
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2473/comments | https://api.github.com/repos/huggingface/datasets/issues/2473/events | https://github.com/huggingface/datasets/pull/2473 | 917,538,629 | MDExOlB1bGxSZXF1ZXN0NjY3MDU5MjI5 | 2,473 | Add Disfl-QA | [] | closed | false | null | 2 | 2021-06-10T16:18:00Z | 2021-07-29T11:56:19Z | 2021-07-29T11:56:18Z | null | Dataset: https://github.com/google-research-datasets/disfl-qa
To-Do: Update README.md and add YAML tags | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2473/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2473/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2473.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2473",
"merged_at": "2021-07-29T11:56:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2473.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2473"
} | true | [
"Sounds great! It'll make things easier for the user while accessing the dataset. I'll make some changes to the current file then.",
"I've updated with the suggested changes. Updated the README, YAML tags as well (not sure of Size category tag as I couldn't pass the path of `dataset_infos.json` for this dataset)\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/35 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/35/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/35/comments | https://api.github.com/repos/huggingface/datasets/issues/35/events | https://github.com/huggingface/datasets/pull/35 | 611,413,731 | MDExOlB1bGxSZXF1ZXN0NDEyNjAyMTc0 | 35 | [Tests] fix typo | [] | closed | false | null | 0 | 2020-05-03T13:23:49Z | 2020-05-03T13:24:21Z | 2020-05-03T13:24:20Z | null | @lhoestq - currently the slow test fail with:
```
_____________________________________________________________________________________ DatasetTest.test_load_real_dataset_xnli _____________________________________________________________________________________
self = <tests.test_dataset_common.DatasetTest testMethod=test_load_real_dataset_xnli>, dataset_name = 'xnli'
@slow
def test_load_real_dataset(self, dataset_name):
with tempfile.TemporaryDirectory() as temp_data_dir:
> dataset = load(dataset_name, data_dir=temp_data_dir)
tests/test_dataset_common.py:153:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
../../python_bin/nlp/load.py:497: in load
dbuilder.download_and_prepare(**download_and_prepare_kwargs)
../../python_bin/nlp/builder.py:383: in download_and_prepare
self._download_and_prepare(dl_manager=dl_manager, download_config=download_config)
../../python_bin/nlp/builder.py:627: in _download_and_prepare
dl_manager=dl_manager, max_examples_per_split=download_config.max_examples_per_split,
../../python_bin/nlp/builder.py:431: in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
../../python_bin/nlp/datasets/xnli/8bf4185a2da1ef2a523186dd660d9adcf0946189e7fa5942ea31c63c07b68a7f/xnli.py:95: in _split_generators
dl_dir = dl_manager.download_and_extract(_DATA_URL)
../../python_bin/nlp/utils/download_manager.py:246: in download_and_extract
return self.extract(self.download(url_or_urls))
../../python_bin/nlp/utils/download_manager.py:186: in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
../../python_bin/nlp/utils/download_manager.py:166: in _record_sizes_checksums
self._recorded_sizes_checksums[url] = get_size_checksum(path)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
path = ('', '/tmp/tmpkajlg9yc/downloads/c0f7773c480a3f2d85639d777e0e17e65527460310d80760fd3fc2b2f2960556.c952a63cb17d3d46e412ceb7dbcd656ce2b15cc9ef17f50c28f81c48a7c853b5')
def get_size_checksum(path: str) -> Tuple[int, str]:
"""Compute the file size and the sha256 checksum of a file"""
m = sha256()
> with open(path, "rb") as f:
E TypeError: expected str, bytes or os.PathLike object, not tuple
../../python_bin/nlp/utils/checksums_utils.py:81: TypeError
```
- the checksums probably need to be updated no? And we should also think about how to write a test for the checksums. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/35/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/35/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/35.diff",
"html_url": "https://github.com/huggingface/datasets/pull/35",
"merged_at": "2020-05-03T13:24:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/35.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/35"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4979 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4979/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4979/comments | https://api.github.com/repos/huggingface/datasets/issues/4979/events | https://github.com/huggingface/datasets/pull/4979 | 1,374,820,758 | PR_kwDODunzps4_CouM | 4,979 | Fix missing tags in dataset cards | [] | closed | false | null | 1 | 2022-09-15T16:51:03Z | 2022-09-22T12:37:55Z | 2022-09-15T17:12:09Z | null | Fix missing tags in dataset cards:
- amazon_us_reviews
- art
- discofuse
- indic_glue
- ubuntu_dialogs_corpus
This PR partially fixes the missing tags in dataset cards. Subsequent PRs will follow to complete this task.
Related to:
- #4833
- #4891
- #4896
- #4908
- #4921
- #4931 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4979/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4979/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4979.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4979",
"merged_at": "2022-09-15T17:12:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4979.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4979"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5797 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5797/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5797/comments | https://api.github.com/repos/huggingface/datasets/issues/5797/events | https://github.com/huggingface/datasets/issues/5797 | 1,685,501,199 | I_kwDODunzps5kdrUP | 5,797 | load_dataset is case sentitive? | [] | open | false | null | 2 | 2023-04-26T18:19:04Z | 2023-04-27T11:56:58Z | null | null | ### Describe the bug
load_dataset() function is case sensitive?
### Steps to reproduce the bug
The following two code, get totally different behavior.
1. load_dataset('mbzuai/bactrian-x','en')
2. load_dataset('MBZUAI/Bactrian-X','en')
### Expected behavior
Compare 1 and 2.
1 will download all 52 subsets, shell output:
```Downloading and preparing dataset json/MBZUAI--bactrian-X to xxx```
2 will only download single subset, shell output
```Downloading and preparing dataset bactrian-x/en to xxx```
### Environment info
Python 3.10.11
datasets Version: 2.11.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5797/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5797/timeline | null | null | null | null | false | [
"Hi @haonan-li , thank you for the report! It seems to be a bug on the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) site, there is even no such dataset as `mbzuai/bactrian-x` on the Hub. I opened and [issue](https://github.com/huggingface/huggingface_hub/issues/1453) there.",
"I think `load_dataset(\"mbzuai/bactrian-x\")` shouldn't be loaded at all and raise an error but because of [this fallback](https://github.com/huggingface/datasets/blob/main/src/datasets/load.py#L1194) to packaged loaders when no other options are applicable, it loads the dataset with standard `json` loader instead of the custom loading script."
] |
https://api.github.com/repos/huggingface/datasets/issues/1775 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1775/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1775/comments | https://api.github.com/repos/huggingface/datasets/issues/1775/events | https://github.com/huggingface/datasets/issues/1775 | 792,742,120 | MDU6SXNzdWU3OTI3NDIxMjA= | 1,775 | Efficient ways to iterate the dataset | [] | closed | false | null | 2 | 2021-01-24T07:54:31Z | 2021-01-24T09:50:39Z | 2021-01-24T09:50:39Z | null | For a large dataset that does not fits the memory, how can I select only a subset of features from each example?
If I iterate over the dataset and then select the subset of features one by one, the resulted memory usage will be huge. Any ways to solve this?
Thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1775/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1775/timeline | null | completed | null | null | false | [
"It seems that selecting a subset of colums directly from the dataset, i.e., dataset[\"column\"], is slow.",
"I was wrong, ```dataset[\"column\"]``` is fast."
] |
https://api.github.com/repos/huggingface/datasets/issues/291 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/291/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/291/comments | https://api.github.com/repos/huggingface/datasets/issues/291/events | https://github.com/huggingface/datasets/pull/291 | 642,688,450 | MDExOlB1bGxSZXF1ZXN0NDM3NjM1NjMy | 291 | break statement not required | [] | closed | false | null | 3 | 2020-06-22T01:40:55Z | 2020-06-23T17:57:58Z | 2020-06-23T09:37:02Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/291/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/291/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/291.diff",
"html_url": "https://github.com/huggingface/datasets/pull/291",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/291.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/291"
} | true | [
"I guess,test failing due to connection error?",
"We just fixed the other dataset on master. Could you rebase from master and push to rerun the CI ?",
"If I'm not wrong this function returns None if no main class was found.\r\nI think it makes things less clear not to have a return at the end of the function.\r\nI guess we can have one return in the for loop instead of the break statement, AND one return at the end to explicitly return None.\r\nWhat do you think ?"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3042 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3042/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3042/comments | https://api.github.com/repos/huggingface/datasets/issues/3042/events | https://github.com/huggingface/datasets/pull/3042 | 1,020,047,289 | PR_kwDODunzps4s5Lxo | 3,042 | Improving elasticsearch integration | [] | open | false | null | 1 | 2021-10-07T13:28:35Z | 2022-07-06T15:19:48Z | null | null | - adding murmurhash signature to sample in index
- adding optional credentials for remote elasticsearch server
- enabling sample update in index
- upgrade the elasticsearch 7.10.1 python client
- adding ElasticsearchBulider to instantiate a dataset from an index and a filtering query | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3042/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3042/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3042.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3042",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3042.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3042"
} | true | [
"@lhoestq @albertvillanova Iwas trying to fix the failing tests in circleCI but is there a test elasticsearch instance somewhere? If not, can I launch a docker container to have one?"
] |
https://api.github.com/repos/huggingface/datasets/issues/5211 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5211/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5211/comments | https://api.github.com/repos/huggingface/datasets/issues/5211/events | https://github.com/huggingface/datasets/pull/5211 | 1,438,544,617 | PR_kwDODunzps5CVgBx | 5,211 | Update Overview.ipynb google colab | [] | closed | false | null | 3 | 2022-11-07T15:23:52Z | 2022-11-29T15:59:48Z | 2022-11-29T15:54:17Z | null | - removed metrics stuff
- added image example
- added audio example (with ffmpeg instructions)
- updated the "add a new dataset" section | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5211/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5211/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5211.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5211",
"merged_at": "2022-11-29T15:54:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5211.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5211"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"WDYT @albertvillanova ?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5211). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/3601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3601/comments | https://api.github.com/repos/huggingface/datasets/issues/3601/events | https://github.com/huggingface/datasets/pull/3601 | 1,108,207,131 | PR_kwDODunzps4xROtF | 3,601 | Add conll2003 licensing | [] | closed | false | null | 0 | 2022-01-19T15:00:41Z | 2022-01-19T17:17:28Z | 2022-01-19T17:17:28Z | null | Following https://github.com/huggingface/datasets/issues/3582, this PR updates the licensing section of the CoNLL2003 dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3601/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3601.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3601",
"merged_at": "2022-01-19T17:17:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3601.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3601"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5740/comments | https://api.github.com/repos/huggingface/datasets/issues/5740/events | https://github.com/huggingface/datasets/pull/5740 | 1,664,132,130 | PR_kwDODunzps5OHI08 | 5,740 | Fix CI mock filesystem fixtures | [] | closed | false | null | 5 | 2023-04-12T08:52:35Z | 2023-04-13T11:01:24Z | 2023-04-13T10:54:13Z | null | This PR fixes the fixtures of our CI mock filesystems.
Before, we had to pass `clobber=True` to `fsspec.register_implementation` to overwrite the still present previously added "mock" filesystem. That meant that the mock filesystem fixture was not working properly, because the previously added "mock" filesystem, should have been deleted by the fixture.
This PR fixes the mock filesystem fixtures, so that the "mock" filesystem is properly deleted from the inner `fsspec` registry.
Tests were added to check the correct behavior of the mock filesystem fixtures.
Related to:
- #5733 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5740/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5740/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5740.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5740",
"merged_at": "2023-04-13T10:54:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5740.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5740"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007003 / 0.011353 (-0.004350) | 0.004854 / 0.011008 (-0.006154) | 0.096982 / 0.038508 (0.058474) | 0.033218 / 0.023109 (0.010109) | 0.314088 / 0.275898 (0.038190) | 0.351315 / 0.323480 (0.027835) | 0.005679 / 0.007986 (-0.002307) | 0.005404 / 0.004328 (0.001075) | 0.071773 / 0.004250 (0.067522) | 0.044593 / 0.037052 (0.007540) | 0.323643 / 0.258489 (0.065154) | 0.357172 / 0.293841 (0.063331) | 0.036782 / 0.128546 (-0.091764) | 0.012146 / 0.075646 (-0.063501) | 0.334874 / 0.419271 (-0.084397) | 0.051475 / 0.043533 (0.007942) | 0.305949 / 0.255139 (0.050810) | 0.339326 / 0.283200 (0.056126) | 0.101509 / 0.141683 (-0.040174) | 1.458254 / 1.452155 (0.006099) | 1.535252 / 1.492716 (0.042535) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.264837 / 0.018006 (0.246831) | 0.441444 / 0.000490 (0.440955) | 0.003331 / 0.000200 (0.003131) | 0.000084 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026529 / 0.037411 (-0.010882) | 0.105924 / 0.014526 (0.091398) | 0.117191 / 0.176557 (-0.059365) | 0.176606 / 0.737135 (-0.560529) | 0.123452 / 0.296338 (-0.172887) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412351 / 0.215209 (0.197142) | 4.135468 / 2.077655 (2.057813) | 1.912820 / 1.504120 (0.408700) | 1.738993 / 1.541195 (0.197798) | 1.754228 / 1.468490 (0.285738) | 0.692239 / 4.584777 (-3.892538) | 3.765672 / 3.745712 (0.019959) | 2.081141 / 5.269862 (-3.188720) | 1.425153 / 4.565676 (-3.140523) | 0.085055 / 0.424275 (-0.339220) | 0.011918 / 0.007607 (0.004311) | 0.517573 / 0.226044 (0.291529) | 5.179809 / 2.268929 (2.910881) | 2.471620 / 55.444624 (-52.973005) | 2.140634 / 6.876477 (-4.735843) | 2.200150 / 2.142072 (0.058077) | 0.831662 / 4.805227 (-3.973566) | 0.168828 / 6.500664 (-6.331836) | 0.062755 / 0.075469 (-0.012714) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.196890 / 1.841788 (-0.644898) | 14.826423 / 8.074308 (6.752114) | 14.020782 / 10.191392 (3.829390) | 0.161275 / 0.680424 (-0.519149) | 0.017467 / 0.534201 (-0.516734) | 0.422278 / 0.579283 (-0.157005) | 0.424053 / 0.434364 (-0.010311) | 0.490768 / 0.540337 (-0.049570) | 0.584490 / 1.386936 (-0.802446) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007102 / 0.011353 (-0.004250) | 0.005145 / 0.011008 (-0.005863) | 0.073823 / 0.038508 (0.035315) | 0.032947 / 0.023109 (0.009838) | 0.336978 / 0.275898 (0.061080) | 0.368961 / 0.323480 (0.045481) | 0.006052 / 0.007986 (-0.001934) | 0.003970 / 0.004328 (-0.000358) | 0.072925 / 0.004250 (0.068674) | 0.044502 / 0.037052 (0.007450) | 0.340849 / 0.258489 (0.082360) | 0.381487 / 0.293841 (0.087646) | 0.037207 / 0.128546 (-0.091339) | 0.012095 / 0.075646 (-0.063551) | 0.085206 / 0.419271 (-0.334065) | 0.056236 / 0.043533 (0.012703) | 0.334048 / 0.255139 (0.078909) | 0.360442 / 0.283200 (0.077242) | 0.104402 / 0.141683 (-0.037281) | 1.446907 / 1.452155 (-0.005248) | 1.542430 / 1.492716 (0.049713) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.238720 / 0.018006 (0.220714) | 0.445857 / 0.000490 (0.445367) | 0.009280 / 0.000200 (0.009080) | 0.000150 / 0.000054 (0.000095) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028414 / 0.037411 (-0.008998) | 0.110506 / 0.014526 (0.095981) | 0.124593 / 0.176557 (-0.051964) | 0.170951 / 0.737135 (-0.566184) | 0.128033 / 0.296338 (-0.168305) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426206 / 0.215209 (0.210997) | 4.267289 / 2.077655 (2.189634) | 2.026880 / 1.504120 (0.522760) | 1.844052 / 1.541195 (0.302858) | 1.897697 / 1.468490 (0.429207) | 0.713545 / 4.584777 (-3.871232) | 3.815052 / 3.745712 (0.069339) | 3.217091 / 5.269862 (-2.052770) | 1.790546 / 4.565676 (-2.775130) | 0.087501 / 0.424275 (-0.336774) | 0.012136 / 0.007607 (0.004529) | 0.534495 / 0.226044 (0.308451) | 5.325913 / 2.268929 (3.056984) | 2.484309 / 55.444624 (-52.960315) | 2.149721 / 6.876477 (-4.726756) | 2.158764 / 2.142072 (0.016692) | 0.855273 / 4.805227 (-3.949954) | 0.170374 / 6.500664 (-6.330290) | 0.064053 / 0.075469 (-0.011416) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253171 / 1.841788 (-0.588617) | 15.254562 / 8.074308 (7.180254) | 14.242119 / 10.191392 (4.050727) | 0.159298 / 0.680424 (-0.521126) | 0.017504 / 0.534201 (-0.516696) | 0.419710 / 0.579283 (-0.159574) | 0.417879 / 0.434364 (-0.016485) | 0.486328 / 0.540337 (-0.054009) | 0.578933 / 1.386936 (-0.808003) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008476 / 0.011353 (-0.002877) | 0.005745 / 0.011008 (-0.005263) | 0.115307 / 0.038508 (0.076799) | 0.039356 / 0.023109 (0.016247) | 0.367155 / 0.275898 (0.091257) | 0.422147 / 0.323480 (0.098667) | 0.006817 / 0.007986 (-0.001168) | 0.004652 / 0.004328 (0.000323) | 0.084045 / 0.004250 (0.079795) | 0.055483 / 0.037052 (0.018431) | 0.364249 / 0.258489 (0.105760) | 0.415975 / 0.293841 (0.122134) | 0.041322 / 0.128546 (-0.087224) | 0.014178 / 0.075646 (-0.061469) | 0.392658 / 0.419271 (-0.026614) | 0.060156 / 0.043533 (0.016623) | 0.373938 / 0.255139 (0.118799) | 0.397494 / 0.283200 (0.114294) | 0.113811 / 0.141683 (-0.027872) | 1.688581 / 1.452155 (0.236427) | 1.790374 / 1.492716 (0.297658) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222203 / 0.018006 (0.204196) | 0.471109 / 0.000490 (0.470619) | 0.007071 / 0.000200 (0.006871) | 0.000156 / 0.000054 (0.000102) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032112 / 0.037411 (-0.005299) | 0.118726 / 0.014526 (0.104200) | 0.134918 / 0.176557 (-0.041639) | 0.207766 / 0.737135 (-0.529369) | 0.139756 / 0.296338 (-0.156582) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.479858 / 0.215209 (0.264649) | 4.798428 / 2.077655 (2.720773) | 2.221573 / 1.504120 (0.717453) | 1.964956 / 1.541195 (0.423761) | 2.021763 / 1.468490 (0.553273) | 0.820401 / 4.584777 (-3.764376) | 4.533887 / 3.745712 (0.788175) | 4.121332 / 5.269862 (-1.148529) | 2.195807 / 4.565676 (-2.369869) | 0.103133 / 0.424275 (-0.321142) | 0.014620 / 0.007607 (0.007013) | 0.605012 / 0.226044 (0.378967) | 5.966623 / 2.268929 (3.697694) | 2.844118 / 55.444624 (-52.600506) | 2.463569 / 6.876477 (-4.412907) | 2.597177 / 2.142072 (0.455105) | 0.983201 / 4.805227 (-3.822026) | 0.199500 / 6.500664 (-6.301164) | 0.078387 / 0.075469 (0.002918) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.401083 / 1.841788 (-0.440705) | 17.258725 / 8.074308 (9.184417) | 16.825992 / 10.191392 (6.634600) | 0.216762 / 0.680424 (-0.463662) | 0.021135 / 0.534201 (-0.513066) | 0.513688 / 0.579283 (-0.065595) | 0.488892 / 0.434364 (0.054529) | 0.566745 / 0.540337 (0.026408) | 0.688958 / 1.386936 (-0.697978) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007948 / 0.011353 (-0.003405) | 0.005981 / 0.011008 (-0.005027) | 0.084474 / 0.038508 (0.045966) | 0.037952 / 0.023109 (0.014843) | 0.383359 / 0.275898 (0.107461) | 0.409324 / 0.323480 (0.085844) | 0.006641 / 0.007986 (-0.001344) | 0.004785 / 0.004328 (0.000456) | 0.083214 / 0.004250 (0.078964) | 0.053177 / 0.037052 (0.016125) | 0.393147 / 0.258489 (0.134658) | 0.438496 / 0.293841 (0.144655) | 0.042090 / 0.128546 (-0.086456) | 0.013373 / 0.075646 (-0.062273) | 0.097585 / 0.419271 (-0.321686) | 0.056359 / 0.043533 (0.012826) | 0.378113 / 0.255139 (0.122974) | 0.403874 / 0.283200 (0.120674) | 0.123503 / 0.141683 (-0.018180) | 1.639557 / 1.452155 (0.187403) | 1.759787 / 1.492716 (0.267071) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.242534 / 0.018006 (0.224528) | 0.459040 / 0.000490 (0.458550) | 0.000454 / 0.000200 (0.000254) | 0.000066 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031747 / 0.037411 (-0.005664) | 0.125823 / 0.014526 (0.111297) | 0.138985 / 0.176557 (-0.037571) | 0.194371 / 0.737135 (-0.542764) | 0.148905 / 0.296338 (-0.147433) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.508201 / 0.215209 (0.292992) | 5.007519 / 2.077655 (2.929865) | 2.412956 / 1.504120 (0.908836) | 2.143378 / 1.541195 (0.602183) | 2.192966 / 1.468490 (0.724476) | 0.828497 / 4.584777 (-3.756280) | 4.496457 / 3.745712 (0.750745) | 2.397546 / 5.269862 (-2.872315) | 1.522889 / 4.565676 (-3.042787) | 0.099904 / 0.424275 (-0.324371) | 0.014561 / 0.007607 (0.006954) | 0.627417 / 0.226044 (0.401373) | 6.296441 / 2.268929 (4.027512) | 2.962858 / 55.444624 (-52.481767) | 2.543083 / 6.876477 (-4.333394) | 2.711884 / 2.142072 (0.569811) | 0.997969 / 4.805227 (-3.807259) | 0.200283 / 6.500664 (-6.300382) | 0.075934 / 0.075469 (0.000465) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.541707 / 1.841788 (-0.300081) | 17.791559 / 8.074308 (9.717251) | 16.782877 / 10.191392 (6.591485) | 0.171954 / 0.680424 (-0.508470) | 0.020506 / 0.534201 (-0.513695) | 0.504189 / 0.579283 (-0.075094) | 0.501655 / 0.434364 (0.067291) | 0.583120 / 0.540337 (0.042782) | 0.694931 / 1.386936 (-0.692005) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007613 / 0.011353 (-0.003740) | 0.005057 / 0.011008 (-0.005951) | 0.099147 / 0.038508 (0.060639) | 0.035358 / 0.023109 (0.012249) | 0.303442 / 0.275898 (0.027544) | 0.336898 / 0.323480 (0.013418) | 0.006216 / 0.007986 (-0.001770) | 0.004085 / 0.004328 (-0.000244) | 0.074567 / 0.004250 (0.070317) | 0.050917 / 0.037052 (0.013865) | 0.301786 / 0.258489 (0.043297) | 0.341362 / 0.293841 (0.047521) | 0.037019 / 0.128546 (-0.091528) | 0.011977 / 0.075646 (-0.063669) | 0.334688 / 0.419271 (-0.084583) | 0.051326 / 0.043533 (0.007793) | 0.299878 / 0.255139 (0.044739) | 0.325571 / 0.283200 (0.042371) | 0.110744 / 0.141683 (-0.030939) | 1.480898 / 1.452155 (0.028743) | 1.566917 / 1.492716 (0.074201) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.253249 / 0.018006 (0.235242) | 0.558576 / 0.000490 (0.558086) | 0.003838 / 0.000200 (0.003638) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028731 / 0.037411 (-0.008681) | 0.110643 / 0.014526 (0.096117) | 0.119560 / 0.176557 (-0.056996) | 0.178010 / 0.737135 (-0.559126) | 0.130286 / 0.296338 (-0.166053) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400190 / 0.215209 (0.184981) | 3.999326 / 2.077655 (1.921672) | 1.797332 / 1.504120 (0.293212) | 1.610808 / 1.541195 (0.069613) | 1.679949 / 1.468490 (0.211459) | 0.696539 / 4.584777 (-3.888238) | 3.784766 / 3.745712 (0.039054) | 2.205008 / 5.269862 (-3.064854) | 1.501697 / 4.565676 (-3.063979) | 0.085553 / 0.424275 (-0.338723) | 0.012223 / 0.007607 (0.004616) | 0.494858 / 0.226044 (0.268813) | 4.968535 / 2.268929 (2.699606) | 2.258759 / 55.444624 (-53.185865) | 1.926236 / 6.876477 (-4.950241) | 2.072155 / 2.142072 (-0.069917) | 0.838354 / 4.805227 (-3.966873) | 0.168810 / 6.500664 (-6.331854) | 0.064347 / 0.075469 (-0.011122) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.166696 / 1.841788 (-0.675091) | 14.721287 / 8.074308 (6.646979) | 14.319272 / 10.191392 (4.127880) | 0.144534 / 0.680424 (-0.535890) | 0.017502 / 0.534201 (-0.516699) | 0.422682 / 0.579283 (-0.156601) | 0.424426 / 0.434364 (-0.009938) | 0.493561 / 0.540337 (-0.046777) | 0.586765 / 1.386936 (-0.800171) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007764 / 0.011353 (-0.003589) | 0.005516 / 0.011008 (-0.005492) | 0.074745 / 0.038508 (0.036237) | 0.034364 / 0.023109 (0.011255) | 0.344318 / 0.275898 (0.068420) | 0.374779 / 0.323480 (0.051299) | 0.005904 / 0.007986 (-0.002082) | 0.004323 / 0.004328 (-0.000005) | 0.073191 / 0.004250 (0.068941) | 0.051549 / 0.037052 (0.014496) | 0.341792 / 0.258489 (0.083303) | 0.387576 / 0.293841 (0.093735) | 0.037483 / 0.128546 (-0.091063) | 0.012410 / 0.075646 (-0.063237) | 0.086480 / 0.419271 (-0.332791) | 0.050035 / 0.043533 (0.006502) | 0.335475 / 0.255139 (0.080336) | 0.361436 / 0.283200 (0.078236) | 0.106890 / 0.141683 (-0.034792) | 1.464032 / 1.452155 (0.011877) | 1.563490 / 1.492716 (0.070774) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268765 / 0.018006 (0.250758) | 0.563811 / 0.000490 (0.563321) | 0.004904 / 0.000200 (0.004704) | 0.000096 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029885 / 0.037411 (-0.007526) | 0.113885 / 0.014526 (0.099359) | 0.124283 / 0.176557 (-0.052274) | 0.173619 / 0.737135 (-0.563517) | 0.131781 / 0.296338 (-0.164557) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420296 / 0.215209 (0.205087) | 4.167656 / 2.077655 (2.090001) | 1.982356 / 1.504120 (0.478237) | 1.792181 / 1.541195 (0.250986) | 1.871459 / 1.468490 (0.402969) | 0.707066 / 4.584777 (-3.877711) | 3.835922 / 3.745712 (0.090210) | 3.506796 / 5.269862 (-1.763066) | 1.857172 / 4.565676 (-2.708505) | 0.086219 / 0.424275 (-0.338056) | 0.012404 / 0.007607 (0.004796) | 0.512393 / 0.226044 (0.286348) | 5.111623 / 2.268929 (2.842695) | 2.493523 / 55.444624 (-52.951101) | 2.188220 / 6.876477 (-4.688257) | 2.319096 / 2.142072 (0.177024) | 0.844084 / 4.805227 (-3.961144) | 0.171130 / 6.500664 (-6.329534) | 0.065913 / 0.075469 (-0.009556) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.284768 / 1.841788 (-0.557020) | 15.334610 / 8.074308 (7.260301) | 14.724436 / 10.191392 (4.533044) | 0.188425 / 0.680424 (-0.491999) | 0.017984 / 0.534201 (-0.516217) | 0.428150 / 0.579283 (-0.151133) | 0.429013 / 0.434364 (-0.005351) | 0.500818 / 0.540337 (-0.039519) | 0.592879 / 1.386936 (-0.794057) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006870 / 0.011353 (-0.004483) | 0.004702 / 0.011008 (-0.006306) | 0.099258 / 0.038508 (0.060750) | 0.029008 / 0.023109 (0.005899) | 0.330599 / 0.275898 (0.054701) | 0.361163 / 0.323480 (0.037683) | 0.005020 / 0.007986 (-0.002965) | 0.003474 / 0.004328 (-0.000855) | 0.075902 / 0.004250 (0.071651) | 0.037462 / 0.037052 (0.000410) | 0.336213 / 0.258489 (0.077724) | 0.370645 / 0.293841 (0.076804) | 0.032435 / 0.128546 (-0.096111) | 0.011686 / 0.075646 (-0.063960) | 0.326040 / 0.419271 (-0.093232) | 0.043750 / 0.043533 (0.000217) | 0.332629 / 0.255139 (0.077490) | 0.353302 / 0.283200 (0.070102) | 0.090421 / 0.141683 (-0.051262) | 1.470097 / 1.452155 (0.017942) | 1.544908 / 1.492716 (0.052191) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.213418 / 0.018006 (0.195411) | 0.434808 / 0.000490 (0.434319) | 0.005949 / 0.000200 (0.005749) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023085 / 0.037411 (-0.014327) | 0.098222 / 0.014526 (0.083696) | 0.104543 / 0.176557 (-0.072013) | 0.165423 / 0.737135 (-0.571713) | 0.108732 / 0.296338 (-0.187606) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433933 / 0.215209 (0.218724) | 4.334358 / 2.077655 (2.256704) | 2.013984 / 1.504120 (0.509864) | 1.862981 / 1.541195 (0.321787) | 1.873936 / 1.468490 (0.405446) | 0.699857 / 4.584777 (-3.884920) | 3.417815 / 3.745712 (-0.327897) | 1.946403 / 5.269862 (-3.323459) | 1.308683 / 4.565676 (-3.256994) | 0.083297 / 0.424275 (-0.340978) | 0.012610 / 0.007607 (0.005003) | 0.540877 / 0.226044 (0.314832) | 5.408293 / 2.268929 (3.139365) | 2.529574 / 55.444624 (-52.915050) | 2.201047 / 6.876477 (-4.675429) | 2.392966 / 2.142072 (0.250894) | 0.812719 / 4.805227 (-3.992509) | 0.154013 / 6.500664 (-6.346651) | 0.067614 / 0.075469 (-0.007855) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.228150 / 1.841788 (-0.613638) | 14.037090 / 8.074308 (5.962782) | 14.259416 / 10.191392 (4.068024) | 0.155554 / 0.680424 (-0.524870) | 0.016521 / 0.534201 (-0.517680) | 0.379615 / 0.579283 (-0.199668) | 0.421352 / 0.434364 (-0.013012) | 0.446512 / 0.540337 (-0.093825) | 0.531802 / 1.386936 (-0.855134) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006629 / 0.011353 (-0.004724) | 0.004432 / 0.011008 (-0.006577) | 0.076662 / 0.038508 (0.038154) | 0.027674 / 0.023109 (0.004565) | 0.341667 / 0.275898 (0.065769) | 0.376493 / 0.323480 (0.053014) | 0.005076 / 0.007986 (-0.002910) | 0.004655 / 0.004328 (0.000326) | 0.075698 / 0.004250 (0.071448) | 0.036905 / 0.037052 (-0.000147) | 0.342394 / 0.258489 (0.083905) | 0.383330 / 0.293841 (0.089489) | 0.031729 / 0.128546 (-0.096817) | 0.011582 / 0.075646 (-0.064064) | 0.085721 / 0.419271 (-0.333551) | 0.042012 / 0.043533 (-0.001521) | 0.342063 / 0.255139 (0.086924) | 0.367335 / 0.283200 (0.084136) | 0.089641 / 0.141683 (-0.052042) | 1.520353 / 1.452155 (0.068198) | 1.643653 / 1.492716 (0.150937) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178995 / 0.018006 (0.160989) | 0.436544 / 0.000490 (0.436055) | 0.002311 / 0.000200 (0.002111) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025386 / 0.037411 (-0.012026) | 0.099717 / 0.014526 (0.085192) | 0.110809 / 0.176557 (-0.065747) | 0.162931 / 0.737135 (-0.574204) | 0.110430 / 0.296338 (-0.185909) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.438592 / 0.215209 (0.223382) | 4.372560 / 2.077655 (2.294905) | 2.069686 / 1.504120 (0.565567) | 1.860576 / 1.541195 (0.319382) | 1.898161 / 1.468490 (0.429671) | 0.698353 / 4.584777 (-3.886424) | 3.462440 / 3.745712 (-0.283272) | 1.868602 / 5.269862 (-3.401260) | 1.160498 / 4.565676 (-3.405179) | 0.082869 / 0.424275 (-0.341406) | 0.012690 / 0.007607 (0.005083) | 0.533278 / 0.226044 (0.307233) | 5.386214 / 2.268929 (3.117285) | 2.519243 / 55.444624 (-52.925382) | 2.171109 / 6.876477 (-4.705368) | 2.272617 / 2.142072 (0.130544) | 0.805843 / 4.805227 (-3.999384) | 0.152275 / 6.500664 (-6.348389) | 0.068038 / 0.075469 (-0.007431) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.291967 / 1.841788 (-0.549821) | 14.386474 / 8.074308 (6.312166) | 14.180693 / 10.191392 (3.989301) | 0.131714 / 0.680424 (-0.548710) | 0.016596 / 0.534201 (-0.517605) | 0.384293 / 0.579283 (-0.194990) | 0.404051 / 0.434364 (-0.030313) | 0.452167 / 0.540337 (-0.088170) | 0.542718 / 1.386936 (-0.844218) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1618/comments | https://api.github.com/repos/huggingface/datasets/issues/1618/events | https://github.com/huggingface/datasets/issues/1618 | 772,248,730 | MDU6SXNzdWU3NzIyNDg3MzA= | 1,618 | Can't filter language:EN on https://huggingface.co/datasets | [] | closed | false | null | 3 | 2020-12-21T15:23:23Z | 2020-12-22T17:17:00Z | 2020-12-22T17:16:09Z | null | When visiting https://huggingface.co/datasets, I don't see an obvious way to filter only English datasets. This is unexpected for me, am I missing something? I'd expect English to be selectable in the language widget. This problem reproduced on Mozilla Firefox and MS Edge:
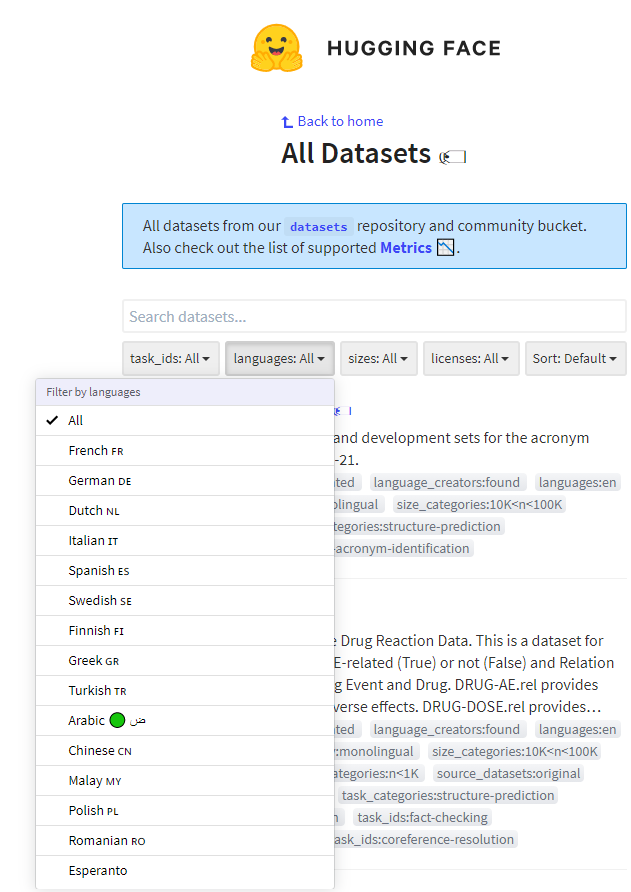
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1618/timeline | null | completed | null | null | false | [
"cc'ing @mapmeld ",
"Full language list is now deployed to https://huggingface.co/datasets ! Recommend close",
"Cool @mapmeld ! My 2 cents (for a next iteration), it would be cool to have a small search widget in the filter dropdown as you have a ton of languages now here! Closing this in the meantime."
] |
https://api.github.com/repos/huggingface/datasets/issues/3516 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3516/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3516/comments | https://api.github.com/repos/huggingface/datasets/issues/3516/events | https://github.com/huggingface/datasets/pull/3516 | 1,092,657,738 | PR_kwDODunzps4weYhE | 3,516 | dataset `asset` - change to raw.githubusercontent.com URLs | [] | closed | false | null | 0 | 2022-01-03T16:43:57Z | 2022-01-03T17:39:02Z | 2022-01-03T17:39:01Z | null | Changed the URLs to the ones it was automatically re-directing.
Before, the download was failing | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3516/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3516/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3516.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3516",
"merged_at": "2022-01-03T17:39:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3516.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3516"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | https://api.github.com/repos/huggingface/datasets/issues/5366/events | https://github.com/huggingface/datasets/pull/5366 | 1,498,530,851 | PR_kwDODunzps5FjSFl | 5,366 | ExamplesIterable fixes | [] | closed | false | null | 1 | 2022-12-15T14:23:05Z | 2022-12-15T14:44:47Z | 2022-12-15T14:41:45Z | null | fix typing and ExamplesIterable.shard_data_sources | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5366/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"merged_at": "2022-12-15T14:41:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5366"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3244/comments | https://api.github.com/repos/huggingface/datasets/issues/3244/events | https://github.com/huggingface/datasets/pull/3244 | 1,048,675,741 | PR_kwDODunzps4uSgG5 | 3,244 | Fix filter method for batched=True | [] | closed | false | null | 0 | 2021-11-09T14:30:59Z | 2021-11-09T15:52:58Z | 2021-11-09T15:52:57Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3244/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3244.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3244",
"merged_at": "2021-11-09T15:52:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3244.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3244"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2765/comments | https://api.github.com/repos/huggingface/datasets/issues/2765/events | https://github.com/huggingface/datasets/issues/2765 | 962,861,395 | MDU6SXNzdWU5NjI4NjEzOTU= | 2,765 | BERTScore Error | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-08-06T15:58:57Z | 2021-08-09T11:16:25Z | 2021-08-09T11:16:25Z | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
predictions = ["hello there", "general kenobi"]
references = ["hello there", "general kenobi"]
bert = load_metric('bertscore')
bert.compute(predictions=predictions, references=references,lang='en')
```
# Bug
`TypeError: get_hash() missing 1 required positional argument: 'use_fast_tokenizer'`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Colab
- Python version:
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2765/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nThe `use_fast_tokenizer` argument has been recently added to the bert-score lib. I've opened a PR with the fix. In the meantime, you can try to downgrade the version of bert-score with the following command to make the code work:\r\n```\r\npip uninstall bert-score\r\npip install \"bert-score<0.3.10\"\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/2955 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2955/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2955/comments | https://api.github.com/repos/huggingface/datasets/issues/2955/events | https://github.com/huggingface/datasets/pull/2955 | 1,003,999,469 | PR_kwDODunzps4sHuRu | 2,955 | Update legacy Python image for CI tests in Linux | [] | closed | false | null | 1 | 2021-09-22T08:25:27Z | 2021-09-24T10:36:05Z | 2021-09-24T10:36:05Z | null | Instead of legacy, use next-generation convenience images, built from the ground up with CI, efficiency, and determinism in mind. Here are some of the highlights:
- Faster spin-up time - In Docker terminology, these next-gen images will generally have fewer and smaller layers. Using these new images will lead to faster image downloads when a build starts, and a higher likelihood that the image is already cached on the host.
