are a good sign. We'll know we're really in trouble
when they stop bothering to invent pretenses for banning ideas —
when, like the medieval church, they say "Damn right we're banning
ideas, and in fact here's a list of them."[6]
People only have the luxury of ignoring the medical consensus
about vaccines because vaccines have worked so well. If we didn't
have any vaccines at all, the mortality rate would be so high that
most current anti-vaxxers would be begging for them. And the situation
with freedom of expression is similar. It's only because they live
in a world created by the Enlightenment that kids from the suburbs
can play at banning ideas.Thanks to <NAME>, <NAME>,
<NAME>, <NAME>, <NAME>, <NAME>, <NAME>, <NAME>, <NAME>, <NAME>, and <NAME> for reading
drafts of this.
|
|
https://github.com/xsro/xsro.github.io | https://raw.githubusercontent.com/xsro/xsro.github.io/zola/typst/nlct/main.typ | typst | #set text(font: ("Noto Serif CJK SC","Noto Serif CJK SC"))
#set page(background: rotate(24deg,
[
#text(180pt, fill: gray.lighten(80%))[
*NLCT*\
]
#text(50pt, fill: gray.lighten(80%))[
(Working In Progress)
]
]
))
#align(center)[
#text(gray,size: 20pt)[
Supplement
for
]
#text(size:24pt)[Nonlinear Systems and Control]\
#link("mailto:<EMAIL>")\
#datetime.today().display()\
Work In Progress
]
#outline(depth: 2,indent:2em)
Some exercises are mentioned in the textbook's mainbody.
So I organize some solutions here for reference.
Only a little solutions is presented in this supplement.
They are
#locate(loc => {
for e in query(<exercise>, loc) [
#link(e.location())[#e.value]
]
}).
#let part(short:"1",long:"1",body)={
[
#pagebreak()
#set page(header: [
#set text(gray)
#long
])
#align(
end + horizon,
rect(inset: 12pt,(text(size:26pt,weight:"bold")[
#short
]))
)
#pagebreak()
#body
]
}
#set math.equation(supplement: none)
#show ref: it => {
if it.element != none and it.element.func() == math.equation {
[(#it)]
} else {
it
}
}
#set math.equation(numbering: "(1)")
#part(
short:"Math Review",
long:"Missing Math for Control"
)[
#set heading(numbering: "1.1")
#include "math/mechanic.typ"
#include "math/ode.typ"
#include "math/ode_numerical.typ"
#include "math/space.typ"
#include "math/diffgeo.typ"
]
#part(
short:"Solutions",
long:"Some Solutions to Nonlinear Systems(3rd edition)"
)[
#set heading(numbering: none)
= chapter 1 Introduction
#include "solution/1.1.typ"
= chapter 2 Second Order Systems
= chapter 3 Fundamental Properties
#include "solution/3.24.typ"
= chapter 4 Lyapunov Stability
= chapter 5 Input-Output Stability
#include "solution/5.6.typ"
= chapter 6 Passivity
= chapter 7 Frequency Domain analysis of Feedback Systems
= chapter 8 Advanced Stability Analysis
= chapter 9 Stability of Perturbed Systems
= chapter 10 Perturbation Theory and Averaging
= chapter 11 Singular Perturbations
= chapter 12 Feedback Control
= chapter 13 Feedback Linearization
= chapter 14 Nonlinear Design Tools
]
#include "references.typ"
|
|
https://github.com/metamuffin/typst | https://raw.githubusercontent.com/metamuffin/typst/main/tests/typ/text/shaping.typ | typst | Apache License 2.0 | // Test shaping quirks.
---
// Test separation by script.
ABCअपार्टमेंट
// This is how it should look like.
अपार्टमेंट
// This (without the spaces) is how it would look
// if we didn't separate by script.
अ पा र् ट में ट
---
// Test that RTL safe-to-break doesn't panic even though newline
// doesn't exist in shaping output.
#set text(dir: rtl, font: "Noto Serif Hebrew")
\ ט
|
https://github.com/mroberts1/fsu-smt-su24 | https://raw.githubusercontent.com/mroberts1/fsu-smt-su24/main/index.typ | typst | MIT License | // Some definitions presupposed by pandoc's typst output.
#let blockquote(body) = [
#set text( size: 0.92em )
#block(inset: (left: 1.5em, top: 0.2em, bottom: 0.2em))[#body]
]
#let horizontalrule = [
#line(start: (25%,0%), end: (75%,0%))
]
#let endnote(num, contents) = [
#stack(dir: ltr, spacing: 3pt, super[#num], contents)
]
#show terms: it => {
it.children
.map(child => [
#strong[#child.term]
#block(inset: (left: 1.5em, top: -0.4em))[#child.description]
])
.join()
}
// Some quarto-specific definitions.
#show raw.where(block: true): block.with(
fill: luma(230),
width: 100%,
inset: 8pt,
radius: 2pt
)
#let block_with_new_content(old_block, new_content) = {
let d = (:)
let fields = old_block.fields()
fields.remove("body")
if fields.at("below", default: none) != none {
// TODO: this is a hack because below is a "synthesized element"
// according to the experts in the typst discord...
fields.below = fields.below.amount
}
return block.with(..fields)(new_content)
}
#let empty(v) = {
if type(v) == "string" {
// two dollar signs here because we're technically inside
// a Pandoc template :grimace:
v.matches(regex("^\\s*$")).at(0, default: none) != none
} else if type(v) == "content" {
if v.at("text", default: none) != none {
return empty(v.text)
}
for child in v.at("children", default: ()) {
if not empty(child) {
return false
}
}
return true
}
}
// Subfloats
// This is a technique that we adapted from https://github.com/tingerrr/subpar/
#let quartosubfloatcounter = counter("quartosubfloatcounter")
#let quarto_super(
kind: str,
caption: none,
label: none,
supplement: str,
position: none,
subrefnumbering: "1a",
subcapnumbering: "(a)",
body,
) = {
context {
let figcounter = counter(figure.where(kind: kind))
let n-super = figcounter.get().first() + 1
set figure.caption(position: position)
[#figure(
kind: kind,
supplement: supplement,
caption: caption,
{
show figure.where(kind: kind): set figure(numbering: _ => numbering(subrefnumbering, n-super, quartosubfloatcounter.get().first() + 1))
show figure.where(kind: kind): set figure.caption(position: position)
show figure: it => {
let num = numbering(subcapnumbering, n-super, quartosubfloatcounter.get().first() + 1)
show figure.caption: it => {
num.slice(2) // I don't understand why the numbering contains output that it really shouldn't, but this fixes it shrug?
[ ]
it.body
}
quartosubfloatcounter.step()
it
counter(figure.where(kind: it.kind)).update(n => n - 1)
}
quartosubfloatcounter.update(0)
body
}
)#label]
}
}
// callout rendering
// this is a figure show rule because callouts are crossreferenceable
#show figure: it => {
if type(it.kind) != "string" {
return it
}
let kind_match = it.kind.matches(regex("^quarto-callout-(.*)")).at(0, default: none)
if kind_match == none {
return it
}
let kind = kind_match.captures.at(0, default: "other")
kind = upper(kind.first()) + kind.slice(1)
// now we pull apart the callout and reassemble it with the crossref name and counter
// when we cleanup pandoc's emitted code to avoid spaces this will have to change
let old_callout = it.body.children.at(1).body.children.at(1)
let old_title_block = old_callout.body.children.at(0)
let old_title = old_title_block.body.body.children.at(2)
// TODO use custom separator if available
let new_title = if empty(old_title) {
[#kind #it.counter.display()]
} else {
[#kind #it.counter.display(): #old_title]
}
let new_title_block = block_with_new_content(
old_title_block,
block_with_new_content(
old_title_block.body,
old_title_block.body.body.children.at(0) +
old_title_block.body.body.children.at(1) +
new_title))
block_with_new_content(old_callout,
new_title_block +
old_callout.body.children.at(1))
}
// 2023-10-09: #fa-icon("fa-info") is not working, so we'll eval "#fa-info()" instead
#let callout(body: [], title: "Callout", background_color: rgb("#dddddd"), icon: none, icon_color: black) = {
block(
breakable: false,
fill: background_color,
stroke: (paint: icon_color, thickness: 0.5pt, cap: "round"),
width: 100%,
radius: 2pt,
block(
inset: 1pt,
width: 100%,
below: 0pt,
block(
fill: background_color,
width: 100%,
inset: 8pt)[#text(icon_color, weight: 900)[#icon] #title]) +
if(body != []){
block(
inset: 1pt,
width: 100%,
block(fill: white, width: 100%, inset: 8pt, body))
}
)
}
#let PrettyPDF(
// The document title.
title: "PrettyPDF",
// Logo in top right corner.
typst-logo: none,
// The document content.
body
) = {
// Set document metadata.
set document(title: title)
// Configure pages.
set page(
margin: (left: 2cm, right: 1.5cm, top: 2cm, bottom: 2cm),
numbering: "1",
number-align: right,
background: place(right + top, rect(
fill: rgb("#E6E6FA"),
height: 100%,
width: 3cm,
))
)
// Set the body font.
set text(10pt, font: "Ubuntu")
// Configure headings.
show heading.where(level: 1): set block(below: 0.8em)
show heading.where(level: 1): underline
show heading.where(level: 2): set block(above: 0.5cm, below: 0.5cm)
// Links should be purple.
show link: set text(rgb("#800080"))
// Configure light purple border.
show figure: it => block({
move(dx: -3%, dy: 1.5%, rect(
fill: rgb("FF7D79"),
inset: 0pt,
move(dx: 3%, dy: -1.5%, it.body)
))
})
// Purple border column
grid(
columns: (1fr, 0.75cm),
column-gutter: 2.5cm,
// Title.
text(font: "Ubuntu", 20pt, weight: 800, upper(title)),
// The logo in the sidebar.
locate(loc => {
set align(right)
// Logo.
style(styles => {
if typst-logo == none {
return
}
let img = image(typst-logo.path, width: 1.5cm)
let img-size = measure(img, styles)
grid(
columns: (img-size.width, 1cm),
column-gutter: 16pt,
rows: img-size.height,
img,
)
})
}),
// The main body text.
{
set par(justify: true)
body
v(1fr)
},
)
}
#show: PrettyPDF.with(
typst-logo: (
path: "\_extensions/nrennie/PrettyPDF/logo.png",
caption: []
),
)
= COMM 7018: Social Media Theory
<comm-7018-social-media-theory>
== Introduction
<introduction>
The term #strong[social media] is popularly understood as referring to corporate-owned, advertising-funded communication #strong[platforms] based on #strong[user-generated content];: YouTube, Instagram, Facebook, Twitter, Twitch, Discord, TikTok. It can also be defined more broadly, however, as a set of networked, technologically-mediated #strong[practices] of communication, structured by economic and political forces that both inflect and are inflected by social and cultural identities. These platforms, the social practices that they enable, and the relationship between the two are the objects of #strong[social media theory];. But what does it mean to theorize social media? Why do we need social media theory at all?
To theorize something involves a number of processes:
- first, how do we define the phenomenon or object of study itself? How does it differ from previous or other related phenomena?
- how are we to account for it? Why did it happen/is it happening now rather than at some other time? What are its conditions of possibility?
- what is its relation to larger areas of society? What are its implications for those areas?
- how are we to evaluate it, in terms of its implications (political, economic, social, ethical, legal, environmental, aesthetic)? What are its possibilities and limits, its progressive and oppressive aspects? How can we change it for the better?
These processes involve developing analytical frameworks or models comprising concepts that are useful for identifying and analyzing key aspects of and issues raised by the phenomenon/object in question. These frameworks and concepts typically draw from existing ones in different fields of study, but often involve the proposal of new frameworks and concepts specific to the field in question.
== Objectives
<objectives>
By the end of the course, students will be able to:
- analyze technologies past, present, and imagined
- describe the ways in which technologies shape our world the ways in which we shape those technologies
- explain how social media is a result of the intersection between technologies and existing human communication dynamics
- discuss how theory of technology and social media can improve the vocational outlook of a student
- play a productive role in and facilitate conversations that tease out the relationships between values and technology. \
- through the skills you will refine in writing your research papers, clearly explain how a specific technology shapes the social world that we live in.
== Course Texts
<course-texts>
- These sources are either available online or excerpts will be posted on Blackboard.
- <NAME>, #strong[In The Swarm: Digital Prospects] (Cambridge, MA: MIT Press, 2017).
- <NAME>, #strong[Interpassivity: The Aesthetics of Delegated Enjoyment] (Edinburgh: Edinburgh University Press, 2017).
- <NAME> and <NAME>, #strong[You Are Here: A Field Guide for Navigating Polarized Speech, Conspiracy Theories, and Our Polluted Media Landscape] (Cambridge: MIT Press, 2021).
- <NAME>, #strong[Everything I Need I Get From You: How Fangirls Created the Internet as We Know It] (Oxford: Blackwell’s, 2022).
== Course Info
<course-info>
#strong[Blackboard] \
We will be using the Blackboard Learning Management System (LMS) as the primary platform for the course. Please be sure to check in to the site at least once daily M-F to check the Announcements page and the Discussion forum for the week.
#strong[Sources] \
Reading assignments will be either from Required texts, linked to online, or available as PDF documents.
PDF documents and the syllabus will be available for download in the #link("https://github.com/mroberts1/social-media-theory-summer-2022")[Course Repository] hosted on GitHub: please bookmark this link. The folder on the repo will have copies of all PDF chapters and articles, which may be downloaded either individually (click on the document in question and then the Download button) or collectively in the zip file.
== Assignments / Evaluation
<assignments-evaluation>
- #strong[Review];: 6, weekly from Week 1, one short post responding to readings, 250 words (maximum), due by Friday (20%) \
- #strong[Discussion];: weekly after Week 1, 2-3 responses to other students’ posts., 100 words max., due by the #emph[following] Friday (20%) \
- #strong[Commentary];: 2 short papers, 750-1000 words, due Sunday of Week 2 and Week 4 (20%) \
- #strong[Research paper/report/other project];: 2,000 words, due Sunday of week 7 (20%)
- #strong[Digital Garden] (practical project, ongoing - information will be provided) (20%)
#strong[Discussion: Agenda, Review, Reply Posts] \
For Weeks 1-6, each of the weekly topics will be active across a cycle of two weeks.
By #strong[Wednesday] of each week, I will post an Agenda item in the Discussion forum for the topic of the week, that introduces and contextualizes the reading assignments for the week, identifying key themes, concepts, and/or issues to look out for as you read. Be sure to read the Agenda post before beginning the reading assignments.
In the first week, complete the reading assignments and make an initial response post called a Review, with question and/or comments on them, by #strong[Sunday] of the week in question.
In the second week, read through the Review posts of the group and post at least one Reply to one of them by Friday of that week.
#strong[Commentary Papers] \
These short papers (750-1,000 words) are due at the end of Week 2 and Week 4 (Sunday). They should consist of close analytical readings of any of the reading assignments for the period Weeks 1-2 or 3-4. You are encouraged to focus in detail on particular sections, arguments, and/or concepts from the readings and develop them.
#strong[Research Paper/Project] \
The culminating written assignment for the course (2,000 words) may consist of various formats: a research paper or report, or a creative project of your choice.
A 1-page preliminary proposal with ideas for your project, with a short bibliography with sources and/or links, should be posted in the Discussion forum for the purpose by the end of Week 3, and you will receive feedback during Week 4.
== Schedule
<schedule>
#strong[Week 1] M 05/20
#strong[Interpassive Aggressive]
<NAME>, #strong[Internal Exile] (blog)
- "#link("https://robhorning.substack.com/p/empires-of-modern-passivity?r=1dbr0j&utm_medium=ios&triedRedirect=true")[Empires of Modern Passivity];" (17 May 2024) \[Please read the linked references also\]
- "#link("https://robhorning.substack.com/p/a-delightful-intuitive-companion?utm_source=substack&publication_id=1073994&post_id=141075725&utm_medium=email&utm_content=share&utm_campaign=email-share&isFreemail=true&r=1dbr0j&triedRedirect=true")[A Delightful Intuitive Companion];" (26 January 2024)
- <NAME>, "Introduction" \[#link("pdf/interpassivity-intro.pdf")[pdf];\] (#emph[Interpassivity: The Aesthetics of Delegated Enjoyment];)
#horizontalrule
#strong[Week 2] M 05/27
#strong[Digital Swarms]
- <NAME>, "No Respect"; "Outrage Society"; "In The Swarm" (#strong[In The Swarm: Digital Prospects];, chs.~1-3) \[#link("pdf/in-the-swarm.pdf")[pdf];\]
- <NAME>, "Humiliation and Defiance" (#strong[The Shame Machine: Who Profits in the New Age of Humiliation];, ch.~6) \[#link("pdf/shame-machine-karens.pdf")[pdf];\]
#horizontalrule
#strong[Week 3] M 06/03
#strong[Smile for the Camera: Selfies]
- <NAME>, "#link("https://medium.com/@socialcreature/ai-and-the-american-smile-76d23a0fbfaf")[AI and the American Smile];" (#strong[Medium];, 17 March 2023)
- <NAME>, "#link("https://www.theguardian.com/global-development/2021/mar/03/china-positive-energy-emotion-surveillance-recognition-tech")[Smile for the Camera: The Dark Side of China’s Emotion-Recognition Tech];" (#strong[The Guardian];, 3 March 2021)
#horizontalrule
#strong[Week 4] M 06/10
#strong[Fangirls]
- <NAME>, "#link("pdf/playing-to-the-crowd-intro.pdf")[Introduction: The Intimate Work of Connection];" (#strong[Playing to the Crowd];, Introduction)
- <NAME>, #link("pdf/kaitlyn-tiffany.pdf")[#strong[Everything I Need I Get From You];] (it’s a big excerpt - read at least the Introduction and the first couple of chapters)
#horizontalrule
#strong[Week 5] M 06/17
#strong[Females]
- #link("https://amfq.xyz/")[<NAME>];, "#link("https://www.wired.com/story/girls-online-culture/")[Everyone is a Girl Online];" (#strong[WIRED];, 11 September 2023)
- <NAME>, "#link("https://www.heyalma.com/notes-on-frump-a-style-for-the-rest-of-us/")[Notes on Frump: A Style for the Rest of Us];" (#strong[heyalma];, 10 August 2017)
#horizontalrule
#strong[Week 6] M 06/24
#strong[Toxic Cleanup]
<NAME> and <NAME>, #strong[You Are Here]
- ch.~5: "#link("pdf/you-are-here-ch5.pdf")[Cultivating Ecological Literacy];" (skip opening section in italics)
- ch.~6: "#link("pdf/you-are-here-ch6.pdf")[Choose Your Own Ethics Adventure];"
#horizontalrule
#strong[Week 7] M 07/01
#strong[The Dark Forest]
- Maggie Appleton, "#link("https://maggieappleton.com/cozy-web")[The Dark Forest & The Cozy Web];"
- Yancey Strickler, "#link("pdf/yancey-strickler-medium-pt1.pdf")[The Dark Forest Theory of the Internet];"; "\[Beyond The Dark Forest Theory of the Internet\]((pdf/yancey-strickler-medium-pt2.pdf)" (2019)
#horizontalrule
== Resources
<resources>
#link("https://www.abbiesr.com/about")[Abbie Richards] (TikTok researcher, Media Matters)
== Bibliography
<bibliography>
danah boyd, #strong[It’s Complicated: The Social Lives of Networked Teens] (New Haven: Yale University Press, 2014).
<NAME>, #strong[Should You Believe Wikipedia? Online Communities and the Construction of Knowledge] (Cambridge: Cambridge University Press, 2022).
<NAME> and <NAME>, #strong[Obfuscation: A User’s Guide for Privacy and Protest] (Cambridge: MIT Press, 2016).
<NAME>, #strong[Hacker, Hoaxer, Whistleblower, Spy: The Many Faces of Anonymous] (London and New York: Verso, 2014).
<NAME>, #strong[Monsters: A Fan’s Dilemma] (New York: A<NAME>. Knopf, 2023).
<NAME>, <NAME>, et al., #strong[\#Hashtag Activism: Networks of Race and Gender Justice] (Cambridge: MIT Press, 2020).
<NAME>, #strong[Race and Media: Critical Approaches] (New York: New York University Press, 2020).
<NAME> & <NAME>, #strong[Rebooting AI: Building Artificial Intelligence We Can Trust] (New York: Pantheon Books, 2019).
<NAME>, #strong[Because Internet: Understanding the New Rules of Language] (New York: Riverhead Books, 2019).
<NAME>, #strong[Kill All Normies: Online Culture Wars From 4Chan and Tumblr to Trump and the Alt-Right] (Alresford, Hampshire, UK: Zero Books, 2017). \* <NAME>, with <NAME>, #strong[The Shame Machine: Who Profits in the New Age of Humiliation] (New York: Crown/Random House, 2022).
<NAME>, #strong[This Is Why We Can’t Have Nice Things: Mapping the Relationship between Online Trolling and Mainstream Culture] (Cambridge: MIT Press, 2015).
Whitney Phillips and R<NAME>, #strong[You Are Here: A Field Guide for Navigating Polarized Speech, Conspiracy Theories, and Our Polluted Media Landscape] (Cambridge: MIT Press, 2021).
<NAME>, Richardson, #strong[Bearing Witness While Black: African Americans, Smartphones, and the New Protest \#Journalism] (Oxford: Oxford University Press, 2020).
== Late Policy
<late-policy>
Assignments that are late will lose 1/2 of a grade per day, beginning at the end of class and including weekends and holidays. This means that a paper, which would have received an A if it was on time, will receive a B+ the next day, B- for two days late, and so on. Time management, preparation for our meetings, and timely submission of your work comprise a significant dimension of your professionalism. As such, your work must be completed by the beginning of class on the day it is due. If you have a serious problem that makes punctual submission impossible, you must discuss this matter with me before the due date so that we can make alternative arrangements. Because you are given plenty of time to complete your work, and major due dates are given to you well in advance, last minute problems should not preclude handing in assignments on time.
== Mandatory Reporter
<mandatory-reporter>
Fitchburg State University is committed to providing a safe learning environment for all students that is free of all forms of discrimination and harassment. Please be aware all FSU faculty members are "mandatory reporters," which means that if you tell me about a situation involving sexual harassment, sexual assault, dating violence, domestic violence, or stalking, I am legally required to share that information with the Title IX Coordinator. If you or someone you know has been impacted by sexual harassment, sexual assault, dating or domestic violence, or stalking, FSU has staff members trained to support you. If you or someone you know has been impacted by sexual harassment, sexual assault, dating or domestic violence, or stalking, please visit #link("http://fitchburgstate.edu/titleix") to access information about university support and resources.
== Health
<health>
#link("http://www.google.com/url?q=http%3A%2F%2Fwww.fitchburgstate.edu%2Foffices-services-directory%2Fhealth-services%2F&sa=D&sntz=1&usg=AFQjCNEw5V0i0hL5DVO5b43gejNNaAt4ig")[Health Services]
Hours: Monday-Friday 8:30AM-5PM Location: Ground Level of Russell Towers (across from the entrance of Holmes Dining Hall) Phone: (978) 665-3643/3894
#link("http://www.google.com/url?q=http%3A%2F%2Fwww.fitchburgstate.edu%2Foffices-services-directory%2Fcounseling-services%2F&sa=D&sntz=1&usg=AFQjCNEYiS4EmSvWerpp2bKr5lTpouPuqQ")[Counseling Services]
The Counseling Services Office offers a range of services including individual, couples and group counseling, crisis intervention, psychoeducational programming, outreach ALTERNATIVE ECOSYSTEMSs, and community referrals. Counseling services are confidential and are offered at no charge to all enrolled students. Staff at Counseling Services are also available for consultation to faculty, staff and students. Counseling Services is located in the Hammond, 3rd Floor, Room 317.
#link("http://www.google.com/url?q=http%3A%2F%2Fwww.fitchburgstate.edu%2Foffices-services-directory%2Ffitchburg-anti-violence-education%2F&sa=D&sntz=1&usg=AFQjCNFi5qy-wunMxX-hoWbA9YwT8aa4Ig")[Fitchburg Anti-Violence Education (FAVE)]
FAVE collaborates with a number of community partners (e.g., YWCA Domestic Violence Services, Pathways for Change) to meet our training needs and to link survivors with community based resources. This site also features #link("http://www.google.com/url?q=http%3A%2F%2Fwww.fitchburgstate.edu%2Foffices-services-directory%2Ffitchburg-anti-violence-education%2Ffitchburg-anti-violence-education-resources%2F&sa=D&sntz=1&usg=AFQjCNF9KZ2O1AvPMLJTHdNg1DfmYYtgog")[resources] for help or information about dating violence, domestic violence, sexual assault and stalking. If you or someone you know is in an abusive relationship or has been a victim of sexual assault, there are many places to go for help. Many can be accessed 24 hours a day, seven days a week, 365 days a year. On campus, free and confidential support is provided at both Counseling Services and Health Services.
#emph[Community Food Pantry] Food insecurity is a growing issue and it certainly can affect student learning. The ability to have access to nutritious food is incredibly vital. The Falcon Bazaar, located in Hammond G 15, is stocked with food, basic necessities, and can provide meal swipes to support all Fitchburg State students experiencing food insecurity for a day or a semester.
The university continues to partner with Our Father’s House to support student needs and access to food and services. All Fitchburg State University students are welcome at the Our Father’s House Community Food Pantry. This Pantry is located at the Faith Christian Church at 40 Boutelle St., Fitchburg, MA and is open from 5-7pm. Each "household" may shop for nutritious food once per month by presenting a valid FSU ID.
== Academic Integrity
<academic-integrity>
The University "Academic Integrity" policy can be found online at #link("http://www.fitchburgstate.edu/offices-services-directory/office-of-student-conduct-mediation-education/academic-integrity/")[http:\/\/ www.fitchburgstate.edu/offices-services-directory/office-of-student-conductmediation-education/academic-integrity/.] Students are expected to do their own work. Plagiarism and cheating are inexcusable. Any instance of plagiarism or cheating will automatically result in a zero on the assignment and may be reported the Office of Student and Academic Life at the discretion of the instructor.
Plagiarism includes, but is not limited to: - Using papers or work from another class. - Using another student’s paper or work from any class. - Copying work or a paper from the Internet. - The egregious lack of citing sources or documenting research.
#emph[If you’re not clear on what is or is not plagiarism, ASK. The BEST case scenario if caught is a zero on that assignment, and ignorance of what does or does not count is not an excuse. That being said, I’m a strong supporter of] #link("https://en.wikipedia.org/wiki/Fair_Use")[#emph[Fair Use];] #emph[doctrine. Just attribute what you use–and, again, ASK if there’s any doubt.]
== Americans With Disabilities Act (ADA)
<americans-with-disabilities-act-ada>
If you need course adaptations or accommodations because of a disability, if you have emergency medical information to share with the instructor, or if you need special arrangements in case the building must be evacuated, please inform the faculty member as soon as possible.
== Technology
<technology>
At some point during the semester you will likely have a problem with technology. Your laptop will crash; your iPad battery will die; a recording you make will disappear; you will accidentally delete a file; the wireless will go down at a crucial time. These, however, are inevitabilities of life, not emergences. Technology problems are not excuses for unfinished or late work. Bad things may happen, but you can protect yourself by doing the following:
- Plan ahead: A deadline is the last minute to turn in material. You can start—and finish—early, particularly if challenging resources are required, or you know it will be time consuming to finish this project.
- Save work early and often: Think how much work you do in 10 minutes. I auto save every 2 minutes.
- Make regular backups of files in a different location: Between Box, Google Drive, Dropbox, and iCloud, you have ample places to store and backup your materials. Use them.
- Save drafts: When editing, set aside the original and work with a copy.
- Practice safe computing: On your personal devices, install and use software to control viruses and malware.
== Grading Policy
<grading-policy>
Grading for the course will follow the FSU grading policy below:
4.0: 95-100 \
3.7: 92-94 \
3.5: 89-91 \
3.3: 86-88 \
3.0: 83-85 \
2.7: 80-82 \
2.5: 77-79 \
2.3: 74-76 \
2.0: 71-73 \
0.0: \< 70
== Academic Resources
<academic-resources>
#link("http://www.fitchburgstate.edu/offices-services-directory/tutor-center/writing-help/")[Writing Center]
#link("http://catalog.fitchburgstate.edu/content.php?catoid=13&navoid=851")[Academic Policies]
#link("http://www.fitchburgstate.edu/offices-services-directory/disability-services/")[Disability Services]
#link("https://www.getrave.com/login/fitchburgstate/")[Fitchburg State Alert system for emergencies, snow closures/delays, and faculty absences]
#link("http://www.fitchburgstate.edu/offices-services-directory/career-counseling-and-advising/careerservices/")[University Career Services]
|
https://github.com/storopoli/Bayesian-Statistics | https://raw.githubusercontent.com/storopoli/Bayesian-Statistics/main/README.md | markdown | Creative Commons Attribution Share Alike 4.0 International | # Bayesian Statistics
[](http://creativecommons.org/licenses/by-sa/4.0/)
<div class="figure" style="text-align: center">
<img src="slides/images/memes/main.jpg" alt="Bayesian for Everyone!" width="500" />
<p class="caption">
Bayesian for Everyone!
</p>
</div>
This repository holds slides and code for a full Bayesian statistics graduate course.
**Bayesian statistics** is an approach to inferential statistics based on Bayes' theorem,
where available knowledge about parameters in a statistical model is updated with the information in observed data.
The background knowledge is expressed as a prior distribution and combined with observational data in the form of a likelihood function to determine the posterior distribution.
The posterior can also be used for making predictions about future events.
**Bayesian statistics** is a departure from classical inferential statistics that prohibits probability statements about parameters and is based on asymptotically sampling infinite samples from a theoretical population and finding parameter values that maximize the likelihood function.
Mostly notorious is null-hypothesis significance testing (NHST) based on _p_-values.
Bayesian statistics **incorporate uncertainty** (and prior knowledge) by allowing probability statements about parameters,
and the process of parameter value inference is a direct result of the **Bayes' theorem**.
## Content
The whole content is a set of several slides found at [`the latest release`](https://github.com/storopoli/Bayesian-Statistics/releases/latest/download/slides.pdf) (382 slides).
Here is a brief table of contents:
1. **What is Bayesian Statistics?**
1. **Common Probability Distributions**
1. **Priors**
1. **Bayesian Workflow**
1. **Bayesian Linear Regression**
1. **Bayesian Logistic Regression**
1. **Bayesian Ordinal Regression**
1. **Bayesian Regression with Count Data: Poisson Regression**
1. **Robust Bayesian Regression**
1. **Bayesian Sparse Regression**
1. **Hierarchical Models**
1. **Markov Chain Monte Carlo (MCMC) and Model Metrics**
1. **Model Comparison: Cross-Validation and Other Metrics**
## Probabilistic Programming Languages (PPLs)
Along with slides for the content, this repository also holds Stan code and also Turing code for all models.
Stan and Turing represents, respectively, the present and future of [probabilistic programming](https://en.wikipedia.org/wiki/Probabilistic_programming) languages.
All model files are tested in [GitHub Actions](https://github.com/storopoli/Bayesian-Statistics/actions/workflows/models.yml)
against the latest Stan and Julia/Turing versions.
### Stan
[**Stan**](https://mc-stan.org) (Carpenter et al., 2017) Stan is a state-of-the-art platform for statistical modeling and high-performance statistical computation.
Thousands of users rely on Stan for statistical modeling, data analysis, and prediction in the social, biological, and physical sciences, engineering, and business.
Stan models are specified in its own language (similar to C++) and compiled into an executable binary that can generate Bayesian statistical inferences using a high-performance Markov Chain Montecarlo (MCMC).
You can find Stan models for all the content discussed in the slides at [`stan/`](stan/) folder.
### Turing
[**Turing**](http://turinglang.org/) (Ge, Xu & Ghahramani, 2018) is an ecosystem of [**Julia**](https://www.julialang.org) packages for Bayesian Inference using [probabilistic programming](https://en.wikipedia.org/wiki/Probabilistic_programming).
Models specified using Turing are easy to read and write — models work the way you write them.
Like everything in Julia, Turing is [fast](https://arxiv.org/abs/2002.02702).
You can find Turing models for all the content discussed in the slides at [`turing/`](turing/) folder.
## Datasets
- `kidiq` (linear regression): data from a survey of adult American women and their children
(a subsample from the National Longitudinal Survey of Youth).
Source: Gelman and Hill (2007).
- `wells` (logistic regression): a survey of 3200 residents in a small area of Bangladesh suffering
from arsenic contamination of groundwater.
Respondents with elevated arsenic levels in their wells had been encouraged to switch their water source
to a safe public or private well in the nearby area
and the survey was conducted several years later to
learn which of the affected residents had switched wells.
Source: Gelman and Hill (2007).
- `esoph` (ordinal regression): data from a case-control study of (o)esophageal cancer in Ille-et-Vilaine, France.
Source: Breslow and Day (1980).
- `roaches` (Poisson regression): data on the efficacy of a pest management system at reducing the number of roaches in urban apartments.
Source: Gelman and Hill (2007).
- `duncan` (robust regression): data from occupation's prestige filled with outliers.
Source: Duncan (1961).
- `sparse_regression` (sparse regression): simulated data from the [`glmnet` R package](https://cran.r-project.org/package=glmnet).
Source: Tay, Narasimhan and Hastie (2023).
- `cheese` (hierarchical models): data from cheese ratings.
A group of 10 rural and 10 urban raters rated 4 types of different cheeses (A, B, C and D) in two samples.
Source: Boatwright, McCulloch and Rossi (1999).
## Author
<NAME>, PhD - [ORCID](https://orcid.org/0000-0002-0559-5176) - <https://storopoli.io>
## How to use the content?
The content is licensed under a very permissive Creative Commons license (CC BY-SA).
You are mostly welcome to contribute with [issues](https://www.github.com/storopoli/Bayesian-Statistics/issues)
and [pull requests](https://github.com/storopoli/Bayesian-Statistics/pulls).
My hope is to have **more people into Bayesian statistics**.
The content is aimed towards PhD candidates in applied sciences.
I chose to provide an **intuitive approach** along with some rigorous mathematical formulations.
I've made it to be how I would have liked to be introduced to Bayesian statistics.
If you want to build the slides locally without having to worry with [Typst](https://typst.app)
packages, [install Nix](https://nixos.org/download.html) and run:
```shell
nix build github:storopoli/Bayesian-Statistics
```
## References
The references are divided in **books**, **papers**, **software**, and **datasets**.
### Books
- <NAME>., <NAME>., <NAME>., <NAME>., <NAME>.,
& <NAME>. (2013). _Bayesian Data Analysis_. Chapman and
Hall/CRC.
