
A large fine-tuned model in the field of pedestrian re-identification
Introduction
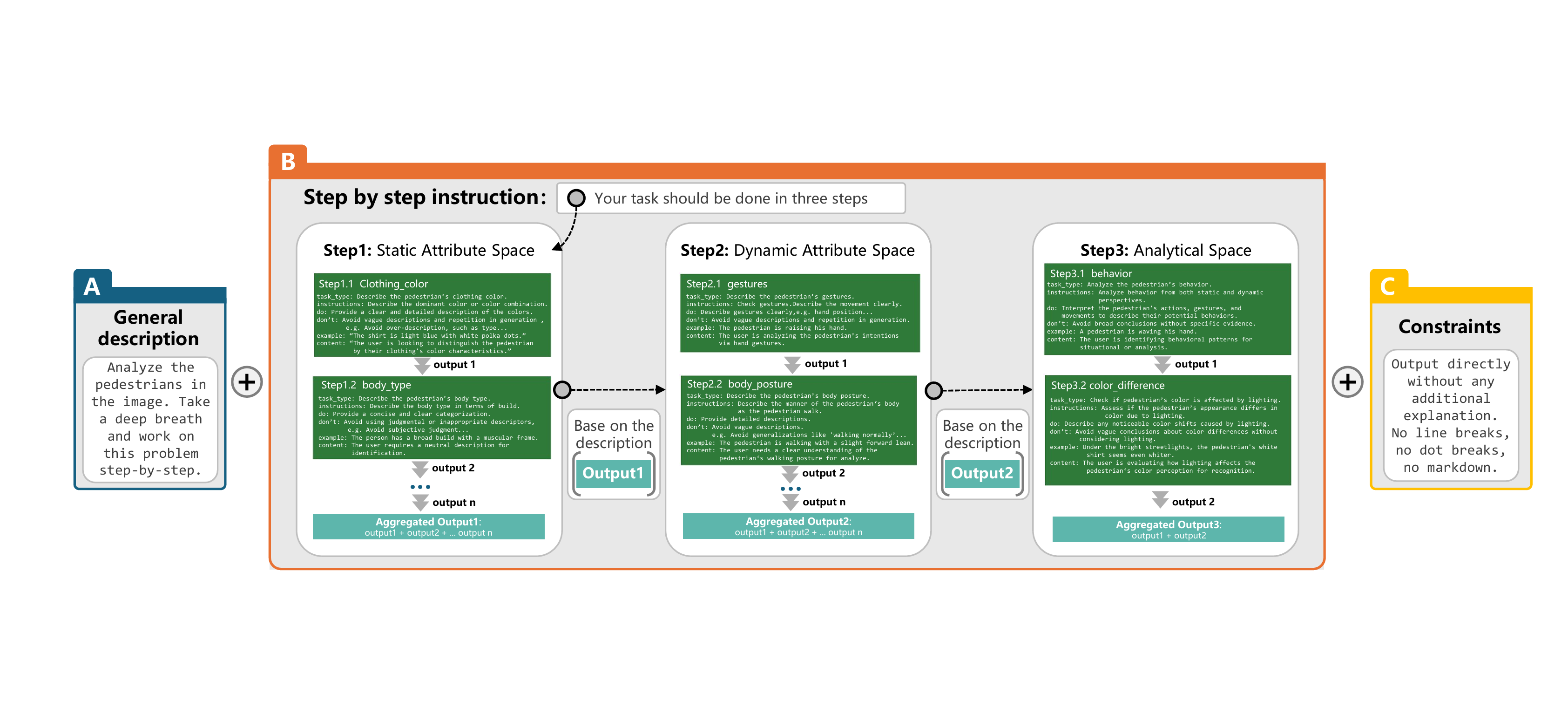
By integrating domain expert knowledge, PromptChain, and TIDD-EC, a pedestrian image semantic annotation generation framework was constructed. Based on this framework, we obtained a fine-grained pedestrian image semantic annotation dataset (see the DataSet_ReID folder in the repository). Using Qwen2-VL as the base model, we fine-tuned this dataset to obtain a large fine-tuned model in the field of pedestrian re-identification(see the Model_Qwen2-VL-tune folder in the repository), used for outputting fine-grained pedestrian image descriptions.
The Original Dataset
The Market-1501 dataset was collected on the Tsinghua University campus, filmed in the summer, and was constructed and made publicly available in 2015. It includes 1,501 pedestrians and 32,668 detected pedestrian bounding boxes captured by 6 cameras (5 high-definition cameras and 1 low-definition camera). Each pedestrian is captured by at least 2 cameras, and multiple images of the same person may be available from a single camera. The training set contains 751 individuals, with 12,936 images, averaging 17.2 images per person for training; the test set contains 750 individuals, with 19,732 images, averaging 26.3 images per person for testing. The 3,368 query images' pedestrian bounding boxes are manually annotated, while the bounding boxes in the gallery are detected using a DPM detector. The dataset provides a fixed number of training and test sets, which can be used in both single-shot and multi-shot test settings.