- Improved reliability and stability - The existing legacy convenience images are rebuilt practically every day with potential changes from upstream that we cannot always test fast enough. This leads to frequent breaking changes, which is not the best environment for stable, deterministic builds. Next-gen images will only be rebuilt for security and critical-bugs, leading to more stable and deterministic images.
More info: https://circleci.com/docs/2.0/circleci-images | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2955/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2955/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2955.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2955",
"merged_at": "2021-09-24T10:36:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2955.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2955"
} | true | [
"There is an exception when running `pip install .[tests]`:\r\n```\r\nProcessing /home/circleci/datasets\r\nCollecting numpy>=1.17 (from datasets==1.12.2.dev0)\r\n Downloading https://files.pythonhosted.org/packages/45/b2/6c7545bb7a38754d63048c7696804a0d947328125d81bf12beaa692c3ae3/numpy-1.19.5-cp36-cp36m-manylinux1_x86_64.whl (13.4MB)\r\n 100% |████████████████████████████████| 13.4MB 3.9MB/s eta 0:00:011\r\n\r\n...\r\n\r\nCollecting faiss-cpu (from datasets==1.12.2.dev0)\r\n Downloading https://files.pythonhosted.org/packages/87/91/bf8ea0d42733cbb04f98d3bf27808e4919ceb5ec71102e21119398a97237/faiss-cpu-1.7.1.post2.tar.gz (41kB)\r\n 100% |████████████████████████████████| 51kB 30.9MB/s ta 0:00:01\r\n Complete output from command python setup.py egg_info:\r\n Traceback (most recent call last):\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 154, in save_modules\r\n yield saved\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 195, in setup_context\r\n yield\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 250, in run_setup\r\n _execfile(setup_script, ns)\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 45, in _execfile\r\n exec(code, globals, locals)\r\n File \"/tmp/easy_install-1pop4blm/numpy-1.21.2/setup.py\", line 34, in <module>\r\n method can be invoked.\r\n RuntimeError: Python version >= 3.7 required.\r\n```\r\n\r\nApparently, `numpy-1.21.2` tries to be installed in the temporary directory `/tmp/easy_install-1pop4blm` instead of the downloaded `numpy-1.19.5` (requirement of `datasets`).\r\n\r\nThis is caused because `pip` downloads the `.tar.gz` (instead of the `.whl`) and tries to build it in a tmp dir."
] |
https://api.github.com/repos/huggingface/datasets/issues/157 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/157/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/157/comments | https://api.github.com/repos/huggingface/datasets/issues/157/events | https://github.com/huggingface/datasets/issues/157 | 620,356,542 | MDU6SXNzdWU2MjAzNTY1NDI= | 157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | [] | closed | false | null | 11 | 2020-05-18T16:46:38Z | 2020-06-05T08:08:58Z | 2020-06-05T08:08:58Z | null | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/157/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/157/timeline | null | completed | null | null | false | [
"You can just run: \r\n`val = nlp.load_dataset('squad')` \r\n\r\nif you want to have just the validation script you can also do:\r\n\r\n`val = nlp.load_dataset('squad', split=\"validation\")`",
"If you want to load a local dataset, make sure you include a `./` before the folder name. ",
"This happens by just doing run all cells on colab ... I assumed the colab example is broken. ",
"Oh I see you might have a wrong version of pyarrow install on the colab -> could you try the following. Add these lines to the beginning of your notebook, restart the runtime and run it again:\r\n```\r\n!pip uninstall -y -qq pyarrow\r\n!pip uninstall -y -qq nlp\r\n!pip install -qq git+https://github.com/huggingface/nlp.git\r\n```",
"> Oh I see you might have a wrong version of pyarrow install on the colab -> could you try the following. Add these lines to the beginning of your notebook, restart the runtime and run it again:\r\n> \r\n> ```\r\n> !pip uninstall -y -qq pyarrow\r\n> !pip uninstall -y -qq nlp\r\n> !pip install -qq git+https://github.com/huggingface/nlp.git\r\n> ```\r\n\r\nTried, having the same error.",
"Can you post a link here of your colab? I'll make a copy of it and see what's wrong",
"This should be fixed in the current version of the notebook. You can try it again",
"Also see: https://github.com/huggingface/nlp/issues/222",
"I am getting this error when running this command\r\n```\r\nval = nlp.load_dataset('squad', split=\"validation\")\r\n```\r\n\r\nFileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/datasets/squad/plain_text/1.0.0/dataset_info.json'\r\n\r\nCan anybody help?",
"It seems like your download was corrupted :-/ Can you run the following command: \r\n\r\n```\r\nrm -r /root/.cache/huggingface/datasets\r\n```\r\n\r\nto delete the cache completely and rerun the download? ",
"I tried the notebook again today and it worked without barfing. 👌 "
] |
https://api.github.com/repos/huggingface/datasets/issues/4833 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4833/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4833/comments | https://api.github.com/repos/huggingface/datasets/issues/4833/events | https://github.com/huggingface/datasets/pull/4833 | 1,336,946,965 | PR_kwDODunzps49E_Nk | 4,833 | Fix missing tags in dataset cards | [] | closed | false | null | 1 | 2022-08-12T09:04:52Z | 2022-09-22T14:41:23Z | 2022-08-12T09:45:55Z | null | Fix missing tags in dataset cards:
- boolq
- break_data
- definite_pronoun_resolution
- emo
- kor_nli
- pg19
- quartz
- sciq
- squad_es
- wmt14
- wmt15
- wmt16
- wmt17
- wmt18
- wmt19
- wmt_t2t
This PR partially fixes the missing tags in dataset cards. Subsequent PRs will follow to complete this task. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4833/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4833/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4833.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4833",
"merged_at": "2022-08-12T09:45:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4833.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4833"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2643/comments | https://api.github.com/repos/huggingface/datasets/issues/2643/events | https://github.com/huggingface/datasets/issues/2643 | 944,220,273 | MDU6SXNzdWU5NDQyMjAyNzM= | 2,643 | Enum used in map functions will raise a RecursionError with dill. | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 4 | 2021-07-14T09:16:08Z | 2021-11-02T09:51:11Z | null | null | ## Describe the bug
Enums used in functions pass to `map` will fail at pickling with a maximum recursion exception as described here: https://github.com/uqfoundation/dill/issues/250#issuecomment-852566284
In my particular case, I use an enum to define an argument with fixed options using the `TraininigArguments` dataclass as base class and the `HfArgumentParser`. In the same file I use a `ds.map` that tries to pickle the content of the module including the definition of the enum that runs into the dill bug described above.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from enum import Enum
class A(Enum):
a = 'a'
def main():
a = A.a
def f(x):
return {} if a == a.a else x
ds = load_dataset('cnn_dailymail', '3.0.0')['test']
ds = ds.map(f, num_proc=15)
if __name__ == "__main__":
main()
```
## Expected results
The known problem with dill could be prevented as explained in the link above (workaround.) Since `HFArgumentParser` nicely uses the enum class for choices it makes sense to also deal with this bug under the hood.
## Actual results
```python
File "/home/xxxx/miniconda3/lib/python3.8/site-packages/dill/_dill.py", line 1373, in save_type
pickler.save_reduce(_create_type, (type(obj), obj.__name__,
File "/home/xxxx/miniconda3/lib/python3.8/pickle.py", line 690, in save_reduce
save(args)
File "/home/xxxx/miniconda3/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/xxxx/miniconda3/lib/python3.8/pickle.py", line 899, in save_tuple
save(element)
File "/home/xxxx/miniconda3/lib/python3.8/pickle.py", line 534, in save
self.framer.commit_frame()
File "/home/xxxx/miniconda3/lib/python3.8/pickle.py", line 220, in commit_frame
if f.tell() >= self._FRAME_SIZE_TARGET or force:
RecursionError: maximum recursion depth exceeded while calling a Python object
```
## Environment info
- `datasets` version: 1.8.0
- Platform: Linux-5.9.0-4-amd64-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2643/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2643/timeline | null | null | null | null | false | [
"I'm running into this as well. (Thank you so much for reporting @jorgeecardona — was staring at this massive stack trace and unsure what exactly was wrong!)",
"Hi ! Thanks for reporting :)\r\n\r\nUntil this is fixed on `dill`'s side, we could implement a custom saving in our Pickler indefined in utils.py_utils.py\r\nThere is already a suggestion in this message about how to do it:\r\nhttps://github.com/uqfoundation/dill/issues/250#issuecomment-852566284\r\n\r\nLet me know if such a workaround could help, and feel free to open a PR if you want to contribute !",
"I have the same bug.\r\nthe code is as follows:\r\n\r\nthe error is: \r\n\r\n\r\nLook for the solution for this bug.",
"Hi ! I think your RecursionError comes from a different issue @BitcoinNLPer , could you open a separate issue please ?\r\n\r\nAlso which dataset are you using ? I tried loading `CodedotAI/code_clippy` but I get a different error\r\n```python\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/quentinlhoest/Desktop/hf/datasets/src/datasets/load.py\", line 1615, in load_dataset\r\n **config_kwargs,\r\n File \"/Users/quentinlhoest/Desktop/hf/datasets/src/datasets/load.py\", line 1446, in load_dataset_builder\r\n builder_cls = import_main_class(dataset_module.module_path)\r\n File \"/Users/quentinlhoest/Desktop/hf/datasets/src/datasets/load.py\", line 101, in import_main_class\r\n module = importlib.import_module(module_path)\r\n File \"/Users/quentinlhoest/.virtualenvs/hf-datasets/lib/python3.7/importlib/__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 1006, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 983, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 967, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 677, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 728, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"/Users/quentinlhoest/.cache/huggingface/modules/datasets_modules/datasets/CodedotAI___code_clippy/d332f69d036e8c80f47bc9a96d676c3fa30cb50af7bb81e2d4d12e80b83efc4d/code_clippy.py\", line 66, in <module>\r\n url_elements = results.find_all(\"a\")\r\nAttributeError: 'NoneType' object has no attribute 'find_all'\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/1563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1563/comments | https://api.github.com/repos/huggingface/datasets/issues/1563/events | https://github.com/huggingface/datasets/pull/1563 | 766,211,931 | MDExOlB1bGxSZXF1ZXN0NTM5MzA4Mzg4 | 1,563 | adding tmu-gfm-dataset | [] | closed | false | null | 2 | 2020-12-14T09:45:30Z | 2020-12-21T10:21:04Z | 2020-12-21T10:07:13Z | null | Adding TMU-GFM-Dataset for Grammatical Error Correction.
https://github.com/tmu-nlp/TMU-GFM-Dataset
A dataset for GEC metrics with manual evaluations of grammaticality, fluency, and meaning preservation for system outputs.
More detail about the creation of the dataset can be found in [Yoshimura et al. (2020)](https://www.aclweb.org/anthology/2020.coling-main.573.pdf). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1563/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1563/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1563.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1563",
"merged_at": "2020-12-21T10:07:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1563.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1563"
} | true | [
"@lhoestq Thank you for your code review! I think I could do the necessary corrections. Could you please check it again when you have time?",
"Thank you for merging!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4891 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4891/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4891/comments | https://api.github.com/repos/huggingface/datasets/issues/4891/events | https://github.com/huggingface/datasets/pull/4891 | 1,350,589,813 | PR_kwDODunzps49x382 | 4,891 | Fix missing tags in dataset cards | [] | closed | false | null | 0 | 2022-08-25T09:14:17Z | 2022-09-22T14:39:02Z | 2022-08-25T13:43:34Z | null | Fix missing tags in dataset cards:
- aslg_pc12
- librispeech_lm
- mwsc
- opus100
- qasc
- quail
- squadshifts
- winograd_wsc
This PR partially fixes the missing tags in dataset cards. Subsequent PRs will follow to complete this task.
Related to:
- #4833
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4891/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4891/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4891.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4891",
"merged_at": "2022-08-25T13:43:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4891.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4891"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2380/comments | https://api.github.com/repos/huggingface/datasets/issues/2380/events | https://github.com/huggingface/datasets/pull/2380 | 895,367,201 | MDExOlB1bGxSZXF1ZXN0NjQ3NTk3NTc3 | 2,380 | maintain YAML structure reading from README | [] | closed | false | null | 0 | 2021-05-19T12:12:07Z | 2021-05-19T13:08:38Z | 2021-05-19T13:08:38Z | null | How YAML used be loaded earlier in the string (structure of YAML was affected because of this and YAML for datasets with multiple configs was not being loaded correctly):
```
annotations_creators:
labeled_final:
- expert-generated
labeled_swap:
- expert-generated
unlabeled_final:
- machine-generated
language_creators:
- machine-generated
languages:
- en
licenses:
- other
multilinguality:
- monolingual
size_categories:
labeled_final:
- 10K<n<100K
labeled_swap:
- 10K<n<100K
unlabeled_final:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
- text-scoring
task_ids:
- semantic-similarity-classification
- semantic-similarity-scoring
- text-scoring-other-paraphrase-identification
```
How YAML is loaded in string now:
```
annotations_creators:
labeled_final:
- expert-generated
labeled_swap:
- expert-generated
unlabeled_final:
- machine-generated
language_creators:
- machine-generated
languages:
- en
licenses:
- other
multilinguality:
- monolingual
size_categories:
labeled_final:
- 10K<n<100K
labeled_swap:
- 10K<n<100K
unlabeled_final:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
- text-scoring
task_ids:
- semantic-similarity-classification
- semantic-similarity-scoring
- text-scoring-other-paraphrase-identification
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2380/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2380/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2380.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2380",
"merged_at": "2021-05-19T13:08:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2380.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2380"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3054 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3054/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3054/comments | https://api.github.com/repos/huggingface/datasets/issues/3054/events | https://github.com/huggingface/datasets/pull/3054 | 1,022,108,186 | PR_kwDODunzps4s_TmE | 3,054 | Update Biosses | [] | closed | false | null | 0 | 2021-10-10T22:25:12Z | 2021-10-13T09:04:27Z | 2021-10-13T09:04:27Z | null | Fix variable naming | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3054/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3054/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3054.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3054",
"merged_at": "2021-10-13T09:04:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3054.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3054"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/882 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/882/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/882/comments | https://api.github.com/repos/huggingface/datasets/issues/882/events | https://github.com/huggingface/datasets/pull/882 | 749,662,188 | MDExOlB1bGxSZXF1ZXN0NTI2NDQyMjA2 | 882 | Update README.md | [] | closed | false | null | 0 | 2020-11-24T12:23:52Z | 2021-01-29T10:41:07Z | 2021-01-29T10:41:07Z | null | "no label" is "-" in the original dataset but "-1" in Huggingface distribution. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/882/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/882/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/882.diff",
"html_url": "https://github.com/huggingface/datasets/pull/882",
"merged_at": "2021-01-29T10:41:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/882.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/882"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5948 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5948/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5948/comments | https://api.github.com/repos/huggingface/datasets/issues/5948/events | https://github.com/huggingface/datasets/pull/5948 | 1,754,794,611 | PR_kwDODunzps5S4dUt | 5,948 | Fix sequence of array support for most dtype | [] | closed | false | null | 2 | 2023-06-13T12:38:59Z | 2023-06-14T15:11:55Z | 2023-06-14T15:03:33Z | null | Fixes #5936
Also, a related fix to #5927 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5948/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5948/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5948.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5948",
"merged_at": "2023-06-14T15:03:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5948.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5948"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007220 / 0.011353 (-0.004133) | 0.004558 / 0.011008 (-0.006451) | 0.116647 / 0.038508 (0.078139) | 0.046845 / 0.023109 (0.023736) | 0.352429 / 0.275898 (0.076531) | 0.429739 / 0.323480 (0.106259) | 0.006620 / 0.007986 (-0.001366) | 0.003731 / 0.004328 (-0.000597) | 0.088683 / 0.004250 (0.084433) | 0.070583 / 0.037052 (0.033530) | 0.366699 / 0.258489 (0.108210) | 0.420730 / 0.293841 (0.126889) | 0.037342 / 0.128546 (-0.091204) | 0.010041 / 0.075646 (-0.065605) | 0.383477 / 0.419271 (-0.035795) | 0.060279 / 0.043533 (0.016746) | 0.349988 / 0.255139 (0.094849) | 0.371423 / 0.283200 (0.088224) | 0.026725 / 0.141683 (-0.114958) | 1.736886 / 1.452155 (0.284731) | 1.812874 / 1.492716 (0.320157) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.253256 / 0.018006 (0.235250) | 0.563470 / 0.000490 (0.562980) | 0.010475 / 0.000200 (0.010275) | 0.000164 / 0.000054 (0.000110) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030518 / 0.037411 (-0.006893) | 0.133324 / 0.014526 (0.118798) | 0.137095 / 0.176557 (-0.039461) | 0.202227 / 0.737135 (-0.534909) | 0.144195 / 0.296338 (-0.152143) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.480870 / 0.215209 (0.265661) | 4.822713 / 2.077655 (2.745058) | 2.124183 / 1.504120 (0.620064) | 1.910733 / 1.541195 (0.369538) | 1.970266 / 1.468490 (0.501776) | 0.624695 / 4.584777 (-3.960082) | 4.459659 / 3.745712 (0.713947) | 2.210123 / 5.269862 (-3.059739) | 1.300520 / 4.565676 (-3.265157) | 0.077096 / 0.424275 (-0.347180) | 0.013333 / 0.007607 (0.005726) | 0.596841 / 0.226044 (0.370797) | 5.917397 / 2.268929 (3.648469) | 2.699397 / 55.444624 (-52.745228) | 2.274833 / 6.876477 (-4.601644) | 2.525376 / 2.142072 (0.383304) | 0.755718 / 4.805227 (-4.049510) | 0.163587 / 6.500664 (-6.337077) | 0.072817 / 0.075469 (-0.002653) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.524306 / 1.841788 (-0.317481) | 18.843312 / 8.074308 (10.769004) | 15.694644 / 10.191392 (5.503252) | 0.177400 / 0.680424 (-0.503024) | 0.020104 / 0.534201 (-0.514097) | 0.466421 / 0.579283 (-0.112862) | 0.537274 / 0.434364 (0.102910) | 0.576920 / 0.540337 (0.036583) | 0.718889 / 1.386936 (-0.668047) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007671 / 0.011353 (-0.003682) | 0.004850 / 0.011008 (-0.006158) | 0.090085 / 0.038508 (0.051576) | 0.052023 / 0.023109 (0.028914) | 0.508575 / 0.275898 (0.232677) | 0.590024 / 0.323480 (0.266544) | 0.004564 / 0.007986 (-0.003422) | 0.005345 / 0.004328 (0.001017) | 0.087904 / 0.004250 (0.083653) | 0.064446 / 0.037052 (0.027394) | 0.525625 / 0.258489 (0.267136) | 0.584307 / 0.293841 (0.290466) | 0.037221 / 0.128546 (-0.091325) | 0.010588 / 0.075646 (-0.065059) | 0.098612 / 0.419271 (-0.320659) | 0.059597 / 0.043533 (0.016064) | 0.488064 / 0.255139 (0.232925) | 0.522330 / 0.283200 (0.239131) | 0.030004 / 0.141683 (-0.111679) | 1.732512 / 1.452155 (0.280357) | 1.809027 / 1.492716 (0.316310) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.218741 / 0.018006 (0.200735) | 0.494946 / 0.000490 (0.494456) | 0.004580 / 0.000200 (0.004380) | 0.000104 / 0.000054 (0.000049) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034916 / 0.037411 (-0.002495) | 0.133695 / 0.014526 (0.119169) | 0.147964 / 0.176557 (-0.028592) | 0.213210 / 0.737135 (-0.523926) | 0.148850 / 0.296338 (-0.147488) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.508855 / 0.215209 (0.293646) | 5.065088 / 2.077655 (2.987433) | 2.473110 / 1.504120 (0.968990) | 2.259765 / 1.541195 (0.718570) | 2.359189 / 1.468490 (0.890699) | 0.639082 / 4.584777 (-3.945695) | 4.768195 / 3.745712 (1.022482) | 2.253803 / 5.269862 (-3.016059) | 1.442996 / 4.565676 (-3.122680) | 0.078761 / 0.424275 (-0.345514) | 0.013936 / 0.007607 (0.006329) | 0.625977 / 0.226044 (0.399933) | 6.260817 / 2.268929 (3.991888) | 3.149640 / 55.444624 (-52.294985) | 2.753555 / 6.876477 (-4.122921) | 2.831872 / 2.142072 (0.689799) | 0.781294 / 4.805227 (-4.023933) | 0.169109 / 6.500664 (-6.331555) | 0.075810 / 0.075469 (0.000341) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.533282 / 1.841788 (-0.308506) | 19.460579 / 8.074308 (11.386271) | 17.250424 / 10.191392 (7.059032) | 0.193485 / 0.680424 (-0.486939) | 0.020650 / 0.534201 (-0.513551) | 0.472110 / 0.579283 (-0.107173) | 0.532276 / 0.434364 (0.097912) | 0.613152 / 0.540337 (0.072814) | 0.684684 / 1.386936 (-0.702252) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2622/comments | https://api.github.com/repos/huggingface/datasets/issues/2622/events | https://github.com/huggingface/datasets/issues/2622 | 941,127,785 | MDU6SXNzdWU5NDExMjc3ODU= | 2,622 | Integration with AugLy | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2021-07-10T00:03:09Z | 2023-07-20T13:18:48Z | 2023-07-20T13:18:47Z | null | **Is your feature request related to a problem? Please describe.**
Facebook recently launched a library, [AugLy](https://github.com/facebookresearch/AugLy) , that has a unified API for augmentations for image, video and text.
It would be pretty exciting to have it hooked up to HF libraries so that we can make NLP models robust to misspellings or to punctuation, or emojis etc. Plus, with Transformers supporting more CV use cases, having augmentations support becomes crucial.
**Describe the solution you'd like**
The biggest difference between augmentations and preprocessing is that preprocessing happens only once, but you are running augmentations once per epoch. AugLy operates on text directly, so this breaks the typical workflow where we would run the tokenizer once, set format to pt tensors and be ready for the Dataloader.
**Describe alternatives you've considered**
One possible way of implementing these is to make a custom Dataset class where getitem(i) runs the augmentation and the tokenizer every time, though this would slow training down considerably given we wouldn't even run the tokenizer in batches.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2622/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2622/timeline | null | not_planned | null | null | false | [
"Hi,\r\n\r\nyou can define your own custom formatting with `Dataset.set_transform()` and then run the tokenizer with the batches of augmented data as follows:\r\n```python\r\ndset = load_dataset(\"imdb\", split=\"train\") # Let's say we are working with the IMDB dataset\r\ndset.set_transform(lambda ex: {\"text\": augly_text_augmentation(ex[\"text\"])}, columns=\"text\", output_all_columns=True)\r\ndataloader = torch.utils.data.DataLoader(dset, batch_size=32)\r\nfor epoch in range(5):\r\n for batch in dataloader:\r\n tokenizer_output = tokenizer(batch.pop(\"text\"), padding=True, truncation=True, return_tensors=\"pt\")\r\n batch.update(tokenizer_output)\r\n output = model(**batch)\r\n ...\r\n```",
"Preprocessing functions/augmentations, unless super generic, should be defined in separate libraries, so I'm closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/4589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4589/comments | https://api.github.com/repos/huggingface/datasets/issues/4589/events | https://github.com/huggingface/datasets/issues/4589 | 1,287,600,029 | I_kwDODunzps5Mvzed | 4,589 | Permission denied: '/home/.cache' when load_dataset with local script | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-06-28T16:26:03Z | 2022-06-29T06:26:28Z | 2022-06-29T06:25:08Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4589/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4589/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4363/comments | https://api.github.com/repos/huggingface/datasets/issues/4363/events | https://github.com/huggingface/datasets/issues/4363 | 1,238,897,652 | I_kwDODunzps5J2BP0 | 4,363 | The dataset preview is not available for this split. | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 7 | 2022-05-17T16:34:43Z | 2022-06-08T12:32:10Z | 2022-06-08T09:26:56Z | null | I have uploaded the corpus developed by our lab in the speech domain to huggingface [datasets](https://huggingface.co/datasets/Roh/ryanspeech). You can read about the companion paper accepted in interspeech 2021 [here](https://arxiv.org/abs/2106.08468). The dataset works fine but I can't make the dataset preview work. It gives me the following error that I don't understand. Can you help me to begin debugging it?
```
Status code: 400
Exception: AttributeError
Message: 'NoneType' object has no attribute 'split'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4363/timeline | null | completed | null | null | false | [
"Hi! A dataset has to be streamable to work with the viewer. I did a quick test, and yours is, so this might be a bug in the viewer. cc @severo \r\n",
"Looking at it. The message is now:\r\n\r\n```\r\nMessage: cannot cache function '__shear_dense': no locator available for file '/src/services/worker/.venv/lib/python3.9/site-packages/librosa/util/utils.py'\r\n```\r\n\r\nso possibly it's related to the libraries versions?\r\n",
"Maybe this SO thread can help: https://stackoverflow.com/questions/59290386/runtimeerror-at-cannot-cache-function-shear-dense-no-locator-available-fo",
"Same error for https://huggingface.co/datasets/LIUM/tedlium/viewer/release1/test. cc @sanchit-gandhi . I'm on it",
"Fixed in the datasets viewer, by setting the `NUMBA_CACHE_DIR` env var to a writable directory.",
"https://huggingface.co/datasets/Roh/ryanspeech/viewer/male/train\r\n\r\n<img width=\"1538\" alt=\"Capture d’écran 2022-06-08 à 11 30 08\" src=\"https://user-images.githubusercontent.com/1676121/172583285-4cd49a0f-5715-423b-95dd-5f6ace3b2416.png\">\r\n",
"https://huggingface.co/datasets/LIUM/tedlium/viewer/\r\n\r\n<img width=\"1538\" alt=\"Capture d’écran 2022-06-08 à 14 31 52\" src=\"https://user-images.githubusercontent.com/1676121/172616897-fbcb7df7-0308-4d09-a17d-48826bc91374.png\">\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1978 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1978/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1978/comments | https://api.github.com/repos/huggingface/datasets/issues/1978/events | https://github.com/huggingface/datasets/pull/1978 | 820,956,806 | MDExOlB1bGxSZXF1ZXN0NTgzODI5Njgz | 1,978 | Adding ro sts dataset | [] | closed | false | null | 3 | 2021-03-03T10:08:53Z | 2021-03-05T10:00:14Z | 2021-03-05T09:33:55Z | null | Adding [RO-STS](https://github.com/dumitrescustefan/RO-STS) dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1978/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1978/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1978.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1978",
"merged_at": "2021-03-05T09:33:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1978.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1978"
} | true | [
"@lhoestq thank you very much for the quick review and useful comments! \r\n\r\nI have tried to address them all, and a few comments that you left for ro_sts I have applied to the ro_sts_parallel as well (in read-me: fixed source_datasets, links to homepage, repository, leaderboard, thanks to me message, in ro_sts_parallel.py changed to camel case as well). In the ro_sts_parallel I have changed the order on the languages, also in the example, as you said order doesn't matter, but just to have them listed in the readme in the same order.\r\n\r\nI have commented above on why we would like to keep them as separate datasets, hope it makes sense.\r\n\r\nIf there is anything else I should change please let me know.\r\n\r\nThanks again!",
"@lhoestq I tried to adjust the ro_sts_parallel, locally when I run the tests they are passing, but somewhere it has the old name of rosts-parallel-ro-en which I am trying to change to ro_sts_parallel. I don't think I have left anything related to rosts-parallel-ro-en, but when the dataset_infos.json is regenerated it adds it. Could you please help me out, how can I fix this? Thanks in advance!",
"Great, thanks for all your help! "
] |
https://api.github.com/repos/huggingface/datasets/issues/4393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4393/comments | https://api.github.com/repos/huggingface/datasets/issues/4393/events | https://github.com/huggingface/datasets/pull/4393 | 1,244,876,662 | PR_kwDODunzps44RxWN | 4,393 | Update CI deprecated legacy image | [] | closed | false | null | 1 | 2022-05-23T09:35:42Z | 2022-05-23T10:08:28Z | 2022-05-23T09:59:55Z | null | Now our CI still uses a deprecated legacy image:
> You’re using a [deprecated Docker convenience image.](https://discuss.circleci.com/t/legacy-convenience-image-deprecation/41034) Upgrade to a next-gen Docker convenience image.
This PR updates to next-generation convenience image.
Related to:
- #2955 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4393/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4393/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4393.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4393",
"merged_at": "2022-05-23T09:59:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4393.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4393"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4480/comments | https://api.github.com/repos/huggingface/datasets/issues/4480/events | https://github.com/huggingface/datasets/issues/4480 | 1,268,921,567 | I_kwDODunzps5LojTf | 4,480 | Bigbench tensorflow GPU dependency | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2022-06-13T05:24:06Z | 2022-06-14T19:45:24Z | 2022-06-14T19:45:23Z | null | ## Describe the bug
Loading bigbech
```py
from datasets import load_dataset
dataset = load_dataset("bigbench","swedish_to_german_proverbs")
```
tries to use gpu and fails with OOM with the following error
```
Downloading and preparing dataset bigbench/swedish_to_german_proverbs (download: Unknown size, generated: 68.92 KiB, post-processed: Unknown size, total: 68.92 KiB) to /home/ceyda/.cache/huggingface/datasets/bigbench/swedish_to_german_proverbs/1.0.0/7d2f6e537fa937dfaac8b1c1df782f2055071d3fd8e4f4ae93d28012a354ced0...
Generating default split: 0%| | 0/72 [00:00<?, ? examples/s]2022-06-13 14:11:04.154469: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-06-13 14:11:05.133600: F tensorflow/core/platform/statusor.cc:33] Attempting to fetch value instead of handling error INTERNAL: failed initializing StreamExecutor for CUDA device ordinal 3: INTERNAL: failed call to cuDevicePrimaryCtxRetain: CUDA_ERROR_OUT_OF_MEMORY: out of memory; total memory reported: 25396838400
Aborted (core dumped)
```
I think this is because bigbench dependency (below) installs tensorflow (GPU version) and dataloading tries to use GPU as default.
`pip install bigbench@https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz`
while just doing 'pip install bigbench' results in following error
```
File "/home/ceyda/.local/lib/python3.7/site-packages/datasets/load.py", line 109, in import_main_class
module = importlib.import_module(module_path)
File "/usr/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/ceyda/.cache/huggingface/modules/datasets_modules/datasets/bigbench/7d2f6e537fa937dfaac8b1c1df782f2055071d3fd8e4f4ae93d28012a354ced0/bigbench.py", line 118, in <module>
class Bigbench(datasets.GeneratorBasedBuilder):
File "/home/ceyda/.cache/huggingface/modules/datasets_modules/datasets/bigbench/7d2f6e537fa937dfaac8b1c1df782f2055071d3fd8e4f4ae93d28012a354ced0/bigbench.py", line 127, in Bigbench
BigBenchConfig(name=name, version=datasets.Version("1.0.0")) for name in bb_utils.get_all_json_task_names()
AttributeError: module 'bigbench.api.util' has no attribute 'get_all_json_task_names'
```
## Steps to avoid the bug
Not ideal but can solve with (since I don't really use tensorflow elsewhere)
`pip uninstall tensorflow`
`pip install tensorflow-cpu`
## Environment info
- datasets @ master
- Python version: 3.7
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4480/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4480/timeline | null | completed | null | null | false | [
"Thanks for reporting ! :) cc @andersjohanandreassen can you take a look at this ?\r\n\r\nAlso @cceyda feel free to open an issue at [BIG-Bench](https://github.com/google/BIG-bench) as well regarding the `AttributeError`",
"I'm on vacation for the next week, so won't be able to do much debugging at the moment. Sorry for the inconvenience.\r\nBut I did quickly take a look:\r\n\r\n**pypi**:\r\nI managed to reproduce the above error with the pypi version begin out of date. \r\nThe version on `https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz` should be up to date, but it was my understanding that there was some issue with the pypi upload, so I don't even understand why there is a version [on pypi from April 1](https://pypi.org/project/bigbench/0.0.1/). Perhaps @ethansdyer, who's handling the pypi upload, knows the answer to that?\r\n\r\n**OOM error**:\r\nBut, I'm unable to reproduce the OOM error in a google colab with GPU enabled.\r\nThis is what I ran:\r\n```\r\n!pip install bigbench@https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz\r\n!pip install datasets\r\n\r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"bigbench\",\"swedish_to_german_proverbs\")\r\n``` \r\nThe `swedish_to_german_proverbs`task is only 72 examples, so I don't understand what could be causing the OOM error. Loading the task has no effect on the RAM for me. @cceyda Can you confirm that this does not occur in a [colab](https://colab.research.google.com/)?\r\nIf the GPU is somehow causing issues on your system, disabling the GPU from TF might be an option too\r\n```\r\nimport os\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"-1\"\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n",
"Solved.\r\nYes it works on colab, and somehow magically on my machine too now. hmm not sure what was wrong before I had used a fresh venv both times with just the dataloading code, and tried multiple times. (maybe just a wrong tensorflow version got mixed up somehow) The tensorflow call seems to come from the bigbench side anyway.\r\n\r\nabout bigbench pypi version update, I opened an issue over there https://github.com/google/BIG-bench/issues/846\r\n\r\nanyway closing this now. If anyone else has the same problem can re-open."
] |
https://api.github.com/repos/huggingface/datasets/issues/3106 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3106/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3106/comments | https://api.github.com/repos/huggingface/datasets/issues/3106/events | https://github.com/huggingface/datasets/pull/3106 | 1,030,112,473 | PR_kwDODunzps4tYA6i | 3,106 | Fix URLs in blog_authorship_corpus dataset | [] | closed | false | null | 0 | 2021-10-19T10:06:05Z | 2021-10-19T12:50:40Z | 2021-10-19T12:50:39Z | null | After contacting the authors of the paper "Effects of Age and Gender on Blogging", they confirmed:
- the old URLs are no longer valid
- there are alternative host URLs
Fix #3091. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3106/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3106/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3106.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3106",
"merged_at": "2021-10-19T12:50:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3106.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3106"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/457/comments | https://api.github.com/repos/huggingface/datasets/issues/457/events | https://github.com/huggingface/datasets/pull/457 | 668,898,386 | MDExOlB1bGxSZXF1ZXN0NDU5MzMyOTM1 | 457 | add set_format to DatasetDict + tests | [] | closed | false | null | 0 | 2020-07-30T15:53:20Z | 2020-07-30T17:34:36Z | 2020-07-30T17:34:34Z | null | Add the `set_format` and `formated_as` and `reset_format` to `DatasetDict`.
Add tests to these for `Dataset` and `DatasetDict`.
Fix some bugs uncovered by the tests for `pandas` formating. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/457/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/457.diff",
"html_url": "https://github.com/huggingface/datasets/pull/457",
"merged_at": "2020-07-30T17:34:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/457.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/457"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3932 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3932/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3932/comments | https://api.github.com/repos/huggingface/datasets/issues/3932/events | https://github.com/huggingface/datasets/pull/3932 | 1,170,221,773 | PR_kwDODunzps40fd0T | 3,932 | Create SARI metric card | [] | closed | false | null | 1 | 2022-03-15T20:37:23Z | 2022-03-18T17:37:01Z | 2022-03-18T17:32:55Z | null | SARI metric card! (do we have an expert in text simplification to validate?.. :sweat_smile: ) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3932/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3932/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3932.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3932",
"merged_at": "2022-03-18T17:32:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3932.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3932"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2082 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2082/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2082/comments | https://api.github.com/repos/huggingface/datasets/issues/2082/events | https://github.com/huggingface/datasets/pull/2082 | 835,401,555 | MDExOlB1bGxSZXF1ZXN0NTk2MDY1NTM0 | 2,082 | Updated card using information from data statement and datasheet | [] | closed | false | null | 0 | 2021-03-19T00:39:38Z | 2021-03-19T14:29:09Z | 2021-03-19T14:29:09Z | null | I updated and clarified the REFreSD [data card](https://github.com/mcmillanmajora/datasets/blob/refresd_card/datasets/refresd/README.md) with information from the Eleftheria's [website](https://elbria.github.io/post/refresd/). I added brief descriptions where the initial card referred to the paper, and I also recreated some of the tables in the paper to show relevant dataset statistics.
I'll email Eleftheria to see if she has any comments on the card. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2082/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2082/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2082.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2082",
"merged_at": "2021-03-19T14:29:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2082.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2082"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3350/comments | https://api.github.com/repos/huggingface/datasets/issues/3350/events | https://github.com/huggingface/datasets/pull/3350 | 1,068,078,160 | PR_kwDODunzps4vO1aj | 3,350 | Avoid content-encoding issue while streaming datasets | [] | closed | false | null | 0 | 2021-12-01T07:56:48Z | 2021-12-01T08:15:01Z | 2021-12-01T08:15:00Z | null | This PR will fix streaming of datasets served with gzip content-encoding:
```
ClientPayloadError: 400, message='Can not decode content-encoding: gzip'
```
Fix #2918.
CC: @severo | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3350/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3350",
"merged_at": "2021-12-01T08:15:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3350"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5759 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5759/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5759/comments | https://api.github.com/repos/huggingface/datasets/issues/5759/events | https://github.com/huggingface/datasets/issues/5759 | 1,669,977,848 | I_kwDODunzps5jidb4 | 5,759 | Can I load in list of list of dict format? | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2023-04-16T13:50:14Z | 2023-04-19T12:04:36Z | null | null | ### Feature request
my jsonl dataset has following format:
```
[{'input':xxx, 'output':xxx},{'input:xxx,'output':xxx},...]
[{'input':xxx, 'output':xxx},{'input:xxx,'output':xxx},...]
```
I try to use `datasets.load_dataset('json', data_files=path)` or `datasets.Dataset.from_json`, it raises
```
File "site-packages/datasets/arrow_dataset.py", line 1078, in from_json
).read()
File "site-packages/datasets/io/json.py", line 59, in read
self.builder.download_and_prepare(
File "site-packages/datasets/builder.py", line 872, in download_and_prepare
self._download_and_prepare(
File "site-packages/datasets/builder.py", line 967, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "site-packages/datasets/builder.py", line 1749, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "site-packages/datasets/builder.py", line 1892, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Motivation
I wanna use features like `Datasets.map` or `Datasets.shuffle`, so i need the dataset in memory to be `arrow_dataset.Datasets` format
### Your contribution
PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5759/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5759/timeline | null | null | null | null | false | [
"Thanks for reporting, @LZY-the-boys.\r\n\r\nCould you please give more details about what is your intended dataset structure? What are the names of the columns and the value of each row?\r\n\r\nCurrently, the JSON-Lines format is supported:\r\n- Each line correspond to one row of the dataset\r\n- Each line is composed of one JSON object, where the names are the names of the columns, and the values are the values for the row-column pair."
