

Submitted by
 yilunzhao
yilunzhao
yilunzhaoGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
yilunzhao Liuff23
Liuff23
 songtingyu
songtingyu
 AngLv
AngLv
 cyyang822
cyyang822 lyx97
lyx97
 chaoscodes
chaoscodes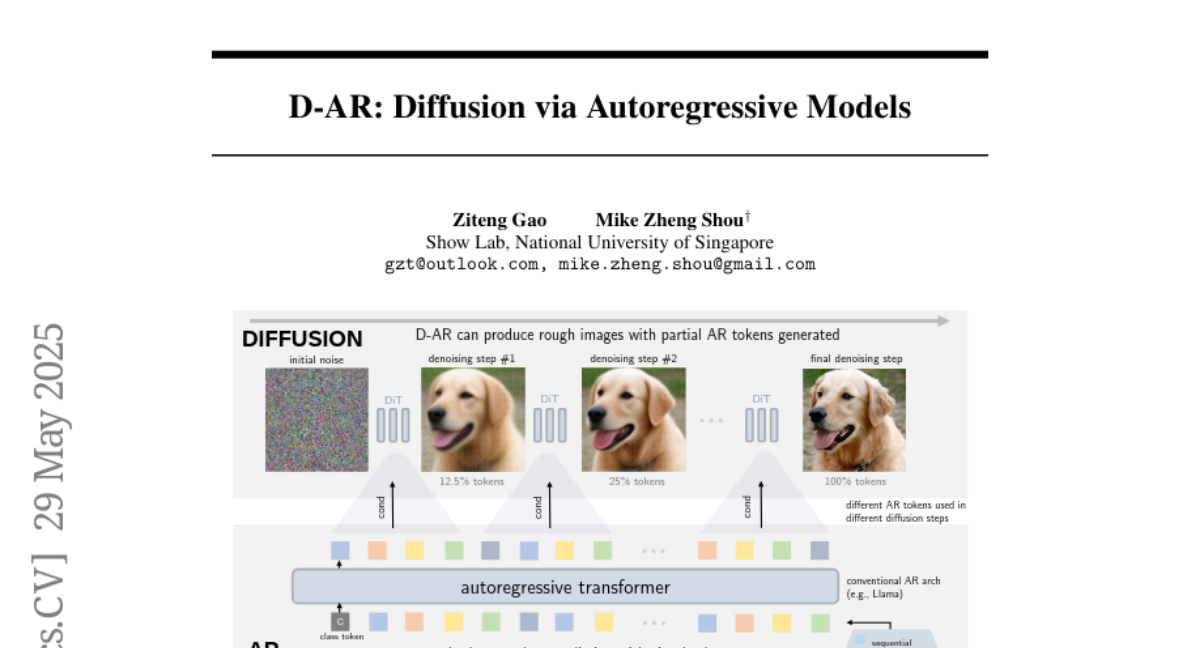
 sebgao
sebgao
 shizhediao
shizhediao
 RicardoL1u
RicardoL1u
 benzweijia
benzweijia
 maksimko123
maksimko123
 vyokky
vyokky
 lhjiang
lhjiang
 nitay
nitay
 spapi
spapi
 dlaptev
dlaptev
 TharinduSK
TharinduSK
 ydalva
ydalva
 AliBehrouz
AliBehrouz
 BryanW
BryanW
 unilm
unilm
 gallilmaimon
gallilmaimon
 KunlunZhu
KunlunZhu
 antonio-c
antonio-c
 Jiahao004
Jiahao004
 d3tk
d3tk
 Jang-Hyun
Jang-Hyun
 m-serious
m-serious
 dek924
dek924
 sy1998
sy1998
 jefflai
jefflai
 BestWishYsh
BestWishYsh
 Elfsong
