
Updating library_name for better snippets and download tracking!
#2
by
reach-vb
HF Staff
- opened
- .gitattributes +1 -0
- README.md +116 -0
- added_tokens.json +24 -0
- config.json +34 -0
- generation_config.json +14 -0
- merges.txt +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +346 -0
- special_tokens_map.json +31 -0
- tokenizer.json +3 -0
- tokenizer_config.json +208 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
datasets:
|
| 4 |
+
- SWE-Gym/SWE-Gym
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
base_model:
|
| 8 |
+
- Qwen/Qwen2.5-Coder-7B-Instruct
|
| 9 |
+
tags:
|
| 10 |
+
- agent
|
| 11 |
+
- coding
|
| 12 |
+
library_name: transformers
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
<div align="center">
|
| 16 |
+
<img src="https://github.com/All-Hands-AI/OpenHands/blob/main/docs/static/img/logo.png?raw=true" alt="Logo" width="200">
|
| 17 |
+
<h1 align="center">OpenHands LM v0.1</h1>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
<a href="https://www.all-hands.dev/blog/introducing-openhands-lm-32b----a-strong-open-coding-agent-model">Blog</a>
|
| 22 |
+
•
|
| 23 |
+
<a href="https://docs.all-hands.dev/modules/usage/llms/local-llms" >Use it in OpenHands</a>
|
| 24 |
+
</p>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
**This is a smaller 7B model trained following the recipe of [all-hands/openhands-lm-32b-v0.1](https://huggingface.co/all-hands/openhands-lm-32b-v0.1).**
|
| 28 |
+
|
| 29 |
+
---
|
| 30 |
+
|
| 31 |
+
Autonomous agents for software development are already contributing to a [wide range of software development tasks](/blog/8-use-cases-for-generalist-software-development-agents).
|
| 32 |
+
But up to this point, strong coding agents have relied on proprietary models, which means that even if you use an open-source agent like [OpenHands](https://github.com/All-Hands-AI/OpenHands), you are still reliant on API calls to an external service.
|
| 33 |
+
|
| 34 |
+
Today, we are excited to introduce OpenHands LM, a new open coding model that:
|
| 35 |
+
|
| 36 |
+
- Is open and [available on Hugging Face](https://huggingface.co/all-hands/openhands-lm-32b-v0.1), so you can download it and run it locally
|
| 37 |
+
- Is a reasonable size, 32B, so it can be run locally on hardware such as a single 3090 GPU
|
| 38 |
+
- Achieves strong performance on software engineering tasks, including 37.2% resolve rate on SWE-Bench Verified
|
| 39 |
+
|
| 40 |
+
Read below for more details and our future plans!
|
| 41 |
+
|
| 42 |
+
## What is OpenHands LM?
|
| 43 |
+
|
| 44 |
+
OpenHands LM is built on the foundation of [Qwen Coder 2.5 Instruct 32B](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct), leveraging its powerful base capabilities for coding tasks. What sets OpenHands LM apart is our specialized fine-tuning process:
|
| 45 |
+
|
| 46 |
+
- We used training data generated by OpenHands itself on a diverse set of open-source repositories
|
| 47 |
+
- Specifically, we use an RL-based framework outlined in [SWE-Gym](https://arxiv.org/abs/2412.21139), where we set up a training environment, generate training data using an existing agent, and then fine-tune the model on examples that were resolved successfully
|
| 48 |
+
- It features a 128K token context window, ideal for handling large codebases and long-horizon software engineering tasks
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Performance: Punching Above Its Weight
|
| 52 |
+
|
| 53 |
+
We evaluated OpenHands LM using our latest [iterative evaluation protocol](https://github.com/All-Hands-AI/OpenHands/tree/main/evaluation/benchmarks/swe_bench#run-inference-rollout-on-swe-bench-instances-generate-patch-from-problem-statement) on the [SWE-Bench Verified benchmark](https://www.swebench.com/#verified).