- <NAME>. (2020). _Statistical rethinking: A Bayesian course
with examples in R and Stan_. CRC press.
- <NAME>., <NAME>., & <NAME>. (2020). _Regression and other
stories_. Cambridge University Press.
- <NAME>., <NAME>., <NAME>., & <NAME>.-L. (2011). _Handbook
of Markov Chain Monte Carlo_. CRC Press.
<http://books.google.com?id=qfRsAIKZ4rIC>
- <NAME>. (2011). Introduction to markov chain monte carlo.
In <NAME>, <NAME>, <NAME>, & <NAME> (Eds.),
_Handbook of markov chain monte carlo_.
### Papers
The papers section of the references are divided into **required** and **complementary**.
#### Required
- <NAME>., <NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., <NAME>., <NAME>., <NAME>., <NAME>., &
<NAME>. (2021). Bayesian statistics and modelling. _Nature Reviews
Methods Primers_, _1_(1, 1), 1–26.
https://doi.org/[10.1038/s43586-020-00001-2](https://doi.org/10.1038/s43586-020-00001-2)
- <NAME>., <NAME>., <NAME>., <NAME>., & <NAME>.
(2019). Visualization in Bayesian workflow. _Journal of the Royal
Statistical Society: Series A (Statistics in Society)_, _182_(2),
389–402.
https://doi.org/[10.1111/rssa.12378](https://doi.org/10.1111/rssa.12378)
- <NAME>., <NAME>., <NAME>., <NAME>., Carpenter,
B., <NAME>., <NAME>., <NAME>., <NAME>., & <NAME>.
(2020, November 3). _Bayesian Workflow_.
<http://arxiv.org/abs/2011.01808>
- <NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., <NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., <NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., <NAME>., <NAME>., <NAME>., <NAME>., …
<NAME>. (2018). Redefine statistical significance. _Nature
Human Behaviour_, _2_(1), 6–10.
https://doi.org/[10.1038/s41562-017-0189-z](https://doi.org/10.1038/s41562-017-0189-z)
- <NAME>. (2018). Introduction to the Concept of Likelihood and Its
Applications. _Advances in Methods and Practices in Psychological
Science_, _1_(1), 60–69.
https://doi.org/[10.1177/2515245917744314](https://doi.org/10.1177/2515245917744314)
- <NAME>., <NAME>., <NAME>., <NAME>., &
<NAME>. (2018). How to become a Bayesian in eight easy steps:
An annotated reading list. _Psychonomic Bulletin & Review_, _25_(1),
219–234.
https://doi.org/[10.3758/s13423-017-1317-5](https://doi.org/10.3758/s13423-017-1317-5)
- <NAME>., <NAME>., <NAME>., <NAME>., & <NAME>.
(2019). Abandon Statistical Significance. _American Statistician_,
_73_, 235–245.
https://doi.org/[10.1080/00031305.2018.1527253](https://doi.org/10.1080/00031305.2018.1527253)
- <NAME>., <NAME>., & <NAME>. (2019). Scientists rise up
against statistical significance. _Nature_, _567_(7748), 305–307.
https://doi.org/[10.1038/d41586-019-00857-9](https://doi.org/10.1038/d41586-019-00857-9)
- <NAME>. & <NAME>. (2017). Sparsity information and regularization in the
horseshoe and other shrinkage priors.
_Electronic Journal of Statistics_. _11_(2), 5018-5051.
https://doi.org/10.1214/17-EJS1337SI
- <NAME>., <NAME>., & <NAME>. (2018). A simple
introduction to Markov Chain Monte–Carlo sampling. _Psychonomic
Bulletin and Review_, _25_(1), 143–154.
https://doi.org/[10.3758/s13423-016-1015-8](https://doi.org/10.3758/s13423-016-1015-8)
- <NAME>., <NAME>., <NAME>., & others.
(2015). Model comparison and the principle of parsimony. In <NAME>.
Busemeyer, <NAME>, <NAME>, & <NAME> (Eds.), _Oxford
handbook of computational and mathematical psychology_ (pp.
300–319). Oxford University Press Oxford.
- <NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., & <NAME>. (2014). A Gentle Introduction to
Bayesian Analysis: Applications to Developmental Research. _Child
Development_, _85_(3), 842–860.
https://doi.org/[10.1111/cdev.12169](https://doi.org/10.1111/cdev.12169)
<span class="csl-block">\_eprint:
https://srcd.onlinelibrary.wiley.com/doi/pdf/10.1111/cdev.12169</span>
- <NAME>. (2007). A practical solution to the pervasive
problems of p values. _Psychonomic Bulletin & Review_, _14_(5),
779–804.
https://doi.org/[10.3758/BF03194105](https://doi.org/10.3758/BF03194105)
- <NAME>., <NAME>., <NAME>., & others. (2015).
Model comparison and the principle of parsimony.
In <NAME>, <NAME>, <NAME>, & <NAME> (Eds.),
Oxford handbook of computational and mathematical psychology (pp. 300–319).
Oxford University Press Oxford.
- <NAME>., <NAME>., & <NAME>. (2015). Practical Bayesian model evaluation
using leave-one-out cross-validation and WAIC.
https://doi.org/10.1007/s11222-016-9696-4
#### Complementary
- <NAME>. (1994). The earth is round (p < .05). _American
Psychologist_, _49_(12), 997–1003.
https://doi.org/[10.1037/0003-066X.49.12.997](https://doi.org/10.1037/0003-066X.49.12.997)
- <NAME>. (2011). Bayesian Versus Orthodox Statistics: Which Side
Are You On? _Perspectives on Psychological Science_, _6_(3),
274–290.
https://doi.org/[10.1177/1745691611406920](https://doi.org/10.1177/1745691611406920)
- <NAME>., & <NAME>. (2018). Introduction to Bayesian
Inference for Psychology. _Psychonomic Bulletin & Review_, _25_(1),
5–34.
https://doi.org/[10.3758/s13423-017-1262-3](https://doi.org/10.3758/s13423-017-1262-3)
- <NAME>. (2020). Quanto vale o valor-p? _Arquivos de
Ciências Do Esporte_, _7_(2).
- <NAME>. (1998). HARKing: Hypothesizing after the results are
known. _Personality and Social Psychology Review_, _2_(3), 196–217.
https://doi.org/[10.1207/s15327957pspr0203\_4](https://doi.org/10.1207/s15327957pspr0203_4)
- <NAME>., & <NAME>. (2015). Bayesian estimation in
hierarchical models. In <NAME>, <NAME>, <NAME>,
& <NAME> (Eds.), _The Oxford handbook of computational and
mathematical psychology_ (pp. 279–299). Oxford University Press
Oxford, UK.
- <NAME>., & <NAME>. (2018). Bayesian data analysis for
newcomers. _Psychonomic Bulletin & Review_, _25_(1), 155–177.
https://doi.org/[10.3758/s13423-017-1272-1](https://doi.org/10.3758/s13423-017-1272-1)
- <NAME>., & <NAME>. (2018). The Bayesian New
Statistics: Hypothesis testing, estimation, meta-analysis, and power
analysis from a Bayesian perspective. _Psychonomic Bulletin &
Review_, _25_(1), 178–206.
https://doi.org/[10.3758/s13423-016-1221-4](https://doi.org/10.3758/s13423-016-1221-4)
- <NAME>., <NAME>., <NAME>., <NAME>., <NAME>.
J., <NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., <NAME>., <NAME>., <NAME>.,
<NAME>., <NAME>., <NAME>., <NAME>., <NAME>.
S., <NAME>., … <NAME>. (2018). Justify your alpha. _Nature
Human Behaviour_, _2_(3), 168–171.
https://doi.org/[10.1038/s41562-018-0311-x](https://doi.org/10.1038/s41562-018-0311-x)
- <NAME>., <NAME>., <NAME>., <NAME>., &
<NAME>. (2016). <span class="nocase">The fallacy of
placing confidence in confidence intervals</span>. _Psychonomic
Bulletin & Review_, _23_(1), 103–123.
https://doi.org/[10.3758/s13423-015-0947-8](https://doi.org/10.3758/s13423-015-0947-8)
- <NAME>., & <NAME>. (2019). HARKing: How Badly Can
Cherry-Picking and Question Trolling Produce Bias in Published
Results? _Journal of Business and Psychology_, _34_(1).
https://doi.org/[10.1007/s10869-017-9524-7](https://doi.org/10.1007/s10869-017-9524-7)
- <NAME>., & <NAME>. (2018). Cargo-cult statistics and
scientific crisis. _Significance_, _15_(4), 40–43.
https://doi.org/[10.1111/j.1740-9713.2018.01174.x](https://doi.org/10.1111/j.1740-9713.2018.01174.x)
### Software
- <NAME>., <NAME>., <NAME>., <NAME>., <NAME>.,
Betancourt, M., <NAME>., <NAME>., <NAME>., & <NAME>. (2017).
Stan : A Probabilistic Programming Language. _Journal of Statistical
Software_, _76_(1).
https://doi.org/[10.18637/jss.v076.i01](https://doi.org/10.18637/jss.v076.i01)
- <NAME>., <NAME>., & <NAME>. (2018). Turing: A Language for Flexible Probabilistic Inference. International Conference on Artificial Intelligence and Statistics, 1682–1690. http://proceedings.mlr.press/v84/ge18b.html
- <NAME>., <NAME>., <NAME>., <NAME>., & <NAME>. (2020). DynamicPPL: Stan-like Speed for Dynamic Probabilistic Models. ArXiv:2002.02702 [Cs, Stat]. http://arxiv.org/abs/2002.02702
- <NAME>., <NAME>., <NAME>., <NAME>., <NAME>., & <NAME>. (2020). AdvancedHMC.jl: A robust, modular and efficient implementation of advanced HMC algorithms. Symposium on Advances in Approximate Bayesian Inference, 1–10. http://proceedings.mlr.press/v118/xu20a.html
### Datasets
- <NAME>., <NAME>., & <NAME>. (1999). Account-level modeling for trade promotion: An application of a constrained parameter hierarchical model. _Journal of the American Statistical Association_, 94(448), 1063–1073.
- <NAME>. & <NAME>. (1980). **Statistical Methods in Cancer Research. Volume 1: The Analysis of Case-Control Studies**. IARC Lyon / Oxford University Press.
- <NAME>. (1961). A socioeconomic index for all occupations. Class: Critical Concepts, 1, 388–426.
- <NAME>, <NAME>, <NAME> (2023). Elastic Net Regularization Paths for All Generalized Linear Models. _Journal of Statistical Software_, 106(1), 1–31. doi:10.18637/jss.v106.i01.
- <NAME>., & <NAME>. (2007). **Data analysis using regression and
multilevel/hierarchical models**. Cambridge university press.
## How to cite
To cite this course, please use:
Storopoli (2022). Bayesian Statistics: a graduate course. https://github.com/storopoli/Bayesian-Statistics.
Or in BibTeX format ($\LaTeX$):
@misc{storopoli2022bayesian,
author = {<NAME>},
title = {Bayesian Statistics: a graduate course},
url = {https://github.com/storopoli/Bayesian-Statistics},
year = {2022}
}
## License
This content is licensed under [Creative Commons Attribution-ShareAlike 4.0 International](http://creativecommons.org/licenses/by-sa/4.0/).
[](http://creativecommons.org/licenses/by-sa/4.0/)
|
https://github.com/xbunax/tongji-undergrad-thesis | https://raw.githubusercontent.com/xbunax/tongji-undergrad-thesis/main/init-files/sections/acknowledgments.typ | typst | MIT License | #import "../../tongji-undergrad-thesis/elements.typ": *
#heading("谢辞", numbering: none)
#empty-par()
本节通常用于感谢在研究过程中给予帮助和支持的人们,例如指导老师、实验室同学、朋友和家人等。
在谢辞中,需要真诚地表达感谢之情,回顾一下在研究过程中所受到的帮助和支持,并提到他们的具体贡献和重要性。同时,也可以简要说明一下自己在研究过程中的收获和体会,表达对他们的感激之情和祝福。
最后,需要注意不要出现太多的感情用词,语言简洁明了,表达真诚和诚恳即可。
谢谢支持本项目的所有朋友们。并且希望选用该模板的朋友们都能顺利通过查重与答辩。 |
https://github.com/yhtq/Notes | https://raw.githubusercontent.com/yhtq/Notes/main/抽象代数/作业/hw10.typ | typst | #import "../../template.typ": *
// Take a look at the file `template.typ` in the file panel
// to customize this template and discover how it works.
#show: note.with(
title: "作业10",
author: "YHTQ ",
date: none,
logo: none,
withOutlined: false
)
= 11.30 P101
== 1 <exercise>
断言 $QQ[x, x^(1/2), x^(1/3), ..., x^(1/n), ...]$ 不满足因子链条件。事实上,在这个环上定义通常的次数,同样有:
$
deg(f g) = deg(f) + deg(g)
$
从而 $x^r, r!= 0$ 将成为不可逆元。同时:
$
x^r = (x^(r/2))^2
$
表明 $x^r$ 不是不可约元\】】
现设:
$
x = product_{i=1}^m f_i (x)
$
并设 $f_i$ 的最低次项次数为 $a_i/b_i$\
由于仅有有限多个 $f_i$,可取:
$
n = lcm(b_1, b_2, ..., b_m)
$
从而:
$
x^n = product_{i=1}^m f_i (x^n)
$
此时等式两端所有多项式都 $in QQ[x]$,进而:
$
f_i (x^n) = x^(m_i) => f_i(x) = x^(m_i/n)
$
(这是因为:$phi := [f(x) | f(x) -> f(x^2)]$ 是环上的自同态,且 $ker(phi) = {0}$ 表明 $phi$ 是单射)\
然而已经证明了这样的元素不是 $QQ[x, x^(1/2), x^(1/3), ..., x^(1/n), ...]$ 中不可约元,因此 $x$ 不能写成有限个不可约元的乘积。
== 2
- 假设 $R$ 是唯一分解整环,断言 $a, b$ 的唯一分解中,(在相伴意义下)最长的公共部分就是它们的最大公约数。也即可设:
$
a = d p_1 p_2 ... p_m\
b = d q_1 q_2 ... q_n
$
其中 $p_1 p_2 ... p_m$ 与 $q_1 q_2 ... q_n$ 之间任何两元素都不相伴。\ 此时 $d$ 显然是公因子。为了证明它是最大公因子,设:
$
d' | a, d' | b
$
同时设 $d, d'$ 的唯一分解分别为:
$
d = d_1 d_2 ... d_k\
d' = d'_1 d'_2 ... d'_l
$
由于 $R$ 中不可约元就是素元,因此对每个 $i$,$d'_i | d'_1 d'_2 ... d'_l | a, b$ 表明存在 $j, k$ 使得 $d'_i | p_j, q_k$,进而 $d'_i$ 与 $p_j, q_k$ 相伴。这就表明 $p_j$ 与 $q_k$ 相伴,因此 $p_j, q_i | d => d'_i | d$。\
换言之,$d$ 包含 $d'$ 所有素因子,同时容易验证每个素因子在 $d$ 中的次数不小于在 $d'$ 中的次数,因此 $d | d'$,即 $d$ 是 $d'$ 的因子。\
综上,$d$ 是 $a, b$ 的最大公因子。
- 假设 $R$ 中任意两元素都有最大公因子,我们来证明 $R$ 中不可约元就是素元。事实上,设 $p$ 是不可约元,且:
$
a b = r p
$
则设 $d$ 是 $a, p$ 的最大公因子。若其恰为(相伴于)$p$,则 $p | a$,因此 $p$ 是素元。否则由不可约性,可设 $d = 1$,将有:
$
b = b (a, p) = (a b, b p) = (r p, b p) = p (r, b)
$
这就表明 $p | b$,证毕
== 4
容易验证:
$
R = {a+2 b i | a, b in ZZ}
$
是 $ZZ[i]$ 的一个子环,而后者是唯一分解子环。断言:
- $2i$ 是 $R$ 中不可约元
事实上,$a, b in R, a b = 2 i => - i a b = 2$,而 $2$ 在 $ZZ[i]$ 中不可约,当然在 $R$ 中不可约,因此:
$
&{a, b} = plus.minus 1{i, 2} " 或"\
&{a, b} = plus.minus 1{1, 2i}
$
而 $i in.not R$,因此 ${a, b} = plus.minus 1{2i, 1}$,这表明 $2i$ 是 $R$ 中不可约元。
- $4 = 2 dot 2 = -(2i) dot (2i)$,而 $2, 2i$ 都是 $R$ 中不可约元,因此 $4$ 存在两种不同的不可约分解,因而 $R$ 不是唯一分解整环。
== 5
注意到:
$
ZZ[sqrt(-5)] tilde.eq quotient(ZZ[x], (x^2 + 5))
$
而 $x^2 + 5$ 在 $ZZ[x]$ 中是不可约的,$ZZ[x]$ 是唯一分解整环,但 $ZZ[sqrt(-5)]$ 不是唯一分解整环。\
== 6
若 $f(x)$ 是常多项式,则 $(f(x), x^2)$ 当然是更大的非平凡理想。\
反之,取 $k$ 使得它与 $f(x)$ 所有系数均互素,此时断言 $(f(x), k)$ 是更大的非平凡理想
- 若 $k in (f(x)) => k = f(x)g(x)$,显然 $f(x)$ 一定是常多项式,回到常多项式的情形
- 反之,$(f(x), k)$ 一定较 $(f(x))$ 更大,只需证明这是非平凡理想。事实上,若:
$
1 = f(x)u(x) + k v(x)
$
取自然同态:$phi: ZZ[x] -> (quotient(ZZ, k ZZ))[x]$,将有:
$
1 = phi(f(x))phi(u(x))
$
这意味着 $phi(f(x))$ 将成为 $(quotient(ZZ, k ZZ))[x]$ 上的可逆元,但这样的多项式(由上节习题)必然满足所有非常数项系数都是幂零元,而这与之前假设所有系数均与 $k$ 互素(从而成为 $quotient(ZZ, k ZZ)$ 中可逆元)矛盾!\
从而 $1 in.not (f(x), k)$,表明这不是平凡理想
== 12
#lemma[][
代数整数集合对加法封闭
]
#proof[
设 $alpha, beta$ 是两个 $K$ 上的代数整数,以其为根的多项式分别为
$
f(x) = sum_i a_i x^i, g(x) = sum_i b_i x^i
$
(这里我们排除 $alpha$ 或 $beta$ 恰好为 $0$ 的平凡情况,从而两个多项式至少是一次的)\
事实上,我们可以假设它们已经在 $ZZ[x]$ 上不可约了。如果可约,例如:
$
f(x) = i(x)j(x)
$
则 $i(alpha), j(alpha)$ 将至少有一个为零,不妨取其为新的 $f(x)$($i(x), j(x)$ 当然是 $ZZ[x}$ 上首 1 的多项式)。由于这样的操作每次都会降低多项式的次数,因此总可以在有限步终止,从而得到不可约的 $f(x)$。\
再令:
$
l(x, y) = sum_i a_i (x-y)^i = f(x-y)\
$
容易看出 $l(alpha + beta, beta) = 0$\
我们的目标是寻找 $h(x) in (l(x, y), g(y))$,从而这样的 $h(x)$ 满足:
$
h(x) = u(x, y)l(x, y) + v(x, y)g(y) \
=> h(alpha + beta) = u(alpha + beta, beta)l(alpha + beta, beta) + v(alpha + beta, beta)g(beta) = 0
$<cond-h>
//(这里暂时不要求 $h(x)$ 首 1)\
事实上,设 $ZZ[x]$ 的分式域为 $Frac[x]$,我们不妨在 $(Frac[x])[y]$ 中考虑上述等式,最后去掉 $h(x), u(x, y), v(x, y)$ 的公分母就可以得到满足@cond-h 的 $h(x)$\
而 $Frac[x]$ 是域,$(Frac[x])[y]$ 是欧几里得整环,因此这就相当于证明 $g(y), l(x, y)$ 在其中互素。\
另一方面,注意到我们将 $ZZ[y]$ 上的不可约多项式 $g(y)$ 做了以下系数的延拓:
$
ZZ[y] -> (ZZ[x])[y] -> (Frac[x])[y]
$
- 第一步不改变其不可约性,只需考虑自同构:
$
[f | f(x, y) -> f(y, x)] : ZZ[x, y] -> ZZ[x, y]
$
它将 $g(y)$ 变为整环 $ZZ[x]$ 上的零次多项式,而整环上的零次多项式不可约当然等价于其本身不可约。
- 第二步也不改变其不可约性,只需注意到 $ZZ[x]$ 是唯一分解整环,$Frac[x]$ 是其分式域,我们又假设了 $deg(g) >= 1$,因此这就是高斯引理的结果。
从而 $g(y)$ 成为 $(Frac[x])[y]$ 上不可约多项式,当然有:
$
(g(y)) + (l(x, y)) = (Frac[x])[y]
$
进而@cond-h 的结果成立。\
]
回到题设,考虑 $QQ[sqrt(d)]$ 上的代数整数:
- 显然 $forall a, b in ZZ, a, b sqrt(d)$ 都是代数整数,因此 ${a + b sqrt(d) | a, b in ZZ}$ 都是代数整数
- 设 $a + b sqrt(d)$ 是代数整数,则取共轭知 $a - b sqrt(d)$ (它们是同一个整系数多项式的两个根)也是代数整数,从而 $2 a, 2 b$ 应当都是整数,换言之,$a, b = n/2, m/2$,其中 $n, m in ZZ$
从而我们只需考虑形如 $a/2 + b/2 sqrt(d)$ 的数,它在 $QQ$ 中的最小多项式为:
$
(x-a/2)^2-(b^2 d)/4 = 0\
x^2 - a + (a^2 - b^2 d)/4 = 0
$
要使 $a/2 + b/2 sqrt(d)$ 为代数整数,上面的多项式必须是整系数多项式,因此 $(a^2 - b^2 d)/4$ 是整数:
- 若 $d = 1 mod 4$,则 $a^2 - b^2 = 0 mod 4$,因此 $(a, b) mod 2$ 的可能结果为:
- $(1, 1)$
- $(0, 0)$
- 若 $d = 2, 3 mod 4$,则 $a^2 - b^2 d = 1 mod 4$,因此 $(a, b) mod 2$ 的可能结果仅有 $(0, 0)$
从而结果就是题目中结果,同时容易验证对乘法封闭,因此构成环。
== 13
#let AlgebraZ(a, b) = $#a + #b (1 + sqrt(-3))/2$
取自然的模函数:
$
N(AlgebraZ(a, b)) = ((2a+b)^2 + 3b^2)/4 = a^2 + b^2 + a b
$
自然满足 $N(x y) = N(x) N(y)$\
在 $QQ[sqrt(-3)]$ 上,设:
$
AlgebraZ(a, b)/AlgebraZ(c, d) = AlgebraZ((m + Delta m), (n + Delta n))
$
其中 $|Delta m|, |Delta n| <= 1/2$\
如此便有:
$
AlgebraZ(a, b) \
= (AlgebraZ(m, n))(AlgebraZ(c, d)) + (AlgebraZ(Delta m, Delta n))(AlgebraZ(c, d))
$
且:
$
N((AlgebraZ(Delta m, Delta n))(AlgebraZ(c, d))) = N(AlgebraZ(Delta m, Delta n))N(AlgebraZ(c, d))\
<= (1/4 + 1/4 + 1/4)N(AlgebraZ(c, d)) = 3/4 N(AlgebraZ(c, d))
$
这表明欧几里得整环成立。
== 14
#let AlgebraZ(a, b) = $#a + #b sqrt(2)$
取自然的模函数:
$
N(AlgebraZ(a, b)) = |a^2 - 2b^2|
$
自然满足 $N(x y) = N(x) N(y)$\
在 $QQ[sqrt(2)]$ 上,设:
$
AlgebraZ(a, b)/AlgebraZ(c, d) = AlgebraZ((m + Delta m), (n + Delta n))
$
其中 $|Delta m|, |Delta n| <= 1/2$\
类似的,只需验证:
$
N(AlgebraZ(Delta m, Delta n)) = |Delta m^2 - 2 Delta n^2| <= max{Delta m^2, 2 Delta n^2} <= 1/2 < 1
$
从而结论成立
== 15
#let AlgebraZ(a, b) = $#a + #b (1 + sqrt(5))/2$
取自然的模函数:
$
N(AlgebraZ(a, b)) = |((2a+b)^2 - 5b^2)/4| = |a^2 + a b - b^2|
$
自然满足 $N(x y) = N(x) N(y)$\
在 $QQ[sqrt(-3)]$ 上,设:
$
AlgebraZ(a, b)/AlgebraZ(c, d) = AlgebraZ((m + Delta m), (n + Delta n))
$
其中 $|Delta m|, |Delta n| <= 1/2$\
类似的,只需验证:
$
N(AlgebraZ(Delta m, Delta n)) = |Delta m^2 + Delta m Delta n -Delta n^2| <= max{Delta m^2 + Delta m Delta n, Delta n^2}\
<= 1/2 < 1
$
从而结论成立
== 17
#let AlgebraZ(a, b) = $#a + #b sqrt(-1)$
#let ConjAlgebraZ(a, b) = $#a - #b sqrt(-1)$
首先 $ZZ[sqrt(-1)]$ 是欧几里得整环,因此其上素元等价于不可约元。\
取自然的模函数:
$
N(AlgebraZ(a, b)) = a^2 + b^2
$
题中等式可化为:
$
(AlgebraZ(a, b))(ConjAlgebraZ(a, b)) = p
$<equ>
#lemma[][
@equ 有解当且仅当 $p$ 在 $ZZ[sqrt(-1)]$ 中可约
]<lemma-irreducible>
#proof[
必要性是显然的。充分性是由于设:
$
p = x y
$
其中 $x, y$ 都不是可逆元,则:
$
N(x)N(y) = p^2 => N(x) = N(y) = p
$
从而 $N(x) = x overline(x) = p = x y$,由整环性质知 $y = overline(x)$ 从而就是上述方程的解。
]
从而我们只需要证明 $p$ 可约即可。事实上,假设 $p$ 不可约,从而 $(p)$ 成为素理想
$
quotient(ZZ[i], (p))
$
成为整环。(所有元素无非是 $ZZ_p + i ZZ_p$)\
但另一方面,$quotient(ZZ,(p))$ 是域,其上的乘法群也是循环群,取其生成元为 $a in ZZ_p$ ,则有:
$
ord(a) = p - 1 (a in ZZ[i])\
a^((p-1)/2) = -1 mod p\
(a^((p-1)/4)+i)(a^((p-1)/4)-i) = a^((p-1)/2) + 1 = 0 mod p
$
由于 $quotient(ZZ[i], (p))$ 是整环,因此:
$
a^((p-1)/4)+i = 0 mod p or a^((p-1)/4) = -i mod p
$
但 $a^((p-1)/4) in ZZ$,故这显然是荒谬的。
== 18
#lemma[][
设 $p$ 为一素数,$a in ZZ[sqrt(-1)]$ ,$N(a) = p => a$ 不可约
]
#proof[
设 $a = x y => N(x)N(y) = p $,不妨设 $N(x) = 1$, 进而:
$
x = 1, -1, i, -i
$
这些都是可逆元,从而当然有 $a$ 不可约。
]
#lemma[][
设 $x in ZZ[i]$ 是不可约元,则 $N(x) = p$ 或 $x ~ p$,其中 $p$ 为素数
]
#proof[
由于 $(x)$ 是 $ZZ[i]$ 中素理想,考虑嵌入同态:
$
phi: ZZ -> ZZ[i]
$
将有 $Inv(phi)((x))$ 成为 $ZZ$ 中素理想,因此存在素数 $p$ 使得:
$
exists k in ZZ[i], k x = p in ZZ
$
进而 $N(k)N(x) = N(p) = p^2 $,进而要么:
$
N(p) = p
$
要么:
$
N(k) = 1 => x ~ p
$
因此结论成立
]
我们考虑所有 $ZZ$ 上素数 $p$:
+ $p=2$ 时,$N(x) = p, p^2$ 的元素仅有:
$
1 plus.minus i\
$
它们是不可约元
+ $p = 1 mod 4$ 时,由上题结论存在 $x$ 使得:
$
x overline(x) = p, N(x) = p
$
由引理这些元素当然是不可约元。同时,之前也证明了 $p$ 不是不可约元,因此由引理不存在 $N(x) = p^2$ 的不可约元
+ $p = 3 mod 4$ 时,@lemma-irreducible 的结论同样成立,由于平方数 $mod 4$ 的结果只能为 $0, 1$,因此@equ 无解,进而 $p$ 成为不可约元,没有 $N(x) = p$ 的元素
= 补充题
==
- 乘法单位元存在,加法构成子群是显然的
- 对于乘法封闭性,注意到:
$
(a + x^2f(x))(b + x^2g(x)) = a b + x^2(a f(x) + b g(x)) + x^4f(x) g(x)
$
因此对乘法也封闭。
注意到 $x^2, x^3$ 在 $F[x]$ 上的分解只能为:
$
x^2 = x x\
x^3 = x x x, x^2 x
$
在题中子环上这些分解都不存在,因此是不可约元。\
但另一方面:
$
x^2, x^3 | x^6 = x^2 x^4 = x^3 x^3\
$
但 $x^2, x^4$ 都不是 $x^3$ 的倍数,$x^3, x^3$ 都不是 $x^2$ 的倍数,因此不是素元
==
取 $a in P$,找到 $a$ 的唯一素分解:
$
a = product_i p_i
$
由于 $product_i p_i in P$,由素理想性质知必然存在 $p_j in P$,这个 $p_j$ 就是我们要找的素元
==
设:$phi: R -> R'$ 是满同态,且 $R$ 是 Noether 环。由对应原理,$R'$ 中的理想与 $R$ 中包含 $ker(phi)$ 的理想一一对应,且生成元也互相对应。但 $R$ 中理想都是有限生成的,从而 $R'$ 中理想当然也有限生成。\
注意到 $ZZ[sqrt(-5)] tilde.eq quotient(ZZ[x], (x^2+5))$ 不是 UFD,但可以取 $ZZ[x]-> ZZ[sqrt(-5)]$ 的自然同态,表明它是 Noether 环。\
@exercise 给出了不是 Noether 环的整环,取其分式域当然是 Noether 环,从而它存在不是 Noether 环的子环。
==
取 $c$ 的唯一素分解:
$
c = product_i p_i^(alpha_i)
$
其中 $p_i$ 互不相同。由于 $a, b$ 互素,每个 $p_i$ 要么是 $a$ 的因子,要么是 $b$ 的因子。同时 $a b = c^n$ 中,$p_i$ 的个数为 $n alpha_i$,进而 $p_i^(n alpha_i)$ 要么是 $a$ 的因子,要么是 $b$ 的因子。\
同时,$a, b$ 不会有其他素因子,这意味着在相伴意义下,有:
$
a ~ product_k p_(i_k)^(n alpha_(i_k))\
\
b ~ product_k p_(j_k)^(n alpha_(j_k))\
\
$
进而结论成立
==
不难发现:
$
(x+sqrt(2)i)(x-sqrt(2)i) = y^3
$
我们在唯一分解整环 $ZZ[sqrt(2)i]$ 上考虑问题。\
取唯一素分解:
$
x+sqrt(2)i = p_1 p_2 ... p_n
$
同时设(用 $||$ 表示恰好整除):
$
p_i^(alpha) || x + sqrt(2)i\
p_i^(beta) || x - sqrt(2)i
$
表明:
$
p^(alpha + beta) || (x + sqrt(2)i)(x - sqrt(2)i) = y^3
$
进而 $alpha + beta$ 一定是三的倍数、
但另一方面,不难验证 $x+sqrt(2)i$ 不会有实整数因子,而若 $p_i | x + sqrt(2), p_i | x - sqrt(2)i$,取共轭知 $overline(p_i) | x + sqrt(2), overline(p_i) | x - sqrt(2)$ 进而 $p_i overline(p_i) | x + sqrt(2)$,与其没有整数因子矛盾!\
因此一定有 $beta = 0$,进而 $x+sqrt(2)i$ 是立方数。\
令:
$
x+sqrt(2)i = (a + b sqrt(2)i)^3=>
x+sqrt(2)i = a^3 +3a^2 b sqrt(2) i -6 a b -2 b^3 sqrt(2)i
$
这告诉我们:
$
a^3 - 6 a b = x\
3a^2 b - 2b^3 = 1 => b(3a^2-2b^2) = 1 => b = plus.minus 1
$
- $b=1$ 时,有 $a=plus.minus 1, x = plus.minus 5, y=3$
- $b = -1$ 时,无解
==
首先,由于 $R$ 可以看作 $R[x]$ 的子环,因此有条件知 $R$ 至少是整环。\
其次,注意到 $R tilde.eq quotient(R[x], (x))$ ,由对应法则它将 $R$ 上的理想映成 $R[x]$ 中包含 $(x)$ 的理想,而这样的理想仅有两个平凡理想,因此 $R$ 一定是域。
==
对 $a, 1$ 做辗转相除,将有:
$
1 = b dot a + r
$
且 $delta(r) < delta(a)$ 表明 $r=0$ 也即 $a$ 可逆。
==
我们只要证明它在 $R[x]$ 中不可约,从而由高斯引理自然在 $F[x]$ 中不可约。\
假设它在 $R[x]$ 中可约,设:
$
f(x) = g(x)h(x) = (sum_(i=0)^n c_i x^i)(sum_(i=0)^m b_i x^i)
$
由条件我们有:
$
p | b_0 c_0
$
且不会同时整除,不妨设 $p|b_0$ 有:
$
p | a_0 b_1 + a_1 b_0 => p | a_0 b_1 => p | b_1\
p | a_0 b_2 + a_1 b_1 + a_2 b_0 => p | a_0 b_2 => p | b_2
$
以此类推,将有 $p | b_i$ ,但这将表明 $p | a_n$ ,矛盾!
