
Upload 4 files
Browse files- .gitattributes +1 -0
- README (2).md +52 -0
- config.py +248 -0
- gitattributes +31 -0
- pytorch_model.pth +3 -0
.gitattributes
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
pytorch_model.pth filter=lfs diff=lfs merge=lfs -text
|
README (2).md
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Hugging Face's logo
|
| 2 |
+
---
|
| 3 |
+
tags:
|
| 4 |
+
- object-detection
|
| 5 |
+
- vision
|
| 6 |
+
library_name: mask_rcnn
|
| 7 |
+
datasets:
|
| 8 |
+
- coco
|
| 9 |
+
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# Mask R-CNN
|
| 14 |
+
|
| 15 |
+
## Model desription
|
| 16 |
+
|
| 17 |
+
Mask R-CNN is a model that extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. The model locates pixels of images instead of just bounding boxes as Faster R-CNN was not designed for pixel-to-pixel alignment between network inputs and outputs.
|
| 18 |
+
|
| 19 |
+
*This Model is based on the Pretrained model from [OpenMMlab](https://github.com/open-mmlab/mmdetection)*
|
| 20 |
+
|
| 21 |
+
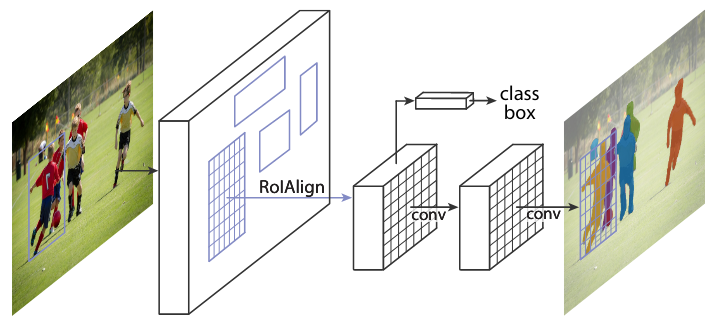
|
| 22 |
+
|
| 23 |
+
### More information on the model and dataset:
|
| 24 |
+
|
| 25 |
+
#### The model
|
| 26 |
+
Mask R-CNN works towards the approach of instance segmentation, which involves object detection, and semantic segmentation. For object detection, Mask R-CNN uses an architecture that is similar to Faster R-CNN, while it uses a Fully Convolutional Network(FCN) for semantic segmentation.
|
| 27 |
+
The FCN is added to the top of features of a Faster R-CNN to generate a mask segmentation output. This segmentation output is in parallel with the classification and bounding box regressor network of the Faster R-CNN model. From the advancement of Fast R-CNN Region of Interest Pooling(ROI), Mask R-CNN adds refinement called ROI aligning by addressing the loss and misalignment of ROI Pooling; the new ROI aligned leads to improved results.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
#### Datasets
|
| 31 |
+
[COCO Datasets](https://cocodataset.org/#home)
|
| 32 |
+
|
| 33 |
+
## Training Procedure
|
| 34 |
+
Please [read the paper](https://arxiv.org/pdf/1703.06870.pdf) for more information on training, or check OpenMMLab [repository](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn)
|
| 35 |
+
|
| 36 |
+
The model architecture is divided into two parts:
|
| 37 |
+
- Region proposal network (RPN) to propose candidate object bounding boxes.
|
| 38 |
+
- Binary mask classifier to generate a mask for every class
|
| 39 |
+
|
| 40 |
+
#### Technical Summary.
|
| 41 |
+
- Mask R-CNN is quite similar to the structure of faster R-CNN.
|
| 42 |
+
- Outputs a binary mask for each Region of Interest.
|
| 43 |
+
- Applies bounding-box classification and regression in parallel, simplifying the original R-CNN's multi-stage pipeline.
|
| 44 |
+
- The network architectures utilized are called ResNet and ResNeXt. The depth can be either 50 or 101
|
| 45 |
+
|
| 46 |
+
#### Results Summary
|
| 47 |
+
- Instance Segmentation: Based on the COCO dataset, Mask R-CNN outperforms all categories compared to MNC and FCIS, which are state-of-the-art models.
|
| 48 |
+
- Bounding Box Detection: Mask R-CNN outperforms the base variants of all previous state-of-the-art models, including the COCO 2016 Detection Challenge winner.
