

Submitted by
 CodeGoat24
CodeGoat24
CodeGoat24Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
CodeGoat24
 andrewzh
andrewzh
 SmerkyG
SmerkyG
 shiyi0408
shiyi0408
 iofu728
iofu728
 Xingyu-Zheng
Xingyu-Zheng
 scaperex
scaperex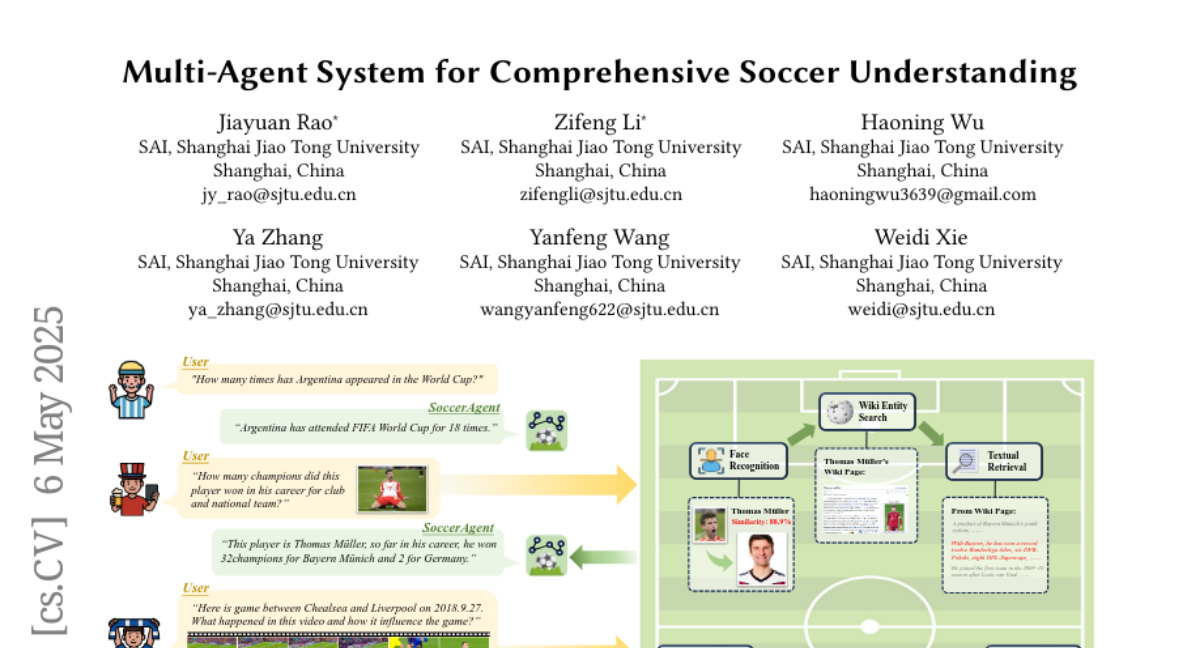
 Homie0609
Homie0609
 kevinr
kevinr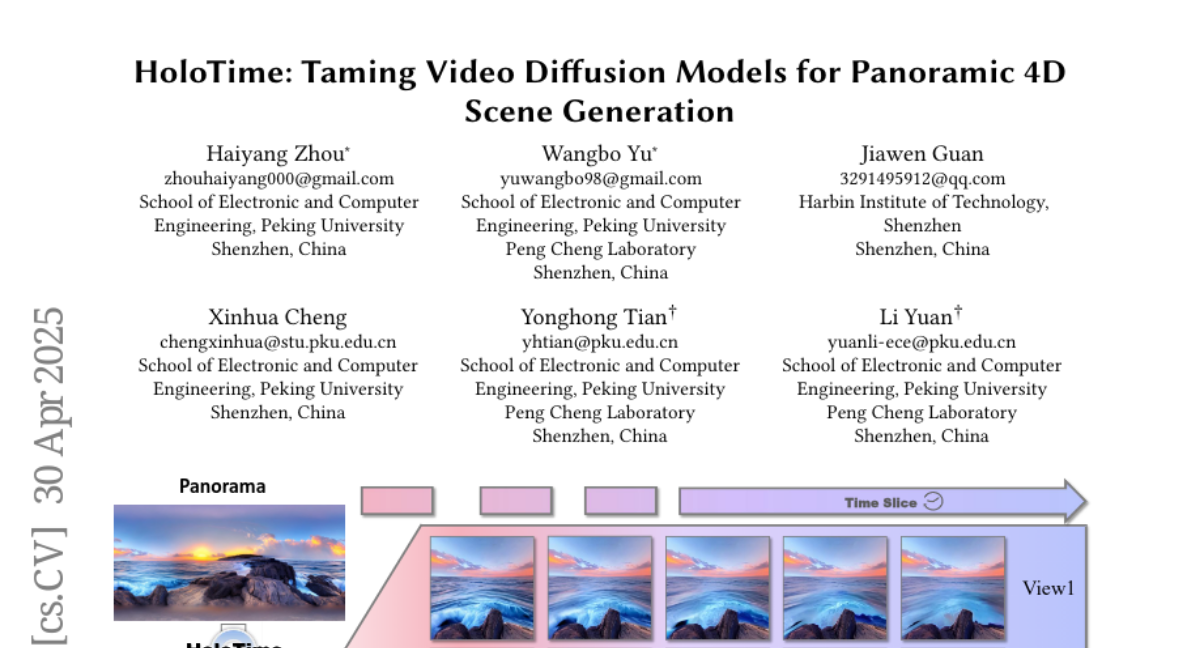
 Marblueocean
Marblueocean
 shenyunhang
shenyunhang
 Franck-Dernoncourt
Franck-Dernoncourt
 john-b-yang
john-b-yang
 mattf1n
mattf1n
 LuLing
LuLing
 Robot2050
Robot2050
 lorashen
lorashen
 Kevin355
Kevin355
 dnoever
dnoever