= 12.4 P112
== 3
首先,不难验证合法的域嵌入只能将 $QQ$ 嵌入到 $CC$ 的子域 $QQ$\
其次,这意味着域嵌入保持多项式:
$
x^2 + 1
$
将它的根映成它的根,从而只能将 $i$ 映为 $i$ 或 $-i$\
这就给出了所有域嵌入。
== 4
同样的,域嵌入在 $QQ$ 上保持不动,因此保持多项式:
$
x^2 + 1
$
将它的根映成它的根。\
但这个多项式在 $QQ[i]$ 中恰有两根,在 $QQ[sqrt(2)]$ 中没有根,因此不存在合法的域嵌入。
== 5
由于对于任意 $n$ :
$
[f(x) in Frac(x) | x -> x^n]
$
都是 $Frac(x)$ 到自身的不同嵌入,而 $K(alpha) tilde.eq Frac(x)$ 故结论成立
== 6
+ 显然:
$
(x - a)^2 + b^2
$
是其一个零化多项式,且在 $QQ$ 上已经不可约(在 $QQ$ 上没有根),因此就是它的极小多项式
+ 显然:
$
x^p + 1
$
是其一个零化多项式,它可被分解为:
$
(x+1)(x^(p-1) - x^(p-2) + ... + 1) := f(x)g(x)
$
显然 $e^((2 pi i)/p)$ 不是前者的根,因此它是后者的根,从而后者是一个零化多项式。\
同时,用 $x = x - 1$ 代入 $x^p + 1$ ,得:
$
(x-1)^p + 1 = sum_(i=1)^p (-1)^i C_p^i x^i = x (sum_(i=1)^(p) (-1)^i C_p^i x^(i-1))
$
上式后者当然就是 $g(x-1)$ ,它恰好符合 Eisenstein 判别法的要求,因此是不可约多项式,进而 $g(x)$ 就是一个最小多项式
== 7
$[F(alpha) : F] | [K : F] => [F(alpha) : F] = [K : F] => F(alpha) = K$
== 8
$n = [F(alpha) : F] | [K : F]$
== 9
注意到 $F(alpha^2) <= F(alpha)$,因此:
$
[F(alpha)^2 : F] | [F(alpha) : F]
$
另一方面,若 $f(x)$ 是 $alpha^2$ 的零化多项式,则当然有 $f(x^2)$ 是 $alpha$ 的零化多项式,因此:
$
[F(alpha) : F] <= 2 [F(alpha^2) : F]
$
同时 $[F(alpha) : F]$ 是奇数,上式无法取等,两式结合即得结论
== 10
设 $n = d m$,注意到代入同态:
$
[f(x) | x -> x^d]
$
是 $K[x]$ 上的单同态,同时不会将不可逆元映为可逆元,从而保持不可分解性。因此若 $x^m - a$ 不可分解,它的像 $x^n - a$ 也不可分解
== 11
+ $1, sqrt(2), sqrt(3), sqrt(6)$ 足以作为一组基
+
显然 $omega in QQ[i, sqrt(3)]$\
因此 $1, i, sqrt(3), sqrt(3)i$ 足以作为一组基
+
$e^((2i pi)/p), i = 0, 1, 2, ..., p-2$ 足以作为一组基(注意到这些元素除了 $1$ 以外最小多项式是 $p-1$ 次的,因此扩张次数就是 $p-1$)
== 12
$
[E K : F] = [E K : K][K : F] = [E K : E] [E : F]
$
因此必要性显然。\
充分性,设 $E = F(alpha_1, alpha_2, ..., alpha_n), K = F(beta_1, beta_2, beta_m)$,其中 $alpha_i, beta_i$ 分别是域扩张的基。\
容易验证 $alpha_i beta_j$ 这些元素可以线性表出 $E K$ 上所有元素,因此当然有 $[E K : F]$ 有限,且 $[E K : F] <= [E : F][K : F]$。\
同时有:
$
[E : F] | [E K : F]\
[K : F] | [E K : F]
$
从而 $[E : F][K : F]$ 互素时有:
$
[E : F][K : F] | [E K : F]
$
从而 $[E K : F] = [E : F][K : F]$,结论成立。
== 13
设 $phi$ 是 $F$ 自同态,任取 $alpha in K$, 设其在 $F$ 上的最小多项式为 $m(x)$\
由于 $phi$ 保持 $m(x)$ 不变,因此把 $m(x)$ 的根映成根。而 $m(x)$ 的根仅有有限个,同时 $phi$ 是单射,因此 $phi$ 在这些根上的作用无非是全置换,从而存在某个根的像恰为 $alpha$\
这就证明了 $phi$ 是满射,从而是自同构。\
= 补充题
==
只需证明 $L - F$ 中的元素都可逆即可。\
事实上,任取 $alpha in L - K$ ,取它在 $F$ 中的最小多项式(注意到 $a_0 !=0$ 否则与最小多项式不可约矛盾):
$
sum_(i=0)^n a_i alpha^i = 0 => sum_(i=1)^n -(a_i)/(a_0) alpha^i = 1 => alpha sum_(i=1)^n -(a_i)/(a_0) alpha^(i-1) = 1
$
这就给出了 $alpha$ 的逆(显然在 $L$ 中),证毕。
==
注意到 $root(5, 3)$ 的最小多项式为:
$
x^5 - 3 = 0
$
(由 Eisenstein 它确实是不可约多项式)\
而它是五次多项式,表明 $[QQ[root(5, 3)] : QQ] = 5$,而它是素数,因而不存在任何非平凡的子扩张,故结论成立。
==
取 $F = QQ(root(3, 2)), alpha = e^((2 pi i)/3)$\
$[F : Q] = 3$ 是显然的。同时注意到:
$
x^3 - 1
$
在 $F$ 上仍然是不可约多项式(没有根),因此第二次扩张也是三次扩张。
==
+ \
常多项式当然是代数元,而对一般的有理分式,显然不存在多项式使其为零(观察首项即可)
+ \
设 $alpha = u(x)/v(x) = (sum_i a_i x^i)/(sum_i b_i x^i)$,从而:
$
alpha v(x) = sum_j b_j alpha x^j = u(x)\
alpha v(x) - u(x) = 0
$
将上式左侧看作以 $F(alpha)$ 上元素为系数的多项式,这就给出了 $x$ 的一个零化多项式
+ \
注意到:
$
1/alpha = (x^3 + x + 1)/(x^2 - 1) = x + (2x+1)/(x^2 - 1) in F(alpha)
$
因此:
$
(1/alpha)(x^2 - 1) = x^3 + x + 1\
x^3 - (1/alpha) x^2 + x + (1 + 1/alpha) = 0
$
同时,假设 $f(x) in F(alpha)$ 是上式的根,反推之,有:
$
alpha = (f(x)^2 - 1)/(f(x)^3 + f(x) + 1)
$
由于 $f(x)$ 本身也是 $g(alpha)$ 的形式,其中 $g(x) in F(x)$,上式将表明:
$
alpha = (g(alpha)^2 - 1)/(g(alpha)^3 + g(alpha) + 1)
$
这将给出 $alpha$ 的一个系数在 $F$ 上的零化多项式,这与第一问的结果矛盾!因此上述多项式已经没有根,从而成为不可约多项式,因此就是 $x$ 的最小多项式。
== 5
#lemma[][
设 $F$ 是包含 $QQ$ 的域,$sqrt(a), sqrt(b), sqrt(a b) in.not F$,则:
$
[F(sqrt(a), sqrt(b)) : F] = 4
$
]
#proof[
只需证明 $sqrt(b) in.not F(sqrt(a))$ 即可。如若不然,则有:
$
x + y sqrt(a) = sqrt(b) => x^2 + 2 x y sqrt(a) + y^2 a = b
$
由于 $x, y in FF$ ,且 $1, sqrt(a)$ 是一组基,故我们有:
$
x y = 0
$
- 若 $x = 0$,则 $sqrt(b) = y sqrt(a) => sqrt(a) sqrt(b) = y a in F$ 矛盾
- 若 $y = 0$,则 $sqrt(b) = x => b = x^2 in F$ 矛盾
]
这首先表明 $[F(sqrt(a_1), sqrt(a_2)) : F] = 4, [F(sqrt(a_1), sqrt(a_3)) : F] = 4, [F(sqrt(a_1), sqrt(a_2 a_3)) : F] = 4$\
进一步,我们有 $a_2, a_3, a_2 a_3 in.not F(sqrt(a_1))$,再次利用引理便有:
$
[F(sqrt(a_1), sqrt(a_2), sqrt(a_3)) : F(sqrt(a_1))] = 4 => [F(sqrt(a_1), sqrt(a_2), sqrt(a_3)) : F] = 8
$
反复进行即得原结论
== 6
显然 $QQ[sqrt(alpha_1), sqrt(alpha_2), sqrt(alpha_3), ..., sqrt(alpha_n): QQ]$ 将是 $2$ 的幂次,但对任意 $F$ 满足 $root(6, 2)$ 至少有 $3 | [F : QQ]$ ,因此结论成立。
== 7
//$
//a_1 := root(3, 7) + 2i\
//a_2 := (root(3, 7) + 2i)^2 = root(3, 7^2) + 4 i root(3, 7) - 4 \
//a_3 := (root(3, 7) + 2i)^3 = 7 + 6 i root(3, 7) - 6 root(3, 7^2) - 8i
//$
//显然 $a_1, a_2, a_3$ 的任意运算都在 $QQ[a_1]$ 中,我们只需要消去 $root(3, 7)$ 即可。\
//这是容易的,取:
//$
//6 a_2 + a_3 = 30i root(3, 7) -24 + 7 - 8i = 30i root(3, 7) -8i - 17\
//4a_1 + 6a_2 + a_3 + 17 = (30 i + 4)root(3, 7)\
//(4a_1 + 6a_2 + a_3 + 17)^3 = 7(30i + 4)^3
//$
令 $a_1 = root(3, 7) + 2i$ ,计算得:
$
(a_1 - i)^3 = 7 = a_1^3 - 3 a_1^2 i + 3 a_1 i^2 - i^3 = a_1^3 - 3a_1 - 3a_1^2 i\
i = (a_1^3 - 3a_1 - 7)/(3a_1^2)
$
整理即得 $i in QQ(root(3, 7) + 2i)$ ,从而 $QQ(root(3, 7) + 2i) = QQ(i, root(3, 7))$\
同时,我们熟知(由于 $2, 3$ 互素) $[QQ(root(3, 7), 2i) : QQ] =6$,因此 $a_1$ 的最小多项式应该是六次的。\
继续化简上式得:
$
-1 = (a_1^3 - 3a_1 - 7)^2/(9a_1^4) \
9a_1^4 = (a_1^3 - 3a_1 - 7)^2
$
这便是一个六次的零化多项式,从而是最小多项式
== 8
熟知 $RR$ 上不可约多项式只能为一次或二次多项式。考虑 $K = RR[alpha]$
- 若 $alpha$ 最小多项式为一次,则 $alpha in RR => K = RR$
- 若 $alpha$ 最小多项式为二次,则:
$
alpha = a + b i, a, b in RR => i in K
$
从而 $K = CC$
== 9
- 假设 $quotient(E, F)$ 是代数扩张
- 任取 $alpha in F$ 和它在 $E$ 上的最小多项式 $m_(E, alpha)(x)$ ,显然这也是它在 $H$ 上的一个零化多项式,因此它在 $quotient(E, H)$ 中也是代数的,这表明 $quotient(E, H)$ 是代数扩张。
- 由于 $H <= F$ ,显然所有 $F$ 中的元素都在 $E$ 上代数,因此 $quotient(E, H)$ 是代数扩张。
- 假设 $quotient(E, H), quotient(H, F)$ 都是代数扩张。
//任取 $alpha_i$ 是 $quotient(E, H)$ 一组基,$beta_i$ 是 $quotient(H, F)$ 一组基。\
//对任意 $x in E$ 有:
//$
//x = (alpha_1, alpha_2, ..., alpha_n)X, X in H^n
//$
//而 $H$ 中任意元素又可被 $beta_i$ 线性表出,因此可设:
//$
//X = Y vec(beta_1, beta_2, dots.v, beta_m), Y in M_(n times m)(F)\
//(alpha_1, alpha_2, ..., alpha_n) = (beta_1, beta_2, ..., beta_m)A, A in M_(m times n)(F)
//$
//两式结合即有:
//$
//x = (beta_1, beta_2, ..., beta_m)A Y vec(beta_1, beta_2, dots.v, beta_m)
//$
任取 $alpha in E$ ,找其在 $H$ 上的最小多项式 $m_(H, alpha)(x)$。由于这个多项式中只涉及有限多个 $H$ 中元素,不妨设为 $beta_1, beta_2, ..., beta_m$,因此有:
$
m_(H, alpha)(x) in F(beta_1, beta_2, ..., beta_m)[x]
$
而 $F(beta_1, beta_2, ..., beta_m)$ 是有限代数扩张,我们当然有:
$
[F(beta_1, beta_2, ..., beta_m)(alpha) : F] \
= [F(beta_1, beta_2, ..., beta_m)(alpha) : F(beta_1, beta_2, ..., beta_m)][F(beta_1, beta_2, ..., beta_m) : F] \< infinity
$
因此 $alpha$ 在 $F$ 上代数,由 $alpha$ 的任意性,这表明 $quotient(E, F)$ 是代数扩张。
== 10
+
注意到 $ZZ_2$ 上的二次多项式分别为:
$
x^2 , x^2 + x = x(x +1), x^2 + x + 1, x^2 + 1 = (x+1)^2
$
其中仅有 $x^2 + x + 1$ 不可约,而容易验证它不是 $x^5 + x^4 + x^2 + x + 1$
的因子,因此 $x^5 + x^4 + x^2 + x + 1$ 没有二次不可约因子。\
同时,它也没有根,因此不含一次因子。\
因此它是不可约多项式。
+
设 $E = QQ[omega], K = QQ[root(5, 2), omega], H = K(alpha)$ 其中 $omega$ 是五次单位根。\
由于 $[E : QQ] = 4, [QQ(root(5, 2)) : QQ] = 5$,故显有 $[K : QQ] = 20$
容易验证,对 $i = 1, 2, 3, 4, 5$:
$
root(5, 2) -> root(5, 2) omega^i
$
诱导出一个 $H$ 上的 $E-$ 自同构,且这些自同构构成群。
- 由于 $alpha in H$,则由于 $G$ 保持 $QQ$ 不动,从而保持 $f(x)$ 不动,从而将它的根映为它的根。\
设 $f(x)$ 在 $K$ 中有 $m$ 个不同的根,则 $G$ 作用于这些根构成的集合 $X$ 上构成群作用,诱导出群同态 $phi: G -> S_m$。\
另一方面,被 $G$ 中所有元素保持不动的 $K$ 中元素恰为 $QQ(omega)$,而五元群没有非平凡子群,表明以下两者有且只有一个成立:
+ $ker(phi) = G$,进而 $X subset QQ(omega)$ 。考虑扩张次数这是荒谬的
+ $ker(phi) = {e}$,进而 $G$ 同构与 $S_m$ 的某个子群,这就给出 $m >= 5$。而 $f(x)$ 至多有五个不同的根,因此 $m = 5$(同时表明 $f(x)$ 无重根)
- 注意到要么 $alpha in K$,要么 $alpha in.not K$
- 若前者成立,则 $K = H$ 将拥有 $f(x)$ 的所有根。考虑 $f(x)$ 于 $QQ(root(5, 2))$ 上的可约性:
- 若它是二次和三次不可约多项式的乘积,则在 $K$ 中将出现最小多项式为三次的元素,这与 $[K : QQ(root(5, 2))] = 20$ 是矛盾的。
因此 $f(x)$ 在 $QQ(root(5, 2))$ 一定有根,不妨设 $alpha in QQ(root(5, 2))$\
进而 $QQ(root(5, 2)) = QQ(alpha)$,设:
$
root(5, 2) = a + b alpha + c alpha^2 + d alpha^3 + e alpha^4
$
只需令 $(root(5, 2))^5 = 2$。事实上,由于这是首一多项式,因此可设这些系数都是整数。\
对系数 $mod 5$ 考虑,有:
$
2 = (a + b alpha + c alpha^2 + d alpha^3 + e alpha^4)^5 = a^5 + b^5 alpha^5 + c^5 alpha^10 + d^5 alpha^15 + e^5 alpha^20\
$
注意到 $alpha^5 in QQ(alpha)=> QQ(alpha^5) <= QQ(alpha) => [QQ(alpha^5) | QQ] | [QQ(alpha) | QQ] = 5$,因此在 $QQ$ 上 $alpha^5$ 的最小多项式次数只能为 $1, 5$\
同时,若 $alpha^5 in QQ$,则 $alpha$ 将在 $QQ$ 上拥有不高于四次的零化多项式,与 $f(x)$ 不可约矛盾,因此 $alpha^5 in.not QQ$,进而 $alpha^5$ 的最小多项式次数为 $5$,这就表明 $alpha^5, alpha^10, alpha^15, alpha^20$ 在 $ZZ$ 上也线性无关。\
故 $a = 2 mod 5, b, c, d, e = 0 mod 5$\
再对系数 $mod 25$ (此时非零项至少选取四次 $a$)有:
$
2 = (a + b alpha + c alpha^2 + d alpha^3 + e alpha^4)^5 = a^5 + a^4(b alpha + c alpha^2 + d alpha^3 + e alpha^4)
$
这表明 $a^4 = 0 mod 5 => 5 | a$,进而 $a, b, c, d$ 全部都是 $5$ 的倍数,显然与等式矛盾。
因此此种情况不成立。
//$
//20 = [K : QQ] = [H : QQ] = [H : QQ(root(5, 2), alpha)][QQ(root(5, 2), alpha) : QQ] >= 5 [H : QQ(root(5, 2), alpha)]
//$
//同时,由于五次单位根的循环性,故 $[H : QQ(root(5, 2), alpha)]$ 只能是 $4$ 或 $1$
//- $[H : QQ(root(5, 2), alpha)] = 4 => [QQ(root(5, 2), alpha) : QQ] = 5$,进而 $QQ(alpha) = QQ(root(5, 2))$\
//- $[H : QQ(root(5, 2), alpha)] = 1 => omega in QQ(root(5, 2), alpha)$,从而上述推理仍然可以进行,进而 $QQ(root(5, 2), alpha)$ 将包含 $f(x), x^5 - 2$ 的所有根。\
// 再考虑 $f(x)$ 在 $QQ[root(5, 2)]$ 中的可约性,此时一定可约(否则 $[QQ(root(5, 2), alpha) : QQ] = 25$)。若其能写成二次和三次不可约多项式的乘积,则 $QQ[root(5, 2), alpha]$ 中将出现三次
- 若后者成立,则类似可以证明 $f(x)$ 在 $K$ 中一定没有根(否则拥有所有的根)。\
同时,若 $f(x)$ 在 $K$ 中是二次和三次不可约多项式的乘积,取 $g(x)$ 是三次因子,三个根分别构成集合 $Y$。利用类似上面的论证可以知道 $Y subset QQ(omega)$,这是荒谬的。 \
这表明 $f(x)$ 在 $K$ 中仍然不可约,从而在 $QQ[root(5, 3)]$ 中不可约,进而结论成立。
== 11
+
保持乘法和乘法单位元是显然的。对于加法,只需注意到:
$
0^p = 0\
(phi(x) + phi(y))^p = phi(x)^p + phi(y)^p\
(-phi(x))^p = -phi(x)^p
$
同态性质也成立。
+
首先证明它是单射,事实上显然有:
$
x^p = 0 => x = 0
$
其次,有限域上的单射就是满射,因此它是同构。
+
容易验证 $F$ 也是特征 $p$ 的域。同时,因此由上面知单射性。然而,显然不存在 $f(x)$ 使得:
$
(f(x))^p = x
$
(考察次数即可)
因此不是满射
== 12
+
显然只需以 $F$ 为系数, $t$ 足以生成 $K$ 上所有元素,当然有 $K = E(t)$
+
$
p(t) = h(t)g(t) - f(t) = 0
$
+
考察 $p(x)$ (化简前的)的最高次项。若只出现在 $f(x)$ 或 $g(x)$ 中,结论当然成立。\
若同时出现,设分别为 $a x^n,b x^n, a, b in K$,则 $p(x)$ 的 $n$ 次系数为:
$
a h(t) + b
$
显然它不是零,否则 $h(t) in K$
+
设:
$
h(t)f(x) - g(x) = k(x)l(x) = sum_i a_i (h(t)) x^i
$
考虑二元有理分式式:
$
y f(x) - g(x) - sum_i a_i (y) x^i
$
将其视作各项系数都在 $Frac(y)$ 上的分式多项式。若某项系数不是零有理分式项式,则成为 $h(t)$ 的一个非零零化多项式,与 $h(t)$ 在 $F$ 上超越是矛盾的。\
因此有:
$
y f(x) - g(x) = k(x, y)l(x, y)
$
相等是在 $(Frac(y))[x]$ 意义下的相等。我们只需考虑 $y f(x) - g(x)$ 在该多项式环下的可约性即可。\
又由高斯引理(注意到 $F[y]$ 是唯一分解整环),$y f(x) - g(x)$ 在 $(Frac(y))[x]$ 上的不可约性等价于 $(F[y])[x]$ 上的不可约性,因此不妨假设 $k, l in (F[y])[x]$。\
再将两侧视作 $y$ 的多项式,观察次数不难发现 $k, l$ 恰有一个是 $(F[x])[y]$ 上的常多项式,另一个是一次多项式,不妨设:
$
k(x, y) = k(x)\
l(x, y) = u(x)y + v(x)
$
计算不难发现:
$
k(x)u(x) = f(x)\
k(x)v(x) = g(x)
$
但由于 $f, g$ 互素,故 $k(x) ~ 1$,进而 $k(x, y) ~ 1$ ,这就表明原式不可约!
|
|
https://github.com/magicwenli/keyle | https://raw.githubusercontent.com/magicwenli/keyle/main/test/tests.typ | typst | MIT License | #import "@preview/codelst:2.0.0": sourcecode
#import "@preview/showybox:2.0.1": showybox
#import "../src/keyle.typ"
#set document(date: none)
#set page(margin: 0.5cm, width: auto, height: auto)
#let example-scope = (keyle: keyle)
#let frame(..args) = showybox(
frame: (
border-color: gray,
title-color: black,
thickness: .5pt,
inset: 8pt,
),
..args,
)
/// Generate a keyboard renderer and code sources.
#let example-with-source(source, vertical: false, title: []) = {
let rendered = frame(align(eval(source.text, mode: "markup", scope: example-scope), horizon))
let code = [#title #sourcecode(source, lang: "typ")]
block(
if vertical {
align(
center,
stack(
dir: ttb,
spacing: 1em,
align(left, code),
block(
width: 100%,
rendered,
inset: 1em,
),
),
)
} else {
table(
columns: (1fr, 1fr),
align: horizon,
stroke: none,
code, rendered,
)
},
breakable: false,
)
}
/// Generate a pure keyboard renderer.
#let example(source, vertical: false, title: []) = {
let rendered = eval(source.text, mode: "markup", scope: example-scope)
rendered
}
#show raw.where(lang: "example"): text => {
example(raw(text.text, lang: "typc"))
}
#example(
```tpy
#let kbd = keyle.config()
#kbd("Ctrl", "Shift", "K", delim: "-")
```,
title: [== Custom Delimiter],
)
#pagebreak()
#example(
```tpy
#let kbd = keyle.config()
#kbd("Ctrl", "Shift", "K", compact: true)
```,
title: [== Compact Mode],
)
#pagebreak()
#example(
```tpy
#let kbd = keyle.config(theme: keyle.themes.standard)
#keyle.gen-examples(kbd)
```,
title: [== Standard Theme],
)
#pagebreak()
#example(
```tpy
#let kbd = keyle.config(theme: keyle.themes.deep-blue)
#keyle.gen-examples(kbd)
```,
title: [== Deep Blue Theme],
)
#pagebreak()
#example(
```tpy
#let kbd = keyle.config(theme: keyle.themes.type-writer)
#keyle.gen-examples(kbd)
```,
title: [== Type Writer Theme],
)
#pagebreak()
#example(
```tpy
#let kbd = keyle.config(theme: keyle.themes.biolinum, delim: keyle.biolinum-key.delim_plus)
#keyle.gen-examples(kbd)
```,
title: [== Biolinum Theme],
)
#pagebreak()
#example(
```tpy
// https://www.radix-ui.com/themes/playground#kbd
#let radix_kdb(content) = box(
rect(
inset: (x: 0.5em),
outset: (y:0.05em),
stroke: rgb("#1c2024") + 0.3pt,
radius: 0.35em,
fill: rgb("#fcfcfd"),
text(fill: black, font: (
"Roboto",
"Helvetica Neue",
), content),
),
)
#let kbd = keyle.config(theme: radix_kdb)
#keyle.gen-examples(kbd)
```,
title: [== Custom Theme],
) |
https://github.com/Wallbreaker5th/vuqa | https://raw.githubusercontent.com/Wallbreaker5th/vuqa/master/vuqa.typ | typst | #import "@preview/fontawesome:0.2.0": *
#set text(font: ("Source Han Sans SC", ), size: 14pt, lang: "zh", region: "CN")
#show raw: set text(font: "LXGW WenKai Mono GB", weight: 700)
#set page(width: auto, height: auto, margin: 1cm)
#let taowa(it, size) = [
#let title(it) = {
move(box(
text(stroke: black + 0.01em, size: 1.8em, it),
fill: blue.lighten(60%),
outset: 0.5cm,
radius: (top-left: 0.5cm, bottom-right: 0.5cm),
), dx: -0.2cm)
}
#let under-heavy-line(it) = {
underline(it, stroke: blue.lighten(80%) + 0.5em, evade: false, background: true, offset: -0.5pt)
}
#let subtitle(it) = {
set text(stroke: 0.01em, size: 1.4em)
under-heavy-line(it)
}
#show heading.where(level: 1): it => {
align(center, under-heavy-line(it))
}
#show heading.where(level: 2): it => {
align(center, under-heavy-line(it))
}
#let turing-poly = [
可以除 $w$ 或除 $log$,很难降次数。$omega$ 为矩阵乘法复杂度指数下界。
#figure(table(
stroke: 0.5pt,
inset: .5em,
columns: 2,
align: left,
[logbit-OV、LCS、\ 两数最大 or/最小 and], $O(n^2)$,
[nbit-OV], $O(n^omega)$,
[链 mex], $O(n^(omega slash 2))$,
[$min +$ 卷积], $O(n^2)$,
[3SUM、4SUM、两对数和相等、\ 三点共线、三线共点、\ 长为 $3$ 等差数列], $O(n^2)$,
[3XOR], $O(n^2)$,
[APSP、$min +$ 矩阵乘法], $O(n^3)$,
[$+ times$/$01$ 矩阵乘/矩阵求逆/高斯消元], $O(n^omega)$,
[$min max$ 矩阵乘], $O(n^(2 tilde (omega+3) slash 2))$,
[$op("and") op("or")$ 矩阵乘、稠密图传递闭包], $O(n^(2 tilde omega))$,
[稀疏图传递闭包], $O(n^2)$,
[区间相等对/逆序对、链颜色数、\ 稀疏图三元环计数、行加列求和、\
区间 $plus.minus 1$ 全局数 $0$], $O(n^(omega slash 2 tilde 2 omega slash (omega+1)))$,
))
——From CommonAnts
]
#let turing-npc = [
- #text(lang: "en")[Karp's 21 NP-Complete Problems]
- $m$ 个大小均为 $c$ 的背包能否装下给定物品\
(强 NPC,即不存在伪多项式算法)
- 简单环计数
- 二分图完美匹配计数
- 2-SAT 计数
- 拓扑序计数
- 无向图欧拉回路/欧拉路径计数
]
#let turing-reference = [
#set text(size: 12pt)
*参考资料*:学会计算模型,复杂性,归约/问题类等计算理论基本思想后,自行搜索精细复杂性理论入门讲解 [Fine-grained complexity]
*相关OI博客*:
- lca的讲解(bilibili 视频 \@蔡德仁)
- lxl/crz 的相关讲解(资料集)
- EI《一些经典问题比暴力快一点点的算法》(博客)
- Ynoi《浅谈归约矩乘》(洛谷博客)
- Futari《归约矩乘》(洛谷博客)
- do-while-true《一小类矩阵乘法相关归约》(博客)
- hqztrue《浅谈矩阵乘法在算法竞赛中的应用》(知乎)
- 杨敏行《浅谈复杂度及其在解决问题方面的应用》\
闫陈效《计算理论与 OI 中的难解问题》(2024 集训队论文集)
——From CommonAnts
]
#let tables = [
#let w = (2, 3, 4, 5, 6, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 13, 14, 15)
#let d = (4, 12, 32, 64, 128, 240, 448, 768, 1344, 2304, 4032, 6720, 10752, 17280, 26880, 41472, 64512, 103680)
#let col = 9
#figure(table(
columns: col + 1,
fill: (x, y) => {
if (calc.rem(y, 3) == 0) {
gray.lighten(45%)
}
},
..{
let res = ()
for i in range(2) {
res.push($n <= $)
res += range(1+i*col, 10+i*col).map(j => $10^#j$)
res.push($max {omega(n)}$)
res += range(1+i*col, 10+i*col).map(j => $#w.at(j - 1)$)
res.push($max {d(n)}$)
res += range(1+i*col, 10+i*col).map(j => $#d.at(j - 1)$)
}
res
}
))
]
#let others = [
- vuqa 是什么意思?\
van 能的 UOJ 群啊
- 那个画图的网站?\
csacademy.com/app/graph_editor/
- 那个查原题的网站?\
www.yuantiji.ac/zh
- 那个 AtCoder 评分的网站?\
kenkoooo.com/atcoder/\#/table/
- 那个能看 Codeforces 题目整理的网站?\
cftracker.netlify.app/contests
- 那个看编译得到的汇编的网站?\
godbolt.org
- 那个把 C 语言类型转成人话的网站?\
cdecl.org
- XXX 用 LaTeX 怎么打?\
detexify.kirelabs.org/classify.html\
许多网站使用 KaTeX 渲染公式,相应文档见\
katex.org/docs/supported
- 怎么做 NOI 排版风格的题面?\
官方工具:TUACK + LaTeX\
广告:#fa-github()/Wallbreaker5th/fuzzy-cnoi-statement\
#h(3em)#fa-github()/Wallbreaker5th/OI-statement-LaTeX
- 那个 U 群常见问题速查的图?\
#{
let ratio = 20%
scale(box(it, width: size.width, height: size.height), ratio, reflow: true)
}
]
#let credits = [
#set text(fill: gray)
Visit #fa-github()/Wallbreaker5th/vuqa for the source code and the latest version.
]
#title[U 群常见问题速查]
#v(-2em)
#grid(
columns: (auto, 28em, auto),
inset: 1em,
grid.cell(colspan: 2)[= 图灵奖],
grid.cell(x: 0, y: 1)[== 多项式复杂度],
grid.cell(x: 0, y: 2, rowspan: 3, turing-poly),
grid.cell(x: 1, y: 3)[== NPC/NP-Hard/\#P-Hard],
grid.cell(x: 1, y: 4, turing-npc),
grid.cell(x: 1, y: 1, rowspan: 2, turing-reference),
grid.cell(x: 0, y: 5, colspan: 2)[= 约数个数/不同质因子个数表],
grid.cell(x: 0, y: 6, colspan: 2, tables),
grid.cell(x: 2, y: 0)[= 其他],
grid.cell(x: 2, y: 1, rowspan: 4, others),
)
#place(bottom+right, credits)
]
#context{
let size = measure(taowa(none, (width: 0pt, height: 0pt)))
let it = []
for i in range(5) {
it = taowa(it, size)
}
it
}
|
|
https://github.com/DashieTM/ost-5semester | https://raw.githubusercontent.com/DashieTM/ost-5semester/main/compiler/weeks/week11.typ | typst | #import "../../utils.typ": *
#section("Garbage Collection")
#subsection("Explicit Memory Handling")
- noobs can't handle it
- languages like C don't make it easy to work with -> return stack reference, get
shit on
- C++ has old features -> shit, not everyone uses the newer ones...
- memory leaks -> always going to be an issue tbh
#subsubsection("Danling Pointer")
- Pointer directing to deleted object
- can happen with stack or heap
- stack easy to fix -> simple lsp check, don't allow stack pointer returns
- heap problematic -> how to check when deleted?
#subsection("Reference Counting")
- every pointer is a single count
- heap memory can't be deleted when count is not 0
- problem -> cyclic references
- A has reference to B
- B has reference to A
- result: neither A nor B can be deleted
- *memory leak by locking!*
- solution: weak references!
#subsubsection("Weak / Strong")
- weak reference
- does not count for delete check
- can be "upgraded" to strong reference
- used for references that *might* at some point matter -> good example buttons
- strong reference
- regular counting reference
#subsubsection("Atomic")
For concurrency, you need atomic reference counting to ensure correct behavior
-> "Teure Updates".\
In a certain good language this is handled by Arc\<T\>.
#subsection("Garbage Collector")
- Checks whether or not a heap object can still be accessed or not -> *"Root Set"*
- #text(
teal,
)[Root Set is the quantity of all references in paremeters, variables, evaluation
stack and static variables]
- Uses Mark and sweep algorithm ```cs
void Collect() {
Mark();
Sweep();
}
// similar to mark and delete for a game loop
// idea: first mark all then delete -> mark is not noticeable for users, delete
is -> minimize delete to 1 instance
// 1 delete improves memory coherency -> free everything not small parts
```
#subsubsection("Mark Phase")
#align(
center,
[#image("../../Screenshots/2023_11_27_08_54_15.png", width: 100%)],
)
```cs
void Mark() {
foreach (var root in RootSet) {
Traverse(root);
}
}
```
Traverse Code:\
```cs
void Traverse(Pointer current) {
long block = heap.GetAddress(current)-BLOCK_HEADER_SIZE;
if (!IsMarked(block)) {
SetMark(block);
foreach (var next in GetPointers(current)) {
Traverse(next);
// recursion ... problematic -> see next
}
}
}
```
#subsubsubsection("Recursive Traversal")
- garbage collector needs additional memory
- problematic since memory inside gc is small either way
- algorithms that don't need additional memory -> pointer rotation algorithm by
Deutsch-Schorr-Waite
#subsubsection("Sweep")
Sweep Phase:
#align(
center,
[#image("../../Screenshots/2023_11_27_08_54_53.png", width: 100%)],
)
```cs
void Sweep() {
long current = HEAP_START;
while (current < HEAP_SIZE) {
if (!IsMarked(current)) {
Free(current);
}
ClearMark(current);
current += heap.GetBlockSize(current);
}
}
```
#subsubsection("Time Interval for GC")
- delayed
- can't be identified immediately
- at latest when heap is full
- interval
- pre-emptive? (later)
#subsubsubsection("Stop&Go")
- sequential and exclusive -> no other program can run during GC
- Mutator: this is the regular program here, ignore it
- however the name does say something: The mutator mutates memory -> hence no GC
marking or sweeping during that time as otherwise not everything can be
identified
#align(
center,
[#image("../../Screenshots/2023_11_27_09_18_12.png", width: 100%)],
)
Root Set identification:\
```cs
IEnumerable<Pointer> GetRootSet(CallStack callStack) {
var list = new List<Pointer>();
foreach (var frame in stack) {
CollectPointers(frame.Parameters);
CollectPointers(frame.Locals);
CollectPointers(frame.EvaluationStack.ToArray());
list.add(frame.ThisReference);
}
return list;
}
```
#subsubsubsection("Mark Flag")
#align(
center,
[#image("../../Screenshots/2023_11_27_09_21_27.png", width: 70%)],
)
#subsubsubsection("Pointer offsets")
#align(
center,
[#image("../../Screenshots/2023_11_27_09_23_28.png", width: 70%)],
)
The problem with this is that we need to also find each pointer for the main
object -> aka we need to recursively mark and delete:\
```cs
IEnumerable<Pointer> GetPointers(Pointer current) {
var list = new List<Pointer>();
var descriptor = heap.GetDescriptor(current);
var fields = ((ClassDescriptor)descriptor).AllFields;
for (var index = 0; index < fields.Length; index++) {
if (IsPointerType(fields[index].GetType())) {
var value = heap.ReadField(current, index);
if (value != null) {
list.Add((Pointer) value);
}
}
}
return list;
}
```
#subsubsubsection("Free call")
```cs
void Sweep() {
var current = HEAP_START;
while (current < HEAP_SIZE) {
if (!IsMarked(current)) {
Free(current);
}
ClearMark(current);
current += heap.GetBlockSize(current);
}
}
```
#subsubsubsection("Free List")
#columns(
2,
[
When allocating memory, the biggest challange is to find a "big enough" space
within memory. This is usually done with a free list, which will be used to
search for a space.