] |
https://api.github.com/repos/huggingface/datasets/issues/6072 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6072/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6072/comments | https://api.github.com/repos/huggingface/datasets/issues/6072/events | https://github.com/huggingface/datasets/pull/6072 | 1,822,123,560 | PR_kwDODunzps5WbWFN | 6,072 | Fix fsspec storage_options from load_dataset | [] | closed | false | null | 6 | 2023-07-26T10:44:23Z | 2023-07-27T12:51:51Z | 2023-07-27T12:42:57Z | null | close https://github.com/huggingface/datasets/issues/6071 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6072/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6072/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6072.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6072",
"merged_at": "2023-07-27T12:42:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6072.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6072"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007617 / 0.011353 (-0.003736) | 0.004580 / 0.011008 (-0.006428) | 0.100913 / 0.038508 (0.062405) | 0.087703 / 0.023109 (0.064594) | 0.424159 / 0.275898 (0.148261) | 0.467195 / 0.323480 (0.143715) | 0.006890 / 0.007986 (-0.001096) | 0.003765 / 0.004328 (-0.000564) | 0.077513 / 0.004250 (0.073262) | 0.064889 / 0.037052 (0.027837) | 0.422349 / 0.258489 (0.163860) | 0.477391 / 0.293841 (0.183550) | 0.036025 / 0.128546 (-0.092522) | 0.009939 / 0.075646 (-0.065707) | 0.342409 / 0.419271 (-0.076862) | 0.061568 / 0.043533 (0.018035) | 0.431070 / 0.255139 (0.175931) | 0.462008 / 0.283200 (0.178809) | 0.027480 / 0.141683 (-0.114203) | 1.802271 / 1.452155 (0.350116) | 1.861336 / 1.492716 (0.368620) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255806 / 0.018006 (0.237800) | 0.507969 / 0.000490 (0.507479) | 0.010060 / 0.000200 (0.009860) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032286 / 0.037411 (-0.005125) | 0.104468 / 0.014526 (0.089942) | 0.112707 / 0.176557 (-0.063850) | 0.181285 / 0.737135 (-0.555850) | 0.113180 / 0.296338 (-0.183158) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.449265 / 0.215209 (0.234056) | 4.465941 / 2.077655 (2.388287) | 2.177889 / 1.504120 (0.673769) | 1.969864 / 1.541195 (0.428669) | 2.077502 / 1.468490 (0.609011) | 0.561607 / 4.584777 (-4.023170) | 4.281873 / 3.745712 (0.536161) | 4.975352 / 5.269862 (-0.294510) | 2.907121 / 4.565676 (-1.658555) | 0.070205 / 0.424275 (-0.354070) | 0.009164 / 0.007607 (0.001557) | 0.581921 / 0.226044 (0.355876) | 5.538667 / 2.268929 (3.269739) | 2.798853 / 55.444624 (-52.645771) | 2.314015 / 6.876477 (-4.562462) | 2.584836 / 2.142072 (0.442763) | 0.672333 / 4.805227 (-4.132894) | 0.153828 / 6.500664 (-6.346836) | 0.069757 / 0.075469 (-0.005712) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.559670 / 1.841788 (-0.282118) | 23.994639 / 8.074308 (15.920331) | 16.856160 / 10.191392 (6.664768) | 0.195555 / 0.680424 (-0.484869) | 0.021586 / 0.534201 (-0.512615) | 0.469295 / 0.579283 (-0.109989) | 0.481582 / 0.434364 (0.047218) | 0.588667 / 0.540337 (0.048329) | 0.734347 / 1.386936 (-0.652589) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009614 / 0.011353 (-0.001739) | 0.004616 / 0.011008 (-0.006392) | 0.077223 / 0.038508 (0.038715) | 0.103074 / 0.023109 (0.079965) | 0.447834 / 0.275898 (0.171936) | 0.524696 / 0.323480 (0.201216) | 0.007120 / 0.007986 (-0.000866) | 0.003890 / 0.004328 (-0.000438) | 0.076406 / 0.004250 (0.072156) | 0.073488 / 0.037052 (0.036436) | 0.466221 / 0.258489 (0.207732) | 0.532206 / 0.293841 (0.238365) | 0.037596 / 0.128546 (-0.090950) | 0.010029 / 0.075646 (-0.065617) | 0.084313 / 0.419271 (-0.334959) | 0.060088 / 0.043533 (0.016555) | 0.437792 / 0.255139 (0.182653) | 0.512850 / 0.283200 (0.229650) | 0.032424 / 0.141683 (-0.109259) | 1.762130 / 1.452155 (0.309975) | 1.946097 / 1.492716 (0.453381) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250774 / 0.018006 (0.232768) | 0.506869 / 0.000490 (0.506379) | 0.008232 / 0.000200 (0.008032) | 0.000164 / 0.000054 (0.000110) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037779 / 0.037411 (0.000368) | 0.111933 / 0.014526 (0.097407) | 0.122385 / 0.176557 (-0.054172) | 0.190372 / 0.737135 (-0.546763) | 0.122472 / 0.296338 (-0.173866) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488502 / 0.215209 (0.273293) | 4.878114 / 2.077655 (2.800459) | 2.504144 / 1.504120 (1.000024) | 2.321077 / 1.541195 (0.779883) | 2.416797 / 1.468490 (0.948307) | 0.583582 / 4.584777 (-4.001195) | 4.277896 / 3.745712 (0.532184) | 3.874780 / 5.269862 (-1.395082) | 2.540099 / 4.565676 (-2.025577) | 0.068734 / 0.424275 (-0.355541) | 0.009158 / 0.007607 (0.001550) | 0.578401 / 0.226044 (0.352357) | 5.763354 / 2.268929 (3.494426) | 3.167771 / 55.444624 (-52.276853) | 2.675220 / 6.876477 (-4.201257) | 2.920927 / 2.142072 (0.778855) | 0.673948 / 4.805227 (-4.131280) | 0.157908 / 6.500664 (-6.342756) | 0.071672 / 0.075469 (-0.003797) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.635120 / 1.841788 (-0.206668) | 24.853480 / 8.074308 (16.779172) | 17.162978 / 10.191392 (6.971586) | 0.209577 / 0.680424 (-0.470847) | 0.030110 / 0.534201 (-0.504091) | 0.546970 / 0.579283 (-0.032313) | 0.581912 / 0.434364 (0.147548) | 0.571460 / 0.540337 (0.031123) | 0.823411 / 1.386936 (-0.563525) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006674 / 0.011353 (-0.004679) | 0.004198 / 0.011008 (-0.006810) | 0.084859 / 0.038508 (0.046351) | 0.076065 / 0.023109 (0.052955) | 0.316065 / 0.275898 (0.040167) | 0.352097 / 0.323480 (0.028617) | 0.005610 / 0.007986 (-0.002376) | 0.003600 / 0.004328 (-0.000729) | 0.064921 / 0.004250 (0.060671) | 0.054493 / 0.037052 (0.017441) | 0.318125 / 0.258489 (0.059636) | 0.370183 / 0.293841 (0.076342) | 0.031141 / 0.128546 (-0.097405) | 0.008755 / 0.075646 (-0.066891) | 0.288241 / 0.419271 (-0.131030) | 0.052379 / 0.043533 (0.008846) | 0.328147 / 0.255139 (0.073008) | 0.347548 / 0.283200 (0.064348) | 0.024393 / 0.141683 (-0.117290) | 1.480646 / 1.452155 (0.028492) | 1.575867 / 1.492716 (0.083151) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268978 / 0.018006 (0.250971) | 0.586470 / 0.000490 (0.585980) | 0.003190 / 0.000200 (0.002990) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030595 / 0.037411 (-0.006816) | 0.083037 / 0.014526 (0.068511) | 0.103706 / 0.176557 (-0.072850) | 0.164104 / 0.737135 (-0.573031) | 0.104536 / 0.296338 (-0.191802) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.382274 / 0.215209 (0.167065) | 3.811878 / 2.077655 (1.734223) | 1.840098 / 1.504120 (0.335978) | 1.670949 / 1.541195 (0.129754) | 1.763755 / 1.468490 (0.295264) | 0.479526 / 4.584777 (-4.105251) | 3.544443 / 3.745712 (-0.201269) | 3.263004 / 5.269862 (-2.006858) | 2.092801 / 4.565676 (-2.472875) | 0.057167 / 0.424275 (-0.367108) | 0.007450 / 0.007607 (-0.000157) | 0.463731 / 0.226044 (0.237686) | 4.624630 / 2.268929 (2.355701) | 2.327078 / 55.444624 (-53.117546) | 1.977734 / 6.876477 (-4.898743) | 2.237152 / 2.142072 (0.095079) | 0.573210 / 4.805227 (-4.232018) | 0.132095 / 6.500664 (-6.368569) | 0.060283 / 0.075469 (-0.015186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.243404 / 1.841788 (-0.598384) | 20.306778 / 8.074308 (12.232470) | 14.561660 / 10.191392 (4.370268) | 0.170826 / 0.680424 (-0.509598) | 0.018574 / 0.534201 (-0.515627) | 0.392367 / 0.579283 (-0.186916) | 0.402918 / 0.434364 (-0.031446) | 0.476629 / 0.540337 (-0.063708) | 0.653709 / 1.386936 (-0.733227) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006562 / 0.011353 (-0.004791) | 0.004092 / 0.011008 (-0.006916) | 0.065951 / 0.038508 (0.027443) | 0.078090 / 0.023109 (0.054981) | 0.369679 / 0.275898 (0.093781) | 0.411442 / 0.323480 (0.087962) | 0.005646 / 0.007986 (-0.002339) | 0.003537 / 0.004328 (-0.000791) | 0.066024 / 0.004250 (0.061773) | 0.058947 / 0.037052 (0.021895) | 0.389219 / 0.258489 (0.130730) | 0.414200 / 0.293841 (0.120359) | 0.030372 / 0.128546 (-0.098174) | 0.008631 / 0.075646 (-0.067015) | 0.071692 / 0.419271 (-0.347580) | 0.048035 / 0.043533 (0.004502) | 0.376960 / 0.255139 (0.121821) | 0.389847 / 0.283200 (0.106648) | 0.023940 / 0.141683 (-0.117743) | 1.487633 / 1.452155 (0.035479) | 1.561680 / 1.492716 (0.068964) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.301467 / 0.018006 (0.283461) | 0.544159 / 0.000490 (0.543669) | 0.000408 / 0.000200 (0.000208) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030939 / 0.037411 (-0.006472) | 0.087432 / 0.014526 (0.072906) | 0.103263 / 0.176557 (-0.073293) | 0.154551 / 0.737135 (-0.582585) | 0.104631 / 0.296338 (-0.191707) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422348 / 0.215209 (0.207139) | 4.206003 / 2.077655 (2.128348) | 2.212619 / 1.504120 (0.708499) | 2.049616 / 1.541195 (0.508421) | 2.139093 / 1.468490 (0.670603) | 0.489647 / 4.584777 (-4.095130) | 3.523291 / 3.745712 (-0.222422) | 3.277657 / 5.269862 (-1.992205) | 2.111353 / 4.565676 (-2.454324) | 0.057597 / 0.424275 (-0.366679) | 0.007675 / 0.007607 (0.000068) | 0.493068 / 0.226044 (0.267023) | 4.939493 / 2.268929 (2.670565) | 2.695995 / 55.444624 (-52.748630) | 2.374904 / 6.876477 (-4.501573) | 2.600110 / 2.142072 (0.458038) | 0.586306 / 4.805227 (-4.218921) | 0.134137 / 6.500664 (-6.366527) | 0.061897 / 0.075469 (-0.013572) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.330628 / 1.841788 (-0.511160) | 20.557964 / 8.074308 (12.483656) | 14.251632 / 10.191392 (4.060240) | 0.148772 / 0.680424 (-0.531652) | 0.018383 / 0.534201 (-0.515817) | 0.392552 / 0.579283 (-0.186731) | 0.403959 / 0.434364 (-0.030405) | 0.462154 / 0.540337 (-0.078184) | 0.608832 / 1.386936 (-0.778104) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007659 / 0.011353 (-0.003694) | 0.004500 / 0.011008 (-0.006508) | 0.100379 / 0.038508 (0.061871) | 0.079731 / 0.023109 (0.056622) | 0.381788 / 0.275898 (0.105890) | 0.416524 / 0.323480 (0.093044) | 0.004446 / 0.007986 (-0.003539) | 0.003752 / 0.004328 (-0.000577) | 0.074956 / 0.004250 (0.070706) | 0.062885 / 0.037052 (0.025832) | 0.383849 / 0.258489 (0.125360) | 0.433906 / 0.293841 (0.140065) | 0.036079 / 0.128546 (-0.092468) | 0.009927 / 0.075646 (-0.065719) | 0.343879 / 0.419271 (-0.075393) | 0.061055 / 0.043533 (0.017523) | 0.376703 / 0.255139 (0.121564) | 0.428111 / 0.283200 (0.144911) | 0.028667 / 0.141683 (-0.113016) | 1.777755 / 1.452155 (0.325600) | 1.878283 / 1.492716 (0.385567) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220829 / 0.018006 (0.202823) | 0.506406 / 0.000490 (0.505916) | 0.005550 / 0.000200 (0.005350) | 0.000123 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034928 / 0.037411 (-0.002483) | 0.103873 / 0.014526 (0.089347) | 0.114352 / 0.176557 (-0.062204) | 0.188218 / 0.737135 (-0.548918) | 0.117343 / 0.296338 (-0.178995) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.459148 / 0.215209 (0.243939) | 4.582092 / 2.077655 (2.504437) | 2.275603 / 1.504120 (0.771483) | 2.058155 / 1.541195 (0.516960) | 2.163886 / 1.468490 (0.695396) | 0.573033 / 4.584777 (-4.011744) | 4.414891 / 3.745712 (0.669178) | 7.280433 / 5.269862 (2.010572) | 4.119414 / 4.565676 (-0.446262) | 0.067432 / 0.424275 (-0.356843) | 0.008687 / 0.007607 (0.001080) | 0.556029 / 0.226044 (0.329984) | 5.557192 / 2.268929 (3.288264) | 2.921596 / 55.444624 (-52.523028) | 2.520249 / 6.876477 (-4.356228) | 2.778965 / 2.142072 (0.636893) | 0.684765 / 4.805227 (-4.120462) | 0.159228 / 6.500664 (-6.341436) | 0.074015 / 0.075469 (-0.001454) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.534470 / 1.841788 (-0.307318) | 23.630693 / 8.074308 (15.556385) | 17.058142 / 10.191392 (6.866750) | 0.200909 / 0.680424 (-0.479515) | 0.021637 / 0.534201 (-0.512564) | 0.467417 / 0.579283 (-0.111866) | 0.460456 / 0.434364 (0.026092) | 0.541131 / 0.540337 (0.000793) | 0.728560 / 1.386936 (-0.658376) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007625 / 0.011353 (-0.003727) | 0.004495 / 0.011008 (-0.006513) | 0.076373 / 0.038508 (0.037865) | 0.085260 / 0.023109 (0.062151) | 0.475778 / 0.275898 (0.199880) | 0.504604 / 0.323480 (0.181124) | 0.006733 / 0.007986 (-0.001253) | 0.003751 / 0.004328 (-0.000578) | 0.074993 / 0.004250 (0.070743) | 0.064704 / 0.037052 (0.027652) | 0.490072 / 0.258489 (0.231583) | 0.507560 / 0.293841 (0.213719) | 0.036765 / 0.128546 (-0.091781) | 0.009955 / 0.075646 (-0.065692) | 0.082452 / 0.419271 (-0.336820) | 0.057131 / 0.043533 (0.013598) | 0.467664 / 0.255139 (0.212525) | 0.482143 / 0.283200 (0.198943) | 0.025396 / 0.141683 (-0.116287) | 1.807587 / 1.452155 (0.355433) | 1.853355 / 1.492716 (0.360639) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250543 / 0.018006 (0.232537) | 0.495685 / 0.000490 (0.495196) | 0.000415 / 0.000200 (0.000215) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035795 / 0.037411 (-0.001616) | 0.105954 / 0.014526 (0.091428) | 0.120158 / 0.176557 (-0.056399) | 0.181714 / 0.737135 (-0.555422) | 0.121242 / 0.296338 (-0.175097) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488241 / 0.215209 (0.273032) | 4.866916 / 2.077655 (2.789262) | 2.531530 / 1.504120 (1.027410) | 2.360642 / 1.541195 (0.819448) | 2.457320 / 1.468490 (0.988830) | 0.571224 / 4.584777 (-4.013553) | 4.339042 / 3.745712 (0.593330) | 3.672812 / 5.269862 (-1.597050) | 2.364535 / 4.565676 (-2.201142) | 0.067004 / 0.424275 (-0.357271) | 0.009019 / 0.007607 (0.001412) | 0.563751 / 0.226044 (0.337707) | 5.664917 / 2.268929 (3.395989) | 3.043316 / 55.444624 (-52.401308) | 2.682722 / 6.876477 (-4.193755) | 2.863482 / 2.142072 (0.721409) | 0.666171 / 4.805227 (-4.139056) | 0.151862 / 6.500664 (-6.348802) | 0.071199 / 0.075469 (-0.004271) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.601880 / 1.841788 (-0.239907) | 23.069073 / 8.074308 (14.994765) | 16.918377 / 10.191392 (6.726985) | 0.173614 / 0.680424 (-0.506810) | 0.021843 / 0.534201 (-0.512358) | 0.470531 / 0.579283 (-0.108753) | 0.471152 / 0.434364 (0.036788) | 0.550968 / 0.540337 (0.010631) | 0.718869 / 1.386936 (-0.668067) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007530 / 0.011353 (-0.003823) | 0.004151 / 0.011008 (-0.006858) | 0.098490 / 0.038508 (0.059982) | 0.086955 / 0.023109 (0.063846) | 0.362133 / 0.275898 (0.086235) | 0.391402 / 0.323480 (0.067922) | 0.006274 / 0.007986 (-0.001712) | 0.003711 / 0.004328 (-0.000618) | 0.073519 / 0.004250 (0.069269) | 0.066170 / 0.037052 (0.029118) | 0.379057 / 0.258489 (0.120568) | 0.398132 / 0.293841 (0.104291) | 0.033936 / 0.128546 (-0.094610) | 0.009977 / 0.075646 (-0.065670) | 0.323766 / 0.419271 (-0.095505) | 0.078615 / 0.043533 (0.035082) | 0.352403 / 0.255139 (0.097264) | 0.386607 / 0.283200 (0.103407) | 0.036579 / 0.141683 (-0.105103) | 1.691899 / 1.452155 (0.239745) | 1.819396 / 1.492716 (0.326680) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216888 / 0.018006 (0.198882) | 0.465781 / 0.000490 (0.465291) | 0.006197 / 0.000200 (0.005997) | 0.000086 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032870 / 0.037411 (-0.004542) | 0.096026 / 0.014526 (0.081500) | 0.111093 / 0.176557 (-0.065464) | 0.185982 / 0.737135 (-0.551154) | 0.106967 / 0.296338 (-0.189371) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441567 / 0.215209 (0.226358) | 4.353813 / 2.077655 (2.276158) | 2.176034 / 1.504120 (0.671914) | 1.969631 / 1.541195 (0.428437) | 2.048821 / 1.468490 (0.580330) | 0.549144 / 4.584777 (-4.035633) | 4.016166 / 3.745712 (0.270453) | 3.764249 / 5.269862 (-1.505613) | 2.293995 / 4.565676 (-2.271681) | 0.065227 / 0.424275 (-0.359048) | 0.008303 / 0.007607 (0.000695) | 0.513783 / 0.226044 (0.287738) | 5.247617 / 2.268929 (2.978689) | 2.782114 / 55.444624 (-52.662510) | 2.342776 / 6.876477 (-4.533701) | 2.621569 / 2.142072 (0.479497) | 0.679336 / 4.805227 (-4.125891) | 0.152061 / 6.500664 (-6.348603) | 0.070294 / 0.075469 (-0.005175) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.471778 / 1.841788 (-0.370010) | 22.714904 / 8.074308 (14.640596) | 15.607991 / 10.191392 (5.416599) | 0.172592 / 0.680424 (-0.507832) | 0.021799 / 0.534201 (-0.512402) | 0.462740 / 0.579283 (-0.116543) | 0.490885 / 0.434364 (0.056521) | 0.552997 / 0.540337 (0.012660) | 0.763784 / 1.386936 (-0.623152) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007466 / 0.011353 (-0.003886) | 0.004322 / 0.011008 (-0.006686) | 0.074331 / 0.038508 (0.035823) | 0.085315 / 0.023109 (0.062206) | 0.409284 / 0.275898 (0.133386) | 0.464584 / 0.323480 (0.141104) | 0.005651 / 0.007986 (-0.002335) | 0.003577 / 0.004328 (-0.000751) | 0.070250 / 0.004250 (0.066000) | 0.059780 / 0.037052 (0.022727) | 0.419668 / 0.258489 (0.161179) | 0.462984 / 0.293841 (0.169143) | 0.034159 / 0.128546 (-0.094387) | 0.008999 / 0.075646 (-0.066647) | 0.076302 / 0.419271 (-0.342969) | 0.052274 / 0.043533 (0.008741) | 0.425938 / 0.255139 (0.170799) | 0.430399 / 0.283200 (0.147200) | 0.025017 / 0.141683 (-0.116666) | 1.680697 / 1.452155 (0.228542) | 1.774677 / 1.492716 (0.281960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291514 / 0.018006 (0.273508) | 0.461175 / 0.000490 (0.460685) | 0.023061 / 0.000200 (0.022861) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033950 / 0.037411 (-0.003462) | 0.100032 / 0.014526 (0.085506) | 0.118308 / 0.176557 (-0.058249) | 0.183601 / 0.737135 (-0.553535) | 0.116936 / 0.296338 (-0.179402) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.478779 / 0.215209 (0.263570) | 4.709505 / 2.077655 (2.631850) | 2.457442 / 1.504120 (0.953322) | 2.213737 / 1.541195 (0.672542) | 2.340642 / 1.468490 (0.872152) | 0.567187 / 4.584777 (-4.017590) | 3.923061 / 3.745712 (0.177349) | 3.752989 / 5.269862 (-1.516873) | 2.324028 / 4.565676 (-2.241649) | 0.064471 / 0.424275 (-0.359804) | 0.008845 / 0.007607 (0.001238) | 0.547447 / 0.226044 (0.321402) | 5.599435 / 2.268929 (3.330506) | 2.980547 / 55.444624 (-52.464077) | 2.754908 / 6.876477 (-4.121569) | 2.832978 / 2.142072 (0.690906) | 0.635059 / 4.805227 (-4.170168) | 0.153478 / 6.500664 (-6.347187) | 0.067146 / 0.075469 (-0.008323) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.555588 / 1.841788 (-0.286200) | 22.828906 / 8.074308 (14.754597) | 16.211008 / 10.191392 (6.019616) | 0.168009 / 0.680424 (-0.512415) | 0.021966 / 0.534201 (-0.512235) | 0.464872 / 0.579283 (-0.114411) | 0.460429 / 0.434364 (0.026065) | 0.530498 / 0.540337 (-0.009839) | 0.705020 / 1.386936 (-0.681916) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005964 / 0.011353 (-0.005389) | 0.003644 / 0.011008 (-0.007364) | 0.079607 / 0.038508 (0.041099) | 0.058387 / 0.023109 (0.035278) | 0.312226 / 0.275898 (0.036328) | 0.349206 / 0.323480 (0.025726) | 0.004715 / 0.007986 (-0.003271) | 0.002869 / 0.004328 (-0.001460) | 0.061668 / 0.004250 (0.057417) | 0.045694 / 0.037052 (0.008642) | 0.313516 / 0.258489 (0.055027) | 0.357543 / 0.293841 (0.063702) | 0.027179 / 0.128546 (-0.101367) | 0.007961 / 0.075646 (-0.067686) | 0.262473 / 0.419271 (-0.156798) | 0.045588 / 0.043533 (0.002055) | 0.313102 / 0.255139 (0.057963) | 0.368686 / 0.283200 (0.085486) | 0.020556 / 0.141683 (-0.121127) | 1.447258 / 1.452155 (-0.004897) | 1.527319 / 1.492716 (0.034602) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199417 / 0.018006 (0.181411) | 0.422155 / 0.000490 (0.421665) | 0.004972 / 0.000200 (0.004772) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023539 / 0.037411 (-0.013872) | 0.073055 / 0.014526 (0.058529) | 0.083631 / 0.176557 (-0.092926) | 0.145923 / 0.737135 (-0.591212) | 0.083820 / 0.296338 (-0.212518) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396305 / 0.215209 (0.181096) | 3.967065 / 2.077655 (1.889410) | 2.101109 / 1.504120 (0.596989) | 1.958817 / 1.541195 (0.417622) | 2.037894 / 1.468490 (0.569404) | 0.496955 / 4.584777 (-4.087822) | 3.078948 / 3.745712 (-0.666764) | 3.363655 / 5.269862 (-1.906207) | 2.087659 / 4.565676 (-2.478018) | 0.057171 / 0.424275 (-0.367104) | 0.006410 / 0.007607 (-0.001197) | 0.470535 / 0.226044 (0.244491) | 4.715259 / 2.268929 (2.446330) | 2.355510 / 55.444624 (-53.089114) | 2.025270 / 6.876477 (-4.851207) | 2.210401 / 2.142072 (0.068329) | 0.580538 / 4.805227 (-4.224689) | 0.125068 / 6.500664 (-6.375596) | 0.059871 / 0.075469 (-0.015598) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.245468 / 1.841788 (-0.596320) | 18.322042 / 8.074308 (10.247734) | 13.609726 / 10.191392 (3.418334) | 0.143623 / 0.680424 (-0.536801) | 0.017068 / 0.534201 (-0.517133) | 0.330758 / 0.579283 (-0.248525) | 0.339946 / 0.434364 (-0.094418) | 0.377861 / 0.540337 (-0.162476) | 0.524593 / 1.386936 (-0.862343) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006049 / 0.011353 (-0.005304) | 0.003737 / 0.011008 (-0.007271) | 0.062816 / 0.038508 (0.024308) | 0.063768 / 0.023109 (0.040658) | 0.362001 / 0.275898 (0.086103) | 0.395251 / 0.323480 (0.071772) | 0.004823 / 0.007986 (-0.003163) | 0.002881 / 0.004328 (-0.001447) | 0.061987 / 0.004250 (0.057737) | 0.049950 / 0.037052 (0.012898) | 0.362442 / 0.258489 (0.103953) | 0.399321 / 0.293841 (0.105480) | 0.027616 / 0.128546 (-0.100930) | 0.007965 / 0.075646 (-0.067681) | 0.068584 / 0.419271 (-0.350687) | 0.044700 / 0.043533 (0.001168) | 0.361011 / 0.255139 (0.105872) | 0.386007 / 0.283200 (0.102807) | 0.024621 / 0.141683 (-0.117061) | 1.441497 / 1.452155 (-0.010657) | 1.533145 / 1.492716 (0.040429) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223446 / 0.018006 (0.205440) | 0.411147 / 0.000490 (0.410657) | 0.001821 / 0.000200 (0.001621) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025661 / 0.037411 (-0.011751) | 0.077838 / 0.014526 (0.063313) | 0.086148 / 0.176557 (-0.090408) | 0.140386 / 0.737135 (-0.596750) | 0.088793 / 0.296338 (-0.207546) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425209 / 0.215209 (0.210000) | 4.250723 / 2.077655 (2.173068) | 2.403437 / 1.504120 (0.899317) | 2.283584 / 1.541195 (0.742390) | 2.326870 / 1.468490 (0.858380) | 0.504781 / 4.584777 (-4.079996) | 3.017042 / 3.745712 (-0.728670) | 4.643068 / 5.269862 (-0.626794) | 2.535710 / 4.565676 (-2.029967) | 0.058520 / 0.424275 (-0.365755) | 0.006766 / 0.007607 (-0.000841) | 0.500664 / 0.226044 (0.274620) | 5.017073 / 2.268929 (2.748145) | 2.668661 / 55.444624 (-52.775963) | 2.335486 / 6.876477 (-4.540991) | 2.486518 / 2.142072 (0.344445) | 0.598795 / 4.805227 (-4.206432) | 0.126395 / 6.500664 (-6.374269) | 0.063154 / 0.075469 (-0.012315) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.358059 / 1.841788 (-0.483728) | 18.615724 / 8.074308 (10.541416) | 13.670934 / 10.191392 (3.479542) | 0.134650 / 0.680424 (-0.545774) | 0.016941 / 0.534201 (-0.517260) | 0.335215 / 0.579283 (-0.244068) | 0.356118 / 0.434364 (-0.078246) | 0.393109 / 0.540337 (-0.147228) | 0.534165 / 1.386936 (-0.852771) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5788 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5788/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5788/comments | https://api.github.com/repos/huggingface/datasets/issues/5788/events | https://github.com/huggingface/datasets/pull/5788 | 1,681,136,256 | PR_kwDODunzps5O_v4B | 5,788 | Prepare tests for hfh 0.14 | [] | closed | false | null | 6 | 2023-04-24T12:13:03Z | 2023-04-25T14:32:56Z | 2023-04-25T14:25:30Z | null | Related to the coming release of `huggingface_hub==0.14.0`. It will break some internal tests. The PR fixes these tests. Let's double-check the CI but I expect the fixed tests to be running fine with both `hfh<=0.13.4` and `hfh==0.14`. Worth case scenario, existing PRs will have to be rebased once this fix is merged.
See related [discussion](https://huggingface.slack.com/archives/C02V5EA0A95/p1682337463368609?thread_ts=1681994202.635609&cid=C02V5EA0A95) (private slack).
cc @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5788/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5788/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5788.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5788",
"merged_at": "2023-04-25T14:25:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5788.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5788"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007343 / 0.011353 (-0.004010) | 0.005145 / 0.011008 (-0.005863) | 0.099820 / 0.038508 (0.061312) | 0.033487 / 0.023109 (0.010378) | 0.313069 / 0.275898 (0.037171) | 0.335420 / 0.323480 (0.011940) | 0.005959 / 0.007986 (-0.002027) | 0.005373 / 0.004328 (0.001044) | 0.076568 / 0.004250 (0.072317) | 0.048702 / 0.037052 (0.011650) | 0.322957 / 0.258489 (0.064468) | 0.363044 / 0.293841 (0.069203) | 0.035070 / 0.128546 (-0.093476) | 0.012029 / 0.075646 (-0.063618) | 0.334664 / 0.419271 (-0.084607) | 0.050549 / 0.043533 (0.007017) | 0.310113 / 0.255139 (0.054974) | 0.324405 / 0.283200 (0.041205) | 0.097596 / 0.141683 (-0.044087) | 1.440741 / 1.452155 (-0.011414) | 1.531194 / 1.492716 (0.038478) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220799 / 0.018006 (0.202793) | 0.438158 / 0.000490 (0.437668) | 0.007737 / 0.000200 (0.007537) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026888 / 0.037411 (-0.010523) | 0.106281 / 0.014526 (0.091755) | 0.117419 / 0.176557 (-0.059138) | 0.179144 / 0.737135 (-0.557992) | 0.122477 / 0.296338 (-0.173861) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412667 / 0.215209 (0.197458) | 4.108784 / 2.077655 (2.031129) | 1.834300 / 1.504120 (0.330180) | 1.627256 / 1.541195 (0.086061) | 1.691036 / 1.468490 (0.222546) | 0.713405 / 4.584777 (-3.871372) | 3.839262 / 3.745712 (0.093550) | 2.108453 / 5.269862 (-3.161408) | 1.340740 / 4.565676 (-3.224936) | 0.087776 / 0.424275 (-0.336499) | 0.012730 / 0.007607 (0.005123) | 0.505323 / 0.226044 (0.279279) | 5.085176 / 2.268929 (2.816247) | 2.307165 / 55.444624 (-53.137459) | 1.936771 / 6.876477 (-4.939706) | 2.097391 / 2.142072 (-0.044681) | 0.856215 / 4.805227 (-3.949012) | 0.171826 / 6.500664 (-6.328838) | 0.066603 / 0.075469 (-0.008866) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.202126 / 1.841788 (-0.639661) | 15.173598 / 8.074308 (7.099290) | 15.012645 / 10.191392 (4.821253) | 0.162187 / 0.680424 (-0.518237) | 0.017462 / 0.534201 (-0.516739) | 0.423895 / 0.579283 (-0.155388) | 0.432010 / 0.434364 (-0.002354) | 0.503234 / 0.540337 (-0.037104) | 0.598948 / 1.386936 (-0.787988) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007099 / 0.011353 (-0.004254) | 0.005167 / 0.011008 (-0.005841) | 0.075551 / 0.038508 (0.037043) | 0.033050 / 0.023109 (0.009940) | 0.339629 / 0.275898 (0.063731) | 0.380486 / 0.323480 (0.057006) | 0.005776 / 0.007986 (-0.002209) | 0.004029 / 0.004328 (-0.000299) | 0.075074 / 0.004250 (0.070823) | 0.046709 / 0.037052 (0.009656) | 0.340203 / 0.258489 (0.081714) | 0.380849 / 0.293841 (0.087008) | 0.035027 / 0.128546 (-0.093519) | 0.012226 / 0.075646 (-0.063420) | 0.087525 / 0.419271 (-0.331747) | 0.049361 / 0.043533 (0.005828) | 0.341854 / 0.255139 (0.086715) | 0.359590 / 0.283200 (0.076390) | 0.100102 / 0.141683 (-0.041581) | 1.482759 / 1.452155 (0.030605) | 1.569905 / 1.492716 (0.077189) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.213615 / 0.018006 (0.195609) | 0.441117 / 0.000490 (0.440628) | 0.004932 / 0.000200 (0.004732) | 0.000093 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031313 / 0.037411 (-0.006098) | 0.110191 / 0.014526 (0.095665) | 0.125320 / 0.176557 (-0.051237) | 0.177658 / 0.737135 (-0.559477) | 0.127928 / 0.296338 (-0.168410) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426952 / 0.215209 (0.211743) | 4.247731 / 2.077655 (2.170076) | 2.107318 / 1.504120 (0.603198) | 1.843845 / 1.541195 (0.302650) | 1.894822 / 1.468490 (0.426332) | 0.696232 / 4.584777 (-3.888545) | 3.826516 / 3.745712 (0.080804) | 2.126688 / 5.269862 (-3.143174) | 1.327062 / 4.565676 (-3.238615) | 0.085693 / 0.424275 (-0.338582) | 0.012226 / 0.007607 (0.004619) | 0.521904 / 0.226044 (0.295859) | 5.219798 / 2.268929 (2.950869) | 2.524908 / 55.444624 (-52.919716) | 2.212078 / 6.876477 (-4.664399) | 2.373944 / 2.142072 (0.231871) | 0.833846 / 4.805227 (-3.971381) | 0.169639 / 6.500664 (-6.331025) | 0.064538 / 0.075469 (-0.010931) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254930 / 1.841788 (-0.586858) | 15.585277 / 8.074308 (7.510969) | 14.762857 / 10.191392 (4.571465) | 0.146959 / 0.680424 (-0.533465) | 0.017451 / 0.534201 (-0.516750) | 0.424469 / 0.579283 (-0.154814) | 0.422359 / 0.434364 (-0.012004) | 0.489930 / 0.540337 (-0.050408) | 0.595856 / 1.386936 (-0.791080) |\n\n</details>\n</details>\n\n\n",
"@albertvillanova thanks for the review. As you prefer for the github CI config. I just took it from @lhoestq's branch when testing hfh==0.14.0. I think it's still relevant for next releases. In any case, I let you handle merging the PR :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008371 / 0.011353 (-0.002982) | 0.005210 / 0.011008 (-0.005798) | 0.105639 / 0.038508 (0.067131) | 0.045903 / 0.023109 (0.022794) | 0.391231 / 0.275898 (0.115333) | 0.438824 / 0.323480 (0.115345) | 0.006270 / 0.007986 (-0.001715) | 0.005950 / 0.004328 (0.001621) | 0.079685 / 0.004250 (0.075434) | 0.052121 / 0.037052 (0.015069) | 0.387787 / 0.258489 (0.129298) | 0.434322 / 0.293841 (0.140481) | 0.032598 / 0.128546 (-0.095948) | 0.012126 / 0.075646 (-0.063520) | 0.359658 / 0.419271 (-0.059613) | 0.046686 / 0.043533 (0.003154) | 0.391973 / 0.255139 (0.136834) | 0.421149 / 0.283200 (0.137949) | 0.105920 / 0.141683 (-0.035763) | 1.483008 / 1.452155 (0.030854) | 1.617010 / 1.492716 (0.124294) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199111 / 0.018006 (0.181105) | 0.407995 / 0.000490 (0.407505) | 0.006706 / 0.000200 (0.006506) | 0.000229 / 0.000054 (0.000175) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030247 / 0.037411 (-0.007164) | 0.115977 / 0.014526 (0.101451) | 0.118112 / 0.176557 (-0.058444) | 0.182710 / 0.737135 (-0.554426) | 0.122483 / 0.296338 (-0.173855) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.430455 / 0.215209 (0.215246) | 4.314298 / 2.077655 (2.236643) | 1.898124 / 1.504120 (0.394005) | 1.734909 / 1.541195 (0.193715) | 1.802400 / 1.468490 (0.333910) | 0.717237 / 4.584777 (-3.867539) | 4.004705 / 3.745712 (0.258993) | 2.138901 / 5.269862 (-3.130960) | 1.254037 / 4.565676 (-3.311640) | 0.085594 / 0.424275 (-0.338681) | 0.013774 / 0.007607 (0.006166) | 0.535218 / 0.226044 (0.309174) | 5.373730 / 2.268929 (3.104801) | 2.371194 / 55.444624 (-53.073430) | 2.111206 / 6.876477 (-4.765270) | 2.225137 / 2.142072 (0.083064) | 0.838325 / 4.805227 (-3.966902) | 0.159176 / 6.500664 (-6.341488) | 0.072285 / 0.075469 (-0.003184) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.352232 / 1.841788 (-0.489555) | 16.926722 / 8.074308 (8.852414) | 16.709531 / 10.191392 (6.518139) | 0.159249 / 0.680424 (-0.521175) | 0.017667 / 0.534201 (-0.516534) | 0.426894 / 0.579283 (-0.152390) | 0.539903 / 0.434364 (0.105539) | 0.537471 / 0.540337 (-0.002866) | 0.619592 / 1.386936 (-0.767344) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008354 / 0.011353 (-0.002999) | 0.005366 / 0.011008 (-0.005642) | 0.080961 / 0.038508 (0.042453) | 0.046574 / 0.023109 (0.023465) | 0.345949 / 0.275898 (0.070051) | 0.394041 / 0.323480 (0.070562) | 0.006209 / 0.007986 (-0.001777) | 0.005980 / 0.004328 (0.001651) | 0.076235 / 0.004250 (0.071984) | 0.051833 / 0.037052 (0.014780) | 0.348786 / 0.258489 (0.090297) | 0.397421 / 0.293841 (0.103580) | 0.033026 / 0.128546 (-0.095520) | 0.012217 / 0.075646 (-0.063429) | 0.087439 / 0.419271 (-0.331832) | 0.045488 / 0.043533 (0.001955) | 0.352160 / 0.255139 (0.097021) | 0.379079 / 0.283200 (0.095879) | 0.116111 / 0.141683 (-0.025572) | 1.470177 / 1.452155 (0.018022) | 1.587499 / 1.492716 (0.094783) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296149 / 0.018006 (0.278143) | 0.592362 / 0.000490 (0.591872) | 0.000492 / 0.000200 (0.000292) | 0.000064 / 0.000054 (0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036599 / 0.037411 (-0.000813) | 0.113768 / 0.014526 (0.099242) | 0.116198 / 0.176557 (-0.060358) | 0.180329 / 0.737135 (-0.556806) | 0.123942 / 0.296338 (-0.172396) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.452445 / 0.215209 (0.237236) | 4.504330 / 2.077655 (2.426675) | 2.275645 / 1.504120 (0.771525) | 2.107765 / 1.541195 (0.566571) | 2.086363 / 1.468490 (0.617873) | 0.723721 / 4.584777 (-3.861056) | 3.825330 / 3.745712 (0.079618) | 2.162743 / 5.269862 (-3.107119) | 1.255953 / 4.565676 (-3.309724) | 0.085860 / 0.424275 (-0.338415) | 0.013790 / 0.007607 (0.006183) | 0.560257 / 0.226044 (0.334213) | 5.618180 / 2.268929 (3.349251) | 2.625423 / 55.444624 (-52.819202) | 2.374381 / 6.876477 (-4.502095) | 2.496560 / 2.142072 (0.354488) | 0.841120 / 4.805227 (-3.964107) | 0.161541 / 6.500664 (-6.339123) | 0.075270 / 0.075469 (-0.000199) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.432916 / 1.841788 (-0.408872) | 14.858534 / 8.074308 (6.784226) | 14.973521 / 10.191392 (4.782129) | 0.148312 / 0.680424 (-0.532112) | 0.016811 / 0.534201 (-0.517390) | 0.382623 / 0.579283 (-0.196660) | 0.389767 / 0.434364 (-0.044596) | 0.449657 / 0.540337 (-0.090680) | 0.533723 / 1.386936 (-0.853214) |\n\n</details>\n</details>\n\n\n",
"I agree it is good to have a way to run the CI on push, without needing to open a PR.\r\n\r\nBut I think the branch name should be more generic (and this is not specific to this PR). See:\r\n- #5790 ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007208 / 0.011353 (-0.004145) | 0.005600 / 0.011008 (-0.005408) | 0.096129 / 0.038508 (0.057621) | 0.027834 / 0.023109 (0.004725) | 0.295106 / 0.275898 (0.019208) | 0.323983 / 0.323480 (0.000503) | 0.005164 / 0.007986 (-0.002822) | 0.003962 / 0.004328 (-0.000366) | 0.078339 / 0.004250 (0.074089) | 0.036974 / 0.037052 (-0.000078) | 0.310315 / 0.258489 (0.051826) | 0.338036 / 0.293841 (0.044195) | 0.042124 / 0.128546 (-0.086422) | 0.015886 / 0.075646 (-0.059760) | 0.337961 / 0.419271 (-0.081310) | 0.051507 / 0.043533 (0.007974) | 0.297505 / 0.255139 (0.042366) | 0.310728 / 0.283200 (0.027528) | 0.086312 / 0.141683 (-0.055371) | 1.356923 / 1.452155 (-0.095232) | 1.429366 / 1.492716 (-0.063350) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.205495 / 0.018006 (0.187489) | 0.460639 / 0.000490 (0.460149) | 0.003996 / 0.000200 (0.003796) | 0.000093 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021970 / 0.037411 (-0.015442) | 0.090283 / 0.014526 (0.075757) | 0.098579 / 0.176557 (-0.077978) | 0.160437 / 0.737135 (-0.576699) | 0.102738 / 0.296338 (-0.193600) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.494474 / 0.215209 (0.279265) | 4.967453 / 2.077655 (2.889799) | 2.045852 / 1.504120 (0.541732) | 1.858022 / 1.541195 (0.316827) | 1.771874 / 1.468490 (0.303384) | 1.186368 / 4.584777 (-3.398408) | 4.974762 / 3.745712 (1.229050) | 2.616225 / 5.269862 (-2.653636) | 1.702971 / 4.565676 (-2.862705) | 0.124929 / 0.424275 (-0.299346) | 0.011774 / 0.007607 (0.004167) | 0.569643 / 0.226044 (0.343598) | 5.793114 / 2.268929 (3.524186) | 2.441561 / 55.444624 (-53.003064) | 1.862233 / 6.876477 (-5.014243) | 1.931142 / 2.142072 (-0.210931) | 1.148915 / 4.805227 (-3.656313) | 0.203914 / 6.500664 (-6.296750) | 0.062468 / 0.075469 (-0.013001) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.188708 / 1.841788 (-0.653080) | 13.710830 / 8.074308 (5.636522) | 15.695153 / 10.191392 (5.503761) | 0.171467 / 0.680424 (-0.508957) | 0.024509 / 0.534201 (-0.509692) | 0.450270 / 0.579283 (-0.129014) | 0.500712 / 0.434364 (0.066348) | 0.488632 / 0.540337 (-0.051706) | 0.574893 / 1.386936 (-0.812043) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007254 / 0.011353 (-0.004099) | 0.006199 / 0.011008 (-0.004809) | 0.072079 / 0.038508 (0.033571) | 0.026909 / 0.023109 (0.003800) | 0.355538 / 0.275898 (0.079640) | 0.358625 / 0.323480 (0.035145) | 0.005564 / 0.007986 (-0.002421) | 0.005278 / 0.004328 (0.000950) | 0.076469 / 0.004250 (0.072219) | 0.038269 / 0.037052 (0.001216) | 0.355214 / 0.258489 (0.096725) | 0.383219 / 0.293841 (0.089378) | 0.046516 / 0.128546 (-0.082030) | 0.015393 / 0.075646 (-0.060254) | 0.088506 / 0.419271 (-0.330765) | 0.050326 / 0.043533 (0.006793) | 0.327265 / 0.255139 (0.072126) | 0.370176 / 0.283200 (0.086976) | 0.102438 / 0.141683 (-0.039245) | 1.378969 / 1.452155 (-0.073186) | 1.441998 / 1.492716 (-0.050719) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209044 / 0.018006 (0.191038) | 0.455733 / 0.000490 (0.455243) | 0.005856 / 0.000200 (0.005656) | 0.000116 / 0.000054 (0.000061) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025336 / 0.037411 (-0.012075) | 0.097449 / 0.014526 (0.082923) | 0.106301 / 0.176557 (-0.070255) | 0.153053 / 0.737135 (-0.584082) | 0.107938 / 0.296338 (-0.188401) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.491070 / 0.215209 (0.275861) | 5.049637 / 2.077655 (2.971982) | 2.064709 / 1.504120 (0.560589) | 1.782266 / 1.541195 (0.241072) | 1.798570 / 1.468490 (0.330080) | 0.988886 / 4.584777 (-3.595891) | 4.690324 / 3.745712 (0.944612) | 4.317355 / 5.269862 (-0.952507) | 2.347596 / 4.565676 (-2.218081) | 0.117249 / 0.424275 (-0.307026) | 0.011614 / 0.007607 (0.004007) | 0.630033 / 0.226044 (0.403988) | 6.140108 / 2.268929 (3.871180) | 2.638080 / 55.444624 (-52.806545) | 2.133017 / 6.876477 (-4.743459) | 2.123392 / 2.142072 (-0.018680) | 1.178056 / 4.805227 (-3.627171) | 0.209465 / 6.500664 (-6.291199) | 0.063234 / 0.075469 (-0.012235) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.238089 / 1.841788 (-0.603699) | 14.066866 / 8.074308 (5.992558) | 16.225480 / 10.191392 (6.034088) | 0.206466 / 0.680424 (-0.473958) | 0.027279 / 0.534201 (-0.506922) | 0.443006 / 0.579283 (-0.136277) | 0.509512 / 0.434364 (0.075148) | 0.479075 / 0.540337 (-0.061263) | 0.573546 / 1.386936 (-0.813390) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2433/comments | https://api.github.com/repos/huggingface/datasets/issues/2433/events | https://github.com/huggingface/datasets/pull/2433 | 907,488,711 | MDExOlB1bGxSZXF1ZXN0NjU4MzI5MDQ4 | 2,433 | Fix DuplicatedKeysError in adversarial_qa | [] | closed | false | null | 0 | 2021-05-31T13:48:47Z | 2021-06-01T08:52:11Z | 2021-06-01T08:52:11Z | null | Fixes #2431 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2433/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2433.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2433",
"merged_at": "2021-06-01T08:52:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2433.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2433"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1827 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1827/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1827/comments | https://api.github.com/repos/huggingface/datasets/issues/1827/events | https://github.com/huggingface/datasets/issues/1827 | 802,353,974 | MDU6SXNzdWU4MDIzNTM5NzQ= | 1,827 | Regarding On-the-fly Data Loading | [] | closed | false | null | 4 | 2021-02-05T17:43:48Z | 2021-02-18T13:55:16Z | 2021-02-18T13:55:16Z | null | Hi,
I was wondering if it is possible to load images/texts as a batch during the training process, without loading the entire dataset on the RAM at any given point.