Elfsong
 smallAI
smallAI
 Bang-UdeM-Mila
Bang-UdeM-Mila
 ttumyche
ttumyche
 lyxun
lyxun
 crc5577
crc5577
 wangsssssss
wangsssssss
 davidchan
davidchan
 hdong51
hdong51
 ChaoHuangCS
ChaoHuangCS angtian
angtian
 ahnpersie
ahnpersie
 zgao3186
zgao3186
 JingzeShi
JingzeShi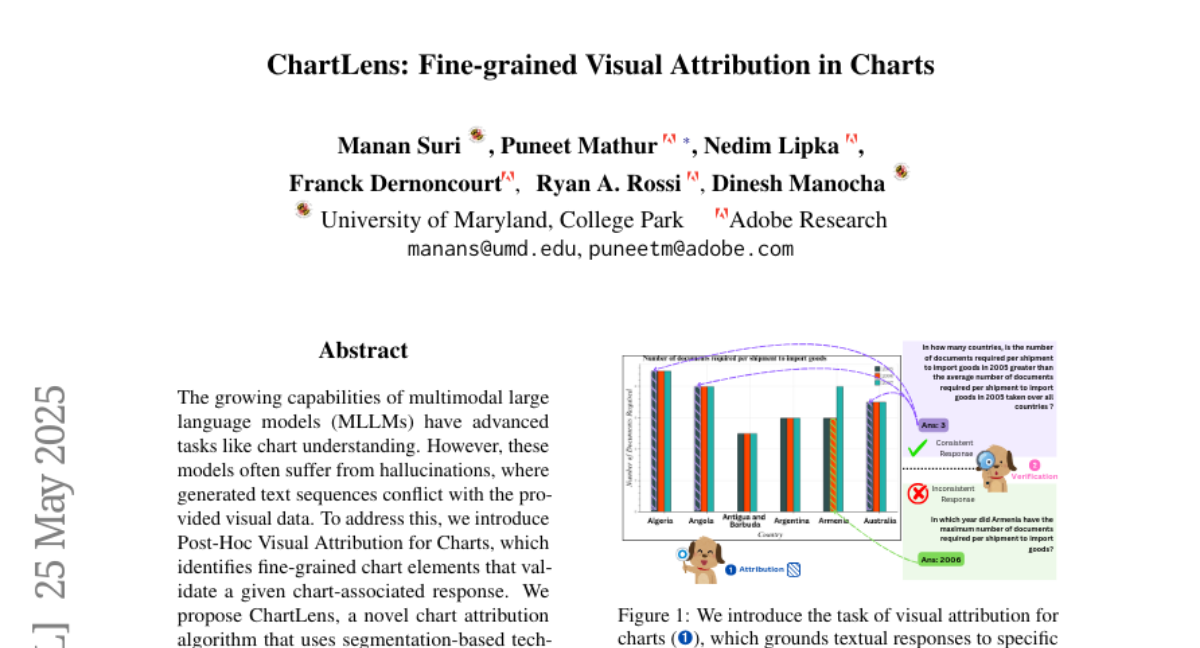
 Franck-Dernoncourt
Franck-Dernoncourt
 yunjae-won
yunjae-won
 gsarch
gsarch
 JRQi
JRQi kornelhowil
kornelhowil
 kpzhang996
kpzhang996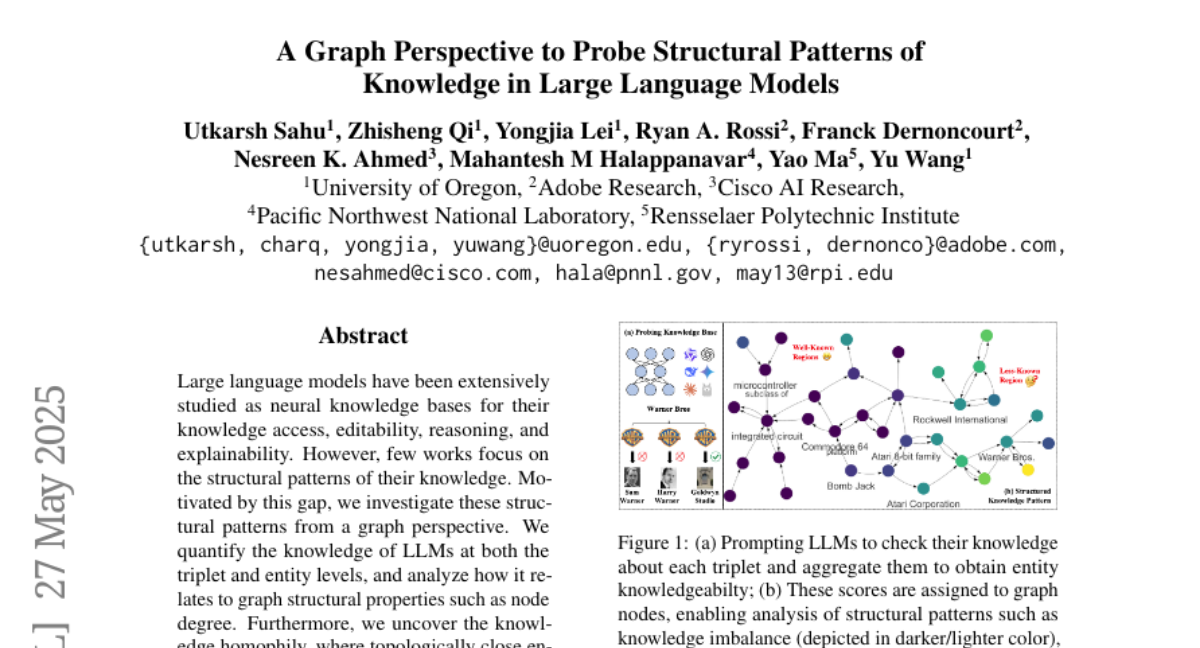 Franck-Dernoncourt
Franck-Dernoncourt
 Aman
Aman
 RunsenXu
RunsenXu xiaojwan
xiaojwan lhmd
lhmd
 StringChaos
StringChaos
 gsarti
gsarti
 SuperSupermoon
SuperSupermoon
 pengxiang
pengxiang
 Junfeng5
Junfeng5
 at676
at676
 ctma
ctma
 TeddyXGZ
TeddyXGZ




