|
| 49 |
+
|
| 50 |
+
## Intended uses & limitations
|
| 51 |
+
The identification of object relationships and the context of objects in a picture are both aided by image segmentation. Some of the applications include face recognition, number plate recognition, and satellite image analysis. With great model generality, Mask RCNN can be extended to human pose estimation; it can be used to estimate on-site approaching live traffic to aid autonomous driving.
|
| 52 |
+
|
config.py
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='MaskRCNN',
|
| 3 |
+
backbone=dict(
|
| 4 |
+
type='ResNeXt',
|
| 5 |
+
depth=101,
|
| 6 |
+
num_stages=4,
|
| 7 |
+
out_indices=(0, 1, 2, 3),
|
| 8 |
+
frozen_stages=1,
|
| 9 |
+
norm_cfg=dict(type='BN', requires_grad=True),
|
| 10 |
+
norm_eval=True,
|
| 11 |
+
style='pytorch',
|
| 12 |
+
init_cfg=dict(
|
| 13 |
+
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d'),
|
| 14 |
+
groups=64,
|
| 15 |
+
base_width=4),
|
| 16 |
+
neck=dict(
|
| 17 |
+
type='FPN',
|
| 18 |
+
in_channels=[256, 512, 1024, 2048],
|
| 19 |
+
out_channels=256,
|
| 20 |
+
num_outs=5),
|
| 21 |
+
rpn_head=dict(
|
| 22 |
+
type='RPNHead',
|
| 23 |
+
in_channels=256,
|
| 24 |
+
feat_channels=256,
|
| 25 |
+
anchor_generator=dict(
|
| 26 |
+
type='AnchorGenerator',
|
| 27 |
+
scales=[8],
|
| 28 |
+
ratios=[0.5, 1.0, 2.0],
|
| 29 |
+
strides=[4, 8, 16, 32, 64]),
|
| 30 |
+
bbox_coder=dict(
|
| 31 |
+
type='DeltaXYWHBBoxCoder',
|
| 32 |
+
target_means=[0.0, 0.0, 0.0, 0.0],
|
| 33 |
+
target_stds=[1.0, 1.0, 1.0, 1.0]),
|
| 34 |
+
loss_cls=dict(
|
| 35 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
| 36 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
| 37 |
+
roi_head=dict(
|
| 38 |
+
type='StandardRoIHead',
|
| 39 |
+
bbox_roi_extractor=dict(
|
| 40 |
+
type='SingleRoIExtractor',
|
| 41 |
+
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
|
| 42 |
+
out_channels=256,
|
| 43 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 44 |
+
bbox_head=dict(
|
| 45 |
+
type='Shared2FCBBoxHead',
|
| 46 |
+
in_channels=256,
|
| 47 |
+
fc_out_channels=1024,
|
| 48 |
+
roi_feat_size=7,
|
| 49 |
+
num_classes=80,
|
| 50 |
+
bbox_coder=dict(
|
| 51 |
+
type='DeltaXYWHBBoxCoder',
|
| 52 |
+
target_means=[0.0, 0.0, 0.0, 0.0],
|
| 53 |
+
target_stds=[0.1, 0.1, 0.2, 0.2]),
|
| 54 |
+
reg_class_agnostic=False,
|
| 55 |
+
loss_cls=dict(
|
| 56 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
| 57 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
| 58 |
+
mask_roi_extractor=dict(
|
| 59 |
+
type='SingleRoIExtractor',
|
| 60 |
+
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
|
| 61 |
+
out_channels=256,
|
| 62 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 63 |
+
mask_head=dict(
|
| 64 |
+
type='FCNMaskHead',
|
| 65 |
+
num_convs=4,
|
| 66 |
+
in_channels=256,
|
| 67 |
+
conv_out_channels=256,
|
| 68 |
+
num_classes=80,
|
| 69 |
+
loss_mask=dict(
|
| 70 |
+
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
|
| 71 |
+
train_cfg=dict(
|
| 72 |
+
rpn=dict(
|
| 73 |
+
assigner=dict(
|
| 74 |
+
type='MaxIoUAssigner',
|
| 75 |
+
pos_iou_thr=0.7,
|
| 76 |
+
neg_iou_thr=0.3,
|
| 77 |
+
min_pos_iou=0.3,