Thanks,
Gunjan | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1827/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1827/timeline | null | completed | null | null | false | [
"Possible duplicate\r\n\r\n#1776 https://github.com/huggingface/datasets/issues/\r\n\r\nreally looking PR for this feature",
"Hi @acul3 \r\n\r\nIssue #1776 talks about doing on-the-fly data pre-processing, which I think is solved in the next release as mentioned in the issue #1825. I also look forward to using this feature, though :)\r\n\r\nI wanted to ask about on-the-fly data loading from the cache (before pre-processing).",
"Hi ! Currently when you load a dataset via `load_dataset` for example, then the dataset is memory-mapped from an Arrow file on disk. Therefore there's almost no RAM usage even if your dataset contains TB of data.\r\nUsually at training time only one batch of data at a time is loaded in memory.\r\n\r\nDoes that answer your question or were you thinking about something else ?",
"Hi @lhoestq,\r\n\r\nI apologize for the late response. This answers my question. Thanks a lot."
] |
https://api.github.com/repos/huggingface/datasets/issues/5126 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5126/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5126/comments | https://api.github.com/repos/huggingface/datasets/issues/5126/events | https://github.com/huggingface/datasets/pull/5126 | 1,411,757,124 | PR_kwDODunzps5A8Iw3 | 5,126 | Fix class name of symbolic link | [] | closed | false | null | 4 | 2022-10-17T15:11:02Z | 2022-11-14T14:40:18Z | 2022-11-14T14:40:18Z | null | Fix #5098 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5126/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5126/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5126.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5126",
"merged_at": "2022-11-14T14:40:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5126.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5126"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5126). All of your documentation changes will be reflected on that endpoint.",
"I have removed the reference to the Issue in the PR title, so that we avoid to have both references (to the issue and to the PR) in the merge commit to the main branch.\r\n\r\nInstead, it should be commented in the PR description, so that the PR is appropriately linked by GitHub to its corresponding Issue:\r\n\r\n> Fix #5098.",
"@albertvillanova What should I test in your opinion? Also, where should I save the test file and how should I name it? Thanks for your support",
"The regression test to be implemented should test what your PR fixes: that is, that `_resolve_single_pattern_locally` function does not resolve any symbolic link when passed a directory that does contain any.\r\n\r\nAs you are testing a function in `data_files.py`, the corresponding test should be in `tests/test_data_files.py`.\r\n\r\nYou could name the test something lilke: `test_resolve_single_pattern_locally_does_not_resolve_symbolic_links`\r\n\r\nYou could take inspiration from other tests there in that file."
] |
https://api.github.com/repos/huggingface/datasets/issues/4226 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4226/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4226/comments | https://api.github.com/repos/huggingface/datasets/issues/4226/events | https://github.com/huggingface/datasets/pull/4226 | 1,216,331,073 | PR_kwDODunzps420kAv | 4,226 | Add pearsonr mc, update functionality to match the original docs | [] | closed | false | null | 2 | 2022-04-26T18:30:46Z | 2022-05-03T17:09:24Z | 2022-05-03T17:02:28Z | null | - adds pearsonr metric card
- adds ability to return p-value
- p-value was mentioned in the original docs as a return value, but there was no option to return it. I updated the _compute function slightly to have an option to return the p-value. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4226/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4226/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4226.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4226",
"merged_at": "2022-05-03T17:02:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4226.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4226"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"thank you @lhoestq!! :hugs: "
] |
https://api.github.com/repos/huggingface/datasets/issues/5586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5586/comments | https://api.github.com/repos/huggingface/datasets/issues/5586/events | https://github.com/huggingface/datasets/issues/5586 | 1,602,961,544 | I_kwDODunzps5fi0CI | 5,586 | .sort() is broken when used after .filter(), only in 2.10.0 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2023-02-28T12:18:09Z | 2023-02-28T18:17:26Z | 2023-02-28T17:21:59Z | null | ### Describe the bug
Hi, thank you for your support!
It seems like the addition of multiple key sort (#5502) in 2.10.0 broke the `.sort()` method.
After filtering a dataset with `.filter()`, the `.sort()` seems to refer to the query_table index of the previous unfiltered dataset, resulting in an IndexError.
This only happens with the 2.10.0 release.
### Steps to reproduce the bug
```Python
from datasets import load_dataset
# dataset with length of 1104
ds = load_dataset('glue', 'ax')['test']
ds = ds.filter(lambda x: x['idx'] > 1100)
ds.sort('premise')
print('Done')
```
File "/home/dongkeun/datasets_test/test.py", line 5, in <module>
ds.sort('premise')
File "/home/dongkeun/miniconda3/envs/datasets_test/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 528, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/dongkeun/miniconda3/envs/datasets_test/lib/python3.9/site-packages/datasets/fingerprint.py", line 511, in wrapper
out = func(dataset, *args, **kwargs)
File "/home/dongkeun/miniconda3/envs/datasets_test/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 3959, in sort
sort_table = query_table(
File "/home/dongkeun/miniconda3/envs/datasets_test/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 588, in query_table
_check_valid_index_key(key, size)
File "/home/dongkeun/miniconda3/envs/datasets_test/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 537, in _check_valid_index_key
_check_valid_index_key(max(key), size=size)
File "/home/dongkeun/miniconda3/envs/datasets_test/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 531, in _check_valid_index_key
raise IndexError(f"Invalid key: {key} is out of bounds for size {size}")
IndexError: Invalid key: 1103 is out of bounds for size 3
### Expected behavior
It should sort the dataset and print "Done". Which it does on 2.9.0.
### Environment info
- `datasets` version: 2.10.0
- Platform: Linux-5.15.0-41-generic-x86_64-with-glibc2.31
- Python version: 3.9.16
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5586/timeline | null | completed | null | null | false | [
"Thanks for reporting and thanks @mariosasko for fixing ! We just did a patch release `2.10.1` with the fix"
] |
https://api.github.com/repos/huggingface/datasets/issues/1263 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1263/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1263/comments | https://api.github.com/repos/huggingface/datasets/issues/1263/events | https://github.com/huggingface/datasets/pull/1263 | 758,663,787 | MDExOlB1bGxSZXF1ZXN0NTMzNzk5NzU5 | 1,263 | Added kannada news headlines classification dataset. | [] | closed | false | null | 1 | 2020-12-07T16:35:37Z | 2020-12-10T14:30:55Z | 2020-12-09T18:01:31Z | null | Manual Download of a kaggle dataset. Mostly followed process as ms_terms. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1263/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1263/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1263.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1263",
"merged_at": "2020-12-09T18:01:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1263.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1263"
} | true | [
"Hi! Let me know if any more comments! Will fix it! :-)"
] |
https://api.github.com/repos/huggingface/datasets/issues/672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/672/comments | https://api.github.com/repos/huggingface/datasets/issues/672/events | https://github.com/huggingface/datasets/issues/672 | 709,575,527 | MDU6SXNzdWU3MDk1NzU1Mjc= | 672 | Questions about XSUM | [] | closed | false | null | 14 | 2020-09-26T17:16:24Z | 2022-10-04T17:30:17Z | 2022-10-04T17:30:17Z | null | Hi there ✋
I'm looking into your `xsum` dataset and I have several questions on that.
So here is how I loaded the data:
```
>>> data = datasets.load_dataset('xsum', version='1.0.1')
>>> data['train']
Dataset(features: {'document': Value(dtype='string', id=None), 'summary': Value(dtype='string', id=None)}, num_rows: 204017)
>>> data['test']
Dataset(features: {'document': Value(dtype='string', id=None), 'summary': Value(dtype='string', id=None)}, num_rows: 11333)
```
The first issue is, the instance counts don’t match what I see on [the dataset's website](https://github.com/EdinburghNLP/XSum/tree/master/XSum-Dataset#what-builds-the-xsum-dataset) (11,333 vs 11,334 for test set; 204,017 vs 204,045 for training set)
```
… training (90%, 204,045), validation (5%, 11,332), and test (5%, 11,334) set.
```
Any thoughts why? Perhaps @mariamabarham could help here, since she recently had a PR on this dataaset https://github.com/huggingface/datasets/pull/289 (reviewed by @patrickvonplaten)
Another issue is that the instances don't seem to have IDs. The original datasets provides IDs for the instances: https://github.com/EdinburghNLP/XSum/blob/master/XSum-Dataset/XSum-TRAINING-DEV-TEST-SPLIT-90-5-5.json but to be able to use them, the dataset sizes need to match.
CC @jbragg
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/672/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/672/timeline | null | completed | null | null | false | [
"We should try to regenerate the data using the official script.\r\nBut iirc that's what we used in the first place, so not sure why it didn't match in the first place.\r\n\r\nI'll let you know when the dataset is updated",
"Thanks, looking forward to hearing your update on this thread. \r\n\r\nThis is a blocking issue for us; would appreciate any progress on this front. We can also help with the fix, if you deem it appropriately. ",
"I just started the generation on my side, I'll let you know how it goes :) ",
"Hmm after a first run I'm still missing 136668/226711 urls.\r\nI'll relaunch it tomorrow to try to get the remaining ones.",
"Update: I'm missing 36/226711 urls but I haven't managed to download them yet",
"Thanks! That sounds like a reasonable number! ",
"So I managed to download them all but when parsing only 226,181/226,711 worked.\r\nNot sure if it's worth digging and debugging parsing at this point :/ ",
"Maybe @sshleifer can help, I think he's already played with xsum at one point",
"Thanks @lhoestq\r\nIt would be great to improve coverage, but IDs are the really crucial part for us. We'd really appreciate an update to the dataset with IDs either way!",
"I gave up at an even earlier point. The dataset I use has 204,017 train examples.",
"@lhoestq @sshleifer like @jbragg said earlier, the main issue for us is that the current XSUM dataset (in your package) does not have IDs suggested by the original dataset ([here is the file](https://raw.githubusercontent.com/EdinburghNLP/XSum/master/XSum-Dataset/XSum-TRAINING-DEV-TEST-SPLIT-90-5-5.json).) Would appreciate if you update the XSUM dataset to include the instance IDs. \r\n\r\nThe missing instances is also a problem, but likely not worth pursuing given its relatively small scale. ",
">So I managed to download them all but when parsing only 226,181/226,711 worked.\r\n\r\n@lhoestq any chance we could update the HF-hosted dataset with the IDs in your new version? Happy to help if there's something I can do.",
"Well I couldn't parse what I downloaded.\r\nUnfortunately I think I won't be able to take a look at it this week.\r\nI can try to send you what I got if you want to give it a shot @jbragg \r\nOtherwise feel free to re-run the xsum download script, maybe you'll be luckier than me",
"Resolved via #754"
] |
https://api.github.com/repos/huggingface/datasets/issues/4648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4648/comments | https://api.github.com/repos/huggingface/datasets/issues/4648/events | https://github.com/huggingface/datasets/issues/4648 | 1,296,659,335 | I_kwDODunzps5NSXOH | 4,648 | Add WikiAnswers dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2022-07-07T01:06:37Z | 2022-07-14T02:03:40Z | 2022-07-14T02:03:40Z | null | ## Adding a Dataset
- **Name:** *WikiAnswers*
- **Description:** *The WikiAnswers corpus contains clusters of questions tagged by WikiAnswers users as paraphrases. Each cluster optionally contains an answer provided by WikiAnswers users.*
- **Paper:** *https://dl.acm.org/doi/10.1145/2623330.2623677*
- **Data:** *https://github.com/afader/oqa#wikianswers-corpus*
- **Motivation:** *Dataset for training and evaluating models of conversational response*
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4648/timeline | null | completed | null | null | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/WikiAnswers)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4726/comments | https://api.github.com/repos/huggingface/datasets/issues/4726/events | https://github.com/huggingface/datasets/pull/4726 | 1,312,082,175 | PR_kwDODunzps47ykPI | 4,726 | Fix broken link to the Hub | [] | closed | false | null | 1 | 2022-07-20T22:57:27Z | 2022-07-21T14:33:18Z | 2022-07-21T08:00:54Z | null | The Markdown link fails to render if it is in the same line as the `<span>`. This PR implements @mishig25's fix by using `<a href=" ">` instead.
 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4726/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4726/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4726.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4726",
"merged_at": "2022-07-21T08:00:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4726.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4726"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/530 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/530/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/530/comments | https://api.github.com/repos/huggingface/datasets/issues/530/events | https://github.com/huggingface/datasets/pull/530 | 684,825,612 | MDExOlB1bGxSZXF1ZXN0NDcyNjQ5NTk2 | 530 | use ragged tensor by default | [] | closed | false | null | 4 | 2020-08-24T17:06:15Z | 2021-10-22T19:38:40Z | 2020-08-24T19:22:25Z | null | I think it's better if it's clear whether the returned tensor is ragged or not when the type is set to tensorflow.
Previously it was a tensor (not ragged) if numpy could stack the output (which can change depending on the batch of example you take), which make things difficult to handle, as it may sometimes return a ragged tensor and sometimes not.
Therefore I reverted this behavior to always return a ragged tensor as we used to do. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/530/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/530/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/530.diff",
"html_url": "https://github.com/huggingface/datasets/pull/530",
"merged_at": "2020-08-24T19:22:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/530.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/530"
} | true | [
"Yes I agree. Maybe something that lets specify different format depending on the column ? Especially to better control dtype and shape (and ragged for tf)\r\n\r\nOh and I forgot: this one should also fix the second issue found in #477 for the next release",
"I am running into the same issue with the error message on my local windows machine -\r\nAttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'to_tensor'. Tensorflow version is 2.6. Anything that I can do to fix it?\r\ntrain_features = {x: tf_train_dataset[x].to_tensor() for x in tokenizer.model_input_names}\r\ntrain_tf_dataset = tf.data.Dataset.from_tensor_slices((train_features, tf_train_dataset[\"label\"]))\r\ntrain_tf_dataset = train_tf_dataset.shuffle(len(tf_train_dataset)).batch(8)\r\n\r\neval_features = {x: tf_eval_dataset[x].to_tensor() for x in tokenizer.model_input_names}\r\neval_tf_dataset = tf.data.Dataset.from_tensor_slices((eval_features, tf_eval_dataset[\"label\"]))\r\neval_tf_dataset = eval_tf_dataset.batch(8)\r\n\r\nttributeError Traceback (most recent call last)\r\n<ipython-input-59-f50e45c2c0dc> in <module>\r\n----> 1 train_features = {x: tf_train_dataset[x].convert_to_tensor() for x in tokenizer.model_input_names}\r\n 2 train_tf_dataset = tf.data.Dataset.from_tensor_slices((train_features, tf_train_dataset[\"label\"]))\r\n 3 train_tf_dataset = train_tf_dataset.shuffle(len(tf_train_dataset)).batch(8)\r\n 4 \r\n 5 eval_features = {x: tf_eval_dataset[x].to_tensor() for x in tokenizer.model_input_names}\r\n\r\n<ipython-input-59-f50e45c2c0dc> in <dictcomp>(.0)\r\n----> 1 train_features = {x: tf_train_dataset[x].convert_to_tensor() for x in tokenizer.model_input_names}\r\n 2 train_tf_dataset = tf.data.Dataset.from_tensor_slices((train_features, tf_train_dataset[\"label\"]))\r\n 3 train_tf_dataset = train_tf_dataset.shuffle(len(tf_train_dataset)).batch(8)\r\n 4 \r\n 5 eval_features = {x: tf_eval_dataset[x].to_tensor() for x in tokenizer.model_input_names}\r\n\r\n~\\AppData\\Roaming\\Python\\Python38\\site-packages\\tensorflow\\python\\framework\\ops.py in __getattr__(self, name)\r\n 399 from tensorflow.python.ops.numpy_ops import np_config\r\n 400 np_config.enable_numpy_behavior()\"\"\".format(type(self).__name__, name))\r\n--> 401 self.__getattribute__(name)\r\n 402 \r\n 403 @staticmethod\r\n\r\nAttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'convert_to_tensor'\r\n\r\n",
"Hi ! Before calling `to_tensor`, make sure that your object is a RaggedTensor, because it may already be a regular Tensor if the shapes of your examples are all the same",
"Okay. i am not familiar with how to check the difference between the two. I will research on this."
] |
https://api.github.com/repos/huggingface/datasets/issues/420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/420/comments | https://api.github.com/repos/huggingface/datasets/issues/420/events | https://github.com/huggingface/datasets/pull/420 | 662,029,782 | MDExOlB1bGxSZXF1ZXN0NDUzNjI5OTk2 | 420 | Better handle nested features | [] | closed | false | null | 0 | 2020-07-20T16:44:13Z | 2020-07-21T08:20:49Z | 2020-07-21T08:09:52Z | null | Changes:
- added arrow schema to features conversion (it's going to be useful to fix #342 )
- make flatten handle deep features (useful for tfrecords conversion in #339 )
- add tests for flatten and features conversions
- the reader now returns the kwargs to instantiate a Dataset (fix circular dependencies) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/420/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/420/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/420.diff",
"html_url": "https://github.com/huggingface/datasets/pull/420",
"merged_at": "2020-07-21T08:09:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/420.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/420"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4676/comments | https://api.github.com/repos/huggingface/datasets/issues/4676/events | https://github.com/huggingface/datasets/issues/4676 | 1,302,202,028 | I_kwDODunzps5Nngas | 4,676 | Dataset.map gets stuck on _cast_to_python_objects | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 9 | 2022-07-12T15:09:58Z | 2022-10-03T13:01:04Z | 2022-10-03T13:01:03Z | null | ## Describe the bug
`Dataset.map`, when fed a Huggingface Tokenizer as its map func, can sometimes spend huge amounts of time doing casts. A minimal example follows.
Not all usages suffer from this. For example, I profiled the preprocessor at https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb , and it did _not_ have this problem. However, I'm at a loss to figure out how it avoids it, as the example below is simple and minimal and still has this problem.
This casting, where it occurs, causes the `Dataset.map` to run approximately 7x slower than it runs for code which does not cause this casting.
This may be related to https://github.com/huggingface/datasets/issues/1046 . However, the tokenizer is _not_ set to return Tensors.
## Steps to reproduce the bug
A minimal, self-contained example to reproduce is below:
```python
import transformers
from transformers import AutoTokenizer
from datasets import load_dataset
import torch
import cProfile
pretrained = 'distilbert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(pretrained)
squad = load_dataset('squad')
squad_train = squad['train']
squad_tiny = squad_train.select(range(5000))
assert isinstance(tokenizer, transformers.PreTrainedTokenizerFast)
def tokenize(ds):
tokens = tokenizer(text=ds['question'],
text_pair=ds['context'],
add_special_tokens=True,
padding='max_length',
truncation='only_second',
max_length=160,
stride=32,
return_overflowing_tokens=True,
return_offsets_mapping=True,
)
return tokens
cmd = 'squad_tiny.map(tokenize, batched=True, remove_columns=squad_tiny.column_names)'
cProfile.run(cmd, sort='tottime')
```
## Actual results
The code works, but takes 10-25 sec per batch (about 7x slower than non-casting code), with the following profile. Note that `_cast_to_python_objects` is the culprit.
```
63524075 function calls (58206482 primitive calls) in 121.836 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
5274034/40 68.751 0.000 111.060 2.776 features.py:262(_cast_to_python_objects)
42223832 24.077 0.000 33.310 0.000 {built-in method builtins.isinstance}
16338/20 5.121 0.000 111.053 5.553 features.py:361(<listcomp>)
5274135 4.747 0.000 4.749 0.000 {built-in method _abc._abc_instancecheck}
80/40 4.731 0.059 116.292 2.907 {pyarrow.lib.array}
5274135 4.485 0.000 9.234 0.000 abc.py:96(__instancecheck__)
2661564/2645196 2.959 0.000 4.298 0.000 features.py:1081(_check_non_null_non_empty_recursive)
5 2.786 0.557 2.786 0.557 {method 'encode_batch' of 'tokenizers.Tokenizer' objects}
2668052 0.930 0.000 0.930 0.000 {built-in method builtins.len}
5000 0.930 0.000 0.938 0.000 tokenization_utils_fast.py:187(_convert_encoding)
5 0.750 0.150 0.808 0.162 {method 'to_pydict' of 'pyarrow.lib.Table' objects}
1 0.444 0.444 121.749 121.749 arrow_dataset.py:2501(_map_single)
40 0.375 0.009 116.291 2.907 arrow_writer.py:151(__arrow_array__)
10 0.066 0.007 0.066 0.007 {method 'write_batch' of 'pyarrow.lib._CRecordBatchWriter' objects}
1 0.060 0.060 121.835 121.835 fingerprint.py:409(wrapper)
11387/5715 0.049 0.000 0.175 0.000 {built-in method builtins.getattr}
36 0.049 0.001 0.049 0.001 {pyarrow._compute.call_function}
15000 0.040 0.000 0.040 0.000 _collections_abc.py:719(__iter__)
3 0.023 0.008 0.023 0.008 {built-in method _imp.create_dynamic}
77 0.020 0.000 0.020 0.000 {built-in method builtins.dir}
37 0.019 0.001 0.019 0.001 socket.py:543(send)
15 0.017 0.001 0.017 0.001 tokenization_utils_fast.py:460(<listcomp>)
432/421 0.015 0.000 0.024 0.000 traitlets.py:1388(_notify_observers)
5000 0.015 0.000 0.018 0.000 _collections_abc.py:672(keys)
51 0.014 0.000 0.042 0.001 traitlets.py:276(getmembers)
5 0.014 0.003 3.775 0.755 tokenization_utils_fast.py:392(_batch_encode_plus)
3/1 0.014 0.005 0.035 0.035 {built-in method _imp.exec_dynamic}
5 0.012 0.002 0.950 0.190 tokenization_utils_fast.py:438(<listcomp>)
31626 0.012 0.000 0.012 0.000 {method 'append' of 'list' objects}
1532/1001 0.011 0.000 0.189 0.000 traitlets.py:643(get)
5 0.009 0.002 3.796 0.759 arrow_dataset.py:2631(apply_function_on_filtered_inputs)
51 0.009 0.000 0.062 0.001 traitlets.py:1766(traits)
5 0.008 0.002 3.784 0.757 tokenization_utils_base.py:2632(batch_encode_plus)
368 0.007 0.000 0.044 0.000 traitlets.py:1715(_get_trait_default_generator)
26 0.007 0.000 0.022 0.001 traitlets.py:1186(setup_instance)
51 0.006 0.000 0.010 0.000 traitlets.py:1781(<listcomp>)
80/32 0.006 0.000 0.052 0.002 table.py:1758(cast_array_to_feature)
684 0.006 0.000 0.007 0.000 {method 'items' of 'dict' objects}
4344/1794 0.006 0.000 0.192 0.000 traitlets.py:675(__get__)
...
```
## Environment info
I observed this on both Google colab and my local workstation:
### Google colab
- `datasets` version: 2.3.2
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- PyArrow version: 6.0.1
- Pandas version: 1.3.5
### Local
- `datasets` version: 2.3.2
- Platform: Windows-7-6.1.7601-SP1
- Python version: 3.8.10
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4676/timeline | null | completed | null | null | false | [
"Are you able to reproduce this? My example is small enough that it should be easy to try.",
"Hi! Thanks for reporting and providing a reproducible example. Indeed, by default, `datasets` performs an expensive cast on the values returned by `map` to convert them to one of the types supported by PyArrow (the underlying storage format used by `datasets`). This cast is not needed on NumPy arrays as PyArrow supports them natively, so one way to make this transform faster is to add `return_tensors=\"np\"` to the tokenizer call. \r\n\r\nI think we should mention this in the docs (cc @stevhliu)",
"I tested this tokenize function and indeed noticed a casting. However it seems to only concerns the `offset_mapping` field, which contains a list of tuples, that is converted to a list of lists. Since `pyarrow` also supports tuples, we actually don't need to convert the tuples to lists. \r\n\r\nI think this can be changed here: \r\n\r\nhttps://github.com/huggingface/datasets/blob/ede72d3f9796339701ec59899c7c31d2427046fb/src/datasets/features/features.py#L382-L383\r\n\r\n```diff\r\n- if isinstance(obj, list): \r\n+ if isinstance(obj, (list, tuple)): \r\n```\r\n\r\nand here: \r\n\r\nhttps://github.com/huggingface/datasets/blob/ede72d3f9796339701ec59899c7c31d2427046fb/src/datasets/features/features.py#L386-L387\r\n\r\n```diff\r\n- return obj if isinstance(obj, list) else [], isinstance(obj, tuple)\r\n+ return obj, False\r\n```\r\n\r\n@srobertjames can you try applying these changes and let us know if it helps ? If so, feel free to open a Pull Request to contribute this improvement if you want :)",
"Wow, adding `return_tensors=\"np\"` sped up my example by a **factor 17x** of and completely eliminated the casting! I'd recommend not only to document it, but to make that the default.\r\n\r\nThe code at https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb does not specify `return_tensors=\"np\"` but yet avoids the casting penalty. How does it do that? (The ntbk seems to do `return_overflowing_tokens=True, return_offsets_mapping=True,`).\r\n\r\nAlso, surprisingly enough, using `return_tensors=\"pt\"` (which is my eventual application) yields this error:\r\n```\r\nTypeError: Provided `function` which is applied to all elements of table returns a `dict` of types \r\n[<class 'torch.Tensor'>, <class 'torch.Tensor'>, <class 'torch.Tensor'>, <class 'torch.Tensor'>]. \r\nWhen using `batched=True`, make sure provided `function` returns a `dict` of types like \r\n`(<class 'list'>, <class 'numpy.ndarray'>)`.\r\n```",
"Setting the output to `\"np\"` makes the whole pipeline fast because it moves the data buffers from rust to python to arrow using zero-copy, and also because it does eliminate the casting completely ;)\r\n\r\nHave you had a chance to try eliminating the tuple casting using the trick above ?",
"@lhoestq I just benchmarked the two edits to `features.py` above, and they appear to solve the problem, bringing my original example to within 20% the speed of the output `\"np\"` example. Nice!\r\n\r\nFor a pull request, do you suggest simply following https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md ?",
"Cool ! Sure feel free to follow these instructions to open a PR :) thanks !",
"#take",
"Resolved via https://github.com/huggingface/datasets/pull/4993."
] |
https://api.github.com/repos/huggingface/datasets/issues/2933 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2933/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2933/comments | https://api.github.com/repos/huggingface/datasets/issues/2933/events | https://github.com/huggingface/datasets/pull/2933 | 999,392,566 | PR_kwDODunzps4r5MHs | 2,933 | Replace script_version with revision | [] | closed | false | null | 1 | 2021-09-17T14:04:39Z | 2021-09-20T09:52:10Z | 2021-09-20T09:52:10Z | null | As discussed in https://github.com/huggingface/datasets/pull/2718#discussion_r707013278, the parameter name `script_version` is no longer applicable to datasets without loading script (i.e., datasets only with raw data files).
This PR replaces the parameter name `script_version` with `revision`.
This way, we are also aligned with:
- Transformers: `AutoTokenizer.from_pretrained(..., revision=...)`
- Hub: `HfApi.dataset_info(..., revision=...)`, `HfApi.upload_file(..., revision=...)` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2933/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2933/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2933.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2933",
"merged_at": "2021-09-20T09:52:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2933.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2933"
} | true | [
"I'm also fine with the removal in 1.15"
] |
https://api.github.com/repos/huggingface/datasets/issues/2832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2832/comments | https://api.github.com/repos/huggingface/datasets/issues/2832/events | https://github.com/huggingface/datasets/issues/2832 | 978,012,800 | MDU6SXNzdWU5NzgwMTI4MDA= | 2,832 | Logging levels not taken into account | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-08-24T11:50:41Z | 2023-07-12T17:19:30Z | 2023-07-12T17:19:29Z | null | ## Describe the bug
The `logging` module isn't working as intended relative to the levels to set.
## Steps to reproduce the bug
```python
from datasets import logging
logging.set_verbosity_debug()
logger = logging.get_logger()
logger.error("ERROR")
logger.warning("WARNING")
logger.info("INFO")
logger.debug("DEBUG"
```
## Expected results
I expect all logs to be output since I'm putting a `debug` level.
## Actual results
Only the two first logs are output.
## Environment info
- `datasets` version: 1.11.0
- Platform: Linux-5.13.9-arch1-1-x86_64-with-glibc2.33
- Python version: 3.9.6
- PyArrow version: 5.0.0
## To go further
This logging issue appears in `datasets` but not in `transformers`. It happens because there is no handler defined for the logger. When no handler is defined, the `logging` library will output a one-off error to stderr, using a `StderrHandler` with level `WARNING`.
`transformers` sets a default `StreamHandler` [here](https://github.com/huggingface/transformers/blob/5c6eca71a983bae2589eed01e5c04fcf88ba5690/src/transformers/utils/logging.py#L86) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2832/timeline | null | completed | null | null | false | [
"I just take a look at all the outputs produced by `datasets` using the different log-levels.\r\nAs far as i can tell using `datasets==1.17.0` they overall issue seems to be fixed.\r\n\r\nHowever, I noticed that there is one tqdm based progress indicator appearing on STDERR that I can simply not suppress.\r\n```\r\nResolving data files: 100%|██████████| 652/652 [00:00<00:00, 1604.52it/s]\r\n```\r\n\r\nAccording to _get_origin_metadata_locally_or_by_urls it shold be supressable by using the `NOTSET` log-level\r\nhttps://github.com/huggingface/datasets/blob/1406a04c3e911cec2680d8bc513653e0cafcaaa4/src/datasets/data_files.py#L491-L501\r\nSadly when specifiing the log-level `NOTSET` it seems to has no effect.\r\n\r\nBut appart from it not having any effect I must admit that it seems unintuitive to me.\r\nI would suggest changing this such that it is only shown when the log-level is greater or equal to INFO.\r\n\r\nThis would conform better to INFO according to the [documentation](https://huggingface.co/docs/datasets/v1.0.0/package_reference/logging_methods.html#datasets.logging.set_verbosity_info).\r\n> This will display most of the logging information and tqdm bars.\r\n\r\nAny inputs on this?\r\nI will be happy to supply a PR if desired 👍 ",
"Hi! This should disable the tqdm output:\r\n```python\r\nimport datasets\r\ndatasets.set_progress_bar_enabled(False)\r\n```\r\n\r\nOn a side note: I believe the issue with logging (not tqdm) is still relevant on master."
] |
https://api.github.com/repos/huggingface/datasets/issues/1184 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1184/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1184/comments | https://api.github.com/repos/huggingface/datasets/issues/1184/events | https://github.com/huggingface/datasets/pull/1184 | 757,807,583 | MDExOlB1bGxSZXF1ZXN0NTMzMTExNjk4 | 1,184 | Add Adversarial SQuAD dataset | [] | closed | false | null | 5 | 2020-12-05T23:51:57Z | 2020-12-16T16:12:58Z | 2020-12-16T16:12:58Z | null | # Adversarial SQuAD
Adding the Adversarial [SQuAD](https://github.com/robinjia/adversarial-squad) dataset as part of the sprint 🎉
This dataset adds adversarial sentences to a subset of the SQuAD dataset's dev examples. How to get the original squad example id is explained in readme->Data Instances. The whole data is intended for use in evaluation. (Which could of course be also used for training if one wants). So there is no classical train/val/test split, but a split based on the number of adversaries added.
There are 2 splits of this dataset:
- AddSent: Has up to five candidate adversarial sentences that don't answer the question, but have a lot of words in common with the question. This adversary is does not query the model in any way.
- AddOneSent: Similar to AddSent, but just one candidate sentences was picked at random. This adversary is does not query the model in any way.
(The AddAny and AddCommon datasets mentioned in the paper are dynamically generated based on model's output distribution thus are not included here)
The failing test look like some unrelated timeout thing, will probably clear if rerun.
- [x] All tests passed
- [x] Added dummy data
- [x] Added data card (as much as I could) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1184/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1184/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1184.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1184",
"merged_at": "2020-12-16T16:12:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1184.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1184"
} | true | [
"the CI error was just a connection error due to all the activity on the repo this week ^^'\r\nI re-ran it so it should be good now",
"I hadn't realized the problem with the dummies since it had passed without errors.\r\nSuggestion: maybe we can show the user a warning based on the generated dummy size.",
"Thanks for changing to configs ! Looks all good now :) \r\n\r\nBefore we merge, can you re-lighten the dummy data please if you don't mind ? The idea is to have them weigh only a few KB (currently it's 50KB each). Feel free to remove any unnecessary files or chunk of text",
"(also you can ignore the `RemoteDatasetTest ` CI errors, they're fixed on master )",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/362/comments | https://api.github.com/repos/huggingface/datasets/issues/362/events | https://github.com/huggingface/datasets/issues/362 | 653,766,245 | MDU6SXNzdWU2NTM3NjYyNDU= | 362 | [dateset subset missing] xtreme paws-x | [] | closed | false | null | 1 | 2020-07-09T05:04:54Z | 2020-07-09T12:38:42Z | 2020-07-09T12:38:42Z | null | I tried nlp.load_dataset('xtreme', 'PAWS-X.es') but get the value error
It turns out that the subset for Spanish is missing
https://github.com/google-research-datasets/paws/tree/master/pawsx | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/362/timeline | null | completed | null | null | false | [
"You're right, thanks for pointing it out. We will update it "
] |
https://api.github.com/repos/huggingface/datasets/issues/5320 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5320/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5320/comments | https://api.github.com/repos/huggingface/datasets/issues/5320/events | https://github.com/huggingface/datasets/pull/5320 | 1,471,360,910 | PR_kwDODunzps5ED_UQ | 5,320 | [Extract] Place the lock file next to the destination directory | [] | closed | false | null | 1 | 2022-12-01T13:55:49Z | 2022-12-01T15:36:44Z | 2022-12-01T15:33:58Z | null | Previously it was placed next to the archive to extract, but the archive can be in a read-only directory as noticed in https://github.com/huggingface/datasets/issues/5295
Therefore I moved the lock location to be next to the destination directory, which is required to have write permissions | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5320/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5320/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5320.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5320",
"merged_at": "2022-12-01T15:33:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5320.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5320"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/525 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/525/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/525/comments | https://api.github.com/repos/huggingface/datasets/issues/525/events | https://github.com/huggingface/datasets/issues/525 | 683,875,483 | MDU6SXNzdWU2ODM4NzU0ODM= | 525 | wmt download speed example | [] | closed | false | null | 8 | 2020-08-21T23:29:06Z | 2022-10-04T17:45:39Z | 2022-10-04T17:45:39Z | null | Continuing from the slack 1.0 roadmap thread w @lhoestq , I realized the slow downloads is only a thing sometimes. Here are a few examples, I suspect there are multiple issues. All commands were run from the same gcp us-central-1f machine.