|
| 54 |
+
|
| 55 |
+
The results are impressive:
|
| 56 |
+
|
| 57 |
+
- **37.2% verified resolve rate** on SWE-Bench Verified
|
| 58 |
+
- Performance comparable to models with **20x more parameters**, including Deepseek V3 0324 (38.8%) with 671B parameters
|
| 59 |
+
|
| 60 |
+
Here's how OpenHands LM compares to other leading open-source models:
|
| 61 |
+
|
| 62 |
+
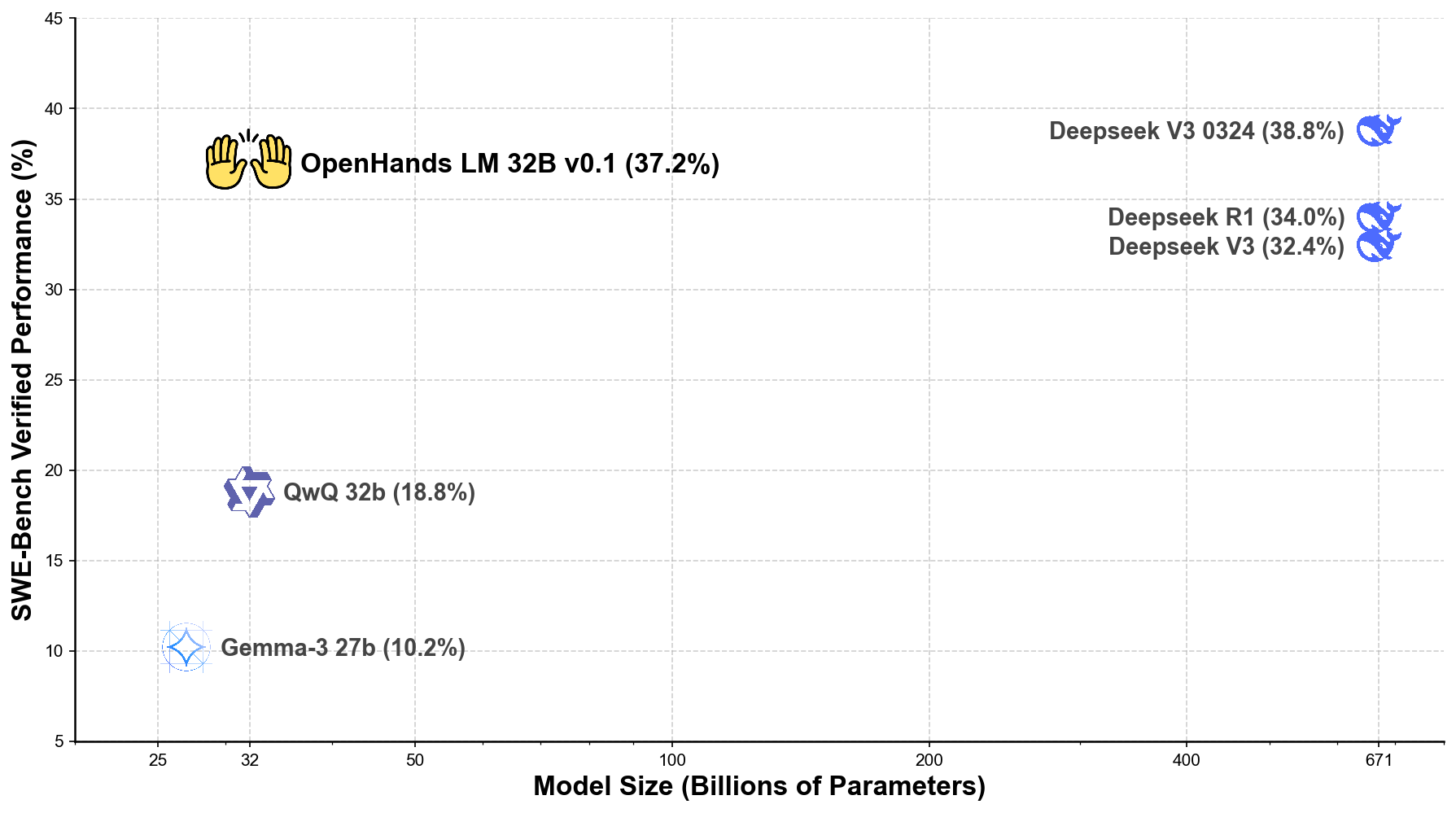
|
| 63 |
+
|
| 64 |
+
As the plot demonstrates, our 32B parameter model achieves efficiency that approaches much larger models. While the largest models (671B parameters) achieve slightly higher scores, our 32B parameter model performs remarkably well, opening up possibilities for local deployment that are not possible with larger models.