|
| 78 |
+
match_low_quality=True,
|
| 79 |
+
ignore_iof_thr=-1),
|
| 80 |
+
sampler=dict(
|
| 81 |
+
type='RandomSampler',
|
| 82 |
+
num=256,
|
| 83 |
+
pos_fraction=0.5,
|
| 84 |
+
neg_pos_ub=-1,
|
| 85 |
+
add_gt_as_proposals=False),
|
| 86 |
+
allowed_border=-1,
|
| 87 |
+
pos_weight=-1,
|
| 88 |
+
debug=False),
|
| 89 |
+
rpn_proposal=dict(
|
| 90 |
+
nms_pre=2000,
|
| 91 |
+
max_per_img=1000,
|
| 92 |
+
nms=dict(type='nms', iou_threshold=0.7),
|
| 93 |
+
min_bbox_size=0),
|
| 94 |
+
rcnn=dict(
|
| 95 |
+
assigner=dict(
|
| 96 |
+
type='MaxIoUAssigner',
|
| 97 |
+
pos_iou_thr=0.5,
|
| 98 |
+
neg_iou_thr=0.5,
|
| 99 |
+
min_pos_iou=0.5,
|
| 100 |
+
match_low_quality=True,
|
| 101 |
+
ignore_iof_thr=-1),
|
| 102 |
+
sampler=dict(
|
| 103 |
+
type='RandomSampler',
|
| 104 |
+
num=512,
|
| 105 |
+
pos_fraction=0.25,
|
| 106 |
+
neg_pos_ub=-1,
|
| 107 |
+
add_gt_as_proposals=True),
|
| 108 |
+
mask_size=28,
|
| 109 |
+
pos_weight=-1,
|
| 110 |
+
debug=False)),
|
| 111 |
+
test_cfg=dict(
|
| 112 |
+
rpn=dict(
|
| 113 |
+
nms_pre=1000,
|
| 114 |
+
max_per_img=1000,
|
| 115 |
+
nms=dict(type='nms', iou_threshold=0.7),
|
| 116 |
+
min_bbox_size=0),
|
| 117 |
+
rcnn=dict(
|
| 118 |
+
score_thr=0.05,
|
| 119 |
+
nms=dict(type='nms', iou_threshold=0.5),
|
| 120 |
+
max_per_img=100,
|
| 121 |
+
mask_thr_binary=0.5)))
|
| 122 |
+
dataset_type = 'CocoDataset'
|
| 123 |
+
data_root = 'data/coco/'
|
| 124 |
+
img_norm_cfg = dict(
|
| 125 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 126 |
+
train_pipeline = [
|
| 127 |
+
dict(type='LoadImageFromFile'),
|
| 128 |
+
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
|
| 129 |
+
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
|
| 130 |
+
dict(type='RandomFlip', flip_ratio=0.5),
|
| 131 |
+
dict(
|
| 132 |
+
type='Normalize',
|
| 133 |
+
mean=[123.675, 116.28, 103.53],
|
| 134 |
+
std=[58.395, 57.12, 57.375],
|
| 135 |
+
to_rgb=True),
|
| 136 |
+
dict(type='Pad', size_divisor=32),
|
| 137 |
+
dict(type='DefaultFormatBundle'),
|
| 138 |
+
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
|
| 139 |
+
]
|
| 140 |
+
test_pipeline = [
|
| 141 |
+
dict(type='LoadImageFromFile'),
|
| 142 |
+
dict(
|
| 143 |
+
type='MultiScaleFlipAug',
|
| 144 |
+
img_scale=(1333, 800),
|
| 145 |
+
flip=False,
|
| 146 |
+
transforms=[
|
| 147 |
+
dict(type='Resize', keep_ratio=True),
|
| 148 |
+
dict(type='RandomFlip'),
|
| 149 |
+
dict(
|
| 150 |
+
type='Normalize',
|
| 151 |
+
mean=[123.675, 116.28, 103.53],
|
| 152 |
+
std=[58.395, 57.12, 57.375],
|
| 153 |
+
to_rgb=True),
|
| 154 |
+
dict(type='Pad', size_divisor=32),
|
| 155 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 156 |
+
dict(type='Collect', keys=['img'])
|
| 157 |
+
])
|
| 158 |
+
]
|
| 159 |
+
data = dict(
|
| 160 |
+
samples_per_gpu=2,
|
| 161 |
+
workers_per_gpu=2,
|
| 162 |
+
train=dict(
|
| 163 |
+
type='CocoDataset',
|
| 164 |
+
ann_file='data/coco/annotations/instances_train2017.json',
|
| 165 |
+
img_prefix='data/coco/train2017/',
|
| 166 |
+
pipeline=[
|
| 167 |
+
dict(type='LoadImageFromFile'),
|
| 168 |
+
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
|
| 169 |
+
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