```
import nlp
nlp.load_dataset('wmt16', 'de-en')
```
Downloads at 49.1 KB/S
Whereas
```
pip install gdown # download from google drive
!gdown https://drive.google.com/uc?id=1iO7um-HWoNoRKDtw27YUSgyeubn9uXqj
```
Downloads at 127 MB/s. (The file is a copy of wmt-en-de raw).
```
nlp.load_dataset('wmt16', 'ro-en')
```
goes at 27 MB/s, much faster.
if we wget the same data from s3 is the same download speed, but ¼ the file size:
```
wget https://s3.amazonaws.com/datasets.huggingface.co/translation/wmt_en_ro_packed_200_rand.tgz
```
Finally,
```
nlp.load_dataset('wmt19', 'zh-en')
```
Starts fast, but broken. (duplicate of #493 )
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/525/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/525/timeline | null | completed | null | null | false | [
"Thanks for creating the issue :)\r\nThe download link for wmt-en-de raw looks like a mirror. We should use that instead of the current url.\r\nIs this mirror official ?\r\n\r\nAlso it looks like for `ro-en` it tried to download other languages. If we manage to only download the one that is asked it'd be cool\r\n\r\nAlso cc @patrickvonplaten ",
"Mirror is not official.",
"Shall we host the files ourselves or it is fine to use this mirror in your opinion ?",
"Should we add an argument in `load_dataset` to override some URL with a custom URL (e.g. mirror) or a local path?\r\n\r\nThis could also be used to provide local files instead of the original files as requested by some users (e.g. when you made a dataset with the same format than SQuAD and what to use it instead of the official dataset files).",
"@lhoestq I think we should host it ourselves. I'll put the subset of wmt (without preprocessed files) that we need on s3 and post a link over the weekend.",
"Is there a solution yet? The download speed is still too slow. 60-70kbps download for wmt16 and around 100kbps for wmt19. @sshleifer ",
"I'm working on mirror links which will provide high download speed :)\r\nSee https://github.com/huggingface/datasets/issues/1892",
"Resolved via https://github.com/huggingface/datasets/pull/1912"
] |
https://api.github.com/repos/huggingface/datasets/issues/3236 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3236/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3236/comments | https://api.github.com/repos/huggingface/datasets/issues/3236/events | https://github.com/huggingface/datasets/issues/3236 | 1,048,026,358 | I_kwDODunzps4-d5z2 | 3,236 | Loading of datasets changed in #3110 returns no examples | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 7 | 2021-11-08T23:29:46Z | 2021-11-09T16:46:05Z | 2021-11-09T16:45:47Z | null | ## Describe the bug
Loading of datasets changed in https://github.com/huggingface/datasets/pull/3110 returns no examples:
```python
DatasetDict({
train: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 0
})
validation: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 0
})
})
```
## Steps to reproduce the bug
Load any of the datasets that were changed in https://github.com/huggingface/datasets/pull/3110:
```python
from datasets import load_dataset
load_dataset("qasper")
# The problem only started with the commit of #3110
load_dataset("qasper", revision="b6469baa22c174b3906c631802a7016fedea6780")
```
## Expected results
```python
DatasetDict({
train: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 888
})
validation: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 281
})
})
```
Which can be received when specifying revision of the commit before https://github.com/huggingface/datasets/pull/3110:
```python
from datasets import load_dataset
load_dataset("qasper", revision="acfe2abda1ca79f0ce5c1896aa83b4b78af76b7d")
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.2.dev0 (master)
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3236/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3236/timeline | null | completed | null | null | false | [
"Hi @eladsegal, thanks for reporting.\r\n\r\nI am sorry, but I can't reproduce the bug:\r\n```\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"qasper\")\r\nDownloading: 5.11kB [00:00, ?B/s]\r\nDownloading and preparing dataset qasper/qasper (download: 9.88 MiB, generated: 35.11 MiB, post-processed: Unknown size, total: 44.99 MiB) to .cache\\qasper\\qasper\\0.1.0\\b99154d2a15aa54bfc669f82b2eda715a2e342e81023d39613b0e2920fdb3ad8...\r\nDataset qasper downloaded and prepared to .cache\\qasper\\qasper\\0.1.0\\b99154d2a15aa54bfc669f82b2eda715a2e342e81023d39613b0e2920fdb3ad8. Subsequent calls will reuse this data.\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<?, ?it/s]\r\n\r\nIn [3]: ds\r\nOut[3]:\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'title', 'abstract', 'full_text', 'qas'],\r\n num_rows: 888\r\n })\r\n validation: Dataset({\r\n features: ['id', 'title', 'abstract', 'full_text', 'qas'],\r\n num_rows: 281\r\n })\r\n})\r\n``` \r\n\r\nThis makes me suspect that the origin of the problem might be the cache: I didn't have this dataset in my cache, although I guess you already had it, before the code change introduced by #3110.\r\n\r\n@lhoestq might it be possible that the code change introduced by #3110 makes \"inaccessible\" all previously cached TAR-based datasets?\r\n- Before the caching system downloaded and extracted the tar dataset\r\n- Now it only downloads the tar dataset (no extraction is done)",
"I can't reproduce either in my environment (macos, python 3.7).\r\n\r\nIn your case it generates zero examples. This can only happen if the extraction of the TAR archive doesn't output the right filenames. Indeed if the `qasper` script can't find the right file to load, it's currently ignored and it returns zero examples. This case was not even considered when #3110 was developed since we considered the file names to be deterministic - and not depend on your environment.\r\n\r\nTherefore here is my hypothesis:\r\n- either the cache is corrupted somehow with an empty TAR archive\r\n- OR I suspect that the issue comes from python 3.8\r\n",
"I just tried again on python 3.8 and I was able to reproduce the issue. Let me work on a fix",
"Ok I found the issue. It's not related to python 3.8 in itself though. This issue happens because your local installation of `datasets` is outdated compared to the changes to datasets in #3110\r\n\r\nTo fix this you just have to pull the latest changes from `master` :)\r\n\r\nLet me know if that helps !\r\n\r\n--------------\r\n\r\nHere are more details about my investigation:\r\n\r\nIt's possible to reproduce this issue if you use `datasets<=1.15.1` or before b6469baa22c174b3906c631802a7016fedea6780 and if you load the dataset after revision b6469baa22c174b3906c631802a7016fedea6780. This is because `dl_manager.iter_archive` had issues at that time (and it was not used anywhere anyway).\r\n\r\nIn particular it was returning the absolute path to extracted files instead of the relative path of the file inside the archive. This was an issue because `dl_manager.iter_archive` isn't supposed to extract the TAR archive. Instead, it iterates over all the files inside the archive, without creating a directory with the extracted content.\r\n\r\nTherefore if you want to use the datasets on `master`, make sure that you have an up-to-date local installation of `datasets` as well, or you may face incompatibilities like this.",
"Thanks!\r\nBut what about code that is already using older version of datasets? \r\nThe reason I encountered this issue was that suddenly one of my repos with version 1.12.1 started getting 0 examples.\r\nI handled it by adding `revision` to `load_dataset`, but I guess it would still be an issue for other users who doesn't know this.",
"Hi, in 1.12.1 it uses the dataset scripts from that time, not the one on master.\r\n\r\nIt only uses the datasets from master if you installed `datasets` from source, or if the dataset isn't available in your local version (in this case it shows a warning and it loads from master).\r\n",
"OK, I understand the issue a bit better now.\r\nI see I wasn't on 1.12.1, but on 1.12.1.dev0 and since it is a dev version it uses master.\r\nSo users that use an old dev version must specify revision or else they'll encounter this problem.\r\n\r\nBTW, when I opened the issue I installed the latest master version with\r\n```\r\npip install git+git://github.com/huggingface/datasets@master#egg=datasets\r\n```\r\nand also used `download_mode=\"force_redownload\"`, and it still returned 0 examples.\r\nNow I deleted all of the cache and ran the code again, and it worked.\r\nI'm not sure what exactly happened here, but looks like it was due to a mix of an unofficial version and its cache.\r\n\r\nThanks again!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2810 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2810/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2810/comments | https://api.github.com/repos/huggingface/datasets/issues/2810/events | https://github.com/huggingface/datasets/pull/2810 | 972,040,022 | MDExOlB1bGxSZXF1ZXN0NzEzNjkzMTI1 | 2,810 | Add WIT Dataset | [] | closed | false | null | 1 | 2021-08-16T19:34:09Z | 2022-05-06T12:27:29Z | 2022-05-06T12:26:16Z | null | Adds Google's [WIT](https://github.com/google-research-datasets/wit) dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2810/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2810/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/2810.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2810",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2810.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2810"
} | true | [
"Google's version of WIT is now available here: https://huggingface.co/datasets/google/wit"
] |
https://api.github.com/repos/huggingface/datasets/issues/1774 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1774/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1774/comments | https://api.github.com/repos/huggingface/datasets/issues/1774/events | https://github.com/huggingface/datasets/issues/1774 | 792,730,559 | MDU6SXNzdWU3OTI3MzA1NTk= | 1,774 | is it possible to make slice to be more compatible like python list and numpy? | [] | open | false | null | 2 | 2021-01-24T06:15:52Z | 2022-06-01T15:54:50Z | null | null | Hi,
see below error:
```
AssertionError: Requested slice [:10000000000000000] incompatible with 20 examples.
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1774/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1774/timeline | null | null | null | null | false | [
"Hi ! Thanks for reporting.\r\nI am working on changes in the way data are sliced from arrow. I can probably fix your issue with the changes I'm doing.\r\nIf you have some code to reproduce the issue it would be nice so I can make sure that this case will be supported :)\r\nI'll make a PR in a few days ",
"Good if you can take care at your side.\r\nHere is the [colab notebook](https://colab.research.google.com/drive/19c-abm87RTRYgW9G1D8ktfwRW95zDYBZ?usp=sharing)"
] |
https://api.github.com/repos/huggingface/datasets/issues/722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/722/comments | https://api.github.com/repos/huggingface/datasets/issues/722/events | https://github.com/huggingface/datasets/pull/722 | 718,689,117 | MDExOlB1bGxSZXF1ZXN0NTAxMDI3NjAw | 722 | datasets(RWTH-PHOENIX-Weather 2014 T): add initial loading script | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 3 | 2020-10-10T19:44:08Z | 2022-09-30T14:53:37Z | 2022-09-30T14:53:37Z | null | This is the first sign language dataset in this repo as far as I know.
Following an old issue I opened https://github.com/huggingface/datasets/issues/302.
I added the dataset official REAMDE file, but I see it's not very standard, so it can be removed.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/722/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/722.diff",
"html_url": "https://github.com/huggingface/datasets/pull/722",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/722.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/722"
} | true | [
"This might be interesting to @kayoyin the author of https://github.com/kayoyin/transformer-slt – pinging you just in case :)",
"Thanks Amit, this is a great idea! I'm thinking of porting the SLT models from my paper here as well, having this dataset would be perfect for that :)",
"Thanks for your contribution, @AmitMY. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/2272 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2272/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2272/comments | https://api.github.com/repos/huggingface/datasets/issues/2272/events | https://github.com/huggingface/datasets/issues/2272 | 869,017,977 | MDU6SXNzdWU4NjkwMTc5Nzc= | 2,272 | Bug in Dataset.class_encode_column | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-04-27T16:13:18Z | 2021-04-30T12:54:27Z | 2021-04-30T12:54:27Z | null | ## Describe the bug
All the rest of the columns except the one passed to `Dataset.class_encode_column` are discarded.
## Expected results
All the original columns should be kept.
This needs regression tests.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2272/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2272/timeline | null | completed | null | null | false | [
"This has been fixed in this commit: https://github.com/huggingface/datasets/pull/2254/commits/88676c930216cd4cc31741b99827b477d2b46cb6\r\n\r\nIt was introduced in #2246 : using map with `input_columns` doesn't return the other columns anymore"
] |
https://api.github.com/repos/huggingface/datasets/issues/4883 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4883/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4883/comments | https://api.github.com/repos/huggingface/datasets/issues/4883/events | https://github.com/huggingface/datasets/issues/4883 | 1,349,083,235 | I_kwDODunzps5QaWBj | 4,883 | With dataloader RSS memory consumed by HF datasets monotonically increases | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 40 | 2022-08-24T08:42:54Z | 2022-09-29T16:16:31Z | null | null | ## Describe the bug
When the HF datasets is used in conjunction with PyTorch Dataloader, the RSS memory of the process keeps on increasing when it should stay constant.
## Steps to reproduce the bug
Run and observe the output of this snippet which logs RSS memory.
```python
import psutil
import os
from transformers import BertTokenizer
from datasets import load_dataset
from torch.utils.data import DataLoader
BATCH_SIZE = 32
NUM_TRIES = 10
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def transform(x):
x.update(tokenizer(x["text"], return_tensors="pt", max_length=64, padding="max_length", truncation=True))
x.pop("text")
x.pop("label")
return x
dataset = load_dataset("imdb", split="train")
dataset.set_transform(transform)
train_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
mem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
count = 0
while count < NUM_TRIES:
for idx, batch in enumerate(train_loader):
mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
print(count, idx, mem_after - mem_before)
count += 1
```
## Expected results
Memory should not increase after initial setup and loading of the dataset
## Actual results
Memory continuously increases as can be seen in the log.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-4.19.0-21-cloud-amd64-x86_64-with-glibc2.10
- Python version: 3.8.13
- PyArrow version: 7.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 3,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4883/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4883/timeline | null | null | null | null | false | [
"Are you sure there is a leak? How can I see it? You shared the script but not the output which you believe should indicate a leak.\r\n\r\nI modified your reproduction script to print only once per try as your original was printing too much info and you absolutely must add `gc.collect()` when doing any memory measurements, since python's GC is scheduled so you might be measuring the wrong thing. This gives us:\r\n\r\n```\r\nimport psutil\r\nimport os\r\nimport gc\r\nfrom transformers import BertTokenizer\r\nfrom datasets import load_dataset\r\nfrom torch.utils.data import DataLoader\r\n\r\nBATCH_SIZE = 32\r\nNUM_TRIES = 100\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\ndef transform(x):\r\n x.update(tokenizer(x[\"text\"], return_tensors=\"pt\", max_length=64, padding=\"max_length\", truncation=True))\r\n x.pop(\"text\")\r\n x.pop(\"label\")\r\n return x\r\ndataset = load_dataset(\"imdb\", split=\"train\")\r\ndataset.set_transform(transform)\r\ntrain_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)\r\n\r\nmem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n\r\ncount = 0\r\nwhile count < NUM_TRIES:\r\n for idx, batch in enumerate(train_loader): pass\r\n gc.collect()\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n print(count, mem_after - mem_before)\r\n count += 1\r\n```\r\n\r\nNow running it:\r\n\r\n```\r\n$ python dl-leak.py \r\nReusing dataset imdb (/home/stas/.cache/huggingface/datasets/imdb/plain_text/1.0.0/2fdd8b9bcadd6e7055e742a706876ba43f19faee861df134affd7a3f60fc38a1)\r\n0 4.43359375\r\n1 4.4453125\r\n2 4.44921875\r\n3 4.44921875\r\n4 4.4609375\r\n5 4.46484375\r\n6 4.46484375\r\n7 4.46484375\r\n8 4.46484375\r\n9 4.46484375\r\n10 4.46484375\r\n11 4.46484375\r\n12 4.46484375\r\n13 4.46484375\r\n14 4.46484375\r\n15 4.46484375\r\n16 4.46484375\r\n```\r\n\r\nIt's normal that at the beginning there is a small growth in memory usage, but after 5 cycles it gets steady.",
"Unless of course you're referring the memory growth during the first try. Is that what you're referring to? And since your ds is small it's hard to see the growth - could it be just because some records are longer and it needs to allocate more memory for those?\r\n\r\nThough while experimenting with this I have observed a peculiar thing, if I concatenate 2 datasets, I don't see any growth at all. But that's probably because the program allocated additional peak RSS memory to concatenate and then is re-using the memory\r\n\r\nI basically tried to see if I make the dataset much longer, I'd expect not to see any memory growth once the 780 records of the imdb ds have been processed once.",
"It is hard to say if it is directly reproducible in this setup. Maybe it is specific to the images stored in the CM4 case which cause a memory leak. I am still running your script and seeing if I can reproduce that particular leak in this case.",
"I was able to reproduce the leak with:\r\n\r\n```\r\nimport psutil\r\nimport os\r\nimport gc\r\nfrom datasets import load_from_disk\r\nimport time\r\n\r\nDATASET_PATH = \"/hf/m4-master/data/cm4/cm4-10000-v0.1\"\r\n\r\ndataset = load_from_disk(DATASET_PATH)\r\n\r\n# truncate to a tiny dataset\r\ndataset = dataset.select(range(1000))\r\n\r\nprint(f\"dataset: {len(dataset)} records\")\r\n\r\nmem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\nfor idx, rec in enumerate(dataset):\r\n if idx % 100 == 0:\r\n gc.collect()\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n print(f\"{idx:4d} {mem_after - mem_before:12.4f}MB\")\r\n```\r\nYou need to adjust the DATASET_PATH record.\r\n\r\nwhich you get from\r\n\r\n```\r\ngsutil -m cp \"gs://hf-science-m4/cm4/cm4-10000-v0.1/dataset.arrow\" \"gs://hf-science-m4/cm4/cm4-10000-v0.1/dataset_info.json\" \"gs://hf-science-m4/cm4/cm4-10000-v0.1/state.json\" .\r\n```\r\n(I assume the hf folks have the perms) - it's a smallish dataset (10k)\r\n\r\nthen you run:\r\n```\r\n$ python ds.py\r\ndataset: 1000 records\r\n 0 1.0156MB\r\n 100 126.3906MB\r\n 200 142.8906MB\r\n 300 168.5586MB\r\n 400 218.3867MB\r\n 500 230.7070MB\r\n 600 238.9570MB\r\n 700 263.3789MB\r\n 800 288.1289MB\r\n 900 300.5039MB\r\n```\r\n\r\nyou should be able to see the leak ",
"This issue has nothing to do with `PIL`'s decoder. I removed it and the problem is still there.\r\n\r\nI then traced this leak to this single call: `pa_table.to_pydict()` here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/08a7b389cdd6fb49264a72aa8ccfc49a233494b6/src/datasets/formatting/formatting.py#L138-L140\r\n\r\nI can make it leak much faster by modifying that code to repeat `pa_table.to_pydict()` many times in a row. It shouldn't have that impact:\r\n\r\n```\r\nclass PythonArrowExtractor(BaseArrowExtractor[dict, list, dict]):\r\n def extract_row(self, pa_table: pa.Table) -> dict:\r\n x = [pa_table.to_pydict() for x in range(200)]\r\n return _unnest(pa_table.to_pydict())\r\n```\r\n\r\n@lhoestq - do you know what might be happening inside `pa_table.to_pydict()`, as this is in the `pyarrow` domain. Perhaps you know someone to tag from that project?\r\n\r\nProbably next need to remove `datasets` from the equation and make a reproducible case with just `pyarrow` directly.\r\n\r\nThe problem already happens with `pyarrow==6.0.0` or later (minimum for current `datasets`)\r\n\r\nI'm also trying to dig in with `objgraph` to see if there are any circular references which prevent objects from being freed, but no luck there so far. And I'm pretty sure `to_pydict` is not a python code, so the problem is likely to happen somewhere outside of python's GC.",
"This appears to be the same issue I think: https://github.com/huggingface/datasets/issues/4528\r\nI dug into the repro code there and it's the same behavior with the same leak, but it's a pure nlp dataset and thus much faster to work with. \r\n",
"I went all the way back to `pyarrow==1.0.0` and `datasets==1.12.0` and the problem is still there. How is it even possible that it wasn't noticed all this time. \r\n\r\nCould it be that the leak is in some 3rd party component `pyarrow` relies on? as while downgrading I have only downgraded the above 2 packages.\r\n",
"Also found this warning \r\n\r\n> Be careful: if you don't pass the ArrowArray struct to a consumer,\r\n> array memory will leak. This is a low-level function intended for\r\n> expert users.\r\n\r\nsee: https://github.com/apache/arrow/blob/99b57e84277f24e8ec1ddadbb11ef8b4f43c8c89/python/pyarrow/table.pxi#L2515-L2517\r\n\r\nperhaps something triggers this condition?\r\n\r\nI have no idea if it's related - this is just something that came up during my research.",
"Does it crash with OOM at some point? If it doesn't, it isn't a leak, just agressive caching or a custom allocator that doesn't like to give memory back (not uncommon). #4528 looks like it hits a steady state.\r\n\r\nI believe the underlying arrow libs use a custom C allocator. Some of those are designed not to give back to OS, but keep heap memory for themselves to re-use (hitting up the OS involves more expensive mutex locks, contention, etc). The greedy behaviour can be undesirable though. There are likely flags to change the allocator behaviour, and one could likely build without any custom allocators (or use a different one).",
"> Does it crash with OOM at some point?\r\n\r\nIn the original setup where we noticed this problem, it was indeed ending in an OOM",
"> https://github.com/huggingface/datasets/issues/4528 looks like it hits a steady state.\r\n\r\n@rwightman in the plot I shared, the steady state comes from the `time.sleep(100)` I added in the end of the script, to showcase that even the garbage collector couldn't free that allocated memory.\r\n",
"Could this be related to this discussion about a potential memory leak in pyarrow: https://issues.apache.org/jira/browse/ARROW-11007 ?\r\n\r\n(Note: I've tried `import pyarrow; pyarrow.jemalloc_set_decay_ms(0)` and the memory leak is still happening on your toy example)",
"> @lhoestq - do you know what might be happening inside pa_table.to_pydict(), as this is in the pyarrow domain. Perhaps you know someone to tag from that project?\r\n\r\n`to_pydict` calls `to_pylist` on each column (i.e. on each PyArrow Array). Then it iterates on the array and calls `as_py` on each element. The `as_py` implementation depends on the data type. For strings I think it simply gets the buffer that contains the binary string data that is defined in C++\r\n\r\nThe Arrow team is pretty responsive at [email protected] if it can help\r\n\r\n> Probably next need to remove datasets from the equation and make a reproducible case with just pyarrow directly.\r\n\r\nThat would be ideal indeed. Would be happy to help on this, can you give me access to the bucket so I can try with your data ?",
"> That would be ideal indeed. Would be happy to help on this, can you give me access to the bucket so I can try with your data ?\r\n\r\nI added you to the bucket @lhoestq ",
"It looks like an issue with memory mapping:\r\n- the amount of memory used in the end corresponds to the size of the dataset\r\n- setting `keep_in_memory=True` in `load_from_disk` loads the dataset in RAM, and **doesn't cause any memory leak**",
"Here is a code to reproduce this issue using only PyArrow and a dummy arrow file:\r\n```python\r\nimport psutil\r\nimport os\r\nimport gc\r\nimport pyarrow as pa\r\nimport time\r\n\r\nARROW_PATH = \"tmp.arrow\"\r\n\r\nif not os.path.exists(ARROW_PATH):\r\n arr = pa.array([b\"a\" * (200 * 1024)] * 1000) # ~200MB\r\n table = pa.table({\"a\": arr})\r\n\r\n with open(ARROW_PATH, \"wb\") as f:\r\n writer = pa.RecordBatchStreamWriter(f, schema=table.schema)\r\n writer.write_table(table)\r\n writer.close()\r\n\r\n\r\ndef memory_mapped_arrow_table_from_file(filename: str) -> pa.Table:\r\n memory_mapped_stream = pa.memory_map(filename)\r\n opened_stream = pa.ipc.open_stream(memory_mapped_stream)\r\n pa_table = opened_stream.read_all()\r\n return pa_table\r\n\r\n\r\ntable = memory_mapped_arrow_table_from_file(ARROW_PATH)\r\narr = table[0]\r\n\r\nmem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\nfor idx, x in enumerate(arr):\r\n if idx % 100 == 0:\r\n gc.collect()\r\n time.sleep(0.1)\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n print(f\"{idx:4d} {mem_after - mem_before:12.4f}MB\")\r\n```\r\nprints\r\n```\r\n 0 0.2500MB\r\n 100 19.8008MB\r\n 200 39.3320MB\r\n 300 58.8633MB\r\n 400 78.3945MB\r\n 500 97.9258MB\r\n 600 117.4570MB\r\n 700 136.9883MB\r\n 800 156.5195MB\r\n 900 176.0508MB\r\n```\r\nNote that this example simply iterates over the `pyarrow.lib.BinaryScalar` objects in the array. Running `.as_py()` is not needed to experience the memory issue.",
"@lhoestq that does indeed increase in memory, but if you iterate over array again after the first time, or re-open and remap the same file (repeat `table = memory_mapped_arrow_table_from_file(ARROW_PATH)`) before re-iterating, it doesn't move pas 195MB.... it would appear another step is needed to continue consuming memory past that.. hmmm\r\n\r\nAre the pa_tables held on to anywhere after they are iterated in the real code?\r\n\r\nin my hack, if you do a bunch cut & paste and then change the arr name for each iter \r\n\r\n```\r\ntable = memory_mapped_arrow_table_from_file(ARROW_PATH)\r\narr = table[0]\r\n\r\nfor idx, x in enumerate(arr):\r\n if idx % 100 == 0:\r\n gc.collect()\r\n time.sleep(0.1)\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n print(f\"{idx:4d} {mem_after - mem_before:12.4f}MB\")\r\n\r\ntable = memory_mapped_arrow_table_from_file(ARROW_PATH)\r\narr1 = table[0]\r\n\r\nfor idx, x in enumerate(arr1):\r\n if idx % 100 == 0:\r\n gc.collect()\r\n time.sleep(0.1)\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n print(f\"{idx:4d} {mem_after - mem_before:12.4f}MB\")\r\n\r\ntable = memory_mapped_arrow_table_from_file(ARROW_PATH)\r\narr2 = table[0]\r\n\r\nfor idx, x in enumerate(arr2):\r\n if idx % 100 == 0:\r\n gc.collect()\r\n time.sleep(0.1)\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)\r\n print(f\"{idx:4d} {mem_after - mem_before:12.4f}MB\")\r\n```\r\n\r\nit leaks, if all arr are the same name (so prev one gets cleaned up) it does not and goes back to 0, anything that could be holding onto a reference of an intermediary equivalent like arr in the real use case?\r\n\r\n\r\n\r\n",
"Yes, we have already established here https://github.com/huggingface/datasets/issues/4883#issuecomment-1232063891 that when one iterates over the whole dataset multiple times, it consumes a bit more memory in the next few repetitions and then remains steady. \r\n\r\nWhich means that when a new iterator is created over the same dataset, all the memory from the previous iterator is re-used.\r\n\r\nSo the leak happens primarily when the iterator is \"drained\" the first time. which tells me that either a circular reference is created somewhere which only gets released when the iterator is destroyed, or there is some global variable that keeps piling up the memory and doesn't release it in time.\r\n\r\nAlso I noticed some `__del__` methods which won't destroy objects automatically and there is usually a warning against using it https://stackoverflow.com/a/1481512/9201239\r\n\r\nThere are also some `weakref`s in the code which too may lead to leaks or weird problems at times.\r\n",
"@stas00 my point was, I'm not convinced @lhoestq last example illustrates the leak, but rather the differences between memory mapping and in memory usage patterns. If you destroy arr, memory map impl goes back to 0 each iteration. The amount of memory that 'looks' like it is leaked in first pass differes quite a bit between memory mapped vs in memory, but the underlying issue likely a circular reference, or reference(s) which were not cleaned up that would impact either case, but likely much more visible with mmap.",
"Thank you for clarifying, Ross. \r\n\r\nI think we agree that it's almost certain that the `datasets` iterator traps some inner variable that prevents object freeing, since if we create the iterator multiple times (and drain it) after a few runs no new memory is allocated. We could try to dig in more with `objgraph` - my main concern is if the problem happens somewhere outside of python, (i.e. in pyarrow cpp implementation) in which case it'd be much more difficult to trace. \r\n\r\nI wish there was a way on linux to tell the program to free no longer used memory at will.",
"FWIW, I revisted some code I had in the works to use HF datasets w/ timm train & val scripts. There is no leak there across multipe epochs. It uses the defaults. \r\n\r\nIt's worth noting that with imagenet `keep_in_memory=True` isn't even an option because the train arrow file is ~140GB and my local memory is less. The virtual address space reflects mmap (> 150GB) and doesn't increase over epochs that I noticed. I have some perf issues to bring up wrt to the current setup, but that's a separate and lower prio discussion to have elsewhere...",
"# Notes \r\n\r\nAfter reading many issues and trying many things here is the summary of my learning\r\n\r\nI'm now using @lhoestq repro case as it's pyarrow-isolated: https://github.com/huggingface/datasets/issues/4883#issuecomment-1242034985\r\n\r\n\r\n## 1. pyarrow memory backends\r\n\r\nit has 3 backends, I tried them all with the same results\r\n\r\n```\r\npa.set_memory_pool(pa.jemalloc_memory_pool())\r\npa.set_memory_pool(pa.mimalloc_memory_pool())\r\npa.set_memory_pool(pa.system_memory_pool())\r\n```\r\n\r\n## 2. quick release\r\n\r\nThe `jemalloc` backend supports quick release\r\n\r\n```\r\npa.jemalloc_set_decay_ms(0)\r\n```\r\n\r\nit doesn't make any difference in this case\r\n\r\n## 3. actual memory allocations\r\n\r\nthis is a useful tracer for PA memory allocators\r\n```\r\npa.log_memory_allocations(enable=True)\r\n```\r\n\r\nit nicely reports memory allocations and releases when the arrow file is created the first time.\r\n\r\nbut when we then try to do `enumerate(arr)` this logger reports 0 allocations.\r\n\r\nThis summary also reports no allocations when the script run the second time (post file creation):\r\n```\r\nmem_pool = pa.default_memory_pool()\r\nprint(f\"PyArrow mem pool info: {mem_pool.backend_name} backend, {mem_pool.bytes_allocated()} allocated, \"\r\n f\"{mem_pool.max_memory()} max allocated, \")\r\n\r\nprint(f\"PyArrow total allocated bytes: {pa.total_allocated_bytes()}\")\r\n```\r\n\r\nHowever it's easy to see by using `tracemalloc` which only measures python's memory allocations that it's PA that leaks, since `tracemalloc` shows fixed memory\r\n\r\n(this is bolted on top of the original repro script)\r\n\r\n```\r\nimport tracemalloc\r\ntracemalloc.start()\r\n\r\n[...]\r\nfor idx, x in enumerate(arr):\r\n if idx % 10 == 0:\r\n gc.collect()\r\n time.sleep(0.1)\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / 2**20\r\n mem_use = pa.total_allocated_bytes() - start_use\r\n mem_peak = pool.max_memory() - start_peak_use\r\n\r\n second_size, second_peak = tracemalloc.get_traced_memory()\r\n mem_diff = (second_size - first_size) / 2**20\r\n mem_peak_diff = (second_peak - first_peak) / 2**20\r\n\r\n # pa.jemalloc_memory_pool().release_unused()\r\n # pa.mimalloc_memory_pool().release_unused()\r\n # pa.system_memory_pool().release_unused()\r\n\r\n print(f\"{idx:4d} {mem_after - mem_before:12.4f}MB {mem_diff:12.4f} {mem_peak_diff:12.4f} {memory_mapped_stream.size()/2**20:4.4}MB {mem_use/2**20:4.4}MB {mem_peak/2**20:4.4}MB\")\r\n\r\n```\r\n\r\ngives:\r\n\r\n```\r\n 0 5.4258MB 0.0110 0.0201 195.3MB 0.0MB 0.0MB\r\n 10 25.3672MB 0.0112 0.0202 195.3MB 0.0MB 0.0MB\r\n 20 45.9336MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 30 62.4336MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 40 83.0586MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 50 103.6836MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 60 124.3086MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 70 140.8086MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 80 161.4336MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n 90 182.0586MB 0.0112 0.0203 195.3MB 0.0MB 0.0MB\r\n```\r\n\r\nthe 3rd and 4th columns are `tracemalloc`'s report.\r\n\r\nthe 5th column is the size of mmaped stream - fixed.\r\n\r\nthe last 2 are the PA's malloc reports - you can see it's totally fixed and 0.\r\n\r\nSo what gives? PA's memory allocator says nothing was allocated and we can see python doesn't allocate any memory either.\r\n\r\nAs someone suggested in one of the PA issues that **IPC/GRPC could be the issue.** Any suggestions on how debug this one?\r\n\r\nThe main issue is that one can't step through with a python debugger as `arr` is an opaque cpp object binded to python.\r\n\r\nPlease see the next comment for a possible answer.\r\n\r\n# ref-count\r\n\r\nI also traced reference counts and they are all fixed using either `sys.getrefcount(x)` or `len(gc.get_referrers(x))`\r\n\r\nso it's not the python object\r\n\r\n# Important related discussions\r\n\r\nhttps://issues.apache.org/jira/browse/ARROW-11007 - looks very similar to our issue\r\nin particular this part of the report:\r\nhttps://issues.apache.org/jira/browse/ARROW-11007?focusedCommentId=17279642&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-17279642\r\n",
"# There is no leak, just badly communicated linux RSS memory usage stats\r\n\r\nNext, lets revisit @rwightman's suggestion that there is actually no leak.\r\n\r\nAfter all - we are using mmap which **will try to map** the file to RAM as much as it can and then page out if there is no memory. i.e. MMAP is only fast if you have a lot of CPU RAM.\r\n\r\nSo let's do it:\r\n\r\n# Memory mapping OOM test\r\n\r\nWe first quickly start a cgroups-controlled shell which will instantly kill any program that consumes more than 1GB of memory:\r\n\r\n```\r\n$ systemd-run --user --scope -p MemoryHigh=1G -p MemoryMax=1G -p MemorySwapMax=1G --setenv=\"MEMLIMIT=1GB\" bash\r\n```\r\n\r\nLet's check that it indeed does so. Let's change @lhoestq's script to allocate a 10GB arrow file:\r\n\r\n```\r\n$ python -c 'import pyarrow as pa; pa.array([b\"a\" * (2000 * 1024)] * 5000)'\r\nKilled\r\n```\r\noops, that didn't work, as we tried to allocate 10GB when only 1GB is allowed. This is what we want!\r\n\r\nLet's do a sanity check - can we allocate 0.1GB?\r\n```\r\npython -c 'import pyarrow as pa; pa.array([b\"a\" * (2000 * 1024)] * 50)'\r\n```\r\n\r\nYes. So the limited shell does the right thing. It let's allocate `< 1GB` of RSS RAM.\r\n\r\nNext let's go back to @lhoestq's script but with 10GB arrow file.\r\n\r\nwe change his repro script https://github.com/huggingface/datasets/issues/4883#issuecomment-1242034985 to 50x larger file\r\n```\r\n arr = pa.array([b\"a\" * (2000 * 1024)] * 5000) # ~10000MB\r\n```\r\nwe first have to run into a normal unlimited shell so that we don't get killed (as the script allocates 10GB)\r\n\r\nlet's run the script now in the 1GB-limited shell while running a monitor:\r\n\r\n```\r\n$ htop -F python -s M_RESIDENT -u `whoami`\r\n```\r\n\r\nso we have 2 sources of RSS info just in case.\r\n\r\n```\r\n$ python pyar.py\r\n 0 4.3516MB 0.0103 0.0194 9.766e+03MB 0.0MB 0.0MB\r\n 10 24.3008MB 0.0104 0.0195 9.766e+03MB 0.0MB 0.0MB\r\n[...]\r\n4980 9730.3672MB 0.0108 0.0199 9.766e+03MB 0.0MB 0.0MB\r\n4990 9750.9922MB 0.0108 0.0199 9.766e+03MB 0.0MB 0.0MB\r\nPyArrow mem pool info: jemalloc backend, 0 allocated, 0 max allocated,\r\nPyArrow total allocated bytes: 0\r\n```\r\n\r\nBut wait, it reported 10GB RSS both in `htop` and in our log!\r\n\r\nSo that means it never allocated 10GB otherwise it'd have been killed.\r\n\r\n**Which tells us that there is no leak whatsoever** and this is just a really difficult situation where MMAPPED memory is reported as part of RSS which it probably shouldn't. As now we have no way how to measure real memory usage.\r\n\r\nI also attached the script with all the different things I have tried in it, so it should be easy to turn them on/off if you want to reproduce any of my findings.\r\n\r\n[pyar.txt](https://github.com/huggingface/datasets/files/9539430/pyar.txt)\r\n\r\njust rename it to `pyra.py` as gh doesn't let attaching scripts...\r\n\r\n(I have to remember to exit that special mem-limited shell or else I won't be able to do anything serious there.)\r\n\r\n",
"The original leak in the multi-modal code is very likely something else. But of course now it'd be very difficult to trace it using mmap.\r\n\r\nI think to debug we have to set `keep_in_memory=True` in `load_from_disk` to load the small dataset in RAM, so there will be no mmap misleading reporting component and then continue searching for another source of a leak.",
"To add to what @stas00 found, I'm gonna leave some links to where I believe the confusion came from in pyarrow's APIs, for future reference:\r\n* In the section where they talk about [efficiently writing and reading arrow data](https://arrow.apache.org/docs/dev/python/ipc.html?#efficiently-writing-and-reading-arrow-data), they give an example of how \r\n\r\n> Arrow can directly reference the data mapped from disk and avoid having to allocate its own memory. \r\n\r\nAnd where their example shows 0 RSS memory allocation, the way we used to measure RSS shows 39.6719MB allocated. Here's the script to reproduce:\r\n```\r\nimport psutil\r\nimport os\r\nimport gc\r\nimport pyarrow as pa\r\nimport time\r\nimport sys\r\n\r\n# gc.set_debug(gc.DEBUG_LEAK)\r\n# gc.set_threshold(0,0,0)\r\n\r\n#pa.set_memory_pool(pa.mimalloc_memory_pool())\r\n#pa.set_memory_pool(pa.system_memory_pool())\r\n\r\nimport tracemalloc\r\n\r\n#pa.jemalloc_set_decay_ms(0)\r\n# pa.log_memory_allocations(enable=True)\r\n\r\nBATCH_SIZE = 10000\r\nNUM_BATCHES = 1000\r\nschema = pa.schema([pa.field('nums', pa.int32())])\r\nwith pa.OSFile('bigfile.arrow', 'wb') as sink:\r\n with pa.ipc.new_file(sink, schema) as writer:\r\n for row in range(NUM_BATCHES):\r\n batch = pa.record_batch([pa.array(range(BATCH_SIZE), type=pa.int32())], schema)\r\n writer.write(batch)\r\n\r\nstart_use = pa.total_allocated_bytes()\r\npool = pa.default_memory_pool()\r\nstart_peak_use = pool.max_memory()\r\ntracemalloc.start()\r\nfirst_size, first_peak = tracemalloc.get_traced_memory()\r\nmem_before = psutil.Process(os.getpid()).memory_info().rss / 2**20\r\n\r\n\r\n# with pa.OSFile('bigfile.arrow', 'rb') as source:\r\n# loaded_array = pa.ipc.open_file(source).read_all()\r\n\r\nwith pa.memory_map('bigfile.arrow', 'rb') as source:\r\n loaded_array = pa.ipc.open_file(source).read_all()\r\n\r\n\r\nprint(\"LEN:\", len(loaded_array))\r\nprint(\"RSS: {}MB\".format(pa.total_allocated_bytes() >> 20))\r\n\r\ngc.collect()\r\ntime.sleep(0.1)\r\nmem_after = psutil.Process(os.getpid()).memory_info().rss / 2**20\r\nmem_use = pa.total_allocated_bytes() - start_use\r\nmem_peak = pool.max_memory() - start_peak_use\r\nsecond_size, second_peak = tracemalloc.get_traced_memory()\r\nmem_diff = (second_size - first_size) / 2**20\r\nmem_peak_diff = (second_peak - first_peak) / 2**20\r\n\r\nidx = 0\r\nprint(f\"{idx:4d} {mem_after - mem_before:12.4f}MB {mem_diff:12.4f} {mem_peak_diff:12.4f} {mem_use/2**20:4.4}MB {mem_peak/2**20:4.4}MB\")\r\n```\r\ngives:\r\n```\r\n\r\nLEN: 10000000\r\nRSS: 0MB\r\n 0 39.6719MB 0.0132 0.0529 0.0MB 0.0MB\r\n```\r\nWhich again just proves that we uncorrectly measure RSS, in the case of MMAPPED memory\r\n\r\n\r\n* [The recommended way to do memory profiling from Arrow's docs](https://arrow.apache.org/docs/dev/cpp/memory.html#memory-profiling)\r\n",
