Spaces:
Running

Running

Update README.md
Browse files
README.md
CHANGED
|
@@ -7,4 +7,34 @@ sdk: static
|
|
| 7 |
pinned: false
|
| 8 |
---
|
| 9 |
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
pinned: false
|
| 8 |
---
|
| 9 |
|
| 10 |
+
<h1 align="center"> Learning Adaptive Reasoning Search in Language </h1>
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
<a href="https://www.jiayipan.com/" style="text-decoration: none;">Jiayi Pan</a><sup>*</sup>,
|
| 14 |
+
<a href="https://xiuyuli.com/" style="text-decoration: none;">Xiuyu Li</a><sup>*</sup>,
|
| 15 |
+
<a href="https://tonylian.com/" style="text-decoration: none;">Long Lian</a><sup>*</sup>,
|
| 16 |
+
<a href="https://sea-snell.github.io/" style="text-decoration: none;">Charlie Victor Snell</a>,
|
| 17 |
+
<a href="https://yifeizhou02.github.io/" style="text-decoration: none;">Yifei Zhou</a>,<br>
|
| 18 |
+
<a href="https://www.adamyala.org/" style="text-decoration: none;">Adam Yala</a>,
|
| 19 |
+
<a href="https://people.eecs.berkeley.edu/~trevor/" style="text-decoration: none;">Trevor Darrell</a>,
|
| 20 |
+
<a href="https://people.eecs.berkeley.edu/~keutzer/" style="text-decoration: none;">Kurt Keutzer</a>,
|
| 21 |
+
<a href="https://www.alanesuhr.com/" style="text-decoration: none;">Alane Suhr</a>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
<p align="center">
|
| 25 |
+
UC Berkeley and UCSF <sup>*</sup> Equal Contribution
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
<p align="center">
|
| 29 |
+
<a href="TODO">📃 Paper</a>
|
| 30 |
+
•
|
| 31 |
+
<a href="https://huggingface.co/Parallel-Reasoning" >🤗 Data & Models</a>
|
| 32 |
+
</p>
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
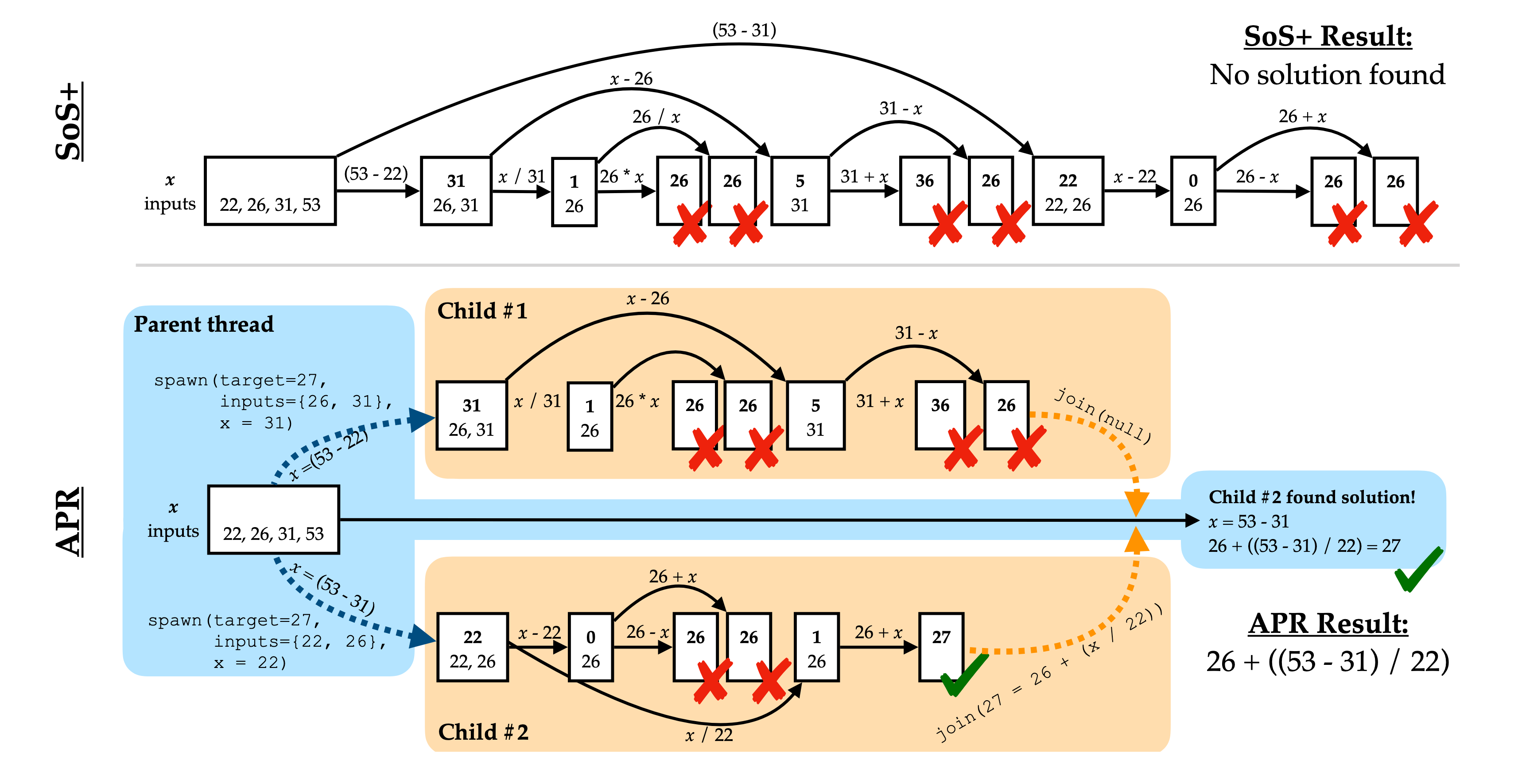
**TL;DR**:
|
| 39 |
+
We present Adaptive Parallel Reasoning (APR), a novel framework that enables language models to learn to orchestrate both serialized and parallel computations. APR trains language models to use `spawn()` and `join()` operations through end-to-end supervised training and reinforcement learning, allowing models to dynamically orchestrate their own computational workflows.
|
| 40 |
+
APR efficiently distributes compute, reduces latency, overcomes context window limits, and achieves state‑of‑the‑art performance on complex reasoning tasks (e.g., 83.4% vs. 60.0% accuracy at 4K context on Countdown).
|