|
| 65 |
+
|
| 66 |
+
## Getting Started: How to Use OpenHands LM Today
|
| 67 |
+
|
| 68 |
+
You can start using OpenHands LM immediately through these channels:
|
| 69 |
+
|
| 70 |
+
1. **Download the model from Hugging Face**
|
| 71 |
+
The model is available on [Hugging Face](https://huggingface.co/all-hands/openhands-lm-32b-v0.1) and can be downloaded directly from there.
|
| 72 |
+
|
| 73 |
+
2. **Create an OpenAI-compatible endpoint with a model serving framework**
|
| 74 |
+
For optimal performance, it is recommended to serve this model with a GPU using [SGLang](https://github.com/sgl-project/sglang) or [vLLM](https://github.com/vllm-project/vllm).
|
| 75 |
+
|
| 76 |
+
3. **Point your OpenHands agent to the new model**
|
| 77 |
+
Download [OpenHands](https://github.com/All-Hands-AI/OpenHands) and follow the instructions for [using an OpenAI-compatible endpoint](https://docs.all-hands.dev/modules/usage/llms/openai-llms#using-openai-compatible-endpoints).
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## The Road Ahead: Our Development Plans
|
| 81 |
+
|
| 82 |
+
This initial release marks just the beginning of our journey. We will continue enhancing OpenHands LM based on community feedback and ongoing research initiatives.
|
| 83 |
+
|
| 84 |
+
In particular, it should be noted that the model is still a research preview, and (1) may be best suited for tasks regarding solving github issues and perform less well on more varied software engineering tasks, (2) may sometimes generate repetitive steps, and (3) is somewhat sensitive to quantization, and may not function at full performance at lower quantization levels.
|
| 85 |
+
Our next releases will focus on addressing these limitations.
|
| 86 |
+
|
| 87 |
+
We're also developing more compact versions of the model (including a 7B parameter variant) to support users with limited computational resources. These smaller models will preserve OpenHands LM's core strengths while dramatically reducing hardware requirements.
|
| 88 |
+
|
| 89 |
+
We encourage you to experiment with OpenHands LM, share your experiences, and participate in its evolution. Together, we can create better tools for tomorrow's software development landscape.
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
## Try OpenHands Cloud
|
| 93 |
+
|
| 94 |
+
While OpenHands LM is a powerful model you can run locally, we also offer a fully managed cloud solution that makes it even easier to leverage AI for your software development needs.
|
| 95 |
+
|
| 96 |
+
[OpenHands Cloud](https://www.all-hands.dev/blog/introducing-the-openhands-cloud) provides:
|
| 97 |
+
|
| 98 |
+
- Seamless GitHub integration with issue and PR support
|
| 99 |
+
- Multiple interaction methods including text, voice, and mobile
|
| 100 |
+
- Parallel agent capabilities for working on multiple tasks simultaneously
|
| 101 |
+
- All the power of OpenHands without managing infrastructure
|
| 102 |
+
|
| 103 |
+
OpenHands Cloud is built on the same technology as our open-source solution but adds convenient features for teams and individuals who want a ready-to-use platform. [Visit app.all-hands.dev](https://app.all-hands.dev) to get started today!