"@lhoestq, I have been working on a detailed article that shows that MMAP doesn't leak and it's mostly ready. I will share when it's ready.\r\n\r\nThe issue is that we still need to be able to debug memory leaks by turning MMAP off.\r\n\r\nBut, once I tried to show the user that using `load_dataset(... keep_in_memory=True)` is the way to debug an actual memory leak - guess I what I discovered? A potential actual leak.\r\n\r\nHere is the repro:\r\n\r\n```\r\n$ cat ds-mmap.py\r\nfrom datasets import load_dataset\r\nimport gc\r\nimport os\r\nimport psutil\r\n\r\nproc = psutil.Process(os.getpid())\r\ndef mem_read():\r\n gc.collect()\r\n return proc.memory_info().rss / 2**20\r\n\r\ndataset = load_dataset(\"wmt19\", 'cs-en', keep_in_memory=True, streaming=False)['train']\r\n\r\nprint(f\"{'idx':>6} {'RSS':>10} {'Δ RSS':>15}\")\r\nstep = 20000\r\nfor i in range(0, 10*step, step):\r\n mem_before = mem_read()\r\n _ = dataset[i:i+step]\r\n mem_after = mem_read()\r\n print(f\"{i:6d} {mem_after:12.4f}MB {mem_after - mem_before:12.4f}MB \")\r\n```\r\n\r\n```\r\npython ds-io.py\r\nReusing dataset wmt19 (/home/stas/.cache/huggingface/datasets/wmt19/cs-en/1.0.0/c3db1bf4240362ed1ef4673b354f468d70aac66d4e67d45f536d493a0840f0d3)\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 5.66it/s]\r\n idx RSS Δ RSS\r\n 0 1398.4609MB 3.5195MB\r\n 20000 1398.5742MB 0.1133MB\r\n 40000 1398.6016MB 0.0273MB\r\n 60000 1398.6016MB 0.0000MB\r\n 80000 1398.6016MB 0.0000MB\r\n100000 1398.6328MB 0.0312MB\r\n120000 1398.6953MB 0.0625MB\r\n140000 1398.6953MB 0.0000MB\r\n160000 1398.7500MB 0.0547MB\r\n180000 1398.7500MB 0.0000MB\r\n```",
"as I suggested on slack perhaps it was due to dataset records length variation, so with your help I wrote another repro with synthetic records which are all identical - which should remove my hypothese from the equation and we should expect 0 incremental growth as we iterate over the datasets. But alas this is not the case. There is a tiny but definite leak-like behavior.\r\n\r\nHere is the new repro:\r\n\r\n```\r\n$ cat ds-synthetic-no-mmap.py\r\nfrom datasets import load_from_disk, Dataset\r\nimport gc\r\nimport sys\r\nimport os\r\nimport psutil\r\n\r\nproc = psutil.Process(os.getpid())\r\ndef mem_read():\r\n gc.collect()\r\n return proc.memory_info().rss / 2**20\r\n\r\nDS_PATH = \"synthetic-ds\"\r\nif not os.path.exists(DS_PATH):\r\n records = 1_000_000\r\n print(\"Creating a synthetic dataset\")\r\n row = dict(foo=[dict(a='a'*500, b='b'*1000)])\r\n ds = Dataset.from_dict({k: [v] * records for k, v in row.items()})\r\n ds.save_to_disk(DS_PATH)\r\n print(\"Done. Please restart the program\")\r\n sys.exit()\r\n\r\ndataset = load_from_disk(DS_PATH, keep_in_memory=True)\r\nprint(f\"Dataset len={len(dataset)}\")\r\n\r\nprint(f\"{'idx':>8} {'RSS':>10} {'Δ RSS':>15}\")\r\nmem_start = 0\r\nstep = 25_000\r\nwarmup_iterations = 4\r\nfor idx, i in enumerate(range(0, len(dataset), step)):\r\n if idx == warmup_iterations: # skip the first few iterations while things get set up\r\n mem_start = mem_read()\r\n mem_before = mem_read()\r\n _ = dataset[i:i+step]\r\n mem_after = mem_read()\r\n print(f\"{i:8d} {mem_after:12.4f}MB {mem_after - mem_before:12.4f}MB\")\r\nmem_end = mem_read()\r\n\r\nprint(f\"Total diff: {mem_end - mem_start:12.4f}MB (after {warmup_iterations} warmup iterations)\")\r\n```\r\n\r\nand the run:\r\n\r\n```\r\n$ python ds-synthetic-no-mmap.py\r\nDataset len=1000000\r\n idx RSS Δ RSS\r\n 0 1601.9258MB 47.9688MB\r\n 25000 1641.6289MB 39.7031MB\r\n 50000 1641.8594MB 0.2305MB\r\n 75000 1642.1289MB 0.2695MB\r\n 100000 1642.1289MB 0.0000MB\r\n 125000 1642.3789MB 0.2500MB\r\n 150000 1642.3789MB 0.0000MB\r\n 175000 1642.6289MB 0.2500MB\r\n 200000 1642.6289MB 0.0000MB\r\n 225000 1642.8789MB 0.2500MB\r\n 250000 1642.8828MB 0.0039MB\r\n 275000 1643.1328MB 0.2500MB\r\n 300000 1643.1328MB 0.0000MB\r\n 325000 1643.3828MB 0.2500MB\r\n 350000 1643.3828MB 0.0000MB\r\n 375000 1643.6328MB 0.2500MB\r\n 400000 1643.6328MB 0.0000MB\r\n 425000 1643.8828MB 0.2500MB\r\n 450000 1643.8828MB 0.0000MB\r\n 475000 1644.1328MB 0.2500MB\r\n 500000 1644.1328MB 0.0000MB\r\n 525000 1644.3828MB 0.2500MB\r\n 550000 1644.3828MB 0.0000MB\r\n 575000 1644.6328MB 0.2500MB\r\n 600000 1644.6328MB 0.0000MB\r\n 625000 1644.8828MB 0.2500MB\r\n 650000 1644.8828MB 0.0000MB\r\n 675000 1645.1328MB 0.2500MB\r\n 700000 1645.1328MB 0.0000MB\r\n 725000 1645.3828MB 0.2500MB\r\n 750000 1645.3828MB 0.0000MB\r\n 775000 1645.6328MB 0.2500MB\r\n 800000 1645.6328MB 0.0000MB\r\n 825000 1645.8828MB 0.2500MB\r\n 850000 1645.8828MB 0.0000MB\r\n 875000 1646.1328MB 0.2500MB\r\n 900000 1646.1328MB 0.0000MB\r\n 925000 1646.3828MB 0.2500MB\r\n 950000 1646.3828MB 0.0000MB\r\n 975000 1646.6328MB 0.2500MB\r\nTotal diff: 4.5039MB (after 4 warmup iterations)\r\n```\r\nso I'm still not sure why we get this.\r\n\r\nAs you can see I started skipping the first few iterations where memory isn't stable yet. As the actual diff is much larger if we count all iterations.\r\n\r\nWhat do you think?",
"@stas00 my 2 cents from having looked at a LOT of memory leaks over the years, esp in Python, .3% memory increase over that many iterations of something is difficult to say with certainty it is a leak. \r\n\r\nAlso, just looking at RSS makes it hard to analyze leaks. RSS can stay near constant while you are leaking. RSS is paged in mem, if you have a big leak your RSS might not increase much (leaked mem tends not to get used again so often paged out) while your virtual page allocation could be going through the roof...",
"yes, that's true, but unless the leak is big, I'm yet to find another measurement tool.\r\n\r\nTo prove your point here is a very simple IO in a loop program that also reads the same line all over again:\r\n\r\n```\r\n$ cat mmap-no-leak-debug.py\r\nimport gc\r\nimport mmap\r\nimport os\r\nimport psutil\r\nimport sys\r\n\r\nproc = psutil.Process(os.getpid())\r\n\r\nPATH = \"./tmp.txt\"\r\n\r\ndef mem_read():\r\n gc.collect()\r\n return proc.memory_info().rss / 2**20\r\n\r\n# create a large data file with a few long lines\r\nif not os.path.exists(PATH):\r\n with open(PATH, \"w\") as fh:\r\n s = 'a'* 2**27 + \"\\n\" # 128MB\r\n # write ~2GB file\r\n for i in range(16):\r\n fh.write(s)\r\n\r\nprint(f\"{'idx':>4} {'RSS':>10} {'Δ RSS':>12} {'Δ accumulated':>10}\")\r\n\r\ntotal_read = 0\r\ncontent = ''\r\nmem_after = mem_before_acc = mem_after_acc = mem_before = proc.memory_info().rss / 2**20\r\nprint(f\"{0:4d} {mem_after:10.2f}MB {mem_after - 0:10.2f}MB {0:10.2f}MB\")\r\n\r\nmmap_mode = True if \"--mmap\" in sys.argv else False\r\n\r\nwith open(PATH, \"r\") as fh:\r\n\r\n if mmap_mode:\r\n mm = mmap.mmap(fh.fileno(), 0, access=mmap.ACCESS_READ)\r\n\r\n idx = 0\r\n while True:\r\n idx += 1\r\n mem_before = mem_read()\r\n line = mm.readline() if mmap_mode else fh.readline()\r\n if not line:\r\n break\r\n\r\n #total_read += len(line)\r\n\r\n if \"--accumulate\" in sys.argv:\r\n mem_before_acc = mem_read()\r\n content += str(line)\r\n mem_after_acc = mem_read()\r\n\r\n mem_after = mem_read()\r\n\r\n print(f\"{idx:4d} {mem_after:10.2f}MB {mem_after - mem_before:10.2f}MB {mem_after_acc - mem_before_acc:10.2f}MB\")\r\n```\r\n\r\nit has some other instrumentations to do mmap and accumulate data, but let's ignore that for now.\r\n\r\nHere it is running in a simple non-mmap IO:\r\n\r\n```\r\n$ python mmap-no-leak-debug.py\r\n idx RSS Δ RSS Δ accumulated\r\n 0 12.43MB 12.43MB 0.00MB\r\n 1 269.72MB 257.29MB 0.00MB\r\n 2 269.73MB 0.02MB 0.00MB\r\n 3 269.73MB 0.00MB 0.00MB\r\n 4 269.74MB 0.01MB 0.00MB\r\n 5 269.74MB 0.00MB 0.00MB\r\n 6 269.75MB 0.01MB 0.00MB\r\n 7 269.75MB 0.00MB 0.00MB\r\n 8 269.76MB 0.01MB 0.00MB\r\n 9 269.76MB 0.00MB 0.00MB\r\n 10 269.77MB 0.01MB 0.00MB\r\n 11 269.77MB 0.00MB 0.00MB\r\n 12 269.77MB 0.00MB 0.00MB\r\n 13 269.77MB 0.00MB 0.00MB\r\n 14 269.77MB 0.00MB 0.00MB\r\n 15 269.77MB 0.00MB 0.00MB\r\n 16 146.02MB -123.75MB 0.00MB\r\n```\r\n\r\nas you can see even this super-simplistic program that just performs `readline()` slightly increases in RSS over iterations.\r\n\r\nIf you have a better tool for measurement other than RSS, I'm all ears.",
"@stas00 if you aren't using memory maps, you should be able to clearly see the increase in the virtual mem for the process as well. Even then, it could still be challenging to determine if it's leak vs fragmentation due to problematic allocation patterns (not uncommon with Python). Using a better mem allocator like tcmalloc via LD_PRELOAD hooks could reduce impact of fragmentation across both Python and c libs. Not sure that plays nice with any allocator that arrow might use itself though. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3433/comments | https://api.github.com/repos/huggingface/datasets/issues/3433/events | https://github.com/huggingface/datasets/issues/3433 | 1,080,910,724 | I_kwDODunzps5AbWOE | 3,433 | Add Multilingual Spoken Words dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] | closed | false | null | 0 | 2021-12-15T11:14:44Z | 2022-02-22T10:03:53Z | 2022-02-22T10:03:53Z | null | ## Adding a Dataset
- **Name:** Multilingual Spoken Words
- **Description:** Multilingual Spoken Words Corpus is a large and growing audio dataset of spoken words in 50 languages for academic research and commercial applications in keyword spotting and spoken term search, licensed under CC-BY 4.0. The dataset contains more than 340,000 keywords, totaling 23.4 million 1-second spoken examples (over 6,000 hours).
Read more: https://mlcommons.org/en/news/spoken-words-blog/
- **Paper:** https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/fe131d7f5a6b38b23cc967316c13dae2-Paper-round2.pdf
- **Data:** https://mlcommons.org/en/multilingual-spoken-words/
- **Motivation:**
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3433/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3698/comments | https://api.github.com/repos/huggingface/datasets/issues/3698/events | https://github.com/huggingface/datasets/pull/3698 | 1,129,864,282 | PR_kwDODunzps4yXtyQ | 3,698 | Add finetune-data CodeFill | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2022-02-10T11:12:51Z | 2022-10-03T09:36:18Z | 2022-10-03T09:36:18Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3698/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3698/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3698.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3698",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3698.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3698"
} | true | [
"Thanks for your contribution, @rgismondi. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/3243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3243/comments | https://api.github.com/repos/huggingface/datasets/issues/3243/events | https://github.com/huggingface/datasets/pull/3243 | 1,048,630,754 | PR_kwDODunzps4uSWtB | 3,243 | Remove redundant isort module placement | [] | closed | false | null | 0 | 2021-11-09T13:50:30Z | 2021-11-12T14:02:45Z | 2021-11-12T14:02:45Z | null | `isort` can place modules by itself from [version 5.0.0](https://pycqa.github.io/isort/docs/upgrade_guides/5.0.0.html#module-placement-changes-known_third_party-known_first_party-default_section-etc) onwards, making the `known_first_party` and `known_third_party` fields in `setup.cfg` redundant (this is why our CI works, even though we haven't touched these options in a while). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3243/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3243",
"merged_at": "2021-11-12T14:02:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3243"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/6007 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6007/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6007/comments | https://api.github.com/repos/huggingface/datasets/issues/6007/events | https://github.com/huggingface/datasets/issues/6007 | 1,789,782,693 | I_kwDODunzps5qreql | 6,007 | Get an error "OverflowError: Python int too large to convert to C long" when loading a large dataset | [
{
"color": "c2e0c6",
"default": false,
"description": "Related to Apache Arrow",
"id": 5705560427,
"name": "arrow",
"node_id": "LA_kwDODunzps8AAAABVBPxaw",
"url": "https://api.github.com/repos/huggingface/datasets/labels/arrow"
}
] | open | false | null | 7 | 2023-07-05T15:16:50Z | 2023-07-10T19:11:17Z | null | null | ### Describe the bug
When load a large dataset with the following code
```python
from datasets import load_dataset
dataset = load_dataset("liwu/MNBVC", 'news_peoples_daily', split='train')
```
We encountered the error: "OverflowError: Python int too large to convert to C long"
The error look something like:
```
OverflowError: Python int too large to convert to C long
During handling of the above exception, another exception occurred:
OverflowError Traceback (most recent call last)
<ipython-input-7-0ed8700e662d> in <module>
----> 1 dataset = load_dataset("liwu/MNBVC", 'news_peoples_daily', split='train', cache_dir='/sfs/MNBVC/.cache/')
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1749 ignore_verifications=ignore_verifications,
1750 try_from_hf_gcs=try_from_hf_gcs,
-> 1751 use_auth_token=use_auth_token,
1752 )
1753
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
703 if not downloaded_from_gcs:
704 self._download_and_prepare(
--> 705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
706 )
707 # Sync info
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos)
1225
1226 def _download_and_prepare(self, dl_manager, verify_infos):
-> 1227 super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
1228
1229 def _get_examples_iterable_for_split(self, split_generator: SplitGenerator) -> ExamplesIterable:
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
791 try:
792 # Prepare split will record examples associated to the split
--> 793 self._prepare_split(split_generator, **prepare_split_kwargs)
794 except OSError as e:
795 raise OSError(
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys)
1219 writer.write(example, key)
1220 finally:
-> 1221 num_examples, num_bytes = writer.finalize()
1222
1223 split_generator.split_info.num_examples = num_examples
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/arrow_writer.py in finalize(self, close_stream)
536 # Re-intializing to empty list for next batch
537 self.hkey_record = []
--> 538 self.write_examples_on_file()
539 if self.pa_writer is None:
540 if self.schema:
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
407 # Since current_examples contains (example, key) tuples
408 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 409 self.write_batch(batch_examples=batch_examples)
410 self.current_examples = []
411
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
506 col_try_type = try_features[col] if try_features is not None and col in try_features else None
507 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 508 arrays.append(pa.array(typed_sequence))
509 inferred_features[col] = typed_sequence.get_inferred_type()
510 schema = inferred_features.arrow_schema if self.pa_writer is None else self.schema
/sfs/MNBVC/venv/lib64/python3.6/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
/sfs/MNBVC/venv/lib64/python3.6/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
/sfs/MNBVC/venv/lib64/python3.6/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
180 else:
181 trying_cast_to_python_objects = True
--> 182 out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))
183 # use smaller integer precisions if possible
184 if self.trying_int_optimization:
/sfs/MNBVC/venv/lib64/python3.6/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
/sfs/MNBVC/venv/lib64/python3.6/site-packages/pyarrow/array.pxi in pyarrow.lib._sequence_to_array()
/sfs/MNBVC/venv/lib64/python3.6/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
OverflowError: Python int too large to convert to C long
```
However, that dataset can be loaded in a streaming manner:
```python
from datasets import load_dataset
dataset = load_dataset("liwu/MNBVC", 'news_peoples_daily', split='train', streaming=True)
for i in dataset:
pass # it work well
```
Another issue is reported in our dataset hub:
https://huggingface.co/datasets/liwu/MNBVC/discussions/2
### Steps to reproduce the bug
from datasets import load_dataset
dataset = load_dataset("liwu/MNBVC", 'news_peoples_daily', split='train')
### Expected behavior
the dataset can be safely loaded
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-3.10.0-1160.an7.x86_64-x86_64-with-centos-7.9
- Python version: 3.6.8
- PyArrow version: 6.0.1
- Pandas version: 1.1.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6007/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6007/timeline | null | null | null | null | false | [
"This error means that one of the int32 (`Value(\"int32\")`) columns in the dataset has a value that is out of the valid (int32) range.\r\n\r\nI'll open a PR to print the name of a problematic column to make debugging such errors easier.",
"I am afraid int32 is not the reason for this error.\r\n\r\nI have submitted a commit to use int64 for all ints in the dataset:\r\nhttps://huggingface.co/datasets/liwu/MNBVC/commit/857ac00d9eab96a6708ad6a82bd9001686042a9e\r\n\r\nand I have updated my env to the latest datasets release:\r\nCopy-and-paste the text below in your GitHub issue.\r\n\r\n- `datasets` version: 2.13.1\r\n- Platform: macOS-13.2.1-arm64-arm-64bit\r\n- Python version: 3.11.2\r\n- Huggingface_hub version: 0.13.4\r\n- PyArrow version: 11.0.0\r\n- Pandas version: 1.5.3\r\n\r\nBut the error still exist\r\n\r\n```\r\nDownloading and preparing dataset mnbvc/news_peoples_daily to /Users/silver/.cache/huggingface/datasets/liwu___mnbvc/news_peoples_daily/0.0.1/ee380f6309fe9b8b0d1fb14d77118f132444f22c8c4b28bf5c1645312688e051...\r\nDownloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 9070.40it/s]\r\nExtracting data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 2697.16it/s]\r\n---------------------------------------------------------------------------\r\nOverflowError Traceback (most recent call last)\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:1647, in GeneratorBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, split_info, check_duplicate_keys, job_id)\r\n 1646 example = self.info.features.encode_example(record) if self.info.features is not None else record\r\n-> 1647 writer.write(example, key)\r\n 1648 num_examples_progress_update += 1\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:490, in ArrowWriter.write(self, example, key, writer_batch_size)\r\n 488 self.hkey_record = []\r\n--> 490 self.write_examples_on_file()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:448, in ArrowWriter.write_examples_on_file(self)\r\n 444 batch_examples[col] = [\r\n 445 row[0][col].to_pylist()[0] if isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) else row[0][col]\r\n 446 for row in self.current_examples\r\n 447 ]\r\n--> 448 self.write_batch(batch_examples=batch_examples)\r\n 449 self.current_examples = []\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:553, in ArrowWriter.write_batch(self, batch_examples, writer_batch_size)\r\n 552 typed_sequence = OptimizedTypedSequence(col_values, type=col_type, try_type=col_try_type, col=col)\r\n--> 553 arrays.append(pa.array(typed_sequence))\r\n 554 inferred_features[col] = typed_sequence.get_inferred_type()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:236, in pyarrow.lib.array()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:110, in pyarrow.lib._handle_arrow_array_protocol()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:189, in TypedSequence.__arrow_array__(self, type)\r\n 188 trying_cast_to_python_objects = True\r\n--> 189 out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n 190 # use smaller integer precisions if possible\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:320, in pyarrow.lib.array()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:39, in pyarrow.lib._sequence_to_array()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/error.pxi:144, in pyarrow.lib.pyarrow_internal_check_status()\r\n\r\nOverflowError: Python int too large to convert to C long\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nOverflowError Traceback (most recent call last)\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:1656, in GeneratorBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, split_info, check_duplicate_keys, job_id)\r\n 1655 num_shards = shard_id + 1\r\n-> 1656 num_examples, num_bytes = writer.finalize()\r\n 1657 writer.close()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:584, in ArrowWriter.finalize(self, close_stream)\r\n 583 self.hkey_record = []\r\n--> 584 self.write_examples_on_file()\r\n 585 # If schema is known, infer features even if no examples were written\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:448, in ArrowWriter.write_examples_on_file(self)\r\n 444 batch_examples[col] = [\r\n 445 row[0][col].to_pylist()[0] if isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) else row[0][col]\r\n 446 for row in self.current_examples\r\n 447 ]\r\n--> 448 self.write_batch(batch_examples=batch_examples)\r\n 449 self.current_examples = []\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:553, in ArrowWriter.write_batch(self, batch_examples, writer_batch_size)\r\n 552 typed_sequence = OptimizedTypedSequence(col_values, type=col_type, try_type=col_try_type, col=col)\r\n--> 553 arrays.append(pa.array(typed_sequence))\r\n 554 inferred_features[col] = typed_sequence.get_inferred_type()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:236, in pyarrow.lib.array()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:110, in pyarrow.lib._handle_arrow_array_protocol()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/arrow_writer.py:189, in TypedSequence.__arrow_array__(self, type)\r\n 188 trying_cast_to_python_objects = True\r\n--> 189 out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n 190 # use smaller integer precisions if possible\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:320, in pyarrow.lib.array()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/array.pxi:39, in pyarrow.lib._sequence_to_array()\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/pyarrow/error.pxi:144, in pyarrow.lib.pyarrow_internal_check_status()\r\n\r\nOverflowError: Python int too large to convert to C long\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nDatasetGenerationError Traceback (most recent call last)\r\nCell In[2], line 1\r\n----> 1 dataset = load_dataset(\"liwu/MNBVC\", 'news_peoples_daily', split='train')\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/load.py:1809, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, storage_options, **config_kwargs)\r\n 1806 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES\r\n 1808 # Download and prepare data\r\n-> 1809 builder_instance.download_and_prepare(\r\n 1810 download_config=download_config,\r\n 1811 download_mode=download_mode,\r\n 1812 verification_mode=verification_mode,\r\n 1813 try_from_hf_gcs=try_from_hf_gcs,\r\n 1814 num_proc=num_proc,\r\n 1815 storage_options=storage_options,\r\n 1816 )\r\n 1818 # Build dataset for splits\r\n 1819 keep_in_memory = (\r\n 1820 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)\r\n 1821 )\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:909, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, verification_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)\r\n 907 if num_proc is not None:\r\n 908 prepare_split_kwargs[\"num_proc\"] = num_proc\r\n--> 909 self._download_and_prepare(\r\n 910 dl_manager=dl_manager,\r\n 911 verification_mode=verification_mode,\r\n 912 **prepare_split_kwargs,\r\n 913 **download_and_prepare_kwargs,\r\n 914 )\r\n 915 # Sync info\r\n 916 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:1670, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_splits_kwargs)\r\n 1669 def _download_and_prepare(self, dl_manager, verification_mode, **prepare_splits_kwargs):\r\n-> 1670 super()._download_and_prepare(\r\n 1671 dl_manager,\r\n 1672 verification_mode,\r\n 1673 check_duplicate_keys=verification_mode == VerificationMode.BASIC_CHECKS\r\n 1674 or verification_mode == VerificationMode.ALL_CHECKS,\r\n 1675 **prepare_splits_kwargs,\r\n 1676 )\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:1004, in DatasetBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)\r\n 1000 split_dict.add(split_generator.split_info)\r\n 1002 try:\r\n 1003 # Prepare split will record examples associated to the split\r\n-> 1004 self._prepare_split(split_generator, **prepare_split_kwargs)\r\n 1005 except OSError as e:\r\n 1006 raise OSError(\r\n 1007 \"Cannot find data file. \"\r\n 1008 + (self.manual_download_instructions or \"\")\r\n 1009 + \"\\nOriginal error:\\n\"\r\n 1010 + str(e)\r\n 1011 ) from None\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:1508, in GeneratorBasedBuilder._prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)\r\n 1506 job_id = 0\r\n 1507 with pbar:\r\n-> 1508 for job_id, done, content in self._prepare_split_single(\r\n 1509 gen_kwargs=gen_kwargs, job_id=job_id, **_prepare_split_args\r\n 1510 ):\r\n 1511 if done:\r\n 1512 result = content\r\n\r\nFile ~/git/venv/lib/python3.11/site-packages/datasets/builder.py:1665, in GeneratorBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, split_info, check_duplicate_keys, job_id)\r\n 1663 if isinstance(e, SchemaInferenceError) and e.__context__ is not None:\r\n 1664 e = e.__context__\r\n-> 1665 raise DatasetGenerationError(\"An error occurred while generating the dataset\") from e\r\n 1667 yield job_id, True, (total_num_examples, total_num_bytes, writer._features, num_shards, shard_lengths)\r\n\r\nDatasetGenerationError: An error occurred while generating the dataset\r\n```\r\n\r\nBesides, it works fine when I am using streamed dataset.",
"`simhash` is the problematic column - it has values such as `18329103420363166823` that are out of the int64 range. You can fix this by setting the feature type to `Value(\"string\")` (it's advised to use this type for hash values in general)\r\n\r\n> Besides, it works fine when I am using streamed dataset.\r\n\r\nStreaming yields Python dictionaries from the script without converting them to the Arrow representation, as this conversion step is not that cheap performance-wise.",
"i am using uint64 for simhash\r\n\r\nuint64 ranges up to about 3.69E19.\r\n\r\n18329103420363166823 is less than this value.\r\n\r\nmoreover, our simhash algorithm use 64 bits. it should fit in uint64.\r\n\r\n\r\n\r\n",
"You are right. I overlooked the feature type.\r\n\r\nThis is a reproducer:\r\n```python\r\nimport pyarrow as pa\r\nfrom datasets.arrow_writer import TypedSequence\r\n\r\npa.array(TypedSequence([18329103420363166823], type=Value(\"uint64\")))\r\n```\r\n\r\n`pa.array([18329103420363166823])` also fails with the same error, so it seems PyArrow does not always infer the correct type as NumPy does (`uint64` in this case).\r\n\r\nI'll report this issue in the Arrow repo.\r\n\r\n`pa.array([18329103420363166823], pa.uint64)` works, so maybe we can implement a temporary fix (supporting complex input such as `[{\"image\": pil_image, \"num\": uint64_value}]` would be hard though).\r\n\r\nIn the meantime, you should be able to bypass this error by returning the `simhash` values as NumPy scalars in the script:\r\n```python\r\ndef _generate_examples(self, ...):\r\n ...\r\n yield {..., \"simhash\": np.uint64(simhash), ...}\r\n```",
"Thank you for checking this issue in detail.\r\n\r\nHowever, it seems that using `np.uint64(simhash)` does not work. The same issue still exists.\r\n\r\nhttps://huggingface.co/datasets/liwu/MNBVC/commit/1e44f1e400b7e61052647d44c99cdae3bae9c830\r\n\r\nAnyway, we decide to use string type for these simhash values. Hope pyarrow can fix their bug soon.",
"Arrow issue: https://github.com/apache/arrow/issues/36520"
] |
https://api.github.com/repos/huggingface/datasets/issues/614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/614/comments | https://api.github.com/repos/huggingface/datasets/issues/614/events | https://github.com/huggingface/datasets/pull/614 | 699,177,110 | MDExOlB1bGxSZXF1ZXN0NDg0OTQ2MzA1 | 614 | [doc] Update deploy.sh | [] | closed | false | null | 0 | 2020-09-11T11:06:13Z | 2020-09-14T08:49:19Z | 2020-09-14T08:49:17Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/614/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/614/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/614.diff",
"html_url": "https://github.com/huggingface/datasets/pull/614",
"merged_at": "2020-09-14T08:49:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/614.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/614"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/3065 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3065/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3065/comments | https://api.github.com/repos/huggingface/datasets/issues/3065/events | https://github.com/huggingface/datasets/pull/3065 | 1,023,951,322 | PR_kwDODunzps4tFDjk | 3,065 | Fix test command after refac | [] | closed | false | null | 0 | 2021-10-12T15:23:30Z | 2021-10-12T15:28:47Z | 2021-10-12T15:28:46Z | null | Fix the `datasets-cli` test command after the `prepare_module` change in #2986 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3065/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3065/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3065.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3065",
"merged_at": "2021-10-12T15:28:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3065.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3065"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4751 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4751/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4751/comments | https://api.github.com/repos/huggingface/datasets/issues/4751/events | https://github.com/huggingface/datasets/pull/4751 | 1,319,440,903 | PR_kwDODunzps48LJ7U | 4,751 | Added dataset information in clinic oos dataset card | [] | closed | false | null | 1 | 2022-07-27T11:44:28Z | 2022-07-28T10:53:21Z | 2022-07-28T10:40:37Z | null | This PR aims to add relevant information like the Description, Language and citation information of the clinic oos dataset card. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4751/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4751/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4751.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4751",
"merged_at": "2022-07-28T10:40:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4751.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4751"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4856 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4856/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4856/comments | https://api.github.com/repos/huggingface/datasets/issues/4856/events | https://github.com/huggingface/datasets/issues/4856 | 1,339,779,957 | I_kwDODunzps5P22t1 | 4,856 | file missing when load_dataset with openwebtext on windows | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-08-16T04:04:22Z | 2023-01-04T03:39:12Z | 2023-01-04T03:39:12Z | null | ## Describe the bug
0015896-b1054262f7da52a0518521e29c8e352c.txt is missing when I run run_mlm.py with openwebtext. I check the cache_path and can not find 0015896-b1054262f7da52a0518521e29c8e352c.txt. but I can find this file in the 17ecf461bfccd469a1fbc264ccb03731f8606eea7b3e2e8b86e13d18040bf5b3/urlsf_subset00-16_data.xz with 7-zip.
## Steps to reproduce the bug
```sh
python run_mlm.py --model_type roberta --tokenizer_name roberta-base --dataset_name openwebtext --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --do_train --do_eval --output_dir F:/model/roberta-base
```
or
```python
from datasets import load_dataset
load_dataset("openwebtext", None, cache_dir=None, use_auth_token=None)
```
## Expected results
Loading is successful
## Actual results
Traceback (most recent call last):
File "D:\Python\v3.8.5\lib\site-packages\datasets\builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "D:\Python\v3.8.5\lib\site-packages\datasets\builder.py", line 1227, in _download_and_prepare
super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File "D:\Python\v3.8.5\lib\site-packages\datasets\builder.py", line 795, in _download_and_prepare
raise OSError(
OSError: Cannot find data file.
Original error:
[Errno 22] Invalid argument: 'F://huggingface/datasets/downloads/extracted/0901d27f43b7e9ac0577da0d0061c8c632ba0b70ecd1b4bfb21562d9b7486faa/0015896-b1054262f7da52a0518521e29c8e352c.txt'
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: windows
- Python version: 3.8.5
- PyArrow version: 9.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4856/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4856/timeline | null | completed | null | null | false | [
"I have tried to extract ```0015896-b1054262f7da52a0518521e29c8e352c.txt``` from ```17ecf461bfccd469a1fbc264ccb03731f8606eea7b3e2e8b86e13d18040bf5b3/urlsf_subset00-16_data.xz``` with 7-zip\r\nand put the file into cache_path ```F://huggingface/datasets/downloads/extracted/0901d27f43b7e9ac0577da0d0061c8c632ba0b70ecd1b4bfb21562d9b7486faa```\r\nthere is still raise the same error and I find the file was removed from cache_path after I run the run_mlm.py with ```python run_mlm.py --model_type roberta --tokenizer_name roberta-base --dataset_name openwebtext --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --do_train --do_eval --output_dir F:/model/roberta-base```."
] |
https://api.github.com/repos/huggingface/datasets/issues/2553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2553/comments | https://api.github.com/repos/huggingface/datasets/issues/2553/events | https://github.com/huggingface/datasets/issues/2553 | 931,365,926 | MDU6SXNzdWU5MzEzNjU5MjY= | 2,553 | load_dataset("web_nlg") NonMatchingChecksumError | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-06-28T09:26:46Z | 2021-06-28T17:23:39Z | 2021-06-28T17:23:16Z | null | Hi! It seems the WebNLG dataset gives a NonMatchingChecksumError.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('web_nlg', name="release_v3.0_en", split="dev")
```
Gives
```
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://gitlab.com/shimorina/webnlg-dataset/-/archive/master/webnlg-dataset-master.zip']
```
## Environment info
- `datasets` version: 1.8.0
- Platform: macOS-11.3.1-x86_64-i386-64bit
- Python version: 3.9.4
- PyArrow version: 3.0.0
Also tested on Linux, with python 3.6.8 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2553/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting. This is due to the WebNLG repository that got updated today.\r\nI just pushed a fix at #2558 - this shouldn't happen anymore in the future.",
"This is fixed on `master` now :)\r\nWe'll do a new release soon !"
] |
https://api.github.com/repos/huggingface/datasets/issues/1388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1388/comments | https://api.github.com/repos/huggingface/datasets/issues/1388/events | https://github.com/huggingface/datasets/pull/1388 | 760,373,136 | MDExOlB1bGxSZXF1ZXN0NTM1MjE1Nzk2 | 1,388 | hind_encorp | [] | closed | false | null | 0 | 2020-12-09T14:22:59Z | 2020-12-09T14:46:51Z | 2020-12-09T14:46:37Z | null | resubmit of hind_encorp file changes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1388/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1388.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1388",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1388.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1388"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5545/comments | https://api.github.com/repos/huggingface/datasets/issues/5545/events | https://github.com/huggingface/datasets/pull/5545 | 1,590,315,972 | PR_kwDODunzps5KRKct | 5,545 | Added return methods for URL-references to the pushed dataset | [] | open | false | null | 4 | 2023-02-18T11:26:25Z | 2023-02-21T14:17:28Z | null | null | Hi,
I was missing the ability to easily open the pushed dataset and it seemed like a quick fix.
Maybe we also want to log this info somewhere, but let me know if I need to add that too.
Cheers,
David | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5545/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5545/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5545.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5545",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5545.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5545"
} | true | [
"Hi ! Maybe we'd need to align with `transformers` and other libraries that implement `push_to_hub` to agree on what it should return.\r\n\r\ne.g. in `transformers` the typing says it returns a string, but in practice it returns a `CommitInfo`.\r\n\r\nTherefore I'd not add an output to `push_to_hub` here unless we had a chance to discuss more broadly.\r\n\r\nAnyway in my opinion it should no just return the URL of the repository, but ideally the URL at the revision where the data were pushed",
"Perhaps a mixin or something similar could be defined on the `hfh` side to ensure the `push_to_hub` API is aligned across our projects. \r\n\r\nPS: this would also mean that the PRs such as https://github.com/huggingface/datasets/pull/5528 would no longer be our responsibility\r\n\r\ncc @Wauplin ",
"I agree, with universability and the idea is more about returning at least something that references where to find the uploaded file/model or otherwise. \r\n\r\nIdeally, the referenced PR would work.",
"imo this would be a good use case to just use `huggingface_hub` and align to what we do there :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3617/comments | https://api.github.com/repos/huggingface/datasets/issues/3617/events | https://github.com/huggingface/datasets/pull/3617 | 1,111,938,691 | PR_kwDODunzps4xdb8K | 3,617 | PR for the CFPB Consumer Complaints dataset | [] | closed | false | null | 8 | 2022-01-23T17:47:12Z | 2022-02-07T21:08:31Z | 2022-02-07T21:08:31Z | null | Think I followed all the steps but please let me know if anything needs changing or any improvements I can make to the code quality | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3617/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3617/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3617.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3617",
"merged_at": "2022-02-07T21:08:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3617.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3617"
} | true | [
"> Nice ! Thanks for adding this dataset :)\n> \n> \n> \n> I left a few comments:\n\nThanks!\n\nI'd be interested in contributing to the core codebase - I had to go down the custom loading approach because I couldn't pull this dataset in using the load_dataset() method. Using either the json or csv files available for this dataset as it was erroring. \n\nI'll rerun it and share the errors and try debug",
"Hey @lhoestq ,\r\n\r\nWhen I use this dataset as part of my project, I'm using this method\r\n\r\n`text_dataset = text_dataset['train'].train_test_split(test_size=0.2)`\r\n\r\nto create a train and test split as this dataset doesn't have one. \r\n\r\nCan I add this directly in the script itself somehow, or is it better to give users the flexibility to slice and split their datasets after loading?",
"> I'd be interested in contributing to the core codebase - I had to go down the custom loading approach because I couldn't pull this dataset in using the load_dataset() method. Using either the json or csv files available for this dataset as it was erroring.\r\n>\r\n> I'll rerun it and share the errors and try debug\r\n\r\nCool ! Let me know if you have questions or if I can help :)\r\n\r\n> Can I add this directly in the script itself somehow, or is it better to give users the flexibility to slice and split their datasets after loading?\r\n\r\nUsually we let the users the flexibility to split the datasets themselves (unless the dataset is already split, or if there is already a standard way to split it in the papers that use it)",
"Thanks Quentin!\r\nAll okay to merge now?",
"Thanks for the feedback Quentin and Mario - implemented all changes :)\r\n\r\n",
"Hey @lhoestq / @mariosasko \r\nAny other changes required to merge? 🤗",
"Hi ! Thanks and sorry for the late response \r\n\r\nIt looks very good ! The CI is still failing because it can't file the dummy_data.zip file, you can fix that by moving `datasets/consumer-finance-complaints/dummy/1.0.0/dummy_data.zip` to `datasets/consumer-finance-complaints/dummy/0.0.0/dummy_data.zip` and it should be all good !",
"@lhoestq - hopefully that should do it!\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3762 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3762/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3762/comments | https://api.github.com/repos/huggingface/datasets/issues/3762/events | https://github.com/huggingface/datasets/issues/3762 | 1,144,849,557 | I_kwDODunzps5EPQSV | 3,762 | `Dataset.class_encode` should support custom class names | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 3 | 2022-02-19T21:21:45Z | 2022-02-21T12:16:35Z | 2022-02-21T12:16:35Z | null | I can make a PR, just wanted approval before starting.