#colbreak()
#align(
center,
[#image("../../Screenshots/2023_11_27_09_25_16.png", width: 100%)],
)
],
)
#subsubsubsection("Heap Block Layouts")
#text(teal)[Each header needs to be the same size -> sweep requirement]
#align(
center,
[#image("../../Screenshots/2023_11_27_09_26_03.png", width: 100%)],
)
#subsubsubsection("Fit strategies -> see operating systems 1")
- first fit
- no sorting
- traversal till first found
- best fit
- sort by smallest possible
- leaves small and unusable fragments
- worst fit
- sort by biggest
- always finds a fitting block
- fragmentation problems
#subsubsubsection("Buddy System")
#columns(
2,
[
At the start we have the full memory, then when we get an allocation request
that is smaller than this size divided by 2, we split the memory into 2
sections, these 2 sections are now considered "buddies", as the merge into the
bigger part together. Since we requested 64bytes from the max of 512 bytes, we
can split again, and again, we do this until the split would be smaller than the
size we want, this size will then be allocated. Each new value that should be
allocated will be done in the same way.
#colbreak()
#align(
center,
[#image("../../Screenshots/2023_11_27_09_31_17.png", width: 100%)],
)
],
)
When freeing memory, it will always be checked whether or not the "buddy" is
also free, if it is, then the entire block can be combined and freed, otherwise
only this block is freed. Here is an example to check whether or not 2 addresses
are buddies: Let’s say we want to check if 2 addresses with the allocated size
of 16KB are buddies. This means that we first need to *figure out what power k
we are at*. This can be done by calculating 16KB, which is $2^1$4 -> 1 byte = 8
bit -> $2^3$ bit, then multiple this by 10 and double it as 16 is 8 \* 2. So, k
= 14.
```C
#include <stddef.h>
#include <stdio.h>
void expect(int a, int b) { fputs(a == b ? "OK\n" : "ERROR\n", stdout); }
int are_buddies(size_t a, size_t b, size_t level) {
// shift k times until we get the binary number k
size_t bit_k = 1 << level; // k in binary
// xor address a and b -> results in 1 bit being different, aka 1 bit being 1
// example 110000000000000 and 100000000000000, the 14 bit is different
// if this result is the same as bitk, then you have buddies
// 010000000000000 and 10000000000000, note the left address has 1 leading 0!
// leading 0s are ignored! treated as the same number!
return (a ^ b) == bit_k ;
}
int main(int argc, char **argv) {
expect(are_buddies(0, 1, 0), 1);
expect(are_buddies(0, 0x40, 7), 0);
expect(are_buddies(0, 0x40, 6), 1);
expect(are_buddies(0, 0x40, 5), 0);
expect(are_buddies(0xabd40, 0xabd00, 6), 1);
expect(are_buddies(0x40, 0x40, 6), 0);
expect(are_buddies(0x40, 0x40, 6), 0);
}
```
#subsubsubsection("Free list variants")
#align(
center,
[#image("../../Screenshots/2023_11_27_09_29_04.png", width: 100%)],
)
|
|
https://github.com/jonaspleyer/peace-of-posters | https://raw.githubusercontent.com/jonaspleyer/peace-of-posters/main/docs/content/_index.md | markdown | MIT License | ---
title: Introduction
type: docs
---
# Overview
> piece of cake<br>
> peace of mind<br>
> peace of posters
`peace-of-posters` allows to create simple but elegant posters.
It does not make any assumptions about layout (eg. 2/3 column), size of the poster (eg. a0, a1) or orientation.
Its main functionality is provided by a handful of functions that create [boxes](documentation/boxes) with optional titles.
There are specific functions for defining title boxes and bottom boxes.
It provides predefined [themes](documentation/themes) which can be adjusted to customize the design of the boxes.
To find out what you can do today with `peace-of-posters`, have a look at the [showcased examples](showcase).
## Example
{{< codeFromFile file="examples/getting_started/main.typ" start="1" end="15" >}}
We can adjust any property of the theme via the `update_theme` method of the [themes](documentation/themes) module.
The poster consists of multiple boxes which can be adjusted by specifying [column layouts](https://typst.app/docs/reference/layout/columns/).
`peace-of-posters` provideds some predefiend methods for creating a title-box, regular column-boxes in between, a bottom box and bibliography to finish it of.
{{% codeFromFile file="examples/getting_started/main.typ" start="21" end="63" %}}
## Final Result
<div class="showcase-single" style="text-align: center; padding: 0em;">
<a href="examples/getting_started/main.pdf"><img src="examples/getting_started/main.png" width=100%></a>
</div>
|
https://github.com/LEXUGE/typzk | https://raw.githubusercontent.com/LEXUGE/typzk/main/lib.typ | typst | MIT License | #import "graph.typ": digraphState, node, subgraph, gen_graphviz, render_graph, heading_subgraph, heading_to_label
|
https://github.com/TechnoElf/mqt-qcec-diff-thesis | https://raw.githubusercontent.com/TechnoElf/mqt-qcec-diff-thesis/main/content/background/lcs.typ | typst | #import "@preview/fletcher:0.5.1": diagram, node, edge
#import "@preview/gentle-clues:0.9.0": example
#import "@preview/quill:0.3.0": quantum-circuit, lstick, rstick, ctrl, targ
== The Longest Common Subsequence Problem
The @lcs problem seeks to find the maximum length of a sequence of symbols common to two lists of symbols, where the order of symbols in their original lists is maintained.
It is of interest to quantum circuit equivalence checking due to its close relation to the problem of finding the minimal edit script @myers1986diff.
Edit scripts, colloquially known as "diffs", have various uses in information technology.
Notably, diffs are used anywhere were it usually takes fewer resources to store the changes to data rather than the data itself, for instance in version control systems, file systems and backup systems.
An edit script is a description of the steps needed to transform one sequence of symbols into another.
It consists of three operations: Insert, remove and keep.
As quantum circuits may be represented as sequence of gates, an edit script can be constructed that transforms one circuit into another using these operations.
The notation used for edit scripts in this thesis is as follows:
- Insertion operations are represented by a `+` followed by the value to be inserted.
- Deletion operations are represented by a `-` followed by the value to be deleted.
- Keep operations (where no change is made the sequence) are represented by a `=` followed by the value.
Additionally, a notation based on a list of tuples of two values is sometimes used.
In this case, each tuple represents one or more operations in the edit script.
The entries of the tuple represent counts in the first and second sequence respectively.
As such, a tuple where there is a zero in either of these positions represents an insertion or deletion operation.
A set of keep operations is therefore represented by a tuple where both entries have the same non-zero value.
Note that the items operated on do not need to be stated explicitly, as they are known from their position in the sequence, making this a very compact description of an edit script.
The significance of this notation to the application of @lcs algorithms to quantum circuit equivalence checking will be explored in the following sections.
#example(breakable: true)[
To illustrate the concept of edit scripts, the circuits in @example_circuits will be used as example sequences.
For brevity, they will be represented by the strings "hxhy" and "yhhx".
#figure(
grid(
columns: (1fr, 1fr),
quantum-circuit(lstick($|q_0〉$), $H$, $X$, $H$, $Y$, 1),
quantum-circuit(lstick($|q_0〉$), $Y$, $H$, $H$, $X$, 1)
),
caption: [Two quantum circuits that are to be compared using an edit script.]
) <example_circuits>
The length of the @lcs for these strings is 2, representing the maximum number of keep operations that can be in a corresponding edit script.
The @lcs[s] themselves are "hx" and "hh".
One possible minimal edit script that contains the @lcs "hx" is `+y, =h, +h, =x, -h, -y`.
This corresponds to $[(0, 1), (1, 1), (1, 0), (1, 1), (0, 2)]$ when using the notation introduced in this section.
The length of the shortest edit script is therefore 6, which is equivalent to the @lcs length subtracted from the sum of the input sequences.
]
There exist various solutions to the @lcs problem.
The primary goal of these algorithms, however, is usually to produce an edit script, which only happens to solve the @lcs problem as well.
One possible method is to use an edit graph that represents all possible edit scripts and finding the shortest path from one sequence to the other.
While it is possible to use standard @sssp algorithms for this task, specialised approaches exist that make better use of the structure of the edit graph.
Two such algorithms will be explored in the following sections.
#pagebreak()
#example(breakable: true)[
@example_edit_graph shows the entire edit graph of the sequences "hxhy" and "yhhx".
Any path along this graph from the top left vertex to the bottom right vertex is a valid edit script.
@example_path presents a possible shortest path through the graph and the associated edit script.
#figure(
diagram(
spacing: 2em,
node-stroke: .1em,
node((0, 0), [hxhy], radius: 2em),
node((1, 0), [xhy], radius: 2em),
node((2, 0), [hy], radius: 2em),
node((3, 0), [y], radius: 2em),
node((4, 0), [], radius: 2em),
node((0, 1), [yhxhy], radius: 2em),
node((1, 1), [yxhy], radius: 2em),
node((2, 1), [yhy], radius: 2em),
node((3, 1), [yy], radius: 2em),
node((4, 1), [y], radius: 2em),
node((0, 2), [yhhxhy], radius: 2em),
node((1, 2), [yhxhy], radius: 2em),
node((2, 2), [yhhy], radius: 2em),
node((3, 2), [yhy], radius: 2em),
node((4, 2), [yh], radius: 2em),
node((0, 3), [yhhhxhy], radius: 2em),
node((1, 3), [yhhxhy], radius: 2em),
node((2, 3), [yhhhy], radius: 2em),
node((3, 3), [yhhy], radius: 2em),
node((4, 3), [yhh], radius: 2em),
node((0, 4), [yhhxhxhy], radius: 2em),
node((1, 4), [yhhxxhy], radius: 2em),
node((2, 4), [yhhxhy], radius: 2em),
node((3, 4), [yhhxy], radius: 2em),
node((4, 4), [yhhx], radius: 2em),
edge((3, 0), (4, 1), "->"),
edge((0, 1), (1, 2), "->"),
edge((2, 1), (3, 2), "->"),
edge((0, 2), (1, 3), "->"),
edge((2, 2), (3, 3), "->"),
edge((1, 3), (2, 4), "->"),
edge((0, 0), (1, 0), [-h], "->"),
edge((1, 0), (2, 0), [-x], "->"),
edge((2, 0), (3, 0), [-h], "->"),
edge((3, 0), (4, 0), [-y], "->"),
edge((0, 1), (1, 1), [-h], "->"),
edge((1, 1), (2, 1), [-x], "->"),
edge((2, 1), (3, 1), [-h], "->"),
edge((3, 1), (4, 1), [-y], "->"),
edge((0, 2), (1, 2), [-h], "->"),
edge((1, 2), (2, 2), [-x], "->"),
edge((2, 2), (3, 2), [-h], "->"),
edge((3, 2), (4, 2), [-y], "->"),
edge((0, 3), (1, 3), [-h], "->"),
edge((1, 3), (2, 3), [-x], "->"),
edge((2, 3), (3, 3), [-h], "->"),
edge((3, 3), (4, 3), [-y], "->"),
edge((0, 4), (1, 4), [-h], "->"),
edge((1, 4), (2, 4), [-x], "->"),
edge((2, 4), (3, 4), [-h], "->"),
edge((3, 4), (4, 4), [-y], "->"),
edge((0, 0), (0, 1), [+y], "->"),
edge((0, 1), (0, 2), [+h], "->"),
edge((0, 2), (0, 3), [+h], "->"),
edge((0, 3), (0, 4), [+x], "->"),
edge((1, 0), (1, 1), [+y], "->"),
edge((1, 1), (1, 2), [+h], "->"),
edge((1, 2), (1, 3), [+h], "->"),
edge((1, 3), (1, 4), [+x], "->"),
edge((2, 0), (2, 1), [+y], "->"),
edge((2, 1), (2, 2), [+h], "->"),
edge((2, 2), (2, 3), [+h], "->"),
edge((2, 3), (2, 4), [+x], "->"),
edge((3, 0), (3, 1), [+y], "->"),
edge((3, 1), (3, 2), [+h], "->"),
edge((3, 2), (3, 3), [+h], "->"),
edge((3, 3), (3, 4), [+x], "->"),
edge((4, 0), (4, 1), [+y], "->"),
edge((4, 1), (4, 2), [+h], "->"),
edge((4, 2), (4, 3), [+h], "->"),
edge((4, 3), (4, 4), [+x], "->"),
),
caption: [An edit graph.]
) <example_edit_graph>
Rewriting the edit script in @example_path in the compact notation would result in the list $[(0, 2), (2, 2), (2, 0)]$
#figure(
diagram(
node-stroke: .1em,
for y in range(0, 5) {
for x in range(0, 5) {
node((x, y), radius: 1em)
}
},
edge((3, 0), (4, 1), "->"),
edge((0, 1), (1, 2), "->"),
edge((2, 1), (3, 2), "->"),
edge((0, 2), (1, 3), "->", [`=h`], stroke: 2pt),
edge((2, 2), (3, 3), "->"),
edge((1, 3), (2, 4), "->", [`=x`], stroke: 2pt),
edge((0, 0), (1, 0), "->"),
edge((1, 0), (2, 0), "->"),
edge((2, 0), (3, 0), "->"),
edge((3, 0), (4, 0), "->"),
edge((0, 1), (1, 1), "->"),
edge((1, 1), (2, 1), "->"),
edge((2, 1), (3, 1), "->"),
edge((3, 1), (4, 1), "->"),
edge((0, 2), (1, 2), "->"),
edge((1, 2), (2, 2), "->"),
edge((2, 2), (3, 2), "->"),
edge((3, 2), (4, 2), "->"),
edge((0, 3), (1, 3), "->"),
edge((1, 3), (2, 3), "->"),
edge((2, 3), (3, 3), "->"),
edge((3, 3), (4, 3), "->"),
edge((0, 4), (1, 4), "->"),
edge((1, 4), (2, 4), "->"),
edge((2, 4), (3, 4), "->", [`-h`], stroke: 2pt),
edge((3, 4), (4, 4), "->", [`-y`], stroke: 2pt),
edge((0, 0), (0, 1), "->", [`+y`], stroke: 2pt),
edge((0, 1), (0, 2), "->", [`+h`], stroke: 2pt),
edge((0, 2), (0, 3), "->"),
edge((0, 3), (0, 4), "->"),
edge((1, 0), (1, 1), "->"),
edge((1, 1), (1, 2), "->"),
edge((1, 2), (1, 3), "->"),
edge((1, 3), (1, 4), "->"),
edge((2, 0), (2, 1), "->"),
edge((2, 1), (2, 2), "->"),
edge((2, 2), (2, 3), "->"),
edge((2, 3), (2, 4), "->"),
edge((3, 0), (3, 1), "->"),
edge((3, 1), (3, 2), "->"),
edge((3, 2), (3, 3), "->"),
edge((3, 3), (3, 4), "->"),
edge((4, 0), (4, 1), "->"),
edge((4, 1), (4, 2), "->"),
edge((4, 2), (4, 3), "->"),
edge((4, 3), (4, 4), "->"),
),
caption: [One possible shortest path through the edit graph.]
) <example_path>
]
|
|
https://github.com/wjakethompson/wjt-quarto-ext | https://raw.githubusercontent.com/wjakethompson/wjt-quarto-ext/main/ku-letter/README.md | markdown | Creative Commons Zero v1.0 Universal | # KU Letter Format
Based on the KU letterhead format for Accessible Teaching, Learning, and Assessment Systems.
**NOTE**: This format requires the pre-release version of Quarto v1.4, which you can download here: <https://quarto.org/docs/download/prerelease>.
## Installing
```bash
quarto use template wjakethompson/wjt-quarto-ext/ku-letter
```
This will install the format extension and create an example qmd file that you can use as a starting place for your document.
## Using
The example qmd demonstrates the document options supported by the ku-letter format (subject, recipient, logos, etc.).
For example, your document options might look something like this:
```yaml
---
subject: "Reference for Employee X"
recipient: |
Mr. <NAME> \
Acme Corp. \
123 Glenwood Ave \
Quarto Creek, VA 22438
sender: |
<NAME>, Ph.D. \
Assistant Director of Psychometrics \
Accessible Teaching, Learning, and Assessment Systems \
Achievement and Assessment Institute | University of Kansas \
[<EMAIL>](mailto:<EMAIL>) | (785) 643-9244
header-logo: "atlas-horizontal.svg"
footer-logo: "atlas-vertical.svg"
date: today
date-format: "MMMM D, YYYY"
format:
ku-letter-typst: default
---
```
KU letter documents are rendered as follows:

|
https://github.com/Vanille-N/mpri2-edt | https://raw.githubusercontent.com/Vanille-N/mpri2-edt/master/demo/1.typ | typst | #import "../edt.typ"
#import "../typtyp.typ"
#let tt = typtyp
#import "../classes.typ"
#import "../mpri.typ"
#import "../ext.typ"
// Edit this: uncomment exactly the classes you take
#let chosen = tt.ret(tt.array(mpri.Class), (
/* === Monday === */
/*-- 8h45 --*/
mpri.proof_asst,
//mpri.automata_mod,
/*-- 12h45 --*/
mpri.symbolic_dyn,
//mpri.advanced_verif,
/*-- 16h15 --*/
mpri.proof_systems,
//mpri.algo_wqo,
mpri.network_mod,
//mpri.biochem_prog,
/* === Tuesday === */
/*-- 8h45 --*/
mpri.sync_sys,
//mpri.sec_protocols,
/*-- 12h45 --*/
mpri.lang_mod,
//mpri.graph_mining,
mpri.param_compl,
//mpri.quantum_crypto,
/*-- 16h15 --*/
mpri.linear_logic,
//mpri.poly_sys,
/* === Wednesday === */
/*-- 8h45 --*/
mpri.cryptanalysis,
mpri.error_corr,
//mpri.da_networks,
/*-- 12h45 --*/
mpri.fp_and_types,
//mpri.combinatorics,
/*-- 16h15 --*/
mpri.analysis_algo,
/* === Thursday === */
/*-- 8h45 --*/
mpri.abstract_interp,
//mpri.search_heuristics,
//mpri.geometric_graphs,
/*-- 12h45 --*/
mpri.topology,
//mpri.quantum_info,
mpri.proba_prog,
/*-- 16h15 --*/
mpri.rand_compl,
//mpri.comp_algebra,
mpri.graph_theory,
/* === Friday === */
/*-- 8h45 --*/
mpri.arith_crypto,
mpri.concurrency,
//mpri.uncertainty,
//mpri.proof_of_prog,
/*-- 12h45 --*/
mpri.da_shared,
//mpri.game_theory,
/*-- 16h15 --*/
mpri.categories,
//mpri.algo_verif,
//mpri.data_analysis,
))
#show: doc => [
#edt.conf(classes.merge(mpri.week, ext.week), chosen)
]
|
|
https://github.com/taylorh140/typst-pintora | https://raw.githubusercontent.com/taylorh140/typst-pintora/main/package/README.md | markdown | # [Pintorita - Pintora plugin for typst ](https://github.com/taylorh140/typst-pintora)
[Pintora](https://pintorajs.vercel.app/)
Typst package for drawing the following from markup:
- Sequence Diagram
- Entity Relationship Diagram
- Component Diagram
- Activity Diagram
- Mind Map Experiment
- Gantt Diagram Experiment
- DOT Diagram Experiment

````typ
#import "@preview/pintorita:0.1.2"
#set page(height: auto, width: auto, fill: black, margin: 2em)
#set text(fill: white)
#show raw.where(lang: "pintora"): it => pintorita.render(it.text)
= pintora
Typst just got a load of diagrams.
```pintora
mindmap
@param layoutDirection TB
+ UML Diagrams
++ Behavior Diagrams
+++ Sequence Diagram
+++ State Diagram
+++ Activity Diagram
++ Structural Diagrams
+++ Class Diagram
+++ Component Diagram
```
```
mindmap
@param layoutDirection TB
+ UML Diagrams
++ Behavior Diagrams
+++ Sequence Diagram
+++ State Diagram
+++ Activity Diagram
++ Structural Diagrams
+++ Class Diagram
+++ Component Diagram
```
````
## Documentation
### `render`
Render a pintora string to an image
#### Arguments
* `src`: `str` - pintora source string
* `factor`: scale output svg, "factor:0.5" will scale images down by half, so scale can be consistent across renders.
* `style`: `str` diagram style, `default` or `dark` or `larkLight` or `larkDark`
* `font`: `str` font family, default is `Source Code Pro, sans-serif`
* All other arguments are passed to `image.decode` so you can customize the image size
#### Returns
The image, of type `content`
### `render-svg`
Render a pintora string to an image
#### Arguments
* `src`: `str` - pintora source string
* `factor`: scale output svg, "factor:0.5" will scale images down by half, so scale can be consistent across renders.
* `style`: `str` diagram style, `default` or `dark` or `larkLight` or `larkDark`
* `font`: `str` font family, default is `Source Code Pro, sans-serif`
* All other arguments are passed to `image.decode` so you can customize the image size
#### Returns
The svg image
## History
* 0.1.0 - Inital Release
* 0.1.1 - Updated to Jogs 0.2.3 and pintora 0.7.3
* 0.1.2 - Fixed strange offset of text rows in class diagram, added `render-svg` function and more customization options
|
|
https://github.com/antonWetzel/Masterarbeit | https://raw.githubusercontent.com/antonWetzel/Masterarbeit/main/arbeit/lt.typ | typst | //#show: lt()
//#show: lt(overwrite: true)
#let lt(overwrite: false) = {
if not sys.inputs.at("spellcheck", default: overwrite) {
return (doc) => doc
}
return (doc) => {
show math.equation.where(block: false): it => [0]
show math.equation.where(block: true): it => []
show bibliography: it => []
show par: set par(justify: false, leading: 0.65em)
set page(height: auto)
show block: it => it.body
show page: set page(numbering: none)
show heading: it => if it.level <= 3 {
pagebreak() + it
} else {
it
}
doc
}
}
|
|
https://github.com/lebinyu/typst-thesis-template | https://raw.githubusercontent.com/lebinyu/typst-thesis-template/main/template/tableofcontent_style.typ | typst | Apache License 2.0 | #import "global_style.typ": *
#let tableofcontent() = {
set page(
// footer: [
// #counter(page).display("I")
// ],
numbering: "I"
)
show outline.entry.where(
level: 1
): it => {
v(12pt, weak: true)
strong(it)
}
// show heading.where(level: 1): it => {
// block(
// inset: (top: 20pt, bottom: 10pt),
// block(
// block(
// stroke: (left: 12pt + blue),
// inset: (left: 24pt, top: 12pt, bottom: 6pt),
// outset: (left: -6pt),
// )[
// #text(size: 28pt, fill: blue, it.body)
// ])
// )
// }
// show: styleheading1("Table of Content")
show outline: it => {
show heading: styleheading1("Table of Content")
it
}
outline(
indent: true,
title: "Table of Content",
)
pagebreak(weak: true)
// counter(page).update(0)
// counter(heading).update(1)
} |
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/haw-hamburg/0.1.0/examples/bachelor-thesis/chapters/03_article_2.typ | typst | Apache License 2.0 | #import("../dependencies.typ"): *
= The Second Article
Everyone is entitled to all the rights and freedoms set forth in this Declaration, without distinction of any kind, such as race, colour, sex, language, religion, political or other opinion, national or social origin, property, birth or other status. Furthermore, no distinction shall be made on the basis of the political, jurisdictional or international status of the country or territory to which a person belongs, whether it be independent, trust, non-self-governing or under any other limitation of sovereignty. @UN[Article 2]
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/tidy/0.1.0/src/tidy.typ | typst | Apache License 2.0 | // Source code for the typst-doc package
#import "styles.typ"
#import "tidy-parse.typ"
/// Parse the docstrings of a typst module. This function returns a dictionary with the keys
/// - `name`: The module name as a string.
/// - `functions`: A list of function documentations as dictionaries.
/// - `label-prefix`: The prefix for internal labels and references.
/// The label prefix will automatically be the name of the module if not given explicity.
///
/// The function documentation dictionaries contain the keys
/// - `name`: The function name.
/// - `description`: The function's docstring description.
/// - `args`: A dictionary of info objects for each function argument.
///
/// These again are dictionaries with the keys
/// - `description` (optional): The description for the argument.
/// - `types` (optional): A list of accepted argument types.
/// - `default` (optional): Default value for this argument.
///
/// See @@show-module() for outputting the results of this function.
///
/// - content (string): Content of `.typ` file to analyze for docstrings.
/// - name (string): The name for the module.
/// - label-prefix (auto, string): The label-prefix for internal function references. If `auto`, the label-prefix name will be the module name.
/// - require-all-parameters (boolean): Require that all parameters of a functions are documented and fail if some are not.
/// - scope (dictionary): A dictionary of definitions that are then available in all function and parameter descriptions.
#let parse-module(
content,
name: "",
label-prefix: auto,
require-all-parameters: false,
scope: (:)
) = {
if label-prefix == auto { label-prefix = name }
if "example" not in scope {
scope.insert("example", tidy-parse.example)
}
let parse-info = (
label-prefix: label-prefix,
require-all-parameters: require-all-parameters,
scope: scope
)
let matches = content.matches(tidy-parse.docstring-matcher)
let function-docs = ()
for match in matches {
function-docs.push(tidy-parse.parse-function-docstring(content, match, parse-info))
}
return (
name: name,
functions: function-docs,
label-prefix: label-prefix
)
}
/// Show given module in the given style.
/// This displays all (documented) functions in the module.
///
/// - module-doc (dictionary): Module documentation information as returned by
/// @@parse-module.
/// - first-heading-level (integer): Level for the module heading. Function names are
/// created as second-level headings and the "Parameters" heading is two levels
/// below the first heading level.
/// - show-module-name (boolean): Whether to output the name of the module at the top.
/// - break-param-descriptions (boolean): Whether to allow breaking of parameter description blocks.
/// - omit-empty-param-descriptions (boolean): Whether to omit description blocks for
/// parameters with empty description.
/// - show-outline (function): Whether to output an outline of all functions in the module at the beginning.
/// - sort-functions (auto, none, function): Function to use to sort the function documentations.
/// With `auto`, they are sorted alphabetatically by name and with `none` they
/// are not sorted. Otherwise a function can be passed that each function documentation object is passed to and that should return some key to sort the functions by.
/// - style (module, dictionary): The output style to use. This can be a module defining the
/// functions `show-outline`, `show-type`, `show-function`, `show-parameter-list` and
/// `show-parameter-block` or a dictionary with functions for the same keys.
/// -> content
#let show-module(
module-doc,
style: styles.default,
first-heading-level: 2,
show-module-name: true,
break-param-descriptions: false,
omit-empty-param-descriptions: true,
show-outline: true,
sort-functions: auto
) = {
let label-prefix = module-doc.label-prefix
if "name" in module-doc and show-module-name and module-doc.name != "" {
heading(module-doc.name, level: first-heading-level)
parbreak()
}
if sort-functions == auto {
module-doc.functions = module-doc.functions.sorted(key: x => x.name)
} else if type(sort-functions) == "function" {
module-doc.functions = module-doc.functions.sorted(key: sort-functions)
}
let style-args = (
style: style,
label-prefix: label-prefix,
first-heading-level: first-heading-level,
break-param-descriptions: break-param-descriptions,
omit-empty-param-descriptions: omit-empty-param-descriptions,
scope: (:)
)
if show-outline {
(style.show-outline)(module-doc)
}
for (index, fn) in module-doc.functions.enumerate() {
(style.show-function)(fn, style-args)
if index < module-doc.functions.len() - 1 { v(3em) }
}
}
|
https://github.com/Myriad-Dreamin/typst.ts | https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/lint/markup_01.typ | typst | Apache License 2.0 |
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// Warning: 1-3 no text within stars
// Hint: 1-3 using multiple consecutive stars (e.g. **) has no additional effect
// Warning: 11-13 no text within stars
// Hint: 11-13 using multiple consecutive stars (e.g. **) has no additional effect
**not bold**
|
https://github.com/LEXUGE/poincare | https://raw.githubusercontent.com/LEXUGE/poincare/main/src/slides/tensor-and-physics/main.typ | typst | MIT License | // Get Polylux from the official package repository
#import "@preview/polylux:0.3.1": *
#import "@preview/physica:0.9.2": *
#import "@preview/gentle-clues:0.4.0": *
#import "@lexuge/templates:0.1.0": *
#import shorthands: *
#import pf3: *
// Make the paper dimensions fit for a presentation and the text larger
#set page(paper: "presentation-16-9", margin: (y: 6pt))
#set text(size: 20pt)
// FIXME: Title being funny
#show: simple.with(
title: [#v(1em) Tensor and Physics], authors: ((name: "<NAME>", email: "<EMAIL>"),), disp_content: false,
)
#set heading(numbering: none)
#set math.equation(numbering: none)
#let caniso = sym.tilde.equiv
#let becomes = sym.arrow.r.double
#pagebreak()
// Use #polylux-slide to create a slide and style it using your favourite Typst functions
#polylux-slide[
== How Tensor is Used in Physics
- Quantum Mechanics: Symmetric and Asymmetric Tensors
- Special Relativity: Metric Tensor, Indices Lowering / Raising
- General Relativity: Tensor Fields, Tensor Calculus, Classical Differential
Geometry
== Also for mathematics
- Antisymmetric Tensors $becomes$ Differential Forms $becomes$ Calculus in $RR^n$
]
#polylux-slide[
= Example: Separation of Variable
#one-by-one[Wave equation
$ c^2 pdv(phi, x, 2) = pdv(phi, t, 2) $
With appropriate boundary condition, e.g.
$ "Fixed ends": phi(0, t) &= phi(L, t) = 0 "for all " t>= 0 \
"Periodic": phi(x, 0) &= phi(x, L/c) "for all " x in [0,L] $][With separation of variable, we can find $phi(x, t) = F(x) G(t)$ with
$ F(x) &= sin((n pi) / L x) \
G(t) &= cos((c n pi) / L t), sin((c n pi) / L t) $]
]
#polylux-slide[
#one-by-one[Multiply together and do a linear combination
$ phi(x, t) = sum_(n=0)^oo sin((n pi) / L x) [A_n cos((c n pi) / L t) + B_n sin((c n pi) / L t)] $][*Why does it sufficiently gives the general solution?*][Tensor Product offer a different perspective.
$ cal(L)^2([0,L] times [0, T]) caniso cal(L)^2([0,L]) tp cal(L)^2([0,T]) $][- And ${sin((n pi) / L x)}, {cos((c n pi) / L t), sin((c n pi) / L t)}$ each form
a basis for their spaces.][- "Multiply" them together ${sin((n pi) / L x) cos((c n pi) / L t), sin((n pi) / L x) sin((c n pi) / L t)}$ *gives a basis* for $cal(L)^2([0,L]) tp cal(L)^2([0,T])$][- Any general solution can them be decomposed into basis.][Similar examples in quantum mechanics:
$ L2(RR^3) caniso L2(RR) tp L2(RR) tp L2(RR) \
L2(RR^3) caniso L2(RR) tp S^2([0, pi] times [-pi, pi]) $]
]
#polylux-slide[
= What this talk is about?
#one-by-one[- $V tp W$? $vb(v) tp vb(w)$?][- $V tp (W tp Z)? (V tp W) tp Z? V tp W tp Z?$][- Why can $dagger$ in Dirac notation act on complex numbers, operators, and (dual)
vectors? What exactly is $dagger$?][And
- Quantum Steering and How tensor is used in proving No-Signaling Theorem.]
]
#polylux-slide[
= Recaps from Linear Algebra
#only(
1,
)[#def(
"Dual Space",
)[
A dual vector $f$ is roughly "a function that eats in a vector, spits out a
scalar".
The space they force is written as $V' equiv cal(L)(V,FF) equiv cal(L)(V)$.
]]
#only(2)[
#def("Metric Dual")[
$ L: vb(v) in V sendto al vb(v), cdot ar $
]
Can be proven: this $L$ is bijective if $V$ is finite-dimensional.
]
#only(
3,
)[#thm[$V''$ is#footnote[up to canonical isomorphism] $V$][
We define the map $L: V to V''$#footnote[The $L$ here has nothing to do with the $L$ defined for metric dual] by
$ L(vb(v))(phi) := phi(vb(v)) $
$L$ is bijective if $V$ is finite-dimensional.
]
In finite-dimensional case (I will assume this henceforth),
$ V caniso V' caniso V'' $
]
]
#polylux-slide[
= The settings of the game
#only(
1,
)[#def(
"Tensor",
)[
Let $V_1, V_2, dots V_n$ be finite dimensional vector spaces over the same field $FF$.
A tensor is a multi-linear functional
$ tau: V_1 times V_2 times dots.c times V_n to FF $
They form a vector space $cal(L)(V_1, dots.c, V_n)$.
] #def[Tensor product of two vectors][
Given $vb(v) in V, vb(w) in W$, define
$ vb(v) tp vb(w): V' times W' &to FF\
(h, g) &sendto vb(v)(h) vb(w)(g) equiv h(vb(v)) g(vb(w)) $
]
]
#only(2)[#def[Tensor Product for Two Vector Spaces][
Define
$ V tp W := span { vb(v) tp vb(w) | vb(v) in V, vb(w) in W } $
i.e. linear combination of the "simple tensor product".