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
## Join Our Community
|
| 107 |
+
|
| 108 |
+
We invite you to be part of the OpenHands LM journey:
|
| 109 |
+
|
| 110 |
+
- Explore our [GitHub repository](https://github.com/All-Hands-AI/OpenHands)
|
| 111 |
+
- Connect with us on [Slack](https://join.slack.com/t/openhands-ai/shared_invite/zt-2tom0er4l-JeNUGHt_AxpEfIBstbLPiw)
|
| 112 |
+
- Follow our [documentation](https://docs.all-hands.dev) to get started
|
| 113 |
+
|
| 114 |
+
By contributing your experiences and feedback, you'll help shape the future of this open-source initiative. Together, we can create better tools for tomorrow's software development landscape.
|
| 115 |
+
|
| 116 |
+
We can't wait to see what you'll create with OpenHands LM!
|
added_tokens.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</tool_call>": 151658,
|
| 3 |
+
"<tool_call>": 151657,
|
| 4 |
+
"<|box_end|>": 151649,
|
| 5 |
+
"<|box_start|>": 151648,
|
| 6 |
+
"<|endoftext|>": 151643,
|
| 7 |
+
"<|file_sep|>": 151664,
|
| 8 |
+
"<|fim_middle|>": 151660,
|
| 9 |
+
"<|fim_pad|>": 151662,
|
| 10 |
+
"<|fim_prefix|>": 151659,
|
| 11 |
+
"<|fim_suffix|>": 151661,
|
| 12 |
+
"<|im_end|>": 151645,
|
| 13 |
+
"<|im_start|>": 151644,
|
| 14 |
+
"<|image_pad|>": 151655,
|
| 15 |
+
"<|object_ref_end|>": 151647,
|
| 16 |
+
"<|object_ref_start|>": 151646,
|
| 17 |
+
"<|quad_end|>": 151651,
|
| 18 |
+
"<|quad_start|>": 151650,
|
| 19 |
+
"<|repo_name|>": 151663,
|
| 20 |
+
"<|video_pad|>": 151656,
|
| 21 |
+
"<|vision_end|>": 151653,
|
| 22 |
+
"<|vision_pad|>": 151654,
|
| 23 |
+
"<|vision_start|>": 151652
|
| 24 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/mnt/fs/code/research/data/verl-models/agent-llm/agentllm-qwen25-coder-7bi-2025-03-11-sonnet3.7-3.5-swegym-3468i-v1p1prompt-policy_traj_128k_3468i-fullparam-1e-cp131072ctx-1e-5lr-wsdlrsch/global_step_420",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151645,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 3584,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 18944,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"max_window_layers": 28,
|
| 15 |
+
"model_type": "qwen2",
|
| 16 |
+
"num_attention_heads": 28,
|
| 17 |
+
"num_hidden_layers": 28,
|
| 18 |
+
"num_key_value_heads": 4,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"rope_scaling": {
|
| 21 |
+
"factor": 4.0,
|
| 22 |
+
"original_max_position_embeddings": 32768,
|
| 23 |
+
"rope_type": "yarn",
|
| 24 |
+
"type": "yarn"
|
| 25 |
+
},
|
| 26 |
+
"rope_theta": 1000000.0,
|
| 27 |
+
"sliding_window": null,
|
| 28 |
+
"tie_word_embeddings": false,
|
| 29 |
+
"torch_dtype": "bfloat16",
|
| 30 |
+
"transformers_version": "4.47.1",
|
| 31 |
+
"use_cache": true,
|
| 32 |
+
"use_sliding_window": false,
|
| 33 |
+
"vocab_size": 152064
|
| 34 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151643,
|
| 9 |
+
"repetition_penalty": 1.1,
|
| 10 |
+
"temperature": 0.7,
|
| 11 |
+
"top_k": 20,
|
| 12 |
+
"top_p": 0.8,
|
| 13 |
+
"transformers_version": "4.47.1"
|
| 14 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0a7da683fe5d3fb4c17d6e34775486efdafad25b219204dcdc5ab85bc1395891
|
| 3 |
+
size 4877660776
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:66641a1b025f8fa4724390ac167bde34f10d3876014e82ae372948ecb2a9625b
|
| 3 |
+
size 4932751008
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:de0bcfe94ed6f52b9f912417a11ebc290100de9a8cd3e7abc6a6b4956104706d
|
| 3 |
+
size 4330865200
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bb0af8a8110edd7d0679ab401eb7b57a935ab2ea1df306a822240ba54e3fe40c
|
| 3 |
+
size 1089994880
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,346 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 15231233024
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 29 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 31 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 32 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 38 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 41 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 43 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 50 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 53 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 55 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 62 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 65 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 67 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"model.layers.13.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 74 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"model.layers.13.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 77 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"model.layers.13.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 79 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"model.layers.14.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 86 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"model.layers.14.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 89 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"model.layers.14.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 91 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"model.layers.15.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 98 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"model.layers.15.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 101 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"model.layers.15.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 103 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"model.layers.16.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 110 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"model.layers.16.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 113 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"model.layers.16.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 115 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 117 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 118 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 119 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 120 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 121 |
+
"model.layers.17.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 122 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 123 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 124 |
+
"model.layers.17.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 125 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 126 |
+
"model.layers.17.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 127 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 129 |
+
"model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 133 |
+
"model.layers.18.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 134 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 135 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 136 |
+
"model.layers.18.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 137 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 138 |
+
"model.layers.18.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 139 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 140 |
+
"model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 141 |
+
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"model.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 146 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"model.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 149 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"model.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 151 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 152 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 153 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 154 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 155 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 156 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 157 |
+
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 158 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 159 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 160 |
+
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 161 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 162 |
+