|
| 170 |
+
dict(type='RandomFlip', flip_ratio=0.5),
|
| 171 |
+
dict(
|
| 172 |
+
type='Normalize',
|
| 173 |
+
mean=[123.675, 116.28, 103.53],
|
| 174 |
+
std=[58.395, 57.12, 57.375],
|
| 175 |
+
to_rgb=True),
|
| 176 |
+
dict(type='Pad', size_divisor=32),
|
| 177 |
+
dict(type='DefaultFormatBundle'),
|
| 178 |
+
dict(
|
| 179 |
+
type='Collect',
|
| 180 |
+
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
|
| 181 |
+
]),
|
| 182 |
+
val=dict(
|
| 183 |
+
type='CocoDataset',
|
| 184 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 185 |
+
img_prefix='data/coco/val2017/',
|
| 186 |
+
pipeline=[
|
| 187 |
+
dict(type='LoadImageFromFile'),
|
| 188 |
+
dict(
|
| 189 |
+
type='MultiScaleFlipAug',
|
| 190 |
+
img_scale=(1333, 800),
|
| 191 |
+
flip=False,
|
| 192 |
+
transforms=[
|
| 193 |
+
dict(type='Resize', keep_ratio=True),
|
| 194 |
+
dict(type='RandomFlip'),
|
| 195 |
+
dict(
|
| 196 |
+
type='Normalize',
|
| 197 |
+
mean=[123.675, 116.28, 103.53],
|
| 198 |
+
std=[58.395, 57.12, 57.375],
|
| 199 |
+
to_rgb=True),
|
| 200 |
+
dict(type='Pad', size_divisor=32),
|
| 201 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 202 |
+
dict(type='Collect', keys=['img'])
|
| 203 |
+
])
|
| 204 |
+
]),
|
| 205 |
+
test=dict(
|
| 206 |
+
type='CocoDataset',
|
| 207 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 208 |
+
img_prefix='data/coco/val2017/',
|
| 209 |
+
pipeline=[
|
| 210 |
+
dict(type='LoadImageFromFile'),
|
| 211 |
+
dict(
|
| 212 |
+
type='MultiScaleFlipAug',
|
| 213 |
+
img_scale=(1333, 800),
|
| 214 |
+
flip=False,
|
| 215 |
+
transforms=[
|
| 216 |
+
dict(type='Resize', keep_ratio=True),
|
| 217 |
+
dict(type='RandomFlip'),
|
| 218 |
+
dict(
|
| 219 |
+
type='Normalize',
|
| 220 |
+
mean=[123.675, 116.28, 103.53],
|
| 221 |
+
std=[58.395, 57.12, 57.375],
|
| 222 |
+
to_rgb=True),
|
| 223 |
+
dict(type='Pad', size_divisor=32),
|
| 224 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 225 |
+
dict(type='Collect', keys=['img'])
|
| 226 |
+
])
|
| 227 |
+
]))
|
| 228 |
+
evaluation = dict(metric=['bbox', 'segm'])
|
| 229 |
+
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
|
| 230 |
+
optimizer_config = dict(grad_clip=None)
|
| 231 |
+
lr_config = dict(
|
| 232 |
+
policy='step',
|
| 233 |
+
warmup='linear',
|
| 234 |
+
warmup_iters=500,
|
| 235 |
+
warmup_ratio=0.001,
|
| 236 |
+
step=[16, 22])
|
| 237 |
+
runner = dict(type='EpochBasedRunner', max_epochs=24)
|
| 238 |
+
checkpoint_config = dict(interval=1)
|
| 239 |
+
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
|
| 240 |
+
custom_hooks = [dict(type='NumClassCheckHook')]
|
| 241 |
+
dist_params = dict(backend='nccl')
|
| 242 |
+
log_level = 'INFO'
|
| 243 |
+
load_from = None
|
| 244 |
+
resume_from = None
|
| 245 |
+
workflow = [('train', 1)]
|
| 246 |
+
opencv_num_threads = 0
|
| 247 |
+
mp_start_method = 'fork'
|
| 248 |
+
auto_scale_lr = dict(enable=False, base_batch_size=16)
|
gitattributes
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
pytorch_model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:39d6f70cff1219b012d2f0663d0eeb8958f179ea083b67d8f5ed6a99d77d38e2
|
| 3 |
+
size 410109324
|