]
$ vb(v) tp vb(w) in V tp W subset.eq cal(L)(V', W') $
*Indeed*, can be proven (use the "standard" basis of $V tp W$)
$ vb(v) tp vb(w) in V tp W = cal(L)(V', W') $
]
]
#polylux-slide[
== Properties
1. Commutativity
$ V tp W caniso W tp V $
2. Commutativity with dual.
$ V' tp W' caniso (V tp W)' $
3. Associativity
$ (V tp W) tp Z caniso V tp (W tp Z) caniso cal(L)(V', W', Z') $
#one-by-one[*How to prove them?*][ _Universal Properties_ ]
]
#polylux-slide[
= Universal Properties and Canonical Isomorphism
Universal property is what we needed to understand why
$ (V tp W)' "and" V' tp W' "are the same" $
Now, $V' tp W' = cal(L)(V, W)$ by previous slide and $V'' = V$. So what we are
really heading to is
#one-by-one[#align(
center,
)[*Linear mappings that eats $V tp W$ are uniquely matched with bilinear mappings
that eats in $V times W$.*]][Indeed this is what universal property says!]
]
#polylux-slide[
== Universal Property - Statement
#thm[Universal Property][
1. Let $tau in cal(L)(V, W)$, there exists a unique function $hat(tau) in (V tp W)'$ such
that
$ hat(tau)(vb(v) tp vb(w)) = tau(vb(v), vb(w)) $
for all $vb(v),vb(w)$.
2. Let $hat(tau) in (V tp W)'$, there exists a unique $tau in cal(L)(V, W)$ such
that
$ tau(vb(v), vb(w)) = hat(tau)(vb(v) tp vb(w)) $
for all $vb(v),vb(w)$.
]
]
#polylux-slide[
= A detour on $dagger$
$dagger$ seems to acts on all sorts of things:
- Complex numbers: $(i)^dagger = -i$
- Operators: $A^dagger$
- Vectors and dual vectors: $ket(phi)^dagger = bra(phi)$
*What exactly is this then?*
]
#polylux-slide[
= A detour on $dagger$
$dagger$ is just taking *metric dual* of tensors!
#only(
1,
)[- $CC$ is a vector space over $CC$, and vector space is a tensor space. The inner
product is just $a^* b$ and the metric dual mapping is just taking $i$ to $i^*$!]
#only(
2,
)[- And for operators,
$ A = sum_(k,l) tensor(A, +k, -l) vb(e)_k tp vb(e)^l $
And
$ A^dagger = sum_(k,l) tensor(A, +k, -l)^* vb(e)^k tp vb(e)_l $
*Note: The dual basis is equal to the metric dual of a basis iff. the basis is
orthonormal.*
So indeed $tensor(A^dagger, -k, +l) = tensor(A, +k, -l)^*$. And taking dual of
an operator gives us the Hermitian!
- Vector: this is trivial.]
]
#polylux-slide[
= A detour on $dagger$
This is less like a mathematical nit-picking: We are accustomed to write
$ i hbar pdv(ket(phi), t) = hat(H) ket(phi) arrow.double -i hbar pdv(bra(phi), t) = hat(H) bra(phi) $
or
$ (pdv(ket(phi), t))^dagger = pdv(, t) ket(phi)^dagger = pdv(bra(phi), t) $
But how about
$ (pdv(, t) ket(phi))^dagger = ket(phi)^dagger compose (pdv(, t))^dagger $
]
#polylux-slide[
= A detour on $dagger$
Moreover, we know
$ (pdv(, x))^dagger = - pdv(, x) $
But then
$ (pdv(, x) ket(phi))^dagger = - bra(phi) compose pdv(, x) $
While with the same argument as before,
$ (pdv(, x) ket(phi))^dagger = pdv(, x) bra(phi) $
]
/*#polylux-slide[
= Writing Tensors Explicitly out in Quantum
#one-by-one[$ bra(phi), ket(psi) $][$ ketbra(psi, phi) becomes ket(psi) tp bra(phi) $][$ "contraction" braket(phi, psi) $][$ hat(H)_A tp hat(H)_B in cal(H)_A tp cal(H)_A ' tp cal(H)_B tp cal(H)_B ' caniso (cal(H)_A tp cal(H)_A ') tp (cal(H)_B tp cal(H)_B ') $]
]*/
#polylux-slide[
= Entanglement to Communicate?
#eg[Alice and Bob shares some entangled state $ket(chi)$. Alice can measure the
particle on her half in different basis. Can Bob detects (through measurement on
his half) which basis Alice measured against, or does Alice even measure?]
]
#polylux-slide[
#proof[
#pfstep[Marginal probability of Bob measuring some basis vector doesn't depends on
Alice's measurement.][
$ PP(ket(beta_n)) &= sum_m PP(ket(beta_n) and ket(alpha_m)) = sum_m |(bra(beta_n) tp bra(alpha_m)) ket(chi)|^2 \
&= sum_m bra(chi) (ket(beta_n) tp ket(alpha_m)) (bra(beta_n) tp bra(alpha_m)) ket(chi) \
&= sum_m bra(chi) (ket(beta_n) tp ket(alpha_m)) tp (bra(beta_n) tp bra(alpha_m)) ket(chi) \
&= bra(chi) (ket(beta_n) tp bra(beta_n)) tp (sum_m ket(alpha_m) tp bra(alpha_m)) ket(chi) \
&= bra(chi) (ket(beta_n) tp bra(beta_n) tp II) ket(chi) \ $
]
]
]
#polylux-slide[
== What I left out
- Contraction!
- Not all tuples of numbers are tensors. (_"Tensors transform like a tensor"_)
- Symmetric and asymmetric tensors
- Metric, Indices Raising / Lowering
- Einstein Notation, Penrose Abstract Indices
#bibliography("bib.yaml", full: true, style: "american-physics-society")
]
#polylux-slide[
= Contraction
#eg[
Consider the tensor $tau in V' tp V' = cal(L)(V, V)$, we can define a new tensor $f in V'$ through
$ f(cdot):= sum_k tau(vb(a)_k, cdot) vb(v)(vb(a)^k) $
(This is indeed well-defined) It's evident that this is equivalent to
$ f(cdot):= tau(vb(v), cdot) $
]
This "annihilates" one set of spaces dual to each other (here $V, V'$). Thus the
name "contraction".
]
#polylux-slide[
== Explicit Example Demonstrating the Canonical Isomorphism
This isomorphism is indeed very explicit. We know $vb(a)^i tp vb(b)^j in cal(L)(V, W)$.
By definition of universal property,
$ ( L_1 overbrace(vb(a)^i tp vb(b)^j, V' tp V') )( underbrace(vb(a)_k tp vb(b)_l, V tp V)) &= vb(a)^i tp vb(b)^j (vb(a)_k, vb(b)_l) \
&= vb(a)^i (vb(a)_k) vb(b)^j (vb(b)_l) = tensor(delta, -k, +i) tensor(delta, -l, +j) $
where $L_1$ just outputs the unique mapping dictated by the universal property.
This actually shows us why
$ underbrace((ket(psi) tp ket(phi)), V tp V)^dagger caniso underbrace(bra(psi) tp bra(phi), V' tp V') "and" (ket(psi) tp bra(phi))^dagger caniso ket(phi) tp bra(psi) $
And we may just replace $caniso$ with $=$. _Why bother with $L_1$ if you know what to evaluate?_
]
#polylux-slide[
== Extended Universal Property
#thm[Universal Property - Extended][
1. Let $Gamma in cal(L)(V, W, Z)$, there exists a unique function $hat(Gamma) in cal(L)(V, W tp Z)$ such
that
$ hat(Gamma)(vb(v), vb(w) tp vb(z)) = Gamma(vb(v), vb(w), vb(z)) $
for all $vb(v),vb(w), vb(z)$.
2. Let $hat(Gamma) in cal(L)(V, W tp Z)$, there exists a unique $Gamma in cal(L)(V, W, Z)$ such
that
$ Gamma(vb(v), vb(w), vb(z)) = hat(Gamma)(vb(v),vb(w) tp vb(z)) $
for all $vb(v),vb(w), vb(z)$.
]
But
$ cal(L)(V, W tp Z) = V' tp (W tp Z)' $
]
#polylux-slide[
= "$dagger$ puzzle"
By writing in limit we can argue
$ pdv(, x) bra(phi) &= L(pdv(, x) ket(phi)) = -L((pdv(, x))^dagger ket(phi)) $
Now $A^dagger = L^(-1) A^t L$, $A^t compose f = f compose A$,
$ pdv(, x) bra(phi) &= -L compose L^(-1) (pdv(, x))^t L ket(phi) \
&= (- pdv(, x))^t bra(phi) = ((pdv(, x))^dagger)^t bra(phi) \
&= bra(phi) compose (pdv(, x))^dagger $
]
|
https://github.com/RaphGL/ElectronicsFromBasics | https://raw.githubusercontent.com/RaphGL/ElectronicsFromBasics/main/core/core.typ | typst | Other | #let radius_size = 1em
#let volume_title(title: "", description: "") = [
#layout(size => [
#block(width: size.width, height: size.height)[
#align(center + horizon)[
= #title
#description
]
]
])
]
// todo rename everywhere to text_figure
#let voltage_listing(body, description: "") = [
#align(center)[
#box[
#align(left)[#body]
]
#if description.len() != "" [
#description
]
]
]
// a box that contains a list of points made in the lesson
// the box already contains a review title
#let review(body) = [
#pad(rest: 2em)[
#set align(center)
#rect(radius: radius_size, stroke: 1.2pt)[
#pad(rest: 1em)[
#text(size: 1.2em)[*Review*]
#set list(marker: [--])
#align(left)[#body]
]
]
]
]
#let boxed_text(body) = [
#align(center)[
#rect(inset: 10pt, radius: radius_size)[
#body
]
]
]
|
https://github.com/teshu0/uec24-exp-a-typst | https://raw.githubusercontent.com/teshu0/uec24-exp-a-typst/main/main.typ | typst | The Unlicense |
// ←これで始まる行はコメントなのでPDFでは表示されない
// テンプレートの呼び出し
#import "./uec_exp_a.typ": uec_exp_a, title, description, table_figure
#import "./logos.typ": Typst, LaTeX
// 図表
#import "@preview/cetz:0.2.2"
// 単位
#import "@preview/metro:0.2.0": *
// ロゴの置き換え
#show "LaTeX": name => LaTeX
// テンプレートを使う
#show: uec_exp_a
// タイトル
#title("レポートのためのテンプレート - Typst版")
// 名前など
#description(
"
電気通信大学 Ⅳ 類 Typstを使おうプログラム
2400123 電通太郎
2024 年 0 月 0 日作成
2024 年 1 月 32 日更新
"
)
// ここから本文
= 目的
長年 LaTeX @latex を用いたレポート執筆が主流であった。しかし、新たな組版システム #Typst の登場により LaTeX に代わる新たな選択肢の一つとなった。今回は、 #Typst を用いたレポートの例を示す。
= Typstの記法
LaTeXと同様に #Typst でもさまざまな表示が可能である。LaTeXでは非常に複雑な記法を用いるが、 #Typst は Markdown に似た比較的簡易的な記法で表記できる。LaTeXで見出しを表示するには ```tex \section{見出し}``` や ```tex \subsection{小見出し}``` で表すが、 #Typst ではそれぞれMarkdownのように `= 見出し` や ` == 小見出し` と表すことができる。この章の見出しでは `= Typstの記法` と表記しており、```typ #set heading(numbering: "1.1")``` と書くことで左側に勝手に番号を振ってくれる。他にもさまざまな記法が存在するが、詳細については多くの解説記事がインターネット上に存在するので、そちらを参照してほしい。
また、数式を表したい場合は```typ $x$``` のように記述すると $x$ と表示される。中に式を含めることも可能で、```typ $2 + 3 = 5$``` とすれば $2 + 3 = 5$ と表示される。一部の記号は ```typ $1 + 2 times 3$``` ($1 + 2 times 3$) のように、記号の名前で表す必要がある。
数式は行中に表示する代わりに複数行に分けて書くこともできる。例えば以下のように記述することで、
#figure()[
```typ
// これは数式の右側に (1) のスタイルで番号をつけるというの意味
#set math.equation(numbering: "(1)")
$ // $$ で囲むと数式表示モードになる
T = 2 pi sqrt(
h/g (1 + (2r^2) / (5h^2))
) times (1+ (theta^2) / 16 )
$
```
]
以下のように表示される。
// これは数式の右側に (1) のスタイルで番号をつけるよの意味
#set math.equation(numbering: "(1)")
$ // $$ で囲むと数式表示モードになる
T = 2 pi sqrt(
h/g (1 + (2r^2) / (5h^2))
) times (1+ (theta^2) / 16 )
$
途中で現れた ```typ sqrt``` は根号 (#underline[sq]uare #underline[r]oo#underline[t] から) を意味する記号だが、これの代わりにユニコードである ```typst √``` を用いることも可能である。```typ √4 = 2``` と記述すると、$√4 = 2$ と表示される。
このように、LaTeXと比較して記法や数式の記述方法も非常に簡単であることがわかると思う。記法の他にもメリットが存在するため、#Typst を使ってみたいと思った人のために紹介しよう。
== 表の描画
テンプレートに付属している `table_figure` 関数を使うことで簡単に表を描画することができる。
#grid(
columns: (1fr, 1fr),
figure()[
```typst
#table_figure(
caption: [
振子の長さと周期の関係
],
columns: 2,
table.header(
$h#unit("/cm")$, $T#unit("/s")$,
),
$78.0$, $1.5$,
$50.0$, $1.2$,
$36.0$, $1.1$,
) #label("振子の長さと周期の関係の表")
```
],
[#table_figure(
caption: [
振子の長さと周期の関係
],
columns: 2,
table.header(
$h#unit("/cm")$, $T#unit("/s")$,
),
$78.0$, $1.5$,
$50.0$, $1.2$,
$36.0$, $1.1$,
) #label("振子の長さと周期の関係の表")]
)
== グラフの描画
`cetz` パッケージを使うことで、シンプルなグラフであれば #Typst 単体で描画することができる。少々複雑なコードになってしまうが、自由に描画できるのでプログラミング経験者にはおすすめだ。もちろん、画像ファイルを読み込むのでも全く問題ないだろう。具体的なコードについては、`main.typ` ファイルを参照されたい。
#let 点のデータ = csv("data/dummy_data.csv")
#let 傾き = 0.0388715
// 重力加速度のグラフ
#let gravity-graph = (
name: str,
x-min: float,
x-max: float,
x-tick-step: float,
y-min: float,
y-max: float,
y-tick-step: float,
size-width: float,
size-height: float,
x-label: content,
y-label: content,
slope: float, // 傾き
caption: content,
data
) => [
#figure(
cetz.canvas({
import cetz.plot
import cetz.draw: *
let draw-point(pos, text, color, anchor) = {
circle(pos, radius: 0.1, fill: color, stroke: none)
content((), block(inset: 0.3em)[#text], anchor: anchor)
}
// 上と右の目盛りは非表示
set-style(
top: (
tick: (
stroke: 0pt,
),
),
right: (
tick: (
stroke: 0pt,
),
)
)
plot.plot(
size: (size-width, size-height),
x-min: x-min,
x-max: x-max,
y-min: y-min,
y-max: y-max,
x-tick-step: x-tick-step,
y-tick-step: y-tick-step,
x-label: x-label,
y-label: y-label,
{
// 線のために配列を追加
plot.add(
(
(0, 0), // start point
(x-max, x-max * slope) // end point
)
)
}
)
// 点のプロット
for ar in data.map(ar => ar.map(v => float(v))) {
let x = (ar.at(0) - x-min) / (x-max - x-min) * size-width
let y = (ar.at(1) - y-min) / (y-max - y-min) * size-height
draw-point((x, y), "", blue, "east")
}
}),
caption: caption,
) #label(str(name))
]
#gravity-graph(
name: "重力加速度のグラフ",
x-min: 20.0,
x-max: 80.0,
x-tick-step: 10,
y-min: 1.0,
y-max: 3.5,
y-tick-step: 0.5,
size-width: 8,
size-height: 5,
x-label: $h#unit("/cm")$,
y-label: $overline(T)^2#unit("/s^2")$,
caption: [
振子の長さ $h$ と1周期の平均時間の二乗 $overline(T)^2$ の関係
],
slope: 傾き,
点のデータ
)
ちなみに、 #Typst では CSV からデータを読み込んで加工、表示することが可能であるため、Excel等から出力したデータをそのまま使うこともできる。@重力加速度のグラフ の例では、CSV を読み込んで使用している。
#figure(
[
```typst
#let 点のデータ = csv("data/dummy_data.csv")
#let 傾き = 0.0388715
// 途中略
#gravity-graph(
name: "重力加速度のグラフ",
x-min: 20.0,
x-max: 80.0,
x-tick-step: 10,
y-min: 1.0,
y-max: 3.5,
y-tick-step: 0.5,
size-width: 8,
size-height: 5,
x-label: $h#unit("/cm")$,
y-label: $overline(T)^2#unit("/s^2")$,
caption: [
振子の長さ $h$ と1周期の平均時間の二乗 $overline(T)^2$ の関係
],
slope: 傾き,
点のデータ
)
```
]
)
= Typst のインストール
== macOS
macOS を使っているユーザーであれば、Homebrew @homebrew を用いてコマンド一つでインストールすることが可能である。
```bash
brew install typst
```
== Windows
Windows ユーザーも `winget` コマンドを使ってインストールができる。
```bash
winget install --id Typst.Typst
```
== VSCode 拡張機能
VSCode の拡張機能も存在し、これを利用することでより効率的に執筆を行うことができる。
// 引用の読み込み
#bibliography("citing.bib")
|
https://github.com/LDemetrios/Typst4k | https://raw.githubusercontent.com/LDemetrios/Typst4k/master/src/test/resources/suite/math/primes.typ | typst | --- math-primes ---
// Test dedicated syntax for primes
$a'$, $a'''_b$, $'$, $'''''''$
--- math-primes-spaces ---
// Test spaces between
$a' ' '$, $' ' '$, $a' '/b$
--- math-primes-complex ---
// Test complex prime combinations
$a'_b^c$, $a_b'^c$, $a_b^c'$, $a_b'^c'^d'$
$(a'_b')^(c'_d')$, $a'/b'$, $a_b'/c_d'$
$∫'$, $∑'$, $a'^2^2$, $a'_2_2$
$f_n'^a'$, $f^a'_n'$
$ ∑'_S' $
--- math-primes-attach ---
// Test attaching primes only
$a' = a^', a_', a_'''^''^'$
--- math-primes-scripts ---
// Test primes always attaching as scripts
$ x' $
$ x^' $
$ attach(x, t: ') $
$ <' $
$ attach(<, br: ') $
$ op(<, limits: #true)' $
$ limits(<)' $
--- math-primes-limits ---
// Test forcefully attaching primes as limits
$ attach(<, t: ') $
$ <^' $
$ attach(<, b: ') $
$ <_' $
$ limits(x)^' $
$ attach(limits(x), t: ') $
--- math-primes-after-code-expr ---
// Test prime symbols after code mode.
#let g = $f$
#let gg = $f$
$
#(g)' #g' #g ' \
#g''''''''''''''''' \
gg'
$
--- math-primes-with-superscript ---
// Test prime symbols don't raise the superscript position
$
sqrt(f)/f
sqrt(f^2)/f^2
sqrt(f'^2)/f'^2
sqrt(f''_n^2)/f''^2_n
$
|
|
https://github.com/Pablo-Gonzalez-Calderon/apuntes-botanica | https://raw.githubusercontent.com/Pablo-Gonzalez-Calderon/apuntes-botanica/main/src/months/october.typ | typst | Other | #import "../template.typ": new-class, examplebox, obsbox, figure-box, gloss
#import "@preview/showybox:2.0.1": *
#import "@preview/tablex:0.0.4": *
#let micro = sym.mu + "m"
#let clase-12 = [
#new-class(new-page: true, "Crecimiento secundario I", "16 de octubre de 2023")
Antes de entrar de lleno con el crecimiento secundario, es necesario visualizar la serie de diferencias que existen entre este crecimiento con el crecimiento primario:
+ El crecimiento secundario *no está presente en todas las plantas,* a diferencia del crecimiento primario (el cual es _necesario_ para todas las plantas). *Únicamente se encuentra presente en las plantas leñosas.*
+ Los *meristemas* del crecimiento secundario, a diferencia del crecimiento primario, *no vienen en el embrión de la planta,* sino que se generan en "la vida" de la planta, a partir de células adultas.
+ Además, mientras que el crecimiento primario era un crecimiento en longitud, el crecimiento secundario es un *crecimiento en grosor, radial o transversal.*
+ Así como en el crecimiento primario el meristema apical radicular, el meristema apical caulinar, el meristema intercalar y el meristema marginal eran los meristemas primarios. El *cambium vascular* y el *cambium suberoso* son los meristemas secundarios.
Los meristemas secundarios ya no necesitan estar en las zonas apicales, sino que ahora *estarán en la periferia de los troncos,* por lo que también se les denomina *meristemas laterales.*
#obsbox()[
Mientras que en el crecimiento primario los meristemas apicales eran persistentes (excepto cuando forman flores), y los meristemas intercalares y marginales eran transitorios; en el crecimiento secundario todos *los meristemas laterales son persistentes o permanentes.*
]
El cambium vascular, comparado con el cambium suberoso, es más interno en el tallo y las raíces. Además, diremos que el *producto del cambium vascular es la madera.* Botánicamente, entenderemos la madera como xilema secundario. Por su parte, el cambium suberoso o _felógeno_ *generará corteza,* lo cual corresponde a peridermis o felema.
= Cambium vascular
Se forma a partir de los haces vasculares colaterales _abiertos,_ pues estos están "ordenados", permitiendo que se forme un anillo de haces vasculares. *Solamente se formará, entonces, en las dicotiledóneas,* debido a que solo en estas hay haces vasculares ordenados en forma de anillo.
Recordemos que en las dicotiledóneas, en medio del xilema primario y el floema primario está el *meristema del cambium fascicular.* Y, entre medio de cambiums fasciculares adyacentes, en el _parénquima interfascicular_, hay células adultas que se "desdiferencian", volviendo a ser meristemáticas (forman el *cambium interfascicular*), permitiendo conectar los meristemas de los cambiums fasciculares, formando un *anillo completo de tejido meristemático,* el cual, en última instancia *corresponde al cambium vascular.*
#obsbox()[
El cambium vascular tiene un *origen mixto,* pues parte de su meristema viene del crecimiento primario (cambium fascicular) y otra parte proviene del crecimiento secundario (cambium interfascicular).
]
Para que el cambium pueda hacer crecer al tronco, las células del cambium vascular deben crecer tanto periclinalmente como anticlinalmente. En las divisiones periclinales, si la célula derivada va hacia el interior del tronco, produce *xilema secundario,* mientras que si la célula derivada va hacia el exterior del tronco, produce *floema secundario.* Por su parte, en las divisiones anticlinales, lo único que se genera es más meristemas del cambium vascular, debido a que el tamaño del tronco aumenta. Más adelante, detallaremos más cuáles son estas divisiones y qué genera, finalmente, cada una.
== Planos de estudio de tejidos secundarios y células vegetales
La madera, a diferencia de otros tejidos, no se elimina, pues da dureza y resistencia al árbol, permitiéndole seguir normalmente su crecimiento. En este contexto, resulta útil estudiar internamente los troncos de madera, para lo cual se cuenta con distintos planos de corte para poder visualizarlos mejor en ciertos aspectos. Los planos en los que se puede estudiar este tejido son:
+ *Plano transversal:* Aquel plano que se ubica perpendicular al eje vertical.
+ *Plano longitudinal radial:* Aquel plano que pasa por el centro del tronco. Existen infinitos de estos planos.
+ *Plano longitudinal tangencial:* Aquel plano que pasa tangente a una de las circunferencias del tronco, sin pasar por su centro.
=== Plano transversal
#grid(
columns: (1fr, 1fr),
column-gutter: 11pt,
[
En este plano se pueden ver anillos concéntricos (*anillos anuales de crecimiento*), los cuales representan la edad de esa parte del árbol. En el centro de estos anillos se encuentra la *médula* y a su alrededor están los anillos _más viejos,_ mientras que en la periferia están los anillos _más nuevos._
Los anillos son diferenciables gracias a distintas tonalidades de la madera, las cuales se deben a los distintos tamaños de las células en las diferentes estaciones. Al comienzo de una temporada ---en primavera---, las células tienen un mayor tamaño (*leño temprano* o *leño de primavera*), mientras que, conforme esta avanza ---llega el verano---, su tamaño va disminuyendo progresivamente (*leño tardío* o *leño de verano*), comportamiento que se prolonga hasta avanzadas las épocas frías.
],
figure(
caption: "Plano transversal de un tronco",
image("../figures/fig_plano_transversal.svg")
)
)
#obsbox()[
En aquellas plantas que viven en ambientes muy templados o muy benignos, donde las temperaturas no cambian tanto, los anillos no serán tan marcados.
]
Además, podemos notar que los anillos de la periferia (*albura*) poseen, en conjunto, una tonalidad más clara, comparada con los anillos más internos (*duramen*). La diferencia de tonalidad se debe a que el duramen ya no transporta agua, pues las tráqueas se han tapado con compuestos secundarios (*tílide o tilosa,* células parenquimáticas invaginadas dentro del elemento del vaso), para disminuir su posibilidad de pudrirse y hacer que solo sirva de soporte para la planta. Por su parte, la albura seguirá transportando agua y solutos. Finalmente, el duramen puede tener distinta coloración, dependiendo de si hay ciertos tintes o no.
==== Anillos de crecimiento excéntrico
La médula no siempre se encuentra en el centro del tronco. Esto sucede debido a que, en una sección del anillo del cambium vascular hay un mayor grosor que en otras partes, desplazando la médula. Usualmente, esto ocurre por efecto de fuerzas externas que generan una presión sobre el crecimiento del árbol (e.g. la gravedad, el viento, etc.).
La madera que se forma como respuesta a estas fuerzas externas se denomina *madera de reacción,* donde, además de que la médula no está en el centro, los anillos no poseen el mismo grosor.
Como cualquier parte del tallo puede estar expuesta a fuerzas externas, la madera de reacción no solo estará presente en el tronco principal de la planta, sino que también estará, por ejemplo, en las ramas laterales (que sufren de la fuerza de gravedad).
Las Gimnospermas no responden de la misma forma que las dicotiledóneas a las presiones externas del medio:
- En las *Gimnospermas* (como las Coníferas) se genera un *leño de compresión,* pues la madera de reacción se genera en la _zona donde se ejerce la fuerza_. Aquí se puede evidenciar un color más rojizo en la madera, además de una mayor proporción de leño tardío y lignina, y una menor proporción de celulosa.
- En las *Dicotiledóneas* se genera un *leño de tensión* o *leño de tracción,* pues la madera de reacción se genera en la _zona opuesta a donde se ejerce la fuerza_. Aquí, hay una mayor proporción de celulosa y menor de lignina, y existe un color más claro en la madera, comparado con lo normal.
#obsbox()[
Los rastros de las ramas también serán visibles en el plano transversal _(Véase la @plano-radial para saber qué son los rastros de las ramas)_.
]
=== Plano longitudinal radial<plano-radial>
#grid(
columns: (1fr, 1fr),
column-gutter: 11pt,
figure(
caption: "Plano radial de un tronco",
image("../figures/fig_plano_radial.svg")
),
[
En este corte pueden verse los anillos anuales de crecimiento como *franjas paralelas,* las cuales están alrededor de la médula, la que está _generalmente_ en el centro. Además, se puede distinguir tanto el duramen como la albura.
A veces, puede aparecer una marca horizontal que atraviesa todos los anillos. Esta marca se debe a la presencia de un tallo lateral que fue cubierto por el crecimiento del tronco. Denominaremos esta marca como *rastro de la rama.*
La rama lateral del tronco podrá o no desprenderse dependiendo de si el nudo es un *nudo vivo* (tallo no se desprende) o *nudo muerto* (tallo se desprende). Muchas veces, incluso, es posible ver ramas muertas que aún están aparentemente conectadas con el tallo, pero en realidad sus xilemas ya no están unidos, por lo que solo factores externos mantienen unida la rama al tronco principal.
]
)
#grid(
columns: (1fr, 1fr),
column-gutter: 11pt,
[
=== Plano longitudinal tangencial
En estos planos también se ven los anillos anuales de crecimiento, pero ya no se ven paralelos, sino que se ven más desordenados y muchas veces como si fuesen a "desaparecer" conforme se asciende en el plano, ya que los anillos de crecimiento son cada vez menos conforme uno se aproxima a las partes más nuevas de la planta.
También es posible ver en varios casos los rastros de las ramas, los cuales, igual que en el plano longitudinal radial, aparecen usualmente como marcas horizontales.
Finalmente, debido a que existe una mayor libertad de "corte" para estos planos, comparado con los planos radiales, es obvio que la cantidad de estos planos que pueden hacerse en un tronco es infinita.
],
figure(
caption: "Plano tangencial de un tronco",
image("../figures/fig_plano_tangencial.svg")
)
)
== Características del cambium vascular
Como mencionamos previamente, el cambium vascular se puede dividir periclinalmente (genera tejidos secundarios: xilema secundario y floema secundario) o anticlinalmente (genera tejido meristemático). Recordemos que si la célula derivada periclinalmente va hacia afuera, será del floema secundario, mientras que si va hacia adentro será del xilema secundario.
=== Tipos de divisiones de las células del cambium
#grid(
columns: (1fr, 1.1fr),
column-gutter: 11pt,
[
Para comprender mejor los posibles tipos de planos de división 3D, se debe observar la @planos-3d, donde se puede ver fácilmente cómo se denominan todos los planos en los que una célula puede dividirse, respecto a una superficie de referencia.
Lo que es más, es importante recordar que en la división periclinal de una célula del cambium vascular, no solo la pared superior e inferior se dividen, sino que también las paredes radiales deben dividirse. Por ello, esta división se denomina *periclinal longitudinal.*
Por otro lado, en la división anticlinal, no solo las paredes superior e inferior deben dividirse, sino que también las paredes tangenciales. Por ello, esta división se denomina *anticlinal longitudinal.*
],
[
#figure(
caption: "Planos de división celular 3D",
image("../figures/fig_planos_división.svg")
)<planos-3d>
]
)
También existe otra división anticlinal, en la cual las paredes radiales y tangenciales son las que se dividen. Aquí, este tipo de división se denomina *transversal anticlinal.*
#align(center, "*" * 10)
*Las células del cambium vascular* forman un tejido meristemático que, *en el plano transversal*, tiene células rectangulares, con filas tangenciales y columnas radiales. Adicionalmente, las paredes tangenciales de estas células son más gruesas que sus paredes radiales.
#obsbox()[
Todos los cambium (tejidos meristemáticos) poseen una distribución similar a la señalada.
]
#grid(
columns: (1fr, 1fr),
column-gutter: 11pt,
[
Por su parte, *en un corte longitudinal*, vamos a encontrar una células alargadas y terminadas en puntas, a la vez que veremos otras células "más cortas". Las primeras se llaman *células iniciales fusiformes,* mientras que las segundas se llaman *células iniciales radiales.* Cada una de ellas, cuando se divide (anticlinalmente, periclinalmente o transversalmente), genera células características: las células iniciales fusiformes originan células que se ordenan *verticalmente* (longitudinalmente), mientras que las células iniciales radiales originan células que se ordenan *horizontalmente* (radialmente).
Las células producidas por las células iniciales fusiformes generarán un *transporte vertical*, mientras que las células producidas or las células iniciales radiales generarán un *transporte horizontal,* como se ve en la @direccion-transporte-celulas-iniciales
],
[
#figure(
caption: "Direcciones de transporte de las células iniciales del cambium vascular",
image("../figures/fig_transporte_celulas_iniciales.svg")
)<direccion-transporte-celulas-iniciales>
]
)
De la @división-fusiformes, observamos que las células iniciales radiales se originan a partir de divisiones transversales de células radiales fusiformes.
#figure(
caption: "Células generadas en los distintos planos de división de las células iniciales fusiformes",
placement: bottom,
image("../figures/fig_divisiones_celulas_fusiformes.svg", width: 60%)
)<división-fusiformes>
Por su parte, de las divisiones periclinales de células iniciales fusiformes se va a generar:
#box(height: 2.5cm,
columns(2)[
#enum(
numbering: "(a)",
[
Xilema secundario
+ Elementos de vaso o tráquea
+ Traqueideas
+ Fibras xilemáticas
+ Parénquima axial
], [
Floema secundario
+ Elemento de vaso criboso
+ Células acompañantes
+ Fibras floemáticas
+ Parénquima axial
]
)
]
)
Finalmente, las divisiones periclinales de células iniciales radiales solamente generarán *parénquima radial,* también conocido como *radios vasculares*, los cuales estarán localizados tanto en el xilema secundario como en el floema secundario, atravesándolos ---como el nombre lo indica--- igual que radios. Las divisiones anticlinales, mientras tanto, originarán nuevas células iniciales radiales.
#obsbox()[
Las células iniciales radiales, están dispuestas transversalmente (formando radios) y transportan sustancias elaboradas; mientras que las células iniciales fusiformes están dispuestas longitudinalmente y transportan agua y solutos.
]
]
#let clase-13-14 = [
#new-class(new-page: true, "Crecimiento secundario II", "23 de octubre de 2023")
= Elementos celulares generales del xilema secundario en plantas
Como mencionamos, las células iniciales fusiformes e iniciales radiales originan células derivadas gracias a sus divisiones periclinales, tanto centrípetamente como centrífugamente. En la @tabla-celulas-derivadas-de-iniciales se haya un resumen de las células derivadas que genera cada una.
#figure(
caption: "Células derivadas de los dos tipos de células iniciales del cambium vascular, según hacia dónde se forman.",
tablex(
header-rows: 1,
auto-lines: false,
align: left,
columns: (120pt, 1fr, 1fr),
(), vlinex(start: 1), (), (),
[], [*Iniciales fusiformes \ (se ordenan verticalmente)*], [*Iniciales radiales \ (se ordenan transversalmente)*],
hlinex(),
cellx(fill: silver)[Centrípetamente (*Xilema secundario*)],
cellx(fill: silver)[#enum(numbering: "1.", indent: 0pt)[Elementos de vaso o tráquea][Traqueidas][Fibras xilemáticas][Parénquima axial]],
cellx(fill: silver)[
#enum(numbering: "1.", indent: 0pt)[Parénquima radial (radios vasculares)]
],
[Centrífugamente (*Floema secundario*)],
{
set enum(indent: 0pt)
[
+ Elemento o miembro de vaso criboso
+ Célula anexa y célula albuminosa
+ Fibras floemáticas
+ Parénquima axial
]
},
{
set enum(indent: 0pt)
[
+ Parénquima radial (radios vasculares)
]
}
),
kind: table
)<tabla-celulas-derivadas-de-iniciales>
Ahora, procederemos a caracterizar cada una de estas células, pero solamente poniendo especial atención en las que componen el xilema secundario.