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 163 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 164 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"model.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 170 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"model.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 173 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"model.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 175 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"model.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 182 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"model.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 185 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"model.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 187 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"model.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 194 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"model.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 197 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"model.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 199 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"model.layers.23.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 206 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"model.layers.23.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 209 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"model.layers.23.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 211 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"model.layers.24.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 218 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"model.layers.24.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 221 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"model.layers.24.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 223 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"model.layers.25.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 230 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"model.layers.25.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 233 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"model.layers.25.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 235 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"model.layers.26.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 242 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"model.layers.26.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 245 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"model.layers.26.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 247 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 249 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 250 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 251 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 252 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 253 |
+
"model.layers.27.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 254 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 255 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 256 |
+
"model.layers.27.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 257 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 258 |
+
"model.layers.27.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 259 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 260 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 266 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 269 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 271 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 274 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 276 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 277 |
+
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 278 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 280 |
+
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 281 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 282 |
+
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 283 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 284 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 285 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 286 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 288 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 289 |
+
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 290 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 291 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 292 |
+
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 293 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 294 |
+
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 295 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 296 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 297 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 298 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 299 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 300 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 301 |
+
"model.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 302 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 303 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 304 |
+
"model.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 305 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 306 |
+
"model.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 307 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 308 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 309 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 310 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 311 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 312 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 313 |
+
"model.layers.7.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 314 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 315 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 316 |
+
"model.layers.7.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 317 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 318 |
+
"model.layers.7.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 319 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 320 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 321 |
+
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 322 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 323 |
+
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 324 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 325 |
+
"model.layers.8.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 326 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 327 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 328 |
+
"model.layers.8.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 329 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 330 |
+
"model.layers.8.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 331 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 332 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 333 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 334 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 335 |
+
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 336 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 337 |
+
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 338 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 339 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 340 |
+
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 341 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 342 |
+
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 343 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 344 |
+
"model.norm.weight": "model-00003-of-00004.safetensors"
|
| 345 |
+
}
|
| 346 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c5ae00e602b8860cbd784ba82a8aa14e8feecec692e7076590d014d7b7fdafa
|
| 3 |
+
size 11421896
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 199 |
+
"clean_up_tokenization_spaces": false,
|
| 200 |
+
"eos_token": "<|im_end|>",
|
| 201 |
+
"errors": "replace",
|
| 202 |
+
"extra_special_tokens": {},
|
| 203 |
+
"model_max_length": 131072,
|
| 204 |
+
"pad_token": "<|endoftext|>",
|
| 205 |
+
"split_special_tokens": false,
|
| 206 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 207 |
+
"unk_token": null
|
| 208 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|