**Is your feature request related to a problem? Please describe.**
It is often the case that classes are not ordered in alphabetical order. Current `class_encode_column` sort the classes before indexing.
https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1235
**Describe the solution you'd like**
I would like to add a **optional** parameter `class_names` to `class_encode_column` that would be used for the mapping instead of sorting the unique values.
**Describe alternatives you've considered**
One can use map instead. I find it harder to read.
```python
CLASS_NAMES = ['apple', 'orange', 'potato']
ds = ds.map(lambda item: CLASS_NAMES.index(item[label_column]))
# Proposition
ds = ds.class_encode_column(label_column, CLASS_NAMES)
```
**Additional context**
I can make the PR if this feature is accepted.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3762/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3762/timeline | null | completed | null | null | false | [
"Hi @Dref360, thanks a lot for your proposal.\r\n\r\nIt totally makes sense to have more flexibility when class encoding, I agree.\r\n\r\nYou could even further customize the class encoding by passing an instance of `ClassLabel` itself (instead of replicating `ClassLabel` instantiation arguments as `Dataset.class_encode_column` arguments).\r\n\r\nAnd the latter made me think of `Dataset.cast_column`...\r\n\r\nMaybe better to have some others' opinions @lhoestq @mariosasko ",
"Hi @Dref360! You can use [`Dataset.align_labels_with_mapping`](https://huggingface.co/docs/datasets/master/package_reference/main_classes.html#datasets.Dataset.align_labels_with_mapping) after `Dataset.class_encode_column` to assign a different mapping of labels to ids.\r\n\r\n@albertvillanova I'd like to avoid adding more complexity to the API where it's not (absolutely) needed, so I don't think introducing a new param in `Dataset.class_encode_column` is a good idea.\r\n\r\n",
"I wasn't aware that it existed thank you for the link.\n\nClosing then! "
] |
https://api.github.com/repos/huggingface/datasets/issues/4569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4569/comments | https://api.github.com/repos/huggingface/datasets/issues/4569/events | https://github.com/huggingface/datasets/issues/4569 | 1,284,833,694 | I_kwDODunzps5MlQGe | 4,569 | Dataset Viewer issue for sst2 | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 2 | 2022-06-26T07:32:54Z | 2022-06-27T06:37:48Z | 2022-06-27T06:37:48Z | null | ### Link
https://huggingface.co/datasets/sst2
### Description
Not sure what is causing this, however it seems that `load_dataset("sst2")` also hangs (even though it downloads the files without problem):
```
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with ConnectionError
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4569/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4569/timeline | null | completed | null | null | false | [
"Hi @lewtun, thanks for reporting.\r\n\r\nI have checked locally and refreshed the preview and it seems working smooth now:\r\n```python\r\nIn [8]: ds\r\nOut[8]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 67349\r\n })\r\n validation: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 872\r\n })\r\n test: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 1821\r\n })\r\n})\r\n```\r\n\r\nCould you confirm? ",
"Thanks @albertvillanova - it is indeed working now (not sure what caused the error in the first place). Closing this :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/6004 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6004/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6004/comments | https://api.github.com/repos/huggingface/datasets/issues/6004/events | https://github.com/huggingface/datasets/pull/6004 | 1,786,636,368 | PR_kwDODunzps5UjN2h | 6,004 | Misc improvements | [] | closed | false | null | 4 | 2023-07-03T18:29:14Z | 2023-07-06T17:04:11Z | 2023-07-06T16:55:25Z | null | Contains the following improvements:
* fixes a "share dataset" link in README and modifies the "hosting" part in the disclaimer section
* updates `Makefile` to also run the style checks on `utils` and `setup.py`
* deletes a test for GH-hosted datasets (no longer supported)
* deletes `convert_dataset.sh` (outdated)
* aligns `utils/release.py` with `transformers` (the current version is outdated) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6004/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6004/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6004.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6004",
"merged_at": "2023-07-06T16:55:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6004.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6004"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006897 / 0.011353 (-0.004456) | 0.004207 / 0.011008 (-0.006802) | 0.104828 / 0.038508 (0.066320) | 0.048054 / 0.023109 (0.024945) | 0.373991 / 0.275898 (0.098093) | 0.426740 / 0.323480 (0.103260) | 0.005540 / 0.007986 (-0.002446) | 0.003531 / 0.004328 (-0.000797) | 0.079304 / 0.004250 (0.075053) | 0.066996 / 0.037052 (0.029944) | 0.370675 / 0.258489 (0.112186) | 0.414154 / 0.293841 (0.120313) | 0.031567 / 0.128546 (-0.096979) | 0.008843 / 0.075646 (-0.066803) | 0.357426 / 0.419271 (-0.061845) | 0.067040 / 0.043533 (0.023508) | 0.362384 / 0.255139 (0.107245) | 0.376056 / 0.283200 (0.092856) | 0.032985 / 0.141683 (-0.108697) | 1.560603 / 1.452155 (0.108448) | 1.619024 / 1.492716 (0.126308) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229059 / 0.018006 (0.211053) | 0.440513 / 0.000490 (0.440023) | 0.004647 / 0.000200 (0.004447) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029517 / 0.037411 (-0.007894) | 0.120974 / 0.014526 (0.106448) | 0.125070 / 0.176557 (-0.051486) | 0.184695 / 0.737135 (-0.552441) | 0.130244 / 0.296338 (-0.166095) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436930 / 0.215209 (0.221721) | 4.356118 / 2.077655 (2.278463) | 2.049169 / 1.504120 (0.545049) | 1.842898 / 1.541195 (0.301703) | 1.918948 / 1.468490 (0.450458) | 0.553573 / 4.584777 (-4.031204) | 3.883195 / 3.745712 (0.137483) | 3.209780 / 5.269862 (-2.060081) | 1.551707 / 4.565676 (-3.013970) | 0.068181 / 0.424275 (-0.356094) | 0.012370 / 0.007607 (0.004762) | 0.539899 / 0.226044 (0.313854) | 5.380008 / 2.268929 (3.111079) | 2.518178 / 55.444624 (-52.926446) | 2.174190 / 6.876477 (-4.702286) | 2.317812 / 2.142072 (0.175740) | 0.674154 / 4.805227 (-4.131073) | 0.149313 / 6.500664 (-6.351351) | 0.068297 / 0.075469 (-0.007172) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.261426 / 1.841788 (-0.580362) | 15.316378 / 8.074308 (7.242070) | 13.573512 / 10.191392 (3.382120) | 0.190022 / 0.680424 (-0.490401) | 0.018697 / 0.534201 (-0.515504) | 0.448122 / 0.579283 (-0.131161) | 0.435044 / 0.434364 (0.000681) | 0.550065 / 0.540337 (0.009728) | 0.653547 / 1.386936 (-0.733389) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007116 / 0.011353 (-0.004237) | 0.004375 / 0.011008 (-0.006633) | 0.081793 / 0.038508 (0.043285) | 0.047980 / 0.023109 (0.024871) | 0.392185 / 0.275898 (0.116287) | 0.462263 / 0.323480 (0.138783) | 0.005574 / 0.007986 (-0.002412) | 0.003552 / 0.004328 (-0.000776) | 0.080413 / 0.004250 (0.076162) | 0.065539 / 0.037052 (0.028487) | 0.413137 / 0.258489 (0.154648) | 0.467377 / 0.293841 (0.173536) | 0.034386 / 0.128546 (-0.094160) | 0.009183 / 0.075646 (-0.066464) | 0.087542 / 0.419271 (-0.331730) | 0.053954 / 0.043533 (0.010421) | 0.385096 / 0.255139 (0.129957) | 0.404900 / 0.283200 (0.121701) | 0.025908 / 0.141683 (-0.115775) | 1.550159 / 1.452155 (0.098005) | 1.598794 / 1.492716 (0.106078) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246222 / 0.018006 (0.228216) | 0.441095 / 0.000490 (0.440605) | 0.006863 / 0.000200 (0.006663) | 0.000109 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032179 / 0.037411 (-0.005233) | 0.120112 / 0.014526 (0.105586) | 0.129326 / 0.176557 (-0.047230) | 0.184542 / 0.737135 (-0.552593) | 0.135038 / 0.296338 (-0.161300) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.459002 / 0.215209 (0.243793) | 4.580258 / 2.077655 (2.502604) | 2.296689 / 1.504120 (0.792569) | 2.104338 / 1.541195 (0.563143) | 2.182896 / 1.468490 (0.714406) | 0.546447 / 4.584777 (-4.038330) | 3.854047 / 3.745712 (0.108335) | 1.873829 / 5.269862 (-3.396032) | 1.116484 / 4.565676 (-3.449193) | 0.067158 / 0.424275 (-0.357117) | 0.012035 / 0.007607 (0.004428) | 0.556642 / 0.226044 (0.330597) | 5.574436 / 2.268929 (3.305508) | 2.828223 / 55.444624 (-52.616402) | 2.519851 / 6.876477 (-4.356626) | 2.668594 / 2.142072 (0.526521) | 0.675989 / 4.805227 (-4.129238) | 0.146075 / 6.500664 (-6.354589) | 0.067788 / 0.075469 (-0.007681) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.345958 / 1.841788 (-0.495830) | 15.672748 / 8.074308 (7.598440) | 14.937583 / 10.191392 (4.746191) | 0.163479 / 0.680424 (-0.516945) | 0.018364 / 0.534201 (-0.515837) | 0.433296 / 0.579283 (-0.145987) | 0.432463 / 0.434364 (-0.001901) | 0.512000 / 0.540337 (-0.028338) | 0.619397 / 1.386936 (-0.767539) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010097 / 0.011353 (-0.001256) | 0.005070 / 0.011008 (-0.005939) | 0.118638 / 0.038508 (0.080130) | 0.043651 / 0.023109 (0.020542) | 0.356074 / 0.275898 (0.080176) | 0.414578 / 0.323480 (0.091098) | 0.005939 / 0.007986 (-0.002046) | 0.004927 / 0.004328 (0.000598) | 0.089545 / 0.004250 (0.085294) | 0.067533 / 0.037052 (0.030481) | 0.371550 / 0.258489 (0.113061) | 0.417808 / 0.293841 (0.123967) | 0.045186 / 0.128546 (-0.083361) | 0.015763 / 0.075646 (-0.059883) | 0.393304 / 0.419271 (-0.025967) | 0.065123 / 0.043533 (0.021591) | 0.345057 / 0.255139 (0.089918) | 0.378809 / 0.283200 (0.095610) | 0.033243 / 0.141683 (-0.108440) | 1.679956 / 1.452155 (0.227802) | 1.775456 / 1.492716 (0.282739) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229723 / 0.018006 (0.211717) | 0.554630 / 0.000490 (0.554140) | 0.008729 / 0.000200 (0.008529) | 0.000183 / 0.000054 (0.000129) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027284 / 0.037411 (-0.010128) | 0.114741 / 0.014526 (0.100215) | 0.129188 / 0.176557 (-0.047369) | 0.189270 / 0.737135 (-0.547866) | 0.126000 / 0.296338 (-0.170339) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.580417 / 0.215209 (0.365208) | 5.829337 / 2.077655 (3.751683) | 2.421191 / 1.504120 (0.917071) | 2.063673 / 1.541195 (0.522479) | 2.133427 / 1.468490 (0.664937) | 0.830964 / 4.584777 (-3.753813) | 5.107139 / 3.745712 (1.361427) | 4.599451 / 5.269862 (-0.670410) | 2.406502 / 4.565676 (-2.159175) | 0.100422 / 0.424275 (-0.323853) | 0.011850 / 0.007607 (0.004243) | 0.741881 / 0.226044 (0.515836) | 7.425689 / 2.268929 (5.156760) | 3.068948 / 55.444624 (-52.375676) | 2.496292 / 6.876477 (-4.380184) | 2.566420 / 2.142072 (0.424348) | 1.093084 / 4.805227 (-3.712144) | 0.224106 / 6.500664 (-6.276558) | 0.084549 / 0.075469 (0.009080) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.416315 / 1.841788 (-0.425473) | 16.306901 / 8.074308 (8.232593) | 19.792419 / 10.191392 (9.601027) | 0.224223 / 0.680424 (-0.456201) | 0.026385 / 0.534201 (-0.507816) | 0.463460 / 0.579283 (-0.115823) | 0.598385 / 0.434364 (0.164021) | 0.543981 / 0.540337 (0.003644) | 0.647454 / 1.386936 (-0.739482) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009470 / 0.011353 (-0.001883) | 0.004800 / 0.011008 (-0.006208) | 0.094276 / 0.038508 (0.055768) | 0.045157 / 0.023109 (0.022048) | 0.397302 / 0.275898 (0.121404) | 0.474213 / 0.323480 (0.150733) | 0.005826 / 0.007986 (-0.002160) | 0.003724 / 0.004328 (-0.000605) | 0.090060 / 0.004250 (0.085809) | 0.066671 / 0.037052 (0.029618) | 0.439560 / 0.258489 (0.181071) | 0.468598 / 0.293841 (0.174757) | 0.044549 / 0.128546 (-0.083997) | 0.014000 / 0.075646 (-0.061646) | 0.110457 / 0.419271 (-0.308815) | 0.065898 / 0.043533 (0.022365) | 0.408101 / 0.255139 (0.152962) | 0.433473 / 0.283200 (0.150273) | 0.038438 / 0.141683 (-0.103245) | 1.767781 / 1.452155 (0.315626) | 1.791575 / 1.492716 (0.298859) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230257 / 0.018006 (0.212251) | 0.492280 / 0.000490 (0.491790) | 0.005110 / 0.000200 (0.004910) | 0.000119 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028854 / 0.037411 (-0.008557) | 0.111702 / 0.014526 (0.097176) | 0.122040 / 0.176557 (-0.054517) | 0.179103 / 0.737135 (-0.558032) | 0.128869 / 0.296338 (-0.167470) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.634795 / 0.215209 (0.419586) | 6.204760 / 2.077655 (4.127105) | 2.692479 / 1.504120 (1.188359) | 2.324260 / 1.541195 (0.783066) | 2.380640 / 1.468490 (0.912149) | 0.887827 / 4.584777 (-3.696950) | 5.251648 / 3.745712 (1.505935) | 2.632767 / 5.269862 (-2.637095) | 1.745721 / 4.565676 (-2.819955) | 0.108364 / 0.424275 (-0.315911) | 0.013409 / 0.007607 (0.005802) | 0.783427 / 0.226044 (0.557383) | 7.765144 / 2.268929 (5.496216) | 3.340686 / 55.444624 (-52.103938) | 2.715340 / 6.876477 (-4.161137) | 2.768604 / 2.142072 (0.626531) | 1.119746 / 4.805227 (-3.685481) | 0.210804 / 6.500664 (-6.289860) | 0.072600 / 0.075469 (-0.002869) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.517334 / 1.841788 (-0.324454) | 17.046837 / 8.074308 (8.972529) | 19.371090 / 10.191392 (9.179698) | 0.194275 / 0.680424 (-0.486148) | 0.026712 / 0.534201 (-0.507488) | 0.462731 / 0.579283 (-0.116552) | 0.568958 / 0.434364 (0.134595) | 0.555707 / 0.540337 (0.015370) | 0.663654 / 1.386936 (-0.723283) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006423 / 0.011353 (-0.004930) | 0.003882 / 0.011008 (-0.007126) | 0.082976 / 0.038508 (0.044468) | 0.071281 / 0.023109 (0.048171) | 0.311367 / 0.275898 (0.035469) | 0.348228 / 0.323480 (0.024748) | 0.005315 / 0.007986 (-0.002671) | 0.003326 / 0.004328 (-0.001003) | 0.064641 / 0.004250 (0.060391) | 0.056134 / 0.037052 (0.019081) | 0.314071 / 0.258489 (0.055582) | 0.360534 / 0.293841 (0.066693) | 0.030642 / 0.128546 (-0.097904) | 0.008301 / 0.075646 (-0.067345) | 0.285820 / 0.419271 (-0.133451) | 0.069241 / 0.043533 (0.025708) | 0.313995 / 0.255139 (0.058856) | 0.336656 / 0.283200 (0.053457) | 0.031686 / 0.141683 (-0.109997) | 1.467627 / 1.452155 (0.015472) | 1.536493 / 1.492716 (0.043777) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.196518 / 0.018006 (0.178512) | 0.458235 / 0.000490 (0.457745) | 0.005599 / 0.000200 (0.005399) | 0.000088 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027371 / 0.037411 (-0.010040) | 0.080986 / 0.014526 (0.066460) | 0.093296 / 0.176557 (-0.083260) | 0.150592 / 0.737135 (-0.586543) | 0.094150 / 0.296338 (-0.202188) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.379412 / 0.215209 (0.164202) | 3.797927 / 2.077655 (1.720272) | 1.830654 / 1.504120 (0.326534) | 1.669569 / 1.541195 (0.128374) | 1.746738 / 1.468490 (0.278248) | 0.479536 / 4.584777 (-4.105241) | 3.592867 / 3.745712 (-0.152845) | 5.468098 / 5.269862 (0.198237) | 3.268013 / 4.565676 (-1.297663) | 0.056635 / 0.424275 (-0.367640) | 0.007224 / 0.007607 (-0.000383) | 0.456681 / 0.226044 (0.230636) | 4.566736 / 2.268929 (2.297807) | 2.362831 / 55.444624 (-53.081793) | 1.965141 / 6.876477 (-4.911336) | 2.156905 / 2.142072 (0.014833) | 0.572543 / 4.805227 (-4.232684) | 0.132203 / 6.500664 (-6.368461) | 0.059254 / 0.075469 (-0.016215) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256134 / 1.841788 (-0.585654) | 19.905438 / 8.074308 (11.831130) | 14.179556 / 10.191392 (3.988164) | 0.168043 / 0.680424 (-0.512381) | 0.018215 / 0.534201 (-0.515986) | 0.392740 / 0.579283 (-0.186543) | 0.398397 / 0.434364 (-0.035967) | 0.463806 / 0.540337 (-0.076531) | 0.616248 / 1.386936 (-0.770688) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006564 / 0.011353 (-0.004789) | 0.003923 / 0.011008 (-0.007085) | 0.063929 / 0.038508 (0.025421) | 0.073780 / 0.023109 (0.050671) | 0.360242 / 0.275898 (0.084344) | 0.395078 / 0.323480 (0.071598) | 0.005265 / 0.007986 (-0.002720) | 0.003229 / 0.004328 (-0.001100) | 0.064094 / 0.004250 (0.059843) | 0.057468 / 0.037052 (0.020416) | 0.369530 / 0.258489 (0.111041) | 0.411159 / 0.293841 (0.117318) | 0.031278 / 0.128546 (-0.097268) | 0.008424 / 0.075646 (-0.067222) | 0.070411 / 0.419271 (-0.348860) | 0.048714 / 0.043533 (0.005181) | 0.361280 / 0.255139 (0.106141) | 0.382468 / 0.283200 (0.099269) | 0.023059 / 0.141683 (-0.118624) | 1.452369 / 1.452155 (0.000215) | 1.519192 / 1.492716 (0.026475) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223745 / 0.018006 (0.205739) | 0.442086 / 0.000490 (0.441596) | 0.000379 / 0.000200 (0.000179) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030919 / 0.037411 (-0.006493) | 0.088483 / 0.014526 (0.073958) | 0.101165 / 0.176557 (-0.075391) | 0.154332 / 0.737135 (-0.582804) | 0.103030 / 0.296338 (-0.193309) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414520 / 0.215209 (0.199311) | 4.126754 / 2.077655 (2.049099) | 2.142677 / 1.504120 (0.638557) | 1.995300 / 1.541195 (0.454106) | 2.101678 / 1.468490 (0.633188) | 0.481099 / 4.584777 (-4.103678) | 3.562813 / 3.745712 (-0.182900) | 3.392463 / 5.269862 (-1.877399) | 1.983943 / 4.565676 (-2.581734) | 0.056594 / 0.424275 (-0.367681) | 0.007216 / 0.007607 (-0.000391) | 0.495085 / 0.226044 (0.269041) | 4.955640 / 2.268929 (2.686712) | 2.629434 / 55.444624 (-52.815191) | 2.269577 / 6.876477 (-4.606900) | 2.357708 / 2.142072 (0.215635) | 0.612370 / 4.805227 (-4.192857) | 0.131169 / 6.500664 (-6.369495) | 0.061029 / 0.075469 (-0.014440) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.339438 / 1.841788 (-0.502350) | 19.757611 / 8.074308 (11.683303) | 14.246254 / 10.191392 (4.054862) | 0.170750 / 0.680424 (-0.509674) | 0.018192 / 0.534201 (-0.516009) | 0.395693 / 0.579283 (-0.183590) | 0.411003 / 0.434364 (-0.023361) | 0.478531 / 0.540337 (-0.061806) | 0.650291 / 1.386936 (-0.736645) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4404/comments | https://api.github.com/repos/huggingface/datasets/issues/4404/events | https://github.com/huggingface/datasets/issues/4404 | 1,248,572,899 | I_kwDODunzps5Ka7Xj | 4,404 | Dataset should have a `.name` field | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2022-05-25T18:56:08Z | 2022-09-13T15:09:30Z | 2022-06-16T10:47:53Z | null | **Is your feature request related to a problem? Please describe.**
If building pipelines that can evaluate on more than one dataset, it would be nice to be able to log results of things like `Evaluating on {dataset.name}` or `results for {dataset.name} are: {results}`
Without some way of concisely identifying a dataset from the dataset object, tools which might run on more than one dataset must be passed the dataset object _and_ the name/id of the dataset being used.
**Describe the solution you'd like**
The DatasetInfo class should have a `name` field which is the name of a dataset. then for a given dataset if it evolves in time the `version` can be updated but its different versions of the same dataset with a unique `name`. The name could then all be accessed by `dataset.name`
**Describe alternatives you've considered**
For my own purposes I am considering making `NamedDataset[Dataset]` where the subclass just has a .name field.
**Additional context**
My guess is that most usecases are not working with more than one dataset in a given pipeline so a name is not really needed. This has surprised me though as one of the advantages of a standard dataset interface is to be able to build pipelines which can be passed in a dataset and separate responsibilities of the dataset loading from the train or eval pipeline.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4404/timeline | null | completed | null | null | false | [
"Hi! You can already use `dset.builder_name` and `dset.config_name` for that purpose. And when it comes to versioning, it's better to use `dset._fingerprint` than the `version` attribute as the former represents a deterministic hash that encodes all the mutable ops executed on a dataset, and the latter stays the same unless it's manually updated after each op.",
"@mariosasko Can we make ._fingerprint not private? seems a critical component for tracking how a model was generated to ensure reproducibility."
] |
https://api.github.com/repos/huggingface/datasets/issues/2912 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2912/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2912/comments | https://api.github.com/repos/huggingface/datasets/issues/2912/events | https://github.com/huggingface/datasets/pull/2912 | 996,256,005 | PR_kwDODunzps4rvhgp | 2,912 | Update link to Blog in docs footer | [] | closed | false | null | 0 | 2021-09-14T17:23:14Z | 2021-09-15T07:59:23Z | 2021-09-15T07:59:23Z | null | Update link. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2912/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2912/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2912.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2912",
"merged_at": "2021-09-15T07:59:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2912.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2912"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4219 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4219/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4219/comments | https://api.github.com/repos/huggingface/datasets/issues/4219/events | https://github.com/huggingface/datasets/pull/4219 | 1,214,934,025 | PR_kwDODunzps42v6rE | 4,219 | Add F1 Metric Card | [] | closed | false | null | 1 | 2022-04-25T19:14:56Z | 2022-04-26T20:44:18Z | 2022-04-26T20:37:46Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4219/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4219/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4219.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4219",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4219.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4219"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2118 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2118/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2118/comments | https://api.github.com/repos/huggingface/datasets/issues/2118/events | https://github.com/huggingface/datasets/pull/2118 | 841,563,329 | MDExOlB1bGxSZXF1ZXN0NjAxMjgzMDUx | 2,118 | Remove os.environ.copy in Dataset.map | [] | closed | false | null | 1 | 2021-03-26T03:48:17Z | 2021-03-26T12:03:23Z | 2021-03-26T12:00:05Z | null | Replace `os.environ.copy` with in-place modification
Fixes #2115 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2118/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2118/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2118.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2118",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2118.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2118"
} | true | [
"I thought deepcopy on `os.environ` is unsafe (see [this](https://stackoverflow.com/questions/13142972/using-copy-deepcopy-on-os-environ-in-python-appears-broken)), but I can't replicate the behavior described in the linked SO thread.\r\n\r\nClosing this one because #2119 has a much cleaner approach."
] |
https://api.github.com/repos/huggingface/datasets/issues/4207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4207/comments | https://api.github.com/repos/huggingface/datasets/issues/4207/events | https://github.com/huggingface/datasets/pull/4207 | 1,213,604,615 | PR_kwDODunzps42rmbK | 4,207 | [Minor edit] Fix typo in class name | [] | closed | false | null | 0 | 2022-04-24T09:49:37Z | 2022-05-05T13:17:47Z | 2022-05-05T13:17:47Z | null | Typo: `datasets.DatsetDict` -> `datasets.DatasetDict` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4207/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4207/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4207.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4207",
"merged_at": "2022-05-05T13:17:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4207.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4207"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5750/comments | https://api.github.com/repos/huggingface/datasets/issues/5750/events | https://github.com/huggingface/datasets/issues/5750 | 1,668,289,067 | I_kwDODunzps5jcBIr | 5,750 | Fail to create datasets from a generator when using Google Big Query | [] | closed | false | null | 4 | 2023-04-14T13:50:59Z | 2023-04-17T12:20:43Z | 2023-04-17T12:20:43Z | null | ### Describe the bug
Creating a dataset from a generator using `Dataset.from_generator()` fails if the generator is the [Google Big Query Python client](https://cloud.google.com/python/docs/reference/bigquery/latest). The problem is that the Big Query client is not pickable. And the function `create_config_id` tries to get a hash of the generator by pickling it. So the following error is generated:
```
_pickle.PicklingError: Pickling client objects is explicitly not supported.
Clients have non-trivial state that is local and unpickleable.
```
### Steps to reproduce the bug
1. Install the big query client and datasets `pip install google-cloud-bigquery datasets`
2. Run the following code:
```py
from datasets import Dataset
from google.cloud import bigquery
client = bigquery.Client()
# Perform a query.
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # API request
rows = query_job.result() # Waits for query to finish
ds = Dataset.from_generator(rows)
for r in ds:
print(r)
```
### Expected behavior
Two options:
1. Ignore the pickle errors when computing the hash
2. Provide a scape hutch so that we can avoid calculating the hash for the generator. For example, allowing to provide a hash from the user.
### Environment info
python 3.9
google-cloud-bigquery 3.9.0
datasets 2.11.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5750/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5750/timeline | null | completed | null | null | false | [
"`from_generator` expects a generator function, not a generator object, so this should work:\r\n```python\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\nclient = bigquery.Client()\r\n\r\ndef gen()\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '\r\n 'WHERE state = \"TX\" '\r\n 'LIMIT 100')\r\n query_job = client.query(QUERY) # API request\r\n yield from query_job.result() # Waits for query to finish\r\n\r\nds = Dataset.from_generator(rows)\r\n\r\nfor r in ds:\r\n print(r)\r\n```",
"@mariosasko your code was incomplete, so I tried to fix it:\r\n\r\n```py\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\nclient = bigquery.Client()\r\n\r\ndef gen():\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '\r\n 'WHERE state = \"TX\" '\r\n 'LIMIT 100')\r\n query_job = client.query(QUERY) # API request\r\n yield from query_job.result() # Waits for query to finish\r\n\r\nds = Dataset.from_generator(gen)\r\n\r\nfor r in ds:\r\n print(r)\r\n```\r\n\r\nThe error is also present in this case:\r\n\r\n```\r\n_pickle.PicklingError: Pickling client objects is explicitly not supported.\r\nClients have non-trivial state that is local and unpickleable.\r\n```\r\n\r\nI think it doesn't matter if the generator is an object or a function. The problem is that the generator is referencing an object that is not pickable (the client in this case). ",
"It does matter: this function expects a generator function, as stated in the docs.\r\n\r\nThis should work:\r\n```python\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\ndef gen():\r\n client = bigquery.Client()\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '\r\n 'WHERE state = \"TX\" '\r\n 'LIMIT 100')\r\n query_job = client.query(QUERY) # API request\r\n yield from query_job.result() # Waits for query to finish\r\n\r\nds = Dataset.from_generator(gen)\r\n\r\nfor r in ds:\r\n print(r)\r\n```\r\n\r\nWe could allow passing non-picklable objects and use a random hash for the generated arrow file. In that case, the caching mechanism would not work, meaning repeated calls with the same set of arguments would generate new datasets instead of reusing the cached version, but this behavior is still better than raising an error.",
"Thank you @mariosasko . Your last code is working indeed. Curiously, the important detail here was to wrap the client instantiation within the generator itself. If the line `client = bigquery.Client()` is moved outside, then the error is back.\r\n\r\nI see now also your point in regard to the generator being a generator function. We can close the issue if you want."
] |
https://api.github.com/repos/huggingface/datasets/issues/4610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4610/comments | https://api.github.com/repos/huggingface/datasets/issues/4610/events | https://github.com/huggingface/datasets/issues/4610 | 1,290,603,827 | I_kwDODunzps5M7Q0z | 4,610 | codeparrot/github-code failing to load | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 8 | 2022-06-30T20:24:48Z | 2022-07-05T14:24:13Z | 2022-07-05T09:19:56Z | null | ## Describe the bug
codeparrot/github-code fails to load with a `TypeError: get_patterns_in_dataset_repository() missing 1 required positional argument: 'base_path'`
## Steps to reproduce the bug
```python
from datasets import load_dataset
```
## Expected results
loaded dataset object
## Actual results
```python
[3]: dataset = load_dataset("codeparrot/github-code")
No config specified, defaulting to: github-code/all-all
Downloading and preparing dataset github-code/all-all to /home/bebr/.cache/huggingface/datasets/codeparrot___github-code/all-all/0.0.0/a55513bc0f81db773f9896c7aac225af0cff5b323bb9d2f68124f0a8cc3fb817...
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [3], in <cell line: 1>()
----> 1 dataset = load_dataset("codeparrot/github-code")
File ~/miniconda3/envs/fastapi-kube/lib/python3.10/site-packages/datasets/load.py:1679, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1676 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1678 # Download and prepare data
-> 1679 builder_instance.download_and_prepare(
1680 download_config=download_config,
1681 download_mode=download_mode,
1682 ignore_verifications=ignore_verifications,
1683 try_from_hf_gcs=try_from_hf_gcs,
1684 use_auth_token=use_auth_token,
1685 )
1687 # Build dataset for splits
1688 keep_in_memory = (
1689 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1690 )
File ~/miniconda3/envs/fastapi-kube/lib/python3.10/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
706 )
707 # Sync info
708 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File ~/miniconda3/envs/fastapi-kube/lib/python3.10/site-packages/datasets/builder.py:1221, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verify_infos)
1220 def _download_and_prepare(self, dl_manager, verify_infos):
-> 1221 super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File ~/miniconda3/envs/fastapi-kube/lib/python3.10/site-packages/datasets/builder.py:771, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
769 split_dict = SplitDict(dataset_name=self.name)
770 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 771 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
773 # Checksums verification
774 if verify_infos and dl_manager.record_checksums:
File ~/.cache/huggingface/modules/datasets_modules/datasets/codeparrot--github-code/a55513bc0f81db773f9896c7aac225af0cff5b323bb9d2f68124f0a8cc3fb817/github-code.py:169, in GithubCode._split_generators(self, dl_manager)
162 def _split_generators(self, dl_manager):
164 hfh_dataset_info = HfApi(datasets.config.HF_ENDPOINT).dataset_info(
165 _REPO_NAME,
166 timeout=100.0,
167 )
--> 169 patterns = datasets.data_files.get_patterns_in_dataset_repository(hfh_dataset_info)
170 data_files = datasets.data_files.DataFilesDict.from_hf_repo(
171 patterns,
172 dataset_info=hfh_dataset_info,
173 )
175 files = dl_manager.download_and_extract(data_files["train"])
TypeError: get_patterns_in_dataset_repository() missing 1 required positional argument: 'base_path'
```
## Environment info
- `datasets` version: 2.3.2
- Platform: Linux-5.18.7-arch1-1-x86_64-with-glibc2.35
- Python version: 3.10.5
- PyArrow version: 8.0.0
- Pandas version: 1.4.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4610/timeline | null | completed | null | null | false | [
"I believe the issue is in `codeparrot/github-code`. `base_path` param is missing - https://huggingface.co/datasets/codeparrot/github-code/blob/main/github-code.py#L169\r\n\r\nFunction definition has changed.\r\nhttps://github.com/huggingface/datasets/blob/0e1c629cfb9f9ba124537ba294a0ec451584da5f/src/datasets/data_files.py#L547\r\n\r\n@mariosasko could you please confirm my finding? And are there any changes that need to be done from my side?",
"Good catch ! We recently did a breaking change in `get_patterns_in_dataset_repository`, I think we can revert it",
"> Good catch ! We recently did a breaking change in `get_patterns_in_dataset_repository`, I think we can revert it\n\nI can't wait for that releasee. Broke my application",
"This simple workaround should fix: https://huggingface.co/datasets/codeparrot/github-code/discussions/2\r\n\r\n`get_patterns_in_dataset_repository` can treat whether `base_path=None`, so we just need to make sure that codeparrot/github-code `_split_generators` calls with such an argument.",
"I am afraid your suggested change @gugarosa will break compatibility with older datasets versions that don't have `base_path` argument in `get_patterns_in_dataset_repository`, as a workaround while the issue gets resolved in `datasets` can you downgrade your datasets version to `<=2.1.0` ? \r\n@lvwerra do you think we should adapt the script to check the datasets version before calling `get_patterns_in_dataset_repository`?",
"Actually I think it's just simpler to fix it in the dataset itself, let me open a PR\r\n\r\nEDIT: PR opened here: https://huggingface.co/datasets/codeparrot/github-code/discussions/3",
"PR is merged, it's working now ! Closing this one :)",
"> I am afraid your suggested change @gugarosa will break compatibility with older datasets versions that don't have `base_path` argument in `get_patterns_in_dataset_repository`, as a workaround while the issue gets resolved in `datasets` can you downgrade your datasets version to `<=2.1.0` ?\r\n> @lvwerra do you think we should adapt the script to check the datasets version before calling `get_patterns_in_dataset_repository`?\r\n\r\nYou are definitely right, sorry about it. I always keep forgetting that we need to keep in mind users from past versions, my bad."
] |
https://api.github.com/repos/huggingface/datasets/issues/683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/683/comments | https://api.github.com/repos/huggingface/datasets/issues/683/events | https://github.com/huggingface/datasets/pull/683 | 710,942,704 | MDExOlB1bGxSZXF1ZXN0NDk0NzAwNzY1 | 683 | Fix wrong delimiter in text dataset | [] | closed | false | null | 0 | 2020-09-29T09:43:24Z | 2021-05-05T18:24:31Z | 2020-09-29T09:44:06Z | null | The delimiter is set to the bell character as it is used nowhere is text files usually.
However in the text dataset the delimiter was set to `\b` which is backspace in python, while the bell character is `\a`.
I replace \b by \a
Hopefully it fixes issues mentioned by some users in #622 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/683/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/683/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/683.diff",
"html_url": "https://github.com/huggingface/datasets/pull/683",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/683.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/683"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2037 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2037/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2037/comments | https://api.github.com/repos/huggingface/datasets/issues/2037/events | https://github.com/huggingface/datasets/pull/2037 | 829,919,685 | MDExOlB1bGxSZXF1ZXN0NTkxNTA4MTQz | 2,037 | Fix: Wikipedia - save memory by replacing root.clear with elem.clear | [] | closed | false | null | 1 | 2021-03-12T09:22:00Z | 2021-03-23T06:08:16Z | 2021-03-16T11:01:22Z | null | see: https://github.com/huggingface/datasets/issues/2031
What I did:
- replace root.clear with elem.clear
- remove lines to get root element
- $ make style
- $ make test
- some tests required some pip packages, I installed them.
test results on origin/master and my branch are same. I think it's not related on my modification, isn't it?
```
==================================================================================== short test summary info ====================================================================================
FAILED tests/test_arrow_writer.py::TypedSequenceTest::test_catch_overflow - AssertionError: OverflowError not raised
============================================================= 1 failed, 2332 passed, 5138 skipped, 70 warnings in 91.75s (0:01:31) ==============================================================
make: *** [Makefile:19: test] Error 1
```
Is there anything else I should do? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2037/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2037/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2037.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2037",
"merged_at": "2021-03-16T11:01:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2037.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2037"
} | true | [
"The error you got is minor and appeared in the last version of pyarrow, we'll fix the CI to take this into account. You can ignore it"
] |
https://api.github.com/repos/huggingface/datasets/issues/25 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/25/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/25/comments | https://api.github.com/repos/huggingface/datasets/issues/25/events | https://github.com/huggingface/datasets/pull/25 | 609,708,863 | MDExOlB1bGxSZXF1ZXN0NDExMjQ4Nzg2 | 25 | Add script csv datasets | [] | closed | false | null | 3 | 2020-04-30T08:28:08Z | 2022-10-04T09:32:13Z | 2020-05-07T21:14:49Z | null | This is a PR allowing to create datasets from local CSV files. A usage might be:
```python
import nlp
ds = nlp.load(
path="csv",
name="bbc",
dataset_files={
nlp.Split.TRAIN: ["datasets/dummy_data/csv/train.csv"],
nlp.Split.TEST: [""datasets/dummy_data/csv/test.csv""]
},
csv_kwargs={
"skip_rows": 0,
"delimiter": ",",
"quote_char": "\"",
"header_as_column_names": True
}
)
```
```
Downloading and preparing dataset bbc/1.0.0 (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/jplu/.cache/huggingface/datasets/bbc/1.0.0...
Dataset bbc downloaded and prepared to /home/jplu/.cache/huggingface/datasets/bbc/1.0.0. Subsequent calls will reuse this data.
{'test': Dataset(schema: {'category': 'string', 'text': 'string'}, num_rows: 49), 'train': Dataset(schema: {'category': 'string', 'text': 'string'}, num_rows: 99), 'validation': Dataset(schema: {'category': 'string', 'text': 'string'}, num_rows: 0)}
```
How it is read:
- `path`: the `csv` word means "I want to create a CSV dataset"
- `name`: the name of this dataset is `bbc`
- `dataset_files`: this is a dictionary where each key is the list of files corresponding to the key split.
- `csv_kwargs`: this is the keywords arguments to "explain" how to read the CSV files
* `skip_rows`: number of rows have to be skipped, starting from the beginning of the file
* `delimiter`: which delimiter is used to separate the columns
* `quote_char`: which quote char is used to represent a column where the delimiter appears in one of them
* `header_as_column_names`: will use the first row (header) of the file as name for the features. Otherwise the names will be automatically generated as `f1`, `f2`, etc... Will be applied after the `skip_rows` parameter.