== Elemento de vaso (o elementos de tráqueas)
#grid(
columns: (1fr, .9fr),
column-gutter: 11pt,
[
+ Son células muertas.
+ Poseen pared secundaria lignificada.
+ Carece de contenido celular.
+ Presentan *placas de perforación* que corresponden a las paredes transversas (superiores) modificadas.
+ Las paredes laterales tienen *punteaduras areoladas.*
+ *Varios elementos de vaso superpuestos forman una tráquea o vaso.*
+ Se encargan del transporte de *agua y solutos*, principalmente, dando posibilidad de que ocurra la transpiración.
],
figure(
caption: "Elemento de vaso con placa de perforación simple|",
image("../figures/fig_elemento_de_vaso.svg", height: 6cm)
)
)
=== Placas de perforación
Las placas de perforación son unos orificios que se hayan en las paredes transversas. Pueden presentarse de dos formas:
+ Como un orificio único (_placa de perforación simple_ ---más común).
+ Como un conjunto de orificios, formando una especie de "rejilla" (_placa de perforación escaleriforme_ ---más arcaica y menos común).
=== Punteaduras
Por su parte, las *punteaduras* son perforaciones de las paredes secundarias laterales, permitiendo *comunicaciones laterales* con las células vecinas. Su existencia permite que el flujo de sustancias siga su curso ante situaciones donde se obstruyen las placas de perforación.
La formación de punteaduras se debe a una interrupción de la fijación de lignina en la pared secundaria, quedando solamente pared primaria y lámina media en cada punteadura.
Cuando observamos una punteadura, esta puede verse *simple* (si solo se ve una circunferencia uniforme) o *areolada* (si se ve una circunferencia engrosada, debido a una fijación irregular de lignina alrededor de las punteaduras). Véase la @punteaduras para más detalles.
#figure(
caption: "Tipos de punteaduras: simple y areolada; vistas desde el plano lateral y frontal.",
image("../figures/fig_punteaduras.svg", height: 9cm),
placement: bottom
)<punteaduras>
== Traqueidas
+ Son células muertas.
+ Posee pared secundaria lignificada.
+ Se encargan del transporte de agua y solutos.
+ Termina en punta.
+ No poseen placas de perforación.
+ Poseen *punteaduras areoladas*, siendo esta la única forma de comunicación entre traqueidas.
+ Es más alargada que un elemento de vaso.
+ No posee contenido celular.
#obsbox()[
Las tráqueas son un _conjunto_ de células, mientras que las traqueidas son solamente _una_ célula.
]
== Fibras xilemáticas
+ Son células muertas.
+ No poseen contenido celular.
+ Terminan en punta.
+ *Todas sus punteaduras son simples.*
+ Su función es mecánica, dándole soporte a la planta.
+ No poseen placa de perforación.
== Parénquima axial
+ Está compuesto por células vivas.
+ No poseen pared secundaria.
+ Se forma a partir de una célula inicial fusiforme que se divide periclinalmente dando origen a una célula derivada que, posteriormente, se dividirá transversalmente para originar un conjunto de células que se ordenan verticalmente, conformando el parénquima axial.
+ Su función principal es almacenar agua. A veces puede almacenar otras sustancias, como cristales, taninos, etc.
+ En un plano transversal se puede observar difuso o puede tener una *distribución apotraqueal* (no relacionado con los vasos; separados de ellos) o una *distribución paratraqueal* (relacionado con los vasos; en conjunto con ellos).
== Parénquima radial (radios vasculares)
+ Se origina de divisiones periclinales de las células iniciales radiales.
+ Son células parenquimáticas vivas.
+ Reservan y transportan sustancias en sentido transversal (radial) a través del xilema secundario.
Dependiendo de la cantidad de células que lo conformen a lo ancho, se puede denominar como *uniseriado, biseriado* o *multiseriado.* Por su parte, a lo largo (en longitud) se puede describir dando unidades de medida en micrones (#micro). Finalmente, a lo alto, se puede medir en micrones igualmente, o en número de células, según se desee.
Para medir correctamente la anchura (con certeza), esta debe medirse en el plano longitudinal tangencial. Para la longitud, en el plano transversal (aunque a veces puede usarse el plano longitudinal radial). Y, finalmente, para la altura, en el plano longitudinal tangencial.
#obsbox()[
La anchura del radio se toma siempre en el centro vertical de este
]
#figure(
caption: [Ejemplo ilustrativo de una sección de parénquima radial cortado a la mitad en su plano transversal. En este caso, se trata de un parénquima radial *biseriado* (hay dos células en su ancho radial), y con un largo de 1 #micro. En caso de tener la medida en altura de este corte, el doble de aquella medida constituiría la altura teórica del parénquima radial completo.],
image("../figures/fig_parenquima_radial.svg")
)
= Elementos celulares del xilema secundario en las Coníferas
Un grupo de plantas muy importante en el estudio del xilema secundario son las Coníferas, pues poseen cualidades "atípicas" a las estudiadas previamente para los xilemas de plantas en general.
#grid(
columns: (1fr, 1.2fr),
column-gutter: 11pt,
[
En primer lugar, encontramos que *las Coníferas no poseen tráqueas, fibras xilemáticas, ni parénquima axial* por lo que son más blandas que otras plantas que sí las poseen. No obstante, sí poseen *traqueidas y sus radios parenquimáticos son _uniseriados_* con una altura variable.
En _algunas_ Coníferas, aparecen, además, un grupo de células parenquimáticas (células vivas con pared primaria) que rodean un espacio "vacío" del xilema. Este grupo de células se denominan *células epiteliales*, y conforman los *vasos resiníferos.* Aquí, la función de las células epiteliales es secretar (no producir) resina hacia los vasos resiníferos.
],
figure(
caption: "Representación de un vaso resinífero. La flecha rojiza representa la dirección de formación del vaso; es decir, el origen esquizogénico",
image("../figures/fig_vaso_resinifero.svg")
)
)
Alrededor de las células epiteliales, se hayan las *células de la vaina,* las cuales son las encargadas de sintetizar la resina que recibirán las células epiteliales y que, posteriormente, circularán por los vasos resiníferos.
El vaso resinífero se origina, inicialmente, de la _separación_ de las células epiteliales y de la vaina, las cuales dejan una abertura o hueco en medio de ellas, dando origen al vaso. Este tipo de origen se denomina *esquizogénico.*
#obsbox()[
Producir resina #sym.eq.not Secretar resina
]
= Cambium vascular (continuación)
Ahora continuaremos con el estudio del crecimiento secundario. Ya vimos cómo este se producía en tallos para formar madera, pero todavía nos falta ver cómo actúa el cambium vascular en las raíces (porque sí, también hay crecimiento secundario en las raíces).
Antes de comenzar con el desarrollo del cambium vascular en raíces, queda por mencionar un aspecto relacionado a la actividad estacional que presenta el cambium: al inicio de la época de crecimiento, la cantidad de células a lo largo del cambium vascular es mayor que en la época de inactividad, donde usualmente solo hay una hilera de estas células. Cuando el cambium está activo, diremos que se puede observar notablemente la *zona cambial,* es decir, donde hay cambium (células rectangulares con paredes radiales gruesas y tangenciales delgadas ---en un corte transversal).
#box()[
== Cambium vascular en las raíces
#grid(
columns: (1fr, 1fr),
column-gutter: 11pt,
[
En las raíces, el crecimiento secundario parte con la *desdiferenciación de la parte interna del metafloema*, creando un tejido meristemático con forma de semicírculos, como se observa en la @cambium-vascular-raices.
Ahora, es necesario formar un "círculo meristemático" para poder iniciar el crecimiento secundario propiamente tal. Para ello, en las regiones donde no haya meristema proveniente del metafloema, se utilizará el meristema del periciclo para "cerrar" la circunferencia.
De esta manera, el cambium vascular es la mezcla del meristema creado en el metafloema, más el meristema del periciclo que se haya en las zonas del protoxilema.
*En el cambium de las raíces también existirán células iniciales fusiformes y células iniciales radiales,* y se generará xilema secundario de forma centrípeta y floema secundario de forma centrífuga.
],
[
#figure(
caption: "Cambium vascular en una raíz, formado por metafloema desdiferenciado en la zona interna, y trazas del periciclo en las zonas donde no hay floema.",
image("../figures/fig_cambium_vascular_raices.svg")
)<cambium-vascular-raices>
]
)
De esta manera, la única diferencia con el cambium vascular de los tallos es el origen.
]
=== Funciones del periciclo (actualizadas)
+ Participa en el origen del cambium vascular en raíces
+ Origina raíces laterales (tanto en el sistema radical axonomorfo alorrizo como en el sistema radical homorrizo fibroso).
La generación de raíces laterales se produce debido a divisiones periclinales y anticlinales del periciclo. La ruptura y extensión de la raíz en los momentos iniciales será gracias a la elongación celular de las células derivadas.
+ Forma felógeno en raíces con crecimiento secundario.
= Cambium suberoso o felógeno (corteza)
Una vez estudiado cómo se forma la madera, es momento de adentrarse en la formación de la corteza. En botánica, a la corteza la denominamos *peridermis*, la cual es la suma de *felema, felógeno* y *felodermis,* en el orden indicado por la @partes-de-la-peridermis
Entre distintas especies de plantas pueden haber muchas diferencias en sus cortezas, lo cual se debe a la variabilidad de desarrollo y características del cambium.
#figure(
caption: [Disposición de las capas de la peridermis, desde el interior del tallo (izquierda) hacia el exterior (derecha). Es importante destacar que la peridermis _no_ tiene contacto directo con el exterior.],
figure-box(align(center)[
*Peridermis*
(Interior) #h(1fr) Felodermis #sym.arrow.long Felógeno #sym.arrow.long Felema #h(1fr) Epidermis #sym.arrow.long (Exterior)
])
)<partes-de-la-peridermis>
== Felógeno
El cambium suberoso o felógeno es un anillo más externo que el del cambium vascular, siendo formado por las células vivas ya sea del floema, el clorénquima, el parénquima cortical o la epidermis (puede provenir de la desdiferenciación de diversos tejidos). *No participan células meristemáticas; solamente tejidos adultos.*
El felógeno se caracteriza por:
+ Ser un meristema secundario.
+ Solo estar formado por células iniciales aplanadas tangencialmente (visto desde un plano transversal).
+ Divisiones anticlinales originan nuevas células iniciales.
+ Divisiones periclinales originan dos tipos celulares:
+ *Centrífugamente forma felema.*
+ *Centrípetamente forma felodermis.*
== Felema
El felema corresponde a capas de *células muertas* que tienen las *paredes con suberina.* Por ello, se encargan de proteger a los tallos con crecimiento secundario, pudiendo formar varias capaz y, con ello, determinar las diversas formas que poseen las cortezas de las plantas.
Como el felema aísla el interior del exterior de la planta, cada cierto tramo se forman aberturas denominadas *lenticelas,* las cuales permiten el intercambio gaseoso con el exterior. Las lenticelas son, en esencia, un canal relleno de células _vivas_ formadas en zonas de alta actividad cambial, y que han roto el felema gracias a que han hecho presión sobre él debido a su gran cantidad.
== Felodermis
La felodermis se caracteriza por:
+ Ser células parenquimáticas vivas.
+ Poseer pared primaria celulósica.
+ Formar parte del parénquima cortical en el futuro.
== Ritidoma
En algunos casos no se forma un solo cambium suberoso, sino que se va formando cada año un nuevo cambium cada vez más interno, formando capas de corteza más y más gruesas. Estas capaz de tejidos muertos se denomina *ritidona,* y puede contener tanto felema como felógeno muerto o felodermis muerta.
= Cambium suberoso en las raíces
En raíces, el cambium suberoso se forma muy adentro, en el periciclo, causando que todas las capas externas a él se eliminen, incluido parénquima cortical y rizodermis.
Sin embargo, *en Monocotiledóneas no se forma felógeno,* porque no tienen crecimiento secundario. Sin embargo, para proteger la raíz se forma la *exodermis,* la cual es similar a un felema; es decir, que está constituida por células muertas con paredes suberificadas. Su diferencia con el felema es que la exodermis se forma a partir de células subrizodérmicas que se modifican.
]
#let clase-15-16 = [
#new-class(new-page: true, "Reproducción en plantas I", "30 de octubre de 2023")
Ahora, llegó el momento en el que vamos a estudiar cómo se reproducen las plantas, las características de las flores y las características de las semillas.
= Tipos de reproducción en plantas
Recordemos que la reproducción es fundamental para los seres vivos, pues les permite perpetuar la especia a lo largo del tiempo. En este contexto, se dan dos tipos de reproducción: la *reproducción sexual* (hay participación de gametos de dos individuos) y la *reproducción asexual* (no hay participación de gametos, hay un solo individuo).
En las plantas que se reproducen asexualmente, una planta madre dará origen a clones. Esta reproducción puede clasificarse como "más rápida" que la reproducción sexual, por lo que le ha sido útil a los seres humanos en el proceso de cultivar plantas de manera más rápida para obtener alimento, valga la redundancia, más rápidamente.
#examplebox()[
Ejemplos de plantas con este tipo de reproducción son aquellas que poseen, en su estructura, rizomas, estolones, tubérculos, etcétera.
]
Por su parte, en la reproducción sexual hay tanto plantas *Antófitas o Angiospermas* (plantas con flores que darán frutos con semillas) como plantas *Coniferófitas* (Coníferas que producen *estróbilos* que tendrán semillas). En conjunto, ambos grupos serán *espermatófitas,* o plantas que producen semillas.
#figure(
caption: "Tipos de plantas con reproducción sexual.",
figure-box(text(size: 1.25em)[
$ "Reproducción\nsexual"& cases(limits("Espermatófitas")_"(plantas que producen semillas)" cases("Antófitas o Angiospermas" limits(arrow.long)_"pueden\nser" "Unisexuales o \n Hermafroditas", "Coniferófitas" limits(arrow.long)^"reprod.\nvía" "Estróbilos" limits(arrow.long)^"son" "Unisexuales"), #v(1em), limits("No espermatófitas")_"(plantas que no producen semillas)" cases("Helechos" limits(arrow.long)_"poseen\nlos" "Soros", "Musgos" limits(arrow.long)_"poseen\nlas" "Cápsulas esporangiales")) $
]),
placement: bottom
)
#obsbox()[
De esta forma se puede inferir que las semillas provienen evolutivamente antes que la formación de flores y frutos.
]
Adicionalmente, en la reproducción sexual también encontraremos otro grupo denominado *no espermatófitas,* donde se encuentran los *helechos* y los *musgos.* Aquí, el embrión no se encuentra en latencia, sino que se desarrolla inmediatamente
#obsbox()[
La semilla es una estructura que tiene un embrión latente que se va a desarrollar cuando las condiciones sean las adecuadas.
]
Como se mencionó, en las espermatófitas, la estructura característica de las Angiospermas son las flores, las cuales pueden presentar estructuras masculinas (*estambre*) y/o femeninas (*pistilos*). Si tienen ambas, se denominan *hermafroditas,* si tienen solo una se denominan *unisexuales.*
Por su parte, como se mencionó, en las Coniferófitas, están los *estróbilos*, los cuales *siempre son unisexuales.*
Luego, en las no espermatófitas, como los helechos, hay estructuras como los *soros,* los cuales se ubican debajo de las *frondas* u hojas de la planta. Y, finalmente, en los musgos, se encuentran las *cápsulas esporangiales.*
= Reproducción asexual
#figure-box()[
$ "Progenitores" limits(arrow.long)^"Generan una" "Unidad reproductiva" limits(arrow.long)^"Genera la" "Progenie" $
]
Siempre habrán 3 componentes:
+ Los progenitores
+ La estructura de la que aparezca la progenie, denominada *unidad reproductiva*
+ La progenie
== Vegetativa
En este tipo de reproducción asexual, la característica principal que la diferencia de sus homólogas es que aquí *la unidad de reproducción es pluricelular,* pudiendo ser una hoja, un tallo, un tubérculo, etc.
#examplebox()[
Un ejemplo claro de este tipo de reproducción asexual son las frutillas, las cuales se pueden reproducir mediante sus estolones, estructuras pluricelulares que le permiten generar clones de la planta madre.
]
== Esporulación
En estos casos, el progenitor (esporofito) produce *esporas* (unidad reproductiva), las cuales se desarrollarán dando origen a la progenie.
#figure(
caption: "Proceso de creación de esporas a partir de los esporofitos progenitores.",
align(
center,
[
#grid(
columns: (100pt, 45pt, 150pt, 50pt, 120pt),
box(stroke: 1pt, inset: 1em, align(center)[
*Progenitor*
Diploide (2n)\
Es un esporofito
]),
align(center+horizon, $ limits(arrow.long)^"posee" $),
box(stroke: 1pt, inset: 1em, align(center)[
*Esporangios*
Contienen a los _esporocitos,_\
células que hacen *meiosis*.
]),
align(horizon, $ limits(arrow.long)^"forman y"_"contienen" $),
box(stroke: 1pt, inset: 1em, align(center)[
*Esporas*
4 por c/esporocito\
Son haploides (n)
]),
)
#box(inset: 1em, width: 80%, fill: luma(230))[
$ "Esporocito (2n)" arrow.long "2 células hijas (2n)" arrow.long "4 Esporas (n)" $
La progenie será, por tanto, _haploide y unicelular._ Además, no será idéntica al progenitor y va a constituir un gametofito.
]
]
),
placement: bottom
)
De esta manera, para llevar a cabo la reproducción, el progenitor deberá crear *unidades haploides unicelulares* (las esporas). Y, para conseguir aquello ---unidades haploides---, las células generativas deberán sufrir un proceso de *meiosis.*
En este caso, la progenie terminará también siendo haploide, poseyendo, por tanto, distinto material genético al de los progenitores. *Este tipo de reproducción sexual se da en todas las plantas.*
En el helecho, donde se producen esporas, la progenie se obtiene por reproducción asexual, mientras que el progenitor provino de la reproducción sexual. Por lo tanto *la progenie es una etapa intermedia de la vida del helecho.* Más adelante veremos que esto se relaciona con lo que denominamos generación alternante.
De esta manera, es evidente que la progenie será vital para, por ejemplo, un helecho, pues, como el helecho no produce gametos, ella será la encargada de producir los gametos. Entonces, la progenie generada por la esporulación corresponderá a *gametofitos.* Además, como el individuo (progenie) es haploide (n), tendrá que producir los gametos sí o sí por mitosis, en los *gametangios* (análogos a los esporangios).
Finalmente, como el gametofito es igual en todos los casos, será *hermafrodita,* teniendo, por tanto, gametangios que producen gametos masculinos (*anteridio*) y gametangios que producen gametos femeninos (*arquegonio*). El gameto masculino se denomina *espermio* o *espermatocito*, mientras que el gameto femenino se llama *ovocito, óvulo* u *ovocélula.*
El resto del proceso: fecundación y formación de los esporofitos, es bastante similar con su equivalente de la reproducción sexual.
= Reproducción sexual
Si bien una planta puede reproducirse sexualmente consigo misma cuando es hermafrodita (*autogamia*), las plantas generalmente propiciarán la reproducción con otras de su especie (*alogamia*).
Ahora, los progenitores generarán unidades de reproducción llamadas simplemente como gametos, los cuales serán producidos por los anteridios y los arquegonios. *El gameto femenino siempre queda unido al reproductor.*
Cuando los gametos se unan, formarán el cigoto, el cual es diploide, y, más tarde, formará un embrión. Este embrión podrá desarrollarse inmediatamente (no espermatófitas) o quedar en latencia dentro de un fruto (espermatófitas).
= Generación alternante
Una parte importante de las vidas de casi la totalidad de las plantas consiste en ser esporofitos diploides, produciendo esporas haploides por meiosis que generan una progenie de gametofitos haploides. Luego de esta fase, los gametofitos producen gametos por mitosis, los cuales generarán un cigoto, que dará origen a un embrión, repitiendo el ciclo. Esta situación cíclica se puede observar en la @generacion-alternante
En los helechos, Coníferas y Antófitas la etapa de ser esporofito es más extensa que las demás fases. El diagrama de la @generacion-alternante-en-coniferas representa una dominancia de la época esporófita de la planta, estando las demás etapas en menor medida durante el ciclo de vida de la planta. La _excepción_ a esta dominancia ocurre en las briófitas (musgos, hepáticas, antoceros, etc.), donde la etapa gametófila es la dominante.
#obsbox()[
La mayoría de las plantas producen esporas en primavera.
][
Todas las plantas son embriófitas, pues todas generan embrión
]
#figure(
placement: top,
align(center, grid(
columns: (100pt, 45pt, 150pt, 50pt, 120pt),
row-gutter: 10pt,
box(stroke: 1pt, inset: 1em, align(center)[
*Esporofitos*
Diploides (2n)\
Son la planta
]),
align(center+horizon, $ limits(arrow.long)^"contiene" $),
box(stroke: 1pt, inset: 1em, align(center)[
*Esporangios*
Contienen a los _esporocitos,_ células que hacen *meiosis*.
]),
align(horizon, $ limits(arrow.long)^"forman y"_"contienen" $),
box(stroke: 1pt, inset: 1em, align(center)[
*Esporas*
4 por c/esporocito\
Son haploides (n)
]),
[$ limits(arrow.t)_"forman gametos que \nfecundan y forman" $],[],[],[],$ limits(arrow.b)^"constituyen" $,
align(horizon, box(stroke: 1pt, inset: 1em, align(center)[
*Anteridio (M)*
*Arquegonio (F)*
])),
align(horizon, $ limits(arrow.long.l)^"son dos" $),
box(stroke: 1pt, inset: 1em, align(center)[
*Gametangios*
En ellos ocurre mitosis para formar los gametos (n).
]), align(horizon, $ limits(arrow.long.l)^"contiene" $),
box(stroke: 1pt, inset: 1em, align(center)[
*Gametofitos*
Haploides (n)\
Son hermafroditas
]),
)
),
caption: "Diagrama que representa los participantes de la generación alternante."
)<generacion-alternante>
#figure(
caption: "Diagrama a escala temporal de las etapas de la generación alternante en helechos, Coníferas y Antófitas.",
image("../figures/fig_generacion_alterna.svg")
)<generacion-alternante-en-coniferas>
== Generación alternante en briófitas (musgos)
#grid(
columns: (1.3fr, 1fr),
column-gutter: 11pt,
[
En los musgos, las partes que sujetan al sustrato se llaman *rizoides,* el eje principal se llama *caulidio,* y las estructuras con forma de hoja se llaman *filodios.* El caulidio se extiende como un *filamento,* en cuya punta se haya la *cápsula esporangial.*
La zona inferior compuesta por el rizoide, el caulidio y los filodios corresponde a una zona gametófita, siendo producto de una espora y con la característica de ser *autónoma,* pues produce su propio alimento.
Por su parte, la zona superior compuesta por el filamento y la cápsula esporangial corresponde a una esporofita, la cual es dependiente del gametofito para vivir. Por ello, analizaremos la reproducción alternada de las briófitas con el proceso del gametofito primero...
Antes de comenzar la formación de un cigoto, el gametofito va a *desarrollar los gametangios en la zona apical.* En el gametangio femenino se forma el ovocito, mientras que en el gametangio masculino se forman muchos espermatocitos con flagelo, los cuales se liberan al ambiente.
Los espermatocitos salen por el canal del anteridio (son móviles) y entran al arquegonio, donde _solo uno_ fecunda al óvulo.
],
figure(
caption: "Estructura de una briófita, donde se aprecian sus estructuras...",
image("../figures/fig_briofita.svg")
)
)
#figure(
caption: "Ciclo de generación alternante de las briófitas",
image("../figures/fig_ciclo_briofita.svg"),
placement: bottom
)
Posteriormente, en el arquegonio se comienza a desarrollar el embrión, formándose una estructura filamentosa (el filamento) que terminará en una cápsula esporangial.
Luego, al interior de la cápsula esporangial, se hallaran numerosos esporocitos, los cuales se dividirán por meiosis para generar esporas haploides, proceso conocido como *esporulación.*
Finalmente, las esporas caerán al suelo ---se depositan en el sustrato--- y se desarrollarán, dando origen a nuevos gametofitos.
#obsbox()[
Todas las esporas son iguales (*homosporas* o *isosporas*), por lo que generan gametofitos hermafroditas.
]
== Generación alternante en Antófitas
Las Antófitas o Angiospermas son plantas terrestres, árboles y arbustos, herbáceas anuales y perennes. Además, son organismos vasculares (poseen xilema y floema), desarrollando sus flores en los lugares donde se ubican los esporangios. Las semillas que producen se caracterizan por estar protegidas por el ovario desarrollado ---el fruto---, poseyendo un ciclo reproductivo que no precisa de fase acuosa.
En las Angiospermas, cuando la planta se reproduce, produce, lógicamente, flores, las cuales son tallos que han sido modificados completamente para cumplir la función reproductiva. Las principales diferencias morfológicas entre un tallo normal y una flor, se encuentran listadas en la @diferencias-flor-tallo. Más detalles de la morfología de la flor serán profundizados posteriormente.
#figure(
caption: "Diferencias entre un tallo normal y una flor (tallo modificado).",
table(
columns: (.5fr, 1fr, 1fr),
[], [*Tallo*], [*Flor*],
[*Entrenudos*], [Visibles a simple vista], [Muy estrechos],
[*Hojas*], [Nomófilos], [
Antófilos (piezas o elementos que forman la flor):
#align(left, enum(indent: 0pt)[Sépalos $limits(arrow.long)^"forman"$ Cáliz][Elemento o Pieza $limits(arrow.long)^"forman"$ Verticilo][Pétalos $limits(arrow.long)^"forman"$ Corola][Estambres $limits(arrow.long)^"forman"$ Androceo][Carpelos $limits(arrow.long)^"forman"$ Gineceo])
#obsbox()[Los carpelos forman también uno o más pistilos]
],
[*Función*], [Fotosintética], [Reproductiva]
)
)<diferencias-flor-tallo>
=== Androceo
Estructura reproductiva masculina que corresponde a un conjunto de estambres, los cuales están formado por dos partes:
+ Filamento: Haz vascular por donde va el xilema y el floema, uniéndolo a la flor.
+ Antera: Estructura modificada donde se van a producir las unidades de reproducción (esporas).
- Posee 2 tecas cada una con 2 sacos polínicos.
- En total hay 4 sacos polínicos.
- Los sacos polínicos son esporangios (producen y almacenan esporas).
- Los sacos polínicos contienen esporocitos que sufren meiosis, formando así 4 esporas por cada esporocito.
- Para liberar las esporas, lo puede hacer de distintas maneras, ya sea longitudinal, transversal, etcétera.
#obsbox()[
Se producen esporas en las anteras porque son parte de la flor, la cual, a su vez, es parte de la planta a la cual está unida. Y, finalmente, esta planta corresponde a un esporofito, permitiendo concluir que la unidad reproductiva que se produce son esporas.
]
=== Gineceo
Estructura reproductiva femenina, la cual corresponde a un conjunto de carpelos que forman un pistilo o varios pistilos. Algunas posibles configuraciones de ordenamiento de los carpelos y pistilos se hayan en la @carpelos-pistilos
#figure(
caption: "Distintas configuraciones o formas de ordenarse de los carpelos para formar una determinada cantidad de pistilos.",
tablex(
width: 100%,
align: center+horizon,
columns: (1fr, 1fr, 1fr),
header-rows: 1,
[*N° de carpelos*], [*N° de pistilos*], [*Nombre de la estructura*],
[1 carpelo], [1 pistilo], [Monocarpelar \ Unilocular],
rowspanx(2)[2 carpelos], [1 pistilos], [Bicarpelar \ Uni o bilocular.], [2 pistilos], [Monocarpelar \ Unilocular],
rowspanx(2)[3 carpelos], [1 pistilo], [Tricarpelar \ Uni o trilocular],
[3 pistilos], [Monocarpelar \ Unilocular]
),
kind: table
)<carpelos-pistilos>
Finalmente, los pistilos están formados por 3 partes
+ Estigma: Donde llega el polen, parte más externa y superior.
+ Estilo: Donde crecerá el tubo polínico (cuando llegue el polen al estigma).
+ Ovario: Parte del fruto.
- Pueden haber varias "cámaras" llamadas *lóculos,* donde puede haber uno o muchos *primordios seminales*
- En los primordios seminales es en donde se dará origen a una semilla.
- El primordio seminal se ubica en la placenta.
#obsbox()[
El número de carpelos _no siempre_ equivale al número de pistilos.
][
Los lóculos son los "espacios" que hay dentro de los pistilos.
]
#figure(
caption: [Ilustración con la mayoría de las partes florales mencionadas. Extraído de #link("https://pin.it/7ihnJ46", text(blue, "https://pin.it/7ihnJ46"))],
image("../figures/fig_partes_de_la_flor.jpg", height: 7cm)
)
] |
https://github.com/LilNick0101/Bachelor-thesis | https://raw.githubusercontent.com/LilNick0101/Bachelor-thesis/main/content/project.typ | typst | #v(10pt)
= Il progetto
In questo capitolo viene descritto il progetto di stage in largo, in particolare come è stato pianificato, le tecnologie usate per realizzare il prodotto, gli strumenti utilizzati per lo sviluppo, gli strumenti utilizzati per la gestione del lavoro e in breve cosa si è fatto nel periodo di formazione.
== Pianificazione
Prima dell'inizio del tirocinio è stato pianificato un piano di lavoro organizzando il programma di lavoro in 5 periodi, ognuno di due settimane a eccezione del primo e del ultimo periodo che durano una sola settimana, con un obiettivo da raggiungere per ogni periodo.
=== Vincoli temporali
Il tirocinio aveva una durata prevista di 8 settimane con 40 ore per settimana, con orario di lavoro dalle 8:30 alle 17:30 con un'ora di pausa pranzo dalle ore 13:00 alle 14:00 e altre due pause intermedie, una alla mattina dalle 10:30 alle 11:00 e l'altra dalle 15:30 alle 16:00, per un totale di 8 ore giornaliere.
In seguito, il programma di lavoro inizialmente pianificato per il tirocinio:
#figure(
table(
columns: (1fr, 2fr),
align: horizon,
[*Periodo*], [*Descrizione*],
[Periodo 1 (1 settimana)], [Introduzione al linguaggio di programmazione _Kotlin_ e modalità di deploy automatico in ambito mobile],
[Periodo 2 (2 settimane)], [Progettazione e sviluppo sezione dell'applicazione relativa a schermate di registrazione, login e recupero password],
[Periodo 3 (2 settimane)], [Progettazione e sviluppo sezione dell'applicazione relativa alla gestione profilo e dati personali e per la ricerca di location per fare smart working],
[Periodo 4 (2 settimane)], [Progettazione e sviluppo sezione dell'applicazione relativa alla segnalazione location di smart working e le funzioni per la recensire location e/o segnalatore],
[Periodo 5 (1 settimana)], [Testing finale e scrittura documentazione di quanto sviluppato]
),
caption: [Programma di lavoro pianificato.]
)
=== Obiettivi formativi
Nel piano di lavoro sono stati identificati i seguenti obiettivi formativi:
- *O-1*: Approfondire le tematiche di sviluppo mobile;
- *O-2*: Approfondire le tematiche di interazione con servizi esterni;
- *O-3*: Apprendere metodologie di lavoro agile.
=== Analisi dei rischi
I possibili rischi individuati nel piano di lavoro sono stati i seguenti:
- *R-1*: Difficoltà apprendimento del linguaggio di programmazione e sviluppo mobile;
- *R-2*: Difficoltà apprendimento API back-end;
- *R-3*: Difficoltà nello sviluppo applicazione mobile;
- *R-4*: Difficoltà nello sviluppo e gestione del deploy attraverso sistemi di CI/CD in ambito mobile.
=== Prodotti aspettati
In seguito, vengono elencati i prodotti inizialmente pianificati nel piano di lavoro:
- *P-1*: Sviluppare applicazione mobile funzionante;
- *P-2*: Sviluppare test automatici;
- *P-3*: Documentazione dell'intero progetto di stage;
- *P-4*: Articolo per il blog di _Zero12_ dove raccontare l'esperienza vissuta in azienda.
== Tecnologie utilizzate
Le seguenti tecnologie sono state usate per lo sviluppo del prodotto:
- *Kotlin* @kotlin: linguaggio di programmazione _general purpose_, multi-paradigma, svillupato da _JetBrains_ e utilizzato per lo sviluppo dell'applicazione _Android_ e per la scrittura dei test automatici;
- *Gradle* @gradle: sistema di automazione dello sviluppo basato su _Apache Ant_ e _Maven_, utilizzato per la compilazione del codice sorgente e la gestione delle dipendenze; rispetto a _Maven_, _Gradle_ usa un DSL basato su _Groovy_ invece di XML;
- *Jetpack Compose* @compose: moderno toolkit di UI per _Android_ per lo sviluppo di UI native in _Kotlin_, utilizzato per lo sviluppo dell'interfaccia grafica dell'applicazione _Android_. Permette di implementare interfacce grafiche usando un linguaggio conciso, scrivendo meno righe di codice ed è compatibile con codice _Android_ già esistente;
- *Material Design 3* @m3: sistema di design open-source sviluppato da _Google_, definisce le componenti e le linee guida dell'interfaccia grafica supportando le migliori best practices; per il progetto è stato usato con _Jetpack Compose_;
- *Hilt* @hilt: libreria di _Dependency injection_ per _Android_, sviluppata al di sopra della libreria _Dagger_ e utilizzata per implementare il pattern di _Dependency injection_ nell'applicazione _Android_;
- *Ktor* @ktor: framework per la creazione di client e server web asincroni; per il progetto ho utilizzato il client di _Ktor_ per fare chiamate al back-end remoto;
- *Room* @room: una libreria di persistenza locale che fornisce un layer d'astrazione per SQLite, un database relazionale; utilizzato per la creazione e la gestione del database locale;
- *AWS Amplify* @amplify: framework di sviluppo per applicazioni web e mobili di _Amazon Web Services_, utilizzato per configurare _AWS Cognito_;
- *AWS Cognito* @cognito: servizio fornito da _Amazon Web Services_ utilizzato per la registrazione e l'autenticazione degli utenti all'interno dell'applicazione; permette di gestire gli utenti e le loro autorizzazioni.
== Strumenti di sviluppo
=== Sistema operativo
Per l'intera durata dello stage ho utilizzato il notebook fornito dall'azienda, cioè un _MacBook Pro 2017_ con processore _Intel_ con installato _macOS Ventura 13.4_
=== Android Studio
Per la codifica del prodotto mi sono servito di _Android Studio_ @android-studio, l'ambiente di sviluppo integrato gratuito fornito da _JetBrains_, essendo ufficiale per lo sviluppo di applicazioni _Android_ semplifica il processo di build dell'applicazione con _Gradle_ e nell'installazione è incluso un emulatore _Android_. Per il debugging e l'installazione dell'applicazione su dispositivi _Android_ mi sono servito del tool _Android Debug Bridge_ (o _ADB_).
=== Altri strumenti
Per il versionamento del codice sorgente ho utilizzato _Git_, un sistema di controllo versione distribuito _open source_, e _Bitbucket_ come repository del codice remota.
Durante lo stage ho utilizzato anche _Fork_, un'interfaccia grafica per _Git_, e _Postman_, un client API che ho usato per testare le API del back-end.
== Strumenti organizzativi
Per la gestione del lavoro è stata utilizzata la suite di _Atlassian_:
- *Jira*: software di _Issue tracking system_ che consente il bug tracking e la gestione dei progetti sviluppati con metodologie agili. Durante lo stage è stata utilizzata la _Scrum_ board per il tracciamento del lavoro contrassegnando il lavoro fatto e visualizzando i prossimi lavori da fare;
- *Bitbucket*: servizio di hosting remoto del repository del codice sorgente basato su _Git_. Per lo stage è stato utilizzato come repository remoto del codice sorgente ed è stato utilizzato per le revisioni del codice scritto tramite _Pull Request_.
Per la comunicazione e la collaborazione sono stati utilizzati i seguenti strumenti:
- *Slack*: software di collaborazione aziendale sviluppato da _Slack technologies_, utilizzato dall'azienda per comunicazioni rapide, con possibilità di creare canali all'interno dello stesso server ed effettuare incontri. Per lo stage è stato creato un canale condiviso con altri collaboratori e tirocinanti per comunicare e condividere informazioni;
- *Google Meet*: applicazione per effettuare teleconferenze sviluppata da _Google_, usata in azienda anche nel corso del tirocinio per effettuare gli stand-up giornalieri.
== Formazione
Nella prima fase del tirocinio si è concentrato sulla formazione tecnica necessaria, utilizzando risorse online come il corso ufficiale *Android Basics with Compose* e la documentazione di _Google_.
Ho cominciato lo studio delle tecnologie con il linguaggio di programmazione *Kotlin*, studiandone la sintassi e i costrutti, in seguito sono passato a studiare il framework di UI _Jetpack Compose_ e i fondamenti dell'architettura di un'applicazione _Android_, quindi l'utilizzo del pattern Model-view-ViewModel in un'applicazione _Android_, l'architettura a tre strati (UI, dominio, data), il _Dependency injection_ tramite la libreria _Hilt_ e l'utilizzo della libreria _Room_.
Il periodo di formazione poi finì con una breve demo tramite lo sviluppo controllato di una app, con poche funzionalità utili ma strutturata. Durante la demo, ogni funzionalità creata passava sotto revisione tramite *Pull Request* su _Bitbucket_. |
|
https://github.com/xTeamStanly/typst-lib-wrapper | https://raw.githubusercontent.com/xTeamStanly/typst-lib-wrapper/main/README.md | markdown | Apache License 2.0 | **Note**: This library is intended for personal use. It will not be added to `crates.io`. \
If you wish to use this:
```toml
typst-lib-wrapper = { git = "https://github.com/xTeamStanly/typst-lib-wrapper.git" }
```
# Overview
Rust library that synchronously wraps Typst compiler, enabling you to compile documents and
capture output in code.
# Features
- ✅ **Capture compilation result**:
Typst projects are compiled in memory, compilation result is immediately available as a
collection of bytes. You don't have to invoke the [official CLI][typst-cli]. Compiler input
can be either **Content** (string) or **File** (entry filename and project root).
- 🔃 **Custom data loading**:
Provides a way to override Typst standard library and add custom symbols to the global context.
This will overload **ANY** symbol, use it with caution. It is recommended that
**all custom data starts with underscore "_".** Another way to load custom data is
to use `sys.inputs` dictionary, but it's limited as it only allows strings as values.
- 🔠 **Lazily loaded fonts**:
Fonts are loaded lazily on-demand. Font cache keeps all fonts metadata in memory, but the
actual font data is lazy loaded.
- 🗃️ **Font caching**:
Global font cache keeps track of all fonts. The cache is updated if new fonts are loaded after
compilation.
- 📜 **Fully documented with examples**:
This library is fully documented and important functions are documented with examples.
# Examples
### PDF compilation
```rust
let entry = "main.typ";
let root = "./project";
// Build the compiler and compile to PDF.
let compiler = CompilerBuilder::with_file_input(entry, root)
.build()
.expect("Couldn't build the compiler");
let compiled = compiler.compile_pdf();
if let Some(pdf) = compiled.output {
std::fs::write("./main.pdf", pdf)
.expect("Couldn't write PDF"); // Writes PDF file.
} else {
dbg!(compiled.errors); // Compilation failed, show errors.
}
```
### PNG compilation
```rust
let entry = "main.typ";
let root = "./project";
// Build the compiler and compile to PNG.
let compiler = CompilerBuilder::with_file_input(entry, root)
.build()
.expect("Couldn't build the compiler");
let compiled = compiler.compile_png();
if let Some(pages) = compiled.output {
// Writes images one by one.
pages.iter().enumerate().for_each(|(index, page)| {
let filename = format!("./output/{index}.png");
std::fs::write(filename, page)
.expect("Couldn't write PNG");
});
} else {
dbg!(compiled.errors); // Compilation failed, show errors.
}
```
### Custom fonts
```rust
// Add fonts to cache
let font_paths = vec![
"./assets/fonts/times_new_roman.ttf",
"~/path/to/custom/fonts/comic_sans.ttf"
];
FontCache::insert_many(font_paths)
.expect("Cache error");
let content = r##"
#set page(paper: "a4");
#set text(font: "Times New Roman");
This is Times New Roman.
#set text(font: "Comic Sans");
This is Comic Sans.
"##;
let compiler = CompilerBuilder::with_content_input(content)
.with_font_paths(font_paths)
.build()
.expect("Couldn't build the compiler");
let compiled = compiler.compile_pdf();
if let Some(pdf) = compiled.output {
std::fs::write("./main.pdf", pdf)
.expect("Couldn't write PDF"); // Writes PDF file.
} else {
dbg!(compiled.errors); // Compilation failed, show errors.
}
```
### Custom data
This creates a document with text **_"Rust 1.0 was released on 15.05.2015."_**.
The text "Rust" is orange.
Currently typst floats aren't displaying a decimal
point when passed a floating point that can be converted to integer without loss.
That's why there's `".0"` after `"#_VERSION"`, it is not a tuple index.
```rust
use typst_lib_wrapper::reexports::{IntoValue, Datetime, Color};
let content = r##"
#set page(paper: "a4");
#text(fill: _COLOR)[#_LANGUAGE]
#_VERSION.0 was released on
#_DATE.display("[day].[month].[year]").
"##;
let language = "Rust".into_value();
let date = Datetime::from_ymd(2015, 5, 15).expect("Invalid date").into_value();
let color = Color::from_u8(247, 75, 0, 255).into_value();
let version = 1.0_f64.into_value();
let custom_data = vec![
("_LANGUAGE", language),
("_DATE", date),
("_COLOR", color),
("_VERSION", version)
];
let compiler = CompilerBuilder::with_content_input(content)
.with_custom_data(custom_data)
.build()
.expect("Couldn't build the compiler");
let compiled = compiler.compile_pdf();
if let Some(pdf) = compiled.output {
std::fs::write("./main.pdf", pdf)
.expect("Couldn't write PDF"); // Writes PDF file.
} else {
dbg!(compiled.errors); // Compilation failed, show errors.
}
```
There are more specific examples alongside every functions.
# Notes / Warnings
- ⌚ **Synchronous**:
Every mutex in this library is sync `parking_lot::Mutex`.
Meaning, font caching and (opt-in) parallel PNG/SVG compilation and cache size calculation
with `rayon` are both **blocking**. Use **`blocking_task`** provided by your async runtime
if you with to compile documents in an async environment while interracting with this library. \
[On mixing `rayon` with `tokio`!](https://blog.dureuill.net/articles/dont-mix-rayon-tokio/)
- 🔀 **Font cache cloning**:
Before building the compiler, builder locks the cache and **clones** it for itself. To reduce
cache size it is recommended to avoid loading all system fonts and to load only needed fonts.
In practise this won't be that big of a deal, because all fonts are lazily loaded on-demand.
But once loaded they stay in cache, so **manually emptying** is an option.
- 📥 **Automatic package downloads**: This library will automatically download packages from the
Typst package registry. This is also done by the [official CLI][typst-cli].
[typst-cli]: https://github.com/typst/typst/tree/main/crates/typst-cli |
https://github.com/tymbalodeon/job-application | https://raw.githubusercontent.com/tymbalodeon/job-application/main/src/resume.typ | typst | #import "_content.typ": name, experiences, awards, education, skills
#import "_header.typ": space
#let make-experience(experience) = [
#let (
employer,
location,
position,
start,
end,
highlights
) = experience
#grid(
columns: (auto, 1fr),
align(left)[
#strong[#employer] \
#emph[#position]
],
align(right)[
#strong[#start -- #end] \
#emph[#location]
]
)
#pad(left: 1em)[
#for highlight in highlights [
- #highlight
]
]
]
#let make-award(award) = [
#let (name, year) = award
#grid(
columns: (auto, 1fr),
align(left)[
#emph[#name]
],
align(right)[
#strong[#year]
]
)
]
#let make-degree(degree) = [
#let (institution, location, degree, concentration, year) = degree
#if concentration != none {
degree = [#degree, #concentration]
}
#grid(
columns: (auto, 1fr),
align(left)[
#strong[#institution] \
#emph[#degree]
],
align(right)[
#strong[#year] \
#emph[#location]
]
)
#v(-0.3em)
]
#let make-skill(skill) = box[
#let (name, skills) = skill
#strong[#name:]
#for skill in skills.slice(0, -1) [
#skill,
]
#skills.last()
]
#set document(
title: name + " Resume",
author: name
)
#set page(paper: "us-letter")
#set text(10pt)
#show heading.where(level: 2): heading => [
#smallcaps(heading)
#v(-0.7em)
#line(length: 100%)
]
#include "_header.typ"
== Work Experience
#for experience in experiences {
make-experience(experience)
}
#space
== Awards
#for award in awards {
make-award(award)
}
#space
== Education
#for degree in education {
make-degree(degree)
}
#space
== Skills
#for skill in skills [
#make-skill(skill) \
]
|
|
https://github.com/typst/packages | https://raw.githubusercontent.com/typst/packages/main/packages/preview/fletcher/0.4.0/docs/examples/example.typ | typst | Apache License 2.0 | #import "/src/exports.typ" as fletcher: node, edge
#for dark-mode in (false, true) [
#let c = if dark-mode { white } else { black }
#set page(width: 22cm, height: 9cm, margin: 1cm)
#set text(fill: white) if dark-mode
#show: scale.with(200%, origin: top + left)
#let edge = edge.with(stroke: c)
#stack(
dir: ltr,
spacing: 1cm,
fletcher.diagram(cell-size: 15mm, crossing-fill: none, $
G edge(f, ->) edge("d", pi, ->>) & im(f) \
G slash ker(f) edge("ur", tilde(f), "hook-->")
$),
fletcher.diagram(
node-stroke: c,
node-fill: rgb("aafa"),
node-outset: 2pt,
axes: (ltr, btt),
node((0,0), `typst`),
node((1,0), "A"),
node((2.5,0), "B", stroke: c + 2pt),
node((2,1), "C", extrude: (+1, -1)),
for i in range(3) {
edge((0,0), (1,0), bend: (i - 1)*30deg)
},
edge((1,0), (2,1), "..}>", corner: right),
edge((1,0), (2.5,0), "-||-|>", bend: -0deg),
),
)
] |
https://github.com/gianzamboni/cancionero | https://raw.githubusercontent.com/gianzamboni/cancionero/main/wip/while-the-whole-world-ends.typ | typst | #import "../theme.typ": *;
== While The Whole World Ends
=== KROWNS
Trying to build a life with broken parts \
Trying to hold on tight with a stitched up heart \
Caring is anarchy, filling up your head with dreams \
'Til it all goes dark \
#newVerse
So, baby, let's face it \
You know that we could be the last generation \
Ain't complicated, drink in our hands, 22 grams \
We can get high while the whole world ends
#newVerse
Take a ride on my spaceship \
We can take it on a permanent vacation \
No destination, drink in our hands, 22 grams \
We can get high while the whole world
#newVerse
High while the whole world ends, ``
Ends, Ends \
We can get high while the whole world ends \
Ends, Ends \
We can get high while the whole world \
High while the whole world ends
#newVerse
Climbing these towers to the clouds \
Levitate while they tear this whole place down \
Diamonds in ecstasy, ripples in our gravity \
'Til it all burns out
#newVerse
So, baby, let's face it \
You know that we could be the last generation \
Ain't complicated, drink in our hands, 22 grams \
We can get high while the whole world ends
#newVerse
Take a ride on my spaceship \
We can take it on a permanent vacation \
No destination, drink in our hands, 22 grams \
We can get high while the whole world
#newVerse
High while the whole world ends \
Ends, ends \
We can get high while the whole world ends \
Ends, ends \
We can get high while the whole world \
High while the whole world ends \
#newVerse
Feel like you're choking \
The life that you ripped open \
Every way’s the wrong way going \
Going nowhere, bruised and broken \
Don't wanna be here when I wake up
#newVerse
I wanna be in outer space \
Up like the comets, they blaze up \
Through the atmosphere they break up \
Some of the hurt, we can't foresee \
Some of the hurt that never bleeds \
Our schemes, and machines \
And our dreams that we never see
#newVerse
Now we're standing on the brink \
It's getting harder not to think \
We messed this up, and now we're sinking \
And it's all gone in a blink
#newVerse
So, baby, let's face it \
You know that we could be the last generation \
Ain't complicated, drink in our hands, 22 grams \
We can get high while the whole world ends \
Take a ride on my spaceship
#newVerse
We can take it on a permanent vacation \
No destination, drink in our hands, 22 grams \
We can get high while the whole world
#newVerse
High while the whole world ends \
There ain't nothing in the world I want more than this \
Now we're flying like kites through a black abyss \
There ain't nothing in the world that I'm gonna miss
#newVerse
We can get high while the whole world ends \
There ain't nothing in the world I want more than this \
Now we're flying like kites through a black abyss \
There ain't nothin' in the world that I'm gonna miss \
More than this, more than this
|
|
https://github.com/mumblingdrunkard/mscs-thesis | https://raw.githubusercontent.com/mumblingdrunkard/mscs-thesis/master/src/introduction-and-motivation/index.typ | typst | = Introduction and Motivation
While more and more compute-intensive applications have been moved to massively parallel processors such as graphics processors or using vector processing extensions in normal processors, some applications are inherently single-threaded for large computations.
Even with fundamentally single-threaded applications, there is likely a lot of work that can be performed in parallel, but with a granularity that is too fine-grained to split across multiple processors without performance-decimating overhead.
Modern processors handle instructions out of order.
As instructions enter the processor, newer instructions may complete before older ones if their dependencies are ready or they have lower latencies.
This allows for maximally exploiting the available parallelism in a program as the processor is allowed to make progress as soon as the dependencies are ready.
Contrasted with a processor that does all the work in order, out-of-order processors can be multiple times faster for the same applications.
Certain instructions have long latencies such as memory accesses that miss in caches.
When branches depend on these long-latency instructions, the processor is likely to run out of work to do before the branch is fully resolved because it is unknown which instructions to start fetching next.
Because of this, processors _speculate_, making predictions about which way a branch is going to resolve and where execution should be directed.
When the guess is correct, this makes a lot of work available to the processor, increasing the chances of finding work that can be performed in parallel.
If a prediction is wrong, the processor can potentially perform a lot of unnecessary work before the guess is determined to be wrong.
This work has to be _squashed_ and the state of the processor is rolled back and it continues executing along the correct path.
The squashed work is referred to as _transient execution_ and it is not observable from an architectural perspective.
However, transient execution may leave traces in microarchitectural state---state that is not normally visible.
By using knowledge about the microarchitecture and code running on the processor, it is possible to inspect microarchitectural state through various techniques to make inferences about previous execution that has taken place, transient or not.
The mechanisms of microarchitectural state combined with ways to inspect it forms a _side-channel_ that potentially leaks sensitive information during execution which malicious applications can observe.
Exploiting these mechanisms gives rise to a side-channel attack.
Side-channel attacks have been known for decades and various programming techniques make good efforts to work around them when it is needed.
On in-order processors, where instructions are executed in order and instructions after a branch are not allowed to change microarchitectural state until the branch is resolved, programmers have some control over what is leaked through a side-channel.
In out-of-order systems, this control is gone and applications are at the mercy of the branch predictor if the program contains leaky paths of execution that should not be entered.
Worse yet, because the state of the branch predictor is shared between multiple applications in the system a malicious application can intentionally train the branch predictor in a way that it causes the processor to enter a leaky path in a victim application.
This is known as a _speculative execution attack_.
At the time of writing, speculative execution vulnerabilities have been a fact for at least half a decade, made widely known by papers on Spectre @bib:spectre and Meltdown @bib:meltdown.
This has necessitated new approaches to designing hardware and software.
Various mitigations have been employed, but instead of being one simple, easy-to-fix issue, speculative execution presents a whole class of vulnerabilities that rely on various speculation mechanisms and side-channels.
The most popular side-channel and the one used in attack demonstrations is the cache side-channel where the cache hierarchy is updated during transient execution.
By timing accesses to memory, a malicious application can determine which addresses were accessed during transient execution and in this way infer information that would not be visible in an in-order processor.
Mitigations focus on blocking various side-channels by delaying the effects of speculative execution on microarchitectural state until the execution is confirmed to be non-speculative.
This is achieved by a few different techniques where the strictest approaches may delay all dependent execution until the data that are used are confirmed to be used in a non-speculative manner.
These approaches only seek to make execution appear similar to in-order execution from the perspective of various side-channels, meaning a program that is leaky on an in-order processor will still be leaky in an out-of-order processor with these mitigations applied.
This is generally regarded as an acceptable solution.
Developing a mitigation starts with analysing the problem space by determining which values are potentially secret and where they are located.
Generally, secrets are considered to reside either in both registers and in memory, or only in memory.
Said in a different way: all values in memory are potentially secret and must be protected.
Some models consider values that are already loaded from memory (and thus are placed in registers) to still be secrets, others do not.
The different mitigations generally lead to a performance loss of 10-20%.
Much of this performance loss is due to the loss of parallelism for memory instructions.
Memory instructions access the memory hierarchy and may thus modify the cache hierarchy, leaking information about the accessed address.
Kvalsvik et al. observed that a considerable amount of this parallelism can be regained by making predictions for accessed addresses and performing the loads ahead of time @bib:doppelganger.
To ensure this is safe, the predictions are only made based on committed load instructions such that the predictor can only reveal previously known non-speculative execution.
When load instructions depend on values that are determined to be secrets, the predicted address can be safely used instead as it only reveals past execution.
If the prediction is correct, the access does not need to be performed again and the apparent access latency is reduced.
If the prediction is incorrect, the stand-in load is ignored.
These stand-in loads are dubbed "doppelganger loads" or just "doppelgangers".
Doppelganger loads are shown to be a cheap and safe optimisation on top of these mitigations.
A doppelganger can re-use many of the resources of a normal out-of-order architecture used by traditional loads, its needs never overlapping with those of the real load.
In fact, the only considerable hardware cost of doppelgangers presented in the original paper is that of the predictor itself.
== Motivation
Doppelganger loads have been implemented in a cycle-accurate simulator.
Simulators are useful tools for computer architecture researchers as they allow for rapid prototyping and testing of high-level concepts without worrying about low-level implementation details such as port counts, wiring contenion, and other problems that pop up during physical design besides the arduous process of implementing and debugging real hardware itself.
Simulations showed promising results.
Once simulation is complete and the concept shows promise, however, it is useful to implement it as a real circuit to uncover and tackle the specific challenges that arise.
This is the goal of this project, to implement doppelganger loads in hardware, basing our implementation on an open source out-of-order processor design.
== Contribution
In this report, we describe our implementation process for doppelganger loads and various challenges that arise during implementation in the specific design.
We describe challenges specific to superscalar architectures and the techniques we have applied to alleviate these issues.
We have collected performance statistics for the final implementation for both the processor itself and statistics specific to only the predictor.
We also show that there is room for a more complex predictor than the one implemented here as very few predictions are compared to their real address counterpart before many cycles later.
Because of the low access latency of the first-level cache in the base processor implementation, doppelganger loads struggle to compete with techniques such as speculative waking of dependents when a load result is expected.
We collected statistics for various configurations of the processor with and without doppelganger loads enabled and we show that doppelganger loads were able to achieve fair performance improvements when compared to a baseline that did not perform speculative wakeups, although not as good as simply performing the speculative wakeups.
As we have implemented doppelganger loads without any of the mitigations applied, our results are in line with the observations made in @bib:doppelganger where doppelganger loads at most increased performance by around .5%.
Finally, we present various discussion around the results and implementation.
We present known flaws of our implementation and recommendations for how to fix them.
We also present future work that should be done for a complete implementation and various tests that should be run once implementation is done.
== Structure of This Report
This report is filled with a considerable amount of background information that is required to understand the work performed.
=== Background Chapters
@ch:computer-architecture-fundamentals presents foundational knowledge for computer architecture and serves to build up a shared understanding of the concepts and terminology.
Readers already familiar with the field will likely already be familiar with most of the terminology presented in this chapter.
@ch:modern-hardware-design describes the process of designing hardware with modern techniques and some of the challenges faced when going from the high-level descriptions of circuits to actual physical implementation.
In @ch:boom we present the open source out-of-order processor design that we implement our predictor in as well as various tools we have used during development.
@ch:processor-security gives a more detailed description of the problem of speculative execution vulnerabilities and the possible mitigations.
@ch:doppelganger is a similarly detailed description of doppelganger loads and special considerations that have to be made for the technique to remain safe under the assumptions of security models that form the bases of the aforementioned mitigations.
=== Content Chapters
@ch:architecture-and-implementation describes our process with implementing doppelganger loads and various challenges associated with it.
In @ch:methodology-and-results we describe how we have gathered results for the final implementation, which statistics we recovered, and present various tables that show the impact of the implemented technique.
@ch:discussion contains involved discussion and reflection on the results, implementation, and lays out future work that should be done.
Finally, @ch:conclusion concludes the report.
=== Accessibility and Navigation
This document contains a considerable number of links.
The glossary contains a list of acronyms with references to each page where they are used.
Acronyms where they appear in the text also link back to their entry in the glossary.
Besides the glossary, there are lists for figures, tables, and listings (code blocks).
Entries in these lists link to their position in the text.
In-text references to figures, tables, and listings are made in *bold* text.
|
|
https://github.com/fyuniv/CornellNoteTemplate | https://raw.githubusercontent.com/fyuniv/CornellNoteTemplate/main/README.md | markdown | Other | # Cornell Note Template
This typst template is design to create Cornell Note style worksheets.
See [https://github.com/fyuniv/CornellNoteTemplate/blob/main/example.pdf](https://github.com/fyuniv/CornellNoteTemplate/blob/main/example.pdf) for the outlook of an example.
|
https://github.com/Enter-tainer/typstyle | https://raw.githubusercontent.com/Enter-tainer/typstyle/master/tests/assets/unit/comment/comment-in-dict.typ | typst | Apache License 2.0 | #(
:
// empty dict
)
#(
a: 1 /* comment */, // another comment
b /* comment */: 2,
/* comment */ c: 3,
)
|
https://github.com/kdog3682/2024-typst | https://raw.githubusercontent.com/kdog3682/2024-typst/main/src/fen.typ | typst |
#let fen(pieces) = {
let piece-map = (
"K": "♔", // "\u{2654}"
"Q": "♕", // "\u{2655}"
"R": "♖", // "\u{2656}"
"B": "♗", // "\u{2657}"
"N": "♘", // "\u{2658}"
"P": "♙", // "\u{2659}"
"k": "♚", // "\u{265a}"
"q": "♛", // "\u{265b}"
"r": "♜", // "\u{265c}"
"b": "♝", // "\u{265d}"
"n": "♞", // "\u{265e}"
"p": "♟", // "\u{265f}"
)
let board = ()
let count = 0
for c in pieces {
if c == " " {
assert(count != 7, message: "count != 8")
break
}
count = "12345678".position(c)
if count != none {
for i in range(0, count+1) {
board.push(" ")
count += 1
}
} else if c == "/" {
assert(count != 7, message: " count")
count = 0
} else {
assert(c in "KQBNRPkqbnrp", message: "bad char")
board.push(piece-map.at(c))
count += 1
}
}
assert(board.len() == 64, message: "bad FEN")
let white = rgb(229,229,229);
let black = rgb(102,102,102);
let cell = rect.with(
height: 100%,
width: 100%,
fill: black,
inset: 10pt
)
let rows = range(0, 8)
let cols = range(0, 8)
let blankboard = range(0,64).map(i =>if calc.even(int(i/8)+int(calc.rem(i,2))) {[1]} else [0])
//let blankboard = range(0,64).map(i =>if calc.even(int(i/8)+int(calc.rem(i,2))) {"1"} else {"0"})
//let board = cols.map(col =>if calc.even(col) {"1"} else {"0"})
if board == none {
[board is empty]
} else {
return table(columns:8, rows:8,
//..for row in nums [nums.map(col =>if (row+col)/2 == 0 {"1"} else {"0"})]
//..for row in nums {if (row)/2 == 0 {"1"} else {"0"}}
//..cols.map(col =>if calc.even(col) {"1"} else {"0"})
//..rows.map(row =>{cols.map(col => if (col)/2 == 0 ["1"] else ["0"])})
..board
//..board.map(s => cell[s])
)
}
}
|
|
https://github.com/Hithereland/whu-typst-template | https://raw.githubusercontent.com/Hithereland/whu-typst-template/main/README.md | markdown | # WHU Typst Template
用于武汉大学本科毕业设计(论文)的 typst 模板。

## 什么是 typst
[typst](https://github.com/typst/typst) 是一个较新的标记文本语言,定位与 LaTeX 类似,具有极强的排版能力,通过一定的语法写文档,然后生成 pdf 文件。与 LaTeX 相比有以下的优势:
1. 编译巨快:因为提供增量编译的功能所以在修改后基本能在一秒内编译出 pdf 文件,typst 提供了监听修改自动编译的功能,可以像 Markdown 一样边写边看效果。
2. 环境搭建简单:原生支持中日韩等非拉丁语言,不用再大量折腾字符兼容问题以及下载好几个 G 的环境。只需要下载命令行程序就能开始编译生成 pdf。
3. 语法友好:对于普通的排版需求,上手难度跟 Markdown 相当,同时文本源码阅读性高:不会再充斥一堆反斜杠跟花括号
友校(HUST)学长的观点:跟 Markdown 一样好用,跟 LaTeX 一样强大。
可以从[这里速通 typst](https://typst.app/docs/tutorial)
跟 Word 比的优势:格式好调,玄学问题少。Word 功能强大,但是如果想要随心所欲地排版,学习成本将非常高。
## 说明
- 格式参照 2024 年新要求,模板有相当程度的肉眼排版内容,存在不被认可的风险,如果遇到不对的间距、字体等请提交 issue 说明,也欢迎 pull request 贡献。
- 原创性声明页面,为了使得插入手写的签名和日期看起来更美观,可以使用 [typst-pinit](https://github.com/OrangeX4/typst-pinit) 库。
- 推荐最终编译在 Windows 下本地编译进行。如果使用 Linux,可能会遇到一些字体配置上的问题。
- 作者用不明白 LaTeX 所以使用了 typst。作者使用该模板成功本科毕业(计算机学院)。
## 参考和致谢
- https://github.com/whutug/whu-thesis 武汉大学 LaTeX 模板
- https://github.com/werifu/HUST-typst-template 华中科技大学毕业论文 typst 模板
- https://github.com/nju-lug/modern-nju-thesis 南京大学毕业论文 typst 模板
- https://github.com/lf-/typst-algorithmic 本模板所使用的伪代码库
- https://github.com/OrangeX4/typst-pinit typst-pinit 库
---
---
东湖之滨,珞珈山上,
这是我们亲爱的学堂。
百年沧桑,弘毅自强,
根深叶茂育桃李,满园芬芳。
啊,美丽的珞珈山,
多少雄鹰竞翱翔、竞翱翔。
扬帆长江,奔向海洋,
这是我们成长的地方。
德业并进,求是拓新,
大同寰宇向未来,我创辉煌。
啊,心中的珞珈山,
今朝多磨砺,明日作栋梁、作栋梁。
|
|
https://github.com/denkspuren/typst_programming | https://raw.githubusercontent.com/denkspuren/typst_programming/main/LiterateProgramming/test.typ | typst | #let renderLabel(label) = {
locate(loc => {
let res = query(label, loc)
return eval(res.first().text, mode: "markup")
}
)
}
// #[Hello] #[World]
#{[Hello] + [ ] + [World 1]}<one>
#([Hello] + [ ] + [World 2])<two>
#([Hello], [ ], [World 3])<three>
#("name" : 3).name<four>
#let first = locate(loc => query(<one>, loc).first())
#let second = locate(loc => query(<two>, loc).first())
#{first + second}
#(first + second)
#first + #second
#[ #first \ #second ]
#let codeblock = [
```typst
#{[Hello] + [ ] + [World 1]}<onemore>
```<hwtypst>
]
#codeblock
#renderLabel(<hwtypst>)
#locate(loc => query(<onemore>, loc).first())
Test
#let space = [ ]
#{[Hello] + space + [World!]}
|
|
https://github.com/NMD03/typst-uds | https://raw.githubusercontent.com/NMD03/typst-uds/main/template.typ | typst |
#let acronyms = yaml("acronyms.yml");
#let acroStates = state("acronymStates", ());
#let english_pack = (
by: "by",
time_period: "Time Period",
student_id: "Student ID",
company: "Company",
supervisor: "Advisor",
first_referee: "1. Referee",
second_referee: "2. Referee",
decleration: (type, title) => [
= Author's Declaration
I declare under oath that I have prepared the paper at hand independently
and without the help of others and that I have not used any other sources
and resources than the ones stated. Parts that have been taken literally or
correspondingly from published or unpublished texts or other sources have
been labelled as such. This paper has not been presented to any examination
board in the same or similar form before.
],
abstract: "Abstract",
contents: "Contents",
list_of_figures: "List of Figures",
acronyms: "Acronyms",
bibliography: "Bibliography",
appendix: "Appendix",
chapter: "Chapter",
section: "Section",
confidentiality_clause: [
= Confidentiality Clause
The content of this work may not be made accessible to people outside of the
testing process and the evaluation process neither as a whole nor as excerpts,
unless an authorization stating otherwise is presented by the training facility.
]
)
// TODO: Check alignment to LaTeX template
#let german_pack = (
by: "von",
time_period: "Bearbeitungszeitraum",
student_id_course: "Matrikelnummer, Kurs",
company: "Ausbildungsfirma",
supervisor: "Betreuer",
first_referee: "1. Korrekteur",
second_referee: "2. Korrekteur",
decleration: (type, title) => [
== Erklärung
Ich erkläre hiermit ehrenwörtlich:
+ dass ich meine #type mit dem Thema #title ohne fremde Hilfe
angefertigt habe;
+ dass ich die Übernahme wörtlicher Zitate aus der Literatur sowie die Verwendung
der Gedanken anderer Autoren an den entsprechenden Stellen innerhalb der
Arbeit gekennzeichnet habe;
+ dass ich meine T1000 bei keiner anderen Prüfung vorgelegt habe;
Ich bin mir bewusst, dass eine falsche Erklärung rechtliche Folgen haben wird.
#title
*a big & fat _TODO_!*
],
abstract: "Abstract",
contents: "Inhaltsverzeichnis",
list_of_figures: "Abbildungsverzeichnis",
acronyms: "Abkürzungsverzeichnis",
bibliography: "Literaturverzeichnis",
appendix: "Anhang",
chapter: "Kapitel",
section: "Abschnitt",
confidentiality_clause: [
= Sperrvermerk
Der Inhalt dieser Arbeit darf weder als Ganzes noch in Auszügen Personen außerhalb des
Prüfungs- und des Evaluationsverfahrens zugänglich gemacht werden, sofern keine anders
lautende Genehmigung des Dualen Partners vorliegt.
]
)
#let thesis(
// the title of your thesis
title: none,
// your name
author: none,
// your student id / matriculation number
student_id: none,
// the name of your course, such as "TINF21A"
signature: none,
// the name of your supervisor
supervisor: none,
first_referee: none,
second_referee: none,
// the due date of your thesis
date: none,
// the time period that the work described in your thesis took place in
time_period: none,
// the type of your thesis, such as T1000, T2000, etc.
type: none,
// your degree, such as "Bachelor of Science"
degree: "Master of Science",
// your major, such as "Computer Science"
major: "Cyber Security",
// Change the language to `de` if desired
language: "en",
// Details on your university
university: (
name: "Saarland university",
location: "Saarbrücken",
image: "assets/uds.svg",
),
//// Details on your company
//company: (
// name: "Hewlett Packard Enterprise",
// image: "assets/hpe.svg",
//),
// Does the document require a Confidentiality Clause?
confidentiality_clause: false,
// Path to your bibliography file
// You may use `.yml` for Hayagriva format
// or `.bib` for BibLaTeX format
bibliography_path: "literature.yml",
// Citation style:
// Customized includes ISBNs and
// writes DOI in capital letters
customized_ieee_citations: false,
// The contents of your abstract
abstract: include "./abstract.typ",
// To be append after the bibliography
appendix: none,
// First chapter of your thesis
// This is *not* required anymore
// first_chapter_title: none,
// Factor of page location when to pagebreak headings
// to avoid a heading without content on the same page.