**TODO**: for now the `csv.py` is copied each time we create a new dataset as `ds_name.py`, this behavior will be modified to have only the `csv.py` script copied only once and not for all the CSV datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/25/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/25/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/25.diff",
"html_url": "https://github.com/huggingface/datasets/pull/25",
"merged_at": "2020-05-07T21:14:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/25.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/25"
} | true | [
"Very interesting thoughts, we should think deeper about all what you raised indeed.",
"Ok here is a proposal for a more general API and workflow.\r\n\r\n# New `ArrowBasedBuilder`\r\n\r\nFor all the formats that can be directly and efficiently loaded by Arrow (CSV, JSON, Parquet, Arrow), we don't really want to have to go through a conversion to python and back to Arrow. This new builder has a `_generate_tables` method to yield `Arrow.Tables` instead of single examples.\r\nThe tables can be directly casted in Arrow so it's not necessary to supply `Features`, they can be deduced from the `Table` column.\r\n\r\n# Central role of the `BuilderConfig` to store all the arguments necessary for the Dataset creation.\r\n \r\n`BuilderConfig` provide a few defaults fields `name`, `version`, `description`, `data_files` and `data_dir` which can be used to store values necessary for the creation of the dataset. It can be freely extended to store additional information (see the example for `CsvConfig`).\r\n\r\nOn the contrary, `DatasetInfo` is designed as an organized and delimited information storage class with predefined fields.\r\n\r\n`DatasetInfo` now store two names:\r\n- `builder_name`: Name of the builder script used to create the dataset\r\n- `config_name`: Name of the configuration used to create the dataset.\r\n\r\n# Refactoring `load()` arguments and all the chain of processing including the `DownloadManager`\r\n\r\n`load()` now accept a selection of arguments which are used to update the `BuilderConfig` and some kwargs which are used to handle the download process.\r\n\r\nSupplying a `BuilderConfig` as `config` will override the config provided in the dataset. Supplying a `str` will get the associated config from the dataset. Default is to fetch the first config of the dataset.\r\n\r\nGiving additional arguments to `load()` will override the arguments in the `BuilderConfig`.\r\n\r\n# CSV script\r\n\r\nThe `csv.py` script is provided as an example, usage is:\r\n```python\r\nbbc = nlp.load('/Users/thomwolf/Documents/GitHub/datasets/datasets/nlp/csv',\r\n name='bbc',\r\n version=\"1.0.1\",\r\n split='train',\r\n data_files={'train': ['/Users/thomwolf/Documents/GitHub/datasets/datasets/dummy_data/csv/test.csv']},\r\n skip_rows=10,\r\n download_mode='force_redownload')\r\n```\r\n\r\n# Checksums\r\n\r\nWe now don't raise an error if the checksum file is not found.\r\n\r\n# `DownloadConfig`\r\n\r\nWe now have a download configuration class to handle all the specific arguments for file caching like proxies, using only local files or user-agents.",
"Ok merging this for now.\r\n\r\nOne general note is that it's a bit hard to handle the `ClassLabel` generally in both `nlp` and `Arrow` since a class label typically need some metadata for the class names. For now, I raise a `NotImplementedError` when an `ArrowBuilder` output a table with a `DictionaryType` is encountered (which could be a simple equivalent for a `ClassLabel` Feature in Arrow tables).\r\n\r\nIn general and if we need this in the future for some Beam Datasets for instance, I think we should use one of the `metadata` fields in the `Arrow` type or table's schema to store the relation with indices and class names.\r\n\r\nSo ping me if you meet Beam datasets which uses `ClassLabels` (cc @lhoestq @patrickvonplaten @mariamabarham)."
] |
https://api.github.com/repos/huggingface/datasets/issues/909 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/909/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/909/comments | https://api.github.com/repos/huggingface/datasets/issues/909/events | https://github.com/huggingface/datasets/pull/909 | 752,508,299 | MDExOlB1bGxSZXF1ZXN0NTI4ODE1NDYz | 909 | Add FiNER dataset | [] | closed | false | null | 9 | 2020-11-27T23:54:20Z | 2020-12-07T16:56:23Z | 2020-12-07T16:56:23Z | null | Hi,
this PR adds "A Finnish News Corpus for Named Entity Recognition" as new `finer` dataset.
The dataset is described in [this paper](https://arxiv.org/abs/1908.04212). The data is publicly available in [this GitHub](https://github.com/mpsilfve/finer-data).
Notice: they provide two testsets. The additional test dataset taken from Wikipedia is named as "test_wikipedia" split. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/909/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/909/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/909.diff",
"html_url": "https://github.com/huggingface/datasets/pull/909",
"merged_at": "2020-12-07T16:56:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/909.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/909"
} | true | [
"> That's really cool thank you !\r\n> \r\n> Could you also add a dataset card ?\r\n> You can find a template here : https://github.com/huggingface/datasets/blob/master/templates/README.md\r\n\r\nThe full information for adding a dataset card can be found here :) \r\nhttps://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#manually-tag-the-dataset-and-write-the-dataset-card\r\n",
"Thanks your suggestions! I've fixed them, and currently working on the dataset card!",
"@yjernite and @lhoestq I will add the dataset card a bit later in a separate PR if that's ok for you!",
"Yes I want to re-emphasize if it was not clear that dataset cards are optional for the sprint. \r\n\r\nOnly the tags are required for merging a datasets.\r\n\r\nPlease try to enforce this rule as well @lhoestq and @yjernite ",
"Yes @stefan-it if you could just add the tags (the yaml part at the top of the dataset card) that'd be perfect :) ",
"Oh, sorry, will add them now!\r\n",
"Initial README file is now added :) ",
"the `RemoteDatasetTest ` errors in the CI are fixed on master so it's fine",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/1284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1284/comments | https://api.github.com/repos/huggingface/datasets/issues/1284/events | https://github.com/huggingface/datasets/pull/1284 | 759,269,920 | MDExOlB1bGxSZXF1ZXN0NTM0MzAzNDk0 | 1,284 | Update coqa dataset url | [] | closed | false | null | 0 | 2020-12-08T09:16:38Z | 2020-12-08T18:19:09Z | 2020-12-08T18:19:09Z | null | `datasets.stanford.edu` is invalid. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1284/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1284/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1284.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1284",
"merged_at": "2020-12-08T18:19:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1284.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1284"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5921 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5921/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5921/comments | https://api.github.com/repos/huggingface/datasets/issues/5921/events | https://github.com/huggingface/datasets/pull/5921 | 1,736,563,023 | PR_kwDODunzps5R6j-y | 5,921 | Fix streaming parquet with image feature in schema | [] | closed | false | null | 4 | 2023-06-01T15:23:10Z | 2023-06-02T10:02:54Z | 2023-06-02T09:53:11Z | null | It was not reading the feature type from the parquet arrow schema | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5921/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5921/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5921.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5921",
"merged_at": "2023-06-02T09:53:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5921.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5921"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007088 / 0.011353 (-0.004265) | 0.005216 / 0.011008 (-0.005793) | 0.097572 / 0.038508 (0.059064) | 0.036510 / 0.023109 (0.013401) | 0.316885 / 0.275898 (0.040987) | 0.348541 / 0.323480 (0.025061) | 0.006513 / 0.007986 (-0.001473) | 0.004579 / 0.004328 (0.000251) | 0.073779 / 0.004250 (0.069529) | 0.057500 / 0.037052 (0.020448) | 0.329840 / 0.258489 (0.071351) | 0.357530 / 0.293841 (0.063690) | 0.028515 / 0.128546 (-0.100031) | 0.009156 / 0.075646 (-0.066491) | 0.328340 / 0.419271 (-0.090932) | 0.068400 / 0.043533 (0.024867) | 0.313692 / 0.255139 (0.058553) | 0.329170 / 0.283200 (0.045971) | 0.111969 / 0.141683 (-0.029714) | 1.422096 / 1.452155 (-0.030059) | 1.550042 / 1.492716 (0.057326) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.285113 / 0.018006 (0.267107) | 0.546788 / 0.000490 (0.546298) | 0.006992 / 0.000200 (0.006792) | 0.000097 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026841 / 0.037411 (-0.010570) | 0.108413 / 0.014526 (0.093887) | 0.118375 / 0.176557 (-0.058181) | 0.174889 / 0.737135 (-0.562246) | 0.122781 / 0.296338 (-0.173558) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.404187 / 0.215209 (0.188978) | 4.039673 / 2.077655 (1.962019) | 1.894616 / 1.504120 (0.390496) | 1.729182 / 1.541195 (0.187987) | 1.772917 / 1.468490 (0.304427) | 0.524046 / 4.584777 (-4.060731) | 3.628111 / 3.745712 (-0.117601) | 1.866075 / 5.269862 (-3.403787) | 1.026435 / 4.565676 (-3.539242) | 0.065328 / 0.424275 (-0.358947) | 0.012717 / 0.007607 (0.005110) | 0.505821 / 0.226044 (0.279777) | 5.049518 / 2.268929 (2.780589) | 2.338486 / 55.444624 (-53.106139) | 2.002874 / 6.876477 (-4.873602) | 2.193049 / 2.142072 (0.050976) | 0.664638 / 4.805227 (-4.140589) | 0.151323 / 6.500664 (-6.349341) | 0.063774 / 0.075469 (-0.011695) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.168168 / 1.841788 (-0.673620) | 15.289200 / 8.074308 (7.214891) | 13.614249 / 10.191392 (3.422857) | 0.167950 / 0.680424 (-0.512474) | 0.017522 / 0.534201 (-0.516679) | 0.393480 / 0.579283 (-0.185803) | 0.420549 / 0.434364 (-0.013815) | 0.461425 / 0.540337 (-0.078912) | 0.563583 / 1.386936 (-0.823353) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006859 / 0.011353 (-0.004493) | 0.004864 / 0.011008 (-0.006144) | 0.075084 / 0.038508 (0.036576) | 0.033989 / 0.023109 (0.010880) | 0.372512 / 0.275898 (0.096614) | 0.394725 / 0.323480 (0.071246) | 0.006382 / 0.007986 (-0.001604) | 0.004521 / 0.004328 (0.000193) | 0.076422 / 0.004250 (0.072172) | 0.055383 / 0.037052 (0.018331) | 0.400974 / 0.258489 (0.142485) | 0.411570 / 0.293841 (0.117729) | 0.028264 / 0.128546 (-0.100282) | 0.009123 / 0.075646 (-0.066523) | 0.081257 / 0.419271 (-0.338015) | 0.048147 / 0.043533 (0.004614) | 0.390735 / 0.255139 (0.135596) | 0.376426 / 0.283200 (0.093226) | 0.108164 / 0.141683 (-0.033518) | 1.429667 / 1.452155 (-0.022488) | 1.556291 / 1.492716 (0.063575) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.289514 / 0.018006 (0.271508) | 0.532860 / 0.000490 (0.532370) | 0.003810 / 0.000200 (0.003611) | 0.000121 / 0.000054 (0.000066) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031292 / 0.037411 (-0.006119) | 0.116530 / 0.014526 (0.102005) | 0.127624 / 0.176557 (-0.048932) | 0.178276 / 0.737135 (-0.558859) | 0.133742 / 0.296338 (-0.162597) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431505 / 0.215209 (0.216296) | 4.309206 / 2.077655 (2.231551) | 2.174779 / 1.504120 (0.670659) | 1.998122 / 1.541195 (0.456927) | 2.126478 / 1.468490 (0.657988) | 0.528971 / 4.584777 (-4.055806) | 3.797608 / 3.745712 (0.051895) | 1.876275 / 5.269862 (-3.393586) | 1.087458 / 4.565676 (-3.478218) | 0.066940 / 0.424275 (-0.357335) | 0.012432 / 0.007607 (0.004825) | 0.538346 / 0.226044 (0.312301) | 5.370968 / 2.268929 (3.102039) | 2.613718 / 55.444624 (-52.830906) | 2.246585 / 6.876477 (-4.629892) | 2.375695 / 2.142072 (0.233622) | 0.652227 / 4.805227 (-4.153001) | 0.143246 / 6.500664 (-6.357418) | 0.066163 / 0.075469 (-0.009306) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.291263 / 1.841788 (-0.550524) | 16.532281 / 8.074308 (8.457973) | 15.038471 / 10.191392 (4.847079) | 0.168139 / 0.680424 (-0.512285) | 0.017724 / 0.534201 (-0.516477) | 0.391636 / 0.579283 (-0.187648) | 0.429690 / 0.434364 (-0.004674) | 0.474941 / 0.540337 (-0.065396) | 0.579461 / 1.386936 (-0.807475) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006083 / 0.011353 (-0.005269) | 0.004085 / 0.011008 (-0.006923) | 0.098337 / 0.038508 (0.059829) | 0.027573 / 0.023109 (0.004464) | 0.305688 / 0.275898 (0.029790) | 0.341767 / 0.323480 (0.018287) | 0.005143 / 0.007986 (-0.002842) | 0.003396 / 0.004328 (-0.000932) | 0.076925 / 0.004250 (0.072674) | 0.041027 / 0.037052 (0.003975) | 0.307877 / 0.258489 (0.049388) | 0.346559 / 0.293841 (0.052718) | 0.025183 / 0.128546 (-0.103363) | 0.008575 / 0.075646 (-0.067071) | 0.319449 / 0.419271 (-0.099823) | 0.043378 / 0.043533 (-0.000154) | 0.304563 / 0.255139 (0.049424) | 0.332019 / 0.283200 (0.048819) | 0.087725 / 0.141683 (-0.053958) | 1.484904 / 1.452155 (0.032749) | 1.582780 / 1.492716 (0.090064) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.197503 / 0.018006 (0.179497) | 0.410370 / 0.000490 (0.409880) | 0.003840 / 0.000200 (0.003640) | 0.000067 / 0.000054 (0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024179 / 0.037411 (-0.013232) | 0.098876 / 0.014526 (0.084350) | 0.106189 / 0.176557 (-0.070367) | 0.168964 / 0.737135 (-0.568171) | 0.109723 / 0.296338 (-0.186616) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429453 / 0.215209 (0.214244) | 4.295584 / 2.077655 (2.217929) | 2.014330 / 1.504120 (0.510210) | 1.841119 / 1.541195 (0.299924) | 1.928378 / 1.468490 (0.459888) | 0.554571 / 4.584777 (-4.030206) | 3.431769 / 3.745712 (-0.313943) | 1.716204 / 5.269862 (-3.553658) | 0.995054 / 4.565676 (-3.570622) | 0.067374 / 0.424275 (-0.356902) | 0.012557 / 0.007607 (0.004950) | 0.533785 / 0.226044 (0.307740) | 5.363360 / 2.268929 (3.094431) | 2.535190 / 55.444624 (-52.909434) | 2.191646 / 6.876477 (-4.684831) | 2.400799 / 2.142072 (0.258727) | 0.663961 / 4.805227 (-4.141266) | 0.135992 / 6.500664 (-6.364672) | 0.067378 / 0.075469 (-0.008092) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235110 / 1.841788 (-0.606678) | 13.820695 / 8.074308 (5.746387) | 13.667202 / 10.191392 (3.475810) | 0.143025 / 0.680424 (-0.537399) | 0.016757 / 0.534201 (-0.517444) | 0.356262 / 0.579283 (-0.223021) | 0.401871 / 0.434364 (-0.032493) | 0.423928 / 0.540337 (-0.116410) | 0.514598 / 1.386936 (-0.872338) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006260 / 0.011353 (-0.005093) | 0.004159 / 0.011008 (-0.006850) | 0.076780 / 0.038508 (0.038272) | 0.027899 / 0.023109 (0.004789) | 0.412756 / 0.275898 (0.136858) | 0.455145 / 0.323480 (0.131665) | 0.005029 / 0.007986 (-0.002956) | 0.003482 / 0.004328 (-0.000847) | 0.076148 / 0.004250 (0.071898) | 0.038969 / 0.037052 (0.001917) | 0.429975 / 0.258489 (0.171486) | 0.465880 / 0.293841 (0.172039) | 0.025555 / 0.128546 (-0.102991) | 0.008612 / 0.075646 (-0.067034) | 0.082604 / 0.419271 (-0.336667) | 0.039690 / 0.043533 (-0.003842) | 0.403644 / 0.255139 (0.148505) | 0.440438 / 0.283200 (0.157238) | 0.090984 / 0.141683 (-0.050699) | 1.465915 / 1.452155 (0.013760) | 1.564227 / 1.492716 (0.071511) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010502 / 0.018006 (-0.007504) | 0.410573 / 0.000490 (0.410083) | 0.000384 / 0.000200 (0.000184) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025726 / 0.037411 (-0.011686) | 0.101760 / 0.014526 (0.087235) | 0.110102 / 0.176557 (-0.066454) | 0.161321 / 0.737135 (-0.575815) | 0.112507 / 0.296338 (-0.183832) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469925 / 0.215209 (0.254716) | 4.718740 / 2.077655 (2.641085) | 2.466272 / 1.504120 (0.962152) | 2.267357 / 1.541195 (0.726162) | 2.331343 / 1.468490 (0.862853) | 0.553448 / 4.584777 (-4.031329) | 3.464228 / 3.745712 (-0.281484) | 3.060957 / 5.269862 (-2.208905) | 1.387261 / 4.565676 (-3.178415) | 0.067989 / 0.424275 (-0.356286) | 0.012349 / 0.007607 (0.004741) | 0.575046 / 0.226044 (0.349001) | 5.740322 / 2.268929 (3.471394) | 2.925666 / 55.444624 (-52.518958) | 2.606535 / 6.876477 (-4.269942) | 2.658144 / 2.142072 (0.516072) | 0.655157 / 4.805227 (-4.150071) | 0.138520 / 6.500664 (-6.362144) | 0.069442 / 0.075469 (-0.006027) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.306523 / 1.841788 (-0.535265) | 14.400380 / 8.074308 (6.326072) | 14.231519 / 10.191392 (4.040127) | 0.146194 / 0.680424 (-0.534230) | 0.016632 / 0.534201 (-0.517569) | 0.361151 / 0.579283 (-0.218132) | 0.388838 / 0.434364 (-0.045526) | 0.419337 / 0.540337 (-0.121001) | 0.500483 / 1.386936 (-0.886453) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009430 / 0.011353 (-0.001923) | 0.006673 / 0.011008 (-0.004335) | 0.125151 / 0.038508 (0.086643) | 0.038258 / 0.023109 (0.015149) | 0.426383 / 0.275898 (0.150485) | 0.432327 / 0.323480 (0.108847) | 0.006964 / 0.007986 (-0.001022) | 0.005140 / 0.004328 (0.000811) | 0.100767 / 0.004250 (0.096517) | 0.058663 / 0.037052 (0.021610) | 0.424709 / 0.258489 (0.166220) | 0.453049 / 0.293841 (0.159208) | 0.051042 / 0.128546 (-0.077505) | 0.015291 / 0.075646 (-0.060355) | 0.456549 / 0.419271 (0.037278) | 0.067106 / 0.043533 (0.023573) | 0.408959 / 0.255139 (0.153820) | 0.445067 / 0.283200 (0.161867) | 0.115590 / 0.141683 (-0.026092) | 1.929439 / 1.452155 (0.477284) | 2.045709 / 1.492716 (0.552992) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250726 / 0.018006 (0.232720) | 0.598976 / 0.000490 (0.598486) | 0.007542 / 0.000200 (0.007342) | 0.000101 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030317 / 0.037411 (-0.007094) | 0.133177 / 0.014526 (0.118651) | 0.152761 / 0.176557 (-0.023795) | 0.233708 / 0.737135 (-0.503428) | 0.147303 / 0.296338 (-0.149036) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.633562 / 0.215209 (0.418353) | 6.235021 / 2.077655 (4.157366) | 2.652573 / 1.504120 (1.148454) | 2.223363 / 1.541195 (0.682168) | 2.231022 / 1.468490 (0.762531) | 0.942218 / 4.584777 (-3.642559) | 6.068661 / 3.745712 (2.322949) | 2.778604 / 5.269862 (-2.491257) | 1.787939 / 4.565676 (-2.777737) | 0.117749 / 0.424275 (-0.306526) | 0.015613 / 0.007607 (0.008006) | 0.810222 / 0.226044 (0.584177) | 7.931509 / 2.268929 (5.662581) | 3.260679 / 55.444624 (-52.183945) | 2.609085 / 6.876477 (-4.267391) | 2.867838 / 2.142072 (0.725766) | 1.144672 / 4.805227 (-3.660555) | 0.224379 / 6.500664 (-6.276285) | 0.084490 / 0.075469 (0.009021) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.650608 / 1.841788 (-0.191179) | 18.919748 / 8.074308 (10.845440) | 20.163162 / 10.191392 (9.971770) | 0.229427 / 0.680424 (-0.450997) | 0.033090 / 0.534201 (-0.501111) | 0.535549 / 0.579283 (-0.043734) | 0.658629 / 0.434364 (0.224265) | 0.631526 / 0.540337 (0.091189) | 0.748701 / 1.386936 (-0.638235) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009157 / 0.011353 (-0.002196) | 0.006153 / 0.011008 (-0.004856) | 0.106294 / 0.038508 (0.067786) | 0.040947 / 0.023109 (0.017837) | 0.493242 / 0.275898 (0.217344) | 0.563525 / 0.323480 (0.240045) | 0.007256 / 0.007986 (-0.000730) | 0.006757 / 0.004328 (0.002429) | 0.105151 / 0.004250 (0.100901) | 0.056262 / 0.037052 (0.019209) | 0.573341 / 0.258489 (0.314852) | 0.591125 / 0.293841 (0.297284) | 0.047935 / 0.128546 (-0.080611) | 0.015385 / 0.075646 (-0.060262) | 0.119457 / 0.419271 (-0.299814) | 0.066510 / 0.043533 (0.022977) | 0.485622 / 0.255139 (0.230483) | 0.540929 / 0.283200 (0.257730) | 0.132619 / 0.141683 (-0.009064) | 1.916905 / 1.452155 (0.464750) | 2.152722 / 1.492716 (0.660006) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.294823 / 0.018006 (0.276817) | 0.569371 / 0.000490 (0.568882) | 0.000642 / 0.000200 (0.000442) | 0.000091 / 0.000054 (0.000036) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034321 / 0.037411 (-0.003090) | 0.134165 / 0.014526 (0.119639) | 0.157871 / 0.176557 (-0.018685) | 0.210753 / 0.737135 (-0.526382) | 0.152961 / 0.296338 (-0.143377) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.686810 / 0.215209 (0.471601) | 6.890432 / 2.077655 (4.812778) | 3.182875 / 1.504120 (1.678755) | 2.770836 / 1.541195 (1.229641) | 2.790785 / 1.468490 (1.322295) | 0.938145 / 4.584777 (-3.646632) | 5.861093 / 3.745712 (2.115381) | 2.719862 / 5.269862 (-2.550000) | 1.760834 / 4.565676 (-2.804842) | 0.111317 / 0.424275 (-0.312958) | 0.015722 / 0.007607 (0.008115) | 0.863032 / 0.226044 (0.636988) | 8.482433 / 2.268929 (6.213504) | 3.892621 / 55.444624 (-51.552003) | 3.207370 / 6.876477 (-3.669106) | 3.344412 / 2.142072 (1.202339) | 1.133903 / 4.805227 (-3.671324) | 0.223456 / 6.500664 (-6.277209) | 0.084335 / 0.075469 (0.008866) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.794116 / 1.841788 (-0.047672) | 19.077447 / 8.074308 (11.003139) | 23.102309 / 10.191392 (12.910917) | 0.268806 / 0.680424 (-0.411617) | 0.027709 / 0.534201 (-0.506492) | 0.540488 / 0.579283 (-0.038796) | 0.658478 / 0.434364 (0.224114) | 0.604769 / 0.540337 (0.064431) | 0.722768 / 1.386936 (-0.664168) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4159 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4159/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4159/comments | https://api.github.com/repos/huggingface/datasets/issues/4159/events | https://github.com/huggingface/datasets/pull/4159 | 1,202,522,153 | PR_kwDODunzps42Izmd | 4,159 | Add `TruthfulQA` dataset | [] | closed | false | null | 2 | 2022-04-12T23:19:04Z | 2022-06-08T15:51:33Z | 2022-06-08T14:43:34Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4159/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4159/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4159.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4159",
"merged_at": "2022-06-08T14:43:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4159.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4159"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Bump. (I'm not sure which reviewer to `@` but, previously, @lhoestq has been very helpful 🤗 )"
] |
https://api.github.com/repos/huggingface/datasets/issues/3520 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3520/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3520/comments | https://api.github.com/repos/huggingface/datasets/issues/3520/events | https://github.com/huggingface/datasets/pull/3520 | 1,093,747,753 | PR_kwDODunzps4wh6oD | 3,520 | Audio datacard update - first pass | [] | closed | false | null | 2 | 2022-01-04T20:58:25Z | 2022-01-05T12:30:21Z | 2022-01-05T12:30:20Z | null | Filling out data card "Personal and Sensitive Information" for speech datasets to note PII concerns | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3520/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3520/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3520.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3520",
"merged_at": "2022-01-05T12:30:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3520.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3520"
} | true | [
"I'm not sure that we want to change the tags at the top of the cards by hand. Those are used to create the tags in the hub. Although looking at all the tags now, we might want to normalize the current tags again (hyphens or no, \".0\" or no). Maybe we could add a binary tag for public domain or not?",
"> \r\n\r\nThat's a good point, I didn't realize these were auto-populated.\r\nAt the same time, some of them are wrong -- how/where are they auto-populated? Seems like we should fix it at that source for the future.\r\nIn the mean time, I see that \"cc0-1.0\" is the desired tag for public domain, so I will change that for now."
] |
https://api.github.com/repos/huggingface/datasets/issues/5876 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5876/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5876/comments | https://api.github.com/repos/huggingface/datasets/issues/5876/events | https://github.com/huggingface/datasets/issues/5876 | 1,717,978,985 | I_kwDODunzps5mZkdp | 5,876 | Incompatibility with DataLab | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 2 | 2023-05-20T01:39:11Z | 2023-05-25T06:42:34Z | 2023-05-25T06:42:34Z | null | ### Describe the bug
Hello,
I am currently working on a project where both [DataLab](https://github.com/ExpressAI/DataLab) and [datasets](https://github.com/huggingface/datasets) are subdependencies.
I noticed that I cannot import both libraries, as they both register FileSystems in `fsspec`, expecting the FileSystems not being registered before.
When running the code below, I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\__init__.py", line 28, in <module>
from datalabs.arrow_dataset import concatenate_datasets, Dataset
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\arrow_dataset.py", line 60, in <module>
from datalabs.arrow_writer import ArrowWriter, OptimizedTypedSequence
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\arrow_writer.py", line 28, in <module>
from datalabs.features import (
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\features\__init__.py", line 2, in <module>
from datalabs.features.audio import Audio
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\features\audio.py", line 21, in <module>
from datalabs.utils.streaming_download_manager import xopen
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\utils\streaming_download_manager.py", line 16, in <module>
from datalabs.filesystems import COMPRESSION_FILESYSTEMS
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\datalabs\filesystems\__init__.py", line 37, in <module>
fsspec.register_implementation(fs_class.protocol, fs_class)
File "C:\Users\Bened\anaconda3\envs\ner-eval-dashboard2\lib\site-packages\fsspec\registry.py", line 51, in register_implementation
raise ValueError(
ValueError: Name (bz2) already in the registry and clobber is False
```
I think as simple solution would be to just set `clobber=True` in https://github.com/huggingface/datasets/blob/main/src/datasets/filesystems/__init__.py#L28. This allows the register to discard previous registrations. This should work, as the datalabs FileSystems are copies of the datasets FileSystems. However, I don't know if it is guaranteed to be compatible with other libraries that might use the same protocols.
I am linking the symmetric issue on [DataLab](https://github.com/ExpressAI/DataLab/issues/425) as ideally the issue is solved in both libraries the same way. Otherwise, it could lead to different behaviors depending on which library gets imported first.
### Steps to reproduce the bug
1. Run `pip install datalabs==0.4.15 datasets==2.12.0`
2. Run the following python code:
```
import datalabs
import datasets
```
### Expected behavior
It should be possible to import both libraries without getting a Value Error
### Environment info
datalabs==0.4.15
datasets==2.12.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5876/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5876/timeline | null | completed | null | null | false | [
"Indeed, `clobber=True` (with a warning if the existing protocol will be overwritten) should fix the issue, but maybe a better solution is to register our compression filesystem before the script is executed and unregister them afterward. WDYT @lhoestq @albertvillanova?",
"I think we should use clobber and show a warning if it overwrote a registered filesystem indeed ! This way the user can re-register the filesystems if needed. Though they should probably be compatible (and maybe do the exact same thing) so I wouldn't de-register the `datasets` filesystems"
] |
https://api.github.com/repos/huggingface/datasets/issues/2997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2997/comments | https://api.github.com/repos/huggingface/datasets/issues/2997/events | https://github.com/huggingface/datasets/issues/2997 | 1,013,270,069 | I_kwDODunzps48ZUY1 | 2,997 | Dataset has incorrect labels | [] | closed | false | null | 3 | 2021-10-01T12:09:06Z | 2021-10-01T15:32:00Z | 2021-10-01T13:54:34Z | null | The dataset https://huggingface.co/datasets/turkish_product_reviews has incorrect labels - all reviews are labelled with "1" (positive sentiment). None of the reviews is labelled with "0". See screenshot attached:

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2997/timeline | null | completed | null | null | false | [
"Hi @marshmellow77, thanks for reporting.\r\n\r\nThat issue is fixed since `datasets` version 1.9.0 (see 16bc665f2753677c765011ef79c84e55486d4347).\r\n\r\nPlease, update `datasets` with: `pip install -U datasets`",
"Thanks. Please note that the dataset explorer (https://huggingface.co/datasets/viewer/?dataset=turkish_product_reviews) still shows the incorrect state. The sentiment for the first few customer reviews is actually negative and should be labelled with \"0\", see screenshot:\r\n\r\n\r\n\r\n\r\n",
"Thanks @marshmellow77, good catch! I'm transferring this issue to https://github.com/huggingface/datasets-viewer. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3630/comments | https://api.github.com/repos/huggingface/datasets/issues/3630/events | https://github.com/huggingface/datasets/issues/3630 | 1,114,578,625 | I_kwDODunzps5Cbx7B | 3,630 | DuplicatedKeysError of NewsQA dataset | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 1 | 2022-01-26T03:05:49Z | 2022-02-14T08:37:19Z | 2022-02-14T08:37:19Z | null | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/default to /root/.cache/huggingface/datasets/newsqa/default-data_dir=news/1.0.0/b0b23e22d94a3d352ad9d75aff2b71375264a122fae301463079ee8595e05ab9...
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 1084, in _prepare_split
writer.write(example, key)
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 442, in write
self.check_duplicate_keys()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 453, in check_duplicate_keys
raise DuplicatedKeysError(key)
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: ./cnn/stories/6a0f9c8a5d0c6e8949b37924163c92923fe5770d.story
Keys should be unique and deterministic in nature
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/datasets/load.py", line 1694, in load_dataset
builder_instance.download_and_prepare(
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 595, in download_and_prepare
self._download_and_prepare(
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 684, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/usr/local/lib/python3.8/dist-packages/datasets/builder.py", line 1086, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 524, in finalize
self.check_duplicate_keys()
File "/usr/local/lib/python3.8/dist-packages/datasets/arrow_writer.py", line 453, in check_duplicate_keys
raise DuplicatedKeysError(key)
datasets.keyhash.DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: ./cnn/stories/6a0f9c8a5d0c6e8949b37924163c92923fe5770d.story
Keys should be unique and deterministic in nature
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3630/timeline | null | completed | null | null | false | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm fixing it. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3057 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3057/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3057/comments | https://api.github.com/repos/huggingface/datasets/issues/3057/events | https://github.com/huggingface/datasets/issues/3057 | 1,022,508,315 | I_kwDODunzps488j0b | 3,057 | Error in per class precision computation | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-10-11T10:05:19Z | 2021-10-11T10:17:44Z | 2021-10-11T10:16:16Z | null | ## Describe the bug
When trying to get the per class precision values by providing `average=None`, following error is thrown `ValueError: can only convert an array of size 1 to a Python scalar`
## Steps to reproduce the bug
```python
from datasets import load_dataset, load_metric
precision_metric = load_metric("precision")
predictions = [0, 2, 1, 0, 0, 1]
references = [0, 1, 2, 0, 1, 2]
results = precision_metric.compute(predictions=predictions, references=references, average=None)
```
## Expected results
` {'precision': array([0.66666667, 0. , 0. ])}`
as per https://github.com/huggingface/datasets/blob/master/metrics/precision/precision.py
## Actual results
```
output = self._compute(predictions=predictions, references=references, **kwargs)
File "~/.cache/huggingface/modules/datasets_modules/metrics/precision/94709a71c6fe37171ef49d3466fec24dee9a79846c9f176dff66a649e9811690/precision.py", line 110, in _compute
sample_weight=sample_weight,
ValueError: can only convert an array of size 1 to a Python scalar
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: linux
- Python version: 3.6.9
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3057/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3057/timeline | null | completed | null | null | false | [
"Hi @tidhamecha2, thanks for reporting.\r\n\r\nIndeed, we fixed this issue just one week ago: #3008\r\n\r\nThe fix will be included in our next version release.\r\n\r\nIn the meantime, you can incorporate the fix by installing `datasets` from the master branch:\r\n```\r\npip install -U git+ssh://[email protected]/huggingface/datasets.git@master#egg=datasest\r\n```\r\nor\r\n```\r\npip install -U git+https://github.com/huggingface/datasets.git@master#egg=datasets\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/6006 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6006/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6006/comments | https://api.github.com/repos/huggingface/datasets/issues/6006/events | https://github.com/huggingface/datasets/issues/6006 | 1,788,855,582 | I_kwDODunzps5qn8Ue | 6,006 | NotADirectoryError when loading gigawords | [] | closed | false | null | 1 | 2023-07-05T06:23:41Z | 2023-07-05T06:31:02Z | 2023-07-05T06:31:01Z | null | ### Describe the bug
got `NotADirectoryError` whtn loading gigawords dataset
### Steps to reproduce the bug
When running
```
import datasets
datasets.load_dataset('gigaword')
```
Got the following exception:
```bash
Traceback (most recent call last): [0/1862]
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/builder.py", line 1629, in _prepare_split_single
for key, record in generator:
File "/home/x/.cache/huggingface/modules/datasets_modules/datasets/gigaword/ea83a8b819190acac5f2dae011fad51dccf269a0604ec5dd24795b
64efb424b6/gigaword.py", line 115, in _generate_examples
with open(src_path, encoding="utf-8") as f_d, open(tgt_path, encoding="utf-8") as f_s:
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/streaming.py", line 71, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/download/streaming_download_manager.py", line 493, in xope
n
return open(main_hop, mode, *args, **kwargs)
NotADirectoryError: [Errno 20] Not a directory: '/home/x/.cache/huggingface/datasets/downloads/6da52431bb5124d90cf51a0187d2dbee9046e
89780c4be7599794a4f559048ec/org_data/train.src.txt'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "gigaword.py", line 38, in <module>
main()
File "gigaword.py", line 35, in main
train, dev, test = dataset.generate_k_shot_data(k=32, seed=seed, path="../data/")
File "/home/x/MICL/preprocess/fewshot_gym_dataset.py", line 199, in generate_k_shot_data
dataset = self.load_dataset()
File "gigaword.py", line 29, in load_dataset
return datasets.load_dataset('gigaword')
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/load.py", line 1809, in load_dataset
builder_instance.download_and_prepare(
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/builder.py", line 909, in download_and_prepare
self._download_and_prepare(
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/builder.py", line 1670, in _download_and_prepare
super()._download_and_prepare(
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/builder.py", line 1004, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/builder.py", line 1508, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/x/.conda/envs/dataproc/lib/python3.8/site-packages/datasets/builder.py", line 1665, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Expected behavior
Download and process the dataset successfully
### Environment info
- `datasets` version: 2.13.1
- Platform: Linux-5.0.0-1032-azure-x86_64-with-glibc2.10
- Python version: 3.8.0
- Huggingface_hub version: 0.15.1
- PyArrow version: 12.0.1
- Pandas version: 2.0.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6006/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6006/timeline | null | completed | null | null | false | [
"issue due to corrupted download files. resolved after cleaning download cache. sorry for any inconvinence."
] |
https://api.github.com/repos/huggingface/datasets/issues/3341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3341/comments | https://api.github.com/repos/huggingface/datasets/issues/3341/events | https://github.com/huggingface/datasets/issues/3341 | 1,067,449,569 | I_kwDODunzps4_n_zh | 3,341 | Mirror the canonical datasets to the Hugging Face Hub | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2021-11-30T16:42:05Z | 2022-01-26T14:47:37Z | 2022-01-26T14:47:37Z | null | - [ ] create a repo on https://hf.co/datasets for every canonical dataset
- [ ] on every commit related to a dataset, update the hf.co repo
See https://github.com/huggingface/moon-landing/pull/1562
@SBrandeis: I let you edit this description if needed to precise the intent. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3341/timeline | null | completed | null | null | false | [
"I created a GitHub project to keep track of what needs to be done:\r\nhttps://github.com/huggingface/datasets/projects/3\r\n\r\nI also store my code in a (private for now) repository at https://github.com/huggingface/mirror_canonical_datasets_on_hub",
"I understand that the datasets are mirrored on the Hub now, right? Might I close @lhoestq @SBrandeis?"
] |
https://api.github.com/repos/huggingface/datasets/issues/3828 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3828/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3828/comments | https://api.github.com/repos/huggingface/datasets/issues/3828/events | https://github.com/huggingface/datasets/issues/3828 | 1,160,064,029 | I_kwDODunzps5FJSwd | 3,828 | The Pile's _FEATURE spec seems to be incorrect | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-03-04T21:25:32Z | 2022-03-08T09:30:49Z | 2022-03-08T09:30:48Z | null | ## Describe the bug
If you look at https://huggingface.co/datasets/the_pile/blob/main/the_pile.py:
For "all"
* the pile_set_name is never set for data
* there's actually an id field inside of "meta"
For subcorpora pubmed_central and hacker_news:
* the meta is specified to be a string, but it's actually a dict with an id field inside.
## Steps to reproduce the bug
## Expected results
Feature spec should match the data I'd think?
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform:
- Python version:
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3828/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3828/timeline | null | completed | null | null | false | [
"Hi @dlwh, thanks for reporting.\r\n\r\nPlease note, that the source data files for \"all\" config are different from the other configurations.\r\n\r\nThe \"all\" config contains the official Pile data files, from https://mystic.the-eye.eu/public/AI/pile/\r\nAll data examples contain a \"meta\" dict with a single \"pile_set_name\" key:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ds = load_dataset(\"the_pile\", \"all\", split=\"train\", streaming=True)\r\n item = next(iter(ds))\r\nDownloading builder script: 9.09kB [00:00, 4.42MB/s]\r\n\r\nIn [3]: item[\"meta\"]\r\nOut[3]: {'pile_set_name': 'Pile-CC'}\r\n```\r\n\r\nOn the other hand, all the other subset configs data files come from the Pile preliminary components directory: https://mystic.the-eye.eu/public/AI/pile_preliminary_components/\r\nFor theses components, the \"meta\" field may have different keys depending on the subset: \"id\", \"language\", \"pmid\",... Because of that, if we had kept the `dict` data format for the \"meta\" field, we would have an error when trying to concatenate different subsets, whose \"meta\" keys are not identical. In order to avoid that, the \"meta\" field is cast to `str` in all these cases, so that there is no incompatibility in their \"meta\" data type when concatenating.\r\n\r\nYou can check, for example, that for \"pubmed_central\" the \"meta\" field is cast to `str`:\r\n```python\r\nIn [4]: from datasets import load_dataset\r\n ds = load_dataset(\"the_pile\", \"pubmed_central\", split=\"train\", streaming=True)\r\n item = next(iter(ds))\r\n\r\nIn [5]: item[\"meta\"]\r\nOut[5]: \"{'id': 'PMC6071596'}\"\r\n```\r\n\r\nFeel free to reopen this issue if you have further questions. "
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.