// Can be disabled by setting it to none
// WARNING: can result in "layout did not converge within 5 attempts" issue
heading_pagebreak_percentage: none,
// set automatically by using the template via `#show: thesis.with(...)
body,
) = [
// Assert all parameters are set
#assert.ne(title, none)
#assert.ne(author, none)
#assert.ne(student_id, none)
#assert.ne(type, none)
#assert.ne(date, none)
#assert.ne(time_period, none)
#assert.ne(supervisor, none)
#assert.ne(first_referee, none)
#assert.ne(second_referee, none)
// Use english by default
#let selected_lang = if language == "de" {german_pack} else {english_pack}
#set document(
title: title,
author: author,
date: date,
)
#set page(
paper: "a4",
margin: 2.5cm,
numbering: none, // don't number the first pages, i.e. titlepage and abstract
)
// suggested font and font size by the DHBW style guide
#set text(
font: "Linux Libertine",
// font: "New Computer Modern Sans",
size: 12pt,
hyphenate: false,
lang: language,
ligatures: true,
)
#set par(
leading: 8pt, // 1.5x line spacing
justify: true,
linebreaks: "optimized",
)
// do not justify inside of figures, incl. tables
#show figure: set par (justify: false)
#set figure(
numbering: "I"
)
// don't outline or number the first headings
#set heading(
numbering: none,
outlined: false,
)
// modify the spacing between various headings and the content below them
#show heading: it => {
let sizes = if it.level == 1 {
(64pt, 24pt, 24pt)
} else if it.level == 2 {
(32pt, 20pt, 18pt)
} else {
(24pt, 16pt, 14pt)
}
// On top-level headers, do a weak pagebreak
// (weak = no pagebreak on already blank pages)
if it.level == 1 {
pagebreak(weak: true)
} else if heading_pagebreak_percentage != none {
// If a heading would start at the very end of a page,
// it would not look right => pagebreak
context {
let here_abs = here().position().y
let here_rel = here_abs.abs / page.height
if here_rel > heading_pagebreak_percentage {
// Write but hide to assess location correctly
// Hidden will not have any influence
// on the output besides correct calculation
hide[#here_abs.abs #page.height rel: #here_rel%]
pagebreak(weak: true)
}
}
}
[
#set text(size: sizes.at(2))
#v(sizes.at(0))
#if it.numbering != none [
#counter(heading).display(it.numbering) #h(4pt) #it.body
] else [#it.body]
#v(sizes.at(1))
]
}
// rename level 1 headings to "Chapter", otherwise "Section"
#set ref(supplement: it => {
if it.func() == heading {
if it.level == 1 {
selected_lang.chapter
} else {
selected_lang.section
}
} else {
it.supplement
}
})
// ==========================
// beginning of the document
// ==========================
// ==========================
// Start of the title pages
// ==========================
#set align(center)
// nice
#grid(
columns: (1fr),
align(center)[
#image(university.image, width: 69%)
],
)
#v(64pt)
#set par(justify: false)
#text(20pt)[*#title*]
#v(32pt)
#set par(justify: true)
#text(16pt)[*#type*]
//#v(14pt)
//#text(14pt, selected_lang.degree_1)
//#text(14pt)[*#degree*]
//#text(14pt)[#selected_lang.degree_2 #major]
//#v(32pt)
#text(14pt, selected_lang.by)
#text(16pt)[*#author*]
#v(16pt)
#text(14pt)[#date.display("[day].[month].[year]")]
#set align(bottom)
#grid(
columns: (1fr, 0.5fr, 1fr),
align(left)[
//*#selected_lang.time_period* \
//*#selected_lang.student_id* \
*#selected_lang.supervisor* \
*#selected_lang.first_referee* \
*#selected_lang.second_referee*
],
none,
align(left)[
//#time_period \
//#student_id \
#supervisor \
#first_referee \
#second_referee
],
)
#pagebreak()
#set align(top)
#set align(left)
// End of title page
// initially set the page numbering to roman
#set page(numbering: "I")
#counter(page).update(1)
// ==========================
// Sworn Declaration
// ==========================
#set align(top)
#set align(start)
#(selected_lang.decleration)(type, title)
#set align(bottom)
// #v(48pt)
// #university.location, #date.display("[day].[month].[year]")
// #v(48pt)
#box(width: 196pt, height: 40pt)[
#if signature == "hide" {
box(height: 50pt)
} else if signature == none {
[
Set your signature by setting the `signature` argument
to an image or set it to `hide`, to leave place for signing otherwise
#v(2pt)
]
} else {
image(signature)
}
#v(0pt, weak: true)
#line(length: 100%)
// #author
#university.location, #date.display("[day].[month].[year]")
]
#v(48pt)
#pagebreak()
// end of sworn declaration
// ==========================
// Abstract
// ==========================
#set align(horizon)
#set align(center)
#heading(outlined: true, selected_lang.abstract)
#block(width: 80%)[
#set align(left)
#abstract
]
#pagebreak()
// End of abstract
#set align(top)
#set align(left)
#set outline(
indent: n => {
// Max indent is 2
if n > 2 { n = 2 }
return n * 2em
},
fill: repeat(" . ")
)
#show outline.entry.where(level: 1): it => {
if it.element.func() != heading { return it }
show ".": ""
v(2pt)
strong(it)
}
#outline(target: heading, depth: 2, title: selected_lang.contents)
// start adding headings to the outline after the table of contents
#set heading(outlined: true)
#pagebreak(weak: true)
= #selected_lang.list_of_figures
#show outline.entry: it => [
#v(12pt, weak: true) #it
]
#outline(target: figure, title: none)
#pagebreak(weak: true)
= #selected_lang.acronyms
#let acroArr = ();
#for (k, v) in acronyms.pairs().sorted(key: s => lower(s.at(0))) {
acroArr.push([*#k* #label(k)]);
acroArr.push([#v]);
}
#table(
columns: (1fr, 6fr),
align: horizon,
stroke: none,
..acroArr,
)
// this will be used later to continue the Roman counter for pages where it left off
<roman_counter_preliminary_end>
// update heading and page numberings to begin the main part of the document
#set heading(numbering: "1.1")
#set page(
numbering: "1 / 1",
// manipulate the footer to display the correct total page count
// otherwise it would show the value of the very last, Roman-numbered page
footer: align(center, context numbering(
"1 / 1",
..counter(page).get(),
// get the last page counted with Arabic numbers
..counter(page).at(<arabic_counter_end>).map(i => i - 1))
)
)
#counter(page).update(1)
#pagebreak(weak: true)
// Format code blocks
#show raw.where(block: true): set align(left)
#show raw.where(block: true): set par(justify: false)
#show raw.where(block: true): set text(size: 8pt)
#show raw.where(block: true): set block(
radius: 2pt,
inset: 12pt,
width: 100%,
stroke: luma(128),
fill: luma(240),
)
// the actual chapters
#body
// reset footer to how it looked before
#set page(numbering: "I", footer:
align(center, context numbering("I", ..counter(page).get()))
)
// reset the page numberings to the following value of the last page counted in Roman numerals
#context counter(page).update(
counter(page).at(<roman_counter_preliminary_end>).first() + 1
)
// used to obtain the total page count of Arabic numbered pages
<arabic_counter_end> // Placing this above does not work
// finally, include the bibliography chapter at the end of the document
#pagebreak()
#bibliography(bibliography_path, title: selected_lang.bibliography,
style: if customized_ieee_citations {"/ieee-modified.csl"} else {"ieee"})
#if appendix != none [
#pagebreak(weak: true)
#heading(numbering: none, selected_lang.appendix)
#set heading(
outlined: true,
bookmarked: true,
numbering: (..nums) => {
let n = nums.pos()
n.remove(0)
return numbering("A.1", ..n)
}
)
#appendix
]
]
// `pref` if to prefer the long form
// may be normal, short or long
#let acro(short, pref: "normal", append: "") = {
let item = acronyms.at(short)
locate(loc => {
let entries = acroStates.at(loc).filter(e => e == short);
// Already used once
if entries.len() > 0 {
if pref == "long" {
link(label(short))[#item#append]
} else {
link(label(short))[#short#append]
}
// First usage
} else {
acroStates.update(e => {e.push(short); e;});
if pref == "short" {
link(label(short))[#short#append (#item)]
} else {
link(label(short))[#item#append (#short)]
}
}
});
}
#let acroOnce(main, inside) = [#main (#inside)]
#let todo(content) = par(emph([
#h(5pt) #text(weight: "bold")[To-do/WIP:] #content
]))
|
|
https://github.com/crd2333/crd2333.github.io | https://raw.githubusercontent.com/crd2333/crd2333.github.io/main/src/docs/Languages/Python/Python.typ | typst | #import "/src/components/TypstTemplate/lib.typ": *
#show: project.with(
title: "Python 笔记",
lang: "zh",
)
= TonyCrane 的视频笔记
== 注释
- 单行注释用 `#`
- 严格上没有多行注释,但可以用三个"来代替
== 列表list
- 类似其他语言的数组,内部类型可以不统一
- 用`[]`表示,`lst=[1,2,3,"abc",True]`
- 用`[]`索引,从0开始;可以加负号,表示从后往前数
- 切片功能`lst[a:b:c]`
- `lst[1:3]`,得到下标1到3-1的分割出来的列表
- 之所以设计成减1,是为了直接得到b-a的长度,同时可以理解为半闭半开的区间,使用更方便
- 前后都可以省略,表示取完;也可以都省略,相当于拷贝一份列表
- 若有三个元素,则c表示选取步长
- c也可以是负数,这时需要a>b才能获取到值
- `lst[::-1]`表示将整个列表翻转
- 列表切片修改
- `lst[2:4]=[1]`表示列表下标的2~3的值被替换成了1(变短了)
- 自带栈的功能
- `lst.append(x)`在列表末尾加入元素x
- `lst.pop()`弹出列表末尾元素并返回
- 任意位置插入弹出
- `lst.insert(1,x)`在索引1的位置插入x,后面依次后移
- `lst.pop(1)`弹出索引1的位置的元素,后面依次前移
- 列表拼接
- 直接相加(不改变原列表,得到新的列表)
- `lst.extend([1,2,3])`把一个列表接到原列表末尾
- 注意与append的区别
- 根据值删除元素
- `lst.remove(value)`删除第一个值为value的元素
- 列表排序
- `lst.sort()`对原列表操作,升序排序
- `lst.sort(reverse=True)`降序
- `sorted(lst)`得到一个排序后的新列表
- 列表反转
- `lst.reverse()`
- 当然也可以用切片功能
- `list(reversed(lst))`
- 直接`reversed(lst)`得到的是一个列表生成器(为的是提高效率)
- 列表统计
- `len(lst)`
- `sum(lst)`
- 可以传入start参数指定加和的起始值和类型
- `max(lst)`,`min(lst)`
== 元组tuple
- 可以看做元素不可变的列表,内部也可以包含不同类型的元素
- 但不能保证元素完全不可变,所以要避免在元组内放入可变元素(如列表)
- 可以使用和列表一样的方法读取元素(用`[]`),但不可修改
- 用`()`表示,内部用`,`分隔
- python默认用,分隔的元素会转成元组输出
- 当只有一个元素时,应写成`(a,)`而不是`(a)`(后者是单个值加括号而已)
- 可以用`tuple(...)`来将可迭代对象(列表、字符串等)转为元组
== 集合set
- 用`{}`表示,自动去重
- 集合中不能包含如列表等不能hash化的元素
- 可以用`set(...)`来将可迭代对象(列表、字符串等)转为集合
- 集合修改
- `s.add(x)`加入元素x
- `s.remove(x)`删除元素x,如果没有会抛出异常
- `s.discard(x)`删除元素x,如果没有则忽略
- 集合运算
- `s1 & s2`交集,`s1 | s2`并集,`s1 - s2`差集,`s1 ^ s2`对称差集
== 字典
- 也是用`{}`括起来,存储键值对,用`,`分隔,如`d={key:value,}`
- `{}`是空字典而不是空集合
- 用`d[key]`访问对应的值,如果不存在这个键会抛出异常
- 通过`d.get(key)`访问值时如果不存在key这个键会返回None
- 通过`d.get(key,default)`访问值时如果不存在key这个键会返回default值,如`default="not found"`
- 添加键值对,直接`d[key_2]=value_2`
- 删除键值对,用`del d[key2]`
- 更新键值对,`d.update(d2)`用d2对应的值更新d对应的值
== 条件语句
- `if-elif-else`结构(不是else if)
- 注意缩进
- 类三目运算符写法`B if A else C`(没有`A?B:C`)
== for循环
- python中的for循环不是像c一样指定一个变量的变化方式,而是从列表/元组/迭代器等可迭代对象中遍历值,如:`for value in lst:`,`for value in range(...):`
- python中为了循环产生的变量不是那么严格的局部变量(结束后不删除),在循环外部,它保留最后一次循环值
- 可以使用`range`生成一串数字用于循环
- `range(a,b)`生成从a到b-1的连续整数
- `range(a,b,c)`以c为步长生成
- `range`得到的不是列表,如果要用其生成列表可以用`list(range(...))`
- 循环遍历字典(三种方法)
- 遍历键:`for key in d.keys():`
- 遍历值:`for value in d.values():`
- 遍历键值对:`for item in d.items():`或`for key,value in d.items():`(解包)
- 枚举enumerate
- 枚举可迭代对象
- 可以加参数`start=1`,从1开始数
```python
lst=[1,2,"a","c"]
for i,value in enumerate(lst): = 这里用到了解包
print(f"{i}-->{value}")
```
- 打包zip
- 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组
== 元素解包
- 赋值时等号左侧可以使用逗号分隔的多个值,这时会将右侧解包分别赋值给左侧的各个变量
- 右侧也可以是多个值(出现逗号成为元组)
- 可以通过`a,b=b,a`实现元素交换
- 星号表达式
- 可以用来在可迭代对象内部解包
- 也可以用来标记一个变量包含多个值
```python
t=(1,2,3)
a,b,c=t = a=1,b=2,c=3
t=(1,2,(3,4))
a,b,(c,d)=t = c=3,d=4
t=[1,2,-[3,4]] = t=[1,2,3,4]
a,-b=[1,2,3,4]
```
== 列表推导,生成元组、字典
- 一种很方便的生成列表的方式
- 即在列表中包含循环,遂次记录
- 可以有多重循环,即生成笛卡尔积集
- 可以包含条件,即在条件成立时才记录值
- 列表推导中的循环变量有局部作用域,和for循环不一样
- 类似的,有生成元组和字典
```python
lst=[]
for i in range(1,10)
lst.append(i--2)
= 等价于
lst=[i--2 for i in range(1,10)]
lst1=[x-y for x in l1 for y in l2]
lst2=[... for ... in ... if ... ]
t=tuple(i--2 for i in range(1,10))
d={a:b for a in ... for b in ... }
```
== 函数
- 定义方式,形状
- 用`return`返回
- 没有`return`运行到结尾或者只有`return`,返回`None`
- return的值类型不要求一致
- return可以返回多个值(利用元组)
- 函数参数
- 括号中列出参数名,可以指定默认值
- 使用`-`来接受任意多个参素
- 接收进来的是一个元组
- `-`参数后面不能跟非关键字参数
- 使用`--`来接受任意多关键字参数
- 接受进来的是一个字典
- 函数调用
- 直接传参要将参数与定义对应上顺序
- 通过关键字传参可以打乱顺序
== 变量引用
- python中的变量都是引用的
- 用=实际上是定义了一个别名
- Lst1=1st2,则Lst1和Lst2会同时变化(要用[:]创建副本)
- 数值类型有优化,所以不会这样
- `==`检查值是否相等,`is`检查值是否相同(比较id)
- 函数参数传递只有“共享传参”一种形式(即传引用)
- 可变变量(例如列表)在函数内部可以被改变
- 避免向函数传递可变变量(列表可传入[:]创建的副本)
== 匿名函数与高阶函数
- 可以通过lambda表达式来定义匿名函数
- 格式:`lambda 输入:输出表达式`
- 可以有多个输入
- 可以将匿名函数赋值给一个变量
- 接受函数作为参数的函数叫做高阶函数
- 常见如`map`和`filter`
- `map(A,B)`将函数A作用于可迭代对象B,输出`A(B)`
- `filter(A,B)`,将函数A作用于可迭代对象B,当值为`True`时输出,否则过滤
== 用户输入
- 使用内置的`input`函数
- 函数参数为要显示的提示符,如`input("please input number>>> ")`
- 函数返回值为字符串
- 每次读到换行为止
- 读入数字类型`a,b=map(int,input().strip().split())`
- 读入奇数`list(filter(lambda a:a%2==1,map(int,input().strip().split())))`
== 类与类的继承(没懂)
- 类可以看成包含一些属性和方法的框架
- 根据类来创建对象→实例化
- 用class关键字来定义类
- 类中的函数→方法
- 特殊方法`__init__`,在类实例化的时候会被自动调用
- 其它一般的方法第一个参数都要为"self",调用的时候会自动传入
- 直接写在类中的是属性,也可以通过为`self.<name>`赋值的形式创建属性
- 用类似函数调用的形式实例化类,参数为`__init__`方法的参数
- 直接通过`.<method>.<attribute>`的形式调用方法/获取属性
```
class ClassName():
a=1
def __init__(self,arg1,arg2):
self.arg1 = arg1
self.arg2 = arg2
def method(self):
print(self.arg1,self.arg2,self.a)
obj.ClassName(2,3)
obj.method() =2 3 1
print(obj.a,obj.arg1) =1 2
```
- 在class定义的括号中加上另一个类名则表示继承自那个类定义一个子类
- 子类会继承父类的所有属性和方法
- 子类编写和父类名字一样的方法会重载
- 在重载的方法中调用父类的原方法使用super()
- 也可以为子类定义独有的方法
```
class ClassA():
def init_(self,a):
self.a = a
def print(self):
print(self.a)
class ClassB(CLassA):
def__init__(self,a):
super().__init__(a)
self.a -=2
obj = ClassB(1)
obj.print() =2
```
== 私有?
- `python`中类并没有严格私有的属性
- 双下划线开头的属性会被隐藏,不能直接读取
- 使用双下划线开头的属性可以轻微保护属性,但并不代表其是私有的
- 但这种属性可以通过 `_类名__属性` 的方式读取到
== 一切皆对象?
- `python`中即使最简单的整数也是一个类(`object`)的实例
- 通过`dir(...)`查看一个对象的所有属性/方法
- 有很多双下划线开头、双下划线结尾的方法,成为魔术方法(dunder method)
== 魔术方法
- 很多函数、表达式其实是通过调用类的魔术方法来实现的,如:
- `len(obj)`调用`obj.__len__()`
- `obj[...]`调用`obj.__getitem__(...)`
- `a in obj`调用`obj.__contains__(a)`
- `booL(obj)`调用`obj.__bool__()`
- 函数的调用本质上是调用`func.__cal__`
- `a + b`调用`a.__add__(b)`
- ......
== python进阶
- python中类还有更多更多更好玩的用法
- 静态方法、类方法……
- 多重继承、mro顺序……
- 接口协议、鸭子类型、抽象基类……
- 猴子补丁……
- 元类……
- 垃圾回收……
- ......
== 文件操作
- open函数,传入文件名、打开模式
- 打开模式(可以叠加):`r`读(默认)、`w`写、`x`创建并写、`a`写在末尾、`b`字节模式、`t`文本模式(默认)
- 读取
- 文本模式建议加上`encoding`,不然容易报错
- `f,read()`读取全部内容(字节模式得到字节序列)
- `f.readline()`读取一行
- `f.readlines()`读取所有行,返回一个列表
- 写入
- 文本模式同样建议加上`encoding`
- `f.write(...)`直接写入,返回值为写入字符数
- `f.writelines(...)`传入列表,元素间换行写入
- 通过这种形式操作文件记得用完后要`f.close()`
== with 块
- `with ... as ... :`开启一个上下文管理器
- 常用在文件open上
- with块开始自动打开
- with块结束自动结束
- with块结束后变量仍会留存
```
with open("file","r",encoding="utf-8") as f:
s = f.read()
print(f.closed) =True
```
== 异常与处理
- 产生错误→抛出异常→程序结束
- raise关键字抛出异常
- try-except块捕获异常
- 可以有多个except、不可以没有
- except后接异常类(没有则捕获所有)
- as字句存下异常
- finally语句,不管是否有异常都会运行
```
try:
print(1 0)
except ZeroDivisionError as e:
print("can't devide by zero")
raise e
finally:
print("finished")
```
== if 外的 else 语句
- else块不仅仅跟着if才能运行
- `for-else`和`while-else`
- for正常结束运行else,while不满足condition退出运行else
- break异常退出则不会运行
- 不用这个功能的话,则需要用flag来标记之类的
- `try-else`
- try块中没有异常出现才会运行
- else块中异常不会被前面的except捕获
- 程序流跳到块外了不会运行(return等)
== 模块与导入
- 模块可以是一个单独的.py文件,也可以是一个文件夹
- 文件夹相当于导入其下`__init____.py`文件
- `__init____.py`里面导入`main.py`里的函数
- 模块中正常编写函数、类、语句
- 通过import语句导入模块
- `import code`
- `import code as cd`
- `from code import ...`
- `from code import -`
- 导入时相当于运行了一遍导入的代码
== “main函数”
- 防止导入时运行代码,只允许直接运行脚本时运行
- 通过判断`__name__`
- 如果是直接运行,则其等于字符串`__main__`
- 如果是被导入的,则其等于模块名
== python内部模块
- `python`内置了很多内部模块(标准库),如:
- os、sys:系统操作
- math:数学运算
- re:正则表达式
- datetime:日期与时间
- subprocess:子进程管理
- argparse:命令行参数解析
- Logging:日志记录
- hashlib:哈希计算
- random:随机数
- csv、json:数据格式解析
- collections:更多类型
- ……
- 详情见:"docs.python.org/zh-cn/3/library"
== 文档字符串
- 模块开头的三引号字符串,或者函数、类定义下面的三引号字符串
- `help(...)`的时候可以显示
- `obj.__doc__`表示这串字符
- 编辑器用来提示
- 一些文档生成工具(sphinx等)从中获取文档
- 以上均为 xg 的 python 授课中摘录的内容
== 高阶函数
- 操作函数的函数叫做高阶函数。这一叫法跟 Python 可以将函数作为参数传递的特性有关,不仅如此,还能做到函数的嵌套定义
- python 中所谓函数的环境,在这里就分出两个含义
1. 每个用户定义的函数都有一个关联环境:它的定义所在的环境。
2. 当一个用户定义的函数调用时,它的局部帧扩展于函数所关联的环境。
- 词法作用域的两个关键优势
1. 局部函数的名称并不影响定义所在函数外部的名称,因为局部函数的名称绑定到了定义处的当前局部环境中,而不是全局环境。
2. 局部函数可以访问外层函数的环境。这是因为局部函数的函数体的求值环境扩展于定义处的求值环境。
- 事实上,这感觉跟 C 语言中的生存期、作用域等概念真的很像。复杂之处在于,python 可以嵌套定义
- 这样定义的环境模型有一个好处就是可以将函数自己作为结果返回,例如:
```python
def square(x):
return x - x
def successor(x):
return x + 1
def compose1(f, g):
def h(x):
return f(g(x))
return h
add_one_and_square = compose1(square, successor)
add_one_and_square(12)
= The result is 169.
```
- 上面的例子中,我们注意到,我们在 Global 环境中创建了 square 函数和 successor 函数,将 `x - x` 和 `x + 1` 这种表达式关联到一个名称上,这种实现方式不是那么优雅(我不知道会不会相对造成更大的开销)。Python 中提供匿名函数(lambda)机制来简化这一问题
- 例如,上文的 `compose1` 可以写成
```py
def compose1(f,g):
return lambda x: f(g(x))
```
- 将表达式重构为应为语句来理解 lambda 语句
```py
lambda x : f(g(x))
"A function that takes x and returns f(g(x))"
```
- 有关 frame 和高阶函数的这一块是真的很复杂,建议是把代码放到 python tutor 里可视化查看
= Python 笔记之自我探索
== Python Decorator(装饰器)
- 是以前没有见过的语法
- 可以参考这个视频 #link("https://www.bilibili.com/video/BV11s411V7Dt/?spm_id_from=333.337.search-card.all.click&vd_source=39c8439d36378fa7ed46eae9e393a316")[Python小技巧:装饰器(Decorator)\_bilibili]
- 有什么用呢?根据我目前的了解,它可以给函数附加功能。比如,一个计算函数,我们要让它同时输出运行的时间,正常的方法是在代码中加计算时间的片段,但这会导致附加代码和实际计算代码混在一起,比较难看。这就是装饰器发挥作用的地方了。在想要运行的计算函数前加个 `@<装饰器名>`,再额外写一个装饰器函数,这样,所有的计算函数就都可以享受到装饰器了
- 说得高级一些,就是:--装饰器的作用就是为了解耦一些通用处理或者不必要功能的,尽可能让一个函数只负责一个任务,避免后续维护时散弹式修改代码--
```py
def xx1(<被装饰函数>):
def xx2(如果被装饰函数有参数那么输入):
xxxxxxxxxxxxxxx
<被装饰函数>(如果被装饰函数有参数那么输入)
xxxxxxxxxxxxxxx
= 如果被装饰函数中含有return则需要返回被装饰函数,没有则不需要
return xx2
```
- 用处例如,函数自动输出运行时间、函数自动追踪(效果如下)等等
```
>>> traced_reverse(123)
-> 123
-> 12
-> 1
<- 1
<- 21
<- 321
321
```
- 有一个问题是为什么要做的这么复杂,创建装饰器的语法,而不能直接 `new_func = decorator(old_func)`,这样方便理解得多。问题在于,这样就没法确保递归函数的效果,比如,如果被装饰函数是自引用的,装饰器的语法确保了调用的还是 `old_func` 它自己(只不过被装饰了),否则,会造成一次又一次的给调用函数加 `decorator`
|
|
https://github.com/kotfind/hse-se-2-notes | https://raw.githubusercontent.com/kotfind/hse-se-2-notes/master/algo/lectures/2024-09-10.typ | typst | #import "/utils/math.typ": *
= Символы Ландау
#def[
#defitem[$f(x) = O(g(x)):$]
$
exists C > 0
exists x_0 >= 0:
forall x >= x_0:
abs(f(x)) <= C abs(g(x))
$
]
#def[
#defitem[$f(x) = o(g(x)):$]
$
forall epsilon > 0
exists x_0:
forall x >= x_0:
abs(f(x)) <= epsilon abs(g(x))
$
]
#def[
#defitem[$f(x) = Theta(g(x)):$]
$
exists 0 < C_1 <= C_2
exists x_0:
C_1 abs(g(x)) <= abs(f(x)) <= C_2 abs(g(x))
$
]
== Примеры
+ $3n + 5sqrt(n) = O(n)$
+ $n = O(n^2)$
+ $n! = O(n^n)$
+ $log n^2 = O(log n)$
+ $k log k = n => k = O(?)$
= Мастер-теорема
$T(n)$ --- время работы (количество операций)
*Теор.* Пусть $
a in NN,
b in RR,
b > 1,
c >= 0 \
T(n) = cases(
O(1) &" if" n <= n_0,
a T(n/b) + O(n^c) &" otherwise"
)
$ тогда: $ T(n) = cases(
O(n^c) &" if " c > log_b a,
O(n^c log n) &" if " c = log_b a,
O(n^(log_b a)) &" if " c < log_b a,
) $
== Доказательство
Max глубина $= log_b n$
На $i$-ом слое: $a^i dot (n/(b^i))^c$ операций
В листьях (слой $log_b n$): $ a^(log_b n) $ операций
$
T(n)
= sum^(log_b n)_(k = 0) O(a^i (n/(b^i))^c)
= O(sum^(log_b n)_(k = 0) a^i (n/(b^i))^c)
= O(n^c sum^(log_b n)_(k = 0) (a/(b^c))^i)
$
Let $q = a/(b^c)$
$
q < 1:
a < b^c <=>
c > log_b a: \
O(n^c sum_i q^i)
<= O(n^c sum^infinity_i q^i)
= O(n^c dot 1/(1-q))
= O(n^c)
$
$
q = 1:
O(n^c dot log_b n)
$
$
q = 1:
O(n^c dot (a/(b^c))^(log_b n))
= O(n^c dot (a^(log_b n))/(b^(c dot log_b n)))
= O(n^c dot (a^(log_b n))/(n^c)) = \
= O(a^(log_b n))
= O(a^((log_a n)/(log_a b)))
= O(n^(1/(log_a b)))
= O(n^(log_b a))
$
== Примеры
=== Merge sort
$
T(n) = 2 dot T(n/2) + O(n)\
a = 2\
b = 2\
c = 1
$
$ log_2 2 = 1 => T(n) = O(n^c log n) = O(n log n) $
=== Бинпоиск
$
T(n) = T(n/2) + O(1)\
a = 1\
b = 2\
c = 0
$
$ log_2 1 = 0 => T(n) = O(n^c log n) = O(log n) $
=== Обход полного двоичного дерева
$
T(n) = 2 T(n/2) + O(1)\
a = b = 2\
c = 0
$
$ log_2 2 > 0 => T(n) = O(n^(log_b a)) = O(n^1) = O(n) $
== Обобщение
$ T(n) = a T(n/b) + O(n^c dot log^k n) $
$ c = log_b a=> T(n) = O(n^c log^(k + 1) n) $
|
|
https://github.com/jneug/typst-typopts | https://raw.githubusercontent.com/jneug/typst-typopts/main/manual.typ | typst | MIT License | //#import "@local/mantys:0.0.1": *
#import "../mantys-0.0.1/mantys.typ": *
#import "options.typ"
#show: mantys.with(
name: "typopts",
title: "The typopts Package",
subtitle: [#strong("Typ")st #strong("opt")ion#strong("s") management],
info: [A *Typst* package to conveniently handle options and arguments.],
authors: "<NAME>",
url: "https://github.com/jneug/typst-typopts",
version: "0.0.4",
date: "2023-07-05",
abstract: [
#pkg[typopts] is a *Typst* package with the intend to make handling options for packages and templates as easy as possible.
It provides functionality to load options from various sources, merge them together and make them accessible throughout the document.
]
)
#let ns = mty.rawi
= About
TYPOPTS was inspired by _LaTeX_ packages like #mty.rawi[pgfkeys]#footnote[https://ctan.org/pkg/pgfkeys] and modules like #mty.rawi[argparse]#footnote[https://docs.python.org/3/library/argparse.html] in _Python_.
= Usage
== Use as a module
To use TYPOPTS as a module for one project, get the file `options.typ` from the repository and save it in your project folder.
Import the module as usual:
#sourcecode[
```typc
#import "options.typ"
```
]
To use the `state` module do the same with the file `states.typ`:
#sourcecode[
```typc
#import "states.typ"
```
]
== Use as a package
Currently the package needs to be installed into the local package repository.
Either download the current release from GitHub#footnote[#link("https://github.com/jneug/typst-typopts/releases/latest")] and unpack the archive into yout system dependent local repository folder or clone it directly:
#shell(title:"cmd")[
```shell-unix-generic
git clone https://github.com/jneug/typst-typopts.git typopts-0.0.4
```
]
In either case make sure the files are placed in a folder with the correct version number: `typopts-0.0.4`
After installing the package just import it inside your `typ` file:
#sourcecode[
```typc
#import "@local/typopts:0.0.4": options
```
]
== Available functions
TYPOPTS provides several commands in three categories: Options access, argument parsing and configuration loading.
=== Accessing options
Options are simply key/value-pairs that are stored in a global state variable. This allows them to be access anywhere, even outside a main template function.
#idx(term:"Namespace")[Namespaces] are a way to create logical groups of options. All commands handling options accept an #arg[ns] argument to specify the namespace. Alternatively the namespace may be defined in dot-notation with thr option name.
`#options.get("colors.red")` and `#options.get("red", ns:"colors")` will both retrieve the option #opt-[red] from the namespace #ns[colors]. The argument takes precedence though and will prevent any namespaces before a dot to take effect. This means `#options.get("colors.red", ns:"colors")` will look for an option #opt-[colors.red] in the namespace #ns[colors].
#command("get", ..args("name", "func", default:none, ns:none, final:false, loc:none))[
#argument("name", type:"string")[
Name of the option.
]
#argument("func", type:"any => none")[
Function to pass the value to.
]
#argument("default", type:"any", default:none)[
Default value, if an option #arg("name") does not exist.
]
#argument("final", type:"boolean", default:false)[
If set to #value(true), the options final value is retrieved, otherwise the local value.
]
#argument("loc", type:"location", default:none)[
A #dtype("location") to use for retrieving the value.
]
#argument("ns", type:"string", default:none)[
The namespace to look for the value in.
]
Retrieves the value for the option by the given #arg("name") and passes it to #arg("func"), which is a function of one argument.
If no option #arg("name") exists, the given #arg("default") is passed on.
If #arg(final: true), the final value for the option is retrieved, otherwise the current value. If #arg("loc") is given, the call is not wrapped inside a #doc("meta/locate") call and the given #dtype("location") is used.
]
#command("update", ..args("name", "value", ns:none))[
Sets the option #arg[name] to #arg[value].
]
#command("update-all", ..args("values", ns:none))[
Updates all key/value-pairs in the dictionary #arg[values]. Each key is used as the option name.
]
#command("remove", ..args("name", ns:none))[
Remove the option #arg[name].
]
#command("display", ..args("name", format: "(v) => v", default:none, final:false, ns:none))[
Show the value of option #arg[name] formated with the function #arg[format].
If no such option exists, #arg[default] is used instead.
#argument("format", type:"(any) => content", default:"(v) => v")[
A function of one argument, that receives the optons value and transforms it into the content to be set.
]
]
== Parsing arguments
#command("add-argument", ..args("name",
type: ("string", "content"),
required: false,
default: none,
choices: none,
store: true,
pipe: none,
code: none))[
]
#command("parseconfig", ..args(_unknown:none, _opts:none), sarg("args"))[
]
#command("extract", ..args("var", _prefix:"", _positional:false), sarg("keys") )[
]
#command("getconfig", ..args("name", final:false))[
]
== Loading configuration files
#command("load", arg("filename"))[
#argument("filename", type:("string", "dict"))[
The file to load options from or a #dtype("dictionary") options. Supported are YAML, TOML and JSON files.
]
Loads options from a json, toml or yaml file.
Any key on the girst level that has a #dtype("dict") as a value will be considered a namespace and the dictionary will be unpacked as options within this namespace.
#sourcecode(title:"config.toml")[
```toml
[colors]
red = 255,0,0
green = 0,255,0
blue = 0,0,255
```
]
#sourcecode[
```typc
#options.load("config.toml")
#text(
fill:#options.get(
"colors.red",
v => rgb(..v.split(",")
),
[Hello World!]
)
```
]
#arg[filename] may be a prepopulated #dtype("dict") to load in the same way described above.
If you want to load a file without namespaces, just do something like this:
#sourcecode[
```typc
#options.update-all(toml("config.toml"))
```
]
]
= Index
#make-index()
|
https://github.com/AliothCancer/AppuntiUniversity | https://raw.githubusercontent.com/AliothCancer/AppuntiUniversity/main/capitoli_fisica/esercizi/esercitazione1p2.typ | typst | #import "../../custom_functions.typ": c
= TODO! Esercitazione 1+2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.